././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000034�00000000000�010212� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������28 mtime=1670870312.0858693
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fABBA-1.0.8/����������������������������������������������������������������������������������������0000755�0001757�0001757�00000000000�00000000000�013140� 5����������������������������������������������������������������������������������������������������ustar�00xinyechen�����������������������xinyechen��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1670857044.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fABBA-1.0.8/.gitattributes��������������������������������������������������������������������������0000644�0001757�0001757�00000000176�00000000000�016037� 0����������������������������������������������������������������������������������������������������ustar�00xinyechen�����������������������xinyechen��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������*.ipynb linguist-detectable=false
*.cpp linguist-detectable=true
*.py linguist-detectable=true
*.pyx linguist-detectable=true
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1670857044.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fABBA-1.0.8/.travis.yml�����������������������������������������������������������������������������0000644�0001757�0001757�00000000247�00000000000�015254� 0����������������������������������������������������������������������������������������������������ustar�00xinyechen�����������������������xinyechen��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������language: python
python:
- 3.8
- 3.9
before_install:
- pip3 install -r requirements.txt
- python3 setup.py build_ext --inplace
script:
- python3 runtest.py
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1670857044.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fABBA-1.0.8/CODE_OF_CONDUCT.md����������������������������������������������������������������������0000644�0001757�0001757�00000012217�00000000000�015742� 0����������������������������������������������������������������������������������������������������ustar�00xinyechen�����������������������xinyechen��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Contributor Covenant Code of Conduct
## Our Pledge
We as members, contributors, and leaders pledge to make participation in our
community a harassment-free experience for everyone, regardless of age, body
size, visible or invisible disability, ethnicity, sex characteristics, gender
identity and expression, level of experience, education, socio-economic status,
nationality, personal appearance, race, religion, or sexual identity
and orientation.
We pledge to act and interact in ways that contribute to an open, welcoming,
diverse, inclusive, and healthy community.
## Our Standards
Examples of behavior that contributes to a positive environment for our
community include:
* Demonstrating empathy and kindness toward other people
* Being respectful of differing opinions, viewpoints, and experiences
* Giving and gracefully accepting constructive feedback
* Accepting responsibility and apologizing to those affected by our mistakes,
and learning from the experience
* Focusing on what is best not just for us as individuals, but for the
overall community
Examples of unacceptable behavior include:
* The use of sexualized language or imagery, and sexual attention or
advances of any kind
* Trolling, insulting or derogatory comments, and personal or political attacks
* Public or private harassment
* Publishing others' private information, such as a physical or email
address, without their explicit permission
* Other conduct which could reasonably be considered inappropriate in a
professional setting
## Enforcement Responsibilities
Community leaders are responsible for clarifying and enforcing our standards of
acceptable behavior and will take appropriate and fair corrective action in
response to any behavior that they deem inappropriate, threatening, offensive,
or harmful.
Community leaders have the right and responsibility to remove, edit, or reject
comments, commits, code, wiki edits, issues, and other contributions that are
not aligned to this Code of Conduct, and will communicate reasons for moderation
decisions when appropriate.
## Scope
This Code of Conduct applies within all community spaces, and also applies when
an individual is officially representing the community in public spaces.
Examples of representing our community include using an official e-mail address,
posting via an official social media account, or acting as an appointed
representative at an online or offline event.
## Enforcement
Instances of abusive, harassing, or otherwise unacceptable behavior may be
reported to the community leaders responsible for enforcement at
stefan.guettel@manchester.ac.uk; xinye.chen@manchester.ac.uk .
All complaints will be reviewed and investigated promptly and fairly.
All community leaders are obligated to respect the privacy and security of the
reporter of any incident.
## Enforcement Guidelines
Community leaders will follow these Community Impact Guidelines in determining
the consequences for any action they deem in violation of this Code of Conduct:
### 1. Correction
**Community Impact**: Use of inappropriate language or other behavior deemed
unprofessional or unwelcome in the community.
**Consequence**: A private, written warning from community leaders, providing
clarity around the nature of the violation and an explanation of why the
behavior was inappropriate. A public apology may be requested.
### 2. Warning
**Community Impact**: A violation through a single incident or series
of actions.
**Consequence**: A warning with consequences for continued behavior. No
interaction with the people involved, including unsolicited interaction with
those enforcing the Code of Conduct, for a specified period of time. This
includes avoiding interactions in community spaces as well as external channels
like social media. Violating these terms may lead to a temporary or
permanent ban.
### 3. Temporary Ban
**Community Impact**: A serious violation of community standards, including
sustained inappropriate behavior.
**Consequence**: A temporary ban from any sort of interaction or public
communication with the community for a specified period of time. No public or
private interaction with the people involved, including unsolicited interaction
with those enforcing the Code of Conduct, is allowed during this period.
Violating these terms may lead to a permanent ban.
### 4. Permanent Ban
**Community Impact**: Demonstrating a pattern of violation of community
standards, including sustained inappropriate behavior, harassment of an
individual, or aggression toward or disparagement of classes of individuals.
**Consequence**: A permanent ban from any sort of public interaction within
the community.
## Attribution
This Code of Conduct is adapted from the [Contributor Covenant][homepage],
version 2.0, available at
https://www.contributor-covenant.org/version/2/0/code_of_conduct.html.
Community Impact Guidelines were inspired by [Mozilla's code of conduct
enforcement ladder](https://github.com/mozilla/diversity).
[homepage]: https://www.contributor-covenant.org
For answers to common questions about this code of conduct, see the FAQ at
https://www.contributor-covenant.org/faq. Translations are available at
https://www.contributor-covenant.org/translations.
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1670857044.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fABBA-1.0.8/LICENSE���������������������������������������������������������������������������������0000644�0001757�0001757�00000002776�00000000000�014161� 0����������������������������������������������������������������������������������������������������ustar�00xinyechen�����������������������xinyechen��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������BSD 3-Clause License
Copyright (c) 2021, Stefan Güttel, Xinye Chen
All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
1. Redistributions of source code must retain the above copyright notice, this
list of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
3. Neither the name of the copyright holder nor the names of its
contributors may be used to endorse or promote products derived from
this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
��././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000034�00000000000�010212� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������28 mtime=1670870312.0858693
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fABBA-1.0.8/PKG-INFO��������������������������������������������������������������������������������0000644�0001757�0001757�00000017334�00000000000�014245� 0����������������������������������������������������������������������������������������������������ustar�00xinyechen�����������������������xinyechen��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������Metadata-Version: 2.1
Name: fABBA
Version: 1.0.8
Summary: An efficient aggregation method for the symbolic representation of temporal data
Home-page: https://github.com/nla-group/fABBA
Author: Xinye Chen, Stefan Güttel
Author-email: xinye.chen@manchester.ac.uk, stefan.guettel@manchester.ac.uk
License: BSD 3-Clause
Platform: UNKNOWN
Classifier: Intended Audience :: Science/Research
Classifier: Intended Audience :: Developers
Classifier: Programming Language :: Python
Classifier: Topic :: Software Development
Classifier: Topic :: Scientific/Engineering
Classifier: Operating System :: Microsoft :: Windows
Classifier: Operating System :: Unix
Classifier: Programming Language :: Python :: 3
Classifier: Programming Language :: Python :: 3.6
Classifier: Programming Language :: Python :: 3.7
Classifier: Programming Language :: Python :: 3.8
Classifier: Programming Language :: Python :: 3.9
Classifier: Programming Language :: Python :: 3.10
Description-Content-Type: text/x-rst
License-File: LICENSE
.. image:: https://app.travis-ci.com/nla-group/fABBA.svg?branch=master
:target: https://app.travis-ci.com/nla-group/fABBA.svg?branch=master
:alt: Build Status
.. image:: https://img.shields.io/badge/License-BSD%203--Clause-blue.svg
:target: https://github.com/nla-group/fABBA/blob/master/LICENSE
:alt: License
.. image:: https://img.shields.io/pypi/v/fABBA?color=orange
:target: https://pypi.org/project/fABBA/
:alt: pypi
.. image:: https://img.shields.io/pypi/pyversions/fABBA.svg
:target: https://pypi.python.org/pypi/fABBA/
:alt: PyPI pyversions
.. image:: https://zenodo.org/badge/DOI/10.5281/zenodo.6206977.svg
:target: https://doi.org/10.5281/zenodo.6206977
:alt: DOI
.. image:: https://static.pepy.tech/badge/fABBA
:target: https://pypi.python.org/pypi/fABBA/
:alt: Download Status
fABBA is a fast and accurate symbolic representation method for temporal data.
It is based on a polygonal chain approximation of the time series followed by an aggregation of the polygonal pieces into groups.
The aggregation process is sped up by sorting the polygonal pieces and exploiting early termination conditions.
In contrast to the ABBA method [S. Elsworth and S. Güttel, Data Mining and Knowledge Discovery, 34:1175-1200, 2020], fABBA avoids repeated within-cluster-sum-of-squares computations which reduces its computational complexity significantly.
Furthermore, fABBA is fully tolerance-driven and does not require the number of time series symbols to be specified by the user.
--------
Install
--------
fABBA has the following essential dependencies for its functionality:
- cython
- numpy
- scipy
- requests
To install the current release via PIP use:
.. code:: bash
pip install fABBA
Download this repository:
.. code:: bash
git clone https://github.com/nla-group/fABBA.git
--------
Examples
--------
- *Compress and reconstruct a time series*
The following example approximately transforms a time series into a symbolic string representation (`transform`) and then converts the string back into a numerical format (`inverse_transform`). fABBA essentially requires two parameters `tol` and `alpha`. The tolerance `tol` determines how closely the polygonal chain approximation follows the original time series. The parameter `alpha` controls how similar time series pieces need to be in order to be represented by the same symbol. A smaller `tol` means that more polygonal pieces are used and the polygonal chain approximation is more accurate; but on the other hand, it will increase the length of the string representation. A smaller `alpha` typically results in a larger number of symbols.
The choice of parameters depends on the application, but in practice, one often just wants the polygonal chain to mimic the key features in time series and not to approximate any noise. In this example the time series is a sine wave and the chosen parameters result in the symbolic representation `#$!"!"!"!"!"!"!"%`. Note how the periodicity in the time series is nicely reflected in repetitions in its string representation.
.. code:: python
import numpy as np
import matplotlib.pyplot as plt
from fABBA import fabba_model
ts = [np.sin(0.05*i) for i in range(1000)] # original time series
fabba = fabba_model(tol=0.1, alpha=0.1, sorting='2-norm', scl=1, verbose=0)
string = fabba.fit_transform(ts) # string representation of the time series
print(string) # prints BbAaAaAaAaAaAaAaC
inverse_ts = fabba.inverse_transform(string, ts[0]) # numerical time series reconstruction
- *Adaptive polygonal chain approximation*
Instead of using `transform` which combines the polygonal chain approximation of the time series and the symbolic conversion into one, both steps of fABBA can be performed independently. Here’s how to obtain the compression pieces and reconstruct time series by inversely transforming the pieces:
.. code:: python
import numpy as np
from fABBA import compress
from fABBA import inverse_compress
ts = [np.sin(0.05*i) for i in range(1000)]
pieces = compress(ts, tol=0.1) # pieces is a list of the polygonal chain pieces
inverse_ts = inverse_compress(pieces, ts[0]) # reconstruct polygonal chain from pieces
Similarly, the digitization can be implemented after compression step as belows:
.. code:: python
from fABBA import digitize
from fABBA import inverse_digitize
string, parameters = digitize(pieces, alpha=0.1, sorting='2-norm', scl=1) # compression of the polygon
print(''.join(string)) # prints BbAaAaAaAaAaAaAaC
inverse_pieces = inverse_digitize(string, parameters)
inverse_ts = inverse_compress(inverse_pieces, ts[0]) # numerical time series reconstruction
- *Alternative ABBA approach*
We also provide other clustering based ABBA methods, it is easy to use with the support of scikit-learn tools. The user guidance is as follows
.. code:: python
import numpy as np
from sklearn.cluster import KMeans
from fABBA import ABBAbase
ts = [np.sin(0.05*i) for i in range(1000)] # original time series
# specifies 5 symbols using kmeans clustering
kmeans = KMeans(n_clusters=5, random_state=0, init='k-means++', verbose=0)
abba = ABBAbase(tol=0.1, scl=1, clustering=kmeans)
string = abba.fit_transform(ts) # string representation of the time series
print(string) # prints BbAaAaAaAaAaAaAaC
inverse_ts = abba.inverse_transform(string) # reconstruction
- *Image compression*
The following example shows how to apply fABBA to image data.
.. code:: python
import matplotlib.pyplot as plt
from fABBA.load_datasets import load_images
from fABBA import image_compress
from fABBA import image_decompress
from fABBA import fabba_model
from cv2 import resize
img_samples = load_images() # load test images
img = resize(img_samples[0], (100, 100)) # select the first image for test
fabba = fabba_model(tol=0.1, alpha=0.01, sorting='2-norm', scl=1, verbose=1)
string = image_compress(fabba, img) # compress image
inverse_img = image_decompress(fabba, string) # decompress image
--------
Citation
--------
If you use fABBA in a scientific publication, we would appreciate your citing:
.. code:: bibtex
@techreport{CG22a,
title = {An efficient aggregation method for the symbolic representation of temporal data},
author = {Chen, Xinye and G\"{u}ttel, Stefan},
year = {2022},
number = {arXiv:2201.05697},
pages = {23},
institution = {The University of Manchester},
address = {UK},
type = {arXiv EPrint},
url = {https://arxiv.org/abs/2201.05697}
}
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1670857044.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fABBA-1.0.8/README.md�������������������������������������������������������������������������������0000644�0001757�0001757�00000023004�00000000000�014416� 0����������������������������������������������������������������������������������������������������ustar�00xinyechen�����������������������xinyechen��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
fABBA :frog:
An efficient aggregation method for the symbolic representation of temporal data
:whale: :dolphin:
[](https://app.travis-ci.com/github/nla-group/fABBA)
[](https://opensource.org/licenses/BSD-3-Clause)
[](https://dev.azure.com/conda-forge/feedstock-builds/_build/latest?definitionId=16216&branchName=main)
[](https://pypi.org/project/fABBA/)
[](https://fabba.readthedocs.io/en/latest/?badge=latest)
[](https://pypi.python.org/pypi/fABBA/)
[](https://mybinder.org/v2/gh/nla-group/fABBA/HEAD)
[](https://pypi.python.org/pypi/fABBA/)
:sparkles: fABBA is a fast and accurate symbolic representation method for temporal data.
It is based on a polygonal chain approximation of the time series followed by an aggregation of the polygonal pieces into groups.
The aggregation process is sped up by sorting the polygonal pieces and exploiting early termination conditions.
In contrast to the ABBA method [S. Elsworth and S. Güttel, Data Mining and Knowledge Discovery, 34:1175-1200, 2020], fABBA avoids repeated within-cluster-sum-of-squares computations which reduces its computational complexity significantly.
Furthermore, fABBA is fully tolerance-driven and does not require the number of time series symbols to be specified by the user.
## :rocket: Install
fABBA has the following essential dependencies for its functionality:
- cython
- numpy>=1.17.3
- scipy>=1.2.1
- requests
- scikit-learn
- matplotlib
#### To ensure successful Cython compiling, please update your NumPy to the latest version>= 1.22.0.
To install the current release via PIP use:
```pip install fabba```
Download this repository:
```git clone https://github.com/nla-group/fABBA.git```
## :checkered_flag: Examples
#### :star: *Compress and reconstruct a time series*
The following example approximately transforms a time series into a symbolic string representation (`transform`) and then converts the string back into a numerical format (`inverse_transform`). fABBA essentially requires two parameters `tol` and `alpha`. The tolerance `tol` determines how closely the polygonal chain approximation follows the original time series. The parameter `alpha` controls how similar time series pieces need to be in order to be represented by the same symbol. A smaller `tol` means that more polygonal pieces are used and the polygonal chain approximation is more accurate; but on the other hand, it will increase the length of the string representation. A smaller `alpha` typically results in a larger number of symbols.
The choice of parameters depends on the application, but in practice, one often just wants the polygonal chain to mimic the key features in time series and not to approximate any noise. In this example the time series is a sine wave and the chosen parameters result in the symbolic representation `BbAaAaAaAaAaAaAaC`. Note how the periodicity in the time series is nicely reflected in repetitions in its string representation.
```python
import numpy as np
import matplotlib.pyplot as plt
from fABBA import fABBA
ts = [np.sin(0.05*i) for i in range(1000)] # original time series
fabba = fABBA(tol=0.1, alpha=0.1, sorting='2-norm', scl=1, verbose=0)
string = fabba.fit_transform(ts) # string representation of the time series
print(string) # prints BbAaAaAaAaAaAaAaC
inverse_ts = fabba.inverse_transform(string, ts[0]) # numerical time series reconstruction
```
Plot the time series and its polygonal chain reconstruction:
```python
plt.plot(ts, label='time series')
plt.plot(inverse_ts, label='reconstruction')
plt.legend()
plt.grid(True, axis='y')
plt.show()
```
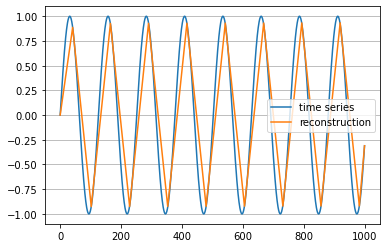
#### :star: *Adaptive polygonal chain approximation*
Instead of using `fit_transform` which combines the polygonal chain approximation of the time series and the symbolic conversion into one, both steps of fABBA can be performed independently. Here’s how to obtain the compression pieces and reconstruct time series by inversely transforming the pieces:
```python
import numpy as np
from fABBA import compress
from fABBA import inverse_compress
ts = [np.sin(0.05*i) for i in range(1000)]
pieces = compress(ts, tol=0.1) # pieces is a list of the polygonal chain pieces
inverse_ts = inverse_compress(pieces, ts[0]) # reconstruct polygonal chain from pieces
```
Similarly, the digitization can be implemented after compression step as below:
```python
from fABBA import digitize
from fABBA import inverse_digitize
string, parameters = digitize(pieces, alpha=0.1, sorting='2-norm', scl=1) # compression of the polygon
print(''.join(string)) # prints BbAaAaAaAaAaAaAaC
inverse_pieces = inverse_digitize(string, parameters)
inverse_ts = inverse_compress(inverse_pieces, ts[0]) # numerical time series reconstruction
```
#### :star: *Alternative ABBA approach*
We also provide other clustering based ABBA methods, it is easy to use with the support of scikit-learn tools. The user guidance is as follows
```python
import numpy as np
from sklearn.cluster import KMeans
from fABBA import ABBAbase
ts = [np.sin(0.05*i) for i in range(1000)] # original time series
# specifies 5 symbols using kmeans clustering
kmeans = KMeans(n_clusters=5, random_state=0, init='k-means++', verbose=0)
abba = ABBAbase(tol=0.1, scl=1, clustering=kmeans)
string = abba.fit_transform(ts) # string representation of the time series
print(string) # prints BbAaAaAaAaAaAaAaC
inverse_ts = abba.inverse_transform(string) # reconstruction
```
#### :star: *Image compression*
The following example shows how to apply fABBA to image data.
```python
import matplotlib.pyplot as plt
from fABBA.load_datasets import load_images
from fABBA import image_compress
from fABBA import image_decompress
from fABBA import fABBA
from cv2 import resize
img_samples = load_images() # load test images
img = resize(img_samples[0], (100, 100)) # select the first image for test
fabba = fABBA(tol=0.1, alpha=0.01, sorting='2-norm', scl=1, verbose=1)
string = image_compress(fabba, img)
inverse_img = image_decompress(fabba, string)
```
Plot the original image:
```python
plt.imshow(img)
plt.show()
```
Plot the reconstructed image:
```python
plt.imshow(inverse_img)
plt.show()
```

## :art: Experiments
The folder ["exp"](https://github.com/nla-group/fABBA/tree/master/exp) contains all code required to reproduce the experiments in the manuscript "An efficient aggregation method for the symbolic representation of temporal data".
Some of the experiments also require the UCR Archive 2018 datasets which can be downloaded from [UCR Time Series Classification Archive](https://www.cs.ucr.edu/~eamonn/time_series_data_2018/).
There are a number of dependencies listed below. Most of these modules, except perhaps the final ones, are part of any standard Python installation. We list them for completeness:
`os, csv, time, pickle, numpy, warnings, matplotlib, math, collections, copy, sklearn, pandas, tqdm, tslearn`
Please ensure that these modules are available before running the codes. A `numpy` version newer than 1.19.0 and less than 1.20 is required.
It is necessary to compile the Cython files in the experiments folder (though this is already compiled in the main module, the experiments code is separated). To compile the Cython extension in ["src"](https://github.com/nla-group/fABBA/tree/master/exp/src) use:
```
cd exp/src
python3 setup.py build_ext --inplace
```
or
```
cd exp/src
python setup.py build_ext --inplace
```
## :love_letter: Others
We also provide C++ implementation for fABBA in the repository [``cabba``](https://github.com/nla-group/cabba), it would be nice to give a shot!
Also for the original draft, the folder[``/cpp``](https://github.com/nla-group/fABBA/tree/master/cpp) maybe a good reference.
Run example:
```
git clone https://github.com/nla-group/fABBA.git
cd fABBA/cpp
g++ -o test runtime.cpp
./test
```
## :paperclip: Citation
If you use fABBA in a scientific publication, we would appreciate your citing:
```bibtex
@article{CG22a,
title = {An efficient aggregation method for the symbolic representation of temporal data},
author = {Chen, Xinye and G\"{u}ttel, Stefan},
year = {2022},
number = {},
pages = {},
journal = {Accepted for publication in ACM Transactions on Knowledge Discovery from Data},
url = {https://arxiv.org/abs/2201.05697}
}
```
##### If you have any questions, please be free to reach us!
## 📝 License
This project is licensed under the terms of the [BSD-3-Clause](https://github.com/nla-group/fABBA/blob/master/LICENSE).

����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1670857044.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fABBA-1.0.8/README.rst������������������������������������������������������������������������������0000644�0001757�0001757�00000015353�00000000000�014636� 0����������������������������������������������������������������������������������������������������ustar�00xinyechen�����������������������xinyechen��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������.. image:: https://app.travis-ci.com/nla-group/fABBA.svg?branch=master
:target: https://app.travis-ci.com/nla-group/fABBA.svg?branch=master
:alt: Build Status
.. image:: https://img.shields.io/badge/License-BSD%203--Clause-blue.svg
:target: https://github.com/nla-group/fABBA/blob/master/LICENSE
:alt: License
.. image:: https://img.shields.io/pypi/v/fABBA?color=orange
:target: https://pypi.org/project/fABBA/
:alt: pypi
.. image:: https://img.shields.io/pypi/pyversions/fABBA.svg
:target: https://pypi.python.org/pypi/fABBA/
:alt: PyPI pyversions
.. image:: https://zenodo.org/badge/DOI/10.5281/zenodo.6206977.svg
:target: https://doi.org/10.5281/zenodo.6206977
:alt: DOI
.. image:: https://static.pepy.tech/badge/fABBA
:target: https://pypi.python.org/pypi/fABBA/
:alt: Download Status
fABBA is a fast and accurate symbolic representation method for temporal data.
It is based on a polygonal chain approximation of the time series followed by an aggregation of the polygonal pieces into groups.
The aggregation process is sped up by sorting the polygonal pieces and exploiting early termination conditions.
In contrast to the ABBA method [S. Elsworth and S. Güttel, Data Mining and Knowledge Discovery, 34:1175-1200, 2020], fABBA avoids repeated within-cluster-sum-of-squares computations which reduces its computational complexity significantly.
Furthermore, fABBA is fully tolerance-driven and does not require the number of time series symbols to be specified by the user.
--------
Install
--------
fABBA has the following essential dependencies for its functionality:
- cython
- numpy
- scipy
- requests
To install the current release via PIP use:
.. code:: bash
pip install fABBA
Download this repository:
.. code:: bash
git clone https://github.com/nla-group/fABBA.git
--------
Examples
--------
- *Compress and reconstruct a time series*
The following example approximately transforms a time series into a symbolic string representation (`transform`) and then converts the string back into a numerical format (`inverse_transform`). fABBA essentially requires two parameters `tol` and `alpha`. The tolerance `tol` determines how closely the polygonal chain approximation follows the original time series. The parameter `alpha` controls how similar time series pieces need to be in order to be represented by the same symbol. A smaller `tol` means that more polygonal pieces are used and the polygonal chain approximation is more accurate; but on the other hand, it will increase the length of the string representation. A smaller `alpha` typically results in a larger number of symbols.
The choice of parameters depends on the application, but in practice, one often just wants the polygonal chain to mimic the key features in time series and not to approximate any noise. In this example the time series is a sine wave and the chosen parameters result in the symbolic representation `#$!"!"!"!"!"!"!"%`. Note how the periodicity in the time series is nicely reflected in repetitions in its string representation.
.. code:: python
import numpy as np
import matplotlib.pyplot as plt
from fABBA import fabba_model
ts = [np.sin(0.05*i) for i in range(1000)] # original time series
fabba = fabba_model(tol=0.1, alpha=0.1, sorting='2-norm', scl=1, verbose=0)
string = fabba.fit_transform(ts) # string representation of the time series
print(string) # prints BbAaAaAaAaAaAaAaC
inverse_ts = fabba.inverse_transform(string, ts[0]) # numerical time series reconstruction
- *Adaptive polygonal chain approximation*
Instead of using `transform` which combines the polygonal chain approximation of the time series and the symbolic conversion into one, both steps of fABBA can be performed independently. Here’s how to obtain the compression pieces and reconstruct time series by inversely transforming the pieces:
.. code:: python
import numpy as np
from fABBA import compress
from fABBA import inverse_compress
ts = [np.sin(0.05*i) for i in range(1000)]
pieces = compress(ts, tol=0.1) # pieces is a list of the polygonal chain pieces
inverse_ts = inverse_compress(pieces, ts[0]) # reconstruct polygonal chain from pieces
Similarly, the digitization can be implemented after compression step as belows:
.. code:: python
from fABBA import digitize
from fABBA import inverse_digitize
string, parameters = digitize(pieces, alpha=0.1, sorting='2-norm', scl=1) # compression of the polygon
print(''.join(string)) # prints BbAaAaAaAaAaAaAaC
inverse_pieces = inverse_digitize(string, parameters)
inverse_ts = inverse_compress(inverse_pieces, ts[0]) # numerical time series reconstruction
- *Alternative ABBA approach*
We also provide other clustering based ABBA methods, it is easy to use with the support of scikit-learn tools. The user guidance is as follows
.. code:: python
import numpy as np
from sklearn.cluster import KMeans
from fABBA import ABBAbase
ts = [np.sin(0.05*i) for i in range(1000)] # original time series
# specifies 5 symbols using kmeans clustering
kmeans = KMeans(n_clusters=5, random_state=0, init='k-means++', verbose=0)
abba = ABBAbase(tol=0.1, scl=1, clustering=kmeans)
string = abba.fit_transform(ts) # string representation of the time series
print(string) # prints BbAaAaAaAaAaAaAaC
inverse_ts = abba.inverse_transform(string) # reconstruction
- *Image compression*
The following example shows how to apply fABBA to image data.
.. code:: python
import matplotlib.pyplot as plt
from fABBA.load_datasets import load_images
from fABBA import image_compress
from fABBA import image_decompress
from fABBA import fabba_model
from cv2 import resize
img_samples = load_images() # load test images
img = resize(img_samples[0], (100, 100)) # select the first image for test
fabba = fabba_model(tol=0.1, alpha=0.01, sorting='2-norm', scl=1, verbose=1)
string = image_compress(fabba, img) # compress image
inverse_img = image_decompress(fabba, string) # decompress image
--------
Citation
--------
If you use fABBA in a scientific publication, we would appreciate your citing:
.. code:: bibtex
@techreport{CG22a,
title = {An efficient aggregation method for the symbolic representation of temporal data},
author = {Chen, Xinye and G\"{u}ttel, Stefan},
year = {2022},
number = {arXiv:2201.05697},
pages = {23},
institution = {The University of Manchester},
address = {UK},
type = {arXiv EPrint},
url = {https://arxiv.org/abs/2201.05697}
}
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1670857044.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fABBA-1.0.8/auto_config.sh��������������������������������������������������������������������������0000755�0001757�0001757�00000000531�00000000000�015773� 0����������������������������������������������������������������������������������������������������ustar�00xinyechen�����������������������xinyechen��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������#!/bin/bash
if [[ ! -z "$1" ]] ; then
if [ "$1" == true ]
then
echo 'compiling.'
rm -r dist
rm -r build
touch ~/.pypirc
python3 setup.py sdist bdist_wheel
echo 'compiling complete!'
fi
fi
if [[ ! -z "$2" ]]
then
echo 'test begin.'
pip install $2
echo 'test complete!'
fi
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000034�00000000000�010212� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������28 mtime=1670870309.9817953
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fABBA-1.0.8/conda/����������������������������������������������������������������������������������0000755�0001757�0001757�00000000000�00000000000�014224� 5����������������������������������������������������������������������������������������������������ustar�00xinyechen�����������������������xinyechen��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1670857044.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fABBA-1.0.8/conda/recipe.yaml�����������������������������������������������������������������������0000644�0001757�0001757�00000001750�00000000000�016362� 0����������������������������������������������������������������������������������������������������ustar�00xinyechen�����������������������xinyechen��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������{% set name = "fABBA" %}
{% set version = "0.9.9" %}
package:
name: {{ name|lower }}
version: {{ version }}
source:
url: https://pypi.io/packages/source/{{ name[0] }}/{{ name }}/{{ name }}-{{ version }}.tar.gz
sha256: c2ca4233d73afb6727a99c028dcfa23fd565d5d1dcf779a2b6307fbb5543a521
build:
number: 0
script: "{{ PYTHON }} -m pip install . -vv"
requirements:
build:
- {{ compiler('c') }}
host:
- python
- pip
- numpy
- cython
run:
- python
- pandas
- requests
- matplotlib-base
- {{ pin_compatible('numpy') }}
- scikit-learn
- scipy >=1.2.1
test:
imports:
- fABBA
requires:
- pip
commands:
- pip check
about:
home: https://github.com/nla-group/fABBA
summary: 'An efficient aggregation method for the symbolic representation of temporal data.'
license: BSD-3-Clause
license_file: LICENSE
dev_url: https://github.com/nla-group/fABBA
extra:
recipe-maintainers:
- guettel
- chenxinye
������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000034�00000000000�010212� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������28 mtime=1670870309.9897954
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fABBA-1.0.8/cpp/������������������������������������������������������������������������������������0000755�0001757�0001757�00000000000�00000000000�013722� 5����������������������������������������������������������������������������������������������������ustar�00xinyechen�����������������������xinyechen��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1670857044.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fABBA-1.0.8/cpp/ABBA.h������������������������������������������������������������������������������0000644�0001757�0001757�00000011675�00000000000�014572� 0����������������������������������������������������������������������������������������������������ustar�00xinyechen�����������������������xinyechen��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������/*
* Copyright (c) 2021, Stefan Güttel, Xinye Chen
* Licensed under BSD 3-Clause License
* All rights reserved.
*
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
1. Redistributions of source code must retain the above copyright notice, this
list of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
3. Neither the name of the copyright holder nor the names of its
contributors may be used to endorse or promote products derived from
this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
*
* fABBA -- an accelerated ABBA based on adaptive polygonal chain approximation of time series
*
* Parameters
* ----------
* tol - default=0.1
* Control tolerence for compression.
*
* alpha - default=0.5
* Control tolerence for digitization.
*
* sorting - default='2-norm', {'lexi', '1-norm', '2-norm'}
* by which the sorting pieces prior to aggregation.
*
* scl - default=1
* Scale for length, default as 1, refers to 2d-digitization, otherwise implement 1d-digitization.
*
* verbose - default=1
* Verbosity mode, control logs print, default as 1; print logs.
*
* max_len - default=1
* The max length for each segment, optional choice for compression.
*
* string_form - boolean, default=true
* Whether to return with string form
*
* Methods:
* ----------
* std::string ABBA::fit_transform(std::vector&)
* Transform time series into symbols.
*
* std::vector ABBA::inverse_transform(std::string& symbols, T& start)
* Reconstruct the symbols back into time series.
*
* Attributes
* ----------
* parameters - Model, store the parameters of fABBA
*/
#ifndef ABBA_H
#define ABBA_H
#include
#include
#include "compress.h"
#include "digitization.h"
#include "reconstruction.h"
namespace fABBA{
class ABBA {
protected:
double tol; double alpha;
std::string sorting;
int scl; int maxlen; bool verbose;
Model parameters;
public:
ABBA(double _tol=0.5, double _alpha=0.5, std::string _sorting="lexi",
int _scl=1, int _maxlen=std::numeric_limits::max(), bool _verbose=true):
tol(_tol), alpha(_alpha), sorting(_sorting),
scl(_scl), maxlen(_maxlen), verbose(_verbose){}
template std::vector fit_transform(std::vector&);
template std::vector inverse_transform(T&);
void print_parameters();
~ABBA(){};
};
template
std::vector ABBA::fit_transform(std::vector& series){
std::vector > pieces = Compress(series, tol, maxlen, verbose);
this->parameters = Digitize(pieces, alpha, sorting, scl, verbose);
return this->parameters._symbols;
}
template
std::vector ABBA::inverse_transform(T& start){
std::vector > r_pieces = inverse_digitize(this->parameters);
// std::cout << std::endl << "id pieces:" << std::endl; print_matrix("inverse digitization:", r_pieces);
r_pieces = quantize(r_pieces);
// std::cout << std::endl << "iq pieces:" << std::endl; print_matrix("quantize:", r_pieces);
std::vector r_series = inverse_compress(r_pieces, start);
return r_series;
}
void ABBA::print_parameters(){
print_matrix("Centers: ", this->parameters._centers);
std::cout << std::endl << "Hashmap 1:" << std::endl;
for(auto item : this->parameters._hashmap){
std::cout << "key: " << item.first << " value: "<< item.second << "\n";
}
std::cout << std::endl << "Hashmap 2:" << std::endl;
for(auto item : this->parameters._inverse_hashmap){
std::cout << "key: " << item.first << " value: "<< item.second << "\n";
}
}
}
#endif // ABBA_H�������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1670857044.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fABBA-1.0.8/cpp/ABBA.i������������������������������������������������������������������������������0000644�0001757�0001757�00000000057�00000000000�014563� 0����������������������������������������������������������������������������������������������������ustar�00xinyechen�����������������������xinyechen�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������� // ABBA.i - SWIG interface
// to be continued���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1670857044.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fABBA-1.0.8/cpp/DTW.cpp�����������������������������������������������������������������������������0000644�0001757�0001757�00000006661�00000000000�015075� 0����������������������������������������������������������������������������������������������������ustar�00xinyechen�����������������������xinyechen��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������/*
* Copyright (c) 2021, Stefan Güttel, Xinye Chen
* Licensed under BSD 3-Clause License
* All rights reserved.
*
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
1. Redistributions of source code must retain the above copyright notice, this
list of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
3. Neither the name of the copyright holder nor the names of its
contributors may be used to endorse or promote products derived from
this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
*/
#include
#include
#include
using namespace std;
template
T dist_manhattan(T value1, T value2){
return abs(value1 - value2);
}
template
T dist_euclidean(T value1, T value2){
return pow((value1 - value2),2);
}
// auto dist = [](auto a, auto b) { return abs(a - b);};
// auto dist = [](auto a, auto b) { return pow((a - b),2);};
template
float DTW(std::vector const &series1, std::vector const &series2, float (*dist)(float, float), bool i_sqrt){
int nrows(series1.size()), ncols(series2.size());
float distance_matrix[nrows + 1][ncols + 1];
for (int i=0; i::infinity();
}
}
distance_matrix[0][0] = 0.0;
float store_elements[3];
float cost, min_last;
for (int i=1; i ts1 = {2,3,3,2,3,4,2,1,3,2,9.234,9.12312, 9.02,5.2};
std::vector ts2 = {1.2,2,1,2,3.5,4.1,1.8,2.5,3,2, 3,2,9.234};
cout << "manhattan: " << DTW(ts1, ts2, dist_manhattan, 0) << endl;
cout << "euclidean: " << DTW(ts1, ts2, dist_euclidean, 1) << endl;
return 0;
}�������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1670857044.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fABBA-1.0.8/cpp/benchmark_test.csv������������������������������������������������������������������0000644�0001757�0001757�00016030655�00000000000�017450� 0����������������������������������������������������������������������������������������������������ustar�00xinyechen�����������������������xinyechen��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������Index,test 1,reconst test 1,test 2,reconst test 2,test 3,reconst test 3,test 4,reconst test 4,test 5,reconst test 5,test 6,reconst test 6,test 7,reconst test 7,test 8,reconst test 8,test 9,reconst test 9,test 10,reconst test 10,test 11,reconst test 11,test 12,reconst test 12,test 13,reconst test 13,test 14,reconst test 14,test 15,reconst test 15,test 16,reconst test 16,test 17,reconst test 17,test 18,reconst test 18,test 19,reconst test 19,test 20,reconst test 20
0,0.131538,0.131538,0.691992,0.691992,0.495383,0.495383,0.546558,0.546558,0.214755,0.214755,0.443758,0.443758,0.641503,0.641503,0.669296,0.669296,0.931651,0.931651,0.609525,0.609525,-1.27231,-1.27231,-1.05765,-1.05765,0.736787,0.736787,1.2331,1.2331,1.05834,1.05834,-0.345853,-0.345853,0.635249,0.635249,-0.315728,-0.315728,-0.221772,-0.221772,0.928999,0.928999
1,0.45865,0.459114,0.0118097,0.0113956,0.563309,0.562018,0.80172,0.801718,0.345232,0.344245,0.631299,0.632645,0.264788,0.26554,0.716054,0.714686,0.886746,0.886945,0.31183,0.393828,0.765526,0.764451,-0.430512,-0.426564,1.46734,1.47479,0.341238,0.368146,1.59848,1.59787,-0.875316,-0.870857,1.5594,1.55647,0.524397,0.521076,0.798659,0.79997,-0.665102,-0.671173
2,0.218959,0.220649,0.997314,0.9969,0.423144,0.498094,0.323341,0.324867,0.987132,0.98345,0.612606,0.606617,0.469596,0.471435,0.526889,0.563064,0.213649,0.211954,0.178639,0.178131,-2.04388,-2.04361,-0.649935,-0.638677,0.694062,0.612541,-0.497262,-0.496806,0.712079,0.712566,-0.792124,-0.795226,-1.72681,-1.73434,0.76361,0.76081,0.584806,0.593186,0.481348,0.471414
3,0.678865,0.682875,0.289429,0.286765,0.435856,0.43417,0.784426,0.7874,0.694165,0.699854,0.687774,0.580588,0.127869,0.131398,0.354964,0.411442,0.890747,0.889808,0.834467,0.832677,0.79214,0.793433,-1.39428,-1.38707,-0.2531,-0.249705,-0.856406,-0.856614,0.266483,0.268994,-0.0800615,-0.173552,-0.0542934,-0.055455,0.786456,0.783788,-0.221954,-0.216179,0.617517,0.613471
4,0.934693,0.939316,0.140834,0.137941,0.910553,0.907764,0.280551,0.284471,0.464043,0.416257,0.686675,0.55456,0.115698,0.0775005,0.263234,0.25982,0.818304,0.819464,0.748013,0.744724,0.534299,0.543018,1.81849,1.81921,-1.38846,-1.37864,-0.245884,-0.24972,0.966617,0.963476,0.445309,0.448122,0.953045,0.929651,0.39925,0.396345,0.471029,0.47722,-1.7326,-1.73994
5,0.519416,0.488764,0.767828,0.763586,0.809177,0.807092,0.872266,0.876804,0.13458,0.132661,0.595277,0.528531,0.0224188,0.0236031,0.879602,0.874733,0.299492,0.300222,0.0691092,0.0636653,-0.278996,-0.263413,0.994502,0.994209,1.7474,1.75722,-0.450091,-0.452453,2.41875,2.41001,-0.193422,-0.187418,1.91601,1.91476,0.692767,0.695634,-2.26287,-2.25081,0.117373,0.112623
6,0.0345721,0.0382127,0.521575,0.529289,0.973176,0.973252,0.00984342,0.0125637,0.588099,0.585296,0.501156,0.502503,0.354728,0.455235,0.657178,0.652322,0.240951,0.189709,0.0199906,0.0332829,0.528979,0.538699,1.02305,1.027,0.190881,0.200467,-0.106029,-0.104061,0.578656,0.57094,1.92409,1.93356,-0.88359,-0.884332,-0.151874,-0.152631,-1.76595,-1.76041,-0.438448,-0.440361
7,0.5297,0.534618,0.291475,0.294991,0.118699,0.116551,0.767679,0.770996,0.428111,0.503063,0.366013,0.302074,0.883362,0.886867,0.22498,0.221219,0.0782181,0.0791961,0.00693536,0.00290038,-1.34868,-1.34522,-2.04528,-2.04162,1.11471,1.12188,-0.801797,-0.801929,0.0144769,0.00704755,0.964659,0.895477,0.498289,0.502293,-2.77103,-2.77724,0.55448,0.566927,-0.772648,-0.781462
8,0.00769819,0.0139774,0.0660382,0.0606941,0.770737,0.770998,0.468126,0.447775,0.445434,0.420829,0.100995,0.101645,0.892967,0.894459,0.317437,0.236408,0.345292,0.345823,0.386893,0.382634,-0.0963835,-0.0972194,-1.56551,-1.56538,-0.514417,-0.512207,0.861878,0.864277,0.263322,0.257767,-0.158826,-0.14261,-0.629369,-0.623156,-0.262751,-0.262259,1.77797,1.7905,-0.331763,-0.338154
9,0.0668422,0.0742304,0.7018,0.695987,0.132247,0.132834,0.123401,0.124553,0.343508,0.338596,0.213745,0.307556,0.583137,0.548009,0.259776,0.251596,0.245561,0.244682,0.303961,0.283676,0.574892,0.566533,-0.104316,-0.099908,-0.91891,-0.924704,-1.41393,-1.41572,-1.05019,-1.05968,0.89533,0.915781,0.161029,0.173764,0.901806,0.89557,-0.302977,-0.286898,-1.17226,-1.17423
10,0.686773,0.694419,0.762851,0.755659,0.967512,0.968286,0.95194,0.951427,0.665026,0.661014,0.512817,0.513467,0.202665,0.20156,0.271107,0.266785,0.407249,0.387029,0.18768,0.184717,-1.16642,-1.17407,0.157962,0.16331,0.0511755,0.0432681,-1.45005,-1.45137,-0.395336,-0.411869,-0.226059,-0.209723,1.27941,1.29416,-0.0250664,-0.029778,-0.226325,-0.215141,0.719935,0.724319
11,0.930436,0.935474,0.209937,0.203784,0.00586172,0.00607617,0.707285,0.617748,0.328411,0.323805,0.207526,0.209767,0.705281,0.703876,0.062694,0.14317,0.612383,0.529376,0.860073,0.858624,-0.881296,-0.891143,-0.22875,-0.218357,-1.43436,-1.43807,0.177068,0.170262,0.550494,0.52936,0.401426,0.418609,0.432941,0.450667,-0.535055,-0.540878,-1.86463,-1.85915,0.36926,0.367169
12,0.526929,0.530265,0.532809,0.525266,0.521803,0.52009,0.286681,0.284068,0.296273,0.289449,0.27171,0.276208,0.819749,0.818936,0.0255113,0.0195538,0.671963,0.671724,0.00889033,0.00645528,0.504284,0.497585,-0.0773709,-0.0637918,-1.70164,-1.71181,-0.9636,-0.962953,0.379298,0.361535,0.728405,0.738899,0.419354,0.436686,1.62253,1.62111,1.04404,1.05213,-0.321711,-0.318255
13,0.653919,0.608313,0.343029,0.335754,0.424344,0.424108,0.773591,0.772533,0.992498,0.985833,0.743178,0.748668,0.142812,0.142331,0.742536,0.737195,0.0624649,0.0614706,0.615956,0.615321,0.673411,0.671119,-1.80839,-1.79574,-0.931439,-1.03185,0.814338,0.81501,0.817253,0.794683,1.36277,1.36723,-0.732672,-0.717035,-0.883138,-0.890446,-1.1501,-1.14986,0.033503,0.0336787
14,0.701191,0.686361,0.444534,0.439758,0.662028,0.694958,0.798933,0.791658,0.921639,0.832884,0.354708,0.361215,0.838,0.835152,0.741199,0.736832,0.490739,0.491927,0.182761,0.184652,-1.17459,-1.18282,-0.951863,-0.935159,-0.336133,-0.351896,2.04234,2.04211,-1.31931,-1.33751,0.630951,0.640803,0.604911,0.62461,0.183044,0.17771,-1.45867,-1.46573,-0.323356,-0.323471
15,0.762198,0.76441,0.0436781,0.0403177,0.966326,0.965809,0.825156,0.810784,0.68563,0.679935,0.36195,0.368303,0.135188,0.134008,0.340842,0.335811,0.260716,0.263793,0.438151,0.437857,0.679652,0.668184,-1.73034,-1.71607,-0.592157,-0.610707,-1.4174,-1.41339,0.185724,0.170179,1.43479,1.45209,1.66794,1.68362,0.564285,0.556421,1.99441,1.99396,0.683984,0.682568
16,0.0474645,0.0498082,0.430012,0.352677,0.223144,0.219889,0.854114,0.82991,0.0308222,0.0256973,0.581816,0.606007,0.461749,0.461324,0.314956,0.310062,0.611852,0.603804,0.482907,0.523508,1.15345,1.13508,-0.534991,-0.514914,-0.0924465,-0.168582,-0.0861267,-0.0790535,0.527078,0.430648,-2.21878,-2.19735,0.522965,0.576397,1.39048,1.37747,1.31438,1.30881,1.26361,1.26324
17,0.328234,0.405272,0.667793,0.665035,0.0877763,0.0831895,0.850095,0.849036,0.504754,0.491992,0.83845,0.843712,0.375947,0.388563,0.875375,0.872298,0.940483,0.943814,0.610282,0.60916,0.903448,0.884663,-0.0540461,-0.0386732,0.286791,0.273542,-0.62368,-0.622228,0.706661,0.691117,-0.530261,-0.509675,-0.552776,-0.530829,0.891309,0.881718,-0.473846,-0.481339,0.899617,0.891017
18,0.75641,0.760735,0.0822428,0.0788738,0.583849,0.581508,0.374398,0.372185,0.962039,0.958286,0.416468,0.422398,0.33302,0.315802,0.841608,0.836184,0.332706,0.338154,0.152404,0.152944,-1.30442,-1.33041,-0.344838,-0.370523,-3.20964,-3.22727,0.864805,0.871416,-0.217184,-0.223696,1.81887,1.83417,-0.915981,-0.898006,-0.0839012,-0.0906014,1.34628,1.34075,-2.22774,-2.2321
19,0.365339,0.370912,0.505208,0.50332,0.192291,0.192028,0.969382,0.96903,0.334894,0.333248,0.833789,0.841755,0.245642,0.243041,0.125366,0.121705,0.962182,0.969074,0.99522,0.996929,-1.67357,-1.70415,-0.713011,-0.702372,-0.0370251,-0.0525364,-0.130015,-0.122529,-0.503675,-0.512106,1.42695,1.43432,1.53738,1.54816,1.81373,1.80757,-1.26281,-1.27088,-0.19587,-0.19676
20,0.98255,0.986243,0.718861,0.715976,0.290738,0.288832,0.799018,0.7804,0.382457,0.380739,0.343592,0.351498,0.780122,0.779442,0.789401,0.786029,0.698585,0.729033,0.160923,0.161045,-0.537057,-0.565732,-0.430363,-0.423105,0.372957,0.362753,0.876152,0.889968,0.13892,0.135703,-0.769787,-0.754467,-0.0509735,-0.0477994,-1.24141,-1.24465,0.253825,0.251832,0.0743296,0.0813307
21,0.753356,0.75759,0.445009,0.44063,0.941665,0.937725,0.591393,0.59177,0.720903,0.718117,0.937081,0.947287,0.16018,0.158698,0.47876,0.473952,0.482025,0.488992,0.493244,0.532521,0.00234965,-0.0227747,-1.45334,-1.45091,0.363218,0.348007,-0.0399629,-0.0283394,1.20845,1.19911,0.423695,0.440539,-0.314094,-0.306219,-0.379705,-0.378707,0.495091,0.52426,1.16363,1.16367
22,0.0726859,0.0763475,0.400616,0.364779,0.323286,0.319185,0.146309,0.145879,0.550452,0.547498,0.0283714,0.0376613,0.608387,0.604844,0.679846,0.675791,0.465777,0.47357,0.902893,0.903997,-1.93647,-1.96832,-0.289375,-0.282438,-1.9177,-1.93917,-1.45252,-1.43998,0.861847,0.848026,-0.711381,-0.69907,0.328573,0.34068,-0.143994,-0.138973,0.800777,0.796688,-0.305363,-0.299545
23,0.884707,0.888627,0.294132,0.288928,0.908571,0.902699,0.0372091,0.0382549,0.910235,0.905124,0.525062,0.535142,0.339365,0.333911,0.231894,0.22948,0.012624,0.0189868,0.620116,0.62308,1.64864,1.61573,-0.798874,-0.799243,-0.0156538,-0.0315658,0.0905143,0.0995908,1.20074,1.19034,1.95497,1.97414,0.138471,0.194204,-1.73897,-1.73847,-1.4129,-1.42128,-0.796301,-0.789394
24,0.436411,0.438202,0.708113,0.704037,0.78267,0.776471,0.714833,0.714952,0.736893,0.692123,0.407562,0.417757,0.653575,0.645971,0.19005,0.2607,0.707457,0.715576,0.104885,0.107729,0.272772,0.244617,-0.112602,-0.10704,-1.21601,-1.23714,-0.540245,-0.536415,-0.187136,-0.202559,-2.30353,-2.28436,0.0402056,0.0477273,-1.83812,-1.83622,-0.731292,-0.742173,0.522611,0.522742
25,0.477732,0.478379,0.577384,0.574905,0.354442,0.34656,0.403459,0.40185,0.484953,0.479122,0.832779,0.841369,0.640305,0.533816,0.292594,0.291921,0.85022,0.86002,0.751498,0.75654,-0.814621,-0.836873,-1.14817,-1.14906,0.409293,0.389001,-0.183869,-0.171978,1.0097,0.999774,-0.994842,-0.968229,1.30396,1.30889,0.929468,0.929803,1.67815,1.66672,-0.653297,-0.651685
26,0.274907,0.322275,0.883491,0.881364,0.729052,0.719346,0.46763,0.501613,0.0698011,0.065051,0.0235959,0.034145,0.427819,0.42166,0.785361,0.783206,0.377027,0.385347,0.277662,0.280429,-0.407742,-0.431072,0.102124,0.0997304,-1.75697,-1.77064,-0.163516,-0.146077,-0.667526,-0.68495,-1.35299,-1.32182,0.116011,0.121772,0.925645,0.920384,0.00758097,-0.00955617,-0.7079,-0.704905
27,0.166507,0.166172,0.219267,0.215687,0.667282,0.659089,0.602314,0.601376,0.185684,0.179173,0.258655,0.287241,0.790932,0.784121,0.425002,0.421069,0.847733,0.855898,0.431498,0.394185,-0.960271,-0.989641,-0.506088,-0.509927,0.158542,0.136961,0.0628703,0.0824122,0.586917,0.564153,0.555653,0.593076,-0.303324,-0.292343,0.370148,0.363433,0.425514,0.402868,-0.181218,-0.185453
28,0.897656,0.898794,0.314079,0.310026,0.355752,0.368504,0.3799,0.448377,0.673334,0.667504,0.529041,0.540337,0.115752,0.107516,0.988825,0.983304,0.686691,0.693104,0.4488,0.507941,0.0870221,0.0585284,0.964031,0.955548,-0.16616,-0.185231,0.709505,0.737411,-0.369729,-0.397433,0.241479,0.284358,-0.386428,-0.381662,-0.811718,-0.821787,0.131557,0.102121,1.4716,1.46384
29,0.0605643,0.0618983,0.0877307,0.085748,0.0880032,0.077919,0.296497,0.295378,0.174184,0.169257,0.0550245,0.0653735,0.567442,0.558766,0.689764,0.748347,0.196484,0.203088,0.616597,0.621697,0.083576,-0.00768065,-0.504715,-0.510201,1.47516,1.45746,0.0494661,0.0701854,-0.531786,-0.565258,-0.913205,-0.870619,-1.1875,-1.18078,-1.23476,-1.24151,2.11109,2.08343,-0.112725,-0.119942
30,0.504523,0.504576,0.959846,0.959993,0.299706,0.302225,0.915154,0.913061,0.898354,0.891519,0.822649,0.833261,0.491519,0.497695,0.519525,0.51339,0.416843,0.434498,0.358394,0.360591,-0.0502474,-0.0738897,2.51501,2.51282,0.392752,0.376358,-1.23814,-1.21685,-1.09095,-1.12915,-0.215425,-0.165494,1.12693,1.13824,1.5849,1.57358,-1.16565,-1.18625,0.379651,0.369078
31,0.319033,0.321622,0.268812,0.269548,0.536097,0.526531,0.0846163,0.0809886,0.684407,0.679723,0.0764252,0.0879002,0.442649,0.436624,0.844684,0.839794,0.65768,0.665908,0.433644,0.436398,2.00222,1.97805,0.138879,0.131325,0.540314,0.528839,-0.382225,-0.36076,-0.531041,-0.57441,-0.890809,-0.847592,-0.322655,-0.313182,-0.323641,-0.340023,-0.921303,-0.946944,-0.214862,-0.227122
32,0.493977,0.497029,0.757764,0.757248,0.0847456,0.0774606,0.343606,0.341817,0.686389,0.664385,0.954253,0.963196,0.102299,0.0965878,0.00997081,0.00714655,0.380925,0.387391,0.255274,0.256059,-0.650262,-0.677191,0.655342,0.640877,-0.35983,-0.365596,0.0328377,-0.0078179,-0.979641,-1.01798,-1.85919,-1.82005,0.170615,0.267456,0.0673165,0.0527627,1.58489,1.56042,-0.0522039,-0.0694611
33,0.0907329,0.0918199,0.447359,0.446657,0.542716,0.536296,0.81009,0.809761,0.655213,0.649047,0.168759,0.17672,0.836705,0.831153,0.376541,0.374234,0.492788,0.496973,0.961053,0.960485,0.544301,0.524795,-1.26511,-1.28085,-0.267037,-0.275384,0.325811,0.345125,-0.0554755,-0.0923366,0.901284,0.941992,0.841743,0.848094,-2.97053,-2.98562,1.14817,1.1153,0.415325,0.403456
34,0.0737491,0.0767184,0.876633,0.876228,0.388033,0.379623,0.941152,0.851202,0.0743938,0.0704782,0.12313,0.129531,0.754351,0.746791,0.256865,0.253105,0.118823,0.122789,0.544444,0.544491,-1.53264,-1.54833,-0.575694,-0.588649,-1.07915,-1.09274,-0.455085,-0.431249,-1.5204,-1.56101,1.22307,1.26228,0.41517,0.418521,-0.473752,-0.492172,0.699358,0.67017,-0.47309,-0.480052
35,0.384142,0.388356,0.468194,0.46682,0.482665,0.529462,0.895342,0.892643,0.347222,0.36387,0.528654,0.474685,0.958612,0.952686,0.817372,0.81534,0.45001,0.453328,0.811399,0.812834,-1.24487,-1.2654,0.419716,0.41102,0.304144,0.285347,0.140646,0.160869,-0.480559,-0.547122,-0.0921067,-0.0492626,-0.971297,-0.970146,-1.2671,-1.28091,-0.0956739,-0.131608,0.112409,0.100616
36,0.913817,0.919695,0.473834,0.471194,0.716829,0.679301,0.670347,0.669753,0.683063,0.657262,0.81477,0.819839,0.369158,0.361159,0.862751,0.86073,0.0977509,0.098606,0.637378,0.637502,0.838258,0.817441,-0.744605,-0.75503,-0.223461,-0.250078,-0.785155,-0.757438,0.508552,0.466763,-1.40117,-1.36081,-0.22458,-0.247811,0.936986,0.92819,-0.904197,-0.933385,0.487464,0.481644
37,0.464446,0.486512,0.0275941,0.0227379,0.838509,0.82914,0.131177,0.131665,0.95457,0.950655,0.753689,0.765251,0.439576,0.437184,0.230591,0.228903,0.131157,0.144204,0.112397,0.111513,-0.166289,-0.188459,0.59049,0.583799,1.07609,1.05298,0.175168,0.206489,-0.669873,-0.709332,-1.76527,-1.72977,0.479892,0.474524,0.560994,0.453406,-0.858134,-0.8911,0.268578,0.26145
38,0.050084,0.053328,0.252916,0.287717,0.261515,0.250311,0.496819,0.495592,0.388753,0.386748,0.799542,0.710664,0.521751,0.51321,0.34884,0.291535,0.191562,0.189802,0.553996,0.555069,0.651173,0.627863,-1.66125,-1.66665,-0.761816,-0.787782,0.480285,0.510351,1.48856,1.44317,1.24123,1.27669,-0.174261,-0.184145,-0.00978901,-0.0213778,0.316166,0.287187,-0.846378,-0.852682
39,0.770205,0.774119,0.66011,0.552696,0.315384,0.302875,0.0953423,0.0939789,0.129548,0.129694,0.651008,0.656077,0.960278,0.950105,0.354719,0.354168,0.562642,0.560267,0.760537,0.693489,-0.0829432,-0.100877,-1.44435,-1.44832,1.92227,1.90333,0.2937,0.320563,-1.11954,-1.16595,0.987226,1.01554,-0.150126,-0.153244,-0.201306,-0.211034,-0.372494,-0.397959,-0.806757,-0.781675
40,0.125365,0.127932,0.822532,0.817676,0.680443,0.670196,0.736582,0.736006,0.781832,0.779914,0.908272,0.830291,0.355852,0.343978,0.113522,0.111254,0.043286,0.0410258,0.830137,0.831909,-0.369144,-0.382001,0.977633,0.969779,-1.02942,-1.05202,-0.596496,-0.565842,0.656285,0.61659,-0.61453,-0.586783,1.68991,1.68432,-1.36977,-1.37918,1.231,1.20283,-0.702036,-0.710668
41,0.688455,0.689185,0.798464,0.700308,0.000180748,-0.0095107,0.685041,0.628255,0.222327,0.221369,0.998095,1.0045,0.690557,0.676406,0.748674,0.746193,0.162351,0.160194,0.811932,0.812403,0.37917,0.359273,0.233802,0.221382,1.09358,1.0763,-1.74783,-1.71433,-1.14218,-1.17781,0.690346,0.71387,-0.211196,-0.223342,1.41713,1.40173,-1.07623,-1.09852,0.626291,0.615716
42,0.629543,0.708024,0.591001,0.58294,0.918619,0.91049,0.521176,0.520505,0.0720129,0.0704144,0.706442,0.710355,0.0799401,0.0652623,0.283452,0.27955,0.0689717,0.0647292,0.0878602,0.0899224,0.914686,0.88857,-0.829756,-0.905257,0.173144,0.179275,1.05125,1.08628,1.44232,1.41142,-0.218355,-0.198468,1.5269,1.5174,-1.24786,-1.25577,-1.49675,-1.52289,0.0518642,0.0342419
43,0.725412,0.726862,0.900359,0.894055,0.883307,0.892656,0.982361,0.983038,0.74105,0.741305,0.735143,0.736779,0.247444,0.230819,0.0800606,0.0774811,0.679702,0.676347,0.355653,0.358265,-0.416914,-0.439184,-2.01836,-2.0319,-0.703032,-0.717751,-0.3104,-0.276529,1.80796,1.78593,0.225627,0.247873,1.04379,1.04027,-0.312185,-0.326457,-0.591024,-0.621105,0.656589,0.64497
44,0.888572,0.891846,0.498156,0.490401,0.88401,0.874821,0.264191,0.26597,0.896941,0.896312,0.00673464,0.00734214,0.154902,0.136962,0.512332,0.50913,0.539811,0.537944,0.953199,0.956746,0.926119,0.902873,0.066378,0.0563611,-0.357489,-0.363699,1.14815,1.18594,-0.286489,-0.314666,-0.684437,-0.664465,-1.98178,-1.98318,-1.22563,-1.23576,0.303574,0.280682,0.017213,0.00212253
45,0.306322,0.311034,0.79944,0.791836,0.0553113,0.045009,0.947525,0.948169,0.138222,0.138712,0.259456,0.26078,0.771964,0.753138,0.132707,0.12786,0.0555171,0.0530411,0.869563,0.873546,-0.0574166,-0.0656082,-1.33362,-1.34634,-2.30899,-2.31593,0.0964653,0.128042,-0.225542,-0.247557,-0.425138,-0.406028,-1.57881,-1.58423,0.210694,0.198685,0.0898022,0.0738981,-0.0862568,-0.0956413
46,0.513274,0.580461,0.533438,0.506116,0.786331,0.776004,0.44059,0.440259,0.95324,0.955399,0.961648,0.961441,0.237538,0.220951,0.524263,0.556565,0.621792,0.618441,0.36739,0.372887,-1.00784,-1.03409,-0.907521,-0.915775,0.1368,0.12761,0.773719,0.81259,1.48429,1.45785,-0.96405,-0.947533,2.23,2.22154,1.90129,1.89612,-0.835937,-0.847624,0.176664,0.165757
47,0.845982,0.849887,0.230865,0.220395,0.542484,0.599864,0.651091,0.651244,0.307689,0.311127,0.552719,0.550436,0.878791,0.862238,0.991599,0.98527,0.930739,0.929224,0.101609,0.107914,-0.87614,-0.906268,-0.956121,-0.960541,-0.808238,-0.812118,0.376671,0.422917,1.19594,1.16944,-2.58903,-2.57758,-0.127506,-0.131771,1.36163,1.35459,0.0276412,0.00950108,1.3044,1.29311
48,0.841511,0.845245,0.194332,0.151406,0.30299,0.423724,0.410587,0.370235,0.18211,0.184789,0.764567,0.763523,0.0588987,0.0398475,0.804243,0.726926,0.161857,0.160205,0.122433,0.130104,-0.442223,-0.472021,-2.11408,-2.11143,0.936605,0.926314,-0.276675,-0.229437,-1.04034,-1.07163,0.375608,0.390112,-0.263377,-0.268143,0.548866,0.536916,0.879577,0.866626,-1.40965,-1.42789
49,0.415395,0.41962,0.0914077,0.0824175,0.248844,0.247584,0.0866523,0.0892268,0.574354,0.577557,0.525874,0.525068,0.04398,0.0271843,0.477043,0.468581,0.335705,0.335172,0.908627,0.916835,0.252117,0.222981,-1.12918,-1.12805,0.300813,0.29539,-0.372715,-0.325227,-0.81141,-0.816483,0.285398,0.297043,-0.923051,-0.926812,0.798048,0.792698,-0.36004,-0.368089,0.438259,0.424665
50,0.467917,0.469869,0.455614,0.447151,0.0817706,0.0714434,0.992463,0.993537,0.458693,0.460925,0.0188549,0.0196953,0.902652,0.885634,0.797968,0.790048,0.758139,0.756237,0.59196,0.513892,-0.680128,-0.706264,0.576037,0.569572,-0.854978,-0.864511,1.6315,1.67383,-0.528538,-0.561335,-2.06537,-2.05026,0.237426,0.22866,-0.120375,-0.132651,-1.09997,-1.10046,-0.857146,-0.87069
51,0.178328,0.180453,0.170064,0.16149,0.0818618,0.0727979,0.375535,0.375885,0.0381237,0.0418865,0.462244,0.4629,0.811624,0.796691,0.812407,0.831585,0.89991,0.896216,0.103105,0.110949,2.10656,2.08131,-1.03705,-1.05041,-1.1683,-1.1867,-0.703645,-0.655314,0.693006,0.656565,-0.0711967,-0.0576324,0.251701,0.243195,1.31379,1.30179,-0.149724,-0.156517,0.0121035,-0.0764767
52,0.571655,0.573401,0.955113,0.948437,0.575394,0.566196,0.514575,0.515413,0.605984,0.610627,0.174717,0.173988,0.519025,0.504958,0.879732,0.873121,0.169079,0.165025,0.352679,0.359297,-1.20824,-1.22941,-1.51703,-1.53682,1.82806,1.80401,1.11729,1.17204,0.479825,0.443464,-1.61681,-1.59714,-0.0103609,-0.0152251,0.260872,0.254215,1.87057,1.85904,0.724942,0.717737
53,0.0330538,0.0371435,0.50863,0.499981,0.647175,0.637315,0.889298,0.889255,0.248286,0.328168,0.31061,0.266437,0.0134715,-0.00136047,0.0411609,0.0360711,0.533722,0.494202,0.940294,0.948431,0.935675,0.912981,0.139273,0.113855,0.734637,0.707291,0.00430005,0.0316008,2.58751,2.54441,-0.968563,-0.953106,-0.00680001,-0.0141123,0.366234,0.356262,-0.20919,-0.218357,0.629764,0.619973
54,0.49848,0.50381,0.545985,0.538355,0.512735,0.4455,0.884673,0.900231,0.042681,0.045709,0.400117,0.358886,0.380401,0.438715,0.155474,0.116327,0.826208,0.823378,0.326775,0.333229,-0.98215,-1.00143,-1.10553,-1.12906,-1.77145,-1.80135,-1.16002,-1.10884,-0.728879,-0.773378,0.0875642,0.105286,-0.787783,-0.796483,0.171877,0.197695,-0.16369,-0.199215,-0.346248,-0.353157
55,0.748293,0.700321,0.826214,0.820131,0.260892,0.253685,0.912549,0.911206,0.898752,0.901116,0.449877,0.451335,0.894508,0.87879,0.319323,0.196583,0.0567126,0.0543589,0.430191,0.397107,-0.278078,-0.292133,-0.0204254,-0.0514171,0.803916,0.774219,-0.789538,-0.7444,0.621256,0.579232,-0.172186,-0.155867,-0.603547,-0.61394,0.0430348,0.0391275,-0.176246,-0.180073,0.461772,0.455107
56,0.890737,0.896833,0.0893124,0.0844896,0.933996,0.928895,0.71304,0.713795,0.990579,0.996007,0.161588,0.162423,0.951899,0.937764,0.281954,0.276839,0.062269,0.0598005,0.455936,0.460986,1.10743,1.09659,-0.0182165,0.045029,1.14657,1.112,0.647335,0.756815,-0.431269,-0.474623,0.197189,0.209527,0.0961242,0.0931019,0.176504,0.189307,-0.33772,-0.342347,-0.700622,-0.703042
57,0.84204,0.849941,0.18412,0.132722,0.217896,0.214436,0.810342,0.735281,0.284008,0.290518,0.469134,0.502088,0.17688,0.161894,0.225158,0.198302,0.722415,0.718112,0.20009,0.206183,-1.84635,-1.85573,0.170676,0.141475,0.535886,0.494641,2.21289,2.25803,-0.128661,-0.179162,-0.48655,-0.472571,1.20952,1.2135,0.340634,0.339486,0.313253,0.303822,0.709826,0.700907
58,0.212752,0.218815,0.186655,0.180954,0.540854,0.535974,0.754033,0.756767,0.0769501,0.0840313,0.841168,0.841754,0.765557,0.748156,0.122972,0.119766,0.564182,0.564242,0.549881,0.555788,-1.44999,-1.46673,0.538071,0.510136,-1.65256,-1.69559,-1.13564,-1.09308,-0.689061,-0.743054,-0.535717,-0.518976,1.25735,1.2594,-1.84784,-1.84291,-2.6771,-2.68271,0.503477,0.496564
59,0.130427,0.135775,0.814434,0.806599,0.427809,0.424441,0.382762,0.384849,0.738969,0.744417,0.617398,0.61884,0.207342,0.190723,0.60023,0.596291,0.414144,0.410373,0.319771,0.324971,1.13599,1.12259,0.230113,0.203965,-0.993521,-1.03627,-0.901623,-0.784915,0.10251,0.0451346,0.0307822,0.0485523,-0.0504881,-0.0533859,0.719963,0.723633,-1.34358,-1.34681,-0.303884,-0.310579
60,0.274588,0.328906,0.527644,0.520938,0.755764,0.752201,0.860931,0.862339,0.259529,0.265462,0.112477,0.113467,0.477369,0.461919,0.817405,0.814527,0.0544565,0.0512208,0.512683,0.517019,0.759401,0.676667,-1.51348,-1.54195,-0.117259,-0.159057,-0.526223,-0.476753,-0.219256,-0.276069,-0.137938,-0.120235,0.437229,0.438593,-0.0924909,-0.094044,1.57567,1.56447,-0.118858,-0.123751
61,0.414293,0.522037,0.787379,0.712093,0.666397,0.661235,0.355047,0.354429,0.536184,0.542059,0.333149,0.332182,0.277132,0.262262,0.646748,0.642958,0.99861,0.99552,0.437654,0.442921,0.239311,0.230743,0.748839,0.726588,-2.26065,-2.30123,2.51028,2.56669,0.29761,0.16206,0.285331,0.308999,-0.352563,-0.343778,0.238421,0.237842,0.0985986,0.0919389,1.45896,1.4493
62,0.70982,0.715167,0.908805,0.903247,0.823795,0.817876,0.792482,0.793096,0.26468,0.276558,0.968307,0.968161,0.371596,0.356203,0.708355,0.778926,0.382667,0.379716,0.0450591,0.0529278,-0.423005,-0.434151,-0.0624503,-0.0819878,1.18613,1.14096,-0.0217586,0.0331005,0.652543,0.600189,0.13455,0.153387,-2.06194,-2.04907,-0.465157,-0.458424,-0.0875574,-0.100959,-0.804092,-0.818848
63,0.239911,0.244697,0.623033,0.617586,0.0807723,0.0719561,0.088407,0.0903388,0.00614329,0.0110566,0.396671,0.398389,0.215585,0.201711,0.918786,0.914894,0.464055,0.46243,0.72511,0.731788,0.449615,0.442326,2.37764,2.3645,1.17892,1.14093,-1.58911,-1.53003,-1.49369,-1.54665,-0.253989,-0.230835,-0.783771,-0.759569,-0.510649,-0.498673,1.60285,1.59476,-0.563458,-0.572486
64,0.31754,0.320343,0.649779,0.646036,0.31621,0.322615,0.658811,0.662787,0.66,0.666234,0.408239,0.410201,0.27223,0.228456,0.467237,0.464071,0.763813,0.762381,0.921062,0.929081,-1.36725,-1.37882,0.219808,0.209941,-0.00103528,-0.0346627,0.548306,0.613421,0.164109,0.112737,-1.79561,-1.77034,0.517062,0.529932,-0.239219,-0.259312,-0.450073,-0.451934,-0.925649,-0.892598
65,0.652059,0.657442,0.0276734,0.0251634,0.610785,0.573274,0.682401,0.735135,0.527466,0.53461,0.851283,0.853405,0.270257,0.255201,0.851263,0.846306,0.785715,0.733753,0.75379,0.764079,-0.822754,-0.835866,-0.695307,-0.706849,0.378913,0.301944,1.12716,1.19003,-1.8157,-1.86675,-1.18904,-1.25035,-0.816603,-0.796974,-0.0306872,-0.0199519,0.608168,0.601768,-1.20021,-1.21271
66,0.681346,0.687873,0.00669884,0.00450437,0.832749,0.823933,0.804884,0.807482,0.683858,0.689617,0.390977,0.392496,0.99551,0.978786,0.718039,0.697919,0.704895,0.705125,0.791673,0.728845,0.617435,0.599044,-0.569087,-0.583596,0.667295,0.63855,-0.933311,-0.867907,-0.334346,-0.389966,-0.753885,-0.730359,0.242468,0.262038,0.597802,0.601571,-0.12119,-0.130602,-0.841047,-0.860777
67,0.387725,0.421647,0.318926,0.315619,0.495514,0.501411,0.0983723,0.100138,0.204457,0.210662,0.344209,0.441458,0.481996,0.467185,0.555805,0.549532,0.900411,0.900708,0.685074,0.693611,1.00361,0.988046,0.190302,0.17091,0.569684,0.545282,1.59874,1.6634,-1.00509,-1.06175,1.62758,1.64658,-0.577486,-0.564006,-0.156439,-0.156406,-0.543208,-0.554971,0.0442102,0.0222896
68,0.147533,0.15542,0.353004,0.349536,0.189691,0.178888,0.67555,0.678018,0.388768,0.395719,0.465893,0.49042,0.563916,0.55101,0.831331,0.825794,0.660577,0.576805,0.0745981,0.0836573,-1.23133,-1.24393,-0.431627,-0.453622,-1.64074,-1.66172,-0.0172942,0.0509657,-1.28756,-1.35016,-0.466857,-0.450515,1.26831,1.28885,-0.710665,-0.713357,-0.355637,-0.36241,-0.906109,-0.921675
69,0.845576,0.851087,0.780882,0.779107,0.43587,0.523996,0.477021,0.480606,0.260222,0.269382,0.537862,0.539382,0.872649,0.857963,0.795607,0.789679,0.252537,0.252902,0.131787,0.140841,0.162115,0.144797,1.79518,1.76908,0.692539,0.66322,0.289956,0.354828,-1.05842,-1.11658,0.396172,0.405872,-0.434499,-0.416441,1.21181,1.20079,-1.18129,-1.18846,0.288655,0.269547
70,0.955409,0.961795,0.856487,0.883125,0.878251,0.869104,0.858511,0.86371,0.61307,0.527018,0.805187,0.808153,0.0914987,0.0772864,0.528511,0.522624,0.572327,0.573569,0.503541,0.510781,-0.619099,-0.630001,0.149576,0.116665,1.28346,1.26069,0.391337,0.457395,0.146508,0.0857577,-0.924458,-0.919474,1.42897,1.45315,1.12262,1.11684,-0.06488,-0.0744295,-0.525453,-0.537597
71,0.148152,0.155521,0.989105,0.987144,0.285995,0.274662,0.0243709,0.0316381,0.775497,0.784655,0.624348,0.625575,0.256359,0.31348,0.972193,0.964861,0.0500517,0.049502,0.604633,0.574659,0.622308,0.618004,1.44968,1.4123,-0.555418,-0.580078,0.890357,0.957142,-1.35185,-1.41519,-1.35035,-1.3506,1.01749,1.07308,1.94825,1.93789,1.95018,1.94113,-0.75898,-0.771745
72,0.408767,0.364709,0.0940066,0.09309,0.579686,0.587963,0.174787,0.1725,0.222278,0.230866,0.713283,0.716343,0.563639,0.549674,0.366604,0.358863,0.231548,0.230848,0.632796,0.638538,-0.043307,-0.0468897,-0.121084,-0.159979,0.514724,0.495156,-0.442269,-0.375503,-0.346459,-0.413339,1.05963,1.05246,0.671593,0.693011,-0.359637,-0.364858,1.59155,1.5793,1.08963,1.08082
73,0.564899,0.573897,0.212665,0.309735,0.912244,0.901263,0.304813,0.313361,0.0390054,0.0485483,0.155216,0.157495,0.449265,0.435261,0.728605,0.64056,0.934061,0.933468,0.335627,0.428161,0.434223,0.437285,-1.27346,-1.31087,0.419424,0.401888,0.158793,0.231391,0.369506,0.288728,0.0481567,0.0339995,0.989074,1.01476,-1.15511,-1.1536,0.0484292,0.0294099,0.552986,0.542583
74,0.488515,0.497185,0.526852,0.52638,0.0261828,0.0154069,0.0972387,0.106485,0.360223,0.370966,0.888601,0.888709,0.666094,0.651727,0.931237,0.922257,0.891557,0.888762,0.210251,0.217783,2.87871,2.87866,0.411069,0.372132,1.33768,1.3233,-0.928291,-0.857243,1.05868,0.990795,0.280766,0.263053,-0.137879,-0.110687,0.888793,0.886321,0.435503,0.483994,0.42267,0.413252
75,0.961095,0.969076,0.397072,0.397248,0.336079,0.326694,0.111028,0.119607,0.317767,0.326532,0.537106,0.461813,0.366451,0.439593,0.613594,0.638136,0.527975,0.524457,0.836946,0.84224,-0.0312108,-0.0375551,-0.364246,-0.408776,0.449771,0.428868,1.15297,1.2218,0.880352,0.867863,-0.235989,-0.247546,-1.62252,-1.59434,1.55064,1.55506,0.957597,0.938577,-0.959896,-0.974659
76,0.199757,0.208096,0.900474,0.90006,0.99854,0.991411,0.716114,0.726496,0.548973,0.557119,0.0348092,0.0349165,0.241657,0.22746,0.42417,0.354016,0.45067,0.449513,0.259634,0.266545,2.52,2.51576,-0.420337,-0.467923,-0.994243,-1.02184,0.53287,0.602488,0.812878,0.744931,-0.434505,-0.447489,0.0267112,0.0540554,0.164898,0.167398,0.0903062,0.0301563,0.683501,0.674634
77,0.629269,0.63596,0.496023,0.496406,0.311323,0.30246,0.330926,0.339776,0.418646,0.425495,0.577679,0.488101,0.51169,0.492062,0.0788748,0.069895,0.067098,0.0650472,0.120098,0.126774,0.30168,0.300691,1.52128,1.47578,1.48708,1.45361,-0.664543,-0.5931,-0.642933,-0.708663,-0.372951,-0.464416,0.966136,0.990923,-0.239889,-0.23636,-0.861472,-0.878265,2.56517,2.55691
78,0.651254,0.723579,0.899508,0.902079,0.895375,0.885974,0.574656,0.558028,0.95651,0.964381,0.940054,0.941285,0.770292,0.756664,0.221012,0.308205,0.313,0.311124,0.190754,0.198801,-0.173498,-0.181859,-0.71405,-0.760067,0.45637,0.418409,-0.654984,-0.581533,0.806211,0.737873,-0.464777,-0.481342,-1.45794,-1.42334,-0.248981,-0.199798,0.0558178,0.0330185,-0.82739,-0.836682
79,0.803073,0.811198,0.915425,0.916239,0.504738,0.586704,0.768515,0.776281,0.815721,0.82255,0.802724,0.803082,0.196691,0.184465,0.556557,0.546515,0.087158,0.0876698,0.809679,0.817455,0.776762,0.772239,0.844643,0.800076,0.156254,0.113892,1.29843,1.3719,-0.342932,-0.405793,1.58759,1.57967,0.399627,0.429512,-0.169273,-0.163236,1.39401,1.36892,0.599467,0.582454
80,0.476432,0.511833,0.0121566,0.0119887,0.298614,0.287434,0.297405,0.304103,0.150436,0.157718,0.413165,0.41563,0.916062,0.903544,0.446238,0.520516,0.661142,0.662398,0.773953,0.716147,-0.981567,-0.986219,0.531487,0.481875,1.12465,1.08186,-0.818514,-0.746697,-0.559413,-0.618893,-1.01163,-1.01528,1.81944,1.84796,-0.424096,-0.414726,0.569951,0.54287,-0.0745447,-0.0902503
81,0.20325,0.212467,0.0725909,0.0716603,0.975641,0.962644,0.232789,0.16339,0.431625,0.501531,0.479729,0.434695,0.686004,0.672219,0.404588,0.494516,0.591807,0.624219,0.608707,0.614838,0.034365,0.0306921,-2.15099,-2.20122,-0.447475,-0.49042,0.162588,0.234661,-1.40977,-1.47404,-0.54834,-0.553708,-0.546347,-0.522089,-0.246275,-0.238334,1.17619,1.14236,-1.15114,-1.17314
82,0.901673,0.91316,0.705205,0.702281,0.0720005,0.0624571,0.0148697,0.0226765,0.835941,0.845345,0.392297,0.453761,0.0262273,0.0105247,0.479471,0.468517,0.570111,0.586039,0.124926,0.128893,0.425533,0.419695,-1.94937,-1.99925,-0.426041,-0.474589,-1.31536,-1.23654,0.602042,0.535291,0.957361,0.945637,-0.191652,-0.0860771,-1.00805,-0.996312,0.0108778,-0.0304571,-0.157605,-0.183495
83,0.142021,0.15218,0.78669,0.781365,0.678979,0.67032,0.136129,0.142134,0.158172,0.165159,0.517639,0.472826,0.03794,0.0372697,0.753587,0.744779,0.549112,0.54786,0.716711,0.723112,0.589809,0.577655,-0.949916,-0.999581,1.54193,1.49446,1.84595,1.92376,0.795742,0.723404,-1.14997,-1.16577,0.330338,0.349935,0.365055,0.375983,-0.499294,-0.546973,-1.11422,-1.14207
84,0.410313,0.419055,0.0386594,0.030834,0.795829,0.787507,0.585277,0.590364,0.609263,0.584238,0.525207,0.491892,0.0785355,0.0640147,0.259048,0.249094,0.0635222,0.062957,0.0314562,0.0359575,0.0910401,0.0788428,2.00708,1.95279,0.623182,0.569671,0.146947,0.233052,0.0116744,-0.0531709,2.49936,2.48961,-0.449422,-0.432436,0.325387,0.335735,-0.622626,-0.676818,-0.0791279,-0.106409
85,0.885648,0.896017,0.994406,0.986581,0.568845,0.560079,0.782095,0.786656,0.995658,1.00332,0.508492,0.510957,0.658597,0.645166,0.844469,0.832507,0.480942,0.389484,0.859436,0.863851,-0.873954,-0.880057,0.189912,0.142334,0.84839,0.80062,0.0308636,0.121333,1.68524,1.62211,0.565134,0.551459,1.56345,1.57589,0.836103,0.850729,1.75994,1.71248,0.0346114,0.00672042
86,0.162199,0.172126,0.517847,0.509144,0.859019,0.851535,0.209202,0.213994,0.0150485,0.0227079,0.954789,0.959391,0.183083,0.169021,0.0790328,0.0660969,0.716515,0.716011,0.838609,0.775038,1.28823,1.27683,-1.41018,-1.46201,-0.711292,-0.756132,-2.41144,-2.31263,-1.60757,-1.67856,0.450935,0.444077,1.06826,1.08436,1.0555,1.07523,0.0908027,0.0362029,0.48392,0.450028
87,0.365339,0.372651,0.559776,0.552551,0.0440276,0.0371183,0.977318,0.982877,0.304465,0.280344,0.603916,0.607072,0.243671,0.227995,0.0748925,0.0612985,0.814308,0.814545,0.682324,0.686225,-1.08007,-1.09199,-1.62036,-1.67412,-1.09002,-1.13734,0.947563,1.04414,0.33516,0.262722,2.17784,2.17732,1.92532,1.9411,2.0444,2.06441,-1.93431,-1.99404,0.31354,0.276046
88,0.135109,0.143998,0.860825,0.853986,0.24062,0.232444,0.102184,0.107802,0.529186,0.537981,0.593179,0.506935,0.0961536,0.0784654,0.478358,0.462857,0.138222,0.139553,0.885656,0.888211,-0.783446,-0.792533,0.25544,0.194832,-0.666687,-0.708378,0.175236,0.267763,0.206849,0.140087,0.247294,0.252546,0.356311,0.377545,0.35933,0.371208,-0.404538,-0.47133,-0.758233,-0.788821
89,0.455307,0.465395,0.526669,0.591164,0.126483,0.115902,0.113895,0.120924,0.204441,0.215605,0.405711,0.406799,0.782466,0.765987,0.124547,0.110736,0.389552,0.42583,0.290521,0.292635,-1.42114,-1.42847,-0.267224,-0.321973,0.761261,0.715957,0.712269,0.799259,-0.734897,-0.807991,0.208371,0.219826,0.47802,0.5003,2.13885,2.14394,-1.67725,-1.7354,-1.45003,-1.47424
90,0.4523,0.460752,0.334776,0.328341,0.720746,0.708925,0.795348,0.803122,0.654803,0.663807,0.122471,0.124046,0.727659,0.713252,0.85725,0.843283,0.762009,0.712106,0.275927,0.304871,1.00812,0.996027,2.94975,2.89994,0.137486,0.0850329,-0.20242,-0.119048,0.0600556,-0.00750953,0.565592,0.572451,0.330255,0.350203,1.01862,1.01887,1.0043,0.93898,-0.956413,-0.985224
91,0.931674,0.942068,0.864882,0.860493,0.081614,0.0707602,0.26114,0.270123,0.722824,0.732979,0.423077,0.425437,0.671006,0.660518,0.199553,0.186226,0.997051,0.998383,0.325319,0.317106,-0.977155,-0.981917,-1.43537,-1.48255,0.722332,0.668462,2.25596,2.34301,1.13414,1.07119,-0.235552,-0.231161,-0.118958,-0.0958467,1.02801,1.0262,2.23847,2.17992,-0.120571,-0.147922
92,0.215248,0.227466,0.00977606,0.00436693,0.998253,0.984566,0.45849,0.466415,0.58614,0.597038,0.460392,0.515398,0.625298,0.607784,0.61707,0.602794,0.983517,0.982961,0.327227,0.329342,0.854188,0.853681,-0.692356,-0.742911,-0.504777,-0.532491,-1.49584,-1.41544,-0.269873,-0.336987,-0.00892928,-0.00210754,0.753924,0.778679,-0.656349,-0.651562,-2.354,-2.41254,-0.951731,-0.983997
93,0.908922,0.923133,0.037397,0.0328163,0.611592,0.535334,0.176045,0.254733,0.977198,0.989805,0.600481,0.605359,0.88033,0.864384,0.706665,0.693677,0.159843,0.158787,0.896502,0.897738,-2.37743,-2.37027,-0.983125,-1.03193,-1.68477,-1.73344,0.983755,1.06522,-2.06795,-2.13139,-0.440027,-0.433236,0.132748,0.163904,0.019938,0.0317458,0.874153,0.819358,-0.57525,-0.60297
94,0.86086,0.876241,0.974643,0.970965,0.101445,0.0861022,0.0372234,0.0430505,0.31809,0.330252,0.412754,0.416879,0.213789,0.197613,0.154952,0.142698,0.66819,0.576534,0.650399,0.652427,-1.31288,-1.38719,0.0559993,0.0124299,-0.574707,-0.6298,-0.543011,-0.466271,1.21182,1.14559,-0.656606,-0.648881,1.44418,1.47546,-0.612524,-0.603841,1.10685,1.05866,1.7119,1.69058
95,0.505956,0.520943,0.363343,0.360001,0.946977,0.932499,0.94717,0.952102,0.403136,0.414092,0.722784,0.727069,0.0959965,0.0778489,0.434665,0.42373,0.997461,0.994281,0.764789,0.811367,-0.406428,-0.404119,-0.246289,-0.293741,1.39576,1.33925,-0.708352,-0.639767,0.503649,0.430961,0.519419,0.52965,-1.18016,-1.15405,-0.0971592,-0.0888466,-1.28597,-1.33929,0.662777,0.641827
96,0.817561,0.83258,0.0974563,0.0937568,0.0521271,0.0358666,0.368872,0.373489,0.211909,0.222033,0.194562,0.19715,0.807465,0.791024,0.0981768,0.0869928,0.216061,0.214444,0.969675,0.970307,-0.339187,-0.337021,0.835434,0.783906,0.259112,0.207106,0.578327,0.647514,0.0967882,0.0186054,0.0968271,0.113318,-0.322554,-0.297304,-0.727009,-0.724433,-0.509892,-0.569685,0.594295,0.57551
97,0.462245,0.477282,0.771729,0.768546,0.785621,0.771208,0.19161,0.195822,0.331455,0.228105,0.424604,0.425835,0.999678,0.982514,0.457527,0.444501,0.0326341,0.0310134,0.362805,0.364256,1.20737,1.20927,-0.565877,-0.618798,-0.873758,-0.925041,-0.181158,-0.114366,0.510203,0.437222,1.6082,1.62893,-0.445786,-0.416918,-0.468315,-0.472248,0.657694,0.591528,-0.750699,-0.766397
98,0.632739,0.657965,0.591963,0.588647,0.316342,0.401194,0.956729,0.959221,0.303381,0.234176,0.178743,0.177586,0.340783,0.325066,0.000978588,-0.0119523,0.591503,0.59078,0.684039,0.598275,0.247838,0.250373,0.816674,0.767555,-1.17477,-1.22956,0.900706,0.97219,1.29762,1.22541,-1.42842,-1.40976,-0.040777,-0.0179681,-0.223555,-0.220063,-1.68227,-1.74419,-0.651144,-0.670279
99,0.824697,0.838648,0.710371,0.707129,0.0437558,0.0311798,0.986402,0.987176,0.232407,0.240247,0.663908,0.66473,0.803525,0.786375,0.0563962,0.0437869,0.580202,0.580364,0.829939,0.832294,0.856897,0.853912,0.294929,0.25075,-2.52106,-2.57531,-0.0174762,0.107238,-0.0826947,-0.153839,-0.827125,-0.720347,-1.32153,-1.29924,0.47648,0.479024,-0.665954,-0.722452,-1.10805,-1.13037
100,0.702207,0.714703,0.487766,0.469111,0.351492,0.33821,0.801341,0.843511,0.51999,0.567137,0.89891,0.898109,0.489227,0.470116,0.628188,0.617404,0.120345,0.120265,0.0919365,0.0946037,-1.97142,-1.96991,-0.695949,-0.744507,1.57078,1.51775,-0.831948,-0.757714,2.01124,1.94711,-0.0544251,-0.0309338,-0.601148,-0.577397,1.81218,1.81849,-0.283522,-0.374847,-1.28378,-1.30435
101,0.954415,0.965819,0.236331,0.231093,0.863406,0.852224,0.701586,0.699846,0.885829,0.894027,0.672257,0.669647,0.659149,0.640828,0.386946,0.422805,0.52828,0.526225,0.6316,0.633997,-0.511307,-0.447679,-0.196172,-0.193325,0.866178,0.810444,-0.00618532,0.0657518,-1.3296,-1.38774,0.199552,0.227504,0.621769,0.639124,0.988809,1.00081,0.0338933,-0.0272427,-3.17444,-3.19802
102,0.289316,0.299563,0.723404,0.718793,0.48791,0.477389,0.320871,0.3175,0.814958,0.726425,0.893489,0.893677,0.176372,0.159204,0.239093,0.228207,0.497386,0.496479,0.0873416,0.0872331,1.06636,1.07456,0.403343,0.357857,-0.872784,-0.934905,-0.510094,-0.431871,0.553412,0.489568,0.707458,0.7346,-1.15193,-1.12963,0.673601,0.687483,-1.96689,-2.02518,-0.569286,-0.586009
103,0.514435,0.526118,0.0566154,0.0531153,0.587323,0.578712,0.440043,0.397885,0.596989,0.558823,0.867976,0.865936,0.918104,0.903609,0.924898,0.913993,0.940589,0.941679,0.749496,0.750578,-0.607399,-0.604215,-0.285191,-0.328385,1.82797,1.76897,-0.409986,-0.361555,-0.472875,-0.534434,-0.706253,-0.683382,1.89832,1.92166,-0.649091,-0.638257,-0.741593,-0.801602,0.360847,0.342052
104,0.414028,0.423516,0.152817,0.147454,0.314249,0.304294,0.484163,0.47827,0.385346,0.39122,0.231106,0.230562,0.453828,0.437877,0.0641499,0.0535006,0.612004,0.642378,0.992819,0.993671,-0.632817,-0.627689,-1.25043,-1.29303,-0.494566,-0.549083,-0.37605,-0.29124,0.0221382,-0.0388903,0.502092,0.526909,-1.42116,-1.39771,0.0993781,0.105821,-0.719069,-0.715813,0.641194,0.620143
105,0.876566,0.885743,0.560131,0.553128,0.338518,0.269545,0.85392,0.846891,0.110244,0.114226,0.5215,0.519728,0.542982,0.573769,0.39399,0.2857,0.362458,0.343078,0.418913,0.417977,-0.087663,-0.0847316,1.51313,1.46417,1.14744,1.09361,-3.14754,-3.05859,1.50299,1.43789,-1.1514,-1.12139,1.26456,1.28944,-0.752764,-0.742444,-0.5736,-0.630024,-0.523902,-0.538006
106,0.729748,0.8292,0.497608,0.488995,0.241267,0.234797,0.408943,0.400999,0.197123,0.20275,0.0636269,0.0638998,0.614149,0.709661,0.545394,0.5179,0.0428206,0.0437776,0.752384,0.751602,-1.58844,-1.57979,0.499684,0.452918,-1.59138,-1.64369,0.619824,0.711523,0.780302,0.723264,-0.175353,-0.141879,-0.97266,-0.949132,0.502756,0.520334,0.605564,0.548263,0.605339,0.589352
107,0.715642,0.772658,0.164763,0.15392,0.187193,0.200048,0.549768,0.540528,0.6627,0.665913,0.83497,0.83711,0.859122,0.845553,0.761417,0.7501,0.480721,0.483264,0.0846759,0.0853567,0.306346,0.316961,0.665496,0.624186,1.89227,1.83282,0.0405336,0.13695,-1.44283,-1.5027,-1.07009,-1.03942,-0.0146221,0.0037564,-0.142249,-0.0861288,0.218207,0.1569,0.733882,0.713575
108,0.706535,0.716115,0.62668,0.616997,0.258257,0.165299,0.181297,0.173719,0.891576,0.8965,0.130717,0.132089,0.269488,0.254027,0.162672,0.149046,0.254979,0.259811,0.579793,0.579259,0.280619,0.293487,0.439642,0.393195,1.04724,0.985267,0.209795,0.301965,-0.382478,-0.488819,-1.04605,-1.00914,1.71751,1.73,-0.702645,-0.692592,1.69592,1.63279,0.0886351,0.0707274
109,0.0190924,0.0293888,0.0105142,0.000444586,0.140506,0.130551,0.465938,0.459084,0.596402,0.634697,0.613742,0.614468,0.868891,0.854542,0.915344,0.901682,0.839518,0.845047,0.116811,0.1184,1.53422,1.54149,-1.00313,-1.05586,1.4447,1.38556,0.824865,0.908859,0.580385,0.525065,0.544091,0.58438,-1.17234,-1.15817,0.562039,0.570186,0.46835,0.398071,-0.216602,-0.24
110,0.524987,0.536543,0.664618,0.654612,0.525367,0.517558,0.0327665,0.0271879,0.369852,0.372894,0.524038,0.551038,0.929377,0.913516,0.08498,0.0690354,0.251555,0.255999,0.412533,0.415829,0.0529162,0.0629298,-0.285666,-0.309682,-1.81018,-1.87611,0.872087,0.95018,0.0806685,0.0209385,0.781488,0.828627,-0.337281,-0.330635,-0.178051,-0.173324,0.141009,0.0671166,-0.200922,-0.217529
111,0.0651939,0.0754893,0.0882035,0.0779407,0.574524,0.633093,0.59614,0.496291,0.711595,0.715492,0.507694,0.487609,0.218938,0.201267,0.406884,0.356835,0.38755,0.463689,0.225118,0.23042,0.0422839,0.00322739,0.495893,0.436494,-1.22452,-1.29268,0.525788,0.606958,-2.2335,-2.28583,-0.795319,-0.74214,0.88481,0.885886,0.333302,0.34167,1.20066,1.12082,-0.794167,-0.813729
112,0.488943,0.498581,0.0368775,0.0280738,0.757622,0.748629,0.970972,0.965393,0.567717,0.569083,0.42171,0.424179,0.753986,0.737667,0.661028,0.644634,0.574295,0.67138,0.610116,0.614583,-0.0663516,-0.056475,-0.553473,-0.605524,-0.40518,-0.477253,-0.730943,-0.650458,-1.43201,-1.48534,-0.321782,-0.264896,-0.285618,-0.286495,1.51682,1.52818,-0.507504,-0.587153,-0.141142,-0.156676
113,0.682049,0.713356,0.808111,0.798929,0.621456,0.583061,0.207733,0.201858,0.0671483,0.0708354,0.666618,0.666831,0.166416,0.15036,0.137797,0.123536,0.874627,0.87907,0.771584,0.718191,-0.897672,-0.893614,-0.87881,-0.850077,0.411182,0.338176,-0.0650536,0.0189262,0.687484,0.63267,-0.713333,-0.649118,-0.147758,-0.149022,-0.226602,-0.213601,1.08252,0.99732,0.805238,0.788248
114,0.916634,0.928132,0.938235,0.927051,0.427198,0.417494,0.0480811,0.0441282,0.630262,0.633787,0.106872,0.107983,0.230357,0.118931,0.466993,0.463154,0.555939,0.559793,0.889463,0.821799,0.0678096,0.0894596,-1.0448,-1.09463,-1.97802,-2.04454,-0.960603,-0.881327,-0.539624,-0.591211,-0.0701885,0.0310877,0.428183,0.420948,-0.983079,-0.971579,0.982054,0.898604,-0.413897,-0.431449
115,0.890019,0.902848,0.847414,0.836333,0.682506,0.6418,0.830457,0.827985,0.098458,0.100641,0.458063,0.458869,0.105169,0.0875012,0.81795,0.802771,0.837689,0.840971,0.923368,0.925407,1.06583,1.07253,0.120797,0.0738369,-0.792993,-0.862691,-1.57113,-1.48685,1.69786,1.64384,0.649432,0.711294,-1.56411,-1.56673,0.677097,0.6929,-1.46712,-1.55115,-0.343216,-0.363225
116,0.139195,0.152102,0.720763,0.745616,0.876379,0.866106,0.553887,0.458995,0.975572,0.98028,0.59739,0.650018,0.0721283,0.0560718,0.210915,0.196773,0.227543,0.230718,0.249919,0.254258,-0.176264,-0.161405,-1.34329,-1.39191,-0.469391,-0.539977,-1.58291,-1.48988,0.470793,0.419958,-0.394481,-0.337277,-0.495789,-0.485714,0.351532,0.302213,1.1232,1.03394,1.46182,1.44327
117,0.989362,1.00421,0.55632,0.654898,0.923268,0.912791,0.0930985,0.090005,0.521929,0.52689,0.8397,0.841168,0.407211,0.459856,0.905458,0.893216,0.432131,0.437425,0.0719553,0.0739189,-0.273792,-0.263241,-0.154327,-0.20673,-2.5925,-2.66612,0.662161,0.751245,0.272563,0.154652,1.19798,1.25624,0.602916,0.595298,-0.109336,-0.0884742,-0.570631,-0.659037,-0.327295,-0.341769
118,0.446023,0.463117,0.577407,0.56418,0.555961,0.622206,0.745944,0.742269,0.292652,0.299551,0.635672,0.537233,0.881091,0.863641,0.312546,0.301893,0.310176,0.314649,0.196587,0.199908,0.561701,0.568014,0.0602271,0.0116014,1.61271,1.53909,-1.9362,-1.85045,-0.0654051,-0.110654,-0.806959,-0.746717,-1.27653,-1.27996,0.0386404,0.0590155,-0.951029,-1.03541,-0.458226,-0.4711
119,0.514659,0.459029,0.886199,0.87064,0.340146,0.331621,0.44547,0.439837,0.347373,0.372442,0.233186,0.233299,0.208614,0.191394,0.37413,0.415026,0.655761,0.661025,0.575236,0.579642,0.0316979,0.040101,-0.920836,-0.967382,0.550504,0.53105,1.2696,1.35327,-0.0641446,-0.104817,1.16108,1.2144,-1.36367,-1.36928,-0.794668,-0.774785,1.1885,1.10092,0.771226,0.764334
120,0.439726,0.454941,0.675569,0.692579,0.744793,0.660316,0.747283,0.740228,0.439185,0.445332,0.994902,0.994988,0.187205,0.168412,0.547286,0.528159,0.100557,0.106531,0.658628,0.661262,-1.08722,-1.07356,-1.12349,-1.16495,-0.409209,-0.476993,-0.699687,-0.611318,1.12966,1.08136,0.480547,0.532304,1.61577,1.6137,0.298835,0.322013,0.270399,0.1794,0.633636,0.621599
121,0.80665,0.8227,0.527554,0.514519,0.995643,0.989011,0.848237,0.839451,0.106725,0.113188,0.0865437,0.0853621,0.439885,0.420576,0.601074,0.641292,0.48734,0.492281,0.989694,0.990141,0.310996,0.329957,0.112011,0.069602,1.20687,1.13296,-1.43202,-1.34059,1.52,1.46976,-0.999054,-0.948556,-0.0206051,-0.0262565,-1.25971,-1.23179,0.213968,0.126281,-1.23736,-1.2557
122,0.211519,0.227115,0.676981,0.684261,0.910088,0.903146,0.630801,0.626803,0.251495,0.257643,0.0871311,0.0874326,0.476504,0.458991,0.684823,0.754425,0.20119,0.305916,0.00452247,0.00537794,0.682634,0.704576,-0.362161,-0.402199,0.255581,0.177349,-0.612607,-0.517127,-1.41604,-1.46924,-0.536323,-0.486987,0.858214,0.84827,1.26595,1.30013,1.03729,0.943615,0.276637,0.257629
123,0.153604,0.170446,0.867315,0.854003,0.430412,0.423444,0.430545,0.414155,0.912278,0.918028,0.984633,0.98415,0.0671064,0.0478731,0.87821,0.867557,0.114597,0.119552,0.396188,0.30413,0.506021,0.528842,-0.629531,-0.676203,-0.290802,-0.373474,-1.27108,-1.16948,0.948169,0.900288,1.14837,1.20068,-1.77707,-1.79476,-0.891614,-0.852829,-0.554276,-0.65181,-0.546999,-0.564138
124,0.61635,0.632673,0.467683,0.454563,0.175324,0.223715,0.210023,0.201507,0.266293,0.273756,0.719691,0.721031,0.834716,0.817256,0.737353,0.715122,0.232696,0.23872,0.599781,0.602883,-1.11294,-1.08648,-0.372333,-0.412985,0.827971,0.746624,-1.17664,-1.08326,-1.79654,-1.84042,1.10891,1.15428,-1.70125,-1.71675,-0.272052,-0.231306,0.716947,0.618654,-0.8895,-0.905239
125,0.000878999,0.0165681,0.403999,0.39043,0.0317001,0.0239861,0.685308,0.678998,0.348403,0.357596,0.0562845,0.0560843,0.210634,0.190888,0.549618,0.562687,0.582178,0.559547,0.633598,0.588277,0.0389188,0.067997,0.952412,0.911207,2.23501,2.15485,0.103401,0.190571,0.0568728,0.00634565,0.177378,0.205177,0.465803,0.455672,0.556215,0.589745,0.10674,0.00915929,-0.32573,-0.339263
126,0.727335,0.743061,0.678941,0.666669,0.646002,0.637594,0.808104,0.803868,0.0277775,0.0352194,0.689007,0.686766,0.991925,0.971562,0.381195,0.410252,0.874981,0.880374,0.573101,0.573671,0.317667,0.350926,-0.667336,-0.708775,-0.608988,-0.686626,-0.872443,-0.788449,0.725412,0.67078,-0.787879,-0.743925,1.00157,0.992761,-1.32801,-1.29472,1.93189,1.83125,-1.41282,-1.42215
127,0.417724,0.434014,0.438817,0.354714,0.957849,0.948882,0.70096,0.696244,0.361602,0.3674,0.24264,0.240716,0.660817,0.641158,0.379161,0.257817,0.0855205,0.0905677,0.172796,0.17311,3.11709,3.15459,-1.53242,-1.5803,1.14396,1.06599,-0.423446,-0.348442,-2.59419,-2.64701,-0.536087,-0.499678,-1.89216,-1.89541,-1.73805,-1.69848,1.49886,1.39134,-0.500843,-0.509418
128,0.680562,0.643203,0.0546117,0.0427593,0.0167553,0.00678382,0.292772,0.28922,0.487957,0.495465,0.573782,0.553847,0.127939,0.108971,0.116034,0.105382,0.341387,0.346716,0.888129,0.887468,-0.163535,-0.128245,-0.170527,-0.224902,0.865588,0.792257,0.00986524,0.0915654,-0.024316,-0.0767608,-1.63789,-1.5956,1.21276,1.21239,-0.664695,-0.630322,-1.09005,-1.20011,1.65007,1.64005
129,0.83642,0.852391,0.806474,0.792289,0.805392,0.79553,0.1518,0.147685,0.505495,0.623531,0.868574,0.866978,0.315638,0.294929,0.376873,0.389295,0.84681,0.852371,0.813679,0.749589,1.27353,1.30666,-1.37127,-1.42141,0.0109343,-0.0552997,0.838263,0.915031,-0.283709,-0.33762,0.933129,0.979649,-1.48996,-1.49747,0.15217,0.180625,-1.40533,-1.51599,0.097975,0.0842703
130,0.828708,0.843366,0.388937,0.37362,0.241747,0.231273,0.576779,0.571947,0.642567,0.751597,0.222147,0.221636,0.845521,0.826082,0.682951,0.673209,0.421879,0.505489,0.609557,0.611709,-0.360815,-0.322729,1.11254,1.05718,1.09388,1.03414,0.07313,0.153151,-0.3376,-0.411354,-1.49118,-1.44648,1.87772,1.87564,0.957853,0.991572,0.957066,0.840713,0.709477,0.694998
131,0.0817376,0.0984488,0.998777,0.983953,0.343559,0.332596,0.524327,0.52032,0.873865,0.879662,0.721932,0.719117,0.500225,0.480858,0.485422,0.558463,0.15461,0.158607,0.222515,0.226396,-0.668089,-0.634261,-0.0697866,-0.123897,0.250908,0.186578,0.290941,0.363793,-0.435229,-0.485087,-0.471904,-0.420082,-0.509969,-0.508898,0.424906,0.385109,-0.555366,-0.67747,1.76848,1.761
132,0.629572,0.644846,0.731674,0.717709,0.119895,0.110598,0.82201,0.820711,0.407522,0.411358,0.58718,0.545368,0.391641,0.371629,0.450789,0.443717,0.878535,0.881139,0.931297,0.935122,0.556746,0.59572,-0.492781,-0.548402,-0.280571,-0.348846,-0.021254,0.0507849,0.701723,0.65565,0.973984,1.03174,1.82222,1.82433,-0.257519,-0.221354,0.535681,0.406447,-0.169374,-0.18137
133,0.213547,0.229483,0.797318,0.781783,0.145179,0.137885,0.329097,0.328,0.81983,0.823981,0.373324,0.371619,0.910375,0.887914,0.902806,0.895416,0.478373,0.482195,0.448037,0.45456,1.15352,1.19926,0.630939,0.577329,-1.62961,-1.6946,0.317779,0.38379,-0.171461,-0.2159,-0.0744465,-0.016831,-0.296434,-0.288321,0.90046,0.936475,-1.68649,-1.81152,1.47635,1.46792
134,0.388823,0.40489,0.220538,0.205111,0.5213,0.515284,0.618242,0.55718,0.725769,0.823586,0.898211,0.898296,0.661862,0.568894,0.876494,0.869668,0.863046,0.867944,0.314932,0.319987,0.859928,0.924042,-1.02968,-1.09092,0.410304,0.339337,1.63669,1.70201,-1.73598,-1.77705,-0.202903,-0.142123,0.175079,0.188289,-0.80238,-0.772847,0.49974,0.369903,-2.23453,-2.24001
135,0.947545,0.961438,0.853994,0.840405,0.665452,0.657236,0.787014,0.78636,0.81743,0.82319,0.385187,0.383864,0.272568,0.249874,0.0957778,0.0881276,0.638662,0.644491,0.822116,0.828489,0.619559,0.648826,-0.763247,-0.8277,-2.39688,-2.46487,0.978709,1.04965,1.89423,1.8615,0.737799,0.79234,-1.99551,-1.98677,-1.01954,-0.992641,-0.513419,-0.646529,1.03488,1.02217
136,0.269215,0.283626,0.794416,0.781215,0.188752,0.18226,0.417223,0.448793,0.431364,0.434855,0.418149,0.415419,0.857008,0.836136,0.294472,0.361295,0.128454,0.134792,0.225762,0.232913,0.328523,0.37361,1.00415,0.933581,-1.00671,-1.06274,-1.17713,-1.10068,1.76117,1.72401,-1.05027,-0.993916,-0.778482,-0.77025,1.63985,1.67365,-0.672726,-0.781954,-0.312866,-0.319737
137,0.284035,0.298819,0.0733972,0.0613136,0.796765,0.790123,0.112612,0.111225,0.938187,0.943193,0.935172,0.932746,0.693238,0.672319,0.642025,0.634462,0.40975,0.360277,0.866333,0.871693,2.07405,2.11916,-0.732391,-0.798372,0.407391,0.339397,-0.539754,-0.462737,-0.0451742,-0.083099,-0.802664,-0.749669,-1.32043,-1.30995,0.201189,0.240671,-0.779546,-0.917379,0.0828279,0.0769968
138,0.783865,0.800948,0.223776,0.210318,0.759844,0.751304,0.0625125,0.0595989,0.348191,0.354479,0.30463,0.302831,0.230885,0.211856,0.165618,0.158956,0.581447,0.585762,0.720968,0.726587,-0.285093,-0.233278,-0.292646,-0.352459,-0.373449,-0.446153,-0.130171,-0.053759,-0.914408,-0.954649,0.891292,0.938002,-0.908249,-0.89467,0.20614,0.248002,0.13868,-0.00609546,-1.01915,-1.02056
139,0.282156,0.299819,0.768627,0.758187,0.237703,0.227881,0.811159,0.808061,0.0926492,0.0974252,0.0896849,0.205411,0.39533,0.404498,0.712919,0.70677,0.0808794,0.0860089,0.892219,0.898759,2.61886,2.66537,-0.40079,-0.415223,-1.63289,-1.71113,-0.444677,-0.366768,-0.0666506,-0.105703,0.20826,0.255904,-0.857336,-0.848771,-0.941309,-0.904701,-1.51537,-1.66651,-1.15481,-1.14989
140,0.0113162,0.0305857,0.576113,0.548567,0.0573464,0.0460959,0.883097,0.881162,0.224173,0.226915,0.0707596,0.10799,0.69394,0.597139,0.880821,0.873715,0.25301,0.22827,0.843077,0.84966,0.780211,0.830059,-0.421011,-0.477988,-1.41956,-1.49643,0.311731,0.396518,-0.882409,-0.913856,-0.0671448,-0.0210089,-0.584523,-0.573211,1.38468,1.41833,-1.25311,-1.41121,0.361995,0.363432
141,0.983236,1.00089,0.349488,0.338947,0.589498,0.579636,0.175266,0.173817,0.970725,0.975746,0.0141492,0.0105695,0.80881,0.789781,0.381331,0.372447,0.36595,0.370532,0.421595,0.429071,-1.334,-1.28554,-1.16168,-1.22638,0.716233,0.631897,-0.0449945,0.0367096,1.68966,1.6564,-0.96415,-0.94156,0.104492,0.118306,-0.0402649,-0.0146499,0.137478,-0.0278827,-0.243216,-0.201858
142,0.819726,0.837877,0.389529,0.377321,0.319538,0.310294,0.410441,0.40939,0.181925,0.186001,0.578741,0.576998,0.194555,0.173486,0.49097,0.483155,0.245216,0.257364,0.500364,0.570954,-0.401256,-0.346497,1.13812,1.07474,-0.13501,-0.21566,0.281126,0.369715,-1.06667,-1.09898,-1.90914,-1.86211,-1.01516,-1.00714,1.39309,1.41979,0.0875502,-0.0810012,-0.763111,-0.767148
143,0.398144,0.417558,0.755485,0.742054,0.962142,0.954005,0.860971,0.85762,0.45769,0.462598,0.492322,0.497872,0.243449,0.203011,0.17271,0.166662,0.139938,0.144196,0.653541,0.712837,0.0992728,0.150116,0.200705,0.14249,0.518027,0.443666,1.33907,1.42626,0.407626,0.3778,-0.0940444,-0.0518378,0.474606,0.484658,0.629747,0.661814,1.19081,1.01865,0.530609,0.528871
144,0.17688,0.198323,0.581693,0.567479,0.241504,0.233008,0.0435783,0.0406881,0.3045,0.311643,0.295927,0.418746,0.252359,0.232535,0.247016,0.191507,0.335556,0.375606,0.874388,0.85472,-0.0302086,0.0203548,-1.10206,-1.16176,-0.354998,-0.435504,-1.51422,-1.43391,-0.741242,-0.765866,-0.304755,-0.267483,-0.00921343,0.00753675,1.36235,1.39313,-0.65805,-0.837185,1.43661,1.42743
145,0.157731,0.172778,0.0844458,0.0691974,0.873404,0.866778,0.484271,0.479355,0.820724,0.825764,0.341364,0.339621,0.532214,0.513601,0.225083,0.216352,0.604591,0.607016,0.989128,0.996604,-1.41683,-1.36743,-0.346678,-0.407259,-0.776869,-0.862366,0.696425,0.775726,0.583091,0.558553,0.0704264,0.115408,0.810231,0.819204,-0.269125,-0.237774,0.34336,0.169299,0.641667,0.634763
146,0.257169,0.147234,0.437038,0.419701,0.811856,0.806522,0.425981,0.422112,0.131137,0.13588,0.798056,0.797852,0.483841,0.465356,0.786516,0.778587,0.168957,0.17228,0.0491039,0.0586668,-1.52479,-1.46926,0.920979,0.856172,1.5461,1.46257,1.16103,1.24493,-0.444785,-0.465449,-0.540112,-0.488525,0.597513,0.606762,1.5793,1.61393,-0.640953,-0.813918,0.221928,0.218196
147,0.101637,0.121689,0.214947,0.195423,0.490079,0.486835,0.112633,0.109011,0.0826562,0.0861108,0.581556,0.579328,0.642494,0.626777,0.133341,0.126102,0.563721,0.568156,0.713651,0.722012,-0.235751,-0.175551,0.0224888,-0.045977,-1.11362,-1.1979,1.37127,1.41235,-0.421319,-0.444338,0.529043,0.584265,-0.538269,-0.533244,0.80866,0.84148,0.527144,0.347295,0.163318,0.164976
148,0.634717,0.653028,0.770772,0.752252,0.481121,0.513634,0.353507,0.34894,0.728152,0.731012,0.907664,0.904465,0.0124479,-0.00530117,0.0308155,0.0261672,0.538198,0.548662,0.0273066,0.0348574,1.51232,1.57,1.11244,1.04891,-0.112661,-0.198402,1.4955,1.57977,0.543718,0.528923,-1.22395,-1.1705,1.14108,1.14564,-0.59486,-0.558616,-0.654444,-0.841197,0.662072,0.669206
149,0.79477,0.813226,0.567303,0.547307,0.434807,0.540433,0.263842,0.260747,0.75703,0.758408,0.67093,0.666011,0.800603,0.780275,0.753654,0.748489,0.523161,0.529167,0.164827,0.171915,-0.11771,-0.0593923,0.11614,0.0536514,-0.539305,-0.625265,0.503145,0.585825,0.661717,0.640617,-0.219214,-0.160935,-0.932743,-0.934579,0.654927,0.635946,0.435568,0.242719,-1.00268,-0.992087
150,0.75294,0.746979,0.576623,0.556351,0.570476,0.567231,0.43387,0.430881,0.37457,0.37472,0.0200412,0.0159583,0.783825,0.790943,0.204795,0.197511,0.840983,0.844011,0.77541,0.780781,-0.289123,-0.235127,-0.189656,-0.237908,-0.184428,-0.319171,0.60803,0.688392,0.282076,0.211326,-0.636532,-0.577267,-0.0620439,-0.060053,1.79426,1.83051,-0.210821,-0.396576,-2.32164,-2.31774
151,0.63343,0.680731,0.89927,0.877832,0.792915,0.762511,0.121094,0.117779,0.882363,0.883058,0.557556,0.553281,0.823166,0.801611,0.299937,0.377734,0.407766,0.409275,0.326097,0.329472,0.0102262,0.0643261,-0.469604,-0.529468,0.129374,-0.0130768,0.477563,0.562116,-0.200863,-0.217964,1.45889,1.51196,-0.200273,-0.196425,0.362195,0.397531,1.15421,0.971506,-0.953637,-0.94554
152,0.598217,0.614484,0.718891,0.697934,0.96136,0.957791,0.210815,0.205913,0.149212,0.151531,0.460889,0.45539,0.423167,0.401274,0.563988,0.557957,0.435413,0.438835,0.327946,0.43308,-0.246771,-0.186089,1.31531,1.26145,0.378977,0.293017,1.15497,1.24666,-0.098756,-0.120195,1.19875,1.25081,0.269972,0.280186,0.450625,0.48212,-0.551121,-0.736465,-0.217786,-0.213033
153,0.318778,0.373491,0.275268,0.254561,0.262553,0.258381,0.548775,0.544495,0.616658,0.52869,0.144842,0.141629,0.486518,0.559858,0.46561,0.401353,0.695751,0.612261,0.523583,0.536688,-1.50415,-1.43689,1.64378,1.58629,-0.625258,-0.710661,0.456132,0.548796,0.488954,0.465853,0.678911,0.655377,-1.52598,-1.51867,-0.0955158,-0.059406,0.326081,0.144467,0.0462482,0.0483645
154,0.117437,0.132498,0.669254,0.65001,0.243071,0.2092,0.165368,0.162149,0.901952,0.905848,0.615857,0.614089,0.730404,0.718443,0.250766,0.24475,0.780882,0.785688,0.635162,0.640296,0.215331,0.276726,-1.54769,-1.60555,0.472531,0.392983,-1.02423,-0.937571,0.039051,0.021537,0.0145816,0.0599482,0.363837,0.366047,2.42588,2.45557,0.360903,0.186753,-0.296249,-0.382035
155,0.526123,0.540358,0.813995,0.793561,0.0940069,0.160019,0.62564,0.619834,0.53203,0.537078,0.300271,0.300329,0.89892,0.877027,0.4893,0.47695,0.230079,0.236392,0.504256,0.447344,-0.0727633,0.00150957,-1.22899,-1.28071,-0.176435,-0.253145,-1.82893,-1.74515,-0.378709,-0.422779,0.938309,0.978449,-1.36641,-1.37043,0.409073,0.433367,-1.10326,-1.28578,-0.807236,-0.812435
156,0.587989,0.627977,0.321135,0.399759,0.113097,0.110838,0.600311,0.592962,0.491927,0.424027,0.864605,0.866758,0.747559,0.727497,0.771817,0.70915,0.121754,0.129112,0.251574,0.254392,-0.308045,-0.273707,-0.489398,-0.541074,-0.358886,-0.434993,-0.501338,-0.410813,-0.840181,-0.867096,0.24277,0.28778,-1.10386,-1.11085,0.0435537,0.0606709,-1.04394,-1.23004,-0.589663,-0.596186
157,0.702989,0.715597,0.0251729,0.00595672,0.310568,0.306164,0.942843,0.936306,0.315176,0.310977,0.0218274,0.0236885,0.849918,0.827933,0.946697,0.941349,0.590229,0.508813,0.63478,0.638555,-0.615215,-0.548923,1.44211,1.38975,-0.247565,-0.328492,-0.174401,-0.0778081,-0.615765,-0.647155,-0.446669,-0.402889,-0.447572,-0.449627,-1.23344,-1.21856,0.261105,0.0718652,1.27773,1.27372
158,0.161688,0.174499,0.973509,0.954822,0.0956244,0.158141,0.990194,0.985236,0.105992,0.197926,0.311484,0.34175,0.0901356,0.0671632,0.282113,0.275062,0.881157,0.888515,0.49921,0.466409,0.0216153,0.0857577,-1.29098,-1.33974,-0.364821,-0.448449,-0.515835,-0.42103,1.02102,0.996262,0.323544,0.362675,-1.22914,-1.232,2.29,2.30488,0.972507,0.78161,1.01088,1.00917
159,0.860226,0.875192,0.486915,0.467046,0.0116976,0.0101186,0.0023702,-0.00234243,0.0798263,0.0848748,0.546618,0.659811,0.811281,0.790748,0.816307,0.807645,0.486786,0.469465,0.287857,0.294262,-0.2665,-0.195366,0.654375,0.60396,1.02608,0.944322,0.81254,0.913307,0.181423,0.155193,0.528753,0.560748,-0.654968,-0.662028,1.53587,1.5469,1.88492,1.69289,1.90262,1.90772
160,0.556836,0.601912,0.300872,0.282796,0.777164,0.777002,0.869364,0.866664,0.518191,0.53114,0.974657,0.977872,0.0633392,0.0428131,0.535706,0.526067,0.0435474,0.050416,0.94738,0.952647,-0.216845,-0.144696,0.604873,0.559194,1.63842,1.55673,0.937736,0.990278,-1.10092,-1.12874,1.78936,1.81601,-0.481107,-0.564889,-0.5683,-0.554534,-1.08322,-1.27435,-0.483915,-0.477382
161,0.316007,0.328633,0.576901,0.559035,0.127111,0.1282,0.577386,0.574151,0.972357,0.977405,0.961796,0.965725,0.36478,0.344543,0.00386674,-0.00498188,0.45281,0.460679,0.993689,0.999682,0.990684,1.05729,-1.40596,-1.45396,-0.810277,-0.891643,0.965961,1.06725,-1.77424,-1.80052,-0.507203,-0.485634,-0.454518,-0.467749,-1.32356,-1.31251,0.762384,0.57941,-0.275859,-0.274699
162,0.528548,0.46509,0.123519,0.105817,0.236052,0.259848,0.813798,0.809724,0.329723,0.333133,0.747277,0.751944,0.440426,0.418679,0.275974,0.265696,0.275375,0.240657,0.333146,0.338329,0.74099,0.806875,0.852011,0.801182,0.0134937,-0.0596409,-0.944958,-0.845611,-3.61185,-3.63959,-0.373763,-0.34835,1.75895,1.75095,-0.137447,-0.126002,-0.113987,-0.294373,0.340499,0.33603
163,0.588119,0.601548,0.711727,0.691276,0.391953,0.391496,0.327459,0.322811,0.765711,0.770891,0.757423,0.860809,0.896837,0.874559,0.288662,0.21034,0.0103959,0.0206358,0.37615,0.380204,1.44028,1.50188,-2.29716,-2.35393,-0.81846,-0.89331,1.54309,1.63504,-0.757202,-0.779117,1.8478,1.8695,0.838963,0.82773,-0.0991546,-0.0869926,1.22196,1.04152,-0.301023,-0.306818
164,0.430848,0.491539,0.562281,0.442803,0.929382,0.929139,0.0607804,0.0548835,0.37178,0.377325,0.962802,0.969673,0.642052,0.67176,0.284737,0.154985,0.781113,0.792148,0.627938,0.551533,1.7804,1.8436,-1.59393,-1.6461,-0.509553,-0.585428,-1.31364,-1.22513,-1.10834,-1.1302,0.146558,0.162813,-0.788974,-0.795519,-0.708935,-0.690074,1.99691,1.81113,2.10932,2.10069
165,0.370226,0.38153,0.213682,0.194331,0.193166,0.19354,0.673669,0.667758,0.270405,0.276036,0.659675,0.665974,0.489557,0.46896,0.11226,0.099629,0.631032,0.545157,0.7179,0.722863,0.313031,0.379622,0.583653,0.525355,0.217235,0.136873,-0.094128,0.00196612,-0.72987,-0.755688,1.26976,1.28151,1.04682,1.04204,-0.170121,-0.143884,1.41341,1.23266,0.694342,0.683329
166,0.446866,0.390991,0.313851,0.293263,0.859818,0.858257,0.867133,0.81728,0.859581,0.866003,0.0799264,0.0862103,0.695687,0.674855,0.959141,0.944754,0.288672,0.298166,0.37383,0.376937,-2.17553,-2.10533,0.243546,0.190789,-0.297137,-0.383342,-0.706887,-0.603553,-0.783227,-0.815326,0.487239,0.474453,0.669494,0.659717,-0.0348833,-0.0119634,-0.132417,-0.31723,-1.47267,-1.48833
167,0.387831,0.400452,0.672142,0.554492,0.187343,0.18446,0.974269,0.966801,0.521997,0.537604,0.958801,0.96635,0.05908,0.0374118,0.049054,0.0321996,0.60469,0.61301,0.473234,0.477349,0.583724,0.650078,0.862574,0.806706,0.775564,0.691892,-0.723569,-0.6231,-0.152851,-0.18244,-0.341623,-0.332604,0.883992,0.872552,-1.54491,-1.51996,0.599153,0.407256,-0.988612,-0.999308
168,0.0782632,0.0914058,0.836187,0.815722,0.985724,0.983893,0.506076,0.500144,0.205554,0.209204,0.622869,0.628714,0.941046,0.917765,0.78509,0.769461,0.538683,0.624603,0.262121,0.266552,-0.173708,-0.108521,-0.201282,-0.251128,-0.378282,-0.46801,1.23575,1.33033,0.827465,0.804621,-0.303519,-0.28758,0.0669896,0.0602953,-0.0401387,-0.0112062,-0.0463589,-0.232039,0.386414,0.37289
169,0.253922,0.266812,0.0586982,0.0383138,0.131247,0.127193,0.716333,0.624311,0.805646,0.808946,0.584151,0.60184,0.196062,0.174522,0.51501,0.496928,0.627855,0.636196,0.727195,0.730637,-0.0469648,0.0193002,1.03461,0.983428,-0.470126,-0.561278,1.48706,1.58676,-0.825665,-0.847896,0.383638,0.433686,0.3113,0.304298,-1.41946,-1.39887,-0.436729,-0.623402,-0.396357,-0.404895
170,0.676237,0.689904,0.0261843,0.0197976,0.856263,0.852846,0.755643,0.748479,0.653571,0.657991,0.570055,0.574966,0.345168,0.324947,0.952318,0.93411,0.912906,0.92194,0.155135,0.159463,0.533035,0.593442,1.0205,0.968631,0.168021,0.0835903,1.2641,1.44661,-0.452044,-0.473384,1.13825,1.15495,-2.60491,-2.61767,0.166646,0.187933,0.018593,-0.164898,-1.54184,-1.54903
171,0.728608,0.778048,0.020859,0.00128127,0.722043,0.721319,0.123324,0.116264,0.231487,0.23409,0.932171,0.935059,0.0940021,0.0741239,0.432955,0.413012,0.207494,0.216021,0.900083,0.90338,-0.13121,-0.0714514,0.025598,-0.0266256,1.22706,1.14407,1.20782,1.30645,-1.20705,-1.23631,-0.156134,-0.138788,-0.0413084,-0.0600916,-0.0358324,-0.0171154,-0.345015,-0.526734,-0.604794,-0.604108
172,0.944753,0.866192,0.88191,0.860734,0.30639,0.306894,0.562335,0.55493,0.908833,0.910773,0.115652,0.11772,0.84764,0.829329,0.272172,0.250252,0.460593,0.467765,0.182661,0.187089,0.816443,0.882646,0.597507,0.543519,0.314837,0.234186,1.7755,1.86799,-1.10555,-1.13854,-1.20618,-1.18736,-0.519277,-0.537213,0.600127,0.620141,0.351847,0.166665,0.644878,0.645147
173,0.940163,0.954335,0.258413,0.235182,0.780124,0.780489,0.284856,0.277202,0.771296,0.891276,0.552195,0.556076,0.0041255,-0.0163043,0.790953,0.767543,0.206803,0.259466,0.324899,0.390216,-2.21574,-2.14408,-0.0945001,-0.0542593,-1.72555,-1.81223,0.00623094,0.100504,1.6543,1.61816,-1.11965,-1.09596,0.131576,0.109686,0.786413,0.81369,-0.0542878,-0.241162,0.541617,0.547383
174,0.460434,0.473388,0.721769,0.698259,0.826535,0.827174,0.285243,0.188512,0.769404,0.871779,0.296262,0.298088,0.404863,0.385633,0.321599,0.29652,0.0425855,0.0511663,0.642661,0.593343,-0.129371,-0.0612337,-0.603393,-0.652038,0.403389,0.316093,1.47865,1.57759,0.42015,0.379672,0.560199,0.591715,1.19747,1.18217,0.627443,0.65573,1.70899,1.51607,0.150887,0.162344
175,0.661355,0.673914,0.632226,0.636948,0.0444501,0.0466887,0.107266,0.0998222,0.796301,0.852283,0.246306,0.291698,0.242068,0.288932,0.35373,0.326735,0.683808,0.693638,0.792042,0.79647,0.537169,0.602518,1.44018,1.39225,-0.37925,-0.469457,-1.22561,-1.1198,0.777934,0.738018,1.12859,1.15924,1.00635,0.986356,0.16763,0.190602,-1.64658,-1.83878,0.710864,0.72832
176,0.60564,0.617245,0.600926,0.575638,0.29509,0.29192,0.760979,0.752086,0.835972,0.832786,0.285133,0.285308,0.211641,0.192231,0.0200501,-0.0046181,0.547668,0.552665,0.649601,0.664993,-0.536893,-0.478972,-0.23075,-0.275993,-0.737546,-0.819964,0.411653,0.515851,-1.52427,-1.56875,0.767482,0.805649,-0.361734,-0.386709,0.411926,0.430336,-1.07902,-1.2521,-0.438715,-0.415817
177,0.150394,0.162147,0.0186687,-0.00539496,0.405916,0.537151,0.0510383,0.0447418,0.811349,0.813289,0.605774,0.605415,0.584941,0.563889,0.691603,0.666424,0.405076,0.411693,0.527099,0.533517,0.371671,0.429763,-0.238892,-0.29079,0.67707,0.588266,-0.466603,-0.355595,1.03921,1.00151,-0.177594,-0.137429,-0.0555879,-0.0790088,0.455277,0.469345,-0.478408,-0.665423,-0.888658,-0.861668
178,0.343818,0.349482,0.107716,0.0767336,0.778971,0.782382,0.655536,0.6475,0.913335,0.917088,0.703925,0.729784,0.4994,0.381821,0.310061,0.285154,0.236444,0.27072,0.600277,0.605545,-0.347482,-0.20209,-1.42821,-1.4873,1.32031,1.23313,1.13889,1.24898,-1.272,-1.30526,0.257244,0.291805,-0.987242,-1.01911,-0.782382,-0.762476,1.60043,1.41824,-0.481808,-0.449606
179,0.522808,0.536816,0.182306,0.158862,0.335728,0.337891,0.412479,0.404368,0.56302,0.616167,0.853655,0.854153,0.222186,0.199754,0.863444,0.838351,0.119917,0.129747,0.395175,0.467011,-0.896272,-0.833943,-0.293409,-0.349463,-0.0878185,-0.17282,0.404511,0.519706,0.99092,0.965863,-0.400912,-0.360528,0.928478,0.897619,0.88725,0.902003,1.85451,1.67354,0.702943,0.741616
180,0.0149506,0.0313237,0.554671,0.53307,0.413844,0.414363,0.55012,0.491241,0.309528,0.315246,0.46292,0.46202,0.608036,0.586507,0.188108,0.160994,0.898543,0.906759,0.247844,0.328477,-2.21013,-2.14398,1.80766,1.75844,1.02715,0.947277,0.376254,0.484061,0.704835,0.677453,-0.080768,-0.0402384,-1.99518,-2.02435,-0.709783,-0.697493,-0.44566,-0.627812,0.517092,0.552326
181,0.642979,0.656855,0.566388,0.433729,0.935577,0.937833,0.58597,0.578114,0.532331,0.535926,0.436495,0.488888,0.140242,0.120775,0.563134,0.538412,0.793723,0.799479,0.181295,0.189944,-1.83503,-1.76936,0.849459,0.793798,0.694809,0.611533,-0.72066,-0.619941,0.765788,0.744562,1.08057,1.12465,-0.0144267,-0.0480015,1.1139,1.12361,1.31987,1.12942,-0.776554,-0.74303
182,0.917848,0.933533,0.438381,0.334389,0.438698,0.443552,0.672889,0.664987,0.241375,0.32558,0.515051,0.515756,0.634243,0.612865,0.625056,0.599061,0.393721,0.400535,0.0461419,0.05141,0.35696,0.419773,0.474099,0.412132,-0.890094,-0.946887,-1.27224,-1.17826,2.64194,2.62187,0.334412,0.382586,0.272336,0.244294,0.491695,0.504573,-0.24511,-0.435488,-0.504598,-0.464939
183,0.970087,0.895527,0.258327,0.235049,0.907874,0.912134,0.204406,0.198329,0.10973,0.115234,0.279239,0.366514,0.926446,0.904021,0.0751528,0.0480829,0.884904,0.891329,0.0462251,0.0522982,-0.204561,-0.138796,-1.96136,-2.02931,-2.42203,-2.50531,-0.117169,-0.0284803,-0.97213,-0.993288,-0.635593,-0.589872,-0.253322,-0.278882,0.551802,0.557561,1.30963,1.11744,0.0652828,0.101037
184,0.843975,0.857522,0.664677,0.640722,0.962131,0.964699,0.216776,0.211451,0.933404,0.937098,0.215859,0.217272,0.0123405,-0.0114729,0.708881,0.683023,0.37866,0.386217,0.929766,0.935663,-0.00797033,0.0644751,-0.0784927,-0.143823,1.64989,1.56661,0.266237,0.349951,-0.800877,-0.819225,-0.336652,-0.287813,0.810181,0.780131,-0.880953,-0.875417,0.663335,0.478144,0.162085,0.197154
185,0.455752,0.445485,0.0161451,-0.00980121,0.0661318,0.0680664,0.440994,0.33783,0.41045,0.414084,0.36012,0.362257,0.159724,0.134317,0.743636,0.718296,0.527752,0.535607,0.0690846,0.0722869,-1.63105,-1.55085,-1.6178,-1.68619,0.112237,0.0232914,0.0638716,0.147218,-0.96817,-0.98705,-0.705795,-0.656781,-0.43023,-0.452793,0.510299,0.513013,-0.309175,-0.490234,1.02914,1.06603
186,0.0220837,0.0334491,0.797106,0.771294,0.822586,0.824534,0.470312,0.464209,0.592929,0.594121,0.0891782,0.0893347,0.943156,0.919893,0.0650805,0.0409384,0.176131,0.185995,0.222518,0.22439,-0.0281267,0.0559805,1.91453,1.84455,1.17623,1.08377,-0.647225,-0.566898,1.65609,1.63602,1.03047,1.07646,0.201697,0.17804,-0.323116,-0.285074,-0.160568,-0.342932,-0.723113,-0.689331
187,0.70695,0.719606,0.161161,0.135833,0.98832,0.990694,0.98887,0.982258,0.0685587,0.0711067,0.778112,0.780611,0.119187,0.0975023,0.742829,0.717118,0.83124,0.839647,0.79851,0.798473,-0.0287665,0.0614023,-0.316285,-0.391296,0.362279,0.178496,0.787114,0.86259,0.294569,0.271799,-1.72203,-1.67962,-0.358375,-0.375458,-1.08326,-1.08316,-0.890306,-1.0753,-0.57135,-0.53167
188,0.436638,0.450373,0.767794,0.741274,0.0424502,0.0430706,0.978243,0.969932,0.311487,0.312338,0.25665,0.260539,0.402428,0.378568,0.623493,0.595989,0.645951,0.652558,0.357834,0.357413,-2.16517,-2.07284,0.996605,0.918361,-0.640825,-0.72678,-0.0355557,0.0390333,-0.0802664,-0.0951638,1.39126,1.44283,-0.353952,-0.374346,-0.718898,-0.721536,-0.719652,-0.854153,-1.67957,-1.6458
189,0.75171,0.766875,0.266169,0.237876,0.954788,0.956877,0.36803,0.361949,0.309571,0.30979,0.0520363,0.0562676,0.325107,0.274368,0.16258,0.13458,0.734774,0.676196,0.689786,0.691038,-1.94147,-1.85395,0.129081,-0.0038292,0.648809,0.560324,0.149188,0.220089,-1.59329,-1.61059,-0.246028,-0.187217,1.31646,1.29016,0.708566,0.684038,-0.467361,-0.633004,1.19504,1.23324
190,0.695679,0.768688,0.974434,0.948297,0.113049,0.116423,0.380469,0.375071,0.954285,0.954691,0.180009,0.259208,0.106251,0.170167,0.54728,0.521192,0.691388,0.699834,0.170193,0.170777,0.00470636,0.0890456,-0.851708,-0.92602,-1.64062,-1.72685,-0.362584,-0.293368,-1.23998,-1.25224,1.16563,1.22175,1.22646,1.20084,2.09225,2.08961,-0.224045,-0.411855,-0.0131991,0.0291737
191,0.753863,0.770502,0.404538,0.376925,0.0818964,0.0828792,0.823395,0.818481,0.99655,0.996871,0.457917,0.462148,0.0888141,0.0659671,0.125031,0.0992366,0.427264,0.434976,0.758233,0.759912,0.462919,0.539501,0.0716157,-0.00475697,-0.600486,-0.68348,-0.586931,-0.512739,-0.530767,-0.524807,-1.5041,-1.45107,1.50957,1.4764,-1.381,-1.38586,-0.0057101,-0.190706,1.56459,1.60222
192,0.00425392,0.0197554,0.98375,0.957886,0.833053,0.83422,0.531356,0.580671,0.597154,0.561903,0.44034,0.443977,0.828478,0.80492,0.0686432,0.0435713,0.863707,0.869875,0.0776904,0.0788531,0.555462,0.635712,2.03745,1.95838,1.21047,1.1334,0.585591,0.653842,0.211481,0.202628,-0.248974,-0.195807,-0.507248,-0.54118,1.49382,1.48631,-0.885692,-1.06449,-0.43646,-0.40034
193,0.0799169,0.0954012,0.144787,0.117677,0.351976,0.354518,0.350021,0.342862,0.126025,0.126935,0.0894325,0.0916579,0.763651,0.740789,0.527768,0.403108,0.312433,0.320579,0.777634,0.778483,-0.391951,-0.408896,0.127426,0.0521915,1.5724,1.50087,-0.890637,-0.81736,0.278483,0.269737,0.153765,0.202772,0.409038,0.380042,0.741281,0.728332,0.491757,0.277899,-0.842933,-0.802371
194,0.903301,0.919205,0.339132,0.310457,0.180279,0.182679,0.285363,0.275922,0.615229,0.553498,0.618083,0.618335,0.272797,0.249679,0.789507,0.762644,0.804036,0.811373,0.156561,0.157783,-1.52641,-1.4535,1.66839,1.59479,1.48244,1.4076,-1.61113,-1.53148,-0.472704,-0.477581,0.942029,0.994934,0.0168046,-0.018171,1.63756,1.62511,1.80662,1.62029,1.67386,1.71266
195,0.746679,0.76144,0.14126,0.110994,0.909355,0.913674,0.472597,0.488373,0.978189,0.980062,0.33419,0.356296,0.325402,0.315606,0.909053,0.883944,0.760106,0.766667,0.288527,0.289845,0.951476,1.02035,-0.868183,-0.944522,0.930612,0.85678,-1.08711,-0.999981,0.725094,0.724752,-0.630006,-0.575833,-0.80656,-0.844216,-0.932624,-0.950409,0.162234,-0.0237197,-0.15696,-0.114942
196,0.00634169,0.0218401,0.9717,0.943217,0.616164,0.619705,0.709896,0.700824,0.109887,0.112746,0.0949145,0.0942571,0.364202,0.381533,0.210778,0.185471,0.419898,0.427412,0.749286,0.74886,-0.306285,-0.230449,-0.477871,-0.559038,0.746584,0.674932,0.3596,0.444584,-1.14424,-1.1449,-0.789629,-0.731445,0.139816,0.108673,1.11162,1.08951,-1.17105,-1.35523,0.162974,0.207934
197,0.518478,0.533759,0.891879,0.865423,0.854341,0.859758,0.457843,0.447929,0.138636,0.105898,0.835949,0.836183,0.4926,0.44746,0.276194,0.251865,0.436163,0.44238,0.641496,0.643155,-0.356672,-0.284622,-0.569129,-0.649943,-2.87113,-2.95,0.159251,0.241851,1.2277,1.22463,0.637946,0.690263,-0.0979657,-0.135005,-1.45772,-1.48601,0.242395,0.0597282,1.6986,1.74922
198,0.544023,0.558827,0.480329,0.451729,0.248666,0.255378,0.774243,0.696786,0.0585367,0.0990509,0.207603,0.206269,0.536504,0.513386,0.0325731,0.00895088,0.867932,0.872837,0.847146,0.850051,0.210111,0.202745,1.43972,1.36016,-0.295145,-0.374432,0.628891,0.711057,-0.581639,-0.582473,-1.54908,-1.49853,1.08423,1.04976,-1.66284,-1.69106,-0.0388347,-0.224298,0.332212,0.377671
199,0.215826,0.229113,0.827283,0.797905,0.152174,0.159395,0.956025,0.945642,0.0905005,0.0922036,0.138635,0.138189,0.863617,0.840703,0.378963,0.38334,0.180491,0.187398,0.337926,0.339142,0.618061,0.690112,-1.08618,-1.16462,0.97668,0.897662,0.298455,0.383376,2.14315,2.14254,0.630942,0.688026,-1.03295,-1.06289,0.747656,0.720022,-0.983672,-1.16389,0.132433,0.173328
200,0.626861,0.642435,0.0905039,0.0622632,0.730999,0.73754,0.499379,0.506402,0.982105,0.981863,0.881828,0.880115,0.207071,0.183255,0.781267,0.75773,0.511213,0.517937,0.110623,0.11318,-0.414558,-0.346038,0.275187,0.190779,1.00491,0.928306,-0.970739,-0.888006,-0.0956734,-0.098527,0.3616,0.411113,-0.626333,-0.663941,-0.201313,-0.236242,0.496279,0.311994,0.305483,0.345776
201,0.70932,0.723081,0.234892,0.205814,0.0446445,0.0485886,0.0755864,0.067162,0.456908,0.458849,0.00265777,0.00228954,0.884663,0.860745,0.868793,0.863368,0.0663807,0.0733606,0.796292,0.79731,1.34746,1.41214,1.34544,1.25393,1.49382,1.41752,-1.86525,-1.78826,0.665365,0.657027,-2.56367,-2.52031,0.929914,0.889886,0.447033,0.416983,0.324216,0.0965932,0.702318,0.742509
202,0.280289,0.292319,0.723119,0.693513,0.0363235,0.0400581,0.592595,0.585211,0.397309,0.521902,0.082734,0.0831117,0.806655,0.781409,0.994211,0.969007,0.380427,0.45107,0.31166,0.311365,-0.232906,-0.175404,-0.82148,-0.916654,-0.488057,-0.564399,-0.16718,-0.0905204,-0.569823,-0.581457,-0.0695166,-0.0268187,-1.17275,-1.20735,-0.00502107,-0.0323733,0.073184,-0.118808,0.852831,0.900169
203,0.37191,0.30701,0.514981,0.483928,0.512331,0.518241,0.408081,0.466058,0.531599,0.584954,0.635556,0.634797,0.147177,0.123961,0.0994674,0.0766882,0.821768,0.82878,0.891878,0.8907,-0.0890799,-0.0327303,0.609312,0.515701,0.401199,0.327473,-0.496056,-0.418201,-1.34541,-1.35803,-0.488003,-0.443151,-0.469662,-0.500304,-1.31359,-1.34375,0.968013,0.77624,0.177168,0.227465
204,0.310169,0.321701,0.0610611,0.0307104,0.124385,0.128761,0.356042,0.346906,0.646065,0.648007,0.810988,0.809571,0.323657,0.300422,0.488104,0.495729,0.109318,0.118383,0.413262,0.410138,1.09698,1.15342,-0.960407,-1.05658,0.867399,0.786348,0.559092,0.638344,-1.32364,-1.33692,0.655849,0.703898,0.598596,0.572178,-1.92229,-1.94683,-0.962478,-1.15633,1.5569,1.59966
205,0.103797,0.112856,0.883812,0.853686,0.789684,0.793478,0.705342,0.695693,0.301553,0.304432,0.664279,0.661553,0.838315,0.816707,0.93951,0.914769,0.718782,0.730001,0.199961,0.194838,1.23414,1.2961,-0.837685,-0.933327,1.56048,1.47831,0.0424133,0.124887,0.627586,0.618336,-0.315343,-0.26856,2.21276,2.1891,0.818167,0.785094,1.28587,1.08726,-0.181144,-0.138397
206,0.77588,0.784078,0.249824,0.218225,0.293916,0.299197,0.693106,0.683367,0.397616,0.399323,0.136212,0.131634,0.789958,0.755343,0.513427,0.48831,0.106861,0.119748,0.896379,0.889101,0.357849,0.413445,0.961555,0.871059,-0.505007,-0.584331,2.19989,2.28024,-0.0101291,-0.0218585,1.3675,1.41911,-1.18509,-1.20835,-0.19014,-0.216652,1.21699,1.02048,-0.973838,-0.931062
207,0.0552788,0.0646162,0.255441,0.147876,0.809862,0.81321,0.377587,0.365412,0.222774,0.222691,0.409571,0.406631,0.819682,0.693978,0.418765,0.392001,0.361051,0.356095,0.248435,0.242942,-1.07909,-1.02222,-1.02809,-1.12407,-0.00859472,-0.123607,1.80948,1.89057,2.6708,2.65486,-1.16459,-1.11101,-0.443027,-0.471282,-1.39908,-1.43332,-1.7888,-1.98223,1.72017,1.766
208,0.160274,0.180794,0.0886825,0.0775263,0.80306,0.80468,0.54345,0.530253,0.957489,0.955443,0.150566,0.148643,0.654398,0.632614,0.743919,0.718405,0.581193,0.592443,0.328111,0.366798,-0.473548,-0.418681,0.107067,0.0137627,0.418585,0.337117,1.09933,1.17645,-0.656443,-0.679984,0.1885,0.142827,0.692757,0.666609,0.784007,0.747071,0.941519,0.747932,0.262252,0.302783
209,0.297022,0.296971,0.0387759,0.00717705,0.238872,0.240422,0.469862,0.507816,0.0425697,0.0400485,0.566265,0.563217,0.0801534,0.0604146,0.607432,0.582025,0.130392,0.142646,0.496588,0.490654,-0.873779,-0.822395,0.0297704,-0.0607025,1.4516,1.36764,1.24812,1.32721,1.47926,1.45558,1.34307,1.39666,-2.06701,-2.09028,0.93401,0.894561,-0.876964,-1.07609,0.028475,0.0686349
210,0.477804,0.413148,0.98827,0.956043,0.177357,0.180165,0.496472,0.485378,0.581287,0.518633,0.582557,0.578837,0.625829,0.60668,0.119542,0.0958568,0.960121,0.971146,0.978143,0.974355,0.101423,0.148856,-0.281587,-0.366874,0.132218,0.0557467,-0.516839,-0.440275,-0.556391,-0.578827,0.373896,0.424202,-1.90016,-1.92212,-1.21496,-1.2584,-2.33517,-2.53086,-1.44924,-1.40846
211,0.519988,0.529326,0.720496,0.689798,0.94923,0.951392,0.94987,0.93846,0.999739,0.997218,0.674851,0.594457,0.848297,0.82776,0.516187,0.492494,0.264767,0.274991,0.322033,0.318051,-1.52614,-1.48054,0.0267903,-0.0569911,1.7673,1.69844,-0.00445322,0.0748151,-0.939072,-0.96115,0.851476,0.901446,-0.607595,-0.628871,-2.662,-2.70545,1.20686,1.00611,-0.0356487,0.0106782
212,0.150312,0.159574,0.229603,0.196884,0.0659522,0.0655356,0.550894,0.541615,0.0838222,0.0818235,0.738343,0.610077,0.148833,0.126616,0.271191,0.24958,0.278514,0.291885,0.105907,0.102751,0.040629,0.0794317,1.34044,1.25267,0.570904,0.509309,-1.98772,-1.90543,-0.095911,-0.112204,0.303154,0.306017,-0.563874,-0.582972,-0.126958,-0.173532,-0.265091,-0.466421,2.06064,2.10849
213,0.833682,0.840781,0.759967,0.729036,0.250783,0.325674,0.485959,0.474674,0.742712,0.742209,0.624135,0.625696,0.510106,0.489076,0.88142,0.859354,0.299703,0.308779,0.225845,0.224199,0.018123,0.0559571,0.387878,0.304267,-0.215132,-0.27624,0.8289,0.91294,0.0748823,0.0618594,-0.338198,-0.289412,0.773729,0.758674,0.348171,0.294998,2.00254,1.79546,-0.182834,-0.128686
214,0.577776,0.590711,0.542352,0.509657,0.587286,0.585812,0.857606,0.848516,0.492021,0.446771,0.644364,0.641316,0.273932,0.25276,0.925269,0.904743,0.0296187,0.0399074,0.763605,0.763592,0.235827,0.274844,0.240686,0.154577,1.14399,1.08773,-0.0306269,0.0572381,-0.18811,-0.199,1.13163,1.18024,-0.047733,-0.0673709,2.07648,2.02176,0.404426,0.200034,-0.848156,-0.801391
215,0.331175,0.340642,0.665502,0.57692,0.0757324,0.072248,0.151183,0.141171,0.154462,0.151334,0.171376,0.166353,0.810502,0.78916,0.707889,0.687656,0.329004,0.339859,0.593709,0.593412,1.23425,1.27705,-0.382601,-0.469955,-1.40305,-1.45362,0.318258,0.40563,0.382866,0.372928,-1.48462,-1.44147,0.487678,0.469718,-0.0563511,-0.112554,-0.160272,-0.334881,0.370557,0.419359
216,0.986883,0.997035,0.767181,0.644183,0.36598,0.425421,0.49507,0.565769,0.966855,0.96339,0.146367,0.143177,0.397298,0.378042,0.261148,0.241344,0.0644306,0.0750006,0.998364,0.997717,0.556877,0.59504,1.03774,0.947862,1.80813,1.76257,-1.33089,-1.23827,-1.34864,-1.35741,-1.33923,-1.29094,-0.387835,-0.407028,0.529151,0.415669,-0.667063,-0.869796,-0.574294,-0.524606
217,0.00165742,0.0128084,0.745837,0.711446,0.781463,0.778594,0.998349,0.990368,0.483057,0.479708,0.604258,0.601408,0.526335,0.508562,0.569264,0.547931,0.719686,0.728653,0.883699,0.881925,-0.368919,-0.334206,0.932891,0.842392,0.138341,0.0963931,0.0560349,0.142523,-2.39515,-2.41126,-1.85595,-1.80154,-0.449436,-0.466823,1.0029,0.943892,0.281098,0.0741454,-0.0632883,-0.0203758
218,0.0293555,0.0378767,0.669394,0.633652,0.47361,0.469468,0.977,0.968462,0.508388,0.507103,0.851135,0.849516,0.989677,0.969871,0.394154,0.371092,0.265552,0.27407,0.524731,0.520825,0.777646,0.820274,-2.53799,-2.62714,-0.946286,-0.984712,1.72762,1.80873,0.315206,0.298353,-1.17147,-1.1142,0.323532,0.300274,0.0281314,-0.0284272,0.159124,-0.0881293,-0.696582,-0.646296
219,0.489652,0.500103,0.958778,0.92452,0.989729,0.983482,0.328418,0.32083,0.88417,0.884768,0.723259,0.720926,0.495938,0.474069,0.589126,0.567771,0.302793,0.312515,0.440186,0.506219,-1.9535,-1.9128,1.20608,1.12068,0.70528,0.6719,-0.480991,-0.403351,-1.35636,-1.37084,0.565274,0.619044,0.463938,0.351219,-0.536489,-0.600044,0.0431489,-0.250404,-0.647667,-0.593463
220,0.738959,0.751219,0.376386,0.343487,0.160705,0.15367,0.336162,0.328705,0.533849,0.474659,0.0024194,-0.000285255,0.595139,0.542959,0.220906,0.200984,0.0290989,0.0386213,0.495283,0.491613,-1.41419,-1.36985,0.154926,0.0628414,1.36476,1.33123,-1.87171,-1.79831,-0.768659,-0.784796,0.580418,0.63341,0.429585,0.402164,0.348986,0.281946,-0.205726,-0.412679,0.367786,0.427988
221,0.536267,0.547353,0.412684,0.286771,0.905178,0.89983,0.624228,0.619158,0.0658256,0.0645494,0.231295,0.168479,0.564865,0.611849,0.723487,0.702218,0.564562,0.573213,0.0641401,0.0609442,0.941219,0.992535,-1.97327,-2.05842,-0.80101,-0.828417,-0.868187,-0.801098,1.32033,1.30105,-0.356519,-0.227572,0.0725401,0.0493883,-0.658403,-0.7198,-0.590882,-0.804042,-0.26189,-0.197933
222,0.122507,0.13199,0.263083,0.230054,0.12308,0.119345,0.593822,0.587146,0.0184543,0.112327,0.339774,0.337242,0.702609,0.68074,0.274647,0.251395,0.463514,0.472286,0.81825,0.81601,-0.451484,-0.395247,-0.476859,-0.563869,0.914367,0.893969,0.692909,0.756396,0.425538,0.371373,-1.14385,-1.08855,0.532252,0.510255,-0.0401476,-0.0982769,1.14059,0.922767,-0.150418,-0.0848039
223,0.188276,0.19732,0.535112,0.50109,0.826507,0.824838,0.839354,0.832369,0.135424,0.160105,0.508711,0.506006,0.503802,0.481082,0.14241,0.119607,0.361028,0.371359,0.711551,0.710305,0.671494,0.726518,-2.37981,-2.47006,-0.115526,-0.141235,1.74848,1.81294,-0.530648,-0.558308,-0.217953,-0.170054,1.32629,1.30717,1.52768,1.47392,0.527761,0.313272,-0.570618,-0.501371
224,0.614126,0.625184,0.226856,0.190499,0.263523,0.26058,0.444655,0.435524,0.210521,0.207883,0.421391,0.335392,0.787014,0.704133,0.221014,0.196024,0.903247,0.912035,0.862728,0.781805,1.43154,1.48416,0.414905,0.318998,1.07169,1.04062,1.0374,1.09882,-0.255184,-0.277258,-1.47965,-1.43365,1.88956,1.87714,-1.0517,-1.1016,0.633882,0.415911,-0.450942,-0.377148
225,0.125933,0.13859,0.467611,0.432617,0.0229343,0.0222155,0.54158,0.534746,0.781346,0.776623,0.169315,0.164778,0.949974,0.927184,0.663572,0.638261,0.688361,0.698648,0.844563,0.853306,1.43476,1.48958,2.34706,2.24983,-2.23173,-2.26833,0.80454,0.864707,-1.29494,-1.31627,0.735454,0.784202,0.135479,0.125742,0.984213,0.938317,0.485614,0.269708,1.29202,1.36381
226,0.954028,0.967158,0.0572544,0.0232104,0.415307,0.412557,0.0622791,0.0578953,0.86463,0.860462,0.571627,0.568654,0.640626,0.6155,0.642273,0.617917,0.0135431,0.023656,0.923886,0.924806,-0.95604,-0.895717,0.176077,0.0713629,1.05991,1.02176,0.331013,0.396688,-0.0647874,-0.0827715,0.518425,0.568557,-1.13778,-1.15553,-0.504223,-0.553592,0.0152653,-0.199944,-1.28828,-1.22279
227,0.838102,0.853117,0.560962,0.526022,0.805626,0.802899,0.783296,0.781629,0.327027,0.322309,0.514327,0.476513,0.819799,0.796257,0.0506609,0.0265942,0.683008,0.691342,0.404469,0.404545,-0.128936,-0.0644618,-2.00986,-2.1071,2.18493,2.14185,-1.14787,-1.07451,-0.64832,-0.662532,0.783445,0.826995,-0.464534,-0.480358,-0.660898,-0.711552,-2.60085,-2.81157,-0.518396,-0.459797
228,0.259014,0.272305,0.331982,0.296126,0.876559,0.874018,0.970723,0.967133,0.907203,0.902045,0.388796,0.384371,0.702817,0.681844,0.886761,0.860191,0.607994,0.616398,0.273299,0.307652,0.468451,0.539077,-1.052,-1.15434,1.32647,1.30536,2.67356,2.75077,0.654937,0.647448,-0.610478,-0.56216,1.6816,1.66131,1.80044,1.7502,0.897327,0.679717,-0.820808,-0.770524
229,0.424336,0.437289,0.333251,0.295748,0.451277,0.449519,0.357099,0.35412,0.460149,0.454034,0.842544,0.837692,0.339765,0.356851,0.247194,0.21924,0.868063,0.878057,0.200034,0.210758,0.223416,0.30604,-1.12915,-1.22881,0.518453,0.468871,0.183403,0.267375,-0.486172,-0.496218,-0.0785563,-0.0261207,-0.0141674,-0.0277406,0.435046,0.379994,0.16907,0.00157755,0.249519,0.295476
230,0.897914,0.909179,0.671275,0.63189,0.960736,0.95775,0.442728,0.425182,0.230238,0.222471,0.799254,0.795725,0.0533739,0.031859,0.831826,0.802653,0.846663,0.857201,0.113308,0.113864,-0.00335943,0.0730035,-0.423052,-0.52098,0.896459,0.816869,-1.03246,-0.943335,-1.02751,-0.966225,1.33606,1.38284,2.79074,2.77939,-1.45798,-1.51763,-0.45373,-0.676562,0.995709,1.04391
231,0.760617,0.686677,0.679526,0.738591,0.279438,0.278043,0.414203,0.496244,0.729233,0.720396,0.353022,0.349675,0.10877,0.085133,0.102635,0.0724355,0.62278,0.633747,0.948929,0.947732,0.332462,0.447016,-0.99491,-1.19174,1.21687,1.16487,0.853395,0.946216,-1.43197,-1.43623,-1.49936,-1.45215,-1.37534,-1.38669,0.0913956,0.038818,1.04712,0.829014,0.454546,0.505681
232,0.451851,0.464174,0.884209,0.845292,0.64566,0.557944,0.572489,0.567307,0.532379,0.55824,0.530301,0.528777,0.706164,0.681126,0.23999,0.122426,0.824042,0.834225,0.0322205,0.0311936,0.741576,0.821029,-1.76059,-1.8625,0.471707,0.426911,0.688983,0.788527,-1.57411,-1.57373,0.563926,0.608858,0.640481,0.621642,-0.37643,-0.42631,-0.278218,-0.502494,-1.16813,-1.11045
233,0.665503,0.675503,0.152529,0.114739,0.84047,0.837845,0.078172,0.0745958,0.406796,0.396083,0.168473,0.16705,0.761802,0.713412,0.200952,0.172417,0.56166,0.594656,0.357266,0.354929,2.17554,2.25594,-2.17051,-2.27298,0.813811,0.764687,-0.49017,-0.390489,0.00682436,0.00940034,1.41355,1.46524,0.653728,0.636177,0.384723,0.332606,-0.00619003,-0.232038,-0.720806,-0.667141
234,0.209562,0.220405,0.395935,0.356858,0.177395,0.174419,0.446577,0.443216,0.704035,0.693659,0.78498,0.782719,0.769072,0.745699,0.789997,0.760352,0.216461,0.355087,0.134735,0.134279,0.528976,0.608292,0.207347,0.110533,0.354021,0.307153,1.18726,1.29256,-1.17812,-1.17896,3.79646,3.84219,0.0661771,0.0512232,0.213048,0.158834,0.0267767,-0.205402,1.48355,1.54378
235,0.546975,0.557505,0.966048,0.928241,0.0584616,0.0532393,0.58925,0.588261,0.0845955,0.0742668,0.175118,0.173237,0.137201,0.113621,0.58798,0.606482,0.106294,0.115518,0.270681,0.241055,-0.500548,-0.427859,1.06298,0.971118,0.382145,0.337797,-1.25228,-1.1414,0.100004,0.0999709,-1.26871,-1.22299,-0.18629,-0.207197,-1.11957,-1.1669,-0.273819,-0.506149,0.403833,0.483922
236,0.175974,0.187753,0.560144,0.602556,0.967602,0.963009,0.353007,0.350654,0.154432,0.143439,0.616753,0.616442,0.51346,0.474769,0.482231,0.452612,0.412764,0.421294,0.260911,0.347832,0.803213,0.881202,0.600665,0.514343,-1.34509,-1.39179,0.705881,0.812034,-2.04239,-2.04686,0.449125,0.4953,0.589682,0.576506,0.562815,0.514725,0.0518902,-0.187571,-0.632585,-0.575937
237,0.431908,0.387096,0.314497,0.276872,0.497672,0.493277,0.611089,0.611482,0.961451,0.950338,0.529245,0.528572,0.860107,0.835918,0.0748244,0.0453933,0.938664,0.946511,0.4794,0.454608,-0.178413,-0.0923831,-0.754395,-0.840185,0.0721342,0.0325479,-0.983569,-0.878676,-0.933157,-0.938743,0.0735,0.126332,-0.801731,-0.812161,-0.110171,-0.152535,-0.173636,-0.410998,0.406114,0.395308
238,0.687414,0.586439,0.449286,0.433172,0.552418,0.543421,0.4018,0.428538,0.697871,0.688034,0.981732,0.981893,0.106701,0.0812405,0.43983,0.41248,0.629179,0.637452,0.445067,0.561384,-0.181316,-0.101663,0.0993335,0.0204008,-1.13716,-1.17303,-0.924214,-0.82029,-1.82982,-1.83848,0.7059,0.754665,0.759959,0.75521,-0.323626,-0.359005,-2.4469,-2.69127,1.30623,1.36655
239,0.836207,0.785782,0.559692,0.589473,0.473672,0.593564,0.244548,0.245593,0.768705,0.667072,0.692608,0.761573,0.108927,0.0760419,0.0845701,0.0555237,0.779782,0.786841,0.668616,0.66816,-1.56898,-1.48945,0.616779,0.544436,-0.749519,-0.789996,1.11105,1.21237,0.353988,0.348136,0.404716,0.363644,1.10716,1.10906,-0.524933,-0.565475,0.198007,-0.0561116,-1.35264,-1.29037
240,0.973346,0.985125,0.708828,0.745773,0.592004,0.643708,0.678937,0.679009,0.652937,0.646111,0.539057,0.541252,0.262747,0.0708432,0.978862,0.950926,0.292991,0.301939,0.373349,0.372753,0.358667,0.436209,0.263234,0.19447,0.67684,0.634339,-0.609413,-0.512257,0.00190001,-0.00294699,0.0326748,-0.0273764,0.450809,0.401067,-0.0447568,-0.0807848,-0.821046,-1.07254,-0.54799,-0.482104
241,0.0803531,0.0906473,0.939698,0.902073,0.683343,0.693851,0.293075,0.292288,0.98141,0.973484,0.93551,0.935474,0.136175,0.0656446,0.844854,0.819139,0.239243,0.246374,0.960323,0.961887,1.23743,1.31269,-1.50863,-1.58218,0.378925,0.329821,1.21719,1.3151,-1.07689,-1.08706,-0.461806,-0.418397,-0.309279,-0.306929,-0.845167,-0.884017,1.83508,1.58795,1.69582,1.76207
242,0.769437,0.781367,0.378279,0.339885,0.74839,0.743995,0.452926,0.451912,0.370666,0.363983,0.890003,0.888285,0.0859065,0.0604459,0.160501,0.136963,0.540816,0.546326,0.082207,0.0828946,-1.01529,-0.932634,-0.287442,-0.361806,-1.07295,-1.12089,-0.582018,-0.483082,0.854544,0.837658,-1.6428,-1.60452,-0.755139,-0.752978,-1.90922,-1.94635,-0.266886,-0.519719,1.16298,1.22384
243,0.250155,0.260726,0.594465,0.557216,0.335725,0.329569,0.224757,0.223742,0.927213,0.918477,0.15448,0.153682,0.511632,0.487078,0.625211,0.603869,0.614842,0.619984,0.564677,0.566596,-1.18595,-1.10837,-0.257712,-0.433265,-1.17175,-1.2274,-1.10137,-0.996538,0.789394,0.77802,0.193454,0.236644,-0.79454,-0.797801,0.215747,0.170286,-0.9092,-1.15901,0.208205,0.265265
244,0.769114,0.777333,0.553621,0.449052,0.266694,0.328427,0.400319,0.398796,0.128041,0.117775,0.166662,0.165494,0.0842184,0.062073,0.547306,0.527162,0.176843,0.180778,0.110217,0.11038,0.415341,0.498461,-0.422912,-0.504723,1.12685,1.06659,-0.635668,-0.527333,-0.0148628,-0.0301326,0.85943,0.91159,0.921225,0.912216,-1.02653,-1.07649,0.394744,0.142889,0.090232,0.151788
245,0.749252,0.734467,0.376617,0.340887,0.232468,0.327285,0.0970216,0.0963641,0.18177,0.262921,0.391018,0.389525,0.172099,0.151707,0.701815,0.68456,0.291242,0.295341,0.673172,0.673768,1.02988,1.11764,-0.143026,-0.225456,0.759287,0.699786,0.879855,0.981054,0.409176,0.388484,0.250579,0.277335,-1.1847,-1.20044,0.0678148,0.0203057,-0.7094,-0.964383,-1.13158,-1.06791
246,0.681666,0.691601,0.736309,0.701,0.314112,0.326142,0.11496,0.165099,0.42116,0.408068,0.235162,0.295194,0.813711,0.792994,0.254604,0.238248,0.845985,0.850555,0.492536,0.493429,-0.903101,-0.81166,-1.17503,-1.25326,-0.380909,-0.341105,1.68619,1.79053,0.141719,0.113749,-0.406326,-0.35692,0.278323,0.263129,-2.73349,-2.7811,0.471869,0.213904,0.0312041,0.0911474
247,0.0363676,0.0454139,0.620081,0.582952,0.331156,0.325,0.235163,0.233834,0.949419,0.937093,0.20271,0.200862,0.0974758,0.0752146,0.603465,0.585493,0.458505,0.460508,0.757364,0.756458,-0.158179,-0.0703865,-0.282249,-0.361506,-1.32365,-1.382,-1.26019,-1.155,0.151483,0.18472,-0.496315,-0.548932,0.737927,0.723996,-0.547394,-0.588302,-0.186076,-0.440407,-1.16984,-1.11292
248,0.221667,0.231444,0.925085,0.889411,0.0531221,0.046417,0.0909741,0.0922987,0.798204,0.786138,0.974115,0.974073,0.315913,0.353594,0.145794,0.129039,0.386485,0.390164,0.783264,0.782751,-0.239669,-0.156563,-1.17804,-1.26366,0.681296,0.619404,0.498374,0.607125,0.282682,0.25569,-0.784994,-0.740944,0.226479,0.217845,-0.92961,-0.975745,0.197594,-0.0584248,0.209875,0.259274
249,0.652622,0.664406,0.203212,0.16951,0.683716,0.674914,0.595705,0.594633,0.274643,0.263124,0.0578859,0.0588118,0.656073,0.631972,0.53666,0.480106,0.00450671,0.00569753,0.327806,0.326535,-0.755702,-0.671205,-0.252766,-0.314618,0.782759,0.725905,-0.687251,-0.571891,0.887033,0.856673,1.15465,1.20365,-1.73136,-1.73785,0.378201,0.333243,-0.79707,-1.05797,-0.371504,-0.3222
250,0.371466,0.455379,0.424417,0.355274,0.962919,0.956199,0.483277,0.48217,0.798407,0.786644,0.170928,0.172595,0.321828,0.296813,0.849064,0.831173,0.157437,0.160666,0.235626,0.314672,-0.862072,-0.773041,0.713146,0.63442,1.30815,1.24694,0.831528,0.951339,0.943251,1.00446,0.823102,0.865233,-0.757575,-0.770498,0.614452,0.572977,-0.488833,-0.755059,2.49591,2.53835
251,0.233691,0.246351,0.576436,0.541038,0.320081,0.311908,0.0206619,0.0207052,0.941589,0.931098,0.737867,0.739024,0.593802,0.512735,0.0560129,0.039439,0.879317,0.883198,0.30573,0.302809,0.561741,0.646145,0.163725,0.0847792,2.81013,2.7482,0.0309503,0.0981825,1.18226,1.15224,-1.02867,-0.982744,0.689192,0.676456,-0.301534,-0.336322,-0.555746,-0.821835,-0.444869,-0.410009
252,0.165928,0.208346,0.0589123,0.0233949,0.657001,0.649071,0.956866,0.958932,0.832018,0.819467,0.610728,0.677256,0.750437,0.728657,0.671814,0.654352,0.0547325,0.0590246,0.814436,0.811311,0.388055,0.492787,0.193411,0.117568,0.998463,0.937776,-0.867793,-0.754974,-1.3878,-1.42289,-0.561704,-0.521175,-1.79567,-1.80537,0.842486,0.805047,-0.0395368,-0.299381,-1.40254,-1.36858
253,0.159758,0.17034,0.337315,0.299634,0.610919,0.604799,0.492638,0.497467,0.351969,0.340512,0.650054,0.615488,0.628767,0.608893,0.0717356,0.053298,0.791082,0.795782,0.133877,0.130252,0.260672,0.339429,-0.647593,-0.724449,-0.399103,-0.453436,-0.839367,-0.729073,2.7641,2.72891,2.22357,2.26855,1.195,1.17761,-1.92984,-1.97417,-0.220503,-0.476954,0.0740189,0.11341
254,0.661994,0.67247,0.14857,0.148699,0.0229476,0.0160578,0.295605,0.383664,0.610422,0.597363,0.552564,0.55372,0.926239,0.906051,0.644336,0.626915,0.165197,0.170969,0.697767,0.693641,-1.01233,-0.926102,-0.749169,-0.893972,1.11105,1.06268,-1.71963,-1.61548,-1.17406,-1.20926,0.121545,0.171455,1.06506,1.04124,-1.43612,-1.47426,1.91711,1.65938,-0.709092,-0.664375
255,0.949157,0.959316,0.0380897,-0.00223657,0.0553007,0.0359739,0.202042,0.269861,0.483968,0.484575,0.096406,0.0978917,0.551691,0.476209,0.465336,0.480726,0.838098,0.843758,0.715103,0.762199,-1.35263,-1.26806,-0.991471,-1.0635,0.826153,0.773226,-0.988368,-0.88243,-1.37115,-1.40807,-0.950675,-0.907715,-0.0856502,-0.112482,-0.502212,-0.630381,0.215633,-0.0485894,-2.46326,-2.41973
256,0.621046,0.629602,0.79593,0.753266,0.0639443,0.05589,0.151001,0.156059,0.38255,0.371786,0.242962,0.250431,0.06718,0.0463677,0.358008,0.334536,0.893458,0.897914,0.928753,0.830757,0.959246,1.04397,0.54174,0.464218,0.219736,0.172008,1.30772,1.41358,-1.97799,-2.01869,0.179827,0.225161,0.0506108,0.0249918,0.255742,0.213501,0.395796,0.129203,1.03626,1.08172
257,0.0179445,0.0284328,0.405102,0.41097,0.883635,0.876672,0.228415,0.325523,0.851604,0.839606,0.264094,0.40297,0.0968153,0.0741792,0.205528,0.188347,0.555015,0.558659,0.902552,0.899314,0.286001,0.37908,-1.46277,-1.53091,0.0884819,0.0370583,0.394746,0.495277,0.700793,0.658028,0.228295,0.281734,0.814848,0.792089,0.544904,0.500185,0.832958,0.572461,-0.138163,-0.0927068
258,0.721872,0.733775,0.110181,0.0686745,0.579644,0.602452,0.469709,0.494986,0.550287,0.537072,0.552587,0.55551,0.540322,0.51594,0.879951,0.864527,0.715894,0.775327,0.469362,0.468645,-0.101254,-0.00903969,-0.424244,-0.486554,0.909892,0.852456,0.620064,0.723766,0.401237,0.35333,0.296323,0.338307,0.357432,0.259835,0.371547,0.326414,-0.36466,-0.631687,0.67967,0.730247
259,0.0536944,0.0675189,0.445073,0.404816,0.332694,0.328233,0.659393,0.66445,0.00986473,-0.00108179,0.297374,0.302519,0.376446,0.352123,0.0674475,0.0527506,0.989979,0.991995,0.921735,0.923105,-1.64375,-1.5498,-0.780828,-0.836519,-0.968784,-1.01866,0.179354,0.286501,-0.748253,-0.790336,0.771503,0.815551,-0.245868,-0.272419,-0.229986,-0.276668,-0.334954,-0.579304,-3.02532,-2.97768
260,0.519175,0.534185,0.172467,0.134064,0.446939,0.440027,0.967099,0.974173,0.489948,0.476828,0.377003,0.383341,0.663981,0.632699,0.369135,0.403818,0.0594509,0.0626966,0.544187,0.546928,-0.734583,-0.641069,-0.696852,-0.758341,1.48202,1.43675,1.49305,1.60472,0.178699,0.13531,-0.971565,-0.923116,0.583114,0.555115,0.606055,0.560136,-0.201278,-0.526921,0.304376,0.358085
261,0.0653563,0.0790875,0.864605,0.82373,0.267141,0.258242,0.404633,0.410436,0.253011,0.23988,0.727407,0.734227,0.93616,0.913275,0.77067,0.754885,0.343951,0.30919,0.625329,0.628548,1.25896,1.34739,1.39398,1.32992,0.452148,0.401546,1.30178,1.41493,-0.329467,-0.368817,0.371274,0.423191,0.0627342,0.0319394,-0.511174,-0.564935,-0.207512,-0.474539,0.872689,0.995556
262,0.97718,0.992545,0.379435,0.34044,0.785893,0.777147,0.637101,0.686752,0.287216,0.280833,0.443523,0.451474,0.61219,0.639909,0.099257,0.0829869,0.552283,0.555684,0.362524,0.367442,0.0225029,0.113451,-0.770473,-0.840666,-0.346789,-0.399876,-1.04471,-0.932837,-1.11012,-1.14539,0.159105,0.207546,-0.158384,-0.195982,-0.412067,-0.462887,1.04057,0.780302,1.5857,1.63303
263,0.329056,0.346358,0.32295,0.193548,0.0914803,0.0831593,0.959908,0.963067,0.333872,0.321786,0.743326,0.752865,0.475807,0.366543,0.927758,0.910875,0.608078,0.567277,0.368603,0.332208,-0.642567,-0.551443,-0.212175,-0.287179,0.353715,0.306908,-0.476152,-0.371303,-1.31436,-1.3442,-3.08095,-3.02815,-0.837668,-0.870581,-0.895803,-0.943118,1.40681,1.14593,-0.27652,-0.230058
264,0.743274,0.759679,0.0840844,0.0466565,0.540661,0.532414,0.902367,0.836932,0.972581,0.960991,0.361953,0.37138,0.116062,0.093177,0.629302,0.613941,0.576617,0.57887,0.29238,0.296974,-1.73456,-1.64958,0.67793,0.604571,-0.251801,-0.294311,1.56601,1.67636,0.491253,0.45531,0.865388,0.913778,-0.811677,-0.839679,-1.02048,-1.07191,0.335308,0.0684673,0.111536,0.15097
265,0.171379,0.189059,0.248105,0.163025,0.00367559,-0.00665621,0.706302,0.710797,0.0662868,0.0567582,0.676131,0.686958,0.312455,0.26078,0.11884,0.102671,0.939305,0.939791,0.980924,0.98555,0.752962,0.838631,0.149597,0.0711374,-1.9552,-1.9942,0.67023,0.776108,0.634697,0.59705,1.22175,1.2664,-0.536495,-0.564119,0.155235,0.101645,-1.81155,-2.08664,-0.555483,-0.521735
266,0.939725,0.959537,0.313814,0.279394,0.277017,0.264612,0.881589,0.885851,0.413076,0.403493,0.525763,0.53894,0.574949,0.428383,0.469636,0.455023,0.693075,0.668804,0.459885,0.465289,0.778405,0.859927,0.354402,0.27311,0.113748,0.0712713,0.902086,1.0046,0.455217,0.413718,1.24835,1.29668,-1.76673,-1.79704,-0.85683,-0.916457,-0.415435,-0.686916,-0.298189,-0.260337
267,0.254957,0.27281,0.0202428,-0.015918,0.326807,0.317177,0.152094,0.158209,0.0530782,0.0444142,0.599569,0.70997,0.725007,0.595986,0.367046,0.439255,0.396864,0.397817,0.227378,0.234472,-0.5361,-0.367788,-0.995869,-1.08142,-0.266765,-0.309941,-0.185337,-0.0840364,-1.40599,-1.44389,-0.916519,-0.860428,-0.816002,-0.892021,1.69772,1.63124,1.42371,1.14937,0.404991,0.44687
268,0.123849,0.222886,0.632159,0.594415,0.976668,0.966069,0.54178,0.546979,0.00947663,-1.98199e-05,0.867358,0.881,0.786474,0.763589,0.436212,0.423488,0.49075,0.419152,0.702745,0.708476,-1.67702,-1.5955,-1.09299,-1.17232,-1.03373,-1.08064,1.35995,1.45553,-1.15519,-1.19317,-1.24838,-1.19884,0.0397558,0.0130021,-0.400904,-0.470197,-0.496202,-0.768801,1.11881,1.15408
269,0.160083,0.172962,0.787406,0.698434,0.503715,0.491093,0.686337,0.692023,0.819638,0.812037,0.66704,0.682231,0.730499,0.696241,0.918833,0.905517,0.439747,0.440487,0.212489,0.217798,-0.410278,-0.331246,1.26173,1.17889,0.335275,0.283334,-0.279065,-0.188374,1.32623,1.28749,0.294994,0.347813,-1.70828,-1.7384,-3.21734,-3.28563,-0.0981065,-0.371902,0.709299,0.737509
270,0.105185,0.123037,0.838318,0.802452,0.394743,0.379561,0.0439676,0.049774,0.0149124,0.00589124,0.157181,0.172364,0.539414,0.628893,0.66203,0.648697,0.151855,0.151336,0.794798,0.802086,-0.148268,-0.0250145,-1.29057,-1.37808,-2.17085,-2.22531,1.94441,2.03579,-0.195272,-0.227933,-0.762198,-0.717016,0.244594,0.206758,-0.416293,-0.486564,1.13277,0.851673,-1.63984,-1.6159
271,0.368562,0.384961,0.168213,0.131434,0.667153,0.650829,0.596618,0.602352,0.913595,0.907053,0.370206,0.38545,0.584087,0.561546,0.89194,0.877998,0.312932,0.237841,0.438992,0.4463,0.201788,0.281217,2.59726,2.5049,1.12751,1.07366,0.290994,0.374195,-2.43831,-2.469,-0.386563,-0.334125,-0.0679091,-0.0983204,-1.20246,-1.2753,1.77385,1.49784,-1.8308,-1.80519
272,0.327228,0.34382,0.197726,0.136478,0.0028631,-0.0125972,0.0569846,0.0642639,0.434027,0.428099,0.806773,0.823806,0.8135,0.79252,0.617451,0.601313,0.298849,0.324346,0.403187,0.390097,0.0164664,0.193297,0.930669,0.836651,0.603689,0.553445,0.444527,0.524951,-1.15974,-1.17141,0.23683,0.294207,0.637533,0.608721,0.150601,-0.0152412,-0.868687,-1.1482,-0.586886,-0.555934
273,0.576776,0.558595,0.29939,0.141522,0.645047,0.631113,0.829588,0.838441,0.937624,0.931997,0.596623,0.614618,0.666415,0.64299,0.795825,0.778704,0.559873,0.410851,0.326031,0.333895,0.0306658,0.105377,0.332978,0.241545,-0.561332,-0.606457,1.82529,1.90575,0.0975928,0.126172,0.565775,0.628735,-1.1606,-1.19013,1.31438,1.24482,-0.64133,-0.922977,0.220217,0.252331
274,0.758246,0.773371,0.224513,0.146566,0.862275,0.846438,0.362846,0.371783,0.359898,0.353429,0.714271,0.704578,0.0765931,0.0514628,0.560365,0.540889,0.551684,0.497355,0.0127682,0.0225016,-0.390485,-0.313932,-1.44154,-1.5351,0.148781,0.0434919,-1.50419,-1.4205,1.45445,1.42376,-1.32407,-1.26444,-0.602579,-0.63598,-0.886886,-0.955758,-2.68734,-2.96967,0.340898,0.376553
275,0.699791,0.716702,0.18839,0.151611,0.828138,0.812894,0.818611,0.829468,0.944427,0.938842,0.777623,0.794539,0.474401,0.447941,0.654568,0.636619,0.584379,0.58386,0.302756,0.332325,-2.53103,-2.46062,0.377825,0.286712,0.742666,0.69344,1.679,1.7628,0.473464,0.364726,1.11646,1.16918,-0.262767,-0.298932,-0.777191,-0.839506,-0.120111,-0.400756,0.106432,0.142405
276,0.935242,0.952915,0.522527,0.417903,0.447294,0.433563,0.812051,0.822685,0.491247,0.518672,0.51463,0.53142,0.121151,0.0927944,0.209663,0.190308,0.317351,0.377361,0.502826,0.642148,1.20327,1.28001,1.06729,0.978915,0.156772,0.107233,-0.0102626,0.0720943,-0.663616,-0.694306,0.000160861,0.0595768,0.876649,0.838959,0.461458,0.391935,-0.298579,-0.610388,-1.06085,-1.03202
277,0.362084,0.382295,0.722444,0.684195,0.47074,0.454839,0.485004,0.455898,0.102444,0.0985021,0.582189,0.597862,0.0875163,0.0587408,0.631198,0.574394,0.171747,0.170861,0.942237,0.951971,-0.0292512,0.0460769,-0.943439,-1.03424,0.926638,0.875923,-0.826653,-0.751462,0.854287,0.82826,0.276462,0.333904,-0.0731308,-0.114935,0.0346127,-0.126208,-0.539376,-0.820021,1.39589,1.42726
278,0.455072,0.473342,0.328249,0.290104,0.112258,0.0952164,0.0770658,0.089111,0.426781,0.42092,0.0095303,0.0234977,0.332993,0.305027,0.978082,0.958481,0.63736,0.63603,0.856224,0.864018,-0.638025,-0.558408,-1.66575,-1.75043,-0.684159,-0.728928,-1.21226,-1.14113,-1.15791,-1.18448,0.957873,1.02124,-0.349858,-0.388843,-0.574169,-0.644352,-1.00491,-1.28967,0.446218,0.483297
279,0.24044,0.259466,0.810288,0.773823,0.927545,0.910304,0.140834,0.133165,0.346477,0.355786,0.812798,0.827609,0.146366,0.119588,0.665174,0.646404,0.831102,0.831612,0.4031,0.412709,0.397034,0.472442,0.566846,0.485883,1.24983,1.20924,-1.14429,-1.06802,0.493966,0.474907,-1.37046,-1.31322,-0.0905798,-0.129266,1.23083,1.1609,-0.998333,-1.28036,0.591483,0.625354
280,0.421579,0.439991,0.733252,0.696029,0.683412,0.665849,0.163317,0.17722,0.295358,0.290653,0.359917,0.376302,0.248746,0.220024,0.0578155,0.0404057,0.468825,0.467307,0.849832,0.861796,-0.309188,-0.251226,-0.259183,-0.339118,-0.225961,-0.272097,-0.406012,-0.334976,0.698643,0.678657,-0.544864,-0.48831,-0.530229,-0.575315,0.267188,0.295064,-1.45444,-1.73573,-0.99595,-0.958429
281,0.289766,0.338367,0.101043,0.0656999,0.920708,0.901219,0.652354,0.665684,0.655995,0.653997,0.397738,0.412582,0.757559,0.726445,0.735033,0.716585,0.560433,0.560205,0.226613,0.236239,-1.04993,-0.974894,0.720476,0.644265,0.390862,0.340309,-1.03374,-0.954287,0.188773,0.17453,0.783128,0.899037,-1.48453,-1.52921,-0.508043,-0.570775,0.0473291,-0.230156,-0.0706964,-0.0303678
282,0.216386,0.236742,0.334683,0.298115,0.222113,0.201809,0.30141,0.313971,0.602956,0.516794,0.950376,0.964267,0.0551542,0.0253011,0.0560746,0.0392272,0.333236,0.332071,0.159055,0.167907,-0.232285,-0.158572,-0.295558,-0.366982,-0.108709,-0.163323,-0.403317,-0.332245,1.11038,1.10018,2.22983,2.28638,-0.612013,-0.654683,-1.02284,-1.08187,-0.615432,-0.884467,0.533029,0.549609
283,0.527439,0.561402,0.294396,0.258743,0.370086,0.348681,0.5785,0.589225,0.381579,0.37959,0.163267,0.177791,0.0443442,0.0126379,0.76949,0.751238,0.850412,0.847156,0.470704,0.481344,0.0986859,0.169121,0.00271107,-0.0713779,0.363531,0.311594,0.90985,0.985975,-1.1026,-1.11102,0.8541,0.912442,-1.0243,-1.0688,0.54421,0.490318,-2.23501,-2.51197,1.09294,1.12959
284,0.863643,0.886062,0.00479823,-0.0314161,0.196446,0.176843,0.405114,0.339054,0.470013,0.468113,0.135611,0.15005,0.468965,0.43927,0.34967,0.329283,0.966075,0.961719,0.199536,0.210898,-1.61854,-1.55725,-1.39424,-1.47408,-0.161712,-0.234229,0.0367438,0.204614,0.320779,0.320435,0.265016,0.403485,-0.435708,-0.48377,-1.51254,-1.56181,0.658112,0.384896,0.115211,0.164876
285,0.711564,0.645069,0.600477,0.564889,0.769478,0.74939,0.079816,0.0888834,0.0941228,0.0940844,0.449309,0.465628,0.335971,0.305144,0.962178,0.944197,0.128921,0.122675,0.193978,0.206404,1.24413,1.31247,1.47697,1.39027,-0.729097,-0.780051,-0.646703,-0.576746,-0.326565,-0.31976,-0.15852,-0.105472,-0.704939,-0.757677,-0.149334,-0.204187,-2.46227,-2.73252,-0.829521,-0.799835
286,0.382822,0.404076,0.0425065,0.00790732,0.697665,0.680081,0.36991,0.304518,0.523127,0.522368,0.497929,0.516364,0.561489,0.438895,0.442857,0.468901,0.705621,0.697404,0.980245,0.993135,-0.398082,-0.335174,1.15691,1.07207,-0.307187,-0.364762,1.98492,2.0536,0.822142,0.834652,-0.0998854,-0.0446911,0.555274,0.503489,0.298123,0.249128,-1.55486,-1.82123,-0.666311,-0.642174
287,0.459763,0.479721,0.139578,0.106839,0.0116035,-0.00421563,0.511658,0.520153,0.479064,0.477934,0.333802,0.331066,0.617106,0.572646,0.0115859,-0.00639512,0.100664,0.0917432,0.305525,0.317048,2.01199,2.07477,1.74312,1.65783,0.488426,0.434261,-0.561481,-0.495501,0.117637,0.133446,0.884214,0.934825,-0.138748,-0.255974,1.19985,1.1459,-0.925994,-1.18991,-1.67399,-1.64596
288,0.795353,0.816821,0.973889,0.939062,0.299302,0.282301,0.358481,0.368031,0.772796,0.769888,0.12834,0.145768,0.832944,0.706397,0.0155675,-0.000740529,0.15168,0.14081,0.564186,0.575773,-1.17446,-1.11292,0.404072,0.31858,0.782129,0.726333,0.392896,0.453353,0.839687,0.859121,1.61071,1.66786,-0.966804,-1.01544,-0.717767,-0.767696,-0.84971,-1.11816,0.341982,0.375372
289,0.00322878,0.0235303,0.0445437,0.0107668,0.23677,0.160417,0.750152,0.761578,0.427768,0.426313,0.275122,0.290753,0.870975,0.840148,0.825475,0.807936,0.611284,0.601107,0.412708,0.425413,0.371711,0.433374,0.681079,0.597847,-1.04233,-1.10047,0.810991,0.877747,0.962982,0.985645,0.0616164,0.111808,0.62302,0.571958,0.65637,0.604599,-0.500331,-0.76714,-0.0255253,0.00315369
290,0.664689,0.685262,0.341333,0.265595,0.0558836,0.0385334,0.29947,0.30971,0.549088,0.545708,0.962248,0.976825,0.0199317,-0.00996712,0.823171,0.723517,0.0118399,0.00130563,0.484542,0.47543,1.51204,1.57179,-1.88005,-1.95913,0.800165,0.746209,-1.25618,-1.19547,-0.271164,-0.252838,0.508018,0.55815,0.324054,0.266879,-1.85279,-1.90696,-1.08359,-1.34561,0.682752,0.705152
291,0.186825,0.209614,0.555821,0.520424,0.808759,0.789874,0.653878,0.663602,0.934845,0.93401,0.251469,0.267122,0.682816,0.653244,0.632848,0.639099,0.300546,0.292604,0.565859,0.525446,-1.14733,-1.08345,-1.14359,-1.21949,-1.41715,-1.4768,1.50909,1.56571,-1.86894,-1.84329,-1.69109,-1.64771,-0.712218,-0.764785,1.29509,1.24758,-1.38503,-1.64636,-0.992298,-0.971804
292,0.134039,0.158241,0.182851,0.145812,0.915362,0.896506,0.241168,0.251282,0.0347035,0.0340419,0.0711992,0.0845436,0.679419,0.62041,0.572936,0.554681,0.968638,0.96029,0.661013,0.575462,-1.30665,-1.24556,1.51827,1.43835,-0.437159,-0.493477,0.811525,0.867838,1.08249,1.10368,-0.454934,-0.454087,-0.335909,-0.396257,0.000477795,-0.0482854,-1.01047,-1.26437,-0.282394,-0.269806
293,0.946045,0.97052,0.119182,0.140262,0.289824,0.272387,0.949349,0.958618,0.67579,0.673247,0.99997,1.01193,0.614483,0.587576,0.147144,0.128222,0.431803,0.420687,0.614418,0.625478,0.707332,0.774705,0.971174,0.888707,-2.57476,-2.63565,-0.117012,-0.065681,-0.197991,-0.256824,0.701244,0.739537,0.348937,0.29526,2.18211,2.13211,-0.321218,-0.570976,-0.639286,-0.626956
294,0.606001,0.671155,0.171724,0.134712,0.436963,0.422969,0.0610066,0.069279,0.631483,0.654672,0.318483,0.331408,0.118385,0.091773,0.467714,0.449688,0.189523,0.177497,0.239332,0.249302,-0.300888,-0.231196,-0.734167,-0.808869,-1.19656,-1.25756,0.846298,0.898246,-1.63853,-1.61733,1.67533,1.71905,2.59123,2.53008,-0.204695,-0.249216,-0.928021,-1.18047,1.20422,1.21228
295,0.347492,0.371789,0.995388,0.957687,0.589702,0.573552,0.148004,0.157412,0.640306,0.636097,0.474257,0.486198,0.155569,0.130188,0.0809815,0.0632164,0.331357,0.354386,0.4507,0.426367,0.808136,0.876313,-0.430364,-0.498986,-1.23632,-1.30192,0.732026,0.786527,-0.521994,-0.509213,-0.921704,-0.875889,-1.54711,-1.60826,1.32405,1.27499,0.0858218,-0.173987,-1.14623,-1.14113
296,0.509658,0.614309,0.528856,0.535057,0.429397,0.350171,0.883535,0.894761,0.216515,0.212196,0.174157,0.187398,0.934792,0.910862,0.96067,0.944236,0.545111,0.531276,0.590832,0.603433,-0.0116287,0.0549612,-1.02072,-1.09409,0.862515,0.796106,-0.477572,-0.424183,-0.438148,-0.455734,-1.37885,-1.3404,-0.287156,-0.347093,-0.648815,-0.701981,0.0404506,-0.164066,-0.545346,-0.618393
297,0.834338,0.856829,0.151918,0.112428,0.143487,0.126791,0.680825,0.69245,0.196237,0.222746,0.300391,0.312303,0.977763,0.953473,0.36269,0.348418,0.139141,0.126166,0.0763119,0.0880822,2.39882,2.4649,-2.11375,-2.18238,1.52155,1.45543,0.399705,0.447786,-0.413568,-0.402255,-0.404805,-0.360883,-0.789675,-0.853243,0.637126,0.591172,0.10259,-0.154145,-0.100757,-0.0956581
298,0.329434,0.351336,0.650911,0.610907,0.348275,0.33216,0.229732,0.240582,0.239696,0.233295,0.785274,0.799447,0.315925,0.291779,0.759839,0.745055,0.180044,0.171765,0.304923,0.346872,0.157628,0.219585,0.903032,0.840636,-1.46867,-1.53199,-1.1836,-1.1306,1.68468,1.69869,0.0627327,0.100685,0.71152,0.654908,-0.619154,-0.746724,1.20136,0.945509,0.0615283,-0.00629008
299,0.631763,0.653199,0.741125,0.700125,0.23717,0.220628,0.863857,0.873275,0.528399,0.607898,0.313355,0.329371,0.448999,0.426876,0.0506069,0.0364237,0.22887,0.217363,0.59213,0.605661,-0.760251,-0.694474,-0.0419218,-0.107763,0.223235,0.156936,2.08631,2.14791,-1.55069,-1.53981,1.85382,1.89377,1.25663,1.192,-2.03218,-2.08462,-0.417017,-0.666283,0.0863076,0.0830779
300,0.0414204,0.0625507,0.448862,0.409966,0.362902,0.346839,0.209663,0.220954,0.991659,0.9825,0.315782,0.237229,0.158822,0.218887,0.785525,0.768971,0.00114945,-0.0107714,0.474668,0.489869,-0.833809,-0.7656,-1.46484,-1.52416,-0.922244,-0.985979,-0.459956,-0.401191,1.92887,1.94779,0.5604,0.600025,0.624447,0.563219,-0.0313599,-0.0912715,-0.0303082,-0.2843,-0.602157,-0.602346
301,0.767065,0.789043,0.567095,0.528447,0.692715,0.674599,0.780973,0.793402,0.552162,0.52091,0.128226,0.145087,0.0336209,0.0108987,0.0129645,-0.00255345,0.0331595,0.0228963,0.0320471,0.0488101,0.962252,1.02452,-0.300006,-0.355694,0.783541,0.719495,-1.38084,-1.3195,-0.168697,-0.152805,-1.13914,-1.09407,0.754976,0.685974,-1.30406,-1.37051,-1.75702,-2.00911,-2.36781,-2.37135
302,0.519303,0.563224,0.464728,0.425186,0.800274,0.781231,0.945677,0.958243,0.0684774,0.059319,0.300686,0.319861,0.422962,0.401949,0.321987,0.308637,0.993243,0.982019,0.347343,0.448418,-0.392692,-0.33083,-1.94949,-2.00811,0.444725,0.370144,-1.30117,-1.23328,-1.14993,-1.13173,0.96814,1.01482,1.31065,1.24012,-0.278184,-0.406287,-0.807134,-1.06517,-0.844156,-0.843845
303,0.220516,0.337405,0.737017,0.696221,0.296712,0.277094,0.848933,0.860691,0.86598,0.856762,0.963114,0.981595,0.413163,0.394522,0.954534,0.93886,0.110553,0.0973092,0.832743,0.848026,0.738922,0.807589,-0.0387962,-0.092584,0.0587216,0.0207928,-0.709746,-0.641161,0.701204,0.715031,-1.71052,-1.658,1.00762,0.935045,0.581321,0.557932,1.09102,0.835249,-0.176798,-0.171423
304,0.0889927,0.111586,0.522523,0.481766,0.406121,0.35039,0.0621376,0.0759966,0.665738,0.638521,0.172864,0.190641,0.03544,0.0185587,0.304703,0.286375,0.959871,0.947384,0.00314142,0.017091,2.83354,2.90353,-1.33223,-1.38298,-0.264513,-0.328558,-2.20943,-2.14369,1.17985,1.19312,0.196216,0.243476,-0.167068,-0.237335,1.5886,1.52215,0.393626,0.134678,0.223032,0.225311
305,0.706461,0.726917,0.863238,0.822409,0.44276,0.423685,0.341747,0.401541,0.432026,0.42028,0.203464,0.222196,0.611631,0.595059,0.83849,0.818958,0.37697,0.362404,0.0440954,0.0589662,0.0187628,0.0954637,-0.0960513,-0.0907901,1.11278,1.04952,-1.46076,-1.39508,-0.410843,-0.39734,-0.654107,-0.605915,0.0982829,0.0222414,-1.19234,-1.25706,-1.21506,-1.47711,0.0888686,0.0975121
306,0.261779,0.28107,0.213289,0.171885,0.758258,0.740398,0.71464,0.727085,0.647902,0.553322,0.504377,0.560177,0.168261,0.154324,0.544439,0.460306,0.838805,0.822701,0.963426,0.977368,-0.470534,-0.387086,1.25425,1.2014,-0.339212,-0.401185,-1.01433,-0.955941,0.27246,0.282668,-1.71529,-1.67074,1.89325,1.82649,0.366753,0.299382,-0.255022,-0.519313,-0.0303213,-0.0302867
307,0.378366,0.397078,0.859754,0.8166,0.575239,0.558613,0.797925,0.810638,0.695066,0.686365,0.878575,0.898159,0.4853,0.532441,0.122488,0.101654,0.627357,0.609313,0.171725,0.18703,0.293496,0.370553,-1.9828,-2.02982,1.462,1.39709,-0.0813154,-0.0225543,-0.194636,-0.190352,-0.156617,-0.178877,-0.223788,-0.286162,0.759289,0.692168,-1.23735,-1.50253,0.762719,0.762994
308,0.232608,0.248936,0.149475,0.106465,0.174146,0.158499,0.187155,0.197625,0.182793,0.173243,0.399574,0.418021,0.924576,0.910557,0.855209,0.834201,0.670033,0.652786,0.246295,0.235509,0.122556,0.194818,-2.04977,-2.08896,0.290374,0.221491,-0.297074,-0.241926,0.668504,0.673783,1.26845,1.31299,-1.28414,-1.34877,0.871836,0.80842,-1.00541,-1.26323,1.31727,1.312
309,0.469498,0.485148,0.293723,0.250016,0.764972,0.751522,0.3247,0.337154,0.601308,0.590747,0.801064,0.817652,0.517358,0.504469,0.206348,0.186822,0.3876,0.369504,0.28403,0.283989,1.17341,1.24299,2.63332,2.59412,0.207308,0.145737,1.74305,1.80574,1.80131,1.81452,-0.753983,-0.703562,-0.142136,-0.210879,-1.37843,-1.44255,-0.349958,-0.601634,-0.641259,-0.645593
310,0.977238,0.992303,0.689469,0.645465,0.396867,0.382178,0.101999,0.114264,0.562034,0.551941,0.176194,0.193064,0.392392,0.379858,0.363966,0.34422,0.983305,0.965975,0.316675,0.332469,0.795566,0.869247,0.754347,0.716429,-1.75549,-1.81934,-0.579083,-0.52341,-0.270099,-0.253466,0.215602,0.25996,-0.00206259,-0.073405,1.40979,1.33836,1.71332,1.46501,-1.40902,-1.4084
311,0.0342431,0.0502096,0.0952824,0.0493013,0.919743,0.905648,0.688109,0.701569,0.0681601,0.0586048,0.353059,0.367838,0.935723,0.921512,0.138441,0.117259,0.245736,0.229654,0.747151,0.761069,1.32327,1.39854,-0.782857,-0.825934,-0.958409,-1.02032,-1.61495,-1.56285,-0.787803,-0.771501,-1.0908,-1.04933,-0.649007,-0.717543,0.715558,0.64209,0.527272,0.276515,1.08983,1.08611
312,0.0316388,0.0455669,0.00552438,-0.0390623,0.915696,0.827532,0.339834,0.354842,0.0187031,0.0432667,0.216078,0.229635,0.298105,0.284069,0.507056,0.541949,0.774062,0.759247,0.548369,0.560329,1.43017,1.50999,0.0306593,-0.0109071,0.139746,0.0833282,0.605585,0.661313,-0.691759,-0.673732,-0.866523,-0.858703,0.244013,0.171116,-1.05815,-1.12896,-0.297958,-0.54953,0.224331,0.216719
313,0.591588,0.60682,0.969619,0.924179,0.86897,0.749416,0.572351,0.585392,0.0371403,0.0279287,0.594396,0.529575,0.70248,0.691037,0.988884,0.966639,0.640884,0.626751,0.142003,0.153938,-2.34675,-2.26652,-0.815738,-0.852924,-1.29161,-1.35273,-0.717636,-0.655194,0.767065,0.787264,-0.707702,-0.668079,-0.899894,-0.96889,-1.16536,-1.24281,-0.652914,-0.911366,2.0726,2.06928
314,0.329579,0.343317,0.764977,0.719234,0.685068,0.6713,0.00755918,0.0216557,0.322013,0.225535,0.816582,0.829514,0.454999,0.444973,0.162281,0.139124,0.260594,0.247031,0.961163,0.972223,1.23964,1.31753,0.297934,0.256461,-0.29423,-0.353232,-0.0397033,-0.0359558,1.58341,1.60454,0.646492,0.678228,0.22652,0.151508,-0.8281,-0.91092,1.61239,1.35051,-1.26238,-1.26075
315,0.536528,0.549538,0.999942,0.956542,0.857283,0.842028,0.590166,0.604573,0.432969,0.423141,0.719849,0.731623,0.523261,0.605979,0.561661,0.540683,0.691901,0.582502,0.793809,0.807222,-1.14508,-1.06777,0.0294089,-0.0175431,-0.221273,-0.276008,0.515467,0.583282,0.681312,0.607178,-1.2652,-1.23254,0.279526,0.197407,-0.835357,-0.920339,1.1642,0.895142,0.909104,0.905245
316,0.403581,0.416258,0.21905,0.174628,0.127256,0.11249,0.577242,0.592247,0.437442,0.425931,0.95812,0.969944,0.782032,0.766985,0.0649348,0.0449984,0.933913,0.917973,0.950218,0.964483,0.323527,0.39988,0.0790653,0.0296483,0.719012,0.6605,-1.16204,-1.09312,-0.409575,-0.390188,0.893083,0.922313,-0.982828,-1.06553,-0.263217,-0.343963,-0.842472,-1.10279,0.0351735,0.0358497
317,0.96691,0.977511,0.473009,0.383526,0.715612,0.70086,0.204767,0.220329,0.129044,0.118417,0.974357,0.889858,0.935693,0.927991,0.629042,0.607234,0.544784,0.571091,0.153699,0.168903,-1.24626,-1.17211,-0.720294,-0.765022,1.24119,1.18153,-0.635545,-0.561628,-0.194476,-0.170248,0.553484,0.583898,0.601789,0.521862,1.22822,1.14992,0.686556,0.419914,-0.441533,-0.43961
318,0.867514,0.880073,0.634854,0.592424,0.76873,0.753424,0.941432,0.957677,0.851454,0.84068,0.797216,0.809771,0.366369,0.360578,0.52289,0.500304,0.241401,0.22421,0.369269,0.386283,0.184128,0.212151,1.03611,0.996258,-0.253694,-0.314991,0.146563,0.216658,-1.22531,-1.19425,1.49394,1.51836,0.470619,0.38549,0.506558,0.421379,-1.0939,-1.35602,1.0566,1.05654
319,0.14839,0.160611,0.132117,0.0890255,0.207824,0.194578,0.542859,0.588687,0.721688,0.709056,0.211576,0.224818,0.238029,0.230883,0.982606,0.961343,0.797374,0.779424,0.0322843,0.0498523,1.52227,1.59642,1.39761,1.35145,0.0504732,-0.00710918,0.270585,0.335391,-0.0387363,-0.00807737,0.643227,0.66897,-0.597918,-0.677118,-1.10269,-1.19436,-0.829872,-1.08556,0.603846,0.610694
320,0.639523,0.551057,0.0158367,-0.0290224,0.169241,0.155758,0.200548,0.219697,0.231545,0.22023,0.412407,0.423683,0.790891,0.782593,0.223994,0.199879,0.742947,0.724563,0.592018,0.608726,-0.0684171,0.00887697,2.1984,2.15278,0.00121713,-0.0514634,1.4106,1.47067,0.126847,0.15132,-1.05062,-1.02512,0.350695,0.275771,-0.978945,-1.07811,0.0928174,-0.15799,0.364571,0.376546
321,0.931915,0.941503,0.632269,0.585985,0.93265,0.917649,0.606912,0.624179,0.178053,0.110713,0.206159,0.219412,0.454685,0.447433,0.603784,0.582114,0.707698,0.669703,0.871542,0.88654,-1.89395,-1.81227,0.0373756,-0.00177486,1.96648,1.91759,-0.782835,-0.72514,-0.125713,-0.10954,1.56656,1.59717,0.0658289,-0.0138017,1.82348,1.72096,0.803905,0.551755,1.0328,1.04897
322,0.815407,0.761027,0.6227,0.575465,0.439529,0.456083,0.713052,0.728579,0.0135748,0.00119643,0.202348,0.216327,0.342497,0.250466,0.152043,0.131291,0.623614,0.614842,0.30931,0.325469,-0.936288,-0.858174,1.37326,1.33705,1.42878,1.38217,0.942598,1.00386,-2.05831,-2.04202,0.269778,0.303433,-0.484069,-0.5673,-0.274111,-0.38047,-1.43932,-1.69536,-0.490129,-0.474887
323,0.572807,0.58055,0.929179,0.881924,0.0122683,-0.00548287,0.33497,0.350963,0.537919,0.524716,0.761908,0.777614,0.0593687,0.0534992,0.62226,0.603369,0.577932,0.559981,0.869033,0.884343,1.02554,1.10042,0.500536,0.465526,1.72019,1.67424,-0.399753,-0.343264,0.637291,0.652013,0.704898,0.732667,0.505666,0.357516,1.35828,1.25311,-0.0624938,-0.312039,0.822355,0.837249
324,0.94525,0.952854,0.546552,0.543281,0.149565,0.13095,0.613247,0.630869,0.140628,0.126202,0.525691,0.52376,0.918087,0.911949,0.193577,0.17691,0.309147,0.29111,0.569532,0.583415,-0.84865,-0.768818,0.914252,0.881677,0.551931,0.498643,-0.58927,-0.533051,1.12882,1.14756,0.317823,0.348445,1.36086,1.28233,0.94358,0.83339,-2.50383,-2.7472,-1.90175,-1.88376
325,0.155414,0.164437,0.253042,0.204638,0.593342,0.574696,0.156199,0.173865,0.207611,0.127827,0.2537,0.269905,0.518818,0.511611,0.745517,0.730108,0.387583,0.401675,0.560994,0.661031,0.236853,0.322633,-1.54141,-1.57834,0.823412,0.846641,2.69398,2.74546,-0.103945,-0.0909269,0.466815,0.498981,-0.283863,-0.357627,-0.969821,-1.08021,2.16258,1.91922,-0.868117,-0.8481
326,0.343613,0.354817,0.611125,0.50165,0.389163,0.373221,0.454073,0.453411,0.212747,0.129452,0.504208,0.599572,0.593487,0.585747,0.109372,0.0934645,0.5543,0.51224,0.726244,0.738648,-0.460404,-0.373988,-0.218134,-0.254153,1.24171,1.19464,0.00652544,0.0605412,0.164832,0.174591,-0.125278,-0.0895477,-0.660162,-0.739952,-1.61677,-1.73114,0.0972535,-0.141638,2.68122,2.70336
327,0.0965383,0.193606,0.848149,0.798663,0.586412,0.496178,0.71703,0.732957,0.143687,0.131077,0.913262,0.929239,0.141526,0.134907,0.101862,0.0952774,0.642369,0.622805,0.0873117,0.097985,-1.51025,-1.42522,-0.498412,-0.528156,0.88154,0.82783,1.16038,1.21032,1.60774,1.62113,-0.331907,-0.289491,-0.368904,-0.447656,0.442885,0.324728,-1.24874,-1.4882,-0.22091,-0.200269
328,0.022405,0.032394,0.260958,0.212501,0.697782,0.619134,0.0693311,0.0853252,0.598396,0.538497,0.911688,0.926154,0.716492,0.711408,0.113931,0.0970903,0.369678,0.348912,0.64956,0.661373,-1.61305,-1.49782,1.04951,1.01445,-0.625888,-0.684022,0.101492,0.15242,-0.238274,-0.217945,0.327092,0.36851,1.32443,1.24676,1.1484,1.02381,-0.73223,-0.965746,-0.174202,-0.147435
329,0.856876,0.867542,0.492448,0.444916,0.758032,0.742091,0.779169,0.792661,0.956959,0.945917,0.134242,0.150382,0.654694,0.690958,0.463419,0.444335,0.321479,0.398681,0.113467,0.125532,-1.66281,-1.57043,-0.712549,-0.748076,-1.13883,-1.20424,1.6099,1.66081,-1.17301,-1.15001,0.57719,0.586067,1.0827,1.00308,-0.91679,-1.04564,1.47568,1.248,-1.7728,-1.74761
330,0.674525,0.684588,0.275784,0.230461,0.297601,0.282926,0.937387,0.952285,0.329327,0.316102,0.856078,0.871738,0.674317,0.670508,0.524713,0.570369,0.439662,0.44845,0.579682,0.589617,-0.567189,-0.478977,2.17441,2.13839,1.95416,1.88521,-0.658988,-0.603166,-0.385196,-0.361823,0.761482,0.803625,0.333272,0.252282,1.30286,1.17576,-0.269674,-0.494685,1.03516,1.05864
331,0.69846,0.709656,0.466757,0.502767,0.264188,0.249382,0.79828,0.856861,0.360473,0.368333,0.538311,0.55249,0.921056,0.916794,0.715103,0.696403,0.421936,0.498219,0.605433,0.615909,0.803187,0.893395,-2.32476,-2.36077,-0.152937,-0.225057,-1.25678,-1.19441,1.35319,1.37649,0.276657,0.324564,1.22515,1.14094,0.357494,0.234731,0.478231,0.259018,2.36308,2.38502
332,0.191984,0.204164,0.818959,0.775072,0.628704,0.61176,0.747831,0.761437,0.435981,0.420565,0.524874,0.494702,0.880005,0.785002,0.507551,0.489524,0.568755,0.547989,0.0496045,0.0600996,-0.890876,-0.800904,-1.21669,-1.25139,0.108605,0.0374082,0.430579,0.488636,-1.13874,-1.11232,3.13951,3.19176,-0.909628,-1.00169,-0.90462,-1.02909,-1.17713,-1.4014,1.29929,1.32015
333,0.345872,0.359456,0.866809,0.823105,0.771756,0.730718,0.315935,0.329541,0.847148,0.833188,0.368599,0.436914,0.656953,0.653209,0.814587,0.796111,0.904652,0.884421,0.650501,0.65858,0.416941,0.508157,0.189198,0.150218,-1.09355,-1.16817,-0.869638,-0.814108,-0.695275,-0.664545,1.04227,1.08685,-1.37257,-1.46314,-0.0251415,-0.147105,-0.490842,-0.814719,-0.381065,-0.293878
334,0.14071,0.155589,0.535583,0.492849,0.829033,0.849675,0.285719,0.297529,0.284906,0.269282,0.365231,0.379126,0.318653,0.313173,0.260119,0.239998,0.255312,0.234238,0.219978,0.227911,-1.18764,-1.09466,0.884849,0.842422,0.368936,0.30121,-0.0475467,0.00935756,0.446384,0.476192,-1.07031,-1.01806,-0.957127,-1.04786,0.508127,0.383962,0.0027754,-0.22804,-1.92491,-1.90791
335,0.221656,0.236236,0.862194,0.819007,0.985577,0.968633,0.992076,1.00487,0.156464,0.142944,0.483813,0.498744,0.683877,0.680055,0.431748,0.356644,0.987232,0.965939,0.639946,0.647239,-1.11052,-1.01353,0.114184,0.0779445,0.825265,0.760085,1.26757,1.32758,2.16874,2.19768,-0.31159,-0.252493,1.28854,1.20219,2.54089,2.42388,1.08243,0.855876,0.652678,0.673254
336,0.586016,0.598705,0.0222396,-0.0212022,0.82755,0.81196,0.500866,0.512155,0.828243,0.813835,0.962168,0.976058,0.723803,0.71847,0.551719,0.47329,0.697588,0.676789,0.0331198,0.0411891,0.484783,0.577533,-0.435335,-0.471696,-0.278811,-0.33663,1.43624,1.52306,1.44096,1.46487,-0.825577,-0.763093,1.41463,1.32494,1.29619,1.1771,2.41946,2.19177,-0.746373,-0.729362
337,0.0263397,0.0369891,0.0576383,0.113268,0.280991,0.266978,0.783428,0.792061,0.0199148,0.00372137,0.181275,0.195631,0.25052,0.247365,0.610057,0.589936,0.905407,0.883496,0.295327,0.304218,-0.428065,-0.336525,0.273458,0.236135,-0.598347,-0.658823,1.66684,1.71854,-0.206233,-0.187645,-0.128792,-0.0579674,-1.24343,-1.33274,0.533962,0.484539,-0.0748072,-0.293585,0.247988,0.26028
338,0.762344,0.774744,0.215159,0.247737,0.879797,0.864685,0.684319,0.641667,0.989516,0.973498,0.601182,0.614988,0.0254297,0.0209971,0.592391,0.573954,0.221009,0.198058,0.990994,0.998482,-0.18458,-0.12002,-0.512657,-0.544774,0.521237,0.461275,0.559271,0.614533,0.168336,0.186866,-0.315783,-0.241754,0.14515,0.0538891,-0.0851413,-0.208023,-0.492707,-0.717954,1.96449,1.97253
339,0.0773243,0.0880171,0.447517,0.382207,0.809353,0.795376,0.485621,0.491273,0.99569,0.981493,0.790166,0.803875,0.217449,0.212487,0.965827,0.946414,0.507412,0.483802,0.544991,0.552091,0.0101218,0.0964847,0.474712,0.438609,0.587545,0.523652,-1.33813,-1.28328,-1.34244,-1.32856,0.493913,0.569531,0.409331,0.313466,0.459978,0.338167,1.27864,1.05499,-2.18493,-2.17689
340,0.925503,0.935472,0.501316,0.516677,0.236762,0.221727,0.886846,0.89062,0.255877,0.240158,0.456509,0.470393,0.899684,0.895379,0.242314,0.221704,0.388118,0.366631,0.704303,0.709353,-1.65178,-1.56802,-0.107859,-0.140314,1.99531,1.93188,0.592028,0.65324,-0.492261,-0.479611,-0.386985,-0.310716,-0.777972,-0.873656,0.0135811,-0.11119,-0.77795,-1.00586,0.0132055,0.0191581
341,0.430446,0.440078,0.694589,0.651147,0.441731,0.358084,0.668336,0.673096,0.601746,0.499565,0.48819,0.560353,0.18805,0.183129,0.960483,0.939345,0.901899,0.881716,0.27768,0.283398,-1.30419,-1.2263,-1.84833,-1.88623,1.18722,1.13046,0.149666,0.215974,-0.3601,-0.353086,-0.369946,-0.29635,-0.211569,-0.303686,1.09934,0.970467,0.872867,0.643121,-0.545689,-0.533826
342,0.831256,0.843021,0.474533,0.431768,0.509007,0.49444,0.682914,0.686218,0.7748,0.758972,0.636054,0.650314,0.354726,0.348686,0.0547394,0.0332552,0.588389,0.472514,0.595332,0.601619,-0.5111,-0.439426,-2.07667,-2.11722,-0.169614,-0.2288,1.28658,1.35125,0.386613,0.387758,0.192765,0.271178,0.677622,0.584972,1.32508,1.19497,0.0417456,-0.182924,0.551759,0.562871
343,0.601638,0.619743,0.479392,0.490987,0.354393,0.337768,0.188691,0.193507,0.115546,0.099419,0.913814,0.928799,0.72492,0.720344,0.498044,0.475493,0.0817672,0.0633127,0.216977,0.221212,1.28033,1.35069,-0.687136,-0.730867,0.830214,0.770693,1.4036,1.46998,-0.470622,-0.467389,1.20523,1.28075,0.212243,0.123521,-0.533264,-0.658255,0.869777,0.651391,0.926668,0.943899
344,0.519337,0.396464,0.592333,0.550207,0.620468,0.654332,0.932103,0.936217,0.672203,0.653913,0.352581,0.369951,0.78256,0.779319,0.517949,0.529371,0.386852,0.369088,0.7137,0.719843,-0.0560366,0.00924504,-0.422534,-0.467649,0.424859,0.358196,-1.32066,-1.26048,-0.781279,-0.772086,0.158493,0.232175,-0.736155,-0.830373,-0.560707,-0.68152,0.887763,0.678027,0.361711,0.377313
345,0.161419,0.173185,0.245688,0.282315,0.986191,0.970896,0.136372,0.140668,0.985821,0.965931,0.670293,0.667483,0.538448,0.533254,0.682382,0.58325,0.977916,0.959727,0.00469688,0.0119794,1.73376,1.79936,-1.0947,-1.13888,0.789462,0.725662,0.180542,0.233159,0.574318,0.580524,0.263059,0.338962,-1.21398,-1.30749,-0.072754,-0.19683,-0.448081,-0.653481,0.838939,0.85023
346,0.57436,0.586506,0.0574654,0.0144235,0.858205,0.861156,0.283066,0.285713,0.5976,0.577596,0.948797,0.965015,0.840325,0.834984,0.66035,0.637129,0.159604,0.140454,0.795501,0.804281,1.42605,1.48783,-0.303228,-0.350533,-1.56243,-1.62612,-0.905635,-0.855474,0.408552,0.412699,-0.364931,-0.296578,-0.146052,-0.235014,0.73208,0.609031,-0.113808,-0.31904,-0.305361,-0.293906
347,0.531427,0.585951,0.0712583,0.0285833,0.76932,0.751417,0.214244,0.218772,0.932453,0.914973,0.493612,0.509186,0.633365,0.629862,0.532331,0.51038,0.125183,0.110192,0.217244,0.22407,0.253828,0.315362,-0.183665,-0.22728,0.247742,0.190767,0.3984,0.447198,1.31109,1.32216,0.000213621,0.0688155,-0.659491,-0.741165,-0.245314,-0.363288,0.651089,0.450563,0.115314,0.134004
348,0.667049,0.585395,0.360751,0.319451,0.37932,0.361937,0.86236,0.865631,0.0656611,0.0476569,0.275421,0.290662,0.850357,0.846327,0.922869,0.902523,0.186533,0.0799305,0.329551,0.334897,-0.180616,-0.118989,-0.519014,-0.561846,-1.11247,-1.16849,0.280918,0.335479,-0.758904,-0.745824,-0.382961,-0.315406,1.30605,1.22067,0.647185,0.533487,0.290634,0.0887268,-0.228379,-0.207096
349,0.548736,0.58484,0.982209,0.939935,0.352173,0.333928,0.815221,0.818758,0.221813,0.249442,0.773756,0.788143,0.664325,0.660889,0.380638,0.3611,0.058679,0.0496688,0.104857,0.108935,-0.202034,-0.142464,-0.542015,-0.589917,-2.19188,-2.2496,-0.431347,-0.378638,0.131647,0.149918,-0.242042,-0.178123,0.362765,0.28057,-1.01308,-1.12889,0.272761,0.0677813,0.106432,0.166516
350,0.667965,0.584284,0.119899,0.0786386,0.574136,0.538068,0.231824,0.235471,0.472053,0.451227,0.0197177,0.033708,0.82919,0.799805,0.384711,0.35345,0.0385571,0.0194071,0.939821,0.942803,-0.9988,-0.933587,0.497733,0.454438,-1.04953,-1.11276,0.587052,0.633859,0.727082,0.750901,0.161673,0.220456,-0.165349,-0.182521,-0.232686,-0.354371,1.10134,0.902097,0.519874,0.540129
351,0.571583,0.583728,0.642961,0.601647,0.718412,0.742208,0.747898,0.75352,0.128869,0.107652,0.78072,0.795397,0.939901,0.93872,0.215521,0.345801,0.462421,0.444092,0.926201,0.928605,-0.601595,-0.461139,0.559242,0.517128,1.13947,1.07979,-0.908136,-0.868668,0.341524,0.368579,0.0246869,0.0417441,-0.562273,-0.645613,-0.000320736,-0.114637,0.988041,0.78848,-0.2893,-0.267014
352,0.441313,0.548563,0.665738,0.625064,0.964593,0.946348,0.325622,0.332168,0.384729,0.364503,0.477547,0.491697,0.720463,0.776018,0.28266,0.338151,0.384249,0.440781,0.0396815,0.0435988,-0.0503921,0.0113082,-0.26838,-0.307873,0.167807,0.104902,1.62682,1.66264,-1.81058,-1.77826,-0.19575,-0.136968,-0.11668,-0.198712,-0.650977,-0.765572,2.16035,1.96677,1.32718,1.35395
353,0.502275,0.513398,0.392925,0.354312,0.596007,0.577004,0.225919,0.325054,0.0686695,0.0468229,0.394385,0.408563,0.613806,0.613315,0.350039,0.330501,0.454784,0.43747,0.524872,0.5273,-0.282496,-0.224797,0.968939,0.926684,-1.82047,-1.87702,1.53156,1.56685,0.913804,0.946758,-0.858685,-0.803029,-1.38274,-1.46165,2.19872,2.08364,1.59727,1.40436,-0.50616,-0.473661
354,0.0316565,0.0429279,0.365528,0.329117,0.723592,0.703215,0.312054,0.317941,0.17822,0.159902,0.809366,0.823137,0.697104,0.69714,0.593247,0.576058,0.680598,0.664078,0.632048,0.633525,0.54314,0.606459,0.606234,0.56227,-0.482757,-0.543945,0.781877,0.820596,0.605429,0.642061,0.746579,0.805905,0.506193,0.423062,-1.21035,-1.31973,-1.11804,-1.30453,0.0854945,0.120577
355,0.522063,0.534455,0.706293,0.66976,0.326498,0.308131,0.471759,0.477565,0.296203,0.27298,0.402562,0.481553,0.14753,0.150285,0.269783,0.254138,0.289369,0.27403,0.159255,0.162511,0.1768,0.232718,1.17502,1.13241,-0.493543,-0.55869,-1.72289,-1.67967,-0.861777,-0.826609,-1.11314,-1.05558,-0.288224,-0.376056,-1.50896,-1.61527,-0.0147804,-0.204881,-0.307635,-0.264462
356,0.0350595,0.0478609,0.104274,0.0682193,0.356937,0.339855,0.987503,0.995614,0.0603251,0.0360321,0.126417,0.139969,0.631359,0.632534,0.462366,0.445768,0.53853,0.517459,0.974861,0.976016,-1.72815,-1.66709,0.0947336,0.0583228,-0.860064,-0.925499,-0.69395,-0.671661,0.910068,0.940884,0.954984,1.01824,-2.24771,-2.33175,0.443022,0.331695,1.49564,1.30069,0.307929,0.346266
357,0.107181,0.118594,0.559559,0.522575,0.593756,0.575225,0.543109,0.556374,0.729722,0.706923,0.228673,0.244125,0.624977,0.625106,0.408137,0.390102,0.776699,0.760889,0.817088,0.831445,-1.10446,-1.04791,0.141182,0.105514,1.76391,1.6994,0.295259,0.336349,-0.204736,-0.173726,-0.600002,-0.537812,-1.37599,-1.45722,-0.116799,-0.286856,0.386065,0.212453,-0.390793,-0.355742
358,0.551829,0.561272,0.0075874,-0.0292997,0.61314,0.596502,0.110587,0.117133,0.016705,-0.0039633,0.834582,0.849911,0.829441,0.736085,0.924153,0.907393,0.78848,0.845588,0.684262,0.686875,-0.133733,-0.0766588,0.558035,0.521665,0.212171,0.142644,-1.69479,-1.65813,-0.00590634,0.0300243,-0.917009,-0.870021,-1.28991,-1.36505,-0.790811,-0.905408,-0.682267,-0.875788,-0.336639,-0.309363
359,0.611111,0.67047,0.911665,0.874262,0.84928,0.831872,0.452984,0.460478,0.489694,0.389583,0.939981,0.954066,0.845592,0.847064,0.534834,0.520921,0.945275,0.930287,0.150524,0.151034,-1.36961,-1.3106,-2.17778,-2.20783,0.296603,0.232855,0.743537,0.784871,-0.823643,-0.794741,-1.20455,-1.20223,1.07169,0.999487,-0.0645266,-0.228745,0.304675,0.115697,-0.298127,-0.262984
360,0.77203,0.779668,0.233887,0.198462,0.117082,0.102334,0.0623575,0.0687035,0.801742,0.783129,0.479627,0.493158,0.260883,0.259757,0.392528,0.321151,0.783467,0.767493,0.711816,0.709907,-0.873487,-0.813983,0.94347,0.908849,-1.35327,-1.41906,0.354724,0.395199,-2.1104,-2.07867,-1.59629,-1.53444,-0.458043,-0.532777,0.554452,0.447919,-0.46593,-0.648127,-1.1358,-1.09906
361,0.486681,0.49562,0.350417,0.316944,0.330689,0.307776,0.902163,0.910782,0.70868,0.692425,0.802973,0.818294,0.087705,0.138032,0.13684,0.12138,0.974076,0.957989,0.332119,0.383338,0.476357,0.560255,1.48862,1.44778,-0.615029,-0.681058,-1.10599,-1.06114,0.520709,0.557922,0.669607,0.732674,-0.0777192,-0.150332,-0.299999,-0.400346,0.644991,0.465899,-1.62479,-1.58891
362,0.696996,0.70695,0.822139,0.790607,0.526333,0.513217,0.0892475,0.0991288,0.392914,0.374745,0.592722,0.650665,0.0185104,0.0163082,0.388466,0.276084,0.434169,0.418386,0.0580801,0.0567699,1.87461,1.93449,0.0325803,-0.00127362,1.32219,1.25711,-0.823397,-0.772719,1.4915,1.53118,0.995323,1.05296,0.82928,0.754443,-0.546733,-0.651835,-0.793338,-0.973459,1.46286,1.49957
363,0.48685,0.498105,0.867046,0.834014,0.427926,0.386141,0.659546,0.666812,0.904308,0.888866,0.466643,0.483035,0.969738,0.966471,0.443707,0.430788,0.718701,0.70413,0.270113,0.269284,1.47812,1.53078,0.630358,0.600573,-0.133869,-0.193596,1.08738,1.13235,-1.69847,-1.66073,-1.14541,-1.09177,-0.387358,-0.463087,0.992952,0.889114,0.116198,-0.0621762,-0.863855,-0.833426
364,0.71045,0.719905,0.352112,0.321174,0.398277,0.259065,0.350661,0.359027,0.985217,0.923327,0.92429,0.941266,0.0999033,0.0947353,0.191195,0.177778,0.588374,0.571634,0.263981,0.264789,-1.62355,-1.57552,-1.23957,-1.27712,-0.816366,-0.87209,-0.0188357,0.0283451,0.45965,0.49177,0.768352,0.823129,-0.07869,-0.155387,1.37698,1.26782,-0.356028,-0.531828,-0.152182,-0.115427
365,0.276647,0.284103,0.711382,0.681286,0.14276,0.13199,0.648839,0.659417,0.976049,0.957789,0.00371912,0.0198675,0.277788,0.237784,0.753959,0.740014,0.212949,0.19745,0.656855,0.659355,-0.633841,-0.684823,1.0636,1.02401,0.202467,0.142595,0.520458,0.576399,-0.552409,-0.517816,-0.643564,-0.594852,-0.468984,-0.537712,0.474904,0.371664,-1.40429,-1.57923,0.124431,0.162664
366,0.280104,0.289253,0.0744681,0.0458255,0.674359,0.66553,0.49336,0.418669,0.434361,0.414298,0.114075,0.194081,0.387894,0.380832,0.905197,0.891279,0.309851,0.301715,0.741094,0.745476,0.204517,0.20587,-0.963967,-1.00686,-0.857297,-0.880586,-0.742635,-0.681017,0.869032,0.897582,0.000756025,0.0491832,0.991087,0.925853,-1.50204,-1.60531,-1.86027,-2.0346,-0.542943,-0.510041
367,0.53049,0.540368,0.852753,0.821404,0.51903,0.508857,0.165056,0.17792,0.969254,0.94806,0.354638,0.368295,0.00476904,-0.0001087,0.56926,0.560309,0.34636,0.40598,0.575872,0.580474,1.04853,1.09656,1.65328,1.61533,-1.84587,-1.90377,-0.34229,-0.286957,-1.42487,-1.395,-0.854373,-0.800207,0.186478,0.126736,-1.83325,-1.9326,-1.40728,-1.5761,-0.284143,-0.248643
368,0.235403,0.245856,0.319682,0.28933,0.906556,0.895865,0.800546,0.815263,0.121868,0.100159,0.091814,0.105177,0.444236,0.441652,0.245628,0.229339,0.527563,0.510246,0.995388,0.999803,-0.12491,-0.0759073,-1.00812,-1.04894,-2.59679,-2.65799,-0.337851,-0.275389,-0.535294,-0.499257,0.193955,0.242256,2.31786,2.25027,0.412327,0.305598,0.50733,0.338803,1.60993,1.6499
369,0.597476,0.588011,0.269341,0.239463,0.717256,0.744206,0.441095,0.453178,0.0122693,-0.011472,0.988801,1.00189,0.596535,0.638177,0.253084,0.329114,0.00616131,-0.00899543,0.297062,0.302146,-0.647239,-0.603821,-0.475321,-0.510006,0.521983,0.462857,-0.752736,-0.696314,-1.21077,-1.17104,1.80128,1.85119,0.488947,0.420676,-1.9197,-2.02722,-0.904091,-1.06951,-0.141489,-0.105452
370,0.920252,0.930167,0.83609,0.805946,0.605352,0.592547,0.730024,0.74363,0.741909,0.716526,0.139726,0.152933,0.836514,0.834703,0.443334,0.428889,0.251637,0.237081,0.660517,0.667337,-0.920725,-0.870376,-2.93543,-2.97003,-1.99257,-2.04578,0.667738,0.733175,0.807541,0.850652,0.576899,0.620635,-0.237352,-0.299492,-0.526064,-0.638791,1.6304,1.4676,-1.26845,-1.23524
371,0.821177,0.832728,0.12788,0.0958108,0.892542,0.879063,0.715759,0.740007,0.300436,0.27309,0.51545,0.527834,0.513871,0.514135,0.692224,0.679087,0.0770201,0.0638176,0.804011,0.809861,-0.38437,-0.327419,-2.03121,-2.06258,0.573147,0.514511,0.30738,0.373367,0.35099,0.391966,0.111793,0.156125,0.850593,0.788457,0.376354,0.257985,-0.200662,-0.369538,-0.834479,-0.807326
372,0.23027,0.24208,0.212365,0.180174,0.472921,0.518283,0.594575,0.736385,0.106067,0.0810316,0.458034,0.469978,0.669354,0.744167,0.200769,0.18801,0.871655,0.856448,0.446211,0.514027,-1.32437,-1.26933,0.638839,0.609601,-0.315913,-0.379923,-0.385314,-0.302314,2.05015,2.09737,1.55229,1.59461,0.835864,0.774476,0.585711,0.465589,0.132246,-0.0350972,0.634644,0.658763
373,0.899521,0.913302,0.630383,0.5247,0.171698,0.157503,0.720278,0.732762,0.81246,0.786749,0.722118,0.733414,0.973637,0.974198,0.753071,0.741207,0.516947,0.501727,0.212876,0.218193,-0.271451,-0.221161,-0.467573,-0.494861,0.7097,0.650601,-1.04373,-0.977996,-0.936829,-0.890675,-0.185454,-0.144057,-0.0976262,-0.174976,-1.29165,-1.41888,1.87233,1.70573,1.14014,1.16299
374,0.651515,0.664577,0.90079,0.869227,0.262917,0.319458,0.175163,0.189194,0.932325,0.906144,0.41174,0.424372,0.953636,0.956436,0.101341,0.0887223,0.460991,0.446162,0.771819,0.777066,0.540265,0.595161,0.969665,0.937494,1.50061,1.43331,1.05256,1.11664,0.237989,0.280393,0.562161,0.605526,-1.05748,-1.12443,-1.31134,-1.44214,0.732662,0.601271,-0.0829969,-0.0567038
375,0.935936,0.951424,0.195276,0.163828,0.498354,0.481413,0.262996,0.277328,0.0953748,0.0689742,0.572079,0.583842,0.0401291,0.0409419,0.0320449,0.0177533,0.0379064,0.0227375,0.12078,0.12607,-1.68686,-1.63682,-0.408195,-0.432752,0.663787,0.599639,-0.654964,-0.591034,-1.04599,-1.00354,0.499648,0.543276,0.620214,0.554452,0.541075,0.409557,-0.293681,-0.503185,0.313441,0.34003
376,0.858766,0.958731,0.0701682,0.0399368,0.337505,0.319483,0.859088,0.874173,0.462552,0.43664,0.0927181,0.103704,0.458303,0.457714,0.826602,0.811098,0.311743,0.235902,0.10547,0.111872,0.324772,0.383451,-1.25164,-1.27477,-1.86701,-1.92369,1.03971,1.1067,0.102354,0.150873,0.044949,0.0949309,0.177754,0.108403,-0.0574935,-0.193524,-1.44104,-1.60764,-0.28881,-0.25617
377,0.952431,0.966039,0.547794,0.517704,0.841376,0.823044,0.191666,0.206605,0.55502,0.603917,0.369902,0.38219,0.297116,0.298664,0.996984,0.982293,0.465077,0.449066,0.656505,0.660808,-0.221837,-0.159862,0.770347,0.752942,1.02597,0.968699,0.580529,0.655365,-1.4554,-1.41027,0.267643,0.323985,1.795,1.72532,0.594282,0.359287,-0.0607021,-0.224318,0.0943867,0.124858
378,0.12295,0.13786,0.174504,0.143092,0.371341,0.353312,0.394522,0.409042,0.811056,0.771193,0.145099,0.159276,0.719868,0.720434,0.382333,0.365956,0.0881974,0.0693456,0.929453,0.933977,0.320185,0.383095,0.288966,0.266535,-0.59032,-0.652461,0.742499,0.82038,-1.28368,-1.23621,0.801248,0.860024,-1.19911,-1.26348,1.05294,0.912099,0.781488,0.609997,-1.36654,-1.33836
379,0.702471,0.719256,0.521971,0.489267,0.855031,0.836327,0.520306,0.611479,0.96363,0.93847,0.732951,0.744937,0.0215098,0.0240392,0.798886,0.782524,0.365702,0.352237,0.892482,0.903595,-0.372612,-0.313525,0.436678,0.336187,0.989926,0.927935,1.35886,1.44242,-0.22211,-0.172806,0.742937,0.797775,0.1544,0.0922858,0.342822,0.199819,-0.129868,-0.297743,-1.48666,-1.45183
380,0.107739,0.123672,0.617822,0.589113,0.828803,0.787146,0.798108,0.813916,0.705727,0.681416,0.968275,0.978316,0.771421,0.773552,0.0944826,0.0791123,0.656783,0.635128,0.867145,0.873212,0.482805,0.548425,0.424758,0.40584,-0.138289,-0.201001,-0.583699,-0.501559,0.380071,0.428177,-0.368218,-0.311828,0.951463,0.889206,1.22379,1.08181,-0.125167,-0.288431,0.465037,0.506556
381,0.0998656,0.114647,0.620621,0.688959,0.743253,0.737965,0.621479,0.636249,0.719833,0.794494,0.571478,0.58164,0.239813,0.241365,0.142833,0.129127,0.697057,0.673572,0.629746,0.637533,-1.04324,-0.97536,-0.85103,-0.869157,-0.303163,-0.367415,0.760036,0.84658,0.0330618,0.077094,-0.0858489,-0.0225886,1.43877,1.38118,-1.35393,-1.49371,1.06224,0.902278,2.64568,2.68677
382,0.344576,0.443972,0.821017,0.788805,0.709401,0.688784,0.921647,0.93664,0.932581,0.907573,0.730209,0.74111,0.493235,0.493529,0.834294,0.820442,0.00416367,-0.0174022,0.0074737,0.0168329,0.921451,0.983234,0.63164,0.610555,-0.176041,-0.246591,0.063401,0.148711,2.74417,2.78671,-0.982484,-0.920128,-1.28574,-1.34406,-0.23842,-0.380793,-0.201311,-0.361794,1.54115,1.58921
383,0.757621,0.773296,0.453214,0.419701,0.337784,0.31944,0.404918,0.483109,0.828115,0.800668,0.423202,0.432068,0.15617,0.158369,0.836438,0.814567,0.505054,0.482818,0.382236,0.39131,-0.0779154,-0.0226663,0.322621,0.304384,0.885409,0.81389,0.077952,0.160279,0.395705,0.431904,-0.0983982,-0.0317774,-0.265723,-0.330709,0.274342,0.134201,1.0445,0.879148,-0.571731,-0.522229
384,0.330758,0.347672,0.909537,0.874056,0.333205,0.315709,0.0155715,0.0295793,0.937204,0.909686,0.884568,0.895017,0.637015,0.640618,0.820339,0.808693,0.124181,0.103097,0.300376,0.30811,-0.609642,-0.55058,-1.08588,-1.09832,1.6738,1.5966,-0.898459,-0.818741,0.382354,0.421476,-0.28468,-0.215564,0.520171,0.452994,1.08957,0.955253,1.6085,1.44772,1.30474,1.36005
385,0.573183,0.588727,0.297766,0.263092,0.057001,0.041291,0.758881,0.772289,0.0353779,0.0054532,0.975031,0.985786,0.835218,0.837271,0.537594,0.527114,0.544471,0.524162,0.837565,0.843006,-0.57088,-0.516655,-0.684625,-0.698529,0.177945,0.133497,0.996132,1.07081,-0.53625,-0.493337,0.113088,0.183015,-1.6005,-1.67313,-0.334624,-0.382643,1.05464,0.900892,-0.674185,-0.613466
386,0.202482,0.218975,0.185767,0.143391,0.59205,0.574831,0.605462,0.620167,0.177556,0.145218,0.672918,0.588703,0.312369,0.314955,0.839392,0.828107,0.694865,0.651841,0.855139,0.858353,-0.943811,-0.890396,0.660564,0.6403,-1.2524,-1.3296,-0.289569,-0.216221,-0.916922,-0.875659,0.876149,0.948578,0.817263,0.741317,-1.59045,-1.72054,-0.26069,-0.41435,-0.00293421,0.0589565
387,0.974348,0.989452,0.0573119,0.0236905,0.591787,0.576185,0.848769,0.86539,0.0605242,0.0285863,0.181499,0.191621,0.518546,0.52085,0.899326,0.888757,0.798537,0.77952,0.380187,0.382241,0.234394,0.295758,0.551954,0.534829,-0.337458,-0.408189,0.586244,0.655748,-0.0383,0.00341977,0.480807,0.548729,-0.111527,-0.181903,-0.6902,-0.823763,-0.245007,-0.405037,0.135717,0.201014
388,0.491841,0.508505,0.190917,0.157544,0.240704,0.226104,0.431601,0.527822,0.817211,0.787211,0.248781,0.258062,0.925393,0.927819,0.292569,0.282758,0.626874,0.606256,0.611875,0.61502,1.98516,2.04131,-1.0275,-1.03745,-1.47179,-1.53712,0.624501,0.697069,0.179712,0.22336,-0.320239,-0.254883,-0.463568,-0.534679,-0.565551,-0.617867,0.108079,-0.0540202,-0.731794,-0.668382
389,0.804912,0.820143,0.728316,0.694779,0.63052,0.532,0.175387,0.190255,0.790306,0.673612,0.812078,0.819349,0.309147,0.311524,0.573474,0.516179,0.207359,0.187391,0.515732,0.493428,-1.26513,-1.20224,0.846397,0.831501,0.623014,0.560899,-0.527707,-0.451417,0.814748,0.856247,1.11431,1.1836,-0.5589,-0.623998,-0.278728,-0.411972,0.0146266,-0.152735,-0.469395,-0.406984
390,0.15958,0.173957,0.998333,0.965814,0.850469,0.837897,0.938749,0.953654,0.672707,0.560014,0.42997,0.437864,0.600265,0.547718,0.760387,0.749599,0.427488,0.38046,0.415863,0.371836,-0.748409,-0.688203,-0.294141,-0.30414,-1.01153,-1.07319,0.0545603,0.125197,-1.49193,-1.45052,-0.572179,-0.51049,-1.56926,-1.64067,0.865785,0.729396,1.28812,1.11773,0.269865,0.325523
391,0.149251,0.164932,0.695331,0.659969,0.183868,0.168774,0.16431,0.179372,0.476415,0.446415,0.396833,0.451904,0.781927,0.783912,0.658538,0.677559,0.592981,0.573529,0.248211,0.250243,-0.9894,-0.924308,0.358004,0.344066,-0.567177,-0.627862,0.35795,0.429059,-0.274795,-0.232617,0.648008,0.713783,1.27069,1.20217,0.453778,0.309678,0.50988,0.24538,-0.218031,-0.164327
392,0.380608,0.33228,0.366522,0.354124,0.456826,0.440043,0.397043,0.409922,0.093096,0.0627267,0.457725,0.465945,0.171411,0.172768,0.510397,0.605519,0.449917,0.414956,0.985285,0.988628,0.461077,0.527574,-0.152454,-0.172739,0.428528,0.371631,1.33154,1.41042,-0.493461,-0.536044,0.684388,0.74406,0.876622,0.803957,-1.07537,-1.21459,-0.455111,-0.62697,0.647045,0.704544
393,0.424134,0.499627,0.0829282,0.0482791,0.0755191,0.060711,0.959699,0.973266,0.435631,0.405325,0.717846,0.725223,0.863267,0.865589,0.544268,0.53348,0.277391,0.256383,0.470346,0.473277,-0.875427,-0.813874,-1.66503,-1.68311,-0.642989,-0.694222,-0.652556,-0.569826,-0.877936,-0.839471,-0.197992,-0.136187,1.08167,1.00276,0.372762,0.232924,0.0751827,-0.104516,0.457564,0.515255
394,0.651295,0.666975,0.630136,0.506165,0.489941,0.495457,0.0120362,0.0241795,0.449578,0.511417,0.370067,0.37804,0.986209,0.990966,0.783268,0.773318,0.595705,0.57705,0.600664,0.605339,-0.033877,0.0334869,1.21442,1.20335,-0.606436,-0.663578,0.897686,0.987668,1.69789,1.73078,0.268969,0.325382,-0.580894,-0.653882,-0.137192,-0.314514,1.1065,0.93395,-1.84401,-1.78631
395,0.0601425,0.0763271,0.9987,0.964051,0.94501,0.930202,0.321342,0.333902,0.649473,0.617509,0.537397,0.547977,0.337073,0.342791,0.294932,0.28715,0.0796241,0.0621984,0.143687,0.149123,1.49524,1.56286,1.52496,1.42755,-0.106313,-0.160055,-1.21092,-1.11655,-1.91257,-1.88437,-1.05505,-0.999964,2.88097,2.81565,-0.720334,-0.861951,-0.0732504,-0.238866,-0.300849,-0.245029
396,0.897657,0.911475,0.20706,0.170313,0.616067,0.600457,0.991641,1.00668,0.166203,0.133826,0.184368,0.195658,0.715765,0.71955,0.76994,0.763675,0.625175,0.607135,0.0506925,0.0552833,-0.0373761,0.0220916,1.66716,1.65175,-0.714147,-0.761274,1.19959,1.29545,-0.377731,-0.346757,1.40264,1.46273,0.548852,0.478938,-0.129377,-0.271355,0.414355,0.251531,0.77375,0.83731
397,0.901218,0.916625,0.365416,0.347038,0.0218712,0.00601463,0.473819,0.488812,0.362483,0.297261,0.152497,0.163521,0.502769,0.573245,0.145278,0.137296,0.385929,0.368624,0.532462,0.538985,-1.21733,-1.15038,0.0779749,0.0641504,0.584909,0.541787,-0.968302,-0.869606,0.788446,0.824311,-0.971992,-0.917274,0.304612,0.23526,-0.490345,-0.630292,0.293428,0.137914,1.13297,1.09545
398,0.170796,0.18738,0.477792,0.523764,0.488069,0.469573,0.37493,0.39126,0.533424,0.460695,0.34902,0.362386,0.423487,0.426939,0.414925,0.407974,0.600836,0.584722,0.103024,0.108315,-0.389903,-0.319123,-1.12715,-1.14789,0.0733273,0.0797039,0.492875,0.592867,-0.358602,-0.319355,0.325509,0.383379,0.310108,0.236373,0.543564,0.405721,0.37947,0.225924,1.29542,1.35359
399,0.0314038,0.0495727,0.738886,0.70049,0.546841,0.625355,0.954366,0.96914,0.775586,0.624129,0.0408547,0.0533436,0.491705,0.495733,0.176424,0.170159,0.392724,0.377089,0.16468,0.170558,0.188166,0.255019,1.8568,1.83692,-0.332348,-0.382379,1.50772,1.60536,1.11439,1.15742,0.282761,0.336974,0.108684,0.0405614,0.782677,0.645456,0.683686,0.52883,-0.00150903,0.0582389
400,0.522215,0.5411,0.0672108,0.0294718,0.799152,0.781137,0.0799446,0.0940646,0.818693,0.787564,0.688962,0.699769,0.122814,0.12502,0.433253,0.425866,0.822456,0.807546,0.745048,0.749892,-0.107752,-0.0419449,-0.338067,-0.351205,1.32517,1.27423,-0.106277,-0.00707029,0.117421,0.163777,-0.292657,-0.233512,-0.562499,-0.634038,-0.442662,-0.586365,-0.536066,-0.68803,2.06199,2.12604
401,0.277198,0.297438,0.503777,0.397241,0.00991327,-0.0096403,0.453998,0.467906,0.408022,0.378374,0.459291,0.486106,0.863811,0.863972,0.266143,0.237407,0.744728,0.722254,0.850724,0.856118,-1.84963,-1.78255,-1.58297,-1.59412,-0.758403,-0.804018,-1.08164,-0.98609,0.119377,0.169614,-0.399511,-0.340893,-2.15371,-2.23,-0.533295,-0.670314,0.248077,0.11381,0.711909,0.768938
402,0.586862,0.517853,0.803105,0.76501,0.646673,0.6295,0.0987296,0.110893,0.912898,0.882273,0.316576,0.272442,0.2126,0.211728,0.0541197,0.0489475,0.651781,0.636962,0.353982,0.36071,-1.23105,-1.16337,0.453352,0.450166,1.08751,1.04267,0.733619,0.825133,1.15302,1.20308,0.626678,0.685505,-0.422536,-0.503756,-0.154993,-0.291603,1.07031,0.91565,-0.847628,-0.786842
403,0.811895,0.738269,0.817703,0.77917,0.236014,0.219868,0.829602,0.843368,0.109577,0.0761275,0.0479703,0.0587779,0.0714401,0.157831,0.348766,0.26567,0.0593561,0.0427297,0.0789885,0.0850501,1.39289,1.45972,0.443069,0.435369,-0.973139,-1.01998,1.90521,1.99171,1.59804,1.65085,-0.121028,-0.0565637,2.14348,2.06735,-0.274101,-0.356657,0.856812,0.708866,-0.665057,-0.600014
404,0.939871,0.958684,0.471644,0.434168,0.687595,0.673377,0.40005,0.411472,0.221076,0.149018,0.756079,0.765301,0.106291,0.103933,0.486544,0.482393,0.876349,0.861021,0.750441,0.754445,-0.692016,-0.626892,1.55139,1.54475,-0.629157,-0.682202,-0.331838,-0.238139,-0.0420449,0.0126063,-1.60254,-1.53742,-0.962893,-1.04639,-0.279186,-0.421711,2.04169,1.89958,0.383836,0.45083
405,0.579863,0.599017,0.801792,0.765034,0.586282,0.572705,0.248874,0.25935,0.254554,0.221909,0.461745,0.471152,0.798367,0.796754,0.343319,0.340259,0.844541,0.820568,0.490068,0.493339,0.355516,0.421278,1.03766,1.02795,0.205355,0.1498,-0.718867,-0.627811,-0.981168,-0.91946,-1.74643,-1.67675,0.167624,0.091505,0.0607941,-0.0760049,-1.19612,-1.33754,0.213107,0.276848
406,0.880784,0.90088,0.417772,0.386236,0.0335183,0.0185642,0.645295,0.607057,0.757613,0.725808,0.659916,0.670017,0.763568,0.762701,0.694537,0.692611,0.858273,0.780116,0.95909,0.962296,-1.43719,-1.36734,0.00547811,0.000147679,0.838711,0.77803,0.713879,0.801677,-2.95345,-2.88573,-1.36367,-1.29386,-0.933073,-1.00089,-0.325232,-0.463448,-2.63932,-2.7769,-0.700086,-0.636894
407,0.189549,0.208657,0.0458076,0.00743822,0.625993,0.611587,0.944015,0.954765,0.97377,0.941065,0.492241,0.50238,0.26188,0.261662,0.589609,0.551186,0.688134,0.739664,0.371588,0.376601,0.573518,0.637757,1.15502,1.15319,-0.732304,-0.769195,0.262307,0.350337,-1.24209,-1.26192,0.00650758,0.0823788,0.993418,0.930159,-2.03849,-2.17277,-0.851449,-0.989934,-1.89816,-1.84097
408,0.718919,0.739997,0.67976,0.642732,0.382737,0.367132,0.108425,0.117439,0.313785,0.281512,0.597416,0.606535,0.0947224,0.0919828,0.493484,0.409761,0.71454,0.699212,0.96633,0.97082,0.653742,0.718887,-0.26771,-0.263213,-2.25574,-2.31642,-1.60415,-1.51447,0.29221,0.361883,2.25207,2.33248,-0.698533,-0.758894,-0.461983,-0.600577,-0.000499311,-0.138399,-1.56075,-1.50331
409,0.072869,0.0938101,0.909288,0.869973,0.649732,0.633246,0.383954,0.392693,0.524475,0.491287,0.0244672,0.0321713,0.840651,0.836388,0.270568,0.268336,0.121516,0.10498,0.493823,0.499806,-1.07518,-1.00748,-0.62636,-0.627627,-0.616971,-0.673726,-0.0852703,0.00875979,0.688189,0.765436,-1.40866,-1.33552,-1.48572,-1.54127,-0.74477,-0.854654,-0.331497,-0.469354,-1.00527,-0.954308
410,0.87906,0.902288,0.330546,0.293302,0.506898,0.49124,0.0197799,0.0306079,0.213795,0.178593,0.241677,0.250886,0.734934,0.73162,0.976134,0.975706,0.147824,0.129323,0.454699,0.505192,0.158601,0.222498,0.754725,0.758726,-0.686738,-0.74948,-0.153824,-0.057547,-0.294764,-0.213491,0.0953331,0.163819,-0.68639,-0.81893,-0.968871,-1.10873,0.180729,0.038822,-1.91815,-1.86805
411,0.0898531,0.113872,0.0182472,-0.0172886,0.788689,0.772524,0.780736,0.794007,0.774993,0.737863,0.821296,0.831738,0.379479,0.376473,0.0158828,0.01398,0.511213,0.490244,0.503074,0.510578,-1.83256,-1.77036,-1.46631,-1.46058,1.71287,1.65509,0.652454,0.751927,0.520443,0.60379,0.502544,0.575485,-0.0435501,-0.0965954,0.273076,0.138489,-1.04577,-1.17804,-0.831806,-0.785712
412,0.416796,0.355483,0.891115,0.856956,0.636312,0.620627,0.518726,0.529818,0.815268,0.780043,0.608645,0.617957,0.791796,0.787999,0.378769,0.376865,0.120591,0.100196,0.683574,0.692903,-0.620482,-0.556072,0.194693,0.207807,-0.227215,-0.280792,-0.220689,-0.119519,-0.826128,-0.745017,-0.319238,-0.242885,-1.77817,-1.83307,0.526037,0.394271,-1.26613,-1.40147,1.61811,1.65804
413,0.674693,0.597095,0.834789,0.802474,0.265988,0.251283,0.253577,0.26563,0.63861,0.60341,0.765394,0.772747,0.509618,0.508796,0.985293,0.981406,0.0291562,0.00993068,0.409289,0.490789,-0.290005,-0.228379,0.541924,0.548781,0.69133,0.640622,2.17105,2.27792,-0.0223138,0.0554638,0.620972,0.691577,0.719865,0.667017,-0.239334,-0.363706,0.600204,0.46765,1.98547,2.02593
414,0.813047,0.838706,0.0129615,-0.0176377,0.124447,0.109277,0.464887,0.444815,0.199737,0.164903,0.684538,0.786788,0.232174,0.229592,0.767054,0.764319,0.416239,0.39568,0.277353,0.288676,-0.180813,-0.163342,0.214981,0.214215,-0.445645,-0.502292,-0.650213,-0.549201,1.08054,1.16358,0.276924,0.37115,-0.361933,-0.411761,0.36096,0.242756,-1.73424,-1.86807,0.338764,0.379409
415,0.76936,0.880077,0.297867,0.268806,0.719849,0.702299,0.610168,0.624,0.427583,0.390358,0.792001,0.800828,0.467103,0.529812,0.864515,0.860049,0.107013,0.0866209,0.359972,0.370296,-0.162386,-0.0983043,0.529375,0.524098,-1.89179,-1.953,1.82479,1.93145,-2.28695,-2.20479,-0.0253793,0.0507224,1.15102,1.09639,-0.117037,-0.237475,1.30458,1.17838,0.111562,0.145262
416,0.896524,0.921449,0.037133,0.00771194,0.973416,0.957779,0.177968,0.192103,0.232255,0.237408,0.36369,0.406433,0.832736,0.830032,0.535585,0.528696,0.469213,0.447542,0.841443,0.853997,-1.05962,-0.996252,2.17748,2.17477,-0.695542,-0.749584,0.0160578,0.113629,-0.375455,-0.297418,-0.0910314,-0.0115271,0.492577,0.437721,-0.258812,-0.381935,-1.88977,-2.01167,0.770208,0.802315
417,0.486471,0.511518,0.674829,0.647063,0.279074,0.263791,0.996086,1.00868,0.123384,0.0844592,0.00609804,0.0120372,0.123976,0.122816,0.749583,0.706311,0.2761,0.282171,0.361226,0.373435,0.545907,0.610577,-0.719277,-0.729184,0.515046,0.453833,0.460599,0.552772,-0.5308,-0.44852,0.383399,0.465717,0.244237,0.194044,-0.864014,-0.985016,-2.42908,-2.54426,0.290018,0.230223
418,0.377485,0.402497,0.19766,0.169626,0.429478,0.415389,0.082317,0.0970457,0.724668,0.684201,0.343899,0.380123,0.379024,0.379416,0.889001,0.883926,0.13889,0.116801,0.714991,0.727317,-0.60884,-0.547292,-2.43187,-2.44235,0.642528,0.574657,-0.666781,-0.580444,-1.39365,-1.32007,-1.49755,-1.41067,0.211955,0.165272,0.938717,0.820237,0.0289407,-0.0885029,-0.369761,-0.341868
419,0.687578,0.714135,0.579339,0.549363,0.879347,0.864644,0.62551,0.639934,0.33248,0.290635,0.742246,0.748209,0.231859,0.229886,0.129972,0.122461,0.931009,0.909432,0.504431,0.462461,-0.716665,-0.649128,2.81536,2.80488,-0.930301,-0.997626,-0.752372,-0.663644,2.53116,2.60952,-0.372268,-0.277789,0.433584,0.393452,-1.87342,-1.9952,0.409019,0.293479,1.23289,1.26201
420,0.0768218,0.102379,0.445137,0.415521,0.437889,0.46374,0.4073,0.441526,0.654483,0.613052,0.105968,0.112835,0.444308,0.520314,0.589024,0.579184,0.757001,0.736169,0.185548,0.197605,0.540907,0.615128,0.432519,0.423382,1.1966,1.1307,-0.940177,-0.746843,-0.256167,-0.176914,0.23288,0.421516,-0.0133445,-0.0525975,-0.659883,-0.778519,-0.198256,-0.316015,-0.410039,-0.384507
421,0.477641,0.505322,0.968813,0.938529,0.0762068,0.0628365,0.180208,0.243118,0.525789,0.422468,0.846731,0.854761,0.810867,0.810741,0.767281,0.756574,0.132306,0.111355,0.759785,0.771688,0.487933,0.560955,0.137545,0.134368,-0.114438,-0.181194,-0.91638,-0.830043,1.48491,1.5614,1.01914,1.12082,0.240432,0.206979,0.0673392,-0.143773,-0.0993044,-0.210664,0.72213,0.742851
422,0.238019,0.266857,0.229202,0.198602,0.249944,0.1414,0.0302032,0.0447106,0.271042,0.231884,0.671912,0.658168,0.741014,0.741723,0.62451,0.515648,0.0151675,-0.00581532,0.795248,0.808405,-0.0510914,0.0176421,-0.515452,-0.520979,-0.437308,-0.503387,1.59447,1.68109,-0.79476,-0.716226,-0.194895,-0.0942077,-0.202892,-0.23907,0.614698,0.490974,0.0113147,-0.105314,-2.02197,-2.00596
423,0.975881,1.00461,0.73376,0.701413,0.235013,0.219963,0.378405,0.393497,0.617355,0.586959,0.45485,0.461574,0.0486895,0.0497978,0.283883,0.274721,0.470847,0.47855,0.278049,0.293054,0.759366,0.833964,-0.410229,-0.414054,-0.115207,-0.180673,0.228343,0.318279,0.329035,0.406815,-0.09364,0.0125789,-0.122425,-0.16106,0.100252,-0.0201266,-0.606218,-0.728377,-1.89946,-1.88173
424,0.681199,0.697345,0.206536,0.174002,0.742824,0.728193,0.153465,0.170607,0.978967,0.942034,0.0336579,0.0402602,0.235982,0.161505,0.734262,0.726421,0.983898,0.962915,0.443961,0.45999,-0.594038,-0.541637,-1.98474,-1.98633,-0.205837,-0.273941,-0.0962686,-0.00940164,0.396006,0.473924,-0.639448,-0.528926,0.182927,0.137232,-2.2987,-2.41707,-0.479522,-0.595352,-1.52661,-1.51384
425,0.3624,0.390079,0.883379,0.848791,0.676198,0.663153,0.999283,1.01728,0.0442274,0.00500671,0.629509,0.636049,0.274908,0.273212,0.541629,0.567501,0.034915,0.0116161,0.923778,0.938993,-1.99754,-1.91724,-0.353525,-0.350687,0.281296,0.215276,1.58054,1.67364,1.31362,1.4232,1.30915,1.41567,0.414465,0.435524,0.364503,0.249215,0.726814,0.613364,0.181537,0.198414
426,0.794278,0.823042,0.464802,0.432579,0.176996,0.163457,0.351524,0.369652,0.954862,0.917513,0.143335,0.15133,0.384914,0.384919,0.472695,0.408581,0.744551,0.723854,0.75874,0.773991,-0.00695783,0.0712178,0.110321,0.111135,1.5919,1.51834,-0.884557,-0.792097,2.29455,2.37247,1.2585,1.36926,0.772451,0.733816,0.160277,0.0441669,-0.501114,-0.62135,0.54812,0.51677
427,0.073511,0.10358,0.0524518,0.0163666,0.241966,0.166752,0.895212,0.91254,0.175668,0.137983,0.577732,0.585455,0.0638684,0.0643522,0.255829,0.249662,0.145452,0.124052,0.248873,0.263082,-0.558757,-0.487351,-1.64594,-1.65139,0.233704,0.159077,-1.16079,-1.07457,0.258425,0.338058,0.784394,0.8902,0.0793982,0.0432935,0.670242,0.559161,2.59225,2.47305,0.813143,0.835126
428,0.483873,0.51144,0.746111,0.711137,0.186694,0.170047,0.0467491,0.0640019,0.570782,0.53075,0.535127,0.543488,0.117999,0.117626,0.731715,0.726187,0.245858,0.319789,0.32072,0.335109,1.47634,1.54941,1.50667,1.49978,0.254748,0.174908,-0.947918,-0.863929,0.585425,0.664677,1.91926,2.02308,0.204605,0.166048,0.310672,0.200225,-0.393711,-0.513482,-0.787331,-0.765047
429,0.499657,0.526632,0.489172,0.455082,0.0221714,0.00390052,0.852807,0.870355,0.451432,0.352326,0.220955,0.229727,0.698443,0.698777,0.748394,0.742007,0.534322,0.515527,0.868105,0.884045,1.116,1.19149,-0.880317,-0.881713,-0.235478,-0.370915,0.0120524,0.099998,0.3819,0.465864,-1.01949,-0.908343,-1.55102,-1.58535,-0.86562,-0.967917,-0.553014,-0.675757,0.02746,0.0432176
430,0.932843,0.959595,0.73828,0.702089,0.952387,0.934779,0.250279,0.267041,0.213951,0.173901,0.718082,0.727208,0.802425,0.80389,0.483032,0.474951,0.905495,0.885991,0.868092,0.884933,-0.930391,-0.848977,0.101663,0.10167,-0.840048,-0.916737,0.18698,0.281054,0.62341,0.699446,-0.23219,-0.116181,0.386826,0.345697,-0.487231,-0.589206,0.0307431,-0.0924449,-0.338979,-0.329001
431,0.146196,0.171179,0.51917,0.482709,0.956093,0.936133,0.762546,0.779839,0.759565,0.71827,0.189566,0.197289,0.433113,0.433177,0.439675,0.482359,0.59764,0.576932,0.125058,0.141843,-0.782932,-0.706304,-0.52529,-0.522862,1.02839,0.945285,1.91622,2.01005,-0.971408,-0.891009,-0.500841,-0.377334,-1.55732,-1.59454,-1.54224,-1.63678,-0.825345,-0.948691,1.10013,1.10664
432,0.080322,0.1049,0.85655,0.818851,0.538251,0.516467,0.138195,0.156814,0.909381,0.868457,0.0593043,0.0686993,0.888346,0.889057,0.493736,0.489766,0.0772842,0.0576906,0.0996319,0.213561,-0.359906,-0.286452,-0.000435323,0.00117332,2.04948,1.95997,-0.753081,-0.651847,0.539453,0.616684,1.22349,1.34095,0.0733616,0.0392227,-0.163493,-0.264487,0.420303,0.292251,1.02338,1.02219
433,0.408177,0.432476,0.645591,0.522793,0.523796,0.564248,0.518598,0.535127,0.0727032,0.0312874,0.459017,0.363087,0.344407,0.346793,0.505871,0.497174,0.230371,0.212659,0.26876,0.28528,-0.977322,-0.90797,0.820634,0.8162,0.183844,0.0888524,-0.419202,-0.318842,-0.704571,-0.621799,-0.790262,-0.675597,-1.1059,-1.13316,0.259839,0.15872,0.142621,0.00822443,0.00902182,0.00289927
434,0.96316,0.989025,0.265374,0.226735,0.63423,0.612029,0.17121,0.1884,0.98895,0.947744,0.738852,0.657474,0.598051,0.598957,0.714581,0.711001,0.0452441,0.0255702,0.481698,0.469904,-0.905354,-0.840871,-0.705683,-0.710954,-0.598197,-0.696697,-0.99561,-0.893415,0.562222,0.643344,0.138487,0.208122,0.658301,0.623067,-1.60625,-1.70849,1.51915,1.37631,-2.04242,-2.04517
435,0.19808,0.223776,0.650348,0.611501,0.126417,0.103641,0.918982,0.936862,0.0255068,-0.0137343,0.942467,0.951862,0.0625514,0.0621761,0.932014,0.924828,0.612232,0.59097,0.636324,0.654528,-0.307811,-0.246519,-0.774328,-0.785419,-0.274436,-0.431204,0.720421,0.818218,-0.259375,-0.181421,0.970918,1.09184,0.498919,0.381283,-0.815358,-0.919129,-1.58527,-1.72811,0.990395,0.993394
436,0.196307,0.224343,0.737192,0.700719,0.603829,0.581824,0.95528,0.975727,0.615218,0.576233,0.890558,0.89968,0.368683,0.369129,0.932131,0.940989,0.971616,0.951891,0.420339,0.439228,0.290422,0.347833,-0.38363,-0.451788,-0.0643914,-0.165712,0.661473,0.751911,1.4106,1.49386,0.466461,0.581242,0.175263,0.1395,-0.47428,-0.573423,1.50548,1.35557,-1.08,-1.07171
437,0.575679,0.602419,0.58769,0.551895,0.538526,0.516783,0.346252,0.367743,0.58682,0.644595,0.00750587,0.0176928,0.462831,0.427356,0.963876,0.957149,0.130334,0.112847,0.931963,0.952745,-1.57366,-1.5214,-0.111094,-0.118156,0.585279,0.479156,-0.479266,-0.305744,-0.151838,-0.0672893,-1.03051,-0.914818,-0.347488,-0.383676,0.379739,0.278725,-0.593387,-0.740054,-1.52796,-1.51757
438,0.585675,0.612724,0.0386595,0.00517514,0.115754,0.0922841,0.00276849,0.0262778,0.75049,0.712957,0.30265,0.313315,0.483692,0.485584,0.285839,0.279792,0.902019,0.884359,0.38273,0.401948,1.14812,1.20089,-0.807946,-0.819299,-0.160366,-0.258801,-1.45691,-1.3634,-0.926801,-0.843864,1.40656,1.5188,0.613223,0.583673,0.589505,0.486329,0.36114,0.217746,0.486531,0.503769
439,0.368203,0.393489,0.565039,0.532928,0.351259,0.327654,0.849554,0.872955,0.400391,0.365529,0.889038,0.898976,0.29763,0.300145,0.428134,0.421146,0.678822,0.665628,0.0529424,0.0703683,0.852846,0.903924,-0.303167,-0.231357,0.233261,0.141492,0.655365,0.747661,1.28433,1.35914,-0.390813,-0.28249,-1.62431,-1.6549,-0.122246,-0.22595,-0.54146,-0.689994,-0.739902,-0.715928
440,0.600133,0.625339,0.165173,0.133488,0.244578,0.22161,0.997672,1.02323,0.962442,0.92848,0.691687,0.700207,0.705402,0.647454,0.566291,0.562501,0.359491,0.446896,0.961262,0.978959,-0.108797,-0.0549763,0.360494,0.356584,-1.3961,-1.4926,0.175643,0.2665,-0.179804,-0.109532,-0.466908,-0.360226,1.71718,1.68724,0.320598,0.211573,-0.466358,-0.708876,0.885509,0.905032
441,0.148787,0.174915,0.789531,0.759133,0.501375,0.451524,0.452333,0.479662,0.619297,0.584905,0.00453858,0.0154401,0.990105,0.994763,0.933271,0.929588,0.245824,0.228164,0.839462,0.854352,-0.300184,-0.244855,-0.606571,-0.608062,-0.158301,-0.249582,0.00425243,0.0930044,-0.342824,-0.277357,0.597784,0.698165,-0.825955,-0.858794,-0.864021,-0.973648,-0.580273,-0.727757,-1.30325,-1.28402
442,0.995401,1.02237,0.991498,0.961594,0.705238,0.681437,0.145038,0.171877,0.983327,0.948249,0.814431,0.825366,0.0264514,0.0326188,0.307996,0.30321,0.84104,0.824635,0.816546,0.729745,0.39921,0.450147,-0.672623,-0.667209,-1.11419,-1.20519,0.432434,0.517398,0.88757,0.956145,-0.208258,-0.105447,0.78791,0.758128,0.133375,0.0155254,-0.782843,-0.934541,-0.29974,-0.277977
443,0.40274,0.431722,0.334634,0.305321,0.575034,0.54991,0.0456862,0.0743251,0.875727,0.859318,0.142445,0.154918,0.490751,0.506159,0.495532,0.490176,0.56284,0.624212,0.588003,0.605138,0.0886038,0.138615,-0.190551,-0.190969,-1.13568,-1.21994,-0.783998,-0.693311,1.73527,1.80509,-0.798044,-0.693976,0.656819,0.621756,-1.04665,-1.1697,1.25556,1.09837,1.14325,1.17123
444,0.819527,0.849786,0.256884,0.227527,0.822076,0.795233,0.249112,0.275784,0.852543,0.770386,0.30769,0.320079,0.973532,0.979699,0.385839,0.378598,0.441648,0.423788,0.773383,0.809872,0.0996741,0.144037,-0.104127,-0.0984633,-0.124427,-0.205254,-0.504484,-0.420771,-0.805963,-0.737962,1.16024,1.26714,-0.312246,-0.347887,-1.35426,-1.48303,-0.31132,-0.466537,0.233142,0.257485
445,0.374249,0.40394,0.848448,0.818376,0.439758,0.410617,0.842705,0.868116,0.711195,0.681455,0.219116,0.23221,0.904569,0.91068,0.854646,0.845504,0.746931,0.729564,0.997379,1.01461,-0.538601,-0.491898,-1.94272,-1.94152,0.0161342,-0.0673902,0.44023,0.528083,2.16994,2.23183,0.812353,0.913548,1.1747,1.14391,0.856174,0.726074,0.615649,0.461033,-1.32754,-1.2983
446,0.479779,0.545535,0.00921512,-0.021833,0.87615,0.844721,0.435731,0.461091,0.657221,0.592524,0.938838,0.953566,0.559959,0.599863,0.0561121,0.0488201,0.429488,0.528236,0.127286,0.146954,-1.65855,-1.61898,-0.887198,-0.861367,-2.25949,-2.3397,0.590069,0.678839,1.59996,1.66794,1.3177,1.42064,1.00523,0.931762,-1.71427,-1.84944,0.127702,-0.0234814,-0.170622,-0.139239
447,0.646495,0.68713,0.592431,0.559128,0.951309,0.839518,0.864819,0.889776,0.53867,0.503593,0.578104,0.59184,0.281416,0.289045,0.0860225,0.0790347,0.282195,0.326908,0.645439,0.666542,0.924634,0.970341,0.218174,0.21879,0.984468,0.908363,-0.486517,-0.39308,-1.15885,-1.08743,2.29199,2.40016,0.676972,0.719609,-1.4573,-1.59366,-0.0948202,-0.246909,-1.87585,-1.84929
448,0.799035,0.828725,0.476775,0.445907,0.864992,0.834316,0.751032,0.777313,0.245024,0.210962,0.80127,0.81587,0.390194,0.439943,0.948595,0.939441,0.142947,0.125579,0.253653,0.358066,-0.413022,-0.371107,-0.894774,-0.901173,0.616553,0.541555,-0.792353,-0.706089,0.149177,0.222545,0.903701,1.011,0.538239,0.507456,0.65705,0.522976,0.723189,0.570425,-1.77836,-1.75318
449,0.357672,0.388217,0.0914311,0.0615453,0.0427997,0.00975471,0.38457,0.410504,0.694941,0.659165,0.0580452,0.0705093,0.684984,0.590842,0.372963,0.363296,0.761119,0.741626,0.0291343,0.0495886,0.0444978,0.0793486,-0.0110814,-0.000189788,0.724161,0.648056,1.08296,1.16573,-0.510617,-0.431806,0.211741,0.314442,-0.1139,-0.136681,-0.622026,-0.756258,0.999314,0.840881,-0.760977,-0.731726
450,0.334307,0.281191,0.0456283,0.0169117,0.459403,0.427983,0.552939,0.533427,0.0833792,0.0496638,0.533569,0.547824,0.727713,0.741741,0.564883,0.554925,0.880256,0.860794,0.671039,0.692934,-0.164682,-0.126105,0.912544,0.900793,0.318452,0.167051,-1.68965,-1.61328,-0.103026,-0.0282534,-1.9062,-1.79697,-1.52979,-1.55862,-1.58057,-1.71252,-0.852227,-1.01496,-0.192617,-0.165751
451,0.144897,0.174164,0.211342,0.180646,0.413008,0.383712,0.595879,0.656349,0.241029,0.228079,0.271662,0.284705,0.885011,0.892639,0.0468108,0.0391173,0.185924,0.164639,0.0992977,0.12176,-1.35008,-1.31496,0.479027,0.459762,-0.232946,-0.313954,0.978579,1.0521,-0.656707,-0.577029,1.2988,1.40983,0.600092,0.564911,-1.47534,-1.61047,-0.744074,-0.986387,-1.09181,-1.06354
452,0.666856,0.696123,0.683594,0.654309,0.608113,0.597708,0.674257,0.779272,0.568768,0.406493,0.663249,0.674037,0.462638,0.471617,0.849007,0.842388,0.583833,0.560516,0.301945,0.323746,1.98803,2.02339,-0.560078,-0.483653,-0.36291,-0.448904,-0.919039,-0.845711,0.7963,0.869507,0.00913265,0.116086,-0.976677,-1.0153,-0.543403,-0.681163,-0.803128,-0.957818,-1.45241,-1.42069
453,0.314699,0.346062,0.350871,0.319235,0.839656,0.811704,0.716149,0.902195,0.616937,0.584908,0.835031,0.843974,0.454516,0.541414,0.332402,0.32658,0.302452,0.277235,0.959289,0.98213,-1.02951,-0.988664,-1.4078,-1.42707,0.221261,0.134525,-0.516945,-0.436733,1.13979,1.21182,-0.346994,-0.332262,-0.834417,-0.877827,-0.677433,-0.80996,-0.396232,-0.545393,-0.324275,-0.293334
454,0.602249,0.648236,0.45177,0.418167,0.174459,0.148277,0.999183,1.02512,0.201433,0.170837,0.396248,0.40242,0.603067,0.611211,0.936142,0.931121,0.970437,0.944921,0.756562,0.78139,-1.41978,-1.37678,-0.102013,-0.11741,-0.105906,-0.279658,1.2607,1.34123,-1.26257,-1.19424,-0.884465,-0.78061,0.0108867,-0.0353447,2.23722,2.10133,-1.26803,-1.41918,1.64281,1.67965
455,0.92083,0.95041,0.824163,0.792374,0.725765,0.700793,0.776591,0.802227,0.416897,0.337693,0.898344,0.904767,0.185936,0.195202,0.660162,0.654436,0.149454,0.125648,0.225721,0.249935,1.4541,1.49294,0.468698,0.452734,-0.607106,-0.693842,-1.62019,-1.5314,-0.223578,-0.160775,-1.83976,-1.73754,-0.368958,-0.417669,-0.101957,-0.23149,-0.295918,-0.377462,-1.20179,-1.15916
456,0.516531,0.622354,0.0267174,-0.00521208,0.382023,0.438613,0.0516923,0.0745853,0.534066,0.504549,0.853757,0.8628,0.543209,0.552588,0.18043,0.173356,0.323143,0.300615,0.0648745,0.0895594,0.302856,0.335068,0.80472,0.793709,-0.0387842,-0.126785,-0.208295,-0.118014,-0.856573,-0.800969,-2.31082,-2.20205,0.657514,0.609475,0.931439,0.804523,0.8154,0.664252,0.749771,0.799228
457,0.264133,0.294298,0.851534,0.817763,0.200363,0.176433,0.377507,0.398883,0.225401,0.197035,0.199953,0.208068,0.0446903,0.0567856,0.194943,0.189176,0.945405,0.921734,0.956198,0.982836,0.748812,0.785524,0.700683,0.688238,1.18101,1.10077,0.585402,0.676403,-0.331057,-0.276199,0.203165,0.308757,0.521648,0.473103,0.884359,0.751436,-0.129522,-0.275342,0.389846,0.442078
458,0.833648,0.865759,0.951228,0.916695,0.366187,0.350364,0.326953,0.347256,0.200422,0.17291,0.879606,0.888794,0.879264,0.89049,0.683872,0.582516,0.936,0.887783,0.353615,0.382003,-1.1496,-1.11428,1.34612,1.33644,0.43236,0.346541,0.0575913,0.148308,1.30366,1.35435,0.341251,0.35191,-0.442732,-0.496539,-0.58154,-0.711486,0.32375,0.183162,0.689221,0.734303
459,0.634619,0.639939,0.0352889,0.00126268,0.54845,0.524295,0.583073,0.602417,0.511846,0.401871,0.777895,0.791461,0.948617,0.903231,0.978586,0.975857,0.821402,0.853832,0.533038,0.559558,-0.900915,-0.863121,-1.71211,-1.71868,-0.62376,-0.703988,0.483783,0.572702,0.998859,1.04965,0.289777,0.395063,-0.92227,-0.973661,0.0307813,-0.105024,-0.840801,-0.974582,1.30812,1.36088
460,0.458046,0.41412,0.675486,0.640613,0.133119,0.109869,0.625257,0.738222,0.658425,0.630832,0.685946,0.694127,0.904605,0.915973,0.901732,0.81463,0.752401,0.819881,0.121419,0.148087,1.63193,1.67464,-1.08601,-1.0876,-0.41036,-0.489283,0.397834,0.552903,-1.65532,-1.60253,0.0401984,0.14827,1.27667,1.22886,0.894265,0.760915,-1.41597,-1.55305,1.32916,1.38335
461,0.155873,0.188301,0.847311,0.814466,0.111602,0.0860922,0.853491,0.874027,0.21711,0.187396,0.0263394,0.0342031,0.590142,0.680611,0.655548,0.653403,0.809601,0.78593,0.171648,0.15697,-0.0807511,-0.0365474,0.953962,0.95669,-0.959023,-1.04011,0.438412,0.533103,-0.520614,-0.41872,-0.729984,-0.624719,-0.541528,-0.585102,-0.410084,-0.550465,0.740275,0.596943,-0.540897,-0.479735
462,0.665973,0.70022,0.33752,0.305916,0.673009,0.648325,0.71267,0.730361,0.407809,0.377382,0.998142,1.00506,0.331979,0.445249,0.714352,0.794758,0.0976551,0.0755327,0.129839,0.165854,0.977259,1.02534,-1.85852,-1.85682,-0.101167,-0.179807,-0.199001,-0.102902,0.712644,0.76509,0.686168,0.796989,0.276516,0.226565,0.620537,0.485548,-1.16195,-1.30664,-0.721816,-0.653717
463,0.794881,0.830234,0.165618,0.221007,0.179286,0.154043,0.565378,0.586696,0.992721,0.962796,0.466143,0.47514,0.196361,0.209887,0.93747,0.936113,0.229683,0.203212,0.0231385,0.174738,-0.290761,-0.240191,-0.993001,-0.996231,-0.659926,-0.73063,-1.79683,-1.69925,0.395462,0.443886,-0.674173,-0.560884,-0.19642,-0.201844,0.43478,0.295892,-1.29206,-1.43648,-1.86894,-1.79785
464,0.288654,0.324742,0.166435,0.136098,0.157033,0.147946,0.630115,0.736218,0.868632,0.836458,0.484563,0.546775,0.150764,0.166524,0.426566,0.424843,0.355623,0.33089,0.156954,0.183622,-0.157882,-0.11237,-0.461358,-0.4573,-0.517799,-0.592766,0.384017,0.473048,-1.53221,-1.48859,1.01032,1.12679,-0.576573,-0.630252,-2.09819,-2.23019,0.914543,0.777267,-0.231994,-0.222768
465,0.320611,0.355173,0.619385,0.590454,0.0397628,0.141849,0.864612,0.885739,0.172861,0.140615,0.60751,0.618409,0.985304,1.00023,0.826324,0.826402,0.0305037,0.00634722,0.384673,0.411402,1.0778,1.11761,-0.394789,-0.387648,1.93573,1.86265,-0.609952,-0.520896,1.35682,1.40388,0.333546,0.444689,-0.358227,-0.417417,-0.539294,-0.673749,-0.135412,-0.270134,1.28123,1.35232
466,0.719155,0.752938,0.671332,0.644257,0.049615,0.135752,0.761979,0.783164,0.235119,0.203107,0.929818,0.938516,0.00220401,0.0187423,0.429205,0.429896,0.42465,0.402224,0.852254,0.88036,-1.79237,-1.75433,-0.327383,-0.317995,-0.162345,-0.232576,1.10084,1.19074,-0.824852,-0.776241,0.74031,0.856355,-0.786937,-0.84699,-0.00618378,-0.142682,-0.595627,-0.700883,0.349111,0.422686
467,0.231895,0.266344,0.134681,0.107159,0.0653296,0.129655,0.0696634,0.0910474,0.807001,0.7774,0.679985,0.618855,0.0327756,0.0512537,0.519686,0.520778,0.617342,0.633634,0.483247,0.509851,-0.515844,-0.474653,-1.34442,-1.32924,0.17249,0.105201,-1.02732,-0.943529,-1.24227,-1.1886,-0.198191,-0.0867226,-0.0752017,-0.139949,2.02366,1.882,-0.993937,-1.13163,-2.59221,-2.52567
468,0.373359,0.406698,0.172229,0.145533,0.1488,0.123558,0.824718,0.843644,0.522723,0.494981,0.292061,0.299194,0.345302,0.363313,0.0903646,0.0896752,0.888241,0.865044,0.579291,0.606016,0.0239194,0.0683044,-0.0262017,-0.00505089,0.283541,0.25707,0.250626,0.330304,0.613511,0.671502,2.68371,2.80207,-0.107287,-0.16872,0.721455,0.586141,0.422503,0.283323,-0.370526,-0.296265
469,0.0738503,0.107067,0.761038,0.736382,0.571455,0.547726,0.371141,0.391777,0.95958,0.932739,0.925501,0.935173,0.280197,0.299183,0.104874,0.105495,0.781701,0.8485,0.125593,0.1498,-1.67409,-1.626,0.824048,0.840086,0.476985,0.40894,0.385935,0.464319,-0.211179,-0.153262,1.34243,1.46129,-1.21945,-1.27757,-0.350253,-0.493238,-1.46018,-1.60334,0.46093,0.541037
470,0.566183,0.598594,0.165417,0.140218,0.176326,0.152642,0.845399,0.864785,0.0680643,0.0403667,0.847674,0.856945,0.510009,0.530157,0.625989,0.627801,0.85364,0.831956,0.101261,0.0967302,-1.53955,-1.49817,-0.388831,-0.371952,-1.45174,-1.52695,0.0658441,0.15131,0.639473,0.650914,-0.283247,-0.168757,1.67159,1.62053,1.8781,1.72816,-0.366955,-0.503682,-0.270576,-0.190624
471,0.422552,0.461342,0.339611,0.314071,0.99158,0.96773,0.211718,0.232569,0.93026,0.901241,0.490293,0.499379,0.166219,0.184933,0.569922,0.479414,0.446235,0.423041,0.0188455,0.0436602,2.20744,2.24246,-0.594559,-0.584066,0.222074,0.14748,-2.16088,-2.07854,1.39717,1.45509,1.1196,1.28757,0.249742,0.198591,-0.355912,-0.509375,1.09058,0.958942,0.906069,0.983259
472,0.293043,0.324089,0.905452,0.880554,0.92244,0.898422,0.37454,0.397411,0.930761,0.904031,0.988604,0.99686,0.970478,0.990405,0.327026,0.331027,0.371428,0.348097,0.73967,0.763189,-0.313376,-0.271971,1.94038,1.95678,-1.13612,-1.21178,0.755664,0.844241,-1.92964,-1.87976,2.6294,2.74389,1.02049,0.965688,0.252877,0.0970871,0.330997,0.195118,3.66534,3.74373
473,0.357526,0.471362,0.783512,0.756663,0.420069,0.394286,0.82813,0.850492,0.460141,0.435726,0.260729,0.267423,0.0808858,0.102273,0.75308,0.757641,0.542534,0.517783,0.577507,0.674376,-0.381359,-0.343098,0.336696,0.352439,-0.489015,-0.566912,-0.794357,-0.702162,-0.827061,-0.771636,0.653121,0.771217,0.268555,0.214885,1.31255,1.16524,-0.00596966,-0.135837,1.17749,1.2547
474,0.589419,0.618635,0.272283,0.243822,0.319959,0.293613,0.245648,0.267206,0.298269,0.274361,0.133696,0.170089,0.975268,0.998666,0.186902,0.190996,0.209653,0.183948,0.560699,0.585563,-1.4006,-1.365,0.551639,0.57077,-1.08884,-1.16813,0.347338,0.380637,-0.450198,-0.397125,0.173042,0.292157,2.02608,1.97111,1.14272,0.991471,0.256566,0.119467,-0.505643,-0.422253
475,0.463059,0.490078,0.118678,0.0903258,0.710117,0.685532,0.64765,0.671687,0.516856,0.499022,0.0653398,0.0727561,0.0234177,0.0479869,0.171073,0.175014,0.76301,0.739162,0.735372,0.757735,-0.314889,-0.273552,0.992837,0.981401,0.537019,0.458013,1.36906,1.46344,1.56232,1.61221,0.0815941,0.199088,-1.42735,-1.48275,-0.781117,-0.93724,0.0274339,-0.10396,-0.387467,-0.309123
476,0.944452,0.971394,0.495038,0.523519,0.484101,0.458105,0.00971969,0.0344306,0.74921,0.723684,0.910288,0.918765,0.721763,0.745236,0.479125,0.481601,0.780567,0.758947,0.498244,0.434443,1.53536,1.57745,1.3807,1.39203,-0.592993,-0.670923,1.9293,2.02497,-0.0585301,-0.0109318,0.934797,1.05547,1.89617,1.83916,0.481885,0.325538,0.617642,0.479352,0.259963,0.332782
477,0.0504816,0.0769164,0.984279,0.956713,0.519413,0.474919,0.256604,0.279653,0.269785,0.244729,0.512678,0.522089,0.574601,0.553849,0.271872,0.274722,0.580346,0.556141,0.0916124,0.111152,0.854258,0.89544,-0.0356528,-0.0243661,1.05404,0.97177,1.79528,1.8987,1.25252,1.29905,-0.707604,-0.592829,-0.976818,-1.03228,-0.435422,-0.583761,-1.20908,-1.34467,-0.636568,-0.565009
478,0.595927,0.623314,0.049001,0.0228748,0.51749,0.491732,0.917523,0.940776,0.52543,0.50158,0.888445,0.89699,0.338355,0.362463,0.713428,0.716959,0.885939,0.861917,0.253381,0.203307,-0.250227,-0.202692,-1.66627,-1.66058,-0.499977,-0.584981,-1.41106,-1.30642,-0.389716,-0.339197,0.136765,0.249296,-0.0753358,-0.127507,0.650655,0.497895,0.839658,0.705945,0.780775,0.854127
479,0.864172,0.890189,0.727805,0.702566,0.183127,0.157071,0.134879,0.156081,0.138041,0.113245,0.986249,0.996213,0.681615,0.704444,0.431823,0.435381,0.513678,0.471621,0.377369,0.295461,-1.03222,-0.97749,-0.0384972,-0.0396526,-0.651111,-0.736057,0.0326086,0.138145,-0.420742,-0.3048,2.20164,2.3103,-2.63994,-2.68905,2.35639,2.21269,-1.25556,-1.38968,-0.23856,-0.16516
480,0.104579,0.129209,0.746911,0.655715,0.935803,0.908412,0.844615,0.863417,0.406118,0.375551,0.599021,0.60876,0.607212,0.54592,0.873754,0.877618,0.107082,0.0813244,0.368076,0.387616,-1.14017,-1.11573,1.88929,1.89117,0.222002,0.141151,-1.08287,-0.979668,-0.319308,-0.270403,-0.40491,-0.29777,-0.651213,-0.69783,-0.143378,-0.283797,-1.29866,-1.42574,1.41985,1.499
481,0.833378,0.855701,0.606588,0.608865,0.340146,0.31397,0.261983,0.28013,0.639141,0.637858,0.789237,0.797648,0.362086,0.387396,0.527058,0.49,0.342827,0.284734,0.105073,0.122643,-1.30687,-1.25397,1.38643,1.38949,-0.415053,-0.489773,0.122313,0.232067,-0.0431251,0.010647,-1.05132,-0.950103,2.50293,2.46155,-1.53535,-1.67146,-0.240515,-0.372035,-1.2409,-1.15792
482,0.658594,0.683704,0.587835,0.562014,0.889187,0.861456,0.720708,0.737815,0.92496,0.900164,0.265954,0.273391,0.626902,0.653813,0.0997756,0.102381,0.513637,0.488143,0.187858,0.204263,0.835723,0.888417,-2.2565,-2.25944,0.147711,0.0772844,-1.47327,-1.36428,0.678741,0.736322,0.952628,1.05625,-0.851886,-0.889588,0.940201,0.806075,0.222198,0.0864689,-0.0265779,0.0628314
483,0.018916,0.042315,0.298061,0.271855,0.432886,0.407462,0.721819,0.75145,0.872161,0.844956,0.0506279,0.0596102,0.676036,0.702307,0.667018,0.669891,0.337938,0.335528,0.855517,0.873658,1.0023,1.06195,-0.519554,-0.516283,0.420322,0.354886,1.88196,1.99248,1.18411,1.24673,0.609565,0.717832,1.37584,1.34523,-1.22465,-1.35988,-0.245615,-0.383183,-0.010595,0.0853027
484,0.194679,0.246515,0.265947,0.241609,0.728701,0.703745,0.749663,0.765084,0.042609,0.0170587,0.142898,0.173179,0.255732,0.281285,0.619627,0.570565,0.228656,0.182912,0.824013,0.902007,-0.741269,-0.678654,-0.348767,-0.381371,-0.984017,-1.05107,-0.808737,-0.704903,0.66001,0.728696,-0.799716,-0.686138,0.704541,0.670632,-1.81861,-1.94881,1.17846,1.04695,0.531484,0.550779
485,0.523072,0.450715,0.680065,0.656718,0.0980395,0.0750347,0.363192,0.378363,0.872952,0.849162,0.276504,0.286748,0.7531,0.778138,0.468,0.471238,0.0557906,0.030297,0.824526,0.930356,1.67844,1.74584,-0.254679,-0.246459,0.142656,0.0690292,-0.867766,-0.77121,0.586898,0.653264,-1.06498,-0.947291,0.233449,0.193511,-0.243465,-0.376621,0.124137,-0.0144905,0.9283,1.01626
486,0.719795,0.654915,0.619949,0.597529,0.754594,0.729482,0.40371,0.464062,0.927816,0.901501,0.740393,0.749697,0.0408967,0.0658889,0.966648,0.968495,0.181623,0.154838,0.940564,0.958705,-0.328963,-0.26453,-0.747151,-0.732866,-1.21462,-1.29023,-0.118241,-0.0226064,-2.03634,-1.96864,-0.314655,-0.197708,-0.012552,0.0319737,0.756395,0.630357,0.871244,0.725942,0.440286,0.526406
487,0.837082,0.859115,0.782467,0.761263,0.40027,0.375751,0.533011,0.54976,0.758475,0.730882,0.159546,0.169934,0.35297,0.377949,0.800341,0.866441,0.935531,0.907499,0.14311,0.163125,-0.441889,-0.382004,0.187474,0.204693,-2.2947,-2.37134,-1.91616,-1.82078,-1.67181,-1.61029,0.70854,0.828691,-0.0887987,-0.129563,0.076528,-0.0934179,0.374516,0.224652,0.909893,0.999323
488,0.659888,0.730702,0.13025,0.110739,0.985654,0.959265,0.884693,0.903652,0.229527,0.20242,0.91765,0.9268,0.888464,0.914349,0.760446,0.764386,0.225824,0.197101,0.127361,0.148927,0.239653,0.297999,-0.978692,-0.961357,-0.948272,-1.02201,-0.618864,-0.518111,1.53166,1.59075,-0.00120952,0.117315,-1.84435,-1.88097,-0.691156,-0.817193,1.86186,1.71688,-1.13849,-1.04875
489,0.643027,0.602288,0.373302,0.352857,0.699512,0.737318,0.304675,0.325038,0.294944,0.231607,0.0412259,0.0489746,0.0812643,0.109271,0.431481,0.506042,0.828123,0.798975,0.966254,0.987701,-0.00326628,0.0618938,1.065,1.08293,0.929826,0.856685,0.261962,0.369749,-1.28924,-1.22909,0.719436,0.836503,0.0969393,0.0641929,-1.183,-1.31295,2.33004,2.19186,-0.372207,-0.285756
490,0.534876,0.473875,0.816612,0.796647,0.54176,0.515371,0.953302,0.971897,0.289531,0.260793,0.119144,0.216238,0.230218,0.259695,0.24255,0.247697,0.234601,0.204743,0.00759213,0.0280017,0.466335,0.528787,-0.0422794,-0.0130781,1.01418,0.97344,-3.2526,-3.14959,-0.868337,-0.810477,-1.20918,-1.08827,0.40552,0.371893,-0.123618,-0.26171,-1.20349,-1.34665,1.03922,1.11819
491,0.323429,0.345462,0.547669,0.525895,0.729646,0.701158,0.342114,0.358884,0.882373,0.85558,0.343992,0.383502,0.986099,1.0149,0.485094,0.570327,0.115696,0.0875718,0.0202147,0.0387188,-0.540527,-0.477113,-1.12702,-1.10909,1.16823,1.09019,0.748514,0.854342,1.04916,1.11425,2.60527,2.73023,-0.964507,-1.00117,1.19446,1.06332,0.149404,0.00883874,-0.118846,-0.0399556
492,0.44237,0.46568,0.900634,0.881421,0.503196,0.473731,0.791778,0.807114,0.986463,0.959379,0.458345,0.550766,0.974064,1.00224,0.886851,0.892956,0.895947,0.869754,0.532726,0.552235,1.07595,1.14576,2.02627,2.04208,0.332103,0.256526,1.11441,1.21878,0.539533,0.610119,2.26124,2.39181,-0.0880529,-0.0614772,-1.44015,-1.57818,0.431841,0.295571,-0.105942,-0.0323752
493,0.276668,0.304468,0.461611,0.443666,0.526729,0.495007,0.383665,0.400089,0.796507,0.746378,0.71125,0.71803,0.219007,0.24756,0.553945,0.561603,0.486687,0.460839,0.786158,0.805441,0.0126527,0.0782639,0.89351,0.972793,0.88405,0.808485,1.02056,1.02514,0.861926,0.936737,1.70288,1.83622,0.914881,0.878217,0.418874,0.27352,0.44323,0.304884,-0.717339,-0.570118
494,0.117238,0.143257,0.731229,0.714701,0.952534,0.919175,0.583311,0.629269,0.559009,0.533377,0.618568,0.625142,0.569042,0.599543,0.571527,0.617101,0.756184,0.731814,0.299015,0.319496,-0.431368,-0.370147,-0.111799,-0.0964921,-0.947787,-1.01832,0.77944,0.831506,0.0574964,0.128584,0.902815,1.03261,-1.04705,-1.07747,0.924952,0.705178,0.77222,0.639325,-1.17711,-1.10786
495,0.836375,0.864048,0.278459,0.261484,0.630599,0.599488,0.842469,0.858449,0.00472759,-0.0204122,0.11118,0.119769,0.449572,0.479779,0.665026,0.672598,0.320715,0.297077,0.999939,1.01913,-0.22004,-0.15126,-0.721858,-0.70615,0.488608,0.422177,0.540479,0.637869,1.36124,1.43856,-1.01768,-0.892168,0.383593,0.354937,1.27735,1.13684,-0.150854,-0.282197,-0.710556,-0.634943
496,0.332928,0.358556,0.481531,0.477807,0.511815,0.482947,0.425448,0.494825,0.8711,0.845836,0.948338,0.955072,0.959528,0.990597,0.220678,0.226286,0.727055,0.626253,0.428288,0.447952,-0.578038,-0.509181,0.172942,0.1856,-0.565863,-0.628352,-1.44186,-1.34237,-0.23093,-0.151891,1.27209,1.40476,-0.697689,-0.723841,0.178006,0.043619,-2.53383,-2.66643,-2.89874,-2.82399
497,0.535956,0.656521,0.731291,0.69413,0.666409,0.605264,0.113415,0.1312,0.772342,0.722178,0.0362422,0.0454459,0.159335,0.191378,0.81528,0.819435,0.980292,0.955429,0.618304,0.640001,0.00699031,0.0804115,-0.447169,-0.509725,-0.342236,-0.397403,-0.38619,-0.285829,-0.961233,-0.8847,1.43269,1.57204,0.44229,0.414051,0.425167,0.283353,0.666632,0.530763,-0.690923,-0.613069
498,0.92989,0.954487,0.928,0.910453,0.757113,0.72758,0.461054,0.479986,0.622461,0.598521,0.567605,0.577068,0.966695,0.99685,0.130049,0.132397,0.581994,0.556485,0.53143,0.552048,-0.0699152,-0.0488311,-1.21848,-1.20505,1.66506,1.604,-0.312441,-0.208858,-0.496941,-0.420583,-0.0267884,0.106897,-1.2206,-1.2426,2.36016,2.21602,-1.57914,-1.71635,-0.852397,-0.772156
499,0.243229,0.26776,0.551252,0.508592,0.457591,0.428398,0.148597,0.166885,0.728828,0.713956,0.766199,0.775933,0.252485,0.284601,0.653522,0.654703,0.720436,0.670994,0.989343,1.01106,-0.247385,-0.178074,-0.567768,-0.556843,-1.53045,-1.59964,-0.234357,-0.131886,-0.425832,-0.353474,0.748687,0.796311,0.381791,0.359676,0.0141309,-0.132053,2.188,2.05739,-1.72027,-1.64155
500,0.596723,0.619581,0.124277,0.10673,0.862483,0.831765,0.0381417,0.0544219,0.850608,0.829392,0.1072,0.116009,0.779839,0.811463,0.767204,0.770459,0.812014,0.785503,0.768393,0.790414,0.0475668,0.121379,0.326185,0.334907,-0.526176,-0.600148,-1.49177,-1.3893,1.18404,1.26006,1.35866,1.48572,-0.90117,-0.921598,0.699379,0.577037,0.515824,0.381116,-0.480011,-0.406118
501,0.246974,0.26952,0.598504,0.580393,0.0687874,0.0409874,0.519255,0.537024,0.16411,0.143358,0.0468392,0.137615,0.240419,0.274682,0.195805,0.199443,0.651518,0.62271,0.0123714,0.0310583,-0.530348,-0.452895,-0.384417,-0.381283,-0.829902,-0.904665,0.82462,0.922107,0.377781,0.451911,-0.794532,-0.671384,0.539041,0.510813,1.43199,1.28613,-0.248172,-0.382708,1.76629,1.83806
502,0.196178,0.218147,0.232755,0.215879,0.33384,0.352659,0.669522,0.687299,0.586361,0.480407,0.148609,0.159221,0.139968,0.175024,0.57908,0.581679,0.132948,0.103469,0.766511,0.786124,-0.00278634,0.0764025,1.07096,1.06691,0.7671,0.690781,-0.883205,-0.785566,-0.140465,-0.0661245,0.581291,0.704855,0.176861,0.143636,-0.813036,-0.964839,-0.279824,-0.418762,0.0941673,0.161103
503,0.835997,0.859354,0.710289,0.693646,0.690212,0.66433,0.138273,0.1543,0.83682,0.817455,0.990916,0.999374,0.264853,0.300401,0.744051,0.690106,0.904953,0.874981,0.454973,0.474731,-0.533237,-0.451511,-2.3186,-2.32265,1.0146,0.937805,0.313075,0.365987,0.643239,0.722064,-0.920566,-0.791204,0.157638,0.129655,2.45282,2.30778,1.81388,1.68189,-0.0487255,0.0183678
504,0.623243,0.645478,0.292478,0.274977,0.160508,0.135856,0.812452,0.827083,0.219654,0.198063,0.56808,0.57806,0.742918,0.776925,0.796785,0.798533,0.796081,0.767701,0.489833,0.604947,-0.192867,-0.109791,0.807916,0.809913,1.78391,1.70649,1.4199,1.51754,0.276491,0.355102,2.31048,2.43328,-0.196287,-0.223121,-0.188152,-0.33371,-1.38827,-1.52124,0.177852,0.251399
505,0.671648,0.768908,0.531205,0.512285,0.146081,0.122368,0.336411,0.350231,0.469028,0.449578,0.696899,0.675864,0.800456,0.882297,0.392992,0.397512,0.451577,0.42284,0.714916,0.735164,-0.577555,-0.497911,0.579777,0.536273,-1.29624,-1.36967,0.140189,0.230509,1.01214,1.09595,2.07656,2.20233,-1.58004,-1.61179,1.42659,1.28496,1.23709,1.10144,1.6458,1.71749
506,0.871284,0.892339,0.0394088,0.0193703,0.384445,0.399792,0.304567,0.31822,0.0204229,0.00156767,0.761237,0.773667,0.953288,0.98767,0.927265,0.930095,0.708118,0.678988,0.210893,0.229488,0.780331,0.859536,0.255964,0.262632,-0.898159,-0.969376,-0.839815,-0.748512,0.685794,0.774742,-1.28699,-1.15841,-0.38657,-0.410915,1.11245,0.993343,0.721243,0.584922,-0.178993,-0.110118
507,0.115607,0.137039,0.0769349,0.0577441,0.569422,0.677216,0.866383,0.881563,0.0778046,0.122359,0.676017,0.690534,0.596827,0.701885,0.376642,0.379116,0.624592,0.570533,0.96009,0.977753,0.178096,0.255051,-0.38585,-0.376933,1.6225,1.55474,0.742453,0.838715,0.124555,0.21085,1.26813,1.40097,-0.281592,-0.302618,0.845231,0.70173,1.93516,1.79364,0.433787,0.50061
508,0.676065,0.698292,0.475537,0.42284,0.9813,0.954639,0.211122,0.224306,0.260141,0.243151,0.180705,0.195315,0.378591,0.416101,0.525961,0.530381,0.493593,0.462079,0.647563,0.666359,0.34996,0.428585,-0.572018,-0.568441,-0.521898,-0.587429,-0.603992,-0.508406,-1.4566,-1.36579,-0.790669,-0.664197,1.79641,1.77014,1.13393,0.988414,-0.600874,-0.742092,0.0415755,0.115572
509,0.454547,0.474734,0.806578,0.787936,0.104441,0.0800061,0.0323055,0.046639,0.951222,0.934409,0.140505,0.153348,0.546749,0.601295,0.972031,0.977363,0.989276,0.957822,0.114227,0.134904,0.088625,0.162029,-0.770982,-0.759949,1.16499,1.1015,-0.255235,-0.160013,0.927995,1.02083,1.53714,1.66566,-1.23328,-1.25332,-0.111346,-0.258364,-1.05225,-1.19746,0.904203,0.984443
510,0.0322694,0.0544146,0.24775,0.230954,0.912383,0.890264,0.371282,0.385221,0.414851,0.396256,0.514949,0.543035,0.865836,0.786489,0.556389,0.560871,0.504829,0.47292,0.362012,0.383252,0.939491,1.00939,1.13394,1.13781,0.129858,0.0662908,1.10162,1.20493,-0.251214,-0.15526,-0.182153,-0.0566439,-0.404426,-0.425784,0.470861,0.318012,0.974252,0.835449,-0.0975011,-0.0193462
511,0.855082,0.878219,0.596045,0.581458,0.299906,0.276262,0.0395138,0.0524497,0.622064,0.528989,0.922054,0.932722,0.932989,0.971683,0.801683,0.806428,0.644279,0.612898,0.407376,0.430288,0.774897,0.84728,0.736021,0.742038,0.089362,0.0219366,-0.213285,-0.111578,-0.389488,-0.292754,-0.229873,-0.103049,-0.787343,-0.741355,0.309803,0.160051,-1.4696,-1.61431,-0.149769,-0.0725658
512,0.661425,0.684355,0.0830427,0.0686168,0.0539856,0.0318071,0.263452,0.178829,0.678256,0.661722,0.190576,0.203285,0.443823,0.480573,0.0335545,0.0400177,0.0593554,0.0279181,0.179547,0.204326,-0.604971,-0.540502,-0.000428488,0.0712784,-1.19609,-1.25895,-0.118957,-0.0253582,-0.307947,-0.210568,-1.39813,-1.27202,-1.03846,-1.05693,-1.08458,-1.24004,-1.16235,-1.3114,0.635213,0.703788
513,0.0599598,0.0831851,0.166854,0.247969,0.43572,0.497602,0.291305,0.305208,0.722047,0.794455,0.311702,0.322903,0.308776,0.346448,0.367387,0.301422,0.5966,0.493036,0.382333,0.413738,-0.495755,-0.429054,-0.606187,-0.599481,0.378859,0.321442,-1.66209,-1.57176,0.61557,0.715078,1.13761,1.269,0.164445,0.143947,-1.70294,-1.85908,0.25437,0.103555,-0.195743,-0.132287
514,0.279493,0.304985,0.44209,0.42732,0.985712,0.963396,0.757381,0.773153,0.945783,0.927187,0.163526,0.174885,0.558784,0.598612,0.558813,0.562827,0.989591,0.958153,0.598372,0.62315,0.513149,0.573151,0.691654,0.696156,-0.628332,-0.682236,1.30584,1.39836,-0.249503,-0.156472,-1.10629,-0.96745,1.9608,1.9482,-0.125423,-0.286886,-1.88643,-2.03597,-0.229019,-0.170654
515,0.17642,0.202383,0.927855,0.915019,0.0229425,0.00118594,0.282465,0.296302,0.627448,0.542509,0.854246,0.866161,0.396229,0.384886,0.818674,0.824231,0.135105,0.103922,0.0289818,0.0519766,0.538775,0.594447,-0.152416,-0.14586,3.30524,3.2567,-0.98817,-0.896395,0.130517,0.21804,1.79362,1.93225,2.35912,2.34715,-1.0521,-1.21223,0.945749,0.7919,0.516277,0.577783
516,0.897245,0.923174,0.235889,0.224575,0.432768,0.409329,0.701085,0.714458,0.176766,0.157831,0.313815,0.326945,0.131563,0.17116,0.637425,0.642059,0.208088,0.17758,0.886952,0.911005,0.0032939,0.0665335,-1.23026,-1.21995,0.624709,0.571153,0.239087,0.3307,1.1911,1.28145,1.55017,1.68546,-0.458964,-0.467863,1.85266,1.69905,0.140762,-0.0174655,2.52742,2.58313
517,0.594159,0.618514,0.264983,0.253024,0.0926314,0.069458,0.193236,0.206548,0.846207,0.828722,0.972446,0.983444,0.787655,0.829053,0.887739,0.892257,0.654803,0.622779,0.602195,0.584436,1.15498,1.22101,-0.251678,-0.236569,-0.826537,-0.879556,-1.24358,-1.15567,-1.27917,-1.1931,-0.550803,-0.411643,-0.925417,-0.929314,0.010381,-0.138672,0.779416,0.613853,-0.170861,-0.115885
518,0.690932,0.7141,0.783026,0.770796,0.845218,0.820799,0.0178736,0.0288811,0.611766,0.58006,0.738481,0.750146,0.792336,0.908458,0.0163655,0.0203477,0.205713,0.172982,0.233851,0.257868,1.64474,1.70519,-0.254162,-0.156946,1.0754,1.02805,0.204019,0.288898,0.0233461,0.116877,-0.947733,-0.811492,-0.649744,-0.653754,-1.56489,-1.70838,-1.00895,-1.1763,-0.477583,-0.426613
519,0.56934,0.551509,0.452906,0.44054,0.648798,0.659868,0.993714,1.00526,0.346291,0.331397,0.0478204,0.060047,0.948906,0.987862,0.156821,0.161745,0.771076,0.738381,0.26862,0.294586,-0.871631,-0.809247,-0.0999155,-0.0773234,0.763303,0.72353,-0.43622,-0.347108,-0.791191,-0.691276,-0.143467,-0.000206723,0.709033,0.702012,-0.753101,-0.801524,0.489501,0.315932,1.09801,1.14644
520,0.434503,0.388918,0.370419,0.357209,0.523171,0.498938,0.946592,0.958391,0.88296,0.870284,0.268227,0.278762,0.601022,0.665423,0.531906,0.539163,0.0154201,-0.0145232,0.918842,0.943397,-1.89268,-1.83115,0.994347,1.01756,-1.09851,-1.13351,-0.83751,-0.752272,-0.519231,-0.425758,-1.47062,-1.32555,-0.83536,-0.847024,0.160866,0.105335,0.516996,0.342568,-0.562787,-0.514856
521,0.203158,0.226327,0.810188,0.796583,0.638789,0.637981,0.518362,0.531228,0.525669,0.511205,0.818879,0.830447,0.30312,0.342983,0.346969,0.352218,0.457839,0.359103,0.635698,0.576662,-0.0486866,0.0198495,-0.00514192,0.0223051,-0.89625,-0.934665,-0.417676,-0.423922,0.527181,0.588127,-1.11419,-0.972928,-1.13632,-1.1521,1.15569,1.01219,1.75772,1.58351,1.21373,1.26085
522,0.272443,0.247776,0.524436,0.510922,0.897007,0.777024,0.6598,0.670757,0.703633,0.691242,0.573674,0.587027,0.504073,0.54458,0.448981,0.368379,0.763166,0.732729,0.182686,0.209928,-0.352748,-0.195216,1.35837,1.39267,-0.449523,-0.428646,-0.175361,-0.0955728,1.50825,1.60201,1.04657,1.18192,1.04264,1.02031,-0.181673,-0.328414,-0.699779,-0.866246,-1.47677,-1.42605
523,0.2443,0.269226,0.941931,0.930036,0.94045,0.916067,0.473697,0.483316,0.0316422,0.0215396,0.65534,0.647116,0.287971,0.323546,0.379185,0.384539,0.95558,0.923225,0.558684,0.584406,-0.474891,-0.410281,0.217032,0.25703,0.117901,0.077373,1.0468,1.13152,0.59571,0.687199,0.0427145,0.254816,0.955784,0.930996,0.595165,0.446102,1.05737,0.890987,-0.158701,-0.113911
524,0.476952,0.501076,0.927155,0.832179,0.726293,0.61035,0.66228,0.673893,0.63673,0.626676,0.692985,0.707206,0.0606431,0.102511,0.988925,0.994313,0.495723,0.53091,0.305406,0.329603,0.248327,0.315385,-1.84744,-1.80075,-0.486361,-0.523846,-2.94467,-2.85995,0.471587,0.564565,-0.811572,-0.67229,-1.43491,-1.45354,0.689923,0.548149,-0.255203,-0.424255,-1.18198,-1.1332
525,0.961436,0.987802,0.784966,0.734323,0.327089,0.304633,0.645072,0.571289,0.490281,0.470193,0.971964,0.985692,0.961352,1.00373,0.415691,0.418168,0.172115,0.138594,0.636042,0.658482,0.605677,0.674826,-0.424563,-0.391273,1.72486,1.68653,-0.573878,-0.548581,-0.23315,-0.136641,0.203206,0.337277,1.11195,1.08728,-0.164725,-0.300115,1.0689,0.8926,-0.618103,-0.567223
526,0.21741,0.242885,0.680394,0.636466,0.381068,0.357198,0.455919,0.468685,0.327058,0.313709,0.617587,0.723652,0.838655,0.935815,0.4937,0.494584,0.588873,0.470221,0.672939,0.6952,-2.2848,-2.21475,0.971517,1.0182,-1.77657,-1.81429,1.67807,1.76279,-0.0282041,0.0719407,-0.841182,-0.711293,-0.925887,-0.948118,1.15102,1.00887,-0.346559,-0.530524,0.354811,0.406424
527,0.782475,0.809428,0.550506,0.53861,0.666727,0.643714,0.890111,0.902101,0.412513,0.397549,0.447862,0.461613,0.826222,0.867897,0.213989,0.213006,0.835139,0.801849,0.245736,0.269245,-0.0861878,-0.00865175,0.953108,0.938392,-1.4566,-1.49158,1.63442,1.7131,0.187065,0.280522,1.02636,1.15828,0.783366,0.761898,-0.23917,-0.378788,1.04444,0.8528,0.392219,0.444762
528,0.960055,0.984835,0.69384,0.761327,0.213593,0.18972,0.834804,0.806677,0.776154,0.760893,0.593296,0.606598,0.358556,0.402166,0.379651,0.37995,0.200979,0.166137,0.332183,0.355366,-0.82975,-0.750783,0.784887,0.85858,-0.704221,-0.738401,-0.865346,-0.787169,-1.39043,-1.29612,-0.622139,-0.490025,1.33989,1.31605,0.0252292,-0.107106,-0.194368,-0.381915,-0.844197,-0.790878
529,0.5734,0.568913,0.99686,0.984045,0.669295,0.643229,0.697939,0.711253,0.456639,0.443212,0.516506,0.457356,0.981128,1.02369,0.340915,0.338648,0.848263,0.813085,0.717851,0.73953,1.60084,1.67371,0.732082,0.778768,-1.23881,-1.27383,0.0808421,0.161685,1.4834,1.58093,0.00167227,0.138307,1.6436,1.62375,0.0221158,-0.116525,-1.64467,-1.83668,1.03057,1.07903
530,0.129043,0.152991,0.799155,0.735572,0.0012134,-0.0258934,0.247017,0.259385,0.586168,0.572702,0.29552,0.308114,0.673129,0.71768,0.563166,0.562573,0.857454,0.823106,0.0539419,0.0732845,-0.00870953,0.0583877,1.4815,1.53327,-0.151879,-0.184391,-0.263272,-0.181537,0.833815,0.926576,-0.811784,-0.680063,0.747492,0.731951,-0.721979,-0.860035,1.22808,1.03736,-0.867028,-0.814638
531,0.501854,0.525295,0.498842,0.4871,0.380681,0.351506,0.698056,0.712467,0.426418,0.411336,0.00609368,0.0192022,0.584063,0.628737,0.00176934,0.00141588,0.0532813,0.0204212,0.197448,0.215809,0.394422,0.464188,-0.968198,-0.908167,1.18429,1.14868,0.225812,0.304993,2.0876,2.17568,-0.231378,-0.0967292,0.608007,0.595579,0.915032,0.773543,2.63462,2.43708,0.741876,0.789246
532,0.505059,0.530444,0.709937,0.699756,0.33316,0.267322,0.197087,0.209539,0.474328,0.458827,0.0979,0.0697911,0.796559,0.840268,0.136736,0.136973,0.982761,0.950063,0.888518,0.904385,-0.0313595,0.0448802,-0.863209,-0.801242,1.16606,1.13394,0.099172,0.270376,-1.67664,-1.58248,-0.0189697,0.117633,-1.77649,-1.78896,-0.268806,-0.411678,-0.717884,-0.917768,-1.47774,-1.43417
533,0.118397,0.144876,0.0759924,0.0642957,0.21353,0.183138,0.904446,0.916875,0.0821505,0.065261,0.10781,0.12038,0.598587,0.64061,0.0488595,0.0511622,0.420215,0.384546,0.369469,0.384124,-0.724551,-0.651741,-1.17213,-1.10741,-1.00121,-1.04076,0.149446,0.235758,-0.451889,-0.36458,1.24626,1.38776,-0.425748,-0.43319,0.781492,0.63956,-0.191701,-0.321259,-1.42875,-1.38134
534,0.668904,0.695894,0.757757,0.743987,0.809168,0.780845,0.839489,0.849935,0.637926,0.619755,0.89631,0.908885,0.610477,0.575697,0.579393,0.583745,0.700825,0.665723,0.734889,0.749315,1.39305,1.4607,0.683358,0.744816,-0.627298,-0.67329,1.35459,1.44749,-0.337688,-0.252886,-0.0579619,0.0784758,0.116901,0.0375079,1.14557,1.00119,0.471423,0.27525,-0.774605,-0.724286
535,0.386707,0.411846,0.713808,0.770232,0.621755,0.540702,0.115647,0.127234,0.0445597,0.0253391,0.242063,0.254153,0.441842,0.510784,0.670966,0.674628,0.625439,0.590779,0.825672,0.840786,-0.0958624,-0.0343515,0.256883,0.32031,1.0755,1.03218,-0.886849,-0.798373,-0.508224,-0.420711,-0.385341,-0.244332,0.519889,0.508206,-1.77534,-1.92165,1.41434,1.21919,1.35194,1.4069
536,0.831097,0.854524,0.811867,0.796478,0.328014,0.30056,0.368413,0.377874,0.946544,0.926501,0.468863,0.413175,0.404236,0.44587,0.560046,0.56305,0.814153,0.781275,0.638229,0.692779,-2.01841,-1.96365,0.329533,0.398488,-3.16242,-3.20264,0.61031,0.695271,-1.09,-1.00047,0.0137615,0.154247,-1.70446,-1.71262,-0.741822,-0.885641,-1.85738,-2.05048,-0.972249,-0.914528
537,0.123444,0.146764,0.0715441,0.0565501,0.48444,0.358923,0.105392,0.114435,0.368926,0.347933,0.562276,0.572196,0.0325686,0.0751568,0.913302,0.915402,0.0825789,0.0500845,0.52987,0.544772,-1.41235,-1.36011,-0.190953,-0.118317,-0.842689,-0.877703,-1.46938,-1.37794,-0.229059,-0.136336,1.00513,1.15087,1.69843,1.68586,1.30128,1.15428,1.08733,0.886636,1.70497,1.76996
538,0.648075,0.67357,0.253549,0.240011,0.456984,0.417286,0.0554385,0.0628089,0.186677,0.165616,0.162126,0.170632,0.121671,0.164791,0.0208908,0.023084,0.770698,0.737302,0.130607,0.14421,0.136742,0.186185,1.47523,1.55007,0.316443,0.288362,-0.603613,-0.505974,-0.945971,-0.850961,-0.495097,-0.345187,-0.0565637,-0.0655404,-0.016592,-0.171464,-1.59934,-1.80565,1.51626,1.58067
539,0.848695,0.874095,0.861888,0.850344,0.594909,0.47565,0.442459,0.47452,0.281261,0.227711,0.398098,0.408953,0.739533,0.780967,0.567401,0.570898,0.421632,0.38769,0.378798,0.392558,-0.719427,-0.665314,0.443178,0.552849,1.48906,1.45443,-1.53661,-1.43949,0.752868,0.854441,0.00323457,0.146214,1.31212,1.3054,2.32141,2.16957,1.02465,0.817021,-1.44776,-1.38649
540,0.105562,0.129178,0.588917,0.574997,0.561467,0.534013,0.878306,0.886231,0.313343,0.289807,0.0267267,0.0372603,0.739033,0.778296,0.213084,0.218777,0.339231,0.240513,0.935108,0.946671,-0.37414,-0.323594,-0.517239,-0.444368,-0.148658,-0.17966,-1.8058,-1.70618,0.058221,0.153235,1.5868,1.72602,0.0297229,0.0241233,-1.41639,-1.56332,0.34442,0.131875,-0.301958,-0.243905
541,0.360967,0.436249,0.603034,0.623229,0.11587,0.0895219,0.546735,0.553459,0.884466,0.858547,0.399651,0.447505,0.603922,0.775625,0.369889,0.376174,0.12801,0.0933354,0.270578,0.280426,-1.3011,-1.25284,-0.323518,-0.258783,0.347232,0.309557,1.22323,1.32141,-1.01425,-0.915896,0.268035,0.400677,0.957073,0.945346,0.712613,0.569106,0.227597,0.0298477,-0.313455,-0.251284
542,0.719204,0.74332,0.683597,0.671461,0.478756,0.442695,0.617514,0.702981,0.200116,0.172513,0.848357,0.85775,0.733511,0.772953,0.08043,0.084643,0.475415,0.376226,0.356741,0.315018,-1.74305,-1.70125,-0.784894,-0.715558,-0.787276,-0.81938,1.14014,1.24081,-1.69079,-1.58768,0.319759,0.445701,-0.174958,-0.180104,0.384255,0.241808,0.124717,-0.0721797,1.85433,1.91471
543,0.580969,0.605513,0.899922,0.888792,0.823768,0.795867,0.846393,0.852503,0.110493,0.0818094,0.891872,0.902879,0.00855459,0.0506399,0.835844,0.842274,0.693059,0.659117,0.314577,0.34961,0.0882788,0.134348,0.634674,0.702258,-0.0462411,-0.0813794,-1.47655,-1.37784,0.62462,0.732214,-1.52223,-1.40228,1.1788,1.17566,-0.258142,-0.459005,0.0383377,-0.174207,-0.447596,-0.386854
544,0.157154,0.179889,0.0407095,0.0274948,0.259524,0.23161,0.761088,0.685801,0.446187,0.328343,0.449293,0.461325,0.449159,0.516533,0.229607,0.236275,0.277326,0.24505,0.386722,0.384202,-0.482882,-0.515913,-1.24938,-1.18761,-0.647978,-0.682598,-1.09909,-0.999412,-0.689333,-0.585231,2.18208,2.30413,-0.63818,-0.638304,-1.02316,-1.15982,0.921779,0.706725,-1.20423,-1.14966
545,0.16911,0.190194,0.81357,0.79835,0.598618,0.568773,0.559317,0.5191,0.60306,0.574876,0.276727,0.28873,0.941445,0.982425,0.183206,0.189757,0.596938,0.565718,0.407998,0.418794,-1.20889,-1.16617,0.557843,0.616776,1.25494,1.22501,-1.61925,-1.51287,0.271054,0.456124,1.34765,1.46976,-0.0887898,-0.0841545,0.401999,0.25987,0.242631,0.0215795,-2.44255,-2.3853
546,0.671352,0.692323,0.543501,0.527598,0.115099,0.0832114,0.344365,0.352398,0.650302,0.618636,0.305816,0.23041,0.492319,0.595564,0.611226,0.578901,0.669998,0.639376,0.183368,0.192832,0.362796,0.409903,-0.903282,-0.848972,-0.544664,-0.56809,1.08621,1.18571,1.38827,1.49748,0.0861287,0.206165,0.00552191,0.00801809,-0.682705,-0.819508,0.046206,-0.171318,-0.101057,-0.0429351
547,0.88651,0.908902,0.864953,0.84908,0.941381,0.908567,0.517877,0.514245,0.747948,0.662397,0.187781,0.17209,0.168421,0.208703,0.964342,0.968044,0.17217,0.139623,0.283303,0.293244,-0.646589,-0.595997,-3.09685,-3.0371,0.858176,0.840141,-0.602566,-0.505001,0.976411,1.08512,0.0282974,0.158337,0.523532,0.529774,1.49919,1.36088,0.742405,0.52208,0.698565,0.750345
548,0.341848,0.362553,0.195797,0.178062,0.304144,0.270403,0.667531,0.676092,0.734631,0.706158,0.0912879,0.113769,0.248623,0.215739,0.305432,0.310987,0.703467,0.669216,0.7392,0.747703,0.7677,0.823189,-0.0106117,0.045545,1.20899,1.19419,-0.0720404,0.0264953,0.773515,0.886311,-0.00288218,0.110509,0.00972973,-0.0140051,-0.280654,-0.425055,-0.561348,-0.775937,1.98033,2.03038
549,0.699639,0.71937,0.188716,0.149585,0.162231,0.128396,0.596652,0.602946,0.597028,0.552932,0.0442364,0.055449,0.181139,0.222774,0.643225,0.64855,0.926066,0.890888,0.102705,0.112519,0.680082,0.737013,0.330803,0.386519,0.0871234,0.0652562,-1.31949,-1.21555,1.60256,1.71955,-0.437663,-0.320619,-0.56188,-0.557784,-0.252186,-0.402076,-0.211592,-0.406485,0.130467,0.181403
550,0.791982,0.810417,0.140863,0.121109,0.433275,0.399665,0.763654,0.767787,0.530177,0.399706,0.837126,0.849789,0.918395,0.961727,0.436273,0.441671,0.610399,0.575935,0.0343683,0.0441865,0.110215,0.162739,-2.52242,-2.4701,0.341545,0.327722,-2.30331,-2.19457,-0.945502,-0.823499,-1.73067,-1.61436,0.188142,0.195006,-0.74063,-0.897831,0.183273,-0.0370337,-0.35702,-0.308446
551,0.28222,0.299561,0.658397,0.638881,0.303604,0.268138,0.497431,0.539039,0.274954,0.246481,0.514839,0.526565,0.67793,0.720444,0.581417,0.599962,0.963805,0.927219,0.649039,0.657824,1.0967,1.14733,0.247103,0.306718,0.968317,0.955952,0.236629,0.354588,-0.665182,-0.542449,-0.291733,-0.175875,0.393721,0.393813,0.503074,0.34939,-0.862523,-1.08443,1.04423,1.0955
552,0.169961,0.194566,0.254251,0.235227,0.487144,0.469779,0.308303,0.31029,0.0205535,-0.00541205,0.771569,0.785843,0.193364,0.23414,0.648706,0.758252,0.702951,0.701223,0.52176,0.532737,0.929521,0.985223,0.402358,0.461283,-0.404129,-0.420494,-0.865643,-0.749415,0.563122,0.691053,0.030947,0.144415,1.87742,1.87328,-0.56954,-0.729989,-1.2423,-1.46081,-0.761171,-0.705258
553,0.0731837,0.089571,0.98733,0.966822,0.675609,0.671421,0.249958,0.339753,0.802879,0.774526,0.451576,0.466594,0.451749,0.505247,0.911145,0.916543,0.513104,0.475228,0.63768,0.649905,-1.09259,-1.04029,-2.55176,-2.48645,0.957285,0.943478,-0.704844,-0.5844,1.09925,1.23059,0.951363,1.06292,1.32464,1.31979,0.108627,-0.0466817,-2.04734,-2.27018,-0.574905,-0.51843
554,0.750171,0.764839,0.874277,0.853601,0.908528,0.873062,0.365529,0.369215,0.734323,0.703886,0.770336,0.786702,0.735777,0.776354,0.0253129,0.0286521,0.737149,0.6969,0.32387,0.334137,-0.291009,-0.238182,-0.325736,-0.263754,1.432,1.41839,0.728489,0.845088,-1.01092,-0.887455,-0.619367,-0.507852,-0.419542,-0.431617,1.28109,1.12688,0.915325,0.699584,0.934343,0.994897
555,0.1646,0.178651,0.352282,0.330875,0.638744,0.620379,0.104192,0.105776,0.342007,0.31032,0.0681581,0.0873804,0.557425,0.621154,0.438706,0.440396,0.67121,0.631107,0.760056,0.76877,0.275585,0.33596,-0.449656,-0.38424,-0.0229624,-0.0323135,-0.378334,-0.258914,-0.257465,-0.160021,0.0338114,0.150149,0.138191,0.122533,1.32467,1.16589,1.28531,1.06521,0.143674,0.202233
556,0.773202,0.788517,0.574344,0.460054,0.413052,0.367697,0.0926856,0.0934499,0.203202,0.245187,0.512383,0.530585,0.426004,0.465955,0.250786,0.262066,0.283018,0.241059,0.602199,0.662272,-0.264363,-0.207353,-1.6836,-1.61201,1.46368,1.45279,-0.148098,-0.0304252,0.440633,0.567414,-0.27697,-0.158569,-1.98629,-2.00359,0.317224,0.164141,0.919622,0.703374,-0.303624,-0.243618
557,0.433928,0.448282,0.611714,0.589233,0.148562,0.115014,0.71222,0.711133,0.212197,0.180054,0.75127,0.763588,0.552872,0.591332,0.0798741,0.0837352,0.956043,0.913848,0.547449,0.555774,1.3204,1.38371,0.0186244,0.0856137,0.983716,0.980303,-1.02747,-0.916831,0.0724769,0.277964,-0.0462997,0.0704851,-0.0775049,-0.0868598,0.845047,0.695208,0.013274,-0.204367,0.419046,0.474381
558,0.929321,0.944688,0.0222715,-0.00187921,0.136526,0.1687,0.065504,0.063501,0.631005,0.597558,0.98041,0.996592,0.42719,0.46672,0.628181,0.631549,0.683545,0.571991,0.876974,0.884653,-0.935604,-0.875217,2.10089,2.17387,-1.22716,-1.2267,-1.64003,-1.52235,-0.144678,-0.0114851,-0.819401,-0.702504,0.958203,0.954231,1.09683,1.0444,-0.202094,-0.37535,0.0118113,0.072349
559,0.266287,0.282979,0.708376,0.682749,0.254624,0.222386,0.1535,0.151634,0.252647,0.218685,0.379663,0.395957,0.808564,0.848175,0.754871,0.757309,0.270597,0.230133,0.512435,0.614806,-1.69059,-1.63382,-0.139243,-0.0619728,-0.686135,-0.752492,1.26504,1.38775,-0.971757,-0.83625,-0.0998182,0.0166848,-0.541352,-0.545417,1.54006,1.39359,-0.326599,-0.546332,0.0120676,0.0799294
560,0.79278,0.809785,0.193107,0.165106,0.859893,0.825945,0.812968,0.812757,0.74158,0.707016,0.694746,0.711535,0.271788,0.311394,0.370139,0.370837,0.52386,0.465702,0.339054,0.344958,-0.180179,-0.120113,0.0365604,0.0283453,-0.284768,-0.278286,1.35092,1.47397,-0.320778,-0.188441,-0.227331,-0.108607,-2.48265,-2.48566,0.561667,0.42127,-0.812755,-1.03085,0.548431,0.61366
561,0.213916,0.228973,0.982271,0.952053,0.560117,0.526762,0.215402,0.213923,0.644592,0.610094,0.211484,0.226816,0.420164,0.45031,0.672494,0.671831,0.695215,0.70127,0.888761,0.893894,-0.0338094,0.0225604,0.050207,0.118663,0.832662,0.841811,0.234955,0.356157,0.63621,0.767435,0.194903,0.320627,-0.657294,-0.663363,1.07124,0.936265,0.715361,0.491861,-0.0730361,-0.0122607
562,0.380628,0.393957,0.116787,0.0858869,0.000630883,-0.0320845,0.486742,0.548915,0.927525,0.892191,0.430792,0.445531,0.550199,0.589226,0.299419,0.299865,0.979609,0.936838,0.476636,0.482422,2.46236,2.52481,-0.594739,-0.520901,0.679455,0.690735,0.298843,0.414543,-0.360531,-0.226212,-1.22383,-1.09735,-2.2089,-2.2124,-1.3206,-1.46068,1.11357,0.888759,1.20683,1.26778
563,0.928528,0.940354,0.54155,0.510333,0.710754,0.678641,0.885387,0.883908,0.467118,0.435146,0.357452,0.372836,0.457745,0.495369,0.22003,0.219011,0.0756233,0.0306983,0.50111,0.533794,-0.0805754,-0.0185792,-0.113663,-0.0446609,-3.04288,-3.02857,0.640255,0.762935,-0.211753,-0.0844721,-1.17304,-1.05233,-0.338466,-0.351847,0.336649,0.188992,-1.18271,-1.4126,-0.776179,-0.719078
564,0.616563,0.696812,0.165828,0.135721,0.785231,0.755113,0.899893,0.897029,0.0134597,-0.0218999,0.959984,0.974305,0.995296,1.03177,0.667701,0.665994,0.982982,0.938459,0.578159,0.585166,0.611895,0.676423,-0.332844,-0.273226,-0.733949,-0.719628,-0.728093,-0.599876,0.257667,0.395754,-1.33281,-1.20794,1.5122,1.5087,-1.73234,-1.88046,0.208646,-0.0292727,0.00583666,0.0572753
565,0.356334,0.45327,0.642164,0.613488,0.0952292,0.0661622,0.442245,0.464827,0.236655,0.203555,0.285902,0.298755,0.027691,0.063768,0.884976,0.88423,0.266104,0.222537,0.0682665,0.0742563,0.558237,0.538183,-0.574785,-0.501791,0.366564,0.384016,0.62304,0.748263,0.744516,0.875981,2.23192,2.3602,0.362478,0.354983,-1.6991,-1.84145,-0.0366329,-0.266794,0.518127,0.576728
566,0.197901,0.209727,0.609794,0.579427,0.70706,0.67977,0.0363317,0.0326245,0.677824,0.647351,0.781912,0.796236,0.162024,0.296491,0.756155,0.768541,0.868967,0.824411,0.381053,0.387694,0.332732,0.399944,-0.167833,-0.0926341,-1.44697,-1.4264,-0.49073,-0.36955,0.257857,0.389199,1.00257,1.12964,0.560544,0.55379,-0.7455,-0.883224,-1.57813,-1.80121,0.395305,0.447397
567,0.79114,0.800933,0.233488,0.204815,0.28235,0.255271,0.870539,0.86422,0.882628,0.852573,0.191388,0.206445,0.414161,0.529214,0.725035,0.652852,0.73862,0.691916,0.185922,0.192124,2.19186,2.26659,0.233229,0.316523,-0.613439,-0.594403,0.343417,0.470463,-0.654952,-0.525614,1.77595,1.9094,1.17708,1.16958,1.45179,1.30958,1.24086,1.02666,-1.15775,-1.10838
568,0.0182512,0.0289979,0.499168,0.470782,0.495041,0.434471,0.546845,0.541412,0.155702,0.126066,0.754451,0.767733,0.72586,0.761937,0.684174,0.537163,0.158036,0.112494,0.81913,0.826028,-0.669471,-0.585881,0.652686,0.72568,-0.13234,-0.119486,2.49632,2.62582,-0.398996,-0.274894,0.154765,0.292869,-0.180976,-0.188763,0.145148,-0.00180515,-0.868463,-1.08101,-0.166645,-0.118741
569,0.114529,0.124583,0.0645082,0.0376159,0.641064,0.613671,0.983996,0.980079,0.663841,0.634404,0.969856,0.980819,0.684209,0.718573,0.503184,0.421474,0.285117,0.237034,0.813166,0.821533,0.802737,0.881765,-0.172613,-0.0993213,0.804165,0.817022,-1.2009,-1.06967,-1.26492,-1.14644,-0.128578,0.0159553,0.105259,0.103532,-0.0319546,-0.175577,-0.0319559,-0.246692,-0.0695208,-0.0226234
570,0.654629,0.666838,0.278178,0.250272,0.118932,0.0902485,0.893973,0.891886,0.880872,0.849661,0.666997,0.677119,0.22756,0.26267,0.306531,0.305785,0.119588,0.0693351,0.229568,0.235838,-0.54608,-0.473584,1.17935,1.25608,0.746069,0.756364,-2.24259,-2.10911,-1.56129,-1.43485,0.609798,0.748996,-0.320353,-0.29163,-0.467456,-0.610064,0.151356,-0.068899,-1.02752,-0.981198
571,0.382413,0.392988,0.919348,0.889623,0.579661,0.549084,0.217163,0.213977,0.528986,0.496143,0.923759,0.936398,0.136724,0.173727,0.680757,0.678245,0.77911,0.727647,0.34784,0.353006,-0.372715,-0.30005,-1.54668,-1.47342,-1.56417,-1.54943,1.59935,1.73489,-0.356568,-0.232521,-0.799261,-0.654974,-0.679608,-0.686793,1.53271,1.38328,-0.176162,-0.399854,-0.476729,-0.432196
572,0.331292,0.341615,0.805848,0.680003,0.531813,0.579158,0.303151,0.29753,0.985945,0.953764,0.456768,0.470861,0.401203,0.440144,0.289897,0.286448,0.632381,0.514983,0.156071,0.162385,-1.32954,-1.25895,1.80221,1.87606,-0.193012,-0.185457,0.0781474,0.215957,-0.0283161,0.0548505,0.421214,0.5693,-0.755323,-0.762104,0.82765,0.671004,0.707506,0.481079,2.09544,2.14897
573,0.914368,0.923012,0.501072,0.470383,0.538433,0.609233,0.631099,0.626778,0.769147,0.740061,0.328634,0.303232,0.93447,0.971297,0.285336,0.280573,0.354579,0.30232,0.775546,0.781039,-0.0643099,0.00530632,-0.412326,-0.343245,1.9319,1.94287,0.222608,0.366714,0.214294,0.342222,1.02557,1.16771,0.404049,0.393368,1.07909,0.926786,-2.1764,-2.40972,1.01796,0.987782
574,0.393451,0.402371,0.780488,0.75216,0.667422,0.639307,0.757443,0.68633,0.510663,0.526357,0.123207,0.135602,0.402818,0.520697,0.279665,0.274699,0.37621,0.322105,0.504974,0.510593,-0.997632,-0.923939,0.68959,0.766139,-0.517683,-0.505502,0.0166721,0.149485,0.236154,0.363333,-1.08679,-0.943697,-0.63184,-0.638296,1.11433,0.965795,-1.07743,-1.31006,-0.220508,-0.173404
575,0.831551,0.840387,0.794062,0.681132,0.377162,0.349557,0.752169,0.745882,0.344834,0.312653,0.366738,0.378254,0.0310167,0.0700981,0.839183,0.832597,0.0479664,-0.00718982,0.0119444,0.0199151,0.066481,0.137949,0.379669,0.459968,0.180476,0.186462,-0.221418,-0.0677439,-0.00857429,0.119421,-1.74285,-1.59603,-0.663511,-0.680061,0.944261,0.792023,-0.289956,-0.524179,-1.95345,-1.91146
576,0.129609,0.137021,0.638161,0.610104,0.949312,0.922104,0.540373,0.5342,0.766107,0.734993,0.853644,0.865398,0.607411,0.646599,0.308732,0.301549,0.152472,0.0974456,0.587851,0.593998,-0.708538,-0.63685,1.95468,2.03514,0.0116867,0.0200481,-0.749049,-0.595839,1.13666,1.26016,0.552278,0.700896,-0.721213,-0.721826,0.546362,0.388266,0.957452,0.716763,-0.356809,-0.307581
577,0.94207,0.9493,0.875883,0.847412,0.0292595,-0.000204143,0.327749,0.322518,0.762942,0.732445,0.84323,0.853251,0.0389766,0.0791865,0.78116,0.773627,0.815843,0.759778,0.163751,0.168043,1.17621,1.2449,0.350014,0.430803,2.46754,2.47546,0.948949,1.1019,-0.489355,-0.362981,-0.550481,-0.408707,-0.150245,-0.150742,-1.0829,-1.24264,0.0349209,-0.204759,0.478919,0.529721
578,0.35206,0.358652,0.222344,0.191138,0.526146,0.498114,0.460745,0.45667,0.0645485,0.0320171,0.13652,0.148229,0.903369,0.942489,0.0776078,0.070215,0.912792,0.858312,0.200358,0.204761,-1.05792,-0.987077,0.944304,1.03265,0.546261,0.554721,1.05393,1.20447,0.502158,0.62408,-0.598694,-0.455113,0.41494,0.420342,0.814049,0.655539,-1.91101,-2.15193,0.522343,0.568059
579,0.571891,0.604132,0.753489,0.72329,0.397816,0.371886,0.125557,0.119254,0.166879,0.0896089,0.452255,0.40788,0.243415,0.280795,0.839352,0.832647,0.614126,0.559144,0.952519,0.959827,-0.542792,-0.473042,-1.16667,-1.07195,-0.269467,-0.26263,-0.0678622,0.0866543,-0.715237,-0.599801,1.13814,1.27813,-1.04258,-1.03108,-0.316356,-0.469531,-0.578684,-0.816029,-0.0455629,0.00147391
580,0.844201,0.849611,0.670886,0.639959,0.0119033,-0.0127303,0.140929,0.184586,0.268404,0.147201,0.658147,0.667531,0.498768,0.522016,0.0219177,0.0162091,0.0423495,-0.0107861,0.845708,0.953155,0.27946,0.334413,0.0347486,0.176021,0.0113193,0.014972,-0.630801,-0.471665,-0.788057,-0.675234,0.192793,0.33505,-0.820412,-0.802896,0.52367,0.367272,-0.800718,-1.03946,0.48113,0.520926
581,0.817317,0.824328,0.145633,0.112548,0.490472,0.465452,0.329962,0.249918,0.236057,0.204792,0.263226,0.270855,0.72552,0.763238,0.350811,0.342612,0.858928,0.807505,0.938149,0.946484,1.0771,1.14187,1.33375,1.42399,-0.0945387,-0.0915366,2.12861,2.28951,0.388804,0.495834,0.0552675,0.195723,-0.314798,-0.295872,0.827174,0.756912,0.335848,0.0908219,2.0785,2.12481
582,0.435375,0.444591,0.757007,0.722881,0.484486,0.461721,0.323483,0.315249,0.823357,0.79476,0.842153,0.851707,0.151856,0.191039,0.0633676,0.055666,0.49541,0.4432,0.540791,0.551207,-1.09382,-1.02284,-1.54395,-1.44784,-1.03317,-1.03126,0.978312,1.14102,0.358225,0.46895,1.49693,1.63421,-1.13561,-1.12192,1.30915,1.14655,0.296363,-0.0331499,0.303465,0.355807
583,0.349157,0.357616,0.0630852,0.0276501,0.953266,0.930303,0.140828,0.133282,0.262964,0.236215,0.35157,0.36145,0.116924,0.120698,0.223723,0.193897,0.765281,0.714174,0.982441,0.994763,-0.222111,-0.146359,-0.109085,-0.0154875,1.29408,1.29367,0.105767,0.269576,1.32326,1.44221,-0.303512,-0.167085,-0.887799,-0.80027,-0.626052,-0.782159,0.0913822,-0.157122,-0.189543,-0.134043
584,0.919119,0.929076,0.532973,0.496012,0.0187946,-0.00575777,0.870239,0.86125,0.0530073,0.0244189,0.585406,0.607618,0.00887109,0.0503575,0.338969,0.332128,0.313394,0.264377,0.240729,0.251673,-0.204877,-0.186006,0.899509,1.00022,1.95016,1.953,0.396751,0.557994,-0.56264,-0.44322,1.10073,1.24188,-0.502102,-0.478624,0.564388,0.404351,0.885763,0.643911,1.07242,1.13202
585,0.74458,0.757079,0.627595,0.590351,0.561078,0.537142,0.409197,0.399785,0.777409,0.746682,0.842722,0.853785,0.316079,0.35731,0.838427,0.833362,0.499026,0.422411,0.0782052,0.0912972,-0.297669,-0.225652,0.156931,0.304899,0.385035,0.396248,-0.609561,-0.451885,-1.56605,-1.45281,0.318621,0.454967,-0.437073,-0.415425,-0.598268,-0.763791,0.216471,-0.0270415,-1.05456,-0.993882
586,0.776418,0.691614,0.41496,0.458241,0.0648652,0.0428608,0.568543,0.559408,0.284298,0.253345,0.226849,0.238875,0.180411,0.253385,0.0238396,0.0169232,0.758844,0.580445,0.903903,0.915643,0.393271,0.46935,-0.490739,-0.390425,0.0939256,0.00592466,-0.633939,-0.471432,-0.68097,-0.597815,-0.669894,-0.533249,-1.76041,-1.74233,0.183845,0.0107256,1.15236,0.9169,1.75089,1.81236
587,0.612058,0.626148,0.365452,0.32613,0.53649,0.516455,0.264569,0.256977,0.815222,0.782371,0.255175,0.265299,0.110001,0.149459,0.715422,0.708238,0.786397,0.738479,0.0732146,0.0847075,1.32899,1.40839,-0.676263,-0.571791,-0.388131,-0.384399,-0.0380331,0.120685,0.14539,0.257175,-0.182748,-0.0418486,0.269751,0.281543,0.542785,0.372351,0.505562,0.277605,0.722845,0.778264
588,0.314608,0.381944,0.939437,0.901894,0.772546,0.751826,0.277549,0.270098,0.000187091,-0.0338543,0.704971,0.713733,0.296912,0.335417,0.511892,0.506169,0.454539,0.404644,0.813257,0.823092,-0.957471,-0.882095,-0.296341,-0.186308,-0.131357,-0.121933,0.824211,0.976771,1.29113,1.39791,1.44281,1.58259,1.59199,1.6079,-0.0411987,-0.216582,0.616002,0.394204,0.469323,0.528974
589,0.125922,0.13774,0.0600116,0.021282,0.536311,0.513461,0.825431,0.817489,0.726369,0.694143,0.83825,0.788548,0.185522,0.257274,0.920659,0.912614,0.474925,0.424429,0.149338,0.156847,0.0641562,0.134816,-0.222237,-0.10813,-1.77413,-1.75602,1.09921,1.24931,0.0500662,0.159429,0.39331,0.53402,-1.85931,-1.84596,0.476227,0.298412,0.132849,-0.0903104,0.646501,0.701422
590,0.133293,0.136626,0.512985,0.475638,0.620195,0.603186,0.521835,0.515058,0.615404,0.635289,0.854097,0.863364,0.139739,0.17913,0.761834,0.729038,5.45313e-05,-0.0502433,0.629705,0.63585,-0.521915,-0.454584,0.985848,1.09302,1.13469,1.15418,-1.13245,-0.980542,-0.501879,-0.389347,0.0989846,0.242117,-0.340359,-0.321626,0.471195,0.309408,0.874366,0.650122,0.271674,0.329204
591,0.126031,0.135513,0.154257,0.116423,0.713585,0.69291,0.80575,0.800424,0.546046,0.576434,0.670089,0.709312,0.959622,0.999563,0.554475,0.545462,0.864218,0.816478,0.432774,0.440279,-0.653461,-0.584345,0.600235,0.711358,-0.441891,-0.418108,0.539988,0.685665,1.05553,1.16348,0.800847,0.947242,2.12764,2.14092,0.499134,0.320404,-0.204167,-0.427338,1.20162,1.25726
592,0.750525,0.761045,0.842418,0.806089,0.156605,0.134063,0.437496,0.433614,0.550484,0.51758,0.546677,0.55526,0.364737,0.402964,0.716389,0.706927,0.682349,0.572785,0.986749,0.994392,1.00832,1.08304,-0.0930391,0.0251161,0.169287,0.194299,-0.95062,-0.800702,-0.538441,-0.426978,-1.14606,-0.990913,-0.771135,-0.760198,2.40388,2.21858,0.767839,0.546138,1.50831,1.56589
593,0.458914,0.503143,0.281953,0.243901,0.663028,0.642294,0.344957,0.340643,0.17296,0.138708,0.886958,0.894836,0.511965,0.548753,0.626275,0.628391,0.434474,0.329092,0.406773,0.414181,-0.362358,-0.288071,0.00837769,0.132042,0.333908,0.360801,-0.526609,-0.336385,-1.18137,-1.06717,-0.188758,-0.0273899,0.854601,0.873569,-0.40582,-0.596857,1.24953,1.03295,0.886127,0.93997
594,0.234676,0.245242,0.98573,0.949135,0.0190159,-0.00199735,0.668322,0.66494,0.032304,-0.00312295,0.00907516,0.0170098,0.91743,0.955722,0.560724,0.549854,0.131534,0.0853996,0.849382,0.857737,-0.244662,-0.205012,-0.693584,-0.569101,1.08769,1.11398,-0.0185772,0.127933,-1.39453,-1.28027,-0.367394,-0.211177,-0.892873,-0.877833,2.22539,2.03594,1.73647,1.51976,0.0389686,0.0874099
595,0.683946,0.693107,0.713459,0.705686,0.552582,0.531543,0.138672,0.136696,0.244279,0.206652,0.304818,0.289292,0.78646,0.793844,0.851695,0.840489,0.146272,0.100367,0.554722,0.587889,-0.203146,-0.121952,-0.619476,-0.490923,1.13493,1.15876,-0.827756,-0.679646,-0.33238,-0.216867,-0.28397,-0.0367573,-0.421244,-0.401223,0.140064,-0.049012,0.857968,0.645977,-1.19415,-1.14823
596,0.854236,0.863956,0.38214,0.462237,0.833313,0.748744,0.187599,0.185626,0.824877,0.786388,0.555575,0.561574,0.495034,0.631966,0.843994,0.83201,0.773667,0.726755,0.308482,0.318042,0.423577,0.497222,0.0403676,0.172243,-1.17809,-1.15929,-1.2984,-1.14766,-0.306429,-0.195757,-0.0218286,0.137662,-1.00597,-0.986177,-0.133134,-0.315838,0.311471,0.191723,0.253807,0.300974
597,0.120177,0.130035,0.255383,0.218788,0.984589,0.965945,0.54088,0.473282,0.946463,0.905783,0.564858,0.568661,0.431411,0.470088,0.832611,0.823531,0.601575,0.553492,0.558341,0.56639,1.6583,1.7272,1.06431,1.20331,0.945285,0.969032,0.0386667,0.186672,0.451508,0.559797,0.417594,0.584004,0.957289,0.975662,1.61686,1.42861,-0.0459823,-0.262531,0.511819,0.562372
598,0.944193,0.953839,0.319212,0.282861,0.623561,0.606322,0.763227,0.760938,0.606821,0.568575,0.291568,0.31999,0.501005,0.538883,0.426121,0.416312,0.0708407,0.0243257,0.44103,0.52081,-0.552976,-0.487871,-1.06791,-0.934548,0.626682,0.64684,-0.438554,-0.301154,0.00445847,0.116224,-0.133978,-0.0607424,0.971479,0.990196,0.0599489,-0.125193,-0.202509,-0.424805,0.342901,0.38839
599,0.0602624,0.0697301,0.857445,0.820096,0.00857181,-0.00767957,0.0841923,0.0830298,0.793281,0.753632,0.065546,0.0713182,0.0528036,0.093119,0.496342,0.487899,0.503794,0.459225,0.469745,0.47523,0.337716,0.407245,0.344908,0.504181,0.530681,0.553572,-0.927671,-0.788981,-0.688605,-0.590651,-0.8765,-0.705489,-0.910481,-0.885061,0.648344,0.465403,0.312901,0.0833703,-0.251647,-0.20781
600,0.141179,0.15407,0.569791,0.584741,0.848102,0.834773,0.791324,0.790366,0.0531058,0.0122968,0.651218,0.656979,0.0965731,0.0895356,0.940167,0.930137,0.627067,0.583765,0.960128,0.9647,-1.70877,-1.63322,1.80955,1.94291,-0.252903,-0.15695,1.31579,1.45215,-1.41261,-1.29753,-0.916622,-0.751894,-1.01334,-0.990602,-1.70863,-1.89949,0.511545,0.275932,-1.73418,-1.6849
601,0.227488,0.23841,0.386831,0.349386,0.281974,0.270515,0.917728,0.915236,0.336543,0.294394,0.806768,0.811769,0.0473941,0.0859522,0.569515,0.614052,0.205254,0.160341,0.383203,0.389006,-0.38104,-0.307539,-1.49358,-1.3581,-0.889204,-0.867473,-0.359923,-0.22426,-0.421649,-0.310465,0.530128,0.699928,-0.455266,-0.436452,0.0925277,-0.0942374,-0.891898,-1.13238,-0.377529,-0.326245
602,0.599194,0.610713,0.725147,0.690029,0.821988,0.808158,0.265572,0.262915,0.944997,0.904121,0.647764,0.653315,0.315449,0.352369,0.30679,0.297966,0.696152,0.651135,0.883227,0.887637,1.70433,1.77531,-0.637254,-0.497511,-0.437859,-0.422146,0.920203,1.04957,-0.384642,-0.302949,-0.730738,-0.56367,-0.290303,-0.269889,-0.242583,-0.436703,0.542745,0.29776,0.521266,0.572311
603,0.0537268,0.0643633,0.234466,0.197114,0.264516,0.249312,0.330898,0.396574,0.552274,0.510556,0.157392,0.163059,0.142111,0.177478,0.231192,0.22126,0.521428,0.477871,0.112678,0.119365,-0.542119,-0.470014,-0.214489,-0.0813595,1.44432,1.45655,-0.542859,-0.406761,-0.412206,-0.295433,1.16121,1.32317,-0.126294,-0.103326,1.62318,1.43056,2.72867,2.47918,0.79663,0.850401
604,0.812305,0.824205,0.210125,0.17192,0.126608,0.112612,0.502844,0.530233,0.879593,0.837929,0.792758,0.799039,0.576141,0.609129,0.739502,0.728264,0.833999,0.788654,0.704017,0.708499,-0.644917,-0.57185,0.813906,0.949711,0.936115,0.952915,-0.0149403,0.124735,-2.77032,-2.65024,1.64598,1.81457,1.94708,1.96943,-0.194715,-0.391162,1.3,1.05606,0.527046,0.585848
605,0.0318384,0.0422847,0.843356,0.807213,0.717995,0.705634,0.703982,0.663892,0.102459,0.0629588,0.373152,0.430651,0.73893,0.77055,0.584729,0.660789,0.625753,0.581021,0.617552,0.620546,-0.536832,-0.460402,0.230563,0.370788,-0.24982,-0.236217,0.806396,0.9482,-0.405352,-0.28071,-1.09682,-0.923273,0.728008,0.751902,0.92211,0.721752,-0.528021,-0.76797,1.25546,1.31835
606,0.974467,0.982868,0.400819,0.457479,0.429614,0.415884,0.800208,0.797551,0.634438,0.596721,0.0540473,0.0622638,0.428325,0.458865,0.60597,0.593313,0.963635,0.917453,0.961881,0.964868,1.41612,1.49819,0.867412,1.00187,-0.847593,-0.837436,0.885557,1.02131,0.244238,0.367099,1.18598,1.35826,0.0815174,0.107765,0.537035,0.334309,0.308823,0.0663455,-0.169283,-0.0405142
607,0.67108,0.613896,0.146483,0.107745,0.52078,0.507001,0.608817,0.605952,0.579404,0.541512,0.171972,0.182124,0.448318,0.476653,0.163127,0.151735,0.379342,0.332473,0.947917,0.95067,-0.636471,-0.557518,1.23882,1.37053,2.55651,2.56107,-1.36626,-1.22456,0.544949,0.66256,1.42625,1.60251,0.477403,0.506715,-0.122062,-0.332951,-0.352717,-0.587965,-1.45599,-1.39938
608,0.238217,0.244924,0.44087,0.38371,0.879989,0.864107,0.807474,0.802244,0.309769,0.31408,0.293124,0.301985,0.924725,0.953176,0.248868,0.218029,0.197285,0.245053,0.52441,0.53878,-1.62244,-1.54776,0.502927,0.63852,1.25674,1.26413,0.0327651,0.170418,0.128166,0.250204,0.642833,0.846742,-1.91695,-1.89405,0.748652,0.532989,0.0307018,-0.296512,1.47805,1.52885
609,0.589708,0.596745,0.637948,0.659675,0.344535,0.330291,0.167259,0.159995,0.123794,0.0866479,0.117722,0.156144,0.702875,0.673972,0.18924,0.284324,0.206368,0.157634,0.12206,0.12689,2.28434,2.35888,1.73049,1.87308,-0.317808,-0.308154,0.199633,0.24739,-0.525718,-0.404147,-0.0911089,0.0909747,1.56494,1.59322,1.91837,1.70655,0.226447,-0.00505789,-0.542826,-0.490654
610,0.227762,0.237078,0.974819,0.93564,0.277453,0.172629,0.00361664,-0.0028695,0.293956,0.245598,0.00328684,0.010304,0.365711,0.394769,0.346437,0.350619,0.350374,0.320866,0.842496,0.846418,1.39848,1.47623,-0.357393,-0.216459,1.16572,1.17695,0.184759,0.324361,-0.690567,-0.571972,0.999854,1.17822,-0.034186,-0.00273473,-0.127149,-0.332006,-0.0915643,-0.320935,-1.18641,-1.1335
611,0.447814,0.458878,0.245172,0.205088,0.0294362,0.0149672,0.119189,0.0237709,0.443308,0.404548,0.848417,0.856313,0.458592,0.48871,0.428898,0.416913,0.533817,0.484097,0.942266,0.94683,0.282259,0.36257,-0.495145,-0.352435,-1.27501,-1.27143,-0.959104,-0.824125,0.557962,0.67713,-1.40402,-1.2182,-0.309027,-0.373215,1.49251,1.28666,0.225713,-0.00235623,-1.41213,-1.3537
612,0.933005,0.945605,0.0231313,-0.0191898,0.779128,0.766308,0.0547064,0.0504114,0.0912905,0.0510305,0.354474,0.361095,0.0837168,0.112746,0.713302,0.627066,0.488412,0.439391,0.243571,0.249173,0.0403702,0.126466,0.706134,0.848719,0.553983,0.558514,-0.42304,-0.292629,0.407101,0.603397,-0.636748,-0.452635,-0.778665,-0.743694,-0.749944,-0.950871,-0.38072,-0.611851,-0.215631,-0.162474
613,0.513499,0.525286,0.452776,0.351787,0.130017,0.117507,0.619516,0.613755,0.628917,0.589917,0.717064,0.725414,0.22136,0.262007,0.849707,0.83722,0.953009,0.90456,0.524005,0.464527,0.355323,0.439691,0.945196,1.08051,2.79855,2.80301,0.490745,0.625826,0.406684,0.529663,0.366445,0.556932,-0.421676,-0.389842,-1.83314,-2.03025,0.892917,0.658613,0.610691,0.66048
614,0.859511,0.872281,0.766278,0.722764,0.156563,0.144793,0.946019,0.938052,0.157617,0.116911,0.229861,0.240695,0.417747,0.411267,0.266901,0.256401,0.512999,0.465354,0.673303,0.67988,-1.60256,-1.51884,-1.37957,-1.23721,1.22858,1.23073,1.00398,1.14092,-0.0118135,0.117307,-0.577766,-0.386146,0.996794,1.02861,-0.517542,-0.751675,-0.853683,-1.08408,-0.226631,-0.175595
615,0.609468,0.623557,0.203825,0.160576,0.654269,0.643112,0.0128883,0.00466085,0.97067,0.928967,0.59381,0.605014,0.532963,0.560527,0.522134,0.512108,0.39407,0.374502,0.254272,0.259291,-0.515415,-0.42739,-1.76001,-1.61888,-0.0960031,-0.0976524,0.561621,0.70365,0.945394,1.07318,0.620144,0.80886,1.66998,1.70378,0.719497,0.5269,-0.982595,-1.21392,0.951305,0.998288
616,0.624005,0.642395,0.759,0.717405,0.55697,0.54713,0.632115,0.622344,0.596954,0.554938,0.336092,0.438573,0.978532,1.00667,0.257398,0.250274,0.256073,0.283649,0.187797,0.196898,-2.751,-2.65937,-1.76091,-1.61657,-0.6948,-0.698871,0.442543,0.577375,0.499908,0.629611,-0.80535,-0.609121,0.58831,0.625005,0.227165,0.0311462,-0.875025,-1.11128,0.517126,0.566897
617,0.64439,0.661234,0.774097,0.684811,0.850081,0.838585,0.311959,0.299536,0.752186,0.709945,0.236976,0.272131,0.668613,0.79454,0.806517,0.798088,0.240441,0.192796,0.130214,0.134504,-0.0406409,0.0450184,1.79886,1.94212,1.96881,1.95991,0.542969,0.679942,-0.938505,-0.807808,-0.974238,-0.777908,1.34344,1.3778,-0.539464,-0.741299,1.05891,0.820057,1.09543,1.14756
618,0.0260003,0.045129,0.691243,0.652217,0.36638,0.437681,0.719371,0.708908,0.293265,0.251214,0.092045,0.10569,0.554435,0.582407,0.510967,0.501154,0.992212,0.945457,0.515666,0.518667,0.41134,0.495474,2.2974,2.4363,-0.0316527,-0.0376873,-0.2853,-0.143614,0.982029,1.11691,-0.322095,-0.119907,-0.22765,-0.185763,-0.715301,-0.915071,0.69581,0.458221,-0.265444,-0.209538
619,0.207749,0.312088,0.26812,0.228285,0.0471273,0.0367774,0.302693,0.292139,0.190559,0.149925,0.200877,0.214732,0.822308,0.848824,0.942038,0.932803,0.937093,0.889893,0.486603,0.489296,-0.734354,-0.647775,1.4291,1.56477,0.772194,0.761336,0.25072,0.387882,-0.0320642,0.107328,0.534988,0.73648,0.112417,0.151285,-0.0338686,-0.231764,-1.83845,-2.07751,0.633646,0.689018
620,0.560325,0.579047,0.195549,0.154371,0.68743,0.675918,0.868237,0.859822,0.778968,0.739892,0.056675,0.0711244,0.746867,0.82025,0.798452,0.703469,0.446142,0.399876,0.792031,0.797074,-0.857809,-0.76525,1.49964,1.62746,-0.101481,-0.117834,1.43975,1.56759,1.00684,1.1408,-0.494188,-0.296356,0.886827,0.918382,0.39581,0.191443,0.660528,0.414899,-0.993118,-0.943357
621,0.120691,0.138539,0.425482,0.351431,0.879825,0.866271,0.769,0.76227,0.976586,0.939445,0.357379,0.372516,0.765369,0.791676,0.484104,0.474136,0.658112,0.511255,0.759015,0.763054,1.39139,1.485,0.177244,0.304314,-0.347796,-0.362315,1.50251,1.62597,-0.847542,-0.716808,-1.15802,-0.962417,-0.469236,-0.439961,-0.285662,-0.450751,0.688247,0.441535,-0.559861,-0.515446
622,0.137716,0.153731,0.589667,0.54849,0.158661,0.145275,0.932254,0.927111,0.299573,0.264246,0.0327196,0.0492912,0.192715,0.219476,0.578287,0.569866,0.671608,0.622634,0.45335,0.457865,-0.483638,-0.384237,1.04194,1.1649,-1.42507,-1.44342,-1.27722,-1.15304,-0.510964,-0.374495,0.666916,0.863325,-0.394712,-0.361951,-0.889136,-1.09294,1.05834,0.80716,-0.878616,-0.841036
623,0.5426,0.527517,0.27043,0.228137,0.768483,0.753137,0.0367303,0.0309965,0.608443,0.571507,0.214723,0.234075,0.334074,0.265983,0.411614,0.402016,0.633672,0.582991,0.701807,0.706213,0.276291,0.373402,-0.713636,-0.597621,0.0108086,-0.00292054,-0.793825,-0.666513,2.13142,2.2621,-0.329717,-0.140376,0.885595,0.914278,0.572216,0.362442,1.73688,1.48626,-0.948787,-0.907354
624,0.8866,0.901303,0.90014,0.858758,0.656052,0.682606,0.402593,0.391794,0.0956636,0.0583847,0.0680867,0.0860569,0.283671,0.312491,0.926368,0.919307,0.366388,0.314119,0.40065,0.364758,0.568919,0.672854,0.927719,1.03803,-0.924763,-0.942648,-0.901981,-0.778233,-0.760972,-0.6291,0.869051,1.05463,-1.06541,-1.04141,2.02164,1.81783,-1.73745,-1.98986,3.43108,3.47882
625,0.362593,0.375272,0.62912,0.588006,0.682611,0.612075,0.758917,0.752591,0.91657,0.880249,0.141833,0.162022,0.598089,0.665821,0.409366,0.4035,0.459202,0.407017,0.0174758,0.0233019,-1.71334,-1.60353,-0.955,-0.839666,0.695375,0.683495,0.494967,0.616741,-2.01011,-1.88398,-0.316315,-0.131491,0.396469,0.422152,-0.217447,-0.419704,-1.00758,-1.26537,1.35076,1.39916
626,0.299211,0.313899,0.00161576,-0.0375459,0.557422,0.541543,0.697676,0.690011,0.185766,0.148722,0.655634,0.674834,0.992104,1.01915,0.693202,0.689417,0.350386,0.299737,0.313606,0.41948,-2.51582,-2.40996,-1.71234,-1.60414,-0.0582928,-0.070732,0.191878,0.408915,0.593132,0.72333,1.01101,1.20088,-1.29008,-1.2669,2.97237,2.77561,0.290084,0.0365322,0.371006,0.426031
627,0.913002,0.92923,0.500357,0.460934,0.739503,0.722866,0.404536,0.454921,0.54264,0.406358,0.517064,0.471858,0.509771,0.537527,0.0861818,0.0834189,0.505361,0.454706,0.808091,0.815659,0.183878,0.294425,0.477445,0.583205,1.02129,1.0045,0.0768986,0.201089,-0.380551,-0.255597,-1.30887,-1.11882,0.60314,0.634719,0.174349,-0.0257972,0.237405,-0.0165863,-0.874295,-0.823105
628,0.970299,0.984892,0.0699517,0.0323566,0.628336,0.684063,0.229994,0.219831,0.701977,0.663995,0.247554,0.268881,0.587928,0.699959,0.232,0.229801,0.392777,0.270622,0.437156,0.44515,0.683167,0.791038,-0.137353,-0.0264529,0.762837,0.745691,-1.63701,-1.50658,-1.11975,-1.00291,0.55229,0.736963,0.514364,0.5454,-0.186092,-0.384733,0.572578,0.317855,0.0330777,0.0896268
629,0.797872,0.724327,0.715578,0.677071,0.663867,0.64526,0.654566,0.644093,0.799147,0.720966,0.54328,0.55475,0.836233,0.862392,0.117308,0.189352,0.134997,0.0865385,0.963097,0.969582,-0.955293,-0.838355,-0.547537,-0.436934,-0.331806,-0.351025,0.470881,0.604475,-1.10157,-0.981803,-0.157437,0.0255868,0.671125,0.627713,1.27725,1.07941,-0.354506,-0.603667,0.698552,0.762049
630,0.44872,0.463762,0.802802,0.766289,0.163988,0.145564,0.355119,0.346509,0.817092,0.777938,0.817674,0.840618,0.620326,0.646489,0.150118,0.148902,0.573652,0.526025,0.810238,0.819223,-0.463731,-0.341741,0.358567,0.470511,-0.514365,-0.622337,0.0975595,0.229903,-0.573204,-0.457034,0.258183,0.437253,0.679246,0.710026,0.600368,0.310881,-0.269525,-0.515658,-0.457172,-0.3961
631,0.693926,0.709723,0.581737,0.591064,0.188214,0.234523,0.761632,0.750991,0.436267,0.436166,0.207326,0.231137,0.0362263,0.0640616,0.983841,0.982499,0.037675,-0.00802238,0.410954,0.418662,1.69,1.81514,-1.20554,-1.08733,-0.816154,-0.89365,1.63623,1.76947,-1.16229,-1.05075,-1.09353,-0.92062,0.552555,0.541696,-0.256836,-0.457652,1.78752,1.53496,0.859391,0.916037
632,0.468209,0.563286,0.47146,0.415839,0.359198,0.323481,0.176318,0.167704,0.131088,0.0943948,0.466596,0.490415,0.398361,0.426522,0.235541,0.236754,0.246501,0.127898,0.967625,0.977535,0.0211894,0.150636,0.528227,0.640886,-1.14574,-1.16496,0.55515,0.680835,-1.12366,-1.01494,-0.819262,-0.646293,0.338593,0.373366,-0.707551,-0.907009,-0.67606,-0.860192,-0.273312,-0.213748
633,0.401555,0.416849,0.277127,0.240614,0.432162,0.41244,0.557264,0.506392,0.989713,0.955269,0.0890119,0.11359,0.999181,1.02704,0.770254,0.769337,0.311496,0.263819,0.818354,0.827176,-0.298268,-0.175029,1.27154,1.38053,0.230612,0.21312,-0.299198,-0.174867,1.40703,1.52201,0.81902,0.995949,-0.855908,-0.813756,0.0798544,-0.117646,-3.00279,-3.25535,-1.67182,-1.61636
634,0.467209,0.473799,0.56244,0.527058,0.21792,0.199281,0.853121,0.84508,0.760011,0.723705,0.954036,0.976618,0.755068,0.780973,0.788942,0.790046,0.09749,0.0504312,0.391216,0.440485,0.091126,0.213973,-0.28169,-0.177313,0.566583,0.550897,0.911193,1.03687,-0.580298,-0.457476,-0.289434,-0.198107,-0.0891259,-0.045012,-1.20527,-1.39688,0.338777,0.0767848,2.10973,2.16782
635,0.517596,0.530748,0.382065,0.278586,0.204191,0.221716,0.117574,0.106872,0.054992,0.0182167,0.594927,0.619053,0.930286,0.856008,0.303923,0.303877,0.137652,0.0649004,0.0460302,0.0537941,-1.41928,-1.29554,1.18858,1.28816,0.0589893,0.0472641,0.5574,0.677059,-0.351454,-0.223893,-1.56393,-1.39216,0.68158,0.723732,-1.28079,-1.46492,-0.620451,-0.877838,0.0651774,0.119748
636,0.899267,0.913571,0.0673246,0.030113,0.38159,0.24415,0.878236,0.865305,0.0872948,0.0501794,0.954843,0.979146,0.916923,0.931043,0.561337,0.559584,0.124352,0.0793696,0.263951,0.271174,-0.636659,-0.508665,-0.677629,-0.571687,-0.767583,-0.786405,-0.105357,0.0098334,1.28309,1.40666,-1.91313,-1.74576,0.317298,0.356555,-0.252797,-0.442097,1.44773,1.1888,-0.745052,-0.687396
637,0.136994,0.152591,0.186984,0.148594,0.396573,0.266584,0.809007,0.798364,0.778677,0.741438,0.987685,1.0107,0.980173,1.00608,0.14336,0.143092,0.430175,0.385145,0.793063,0.800673,1.50381,1.63372,-0.246295,-0.14112,-1.06944,-1.09092,0.518548,0.631875,-1.17582,-1.04856,0.0893546,0.260591,-0.603714,-0.566665,-0.461923,-0.621477,-2.02642,-2.28732,-0.669784,-0.606719
638,0.689134,0.703609,0.601628,0.563703,0.307657,0.289019,0.14428,0.135071,0.587067,0.54938,0.416715,0.440928,0.473295,0.499759,0.800224,0.797906,0.516578,0.473318,0.658795,0.640349,0.248472,0.382924,-1.19668,-1.08952,2.30868,2.28937,0.59809,0.718095,-0.851888,-0.72194,1.20851,1.37929,0.44928,0.492347,-0.690732,-0.800857,1.4341,1.17238,-0.996583,-0.932309
639,0.409278,0.375553,0.226474,0.189091,0.0512674,0.0354998,0.74171,0.731917,0.968646,0.932792,0.834572,0.860284,0.465277,0.492332,0.790574,0.78791,0.944944,0.903775,0.458947,0.480026,0.145918,0.281088,0.871864,0.982988,0.618241,0.589481,0.27881,0.405086,-0.831384,-0.700829,-0.048654,0.115689,0.17578,0.21844,-0.790938,-0.980238,1.46341,1.19901,0.256015,0.316946
640,0.0312551,0.0474963,0.325116,0.288023,0.145826,0.0493474,0.388091,0.380204,0.791575,0.75616,0.793264,0.751988,0.0983596,0.12603,0.144852,0.140531,0.201852,0.162592,0.389137,0.319703,-1.70039,-1.57285,-0.520736,-0.403634,-0.155844,-0.181217,0.71435,0.844229,0.790361,0.92972,1.7086,1.87741,0.944946,0.985537,0.421972,0.236443,-0.175356,-0.444995,-0.186151,-0.128905
641,0.192647,0.173287,0.757941,0.722172,0.0815728,0.063195,0.849014,0.842736,0.183279,0.146659,0.590223,0.643691,0.329382,0.357004,0.955798,0.949207,0.931356,0.889948,0.15177,0.15938,1.17259,1.29687,-0.650521,-0.53961,0.397821,0.370742,-1.05433,-0.923255,-0.180706,3.81056e-05,-0.404106,-0.234002,0.89874,0.940714,0.0379477,-0.151,0.432375,0.170581,0.121074,0.179721
642,0.274869,0.299077,0.0996457,0.0618958,0.325548,0.308537,0.849267,0.831854,0.205219,0.229368,0.511282,0.535395,0.215307,0.242591,0.745295,0.737597,0.244097,0.20451,0.561303,0.568694,0.332974,0.459734,0.142219,0.248736,-1.00287,-1.03521,-0.498911,-0.361721,-1.07337,-0.929643,1.35457,1.52772,0.315469,0.355761,-0.815673,-0.999264,0.0935507,-0.129638,0.821331,0.881719
643,0.408626,0.424868,0.698669,0.661915,0.571115,0.553878,0.875863,0.820971,0.348309,0.312077,0.780304,0.718481,0.690561,0.719114,0.204235,0.196175,0.208278,0.169439,0.494904,0.500361,1.03355,1.15474,0.317781,0.420004,1.52582,1.4889,0.51448,0.650775,-1.54891,-1.40266,0.953608,1.12787,0.602729,0.648056,-0.865,-1.05235,-0.0629329,-0.429857,-0.407453,-0.353921
644,0.722293,0.736505,0.308384,0.272318,0.585945,0.570305,0.81561,0.810089,0.0281121,-0.0102996,0.876003,0.901566,0.204317,0.232811,0.162873,0.177039,0.79296,0.754676,0.678528,0.682686,-0.44117,-0.323826,-0.171986,-0.066404,1.77449,1.73593,-0.742384,-0.606641,1.02263,1.16759,-0.605525,-0.428189,0.333769,0.374149,0.681853,0.488597,-0.347605,-0.730076,0.704581,0.757892
645,0.632939,0.64953,0.283648,0.334798,0.273158,0.255776,0.0249762,0.0209973,0.942313,0.902207,0.56994,0.499951,0.197595,0.225383,0.204379,0.157903,0.0128207,-0.0251611,0.151747,0.156697,-2.24794,-2.13036,0.976445,1.08663,-0.110542,-0.150372,1.12716,1.26518,1.22314,1.37134,-1.1694,-0.998674,-0.486694,-0.451896,2.56348,2.3697,-0.768502,-1.0303,0.325845,0.372853
646,0.000275349,0.0184036,0.349167,0.397279,0.514522,0.49583,0.833344,0.82735,0.307357,0.26731,0.0715664,0.098337,0.412717,0.441849,0.148781,0.138767,0.559177,0.519776,0.593349,0.600253,-0.436803,-0.323719,1.21994,1.33396,-2.3069,-2.3406,1.39349,1.53772,0.427752,0.578181,0.201388,0.377565,1.41475,1.44972,-0.149174,-0.343814,0.0922882,-0.164006,0.632867,0.68148
647,0.346431,0.365399,0.494514,0.459759,0.203697,0.186705,0.167389,0.159783,0.452628,0.384936,0.412819,0.522199,0.0288429,0.0560874,0.335517,0.394155,0.703493,0.685218,0.0153255,0.0245591,0.451313,0.571396,-0.899653,-0.787304,2.16266,2.12387,0.437949,0.588045,0.985585,1.13292,0.636478,0.806798,0.151402,0.186786,-0.0676886,-0.259224,-1.70158,-1.95416,-0.575523,-0.522591
648,0.492207,0.510215,0.170191,0.134235,0.269695,0.195145,0.313057,0.304827,0.543567,0.502562,0.91756,0.946061,0.503931,0.457035,0.658709,0.649543,0.890863,0.850661,0.578419,0.587948,0.721609,0.837279,-1.89801,-1.78256,-0.115539,-0.148443,-1.77776,-1.62403,2.25748,2.41185,0.667509,0.837075,1.95921,1.99103,-1.01814,-1.21549,-1.03319,-1.29257,-0.631942,-0.575811
649,0.318549,0.332039,0.51186,0.474878,0.220243,0.203586,0.974119,0.965949,0.927659,0.885974,0.894166,0.922885,0.832001,0.857982,0.498453,0.479271,0.478897,0.436594,0.395229,0.335274,0.141933,0.263005,1.80242,1.91788,-1.2351,-1.26169,0.431417,0.585604,0.0321407,0.185883,-0.307674,-0.135382,-1.82335,-1.79761,0.627759,0.434187,-2.54143,-2.79625,0.524389,0.583246
650,0.138002,0.153863,0.566531,0.47706,0.969634,0.954927,0.627959,0.619222,0.0901558,0.0488045,0.121402,0.152769,0.254671,0.280909,0.316621,0.309,0.814929,0.773026,0.0738366,0.0826008,0.980938,1.09426,-0.675204,-0.55693,-0.713414,-0.740656,-0.377974,-0.221975,0.94409,1.09535,0.689881,0.861244,-0.715132,-0.693263,-0.346888,-0.538133,0.902967,0.64334,1.033,1.0844
651,0.386913,0.404979,0.514848,0.479243,0.523279,0.510436,0.00316909,-0.00380241,0.476743,0.437107,0.232477,0.261812,0.122974,0.151214,0.426977,0.419708,0.919633,0.877661,0.336098,0.34563,-2.69313,-2.58613,1.81162,1.9337,-1.46084,-1.49488,-0.194241,-0.0409196,-2.268,-2.11516,2.02449,2.19362,-0.89067,-0.874994,0.60537,0.420092,-1.93044,-2.18416,1.5225,1.58556
652,0.0561348,0.0752648,0.0547027,0.0210253,0.861594,0.847599,0.887929,0.882312,0.403501,0.362079,0.813055,0.842664,0.391178,0.368557,0.801331,0.792167,0.226892,0.186687,0.844901,0.854132,-1.91823,-1.84579,1.96438,2.08827,-0.553181,-0.587762,0.822519,0.971577,-0.399396,-0.25506,0.16751,0.332134,-0.0195612,-0.000468102,2.22333,2.03876,0.540564,0.285714,0.113448,0.182943
653,0.765532,0.785896,0.451876,0.416474,0.792302,0.778141,0.495615,0.490538,0.764834,0.725423,0.701674,0.715432,0.610472,0.585899,0.384919,0.375675,0.133242,0.0912217,0.575108,0.583686,-1.20721,-1.10545,1.23694,1.35626,2.00774,1.97253,-0.937406,-0.782457,0.57927,0.718201,-0.794033,-0.624793,0.38442,0.398482,-0.135241,-0.326136,-0.317344,-0.570532,-0.722795,-0.653132
654,0.961921,0.901482,0.346203,0.313213,0.794288,0.708683,0.507617,0.592397,0.530613,0.49386,0.517134,0.588201,0.776736,0.803242,0.506909,0.496975,0.994704,0.952857,0.933524,0.943814,0.597211,0.701197,0.807692,0.93175,-1.26088,-1.28914,-0.41673,-0.267367,0.762848,0.906314,-0.995484,-0.824736,-1.22455,-1.21146,0.566023,0.37295,-0.395017,-0.653691,-1.04082,-0.978722
655,0.999092,1.01707,0.917459,0.884596,0.663327,0.639225,0.708907,0.694255,0.556381,0.595934,0.432887,0.46097,0.599725,0.667965,0.267113,0.25916,0.784966,0.745224,0.0470218,0.0588072,-0.252187,-0.150302,0.846614,0.964538,-1.36738,-1.39565,2.32651,2.47626,0.537635,0.676299,0.341724,0.507637,-0.331675,-0.322806,-0.628018,-0.827605,-1.42289,-1.68329,-0.102431,-0.0337984
656,0.349783,0.365468,0.799526,0.722786,0.459371,0.569767,0.801214,0.796113,0.735048,0.698009,0.878132,0.904175,0.48303,0.532688,0.641634,0.560261,0.984479,0.945701,0.723855,0.737667,0.540433,0.636573,0.531146,0.646337,1.54103,1.51455,-0.704452,-0.553882,1.34887,1.49358,0.573867,0.736691,-0.685193,-0.675581,-0.618825,-0.820274,-0.430936,-0.620981,-0.603504,-0.540288
657,0.199,0.212876,0.666824,0.560976,0.514304,0.50031,0.518087,0.513163,0.219938,0.184887,0.657401,0.681261,0.342389,0.39741,0.869274,0.861362,0.729709,0.691996,0.474283,0.459083,-1.13574,-1.0422,-0.221333,-0.102059,1.28369,1.25574,0.136442,0.334759,1.0395,1.18888,2.35645,2.51669,1.74559,1.75247,0.479436,0.276524,0.704226,0.441329,0.753756,0.818369
658,0.542825,0.554825,0.432167,0.399166,0.0792194,0.0649808,0.987387,0.981107,0.00615677,-0.0269094,0.775107,0.800879,0.133704,0.262133,0.484193,0.455231,0.963329,0.827917,0.167264,0.180498,1.33761,1.43166,-0.222803,-0.099755,-0.573081,-0.601306,1.0671,1.2234,-1.25274,-1.1037,-0.567399,-0.398917,0.641164,0.643621,-1.61924,-1.82491,-0.781818,-1.04647,-0.276445,-0.215728
659,0.201617,0.21459,0.132901,0.0993153,0.472683,0.4569,0.804156,0.76654,0.336656,0.342023,0.0409559,0.0662767,0.10035,0.126856,0.0565517,0.0491007,0.999886,0.963837,0.92207,0.935564,-0.517624,-0.422282,0.408042,0.531328,-1.26964,-1.29375,0.773839,0.92565,-1.25361,-1.09786,-1.05837,-0.892117,0.499538,0.507249,-1.31134,-1.52562,1.00404,0.740498,0.524475,0.592537
660,0.513759,0.526228,0.539176,0.504989,0.120434,0.103168,0.560529,0.551973,0.742035,0.710955,0.801151,0.827965,0.889772,0.917139,0.647169,0.642249,0.983177,0.948415,0.00499693,0.019025,-0.949187,-0.856634,-2.51166,-2.39264,0.392766,0.362864,-1.57982,-1.43498,0.472508,0.623625,-0.988409,-0.816487,0.823677,0.829001,0.629494,0.42134,0.370103,0.101203,2.76987,2.83671
661,0.60802,0.669314,0.606146,0.573526,0.7181,0.700875,0.660074,0.651196,0.647098,0.706739,0.606347,0.633629,0.119644,0.146645,0.0495488,0.0464302,0.10603,0.0732959,0.801611,0.817158,-1.09278,-1.00371,1.52541,1.64431,0.950793,0.914823,-1.32594,-1.17855,-0.403907,-0.247925,1.37703,1.54486,-0.083969,-0.0780158,1.58933,1.37956,-0.523459,-0.786735,-0.467154,-0.406191
662,0.79845,0.812401,0.181186,0.149593,0.266688,0.251805,0.141605,0.133323,0.732334,0.702522,0.755194,0.783424,0.684151,0.713155,0.623306,0.620047,0.436837,0.403835,0.174046,0.191602,-1.47083,-1.37746,0.10816,0.227909,-0.473338,-0.50629,-1.44766,-1.30482,-0.613031,-0.461025,1.26852,1.43748,0.519461,0.521679,0.461733,0.254494,0.819045,0.549162,0.555444,0.615259
663,0.146671,0.160801,0.347078,0.313328,0.58979,0.545465,0.556298,0.547344,0.42157,0.389829,0.32631,0.409998,0.638271,0.619919,0.183208,0.178468,0.0324238,-0.00127463,0.739996,0.75499,-0.115798,-0.0200091,-0.425743,-0.305525,-0.288776,-0.32316,-0.728566,-0.521164,1.36021,1.5138,-1.197,-1.01979,-1.83519,-1.83163,-1.20709,-1.40788,0.165331,-0.105149,-0.0472386,0.0190601
664,0.523785,0.538876,0.127899,0.0939481,0.854326,0.839126,0.734735,0.728187,0.961275,0.928715,0.0081636,0.0365724,0.594059,0.526683,0.258813,0.254885,0.0249012,-0.00691941,0.365606,0.378814,0.41153,0.509288,0.419628,0.539612,1.61044,1.56972,0.121541,0.262496,-0.267195,-0.109335,-1.01108,-0.836675,-0.237267,-0.229361,-0.712536,-0.864563,-0.171874,-0.436104,0.327447,0.400088
665,0.571627,0.645828,0.809038,0.773639,0.485141,0.526744,0.58009,0.576066,0.648531,0.571247,0.0084199,0.0386428,0.404444,0.433448,0.544865,0.540802,0.984813,0.952203,0.482848,0.453285,0.395762,0.436682,-0.288639,-0.16153,1.33221,1.29598,-0.171187,-0.0352534,0.11517,0.259679,0.570958,0.743134,-0.162839,-0.151351,-0.124187,-0.321245,0.0101545,-0.258311,-0.256437,-0.181386
666,0.678709,0.75278,0.302056,0.265089,0.230042,0.214362,0.0762156,0.073137,0.244595,0.213779,0.275476,0.307414,0.192074,0.223078,0.106547,0.103907,0.00755421,-0.0231825,0.516049,0.527757,0.272509,0.364075,0.834357,0.9642,-0.39943,-0.433605,1.1599,1.29908,0.472237,0.628693,0.626794,0.803914,2.65309,2.65578,0.818281,0.624258,0.496617,0.232085,1.64442,1.71716
667,0.844641,0.859732,0.290486,0.254569,0.929284,0.914725,0.637338,0.63648,0.12326,0.0919319,0.849437,0.883483,0.23924,0.271573,0.957877,0.95414,0.766588,0.734222,0.956802,0.967052,0.864766,0.953667,-0.393173,-0.263569,1.69735,1.66442,0.478455,0.616256,1.67611,1.83103,-0.209354,-0.0304559,0.588725,0.588586,0.392593,0.20454,-0.965853,-1.22268,0.765857,0.833654
668,0.332073,0.348876,0.480824,0.443306,0.00171215,-0.0148831,0.165482,0.164303,0.455993,0.462357,0.766632,0.800349,0.648922,0.638277,0.794899,0.79138,0.193833,0.159636,0.309844,0.320893,-1.87235,-1.77941,1.36112,1.49771,0.456779,0.428128,-0.693289,-0.562759,-1.15617,-1.00349,-0.824074,-0.650745,-0.291322,-0.288161,0.839427,0.657855,0.541017,0.282897,-0.783537,-0.722126
669,0.744075,0.762197,0.378618,0.340044,0.454823,0.438626,0.658792,0.657644,0.86411,0.832781,0.227932,0.261133,0.972559,1.00498,0.343192,0.412381,0.720657,0.684854,0.819766,0.829395,-0.732781,-0.683186,-0.0581928,0.0813123,0.407761,0.383773,-1.42943,-1.29203,0.584753,0.734814,0.775158,0.942777,3.41837,3.42379,-1.08013,-1.25575,-0.292909,-0.556739,0.970962,1.038
670,0.402784,0.421962,0.863743,0.823763,0.391557,0.374702,0.0236974,0.0203876,0.106472,0.0751805,0.263165,0.297414,0.0924209,0.123338,0.0365004,0.0333826,0.666256,0.629289,0.75184,0.725353,0.317648,0.413038,2.05976,2.20519,0.943119,0.92005,-0.354696,-0.219758,-0.357261,-0.213264,-2.83441,-2.66993,0.948627,0.960376,0.657087,0.488698,-0.851913,-1.11915,0.650909,0.652992
671,0.555453,0.493093,0.746958,0.705715,0.325883,0.310778,0.628008,0.623146,0.771728,0.740425,0.514935,0.550852,0.0565501,0.0850183,0.274259,0.219491,0.0227301,-0.0153883,0.610161,0.621311,-0.715328,-0.623113,-1.02613,-0.880785,0.360529,0.244525,-1.20403,-1.07546,-1.09264,-0.946073,-0.100276,0.0731746,1.19585,1.20438,-1.61762,-1.77943,0.919282,0.653799,0.201698,0.267983
672,0.614501,0.564224,0.0665518,0.0251182,0.579629,0.566258,0.716451,0.711279,0.6422,0.608801,0.969997,1.00417,0.398012,0.458701,0.406941,0.405599,0.833695,0.797499,0.824609,0.833825,0.0346516,0.134526,0.651181,0.80222,-0.405002,-0.431,-1.51496,-1.38847,-0.240285,-0.0971271,0.432864,0.609214,1.0874,1.09884,0.23615,0.0722712,-0.394184,-0.661443,-0.932072,-0.861802
673,0.613926,0.635356,0.463703,0.420567,0.186724,0.171174,0.376603,0.359329,0.930172,0.896073,0.426708,0.459755,0.804032,0.832383,0.335121,0.33463,0.376772,0.342916,0.757382,0.765492,-0.0577553,0.0483497,-0.149656,0.00754928,0.613338,0.583686,-0.190675,-0.0702492,-0.905428,-0.768909,-0.168916,0.00528109,1.75884,1.77401,-0.480484,-0.640008,-0.0269407,-0.246961,1.64878,1.71936
674,0.0396633,0.0591058,0.504754,0.463975,0.310983,0.297385,0.00979067,0.00737871,0.25996,0.226371,0.500701,0.455439,0.164664,0.19494,0.938624,0.939171,0.514987,0.482894,0.0633399,0.0729902,-1.57482,-1.47544,0.669293,0.822576,-0.0352327,-0.0624422,-1.56388,-1.44845,-0.982938,-0.844342,0.43244,0.603694,0.843258,0.813386,0.791725,0.636119,0.434779,0.16752,-1.02329,-0.95068
675,0.343489,0.360968,0.179069,0.138451,0.0817085,0.0699582,0.0624331,0.124437,0.485431,0.451825,0.401389,0.451123,0.0387045,0.0703283,0.322748,0.322835,0.118341,0.0886917,0.249916,0.260183,0.724308,0.821756,0.0572326,0.212918,-0.965785,-0.987236,-0.127816,-0.00388795,-1.40003,-1.2567,0.311285,0.437727,-0.16241,-0.147239,2.58741,2.42527,0.198276,-0.0700005,-0.209074,-0.142415
676,0.171394,0.188971,0.868173,0.828117,0.967857,0.95531,0.24278,0.241494,0.453643,0.422211,0.415499,0.446806,0.25004,0.235031,0.893584,0.896452,0.73815,0.70981,0.919425,0.929578,0.224239,0.322944,-2.57063,-2.41952,0.767764,0.751196,0.113537,0.238215,-1.00973,-0.868297,0.0950496,0.27176,0.703309,0.727288,1.18711,1.02518,-0.5689,-0.833825,0.395212,0.468313
677,0.423845,0.467283,0.786906,0.744786,0.768043,0.753835,0.923426,0.923693,0.701562,0.668936,0.731761,0.762384,0.369157,0.399733,0.175887,0.177327,0.423631,0.394858,0.963126,0.971453,1.23567,1.33985,1.10963,1.26074,-1.00297,-1.02618,-0.602922,-0.475902,1.87904,2.02417,-0.37843,-0.207301,-1.80304,-1.78094,0.286249,0.129017,0.380843,0.110117,-1.72493,-1.65759
678,0.730373,0.745596,0.460277,0.419262,0.207331,0.194988,0.294977,0.296017,0.539383,0.49416,0.804016,0.833432,0.824992,0.855614,0.196888,0.198035,0.392309,0.365113,0.085504,0.0924605,-0.553539,-0.448766,0.123399,0.281753,0.161052,0.140306,0.288976,0.411958,0.944484,1.09211,0.236938,0.406914,-0.538698,-0.519778,0.15489,0.000219834,-0.729958,-0.997156,1.0733,1.134
679,0.365644,0.423349,0.868975,0.829345,0.776534,0.763071,0.740946,0.744247,0.352801,0.319384,0.146946,0.178699,0.408293,0.439604,0.820429,0.823481,0.117685,0.0912193,0.745215,0.750845,0.0130817,0.125376,-0.0706921,0.0841806,-0.697228,-0.723371,-0.621549,-0.546826,1.76546,1.90939,-0.897803,-0.732695,-0.0560658,-0.0431673,0.824278,0.668957,0.689268,0.4178,-1.12469,-1.07016
680,0.0866058,0.101103,0.842448,0.804151,0.20818,0.194338,0.489391,0.491352,0.41386,0.460716,0.748938,0.780168,0.566414,0.69734,0.616711,0.639905,0.214814,0.189753,0.0532413,0.0583427,0.130898,0.236823,1.18591,1.34761,1.26503,1.23051,-1.62376,-1.50561,0.0934267,0.24019,1.86512,2.02935,1.18257,1.18802,-0.661622,-0.822952,-0.916448,-1.19399,1.05662,1.11005
681,0.418166,0.433257,0.2745,0.238009,0.998717,0.983085,0.891757,0.895834,0.634789,0.602047,0.787783,0.82055,0.922197,0.955075,0.454983,0.456329,0.0636202,0.0361566,0.332111,0.336157,-0.497185,-0.384694,1.80386,1.96353,0.792805,0.75803,-1.42793,-1.30987,0.0719443,0.283631,-1.28776,-1.11814,0.476269,0.482833,-0.742728,-0.9069,0.964127,0.690514,1.16032,1.20617
682,0.325262,0.341192,0.792323,0.75578,0.77977,0.775582,0.885829,0.88905,0.999373,0.965391,0.208663,0.240787,0.921417,0.953355,0.463658,0.467023,0.662323,0.632628,0.847739,0.849673,1.41499,1.52692,0.250288,0.40569,-0.419305,-0.447547,-0.366733,-0.253322,0.175615,0.327073,0.382777,0.553089,1.31792,1.32532,0.137269,-0.0249108,-0.13106,-0.400437,-0.553928,-0.503885
683,0.563984,0.577405,0.853488,0.815452,0.58956,0.568079,0.651451,0.656402,0.821437,0.788758,0.998491,1.02929,0.320377,0.352305,0.475534,0.477717,0.877274,0.848725,0.83572,0.839433,-0.268048,-0.151847,0.473241,0.624022,0.752804,0.718935,-0.951919,-0.844567,-1.57507,-1.42064,-0.10017,0.0740281,0.345213,0.393508,-0.61607,-0.782888,-0.134278,-0.405753,-1.42127,-1.37328
684,0.53186,0.546122,0.62461,0.585556,0.374296,0.360576,0.895972,0.901625,0.927696,0.892557,0.573548,0.603572,0.659855,0.689984,0.288807,0.283119,0.206295,0.177847,0.410631,0.413479,1.40207,1.51554,-0.240739,-0.0921683,-0.201251,-0.236677,-0.849913,-0.742,-0.420347,-0.266226,-0.093052,0.0728356,-0.551044,-0.538299,-1.01735,-1.18665,-0.854653,-1.12151,-1.95562,-1.91151
685,0.0602413,0.0756517,0.163245,0.122193,0.998645,0.983908,0.248875,0.253993,0.582364,0.548982,0.612576,0.643955,0.423751,0.453668,0.0847108,0.0885203,0.851945,0.824795,0.494343,0.517086,0.210913,0.326681,-1.6489,-1.49487,0.276675,0.238241,1.06154,1.16307,-1.24345,-1.09099,0.60049,0.760174,-0.104821,-0.0913987,1.92831,1.75824,-0.10245,-0.367805,0.252062,0.299408
686,0.110132,0.1259,0.165218,0.126566,0.884977,0.805236,0.641291,0.647539,0.938812,0.906608,0.307558,0.340255,0.827492,0.855605,0.197657,0.199228,0.468716,0.440329,0.66762,0.620694,-0.745181,-0.632219,-0.593458,-0.431722,-0.662668,-0.701487,0.860476,1.03537,1.11518,1.26255,0.291352,0.451456,-1.17871,-1.17018,-0.389955,-0.557664,0.257692,-0.00217972,-1.10605,-1.05769
687,0.549515,0.563916,0.643607,0.604334,0.638851,0.626563,0.0465962,0.0541154,0.223917,0.191023,0.605778,0.60674,0.428282,0.447458,0.629074,0.630877,0.355019,0.32834,0.720437,0.724302,-1.02312,-0.913342,1.69839,1.85298,1.22138,1.17721,0.806147,0.90767,-0.817125,-0.669927,0.402048,0.558243,-0.715595,-0.793543,0.929554,0.767361,-1.33308,-1.59761,0.892145,0.947647
688,0.127237,0.143596,0.365211,0.32431,0.877911,0.866617,0.396265,0.402902,0.617302,0.58379,0.843067,0.873225,0.0115989,0.0393102,0.786834,0.788275,0.660548,0.634116,0.130334,0.133641,-2.09788,-1.99483,-0.356098,-0.204804,-0.18846,-0.228748,0.422461,0.488193,-0.617448,-0.466176,-0.173546,-0.0122429,-0.427392,-0.41691,0.488429,0.332874,-1.1649,-1.43448,-1.72547,-1.6705
689,0.059347,0.0773175,0.898275,0.856462,0.717855,0.704688,0.501804,0.507302,0.778507,0.742965,0.761928,0.790091,0.211429,0.240907,0.441078,0.441692,0.498198,0.471322,0.442247,0.395257,-0.356393,-0.249281,0.0566755,0.177302,-1.0307,-1.0763,-0.0275607,0.0687173,1.09095,1.23923,-0.308266,-0.15157,-0.863331,-0.846483,-0.224482,-0.379405,-0.689992,-0.959502,1.53417,1.59168
690,0.917977,0.934104,0.227922,0.185444,0.267627,0.255618,0.157205,0.160575,0.00194694,-0.0320048,0.163187,0.189457,0.772999,0.802419,0.499624,0.502342,0.0121853,-0.0135803,0.655077,0.656873,0.800776,0.905198,0.406356,0.559408,1.51108,1.46938,-1.00641,-0.910303,0.861374,1.00921,0.286316,0.446843,1.35275,1.37222,0.427642,0.273821,-0.43487,-0.704198,-0.185474,-0.130896
691,0.858511,0.872732,0.575001,0.531619,0.181284,0.12941,0.497664,0.499158,0.306822,0.204021,0.248913,0.274633,0.617551,0.584646,0.198365,0.200779,0.611808,0.588294,0.351286,0.351684,0.176696,0.283681,1.34864,1.49697,-1.35233,-1.38866,2.04465,2.13314,-1.3136,-1.17091,2.24718,2.40796,-1.03777,-1.01232,-0.944977,-1.09638,0.614728,0.349504,-0.217389,-0.169263
692,0.549302,0.563685,0.486214,0.443256,0.0174173,0.00320304,0.0899496,0.092133,0.502426,0.440046,0.69891,0.723067,0.336348,0.366872,0.603276,0.607224,0.711596,0.614643,0.78955,0.790979,-0.757043,-0.645564,0.0701745,0.22197,-0.191403,-0.207911,-0.313148,-0.227493,0.643795,0.784345,-0.423224,-0.264857,-0.104267,-0.0754499,0.182006,0.032528,-0.012864,-0.3721,1.75518,1.80372
693,0.846325,0.860996,0.170207,0.127484,0.820412,0.808472,0.121043,0.0755876,0.707854,0.676072,0.095511,0.118047,0.835395,0.863725,0.0661947,0.0711261,0.663282,0.640992,0.914841,0.916968,0.770002,0.883804,-0.182745,-0.0370013,1.00795,0.972839,-0.00670135,0.0763694,-0.401529,-0.254672,2.47618,2.63484,0.521075,0.555383,1.52348,1.372,-0.823835,-1.0937,1.25735,1.31387
694,0.664346,0.678042,0.23106,0.103857,0.930887,0.920267,0.0575915,0.0590421,0.0683032,0.0364404,0.217974,0.242952,0.37369,0.403262,0.683932,0.691241,0.386014,0.454845,0.000105771,0.00042961,0.450318,0.558139,0.28909,0.439239,-1.49311,-1.5358,1.81011,1.88759,1.14175,1.28295,0.247892,0.412749,-0.249207,-0.211565,0.762771,0.695536,-1.26722,-1.53361,-0.616721,-0.563422
695,0.973193,0.984763,0.145807,0.0802306,0.219496,0.210946,0.585087,0.586703,0.104023,0.0733707,0.763292,0.789037,0.26642,0.294033,0.53084,0.539995,0.21955,0.268698,0.756274,0.755495,1.18627,1.29941,0.19193,0.348334,1.99971,1.95757,0.522626,0.600562,-0.155172,-0.017309,-0.761864,-0.590953,1.42993,1.46732,0.170562,0.0190777,1.79099,1.52461,0.159375,0.212932
696,0.159347,0.172869,0.0993264,0.0566038,0.33956,0.406225,0.17722,0.179678,0.914691,0.885427,0.660036,0.685444,0.701666,0.730928,0.611421,0.549811,0.105085,0.0825502,0.708265,0.732321,0.0927026,0.20128,2.08234,2.23382,-0.23051,-0.265439,-2.1745,-2.09683,0.626505,0.770879,-0.078546,0.0963861,0.585923,0.623821,0.0182113,-0.138883,0.507533,0.241839,-0.892203,-0.835817
697,0.283333,0.391921,0.297462,0.226346,0.610962,0.601505,0.276703,0.278901,0.996707,0.969266,0.0718185,0.0956532,0.347458,0.375781,0.643013,0.559626,0.831856,0.809907,0.827501,0.709146,0.878717,0.988156,1.37828,1.53268,0.679603,0.641683,0.872103,0.946613,1.80588,1.95705,-1.13634,-0.968443,0.941667,0.977674,1.86656,1.71282,0.864008,0.592855,0.9035,0.956087
698,0.597956,0.610972,0.4386,0.396088,0.52517,0.51564,0.136315,0.137366,0.86964,0.842929,0.345256,0.378464,0.852163,0.882202,0.560047,0.569442,0.0112545,-0.00936577,0.689519,0.685972,-0.0955359,0.0145707,0.21786,0.366627,0.691793,0.657514,-0.765671,-0.697291,0.599366,0.752305,1.36981,1.54236,-0.283568,-0.239856,0.0663354,-0.0939024,-0.464578,-0.738652,0.812681,0.858323
699,0.062886,0.0747152,0.119011,0.0757348,0.824624,0.816887,0.418002,0.417272,0.339796,0.314467,0.639865,0.661275,0.693106,0.723152,0.806603,0.814998,0.543249,0.520227,0.0137698,0.00988511,1.09877,1.11079,1.6443,1.79898,0.950948,0.866205,0.649209,0.716094,0.828189,0.985887,-1.3651,-1.19548,2.67555,2.72089,-0.0153428,-0.177851,0.567375,0.299813,-1.12937,-1.08405
700,0.949394,0.961816,0.259431,0.247985,0.508394,0.502358,0.245558,0.245033,0.33349,0.30719,0.0571133,0.0763223,0.776549,0.806977,0.764598,0.773696,0.835043,0.811526,0.273584,0.26861,2.09936,2.20702,-0.228179,-0.0787101,1.11509,1.0749,-0.219511,-0.155352,1.72852,1.88163,1.38026,1.54763,-0.445061,-0.392848,0.320513,0.154035,0.0661063,-0.201477,1.39211,1.43099
701,0.282231,0.29556,0.46166,0.420236,0.415112,0.411393,0.964711,0.963647,0.626788,0.624463,0.511242,0.529643,0.225052,0.254233,0.194692,0.20268,0.175098,0.151006,0.778329,0.772567,-2.29916,-2.1862,0.0842463,0.175836,-0.400475,-0.436957,0.319299,0.305748,-0.469349,-0.314211,0.98024,1.17136,-1.8507,-1.79742,-0.483256,-0.649197,2.70123,2.43368,0.9959,1.02896
702,0.430824,0.445651,0.830084,0.789948,0.615224,0.611853,0.341374,0.340622,0.967115,0.941737,0.717492,0.738132,0.00214555,0.0330727,0.0358764,0.0461645,0.593683,0.572071,0.161315,0.157365,1.35907,1.46578,0.280371,0.430383,0.143893,0.115003,0.795478,0.766848,0.54216,0.704309,0.622894,0.795085,1.16371,1.20798,1.11629,0.954939,-0.800869,-1.06204,1.50888,1.54841
703,0.198631,0.212437,0.123547,0.0845488,0.337232,0.33327,0.0287007,0.0275206,0.500022,0.531628,0.235099,0.257994,0.778852,0.808987,0.825115,0.833975,0.177618,0.158003,0.581412,0.576693,1.45809,1.56199,-0.413006,-0.255859,-1.72589,-1.75612,1.16379,1.22795,1.25257,1.41316,-0.373921,-0.208616,0.442736,0.487809,0.11516,-0.0468068,0.281429,0.0218725,-0.134754,-0.098111
704,0.759196,0.77369,0.738525,0.699557,0.691268,0.685986,0.974293,0.973572,0.145021,0.121518,0.409651,0.432768,0.407741,0.491943,0.500605,0.599018,0.0442112,0.025508,0.679514,0.750821,-0.0421932,0.0669402,0.860277,1.02272,-0.686655,-0.62569,1.20617,1.26927,-1.56925,-1.40669,0.401248,0.571141,0.0097795,0.0582358,-0.209058,-0.374105,0.191742,-0.0612864,0.31272,0.288051
705,0.672739,0.735684,0.467493,0.413836,0.108854,0.102282,0.705294,0.657073,0.2099,0.102944,0.22198,0.326767,0.143946,0.1749,0.355176,0.364061,0.328973,0.266963,0.927431,0.924948,0.611628,0.717363,0.324292,0.489285,0.53496,0.504736,0.359146,0.429671,1.72832,1.89191,1.54796,1.71819,0.718378,0.765277,-1.61475,-1.7742,-0.819264,-1.07772,0.635392,0.674212
706,0.683365,0.697679,0.167149,0.128116,0.0536386,0.0470144,0.340717,0.340574,0.107668,0.0843686,0.199344,0.220766,0.833453,0.862421,0.734085,0.741478,0.527495,0.508418,0.206285,0.202468,0.577841,0.678129,-1.44502,-1.27324,0.230842,0.200219,2.18952,2.25702,-0.0530625,0.112516,-0.0369318,0.132275,0.883237,0.839525,0.151183,-0.0144583,1.13149,0.870392,1.99985,2.03287
707,0.168483,0.18226,0.410377,0.390276,0.292155,0.287068,0.51284,0.510708,0.508283,0.439444,0.308665,0.339101,0.820063,0.849758,0.217763,0.22567,0.569548,0.55189,0.656398,0.651555,-0.119184,-0.0158603,-1.40479,-1.22605,0.98334,0.953395,-1.14486,-1.06923,0.815806,0.976651,-0.273551,-0.098678,0.869382,0.913773,1.41551,1.24832,0.661448,0.40074,-0.121939,-0.0930347
708,0.920936,0.93741,0.702326,0.652437,0.779552,0.775335,0.062524,0.0588405,0.818242,0.794518,0.376329,0.457436,0.439129,0.468817,0.154116,0.233318,0.284887,0.276086,0.460934,0.455985,-0.81226,-0.709849,0.8753,1.05865,-0.170869,-0.206507,-0.353042,-0.366377,-1.1081,-0.938735,0.729082,0.897948,1.46708,1.51347,0.766007,0.629768,1.28143,1.01632,1.02353,1.04955
709,0.00381843,0.0214411,0.95363,0.914597,0.666658,0.663803,0.209816,0.203885,0.177667,0.154887,0.414862,0.575771,0.89813,0.930126,0.231449,0.240966,0.0194062,0.000281037,0.834003,0.830462,-0.126808,-0.0298462,0.721137,0.804671,-1.90199,-1.93609,0.26115,0.336475,0.225321,0.399881,-2.24642,-2.07614,0.808878,0.854799,0.183949,0.0112157,-0.400289,-0.659962,-0.664041,-0.642651
710,0.178152,0.196848,0.553826,0.515157,0.335975,0.334057,0.752374,0.746773,0.577125,0.552609,0.672685,0.694107,0.412997,0.443822,0.447906,0.493234,0.710443,0.691834,0.18713,0.184302,-0.00542043,0.0979746,0.367338,0.55069,0.473339,0.439192,0.746863,0.823005,0.74265,0.910291,-0.370837,-0.206572,0.942575,0.992273,0.46256,0.2979,-1.04177,-1.29926,0.940413,0.961232
711,0.668274,0.688375,0.659525,0.619161,0.53434,0.534517,0.121455,0.114557,0.24062,0.2154,0.902199,0.922791,0.593121,0.62458,0.735128,0.745503,0.501742,0.484201,0.184573,0.179808,0.753072,0.855613,0.326754,0.505924,0.31898,0.195302,-1.52891,-1.457,-0.253828,-0.0833564,0.561182,0.727891,0.795358,0.750489,-0.236371,-0.398367,2.92067,2.66318,-0.463319,-0.441384
712,0.517482,0.58675,0.516311,0.475454,0.0900056,0.0900257,0.410008,0.369381,0.593387,0.487978,0.234639,0.257844,0.347265,0.393127,0.540006,0.548552,0.545201,0.527673,0.778592,0.774026,-0.369495,-0.271471,-0.164023,0.0195162,-0.0211398,-0.0485873,1.68077,1.74672,1.91243,2.08552,0.00980108,0.172294,0.454556,0.508706,-0.431356,-0.588023,0.406905,0.142218,-0.176304,-0.149158
713,0.466967,0.485125,0.0773099,0.0376997,0.200884,0.130023,0.632506,0.624205,0.784499,0.760556,0.639342,0.66172,0.128292,0.161674,0.00664814,0.0175035,0.139023,0.122564,0.5906,0.583406,0.720094,0.81998,0.275388,0.465429,0.411649,0.380378,0.231961,0.290383,0.37075,0.542151,-1.61478,-1.45775,-0.364778,-0.30355,0.775512,0.615582,2.8271,2.56529,-1.72574,-1.70494
714,0.0936437,0.110802,0.59169,0.550139,0.171796,0.17002,0.34626,0.435575,0.16108,0.135519,0.253786,0.360945,0.340807,0.373205,0.221478,0.318604,0.00618548,-0.00993186,0.756346,0.750341,-0.781083,-0.675074,0.960466,1.15763,1.09619,1.05702,0.700695,0.759589,-0.679719,-0.511704,0.842214,1.00494,-1.52292,-1.45727,0.513471,0.348756,0.347497,0.0799335,-0.545816,-0.531055
715,0.445121,0.374337,0.269221,0.229786,0.881141,0.880746,0.255497,0.246945,0.742958,0.715255,0.0348041,0.0601695,0.0428765,0.0765368,0.60934,0.619705,0.325917,0.310735,0.437111,0.429103,-1.75251,-1.64866,-0.621504,-0.429965,-0.387819,-0.42432,0.0141362,0.0767624,0.732806,0.903694,-0.140568,0.0167238,-0.0496055,0.0221989,-0.512479,-0.682929,1.61975,1.3504,0.952705,0.9651
716,0.652046,0.637871,0.963031,0.924556,0.460028,0.46108,0.178784,0.168622,0.363706,0.336383,0.286509,0.352663,0.620685,0.653038,0.0667565,0.0782827,0.936167,0.922353,0.75107,0.742541,0.771512,0.871785,0.572822,0.755217,-0.874201,-0.913216,1.15434,1.21204,-0.771669,-0.597259,0.447318,0.600058,-1.81967,-1.74655,1.95057,1.77882,0.43141,0.161906,1.60093,1.60701
717,0.88235,0.901406,0.791669,0.756002,0.734244,0.737018,0.335579,0.323254,0.471607,0.370844,0.676425,0.645156,0.894859,0.929135,0.708385,0.717961,0.291344,0.277676,0.0168247,0.00942433,-0.87736,-0.775862,-0.613724,-0.425862,-0.841107,-0.882572,-1.17672,-1.11711,-1.60889,-1.43833,-0.903091,-0.757816,0.0185483,0.0910071,-1.2702,-1.44898,-0.172116,-0.447589,-0.665363,-0.661142
718,0.203913,0.223594,0.921088,0.795524,0.0764937,0.0780428,0.714687,0.701567,0.433646,0.405305,0.912655,0.937649,0.285,0.317991,0.75721,0.767976,0.953482,0.940008,0.146599,0.180754,0.00905132,0.119253,-0.138821,0.0503787,0.0134862,-0.0222735,-1.02327,-0.966354,-1.20163,-1.03478,0.239349,0.389233,0.118759,0.18318,-0.263162,-0.442003,-0.394982,-0.671017,-0.190393,-0.188225
719,0.0160746,0.034931,0.87027,0.835046,0.259673,0.259365,0.698017,0.684393,0.966112,0.939067,0.666011,0.689401,0.980985,1.01524,0.000583123,0.0124608,0.891676,0.845837,0.359502,0.352083,1.48886,1.60289,-0.422532,-0.238636,-0.666364,-0.700768,-2.29954,-2.23774,0.58621,0.747768,0.244122,0.388041,-1.12434,-1.06575,-0.194335,-0.372748,0.87241,0.599448,0.876121,0.877775
720,0.109083,0.130516,0.607294,0.573952,0.0850925,0.0829976,0.476399,0.461503,0.209842,0.181466,0.625052,0.647433,0.730984,0.764417,0.932127,0.944868,0.78645,0.751667,0.948567,0.941217,-0.245178,-0.137717,-0.40898,-0.222552,0.860136,0.83004,0.579888,0.640384,2.10679,2.27033,1.60465,1.74995,-0.490784,-0.434917,-0.36706,-0.54652,-0.505011,-0.777815,0.272344,0.281576
721,0.561133,0.582977,0.562755,0.529319,0.125031,0.124406,0.0319292,0.0156119,0.854089,0.826368,0.15182,0.17247,0.980694,1.01658,0.710401,0.722456,0.673424,0.657496,0.88952,0.855342,-0.299662,-0.191889,-1.33218,-1.13934,1.88624,1.86056,-1.19901,-1.14414,0.498937,0.663836,0.168882,0.317526,-0.102217,-0.0524713,0.762874,0.582393,1.07541,0.806657,0.260383,0.341046
722,0.245494,0.31675,0.862379,0.830753,0.374637,0.383326,0.557838,0.543273,0.978954,0.950763,0.170826,0.189164,0.424174,0.459147,0.203161,0.216177,0.964512,0.948795,0.778517,0.769466,1.55432,1.65911,0.750326,0.948916,0.565911,0.54867,0.408869,0.460431,-1.32092,-1.16047,0.0334888,0.178199,-0.822321,-0.772639,0.0538264,-0.129886,0.0998911,-0.161721,0.390431,0.400517
723,0.0300402,0.050524,0.725177,0.695538,0.686499,0.642247,0.123141,0.107037,0.845237,0.894508,0.931514,0.950853,0.990039,1.02566,0.983969,0.999052,0.639458,0.624252,0.44424,0.433036,-0.675074,-0.572864,-1.31081,-1.10886,-1.61294,-1.62603,0.500494,0.54665,-0.235161,-0.0817641,-0.57142,-0.425734,0.476798,0.520608,-0.126876,-0.303658,-0.10572,-0.368505,1.3544,1.36003
724,0.886352,0.907311,0.572108,0.560323,0.901793,0.901168,0.164673,0.150478,0.864748,0.838252,0.152532,0.170425,0.59694,0.578022,0.309556,0.327154,0.611513,0.571555,0.702488,0.69176,2.07863,2.18255,1.44668,1.64833,-0.242493,-0.262053,-0.815834,-0.769857,0.634664,0.782372,0.435437,0.583833,1.05143,1.09058,-0.94782,-1.12133,0.725719,0.465811,0.679298,0.687323
725,0.547401,0.567075,0.457824,0.425108,0.478855,0.476669,0.644161,0.536624,0.0221862,-0.004131,0.187041,0.207981,0.0955189,0.130386,0.113089,0.130204,0.534099,0.518859,0.339358,0.33066,2.13034,2.23322,0.703232,0.899937,-1.18671,-1.20178,-0.379218,-0.330715,0.651948,0.803482,0.495203,0.644613,-0.843536,-0.801729,0.143537,-0.00521237,-0.873203,-1.12961,-0.826131,-0.820485
726,0.487048,0.505703,0.0844448,0.0504955,0.667688,0.685044,0.938488,0.922769,0.461001,0.433627,0.228986,0.245536,0.0972965,0.133837,0.856264,0.872598,0.212007,0.194316,0.780321,0.769956,0.0456696,0.146601,0.233959,0.428136,-1.54095,-1.55229,0.685685,0.741562,0.409603,0.55957,-1.37796,-1.23177,2.20653,2.24956,1.27915,1.11091,0.0878262,-0.171815,-0.623201,-0.646083
727,0.936609,0.953568,0.29161,0.284888,0.89729,0.89342,0.179314,0.16352,0.225633,0.196679,0.826814,0.841325,0.898234,0.933579,0.00770357,0.0227362,0.661578,0.643925,0.85218,0.841983,-0.119847,-0.0155092,-0.00422737,0.184232,1.40506,1.40079,-0.523251,-0.469148,1.54007,1.68261,-0.519777,-0.375382,-2.26694,-2.22394,0.528532,0.352933,1.28819,1.0369,-0.484453,-0.47168
728,0.548907,0.563745,0.553004,0.51928,0.260735,0.255255,0.00277513,-0.0141469,0.46305,0.379225,0.820908,0.833506,0.528285,0.562865,0.0382865,0.047581,0.207036,0.189342,0.251209,0.24115,1.45762,1.56057,2.52058,2.7097,1.43385,1.43144,2.17466,2.22943,-1.29907,-1.15191,-0.882921,-0.74435,-1.33061,-1.28707,-0.536813,-0.7094,0.529678,0.241816,1.08897,1.10137
729,0.753337,0.769965,0.46242,0.430916,0.447609,0.427426,0.55148,0.533244,0.588339,0.561772,0.487947,0.500023,0.414276,0.425282,0.0582481,0.0724258,0.318414,0.298924,0.512442,0.522926,0.641831,0.739217,0.143946,0.328201,-1.19119,-1.19651,2.4431,2.50197,1.58415,1.72514,0.168484,0.314041,2.89832,2.94071,-2.97787,-3.15875,-0.189362,-0.553268,0.586568,0.594881
730,0.172459,0.189153,0.808767,0.777091,0.613436,0.599596,0.228305,0.304496,0.545912,0.517338,0.93132,0.943228,0.255102,0.287699,0.755508,0.768869,0.147126,0.12566,0.815786,0.804702,0.841288,0.942488,-0.649922,-0.46647,-1.02693,-1.02306,0.831072,0.889537,-0.377727,-0.241131,-0.511788,-0.368056,0.916432,0.953032,-0.50442,-0.681216,-1.09707,-1.34835,-0.328929,-0.318862
731,0.380426,0.395373,0.623701,0.5092,0.777246,0.771766,0.0947183,0.075747,0.270978,0.240344,0.380018,0.393881,0.679358,0.714331,0.23965,0.253061,0.198056,0.174728,0.321407,0.309294,-1.85672,-1.75693,0.479139,0.659261,-0.838418,-0.849605,1.12692,1.1934,-0.116524,0.0243869,0.260647,0.411701,1.99498,2.02551,0.607139,0.431699,-2.26411,-2.52117,0.231617,0.247113
732,0.967038,0.981003,0.275508,0.241308,0.446117,0.44202,0.938871,0.917826,0.579487,0.547605,0.654727,0.668878,0.713848,0.746843,0.507875,0.48859,0.811342,0.786345,0.153571,0.236056,-0.12564,-0.0276493,0.533759,0.706452,0.0137928,-0.0031116,0.0408142,0.104765,0.73008,0.873333,-0.304574,-0.158785,-1.3413,-1.30644,1.26377,1.08492,-1.19815,-1.45269,-0.23601,-0.212981
733,0.30139,0.314747,0.934233,0.900643,0.543353,0.538824,0.786776,0.765704,0.286966,0.254975,0.292554,0.307151,0.355129,0.385891,0.712701,0.724118,0.843916,0.820013,0.176229,0.162818,1.26646,1.36108,0.369835,0.54009,1.42148,1.40512,-1.69328,-1.63468,1.05658,1.19995,1.17381,1.32514,1.29516,1.32975,0.0319079,-0.146896,-0.801948,-1.05579,0.508589,0.535457
734,0.890453,0.905952,0.811139,0.709012,0.897153,0.89154,0.917823,0.895233,0.60245,0.571958,0.310042,0.333064,0.571261,0.602357,0.519512,0.531998,0.0150467,-0.00842186,0.801159,0.787274,-1.53409,-1.44698,0.33932,0.373728,0.328565,0.308403,0.843919,0.896629,-1.11367,-0.965555,0.364789,0.521533,-1.17146,-1.13365,-0.309989,-0.400974,0.402368,0.152926,-1.61596,-1.59045
735,0.250356,0.264564,0.571583,0.517382,0.572224,0.642341,0.359582,0.336993,0.19388,0.162769,0.307436,0.358978,0.419452,0.402537,0.9708,0.983697,0.752443,0.728336,0.742144,0.728937,-1.57237,-1.48622,0.0344024,0.207366,-1.48274,-1.50202,-0.761812,-0.715804,-0.969293,-0.823815,1.58695,1.74581,0.817887,0.857565,-0.471364,-0.655051,-0.43188,-0.68671,-1.07201,-1.12497
736,0.839556,0.855769,0.357386,0.325752,0.396789,0.393141,0.905991,0.884384,0.45915,0.429081,0.370105,0.384891,0.172215,0.202716,0.342361,0.357319,0.267528,0.243433,0.114023,0.0981741,1.40408,1.48731,-0.197052,-0.0236243,1.40651,1.39037,-0.31314,-0.348546,0.0618805,0.209652,2.20191,2.36002,-1.04124,-1.00205,-1.03176,-1.29014,-0.496476,-0.810682,-0.687364,-0.659494
737,0.708479,0.699665,0.998941,0.965103,0.821898,0.817309,0.756427,0.736652,0.234011,0.201742,0.841762,0.857351,0.781517,0.814088,0.653203,0.668509,0.992614,0.97079,0.751027,0.736954,0.706923,0.790684,0.785528,0.959759,-1.5465,-1.56498,0.0389833,0.0187124,-0.931035,-0.783995,0.179754,0.343471,-0.594528,-0.555148,-1.73836,-1.92524,-0.676423,-0.934654,1.56549,1.58468
738,0.5263,0.543562,0.525718,0.491459,0.0404735,0.0368244,0.923973,0.901493,0.436286,0.401294,0.621167,0.650395,0.934706,0.969446,0.518212,0.53213,0.346778,0.326112,0.532151,0.516305,0.745423,0.824609,0.206231,0.380836,-0.257504,-0.277878,0.343784,0.385971,2.37186,2.5146,0.376689,0.541545,0.895083,0.936654,-1.57554,-1.7631,0.824368,0.570922,0.800254,0.821877
739,0.0915335,0.10776,0.664694,0.629801,0.727178,0.721709,0.0650388,0.042503,0.387358,0.351525,0.290122,0.443438,0.623186,0.60835,0.619739,0.587627,0.220481,0.199144,0.0697537,0.0554459,1.49988,1.58225,2.63659,2.81146,0.713015,0.690094,-1.12837,-1.08523,1.78776,1.99276,0.22138,0.385933,0.773773,0.817039,0.61505,0.4297,0.709285,0.457305,-0.6391,-0.612299
740,0.78213,0.79848,0.1329,0.0977274,0.145238,0.138005,0.533901,0.510448,0.934165,0.900236,0.209556,0.236482,0.214054,0.247253,0.630811,0.643125,0.313691,0.292042,0.553359,0.539147,0.0750827,0.162676,0.129627,0.303787,-0.334697,-0.360434,-0.532096,-0.493114,1.33287,1.47092,-0.240824,-0.0785772,0.289256,0.325507,-0.522496,-0.709498,0.0582254,-0.197006,-1.84861,-1.81637
741,0.307859,0.322832,0.956562,0.920703,0.466791,0.459542,0.504179,0.403109,0.0873002,0.0523349,0.0139373,0.0295261,0.257141,0.376419,0.337647,0.351593,0.84,0.817259,0.0152747,0.00330603,-0.853086,-0.76657,-0.325494,-0.152989,0.231283,0.206623,-0.277991,-0.236684,0.0266634,0.17066,1.29883,1.45266,-1.65808,-1.61473,1.30671,1.1116,-0.37537,-0.67229,0.0510853,0.0821774
742,0.756626,0.770697,0.735055,0.794343,0.118159,0.109461,0.367444,0.29577,0.301641,0.180475,0.176709,0.169664,0.474489,0.505584,0.751551,0.763337,0.442645,0.418315,0.943527,0.932034,-0.993009,-0.913651,-1.88936,-1.71083,-0.1342,-0.160185,-2.17485,-2.1345,-0.660763,-0.512367,-0.31236,-0.163872,-0.0955747,-0.0473627,-0.0892833,-0.288493,-0.883739,-1.14757,-1.80233,-1.7668
743,0.645346,0.656656,0.704834,0.667983,0.180109,0.15947,0.211885,0.188431,0.342096,0.308615,0.29114,0.309802,0.227575,0.25952,0.732344,0.742993,0.75742,0.733159,0.409666,0.396192,0.0337204,0.117199,0.599567,0.779806,-1.83909,-1.86008,-0.362164,-0.323272,1.37989,1.5239,-0.349037,-0.196591,0.285303,0.335083,0.150322,-0.0487592,-0.281467,-0.548086,-0.0112736,0.0251039
744,0.154232,0.1656,0.703511,0.602629,0.224509,0.209479,0.3762,0.353272,0.705616,0.671959,0.699229,0.719455,0.700079,0.7312,0.309904,0.321038,0.802452,0.776632,0.563771,0.493435,-0.0223674,0.140634,0.487091,0.674336,0.882974,0.863205,-0.628679,-0.589964,0.761828,0.898775,1.79515,1.94026,0.0610253,0.107161,-0.270905,-0.559855,-1.12665,-1.38772,-0.32419,-0.285624
745,0.455199,0.467463,0.574592,0.537275,0.268185,0.259487,0.332525,0.311581,0.833643,0.801449,0.273088,0.293735,0.666067,0.690096,0.647264,0.6586,0.569739,0.51938,0.686916,0.590677,0.0741712,0.164068,-1.32468,-1.13612,0.555172,0.520714,-0.588113,-0.548643,0.878187,1.01047,1.81493,1.95463,0.128133,0.170361,-0.872394,-1.07095,-0.0738916,-0.334021,0.687845,0.720415
746,0.162428,0.17295,0.796494,0.760135,0.127062,0.117481,0.59527,0.572409,0.273943,0.242904,0.861065,0.879396,0.643551,0.648991,0.540956,0.539457,0.19244,0.262129,0.711326,0.687919,0.761858,0.859071,0.863707,1.05123,0.194176,0.178223,0.249912,0.29137,-0.548793,-0.412144,0.324578,0.45857,1.59438,1.63393,-1.62184,-1.81446,-1.21093,-1.4741,1.05858,1.08831
747,0.409058,0.418912,0.0696654,0.0347985,0.269424,0.259433,0.137194,0.115404,0.240971,0.125282,0.64203,0.660872,0.577287,0.607886,0.308706,0.420315,0.0296848,0.00487814,0.817043,0.785161,-0.626273,-0.528711,1.18756,1.37606,0.203524,0.194054,-0.101015,-0.0518514,-0.136923,0.00647243,-0.542535,-0.405817,-0.564879,-0.523379,0.733935,0.544779,0.0918409,-0.175949,-0.460319,-0.435545
748,0.167285,0.175251,0.468832,0.434835,0.821982,0.811949,0.536478,0.514752,0.0390697,0.00765972,0.834197,0.854616,0.801147,0.782769,0.289524,0.301172,0.278066,0.291027,0.895877,0.882403,-0.422842,-0.32544,0.856293,1.04149,1.88415,1.86848,1.57931,1.6312,-0.905163,-0.75645,0.0428741,0.177517,-0.346582,-0.310544,-0.82664,-1.00902,1.38357,1.12221,0.687859,0.707043
749,0.985431,0.993114,0.400841,0.365793,0.21784,0.207568,0.488409,0.467878,0.253353,0.222916,0.0682525,0.0894728,0.928197,0.957653,0.558043,0.550368,0.60085,0.577176,0.7712,0.778361,-0.791684,-0.699181,-0.085765,0.0930958,0.210673,0.2023,1.01059,1.05662,0.606692,0.751243,-0.11668,0.0219052,0.615,0.656804,-1.32001,-1.50477,-0.809279,-1.0648,1.63185,1.65197
750,0.33357,0.341514,0.124166,0.0904465,0.863102,0.851279,0.779802,0.758331,0.164291,0.0992587,0.952708,0.976616,0.0337279,0.0635179,0.785897,0.799564,0.590307,0.56676,0.689313,0.674319,0.540244,0.6265,-0.278454,-0.104477,-1.20131,-1.20365,0.0735655,0.123104,1.01604,1.1548,-0.523325,-0.377944,-0.708443,-0.670101,1.76128,1.56889,0.917849,0.662006,-0.947362,-0.934633
751,0.354326,0.335345,0.756452,0.721068,0.137797,0.126117,0.44447,0.420915,0.00889026,-0.0243988,0.930531,0.926402,0.150552,0.178577,0.362504,0.377609,0.811146,0.788432,0.892992,0.876305,-0.486256,-0.395406,0.853709,1.03336,1.30961,1.30435,0.230704,0.27386,-0.411346,-0.267816,-1.92481,-1.78191,-0.993063,-0.959674,0.0964542,-0.093485,0.0351875,-0.225933,-0.0245792,-0.00657206
752,0.32215,0.329176,0.978609,0.943928,0.351096,0.341442,0.90693,0.883447,0.148364,0.122782,0.851356,0.876188,0.491524,0.520559,0.315816,0.300335,0.355341,0.333849,0.561666,0.544725,-1.07399,-0.984806,0.340034,0.51655,0.213774,0.207638,2.13767,2.17893,0.672519,0.810888,-0.356634,-0.218253,-0.796527,-0.760867,-1.04998,-1.23268,0.406093,0.139693,0.474146,0.497658
753,0.641376,0.650573,0.313818,0.278251,0.0722499,0.0628595,0.338194,0.315264,0.302541,0.269962,0.0874794,0.111044,0.441213,0.491309,0.0861478,0.22306,0.173463,0.150418,0.804584,0.787818,-0.364403,-0.275511,-0.418261,-0.178774,-0.19648,-0.105572,-0.294698,-0.255032,-0.158787,-0.0138769,0.813767,0.94664,1.18828,1.23035,0.303376,0.124935,-2.49583,-2.76583,-0.198687,-0.175047
754,0.0376828,0.0451357,0.445921,0.412104,0.787465,0.778847,0.251061,0.226574,0.0321914,-0.00204366,0.148687,0.172597,0.532385,0.46206,0.131937,0.145786,0.277902,0.255053,0.509117,0.492411,-2.09114,-2.00188,-1.05025,-0.874099,-0.417736,-0.418782,2.11504,2.15697,1.02769,1.1723,-0.72277,-0.592869,0.199804,0.224074,1.02346,0.839541,1.09075,0.821079,-0.226846,-0.198083
755,0.0782141,0.085312,0.0271565,-0.00656483,0.258001,0.250373,0.159758,0.137884,0.0109288,-0.0210073,0.822558,0.844659,0.403954,0.43281,0.236576,0.252123,0.861548,0.84029,0.501061,0.439341,-0.2175,-0.135234,-0.501298,-0.320612,-1.94622,-1.94551,-0.745936,-0.703202,-1.55085,-1.40284,-0.476757,-0.432526,-0.81972,-0.782205,0.722882,0.544005,-0.632268,-0.903733,0.28424,0.306147
756,0.491122,0.498633,0.118854,0.00757884,0.194553,0.185332,0.652265,0.631225,0.275733,0.245305,0.383413,0.453353,0.032697,0.0620967,0.0640872,0.0805538,0.718255,0.750064,0.400413,0.386271,0.350822,0.438908,0.350008,0.524525,-1.24285,-1.23873,-0.222605,-0.185984,-0.845064,-0.626248,-0.395467,-0.272182,2.66939,2.70507,1.24278,1.059,-0.448023,-0.725941,-0.679059,-0.652428
757,0.252718,0.260168,0.0555772,0.0217225,0.476492,0.466617,0.113154,0.0931371,0.278781,0.248095,0.0416705,0.0620466,0.108975,0.136232,0.355403,0.332822,0.683067,0.659839,0.841963,0.829827,-1.12068,-1.03965,0.212235,0.388549,0.119827,0.125247,0.197437,0.331235,0.0190159,0.150342,2.70334,2.82486,-2.08543,-2.04439,1.08896,0.901039,-2.35548,-2.62952,1.59463,1.62387
758,0.658614,0.668028,0.446506,0.485861,0.375312,0.365945,0.380494,0.358454,0.878548,0.847837,0.537057,0.559527,0.844678,0.870797,0.568436,0.585091,0.3627,0.364051,0.820019,0.805875,0.298089,0.379532,-1.46604,-1.29555,-2.1102,-2.09776,0.805719,0.848453,0.778916,0.926932,-1.65235,-1.5255,-1.15667,-1.12317,-0.229775,-0.4247,0.998688,0.724867,0.252994,0.281959
759,0.00166435,0.0116531,0.985498,0.95,0.785301,0.774087,0.435464,0.412688,0.765294,0.736206,0.233783,0.255828,0.104561,0.13323,0.103264,0.118447,0.0912719,0.0682627,0.565409,0.551073,0.232117,0.308406,-0.880024,-0.70979,0.548719,0.561019,0.502727,0.550703,-0.412104,-0.261425,0.152144,0.28477,-0.44109,-0.401321,-0.189025,-0.385691,0.174517,-0.101178,-0.768692,-0.737328
760,0.10087,0.112023,0.664546,0.629647,0.751814,0.740543,0.0406346,0.0158431,0.353913,0.357804,0.626614,0.650049,0.407688,0.43496,0.540864,0.555629,0.82269,0.799964,0.914048,0.900677,-0.87049,-0.789727,1.21123,1.37847,0.885686,0.898796,0.73293,0.779193,-1.9454,-1.79257,-0.555466,-0.426606,1.12405,1.16605,-1.1501,-1.34196,-0.148963,-0.358705,0.430671,0.466346
761,0.955516,0.96881,0.757975,0.723986,0.411317,0.403713,0.728896,0.703577,0.0102418,-0.0205979,0.234344,0.257916,0.136179,0.23216,0.774007,0.79059,0.400906,0.37654,0.341686,0.329504,-0.234291,-0.155046,-0.278959,-0.116413,-1.59451,-1.57984,-1.78172,-1.73714,-0.0576598,0.101517,-1.48303,-1.35282,0.887003,0.922372,0.389666,0.198994,-0.344381,-0.616232,1.09336,1.1234
762,0.165406,0.180394,0.386677,0.354881,0.0769492,0.0668835,0.586614,0.637001,0.977755,0.949179,0.256985,0.35572,0.000198839,0.0293608,0.485969,0.503644,0.411033,0.28912,0.708525,0.628256,0.729767,0.816206,0.374245,0.531793,-0.151731,-0.139342,-1.98008,-1.93988,-1.07948,-0.922485,0.377486,0.50296,-0.496671,-0.466295,1.57365,1.3855,-0.376057,-0.652286,-1.13463,-1.10002
763,0.116442,0.133502,0.849843,0.817958,0.0533136,0.0431066,0.596178,0.570425,0.400284,0.37061,0.431358,0.453523,0.0301505,0.0571723,0.72423,0.623923,0.224098,0.201701,0.941438,0.927008,-0.57434,-0.493835,0.290828,0.547185,0.642894,0.705609,1.0595,1.10356,-0.504126,-0.350557,-0.847877,-0.727596,-1.40596,-1.37331,0.653811,0.460155,0.966056,0.683611,0.0263521,0.0590371
764,0.960956,0.980957,0.724149,0.665374,0.62133,0.611189,0.874811,0.850331,0.766039,0.738276,0.17908,0.200532,0.982282,1.00734,0.777403,0.744202,0.742346,0.722142,0.746442,0.71273,-0.543428,-0.45991,0.405029,0.562576,1.54305,1.55056,0.798344,0.83687,0.512888,0.667963,-0.17042,-0.0526496,-0.612229,-0.576391,-1.76303,-1.95395,-0.866521,-1.15352,0.416181,0.455771
765,0.22039,0.241356,0.428149,0.51279,0.236036,0.226573,0.391634,0.36852,0.497656,0.471037,0.796109,0.816201,0.22944,0.252658,0.900348,0.864481,0.604261,0.583739,0.471657,0.498451,-2.39184,-2.31385,1.39862,1.56225,0.0712543,0.0839699,1.40506,1.44376,0.838505,0.994581,-0.444158,-0.329563,0.591538,0.624481,-0.440158,-0.628925,-1.14339,-1.43755,-1.71436,-1.67013
766,0.254563,0.252974,0.391847,0.360205,0.962418,0.952227,0.973871,0.951437,0.65529,0.543928,0.633373,0.739664,0.270697,0.29527,0.967085,0.98476,0.696796,0.676637,0.44213,0.284173,-0.282519,-0.201404,1.60603,1.76422,-0.687172,-0.670258,0.760105,0.791409,-2.86276,-2.7063,0.101603,0.222934,0.0085639,0.0395277,0.0125722,-0.17561,0.00605329,-0.291726,-0.146887,-0.0970831
767,0.243011,0.264592,0.360607,0.32996,0.97942,0.968654,0.205472,0.182032,0.64349,0.616819,0.641404,0.663126,0.670645,0.697207,0.716685,0.731751,0.0431595,0.020812,0.0843236,0.0698943,0.673918,0.752694,-0.346446,-0.188451,1.29166,1.31738,0.752563,0.788372,1.13173,1.28319,-0.547184,-0.429399,0.0669228,0.102727,1.38905,1.19669,0.12735,-0.175128,0.0210045,0.0753642
768,0.549228,0.568819,0.101937,0.0688659,0.598971,0.589322,0.587428,0.565136,0.591849,0.567049,0.990282,1.01401,0.349122,0.37664,0.0152327,0.0283395,0.0268069,0.0471613,0.21613,0.114522,-0.456787,-0.374391,0.776199,0.93728,-0.127976,-0.103735,-0.968616,-0.936251,0.60134,0.777189,-0.879333,-0.767815,0.739526,0.777901,-0.750384,-0.937629,-0.658588,-0.95417,1.15325,1.20272
769,0.851649,0.873047,0.551863,0.517112,0.428181,0.419066,0.725616,0.704664,0.779728,0.757035,0.316095,0.338462,0.394912,0.487618,0.076565,0.088989,0.0990368,0.0735106,0.171763,0.159151,2.22206,2.30067,-0.541456,-0.385868,0.0892167,0.110969,0.633102,0.668325,-0.0130155,0.271185,1.34396,1.45004,0.471545,0.503994,-1.37478,-1.55666,-0.301642,-0.603153,-0.634147,-0.582315
770,0.55761,0.578534,0.12612,0.0931795,0.258394,0.24881,0.544039,0.522697,0.484892,0.459088,0.179203,0.217488,0.571655,0.598597,0.588869,0.600983,0.920083,0.896341,0.0724632,0.0601202,1.15254,1.25606,0.802895,0.952961,-0.945085,-0.924235,-0.197916,-0.155231,-0.386281,-0.23482,-0.756738,-0.647061,1.09486,1.13483,-0.0435661,-0.231638,-1.21373,-1.51089,-0.295856,-0.24466
771,0.901996,0.92553,0.455548,0.424046,0.708773,0.698065,0.994273,0.970927,0.185151,0.161141,0.0743561,0.0965143,0.148607,0.173592,0.510593,0.570631,0.801309,0.747862,0.249777,0.252904,0.125498,0.211456,-1.61451,-1.45816,0.0685137,0.0904503,-0.279347,-0.235834,0.0185206,0.168733,-0.948524,-0.830847,1.18161,1.227,-1.17661,-1.37084,0.825103,0.522019,1.09515,1.14317
772,0.759697,0.782521,0.0637512,0.0299541,0.524835,0.516279,0.976986,0.953753,0.54361,0.518767,0.467876,0.490736,0.835947,0.861114,0.59356,0.54028,0.685421,0.599383,0.45473,0.445688,1.26905,1.34988,-0.302849,-0.148502,-0.62944,-0.601992,-0.146901,-0.0149878,0.028063,0.17457,-1.91729,-1.80331,0.109677,0.148222,-0.0852673,-0.274038,-0.150855,-0.461198,0.602675,0.653324
773,0.99829,1.01873,0.00285719,-0.0292355,0.0672046,0.0571145,0.090169,0.0644138,0.0477808,0.0205193,0.293286,0.318141,0.00849607,0.0331386,0.497813,0.509928,0.474982,0.450904,0.0773604,0.069512,0.259133,0.343975,1.5272,1.69043,0.288031,0.319422,0.15715,0.205858,1.28313,1.42367,0.922356,1.03657,0.0384831,0.0729109,-2.10878,-2.29624,0.620029,0.308405,1.035,1.08123
774,0.37504,0.398018,0.219742,0.135403,0.601151,0.590654,0.493802,0.468896,0.0538885,0.028514,0.711784,0.737497,0.174558,0.152864,0.732112,0.748238,0.970068,0.946647,0.60643,0.599011,-0.119812,-0.029766,0.526122,0.695171,1.46888,1.50127,-0.625253,-0.570515,-0.234204,-0.0917511,-2.0298,-1.91638,-0.259641,-0.233562,1.54658,1.35371,-0.771819,-1.08287,0.212432,0.314952
775,0.745522,0.770321,0.344002,0.300041,0.568609,0.55711,0.345292,0.321163,0.700723,0.673416,0.151758,0.178649,0.168816,0.27259,0.975517,0.986548,0.57954,0.585367,0.672613,0.682723,1.30483,1.38942,0.47814,0.650405,0.721046,0.747047,-0.968965,-0.913737,0.74132,0.88151,-0.0072918,0.109256,-0.574413,-0.540035,0.057739,-0.1382,0.323851,-0.0288035,-0.497565,-0.45133
776,0.766313,0.7192,0.549819,0.464679,0.892872,0.878648,0.79048,0.764573,0.523509,0.496783,0.694708,0.720424,0.358658,0.392316,0.229564,0.240803,0.246592,0.224086,0.687523,0.766434,1.14497,1.22731,-2.21713,-2.04758,-2.5228,-2.50054,0.303577,0.360097,1.42423,1.56152,-0.0414834,0.0765366,2.059,2.09616,0.289435,0.0902458,1.33835,1.02527,1.34768,1.38791
777,0.641665,0.66808,0.727225,0.629317,0.697116,0.681777,0.0973896,0.0724559,0.849695,0.824156,0.337175,0.454432,0.4874,0.512042,0.420691,0.45463,0.133793,0.142261,0.921906,0.850146,0.44364,0.584261,0.987865,1.1587,-0.327135,-0.307985,-0.626911,-0.573422,0.137859,0.277587,-0.527324,-0.402524,1.30354,1.34535,0.510457,0.318691,0.317387,0.00883363,0.701543,0.745058
778,0.102468,0.126982,0.826048,0.793955,0.141314,0.127637,0.642831,0.619847,0.0743247,0.0491861,0.163133,0.18844,0.84954,0.874502,0.658959,0.668458,0.0809607,0.0604352,0.941277,0.933858,-0.141132,-0.0587884,-0.0293355,0.147451,-0.32793,-0.308011,1.25467,1.31613,0.625666,0.77313,0.636841,0.762369,0.324067,0.359553,-1.37328,-1.56577,0.247094,-0.0579423,-1.40177,-1.3504
779,0.863361,0.886824,0.834994,0.802999,0.942087,0.92707,0.825111,0.80069,0.187071,0.163308,0.316565,0.343231,0.489747,0.513551,0.277829,0.287187,0.98227,0.96209,0.323521,0.318655,-1.35009,-1.26278,-0.101438,0.0729863,0.513776,0.538483,0.706298,0.772955,-0.89273,-0.742293,0.958856,1.02225,0.503101,0.542097,-0.38586,-0.576601,-0.477131,-0.773697,2.00302,2.04977
780,0.930975,0.952155,0.414895,0.38433,0.483925,0.503934,0.581276,0.557558,0.958802,0.937479,0.696048,0.72212,0.99926,1.02437,0.458871,0.46831,0.762151,0.743249,0.942316,0.937309,-0.181785,-0.0299272,0.76908,0.950087,0.894859,0.921516,1.16897,1.24216,-0.00656514,0.136786,1.15866,1.28213,1.38548,1.43075,-0.167089,-0.309085,1.51013,1.20761,2.12309,2.17399
781,0.291166,0.310766,0.96616,0.93609,0.0977012,0.0807992,0.714539,0.691711,0.12434,0.105086,0.0872895,0.112638,0.546733,0.573529,0.910381,0.920009,0.202803,0.183402,0.1035,0.0954695,1.11562,1.20293,1.07727,1.25997,-0.8613,-0.839801,0.020507,0.0936749,1.0911,1.23053,0.695052,0.817616,0.548614,0.58726,0.149043,-0.0415687,0.405084,0.0632606,-1.87387,-1.82296
782,0.9754,0.996923,0.276914,0.245645,0.023793,0.00587913,0.634122,0.613388,0.686265,0.668037,0.875519,0.901144,0.708416,0.759174,0.165527,0.174264,0.850781,0.830349,0.837684,0.829428,-1.26213,-1.18237,0.710728,0.895555,0.515649,0.538281,0.175869,0.244431,-1.25968,-1.12428,0.905813,1.03198,1.48193,1.52413,0.682126,0.489498,-0.780117,-1.08109,0.389478,0.43734
783,0.830669,0.853915,0.395173,0.333323,0.673532,0.654771,0.187365,0.167496,0.736324,0.752503,0.00597615,0.0297418,0.919864,0.944819,0.825462,0.834289,0.159957,0.139375,0.0121364,0.00421659,-0.348409,-0.273634,0.0905306,0.271024,-0.567539,-0.542824,-0.538906,-0.469685,-2.26664,-2.13387,-0.2241,-0.0935261,1.12929,1.17135,0.688312,0.496829,-0.153761,-0.449769,-0.751982,-0.706796
784,0.189622,0.212526,0.345002,0.421,0.581399,0.600958,0.460903,0.44275,0.761014,0.836968,0.854004,0.875751,0.201606,0.22704,0.249556,0.258144,0.746699,0.724611,0.407129,0.398782,-0.638103,-0.570597,-1.14113,-0.956746,-0.307968,-0.280358,-0.557458,-0.489232,-0.0829949,0.0527541,-1.63825,-1.51151,-1.07625,-1.03368,-2.11681,-2.30458,-0.357444,-0.656553,0.309941,0.359205
785,0.765209,0.789071,0.539947,0.508678,0.564108,0.547145,0.120015,0.101285,0.938922,0.921433,0.904815,0.926487,0.0900767,0.11781,0.185386,0.192391,0.988401,0.966105,0.365044,0.389246,0.725328,0.786849,1.58458,1.76383,0.505697,0.53504,-2.09155,-2.02072,1.85554,1.99403,-0.652992,-0.531992,0.886996,0.928163,-0.253301,-0.437312,-0.960697,-1.26605,0.0131182,0.0652039
786,0.0323388,0.05515,0.204864,0.173603,0.932418,0.914465,0.540916,0.519441,0.186746,0.1684,0.414783,0.43623,0.598023,0.562496,0.433491,0.442589,0.608203,0.586384,0.386636,0.37971,-1.53701,-1.47208,-0.0425973,0.143845,-1.22725,-1.19454,-1.44849,-1.38277,1.30609,1.41874,-0.752595,-0.625061,-0.176101,-0.134444,-0.333388,-0.52126,1.24715,0.947704,1.44446,1.50084
787,0.375437,0.397099,0.389548,0.357064,0.395495,0.469071,0.141289,0.117828,0.269395,0.25224,0.722549,0.74244,0.979447,1.00718,0.277962,0.286074,0.649973,0.629856,0.948472,0.943099,-0.601446,-0.533039,-0.613178,-0.421384,-0.874695,-0.929052,0.733105,0.805639,0.734509,0.843458,0.894753,1.01718,0.210502,0.248001,0.14961,-0.0365697,1.09842,0.8015,0.713766,0.769183
788,0.193147,0.214145,0.110104,0.0770407,0.0403498,0.0236767,0.310217,0.287962,0.663646,0.645007,0.545171,0.529887,0.896852,0.922819,0.908328,0.916296,0.934165,0.9156,0.334862,0.327897,-0.507976,-0.436828,-0.737389,-0.54187,-0.69051,-0.66356,-0.390951,-0.312173,0.183274,0.26817,0.270088,0.396893,-1.42546,-1.39196,0.895811,0.707508,-0.129585,-0.433214,-0.443985,-0.388966
789,0.596947,0.617088,0.579367,0.545403,0.346078,0.243397,0.894406,0.870879,0.853978,0.834993,0.297127,0.317335,0.0455301,0.0727039,0.428412,0.435216,0.323787,0.305347,0.424851,0.419368,-1.62299,-1.55049,-2.14877,-1.95827,0.680867,0.714522,0.0620432,0.143549,-0.445609,-0.307117,0.324842,0.453466,1.16677,1.19513,1.41231,1.2225,0.365807,0.0571824,-0.983249,-0.927199
790,0.549478,0.570197,0.196878,0.161041,0.48199,0.463118,0.0744753,0.048926,0.690675,0.588483,0.922016,0.942792,0.074099,0.100515,0.792104,0.798101,0.506927,0.486693,0.829395,0.823673,-0.674088,-0.613286,-0.450051,-0.260645,1.01387,1.0523,-0.377711,-0.293716,1.47148,1.61761,0.384173,0.510038,-1.82702,-1.79367,0.421514,0.236178,-0.67165,-0.972419,0.208322,0.264023
791,0.776984,0.796752,0.732959,0.698276,0.0176774,-0.00131047,0.193943,0.210773,0.362406,0.341974,0.722705,0.744022,0.927327,0.952319,0.497402,0.539756,0.227649,0.208176,0.550355,0.532545,0.255583,0.323915,1.54819,1.73477,-1.74518,-1.70065,0.108825,0.252225,0.446385,0.593603,0.0678192,0.18723,0.466651,0.507788,-1.17553,-1.36332,-0.380208,-0.638701,0.683039,0.73694
792,0.708398,0.730473,0.498155,0.463773,0.486558,0.467272,0.39626,0.372619,0.386218,0.378971,0.173887,0.194676,0.149556,0.176449,0.27456,0.281411,0.609952,0.58893,0.249093,0.241417,-0.0479258,0.026951,-0.721263,-0.534739,0.926994,0.976025,0.7189,0.798167,-0.0112877,0.134917,-1.00159,-0.877598,-0.324181,-0.291329,-1.90146,-2.09186,-0.00668422,-0.304983,0.48341,0.532597
793,0.883565,0.87356,0.959662,0.92685,0.18783,0.168089,0.0151573,-0.00972654,0.435391,0.415969,0.889431,0.910669,0.789624,0.817735,0.2431,0.350772,0.51464,0.493465,0.533788,0.524773,2.12788,2.20198,-0.309712,-0.118588,0.699327,0.747211,-0.300047,-0.226382,-2.30676,-2.15766,0.266478,0.392532,1.1112,1.14108,-0.86523,-1.09086,-0.285391,-0.589009,-1.0212,-0.975212
794,0.994661,1.01665,0.621993,0.586811,0.915775,0.893743,0.950194,0.924506,0.257765,0.244508,0.524757,0.560602,0.0229751,0.0518788,0.367365,0.420132,0.855752,0.834186,0.413846,0.404289,1.9169,1.99653,-0.153521,0.0359772,0.820795,0.868035,-0.437696,-0.380431,0.514914,0.667964,0.304179,0.422809,2.78988,2.81996,0.100535,-0.0898678,0.655649,0.354932,-0.340763,-0.28915
795,0.499773,0.521252,0.871552,0.838494,0.564726,0.543661,0.553612,0.492303,0.0949602,0.0730469,0.190206,0.210535,0.526418,0.554195,0.46783,0.489492,0.643699,0.548739,0.62261,0.554071,2.01172,2.09274,1.64691,1.84036,0.0168909,0.0666126,-0.604207,-0.534479,-0.301418,-0.190387,1.74343,1.86129,1.74517,1.77235,-1.33826,-1.52284,0.439827,0.131505,-1.06815,-1.02081
796,0.748435,0.767214,0.641962,0.608597,0.736099,0.714389,0.0837549,0.0601008,0.691402,0.667833,0.218264,0.236959,0.218312,0.329168,0.553386,0.558853,0.284795,0.263291,0.709829,0.703854,0.186669,0.271589,0.157747,0.345481,0.799435,0.84932,-1.33464,-1.26375,-1.19575,-1.04874,-0.792722,-0.668822,1.4456,1.46727,0.825779,0.639142,-1.08288,-1.38668,-0.554162,-0.501359
797,0.689707,0.710545,0.804178,0.772331,0.107689,0.085679,0.900005,0.876676,0.21425,0.188878,0.51686,0.538351,0.0763629,0.10414,0.0426041,0.0475827,0.241778,0.218586,0.861008,0.853636,-0.623604,-0.534842,-0.018173,0.164115,1.33293,1.3856,0.88071,0.945884,-0.899073,-0.753277,0.0068419,0.123341,0.89706,0.913775,-1.39819,-1.57874,-0.369135,-0.676934,1.75202,1.8095
798,0.171227,0.189904,0.701218,0.66907,0.978425,0.957149,0.803661,0.779124,0.355263,0.234494,0.225971,0.249439,0.849632,0.880054,0.195333,0.198847,0.478061,0.455359,0.718938,0.713864,-0.37423,-0.283683,1.24092,1.42755,1.35515,1.40143,0.454948,0.52496,-0.339207,-0.198536,1.2442,1.36295,1.31796,1.32906,-0.0538538,-0.239269,1.38711,1.0803,-1.51295,-1.45829
799,0.282828,0.300612,0.798567,0.768001,0.684892,0.66318,0.493303,0.49546,0.307412,0.280109,0.170921,0.181666,0.789179,0.834612,0.552945,0.486646,0.0376079,0.0161526,0.257724,0.253005,-1.74632,-1.6548,-0.417944,-0.224865,2.61463,2.65827,0.912093,0.980683,-0.577005,-0.340233,1.21828,1.33023,-0.202396,-0.186877,-0.631677,-0.810885,-0.889762,-1.19997,1.46483,1.52022
800,0.910853,0.926144,0.318808,0.290564,0.66042,0.639403,0.234832,0.211795,0.89408,0.865522,0.0922474,0.113893,0.760592,0.78917,0.772529,0.774446,0.0712124,0.0498203,0.890537,0.88691,0.870651,0.968302,1.22852,1.42581,-0.703128,-0.650679,1.62173,1.69689,-0.626752,-0.48193,-0.873861,-0.766868,0.0115145,-0.06026,0.0646937,-0.111799,0.515858,0.199755,0.0303343,0.0860399
801,0.399308,0.415287,0.385572,0.359101,0.0233132,0.00123812,0.184065,0.189358,0.566656,0.538359,0.946714,0.969603,0.0112973,0.041235,0.825118,0.805666,0.752389,0.732098,0.347611,0.34575,1.0485,1.14184,0.546824,0.65233,-1.58918,-1.52985,-0.14307,-0.0705939,1.3887,1.53976,1.90078,2.00523,0.0568849,0.0663567,0.397592,0.220087,0.359285,0.0374808,-0.872229,-0.811752
802,0.902494,0.917416,0.820376,0.79325,0.00821984,0.0468825,0.192118,0.16692,0.473339,0.519784,0.471502,0.531872,0.652078,0.682522,0.835755,0.836887,0.771679,0.751884,0.431202,0.42737,-0.470439,-0.38195,-0.315299,-0.121148,-1.13046,-1.07097,1.45171,1.51663,-2.08539,-1.92837,-0.697886,-0.589711,-1.13035,-1.12076,-0.174955,-0.351529,-0.895309,-1.21323,-0.299004,-0.245776
803,0.548365,0.598176,0.602344,0.57387,0.169405,0.0925268,0.836496,0.808947,0.528562,0.50121,0.0717981,0.0941399,0.391477,0.42182,0.553426,0.555309,0.382434,0.456095,0.880694,0.876456,0.436255,0.526785,0.0270151,0.219827,-0.87415,-0.715803,0.410023,0.477194,-0.30595,-0.145827,0.29705,0.406915,0.250167,0.265861,0.353247,0.179538,-0.288308,-0.671644,-0.0298435,0.0725796
804,0.263153,0.278936,0.928315,0.900029,0.158658,0.138171,0.390516,0.363056,0.148878,0.122337,0.695435,0.719597,0.478975,0.511454,0.678145,0.681069,0.180063,0.160307,0.68679,0.780838,-1.17106,-1.07603,-1.41027,-1.21418,-0.420646,-0.360631,0.741677,0.759836,0.24206,0.408914,-0.0489572,0.0685001,1.12844,1.14039,-1.16903,-1.34473,0.180977,-0.130058,0.331893,0.390935
805,0.235834,0.342179,0.792296,0.857684,0.455574,0.491344,0.816485,0.787317,0.899717,0.871168,0.012654,0.0348305,0.92807,0.962704,0.401454,0.404384,0.0357854,0.0167951,0.68924,0.68522,-0.0271928,-0.0219287,-0.568333,-0.369044,0.691169,0.743013,0.920248,1.04248,-0.11535,0.0578311,0.558919,0.60869,1.49997,1.50892,-0.844624,-1.09254,-0.678789,-0.986304,1.22369,1.28949
806,0.335606,0.405423,0.842487,0.81534,0.864165,0.844517,0.518293,0.489733,0.910016,0.879163,0.452569,0.473187,0.0995724,0.134729,0.812352,0.816128,0.574326,0.458547,0.266685,0.264631,0.937146,1.03218,-0.379752,-0.183459,0.048587,0.0324904,1.25795,1.32512,0.330449,0.505602,1.03283,1.14888,0.224072,0.227641,-0.663742,-0.840357,1.06474,0.754521,-0.926273,-0.852923
807,0.452883,0.468666,0.90222,0.875011,0.41551,0.395447,0.840397,0.814031,0.327286,0.295224,0.452462,0.475257,0.000946788,0.0350708,0.0681607,0.0703828,0.919289,0.900299,0.527099,0.523356,1.23785,1.33163,-0.553556,-0.35028,-0.725054,-0.678032,-0.0872434,-0.0220002,-0.124661,0.0469159,-0.934028,-0.823791,-0.297402,-0.200768,0.840832,0.683119,-0.0388387,-0.352751,-0.975027,-0.906142
808,0.667104,0.652032,0.141969,0.113611,0.581338,0.495554,0.88489,0.857472,0.30264,0.271099,0.874647,0.898869,0.340844,0.37275,0.436246,0.374633,0.0933714,0.0761255,0.00114621,-0.00263275,-0.63658,-0.537611,1.56961,1.7736,0.115269,0.168462,1.46387,1.53549,1.29272,1.46231,-0.668405,-0.565354,-0.629284,-0.629177,2.39011,2.2066,-0.881784,-1.19239,0.10005,0.176197
809,0.819205,0.835398,0.715141,0.684994,0.615863,0.595661,0.0577032,0.0299141,0.881679,0.850835,0.763882,0.731239,0.410678,0.535182,0.63592,0.678884,0.702827,0.687743,0.0563052,0.054551,-1.64748,-1.54351,-0.984056,-0.783375,1.4993,1.54654,0.372292,0.44686,0.0868745,0.302395,-1.01863,-0.918948,1.07295,1.08084,-0.876209,-1.05931,-0.397822,-0.701991,0.846496,0.924635
810,0.541796,0.556402,0.904538,0.873731,0.213845,0.195548,0.34512,0.31528,0.117408,0.0868994,0.541868,0.563609,0.664112,0.697615,0.982343,0.983135,0.152336,0.138447,0.622925,0.622947,0.680291,0.785531,-1.51151,-1.31681,-1.94388,-1.89639,0.680013,0.750722,-1.02631,-0.857523,-0.161466,-0.0625614,0.449849,0.452062,-0.601291,-0.787633,0.974347,0.666091,-0.162618,-0.0791543
811,0.746284,0.6656,0.366023,0.336632,0.0981663,0.0790063,0.90756,0.878623,0.329561,0.345802,0.625436,0.648786,0.567578,0.603757,0.404443,0.40699,0.500736,0.484823,0.0304526,0.0322853,-2.73539,-2.6325,1.24484,1.44039,2.16804,2.21553,0.109339,0.176149,0.36645,0.543007,0.460942,0.565771,1.6497,1.65293,0.177007,-0.0263155,0.657108,0.350215,0.0321244,0.12353
812,0.758699,0.774798,0.654494,0.623076,0.703515,0.682565,0.0100333,-0.0174918,0.696581,0.604704,0.996458,1.01834,0.747035,0.784515,0.358552,0.360471,0.0562583,0.0402463,0.7769,0.776202,-1.46598,-1.36974,-0.0571969,0.136134,0.420435,0.470183,0.793004,0.860697,-0.136052,0.00518527,0.500778,0.610794,-0.397642,-0.396374,0.916154,0.735002,0.702687,0.3925,1.72628,1.81921
813,0.40675,0.424737,0.641225,0.662598,0.507997,0.485695,0.692279,0.664707,0.894848,0.863606,0.107626,0.128735,0.120101,0.158147,0.612975,0.616178,0.292246,0.277019,0.653186,0.651115,-0.211113,-0.106981,0.756621,0.951161,-0.749653,-0.691688,-1.49098,-1.4193,-0.715562,-0.532636,0.121701,0.226573,-0.176517,-0.183539,0.374089,0.193475,-0.49454,-0.811648,0.772141,0.860639
814,0.70228,0.722048,0.734546,0.70212,0.578785,0.556814,0.292778,0.334174,0.783646,0.792305,0.951663,0.974744,0.464562,0.500129,0.00781272,0.0101799,0.225473,0.211226,0.778521,0.777105,-2.54198,-2.4434,0.282051,0.47936,-1.90439,-1.85356,-0.582265,-0.515859,0.754335,0.944143,1.93145,2.03685,-1.19294,-1.20021,-1.79058,-1.97248,-1.36229,-1.68543,0.671873,0.762875
815,0.661177,0.680907,0.318028,0.283451,0.285586,0.262844,0.0294017,0.00364177,0.752835,0.721004,0.461828,0.555003,0.319192,0.294274,0.232752,0.234105,0.783123,0.770993,0.143756,0.14192,-0.265716,-0.161378,-2.51536,-2.3166,0.620687,0.670556,-0.295096,-0.227441,0.136948,0.333519,0.094129,0.205381,0.712546,0.701408,-1.40898,-1.59377,1.92493,1.60773,-0.565082,-0.472765
816,0.276393,0.295339,0.72857,0.693535,0.327498,0.366654,0.670555,0.645669,0.124246,0.091189,0.112181,0.135263,0.0522809,0.0884193,0.731871,0.731361,0.488515,0.476766,0.0754883,0.0735877,0.303264,0.412765,0.050808,0.254534,-0.108254,-0.0550439,1.82776,1.89625,1.0774,1.27475,0.427685,0.539909,0.893683,0.960517,-0.772884,-0.956513,-1.74749,-2.06332,0.794689,0.885892
817,0.301463,0.320407,0.00146795,-0.0318019,0.429084,0.470463,0.576343,0.516066,0.686068,0.65414,0.299358,0.32415,0.506272,0.5443,0.350865,0.350091,0.461002,0.447021,0.839017,0.838038,0.293841,0.403485,0.13053,0.290059,1.27114,1.32304,-1.35412,-1.28734,-0.156714,0.0362651,0.410049,0.524139,1.22361,1.21963,0.389257,0.201316,0.421786,0.0995755,-2.03921,-1.95292
818,0.954292,0.971952,0.0656536,0.0322715,0.5952,0.574273,0.346285,0.386463,0.97044,0.936237,0.137808,0.256377,0.206817,0.243109,0.771554,0.771448,0.730576,0.717996,0.0287003,0.0284326,-0.0388787,0.0778198,0.118907,0.325584,-1.21254,-1.1556,-0.449118,-0.383892,0.715148,0.915344,-1.6198,-1.50955,2.16496,2.15649,-1.1101,-1.29059,-1.03032,-1.35519,-0.180939,-0.0866173
819,0.902304,0.981413,0.382625,0.422086,0.839781,0.819595,0.282855,0.25686,0.390604,0.357669,0.164355,0.188605,0.576755,0.614767,0.653297,0.654901,0.115987,0.102192,0.0547486,0.0547249,0.0943129,0.205641,0.426111,0.635467,0.841987,0.891862,-1.2513,-1.19147,-0.910494,-0.707794,-1.93413,-1.81827,0.480135,0.467439,0.344534,0.156919,1.39333,1.06789,1.6934,1.77969
820,0.97424,0.990874,0.844185,0.8119,0.414981,0.395097,0.899081,0.874543,0.773822,0.653053,0.336079,0.358542,0.440662,0.480642,0.871481,0.873136,0.276956,0.261575,0.657805,0.658508,-0.522369,-0.415877,1.60567,1.82065,-1.07731,-1.02888,0.417326,0.474735,-0.291342,-0.0906795,-1.3281,-1.20406,0.596329,0.590194,-0.889293,-1.0749,-1.095,-1.41747,0.447376,0.530554
821,0.409958,0.424911,0.739132,0.708639,0.910827,0.893415,0.36874,0.3463,0.979728,0.948438,0.0614463,0.0856196,0.535093,0.574583,0.153075,0.154011,0.144673,0.129079,0.324307,0.326928,0.178802,0.279126,-0.273839,-0.0570433,-0.438904,-0.38401,0.42948,0.486303,-0.792534,-0.594806,0.0936951,0.217651,-0.382759,-0.395606,1.84369,1.65703,1.87497,1.55229,0.915427,1.00347
822,0.796038,0.813414,0.211699,0.181227,0.698118,0.587698,0.0569992,0.0331982,0.316204,0.283605,0.571356,0.593229,0.832103,0.787591,0.636717,0.636041,0.848804,0.831699,0.600292,0.604742,-1.33632,-1.23039,-0.930332,-0.71239,0.765675,0.825603,1.06885,1.12425,1.70613,1.8998,0.191454,0.309054,0.589979,0.571742,-0.881638,-1.07402,-1.25355,-1.58155,-0.674072,-0.580312
823,0.602006,0.61955,0.574225,0.548996,0.297891,0.281981,0.678604,0.655771,0.105025,0.0718086,0.240658,0.264648,0.962863,1.0006,0.781813,0.782424,0.490124,0.472548,0.210126,0.214749,-0.394991,-0.291348,-0.0628459,0.148195,0.433128,0.489859,-0.579677,-0.519657,-0.0596445,0.137595,-0.571357,-0.449954,0.342409,0.328064,-0.0901599,-0.323749,-0.287416,-0.623755,0.590609,0.685752
824,0.109927,0.128495,0.948366,0.916766,0.32497,0.348881,0.359606,0.337817,0.361965,0.32866,0.994005,1.01654,0.466309,0.567629,0.339993,0.340845,0.447621,0.427842,0.0843485,0.0896617,-0.768749,-0.665089,-0.801012,-0.583817,1.84527,1.89809,0.699502,0.754177,0.388085,0.585366,0.239516,0.361331,0.508433,0.496224,0.612607,0.426527,-1.74316,-2.07852,-0.528983,-0.42838
825,0.0730384,0.092124,0.240969,0.211366,0.516432,0.415781,0.805816,0.786047,0.233604,0.202322,0.35663,0.381163,0.0956126,0.134659,0.668444,0.667248,0.00339757,-0.0167345,0.381627,0.387091,-0.477677,-0.397209,0.368009,0.584651,-1.09648,-1.03647,-0.550373,-0.503239,-0.244991,-0.0548282,-0.225995,-0.103179,-1.88892,-1.90454,-0.485357,-0.666691,0.756391,0.428846,-0.588357,-0.464915
826,0.383381,0.403762,0.723721,0.695085,0.499449,0.482681,0.915493,0.894938,0.382171,0.366061,0.214486,0.237555,0.633373,0.67106,0.07323,0.0714298,0.0352193,0.0128255,0.0441239,0.0506602,-0.229355,-0.129329,-0.0826459,0.127875,-0.33871,-0.283292,0.0316334,0.0733743,0.056887,0.240633,1.6458,1.76639,-0.735249,-0.749067,-0.125737,-0.305065,1.3538,1.02833,-0.596932,-0.501451
827,0.390933,0.508978,0.135342,0.108923,0.985331,0.970948,0.450334,0.42828,0.643576,0.5298,0.337394,0.362459,0.334722,0.363328,0.68242,0.681204,0.641493,0.619187,0.206034,0.252618,-0.257052,-0.152803,0.141378,0.346207,-1.19944,-1.14697,-0.291875,-0.254306,-0.339893,-0.155865,0.257977,0.377237,0.167945,0.155708,-0.58719,-0.770193,-1.03481,-1.3559,2.36099,2.46296
828,0.559109,0.614194,0.864582,0.840518,0.439787,0.425966,0.610636,0.587903,0.726455,0.69354,0.775507,0.800816,0.0150843,0.0555961,0.634572,0.596786,0.0513483,0.0301386,0.447154,0.454576,-1.75062,-1.64786,1.58944,1.7944,1.08263,1.12873,0.00827989,0.0495556,1.03523,1.21245,-0.333453,-0.211291,-0.826479,-0.846096,1.45637,1.26972,0.165475,-0.147181,1.11213,1.21382
829,0.69903,0.71941,0.353798,0.327677,0.373483,0.360925,0.44237,0.359155,0.144092,0.109601,0.952141,0.97559,0.877315,0.918898,0.424507,0.512367,0.361103,0.407848,0.0879069,0.0934758,0.558848,0.664175,1.28821,1.48823,0.289587,0.343179,0.0579708,0.107941,-0.644216,-0.472272,0.419192,0.538291,0.810918,0.78767,-0.144287,-0.329772,1.68283,1.37553,-0.390464,-0.293988
830,0.0111431,0.0326838,0.643819,0.584858,0.940968,0.929008,0.151042,0.130406,0.939765,0.907043,0.146096,0.168366,0.882128,0.92235,0.42845,0.427949,0.8053,0.785558,0.280426,0.285525,0.00819529,0.120862,0.000761032,0.197831,-0.976542,-0.921802,0.713293,0.76294,-0.00996803,0.160615,0.588712,0.705575,-0.641479,-0.663748,-0.0111335,-0.197852,-0.0343981,-0.349286,-0.319963,-0.222981
831,0.387383,0.310996,0.867156,0.842038,0.556957,0.592178,0.535534,0.51351,0.472424,0.438739,0.318077,0.338304,0.0350122,0.0767159,0.896988,0.894855,0.680459,0.65859,0.97493,0.979788,-0.284048,-0.176102,1.31547,1.50749,0.514928,0.563297,-2.23646,-2.18258,-1.17274,-1.00047,-1.43964,-1.32812,0.89861,0.874214,0.921276,0.73146,-0.149208,-0.46357,-0.255522,-0.151974
832,0.56569,0.589309,0.723974,0.698332,0.26899,0.255348,0.172373,0.151425,0.384595,0.352988,0.885984,0.904732,0.343318,0.383669,0.0934,0.0935952,0.827989,0.80798,0.28636,0.292634,-0.157344,-0.0482808,-0.660245,-0.474933,0.107594,0.1508,-1.16296,-1.11031,-1.09697,-0.918287,-0.128984,-0.0119894,-0.288249,-0.312908,0.734807,0.541804,-0.286793,-0.577855,-0.845342,-0.748173
833,0.268586,0.387213,0.289314,0.265166,0.470675,0.457427,0.10299,0.0844843,0.569349,0.538045,0.800937,0.858071,0.43512,0.473303,0.646042,0.646793,0.733716,0.735926,0.709845,0.716923,-0.655468,-0.547093,-0.567491,-0.391447,0.745666,0.862388,0.188506,0.237832,0.353823,0.528249,0.417071,0.540507,0.561566,0.529575,-0.54042,-0.737431,-0.377251,-0.692139,-0.412038,-0.255567
834,0.16162,0.185118,0.895689,0.870607,0.673175,0.659507,0.736726,0.717177,0.317111,0.286152,0.792525,0.81141,0.161494,0.197711,0.962447,0.963132,0.683292,0.663872,0.452143,0.529262,-0.127894,-0.0746452,-0.57874,-0.30796,1.53804,1.57398,0.647501,0.693554,-0.261426,-0.0823748,-0.0152202,0.109379,-0.0260664,-0.0553791,-0.40876,-0.60551,2.47259,2.15274,0.133918,0.23704
835,0.80831,0.83127,0.933281,0.908981,0.16618,0.151119,0.707454,0.690305,0.950562,0.920685,0.362307,0.38069,0.604478,0.639472,0.111512,0.11327,0.870754,0.751605,0.390388,0.341601,0.285065,0.397802,-0.409786,-0.224474,0.180722,0.214717,2.05772,2.10694,-1.81514,-1.64352,-0.175895,-0.0462332,-0.171133,-0.231143,0.975353,0.78292,-0.588316,-0.908398,-1.3495,-1.24005
836,0.191671,0.215165,0.633861,0.60913,0.703307,0.688762,0.138694,0.122121,0.636476,0.607991,0.487557,0.599982,0.431352,0.425746,0.659051,0.661085,0.859697,0.839338,0.145592,0.15394,-0.114151,-0.00591225,1.1156,1.30324,2.00095,2.0316,-0.764765,-0.720185,0.701311,0.871775,-1.85813,-1.72274,-0.370729,-0.406907,-1.54801,-1.74317,-0.153038,-0.46514,1.56328,1.67283
837,0.648154,0.672848,0.798902,0.772864,0.946933,0.934085,0.311772,0.297175,0.60808,0.578377,0.8023,0.819275,0.178106,0.21202,0.211489,0.214773,0.152873,0.133419,0.22435,0.159326,-1.17766,-1.07341,0.384352,0.571227,-2.15548,-2.12098,0.0442586,0.0892888,-0.798028,-0.629177,-2.07071,-1.93838,1.24542,1.21001,0.193814,0.00127788,0.963417,0.648886,-0.757042,-0.648603
838,0.0728548,0.0965984,0.60951,0.583352,0.983619,0.970452,0.211596,0.1946,0.824554,0.793634,0.811365,0.74525,0.508391,0.585702,0.944028,0.94732,0.866386,0.845657,0.1542,0.164712,0.333097,0.440297,-0.0949282,0.0848196,-1.44471,-1.4026,-1.52409,-1.47384,1.05636,1.23092,-0.818453,-0.683116,0.0114842,-0.0229095,-1.1552,-1.3548,1.49803,1.18754,1.27177,1.38673
839,0.378955,0.305787,0.167424,0.139979,0.674623,0.736487,0.791864,0.777517,0.0217603,-0.00706781,0.652523,0.671225,0.923399,0.959385,0.276478,0.281033,0.572861,0.55143,0.96068,0.973254,0.833089,0.936911,-0.949868,-0.771085,-0.720704,-0.684229,1.7637,1.81771,-1.18225,-1.01015,1.13611,1.278,0.689442,0.652265,1.91932,1.71886,-0.420217,-0.730634,-0.957139,-0.836686
840,0.493255,0.514975,0.613978,0.588225,0.517542,0.502523,0.406191,0.461018,0.635413,0.60703,0.160899,0.180968,0.817604,0.854617,0.456401,0.514453,0.94257,0.921895,0.375616,0.387559,-2.72607,-2.6198,0.404118,0.584315,-0.674328,-0.639444,-0.999979,-0.949647,-0.175298,-0.00828888,0.765791,0.909035,-1.79144,-1.82956,0.612859,0.407484,-0.690939,-0.92674,0.725816,0.844217
841,0.216246,0.235978,0.328585,0.347614,0.627392,0.614317,0.161031,0.144519,0.701864,0.694693,0.564923,0.584845,0.301398,0.338583,0.74549,0.747873,0.867708,0.788915,0.802831,0.816159,-0.822631,-0.723054,0.494593,0.676821,0.200285,0.237765,-1.33624,-1.29287,-0.677015,-0.512416,-0.563943,-0.41631,1.58931,1.54355,1.75795,1.54885,-0.847858,-1.12285,1.22551,1.34845
842,0.353126,0.371805,0.133117,0.107004,0.161739,0.149888,0.559487,0.543866,0.80907,0.782356,0.0522841,0.0704122,0.57846,0.593452,0.191339,0.19176,0.676598,0.655935,0.117295,0.129004,0.499631,0.602627,-0.400947,-0.225329,-0.468245,-0.424229,0.882006,0.931293,-0.466391,-0.308666,0.178436,0.333272,0.485718,0.434699,0.936977,0.731176,-1.00854,-1.31895,0.192187,0.314349
843,0.892149,0.908584,0.227342,0.201343,0.971564,0.960146,0.198817,0.181781,0.105008,0.0768673,0.698592,0.716838,0.809206,0.848322,0.902343,0.903771,0.110077,0.0904177,0.988665,0.998019,0.21574,0.321504,0.691863,0.869557,0.544223,0.590457,1.24816,1.29573,1.02175,1.18284,-1.01478,-0.868166,0.972503,0.926678,-0.716013,-0.917801,2.40962,2.10314,-1.3719,-1.2533
844,0.43915,0.453486,0.948838,0.922063,0.503793,0.532673,0.382181,0.367285,0.562152,0.534488,0.539118,0.566122,0.502665,0.589057,0.512652,0.511975,0.58504,0.565865,0.604807,0.698741,1.69441,1.80514,-0.326282,-0.141691,-1.05857,-1.01439,-0.0711078,-0.0207775,-0.438928,-0.270757,-1.35117,-1.20658,0.0799146,0.0348807,-0.0484911,-0.249063,0.106069,-0.198216,1.16577,1.27762
845,0.982168,0.995741,0.466054,0.438773,0.119527,0.105199,0.112802,0.0993575,0.231945,0.202344,0.381753,0.415407,0.289086,0.329792,0.725919,0.647943,0.412138,0.392602,0.391281,0.399464,-0.679797,-0.563674,0.144278,0.33455,-0.223533,-0.0883192,0.595739,0.648606,-0.155844,0.0102934,0.423441,0.573419,-1.44795,-1.49738,-0.529747,-0.729294,0.121382,-0.188904,1.08268,1.19316
846,0.576638,0.575963,0.189449,0.163426,0.756322,0.744339,0.242368,0.228886,0.67742,0.646141,0.159867,0.264691,0.406777,0.449861,0.786607,0.783911,0.996932,0.977838,0.535851,0.546181,-0.0471162,0.0710069,-0.7398,-0.552416,0.784653,0.837755,0.874597,0.921147,1.64017,1.80981,0.149474,0.296506,-0.734933,-0.790342,-0.229349,-0.430005,-0.483857,-0.795015,0.301972,0.415379
847,0.143244,0.156186,0.683339,0.656474,0.838244,0.826269,0.696636,0.681968,0.698324,0.669649,0.0957292,0.113976,0.89712,0.94195,0.68787,0.683976,0.170394,0.149404,0.123222,0.13471,0.223007,0.336889,1.42361,1.60456,-0.255369,-0.19745,-0.518321,-0.47381,-1.28768,-1.11445,2.02198,2.16608,0.342945,0.282139,-0.383574,-0.587965,-1.08584,-1.40113,-0.832422,-0.714406
848,0.499835,0.513003,0.450777,0.421971,0.628617,0.612349,0.829261,0.81612,0.117712,0.0910803,0.562422,0.581574,0.511419,0.627653,0.383101,0.400551,0.410945,0.314846,0.84529,0.85802,0.129359,0.321481,-0.124953,0.0622014,0.0423771,0.0946223,-0.19002,-0.140805,-0.344555,-0.17322,0.61861,0.833588,-0.408924,-0.468664,-2.4038,-2.61017,-0.285715,-0.600093,-0.187196,-0.0725005
849,0.0825976,0.0976401,0.848555,0.822008,0.40085,0.398429,0.235908,0.222697,0.000275686,-0.0255509,0.297811,0.318456,0.268302,0.313357,0.1217,0.117126,0.499776,0.480288,0.860346,0.78245,0.190703,0.306073,-1.06642,-0.886198,0.839025,0.893646,-1.42585,-1.38285,-0.00759843,0.169094,-0.641962,-0.498901,0.180131,0.116365,0.189287,-0.0119,0.0951713,-0.218111,-0.590407,-0.473361
850,0.172927,0.244913,0.631857,0.602629,0.197746,0.18451,0.740535,0.725031,0.57979,0.554185,0.496831,0.529101,0.861323,0.904725,0.875442,0.869762,0.935374,0.915187,0.693314,0.70688,-0.371569,-0.252496,0.350699,0.531619,-1.33544,-1.28105,0.198606,0.238778,0.738948,0.909938,-1.02605,-0.883123,-1.19593,-1.2567,-0.336834,-0.530043,-0.303831,-0.609474,-0.991254,-0.874221
851,0.374622,0.392187,0.924156,0.893496,0.671716,0.658104,0.648519,0.63206,0.554903,0.53006,0.720414,0.739747,0.105596,0.150047,0.758169,0.753214,0.491658,0.470611,0.977752,0.990237,0.278325,0.397927,0.079501,0.317976,-0.652092,-0.604408,0.184834,0.219231,-0.22302,-0.0516473,0.815293,0.958039,0.150397,0.0849459,-0.853799,-1.04819,0.237628,-0.0708177,-1.79063,-1.66689
852,0.164685,0.183342,0.215954,0.183361,0.384536,0.361097,0.190688,0.175055,0.845,0.822014,0.566908,0.58679,0.57624,0.621728,0.0728245,0.0661764,0.611079,0.558344,0.42099,0.434427,-0.0372986,0.0863953,-0.0712863,0.104333,1.48304,1.52392,-0.089451,-0.0474612,-0.323695,-0.158295,-0.998476,-0.858603,-0.0939142,-0.158732,0.132555,-0.059013,1.06703,0.763498,2.13374,2.25748
853,0.245427,0.263988,0.786713,0.754744,0.075811,0.0640894,0.286856,0.304415,0.636057,0.615527,0.112984,0.130962,0.52917,0.573483,0.5527,0.548206,0.665337,0.646077,0.0695978,0.083346,1.95185,2.07485,1.2311,1.41399,0.943381,0.988494,-1.37,-1.33449,-1.77384,-1.61189,-0.168907,-0.0336941,-0.0653361,-0.12783,-1.14383,-1.33825,0.242667,-0.062548,0.913944,1.03779
854,0.791156,0.810386,0.535017,0.504178,0.0316742,0.0198177,0.447617,0.433776,0.10457,0.0823816,0.478962,0.554824,0.763957,0.809333,0.122035,0.117103,0.444045,0.422623,0.384947,0.443781,1.12816,1.2535,0.379605,0.558086,-1.24956,-1.20174,0.570231,0.602025,-0.184792,-0.0287617,-0.237939,-0.0959436,-1.4631,-1.5324,-0.959852,-1.16186,0.146284,-0.161263,0.488445,0.606395
855,0.250746,0.269288,0.696347,0.667912,0.569656,0.557461,0.149228,0.229778,0.113588,0.0903763,0.962439,0.978686,0.705776,0.750954,0.408542,0.366299,0.839632,0.8185,0.79331,0.804215,-0.370021,-0.241554,0.506671,0.681339,-1.04055,-1.08498,0.735208,0.853906,0.660755,0.820184,0.925502,1.06895,0.788095,0.717645,0.0284496,-0.172683,0.5655,0.251161,0.791517,0.915022
856,0.549814,0.566599,0.499837,0.473282,0.649302,0.581564,0.0423771,0.0257796,0.79574,0.771368,0.072154,0.0890773,0.371772,0.415794,0.622254,0.615495,0.548658,0.52935,0.538801,0.549413,1.05697,1.19336,0.0367834,0.209537,-1.02141,-0.968229,1.07615,1.10579,-0.567269,-0.403697,-1.13034,-0.979794,-0.254607,-0.329967,-0.402763,-0.607171,-0.467549,-0.77844,0.536095,0.665732
857,0.51529,0.520731,0.962166,0.936358,0.617587,0.605667,0.892858,0.877641,0.464861,0.439224,0.373916,0.365138,0.732518,0.778254,0.306936,0.299002,0.483065,0.463557,0.510671,0.579534,0.925662,1.06359,2.34321,2.51066,-2.2588,-2.20452,0.826219,0.854064,0.433452,0.59816,-0.374913,-0.230211,-0.788744,-0.869671,0.1261,-0.0761035,0.292556,-0.0247368,-0.489002,-0.353555
858,0.351869,0.474863,0.183213,0.15895,0.187039,0.175756,0.44063,0.425773,0.572579,0.577748,0.729117,0.641199,0.676559,0.724112,0.632205,0.625405,0.0504358,0.02882,0.553611,0.609655,-0.603179,-0.460192,0.488959,0.650814,0.653984,0.705677,-1.01727,-0.992208,-1.86432,-1.69442,-0.186937,-0.047101,0.480638,0.406559,-0.612276,-0.819614,-0.0914178,-0.401114,0.150388,0.28835
859,0.41221,0.428995,0.0492007,0.0251082,0.0637574,0.124477,0.79001,0.77456,0.743563,0.716272,0.902536,0.91726,0.205894,0.253007,0.143296,0.134328,0.434481,0.352402,0.629206,0.639776,0.290579,0.434924,0.441242,0.606048,0.198327,0.248142,-0.700424,-0.67421,0.165666,0.327268,1.65273,1.79406,-0.216343,-0.283964,-0.940182,-1.14691,0.0320771,-0.284515,1.29722,1.43094
860,0.915687,0.931125,0.522846,0.498771,0.0846312,0.073198,0.698351,0.681588,0.422444,0.433813,0.970664,0.983701,0.992905,1.03858,0.722379,0.712203,0.698793,0.675984,0.936741,0.947554,-0.129802,0.0156154,-1.13703,-0.966232,0.899438,0.954927,-0.386645,-0.356213,-0.853309,-0.696734,-0.950928,-0.814012,0.421194,0.34687,-0.231039,-0.432307,0.50098,0.190464,-1.15032,-1.01794
861,0.568632,0.673223,0.156841,0.134257,0.868204,0.855874,0.355126,0.340123,0.178847,0.151354,0.42656,0.439283,0.323101,0.366336,0.0613698,0.0500992,0.775665,0.745144,0.0239198,0.0363005,-1.27689,-1.12763,-1.88965,-1.71463,0.767738,0.819978,0.363637,0.392391,0.683221,0.840884,0.0821826,0.212387,0.317616,0.241328,0.939519,0.741253,1.20196,0.883862,-0.686802,-0.560506
862,0.400523,0.415322,0.603461,0.582503,0.200813,0.186751,0.683715,0.66937,0.698052,0.670285,0.886505,0.897514,0.25828,0.377004,0.361244,0.339913,0.837991,0.814304,0.758683,0.770259,-0.959072,-0.814408,-0.845875,-0.670274,-0.331102,-0.276738,-0.230544,-0.198854,0.893277,1.04463,-1.9305,-1.80416,3.2696,3.18631,0.852312,0.595853,-1.4639,-1.778,1.73943,1.86383
863,0.806355,0.823182,0.408741,0.387872,0.824707,0.810084,0.0828202,0.0660559,0.951088,0.921801,0.891863,0.904601,0.345635,0.387672,0.64043,0.629726,0.310262,0.285139,0.861661,0.870671,-1.12276,-0.976518,0.494443,0.668555,0.680971,0.737948,-0.253505,-0.218401,1.83231,1.98586,0.520525,0.641499,-0.105304,-0.191579,0.652869,0.450454,1.10543,0.790914,-2.23248,-2.10855
864,0.0434072,0.062202,0.452579,0.43128,0.354929,0.340352,0.9632,0.945349,0.27001,0.241615,0.448879,0.463048,0.0266973,0.067105,0.0877931,0.0787479,0.913897,0.887012,0.414851,0.424279,-0.202512,-0.0518187,0.368064,0.548069,2.59469,2.64555,-1.60104,-1.56552,-0.746691,-0.58927,-0.168455,-0.0405981,1.70266,1.61267,-0.418876,-0.628925,-1.29961,-1.60703,1.56832,1.69296
865,0.130099,0.148264,0.0401833,0.0175862,0.189946,0.174205,0.792611,0.77311,0.629831,0.599241,0.804095,0.818336,0.886678,0.925555,0.554301,0.503438,0.128734,0.102136,0.806779,0.813282,-0.686442,-0.534369,1.83865,2.01354,0.440727,0.485908,0.312562,0.351701,0.1115,0.274866,-0.412814,-0.28739,1.04814,0.953999,0.324533,0.115153,2.57954,2.27712,-0.266886,-0.134644
866,0.96922,0.990017,0.932256,0.91126,0.649247,0.63304,0.140526,0.120789,0.510979,0.48261,0.675535,0.667433,0.145749,0.182312,0.934975,0.928128,0.736853,0.708497,0.560936,0.567972,-0.910083,-0.755017,-0.123773,0.046769,0.686278,0.7514,-0.208033,-0.161755,-0.631014,-0.472452,0.660526,0.7854,-0.799139,-0.890164,-0.409675,-0.61339,0.723084,0.421284,-0.451578,-0.323934
867,0.207209,0.229038,0.909167,0.886065,0.150077,0.133344,0.00351617,-0.0164309,0.165364,0.135182,0.609767,0.51653,0.404399,0.438912,0.203221,0.19791,0.403028,0.42305,0.0457378,0.0526207,-0.0912466,0.061305,0.438891,0.616914,0.972147,1.01689,-1.84336,-1.78939,-0.424608,-0.268702,-1.16347,-1.03124,-0.437593,-0.558491,-0.130201,-0.326707,1.29294,0.989858,0.648375,0.731553
868,0.830683,0.854569,0.372871,0.348967,0.798531,0.782237,0.236011,0.259711,0.212819,0.150524,0.352805,0.365626,0.191696,0.228543,0.6443,0.551391,0.165124,0.137602,0.531433,0.499212,-1.59144,-1.43375,0.0745136,0.2525,-0.302673,-0.263997,-0.923271,-0.870938,0.0943954,0.256068,-0.984039,-0.848133,-0.138815,-0.226817,-0.150624,-0.349972,-1.09105,-1.39437,1.66383,1.78704
869,0.306062,0.328537,0.362235,0.338447,0.155523,0.137946,0.664694,0.535854,0.183907,0.165866,0.0723659,0.0878386,0.448755,0.485143,0.908471,0.904871,0.707536,0.678279,0.93892,0.945803,1.76923,1.92657,0.16939,0.424896,-1.18103,-1.14317,-1.23416,-1.18395,-0.670607,-0.506855,-0.484263,-0.341037,-1.03857,-1.13383,0.622383,0.424544,0.0902445,-0.216088,0.0462688,0.24028
870,0.984922,1.00974,0.767407,0.744121,0.305064,0.289544,0.831943,0.811996,0.211048,0.181208,0.745887,0.759901,0.42387,0.462161,0.12625,0.12333,0.0224213,-0.00715966,0.61023,0.583615,-0.395003,-0.238136,0.423923,0.597292,-0.348719,-0.217092,0.117271,0.164192,1.86142,2.0301,0.464521,0.608795,0.332936,0.237104,0.914027,0.711228,0.126652,-0.219805,-1.42969,-1.30648
871,0.332869,0.358145,0.490034,0.491622,0.115699,0.102067,0.919948,0.807397,0.761697,0.729919,0.667461,0.600036,0.767116,0.804143,0.333713,0.402269,0.389452,0.358685,0.213613,0.221427,-1.64856,-1.48893,-3.34299,-3.1736,0.67647,0.708982,-0.943358,-0.893709,0.770102,0.945979,-0.654028,-0.516709,-1.88536,-1.98372,0.953557,0.750237,0.0807815,-0.223523,-0.165478,-0.0404144
872,0.0823947,0.10942,0.234871,0.239123,0.254558,0.17042,0.824668,0.802797,0.368654,0.336353,0.42452,0.440172,0.513711,0.518358,0.58648,0.681209,0.391594,0.358737,0.768816,0.775539,0.470391,0.62351,-0.95539,-0.790089,0.430726,0.4645,-0.0467525,0.009736,1.46836,1.64046,0.0235793,0.158237,0.438238,0.335293,-0.18462,-0.388962,0.904061,0.593811,1.34773,1.47291
873,0.681656,0.710172,0.0112662,-0.0133757,0.254362,0.238773,0.10809,0.0857299,0.930745,0.899304,0.815629,0.829503,0.197072,0.232573,0.963068,0.960148,0.116451,0.0848436,0.407933,0.414439,1.34972,1.49999,-0.510636,-0.344176,-0.509221,-0.475227,0.555268,0.61663,0.783033,0.957434,0.06683,0.20326,0.736533,0.627589,0.0658677,-0.13318,-1.09096,-1.40412,-0.00599987,0.11581
874,0.204153,0.234524,0.382566,0.356337,0.893508,0.877914,0.482829,0.459571,0.51731,0.485233,0.420605,0.469236,0.979322,1.01325,0.167291,0.163464,0.282315,0.24972,0.589632,0.662169,-1.27286,-1.1227,-1.09247,-0.923099,0.921424,0.949108,0.25343,0.31888,-0.63253,-0.450747,-0.955891,-0.815196,-0.368071,-0.481257,-0.543375,-0.736261,0.637647,0.322685,0.230204,0.348841
875,0.163937,0.230436,0.464291,0.43542,0.551518,0.533629,0.49176,0.440207,0.492299,0.510404,0.0929208,0.108969,0.195869,0.232571,0.82099,0.818278,0.748237,0.714889,0.902097,0.909899,-0.464671,-0.315247,0.876781,1.04004,0.0352672,-0.012015,-0.499211,-0.427372,0.176696,0.349734,1.28122,1.42242,-0.746497,-0.863582,0.265081,0.0696002,1.97901,1.65858,0.253369,0.371312
876,0.197465,0.226348,0.811634,0.781595,0.610341,0.637439,0.442113,0.420843,0.646479,0.535575,0.111392,0.190124,0.020258,0.0576791,0.940743,0.939577,0.466146,0.431608,0.510118,0.519906,0.338791,0.492208,0.344699,0.506604,-1.00082,-0.973138,-0.996159,-0.924995,-0.874566,-0.704121,-0.969895,-0.832819,-1.79802,-1.91119,0.601201,0.401486,-1.578,-1.8966,0.880442,0.997887
877,0.871827,0.901615,0.248199,0.219407,0.749671,0.741248,0.856019,0.834864,0.590876,0.560746,0.254274,0.271279,0.423306,0.370897,0.0850325,0.0842412,0.694962,0.687609,0.76659,0.778631,-0.365885,-0.22006,0.879105,1.04554,-1.16387,-1.13955,0.800545,0.898801,0.572638,0.742415,0.27589,0.406792,-0.582233,-0.694673,0.0362854,-0.17013,0.157766,-0.155778,0.659055,0.777694
878,0.0907455,0.119695,0.304095,0.27321,0.864231,0.845058,0.616626,0.597258,0.246641,0.27485,0.571963,0.586857,0.646252,0.684115,0.110221,0.109945,0.978885,0.94361,0.427349,0.522201,0.9968,1.13739,-0.246974,-0.0744275,-0.39894,-0.370862,2.65143,2.7226,-1.05515,-0.880724,-0.702528,-0.565666,-1.2013,-1.30945,1.41566,1.20216,0.145624,-0.161095,-0.280366,-0.166271
879,0.247026,0.378777,0.011762,-0.0169493,0.692118,0.673219,0.0498257,0.0290743,0.0199667,-0.0110454,0.385204,0.398377,0.682139,0.738995,0.906846,0.90847,0.562933,0.508971,0.253223,0.265771,0.874598,1.01991,0.25726,0.435124,0.646916,0.672509,-1.48843,-1.41727,-0.0352839,0.137796,0.433915,0.567211,-0.557315,-0.662549,0.436949,0.183533,-1.88404,-2.19134,-0.742487,-0.626365
880,0.51707,0.637859,0.735453,0.70908,0.866385,0.801479,0.733752,0.711273,0.698421,0.665637,0.715616,0.728486,0.755447,0.793875,0.494974,0.49678,0.109606,0.0743314,0.329388,0.341578,-0.475166,-0.335437,-0.152388,0.0246434,0.190719,0.214975,-0.541739,-0.468411,-1.08942,-0.916059,-1.43122,-1.29427,0.635064,0.522217,-0.622024,-0.835098,-0.63819,-0.950393,-0.325983,-0.214303
881,0.867991,0.896941,0.621429,0.59586,0.949237,0.929739,0.348234,0.324552,0.710222,0.678569,0.0798888,0.0931112,0.341268,0.377865,0.557178,0.504428,0.0503022,0.0145621,0.135826,0.190859,-0.171225,-0.0359844,0.528658,0.703003,0.805436,0.827381,-0.736885,-0.658199,0.616635,0.789343,-0.89007,-0.758233,-0.437902,-0.556561,0.0921421,-0.120493,-0.73442,-1.04911,-0.802961,-0.689762
882,0.596703,0.627708,0.0472975,0.0191882,0.809576,0.74072,0.991738,0.966579,0.00476378,-0.02692,0.490054,0.385604,0.13238,0.167496,0.511401,0.512075,0.298493,0.260638,0.0257679,0.0401408,-0.409167,-0.272089,0.989219,1.16482,0.237356,0.260808,-0.725671,-0.646631,-0.169153,-0.00381345,-0.939142,-0.804638,-0.694325,-0.814981,1.56058,1.34365,-0.254737,-0.57413,-1.71962,-1.60351
883,0.986729,1.01621,0.541351,0.512236,0.559786,0.5517,0.757208,0.733931,0.777222,0.747251,0.730225,0.678098,0.134436,0.170947,0.994296,0.994105,0.787736,0.751433,0.930701,0.944168,-0.336941,-0.204991,-1.41185,-1.23314,1.00012,1.0295,-1.50236,-1.423,0.694526,0.860322,-0.684874,-0.529333,1.07712,0.956172,-0.0680893,-0.287248,-1.62352,-1.93441,0.794231,0.911531
884,0.822799,0.902876,0.397533,0.432033,0.387734,0.362681,0.078097,0.0560226,0.812496,0.784181,0.956998,0.970591,0.934586,0.970689,0.286031,0.285474,0.495883,0.551009,0.933944,0.930777,0.0811357,0.214861,-1.06766,-0.892165,-2.1114,-2.08436,3.01039,3.08974,0.0214458,0.18854,-0.462372,-0.254028,0.361964,0.180432,1.52,1.29955,0.883725,0.572956,1.14976,1.26346
885,0.686431,0.78954,0.414121,0.351829,0.242135,0.173662,0.68041,0.658781,0.444178,0.461742,0.764698,0.776254,0.229357,0.263473,0.113435,0.113904,0.387921,0.350586,0.953999,0.917385,1.0898,1.21707,-0.973798,-0.775149,-0.301916,-0.267473,0.558954,0.640873,-0.149184,0.0207151,-0.113227,0.0212766,-0.482286,-0.595309,0.252013,0.0357263,1.79419,1.48424,0.569758,0.68199
886,0.627998,0.676204,0.301968,0.271626,0.00414025,-0.0153578,0.361454,0.340827,0.167812,0.139303,0.909326,0.921239,0.573593,0.605455,0.98281,0.985425,0.3593,0.320841,0.891945,0.903993,0.819542,0.971908,-0.837303,-0.658133,-0.323893,-0.230813,0.133083,0.219949,0.443618,0.606764,0.892925,1.03084,0.431651,0.325913,0.95294,0.734813,-1.70548,-2.01148,0.636065,0.750215
887,0.396655,0.562869,0.481016,0.450313,0.521991,0.503548,0.632926,0.61136,0.790637,0.76349,0.602754,0.646352,0.455173,0.492491,0.867981,0.967461,0.0364379,-0.00370238,0.244676,0.257834,0.593701,0.72675,-0.214565,-0.0422161,-0.229618,-0.194154,-1.09918,-1.00599,-0.206099,-0.0475875,0.572462,0.708036,1.09496,0.987135,0.856644,0.538173,0.398556,0.0891721,0.374522,0.485662
888,0.420051,0.449533,0.00745562,-0.0233298,0.278247,0.259093,0.485032,0.463627,0.321045,0.295186,0.274318,0.371464,0.335612,0.379527,0.946075,0.949498,0.0393198,0.00173925,0.481023,0.454887,0.144432,0.278339,0.927813,1.09562,0.226867,0.264721,0.163802,0.251574,0.831267,0.985879,-0.334885,-0.204303,1.23158,1.12461,0.563295,0.341533,-0.190384,-0.542202,2.28075,2.39812
889,0.477759,0.505195,0.243772,0.213978,0.838664,0.821325,0.914988,0.892312,0.738224,0.71269,0.0846637,0.0965765,0.222752,0.266562,0.669088,0.641952,0.731772,0.693292,0.637435,0.651941,-0.0119605,0.116229,-0.1285,0.0377818,-0.622157,-0.582836,-0.658613,-0.571982,0.65749,0.818054,1.24465,1.37551,0.872667,0.771833,-0.132831,-0.354733,-0.8629,-1.17358,-0.459292,-0.339209
890,0.813622,0.842294,0.081153,0.0507684,0.0191717,0.00184046,0.796076,0.774385,0.314047,0.288789,0.156642,0.167624,0.279888,0.153598,0.33223,0.334406,0.269927,0.233193,0.194836,0.210881,-1.63035,-1.4991,0.82602,0.990537,0.980781,1.02712,0.788436,0.872583,-1.13573,-0.976347,-2.66039,-2.52637,-0.192892,-0.290775,0.561425,0.344354,0.409785,0.096888,-0.988104,-0.877442
891,0.294793,0.321653,0.776523,0.745538,0.570343,0.554356,0.944252,0.92466,0.568875,0.555374,0.45341,0.480755,0.00877245,0.0406341,0.366161,0.369679,0.581907,0.556775,0.464196,0.479224,0.657777,0.782932,-1.26157,-1.099,-0.121025,-0.0695981,0.877824,0.958802,-0.858109,-0.695297,0.547245,0.680422,-0.366781,-0.457638,-1.06074,-1.27138,-0.0134456,-0.327482,-2.10661,-1.99157
892,0.47432,0.502178,0.822724,0.793571,0.332854,0.315992,0.666039,0.646932,0.848782,0.82196,0.783341,0.793886,0.797955,0.830917,0.833184,0.836585,0.915816,0.880357,0.225881,0.239569,-0.510429,-0.389538,-0.693963,-0.528854,0.863244,0.91372,0.347444,0.430707,-0.212005,-0.0474878,-0.211244,-0.0785868,0.475912,0.384844,0.495363,0.285061,-1.60717,-1.92291,1.71586,1.83089
893,0.429241,0.49809,0.516266,0.487601,0.852497,0.834897,0.683132,0.664849,0.116264,0.0904336,0.0875301,0.0978122,0.781616,0.813155,0.386861,0.390273,0.522402,0.486155,0.406995,0.421894,0.921796,1.04537,0.501955,0.6723,0.262472,0.312502,-0.64539,-0.563238,0.0187577,0.186095,0.0902869,0.223472,0.0530843,-0.0447291,0.529121,0.32407,0.814193,0.500166,-0.950157,-0.839152
894,0.464033,0.494002,0.596482,0.566684,0.0423665,0.0268225,0.482932,0.462538,0.184794,0.203327,0.23988,0.17023,0.20452,0.236082,0.772249,0.776884,0.692006,0.65584,0.124796,0.140977,1.64242,1.77104,-0.836873,-0.666949,0.145136,0.192544,-0.780507,-0.705143,-0.578489,-0.486515,-1.16074,-1.02497,0.30763,0.214848,1.17526,0.977296,-1.02935,-1.33697,0.326041,0.440884
895,0.658065,0.689973,0.942392,0.912859,0.512782,0.495405,0.715312,0.693088,0.326308,0.316221,0.281042,0.242648,0.0628025,0.0963302,0.0980218,0.104987,0.574821,0.538669,0.545409,0.560305,-0.769012,-0.646184,0.0961769,0.270611,-2.16673,-2.12551,0.879447,0.961063,-1.3203,-1.15912,0.200431,0.336939,-0.853159,-0.938874,-0.716072,-0.920324,-0.328617,-0.64357,-0.945494,-0.824806
896,0.562306,0.592534,0.0385551,0.00860839,0.488531,0.471628,0.0908552,0.0700635,0.456486,0.429114,0.379335,0.315066,0.124068,0.159844,0.107872,0.115266,0.853945,0.819847,0.328589,0.345005,-0.399793,-0.271565,-1.23542,-1.06864,0.696474,0.730375,0.00274193,0.0896175,0.734307,0.893379,0.0922821,0.229558,-1.07746,-1.1668,-1.56518,-1.76859,-0.263721,-0.571813,-0.795426,-0.667146
897,0.667623,0.63661,0.296848,0.265222,0.971868,0.954643,0.816116,0.793797,0.154995,0.12658,0.377209,0.387484,0.68906,0.726354,0.447158,0.486072,0.835263,0.868263,0.386593,0.36617,1.5837,1.71689,1.06818,1.23249,-1.87464,-1.84561,-1.63985,-1.55429,0.251548,0.406597,-0.308565,-0.170291,1.64505,1.55729,1.02418,0.812655,0.457519,0.159854,1.13204,1.26059
898,0.652465,0.680686,0.233834,0.286088,0.387877,0.370939,0.548041,0.610853,0.226896,0.200736,0.842273,0.850433,0.584022,0.631794,0.850329,0.856879,0.951668,0.916678,0.310019,0.387335,-0.613944,-0.483571,-1.01422,-0.844681,1.7731,1.79406,-0.344046,-0.251614,1.95441,2.112,-0.155526,-0.0197553,-1.61205,-1.70415,-1.78741,-2.00278,1.19298,0.89152,-0.924095,-0.787482
899,0.279692,0.356546,0.338834,0.306954,0.0468295,0.0310684,0.449311,0.427908,0.905048,0.877418,0.278495,0.286061,0.502483,0.537235,0.913459,0.841111,0.746742,0.713873,0.393004,0.4085,0.430371,0.564598,0.71698,0.883533,-0.538032,-0.511735,-0.170292,-0.106946,1.21092,1.36468,-0.217129,-0.0820049,1.12852,1.038,0.898082,0.678137,1.2421,0.94726,1.51493,1.65627
900,0.00518158,0.0324068,0.0298276,-0.00363655,0.271913,0.256669,0.888008,0.866575,0.0555075,0.029517,0.162114,0.168676,0.812878,0.849295,0.819872,0.825344,0.0906298,0.0580482,0.722789,0.737379,1.0085,1.13874,0.892703,1.0548,0.142008,0.164906,-0.0489056,0.0377208,-0.183906,-0.0282169,0.930044,1.06504,1.00819,0.918382,0.282911,0.0591024,0.219224,-0.0823412,2.09097,2.23693
901,0.0591972,0.115233,0.391539,0.36146,0.12046,0.104772,0.465738,0.445223,0.707214,0.679737,0.565224,0.572553,0.793099,0.831533,0.0240058,0.02866,0.471224,0.438802,0.00963086,0.0254844,-0.0980121,0.0250823,-1.05944,-0.897869,-0.333422,-0.307577,1.00362,1.09427,-0.891068,-0.729423,-0.314635,-0.183396,-0.41512,-0.503557,0.0862637,-0.130554,0.713321,0.482856,-1.23741,-1.0931
902,0.214659,0.19806,0.761711,0.726556,0.759004,0.743912,0.883246,0.863379,0.940969,0.915597,0.62102,0.542741,0.409573,0.466849,0.970429,0.974108,0.0723992,0.0398576,0.135071,0.151474,0.414634,0.539117,0.507209,0.662275,1.24085,1.27282,0.374296,0.45826,0.99983,1.16467,0.0180704,0.151133,0.11791,0.0335316,1.84283,1.62919,1.35018,1.04805,-0.248205,-0.103455
903,0.253661,0.280887,0.496917,0.460312,0.782045,0.765188,0.317335,0.295196,0.880312,0.855749,0.507884,0.512929,0.0627925,0.102164,0.0975836,0.102198,0.0923525,0.0596428,0.938605,0.954887,0.160893,0.288702,-0.704816,-0.549763,-0.16355,-0.133136,-0.612052,-0.52076,0.763067,0.934652,1.46426,1.60295,-0.643524,-0.733417,0.961086,0.813443,-0.620618,-0.921548,0.380621,0.52312
904,0.738162,0.767613,0.904351,0.865986,0.549098,0.532057,0.795734,0.772687,0.181837,0.155321,0.755,0.761037,0.635384,0.673856,0.467647,0.474658,0.527844,0.494542,0.196107,0.211797,-0.541318,-0.407918,0.672175,0.820603,0.814055,0.850183,-0.889578,-0.803235,-0.0870248,0.0795051,2.02715,2.17048,0.77412,0.685033,0.210903,-0.00230255,-0.513771,-0.81891,0.25752,0.393789
905,0.47319,0.504111,0.927754,0.889403,0.912673,0.894436,0.519661,0.494958,0.194704,0.109979,0.0088756,0.0156763,0.50114,0.611238,0.0266263,0.0330791,0.66322,0.593024,0.428254,0.444576,-0.535272,-0.402497,1.2157,1.35953,0.366333,0.408767,0.75956,0.848164,0.326293,0.498122,-0.432556,-0.286785,1.37429,1.28473,0.179396,-0.042551,0.442874,0.13889,-0.229091,-0.0960608
906,0.923061,0.951976,0.0971103,0.0595349,0.692739,0.671055,0.504885,0.38966,0.0925671,0.0646375,0.785709,0.792797,0.550373,0.54862,0.269382,0.35056,0.679479,0.691506,0.22476,0.26263,-0.953043,-0.821805,0.838651,1.02768,-0.924704,-0.888179,-0.166639,-0.085355,0.22353,0.391474,-2.08107,-1.93509,-1.49288,-1.58672,-0.851428,-1.07424,-0.848719,-1.15913,-1.47948,-1.3452
907,0.250655,0.280198,0.405912,0.406792,0.465865,0.447675,0.30761,0.284363,0.395876,0.36954,0.0415396,0.047436,0.448025,0.486002,0.662228,0.668042,0.766743,0.789988,0.0623267,0.0806839,0.150608,0.285704,0.550035,0.695835,0.167164,0.201256,0.937212,1.01676,-1.22671,-1.06212,-1.58655,-1.44369,-0.0908987,-0.183118,0.166596,-0.0514092,0.810149,0.504748,0.781569,0.915107
908,0.68391,0.71316,0.792043,0.754049,0.638254,0.618403,0.79948,0.777704,0.704836,0.674443,0.605557,0.613864,0.68692,0.655481,0.625137,0.565988,0.921773,0.88847,0.227433,0.14686,0.678963,0.815001,-1.4298,-1.28659,-0.631166,-0.600166,-1.81886,-1.73282,2.78462,2.94921,-0.225446,-0.0817813,-1.17795,-1.27551,1.50441,1.28806,-0.023522,-0.334888,-0.204191,-0.0738417
909,0.473922,0.504316,0.721174,0.685007,0.0529742,0.0346992,0.722063,0.699381,0.112703,0.0800275,0.817154,0.826951,0.787562,0.82496,0.460538,0.463933,0.121011,0.0857851,0.195279,0.213036,-0.711736,-0.572781,-0.0256728,0.115022,0.643435,0.671928,-0.835095,-0.751466,-1.33326,-1.16867,-0.291919,-0.144031,0.368814,0.278312,1.44385,1.23497,-1.56689,-1.88477,0.477143,0.61222
910,0.50639,0.534747,0.929945,0.892831,0.0144336,0.0325899,0.391835,0.361813,0.970302,0.935434,0.424991,0.434817,0.465283,0.593436,0.827038,0.83102,0.407198,0.371529,0.741718,0.757167,0.374375,0.518671,-0.608506,-0.37456,0.211561,0.217552,0.530712,0.613477,-0.398369,-0.227445,1.9843,2.1375,-0.188787,-0.275186,1.89598,1.68829,-0.661221,-0.973491,-0.0782891,0.0592353
911,0.835066,0.769663,0.80649,0.76894,0.0498353,0.0304806,0.0451885,0.0242461,0.869258,0.903501,0.764968,0.686167,0.25086,0.361913,0.116468,0.122389,0.0153721,-0.0185184,0.575847,0.621455,-1.79701,-1.64603,-0.999854,-0.864141,-0.260649,-0.236824,-0.0455412,0.0389041,-0.734384,-0.656735,1.51251,1.65844,-1.06132,-1.15193,-0.196608,-0.396668,-1.57816,-1.89501,0.0679351,0.201293
912,0.973102,1.00458,0.242459,0.202798,0.405932,0.387586,0.919528,0.899253,0.913204,0.871568,0.928801,0.937517,0.0943517,0.130389,0.967106,0.972622,0.805713,0.774112,0.468811,0.485743,-0.324209,-0.178386,-0.710459,-0.568536,0.652073,0.670298,-2.31413,-2.22507,-1.26037,-1.08603,-1.30412,-1.15909,0.658071,0.574308,2.21537,2.01441,0.045795,-0.263368,0.489234,0.629203
913,0.148704,0.181859,0.771061,0.730551,0.255772,0.235688,0.78512,0.766867,0.873575,0.839635,0.62991,0.638717,0.815156,0.849468,0.759025,0.765743,0.024868,-0.00572434,0.862412,0.880309,-0.85335,-0.706299,1.29558,1.44156,-0.293131,-0.26943,0.832916,0.914039,-0.235266,-0.0675061,-1.04795,-0.900655,-0.601041,-0.688631,-0.291984,-0.497145,1.27105,0.960208,-0.69108,-0.545224
914,0.396488,0.492269,0.730968,0.725001,0.832773,0.813832,0.25665,0.238624,0.566898,0.53212,0.0996909,0.108799,0.470419,0.614106,0.100504,0.108686,0.0805713,0.0484316,0.467131,0.485032,1.01373,1.16035,-1.33765,-1.19088,0.288404,0.313999,-0.0736161,0.013786,0.280767,0.442904,0.209756,0.354611,-1.06103,-1.15008,0.629216,0.432167,-0.00818033,-0.322559,0.257081,0.399699
915,0.770618,0.802679,0.761587,0.719452,0.557813,0.539415,0.00373752,-0.014271,0.607971,0.611812,0.551869,0.522371,0.298386,0.378744,0.468625,0.475773,0.478438,0.455988,0.56327,0.603761,0.224343,0.369225,0.509195,0.661351,1.30114,1.32869,-0.766287,-0.684082,-1.16002,-0.994515,-1.2783,-1.14145,0.433026,0.34172,-0.221437,-0.416098,0.588964,0.27693,0.615872,0.751633
916,0.454478,0.487685,0.314078,0.270995,0.825074,0.805529,0.408226,0.390211,0.761626,0.691503,0.92727,0.935943,0.111228,0.143382,0.36887,0.375838,0.897787,0.863544,0.706459,0.72249,0.818882,0.958817,-1.30002,-1.14911,0.248193,0.278157,-0.921894,-0.927233,-1.20873,-1.03682,0.843633,0.979532,0.258517,0.159989,0.758675,0.548289,1.61431,1.29867,-0.359408,-0.221498
917,0.636321,0.630771,0.918842,0.876437,0.608963,0.587663,0.418403,0.398086,0.806788,0.771195,0.494232,0.505223,0.923662,0.954231,0.567828,0.572516,0.188073,0.153147,0.460757,0.540544,0.26276,0.400248,0.302036,0.455598,-0.0817558,-0.0575874,-1.25195,-1.17038,0.897081,1.06413,0.285725,0.423936,-0.599917,-0.698366,1.70482,1.51268,1.1584,0.843299,-0.608817,-0.470788
918,0.742002,0.773857,0.728478,0.686924,0.801891,0.768851,0.891572,0.871094,0.259015,0.222688,0.844337,0.856109,0.217517,0.247015,0.353863,0.360906,0.21113,0.177491,0.341063,0.358598,0.710907,0.850704,-0.460761,-0.308879,0.399079,0.426194,2.30953,2.38986,-0.310253,-0.140619,0.288625,0.422744,1.26375,1.17123,-0.649625,-0.835397,-0.784504,-1.10387,0.222149,0.366514
919,0.272135,0.303387,0.767195,0.798238,0.971338,0.950039,0.474465,0.454325,0.848824,0.812655,0.321831,0.331853,0.0299599,0.0580321,0.541798,0.632392,0.76445,0.732705,0.698821,0.718725,-0.750682,-0.613271,0.889541,1.04652,0.881796,0.909975,-0.402142,-0.323166,1.17165,1.33616,-1.44012,-1.29956,1.91618,1.81813,-0.757753,-0.949247,-0.50214,-0.817135,-1.59822,-1.44814
920,0.180408,0.211322,0.952116,0.909552,0.237792,0.214439,0.745824,0.724858,0.598341,0.622071,0.888473,0.898281,0.587836,0.614924,0.897436,0.903879,0.334625,0.303614,0.632011,0.650393,0.425711,0.555939,-0.932397,-0.780553,-0.34987,-0.326316,0.602431,0.68933,-0.332875,-0.164793,-0.519569,-0.381055,2.33335,2.23341,1.68262,1.4954,-0.77151,-1.08662,-0.80781,-0.654864
921,0.787707,0.817299,0.269388,0.228956,0.0251006,0.00128051,0.486389,0.467201,0.465644,0.431487,0.0333796,0.0437277,0.136806,0.164084,0.359227,0.367781,0.893295,0.863381,0.94054,0.958171,0.389782,0.615663,0.0138639,0.172202,-0.173451,-0.143186,-1.25429,-1.17548,1.53275,1.69531,1.59976,1.73993,-1.54329,-1.63587,0.41764,0.297765,-0.0717187,-0.39322,0.355624,0.504193
922,0.077255,0.109539,0.320203,0.288175,0.703403,0.680996,0.989847,0.969536,0.963161,0.929413,0.931067,0.940445,0.952692,0.980174,0.243495,0.268455,0.895637,0.863433,0.0825623,0.100763,0.441706,0.675386,0.244268,0.458488,-0.618088,-0.584602,1.10985,1.19199,-1.03949,-0.879828,0.53911,0.675097,-0.667096,-0.761344,-0.720706,-0.899874,-0.540122,-0.862871,0.988226,1.13077
923,0.841116,0.87391,0.389639,0.347395,0.362391,0.341126,0.18166,0.16352,0.095728,0.0620964,0.576866,0.588126,0.549638,0.544182,0.161147,0.169129,0.449757,0.418857,0.00163513,0.0227081,0.604882,0.73511,0.587585,0.744774,0.16324,0.198105,0.333889,0.496361,1.13208,1.28905,0.345679,0.475154,0.478265,0.376548,-1.00973,-1.19541,-2.48009,-2.79544,-1.64126,-1.50465
924,0.944811,0.925057,0.938815,0.895264,0.492031,0.563663,0.697946,0.681568,0.245667,0.212284,0.00330954,0.0137618,0.0814103,0.108189,0.432761,0.439807,0.655679,0.625564,0.499277,0.521339,0.771135,0.908644,0.513387,0.670309,-1.45111,-1.42305,-0.286465,-0.199271,0.533656,0.695339,1.78235,1.91364,1.37411,1.26521,-0.329007,-0.512102,-0.952292,-1.27273,0.444752,0.581521
925,0.945963,0.976203,0.317889,0.274391,0.809437,0.786201,0.645201,0.629942,0.0783763,0.0456627,0.342522,0.347248,0.696045,0.724366,0.941882,0.946811,0.0420292,0.00975968,0.0356877,0.0553833,-2.46857,-2.3349,0.644412,0.793562,1.32494,1.34839,-1.6143,-1.53192,1.49282,1.65122,0.300898,0.43278,-1.62886,-1.7436,-0.550604,-0.731896,-1.26001,-1.58861,0.0699037,0.209303
926,0.377179,0.405584,0.896382,0.850155,0.590148,0.568335,0.15772,0.143029,0.654253,0.619956,0.668653,0.680735,0.629455,0.655347,0.589905,0.59469,0.301345,0.271419,0.133342,0.234408,-2.47909,-2.34418,0.56951,0.719097,-0.576597,-0.554173,-1.86342,-1.78364,-0.158267,-0.00130118,-1.82378,-1.6922,-0.511443,-0.623204,-0.11742,-0.262769,-0.718377,-1.04996,-0.530437,-0.410245
927,0.828705,0.858044,0.798362,0.738407,0.849031,0.82902,0.73323,0.720909,0.477221,0.443323,0.69301,0.741882,0.299794,0.324943,0.755065,0.761634,0.964618,0.933751,0.392053,0.413433,-1.00676,-0.876537,0.0554832,0.202292,-0.401662,-0.387671,-0.426351,-0.339073,-0.719303,-0.565194,1.42773,1.55295,0.139234,0.0236954,0.382953,0.206359,0.729806,0.395253,-1.17169,-1.02979
928,0.228601,0.256875,0.671879,0.62666,0.0744437,0.0546023,0.0588902,0.0489375,0.0551101,0.0194225,0.701838,0.803029,0.730451,0.756594,0.695049,0.70098,0.535435,0.473726,0.785814,0.807999,0.691369,0.821974,0.205224,0.356856,-1.43345,-1.42288,0.025648,0.0831426,1.19058,1.34218,0.449153,0.580488,-0.718346,-0.834659,0.519046,0.338279,-0.366029,-0.695698,0.0545962,0.190956
929,0.861429,0.887557,0.839053,0.776629,0.332777,0.348487,0.187774,0.178466,0.911897,0.874829,0.852094,0.864176,0.0980612,0.124516,0.34319,0.348858,0.0431371,0.0137014,0.401292,0.422685,-0.017006,0.109706,-1.9694,-1.81373,1.05241,1.06947,0.419568,0.505358,1.68886,1.83772,1.23231,1.36025,0.328704,0.27776,0.205329,0.0249479,-0.640372,-0.965182,1.05496,1.19699
930,0.954651,0.892497,0.970795,0.926597,0.578446,0.642373,0.928901,0.921176,0.873234,0.759717,0.0929848,0.104623,0.0938876,0.122796,0.500807,0.448633,0.141561,0.112235,0.958344,0.981559,-0.170556,-0.0373751,-1.62215,-1.47275,0.725837,0.746531,1.67156,1.76293,-1.05952,-0.917656,1.36877,1.49753,1.50631,1.39018,-1.07515,-1.25429,0.457337,0.134472,0.498748,0.64401
931,0.869014,0.897437,0.234687,0.190956,0.957405,0.936258,0.973392,0.887355,0.702149,0.644604,0.108782,0.074811,0.624737,0.653949,0.542017,0.548407,0.95973,0.930526,0.14498,0.166238,-0.638875,-0.502692,0.704794,0.860213,0.407697,0.423591,0.367134,0.460182,-0.352825,-0.208808,0.348435,0.479073,0.341487,0.217798,-0.943581,-1.12237,-1.84729,-2.16688,-2.31797,-2.17583
932,0.750104,0.778771,0.109192,0.0670652,0.771547,0.74878,0.860043,0.853534,0.56495,0.529492,0.0309672,0.044999,0.575941,0.605703,0.317117,0.321446,0.809608,0.782335,0.511138,0.445052,0.0945318,0.222974,-1.73149,-1.58123,-0.525213,-0.516137,0.402601,0.501503,-0.29861,-0.157662,-2.56819,-2.43654,-1.4332,-1.55095,0.655764,0.48177,1.61624,1.29281,2.26068,2.40805
933,0.417458,0.443619,0.435528,0.321894,0.106026,0.0853542,0.537458,0.530727,0.995686,0.962036,0.371982,0.334873,0.194108,0.224763,0.785776,0.788352,0.0626564,0.0349056,0.701772,0.723867,-1.19232,-1.05861,-0.0290816,0.116396,0.515513,0.527235,-0.943303,-0.845617,1.436,1.58065,-0.565212,-0.430186,0.293339,0.175286,0.170169,0.00153952,0.0691022,-0.257077,-0.923601,-0.777798
934,0.403707,0.371872,0.618731,0.576722,0.260689,0.241995,0.521846,0.513553,0.447064,0.413529,0.61312,0.624748,0.957102,0.989514,0.835416,0.838367,0.377616,0.34975,0.630228,0.649768,0.137682,0.360256,0.655169,0.794755,0.495986,0.512489,0.405663,0.502521,0.722981,0.78804,-0.528278,-0.399909,-0.296669,-0.409668,0.380842,0.209144,-2.04494,-2.36474,-1.03515,-0.891276
935,0.362057,0.300124,0.397153,0.277461,0.759667,0.740313,0.716669,0.722679,0.176459,0.141524,0.225516,0.237295,0.289709,0.322743,0.17554,0.176262,0.435926,0.40791,0.803262,0.82194,1.64542,1.77913,0.303967,0.44479,0.749591,0.759513,-0.283938,-0.180305,-0.151205,-0.00456644,1.61434,1.73695,0.146991,0.0372333,0.886464,0.709047,-0.686275,-1.00926,-0.521956,-0.371823
936,0.203926,0.228376,0.0201868,-0.021801,0.205224,0.186172,0.938081,0.931805,0.733141,0.696017,0.85529,0.867977,0.472787,0.563964,0.248988,0.336617,0.182066,0.207487,0.55969,0.576629,-0.0319804,0.100354,0.8999,1.04664,-1.23563,-1.22241,1.58397,1.69152,0.904482,1.04388,-0.450261,-0.328216,0.061025,-0.0520852,0.90921,0.732026,1.35113,1.02365,1.1769,1.32386
937,0.823579,0.848564,0.900885,0.856858,0.409248,0.391542,0.0775889,0.0728156,0.39591,0.363611,0.0886985,0.102833,0.773166,0.805186,0.496013,0.496971,0.0351249,0.00706334,0.545163,0.562431,1.17987,1.31464,0.957485,1.10933,-0.339742,-0.330536,1.16953,1.27059,0.455133,0.600304,-0.37887,-0.252586,-0.303384,-0.419262,-1.36898,-1.55062,-2.60534,-2.92994,0.126525,0.275112
938,0.965837,0.988919,0.665131,0.622355,0.371635,0.352722,0.303677,0.349131,0.0695387,0.031204,0.808714,0.82419,0.781154,0.904828,0.340973,0.432785,0.324886,0.227488,0.768811,0.785545,-1.55051,-1.41844,0.156624,0.314656,-0.262047,-0.253311,0.0137089,0.122106,-1.18009,-1.03794,-0.664087,-0.544489,0.323966,0.211571,-1.82298,-1.99997,-1.20261,-1.47857,0.180721,0.327946
939,0.416839,0.437783,0.165672,0.124073,0.665033,0.649353,0.630749,0.625446,0.48203,0.443827,0.665453,0.609525,0.970465,1.00447,0.365826,0.3686,0.474263,0.447912,0.105126,0.124192,0.545323,0.677499,-0.263324,-0.182982,0.642455,0.65381,0.7307,0.838314,0.945253,1.08007,-0.255472,-0.132823,-0.86274,-1.02968,0.0529472,-0.118872,0.297403,-0.0271954,0.489377,0.636573
940,0.724963,0.744503,0.303644,0.262415,0.962738,0.945984,0.463601,0.457842,0.173801,0.230826,0.377098,0.394859,0.641937,0.58379,0.588528,0.678933,0.311361,0.285118,0.510472,0.536614,-0.0328747,0.103226,-0.833065,-0.68062,0.320951,0.331618,1.07302,1.18671,1.36764,1.49869,-0.253739,-0.134016,-2.15854,-2.27094,0.155073,-0.016824,-0.738741,-1.0568,0.529466,0.674911
941,0.4151,0.435457,0.9934,0.952082,0.552988,0.590605,0.700309,0.693415,0.0585659,0.0178256,0.700139,0.719996,0.129045,0.16311,0.98903,0.989265,0.760644,0.734727,0.928678,0.949036,0.0407054,0.170324,0.967536,1.12377,2.62928,2.64056,0.174246,0.286453,-0.762108,-0.633509,0.551866,0.67727,0.48314,0.365253,1.45656,1.29216,0.285468,-0.0350543,-0.842728,-0.696634
942,0.60336,0.721558,0.810841,0.767831,0.250946,0.235225,0.700401,0.692195,0.931364,0.892342,0.742564,0.760378,0.462035,0.566895,0.0121173,0.0118477,0.75286,0.729083,0.613706,0.633268,-0.75668,-0.620799,-1.59462,-1.43321,-0.227198,-0.217482,-1.03419,-0.924257,1.15068,1.27386,-0.0631949,0.0569809,-1.35455,-1.47891,-0.2687,-0.433711,-0.49656,-0.814096,0.614911,0.75257
943,0.98743,1.00766,0.95502,0.911382,0.616784,0.572399,0.247957,0.240328,0.841575,0.711067,0.208313,0.226194,0.937727,0.970679,0.990135,0.989642,0.425442,0.399788,0.957789,0.977591,0.54315,0.672913,1.86199,2.02147,-0.774988,-0.768305,0.301944,0.41008,-1.17474,-1.04818,1.22989,1.34268,0.317778,0.19997,-0.295412,-0.456976,-0.56349,-0.880872,0.821105,0.955254
944,0.00420215,0.0234316,0.185924,0.143902,0.923695,0.909574,0.0301055,0.0228041,0.57038,0.529793,0.597792,0.519744,0.913248,0.866754,0.453933,0.453544,0.384369,0.27275,0.848166,0.867228,0.170926,0.299172,0.0801042,0.244823,-0.502282,-0.490704,0.453796,0.560836,-0.2018,-0.104867,0.722043,0.832079,-0.405301,-0.520198,0.833775,0.671937,0.746397,0.435982,0.113854,0.253246
945,0.130178,0.148819,0.153591,0.148993,0.674155,0.660148,0.463572,0.45622,0.0686801,0.0265554,0.795524,0.813295,0.729558,0.762828,0.118731,0.116807,0.171811,0.145712,0.472588,0.519947,0.550105,0.673791,1.49757,1.66264,-1.23098,-1.2163,-2.34518,-2.23451,0.716502,0.838444,0.872484,0.982615,-0.540103,-0.620609,-1.47755,-1.64397,-0.676915,-0.987141,-1.1038,-0.966451
946,0.677832,0.695217,0.19495,0.154085,0.697458,0.682747,0.460829,0.508408,0.559859,0.519816,0.263214,0.279111,0.92014,0.954318,0.275516,0.274204,0.764035,0.736351,0.154302,0.172667,-0.293445,-0.163347,0.133767,0.292394,-0.0406762,-0.0205427,0.796046,0.904593,-0.816905,-0.692704,1.43672,1.55014,-0.601406,-0.72102,-0.255761,-0.427287,-0.117956,-0.348569,-1.15158,-1.01967
947,0.236833,0.254709,0.847134,0.804121,0.721593,0.705345,0.567563,0.560597,0.819597,0.780882,0.435517,0.453885,0.0144099,0.0504885,0.101656,0.138811,0.678684,0.660607,0.112472,0.129384,1.24332,1.36602,-1.00862,-0.843247,-1.09409,-1.07107,1.09418,1.20845,1.07686,1.20139,-0.265376,-0.156547,-0.518283,-0.64301,-0.299534,-0.467535,0.602002,0.290003,-0.673519,-0.546754
948,0.680744,0.697387,0.804259,0.759488,0.947783,0.930946,0.765447,0.756889,0.558018,0.492438,0.155947,0.176097,0.299442,0.337034,0.00410134,0.00341836,0.481758,0.584862,0.683152,0.69778,0.695437,0.822708,-0.375802,-0.212164,0.62246,0.651316,-1.42144,-1.30788,-0.23873,-0.116059,0.871313,0.97633,1.82767,1.7051,-0.577863,-0.748494,-1.27511,-1.58161,-1.42566,-1.29338
949,0.145993,0.16113,0.231872,0.188116,0.598162,0.573424,0.439991,0.429402,0.243336,0.203994,0.104781,0.202965,0.806228,0.843455,0.750565,0.750368,0.536801,0.509117,0.53015,0.583748,0.906511,1.02598,-1.92239,-1.75453,1.24754,1.27955,-0.457175,-0.343954,0.595795,0.717184,1.37939,1.48343,0.494298,0.378199,0.158245,-0.0171785,-1.39278,-1.69522,0.197594,0.327579
950,0.59878,0.61359,0.108796,0.0642251,0.234402,0.215902,0.768658,0.75865,0.806671,0.766945,0.212411,0.229833,0.749923,0.789313,0.307824,0.30879,0.713724,0.684085,0.45283,0.469717,-0.0709844,0.0523935,-3.0114,-2.84282,-0.603073,-0.577498,-0.330765,-0.295758,-0.421627,-0.306818,-1.41592,-1.31954,0.148878,0.025423,-0.368554,-0.543428,1.02291,0.727849,0.569274,0.695475
951,0.0737121,0.0875586,0.86331,0.819728,0.759219,0.739371,0.445975,0.435842,0.163675,0.122673,0.572547,0.589926,0.927861,0.965773,0.484891,0.555655,0.37959,0.35025,0.548133,0.565882,-0.504066,-0.381958,-1.56215,-1.39462,-1.33264,-1.3031,-0.362049,-0.247562,-0.840025,-0.719173,-2.68225,-2.58314,0.102784,-0.0193997,-0.650028,-0.824386,1.86808,1.57938,-1.08961,-0.965818
952,0.202964,0.217573,0.431093,0.386562,0.328099,0.30946,0.778606,0.769597,0.450362,0.433609,0.145127,0.164206,0.464841,0.545093,0.798889,0.802521,0.283028,0.353268,0.954135,0.970187,0.0280193,0.14734,0.0947204,0.25605,-0.958654,-0.935631,0.972957,1.08677,0.23489,0.359531,0.0958228,0.188959,-0.544001,-0.663537,0.555695,0.379219,0.352488,0.0612004,-1.43987,-1.32297
953,0.732599,0.748913,0.315077,0.274814,0.310799,0.282888,0.198093,0.190983,0.784268,0.744545,0.113697,0.132069,0.0850451,0.124414,0.37073,0.376061,0.384073,0.356285,0.367087,0.384492,-0.741637,-0.627458,0.593602,0.750235,-1.13227,-1.10205,-1.45439,-1.34718,2.25362,2.38122,-0.0249754,0.0516492,-0.474598,-0.600338,0.941462,0.772004,1.22647,0.927491,0.655948,0.774841
954,0.958215,0.975469,0.206642,0.163067,0.274855,0.256317,0.425703,0.415953,0.110948,0.0693463,0.395767,0.333143,0.654306,0.696105,0.978469,0.985835,0.999194,0.972332,0.251402,0.2687,-0.617348,-0.499638,1.78942,1.95139,1.18027,1.2069,0.281706,0.381813,0.254819,0.382965,-0.186532,-0.0856607,0.676017,0.555134,-0.102557,-0.275571,-0.0751113,-0.370527,0.733595,0.855517
955,0.740477,0.756234,0.630269,0.587512,0.931451,0.910764,0.336864,0.32776,0.955731,0.914962,0.513498,0.534216,0.438066,0.480203,0.14523,0.153188,0.965007,0.937261,0.417025,0.435636,0.348207,0.422049,0.429739,0.596861,-0.873126,-0.839521,1.12441,1.22183,-1.10603,-0.981256,0.496967,0.601678,0.530374,0.468716,-0.348809,-0.527061,-0.476795,-0.778355,-0.908848,-0.791005
956,0.215447,0.230202,0.745298,0.672822,0.348524,0.32706,0.977117,0.969786,0.978696,0.93847,0.58167,0.588768,0.749515,0.792263,0.413012,0.418791,0.0194653,-0.0081655,0.153346,0.170663,1.22603,1.34374,-1.1413,-0.975419,0.804855,0.834905,-1.43763,-1.3481,-2.1846,-2.06537,-0.502905,-0.402023,0.509207,0.382298,0.169887,-0.0120664,0.18059,-0.116762,0.205758,0.240634
957,0.83916,0.855733,0.802647,0.758132,0.43584,0.391163,0.0649314,0.058154,0.162733,0.122245,0.734047,0.64332,0.315282,0.356182,0.283135,0.287003,0.827261,0.799371,0.66661,0.684179,1.17717,1.37403,0.69772,0.86351,-1.4705,-1.4374,-1.17987,-1.09167,-0.208606,-0.0905455,-1.18735,-1.08412,-0.363042,-0.494448,-1.20275,-1.38227,-0.480694,-0.771072,1.15413,1.27227
958,0.218624,0.235017,0.216785,0.17197,0.613588,0.455266,0.560095,0.551495,0.609897,0.570448,0.743635,0.697872,0.235858,0.276845,0.418532,0.422561,0.51194,0.420843,0.461439,0.479156,1.28159,1.40432,-1.29318,-1.13162,-0.590116,-0.560195,1.30186,1.38899,0.700082,0.818917,1.85613,1.96376,-0.095709,-0.259146,0.402804,0.221864,0.918286,0.628651,-1.16461,-1.04916
959,0.270701,0.285265,0.612922,0.567419,0.542565,0.519369,0.38453,0.373829,0.314022,0.273906,0.731121,0.752424,0.920741,0.959737,0.991114,0.996177,0.0707833,0.0423151,0.732411,0.752325,-1.99193,-1.86185,-0.135989,0.0214198,-1.20453,-1.17755,-0.0196276,0.0724801,-0.069587,0.0559943,-0.189224,-0.0849829,0.106694,-0.0238439,-1.62393,-1.80034,-0.646288,-0.936258,-0.69213,-0.548002
960,0.835845,0.851808,0.438797,0.351924,0.0876801,0.0653755,0.835566,0.826911,0.3436,0.301301,0.23915,0.262167,0.841914,0.8804,0.836124,0.839662,0.0514233,0.0425901,0.445403,0.440207,0.794596,0.92572,-1.30594,-1.14463,0.617331,0.639335,0.544969,0.634014,1.44993,1.57856,0.150948,0.249545,-0.267272,-0.391021,-1.57593,-1.74735,-0.179199,-0.477754,-0.164464,-0.0468457
961,0.622814,0.663861,0.17994,0.136429,0.456836,0.432696,0.804314,0.841296,0.858978,0.815423,0.305854,0.328608,0.330367,0.368799,0.98589,0.990926,0.0734039,0.0428651,0.107529,0.128089,-0.478726,-0.339811,0.331805,0.491017,-1.06739,-1.0437,0.844364,0.937876,0.674172,0.801985,0.750083,0.847958,2.3356,2.21506,-1.06003,-1.23236,0.550859,0.194936,-0.532564,-0.419064
962,0.457732,0.475914,0.789508,0.746762,0.150132,0.12862,0.778273,0.855681,0.996512,0.955187,0.684839,0.707498,0.303427,0.340412,0.419099,0.424281,0.7926,0.75932,0.551501,0.571645,-1.16926,-1.03643,-0.586854,-0.425773,-0.696793,-0.676231,-0.869694,-0.769797,0.526081,0.650884,-1.09317,-1.00002,-0.923711,-1.04637,-0.925777,-1.10044,1.16029,0.867627,0.853537,0.968769
963,0.725235,0.742788,0.98219,0.939542,0.629904,0.606802,0.87852,0.870066,0.904432,0.864483,0.737112,0.758233,0.685771,0.721867,0.43915,0.484427,0.969315,0.934288,0.258132,0.276238,0.210011,0.335941,-0.284586,-0.183204,-1.05462,-1.02674,0.737695,0.834779,-0.78748,-0.666561,-0.807855,-0.710779,1.19814,1.07716,-0.498928,-0.67723,-1.73431,-2.02317,0.32826,0.447154
964,0.412836,0.432049,0.184919,0.141956,0.840677,0.817086,0.0755837,0.0691355,0.598456,0.556969,0.0399879,0.0621596,0.702445,0.739655,0.5396,0.544573,0.319988,0.284105,0.60963,0.594154,0.0588385,0.18886,-0.100506,0.059364,-2.57671,-2.55347,-0.0190792,0.0728986,-0.902937,-0.789195,-0.878223,-0.788516,-0.103052,-0.219794,0.640278,0.464138,-0.421332,-0.706315,0.441302,0.605324
965,0.102257,0.121309,0.161958,0.0919056,0.468969,0.447742,0.0949704,0.0870526,0.53893,0.497121,0.914057,0.937455,0.211072,0.248545,0.837138,0.841217,0.261316,0.224335,0.894524,0.912069,0.519654,0.655753,-0.76421,-0.611866,0.758622,0.786146,-0.498733,-0.408263,0.264778,0.381873,0.261455,0.344361,-1.64611,-1.76883,-0.201945,-0.384127,2.20592,1.91636,0.644601,0.763495
966,0.435772,0.453463,0.082998,0.0418554,0.981276,0.961756,0.733515,0.724395,0.893621,0.849149,0.682159,0.731641,0.551881,0.590527,0.610099,0.561894,0.714256,0.679752,0.941651,0.959105,0.34769,0.480019,1.23506,1.38355,-0.557913,-0.525748,-0.185727,-0.0902915,1.19268,1.30752,0.869436,0.958576,2.24193,2.11922,0.512643,0.330478,0.0534011,-0.238746,-0.0962515,0.0168676
967,0.242478,0.259599,0.38385,0.296684,0.285761,0.267768,0.765251,0.757174,0.259406,0.214252,0.500145,0.525826,0.0671994,0.104223,0.278109,0.282571,0.642602,0.493605,0.121699,0.138416,0.402625,0.440373,0.415356,0.558548,-0.255725,-0.217866,1.38859,1.48403,-1.38071,-1.26762,-1.55029,-1.46755,-1.84742,-1.97166,0.451106,0.262436,0.525998,0.236233,0.0186515,0.129997
968,0.631842,0.648102,0.593117,0.551512,0.522294,0.503138,0.143607,0.134149,0.141351,0.0976207,0.470878,0.498085,0.75186,0.787115,0.454768,0.390997,0.377739,0.307457,0.0224625,0.0393854,0.270544,0.400726,0.797263,0.944032,-2.18821,-2.15375,0.67918,0.769919,0.259991,0.375802,-0.184989,-0.105647,0.518677,0.392874,0.603446,0.387046,0.609566,0.223601,0.75726,0.862503
969,0.54464,0.561126,0.270498,0.321397,0.0836278,0.063915,0.257995,0.311451,0.86801,0.825618,0.999719,1.02476,0.228013,0.264799,0.49415,0.499424,0.153613,0.12131,0.459898,0.503974,0.507134,0.635541,-0.075251,0.0725037,-0.638957,-0.60782,0.726153,0.81124,1.58999,1.70022,-0.474083,-0.397551,-2.0367,-2.16867,0.694569,0.511657,0.499678,0.210968,-0.0321603,0.0698391
970,0.0789411,0.095305,0.133457,0.0912826,0.323113,0.303969,0.529633,0.488753,0.604318,0.563314,0.472571,0.551422,0.209454,0.247037,0.238106,0.242604,0.613479,0.581607,0.950611,0.968562,-0.142359,-0.0153452,-0.232929,-0.0771863,-1.86596,-1.82937,-1.43315,-1.35381,0.372582,0.476341,0.49246,0.565972,-1.16744,-1.29414,-0.536724,-0.720164,-0.186664,-0.553584,-0.116922,-0.0146134
971,0.0482647,0.0640222,0.796013,0.755492,0.257288,0.238928,0.610343,0.666054,0.563768,0.524508,0.0512797,0.0780827,0.444415,0.482886,0.711339,0.714682,0.86105,0.827683,0.647931,0.669446,0.369943,0.49869,-0.861786,-0.701718,-0.990137,-0.952166,-0.0948832,-0.0194782,0.18873,0.303365,-0.839474,-0.759373,-0.568256,-0.694448,-2.16655,-2.35107,-1.02437,-1.31814,-0.502227,-0.399652
972,0.47033,0.487114,0.607493,0.593683,0.716844,0.697763,0.852338,0.843356,0.991374,0.952792,0.686439,0.714062,0.332032,0.368473,0.425598,0.493999,0.861832,0.868244,0.399011,0.370329,0.0280628,0.156733,-0.390853,-0.225477,1.04036,1.08177,-0.511168,-0.440402,0.0296975,0.13039,0.339898,0.419158,-0.799813,-0.92237,-1.89533,-2.07939,2.42896,2.14156,1.11205,1.22131
973,0.338452,0.353834,0.386824,0.431873,0.114109,0.0933826,0.754614,0.648694,0.767254,0.730634,0.0619696,0.0894743,0.876926,0.914738,0.258425,0.273316,0.974415,0.908804,0.0532614,0.0712129,1.94215,2.06835,-1.32651,-1.15773,-0.282753,-0.24661,0.182815,0.260734,-2.27512,-2.17637,0.34079,0.417965,1.90433,1.77893,-0.10073,-0.290232,0.698826,0.416745,-0.393133,-0.287392
974,0.853798,0.870441,0.310447,0.270063,0.876593,0.855274,0.462785,0.454032,0.139661,0.100819,0.0577412,0.0863888,0.643624,0.714918,0.0505752,0.0526329,0.981288,0.949365,0.130675,0.153604,1.73892,1.8629,-2.77825,-2.60678,-0.0456001,0.0794856,1.27129,1.34729,-0.65048,-0.646497,-1.2732,-1.19856,-0.457575,-0.591116,0.651575,0.558117,0.72259,0.443381,-1.90535,-1.79609
975,0.278563,0.294191,0.307025,0.264417,0.876978,0.856628,0.0278894,0.0177963,0.396093,0.323269,0.5593,0.588736,0.47571,0.515098,0.139824,0.105478,0.787459,0.756583,0.217845,0.235994,-0.273589,-0.147473,0.654377,0.8285,0.375176,0.405581,0.582879,0.664463,0.787205,0.883379,-0.498765,-0.348973,1.13107,0.996278,1.59597,1.40647,0.0847578,-0.195914,-1.59208,-1.48746
976,0.703332,0.717282,0.525415,0.481748,0.610568,0.592405,0.789052,0.781195,0.588823,0.545719,0.555845,0.585651,0.772551,0.812256,0.157135,0.158323,0.158678,0.126673,0.134283,0.318385,0.170568,0.302982,-0.910144,-0.729339,0.819552,0.781063,-1.89523,-1.81893,-0.224731,-0.126207,0.431883,0.500616,-0.324078,-0.45514,-0.0739272,-0.271296,1.78899,1.51444,-0.256858,-0.153485
977,0.870376,0.882266,0.181637,0.136745,0.985424,0.969804,0.347551,0.339265,0.80701,0.768168,0.923516,0.955208,0.0836122,0.124685,0.989133,0.991921,0.853612,0.823263,0.382824,0.400775,0.00808817,0.140872,-1.17845,-1.00334,1.12964,1.15654,-0.60933,-0.53165,-0.400132,-0.309538,-0.938915,-0.873327,0.534664,0.401603,-0.858519,-1.06003,-0.00865716,-0.275712,1.07889,1.18049
978,0.181981,0.195539,0.336599,0.290791,0.757457,0.765595,0.574174,0.564234,0.472398,0.531816,0.882883,0.913241,0.699477,0.740861,0.312121,0.314563,0.981374,0.952632,0.57025,0.587968,1.28982,1.42055,0.607396,0.787576,-1.51999,-1.48665,-1.39401,-1.32245,-1.29204,-1.19485,-0.583223,-0.520702,-1.34539,-1.47365,0.729686,0.526766,-1.03546,-1.30531,1.32542,1.42686
979,0.530931,0.468682,0.952734,0.905799,0.643759,0.561385,0.175335,0.167389,0.334306,0.295464,0.437021,0.467191,0.996876,1.03802,0.693969,0.696799,0.502239,0.495698,0.542211,0.558596,0.21129,0.339055,-0.0499987,0.132229,0.0221015,0.0592778,-0.258662,-0.187176,-0.769437,-0.670077,-1.41892,-1.35507,-1.62753,-1.78013,-0.0586336,-0.261972,1.59497,1.32984,1.8698,1.97586
980,0.725291,0.741825,0.917037,0.817857,0.370332,0.357176,0.103343,0.136393,0.626222,0.587418,0.317818,0.349806,0.721653,0.762427,0.68546,0.686803,0.0680098,0.0387643,0.17165,0.188087,1.96782,2.09723,2.34136,2.51574,-1.11827,-1.01516,0.270931,0.34432,1.09035,1.19002,-1.13579,-1.06583,-1.96213,-2.0866,0.456912,0.253022,-2.502,-2.76281,0.687765,0.786858
981,0.235327,0.25077,0.779622,0.729915,0.826076,0.810685,0.113246,0.105397,0.280497,0.23999,0.940591,0.970565,0.877977,0.917785,0.255448,0.2557,0.752228,0.721042,0.841897,0.857482,-0.68252,-0.558015,0.809137,0.988588,-2.12091,-2.08959,1.18601,1.26277,-1.25768,-1.16478,0.734134,0.803739,-0.882824,-1.01412,-1.12852,-1.33083,0.671299,0.41127,-0.122618,-0.0202854
982,0.237746,0.251337,0.425752,0.375733,0.412624,0.396259,0.631096,0.623446,0.67337,0.632757,0.567148,0.598872,0.746152,0.798785,0.960028,0.96307,0.233206,0.201801,0.43499,0.451091,-0.37559,-0.244789,-1.1434,-0.964081,0.039959,0.0714787,2.30643,2.37994,-0.674496,-0.578735,-1.18514,-1.12103,-1.88224,-2.01592,-1.15937,-1.35409,1.02164,0.762286,0.463158,0.560383
983,0.8223,0.836967,0.460744,0.40965,0.887193,0.869854,0.0784172,0.0708062,0.538858,0.496815,0.673008,0.596642,0.593496,0.679785,0.847372,0.851492,0.515625,0.482979,0.982903,1.00003,0.337358,0.445354,-1.02884,-0.791685,-0.689185,-0.654121,-1.4508,-1.37851,-1.05954,-0.961057,0.64911,0.720129,1.25963,1.12693,-0.423218,-0.661359,0.997992,0.741341,-1.53631,-1.44218
984,0.867889,0.882254,0.962925,0.912462,0.505032,0.485238,0.275874,0.267098,0.79919,0.725776,0.635772,0.594413,0.519192,0.560785,0.322083,0.325683,0.581229,0.477265,0.391732,0.409365,1.01155,1.1355,-0.80067,-0.619289,0.785006,0.815258,-0.597185,-0.522427,0.481065,0.576561,-1.03511,-0.956374,0.603996,0.468263,0.242371,0.0313723,-1.02437,-1.27497,0.772482,0.868679
985,0.0386598,0.0540749,0.194741,0.144982,0.975515,0.95382,0.0115585,0.00365877,0.998025,0.954737,0.568316,0.592183,0.810958,0.851941,0.432209,0.436391,0.505325,0.471552,0.750566,0.769493,0.831036,0.959763,0.222466,0.396423,-0.146285,-0.109536,0.735269,0.811909,1.43863,1.53244,0.294727,0.375999,0.277277,0.0474064,0.918825,0.724104,0.908818,0.656367,-1.38261,-1.28782
986,0.487712,0.50194,0.546549,0.495485,0.0796308,0.057188,0.335241,0.327956,0.742142,0.697683,0.552184,0.589954,0.33011,0.370317,0.256682,0.259552,0.0435566,0.0114527,0.746044,0.85256,-1.01069,-0.875553,1.74556,1.92414,0.439918,0.473893,-0.973118,-0.895764,-1.11982,-1.02846,-2.33214,-2.24571,-0.242455,-0.373451,1.83873,1.63655,-0.894062,-1.15001,-0.225637,-0.128766
987,0.355253,0.340728,0.330398,0.28103,0.983225,0.959839,0.994303,0.984993,0.830989,0.786206,0.484567,0.587725,0.439336,0.550504,0.992094,0.996814,0.00874781,0.0031649,0.918739,0.935628,-0.360788,-0.22513,-0.810809,-0.632836,0.24712,0.272626,-1.19283,-1.11514,-1.9516,-1.85323,0.192817,0.279427,2.00274,1.87659,-0.46552,-0.666199,-0.449825,-0.706753,-1.24273,-1.14805
988,0.165043,0.179517,0.889537,0.837859,0.338518,0.315548,0.623749,0.613075,0.283616,0.2377,0.553772,0.585495,0.690831,0.73069,0.379039,0.385954,0.0289796,-0.00512286,0.456628,0.474769,0.800256,0.929349,-0.0677502,0.0407009,0.0373833,0.0713584,0.300304,0.378509,-0.116646,-0.0217324,0.405976,0.571779,-0.646231,-0.766433,2.23213,2.03369,1.83317,1.56969,-0.83861,-0.75132
989,0.310328,0.324332,0.36252,0.310448,0.658466,0.637085,0.639189,0.626196,0.3132,0.265095,0.690702,0.720661,0.0296922,0.0689963,0.819708,0.828191,0.264734,0.26627,0.34667,0.364406,-1.53521,-1.40707,0.538335,0.714238,0.232596,0.270207,-0.600829,-0.521744,0.664947,0.766456,0.778581,0.864131,-0.850208,-0.969007,-0.607784,-0.801873,0.569887,0.305619,1.55573,1.64018
990,0.150371,0.166568,0.0756819,0.0247871,0.37774,0.358502,0.206278,0.1943,0.568385,0.521946,0.49556,0.445339,0.914302,0.952986,0.503297,0.572586,0.570624,0.537664,0.952506,0.968189,0.340494,0.474675,-0.0548843,0.119132,-1.36873,-1.33464,-0.165965,-0.0826019,-1.19492,-1.09115,-0.90687,-0.829962,-1.0457,-1.17158,0.494271,0.294925,0.776861,0.51386,1.6711,1.75331
991,0.906707,0.921718,0.519094,0.468577,0.75534,0.735901,0.212168,0.202175,0.055865,0.00882411,0.139489,0.170017,0.837094,0.840831,0.202951,0.316981,0.468798,0.436523,0.789204,0.803187,-0.50615,-0.376823,0.782498,0.950954,-1.40644,-1.379,-0.757042,-0.673846,1.5822,1.6886,-0.157784,-0.0803793,0.113859,-0.0161073,0.740709,0.534659,0.356575,0.0555321,0.384788,0.472147
992,0.591714,0.606723,0.384739,0.334735,0.748343,0.684623,0.61725,0.606657,0.0786393,0.0323321,0.59832,0.628248,0.691553,0.728676,0.0535035,0.0613757,0.567857,0.535057,0.30575,0.317242,2.06189,2.19386,0.252271,0.41752,0.761672,0.782074,-0.0608976,0.0272899,-0.757642,-0.651059,1.70657,1.78919,1.4838,1.35483,-2.61091,-2.81113,-0.244507,-0.402796,1.59213,1.67582
993,0.829331,0.842936,0.760995,0.708942,0.655259,0.633344,0.264391,0.254944,0.805511,0.76033,0.167862,0.197528,0.0730678,0.112381,0.417521,0.406041,0.0581521,0.0253581,0.363125,0.374426,-0.0289625,0.107241,0.844077,1.00328,0.262247,0.278441,-0.835131,-0.816025,-0.514027,-0.40034,-1.31841,-1.22937,-0.487847,-0.61685,-1.04337,-1.23894,-0.598124,-0.861124,-1.48965,-1.41689
994,0.211342,0.226831,0.57423,0.524692,0.306724,0.355538,0.414331,0.405219,0.838371,0.809925,0.878702,0.908591,0.866292,0.907436,0.744628,0.750706,0.8205,0.786902,0.97351,0.983291,-0.230649,-0.098213,-0.490256,-0.335966,0.61222,0.632493,-1.75095,-1.65934,-1.26164,-1.14766,1.05167,1.14757,0.453643,0.320017,-0.434658,-0.632477,-1.29796,-1.5617,-1.12713,-1.04899
995,0.582117,0.599135,0.944835,0.894404,0.0989787,0.0777321,0.285424,0.277829,0.905772,0.859521,0.63694,0.696792,0.830704,0.959623,0.00856141,0.0150796,0.59005,0.547333,0.321313,0.332295,-1.22083,-1.08846,-1.50509,-1.34721,0.0722757,0.0970681,0.662814,0.752662,0.301916,0.421918,-1.47479,-1.38255,2.4716,2.34389,-0.0619775,-0.253766,-0.190935,-0.447669,0.43108,0.510758
996,0.155059,0.173511,0.753164,0.612231,0.891697,0.872009,0.858718,0.850278,0.0736715,0.027128,0.375044,0.484993,0.971868,1.01181,0.425453,0.431648,0.378674,0.307764,0.681965,0.692423,-0.248663,-0.117206,0.667913,0.824239,-0.121892,-0.100524,0.678908,0.76423,0.465797,0.581315,0.082596,0.181115,1.04269,0.921952,-0.564487,-0.74952,-1.53247,-1.79423,0.49179,0.578982
997,0.307525,0.280177,0.421607,0.330058,0.0699682,0.0525245,0.454084,0.443253,0.580123,0.535466,0.243304,0.273193,0.733317,0.770527,0.496677,0.465315,0.100836,0.0681957,0.571068,0.520276,-1.85538,-1.72002,-0.0226258,0.137997,0.304598,0.328441,0.923724,0.920396,-1.06819,-0.949832,0.562627,0.658359,0.174731,0.0452055,-1.34354,-1.52197,-2.38102,-2.63387,-0.101882,-0.0172169
998,0.368609,0.386843,0.0983156,0.0478848,0.677866,0.660387,0.249665,0.240942,0.0351994,-0.00802402,0.910751,0.939848,0.896169,0.931948,0.492725,0.498983,0.276999,0.243163,0.339194,0.34813,0.891711,1.03539,1.44242,1.60347,-0.109155,-0.0840563,0.986004,1.07656,-1.45115,-1.33215,0.832209,0.932686,0.100427,-0.0301057,-0.614702,-0.812875,-0.730756,-0.984883,-0.296735,-0.206506
999,0.034971,0.0516908,0.425257,0.279787,0.280777,0.265304,0.723382,0.71395,0.161779,0.116371,0.369138,0.400632,0.536218,0.549044,0.105606,0.112511,0.780873,0.748818,0.971513,0.982034,-1.74094,-1.5976,-2.35772,-2.19497,-1.21876,-1.1973,-0.775764,-0.690922,-1.378,-1.26505,-1.38833,-1.28941,0.623264,0.49165,0.069802,-0.103785,0.0181877,-0.23118,-1.69297,-1.60912
1000,0.0652273,0.0821217,0.560154,0.511689,0.933218,0.919751,0.976925,0.96911,0.818566,0.771548,0.279244,0.312762,0.132417,0.166139,0.0220053,0.0266994,0.402901,0.450407,0.0266826,0.0366285,-0.408699,-0.271917,1.00654,1.16715,-0.404338,-0.381902,1.48736,1.56879,0.303058,0.410233,-0.203879,-0.110875,-1.73627,-1.86166,0.450414,0.274926,-1.37945,-1.62246,0.284995,0.363865
1001,0.770594,0.787464,0.38129,0.331791,0.794755,0.785243,0.294827,0.287102,0.77448,0.727114,0.772889,0.805388,0.0488798,0.0817771,0.475659,0.478399,0.186142,0.151996,0.896396,0.905644,-0.0754394,0.0557752,0.975805,1.13908,1.47651,1.49679,0.332237,0.420305,-1.1998,-1.09072,-0.0336832,0.0564082,-0.255131,-0.382191,-0.0120445,-0.190202,-0.00228494,-0.250678,-1.24189,-1.15999
1002,0.302871,0.321643,0.732774,0.682294,0.662745,0.650735,0.885414,0.879434,0.391672,0.343426,0.275406,0.31017,0.709319,0.73967,0.123237,0.126277,0.336971,0.251548,0.854334,0.898418,-0.136123,0.00160231,0.165536,0.330504,1.143,1.16105,0.6872,0.768698,-0.724182,-0.612636,0.798076,0.881318,1.59534,1.47067,0.325955,0.141683,1.36915,1.1211,-0.30698,-0.23193
1003,0.967253,0.987925,0.0576041,0.00649409,0.717499,0.664005,0.590823,0.586921,0.706038,0.655444,0.613021,0.634813,0.748757,0.778085,0.548161,0.519618,0.354576,0.3511,0.957683,0.891193,-0.872369,-0.740529,-0.185723,-0.0413775,0.120875,0.10841,-0.653778,-0.578423,1.72855,1.84869,-0.0150836,0.062947,-1.18298,-1.30848,-0.296437,-0.477351,-0.700091,-0.939755,1.779,1.85424
1004,0.697825,0.718692,0.546026,0.494193,0.686806,0.677274,0.864249,0.862175,0.423649,0.373025,0.925641,0.959457,0.00695771,0.0348424,0.910207,0.912959,0.580067,0.450652,0.826908,0.883968,0.248286,0.381236,-0.571502,-0.413259,-0.958214,-0.944227,-0.689357,-0.614067,0.262491,0.380016,0.552866,0.660514,1.44183,1.312,0.425062,0.237254,1.54085,1.30384,-0.857443,-0.781177
1005,0.154431,0.177594,0.490753,0.439711,0.701577,0.690544,0.829363,0.891637,0.815746,0.765792,0.152836,0.18934,0.0691863,0.0355917,0.155791,0.157444,0.66291,0.550205,0.867495,0.876742,1.0963,1.2286,0.20466,0.356664,0.837379,0.854044,1.525,1.59557,-0.395246,-0.274336,1.18082,1.25808,0.633464,0.49974,-0.884802,-1.07413,0.4266,0.196564,-0.250131,-0.152632
1006,0.565461,0.590915,0.865081,0.813919,0.0261001,0.0167471,0.922547,0.921099,0.252338,0.201886,0.103971,0.188809,0.0516435,0.0363411,0.461831,0.464031,0.683903,0.649757,0.0460856,0.0560529,-2.55139,-2.42584,-1.72562,-1.57962,-1.83077,-1.81607,-0.914943,-0.838388,0.938494,1.06428,-0.372871,-0.297977,-1.35037,-1.48793,0.298002,0.112384,0.0399562,-0.194799,0.403407,0.475912
1007,0.688987,0.716303,0.138619,0.0885822,0.624211,0.614454,0.493974,0.461069,0.227487,0.163568,0.153484,0.188278,0.0096642,0.0370905,0.00858044,0.0132078,0.336373,0.300145,0.498447,0.510512,-0.147183,-0.0158974,-1.20091,-1.05558,1.15452,1.17464,0.997199,1.07883,-1.05443,-0.933976,-0.551805,-0.481764,-2.08869,-2.22533,-0.206728,-0.398716,0.185392,0.0270665,-0.336598,-0.270715
1008,0.458841,0.490484,0.481134,0.429225,0.824946,0.729989,0.00248666,0.00103937,0.297735,0.125251,0.612974,0.64651,0.687618,0.714581,0.717165,0.720577,0.637904,0.600096,0.527109,0.536805,-0.319488,-0.134508,-0.0271359,0.112884,-1.1669,-1.14341,0.0654712,0.145316,0.383296,0.497475,-2.27951,-2.20406,-1.53617,-1.67118,-0.47748,-0.665542,0.491749,0.248932,1.66377,1.73463
1009,0.161797,0.264665,0.152472,0.0989684,0.855362,0.845525,0.733254,0.733515,0.139009,0.0869333,0.369079,0.403089,0.333203,0.412439,0.234318,0.239497,0.704233,0.66852,0.203825,0.215567,-0.380245,-0.253119,-0.118239,0.0219783,0.700604,0.71861,-0.501805,-0.429257,0.543173,0.656872,0.27051,0.336957,-0.441262,-0.583236,0.219934,0.0335445,0.131732,-0.112903,0.326744,0.392721
1010,0.0124615,0.0388455,0.0469489,-0.00429341,0.167676,0.156573,0.89268,0.838748,0.60199,0.550097,0.733403,0.767408,0.0823994,0.110297,0.259874,0.265201,0.497378,0.460221,0.104095,0.116536,1.24262,1.36975,0.565147,0.700338,-0.964322,-0.947569,0.839186,0.905079,-1.90856,-1.79834,-0.507163,-0.436032,-1.1819,-1.32064,-0.283015,-0.46221,2.316,2.06852,0.192136,0.232801
1011,0.805494,0.829926,0.587726,0.537964,0.295508,0.221152,0.944217,0.943982,0.456417,0.462781,0.81825,0.852585,0.609494,0.637159,0.912261,0.920014,0.288899,0.251921,0.215203,0.227364,0.920351,1.04409,0.668997,0.807263,-0.297891,-0.288244,-0.373204,-0.30563,-0.14575,-0.0308485,0.0824455,0.147302,0.699652,0.564075,-0.301513,-0.485475,0.255035,0.00765927,0.0013869,0.0728812
1012,0.563489,0.586265,0.134533,0.0847463,0.295718,0.28573,0.750878,0.784648,0.488151,0.375464,0.142826,0.177035,0.517731,0.543302,0.247198,0.253727,0.601172,0.562704,0.792302,0.806698,-1.36812,-1.2464,-1.50069,-1.36332,0.738482,0.74228,-0.147888,-0.0771407,-0.539817,-0.427346,0.210025,0.269817,0.136116,-0.00555686,-0.7564,-0.934832,0.659919,0.420084,0.776983,0.849235
1013,0.575652,0.668144,0.609991,0.55841,0.131307,0.119583,0.623441,0.625315,0.340041,0.288148,0.19493,0.227771,0.988147,1.01498,0.425703,0.431117,0.492267,0.470214,0.916441,0.928147,-0.23148,-0.10798,0.894783,1.03468,0.2307,0.238648,-0.397914,-0.328863,-1.96238,-1.84996,-0.0506946,0.00866387,0.308742,0.162603,-0.838518,-1.01878,-0.693011,-0.926478,-0.256215,-0.184862
1014,0.728453,0.750024,0.51248,0.460719,0.520943,0.506591,0.747156,0.750185,0.680085,0.630746,0.457605,0.491207,0.97084,0.997221,0.912534,0.918013,0.498087,0.377725,0.694207,0.769863,-0.805602,-0.682254,1.20717,1.34456,-0.958226,-0.950484,0.706589,0.773256,-1.05295,-0.999907,-0.0319768,0.0230298,1.31961,1.17595,0.822787,0.645699,0.0743803,-0.156876,0.121914,0.196165
1015,0.510826,0.623556,0.787224,0.736958,0.626609,0.613223,0.42112,0.402505,0.802523,0.758886,0.359991,0.393316,0.555824,0.520112,0.746562,0.708902,0.469871,0.285235,0.601025,0.61158,1.19479,1.32285,-1.09688,-0.958621,-0.894532,-0.888107,-0.713898,-0.652518,-0.25696,-0.149855,1.17115,1.23332,0.728505,0.578475,0.583928,0.330077,-0.54214,-0.766371,0.0673907,0.142946
1016,0.474775,0.497089,0.479226,0.430987,0.194957,0.183312,0.0520229,0.0548247,0.937692,0.887026,0.869391,0.900925,0.0165304,0.0430041,0.496586,0.499791,0.231214,0.192745,0.974325,0.986057,0.9316,1.05629,-0.591651,-0.407439,0.048479,0.0484002,1.28435,1.34654,-0.17362,-0.0676689,-1.46126,-1.40475,-0.871122,-1.01748,0.198262,0.0144557,-0.622151,-0.84953,0.528693,0.600379
1017,0.585182,0.62263,0.463297,0.415396,0.503358,0.490342,0.837844,0.838681,0.492082,0.443591,0.365101,0.395552,0.215318,0.239658,0.663827,0.666736,0.709207,0.672769,0.123893,0.133888,-0.2873,-0.164604,0.00121121,0.143744,0.643336,0.645867,-0.124491,-0.0650921,-0.344313,-0.258795,-0.0247551,0.033738,0.581529,0.429471,0.360004,0.176594,-1.07469,-1.3049,1.92718,2.00433
1018,0.725622,0.748171,0.649933,0.604133,0.059104,0.0458513,0.0936213,0.095608,0.32374,0.255574,0.717729,0.746437,0.949516,0.974223,0.428722,0.48316,0.573965,0.525591,0.419032,0.426828,0.616155,0.744131,-1.65294,-1.50867,-0.829984,-0.820724,-0.637764,-0.578549,-0.550091,-0.449922,-2.56841,-2.51326,-0.597641,-0.74291,0.159743,-0.0100297,1.06461,0.831434,0.000890355,0.03759
1019,0.345189,0.400698,0.337726,0.293542,0.00403403,-0.00941622,0.984549,0.989058,0.116125,0.0675584,0.226083,0.256181,0.350236,0.373173,0.295937,0.299585,0.412194,0.378414,0.0374474,0.0464213,-0.48378,-0.354002,0.03308,0.174337,-0.941881,-0.927232,-0.204408,-0.139406,0.935327,1.04158,0.580875,0.636471,-0.969328,-1.01866,-0.00788708,-0.196653,-1.73242,-1.95991,-2.00082,-1.92915
1020,0.032957,0.0532251,0.40004,0.357616,0.647911,0.634294,0.151528,0.156986,0.896994,0.847496,0.95892,0.987395,0.363823,0.375542,0.661661,0.666672,0.871381,0.838711,0.0194446,0.0420684,-0.433234,-0.303332,-0.657657,-0.511905,-1.36758,-1.35409,-0.306212,-0.235196,1.16178,1.26152,-0.637197,-0.578559,-1.14406,-1.29442,-2.30689,-2.4994,1.74352,1.51558,-0.85469,-0.786561
1021,0.757572,0.779718,0.236292,0.163232,0.844754,0.829619,0.503467,0.444642,0.466747,0.419029,0.167535,0.196441,0.354079,0.377911,0.632712,0.543056,0.566851,0.627995,0.029573,0.0377154,-1.28973,-1.15483,-0.74917,-0.50523,0.975227,0.988119,-1.25178,-1.18487,-1.07056,-0.964446,0.336652,0.400957,1.7844,1.6341,-0.73892,-0.927207,0.820646,0.594059,1.71252,1.7747
1022,0.409143,0.482936,0.0105361,-0.0311507,0.744915,0.728947,0.725165,0.732298,0.903348,0.856786,0.885397,0.912434,0.666118,0.689971,0.413516,0.41944,0.3859,0.417279,0.896662,0.906731,-0.441807,-0.243839,-0.702333,-0.498556,0.182162,0.20257,1.44468,1.51371,0.416524,0.527056,-0.472824,-0.402655,0.858238,0.710877,-1.58175,-1.77547,0.285373,0.0614715,0.0545403,0.113411
1023,0.162533,0.186155,0.0405734,0.0980284,0.115419,0.100237,0.455295,0.549353,0.652339,0.604894,0.935405,0.96317,0.224577,0.249236,0.135152,0.142755,0.192468,0.206563,0.125277,0.133847,0.535186,0.667152,-0.637634,-0.491881,-1.30377,-1.27877,0.352314,0.425073,0.602684,0.71517,-0.731454,-0.663808,0.295272,0.234974,-1.59165,-1.78489,-1.21029,-1.44221,0.623505,0.679387
1024,0.0346696,0.057598,0.268921,0.227208,0.165693,0.117051,0.361387,0.366409,0.764299,0.719016,0.299833,0.327795,0.322354,0.349672,0.884551,0.889705,0.028517,-0.00415276,0.555099,0.519077,0.191499,0.325196,-1.55061,-1.40867,-0.966749,-0.940993,-0.524036,-0.446373,1.55439,1.67105,0.296669,0.36259,-0.10158,-0.24093,-0.0473545,-0.243942,0.724635,0.489129,2.25126,2.31283
1025,0.171729,0.193425,0.583329,0.443853,0.147723,0.133865,0.730786,0.735029,0.617418,0.572607,0.943226,0.968602,0.879988,0.906564,0.717354,0.698635,0.83833,0.803384,0.896732,0.904307,-0.465151,-0.325691,-0.484321,-0.345521,2.35096,2.38071,-1.08073,-1.00469,-0.208874,-0.0911613,0.364254,0.345664,0.348075,0.205971,-0.472223,-0.66366,0.81806,0.577139,0.966788,1.03166
1026,0.947031,0.968518,0.702217,0.660498,0.400932,0.389345,0.0874619,0.0927799,0.085152,0.0394615,0.644922,0.730605,0.943321,0.970078,0.627042,0.507565,0.348966,0.313367,0.676726,0.743108,-0.582142,-0.443165,0.238273,0.376555,-0.491267,-0.460766,-1.30176,-1.22406,1.13801,1.26145,0.260541,0.328737,-3.098,-3.24789,1.24623,1.05113,1.87761,1.63084,-1.2577,-1.19175
1027,0.820092,0.839961,0.0144205,-0.0299468,0.953064,0.941861,0.430894,0.436124,0.995103,0.951968,0.464501,0.492608,0.208089,0.236629,0.311341,0.316495,0.778895,0.743824,0.574358,0.581908,1.01527,1.1479,-0.366802,-0.233102,0.156141,0.184102,-2.16124,-2.07977,0.5354,0.650826,1.26848,1.3383,-0.460716,-0.611695,0.644543,0.448054,1.23373,0.991546,-2.3042,-2.2405
1028,0.332639,0.353367,0.941029,0.895817,0.433336,0.423069,0.344704,0.421496,0.996951,0.902432,0.227241,0.254612,0.491108,0.517695,0.414032,0.452365,0.488072,0.357907,0.998174,1.0062,0.8049,0.942445,1.34301,1.47914,-0.167487,-0.0597878,0.507824,0.585617,0.55723,0.671936,0.786183,0.859244,0.145796,-0.0119998,1.18111,0.979121,0.1252,-0.115726,0.653125,0.723905
1029,0.835034,0.855496,0.104332,0.058949,0.704677,0.694337,0.341803,0.406869,0.896165,0.852896,0.712931,0.741755,0.566334,0.642546,0.550023,0.588235,0.0088371,-0.0280103,0.260931,0.268506,-1.06969,-0.926794,-0.847454,-0.708981,-0.334107,-0.303678,0.740563,0.814106,0.135113,0.243806,0.0970724,0.177146,0.20367,0.0511995,0.438691,0.170288,-0.288376,-0.523554,0.710039,0.753895
1030,0.441389,0.468501,0.326432,0.203813,0.127815,0.115508,0.387011,0.392241,0.215145,0.172711,0.716823,0.743826,0.608041,0.767397,0.737329,0.724105,0.742167,0.703691,0.491521,0.537559,-0.420614,-0.27637,1.42513,1.55956,0.445011,0.47903,-0.0792211,-0.0390498,0.4297,0.539268,0.940822,1.01927,0.0601425,-0.0851725,-0.436557,-0.638545,1.10364,0.876169,0.75929,0.783886
1031,0.0590458,0.0815052,0.392923,0.348676,0.936446,0.925766,0.557586,0.562376,0.0758222,0.0308799,0.929627,0.956912,0.797872,0.892248,0.852747,0.859974,0.13428,0.098031,0.79763,0.806612,1.18439,1.33046,0.386433,0.517539,-1.16606,-1.12582,-0.966791,-0.892206,-1.4077,-1.2998,-1.11635,-1.04589,-1.64572,-1.79046,0.755695,0.547965,0.27894,0.0501237,0.743097,0.813877
1032,0.644286,0.667135,0.160853,0.11878,0.161802,0.151348,0.226677,0.229604,0.220778,0.143952,0.741839,0.829067,0.990512,1.0171,0.613753,0.622159,0.899807,0.864437,0.84928,0.859285,0.38785,0.539336,1.24374,1.37812,0.532379,0.579653,-1.20309,-1.12632,0.876167,0.986654,1.05802,1.12634,-0.683572,-0.823116,-3.45993,-3.66766,0.501221,0.275351,-0.0108315,0.0672496
1033,0.208885,0.231333,0.273503,0.232072,0.893909,0.882343,0.582152,0.583495,0.353895,0.257023,0.672349,0.701222,0.241476,0.269164,0.141289,0.151136,0.383933,0.349585,0.314999,0.323444,-0.612173,-0.466564,-1.09542,-0.956606,0.463351,0.503899,-0.217466,-0.144966,0.500119,0.604331,1.79871,1.85938,2.21761,2.07498,-1.38062,-1.58242,-0.406136,-0.632389,-0.250619,-0.166898
1034,0.688851,0.712649,0.999551,0.958102,0.326817,0.31361,0.110885,0.111318,0.42555,0.370095,0.0933526,0.121458,0.139555,0.196403,0.481545,0.493167,0.257189,0.222617,0.600195,0.606801,-1.09557,-0.962472,0.30295,0.445002,0.647193,0.687029,1.23104,1.2996,0.390481,0.497684,-0.0799686,-0.0169999,1.80055,1.66086,1.46855,1.26679,-0.160957,-0.293944,0.671269,0.761162
1035,0.36702,0.430891,0.830269,0.789548,0.190983,0.176911,0.220885,0.220209,0.529847,0.483166,0.413023,0.441566,0.148421,0.123642,0.451897,0.558688,0.550414,0.518528,0.612924,0.617518,-1.60536,-1.45838,1.33535,1.47607,-1.73564,-1.69569,-0.803011,-0.743105,-0.552696,-0.450394,0.975939,1.04139,-0.37575,-0.514195,0.757173,0.554513,0.269565,0.0445017,-0.105787,-0.0166225
1036,0.123723,0.149133,0.0680079,0.0281477,0.367037,0.353232,0.772708,0.772787,0.257184,0.211161,0.394223,0.423395,0.0226799,0.0508814,0.608701,0.624208,0.849833,0.814439,0.365975,0.383945,-0.228115,-0.0841415,-0.894063,-0.759772,-0.600734,-0.558851,0.691445,0.743227,-0.787492,-0.680409,-0.753474,-0.680908,-0.593309,-0.726637,-1.79669,-2.00139,0.886904,0.660077,-0.200044,-0.126895
1037,0.813234,0.839853,0.580399,0.540587,0.0703701,0.0540494,0.610822,0.729621,0.993385,0.949676,0.576385,0.63404,0.21704,0.247535,0.6786,0.689729,0.953622,0.919074,0.145543,0.150372,1.1435,1.2901,0.163664,0.303378,-0.236512,-0.191384,2.17647,2.22956,-2.01615,-1.90429,-1.6083,-1.5303,1.34632,1.21852,0.457375,0.252455,-0.178928,-0.401367,-0.323689,-0.237168
1038,0.540555,0.566003,0.79761,0.757917,0.57826,0.56228,0.627478,0.686456,0.934547,0.889828,0.816381,0.844686,0.900154,0.930426,0.955136,0.965991,0.467389,0.434172,0.177108,0.145534,-1.7729,-1.62611,-1.07792,-0.939541,-1.72307,-1.67272,0.130962,0.186855,1.11646,1.23394,-0.497658,-0.411603,1.1739,1.03255,-2.04074,-2.24403,0.77868,0.556433,0.550333,0.631704
1039,0.732887,0.756383,0.681472,0.639869,0.0965281,0.0825778,0.56549,0.64329,0.429778,0.386591,0.339941,0.369722,0.969721,0.999221,0.592482,0.603853,0.765669,0.730303,0.161847,0.140696,-0.0506643,0.103167,0.986198,1.11864,-0.472112,-0.41588,0.524944,0.580915,-0.900851,-0.778791,-1.72038,-1.62663,0.975701,0.846581,-0.466652,-0.67184,-0.740114,-0.96175,-0.267897,-0.190063
1040,0.549682,0.573429,0.117895,0.0776816,0.0247747,0.0992005,0.600046,0.600124,0.319861,0.27496,0.289338,0.31754,0.794616,0.824329,0.771264,0.781243,0.51073,0.510282,0.128866,0.135858,-0.236567,-0.120521,-0.589422,-0.453638,-0.325333,-0.263399,1.37046,1.42093,0.113109,0.239729,-0.114385,-0.0176977,-2.29411,-2.42905,0.541255,0.335138,-0.441751,-0.730729,0.0303978,0.102162
1041,0.706819,0.626007,0.680815,0.639655,0.118601,0.115823,0.0882231,0.0872134,0.869483,0.823672,0.495088,0.521746,0.276597,0.308295,0.349773,0.359288,0.326554,0.29026,0.34306,0.301261,-0.492686,-0.34421,-0.782596,-0.65121,-0.634176,-0.567916,0.644229,0.691653,-1.48318,-1.35073,0.795084,0.886279,0.750153,0.611644,2.12847,1.92194,-0.284846,-0.499708,1.81129,1.87786
1042,0.720948,0.678584,0.218025,0.176292,0.2401,0.132446,0.828497,0.824562,0.458796,0.414482,0.402329,0.494872,0.804715,0.835158,0.493287,0.594817,0.36136,0.323928,0.458791,0.466663,0.928138,1.07498,0.483837,0.612221,0.50567,0.568922,-0.503957,-0.456832,0.687128,0.818152,-1.54678,-1.46103,-0.709541,-0.839774,-0.0067137,-0.212376,-0.712687,-0.924077,-0.282793,-0.217597
1043,0.705298,0.731161,0.983927,0.941493,0.163091,0.149069,0.0765713,0.0719003,0.353079,0.288567,0.439647,0.467998,0.348525,0.379255,0.821626,0.830345,0.877568,0.839013,0.910039,0.91575,-0.21176,-0.0682734,-1.00964,-0.88266,-0.494835,-0.434756,0.221675,0.276216,1.03871,1.1765,-0.306329,-0.221418,1.8097,1.68252,0.447169,0.240939,-0.237303,-0.449099,-0.411666,-0.346928
1044,0.3822,0.470596,0.65928,0.62828,0.625624,0.612627,0.192102,0.142963,0.206302,0.162653,0.859987,0.887355,0.149648,0.179598,0.76352,0.778875,0.127503,0.0915838,0.057189,0.0635812,-0.808292,-0.657673,0.303387,0.426997,0.0987887,0.162711,-1.38374,-1.33622,-0.67809,-0.539749,2.27722,2.36979,0.188822,0.0592666,-1.05617,-1.26705,0.873151,0.664927,0.839356,0.902327
1045,0.184357,0.210031,0.417338,0.315067,0.146626,0.132925,0.279771,0.214025,0.948829,0.905681,0.405315,0.431526,0.535097,0.56635,0.719926,0.727405,0.0176957,-0.0204043,0.00563812,0.00962933,0.699118,0.856029,0.483683,0.612582,-0.767329,-0.700966,-0.247871,-0.200941,-0.967387,-0.828158,-0.476773,-0.386284,-0.0865352,-0.214641,0.53221,0.319747,-1.46636,-1.6708,-2.06421,-2.0013
1046,0.30414,0.330249,0.0442876,0.00185411,0.606989,0.498075,0.287555,0.285087,0.483533,0.441961,0.73844,0.765949,0.0746294,0.105887,0.16354,0.171292,0.663248,0.626543,0.416684,0.390738,0.371294,0.530364,-0.15617,-0.0269833,-1.05774,-0.990416,-0.436196,-0.390729,-0.137143,0.00508488,0.53158,0.623283,-0.161014,-0.289952,-0.361491,-0.576413,-0.952419,-1.16262,-1.4709,-1.40707
1047,0.700235,0.728014,0.290086,0.155149,0.876243,0.863226,0.878738,0.877419,0.817528,0.774142,0.668942,0.697869,0.0464757,0.146024,0.860701,0.867735,0.934599,0.897518,0.766449,0.771847,-2.12583,-1.96793,-0.450842,-0.315998,-0.346962,-0.283632,0.61128,0.650566,-0.301337,-0.16274,-0.0603052,0.0347549,-0.571081,-0.704067,-1.46868,-1.68592,0.640653,0.438172,1.02878,1.08745
1048,0.49026,0.467449,0.352078,0.308445,0.796349,0.783102,0.653577,0.654529,0.854612,0.831733,0.224355,0.251819,0.153618,0.186162,0.664774,0.663138,0.612532,0.53009,0.686407,0.70137,0.375847,0.534326,0.0508706,0.193554,0.667372,0.731054,-0.449381,-0.407335,-0.218542,-0.080554,0.0839123,0.156327,1.01082,0.883327,-1.11336,-1.39312,-0.426058,-0.623272,1.19122,1.24511
1049,0.179238,0.206885,0.153799,0.108982,0.132931,0.119675,0.630547,0.632623,0.834584,0.889325,0.142504,0.242609,0.930362,0.962076,0.404483,0.458541,0.199792,0.162661,0.531821,0.630893,-0.253006,-0.101608,-0.101632,0.0438638,0.873926,0.929903,-0.217228,-0.178846,0.751767,0.892707,0.176269,0.277898,0.226183,0.100956,-0.888199,-1.10033,1.13197,0.929654,-1.15784,-1.1083
1050,0.234011,0.262546,0.557753,0.414772,0.864305,0.85067,0.123325,0.124713,0.990876,0.946917,0.208167,0.233399,0.0818647,0.11196,0.246908,0.253943,0.742534,0.707598,0.539378,0.560416,-0.0563418,0.101662,0.215913,0.368699,0.627255,0.685421,0.498718,0.537362,-0.820202,-0.683937,1.46995,1.57855,1.03948,0.912624,0.328292,0.116353,-0.204399,-0.401854,-0.385375,-0.331947
1051,0.527689,0.554771,0.764561,0.720562,0.283485,0.271841,0.660497,0.662185,0.0474041,0.00515215,0.512502,0.539608,0.951209,0.980538,0.553798,0.56053,0.918812,0.882566,0.48665,0.489939,2.4384,2.58987,-1.48461,-1.32888,-0.468742,-0.411295,-1.69485,-1.65845,0.465422,0.594991,-0.147695,-0.037977,0.38193,0.253954,-0.338909,-0.550907,-0.96673,-1.16568,-0.439636,-0.385167
1052,0.338934,0.366108,0.165384,0.119021,0.985867,0.972204,0.399717,0.354123,0.0117779,-0.0292042,0.386465,0.411018,0.699094,0.729715,0.274775,0.379281,0.652004,0.69525,0.197253,0.199129,-2.01523,-1.86377,-0.157026,-0.00468512,1.29574,1.3558,-0.285118,-0.245062,1.11419,1.2428,-0.934318,-0.824889,0.298905,0.164636,3.04972,2.83244,-1.33294,-1.52751,-0.927325,-0.875016
1053,0.674611,0.703208,0.740143,0.694785,0.612744,0.597369,0.0438215,0.046061,0.43554,0.432907,0.478403,0.501786,0.125119,0.157516,0.191401,0.198033,0.457268,0.507934,0.639558,0.642685,0.186788,0.342333,0.178998,0.228677,0.681859,0.818672,-0.5411,-0.496784,0.128204,0.249153,-0.807316,-0.600127,0.7197,0.57992,0.482331,0.256928,0.146724,-0.0516277,-0.895815,-0.804009
1054,0.596737,0.626496,0.372005,0.32568,0.681059,0.68647,0.407943,0.409988,0.936933,0.895018,0.132401,0.154603,0.726243,0.758031,0.423129,0.427334,0.306149,0.320617,0.87576,0.881433,-0.178489,-0.0656432,0.31539,0.462039,0.221489,0.281549,-0.0291178,-0.0324664,-0.429846,-0.31474,-0.48778,-0.375364,0.219154,0.0737687,0.0740927,-0.146829,-1.17092,-1.36687,-0.778652,-0.733002
1055,0.820933,0.853052,0.510692,0.464022,0.733165,0.775571,0.472584,0.473683,0.313919,0.26998,0.0959767,0.117275,0.115651,0.146887,0.85808,0.864516,0.169548,0.133301,0.505002,0.510924,-0.625784,-0.473619,0.18212,0.326063,0.409076,0.464679,0.394619,0.431851,0.392632,0.502541,-0.0839146,0.0232143,0.0924822,-0.128805,0.680433,0.459633,0.466961,0.264775,-1.44738,-1.40571
1056,0.0518739,0.081117,0.99682,0.951721,0.982796,0.864672,0.0577341,0.0569133,0.982785,0.940871,0.659114,0.678563,0.871232,0.902093,0.095801,0.103052,0.510181,0.474023,0.73031,0.734037,1.84843,2.00023,-0.426295,-0.283595,1.03787,1.09291,2.32046,2.34907,0.591314,0.706291,-0.0377706,0.068238,-0.191666,-0.331378,0.498219,0.285861,1.19863,0.989261,0.55296,0.599635
1057,0.138688,0.167179,0.375608,0.330849,0.968227,0.953773,0.037398,0.0350077,0.813001,0.770253,0.474581,0.495984,0.371948,0.401054,0.820891,0.830703,0.393014,0.386603,0.00820718,0.0115571,-0.232965,-0.0863808,0.758066,0.901587,-0.61446,-0.559004,-0.698848,-0.6691,1.00904,1.12491,-0.870095,-0.766132,0.478598,0.343797,0.746453,0.541643,0.973697,0.765834,0.0350653,0.0780199
1058,0.856061,0.883062,0.703882,0.657007,0.851408,0.7751,0.494006,0.492693,0.289063,0.247239,0.902507,0.924971,0.984811,1.01243,0.606803,0.530711,0.335879,0.299184,0.972323,0.975673,1.55062,1.70374,0.195127,0.336358,0.842144,0.896229,-1.04422,-1.01232,-1.20976,-1.10106,-0.987995,-0.891424,-0.36572,-0.499698,0.152148,-0.0472908,1.09275,0.882432,1.37992,1.41913
1059,0.0222511,0.0502478,0.653078,0.578379,0.60976,0.596428,0.566169,0.565794,0.593821,0.550003,0.573588,0.59639,0.592293,0.532071,0.222322,0.230719,0.616192,0.580362,0.0480722,0.0526591,-0.146457,0.009439,1.03632,1.1815,0.699542,0.684704,-0.623257,-0.587928,0.961775,1.06782,0.309391,0.409229,1.52248,1.38501,-0.195787,-0.389756,0.123285,-0.085946,0.452208,0.429093
1060,0.275584,0.301363,0.546677,0.49975,0.00101097,-0.0125091,0.0652782,0.062865,0.445616,0.403594,0.469652,0.492797,0.0240608,0.051716,0.338619,0.346476,0.316418,0.281194,0.144889,0.190442,-0.0237197,0.13726,1.11246,1.25967,0.36939,0.473178,0.256502,0.299932,1.44089,1.5459,0.0790483,0.178277,1.57446,1.43091,1.34559,1.15119,-0.148107,-0.35543,-0.600262,-0.560946
1061,0.0991747,0.123818,0.228925,0.183979,0.404957,0.390858,0.562393,0.560772,0.823533,0.781259,0.822482,0.848085,0.42943,0.44708,0.146155,0.154355,0.383497,0.339401,0.321161,0.328225,-0.851785,-0.647873,-0.482111,-0.327924,0.211842,0.261652,-0.48938,-0.44632,-2.42352,-2.31851,0.260607,0.361387,1.00219,0.861282,0.832982,0.640092,0.229471,-0.0764459,0.780244,0.826887
1062,0.782175,0.805025,0.307591,0.263062,0.406461,0.39509,0.296037,0.292845,0.237761,0.197321,0.281722,0.308869,0.813151,0.842444,0.636973,0.645641,0.430843,0.397609,0.462599,0.466008,-1.59215,-1.43301,0.404268,0.563826,0.697717,0.750869,-0.656771,-0.619816,-1.04265,-0.932451,-0.356173,-0.258902,0.975638,0.83251,-0.977231,-1.16663,0.409861,0.202538,0.169851,0.249794
1063,0.797382,0.820217,0.046775,0.00196785,0.495008,0.399323,0.732339,0.731512,0.501553,0.518019,0.7389,0.7671,0.651634,0.678627,0.532978,0.480205,0.145779,0.114327,0.844345,0.845742,-0.869331,-0.70734,0.363325,0.51906,0.192617,0.247236,0.662447,0.698404,-0.7535,-0.636989,-0.348606,-0.244536,-0.350184,-0.494395,0.44435,0.253062,1.63914,1.42611,-0.414757,-0.3273
1064,0.0172278,0.0382967,0.797615,0.751498,0.418316,0.403555,0.639761,0.750572,0.878453,0.838717,0.819787,0.847923,0.0632168,0.0913199,0.261951,0.314769,0.402327,0.304574,0.945899,0.904821,-1.23735,-1.08108,-1.97659,-1.81567,-0.041256,0.0184226,-0.143835,-0.02799,-0.889643,-0.774484,0.132912,0.232708,2.18917,2.04642,0.714231,0.524744,-0.565507,-0.775877,-0.94842,-0.904394
1065,0.626824,0.648163,0.100176,0.0562674,0.860725,0.847301,0.720635,0.769631,0.171191,0.133229,0.426844,0.455789,0.031103,0.0572663,0.140166,0.149332,0.52864,0.494821,0.96259,0.963901,1.15699,1.31404,0.988119,1.15048,1.05477,1.10786,-0.796611,-0.754384,0.967955,1.08562,-0.339717,-0.246353,-2.24919,-2.3935,-0.836774,-1.02905,-0.150567,-0.363452,-0.344432,-0.293666
1066,0.311988,0.333169,0.942755,0.898284,0.162165,0.147891,0.789518,0.788691,0.309639,0.272993,0.847964,0.875146,0.794132,0.822017,0.513783,0.462295,0.95393,0.919506,0.861465,0.949295,1.49387,1.65576,0.569744,0.725976,1.14234,1.19807,-0.399234,-0.360324,-0.331853,-0.21464,0.370724,0.458772,-1.7372,-1.88648,0.00144099,-0.192251,0.716246,0.502838,0.687168,0.741995
1067,0.320619,0.343474,0.0776837,0.0321178,0.331123,0.318619,0.556365,0.640803,0.243377,0.207265,0.43865,0.464141,0.134179,0.160323,0.768136,0.775257,0.00303513,-0.0317934,0.931499,0.934689,-0.714535,-0.559312,-1.32855,-1.16389,0.302232,0.416426,0.715615,0.75684,1.11827,1.2319,-0.352783,-0.267656,-0.38764,-0.530711,-0.109549,-0.297616,-0.330718,-0.544563,0.313224,0.436557
1068,0.814288,0.835001,0.761895,0.716746,0.718638,0.705626,0.447467,0.492915,0.383466,0.324891,0.681455,0.706793,0.0833512,0.200461,0.14046,0.148879,0.702423,0.664796,0.0256752,0.0296082,-0.170694,-0.0868642,1.4996,1.66259,-0.421385,-0.365216,-1.42764,-1.3935,-1.16579,-1.06069,0.0281291,0.115235,0.461596,0.311771,-0.211541,-0.402981,-0.0644868,-0.274107,0.0672301,0.131119
1069,0.737055,0.75829,0.910722,0.865751,0.0470973,0.0318299,0.381096,0.345027,0.477053,0.442518,0.0873204,0.111912,0.213011,0.240598,0.915096,0.920853,0.649712,0.648252,0.314859,0.317713,0.226114,0.385583,-1.72963,-1.56863,1.359,1.41815,0.879964,0.917914,0.468509,0.569863,-0.162937,-0.0685521,0.702287,0.555773,0.263683,0.0870453,-1.49194,-1.69723,0.663457,0.725356
1070,0.129753,0.152852,0.136101,0.0929342,0.970816,0.957736,0.197966,0.197139,0.213328,0.284446,0.412455,0.437049,0.500495,0.527143,0.384466,0.389804,0.672017,0.631708,0.361412,0.364749,0.191185,0.346349,-0.503117,-0.356752,0.33486,0.317024,0.867538,0.898367,0.4911,0.590973,-0.858552,-0.765114,-0.320708,-0.4609,0.762936,0.577072,0.210589,-0.00151164,-0.43845,-0.372204
1071,0.316178,0.338882,0.369947,0.325349,0.969125,0.954005,0.893637,0.894523,0.087824,0.126375,0.156114,0.179061,0.147165,0.171997,0.177359,0.182925,0.870564,0.832185,0.810102,0.813836,-0.214484,-0.057366,0.696463,0.855126,-0.843246,-0.784098,-0.522182,-0.49659,-0.502272,-0.402674,0.471294,0.567258,0.645311,0.506448,0.877941,0.693324,0.349922,0.131513,0.720912,0.786853
1072,0.104098,0.125006,0.0351473,-0.00972482,0.0562044,0.0394656,0.0114508,0.0136771,0.00105239,-0.0316966,0.83467,0.856033,0.265402,0.292066,0.59178,0.599493,0.544831,0.525883,0.0687272,0.0707456,0.543041,0.673708,2.6582,2.81826,0.961796,1.01417,-1.11656,-1.08783,0.224122,0.323001,-0.385395,-0.282132,-0.0161704,-0.152221,0.501676,0.320628,-2.28949,-2.51453,-1.47145,-1.40219
1073,0.883811,0.905663,0.246449,0.202932,0.872504,0.854553,0.717823,0.721013,0.296599,0.265879,0.188202,0.210691,0.696259,0.723716,0.524357,0.53374,0.257922,0.219581,0.0524818,0.0565477,1.24783,1.40478,-0.422244,-0.267712,-1.05609,-0.998044,0.74545,0.770044,1.16753,1.26423,-0.763314,-0.629888,-1.49625,-1.63587,-0.437081,-0.6204,0.447553,0.215626,-0.302827,-0.228312
1074,0.616127,0.636429,0.161587,0.187379,0.262152,0.245616,0.723058,0.724822,0.959745,0.931124,0.733438,0.756776,0.906176,0.935248,0.849998,0.860143,0.178914,0.122338,0.754298,0.756178,-0.0703778,0.0947422,0.35216,0.50221,-0.0885751,-0.0300715,-0.366147,-0.347768,-1.72248,-1.62697,-1.00845,-0.977643,1.0693,0.935233,1.08051,0.903805,-1.48641,-1.71694,1.30094,1.37557
1075,0.878211,0.898353,0.214754,0.171827,0.724591,0.709174,0.113033,0.116839,0.257755,0.230696,0.78537,0.807512,0.859015,0.951132,0.928879,0.940915,0.0634371,0.025096,0.0087152,0.00829592,-0.696599,-0.526775,-0.300326,-0.153137,-0.695854,-0.63129,-1.03106,-1.01499,0.876993,0.980341,-1.43226,-1.3254,-0.826571,-0.957073,0.0652894,-0.114297,0.737602,0.511023,-1.84014,-1.76532
1076,0.376962,0.397224,0.535171,0.528138,0.145485,0.130345,0.665562,0.669417,0.398287,0.37046,0.463484,0.484287,0.936511,0.967015,0.198131,0.210697,0.923226,0.886731,0.673818,0.671641,0.222326,0.397925,0.136687,0.277431,-0.862213,-0.797705,0.815078,0.82742,2.03695,2.13475,0.539259,0.652083,0.671653,0.534728,1.63288,1.4579,-1.00173,-1.23167,0.0267855,0.104583
1077,0.803795,0.825087,0.930292,0.88445,0.215446,0.201464,0.269917,0.272572,0.98974,0.960428,0.519132,0.53989,0.166481,0.196522,0.58949,0.60284,0.284658,0.246305,0.793048,0.788809,-0.932966,-0.759945,0.941114,1.07876,-0.512587,-0.443653,-0.252797,-0.2445,-1.20829,-1.10376,-1.30421,-1.19589,1.4355,1.30183,0.069348,-0.111816,2.35885,2.12272,-1.95398,-1.88227
1078,0.647873,0.667322,0.246319,0.199191,0.649595,0.635568,0.520682,0.523212,0.690212,0.674532,0.819078,0.841282,0.180481,0.24843,0.295476,0.311309,0.307395,0.270649,0.581112,0.578012,1.14643,1.3229,-0.434654,-0.291486,-0.49801,-0.528305,0.335492,0.347618,1.3573,1.4665,1.42118,1.52635,-0.887495,-1.02206,2.04772,1.86457,0.25085,0.0150576,2.29943,2.37113
1079,0.0630678,0.0811343,0.771348,0.722199,0.152189,0.135873,0.101041,0.10186,0.416638,0.388637,0.0851488,0.106679,0.334779,0.300338,0.981723,0.997095,0.794185,0.755657,0.113375,0.112056,-0.630022,-0.450486,-1.09087,-0.946833,-0.67481,-0.612957,-0.655699,-0.646327,-0.274568,-0.17175,-0.199313,-0.0901754,0.180608,0.0504172,-0.546163,-0.72773,-0.877024,-1.11077,1.21943,1.28825
1080,0.591894,0.607941,0.999079,0.94944,0.771676,0.753871,0.416201,0.416685,0.961734,0.933006,0.251263,0.204483,0.322372,0.352246,0.391395,0.405772,0.283212,0.245958,0.914134,0.910189,0.787057,0.9687,-0.0739259,0.0688791,0.509752,0.568896,-0.631662,-0.542018,-0.489871,-0.38485,-0.387403,-0.273962,1.03163,0.90716,-0.249808,-0.428441,-0.168022,-0.401024,0.606694,0.675746
1081,0.331282,0.46376,0.815082,0.76519,0.0257315,0.00795109,0.940098,0.939608,0.777666,0.750688,0.281096,0.302287,0.177268,0.265095,0.499683,0.475733,0.211259,0.175614,0.159695,0.157497,-0.197182,-0.0215448,-0.185609,-0.0365911,-1.24974,-1.19242,-0.447441,-0.437709,-0.114138,-0.0103382,0.336661,0.445227,-0.81624,-0.937003,-0.5437,-0.707746,0.0366124,-0.170003,0.250803,0.318596
1082,0.250697,0.31958,0.0955504,0.0452887,0.391916,0.365013,0.368011,0.366946,0.387316,0.362353,0.17927,0.245648,0.149675,0.177944,0.531524,0.545694,0.462434,0.427358,0.323325,0.31926,-0.584182,-0.409665,0.350015,0.50234,0.881505,0.935906,-0.947736,-0.935332,0.533747,0.637471,1.6056,1.71536,-0.656922,-0.783969,-0.809918,-0.98705,0.289654,0.0610179,-1.19204,-1.12981
1083,0.158855,0.1754,0.365589,0.329391,0.741259,0.722076,0.912392,0.909834,0.341571,0.317919,0.166593,0.18901,0.366949,0.394409,0.330286,0.343625,0.218687,0.184168,0.690415,0.684451,0.412539,0.592541,0.301312,0.457574,-0.0870331,-0.0389866,-1.69568,-1.68158,-0.396829,-0.294596,1.42083,1.5133,0.359562,0.229379,-1.29521,-1.46728,-0.622436,-0.846723,-0.238447,-0.170298
1084,0.714764,0.731948,0.662358,0.613494,0.910301,0.892803,0.406145,0.467182,0.591101,0.569435,0.278477,0.339456,0.383054,0.412197,0.669732,0.681187,0.431785,0.394764,0.405563,0.477074,0.244676,0.430431,-0.350456,-0.197773,0.448533,0.49729,-0.0782384,-0.0599527,-0.159085,-0.0610135,1.20617,1.31124,1.16884,1.04105,-1.34169,-1.52037,-0.681875,-0.899841,-0.79243,-0.735588
1085,0.0719813,0.0905595,0.679322,0.632527,0.308891,0.293468,0.0280816,0.0245296,0.606484,0.582366,0.466217,0.489902,0.135772,0.166132,0.608435,0.620532,0.251917,0.217167,0.27526,0.269696,-1.449,-1.26387,-0.720398,-0.562186,-0.886187,-0.831088,-0.239855,-0.217642,1.20594,1.3073,-1.06705,-0.957669,-0.818115,-0.946627,0.0152176,-0.162749,1.14279,0.922245,-1.3745,-1.30088
1086,0.185877,0.139566,0.254642,0.208595,0.3379,0.320754,0.0856515,0.150673,0.392092,0.365308,0.0855007,0.108417,0.103335,0.132079,0.334146,0.347999,0.585867,0.543694,0.259088,0.196458,0.288695,0.481683,0.897866,1.05874,0.155436,0.212283,0.255877,0.282105,0.746392,0.848617,-1.47128,-1.35752,1.56506,1.43551,0.270852,0.0930327,0.00190595,-0.217838,0.279075,0.348415
1087,0.237858,0.188572,0.360126,0.312598,0.921852,0.904268,0.265066,0.276817,0.524395,0.500186,0.0931231,0.115504,0.702205,0.732594,0.506856,0.472238,0.903197,0.870221,0.130567,0.12322,0.335616,0.532353,1.06976,1.23001,2.21408,2.27776,-0.147097,-0.123059,0.908622,1.00801,0.399767,0.512053,-0.577522,-0.707123,1.4056,1.22195,-0.102866,-0.316553,0.436407,0.506076
1088,0.192756,0.237578,0.158096,0.113135,0.292868,0.275559,0.406964,0.40296,0.374521,0.259336,0.697195,0.72129,0.192839,0.220993,0.583764,0.596478,0.702462,0.667416,0.538396,0.532534,-1.52653,-1.33688,-0.463353,-0.297143,0.938866,0.996869,0.572235,0.593149,0.349936,0.444121,-1.51114,-1.39871,-0.0412173,-0.170035,-0.900108,-1.0808,1.56747,1.34732,0.849582,0.918137
1089,0.344397,0.286584,0.447981,0.404003,0.0113899,-0.00302432,0.225748,0.220993,0.0415471,0.0184852,0.518908,0.543992,0.942621,0.970506,0.414417,0.396707,0.709928,0.672857,0.357834,0.352195,0.057905,0.254179,-0.170398,-0.00153882,-0.947121,-0.88943,0.0516955,0.0796924,0.621422,0.709639,1.61404,1.72374,-1.50028,-1.62145,0.0579108,-0.198987,-0.258915,-0.476703,0.358539,0.428288
1090,0.317012,0.33559,0.513807,0.468076,0.395986,0.42774,0.608282,0.508649,0.0993063,0.0755131,0.67226,0.698783,0.132668,0.158806,0.183012,0.196937,0.516926,0.480076,0.879883,0.876627,0.480515,0.67403,1.08739,1.26189,0.166608,0.143408,1.07527,1.10637,0.0681354,0.160864,-1.1415,-1.03234,-0.399601,-0.517101,0.863521,0.682827,-0.256409,-0.48202,0.166137,0.238998
1091,0.980141,0.997322,0.338162,0.292396,0.871836,0.858503,0.798369,0.796304,0.595682,0.573439,0.348884,0.421585,0.0186965,0.0443934,0.671201,0.683833,0.861563,0.826451,0.583224,0.66093,-2.00997,-1.81092,-0.131676,0.0498539,1.11975,1.17625,-1.54772,-1.51229,-0.950228,-0.863138,0.701701,0.808821,-0.129293,-0.241541,0.586002,0.401869,-1.2243,-1.4504,-0.227265,-0.14604
1092,0.662178,0.678103,0.163136,0.116715,0.319482,0.304363,0.968932,0.966439,0.550421,0.529005,0.117578,0.144388,0.672833,0.697153,0.833593,0.845298,0.100368,0.066774,0.447069,0.445233,1.05628,1.24893,-2.99717,-2.82198,0.190309,0.251452,-0.298773,-0.271433,-1.38289,-1.29127,0.249921,0.360476,-1.17831,-1.28915,1.11146,0.932936,0.928173,0.699596,0.991222,1.07471
1093,0.928902,0.944977,0.972661,0.92372,0.660235,0.646314,0.511137,0.509434,0.926039,0.90667,0.474022,0.499676,0.0842442,0.109846,0.520369,0.533221,0.616075,0.581859,3.58973e-05,-0.00115801,-0.535075,-0.338611,0.20031,0.369255,0.161339,0.221972,0.565276,0.584653,0.483436,0.568831,0.472634,0.589529,1.10816,0.994606,0.0322305,-0.146443,-0.849591,-1.07633,-0.447284,-0.359468
1094,0.786237,0.805248,0.949512,0.898525,0.471902,0.458837,0.525939,0.522555,0.13337,0.111742,0.598433,0.624581,0.657135,0.681538,0.775352,0.727054,0.270438,0.236997,0.11655,0.11601,0.76028,0.955101,0.512025,0.679138,-0.482079,-0.424156,-0.178072,-0.1616,-1.35429,-1.27024,1.33166,1.44592,-0.459979,-0.568952,1.55651,1.37776,0.907825,0.680899,-0.317442,-0.235245
1095,0.65124,0.665518,0.612652,0.563451,0.971002,0.957155,0.297214,0.418645,0.93249,0.909185,0.493649,0.520988,0.639863,0.663776,0.909699,0.920886,0.450009,0.418343,0.88002,0.88046,-0.638641,-0.448803,0.264895,0.435234,-0.415592,-0.36178,-1.21706,-1.20104,-0.257227,-0.176501,-2.07675,-1.96838,-0.330783,-0.446197,0.0655776,-0.114147,1.94986,1.71937,-0.696837,-0.620284
1096,0.181159,0.195047,0.933148,0.884933,0.816615,0.710344,0.256948,0.314734,0.955266,0.841004,0.604122,0.591588,0.26948,0.293062,0.914068,0.811798,0.0359067,0.00427593,0.344715,0.44153,0.00395969,0.20162,-0.202749,-0.0365675,1.49536,1.54582,0.775588,0.783049,-0.669608,-0.605792,-0.417846,-0.31316,0.447617,0.337506,0.733493,0.554591,-0.21035,-0.435741,-2.36668,-2.29724
1097,0.257187,0.270693,0.355387,0.308261,0.477789,0.463533,0.214207,0.210824,0.794189,0.772823,0.534808,0.662189,0.799127,0.824215,0.7406,0.70271,0.564315,0.533869,0.00215866,0.00259922,-1.87034,-1.66762,-1.44514,-1.27949,0.417794,0.464719,-0.0594619,-0.056549,-1.11239,-1.03508,-0.476489,-0.37541,0.0943791,-0.0152704,0.51981,0.334797,0.244519,0.0227632,1.34921,1.4121
1098,0.0242924,0.0374786,0.430129,0.307387,0.0704645,0.0539005,0.858077,0.852851,0.145202,0.123629,0.703664,0.732789,0.97317,1.00068,0.580563,0.593622,0.225901,0.194614,0.540655,0.541992,0.556072,0.756877,1.70673,1.87168,0.825044,0.880008,-0.653983,-0.647793,-0.339251,-0.262835,1.49917,1.60207,1.72831,1.6185,-0.100761,-0.284237,0.142119,-0.0759521,0.916858,0.981704
1099,0.483723,0.509166,0.353912,0.306513,0.181748,0.165695,0.660207,0.750246,0.0605762,0.0378776,0.164236,0.193574,0.498606,0.57617,0.381225,0.396671,0.297838,0.181565,0.288706,0.381433,-0.765288,-0.570878,-0.421212,-0.24958,-1.29121,-1.23026,-0.115725,-0.116297,-1.13049,-1.05599,0.132119,0.22813,-0.40474,-0.507628,-1.13634,-1.31592,-3.36742,-3.5872,0.489371,0.551304
1100,0.967667,0.980854,0.616504,0.567383,0.568572,0.507983,0.651529,0.647642,0.608824,0.586589,0.574914,0.603227,0.125547,0.151664,0.708982,0.723074,0.201306,0.168517,0.129428,0.220874,-0.105484,0.0928743,-0.00153526,0.166571,-0.0807943,-0.0206505,-1.36015,-1.35835,-0.390964,-0.342724,0.498834,0.593524,0.38896,0.289292,-0.844966,-1.02924,-1.1276,-1.34361,1.46563,1.52495
1101,0.885485,0.932288,0.356633,0.307331,0.868945,0.850271,0.00823795,0.00539275,0.84511,0.822449,0.573517,0.600141,0.126438,0.155115,0.507258,0.479142,0.937477,0.905275,0.058204,0.060315,0.293111,0.498675,-0.680859,-0.519671,1.65751,1.71778,-0.574513,-0.580059,0.290947,0.370544,-1.60254,-1.50358,0.440808,0.335192,1.05185,0.868938,-0.0919594,-0.305147,-0.739845,-0.679211
1102,0.869281,0.883722,0.0964645,0.0472791,0.931734,0.912452,0.673986,0.671438,0.411228,0.388513,0.991369,1.0195,0.715675,0.746483,0.220207,0.235209,0.286087,0.255092,0.445477,0.431791,-0.608543,-0.399273,-0.348856,-0.163847,-1.40155,-1.33755,0.906738,0.897029,0.10881,0.187212,-0.941188,-0.845575,1.95367,1.84334,-0.677235,-0.856937,-0.33109,-0.542668,-0.664585,-0.598535
1103,0.191843,0.20591,0.205313,0.156042,0.0533504,0.0330345,0.0622883,0.0584256,0.669755,0.645364,0.245853,0.274137,0.577244,0.606732,0.558039,0.572772,0.881027,0.851563,0.801248,0.803267,1.60948,1.81999,0.036777,0.191977,-0.601956,-0.538524,-1.19296,-1.20719,1.13071,1.20573,1.65551,1.74564,-1.00042,-1.10904,-0.644329,-0.817928,-0.897825,-1.10508,-0.288274,-0.217507
1104,0.22577,0.242199,0.592812,0.481399,0.28887,0.268405,0.77833,0.777039,0.342499,0.318201,0.955927,0.985199,0.734548,0.715249,0.483592,0.496065,0.653103,0.578281,0.621623,0.673229,1.63829,1.85392,1.66802,1.82762,-0.0169542,0.0449055,-1.25711,-1.2735,-1.30304,-1.23697,0.20673,0.297403,-0.790258,-0.8962,1.96233,1.78034,0.269692,0.0561359,0.999531,1.06253
1105,0.817946,0.833405,0.855757,0.806756,0.153014,0.13895,0.913004,0.911191,0.404434,0.380693,0.338675,0.370289,0.796727,0.823766,0.161449,0.174145,0.333545,0.305,0.418942,0.54319,0.753999,0.971266,0.761775,0.925476,-0.0909247,-0.0308485,-0.982491,-1.00096,0.173526,0.239813,0.44147,0.526457,0.41554,0.304672,-0.520281,-0.665533,-0.271019,-0.490693,-0.578856,-0.521254
1106,0.543713,0.515767,0.59603,0.574158,0.0292194,0.00949432,0.622233,0.618679,0.890703,0.869024,0.749895,0.779942,0.0777259,0.105986,0.642326,0.656175,0.846518,0.820085,0.412535,0.413151,-1.65708,-1.44595,-0.783396,-0.616887,-1.25246,-1.19075,0.279787,0.256608,0.204327,0.275614,-2.34099,-2.26054,0.402774,0.290691,-2.92941,-3.11141,-0.246709,-0.464057,-0.986504,-0.923286
1107,0.183057,0.19813,0.392497,0.34156,0.198695,0.128379,0.684047,0.682373,0.729995,0.707659,0.198016,0.225756,0.300966,0.353218,0.168413,0.18067,0.74304,0.698109,0.958885,0.957282,-0.520862,-0.307536,-1.26243,-1.10329,0.20278,0.264483,2.00537,1.98561,-1.07654,-1.00832,-0.569867,-0.498817,0.743706,0.627739,0.319123,0.145154,0.310126,0.090586,-1.14551,-1.08237
1108,0.893645,0.908761,0.748991,0.697085,0.268317,0.247264,0.125241,0.124134,0.108255,0.0882665,0.698824,0.728103,0.574658,0.600449,0.588769,0.54818,0.602601,0.576133,0.0817351,0.07829,1.57809,1.7884,2.0055,2.16996,-0.842375,-0.786045,-1.21532,-1.23313,1.63602,1.7013,-0.252307,-0.178527,-0.049256,-0.141344,0.0607221,-0.13415,1.97984,1.75446,0.388647,0.445131
1109,0.279475,0.292656,0.389456,0.33787,0.734144,0.710822,0.254364,0.301,0.797801,0.779525,0.329805,0.360695,0.56328,0.587786,0.905599,0.915691,0.23463,0.206776,0.0846813,0.0791781,-1.12328,-0.911017,0.534646,0.704208,0.662607,0.695184,0.384713,0.371444,0.0887169,0.157926,-0.876754,-0.798816,-0.79367,-0.910428,-0.235746,-0.413454,1.91988,1.70134,-0.222841,-0.167368
1110,0.351769,0.363389,0.320307,0.234819,0.0800149,0.0574278,0.480628,0.477866,0.133256,0.114693,0.272374,0.30284,0.0495288,0.0761855,0.487203,0.499199,0.118502,0.0896057,0.991897,0.987768,0.910206,1.12574,-0.391031,-0.228043,2.12008,2.17641,1.28387,1.27489,1.00875,1.08357,-0.115602,-0.0332524,-0.235438,-0.356278,0.47142,0.301151,0.257516,0.0409279,-0.0727604,-0.087178
1111,0.693228,0.705338,0.184858,0.131769,0.919955,0.899881,0.198132,0.286277,0.00184734,-0.0169313,0.765988,0.795466,0.048372,0.072602,0.753857,0.746064,0.885138,0.856012,0.248258,0.244678,-0.570785,-0.352818,1.67509,1.83014,2.39868,2.45401,0.841012,0.837624,0.540242,0.675514,-0.0554278,0.027528,-0.0106008,-0.0346318,0.690664,0.525654,0.505065,0.296233,-0.0677319,-0.00698761
1112,0.0431582,0.0537381,0.459584,0.408008,0.0433604,0.0252473,0.0987808,0.0946874,0.952392,0.933099,0.431832,0.461983,0.0397939,0.0690186,0.982947,0.99293,0.0570794,0.027577,0.927952,0.923538,1.04718,1.27005,-0.894622,-0.740595,-0.513808,-0.459146,-0.292052,-0.295592,0.192397,0.267456,-2.10615,-2.02122,0.410659,0.287014,-0.351574,-0.521921,0.982519,0.771211,1.31458,1.38085
1113,0.244023,0.317285,0.997481,0.945243,0.745554,0.72561,0.254065,0.317742,0.743009,0.721303,0.745759,0.777561,0.246148,0.29207,0.365364,0.376593,0.693367,0.66481,0.592788,0.587107,-0.30948,-0.0852975,0.760422,0.910077,-0.854921,-0.79489,1.22751,1.22764,0.0867749,0.160809,0.759946,0.845978,-1.50876,-1.6355,1.55972,1.39222,2.1148,1.90149,-0.49898,-0.433813
1114,0.570678,0.580832,0.0493786,-0.00441912,0.923745,0.901932,0.545747,0.540796,0.965409,0.941983,0.68363,0.715615,0.488247,0.515121,0.359165,0.336144,0.0178329,-0.0101815,0.819014,0.814888,-0.0481739,0.180585,0.427326,0.575511,-0.0735156,-0.012183,0.21886,0.217759,0.552317,0.618901,1.54492,1.62574,-0.839954,-0.960329,1.37256,1.20257,2.51839,2.29839,-0.111464,-0.0527852
1115,0.351096,0.441102,0.379464,0.326447,0.782207,0.759926,0.235942,0.233011,0.0517417,0.0265884,0.870199,0.860198,0.0670593,0.0940988,0.282049,0.295694,0.904844,0.878307,0.447963,0.444379,0.752482,0.982696,0.70645,0.854778,0.181992,0.175013,-1.68778,-1.6951,1.00678,1.07699,0.287912,0.293246,0.0514737,-0.0716709,-0.386706,-0.552059,0.279709,0.0649011,-0.428265,-0.363513
1116,0.289279,0.301372,0.0034338,-0.0481651,0.0319542,0.00989489,0.731302,0.726352,0.509896,0.492883,0.972449,1.00478,0.815942,0.843612,0.055748,0.0687327,0.940268,0.923905,0.282031,0.315601,-0.11154,0.116142,-0.0754083,0.0738696,0.300876,0.362209,-0.0779878,-0.0905247,0.527537,0.603972,-1.12522,-1.03924,1.33086,1.20456,-1.05937,-1.21932,-1.32366,-1.53052,0.658985,0.718826
1117,0.320744,0.331803,0.385128,0.258195,0.0293289,0.0709929,0.476964,0.473457,0.985702,0.959177,0.386756,0.419827,0.441333,0.467648,0.372531,0.385072,0.995518,0.969504,0.187835,0.186824,0.176298,0.399071,-0.31255,-0.170035,-0.215146,-0.158006,-0.625165,-0.633699,0.261832,0.343113,-1.26278,-1.17857,-0.0142825,-0.0929768,-0.725328,-0.887433,0.213342,0.0059981,-0.096279,-0.0439785
1118,0.66245,0.638874,0.584208,0.564555,0.154234,0.132091,0.734719,0.728618,0.43713,0.41067,0.44481,0.425123,0.665391,0.693496,0.252648,0.344553,0.469052,0.445437,0.51885,0.523865,-0.250885,-0.0352806,-0.815992,-0.671724,-1.19386,-1.1329,1.99662,1.98394,1.55325,1.63663,0.683298,0.766022,-1.26523,-1.39051,0.177306,0.00934279,-0.322023,-0.526589,1.51176,1.5599
1119,0.933927,0.945945,0.922514,0.870915,0.41053,0.387571,0.444036,0.436105,0.354688,0.3305,0.395835,0.430418,0.514875,0.561704,0.31603,0.304035,0.179851,0.156286,0.864032,0.860905,-1.15533,-0.933228,-1.84706,-1.69952,0.845192,0.901037,0.560458,0.542194,-0.0741482,0.013489,-0.228996,-0.146317,0.221449,0.10129,1.60764,1.44378,-0.372169,-0.579708,1.03591,1.08445
1120,0.795015,0.808138,0.861317,0.811725,0.41134,0.388925,0.714625,0.706638,0.790144,0.763044,0.860804,0.893367,0.402791,0.429912,0.250976,0.263516,0.603348,0.580971,0.293412,0.289732,1.146,1.36396,1.04848,1.19986,1.76028,1.82245,1.57131,1.55469,-0.725244,-0.640862,1.08062,1.16981,-0.0431693,-0.15713,1.43321,1.27001,0.0881072,-0.121203,0.966218,1.10224
1121,0.307525,0.321544,0.0636119,0.0141392,0.0285741,0.00430933,0.719022,0.687274,0.580992,0.459593,0.514734,0.546184,0.820536,0.846684,0.842876,0.856664,0.702073,0.679505,0.873573,0.869066,-0.429533,-0.208031,1.08018,1.23265,0.130185,0.188363,2.07223,2.05444,-0.476924,-0.390143,0.472896,0.565879,0.246043,0.135165,-0.82861,-0.998115,-0.736925,-0.947249,1.07151,1.12004
1122,0.322907,0.336736,0.0266185,-0.019922,0.00347604,-0.0194676,0.678522,0.66791,0.184887,0.156141,0.920576,0.95006,0.0442196,0.0708134,0.731345,0.745086,0.0846307,0.0637013,0.425474,0.422675,-0.264938,-0.0500708,0.826028,0.97368,0.331538,0.387212,0.28577,0.269909,0.48296,0.565733,1.04533,1.13341,-1.73955,-1.85251,0.594492,0.421574,-0.123717,-0.331673,0.145602,0.19041
1123,0.0591831,0.0732336,0.987625,0.943319,0.599437,0.57824,0.333393,0.321183,0.766131,0.735877,0.710782,0.740872,0.251559,0.204755,0.367199,0.472544,0.438149,0.414985,0.843446,0.842003,0.718687,0.934524,-0.182669,-0.0375672,0.764431,0.816178,-0.525561,-0.53767,-1.35094,-1.27334,-0.28208,-0.191937,0.0148543,-0.0962837,-1.73705,-1.91124,-2.20925,-2.4273,-1.15236,-1.10495
1124,0.195004,0.234258,0.29486,0.248088,0.233873,0.213621,0.27042,0.258603,0.757642,0.714916,0.816722,0.845027,0.312102,0.338696,0.186579,0.200001,0.0316727,0.00987582,0.165433,0.165916,-0.29863,-0.0873824,-0.544274,-0.401981,0.768446,0.816152,0.229606,0.24599,-0.036433,0.0366413,-1.11661,-1.02631,-0.306773,-0.36348,-0.449754,-0.618091,0.870247,0.656387,-0.305551,-0.253291
1125,0.515876,0.395282,0.702256,0.653762,0.0827956,0.0617228,0.75968,0.747067,0.726013,0.693955,0.714326,0.786428,0.275411,0.302775,0.663913,0.676527,0.727969,0.706465,0.930401,0.930367,-0.628537,-0.413047,0.659669,0.799173,1.03833,1.09375,1.03988,1.02965,0.758122,0.82483,0.0689963,0.152224,-0.525919,-0.630675,0.221767,0.0506466,-1.96745,-2.18366,-0.4995,-0.44258
1126,0.543225,0.556307,0.0657824,0.0183014,0.533407,0.441301,0.0248968,0.014044,0.956036,0.924542,0.69918,0.727829,0.203053,0.266854,0.106497,0.120414,0.758329,0.736025,0.168669,0.167262,0.466116,0.678404,1.12804,1.261,-0.932679,-0.871322,-0.608085,-0.614254,0.734543,0.797946,0.957666,1.04057,-0.0241025,-0.123651,-0.646224,-0.847359,-0.542347,-0.753521,-1.16249,-1.09902
1127,0.612364,0.62704,0.704764,0.657652,0.839888,0.820879,0.428128,0.418526,0.0933558,0.0645933,0.988298,1.017,0.307992,0.230932,0.840784,0.852961,0.415477,0.39212,0.508133,0.50595,0.872703,1.08421,0.0846356,0.27377,0.362489,0.415782,-0.395254,-0.403611,-1.40975,-1.34889,1.03786,1.11621,1.42819,1.3233,-1.56804,-1.74537,-0.906721,-1.11536,-2.3695,-2.30309
1128,0.981289,0.994798,0.207837,0.15937,0.0527323,0.0363078,0.500502,0.41174,0.418375,0.391966,0.970236,0.998825,0.0839303,0.195011,0.440866,0.494309,0.0678923,0.048215,0.242459,0.319119,0.866379,1.07493,-0.846414,-0.713456,-0.522218,-0.463387,0.055169,0.0521116,-0.326586,-0.270184,0.13843,0.218666,-0.208295,-0.316655,0.861796,0.679345,-0.344578,-0.546783,2.02297,2.08308
1129,0.643222,0.599396,0.775356,0.725853,0.608906,0.594279,0.405992,0.404955,0.456084,0.428896,0.54504,0.573104,0.132497,0.15909,0.121397,0.135657,0.50364,0.483114,0.134049,0.132288,0.426274,0.640574,-0.830484,-0.697373,-0.968579,-0.904803,-0.229877,-0.230363,-0.065421,-0.00466622,0.721771,0.802,1.4577,1.34785,-0.423579,-0.59989,-0.954353,-1.15628,-0.160366,-0.105966
1130,0.191306,0.203993,0.969074,0.918633,0.0429956,0.0300214,0.409941,0.39817,0.0516478,0.0248177,0.67284,0.71508,0.639155,0.665512,0.974841,0.990631,0.316326,0.296025,0.272785,0.269346,-0.890683,-0.669467,0.203506,0.333698,-0.335965,-0.276573,0.196766,0.194031,1.16659,1.22884,-0.808619,-0.722079,-2.38597,-2.50404,0.299392,0.120012,-0.449185,-0.648102,-0.16096,-0.067842
1131,0.171681,0.183913,0.686296,0.632972,0.912349,0.901492,0.615688,0.604856,0.0195211,-0.00953866,0.82718,0.857056,0.667119,0.693323,0.363088,0.379771,0.995446,0.973879,0.6642,0.59449,-0.504333,-0.188072,-0.338256,-0.215942,-1.09491,-1.0308,-1.29229,-1.29234,-0.839841,-0.783899,0.128196,0.212384,0.198407,0.083048,1.01724,0.839914,-0.785275,-0.979057,-0.0868948,-0.0297181
1132,0.928788,0.939063,0.78377,0.731904,0.523041,0.512012,0.366052,0.356922,0.525002,0.49436,0.149672,0.181506,0.142759,0.171007,0.408667,0.42516,0.452292,0.42939,0.92422,0.919634,0.0794865,0.293322,1.67833,1.79416,-0.406489,-0.338836,1.16872,1.16973,0.654906,0.707603,0.792795,0.870385,0.957354,0.835838,0.698904,0.526583,-1.80779,-1.99549,-1.42539,-1.37162
1133,0.397386,0.407845,0.0328028,-0.0186266,0.61623,0.603129,0.864257,0.854829,0.820554,0.791936,0.113818,0.144178,0.520423,0.547767,0.763208,0.777512,0.136623,0.114438,0.298305,0.294077,-0.459982,-0.249991,0.88632,0.999485,-1.09928,-1.03359,-0.648238,-0.648099,0.7569,0.805372,1.04652,1.12882,0.00845179,-0.118056,-0.458171,-0.626121,1.03975,0.849389,-0.431551,-0.381983
1134,0.195916,0.203979,0.999915,0.948486,0.937036,0.924667,0.919459,0.909063,0.146367,0.116737,0.708609,0.739966,0.184145,0.212607,0.275713,0.291344,0.991873,0.970183,0.29144,0.311384,0.0276337,0.234183,-0.197174,-0.0888069,-1.8022,-1.72835,1.58348,1.57606,1.58494,1.63862,-0.613311,-0.531568,-0.256417,-0.444637,-2.05705,-2.22562,0.186366,-0.00685717,1.41335,1.45725
1135,0.801325,0.809956,0.154183,0.103296,0.161626,0.150249,0.305588,0.29605,0.922764,0.890908,0.854853,0.884951,0.873955,0.900128,0.646852,0.663804,0.709858,0.686902,0.330714,0.32869,0.136244,0.345631,0.456121,0.559399,0.388923,0.464204,-2.14496,-2.1592,-1.21127,-1.16438,-0.755186,-0.670895,-0.647923,-0.771219,-1.05427,-1.21864,0.353115,0.156267,-1.53249,-1.4911
1136,0.824259,0.830394,0.510123,0.458822,0.111117,0.101226,0.0484685,0.0383938,0.580226,0.565341,0.210237,0.239609,0.215743,0.24268,0.352047,0.36687,0.739408,0.716461,0.872542,0.868083,-1.15983,-0.951097,0.50813,0.606591,-0.307242,-0.228238,1.04977,1.04452,1.21315,1.25692,0.273003,0.355504,0.902553,0.782608,1.1805,1.01956,-0.349568,-0.544304,0.418153,0.451384
1137,0.570929,0.577476,0.182353,0.228707,0.270831,0.387276,0.271756,0.263363,0.271952,0.239775,0.67324,0.702559,0.661646,0.688827,0.962303,0.976644,0.289488,0.266664,0.285548,0.282388,-0.713357,-0.500641,1.37417,1.46718,0.918194,0.999315,-0.238367,-0.242515,1.37741,1.41632,-1.45494,-1.3668,-1.31461,-1.43822,-0.0994989,-0.259671,2.02002,1.83037,0.177071,0.217236
1138,0.0842391,0.090882,0.0479815,-0.00140795,0.621573,0.673326,0.0349419,0.0257569,0.197348,0.164747,0.492838,0.486791,0.454428,0.483704,0.256954,0.273232,0.680419,0.657555,0.143378,0.161739,1.0982,1.306,-1.42317,-1.32878,1.37772,1.45819,0.761508,0.754694,0.0606434,0.0988727,0.727678,0.819758,-0.378299,-0.50135,0.920459,0.763156,1.29161,1.098,-1.49158,-1.44406
1139,0.109146,0.11595,0.317555,0.269628,0.969267,0.959376,0.815674,0.805764,0.541563,0.507345,0.269794,0.271023,0.626961,0.636302,0.0482015,0.0663535,0.437287,0.414365,0.0436374,0.0410899,-0.30425,-0.0979006,-0.798293,-0.697697,1.27657,1.35168,0.230783,0.25643,0.764467,0.807721,-2.95008,-2.8646,-0.564433,-0.683081,-0.301132,-0.453513,1.39811,1.20064,1.03815,1.08686
1140,0.744114,0.751761,0.215572,0.166366,0.187757,0.178891,0.393519,0.384412,0.0582934,0.0236624,0.0259371,0.0552554,0.868962,0.788899,0.893956,0.911479,0.935951,0.914585,0.756432,0.755448,-0.407145,-0.199737,0.909045,1.01455,0.0547583,0.130127,-0.239795,-0.241834,0.620368,0.670227,0.906995,0.992476,-0.548272,-0.668547,-0.067621,-0.213779,-1.25475,-1.44541,-0.722977,-0.6685
1141,0.659696,0.633078,0.416082,0.368827,0.0724381,0.0623493,0.416563,0.430178,0.226951,0.224643,0.0798545,0.110858,0.91279,0.941497,0.711362,0.729307,0.897003,0.874942,0.872487,0.872616,-1.75294,-1.54118,-0.377779,-0.275853,0.029345,0.100647,-0.135892,-0.197449,-0.20646,-0.154538,0.439169,0.527966,1.13069,1.01033,0.443887,0.301215,-0.0854515,-0.267123,-0.217999,-0.16427
1142,0.506807,0.514395,0.233488,0.184576,0.99688,0.988256,0.431021,0.475944,0.461178,0.425623,0.549681,0.578457,0.386866,0.414671,0.236459,0.253801,0.607394,0.660071,0.213685,0.216312,-1.00514,-0.799911,-2.36898,-2.27098,1.04597,1.11533,-0.215489,-0.153063,0.701106,0.754924,0.427497,0.512196,-0.423605,-0.538702,-0.215977,-0.366045,0.565057,0.379046,-1.70379,-1.65661
1143,0.175787,0.184681,0.937044,0.88981,0.528212,0.518524,0.530456,0.52171,0.661235,0.626604,0.591453,0.618839,0.794963,0.82164,0.792038,0.8117,0.445934,0.445201,0.35552,0.358836,0.160934,0.3693,-1.65946,-1.56315,0.0348722,0.111655,-0.106638,-0.108678,-1.86512,-1.80597,0.746207,0.832486,0.304116,0.183144,-0.534892,-0.679376,-0.574645,-0.761038,-1.04342,-0.99956
1144,0.268008,0.324841,0.090123,0.0446204,0.915503,0.905531,0.0630486,0.0550526,0.16004,0.123366,0.321843,0.350962,0.913999,0.941709,0.869099,0.850871,0.252391,0.23033,0.28202,0.232753,-1.06276,-0.851595,0.060881,0.165063,0.357358,0.434369,-1.33668,-1.33462,0.265203,0.329595,-1.29803,-1.21626,0.123956,0.00141286,-0.523761,-0.672045,-1.07015,-1.26233,0.941001,0.987971
1145,0.454629,0.465,0.77267,0.729249,0.781767,0.774005,0.0289413,0.0230411,0.187328,0.150762,0.471659,0.500758,0.194877,0.223929,0.854993,0.890041,0.51275,0.403757,0.104368,0.10667,0.338386,0.551919,0.685705,0.796146,1.76002,1.8426,1.58186,1.58816,-0.0758533,-0.00785315,1.05904,1.14509,-0.477799,-0.596063,0.50441,0.350782,0.076742,-0.116503,0.869683,0.981633
1146,0.958915,0.96713,0.531652,0.487927,0.382719,0.411078,0.411633,0.406145,0.979987,0.942246,0.846974,0.875659,0.499888,0.531673,0.927217,0.929212,0.598178,0.577184,0.297713,0.298718,-2.25482,-2.03669,-1.3512,-1.2482,1.37601,1.46139,-1.71486,-1.70791,-0.993366,-0.922666,0.430185,0.517473,-0.171747,-0.229878,-1.45379,-1.6096,-1.08391,-1.27425,0.934951,0.975296
1147,0.174194,0.185209,0.988667,0.946422,0.0577515,0.0481515,0.484629,0.50884,0.0652449,0.026852,0.174382,0.20521,0.808176,0.839417,0.947113,0.968383,0.646045,0.583332,0.0808713,0.0834183,0.544044,0.766984,0.953733,1.05293,-0.241577,-0.159773,1.52429,1.53519,0.241499,0.310836,-0.197213,-0.110147,0.258725,0.136307,-1.46531,-1.61901,-0.302764,-0.488361,-0.132143,-0.0895706
1148,0.515791,0.527158,0.393315,0.350258,0.54911,0.541549,0.61513,0.611535,0.640602,0.601145,0.413488,0.502742,0.825108,0.857205,0.789656,0.811868,0.608469,0.58948,0.333897,0.336624,0.0644113,0.284434,0.318452,0.413361,-1.39956,-1.31967,-0.342656,-0.329614,0.815034,0.882764,1.43876,1.5321,-1.36118,-1.48694,-0.520181,-0.686976,0.755581,0.56534,-0.728696,-0.68577
1149,0.59662,0.639747,0.858224,0.813335,0.437645,0.430016,0.420619,0.419937,0.0744425,0.0332214,0.769515,0.800274,0.408758,0.441196,0.893182,0.913413,0.12074,0.0994633,0.132166,0.200912,0.0642413,0.289856,-1.21125,-1.11379,0.0577099,0.135559,0.805904,0.820166,-0.395748,-0.321983,-0.48547,-0.392677,-0.422637,-0.550076,0.398183,0.245061,0.701399,0.512222,1.41635,1.4637
1150,0.743142,0.752335,0.63323,0.536803,0.960186,0.953486,0.0204839,0.0183236,0.225231,0.183409,0.823413,0.855877,0.462477,0.473482,0.363768,0.382364,0.780615,0.757775,0.0617009,0.0652006,1.43012,1.66223,-0.862268,-0.758597,0.278007,0.350263,-0.472372,-0.451217,0.537462,0.603663,-0.229783,-0.134239,0.819811,0.696869,0.284577,0.131211,-0.0493465,-0.238007,-1.66532,-1.61644
1151,0.34589,0.356185,0.335583,0.260271,0.402548,0.394639,0.0811357,0.0766797,0.0358156,-0.00358614,0.381031,0.414323,0.473475,0.505768,0.190123,0.255741,0.323,0.297676,0.991689,0.993928,0.434615,0.671984,-1.38531,-1.2754,-1.18592,-1.11633,1.33652,1.36001,-0.693456,-0.620218,-0.191035,-0.0892158,0.288567,0.0786176,1.55805,1.40734,-0.597819,-0.784836,-0.102601,-0.0566886
1152,0.962922,0.971516,0.0286292,-0.0162603,0.595032,0.584992,0.382272,0.37707,0.121521,0.157692,0.694758,0.729901,0.996758,1.02806,0.110218,0.129119,0.820984,0.797896,0.801528,0.751517,0.0446884,0.331981,-0.286534,-0.273311,2.58943,2.66619,1.08342,1.05443,0.142184,0.213025,-0.456389,-0.350369,-0.41069,-0.539634,-0.884004,-1.04201,1.6374,1.44313,2.70279,2.74956
1153,0.0995498,0.107769,0.714604,0.668368,0.206175,0.195513,0.19608,0.189629,0.252026,0.318969,0.709178,0.741713,0.0539575,0.0838858,0.39602,0.415037,0.776075,0.75319,0.507191,0.509105,-0.247956,-0.00802224,0.612651,0.72878,-1.03554,-0.958741,0.640371,0.74885,-0.0901039,-0.0169902,-0.181717,-0.0760414,-0.249859,-0.3866,0.696979,0.54479,0.354407,0.160365,0.164029,0.207709
1154,0.104408,0.112918,0.233239,0.185078,0.043013,0.0335828,0.225249,0.147791,0.5044,0.480247,0.169758,0.202497,0.791022,0.822838,0.433581,0.45031,0.157936,0.13276,0.725724,0.726484,0.551227,0.794089,0.667344,0.775971,1.11241,1.1839,0.419784,0.443271,0.376414,0.447127,0.90208,1.0112,-0.655111,-0.784813,0.64425,0.417288,-0.288646,-0.47893,-1.30193,-1.25551
1155,0.794239,0.803638,0.0989221,0.0945334,0.555599,0.474741,0.10981,0.105953,0.680926,0.641525,0.415277,0.485308,0.886091,0.916779,0.203487,0.21802,0.237211,0.210773,0.453375,0.504698,0.0377587,0.279447,-1.17108,-1.06709,0.433921,0.50541,0.310163,0.331552,0.0891245,0.158718,0.646805,0.75005,-0.139947,-0.277788,0.404726,0.289787,-1.2034,-1.40045,-0.781024,-0.736054
1156,0.380101,0.475582,0.0551302,0.00398875,0.92533,0.9159,0.509417,0.5053,0.260247,0.222486,0.736096,0.768119,0.289945,0.32018,0.597268,0.610163,0.865498,0.837161,0.282594,0.282911,0.640549,0.882986,2.22389,2.3364,1.65774,1.73296,-1.43102,-1.40789,0.997244,1.06818,0.100766,0.208545,0.622899,0.489309,0.314474,0.162285,0.0486786,-0.145611,0.583083,0.622604
1157,0.139837,0.147526,0.792824,0.740002,0.229207,0.221912,0.288233,0.28241,0.89534,0.857018,0.668279,0.700039,0.74771,0.776061,0.123391,0.134657,0.338762,0.307995,0.48403,0.544527,-1.12471,-0.875472,0.163138,0.278624,-0.498017,-0.42668,1.07336,1.08924,-0.321675,-0.249265,0.985286,1.0969,1.05434,0.921304,0.972022,0.815511,-0.527097,-0.620895,-0.416313,-0.381186
1158,0.0968658,0.138359,0.17538,0.12345,0.95317,0.947565,0.844408,0.839872,0.148386,0.109691,0.850006,0.879141,0.0131658,0.0426117,0.837192,0.846669,0.297854,0.302281,0.805332,0.806143,0.727965,0.975531,0.288,0.375071,-0.992255,-0.915576,-0.134348,-0.121466,-0.626858,-0.553962,0.552217,0.665767,-1.17233,-1.29952,-1.42514,-1.58144,-0.907303,-1.09618,0.846083,0.884879
1159,0.121003,0.129192,0.8271,0.773486,0.128957,0.123004,0.00516187,0.00254677,0.132357,0.0957723,0.400732,0.427834,0.188601,0.219073,0.0602471,0.0702942,0.32538,0.296568,0.552043,0.55347,0.0462754,0.29352,0.354211,0.471517,-0.892219,-0.809075,-0.696556,-0.679786,-0.264088,-0.195617,-1.81578,-1.70375,-0.344104,-0.471987,1.60038,1.44153,0.491278,0.303544,-0.189045,-0.149218
1160,0.71328,0.720397,0.191371,0.138025,0.540671,0.536156,0.774616,0.771431,0.359707,0.321227,0.97853,1.0039,0.767308,0.795573,0.912502,0.920527,0.075303,0.0480476,0.298273,0.300796,-2.07794,-1.82208,-0.340885,-0.229626,0.893288,0.974288,-0.330193,-0.315349,-2.00072,-1.92595,-0.640087,-0.525223,0.190395,0.0651016,-0.0653264,-0.220841,-0.128735,-0.31952,0.485698,0.523204
1161,0.579576,0.658264,0.492082,0.43946,0.616077,0.612628,0.517027,0.513774,0.0106284,-0.0262011,0.201208,0.228131,0.50779,0.534871,0.751261,0.688968,0.957807,0.930868,0.358514,0.363039,0.760375,1.01497,0.582678,0.691637,-1.31563,-1.23271,-0.410689,-0.353651,0.809027,0.884301,0.0315371,0.149722,-0.717913,-0.841915,-2.54053,-2.70139,1.23283,1.04856,0.407994,0.438752
1162,0.587647,0.59613,0.210096,0.159436,0.0671117,0.0635652,0.557774,0.552639,0.177187,0.0488994,0.612577,0.637784,0.50668,0.533152,0.424127,0.457409,0.855093,0.829727,0.171692,0.17763,-1.48199,-1.23035,0.474292,0.529609,0.174974,0.252387,-0.374311,-0.391953,-1.14438,-1.06636,-1.10977,-0.989887,1.10655,0.980379,1.36043,1.20554,-0.612485,-0.788573,-1.77737,-1.7503
1163,0.995334,1.00399,0.758186,0.707305,0.181661,0.180752,0.219939,0.31189,0.145703,0.124,0.442913,0.470147,0.222174,0.247285,0.217825,0.225851,0.233161,0.209297,0.582012,0.586944,0.622604,0.882092,0.260764,0.367582,1.30615,1.38923,-0.445099,-0.430255,-0.38834,-0.310809,-0.86302,-0.74564,-1.49893,-1.62996,1.43982,1.29013,0.317943,0.138997,-0.226604,-0.190546
1164,0.0646321,0.0741596,0.479588,0.427282,0.694287,0.694766,0.0739128,0.0711418,0.237916,0.199101,0.0234843,0.0488336,0.446396,0.547505,0.277161,0.2865,0.996385,0.970841,0.511022,0.518611,1.98122,2.23954,-0.755901,-0.643666,-1.7333,-1.64739,0.844783,0.857027,1.34521,1.4275,-0.944037,-0.823376,-0.963035,-1.09287,0.462881,0.317808,0.900569,0.722309,0.294853,0.328906
1165,0.375871,0.385797,0.749703,0.613045,0.156016,0.155695,0.780445,0.778478,0.904199,0.864345,0.747621,0.774696,0.822845,0.847725,0.0583363,0.0694126,0.466022,0.441675,0.855775,0.862933,-0.692736,-0.433385,-1.36963,-1.25332,-0.146371,-0.0669911,-0.246873,-0.231607,-1.70149,-1.62445,0.285089,0.423247,-0.0353025,-0.171647,-2.09572,-2.2381,-0.200747,-0.384963,-0.297736,-0.267293
1166,0.238461,0.24799,0.849459,0.798809,0.608807,0.609204,0.262653,0.260605,0.917941,0.877277,0.574347,0.602101,0.763418,0.789346,0.801809,0.811807,0.61238,0.586119,0.415645,0.421874,-0.594836,-0.337174,-2.19965,-2.07832,0.510397,0.592334,1.27731,1.29162,0.933144,1.01214,1.55011,1.66987,2.35342,2.21049,0.0192734,-0.12146,1.35773,1.16796,0.475026,0.509061
1167,0.982881,0.991957,0.520341,0.468553,0.214716,0.214121,0.360828,0.359828,0.455425,0.509865,0.643654,0.670924,0.943447,0.970104,0.326537,0.336301,0.0261269,0.00113863,0.474396,0.479058,-0.888566,-0.634138,-1.37866,-1.2633,-0.968915,-0.889005,0.585085,0.593754,1.65574,1.73782,0.0671883,0.18901,-1.30396,-1.44591,0.175227,0.0406784,1.00135,0.806127,-0.0344302,0.00257128
1168,0.134113,0.144511,0.908588,0.858535,0.987532,0.985347,0.709776,0.651888,0.182557,0.142454,0.796147,0.739748,0.0298198,0.0546096,0.69152,0.699186,0.991598,0.966936,0.098093,0.102881,0.953832,1.20146,1.37218,1.4939,0.372631,0.460321,0.5814,0.590717,-1.53674,-1.4541,-0.835718,-0.70853,-0.365752,-0.509042,-1.20479,-1.34698,-0.590138,-0.789299,-0.30532,-0.261982
1169,0.641672,0.651665,0.154681,0.102129,0.656432,0.683466,0.943425,0.943949,0.870428,0.828372,0.736005,0.808571,0.445837,0.447022,0.763264,0.835154,0.39574,0.372703,0.863306,0.867332,0.113044,0.364321,-0.422541,-0.299182,1.18956,1.27572,0.322225,0.338995,1.44404,1.53243,-0.613938,-0.494168,1.30976,1.16984,1.79094,1.65028,0.0845738,-0.110196,0.116093,0.165929
1170,0.655652,0.666857,0.574723,0.521243,0.315127,0.381584,0.674197,0.676022,0.257346,0.213945,0.84964,0.877395,0.815912,0.839434,0.962161,0.971122,0.8978,0.872923,0.0827416,0.0873648,1.81576,2.06283,-0.975527,-0.848823,-2.20378,-2.1155,2.40798,2.41804,1.12448,1.21122,0.40371,0.515399,0.256439,0.122227,0.0572022,-0.091506,-0.24066,-0.441151,-1.18695,-1.12943
1171,0.351099,0.362197,0.343109,0.291346,0.0816802,0.0797031,0.691954,0.693939,0.338103,0.292694,0.355721,0.382177,0.761036,0.785291,0.548168,0.559432,0.0516964,0.0286925,0.73,0.736176,-0.661517,-0.422121,-0.312992,-0.175286,-1.61977,-1.53208,-1.66466,-1.65517,-1.54252,-1.46234,0.872326,0.889081,2.09262,1.95979,-0.84403,-0.987666,0.483917,0.283335,1.87906,1.94057
1172,0.879341,0.889004,0.946347,0.896788,0.310303,0.344036,0.103623,0.106164,0.89914,0.851964,0.105027,0.129186,0.302709,0.324828,0.507528,0.51813,0.696141,0.671164,0.499681,0.418372,0.419191,0.654299,0.363354,0.498252,0.297494,0.391608,0.23194,0.249895,0.165226,0.24306,1.14807,1.26276,0.607716,0.476136,0.712642,0.568778,-0.0863547,-0.295135,-0.339172,-0.282846
1173,0.171586,0.181244,0.25413,0.206343,0.689829,0.608369,0.50776,0.510646,0.790863,0.745059,0.859245,0.886052,0.205336,0.22517,0.0480218,0.0567214,0.0574247,0.0307379,0.0941794,0.100568,-0.449455,-0.212256,1.23137,1.35884,-0.477259,-0.37909,0.311034,0.323005,-0.820152,-0.735867,0.330899,0.444393,0.598636,0.462155,1.26524,1.11497,0.0994891,-0.102574,-1.00093,-0.939286
1174,0.483427,0.492881,0.416104,0.370077,0.87468,0.872703,0.488233,0.516205,0.409462,0.36137,0.499938,0.528487,0.542686,0.56285,0.600869,0.609919,0.378566,0.351405,0.651267,0.659441,1.12854,1.36382,-0.504138,-0.373116,-0.0391219,0.0662368,-0.576672,-0.563401,1.2814,1.36508,0.285079,0.480563,0.280956,0.141124,-1.47387,-1.6313,-0.605009,-0.803145,-0.402199,-0.267669
1175,0.0960075,0.107313,0.329507,0.323197,0.102714,0.103456,0.520033,0.521765,0.989979,0.941107,0.809715,0.838677,0.296262,0.316785,0.940578,0.947481,0.301673,0.276461,0.365051,0.387556,0.570293,0.731969,-0.0506563,0.0727972,-0.5138,-0.406246,-1.04526,-1.03142,2.17268,2.26083,0.403622,0.516733,1.1746,1.02978,-0.691515,-0.841939,0.696058,0.498758,0.338702,0.403948
1176,0.12307,0.119438,0.324449,0.276317,0.484138,0.484371,0.0804944,0.0798347,0.114537,0.0642153,0.841674,0.870232,0.868022,0.888477,0.503168,0.510586,0.795793,0.772205,0.108363,0.115671,-0.133285,0.100116,0.968131,1.08851,0.134534,0.238621,1.50742,1.51774,-0.552276,-0.459253,1.43852,1.5592,-0.597012,-0.73897,0.764356,0.605572,-1.07679,-1.27717,-1.50963,-1.44503
1177,0.12045,0.131563,0.886843,0.83829,0.492946,0.538057,0.854255,0.854012,0.747509,0.698748,0.370349,0.400156,0.438599,0.491044,0.592367,0.601468,0.168886,0.147392,0.259345,0.267774,-1.10153,-0.873469,-0.0142917,0.109525,-0.131969,-0.0201895,-1.01831,-1.01584,-1.40558,-1.3144,-1.98085,-1.8551,0.242231,0.103512,0.446779,0.292241,0.203937,0.00899647,1.6983,1.75807
1178,0.134091,0.143689,0.438135,0.389834,0.5932,0.591743,0.249601,0.250698,0.499811,0.366341,0.240315,0.243002,0.0708988,0.0936103,0.223598,0.234682,0.634864,0.612561,0.621598,0.627901,-0.95029,-0.808432,-0.386554,-0.254889,-0.0646219,0.0421871,-1.47578,-1.46718,0.791104,0.888602,-0.439866,-0.308446,0.580696,0.44056,-0.573426,-0.725861,1.12398,0.936567,0.115703,0.174287
1179,0.421591,0.430535,0.231299,0.184889,0.362215,0.358612,0.143879,0.22826,0.0816409,0.0339346,0.0578696,0.0858481,0.426011,0.450997,0.907317,0.916273,0.427232,0.414506,0.747282,0.679273,-0.970489,-0.743394,-0.108755,0.0243784,-1.89783,-1.79858,0.5552,0.565473,-1.63884,-1.5375,0.514563,0.641386,0.0634497,-0.0826159,-0.220266,-0.364724,0.748468,0.560189,0.693106,0.754955
1180,0.257837,0.267521,0.911224,0.86458,0.72488,0.72099,0.207245,0.205822,0.226282,0.178389,0.849125,0.874354,0.448711,0.473487,0.0156351,0.0239544,0.239902,0.216451,0.724176,0.730645,0.614246,0.847669,1.58583,1.722,0.499548,0.605996,0.303846,0.313751,1.2065,1.30717,0.613695,0.748173,-0.0242214,-0.171934,0.14832,-0.00358615,-0.516495,-0.703883,-0.810474,-0.752854
1181,0.569928,0.579159,0.973884,0.928653,0.466401,0.460991,0.318386,0.314713,0.867261,0.817594,0.268897,0.29459,0.0299111,0.0524649,0.529168,0.535949,0.454733,0.432549,0.620393,0.550357,0.0964675,0.333027,-0.334159,-0.199727,-0.222596,-0.119603,1.35318,1.35505,1.23908,1.34298,-0.108084,0.0217441,0.235467,0.0876424,-0.505245,-0.654521,0.824073,0.632014,1.96874,2.02394
1182,0.187079,0.193591,0.224439,0.178123,0.816247,0.80829,0.992607,0.987496,0.52717,0.452734,0.878982,0.905223,0.82538,0.84752,0.60464,0.684314,0.984895,0.962142,0.446094,0.37007,1.73817,1.96987,-1.68867,-1.55425,0.402789,0.508627,0.942983,0.949881,-0.709214,-0.607688,0.0566697,0.189028,-0.259098,-0.40389,-0.893675,-1.04196,-0.11778,-0.30758,1.15541,1.2168
1183,0.154378,0.162308,0.508747,0.363887,0.482669,0.40537,0.793251,0.790085,0.136429,0.0878747,0.486534,0.51309,0.121521,0.146376,0.84054,0.832679,0.961664,0.93766,0.183225,0.189783,-0.701273,-0.46381,-0.567279,-0.428524,0.225623,0.326779,-0.18359,-0.183334,0.225886,0.406196,-1.48332,-1.35048,0.0534446,-0.0961903,0.987525,0.839139,-1.35288,-1.54229,-0.0356318,0.0277999
1184,0.600612,0.610173,0.59406,0.549651,0.00852988,0.0024512,0.32451,0.323427,0.109718,0.0637498,0.542041,0.564712,0.0459445,0.0725906,0.974026,0.981044,0.552544,0.528745,0.367747,0.372108,-1.19794,-1.02355,-0.16804,-0.0287329,-0.458411,-0.351715,0.73318,0.735121,1.32221,1.42008,0.76957,0.899615,-0.381928,-0.525763,0.178481,0.0359066,-0.541323,-0.72496,-1.95399,-1.89686
1185,0.0971637,0.104681,0.677593,0.634014,0.448733,0.441776,0.202079,0.201294,0.717023,0.673478,0.654473,0.616334,0.970186,0.995263,0.89431,0.852078,0.953623,0.929682,0.847846,0.85111,-1.8251,-1.5833,-2.09052,-1.95046,0.927938,1.04106,0.858441,0.853854,-1.25696,-1.15505,0.765754,0.898423,0.0117857,-0.126813,0.00153558,-0.137865,0.896779,0.694435,-0.749694,-0.693184
1186,0.343297,0.350642,0.353611,0.334752,0.341396,0.304436,0.595944,0.594841,0.0977292,0.0540855,0.562224,0.667957,0.0333342,0.0570758,0.705408,0.723112,0.186578,0.160663,0.282686,0.285519,-0.70976,-0.461531,1.21148,1.34561,1.21229,1.33313,-0.795026,-0.807739,1.53227,1.6387,0.0442392,0.171994,-0.224014,-0.354735,0.499478,0.362038,2.30293,2.11383,-0.508448,-0.446822
1187,0.917023,0.922103,0.0809572,0.0354907,0.17477,0.167096,0.143401,0.142974,0.937822,0.89301,0.693023,0.719579,0.942857,0.964863,0.477785,0.594146,0.217528,0.305819,0.879213,0.883999,-1.05686,-0.803488,1.12045,1.2547,0.545633,0.671135,-0.953952,-0.965428,0.263962,0.369285,0.121378,0.247625,-1.1718,-1.30863,0.35039,0.217578,1.78281,1.59731,-0.693234,-0.636112
1188,0.931294,0.937295,0.952769,0.909736,0.643139,0.635679,0.740351,0.739819,0.975633,0.929941,0.969804,0.998065,0.948507,0.968314,0.458162,0.46518,0.40794,0.450974,0.823891,0.759795,2.02513,2.28269,0.668216,0.797924,0.51188,0.641655,-0.296057,-0.310429,0.703405,0.802433,-0.145494,-0.110208,-0.502141,-0.633454,1.08534,0.948893,-0.812784,-0.994141,-0.420559,-0.358021
1189,0.245458,0.250569,0.314399,0.269438,0.247643,0.240595,0.0540025,0.0527337,0.470518,0.426703,0.549059,0.654663,0.0514181,0.0697775,0.924543,0.932086,0.622045,0.59613,0.63246,0.63559,1.67998,1.94074,0.848155,0.983509,-0.443394,-0.220591,0.979787,0.963404,1.85187,1.95684,-0.599406,-0.468042,0.508602,0.379894,0.589752,0.453139,-1.01024,-1.18704,0.248538,0.254462
1190,0.800032,0.807117,0.207782,0.160432,0.506686,0.430934,0.973677,0.973857,0.419458,0.376933,0.283389,0.311261,0.398569,0.417479,0.0706353,0.0767496,0.0855863,0.0620822,0.997157,1.00078,0.908141,1.16594,2.14063,2.27915,-1.21667,-1.08284,-0.0880403,-0.108516,0.926833,1.02478,-1.19811,-1.07197,0.141678,0.0127165,-0.8508,-0.993911,-0.554039,-0.736839,0.808585,0.866945
1191,0.586755,0.593241,0.873257,0.824642,0.625927,0.621273,0.233133,0.230783,0.807949,0.765236,0.771798,0.798405,0.152086,0.171414,0.499258,0.503364,0.947793,0.923718,0.00321089,0.00754471,-0.275295,-0.0229211,0.294939,0.436085,-1.62091,-1.47963,-0.68447,-0.69976,0.313316,0.414154,0.73367,0.860157,1.34495,1.21359,-0.0736632,-0.219395,-0.118821,-0.28664,-0.777705,-0.716838
1192,0.811845,0.819797,0.167412,0.119242,0.374773,0.371848,0.806079,0.803232,0.139656,0.0955332,0.924661,0.953195,0.179224,0.199226,0.0690817,0.0722612,0.268247,0.243777,0.193642,0.199594,-0.218242,0.0277492,0.801289,0.945636,1.13516,1.27478,2.07167,2.06141,-0.856835,-0.76194,-1.29643,-1.17354,0.66907,0.53899,0.117399,-0.0258454,0.938082,0.767062,0.203024,0.256809
1193,0.516441,0.525284,0.779353,0.729575,0.750699,0.749247,0.859795,0.857466,0.736023,0.69032,0.155185,0.183078,0.958225,0.9799,0.818205,0.819211,0.224049,0.199071,0.0968555,0.100563,-0.550058,-0.297916,-0.395634,-0.250869,0.06724,0.208928,-1.21757,-1.23466,-0.431516,-0.343324,-0.384411,-0.261728,-0.506415,-0.633391,1.2179,1.07095,-1.329,-1.49903,-0.544221,-0.489818
1194,0.658865,0.665639,0.413222,0.36506,0.00315289,0.00332685,0.522442,0.520049,0.90643,0.860847,0.368526,0.396165,0.97425,0.997687,0.0550474,0.0577468,0.730891,0.704726,0.408345,0.496742,-1.24507,-0.994536,-1.34441,-1.19927,-0.0752639,0.0739783,-0.233789,-0.253304,0.424634,0.505623,0.527191,0.650081,-0.363159,-0.457844,-0.733688,-0.873572,-0.500757,-0.66471,0.958081,1.00634
1195,0.383457,0.433643,0.535234,0.488216,0.635977,0.637097,0.460648,0.457469,0.459371,0.412836,0.26298,0.292571,0.750775,0.776527,0.350288,0.354391,0.813331,0.78744,0.890434,0.89292,-0.238874,0.00766953,-0.367799,-0.229401,0.938129,1.08866,0.428806,0.41608,-1.69022,-1.61242,0.817413,0.939321,-0.204108,-0.282297,1.45662,1.31923,0.0969761,-0.0652214,-0.759611,-0.716242
1196,0.19445,0.201648,0.182248,0.134034,0.388324,0.403133,0.810887,0.806256,0.666175,0.664922,0.365957,0.396727,0.995891,1.02281,0.204266,0.207466,0.468088,0.442578,0.0967819,0.09734,-1.69277,-1.44089,-0.248133,-0.106148,-0.66626,-0.516186,0.637363,0.626722,0.751036,0.826364,-0.476668,-0.354421,0.0202265,-0.10675,-0.325395,-0.466711,-1.33321,-1.48834,0.0619518,0.106711
1197,0.559622,0.569406,0.267371,0.184577,0.165851,0.169168,0.0118622,0.00532477,0.964704,0.917007,0.165204,0.278097,0.294693,0.321668,0.527261,0.528933,0.934245,0.907747,0.253979,0.254602,0.331408,0.579373,1.72693,1.87187,1.93803,2.08761,-0.129621,-0.135158,-0.109032,-0.0287834,-0.522403,-0.400826,-1.14765,-1.27913,-0.659236,-0.79401,-1.33245,-1.49366,0.587333,0.626164
1198,0.701768,0.70976,0.285037,0.235119,0.574489,0.577311,0.0129005,0.00913347,0.525804,0.4785,0.12855,0.159467,0.72684,0.753319,0.633965,0.63527,0.444375,0.41773,0.0417391,0.0438053,0.988014,1.2298,-0.771544,-0.618271,-0.781172,-0.63385,-1.57019,-1.5769,1.37944,1.46272,-0.969996,-0.849172,-0.299817,-0.436648,0.624804,0.482118,-0.315716,-0.471919,-2.18891,-2.15368
1199,0.263983,0.273959,0.841749,0.791948,0.357821,0.359445,0.979158,0.97432,0.440129,0.392749,0.87213,0.901393,0.865169,0.893537,0.0789174,0.079157,0.666617,0.639402,0.574709,0.578701,0.0403393,0.287885,0.815764,0.971764,0.799577,0.946546,-0.556871,-0.564406,-0.298474,-0.222004,0.902881,1.0204,-0.544165,-0.680326,1.48479,1.34806,-0.823271,-0.97321,0.371,0.40758
1200,0.117474,0.202211,0.203583,0.151651,0.867172,0.867676,0.328501,0.321998,0.914503,0.86572,0.228708,0.256051,0.744261,0.820776,0.294743,0.297393,0.346329,0.320125,0.518931,0.524749,0.965703,1.21258,0.181842,0.332199,-0.745388,-0.596776,1.57034,1.55929,-0.709045,-0.63436,-0.320165,-0.19463,-0.467006,-0.602316,-0.281938,-0.422988,1.18516,1.03032,0.291323,0.306266
1201,0.0511765,0.130463,0.0954337,0.0426446,0.947084,0.949605,0.240379,0.233805,0.194417,0.143815,0.602221,0.630952,0.80805,0.748015,0.728036,0.729042,0.336067,0.309709,0.151944,0.158589,0.305617,0.54769,2.78149,2.92375,0.00433191,0.156399,0.561897,0.544289,-0.22123,-0.138817,-0.63423,-0.503348,1.72804,1.58576,-0.186669,-0.32094,0.799299,0.730428,0.243455,0.204952
1202,0.047252,0.0587155,0.972075,0.921304,0.296829,0.300804,0.598615,0.592325,0.545739,0.401452,0.419838,0.348381,0.64577,0.675255,0.473501,0.476032,0.705363,0.680174,0.113175,0.12007,-0.582039,-0.278957,-0.630632,-0.481133,0.203992,0.355248,-0.541823,-0.470707,0.707763,0.786829,0.658665,0.78235,0.0912453,-0.0542014,0.31408,0.178963,0.588656,0.430535,0.0694448,0.103638
1203,0.793975,0.80737,0.96164,0.910784,0.679046,0.681719,0.744664,0.737369,0.712131,0.659088,0.0376873,0.0658089,0.442563,0.470132,0.542605,0.54762,0.535277,0.512475,0.814319,0.819701,-1.34772,-1.10561,-0.985995,-0.831099,-0.802535,-0.64843,-1.47465,-1.4857,0.11767,0.193117,-1.87103,-1.74777,-0.340467,-0.483775,-0.525854,-0.654838,0.925841,0.764976,-1.62486,-1.58857
1204,0.280112,0.291951,0.150717,0.100733,0.683892,0.755014,0.419812,0.39292,0.689935,0.634963,0.0232563,0.0901198,0.675432,0.701106,0.222252,0.2257,0.805591,0.783449,0.754096,0.77668,-2.01864,-1.7705,-0.66236,-0.506264,0.167877,0.319542,0.0280961,0.0226823,0.626047,0.703527,1.04659,1.1785,-0.226141,-0.375477,-0.857091,-0.982136,-0.926423,-1.09086,1.48213,1.51849
1205,0.223189,0.235282,0.345848,0.293513,0.82476,0.82831,0.0569058,0.0484714,0.276819,0.220892,0.0889447,0.114431,0.047032,0.074739,0.438948,0.386054,0.842875,0.821894,0.73047,0.733659,0.770159,1.01707,0.662267,0.817928,0.0194794,0.168466,0.956406,0.956069,0.19714,0.275397,-1.01314,-0.886666,-0.469482,-0.619155,1.82317,1.69878,0.0936321,-0.0691188,0.9132,0.98887
1206,0.508137,0.522129,0.304137,0.254141,0.227154,0.228974,0.0335752,0.0265658,0.350336,0.231441,0.551989,0.57738,0.139904,0.16868,0.5432,0.546408,0.381401,0.361795,0.139211,0.142998,-0.27333,-0.0190765,0.341159,0.472045,0.377022,0.522518,-0.298021,-0.301347,0.108553,0.183297,-0.811347,-0.696042,0.179321,0.0277442,-0.0914943,-0.214817,0.079726,-0.0360328,0.42263,0.459254
1207,0.299237,0.323026,0.730857,0.678587,0.667132,0.6683,0.279064,0.271788,0.29652,0.24199,0.666538,0.691164,0.566167,0.595312,0.0753704,0.0797649,0.742337,0.62532,0.484588,0.48732,-0.674041,-0.422791,-0.0295813,0.126163,0.532799,0.674998,0.679796,0.680011,1.3977,1.47681,-0.632154,-0.505419,0.0553547,-0.0918704,-0.561691,-0.679945,0.159306,-0.00294672,-0.721228,-0.684883
1208,0.110282,0.123923,0.568184,0.4809,0.50804,0.50637,0.940263,0.932911,0.678935,0.625403,0.984031,1.00674,0.615077,0.643806,0.89417,0.898004,0.910185,0.888844,0.390375,0.393481,0.922282,1.16827,-1.83804,-1.68429,-1.50772,-1.37142,-1.2895,-1.28457,0.0124994,0.0975618,0.153581,0.274339,-0.48299,-0.631574,1.66057,1.54145,-0.101781,-0.256646,-1.06593,-1.02598
1209,0.146664,0.160212,0.333646,0.283213,0.0459101,0.0419412,0.344832,0.339487,0.00950904,-0.0443001,0.910611,0.934046,0.904781,0.934962,0.882791,0.888008,0.791128,0.778331,0.649993,0.652205,-0.677938,-0.434545,-1.20145,-1.05321,-0.768341,-0.633421,-0.688058,-0.67768,0.10439,0.195331,1.40769,1.5296,-0.199475,-0.356014,-1.06398,-1.1896,0.326544,0.170843,0.52639,0.562056
1210,0.82239,0.83548,0.703108,0.652926,0.669953,0.665273,0.214429,0.207102,0.63892,0.584865,0.472666,0.571639,0.391702,0.423361,0.640811,0.645094,0.688412,0.667818,0.403274,0.406894,-0.629294,-0.383875,1.35763,1.50427,0.300884,0.441813,-1.1368,-1.12902,0.656041,0.750071,-0.867068,-0.739304,1.42872,1.27775,0.680593,0.554843,0.449204,0.270497,-0.239227,-0.200749
1211,0.687589,0.702201,0.421037,0.372902,0.495334,0.488906,0.909517,0.900124,0.815995,0.759951,0.183172,0.209231,0.243505,0.273832,0.168258,0.174071,0.382232,0.363967,0.965737,0.970283,-1.82956,-1.58787,0.186302,0.338219,0.32645,0.472457,1.18369,1.19746,-0.153353,-0.0580812,-1.78256,-1.65164,-1.44317,-1.59369,0.694877,0.518462,0.526121,0.370152,-1.70214,-1.66396
1212,0.226136,0.241147,0.837808,0.788011,0.764192,0.760174,0.0159685,0.00400894,0.786719,0.730337,0.380844,0.408096,0.920382,0.951322,0.34841,0.293308,0.608681,0.590575,0.49994,0.504327,0.0818025,0.32375,1.64551,1.80369,-0.0993772,0.045594,1.10749,1.11686,0.545003,0.693057,0.870145,1.00516,-1.27922,-1.42553,0.613229,0.482081,0.274067,0.116453,0.198696,0.234584
1213,0.163039,0.179775,0.807307,0.757766,0.451607,0.445645,0.222491,0.237132,0.49151,0.421944,0.788021,0.817749,0.986223,1.01484,0.404066,0.412545,0.321039,0.301425,0.582928,0.585946,0.21241,0.451571,1.29892,1.45373,-1.23106,-1.08334,-1.30718,-1.30076,1.34892,1.44419,0.381925,0.52278,1.30124,1.16156,0.0291325,-0.106852,-0.479114,-0.543219,0.0418994,0.0372094
1214,0.699001,0.716554,0.118333,0.0673217,0.572944,0.566793,0.557279,0.470256,0.171339,0.113551,0.516747,0.510616,0.647957,0.674799,0.823135,0.829113,0.753234,0.731882,0.00390061,0.00573495,-0.529798,-0.29056,-0.498425,-0.339354,0.560152,0.714929,-0.2347,-0.228483,-0.483069,-0.380109,-0.0978097,0.0403958,-0.348475,-0.495086,0.56155,0.424215,-1.04548,-1.20289,-0.19829,-0.160166
1215,0.0823489,0.100449,0.952139,0.899545,0.931591,0.923898,0.715339,0.703379,0.855892,0.799468,0.175427,0.203483,0.65416,0.682391,0.510386,0.517036,0.147512,0.126221,0.835466,0.839603,0.719356,0.957445,0.43285,0.598205,1.12355,1.28199,1.18343,1.1849,1.7107,1.80651,-0.276506,-0.143391,2.96091,2.80928,0.0594011,-0.0715394,0.790487,0.633399,0.770226,0.813481
1216,0.12716,0.176159,0.219793,0.168993,0.100257,0.0940862,0.501161,0.491377,0.370752,0.315786,0.524928,0.568975,0.367541,0.396525,0.815969,0.823623,0.817657,0.79901,0.784905,0.790504,-1.03138,-0.801012,-2.16452,-2.00336,1.475,1.63604,-0.856018,-0.857802,0.653772,0.752655,-0.949653,-0.809453,0.180592,0.0301351,-1.07962,-1.21074,0.434582,0.271564,-0.125531,-0.08431
1217,0.23412,0.251869,0.107304,0.0557723,0.686436,0.682456,0.628342,0.620906,0.802904,0.74833,0.905458,0.934467,0.298577,0.327506,0.247472,0.252607,0.420025,0.408714,0.215726,0.21933,-0.360232,-0.13726,0.0513438,0.219335,-0.864043,-0.699251,-2.41963,-2.42093,-1.82372,-1.72189,0.338066,0.476244,0.915139,0.767199,-1.22892,-1.32301,1.05447,0.887139,-0.107589,-0.0618388
1218,0.857696,0.8774,0.851442,0.800892,0.023773,0.0190295,0.264848,0.25882,0.942394,0.888094,0.237314,0.264018,0.972922,1.00023,0.0166286,0.0203174,0.0352965,0.0184175,0.833336,0.837984,1.46628,1.6832,-0.0126517,0.160188,0.0208984,0.192621,-0.311798,-0.309873,-2.43807,-2.33252,-0.314951,-0.176089,-0.480485,-0.621468,-1.36841,-1.43529,-0.431811,-0.600661,0.112763,0.208589
1219,0.368625,0.386345,0.0971479,0.0444863,0.998686,0.994677,0.545404,0.564841,0.0475658,-0.00427747,0.482099,0.541814,0.488281,0.51393,0.404864,0.406929,0.820668,0.805574,0.761226,0.684884,-0.312626,-0.0901884,1.03964,1.20454,0.477277,0.651496,2.28304,2.28888,-0.83279,-0.732592,0.966522,1.10961,0.70397,0.563298,-1.41736,-1.54757,0.258024,0.0927383,0.434886,0.479017
1220,0.201087,0.218756,0.747814,0.694523,0.813468,0.8072,0.876165,0.870862,0.847894,0.797666,0.79216,0.819611,0.778235,0.805087,0.374983,0.355459,0.63391,0.618485,0.527047,0.531784,-1.22736,-1.00425,0.362643,0.585374,0.73336,0.913962,-0.520669,-0.521186,2.41995,2.52383,1.26385,1.41167,-0.138266,-0.280197,-0.201523,-0.330888,-1.16448,-1.33039,0.407929,0.455981
1221,0.689656,0.705483,0.939922,0.887303,0.0867484,0.0820384,0.809709,0.803921,0.25801,0.208952,0.235277,0.260763,0.259309,0.289053,0.303224,0.303989,0.839543,0.756003,0.90354,0.906262,0.74912,0.967599,-0.185651,-0.0337956,-0.901421,-0.720126,0.0652304,0.0709318,-0.580736,-0.478289,0.462201,0.608056,0.557044,0.411319,-0.477916,-0.584965,0.633548,0.474102,1.18393,1.23233
1222,0.763624,0.781128,0.16802,0.114486,0.623386,0.619682,0.289523,0.286048,0.0604876,0.0118311,0.090248,0.117155,0.398879,0.429271,0.456887,0.46852,0.90845,0.893521,0.84277,0.840304,-1.26359,-1.04277,-0.817872,-0.652965,-0.142055,0.0330499,-0.822329,-0.815474,0.000714189,0.10776,1.80099,1.94043,0.895082,0.748367,-0.709062,-0.839042,1.25896,1.10542,-0.617791,-0.568426
1223,0.0131423,0.0303816,0.665859,0.612966,0.845932,0.840077,0.10731,0.104081,0.286246,0.209437,0.797197,0.823678,0.957565,0.986163,0.63281,0.633052,0.117788,0.103715,0.772118,0.774347,0.694673,0.915822,0.156276,0.316902,-0.283277,-0.101899,-2.31444,-2.30184,0.803188,0.908241,-0.347096,-0.204306,-0.255902,-0.405354,1.46984,1.34135,-1.01953,-1.17485,-0.167114,-0.110993
1224,0.235599,0.252182,0.339651,0.290527,0.374287,0.370345,0.78169,0.776864,0.454096,0.407044,0.408133,0.436225,0.196563,0.225393,0.321749,0.384899,0.470335,0.521461,0.26731,0.268671,0.462421,0.679717,0.52686,0.685563,0.403595,0.498293,-1.18981,-1.18468,-1.03248,-0.930831,-1.10129,-0.963314,-0.676719,-0.819469,0.766493,0.585412,0.461694,0.301039,-0.632597,-0.571087
1225,0.184213,0.200809,0.0224746,-0.031911,0.498138,0.491493,0.268358,0.263953,0.0267638,-0.0214237,0.390053,0.418054,0.553258,0.582779,0.134375,0.136747,0.954729,0.939208,0.0705879,0.167362,2.47285,2.68482,1.2396,1.39339,0.913931,1.09849,0.545487,0.544321,-0.336059,-0.26836,-0.27757,-0.138405,0.91675,0.767924,-0.0490642,-0.170525,-2.24904,-2.40785,0.439266,0.494913
1226,0.876697,0.891529,0.0731455,-0.0297287,0.943164,0.935238,0.71475,0.712183,0.909064,0.863662,0.842378,0.871375,0.468682,0.466366,0.434821,0.437741,0.539931,0.525141,0.0632862,0.0660534,0.693285,0.91143,1.31259,1.47157,-0.03564,0.142874,-2.31642,-2.31585,0.303284,0.394111,0.285378,0.429124,0.667151,0.461451,0.52235,0.405851,-0.620451,-0.776208,0.590929,0.652574
1227,0.054297,0.0688083,0.0270436,-0.0275464,0.495288,0.486168,0.258751,0.255178,0.594671,0.503319,0.872137,0.911258,0.321679,0.349952,0.127231,0.131399,0.598777,0.625513,0.109234,0.113089,-1.55252,-1.33389,-0.615532,-0.450158,2.41888,2.59829,0.0615722,0.0626628,0.145366,0.243009,-2.03451,-1.89057,0.308965,0.154979,2.37298,2.25755,0.178959,0.105021,1.31732,1.38508
1228,0.936927,0.950751,0.965959,0.910603,0.925599,0.915247,0.390539,0.384706,0.187349,0.142976,0.924191,0.95114,0.998905,1.02744,0.364366,0.463195,0.821614,0.725885,0.994588,0.996454,-0.0426225,0.179812,-0.759391,-0.599848,-0.541947,-0.357067,0.686336,0.684705,0.933761,1.0312,0.266321,0.406353,-0.192571,-0.351172,0.356312,0.235346,1.1493,0.98625,0.115667,0.181009
1229,0.885486,0.899378,0.458943,0.402052,0.320972,0.310866,0.85376,0.847239,0.53631,0.46025,0.609312,0.647206,0.443046,0.531274,0.78899,0.794991,0.753219,0.826257,0.301269,0.303952,1.04684,1.27126,1.35136,1.50806,-0.984235,-0.798483,-0.137579,-0.138851,-1.32501,-1.22722,0.162324,0.298972,-1.25964,-1.41378,-0.43783,-0.553392,0.344105,0.176885,0.109361,0.17363
1230,0.321922,0.337662,0.762414,0.703487,0.668129,0.658165,0.0129558,0.00532361,0.82299,0.777524,0.317455,0.343272,0.00656881,0.0351058,0.260823,0.269182,0.941419,0.926629,0.495247,0.496001,-0.642225,-0.423036,-1.06962,-0.91852,1.26997,1.46151,0.544754,0.569201,0.512675,0.604276,-0.789525,-0.657955,1.18105,1.03238,0.497467,0.37592,1.0633,0.901371,-0.345548,-0.286464
1231,0.17558,0.256987,0.344676,0.284818,0.376919,0.368414,0.140675,0.134852,0.635338,0.520157,0.270362,0.296083,0.548494,0.57676,0.295305,0.304455,0.156025,0.141753,0.976963,0.979702,0.78023,0.99615,0.664452,0.809693,-0.6171,-0.424792,1.27853,1.27725,0.4484,0.544638,0.588939,0.718284,1.40791,1.26056,0.41864,0.291971,0.516538,0.354541,0.635327,0.687183
1232,0.162713,0.176311,0.784161,0.724192,0.715988,0.705577,0.558278,0.553009,0.308413,0.262791,0.520865,0.544191,0.311268,0.340444,0.61435,0.625922,0.0851646,0.0714092,0.384602,0.389041,-0.832014,-0.619174,0.951988,1.1053,-0.452028,-0.25829,-0.803846,-0.810589,-0.53083,-0.434289,-0.311425,-0.179255,-1.02098,-1.17276,0.612546,0.485521,0.646424,0.487566,-0.0986335,-0.0444776
1233,0.985789,1.00012,0.933314,0.873197,0.33474,0.326245,0.0363273,0.0300714,0.959095,0.913011,0.45369,0.476112,0.683121,0.712102,0.547807,0.560169,0.770638,0.758627,0.115057,0.118595,0.463427,0.674538,-0.232208,-0.0757811,-2.10255,-1.9102,-1.72327,-1.7289,0.276582,0.366192,-1.54724,-1.40981,-1.18257,-1.33962,0.520703,0.38777,0.373663,0.316584,-0.569555,-0.514481
1234,0.643997,0.65988,0.689629,0.627056,0.919846,0.909759,0.80838,0.804248,0.528092,0.484543,0.897575,0.919316,0.177055,0.205784,0.831358,0.846087,0.611338,0.60021,0.356608,0.368697,-0.205952,0.00964375,1.03459,1.18765,-0.707419,-0.543021,-1.13448,-1.13678,0.400111,0.492717,-1.77763,-1.64076,1.38645,1.23148,-0.434751,-0.568494,0.300883,0.145601,-1.04089,-0.984485
1235,0.938363,0.952105,0.80527,0.740349,0.62561,0.57763,0.0402601,0.0348431,0.628718,0.623067,0.743122,0.853923,0.430543,0.406892,0.656301,0.669248,0.83436,0.745895,0.664419,0.618798,1.80454,2.01474,-0.532526,-0.384631,0.631817,0.82416,1.27913,1.27522,-0.66535,-0.576414,-0.349617,-0.219056,0.940213,0.785434,0.482058,0.34395,-1.53578,-1.69153,-0.0252159,0.0369649
1236,0.777723,0.683659,0.368186,0.401706,0.253472,0.2455,0.744971,0.736917,0.805832,0.761591,0.768517,0.78853,0.5381,0.608,0.936711,0.95028,0.904526,0.891581,0.864829,0.8689,-1.42422,-1.2092,0.231187,0.385292,-0.0358659,0.162167,-1.1772,-1.17365,0.478732,0.564323,0.0576293,0.19261,-0.214592,-0.368288,0.0772151,0.0283288,-2.6342,-2.78248,-0.419382,-0.365067
1237,0.442821,0.415212,0.129243,0.0630626,0.205736,0.196476,0.399088,0.39019,0.116707,0.071707,0.493384,0.430912,0.780531,0.809108,0.619899,0.633787,0.245049,0.231061,0.498975,0.50274,2.06571,2.27733,-0.858645,-0.703001,-0.990985,-0.793445,-0.215052,-0.209718,-0.0251283,0.0601961,-0.348918,-0.207239,-0.546012,-0.604084,-0.151274,-0.287293,1.94292,1.79464,-1.42691,-1.36886
1238,0.131522,0.146766,0.528689,0.463099,0.698365,0.689874,0.42635,0.418145,0.459719,0.453249,0.0542761,0.0732952,0.460667,0.488541,0.700128,0.700573,0.190767,0.175496,0.530733,0.534645,-0.831827,-0.62516,-0.268892,-0.117238,-0.825834,-0.626943,0.998169,1.00202,-0.272693,-0.183716,-1.35357,-1.21094,-0.7377,-0.839879,-0.00205141,-0.139803,0.0557031,-0.0920227,-0.940366,-0.818356
1239,0.340833,0.264859,0.406389,0.339208,0.641329,0.634606,0.0853247,0.0766795,0.880279,0.834792,0.36878,0.388873,0.863329,0.890478,0.752941,0.767359,0.438725,0.421572,0.338911,0.344024,-0.228088,-0.0216212,0.900558,1.05123,-0.253609,-0.0598857,0.593088,0.596852,-0.748542,-0.656736,0.625557,0.766541,-0.92198,-1.07568,0.428743,0.283404,-0.264029,-0.407899,-0.325911,-0.267855
1240,0.366313,0.382952,0.96217,0.896037,0.889624,0.885176,0.0707166,0.059506,0.349011,0.301646,0.373847,0.280577,0.809861,0.808274,0.264874,0.281191,0.0332072,0.0164633,0.874512,0.878919,-0.0796996,0.121053,-0.802938,-0.646347,1.37607,1.56626,-1.9117,-1.90341,0.712676,0.80426,0.92728,1.0686,-0.454849,-0.614809,-3.29923,-3.44948,0.833689,0.691754,-2.03757,-1.97791
1241,0.725349,0.739769,0.784725,0.802829,0.238024,0.231782,0.293333,0.35789,0.598561,0.553162,0.217272,0.17228,0.698642,0.726069,0.587686,0.602658,0.858926,0.839294,0.123826,0.126226,1.20929,1.41476,-1.28635,-1.13275,1.74225,1.93372,-0.645501,-0.629581,0.587862,0.681626,0.0942094,0.234231,0.433113,0.273849,0.115586,-0.0363927,-1.02766,-1.16408,0.172782,0.23301
1242,0.77319,0.810565,0.777212,0.709621,0.951673,0.947769,0.704844,0.656274,0.293296,0.250628,0.0437556,0.0639841,0.838831,0.866287,0.0244548,0.0415012,0.831307,0.76724,0.732701,0.735092,-1.03643,-0.830556,1.41504,1.57163,1.09716,1.2876,-0.244674,-0.235521,-1.15257,-1.06608,0.512514,0.645897,0.175689,0.0154295,0.734119,0.58513,-0.896607,-1.03106,-0.802849,-0.74012
1243,0.866038,0.88136,0.400608,0.330831,0.358326,0.353327,0.963872,0.954658,0.622358,0.578001,0.157924,0.177767,0.700575,0.726535,0.422004,0.430645,0.716979,0.695186,0.0100947,0.0126117,1.04676,1.25229,0.908753,1.06994,-0.458298,-0.269156,1.44113,1.44753,0.438847,0.533841,0.24289,0.408143,-0.530448,-0.689754,-0.414923,-0.490577,-1.28318,-1.42242,-0.0525857,0.00831761
1244,0.420443,0.435514,0.719583,0.652313,0.0628778,0.0593574,0.821934,0.725909,0.244109,0.199129,0.899552,0.919694,0.83599,0.861632,0.802416,0.819789,0.363712,0.340464,0.423495,0.426392,0.0498049,0.262045,-0.260677,-0.0961117,-0.4739,-0.283902,-0.180003,-0.180112,1.45642,1.55236,-0.0889426,0.170389,-0.399005,-0.498373,-1.41223,-1.56629,-0.670092,-0.806845,0.913926,0.967829
1245,0.655235,0.671727,0.56884,0.491387,0.752785,0.749415,0.505591,0.497161,0.264093,0.21705,0.276725,0.295106,0.427666,0.542612,0.479778,0.43217,0.677098,0.655309,0.478072,0.479065,1.28475,1.49203,-0.939488,-0.782354,0.0261247,0.158223,1.45675,1.45553,-2.16453,-2.06279,-0.264963,-0.0673644,-0.140697,-0.306992,0.418692,0.270427,0.247518,0.104438,-0.599804,-0.539979
1246,0.623929,0.581465,0.305117,0.330461,0.581259,0.618603,0.599127,0.590833,0.608893,0.517832,0.89506,0.915864,0.195376,0.223592,0.0244351,0.0445515,0.684283,0.638765,0.922282,0.922621,1.00878,1.2109,-0.0404721,0.109396,0.408552,0.600347,1.29407,1.21704,0.106462,0.208327,-0.438501,-0.305118,0.392438,0.230097,-1.75024,-1.89553,-1.26342,-1.41375,-0.49453,-0.42685
1247,0.473192,0.491202,0.271332,0.169535,0.530186,0.48779,0.113361,0.103919,0.863994,0.818613,0.220776,0.240314,0.460385,0.490009,0.237336,0.255963,0.644127,0.622221,0.268016,0.266317,1.52724,1.72494,0.0779956,0.232649,-1.05504,-0.866244,0.979772,0.978555,-2.13096,-2.03274,-0.40577,-0.274841,2.31712,2.16115,0.64527,0.497469,-0.56014,-0.704,0.0403296,0.10688
1248,0.769784,0.788513,0.0758787,0.00860854,0.500749,0.356978,0.887189,0.878096,0.840836,0.794488,0.338973,0.359932,0.508634,0.490759,0.7293,0.747248,0.147891,0.127133,0.0959014,0.0961368,-0.583738,-0.390659,0.753593,0.820591,0.10889,0.300238,-0.576927,-0.584576,-2.11849,-2.0269,0.669021,0.797949,0.641249,0.487299,2.66887,2.52215,-0.372281,-0.511438,-0.775154,-0.714887
1249,0.263746,0.28302,0.385236,0.36492,0.229535,0.226165,0.912029,0.890645,0.0404744,-0.00621393,0.997557,1.01643,0.520056,0.491508,0.248584,0.266168,0.00813602,-0.0112701,0.317277,0.315054,-1.72956,-1.53391,1.25735,1.40853,-0.332217,-0.141178,-0.125758,-0.128853,-1.69509,-1.62907,-0.738356,-0.606021,0.243883,0.0890858,1.62808,1.47458,0.113323,-0.0210417,-0.935539,-0.873973
1250,0.0879195,0.105475,0.7879,0.721231,0.425174,0.421491,0.920445,0.903195,0.783642,0.736814,0.950713,0.969241,0.462175,0.492257,0.758625,0.778162,0.551379,0.533667,0.47734,0.533971,-1.53602,-1.34495,-0.480394,-0.32342,1.8687,2.05137,-0.997718,-1.0003,-1.36301,-1.23124,0.746927,0.877909,0.603858,0.442939,-0.176057,-0.332141,-0.635215,-0.77127,-1.79902,-1.74337
1251,0.566128,0.582437,0.554035,0.525409,0.179648,0.177035,0.926116,0.915744,0.181729,0.132093,0.086604,0.10413,0.973557,1.00308,0.348135,0.453208,0.262763,0.244516,0.750771,0.752888,-0.591634,-0.405913,-1.01068,-0.856854,1.54143,1.72918,0.365251,0.364644,-0.924997,-0.833413,0.237896,0.36731,0.371392,0.215017,0.704972,0.549848,0.439978,0.297209,-1.04272,-0.980378
1252,0.302735,0.3709,0.397297,0.329587,0.91538,0.912377,0.163459,0.152209,0.0673059,0.0639124,0.601504,0.621457,0.324446,0.3549,0.110812,0.128255,0.772667,0.754908,0.343799,0.346497,-0.218485,-0.0435037,-0.0440674,0.113013,-0.882342,-0.698493,0.0554333,0.0516359,2.34759,2.44356,0.644929,0.778976,2.37627,2.22335,-0.108496,-0.267829,-0.031413,-0.172442,0.0337683,0.101962
1253,0.141636,0.159364,0.19932,0.133765,0.42516,0.422491,0.363924,0.305092,0.046267,-0.00426848,0.575009,0.593716,0.738316,0.766426,0.754957,0.772538,0.324911,0.30511,0.938647,0.940716,0.108381,0.318906,-0.507315,-0.343763,0.945372,1.13145,0.0577631,0.0485992,-0.765954,-0.674109,-0.221297,-0.0854107,-1.45358,-1.61136,1.16049,0.994949,0.390397,0.255046,-0.67144,-0.600047
1254,0.719641,0.735909,0.587644,0.523747,0.513596,0.508757,0.57644,0.457975,0.994644,0.945762,0.234688,0.25608,0.102093,0.128983,0.296568,0.316085,0.106477,0.0862696,0.913638,0.816511,0.495595,0.681316,1.62041,1.78012,0.396121,0.580625,0.515149,0.504322,0.669763,0.757342,0.161858,0.29748,-1.11434,-1.27431,1.88848,1.72626,-2.41796,-2.5531,0.733866,0.803902
1255,0.752224,0.76634,0.222997,0.159233,0.291642,0.279813,0.62029,0.610857,0.159388,0.108592,0.662965,0.685066,0.453727,0.517308,0.584753,0.602002,0.309113,0.286747,0.68969,0.692307,-1.25186,-1.05929,-0.34825,-0.186659,-1.82224,-1.64238,0.329203,0.314534,0.976026,1.06672,-0.725573,-0.582767,1.6788,1.51999,0.239251,0.0772877,0.875885,0.740056,-0.903215,-0.828472
1256,0.0645333,0.0796135,0.657234,0.593381,0.0555299,0.0508683,0.558252,0.542262,0.362287,0.313814,0.206843,0.229238,0.879961,0.905633,0.237338,0.25542,0.947117,0.92398,0.257425,0.261638,0.302431,0.500679,-0.638721,-0.475674,0.00350469,0.187562,-0.191652,-0.213561,-0.121303,-0.0339831,-0.164759,-0.0152385,0.066584,-0.0899607,0.746029,0.577191,-1.10004,-1.2421,-0.968871,-0.89479
1257,0.69111,0.705145,0.263812,0.19929,0.0440679,0.0373809,0.547819,0.473666,0.829915,0.781634,0.536673,0.559346,0.900006,0.882558,0.874541,0.89036,0.946347,0.924032,0.514996,0.446262,-1.56858,-1.36856,1.06669,1.23657,-0.583088,-0.398646,-2.17452,-2.1938,1.4083,1.48858,-0.0390765,0.107276,0.674523,0.525829,0.0583629,-0.104948,0.993162,0.858551,-0.486397,-0.494797
1258,0.996059,1.01187,0.169739,0.105325,0.839312,0.831658,0.431405,0.405071,0.318613,0.268512,0.656913,0.678964,0.835099,0.859483,0.972165,0.986091,0.493932,0.469449,0.625449,0.630886,-1.78935,-1.58921,1.21608,1.39114,1.82115,2.00593,2.50664,2.48735,-1.95772,-1.87979,-1.83261,-1.67898,-0.497333,-0.646552,-1.46549,-1.62921,0.835301,0.696277,-0.126055,-0.0948046
1259,0.581827,0.526221,0.724259,0.662154,0.437991,0.431545,0.345908,0.336475,0.809066,0.756843,0.321,0.341328,0.389074,0.413719,0.0404128,0.0548868,0.702342,0.676156,0.373376,0.381069,-0.206502,-0.01313,-1.70658,-1.53283,1.08986,1.26797,0.44165,0.414136,-0.566186,-0.493724,0.608521,0.766684,-0.118891,-0.264106,-0.0153875,-0.0967673,0.111447,-0.0194776,0.231106,0.305188
1260,0.0247698,0.0405763,0.90862,0.845615,0.997424,0.989516,0.491839,0.48152,0.57804,0.52528,0.690767,0.63886,0.962533,0.985411,0.358075,0.408367,0.600727,0.517583,0.448644,0.455541,0.667459,0.863347,-1.40627,-1.23723,0.560079,0.732546,-1.20803,-1.22977,-0.203001,-0.135379,0.596328,0.750914,0.690904,0.547561,1.60367,1.43568,1.01373,0.87557,-1.78936,-1.71431
1261,0.466351,0.483254,0.205599,0.140216,0.229141,0.22027,0.327434,0.318655,0.909705,0.85746,0.914841,0.936392,0.861921,0.885753,0.746933,0.761847,0.383663,0.35901,0.52082,0.530012,-0.0658796,0.134606,0.657451,0.820956,-1.43935,-1.26505,0.705516,0.687455,-0.308731,-0.225341,-2.17941,-2.02064,-1.13628,-1.28203,-0.57899,-0.746722,0.107924,-0.0321708,0.445577,0.515093
1262,0.414182,0.356787,0.397335,0.332996,0.631736,0.623637,0.973486,0.965514,0.782816,0.829756,0.820614,0.843504,0.299934,0.323941,0.123465,0.140604,0.84798,0.824179,0.232465,0.239203,-0.154257,0.032466,-0.565242,-0.406814,0.987469,1.15844,-0.976891,-0.988952,-0.389612,-0.315303,1.74305,1.90182,-1.28363,-1.43213,1.46619,1.29319,-1.48957,-1.6276,-0.290059,-0.133205
1263,0.213207,0.230319,0.926451,0.860749,0.62295,0.654176,0.366058,0.357531,0.753202,0.802051,0.934075,0.957287,0.57653,0.600039,0.654973,0.673187,0.799555,0.774612,0.614754,0.623366,-0.263845,-0.0696743,1.59759,1.75017,-1.7773,-1.61338,-0.607522,-0.624515,-0.706975,-0.636507,1.23317,1.39122,-0.0573921,-0.200944,1.21081,1.04171,1.18003,1.04679,-0.853427,-0.781503
1264,0.835104,0.850507,0.683703,0.522106,0.690131,0.684715,0.711108,0.641718,0.745085,0.774347,0.613039,0.638038,0.50446,0.5991,0.140778,0.157379,0.4328,0.410307,0.428026,0.437957,-0.920399,-0.720561,-1.63701,-1.48105,1.47104,1.63468,0.41065,0.387982,0.109999,0.180773,2.13027,2.29519,-0.687397,-0.829722,-1.54645,-1.71895,-0.993866,-1.1267,0.480071,0.544881
1265,0.185374,0.198908,0.249415,0.183463,0.241496,0.235645,0.933931,0.925904,0.798887,0.746643,0.963504,0.988924,0.577056,0.598162,0.0577624,0.0765251,0.807839,0.786116,0.690145,0.700986,-0.548957,-0.345941,-0.00601322,0.154593,0.651934,0.81733,0.579182,0.552996,0.133525,0.201884,0.149231,0.308003,-0.648015,-0.783822,0.156292,-0.0215165,-0.120888,-0.260412,0.9867,1.04911
1266,0.81746,0.82959,0.210898,0.144091,0.745082,0.739206,0.956398,0.948494,0.880739,0.830482,0.931075,0.956787,0.24798,0.267758,0.580963,0.598831,0.654494,0.632519,0.0503776,0.0603235,0.820905,1.02643,-0.919281,-0.762197,1.47861,1.64933,-0.185617,-0.208884,2.06482,2.12661,-0.645351,-0.47891,1.1085,0.972402,0.515724,0.340109,0.176774,0.0424943,-0.0611861,0.000362148
1267,0.467173,0.479529,0.711032,0.642571,0.901269,0.895846,0.622161,0.615722,0.222015,0.170929,0.373825,0.397938,0.46756,0.546137,0.806048,0.822756,0.208386,0.187943,0.234768,0.239348,0.932905,1.13788,0.279056,0.438957,1.84389,2.0168,0.707952,0.678976,-1.30682,-1.24176,0.0331632,0.196036,-0.00374005,-0.136444,0.31339,0.135061,-0.657561,-0.797142,-0.462139,-0.401669
1268,0.394445,0.408633,0.934937,0.865431,0.29987,0.296511,0.700133,0.694352,0.925629,0.872,0.206213,0.230301,0.802899,0.824516,0.318167,0.336588,0.83105,0.809062,0.409961,0.418373,-0.110968,0.0866514,0.148366,0.302981,-0.265833,-0.0934726,-2.58814,-2.6171,-0.595877,-0.532916,-0.884707,-0.716303,1.51074,1.37171,0.501243,0.32861,0.96859,0.834503,-0.415688,-0.348836
1269,0.325834,0.337738,0.0125014,-0.0543687,0.609201,0.641619,0.0792088,0.0713275,0.118386,0.0658547,0.384384,0.409403,0.809695,0.832107,0.658418,0.678619,0.0254354,0.000678539,0.233885,0.29229,0.0844128,0.275607,0.769273,0.918898,0.792349,0.967008,2.01337,1.98695,1.08039,1.14236,1.49536,1.66064,1.6276,1.49446,-0.000200969,-0.167144,0.77855,0.641605,0.331579,0.399602
1270,0.910829,0.923368,0.56544,0.497391,0.990605,0.986726,0.913459,0.907774,0.939573,0.887718,0.356882,0.309267,0.362836,0.386343,0.44133,0.461531,0.0893252,0.0151477,0.15913,0.166206,-0.86931,-0.683293,0.851972,0.997076,1.15246,1.32106,0.546069,0.515752,0.16227,0.22755,0.869761,0.993907,-0.388759,-0.523116,-1.05642,-1.22948,-0.383772,-0.516139,0.804029,0.872519
1271,0.510776,0.54339,0.188252,0.118601,0.851752,0.850027,0.754369,0.750044,0.626212,0.575025,0.182365,0.20913,0.892395,0.917496,0.918078,0.938057,0.0548757,0.0296169,0.714537,0.720319,-0.882632,-0.692573,0.0335206,0.172075,-0.278949,-0.114994,0.261424,0.233277,1.2549,1.32129,0.167277,0.327174,-0.969819,-1.10807,-0.172068,-0.347488,-0.396269,-0.521456,0.436465,0.500301
1272,0.150726,0.163412,0.982757,0.915421,0.243374,0.24109,0.967978,0.966348,0.0630539,0.0111185,0.852889,0.881192,0.00674962,0.0293648,0.248197,0.266159,0.711674,0.687929,0.551788,0.555317,-1.9195,-1.72872,-0.0166149,0.0854873,0.304134,0.468435,-1.38641,-1.41063,0.393172,0.466143,0.70613,0.937967,-1.77398,-1.90719,0.0353526,-0.139883,-1.53102,-1.66154,-0.579195,-0.518987
1273,0.942107,0.954493,0.414519,0.349279,0.900607,0.900083,0.455855,0.453437,0.667459,0.616255,0.378314,0.406228,0.12011,0.144424,0.163547,0.142543,0.17867,0.153881,0.723816,0.727489,1.28358,1.47395,-0.139089,-0.00110056,1.24035,1.40494,-1.99931,-2.02994,-1.63813,-1.56827,1.38335,1.54876,-1.29201,-1.43058,-0.267982,-0.435419,-0.777144,-0.907836,-0.231722,-0.132825
1274,0.503177,0.513985,0.230731,0.165028,0.760608,0.758077,0.314267,0.311902,0.504129,0.523349,0.901987,0.927722,0.77394,0.797184,0.00206602,0.0189272,0.860016,0.836159,0.524398,0.526749,-1.63666,-1.44227,0.442395,0.584662,-1.27251,-1.1037,0.103486,0.081122,0.0558465,0.122553,0.346552,0.515924,-0.104663,-0.245812,0.287202,0.123847,1.87547,1.75265,0.188511,0.253337
1275,0.490272,0.498883,0.986929,0.920531,0.0649883,0.064089,0.55431,0.551831,0.481802,0.430442,0.601501,0.628921,0.623274,0.647654,0.492317,0.510212,0.0216724,-0.00288466,0.599341,0.602556,-0.518517,-0.3205,-0.0729552,0.0642083,-1.13265,-0.965833,1.57334,1.54359,-1.07508,-1.00777,-0.332369,-0.166174,-1.50608,-1.65038,-1.5703,-1.72938,1.67166,1.54587,-0.87704,-0.81153
1276,0.275718,0.285007,0.247376,0.180604,0.0816291,0.0805161,0.270411,0.268881,0.94102,0.888063,0.763226,0.788392,0.0172676,0.0415272,0.220911,0.237679,0.61639,0.593586,0.96281,0.967747,0.027315,0.222457,-0.604161,-0.456245,0.596716,0.756553,-0.387124,-0.420991,0.345477,0.407625,0.572767,0.737803,-0.0804686,-0.217967,-1.12086,-1.27606,-0.609647,-0.734397,0.127402,0.194508
1277,0.903613,0.910539,0.106301,0.0418167,0.483405,0.483883,0.872723,0.87164,0.838059,0.786774,0.136681,0.163804,0.445329,0.478459,0.856186,0.872619,0.143458,0.118914,0.0116268,0.0147622,-0.445135,-0.242859,1.07335,1.22676,-0.573751,-0.419042,1.68269,1.64166,0.721545,0.782137,-0.662141,-0.492753,-0.906785,-1.04401,0.0195997,-0.134695,1.48937,1.36626,-1.58177,-1.51555
1278,0.0471862,0.0526369,0.487751,0.466401,0.311707,0.312044,0.971841,0.970862,0.202143,0.151877,0.398887,0.443747,0.891132,0.915391,0.959377,0.974164,0.504284,0.479835,0.217207,0.226883,1.43921,1.63889,-1.41098,-1.26338,0.153434,0.303259,-0.547185,-0.588197,-0.85154,-0.794508,0.817676,0.991177,-0.358657,-0.489862,-0.67236,-0.830961,-1.77374,-1.90342,0.514241,0.582261
1279,0.902252,0.909424,0.955351,0.890986,0.83298,0.835514,0.188689,0.186168,0.128869,0.142786,0.695966,0.72369,0.197602,0.223466,0.0979081,0.113672,0.23511,0.210963,0.43491,0.439004,0.0698948,0.16985,-0.527795,-0.386276,0.34668,0.502107,-0.0773866,-0.118991,0.0491305,0.101235,1.99152,2.16971,-1.41998,-1.55247,1.0747,0.913482,-0.275912,-0.411184,0.355317,0.423175
1280,0.535012,0.610058,0.577975,0.4792,0.964409,0.966976,0.890936,0.888241,0.182464,0.133696,0.445085,0.437668,0.743834,0.769731,0.472274,0.486132,0.890327,0.864615,0.410363,0.415053,-1.49887,-1.29919,-1.71596,-1.56735,0.782724,0.931073,1.40262,1.3581,-1.01123,-0.952621,-1.59899,-1.41631,1.00086,0.861978,0.250294,0.0958051,-0.855194,-0.989654,-0.320705,-0.24953
1281,0.30614,0.310693,0.129875,0.0674137,0.73876,0.739549,0.404597,0.401328,0.493512,0.445713,0.125242,0.151646,0.861184,0.855116,0.60395,0.617153,0.615062,0.590722,0.0647719,0.0691272,-1.09802,-0.89339,0.699611,0.85074,-0.779492,-0.625679,1.65622,1.65642,-0.807305,-0.74887,-0.0507055,0.130343,-0.159248,-0.291744,-0.0408023,-0.19973,2.11557,1.98011,0.956701,1.03051
1282,0.366519,0.370946,0.885997,0.822917,0.997514,1.00023,0.314814,0.313134,0.216223,0.255129,0.91343,0.940152,0.845949,0.9405,0.154579,0.16633,0.808674,0.786304,0.0214352,0.0258446,0.869445,1.07845,-0.668113,-0.519506,-1.24823,-1.09816,2.00035,1.95474,-0.00389705,0.124383,0.544541,0.728756,-0.78098,-0.920522,-1.37414,-1.54034,1.19257,0.995034,-0.465811,-0.386857
1283,0.96046,0.965968,0.547444,0.562865,0.998103,1.00159,0.953907,0.950477,0.112368,0.0645452,0.406812,0.434778,0.999988,1.02589,0.881483,0.893982,0.598824,0.578671,0.579359,0.584718,-0.345705,-0.14244,1.19724,1.34945,-0.390773,-0.237863,-0.00826107,-0.0539316,0.940476,0.997637,-0.642293,-0.457365,0.230962,0.0928262,0.199775,0.031855,0.143216,0.00996234,1.41948,1.49542
1284,0.659514,0.666337,0.368774,0.302813,0.721306,0.723005,0.073307,0.069631,0.659267,0.613257,0.945914,0.972101,0.207949,0.233076,0.896257,0.909801,0.777137,0.70635,0.210167,0.214209,2.37726,2.57985,-0.491562,-0.334655,1.26244,1.41875,0.653289,0.601067,0.0890794,0.14249,0.832373,1.01228,-0.712418,-0.847277,2.0561,1.88355,-0.321628,-0.459689,-1.73283,-1.65968
1285,0.583682,0.570469,0.715528,0.648988,0.226154,0.228724,0.75039,0.746328,0.660571,0.616047,0.94765,0.974171,0.917834,0.941168,0.710929,0.728553,0.854255,0.834029,0.525258,0.574644,-0.119914,0.081562,-0.075939,0.0814964,-0.147158,0.0127939,-1.05978,-1.10661,-0.437806,-0.389547,-0.045857,0.132035,-0.149629,-0.277308,-0.295002,-0.464519,0.453062,0.309913,0.0150498,0.0812806
1286,0.516957,0.474601,0.0445361,-0.0220297,0.806103,0.806868,0.185319,0.182591,0.28544,0.242018,0.092399,0.119618,0.913238,0.884409,0.535365,0.547304,0.759423,0.738564,0.930703,0.935078,-0.0912755,0.115487,-0.59177,-0.435309,0.883434,1.04332,0.668877,0.622391,-0.700446,-0.650407,-1.99377,-1.80612,0.876503,0.749837,-1.38505,-1.55774,0.426345,0.288968,1.28596,1.34735
1287,0.37191,0.378733,0.402232,0.338083,0.162928,0.162577,0.51815,0.516346,0.506503,0.462697,0.149752,0.175221,0.803343,0.82765,0.0923828,0.105725,0.449063,0.429504,0.712724,0.762932,-0.668561,-0.458787,0.983269,1.13987,-0.162821,-0.0311172,0.395484,0.355699,0.304745,0.351449,1.41269,1.59663,-0.379842,-0.499093,1.59941,1.42395,-0.577857,-0.710573,-0.501564,-0.437692
1288,0.538491,0.543717,0.303436,0.301246,0.668761,0.670808,0.493566,0.536214,0.100386,0.0586184,0.668809,0.692549,0.114839,0.140079,0.0324657,0.141829,0.96108,0.939896,0.584939,0.590785,1.10485,1.31686,-1.05993,-0.904479,-1.27437,-1.10555,-0.406255,-0.45188,-1.63057,-1.58103,1.7435,1.93116,1.31849,1.19533,1.41194,1.2343,0.983112,0.857262,-0.0266527,0.035225
1289,0.0443746,0.0483227,0.32842,0.26441,0.3947,0.39639,0.661334,0.556082,0.764612,0.723863,0.343091,0.369324,0.649516,0.580155,0.162759,0.177932,0.275165,0.254457,0.748772,0.723508,-0.996613,-0.783194,0.587909,0.746193,0.998198,1.17014,2.50809,2.45822,0.0683707,0.124376,0.81816,1.00495,-0.178291,-0.304322,-0.91633,-1.09852,0.0961253,-0.0306765,-0.0528853,0.0121888
1290,0.100432,0.103984,0.69374,0.629143,0.88465,0.884657,0.624642,0.57595,0.733898,0.694249,0.945677,0.970793,0.996316,1.02023,0.579386,0.545443,0.332244,0.312617,0.874556,0.856231,0.29604,0.510518,-0.428002,-0.265055,0.18138,0.352794,0.644061,0.593413,-1.32774,-1.26852,-1.08241,-0.888227,-1.14654,-1.27396,0.51814,0.335919,0.51616,0.396812,0.356673,0.424251
1291,0.580275,0.5853,0.167204,0.101732,0.0319947,0.0336803,0.75386,0.595818,0.914849,0.874286,0.778737,0.803156,0.288668,0.313015,0.896405,0.912954,0.745676,0.631635,0.983125,0.988954,0.583157,0.793446,-0.555524,-0.385541,0.619802,0.79812,0.949472,0.897275,-0.163922,-0.0974548,0.965957,1.15505,0.416312,0.293407,-1.59163,-1.78069,1.77247,1.65165,-0.498054,-0.42831
1292,0.641703,0.703392,0.241406,0.175398,0.287618,0.386853,0.61749,0.615686,0.0144388,-0.0256824,0.292225,0.318437,0.603873,0.528937,0.233377,0.25085,0.970197,0.950653,0.166895,0.173633,1.48718,1.70218,0.238085,0.415788,-0.8603,-0.683219,-0.663586,-0.715158,-0.629761,-0.570476,1.12996,1.32234,1.22188,1.10507,0.779786,0.59702,-1.83494,-1.96198,0.51394,0.577729
1293,0.816211,0.821485,0.979247,0.911411,0.73852,0.740026,0.0289322,0.0279109,0.90069,0.859403,0.78852,0.815918,0.720836,0.74486,0.685082,0.702549,0.12531,0.106422,0.8022,0.807537,-1.2423,-1.0309,-0.410085,-0.239559,0.748691,0.926734,0.510569,0.464545,1.36264,1.42071,-0.101457,0.0917793,0.270185,0.0887582,-0.211899,-0.367739,-0.54842,-0.675815,-2.03315,-1.96412
1294,0.634231,0.638531,0.954289,0.886216,0.624802,0.630286,0.534061,0.443177,0.317822,0.275464,0.321901,0.350381,0.0545623,0.0780885,0.15531,0.1715,0.836936,0.81866,0.116187,0.120383,-0.53083,-0.321602,-1.6761,-1.51456,0.319184,0.499871,1.19342,1.14909,-0.770471,-0.711484,0.14523,0.336027,-0.81491,-0.927558,-1.14549,-1.3325,0.356903,0.235468,-0.159739,-0.0942124
1295,0.167929,0.17271,0.0557676,-0.0124927,0.519967,0.520546,0.859343,0.858443,0.618741,0.578229,0.439578,0.533152,0.704147,0.726029,0.0870588,0.105746,0.455916,0.438939,0.757652,0.759163,0.996238,1.20777,-0.723108,-0.506891,-0.426942,-0.238085,2.12601,2.08248,0.32329,0.382256,-0.382198,-0.188978,0.817769,0.706209,-0.218837,-0.403186,0.441552,0.323478,0.833583,0.89543
1296,0.743836,0.749256,0.899511,0.829524,0.608409,0.634678,0.452997,0.44372,0.288614,0.246085,0.644406,0.715922,0.993026,1.01718,0.98073,1.00115,0.75391,0.73507,0.1928,0.193571,-0.959486,-0.750767,0.338489,0.500774,1.15862,1.34231,-1.27533,-1.32305,-2.1044,-2.04385,0.207771,0.394356,-0.38712,-0.495972,-1.92462,-2.11251,1.59991,1.48469,-1.31376,-1.24698
1297,0.670025,0.748143,0.0325127,-0.0366423,0.625825,0.748809,0.0298974,0.0289974,0.848765,0.805355,0.869262,0.898692,0.219434,0.241315,0.655057,0.674649,0.13076,0.110257,0.145825,0.144472,-0.791505,-0.577233,0.0566905,0.21176,1.42178,1.60478,1.91294,1.86026,0.317967,0.377454,-0.00794069,0.178711,-0.438158,-0.540794,-2.3233,-2.51627,-1.18516,-1.30665,0.155902,0.124282
1298,0.739727,0.747029,0.452428,0.382471,0.862245,0.86294,0.909109,0.908291,0.152412,0.109511,0.797435,0.825997,0.225555,0.248906,0.0444641,0.063789,0.33021,0.310734,0.613292,0.613429,3.26337,3.48616,0.252749,0.413732,-0.434271,-0.252268,0.273073,0.216352,2.49373,2.54633,1.11321,1.29741,-0.0658479,-0.172266,0.251405,0.0649782,0.597082,0.480316,1.42877,1.49555
1299,0.931529,0.937409,0.122463,0.0522145,0.289108,0.289291,0.559076,0.556578,0.135523,0.180466,0.129255,0.155548,0.803612,0.825407,0.685554,0.703467,0.092284,0.0722235,0.628862,0.726211,-0.000440708,0.219991,-1.53633,-1.37935,0.260856,0.439697,-0.801214,-0.855568,-0.29848,-0.240106,1.26684,1.44794,-0.106518,-0.217089,0.228457,0.0417129,0.372013,0.256889,1.29287,1.35281
1300,0.0611399,0.0669713,0.0586123,-0.0119192,0.379265,0.45601,0.83805,0.836484,0.295275,0.25142,0.390247,0.414826,0.0853263,0.107627,0.541994,0.496926,0.160737,0.140648,0.838662,0.838992,-0.128381,0.0902294,0.986987,1.14611,-1.29202,-1.11706,-0.948319,-0.997473,-2.48191,-2.42023,-0.496571,-0.320914,-0.78672,-0.891688,-0.559577,-0.747025,-0.694083,-0.804555,-0.63973,-0.571845
1301,0.362883,0.368834,0.752752,0.682851,0.620713,0.62273,0.131691,0.12914,0.93005,0.885952,0.442,0.465562,0.088423,0.111079,0.274275,0.290386,0.649916,0.631442,0.386694,0.387684,-1.17081,-0.945921,0.920035,1.08697,0.786647,0.965131,0.0877064,0.0438208,-0.1062,-0.0507006,0.759001,0.934351,0.503921,0.401559,-2.50294,-2.69155,2.21951,2.10673,-0.320021,-0.248969
1302,0.175809,0.180171,0.687966,0.618717,0.513499,0.516686,0.356196,0.354109,0.287707,0.24168,0.275666,0.297925,0.455682,0.477962,0.8224,0.8382,0.848598,0.831919,0.356174,0.263479,-0.590134,-0.371779,-0.122525,0.0449475,-1.40741,-1.2251,-1.2122,-1.25892,0.127132,0.182882,1.49029,1.66739,-1.13167,-1.2384,-0.514868,-0.698203,1.05376,0.933912,-1.35893,-1.28307
1303,0.264646,0.271218,0.000134342,-0.0717274,0.0192013,0.0224051,0.135639,0.131219,0.809659,0.7652,0.646847,0.667483,0.479832,0.500452,0.143428,0.160843,0.270998,0.252497,0.137437,0.139275,0.529875,0.749986,-0.44173,-0.273254,0.34925,0.527518,-0.819583,-0.864864,0.626022,0.678425,1.55263,1.72817,0.504582,0.395367,-0.339672,-0.521811,-0.644001,-0.759069,0.643117,0.722276
1304,0.564113,0.573081,0.388804,0.250507,0.351428,0.354408,0.1378,0.135028,0.914047,0.868999,0.438286,0.458294,0.177098,0.199261,0.416861,0.437105,0.68248,0.66276,0.457021,0.457495,0.696045,0.92352,-0.0944037,0.127561,0.18211,0.361104,-1.33447,-1.37832,0.86255,0.912008,2.88189,3.06055,-0.56152,-0.667241,0.0487724,-0.129026,0.930724,0.808765,0.853284,0.938525
1305,0.480752,0.490041,0.64576,0.572741,0.0748808,0.0799906,0.59381,0.592713,0.549863,0.493341,0.79038,0.80918,0.385938,0.429292,0.926118,0.944109,0.244509,0.223554,0.392422,0.411916,1.50243,1.72563,0.362014,0.528376,-0.46582,-0.285025,-0.376396,-0.37031,-0.898005,-0.8502,-0.38331,-0.205683,0.500991,0.391772,-0.271069,-0.456324,-0.142838,-0.268695,-0.346453,-0.265546
1306,0.699477,0.657485,0.287337,0.307194,0.979788,0.982641,0.0942246,0.0952474,0.160629,0.117682,0.548702,0.56576,0.637754,0.659324,0.487503,0.528156,0.333749,0.31215,0.365801,0.366336,-1.1234,-0.897056,-1.4747,-1.31469,-0.694008,-0.513838,0.679423,0.6377,-1.12968,-1.08021,-2.06114,-1.88219,-0.509633,-0.624902,-1.37336,-1.56583,-0.18533,-0.304749,-0.752133,-0.667578
1307,0.813381,0.82493,0.113087,0.0416468,0.630752,0.714741,0.501339,0.468179,0.458392,0.415258,0.103093,0.11971,0.351736,0.373458,0.0932377,0.112203,0.532735,0.400745,0.72208,0.720218,1.60608,1.82524,0.987167,1.14775,-0.25633,-0.0531142,0.86483,0.883064,-0.344464,-0.292026,-0.406466,-0.226964,-0.0372717,-0.148291,0.378656,0.178616,0.757633,0.639193,-0.284971,-0.194661
1308,0.00203477,0.0130359,0.0310931,-0.0416843,0.446367,0.44684,0.841346,0.84111,0.379204,0.335088,0.544988,0.562914,0.272219,0.251733,0.626962,0.644786,0.510296,0.489341,0.173754,0.173454,0.31168,0.528509,1.36536,1.53323,0.220913,0.40761,1.16353,1.12843,-1.47637,-1.42235,1.79569,1.97459,-0.543484,-0.569148,1.15554,0.953132,-1.12255,-1.24747,-0.328681,-0.233028
1309,0.0705907,0.0119227,0.584509,0.435421,0.947573,0.950401,0.959845,0.960568,0.00817807,-0.0336822,0.145178,0.16135,0.107211,0.130009,0.766954,0.786184,0.46752,0.418104,0.946136,0.944119,0.434856,0.656329,-0.493221,-0.326615,-0.659008,-0.47156,0.570979,0.537184,-0.300516,-0.238543,-0.634241,-0.451538,-0.871576,-0.990005,-0.44847,-0.646364,-0.0207911,-0.147812,-0.124095,-0.0303439
1310,6.26567e-06,0.0108095,0.984743,0.912526,0.335459,0.3364,0.348234,0.347555,0.808262,0.768261,0.444504,0.462741,0.57669,0.597088,0.370382,0.429708,0.429401,0.346866,0.822725,0.855306,0.0336218,0.252615,0.460721,0.62614,-1.19313,-1.00698,-2.13558,-2.17585,0.889605,0.945267,-1.6875,-1.50011,0.591643,0.47356,-0.122611,-0.323731,-1.1345,-1.25508,-0.72595,-0.626543
1311,0.972477,0.98328,0.446377,0.375428,0.879854,0.879299,0.485575,0.487084,0.745626,0.708413,0.202126,0.219321,0.068303,0.0907702,0.0528096,0.0732325,0.296174,0.275629,0.768551,0.766493,-2.02651,-1.8031,-0.58846,-0.415879,0.819824,1.01008,-0.65066,-0.69876,-0.915707,-0.861837,-0.898774,-0.707946,-0.985268,-1.10665,0.193224,-0.00109825,-0.132593,-0.248601,2.52717,2.62201
1312,0.596175,0.655224,0.911326,0.838504,0.889352,0.876811,0.941209,0.944769,0.44407,0.405879,0.754075,0.771006,0.992817,1.01344,0.227177,0.244427,0.0516067,0.0324388,0.984589,0.983873,-1.01727,-0.800889,1.54683,1.72515,-0.0985564,0.0852863,-1.6446,-1.6927,0.0636882,0.111424,1.26483,1.46429,0.895043,0.77806,0.283462,0.0834914,0.380957,0.259575,-0.569274,-0.470697
1313,0.314811,0.327168,0.85184,0.779315,0.820837,0.874323,0.873176,0.877828,0.845439,0.808409,0.227827,0.24675,0.882876,0.822056,0.814234,0.832362,0.863584,0.845326,0.760136,0.745538,0.751163,0.974754,1.3838,1.55833,0.339,0.530613,-1.04896,-1.14676,-0.171491,-0.118591,-1.20999,-1.01746,-2.3972,-2.51275,0.663765,0.462202,-1.06884,-1.19519,-0.508078,-0.402473
1314,0.80363,0.813895,0.553971,0.387323,0.874467,0.871835,0.242144,0.245613,0.679059,0.641788,0.683599,0.704981,0.611909,0.630669,0.401585,0.463891,0.891356,0.874886,0.58934,0.507203,0.871668,1.10257,-0.0829768,0.0925802,-0.312394,-0.0342633,-0.5486,-0.600821,-0.677684,-0.588598,0.528827,0.715784,0.710829,0.595051,-1.23237,-1.43542,-1.65697,-1.78852,-0.788347,-0.682632
1315,0.227608,0.237645,0.067856,-0.00466895,0.406856,0.402103,0.0931742,0.0978796,0.16576,0.128666,0.894512,0.913469,0.831605,0.85175,0.077999,0.0954192,0.103585,0.0850795,0.268961,0.268867,-0.796444,-0.561932,0.545494,0.723663,-0.784824,-0.59914,-1.24642,-1.29869,-1.11723,-1.05861,1.1214,1.3142,-1.19871,-1.31261,1.53853,1.3306,-1.21141,-1.29471,-0.805368,-0.705668
1316,0.266703,0.225146,0.898476,0.827554,0.286351,0.227045,0.211842,0.277064,0.912414,0.877497,0.0418673,0.0589158,0.666813,0.687932,0.926831,0.945652,0.969162,0.951801,0.933897,0.932212,1.71943,1.95851,2.15182,2.32837,0.476245,0.657705,-0.00438205,-0.0578358,-1.22624,-1.16525,-0.142997,0.050599,-0.488344,-0.605566,0.794139,0.514859,-0.672024,-0.800902,1.10204,1.20679
1317,0.202319,0.212647,0.312785,0.241393,0.0571229,0.0519868,0.453119,0.456249,0.462905,0.429487,0.558541,0.576243,0.222386,0.242169,0.982073,1.00139,0.23391,0.21548,0.992908,0.989396,0.913185,1.15208,0.276046,0.450676,0.277063,0.460112,0.635724,0.580108,-0.028261,0.0370806,-1.12834,-0.937617,-1.11814,-1.23434,-0.0868382,-0.300887,-1.67896,-1.80044,-1.02326,-0.919114
1318,0.645802,0.655325,0.0841161,0.0114962,0.216611,0.213255,0.883469,0.884934,0.663241,0.576667,0.0732521,0.0915247,0.513593,0.513275,0.331633,0.348906,0.5029,0.486454,0.322197,0.318248,-1.90904,-1.67174,-0.0615437,0.11611,1.22794,1.41405,-0.605785,-0.66194,0.194492,0.260926,1.00117,1.19924,-0.803214,-0.912593,-1.5022,-1.71748,0.500941,0.380977,-1.02463,-0.926493
1319,0.586794,0.511145,0.610053,0.53925,0.0304574,0.0257779,0.104824,0.10521,0.756916,0.723847,0.995124,1.01334,0.76552,0.784382,0.437495,0.457333,0.246035,0.227644,0.034961,0.0328053,0.937439,1.18107,-0.108907,0.0713442,-0.801427,-0.61435,-0.182801,-0.237546,0.406298,0.484771,0.18754,0.380868,-0.251323,-0.358443,-0.45654,-0.738233,-1.69715,-1.82101,-1.76528,-1.67312
1320,0.429148,0.366965,0.417276,0.344619,0.50995,0.431569,0.479366,0.479051,0.236971,0.205422,0.147023,0.164381,0.68942,0.710597,0.546189,0.56576,0.26428,0.247429,0.102695,0.099547,-0.291794,-0.0528725,-0.506953,-0.324431,-1.42847,-1.24527,0.887456,0.834731,0.648838,0.708617,-0.332733,-0.144136,-0.0138106,-0.114441,0.457772,0.241015,0.547322,0.422578,0.525565,0.620425
1321,0.213618,0.222785,0.91777,0.847431,0.839847,0.83736,0.299647,0.350418,0.590446,0.55745,0.462429,0.479959,0.0581138,0.0785188,0.0187803,0.0399509,0.945685,0.929707,0.417275,0.412985,0.351578,0.597551,0.74121,0.924358,-1.39965,-1.21463,-0.0408588,-0.0987882,-0.0840972,-0.0241923,-0.177207,0.0063996,-0.441955,-0.544014,-0.644087,-0.868488,-0.14724,-0.277994,0.662187,0.762482
1322,0.953473,0.960539,0.912376,0.841785,0.875243,0.873727,0.220329,0.221785,0.0973822,0.0641139,0.469653,0.487046,0.257408,0.285858,0.610929,0.633099,0.225565,0.208881,0.145059,0.142539,-0.203312,0.0389818,-0.521005,-0.334316,-0.438409,-0.246657,1.03746,0.973488,-0.434176,-0.375275,-0.437796,-0.254753,1.32709,1.22714,0.789506,0.565953,0.118792,-0.00753784,-0.0731972,0.0308217
1323,0.353631,0.35937,0.475827,0.40403,0.385363,0.383841,0.580342,0.580305,0.643607,0.608483,0.123941,0.139862,0.541603,0.493198,0.280525,0.301746,0.931904,0.915988,0.628254,0.62624,0.370533,0.613124,-0.195154,-0.0094813,-0.17048,0.0158082,-1.94258,-2.00744,-2.00858,-1.95192,-0.0994212,0.0797747,1.07729,0.983462,1.40433,1.18748,-0.613068,-0.739908,1.91123,2.01835
1324,0.133557,0.140135,0.792472,0.720464,0.97556,0.97221,0.440803,0.485034,0.0470496,0.0140669,0.19644,0.21091,0.678538,0.700538,0.568286,0.587664,0.527423,0.510879,0.310639,0.310472,-0.531652,-0.284824,1.25646,1.43872,0.317941,0.505025,1.059,0.984004,-0.314049,-0.27239,0.935884,1.12224,0.0562955,-0.0332113,-1.15873,-1.36843,-0.101832,-0.231732,0.489858,0.600989
1325,0.220639,0.141949,0.651681,0.581677,0.254809,0.251213,0.446674,0.389763,0.577417,0.543092,0.949216,0.962799,0.128356,0.147793,0.577186,0.597943,0.38875,0.3624,0.22656,0.227272,0.0664011,0.318715,1.6717,1.85487,-0.823494,-0.63789,1.12521,1.05711,1.35048,1.40714,0.17943,0.36323,-0.505359,-0.602843,0.0953343,-0.121208,1.75248,1.62202,0.73273,0.847351
1326,0.136822,0.143763,0.731859,0.66076,0.882025,0.879711,0.294529,0.294492,0.842475,0.809405,0.395208,0.408613,0.0883227,0.109473,0.370452,0.335673,0.194048,0.213921,0.759459,0.762167,-1.54693,-1.29661,-0.0840617,0.0923454,-0.00502874,0.177508,-0.493936,-0.555319,-0.699034,-0.64339,1.52965,1.70954,0.876775,0.783783,-0.594855,-0.817474,-1.14818,-1.2835,-0.123268,-0.00520968
1327,0.682496,0.69016,0.23718,0.167846,0.620144,0.619712,0.960605,0.960538,0.743708,0.708116,0.91316,0.92594,0.289096,0.31107,0.0520494,0.0734033,0.08165,0.0654422,0.995856,1.00091,0.0276986,0.279469,-0.934373,-0.76356,-0.933855,-0.747286,-0.569339,-0.635922,1.45808,1.50911,-1.53346,-1.36025,-1.3548,-1.45479,0.926457,0.706731,0.566983,0.42685,0.573691,0.696789
1328,0.719747,0.726449,0.817708,0.748807,0.118483,0.120016,0.872869,0.973087,0.967162,0.93357,0.179003,0.191338,0.745685,0.76695,0.0464167,0.0686049,0.137044,0.119598,0.948601,0.895388,-0.041269,0.208342,-0.205369,-0.118627,0.137128,0.327948,1.96157,1.89538,1.37708,1.43368,-1.20637,-1.03996,-2.04518,-2.14531,0.161601,-0.0512462,1.31458,1.18055,-1.04145,-0.919342
1329,0.259499,0.265395,0.65874,0.590278,0.269883,0.293947,0.900569,0.985636,0.203418,0.169634,0.996782,1.01038,0.117445,0.140583,0.677284,0.698828,0.897975,0.881142,0.743182,0.789862,-1.35953,-1.1017,0.355493,0.526306,0.39725,0.590413,0.41727,0.348982,-1.40193,-1.35276,1.5065,1.66628,-0.599408,-0.698359,0.0613865,-0.148997,0.682967,0.55749,0.106318,0.223245
1330,0.997153,1.00315,0.0736139,0.00411614,0.468229,0.467877,0.998379,0.998185,0.327821,0.256815,0.46864,0.480459,0.361308,0.386869,0.92917,0.949026,0.12312,0.106778,0.679598,0.684336,-0.568438,-0.314823,0.37972,0.542389,-0.861308,-0.674568,0.30919,0.237262,-0.308537,-0.259019,1.39917,1.5589,1.32464,1.23269,-0.617486,-0.831136,-0.86135,-0.992396,0.192653,0.370835
1331,0.196651,0.204313,0.994305,0.925078,0.175625,0.256251,0.583973,0.581416,0.346842,0.343997,0.37739,0.430245,0.318438,0.415331,0.176019,0.197318,0.156743,0.109795,0.377601,0.393208,-2.18736,-1.93015,1.25117,1.49143,-1.1592,-0.979085,-0.0145005,-0.0461458,-0.672993,-0.625982,1.81282,1.97056,-0.948259,-1.04206,1.10533,0.895626,-0.76518,-0.889757,0.407968,0.518424
1332,0.156116,0.136127,0.0433581,-0.0245835,0.0431908,0.0446246,0.778597,0.777707,0.464962,0.431178,0.368187,0.380031,0.380566,0.443792,0.198584,0.218026,0.127379,0.112813,0.0955124,0.10208,-0.0411604,0.21224,2.28578,2.44046,-0.403745,-0.225909,-0.248659,-0.329553,0.769297,0.820554,0.951693,1.10618,0.0880401,-0.000972402,0.611159,0.399872,0.592673,0.465727,-0.421353,-0.317651
1333,0.061241,0.0679412,0.687369,0.620131,0.133156,0.135742,0.733372,0.78338,0.886502,0.853518,0.76538,0.779661,0.452567,0.472254,0.00697096,0.025906,0.496549,0.483189,0.327428,0.334859,0.331276,0.586859,-0.461936,-0.305502,2.81714,2.99028,-0.895792,-0.981908,-1.44255,-1.39064,1.13756,1.28929,0.740864,0.645927,-0.726717,-0.940736,-1.78118,-1.90126,0.0951013,0.201802
1334,0.619122,0.62449,0.846088,0.779081,0.73344,0.733449,0.685313,0.789052,0.119181,0.08472,0.232043,0.245476,0.492095,0.500716,0.371561,0.388791,0.868409,0.853564,0.28545,0.28992,0.187397,0.439778,0.208216,0.372858,-0.482765,-0.305348,1.05577,0.971527,-2.00837,-1.95453,-0.375305,-0.220499,-0.929594,-1.02792,-0.987409,-1.20756,-1.29994,-1.35967,1.2876,1.39302
1335,0.351874,0.355257,0.365459,0.295791,0.6142,0.52924,0.796408,0.794725,0.633248,0.598841,0.150718,0.162343,0.503617,0.529178,0.317098,0.278451,0.542279,0.529021,0.338717,0.244981,0.467525,0.722707,-1.71844,-1.54887,1.4662,1.64854,0.585487,0.503509,1.42076,1.47575,-0.266181,-0.163926,0.84788,0.743232,1.44431,1.21715,-0.691472,-0.818088,0.28504,0.437353
1336,0.35863,0.360406,0.285664,0.24304,0.375864,0.32503,0.948447,0.945,0.528789,0.402941,0.87616,0.888205,0.942466,0.966073,0.150189,0.168112,0.55909,0.543989,0.158117,0.200043,1.61931,1.87719,-0.590525,-0.423141,-0.123137,0.0594762,-1.01989,-1.10892,-2.46447,-2.40948,-0.254624,-0.107353,0.708669,0.60686,-1.47535,-1.70569,-0.421833,-0.547632,-0.630999,-0.518318
1337,0.146443,0.14653,0.258707,0.190289,0.121589,0.120821,0.429657,0.427126,0.243177,0.207042,0.506027,0.516512,0.732618,0.755703,0.819731,0.839154,0.282035,0.314505,0.219769,0.155104,0.700029,0.963128,0.23631,0.408682,-0.135861,0.0447304,0.414996,0.320563,1.0981,1.14759,-1.15215,-0.999956,-0.517216,-0.626064,-0.274053,-0.571306,-0.753484,-0.878587,-0.224548,-0.106256
1338,0.520889,0.50464,0.460701,0.39275,0.949462,0.949673,0.735434,0.68195,0.559928,0.524025,0.455535,0.46433,0.775203,0.798315,0.823635,0.720011,0.100032,0.0850219,0.233537,0.110165,0.161772,0.419815,0.190863,0.363916,0.44991,0.628159,0.68444,0.593103,0.416136,0.454848,-2.0348,-1.89256,0.851544,0.744873,0.798888,0.563079,0.400557,0.282626,0.9271,1.0528
1339,0.862992,0.86275,0.24142,0.173371,0.000689098,0.00205011,0.937887,0.936774,0.375581,0.341708,0.780833,0.789467,0.55789,0.662878,0.633516,0.600869,0.119478,0.104807,0.0577954,0.0652263,0.890724,1.14548,0.95919,1.13384,-0.945521,-0.763053,-0.327844,-0.416775,-0.382065,-0.237893,0.945091,1.09116,-1.15102,-1.25868,1.22702,0.986286,-0.101236,-0.218664,0.481912,0.60695
1340,0.953591,0.870519,0.504377,0.398158,0.170415,0.172778,0.668063,0.625616,0.821291,0.789911,0.409409,0.417774,0.505375,0.527441,0.462615,0.481726,0.892734,0.87632,0.933341,0.940131,0.530366,0.787559,1.13073,1.30511,-0.274994,-0.0864113,0.213109,0.131279,-1.12127,-0.930634,-0.826213,-0.677695,1.80552,1.70207,0.491518,0.257743,-0.0125671,-0.130654,0.544339,0.696318
1341,0.860072,0.878287,0.691607,0.622945,0.848774,0.852494,0.31318,0.314457,0.246748,0.216573,0.560321,0.56757,0.885406,0.908896,0.725833,0.747329,0.0353798,0.0170293,0.543378,0.528241,0.624089,0.88377,0.524455,0.695448,-1.53258,-1.33657,1.55126,1.46561,-1.67286,-1.62337,0.822501,0.977527,1.14148,1.0434,1.2355,1.00182,-0.767483,-0.880883,0.654812,0.785686
1342,0.907256,0.886055,0.129133,0.0607567,0.715826,0.720967,0.59693,0.599823,0.385258,0.356337,0.376851,0.384991,0.283353,0.307846,0.0631301,0.0852247,0.740871,0.724137,0.111824,0.11635,-0.371351,-0.106475,0.121554,0.284967,-0.116814,0.071662,0.889114,0.798389,0.525697,0.579628,1.29751,1.45477,-0.573923,-0.676117,-0.176172,-0.414775,-0.618423,-0.733581,-0.779052,-0.648491
1343,0.950273,0.893824,0.47133,0.34354,0.337369,0.341635,0.556972,0.583278,0.0514305,0.0241928,0.42186,0.430121,0.539695,0.520854,0.167236,0.191561,0.72948,0.713721,0.971195,0.975379,-0.201728,0.0670592,0.363229,0.596095,0.893833,1.08635,0.604584,0.515915,1.41301,1.47537,-0.177508,-0.0260891,-0.42762,-0.523082,-0.774104,-1.01786,0.132606,0.0201223,1.67711,1.81079
1344,0.901834,0.901592,0.66013,0.626323,0.784121,0.79089,0.566299,0.566732,0.539876,0.512524,0.825705,0.833997,0.707174,0.733862,0.733673,0.759071,0.949141,0.935393,0.922931,0.92628,0.426157,0.70174,0.739671,0.907222,0.163721,0.360748,-0.000603163,-0.0896046,0.901296,0.957335,0.703843,0.862262,-2.55097,-2.64921,-2.45776,-2.69562,0.531052,0.417021,-0.662709,-0.522206
1345,0.367556,0.458018,0.977483,0.909107,0.371628,0.376464,0.145521,0.14538,0.0426474,0.0142762,0.838048,0.845809,0.550267,0.574812,0.378297,0.402115,0.883952,0.8696,0.0439109,0.0472876,-0.0335397,0.236423,-1.07705,-0.903235,-1.9787,-1.78142,0.980203,0.891753,-0.866544,-0.804873,-1.61873,-1.45744,2.30412,2.20588,-0.311147,-0.548205,-0.613412,-0.723062,-1.15056,-1.01206
1346,0.0167438,0.0144434,0.0169751,-0.0530412,0.742606,0.749251,0.721918,0.72326,0.215887,0.142416,0.565248,0.572886,0.0825468,0.109081,0.554471,0.579505,0.337956,0.325111,0.187853,0.189812,1.15503,1.42258,0.690476,0.858045,-1.05271,-0.860006,1.51758,1.42325,2.03261,2.0876,-0.0945431,0.058178,0.646655,0.549237,-0.986336,-1.24902,0.167619,0.0628239,-0.435526,-0.294057
1347,0.327499,0.31889,0.910728,0.840632,0.648003,0.653268,0.19168,0.195016,0.300394,0.270556,0.54465,0.597222,0.395548,0.421141,0.175345,0.202633,0.33584,0.325163,0.561219,0.564289,0.558227,0.818092,0.149316,0.324612,0.848479,1.0476,-0.643146,-0.741805,1.14124,1.20229,-0.971619,-0.822069,-0.542122,-0.637885,-1.70673,-1.94983,-1.39577,-1.50209,-0.189089,-0.0476949
1348,0.583021,0.623337,0.306495,0.234812,0.983806,0.990431,0.115128,0.200576,0.695061,0.663324,0.644608,0.621558,0.931344,0.957541,0.832172,0.857446,0.849114,0.840248,0.417795,0.419183,-0.923811,-0.66047,-1.4848,-1.3116,-0.988418,-0.793167,1.35285,1.25726,-0.558805,-0.497638,-1.24277,-1.09898,-0.0522358,-0.145906,-0.616535,-0.853033,0.683666,0.581577,1.26054,1.40151
1349,0.930085,0.927784,0.235628,0.16577,0.94782,0.899542,0.201007,0.206136,0.0563501,0.023692,0.637872,0.645894,0.678804,0.758641,0.995637,1.01891,0.651646,0.642765,0.575355,0.603808,-0.587397,-0.31875,0.330668,0.510213,-1.15763,-0.959582,-0.64868,-0.751413,1.28121,1.34913,0.485768,0.634259,-0.13566,-0.235225,-0.322491,-0.553745,-0.21885,-0.326163,0.316607,0.457545
1350,0.872381,0.90224,0.436549,0.368231,0.802614,0.808653,0.925455,0.929869,0.201757,0.21464,0.96522,0.971031,0.495394,0.559741,0.09921,0.120846,0.905131,0.894508,0.787129,0.788432,-1.38236,-1.10987,-0.717087,-0.531806,0.287671,0.480918,0.17129,0.0720527,1.23698,1.30682,0.695878,0.848621,-0.916069,-1.0176,-1.41933,-1.64696,-0.750397,-0.85875,0.537751,0.673794
1351,0.916494,0.876695,0.988129,0.91999,0.0466836,0.0535169,0.452338,0.457692,0.324739,0.405587,0.710444,0.675456,0.351199,0.36084,0.555725,0.577568,0.456346,0.444711,0.325093,0.327573,0.193986,0.466205,0.968161,1.1512,0.645266,0.83497,-0.277776,-0.347423,1.78202,1.84636,-0.859639,-0.707436,-0.379228,-0.480506,-0.747891,-0.978225,-0.0600707,-0.165351,-1.61791,-1.48271
1352,0.854533,0.85115,0.136461,0.0691121,0.432149,0.499254,0.915625,0.920225,0.629463,0.596535,0.372801,0.379882,0.13802,0.16194,0.154186,0.176547,0.599959,0.589154,0.362528,0.288941,0.926137,1.19187,-0.180618,0.00030531,-1.2752,-1.08577,-0.672907,-0.7669,0.163045,0.223217,-0.14987,-0.00231131,-1.16381,-1.26288,-2.28897,-2.51611,-1.49705,-1.60471,-0.51269,-0.370895
1353,0.136231,0.131689,0.515804,0.44885,0.936222,0.944992,0.943428,0.94818,0.00500516,-0.0285025,0.882546,0.887491,0.673776,0.698341,0.130245,0.246508,0.082745,0.0699133,0.246922,0.25031,-0.16817,0.0937377,0.228616,0.416457,0.411082,0.603154,-0.61436,-0.708514,1.33241,1.39429,0.837106,0.977204,0.942703,0.84632,-0.574084,-0.801311,-0.556838,-0.660769,1.39669,1.54156
1354,0.143851,0.136838,0.224977,0.15869,0.773805,0.783062,0.655055,0.659785,0.573546,0.540238,0.0893542,0.0965373,0.61002,0.539816,0.296033,0.316468,0.0651504,0.0544912,0.671113,0.674598,0.481518,0.744161,1.06672,1.24828,-0.569958,-0.365533,0.0259098,-0.0705698,-0.32642,-0.258231,0.181791,0.324871,-0.126763,-0.216288,0.073959,-0.148085,1.7105,1.60111,-1.06163,-0.920577
1355,0.627707,0.618154,0.185929,0.181032,0.238474,0.249246,0.95969,0.964202,0.23623,0.203029,0.621371,0.628159,0.357346,0.381292,0.943673,0.965955,0.697932,0.685411,0.249317,0.254009,0.0751958,0.256655,-0.743997,-0.562178,-1.52629,-1.33422,-0.396881,-0.491494,-1.03697,-0.972856,1.74942,1.88853,-0.74331,-0.831063,-1.49587,-1.7178,-1.22108,-1.32521,0.867802,1.00716
1356,0.866559,0.854367,0.269617,0.203373,0.268926,0.28097,0.895882,0.901622,0.909043,0.87392,0.246546,0.251335,0.544112,0.56725,0.702946,0.736622,0.0382393,0.0248907,0.844988,0.848228,-0.488066,-0.230851,0.278625,0.453533,0.0764409,0.275733,0.15413,0.05656,0.520547,0.579968,1.67888,1.8108,-0.0468267,-0.139546,0.665228,0.44419,-1.90679,-2.01036,-1.04976,-0.903336
1357,0.610937,0.687199,0.942031,0.878162,0.870151,0.88453,0.57288,0.492022,0.803583,0.767015,0.934121,0.937406,0.304858,0.302679,0.486573,0.507288,0.834958,0.821796,0.605955,0.54895,-0.684639,-0.396113,0.742488,0.915355,-1.65106,-1.45385,1.06064,0.960005,-1.28537,-1.22714,-0.0469429,0.0884962,-0.561969,-0.662722,1.10222,0.881713,-1.31062,-1.41087,1.12076,1.26266
1358,0.527873,0.520032,0.517384,0.45423,0.660194,0.676751,0.0745922,0.0824214,0.265484,0.228861,0.388036,0.478047,0.0168176,0.0381075,0.962116,0.983813,0.0232877,0.00893098,0.245824,0.249672,-0.798174,-0.561375,1.45692,1.62319,0.413684,0.611625,-0.297155,-0.402806,0.187655,0.249642,-1.29749,-1.15994,-0.132163,-0.230727,0.521231,0.292779,-0.155539,-0.1643,-0.0875882,0.0585889
1359,0.367164,0.352864,0.933202,0.869339,0.0290839,0.0480412,0.863389,0.872438,0.472254,0.346487,0.0176403,0.0186884,0.540769,0.560403,0.898609,0.91806,0.945075,0.928065,0.461723,0.371751,-0.983454,-0.726637,1.65235,1.82516,0.933495,1.13266,-0.819685,-0.930901,-2.06862,-2.00877,2.47253,2.61107,-0.45827,-0.551758,0.295504,0.0729859,1.18251,1.08227,1.47758,1.61834
1360,0.549947,0.533389,0.981899,0.917372,0.442397,0.461193,0.992871,1.00197,0.502865,0.464113,0.164113,0.163673,0.79433,0.812567,0.0967335,0.1168,0.247685,0.23191,0.491606,0.49383,-0.227281,0.0310022,0.588058,0.767324,0.287361,0.457131,-3.06937,-3.17677,-0.547249,-0.486208,0.163686,0.309425,-1.98697,-2.08402,-0.998736,-1.22288,0.919366,0.805448,-0.437013,-0.292154
1361,0.296111,0.280472,0.744131,0.591471,0.305217,0.324494,0.581334,0.608048,0.176564,0.136951,0.711958,0.709759,0.0852811,0.105352,0.452421,0.43943,0.52239,0.508181,0.417033,0.437628,-0.325486,-0.0708339,0.52794,0.708177,-0.425018,-0.218394,-0.814125,-0.917054,-0.765233,-0.699308,-0.738928,-0.588115,-1.1385,-1.24154,-0.121083,-0.340886,0.630873,0.52863,-1.48508,-1.3409
1362,0.577584,0.562168,0.386529,0.26557,0.532106,0.550094,0.20548,0.214129,0.992981,0.953638,0.950032,0.849897,0.214546,0.235872,0.744079,0.762059,0.189619,0.174346,0.378108,0.381425,-1.63009,-1.38087,1.27316,1.44782,0.0196696,0.226933,-0.059198,-0.16845,0.509583,0.57962,-0.730793,-0.573749,0.453565,0.345853,-1.14403,-1.35899,0.868079,0.767933,0.503624,0.646628
1363,0.187135,0.172345,0.00419647,-0.0603303,0.495958,0.494263,0.123564,0.131099,0.124179,0.0863213,0.993773,0.990035,0.0017291,0.0255026,0.679189,0.696306,0.12197,0.108553,0.650891,0.654595,-1.73208,-1.48271,-0.749235,-0.583054,0.00901163,0.212187,-0.137958,-0.249053,0.598704,0.661806,-1.15687,-1.00488,1.28257,1.17339,0.571489,0.355806,-0.222995,-0.323018,0.204961,0.352627
1364,0.771319,0.757974,0.131456,0.0677918,0.38119,0.438431,0.39898,0.406353,0.93267,0.89322,0.565412,0.559315,0.27184,0.362345,0.86096,0.877428,0.757467,0.745786,0.593994,0.596258,1.38701,1.64107,-0.42639,-0.258219,0.512955,0.71571,0.27106,0.159925,0.963584,1.02015,0.205388,0.357029,0.39186,0.28159,-0.544066,-0.753697,-0.301081,-0.406177,2.68474,2.82785
1365,0.548482,0.534416,0.777876,0.712506,0.364612,0.3826,0.154027,0.163221,0.315764,0.278793,0.97727,0.973889,0.677461,0.699187,0.0621195,0.0761684,0.449729,0.429303,0.0868265,0.0905815,0.315935,0.4849,-0.324217,-0.151293,1.54703,1.74623,-0.905017,-1.01909,-1.06511,-1.01426,-1.26206,-1.10812,0.765749,0.650119,0.148565,-0.0546102,0.310562,0.209399,-1.60911,-1.46233
1366,0.0259106,0.0137749,0.532903,0.466365,0.564766,0.625053,0.255186,0.262444,0.600529,0.566065,0.541462,0.537861,0.505694,0.529508,0.805541,0.818563,0.124281,0.11282,0.645123,0.649455,-0.920158,-0.671273,0.536838,0.709292,0.873049,1.07071,1.23059,1.12436,-0.339927,-0.288585,0.51886,0.671885,-0.43356,-0.552061,-1.77845,-1.98332,0.666094,0.560416,-0.440309,-0.288445
1367,0.763549,0.75153,0.787357,0.722979,0.850869,0.867506,0.66106,0.619397,0.235864,0.202637,0.327172,0.32408,0.759429,0.781672,0.976876,0.989757,0.892114,0.879226,0.0742954,0.0782811,-1.61657,-1.36789,-0.308464,-0.08616,0.200519,0.395184,-1.13594,-1.23627,1.83436,1.88029,-0.517791,-0.36095,-0.513661,-0.627373,-0.674674,-0.886523,-0.688735,-0.799863,-0.386488,-0.235612
1368,0.485026,0.472533,0.521213,0.456734,0.00956134,0.0270521,0.968027,0.97635,0.610341,0.575946,0.660786,0.658503,0.093837,0.114901,0.720904,0.732937,0.822507,0.749063,0.407895,0.411906,0.934036,1.18543,-1.06027,-0.881612,0.0349701,0.226195,-0.208064,-0.302881,0.135922,0.180366,-1.10812,-0.949479,-0.307175,-0.414538,-0.691047,-0.909789,-0.135202,-0.24522,-1.07087,-0.921035
1369,0.784384,0.769844,0.626784,0.560738,0.727142,0.743039,0.267141,0.273593,0.440549,0.405327,0.753291,0.680109,0.338756,0.361187,0.711865,0.719756,0.632967,0.618901,0.196303,0.20111,-0.0623588,0.19518,1.58558,1.75778,-0.136547,0.0572051,1.29126,1.19076,-0.398735,-0.351672,-0.853881,-0.691041,-1.316,-1.41634,0.356827,0.141449,0.12691,0.010085,-0.397773,-0.248613
1370,0.0292358,0.0145443,0.019978,-0.0450825,0.60176,0.658856,0.44793,0.486044,0.562909,0.529723,0.703455,0.701715,0.990541,1.01395,0.693361,0.706574,0.718641,0.685214,0.839846,0.844455,0.137931,0.398451,1.67231,1.85028,1.04357,1.23906,-1.42766,-1.52227,0.97347,1.01664,0.431488,0.594656,-0.0554751,-0.155176,1.03132,0.810186,-0.827169,-0.944538,0.973469,1.12359
1371,0.858116,0.843112,0.984309,0.918158,0.560221,0.574672,0.690383,0.698495,0.22073,0.186148,0.485022,0.483192,0.470697,0.563347,0.00400168,0.0195363,0.766788,0.751527,0.664656,0.669122,-2.20419,-1.93797,0.492984,0.669204,-0.967696,-0.773159,-0.0966454,-0.187932,-1.03101,-0.981612,-0.485634,-0.317683,0.881813,0.781691,2.16646,1.95155,-0.212501,-0.328962,-1.10839,-0.956073
1372,0.730151,0.714555,0.976389,0.868108,0.0358082,0.0512492,0.510863,0.520829,0.890301,0.857039,0.846286,0.843285,0.0897957,0.112748,0.638533,0.654476,0.30078,0.286642,0.0756261,0.0784607,-1.91322,-1.63852,0.872887,0.968977,0.687027,0.883453,0.616914,0.528276,2.64105,2.68371,1.66229,1.83717,0.287728,0.184215,0.964299,0.662825,-0.0348298,-0.15117,1.30232,1.45144
1373,0.332442,0.318405,0.886604,0.818058,0.987632,1.00003,0.643785,0.567596,0.528988,0.493611,0.53306,0.529524,0.200568,0.222759,0.63064,0.644481,0.166264,0.154147,0.31588,0.317208,1.28249,1.56415,1.09637,1.26875,0.774566,0.973664,-0.962505,-1.05011,-1.79373,-1.75492,1.75216,1.92857,-0.887451,-0.988165,-0.417567,-0.625905,-0.533624,-0.65246,-1.67163,-1.51572
1374,0.239789,0.226341,0.535613,0.46834,0.872724,0.912779,0.604274,0.614364,0.664124,0.709141,0.603543,0.600572,0.918082,0.941838,0.182955,0.198169,0.330372,0.319024,0.076593,0.0775529,-0.177414,0.100174,0.540113,0.719111,1.81687,2.01704,-0.727937,-0.821625,-1.10511,-1.06044,1.11035,1.29303,0.842006,0.738075,1.00718,0.793784,-1.31343,-1.4315,-0.530396,-0.373137
1375,0.812004,0.797801,0.429378,0.336199,0.92248,0.825528,0.958692,0.968255,0.959104,0.92467,0.262063,0.257823,0.122699,0.14903,0.135591,0.151651,0.862365,0.848617,0.806983,0.806016,-0.00519607,0.273708,-1.28823,-1.10796,1.08777,1.29144,2.07262,1.97898,1.09341,1.14256,1.03997,1.21529,-1.11034,-1.21762,-0.12383,-0.263944,0.802929,0.686424,-1.8902,-1.73024
1376,0.101678,0.0900412,0.373578,0.204058,0.723716,0.738278,0.393306,0.404519,0.576303,0.540982,0.859189,0.853611,0.583224,0.610339,0.593062,0.547483,0.580584,0.565335,0.991897,0.993208,-0.475945,-0.191609,0.513966,0.696421,-2.32342,-2.12322,1.81533,1.72726,-0.434372,-0.388587,0.104438,0.266192,-3.28444,-3.39268,-1.10828,-1.32167,0.815961,0.695737,-0.758473,-0.602882
1377,0.194652,0.125173,0.139583,0.0719171,0.4718,0.484759,0.525572,0.556909,0.995028,0.958486,0.982221,0.978516,0.584863,0.689743,0.92827,0.943315,0.0690853,0.0556363,0.752168,0.675404,0.356017,0.639647,1.19545,1.37478,-0.506604,-0.306336,-1.85857,-1.94622,-0.422823,-0.38275,-0.86115,-0.68291,-0.202416,-0.315392,2.62362,2.41022,-0.214318,-0.333864,-0.380446,-0.221854
1378,0.232136,0.160305,0.470452,0.402783,0.631366,0.646028,0.698085,0.709298,0.175698,0.142261,0.669896,0.664756,0.743866,0.769148,0.918418,0.933319,0.925378,0.911382,0.356189,0.3576,-0.996767,-0.715703,-0.42148,-0.245201,-0.364793,-0.168471,1.04234,0.96388,1.38445,1.43155,-0.154737,0.0222154,0.148634,0.038461,0.366596,0.159258,-0.696615,-0.818379,-0.707463,-0.547444
1379,0.204093,0.195436,0.0259199,-0.0405899,0.48381,0.499036,0.203897,0.216587,0.264812,0.327772,0.0511279,0.0445839,0.053713,0.0772229,0.388534,0.402271,0.720953,0.708576,0.791665,0.792233,-0.718987,-0.419696,-0.103795,0.171592,-0.551017,-0.350319,-1.52676,-1.60604,0.77403,0.820931,-0.861169,-0.689161,0.224407,0.116471,0.298824,0.0912155,2.32734,2.20357,1.97318,2.13704
1380,0.0660737,0.0576288,0.552501,0.392604,0.0676773,0.0846104,0.791056,0.803893,0.547535,0.513283,0.475237,0.468195,0.371448,0.394421,0.694228,0.708857,0.133042,0.119528,0.326866,0.326277,-0.411949,-0.123689,0.372132,0.588385,1.99556,2.19537,0.148455,0.0770064,-0.286634,-0.176435,-0.368923,-0.136682,-2.07907,-2.18809,-0.209132,-0.419885,-0.941691,-1.0661,1.17068,1.3299
1381,0.981169,0.971086,0.893092,0.825797,0.742997,0.759821,0.122041,0.136325,0.476202,0.442643,0.599955,0.5931,0.206088,0.230603,0.642332,0.657567,0.226596,0.267725,0.652138,0.630302,-0.364446,-0.0730187,0.828899,1.00518,-1.41712,-1.21929,0.00078867,-0.0648992,-1.22245,-1.1738,0.243405,0.415796,2.05998,1.94599,1.68279,1.47829,1.57288,1.44126,0.689705,0.85444
1382,0.52742,0.515988,0.401926,0.332883,0.347469,0.364737,0.934979,0.947669,0.0842998,0.0490767,0.225447,0.216275,0.570286,0.593064,0.834897,0.849197,0.495285,0.415923,0.937475,0.934327,-0.563887,-0.278473,1.61863,1.79352,-1.92817,-1.72292,0.773934,0.713387,-0.825125,-0.770249,-1.37145,-1.20073,-1.10409,-1.22121,-0.405413,-0.606662,0.486203,0.350309,2.04769,2.2131
1383,0.364629,0.389521,0.953165,0.884642,0.261424,0.26754,0.928106,0.940886,0.977467,0.945307,0.929718,0.922798,0.320266,0.342241,0.0262128,0.0418933,0.703218,0.56412,0.903484,0.900308,-1.61601,-1.3297,-0.852996,-0.681284,0.105567,0.311014,0.338834,0.276122,0.943896,0.997244,0.0798716,0.251089,1.11996,0.997489,0.0893295,-0.106759,-1.58453,-1.72709,0.397691,0.566575
1384,0.276647,0.263053,0.622322,0.567882,0.153215,0.170343,0.566254,0.5788,0.856771,0.823461,0.590194,0.585162,0.303977,0.324479,0.108124,0.122665,0.725832,0.712318,0.197332,0.192444,0.560747,0.845329,1.33837,1.50606,-1.49625,-1.29384,-0.450655,-0.59817,0.750326,0.798431,-1.63771,-1.47121,1.23085,1.10579,0.0590184,-0.130024,1.35323,1.21003,0.20646,0.377285
1385,0.451776,0.372251,0.315058,0.251121,0.316347,0.237243,0.444191,0.456668,0.163246,0.127617,0.0212392,0.0153896,0.967002,0.987689,0.721031,0.737578,0.788418,0.775208,0.132705,0.128169,-0.25202,0.0388988,0.485124,0.650159,-0.242261,-0.0369924,-1.4024,-1.47246,-0.159404,-0.116382,0.883402,1.05393,-2.56665,-2.69514,-0.288135,-0.472489,-0.140598,-0.277774,-0.350818,-0.175699
1386,0.496214,0.481449,0.0011097,-0.0656401,0.282968,0.304143,0.988517,0.999556,0.868422,0.833335,0.300525,0.201454,0.965026,0.98597,0.524555,0.540628,0.434404,0.487376,0.9434,0.936711,-0.834536,-0.550501,-1.26977,-1.11236,-0.755248,-0.557207,-0.580164,-0.695335,-0.0237432,0.0253579,-1.1931,-1.02616,0.7327,0.609233,1.27631,1.0997,0.704727,0.573761,-1.94565,-1.77587
1387,0.932875,0.919465,0.783724,0.715455,0.354153,0.371044,0.0342173,0.0449221,0.974283,0.937133,0.391983,0.387519,0.742797,0.764809,0.628553,0.646965,0.212405,0.199544,0.630165,0.625318,-0.369007,-0.0475381,-1.15947,-1.00544,-0.31171,-0.11188,0.158689,0.0817913,-0.668057,-0.614836,-0.900592,-0.73692,-1.26281,-1.39432,1.07155,0.894656,-1.13118,-1.26337,-1.3549,-1.27471
1388,0.445769,0.432871,0.490131,0.420143,0.165049,0.278068,0.939652,0.949232,0.303666,0.26743,0.247222,0.243911,0.305337,0.421294,0.339521,0.360018,0.87131,0.857856,0.0340071,0.0297418,0.170566,0.455425,-0.184436,-0.0355697,0.993818,1.19118,-0.0115373,-0.0917045,1.10071,1.15266,0.0593833,0.226603,-0.808614,-0.947416,-0.783158,-0.95857,-0.157127,-0.289898,-0.936663,-0.773558
1389,0.270346,0.28484,0.783775,0.654535,0.167783,0.185093,0.570092,0.546101,0.798722,0.760691,0.360626,0.344991,0.0553777,0.0777795,0.93632,0.958308,0.730961,0.719453,0.785212,0.778007,-1.34144,-1.05409,-2.40986,-2.25487,1.41216,1.60647,-1.20186,-1.28729,0.909457,0.953844,0.550439,0.718004,-1.10332,-1.23699,1.12038,0.939607,0.227256,0.179392,-0.834824,-0.67744
1390,0.150233,0.136808,0.957857,0.888927,0.755675,0.773463,0.134901,0.142971,0.344232,0.307301,0.456556,0.446072,0.677179,0.699303,0.0366744,0.0602423,0.797805,0.787877,0.0431315,0.0349166,0.715429,0.997854,0.502099,0.662466,-1.23899,-1.054,1.27303,1.19336,0.229756,0.270817,0.465654,0.640267,0.781669,0.647723,0.272724,0.091342,0.782998,0.648681,0.00244322,0.159861
1391,0.866342,0.852692,0.579136,0.510137,0.151126,0.169082,0.886768,0.895568,0.271716,0.236661,0.549537,0.547153,0.532756,0.554366,0.576444,0.598014,0.329206,0.318361,0.317295,0.353541,-1.98875,-1.70156,1.02198,1.1865,0.67447,0.853606,0.149447,0.0755476,-0.713333,-0.677261,0.593022,0.762782,1.94116,1.8032,-0.17316,-0.358015,-0.858637,-0.995327,1.70621,1.87211
1392,0.936504,0.879275,0.782538,0.712598,0.223756,0.240201,0.408892,0.495071,0.949358,0.913344,0.238553,0.23811,0.866981,0.886795,0.134243,0.156435,0.354844,0.361118,0.759855,0.672165,-1.15772,-0.870309,1.23468,1.40483,-0.372123,-0.196922,0.292295,0.226304,0.949155,0.982121,-1.48248,-1.3173,-1.69511,-1.83494,-0.144487,-0.335037,2.01542,1.87871,-0.171469,-0.00518278
1393,0.918602,0.905859,0.240853,0.170882,0.838181,0.853809,0.0862033,0.0945742,0.421812,0.384882,0.751469,0.750922,0.914594,0.935289,0.762235,0.786658,0.41642,0.403875,0.999005,0.99079,1.78237,2.06162,0.762939,0.933031,-0.0046531,0.170544,0.0753183,-0.00328805,-1.2782,-1.24385,1.21736,1.38894,-0.24821,-0.387984,-0.788341,-0.985971,0.0746583,-0.0538586,-1.07388,-0.902974
1394,0.0350082,0.0217497,0.694228,0.625238,0.339123,0.354114,0.753225,0.76062,0.366458,0.297585,0.346959,0.344779,0.521313,0.543951,0.260612,0.28539,0.847172,0.834332,0.0602076,0.0528528,0.205125,0.489627,-1.06626,-0.894044,1.4251,1.59488,-0.166889,-0.23288,1.64524,1.68512,-0.412152,-0.241107,1.51463,1.36824,0.303531,0.110827,-0.643466,-0.769613,-1.5837,-1.40946
1395,0.172206,0.191269,0.201141,0.132323,0.668719,0.681874,0.490097,0.497181,0.247137,0.210288,0.191747,0.191823,0.773914,0.796115,0.751819,0.776675,0.755019,0.705676,0.275053,0.305036,0.345021,0.632301,-0.627231,-0.448131,1.47559,1.63966,0.309801,0.236326,1.2203,1.25699,-0.0134082,0.132575,-1.70878,-1.85961,0.0970223,-0.0942211,-1.90408,-2.03369,0.271918,0.443096
1396,0.284482,0.360788,0.72833,0.660077,0.374835,0.387904,0.86824,0.875494,0.574931,0.537661,0.274432,0.272645,0.0821189,0.10419,0.180153,0.205659,0.554624,0.57702,0.565611,0.557219,-0.767292,-0.481357,0.0463034,0.230229,0.792872,0.929141,-0.918175,-0.989617,-0.313061,-0.274159,0.338215,0.506257,-0.270318,-0.427198,-2.0088,-2.19566,-0.201119,-0.344157,0.139912,0.212279
1397,0.543716,0.530307,0.146054,0.0790434,0.953668,0.966048,0.021442,0.0269551,0.492355,0.457491,0.63893,0.636964,0.562858,0.586439,0.465034,0.493459,0.421113,0.448364,0.321922,0.311908,0.756195,1.04801,-0.413368,-0.226547,0.0533517,0.218619,-0.207984,-0.273409,-0.474729,-0.441985,1.54984,1.71655,0.028337,-0.134902,-1.32398,-1.51235,1.47498,1.34537,-0.183308,-0.0185379
1398,0.00197179,-0.0107909,0.340944,0.271823,0.435956,0.447256,0.790232,0.795839,0.881318,0.845793,0.292511,0.28978,0.836056,0.857636,0.753141,0.781258,0.332548,0.319708,0.355416,0.285773,-1.04887,-0.758527,-1.56897,-1.37744,1.35657,1.52168,0.758582,0.690518,0.00789373,0.036099,-1.691,-1.51914,0.733037,0.57214,0.119566,-0.064837,0.963679,0.828855,0.144185,0.304338
1399,0.03166,0.01964,0.258071,0.188492,0.783659,0.707394,0.991156,0.997298,0.733156,0.699384,0.812512,0.811273,0.843446,0.868304,0.78658,0.853901,0.914733,0.899524,0.393146,0.259638,0.691185,0.987025,0.572191,0.763588,-0.615212,-0.443397,-1.00561,-1.07697,-0.159975,-0.131726,0.514606,0.682412,-0.681052,-0.849799,-0.426897,-0.606363,1.59351,1.46017,-1.23632,-1.08357
1400,0.614815,0.601036,0.852701,0.784797,0.954953,0.967532,0.56842,0.603379,0.954917,0.920064,0.251997,0.252425,0.857187,0.878972,0.897716,0.926545,0.81293,0.720608,0.244262,0.233503,-0.659313,-0.368324,0.547432,0.735517,0.737765,0.90593,-0.100147,-0.173521,-1.57707,-1.55434,0.429646,0.604675,-0.233784,-0.402899,0.670924,0.490435,1.15526,1.02027,-0.618227,-0.472845
1401,0.151077,0.135216,0.752044,0.781552,0.35695,0.368197,0.205447,0.20946,0.0287513,-0.00830677,0.964308,0.963488,0.383908,0.474763,0.153046,0.1808,0.592532,0.541692,0.87163,0.863034,-0.585143,-0.287194,1.06567,1.25955,1.06963,1.24371,-1.78511,-1.86423,1.1014,1.12238,-1.61313,-1.44407,-1.53746,-1.69985,-0.861219,-1.04745,-2.4229,-2.55794,-1.0044,-0.857884
1402,0.610731,0.592899,0.849463,0.778306,0.198652,0.211524,0.894216,0.897194,0.315705,0.278965,0.919708,0.92152,0.0503382,0.0705536,0.190468,0.253443,0.320852,0.362776,0.488024,0.510803,-3.09446,-2.80163,-0.69774,-0.502969,-0.659562,-0.485877,0.368552,0.291124,0.592021,0.618257,0.25264,0.425504,-0.512799,-0.672708,1.47506,1.29359,1.06429,0.933341,2.63687,2.78641
1403,0.382257,0.364245,0.546714,0.460612,0.486503,0.401863,0.447359,0.451302,0.102485,0.0671688,0.0305964,0.0319119,0.00791735,0.0271896,0.298293,0.326086,0.199069,0.18386,0.169398,0.158572,-0.658357,-0.360257,-0.00868644,0.189234,0.10538,0.282812,-0.363967,-0.391913,-0.757957,-0.73055,0.634477,0.808395,0.0453842,-0.118558,0.393895,0.214209,0.726299,0.602386,-0.21576,-0.0694353
1404,0.452888,0.434978,0.21375,0.142919,0.579742,0.592202,0.855081,0.860674,0.174904,0.12414,0.0721177,0.0285057,0.721445,0.740364,0.883398,0.909499,0.844428,0.830808,0.325194,0.315834,-0.00139928,0.290166,-0.915062,-0.712915,0.0908737,0.268067,-0.995553,-1.07495,-1.30556,-1.27933,-0.589806,-0.422161,0.911519,0.755968,-1.71133,-1.88723,-0.385386,-0.504886,-0.312968,-0.167199
1405,0.729952,0.711656,0.790599,0.718683,0.0490796,0.0637284,0.878297,0.883264,0.217346,0.181112,0.024007,0.0250994,0.747313,0.744751,0.0336667,0.0596372,0.158894,0.145369,0.76629,0.755129,-0.213431,0.084712,1.30494,1.50978,0.386929,0.560139,-0.816076,-0.893894,-0.0561136,-0.0302236,0.294532,0.46619,1.50878,1.35566,-0.692258,-0.864398,0.441943,0.329429,0.847565,0.991857
1406,0.142256,0.125468,0.145966,0.0729769,0.523473,0.537323,0.123368,0.130602,0.592549,0.55442,0.786402,0.786788,0.728359,0.749137,0.849048,0.873546,0.830065,0.818158,0.00282102,-0.00797519,-0.801746,-0.504688,0.336387,0.512565,-1.83827,-1.66287,-0.196992,-0.271852,0.254122,0.279151,0.800706,0.897706,0.732523,0.573292,-0.166509,-0.333331,2.12685,2.01062,-2.48103,-2.33817
1407,0.107314,0.0890972,0.372314,0.300219,0.422459,0.435511,0.54726,0.554864,0.444207,0.408011,0.0313704,0.0323529,0.242517,0.262834,0.0671366,0.0920059,0.320449,0.308459,0.942812,0.933175,0.258705,0.5572,-0.685859,-0.484651,-0.156081,0.026059,-0.786397,-0.863096,-1.46838,-1.4371,1.16304,1.32922,-0.655063,-0.815374,-0.907574,-1.07684,1.59497,1.47803,0.860309,0.997597
1408,0.968442,0.949974,0.389338,0.342871,0.321689,0.3337,0.300754,0.30693,0.051937,0.0144456,0.47045,0.470709,0.669472,0.689465,0.481823,0.508574,0.124405,0.110975,0.905555,0.894657,0.340783,0.705276,0.699358,0.901702,-1.40486,-1.2241,-2.1915,-2.27473,-0.715568,-0.681542,0.731409,0.898095,1.29838,1.12978,0.695749,0.527295,0.402744,0.289542,-1.09233,-0.959992
1409,0.131947,0.113078,0.45679,0.385523,0.691418,0.70102,0.74135,0.745597,0.299772,0.261171,0.168248,0.16701,0.574953,0.595608,0.167888,0.196497,0.266958,0.255419,0.427735,0.418546,0.553168,0.853353,1.00493,1.21158,-1.80777,-1.62089,-0.259039,-0.338215,0.70272,0.733856,1.25394,1.42025,-1.60336,-1.77133,0.459169,0.29144,0.682424,0.576275,-0.36536,-0.239364
1410,0.128038,0.108435,0.746287,0.676391,0.777418,0.695818,0.0298964,0.0327061,0.272133,0.231557,0.540345,0.449821,0.229734,0.323463,0.867648,0.897574,0.200575,0.189626,0.662395,0.651325,-2.12827,-1.83162,0.27297,0.479572,0.597987,0.783687,-1.10516,-1.17781,0.123822,0.154095,-0.0426098,0.149299,1.96408,1.79883,2.07257,1.91011,0.625585,0.523156,0.343899,0.481265
1411,0.892666,0.872806,0.382294,0.339779,0.681765,0.690615,0.839789,0.84405,0.985305,0.943503,0.732226,0.732632,0.0325583,0.0513179,0.891329,0.837731,0.363877,0.40099,0.0982062,0.0857329,-0.0388753,0.264321,0.287788,0.495656,-0.423027,-0.235912,1.06883,0.994483,-1.33778,-1.31457,-1.28796,-1.12165,-1.30155,-1.4626,-0.526148,-0.682197,-1.43021,-1.5377,0.404328,0.549489
1412,0.606931,0.588758,0.0712532,0.00316747,0.989928,0.997646,0.543992,0.546466,0.721048,0.681199,0.887735,0.887422,0.502669,0.522999,0.745926,0.777888,0.537679,0.612354,0.804209,0.790159,0.196604,0.499135,-0.962087,-0.747264,0.493698,0.619058,-0.621224,-0.696227,-2.02863,-1.9976,0.527904,0.688622,0.151098,-0.0156492,0.0604606,-0.0916016,-0.0701707,-0.182216,0.863603,1.00692
1413,0.0388291,0.0227947,0.120319,0.0512004,0.319954,0.328523,0.637881,0.640138,0.076402,0.0369273,0.785131,0.783829,0.256025,0.272422,0.23437,0.266618,0.832387,0.823718,0.268214,0.254318,-0.736128,-0.43011,-0.228104,-0.00762493,1.28691,1.47403,1.52239,1.44722,1.71674,1.75056,-0.496051,-0.340708,0.0953204,-0.075444,0.375231,0.225602,0.25197,0.226332,0.039199,0.185155
1414,0.232868,0.218765,0.816486,0.74597,0.019986,0.0293401,0.21482,0.218786,0.0792661,0.105289,0.480507,0.480129,0.00272927,0.0218456,0.432024,0.463296,0.560803,0.468447,0.211544,0.19598,-0.30307,0.00413697,-0.229681,-0.102834,1.25184,1.44455,-0.225694,-0.306809,0.823122,0.850824,-1.53522,-1.37004,-0.605119,-0.780627,0.0214428,-0.133334,0.745797,0.634879,0.1401,0.281273
1415,0.16727,0.135706,0.301952,0.233129,0.53887,0.548246,0.897084,0.900984,0.212051,0.173651,0.7647,0.764232,0.710103,0.729937,0.20136,0.231006,0.124684,0.113177,0.374188,0.357744,-0.898862,-0.585263,-0.42126,-0.198043,-0.541087,-0.348548,0.0228289,-0.0647066,0.364807,0.392138,0.334207,0.499535,0.999926,0.821645,-1.07558,-1.22655,-1.57098,-1.68415,-0.155729,-0.0127279
1416,0.0683144,0.0526462,0.123584,0.0532309,0.09706,0.103755,0.351606,0.357417,0.443019,0.309286,0.297841,0.298695,0.363313,0.384714,0.526639,0.543969,0.235765,0.149389,0.892269,0.877332,0.503996,0.818251,-0.687343,-0.457014,-1.22385,-1.02704,1.33598,1.25351,1.36699,1.39399,1.52697,1.69454,-0.240373,-0.411279,0.0513458,-0.0976388,0.226382,0.120335,-0.7652,-0.625228
1417,0.484787,0.470711,0.806934,0.737859,0.487956,0.490039,0.738618,0.746187,0.484714,0.444921,0.163396,0.164779,0.994049,1.01588,0.827371,0.856931,0.194224,0.185601,0.0819784,0.0677269,0.157995,0.476294,1.08187,1.31902,0.356392,0.553354,-0.545258,-0.625002,2.61984,2.6431,0.433078,0.656454,0.546829,0.372424,0.870309,0.723413,-0.711106,-0.819258,-1.73812,-1.59836
1418,0.683257,0.666681,0.0456011,-0.0235412,0.870579,0.876324,0.678993,0.640889,0.29622,0.22668,0.349673,0.349562,0.341554,0.363634,0.630986,0.659981,0.584162,0.584751,0.398274,0.378122,0.0880664,0.490858,1.89881,2.13404,-0.304239,-0.10864,-1.91152,-1.98781,0.434402,0.462974,-0.542459,-0.381633,-0.04107,-0.21253,1.08387,0.931017,-0.454673,-0.563954,-0.711321,-0.576908
1419,0.141342,0.125584,0.609032,0.538432,0.102274,0.107077,0.527728,0.535591,0.0464175,0.00843947,0.923736,0.925631,0.230383,0.254404,0.914013,0.941013,0.991485,0.983901,0.700566,0.688516,0.18323,0.505423,1.33545,1.56882,-0.0181051,0.183432,-0.290276,-0.366181,-0.950053,-0.916276,-0.281553,-0.123195,1.60258,1.43586,0.920802,0.773057,0.909778,0.804128,-0.0974675,0.0338204
1420,0.907386,0.889955,0.478809,0.409299,0.645839,0.649977,0.656844,0.725409,0.185356,0.148204,0.508458,0.509726,0.793502,0.815917,0.86509,0.889722,0.554406,0.549164,0.811584,0.799344,-0.122795,0.193891,-0.338663,-0.0994308,-1.24836,-1.05286,0.19592,0.145977,-0.344606,-0.315293,-1.04338,-0.882204,-0.907674,-1.07237,-0.269481,-0.412164,-0.360301,-0.459944,-0.0242704,0.102045
1421,0.230527,0.212143,0.10243,0.0346874,0.333037,0.335448,0.906469,0.915227,0.724697,0.68709,0.459423,0.514832,0.698138,0.72206,0.490916,0.470774,0.928611,0.924974,0.0390143,0.0264603,0.786597,1.10263,0.242571,0.486331,-0.387297,-0.19256,0.731209,0.658136,1.79057,1.82028,-0.458053,-0.29887,-0.27226,-0.339719,1.69236,1.551,-0.964821,-1.09132,-2.38128,-2.25136
1422,0.248754,0.205974,0.866554,0.799889,0.78898,0.788957,0.660508,0.697759,0.223737,0.183853,0.530767,0.519939,0.0309517,0.0552885,0.0266475,0.0518265,0.871601,0.816519,0.18202,0.168985,-0.172201,0.143725,1.05454,1.30136,0.164101,0.3594,0.466349,0.391444,1.2847,1.31615,1.98772,2.14679,0.549122,0.392928,1.85937,1.71313,-1.62062,-1.72269,-0.105052,0.0249298
1423,0.219152,0.199805,0.224203,0.159592,0.557894,0.548815,0.397505,0.480291,0.203626,0.164889,0.523777,0.525045,0.639049,0.662046,0.791827,0.819069,0.710412,0.708065,0.723028,0.708378,1.40068,1.7198,-0.141351,0.104852,-0.730905,-0.535035,-0.831295,-0.911301,1.90316,1.93326,0.871685,1.03719,1.48447,1.3298,-0.993877,-1.13709,-0.0689617,-0.169767,-0.248018,-0.117805
1424,0.652955,0.632768,0.945379,0.880311,0.308463,0.308672,0.251968,0.262823,0.548138,0.46567,0.0134071,0.0151779,0.300422,0.32201,0.198079,0.223251,0.978194,0.974691,0.437084,0.422935,-0.432053,-0.115513,-0.849327,-0.59629,-0.017387,0.17175,0.211625,0.129994,-0.484185,-0.453702,1.48501,1.65141,-1.48585,-1.64026,0.711164,0.560344,-1.40851,-1.51633,-0.180308,-0.0495807
1425,0.225699,0.207144,0.887807,0.760235,0.372108,0.370853,0.97905,0.99079,0.806554,0.766451,0.068853,0.070781,0.688326,0.708762,0.859564,0.883276,0.720252,0.715881,0.608532,0.580274,0.385975,0.700809,-0.707015,-0.456582,1.27945,1.47481,-0.421275,-0.506012,0.801432,0.825227,-1.76381,-1.601,0.186463,0.0386179,-1.0551,-1.2107,0.534271,0.431781,-1.60468,-1.46694
1426,0.0913529,0.0971346,0.796166,0.640158,0.796619,0.795021,0.622994,0.55155,0.850272,0.808631,0.694376,0.696238,0.1479,0.166498,0.337643,0.362178,0.947822,0.942488,0.835784,0.737613,-0.654752,-0.335341,0.200906,0.406189,0.182791,0.378095,-0.0336019,-0.111952,-1.40888,-1.38597,1.30571,1.46765,0.0755363,-0.0669233,-0.112174,-0.265198,-0.914517,-1.02298,-2.05364,-1.91279
1427,0.00790594,-0.0128746,0.585149,0.520082,0.559,0.643362,0.0985107,0.11231,0.293922,0.250086,0.478594,0.482457,0.558162,0.578025,0.0721811,0.0951226,0.823793,0.869726,0.906363,0.894953,2.28804,2.60965,1.01853,1.26896,-0.0842394,0.104359,-1.00066,-1.07501,0.77453,0.800654,2.65818,2.81396,1.16169,1.02103,0.0619858,-0.0888067,0.179383,0.0766706,0.0522608,0.185014
1428,0.861796,0.839239,0.847782,0.780951,0.491177,0.491703,0.73312,0.745003,0.0760075,0.0330279,0.99982,1.00395,0.428037,0.448329,0.847817,0.872916,0.759856,0.796963,0.23056,0.218866,-1.31535,-0.988233,0.244968,0.488051,1.05786,1.2412,-0.31993,-0.297889,0.958003,0.990814,-0.750722,-0.600342,2.699,2.55899,-0.966294,-1.12049,-0.531874,-0.639084,0.71055,0.842067
1429,0.69123,0.667241,0.589725,0.524897,0.0123322,0.0120013,0.416476,0.501395,0.925968,0.884326,0.599181,0.602385,0.962144,0.979482,0.617842,0.593592,0.729486,0.7242,0.274805,0.308734,-1.56591,-1.23865,0.607212,0.843246,2.4846,2.66553,0.546748,0.479238,1.14801,1.18098,0.512568,0.654923,1.60422,1.46659,0.123528,-0.0236936,0.160401,0.0543149,0.653325,0.871183
1430,0.257662,0.23144,0.689956,0.623828,0.00256092,0.00347084,0.2443,0.257786,0.256126,0.214623,0.748224,0.752181,0.113251,0.129367,0.291119,0.314269,0.919365,0.914696,0.370916,0.398601,-0.456527,-0.131139,-0.56062,-0.322804,-0.497027,-0.321888,-0.697856,-0.76281,-0.393894,-0.362396,-0.0889522,0.0509902,-0.837939,-0.980447,2.06961,1.92327,1.94272,1.84128,0.763026,0.900298
1431,0.947171,0.92216,0.456609,0.389326,0.932792,0.934349,0.435253,0.448364,0.674259,0.632127,0.404261,0.409432,0.0272146,0.117523,0.283297,0.304273,0.092366,0.0862607,0.500163,0.488469,0.25824,0.578156,-0.246799,-0.0129214,-0.817063,-0.644081,1.94259,1.88205,-0.765192,-0.729359,-0.257341,-0.117797,1.0187,0.87241,-0.359608,-0.511869,1.82834,1.72767,0.987506,1.11655
1432,0.281286,0.255904,0.771205,0.705759,0.370568,0.370091,0.883067,0.896594,0.0971878,0.0535585,0.532212,0.53913,0.088681,0.10568,0.0551675,0.0773124,0.646723,0.641475,0.327843,0.318289,-0.0144159,0.3116,-0.933458,-0.699163,0.435659,0.612764,-1.17847,-1.23436,-0.710282,-0.678213,0.492683,0.631786,0.790296,0.644489,1.51936,1.36923,1.13505,1.04252,-1.07636,-0.948562
1433,0.19909,0.172864,0.462496,0.395169,0.146701,0.148094,0.0593462,0.0746404,0.111583,0.0664898,0.436073,0.415974,0.832537,0.850085,0.972783,0.996224,0.209056,0.202269,0.854335,0.842722,-1.37049,-1.04375,0.277171,0.521209,0.521377,0.702975,-0.55841,-0.612314,1.88721,1.91102,0.738196,0.876033,1.19908,1.05977,-0.531754,-0.68289,-1.16276,-1.25883,-0.196626,-0.0654955
1434,0.901877,0.873556,0.586728,0.518325,0.628412,0.631109,0.409906,0.423427,0.617439,0.570389,0.217307,0.292818,0.984185,0.902272,0.193537,0.214683,0.0126172,0.00478533,0.10433,0.09484,0.643442,0.963627,-0.0189034,0.232194,-0.224839,0.000319363,-2.12724,-2.17544,1.74904,1.77353,1.26832,1.41207,0.588699,0.444998,-1.43195,-1.57905,0.105691,0.0116295,0.206137,0.331238
1435,0.61052,0.584141,0.1369,0.0698686,0.164864,0.16668,0.062984,0.0767002,0.238697,0.191517,0.162745,0.169663,0.936222,0.954459,0.817027,0.840129,0.15271,0.144764,0.651912,0.643776,2.64426,2.971,-0.959788,-0.716205,-0.883664,-0.702336,-0.489003,-0.52392,-0.97653,-0.946553,0.655537,0.791784,-0.634941,-0.772532,-1.9467,-2.09015,0.788241,0.690732,-0.335437,-0.206995
1436,0.827823,0.80072,0.21562,0.148952,0.556593,0.558599,0.501583,0.466413,0.11219,0.0651792,0.364067,0.373869,0.297173,0.317016,0.661474,0.610796,0.791187,0.781997,0.692152,0.639423,0.103356,0.427611,0.0406405,0.283465,0.481938,0.661636,1.17581,1.1276,-1.11423,-1.08405,0.33484,0.468976,3.00229,2.86023,-0.125862,-0.26905,0.0106541,-0.0883101,0.020762,0.144939
1437,0.019626,-0.00555466,0.82459,0.759285,0.601014,0.686859,0.841283,0.856126,0.773808,0.725565,0.276875,0.285999,0.338717,0.359627,0.356387,0.381462,0.749111,0.783187,0.644126,0.63507,0.490481,0.816614,0.305429,0.546682,0.264721,0.446761,-0.778118,-0.816377,0.443131,0.468777,0.283024,0.422571,0.773729,0.639409,0.240641,0.0925755,-1.60698,-1.7001,0.794487,0.921292
1438,0.890322,0.864581,0.726493,0.661594,0.812154,0.815119,0.123179,0.139058,0.714202,0.665717,0.957893,0.966725,0.948908,0.970999,0.985854,1.01168,0.764172,0.784376,0.141821,0.134411,0.46694,0.793139,-1.09823,-0.856022,-1.52935,-1.34633,0.0822345,0.0397087,-1.80933,-1.78964,-1.20283,-1.05829,0.592006,0.457678,0.0525111,-0.097081,1.17039,1.07861,-0.693759,-0.57105
1439,0.642054,0.615857,0.855238,0.756548,0.459901,0.461387,0.5382,0.55308,0.945363,0.896304,0.81662,0.717733,0.542965,0.609902,0.356759,0.379857,0.696994,0.785566,0.661318,0.653999,-1.48321,-1.15241,2.04013,2.27654,-1.22002,-1.03845,1.37733,1.32699,1.4121,1.43167,-0.188492,-0.0487224,-0.598575,-0.729444,-0.727958,-0.869527,0.0558887,-0.0286667,-0.505408,-0.384222
1440,0.865903,0.837657,0.914641,0.851502,0.358396,0.360715,0.626172,0.641213,0.947229,0.899094,0.530377,0.468741,0.226843,0.248806,0.20786,0.232933,0.668968,0.786756,0.85974,0.851293,1.77301,2.1039,1.86976,2.10972,0.144187,0.325521,0.231281,0.178504,-0.593927,-0.581061,0.208636,0.349856,-1.34623,-1.48025,0.0330073,-0.11061,-1.36209,-1.45179,0.190618,0.317776
1441,0.0942017,0.0657221,0.540087,0.47689,0.942217,0.944229,0.1396,0.154299,0.377958,0.33117,0.210917,0.219749,0.334124,0.353919,0.789357,0.816346,0.797135,0.787945,0.198795,0.18994,-0.237664,0.0935287,-0.181873,0.0519405,-1.44049,-1.26354,0.62716,0.572564,0.168406,0.174493,-0.265144,-0.129204,2.24946,2.11344,0.0811904,-0.0650976,0.119884,0.0240961,-0.551344,-0.428851
1442,0.861275,0.830093,0.543215,0.411536,0.928906,0.930742,0.34168,0.355758,0.720816,0.673768,0.316903,0.323905,0.023168,0.042234,0.832674,0.832506,0.431047,0.42364,0.162788,0.15592,-1.69498,-1.37045,0.0654818,0.299263,-0.558352,-0.386332,2.06259,2.00205,0.279224,0.286186,1.58508,1.72657,0.433388,0.299475,0.121019,-0.0195849,1.06256,0.968037,0.903383,1.02035
1443,0.518629,0.484841,0.408653,0.346181,0.3087,0.312202,0.960553,0.973442,0.619862,0.628427,0.0960171,0.100991,0.922054,0.938627,0.819875,0.848666,0.571704,0.563619,0.531455,0.468731,0.126993,0.450012,-0.0598657,0.12974,0.809387,0.97764,0.87235,0.806464,-0.0716821,-0.0648966,0.882845,1.03001,-1.83706,-1.97528,-0.572463,-0.715851,0.425968,0.27574,0.339702,0.472718
1444,0.485735,0.453559,0.7088,0.647616,0.528164,0.466452,0.326783,0.341226,0.630686,0.583085,0.452938,0.456279,0.00551666,0.0231328,0.158642,0.186562,0.986639,0.979141,0.787691,0.781542,1.15858,1.48086,-0.274196,-0.0397836,0.369357,0.536224,0.45864,0.38554,-1.93439,-1.9225,1.269,1.4129,-0.284046,-0.421453,1.30568,1.16525,-0.325273,-0.416558,-0.184411,-0.0749179
1445,0.00548941,-0.0273885,0.561204,0.462819,0.6182,0.620702,0.0705873,0.0835693,0.950133,0.900069,0.321238,0.264628,0.0207892,0.0360813,0.103178,0.130897,0.151496,0.144558,0.731647,0.72759,0.87664,1.12193,0.390921,0.623383,1.35587,1.51954,-1.03513,-1.10083,0.265148,0.280502,-0.248629,-0.111176,-1.65411,-1.79452,1.33117,1.18823,-1.60604,-1.69933,1.86911,1.97905
1446,0.166352,0.132809,0.338548,0.278022,0.320578,0.321519,0.0594694,0.108324,0.333252,0.285642,0.0699212,0.0729771,0.676589,0.693975,0.785762,0.812488,0.833617,0.826836,0.394488,0.39116,0.448036,0.763001,0.00853613,0.241716,-0.409395,-0.241774,-1.26204,-1.33494,-1.15373,-1.14211,-0.32435,-0.188913,2.02753,1.89196,-0.0737218,-0.211867,-0.527543,-0.615409,0.864864,0.975256
1447,0.553569,0.536698,0.658488,0.599504,0.849322,0.850054,0.150178,0.133079,0.428345,0.380533,0.616519,0.619062,0.904959,0.919823,0.419239,0.461103,0.483444,0.477224,0.856554,0.855244,-0.32727,-0.0117969,-0.0257489,0.213645,-0.116626,0.0502984,0.445023,0.376688,1.71404,1.71837,0.254586,0.394421,-0.849579,-0.979483,1.05194,0.917046,-0.829151,-0.916156,0.453873,0.55869
1448,0.975457,0.940587,0.632574,0.574309,0.271269,0.271225,0.308993,0.157834,0.250699,0.293236,0.678278,0.680615,0.211127,0.227898,0.0822753,0.109719,0.602684,0.596392,0.371695,0.369299,-0.564411,-0.247902,-0.777366,-0.534752,0.645678,0.818988,-0.322928,-0.385192,2.28587,2.29029,0.298616,0.439445,-0.605068,-0.735481,-1.43488,-1.56351,1.48675,1.39388,-0.968902,-0.858673
1449,0.690166,0.656539,0.129877,0.0709111,0.454678,0.398546,0.167714,0.182589,0.253888,0.205939,0.095563,0.0956622,0.787251,0.804398,0.554375,0.581797,0.944591,0.937114,0.350389,0.349793,0.790474,1.10954,-0.0793095,0.0861433,-0.78667,-0.617066,-0.467336,-0.554669,-0.501002,-0.496145,-0.0909689,0.055223,-1.88,-2.01675,0.251707,0.118125,-3.05247,-3.14534,0.640885,0.74521
1450,0.689595,0.657107,0.642881,0.58335,0.537186,0.525868,0.949472,0.962596,0.687034,0.638483,0.800377,0.802185,0.556074,0.573073,0.031816,0.0606991,0.312568,0.307204,0.702373,0.703675,-0.0525331,0.272406,0.463542,0.707038,-0.444786,-0.279289,-0.656339,-0.724145,0.0575088,-0.0286597,1.3918,1.53915,0.192574,0.056003,-0.859114,-0.991378,0.0858433,-0.00471873,-2.986,-2.88927
1451,0.271148,0.236788,0.180254,0.119988,0.653395,0.653189,0.949145,0.961376,0.471458,0.335031,0.141291,0.142261,0.649948,0.667014,0.322235,0.351334,0.498302,0.493389,0.438964,0.438702,-0.558018,-0.226406,-0.511035,-0.271946,0.746737,0.916471,-0.531285,-0.605412,0.433968,0.438825,-0.436287,-0.292311,-0.826957,-0.96067,0.322374,0.268682,-0.768547,-0.860965,-1.12894,-1.03671
1452,0.420896,0.386879,0.711889,0.65214,0.28866,0.28857,0.382079,0.393193,0.0802729,0.03158,0.391863,0.353774,0.34903,0.365823,0.186235,0.214954,0.218002,0.214873,0.978647,0.978095,0.771266,1.09928,0.237093,0.48256,0.252277,0.427575,0.644492,0.574292,0.288588,0.287724,-0.798691,-0.661279,-1.45264,-1.58945,1.65759,1.52874,1.10237,1.00815,-1.6369,-1.5432
1453,0.234315,0.198216,0.501437,0.442555,0.702654,0.701722,0.890627,0.901034,0.986124,0.937726,0.541488,0.565288,0.934756,0.952086,0.490947,0.614724,0.629711,0.625136,0.902279,0.900041,0.528082,0.863171,-0.280403,-0.0342452,-1.56327,-1.38285,0.419745,0.282442,-0.50789,-0.505432,-0.213527,-0.0985475,0.199715,0.0589465,0.507497,0.37604,0.225225,0.134368,-0.459314,-0.431433
1454,0.421502,0.384246,0.803259,0.743989,0.587764,0.640077,0.226559,0.237741,0.675096,0.620578,0.684487,0.776801,0.843664,0.795827,0.985474,1.0145,0.00682082,0.000322862,0.0433215,0.0426321,0.652412,0.893463,0.420063,0.673585,-0.349516,-0.173233,0.0690486,-0.00940698,1.84634,1.84811,0.331999,0.464184,-1.33005,-1.47332,1.50709,1.38302,0.420036,0.32693,0.593061,0.68033
1455,0.10224,0.0650263,0.261202,0.202273,0.6726,0.578432,0.389526,0.402582,0.353739,0.30343,0.987345,0.988314,0.743427,0.639567,0.846397,0.879102,0.247917,0.158357,0.763354,0.76216,0.588271,0.923755,0.400114,0.658788,2.05175,2.23134,0.311737,0.232696,-1.81368,-1.8135,0.201207,0.338892,-0.483805,-0.630836,-0.267646,-0.388028,-2.06718,-2.15843,-0.442567,-0.353767
1456,0.430754,0.392603,0.303164,0.245681,0.517719,0.516787,0.352392,0.366157,0.655755,0.606195,0.391931,0.393433,0.465978,0.483308,0.714481,0.743709,0.379111,0.316391,0.705223,0.750298,-0.588808,-0.248716,-1.34077,-1.08713,1.39843,1.58521,0.330797,0.258597,-0.591245,-0.595603,0.669224,0.800461,2.42214,2.26726,0.977535,0.859192,-1.44817,-1.54285,0.898203,0.987345
1457,0.461433,0.502035,0.780915,0.723448,0.339802,0.340419,0.00129198,0.0144438,0.581251,0.531167,0.641358,0.641542,0.558479,0.577249,0.36021,0.391587,0.482863,0.474425,0.74219,0.738435,-1.43898,-1.10021,-1.75165,-1.49761,-2.39257,-2.19874,0.1118,0.0392255,-0.468967,-0.469078,-1.16599,-1.031,-0.596008,-0.756199,-0.279023,-0.404633,0.0817293,-0.0201448,-2.13218,-2.03376
1458,0.632557,0.611468,0.320945,0.265231,0.509451,0.511147,0.593203,0.606776,0.221496,0.248708,0.413201,0.41308,0.403379,0.422757,0.231201,0.264838,0.432477,0.424857,0.88486,0.880959,-0.744095,-0.405212,0.071705,0.324208,0.539048,0.737166,0.708945,0.631343,0.35957,0.364165,0.725459,0.855832,-1.29828,-1.46138,2.09415,1.97308,-0.239791,-0.369805,2.54782,2.6513
1459,0.757867,0.720901,0.513079,0.418526,0.961183,0.964656,0.791022,0.803068,0.0131332,-0.0337509,0.531465,0.532698,0.498568,0.516698,0.653736,0.686196,0.989118,0.980072,0.437873,0.434568,-0.828237,-0.491389,0.312113,0.477591,-0.577751,-0.376078,-0.0614982,-0.14503,0.805038,0.811936,-0.473718,-0.345607,0.171945,0.00218313,-1.33628,-1.45253,-0.612455,-0.719465,-0.793451,-0.693329
1460,0.4226,0.385749,0.625519,0.571822,0.760228,0.763181,0.262467,0.274824,0.591041,0.545985,0.0327561,0.0326301,0.919875,0.938468,0.166266,0.200028,0.654421,0.621941,0.916347,0.91357,0.475391,0.817672,0.378371,0.630973,0.206353,0.40663,-1.31854,-1.40245,-0.64045,-0.625484,-0.741999,-0.60676,1.06714,0.890841,-1.68374,-1.795,-0.118789,-0.229069,1.77461,1.86794
1461,0.566197,0.530564,0.039345,-0.0143401,0.326992,0.327852,0.156951,0.1672,0.21339,0.167113,0.674273,0.673437,0.151095,0.167975,0.724268,0.757926,0.273301,0.263811,0.910696,0.890396,-0.599572,-0.316371,-0.740999,-0.48899,-1.64099,-1.43413,1.15099,1.05961,-0.342997,-0.330022,0.752383,0.892584,0.356458,0.165474,1.04186,0.922721,-0.223654,-0.327784,-1.30553,-1.2122
1462,0.432824,0.397285,0.580671,0.527917,0.46414,0.464285,0.439788,0.451387,0.0777673,0.0311715,0.471322,0.469165,0.526441,0.544734,0.953358,0.987228,0.903395,0.894731,0.960187,0.867221,-1.79532,-1.45041,-0.610641,-0.365736,1.14352,1.35632,0.893348,0.807892,1.16418,1.17767,-0.606611,-0.394047,-0.383591,-0.559894,0.449965,0.333787,1.52019,1.41304,0.959793,1.0481
1463,0.603059,0.568135,0.392725,0.242197,0.0562007,0.0546531,0.724303,0.735574,0.797995,0.753434,0.718245,0.728816,0.129616,0.148677,0.0210862,0.0560242,0.913855,0.904752,0.845116,0.844047,0.900829,1.24325,-0.802216,-0.563309,-1.42744,-1.21967,-1.01225,-1.10497,-0.0908895,-0.0772091,-1.82088,-1.68068,0.322003,0.147148,1.85347,1.73767,0.475268,0.365641,-1.94771,-1.85553
1464,0.475158,0.383262,0.00958194,-0.0435236,0.91251,0.911311,0.320658,0.33396,0.751992,0.688301,0.990741,0.988467,0.581089,0.599926,0.244852,0.197379,0.0240657,0.015672,0.334531,0.333138,-0.332283,0.00931642,-1.24665,-1.00434,-1.49673,-1.29542,-1.33228,-1.41798,0.515672,0.523774,1.02636,1.17438,-0.560793,-0.729598,0.374628,0.261082,-0.159926,-0.273653,0.396536,0.486838
1465,0.231401,0.198389,0.48504,0.43014,0.767846,0.76432,0.186408,0.201575,0.669149,0.623168,0.966689,0.965292,0.322661,0.343179,0.304638,0.338734,0.547708,0.477636,0.739319,0.737443,0.568424,0.904432,-1.44541,-1.20191,-0.217492,-0.0233296,1.03623,0.949494,-0.463682,-0.455153,-0.544236,-0.396391,1.2279,1.05549,-0.593083,-0.711238,1.74999,1.64125,0.0964188,0.192837
1466,0.514811,0.572175,0.118197,0.0610351,0.956305,0.954673,0.617643,0.634991,0.992906,0.945585,0.44264,0.441035,0.868993,0.889444,0.0169623,0.0517874,0.947993,0.939599,0.264739,0.261331,-1.54322,-1.21116,0.0256628,0.263563,1.56123,1.76003,0.694521,0.606272,-0.953172,-0.941934,0.675444,0.827883,0.712355,0.532315,0.569974,0.446591,-2.68932,-2.79806,-1.08056,-0.98159
1467,0.978818,0.945961,0.190461,0.134701,0.833426,0.833493,0.787995,0.770796,0.373309,0.326193,0.129851,0.127275,0.148768,0.167131,0.569251,0.604985,0.327927,0.319169,0.183428,0.178131,0.0348043,0.364914,0.346178,0.588398,-0.680774,-0.4793,0.603603,0.510482,-1.74999,-1.73509,0.295879,0.443661,1.85617,1.67021,-0.0791984,-0.204343,-0.313941,-0.423393,0.676628,0.778537
1468,0.425526,0.394825,0.726341,0.671936,0.998814,0.999653,0.890444,0.906601,0.0095911,-0.0372346,0.709021,0.708127,0.500391,0.525368,0.758666,0.796615,0.122574,0.111536,0.604107,0.597459,-0.19096,0.144265,0.990619,1.2366,-1.41845,-1.21726,-0.25394,-0.41758,-0.154191,-0.135166,-0.78597,-0.635509,-1.26341,-1.44353,-1.36419,-1.48358,0.84933,0.73782,-0.956199,-0.853838
1469,0.669812,0.640787,0.54012,0.487686,0.721536,0.700383,0.0546223,0.0692754,0.227947,0.183445,0.329423,0.326642,0.865241,0.883604,0.10633,0.14413,0.845234,0.834068,0.365722,0.357804,-1.54584,-1.21108,-0.153345,0.0857106,-1.91045,-1.70615,-1.24722,-1.34564,1.15682,1.17481,0.84438,0.98893,0.694817,0.518307,-0.656218,-0.768973,0.489167,0.375984,-0.247454,-0.151839
1470,0.19696,0.170317,0.93069,0.877668,0.402444,0.401113,0.893413,0.905722,0.142243,0.0976934,0.288536,0.284674,0.600641,0.59782,0.225918,0.319218,0.195107,0.183885,0.406517,0.399679,-0.113356,0.223825,0.548454,0.793541,-0.567107,-0.356826,-1.41394,-1.51914,-1.05864,-1.03638,-0.871008,-0.73337,1.95409,1.77947,-0.939416,-1.04993,1.13707,1.02215,-0.00663882,0.0945225
1471,0.782289,0.755947,0.530939,0.478228,0.521629,0.518299,0.160898,0.172699,0.774534,0.732226,0.983934,0.981064,0.29285,0.312035,0.455947,0.494306,0.973662,0.960896,0.948786,0.94381,0.338295,0.674281,-1.42999,-1.18888,-0.190688,0.0262061,0.56868,0.464948,-1.26737,-1.24948,0.28804,0.431523,0.151268,-0.0193778,0.55543,0.443954,-0.669238,-0.784224,0.0315256,0.132861
1472,0.194742,0.169758,0.77907,0.725235,0.401751,0.386346,0.304287,0.32222,0.0319162,-0.00910924,0.931652,0.928882,0.479876,0.497993,0.0308978,0.0678469,0.00949151,-0.00198902,0.0734024,0.0701056,-0.650382,-0.308991,1.19631,1.43332,0.537787,0.748507,0.527438,0.429304,0.0440024,0.0605023,0.00451574,0.15461,0.0273644,-0.138992,1.01199,0.897269,-0.0319279,-0.152906,0.628092,0.727098
1473,0.145493,0.118386,0.0703507,0.0150995,0.319805,0.254393,0.461107,0.471742,0.753462,0.713153,0.356935,0.354518,0.372107,0.388764,0.506188,0.544372,0.45197,0.436155,0.816247,0.814023,-1.62825,-1.29226,1.17948,1.41852,-0.115079,0.102378,-1.48717,-1.57937,0.614587,0.63243,0.240107,0.383664,0.302147,0.136568,0.153015,0.0338103,0.0166478,-0.110621,0.912135,1.00519
1474,0.730906,0.704015,0.999323,0.946445,0.125697,0.12244,0.293282,0.304137,0.408978,0.369579,0.889863,0.88614,0.833468,0.850073,0.232059,0.271839,0.886627,0.8743,0.477102,0.472884,-1.0759,-0.735267,1.66994,1.9127,-2.06997,-1.84985,1.09628,1.00275,-1.4631,-1.45364,-1.02015,-0.879934,1.1287,0.964102,-0.188737,-0.308655,-1.54779,-1.67553,-0.0256161,0.061224
1475,0.487891,0.460354,0.0556955,0.00113182,0.766161,0.761581,0.860398,0.87182,0.668069,0.62643,0.465997,0.46042,0.453614,0.469132,0.424223,0.44297,0.659599,0.646166,0.539816,0.535127,-2.54063,-2.19924,0.934837,1.18069,-0.772866,-0.522169,-1.42106,-1.51359,-0.34185,-0.330602,-2.65305,-2.50998,0.298845,0.138058,0.0226438,-0.101051,0.341476,0.208975,0.426363,0.605292
1476,0.764767,0.737031,0.29995,0.24325,0.244026,0.238158,0.893272,0.904599,0.570973,0.55105,0.584332,0.580038,0.473905,0.486919,0.573347,0.614102,0.161731,0.146413,0.0570227,0.0545642,-0.675983,-0.332596,-0.159519,0.0923995,0.581121,0.805514,1.11164,1.01772,0.34148,0.447357,-0.451924,-0.308426,0.335628,0.16896,0.493868,0.367479,0.694014,0.559992,1.05742,1.14936
1477,0.0281228,0.0031098,0.179832,0.125202,0.716607,0.711753,0.141928,0.151938,0.516768,0.47567,0.489363,0.48715,0.160438,0.175235,0.198259,0.23723,0.375649,0.420815,0.256106,0.251858,0.498546,0.836615,0.206337,0.46106,0.145118,0.364099,-1.60421,-1.69532,1.21292,1.22532,-0.15959,-0.0191863,-0.512214,-0.674535,0.120355,-0.0052172,0.293166,0.152164,-0.56895,-0.423952
1478,0.656879,0.633792,0.338037,0.284152,0.891143,0.801477,0.769101,0.779105,0.986661,0.943489,0.631944,0.632135,0.980205,0.995667,0.0702868,0.110481,0.712985,0.695218,0.830525,0.825941,-0.345585,-0.0148841,-0.717577,-0.455729,1.22681,1.43933,0.295744,0.209751,0.78542,0.797185,-0.226133,-0.0814358,1.36647,1.21018,-1.48805,-1.62095,1.74042,1.59737,-2.08634,-1.99726
1479,0.109731,0.0874423,0.738085,0.684189,0.897561,0.891202,0.764163,0.772322,0.935266,0.837885,0.326155,0.328435,0.721599,0.73892,0.176388,0.216818,0.523358,0.526039,0.0978887,0.092824,-0.341805,-0.00946224,1.58594,1.8454,-1.15066,-0.943387,0.681562,0.588183,-0.400604,-0.391173,1.3159,1.46522,-0.151918,-0.305758,1.91053,1.77991,1.7178,1.48772,-2.33194,-2.24655
1480,0.778219,0.753724,0.843282,0.788193,0.0579576,0.0507483,0.982241,0.988626,0.777111,0.73228,0.334779,0.335522,0.2108,0.227319,0.979084,1.02009,0.412424,0.35686,0.132607,0.124728,0.417754,0.748177,0.797599,1.05073,-0.159902,0.0399319,1.69952,1.60068,-0.698833,-0.69587,-1.22636,-1.08178,0.322336,0.212574,-1.02449,-1.15641,1.51771,1.37808,2.11026,2.19564
1481,0.444013,0.442984,0.336291,0.279642,0.881006,0.876104,0.928232,0.937,0.449674,0.405117,0.665028,0.665631,0.578481,0.569118,0.393259,0.435035,0.0594939,0.187681,0.50276,0.494668,-0.130941,0.268846,-2.29458,-2.03525,1.07661,1.28295,-0.626715,-0.72847,0.998106,0.994952,0.835406,0.979226,0.889552,0.730907,0.203095,0.0750267,2.65486,2.50836,0.565736,0.656631
1482,0.154141,0.132244,0.678069,0.601877,0.805896,0.827565,0.444979,0.455189,0.885782,0.842875,0.292251,0.293938,0.892555,0.910916,0.842854,0.886734,0.0362698,0.0185019,0.511162,0.505385,-0.534063,-0.210484,0.788496,1.04739,-0.709682,-0.510149,-0.521157,-0.719228,-1.32101,-1.32709,2.30316,2.44887,-0.281343,-0.441474,0.862513,0.728253,-1.29585,-1.44524,0.333961,0.422483
1483,0.593987,0.471929,0.979693,0.924111,0.783423,0.779027,0.782005,0.793772,0.260649,0.217837,0.218126,0.315544,0.849839,0.867552,0.350353,0.395657,0.734637,0.715091,0.889697,0.885119,1.82748,2.1519,-0.333295,-0.0725709,-0.500743,-0.295445,-0.604929,-0.709987,-0.768886,-0.772345,-1.82019,-1.67806,-0.0883534,-0.175662,-0.266613,-0.469387,2.16927,2.01446,1.00662,1.09491
1484,0.834945,0.811614,0.209196,0.151295,0.345194,0.339804,0.0284218,0.0411104,0.565317,0.520602,0.336262,0.337151,0.512717,0.532392,0.0643635,0.108711,0.741364,0.720533,0.847314,0.82631,-0.503763,-0.184527,-0.0272957,0.237312,0.492324,0.630629,0.392403,0.287223,0.350185,0.350696,0.32165,0.458794,0.245521,0.09015,-1.53053,-1.66703,-0.666317,-0.825588,-1.53852,-1.44694
1485,0.602232,0.493977,0.122646,0.150484,0.858443,0.853817,0.227553,0.214477,0.105669,0.0618701,0.500806,0.502313,0.832074,0.84959,0.438228,0.473975,0.0304388,0.0101354,0.640356,0.767501,0.11406,0.434648,0.0779172,0.344237,1.35492,1.5567,-1.81022,-1.90859,-0.0322089,-0.0634963,-0.618386,-0.484284,1.33862,1.1781,-1.39848,-1.5351,-0.466025,-0.633027,-1.05035,-0.95792
1486,0.199563,0.176339,0.231238,0.149673,0.120509,0.118218,0.367042,0.387843,0.0299993,-0.0131577,0.290421,0.293124,0.268991,0.287778,0.796748,0.83924,0.313802,0.232825,0.713269,0.708692,-0.145735,0.168092,-0.777899,-0.511668,-0.0801718,0.12065,-0.2125,-0.304009,-0.436356,-0.477689,0.933278,1.06237,-0.663799,-0.825451,-0.55487,-0.698301,-0.0164166,-0.163737,-1.31821,-1.22247
1487,0.487855,0.427518,0.0653311,0.148862,0.73605,0.731826,0.726781,0.56121,0.843184,0.798899,0.745477,0.746445,0.840077,0.85947,0.794084,0.834442,0.421072,0.455515,0.0297366,0.027633,0.663769,0.970204,0.239155,0.504044,1.2417,1.44005,2.1226,2.02247,-0.892392,-0.891881,0.216281,0.350997,-0.85277,-1.00718,1.31999,1.16897,0.475026,0.305552,0.473634,0.569431
1488,0.700175,0.678698,0.205952,0.148051,0.00448633,0.00228878,0.771467,0.734576,0.516865,0.471736,0.294526,0.380447,0.970044,0.899607,0.208905,0.249389,0.697381,0.678205,0.649352,0.646287,0.486858,0.783237,-2.29267,-2.02073,0.0557822,0.250918,-1.02486,-1.12214,-0.725379,-0.717818,-0.988646,-0.850442,0.294018,0.14829,-0.292688,-0.446772,1.63632,1.46677,-1.83356,-1.73213
1489,0.409071,0.389282,0.424412,0.365381,0.827686,0.827645,0.895254,0.907943,0.834427,0.78872,0.0119038,0.0144491,0.923679,0.939744,0.183516,0.223641,0.585336,0.633805,0.322517,0.319967,0.289836,0.596271,-0.275098,-0.0106343,-0.440477,-0.252715,-0.0318259,-0.124929,1.54127,1.5533,0.0140296,0.146184,-0.0463631,-0.188648,1.07907,0.925523,-0.0706663,-0.241206,-0.473981,-0.377486
1490,0.900591,0.880809,0.103334,0.0450281,0.552491,0.553227,0.312485,0.324656,0.000579211,-0.0436735,0.785861,0.787659,0.741053,0.843043,0.496285,0.534832,0.606652,0.589404,0.472643,0.47207,-1.09901,-0.791511,1.51573,1.78028,-0.0269789,0.162574,-1.49454,-1.58126,-0.680213,-0.599005,0.593892,0.729518,-0.615872,-0.758279,-0.114937,-0.275032,0.0488866,-0.124608,0.875743,0.977164
1491,0.174854,0.156918,0.646961,0.587285,0.678433,0.679438,0.416845,0.429057,0.0147063,-0.0184725,0.0523855,0.0530572,0.727492,0.746342,0.179363,0.218339,0.79409,0.77559,0.990368,0.991658,-0.565034,-0.262214,-1.55498,-1.28834,-0.328905,-0.141943,-1.84832,-1.94107,-2.76335,-2.75131,0.423369,0.560731,-0.0820589,-0.22119,0.040688,-0.112893,-0.939893,-1.10782,0.866658,0.969785
1492,0.92389,0.905573,0.31941,0.261761,0.130372,0.130375,0.809177,0.822603,0.0492927,0.00672853,0.471942,0.472414,0.0917677,0.108899,0.530997,0.502252,0.343325,0.325792,0.511512,0.511096,0.63816,0.939772,2.72828,2.99233,-2.03234,-1.84184,-0.0174814,-0.113719,-0.0473764,-0.0416992,-0.388457,-0.25764,-0.606928,-0.744366,1.19454,1.04494,1.28042,1.10593,-0.688547,-0.585995
1493,0.558907,0.541094,0.85841,0.798996,0.114292,0.116887,0.389686,0.401251,0.945996,0.902959,0.530248,0.515915,0.37193,0.389965,0.749241,0.786166,0.909413,0.891192,0.885709,0.885573,-0.0750289,0.227504,0.804048,1.07061,-1.40016,-1.25062,1.18912,1.09802,0.18493,0.191883,-0.765615,-0.641861,1.18273,1.04072,0.215331,0.0586113,-0.256617,-0.428487,0.242282,0.342066
1494,0.486288,0.553219,0.0440637,-0.0156205,0.347578,0.275885,0.492779,0.505651,0.520347,0.479058,0.437515,0.559417,0.256255,0.23144,0.255544,0.290482,0.268016,0.250766,0.0051503,0.00658094,0.628507,0.936799,-0.30887,-0.0493568,-0.85253,-0.65941,1.57611,1.49208,0.102425,0.116451,0.878484,1.00038,0.805848,0.658398,0.264163,0.111598,-2.09889,-2.26562,-0.384259,-0.283855
1495,0.532563,0.565345,0.894614,0.832498,0.430176,0.434882,0.941327,0.953881,0.88923,0.846724,0.602448,0.602919,0.053737,0.0729161,0.700247,0.737464,0.248805,0.330489,0.929043,0.930003,0.870455,1.17161,1.01686,1.27484,-1.72549,-1.53858,1.19252,1.09933,0.604468,0.611994,-0.279454,-0.154596,0.175026,0.0296206,-0.79565,-0.950735,0.771374,0.608417,-0.7597,-0.656073
1496,0.593498,0.57747,0.248402,0.186791,0.869651,0.874208,0.0128114,0.0252874,0.015564,-0.0255956,0.775836,0.791879,0.252159,0.26957,0.370056,0.406111,0.427462,0.410212,0.602598,0.567815,0.584044,0.89049,-1.21544,-0.96101,-0.740441,-0.555261,0.782541,0.706583,0.786232,0.800107,-0.0230705,0.103841,0.295233,0.152375,-1.56339,-1.72318,1.01985,0.863722,-0.674461,-0.575397
1497,0.15827,0.141668,0.861401,0.797124,0.712396,0.717535,0.51497,0.527622,0.450535,0.406949,0.982265,0.980839,0.10138,0.12004,0.723794,0.758463,0.0202008,0.00129689,0.203034,0.205627,1.78027,2.00694,-0.849154,-0.592349,0.672932,0.852969,-2.00448,-2.07243,-0.282269,-0.269023,-0.453302,-0.327287,1.01036,0.874221,0.86074,0.70153,-0.449232,-0.608808,0.273156,0.369527
1498,0.718541,0.702921,0.584853,0.587504,0.837347,0.843746,0.234601,0.249894,0.52608,0.481104,0.273753,0.271136,0.778791,0.79753,0.512306,0.546854,0.161375,0.141275,0.75286,0.754562,2.82113,3.1234,1.03785,1.29314,1.51042,1.68497,0.808184,0.745936,-0.502045,-0.3888,1.79759,1.92281,0.11249,-0.0175762,1.98171,1.83044,1.03947,0.883424,-0.566839,-0.466548
1499,0.406977,0.348826,0.440586,0.377884,0.210422,0.215036,0.233157,0.239261,0.373522,0.33015,0.486134,0.484222,0.064538,0.0852807,0.715269,0.748693,0.913853,0.893937,0.0207558,0.0214457,0.678384,0.976704,-0.756686,-0.499945,0.33782,0.509376,1.61579,1.55541,-0.54147,-0.508578,1.29566,1.42961,-1.53443,-1.65753,0.40707,0.260731,1.24673,1.09167,-0.593975,-0.489585
1500,0.0110114,-0.00526779,0.564939,0.50104,0.625521,0.628188,0.212942,0.228628,0.583453,0.576683,0.200614,0.201469,0.641189,0.661781,0.672029,0.707391,0.121568,0.10413,0.764182,0.765363,-0.15359,0.139565,-0.642208,-0.39302,0.0325561,0.204859,-1.73446,-1.7957,-0.767769,-0.628355,1.07482,1.21396,0.611557,0.484136,1.52093,1.37365,-1.2337,-1.39369,-1.22499,-1.11551
1501,0.0586726,0.0400191,0.987983,0.925486,0.191186,0.192859,0.589688,0.606941,0.864724,0.823216,0.202026,0.20354,0.716,0.735917,0.203531,0.240748,0.314592,0.294626,0.111135,0.114367,0.388083,0.682523,-2.19109,-1.93538,-0.747394,-0.58069,1.59698,1.53646,-0.761377,-0.748132,-0.495354,-0.356802,-0.51483,-0.641313,1.76017,1.61338,0.0868966,-0.0768381,-0.801695,-0.687595
1502,0.977116,0.95968,0.464552,0.40276,0.997665,0.998129,0.606782,0.624858,0.573094,0.543178,0.727191,0.730217,0.0829972,0.103839,0.419718,0.470635,0.269961,0.221863,0.781324,0.783762,0.149982,0.446418,0.411127,0.673507,2.53431,2.7094,-0.341595,-0.394194,1.27091,1.28813,-0.540979,-0.403208,-0.629181,-0.760928,0.691656,0.551047,2.13047,1.97378,0.592074,0.700238
1503,0.240794,0.225758,0.338235,0.297465,0.555964,0.597225,0.920379,0.939683,0.306143,0.263139,0.217038,0.22035,0.00575209,0.024503,0.662971,0.700522,0.0348861,0.1491,0.402151,0.403355,0.94626,1.24853,-0.850552,-0.585167,-0.745518,-0.566819,1.45694,1.40024,1.23709,1.26125,-0.273517,-0.12888,-0.314121,-0.439177,-0.937725,-1.07986,0.740235,0.582504,-0.130634,-0.0170872
1504,0.3616,0.345976,0.251655,0.192169,0.195722,0.196321,0.886871,0.897844,0.793418,0.75147,0.403906,0.409238,0.684945,0.701993,0.646569,0.672027,0.094129,0.0763374,0.84698,0.846911,0.63111,0.936998,0.291525,0.552665,-0.597175,-0.414339,0.1075,0.0531192,0.16794,0.19212,-0.562155,-0.420783,-0.757781,-0.885226,-1.71661,-1.8523,1.01623,0.85296,-1.63441,-1.5249
1505,0.820726,0.803659,0.357096,0.296173,0.839059,0.840031,0.838525,0.856006,0.518519,0.474476,0.928088,0.930731,0.762188,0.780985,0.604834,0.643532,0.107247,0.0913053,0.685522,0.696681,-0.0653935,0.330081,-0.907386,-0.643841,0.739023,0.918736,1.85895,1.80018,0.741909,0.764048,-1.29635,-1.14721,-0.0621735,-0.193709,0.435176,0.295111,-0.351697,-0.507319,-0.597207,-0.489235
1506,0.314604,0.298167,0.793764,0.730321,0.287147,0.285891,0.26916,0.287823,0.507267,0.536572,0.856812,0.858036,0.604138,0.621935,0.214438,0.251735,0.984469,0.969801,0.414624,0.546451,-0.592738,-0.276835,0.314587,0.576532,0.187414,0.367914,-2.81431,-2.87307,-1.12987,-1.1056,0.26958,0.416449,-1.85899,-1.99256,-0.0826215,-0.21599,0.313965,0.154274,-0.8513,-0.738525
1507,0.333783,0.318605,0.200747,0.139209,0.108907,0.145592,0.360914,0.381495,0.640446,0.598667,0.169408,0.173269,0.707869,0.727048,0.232972,0.272443,0.148933,0.135218,0.396571,0.396221,-0.671152,-0.363012,1.87278,2.13668,-0.658528,-0.479643,-1.42562,-1.4781,-0.69992,-0.657429,0.29606,0.524744,0.276307,0.14911,-1.73186,-1.86497,-0.0482418,-0.207562,-0.502505,-0.386592
1508,0.645655,0.630242,0.118388,0.0558775,0.00875861,0.00529325,0.738902,0.759808,0.485703,0.442793,0.534473,0.537588,0.429739,0.473387,0.461706,0.501745,0.00736722,-0.0082942,0.967628,0.964616,0.610822,0.916661,1.16294,1.42049,-1.73335,-1.56075,-0.98916,-1.00582,-0.237099,-0.209257,0.494186,0.633039,0.363007,0.190095,0.854743,0.716278,-1.59684,-1.75745,-0.749006,-0.635881
1509,0.369621,0.42997,0.308975,0.248657,0.0479756,0.0416604,0.214558,0.23687,0.67013,0.587939,0.507493,0.507776,0.201962,0.219726,0.303436,0.434269,0.899297,0.884193,0.20077,0.196344,0.292603,0.683624,0.691382,0.870994,-1.79277,-1.62141,-0.473243,-0.533549,-0.704586,-0.682277,-0.0150373,0.12244,0.353484,0.23108,-0.212141,-0.346055,-0.262427,-0.421551,0.148132,0.262675
1510,0.153205,0.229698,0.923081,0.863665,0.654544,0.649523,0.272666,0.295227,0.774905,0.733085,0.476549,0.477964,0.825021,0.84125,0.324603,0.366794,0.692009,0.67656,0.136549,0.132069,0.146205,0.450588,0.0691233,0.321503,-0.182157,-0.0114529,-0.451587,-0.507648,0.214907,0.243368,0.0933832,0.229226,-0.792202,-0.908925,0.731769,0.599448,-0.900223,-1.06085,-0.419751,-0.303911
1511,0.0466009,0.0294261,0.820552,0.755501,0.328951,0.325065,0.641523,0.663847,0.208407,0.165161,0.880861,0.881841,0.350977,0.443816,0.734683,0.778537,0.878346,0.862745,0.539864,0.517299,0.357157,0.653858,-0.0789645,0.171813,-1.20216,-1.03105,0.611547,0.548897,0.11566,0.214338,-0.645929,-0.512842,1.48142,1.35952,-0.50615,-0.632373,0.0605876,-0.103046,2.02353,2.13984
1512,0.607855,0.590679,0.705205,0.647337,0.735905,0.733208,0.0902855,0.111207,0.148633,0.159847,0.762993,0.764456,0.0299297,0.0463828,0.481609,0.464659,0.218062,0.202225,0.905501,0.902529,-0.235045,0.0644583,-2.25223,-1.99877,0.457494,0.62556,1.46865,1.40498,0.156846,0.185307,-0.221287,-0.0836086,1.16081,1.03849,-0.784262,-0.913332,1.42145,1.25244,-0.362802,-0.245268
1513,0.567751,0.495833,0.284688,0.228668,0.769578,0.826173,0.95995,0.980213,0.190134,0.154533,0.269199,0.269237,0.343162,0.358442,0.107852,0.15078,0.025058,0.00944341,0.692615,0.691733,0.839427,1.14088,-1.04578,-0.797616,0.0296141,0.198698,0.629209,0.565384,0.281431,0.311832,-1.87563,-1.744,-1.84728,-1.97032,0.220811,0.0936462,-0.917869,-1.08328,-0.339892,-0.222796
1514,0.416742,0.400987,0.58995,0.535127,0.920902,0.919138,0.142046,0.163281,0.192464,0.149219,0.04494,0.0463239,0.411978,0.427237,0.433473,0.559713,0.708907,0.691722,0.112573,0.111521,0.807901,1.1174,-1.48303,-1.23865,0.763108,0.936698,0.729225,0.667951,1.03661,1.06739,0.241288,0.376982,-0.770763,-0.897837,0.937131,0.808251,1.74341,1.57721,-1.49344,-1.38094
1515,0.633235,0.541146,0.638326,0.548852,0.720603,0.717664,0.90492,0.92668,0.454096,0.403848,0.655168,0.656957,0.131601,0.14632,0.926471,0.968646,0.980362,0.962696,0.850083,0.849906,0.511288,0.82044,0.979627,1.22379,1.13515,1.30416,-1.40243,-1.46631,-0.658423,-0.632542,0.52001,0.651309,-0.829326,-0.957632,-3.0617,-3.19355,-0.622226,-0.789779,-1.10206,-0.984211
1516,0.69626,0.681306,0.576772,0.562578,0.986035,0.983778,0.0779321,0.0991221,0.700438,0.658478,0.540044,0.543595,0.371424,0.417427,0.0532445,0.0967366,0.932053,0.931333,0.672531,0.761093,1.06782,1.37743,-1.61167,-1.36676,0.380726,0.549937,0.257918,0.199891,-1.44297,-1.40912,-1.26084,-1.13495,2.38376,2.25267,-0.665079,-0.800553,0.775939,0.609944,-0.956436,-0.842154
1517,0.245704,0.230882,0.628488,0.576303,0.938104,0.934754,0.438073,0.469263,0.323498,0.279606,0.865661,0.868732,0.675852,0.688533,0.675082,0.716851,0.919367,0.899969,0.67573,0.67228,1.13232,1.44453,0.881995,1.12387,0.10172,0.276201,-0.742782,-0.794053,0.6107,0.643387,-0.250029,-0.199188,1.17676,0.955131,2.74348,2.60031,0.978699,0.818185,-2.1757,-2.06185
1518,0.831407,0.816511,0.219289,0.166896,0.506535,0.504843,0.815993,0.839405,0.648222,0.606496,0.18442,0.188211,0.646451,0.645183,0.902464,0.946153,0.304517,0.284165,0.936398,0.931005,-0.247023,0.0734216,1.05478,1.29514,-0.731406,-0.557468,-0.79081,-0.843745,-1.40255,-1.36935,0.604792,0.736571,-0.203457,-0.342404,-0.953899,-1.09584,-0.575026,-0.7317,1.27969,1.39706
1519,0.64586,0.633557,0.312281,0.261235,0.970062,0.968401,0.659027,0.66153,0.976717,0.933386,0.0179645,0.0205737,0.577968,0.601833,0.177534,0.221442,0.527756,0.505837,0.0646681,0.0573002,-1.40531,-1.08445,-1.13643,-0.892987,-0.135704,0.0399983,0.452312,0.397109,0.0424564,0.0771872,-0.387429,-0.251645,0.89696,0.761947,-0.872223,-1.01125,-0.578517,-0.737017,-0.690948,-0.576452
1520,0.729512,0.719619,0.768509,0.715591,0.255368,0.253942,0.460407,0.483655,0.817691,0.84048,0.662922,0.667,0.544722,0.558483,0.610026,0.653091,0.548287,0.439844,0.0899871,0.0835925,0.319389,0.644834,0.56976,0.819258,0.192455,0.362712,-0.239339,-0.30076,-0.026997,0.00175475,2.02364,2.16419,-0.0871906,-0.223853,1.45994,1.31178,-0.0540165,-0.214564,-1.46702,-1.35424
1521,0.334894,0.323469,0.161234,0.109771,0.515897,0.544536,0.527857,0.476542,0.793582,0.747574,0.881516,0.885714,0.155893,0.167145,0.56093,0.601801,0.393974,0.37385,0.886055,0.881726,0.660665,1.07437,0.182826,0.437592,-0.738723,-0.562082,-1.56598,-1.6334,-0.576569,-0.547021,0.741922,0.884018,0.89666,0.75985,-0.399308,-0.541443,-2.0006,-2.16173,0.853749,0.969905
1522,0.965072,0.954151,0.997235,0.947592,0.836472,0.83513,0.444136,0.469429,0.485799,0.44006,0.793554,0.797845,0.681567,0.694008,0.815221,0.857508,0.709422,0.688695,0.272963,0.266523,1.1853,1.5039,0.427802,0.684914,1.11777,1.29994,2.01557,1.94561,0.576372,0.60739,1.70095,1.84754,0.979107,0.83786,1.22219,1.07722,0.0284706,-0.128817,2.47809,2.59087
1523,0.591994,0.485437,0.537023,0.5076,0.45281,0.450514,0.824217,0.847741,0.911663,0.868343,0.138399,0.143112,0.698266,0.711795,0.140076,0.180151,0.681612,0.734293,0.0839742,0.0759025,0.752635,1.06955,1.09646,1.34808,-0.178128,0.00299493,1.05703,0.982543,-0.793906,-0.756832,-0.890947,-0.7474,-0.112261,-0.254536,-0.498551,-0.648652,0.594276,0.439756,-0.154566,-0.0445504
1524,0.0268041,0.0167226,0.114951,0.0676088,0.538107,0.483561,0.0700836,0.0950801,0.929831,0.886265,0.35947,0.353758,0.991667,1.00295,0.388089,0.430349,0.801685,0.779891,0.969899,0.964283,-0.785478,-0.471211,-0.407608,-0.162293,-0.282158,-0.0553625,0.85262,0.77981,-0.372129,-0.338215,0.979478,1.12217,-0.822985,-0.959719,-0.740449,-0.884507,-2.20266,-2.35159,-0.668612,-0.566166
1525,0.553802,0.543529,0.890342,0.843187,0.519463,0.516609,0.947849,0.974373,0.639705,0.642814,0.558308,0.564404,0.0321789,0.0408078,0.421929,0.412386,0.549259,0.526187,0.0752195,0.0686026,-1.27339,-0.953761,-2.3893,-2.14471,-0.287271,-0.11372,-0.865897,-0.944813,0.823346,0.864118,0.659144,0.799364,0.669264,0.532082,0.873948,0.734159,-0.525613,-0.593292,3.23955,3.33761
1526,0.2902,0.280027,0.993702,0.947191,0.055785,0.0521804,0.317682,0.342158,0.442532,0.399364,0.0328776,0.0401475,0.113584,0.0431772,0.352846,0.394422,0.0810272,0.0566701,0.945512,0.937618,-1.46996,-1.14364,0.11102,0.345918,-1.30077,-1.13332,-0.660189,-0.734171,0.359021,0.405432,-1.65941,-1.52033,-1.14562,-1.28188,-1.08976,-1.22622,1.31393,1.165,0.0833518,0.182506
1527,0.497498,0.486247,0.190858,0.142538,0.625125,0.620263,0.667183,0.690944,0.997575,0.953858,0.512391,0.47075,0.0386987,0.0455466,0.00154509,0.0423006,0.977722,0.954753,0.991481,0.984654,0.621839,0.952298,0.427276,0.655801,-1.15017,-0.980838,-0.897643,-0.968288,-0.732798,-0.678685,1.61821,1.76307,-0.545546,-0.682189,0.743158,0.610494,-0.847951,-0.990103,-0.709049,-0.610158
1528,0.302191,0.242042,0.984215,0.934595,0.366841,0.360264,0.788984,0.810402,0.0104738,-0.03543,0.892449,0.901352,0.362179,0.367438,0.0102507,0.0525795,0.0908248,0.0700433,0.056624,0.0507308,-0.000819597,0.330781,-1.58671,-1.35735,-0.566104,-0.397409,-0.42646,-0.499083,0.0508805,0.109503,1.52926,1.67,-1.54139,-1.68399,0.687243,0.557406,0.199636,0.0807734,0.462025,0.563725
1529,0.00733731,-0.00216199,0.365956,0.313722,0.891792,0.883733,0.509192,0.512209,0.862973,0.815868,0.869591,0.878176,0.0927827,0.0965048,0.73943,0.780231,0.270141,0.234837,0.784173,0.779194,0.125358,0.458602,-0.0295727,0.202791,-1.89482,-1.72579,0.830619,0.758485,-0.120971,-0.0583219,-0.710498,-0.566454,0.798381,0.649236,-1.08798,-1.21364,1.29676,1.15165,0.643343,0.750553
1530,0.753316,0.741805,0.312914,0.259241,0.792826,0.783061,0.191465,0.214016,0.385071,0.336913,0.169526,0.178855,0.342612,0.348669,0.279869,0.318822,0.378366,0.399632,0.144128,0.138531,1.48918,1.81605,-0.607487,-0.376132,0.991603,1.1666,-2.25924,-2.33613,1.34565,1.40267,0.456583,0.598439,-0.462308,-0.613703,0.879136,0.749521,0.0267452,-0.112422,-1.06953,-0.959503
1531,0.428637,0.368321,0.646745,0.595382,0.446433,0.422281,0.389583,0.426468,0.471709,0.51946,0.555428,0.563666,0.189305,0.194177,0.504723,0.542747,0.554586,0.564426,0.533636,0.527534,0.693912,1.03092,0.308054,0.54513,-0.937858,-0.769282,-0.624711,-0.700483,-0.512631,-0.454929,-0.239395,-0.0981234,-0.21708,-0.369701,-1.23873,-1.36709,0.466095,0.330836,0.0857992,0.199554
1532,0.00564456,-0.00516235,0.0764092,0.02401,0.0707466,0.0615011,0.617106,0.638919,0.749477,0.702007,0.300262,0.310675,0.823401,0.830765,0.24092,0.280912,0.749413,0.72922,0.0686664,0.0615778,-0.0814285,0.245783,0.715004,0.944921,0.140585,0.305952,0.679959,0.60219,-1.22019,-1.15613,0.921168,1.06677,-0.854683,-1.01384,-1.19899,-1.32808,-0.867513,-1.00067,-1.37926,-1.26366
1533,0.452756,0.442703,0.0512123,-0.00118462,0.163726,0.152618,0.468047,0.525116,0.321258,0.273539,0.99867,1.00706,0.309575,0.319165,0.648671,0.687357,0.0482804,0.0288135,0.375821,0.329873,-0.476849,-0.142337,0.712451,0.924409,0.105696,0.276472,-1.02368,-1.10548,0.408528,0.474414,1.2728,1.41939,0.269059,0.106559,2.38313,2.24829,0.917484,0.786297,0.274846,0.385632
1534,0.439123,0.427601,0.461631,0.408899,0.480557,0.553167,0.349629,0.411313,0.263443,0.213691,0.212073,0.220589,0.165876,0.194258,0.267913,0.306087,0.99909,0.979327,0.625967,0.598168,1.49689,1.82951,0.675439,0.903898,-1.16528,-0.988509,-0.0792683,-0.15663,0.441545,0.510215,0.809319,0.954884,-0.261941,-0.369344,-1.19799,-1.32643,0.10342,-0.0230688,-0.114654,0.00059332
1535,0.672995,0.659451,0.568019,0.517662,0.962248,0.953715,0.274522,0.29751,0.770809,0.72203,0.2327,0.265977,0.0624959,0.0693519,0.964097,1.00253,0.0964649,0.078495,0.873552,0.866464,-0.73034,-0.402469,-0.354678,-0.123903,-0.183885,-0.00519074,-1.50212,-1.5824,-0.993015,-0.927205,-1.40408,-1.25098,-0.680424,-0.845248,0.497512,0.371007,1.09586,0.968417,0.792763,0.913325
1536,0.551991,0.527598,0.176112,0.12357,0.604384,0.656708,0.505897,0.52806,0.796966,0.749425,0.305155,0.311365,0.856691,0.864407,0.0283434,0.0667247,0.586194,0.569289,0.437689,0.430242,-1.18254,-0.85088,1.3585,1.58834,-0.746218,-0.571764,-0.238089,-0.324836,-0.276122,-0.218356,0.136564,0.29568,1.34927,1.17863,0.308663,0.181351,0.123765,3.84516e-05,-4.24164,-4.12108
1537,0.407436,0.395746,0.41581,0.365688,0.36878,0.359701,0.0270696,0.0512092,0.467986,0.422262,0.817407,0.824177,0.261596,0.267808,0.420936,0.39852,0.235341,0.219677,0.815137,0.809976,-1.30911,-0.980641,1.27068,1.49744,0.502034,0.67125,0.0639436,-0.0209741,-0.707134,-0.670465,1.00148,1.16746,-0.0882682,-0.258831,-0.117639,-0.253137,0.68469,0.554682,-1.50388,-1.39038
1538,0.495659,0.486793,0.306135,0.230295,0.498784,0.491163,0.0376131,0.0824494,0.47158,0.350962,0.778443,0.734893,0.221539,0.189664,0.692429,0.730316,0.559923,0.545773,0.531091,0.524534,-0.26751,0.0675283,1.54307,1.75198,0.457261,0.707909,-0.206468,-0.287666,-1.17514,-1.12257,0.439037,0.611868,1.89037,1.71752,0.485221,0.353325,-0.1707,-0.301564,0.621166,0.740813
1539,0.29497,0.28854,0.14642,0.0949008,0.982509,0.974178,0.0536051,0.113689,0.325861,0.279661,0.636877,0.645609,0.102849,0.111521,0.254824,0.293421,0.167994,0.151571,0.511731,0.58959,-0.37558,-0.0343078,1.78562,2.00653,0.579095,0.744569,-0.835796,-0.923672,-0.3245,-0.295763,0.442805,0.610676,-0.0534499,-0.222723,1.57013,1.43498,1.95263,1.81636,0.701224,0.82149
1540,0.863532,0.855083,0.221572,0.168567,0.381264,0.374842,0.122929,0.14493,0.761794,0.717419,0.274427,0.283882,0.883703,0.892195,0.2459,0.228953,0.652764,0.636578,0.653081,0.654646,-1.28092,-0.948366,0.633024,0.855636,-0.731226,-0.567326,-0.501528,-0.590667,0.473785,0.531048,-0.0721847,0.100077,0.00815892,-0.159524,1.76583,1.62853,0.770649,0.681757,-0.39371,-0.276071
1541,0.333977,0.323865,0.675729,0.622923,0.660589,0.656127,0.353607,0.341173,0.0829734,0.037233,0.761142,0.771026,0.199409,0.21034,0.0442074,0.164486,0.699371,0.685645,0.668801,0.719702,-0.205587,0.128054,1.26119,1.48672,-0.521493,-0.352621,-0.672123,-0.764163,-0.182082,-0.123304,-1.34671,-1.18009,-0.741224,-0.910327,0.06999,-0.064667,-0.316579,-0.452848,0.102639,0.21295
1542,0.866305,0.855204,0.705135,0.744802,0.116347,0.111144,0.517141,0.537417,0.55788,0.510205,0.260372,0.270958,0.610829,0.621866,0.0614217,0.100019,0.131836,0.115715,0.791314,0.784758,-0.330098,-0.00170773,-0.177216,0.0527116,0.696633,0.856992,0.627794,0.53851,-1.1096,-1.05537,0.00195899,0.166215,-0.355627,-0.527882,0.213486,0.0828227,0.0159096,-0.118407,0.19584,0.309067
1543,0.110149,0.0999049,0.919863,0.866682,0.9957,0.988191,0.405708,0.424954,0.693149,0.655351,0.733931,0.743419,0.148692,0.161403,0.303163,0.339857,0.307696,0.290683,0.559362,0.57438,-0.0653891,0.264175,-0.166476,0.0687952,0.275237,0.430129,0.287444,0.195288,0.674735,0.727173,-0.336398,-0.172201,-1.00884,-1.18655,0.0106077,-0.122225,-1.28913,-1.41642,-0.864069,-0.7558
1544,0.0144928,0.00246644,0.432898,0.378906,0.369591,0.364072,0.882541,0.902445,0.846276,0.800497,0.979126,0.986071,0.810862,0.824614,0.0094238,0.0483257,0.698287,0.681574,0.373241,0.364003,-0.524302,-0.201142,0.28152,0.514708,0.433424,0.58261,0.573294,0.483706,0.57592,0.635072,-1.51981,-1.35832,-0.178995,-0.359017,0.225667,0.0853789,0.712005,0.587106,2.23504,2.35125
1545,0.870389,0.859253,0.703373,0.649942,0.0240838,0.019787,0.135459,0.154948,0.499112,0.529587,0.693748,0.667235,0.6309,0.644619,0.199885,0.239955,0.697607,0.681626,0.999905,0.988459,0.339109,0.660809,-1.49355,-1.26194,1.89108,2.03784,0.471157,0.463907,0.835515,0.982555,1.77042,1.92508,-0.0897045,-0.266844,-0.500292,-0.643165,1.02247,0.890013,-1.33612,-1.21909
1546,0.0934018,0.0813287,0.144995,0.0929599,0.65924,0.653558,0.942373,0.961301,0.317249,0.258677,0.383614,0.348398,0.178556,0.193779,0.864195,0.904279,0.287648,0.272711,0.287746,0.276564,-0.0900802,0.226458,1.15793,1.39589,1.2598,1.40692,0.532748,0.444108,1.27719,1.33004,1.90388,2.06236,-0.8528,-1.03379,1.28233,1.14599,0.637451,0.498649,1.08479,1.20525
1547,0.90962,0.899192,0.295684,0.241965,0.0469679,0.0395557,0.059781,0.0804544,0.0347201,-0.0122334,0.0226175,0.0295621,0.12069,0.1354,0.899111,0.891098,0.155397,0.140215,0.822264,0.811459,0.585903,0.906461,1.30175,1.54327,-0.179126,-0.0291343,-0.478814,-0.565771,2.12952,2.17898,0.508123,0.673206,-0.629565,-0.805612,-0.348911,-0.484914,-1.29921,-1.43392,-0.683461,-0.56375
1548,0.757851,0.746601,0.867205,0.813348,0.673357,0.668053,0.819585,0.838887,0.287946,0.208694,0.524237,0.53191,0.594891,0.607081,0.837575,0.877917,0.66195,0.64587,0.803641,0.801896,0.529302,0.852288,1.46114,1.69065,0.416089,0.568332,-0.717447,-0.799889,0.0206191,0.0783858,1.35937,1.52959,-0.89727,-0.991582,-1.24339,-1.38107,0.575199,0.435194,1.42065,1.53406
1549,0.849359,0.864694,0.592599,0.487663,0.33796,0.333392,0.623668,0.641476,0.546235,0.429621,0.180768,0.18916,0.77035,0.783542,0.355115,0.396837,0.228341,0.211134,0.827841,0.792333,-0.895745,-0.567284,-0.69851,-0.46391,2.09652,2.24276,-1.33743,-1.4192,0.201729,0.252449,-0.860403,-0.6925,-0.997884,-1.17755,0.148717,0.00735617,1.0813,0.94337,-0.496511,-0.376434
1550,0.995458,0.982786,0.214297,0.161979,0.729548,0.725311,0.641817,0.714971,0.688829,0.650549,0.739121,0.74544,0.725514,0.650121,0.975405,1.01695,0.747148,0.731575,0.894671,0.78277,-1.51402,-1.1888,-2.07578,-1.83415,1.57223,1.72254,0.887761,0.804961,-0.181503,-0.129873,-0.925185,-0.754749,0.394814,0.209074,2.38304,2.24556,0.725107,0.581534,1.06202,1.18332
1551,0.346509,0.331187,0.985335,0.932834,0.00174513,-0.004227,0.770659,0.788467,0.91843,0.871476,0.548402,0.483401,0.524818,0.516701,0.565627,0.706113,0.489495,0.482133,0.784012,0.773207,-0.981018,-0.659504,2.04751,2.29135,0.2421,0.394166,1.06352,0.986017,0.990927,1.04119,-0.146287,0.0250079,0.457995,0.272273,-0.638675,-0.770457,1.20096,1.05651,1.36858,1.49194
1552,0.231068,0.217146,0.57771,0.499513,0.0655836,0.0579534,0.614764,0.64304,0.84697,0.756364,0.216353,0.221362,0.370088,0.38328,0.355812,0.395275,0.247879,0.232691,0.101931,0.0921481,1.13091,1.45294,2.55232,2.8009,-0.442253,-0.284328,1.52997,1.45522,-0.0300318,0.0171927,1.88926,2.06829,-0.786121,-0.976657,0.348522,0.218717,-1.33734,-1.47922,-1.15313,-1.03162
1553,0.549373,0.533647,0.118693,0.0661921,0.332302,0.249616,0.575619,0.497613,0.680947,0.641251,0.884709,0.888016,0.958366,0.969542,0.704728,0.742519,0.217921,0.268903,0.176952,0.190342,0.0349,0.354807,-0.0500264,0.199332,-1.59739,-1.44423,0.00593072,-0.063711,-0.133349,-0.0894547,0.626573,0.804689,-0.807015,-0.990638,0.0340013,-0.0946146,0.605434,0.468893,-0.5691,-0.450948
1554,0.0893411,0.0725931,0.12493,0.0705658,0.518806,0.441278,0.334377,0.352186,0.574702,0.526139,0.680532,0.751327,0.524407,0.611981,0.840723,0.878077,0.320246,0.305115,0.29752,0.288535,2.14357,2.46725,-0.79102,-0.549065,-0.00837793,0.151216,-0.992713,-1.05766,-1.04574,-1.00427,2.48725,2.66047,0.226769,0.0365069,0.532001,0.405289,0.0759982,-0.063694,-0.477087,-0.35483
1555,0.19875,0.183302,0.529871,0.390614,0.640713,0.63294,0.695127,0.710705,0.917449,0.868737,0.60113,0.614638,0.242679,0.254419,0.548396,0.586546,0.597161,0.624133,0.0861044,0.0777387,0.202971,0.521703,0.0829392,0.328036,-0.683805,-0.527278,-0.241196,-0.309052,0.0538449,0.0894726,0.922086,1.0897,-0.60734,-0.789538,-2.17522,-2.30822,-0.126949,-0.270478,1.28888,1.4053
1556,0.92974,0.915924,0.762396,0.710663,0.0927011,0.0838768,0.523054,0.538466,0.892424,0.844612,0.53165,0.477949,0.770572,0.781281,0.622849,0.662962,0.956705,0.943151,0.207823,0.199187,-0.357047,-0.0567525,0.576168,0.82222,-0.0965239,0.0561512,-0.160528,-0.222832,-0.488936,-0.459303,-2.02952,-1.86325,-1.75455,-1.92954,-0.784718,-0.919794,0.424775,0.284165,1.06467,1.1851
1557,0.49474,0.480123,0.7765,0.769215,0.689115,0.681584,0.899836,0.916779,0.125296,0.0758139,0.337952,0.34126,0.294252,0.305136,0.951534,0.989365,0.570155,0.558685,0.562821,0.553069,-0.953941,-0.635208,-2.37667,-2.12551,-0.505502,-0.298403,0.843903,0.789664,-0.816043,-0.780507,0.573145,0.743919,-0.393058,-0.573778,-1.26966,-1.40002,-1.44321,-1.58745,0.0336051,0.151006
1558,0.362681,0.346843,0.804032,0.827766,0.0317298,0.0226083,0.34695,0.364139,0.38513,0.3279,0.670202,0.671368,0.634005,0.622031,0.227089,0.264655,0.643677,0.582668,0.0839009,0.0725071,0.224302,0.481244,-0.145741,0.110797,-0.80612,-0.652957,-0.684262,-0.741822,2.38297,2.42054,-0.0103743,0.0771864,-0.707898,-0.807535,-0.899485,-1.02131,0.0143527,-0.16805,0.953517,1.06374
1559,0.755422,0.739791,0.938781,0.886318,0.810752,0.800822,0.147539,0.166728,0.631101,0.579985,0.698008,0.791229,0.929392,0.938927,0.802687,0.838271,0.53994,0.606651,0.606667,0.509533,1.27099,1.5977,0.899358,1.15515,0.954381,1.11413,-0.0567879,-0.11978,0.901951,0.936944,-0.758293,-0.589546,-0.861181,-1.04129,0.992441,0.876862,1.38889,1.25134,-1.32526,-1.22092
1560,0.680556,0.583687,0.424251,0.373477,0.0767615,0.065223,0.805541,0.823765,0.592873,0.442781,0.912297,0.91109,0.116253,0.127227,0.291421,0.327001,0.642296,0.630634,0.957953,0.94656,-2.92651,-2.5984,-0.0638401,0.190506,0.151205,0.312712,-0.626698,-0.694353,-1.16699,-1.13104,1.33366,1.49968,0.861341,0.684948,-0.852448,-0.976363,1.27505,1.13773,-1.3996,-1.28724
1561,0.443085,0.427584,0.958097,0.905629,0.0440675,0.0297943,0.981224,0.998819,0.357962,0.305578,0.0136168,0.0101366,0.52253,0.534196,0.0077201,0.0454228,0.474039,0.462935,0.579992,0.570383,2.06702,2.39513,-1.94486,-1.68719,0.799662,0.95758,-0.302864,-0.376382,1.07906,1.1216,-0.630282,-0.457925,-1.11617,-1.28673,0.211604,0.091793,-0.45419,-0.587084,0.0465344,0.161966
1562,0.552801,0.510682,0.52317,0.472463,0.00838696,-0.00563432,0.0265554,0.0441842,0.0242803,-0.0265663,0.742499,0.741351,0.193136,0.203792,0.709001,0.7465,0.0844325,0.0728877,0.896399,0.888604,-0.231007,0.104646,-0.349522,-0.097151,-0.917205,-0.759429,-2.28521,-2.35662,1.83516,1.87715,1.79641,1.9757,1.04238,0.869974,-0.329731,-0.449733,2.11887,1.98183,0.427673,0.542993
1563,0.72093,0.593781,0.724467,0.66656,0.607721,0.592073,0.587271,0.607528,0.634333,0.583161,0.95429,0.954437,0.882568,0.891313,0.927381,0.964736,0.480102,0.430615,0.047874,0.0407954,0.502769,0.84592,-0.938047,-0.692257,1.33269,1.48507,-1.06709,-1.14489,0.183313,0.224637,0.0975973,0.281604,0.452333,0.28502,0.887587,0.766948,0.559422,0.41692,0.496597,0.581117
1564,0.699591,0.67688,0.909998,0.860657,0.525606,0.511949,0.939147,0.961419,0.0941826,0.0450079,0.12734,0.126399,0.685467,0.688513,0.273908,0.312251,0.798832,0.788342,0.453046,0.4451,0.303291,0.612883,-0.113944,0.139565,-0.0929075,0.063953,-0.336557,-0.411841,-1.05823,-1.01385,0.886192,1.07377,-1.88147,-2.05169,1.22666,1.11265,0.840339,0.703653,0.501021,0.619241
1565,0.784688,0.759979,0.152504,0.104252,0.783383,0.767429,0.657794,0.678469,0.845151,0.793839,0.302356,0.301173,0.477957,0.485714,0.185046,0.221472,0.894554,0.88124,0.14821,0.139911,0.0357652,0.379846,-1.84404,-1.59239,1.05151,1.21368,0.955842,0.87544,0.788316,0.832916,0.858144,1.04105,0.441607,0.267325,0.0229889,-0.0879006,-0.840524,-0.972625,1.17428,1.29166
1566,0.858579,0.843078,0.535399,0.489018,0.126508,0.108453,0.673336,0.786859,0.268648,0.21527,0.238726,0.300642,0.556548,0.564706,0.56283,0.59889,0.447148,0.431442,0.426203,0.417726,0.16075,0.603091,0.617206,0.870049,-0.332458,-0.177529,-1.37818,-1.45371,0.221802,0.269024,-0.75578,-0.575482,0.770127,0.589076,0.485291,0.380629,0.123747,-0.0148249,1.03826,1.14893
1567,0.790095,0.776799,0.0277191,-0.0195324,0.434635,0.415484,0.874417,0.89525,0.592912,0.537688,0.299712,0.300111,0.973883,0.981478,0.357995,0.392011,0.376066,0.360018,0.297175,0.288513,0.482803,0.826337,0.706875,0.962554,1.51646,1.66915,0.0105985,-0.0587349,-0.667256,-0.616284,0.762709,0.940131,0.226818,0.0493722,2.33072,2.23233,-1.59941,-1.73964,-0.276441,-0.162014
1568,0.46146,0.447085,0.0491198,0.00388469,0.194938,0.177119,0.556311,0.65744,0.18169,0.128498,0.645679,0.645762,0.746084,0.809304,0.587431,0.521895,0.275428,0.288594,0.739213,0.732069,-1.18276,-0.83817,-0.352533,-0.0952801,0.36544,0.431345,1.17021,1.10785,-0.243074,-0.197668,-1.3287,-1.15697,-0.605243,-0.776672,1.21222,1.10726,-0.0590779,-0.203114,1.03156,1.15012
1569,0.504731,0.47149,0.596014,0.551753,0.684619,0.665386,0.400442,0.419631,0.663904,0.611027,0.608284,0.556478,0.567825,0.637131,0.619762,0.65178,0.0654283,0.217169,0.733314,0.795948,1.02204,1.36793,0.876947,1.13928,-0.960287,-0.806465,-0.254607,-0.317929,1.90598,1.95483,-2.39291,-2.2218,-0.998342,-1.17489,-0.23275,-0.339792,1.26163,1.11374,-1.41967,-1.29875
1570,0.511728,0.495895,0.899367,0.853188,0.732034,0.712071,0.795595,0.813177,0.73978,0.65198,0.468197,0.467193,0.457808,0.464957,0.574085,0.605262,0.161451,0.145745,0.864917,0.859826,0.898954,1.25045,0.595941,0.865273,-0.430779,-0.181807,1.80343,1.74472,0.575326,0.621551,-0.204225,-0.0352432,0.644322,0.473509,0.94293,0.833768,0.940356,0.797864,-1.88529,-1.75885
1571,0.0169739,0.000500398,0.72253,0.678613,0.00799021,-0.0130902,0.282599,0.300266,0.745383,0.692933,0.955818,0.954337,0.532225,0.539093,0.0847392,0.114185,0.970718,0.953281,0.578809,0.611995,0.556447,0.908498,0.702665,0.900798,0.291535,0.442852,-0.204501,-0.263951,-0.965543,-0.92182,-0.040484,0.0932586,1.19553,1.02766,0.000844488,-0.10726,1.43175,1.28826,1.36402,1.48971
1572,0.433937,0.461636,0.123485,0.0770728,0.649929,0.63062,0.74323,0.762799,0.522307,0.470775,0.989211,0.985892,0.964173,0.970744,0.142092,0.169924,0.203379,0.184262,0.431282,0.364164,1.05164,1.40511,0.671109,0.936323,0.497836,0.6417,-1.0925,-1.15036,-0.481594,-0.443737,0.057498,0.22176,-0.102018,-0.269295,1.32893,1.21777,0.49237,0.348667,1.18758,1.36645
1573,0.936867,0.922771,0.67213,0.624941,0.981554,0.962623,0.826595,0.846352,0.778363,0.727626,0.0481976,0.0447683,0.627344,0.717082,0.602246,0.556299,0.514697,0.495045,0.119619,0.116334,-0.96699,-0.620405,-2.1778,-1.90527,-1.09027,-0.947361,0.592057,0.53269,-1.45671,-1.42266,-0.0778161,0.0824332,0.249993,0.0845578,-0.1745,-0.290226,-2.17561,-2.3132,1.14597,1.2432
1574,0.778927,0.700268,0.615458,0.566122,0.958489,0.938846,0.524601,0.560128,0.576756,0.525623,0.190437,0.240527,0.458531,0.463421,0.913914,0.942673,0.29805,0.276204,0.918304,0.914467,1.78569,2.135,0.567704,0.832823,-0.926005,-0.780859,1.21663,1.15473,-0.43086,-0.389197,-0.428277,-0.271162,1.71336,1.54812,-0.289772,-0.404076,0.0502196,-0.0852276,0.994267,1.11995
1575,0.494322,0.477765,0.440326,0.507302,0.131577,0.114285,0.255339,0.273905,0.048646,-0.0028382,0.440943,0.436286,0.727126,0.729838,0.883376,0.911596,0.953126,0.929857,0.263979,0.258162,-0.144903,0.205708,0.677827,0.929269,0.39509,0.538541,0.389739,0.331176,-0.70375,-0.663931,-1.04155,-0.89145,0.182687,0.0158581,-1.11444,-1.22175,-0.821837,-0.959011,-0.797713,-0.680811
1576,0.0803609,0.0624021,0.495672,0.448482,0.458743,0.442045,0.997357,1.01661,0.955137,0.903308,0.0246402,0.0203803,0.393415,0.394679,0.109319,0.135221,0.29365,0.269336,0.319266,0.234724,1.31023,1.65759,0.764123,1.02571,0.967144,1.1056,-1.02522,-1.08046,-0.574232,-0.537407,0.158146,0.303556,-0.924885,-1.09299,1.15403,1.04706,1.22517,1.09161,0.0141655,0.127454
1577,0.945025,0.928903,0.682148,0.637219,0.538193,0.472584,0.66515,0.683843,0.344516,0.293807,0.66151,0.65636,0.510828,0.528157,0.427367,0.45156,0.0224969,0.000464728,0.216721,0.211285,0.413607,0.759642,1.54248,1.81406,-0.229324,-0.0835333,-2.18862,-2.2457,-1.31514,-1.28472,2.39276,2.54117,0.499837,0.325462,0.0873278,-0.0152751,-1.41338,-1.55444,-2.3069,-2.19398
1578,0.707826,0.711798,0.387148,0.341907,0.520436,0.503123,0.573626,0.590871,0.220319,0.167469,0.803956,0.801345,0.694903,0.661635,0.967889,0.99434,0.207046,0.256466,0.599203,0.595449,-2.49193,-2.14285,0.107133,0.380053,-2.50584,-2.35584,0.104861,0.0503106,0.289145,0.315201,-0.967873,-0.819572,0.63533,0.462935,0.228623,0.132215,0.184334,0.046354,0.27728,0.387186
1579,0.509098,0.494694,0.333498,0.363856,0.0436083,0.0281471,0.195219,0.213255,0.517552,0.465045,0.165325,0.161689,0.79256,0.795114,0.664652,0.692777,0.533762,0.512467,0.132688,0.129492,1.25809,1.60953,0.773984,1.04322,-1.03276,-0.886463,0.419108,0.368282,2.10135,2.12951,0.272067,0.420039,-0.148525,-0.319435,-0.181537,-0.271543,1.01755,0.88067,-0.557624,-0.448889
1580,0.0790307,0.0639322,0.331655,0.385805,0.991676,0.976927,0.347246,0.428889,0.0547336,0.00132612,0.686575,0.683182,0.59929,0.57734,0.818334,0.844041,0.235148,0.213299,0.25792,0.255482,-0.648287,-0.30488,-0.506813,-0.231778,0.971028,1.11494,-0.4348,-0.487421,-0.703472,-0.673493,0.366397,0.511442,2.19203,2.01379,-0.307226,-0.40034,0.953382,0.813894,0.160981,0.26911
1581,0.367183,0.350779,0.401977,0.407754,0.659876,0.585012,0.62859,0.644524,0.660921,0.606462,0.030073,0.02845,0.357291,0.359567,0.274146,0.298518,0.363423,0.342669,0.802911,0.799613,-0.271046,0.0697394,-0.403802,-0.124852,1.62214,1.7598,-0.0128011,-0.0630266,0.429304,0.467244,-0.334019,-0.18512,1.184,1.01199,0.377488,0.282967,-1.69998,-1.84797,0.489242,0.591985
1582,0.372159,0.355928,0.474944,0.429703,0.208396,0.193096,0.0894238,0.106436,0.33948,0.284086,0.49364,0.481634,0.472436,0.408436,0.946832,0.96956,0.813358,0.792278,0.0731553,0.0714284,-0.516861,-0.180675,-0.0882684,0.221754,0.774655,0.912248,0.787759,0.731391,-0.176358,-0.143379,-0.733094,-0.584969,0.986031,0.722697,0.378456,0.290298,0.51443,0.365782,-0.48207,-0.381145
1583,0.174004,0.218675,0.596541,0.490905,0.525815,0.463947,0.785338,0.80382,0.272125,0.218359,0.937323,0.934818,0.455362,0.457305,0.416694,0.438511,0.311233,0.292525,0.284277,0.283943,-1.01279,-0.679487,0.293621,0.568361,0.933652,1.06473,-0.433752,-0.494552,-0.0557953,-0.0168546,-0.134089,0.0134436,0.605255,0.433405,1.39075,1.29728,-0.156894,-0.30517,1.35602,1.45809
1584,0.0959763,0.0814225,0.597529,0.552107,0.747569,0.734798,0.929864,0.948864,0.669139,0.616081,0.157622,0.154391,0.281765,0.282414,0.625941,0.645628,0.649967,0.628957,0.0707116,0.0686427,-0.254703,0.0781515,-0.335052,-0.0561704,-0.0308837,0.167702,0.020437,-0.0388289,1.29352,1.33576,-2.33055,-2.17535,1.02717,0.848689,-1.1188,-1.21428,1.36781,1.21754,-0.174056,-0.0657651
1585,0.955034,0.938209,0.0454803,0.0002324,0.770566,0.756074,0.449946,0.467054,0.785191,0.730203,0.227775,0.225439,0.6373,0.6398,0.272619,0.293506,0.453774,0.47497,0.808939,0.807027,-1.64535,-1.30963,0.555893,0.835579,-0.854144,-0.729324,-1.09994,-1.15664,0.244406,0.281901,-0.399396,-0.243216,-2.77028,-2.95224,0.152645,0.0618488,0.483474,0.329599,-3.12755,-3.01412
1586,0.389076,0.372246,0.971427,0.925996,0.426723,0.411789,0.224078,0.238883,0.2034,0.146264,0.700326,0.697899,0.536356,0.540142,0.865837,0.886655,0.401956,0.320982,0.885594,0.882834,-1.22081,-0.889779,1.86078,2.14524,0.329319,0.452528,-0.0392732,-0.100097,-0.186624,-0.146229,0.220933,0.370999,1.05427,0.871974,-0.423245,-0.509768,0.0255089,-0.125774,0.712476,0.825902
1587,0.610995,0.594046,0.123183,0.0751176,0.784465,0.768895,0.956639,0.971359,0.215414,0.159195,0.855382,0.814002,0.207722,0.209738,0.219683,0.239275,0.281078,0.166995,0.0258647,0.0254256,0.443128,0.777607,-0.127537,0.162815,-0.114617,0.0111124,-1.74047,-1.80777,-0.102984,-0.0640428,-0.357676,-0.199487,-0.907533,-1.08372,0.909279,0.815258,-1.62409,-1.76978,1.0871,1.1938
1588,0.197273,0.178683,0.206966,0.159481,0.281175,0.264758,0.212748,0.228286,0.493039,0.43438,0.934959,0.930105,0.619176,0.621264,0.400419,0.420397,0.0340175,0.0130075,0.746153,0.744954,0.107838,0.43565,1.23665,1.53318,-0.180011,0.0228115,-1.35614,-1.42934,2.33065,2.37474,-2.02901,-1.87599,-1.54289,-1.7125,0.420448,0.319503,0.75691,0.60489,-0.430449,-0.330058
1589,0.454107,0.435124,0.919868,0.869902,0.538095,0.520238,0.997886,1.01214,0.766475,0.709564,0.239714,0.234031,0.75998,0.761482,0.0766402,0.0984779,0.315594,0.294185,0.348658,0.42715,0.659011,0.992645,-1.1134,-0.815177,-0.0986594,0.0345107,0.720013,0.649704,1.46948,1.5196,1.76629,1.91583,0.226227,0.0586587,-1.0698,-1.17241,-2.94452,-3.09456,-1.13067,-1.03207
1590,0.36705,0.348148,0.238051,0.189306,0.0412256,0.025957,0.0597291,0.0723716,0.195248,0.136226,0.00326293,-0.00442284,0.50642,0.442463,0.578666,0.542698,0.309421,0.28854,0.110836,0.109346,-0.788985,-0.455918,-0.945799,-0.643909,-1.82925,-1.69507,0.893615,0.830759,-0.355924,-0.304708,-0.52693,-0.368035,0.335273,0.166956,-0.676911,-0.77962,-0.968157,-1.11326,-1.51227,-1.4171
1591,0.762322,0.741095,0.639475,0.589342,0.988826,0.974737,0.595477,0.609843,0.335631,0.27599,0.0406846,0.0318578,0.121625,0.123443,0.965081,0.986919,0.509007,0.489017,0.33784,0.337126,0.580696,0.916455,0.769191,1.06834,0.395888,0.530903,1.42708,1.36226,0.574393,0.620938,-0.851313,-0.690843,0.921797,0.751985,0.920348,0.824516,1.26584,1.11471,0.188902,0.278579
1592,0.0975465,0.0748393,0.63774,0.509139,0.0484041,0.0326389,0.0736003,0.0869063,0.0678928,0.0087504,0.96345,0.953675,0.714661,0.714811,0.59954,0.620133,0.186882,0.245644,0.297838,0.288868,1.6633,1.99287,0.335859,0.627305,-0.498687,-0.363531,1.62677,1.558,1.10286,1.14571,0.691484,0.855814,-0.197238,-0.373465,-0.300769,-0.392153,-1.30213,-1.45793,-0.898547,-0.804308
1593,0.692031,0.669861,0.496808,0.428936,0.755691,0.738132,0.77395,0.78898,0.380611,0.240897,0.257642,0.248653,0.154423,0.152999,0.539445,0.559478,0.0220333,0.00226993,0.241972,0.24061,0.00556574,0.328368,0.363081,0.660093,0.900939,1.02924,0.512036,0.3821,-0.50064,-0.46079,-0.366882,-0.209015,0.12877,-0.0653363,1.23418,1.1488,-0.610645,-0.764536,0.740032,0.829135
1594,0.220423,0.199391,0.398511,0.348732,0.87189,0.855319,0.30171,0.316802,0.530617,0.473043,0.920974,0.910387,0.695866,0.694653,0.255344,0.400558,0.137561,0.116833,0.791147,0.789545,1.36384,1.68581,-0.78662,-0.4908,0.835772,0.968582,-0.716495,-0.793797,1.27239,1.3067,0.105186,0.268229,0.413918,0.242792,1.52374,1.43548,-0.597453,-0.755223,1.26407,1.34859
1595,0.176885,0.15825,0.565049,0.51774,0.374328,0.355623,0.209985,0.168998,0.500734,0.466332,0.787068,0.77647,0.390048,0.388644,0.156645,0.241639,0.507103,0.426469,0.954411,0.951309,-0.0263814,0.298033,-0.779706,-0.488496,1.15403,1.2913,-0.554986,-0.628782,1.1305,1.19377,0.786647,0.955567,0.11041,-0.15237,-0.170925,-0.257718,0.615535,0.453493,0.28394,0.375457
1596,0.811201,0.794061,0.0243212,-0.0239763,0.102211,0.0812053,0.00456739,0.0211944,0.516404,0.459622,0.902468,0.890254,0.831144,0.830405,0.0618952,0.0827189,0.756219,0.736105,0.162687,0.160971,0.656657,0.978036,0.681266,0.976979,-0.157829,-0.0205988,-0.0603638,-0.129035,1.04136,1.08084,-0.523724,-0.35372,-0.384732,-0.547533,0.673978,0.594429,-2.6192,-2.78363,-2.26329,-2.16639
1597,0.246148,0.228098,0.96751,0.920889,0.785024,0.76609,0.504299,0.45541,0.192715,0.137245,0.131961,0.120137,0.401821,0.401021,0.0814895,0.103427,0.829813,0.809763,0.176522,0.1543,0.0245371,0.342101,-1.94474,-1.65546,-2.05466,-1.92316,-0.742204,-0.811861,1.87008,1.91409,-0.96093,-0.814097,-0.20581,-0.36499,1.26462,1.18503,0.43445,0.262831,-0.999003,-0.947214
1598,0.567826,0.549494,0.162267,0.116236,0.137113,0.117288,0.871258,0.889626,0.286808,0.232137,0.635618,0.622484,0.783853,0.782477,0.899872,0.921666,0.533626,0.515537,0.150169,0.147628,0.497574,0.808995,-0.829618,-0.546076,0.645202,0.780719,-0.0245586,-0.0956536,-1.69531,-1.65185,-1.44448,-1.27447,-1.08998,-1.25679,0.665074,0.581944,-1.31726,-1.4954,0.175063,0.271962
1599,0.264742,0.244834,0.651302,0.603935,0.40982,0.388557,0.721099,0.737505,0.736588,0.680339,0.937506,0.923876,0.0907993,0.0905515,0.476013,0.499711,0.00240454,-0.0136293,0.689273,0.687021,0.501011,0.814417,-1.05538,-0.777067,-0.200812,-0.0668375,1.61491,1.53999,1.79747,1.83576,-0.548671,-0.386123,0.00773385,-0.0678212,-0.711939,-0.788262,1.95325,1.7766,-0.307511,-0.265781
1600,0.446475,0.425359,0.379436,0.333183,0.9819,0.961104,0.0466607,0.0655335,0.0483152,-0.00954449,0.0419896,0.029209,0.839315,0.840064,0.597919,0.54453,0.438928,0.42127,0.399249,0.396212,-0.832288,-0.513338,-1.7572,-1.47821,0.974979,1.11501,-1.32825,-1.40553,1.30313,1.34898,-0.157138,0.0124556,1.28765,1.12114,-1.32778,-1.4073,-1.36453,-1.54469,-0.906031,-0.803523
1601,0.0529167,0.0292094,0.976104,0.929489,0.969483,0.947616,0.669932,0.688107,0.534245,0.478786,0.0124631,0.00146796,0.200944,0.202621,0.586663,0.589349,0.317866,0.276552,0.996793,0.994693,-0.914705,-0.599514,0.865336,1.14399,0.709668,0.856204,-0.0855987,-0.164677,-0.402141,-0.35095,1.85434,2.01881,0.913716,0.753967,-1.5776,-1.65879,-0.355347,-0.538207,0.994746,1.09502
1602,0.913758,0.890086,0.133321,0.0892796,0.654388,0.633088,0.582624,0.599914,0.268455,0.211547,0.770898,0.758334,0.977053,0.978535,0.608509,0.634168,0.148585,0.131835,0.1945,0.190164,0.504771,0.819672,0.0637023,0.335412,0.146812,0.289631,0.0494879,-0.0200094,-0.284416,-0.168832,-1.94086,-1.77196,-0.607294,-0.761968,-2.27739,-2.35505,-0.988156,-1.1775,0.453891,0.556792
1603,0.630692,0.606038,0.44093,0.378365,0.106328,0.0840244,0.158042,0.172751,0.970862,0.912617,0.0566377,0.042734,0.263894,0.266286,0.42057,0.447223,0.994652,0.977101,0.587062,0.584729,1.56951,1.88156,-0.0753439,0.199436,-0.0189884,0.123217,0.196638,0.124658,-0.0368065,0.0132855,-2.4662,-2.29696,0.711976,0.564388,-1.60677,-1.68631,1.72372,1.53874,0.369249,0.472339
1604,0.975788,0.953033,0.713756,0.667451,0.865212,0.840492,0.435709,0.545682,0.433437,0.374464,0.598967,0.584509,0.481613,0.482751,0.9734,1.00042,0.33532,0.316581,0.613881,0.516421,-1.94209,-1.62868,-0.625708,-0.350205,-0.957744,-0.816511,1.2929,1.22678,0.37165,0.416838,0.426738,0.591835,-1.67034,-1.82015,-1.2555,-1.34568,0.466039,0.274668,-0.404754,-0.305446
1605,0.353456,0.332317,0.723114,0.676495,0.770382,0.74451,0.90503,0.918613,0.237724,0.177343,0.510761,0.534802,0.991552,0.993569,0.558654,0.583929,0.228191,0.209301,0.451447,0.448113,-1.66973,-1.3628,0.263962,0.541545,-1.69083,-1.55447,-0.852451,-0.923559,-0.582108,-0.53124,0.344057,0.514099,-0.286136,-0.433521,-0.928272,-1.00505,-0.1734,-0.364627,0.786777,0.885776
1606,0.847888,0.828722,0.939183,0.893825,0.024212,-0.00140972,0.536162,0.551804,0.954603,0.89476,0.597286,0.485094,0.342558,0.345393,0.687139,0.693884,0.733145,0.714956,0.621433,0.620285,-0.258251,0.0563849,0.470014,0.743518,1.47982,1.62027,0.111166,0.0403687,-0.439383,-0.3895,-0.451183,-0.221996,0.145716,-0.00152597,-0.168004,-0.246131,-0.522862,-0.712564,1.76535,1.85942
1607,0.961115,0.939431,0.290236,0.243302,0.960013,0.934391,0.845462,0.861526,0.42106,0.361614,0.451607,0.435387,0.560009,0.561316,0.778564,0.803839,0.0120288,-0.00586958,0.241526,0.239879,-0.0441541,0.275272,0.347406,0.623031,-1.25497,-1.11703,0.170846,0.0987546,0.882109,0.934919,-1.13088,-0.95809,-0.619601,-0.768474,2.03165,1.94667,0.876515,0.68716,-1.28039,-1.18141
1608,0.858274,0.894064,0.205358,0.159971,0.759085,0.64658,0.175761,0.193959,0.566492,0.506068,0.0612133,0.0432537,0.775042,0.777238,0.355625,0.381884,0.2858,0.320658,0.853181,0.853516,-0.413916,-0.0984688,-0.587225,-0.30922,-0.503484,-0.363853,-0.901494,-0.973165,-1.77726,-1.71726,0.8711,1.04826,-0.504643,-0.660177,-0.140171,-0.219287,-1.15295,-1.34308,-0.174992,-0.0695941
1609,0.867784,0.848697,0.664606,0.618465,0.38568,0.358769,0.275934,0.293182,0.347244,0.290212,0.646879,0.628915,0.0811031,0.085313,0.39903,0.427274,0.665562,0.647185,0.0453286,0.043911,-0.360188,-0.0477986,1.37724,1.65392,-2.50442,-2.36144,-1.09344,-1.16295,0.595198,0.652266,-1.25003,-1.07672,0.222309,0.0616689,-1.47876,-1.55989,-0.879042,-1.07263,-0.711421,-0.607827
1610,0.00661062,-0.0150498,0.579216,0.535134,0.363596,0.288238,0.05765,0.0756579,0.137034,0.0743556,0.503626,0.38775,0.735538,0.738072,0.96669,0.994783,0.677043,0.657206,0.700103,0.698457,0.422408,0.739077,0.576437,0.836783,0.115465,0.263449,1.98614,1.91379,0.433932,0.486523,1.05093,1.2202,-1.92632,-2.08096,-0.947562,-1.02883,-1.26933,-1.46399,0.631447,0.733285
1611,0.353425,0.29536,0.890614,0.846249,0.206258,0.217706,0.228932,0.245792,0.761675,0.698542,0.16288,0.146584,0.11555,0.117328,0.021782,0.0477749,0.466992,0.458387,0.135492,0.132865,-1.46972,-1.16073,-0.262205,0.019649,-0.618863,-0.474507,-0.157829,-0.236543,0.264845,0.32078,-1.42844,-1.26154,-0.806699,-0.960563,0.00285011,-0.0833251,-3.35211,-3.54139,-0.444788,-0.349602
1612,0.626861,0.60577,0.830183,0.787059,0.173644,0.147175,0.776847,0.793183,0.886186,0.822938,0.411248,0.394693,0.402655,0.403874,0.450119,0.474389,0.194326,0.259567,0.225244,0.224337,-0.254522,0.0535594,1.08902,1.37505,0.976275,1.12094,1.07477,0.990552,0.375614,0.432474,-0.0945497,0.0708316,1.61448,1.45388,0.715116,0.63128,-1.08176,-1.26495,-0.207135,-0.116571
1613,0.744073,0.721777,0.376501,0.333842,0.491035,0.463888,0.0311792,0.0456865,0.432097,0.369548,0.0323519,0.0178682,0.376488,0.465074,0.663024,0.685801,0.0779208,0.060748,0.843665,0.84299,1.24307,1.55269,-1.37268,-1.08497,1.66967,1.8129,0.795261,0.708078,-0.362134,-0.300335,0.548201,0.714867,0.239884,0.0808205,-0.609974,-0.694459,0.179242,-0.0101046,1.33127,1.42471
1614,0.257012,0.235183,0.30213,0.177496,0.557926,0.558197,0.240043,0.256672,0.624714,0.564842,0.666519,0.653848,0.525031,0.526275,0.203072,0.224392,0.597536,0.581189,0.386508,0.386774,-0.738882,-0.425256,0.752098,1.03891,0.0911107,0.240619,-0.631973,-0.717697,0.386997,0.412933,-0.148073,-0.0336464,-0.193157,-0.348753,1.12786,1.04998,-0.190614,-0.386482,0.378662,0.466137
1615,0.485276,0.461739,0.0656928,0.0211508,0.767884,0.652507,0.123227,0.138745,0.169581,0.111453,0.0513035,0.0389374,0.880011,0.883661,0.0872856,0.107845,0.0236827,0.00660349,0.270978,0.366444,0.585458,0.900425,0.0929573,0.383559,-0.118393,0.0350316,-1.64251,-1.72758,1.06964,1.1262,-0.95124,-0.78216,-1.22257,-1.38042,-0.839301,-0.910393,0.538575,0.338004,-0.040036,0.0495703
1616,0.142902,0.121504,0.728157,0.68536,0.773964,0.746816,0.548623,0.563007,0.342319,0.286539,0.817369,0.806825,0.110411,0.113168,0.720393,0.742785,0.506187,0.477955,0.347506,0.346113,-0.167051,0.141826,0.523486,0.730165,-0.329178,-0.170556,0.0591587,-0.0298362,-0.974777,-0.924329,1.10828,1.27885,-1.89067,-2.05502,0.383615,0.306288,-1.25019,-1.45215,-0.877584,-0.786505
1617,0.491754,0.468499,0.0127576,-0.029544,0.126232,0.0980151,0.192403,0.205994,0.17269,0.115921,0.895969,0.887647,0.120236,0.110497,0.976521,0.998492,0.966387,0.949307,0.857204,0.854615,-0.384722,-0.0788225,0.787032,1.07677,-0.00813489,0.152157,4.12902,4.04592,0.886899,0.93577,0.309012,0.475235,-0.076848,-0.232722,-1.96433,-2.04179,2.72758,2.52926,-0.578236,-0.494279
1618,0.295524,0.270246,0.845009,0.802679,0.412622,0.384531,0.878568,0.893727,0.808656,0.750454,0.10451,0.096693,0.194113,0.107826,0.194982,0.216951,0.710928,0.695603,0.728985,0.725402,-1.87076,-1.55738,-1.00418,-0.716311,1.09788,1.2558,-1.2504,-1.3335,-1.1118,-1.06249,1.5003,1.67024,-0.0820031,-0.231609,0.668196,0.591013,-0.158568,-0.361536,1.40361,1.49325
1619,0.967996,0.941467,0.332573,0.289838,0.308769,0.278487,0.359685,0.375854,0.662437,0.604045,0.672539,0.663121,0.100406,0.105154,0.697353,0.718185,0.966138,0.951751,0.150371,0.145191,-0.0522591,0.263075,-1.43714,-1.14082,0.428795,0.545279,-0.222509,-0.306825,1.10235,1.15728,-1.01579,-0.842847,0.750966,0.595925,-0.151789,-0.226664,-0.483905,-0.69249,-1.0572,-0.968889
1620,0.571734,0.545317,0.336361,0.375148,0.469721,0.439756,0.169333,0.184256,0.19471,0.13574,0.117866,0.108935,0.565271,0.572234,0.623008,0.637018,0.54648,0.532886,0.906363,0.900256,-0.621541,-0.311199,1.42732,1.72353,-0.320813,-0.165243,1.25545,1.17026,1.75912,1.82172,0.0669037,0.244397,-3.15163,-3.31143,1.00841,0.931165,0.0200801,-0.253202,-0.396862,-0.311836
1621,0.718894,0.597894,0.500944,0.460458,0.237887,0.237796,0.504011,0.51801,0.728645,0.669502,0.862193,0.855063,0.0218946,0.0299698,0.532768,0.555851,0.345579,0.33008,0.183481,0.177776,1.00681,1.31167,0.156796,0.417105,-2.13483,-1.97566,0.956102,0.872513,-0.0374612,0.0273183,0.408556,0.578925,0.678887,0.51278,-1.54285,-1.62474,0.390104,0.186087,-0.226781,-0.139389
1622,0.775146,0.650472,0.119324,0.076096,0.0668086,0.035836,0.199335,0.215579,0.162248,0.101579,0.764918,0.697909,0.0827753,0.168886,0.865457,0.887709,0.620186,0.546748,0.666085,0.661477,-0.239284,0.060873,-1.18048,-0.889324,-1.30048,-1.14366,1.74769,1.66693,1.59294,1.65787,-1.13216,-0.960584,0.321157,0.160004,-0.155561,-0.236309,-0.131605,-0.330429,-1.45209,-1.35909
1623,0.731582,0.703049,0.336122,0.293426,0.609295,0.578736,0.802246,0.818337,0.6694,0.609917,0.547413,0.540755,0.302004,0.307801,0.939207,0.959296,0.778674,0.763416,0.847706,0.843802,0.778762,1.07778,-0.703312,-0.413083,0.543473,0.703021,0.299106,0.225186,0.222651,0.293645,1.09144,1.25727,0.640392,0.481755,-0.610106,-0.685666,-0.34192,-0.526554,1.16177,1.25292
1624,0.41083,0.383829,0.192516,0.14972,0.864301,0.834216,0.55757,0.575205,0.759583,0.69844,0.195516,0.188436,0.566285,0.574218,0.418913,0.438198,0.74,0.647781,0.7909,0.785465,-1.88062,-1.57746,2.60527,2.897,-1.15265,-0.996873,0.450068,0.375942,-0.906773,-0.836681,0.367659,0.530841,-0.040916,-0.192844,1.68451,1.60396,-0.5176,-0.72268,0.21314,0.308961
1625,0.813283,0.786773,0.534154,0.490363,0.281104,0.250512,0.716342,0.734829,0.00683638,-0.0545927,0.923674,0.914298,0.461576,0.469451,0.651596,0.552574,0.547322,0.532146,0.403328,0.400152,0.244161,0.549857,0.837212,1.13448,-0.917183,-0.765924,-0.32277,-0.400431,0.664,0.732894,-0.986693,-0.827032,1.25216,1.1004,-0.61234,-0.698789,-1.41264,-1.61062,0.596589,0.689988
1626,0.524389,0.497357,0.221495,0.179772,0.596725,0.567225,0.271446,0.288938,0.0300234,0.0803986,0.292976,0.284384,0.997468,1.00585,0.70533,0.66695,0.224318,0.207603,0.492523,0.491624,-0.179114,0.130549,1.62941,1.92282,-1.1569,-1.01041,0.517835,0.439582,-0.915385,-0.843751,-0.579018,-0.415366,1.85656,1.7001,-1.85931,-1.94557,1.57718,1.37255,-1.79064,-1.69512
1627,0.587103,0.604024,0.535999,0.474126,0.3599,0.379742,0.369854,0.321326,0.218421,0.21539,0.456261,0.449546,0.0204965,0.0288794,0.762041,0.781326,0.727437,0.713258,0.127787,0.125464,-1.60392,-1.28902,-0.0585492,0.23872,0.636716,0.787865,0.225974,0.141832,0.56952,0.647752,1.49741,1.65846,-0.259818,-0.412553,2.01895,1.93304,-0.945633,-1.14841,0.82009,0.916895
1628,0.736285,0.71069,0.813181,0.76848,0.269159,0.19226,0.338161,0.353715,0.412626,0.350381,0.946678,0.942172,0.683779,0.69209,0.38853,0.402327,0.617657,0.60127,0.177415,0.172499,-0.491332,-0.181515,0.516722,0.808865,0.910322,1.06547,0.509638,0.393712,-0.737921,-0.652504,-0.614501,-0.452954,-1.16508,-1.31957,0.868704,0.780339,-0.402466,-0.609753,0.870562,0.969729
1629,0.271432,0.244869,0.593443,0.5491,0.0370271,0.00477712,0.904939,0.921398,0.164503,0.159797,0.332022,0.327261,0.867873,0.811233,0.00322088,0.0233288,0.290008,0.271975,0.887775,0.881226,-0.994296,-0.680327,-0.227748,0.0973936,-0.491753,-0.340488,0.725899,0.645593,1.06215,1.14701,1.37767,1.53968,-0.958334,-1.10674,0.956239,0.864928,-1.7686,-1.97003,-0.706637,-0.597918
1630,0.741339,0.71676,0.771904,0.727788,0.479459,0.448523,0.707608,0.756587,0.0338581,-0.0307871,0.968949,0.963241,0.920498,0.930375,0.942273,0.962574,0.466571,0.446943,0.417013,0.410212,-0.309387,-0.000323876,-0.90622,-0.614077,-0.11455,0.0425442,-1.14947,-1.23292,0.0906351,0.168084,0.110852,0.27608,-1.63133,-1.85317,-0.917015,-1.00228,-0.0340815,-0.243223,0.448459,0.561139
1631,0.425502,0.401765,0.0990094,0.0567698,0.300718,0.272155,0.576811,0.591775,0.666073,0.603746,0.347267,0.343069,0.226833,0.23845,0.0594855,0.0791015,0.0979707,0.0775865,0.197443,0.189563,1.16203,1.46732,0.98895,1.28368,-0.234535,0.0130776,0.800602,0.720513,-1.31295,-1.2401,0.727948,0.890296,-2.45025,-2.5996,0.214113,0.12663,0.703666,0.497209,-0.323057,-0.216646
1632,0.844531,0.81983,0.808825,0.767191,0.741042,0.71148,0.61294,0.715943,0.880668,0.819002,0.0756156,0.070147,0.23849,0.251399,0.52081,0.498142,0.781756,0.759865,0.475194,0.467377,-1.26191,-0.949898,0.679462,0.977513,-0.173484,-0.016389,-0.505902,-0.582231,0.410222,0.481391,0.871479,1.02758,-0.98171,-1.13603,0.835197,0.748153,-0.752101,-0.957555,-1.69969,-1.58819
1633,0.113458,0.0905856,0.0461685,0.00579113,0.30381,0.272257,0.825572,0.840111,0.662058,0.601944,0.794882,0.791503,0.639904,0.564617,0.89634,0.917183,0.354683,0.330774,0.0749599,0.0668158,0.951863,1.26937,-1.11403,-0.815569,0.81287,0.96693,-0.250293,-0.325802,-0.0294635,0.0378185,1.2445,1.39297,1.34024,1.18298,-1.43689,-1.51997,-0.800407,-1.01067,0.59995,0.705355
1634,0.684561,0.662046,0.0362041,-0.00472891,0.0817709,0.0502599,0.358342,0.373453,0.233428,0.173476,0.238074,0.232655,0.865732,0.877835,0.128786,0.150773,0.648405,0.590986,0.703166,0.696346,0.139136,0.521146,0.582849,0.882054,-1.50995,-1.35113,0.563242,0.483672,0.446164,0.515902,-0.922113,-0.782097,0.0221105,-0.129804,0.125448,0.0364708,-2.02071,-2.22753,-0.33192,-0.224277
1635,0.28767,0.265896,0.408855,0.441128,0.552927,0.523854,0.846017,0.861918,0.292697,0.230504,0.692576,0.685976,0.784512,0.798499,0.773992,0.795056,0.876725,0.851197,0.618498,0.613146,-0.548127,-0.227077,1.41306,1.71388,-1.03262,-0.876209,0.924803,0.848109,-1.15882,-1.0906,-1.26957,-1.13569,1.01632,0.870065,-0.857635,-0.949853,0.657033,0.446849,1.18657,1.28905
1636,0.249164,0.229526,0.929706,0.886985,0.00643632,-0.0211281,0.816794,0.835045,0.612391,0.547488,0.783715,0.776745,0.21724,0.231086,0.682654,0.757199,0.315329,0.29135,0.738879,0.734595,-1.1216,-0.80135,-0.232275,0.0614655,-1.49574,-1.33374,-0.517608,-0.593636,-0.055693,0.0175245,1.88604,2.01404,-0.768245,-0.912712,0.654452,0.558896,1.45177,1.24788,0.613724,0.722464
1637,0.661595,0.642847,0.304493,0.261434,0.575483,0.546955,0.000761165,0.0181133,0.718266,0.651287,0.619159,0.614125,0.967124,0.980599,0.703257,0.719342,0.659663,0.637726,0.343044,0.339318,0.732083,1.04965,-0.569321,-0.273101,1.45501,1.61934,-1.07434,-1.15196,-0.721603,-0.654258,-1.82363,-1.69284,0.50962,0.363518,0.0925092,-0.0832984,-1.04834,-1.25598,-0.475352,-0.360423
1638,0.0190167,0.00145807,0.693435,0.651416,0.754631,0.728277,0.353121,0.372005,0.449247,0.299922,0.851903,0.847504,0.378125,0.393292,0.660422,0.681485,0.718462,0.695885,0.866781,0.86375,0.488039,0.799238,0.144896,0.43473,0.310932,0.476422,-1.12368,-1.20165,-0.428189,-0.358796,0.471122,0.604089,1.0317,0.885273,-0.635193,-0.725492,0.161218,-0.0472676,-0.197552,-0.082332
1639,0.482199,0.463685,0.445249,0.49507,0.349998,0.39268,0.919141,0.939688,0.0178077,-0.0514434,0.677173,0.603762,0.116902,0.13259,0.0516236,0.0706248,0.392371,0.371342,0.48376,0.483344,1.07422,1.3103,-0.354143,-0.0669592,2.40791,2.57445,-0.183705,-0.268261,1.39571,1.4727,0.403051,0.541839,1.207,1.05343,1.23146,1.14177,-1.53525,-1.74025,0.944986,1.06026
1640,0.125038,0.108386,0.382187,0.338725,0.0837056,0.0570827,0.49638,0.518336,0.842044,0.77042,0.364614,0.36002,0.561845,0.578737,0.761401,0.782636,0.822656,0.801799,0.816263,0.816969,1.51472,1.82136,0.215797,0.503185,0.616294,0.781351,-1.18719,-1.27814,0.725809,0.730749,0.929021,1.06399,-0.757834,-0.918247,-1.07726,-1.16097,0.532757,0.326393,0.0756051,0.19086
1641,0.404797,0.390083,0.947141,0.905207,0.52209,0.475275,0.477546,0.501162,0.426781,0.356349,0.389061,0.484652,0.610621,0.66074,0.538004,0.616359,0.0963258,0.0761027,0.195958,0.196269,0.983286,1.29344,-0.512035,-0.228827,0.866214,1.02838,-0.124413,-0.221595,-0.084873,-0.0112007,0.738923,0.849578,-0.560496,-0.772032,1.29792,1.21674,-0.535248,-0.735052,0.656394,0.771528
1642,0.482227,0.465728,0.68648,0.644113,0.92009,0.893467,0.660776,0.665507,0.522497,0.427303,0.519235,0.609285,0.727675,0.742744,0.430232,0.450081,0.567382,0.546653,0.71086,0.709785,-0.690554,-0.385327,-0.925476,-0.639308,-1.50681,-1.33965,-0.451741,-0.549275,-0.260174,-0.194533,0.504839,0.635162,-0.461034,-0.625816,-0.563077,-0.650472,0.995973,0.801471,-0.950295,-0.828644
1643,0.333424,0.248624,0.911038,0.866974,0.839634,0.806199,0.807619,0.829851,0.566734,0.498257,0.710047,0.733917,0.347288,0.361803,0.600049,0.621276,0.170027,0.147709,0.478255,0.481509,-0.552856,-0.242654,-0.801074,-0.516055,-0.237018,0.0216139,-0.53499,-0.629878,-0.897833,-0.834727,1.86146,1.99707,0.417778,0.24871,1.66526,1.57092,-0.266996,-0.462601,-0.595908,-0.476711
1644,0.0500983,0.0315202,0.777828,0.793252,0.745857,0.718932,0.226147,0.246565,0.228873,0.161049,0.863145,0.85855,0.963144,0.977979,0.0798426,0.100178,0.99966,0.97621,0.135229,0.253232,-1.78158,-1.47659,1.61458,1.90204,1.21922,1.38288,-0.085966,-0.174155,1.67768,1.73552,-0.474889,-0.337394,-2.2945,-2.46115,-0.642705,-0.731826,-1.25126,-1.44582,-1.64787,-1.52546
1645,0.400283,0.309833,0.810925,0.719531,0.467614,0.440349,0.639024,0.660586,0.697035,0.628868,0.546708,0.520432,0.790441,0.803088,0.156936,0.176594,0.471994,0.447044,0.0260314,0.024956,0.42375,0.729508,0.867898,1.14888,0.37049,0.485854,1.58215,1.49205,0.20839,0.266855,-0.887062,-0.753726,2.12514,1.95848,0.233276,0.150164,2.49072,2.29551,-1.11833,-0.991729
1646,0.609319,0.588145,0.687379,0.64581,0.920651,0.893858,0.378199,0.397147,0.385466,0.316175,0.189315,0.182314,0.244475,0.256233,0.599123,0.562969,0.195015,0.168527,0.118965,0.116427,0.4718,0.780178,0.115636,0.395725,-0.578533,-0.411172,0.626048,0.533267,0.913928,0.975703,0.494214,0.622513,0.168876,0.00279368,-0.464738,-0.546103,0.484581,0.297575,-0.0225871,0.104968
1647,0.428414,0.497883,0.256225,0.212643,0.511703,0.444626,0.653025,0.612781,0.833871,0.764377,0.933456,0.928442,0.495197,0.508397,0.930612,0.949343,0.747553,0.723742,0.659578,0.65582,0.195597,0.499055,-1.77134,-1.49414,0.988503,1.15201,-0.340247,-0.425517,0.660339,0.714844,0.0374744,0.158003,-0.0859525,-0.255626,-0.923012,-1.01123,1.57309,1.38149,0.266177,0.397194
1648,0.426834,0.407621,0.580397,0.538802,0.0212405,-0.00460595,0.807897,0.828416,0.973973,0.813973,0.242728,0.238343,0.998008,1.01071,0.921019,0.939348,0.160662,0.138762,0.924072,0.91885,0.194768,0.504477,0.0526734,0.327675,-1.91908,-1.76115,0.459576,0.368901,-2.26505,-2.20941,-3.29422,-3.17035,-1.71533,-1.87888,0.487202,0.392648,0.0726397,-0.122192,0.128919,0.254459
1649,0.0993327,0.0779069,0.17852,0.135148,0.547773,0.523929,0.189917,0.210764,0.933465,0.863569,0.501402,0.497622,0.182633,0.19365,0.210902,0.230716,0.899734,0.875519,0.816866,0.813145,1.80897,2.11131,-1.37372,-1.10633,-0.523511,-0.368375,-1.41524,-1.50961,-0.179832,-0.123563,-0.218667,-0.101696,-0.0513751,-0.214374,0.161162,0.0653496,-0.883934,-1.07681,0.691173,0.820434
1650,0.47602,0.455982,0.792491,0.750155,0.657971,0.654122,0.510555,0.530395,0.0110032,-0.0584076,0.475404,0.469881,0.993672,1.0045,0.16868,0.189414,0.741986,0.680291,0.403625,0.455139,0.702405,0.997648,0.141674,0.404503,0.32919,0.476577,-1.85026,-1.94688,0.75865,0.817667,1.10453,1.21443,1.37769,1.21804,0.387346,0.289853,1.22698,1.04111,-1.39949,-1.27503
1651,0.56899,0.54703,0.711943,0.672362,0.863067,0.784315,0.396584,0.341765,0.0744008,-0.0159156,0.786487,0.780071,0.150013,0.158865,0.5723,0.590973,0.509673,0.485063,0.0993569,0.0971331,-0.753589,-0.450915,-0.22041,0.0400888,1.16713,1.32153,0.818235,0.718504,-0.248688,-0.19192,0.712509,0.814584,-0.118149,-0.28161,-0.558032,-0.651175,0.308635,0.119589,-1.6226,-1.49522
1652,0.0814141,0.0604359,0.386333,0.346837,0.938352,0.914508,0.133773,0.153135,0.0955379,0.0265764,0.0823929,0.0750495,0.405839,0.415465,0.261462,0.278896,0.951467,0.92455,0.463245,0.438803,-0.436702,-0.137689,-0.348844,-0.0958874,-1.57572,-1.41577,0.851736,0.744405,-0.254904,-0.202348,-0.743006,-0.633648,1.31116,1.1508,-1.83644,-1.93041,-0.309588,-0.503474,-0.0447857,0.0778295
1653,0.380451,0.338748,0.320676,0.282704,0.192442,0.168588,0.293689,0.312758,0.705951,0.636304,0.739713,0.731548,0.186413,0.194304,0.572788,0.590086,0.365614,0.339569,0.782213,0.780473,0.658282,0.953763,-0.689215,-0.430453,0.185546,0.35132,2.22294,2.10935,-1.56253,-1.5026,-2.61453,-2.51003,-0.991172,-1.15376,-0.793144,-0.872732,-0.0837841,-0.278247,-1.2279,-1.11117
1654,0.636101,0.617061,0.693084,0.656911,0.711336,0.687494,0.0194614,0.0397309,0.793671,0.724827,0.28043,0.270639,0.521675,0.531983,0.682379,0.700794,0.258786,0.23229,0.636063,0.666442,0.694777,0.987688,1.75439,2.01603,1.5759,1.74409,-0.588434,-0.70072,-1.17036,-1.1142,-1.69989,-1.59153,1.16341,1.00295,0.277688,0.184945,-0.104081,-0.299192,0.208422,0.313839
1655,0.193755,0.176553,0.439164,0.400857,0.0188461,-0.00649394,0.38369,0.403658,0.164577,0.095012,0.333885,0.3606,0.123915,0.135926,0.517549,0.532944,0.475651,0.521273,0.553335,0.55241,-1.15736,-0.86625,-0.801147,-0.540941,0.0952103,0.262752,-0.677434,-0.79651,0.886227,0.938301,0.193944,0.309946,0.0706775,-0.0894498,-1.6724,-1.75958,1.17178,0.971272,1.62159,1.73885
1656,0.0596544,0.0432735,0.980114,0.943114,0.188838,0.164234,0.0162313,0.036849,0.212719,0.165966,0.462268,0.45056,0.358144,0.281149,0.134874,0.151674,0.838008,0.810257,0.201286,0.201329,-0.469359,-0.171247,-1.35307,-1.09058,-0.44709,-0.272673,-0.547556,-0.662495,0.287831,0.344589,-0.998041,-0.876175,0.934192,0.698601,0.105205,0.0131509,-0.967573,-1.16825,1.19786,1.30746
1657,0.591948,0.574613,0.254656,0.217778,0.0104196,-0.012134,0.937781,0.957972,0.308893,0.23692,0.0104155,-0.000747014,0.41725,0.426372,0.67369,0.689445,0.62997,0.623893,0.267323,0.281981,-0.168479,0.128205,-0.106877,0.158207,1.55379,1.72873,1.3427,1.22706,-1.398,-1.34013,-0.7753,-0.647122,1.64678,1.48665,0.22396,0.129403,1.90914,1.70579,-0.596635,-0.493303
1658,0.88569,0.866838,0.851033,0.814083,0.975294,0.951198,0.872343,0.947339,0.085744,0.0147628,0.0465812,0.0261213,0.561144,0.571595,0.0497063,0.0630667,0.464977,0.437528,0.232041,0.362634,1.41679,1.71927,-0.755591,-0.49714,-0.92862,-0.74991,-0.656546,-0.767427,-0.605538,-0.551946,-1.25276,-1.12618,0.235877,0.0820842,1.0711,0.981551,1.14055,0.92782,0.277288,0.375568
1659,0.815259,0.821471,0.265286,0.227921,0.133297,0.110744,0.914306,0.936706,0.535126,0.462966,0.0648912,0.0529896,0.402284,0.371775,0.129495,0.143839,0.991118,0.962746,0.44232,0.443286,-1.53289,-1.23306,0.181972,0.44042,1.20972,1.39273,0.484815,0.367849,-0.458954,-0.410207,0.77928,0.899457,1.07615,0.924567,-0.554807,-0.649352,0.360433,0.149849,-0.269959,-0.177416
1660,0.795447,0.776104,0.597791,0.558787,0.843971,0.82147,0.617409,0.693097,0.721924,0.666383,0.666703,0.654458,0.16368,0.171955,0.867908,0.8811,0.585,0.557637,0.953494,0.951788,-1.23481,-0.933608,1.8275,2.09109,-0.610412,-0.434073,-0.455633,-0.497103,0.196738,0.237602,-1.32553,-1.21195,-0.253181,-0.402339,-0.422215,-0.517431,0.779634,0.562274,-0.54498,-0.457576
1661,0.142941,0.124505,0.365125,0.324285,0.570832,0.547052,0.425298,0.449489,0.942091,0.8698,0.321589,0.311709,0.581841,0.588727,0.666771,0.679031,0.823863,0.794409,0.228991,0.229308,1.39057,1.68949,-1.52258,-1.26464,-1.57206,-1.38968,-1.24188,-1.36205,0.500416,0.546977,0.785626,0.896933,1.17481,1.03007,-0.748279,-0.85789,-0.889716,-1.114,0.361509,0.455156
1662,0.21557,0.208844,0.68584,0.645766,0.949937,0.924451,0.719563,0.74476,0.055906,-0.0180986,0.366704,0.356838,0.305937,0.313135,0.0551559,0.0681711,0.337894,0.309507,0.966989,0.967692,-1.63049,-1.33724,1.79128,2.04544,0.790551,0.966845,-0.97098,-1.08951,-0.398323,-0.352764,-1.614,-1.49948,-1.05729,-1.2085,-1.09528,-1.19835,-1.38802,-1.61529,0.249422,0.341679
1663,0.310631,0.293184,0.175533,0.137216,0.557108,0.529368,0.565759,0.592638,0.90947,0.837308,0.872606,0.864447,0.550142,0.559421,0.472649,0.484739,0.460761,0.42736,0.95388,0.953494,-0.90801,-0.611571,1.11478,1.37421,0.844258,1.02922,0.469033,0.35505,0.91778,0.957217,2.14652,2.25778,-1.15211,-1.29782,-1.64075,-1.73988,0.978864,0.759377,-0.894225,-0.802458
1664,0.608748,0.622509,0.195711,0.15625,0.875336,0.84608,0.972092,0.99712,0.0166523,-0.055064,0.850788,0.866097,0.367487,0.431428,0.128448,0.138157,0.573172,0.545213,0.677953,0.677835,0.682012,0.979492,-0.0331141,0.223313,-0.319832,-0.13068,0.881394,0.764028,0.366422,0.408441,-0.696392,-0.593475,0.597352,0.458406,-0.755508,-0.857887,0.0792211,-0.148363,-0.84111,-0.749624
1665,0.970521,0.951833,0.539094,0.498629,0.655236,0.5839,0.00472714,0.0287084,0.125196,0.0539541,0.833041,0.867747,0.228622,0.303436,0.726593,0.736446,0.129964,0.100636,0.834648,0.808051,-0.238581,0.0502467,1.54373,1.79849,1.43949,1.62194,-0.164655,-0.27541,0.861721,0.903984,-1.2797,-1.182,0.228829,0.0912289,0.528994,0.418241,2.46732,2.24094,0.0183533,0.102031
1666,0.885974,0.846838,0.879326,0.841008,0.352158,0.321721,0.989437,1.01342,0.71185,0.639368,0.877556,0.869397,0.164592,0.175444,0.206353,0.215348,0.752275,0.721755,0.937528,0.938268,-0.473971,-0.185858,-1.9627,-1.70794,1.48575,1.66672,-0.565848,-0.680574,0.35252,0.399858,-1.40764,-1.3073,0.724934,0.583207,-0.27282,-0.384991,-0.831509,-1.06588,-0.284663,-0.208696
1667,0.760733,0.741843,0.111108,0.0735278,0.944588,0.914743,0.844166,0.865686,0.734359,0.662876,0.0723765,0.0621733,0.569462,0.582413,0.593106,0.560013,0.465536,0.478381,0.726191,0.727471,-0.368989,-0.0896471,-2.35661,-2.10372,0.948273,1.1313,-0.741017,-0.854069,-0.453943,-0.408295,0.18612,0.286226,0.0336947,-0.107315,0.456576,0.249755,-1.9352,-2.17315,-0.337917,-0.261916
1668,0.221052,0.200746,0.4221,0.384643,0.581054,0.649519,0.0785197,0.102151,0.138487,0.0684598,0.0182298,0.0941163,0.692948,0.776549,0.896865,0.904678,0.267382,0.235008,0.739674,0.742818,-0.0496132,0.223579,-0.66084,-0.406095,0.834659,1.01134,-0.337297,-0.445092,-0.0713894,-0.019895,-0.439597,-0.334063,0.912678,0.767211,0.991585,0.884502,0.135328,-0.106507,-1.94392,-1.86209
1669,0.416761,0.396716,0.0960643,0.0591184,0.414445,0.384295,0.0552942,0.080245,0.782835,0.713361,0.138568,0.126059,0.957421,0.970685,0.4049,0.413601,0.789863,0.755449,0.43568,0.437629,-0.865775,-0.597773,0.620243,0.872483,0.13241,0.304035,1.46755,1.36613,-0.0838668,-0.109857,0.469841,0.569913,0.786822,0.647596,-1.35251,-1.46357,1.0189,0.774426,-0.371615,-0.289038
1670,0.103751,0.0817218,0.365543,0.330154,0.910949,0.882613,0.349506,0.375516,0.328667,0.259972,0.380213,0.368712,0.279974,0.294081,0.722639,0.641095,0.620723,0.545231,0.45096,0.452977,-1.27651,-1.00149,-2.46184,-2.21349,0.986889,1.16433,0.894336,0.804513,-0.25194,-0.19982,-0.463427,-0.356298,0.379659,0.194219,0.139255,0.0303134,1.09161,0.889975,-0.374298,-0.296417
1671,0.439634,0.421407,0.180842,0.145904,0.457689,0.428619,0.0826421,0.107589,0.235094,0.166946,0.857985,0.846026,0.437204,0.449439,0.858178,0.868588,0.33267,0.335014,0.196167,0.198174,-0.638229,-0.366807,0.637083,0.884334,0.506447,0.69185,0.345773,0.242893,0.315966,0.372108,0.512482,0.623218,-0.169348,-0.259158,1.35903,1.24699,1.24988,1.00552,0.0581416,0.131494
1672,0.781586,0.761092,0.213557,0.179821,0.746035,0.715136,0.500851,0.522855,0.00136363,0.07392,0.810475,0.751695,0.158923,0.269933,0.322008,0.332491,0.159977,0.124796,0.991113,0.990476,-1.48867,-1.21831,1.02462,1.26982,0.91254,1.09214,-1.02103,-1.11992,-2.10357,-2.054,-1.05202,-0.94755,-0.573309,-0.712534,-0.635917,-0.74487,0.560934,0.320379,0.184688,0.255716
1673,0.774786,0.756449,0.697484,0.66354,0.335524,0.305504,0.913735,0.938121,0.0495892,-0.019106,0.669706,0.657364,0.0756147,0.0904275,0.20261,0.211362,0.180367,0.144582,0.525281,0.524519,0.648907,0.924081,0.673163,0.897936,-1.43387,-1.25964,0.174737,0.0763849,2.07676,2.12633,-0.710066,-0.613021,-2.94992,-3.09707,-0.857521,-0.964663,0.78189,0.545606,0.0390883,0.112981
1674,0.0470612,0.0272044,0.96667,0.934575,0.174542,0.245469,0.85249,0.875541,0.36952,0.303311,0.14808,0.137291,0.800105,0.814012,0.515956,0.46675,0.837162,0.802893,0.643402,0.641688,0.805364,1.08204,0.275036,0.526055,0.128815,0.30355,0.252674,0.149495,-0.386628,-0.32888,0.218273,0.321441,-0.823783,-0.973537,0.413975,0.311464,-0.130557,-0.362134,1.32215,1.39302
1675,0.81604,0.797682,0.0178256,-0.0150865,0.213473,0.185434,0.501007,0.523827,0.0745492,0.00676975,0.240481,0.22806,0.298554,0.312973,0.714895,0.722137,0.161357,0.127902,0.131478,0.130778,-0.459838,-0.18349,0.631742,0.881251,-0.782011,-0.606336,-0.994185,-1.09255,-0.124855,-0.0633622,-0.802183,-0.697015,-0.339999,-0.496927,-1.04374,-1.15146,-0.568465,-0.802039,1.1376,1.20373
1676,0.561559,0.544764,0.362265,0.331089,0.982329,0.952317,0.778937,0.803734,0.713206,0.645975,0.0444199,0.0337231,0.92104,0.934497,0.278194,0.285242,0.445246,0.413646,0.644884,0.644294,1.66597,1.94383,0.553494,0.806785,1.71775,1.88601,-0.0496529,-0.143699,0.594676,0.662313,1.24425,1.34626,0.484076,0.330608,0.500226,0.389491,-0.315967,-0.546734,-0.838877,-0.769788
1677,0.0757743,0.05817,0.0433616,0.0107358,0.180615,0.149442,0.650079,0.676344,0.7663,0.698314,0.987166,0.975189,0.505369,0.561081,0.335338,0.340981,0.357722,0.328065,0.163265,0.163732,-0.00639326,0.265057,-0.711706,-0.451889,-0.54658,-0.386298,0.590002,0.494245,-0.327445,-0.2525,-1.3444,-1.24868,-0.683507,-0.841773,-0.265281,-0.311322,-1.88779,-2.11164,-0.669688,-0.660998
1678,0.267695,0.268181,0.640762,0.607041,0.0660803,0.0329002,0.989301,1.01493,0.28264,0.214631,0.0128216,0.000635849,0.172187,0.187664,0.96075,0.966427,0.621507,0.596503,0.933032,0.934397,-0.234595,0.0444079,-0.524116,-0.266304,-0.414492,-0.248434,-1.50499,-1.5936,-1.49346,-1.41359,1.87707,1.97581,0.792047,0.637698,-0.901661,-1.01214,0.0647077,-0.163533,-0.621296,-0.552208
1679,0.578984,0.478192,0.646981,0.611415,0.613243,0.580386,0.150775,0.177601,0.862161,0.794367,0.44935,0.438992,0.645422,0.591449,0.16912,0.174692,0.893359,0.86494,0.934409,0.935285,0.339744,0.61855,-1.3268,-1.07488,1.1887,1.36152,1.4355,1.34305,-1.35243,-1.27185,-1.86606,-1.76732,-0.120316,-0.269319,1.83371,1.71979,1.446,1.21979,0.695587,0.759928
1680,0.640155,0.688202,0.252296,0.217324,0.396374,0.36252,0.375452,0.402571,0.0957565,0.0255689,0.30461,0.293152,0.977207,0.995233,0.49609,0.501096,0.906572,0.879908,0.262568,0.264137,-1.20481,-0.922214,0.330684,0.575793,-0.429943,-0.259641,-0.10409,-0.188441,-0.286824,-0.208443,-2.4404,-2.33781,-0.0462115,-0.191309,0.599808,0.487972,0.511181,0.280197,0.537837,0.600842
1681,0.915817,0.898213,0.421523,0.469284,0.617034,0.582915,0.19854,0.224904,0.122159,0.0529644,0.159052,0.147311,0.127719,0.145118,0.495999,0.518679,0.0215101,-0.00480168,0.919885,0.922521,0.240014,0.529668,-0.764164,-0.512499,-0.878525,-0.701057,-0.254259,-0.34613,0.574687,0.655693,0.0723437,0.172993,3.38326,3.24118,0.492388,0.374122,-1.43479,-1.66697,0.766324,0.833873
1682,0.762175,0.696118,0.757442,0.721245,0.0413783,0.00926577,0.254716,0.279138,0.669398,0.601676,0.895408,0.883364,0.64627,0.661403,0.562497,0.536263,0.381844,0.356119,0.778448,0.782749,0.509185,0.795551,-0.965741,-0.710072,0.815335,0.987868,0.289149,0.201924,-0.464323,-0.383323,0.559367,0.664394,-0.471099,-0.610706,-0.891417,-1.01354,1.65644,1.41672,-0.0733824,-0.00220215
1683,0.509753,0.494023,0.588317,0.558264,0.625735,0.59278,0.601893,0.627925,0.23415,0.16774,0.306815,0.293574,0.82686,0.842161,0.547211,0.553846,0.985981,0.96248,0.213019,0.217158,1.54264,1.8264,0.38496,0.645329,-0.284017,-0.108848,-0.912538,-0.993665,0.992771,1.07767,-2.28826,-2.18686,-0.259994,-0.397871,0.38215,0.262588,1.28802,1.05488,0.237948,0.306424
1684,0.956157,0.941888,0.431124,0.395282,0.373907,0.339261,0.0609479,0.0843573,0.457193,0.388419,0.815452,0.801183,0.25985,0.274748,0.317796,0.326885,0.0382564,0.0170538,0.453486,0.411222,-0.691489,-0.405576,-0.568725,-0.303071,0.415077,0.583116,-0.20433,-0.292529,-0.27598,-0.191742,-1.33587,-1.23703,0.554256,0.413796,-0.829949,-0.954081,-1.46218,-1.69258,0.299314,0.374649
1685,0.779604,0.764342,0.028032,-0.00837202,0.809316,0.773365,0.99834,1.02258,0.370562,0.341504,0.373704,0.359629,0.120513,0.134997,0.641963,0.653288,0.0926345,0.031523,0.602843,0.605287,-2.21967,-1.92936,-0.137702,0.127497,0.569628,0.735597,-0.396128,-0.482317,0.645388,0.733904,-0.959396,-0.854137,0.508794,0.368974,-0.882472,-1.00717,-0.0580526,-0.292861,-0.505881,-0.432494
1686,0.954016,0.939749,0.628156,0.591647,0.852286,0.814773,0.876142,0.965756,0.363789,0.294588,0.894934,0.881122,0.977357,0.993446,0.196352,0.206977,0.0691631,0.0459922,0.209227,0.21001,0.0731429,0.36783,1.49429,1.76314,2.24358,2.41002,0.107719,0.0174305,-0.678737,-0.583541,-1.00049,-0.900543,0.820938,0.676673,0.0454624,-0.0778564,0.585222,0.353308,-0.604824,-0.530258
1687,0.554308,0.539045,0.183813,0.148274,0.460655,0.425294,0.884673,0.908928,0.0986726,0.0273487,0.614324,0.63738,0.925037,1.00411,0.751044,0.760174,0.815233,0.7933,0.201373,0.19977,-0.543772,-0.253687,-0.628229,-0.358116,-0.0566885,0.10423,1.03879,0.950817,-0.231296,-0.13577,-1.4659,-1.36505,-1.03431,-1.18294,0.0644773,-0.0548782,0.08459,-0.147982,0.396411,0.47578
1688,0.910738,0.895862,0.122763,0.119797,0.551039,0.579544,0.0513756,0.0768554,0.349078,0.259495,0.407866,0.393638,0.99869,1.01478,0.422836,0.433675,0.0824337,0.0621097,0.928926,0.928233,0.848509,1.13504,-0.34816,-0.0788489,0.945559,1.10372,0.161205,0.0793719,0.593654,0.68151,0.472218,0.567079,1.50694,1.35787,-0.471012,-0.596404,0.51668,0.279506,-1.31906,-1.2468
1689,0.411858,0.394733,0.125189,0.0913209,0.770042,0.733794,0.681569,0.709548,0.563077,0.491641,0.446312,0.483598,0.547737,0.563943,0.676393,0.627508,0.784445,0.76473,0.717343,0.717436,1.54487,1.83004,1.2272,1.49633,-0.158091,0.00700785,0.323988,0.244387,-0.70932,-0.618745,0.292699,0.383292,0.078152,-0.064064,-0.260578,-0.3888,0.26407,0.0258072,0.280692,0.357085
1690,0.454895,0.44002,0.643463,0.609093,0.291001,0.254092,0.237245,0.263657,0.604304,0.533821,0.585357,0.573559,0.436472,0.408743,0.808745,0.82134,0.88226,0.863264,0.236205,0.236874,0.150952,0.442261,0.666258,0.931097,0.138419,0.29908,1.28911,1.20831,1.92485,2.01785,-0.227265,-0.141713,-1.04543,-1.18951,-0.361994,-0.486551,-0.291667,-0.536602,1.20365,1.28515
1691,0.733423,0.716698,0.411085,0.323372,0.375643,0.340358,0.33637,0.412052,0.261925,0.26832,0.101819,0.0888405,0.236412,0.253544,0.357731,0.370518,0.666057,0.721899,0.298539,0.299116,0.182976,0.476186,-0.594218,-0.327577,1.42364,1.58618,-0.121269,-0.203322,1.82759,1.92575,-0.159291,-0.0809321,-0.590635,-0.728647,-1.31617,-1.44282,-1.84718,-2.08649,-0.250486,-0.163259
1692,0.791614,0.776951,0.0711414,0.0376519,0.212104,0.178428,0.617787,0.560446,0.0725155,0.00281864,0.80146,0.789501,0.927044,0.946365,0.963544,0.975059,0.601439,0.580534,0.865599,0.867512,1.68757,1.97532,1.0902,1.35543,-0.598422,-0.442214,-2.1642,-2.24603,0.0184942,0.118645,0.264486,0.339087,0.357545,0.224241,1.94719,1.81375,1.13199,0.896685,-0.10307,-0.0212019
1693,0.621247,0.655371,0.608941,0.574887,0.704821,0.671826,0.684251,0.70884,0.81654,0.745846,0.698893,0.692168,0.964811,0.98478,0.256274,0.266427,0.0262856,0.0059482,0.56616,0.620513,-2.69985,-2.41791,-0.0887241,0.174349,-1.70208,-1.53893,0.282672,0.196979,-0.133389,-0.0324565,0.673924,0.759106,-0.354547,-0.480942,-0.393987,-0.534328,0.352455,0.117643,2.0277,2.10999
1694,0.550068,0.533791,0.453558,0.42139,0.215732,0.18194,0.579663,0.646972,0.11978,0.0500028,0.605853,0.594835,0.424377,0.442516,0.115563,0.124294,0.0128031,-0.00947391,0.374143,0.373514,-1.05183,-0.76538,0.910208,1.17402,1.07068,1.23251,1.76726,1.67407,0.870842,0.9694,-1.6778,-1.5882,-3.31789,-3.451,0.0588497,-0.0810131,0.579819,0.342871,-1.52017,-1.4321
1695,0.684372,0.633973,0.727335,0.692426,0.609991,0.573858,0.530219,0.585104,0.0136786,0.0112632,0.742336,0.730001,0.667747,0.683628,0.477928,0.498683,0.977614,0.956323,0.860954,0.862984,0.288707,0.576677,-0.533363,-0.275035,-0.31154,-0.143934,0.560599,0.463357,-1.19694,-1.09859,0.560432,0.649411,-0.818855,-0.950916,-0.577703,-0.687476,0.362146,0.119443,2.17101,2.25582
1696,0.749331,0.734155,0.733446,0.666366,0.00578582,-0.0305226,0.498647,0.523236,0.0446921,-0.0274763,0.0196686,0.00476229,0.691255,0.706118,0.864427,0.873073,0.398175,0.376901,0.273827,0.277289,-0.673005,-0.382223,-0.767594,-0.506026,-0.702516,-0.466874,-0.137361,-0.234511,-0.297933,-0.202844,0.845138,0.938651,0.586682,0.452681,-1.15884,-1.29394,0.877711,0.641897,0.19831,0.282308
1697,0.597392,0.581563,0.675297,0.640306,0.62463,0.587476,0.0979886,0.121623,0.195144,0.0884456,0.781777,0.766451,0.23619,0.250216,0.857308,0.868274,0.106865,0.0877508,0.74545,0.751293,0.806098,1.10141,0.115857,0.371074,-0.960338,-0.789814,1.55351,1.46323,-1.00869,-0.917469,-0.372654,-0.276379,0.412189,0.191414,1.76086,1.63198,-1.53685,-1.77594,-1.09975,-1.01305
1698,0.824905,0.808119,0.189258,0.15253,0.0844934,0.0484054,0.0404663,0.06438,0.413223,0.204368,0.256976,0.242195,0.549091,0.562276,0.326631,0.337225,0.112525,0.09711,0.795944,0.803966,-2.72736,-2.4266,0.0729494,0.326308,1.46635,1.63367,-1.10903,-1.19867,-0.907884,-0.8197,0.271505,0.367657,0.061208,-0.0698539,1.69068,1.56394,-0.768041,-1.00633,1.19435,1.2805
1699,0.20906,0.192014,0.980991,0.944587,0.9128,0.877258,0.625258,0.647297,0.394126,0.320289,0.602085,0.587845,0.0851217,0.0965445,0.809867,0.819255,0.215161,0.106469,0.390692,0.397575,-0.479179,-0.176349,-0.842673,-0.590482,-2.03826,-1.86715,-0.596903,-0.683579,-0.214165,-0.125217,0.307772,0.397934,0.809703,0.682936,-0.489979,-0.618464,-0.279089,-0.515937,-1.04117,-0.956675
1700,0.900852,0.882734,0.219884,0.183186,0.273635,0.239094,0.00830289,0.0296448,0.357466,0.285933,0.325578,0.310057,0.880403,0.8916,0.66261,0.672331,0.218477,0.115828,0.68771,0.629049,-1.53651,-1.22758,0.324828,0.577986,-0.786623,-0.610302,0.744798,0.664559,-0.545045,-0.462665,-0.85948,-0.771036,-0.272277,-0.395842,0.392762,0.263526,1.6108,1.36857,-1.557,-1.47829
1701,0.305808,0.28715,0.575466,0.538712,0.909656,0.872864,0.802383,0.823795,0.944542,0.871347,0.67349,0.660943,0.159478,0.169286,0.762065,0.773876,0.275782,0.125188,0.853136,0.860523,0.222656,0.530598,-0.146264,0.106185,-0.332709,-0.151427,-0.484701,-0.561383,-0.0440549,0.0710631,0.704924,0.792625,0.371396,0.251058,-0.997719,-1.12414,0.508363,0.261295,0.780035,0.864073
1702,0.326696,0.366042,0.37427,0.339249,0.126873,0.0882932,0.951036,0.97407,0.638732,0.563832,0.79142,0.780561,0.614483,0.625167,0.291138,0.302853,0.153661,0.134547,0.927833,0.93633,0.376571,0.688558,-1.53771,-1.28044,-0.685786,-0.501934,-0.701605,-0.780755,0.52485,0.604792,-0.0662934,0.0196361,-0.48897,-0.607297,-1.19563,-1.32918,-0.346611,-0.59495,0.497249,0.599177
1703,0.46529,0.444934,0.926647,0.891008,0.0558472,0.116011,0.607496,0.632605,0.700236,0.672262,0.144998,0.135219,0.512654,0.525509,0.896643,0.907394,0.0887098,0.0687542,0.000855405,0.00958111,-0.519252,-0.20939,1.43988,1.70437,-0.62068,-0.439557,-0.236946,-0.311549,0.241005,0.316382,0.256398,0.339926,0.607804,0.497054,1.21883,1.08189,0.343937,0.0984485,0.249208,0.334281
1704,0.140787,0.119534,0.882082,0.846375,0.184481,0.143729,0.707554,0.754066,0.855845,0.780692,0.340481,0.372923,0.123287,0.134172,0.66449,0.675105,0.573144,0.553762,0.970685,0.980092,-1.87358,-1.56474,-0.375704,-0.106089,0.587045,0.770056,-0.525223,-0.594023,0.233311,0.333969,1.2572,1.33655,-1.48451,-1.60018,0.328216,0.185734,0.156106,-0.0944495,1.74986,1.83043
1705,0.820126,0.800741,0.115089,0.0788942,0.648048,0.607287,0.958808,0.875527,0.51705,0.505878,0.619674,0.610628,0.428423,0.396812,0.647728,0.644192,0.810904,0.790535,0.532839,0.54387,-1.4947,-1.19012,1.0726,1.34211,0.518096,0.694302,0.922119,0.850541,0.27733,0.351557,-1.12562,-1.04345,-0.197075,-0.30693,-1.01963,-1.15487,1.51704,1.26104,0.516707,0.669249
1706,0.277015,0.259643,0.505344,0.468876,0.0606364,0.0185458,0.97188,0.996988,0.305914,0.231064,0.219882,0.209063,0.650721,0.659452,0.601402,0.613279,0.421754,0.400487,0.456509,0.465816,0.137931,0.446724,0.61173,0.885332,-0.00494316,0.174088,0.107777,0.0429627,1.08028,1.15204,-0.220843,-0.139474,0.335234,0.230159,2.16677,2.0264,0.417904,0.170085,-0.578944,-0.491937
1707,0.871225,0.854665,0.193658,0.238762,0.793398,0.749541,0.517203,0.539984,0.431882,0.381737,0.859592,0.84987,0.328786,0.338884,0.315828,0.326332,0.352494,0.330143,0.118946,0.129385,0.953307,1.26305,-0.0713559,0.19909,0.41098,0.589377,0.057636,-0.00672958,-0.121194,-0.0527096,-0.492132,-0.416387,-0.544257,-0.646587,-1.5856,-1.73178,0.236768,-0.00748801,-0.421637,-0.334276
1708,0.788704,0.771625,0.0435023,0.00864669,0.299097,0.25526,0.713626,0.736275,0.573718,0.532411,0.00336201,-0.00468342,0.255518,0.265099,0.854394,0.864104,0.0656844,0.0409925,0.809056,0.817961,-0.0076192,0.304146,-0.122427,0.154325,1.99317,2.16977,0.350625,0.281689,1.00895,1.07033,-1.18371,-1.11295,1.6157,1.51012,-1.94728,-2.09071,-1.02218,-1.27156,0.75186,0.839607
1709,0.234234,0.21546,0.173371,0.209726,0.457428,0.4119,0.0619789,0.0839535,0.754942,0.683084,0.415103,0.363403,0.447537,0.456589,0.236444,0.247767,0.846581,0.823175,0.292998,0.30261,0.141872,0.44682,-0.730643,-0.455333,-0.282401,-0.102537,-0.309727,-0.385537,0.501703,0.566205,2.41165,2.48134,-0.0325417,-0.129839,0.0355631,-0.114322,-0.843946,-1.05754,1.03633,1.1177
1710,0.569214,0.557616,0.446407,0.410806,0.295886,0.24997,0.949734,0.970068,0.291521,0.219365,0.741469,0.731489,0.381899,0.392459,0.966827,0.980315,0.490054,0.468453,0.929876,0.941391,-1.86547,-1.56355,-0.067146,0.207833,-0.493461,-0.317411,-0.278421,-0.359636,-1.10345,-1.04029,0.342047,0.416179,-0.0123807,-0.0209191,-1.09763,-1.25352,-0.600012,-0.843513,-1.36577,-1.28203
1711,0.92033,0.899771,0.38867,0.351616,0.38716,0.376515,0.734474,0.752545,0.335217,0.248551,0.671003,0.658794,0.588501,0.598353,0.849996,0.863767,0.970716,0.948476,0.364151,0.375799,-1.58214,-1.28062,0.0876314,0.362398,-1.13963,-0.963539,0.0158156,-0.0712181,0.308931,0.375105,-2.55536,-2.48097,0.187562,0.088001,-1.49176,-1.64096,0.697363,0.458389,-1.39951,-1.3204
1712,0.978456,0.955433,0.822897,0.785765,0.392972,0.503059,0.997183,1.01337,0.34817,0.277738,0.214729,0.202965,0.436238,0.443862,0.224298,0.237388,0.0597019,0.0373468,0.337124,0.286986,0.778149,1.08176,-0.294309,-0.0192685,-1.04301,-0.873328,-0.843036,-0.92692,-2.70201,-2.64306,-1.76423,-1.6888,-0.0996104,-0.201572,-0.340772,-0.483135,-0.608449,-0.839628,0.610023,0.684946
1713,0.814702,0.792419,0.575019,0.539624,0.636773,0.629603,0.50614,0.574133,0.954214,0.882874,0.851687,0.838945,0.742177,0.750814,0.234522,0.247667,0.362411,0.356365,0.185054,0.198173,-0.883431,-0.582749,0.355281,0.628938,0.605611,0.769365,-0.844327,-0.929957,0.225695,0.285908,-0.278403,-0.204874,0.587598,0.489945,-0.322613,-0.460157,1.67629,1.43682,1.10898,1.18918
1714,0.864248,0.839284,0.0168527,-0.0173578,0.802063,0.756147,0.120505,0.134892,0.473441,0.403919,0.488039,0.477218,0.297513,0.305051,0.998049,1.0101,0.695813,0.675382,0.869425,0.882303,-0.224848,0.0810036,-2.00931,-1.73594,-1.37308,-1.21256,0.0756926,-0.0115024,2.1411,2.19328,0.835547,0.913822,0.872198,0.782241,0.830254,0.697672,0.447231,0.202101,-0.146458,-0.0599602
1715,0.910694,0.886149,0.439257,0.432401,0.275116,0.227674,0.0704128,0.0832662,0.799566,0.731292,0.797913,0.787408,0.256989,0.266731,0.940484,0.906205,0.146326,0.126086,0.92772,0.939487,2.09167,2.39304,-0.883395,-0.610205,-0.400808,-0.244584,-1.06272,-1.14472,1.19689,1.2452,-2.09838,-2.0176,-0.0167067,-0.109556,1.40017,1.27405,1.1321,0.881203,1.73432,1.82232
1716,0.629886,0.607153,0.916371,0.88216,0.00488041,-0.0416681,0.85338,0.867123,0.283065,0.212867,0.237853,0.22856,0.824191,0.83324,0.700544,0.802311,0.139199,0.120441,0.356562,0.368313,-1.25436,-0.94476,0.533949,0.807611,-1.29766,-1.13902,0.765256,0.682635,-2.39042,-2.33995,-0.667302,-0.492107,-0.164123,-0.259654,-0.111141,-0.233944,1.15069,0.907839,-0.428734,-0.334183
1717,0.830622,0.807679,0.535808,0.503371,0.0216488,-0.025241,0.0883358,0.103588,0.436153,0.367874,0.826698,0.819206,0.576883,0.587176,0.687756,0.698416,0.916167,0.897453,0.516174,0.530077,-1.43467,-1.12049,0.323205,0.595498,0.472206,0.628073,-0.306073,-0.389285,0.122514,0.175347,0.952601,1.03338,-0.823318,-0.918323,-0.675154,-0.789108,-1.79047,-2.03709,1.75591,1.84603
1718,0.565806,0.544176,0.386421,0.354547,0.362086,0.31671,0.660977,0.676036,0.047886,-0.0204614,0.596971,0.590744,0.856989,0.868242,0.776532,0.789299,0.534902,0.517732,0.0862769,0.0994077,-0.463331,-0.149242,1.88268,2.15564,1.006,1.16435,-1.90036,-1.98563,1.27293,1.32976,-0.547601,-0.462676,0.279007,0.186028,-1.22881,-1.34427,1.4796,1.23492,-1.82884,-1.74344
1719,0.780092,0.760755,0.85021,0.817624,0.115516,0.0722551,0.964585,0.980454,0.284887,0.12087,0.835063,0.829065,0.584677,0.597309,0.316631,0.327891,0.84913,0.832577,0.932961,0.947867,-1.80481,-1.49069,0.524827,0.801114,-0.256374,-0.100632,1.03393,0.951014,0.0339287,0.0912742,0.589693,0.670201,0.0899433,0.00429717,-0.678234,-0.730888,-0.707335,-0.952093,0.553642,0.631632
1720,0.525929,0.507838,0.373141,0.340187,0.799557,0.757139,0.484703,0.577323,0.329217,0.262201,0.230826,0.224045,0.804629,0.818389,0.764666,0.774873,0.122192,0.106881,0.887746,0.904585,-1.3696,-1.05644,-2.06749,-1.78944,1.32106,1.47976,-1.31903,-1.39676,0.345495,0.400648,0.841662,0.914448,-0.569672,-0.672939,-0.00933872,-0.117504,1.29765,1.05144,-0.55714,-0.4825
1721,0.629726,0.61384,0.824278,0.788433,0.822347,0.778416,0.158887,0.174192,0.828231,0.760127,0.00414328,-0.00441659,0.27232,0.286202,0.858595,0.870604,0.116996,0.101236,0.426374,0.443726,-0.537275,-0.225187,0.0922831,0.367541,-1.68163,-1.52452,-0.996771,-1.04381,1.19849,1.24959,-0.522476,-0.443425,-1.25663,-1.35017,1.01081,0.940174,-1.18523,-1.43392,1.25837,1.33922
1722,0.0632955,0.0478768,0.534063,0.498273,0.593181,0.475926,0.584784,0.579365,0.299623,0.231665,0.359143,0.350872,0.269794,0.334028,0.718504,0.800548,0.882111,0.867642,0.370378,0.319521,-0.050613,0.258987,-0.519817,-0.242117,-0.615212,-0.464042,-0.616902,-0.69087,0.405464,0.456438,2.08419,2.16375,1.60926,1.51309,2.10724,1.99785,1.33947,1.08988,1.23247,1.2645
1723,0.411825,0.350051,0.848552,0.814707,0.219589,0.173436,0.97097,0.984538,0.248558,0.154142,0.925207,0.9173,0.413419,0.381853,0.717541,0.730493,0.676892,0.588898,0.177963,0.195317,-1.11512,-0.808506,-0.843304,-0.48789,1.40414,1.55302,0.589747,0.520864,0.351487,0.438758,-0.68918,-0.607812,-0.717731,-0.810805,-0.410608,-0.513704,-1.28251,-1.53557,1.11188,1.18978
1724,0.666895,0.652225,0.923803,0.888373,0.138367,0.0933119,0.131124,0.142622,0.141707,0.0766179,0.138804,0.130824,0.415796,0.429679,0.0959034,0.10925,0.32633,0.310155,0.399267,0.418431,0.43019,0.737787,-1.05317,-0.733663,-1.68015,-1.53721,1.4452,1.37695,0.370336,0.421078,-0.155465,-0.0717722,-2.09435,-2.18387,-1.12206,-1.22598,-2.03957,-2.2994,0.145856,0.231205
1725,0.358241,0.343178,0.409723,0.375532,0.556517,0.511541,0.523118,0.536169,0.655099,0.590739,0.143937,0.141553,0.135297,0.148761,0.478158,0.518183,0.910457,0.895391,0.0681904,0.0868506,0.513697,0.818918,-1.25714,-0.979436,-0.0373741,0.105487,0.188871,0.119533,1.6598,1.71459,-1.04846,-0.969312,-1.49094,-1.58417,-0.494426,-0.60446,-0.157432,-0.414891,0.290586,0.373262
1726,0.509509,0.539989,0.102165,0.0695618,0.286641,0.242199,0.422344,0.433594,0.556602,0.493817,0.159867,0.152282,0.339616,0.354656,0.913871,0.927116,0.9621,0.949547,0.7864,0.806379,-1.72343,-1.41306,-1.02526,-0.747646,0.710101,0.867633,0.0184892,-0.0539627,-0.582528,-0.526475,-0.0803762,-0.00578915,1.12325,1.03631,-0.297177,-0.410911,0.664598,0.402443,-0.0826799,0.00104385
1727,0.62658,0.736799,0.661803,0.631535,0.281756,0.165941,0.733544,0.743316,0.229242,0.166654,0.811101,0.80348,0.300007,0.292038,0.828069,0.841304,0.724329,0.711036,0.453979,0.474799,2.34387,2.65034,1.29501,1.57081,1.48692,1.62978,0.786389,0.709322,0.901421,0.965028,-0.461397,-0.390011,-0.159577,-0.244967,1.01424,0.898077,-0.817214,-1.08536,0.51741,0.595281
1728,0.949752,0.93361,0.499281,0.468325,0.213589,0.0896835,0.333655,0.341703,0.253561,0.119738,0.0552251,0.0490451,0.222481,0.22942,0.385148,0.399726,0.207597,0.196184,0.659839,0.708818,-0.737271,-0.4333,0.355939,0.648615,-1.05328,-0.911573,0.714777,0.643016,-1.10718,-1.04771,2.15371,2.21716,0.794261,0.707921,0.262193,0.1401,1.28503,1.0153,-1.03365,-0.960499
1729,0.431935,0.483058,0.716621,0.685656,0.0578682,0.0134258,0.658007,0.603563,0.136828,0.0728229,0.509426,0.502366,0.149395,0.166802,0.391468,0.405381,0.89839,0.887737,0.920361,0.942837,0.425285,0.735911,-0.551881,-0.273576,0.303626,0.452399,-0.233111,-0.30666,-0.324004,-0.306909,-0.921263,-0.852631,-0.0863434,-0.168825,0.0758361,-0.0495566,0.118111,-0.157517,0.20515,0.274935
1730,0.0482018,0.032506,0.589165,0.556523,0.498837,0.452751,0.856244,0.865423,0.856018,0.790239,0.658767,0.698125,0.888163,0.905755,0.903924,0.917375,0.654468,0.543832,0.618432,0.641909,-1.3828,-1.07063,-0.427283,-0.138663,0.0263387,0.208509,1.43747,1.35955,0.378421,0.433889,1.30013,1.36522,-0.605804,-0.701079,0.650078,0.526819,0.2489,-0.0244922,0.107683,0.115015
1731,0.713588,0.698788,0.763665,0.730376,0.235802,0.188528,0.62443,0.632774,0.728018,0.663902,0.898866,0.893884,0.614349,0.630163,0.910693,0.92303,0.211275,0.199927,0.731947,0.720023,-0.0127606,0.301746,-0.277587,-0.00375147,-0.177932,-0.0353806,-2.3037,-2.37572,-0.402278,-0.342686,0.466743,0.530853,-1.15185,-1.23333,0.496148,0.368859,0.616186,0.341133,-0.109172,-0.0449045
1732,0.134334,0.117976,0.345099,0.311707,0.439341,0.393897,0.879199,0.887935,0.020003,-0.0415866,0.609316,0.568894,0.024971,0.0386357,0.527377,0.541759,0.311952,0.298461,0.66871,0.798137,0.110758,0.429567,1.32395,1.60095,0.641303,0.780017,-0.81611,-0.882072,-1.39098,-1.33633,-1.75605,-1.69124,0.875491,0.79054,-2.54559,-2.66953,-0.272681,-0.546805,1.95355,2.0229
1733,0.788174,0.76952,0.140622,0.106762,0.250113,0.20642,0.41397,0.421277,0.145114,0.015385,0.251204,0.243904,0.0777095,0.155688,0.41011,0.425211,0.0935528,0.0796206,0.852775,0.876252,-0.928693,-0.606583,0.17445,0.45006,0.731276,0.870228,0.0214594,-0.0420585,-1.05097,-0.994019,0.732297,0.802249,1.30728,1.22254,0.334272,0.202639,-0.00172613,-0.276349,0.826759,0.893113
1734,0.452174,0.481172,0.47406,0.442904,0.332739,0.302621,0.824376,0.830649,0.134865,0.0723565,0.460887,0.452393,0.166131,0.272741,0.931821,0.947518,0.718919,0.706008,0.421958,0.445583,-0.0882213,0.238323,0.0117853,0.32531,-1.90275,-1.75772,-0.620047,-0.678064,1.75266,1.81623,-0.574702,-0.507039,0.674962,0.604284,-0.770016,-0.906864,2.42468,2.14672,-2.17323,-2.1097
1735,0.21142,0.192823,0.14798,0.11738,0.444189,0.398823,0.0207485,0.0246322,0.981522,0.917972,0.900033,0.890749,0.376129,0.389794,0.233629,0.249045,0.334036,0.321542,0.941927,0.965171,0.761104,1.08323,-0.0750497,0.20056,-0.453001,-0.302482,1.50571,1.44563,1.1337,1.19111,0.23248,0.304246,0.0647735,-0.0139681,-0.725609,-0.867856,-0.386225,-0.661425,1.68944,1.75297
1736,0.456332,0.487891,0.747037,0.717399,0.915036,0.867405,0.351577,0.353879,0.123567,0.0580238,0.675992,0.667836,0.161268,0.173892,0.160531,0.178076,0.816832,0.806549,0.351013,0.374509,1.25055,1.5674,-1.57421,-1.29432,0.254126,0.404303,0.829104,0.762801,1.252,1.3028,-0.311091,-0.162353,-1.12949,-1.20109,-0.480413,-0.628121,-2.02314,-2.30543,0.252619,0.318795
1737,0.803589,0.782958,0.378111,0.348294,0.651844,0.603182,0.101583,0.105946,0.617545,0.551284,0.717035,0.708218,0.402073,0.415004,0.588228,0.60469,0.684974,0.674054,0.605908,0.617624,-0.141944,0.179622,0.728571,1.0068,-1.74692,-1.59329,-0.324578,-0.385684,0.0352154,0.0789194,-0.705203,-0.628953,-0.307569,-0.373555,0.582419,0.440035,-0.357175,-0.641557,1.42305,1.49268
1738,0.163418,0.14157,0.791253,0.763403,0.890642,0.843236,0.965976,0.969721,0.79011,0.726371,0.965888,0.956327,0.413425,0.427952,0.437656,0.453445,0.207749,0.199381,0.838693,0.860738,-0.205267,0.108496,-0.868438,-0.597535,0.767486,0.914719,-0.269209,-0.282416,0.809378,0.851166,-0.172578,-0.092913,1.13522,1.0734,0.10782,-0.0401959,0.249169,-0.0420686,0.76271,0.836238
1739,0.992865,0.970137,0.665328,0.639512,0.156031,0.107637,0.0558034,0.0580882,0.449303,0.382796,0.666847,0.559244,0.796964,0.809407,0.956941,0.970736,0.271191,0.262272,0.601651,0.596273,1.06799,1.38817,0.850576,1.11471,0.0514561,0.189119,-0.193482,-0.179148,-0.671804,-0.632428,1.60544,1.68709,-1.0838,-1.14743,-0.0527081,-0.198156,0.280417,-0.0154326,0.689694,0.76992
1740,0.389043,0.3647,0.303397,0.274997,0.338797,0.192078,0.372449,0.411753,0.470021,0.406304,0.170579,0.162162,0.249078,0.262553,0.385995,0.39972,0.837971,0.827672,0.226398,0.331807,-0.614047,-0.290603,-0.381988,-0.11306,-2.08134,-1.93702,-0.114708,-0.0758796,-0.856724,-0.81576,0.158204,0.238855,0.507304,0.439966,0.0494896,-0.0961085,2.1458,1.85368,1.89507,1.97359
1741,0.341669,0.274438,0.297047,0.269352,0.323187,0.276519,0.760937,0.765417,0.925836,0.863925,0.50884,0.438222,0.427263,0.439013,0.676399,0.690355,0.337243,0.327919,0.0470605,0.067342,-1.04967,-0.724954,-0.879368,-0.614749,0.00895702,0.161005,0.0884952,0.0273886,-0.479065,-0.441248,0.594071,0.668089,1.08787,0.921818,0.733989,0.587199,-0.618852,-0.906889,-1.95867,-1.88014
1742,0.208449,0.184176,0.948606,0.919388,0.192186,0.144992,0.818305,0.823773,0.702753,0.653506,0.798429,0.714283,0.968498,0.980668,0.265675,0.278665,0.84371,0.833574,0.775561,0.795805,1.30606,1.63743,1.0466,1.31608,-0.337266,-0.189503,0.342672,0.248235,-1.56582,-1.52537,0.675744,0.74372,1.47092,1.40367,-1.03141,-1.18385,-0.81706,-1.09979,-1.0338,-0.952084
1743,0.81333,0.790153,0.734614,0.704934,0.706136,0.659006,0.558564,0.545106,0.634293,0.443087,0.998163,0.990344,0.589197,0.663624,0.710138,0.643929,0.936843,0.820639,0.646251,0.625834,-0.725158,-0.388089,0.693169,0.966113,-0.128972,0.0252019,0.525862,0.469081,-0.0950357,-0.0485867,-0.359963,-0.289116,-0.140802,-0.206276,0.482516,0.242793,1.16376,0.881518,-0.443672,-0.357847
1744,0.435774,0.410416,0.0696754,0.0392563,0.199124,0.150618,0.260833,0.266439,0.293757,0.232668,0.528816,0.520268,0.333948,0.346581,0.996128,1.00919,0.873722,0.807704,0.434015,0.455864,-2.4912,-2.16148,1.41091,1.68819,0.498853,0.653432,-0.391351,-0.449226,0.281201,0.325925,-0.115679,-0.0448684,0.981327,0.914122,1.82899,1.66943,-0.314777,-0.591011,0.692799,0.78474
1745,0.283645,0.257825,0.873588,0.840808,0.193257,0.123908,0.803977,0.809327,0.30508,0.22302,0.996669,0.987867,0.370537,0.384995,0.402795,0.417872,0.804905,0.794769,0.73463,0.75847,-0.225772,0.105288,-1.21205,-0.93094,-2.19853,-2.0513,-0.518269,-0.575501,-0.693158,-0.653002,-0.226169,-0.15225,0.796877,0.732391,-0.78871,-0.955172,1.92658,1.65258,-0.139185,-0.0513348
1746,0.363617,0.373411,0.0854271,0.0529261,0.067345,0.0971982,0.820872,0.827244,0.219783,0.213373,0.833732,0.825247,0.691785,0.706887,0.184872,0.200784,0.188853,0.178965,0.372365,0.430016,-2.20065,-1.87266,3.06604,3.34973,-0.719614,-0.566205,-0.321505,-0.379759,-0.248038,-0.205231,0.413295,0.491786,1.90903,1.85279,0.417644,0.248433,1.18967,1.00641,-2.40163,-2.31948
1747,0.512893,0.488997,0.651876,0.619409,0.118994,0.0704883,0.252371,0.259061,0.373782,0.203725,0.350649,0.340529,0.00207957,0.0149615,0.750479,0.768294,0.0627332,0.0519968,0.078785,0.101561,-0.0122557,0.316482,0.382183,0.666633,-0.604487,-0.445381,0.881097,0.816544,0.456207,0.503617,1.36859,1.44162,-0.921776,-0.98572,-1.14792,-1.32128,0.63107,0.360231,-0.243409,-0.0737874
1748,0.339278,0.316999,0.953541,0.920843,0.409913,0.303471,0.16301,0.259192,0.255166,0.194077,0.99893,0.986954,0.847339,0.860575,0.917275,0.935239,0.771913,0.759104,0.499316,0.520889,1.00381,1.33339,0.167126,0.454519,1.25103,1.41664,1.54627,1.48593,-0.243843,-0.197589,-0.483958,-0.406359,-0.96823,-1.03054,0.519245,0.343201,-0.241042,-0.513552,2.08976,2.17191
1749,0.837318,0.813405,0.202407,0.170313,0.586795,0.536453,0.252751,0.259324,0.590381,0.531455,0.460676,0.447739,0.563799,0.574708,0.243236,0.263341,0.572239,0.4833,0.0140703,0.0349443,-1.27212,-0.942992,-0.517652,-0.231723,0.686222,0.759998,0.592736,0.536252,-0.484995,-0.4415,-0.140893,0.0136597,-0.543373,-0.598548,-1.64549,-1.82275,0.469655,0.196193,0.0827494,0.169343
1750,0.535161,0.562148,0.168735,0.136252,0.54295,0.492182,0.598829,0.602668,0.661084,0.545243,0.890863,0.876725,0.911631,0.92241,0.977359,0.995889,0.222157,0.207495,0.392808,0.400513,0.123404,0.445736,0.23117,0.522783,-0.0715722,0.103354,0.161588,0.0989869,-1.54216,-1.49536,0.363447,0.433679,1.64749,1.58952,0.00567007,-0.17308,-0.980758,-1.25857,-0.317974,-0.232688
1751,0.384958,0.310891,0.573437,0.517547,0.0414275,-0.00751397,0.670565,0.641297,0.6166,0.559031,0.341103,0.327378,0.886044,0.928684,0.0141589,0.0341629,0.310873,0.295668,0.746475,0.766082,-0.206158,0.120071,-0.652572,-0.364183,0.357803,0.532319,0.861442,0.800123,0.48775,0.526335,-0.728315,-0.66224,-0.386671,-0.445871,-0.046349,-0.226167,0.354132,0.0773261,0.322079,0.409217
1752,0.0835465,0.0596338,0.932812,0.898842,0.507561,0.456044,0.599343,0.679925,0.2628,0.205514,0.0710991,0.059501,0.857101,0.934958,0.0940138,0.114935,0.80785,0.791412,0.799354,0.818755,0.533008,0.861345,0.961351,1.25675,-0.238648,-0.0688994,-0.550085,-0.611513,0.634477,0.668075,0.0373607,0.103324,0.0673574,0.00103011,0.711353,0.532749,-2.79373,-3.07012,-1.34973,-1.26774
1753,0.11062,0.151966,0.591367,0.558804,0.685716,0.632366,0.633514,0.718553,0.646288,0.588926,0.98247,0.97107,0.930452,0.941231,0.392256,0.508275,0.0349138,0.0170474,0.446974,0.503631,-0.533986,-0.206148,0.895959,1.1976,-0.54538,-0.373417,-0.19639,-0.263121,-0.0419671,-0.00370673,-1.93039,-1.86935,0.179889,0.109327,0.347857,0.173813,1.60177,1.33292,-0.512755,-0.430437
1754,0.267917,0.244299,0.829473,0.796112,0.661862,0.608589,0.753342,0.757181,0.776104,0.655377,0.735464,0.722821,0.54865,0.560291,0.881941,0.901616,0.568718,0.55164,0.168413,0.188506,-0.458131,-0.125018,0.427057,0.725798,0.584229,0.763422,1.5103,1.44851,-0.148322,-0.110354,-0.798997,-0.736472,0.600188,0.524611,1.84221,1.6677,-1.09908,-1.37597,0.673801,0.760785
1755,0.557788,0.559329,0.625959,0.591167,0.849113,0.794376,0.0483383,0.0544236,0.820871,0.721828,0.271869,0.257285,0.841104,0.851447,0.849215,0.870539,0.812438,0.793133,0.642291,0.66251,0.904176,1.23243,-1.59266,-1.28736,-0.944426,-0.826378,1.45121,1.38221,2.19257,2.22819,0.853499,0.918751,0.738364,0.662085,1.26595,1.09608,-1.03472,-1.30422,-1.13575,-1.05387
1756,0.89988,0.87436,0.717953,0.776931,0.381282,0.324644,0.433036,0.437527,0.845777,0.788278,0.426577,0.412075,0.875607,0.815998,0.112403,0.134913,0.699545,0.681145,0.737862,0.71988,-0.955319,-0.621509,0.992468,1.3042,-2.59537,-2.41618,1.05955,0.992533,0.225401,0.261923,-0.418757,-0.361418,-0.517221,-0.586845,0.939502,0.768783,1.72036,1.44473,-0.750903,-0.629947
1757,0.900944,0.874927,0.99862,0.962695,0.477951,0.421448,0.202821,0.225845,0.563295,0.5228,0.00535498,-0.00923882,0.804842,0.78055,0.0441159,0.0691591,0.188839,0.171446,0.755181,0.777249,0.356068,0.687552,-1.82481,-1.50931,1.10902,1.28804,0.98659,0.91193,0.293355,0.329032,1.27606,1.3415,1.32158,1.25072,1.14118,0.976388,0.365489,0.0844527,-0.294829,-0.206021
1758,0.239468,0.213218,0.746069,0.728397,0.810484,0.753451,0.00748346,0.014163,0.349278,0.257321,0.969208,0.954731,0.736541,0.745101,0.518371,0.541237,0.218409,0.201006,0.0242789,0.0441328,0.0664296,0.390588,-0.805664,-0.493597,-0.22251,-0.040341,2.6323,2.56333,-1.14328,-1.10839,-1.00327,-0.942368,2.44726,2.37111,-1.32962,-1.48795,1.00777,0.730622,-0.159697,-0.0639638
1759,0.811853,0.784679,0.478505,0.4941,0.338757,0.283719,0.888125,0.893456,0.0493408,-0.00815739,0.892135,0.876502,0.446052,0.447472,0.296537,0.318826,0.489037,0.370589,0.150943,0.170122,0.619859,0.947583,-0.214187,0.0921654,-0.759314,-0.575766,-0.592762,-0.655408,1.21271,1.24515,0.573791,0.63744,2.86019,2.7864,0.0732729,-0.0840758,-1.94286,-2.21431,0.216878,0.317064
1760,0.831387,0.805117,0.296706,0.259803,0.913027,0.856266,0.772541,0.77553,0.121145,0.0659984,0.056507,0.0385273,0.139024,0.149843,0.588045,0.60946,0.623687,0.540171,0.0311419,0.0496373,-0.389854,-0.0583171,0.787008,1.09183,-0.463524,-0.283694,-1.30815,-1.36952,-0.412867,-0.377987,0.98291,1.04911,0.180536,0.114219,0.145441,-0.0148216,-1.21686,-1.48982,1.41891,1.52074
1761,0.431661,0.404413,0.973872,0.939494,0.722414,0.619251,0.346274,0.348367,0.950656,0.893866,0.702565,0.684953,0.112512,0.121456,0.0634551,0.0836513,0.728137,0.709754,0.507,0.523641,-0.39735,-0.0675972,1.1412,1.44703,-2.88392,-2.69918,0.218113,0.153705,-0.399449,-0.395667,0.144524,0.214736,-0.802844,-0.835234,0.837414,0.684265,1.42036,1.14533,0.13809,0.320766
1762,0.740154,0.711134,0.82284,0.785998,0.438743,0.382235,0.144145,0.146056,0.280973,0.224163,0.479088,0.46204,0.705485,0.712824,0.885671,0.907706,0.790552,0.772644,0.150221,0.167855,-0.134237,0.198285,-1.88227,-1.57013,-0.191141,-0.00806471,-0.110761,-0.173975,-0.448888,-0.413348,0.271837,0.337251,-1.71447,-1.78469,2.64874,2.48952,0.78446,0.409839,-0.978652,-0.879206
1763,0.218798,0.190493,0.435242,0.396401,0.770802,0.714239,0.804514,0.807178,0.342027,0.290614,0.672276,0.655784,0.255747,0.261984,0.232504,0.25522,0.0608138,0.0414541,0.967247,0.986141,-0.588781,-0.250125,-0.878609,-0.570457,0.541155,0.729935,1.31553,1.25551,-0.961245,-0.931383,-1.24494,-1.17254,0.729287,0.661479,0.969997,0.811758,-0.0454575,-0.325653,1.20264,1.301
1764,0.588182,0.515153,0.315334,0.189722,0.417019,0.360507,0.501368,0.409817,0.500295,0.357065,0.178601,0.160566,0.971361,0.975159,0.795558,0.817456,0.792157,0.773156,0.189812,0.206174,1.33112,1.67553,-1.71812,-1.41247,-1.60753,-1.41223,1.581,1.52805,-0.421314,-0.391847,0.0896746,0.159838,1.245,1.18323,1.74166,1.58627,-0.398638,-0.67359,0.534274,0.716966
1765,0.867864,0.839813,0.0203394,-0.0169577,0.517268,0.46183,0.00888006,0.0124557,0.480189,0.423516,0.912204,0.896618,0.864655,0.870391,0.732521,0.756802,0.195172,0.178923,0.295885,0.260383,-0.140868,0.196967,-1.05648,-0.791578,-0.308989,-0.109172,-0.704945,-0.751949,-1.9014,-1.87544,-0.815893,-0.752501,0.105965,0.0432289,-1.3021,-1.45211,-1.25153,-1.52984,0.0362907,0.132929
1766,0.682191,0.609691,0.935536,0.897338,0.900237,0.842745,0.813115,0.818809,0.7633,0.705613,0.116805,0.100744,0.960992,0.964332,0.143247,0.165479,0.0516644,0.0354111,0.297507,0.314592,1.6305,1.97261,-0.472271,-0.170683,-0.24103,-0.0467957,0.25466,0.211979,-1.32824,-1.30351,-0.137111,-0.0775552,1.14646,1.08432,0.0666123,-0.0798166,1.17519,0.893238,-1.20685,-1.11621
1767,0.447492,0.379568,0.509174,0.547604,0.496875,0.43519,0.571401,0.575677,0.395997,0.336842,0.151955,0.137025,0.414612,0.417477,0.862794,0.883121,0.208567,0.19598,0.951054,0.969138,-1.20498,-0.866846,0.400573,0.706417,-0.740514,-0.550428,-1.03084,-1.07505,-1.11171,-1.08357,0.0375105,0.0897282,-1.03315,-1.09074,1.78171,1.63498,0.795256,0.516861,0.302743,0.39712
1768,0.179788,0.149445,0.235277,0.197869,0.0855308,0.0276341,0.731215,0.7353,0.994217,0.936584,0.570922,0.553186,0.352737,0.397027,0.155924,0.174489,0.37226,0.35655,0.602442,0.616907,1.23674,1.57452,0.785504,1.0919,0.628504,0.813544,0.407328,0.369513,0.856422,0.891255,0.51846,0.566972,0.322829,0.265025,-0.653131,-0.800159,0.770704,0.495915,-0.422212,-0.334541
1769,0.569453,0.537948,0.726916,0.690917,0.408868,0.349172,0.479306,0.482406,0.884632,0.824953,0.984572,0.969347,0.37546,0.376578,0.185657,0.204704,0.817036,0.801749,0.244362,0.264676,-0.654283,-0.309398,-0.336909,-0.0280622,-0.644513,-0.451437,-0.655854,-0.688388,1.64074,1.67944,-0.218827,-0.217733,0.891298,0.834995,-0.101266,-0.253969,-2.95547,-3.23676,0.191234,0.276187
1770,0.439,0.479421,0.847146,0.809398,0.946764,0.886815,0.827847,0.831192,0.405605,0.345998,0.359972,0.344759,0.596193,0.597658,0.85121,0.869028,0.791518,0.777267,0.554295,0.549332,0.71209,1.06297,-0.168661,0.0515607,0.126923,0.317253,0.491493,0.461392,1.66746,1.70055,-0.947983,-1.00244,-0.16561,-0.227613,1.55362,1.39571,0.974725,0.693431,0.537572,0.628121
1771,0.46513,0.420894,0.342274,0.306,0.246284,0.187405,0.46315,0.464383,0.761341,0.703624,0.0857497,0.0718369,0.367784,0.37129,0.701763,0.717782,0.308141,0.292365,0.812536,0.833987,0.578514,0.933213,-0.171288,0.131184,0.247469,0.438077,0.220702,0.1947,0.899937,0.937631,-1.83565,-1.78714,0.0927101,0.031964,-1.0167,-1.17981,0.0840001,-0.0987473,-0.247707,-0.164544
1772,0.425763,0.362368,0.416274,0.470913,0.719081,0.661,0.576466,0.556353,0.437357,0.381248,0.422987,0.40626,0.948224,0.952441,0.0496095,0.0652971,0.992296,0.974643,0.701089,0.723624,0.76087,1.12217,-0.552453,-0.250483,0.851427,1.03554,-1.25849,-1.29167,0.879767,0.910747,-0.391679,-0.348657,-1.21098,-1.26499,0.50967,0.344395,-0.611463,-0.890926,1.21839,1.30155
1773,0.335346,0.303841,0.671698,0.635826,0.0120253,-0.0483213,0.682559,0.648323,0.47958,0.423428,0.998298,0.982329,0.10316,0.106807,0.317171,0.338241,0.0468608,0.0292166,0.119165,0.143413,-0.0329056,0.331045,-0.264123,0.0451217,-1.50754,-1.33248,0.326882,0.295559,-1.11111,-1.08751,-0.0647636,-0.0283672,1.15901,1.09955,0.563974,0.397382,0.178427,-0.10504,-1.17159,-1.09818
1774,0.915491,0.885237,0.557446,0.555433,0.468637,0.410514,0.725144,0.740292,0.059788,0.00438905,0.424471,0.407966,0.238607,0.241904,0.595784,0.611185,0.608148,0.588983,0.351923,0.376192,0.900424,1.27008,1.91123,2.21657,-1.29024,-1.11778,-0.84019,-0.869684,0.094094,0.114824,0.49153,0.524129,-1.94767,-2.01419,-0.503037,-0.664951,-0.50474,-0.790185,0.842405,0.923154
1775,0.134455,0.103317,0.545671,0.475041,0.0372038,-0.0193972,0.831029,0.832262,0.311081,0.255905,0.274894,0.259948,0.682411,0.683665,0.869036,0.884128,0.266735,0.249728,0.975127,1.00065,-0.0179699,0.356027,-0.239964,0.0620182,0.310059,0.477666,-0.185685,-0.214685,0.686545,0.700873,0.115458,0.155161,-2.25763,-2.31927,-0.85407,-1.02389,1.58089,1.29348,0.856407,0.930734
1776,0.14603,0.113623,0.448065,0.394648,0.0478185,-0.00739091,0.221491,0.224278,0.0144348,-0.0406369,0.652484,0.638837,0.248398,0.247584,0.0155427,0.0287923,0.457224,0.440224,0.15319,0.179959,-0.169641,0.208946,-0.520821,-0.211986,-0.254142,-0.0889068,-0.598113,-0.619849,-0.87279,-0.860275,-0.785044,-0.742378,-0.520269,-0.578532,-0.84273,-1.01656,-0.603622,-0.893531,2.19137,2.27185
1777,0.95285,0.922101,0.443738,0.314255,0.61942,0.565156,0.188867,0.192267,0.761204,0.708194,0.629274,0.615661,0.657099,0.654552,0.382826,0.466252,0.0847375,0.0660394,0.929473,0.955346,1.72313,2.10569,0.00176341,0.312049,-1.11056,-0.952584,0.266555,0.276251,-1.79898,-1.79234,0.85358,0.899864,0.843569,0.777234,1.91793,1.74947,-0.97166,-1.25537,0.761696,0.837669
1778,0.383717,0.351481,0.269735,0.233863,0.0752939,0.0201735,0.391166,0.300658,0.00131664,-0.0494069,0.880737,0.786691,0.0287868,0.028185,0.891855,0.903712,0.948365,0.927675,0.571676,0.599561,0.685054,1.06954,1.26108,1.57548,-0.173452,-0.0160767,1.19895,1.17235,-0.0763478,-0.070853,-0.0999145,-0.0570622,-1.40083,-1.46134,-0.10868,-0.272737,0.493642,0.207256,-1.4472,-1.36649
1779,0.922971,0.893736,0.513286,0.475981,0.256255,0.176241,0.402786,0.409048,0.755228,0.703408,0.96973,0.957721,0.388992,0.390645,0.945401,0.959451,0.168521,0.147838,0.940728,0.9695,1.98052,2.36325,0.643067,0.925142,1.27414,1.43916,-0.262158,-0.283984,0.6168,0.623629,-0.179482,-0.134799,0.423208,0.360955,-0.543646,-0.707225,0.39878,0.108541,-0.917814,-0.832762
1780,0.730003,0.708863,0.530644,0.495015,0.501184,0.332308,0.0753184,0.0815621,0.112559,0.0591357,0.537522,0.623655,0.332841,0.336502,0.189563,0.203937,0.566047,0.543715,0.982512,1.01138,0.40639,0.79126,-0.044162,0.274803,0.859067,1.02666,0.239304,0.215763,-0.754322,-0.75562,0.421204,0.463615,-0.0719153,-0.130577,1.05881,0.896911,0.787577,0.490523,0.277887,0.358459
1781,0.553519,0.52399,0.850917,0.816496,0.643906,0.488376,0.695431,0.704135,0.87369,0.817761,0.300642,0.289588,0.682004,0.684204,0.309552,0.325236,0.576072,0.530666,0.562292,0.590787,0.782342,1.16588,-1.12765,-0.813489,-0.831122,-0.656373,-0.140508,-0.158809,1.2024,1.19964,-1.26269,-1.21289,-0.280195,-0.343019,-0.256683,-0.414469,0.185406,-0.118971,-0.0376115,0.0477316
1782,0.866185,0.835628,0.802954,0.772198,0.699743,0.644443,0.881677,0.889639,0.58441,0.540019,0.388788,0.466215,0.643796,0.719078,0.866215,0.883135,0.541429,0.517618,0.585593,0.612976,-1.25061,-0.874586,-0.514361,-0.197572,0.454145,0.630732,1.17007,1.14386,-2.20122,-2.19886,-0.579619,-0.525549,1.79384,1.72974,0.00483248,-0.158687,-0.778809,-1.0689,-0.778568,-0.693912
1783,0.192608,0.16385,0.760093,0.727901,0.358534,0.304572,0.809005,0.816493,0.318407,0.262277,0.6541,0.642842,0.754463,0.753952,0.466999,0.482114,0.931346,0.908509,0.00124203,0.027281,-1.3579,-0.976422,0.916142,1.23478,-0.0604005,0.110518,-0.938719,-0.960358,0.870117,0.869809,1.2655,1.31561,-1.22219,-1.29372,-0.837768,-1.01583,-1.71377,-2.01883,-1.52535,-1.43555
1784,0.865555,0.835071,0.93628,0.906588,0.454178,0.297931,0.313197,0.319028,0.651282,0.594458,0.36299,0.323181,0.398919,0.481806,0.444988,0.461769,0.33543,0.314276,0.929282,0.956009,0.377327,0.75286,0.400674,0.79083,-1.63564,-1.46177,-0.572053,-0.595921,0.546957,0.548605,0.255432,0.311911,-0.789639,-0.861726,-1.70775,-1.87298,0.684868,0.390068,0.168189,0.260129
1785,0.225192,0.193682,0.838852,0.901038,0.361755,0.291289,0.441569,0.448557,0.501637,0.443503,0.0133843,0.00351999,0.207346,0.209661,0.957751,0.973764,0.0954546,0.0757656,0.767321,0.795633,-1.21467,-0.83468,0.0282369,0.346877,1.76195,1.93674,-0.420357,-0.445165,-0.196164,-0.198712,-0.244851,-0.181289,-1.12675,-1.19866,0.63933,0.468056,-0.86545,-1.15982,-2.26299,-2.16938
1786,0.918075,0.884402,0.926066,0.895488,0.337548,0.284648,0.779591,0.787139,0.816549,0.760487,0.21176,0.202385,0.107908,0.127457,0.955964,0.973401,0.0663728,0.0460205,0.167427,0.1948,0.651989,1.03197,-0.946384,-0.632106,-0.108824,0.0656257,0.584708,0.567331,-0.359884,-0.366537,0.855641,0.919321,-0.529953,-0.582059,-0.356947,-0.533689,-1.61684,-1.91005,0.254989,0.345654
1787,0.54693,0.565162,0.232646,0.200258,0.058626,0.00606492,0.788216,0.831194,0.367472,0.312476,0.838379,0.827842,0.043282,0.0452519,0.104218,0.123539,0.30788,0.287514,0.375367,0.479455,-0.349163,0.0260666,0.326402,0.646471,1.64055,1.81825,1.24277,1.22233,-0.0339651,-0.0399187,0.797421,0.857071,0.104976,0.0345462,0.0233009,-0.154979,0.669944,0.379548,-0.731798,-0.643294
1788,0.280889,0.245922,0.463866,0.432673,0.225235,0.151217,0.869623,0.875248,0.22079,0.21957,0.600036,0.589388,0.834333,0.835535,0.311862,0.330656,0.131204,0.109917,0.736919,0.764111,-0.328526,0.0473622,0.936305,1.26239,-1.93837,-1.76874,1.35795,1.34106,0.756279,0.74827,1.29995,1.36417,-0.213639,-0.286485,-0.70193,-0.883522,-2.05641,-2.34848,-0.723752,-0.635713
1789,0.796292,0.762528,0.357887,0.378003,0.347849,0.296369,0.191072,0.19734,0.1807,0.126664,0.917701,0.904966,0.91073,0.821016,0.886715,0.904272,0.19313,0.172808,0.48832,0.514294,0.115665,0.497818,0.862024,1.18792,-1.37978,-1.21678,-1.45667,-1.469,-2.54747,-2.5524,-0.803186,-0.732933,0.990551,0.914388,-0.523612,-0.707131,-0.358943,-0.725973,-1.15837,-1.0671
1790,0.292202,0.257035,0.347422,0.323333,0.15858,0.181958,0.931668,0.940049,0.484439,0.401848,0.961435,0.950095,0.806903,0.806498,0.603734,0.638327,0.0476978,0.0292956,0.874078,0.898457,-0.536661,-0.153068,-0.780632,-0.448292,1.41672,1.58371,0.809254,0.790708,0.160751,0.15722,-1.05845,-0.994085,0.81132,0.780878,1.67365,1.48567,1.1886,0.896532,1.02105,1.11311
1791,0.219872,0.185747,0.440223,0.268663,0.166068,0.0675465,0.135383,0.144501,0.729975,0.677032,0.42837,0.41591,0.644551,0.642681,0.23634,0.372381,0.89476,0.874562,0.83577,0.890148,1.54518,1.92978,0.861566,1.18736,-0.62756,-0.462712,0.680464,0.664433,1.04864,1.05296,-0.92903,-0.871571,0.720228,0.647368,0.755301,0.56032,-1.0076,-1.30546,0.169811,0.260545
1792,0.932158,0.896378,0.245186,0.213993,0.00461615,-0.0468646,0.239988,0.248902,0.286574,0.233597,0.968936,0.957685,0.223196,0.221659,0.0885567,0.106436,0.0737442,0.0552892,0.856303,0.88184,-0.302081,0.0758403,0.705579,0.991743,0.882385,1.0534,1.55256,1.5364,-1.14755,-1.14288,-1.34218,-1.2879,-1.00976,-1.0891,0.776846,0.583299,-0.0232388,-0.313974,-0.440254,-0.351954
1793,0.034999,-0.00278719,0.913157,0.88354,0.905331,0.855786,0.846846,0.855791,0.266503,0.214633,0.672864,0.597418,0.592508,0.588541,0.580722,0.597721,0.49575,0.476354,0.821703,0.873531,0.808349,1.18335,0.374153,0.79613,1.13497,1.30043,1.9806,1.9608,0.184253,0.195738,0.00352793,0.0584048,0.244194,0.157841,-0.423453,-0.617256,1.58958,1.30107,0.116723,0.197048
1794,0.533905,0.493619,0.711439,0.718684,0.916021,0.867792,0.797845,0.808918,0.804675,0.753519,0.248807,0.237151,0.743694,0.738966,0.391825,0.410776,0.290848,0.273548,0.841907,0.865223,0.125032,0.501338,0.274729,0.600518,0.41368,0.574826,0.073507,0.0479363,-0.282185,-0.277282,-1.57231,-1.51236,-0.719748,-0.811802,-0.0784419,-0.19549,-1.03335,-1.32438,-0.76413,-0.68646
1795,0.598839,0.558949,0.585053,0.553828,0.404785,0.359405,0.462745,0.466774,0.346179,0.294788,0.837686,0.827797,0.136384,0.132839,0.700024,0.717363,0.792255,0.773768,0.923142,0.856914,1.46187,1.84339,1.52185,1.84931,-1.33705,-1.17052,0.257423,0.228992,-0.494163,-0.490383,-0.546418,-0.485964,0.70365,0.606648,0.422507,0.226276,-0.597313,-0.881124,1.10414,1.18345
1796,0.46299,0.421142,0.952563,0.92354,0.219111,0.171927,0.112256,0.12463,0.442653,0.464885,0.64061,0.629028,0.715602,0.71399,0.414023,0.476437,0.718864,0.698825,0.824227,0.848606,-0.269687,0.117025,0.883689,1.20974,-0.222587,-0.0504264,-0.313377,-0.345581,0.117481,0.126732,-0.134841,-0.0742976,-0.764055,-0.861972,0.338826,0.113312,0.3667,0.0766758,1.36563,1.44484
1797,0.558232,0.57541,0.0389668,0.00810799,0.820215,0.775486,0.319748,0.331317,0.687482,0.634982,0.723879,0.715485,0.305416,0.302872,0.217027,0.23551,0.919173,0.899302,0.235569,0.257944,-1.36987,-0.981107,-1.03257,-0.711988,0.154722,0.332606,0.181631,0.154166,-0.650416,-0.636191,-0.528189,-0.474147,-0.223718,-0.324883,0.192453,0.000347571,-1.81949,-2.11033,-0.430695,-0.355918
1798,0.773404,0.729679,0.876022,0.84593,0.0350287,-0.00908442,0.201729,0.21339,0.0353006,-0.0192551,0.848301,0.801942,0.568857,0.564445,0.39395,0.406642,0.505758,0.485235,0.692792,0.71696,0.670238,1.05565,-1.30201,-0.985991,1.4262,1.6047,1.0454,1.01025,-0.268029,-0.247791,0.393888,0.444354,-0.344016,-0.444497,0.354977,0.162486,1.67086,1.38095,-0.883586,-0.801769
1799,0.447189,0.404279,0.650535,0.621652,0.96173,0.916822,0.43486,0.468214,0.510111,0.453717,0.899962,0.888399,0.171653,0.168387,0.557814,0.577774,0.69166,0.67142,0.763984,0.829741,0.15912,0.541011,0.304465,0.618713,0.0608628,0.245441,-0.68094,-0.714371,1.12277,1.13827,0.929469,0.980393,0.00317185,-0.0906445,-0.233344,-0.426448,-0.818228,-1.10441,0.51872,0.60218
1800,0.567101,0.524497,0.152875,0.12337,0.635052,0.592364,0.713253,0.723038,0.762674,0.666065,0.735841,0.725779,0.49208,0.429184,0.0125436,0.0322501,0.222736,0.201903,0.91729,0.942523,0.597805,0.975258,-0.779216,-0.469579,-0.900624,-0.710171,1.59982,1.56365,-0.613961,-0.592061,0.0792353,0.131003,-0.00671989,-0.104625,0.686029,0.485997,-0.192188,-0.473089,0.259758,0.337627
1801,0.29403,0.2712,0.330477,0.263767,0.928221,0.88382,0.635643,0.61268,0.935403,0.878413,0.198771,0.186564,0.811508,0.689981,0.757508,0.7792,0.787446,0.767303,0.159664,0.183167,-1.30984,-0.939151,3.3485,3.65592,-0.464747,-0.281205,-0.392837,-0.430835,-1.79364,-1.76816,0.0316521,0.0845975,0.237796,0.139377,0.919504,0.725731,0.197947,-0.07619,1.0113,1.08607
1802,0.0590107,0.0179031,0.433767,0.404164,0.118956,0.0757446,0.492579,0.502323,0.210712,0.151905,0.762526,0.747851,0.953308,0.950778,0.431554,0.4527,0.798778,0.791286,0.00967567,0.0328079,-2.72378,-2.35872,0.215552,0.519925,-0.432406,-0.250561,0.492335,0.457025,0.346702,0.367414,-0.262991,-0.207306,-0.571448,-0.672879,1.62552,1.42482,0.343174,0.0711122,0.309821,0.384057
1803,0.535025,0.408349,0.936299,0.906976,0.00876439,-0.0357881,0.168183,0.179515,0.847902,0.79111,0.494974,0.479974,0.000433595,-0.00378603,0.46608,0.487973,0.858477,0.81527,0.358736,0.301861,0.319248,0.68662,-1.75868,-1.44685,1.67006,1.84746,-1.48762,-1.52322,-1.8407,-1.82843,-1.40718,-1.34692,-1.1699,-1.27036,-0.730161,-0.923256,-0.406325,-0.679116,-1.12781,-1.05012
1804,0.838745,0.798795,0.436214,0.408694,0.668069,0.623205,0.601012,0.612931,0.800402,0.741341,0.5848,0.570743,0.964514,0.96209,0.879002,0.899717,0.860712,0.839253,0.54755,0.570913,0.76775,1.13708,-2.29712,-1.98028,1.85902,2.03059,1.75802,1.71989,-0.2272,-0.214889,-0.981036,-0.917681,0.548803,0.455885,0.167024,-0.0264801,-1.46401,-1.74056,2.44821,2.52058
1805,0.552079,0.512832,0.414205,0.388035,0.299733,0.253862,0.0318096,0.0447475,0.0190321,-0.0381891,0.448116,0.43254,0.0251891,0.0239029,0.47241,0.492498,0.217555,0.194575,0.543812,0.566419,-2.12135,-1.7525,-0.499796,-0.189364,-2.17143,-1.99576,-0.144694,-0.177925,0.670476,0.680854,-0.161683,-0.0927719,2.82527,2.73964,-0.246731,-0.446198,0.86369,0.586776,-0.831979,-0.76485
1806,0.268333,0.226868,0.948835,0.920187,0.33476,0.290229,0.257666,0.269717,0.614437,0.556597,0.0364015,0.0215352,0.437798,0.435429,0.590822,0.608255,0.547006,0.525114,0.185635,0.210633,0.983165,1.35529,-0.749847,-0.433268,-1.14132,-0.965238,0.000713028,-0.0271687,0.0865188,0.101093,-1.14957,-1.08099,-1.4767,-1.56233,0.561044,0.359663,1.31916,1.04528,-0.617886,-0.548601
1807,0.8834,0.8422,0.476687,0.446544,0.987742,0.944676,0.822018,0.83306,0.527572,0.567147,0.830333,0.815875,0.4136,0.412448,0.446017,0.520567,0.252262,0.230887,0.0486716,0.0760592,0.782513,1.14984,1.15994,1.48225,-1.56156,-1.3921,1.3142,1.29105,0.966423,0.980172,-0.0121168,0.0518891,0.48622,0.399511,0.319859,0.142472,-1.69549,-1.97329,0.320788,0.396322
1808,0.828432,0.699691,0.248772,0.292255,0.198196,0.153899,0.109196,0.120169,0.637518,0.577696,0.675477,0.748103,0.00843345,0.00636028,0.414117,0.432879,0.803473,0.780555,0.902729,0.930995,-0.0189044,0.343406,-0.663096,-0.344822,-0.712152,-0.545607,-0.151538,-0.180151,-1.75381,-1.73991,2.35014,2.41324,-0.701452,-0.787611,0.130564,-0.0747194,0.902112,0.631074,-0.17462,-0.0509132
1809,0.601171,0.557182,0.166832,0.137967,0.708158,0.662129,0.945134,0.956615,0.835633,0.777248,0.695026,0.68033,0.841271,0.840064,0.935723,0.955185,0.306817,0.285468,0.928769,0.957288,1.30762,1.66909,-0.746012,-0.435727,-0.53191,-0.362477,-1.05365,-1.0804,1.28905,1.29905,-0.196261,-0.133763,1.96118,1.88275,0.736461,0.531743,2.05862,1.79229,-0.666627,-0.498149
1810,0.88272,0.838878,0.64268,0.615734,0.348221,0.302507,0.517062,0.600709,0.113049,0.0553432,0.979403,0.964433,0.440424,0.439726,0.795228,0.736299,0.187451,0.168297,0.596383,0.625708,0.970695,1.32713,0.53905,0.842851,-0.861689,-0.698221,1.45075,1.41673,-0.298698,-0.291401,1.84098,1.90952,0.162022,0.0839009,-0.108515,-0.316522,0.73279,0.46078,-1.02092,-0.945384
1811,0.506748,0.536287,0.271411,0.246629,0.570337,0.430767,0.23454,0.244802,0.775558,0.715729,0.482217,0.469214,0.508322,0.508521,0.498942,0.517414,0.466568,0.421187,0.499686,0.563314,0.860834,1.20966,-0.353038,-0.0441151,1.5146,1.67706,-0.581155,-0.608418,0.750663,0.757043,-1.32975,-1.25351,1.13626,1.05125,0.444625,0.229667,-0.164051,-0.427159,1.35385,1.42969
1812,0.277907,0.233697,0.47415,0.44909,0.603464,0.559026,0.0948155,0.168338,0.266088,0.20753,0.268726,0.255433,0.0814105,0.0835164,0.745861,0.76297,0.821723,0.674077,0.470152,0.500921,-0.646644,-0.299858,-0.559323,-0.256229,-0.653738,-0.497633,-0.371137,-0.397776,-1.65618,-1.64902,1.5429,1.61368,1.00046,0.914877,-1.18718,-1.40124,-0.468976,-0.727906,-0.224047,-0.154091
1813,0.770617,0.725224,0.950476,0.926857,0.155021,0.109956,0.0813381,0.0918733,0.0764436,0.0154718,0.6845,0.670008,0.414201,0.471841,0.106318,0.122019,0.946121,0.926967,0.173058,0.205513,-0.739255,-0.386034,-0.454333,-0.149303,0.311687,0.470339,0.695622,0.674501,0.357524,0.360312,0.296488,0.365241,-1.00903,-1.08867,0.026296,-0.184554,1.39333,1.14121,0.29676,0.365361
1814,0.176293,0.129639,0.650268,0.627006,0.494558,0.426521,0.603522,0.614797,0.24684,0.185999,0.771733,0.755184,0.856615,0.860166,0.951509,0.967145,0.043747,0.0261353,0.114117,0.2139,-0.0908632,0.264389,0.233103,0.5429,-1.24288,-1.08641,0.882792,0.855556,-1.16033,-1.15511,-0.582092,-0.515006,0.60942,0.528249,-0.711701,-0.93322,1.31861,1.07443,-0.627904,-0.564271
1815,0.352666,0.402618,0.578378,0.553093,0.789688,0.743085,0.347602,0.35714,0.661229,0.598622,0.0874927,0.0704176,0.707264,0.710636,0.535441,0.538384,0.0718311,0.0556952,0.188755,0.222287,1.36221,1.71627,0.531305,0.917502,0.82219,0.979064,-1.79924,-1.82937,-0.209907,-0.199235,0.315703,0.38897,0.25046,0.175473,-1.47425,-1.68189,-1.39393,-1.63446,0.196652,0.258682
1816,0.698386,0.675597,0.900453,0.874575,0.659816,0.611558,0.743382,0.750687,0.243337,0.179583,0.467047,0.449307,0.935033,0.936485,0.0957252,0.109623,0.413928,0.396417,0.915417,0.950749,-0.22138,0.128731,0.986406,1.2921,0.727901,0.885796,0.934202,0.898184,0.0967182,0.110139,0.617689,0.69103,0.748145,0.667451,0.331847,0.123368,-0.595776,-0.91397,0.509014,0.567309
1817,0.99523,0.948576,0.284264,0.258022,0.0874169,0.0379089,0.260207,0.268876,0.811177,0.748323,0.209195,0.191319,0.448636,0.450181,0.282014,0.296589,0.434391,0.444833,0.77141,0.805643,-0.300942,0.0425548,-0.147972,0.156463,0.395857,0.550052,0.422462,0.384727,1.99901,2.01751,-0.211792,-0.14334,-0.642071,-0.721216,0.339171,0.15993,0.0470444,-0.193481,-1.86099,-1.80127
1818,0.602341,0.518344,0.236274,0.208155,0.148327,0.128783,0.0502462,0.0568746,0.939198,0.877813,0.482693,0.371593,0.908921,0.91149,0.094885,0.109644,0.50794,0.493248,0.967126,1.00294,0.653183,0.996653,0.224784,0.525124,0.329368,0.489394,0.721175,0.636608,-0.321075,-0.30453,-0.211136,-0.11259,-0.993862,-1.07399,0.400908,0.196491,-0.460107,-0.694772,-2.03275,-1.97525
1819,0.134081,0.0881124,0.831937,0.804461,0.373146,0.219656,0.857228,0.863227,0.46245,0.398858,0.568827,0.551868,0.320475,0.324183,0.337053,0.333723,0.781664,0.764223,0.613894,0.651856,1.33161,1.67666,1.44667,1.7455,-0.461936,-0.296155,0.927898,0.888489,-0.401031,-0.388203,-0.151637,-0.0818393,-0.681907,-0.766292,-1.29592,-1.49671,0.398826,0.171519,-0.474963,-0.415499
1820,0.386767,0.339228,0.314276,0.286818,0.360975,0.31053,0.703009,0.711106,0.645095,0.583916,0.635406,0.618309,0.0598292,0.0634813,0.646649,0.557801,0.69905,0.683859,0.0372303,0.0761613,0.0762554,0.425858,-1.01223,-0.714525,-0.241858,-0.0814506,0.2079,0.174372,-0.488292,-0.471876,1.64003,1.71124,0.347117,0.260853,-0.501437,-0.716129,-0.415372,-0.637847,-1.0411,-0.982084
1821,0.216716,0.16723,0.729366,0.701927,0.0225131,-0.0293407,0.976768,0.98636,0.239157,0.179837,0.158409,0.143345,0.689085,0.694646,0.76712,0.78188,0.977031,0.960129,0.231022,0.26821,3.55939,3.91239,-0.129408,0.162575,-0.85717,-0.698805,0.402987,0.370115,-0.0550462,-0.0387283,-0.0437527,0.034739,-1.87154,-1.95997,0.262227,0.0644475,1.02347,0.807361,-1.90956,-1.85148
1822,0.989527,0.942324,0.381486,0.352209,0.538234,0.484673,0.698111,0.708632,0.48701,0.38972,0.157335,0.140259,0.303478,0.392504,0.452497,0.465387,0.417562,0.400282,0.65413,0.644036,0.592339,0.94559,-1.65638,-1.36458,0.41927,0.573289,-0.931877,-0.96253,-0.863626,-0.846881,0.671363,0.753928,0.866831,0.782169,-1.52369,-1.72149,0.00172157,-0.209071,0.0733688,0.13605
1823,0.139968,0.0906512,0.422895,0.395617,0.430502,0.378629,0.00396656,0.0165147,0.611223,0.599603,0.397194,0.378581,0.0845208,0.0903624,0.509715,0.518232,0.68632,0.572961,0.983853,1.01986,-0.828017,-0.473982,-0.759602,-0.472828,-0.221869,-0.0728394,-0.186787,-0.213926,0.101333,0.12638,1.59293,1.67243,0.348249,0.258993,-0.0843484,-0.28705,-1.55129,-1.75896,-0.834729,-0.777692
1824,0.819157,0.771858,0.189389,0.161114,0.0441991,-0.00598689,0.795476,0.806532,0.868806,0.809486,0.264213,0.244664,0.890955,0.895834,0.560389,0.571077,0.843285,0.745639,0.666856,0.704095,-1.5461,-1.18625,-0.769872,-0.487625,-1.06968,-0.920396,0.115188,0.016846,-0.36163,-0.332306,-1.97578,-1.89439,0.234759,0.139379,-0.223063,-0.431511,-2.2158,-2.42991,-0.194845,-0.135787
1825,0.860828,0.815934,0.766189,0.736878,0.745787,0.694376,0.32039,0.32968,0.455057,0.395415,0.405155,0.482369,0.998831,1.00585,0.391229,0.330151,0.933828,0.918318,0.698364,0.735999,-1.90576,-1.54417,0.677016,0.960571,-0.669546,-0.520104,0.278633,0.247618,1.34541,1.3731,-0.849137,-0.761512,-0.428047,-0.51929,-1.82624,-2.03101,-1.67122,-1.89125,-0.0375797,0.0218734
1826,0.908209,0.86001,0.219742,0.190158,0.7139,0.660832,0.843204,0.852604,0.94382,0.883745,0.73688,0.720073,0.660363,0.662331,0.0759453,0.0892249,0.977153,0.96179,0.979135,1.01936,-0.454077,-0.0922898,-0.67043,-0.393956,1.98081,2.12611,-0.615079,-0.638787,1.40149,1.42424,-0.957824,-0.868894,-0.56271,-0.655662,-0.604969,-0.876746,-0.804088,-1.02496,-0.991294,-0.936701
1827,0.325281,0.279198,0.115679,0.0868961,0.326233,0.271352,0.800915,0.810913,0.5632,0.504873,0.697437,0.682745,0.310995,0.318816,0.184336,0.260356,0.0351787,0.0204774,0.820851,0.85898,-0.0587047,0.296713,0.0922384,0.375966,0.842475,0.888298,-1.26091,-1.29114,-1.90039,-1.87642,-0.665685,-0.576541,-0.0490619,-0.148638,0.482285,0.277514,-1.91554,-2.13224,-1.36804,-1.30892
1828,0.00565812,-0.0400216,0.609241,0.579944,0.448264,0.3925,0.185464,0.193261,0.567517,0.507663,0.231649,0.217209,0.679847,0.685699,0.418363,0.431488,0.0233438,0.0373713,0.13114,0.166478,-0.667993,-0.365659,-0.347808,-0.065065,-0.49368,-0.349512,-0.171993,-0.204586,-0.396775,-0.368729,-0.368262,-0.284189,-0.295251,-0.392316,0.323733,0.119554,-0.0226518,-0.231815,-1.50843,-1.45165
1829,0.175458,0.130828,0.402673,0.425655,0.2532,0.28276,0.506656,0.512892,0.918159,0.859692,0.000892915,-0.0112532,0.677935,0.575112,0.214333,0.316742,0.067834,0.0542652,0.696522,0.729866,-1.38864,-1.02803,0.160137,0.444487,0.83237,0.983563,0.299948,0.26462,-0.949925,-0.917505,-0.460528,-0.377258,-1.10379,-1.20457,-0.739452,-0.956153,-1.015,-1.23136,-0.934297,-0.870986
1830,0.0377142,-0.00697931,0.301052,0.271367,0.229552,0.17302,0.420698,0.370476,0.698052,0.637534,0.471058,0.456345,0.480373,0.464526,0.189974,0.201996,0.60332,0.588857,0.556652,0.590095,0.181229,0.548047,0.911476,1.19899,0.865185,1.01421,-0.204772,-0.233003,0.558929,0.590189,-0.955866,-0.870458,0.107392,-0.0921529,-1.83275,-2.03186,-1.32257,-1.5321,-2.09607,-2.02913
1831,0.669705,0.623703,0.353565,0.32517,0.789364,0.730992,0.340552,0.228059,0.113031,0.0535952,0.259616,0.242564,0.348088,0.35394,0.328353,0.337554,0.492812,0.476869,0.934517,0.969829,0.849326,1.2118,-0.594268,-0.311382,-1.25658,-1.11193,1.67708,1.65655,-0.199427,-0.172734,0.420038,0.505781,1.12162,1.02027,0.781085,0.583011,0.793546,0.585824,-0.777871,-0.716999
1832,0.698223,0.654134,0.895706,0.867427,0.543453,0.401436,0.0816271,0.0856427,0.399732,0.340867,0.837927,0.818634,0.777005,0.780572,0.818188,0.828839,0.684501,0.667365,0.947398,0.980546,0.417204,0.786289,-0.861041,-0.585386,-0.0270912,0.115622,-0.389143,-0.416665,1.32024,1.34983,-0.239718,-0.160281,-0.198299,-0.30664,-0.0386339,-0.234666,-0.100982,-0.302115,1.39217,1.449
1833,0.991102,0.946359,0.809733,0.735316,0.131683,0.0718798,0.267094,0.271146,0.0867509,0.0281734,0.350754,0.333915,0.807388,0.864553,0.481648,0.573586,0.167035,0.148124,0.226685,0.258066,-0.00647104,0.360779,-1.57948,-1.30158,1.4117,1.55612,1.72797,1.69439,-2.34523,-2.31178,1.38318,1.46416,0.0973327,-0.0143442,1.74439,1.55449,-0.343756,-0.539636,-0.700059,-0.646464
1834,0.303332,0.259632,0.628974,0.603206,0.688522,0.629851,0.0633849,0.0688354,0.776791,0.719432,0.256517,0.241027,0.943689,0.948534,0.309678,0.318333,0.27991,0.290385,0.646535,0.677394,-1.58468,-1.21121,0.0343664,0.319353,-1.86675,-1.7201,-0.188972,-0.218465,-1.2121,-1.12797,-0.52048,-0.446606,-1.5528,-1.67099,0.574879,0.386346,1.81312,1.61036,0.265572,0.313047
1835,0.861968,0.816181,0.801648,0.777059,0.00362432,-0.0544458,0.644907,0.651752,0.834221,0.77646,0.801184,0.787112,0.0138008,0.0164414,0.981269,0.989375,0.450418,0.432646,0.53674,0.64216,1.93286,2.3123,0.22418,0.597698,-1.6238,-1.47307,2.00205,1.96995,0.029364,0.0558415,-1.53202,-1.46506,1.22593,1.10765,0.483343,0.288595,-0.0950589,-0.293223,-1.32158,-1.27074
1836,0.0846605,0.0382563,0.508659,0.564195,0.308853,0.271629,0.0858611,0.093513,0.217076,0.157068,0.747951,0.73493,0.956478,0.960329,0.540228,0.615204,0.973062,0.957864,0.576072,0.606926,-0.267761,0.11184,0.597636,0.876042,-0.643736,-0.489756,-0.385523,-0.409496,-1.4803,-1.45958,0.60371,0.671794,-0.384471,-0.502296,-0.0178599,-0.207159,-0.0585615,-0.250938,-0.405305,-0.358004
1837,0.466669,0.485379,0.377995,0.351332,0.654032,0.597703,0.845056,0.851946,0.887419,0.827959,0.244424,0.229557,0.937006,0.942567,0.233763,0.241033,0.869206,0.771887,0.0644525,0.0960164,-0.280817,0.10256,0.0126072,0.297119,0.725495,0.874216,-0.466581,-0.490099,0.744045,0.760189,1.49779,1.56014,-0.195227,-0.319753,0.110424,-0.0752385,-0.68451,-0.874001,1.27503,1.3229
1838,0.97805,0.932502,0.604509,0.578573,0.475457,0.3902,0.327541,0.334072,0.778853,0.721054,0.433722,0.418445,0.640144,0.645899,0.440382,0.418648,0.630538,0.58591,0.623356,0.65489,0.229155,0.616595,-0.111298,0.176632,-0.77777,-0.622305,-1.30135,-1.3297,0.637745,0.653542,0.487366,0.633039,-2.57027,-2.6898,-0.52148,-0.710825,0.736469,0.540955,0.151341,0.193114
1839,0.497669,0.451555,0.315291,0.288414,0.104064,0.182697,0.128004,0.136661,0.926416,0.871241,0.394129,0.381117,0.735567,0.73984,0.589934,0.596263,0.369126,0.399932,0.852165,0.88267,0.36322,0.744415,-0.574126,-0.280143,-1.15028,-0.989113,-1.20746,-1.32634,1.82178,1.83971,-0.355013,-0.294067,0.640547,0.520494,0.161355,-0.0275178,0.0474787,-0.144191,-0.176375,-0.132476
1840,0.673037,0.626961,0.748878,0.722563,0.0334353,-0.0248055,0.470968,0.499918,0.530304,0.477675,0.0981782,0.0869675,0.0591098,0.0632351,0.34624,0.353348,0.229153,0.213955,0.404632,0.436279,1.16542,1.54653,-0.676757,-0.385613,-0.707847,-0.613631,-1.29098,-1.32299,-0.22737,-0.210815,2.25994,2.3131,0.015568,-0.176879,0.446049,0.259166,1.75481,1.56616,1.24835,1.28666
1841,0.401748,0.357728,0.432914,0.406791,0.327506,0.177274,0.854517,0.863175,0.474782,0.422467,0.517807,0.53694,0.620999,0.624747,0.962407,0.968261,0.895541,0.881641,0.841805,0.875574,-0.931769,-0.553524,-0.401573,-0.106346,-0.397539,-0.23815,0.95243,0.918137,1.35017,1.37231,0.55881,0.606414,-0.758946,-0.874252,-0.833405,-1.02007,1.07428,0.881017,0.435591,0.479517
1842,0.943989,0.899983,0.421884,0.396271,0.440633,0.379353,0.045003,0.0515215,0.883454,0.830426,0.996526,0.986913,0.15051,0.153642,0.808209,0.811746,0.952625,0.939801,0.861189,0.90451,-0.652877,-0.358455,0.46451,0.754239,0.458899,0.622149,-1.31365,-1.34584,0.743458,0.761689,0.521659,0.573694,-0.222481,-0.337163,0.197656,0.0159445,-0.22247,-0.417,-0.973667,-0.923099
1843,0.073777,0.0295451,0.907805,0.88397,0.00525947,-0.0559753,0.00322004,0.00983055,0.560768,0.597453,0.342506,0.332181,0.49146,0.495624,0.915443,0.918083,0.0316939,0.016623,0.896973,0.933446,-0.544698,-0.163385,-1.63565,-1.35036,-0.458888,-0.302645,-0.325772,-0.364477,-0.898831,-0.876556,1.70573,1.75223,-0.509281,-0.626735,0.599244,0.423906,-0.595713,-0.750942,1.26997,1.32108
1844,0.153777,0.110192,0.55367,0.621148,0.253482,0.194594,0.226557,0.2348,0.416637,0.36448,0.68985,0.677831,0.59047,0.539585,0.453487,0.456674,0.407321,0.392432,0.569146,0.607126,0.53171,0.913035,-0.820452,-0.614559,-0.597137,-0.437594,-0.558718,-0.598595,-1.24185,-1.214,0.133481,0.181458,0.436524,0.326153,1.30419,1.14381,-0.978948,-1.08488,1.05707,1.10088
1845,0.778675,0.735723,0.382692,0.358325,0.163576,0.103629,0.158449,0.195042,0.934988,0.883411,0.747256,0.733434,0.580696,0.583546,0.307955,0.30975,0.301783,0.285153,0.663553,0.703291,0.464578,0.841908,-0.167219,0.121244,0.512389,0.66605,-1.87255,-1.9151,-1.8636,-1.83913,0.046747,0.0883894,1.10176,0.987375,2.03118,1.86371,-1.22131,-1.41883,-0.985965,-0.947186
1846,0.534952,0.49832,0.996888,0.973333,0.337799,0.279951,0.145949,0.155284,0.59578,0.546202,0.201789,0.189016,0.428593,0.499773,0.519432,0.521161,0.904924,0.887026,0.242139,0.38,-0.41792,-0.0407443,0.244478,0.537396,0.404486,0.559541,0.212186,0.16394,0.324584,0.347489,-0.825135,-0.775998,1.16076,1.05057,0.811242,0.64704,-1.93955,-2.13458,-0.656637,-0.624311
1847,0.237807,0.260917,0.483643,0.460492,0.760488,0.704119,0.370768,0.380253,0.698269,0.650001,0.0215231,0.00643754,0.402821,0.416,0.982625,0.9822,0.237751,0.22165,0.0155612,0.056709,1.08878,1.45838,-0.893934,-0.598245,-0.294918,-0.0649329,-0.67034,-0.722466,-0.61483,-0.584577,-0.00453164,0.0489118,-0.605391,-0.718178,1.95859,1.78841,2.33095,2.12944,1.75418,1.7832
1848,0.0664659,0.0235138,0.697304,0.596889,0.619201,0.562112,0.159116,0.168252,0.273137,0.2261,0.991432,0.977293,0.242449,0.332227,0.39615,0.397147,0.181413,0.166086,0.93067,0.969767,0.144336,0.516473,-1.14298,-0.842149,-0.844431,-0.689407,-0.555382,-0.603733,-0.74347,-0.707211,1.03878,1.09138,-0.291448,-0.410479,0.374152,0.204561,0.616767,0.421467,0.0109197,0.0451395
1849,0.500956,0.456476,0.7582,0.733286,0.180201,0.122889,0.979853,0.989944,0.928295,0.881277,0.573228,0.561387,0.203486,0.248455,0.10654,0.105616,0.513668,0.496625,0.44515,0.557877,0.50911,0.875914,-0.863455,-0.562882,1.87801,2.03388,0.72188,0.670101,1.13752,1.17009,-0.0110279,0.0428049,-1.52636,-1.6434,-0.944003,-1.12118,-0.234447,-0.434779,-1.95616,-1.92838
1850,0.0444766,0.00137872,0.566842,0.62329,0.0930105,0.112994,0.729432,0.739773,0.652985,0.58584,0.807372,0.794766,0.161832,0.164682,0.94683,0.944761,0.475912,0.456982,0.105772,0.145987,0.651293,1.01859,1.20021,1.4953,-0.149941,0.0054799,0.903897,0.851156,0.362576,0.393519,0.193754,0.240878,-0.986096,-1.10631,-1.44182,-1.61693,-0.345009,-0.548396,1.13907,1.16011
1851,0.448233,0.404322,0.461407,0.513295,0.105549,0.103098,0.48051,0.489603,0.336927,0.290402,0.634054,0.622171,0.423899,0.426254,0.262944,0.262586,0.697192,0.678654,0.814112,0.854713,-0.00386218,0.367701,-0.0377999,0.252382,-0.314138,-0.160934,0.416008,0.319731,0.524727,0.552916,-0.247332,-0.207467,0.135087,0.0140841,0.806892,0.636913,1.62305,1.41847,1.05963,1.07565
1852,0.177788,0.135089,0.428333,0.4033,0.141831,0.093202,0.865272,0.872706,0.378003,0.332582,0.706958,0.693219,0.375309,0.322054,0.229419,0.212348,0.504173,0.420951,0.895016,0.936333,0.804217,1.16981,-0.349934,-0.065819,-0.723304,-0.573432,-0.158954,-0.211695,0.13581,0.0898455,-0.43532,-0.437714,-0.322372,-0.447367,1.11575,0.954117,-0.641772,-0.847614,0.561998,0.572956
1853,0.612816,0.568052,0.479856,0.366464,0.140618,0.0833062,0.270334,0.279283,0.76724,0.720884,0.497893,0.48403,0.126952,0.217854,0.266583,0.16211,0.182629,0.163248,0.302919,0.345671,0.323815,0.687263,0.015881,0.302842,0.0155635,0.164568,-1.19758,-1.25113,-0.403184,-0.373225,-0.708839,-0.667961,-1.43228,-1.55621,1.09154,0.930852,2.18905,1.98025,0.0471575,0.0702598
1854,0.523019,0.475987,0.353386,0.329627,0.61989,0.561489,0.0647003,0.0724066,0.794368,0.722509,0.0349755,0.0231216,0.110587,0.113653,0.11292,0.111872,0.796315,0.774866,0.950398,0.994482,-1.93519,-1.57167,-0.570806,-0.276081,-1.22006,-1.07172,-0.66674,-0.719637,2.1178,2.14207,1.29385,1.33839,-0.152577,-0.279984,-0.972649,-1.1386,0.776465,0.571943,0.137711,0.166378
1855,0.668077,0.620802,0.787492,0.763776,0.155138,0.0970604,0.195805,0.12681,0.889208,0.724134,0.691764,0.67962,0.879911,0.883036,0.592777,0.593902,0.695593,0.576811,0.735575,0.779182,-0.461432,-0.104019,1.56291,1.86495,0.869407,1.01046,0.776614,0.724928,-0.711887,-0.692448,0.229217,0.27356,0.472991,0.310105,-0.287214,-0.455291,-0.953367,-1.15287,1.70549,1.73943
1856,0.537696,0.492245,0.391499,0.369684,0.998402,0.939513,0.173863,0.181213,0.77393,0.725758,0.639325,0.627438,0.0889074,0.0902272,0.217561,0.21703,0.398942,0.378756,0.01454,0.0567019,0.736357,1.09797,-1.71824,-1.42117,1.06568,1.20931,-0.137656,-0.193379,-1.70573,-1.6861,-2.01504,-1.96289,1.02377,0.900194,-0.590675,-0.750827,-2.0435,-2.24382,-0.319079,-0.280073
1857,0.705868,0.614614,0.356056,0.335623,0.767393,0.706382,0.777269,0.783972,0.462825,0.413065,0.0534479,0.0424849,0.639798,0.641937,0.656933,0.654212,0.49415,0.530886,0.402801,0.445705,-1.24482,-0.879978,-1.74317,-1.44924,-0.0402836,0.0960683,0.799901,0.740008,-0.617163,-0.592355,-0.104406,-0.0479925,-0.107797,-0.191063,-1.4198,-1.58463,-1.88676,-2.0807,0.974805,1.01595
1858,0.883197,0.736982,0.802669,0.783869,0.22016,0.157319,0.546297,0.543223,0.394442,0.282191,0.780248,0.768347,0.279566,0.280986,0.184034,0.183189,0.724812,0.683016,0.126943,0.170045,1.4733,1.84231,-1.0939,-0.801037,1.54279,1.67646,0.684576,0.628289,-1.82423,-1.7971,-0.247368,-0.18732,-1.16275,-1.28232,0.348028,0.188104,0.563161,0.375064,-0.90541,-0.861351
1859,0.90501,0.85935,0.649046,0.563898,0.558379,0.536897,0.298049,0.302475,0.200926,0.151317,0.369923,0.357342,0.470676,0.472476,0.892201,0.890558,0.855331,0.835146,0.675583,0.718981,1.83122,2.20176,-0.989532,-0.694112,1.64298,1.78296,2.50211,2.43951,0.729174,0.757464,-1.43479,-1.37344,-0.108346,-0.223307,-1.14215,-1.30381,1.06079,0.86546,0.216828,0.266007
1860,0.343673,0.297635,0.36026,0.343927,0.978064,0.916475,0.542714,0.520727,0.614083,0.563941,0.245653,0.234139,0.40766,0.408345,0.238239,0.238073,0.149416,0.129227,0.994125,1.0372,0.551906,0.920168,1.64068,1.92809,0.13411,0.271113,0.326828,0.258001,0.892899,0.916861,0.523159,0.587678,-3.25169,-3.35997,0.441066,0.282994,0.888279,0.687888,1.03481,1.08896
1861,0.915872,0.869095,0.449082,0.35807,0.152773,0.0919137,0.734879,0.73898,0.0631499,0.0154337,0.36437,0.444784,0.922757,0.92463,0.485214,0.392777,0.531728,0.531702,0.459919,0.50136,1.85646,2.22923,0.160004,0.447895,-0.568075,-0.436194,0.986643,0.913,-1.01038,-0.984384,-1.54337,-1.47748,-0.323145,-0.43146,0.384933,0.229907,-0.350147,-0.546827,0.555958,0.613501
1862,0.546813,0.499343,0.387114,0.372214,0.29771,0.238786,0.433428,0.436548,0.781615,0.73285,0.666965,0.65543,0.232779,0.232705,0.549667,0.547481,0.956381,0.934178,0.470803,0.512077,-0.795159,-0.426015,-0.555883,-0.268295,0.862227,0.98814,-0.918891,-0.999859,-1.24865,-1.2283,-0.966887,-0.894151,-0.10867,-0.218626,0.729255,0.575614,0.59665,0.397114,-0.522967,-0.469385
1863,0.994419,0.947208,0.205812,0.192316,0.0145218,-0.045954,0.524004,0.478479,0.567695,0.612413,0.231323,0.219401,0.910195,0.910195,0.988652,0.984662,0.911312,0.889472,0.79602,0.835812,0.651522,1.02587,-0.11301,0.225628,-1.27306,-1.15403,0.712546,0.635788,-1.86356,-1.83892,-0.152061,-0.0828659,-1.20713,-1.31102,0.0172565,-0.136666,-0.169725,-0.281025,0.853672,0.902813
1864,0.760099,0.713994,0.514208,0.498775,0.991532,0.929694,0.438567,0.52041,0.542982,0.491976,0.40045,0.420475,0.733328,0.761922,0.366371,0.363419,0.323926,0.300424,0.627393,0.665632,-1.59925,-1.21945,0.435892,0.719551,-1.66763,-1.55082,1.62369,1.55424,0.710765,0.731332,-0.93882,-0.869778,0.327467,0.226939,-0.0533737,-0.204708,-0.766806,-0.959164,-0.275318,-0.226972
1865,0.299554,0.25294,0.273841,0.257453,0.154417,0.0941672,0.558644,0.562341,0.0532448,0.00315053,0.635817,0.621548,0.614896,0.613649,0.610559,0.608975,0.0822957,0.0572337,0.999954,1.04011,-1.35005,-0.968295,0.193604,0.475647,0.373815,0.496644,0.0476783,-0.0241482,-0.95878,-0.937866,0.586914,0.661455,-1.16415,-1.27271,-1.16945,-1.31421,0.0283323,-0.158131,0.334336,0.383756
1866,0.851921,0.803958,0.302205,0.238723,0.936071,0.876843,0.00835938,0.0145238,0.0477982,-0.00412727,0.135167,0.121481,0.705882,0.703284,0.230349,0.227705,0.798635,0.773689,0.311714,0.352956,0.0625093,0.450891,0.644858,0.92156,0.207128,0.33023,1.90472,1.83373,-0.841904,-0.826172,1.20916,1.28979,-1.66613,-1.77886,1.41355,1.26703,-0.430327,-0.52157,0.590736,0.645154
1867,0.21216,0.162569,0.367395,0.219993,0.0215002,-0.0376956,0.177613,0.184658,0.280284,0.131508,0.622706,0.608624,0.30685,0.302946,0.571285,0.506201,0.284012,0.258837,0.183555,0.223743,-1.46522,-1.07289,-0.567603,-0.290478,-1.45473,-1.33595,-0.179387,-0.254113,-1.61658,-1.60275,-0.456272,-0.370603,0.54885,0.43984,0.507996,0.357734,-0.702908,-0.885009,-1.26656,-1.21793
1868,0.939316,0.889062,0.218323,0.201264,0.0453748,0.0292045,0.63314,0.63774,0.320699,0.267144,0.0905331,0.0744398,0.446516,0.443164,0.786525,0.784698,0.513046,0.510153,0.468756,0.413441,0.911017,1.30435,-0.0773386,0.203706,-0.0916279,0.0280224,2.58411,2.50706,0.312646,0.321975,-1.25927,-1.17422,-1.01957,-1.12372,-1.86016,-2.00716,-1.83516,-2.01084,0.86691,0.913258
1869,0.949778,0.899368,0.68598,0.669626,0.0917795,0.0961047,0.422226,0.425738,0.802649,0.749672,0.392697,0.399083,0.272793,0.235175,0.803267,0.800518,0.786436,0.76147,0.561882,0.603139,-0.336212,0.0535556,-0.144616,0.165132,-0.494961,-0.368767,-0.576769,-0.66012,0.592213,0.603026,-1.06774,-0.976142,0.318605,0.217928,-2.13133,-2.27399,-1.42552,-1.59841,-0.276772,-0.156001
1870,0.155022,0.106077,0.90537,0.886956,0.220976,0.163005,0.501816,0.504368,0.621629,0.567355,0.740385,0.723727,0.0321365,0.0271865,0.550592,0.547508,0.158023,0.13156,0.330463,0.372322,-1.89307,-1.50148,-0.153565,0.126558,-0.282882,-0.154062,0.421014,0.33709,1.27476,1.28303,0.869911,0.95599,0.78076,0.678794,-0.521091,-0.696059,-1.5614,-1.72826,-1.27315,-1.22526
1871,0.650934,0.602483,0.448177,0.428739,0.721507,0.661323,0.292787,0.297492,0.70298,0.619629,0.497597,0.480307,0.182684,0.177611,0.588644,0.587827,0.063197,0.0360951,0.313854,0.290179,0.968971,1.36825,1.85209,2.13666,1.53591,1.66282,0.0336255,-0.0525824,-0.0325223,-0.0172208,-1.00335,-0.920393,1.68381,1.58357,1.02452,0.881868,0.340191,0.172164,0.351457,0.395701
1872,0.450696,0.404229,0.435566,0.449605,0.930825,0.871607,0.449641,0.464231,0.636155,0.671903,0.72422,0.708991,0.733169,0.729321,0.0749862,0.0720195,0.806645,0.778825,0.165763,0.208036,0.53182,0.880741,-2.28343,-2.00858,0.139348,0.271611,0.134642,0.103584,-0.528749,-0.521348,0.210708,0.289898,-1.20548,-1.3046,-1.06632,-1.20309,0.382611,0.21445,0.936682,0.976369
1873,0.725026,0.680906,0.491476,0.47047,0.489156,0.432384,0.59822,0.630969,0.777693,0.724177,0.740672,0.7865,0.473978,0.468619,0.982809,0.979547,0.622176,0.668311,0.613336,0.593266,-0.0108199,0.393235,1.18398,1.45883,-0.800885,-0.668117,0.350495,0.25975,0.0883485,0.0957671,0.449714,0.534145,0.801921,0.703732,-1.00985,-1.1501,0.946098,0.783023,-0.179705,-0.137763
1874,0.267938,0.225809,0.0935164,0.0710305,0.909095,0.850612,0.762881,0.797708,0.540458,0.39177,0.879698,0.86401,0.419251,0.414476,0.726902,0.730658,0.58772,0.557798,0.93733,0.978496,1.53513,1.93953,0.0925451,0.370542,0.825764,0.958027,0.802947,0.627684,-0.147775,-0.134248,-0.976762,-0.898275,-0.347089,-0.44999,1.87557,1.73242,-1.60196,-1.77344,0.987132,1.03612
1875,0.472938,0.453506,0.381523,0.357474,0.0711393,0.0101588,0.959741,0.964446,0.113443,0.0593632,0.543887,0.475956,0.697431,0.690574,0.589784,0.481769,0.0117491,-0.0167876,0.705769,0.814786,0.248734,0.657941,-0.688729,-0.410366,1.07368,1.20505,1.08683,0.995617,-0.0106258,0.00749193,-0.984194,-0.899467,-0.629884,-0.739562,0.668159,0.531863,-0.727588,-0.892509,0.0996061,0.152613
1876,0.832153,0.681203,0.961681,0.938435,0.403578,0.342162,0.848936,0.924688,0.424946,0.400571,0.102797,0.0879018,0.610336,0.60163,0.236141,0.232879,0.699626,0.67043,0.593395,0.651077,0.459187,0.863681,-2.32229,-2.04658,0.58638,0.716155,-1.83492,-1.92294,-0.677332,-0.66429,0.985035,1.06165,0.700244,0.586793,-0.0271457,-0.164404,-1.19634,-1.36216,0.445701,0.504546
1877,0.949451,0.9089,0.382074,0.357402,0.204301,0.145292,0.879301,0.88493,0.793775,0.741779,0.407124,0.394111,0.192642,0.185621,0.81948,0.816292,0.824098,0.755129,0.446792,0.487367,0.6637,1.06942,1.56557,1.8364,0.464735,0.596198,-0.968524,-1.05097,-0.106031,-0.117279,-0.646875,-0.568397,1.42751,1.30864,0.0766369,-0.062356,0.380934,0.222313,1.17875,1.23705
1878,0.586391,0.544421,0.809886,0.786972,0.296119,0.181064,0.970105,0.973063,0.646326,0.59537,0.322873,0.310977,0.948945,0.940827,0.0670312,0.0645841,0.86704,0.839828,0.762744,0.805588,-0.138573,0.26299,1.24912,1.5182,0.128148,0.260453,1.19773,1.12133,0.42162,0.429732,0.206678,0.28799,0.994422,0.879066,-0.641688,-0.774635,-0.390953,-0.556729,0.095459,0.154166
1879,0.588188,0.544989,0.802796,0.781326,0.276884,0.216836,0.343864,0.345387,0.126514,0.0769448,0.898653,0.887047,0.168275,0.16015,0.244224,0.241974,0.536886,0.510533,0.206759,0.249778,-1.29581,-0.894879,0.368864,0.631233,0.722558,0.85792,-1.33613,-1.41226,0.204223,0.216632,0.416061,0.502353,-1.34906,-1.45764,0.45256,0.322163,-1.44353,-1.60413,-1.75362,-1.69481
1880,0.107076,0.0640419,0.0224545,-0.000587069,0.153282,0.095656,0.645497,0.645778,0.641691,0.591066,0.380363,0.366974,0.718857,0.71186,0.845982,0.846516,0.531044,0.504888,0.966788,1.00913,-1.50285,-1.10033,-0.71431,-0.45706,-1.18414,-1.04464,-0.588165,-0.663656,-0.21794,-0.211498,-0.741091,-0.652625,1.20831,1.09993,0.434604,0.298898,2.11378,1.94532,1.93072,1.99311
1881,0.684852,0.640588,0.168413,0.142964,0.35453,0.296116,0.306187,0.395607,0.0168709,-0.0339717,0.11717,0.103856,0.0530513,0.0450886,0.681476,0.683756,0.177924,0.150166,0.0629297,0.104046,0.932285,1.34104,0.710888,0.975295,-0.028608,0.10509,-1.296,-1.37777,0.00644354,0.00844251,0.569439,0.663505,-0.696434,-0.807724,0.0893381,-0.0917895,-1.43567,-1.60986,0.172873,0.237754
1882,0.749134,0.728207,0.74724,0.723925,0.914711,0.854087,0.146367,0.145436,0.0421859,-0.00657617,0.10453,0.178671,0.757642,0.747505,0.265201,0.267264,0.705512,0.679759,0.540925,0.583049,-1.89569,-1.48279,-0.781012,-0.519586,1.41465,1.54559,-0.173984,-0.260608,-0.289096,-0.279967,-1.06369,-0.966543,0.619788,0.503831,-0.350701,-0.482477,1.76518,1.58733,0.0109688,-0.000225727
1883,0.859661,0.815826,0.484497,0.462831,0.0692944,0.00965119,0.198352,0.153466,0.873224,0.825527,0.26815,0.253486,0.586311,0.485779,0.853795,0.855199,0.315922,0.289712,0.0852399,0.126833,-1.29502,-0.879249,-1.54229,-1.28406,1.43716,1.56142,-0.499346,-0.588288,0.345396,0.352919,-0.74237,-0.646253,-0.0121066,-0.124947,0.642958,0.506697,1.86414,1.68997,-0.256602,-0.238206
1884,0.737805,0.691882,0.421774,0.345463,0.156112,0.0959174,0.0678862,0.161497,0.643707,0.562899,0.0963479,0.0808914,0.232677,0.224053,0.479293,0.515398,0.220362,0.270217,0.746359,0.790178,0.156518,0.572633,-0.0310578,0.226772,0.728619,0.779778,-0.197078,-0.384567,-0.604859,-0.595159,0.119838,0.210134,-2.1093,-2.22218,-0.883575,-1.01757,0.0823891,-0.0859587,-0.542696,-0.476186
1885,0.275877,0.230828,0.249751,0.228095,0.833135,0.771128,0.146278,0.169527,0.484532,0.300271,0.872266,0.858012,0.313395,0.282739,0.175685,0.175598,0.278503,0.250722,0.924172,0.967733,-0.0455685,0.434393,1.78082,2.03116,-0.129739,-0.00186424,-0.083858,-0.180845,0.100122,0.11369,-0.601744,-0.516295,1.96595,1.85308,0.0218638,-0.105124,0.905329,0.731375,-0.135191,-0.0641244
1886,0.350368,0.306474,0.897246,0.878132,0.0853976,0.025208,0.180204,0.177557,0.0853395,0.0376429,0.826003,0.733265,0.36017,0.341424,0.0427051,0.0438099,0.435705,0.48629,0.724381,0.766993,-0.121867,0.296154,-0.0261715,0.2207,0.23132,0.365602,1.27588,1.1841,-1.24634,-1.23512,-0.582212,-0.501929,0.433284,0.320813,-0.0877035,-0.218974,-0.157348,-0.371219,-1.31008,-1.23855
1887,0.0226766,-0.02324,0.0935347,0.0734797,0.94377,0.881866,0.264309,0.185588,0.737801,0.687863,0.639827,0.608519,0.321824,0.40011,0.29623,0.299517,0.667884,0.721859,0.117891,0.160943,0.975789,1.38761,-1.3841,-1.13383,0.391534,0.532104,-0.680849,-0.780487,0.200827,0.211419,-1.75569,-1.6709,1.38158,1.2737,0.45271,0.327215,-1.29986,-1.47381,0.685457,0.748979
1888,0.487276,0.438987,0.875155,0.854574,0.715783,0.654439,0.194549,0.193618,0.141771,0.0934469,0.497493,0.483772,0.469611,0.458796,0.292703,0.306925,0.9829,0.957427,0.433251,0.474381,0.73072,1.13719,-0.00505428,0.252525,-0.362373,-0.222123,0.665635,0.567651,-0.445783,-0.428775,-0.140431,-0.0619635,-0.382505,-0.495051,-0.293617,-0.416295,-0.424916,-0.59288,-0.46351,-0.395158
1889,0.325953,0.275973,0.866246,0.890425,0.824198,0.761071,0.786174,0.78595,0.564214,0.515787,0.0136182,-0.000946595,0.738648,0.725213,0.291043,0.314332,0.523299,0.497328,0.0122945,0.0537917,-1.34685,-0.935938,-0.158867,0.165938,0.210791,0.294231,-0.250859,-0.350656,-0.193049,-0.178056,0.716797,0.794424,1.15931,1.04291,-0.163101,-0.284374,-1.13573,-1.30863,-0.283358,-0.208329
1890,0.368784,0.399403,0.947973,0.926276,0.0157333,-0.0470036,0.49172,0.560637,0.524309,0.558279,0.539704,0.525731,0.397516,0.385177,0.317836,0.321739,0.677707,0.66277,0.0947181,0.135411,1.83364,2.24874,-0.181144,0.0793498,0.678088,0.810585,-0.942254,-1.04852,1.1232,1.13192,-0.472227,-0.391697,-0.844132,-0.960639,-0.64512,-0.764604,1.35565,1.18377,0.909932,0.982892
1891,0.574331,0.522834,0.43674,0.413435,0.170322,0.109637,0.336383,0.335324,0.647916,0.600771,0.0325372,0.0203576,0.417956,0.487888,0.924933,0.931514,0.854886,0.828213,0.851471,0.890477,-1.71756,-1.30798,-1.08755,-0.822799,0.78179,0.917086,-1.00851,-1.11483,-1.17722,-1.17484,0.022114,0.0997031,-0.000274259,-0.118157,0.861344,0.744145,-1.17341,-1.35196,1.40619,1.47191
1892,0.814282,0.763889,0.63783,0.615896,0.789143,0.727635,0.973684,0.972666,0.378322,0.32303,0.975532,0.961823,0.602098,0.5906,0.513125,0.519823,0.731158,0.705437,0.732618,0.769992,-1.03552,-0.627973,0.419927,0.725492,1.70356,1.8385,1.00776,0.903024,2.04596,2.04647,1.09084,1.17249,-0.6527,-0.776826,-0.710725,-0.825567,-1.05042,-1.23536,-0.594763,-0.530651
1893,0.409754,0.35868,0.289919,0.266178,0.240732,0.178572,0.781968,0.781068,0.090776,0.045288,0.00628928,-0.00774839,0.369225,0.453017,0.674885,0.681289,0.233704,0.21035,0.889536,0.927254,2.58538,2.99443,2.00904,2.27378,0.707156,0.85036,0.107867,0.00277107,0.146861,0.145229,-0.552144,-0.47581,-0.805597,-0.926924,-0.585856,-0.693646,-1.66025,-1.84485,-0.419668,-0.358204
1894,0.256468,0.206089,0.873973,0.851637,0.144024,0.0825899,0.988166,0.987754,0.445998,0.402914,0.72965,0.713608,0.327295,0.315434,0.418079,0.429745,0.624865,0.60124,0.732295,0.772046,-0.223777,0.186368,0.0539783,0.321115,0.740383,0.881004,0.0140193,-0.0930188,-1.10412,-1.10965,-0.144342,-0.0641442,-0.0879655,-0.205078,-1.58814,-1.69539,-0.119277,-0.308331,-0.646323,-0.592352
1895,0.659755,0.609032,0.68801,0.667386,0.899673,0.839058,0.932754,0.930512,0.26611,0.220597,0.223576,0.208235,0.369433,0.358046,0.171731,0.178202,0.0245819,0.00143893,0.249275,0.291484,0.409806,0.821049,-0.225276,0.047111,-1.00664,-0.864346,-1.97422,-2.0875,1.60303,1.59996,-0.487234,-0.40256,0.399064,0.286901,0.165249,0.0643508,0.335886,0.150173,-0.504176,-0.450295
1896,0.069665,0.0183842,0.914677,0.894628,0.861152,0.803629,0.157076,0.15623,0.818859,0.775091,0.67316,0.656669,0.165167,0.152924,0.874209,0.87928,0.894292,0.872078,0.329722,0.373104,-0.814574,-0.399846,-2.27644,-1.99723,-0.0333581,0.103626,0.400155,0.279968,0.452262,0.456298,-0.377337,-0.295773,-0.613673,-0.729773,-0.602369,-0.708095,0.011958,-0.180781,-2.33418,-2.2779
1897,0.476308,0.40883,0.696427,0.696942,0.826656,0.768201,0.314883,0.315854,0.520199,0.478549,0.476166,0.4579,0.615321,0.604173,0.785694,0.80309,0.0103866,-0.0126312,0.919677,0.962238,1.14215,1.55875,0.0526214,0.335731,0.629038,0.762952,-0.202937,-0.325552,-1.30507,-1.30591,0.823499,0.899233,0.400423,0.283575,0.253383,0.144053,0.364113,0.170235,2.35595,2.40716
1898,0.849083,0.799276,0.522076,0.499255,0.0115091,-0.0462163,0.0414227,0.0428261,0.632642,0.592671,0.632039,0.61269,0.16676,0.153333,0.720238,0.726901,0.75289,0.730098,0.175155,0.219148,-0.81649,-0.399785,1.74887,2.03335,2.25187,2.3891,1.20553,1.08783,-0.795985,-0.7955,0.197297,0.278944,1.15197,1.03637,0.12515,0.0152557,0.0953507,-0.0992486,1.43775,1.41712
1899,0.358674,0.308221,0.0686338,0.0460373,0.378872,0.250415,0.701532,0.703948,0.517504,0.47604,0.0841109,0.0633432,0.247636,0.20746,0.0146915,0.0234888,0.283323,0.260582,0.192888,0.234495,0.665872,1.08385,-0.84196,-0.557198,-0.978799,-0.836013,-0.52101,-0.63679,0.825025,0.818038,1.48301,1.56464,-0.180818,-0.290541,-0.372647,-0.480499,-1.81234,-2.00283,0.380338,0.427086
1900,0.40852,0.426314,0.51675,0.494283,0.60693,0.547046,0.994785,0.999219,0.0213819,-0.0222074,0.488302,0.387987,0.38165,0.261587,0.385336,0.395949,0.589722,0.47326,0.494648,0.537102,-0.770891,-0.351815,1.47972,1.76125,0.476336,0.619221,-0.556051,-0.672435,-0.177241,-0.191548,-1.71747,-1.63537,1.54866,1.4357,2.69613,2.59316,0.254351,0.0638114,-0.911765,-0.86827
1901,0.595741,0.544407,0.726043,0.702107,0.34257,0.244556,0.816059,0.821552,0.871861,0.829091,0.73161,0.71263,0.3278,0.315714,0.240148,0.2147,0.733779,0.685939,0.308087,0.351692,0.167447,0.587225,0.634504,0.919237,-0.283868,-0.217271,0.779064,0.661901,0.14758,0.13507,-0.189067,-0.104138,-0.0299072,-0.144512,0.178764,0.0816097,0.754517,0.605397,1.78042,1.82879
1902,0.872976,0.821084,0.685162,0.626256,0.00383759,-0.0579339,0.172122,0.179303,0.597059,0.551349,0.719128,0.700483,0.680347,0.602202,0.0200791,0.0334511,0.921359,0.898618,0.402446,0.54139,-1.44612,-1.0281,-1.03333,-0.749009,-1.20315,-1.05376,0.428295,0.31868,-0.935211,-0.949048,-0.800285,-0.708072,-1.20539,-1.31689,1.56404,1.47004,1.33634,1.14698,-0.0631348,-0.0201888
1903,0.0622184,0.00919044,0.574415,0.550406,0.273512,0.233317,0.95074,0.95931,0.31924,0.273608,0.083101,0.0651083,0.900101,0.888689,0.735075,0.751092,0.688513,0.579185,0.68911,0.731088,-1.02607,-0.608248,1.66654,1.9423,-0.35077,-0.207268,2.45448,2.35134,-2.8658,-2.88152,-0.259375,-0.172032,0.400435,0.279971,-0.989091,-1.08586,-0.0432827,-0.23028,0.730072,0.773092
1904,0.143298,0.0898371,0.957239,0.935172,0.707704,0.524569,0.746784,0.756999,0.343327,0.297116,0.907139,0.890042,0.996708,0.907728,0.152922,0.170274,0.283992,0.259753,0.531695,0.526262,0.224687,0.639757,-1.94132,-1.66363,0.863823,1.00234,0.230589,0.121483,0.368906,0.355183,-0.578738,-0.49484,1.98833,1.87683,-0.437546,-0.539675,1.09386,0.899998,-0.0464586,-0.00469324
1905,0.798644,0.74623,0.977188,0.954205,0.877591,0.81582,0.944204,0.867562,0.682281,0.634493,0.115411,0.0990878,0.938085,0.926766,0.10216,0.118984,0.915871,0.890672,0.278552,0.321437,-0.219258,0.191347,-1.74566,-1.46166,0.844761,0.987599,-0.247664,-0.359678,0.375275,0.36102,-0.106001,-0.0175961,0.433626,0.327798,-0.335917,-0.437627,-0.81918,-1.01818,-1.85291,-1.80545
1906,0.1781,0.125514,0.298907,0.273609,0.538714,0.403252,0.966833,0.978126,0.0220098,-0.0250594,0.624677,0.606697,0.600052,0.547318,0.40695,0.460276,0.236659,0.210732,0.343245,0.388178,1.10653,1.51703,-0.600318,-0.25923,0.605008,0.743117,0.323691,0.216935,0.949244,0.932948,1.93918,2.02568,0.326034,0.222257,1.16166,1.05626,1.16606,0.963127,2.60768,2.65514
1907,0.60611,0.553377,0.0749636,0.0493308,0.0532407,-0.0093166,0.336112,0.34591,0.550675,0.503966,0.822111,0.805562,0.180601,0.16787,0.78367,0.801569,0.468398,0.491329,0.936879,0.982397,0.383699,0.805531,0.653184,0.943202,-1.82216,-1.68456,-1.9467,-2.04704,-0.35448,-0.367307,-0.569707,-0.487407,-0.039823,-0.0534956,1.00399,0.898298,-0.641478,-0.843251,-1.11918,-1.06455
1908,0.0971363,0.0425207,0.427017,0.399834,0.622995,0.558766,0.0847138,0.0930154,0.608415,0.560994,0.725727,0.707671,0.0677905,0.0534571,0.61947,0.638809,0.798971,0.771927,0.0347544,0.0819336,-0.318158,0.0940333,0.443849,0.731088,-2.9079,-2.76566,1.13254,1.02971,0.213284,0.195137,-0.737605,-0.656194,-0.232939,-0.329248,-1.19648,-1.30228,-0.0768972,-0.335385,0.904303,0.956785
1909,0.0560196,0.00137997,0.315751,0.286614,0.640116,0.575193,0.988763,0.997325,0.38684,0.338836,0.334133,0.315538,0.526992,0.514766,0.877884,0.899443,0.232561,0.20641,0.497651,0.508515,-0.161375,0.251993,0.866295,1.1319,-0.721343,-0.586471,1.38024,1.27181,0.770407,0.75758,-0.303036,-0.22696,-0.307375,-0.441276,-0.253001,-0.356777,0.372656,0.172482,-0.0489117,-0.00178976
1910,0.890506,0.836528,0.784859,0.754975,0.342308,0.284608,0.892012,0.899774,0.393854,0.386614,0.987451,0.966736,0.525339,0.494316,0.778614,0.799507,0.05802,0.0331464,0.887487,0.935097,-1.45068,-1.04473,1.24596,1.53272,-0.693631,-0.555827,0.566672,0.464233,-0.717489,-0.726014,0.416095,0.492229,-0.456077,-0.553304,1.10838,1.00084,-0.294026,-0.498471,1.05683,1.11002
1911,0.709199,0.653574,0.114402,0.0839573,0.0612577,-0.00597659,0.0535041,0.0624484,0.591181,0.434392,0.78503,0.762465,0.487947,0.473867,0.886444,0.905844,0.811515,0.785807,0.480106,0.528706,-0.100001,0.312712,-1.65531,-1.37124,-0.116154,0.0276018,2.09565,1.98746,0.0947406,0.0912663,-0.590324,-0.511473,0.408362,0.303439,-0.315664,-0.415754,-0.682199,-0.889834,-0.473587,-0.413832
1912,0.085252,0.0276879,0.193633,0.16304,0.242571,0.175346,0.947489,0.955899,0.528811,0.482169,0.869444,0.847641,0.734968,0.720153,0.392786,0.41016,0.893629,0.868521,0.381761,0.429675,1.71884,2.13317,1.4802,1.76133,-0.464614,-0.322906,-1.27947,-1.38124,-1.55124,-1.56125,-1.94739,-1.86935,-1.06471,-1.16518,0.25471,0.160622,-1.46807,-1.66888,-1.02192,-0.966816
1913,0.755784,0.698909,0.58174,0.555159,0.673924,0.604425,0.538285,0.548874,0.874043,0.828904,0.311525,0.288793,0.681807,0.66601,0.163219,0.183199,0.415881,0.388444,0.705388,0.753411,1.23852,1.65062,0.56668,0.844537,-0.252118,-0.108201,0.169436,0.0633257,-0.735976,-0.74397,1.22583,1.30105,1.40403,1.29737,-0.284005,-0.380904,0.841121,0.641158,0.811687,0.872419
1914,0.94785,0.889289,0.978282,0.947278,0.327256,0.26014,0.569993,0.581653,0.393238,0.349949,0.862246,0.840478,0.247687,0.229928,0.921361,0.94083,0.335249,0.294274,0.196864,0.242501,-1.72716,-1.31618,2.37191,2.64892,-1.06642,-0.925552,-0.51177,-0.619501,-1.35299,-1.35459,1.15472,1.19188,0.914176,0.805834,0.699978,0.608269,0.738109,0.542443,0.397618,0.455852
1915,0.378838,0.318669,0.441102,0.41018,0.63398,0.567171,0.274466,0.284068,0.79895,0.757909,0.350263,0.330611,0.557645,0.541988,0.736625,0.753885,0.290136,0.200103,0.249715,0.295175,0.823241,1.23714,-1.84081,-1.5657,0.249843,0.393848,0.666652,0.560203,1.1353,1.12606,1.01054,1.0827,-1.24249,-1.35147,-1.48356,-1.57413,-0.286004,-0.487158,-0.658401,-0.592896
1916,0.417558,0.343074,0.203972,0.175677,0.334528,0.267988,0.781223,0.791909,0.693787,0.651003,0.129641,0.112087,0.0444468,0.0303869,0.117413,0.132641,0.132772,0.105933,0.777568,0.824673,0.00683443,0.415791,-1.87077,-1.59378,-1.10045,-0.951903,0.0810172,-0.0310417,0.0554229,0.00406775,-0.521457,-0.441376,0.146776,0.0351551,-0.278956,-0.370526,-2.93208,-3.1332,0.287164,0.352027
1917,0.428152,0.367479,0.414048,0.388334,0.891219,0.825959,0.598208,0.52533,0.992753,0.948579,0.25988,0.241785,0.535266,0.522476,0.92882,0.94655,0.678029,0.650869,0.0709249,0.116809,-1.19198,-0.788202,-0.0589108,0.21061,0.145207,0.291111,0.075548,-0.0340785,-1.1087,-1.11793,-0.44473,-0.424012,0.638591,0.527134,-1.27245,-1.29249,0.395292,0.198926,2.12298,2.19126
1918,0.0467227,-0.0122572,0.0756549,0.0482959,0.618715,0.551542,0.246417,0.25875,0.455086,0.410425,0.0510292,0.0325967,0.568877,0.554988,0.0368313,0.0542319,0.4293,0.402349,0.171339,0.25517,0.571416,0.969972,-0.018268,0.257801,-0.187886,-0.0634433,0.636845,0.527456,2.0529,2.04687,-0.487305,-0.406648,0.440144,0.331322,-2.12288,-2.21445,1.217,1.01626,0.730085,0.803352
1919,0.45101,0.390686,0.352751,0.324535,0.126432,0.0572605,0.365235,0.399068,0.257843,0.213305,0.278746,0.261281,0.103319,0.0892565,0.766566,0.781883,0.669471,0.630631,0.457806,0.39353,1.10279,1.49927,-1.95883,-1.67848,-0.569431,-0.417997,-1.113,-1.22658,-0.0372129,-0.0392065,-0.823486,-0.745064,-0.939915,-1.04174,0.127536,0.0393961,1.69096,1.49124,0.464314,0.538799
1920,0.110995,0.0504509,0.226041,0.218964,0.0573563,-0.0120477,0.636501,0.539386,0.771603,0.727426,0.0728407,0.0570098,0.892132,0.879539,0.415975,0.429762,0.885482,0.858912,0.443978,0.531891,0.0974842,0.493369,0.233338,0.508866,-0.139189,0.0143537,-0.278581,-0.386565,0.203456,0.194376,-0.144806,-0.0701178,0.787782,0.684498,0.414352,0.367782,0.360414,0.159731,-1.57486,-1.49548
1921,0.769987,0.712183,0.164249,0.113393,0.404508,0.33525,0.6655,0.679704,0.47866,0.414137,0.227762,0.167937,0.0085818,-0.00210392,0.654109,0.6696,0.632479,0.605208,0.623678,0.670251,0.725013,1.12805,1.36446,1.6346,0.297702,0.446705,-1.71876,-1.82831,-1.94541,-1.95246,-0.244009,-0.163187,-0.795215,-0.895714,0.7823,0.696169,-0.356037,-0.556023,0.443981,0.525852
1922,0.785078,0.727375,0.0345404,0.00782265,0.0930239,0.0261247,0.807689,0.820022,0.146799,0.100849,0.296819,0.278863,0.807507,0.797638,0.254983,0.273094,0.0468154,0.0202275,0.135882,0.184306,-0.466696,-0.0608088,-0.704348,-0.442571,1.94902,2.10332,-0.799263,-0.909855,-0.268976,-0.277179,1.84995,1.92604,0.118257,0.00906112,-2.131,-2.21242,-0.287168,-0.484266,1.74278,1.82187
1923,0.521226,0.463873,0.254807,0.265003,0.942239,0.872522,0.129636,0.142113,0.405107,0.347413,0.802349,0.786473,0.492703,0.481378,0.188558,0.20734,0.066853,0.0400126,0.48893,0.538188,0.450588,0.863891,-1.80312,-1.54703,0.249337,0.403422,-2.31414,-2.42879,-0.101967,-0.0219248,1.02683,1.06506,-1.51784,-1.6309,1.06779,0.982898,-1.36326,-1.56173,-1.79352,-1.72021
1924,0.64159,0.490456,0.550161,0.522184,0.506594,0.437193,0.201036,0.215214,0.705436,0.593976,0.813436,0.798284,0.620698,0.611898,0.653098,0.674246,0.683528,0.656059,0.013558,0.0620769,-0.139934,0.232038,0.33105,0.593995,-0.203476,-0.0541125,-0.702754,-0.824213,0.197876,0.23333,0.130293,0.204074,-0.501543,-0.617549,-1.919,-1.99831,1.38457,1.18722,-0.211319,-0.21331
1925,0.574007,0.51704,0.0343553,0.00454101,0.71798,0.606751,0.625396,0.639476,0.887904,0.84054,0.015684,0.00240997,0.197234,0.186893,0.421003,0.441956,0.913883,0.888054,0.966772,1.01479,-0.81543,-0.399815,0.0845989,0.371219,0.868905,1.02112,0.140084,0.0157997,0.442756,0.488585,0.647363,0.726228,0.165178,0.0436723,-0.829593,-0.90151,-1.21571,-1.40423,1.21837,1.2936
1926,0.00391206,-0.0535802,0.670207,0.639834,0.846802,0.776309,0.425388,0.437165,0.332026,0.286751,0.312301,0.244617,0.550454,0.538877,0.837657,0.858524,0.608296,0.584203,0.48778,0.534226,-0.290752,0.129482,-0.236737,0.148443,-0.272344,-0.121793,-0.652284,-0.775003,0.752043,0.743839,0.0228151,0.10594,-0.311704,-0.433449,-1.37558,-1.44304,-0.847028,-1.03861,-0.426128,-0.352927
1927,0.612752,0.556286,0.107515,0.0776464,0.58391,0.512086,0.732832,0.746888,0.614785,0.568848,0.454993,0.486824,0.12151,0.109493,0.551092,0.571578,0.71342,0.688839,0.990658,1.03818,1.18043,1.59713,-0.336653,-0.0743326,-2.11148,-1.96256,1.44289,1.31963,0.344612,0.263694,0.284859,0.364377,-0.234086,-0.355439,0.325761,0.254398,-1.12399,-1.32263,-0.814471,-0.737966
1928,0.90895,0.853597,0.247749,0.202753,0.689804,0.618718,0.717089,0.809497,0.418134,0.3477,0.744697,0.729031,0.863097,0.848446,0.496997,0.584829,0.368315,0.434839,0.156128,0.202299,-0.375601,0.0420982,0.100673,0.356235,0.492289,0.641234,0.0568274,-0.0585719,-0.206751,-0.216451,1.9724,2.05205,1.6632,1.54618,0.585867,0.51018,-0.885796,-1.08333,1.20896,1.28337
1929,0.860036,0.806705,0.359745,0.32786,0.0051032,-0.0655789,0.858603,0.872107,0.170615,0.126552,0.557944,0.540552,0.471126,0.457108,0.576115,0.59808,0.202727,0.180838,0.80759,0.856845,0.74475,1.16386,0.0372717,0.297088,0.494063,0.641208,-0.0223606,-0.139175,2.09235,2.09011,-0.336979,-0.249599,0.749544,0.639165,-0.966499,-1.04362,0.235683,0.0306943,-0.658235,-0.579715
1930,0.474453,0.421137,0.816119,0.782216,0.144848,0.0763732,0.040739,0.0551749,0.157798,0.112633,0.995313,0.978908,0.97529,0.959424,0.062765,0.0868102,0.524929,0.501506,0.7255,0.722937,-0.92289,-0.500644,0.281601,0.544411,-0.191451,-0.0512338,-1.51634,-1.62554,2.16761,2.1723,0.594039,0.684864,0.0596226,-0.0513579,1.39407,1.31562,-0.0352067,-0.23879,-0.418626,-0.346684
1931,0.728923,0.677578,0.307866,0.273666,0.0590546,-0.009492,0.00021612,0.013484,0.798229,0.751838,0.618639,0.602083,0.84316,0.874285,0.964442,0.988974,0.283899,0.258315,0.568413,0.589029,0.969463,1.3961,-0.0296178,0.238239,0.0848474,0.226368,0.539441,0.437106,0.331558,0.333224,0.464243,0.559572,1.44457,1.33527,-1.31779,-1.39789,1.49013,1.28392,-2.4287,-2.34925
1932,0.014469,-0.037024,0.286349,0.253007,0.919255,0.852668,0.660544,0.674606,0.936918,0.891602,0.895112,0.87708,0.805042,0.789146,0.097738,0.123269,0.553719,0.52929,0.300568,0.455121,-0.936507,-0.5037,0.661034,0.930443,-1.29687,-1.15008,-0.793598,-0.895539,0.518511,0.521337,-1.58384,-1.48917,-0.046148,-0.148384,-0.243354,-0.329736,0.921579,0.721509,0.859385,0.932183
1933,0.100882,0.0696421,0.563659,0.565365,0.944478,0.879955,0.405978,0.465451,0.0589963,0.014711,0.275464,0.256909,0.170502,0.157068,0.428257,0.411068,0.153656,0.130346,0.271958,0.321213,0.363924,0.790012,0.38007,0.7168,1.33409,1.47482,-0.427502,-0.531102,1.283,1.29358,-0.6263,-0.525648,0.488155,0.388705,-2.15448,-2.24334,0.585123,0.390554,0.649692,0.72784
1934,0.229924,0.176308,0.909334,0.877724,0.703717,0.64159,0.242763,0.256297,0.202776,0.116181,0.311077,0.206695,0.293692,0.282445,0.67321,0.698867,0.685115,0.659939,0.516484,0.564306,0.472208,0.901459,0.228195,0.503157,2.23214,2.36669,-1.11696,-1.21393,1.36283,1.37577,0.915812,1.02101,-0.0020165,-0.102828,-1.41351,-1.49926,-0.71397,-0.907464,0.050143,0.0408894
1935,0.0859129,0.086046,0.288508,0.256852,0.83698,0.773052,0.298069,0.310531,0.248815,0.21765,0.173997,0.156481,0.0760823,0.0665432,0.210282,0.237459,0.114638,0.0900088,0.15014,0.198146,1.32741,1.76341,-1.51766,-1.24276,1.84188,1.9699,1.34239,1.24813,-0.572176,-0.556704,-1.02797,-0.917146,-0.709342,-0.808011,-0.298083,-0.386344,-0.134028,-0.324152,-0.717901,-0.646061
1936,0.0516147,-0.00421624,0.445406,0.429628,0.211299,0.148933,0.9934,1.00791,0.363405,0.31912,0.501783,0.486589,0.890052,0.882633,0.425653,0.499743,0.019733,-0.00545608,0.153715,0.203459,0.141729,0.574552,-0.387596,-0.117028,0.145738,0.270004,-0.324927,-0.41346,-0.2506,-0.230086,1.67361,1.7891,0.705518,0.610439,0.415835,0.328262,-0.936472,-1.16458,0.732125,0.803143
1937,0.18513,0.0929654,0.741728,0.602404,0.666168,0.602442,0.929522,0.945334,0.661505,0.520905,0.205393,0.187789,0.753428,0.639222,0.732378,0.762027,0.79706,0.771556,0.882044,0.931922,-0.827478,-0.399034,-0.11199,0.238797,-0.75245,-0.62443,0.321868,0.241539,-1.06349,-1.03824,-0.937798,-0.818975,0.809019,0.718736,-2.40804,-2.48718,-1.81018,-2.00501,-0.00248291,0.0714826
1938,0.357565,0.190147,0.806836,0.77518,0.746012,0.713939,0.435077,0.452623,0.766821,0.72269,0.60914,0.591665,0.480931,0.395811,0.662626,0.793248,0.134381,0.111036,0.669114,0.673031,0.0723083,0.496082,0.325961,0.594621,-1.34875,-1.22565,1.3065,1.2229,-0.167313,-0.142496,0.420841,0.542931,-1.29877,-1.39392,0.396937,0.311895,-1.06642,-1.26458,0.109006,0.170349
1939,0.341732,0.287329,0.269782,0.238082,0.88834,0.825435,0.80523,0.821244,0.79946,0.754653,0.0852784,0.0674087,0.161295,0.152399,0.792826,0.824469,0.203656,0.17946,0.365658,0.41414,-1.19277,-0.769449,1.61074,1.8732,-1.68637,-1.56139,-0.840552,-0.927439,1.28633,1.3185,0.116502,0.234213,0.0131686,-0.0823603,-0.481157,-0.56783,0.0462812,-0.150555,0.189824,0.269216
1940,0.169709,0.115331,0.823288,0.789842,0.999213,0.936932,0.843693,0.860108,0.320365,0.275698,0.37461,0.297202,0.345661,0.338357,0.49786,0.527535,0.515315,0.490243,0.433276,0.556709,-1.87788,-1.45146,-1.85764,-1.59633,0.321142,0.440008,-0.750901,-0.84122,0.161799,0.188174,-1.12061,-0.996343,-0.798179,-0.894617,0.129205,0.0386324,-0.727211,-0.929597,-0.896618,-0.813671
1941,0.980367,0.92761,0.500555,0.469489,0.624055,0.562097,0.485066,0.503095,0.78544,0.738862,0.620413,0.526996,0.10026,0.092293,0.985119,1.01443,0.0641939,0.0404453,0.557984,0.699277,2.23697,2.66338,-0.834744,-0.568375,-1.49146,-1.37041,0.68297,0.588268,-0.571757,-0.544636,0.383254,0.503001,0.841466,0.73915,-1.59862,-1.68724,1.88913,1.69308,0.0839615,0.159976
1942,0.469439,0.416754,0.847286,0.815664,0.604575,0.543275,0.517397,0.531626,0.409546,0.364833,0.775845,0.756789,0.460868,0.454753,0.562342,0.592476,0.95424,0.928934,0.793141,0.841846,-0.571074,-0.144681,0.19515,0.459578,0.123716,0.239539,0.380944,0.316872,-0.14057,-0.111488,-0.470949,-0.346389,0.0623301,-0.0739597,-0.341425,-0.424465,0.52503,0.332799,-0.384006,-0.315483
1943,0.224284,0.173092,0.963158,0.928957,0.37243,0.32807,0.533751,0.560156,0.914343,0.868732,0.51005,0.488912,0.349062,0.345524,0.435606,0.465727,0.922503,0.899189,0.362715,0.411177,1.79663,2.2177,0.440677,0.706901,0.625887,0.743063,0.147435,0.0454756,-1.49236,-1.46029,-0.864733,-0.746239,-0.787396,-0.887069,-1.59224,-1.67124,-0.216195,-0.417429,0.773274,0.79628
1944,0.320691,0.268678,0.0246863,-0.0107868,0.174523,0.112865,0.549609,0.588686,0.577397,0.531523,0.744047,0.722291,0.980107,0.976688,0.540556,0.572064,0.485933,0.464452,0.774686,0.824957,1.2204,1.64343,2.7243,2.9916,-0.447665,-0.338042,-0.599683,-0.700777,-0.488349,-0.458438,-0.746183,-0.623724,0.66326,0.559885,-1.49451,-1.5692,0.319555,0.121227,1.83309,1.90804
1945,0.761727,0.711356,0.189417,0.152947,0.329231,0.278023,0.599187,0.617217,0.705948,0.729129,0.508556,0.516476,0.197562,0.196012,0.000999059,0.0306416,0.825398,0.805173,0.200545,0.249263,-0.558279,-0.12996,0.296041,0.565017,-0.699754,-0.596853,-0.0126081,-0.108659,0.0876844,0.113489,1.85572,1.98345,0.961096,0.85218,-0.301999,-0.467525,-1.89403,-2.09674,-0.817255,-0.748877
1946,0.765198,0.716505,0.0619744,0.0238149,0.599232,0.443181,0.0727407,0.0889732,0.972504,0.926736,0.333591,0.310661,0.935058,0.934965,0.589101,0.618577,0.247129,0.225752,0.382279,0.514938,-0.57708,-0.0639451,-1.4646,-1.1975,-0.518392,-0.413723,-0.218969,-0.311392,0.322928,0.347072,-1.75478,-1.62926,0.190889,0.0852319,0.71336,0.634146,-0.275825,-0.481692,1.1367,1.20951
1947,0.541058,0.528558,0.9192,0.883268,0.669997,0.608339,0.543189,0.548993,0.638801,0.594591,0.369733,0.306345,0.118043,0.117901,0.346637,0.350784,0.286574,0.317051,0.730151,0.780614,-0.505777,0.00207024,-1.36555,-1.105,-2.67431,-2.57337,-1.43549,-1.5221,-0.745306,-0.722059,-2.38271,-2.2648,-0.316923,-0.420919,-0.891246,-0.96535,-0.117736,-0.318567,1.03687,1.11175
1948,0.391523,0.340611,0.0620222,0.0271412,0.284782,0.223722,0.992779,1.00901,0.871335,0.825178,0.287174,0.302029,0.209519,0.207535,0.0517362,0.0829913,0.431574,0.40835,0.449214,0.499697,-0.360233,0.0680856,0.529784,0.792763,1.65422,1.75516,1.84601,1.75641,-0.720181,-0.700948,0.0284765,0.151033,-0.0708399,-0.176917,-1.09333,-1.1704,1.35144,1.15732,1.17643,1.25381
1949,0.990208,0.941363,0.512424,0.475387,0.836706,0.776238,0.42786,0.445276,0.579171,0.4405,0.317823,0.297712,0.652923,0.649297,0.810911,0.840622,0.0769867,0.0536284,0.740318,0.792636,0.816317,1.2373,0.983303,1.23868,2.5275,2.63236,0.892202,0.806738,-2.38712,-2.37015,-0.40925,-0.280095,-1.28788,-1.39445,-0.687751,-0.762437,0.220797,0.031492,1.68985,1.77326
1950,0.248439,0.201763,0.437706,0.401474,0.853733,0.792665,0.452687,0.467865,0.104137,0.0558214,0.000655024,-0.0215367,0.765057,0.759308,0.959297,0.987005,0.162201,0.134526,0.588511,0.642277,0.522894,0.940333,-0.118765,0.134214,0.322432,0.425364,0.766013,0.680463,-0.190078,-0.167144,-0.457544,-0.361269,0.175392,0.0691186,0.368729,0.288801,-0.256084,-0.43816,1.41937,1.50871
1951,0.568199,0.523159,0.754308,0.717907,0.236534,0.174126,0.157164,0.170281,0.430387,0.383194,0.155843,0.133254,0.526436,0.457166,0.127282,0.154358,0.114747,0.215423,0.225004,0.276117,-1.3661,-0.94359,-0.0820994,0.167003,0.411996,0.515575,2.26019,2.17411,0.00225425,0.0209689,-0.575621,-0.442443,-1.02249,-1.13306,-0.104998,-0.19143,0.0796223,-0.103719,-1.1007,-1.01485
1952,0.254077,0.208165,0.847875,0.757429,0.644041,0.582268,0.326086,0.340415,0.196796,0.151631,0.0426706,0.0198919,0.161989,0.155024,0.218541,0.24524,0.319678,0.29632,0.211881,0.261919,-0.0773075,0.350121,-0.975109,-0.719963,-0.571489,-0.472565,-0.788456,-0.878532,-0.142987,-0.130132,0.572223,0.704606,-0.645038,-0.801388,1.72953,1.64528,0.841374,0.649984,2.66139,2.74784
1953,0.632843,0.58624,0.833196,0.796951,0.579757,0.517228,0.743354,0.758572,0.42978,0.474458,0.815285,0.793102,0.16867,0.197501,0.695594,0.721765,0.563914,0.542396,0.88849,0.940779,1.41616,1.84925,-0.981062,-0.717659,0.23592,0.280367,1.44388,1.34563,1.06381,1.0722,0.284431,0.313585,-0.362233,-0.469715,0.582502,0.492579,1.1729,0.984425,1.1906,1.27074
1954,0.477774,0.356887,0.292901,0.255235,0.923809,0.859179,0.608565,0.621352,0.842166,0.797285,0.769442,0.745913,0.183184,0.239978,0.181381,0.205958,0.586142,0.562181,0.432323,0.484563,-1.50121,-1.06696,0.0591179,0.326697,0.934374,1.0333,-0.391856,-0.487956,0.164561,0.17246,-0.14963,-0.0774356,-0.47824,-0.589329,-1.22827,-1.31414,-0.412906,-0.596379,1.21773,1.29322
1955,0.173494,0.127534,0.620587,0.491942,0.47742,0.414688,0.848979,0.861281,0.276536,0.233379,0.500847,0.420923,0.289826,0.282455,0.614276,0.637607,0.0732644,0.0473296,0.271596,0.324187,-0.988634,-0.552926,1.6356,1.90187,-0.523147,-0.41741,-1.06331,-1.15518,-1.3736,-1.37091,-0.606195,-0.468456,-1.33431,-1.44768,-1.71186,-1.79437,1.22377,1.03527,0.453622,0.53041
1956,0.821438,0.773686,0.765436,0.728648,0.608972,0.54615,0.0795338,0.0918758,0.759155,0.715908,0.117435,0.0959336,0.840587,0.834165,0.130552,0.151438,0.51506,0.486816,0.906536,0.958091,0.0134334,0.44928,-1.15764,-0.894085,-1.73951,-1.63896,-0.697024,-0.790745,-1.35057,-1.3498,-0.556637,-0.423433,-0.11249,-0.231164,0.405815,0.322265,-0.172932,-0.356012,-1.9747,-1.8991
1957,0.705099,0.652106,0.385208,0.435272,0.402656,0.338372,0.478115,0.491223,0.80143,0.758088,0.997562,0.976074,0.516698,0.469481,0.00372473,0.0246893,0.292352,0.328243,0.099404,0.148486,2.21415,2.65538,0.324175,0.535798,2.95726,3.05781,0.293104,0.206465,-0.780606,-0.777872,0.946852,1.07591,-1.23501,-1.35661,0.73599,0.654151,-0.11949,-0.300272,-0.093616,-0.0168212
1958,0.580371,0.530526,0.177425,0.141895,0.945902,0.881272,0.388187,0.496783,0.556916,0.478049,0.895756,0.81892,0.11045,0.104797,0.722875,0.742331,0.197213,0.16967,0.220507,0.182865,2.09348,2.53791,1.69539,1.96568,0.285684,0.387698,-0.960126,-1.05095,-0.809506,-0.804757,-0.215193,-0.0790658,1.07318,0.944846,-1.18822,-1.27456,0.398634,0.222181,-0.182963,-0.0915408
1959,0.142653,0.0947245,0.0845421,0.0479309,0.00929579,-0.0547895,0.489321,0.502342,0.239898,0.198011,0.684427,0.661766,0.901735,0.895079,0.59253,0.610543,0.453373,0.425818,0.205509,0.217245,0.525507,0.965911,-1.73784,-1.45876,0.451563,0.603224,-0.498165,-0.595229,1.03687,1.04201,0.575438,0.713097,1.35662,1.22041,-0.616821,-0.705241,1.20812,1.03952,-0.239476,-0.16626
1960,0.399252,0.351166,0.587856,0.550743,0.593462,0.528724,0.747434,0.664189,0.581794,0.540609,0.900774,0.880481,0.408772,0.40397,0.17752,0.194051,0.0409137,0.0117513,0.204229,0.251624,-0.496696,-0.055995,-1.15861,-0.88527,0.716362,0.81875,-1.60286,-1.69923,-1.45226,-1.44679,-1.27425,-1.13488,-0.136892,-0.279241,-0.0254681,-0.135922,-0.259021,-0.433014,-0.925377,-0.851684
1961,0.954534,0.907714,0.234763,0.19656,0.401579,0.350052,0.81288,0.826035,0.136513,0.0971734,0.582933,0.538897,0.857977,0.855219,0.455016,0.470313,0.686755,0.658699,0.544688,0.590312,0.800897,1.23772,-0.588387,-0.311779,-0.982089,-0.881145,-0.585206,-0.686735,1.03915,1.04781,1.4537,1.58737,0.69064,0.548293,0.519739,0.433397,2.5496,2.37203,-0.129734,-0.0584037
1962,0.301044,0.256114,0.788117,0.74832,0.237748,0.17138,0.643294,0.658431,0.0584177,0.0170029,0.217055,0.197313,0.731671,0.741162,0.405437,0.419023,0.581198,0.551419,0.538718,0.585817,-0.0188488,0.416365,0.919843,1.19906,-0.282817,-0.147399,-0.467947,-0.568002,-0.70913,-0.699895,-1.39624,-1.26389,-0.614319,-0.764492,0.0802264,-0.00109062,0.172573,-0.0122014,-0.036361,0.0377141
1963,0.349305,0.306362,0.0790381,0.0381848,0.605773,0.5387,0.973487,0.987678,0.504136,0.465206,0.472707,0.450409,0.693962,0.627105,0.71573,0.730213,0.0596065,0.0321779,0.98577,1.0349,-0.0254499,0.407085,-1.25399,-0.971527,0.478096,0.586347,0.345624,0.229418,0.310855,0.318624,2.58317,2.71552,2.47344,2.33235,2.0493,1.96207,-0.672345,-0.851838,0.297127,0.375369
1964,0.995526,0.952515,0.447206,0.407897,0.212714,0.143617,0.989151,1.0056,0.60249,0.563922,0.723994,0.703505,0.513689,0.513048,0.466831,0.482216,0.906632,0.877444,0.650458,0.792492,1.29399,1.73277,-0.722966,-0.487994,0.386997,0.493079,1.12125,1.02684,0.454743,0.460364,0.403758,0.54045,-0.691284,-0.834846,-0.49329,-0.579076,-0.164507,-0.412549,-0.397157,-0.326639
1965,0.603974,0.562691,0.510964,0.471971,0.93414,0.863614,0.497507,0.537041,0.933494,0.896102,0.554438,0.535868,0.756834,0.709573,0.96585,0.979473,0.741964,0.625026,0.502979,0.550081,-1.2635,-0.831861,-0.254605,-0.00446136,-0.499159,-0.386091,-0.939459,-1.0311,-3.15028,-3.13986,0.0614999,0.202034,0.160637,0.0218969,0.0962677,0.0115198,0.206737,0.026739,-0.0802212,-0.0037639
1966,0.783852,0.743216,0.324699,0.28772,0.727015,0.655835,0.0520422,0.068487,0.657078,0.619108,0.921316,0.900186,0.905639,0.906098,0.267262,0.281,0.506434,0.372607,0.725105,0.773194,-0.376389,0.0791304,0.102886,0.479071,-0.63499,-0.52104,-1.89148,-1.98078,0.144845,0.158737,1.26824,1.41233,-0.471728,-0.606881,-0.305149,-0.392238,-0.142584,-0.321198,-0.162837,-0.131563
1967,0.675007,0.72526,0.419128,0.38206,0.302364,0.231336,0.133029,0.232832,0.806955,0.769295,0.148065,0.124414,0.651147,0.649351,0.823148,0.838899,0.14857,0.120189,0.190265,0.237353,0.552186,0.990122,0.746371,0.962604,0.602951,0.721973,1.05906,0.977133,-0.0864597,-0.0712779,0.268824,0.408624,0.873238,0.734765,0.349822,0.260988,0.958406,0.778456,-0.336108,-0.259361
1968,0.750192,0.707304,0.784268,0.746793,0.481037,0.412659,0.382086,0.397176,0.481521,0.442132,0.987123,0.964567,0.18234,0.178246,0.945175,0.960198,0.962327,0.933076,0.954889,1.0018,0.366225,0.800243,1.16368,1.44614,-1.86751,-1.75666,-0.687618,-0.776901,0.820616,0.838185,-1.35732,-1.22142,-0.855653,-1.00171,0.630408,0.547672,-1.92269,-2.09865,-1.43536,-1.35692
1969,0.246729,0.201811,0.235541,0.200073,0.976472,0.906057,0.274047,0.289552,0.845554,0.805476,0.835706,0.81161,0.124235,0.119868,0.294902,0.307713,0.557304,0.527967,0.700996,0.763468,1.51231,1.93866,0.259435,0.543988,0.470009,0.58555,-0.525722,-0.611886,1.1362,1.11806,-0.29367,-0.163032,0.812468,0.662794,0.338522,0.252136,-0.13306,-0.311683,-0.72988,-0.654924
1970,0.957315,0.912443,0.312734,0.279156,0.416541,0.34721,0.728101,0.742634,0.0380063,-0.000669131,0.102531,0.0770081,0.306868,0.300625,0.960014,0.972037,0.460164,0.432502,0.37388,0.525133,-0.838997,-0.413778,0.675261,0.960139,-0.695628,-0.574352,0.291023,0.197588,1.3753,1.39793,1.52782,1.66271,-1.05252,-1.19682,0.31073,0.228871,1.15694,0.974485,0.339037,0.411077
1971,0.141254,0.0950483,0.152959,0.120627,0.560884,0.516768,0.483217,0.499502,0.828117,0.790815,0.290304,0.265896,0.773169,0.767704,0.303474,0.31498,0.632152,0.574763,0.238631,0.286798,-0.430571,-0.00797699,-0.712657,-0.426483,-1.13815,-0.957055,-0.0322079,-0.130093,0.420376,0.449848,-0.191194,-0.0595894,-0.361918,-0.505303,-0.0243372,-0.113594,1.55222,1.37138,0.879654,0.944808
1972,0.515115,0.498937,0.301762,0.269632,0.757504,0.686326,0.951296,0.967447,0.354216,0.317809,0.998703,0.972419,0.925519,0.849708,0.729225,0.741595,0.74248,0.717024,0.481634,0.529891,1.25572,1.67598,-0.504231,-0.224511,-1.46609,-1.33976,1.83227,1.72779,-0.791161,-0.754899,0.893844,1.05942,-0.86308,-1.01145,0.213261,0.12614,-0.789999,-0.964339,-1.19863,-1.13485
1973,0.947706,0.902827,0.0354758,0.00338756,0.558272,0.412107,0.432113,0.449574,0.287563,0.252081,0.887993,0.922712,0.939217,0.931712,0.204232,0.215786,0.0844686,0.0612,0.96648,1.01359,1.88366,2.31066,-0.762739,-0.469064,-1.42731,-1.29497,-1.69611,-1.79156,-0.43481,-0.325436,2.04327,2.17843,-0.3112,-0.457304,1.28942,1.2078,-0.0456359,-0.223907,0.874558,0.932951
1974,0.610991,0.567675,0.281266,0.250394,0.209464,0.137887,0.543395,0.536446,0.648075,0.569355,0.821239,0.873004,0.570667,0.560998,0.247174,0.261175,0.294131,0.271796,0.392274,0.437898,-1.3347,-0.913287,-0.991116,-0.713617,0.241902,0.379454,1.05279,0.952068,0.0621664,0.104027,0.795687,0.929996,-0.935816,-1.08608,-0.423473,-0.501526,1.36438,1.19105,1.68832,1.74122
1975,0.0443993,0.00171143,0.00312941,-0.0296295,0.812509,0.741446,0.589659,0.623319,0.919766,0.886629,0.849405,0.823297,0.663118,0.654939,0.584438,0.598738,0.0709433,0.0483427,0.594698,0.639884,1.11055,1.52808,-1.68108,-1.39986,0.630938,0.762486,-1.27642,-1.37708,1.45132,1.49009,1.08338,1.21924,-1.0719,-1.22245,-0.170395,-0.245744,1.01239,0.793559,-0.665367,-0.612193
1976,0.812413,0.772189,0.421464,0.389484,0.0603664,-0.00858439,0.69294,0.710192,0.630303,0.561062,0.298171,0.27395,0.198921,0.189208,0.707849,0.651583,0.649331,0.62816,0.20495,0.249891,0.00218023,0.414426,2.30676,2.59124,0.199694,0.335623,1.04577,0.9494,-1.27029,-1.22999,-0.164559,-0.029204,-0.1902,-0.333796,-1.05744,-1.12547,0.566065,0.396069,0.157124,0.210761
1977,0.714071,0.636058,0.459223,0.427858,0.448472,0.378423,0.55664,0.572973,0.267252,0.235496,0.80654,0.781559,0.547518,0.536909,0.690077,0.704428,0.649422,0.628212,0.952114,0.998156,-0.596246,-0.190059,0.549788,0.828716,-0.625217,-0.498046,-1.43664,-1.53399,-1.25546,-1.20888,0.2551,0.382462,1.76998,1.62804,-0.394077,-0.50073,-1.5477,-1.7116,-1.0597,-1.00894
1978,0.485273,0.499927,0.776391,0.682686,0.441203,0.369893,0.0243161,0.0399738,0.587811,0.520103,0.0194932,-0.00491652,0.215397,0.206505,0.19447,0.208744,0.214369,0.193475,0.725717,0.772194,-1.84082,-1.44086,-0.904164,-0.620337,-0.362323,-0.23558,-0.01421,-0.104507,1.13671,1.17775,-1.48598,-1.35621,-0.329141,-0.469189,0.191911,0.124009,0.643108,0.486706,-1.29371,-1.24308
1979,0.369876,0.363796,0.967518,0.937514,0.0386645,-0.0356617,0.731771,0.74731,0.838552,0.80471,0.806105,0.783589,0.895834,0.889396,0.159581,0.172629,0.219124,0.166717,0.261615,0.306238,-1.36041,-0.956682,-0.0421639,0.240248,1.16653,1.29523,0.0355302,-0.0461209,-1.47562,-1.43137,1.02847,1.1546,1.28046,1.14773,-0.122696,-0.189322,-0.866519,-1.01698,-0.398016,-0.344528
1980,0.267889,0.227665,0.684858,0.717543,0.0939158,0.0211566,0.710429,0.816045,0.45862,0.425838,0.0536021,0.0291539,0.748207,0.748798,0.985901,0.996683,0.154216,0.13996,0.765379,0.810195,-0.374104,0.0279121,0.360232,0.640039,-1.78646,-1.66013,-1.28081,-1.36263,-1.69749,-1.64447,-0.389487,-0.263384,-0.825414,-0.964918,0.412301,0.341745,-0.881638,-1.03792,-0.339942,-0.291694
1981,0.856972,0.81887,0.529607,0.497572,0.797149,0.72665,0.872008,0.88478,0.680804,0.646518,0.147983,0.12439,0.615741,0.6082,0.149463,0.159633,0.134616,0.113202,0.758726,0.805701,-1.79788,-1.39166,1.02418,1.30321,0.918978,1.04375,-0.605393,-0.693244,-0.29756,-0.24394,0.447972,0.57874,0.349014,0.203658,2.22469,2.147,-0.439365,-0.660499,-0.651483,-0.602422
1982,0.172002,0.132143,0.0632764,0.0293115,0.0814579,0.0121903,0.469481,0.483166,0.365665,0.328837,0.962817,0.939394,0.937851,0.930091,0.424345,0.484045,0.85652,0.835734,0.331914,0.379746,-1.69939,-1.29545,-0.177091,0.1067,-0.896154,-0.76667,0.369626,0.288114,-1.05993,-1.00686,-0.395393,-0.27065,-0.217159,-0.365974,0.0772918,-0.00596461,-0.133083,-0.283076,-1.18606,-1.14065
1983,0.730678,0.688692,0.520982,0.487806,0.482493,0.415557,0.56231,0.573718,0.437723,0.345342,0.279838,0.254628,0.651425,0.644225,0.797383,0.808456,0.193616,0.170358,0.941808,0.988612,1.71312,2.11299,0.832923,1.20333,-0.369403,-0.245639,0.878167,0.803204,0.980293,1.0294,2.23482,2.35165,1.24066,1.09759,0.978796,0.890811,-1.21993,-1.37403,0.189023,0.231544
1984,0.989939,0.950615,0.590384,0.556343,0.56076,0.469243,0.572531,0.664271,0.396525,0.361847,0.789515,0.762237,0.0576769,0.0526977,0.384033,0.474647,0.84327,0.817305,0.333718,0.382561,0.895589,1.29163,2.01311,2.29995,0.369847,0.492361,-0.207248,-0.28543,0.522736,0.570718,2.6147,2.73454,-0.342218,-0.482621,0.764059,0.671018,-0.996334,-1.1488,0.554345,0.59944
1985,0.709069,0.671619,0.966172,0.93055,0.589617,0.522929,0.743213,0.754823,0.025464,-0.00692319,0.431644,0.412171,0.716909,0.710591,0.127698,0.140837,0.665361,0.597284,0.302324,0.35319,0.892558,1.28235,-0.640043,-0.350056,0.366092,0.492336,-1.09069,-1.17184,0.582938,0.637827,-0.60056,-0.482922,0.36276,0.214602,-0.190955,-0.285246,-0.23996,-0.395096,-1.06629,-1.01669
1986,0.991622,0.953315,0.552012,0.514338,0.469247,0.466682,0.10045,0.112574,0.956433,0.92191,0.0890833,0.0621039,0.807227,0.800225,0.900195,0.912811,0.402084,0.377262,0.865485,0.916578,0.285204,0.677869,1.59964,1.88626,-0.973218,-0.853415,-1.49705,-1.577,-0.633622,-0.586054,-0.622083,-0.498691,1.05537,0.911826,0.149472,0.0604601,0.868359,0.71893,0.886745,0.9417
1987,0.271071,0.233853,0.132146,0.0981261,0.479204,0.410435,0.843677,0.855284,0.218127,0.184543,0.960034,0.932155,0.53572,0.560178,0.0643163,0.075761,0.544846,0.521705,0.788952,0.898354,0.813329,1.21804,0.942483,1.23091,0.362807,0.47966,0.36958,0.294822,0.0735681,0.191904,0.964634,1.08112,-0.131689,-0.275296,-0.876088,-0.971225,0.439345,0.294561,0.410298,0.5113
1988,0.262741,0.224829,0.606668,0.571789,0.786729,0.717465,0.626163,0.541333,0.214266,0.181995,0.577451,0.550669,0.380943,0.320131,0.739525,0.75194,0.381651,0.358912,0.828049,0.880131,1.36265,1.75822,-0.174358,0.110946,0.351655,0.464914,-1.92824,-1.99994,0.921664,0.969863,0.655057,0.748908,-0.822817,-0.965818,-0.230188,-0.317999,0.878399,0.737819,0.022289,0.0808997
1989,0.895055,0.855511,0.491394,0.458569,0.840835,0.77003,0.214762,0.227383,0.939797,0.909992,0.836026,0.809948,0.0868636,0.0800845,0.327834,0.34025,0.908506,0.88413,0.542446,0.594688,1.07519,1.4771,0.259975,0.541513,-0.637827,-0.523226,0.671987,0.59882,-0.201485,-0.160464,0.332851,0.416699,1.96302,1.82847,1.48646,1.3968,-0.622232,-0.765864,0.337001,0.403775
1990,0.103718,0.0622201,0.924472,0.892718,0.0441336,-0.0265058,0.169311,0.243832,0.285449,0.255755,0.30651,0.280029,0.994501,0.987871,0.695794,0.707337,0.57191,0.550295,0.616868,0.670495,-1.08351,-0.687607,-0.726904,-0.43747,-0.434949,-0.324377,-1.68674,-1.76181,0.021958,0.0594766,-0.0323328,0.0844903,-0.168624,-0.29765,1.77456,1.68348,1.1029,0.960945,0.867416,0.937506
1991,0.367192,0.324143,0.980179,0.94652,0.272827,0.203145,0.248645,0.260281,0.900497,0.869853,0.707049,0.67966,0.670416,0.661902,0.461033,0.48456,0.533655,0.510652,0.414688,0.469755,-0.639118,-0.237151,1.14706,1.43148,1.28912,1.39801,1.43117,1.35924,-0.811911,-0.781593,-1.13115,-1.01143,-0.410004,-0.541328,0.775458,0.681734,1.20269,1.06358,1.80316,1.86557
1992,0.837568,0.796034,0.666805,0.702886,0.730642,0.661981,0.478203,0.484813,0.724269,0.665668,0.403243,0.37596,0.0892495,0.0794739,0.250307,0.261782,0.0734982,0.0505527,0.886923,0.943759,-1.01526,-0.610892,-0.789716,-0.504801,0.0619265,0.176455,0.275433,0.183348,-1.21845,-1.19395,-0.908204,-0.782375,2.06384,1.93516,0.850384,0.750989,-0.18101,-0.31368,2.48515,2.55163
1993,0.730861,0.687013,0.49215,0.459252,0.585819,0.514989,0.717897,0.709345,0.562031,0.461483,0.766952,0.740279,0.584285,0.529665,0.98188,0.99433,0.218504,0.194996,0.173494,0.231864,0.0889162,0.496616,0.0526467,0.340336,-0.769203,-0.657214,-0.924637,-0.992549,-0.527043,-0.41599,0.655559,0.781286,1.70597,1.58238,0.025474,-0.0666884,1.6734,1.54008,-0.291283,-0.228221
1994,0.962926,0.918862,0.529779,0.590508,0.117625,0.045257,0.920343,0.933877,0.257597,0.257299,0.689262,0.686889,0.99014,0.979856,0.782562,0.797379,0.598687,0.541472,0.442809,0.500207,0.132842,0.547287,-0.0356277,0.249431,-0.434028,-0.319437,0.180895,0.10957,0.339238,0.361968,0.160393,0.332938,-1.58695,-1.70842,0.0462771,-0.0437103,0.643913,0.510475,0.594868,0.654845
1995,0.710977,0.740687,0.754536,0.721763,0.525985,0.373952,0.20316,0.216809,0.0837586,0.053114,0.658625,0.633498,0.00383034,-0.00819573,0.193511,0.206057,0.91173,0.887948,0.450332,0.50552,-0.515613,-0.1036,0.19265,0.48122,-1.01319,-0.905644,-1.95613,-2.0247,0.476946,0.503708,-0.234812,-0.115409,-0.991869,-1.10873,-0.413234,-0.508838,-1.24095,-1.37618,0.153139,0.253985
1996,0.606785,0.562511,0.624012,0.592631,0.773163,0.702646,0.862002,0.873846,0.289366,0.337721,0.829,0.803435,0.994008,0.981361,0.86909,0.882236,0.777229,0.755453,0.88225,0.940153,-0.636832,-0.221074,1.25962,1.54437,-0.475316,-0.314431,-0.571267,-0.6439,-0.82432,-0.796547,1.27265,1.38393,0.414317,0.294869,2.31469,2.22309,0.756889,0.627347,-0.212481,-0.146875
1997,0.939118,0.894664,0.172548,0.139413,0.253999,0.183854,0.217038,0.226214,0.65064,0.622328,0.506354,0.56227,0.728097,0.7154,0.668988,0.680167,0.0419503,0.0191315,0.501102,0.601709,0.993346,1.41577,-0.222151,0.064181,0.177895,0.276783,-0.16851,-0.234922,-0.386672,-0.295257,-0.0137187,0.103765,0.0310964,-0.087456,-1.23665,-1.33499,-1.10472,-1.22849,-1.12386,-1.06062
1998,0.27392,0.228408,0.373019,0.341874,0.379655,0.310066,0.998,1.00622,0.031834,0.00293636,0.345455,0.321105,0.960754,0.946374,0.817076,0.826549,0.142344,0.168084,0.20309,0.263266,1.33531,1.75749,0.0562794,0.343448,1.48679,1.57984,1.08547,1.02265,0.182351,0.206034,1.16556,1.2823,0.812145,0.696247,-0.288673,-0.389485,0.786326,0.656016,0.963589,1.02555
1999,0.103254,0.0564109,0.2833,0.25133,0.166243,0.0969068,0.144839,0.151902,0.416218,0.386349,0.307028,0.283777,0.0743719,0.0582429,0.640084,0.649711,0.339019,0.317036,0.769795,0.831661,-0.484088,-0.0636593,1.58506,1.87116,-0.0293647,0.0679916,-0.460919,-0.620475,1.94631,1.97353,-0.57866,-0.456371,-1.75496,-1.8653,1.01928,0.919503,-1.26936,-1.40484,0.991896,1.04802
2000,0.573295,0.528302,0.190493,0.160785,0.456232,0.388362,0.279831,0.292141,0.592732,0.561435,0.497578,0.550262,0.995072,0.976735,0.150123,0.158633,0.754475,0.732559,0.874927,0.937886,0.590935,1.01276,-0.629837,-0.34814,-1.29141,-1.19699,-2.20364,-2.26359,-0.912017,-0.878042,-0.74226,-0.625158,0.704464,0.597251,0.443947,0.347886,-0.159536,-0.290815,1.25653,1.30942
2001,0.29857,0.305799,0.921999,0.89238,0.191995,0.12414,0.347192,0.43238,0.19807,0.167869,0.838069,0.816747,0.480004,0.460701,0.943992,0.951978,0.965776,0.943155,0.714953,0.777511,0.122673,0.547444,1.17764,1.45624,0.726637,0.820075,-2.49944,-2.56134,0.497703,0.537356,1.59223,1.70469,-0.154136,-0.261104,0.363907,0.263938,0.555861,0.418929,1.19274,1.2431
2002,0.126258,0.0832959,0.208208,0.177475,0.363648,0.215013,0.567488,0.572619,0.602675,0.5704,0.378046,0.355838,0.764629,0.673709,0.199718,0.206233,0.491524,0.468483,0.904677,0.969559,1.31451,1.7336,-0.00465293,0.275166,0.890707,0.986577,2.61224,2.55034,-0.920882,-0.885256,0.561819,0.671859,0.384832,0.275985,-0.880059,-0.982841,-0.789331,-0.927633,-1.58292,-1.53675
2003,0.412172,0.370143,0.495891,0.463919,0.367459,0.305887,0.362268,0.365743,0.641124,0.60733,0.526282,0.505634,0.905394,0.886718,0.675223,0.682759,0.22922,0.284399,0.180849,0.247079,-0.825476,-0.400641,-2.21309,-1.92951,-0.16633,-0.0639511,0.592245,0.525192,3.87747,3.91117,-0.950009,-0.837927,0.704541,0.597736,-0.848479,-0.943832,0.244568,0.110833,0.555816,0.594443
2004,0.15399,0.112065,0.299558,0.288238,0.463679,0.396761,0.754012,0.659938,0.885432,0.854055,0.195812,0.269144,0.0696292,0.0513082,0.716041,0.723078,0.121224,0.100315,0.103484,0.169025,-0.639594,-0.211686,-0.684783,-0.401792,-0.317548,-0.29836,0.970383,0.903623,-0.565028,-0.527469,-0.0477862,0.066049,-0.0972432,-0.201381,0.330509,0.229728,1.90413,1.77471,0.366731,0.405153
2005,0.434212,0.393761,0.144842,0.112558,0.0136191,-0.0523094,0.95119,0.954134,0.0882725,0.059128,0.0533727,0.0326535,0.372615,0.353038,0.994972,1.00411,0.201404,0.172481,0.423258,0.487245,0.170286,0.590426,-1.06023,-0.783458,-0.630959,-0.532768,-0.80193,-0.863861,-0.282522,-0.246418,-2.0899,-1.98269,0.463745,0.352769,-0.150625,-0.250503,0.049628,-0.0811279,0.650441,0.683244
2006,0.287302,0.261909,0.985445,0.954574,0.537608,0.47116,0.930061,0.932229,0.727871,0.698333,0.850573,0.831353,0.947656,0.929539,0.985871,0.994114,0.266381,0.244647,0.428529,0.485531,1.22993,1.65231,0.0640399,0.342272,-0.383091,-0.285744,1.71031,1.64727,-1.22533,-1.1945,0.544082,0.658538,-0.154243,-0.262006,-0.0342549,-0.13425,-0.219533,-0.335702,-0.984963,-0.94913
2007,0.168553,0.130056,0.535501,0.506118,0.114647,0.046661,0.671255,0.624166,0.0808581,0.0540611,0.441111,0.420348,0.613613,0.654162,0.281854,0.290702,0.0266796,0.00613597,0.418632,0.483817,-0.554264,-0.136308,2.3415,2.62697,-0.854007,-0.758227,-1.24729,-1.3143,0.333635,0.358328,1.13928,1.25695,0.0386339,-0.063199,0.9329,0.839021,-0.597877,-0.590276,-1.94967,-1.9077
2008,0.525031,0.486873,0.648668,0.642515,0.10617,0.0381306,0.312582,0.316104,0.682955,0.653803,0.389101,0.368166,0.395124,0.378784,0.382989,0.392247,0.450729,0.430821,0.852583,0.91845,-1.24741,-0.832929,1.78523,2.07733,-0.307253,-0.206267,0.124275,0.0506426,-0.856277,-0.83003,0.493757,0.604618,-0.665388,-0.768382,-0.385322,-0.486718,-0.714093,-0.844849,-0.337393,-0.286744
2009,0.100512,0.0612491,0.808169,0.778912,0.690917,0.621645,0.254538,0.258862,0.874782,0.843789,0.76936,0.747055,0.699663,0.685737,0.994863,1.00202,0.440736,0.420405,0.166368,0.231296,0.90933,1.32396,0.835468,1.12893,-2.54816,-2.4456,0.246933,0.169376,1.52001,1.5395,0.0624958,0.17349,-0.285788,-0.385937,1.5903,1.48967,0.806707,0.677858,0.767805,0.825069
2010,0.194513,0.156835,0.408843,0.379472,0.139962,0.0725813,0.630254,0.632703,0.297769,0.26522,0.0296258,0.00755567,0.433423,0.454284,0.644228,0.722698,0.955319,0.93549,0.286314,0.322655,-0.420336,-0.00379909,0.436841,0.652383,1.05849,1.16689,2.23519,2.15346,-1.97517,-1.95205,-2.02708,-1.92361,0.938469,0.845247,1.2068,1.10223,0.395226,0.270031,0.0220031,0.0784415
2011,0.0470327,0.00869251,0.910021,0.882283,0.954412,0.887669,0.223483,0.225678,0.441337,0.409675,0.516416,0.494699,0.23787,0.222831,0.436631,0.443374,0.332455,0.310677,0.349794,0.414015,1.79301,2.2023,-0.142444,0.175836,1.22094,1.33339,-0.592898,-0.673662,-0.505554,-0.398773,-0.37972,-0.281367,-0.985548,-1.07727,-0.0662699,-0.177006,-0.249684,-0.369264,2.72572,2.7755
2012,0.703405,0.665086,0.0982165,0.0722325,0.745645,0.63847,0.146281,0.147355,0.0578797,0.0259863,0.275995,0.256245,0.297057,0.281805,0.773163,0.780937,0.118709,0.0972894,0.200792,0.263655,-0.214446,0.191929,-0.594172,-0.30071,0.202587,0.292498,-0.908531,-0.98667,1.12684,1.15451,0.491081,0.590418,-0.401318,-0.492242,0.798436,0.688933,0.284646,0.169392,-0.868468,-0.81397
2013,0.173485,0.133868,0.608614,0.584672,0.455847,0.38927,0.529086,0.530459,0.504445,0.474189,0.569583,0.551867,0.870474,0.853497,0.752686,0.767755,0.601731,0.582297,0.64839,0.712742,0.434729,0.842352,-0.133391,0.161112,-0.859398,-0.748393,1.29577,1.22297,0.560014,0.590615,-1.70935,-1.61544,-0.266645,-0.354769,0.864256,0.758188,1.36957,1.25331,-0.797994,-0.745746
2014,0.773571,0.73462,0.450869,0.426143,0.789768,0.721273,0.195981,0.197687,0.300424,0.272186,0.493185,0.397815,0.234264,0.216054,0.747412,0.754574,0.0269156,0.00771103,0.484884,0.54774,0.0305027,0.438638,-0.286992,0.0114218,-0.430951,-0.319428,0.388502,0.284771,-0.258955,-0.23415,-0.0858314,0.00899628,-0.421286,-0.563552,1.24582,1.1369,-1.52924,-1.63749,1.51896,1.56512
2015,0.747022,0.709337,0.598031,0.491191,0.696477,0.711282,0.0913207,0.0951123,0.408203,0.331076,0.259235,0.243764,0.559163,0.563363,0.136656,0.143714,0.906365,0.886207,0.546318,0.562023,0.48728,0.889094,1.5518,1.85035,0.295936,0.4647,-0.578624,-0.653427,0.329596,0.351898,-1.1005,-0.911555,-0.692564,-0.772336,0.847892,0.733141,0.0304714,-0.0845621,-0.370038,-0.328549
2016,0.373752,0.335014,0.580929,0.556239,0.743773,0.701291,0.434495,0.396471,0.416226,0.389965,0.958851,0.944424,0.930928,0.910671,0.24243,0.250051,0.665996,0.647696,0.511372,0.576306,-0.932751,-0.530479,0.939073,1.24069,1.14436,1.24883,0.144538,0.0627806,0.264148,0.292261,-1.92604,-1.83211,0.779859,0.707135,-0.735702,-0.850707,0.770452,0.65587,0.475146,0.508752
2017,0.358184,0.319912,0.156373,0.132306,0.761068,0.691301,0.693768,0.69783,0.781866,0.757631,0.376974,0.364661,0.949195,0.928459,0.843142,0.84834,0.974297,0.958479,0.777244,0.844649,0.905968,1.30512,1.03728,1.3332,0.770019,0.867615,0.63639,0.54931,-0.586386,-0.562886,-1.0092,-0.913605,-0.107219,-0.184662,0.496549,0.380734,-0.907267,-1.02041,0.305725,0.33477
2018,0.102653,0.0669949,0.0334095,0.00841547,0.241891,0.172509,0.780964,0.785963,0.4508,0.500265,0.396366,0.386596,0.763122,0.74302,0.225574,0.232004,0.832799,0.814966,0.497917,0.622862,0.062894,0.46798,-0.252912,0.0427978,-0.915333,-0.815417,-2.50335,-2.5953,-0.456588,-0.364768,2.42484,2.51233,0.0393998,-0.031628,0.00194005,-0.11502,-0.647843,-0.765103,1.00235,1.03677
2019,0.110343,0.0721443,0.503287,0.476777,0.649538,0.580651,0.32336,0.328958,0.268805,0.242898,0.889237,0.879223,0.916789,0.898379,0.783074,0.789903,0.433458,0.462502,0.33445,0.401075,1.50835,1.91986,1.49384,1.78595,-0.954005,-0.859771,1.00715,0.915272,-0.194674,-0.16665,-0.769774,-0.687681,-0.681606,-0.751796,-1.56809,-1.68473,-2.31164,-2.42552,-0.995191,-0.965795
2020,0.380757,0.343285,0.0503223,0.0235597,0.551419,0.484669,0.284473,0.292533,0.686938,0.660402,0.383688,0.373849,0.23933,0.221774,0.379056,0.410904,0.129757,0.110038,0.348898,0.416422,-0.543055,-0.135848,-0.424923,-0.135775,1.57178,1.66434,-0.198197,-0.295437,1.63086,1.66484,1.25755,1.33796,0.738961,0.666654,0.745655,0.623734,0.120117,0.010731,-0.266923,-0.233289
2021,0.211221,0.175696,0.287153,0.284789,0.883351,0.816672,0.940168,0.94957,0.797961,0.706017,0.647361,0.67576,0.284783,0.264386,0.0250822,0.0319053,0.725685,0.706509,0.024464,0.0901022,1.17603,1.57776,1.39409,1.68604,-1.84005,-1.75031,0.84458,0.745857,-0.472727,-0.435754,-1.09281,-1.00935,-1.17102,-1.241,0.429489,0.396864,-1.07975,-1.19342,1.14998,1.18585
2022,0.289607,0.190387,0.570873,0.546019,0.0823049,0.0137968,0.293052,0.301938,0.776679,0.751633,0.987508,0.97767,0.0321834,0.0135635,0.879972,0.88688,0.43955,0.459518,0.608698,0.67439,1.17647,1.58319,1.00437,1.29027,1.45573,1.53978,0.0471087,-0.0449455,1.09768,1.13382,0.401807,0.489996,-0.838883,-0.903956,0.286329,0.169994,-0.802378,-0.922961,-1.21045,-1.18273
2023,0.240539,0.205078,0.483283,0.40131,0.115303,0.0222374,0.0643011,0.158273,0.615291,0.590267,0.304656,0.292903,0.797115,0.778315,0.321436,0.325723,0.229939,0.212526,0.729023,0.795839,1.75126,2.15733,0.951413,1.23112,1.02128,1.09836,0.780293,0.688103,0.297703,0.340664,-0.190243,-0.154751,1.73938,1.66715,0.585939,0.469282,0.0175523,-0.105627,-1.90635,-1.88474
2024,0.51312,0.476219,0.282459,0.2566,0.0979742,0.0306781,0.00380863,0.0146077,0.21782,0.191753,0.988791,0.978975,0.290516,0.271996,0.457335,0.46128,0.689747,0.672823,0.1133,0.180637,0.951008,1.3509,0.3798,0.665891,0.254235,0.327665,-1.19326,-1.29214,1.21751,1.26631,-0.888288,-0.799497,-1.12117,-1.18848,-1.80255,-1.91204,-0.165706,-0.2832,0.243251,0.264732
2025,0.0702451,0.0357107,0.774123,0.749648,0.685976,0.619048,0.280778,0.289862,0.498941,0.47385,0.944868,0.937008,0.903082,0.883368,0.202033,0.20446,0.231787,0.212724,0.39124,0.508752,1.14478,1.53985,-0.628114,-0.345357,-1.37137,-1.2935,0.463012,0.359259,0.293235,0.247966,0.590672,0.684433,0.909625,0.835396,-0.867609,-0.982729,1.94166,1.81745,0.319166,0.345408
2026,0.547478,0.467869,0.634487,0.635475,0.628965,0.56378,0.962749,0.97206,0.242482,0.236425,0.324135,0.316836,0.946118,0.899252,0.281938,0.240563,0.53597,0.518499,0.768959,0.836867,-0.383495,0.0160671,0.44063,0.717794,-0.345606,-0.262971,0.651423,0.540315,-0.819085,-0.770379,-0.15427,-0.0576361,1.0664,0.988431,0.954001,0.838372,-0.448139,-0.566777,-0.457497,-0.432377
2027,0.934867,0.900027,0.546721,0.521303,0.142669,0.0782189,0.710998,0.765877,0.0246757,-0.00100082,0.263511,0.25489,0.937263,0.915136,0.276071,0.276667,0.0650984,0.0489824,0.396812,0.466358,0.735897,1.13783,0.762865,1.04263,-0.200007,-0.11049,-0.663981,-0.776193,-0.273295,-0.230842,-0.183156,-0.0903555,0.0390128,-0.0432336,-0.887775,-0.999355,-0.292012,-0.403653,-2.15073,-2.12458
2028,0.905185,0.862021,0.696207,0.670307,0.987948,0.924616,0.547648,0.559694,0.942443,0.915456,0.975972,0.965953,0.222392,0.197356,0.0318228,0.0337521,0.318481,0.300726,0.393488,0.461863,0.430386,0.8263,-0.30678,-0.0314628,0.78697,0.872828,-1.11675,-1.22753,-1.02605,-0.978159,-0.925426,-0.832424,-0.513392,-0.596732,-0.801496,-0.914765,0.63355,0.523917,2.65227,2.67842
2029,0.856975,0.824016,0.16183,0.138233,0.299861,0.235665,0.828578,0.839601,0.13982,0.114754,0.680549,0.671803,0.957667,0.931921,0.0116485,0.0134076,0.0518639,0.0318546,0.634445,0.704956,2.11202,2.51026,1.83501,2.10957,0.00989342,0.102131,1.85702,1.74259,-0.153507,-0.0990803,0.808638,0.900816,0.83068,0.744914,-0.113389,-0.231457,0.884536,0.779222,0.719578,0.753759
2030,0.299507,0.267851,0.351294,0.32697,0.156303,0.0876419,0.521734,0.531815,0.999568,0.975628,0.841947,0.831274,0.139333,0.114858,0.846509,0.847005,0.39162,0.372576,0.464294,0.534776,0.110868,0.517402,0.434052,0.706862,0.119505,0.208631,0.413735,0.300845,1.2133,1.26924,1.43868,1.52915,-0.203234,-0.286751,-1.21907,-1.34096,0.107135,0.000179637,2.73955,2.77509
2031,0.823419,0.78981,0.747764,0.722419,0.00410834,-0.0603807,0.427701,0.438844,0.633554,0.6122,0.701513,0.693071,0.122351,0.152724,0.696924,0.695759,0.464726,0.471626,0.913425,0.983863,0.690166,1.09154,0.843226,1.12301,-1.0243,-0.934283,-0.709727,-0.816967,-0.0594794,-0.000178689,0.319512,0.403644,0.916619,0.833647,2.50561,2.38192,-1.07455,-1.18831,-0.114087,-0.0807509
2032,0.606855,0.589538,0.430999,0.434358,0.42121,0.357848,0.638783,0.649829,0.62049,0.598281,0.896297,0.886816,0.215872,0.190591,0.154181,0.154337,0.589337,0.570677,0.383754,0.452408,0.00362043,0.409534,0.483938,0.758599,2.41116,2.5079,1.36932,1.26208,0.582717,0.64763,1.02528,1.10877,0.0159819,-0.0733694,-0.918977,-1.04369,0.631942,0.522041,-0.402185,-0.374752
2033,0.37223,0.389266,0.172394,0.146297,0.112558,0.0487223,0.272566,0.28302,0.807498,0.783339,0.634039,0.663521,0.682139,0.564274,0.734126,0.732212,0.472818,0.549011,0.721704,0.791096,-0.439485,0.050603,-1.98696,-1.71621,0.405002,0.495684,-1.49426,-1.5981,-0.696147,-0.636302,-0.626761,-0.539534,1.02098,0.926499,-0.630031,-0.757011,-1.07958,-1.18593,1.14113,1.13215
2034,0.221356,0.188994,0.983042,0.958516,0.536257,0.47289,0.989608,1.00163,0.512779,0.401072,0.452911,0.440226,0.965001,0.937956,0.28577,0.285901,0.548841,0.527345,0.697398,0.767657,-0.721557,-0.308328,0.0602819,0.328083,-1.08356,-1.00084,0.374549,0.273725,0.603972,0.657213,2.05823,2.14722,-1.21908,-1.31207,-0.101217,-0.225944,0.952408,0.846983,2.61354,2.63906
2035,0.748637,0.7158,0.284043,0.258252,0.529907,0.429055,0.845079,0.92224,0.0447722,0.0188044,0.472712,0.462162,0.426305,0.401175,0.38701,0.387446,0.524339,0.505679,0.676033,0.744219,1.30384,1.71194,-0.106649,0.217505,-2.08551,-2.00451,-0.934325,-1.02902,-1.64437,-1.58385,0.185585,0.270839,-0.299584,-0.390851,-0.324962,-0.445737,-0.796262,-0.895707,-1.73655,-1.71564
2036,0.831034,0.70005,0.479348,0.455675,0.47842,0.38522,0.829466,0.842846,0.537797,0.512065,0.823848,0.813047,0.30232,0.299818,0.73032,0.636642,0.842727,0.826346,0.400687,0.408917,1.33959,1.74586,-0.154875,0.106927,-0.450709,-0.378372,-1.01215,-1.10962,0.0688498,0.121548,0.483308,0.572899,0.291964,0.194178,-1.00407,-1.12788,-0.702942,-0.807697,0.915997,0.933558
2037,0.716833,0.684301,0.289247,0.266163,0.403623,0.341385,0.298658,0.309848,0.228311,0.20455,0.241973,0.233284,0.221744,0.19846,0.885592,0.885838,0.760073,0.745982,0.00542946,0.0736157,1.73295,2.13487,-1.16918,-0.904321,-1.35144,-1.27281,-0.356225,-0.454624,0.619603,0.676289,1.81262,1.90527,0.447193,0.347213,-0.219338,-0.338513,0.684734,0.575626,-0.131968,-0.115191
2038,0.00718171,-0.0234593,0.908933,0.886647,0.936912,0.874925,0.844668,0.857239,0.119154,0.0929195,0.606245,0.597603,0.635976,0.615233,0.659247,0.658877,0.192802,0.176052,0.939204,1.00889,-0.0895,0.313717,0.297819,0.561154,0.545897,0.62007,-0.920351,-1.01294,-0.858584,-0.807306,0.220307,0.319357,2.14221,2.04163,0.136864,0.0231122,0.5106,0.398054,-0.935641,-0.922334
2039,0.0860302,0.0571873,0.215911,0.191417,0.455419,0.419239,0.342198,0.35431,0.796014,0.769602,0.133369,0.122639,0.602412,0.544892,0.183641,0.183371,0.872303,0.853906,0.266384,0.337739,0.0843942,0.487252,-0.176538,0.089353,-1.79388,-1.71522,0.543562,0.473389,-0.0148604,0.0416402,-0.340645,-0.23624,-0.707819,-0.813996,-0.87372,-0.99499,0.0406861,-0.0715978,0.246989,0.268888
2040,0.900553,0.869467,0.317335,0.290349,0.0253647,-0.0364473,0.711636,0.722931,0.690014,0.662697,0.812432,0.799611,0.494903,0.474552,0.787015,0.787912,0.575031,0.554738,0.418136,0.489842,-2.25724,-1.84917,0.826678,1.08902,-0.39897,-0.322448,2.04549,1.95972,0.126326,0.18338,-0.247126,-0.144837,1.71005,1.60045,0.0209778,-0.0982144,-2.3771,-2.48943,0.704709,0.72632
2041,0.603941,0.574954,0.762889,0.734138,0.391573,0.271882,0.0710021,0.0806816,0.788735,0.761413,0.842276,0.831166,0.646401,0.624976,0.115735,0.116015,0.734016,0.714121,0.215599,0.289102,0.0383472,0.44802,-0.579758,-0.313682,1.80863,1.88792,-0.000829164,-0.0829827,1.12465,1.18524,1.32081,1.41882,1.1637,1.04695,-1.18768,-1.31488,-0.194584,-0.308012,0.754807,0.779154
2042,0.0189675,-0.0112338,0.522466,0.493167,0.618844,0.580211,0.529662,0.538367,0.273516,0.248291,0.521897,0.511917,0.439509,0.419854,0.729404,0.730928,0.0376249,0.0179657,0.848629,0.923006,0.970466,1.37272,-0.576754,-0.311377,-0.952658,-0.865031,1.08116,1.00357,0.809069,0.864032,0.562918,0.659816,0.0100275,-0.106768,-1.15554,-1.27587,-1.38223,-1.4965,1.26321,1.28338
2043,0.461016,0.431444,0.234316,0.252196,0.948822,0.88854,0.454335,0.465221,0.576294,0.551055,0.000554663,-0.00815554,0.539155,0.569114,0.962314,0.965889,0.411253,0.364442,0.452077,0.527729,-2.14399,-1.73358,-0.211481,0.0572835,-2.76138,-2.67545,0.615936,0.535555,-0.946259,-0.898175,0.486632,0.58208,-1.71786,-1.82628,0.0296823,-0.0893644,-0.448551,-0.568934,0.648595,0.670884
2044,0.498104,0.467733,0.0416542,0.0112243,0.360061,0.299799,0.854398,0.864568,0.420322,0.395181,0.605591,0.59763,0.610197,0.718374,0.102183,0.105397,0.730303,0.710918,0.33081,0.488606,0.895864,1.31177,-1.13084,-0.859506,1.67967,1.76559,-1.84915,-1.93019,-1.96626,-1.92218,-1.66897,-1.57503,0.035095,-0.070059,0.184349,0.0581253,-0.731977,-0.852961,0.48674,0.511798
2045,0.935537,0.905749,0.684411,0.655939,0.0906968,0.030457,0.227188,0.236892,0.566554,0.614056,0.931638,0.922767,0.888168,0.867634,0.554397,0.557096,0.468225,0.44606,0.393824,0.449483,-2.29282,-1.87592,-0.566314,-0.289362,0.73359,0.825864,-0.161779,-0.247141,0.437626,0.482207,1.00828,1.09818,0.42574,0.312386,1.92822,1.80257,-0.133939,-0.253472,1.3924,1.41035
2046,0.790831,0.76274,0.216328,0.187678,0.839738,0.781798,0.540438,0.551717,0.855862,0.832931,0.855611,0.844538,0.151734,0.130067,0.0854485,0.0860732,0.871411,0.846997,0.295424,0.410361,-1.65848,-1.24124,-0.833774,-0.589621,-0.485894,-0.39569,1.05612,0.964593,0.556015,0.5939,-1.53706,-1.44882,-0.28895,-0.407781,-1.16043,-1.28787,-0.0916604,-0.211186,0.574006,0.588587
2047,0.0697546,0.0432786,0.980379,0.95288,0.187127,0.128404,0.01949,0.0287795,0.320335,0.299786,0.130203,0.1193,0.329888,0.306528,0.814805,0.813724,0.862607,0.836581,0.297844,0.371238,0.700763,1.12114,-1.16694,-0.88988,0.224204,0.311095,-0.13683,-0.132239,0.153275,0.197402,-0.924073,-0.834603,2.83571,2.71647,-0.399581,-0.528952,0.364598,0.247318,0.113856,0.128493
2048,0.29288,0.265079,0.745943,0.718377,0.466102,0.369283,0.48694,0.506869,0.858396,0.838672,0.749142,0.740058,0.0938839,0.0702118,0.498398,0.434726,0.616868,0.530279,0.817583,0.890826,0.489191,0.913742,0.261763,0.542475,-1.94476,-1.8636,-1.13754,-1.22907,-1.10505,-1.12885,-1.01628,-0.832093,-0.105312,-0.219778,-0.870252,-0.99408,-0.407807,-0.531724,-0.977701,-0.969067
2049,0.893969,0.865831,0.0626804,0.0331178,0.611689,0.610163,0.976535,0.984958,0.658981,0.592442,0.423261,0.416834,0.400103,0.319668,0.0565698,0.055727,0.248928,0.223977,0.62361,0.784328,0.190824,0.706345,1.3906,1.66821,0.326308,0.412097,0.99745,0.91438,-2.49284,-2.45511,-0.924071,-0.829582,1.74923,1.63308,0.279694,0.147288,0.0768027,-0.0413275,-2.42136,-2.41747
2050,0.674899,0.592551,0.125226,0.176244,0.909765,0.851042,0.162679,0.173305,0.288887,0.346211,0.878013,0.870155,0.59304,0.569123,0.205616,0.162933,0.798145,0.773646,0.606301,0.67783,0.0827358,0.498947,0.326681,0.610372,0.540322,0.626802,-0.738366,-0.825062,-0.566406,-0.530389,-0.775103,-0.679046,1.5961,1.48298,0.332172,0.200276,0.159446,0.0466823,1.37502,1.38404
2051,0.345987,0.319272,0.301274,0.319371,0.321683,0.262301,0.174171,0.227849,0.118243,0.099981,0.791287,0.702525,0.308352,0.315462,0.193675,0.27014,0.030979,0.00462659,0.999309,1.0724,1.54546,1.96659,-1.19156,-0.900002,-0.28175,-0.190549,-0.203392,-0.293566,-1.35906,-1.32355,1.11248,1.20779,-0.0504068,-0.156977,0.140609,0.010619,0.518854,0.412308,-0.478206,-0.464941
2052,0.549707,0.525492,0.49206,0.462498,0.137703,0.0805153,0.229518,0.282394,0.711423,0.694767,0.540542,0.534895,0.0841738,0.0618011,0.377287,0.377346,0.0434433,0.107236,0.535947,0.619134,-0.571212,-0.149002,-0.0588446,0.23783,-0.359873,-0.285892,-0.938277,-1.02284,-0.586794,-0.551299,-2.28289,-2.19027,0.121918,-0.0252831,-0.27321,-0.409099,-1.12606,-1.2317,0.756931,0.770492
2053,0.165453,0.139924,0.897391,0.868172,0.943085,0.885785,0.326312,0.336938,0.882714,0.865295,0.794375,0.788334,0.722022,0.698389,0.866106,0.864242,0.235701,0.209846,0.0929834,0.165871,1.46874,1.88776,-1.54534,-1.24236,-0.469777,-0.381235,-0.6483,-0.734423,-1.33864,-1.29862,-0.150685,-0.0534139,0.203367,0.106411,1.28903,1.14735,0.339658,0.230923,-1.36676,-1.35541
2054,0.773447,0.745901,0.245735,0.217648,0.543589,0.485672,0.120904,0.130062,0.249298,0.230397,0.580874,0.574552,0.243718,0.222245,0.424749,0.464855,0.850175,0.825892,0.471613,0.545606,-1.4603,-1.0478,0.385714,0.688467,-1.8382,-1.75768,0.662039,0.56825,0.302568,0.344802,1.04471,1.14159,0.344676,0.238105,0.18007,0.0378425,-0.0478595,-0.16044,0.551792,0.557046
2055,0.351501,0.325582,0.441666,0.44955,0.997276,0.939181,0.143039,0.152652,0.766302,0.749329,0.821965,0.817205,0.268017,0.244735,0.0650839,0.0654683,0.795068,0.770328,0.102913,0.175097,1.33219,1.73977,-0.51268,-0.213682,-0.126592,-0.0522075,0.517197,0.416219,-0.604514,-0.554939,-0.873763,-0.78318,-1.00303,-1.10633,1.0973,0.950287,0.30975,0.248108,-0.361044,-0.356696
2056,0.160616,0.136919,0.7085,0.681452,0.703909,0.645211,0.449942,0.457069,0.504175,0.451382,0.674846,0.593736,0.600313,0.577163,0.578762,0.577463,0.410857,0.385861,0.137912,0.211814,0.18179,0.596524,0.147619,0.449484,0.424381,0.499752,0.382267,0.264188,0.753686,0.797672,0.335512,0.427111,-0.439294,-0.536359,-1.36281,-1.51405,0.776616,0.656655,-0.5998,-0.590844
2057,0.629866,0.603585,0.622506,0.53456,0.747662,0.686619,0.957058,0.96491,0.170963,0.153434,0.493563,0.370266,0.623619,0.599653,0.10739,0.10644,0.475027,0.468402,0.608222,0.680772,0.96763,1.3834,-0.798087,-0.498915,0.46499,0.544537,0.207853,0.112157,-1.14822,-1.10357,0.0720489,0.165958,-0.206622,-0.308179,-0.349929,-0.507077,0.969613,0.849217,-0.562473,-0.552506
2058,0.279149,0.253524,0.417301,0.387668,0.364168,0.302003,0.078902,0.0840637,0.512293,0.428619,0.152761,0.146797,0.976146,0.951637,0.946415,0.945585,0.438383,0.550943,0.130562,0.20466,2.25718,2.67711,0.875001,1.16947,-1.8598,-1.77352,-1.98428,-2.08365,0.937483,0.982278,-1.33025,-1.23801,0.388501,0.219761,-0.153078,-0.313528,2.01642,1.90292,0.859178,0.86663
2059,0.991817,0.964155,0.605415,0.489132,0.592893,0.531654,0.842435,0.847462,0.72236,0.703803,0.951011,0.945497,0.237301,0.214069,0.832542,0.834007,0.658478,0.633483,0.921775,0.996962,-1.18051,-0.759012,0.708544,1.00265,-0.427227,-0.333019,-0.625921,-0.718707,-1.1118,-1.06825,-0.0492721,0.0476851,0.845374,0.747702,0.672256,0.55142,1.29923,1.18716,-0.485787,-0.475276
2060,0.960691,0.932872,0.721919,0.590597,0.251402,0.191784,0.0251156,0.0305304,0.116129,0.0990825,0.406213,0.401079,0.813608,0.79057,0.0241027,0.0267037,0.0408501,0.0130531,0.263468,0.340657,-0.790074,-0.37001,0.843481,1.14235,0.029042,0.125856,-1.28628,-1.38593,-0.23705,-0.189172,-1.582,-1.49182,0.835913,0.733721,1.57682,1.41637,-1.61205,-1.71836,-1.20763,-1.1926
2061,0.516422,0.487026,0.773075,0.692061,0.896786,0.835494,0.0125358,0.0182045,0.697642,0.678819,0.63377,0.629763,0.842298,0.828158,0.0364438,0.0369826,0.174851,0.147217,0.396422,0.472719,0.0431364,0.461246,-0.274584,0.0223922,-0.193483,-0.102958,0.737496,0.631922,0.987153,1.02873,-0.26093,-0.175695,0.56445,0.459814,0.591475,0.430043,-1.03525,-1.13505,-0.708898,-0.688372
2062,0.815288,0.784336,0.823158,0.793525,0.195692,0.136084,0.79113,0.798211,0.627326,0.522335,0.222131,0.218758,0.833038,0.865746,0.859238,0.861037,0.785436,0.758835,0.101305,0.177312,0.596539,1.01824,-0.324416,-0.0223736,-0.920564,-0.828557,-0.985548,-1.0927,0.647414,0.692752,-0.361338,-0.268764,-0.885045,-0.991604,0.321807,0.163217,-0.254808,-0.350759,0.225422,0.239689
2063,0.854029,0.824512,0.161054,0.133249,0.34573,0.287683,0.650688,0.656676,0.384005,0.365852,0.850861,0.84944,0.941711,0.903335,0.625996,0.532981,0.467101,0.42237,0.773009,0.851219,-0.285642,0.233108,-0.0288435,0.273231,0.741956,0.828055,0.0494183,-0.0514071,0.315201,0.356776,-0.919136,-0.82436,1.34413,1.24322,0.466884,0.310707,0.533332,0.433532,1.85251,1.87313
2064,0.352156,0.323383,0.729518,0.699732,0.194907,0.180191,0.73279,0.740229,0.992636,0.97558,0.122418,0.120003,0.963962,0.940923,0.205124,0.204926,0.112515,0.0859041,0.488867,0.565776,-0.97521,-0.552025,-0.436465,-0.13725,0.599539,0.616529,0.461884,0.357571,1.46802,1.51119,0.313653,0.399914,1.26049,1.1539,1.69763,1.54215,-0.422076,-0.521091,2.74543,2.77169
2065,0.0599838,0.028871,0.315192,0.286038,0.129102,0.0727003,0.272894,0.278764,0.167396,0.147683,0.735724,0.735672,0.7697,0.758856,0.33857,0.230738,0.447417,0.422336,0.676454,0.752969,-1.3483,-0.839569,0.0301175,0.378579,0.388577,0.405003,0.138677,0.02989,-0.785153,-0.747229,1.94495,2.02435,2.39805,2.29179,0.101213,-0.0573481,-0.109939,-0.202512,-1.01368,-0.992244
2066,0.448649,0.417374,0.417722,0.390041,0.664718,0.60624,0.697066,0.703026,0.058589,0.0407776,0.335757,0.334107,0.600894,0.576788,0.364587,0.25655,0.992074,0.967273,0.279325,0.357692,-1.54951,-1.12711,0.59495,0.894409,0.103103,0.193477,-1.15717,-1.27285,1.03328,1.06708,-0.433708,-0.355649,-0.274742,-0.38039,1.71665,1.56132,-0.322723,-0.409296,1.04063,1.06172
2067,0.537966,0.483728,0.30456,0.276821,0.899278,0.84161,0.876355,0.883869,0.26265,0.14687,0.20206,0.20019,0.971065,0.948447,0.357915,0.282362,0.845459,0.819081,0.951848,1.0316,1.56353,1.98068,-1.43243,-1.13646,0.906908,0.992501,-1.26615,-1.38457,1.1475,1.17877,-0.214596,-0.141287,0.104914,0.00205483,0.0335727,-0.116443,0.734261,0.644405,1.1774,1.20378
2068,0.579728,0.550081,0.846138,0.819078,0.677449,0.619613,0.599988,0.606141,0.271205,0.252962,0.717613,0.717518,0.366056,0.34232,0.308372,0.308174,0.34643,0.319329,0.451115,0.53094,-0.750041,-0.326281,0.0361192,0.329014,-0.500162,-0.413454,0.141229,0.0288104,0.517175,0.553643,0.496732,0.563838,-0.00920694,-0.11756,-0.929727,-1.07271,0.923506,0.836967,0.285939,0.305985
2069,0.310049,0.280848,0.189759,0.162805,0.19966,0.139911,0.921169,0.925772,0.736348,0.716125,0.63725,0.639289,0.98463,0.958496,0.881174,0.881791,0.485449,0.459307,0.175014,0.25528,0.801701,1.22001,-0.950631,-0.64997,0.984679,1.07165,-0.232835,-0.269848,0.363016,0.402541,-0.245857,-0.178231,-0.785186,-0.89993,0.104455,-0.0366944,1.71477,1.62285,0.203286,0.221532
2070,0.395466,0.31598,0.867792,0.842496,0.00478914,-0.0569594,0.598497,0.602964,0.798977,0.778618,0.784691,0.789084,0.972192,0.890578,0.520833,0.519653,0.155265,0.130012,0.146641,0.225908,-0.436623,-0.0139253,1.44434,1.74803,2.97435,3.05928,-0.449816,-0.568507,0.468886,0.514235,0.239731,0.31317,0.119333,0.00484451,1.75413,1.61298,-1.86735,-1.95536,-1.13976,-1.12037
2071,0.303747,0.351111,0.131116,0.106855,0.404399,0.285329,0.778795,0.783807,0.250051,0.230111,0.721631,0.727138,0.851244,0.822661,0.86273,0.861684,0.11987,0.0949413,0.430981,0.480608,-0.811053,-0.326763,0.607607,0.888268,-0.090069,0.003953,-0.224135,-0.340017,1.08443,1.13135,0.0568109,0.129383,0.334313,0.217679,-0.709744,-0.851361,0.0154789,-0.0708535,-1.87255,-1.85203
2072,0.416777,0.386243,0.304956,0.280708,0.68813,0.627617,0.0306016,0.0363105,0.813517,0.793062,0.332602,0.339686,0.423198,0.393277,0.0370694,0.0341692,0.595673,0.570389,0.732284,0.735308,-1.06337,-0.639601,-0.280983,0.0285068,-0.286327,-0.19364,-0.700066,-0.821179,0.0273483,0.0774943,-0.359792,-0.286949,-1.03524,-1.15538,-0.974255,-1.11819,-0.39736,-0.478681,-0.698142,-0.678152
2073,0.708618,0.601018,0.131476,0.106133,0.428751,0.367618,0.482313,0.489392,0.670056,0.651231,0.987472,0.996184,0.675574,0.645441,0.19455,0.133944,0.863821,0.837015,0.91074,0.990007,1.08751,1.51728,-0.456665,-0.152859,1.47004,1.55898,0.403913,0.280941,2.24936,2.29727,0.159956,0.235205,0.533932,0.411986,0.156158,0.0107262,2.50852,2.4326,-0.606946,-0.582034
2074,0.844506,0.815794,0.482439,0.456636,0.388239,0.328799,0.175926,0.181607,0.224705,0.207796,0.355617,0.366269,0.70508,0.599999,0.236031,0.233718,0.468614,0.41087,0.986121,1.06581,0.122415,0.558383,0.119866,0.417285,-0.139542,-0.0458705,-0.703306,-0.823062,0.0323914,0.0860734,0.0783759,0.157468,-1.41718,-1.5437,0.699702,0.508471,-0.873904,-0.943671,0.931491,0.959248
2075,0.622166,0.667333,0.155439,0.131112,0.6229,0.564169,0.459023,0.509195,0.8207,0.802582,0.707206,0.717155,0.582671,0.554557,0.741099,0.740723,0.0131308,-0.0152754,0.122916,0.202438,-0.00380974,0.498681,-0.00257965,0.296799,0.448784,0.537559,-0.103889,-0.230944,0.249234,0.306014,-0.379976,-0.307042,0.570838,0.447515,1.15397,1.00622,-1.57043,-1.64424,-1.08357,-1.06025
2076,0.573229,0.518871,0.176184,0.150146,0.100754,0.0407468,0.832263,0.836783,0.453379,0.433812,0.448784,0.459167,0.339978,0.313274,0.0774709,0.0786188,0.939982,0.909241,0.622209,0.701069,0.000469398,0.438978,0.584079,0.882561,-1.22554,-1.12862,-1.91801,-2.04877,0.993579,1.04686,-0.579601,-0.506985,-1.23683,-1.36645,-0.0519999,-0.194339,-0.19987,-0.27616,-0.235106,-0.208598
2077,0.397462,0.37041,0.68992,0.662585,0.293359,0.2311,0.40646,0.40962,0.578988,0.590641,0.673079,0.603749,0.497793,0.468633,0.0988819,0.0993269,0.0820429,0.0499509,0.307246,0.385302,0.897323,1.33409,0.494022,0.791656,-0.539557,-0.436656,1.44741,1.32387,-0.160355,-0.11423,0.810147,0.885381,0.136869,0.00448697,0.495877,0.295688,-0.0235311,-0.0983678,-0.340438,-0.306362
2078,0.953387,0.926959,0.328077,0.298071,0.0786746,0.0179412,0.830719,0.833882,0.808138,0.74747,0.735958,0.748332,0.204788,0.176899,0.71013,0.709101,0.754304,0.72274,0.658186,0.734906,-0.934213,-0.501222,0.94844,1.25348,0.630226,0.729825,-0.744143,-0.871936,0.0313069,0.0943516,0.187839,0.265092,-1.35689,-1.49516,0.933629,0.785714,-1.03809,-1.1148,0.168365,0.197868
2079,0.417817,0.390702,0.66742,0.570376,0.758209,0.697657,0.431652,0.437037,0.923866,0.904299,0.236773,0.248264,0.787419,0.758051,0.970847,0.969734,0.713425,0.638561,0.244737,0.323434,0.705785,1.13562,-0.418272,-0.116767,-0.0493237,0.0513314,0.24578,0.125274,0.263738,0.302933,-0.094204,-0.0118208,1.18713,1.04566,-0.834804,-0.985331,0.38898,0.315337,-0.0404382,-0.0064749
2080,0.793528,0.768777,0.871185,0.842682,0.609141,0.550665,0.884479,0.890119,0.0208508,6.66428e-05,0.369668,0.374515,0.929919,0.898269,0.259314,0.261103,0.638808,0.554383,0.244208,0.244219,1.00682,1.43507,-0.179767,0.115022,1.29054,1.38441,0.671118,0.549668,-0.927294,-0.885424,0.156759,0.232426,0.0704672,-0.063191,-1.52615,-1.6816,-1.00914,-1.07594,-0.580325,-0.544708
2081,0.205415,0.178129,0.0716752,0.0450953,0.95077,0.892616,0.591642,0.597606,0.705978,0.685984,0.355474,0.500766,0.185568,0.155026,0.818459,0.819002,0.631288,0.470204,0.0650948,0.165004,-1.41537,-0.982147,-0.638754,-0.341753,2.05975,2.1531,0.175955,0.120773,-0.0808303,-0.0364783,1.56908,1.64139,0.99301,0.858032,-1.67344,-1.82606,0.106615,0.038085,-0.323069,-0.28331
2082,0.263467,0.318289,0.850903,0.82619,0.243241,0.183296,0.939762,0.946393,0.392509,0.37329,0.53552,0.627016,0.652005,0.622105,0.537254,0.537423,0.41759,0.386026,0.00522769,0.0857892,-0.580121,-0.150892,-1.59105,-1.29015,-0.477192,-0.388256,-0.188776,-0.308122,-1.6503,-1.61312,-0.049541,0.024862,-0.978458,-1.11365,0.712111,0.551655,0.400669,0.324818,1.09912,1.13583
2083,0.488013,0.458449,0.836476,0.810599,0.179034,0.213834,0.321114,0.328741,0.818539,0.801574,0.741776,0.753267,0.504691,0.457597,0.94649,0.949167,0.0265875,-0.00402196,0.851744,0.929775,2.19137,2.61849,1.06816,1.36768,-2.53951,-2.4509,-0.350764,-0.465811,1.93247,1.96964,1.05878,1.12547,0.864256,0.723912,-0.327482,-0.48003,-0.964967,-1.03546,0.315489,0.358042
2084,0.991243,0.960578,0.446337,0.421002,0.30574,0.244373,0.314196,0.321957,0.93881,0.920969,0.459838,0.470514,0.323103,0.29309,0.572995,0.624213,0.35547,0.326517,0.961273,1.0406,-0.365179,0.0538616,0.97222,1.27678,0.323461,0.404986,-1.33748,-1.44483,-1.31155,-1.26886,-0.707733,-0.643386,-0.62076,-0.759741,1.18934,1.02872,-0.0116316,-0.0776615,-1.0696,-1.02987
2085,0.54002,0.510153,0.846074,0.821039,0.0864344,0.026507,0.595922,0.601864,0.124192,0.104744,0.762909,0.771905,0.856004,0.824243,0.294712,0.29926,0.23409,0.253754,0.125006,0.204718,0.859109,1.28384,-0.276169,0.0338567,-1.61201,-1.5309,1.2506,1.13728,-1.94286,-1.89399,0.761948,0.826262,1.18901,1.04451,0.147863,-0.018857,-1.91876,-1.98124,0.299293,0.342329
2086,0.746899,0.716374,0.884812,0.859413,0.196751,0.228586,0.243203,0.250151,0.931147,0.911643,0.0513539,0.0622025,0.583081,0.55331,0.557216,0.559893,0.295549,0.180991,0.67448,0.753653,1.02544,1.45738,0.253727,0.557892,1.29842,1.3793,-0.109065,-0.230867,0.470337,0.510394,-0.368263,-0.299242,-0.368973,-0.519051,2.15324,1.98884,-1.28117,-1.34992,-1.98816,-1.94233
2087,0.512547,0.466304,0.361072,0.336687,0.490213,0.430666,0.704561,0.712683,0.340378,0.322929,0.993709,1.00367,0.108747,0.0771649,0.00777061,0.00891501,0.139405,0.108229,0.306597,0.387493,-0.437897,-0.00659919,-1.18301,-0.876116,1.36151,1.44167,-1.4857,-1.59902,-0.367186,-0.330675,1.74751,1.82174,0.589551,0.433837,0.353598,0.182118,0.919028,0.848378,0.590559,0.638834
2088,0.244357,0.216235,0.53926,0.515375,0.393823,0.334684,0.474512,0.484513,0.498129,0.482104,0.0208494,0.0291152,0.449421,0.419146,0.823654,0.822824,0.321042,0.198433,0.168138,0.247722,-0.977475,-0.549912,-1.2593,-1.03814,-0.508085,-0.429445,-0.177323,-0.359022,-0.492439,-0.45331,-0.300601,-0.227004,-0.359459,-0.520057,-0.87588,-1.0497,0.708665,0.571559,1.71051,1.76619
2089,0.811173,0.782778,0.304096,0.280872,0.527405,0.433222,0.930889,0.942198,0.113547,0.098416,0.122675,0.128338,0.407737,0.375782,0.955289,0.953846,0.407422,0.288637,0.823044,0.902268,0.256773,0.680068,-1.51151,-1.20017,-0.239224,-0.166979,0.994289,0.880972,1.26857,1.31418,-1.49694,-1.42844,-1.61991,-1.783,0.501314,0.322592,0.358632,0.29474,-0.276696,-0.220661
2090,0.381637,0.352016,0.682996,0.660609,0.727606,0.53176,0.691063,0.801485,0.233552,0.217811,0.704952,0.70919,0.0317367,-0.000180906,0.463094,0.462768,0.421449,0.378841,0.304955,0.382007,-0.695622,-0.278832,0.413644,0.730657,-0.938685,-0.859421,0.968063,0.929168,2.65976,2.70025,-0.835049,-0.857509,0.493932,0.326201,-0.232625,-0.405952,1.02967,0.973843,0.676078,0.73885
2091,0.20057,0.169062,0.823763,0.798951,0.691047,0.630298,0.648707,0.660771,0.639733,0.625771,0.015694,0.0190912,0.0454292,0.0127676,0.567696,0.569105,0.500221,0.469045,0.802208,0.880638,-0.427187,-0.0129491,-0.660093,-0.343435,-0.649873,-0.567349,1.08938,0.977364,0.236344,0.274142,-0.351739,-0.286576,-0.320009,-0.433262,1.79225,1.61873,0.593539,0.533938,-0.621212,-0.556506
2092,0.931441,0.901684,0.642372,0.619053,0.66712,0.606521,0.839199,0.851349,0.115383,0.102757,0.567971,0.505469,0.835408,0.80305,0.0930957,0.0935995,0.910877,0.879308,0.692645,0.770275,0.885508,1.29611,-1.45593,-1.13811,0.683061,0.765726,-1.15105,-1.2685,-1.15477,-1.11876,2.36619,2.43567,-1.02882,-1.19272,-2.44204,-2.61555,1.04983,0.992442,-0.0330987,0.0241621
2093,0.979397,0.951932,0.157656,0.135763,0.159088,0.0981331,0.745744,0.758377,0.380505,0.369069,0.98845,0.991848,0.443739,0.411713,0.335375,0.25628,0.11182,0.0825001,0.876453,0.9526,-0.379668,0.0305809,0.49353,0.805595,-0.0163218,0.0732835,-0.531734,-0.64646,0.233306,0.267307,-0.498886,-0.430335,0.567334,0.409548,0.845099,0.671585,-0.745938,-0.79771,1.23226,1.29023
2094,0.482806,0.456538,0.441827,0.422207,0.0498394,-0.0133997,0.179364,0.190193,0.975388,0.963856,0.415141,0.417484,0.693879,0.5919,0.416827,0.418961,0.382885,0.355103,0.307865,0.381426,-0.344363,0.164207,0.248591,0.56169,0.445036,0.532158,-1.05703,-1.17456,0.447349,0.457467,0.804498,0.870318,1.69791,1.54744,-0.0504578,-0.224576,0.0355211,-0.0118244,-0.7448,-0.683289
2095,0.552303,0.540878,0.34723,0.328242,0.306148,0.277194,0.906311,0.918161,0.204565,0.195057,0.477984,0.479036,0.805479,0.772086,0.021532,0.0224548,0.581746,0.627707,0.324762,0.396773,-0.113625,0.297834,1.94529,2.25931,-0.440649,-0.347011,-0.502469,-0.613021,0.620468,0.647628,0.0566422,0.128249,-0.297904,-0.456111,-1.41197,-1.58065,-0.160021,-0.204722,-0.900892,-0.842376
2096,0.654077,0.625218,0.522065,0.46277,0.632635,0.567789,0.923056,0.936078,0.134596,0.124417,0.194832,0.196284,0.0724247,0.0386373,0.550154,0.54933,0.929049,0.90031,0.0295674,0.101366,0.616105,1.0235,-0.601741,-0.280001,1.40652,1.49967,0.726652,0.614074,0.32146,0.34293,0.331367,0.402576,-1.45435,-1.60983,-0.760306,-0.927426,0.470376,0.426596,1.81996,1.87256
2097,0.151073,0.124089,0.644076,0.597298,0.614878,0.672595,0.567999,0.567088,0.847527,0.836364,0.318453,0.40701,0.998591,0.966228,0.0611894,0.0582528,0.977509,0.949377,0.571614,0.645497,0.820708,1.22677,-1.66844,-1.35409,-0.766767,-0.675022,0.264697,0.146056,0.645293,0.670661,-0.144853,-0.0703167,0.73476,0.578241,-0.514875,-0.721531,0.875129,0.839021,0.0857153,0.134497
2098,0.880278,0.850581,0.751925,0.731826,0.786886,0.777402,0.186921,0.198099,0.983643,0.971242,0.624196,0.617737,0.441961,0.489119,0.257565,0.276805,0.0316346,0.00395072,0.639754,0.810899,-0.00833576,0.389631,-1.12505,-0.815162,0.320813,0.357816,0.0984489,-0.0274399,0.975445,0.998392,-0.621707,-0.543209,0.497271,0.328055,-0.35483,-0.515636,-1.09998,-1.14314,-2.68193,-2.63565
2099,0.99159,0.96129,0.553982,0.532363,0.94703,0.882208,0.286077,0.297321,0.0217076,0.00976315,0.825279,0.828463,0.0444672,0.012011,0.46621,0.495357,0.122303,0.0921239,0.90472,0.976302,-1.17676,-0.782839,-0.865306,-0.551944,1.29772,1.39065,1.18202,1.05912,1.09266,1.11009,0.273316,0.345142,0.241072,0.0778704,-1.79544,-1.96269,-0.646493,-0.684634,0.713624,0.764524
2100,0.525457,0.495469,0.959475,0.938037,0.822532,0.73889,0.128923,0.224215,0.129993,0.118781,0.136178,0.138364,0.65268,0.618769,0.716846,0.713909,0.876684,0.844785,0.792713,0.865939,-0.611399,-0.225844,-0.113876,0.202561,-0.200911,-0.105867,0.404092,0.282743,0.792719,0.805388,0.33176,0.405922,-3.61656,-3.77402,0.0761176,-0.0954189,1.51507,1.47826,0.0992787,0.152024
2101,0.782394,0.75191,0.196926,0.176637,0.658762,0.595571,0.13965,0.151109,0.725551,0.713568,0.643654,0.645974,0.0763084,0.0416962,0.549703,0.546059,0.204219,0.173907,0.333328,0.40508,1.47562,1.857,-0.511017,-0.193213,0.250361,0.339459,-0.137643,-0.260432,-1.52253,-1.51665,-0.162054,-0.0872777,-1.1315,-1.29753,-0.677136,-0.853396,0.849008,0.807308,0.577777,0.624941
2102,0.0975062,0.0651835,0.700995,0.679449,0.867643,0.805855,0.698731,0.708571,0.538485,0.526573,0.711875,0.735934,0.113823,0.0801111,0.0459552,0.0447913,0.246976,0.217379,0.572954,0.636554,-0.24721,0.130632,0.512385,0.925928,0.0634589,0.157611,1.01058,0.889348,-0.324475,-0.314317,0.508212,0.587668,0.28886,0.120918,0.0331317,-0.138791,-0.387453,-0.427407,1.40906,1.46224
2103,0.208892,0.0859803,0.16955,0.147375,0.120398,0.059935,0.0706942,0.0808952,0.952872,0.939196,0.824437,0.825895,0.42289,0.387064,0.475543,0.47644,0.518658,0.488354,0.7949,0.868028,0.859555,1.23814,1.72939,2.04507,-1.55052,-1.46355,0.572685,0.452083,0.298673,0.302798,-0.391341,-0.245668,-0.196083,-0.370615,1.47772,1.30872,-1.95269,-1.99232,1.40498,1.45486
2104,0.246382,0.106777,0.214074,0.190783,0.439951,0.337359,0.956479,0.96701,0.615967,0.601987,0.180455,0.180553,0.185975,0.150748,0.158904,0.159947,0.994016,0.963802,0.645526,0.717668,0.710469,1.09106,0.623973,0.940608,1.67541,1.76467,0.371765,0.24935,1.95443,1.96218,-1.15342,-1.079,1.24177,1.0618,3.26784,3.09787,-0.0977868,-0.138561,-0.225151,-0.177511
2105,0.16041,0.127574,0.540157,0.516941,0.66518,0.614782,0.806501,0.814888,0.482912,0.470363,0.134715,0.133364,0.152347,0.116694,0.261755,0.261493,0.994213,0.963854,0.706047,0.812865,-0.254734,0.13216,-1.65532,-1.34139,-0.388946,-0.297976,0.964367,0.841467,1.34807,1.35156,-0.397143,-0.329422,-0.976657,-1.15903,-0.114739,-0.288779,0.282231,0.243422,-0.986637,-0.940316
2106,0.947495,0.913001,0.600826,0.576612,0.951402,0.892206,0.406194,0.414392,0.784335,0.773128,0.411651,0.411849,0.477159,0.346726,0.125282,0.125113,0.615172,0.567979,0.837632,0.908062,1.13047,1.52089,-0.2101,0.106806,0.693616,0.791459,0.173206,0.0506646,-0.0362906,-0.0276928,-0.067763,0.00510611,1.02525,0.849299,0.963396,0.792878,-1.33195,-1.36837,3.03129,3.07761
2107,0.93944,0.903976,0.243912,0.283236,0.949992,0.888474,0.00634729,0.0138949,0.50727,0.496134,0.956896,0.957935,0.61287,0.576757,0.367728,0.364951,0.201744,0.172103,0.45823,0.527656,0.380278,0.778757,0.680364,0.998556,-0.312321,-0.212219,-0.32824,-0.446958,0.991792,1.00577,-1.09324,-1.01335,-1.22922,-1.40871,-1.29467,-1.45809,-0.618676,-0.658625,-0.0839185,-0.0455001
2108,0.702375,0.665511,0.0151623,-0.0101408,0.0668467,0.00261799,0.471154,0.476428,0.945535,0.933891,0.868161,0.812094,0.539452,0.592641,0.281076,0.27914,0.358419,0.327072,0.720672,0.790685,-0.575715,-0.180143,0.964949,1.38066,-0.0190295,0.0798532,0.0819132,-0.0379806,-0.392201,-0.373476,0.715179,0.796923,1.45127,1.27844,-0.144421,-0.300259,0.970442,0.925848,0.502159,0.488851
2109,0.0330282,-0.00626748,0.583675,0.556342,0.688809,0.62595,0.0599583,0.0641081,0.421116,0.410877,0.662617,0.666254,0.644144,0.608525,0.40398,0.351783,0.785578,0.751757,0.0283795,0.0981826,0.428473,0.822062,1.44633,1.76277,-0.502305,-0.409043,-1.46357,-1.58438,0.167299,0.181265,-0.344369,-0.287342,1.27728,1.11158,1.60637,1.44418,0.192696,0.146806,0.984058,1.0232
2110,0.726908,0.689399,0.52399,0.497152,0.911345,0.846346,0.886286,0.890982,0.539476,0.578154,0.915599,0.919692,0.188538,0.152622,0.427549,0.424426,0.051481,0.0154356,0.937136,1.00677,0.426305,0.852354,0.400083,0.72075,-0.617795,-0.529,0.0312508,-0.0907393,0.155642,0.170837,-1.45335,-1.37161,-0.304931,-0.468634,2.02353,1.86739,-1.16803,-1.21347,1.36873,1.40423
2111,0.435416,0.370159,0.879029,0.852678,0.616526,0.552376,0.901893,0.839726,0.735285,0.745431,0.280808,0.284317,0.520732,0.485051,0.146613,0.142848,0.234547,0.196781,0.0705179,0.139121,0.488649,0.882647,-0.0741278,0.248948,0.308536,0.392414,-1.30269,-1.42338,-0.18802,-0.103336,-0.269974,-0.193075,-1.21311,-1.37565,0.028357,-0.124473,0.247507,0.201483,0.322992,0.355481
2112,0.0875512,0.0509185,0.252836,0.227126,0.702183,0.517883,0.783236,0.788471,0.923697,0.912707,0.986232,0.990841,0.0170891,-0.0212676,0.79254,0.787131,0.145653,0.106516,0.458315,0.528124,0.120255,0.508906,0.492005,0.819093,0.787549,0.867331,0.34394,0.209484,-0.388759,-0.377508,-0.117646,-0.0425389,-0.388592,-0.548116,0.371206,0.221234,-0.768208,-0.814949,0.526671,0.558164
2113,0.953985,0.917419,0.984874,0.95872,0.606111,0.48339,0.145665,0.151214,0.252235,0.243004,0.535257,0.555449,0.358137,0.328772,0.917843,0.839976,0.712134,0.671916,0.257711,0.327385,-1.4541,-1.06309,-0.625775,-0.30087,-1.25954,-1.17909,1.96305,1.84235,-0.124053,-0.11199,1.22612,1.30377,1.12033,0.960036,0.0879333,-0.0597246,-0.0553496,-0.105204,0.0806854,0.112313
2114,0.801219,0.764828,0.136698,0.113531,0.513804,0.448897,0.894106,0.899676,0.324536,0.26552,0.115449,0.120057,0.7162,0.678811,0.895946,0.892822,0.0325616,-0.00802525,0.625168,0.692575,-0.0927143,0.23066,-1.16962,-0.898648,-0.781926,-0.704171,1.47564,1.36119,-0.191927,-0.187423,-1.08788,-1.01593,-0.607582,-0.75948,0.35812,0.211957,-0.463781,-0.513032,0.293982,0.328562
2115,0.982149,0.945353,0.408784,0.384566,0.899971,0.835904,0.776793,0.767585,0.295974,0.288035,0.770227,0.776556,0.0853391,0.0467332,0.113626,0.111281,0.923311,0.880464,0.446642,0.586078,1.1404,1.52441,-1.81599,-1.49643,-0.801989,-0.718917,-1.55195,-1.66895,-1.14504,-1.1355,-0.967135,-0.893414,0.577141,0.425286,-1.29528,-1.43702,-2.63847,-2.68652,3.21839,3.25679
2116,0.379801,0.344183,0.129258,0.104543,0.197779,0.131613,0.628297,0.635495,0.596968,0.5908,0.271779,0.276488,0.112957,0.0745447,0.970131,0.966255,0.528904,0.484588,0.410089,0.47958,0.306762,0.68727,0.804601,1.12577,-1.48027,-1.39741,0.63984,0.519466,-2.65467,-2.65092,-2.00007,-1.92625,0.293878,0.135713,0.268444,0.119426,-0.870717,-0.952249,-0.101366,-0.0554853
2117,0.908002,0.870989,0.509588,0.48428,0.204805,0.0856557,0.152733,0.158644,0.180876,0.176729,0.765534,0.769114,0.845715,0.80911,0.0143042,0.0121737,0.132279,0.0887127,0.511728,0.598309,0.618621,1.0005,-1.68367,-1.36437,-0.246444,-0.231346,0.351814,0.236058,-0.122572,-0.113973,-1.91812,-1.85062,0.852331,0.689863,-0.389615,-0.531509,0.827906,0.782022,-0.355361,-0.304775
2118,0.995481,0.957051,0.270033,0.242959,0.107127,0.0396986,0.376509,0.383613,0.956889,0.950899,0.335139,0.338394,0.739987,0.704342,0.170795,0.0695087,0.954304,0.911543,0.648418,0.717038,-1.04825,-0.664011,-0.375471,-0.0547084,0.852234,0.934719,0.0689273,-0.0473495,-0.036573,-0.0317868,0.138858,0.210389,-1.68099,-1.83807,-1.36812,-1.50383,0.0814695,0.0317938,2.38322,2.43605
2119,0.555297,0.570056,0.331581,0.307032,0.480999,0.412485,0.0765041,0.0860293,0.321578,0.316002,0.255017,0.260166,0.395942,0.379349,0.128375,0.126844,0.405379,0.362247,0.423407,0.491076,1.07579,1.46331,-0.574707,-0.252281,0.391835,0.477185,0.366525,0.348743,-0.75729,-0.746412,1.46704,1.54276,-1.52942,-1.68503,-0.109904,-0.241051,-1.81478,-1.87179,-0.11858,-0.0669201
2120,0.221584,0.18306,0.930668,0.907051,0.047952,-0.0228441,0.454,0.512969,0.868292,0.864714,0.792876,0.797488,0.0895205,0.0543569,0.942504,0.940753,0.243557,0.199454,0.642544,0.708456,-1.79897,-1.40863,0.918815,1.24227,-0.443646,-0.356484,0.861113,0.744836,-1.81022,-1.80027,0.0842838,0.153607,-0.123249,-0.281437,-0.594465,-0.721281,0.171745,0.109517,-0.130389,-0.0742992
2121,0.410441,0.37344,0.468453,0.544386,0.500153,0.415904,0.929812,0.939908,0.848683,0.84575,0.370301,0.376174,0.286975,0.173499,0.409355,0.409704,0.832929,0.790093,0.0834944,0.147385,0.38442,0.780508,-0.183758,0.137806,1.8756,1.96845,-0.713519,-0.833554,0.0990113,0.107102,-0.392021,-0.422024,0.298831,0.133847,0.790409,0.667148,-1.33079,-1.39417,-1.95287,-1.90191
2122,0.995981,0.95907,0.205326,0.18172,0.925526,0.854652,0.129743,0.138977,0.576587,0.586293,0.869158,0.873655,0.329371,0.292642,0.181589,0.182743,0.908845,0.868105,0.770615,0.835961,-0.281315,0.115614,-0.50106,-0.180395,0.450538,0.547341,0.418979,0.301722,-0.498191,-0.471467,-1.06066,-0.997655,-0.922292,-1.08368,1.54271,1.41123,-0.769823,-0.836677,-2.30613,-2.25906
2123,0.0530516,0.0169769,0.870693,0.84593,0.495873,0.424741,0.00855051,0.0168447,0.196102,0.326835,0.337583,0.343736,0.0967427,0.0613168,0.675433,0.674028,0.0118273,-0.0261568,0.97215,1.03795,0.814524,1.20707,0.0354389,0.358536,-0.202695,-0.0987878,0.73111,0.619693,-1.06136,-1.05004,0.543507,0.611279,0.55804,0.395788,0.0283381,-0.0967653,-0.208683,-0.279189,0.660549,0.705353
2124,0.225579,0.187827,0.327087,0.304214,0.609228,0.536535,0.309672,0.325039,0.0703611,0.067378,0.213589,0.220532,0.0844667,0.0432144,0.194899,0.192948,0.468016,0.453795,0.266471,0.330083,0.424027,0.818945,-0.604302,-0.281029,1.39583,1.49666,-0.948743,-1.05671,0.00791598,0.0133701,-2.11257,-2.04372,-0.569469,-0.729662,0.740271,0.61784,-0.238624,-0.298071,-0.833538,-0.78699
2125,0.874764,0.839371,0.0535515,0.0288673,0.133832,0.0615592,0.62494,0.633234,0.742042,0.738269,0.571163,0.580625,0.144542,0.025112,0.12797,0.127194,0.971165,0.933747,0.783474,0.849672,1.22854,1.62106,0.653307,0.982402,-0.632192,-0.53174,-0.261049,-0.372166,-0.369703,-0.368952,0.0396284,0.111127,0.777405,0.611984,2.24901,2.12659,-0.251352,-0.316952,-0.177457,-0.129937
2126,0.801883,0.768083,0.38659,0.323221,0.849259,0.777546,0.628806,0.637043,0.141379,0.138913,0.354844,0.362102,0.0417106,0.00700954,0.907129,0.904988,0.703282,0.690054,0.378172,0.443281,0.611092,0.999539,-1.82001,-1.4924,0.9519,1.04866,1.36544,1.24947,-1.90949,-1.91232,0.352137,0.431416,-0.0122223,-0.170387,-1.68069,-1.80018,1.11928,1.05113,-1.27978,-1.2275
2127,0.14901,0.116483,0.640723,0.617575,0.810103,0.731589,0.992366,1.00097,0.857458,0.856329,0.511985,0.521572,0.492136,0.458259,0.0526219,0.0496514,0.459802,0.446362,0.770779,0.837846,-0.331793,0.0576275,-1.73292,-1.3999,1.58042,1.67689,1.5036,1.38348,-0.170175,-0.174015,0.435518,0.52282,-0.109905,-0.239906,0.888555,0.766364,-0.436131,-0.498756,0.812611,0.870311
2128,0.485936,0.516183,0.752713,0.730868,0.756822,0.685632,0.273547,0.283903,0.736812,0.734482,0.166038,0.174389,0.393695,0.358601,0.238608,0.236618,0.239577,0.202669,0.8098,0.874564,0.322893,0.708051,-0.605472,-0.234249,-0.688503,-0.595423,0.332982,0.218237,-0.26583,-0.266115,-0.65678,-0.573099,-0.154455,-0.309424,-0.985728,-1.10085,0.397332,0.33556,-0.304454,-0.243821
2129,0.947178,0.915882,0.434526,0.410515,0.0168037,-0.0551267,0.613136,0.622485,0.234578,0.231245,0.344307,0.372036,0.924455,0.889754,0.0363587,0.0345491,0.633257,0.598546,0.191745,0.253864,-1.77912,-1.392,0.597389,0.931402,-1.24745,-1.14625,-0.527872,-0.637465,0.591197,0.598021,-0.551213,-0.444597,1.61406,1.46173,-0.385172,-0.494386,0.0446606,-0.0123769,0.605205,0.668911
2130,0.401285,0.369532,0.599604,0.574249,0.0870545,0.0159923,0.101279,0.109574,0.961118,0.959242,0.561251,0.569683,0.815814,0.704065,0.770678,0.767096,0.718956,0.626059,0.696697,0.757821,-0.847454,-0.4548,-1.60877,-1.27327,0.441762,0.542678,0.343918,0.234504,-0.523765,-0.516589,-0.401192,-0.316095,-0.764271,-0.922805,-0.452579,-0.562428,-1.26029,-1.31039,-1.24328,-1.18007
2131,0.375099,0.418721,0.349866,0.323682,0.989986,0.918643,0.0339371,0.0426337,0.55416,0.588454,0.277397,0.28693,0.552033,0.518375,0.645653,0.640347,0.720607,0.653573,0.420086,0.482162,0.100003,0.4824,-0.89939,-0.565439,0.215863,0.313864,0.799589,0.690226,0.298661,0.300692,1.22504,1.30834,-2.45101,-2.61186,-1.43987,-1.54875,-1.91769,-1.96471,1.28986,1.35085
2132,0.394403,0.46791,0.761596,0.733766,0.0814466,0.0117328,0.764951,0.775109,0.22009,0.217665,0.821874,0.833016,0.205235,0.173152,0.783721,0.775905,0.715798,0.681087,0.881376,0.941177,0.455763,0.841841,0.956413,1.28679,-0.831758,-0.736664,-0.758514,-0.872904,-0.859694,-0.860397,1.11166,1.20096,-0.240207,-0.409334,0.210818,0.100922,-0.54219,-0.596623,0.132406,0.192698
2133,0.488059,0.517099,0.626929,0.599924,0.87497,0.80601,0.98059,0.991414,0.847239,0.84683,0.16533,0.178283,0.771244,0.739661,0.669652,0.659357,0.512304,0.478281,0.526963,0.585391,-0.491693,-0.100071,-0.579097,-0.255573,-0.787425,-0.691879,0.0357063,-0.0784866,-0.049523,-0.0431165,0.165722,0.257885,-0.55546,-0.730365,0.61866,0.508883,0.272768,0.135043,1.06755,1.12076
2134,0.598041,0.566288,0.773748,0.748929,0.422912,0.352017,0.293589,0.304329,0.216845,0.217014,0.300599,0.259438,0.284661,0.253358,0.0744653,0.0635386,0.107473,0.0731721,0.460501,0.517058,-1.08139,-0.689471,-1.01939,-0.696604,-0.207939,-0.10845,-0.494582,-0.606582,0.087724,0.0986233,-0.221782,-0.126337,1.09981,0.918029,-0.316146,-0.432144,0.927772,0.86671,1.22333,1.27842
2135,0.179254,0.145969,0.215814,0.191947,0.799981,0.729415,0.864167,0.876777,0.600455,0.600427,0.328444,0.340593,0.655057,0.625016,0.942966,0.929799,0.190347,0.155886,0.993551,1.05195,-0.373792,0.019824,1.31645,1.63636,-0.725483,-0.628664,-1.27277,-1.38296,1.88999,1.89814,1.27436,1.37301,-0.511914,-0.691917,-0.634706,-0.745476,-0.314411,-0.368005,0.164656,0.213552
2136,0.804813,0.7715,0.47617,0.452817,0.109645,0.0404643,0.0568409,0.0707603,0.378107,0.378269,0.80781,0.817908,0.562795,0.629402,0.576687,0.650476,0.717683,0.681104,0.17235,0.231264,-0.110014,0.285706,-0.573304,-0.253505,0.0563307,0.154043,-0.221879,-0.326411,0.417585,0.429469,-1.92118,-1.82701,0.308455,0.119751,-0.235966,-0.35269,1.21557,1.1547,0.621178,0.670985
2137,0.772304,0.740217,0.390989,0.298528,0.588714,0.518647,0.876681,0.892453,0.492607,0.492391,0.125192,0.137387,0.66368,0.633789,0.383366,0.371152,0.910858,0.756799,0.731225,0.790137,0.598677,0.995001,0.584522,0.899533,1.49769,1.59454,0.328896,0.221643,1.44546,1.46294,2.12649,2.22066,-1.65454,-1.83594,-0.109347,-0.22077,0.693543,0.679418,2.8067,2.8512
2138,0.39264,0.360481,0.166321,0.144239,0.614454,0.614848,0.698774,0.777427,0.953458,0.955555,0.976361,0.988624,0.0200761,-0.00808605,0.639576,0.578368,0.928529,0.832494,0.391789,0.448998,-0.896479,-0.500053,0.384288,0.70196,0.00935401,0.113203,-0.966406,-1.0811,-0.385482,-0.361369,-0.271905,-0.175755,-0.696836,-0.883052,-1.19381,-1.30015,0.263381,0.204134,0.0729673,0.113866
2139,0.367594,0.335198,0.810896,0.788954,0.778304,0.71105,0.715934,0.662401,0.17882,0.180585,0.221574,0.234189,0.97403,0.946639,0.799104,0.785585,0.942703,0.908188,0.899727,0.9575,-0.259618,0.231021,-0.690632,-0.372131,0.498566,0.60242,1.4784,1.3619,-0.115769,-0.0958507,-1.25669,-1.16397,-0.00882804,-0.191535,0.0548335,-0.0529281,-2.06371,-2.1149,0.100681,0.136337
2140,0.141616,0.11164,0.699338,0.675733,0.581747,0.514179,0.530113,0.547375,0.897825,0.898001,0.00915728,0.0204076,0.152822,0.124248,0.170475,0.159206,0.00353835,-0.0331243,0.875333,0.933549,0.568316,0.962096,0.789587,1.10758,-0.321232,-0.214931,-2.79461,-2.91161,-0.572425,-0.554537,0.0256414,0.121726,0.295258,0.0342891,-0.951576,-1.05467,2.4836,2.43727,-0.486388,-0.445137
2141,0.942099,0.913169,0.225155,0.20209,0.661095,0.596109,0.416578,0.432349,0.476797,0.478962,0.862219,0.871645,0.910204,0.884096,0.229701,0.219855,0.117784,0.105755,0.414962,0.47269,-0.985337,-0.592935,-2.65386,-2.33435,-0.491634,-0.381345,0.972556,0.858505,-0.387932,-0.366423,0.300448,0.396054,0.445388,0.260113,-0.963011,-1.06409,1.41671,1.37582,-0.0527303,-0.0172262
2142,0.625419,0.598175,0.452456,0.489284,0.407962,0.34259,0.150752,0.164422,0.934979,0.936583,0.0476899,0.058943,0.12385,0.0984788,0.868024,0.859533,0.253178,0.244634,0.656307,0.715783,0.999745,1.39552,-1.14168,-0.823517,1.91451,2.02323,-0.755725,-0.866118,0.184621,0.180588,-2.0195,-1.92364,-0.550629,-0.741691,-0.218091,-0.302775,0.734545,0.690677,-1.32923,-1.29839
2143,0.926625,0.900038,0.796877,0.776478,0.528499,0.463737,0.456328,0.506206,0.106565,0.108686,0.798408,0.810832,0.687956,0.664988,0.790609,0.782827,0.420069,0.383513,0.263323,0.320506,-1.46382,-1.06865,-0.710444,-0.39295,-0.407803,-0.294827,1.70677,1.59594,0.702857,0.727599,0.701163,0.798603,-0.474332,-0.663681,0.564813,0.458542,0.452805,0.40665,-0.208119,-0.171033
2144,0.0870202,0.0631417,0.012838,-0.00543508,0.406556,0.329126,0.837339,0.847989,0.163754,0.0790486,0.405523,0.418698,0.980952,0.956145,0.14516,0.135447,0.888683,0.854064,0.676717,0.734286,0.809358,1.19811,-1.46421,-1.14135,0.5696,0.688492,0.537398,0.4307,-0.000380606,0.0263932,0.560127,0.659276,0.627675,0.383207,-1.96861,-2.0826,0.540487,0.469347,1.12665,1.17008
2145,0.764297,0.738409,0.397216,0.379331,0.245488,0.194515,0.383932,0.396122,0.0496777,0.049411,0.223052,0.321365,0.0606318,0.0346182,0.681884,0.673219,0.377916,0.344365,0.0300573,0.0881263,1.09099,1.48104,-0.655452,-0.32632,-1.28424,-1.16855,0.308568,0.196582,-1.43844,-1.41103,-0.15932,-0.0671522,1.61363,1.4301,0.824593,0.716467,0.580687,0.532043,2.06987,2.115
2146,0.619011,0.595401,0.232698,0.255507,0.123597,0.0599031,0.506375,0.520992,0.761605,0.761358,0.209015,0.224032,0.860868,0.83436,0.503314,0.429286,0.871059,0.840108,0.060101,0.117062,-0.449326,-0.0597246,-1.67864,-1.35412,1.06668,1.18798,-0.713004,-0.827967,0.6768,0.706988,-0.636964,-0.606107,2.02999,1.84538,-0.145822,-0.255853,0.0410537,-0.0147864,-0.704383,-0.655146
2147,0.124938,0.100007,0.231329,0.131682,0.692799,0.627986,0.264422,0.367993,0.419009,0.417783,0.563887,0.492544,0.271634,0.242833,0.1953,0.185354,0.083309,0.0503021,0.0899426,0.145998,-0.552986,-0.161561,1.14622,1.47236,0.00638801,0.122124,0.137333,0.0281183,-0.971969,-0.945529,-1.24164,-1.14506,-0.901091,-1.09087,-0.331062,-0.445509,-0.120961,-0.177061,-1.9031,-1.85922
2148,0.564537,0.538023,0.0267998,0.00785789,0.936975,0.873308,0.198358,0.214994,0.324404,0.304994,0.747158,0.761056,0.594565,0.563042,0.794317,0.783644,0.0525679,0.0533198,0.851268,0.905347,-1.0753,-0.689474,0.526753,0.951906,-1.83118,-1.71864,0.0463293,-0.0676716,0.414479,0.440535,1.13612,1.23188,-2.09015,-2.27799,-1.17526,-1.29377,-1.3326,-1.39392,-1.42937,-1.3863
2149,0.333646,0.36532,0.566186,0.545093,0.578966,0.513686,0.23168,0.274547,0.192458,0.192206,0.724832,0.73788,0.913088,0.883251,0.843717,0.833659,0.0913256,0.0563375,0.913988,0.934283,-0.661138,-0.269623,0.100714,0.431453,-1.61377,-1.50394,0.183739,0.0663432,0.0644312,0.0894524,-0.58924,-0.490419,0.181447,-0.00954789,0.214268,0.0946559,1.24414,1.17499,1.94438,1.98275
2150,0.220219,0.192618,0.859179,0.835961,0.730356,0.665284,0.318546,0.334099,0.806381,0.806304,0.354502,0.403814,0.258152,0.225803,0.291234,0.28268,0.418108,0.382434,0.908802,0.963218,-0.0067932,0.3808,0.630589,0.955488,0.379713,0.483699,-0.0647109,-0.185379,-0.0729133,-0.0480421,0.631613,0.733855,-1.12818,-1.32233,-0.175749,-0.292787,0.612911,0.551929,-0.348082,-0.301913
2151,0.236101,0.20781,0.687106,0.649426,0.0454049,-0.0190128,0.700156,0.717203,0.118534,0.11642,0.0542038,0.0697473,0.680654,0.647573,0.337126,0.293374,0.22737,0.189652,0.295359,0.348016,-1.89345,-1.50312,-1.38501,-1.05767,1.73296,1.83303,-0.0366834,-0.159478,0.0263617,0.0103038,-1.25551,-1.15932,0.546785,0.356548,1.72428,1.60539,0.809521,0.744491,0.648411,0.687729
2152,0.799586,0.769062,0.445831,0.462892,0.188931,0.0874799,0.829789,0.846732,0.275584,0.271427,0.599456,0.615833,0.609701,0.578555,0.313622,0.304068,0.879197,0.843305,0.899771,0.951799,0.625966,1.01732,0.0399616,0.374689,-0.574874,-0.472767,-0.527736,-0.657101,0.111452,0.0686496,-1.66467,-1.57565,0.399623,0.287029,-0.0384333,-0.149235,-1.245,-1.31637,-0.715922,-0.669374
2153,0.667558,0.635783,0.228664,0.276357,0.365971,0.193973,0.451525,0.469115,0.852084,0.84572,0.53497,0.553887,0.755439,0.724344,0.655356,0.610618,0.297571,0.263883,0.318122,0.371588,-0.22564,0.165822,-0.0700155,0.269218,0.335921,0.434354,0.17256,0.0440355,0.102124,0.126995,-1.62932,-1.54538,0.417333,0.21751,2.00463,1.89068,0.231114,0.15952,0.0394042,0.0790634
2154,0.758303,0.726831,0.113042,0.0898231,0.364883,0.300465,0.286783,0.306251,0.986058,0.980598,0.248207,0.264975,0.670465,0.639983,0.924259,0.917167,0.200571,0.264158,0.475075,0.528849,-0.240204,0.156542,-1.63804,-1.30306,0.828317,0.923571,-0.460379,-0.59197,1.36682,1.39214,-0.175704,-0.0935551,-0.29402,-0.487673,-0.576255,-0.684835,0.311421,0.291256,-0.714359,-0.667564
2155,0.208468,0.175695,0.56747,0.544179,0.0351306,-0.0292803,0.621485,0.596088,0.31822,0.310895,0.377862,0.394673,0.857775,0.778898,0.244187,0.234992,0.29737,0.264433,0.277822,0.3288,0.550975,0.943418,-0.502586,-0.249784,0.787993,0.879217,-1.92062,-2.04831,-0.825687,-0.803702,-0.646619,-0.558065,-0.471265,-0.599701,-1.38883,-1.50251,0.496333,0.422991,0.107736,0.15539
2156,0.0555241,0.0231038,0.219456,0.194461,0.352105,0.287432,0.865627,0.885926,0.0545423,0.0485909,0.865387,0.881816,0.946388,0.917814,0.961944,0.952633,0.725442,0.69489,0.0754512,0.12875,-1.05462,-0.6594,0.474744,0.803494,-0.574948,-0.480043,1.59384,1.46227,0.285396,0.304418,0.739133,0.834301,-0.525675,-0.711729,1.48363,1.36965,0.244299,0.0898531,-2.37807,-2.33364
2157,0.238571,0.264715,0.229137,0.203505,0.0657625,0.00269291,0.30955,0.327686,0.365355,0.340102,0.167945,0.185743,0.588527,0.562667,0.577814,0.571363,0.717956,0.679609,0.40884,0.462375,0.399316,0.792482,0.467098,0.788697,-0.983337,-0.892541,-2.18938,-2.32581,0.709095,0.723035,-1.16053,-1.05888,0.774932,0.581518,0.215352,0.00204285,-0.177222,-0.243285,-0.337626,-0.298304
2158,0.494976,0.506327,0.0147418,-0.0109498,0.410454,0.260098,0.93522,0.954854,0.646664,0.631613,0.132018,0.148415,0.64725,0.594954,0.983762,0.977808,0.820132,0.664329,0.0718362,0.125944,1.29417,1.6876,0.0503481,0.378216,-0.00791931,0.0754315,0.21024,0.0716341,0.56594,0.58554,-0.620244,-0.522836,-0.375005,-0.572204,-1.24933,-1.36557,-1.36954,-1.43178,-0.773792,-0.729695
2159,0.781999,0.747938,0.65186,0.624344,0.674201,0.517503,0.542341,0.56308,0.929075,0.923124,0.949851,0.967454,0.651963,0.62724,0.00737776,0.000390228,0.680079,0.649048,0.226557,0.283206,1.0175,1.40647,0.551185,0.872401,0.742307,0.828607,0.104877,-0.0400855,0.00798386,0.021648,1.31488,1.40929,0.0284602,-0.173254,0.051016,-0.0724142,-0.486997,-0.550845,0.265242,0.305965
2160,0.432665,0.397877,0.153542,0.126062,0.838916,0.774907,0.371793,0.390841,0.709636,0.78592,0.339105,0.357972,0.274742,0.251277,0.599443,0.593538,0.983136,0.948999,0.818735,0.877425,-0.470862,-0.0885801,-1.88297,-1.55418,0.641489,0.821623,0.549809,0.399057,1.60039,1.62157,0.319209,0.405594,-1.2694,-1.47021,-0.401367,-0.521771,-1.18157,-1.25142,-1.18209,-1.14244
2161,0.906617,0.869768,0.262386,0.26835,0.86837,0.802194,0.64454,0.661374,0.653904,0.648716,0.354234,0.374667,0.960488,0.938798,0.944495,0.940783,0.390064,0.354767,0.235194,0.29173,0.27134,0.652694,-0.302555,0.0209952,0.728339,0.814639,2.62619,2.4781,-1.27463,-1.24746,0.65542,0.740122,-0.641936,-0.839374,-0.123913,-0.250089,0.763662,0.696694,0.143419,0.183944
2162,0.907555,0.916633,0.43742,0.410638,0.605781,0.549511,0.466242,0.483707,0.77347,0.768112,0.884236,0.906289,0.900213,0.898794,0.924732,0.932304,0.746696,0.71109,0.634854,0.599161,0.634923,1.01213,-1.79947,-1.47389,0.927117,1.01349,1.54822,1.40618,-0.0651297,-0.0451282,2.11111,2.19194,0.704176,0.502271,1.33944,1.21406,1.14967,1.07868,-0.0987237,-0.0653458
2163,0.997924,0.963498,0.87959,0.854428,0.316355,0.296829,0.895299,0.912392,0.322583,0.314722,0.319748,0.341917,0.879583,0.858791,0.926605,0.923825,0.679309,0.72556,0.847489,0.906592,-0.561872,-0.191859,1.92491,2.24748,-0.113644,0.00544574,1.83932,1.6946,0.113532,0.193597,-1.24099,-1.1688,-0.912032,-1.10767,0.0314871,-0.0341149,-1.38896,-1.45705,2.45084,2.4819
2164,0.467134,0.432281,0.00726834,-0.0190875,0.112241,0.0441464,0.933546,0.951257,0.782785,0.772343,0.309462,0.334098,0.515772,0.492489,0.125293,0.122566,0.775372,0.740029,0.50864,0.565453,1.57685,1.95053,-0.523165,-0.193964,-1.08452,-1.0026,0.162342,0.0181907,0.41882,0.432321,0.47321,0.549491,-1.42795,-1.63085,-1.15363,-1.28229,0.292541,0.224138,-2.19503,-2.16398
2165,0.799383,0.764434,0.192296,0.164373,0.207656,0.131302,0.136096,0.155709,0.0890766,0.0764993,0.915852,0.939883,0.801529,0.696349,0.101407,0.0968174,0.0684671,0.0341098,0.843884,0.899078,-0.345848,0.0212319,0.30489,0.541839,0.0801588,0.163885,-0.147538,-0.294818,-0.502711,-0.482491,-0.330071,-0.254121,1.81399,1.61769,0.308262,0.181859,-1.03709,-1.10737,-0.334022,-0.294071
2166,0.0350208,-0.00081429,0.0432448,0.0155497,0.287668,0.218457,0.00961405,0.0283194,0.441948,0.428528,0.575702,0.602247,0.923858,0.900208,0.347223,0.342374,0.0916351,0.0584537,0.784636,0.840741,1.28717,1.65808,0.952878,1.27764,-0.2485,-0.171859,-0.224106,-0.322174,0.773299,0.796437,-0.195492,-0.116837,-1.85641,-2.05515,0.419536,0.298112,0.0340007,-0.0388903,-0.00995551,0.0288046
2167,0.293181,0.354649,0.800333,0.771053,0.00973612,-0.0601255,0.226306,0.169181,0.474669,0.46049,0.90376,0.932356,0.569675,0.545062,0.0474287,0.0408105,0.745922,0.712106,0.107631,0.164655,1.03242,1.36337,-1.77616,-1.45185,-0.0751414,-0.00535697,-0.206289,-0.349531,-0.107626,-0.0888712,0.49093,0.570502,0.352008,0.14737,1.04573,0.919634,-0.0587913,-0.186902,0.806255,0.851758
2168,0.748209,0.710113,0.901111,0.869984,0.252081,0.179928,0.292893,0.310043,0.164273,0.147797,0.411006,0.482592,0.760647,0.650434,0.12932,0.121582,0.120253,0.087293,0.58896,0.643657,0.691267,1.06866,0.55654,0.881113,-0.184642,-0.111866,0.167002,0.0289008,0.929297,0.944596,0.809207,0.890791,-0.218873,-0.422262,-0.764621,-0.887085,-0.26037,-0.334913,0.112387,0.14975
2169,0.746216,0.688354,0.31514,0.283823,0.800927,0.727414,0.112603,0.128075,0.622459,0.605417,0.00320027,0.0328277,0.7782,0.755807,0.944352,0.935491,0.664471,0.63223,0.391262,0.448087,-1.07518,-0.70473,-1.05016,-0.723227,0.419145,0.485601,-0.38198,-0.514274,-0.594534,-0.586551,0.268262,0.337022,1.31046,1.10207,0.0594892,-0.066033,-0.717734,-0.790286,0.265131,0.30741
2170,0.703311,0.666595,0.0452165,0.0130709,0.920177,0.8446,0.375381,0.388903,0.378195,0.36263,0.526685,0.554321,0.505904,0.484874,0.194236,0.183784,0.373908,0.343079,0.59305,0.605426,0.587488,0.962656,1.13719,1.46412,-0.814439,-0.75069,0.337316,0.201934,0.687998,0.692377,-0.299841,-0.216748,0.833814,0.650422,0.408287,0.279674,0.323111,0.24818,-0.363383,-0.31851
2171,0.490762,0.452719,0.419831,0.387278,0.797502,0.660432,0.00713749,0.0220942,0.409279,0.453638,0.249798,0.276533,0.530548,0.558314,0.326163,0.314805,0.964472,0.933718,0.785743,0.762766,-1.96476,-1.58074,-0.436655,-0.10816,0.545685,0.613282,-0.0689059,-0.20323,0.398862,0.403967,-0.236249,-0.121257,0.411416,0.198775,0.229358,0.105902,0.381478,0.30392,-0.550039,-0.5078
2172,0.512078,0.393355,0.447498,0.415728,0.553887,0.476264,0.573046,0.589777,0.561223,0.544645,0.795775,0.822618,0.652145,0.631754,0.792211,0.781711,0.350232,0.317914,0.864795,0.920105,0.63056,1.00859,2.94173,3.27132,-0.928067,-0.828091,-1.74225,-1.87964,1.63869,1.63747,-0.114776,-0.0257666,-0.881163,-1.09818,0.320719,0.286372,-0.235117,-0.319143,1.63981,1.68825
2173,0.435566,0.333992,0.171034,0.202864,0.133233,0.0565977,0.0705269,0.0868486,0.986304,0.966985,0.811484,0.877409,0.419588,0.400429,0.895538,0.883256,0.00956007,-0.0213407,0.835567,0.890733,0.162455,0.54327,-0.376535,-0.0482209,-2.34218,-2.26946,1.63868,1.50129,-0.718357,-0.717336,-1.4881,-1.39971,1.80697,1.58898,0.589465,0.466842,0.608427,0.532391,0.377255,0.422556
2174,0.312672,0.274629,0.0211683,-0.00999929,0.253018,0.177745,0.429199,0.45978,0.8363,0.81603,0.902833,0.9322,0.866482,0.846575,0.624764,0.607728,0.892056,0.86148,0.512554,0.618502,0.828059,1.20702,1.8644,2.18809,-0.578488,-0.502374,-0.05902,-0.189419,0.361233,0.361369,-1.31779,-1.23243,-0.467615,-0.68578,-0.531865,-0.658228,0.278328,0.153508,0.89962,0.942008
2175,0.0877835,0.0510705,0.908422,0.878196,0.923983,0.847327,0.814101,0.832711,0.25764,0.237462,0.118945,0.145724,0.239413,0.220208,0.343323,0.3322,0.404201,0.371463,0.231068,0.346271,1.28495,1.65748,-0.778231,-0.46192,-0.547353,-0.47173,1.29966,1.17552,0.197324,0.26031,0.75722,0.841397,-1.87359,-2.09035,-0.224901,-0.35894,-0.141968,-0.225376,-1.36276,-1.32614
2176,0.612789,0.577877,0.70645,0.640178,0.916711,0.838796,0.370546,0.390781,0.00683909,-0.0144308,0.901335,0.928809,0.144518,0.197133,0.671204,0.658603,0.239561,0.215458,0.0188741,0.0740399,-0.902586,-0.523198,-0.0831288,0.230283,1.10923,1.18488,-2.43369,-2.55974,0.161646,0.159251,1.52867,1.60696,-0.77484,-0.985996,-1.70223,-1.83552,-0.229192,-0.308535,0.444365,0.480353
2177,0.824957,0.789206,0.43341,0.402161,0.263638,0.185402,0.913577,0.933669,0.738421,0.718321,0.999402,1.02803,0.193844,0.174058,0.0215645,0.0112237,0.0928605,0.0594527,0.949089,1.00277,0.313453,0.691087,-0.0828284,0.209771,0.919628,0.918022,-1.43366,-1.56253,2.44964,2.44571,0.014703,0.0971743,-0.716748,-0.922796,-1.18818,-1.32053,0.385623,0.307041,0.930398,0.969374
2178,0.206065,0.16849,0.748183,0.718595,0.44044,0.361724,0.313643,0.334835,0.141087,0.118964,0.0233799,0.053479,0.594038,0.575995,0.547019,0.538099,0.145412,0.113609,0.447508,0.502109,-0.207262,0.163174,-0.120635,0.189259,0.571089,0.651163,-1.11986,-1.24456,-0.798576,-0.807825,0.312448,0.399233,-0.0525424,-0.261574,0.482388,0.343949,-0.890136,-0.975726,-0.286061,-0.250323
2179,0.673403,0.635156,0.352928,0.324503,0.032045,-0.0479082,0.757474,0.778246,0.689661,0.667676,0.349456,0.418971,0.45576,0.502356,0.704943,0.695497,0.904861,0.871013,0.968495,1.0217,-0.450202,-0.072931,-0.829007,-0.511883,-0.555567,-0.477773,0.0234285,-0.0947768,-0.306458,-0.312282,0.848956,0.935273,0.240268,-0.0357504,0.744271,0.599731,0.824241,0.734628,0.297215,0.330345
2180,0.365429,0.353398,0.236968,0.259149,0.717305,0.636976,0.126974,0.14603,0.653049,0.633319,0.755652,0.784462,0.44614,0.428717,0.383118,0.373577,0.609763,0.576787,0.102176,0.154045,0.762308,1.14135,0.235908,0.551267,0.622273,0.704079,-1.12001,-1.24326,-0.415142,-0.418929,-0.743856,-0.650642,0.395709,0.190074,-0.157146,-0.296429,0.219839,0.206015,1.78914,1.8265
2181,0.110153,0.0716404,0.222451,0.193795,0.944697,0.862577,0.622428,0.643937,0.860812,0.843094,0.653548,0.619856,0.593671,0.574507,0.820912,0.810759,0.701589,0.669684,0.250212,0.289516,-0.111884,0.2748,0.67239,0.981835,-0.0619932,0.0255854,-0.00046871,-0.126098,0.164933,0.16712,-0.196865,-0.0981453,1.12503,0.911919,-0.0717363,-0.211839,-0.247827,-0.322598,1.79204,1.83408
2182,0.0790915,0.0403577,0.901937,0.873486,0.840334,0.756533,0.82493,0.845396,0.39753,0.379375,0.358753,0.455251,0.308771,0.288641,0.436117,0.424287,0.471148,0.461385,0.373356,0.424987,1.05779,1.44401,-0.098323,0.112883,-2.72396,-2.63488,0.0409648,-0.0847772,-0.40268,-0.396773,-1.40566,-1.31318,0.49698,0.283142,1.21211,1.06429,-0.761599,-0.851212,0.888473,0.936288
2183,0.703097,0.665889,0.428978,0.399843,0.327628,0.242969,0.729724,0.662452,0.606342,0.58915,0.339887,0.290645,0.49872,0.538097,0.671733,0.659248,0.285742,0.253085,0.1884,0.328094,-1.25565,-0.86295,-1.06885,-0.75607,-1.06435,-0.97827,-0.479147,-0.598234,0.534359,0.544457,1.83338,1.93197,1.77084,1.55937,-1.24814,-1.40005,1.02863,0.935757,0.855348,0.897921
2184,0.365035,0.355149,0.597403,0.588092,0.694386,0.61029,0.458555,0.479507,0.10138,0.0859125,0.097229,0.12604,0.807535,0.787552,0.0383903,0.0274206,0.967851,0.935364,0.147441,0.2312,0.183388,0.571959,-0.129206,0.18149,0.139929,0.21749,-0.0410044,-0.159091,-1.64394,-1.63567,1.02388,1.12836,-1.00385,-1.21978,0.6468,0.498122,-0.581476,-0.676035,1.24648,1.29465
2185,0.0835137,0.0444096,0.804112,0.776341,0.0456377,-0.0385113,0.944237,0.967971,0.929097,0.91378,0.655878,0.68232,0.7619,0.714792,0.0689317,0.127195,0.83692,0.802868,0.0828989,0.134306,-0.179645,0.214038,0.239706,0.550151,-1.52177,-1.44869,-0.0165667,-0.13319,1.32378,1.33413,-1.66797,-1.56553,-1.19463,-1.41559,0.779433,0.630043,-0.133191,-0.232777,0.949486,1.00065
2186,0.92957,0.891865,0.500028,0.546226,0.222361,0.13781,0.118511,0.140413,0.378728,0.456735,0.341856,0.36856,0.608142,0.642031,0.238261,0.22697,0.281292,0.248374,0.61951,0.669202,0.545922,0.939704,2.60393,2.91666,1.10189,1.17621,0.407323,0.291204,-0.254706,-0.242516,0.502615,0.606705,0.150516,-0.0739446,0.604708,0.456271,-0.838026,-0.933348,-0.618228,-0.566993
2187,0.0880791,0.0495373,0.343912,0.316112,0.747057,0.66128,0.0695791,0.09354,0.0147594,-0.000310678,0.89434,0.920245,0.591211,0.56927,0.64414,0.633415,0.45654,0.423342,0.153034,0.203245,0.489177,0.885531,-0.715634,-0.402875,1.05277,1.13185,0.140981,0.0245117,-0.382365,-0.36515,-0.72463,-0.623851,-0.742357,-0.965742,-0.958409,-1.11344,-0.302727,-0.394692,0.543947,0.592064
2188,0.298357,0.260867,0.767124,0.740557,0.574761,0.489441,0.595925,0.621201,0.832554,0.816376,0.513426,0.538759,0.000243306,-0.0222568,0.197106,0.187103,0.413482,0.378636,0.238913,0.276343,-0.468698,-0.0733693,-0.400771,-0.0929927,0.538581,0.611637,0.410616,0.297052,-1.09533,-1.07978,0.00839503,0.10919,-1.99652,-2.21467,-0.080533,-0.231451,-0.444503,-0.540895,-1.97744,-1.93149
2189,0.0717595,0.0322136,0.904233,0.878899,0.0881332,0.00387983,0.320845,0.348173,0.79773,0.735101,0.340061,0.432758,0.968154,0.943619,0.130655,0.121349,0.876962,0.843805,0.41253,0.34944,-0.163439,0.226083,1.53551,1.83783,-0.679109,-0.609917,2.68871,2.57507,0.75354,0.766987,-0.362658,-0.259778,0.0679827,-0.157753,-0.490423,-0.635209,-0.317892,-0.40787,0.766981,0.809333
2190,0.978219,0.938408,0.270132,0.243439,0.143118,0.00177054,0.454225,0.482326,0.671303,0.653825,0.301065,0.326757,0.859329,0.834389,0.521102,0.513492,0.833153,0.839739,0.372325,0.422537,0.6689,1.05734,-0.204214,0.0919189,0.675551,0.739409,0.66295,0.549924,-0.529477,-0.516945,-0.48175,-0.38507,0.104724,-0.163223,-0.171039,-0.318005,0.939125,0.846971,-0.34214,-0.304798
2191,0.69096,0.648992,0.254392,0.227848,0.0821022,-0.000338741,0.372364,0.399296,0.954635,0.935922,0.329958,0.358312,0.29902,0.272577,0.368222,0.445534,0.859999,0.835673,0.250207,0.302052,0.849237,1.23087,0.376983,0.677681,0.83198,0.89189,1.07543,0.958902,-0.857265,-0.838148,-0.0942096,-0.00217915,0.0615175,-0.168693,-2.38741,-2.53588,-0.770973,-0.861,-0.438778,-0.402562
2192,0.693267,0.64956,0.94965,0.922618,0.931589,0.850657,0.842141,0.86724,0.7486,0.729435,0.983827,1.00951,0.0991048,0.0729197,0.391752,0.377575,0.866347,0.831606,0.675935,0.726341,0.153354,0.483419,1.48526,1.78707,-1.6502,-1.58675,-0.59453,-0.717505,0.262986,0.284893,-1.28494,-1.1883,2.5341,2.30779,1.74244,1.59396,-0.666393,-0.758362,1.14512,1.18548
2193,0.229875,0.183739,0.43461,0.409777,0.657532,0.658596,0.824159,0.877976,0.101463,0.085163,0.167055,0.192171,0.299357,0.274516,0.417247,0.309616,0.521155,0.486744,0.733289,0.783524,-0.536387,-0.264035,-0.614673,-0.317536,-0.0755205,-0.0063519,-0.822795,-0.951623,-0.462419,-0.447917,0.437227,0.529988,0.235413,0.00323382,-1.75013,-1.90074,0.905674,0.809473,-1.013,-0.971025
2194,0.425465,0.311338,0.422146,0.399257,0.477065,0.466535,0.991836,0.888711,0.294651,0.280457,0.914091,0.938298,0.97674,0.952006,0.249268,0.241658,0.770602,0.738488,0.517144,0.541304,-1.39312,-1.01149,-0.280558,0.0234387,-0.47362,-0.403141,1.08458,0.953444,0.072312,0.09162,0.397163,0.483582,-1.50464,-1.73324,0.253058,0.106957,-0.0969468,-0.190068,-0.549491,-0.513592
2195,0.578737,0.438937,0.208681,0.184802,0.353946,0.274474,0.87343,0.899446,0.948154,0.935634,0.364679,0.388952,0.789462,0.763023,0.835097,0.829593,0.600957,0.570789,0.149892,0.299084,-1.47581,-1.09766,-0.354231,-0.0510264,-2.63008,-2.56278,0.839734,0.701721,0.11117,0.175108,2.13308,2.21682,0.271832,0.0379152,0.687385,0.54448,-1.79605,-1.88305,-0.963619,-0.930159
2196,0.612439,0.566536,0.412543,0.387263,0.161919,0.0824129,0.591062,0.616496,0.853357,0.838712,0.782097,0.808308,0.232217,0.205589,0.38632,0.37877,0.864037,0.832448,0.00662933,0.0568645,0.592632,0.970121,0.603226,0.901729,0.86051,0.930582,1.65123,1.5112,0.233946,0.258597,-1.44014,-1.34999,-1.45484,-1.6816,-0.896345,-1.03937,0.40518,0.315254,1.44252,1.47735
2197,0.345898,0.297303,0.280431,0.253421,0.711222,0.629898,0.721069,0.648885,0.0724273,0.0591817,0.896579,0.922091,0.271503,0.244004,0.696667,0.689961,0.742709,0.709672,0.0156011,0.0675816,1.09273,1.46673,-1.48114,-1.18781,0.221435,0.284453,-0.111156,-0.256289,0.589258,0.616943,0.00707006,0.101828,-1.08747,-1.31307,1.48121,1.33835,-1.10141,-1.18843,1.17437,1.2128
2198,0.393421,0.34259,0.547944,0.519388,0.911495,0.830358,0.655497,0.681273,0.817849,0.802209,0.656683,0.583974,0.801734,0.775157,0.555949,0.539807,0.307866,0.274935,0.354561,0.383033,-1.12526,-0.748339,-0.626067,-0.327221,0.816252,0.88192,0.442231,0.291765,-0.616996,-0.587805,-0.0485564,0.0395782,0.985797,0.759686,-0.463673,-0.60618,-1.00211,-1.08579,0.28341,0.315007
2199,0.209813,0.159636,0.322829,0.341328,0.0981215,0.0159414,0.58997,0.614333,0.988209,0.972737,0.218565,0.245856,0.995118,0.966647,0.390844,0.389654,0.0868685,0.0560948,0.648343,0.698484,-0.668419,-0.221329,-0.995807,-0.691635,0.634027,0.700072,0.573275,0.425779,0.933678,0.965019,-0.461972,-0.376754,-0.907918,-1.13262,-0.333785,-0.474259,1.7318,1.64437,0.851276,0.880982
2200,0.721309,0.671555,0.192444,0.163268,0.0598683,-0.022878,0.0735578,0.0964597,0.543054,0.529301,0.234338,0.26255,0.346749,0.318471,0.246791,0.239501,0.722858,0.693328,0.325877,0.377247,-0.0736084,0.305681,-0.449371,-0.152704,0.159952,0.227589,-1.35567,-1.50487,-0.515306,-0.488575,-0.076617,0.00613686,-0.812081,-1.05031,0.00458198,-0.142374,1.07505,0.990058,-0.79455,-0.76554
2201,0.102408,0.0508385,0.994715,0.96482,0.974149,0.890928,0.996828,1.01758,0.815624,0.801006,0.778158,0.804325,0.178574,0.166449,0.490614,0.485057,0.143192,0.113906,0.707064,0.756981,0.856624,1.23038,-1.23482,-0.933612,0.83778,0.90423,-1.39446,-1.54052,-0.0968311,-0.0699583,-0.721691,-0.646196,-0.738019,-0.967995,-0.197972,-0.348844,-0.932233,-1.02626,-1.97987,-1.95454
2202,0.735437,0.681521,0.89449,0.867129,0.538142,0.4556,0.861193,0.880363,0.785028,0.771392,0.0808221,0.108251,0.0421253,0.0144274,0.0570419,0.0539541,0.147318,0.150118,0.215066,0.266303,-0.312009,0.0579108,2.26372,2.56614,0.58803,0.659748,-0.352597,-0.499225,2.0865,2.11666,-0.483544,-0.372834,0.46422,0.232878,-0.405358,-0.555314,-0.733761,-0.833694,-1.61617,-1.58664
2203,0.451841,0.397472,0.571036,0.541605,0.877723,0.797551,0.217703,0.238114,0.204653,0.192824,0.632783,0.659936,0.280835,0.205546,0.321404,0.329926,0.21647,0.18633,0.460866,0.425243,0.0624442,0.372587,0.338959,0.644414,1.8326,1.90276,1.66133,1.51863,0.991821,1.01596,-0.178328,-0.0994714,2.24422,2.01797,0.328403,0.176001,-0.0226614,-0.123949,-0.343144,-0.32058
2204,0.872046,0.815537,0.875424,0.848064,0.201571,0.123754,0.217508,0.243786,0.446757,0.391771,0.805619,0.754453,0.426943,0.396664,0.607116,0.605899,0.445202,0.377669,0.530491,0.584183,0.317343,0.687263,-0.181161,0.127609,0.111851,0.185753,-0.266583,-0.412025,-1.27385,-1.24245,-0.488201,-0.408189,0.810409,0.580511,-2.58406,-2.73258,-1.20178,-1.29676,-0.225097,-0.207451
2205,0.0259729,-0.031909,0.264006,0.237099,0.0838563,0.00721284,0.328408,0.249459,0.586071,0.590719,0.820686,0.848971,0.0185542,-0.00942393,0.383284,0.383487,0.633089,0.569009,0.250325,0.331509,-0.713967,-0.348887,0.918874,1.22249,0.0825356,0.156273,-0.0793932,-0.230969,-0.97948,-0.946993,-0.349112,-0.270906,-0.956756,-1.18824,0.763837,0.60794,0.619166,0.525322,1.40773,1.42599
2206,0.917344,0.861225,0.821664,0.793928,0.99499,0.916982,0.233927,0.255131,0.801063,0.789667,0.698363,0.725767,0.0702161,0.0438501,0.981043,0.981777,0.788553,0.760348,0.0254688,0.078836,-2.9755,-2.60782,-2.17332,-1.86348,1.22835,1.306,1.63192,1.48066,-0.199466,-0.158805,0.151845,0.23619,-0.839071,-1.06549,-1.5054,-1.66019,0.318347,0.224574,-0.20961,-0.190139
2207,0.391218,0.335193,0.796988,0.768734,0.666472,0.678413,0.547551,0.569956,0.472645,0.462504,0.329797,0.358359,0.453268,0.505317,0.51941,0.520369,0.679315,0.653068,0.499386,0.561981,-0.648346,-0.278774,-0.191796,0.187455,0.860156,0.939195,0.493991,0.347448,1.4097,1.45473,-0.000405992,0.0805776,-0.456811,-0.683042,-0.136111,-0.287892,0.522269,0.432816,0.509332,0.52786
2208,0.539494,0.41816,0.382949,0.35504,0.45686,0.439844,0.65605,0.678847,0.614149,0.602268,0.73067,0.757989,0.994099,0.966783,0.955926,0.957551,0.299025,0.273347,0.991758,1.04513,-2.03067,-1.66656,1.92855,2.23839,1.39614,1.47547,-1.5057,-1.64704,0.393613,0.436388,1.1441,1.22763,1.17625,0.950725,-0.659527,-0.814141,-0.51074,-0.596785,-0.47724,-0.461088
2209,0.571228,0.501128,0.465491,0.439403,0.278623,0.201275,0.44215,0.466845,0.114377,0.104021,0.62391,0.648226,0.594346,0.566446,0.0238279,0.0263469,0.639963,0.614069,0.622151,0.678391,0.852691,1.21772,0.179517,0.492476,1.09148,1.17095,-0.266193,-0.406181,-0.6285,-0.581956,-0.411484,-0.328431,-0.498483,-0.723124,-1.84068,-1.99936,2.02956,1.94032,1.14119,1.15987
2210,0.535012,0.584095,0.347804,0.386652,0.137781,0.0592684,0.923209,0.949447,0.330313,0.319277,0.430134,0.538462,0.410356,0.310305,0.509989,0.513243,0.155098,0.129166,0.259059,0.311657,1.47704,1.83689,1.45853,1.77105,-0.570511,-0.495226,0.0960858,0.00729173,1.42422,1.47055,-0.154601,-0.0550687,-0.724845,-0.951045,-0.00627481,-0.16265,0.741157,0.65755,-1.13731,-1.12479
2211,0.723339,0.667062,0.360122,0.333901,0.854837,0.775256,0.0316729,0.0601071,0.909054,0.899013,0.399555,0.428699,0.0830971,0.054164,0.198236,0.26931,0.515263,0.448184,0.846605,0.900791,1.03727,1.40254,-0.452723,-0.135134,0.0132581,0.0882036,0.561779,0.420765,-0.191885,-0.152591,0.135897,0.218294,-0.419508,-0.643345,-0.0402449,-0.256113,0.747058,0.666863,-0.23448,-0.226231
2212,0.557066,0.515066,0.542508,0.442507,0.903199,0.821941,0.975404,1.00616,0.271403,0.259382,0.65531,0.682137,0.935852,0.905968,0.0224086,0.025378,0.793352,0.767202,0.592831,0.737301,0.960059,1.33141,-0.688746,-0.366125,0.965258,1.04214,-1.54131,-1.68346,-0.548524,-0.503674,1.17911,1.26076,-1.00649,-1.2283,-0.20301,-0.349575,1.13126,1.04885,-0.806109,-0.792816
2213,0.457543,0.363071,0.578315,0.551112,0.162392,0.0811819,0.962679,0.993832,0.679974,0.667341,0.447091,0.396115,0.213807,0.183654,0.0908941,0.0565987,0.203685,0.178154,0.521406,0.573811,0.152421,0.524982,-0.530392,-0.21156,-0.262413,-0.179414,-0.938919,-1.07656,0.226178,0.268573,0.0142567,0.0917878,-0.810529,-1.02949,-0.669164,-0.762063,-1.05399,-1.13816,0.182759,0.196825
2214,0.267351,0.211075,0.520087,0.491923,0.203543,0.12259,0.0578857,0.0880433,0.48193,0.47022,0.084074,0.110093,0.936288,0.907239,0.085196,0.0878194,0.694673,0.668948,0.874554,0.927693,0.102118,0.47081,0.451825,0.771823,-1.06792,-0.980837,-0.750121,-0.88082,0.704858,0.746657,1.16094,1.23884,0.610596,0.388958,-1.03218,-1.17455,-0.666356,-0.756181,-2.0297,-2.00734
2215,0.713575,0.65894,0.947152,0.916369,0.661813,0.487741,0.394214,0.312575,0.804262,0.694882,0.280191,0.248435,0.724431,0.612612,0.661522,0.665695,0.671357,0.644466,0.819116,0.758109,-1.48906,-1.11673,0.906871,1.23365,1.01167,1.10135,-1.16301,-1.28657,-0.66279,-0.617565,-0.245714,-0.165133,1.57852,1.35631,-1.02174,-1.16722,0.103427,0.0134215,1.02989,1.04672
2216,0.249158,0.193119,0.862727,0.802196,0.932878,0.852891,0.556326,0.537107,0.932794,0.919544,0.430143,0.386776,0.346188,0.317985,0.283757,0.288823,0.287321,0.341824,0.587774,0.588525,0.728107,1.10254,-1.76345,-1.43063,-2.75536,-2.65941,-1.5636,-1.69232,-0.0673447,-0.016582,-0.174761,-0.0895027,-0.359717,-0.583934,0.181818,0.0363859,1.31372,1.22214,0.00945978,0.0274297
2217,0.713267,0.655346,0.716684,0.688023,0.500983,0.42298,0.73338,0.761639,0.58322,0.572116,0.497285,0.525118,0.819099,0.789666,0.803579,0.811129,0.0659967,0.0391827,0.365801,0.41894,-1.3336,-0.953174,-1.27971,-0.954386,0.254658,0.343916,0.732701,0.603696,-0.0913851,-0.0434662,-0.94792,-0.862492,-0.511328,-0.734032,-0.0286253,-0.168662,0.89297,0.719181,-0.504472,-0.494186
2218,0.808733,0.750931,0.954421,0.925331,0.675284,0.599302,0.201992,0.228641,0.905838,0.894533,0.956465,0.983349,0.618886,0.590008,0.942847,0.952527,0.294955,0.194301,0.668558,0.721547,-0.215096,0.168591,0.343592,0.666543,1.03679,1.12662,1.6445,1.52215,0.641174,0.682209,0.0474724,0.134135,0.547658,0.324981,-1.91999,-2.06628,0.313487,0.216225,-0.4831,-0.471715
2219,0.687145,0.626986,0.734423,0.705951,0.344561,0.269556,0.797766,0.825486,0.267572,0.254902,0.372775,0.398396,0.194412,0.165004,0.844364,0.852592,0.374031,0.349419,0.341491,0.395227,1.7791,2.15705,-0.214124,0.14609,-1.89051,-1.80793,-0.710156,-0.838477,-0.719655,-0.682013,-0.324699,-0.234833,-1.35101,-1.56733,-0.466502,-0.618771,0.114031,0.0233272,-0.759252,-0.751874
2220,0.095792,0.0363383,0.112948,0.085079,0.821392,0.747739,0.0773306,0.102785,0.524898,0.511753,0.620451,0.548843,0.435625,0.489086,0.995212,1.00386,0.32821,0.291632,0.678158,0.733915,0.807961,1.18346,-0.688737,-0.374363,-2.14313,-2.06674,-0.171744,-0.306981,-0.294489,-0.33453,0.0758472,0.163746,0.700845,0.489592,0.736585,0.584834,0.181239,0.0950842,-0.56747,-0.565046
2221,0.984673,0.923439,0.336699,0.307939,0.218202,0.143358,0.525608,0.551015,0.37894,0.365344,0.673428,0.699289,0.841997,0.813168,0.617999,0.6003,0.259364,0.233846,0.552303,0.695283,0.678113,1.0537,-0.114239,0.195781,2.42104,2.49743,-0.539123,-0.681554,-0.0236249,0.0129534,-0.659754,-0.578323,0.747845,0.535492,-0.255065,-0.40149,-0.977334,-1.06266,0.970868,0.976236
2222,0.651654,0.588287,0.125233,0.0983543,0.584256,0.510679,0.0570338,0.0843568,0.739646,0.728688,0.408772,0.43617,0.574643,0.547207,0.188105,0.196744,0.846931,0.819082,0.600555,0.656652,-0.215244,0.155753,0.966979,1.27343,-1.67971,-1.60022,-2.10805,-2.24468,-1.22704,-1.19179,1.37929,1.46495,-0.700885,-0.915926,1.45842,1.31331,0.027932,-0.0561765,0.078825,0.0784446
2223,0.0550051,-0.00729737,0.528131,0.504028,0.220348,0.14606,0.166149,0.193248,0.0684788,0.0589847,0.951633,0.977945,0.596802,0.626612,0.384891,0.320984,0.674067,0.708569,0.318811,0.375735,0.808954,1.13883,-1.35133,-1.04429,-0.493465,-0.418366,1.81641,1.67961,-0.832589,-0.803394,-1.63286,-1.55361,-0.195645,-0.408901,0.670482,0.524567,0.610267,0.527135,-1.86139,-1.86392
2224,0.956831,0.893834,0.394232,0.370186,0.669101,0.595315,0.576281,0.602619,0.818527,0.807816,0.0710084,0.0959578,0.735773,0.706017,0.434409,0.445223,0.623693,0.598056,0.612301,0.577692,1.7508,2.1219,-2.08435,-1.7763,-1.57716,-1.49947,0.490351,0.346963,-1.6199,-1.59655,-0.603224,-0.587011,-0.77798,-0.993855,-1.27548,-1.41996,-1.19801,-1.27924,-0.54285,-0.551788
2225,0.140634,0.0764392,0.899308,0.872998,0.78682,0.723575,0.477462,0.465548,0.180293,0.168184,0.440453,0.536495,0.958166,0.927097,0.386113,0.398705,0.167863,0.143473,0.721168,0.77965,0.387283,0.76655,-0.876651,-0.57515,0.128778,0.206003,1.71645,1.57406,-0.0281372,0.00337495,0.300338,0.379586,-0.717541,-0.930656,0.153795,0.0144823,0.221549,0.135714,0.184004,0.180718
2226,0.434999,0.368664,0.915522,0.887158,0.925333,0.851834,0.292094,0.328477,0.855687,0.844867,0.953539,0.977032,0.0857537,0.0553611,0.817943,0.830354,0.858713,0.835026,0.357462,0.478253,-0.697739,-0.31494,0.622467,0.919399,-0.745771,-0.673166,-0.973893,-1.12333,-0.473514,-0.440198,-0.826717,-0.745918,0.184096,-0.0258808,0.229231,0.0837366,0.158953,0.0689376,0.705007,0.700171
2227,0.461514,0.35047,0.231075,0.201899,0.190076,0.116235,0.0956021,0.191406,0.441448,0.484524,0.34023,0.362121,0.681154,0.651354,0.518029,0.528791,0.618338,0.596515,0.116616,0.176856,-0.635001,-0.247842,0.0109717,0.309741,1.42739,1.50603,-0.56344,-0.714351,0.462821,0.501032,0.189982,0.263649,0.321088,0.0712584,-1.29725,-1.44053,-1.9407,-2.02669,-0.794594,-0.792172
2228,0.335415,0.332275,0.94443,0.917377,0.202305,0.161879,0.0284474,0.0543344,0.136949,0.124181,0.381056,0.434352,0.794861,0.764803,0.694362,0.706181,0.704129,0.769942,0.949671,1.01072,1.02312,1.40469,-0.0338459,0.264976,0.390842,0.47082,-0.585403,-0.733898,-1.39372,-1.35657,2.11054,2.17855,0.371822,0.168398,0.0398606,-0.101062,0.206527,0.123303,-0.843332,-0.845392
2229,0.380416,0.314081,0.406414,0.380278,0.250301,0.207524,0.992869,1.01952,0.310472,0.299267,0.400482,0.506583,0.907289,0.878251,0.58422,0.576149,0.966111,0.943369,0.34072,0.40077,1.91881,2.2998,-0.652162,-0.359556,-0.243607,-0.160103,-0.351351,-0.505409,-2.57856,-2.54493,1.65914,1.7302,1.37848,1.18175,-0.993783,-1.13275,0.759389,0.677947,-0.506815,-0.507737
2230,0.854386,0.785972,0.375791,0.350033,0.328597,0.253168,0.394739,0.420687,0.772259,0.762431,0.557794,0.578814,0.141052,0.112395,0.435505,0.446117,0.440259,0.419302,0.334883,0.402428,0.181607,0.559196,1.73376,2.02396,-0.641845,-0.556892,-1.74755,-1.90037,-0.893857,-0.8732,0.258202,0.326234,0.460597,0.258526,1.24857,1.10546,2.73339,2.64482,0.0756262,0.0729313
2231,0.572242,0.551887,0.677902,0.601994,0.731944,0.656535,0.811763,0.838844,0.271328,0.259193,0.295124,0.378385,0.917675,0.888308,0.904999,0.918195,0.712556,0.690277,0.343129,0.404085,-1.32478,-0.950318,0.410744,0.700808,0.07106,0.067766,1.71447,1.56849,0.764903,0.798529,1.40184,1.47328,1.69123,1.48971,-0.441804,-0.587742,-0.266407,-0.357894,-0.465955,-0.465301
2232,0.385636,0.317803,0.879685,0.853955,0.753886,0.677812,0.846959,0.871622,0.70929,0.696951,0.156379,0.177956,0.86754,0.840063,0.753699,0.750196,0.172868,0.150674,0.904258,0.962959,-0.408619,-0.041583,-1.55645,-1.26597,0.604934,0.692424,-0.939293,-1.07687,0.975982,1.00228,-0.71936,-0.651699,-0.997165,-1.2023,0.295859,0.156336,-0.285468,-0.37884,-1.31554,-1.31786
2233,0.543398,0.473095,0.651579,0.624058,0.987662,0.913182,0.380107,0.404965,0.291215,0.277912,0.443074,0.467123,0.427345,0.399328,0.470502,0.582197,0.685606,0.665759,0.957963,1.01563,0.97551,1.34714,-0.0389345,0.244869,0.159132,0.251008,-0.305321,-0.438921,0.410705,0.438387,-1.59025,-1.51609,-1.11439,-1.32192,-0.307086,-0.446745,0.0156772,-0.156974,-0.727041,-0.723624
2234,0.0544383,-0.0179605,0.987881,0.9602,0.334084,0.259787,0.412052,0.498503,0.11614,0.10128,0.308611,0.333206,0.931461,0.901645,0.395484,0.414198,0.935865,0.917503,0.00229715,0.0626473,1.62117,1.99757,-1.22157,-0.93621,0.246348,0.34122,1.38237,1.24412,-1.08875,-1.06257,-0.350797,-0.276475,-0.234356,-0.509186,0.984479,0.846408,0.152441,0.064892,0.864984,0.864415
2235,0.370312,0.393251,0.692421,0.722182,0.772355,0.699112,0.566592,0.592042,0.692488,0.675573,0.533132,0.557236,0.456327,0.4255,0.233003,0.246199,0.810539,0.722274,0.273462,0.335817,0.80792,1.19114,0.718904,1.00749,1.22956,1.32454,-0.775482,-0.906211,0.643989,0.675743,-1.93782,-1.86239,0.514684,0.303546,-0.22823,-0.370261,-0.280721,-0.375013,-2.16635,-2.17642
2236,0.876861,0.804462,0.510167,0.484165,0.786009,0.711119,0.829897,0.857359,0.631245,0.634117,0.975814,1.00044,0.981231,0.952362,0.959196,0.97385,0.544942,0.527046,0.213891,0.323954,-0.403586,-0.0128559,-0.336572,-0.0503435,-1.75456,-1.66288,-1.25265,-1.41238,1.00469,1.03409,-0.726166,-0.652099,-1.48044,-1.7,-0.182026,-0.331252,0.444411,0.349473,-0.137849,-0.15508
2237,0.320095,0.248297,0.712198,0.581555,0.0257527,-0.0485755,0.274149,0.29912,0.622575,0.592661,0.398866,0.426077,0.943071,0.914042,0.762966,0.7769,0.893892,0.87833,0.24832,0.312091,1.0757,1.47078,0.88608,1.17003,0.35813,0.449419,-1.77987,-1.91855,0.249128,0.271166,-0.254131,-0.174856,-1.47131,-1.68547,0.174065,0.0303738,-0.311957,-0.474565,1.32431,1.31101
2238,0.0518127,-0.0209356,0.754019,0.678945,0.56423,0.489068,0.337413,0.434675,0.485359,0.551206,0.138768,0.168089,0.0250597,-0.00145168,0.153249,0.166039,0.898846,0.837918,0.461595,0.524605,-0.31232,0.082997,-0.392831,-0.104968,0.31118,0.382191,0.38818,0.253747,0.765314,0.760343,-0.26398,-0.190625,-1.06785,-1.29843,1.3614,1.21688,-1.19687,-1.2986,2.06572,2.05945
2239,0.0526487,-0.0203682,0.804111,0.776335,0.713886,0.628053,0.426735,0.57023,0.561634,0.50975,0.932511,0.962429,0.953372,0.926139,0.575914,0.572347,0.812317,0.797505,0.916808,0.979065,0.532714,0.930358,-1.02258,-0.7295,0.21846,0.314963,0.566297,0.434803,1.22382,1.24952,-1.72624,-1.65577,-0.693361,-0.91139,0.482576,0.337159,0.674692,0.570513,-0.858913,-0.872296
2240,0.393658,0.347162,0.29135,0.263494,0.841769,0.767038,0.680776,0.705785,0.48521,0.468294,0.777449,0.809473,0.511993,0.485404,0.967298,0.978656,0.452393,0.438353,0.78855,0.757278,-3.05965,-2.66752,0.601687,0.891429,1.32212,1.41861,0.395865,0.261307,-0.381248,-0.356977,0.083095,0.154503,0.520618,0.305131,-1.50575,-1.6547,0.593129,0.487354,-0.893513,-0.910663
2241,0.787759,0.714692,0.0137035,-0.0118524,0.564616,0.488455,0.293509,0.319065,0.238853,0.282674,0.203591,0.235109,0.352043,0.326353,0.864495,0.878721,0.841874,0.829244,0.47101,0.535491,-0.357703,0.0368662,-0.488518,-0.196863,1.03664,1.12916,-0.754111,-0.887179,-1.211,-1.18174,0.197732,0.277018,0.717421,0.503938,0.45625,0.308455,-1.09171,-1.20563,-1.48439,-1.50686
2242,0.447321,0.374457,0.950242,0.926297,0.848159,0.674906,0.964957,0.991848,0.114655,0.0970547,0.773712,0.806161,0.454448,0.426789,0.380289,0.392552,0.130981,0.118847,0.845541,0.909969,-1.55511,-1.16713,-0.129825,0.158332,0.294214,0.3912,-0.200346,-0.339125,-1.24276,-1.20863,-1.8033,-1.72594,-0.713497,-0.933518,1.95589,1.80234,0.628479,0.521182,0.208595,0.188822
2243,0.399721,0.32028,0.292794,0.270023,0.939393,0.861356,0.736081,0.763677,0.968633,0.952461,0.694921,0.727932,0.86828,0.838316,0.122839,0.135732,0.0817549,0.14283,0.876209,0.941873,-1.13896,-0.747276,-0.791095,-0.497015,1.43796,1.54093,-0.502937,-0.572668,-0.709149,-0.66909,-1.19086,-1.11173,-0.574343,-0.796045,1.46671,1.30659,0.769561,0.668484,-0.601859,-0.618322
2244,0.310842,0.266102,0.467977,0.442274,0.685166,0.607837,0.037856,0.0665218,0.949848,0.933498,0.384197,0.45553,0.91693,0.789104,0.406028,0.416764,0.104623,0.166813,0.0408494,0.105989,-0.407279,-0.0216103,0.598658,0.889338,0.39208,0.490402,-0.758857,-0.806211,-0.408935,-0.373628,1.20756,1.29133,-0.723344,-0.946142,-2.38484,-2.54496,0.018271,-0.0817448,-1.00581,-0.98736
2245,0.28568,0.211925,0.640054,0.614524,0.835022,0.759436,0.957819,0.987645,0.696397,0.666907,0.148844,0.183129,0.771063,0.739893,0.3602,0.370245,0.200935,0.190796,0.346709,0.431133,-1.12111,-0.733878,-1.87454,-1.58547,-0.128316,-0.0298126,-0.900976,-1.03975,0.62188,0.659838,2.0227,2.10261,1.11667,0.891419,-0.505542,-0.663861,-1.02051,-1.12915,-1.33741,-1.3564
2246,0.842897,0.768474,0.0845969,0.0575424,0.0799248,0.00429917,0.497526,0.526179,0.425957,0.400317,0.545087,0.500781,0.32938,0.299158,0.060335,0.068682,0.826677,0.817184,0.689523,0.756277,-0.376921,0.00739555,0.37053,0.650842,-1.20805,-1.11092,0.916337,0.77147,0.765519,0.801578,-0.124243,-0.0421195,0.110846,-0.110385,1.09756,0.940275,-0.0649516,-0.171345,0.953956,0.937147
2247,0.0305042,-0.0434201,0.63313,0.605411,0.492615,0.387196,0.817604,0.84581,0.148338,0.133727,0.784925,0.818433,0.815499,0.785899,0.378441,0.385021,0.885305,0.875344,0.191138,0.255618,-0.410387,-0.0318391,-0.996952,-0.719403,0.418036,0.515226,-0.727228,-0.872434,0.569253,0.602765,1.44788,1.53769,-0.412785,-0.633561,-1.15397,-1.31069,0.104773,-0.00822099,-0.949701,-0.973345
2248,0.0845912,0.0909858,0.310607,0.285058,0.844073,0.770093,0.0360696,0.0660861,0.363114,0.414992,0.527585,0.560445,0.722621,0.692041,0.354818,0.264285,0.641009,0.632153,0.709403,0.775206,-0.75375,-0.373796,-1.14013,-0.869093,0.424596,0.515201,0.767316,0.62121,-1.53054,-1.49783,-0.208613,-0.122702,1.75658,1.53886,1.33467,1.18276,-0.417726,-0.524736,-0.312783,-0.331439
2249,0.298354,0.225392,0.997369,0.969686,0.72106,0.690579,0.273398,0.230431,0.712646,0.696257,0.0594495,0.0903695,0.208858,0.18044,0.137465,0.143548,0.66062,0.643257,0.114311,0.17963,0.320485,0.702624,0.0428362,0.316089,0.17341,0.270719,-1.43737,-1.5746,-0.126082,-0.0973035,-0.645462,-0.55383,1.1163,0.894719,1.9772,1.82002,0.494886,0.386547,-0.766977,-0.791533
2250,0.989081,0.916112,0.277709,0.249785,0.686177,0.611065,0.365243,0.394775,0.195866,0.177831,0.335973,0.365366,0.572901,0.524706,0.555235,0.560116,0.68056,0.65436,0.576384,0.575809,-1.45349,-1.07076,0.580618,0.85502,0.424954,0.517743,-0.200346,-0.333744,-0.060502,-0.0797162,-1.33473,-1.23593,0.922464,0.698907,1.1119,0.956557,-0.150859,-0.252748,0.909578,0.889369
2251,0.106438,0.0320027,0.833592,0.806614,0.604876,0.531551,0.214522,0.242654,0.67294,0.655741,0.225936,0.233542,0.897994,0.868972,0.230607,0.233617,0.674319,0.665463,0.907784,0.971987,1.22419,1.6043,0.0053267,0.276097,-0.517876,-0.421984,0.759121,0.630183,-0.0864922,-0.0621289,-0.819481,-0.713774,-0.450122,-0.674157,0.899472,0.751509,0.0368332,-0.0601859,0.420618,0.399519
2252,0.591209,0.518729,0.186754,0.160908,0.00773114,-0.0677841,0.355596,0.435738,0.0629288,0.0462398,0.0736415,0.101717,0.435853,0.489524,0.388799,0.391014,0.229115,0.220887,0.291517,0.356785,0.956352,1.33774,1.0162,1.29181,-0.77408,-0.680795,0.834721,0.703293,0.880731,0.911132,0.654142,0.755874,0.880537,0.652198,1.7008,1.55737,1.13816,1.03947,1.45896,1.43518
2253,0.808957,0.653135,0.679906,0.653955,0.733034,0.657869,0.602305,0.628821,0.429031,0.413906,0.945872,0.971768,0.137685,0.110076,0.0508487,0.0542768,0.488136,0.481098,0.029784,0.0956788,-1.28141,-0.894233,-1.26956,-0.99019,0.02528,0.118228,-2.48589,-2.62296,0.00634642,0.0395824,0.201343,0.307528,1.56092,1.32737,-0.346673,-0.494754,1.04913,0.956309,1.36957,1.35073
2254,0.860552,0.787541,0.755307,0.667681,0.439309,0.40867,0.511713,0.535849,0.236958,0.218006,0.0565389,0.0821592,0.0551834,0.0257145,0.252739,0.256116,0.748719,0.74131,0.00452456,0.0717274,-0.790127,-0.397619,-1.96616,-1.69133,-0.999052,-0.90137,-0.397385,-0.528324,0.215895,0.294731,0.433156,0.599881,-1.52066,-1.75302,0.814108,0.663075,-0.658605,-0.751663,0.0834337,0.0695627
2255,0.544071,0.472547,0.799963,0.681406,0.234135,0.15947,0.0989818,0.12353,0.0350684,0.0221061,0.88571,0.912063,0.671306,0.641891,0.116775,0.119737,0.0702734,0.061369,0.921621,0.990129,1.15479,1.54538,-0.838581,-0.594705,-0.955965,-0.856585,0.022239,-0.10393,0.508908,0.549879,0.784471,0.892233,-0.905415,-1.13723,-1.19181,-1.34417,-1.73242,-1.82912,1.8737,1.86147
2256,0.670724,0.655913,0.72165,0.695132,0.425212,0.349824,0.830326,0.856005,0.158864,0.18554,0.576816,0.603021,0.937746,0.908308,0.64455,0.646612,0.88809,0.87966,0.149424,0.217245,0.874623,1.26425,0.230153,0.501923,-0.349275,-0.244179,0.947246,0.814525,-1.57891,-1.53619,-0.410503,-0.309206,1.54111,1.30894,-0.330475,-0.478234,-1.18996,-1.29047,0.00295483,-0.0158299
2257,0.91212,0.839279,0.24725,0.221489,0.000778903,-0.0746753,0.91274,0.939558,0.468963,0.348975,0.80107,0.827052,0.404097,0.376121,0.337027,0.340271,0.855284,0.844589,0.293059,0.355606,0.132046,0.522121,-0.881604,-0.60254,-0.181894,-0.0432199,1.55093,1.42142,-1.03007,-0.981453,-0.122851,-0.0916484,-0.0432608,-0.271274,-1.58467,-1.72501,2.47672,2.38178,0.530521,0.517901
2258,0.82423,0.752303,0.0416405,0.0165439,0.759009,0.681793,0.122251,0.150467,0.503325,0.512409,0.322094,0.346914,0.899767,0.872974,0.888809,0.893469,0.368693,0.359686,0.427733,0.493966,1.34248,1.73641,-0.306583,-0.0323951,0.0531854,0.157739,0.224489,0.0887739,0.00258591,0.0520137,0.0301802,0.125909,0.22659,0.00428674,0.261433,0.126687,0.99153,0.893982,-0.661782,-0.6711
2259,0.0867977,0.012703,0.104195,0.0335704,0.361316,0.28168,0.861097,0.887815,0.690053,0.675843,0.424616,0.451069,0.290185,0.26183,0.187665,0.194996,0.539008,0.529372,0.486749,0.632327,0.304939,0.700256,2.2803,2.55916,-0.0785807,0.0227895,-0.54264,-0.673106,1.80655,1.85153,-0.312053,-0.220988,1.64114,1.42274,-0.559124,-0.69099,1.07355,0.981992,-0.27755,-0.290072
2260,0.481407,0.40565,0.0754518,0.0505969,0.870746,0.78991,0.514489,0.487318,0.329055,0.316765,0.934477,0.958679,0.598618,0.598672,0.602023,0.611564,0.19495,0.18451,0.703554,0.770687,-0.977645,-0.581331,0.147569,0.421298,0.627508,0.729574,1.60789,1.48225,1.37754,1.4234,-0.664099,-0.567885,-1.65278,-1.86807,0.69228,0.55623,0.689041,0.590629,-1.20814,-1.2197
2261,0.180082,0.10602,0.959484,0.933781,0.113476,0.0347734,0.0593089,0.0868215,0.569005,0.557996,0.198055,0.224076,0.962353,0.935514,0.0862909,0.0957558,0.872848,0.862364,0.28446,0.350098,0.933922,1.33029,1.09282,1.35886,-0.102141,0.00397471,0.624845,0.503228,0.167511,0.218651,-0.127279,-0.0318451,0.282064,0.0629805,-1.33543,-1.46597,1.8154,1.72091,0.0438411,0.0295499
2262,0.870323,0.79674,0.700561,0.672687,0.0478752,-0.0302673,0.0461074,0.0744955,0.40966,0.309334,0.192754,0.220991,0.301067,0.27382,0.692669,0.700297,0.761445,0.750376,0.671326,0.734261,2.54112,2.93712,-0.311103,-0.0438468,-0.130168,-0.0255054,-0.846092,-0.967974,-0.716672,-0.666657,-0.373378,-0.278637,0.0272234,-0.195439,0.415089,0.27847,0.444289,0.343643,-1.75707,-1.77121
2263,0.0842173,0.00832342,0.785398,0.630808,0.896647,0.81613,0.916976,0.943502,0.0729629,0.0606715,0.83304,0.861797,0.897965,0.869813,0.850821,0.857695,0.43118,0.411969,0.841258,0.906433,0.549464,0.944263,0.0402076,0.311348,1.13555,1.24659,0.00565411,-0.215505,-1.13449,-1.07901,0.126979,0.228458,1.18061,0.960033,-0.592221,-0.723276,-1.78286,-1.88984,1.49371,1.47734
2264,0.847524,0.772695,0.672214,0.58893,0.112409,0.0315586,0.541024,0.615188,0.112615,0.0976018,0.909024,0.937762,0.366668,0.337626,0.542495,0.571496,0.0863209,0.0735618,0.520839,0.585195,0.125984,0.47437,-1.18319,-0.916421,-1.61125,-1.50636,0.658456,0.536963,0.684237,0.735291,1.51636,1.62082,0.237153,0.0199294,-0.318001,-0.451594,-0.18231,-0.289052,-0.244232,-0.260716
2265,0.737802,0.663673,0.572667,0.547051,0.449088,0.279834,0.261398,0.286874,0.918433,0.904501,0.436638,0.467686,0.337638,0.309239,0.279756,0.285297,0.152464,0.0948967,0.864925,0.929518,-0.395806,0.00447717,0.441358,0.704507,1.70478,1.81534,0.973181,0.854934,0.178998,0.231164,0.0523481,0.15568,0.520373,0.30998,-0.868979,-1.00854,-0.356318,-0.466625,0.0974977,0.0769391
2266,0.857143,0.783891,0.90038,0.873209,0.60981,0.52811,0.846638,0.87418,0.313658,0.29978,0.635813,0.72436,0.617159,0.590305,0.213689,0.219543,0.1294,0.116232,0.487849,0.553341,-0.419086,0.0347693,-0.107304,0.154867,-0.0521423,0.0540265,0.436803,0.31176,0.0978374,0.155732,-0.197962,-0.0911125,0.816964,0.60003,-0.188322,-0.280768,1.36541,1.26018,2.504,2.48445
2267,0.057017,-0.0149456,0.72468,0.592875,0.740695,0.659572,0.0876948,0.11493,0.337847,0.323288,0.949979,0.981034,0.474939,0.495745,0.492223,0.543955,0.925237,0.913137,0.420829,0.485009,-0.329775,0.0650614,0.588756,0.84707,2.08246,2.18235,-0.864842,-0.990984,0.635748,0.695269,1.31488,1.4245,0.421001,0.201817,0.59238,0.447008,-0.520543,-0.626474,1.29958,1.28038
2268,0.735925,0.666261,0.420796,0.312541,0.667284,0.51155,0.71645,0.742098,0.737721,0.72101,0.330413,0.360862,0.428055,0.401186,0.864169,0.868367,0.630568,0.618911,0.899336,0.964011,1.49391,1.88552,-2.71803,-2.45394,0.140081,0.246467,-0.223665,-0.353041,0.245062,0.298771,1.39145,1.50013,0.464537,0.247716,1.01807,0.870215,0.208763,0.098012,-0.523198,-0.547228
2269,0.809852,0.741907,0.0593772,0.0322062,0.446438,0.363527,0.644027,0.668952,0.780004,0.76319,0.356797,0.387286,0.711376,0.682252,0.772026,0.777588,0.664883,0.652578,0.120436,0.184044,-1.74459,-1.35803,0.132937,0.394862,-1.10096,-0.989824,-0.799538,-0.927613,0.323381,0.380957,-0.948329,-0.834331,-0.524426,-0.738084,-2.43092,-2.58018,0.687376,0.567301,-1.64258,-1.66136
2270,0.556774,0.40431,0.484285,0.456652,0.754622,0.670558,0.232743,0.256633,0.485353,0.470559,0.961924,0.993072,0.486876,0.455883,0.431122,0.435495,0.460121,0.449773,0.325553,0.294104,0.67643,1.06647,-0.250564,0.0131959,0.0141651,0.130274,-0.451746,-0.579221,0.641009,0.690331,-0.25242,-0.146992,2.02949,1.8195,0.237795,0.0861079,1.14725,1.03659,-0.106704,-0.120078
2271,0.133184,0.0667136,0.455021,0.353601,0.823777,0.741677,0.375758,0.401677,0.481424,0.43182,0.00566343,0.0378678,0.796525,0.767943,0.883824,0.887194,0.952001,0.940567,0.340137,0.404163,0.917038,1.24322,0.297806,0.572972,-0.65444,-0.531719,0.319346,0.199065,-0.80941,-0.763263,-0.180066,-0.0713616,0.16557,-0.0401184,-0.320408,-0.388676,0.669752,0.552076,-0.0525192,-0.0672442
2272,0.584218,0.519174,0.278189,0.250551,0.184706,0.103512,0.846295,0.874685,0.408042,0.39308,0.574705,0.60892,0.421197,0.39198,0.129275,0.13168,0.722253,0.712433,0.912392,0.978246,1.02597,1.41997,0.874222,1.13275,0.38828,0.511652,0.724097,0.608043,0.769198,0.819865,-2.24947,-2.13652,-0.853386,-1.05679,-0.715411,-0.86346,-0.364298,-0.477525,0.754901,0.74102
2273,0.248035,0.184022,0.62575,0.596726,0.179219,0.0997803,0.446605,0.473072,0.0615931,0.0456523,0.190568,0.227435,0.919824,0.888833,0.391764,0.392313,0.224343,0.21268,0.99955,1.06437,1.60029,1.99412,-1.45658,-1.20198,-0.825376,-0.709902,-0.56784,-0.678988,0.412302,0.468782,-0.0595845,0.0500291,-1.12845,-1.3307,0.590271,0.445528,0.0202053,-0.0955424,-0.119818,-0.128376
2274,0.756453,0.691177,0.343513,0.316702,0.990253,0.910038,0.368613,0.394749,0.0429082,0.0266886,0.585469,0.621656,0.731323,0.699849,0.203731,0.205368,0.101799,0.0899042,0.428367,0.493193,0.578136,0.972211,-0.917004,-0.589918,-0.657979,-0.5434,0.673676,0.561866,1.89402,1.94556,-0.642397,-0.538499,0.134986,0.0312476,-0.95054,-1.09235,-0.435578,-0.550915,0.273815,0.268358
2275,0.124036,0.0600505,0.265662,0.295583,0.153597,0.0745119,0.0538679,0.0816471,0.822599,0.806626,0.0771302,0.111789,0.0946289,0.0624062,0.86272,0.865394,0.758589,0.748216,0.182178,0.247882,0.952937,1.34683,-0.23109,0.0221472,-0.778374,-0.663357,-0.802529,-0.909336,0.939811,1.01588,0.19984,0.303625,1.59545,1.39319,-1.06375,-1.2062,-0.0790358,-0.199898,0.160078,0.154881
2276,0.975761,0.912164,0.301594,0.274463,0.448052,0.370794,0.922148,0.950653,0.848127,0.834022,0.555422,0.589103,0.181202,0.108518,0.530148,0.534041,0.267026,0.258199,0.715578,0.782778,-0.0339402,0.356585,-0.113114,0.1454,1.00524,1.12001,1.17524,1.07475,0.0306395,0.0861978,-0.157603,-0.0432718,1.39643,1.19738,0.205899,0.0565737,0.997524,0.884018,-0.341093,-0.351609
2277,0.754274,0.688605,0.820977,0.792235,0.053088,-0.0242894,0.172004,0.203156,0.568405,0.557028,0.130557,0.163383,0.104504,0.15463,0.497686,0.502963,0.0239816,0.0150091,0.857544,0.925302,-0.705968,-0.308309,-1.72371,-1.45894,0.63033,0.738793,-0.638295,-0.743073,0.137472,0.197891,-0.485574,-0.390169,1.85733,1.65825,-0.415777,-0.562461,-1.09744,-1.21161,0.149385,0.137412
2278,0.785693,0.719036,0.0793723,0.0523078,0.195295,0.117663,0.222047,0.324656,0.562168,0.54975,0.949456,0.982423,0.234722,0.200742,0.237583,0.241128,0.850103,0.84351,0.577061,0.623905,-0.0161237,0.386694,0.700779,0.959155,0.631178,0.738768,-0.319463,-0.425102,-0.45435,-0.395821,-0.368449,-0.279887,1.52525,1.32131,-1.62654,-1.77913,1.31592,1.19728,1.02561,1.02048
2279,0.0717763,0.00443482,0.987783,0.960988,0.991417,0.91194,0.379325,0.446156,0.023436,0.0115964,0.137164,0.169721,0.0292325,-0.0043804,0.361183,0.366888,0.854415,0.848951,0.255742,0.322508,-0.126004,0.269219,0.312841,0.56338,0.309017,0.407116,-1.62689,-1.72785,0.18532,0.207438,-0.147401,-0.169605,-2.1465,-2.35153,1.35794,1.20256,0.607101,0.500411,-0.359847,-0.367432
2280,0.67934,0.610412,0.82329,0.864692,0.295376,0.217952,0.581657,0.567655,0.9445,0.935145,0.218293,0.250543,0.147466,0.189756,0.279492,0.286035,0.0144886,0.00990722,0.387054,0.423357,0.616503,1.01049,-0.884467,-0.633125,-0.0321511,0.0754647,-0.346279,-0.440565,0.758067,0.810696,-0.154728,-0.0593227,-0.440668,-0.641512,0.727668,0.567467,-0.171068,-0.196462,1.21986,1.20562
2281,0.231164,0.159987,0.793319,0.768396,0.804533,0.726182,0.740793,0.689155,0.705392,0.698197,0.912716,0.946932,0.419724,0.383892,0.954197,0.962214,0.971737,0.96903,0.420888,0.524207,-0.339378,0.0515929,-0.576537,-0.323242,-1.14216,-1.03778,-0.347023,-0.443602,1.04135,1.09175,0.660045,0.751963,0.457764,0.180981,0.0877689,-0.0676269,-0.7747,-0.893335,0.0423219,0.0311909
2282,0.449628,0.426946,0.150701,0.128099,0.0664159,-0.0145768,0.779502,0.810654,0.0685823,0.0632994,0.0198176,0.0522658,0.0493617,0.0131785,0.771976,0.780042,0.287833,0.283591,0.55829,0.625056,1.23458,1.62767,-0.499149,-0.245064,1.52203,1.621,0.263756,0.163292,-1.44922,-1.39705,-1.03588,-0.942131,1.20513,1.00347,0.329185,0.0825525,0.482967,0.361506,0.353543,0.339818
2283,0.762218,0.693905,0.422661,0.399134,0.84642,0.763637,0.0619845,0.0935871,0.935035,0.929547,0.71864,0.752927,0.82083,0.782561,0.851129,0.860813,0.807066,0.804033,0.0864176,0.154042,0.601567,0.991736,1.50701,1.76503,-0.300295,-0.20581,-0.0602212,-0.164389,-0.227234,-0.179155,-1.60745,-1.51262,-0.170634,-0.369591,0.390472,0.232732,0.236915,0.107807,-0.392903,-0.40681
2284,0.214584,0.147555,0.108536,0.0833625,0.448546,0.363524,0.0831217,0.209854,0.16451,0.160749,0.862884,0.828501,0.920945,0.882997,0.363457,0.374645,0.731919,0.729089,0.685727,0.752523,-0.430273,-0.0444141,-1.2098,-0.949549,-1.85299,-1.76256,-1.59091,-1.69588,-1.41933,-1.36751,1.18586,1.27711,0.615996,0.414112,-0.317945,-0.479547,0.369745,0.240833,-0.771264,-0.779028
2285,0.708872,0.643961,0.368148,0.344232,0.430498,0.344702,0.235671,0.32612,0.279828,0.274871,0.96624,0.904075,0.604583,0.500092,0.540174,0.552035,0.209072,0.205022,0.363041,0.431285,0.812469,1.20359,1.35703,1.62158,-0.280416,-0.182166,0.285887,0.175946,1.21832,1.26908,-1.38612,-1.2887,-0.800718,-1.00783,-1.88593,-2.04926,-0.0501066,-0.183537,0.12237,0.119528
2286,0.349297,0.306364,0.323408,0.299598,0.615048,0.487168,0.279175,0.442387,0.832019,0.829365,0.945363,0.97965,0.152715,0.117187,0.467549,0.48456,0.0440671,0.0422286,0.326298,0.392767,0.0560832,0.444992,-0.091939,0.172528,-0.332441,-0.226521,-0.0521029,-0.167276,0.467006,0.521765,1.17549,1.27068,-0.421811,-0.625382,1.38556,1.22336,1.07842,0.946741,0.286397,0.277189
2287,0.0329645,-0.0312325,0.989777,0.963808,0.799967,0.629633,0.484673,0.558653,0.200443,0.19955,0.449231,0.484431,0.439777,0.403733,0.403022,0.417084,0.175898,0.152794,0.917408,0.981901,-1.06773,-0.682092,0.234155,0.497363,-0.927432,-0.827739,0.676629,0.565773,2.07301,2.12169,0.26343,0.358342,-0.573408,-0.775479,-0.477692,-0.643847,-1.18035,-1.31935,-1.86546,-1.87931
2288,0.782165,0.717422,0.102496,0.0769042,0.860103,0.772098,0.643317,0.67492,0.133171,0.133822,0.826667,0.86332,0.0858435,0.0485863,0.777356,0.789544,0.206156,0.263359,0.277403,0.341238,1.07492,1.46029,0.294435,0.560053,-0.228846,-0.135775,0.972277,0.869635,-0.272113,-0.217964,0.236476,0.302723,-0.0168458,-0.221329,0.210051,0.0394601,0.581575,0.437887,-0.0750998,-0.0874093
2289,0.736157,0.67053,0.272791,0.245912,0.339056,0.253306,0.0861803,0.116681,0.594093,0.596986,0.0768955,0.113192,0.165144,0.127578,0.900343,0.910844,0.374236,0.373924,0.284372,0.346551,-0.00338508,0.378804,-1.2554,-0.997785,-1.10049,-1.01494,0.0845859,-0.0167706,-1.46009,-1.40632,0.150905,0.247104,-2.22871,-2.42636,-1.85233,-2.02999,0.209087,0.0615094,0.00497395,-0.00673297
2290,0.202453,0.139312,0.988372,0.961389,0.415414,0.329778,0.314206,0.367895,0.426492,0.523128,0.560937,0.595572,0.969001,0.93305,0.053324,0.0651642,0.134486,0.135414,0.986449,1.05098,-0.844948,-0.458334,-1.67612,-1.42229,-0.658518,-0.569618,0.473953,0.377289,-1.26261,-1.20257,0.0965732,0.191485,-0.357428,-0.556763,0.705874,0.536557,-1.45906,-1.59891,-0.337992,-0.347833
2291,0.520622,0.455814,0.654915,0.626315,0.189341,0.102351,0.579476,0.619109,0.446419,0.449271,0.561974,0.591255,0.558862,0.476859,0.544762,0.556449,0.13961,0.140855,0.724894,0.795949,-1.39233,-1.00165,-1.47527,-1.22032,-1.23886,-1.15583,-0.829511,-0.925455,-1.65569,-1.59907,-0.319919,-0.224847,-1.38097,-1.57344,1.65601,1.48206,1.58842,1.44755,0.79525,0.779525
2292,0.560079,0.49599,0.595626,0.567125,0.676875,0.590618,0.839823,0.870324,0.374289,0.375414,0.591669,0.586939,0.055323,0.0206671,0.306981,0.349909,0.984142,0.986122,0.560255,0.54092,0.678184,1.06614,0.986087,1.24212,0.31003,0.390106,1.3807,1.28418,-0.680737,-0.625809,0.108066,0.204387,-0.31909,-0.514424,0.832097,0.664383,1.0762,0.931035,-0.151839,-0.16444
2293,0.113809,0.0501433,0.919591,0.893284,0.272295,0.185064,0.0230284,0.0533918,0.868917,0.868674,0.54764,0.582623,0.226342,0.191379,0.131457,0.143368,0.013486,0.0177146,0.221363,0.285891,1.52921,1.9135,-0.114846,0.137656,0.859258,0.942066,2.57362,2.48049,-0.108721,-0.0538808,-1.03999,-0.95059,1.00623,0.811931,-0.74379,-0.905328,-0.314867,-0.460243,-0.835231,-0.849863
2294,0.872735,0.809985,0.774877,0.749577,0.0726721,-0.0164114,0.181614,0.122126,0.872966,0.887576,0.994612,1.03106,0.0818968,0.0464428,0.239901,0.249705,0.256351,0.259208,0.942993,1.0092,-0.257376,0.124878,-0.85206,-0.594356,-0.501456,-0.417194,0.0413505,-0.0530989,-1.29301,-1.24224,1.50494,1.59043,0.235756,0.0449831,1.66138,1.50575,-0.548986,-0.697764,-0.0310806,-0.0415991
2295,0.307937,0.244021,0.11523,0.0893012,0.706925,0.617359,0.162219,0.190861,0.905773,0.906479,0.954347,0.989089,0.243995,0.133797,0.944409,0.957075,0.0115173,0.0160181,0.144244,0.209191,0.559865,0.941201,-0.0866338,0.175566,0.0216064,0.103837,-0.0810295,-0.179374,-0.518069,-0.528971,0.413785,0.494512,0.0589195,-0.136748,-0.460377,-0.610862,-1.002,-1.15314,0.19866,0.191432
2296,0.206167,0.141419,0.432566,0.405735,0.527961,0.466041,0.530708,0.559482,0.417891,0.417653,0.266429,0.298991,0.257343,0.22115,0.801606,0.814941,0.654717,0.658489,0.611428,0.678148,0.345116,0.720552,0.0334497,0.298819,2.71455,2.79495,1.50809,1.40785,0.137606,0.184297,-0.468427,-0.385735,0.679201,0.479042,-0.743359,-0.89182,0.184262,0.0375732,-0.344466,-0.3468
2297,0.655088,0.589284,0.369035,0.341601,0.51147,0.314723,0.00608972,0.0365446,0.2664,0.266698,0.187408,0.220762,0.959159,0.923567,0.907901,0.921277,0.0973513,0.0986421,0.77465,0.839912,-0.262606,0.116067,-0.487885,-0.217986,0.273349,0.346577,0.151365,0.101687,2.17528,2.22056,0.949171,1.03597,-1.01977,-1.22625,0.077817,-0.0707684,0.912423,0.762059,0.165936,0.15743
2298,0.278534,0.214961,0.836754,0.809963,0.281823,0.163405,0.342079,0.370299,0.783201,0.78563,0.33115,0.403847,0.70463,0.66682,0.617088,0.641954,0.710494,0.71026,0.551587,0.643356,-0.12606,0.29282,-0.398082,-0.12548,-0.394984,-0.315417,-1.10424,-1.20448,0.325485,0.36296,0.415143,0.494468,1.69752,1.49784,-0.45935,-0.612295,-1.52286,-1.6731,1.0385,1.0263
2299,0.819551,0.757216,0.611339,0.585685,0.101653,0.012087,0.16819,0.19806,0.334233,0.337619,0.553274,0.586933,0.819377,0.781879,0.348351,0.36263,0.949666,0.951754,0.382478,0.4468,0.0931714,0.469574,0.307395,0.58235,0.72946,0.804681,0.110333,0.00725587,-0.370059,-0.338245,0.200656,0.278823,-0.398831,-0.599395,1.77482,1.62591,-2.00603,-2.15761,0.623265,0.567613
2300,0.769475,0.705843,0.0680629,0.0439693,0.313783,0.222371,0.932818,0.961459,0.417989,0.421458,0.0898781,0.121396,0.53783,0.500962,0.985946,1.00231,0.260323,0.260779,0.791395,0.856114,-0.837238,-0.459671,0.171989,0.446374,-0.452339,-0.370914,-0.404142,-0.506201,0.94544,0.971735,-1.65845,-1.58266,-0.956483,-1.15289,-1.09029,-1.24105,0.0477951,-0.106994,0.120985,0.108925
2301,0.39414,0.33152,0.375455,0.350428,0.866972,0.774886,0.680617,0.708564,0.191306,0.194119,0.255967,0.286558,0.844984,0.807914,0.368091,0.385972,0.319354,0.318939,0.919034,0.982103,0.427371,0.804585,0.874036,1.1542,-1.22822,-1.14161,0.413259,0.317265,-0.128854,-0.0973958,-0.414619,-0.34305,-0.170338,-0.369191,0.683088,0.531676,-1.03528,-1.18445,1.35662,1.34436
2302,0.647486,0.582635,0.934746,0.912401,0.858907,0.69357,0.926177,0.953787,0.720073,0.723144,0.961487,0.993081,0.936845,0.897549,0.911171,0.928752,0.139304,0.200766,0.534211,0.608891,0.4002,0.78111,-0.50171,-0.216041,0.894002,0.986715,0.561111,0.468021,-0.323752,-0.328437,0.356216,0.422514,1.12208,0.924056,0.982132,0.830965,1.06029,0.916201,-0.77121,-0.781545
2303,0.109507,0.0463781,0.0524587,0.0317896,0.706761,0.612254,0.717278,0.813074,0.169752,0.174637,0.000169189,0.0329923,0.543894,0.529777,0.943188,0.958967,0.0839152,0.0825929,0.173428,0.235679,-1.79825,-1.41935,1.5109,1.79406,1.10872,1.20142,-0.593539,-0.680464,-0.592049,-0.559479,-0.540596,-0.475026,0.644552,0.446934,-0.347391,-0.494775,0.704074,0.554365,0.0039734,-0.0979057
2304,0.479531,0.401842,0.947599,0.925463,0.16954,0.073184,0.644908,0.67236,0.950183,0.954575,0.756104,0.789859,0.200025,0.162005,0.168355,0.182592,0.495129,0.492856,0.212247,0.272397,-0.0233999,0.35629,-0.889969,-0.603907,1.00389,1.09491,-0.135392,-0.224742,0.702093,0.734036,-0.479484,-0.414245,-1.61739,-1.81108,-0.319544,-0.471796,-0.625503,-0.777143,0.591982,0.585734
2305,0.822263,0.757305,0.842391,0.801639,0.281947,0.184978,0.243457,0.270747,0.118982,0.122182,0.811082,0.845462,0.830174,0.79317,0.715382,0.730406,0.645322,0.604235,0.549306,0.611085,-0.713742,-0.34033,0.420174,0.70575,-0.565344,-0.477373,-0.264951,-0.351017,0.175559,0.201999,0.133459,0.19997,-0.821275,-1.01416,1.92005,1.76641,1.24192,1.09197,0.537652,0.532514
2306,0.967335,0.902121,0.704136,0.677815,0.857909,0.763122,0.669126,0.603123,0.0746933,0.0777479,0.660128,0.739461,0.948628,0.913239,0.202333,0.219136,0.719217,0.715614,0.582345,0.599222,-1.07103,-0.728747,-0.920103,-0.633499,1.09129,1.17924,1.17841,1.09355,0.446082,0.467517,1.18801,1.25836,-1.51698,-1.70468,-0.327382,-0.48456,1.98311,1.83241,-0.191348,-0.199147
2307,0.467219,0.4481,0.575069,0.55399,0.680975,0.583806,0.909055,0.935499,0.324146,0.329264,0.596444,0.63346,0.456353,0.42213,0.891871,0.910451,0.441996,0.437097,0.523726,0.587359,-1.48398,-1.11716,1.13153,1.42468,-1.32654,-1.23624,1.77003,1.68567,-0.489706,-0.46455,-1.12421,-1.06134,-0.324585,-0.519914,1.52963,1.36714,-0.466306,-0.617351,0.664113,0.652509
2308,0.0577062,-0.00592045,0.148022,0.125413,0.491859,0.40449,0.14803,0.176249,0.131856,0.137205,0.904575,0.94365,0.507965,0.475404,0.285628,0.304452,0.846171,0.843057,0.292334,0.421524,1.11987,1.48705,0.499348,0.706423,-0.0705888,0.020601,-1.36836,-1.45894,0.0480196,0.0749868,-0.491079,-0.433004,0.116563,-0.0730134,-0.913917,-1.08221,1.36868,1.21894,-1.88736,-1.90129
2309,0.00155961,-0.0625894,0.934944,0.91236,0.36214,0.225174,0.486032,0.514937,0.643359,0.651326,0.0698798,0.110413,0.847592,0.813083,0.105839,0.17783,0.292794,0.288563,0.192195,0.255689,-0.681423,-0.319483,-0.307425,-0.0118385,0.78483,0.8809,1.32963,1.23963,-1.38691,-1.36243,0.520778,0.576563,-0.377873,-0.564546,1.60743,1.43277,-0.384121,-0.539295,1.03503,1.02694
2310,0.569258,0.503954,0.254124,0.231763,0.140645,0.0458575,0.823972,0.853626,0.902059,0.908177,0.11949,0.161149,0.355127,0.321973,0.0326628,0.0512073,0.421243,0.362243,0.672328,0.734691,-0.0404941,0.315197,-0.301494,-0.00953427,0.0392006,0.142943,0.481417,0.383932,-0.0498255,-0.0238163,-0.0104656,0.051559,-0.433143,-0.624341,1.05807,0.875817,-0.436845,-0.592414,0.894055,0.884204
2311,0.698642,0.633968,0.425734,0.420012,0.386928,0.29118,0.504737,0.539675,0.628864,0.656345,0.500945,0.597406,0.809154,0.777854,0.103787,0.122795,0.439566,0.435924,0.0416285,0.103928,0.259942,0.61465,-1.0208,-0.725724,-0.138746,-0.0475907,0.0325494,-0.0674071,-1.06828,-1.04782,-1.4078,-1.35241,0.0740421,-0.117316,-1.35007,-1.53829,0.822886,0.662427,-0.164974,-0.180663
2312,0.113544,0.0477804,0.632621,0.608261,0.224001,0.12925,0.197669,0.225725,0.397285,0.404512,0.989694,1.03366,0.726162,0.673928,0.466344,0.48568,0.724634,0.721668,0.899982,0.962957,-0.0230928,0.333527,1.4022,1.69237,-0.341525,-0.238124,0.476553,0.371735,-0.254127,-0.230538,0.875961,0.929124,0.200674,-0.0538679,-1.28037,-1.46903,-0.294914,-0.4634,-0.917888,-0.927291
2313,0.433406,0.369177,0.208085,0.184329,0.899617,0.804461,0.126424,0.185967,0.341766,0.429713,0.857,0.946559,0.600637,0.570003,0.281325,0.28177,0.287503,0.286931,0.924858,0.989249,1.35716,1.7059,-0.762893,-0.478213,-0.0164538,0.0845891,0.489693,0.383303,-0.894242,-0.870732,-0.632702,-0.580663,0.200938,0.00958005,0.0757845,-0.111415,0.594466,0.417533,0.320941,0.308143
2314,0.357258,0.292465,0.121391,0.0959654,0.661066,0.566096,0.117567,0.146209,0.449451,0.454914,0.816355,0.859455,0.273953,0.244033,0.0586053,0.07786,0.177309,0.174943,0.577539,0.643324,0.850752,1.19126,-0.823617,-0.53736,-0.465601,-0.356827,-0.220229,-0.330813,-0.217085,-0.190723,-1.37793,-1.32273,1.12125,0.885581,-0.956148,-1.1431,-2.2355,-2.40997,-0.886923,-0.895928
2315,0.934654,0.869011,0.329723,0.324155,0.6611,0.56745,0.335657,0.362513,0.621661,0.567993,0.422066,0.467322,0.622955,0.591342,0.742924,0.763646,0.387287,0.385539,0.869126,0.936263,-0.430541,-0.0903299,-0.000896854,0.277667,-1.53906,-1.43793,-0.586572,-0.690621,-0.246132,-0.217607,0.432883,0.487541,1.95294,1.76158,0.236416,0.0434104,0.0236709,-0.148086,-0.778219,-0.782799
2316,0.0188861,-0.046958,0.577179,0.552345,0.416599,0.338506,0.9121,0.940393,0.677261,0.681071,0.559689,0.607258,0.970697,0.938651,0.319073,0.341691,0.116168,0.116667,0.00657089,0.0728867,0.839064,1.17393,-0.0025504,0.279971,-1.22843,-1.13005,-1.46576,-1.57703,-0.735087,-0.704389,1.22268,1.2797,0.0813526,-0.113675,-0.346884,-0.545523,1.18851,1.01313,0.397804,0.391084
2317,0.837924,0.770905,0.530044,0.507712,0.202821,0.109562,0.789524,0.818261,0.465313,0.374894,0.030491,0.0773395,0.914292,0.880272,0.402666,0.411651,0.599917,0.601675,0.127794,0.120809,1.77617,2.11297,1.24218,1.52876,-0.667655,-0.562993,0.563071,0.455629,-0.605551,-0.577864,-0.600039,-0.536939,-0.0708741,-0.263772,0.325566,0.123215,-0.973325,-1.14198,0.434388,0.429422
2318,0.0116003,-0.0572737,0.26112,0.313328,0.377603,0.29076,0.919639,0.94779,0.0630393,0.068716,0.27987,0.325448,0.0415412,0.00853595,0.458391,0.481612,0.239933,0.242523,0.101407,0.168731,1.25304,1.58505,2.23265,2.51214,0.422657,0.526442,0.547829,0.436082,-2.14591,-2.12124,0.258635,0.319448,-0.711861,-0.90791,1.72676,1.52709,-0.136497,-0.307664,1.53651,1.52612
2319,0.160849,0.00907988,0.140376,0.118945,0.469951,0.471958,0.460537,0.490785,0.323917,0.290092,0.175957,0.221855,0.590074,0.554801,0.174874,0.200034,0.630244,0.633414,0.773806,0.842638,0.0563502,0.38106,-0.229969,0.0521211,0.789677,0.893909,-1.00248,-1.11032,0.0520616,0.0817666,-0.685413,-0.62363,1.67863,1.49074,-0.410767,-0.607221,-1.15675,-1.3241,1.94317,1.93818
2320,0.144965,0.0754335,0.664751,0.641953,0.746415,0.653156,0.667189,0.7118,0.506901,0.511468,0.32923,0.468022,0.574075,0.537039,0.983621,1.00871,0.16451,0.16853,0.665745,0.841714,0.564126,0.895094,-1.70845,-1.42807,-0.344057,-0.235027,-0.0230398,-0.128962,-0.156237,-0.131334,0.160851,0.218494,-1.85843,-2.05263,-0.163595,-0.367487,0.226534,0.0592273,0.666411,0.657016
2321,0.68211,0.612212,0.744273,0.721036,0.244847,0.15346,0.904636,0.932816,0.373025,0.375526,0.669614,0.71419,0.766163,0.728529,0.866785,0.892162,0.719268,0.723744,0.70371,0.84079,-0.263361,0.0737429,1.88559,2.15673,1.25047,1.36042,-1.05621,-1.1684,-1.11429,-1.09292,-0.406142,-0.351992,1.00695,0.810634,0.361797,0.16358,0.0214762,-0.147557,-0.0290126,-0.044992
2322,0.723612,0.652389,0.435718,0.486739,0.349523,0.260092,0.379549,0.409878,0.54857,0.447379,0.378271,0.425278,0.348601,0.31252,0.379973,0.405994,0.428928,0.434593,0.771034,0.839866,0.214334,0.557917,-0.208216,0.0671947,1.0302,1.14554,-0.997183,-1.11001,-0.553296,-0.538179,0.493265,0.551985,-0.77304,-0.972142,1.94097,1.73577,-1.52651,-1.69744,0.350558,0.316673
2323,0.313938,0.242458,0.272091,0.252442,0.174903,0.0837245,0.808585,0.838563,0.558573,0.519232,0.864573,0.912422,0.586519,0.54837,0.295708,0.298321,0.374486,0.379029,0.214149,0.284056,0.112134,0.456081,1.00853,1.28757,0.422224,0.544325,0.0684137,-0.0377383,0.61766,0.632889,0.694789,0.75806,-0.656303,-0.931157,-0.473752,-0.678332,2.00097,1.83952,0.69154,0.678337
2324,0.977013,0.90419,0.0397963,0.0181445,0.866182,0.773782,0.0213355,0.0494715,0.586196,0.591085,0.97804,1.0262,0.504608,0.464008,0.265903,0.190649,0.948615,0.953758,0.631431,0.703384,-0.952151,-0.611412,-0.786044,-0.505515,-1.34031,-1.21699,-0.0496696,-0.149458,0.0946838,0.105047,0.903079,0.964135,-0.681048,-0.890173,0.236883,0.0362733,-0.832287,-0.987975,-0.36598,-0.370411
2325,0.0648518,-0.00620019,0.927268,0.90634,0.804625,0.666291,0.733531,0.762296,0.229242,0.232006,0.528881,0.554453,0.625842,0.584077,0.0577839,0.0829766,0.258583,0.262783,0.251127,0.322978,-0.0265278,0.313288,-1.15225,-0.869929,-1.1639,-1.03386,0.299611,0.198934,-0.560627,-0.422795,-0.984215,-0.929042,0.576205,0.370993,0.14507,-0.0614776,-1.10196,-1.25746,1.28013,1.27888
2326,0.668174,0.594552,0.882431,0.861706,0.651509,0.5588,0.592873,0.620761,0.744614,0.746127,0.0345376,0.082702,0.17066,0.128175,0.737636,0.764567,0.580913,0.58345,0.394136,0.453194,-0.950419,-0.615958,1.46708,1.75227,0.720864,0.844833,0.877545,0.775548,-0.940568,-0.950637,1.63313,1.69326,-0.464508,-0.676618,1.12462,0.911794,-0.514196,-0.618887,0.573826,0.576873
2327,0.57365,0.502487,0.465236,0.482908,0.339648,0.329856,0.0203428,0.048099,0.586472,0.580292,0.525732,0.575328,0.432889,0.389747,0.0657254,0.0926694,0.210415,0.214094,0.512348,0.583411,2.45386,2.79248,-0.665787,-0.385594,0.59738,0.724875,-0.711921,-0.820797,-1.49371,-1.47848,0.068991,0.122488,-2.12774,-2.33326,0.958228,0.753834,0.174202,0.0196855,-0.980285,-0.978907
2328,0.204684,0.132735,0.123823,0.104111,0.191235,0.100911,0.0314159,0.0612206,0.455242,0.414456,0.792427,0.844099,0.321546,0.280518,0.454126,0.501602,0.0848502,0.0871261,0.0986534,0.167418,1.07044,1.49218,-1.25994,-0.9807,1.68007,1.81431,0.140989,0.0352885,0.55463,0.574024,-1.03281,-0.97343,0.132956,-0.0648185,0.0482924,-0.155465,-0.450136,-0.603378,0.28053,0.287158
2329,0.966832,0.892576,0.497463,0.478318,0.303133,0.133944,0.767782,0.798569,0.247107,0.248621,0.759911,0.811962,0.683238,0.642978,0.882736,0.910535,0.273808,0.288583,0.491424,0.563596,-0.142577,0.191881,0.84853,1.12721,0.307242,0.437864,-1.2344,-1.34292,-2.48687,-2.45914,-0.876934,-0.822894,-0.330076,-0.52627,1.26298,1.06122,2.22989,2.071,-1.01306,-1.0082
2330,0.860198,0.783555,0.436362,0.419129,0.281861,0.166977,0.0979284,0.126598,0.579601,0.600632,0.177194,0.227009,0.771427,0.732612,0.134889,0.164791,0.485707,0.490041,0.891994,0.959775,0.304633,0.642337,0.764317,1.0363,0.617839,0.745746,-0.201786,-0.316242,1.41806,1.4407,2.0144,2.0659,-0.573493,-0.769948,0.353068,0.151917,-0.61913,-0.76904,0.705784,0.715627
2331,0.469915,0.393732,0.944129,0.926681,0.29012,0.200009,0.963625,0.990373,0.951405,0.952644,0.227634,0.31697,0.604995,0.570734,0.313841,0.342181,0.300669,0.302952,0.646052,0.714464,-0.111509,0.223029,2.38256,2.65723,0.16097,0.288211,-2.3242,-2.43484,1.84957,1.87385,-2.00293,-1.95367,2.06556,1.86624,0.987497,0.789173,1.5145,1.3673,-1.71323,-1.70209
2332,0.88512,0.807053,0.546794,0.527241,0.00488182,-0.0847303,0.652263,0.677271,0.545434,0.548565,0.35625,0.40693,0.485832,0.408856,0.777896,0.80322,0.541055,0.483988,0.934019,1.00257,-0.288712,0.0472944,-0.614637,-0.34159,0.739218,0.87164,-0.0773975,-0.193712,-0.311696,-0.29166,1.02623,1.07708,-0.371571,-0.567081,0.210447,0.0167276,-1.07396,-1.22416,1.40322,1.41744
2333,0.425653,0.387276,0.774122,0.730916,0.581147,0.493414,0.824552,0.847406,0.44804,0.451642,0.897692,0.948705,0.285061,0.246978,0.273252,0.296941,0.671143,0.665024,0.484368,0.55126,0.207475,0.543908,-1.14512,-0.875023,-0.449644,-0.317491,0.336327,0.215265,-0.336509,-0.318544,0.619971,0.677231,-0.108605,-0.307505,-0.970662,-1.16849,-0.453362,-0.608584,-1.32826,-1.31989
2334,0.0449716,-0.0325018,0.955432,0.934591,0.0719857,-0.0149739,0.444369,0.46506,0.874932,0.879926,0.80787,0.778091,0.910462,0.872449,0.611316,0.634503,0.843778,0.84606,0.730922,0.799608,0.0696492,0.414146,-1.14633,-0.872719,-0.906196,-0.775026,-0.469185,-0.592313,-1.61871,-1.60248,2.20941,2.27075,-0.428232,-0.541262,-0.8266,-1.021,-0.675693,-0.832011,0.762544,0.766283
2335,0.51477,0.337905,0.601936,0.628746,0.56185,0.473293,0.824802,0.843373,0.41012,0.416207,0.557545,0.607477,0.594017,0.479811,0.513147,0.538195,0.724807,0.707243,0.405697,0.473288,0.487777,0.833997,-1.3949,-1.11662,1.81763,1.94826,0.419472,0.295546,-0.465655,-0.448065,1.70619,1.76015,-0.568775,-0.77502,-0.373838,-0.646005,0.262234,0.11193,0.528086,0.532136
2336,0.786563,0.708312,0.27751,0.322901,0.759649,0.663632,0.453976,0.471455,0.972025,0.979158,0.0429315,0.0930448,0.123412,0.0871736,0.719133,0.745312,0.566758,0.568426,0.430017,0.495478,-0.479686,-0.139588,0.28998,0.566381,0.213469,0.343409,0.149655,0.0288544,-0.488583,-0.474949,0.767159,0.817075,0.268635,0.0674628,-0.0762416,-0.271007,0.513104,0.367235,2.16123,2.16558
2337,0.243862,0.167215,0.035767,0.0170558,0.941822,0.853971,0.887157,0.904871,0.805102,0.812537,0.0734297,0.124599,0.32332,0.28877,0.482879,0.594483,0.681782,0.69149,0.0256857,0.0890867,-0.632621,-0.286669,0.909263,1.1823,0.4984,0.635481,0.918842,0.792139,-1.11529,-1.10008,1.23138,1.27864,1.86082,1.65486,-1.40225,-1.59675,-1.62736,-1.77229,-1.8156,-1.8068
2338,0.159926,0.0841748,0.0424677,0.0260994,0.424788,0.335179,0.104729,0.120176,0.106077,0.112109,0.325246,0.462581,0.0480802,0.0131778,0.406588,0.443654,0.810949,0.814553,0.56496,0.62848,0.791246,1.13252,-0.994798,-0.72389,-0.997823,-0.86104,-0.557993,-0.679062,1.42224,1.43688,-0.15711,-0.110512,0.415116,0.203438,-1.65454,-1.84824,1.85963,1.719,0.315741,0.324386
2339,0.983881,0.907979,0.487177,0.450684,0.973084,0.882665,0.343127,0.360105,0.972033,0.978357,0.750783,0.800563,0.354011,0.263453,0.220987,0.292825,0.503276,0.505494,0.426156,0.389629,-0.624302,-0.287055,-0.127393,0.177093,1.04664,1.18642,0.51688,0.393214,0.906992,0.91884,-0.656485,-0.603712,-1.29219,-1.50185,-0.242694,-0.428547,1.14082,1.00324,-0.339195,-0.332054
2340,0.223809,0.146999,0.891756,0.875269,0.129953,0.0382289,0.299589,0.318414,0.800322,0.807738,0.205013,0.256145,0.592492,0.513727,0.115817,0.141996,0.911957,0.915757,0.0888362,0.150779,0.876015,1.21207,0.801816,1.07808,0.783845,0.92761,-0.0733713,-0.198031,1.07888,1.0929,-0.119672,-0.0676718,-0.239952,-0.442841,-0.332543,-0.512495,-0.471033,-0.608548,1.10338,1.10359
2341,0.335594,0.281481,0.473323,0.516785,0.882021,0.78957,0.618871,0.60607,0.98672,0.992796,0.566025,0.616238,0.799645,0.764002,0.49445,0.519413,0.60082,0.606697,0.903477,0.964283,0.466998,0.808359,-0.309239,-0.026386,0.251002,0.392185,0.926812,0.799179,-0.879624,-0.873368,0.759067,0.804113,-1.62166,-1.83151,0.936853,0.750282,-1.35424,-1.49649,-0.167664,-0.129655
2342,0.520599,0.415964,0.174789,0.158301,0.818621,0.724529,0.875551,0.893726,0.263733,0.27089,0.0638864,0.11617,0.167353,0.131924,0.559938,0.604305,0.866748,0.873324,0.907755,0.965941,-0.916131,-0.579423,1.104,1.39143,0.474075,0.665045,-0.506492,-0.626595,0.346203,0.360134,0.100346,0.233741,0.0734533,-0.137089,-0.65457,-0.833565,1.15157,1.01088,-1.36034,-1.3629
2343,0.514985,0.550446,0.437541,0.419171,0.203075,0.110527,0.170884,0.190968,0.790237,0.799916,0.188177,0.145887,0.32892,0.201721,0.662876,0.689196,0.7988,0.80298,0.908862,0.967598,-1.75307,-1.41656,-0.663155,-0.371091,0.798138,0.937905,-0.652387,-0.768501,-0.564218,-0.554678,-0.381163,-0.336631,-1.7686,-1.98125,-1.37827,-1.56211,-0.340002,-0.476922,0.796236,0.786572
2344,0.762672,0.684929,0.25046,0.229659,0.436168,0.333933,0.442788,0.461502,0.0145584,0.0249457,0.127282,0.175604,0.307578,0.271518,0.188882,0.21369,0.208187,0.213932,0.622764,0.622832,-1.39158,-1.05712,-1.01813,-0.721056,-0.693127,-0.558617,2.6291,2.51001,-0.0884343,-0.0765949,-1.53391,-1.49161,0.46487,0.253567,1.0193,0.830889,-1.32028,-1.46014,-0.372872,-0.387855
2345,0.174703,0.0987405,0.956409,0.934892,0.652064,0.557339,0.0688094,0.0895834,0.200863,0.210003,0.153037,0.205321,0.855261,0.817783,0.671457,0.69572,0.737648,0.743525,0.219706,0.278067,0.27425,0.610265,-0.355186,-0.0578901,-0.829371,-0.693566,-1.07194,-1.18548,0.822335,0.832868,-0.748595,-0.711851,0.401881,0.193772,0.702953,0.517558,-0.940292,-1.07816,1.18813,1.17189
2346,0.618845,0.541419,0.100929,0.0787659,0.873292,0.780745,0.232819,0.336076,0.618945,0.627507,0.639566,0.692465,0.155743,0.116638,0.731749,0.697533,0.374888,0.379219,0.503384,0.561423,-0.790364,-0.457227,-1.14719,-0.852561,-0.408461,-0.321308,-0.598008,-0.716272,-2.03078,-2.0187,-0.519848,-0.482798,-1.64953,-1.85554,1.6102,1.43,-1.48133,-1.62499,1.48028,1.46412
2347,0.819193,0.672667,0.113688,0.0929257,0.843303,0.794592,0.56294,0.582568,0.674218,0.684535,0.666807,0.786982,0.181202,0.14445,0.675565,0.699346,0.351356,0.354738,0.565692,0.623666,1.50259,1.83996,0.441093,0.737474,-0.17227,0.0509491,0.361371,0.247655,-0.506114,-0.496135,-0.0376361,-0.00555392,-0.524353,-0.735139,-0.253484,-0.437209,-0.650799,-0.79067,-1.35691,-1.3747
2348,0.880939,0.803915,0.845741,0.82452,0.899401,0.80844,0.223694,0.245152,0.987641,0.996553,0.830959,0.881499,0.485041,0.44618,0.234978,0.257767,0.931276,0.934554,0.420082,0.42711,0.630284,0.990904,-1.58017,-1.27568,0.287402,0.423207,0.95607,0.839773,-2.47715,-2.46241,1.20296,1.23406,0.0692483,-0.182408,0.694278,0.508294,1.25367,1.10975,0.148739,0.138631
2349,0.714535,0.685212,0.636841,0.614935,0.0675894,-0.0213719,0.349364,0.370023,0.270191,0.280967,0.217214,0.266589,0.469017,0.490141,0.311929,0.357542,0.191796,0.193371,0.170381,0.230554,-0.199483,0.141845,-0.354245,-0.110029,1.007,1.14551,0.0187784,-0.0937459,1.33813,1.35287,1.85057,1.87809,0.576928,0.370322,0.400703,0.212758,0.200449,0.0623499,1.41141,1.4047
2350,0.72765,0.566509,0.882289,0.861942,0.882444,0.793716,0.236062,0.297845,0.0971865,0.168179,0.247509,0.321379,0.570152,0.534102,0.434376,0.457316,0.838972,0.840319,0.808302,0.869334,1.09788,1.43556,0.752354,1.05562,-0.338712,-0.200244,0.51263,0.406001,-0.0769067,-0.0553136,-0.309463,-0.279016,-0.816068,-1.01834,1.38576,1.20193,-0.101189,-0.238397,-0.806228,-0.818723
2351,0.525321,0.447805,0.393462,0.441463,0.367961,0.280152,0.216348,0.225668,0.0434828,0.0553904,0.326216,0.37617,0.355793,0.3182,0.132429,0.155753,0.384709,0.477076,0.0141748,0.0737543,0.595071,0.936744,0.827039,1.1338,-0.968076,-0.831167,1.40061,1.29386,-0.769545,-0.73834,-0.36876,-0.341266,-0.218566,-0.418649,0.092132,-0.0939302,0.308962,0.174027,0.626044,0.616916
2352,0.960594,0.885821,0.0413319,0.0209849,0.891209,0.803622,0.130638,0.153491,0.765417,0.777653,0.902143,0.952239,0.888773,0.849353,0.542069,0.567497,0.112668,0.113834,0.210955,0.312309,-0.578622,-0.235726,-0.0223527,0.277895,-0.597197,-0.463701,0.745055,0.641507,0.434082,0.463993,-2.30684,-2.27942,1.80704,1.60522,0.58942,0.405973,-1.41862,-1.55078,0.0217388,0.0207171
2353,0.0783787,0.00171209,0.748917,0.726218,0.779211,0.637849,0.250569,0.258724,0.554832,0.565857,0.741072,0.78962,0.24801,0.207478,0.672762,0.694222,0.453915,0.454555,0.490074,0.550863,-0.595238,-0.245006,0.20874,0.589023,-0.980748,-0.887172,2.10046,1.98965,0.82031,0.852393,1.32247,1.35725,1.73402,1.52991,2.27457,2.0876,0.58562,0.452746,0.705742,0.706778
2354,0.49228,0.401412,0.715726,0.692157,0.558822,0.472077,0.343754,0.363958,0.0348237,0.047431,0.885414,0.90948,0.748208,0.709794,0.794494,0.820946,0.552808,0.569064,0.482399,0.573,-1.82016,-1.4659,0.607905,0.90015,-1.448,-1.31064,-0.278022,-0.3898,-1.3752,-1.34345,-0.262926,-0.228663,-0.174254,-0.377746,0.61277,0.425229,-0.606993,-0.735746,-0.583926,-0.588577
2355,0.879009,0.801111,0.268786,0.243701,0.394256,0.306304,0.921939,0.941837,0.00514868,0.017817,0.982997,1.02934,0.667512,0.630458,0.922243,0.947671,0.683147,0.683573,0.53485,0.595138,-0.612977,-0.263915,-1.35375,-1.06662,-0.828342,-0.698236,0.0907418,-0.0718025,1.63297,1.66129,1.15798,1.19305,1.8437,1.64613,0.0140621,-0.177852,-0.0850005,-0.213293,-0.719784,-0.706229
2356,0.708308,0.628795,0.694963,0.576653,0.00139703,-0.0887794,0.593736,0.651922,0.440616,0.450361,0.914076,0.961261,0.260457,0.224371,0.323353,0.346617,0.113168,0.113643,0.866546,0.928763,0.874813,1.21972,-1.37485,-1.08142,0.133302,0.269736,0.363337,0.246195,-0.315348,-0.289375,-0.435937,-0.409277,-0.878067,-1.07911,1.04264,0.844975,-1.40486,-1.52853,-0.826158,-0.82388
2357,0.512531,0.45648,0.933872,0.909605,0.649746,0.560113,0.342636,0.362007,0.41744,0.426236,0.453632,0.500353,0.213287,0.176126,0.588459,0.61222,0.669136,0.668858,0.899528,0.960668,-0.0966068,0.246134,0.753729,1.04246,-0.0427378,0.087888,1.43138,1.31847,0.286324,0.311608,0.81507,0.845989,0.695001,0.488257,0.517515,0.318725,-0.785161,-0.912959,-2.15284,-2.14953
2358,0.361994,0.284164,0.403612,0.377531,0.719434,0.582178,0.293302,0.31038,0.662984,0.672961,0.280132,0.327758,0.376363,0.337547,0.586481,0.611856,0.967496,0.968809,0.33658,0.399597,-1.48438,-1.14165,-1.1538,-0.863731,1.0633,1.19153,-0.488014,-0.594388,-1.30383,-1.27885,-0.166166,-0.142227,2.68768,2.47948,-0.60942,-0.806346,1.64414,1.51011,-0.224943,-0.221798
2359,0.939113,0.86071,0.565876,0.541265,0.673862,0.604243,0.537153,0.483353,0.661375,0.670413,0.917148,0.963737,0.0864341,0.0458136,0.205624,0.230586,0.228447,0.227625,0.290558,0.326359,0.252,0.587634,0.77703,1.0671,-0.15274,-0.0300218,0.244666,0.13866,0.860693,0.890032,-0.0238304,-0.00494379,-0.908549,-1.11813,0.262461,0.0595941,-0.303412,-0.437052,-1.11666,-1.11959
2360,0.823934,0.817844,0.522857,0.496631,0.715941,0.626308,0.640732,0.656326,0.158864,0.167176,0.539842,0.552929,0.955572,0.914391,0.719395,0.74258,0.396379,0.331891,0.189337,0.253121,-0.720369,-0.385951,2.37482,2.65713,1.39172,1.51591,0.214252,0.103015,1.19569,1.23235,-1.32065,-1.29869,0.0924824,-0.118259,-0.96256,-1.17223,1.19398,1.05518,0.0801227,0.0716325
2361,0.852494,0.774978,0.121282,0.0929774,0.091805,0.00218815,0.462085,0.478659,0.23404,0.241332,0.0944543,0.142122,0.571043,0.52863,0.398182,0.420661,0.533235,0.436156,0.875352,0.937251,-0.69073,-0.352026,0.856212,1.12998,-0.182486,-0.056374,1.76469,1.66051,-0.0286709,0.00846412,-0.780899,-0.762645,-1.64382,-1.85473,-0.817889,-1.02474,-1.82632,-1.96339,-0.353199,-0.334952
2362,0.585407,0.505745,0.936308,0.908916,0.577257,0.485203,0.64491,0.659503,0.869334,0.875864,0.220639,0.26492,0.469617,0.428972,0.909048,0.932655,0.539425,0.540421,0.356887,0.41699,0.912364,1.2548,-0.21985,0.0558856,1.97214,2.1047,-0.62959,-0.735307,-2.16996,-2.13837,0.361237,0.384403,-2.17995,-2.39444,0.335862,0.133092,0.0433368,-0.0942759,-0.653878,-0.741537
2363,0.691885,0.611747,0.40935,0.381505,0.823366,0.730525,0.586614,0.667433,0.484051,0.492176,0.267484,0.387719,0.0136467,-0.0269304,0.375908,0.401606,0.366596,0.367158,0.238957,0.296505,-0.390067,-0.041924,0.185322,0.455677,-1.69256,-1.56642,-0.82247,-0.925095,-0.467444,-0.432968,0.901317,0.920443,1.10172,0.894904,-1.33118,-1.52928,1.13979,1.00538,-1.13963,-1.14812
2364,0.566063,0.487802,0.358356,0.331638,0.079725,-0.0153945,0.662213,0.675364,0.627859,0.636631,0.386318,0.510517,0.6016,0.559332,0.485487,0.527641,0.998024,0.998078,0.890761,0.951051,-0.578184,-0.231803,-0.758664,-0.492723,0.07937,0.200671,-0.22797,-0.332978,-0.143584,-0.10635,-0.348824,-0.327996,-0.536579,-0.745054,0.697242,0.495401,-1.2605,-1.39257,0.164615,0.164015
2365,0.691793,0.61319,0.700257,0.588818,0.33615,0.177352,0.277434,0.288643,0.369678,0.368485,0.585648,0.633316,0.322705,0.362365,0.62836,0.653675,0.539189,0.537978,0.225628,0.284806,0.620551,0.970183,-1.26503,-0.994412,1.13238,1.26115,-0.661528,-0.770243,0.422933,0.476843,0.241715,0.255338,-0.283688,-0.485478,0.218665,0.0151708,0.767034,0.640342,-1.41592,-1.41977
2366,0.476185,0.399314,0.874035,0.845999,0.463622,0.370099,0.0960196,0.106676,0.0900288,0.10034,0.462496,0.510112,0.205613,0.165399,0.318165,0.389467,0.439364,0.436838,0.311582,0.370927,-2.52283,-2.17499,-0.875313,-0.608928,-0.522761,-0.390761,-0.195853,-0.301037,1.02498,1.06004,-0.324197,-0.315148,-0.589844,-0.790556,-1.04155,-1.24865,-0.0143109,-0.183696,-1.15138,-1.15837
2367,0.0154994,-0.0617396,0.21643,0.189725,0.501125,0.400173,0.869419,0.880853,0.356495,0.423167,0.0326109,0.0793921,0.299185,0.259339,0.0982318,0.125259,0.995126,0.992052,0.0480689,0.105954,-0.602147,-0.249335,1.18317,1.44926,-0.212818,-0.0828795,-1.58109,-1.67924,1.05924,1.09584,-1.12393,-1.11876,-0.503688,-0.698383,-0.377163,-0.579917,-0.88828,-1.00773,-0.432599,-0.440371
2368,0.181561,0.0706687,0.178217,0.150354,0.458269,0.430248,0.226827,0.238604,0.738282,0.745994,0.957351,1.00678,0.939008,0.900626,0.914964,0.943497,0.402092,0.397819,0.435803,0.494957,-1.123,-0.777249,2.37886,2.65041,0.33819,0.43328,0.307692,0.21031,0.356955,0.438539,-1.05325,-1.04313,0.0328843,-0.161295,-0.401041,-0.603182,-0.986497,-1.10645,1.02912,1.02572
2369,0.159145,0.203077,0.437499,0.472588,0.552565,0.460322,0.350629,0.288083,0.637477,0.570774,0.134431,0.183322,0.612393,0.574656,0.145251,0.171973,0.584892,0.579165,0.582028,0.707078,1.18361,1.53478,-0.261299,0.0179708,0.929084,0.94944,-0.0658562,-0.164262,-0.325051,-0.218759,1.25081,1.2538,0.0401821,-0.160182,-0.892907,-1.09894,-0.831416,-0.959146,0.749669,0.745558
2370,0.411338,0.335485,0.823469,0.794823,0.932712,0.841237,0.363529,0.337563,0.459883,0.395553,0.201192,0.249763,0.896007,0.855722,0.560832,0.588541,0.483253,0.478024,0.85907,0.919199,-1.71676,-1.3677,-0.249125,0.0340544,1.33566,1.4656,1.64702,1.54737,-0.912652,-0.876058,-0.484862,-0.484871,-1.45732,-1.65983,-1.64648,-1.85691,0.554405,0.424177,-0.255612,-0.296907
2371,0.25483,0.177721,0.0791159,0.0490691,0.603584,0.424682,0.383353,0.387043,0.211767,0.220333,0.634462,0.683888,0.761789,0.721597,0.461637,0.488606,0.717371,0.714797,0.628526,0.758,0.197022,0.543915,1.00156,1.28284,0.0753886,0.200619,-0.84878,-0.952897,-0.252959,-0.211623,0.231422,0.234318,-0.272885,-0.475064,-0.578284,-0.788758,-0.648534,-0.779971,-1.33526,-1.33937
2372,0.494654,0.418776,0.411605,0.379935,0.101058,0.0081265,0.565523,0.436523,0.458286,0.467058,0.313625,0.364639,0.406919,0.36645,0.666997,0.695723,0.340675,0.340613,0.53651,0.5968,0.66074,1.01081,-0.18819,0.0863378,-0.451442,-0.319595,-0.625547,-0.724407,-1.34226,-1.29574,-0.588451,-0.584052,-0.844833,-1.0447,0.214205,0.000604794,2.48868,2.34869,-0.847946,-0.850352
2373,0.944509,0.866641,0.948008,0.91717,0.335039,0.243497,0.474227,0.486003,0.306863,0.316103,0.849929,0.901961,0.754304,0.714152,0.108819,0.13961,0.421905,0.462886,0.727673,0.788849,-1.06666,-0.715561,0.0138932,0.28831,0.585197,0.710929,0.610098,0.516446,-0.149674,-0.109568,-1.77189,-1.77017,1.48219,1.28853,-0.574033,-0.788133,0.353411,0.209168,1.15373,1.15499
2374,0.577052,0.496889,0.404735,0.375454,0.830047,0.736894,0.354502,0.368076,0.896945,0.906071,0.644323,0.69769,0.386754,0.34785,0.747681,0.779288,0.606801,0.585158,0.505788,0.5682,1.11844,1.47358,0.857037,1.13345,0.591576,0.710904,1.15188,1.0645,1.48652,1.52098,-0.733014,-0.72771,-0.908879,-1.096,-0.0492138,-0.257066,0.425435,0.237737,0.282114,0.285595
2375,0.816921,0.737944,0.713317,0.65669,0.855313,0.776892,0.622584,0.619929,0.464676,0.472135,0.0552284,0.107899,0.645009,0.60445,0.815571,0.845682,0.707492,0.707431,0.0105326,0.0727918,1.09303,1.4501,0.209254,0.4781,-1.44092,-1.31749,-0.0510721,-0.146209,0.59658,0.609797,-1.02361,-1.01961,-0.259369,-0.449102,-0.236146,-0.446723,0.407089,0.266306,0.849611,0.851571
2376,0.542212,0.381651,0.967179,0.937927,0.911383,0.816889,0.859021,0.871781,0.540187,0.491037,0.611562,0.66418,0.521593,0.479838,0.0724938,0.104428,0.379808,0.394483,0.614895,0.676574,-0.719851,-0.356436,-0.90676,-0.641863,-1.59294,-1.46857,-0.635212,-0.737453,-0.333913,-0.301387,0.0413297,0.0387783,-0.315453,-0.508897,0.710969,0.49878,0.136362,-0.00317807,0.179655,0.178866
2377,0.106304,0.0253584,0.711314,0.633955,0.0962213,0.00247213,0.758682,0.769206,0.500937,0.509939,0.202555,0.253175,0.843321,0.801729,0.469427,0.501065,0.0803043,0.0815357,0.873924,0.935299,0.520272,0.884557,0.809609,1.07038,0.482068,0.613615,0.774445,0.675931,-0.642074,-0.532428,-0.997157,-0.994057,1.62979,1.43626,-0.569902,-0.780455,0.926316,0.782708,0.159492,0.15583
2378,0.25574,0.17545,0.312404,0.329984,0.593891,0.448209,0.448466,0.449341,0.874229,0.883248,0.479721,0.513324,0.516752,0.475759,0.0388389,0.0699621,0.84069,0.843079,0.251881,0.314599,1.76213,2.12555,0.218879,0.475276,0.831856,0.967667,-0.818163,-0.920414,-0.792238,-0.763469,1.50293,1.49943,-0.115528,-0.315141,-0.584927,-0.789874,-2.80452,-2.94997,-0.383889,-0.382403
2379,0.0570976,-0.0228037,0.055265,0.0260126,0.99012,0.893947,0.121722,0.129476,0.925005,0.935587,0.658589,0.773473,0.57433,0.534733,0.0256367,0.0539803,0.799497,0.803437,0.484958,0.557713,-1.23626,-0.870403,-1.88533,-1.62932,0.822257,0.952921,0.550249,0.444529,-0.22373,-0.191542,-1.92667,-1.93487,-0.859282,-1.05254,0.405596,0.1993,0.655988,0.509722,0.560168,0.562521
2380,0.814627,0.737038,0.668678,0.64102,0.741146,0.545906,0.0218551,0.0319249,0.225799,0.235158,0.983001,1.03362,0.269549,0.228724,0.534392,0.560985,0.53004,0.534565,0.736127,0.800828,-1.21074,-0.849107,0.702278,0.96223,0.418713,0.556132,-0.978995,-1.08696,-0.0711593,-0.0321446,-0.0940585,-0.109131,-0.499086,-0.698689,0.0665579,-0.143166,0.508649,0.363519,-0.67786,-0.67312
2381,0.952811,0.877392,0.373365,0.307459,0.294505,0.197866,0.835248,0.843269,0.538908,0.501744,0.991876,1.04071,0.657976,0.615476,0.371452,0.398225,0.658202,0.663935,0.153256,0.220616,-1.98707,-1.62391,-1.51464,-1.25707,0.976,1.10809,0.94583,0.830265,-0.803446,-0.764954,0.0451882,0.0281524,-0.776593,-0.972597,0.265654,0.0503834,0.0305317,-0.120995,-0.0718216,-0.0623917
2382,0.490826,0.416338,0.00150121,-0.0261016,0.545922,0.448436,0.77842,0.786026,0.760065,0.76833,0.673167,0.702591,0.252585,0.209389,0.542271,0.56942,0.310941,0.314322,0.739176,0.804904,1.41027,1.77023,-0.233099,0.0215058,0.301147,0.451447,1.00679,0.888651,-0.241853,-0.210213,-0.0190647,-0.0340971,0.0580356,-0.145062,-0.374462,-0.585203,0.581634,0.433648,-0.144862,-0.128709
2383,0.738135,0.6623,0.941398,0.912047,0.286501,0.188436,0.0823048,0.0888705,0.16092,0.168973,0.314666,0.364473,0.255203,0.21284,0.993236,1.02112,0.24412,0.24853,0.792971,0.857578,0.210739,0.566235,-0.819081,-0.628833,-0.334149,-0.205197,0.137792,0.0172054,0.626268,0.653923,-1.9811,-1.9917,-0.506399,-0.714694,0.705697,0.496453,0.468081,0.320031,0.802351,0.816214
2384,0.56107,0.484754,0.220198,0.192146,0.418474,0.307321,0.0263385,0.0316277,0.0354095,0.0426359,0.443441,0.494171,0.867655,0.824211,0.754066,0.814579,0.593431,0.599813,0.194635,0.256744,-1.63256,-1.26908,-1.52921,-1.27917,-1.83207,-1.70172,0.172216,0.0585266,0.0249043,0.0602106,1.61207,1.60259,0.471531,0.269009,-1.02486,-1.22942,0.0150893,-0.135341,0.285422,0.294599
2385,0.600488,0.524931,0.317823,0.291078,0.522945,0.426206,0.472522,0.506646,0.327167,0.334589,0.147354,0.200022,0.507763,0.46326,0.578577,0.608038,0.463086,0.467318,0.833537,0.895525,-0.0184149,0.337748,-0.269974,0.0689835,-0.950751,-0.823744,-1.08916,-1.19889,-2.5234,-2.48284,-0.178736,-0.183666,1.14311,0.944184,1.89116,1.68187,-0.927353,-1.07493,0.173252,0.181121
2386,0.204333,0.128781,0.724723,0.696752,0.0996399,0.00170752,0.978138,0.981665,0.344592,0.345139,0.934059,0.988527,0.90193,0.859739,0.998891,1.0294,0.610013,0.698728,0.271797,0.334454,-0.364948,0.0502041,1.1671,1.41714,-0.0824014,0.0542293,-0.0656531,-0.172216,-0.383541,-0.347274,-1.08095,-1.08121,-0.447478,-0.651775,-1.39523,-1.60236,-0.0367215,-0.179887,-0.505811,-0.504302
2387,0.395336,0.31916,0.259949,0.233389,0.641045,0.544607,0.798537,0.803998,0.348943,0.355688,0.64362,0.744785,0.691266,0.649369,0.0569301,0.0876505,0.923533,0.930138,0.899651,0.963984,-0.598983,-0.23734,-1.003,-0.753445,-0.137893,-0.00642862,-1.11737,-1.23012,0.28051,0.317161,-0.241185,-0.239081,1.72105,1.52064,1.17502,0.964189,-0.470518,-0.619792,1.37517,1.37798
2388,0.871278,0.796122,0.00509835,-0.0226656,0.0458135,-0.0498349,0.00428271,0.00844998,0.94057,0.945656,0.44552,0.501043,0.165347,0.122543,0.176143,0.20895,0.352897,0.360208,0.248711,0.312988,-0.566013,-0.203415,-0.0695285,0.184115,-0.575522,-0.447845,0.539279,0.421282,-0.365247,-0.323033,0.0461913,0.0501583,2.10508,1.90309,0.253951,0.088488,-0.0183617,-0.161288,-0.549212,-0.546682
2389,0.776138,0.680666,0.468793,0.440411,0.946594,0.852816,0.299064,0.309809,0.487616,0.492266,0.508332,0.683813,0.55862,0.430287,0.928596,0.961587,0.302291,0.31064,0.440653,0.463248,-0.110619,0.247041,0.291149,0.53931,-0.306122,-0.170243,0.791508,0.677711,0.642164,0.678823,-0.61461,-0.615904,1.62898,1.42597,-0.58037,-0.787213,-1.01442,-1.16083,0.126205,0.125741
2390,0.640654,0.56521,0.255479,0.225956,0.848663,0.715476,0.609305,0.611167,0.28489,0.296366,0.762099,0.866583,0.782553,0.738031,0.0703813,0.106251,0.553772,0.611919,0.579505,0.613507,-1.17708,-0.820452,0.0597954,0.308319,0.288507,0.427224,-1.48794,-1.60229,-0.86472,-0.822129,-1.66303,-1.66447,0.732816,0.534169,1.77861,1.57203,-0.540485,-0.685849,0.0658109,0.0725211
2391,0.524964,0.449753,0.61286,0.581482,0.674294,0.578136,0.395027,0.399165,0.097737,0.100466,0.99468,1.04935,0.841215,0.797005,0.607329,0.644022,0.905292,0.913197,0.58043,0.763766,-1.17259,-0.81503,1.68185,1.92925,-0.27496,-0.139349,0.853616,0.743976,-0.556741,-0.512755,0.710269,0.712469,-0.457853,-0.652952,-0.558047,-0.760792,1.49494,1.34706,-0.280469,-0.268579
2392,0.736347,0.661083,0.743211,0.637984,0.242422,0.148225,0.955627,0.962509,0.276573,0.280503,0.421897,0.474989,0.323577,0.280971,0.730574,0.765322,0.702716,0.715143,0.849748,0.914026,-0.141033,0.21582,0.635833,0.887229,-0.178555,-0.0491381,0.164242,-0.0168466,-0.777676,-0.725855,0.125118,0.12394,1.13848,0.94932,0.0249213,-0.184416,0.681103,0.537698,-0.218691,-0.200355
2393,0.385437,0.311021,0.726198,0.694485,0.621508,0.525624,0.951684,0.961289,0.726087,0.728706,0.250845,0.302394,0.0296331,-0.0156966,0.1869,0.219799,0.511329,0.517088,0.667145,0.733686,-1.08101,-0.726092,-0.828623,-0.57852,0.227124,0.29886,-0.669422,-0.777669,1.12205,1.16823,-1.30143,-1.30848,-0.67099,-0.864646,-2.13227,-2.33738,0.145112,-0.0785194,0.586817,0.607909
2394,0.54869,0.550386,0.363052,0.329971,0.383882,0.219907,0.150564,0.160358,0.183726,0.185216,0.672794,0.726005,0.665946,0.620892,0.331826,0.366181,0.658686,0.666478,0.217541,0.282378,2.58485,2.94377,-0.872002,-0.623285,0.519188,0.646858,-0.382786,-0.489251,-1.53532,-1.48395,0.823871,0.812501,0.250249,0.0565761,1.24357,1.04597,-0.551502,-0.694737,-0.537079,-0.521875
2395,0.865346,0.789751,0.693331,0.624325,0.00962096,-0.0858104,0.0834055,0.0934182,0.854553,0.856107,0.19154,0.245868,0.368246,0.324224,0.914275,0.949594,0.10548,0.111984,0.257675,0.324253,-0.660834,-0.299774,-1.16085,-0.9123,-0.636619,-0.513044,-1.05661,-1.15648,-0.00452563,0.0536701,1.16529,1.14703,0.849942,0.656271,1.12413,0.849333,0.753457,0.607166,-0.592415,-0.575095
2396,0.580732,0.439697,0.952552,0.918679,0.430922,0.304531,0.866111,0.877275,0.852776,0.924469,0.410661,0.39836,0.947012,0.900724,0.10237,0.137818,0.790021,0.794262,0.903763,0.967598,-1.3942,-1.02851,-1.0122,-0.732558,-2.07008,-1.9491,0.545068,0.448099,-1.89281,-1.83176,0.780172,0.762807,-0.663808,-0.859664,0.844365,0.652693,0.779681,0.633802,-1.52704,-1.50473
2397,0.16617,0.0896433,0.469326,0.435389,0.788702,0.694873,0.526511,0.535809,0.990152,0.99283,0.497494,0.550852,0.481802,0.434993,0.27329,0.214015,0.43203,0.43511,0.289167,0.352396,1.10391,1.47374,-0.758013,-0.552815,-0.595775,-0.479719,0.351609,0.258311,1.18261,1.23691,1.47793,1.46793,-0.553583,-0.751367,0.426594,0.232975,-1.26013,-1.41289,-0.660175,-0.635856
2398,0.61984,0.542104,0.857487,0.825371,0.437561,0.344792,0.732148,0.742496,0.26313,0.266323,0.0650451,0.120133,0.864381,0.816448,0.25261,0.290212,0.421272,0.382414,0.912063,0.976852,1.48796,1.86274,-0.621623,-0.373073,-0.301991,-0.187647,0.573486,0.470954,1.87287,1.93139,-1.09636,-1.09788,-2.46051,-2.65903,0.21662,0.0279268,0.980423,0.8307,0.795624,0.813348
2399,0.725796,0.648106,0.333368,0.302645,0.837562,0.74267,0.106488,0.114819,0.54816,0.553595,0.454076,0.509464,0.844604,0.835487,0.126343,0.163463,0.327164,0.329718,0.658396,0.72205,0.348939,0.719491,0.506957,0.752658,0.519979,0.62775,0.778542,0.683598,-0.386344,-0.327024,1.09866,1.10368,-1.8671,-2.05933,-1.28966,-1.48006,-1.64519,-1.79475,-0.931494,-0.90923
2400,0.200458,0.122074,0.032288,0.00279378,0.261949,0.16902,0.659472,0.667397,0.0575719,0.064769,0.431153,0.486288,0.904148,0.854526,0.396815,0.407229,0.784592,0.785134,0.0198598,0.0813869,1.49494,1.85791,-1.08088,-0.834939,-0.213234,-0.110206,1.77182,1.68081,-0.131959,-0.177287,-0.192634,-0.190063,0.710392,0.511776,-1.80431,-1.99117,-0.213479,-0.364617,0.556488,0.572763
2401,0.715108,0.638681,0.791283,0.764525,0.386755,0.253461,0.0446111,0.0543847,0.265753,0.286145,0.930582,0.983769,0.174972,0.126693,0.612397,0.650995,0.760938,0.760652,0.699935,0.760247,0.704664,1.06679,-0.701962,-0.449456,0.463395,0.566435,1.26438,1.16735,-0.0167499,-0.0275494,-0.539251,-0.543657,-0.535913,-0.737153,-0.841308,-1.05913,-1.69419,-1.85242,1.28972,1.30527
2402,0.776135,0.698934,0.305491,0.276749,0.431796,0.337902,0.853021,0.860738,0.502864,0.507521,0.584597,0.582155,0.580637,0.533662,0.678761,0.756633,0.194307,0.195135,0.858087,0.917509,1.09184,1.45579,1.03145,1.27876,1.584,1.68653,1.17166,1.07156,0.0678435,0.122188,-1.72017,-1.72978,0.403453,0.199714,0.0561651,-0.12709,-0.313609,-0.469094,-0.584247,-0.572028
2403,0.263619,0.188077,0.159005,0.188807,0.94737,0.851916,0.944731,0.863228,0.467448,0.473165,0.126264,0.18054,0.646796,0.538049,0.821657,0.862271,0.548846,0.549009,0.763318,0.731169,-1.55987,-1.19945,1.35747,1.60359,-1.24681,-1.1419,1.59742,1.49596,0.813834,0.863033,-2.08529,-2.09875,0.807316,0.598664,0.319465,0.144592,-0.567478,-0.722792,1.75122,1.77034
2404,0.309982,0.233364,0.128073,0.100865,0.124468,0.0273551,0.858909,0.865719,0.785358,0.790149,0.443896,0.496118,0.589492,0.542435,0.0860228,0.126645,0.899781,0.902883,0.483035,0.54483,-0.533498,-0.168605,-1.664,-1.41356,-0.55538,-0.449937,0.445893,0.347469,-0.641325,-0.590562,-1.87194,-1.88438,-0.100439,-0.308352,-0.465764,-0.644146,-0.0668032,-0.214926,-0.999741,-0.978471
2405,0.607659,0.530674,0.639283,0.613304,0.910931,0.816102,0.0311499,0.0381605,0.630768,0.689936,0.521013,0.546707,0.414128,0.367543,0.13278,0.172035,0.0179229,0.0231184,0.299068,0.35849,-2.55163,-2.19412,1.76704,2.02172,-0.377282,-0.212727,-1.21095,-1.31412,0.410588,0.457882,0.382056,0.365713,-0.402876,-0.613431,0.0714852,-0.135992,0.440604,0.29294,1.06044,1.07549
2406,0.0805822,0.0046426,0.843487,0.815765,0.801582,0.704569,0.307087,0.270724,0.583297,0.589723,0.545394,0.597296,0.99329,0.948695,0.909047,0.949828,0.319328,0.32307,0.547058,0.606838,0.0251014,0.376558,0.235154,0.494565,-0.0817031,0.0244832,-0.342561,-0.442154,-2.17833,-2.13553,0.314351,0.236145,0.0859016,-0.121452,0.553606,0.372162,-0.87671,-1.0223,-0.530197,-0.508291
2407,0.676582,0.599664,0.436235,0.436968,0.365153,0.363744,0.495715,0.503288,0.0639921,0.0712972,0.0616858,0.112577,0.120817,0.0769587,0.698762,0.75523,0.160962,0.164653,0.48297,0.542563,-0.156982,0.200824,-0.592122,-0.330436,0.604796,0.716448,-0.155816,-0.246675,-1.95079,-1.90195,0.122154,0.106577,0.116355,-0.0905507,-0.141156,-0.262931,0.0917008,-0.0488258,0.922511,0.940914
2408,0.701563,0.663868,0.085048,0.0581698,0.122893,0.0229202,0.36821,0.39799,0.606832,0.615666,0.382819,0.432684,0.0562306,0.0128281,0.52023,0.560631,0.420358,0.442125,0.0469537,0.106342,0.825638,1.18542,1.88244,2.14815,-2.10657,-1.98829,0.0443478,-0.0511955,-0.364885,-0.318821,1.07097,1.05641,0.837701,0.631295,-0.71789,-0.898024,0.042066,-0.101944,1.11871,1.1436
2409,0.878379,0.728072,0.819348,0.794183,0.169645,0.0696053,0.284323,0.292692,0.842683,0.851526,0.499238,0.546468,0.979256,0.9355,0.05246,0.0939878,0.717857,0.719598,0.0561352,0.117059,-1.31484,-0.961274,1.17852,1.47739,-0.823129,-0.701184,-0.313283,-0.411003,0.934306,0.974694,0.342106,0.329981,2.70418,2.50089,0.097129,-0.0769728,-0.254669,-0.402691,-0.554016,-0.533359
2410,0.978598,0.792276,0.241887,0.217512,0.601565,0.503709,0.748581,0.755225,0.113987,0.125019,0.954451,0.999789,0.24177,0.197932,0.75888,0.801357,0.712605,0.687488,0.832599,0.892447,0.826971,1.18111,0.546314,0.806635,-0.0678325,0.0519919,-0.415422,-0.506793,-0.760395,-0.725234,0.92531,0.913315,-1.88779,-2.09108,-1.21526,-1.38835,-0.307893,-0.526663,0.716106,0.732706
2411,0.933398,0.85648,0.675654,0.65166,0.703622,0.605033,0.972914,0.980195,0.332831,0.345698,0.045131,0.090163,0.36172,0.252812,0.0622932,0.102884,0.778417,0.655379,0.589243,0.571707,0.00738723,0.286084,0.561942,0.822719,-0.0979337,0.0225118,0.957645,0.874003,1.67332,1.71355,0.782669,0.773988,0.273005,0.0656222,-1.73242,-1.89945,-0.509531,-0.650635,-1.26508,-1.25415
2412,0.0855888,0.00903408,0.85382,0.830348,0.530288,0.45701,0.849793,0.858062,0.799051,0.813518,0.240399,0.283907,0.350785,0.307692,0.668286,0.707426,0.693288,0.623269,0.193217,0.250967,-0.963086,-0.608945,1.48854,1.74398,0.3043,0.422804,0.371116,0.293291,-0.844082,-0.809112,0.0201308,0.0149794,1.70872,1.49803,-0.579508,-0.782556,1.35848,1.21848,-1.29134,-1.27718
2413,0.0457679,-0.0321066,0.0256712,0.000480086,0.408579,0.308987,0.154229,0.160907,0.488159,0.527623,0.862175,0.904666,0.127599,0.0865312,0.107269,0.146269,0.587592,0.591159,0.33624,0.451096,-1.32997,-0.982685,-0.61723,-0.36062,-0.520687,-0.410865,-0.211807,-0.287422,-2.78779,-2.75978,-0.393238,-0.401353,0.32982,0.124969,0.596633,0.334341,-0.541055,-0.685101,-2.00409,-1.99451
2414,0.444745,0.423382,0.690575,0.66469,0.883543,0.782582,0.152019,0.237555,0.227184,0.241727,0.198995,0.239719,0.393363,0.352948,0.973975,1.01253,0.0972376,0.101142,0.594008,0.651225,-2.22774,-1.88063,0.367736,0.622763,0.0753513,0.186602,0.189464,0.106638,0.155426,0.187202,-0.102575,-0.049898,0.277983,0.130795,1.61827,1.45124,-1.1547,-1.2946,0.454869,0.464774
2415,0.956063,0.87887,0.880442,0.853426,0.0324323,-0.0683949,0.206544,0.314202,0.671503,0.685524,0.955045,0.996585,0.0728193,0.0323813,0.218408,0.257015,0.160389,0.143899,0.561218,0.617205,0.045924,0.386131,0.434045,0.685453,0.103623,0.27472,0.196239,0.118206,0.0074537,0.140638,0.304785,0.301557,0.33875,0.136621,0.0105595,-0.164499,0.657038,0.509892,0.564673,0.577904
2416,0.282973,0.207092,0.0655698,0.0388097,0.958779,0.857511,0.382509,0.390849,0.0685264,0.0808034,0.207027,0.246457,0.754147,0.715273,0.457942,0.496853,0.181087,0.186656,0.284535,0.374794,-0.231766,0.105008,-0.41419,-0.156563,0.255702,0.362838,-0.0727382,-0.148486,0.0590895,0.0940746,-2.54881,-2.5497,2.06689,1.86286,-1.38596,-1.56459,-0.0714258,-0.222478,-0.630901,-0.611097
2417,0.208136,0.174369,0.186146,0.153934,0.176718,0.0770263,0.773682,0.779619,0.295853,0.306258,0.588709,0.625347,0.879346,0.84065,0.136149,0.174934,0.750062,0.756021,0.0755384,0.132382,0.430029,0.76876,-0.3709,-0.109372,-2.25941,-2.1458,-1.99297,-2.06135,0.234462,0.268138,0.663459,0.657099,-1.87781,-2.08494,-0.318706,-0.496439,-0.378963,-0.523225,2.17826,2.19515
2418,0.219529,0.141646,0.444488,0.269059,0.633521,0.535862,0.543028,0.515431,0.810277,0.820379,0.509908,0.519346,0.797247,0.735882,0.163684,0.200637,0.347888,0.350911,0.751937,0.806289,-0.332038,0.010161,1.15963,1.41834,1.53027,1.63672,-0.289053,-0.363606,0.110899,0.145503,1.18478,1.15537,0.878205,0.670029,0.50363,0.324613,-1.09667,-1.23898,-2.45048,-2.4336
2419,0.889854,0.812867,0.428715,0.384184,0.470377,0.373932,0.243877,0.251243,0.674122,0.684437,0.376884,0.413345,0.59733,0.631115,0.476332,0.490451,0.599519,0.602655,0.828047,0.882096,0.877854,1.22445,-0.051273,0.206304,-0.556362,-0.458506,-0.360707,-0.429913,0.992871,1.02458,1.6541,1.65364,0.467879,0.255914,0.209159,0.0290776,-0.0144668,-0.155063,-0.565721,-0.551318
2420,0.617798,0.540619,0.526069,0.499309,0.645326,0.521864,0.721186,0.728734,0.204159,0.216133,0.858165,0.895724,0.493527,0.526347,0.744215,0.780264,0.183635,0.188588,0.471749,0.52631,1.16572,1.50738,0.696666,0.960809,0.319962,0.418703,0.411758,0.348373,-0.301023,-0.275673,-1.50433,-1.50939,-0.391522,-0.60244,-0.30033,-0.482023,1.30968,1.16179,-0.496011,-0.483093
2421,0.405418,0.26837,0.0488771,0.021872,0.681119,0.669796,0.330855,0.40042,0.0978436,0.109228,0.0663682,0.10477,0.460197,0.421579,0.803855,0.856461,0.563099,0.569342,0.968852,1.02494,-1.11418,-0.76901,-0.54118,-0.28211,0.258371,0.358045,-0.98892,-1.04658,-0.0793226,-0.0557321,1.4995,1.49707,1.40139,1.18265,0.33445,0.155234,-0.899332,-1.0402,1.02823,1.04441
2422,0.0754502,-0.00387906,0.443145,0.417321,0.91583,0.817729,0.0635281,0.0721065,0.857861,0.867853,0.137643,0.175818,0.893313,0.85323,0.896229,0.932658,0.417791,0.42583,0.561533,0.61855,0.509901,0.85386,-1.10085,-0.847339,1.36079,1.46169,-0.0327291,-0.09773,-1.22487,-1.1994,-0.342359,-0.350903,-0.39013,-0.616202,-0.450255,-0.633505,0.0324013,-0.11263,0.435286,0.448211
2423,0.737261,0.657853,0.157358,0.13166,0.457255,0.445277,0.194691,0.201635,0.387676,0.399548,0.735394,0.771606,0.466596,0.488546,0.531916,0.653335,0.0600237,0.066678,0.515506,0.648671,1.49225,1.83845,0.364743,0.618136,-0.284067,-0.190224,1.86879,1.80734,0.603185,0.632096,-0.501404,-0.506515,-0.804468,-1.03032,-0.725914,-0.914463,1.79529,1.6446,1.19988,1.2112
2424,0.575293,0.494839,0.0998202,0.0724708,0.171629,0.0728263,0.701041,0.709476,0.928088,0.938435,0.92841,0.96535,0.164244,0.123862,0.336435,0.374011,0.950213,0.955167,0.549512,0.678792,1.52208,1.87238,0.943427,1.2039,0.504686,0.592483,1.59492,1.54064,-0.835693,-0.805323,0.844992,0.839792,-0.112156,-0.338801,1.64798,1.46325,-2.36461,-2.51057,-0.6421,-0.637776
2425,0.0423678,-0.0363788,0.43873,0.413114,0.910762,0.813698,0.566607,0.57709,0.540903,0.591105,0.921059,0.957531,0.846067,0.806753,0.922548,0.961946,0.959314,0.965188,0.651854,0.708913,-0.249276,0.0989923,-0.437865,-0.182725,-0.140461,-0.0536453,0.643619,0.590969,0.941863,0.97722,-0.0972109,-0.103286,0.235845,0.0814003,-0.487318,-0.671065,-1.4922,-1.59177,1.34843,1.34975
2426,0.34474,0.260641,0.0613016,0.0343239,0.381533,0.285224,0.829909,0.842408,0.236311,0.243776,0.394303,0.433275,0.350053,0.310951,0.252609,0.290048,0.587568,0.609918,0.791143,0.845971,-0.936427,-0.583018,-0.649939,-0.394838,-0.411543,-0.327382,0.684999,0.661285,-1.03609,-1.00226,-0.248662,-0.258898,0.720223,0.501601,-1.09194,-1.27415,-0.530824,-0.672967,-0.315904,-0.311539
2427,0.5435,0.55766,0.205254,0.145638,0.97564,0.878247,0.401567,0.439277,0.15507,0.163605,0.26917,0.333138,0.320641,0.282564,0.144954,0.183118,0.247807,0.254647,0.00414551,0.0604798,1.25452,1.60612,0.102492,0.359667,-0.022822,0.0556508,0.790838,0.7316,1.31877,1.35128,0.24545,0.232503,-1.2103,-1.42092,-1.25041,-1.52822,0.391795,0.245833,0.42195,0.420968
2428,0.933427,0.85468,0.283458,0.256952,0.649765,0.585315,0.0246816,0.0361462,0.606614,0.616241,0.194693,0.233002,0.582259,0.544136,0.782484,0.818058,0.690996,0.699847,0.504384,0.559111,-0.159971,0.186547,-0.146781,0.115763,-0.467907,-0.385765,1.84556,1.78814,-1.64645,-1.62057,-0.359616,-0.37143,0.19975,-0.0173197,-1.60629,-1.7823,-0.365041,-0.517991,0.954238,0.954699
2429,0.924544,0.850592,0.106404,0.0770533,0.366314,0.292383,0.374004,0.384933,0.021602,0.0323016,0.367928,0.310511,0.497728,0.459775,0.630326,0.677184,0.563602,0.572879,0.648788,0.701636,-0.420781,-0.0800083,-0.723861,-0.46316,-0.437148,-0.355121,1.35508,1.29052,2.2483,2.27926,-0.401188,-0.417836,-0.938502,-1.08651,-0.658897,-0.836797,-0.231891,-0.418337,-0.060577,-0.0645887
2430,0.92571,0.846504,0.349004,0.319171,0.0968456,-0.000548135,0.943274,0.952616,0.679712,0.692687,0.349266,0.38802,0.163791,0.124615,0.50141,0.53631,0.0686059,0.0777914,0.420592,0.454637,-1.13233,-0.792276,-2.67267,-2.41583,0.544998,0.628198,-0.928152,-0.989479,-2.34321,-2.31224,0.438099,0.424289,-1.9368,-2.15571,1.11043,0.935934,-0.172822,-0.318682,0.291173,0.287345
2431,0.71542,0.637659,0.878742,0.846925,0.987949,0.891639,0.996091,1.00685,0.176017,0.18945,0.975445,1.01348,0.952828,0.914898,0.12728,0.164345,0.644075,0.65252,0.153878,0.207637,-0.371579,-0.0346372,-0.101713,0.155302,-0.765319,-0.683697,1.63227,1.57448,-1.40494,-1.37101,2.10585,2.09552,0.759583,0.545597,0.685683,0.516216,1.19134,1.0494,0.157848,0.158013
2432,0.0606574,-0.0187156,0.961952,0.931288,0.492899,0.397358,0.166186,0.174778,0.82327,0.834351,0.266139,0.303774,0.12904,0.092507,0.735681,0.774119,0.0940781,0.103224,0.795989,0.850982,0.0539586,0.385214,-0.614377,-0.361503,-1.83153,-1.74955,0.56586,0.502556,-0.0880178,-0.0465903,0.24131,0.234038,1.89284,1.68349,-0.878707,-1.0535,-1.49114,-1.62749,-2.90194,-2.89763
2433,0.0383465,-0.0387954,0.17842,0.149374,0.773563,0.678643,0.191862,0.158232,0.833156,0.842346,0.271365,0.314503,0.0183055,-0.0167226,0.979148,1.01967,0.79086,0.799813,0.179609,0.23578,-0.830577,-0.497438,-1.50994,-1.26365,-0.287545,-0.203619,-2.00854,-2.06736,-0.116517,-0.130263,-0.562201,-0.569574,-0.268493,-0.473816,-0.407049,-0.584966,1.04087,0.909613,0.66987,0.673069
2434,0.36776,0.288781,0.488455,0.381276,0.0254819,-0.0713878,0.133473,0.141687,0.0591059,0.0673761,0.288898,0.325232,0.972147,0.938002,0.0330418,0.0726663,0.727997,0.740044,0.41363,0.468559,-2.64772,-2.31859,1.44329,1.68872,-1.54677,-1.4686,-0.17865,-0.240011,-0.255493,-0.213937,0.626196,0.625432,-0.916431,-1.11795,1.66167,1.48619,-0.893879,-1.02296,1.3185,1.31497
2435,0.974732,0.894758,0.642199,0.613178,0.00124131,-0.0356158,0.770468,0.779029,0.830424,0.836424,0.80744,0.842559,0.643565,0.607598,0.608081,0.646283,0.187561,0.200441,0.0654506,0.122634,-0.365558,-0.0365604,0.000393805,0.239666,0.999123,1.07709,0.42234,0.366883,1.96939,2.00583,0.183302,0.177086,-0.160894,-0.365163,-1.46286,-1.64107,0.963756,0.830798,1.13411,1.12569
2436,0.623359,0.544697,0.552763,0.524815,0.0980131,0.000156218,0.247595,0.256092,0.234167,0.242008,0.964844,1.00203,0.935437,0.898755,0.612905,0.651938,0.553113,0.566285,0.479192,0.536414,0.837813,1.16543,-0.13514,0.10369,-0.462482,-0.389503,-0.0950589,-0.146574,-2.04671,-2.01506,1.2385,1.23548,-0.450283,-0.654736,-0.384099,-0.559413,1.14221,0.946347,-0.191517,-0.199966
2437,0.636671,0.559889,0.168255,0.140453,0.528817,0.429235,0.011467,0.0184859,0.414602,0.422045,0.172244,0.211076,0.286626,0.250579,0.0188326,0.0561189,0.0759918,0.0916126,0.605288,0.662403,0.041165,0.374302,-0.748662,-0.505968,2.06652,2.13461,0.553605,0.508425,-1.40697,-1.38218,-1.81001,-1.82057,0.53411,0.328967,-0.218094,-0.397275,1.20214,1.0619,1.58404,1.57574
2438,0.974157,0.896988,0.303613,0.274306,0.532362,0.436248,0.895231,0.904601,0.196291,0.204987,0.535856,0.575395,0.342743,0.290716,0.59611,0.633994,0.652464,0.666341,0.4432,0.502028,0.411732,0.748921,-0.639542,-0.399042,-1.15907,-1.0905,1.79297,1.74928,-0.131216,-0.103247,1.11886,1.10569,-0.883026,-1.09297,0.866954,0.684382,-0.447689,-0.582111,-0.443329,-0.458545
2439,0.227024,0.152071,0.651597,0.624809,0.565973,0.443262,0.754785,0.763066,0.650054,0.657622,0.494847,0.533427,0.366676,0.330854,0.299184,0.33706,0.558939,0.570876,0.528958,0.660968,-0.0541142,0.283605,0.0617656,0.308788,-0.251991,-0.183375,-0.447862,-0.496587,0.45539,0.482801,-0.647528,-0.663168,-0.233495,-0.491483,1.01647,0.831872,2.91739,2.78644,-0.700548,-0.723098
2440,0.191401,0.12307,0.195853,0.166592,0.440473,0.450275,0.0261664,0.0354242,0.0639501,0.0736829,0.0614296,0.0973987,0.873085,0.837275,0.517993,0.555296,0.982027,0.995561,0.76123,0.819908,2.10596,2.44049,-1.49518,-1.24905,0.370685,0.444856,0.373997,0.326879,-1.05564,-1.03262,-0.773229,-0.788459,0.317599,0.110007,-0.320715,-0.508736,-1.20578,-1.33673,-0.703389,-0.730477
2441,0.217737,0.0940686,0.865091,0.836139,0.548274,0.457289,0.161455,0.169577,0.972885,0.979829,0.734006,0.769461,0.474057,0.436937,0.46279,0.499631,0.482436,0.495809,0.59443,0.669678,-0.965941,-0.627147,-1.02918,-0.787228,0.176807,0.247263,1.47832,1.429,0.599666,0.62676,0.0820413,0.0679276,-0.0211928,-0.205564,-2.48617,-2.67469,0.80509,0.678833,1.17044,1.13943
2442,0.140332,0.0650674,0.797942,0.767097,0.563884,0.464302,0.70117,0.707048,0.676348,0.705015,0.52792,0.56519,0.758433,0.68024,0.713328,0.749829,0.716028,0.727803,0.470605,0.519447,-1.93627,-1.60073,1.28102,1.53122,0.758181,0.830692,1.95247,1.8982,0.0806326,0.108725,-0.130169,-0.147717,-0.321031,-0.521134,0.28574,0.0913305,1.25885,1.13734,0.583977,0.557954
2443,0.774702,0.700878,0.410079,0.3775,0.0380718,-0.0591206,0.594046,0.554766,0.424013,0.430201,0.980032,1.01851,0.961696,0.923542,0.0203977,0.0569196,0.0477646,0.0569256,0.310259,0.369217,1.19458,1.52305,-0.168812,0.0821703,-0.82777,-0.758369,0.825782,0.764989,-1.46435,-1.43465,-0.666019,-0.689222,0.935055,0.740032,2.18957,1.98951,0.0838201,-0.0354782,-1.17515,-1.1974
2444,0.230775,0.154528,0.393853,0.361909,0.985699,0.889659,0.442127,0.402483,0.373894,0.472693,0.536,0.552298,0.813016,0.872307,0.731251,0.768931,0.405759,0.322776,0.988657,1.04808,1.02653,1.36094,-1.00048,-0.74283,-0.566784,-0.495903,0.588908,0.530871,2.02613,2.05296,0.285347,0.26061,-0.49095,-0.681907,0.49677,0.296309,-1.59841,-1.71176,-1.41901,-1.44669
2445,0.242405,0.164834,0.858791,0.824986,0.750973,0.656528,0.245608,0.250201,0.511977,0.515185,0.0456639,0.0860846,0.861272,0.821071,0.994286,1.02956,0.646187,0.588626,0.611151,0.594815,-0.548815,-0.211053,-0.463471,-0.203899,0.559314,0.624194,-0.23956,-0.292685,-0.823064,-0.798609,-0.0290798,-0.0481084,0.545499,0.359183,0.48965,0.28689,-1.19197,-1.29933,-1.31345,-1.33356
2446,0.628815,0.553337,0.690125,0.656432,0.838385,0.742794,0.997876,1.0028,0.70895,0.710479,0.90131,0.941795,0.93986,0.900063,0.0428741,0.0754828,0.845315,0.854476,0.0819332,0.141552,0.00512945,0.345942,-1.48343,-1.2317,-1.37575,-1.31169,1.97381,1.91695,-1.00702,-0.981941,-0.689233,-0.71417,0.76211,0.572018,-1.40029,-1.59758,-0.29883,-0.404284,-0.89447,-0.921501
2447,0.234835,0.157187,0.213932,0.178995,0.190068,0.0939932,0.192072,0.196781,0.52203,0.551319,0.945297,0.986924,0.0421913,0.00152675,0.150338,0.18182,0.475543,0.48512,0.923703,0.985538,-0.0408826,0.369376,1.54567,1.79132,0.153195,0.219116,-0.49972,-0.548789,0.88715,0.912149,0.707455,0.678196,-0.532133,-0.724936,0.229108,0.0360021,0.318456,0.211292,0.472537,0.450697
2448,0.420179,0.282996,0.745349,0.711147,0.300052,0.205787,0.744557,0.749359,0.391985,0.39216,0.121196,0.163468,0.104615,0.0650409,0.748774,0.780109,0.345183,0.352624,0.336448,0.399843,0.0584168,0.392811,1.28198,1.53235,0.1538,0.219091,-0.569882,-0.615096,0.30354,0.332389,-0.997924,-1.02849,1.32447,1.12792,1.48428,1.28322,0.428651,0.372469,-0.5653,-0.5834
2449,0.52068,0.408805,0.638929,0.602141,0.892529,0.79881,0.178583,0.181175,0.515836,0.516555,0.627247,0.671078,0.789893,0.752562,0.573068,0.603271,0.715729,0.723089,0.299122,0.324273,-2.57204,-2.24017,0.130908,0.381456,-0.952981,-0.894152,-0.0689764,-0.115349,-1.34927,-1.32013,-1.75579,-1.7875,-1.74136,-1.93632,-0.396377,-0.601244,0.640171,0.533647,-0.827831,-0.847953
2450,0.66892,0.534614,0.0226771,-0.0144116,0.456896,0.363481,0.714305,0.718647,0.278149,0.279607,0.344906,0.363945,0.38842,0.352224,0.599917,0.628975,0.128524,0.134041,0.185394,0.248703,0.37828,0.704813,-0.104615,0.150465,0.132126,0.195283,1.20423,1.15848,-0.575265,-0.547881,0.501731,0.462593,1.60142,1.40582,-0.29302,-0.499196,1.3249,1.21275,-2.38333,-2.40373
2451,0.797661,0.660423,0.731927,0.69601,0.454607,0.35975,0.188373,0.190404,0.396302,0.399002,0.0101558,0.0568123,0.749509,0.714685,0.0666968,0.0979258,0.156519,0.125099,0.550865,0.613894,0.375984,0.695533,-2.02268,-1.77126,2.0398,2.10289,-1.60047,-1.65158,1.21175,1.23466,1.48517,1.44211,1.10408,0.914284,0.949528,0.748024,-1.26767,-1.37871,0.250065,0.227797
2452,0.863881,0.786233,0.795947,0.737725,0.72701,0.631018,0.267978,0.269033,0.859002,0.862166,0.522046,0.569624,0.497803,0.463862,0.0932245,0.12363,0.0742176,0.116157,0.189485,0.252794,-0.681631,-0.355694,1.43353,1.68342,-1.40333,-1.34005,-1.24544,-1.30319,-0.118449,-0.0986207,-0.195299,-0.234394,1.27136,1.08244,0.278868,0.155976,-1.04016,-1.15348,-0.827481,-0.85509
2453,0.589593,0.60291,0.815338,0.779441,0.0224869,-0.0732734,0.819159,0.821612,0.6098,0.613879,0.510835,0.601811,0.667758,0.634574,0.787487,0.814944,0.0996211,0.107216,0.341681,0.404897,0.622242,0.953367,0.625174,0.87484,-0.0458823,0.0239224,0.0907523,0.0311452,2.82175,2.84836,-0.35864,-0.403181,-1.06555,-1.25427,-0.233626,-0.436073,-1.42413,-1.52986,0.0621439,0.0972662
2454,0.390619,0.419587,0.858008,0.821156,0.624706,0.530286,0.817193,0.820392,0.576773,0.555208,0.593182,0.633999,0.0181524,-0.0136011,0.667834,0.719046,0.481214,0.487969,0.878347,0.939792,-0.167786,0.162243,-1.62605,-1.37561,-1.27285,-1.19763,-2.04907,-2.10312,0.156461,0.174791,-2.18493,-2.23465,-1.33794,-1.52817,-0.489545,-0.687562,1.57398,1.4719,1.07176,1.04962
2455,0.314406,0.236264,0.694845,0.657947,0.00650527,-0.0882538,0.381821,0.384156,0.493635,0.496537,0.721404,0.666186,0.76426,0.730804,0.597165,0.623149,0.175056,0.184119,0.864616,0.925594,0.561767,0.887909,-0.0256074,0.229099,-0.553811,-0.475331,2.22028,2.17022,1.03192,1.05387,-0.958367,-1.01037,0.0677989,-0.124577,0.363917,0.164586,-0.99293,-1.10074,0.611797,0.589528
2456,0.491634,0.411671,0.0541837,0.0176493,0.455008,0.34251,0.434537,0.43839,0.679687,0.609608,0.648714,0.698373,0.262502,0.229765,0.783253,0.810115,0.56165,0.569868,0.380882,0.503159,0.364101,0.69803,0.509721,0.76803,-0.888265,-0.811075,0.259504,0.205634,-1.54013,-1.52126,-1.26257,-1.31909,-0.642112,-0.82976,0.994657,0.801842,0.263355,0.154098,0.728294,0.702657
2457,0.158515,0.0765188,0.905497,0.871078,0.869114,0.773274,0.932758,0.936297,0.707655,0.72268,0.886032,0.936694,0.488809,0.50402,0.626283,0.594071,0.0845089,0.0951958,0.0202819,0.0807228,-1.25781,-0.917294,-0.204227,0.0518398,-0.369615,-0.362772,2.56908,2.51704,-2.02385,-2.00804,0.51612,0.460911,1.20876,1.0231,1.19311,0.995391,0.795825,0.692754,1.57506,1.55431
2458,0.959656,0.878049,0.503266,0.467424,0.104003,0.00876421,0.163116,0.166892,0.934768,0.835751,0.479121,0.530551,0.811921,0.778275,0.350207,0.378027,0.175011,0.183369,0.204105,0.263048,-0.794795,-0.4504,0.662251,0.912425,0.0100287,0.0855315,-0.203943,-0.261971,-1.10679,-1.09858,0.244679,0.183998,-0.23632,-0.428321,0.0465712,-0.157312,-0.774067,-0.872155,-0.618906,-0.634735
2459,0.489481,0.462127,0.45299,0.350057,0.830279,0.734418,0.19321,0.194847,0.946401,0.948823,0.896243,0.949907,0.657233,0.623783,0.606357,0.633735,0.563525,0.57426,0.917028,0.977406,1.13187,1.47525,0.168484,0.426018,1.73301,1.80792,1.10962,1.05625,0.95636,0.96667,1.27375,1.2104,0.335794,0.141648,0.518891,0.311218,-0.3289,-0.428897,0.2183,0.202567
2460,0.125183,0.0462053,0.267505,0.232689,0.956341,0.860629,0.843179,0.847111,0.698209,0.700536,0.59987,0.651107,0.24401,0.212665,0.651348,0.763619,0.681785,0.769997,0.425949,0.486728,0.68089,1.02684,-0.621556,-0.368653,-0.134104,-0.0632005,-0.670465,-0.72828,0.0760991,0.081362,0.0825353,0.0242757,0.493943,0.294683,-0.065862,-0.199878,-0.478114,-0.5751,-0.306533,-0.319049
2461,0.713029,0.631835,0.744567,0.710456,0.266387,0.171678,0.631946,0.635109,0.703679,0.708531,0.846003,0.899216,0.0894993,0.13046,0.868773,0.893504,0.956003,0.965735,0.247306,0.357951,1.43647,1.78448,-0.0403684,0.217109,-0.506226,-0.430009,0.749545,0.685104,0.157861,0.163548,-0.120479,-0.175668,-0.388316,-0.582063,-0.499144,-0.710974,-0.243812,-0.335797,-1.58276,-1.60021
2462,0.301513,0.314198,0.604016,0.571669,0.690035,0.595846,0.76228,0.745673,0.934361,0.939118,0.156999,0.209117,0.0799085,0.0482554,0.298344,0.322488,0.288495,0.300359,0.168403,0.229173,-0.529148,-0.174051,-0.02175,0.233193,0.68928,0.765752,-1.47061,-1.52698,0.500263,0.505862,-0.120124,-0.17686,-0.383079,-0.580951,0.777398,0.565154,-1.43617,-1.52429,-1.00242,-1.01955
2463,0.0776404,-0.00343999,0.233959,0.202565,0.745583,0.652664,0.850737,0.856236,0.190459,0.197782,0.662203,0.716726,0.380022,0.349986,0.0882348,0.110878,0.16718,0.177583,0.357249,0.416366,0.596129,0.947714,0.687903,0.941023,1.11761,1.19472,-0.899363,-0.950362,0.571144,0.572971,-0.480087,-0.530455,-1.28219,-1.48797,-0.195661,-0.407166,-0.0584178,-0.140965,-0.664944,-0.68189
2464,0.541516,0.414807,0.713491,0.680332,0.284159,0.193499,0.453404,0.459391,0.256683,0.208332,0.701694,0.757108,0.0519077,0.0195814,0.85009,0.873311,0.862165,0.874172,0.758033,0.815824,0.371164,0.727065,0.676405,0.920511,0.156768,0.239106,0.856871,0.811759,0.0531059,0.0549353,2.14349,2.09184,0.23589,0.0363643,1.17118,0.965129,-0.268071,-0.347749,-1.14029,-1.15735
2465,0.914238,0.833054,0.469533,0.371114,0.782865,0.691818,0.952819,0.957298,0.210501,0.218881,0.262176,0.315555,0.996008,0.963469,0.262376,0.288258,0.186069,0.19918,0.336516,0.395235,-0.483296,-0.124434,0.641904,0.899999,0.483614,0.561819,0.373503,0.313494,0.189151,0.196675,-0.0688822,-0.114019,-0.378229,-0.578411,-1.56383,-1.76592,-0.997724,-1.08012,-0.38388,-0.394359
2466,0.28418,0.201928,0.0958836,0.0618954,0.139813,0.0475265,0.602475,0.605585,0.545251,0.553426,0.97073,1.02662,0.246328,0.215534,0.119719,0.146124,0.912053,0.926537,0.608201,0.668405,-0.469123,-0.103138,-0.388584,-0.127801,-0.635039,-0.505842,-0.145181,-0.18477,1.74632,1.7495,-0.655482,-0.702547,-0.36276,-0.563876,0.384572,0.18104,1.80341,1.72493,-1.41399,-1.42846
2467,0.633888,0.553749,0.832153,0.797909,0.239959,0.080574,0.711073,0.714476,0.877142,0.88797,0.908718,0.964671,0.504525,0.472134,0.840928,0.868446,0.140339,0.157518,0.590912,0.648898,1.12976,1.48793,0.0783621,0.334021,-1.65471,-1.5735,0.824716,0.779157,0.741988,0.739913,0.692668,0.64376,0.673465,0.477215,0.320788,0.112998,-0.0347364,-0.112209,0.207403,0.192504
2468,0.648992,0.568941,0.245716,0.211747,0.203369,0.113621,0.46603,0.534122,0.697217,0.791785,0.359172,0.415324,0.187122,0.155875,0.344599,0.372762,0.385569,0.403595,0.101679,0.15822,-0.495263,-0.141468,-0.672568,-0.414375,0.216527,0.305191,-0.920364,-0.960284,-3.08813,-3.09115,-1.54841,-1.59269,2.89354,2.69591,-1.67337,-1.87887,-1.44897,-1.52052,-2.17957,-2.1926
2469,0.426879,0.354616,0.909119,0.875957,0.861286,0.772615,0.350092,0.353767,0.686343,0.695599,0.683018,0.740461,0.158603,0.127488,0.258858,0.28695,0.918065,0.938187,0.553981,0.61268,-0.337074,0.0164923,1.9033,2.15676,0.151214,0.244533,1.26752,1.22813,0.838939,0.838443,0.583039,0.544164,-0.851357,-1.04898,1.07024,0.866763,0.477292,0.410823,-1.33879,-1.3553
2470,0.22152,0.140292,0.459922,0.468596,0.246052,0.158613,0.458183,0.462658,0.99264,1.00286,0.249768,0.304432,0.818644,0.785381,0.684946,0.713565,0.30759,0.327934,0.284769,0.342234,0.889494,1.24647,-0.769349,-0.507516,0.694136,0.78081,-1.4265,-1.46926,1.13807,1.1339,-0.336412,-0.439914,0.0786209,-0.112116,-1.29529,-1.49813,-1.71979,-1.79117,0.104192,0.093906
2471,0.889153,0.806573,0.094398,0.0612353,0.266702,0.179889,0.23709,0.290663,0.215135,0.22333,0.104529,0.160825,0.897694,0.807702,0.62039,0.647811,0.276848,0.269018,0.557792,0.615403,-1.08535,-0.731472,-0.700898,-0.444826,0.443349,0.536328,-0.712185,-0.75305,-1.07186,-1.07729,-1.38211,-1.42399,0.722565,0.440614,0.343396,0.135447,0.502866,0.4368,0.512403,0.505968
2472,0.772449,0.687907,0.460524,0.425968,0.930735,0.844606,0.113216,0.118668,0.0152855,0.0213275,0.449737,0.526316,0.815848,0.830024,0.96289,0.989842,0.24785,0.210102,0.157703,0.214842,-0.0715774,0.285439,0.519756,0.775546,-0.268759,-0.170979,-1.82665,-1.87086,0.0270531,0.0164522,-0.997365,-1.0411,1.17911,0.993345,0.859757,0.650442,-1.74923,-1.81032,0.341981,0.331986
2473,0.383241,0.298084,0.045433,0.0122747,0.0555598,-0.0300272,0.400498,0.308486,0.22247,0.299986,0.836438,0.891808,0.883892,0.852345,0.0585466,0.0837528,0.130843,0.151186,0.289273,0.414971,-0.616573,-0.257873,0.104249,0.429663,1.2628,1.35983,-0.993517,-0.961098,-0.415573,-0.42712,0.31499,0.275028,0.166931,-0.0233285,0.668215,0.460785,1.25915,1.19144,-1.48112,-1.49562
2474,0.212617,0.126086,0.155262,0.157138,0.424628,0.337293,0.495244,0.498304,0.574187,0.578645,0.836855,0.893878,0.577368,0.546336,0.0561612,0.0833895,0.419488,0.43693,0.55904,0.6151,-0.84175,-0.478522,-0.174891,0.0837807,-1.31202,-1.21616,-0.00138327,-0.0513327,1.10302,1.09545,0.717801,0.673607,-0.535932,-0.728512,-1.6192,-1.82186,0.447551,0.382073,0.831968,0.81524
2475,0.690197,0.603048,0.337273,0.302002,0.328442,0.301865,0.570741,0.581098,0.400914,0.408026,0.00537234,0.0606407,0.704174,0.671713,0.478014,0.54222,0.357584,0.377161,0.314374,0.369789,0.0111921,0.368839,1.73416,1.9993,-1.02396,-0.924088,1.1303,1.08394,-0.411474,-0.419978,0.0864443,0.0380666,-0.46603,-0.665312,0.99496,0.793014,-0.050904,-0.11371,0.10493,0.0835794
2476,0.714456,0.588127,0.00567582,-0.0282547,0.353447,0.266436,0.661611,0.663892,0.905471,0.911925,0.987959,1.04522,0.208013,0.175911,0.973821,1.00105,0.798516,0.816648,0.305361,0.359549,0.219385,0.572109,0.650448,0.91101,1.13656,1.23698,-0.190959,-0.232564,-0.484093,-0.495411,0.261637,0.221177,1.00773,0.814158,-1.20368,-1.40756,-0.544014,-0.609493,1.67642,1.65663
2477,0.72834,0.573205,0.321399,0.291605,0.100289,0.0129173,0.264712,0.267047,0.819094,0.826173,0.406601,0.555491,0.558148,0.527894,0.14259,0.168403,0.179661,0.196218,0.918196,0.973186,1.28876,1.634,0.594123,0.851863,0.689554,0.795568,0.326377,0.282526,-0.174384,-0.186036,-2.40108,-2.43382,-0.908738,-1.10836,0.118081,-0.0825381,-0.760577,-0.83292,0.00369646,-0.0203261
2478,0.641683,0.558283,0.705179,0.611464,0.223184,0.0812706,0.30431,0.305911,0.19427,0.201136,0.00850392,0.0657632,0.0250607,-0.00429288,0.882125,0.905664,0.563538,0.581061,0.47176,0.526795,0.0713768,0.413103,-0.968126,-0.705975,-1.58112,-1.47674,0.51959,0.478269,-0.581644,-0.531352,-3.50774,-3.54343,0.440646,0.247406,0.173948,-0.029551,2.0286,1.94579,-1.12751,-1.15011
2479,0.63051,0.543362,0.965254,0.931324,0.235549,0.149624,0.7486,0.749322,0.492605,0.498712,0.953969,1.01275,0.255706,0.226681,0.0982921,0.124124,0.948187,0.965903,0.939706,0.995752,-0.230281,0.116139,-0.734351,-0.474186,-0.533059,-0.43337,-0.327145,-0.36133,-0.865015,-0.876667,-0.872112,-0.902195,-0.817268,-1.01553,1.54588,1.34274,1.2452,1.16674,0.843915,0.822876
2480,0.336416,0.248849,0.382705,0.350291,0.952787,0.865611,0.726652,0.727416,0.483799,0.491434,0.679241,0.739825,0.18154,0.152896,0.480075,0.491635,0.0816729,0.100905,0.649431,0.71119,-1.34574,-0.997519,0.0626613,0.327143,-0.305037,-0.202421,-0.24968,-0.28822,0.297872,0.294401,-0.0155039,-0.0458085,0.444507,0.245633,-0.820719,-1.02215,0.985872,0.913046,-0.194468,-0.211221
2481,0.446995,0.271705,0.472155,0.439509,0.348259,0.26123,0.99894,0.997949,0.849201,0.8591,0.762213,0.820648,0.915416,0.887461,0.833533,0.859145,0.799349,0.81736,0.371001,0.426627,-0.0643714,0.282154,0.429639,0.695804,-1.13972,-1.03609,0.922149,0.878361,-1.37227,-1.3748,0.536062,0.50667,0.169892,-0.0282747,-0.711895,-0.920103,-0.893798,-0.973612,-0.77253,-0.792695
2482,0.387117,0.294561,0.877883,0.845183,0.0886034,0.0012313,0.935628,0.935369,0.512386,0.521891,0.577444,0.5681,0.505737,0.584551,0.147951,0.172107,0.627055,0.554501,0.882893,0.940144,-0.0788444,0.272874,2.21001,2.47184,0.525291,0.620522,0.673432,0.626639,2.46882,2.46277,1.09688,1.05915,0.402663,0.199905,0.266615,0.0531691,1.65499,1.58074,0.88668,0.871468
2483,0.407172,0.317417,0.0516052,0.0203387,0.430951,0.343183,0.345361,0.347594,0.823,0.833909,0.249309,0.315551,0.253831,0.28164,0.296095,0.31849,0.274189,0.291642,0.713024,0.769964,0.433529,0.786909,2.57609,2.8405,1.15912,1.24875,-1.42872,-1.47758,-0.580691,-0.589181,-0.779379,-0.817235,1.36124,1.15279,-0.960962,-1.17865,-1.98702,-2.06126,-0.623095,-0.63634
2484,0.866047,0.775099,0.57811,0.548092,0.337992,0.252217,0.42204,0.504092,0.853126,0.784373,0.00511075,0.0630033,0.00668528,-0.02127,0.180707,0.201942,0.707094,0.645516,0.278111,0.333742,-0.881085,-0.523132,-0.0195876,0.238929,1.16434,1.24873,-1.93717,-1.99104,-0.458361,-0.462657,-0.325252,-0.355666,-0.430277,-0.646057,-2.8492,-3.06312,0.721848,0.654977,-0.276881,-0.284407
2485,0.992897,0.900487,0.097821,0.0706552,0.688188,0.604933,0.660927,0.660591,0.722558,0.734838,0.161621,0.217794,0.385451,0.35549,0.296005,0.380573,0.981199,0.99939,0.445197,0.500678,0.625843,0.975997,-0.644517,-0.385602,-1.56011,-1.47273,-1.38958,-1.44299,0.22108,0.217352,1.38065,1.34725,0.104048,-0.108969,0.602466,0.391843,-1.33848,-1.40588,-0.86126,-0.865881
2486,0.876618,0.781821,0.852025,0.826158,0.117953,0.0362006,0.564616,0.563039,0.157071,0.170931,0.529594,0.587351,0.506314,0.475559,0.421129,0.559203,0.30641,0.324399,0.128018,0.18491,-0.193746,0.154645,0.247151,0.506147,-1.64264,-1.54848,0.658672,0.604679,0.151683,0.141919,0.605363,0.574262,-0.799677,-1.01599,-0.242597,-0.439367,-0.121515,-0.182304,-0.790498,-0.797656
2487,0.0268344,-0.0698512,0.788784,0.762024,0.555421,0.475526,0.133131,0.131143,0.209117,0.22327,0.561421,0.528752,0.0979275,0.0694709,0.634205,0.737834,0.188766,0.207228,0.134236,0.190223,1.05878,1.40265,0.534775,0.801752,1.09203,1.18827,1.68664,1.63135,0.673208,0.666689,-1.47949,-1.50582,-1.27842,-1.49311,-1.05995,-1.27058,-1.45078,-1.51381,-0.280282,-0.293426
2488,0.769979,0.674116,0.355511,0.328858,0.0843532,0.00579388,0.854823,0.854876,0.47694,0.489583,0.414727,0.470153,0.783444,0.756992,0.89523,0.916465,0.534576,0.475665,0.743899,0.799089,0.0710826,0.412405,-1.17657,-0.911416,0.108677,0.20013,-1.11552,-1.164,-0.644936,-0.650756,0.144715,0.118616,0.161601,-0.0606955,-1.14877,-1.35453,0.301673,0.243421,0.922716,0.910248
2489,0.323485,0.228269,0.54537,0.517595,0.0955632,0.0178001,0.636797,0.637353,0.461646,0.530536,0.683718,0.738924,0.0135974,-0.013501,0.737078,0.75995,0.724789,0.744102,0.218778,0.2731,0.103202,0.446331,0.25874,0.520939,1.77028,1.85674,-0.520055,-0.571881,-0.0119641,-0.0178691,-1.74774,-1.77456,-0.440019,-0.658172,0.746048,0.543651,-0.604993,-0.66432,0.0322005,0.0267408
2490,0.923425,0.829021,0.365503,0.337696,0.967013,0.88927,0.0367222,0.0385188,0.560554,0.571489,0.69287,0.813739,0.402832,0.40678,0.863817,0.88571,0.840111,0.858666,0.430103,0.417171,1.23478,1.58475,-1.36958,-1.11528,-2.03768,-1.95608,0.794779,0.746339,-0.123289,-0.124517,0.875419,0.847736,-0.106154,-0.321124,-1.59757,-1.80442,0.244217,0.187215,0.958011,0.954801
2491,0.460236,0.367968,0.431844,0.44901,0.984898,0.850467,0.69269,0.695555,0.855288,0.869065,0.832643,0.888554,0.8531,0.827061,0.386466,0.410204,0.122754,0.142744,0.506764,0.561242,-1.57155,-1.22331,-0.237546,0.0104546,1.01703,1.09601,-1.41573,-1.46574,0.858184,0.862544,0.538514,0.50932,-0.28419,-0.502855,-0.161048,-0.369982,0.205817,0.151161,-0.386833,-0.387105
2492,0.951619,0.859495,0.587859,0.560324,0.887436,0.811664,0.201938,0.202845,0.86857,0.881996,0.284503,0.339207,0.483924,0.554916,0.487945,0.511749,0.881845,0.900148,0.00336309,0.0555657,-1.66642,-1.32515,-0.974025,-0.721558,0.692485,0.773821,-0.393339,-0.439067,1.24132,1.25094,1.42206,1.39767,-0.17774,-0.394558,-0.614321,-0.819339,0.431291,0.282897,1.05078,1.04853
2493,0.331978,0.238778,0.0472349,0.018608,0.416722,0.341933,0.520855,0.592557,0.601336,0.614756,0.579799,0.598858,0.31057,0.282771,0.030042,0.0552959,0.742004,0.761745,0.635074,0.685096,0.529486,0.863989,-0.569578,-0.321767,-1.02165,-0.943187,-0.703441,-0.752076,1.88457,1.89875,0.832067,0.809143,0.450744,0.236276,0.593916,0.384267,0.46754,0.414632,-0.258727,-0.262408
2494,0.312445,0.218699,0.70259,0.672776,0.798354,0.722848,0.979958,0.98227,0.791785,0.804743,0.802063,0.858509,0.189782,0.242767,0.309964,0.290798,0.150484,0.172697,0.478976,0.571064,0.465251,0.792862,1.45854,1.70594,-1.41767,-1.33998,-1.76084,-1.80998,-0.932975,-0.921094,-0.936195,-0.959714,-0.894174,-1.10816,-0.157891,-0.373711,0.340387,0.284787,-0.364603,-0.375885
2495,0.834826,0.740658,0.66961,0.663951,0.778135,0.704026,0.606138,0.581773,0.364996,0.376275,0.705516,0.74976,0.229139,0.202764,0.492999,0.5263,0.0276324,0.049921,0.407988,0.457033,-1.5845,-1.26285,-0.292089,-0.0399721,-0.25879,-0.173495,0.0691047,0.0173761,0.50532,0.525442,-1.35822,-1.37605,-0.930471,-1.13693,0.0453984,-0.166106,-1.94171,-1.99548,-2.00777,-2.02241
2496,0.435318,0.339954,0.685356,0.655127,0.154222,0.079906,0.17849,0.181276,0.260661,0.217115,0.582253,0.641011,0.823583,0.798756,0.839017,0.761802,0.945982,0.969055,0.61179,0.661767,0.788507,1.1144,0.528481,0.775054,-2.63239,-2.54152,-1.78025,-1.8289,-0.0667252,-0.0543189,-1.31471,-1.33102,0.49774,0.295481,-0.289971,-0.508572,-0.417725,-0.472773,0.794165,0.783836
2497,0.398257,0.360751,0.184986,0.156845,0.823341,0.749488,0.0181936,0.0184122,0.0447742,0.0579559,0.281633,0.342211,0.545638,0.428534,0.97205,0.997304,0.595912,0.527103,0.816749,0.866501,-0.324536,0.000741133,-0.164796,0.0888123,-0.452049,-0.362331,0.930775,0.884782,0.482159,0.500422,-0.444617,-0.459238,-0.557892,-0.767126,0.650094,0.436931,1.51242,1.45857,-0.689933,-0.693256
2498,0.46757,0.381548,0.359832,0.278809,0.700327,0.628308,0.601691,0.601329,0.335691,0.349909,0.322322,0.382593,0.085083,0.058312,0.0798958,0.104986,0.0620767,0.0851502,0.689353,0.741414,-0.672443,-0.341215,-0.175884,0.0740154,0.67297,0.757766,-0.595274,-0.646705,-0.0930312,-0.0132127,-0.263654,-0.276128,0.325195,0.121532,-0.0400465,-0.259335,1.36781,1.31236,2.42908,2.42627
2499,0.498195,0.402345,0.456701,0.400772,0.0731003,-0.00040175,0.167057,0.165093,0.123024,0.138113,0.681203,0.742686,0.115577,0.0908235,0.030725,0.0536956,0.246668,0.169849,0.281786,0.335023,0.715982,1.04751,1.86817,2.11831,1.45341,1.54047,0.273851,0.225264,-0.54511,-0.526847,2.9867,2.96902,-0.961882,-1.15974,-0.224688,-0.426052,0.725942,0.673069,-1.85742,-1.8639
2500,0.878424,0.78042,0.549867,0.522735,0.284704,0.209882,0.657085,0.653557,0.293838,0.30864,0.132642,0.193339,0.882468,0.855575,0.647604,0.668609,0.2327,0.254548,0.379903,0.431188,0.597955,0.930038,0.966043,1.21616,-0.96773,-0.887201,-1.00532,-1.01585,-0.239044,-0.217473,1.59018,1.56505,-1.08561,-1.27936,-0.26467,-0.592768,-0.32629,-0.374331,0.618583,0.611318
2501,0.233887,0.134233,0.919579,0.892448,0.970656,0.894766,0.794197,0.793086,0.22722,0.242912,0.283786,0.284967,0.14216,0.118007,0.468956,0.49177,0.649374,0.67007,0.748076,0.801128,1.01715,1.34989,0.363652,0.606499,-0.0653683,0.0199201,-2.20163,-2.25697,1.56582,1.58204,-0.0164468,-0.0372716,1.31722,1.11929,-0.540196,-0.759485,-2.3879,-2.43519,-1.40918,-1.42296
2502,0.376475,0.274588,0.540602,0.513658,0.46991,0.39507,0.0358179,0.0338366,0.763372,0.776674,0.316208,0.376594,0.468571,0.361916,0.0199926,0.0409475,0.503684,0.60946,0.2057,0.259969,-0.262242,0.0683023,-1.51776,-1.27119,-0.61678,-0.530903,1.23404,1.17377,2.07442,2.09245,-0.856046,-0.871642,-0.372435,-0.56976,0.690037,0.471956,0.223103,0.169177,0.410157,0.398754
2503,0.187558,0.0859245,0.701798,0.730303,0.941642,0.868665,0.602817,0.60152,0.21606,0.228167,0.237222,0.302569,0.641571,0.605825,0.563994,0.583728,0.526445,0.548851,0.641937,0.694601,0.287008,0.61126,-1.72374,-1.48331,0.414906,0.454369,-1.34174,-1.39615,-2.08659,-2.07592,-0.32269,-0.335602,0.419078,0.227161,1.28316,1.06255,1.32979,1.26883,-0.676422,-0.684133
2504,0.2296,0.126101,0.975906,0.946948,0.399125,0.323682,0.397176,0.394644,0.931,0.945584,0.168591,0.228544,0.874481,0.849735,0.770669,0.790844,0.80933,0.830028,0.286985,0.338815,0.0611158,0.390611,-0.490154,-0.167712,1.35376,1.43964,-0.0733895,-0.122318,1.42238,1.43009,0.802097,0.783094,0.724925,0.53486,1.32345,1.10156,0.623208,0.522131,-1.14022,-1.14423
2505,0.693273,0.588327,0.314288,0.286672,0.425252,0.350969,0.973189,0.972523,0.92582,0.938306,0.889174,0.9499,0.503494,0.479021,0.717687,0.639937,0.87385,0.892919,0.694338,0.748129,0.0598944,0.396033,0.903011,1.14788,0.714752,0.793512,1.86375,1.8142,0.707616,0.715462,-0.624112,-0.649326,-0.774718,-0.964787,-1.86746,-2.09358,-0.160067,-0.224569,0.185349,0.182157
2506,0.791754,0.688697,0.11498,0.087209,0.709987,0.637485,0.483981,0.48561,0.299275,0.313268,0.654754,0.663878,0.425824,0.399685,0.468763,0.489029,0.177969,0.196764,0.682487,0.737889,-1.30904,-0.975079,1.0844,1.33347,-0.235576,-0.1621,-0.0757444,-0.214729,2.55263,2.56222,1.03253,1.0059,-1.16862,-1.363,1.04134,0.817709,1.14958,1.09229,-0.239606,-0.249234
2507,0.524506,0.430796,0.333808,0.401686,0.285866,0.212986,0.296224,0.298169,0.0497502,0.0649815,0.318319,0.377856,0.713302,0.686231,0.598643,0.664118,0.588773,0.607027,0.296911,0.352576,0.969029,1.30695,-1.6495,-1.39603,1.93126,1.99897,-2.1941,-2.24366,1.68396,1.69067,-0.389812,-0.412085,0.207702,0.00793731,-0.125432,-0.350432,0.852121,0.694796,0.546542,0.544046
2508,0.277915,0.172895,0.742865,0.716163,0.696298,0.621129,0.618054,0.622466,0.062117,0.189261,0.990554,1.04992,0.394971,0.365664,0.819604,0.839206,0.197645,0.216979,0.53584,0.523905,1.15043,1.4959,-0.229032,0.0217888,0.694806,0.76268,1.89568,1.84615,-0.791544,-0.783873,0.614559,0.597482,1.87291,1.67244,0.56006,0.332875,0.363159,0.297306,-0.300745,-0.308514
2509,0.984431,0.878237,0.451598,0.426004,0.329035,0.251785,0.588891,0.59147,0.214604,0.313541,0.771163,0.742786,0.365275,0.337277,0.626935,0.647086,0.50566,0.616129,0.641325,0.695234,-0.137901,0.214317,0.947361,1.19026,0.477545,0.547806,-0.32878,-0.383704,0.762745,0.768951,-0.818449,-0.834938,0.55499,0.359654,-0.517875,-0.746504,0.586684,0.522534,0.372487,0.363908
2510,0.16151,0.0555162,0.576346,0.54916,0.837508,0.760015,0.55431,0.560474,0.371206,0.43782,0.375722,0.435653,0.715829,0.68926,0.913205,0.933004,0.996984,1.01528,0.289146,0.344153,0.863015,1.21652,-0.487656,-0.243751,-0.765732,-0.702351,-0.466852,-0.52561,-0.516323,-0.514981,0.782675,0.758583,-0.977401,-1.17261,0.594272,0.366411,-0.713684,-0.775484,0.372284,0.356529
2511,0.728365,0.622059,0.418015,0.33954,0.666876,0.588177,0.311765,0.317343,0.546869,0.5621,0.498295,0.490444,0.774183,0.748234,0.0638283,0.0831418,0.205969,0.225473,0.734713,0.787709,-0.0546484,0.302465,1.39568,1.64173,-1.26964,-1.20598,0.38736,0.330476,0.237127,0.240572,-0.461485,-0.489856,-0.0323319,-0.219722,-1.19198,-1.41953,0.930087,0.873501,-0.246475,-0.25597
2512,0.630816,0.524621,0.155572,0.12992,0.968524,0.889424,0.542859,0.644931,0.0739164,0.0890942,0.483418,0.545234,0.116546,0.090786,0.4498,0.469753,0.119276,0.139893,0.563651,0.617529,-1.33805,-0.979122,-0.704947,-0.462867,-0.421284,-0.35949,1.47255,1.41703,-0.895121,-0.889754,-0.572044,-0.597238,1.46254,1.27208,-0.454505,-0.675449,0.0241793,-0.0342392,-0.0824598,-0.0983099
2513,0.823261,0.715001,0.241976,0.214283,0.126879,0.0489702,0.966659,0.972518,0.46607,0.481862,0.340245,0.363955,0.486498,0.462444,0.433489,0.393564,0.358358,0.422784,0.886492,0.941264,0.0533583,0.409606,-0.213429,0.0313178,-0.647984,-0.588304,-0.669451,-0.717235,1.73678,1.74684,-1.11767,-1.13874,-0.359621,-0.557512,-2.16929,-2.38477,1.83761,1.78785,0.617007,0.603688
2514,0.733862,0.628025,0.831065,0.805132,0.237534,0.21569,0.197622,0.203113,0.432361,0.447505,0.120431,0.182675,0.130446,0.107297,0.299013,0.317374,0.685118,0.705675,0.471151,0.554573,-0.787546,-0.427533,-0.681471,-0.440483,0.731635,0.789778,-1.7752,-1.82124,0.691565,0.707824,0.358001,0.330905,2.20089,2.00007,0.294658,0.0769798,0.876974,0.833224,-0.157595,-0.174097
2515,0.186656,0.081675,0.0546326,0.0277241,0.457461,0.382409,0.99679,1.00385,0.771093,0.784883,0.936723,0.99768,0.614786,0.589546,0.62012,0.638841,0.0391901,0.0609968,0.111601,0.167883,-1.98411,-1.61639,-0.0832052,0.161363,1.03738,1.09766,1.15996,1.11541,-0.080604,-0.0687505,-1.68762,-1.71784,1.54949,1.35593,1.11736,0.898031,-0.460019,-0.498284,0.0344763,0.0127316
2516,0.225189,0.121851,0.724752,0.697271,0.969553,0.896423,0.724683,0.730822,0.878484,0.893901,0.839753,0.810023,0.862079,0.835832,0.47895,0.492652,0.72085,0.743275,0.207512,0.219254,0.747597,1.12367,1.15663,1.39592,0.544759,0.608764,-0.414926,-0.462984,0.0429824,0.0577741,0.759858,0.727825,-0.916422,-1.10748,0.29734,0.115424,-0.283096,-0.320491,-0.101913,-0.130003
2517,0.494649,0.392992,0.4638,0.436177,0.587938,0.517092,0.787572,0.794517,0.127764,0.140868,0.563672,0.622366,0.543047,0.576567,0.293761,0.346463,0.125487,0.149043,0.216956,0.270626,-0.0982229,0.297025,-0.744625,-0.510268,-1.46141,-1.40345,1.81149,1.76118,2.79244,2.79882,0.803679,0.772849,-0.0319334,-0.218822,-0.452886,-0.667184,0.14737,0.106997,-0.930565,-0.951771
2518,0.539695,0.438279,0.406386,0.45991,0.931178,0.859043,0.0917603,0.0973613,0.976447,0.992166,0.930396,0.986685,0.343929,0.317302,0.18393,0.200274,0.886433,0.910586,0.620436,0.602515,-0.905653,-0.529623,0.410334,0.692164,1.36013,1.41578,-0.231092,-0.281526,0.297879,0.310019,0.146666,0.120515,2.65076,2.46833,0.46709,0.245261,0.887939,0.847429,0.805533,0.789189
2519,0.955485,0.8516,0.484878,0.483643,0.187123,0.113123,0.18261,0.185495,0.753734,0.770009,0.127717,0.183288,0.474501,0.45078,0.945112,0.962706,0.449897,0.475849,0.883157,0.934404,-1.01755,-0.647097,1.65797,1.89459,-1.00389,-0.952248,-0.0472717,-0.100471,-1.39216,-1.3747,0.114992,0.0273584,-1.46594,-1.64837,-0.420862,-0.6509,1.22992,1.18187,-0.00736333,-0.0179542
2520,0.509446,0.414324,0.536993,0.507375,0.766055,0.691267,0.0651632,0.0675681,0.953699,0.969561,0.183212,0.215231,0.729617,0.584259,0.831985,0.866809,0.420269,0.429665,0.304754,0.354193,-0.231045,0.139778,-0.58666,-0.355851,0.142468,0.197482,1.09676,1.04931,-0.597619,-0.64727,-0.039423,-0.0657986,-0.839427,-1.01753,-2.05257,-2.2818,-0.559424,-0.608282,-1.0697,-1.08282
2521,0.0780138,-0.0229513,0.0205833,-0.0102671,0.892094,0.817478,0.361042,0.263812,0.306507,0.320367,0.190654,0.247174,0.744697,0.717737,0.752501,0.770911,0.271218,0.383481,0.46087,0.511455,2.19411,2.56427,0.311752,0.535899,0.725623,0.780911,0.364458,0.320035,0.066637,0.0801643,-0.897867,-0.8323,-0.49655,-0.680486,-1.59119,-1.82849,-0.261098,-0.305376,1.11028,1.09739
2522,0.197738,0.0972667,0.479704,0.448228,0.220295,0.143682,0.45775,0.460056,0.029243,0.043373,0.755862,0.813603,0.599298,0.5728,0.0769757,0.0935536,0.311183,0.337296,0.959642,1.01009,0.924734,1.29874,-3.12968,-2.90603,-0.4028,-0.348025,0.995802,0.957978,-1.53587,-1.52633,-1.57243,-1.5988,-1.26891,-1.44743,0.424004,0.179207,0.450525,0.404369,-2.07062,-2.08846
2523,0.883265,0.783424,0.546182,0.516764,0.961072,0.884553,0.872051,0.874077,0.0900101,0.105865,0.642917,0.675473,0.665449,0.579836,0.211148,0.229111,0.409501,0.43583,0.196146,0.246982,-1.11445,-0.741724,0.912028,1.13091,-0.532357,-0.482974,0.955429,0.922334,-0.0225373,-0.0186399,0.0504822,0.0256382,-0.101457,-0.311159,1.56327,1.32058,-2.47966,-2.52195,-1.61862,-1.63103
2524,0.854574,0.72129,0.129198,0.0980952,0.827117,0.727685,0.83513,0.811756,0.754441,0.77111,0.613402,0.537343,0.613456,0.586871,0.107088,0.177641,0.9058,0.931574,0.879266,0.931112,0.288323,0.66179,-1.51508,-1.29567,0.706675,0.760039,-1.39766,-1.42544,0.25127,0.262411,0.0194526,-0.00708118,0.998126,0.825116,-0.10739,-0.357186,0.546142,0.499994,0.616236,0.59838
2525,0.758197,0.659157,0.293388,0.261829,0.529504,0.570818,0.750865,0.749435,0.536258,0.554052,0.341472,0.399213,0.904044,0.878028,0.108534,0.126171,0.522203,0.547107,0.486563,0.503463,0.0794783,0.456336,-1.6797,-1.46249,0.124172,0.25106,-0.874794,-0.910346,3.29978,3.31817,1.55096,1.52415,-0.869491,-1.0345,-0.131418,-0.380451,1.45086,1.41128,-0.450526,-0.466487
2526,0.0864218,-0.0126214,0.981913,0.951496,0.490469,0.41395,0.596123,0.687114,0.882635,0.900786,0.552048,0.607701,0.381318,0.355712,0.759131,0.775658,0.919895,0.942984,0.0246084,0.075814,-1.4397,-1.06745,1.75179,1.97279,-0.308855,-0.25792,-0.777448,-0.807779,-0.188456,-0.173384,-0.737804,-0.759715,-0.0826744,-0.250795,0.751722,0.501538,-1.02296,-1.06024,-0.305,-0.282597
2527,0.0710846,-0.0277229,0.531116,0.498278,0.0638439,-0.010549,0.622767,0.624793,0.837639,0.890901,0.433569,0.490316,0.631163,0.607876,0.678664,0.694805,0.387721,0.408937,0.68601,0.739159,-0.374429,-0.00556169,-1.09825,-0.883829,-0.209294,-0.151419,0.759663,0.731787,-0.0682233,-0.0468589,-0.850723,-0.867096,1.34303,1.18162,0.68243,0.433496,-0.652492,-0.694618,-0.0636499,-0.0987072
2528,0.312602,0.213332,0.878086,0.844453,0.680387,0.607449,0.96511,0.968137,0.875872,0.881016,0.839239,0.894193,0.646755,0.612262,0.987624,1.006,0.860524,0.879487,0.811736,0.865148,-0.728999,-0.363483,1.00486,1.22408,-1.09802,-1.04585,-1.58244,-1.61598,0.388751,0.417259,0.932897,0.912904,-0.952574,-1.10741,0.275302,0.0297384,0.293914,0.249324,0.123437,0.0851826
2529,0.15267,0.0555677,0.999176,0.967609,0.889245,0.817733,0.790534,0.795898,0.852342,0.871131,0.296481,0.349775,0.639636,0.616649,0.754131,0.773706,0.949237,0.887127,0.363674,0.491936,-0.2039,0.165814,0.185246,0.399078,0.188127,0.241252,0.798523,0.762532,0.372625,0.40683,-0.438641,-0.461038,-0.0319639,-0.186189,0.547501,0.30142,0.345633,0.305063,0.285033,0.269072
2530,0.216644,0.120899,0.2215,0.190201,0.316877,0.244083,0.962139,0.966032,0.0456263,0.0649854,0.127322,0.182138,0.314696,0.290679,0.847896,0.7844,0.914181,0.894766,0.0636122,0.118724,0.834561,1.19666,0.959246,1.169,-0.952392,-0.901663,-1.40196,-1.43328,-1.39987,-1.37256,0.88973,0.871335,0.424659,0.274677,1.17045,0.922943,0.793771,0.748322,-0.246416,-0.26916
2531,0.823494,0.726875,0.584426,0.554934,0.0227991,-0.0498863,0.671775,0.709553,0.256542,0.27476,0.306722,0.361239,0.923913,0.90205,0.774059,0.795094,0.898188,0.902405,0.946163,1.00209,-1.02539,-0.657273,1.20864,1.41632,0.392075,0.447664,0.0590739,0.0291966,-0.505,-0.476819,-0.155848,-0.177236,-0.374758,-0.524441,0.587554,0.420825,-1.97079,-2.01225,0.501529,0.479277
2532,0.00725077,-0.0905191,0.586344,0.559308,0.286982,0.216228,0.449396,0.453074,0.781277,0.79828,0.885451,0.942091,0.261002,0.240356,0.182361,0.203771,0.891081,0.910045,0.0351147,0.0908353,0.494046,0.856429,0.258706,0.467924,-1.43849,-1.37914,-0.496673,-0.529123,-0.303591,-0.273069,0.427476,0.404245,1.05841,0.907971,0.169737,-0.0812938,-0.0866406,-0.127745,-0.675124,-0.69515
2533,0.323852,0.225982,0.879756,0.850176,0.281172,0.212496,0.825041,0.826915,0.921165,0.938044,0.377732,0.432224,0.31421,0.29363,0.868402,0.889557,0.10397,0.125168,0.31127,0.38519,-0.223093,0.144162,0.0606983,0.270351,1.09937,1.16654,1.59063,1.56551,-0.75157,-0.716641,1.01414,0.985725,0.153737,0.000954069,-0.584513,-0.839271,-0.530991,-0.56765,2.59052,2.56703
2534,0.842968,0.742588,0.802158,0.772382,0.85785,0.790641,0.968829,0.971959,0.727811,0.745986,0.0777507,0.133424,0.998898,0.976521,0.0898834,0.113183,0.959227,0.980914,0.614804,0.679546,0.735713,1.09826,0.89591,1.10217,0.146485,0.210932,-0.441628,-0.459635,-0.179691,-0.144713,-1.09141,-1.12569,-0.307158,-0.460497,-0.201854,-0.478134,-0.73551,-0.774434,-1.03863,-1.06745
2535,0.221906,0.121872,0.34601,0.314165,0.401869,0.336647,0.414775,0.502323,0.318175,0.336796,0.841963,0.895112,0.949641,0.928276,0.450697,0.476068,0.832653,0.917924,0.91818,0.973901,0.402127,0.772595,0.317674,0.52325,0.16569,0.226763,-0.178636,-0.203206,0.643042,0.682098,-0.068288,-0.0992867,0.366592,0.214677,0.133483,-0.116996,-0.444938,-0.487702,-1.85777,-1.88922
2536,0.766262,0.668269,0.418782,0.387831,0.943706,0.879547,0.0301947,0.0326871,0.133399,0.149801,0.559196,0.61236,0.636273,0.616591,0.151422,0.174504,0.831401,0.854934,0.830231,0.80393,0.535996,0.900416,-0.0013783,0.205049,-0.508359,-0.451731,-1.37462,-1.3988,1.47981,1.50891,-1.23515,-1.26826,0.835171,0.675544,-0.382212,-0.562851,-1.0474,-1.0972,0.413241,0.387077
2537,0.82972,0.7336,0.245215,0.213256,0.216392,0.154385,0.68067,0.684951,0.364319,0.380388,0.0358704,0.0881035,0.58631,0.555521,0.947893,0.973029,0.313867,0.335693,0.578583,0.63396,0.387479,0.753334,-1.31203,-1.09921,-0.205776,-0.143849,-0.373423,-0.401585,-0.53252,-0.503827,0.481932,0.450032,0.139771,-0.0149789,-0.753712,-1.00871,1.36386,1.3117,-1.38814,-1.41368
2538,0.620829,0.488442,0.898602,0.867424,0.598796,0.476904,0.758612,0.763581,0.888898,0.903907,0.482174,0.52864,0.513833,0.49445,0.0207628,0.0471251,0.142343,0.162429,0.852687,0.907129,-1.05982,-0.695228,-0.424427,-0.207455,-0.570001,-0.466789,-0.837082,-0.907754,-1.2113,-1.25858,-0.52363,-0.55367,0.428572,0.277317,-0.882486,-1.1375,0.976427,0.920335,-0.355038,-0.378023
2539,0.290677,0.243284,0.946515,0.915457,0.859635,0.799423,0.0956224,0.100288,0.971579,0.987747,0.91437,0.969177,0.269769,0.248386,0.91024,0.937564,0.639819,0.658173,0.173048,0.22607,1.21431,1.57154,0.681,0.901929,-0.845479,-0.789729,-1.39055,-1.41392,-2.03899,-2.01333,1.35965,1.33317,-0.34495,-0.489632,1.23106,0.979134,-1.20141,-1.25315,-0.0291341,-0.0551477
2540,0.0968048,-0.00187381,0.543704,0.461819,0.00133018,-0.0572772,0.188435,0.220268,0.588076,0.581213,0.903244,0.95703,0.626206,0.605772,0.652563,0.680744,0.321217,0.338896,0.871648,0.9257,0.36846,0.760919,-0.0429291,0.185739,1.33437,1.38946,1.12827,1.09721,-0.192774,-0.166562,-1.7415,-1.77557,0.688174,0.537513,-1.22391,-1.47021,-0.121043,-0.169238,1.26559,1.24087
2541,0.780053,0.679333,0.040157,0.00818103,0.347956,0.353955,0.333498,0.340248,0.158511,0.17468,0.668244,0.723732,0.38997,0.369456,0.636404,0.695933,0.739481,0.75996,0.0421236,0.0947653,-0.403695,-0.0496973,0.286087,0.510574,1.47409,1.52733,0.827855,0.79946,-1.0674,-1.03811,-0.13204,-0.166631,0.185841,0.0313623,1.0434,0.798597,-0.790404,-0.84019,1.02778,1.00672
2542,0.598285,0.52323,0.963298,0.933944,0.823795,0.765188,0.916365,0.923165,0.112775,0.0992996,0.993561,1.04887,0.536602,0.515246,0.620851,0.711121,0.473227,0.495102,0.00787319,0.0607456,-0.409264,-0.0589774,0.907938,1.12649,-0.420787,-0.375234,-1.2985,-1.31914,-0.59513,-0.560029,-1.40323,-1.43023,0.179825,0.032475,0.60091,0.34924,-0.942885,-0.986393,0.168303,0.154163
2543,0.468167,0.367126,0.673379,0.643785,0.330991,0.270907,0.190958,0.195523,0.00651839,0.0239196,0.765294,0.820407,0.420154,0.400833,0.697569,0.72631,0.975485,0.995322,0.203769,0.158939,1.02624,1.37593,0.227339,0.440249,1.57954,1.62617,0.612995,0.585927,-1.96174,-1.92425,-0.142325,-0.174963,0.629966,0.479376,-0.97549,-1.22047,-0.238254,-0.276649,-0.142906,-0.156565
2544,0.780995,0.678764,0.672905,0.657511,0.254917,0.195986,0.820658,0.822691,0.584492,0.603656,0.849314,0.819876,0.0717747,0.0502031,0.295189,0.325289,0.70758,0.726451,0.203402,0.257133,-1.13471,-0.788771,1.66831,1.88845,2.36126,2.40887,-0.890741,-0.916599,1.0127,1.04554,-0.967008,-0.993334,1.59774,1.44672,0.142074,-0.107557,1.05388,1.00952,-0.857244,-0.873891
2545,0.626062,0.595704,0.648363,0.671236,0.449049,0.391312,0.55548,0.559252,0.00578212,0.0250873,0.765538,0.819345,0.452424,0.431658,0.754277,0.782011,0.167037,0.186848,0.514965,0.57057,-0.0437167,0.302681,-0.406541,-0.188723,0.581508,0.698538,0.0546069,0.0322549,-0.093604,-0.0551553,2.39013,2.35967,-0.942679,-1.09931,0.359625,0.116947,0.890816,0.847245,0.922492,0.901812
2546,0.617087,0.512645,0.716626,0.684961,0.201716,0.141886,0.740524,0.744755,0.0307516,0.0485953,0.452384,0.51857,0.39201,0.373279,0.191569,0.220855,0.14731,0.255401,0.428228,0.482617,0.797121,1.15004,-0.23606,-0.0174551,-1.05941,-1.0118,0.39474,0.36526,-0.0951997,-0.0207586,0.675581,0.652979,-1.79774,-1.95766,-0.657744,-0.901156,0.00712792,-0.0406934,-0.193749,-0.21232
2547,0.0413246,-0.0636051,0.314394,0.373007,0.720322,0.660792,0.327188,0.332436,0.274595,0.236693,0.16516,0.217794,0.667945,0.589202,0.386534,0.417533,0.298577,0.323954,0.133993,0.18721,0.307958,0.667492,0.826746,1.05281,-0.148521,-0.104676,-0.488529,-0.521145,-0.0318563,0.0136381,-1.38766,-1.41218,-1.65331,-1.82019,1.47587,1.23127,0.0322023,-0.0140574,0.415714,0.398408
2548,0.602515,0.497648,0.0938519,0.0610521,0.37937,0.401321,0.131332,0.135025,0.406228,0.424791,0.979429,1.0328,0.825321,0.805124,0.366437,0.397188,0.37448,0.392508,0.203892,0.259238,0.181724,0.53773,1.90261,2.12307,1.7452,1.7882,-0.208078,-0.232727,-0.95178,-0.901175,-1.88246,-1.90538,1.15195,0.986945,0.898501,0.659649,0.261538,0.21117,0.608907,0.585236
2549,0.766065,0.662631,0.0440661,0.0111851,0.199934,0.141851,0.965156,0.96662,0.978001,0.999084,0.338749,0.393144,0.740408,0.720763,0.919825,0.950386,0.965878,0.983147,0.54906,0.60356,2.36472,2.72687,-0.817942,-0.591516,-1.88502,-1.83673,1.17498,1.14807,2.43541,2.48262,1.04406,1.02088,-0.352204,-0.512703,-0.540681,-0.773328,-0.330764,-0.382157,-0.744806,-0.771867
2550,0.250459,0.147213,0.366525,0.332667,0.725688,0.66532,0.12922,0.129294,0.0358262,0.0573191,0.309637,0.365403,0.955384,0.937228,0.57423,0.565368,0.479809,0.498244,0.385023,0.438558,-1.20638,-0.850289,-0.780363,-0.558728,-0.362883,-0.320621,0.988563,0.958281,1.47277,1.52104,1.6464,1.61929,-1.00609,-1.17137,1.53279,1.29783,-0.699582,-0.743992,0.609629,0.58679
2551,0.112627,0.00940546,0.965782,0.932686,0.784084,0.729898,0.561955,0.56271,0.286132,0.308835,0.483365,0.520894,0.490381,0.471497,0.148664,0.18035,0.835739,0.854567,0.437482,0.491232,-2.65394,-2.29885,0.108507,0.333022,0.911479,0.951474,0.182627,0.150702,-0.933304,-0.885024,-0.394555,-0.4144,-0.200606,-0.359705,-0.886757,-1.11628,-0.267907,-0.316504,-1.61018,-1.63663
2552,0.292066,0.189931,0.252884,0.217781,0.855959,0.794477,0.0898717,0.0905329,0.242141,0.264401,0.608066,0.676385,0.9237,0.903148,0.899617,0.932987,0.712072,0.731792,0.205588,0.260415,-0.373344,-0.0168249,0.139345,0.365811,-0.879912,-0.841621,0.107739,0.0700991,0.00191692,0.0562056,-0.745656,-0.790671,1.21019,1.05875,-1.31322,-1.55076,0.802541,0.751975,-0.12667,-0.154636
2553,0.0422149,-0.058794,0.169063,0.13445,0.711112,0.684737,0.378366,0.380985,0.597645,0.622027,0.774837,0.831877,0.3158,0.297021,0.0631554,0.0959363,0.0679874,0.0871138,0.22578,0.282604,-0.33685,0.0171001,0.439214,0.661415,-0.675466,-0.642772,1.633,1.59333,-1.2031,-1.14854,-1.13888,-1.16694,0.161559,0.0111338,0.842694,0.611223,0.836505,0.794261,-0.981342,-1.0072
2554,0.411221,0.308965,0.586544,0.553563,0.634322,0.574997,0.867711,0.869449,0.455166,0.480196,0.0211366,0.0774417,0.932544,0.913197,0.485292,0.517294,0.675322,0.693475,0.834689,0.89147,0.775058,1.12461,0.38196,0.602269,1.98715,2.016,1.1895,1.15606,0.885447,0.937309,1.4493,1.42427,-1.08733,-1.2378,0.692805,0.466763,-0.650973,-0.693539,-1.06254,-1.09165
2555,0.487036,0.38461,0.714587,0.681686,0.0842266,0.0259338,0.948153,0.948079,0.73169,0.756793,0.365762,0.378513,0.0778681,0.0575198,0.307985,0.340455,0.109573,0.127958,0.545762,0.60066,0.40209,0.654716,-2.48198,-2.25435,1.59717,1.61922,1.03555,0.998374,-0.86606,-0.8104,-0.175195,-0.205778,-0.468613,-0.622006,-0.174004,-0.396696,0.928969,0.890934,-0.45823,-0.48092
2556,0.84482,0.741428,0.310929,0.278032,0.474877,0.417852,0.231828,0.231012,0.637107,0.65987,0.617727,0.679585,0.679953,0.658035,0.891482,0.923868,0.0367634,0.0530141,0.93534,0.989664,-0.169515,0.184823,-0.0155571,0.208083,-0.306683,-0.283345,0.466954,0.510547,0.485853,0.54221,-1.23746,-1.27061,1.08336,0.931821,-0.526535,-0.755632,-1.50015,-1.54422,-0.925633,-0.941014
2557,0.593189,0.455464,0.65815,0.624207,0.42438,0.285899,0.857323,0.858179,0.2594,0.280998,0.924352,0.980657,0.978942,0.955193,0.798814,0.782443,0.717089,0.735292,0.23034,0.2818,1.15961,1.5105,-1.91218,-1.68178,-0.534826,-0.512159,0.055777,0.022721,0.13225,0.191127,-0.392908,-0.428482,-0.171882,-0.365714,0.28473,0.0502287,1.22685,1.18593,-1.15114,-1.16121
2558,0.272493,0.169501,0.0454791,0.0132424,0.181012,0.153946,0.379289,0.436009,0.900575,0.920203,0.764465,0.822203,0.940417,0.916873,0.587358,0.641018,0.376934,0.385854,0.417092,0.391859,0.496341,0.84561,-0.433235,-0.152953,-0.340894,-0.31331,1.192,1.158,1.01984,1.08687,0.122399,0.0936717,-1.51515,-1.66325,0.708302,0.473436,-1.61455,-1.65411,-0.347799,-0.352944
2559,0.218562,0.118128,0.0239162,-0.00741662,0.0787711,0.0219931,0.0147185,0.0138394,0.294055,0.315483,0.215611,0.272856,0.179472,0.156103,0.466428,0.499593,0.0188646,0.0364161,0.44888,0.501919,-0.41304,-0.0684478,1.14549,1.37588,0.12608,0.145565,0.210991,0.178977,0.687519,0.749422,-0.0236844,-0.0456555,0.336286,0.189607,0.362793,0.13097,1.19536,1.15094,1.2103,1.20681
2560,0.965036,0.866782,0.730746,0.697817,0.622491,0.564893,0.264799,0.283065,0.623125,0.642856,0.132422,0.189722,0.871076,0.848924,0.950089,0.981623,0.478298,0.496713,0.277068,0.319972,1.98413,2.32667,-0.445392,-0.21172,1.53859,1.5538,0.949129,0.912026,1.5867,1.64516,-1.29456,-1.30925,0.28167,0.129812,0.614922,0.386752,0.368627,0.324889,-0.271229,-0.270287
2561,0.0441685,-0.0545477,0.985204,0.95443,0.142233,0.0851908,0.503888,0.552291,0.680755,0.699884,0.800353,0.856376,0.0231686,0.00329016,0.0524064,0.083557,0.360299,0.379542,0.086106,0.138026,0.869492,1.21302,0.0825587,0.312315,-0.0398466,-0.0184886,-0.522255,-0.559176,-0.575601,-0.520341,0.376147,0.361979,-1.39122,-1.54404,-0.878514,-1.10516,0.314738,0.271771,1.43937,1.44197
2562,0.814583,0.715929,0.0993815,0.0675265,0.336932,0.189591,0.822396,0.821517,0.341353,0.362675,0.343288,0.400548,0.185818,0.164711,0.497953,0.53054,0.736399,0.755351,0.380872,0.430966,-1.15368,-0.812501,-0.216544,0.00614356,0.622946,0.640837,0.579152,0.542943,-1.31034,-1.17979,1.49519,1.48068,0.548,0.401122,0.088266,-0.146932,1.98352,1.93565,0.488439,0.498001
2563,0.596045,0.496695,0.0323952,0.0414666,0.350136,0.29399,0.506287,0.503563,0.668199,0.690048,0.836843,0.893174,0.739283,0.716421,0.0861035,0.11885,0.00953884,0.0296551,0.161478,0.210316,0.168752,0.513181,1.27254,1.50069,1.61826,1.64033,2.51776,2.47946,-1.89449,-1.83923,-1.72111,-1.73678,0.204918,0.0641838,0.769365,0.536375,-0.0706849,-0.12521,3.55761,3.568
2564,0.851937,0.753136,0.0500609,0.0154068,0.955182,0.89755,0.957298,0.956645,0.568164,0.588759,0.322618,0.378741,0.785201,0.727089,0.707572,0.738964,0.00505878,0.0240103,0.434359,0.483486,2.24114,2.58097,-2.37557,-2.14823,-1.84835,-1.82771,-0.0746302,-0.105487,-1.60346,-1.54377,0.845029,0.838461,-1.3953,-1.53177,-0.113703,-0.34335,0.495817,0.443364,-0.154908,-0.151686
2565,0.49192,0.393469,0.34057,0.312419,0.945933,0.889019,0.581932,0.579028,0.927787,0.946385,0.95808,1.01472,0.761591,0.737757,0.623769,0.601252,0.755237,0.776671,0.909505,0.95749,-1.7883,-1.44847,0.410326,0.640824,-0.451201,-0.434942,0.861769,0.8279,-0.237065,-0.175456,1.06659,1.05282,0.51427,0.384957,-0.527645,-0.763068,0.433313,0.376588,0.911948,0.914315
2566,0.921683,0.821332,0.642514,0.609431,0.329202,0.27048,0.61616,0.708389,0.729424,0.749264,0.861839,0.91683,0.35678,0.33167,0.433937,0.463541,0.42297,0.442836,0.472917,0.521268,1.01392,1.3552,1.35551,1.57838,-2.20277,-2.18029,-0.662661,-0.691033,-0.918709,-0.858483,-0.143342,-0.162206,0.892712,0.767402,0.312489,0.0737359,-1.38848,-1.44744,-0.938905,-0.934663
2567,0.360214,0.259617,0.737344,0.71345,0.210321,0.1493,0.840667,0.83775,0.936554,0.954486,0.283105,0.337067,0.753421,0.728148,0.617328,0.659363,0.402472,0.42198,0.91597,0.964824,-1.59042,-1.25031,-0.886675,-0.657461,-0.256455,-0.242122,0.696976,0.67391,-0.115651,-0.058002,-1.60124,-1.62735,0.013057,-0.109344,-0.162835,-0.406495,-1.48926,-1.54615,0.718794,0.71463
2568,0.582336,0.566688,0.849974,0.817468,0.977796,0.916183,0.452226,0.451029,0.335432,0.355129,0.468904,0.52185,0.486399,0.399918,0.825136,0.855185,0.0391359,0.0576753,0.792478,0.839737,1.3352,1.68162,-0.692347,-0.455489,-0.945144,-0.934564,0.253233,0.236644,-0.427278,-0.3627,0.221729,0.198392,-1.80819,-1.92331,-0.973756,-1.3045,1.41866,1.36513,-0.181743,-0.183161
2569,0.973169,0.873759,0.00681378,-0.0227411,0.78176,0.749945,0.979228,0.97869,0.262592,0.284489,0.425952,0.471636,0.0971184,0.0716882,0.455889,0.488399,0.348373,0.393147,0.0481445,0.0966469,-1.63193,-1.28518,0.413807,0.653895,-0.881915,-0.872187,0.0497495,0.033911,0.202406,0.281756,-1.16515,-1.19076,0.423482,0.311509,-1.96217,-2.20251,0.180858,0.130415,1.16666,1.15795
2570,0.0690816,-0.0321539,0.632703,0.602904,0.605906,0.583707,0.533478,0.581328,0.788084,0.808009,0.370463,0.421422,0.380455,0.440873,0.794523,0.825961,0.709249,0.728618,0.150356,0.197059,0.724442,1.0772,0.447308,0.686684,1.78182,1.78659,-0.529826,-0.540662,0.860107,0.926211,0.254011,0.230945,1.0469,0.942343,0.221099,-0.0221144,-0.169536,-0.248469,-0.443665,-0.45818
2571,0.303003,0.199696,0.386169,0.356763,0.343321,0.417469,0.1856,0.183967,0.103381,0.121975,0.955492,1.00708,0.837618,0.810058,0.261104,0.289864,0.377676,0.399323,0.957089,1.0056,0.161043,0.414827,1.01404,1.25683,0.478552,0.489643,-1.48779,-1.50372,1.16502,1.23559,-1.82281,-1.84914,1.37133,1.26409,1.68546,1.44203,-0.58279,-0.627352,1.48737,1.46955
2572,0.219512,0.164531,0.542272,0.432723,0.314846,0.25123,0.946011,0.9424,0.985116,1.00161,0.0987597,0.15253,0.0154643,-0.0123328,0.734114,0.761942,0.564726,0.585508,0.15397,0.201071,-0.59511,-0.247545,-0.799217,-0.553629,0.0907046,0.108431,-2.2322,-2.24998,0.354344,0.427433,-0.503772,-0.533012,0.152547,0.0465643,-1.18819,-1.42493,-0.25723,-0.308774,0.704358,0.691768
2573,0.231307,0.129365,0.538658,0.508682,0.641651,0.57899,0.226002,0.225332,0.572631,0.553293,0.175408,0.228494,0.915393,0.888888,0.345852,0.37547,0.416029,0.437317,0.0509386,0.189209,-0.706792,-0.365019,0.62243,0.864188,-2.11256,-2.09857,-2.14698,-2.16376,-0.0216907,0.0756221,-1.25063,-1.27508,-0.37724,-0.476611,-0.336928,-0.572783,1.405,1.3551,0.318817,0.306729
2574,0.910792,0.810572,0.322311,0.294228,0.41574,0.351563,0.673448,0.673562,0.0866954,0.104973,0.912457,0.964547,0.781401,0.754763,0.316777,0.343267,0.807303,0.828208,0.128214,0.177346,-0.331866,0.0096003,-0.830458,-0.584866,-1.28139,-1.26657,-1.42198,-1.43071,-0.354768,-0.276189,0.03311,0.0106165,0.685294,0.582401,1.66847,1.43491,-0.353877,-0.403133,0.995855,0.979152
2575,0.160179,0.0598255,0.908953,0.879686,0.404554,0.424859,0.673896,0.672343,0.860802,0.879144,0.0509639,0.105365,0.0195462,-0.00600696,0.302597,0.311065,0.750181,0.772643,0.524276,0.571911,1.17695,1.5233,0.45092,0.693712,-0.0766773,-0.0569542,-0.11545,-0.128036,0.446666,0.524292,1.70197,1.68185,1.09488,0.997685,-1.59279,-1.831,2.35895,2.31311,0.708901,0.685151
2576,0.391544,0.351793,0.130716,0.102278,0.563936,0.498154,0.97726,0.97676,0.829266,0.84953,0.915427,0.968393,0.863391,0.839606,0.251391,0.278862,0.286823,0.307759,0.593899,0.643939,1.46461,1.80623,-2.39374,-2.14788,0.285032,0.310512,-1.37471,-1.38545,0.150846,0.25012,-0.36814,-0.383314,0.81367,0.723777,0.396754,0.162349,0.0444612,-0.00592369,-1.37748,-1.39451
2577,0.744448,0.643761,0.841375,0.8127,0.817172,0.753634,0.285792,0.284643,0.22074,0.240029,0.550102,0.605985,0.821701,0.796242,0.440258,0.465829,0.868482,0.887576,0.881611,0.932044,-0.994306,-0.657945,0.506065,0.751504,-0.0769808,-0.0562962,0.212739,0.201774,-0.105624,-0.024053,-0.656525,-0.675217,-0.824669,-0.916181,3.39768,3.15961,-0.808714,-0.862169,-1.95228,-1.97598
2578,0.275691,0.173291,0.648149,0.604657,0.470143,0.371592,0.793715,0.792484,0.437199,0.455285,0.192594,0.243577,0.493714,0.470272,0.1885,0.212819,0.0426159,0.0634025,0.0382153,0.0902046,-0.130177,0.204006,-0.601393,-0.352958,-1.17201,-1.15301,0.0907651,0.0754991,0.914215,0.994467,-0.419759,-0.446164,0.769588,0.686091,0.668933,0.428557,-0.545115,-0.591714,2.32503,2.30132
2579,0.649526,0.545594,0.505752,0.396614,0.0530871,-0.0104504,0.990342,0.988775,0.263055,0.239429,0.801073,0.85421,0.807937,0.782332,0.256158,0.279214,0.603719,0.623169,0.435915,0.489663,1.42375,1.7503,0.77049,1.01741,-0.615601,-0.601052,-0.459178,-0.467675,-0.00087611,0.079654,0.889016,0.869966,1.08766,1.00784,-0.00775154,-0.253581,-2.27405,-2.31653,0.703459,0.685195
2580,0.426097,0.331275,0.219433,0.188571,0.406599,0.255862,0.833251,0.745167,0.00440311,0.0235724,0.266447,0.320026,0.253949,0.229588,0.679132,0.700571,0.258225,0.278307,0.149869,0.20422,0.838481,1.1609,-1.44189,-1.20189,0.23229,0.245441,0.614248,0.604601,-0.375591,-0.287308,-0.388057,-0.410204,-0.734255,-0.821749,0.0731417,-0.168992,-0.472035,-0.512038,-0.570523,-0.59597
2581,0.113973,0.116955,0.565613,0.534747,0.586111,0.522174,0.503936,0.501559,0.893407,0.913232,0.205972,0.25808,0.314521,0.288562,0.535779,0.558437,0.959269,0.980927,0.258489,0.315048,-0.214277,0.109672,0.0131699,0.246303,0.0318456,0.0478489,0.755446,0.738616,-0.367037,-0.281471,0.041272,-0.0777414,0.335177,0.250732,1.25482,1.01752,-0.119714,-0.161022,-0.804985,-0.901408
2582,0.00439822,-0.0973651,0.122599,0.0913736,0.171433,0.107749,0.785208,0.781465,0.315267,0.334664,0.907254,0.95874,0.0731781,0.047279,0.661455,0.624732,0.407166,0.426433,0.803658,0.859179,-0.966711,-0.648927,0.0384748,0.174845,-0.641794,-0.591416,-0.048183,-0.0689631,0.409914,0.490776,0.282634,0.254721,0.413539,0.328742,3.20585,2.96448,-1.0731,-1.11564,-1.17685,-1.20685
2583,0.168178,0.0676187,0.984486,0.95487,0.843576,0.777331,0.117202,0.113897,0.452877,0.474428,0.478706,0.528021,0.822864,0.796792,0.73644,0.691026,0.288527,0.313266,0.854756,0.911852,1.22997,1.54021,-0.13063,0.103386,-1.25347,-1.23068,0.547232,0.523154,-0.676332,-0.593342,-1.60255,-1.62166,1.58398,1.49732,0.756697,0.515132,0.581417,0.53334,-0.360775,-0.383892
2584,0.98508,0.885482,0.763686,0.82276,0.566276,0.498748,0.983245,0.977673,0.326603,0.348091,0.592686,0.641804,0.197617,0.170424,0.683118,0.757321,0.180906,0.200098,0.673845,0.633268,1.17574,1.48604,-0.856934,-0.628626,0.988593,1.01381,-0.158222,-0.174714,1.47784,1.55916,-0.287604,-0.305532,0.473295,0.388472,-0.242225,-0.486614,-0.123111,-0.258838,-1.53617,-1.55832
2585,0.75391,0.656829,0.718113,0.690649,0.736907,0.669476,0.778442,0.770797,0.559094,0.578677,0.13932,0.190497,0.138803,0.112046,0.800364,0.823615,0.381931,0.420522,0.29701,0.354683,-0.523381,-0.208261,0.103443,0.324129,-0.905588,-0.872485,1.069,1.05238,-0.763307,-0.681907,0.468857,0.44405,-1.45378,-1.53405,0.00686932,-0.230832,-1.00111,-1.05102,0.111026,0.0909734
2586,0.100699,0.00522918,0.117111,0.0891086,0.482367,0.501174,0.792406,0.706711,0.122473,0.14017,0.796171,0.846995,0.772785,0.748634,0.623795,0.708869,0.623435,0.640946,0.732675,0.789316,0.126108,0.442162,-0.371666,-0.147672,0.638696,0.673446,0.29402,0.276008,0.397931,0.472504,-1.40945,-1.43233,1.18054,1.10214,-0.418959,-0.65055,2.54029,2.48595,0.193892,0.17165
2587,0.067372,-0.0376368,0.687974,0.660492,0.401224,0.332872,0.649097,0.642626,0.359452,0.376031,0.972759,1.02177,0.353342,0.327612,0.572658,0.594123,0.137667,0.156044,0.576672,0.647767,-0.651008,-0.332637,-0.192386,0.0379128,1.25635,1.28585,-1.01014,-1.02674,0.382602,0.462076,1.98538,1.95908,0.512262,0.427545,2.00103,1.77416,-0.761493,-0.820861,0.651543,0.629083
2588,0.0175699,-0.0805028,0.3844,0.404401,0.703662,0.634119,0.363176,0.426498,0.915402,0.930525,0.185104,0.235293,0.347487,0.320184,0.839312,0.859726,0.366762,0.40736,0.450078,0.506218,-0.259784,0.0725461,1.49017,1.72092,-1.13833,-1.11359,0.286319,0.275936,1.49311,1.5702,-0.875442,-0.906929,-0.396102,-0.479472,-0.177614,-0.408241,-1.15659,-1.21222,-1.31608,-1.34443
2589,0.937427,0.839158,0.176683,0.148309,0.326553,0.254787,0.0985803,0.210369,0.0388218,0.0536333,0.42214,0.473615,0.0657424,0.0392672,0.379777,0.398318,0.639824,0.658677,0.731248,0.789575,0.15514,0.477729,1.21491,1.44691,0.0159165,0.0361374,-0.205974,-0.221687,0.0293403,0.101526,-0.26682,-0.292714,1.6422,1.56332,-2.81343,-3.04974,0.681546,0.624066,0.466554,0.431269
2590,0.706969,0.610505,0.202626,0.174555,0.58136,0.510267,0.0016912,-0.0057598,0.0626606,0.155708,0.919606,0.971095,0.930397,0.902569,0.451277,0.469905,0.644357,0.664118,0.142713,0.198913,0.56454,0.882912,0.218649,0.451657,-0.380641,-0.360652,0.951966,0.928093,1.03174,1.10338,0.122601,0.0901763,-0.668463,-0.741237,0.23926,0.00234618,1.22683,1.16272,0.505312,0.424932
2591,0.115488,0.0198567,0.228556,0.2008,0.0835657,0.0105715,0.438196,0.432907,0.23995,0.257782,0.0668051,0.116542,0.0331858,0.00403289,0.92251,0.941983,0.245476,0.265174,0.846027,0.903339,-1.39014,-1.07562,-0.435787,-0.20369,-1.5431,-1.52055,-1.21781,-1.23696,0.427071,0.481812,-2.06899,-2.09861,1.59893,1.52721,0.265297,0.0253244,-0.298017,-0.355461,0.451491,0.418595
2592,0.41706,0.405475,0.600759,0.578131,0.754372,0.680153,0.263472,0.279908,0.693477,0.710417,0.259724,0.310286,0.0890464,0.0335572,0.751892,0.770414,0.280808,0.398295,0.570993,0.695961,-0.770097,-0.456447,-0.840074,-0.614171,-0.531876,-0.505868,-1.86633,-1.88932,-0.212609,-0.139757,-0.883388,-0.920083,-0.894834,-0.965313,-0.0826806,-0.317141,0.185719,0.134936,1.27428,1.24155
2593,0.885198,0.791094,0.981223,0.955463,0.548311,0.536835,0.133131,0.126909,0.491703,0.508415,0.116162,0.21015,0.0911056,0.0630814,0.00994439,0.0291601,0.512728,0.531416,0.432105,0.488584,0.163061,0.482593,0.0884383,0.307091,1.39114,1.41782,0.887173,0.871857,1.37712,1.44337,1.71748,1.68709,-1.14339,-1.20899,0.126636,-0.109537,-0.90992,-0.956015,-0.0111957,-0.0396161
2594,0.945044,0.851347,0.401898,0.374429,0.470694,0.393517,0.777152,0.768936,0.0251837,0.0401107,0.0578395,0.110013,0.840143,0.812594,0.237819,0.258462,0.778091,0.798043,0.857297,0.912873,-0.227822,0.0944728,0.093524,0.235633,0.279542,0.304572,-1.03036,-1.041,0.65838,0.728745,-0.313932,-0.346606,0.0113445,-0.0535188,1.08233,0.848688,1.41954,1.37132,-0.633267,-0.665537
2595,0.416393,0.394286,0.229577,0.244758,0.894692,0.817685,0.418643,0.504748,0.0955458,0.109283,0.221131,0.369664,0.160285,0.130739,0.0348812,0.0563927,0.154532,0.17323,0.0103374,0.0650644,0.817261,1.14264,-0.0526082,0.164175,1.13723,1.16487,-0.00367213,-0.0143292,-1.51432,-1.45138,0.249654,0.220922,-1.94033,-2.00921,-0.465474,-0.70511,0.952933,0.901671,0.787202,0.7536
2596,0.029052,-0.0627738,0.141485,0.115086,0.133909,0.0579905,0.248987,0.24056,0.643832,0.657994,0.575417,0.629315,0.379269,0.339593,0.262731,0.285694,0.849322,0.869819,0.872629,0.928643,-0.499562,-0.167398,1.90927,2.12731,0.396558,0.426914,-0.359829,-0.374137,-1.10337,-1.03276,-0.105651,-0.0777376,-0.597397,-0.667564,0.602753,0.363046,-0.407452,-0.458608,0.516443,0.465175
2597,0.180017,0.131128,0.278022,0.25995,0.917229,0.840667,0.647884,0.639907,0.882995,0.899225,0.321116,0.369607,0.53588,0.548446,0.867363,0.890236,0.801768,0.742781,0.542809,0.597063,-0.561021,-0.221571,0.137031,0.350662,0.25244,0.275838,-0.455572,-0.469927,0.129784,0.200741,-0.344678,-0.376398,-0.112102,-0.175586,-0.697796,-0.932816,-0.615786,-0.665392,0.207787,0.176751
2598,0.418039,0.325029,0.431741,0.404813,0.36085,0.286526,0.226458,0.218555,0.502703,0.520353,0.0573472,0.109898,0.786845,0.7573,0.102604,0.123826,0.59493,0.615744,0.416727,0.471976,-2.43595,-2.09081,1.28681,1.5037,1.02093,1.04453,1.28532,1.27714,-0.391573,-0.317295,0.138078,0.100846,0.902944,0.837762,-0.279697,-0.509609,-0.612693,-0.65608,0.289467,0.257428
2599,0.936027,0.841635,0.0383255,0.010722,0.850464,0.774793,0.418947,0.409132,0.798657,0.817929,0.495311,0.548255,0.270322,0.241266,0.858053,0.881457,0.288429,0.306684,0.940093,0.996409,-0.12876,0.221223,0.851366,1.06267,1.09242,1.12175,0.5567,0.547863,0.682466,0.76141,1.0728,1.03531,-1.04804,-1.11793,-1.2736,-1.49593,1.0863,1.03964,0.0675226,0.0372341
2600,0.104518,0.00882077,0.221159,0.194183,0.0819188,0.00554674,0.908222,0.897596,0.622961,0.622869,0.633605,0.688191,0.884636,0.857442,0.0788888,0.0999162,0.61464,0.632781,0.482402,0.537756,-0.993908,-0.645331,-0.264407,-0.0572936,-1.09316,-1.06848,-0.475079,-0.476686,0.323565,0.410327,-0.520616,-0.567013,0.66294,0.592087,1.66932,1.44895,0.595435,0.555125,-1.25949,-1.28842
2601,0.411628,0.315541,0.959291,0.93488,0.851401,0.776773,0.185432,0.174895,0.329279,0.427809,0.0258406,0.0787094,0.431102,0.40154,0.221554,0.241314,0.681224,0.751178,0.0237791,0.0791028,-0.343856,0.00509198,0.206656,0.418947,-0.247546,-0.221986,-0.326616,-0.32593,-0.380728,-0.290879,0.843172,0.794894,0.706863,0.637987,0.721453,0.507926,0.732129,0.68815,-0.203783,-0.305191
2602,0.182855,0.0868884,0.891198,0.865838,0.521228,0.444643,0.939846,0.927493,0.213476,0.232749,0.689422,0.740443,0.311674,0.281776,0.03057,0.0491937,0.815122,0.869574,0.929809,0.98313,1.04396,1.39382,-2.28494,-2.07119,-1.30491,-1.27251,-1.02126,-1.0238,-0.247788,-0.164354,0.0544073,0.00798119,0.242263,0.176535,-1.27529,-1.48394,0.0589474,0.0171972,0.712765,0.678034
2603,0.76067,0.663434,0.35847,0.333765,0.189264,0.112514,0.946084,0.935368,0.288982,0.306904,0.181989,0.23507,0.720218,0.688745,0.323318,0.322137,0.96983,0.987971,0.739507,0.721298,-0.768566,-0.412718,-0.741596,-0.528587,0.164193,0.196865,-0.312344,-0.322662,0.157919,0.239198,0.662605,0.622196,1.1434,1.08131,0.495599,0.288793,-0.324267,-0.35918,0.239221,0.202575
2604,0.936939,0.838841,0.753053,0.729214,0.530014,0.454465,0.311737,0.303152,0.687322,0.704626,0.329454,0.394092,0.574955,0.543808,0.464088,0.595081,0.164757,0.185286,0.406743,0.459466,-1.26411,-0.91153,0.220825,0.44128,-0.893541,-0.853664,-0.107663,-0.112019,-0.951918,-0.875411,-1.4131,-1.45789,0.0914129,0.0336987,-0.436854,-0.636556,0.159982,0.131217,1.35068,1.31439
2605,0.214981,0.11495,0.90779,0.88326,0.340332,0.26243,0.323525,0.308712,0.614977,0.633986,0.49949,0.553113,0.189757,0.158047,0.849986,0.868025,0.813363,0.832233,0.418084,0.470184,0.805089,1.15626,0.125211,0.350375,0.335346,0.37389,0.594995,0.589117,-0.621725,-0.548793,-0.741628,-0.866994,1.59798,1.54185,1.42585,1.23071,-0.0294023,-0.0616812,1.46833,1.42752
2606,0.645986,0.547912,0.409264,0.384978,0.67499,0.594433,0.322292,0.314271,0.776764,0.793161,0.95674,1.01134,0.995355,0.963518,0.463154,0.481553,0.809704,0.705394,0.967686,1.01912,-0.283662,0.0747655,-1.03946,-0.815676,-0.636864,-0.601003,-0.393614,-0.404828,-1.46352,-1.38986,-0.22785,-0.276098,-0.0233566,-0.0813994,-0.95361,-1.15061,1.4203,1.38353,1.0886,1.04248
2607,0.0582809,-0.0382759,0.818031,0.795062,0.757499,0.676362,0.522709,0.51573,0.593334,0.610844,0.129116,0.183307,0.160838,0.128109,0.701532,0.721391,0.610872,0.578554,0.320903,0.37296,0.907647,1.26092,-0.243594,-0.0143471,0.249082,0.29087,-0.119816,-0.132288,-0.607275,-0.540916,-0.562082,-0.614514,0.672781,0.610117,-0.999747,-1.13962,0.898121,0.862118,-1.73924,-1.77736
2608,0.86045,0.763254,0.491007,0.469538,0.0976824,0.0173868,0.298909,0.29284,0.982813,0.999147,0.793326,0.849961,0.701638,0.669763,0.449177,0.52453,0.50774,0.451714,0.227699,0.27912,-0.965626,-0.608319,0.768525,1.00136,-0.672061,-0.633924,1.78297,1.77278,-0.614449,-0.551344,-2.37572,-2.43116,0.836734,0.778278,-0.939049,-1.12862,0.372719,0.34071,0.454756,0.418684
2609,0.772629,0.709076,0.868747,0.849275,0.367873,0.288655,0.974678,0.969537,0.86204,0.808562,0.281118,0.340094,0.0617451,0.0278882,0.309452,0.327669,0.306004,0.324875,0.451113,0.502234,-0.944422,-0.587024,0.872506,1.10829,-1.15287,-1.10641,0.516841,0.501396,1.02716,1.09207,-1.11473,-1.17589,-1.39259,-1.44255,-1.22942,-1.42416,1.52518,1.48653,-0.782879,-0.816957
2610,0.659123,0.654899,0.855537,0.75873,0.231012,0.151955,0.925776,0.880847,0.600638,0.617978,0.25114,0.283455,0.396941,0.365567,0.815181,0.834673,0.773041,0.790044,0.972779,1.02182,1.94066,2.29725,0.32847,0.55865,0.931016,0.975778,0.319258,0.298663,-0.234176,-0.162807,-1.9591,-2.02528,0.294472,0.236332,0.312311,0.116794,-1.09604,-1.13892,-1.52772,-1.56358
2611,0.699156,0.600722,0.687048,0.668186,0.395333,0.318115,0.797928,0.792157,0.224248,0.239106,0.168107,0.226817,0.150562,0.119503,0.0703193,0.0889284,0.88191,0.899626,0.0399739,0.0878995,0.0541829,0.413325,-0.513893,-0.283367,0.592876,0.640034,0.594547,0.571203,1.71624,1.79245,0.43646,0.377776,-1.06906,-1.12201,-0.709314,-0.901309,-0.953603,-0.991616,0.438804,0.409403
2612,0.948427,0.851837,0.0259604,0.00790993,0.307806,0.23225,0.0352555,0.0286218,0.749749,0.762626,0.55544,0.616148,0.819484,0.787375,0.645539,0.662545,0.267453,0.283822,0.358866,0.409486,0.840987,1.2002,2.0435,2.27411,1.06979,1.11495,0.437317,0.413514,0.60484,0.67784,-1.17107,-1.22455,-0.695887,-0.753483,1.05088,0.858434,0.143078,0.108037,0.0681584,0.0371851
2613,0.679579,0.582604,0.263963,0.245218,0.63731,0.56001,0.970725,0.962854,0.388314,0.399198,0.357297,0.417379,0.662473,0.690674,0.216942,0.236086,0.741306,0.759269,0.682003,0.731073,2.69701,3.0512,-0.566419,-0.327454,0.612613,0.657417,0.896832,0.869236,0.417906,0.494508,-0.918146,-1.0642,0.668244,0.617455,1.11524,0.927688,0.892823,0.86174,1.24754,1.21107
2614,0.0754717,-0.0228332,0.807711,0.787475,0.372043,0.295787,0.158996,0.151201,0.777424,0.7875,0.977664,1.03814,0.625418,0.593973,0.963424,0.983035,0.546285,0.551324,0.352065,0.399493,-1.21251,-0.858315,0.872672,1.1049,-0.11476,-0.0681829,0.465124,0.431971,-0.763744,-0.681586,-0.856999,-0.903859,-0.44101,-0.491391,1.65006,1.45876,-0.121078,-0.154692,-0.215964,-0.252147
2615,0.705402,0.607849,0.742953,0.723341,0.816276,0.739533,0.23486,0.223548,0.41932,0.428422,0.579551,0.727322,0.0321046,0.00244595,0.278956,0.30086,0.456135,0.34338,0.675749,0.723228,-1.10233,-0.746867,-1.90515,-1.6752,0.51009,0.560047,-2.26949,-2.2985,0.330359,0.50725,0.322825,0.274673,-1.78796,-1.83583,0.415857,0.226934,1.35748,1.32119,0.666383,0.63092
2616,0.993233,0.894696,0.341868,0.323901,0.596681,0.521667,0.301048,0.295896,0.952113,0.962184,0.353863,0.416506,0.180251,0.15287,0.849183,0.86837,0.117471,0.135435,0.429155,0.493519,1.0228,1.38045,2.19484,2.42005,0.819484,0.867929,-1.59961,-1.67926,1.61393,1.69609,-1.38356,-1.43202,-0.522653,-0.574659,-0.521337,-0.714094,-1.09686,-1.12856,0.500206,0.529606
2617,0.169041,0.0719751,0.410459,0.392438,0.0295366,-0.0470657,0.885844,0.878813,0.428763,0.43917,0.332589,0.416062,0.620701,0.541195,0.84655,0.863572,0.929052,0.948322,0.214405,0.263811,-0.269601,0.0837226,-0.630857,-0.408226,-0.625894,-0.582779,-1.02725,-1.06002,-0.103309,-0.0201601,-0.643625,-0.786463,-0.024601,-0.0826807,0.915741,0.720347,1.20999,1.18147,0.437972,0.428292
2618,0.849853,0.753182,0.699698,0.683306,0.403923,0.32572,0.0141058,0.0087491,0.12242,0.131655,0.220632,0.415619,0.956714,0.92952,0.606115,0.626448,0.484863,0.503745,0.302829,0.349932,-0.684905,-0.335586,-0.168137,0.0535959,-0.936162,-0.887296,-2.29342,-2.3314,-0.567739,-0.478846,-0.022507,-0.140908,-0.134246,-0.27705,0.943009,0.743325,-1.03625,-1.06564,0.360053,0.326977
2619,0.379813,0.282712,0.38925,0.409603,0.316614,0.239855,0.156974,0.153793,0.567151,0.575452,0.352533,0.415175,0.979259,0.952011,0.399943,0.389324,0.542204,0.561905,0.0370409,0.084959,1.11956,1.47106,-1.39118,-1.17417,-1.65723,-1.6129,1.13524,1.09933,0.00682246,0.0930818,0.553108,0.504647,-0.414156,-0.471419,0.333424,0.140244,-0.0392417,-0.074159,1.135,1.10333
2620,0.867909,0.769438,0.15123,0.135901,0.544871,0.547843,0.67551,0.671842,0.0441313,0.0524379,0.519824,0.580337,0.633915,0.606787,0.135179,0.152201,0.953646,0.972168,0.208761,0.257131,-0.572316,-0.223241,0.181863,0.401001,0.286188,0.325274,-2.91478,-2.95069,0.372709,0.467593,0.0773837,0.0255862,-0.393952,-0.456884,-0.68659,-0.877858,1.64728,1.60703,-0.898377,-0.930951
2621,0.0843145,-0.0124819,0.701156,0.687661,0.932032,0.855832,0.835067,0.749908,0.973807,0.981271,0.250974,0.31246,0.943056,0.91374,0.863926,0.879852,0.0208992,0.0370999,0.592723,0.641294,-1.7765,-1.42723,-1.62544,-1.40946,1.26119,1.29325,0.167297,0.126054,0.210493,0.299768,0.350955,0.299914,-1.27774,-1.34868,1.31107,1.11549,1.83197,1.78483,-0.0627812,-0.093649
2622,0.653936,0.558979,0.446325,0.431606,0.320814,0.246895,0.897339,0.827974,0.142048,0.148878,0.811437,0.873747,0.0851709,0.0580622,0.605612,0.623032,0.320567,0.337051,0.619202,0.6586,0.176753,0.53136,-0.378708,-0.160667,0.557224,0.585939,1.01791,0.982139,0.566354,0.658114,0.0919513,0.0387606,-0.0398224,-0.117498,-0.226934,-0.422392,-0.0826919,-0.13335,0.357125,0.334261
2623,0.132979,0.0383379,0.796515,0.782109,0.121806,0.0500242,0.910078,0.90604,0.408112,0.415191,0.835574,0.900172,0.35163,0.324479,0.894054,0.913666,0.419728,0.369166,0.626241,0.675906,-0.62611,-0.275071,0.152014,0.363368,-1.75043,-1.71985,-1.45529,-1.4836,-1.0388,-0.948384,-2.3522,-2.40411,0.231444,0.158063,0.141866,-0.0607668,1.97496,1.91727,0.272045,0.249809
2624,0.0999214,0.00705514,0.354059,0.338736,0.185145,0.112205,0.451551,0.449035,0.221212,0.228196,0.639499,0.737825,0.974153,0.946003,0.334967,0.352509,0.384325,0.40128,0.383333,0.442333,-1.65952,-1.31122,1.3192,1.53184,-0.42089,-0.386779,-0.275279,-0.303899,0.233462,0.330545,0.596248,0.549116,0.784308,0.712213,-1.32175,-1.52369,-0.360763,-0.418453,-1.14171,-1.16755
2625,0.647703,0.553453,0.228103,0.196616,0.829516,0.755915,0.292589,0.291305,0.420574,0.348987,0.508723,0.575478,0.851395,0.821391,0.728484,0.744652,0.0807176,0.0974298,0.161042,0.20876,0.625106,0.970806,0.795615,1.00093,0.599652,0.627907,-0.37091,-0.399689,0.273501,0.366345,0.1648,0.209287,-1.04634,-1.11738,0.815571,0.608733,-0.437145,-0.501612,-1.03009,-1.05442
2626,0.690285,0.604599,0.0701646,0.0544953,0.655021,0.579547,0.751886,0.74899,0.463018,0.469779,0.556097,0.620607,0.0778433,0.0508976,0.553924,0.601738,0.838441,0.854835,0.133475,0.179389,-0.841362,-0.493169,0.262917,0.470016,-1.54076,-1.51426,-1.27749,-1.29994,1.15719,1.24542,-0.0819834,-0.130542,-0.51001,-0.58029,0.659416,0.373935,0.777809,0.707104,0.193152,0.166324
2627,0.749464,0.655746,0.893794,0.877471,0.138343,0.0607551,0.548322,0.459075,0.438383,0.445654,0.366463,0.432127,0.631918,0.602607,0.440912,0.458825,0.0396782,0.0580266,0.523004,0.568392,0.644012,0.990465,0.771716,0.979568,-0.0498846,-0.0291621,-0.255772,-0.273269,0.590706,0.681532,-1.32589,-1.37898,-2.22382,-2.29981,0.337395,0.139137,0.535568,0.469583,0.762347,0.7323
2628,0.407929,0.315511,0.838929,0.869798,0.6454,0.568985,0.171528,0.169159,0.853611,0.863158,0.72684,0.79222,0.423577,0.392238,0.770769,0.790683,0.494151,0.513443,0.574754,0.539159,-1.00986,-0.657182,-1.75963,-1.54521,-0.817907,-0.79986,2.06728,2.05321,-0.642246,-0.556951,-0.900056,-0.949748,-0.400804,-0.477512,-2.11779,-2.31021,2.19404,2.13346,2.16169,2.13625
2629,0.905226,0.811916,0.865971,0.862124,0.720277,0.654258,0.963644,0.959176,0.575999,0.586164,0.680296,0.745031,0.909847,0.878979,0.447274,0.468764,0.0212341,0.0387707,0.479175,0.509925,0.33054,0.684875,-0.0307792,0.183005,0.0395459,0.0604389,1.08573,1.07419,-0.289883,-0.198606,-1.26324,-1.31872,-0.952025,-1.03101,-0.51338,-0.706075,-0.745511,-0.811471,0.579561,0.552466
2630,0.895451,0.802892,0.875566,0.854451,0.835292,0.739532,0.506789,0.502171,0.0655862,0.0779649,0.39171,0.456119,0.832693,0.843132,0.932124,0.95566,0.647931,0.665158,0.435355,0.480692,0.69161,1.04432,-0.0606244,0.154934,-0.611427,-0.585689,-1.10094,-1.10732,1.89087,1.98801,1.02846,0.978211,0.310131,0.230156,0.817388,0.61895,-0.216589,-0.253983,-0.292222,-0.316929
2631,0.616158,0.573539,0.860898,0.846778,0.88237,0.824805,0.353045,0.270182,0.68084,0.692063,0.347677,0.482988,0.837563,0.807285,0.516861,0.539167,0.157832,0.175141,0.859715,0.904981,-2.06202,-1.70247,-0.636425,-0.423989,-0.189191,-0.156724,-1.08439,-1.09575,-0.753367,-0.649907,0.258698,0.205222,-0.148846,-0.231295,-0.765874,-0.964897,0.368766,0.303505,0.549211,0.520372
2632,0.437387,0.344185,0.514055,0.501776,0.986492,0.910078,0.0435194,0.0381926,0.0422442,0.0524311,0.445079,0.509856,0.979918,0.947503,0.707797,0.730797,0.134091,0.198779,0.850333,0.929152,-0.892055,-0.533259,0.0919759,0.298087,-0.218837,-0.186204,-0.00515099,-0.0234758,-1.32362,-1.2138,-0.073942,-0.133194,0.7476,0.657363,1.04418,0.840356,0.0208436,-0.0444317,-0.5376,-0.562514
2633,0.933463,0.840591,0.931632,0.920889,0.264998,0.189081,0.746426,0.740266,0.374238,0.384611,0.656675,0.660302,0.675553,0.641494,0.662667,0.782198,0.20647,0.222417,0.917404,0.953323,-0.620665,-0.267377,1.28577,1.48327,0.84012,0.874277,0.707867,0.692732,0.244095,0.355775,0.0614235,0.00408956,2.25902,2.16551,2.09654,1.89159,0.0951512,0.0273253,-0.529926,-0.554934
2634,0.461421,0.442841,0.728135,0.708026,0.448891,0.374868,0.0787835,0.0726986,0.377386,0.387401,0.745492,0.810748,0.812702,0.776591,0.750847,0.833599,0.704086,0.71816,0.780309,0.977495,1.38463,1.73772,0.320161,0.518622,-1.63861,-1.60436,-0.676845,-0.685472,0.15718,0.263675,-0.909648,-0.968368,0.201975,0.116205,-0.0869274,-0.290807,-0.584927,-0.65782,0.798249,0.77145
2635,0.138866,0.0450913,0.505953,0.495162,0.138282,0.065742,0.44842,0.441319,0.0999465,0.110407,0.290878,0.35492,0.403356,0.448361,0.862,0.885,0.00827697,0.0220052,0.9564,1.00167,0.77786,1.13324,1.26728,1.47138,-0.702971,-0.667854,0.072792,0.0631321,-0.232421,-0.118648,-0.216729,-0.28103,0.268234,0.179405,-0.49323,-0.694564,0.0710278,0.00377258,0.701932,0.673686
2636,0.91632,0.820185,0.0221078,0.0118724,0.713484,0.643886,0.446293,0.4401,0.724581,0.734594,0.650136,0.672572,0.158242,0.120131,0.615497,0.637002,0.0144811,0.0722296,0.58547,0.66021,-0.527988,-0.176803,-0.761077,-0.559493,-0.375777,-0.34514,-0.135595,-0.139601,2.16829,2.28574,0.731412,0.668802,-0.369501,-0.464733,0.570038,0.373592,0.00072467,-0.131652,-1.38361,-1.40597
2637,0.0769351,-0.0167114,0.893655,0.881705,0.531121,0.462101,0.184003,0.176661,0.345426,0.355722,0.924217,0.990225,0.470709,0.432191,0.801498,0.823969,0.108743,0.122454,0.275391,0.318754,-1.00124,-0.642119,-0.122377,0.0715895,-1.68262,-1.65703,-0.815272,-0.822428,0.781222,0.892837,0.581282,0.513191,0.146809,0.0570229,0.707607,0.505512,-0.195229,-0.267077,-0.806932,-0.825304
2638,0.672234,0.57831,0.490663,0.469918,0.659965,0.588312,0.903658,0.895274,0.338444,0.308457,0.481141,0.548671,0.0710677,0.0318531,0.377194,0.39751,0.682307,0.697183,0.233162,0.310911,0.663697,1.02527,-0.301957,-0.109777,-0.489987,-0.461274,0.523349,0.511908,1.28029,1.38838,-1.22594,-1.2881,0.257627,0.16532,-0.78603,-0.986397,1.27621,1.20881,-0.512656,-0.533079
2639,0.913022,0.819366,0.0725005,0.0581323,0.304216,0.23458,0.329064,0.322612,0.138514,0.261193,0.663082,0.659598,0.940936,0.900431,0.583534,0.604627,0.0608187,0.0767524,0.380394,0.303067,-0.0555862,0.312999,0.609784,0.797668,1.35127,1.38541,0.384547,0.370003,-2.56847,-2.45977,1.18023,1.11495,-1.61473,-1.70994,-0.526397,-0.730615,0.445013,0.382763,1.05849,1.03997
2640,0.818037,0.709357,0.00975332,-0.00600137,0.547546,0.479903,0.0573444,0.0495842,0.191233,0.213928,0.701489,0.770524,0.340622,0.29938,0.539429,0.558108,0.148142,0.164926,0.251141,0.295223,0.0397316,0.40921,-0.0326267,0.158103,-1.30966,-1.27506,-0.922717,-0.932741,-1.26879,-1.16626,0.624459,0.559358,0.267971,0.174776,-0.813375,-1.01157,-2.92246,-2.99351,0.244238,0.232829
2641,0.69459,0.599347,0.547984,0.531234,0.487033,0.419646,0.189347,0.183737,0.161365,0.166663,0.0249697,0.0949743,0.765833,0.726012,0.912333,0.930568,0.698361,0.714594,0.675647,0.719512,-0.688912,-0.31953,-2.34477,-2.15962,0.397215,0.430416,2.17392,2.16087,-0.554813,-0.457411,0.990279,0.924752,-0.979154,-1.07415,-2.27939,-2.4745,-0.187874,-0.263351,1.5193,1.51286
2642,0.139856,0.0431824,0.374348,0.356659,0.209402,0.141063,0.943365,0.936334,0.109103,0.119399,0.166516,0.242516,0.908065,0.793312,0.506012,0.54555,0.129815,0.144664,0.00437208,0.0483637,0.237093,0.605169,-0.0704884,0.108922,1.8006,1.83865,-1.40766,-1.41312,-0.55049,-0.451573,-2.60038,-2.66127,0.350957,0.252202,0.956604,0.760866,1.05432,0.977591,-1.74874,-1.75493
2643,0.690755,0.5942,0.42605,0.410462,0.174793,0.107519,0.803437,0.794799,0.53068,0.446289,0.321712,0.390058,0.90009,0.860611,0.142929,0.160532,0.0117647,0.027493,0.215205,0.260878,4.14161,4.51181,-0.0928277,0.0808506,0.245276,0.281895,-0.678886,-0.680068,-0.115137,-0.0184253,-0.512216,-0.572044,0.0239612,-0.0688295,1.11984,0.923004,-0.73096,-0.812562,0.675116,0.669415
2644,0.0583194,-0.0369255,0.234902,0.22095,0.744539,0.675602,0.253174,0.246981,0.764859,0.773179,0.947285,1.01551,0.747482,0.725174,0.801272,0.820557,0.55784,0.57243,0.870475,0.915424,-0.192407,0.180473,0.978191,1.1585,1.92955,1.97082,0.359445,0.361226,1.17375,1.27509,0.307236,0.252866,-0.538077,-0.638461,-0.683169,-0.883715,0.663584,0.587162,-1.02029,-1.02279
2645,0.90712,0.81053,0.958455,0.946979,0.1654,0.0967726,0.567464,0.561806,0.699583,0.707451,0.376655,0.445742,0.628169,0.589737,0.728404,0.749588,0.310267,0.32391,0.0126997,0.0580156,0.880846,1.25689,-1.23085,-1.04617,-0.287505,-0.252185,0.0419462,0.0482178,-1.37556,-1.26796,-0.872083,-0.933255,1.38177,1.27827,-0.858301,-1.05749,-0.354232,-0.42927,0.291573,0.289347
2646,0.822479,0.687709,0.621604,0.611905,0.668552,0.600334,0.467136,0.433173,0.979565,0.989548,0.0660429,0.1367,0.674376,0.686164,0.867051,0.855227,0.904986,0.920381,0.78187,0.82868,-0.933527,-0.564256,1.03147,1.22236,-0.25621,-0.22154,-0.871823,-0.870089,0.547,0.656758,0.277599,0.213793,0.649896,0.540869,1.30014,1.1045,-1.09289,-1.16164,-1.99385,-1.99531
2647,0.723975,0.564888,0.897343,0.888144,0.628086,0.561514,0.308831,0.30454,0.390967,0.400834,0.605832,0.678474,0.82172,0.782592,0.939547,0.960865,0.110577,0.123573,0.624509,0.673473,-0.147513,0.22262,1.98444,2.17512,0.431228,0.470424,-2.05578,-2.0491,-0.168317,-0.0578667,-0.598376,-0.666454,0.377329,0.266961,-0.917569,-1.11338,0.126336,0.0619355,0.809403,0.810932
2648,0.538658,0.442067,0.163022,0.152502,0.101865,0.0330404,0.463481,0.459171,0.187232,0.198832,0.0987704,0.173101,0.111752,0.0703421,0.297739,0.319914,0.0695932,0.0831604,0.215438,0.262001,-0.00828911,0.365293,0.139867,0.332058,0.270807,0.403196,-0.659899,-0.654131,0.476188,0.604604,1.36545,1.29466,-1.76654,-1.87567,-1.85767,-2.05441,-0.204922,-0.269019,0.667146,0.668197
2649,0.0795681,-0.0189865,0.187633,0.175919,0.963251,0.895201,0.993886,0.986832,0.393891,0.404054,0.677637,0.753953,0.131144,0.0881297,0.836272,0.857686,0.0293064,0.0427479,0.474007,0.500555,-1.16473,-0.792576,2.12962,2.32747,0.299306,0.335968,-1.37035,-1.36825,1.15427,1.26708,-1.00018,-1.07486,0.985716,0.879296,1.77072,1.5802,1.32815,1.2675,-0.29977,-0.304933
2650,0.418488,0.318113,0.546943,0.529725,0.272505,0.206249,0.207796,0.202137,0.815808,0.826394,0.895436,0.972668,0.967547,0.921834,0.587229,0.609688,0.698354,0.710434,0.694518,0.73911,-0.320828,0.0547848,-0.433615,-0.2295,0.622088,0.74178,-0.576775,-0.57383,1.54634,1.65548,-1.18193,-1.25864,0.903996,0.803985,-0.97199,-1.16607,-0.609762,-0.665067,-2.48487,-2.49398
2651,0.52696,0.428822,0.896389,0.88353,0.0980135,0.122066,0.452252,0.44736,0.298056,0.307968,0.0107596,0.0906809,0.331808,0.28439,0.950032,0.972573,0.623897,0.63549,0.0316927,0.0777564,-1.02192,-0.641836,1.05871,1.26505,1.1119,1.14759,-0.444213,-0.439815,-0.317494,-0.214174,-0.384021,-0.466482,1.17039,1.06356,-1.25757,-1.44703,-0.392594,-0.43984,1.06703,1.05748
2652,0.124476,0.0281183,0.260486,0.248069,0.101359,0.0378818,0.145227,0.139575,0.244453,0.225735,0.68592,0.767653,0.0169894,-0.0318691,0.806116,0.763234,0.0711093,0.0809966,0.695952,0.741101,0.0962096,0.479929,0.0135975,0.223031,-0.922285,-0.880806,0.849226,0.847467,0.302275,0.40294,-2.09294,-2.17317,0.129372,0.0159503,-0.55524,-0.747946,-0.679959,-0.723866,-1.63143,-1.64153
2653,0.0404727,-0.0549215,0.616275,0.603594,0.159217,0.0947002,0.283943,0.375672,0.0271498,0.143502,0.903072,0.986368,0.802318,0.753707,0.478504,0.553895,0.159248,0.16917,0.706399,0.751818,-1.15147,-0.770869,2.74569,2.96113,-0.00637088,0.040608,0.282708,0.307048,1.1396,1.23618,-0.397508,-0.470255,0.0435773,-0.0733682,-1.02358,-1.21307,-0.449569,-0.498639,-2.52146,-2.52504
2654,0.875232,0.780227,0.210218,0.19994,0.638527,0.572883,0.619099,0.61177,0.0492485,0.0612684,0.550746,0.634048,0.136453,0.0869359,0.321042,0.344556,0.887706,0.896527,0.405468,0.45089,-2.19283,-1.80702,-0.919848,-0.707357,1.94839,1.99449,-0.22989,-0.23337,0.544413,0.642472,1.7296,1.65073,-2.44667,-2.56589,1.84342,1.65909,1.32633,1.27431,1.26535,1.25914
2655,0.0716664,-0.0260481,0.705415,0.692988,0.137923,0.0731873,0.122065,0.114304,0.569242,0.5802,0.680447,0.776662,0.733954,0.682929,0.298125,0.369401,0.638275,0.683863,0.957964,1.005,-1.61191,-1.23288,-0.0923342,0.124465,0.197226,0.249143,1.27494,1.27502,0.153737,0.326914,-0.161307,-0.242451,1.15897,1.04349,0.53228,0.34771,1.9265,1.8738,-0.166477,-0.175034
2656,0.834317,0.738323,0.0146396,0.00254368,0.629126,0.566585,0.124813,0.124925,0.862856,0.781985,0.771987,0.919276,0.388429,0.337705,0.369161,0.394246,0.462306,0.4712,0.865536,0.940554,-0.270376,0.10918,0.100566,0.259377,-0.778801,-0.725749,0.482431,0.484214,-0.0860461,0.0113575,-0.0487274,-0.135664,-1.19115,-1.30982,-0.170075,-0.348556,-0.404067,-0.461926,0.0375919,0.0276501
2657,0.304299,0.207105,0.416484,0.370313,0.4999,0.512772,0.12472,0.135545,0.9721,0.98377,0.979422,1.06189,0.749765,0.700165,0.958222,0.982181,0.538941,0.549213,0.754332,0.876104,0.302079,0.683322,0.183788,0.394289,0.946194,0.996637,-2.1389,-2.13444,-1.25649,-1.16474,-1.09718,-1.18423,-0.244149,-0.356934,1.27519,1.09896,0.993174,0.937798,1.61973,1.61569
2658,0.830736,0.733912,0.750906,0.738082,0.5229,0.458958,0.246146,0.146166,0.0989843,0.11145,0.805554,0.889295,0.500564,0.405538,0.439619,0.461083,0.0566675,0.0691355,0.766468,0.811655,0.628631,1.01101,-1.30176,-1.0859,0.061938,0.117468,-0.899761,-0.893585,0.485066,0.573572,-1.16364,-1.24648,-0.952211,-1.06212,0.205178,0.0366225,0.645793,0.589861,-1.80224,-1.80628
2659,0.124421,0.0261517,0.192375,0.1811,0.0973531,0.0344594,0.164547,0.156786,0.739769,0.750655,0.8405,0.925575,0.161357,0.110911,0.711724,0.73176,0.678226,0.690254,0.847801,0.916225,1.46046,1.84227,-1.18302,-0.962647,-0.428607,-0.371429,-0.0229361,-0.0216163,0.00220275,0.0867905,0.0384531,-0.0514778,1.64592,1.54397,-0.0082667,-0.183171,2.87485,2.81783,-0.384674,-0.387143
2660,0.221612,0.121737,0.608151,0.596209,0.871031,0.805686,0.745979,0.739703,0.247502,0.257319,0.205915,0.290201,0.981126,0.931344,0.285689,0.305301,0.555045,0.572081,0.973874,1.02079,0.519441,0.900358,0.212762,0.438961,1.44711,1.50726,0.189188,0.189026,0.461824,0.485926,0.586865,0.501019,0.198245,0.0925499,1.09907,0.929744,1.05628,0.993803,1.58473,1.58584
2661,0.760437,0.658516,0.20918,0.196769,0.977964,0.912318,0.928667,0.920546,0.844979,0.85706,0.00483926,0.0914318,0.0283258,-0.0232204,0.969813,0.991087,0.439109,0.453908,0.603873,0.650285,-0.131929,0.249472,-0.353554,-0.126268,0.822607,0.876341,0.63132,0.628169,0.806475,0.885061,-0.00264022,-0.08751,0.05817,-0.0438221,1.73148,1.567,0.0360728,-0.0226294,0.177173,0.183228
2662,0.344169,0.243153,0.259052,0.198952,0.174374,0.109443,0.658305,0.652619,0.693974,0.706106,0.737302,0.822646,0.737896,0.684871,0.839668,0.855141,0.594092,0.608877,0.453944,0.437054,-0.566479,-0.184879,1.57913,1.80456,-0.0499258,-0.00282829,-1.22764,-1.23664,-0.410933,-0.33882,-0.0554316,-0.133915,-1.148,-1.246,0.213304,0.0427347,0.588763,0.532014,-0.116533,-0.110772
2663,0.593865,0.494269,0.214717,0.201134,0.997066,0.930224,0.644478,0.704808,0.0520484,0.0664741,0.41238,0.499421,0.191299,0.138016,0.731932,0.719195,0.0433579,0.0595807,0.178206,0.223824,0.923783,1.29876,0.660564,0.887769,0.503385,0.549131,0.697197,0.680584,-0.762863,-0.689903,0.579586,0.494417,-0.0426572,-0.141651,0.299826,0.127324,-2.21257,-2.27614,-1.00603,-0.99428
2664,0.126456,0.0284477,0.662239,0.64938,0.800908,0.733354,0.761616,0.756996,0.349469,0.356304,0.538689,0.624326,0.326581,0.233681,0.582174,0.583249,0.416129,0.369217,0.580633,0.628129,1.01918,1.39497,-0.852999,-0.622605,-0.2293,-0.188825,1.35178,1.33558,-0.557427,-0.486153,2.05108,1.96406,-0.309116,-0.400071,-0.0189074,-0.186007,0.45461,0.384355,0.26747,0.285756
2665,0.660227,0.559787,0.295566,0.280275,0.322471,0.253652,0.42202,0.415531,0.631788,0.646135,0.349769,0.436669,0.423974,0.329347,0.426029,0.447303,0.664079,0.678853,0.501743,0.550074,-1.50356,-1.13274,-1.56499,-1.33879,-1.40787,-1.36442,0.261492,0.246949,0.726162,0.792776,-1.26659,-1.35038,-0.985349,-1.07467,0.000921687,-0.163029,0.179293,0.114871,0.940161,0.958178
2666,0.424379,0.326573,0.858418,0.842248,0.90113,0.831796,0.593031,0.585665,0.708919,0.724884,0.162141,0.249012,0.452693,0.425012,0.0594604,0.0805173,0.36654,0.379685,0.804273,0.852681,0.382561,0.749013,-0.318109,-0.090006,-1.47762,-1.44017,-1.2684,-1.28454,-0.664665,-0.600123,0.205248,0.119271,-0.767845,-0.861835,-0.627855,-0.798615,0.309207,0.247896,-0.139305,-0.124709
2667,0.421158,0.32193,0.961957,0.861313,0.674451,0.604369,0.992029,0.985012,0.0881351,0.105492,0.520794,0.609105,0.57396,0.520677,0.843239,0.863392,0.548595,0.56103,0.158905,0.206521,0.0830747,0.452049,0.0681759,0.295478,0.264673,0.298257,-0.451242,-0.461071,0.734568,0.800407,0.209654,0.118078,-0.101982,-0.200613,0.0331544,-0.129878,-0.658979,-0.720482,0.393268,0.409022
2668,0.773242,0.673751,0.965336,0.880378,0.756775,0.686298,0.678445,0.671911,0.00895367,0.0253217,0.531619,0.525988,0.171418,0.120339,0.331034,0.352122,0.189754,0.201879,0.731944,0.780604,0.979432,1.34716,0.0846677,0.311561,1.76916,1.79952,-0.273582,-0.280016,0.37571,0.362918,-1.29965,-1.39171,0.884998,0.78309,0.10766,-0.0606237,0.327202,0.271003,0.588347,0.611706
2669,0.0569564,-0.0408502,0.915612,0.899443,0.570916,0.484338,0.712338,0.715965,0.358967,0.348149,0.418385,0.442872,0.297425,0.327242,0.235336,0.255813,0.359248,0.371564,0.801497,0.885173,-1.42239,-1.05439,0.38663,0.607166,1.29751,1.32704,-1.41876,-1.4285,-0.134273,-0.0745702,1.65616,1.56152,-0.481699,-0.589974,-1.04426,-1.21333,0.115034,0.0642194,-0.580008,-0.562721
2670,0.565083,0.466304,0.170145,0.153689,0.352842,0.282379,0.764825,0.76002,0.653457,0.670976,0.367878,0.359755,0.585657,0.534146,0.689424,0.707513,0.925975,0.936964,0.942978,0.989742,0.681579,1.04154,0.330227,0.548019,0.184257,0.213793,-0.745485,-0.759117,-0.146957,-0.0849982,-0.328587,-0.425669,-0.521488,-0.634797,-1.08141,-1.25358,0.283605,0.227344,1.61451,1.63332
2671,0.0892869,-0.00934445,0.428429,0.410303,0.899252,0.829864,0.0745879,0.0679028,0.551063,0.569687,0.307061,0.276638,0.502886,0.513696,0.645736,0.75483,0.847191,0.8566,0.0471042,0.0940615,1.72674,2.08971,-1.16657,-0.946862,0.3133,0.334617,0.42604,0.407463,1.06337,1.1329,0.226602,0.126827,1.38992,1.28193,0.943459,0.771109,0.949699,0.888937,-0.613472,-0.590095
2672,0.463286,0.431253,0.0275398,0.0108626,0.996592,0.926668,0.427294,0.502119,0.844666,0.86164,0.10521,0.193521,0.542446,0.493246,0.782126,0.802148,0.28131,0.291082,0.59385,0.638192,-0.736583,-0.374462,-0.255416,-0.0394176,-1.42492,-1.41073,1.14809,1.12367,0.138333,0.200835,-1.82554,-1.92192,-0.0124207,-0.122633,0.862205,0.68716,1.94232,1.88042,-0.86569,-0.78747
2673,0.971684,0.87185,0.136915,0.119625,0.0218921,-0.048279,0.945404,0.936335,0.558381,0.574313,0.636224,0.725143,0.929463,0.879998,0.329972,0.351325,0.518022,0.527855,0.818542,0.861306,0.0295751,0.397367,-1.4895,-1.26719,-0.462037,-0.442761,-0.402927,-0.422731,-0.0989203,0.00970854,-0.503007,-0.605787,-0.294152,-0.39654,-0.678596,-0.850722,0.0631317,-0.00623574,-1.00599,-0.984845
2674,0.08337,-0.0171239,0.467759,0.487394,0.615556,0.544744,0.68284,0.672896,0.958578,0.972035,0.211867,0.299423,0.266832,0.218304,0.161609,0.224703,0.231018,0.238705,0.39455,0.435352,-0.546769,-0.176906,0.175864,0.401195,-0.00946351,0.016114,0.618162,0.603942,-0.245493,-0.181418,-1.99919,-2.10185,1.51205,1.40771,0.901599,0.736078,1.56734,1.49934,-1.02294,-1.02138
2675,0.867367,0.768303,0.870242,0.855164,0.298509,0.230215,0.678467,0.62164,0.0122755,0.0256838,0.181085,0.262974,0.880659,0.829676,0.075506,0.09808,0.476763,0.396418,0.782027,0.824355,-1.78273,-1.41084,0.828428,1.0494,0.839858,0.862608,-1.35178,-1.36064,1.41027,1.47796,-0.725825,-0.831716,-0.220406,-0.328765,-0.674293,-0.833634,-0.915473,-0.986018,-1.08546,-1.05792
2676,0.37172,0.272909,0.094823,0.0777558,0.213455,0.14435,0.581599,0.570384,0.926723,0.93819,0.138449,0.226526,0.919496,0.868091,0.880353,0.90135,0.548035,0.554132,0.33731,0.377963,0.57353,0.951537,0.515467,0.7312,0.594702,0.618126,1.06213,1.05136,0.38949,0.453962,-0.213444,-0.22717,0.123302,0.00828289,-0.488181,-0.640085,0.0119989,-0.0584479,-1.64978,-1.6245
2677,0.65368,0.554605,0.738251,0.72247,0.486788,0.415618,0.782948,0.771843,0.716006,0.726394,0.907149,0.994413,0.617616,0.5669,0.357763,0.380252,0.330875,0.421152,0.780948,0.821519,1.36146,1.73841,-0.852786,-0.639045,-0.908231,-0.878395,-0.102397,-0.113884,2.24768,2.31406,0.45307,0.377375,1.10851,0.991986,-0.561788,-0.708127,0.0718482,-0.0027081,0.605063,0.635801
2678,0.318564,0.219453,0.674834,0.575578,0.296521,0.223583,0.226307,0.213604,0.786674,0.740182,0.428075,0.514275,0.871871,0.819064,0.846951,0.871537,0.283294,0.288172,0.719369,0.711729,-0.780294,-0.408279,-0.400447,-0.193132,0.916799,0.951546,0.612251,0.602324,-1.21578,-1.15407,1.08781,0.98192,0.949706,0.841889,-0.334154,-0.483624,-0.484218,-0.565117,0.964411,0.987734
2679,0.509697,0.393226,0.446257,0.428686,0.657383,0.585961,0.770902,0.756492,0.746042,0.75397,0.541221,0.628059,0.670453,0.530201,0.480452,0.504751,0.652763,0.658636,0.63443,0.601938,-0.834227,-0.462452,-1.21873,-1.01813,0.00527558,0.0416603,0.242583,0.227751,3.02165,3.08658,0.692935,0.582071,-2.02007,-2.12817,-0.767117,-0.919241,0.677495,0.596096,-1.07688,-1.04655
2680,0.667451,0.566999,0.00976984,-0.00906851,0.419612,0.401793,0.645292,0.54481,0.0334458,0.0430833,0.282882,0.370071,0.296141,0.241339,0.850275,0.877211,0.208848,0.21406,0.452646,0.492148,-0.62228,-0.243564,-0.207069,-0.00242091,0.461771,0.500535,-2.85728,-2.86686,0.303255,0.366505,0.836609,0.719354,-0.0867761,-0.197119,-1.2121,-1.35486,1.44235,1.3657,-1.85067,-1.82433
2681,0.396828,0.297766,0.824085,0.803151,0.288454,0.217625,0.348386,0.333128,0.507757,0.516055,0.686107,0.773947,0.72269,0.667971,0.864181,0.875206,0.0287873,0.0364628,0.970477,1.01174,2.49455,2.88022,1.44117,1.64825,-0.989431,-0.950173,-0.647118,-0.657226,-0.468176,-0.367005,0.591391,0.472562,-0.0437667,-0.15122,0.448794,0.309621,-0.924116,-1.00129,1.13391,1.15417
2682,0.814515,0.715831,0.86753,0.846559,0.335661,0.26431,0.788869,0.771795,0.143698,0.152627,0.456205,0.545485,0.695679,0.639584,0.84661,0.8732,0.898283,0.907102,0.613136,0.65595,-2.95394,-2.56827,-0.501994,-0.288031,1.15356,1.19247,-0.0654627,-0.080612,-1.16376,-1.10052,1.10025,0.979658,-0.246377,-0.347031,-0.482694,-0.615727,0.416996,0.334609,0.29482,0.318097
2683,0.911465,0.811416,0.287573,0.265526,0.834557,0.762628,0.171266,0.154143,0.894013,0.901458,0.62913,0.741244,0.290962,0.233496,0.102595,0.127456,0.29143,0.301442,0.625177,0.589993,-1.8003,-1.41379,-1.06502,-0.85326,-0.826176,-0.78945,-0.880168,-0.888191,-0.038962,0.0225258,-0.777821,-0.896725,2.59478,2.49581,-0.0528623,-0.164771,-0.895794,-0.980633,-1.5244,-1.49656
2684,0.334241,0.235167,0.143704,0.121819,0.57275,0.533684,0.772409,0.756901,0.059129,0.0642881,0.849471,0.937003,0.837919,0.779761,0.889608,0.915266,0.246027,0.256736,0.480776,0.524035,-0.147677,0.238733,-2.18905,-1.97322,-0.214369,-0.177043,0.328617,0.323543,-0.954391,-0.892287,-0.664458,-0.789938,-0.571602,-0.671391,0.421399,0.286185,0.228255,0.149645,-1.29292,-1.26353
2685,0.602086,0.502041,0.209332,0.185893,0.378703,0.30474,0.108436,0.0936081,0.45172,0.384986,0.271038,0.357239,0.71261,0.655149,0.848623,0.873964,0.488342,0.49823,0.634744,0.686528,-0.776821,-0.397201,-0.105897,0.115036,-1.39214,-1.35264,-0.842405,-0.841699,-0.768768,-0.704174,1.64865,1.52318,1.52698,1.42254,1.99303,1.85838,0.80358,0.718219,0.63728,0.664203
2686,0.321918,0.293014,0.708649,0.684372,0.897217,0.823645,0.160551,0.204172,0.701345,0.705685,0.320618,0.344551,0.0407454,-0.0170977,0.508785,0.569881,0.986083,0.993973,0.765636,0.849022,-0.610887,-0.15834,0.906154,1.13075,0.677288,0.712838,-0.675941,-0.610927,0.770671,0.833444,0.505325,0.383572,0.162073,0.064196,-0.246641,-0.379153,-0.320503,-0.407608,0.398063,0.430055
2687,0.184304,0.0839864,0.861546,0.838418,0.323742,0.249996,0.327358,0.314735,0.7341,0.737647,0.246625,0.331863,0.85714,0.798992,0.242644,0.265799,0.344359,0.353547,0.968256,1.01152,-0.299098,0.0805216,0.468034,0.641166,-0.788535,-0.753752,-0.378461,-0.380155,0.417419,0.482361,-0.393736,-0.513968,0.244168,0.142206,-0.292332,-0.419402,0.828481,0.738216,0.809179,0.842117
2688,0.242507,0.144239,0.222883,0.198121,0.540426,0.416716,0.0985531,0.0865647,0.101346,0.10275,0.762447,0.849191,0.919252,0.862506,0.800669,0.823698,0.611778,0.621984,0.176193,0.221177,-2.43283,-2.05372,-0.0794194,0.151585,1.78666,1.82182,0.519819,0.52329,-2.2681,-2.20642,0.860183,0.741298,1.89076,1.7906,0.829096,0.709511,0.554503,0.468732,-0.577627,-0.545794
2689,0.626484,0.527062,0.396262,0.371974,0.659058,0.583435,0.43257,0.357602,0.189238,0.204825,0.122417,0.209535,0.460585,0.402043,0.239237,0.262541,0.882212,0.890422,0.878866,0.925603,0.491302,0.860365,-1.24156,-1.01447,0.43674,0.476065,-0.81393,-0.809355,1.28209,1.35064,-0.533966,-0.647858,-0.123921,-0.226978,-0.3736,-0.491044,-1.19538,-1.2895,0.567039,0.596794
2690,0.269123,0.256839,0.777953,0.751712,0.145209,0.0698715,0.638839,0.628639,0.305456,0.3069,0.976746,1.06525,0.762572,0.703774,0.113947,0.135792,0.149472,0.159231,0.642445,0.689185,-1.75038,-1.38496,0.13261,0.343692,-1.13093,-1.09622,-0.83421,-0.828902,-1.43524,-1.36943,0.249616,0.131899,1.74036,1.64261,0.289469,0.177694,-1.5609,-1.65134,0.429457,0.454058
2691,0.0883322,-0.0133832,0.459951,0.43594,0.666062,0.588777,0.448848,0.443265,0.635486,0.539046,0.785056,0.870908,0.198901,0.141962,0.525274,0.547536,0.219209,0.227656,0.306986,0.452767,1.12625,1.49932,1.46993,1.70185,-0.014623,0.023879,-1.99743,-1.99414,-0.462813,-0.396172,-0.423384,-0.548471,-0.0753376,-0.171352,-0.608557,-0.718466,-1.2147,-1.30032,0.0355739,0.0520267
2692,0.606107,0.427214,0.451684,0.364912,0.765763,0.690101,0.177507,0.257892,0.771614,0.771192,0.989584,1.07511,0.114195,0.0575999,0.218973,0.241195,0.0823961,0.0892525,0.168404,0.21635,0.457644,0.8924,1.50827,1.73464,-1.85344,-1.81689,-0.795416,-0.797842,-2.15606,-2.0961,-1.10516,-1.22884,0.426258,0.335673,-1.11227,-1.22957,0.610139,0.521765,0.0465199,0.0596071
2693,0.96788,0.867811,0.318591,0.293885,0.545149,0.468103,0.0834782,0.0725186,0.337965,0.337256,0.616331,0.725048,0.774869,0.720811,0.368033,0.392459,0.556532,0.5647,0.667404,0.714981,-0.084126,0.285483,2.0313,2.25867,0.872655,0.906399,-0.626572,-0.632828,0.150155,0.210462,-0.531594,-0.583402,0.386583,0.29085,-0.103207,-0.222589,1.05273,0.965023,0.825269,0.835961
2694,0.453622,0.352392,0.79419,0.767548,0.722566,0.644425,0.59477,0.585317,0.794649,0.794877,0.28884,0.374981,0.505927,0.492544,0.719623,0.668431,0.500554,0.509136,0.284054,0.329668,0.96681,1.33365,0.822771,1.04663,0.636863,0.677586,-0.0643954,-0.0712932,-1.80407,-1.7402,0.190664,0.0620375,1.42862,1.33194,0.516503,0.398934,-1.51494,-1.60762,0.78137,0.797594
2695,0.567474,0.4684,0.959611,0.931282,0.655326,0.608089,0.511718,0.502287,0.712558,0.691019,0.656557,0.744539,0.31657,0.264278,0.919064,0.944404,0.799863,0.732164,0.297644,0.345015,0.232367,0.604913,-1.20869,-0.984235,-1.26623,-1.22497,1.09031,1.07849,0.0602536,0.119897,-0.393189,-0.526491,0.88414,0.792237,0.0994506,-0.0207837,0.386187,0.2928,-1.09532,-1.0797
2696,0.0943025,-0.00724878,0.423068,0.394184,0.763169,0.571752,0.0328889,0.025436,0.637146,0.587162,0.794389,0.846803,0.983401,0.93215,0.187575,0.214186,0.946204,0.955193,0.675194,0.724749,-0.102338,0.262956,0.497631,0.728009,1.69637,1.74744,0.131448,0.115424,0.44005,0.494409,0.556512,0.423341,-1.11038,-1.19544,-0.601673,-0.818871,0.849419,0.751305,2.80907,2.82407
2697,0.0570476,-0.0436194,0.932076,0.901737,0.614459,0.535416,0.490722,0.483121,0.484874,0.483305,0.859788,0.949067,0.391862,0.340623,0.415862,0.524519,0.33823,0.344939,0.384813,0.43394,0.976274,1.33938,0.79729,1.02361,-0.163968,-0.109601,1.57885,1.55999,-0.187004,-0.130717,0.377206,0.239554,-0.039052,-0.122955,-1.49977,-1.61696,0.296897,0.209656,-1.27188,-1.25352
2698,0.760786,0.661723,0.783591,0.752913,0.483545,0.403889,0.428589,0.42054,0.956158,0.956277,0.517995,0.606318,0.0799939,0.0289387,0.806174,0.834852,0.116517,0.121486,0.502324,0.578557,-0.342592,0.0116214,-1.54352,-1.32474,0.250642,0.305688,-1.93689,-1.95935,1.66146,1.71605,1.26875,1.12791,-1.26851,-1.35588,0.26711,0.142784,-0.239073,-0.331993,0.0197617,0.0480341
2699,0.267045,0.166329,0.200522,0.17188,0.893332,0.812032,0.959594,0.953163,0.12764,0.12838,0.622107,0.636107,0.619576,0.570593,0.592381,0.623242,0.346242,0.353481,0.599668,0.723175,0.745649,1.10307,-1.38625,-1.17018,-1.4934,-1.43966,-0.5647,-0.578556,-1.06564,-1.00403,1.08567,0.944118,0.590701,0.496977,-0.511562,-0.629661,-1.09346,-1.18824,1.33122,1.34959
2700,0.777562,0.678247,0.477575,0.530889,0.689146,0.544131,0.154974,0.147147,0.59935,0.558595,0.578564,0.665895,0.162907,0.11469,0.127012,0.156599,0.805658,0.813778,0.818666,0.867792,-0.880679,-0.52632,-0.636293,-0.415674,0.375946,0.422361,-0.75603,-0.768344,0.815039,0.873274,0.0537203,-0.0887171,-0.419539,-0.519696,0.209444,0.0154983,0.895187,0.793066,0.131763,0.145514
2701,0.529378,0.429523,0.918838,0.889899,0.356672,0.276231,0.233731,0.243508,0.987905,0.98881,0.418144,0.503276,0.117475,0.0713265,0.49117,0.519484,0.270478,0.27973,0.377565,0.426733,1.30605,1.66282,-0.755662,-0.53616,-1.54466,-1.49838,1.42953,1.42007,-0.907613,-0.842973,-0.271295,-0.411525,1.57234,1.47152,0.772892,0.660658,-0.717992,-0.818725,0.1999,0.213739
2702,0.499132,0.490669,0.857635,0.88976,0.549729,0.524506,0.346388,0.339869,0.216745,0.220012,0.569459,0.653072,0.759073,0.712613,0.623876,0.650505,0.797105,0.804948,0.518501,0.50289,-0.279034,0.0752778,-0.673736,-0.457982,1.36834,1.41182,0.549377,0.533665,-1.10077,-1.04179,-1.29193,-1.42998,0.472907,0.379127,-0.907969,-1.0171,0.931441,0.83026,-0.254447,-0.246355
2703,0.59279,0.551814,0.836703,0.889621,0.854878,0.772782,0.0560192,0.0514745,0.557055,0.56122,0.965437,1.04729,0.0918135,0.0458421,0.378901,0.407591,0.775775,0.784092,0.607197,0.579048,1.74146,2.09554,0.507926,0.7272,-0.62509,-0.585775,0.223807,0.205984,-0.0389259,0.0216196,-0.778029,-0.922886,0.795314,0.700879,0.855714,0.74264,0.920453,0.824943,0.593693,0.6053
2704,0.712816,0.61296,0.918232,0.889481,0.561138,0.467065,0.951849,0.949112,0.899539,0.902428,0.770982,0.907003,0.771083,0.723332,0.637201,0.617744,0.349743,0.360667,0.606037,0.655205,0.411346,0.76779,-0.798324,-0.577055,1.47058,1.51225,-1.16772,-1.18897,0.42567,0.485737,-1.05165,-1.1998,-2.01338,-2.11413,-1.37701,-1.49489,1.81091,1.71999,-0.0825902,-0.00537042
2705,0.0697752,-0.0284285,0.536352,0.505119,0.244747,0.161348,0.397937,0.396472,0.0643475,0.065258,0.685081,0.766713,0.789981,0.730368,0.798605,0.827897,0.549915,0.561144,0.153012,0.203897,0.812206,1.17359,-0.550806,-0.329732,-1.40922,-1.36319,-0.711643,-0.73325,-0.0538525,0.0127162,-0.770833,-0.925471,0.853598,0.74913,-1.89137,-2.00599,-0.282759,-0.375638,-0.63241,-0.616041
2706,0.20925,0.111926,0.558758,0.428111,0.276592,0.193072,0.750984,0.750363,0.479757,0.482762,0.147332,0.227498,0.784508,0.737403,0.479653,0.499842,0.541644,0.550728,0.108828,0.160614,-0.435134,-0.0772071,-0.718363,-0.496553,-0.0205622,0.029585,-1.91268,-1.92884,-0.0325838,0.0338267,0.0915143,-0.0690845,-1.27793,-1.37699,-0.12864,-0.246249,0.873475,0.785575,-0.970689,-0.936153
2707,0.989304,0.892582,0.405719,0.351103,0.780093,0.696633,0.0419097,0.0430191,0.277829,0.328563,0.760713,0.843166,0.991387,0.943298,0.139956,0.171786,0.0160624,0.0266613,0.864868,0.91568,-0.572818,-0.206969,-2.07969,-1.85108,0.695542,0.751886,-0.132952,-0.150876,0.80894,0.882773,-0.794324,-0.949332,0.600108,0.507718,-0.134659,-0.212312,-1.13159,-1.21236,-1.2713,-1.25626
2708,0.23971,0.141835,0.305879,0.274094,0.55302,0.415745,0.524195,0.525621,0.128197,0.174364,0.446293,0.474779,0.821161,0.773619,0.492446,0.524138,0.502092,0.511669,0.788732,0.841581,1.27543,1.64403,0.888719,1.11507,-0.601431,-0.54506,0.438232,0.425738,-0.0304678,0.0417036,-0.999555,-1.21826,-0.628743,-0.725141,-0.0516053,-0.178376,-0.0962576,-0.173894,-1.97138,-1.95827
2709,0.532414,0.434061,0.737222,0.703665,0.219846,0.134857,0.355505,0.358017,0.0191635,0.0201656,0.0243124,0.106392,0.976065,0.928977,0.271121,0.388745,0.76988,0.778295,0.479282,0.533104,0.503589,0.869236,1.33745,1.56098,0.0527171,0.114266,-0.00828534,-0.025602,-0.464331,-0.386426,-1.32505,-1.48718,-1.86561,-1.958,-0.0268302,-0.144439,-1.67932,-1.7547,-0.27619,-0.262589
2710,0.0164947,-0.081358,0.59813,0.564878,0.91559,0.830363,0.996692,1.00004,0.343673,0.342583,0.161698,0.241558,0.404469,0.356778,0.221363,0.253352,0.64567,0.655519,0.170766,0.224627,0.756702,1.12039,-0.920001,-0.689462,0.247164,0.313114,0.422761,0.398792,0.597549,0.676979,1.22618,1.0722,0.817672,0.729155,1.69231,1.57036,-1.75654,-1.83786,0.797406,0.803411
2711,0.95159,0.852351,0.945964,0.911053,0.843895,0.761055,0.653288,0.749873,0.369044,0.369979,0.878189,0.957551,0.303705,0.25712,0.670189,0.700335,0.78267,0.789683,0.79455,0.849084,-0.273948,0.0842439,0.822426,1.05369,1.27771,1.34364,-0.339499,-0.363088,-1.47267,-1.39101,0.504544,0.37084,1.13089,1.03685,-1.12069,-1.24508,-2.08242,-2.16881,0.735369,0.737093
2712,0.897896,0.87119,0.506622,0.473298,0.120918,0.035893,0.495566,0.499702,0.877145,0.878317,0.721946,0.81171,0.871105,0.82363,0.390941,0.42365,0.103879,0.109743,0.653861,0.709312,-0.974794,-0.612377,0.401245,0.629189,-1.08249,-1.02439,0.629155,0.600839,0.232294,0.314395,-0.176111,-0.330518,-0.625089,-0.714548,0.597667,0.469714,0.467757,0.385539,-0.91158,-0.909429
2713,0.991052,0.890028,0.369465,0.334511,0.063471,-0.0243637,0.568266,0.585401,0.121174,0.120716,0.584594,0.66587,0.351268,0.301314,0.932957,0.96643,0.382111,0.39034,0.853862,0.911298,-0.431294,-0.0694191,0.615952,0.847521,-1.2454,-1.1908,-0.229539,-0.254863,0.0514051,0.131063,-0.336443,-0.48613,-0.316214,-0.406848,-1.38264,-1.50726,0.579095,0.502138,-0.0263644,-0.0263624
2714,0.651392,0.549793,0.578198,0.542335,0.379677,0.292349,0.667417,0.671099,0.0401741,0.0405454,0.704747,0.785488,0.535876,0.464927,0.83444,0.866495,0.665771,0.670938,0.424351,0.480629,0.686154,1.05235,-0.0123895,0.222989,-2.01696,-1.9615,-0.0521857,-0.0738078,-0.759737,-0.677089,0.645217,0.493386,-0.488921,-0.573712,0.355778,0.237187,-0.117452,-0.198433,1.71549,1.7146
2715,0.0620313,-0.0408552,0.224922,0.188153,0.0137941,-0.07227,0.96853,0.97149,0.507856,0.508365,0.416188,0.451421,0.766384,0.62854,0.000964127,0.0338479,0.623149,0.626232,0.814687,0.869632,-0.39608,-0.0291446,-1.6717,-1.42942,0.404094,0.461982,0.704513,0.689477,-0.301981,-0.212972,0.919202,0.767713,1.44152,1.35734,-1.43864,-1.54875,1.98787,1.90222,0.235222,0.237504
2716,0.236217,0.134551,0.299656,0.261819,0.414588,0.349116,0.368688,0.372656,0.614213,0.612164,0.0384056,0.117355,0.842107,0.792153,0.0188477,0.0496677,0.071977,0.0769359,0.201167,0.25443,0.000458153,0.438042,-0.659443,-0.41371,0.155872,0.217501,-0.181862,-0.196928,0.410142,0.495877,0.69133,0.536761,-0.969568,-1.05693,1.50217,1.39614,-0.60056,-0.689234,2.02873,2.02941
2717,0.197979,0.0275249,0.119267,0.0819202,0.856566,0.770502,0.036189,0.0398845,0.337492,0.430889,0.825325,0.90586,0.803675,0.753833,0.789691,0.821642,0.358297,0.36268,0.959674,1.01378,0.466196,0.905228,0.923532,1.17632,0.781813,0.845731,1.01924,0.999374,0.26532,0.344775,-0.285677,-0.435697,-0.682948,-0.764633,-0.362555,-0.471076,0.617509,0.534341,1.29125,1.29775
2718,0.0205232,-0.0795016,0.857162,0.817933,0.611882,0.526046,0.928394,0.933335,0.251589,0.249615,0.120384,0.200839,0.308786,0.25803,0.390455,0.420621,0.957031,0.959151,0.482676,0.610835,1.00548,1.37241,-1.05663,-0.806097,1.61001,1.67773,-0.347299,-0.363437,0.587246,0.592448,-1.47141,-1.62182,-0.672716,-0.750098,0.166806,0.0599906,-1.62443,-1.71278,0.0742119,0.0780507
2719,0.352124,0.252652,0.926839,0.88647,0.640768,0.576689,0.943476,0.946456,0.864334,0.863713,0.374594,0.454277,0.417932,0.389921,0.416446,0.446325,0.996486,0.997596,0.152335,0.207892,0.125227,0.489762,-0.602551,-0.344274,-0.830477,-0.770638,-0.467945,-0.489712,0.751281,0.840121,-1.21075,-1.36338,0.644793,0.561456,1.41725,1.30721,-0.503781,-0.598751,-0.779,-0.77451
2720,0.475281,0.37804,0.569134,0.443115,0.71399,0.627332,0.611611,0.618143,0.730266,0.727771,0.951607,1.03035,0.574208,0.521811,0.102322,0.129832,0.187071,0.189213,0.6024,0.656979,0.901548,1.26159,2.05675,2.31356,-0.717207,-0.664138,-0.21433,-0.200525,-0.783606,-0.691026,0.87372,0.725845,-0.793509,-0.876,0.0780653,-0.0333972,0.285789,0.187135,-1.99483,-1.99421
2721,0.873324,0.775805,0.0412652,-0.000239562,0.942637,0.856983,0.285425,0.289829,0.815982,0.81161,0.886241,0.971747,0.302332,0.288027,0.069299,0.0987542,0.934308,0.936521,0.190432,0.245507,-0.990408,-0.638212,0.000401649,0.25578,-2.02148,-1.96108,0.113006,0.0886612,-0.219637,-0.119098,0.137559,-0.0162238,0.246033,0.165091,-1.6652,-1.77518,-0.495609,-0.591907,-0.716239,-0.660227
2722,0.707598,0.608216,0.14617,0.103764,0.835883,0.750939,0.203626,0.206799,0.25915,0.253066,0.834448,0.913148,0.104323,0.0542424,0.722525,0.753568,0.330215,0.33086,0.463056,0.518676,-0.0264352,0.33304,0.0873939,0.348286,0.523916,0.584604,-0.139088,-0.163061,0.104261,0.20752,-1.07268,-1.23125,0.198474,0.120268,-0.323571,-0.435712,1.32954,1.23018,0.677177,0.673753
2723,0.859806,0.758308,0.783474,0.739057,0.47679,0.483039,0.956828,0.959396,0.428068,0.423593,0.365429,0.443072,0.914889,0.865091,0.17619,0.208044,0.00326139,0.0015654,0.429623,0.484657,1.4317,1.78492,0.437165,0.7491,-0.502938,-0.434994,0.0523796,0.0326813,1.28139,1.37859,1.26863,1.11259,-0.704753,-0.737169,1.24198,1.13648,0.240892,0.139229,0.654225,0.733223
2724,0.484443,0.383984,0.0155285,-0.0284229,0.298557,0.215139,0.324159,0.32718,0.0653646,0.060165,0.726488,0.803165,0.0765623,0.0243292,0.686546,0.720039,0.598304,0.598036,0.09167,0.148226,-0.792352,-0.447055,0.886427,1.14991,2.45422,2.51809,1.27056,1.24442,-0.921581,-0.832604,0.932685,0.774179,-1.5164,-1.59461,0.423469,0.318804,0.116327,0.00938362,0.793777,0.792694
2725,0.467372,0.368883,0.637195,0.592062,0.93196,0.848909,0.623108,0.627571,0.605064,0.599051,0.702206,0.784325,0.725128,0.672269,0.310144,0.343167,0.162313,0.1633,0.530076,0.587521,1.35268,1.69533,1.07089,1.3355,1.35981,1.42137,-1.86559,-1.88738,-0.964229,-0.87491,-0.515783,-0.674053,0.802335,0.724409,0.183222,0.0829501,-0.360845,-0.540958,-0.0882325,-0.090814
2726,0.778888,0.68052,0.0704344,0.0259195,0.0359427,-0.0477232,0.158783,0.160913,0.36223,0.424276,0.803076,0.765484,0.151619,0.10007,0.501989,0.534796,0.751062,0.753939,0.0678887,0.126662,0.958199,1.36568,-0.816348,-0.554367,2.05195,2.11333,0.747255,0.730259,0.299374,0.390233,1.09504,0.934881,0.499907,0.419331,0.789314,0.689412,-0.991093,-1.0913,-0.767952,-0.776238
2727,0.23863,0.139423,0.945239,0.900164,0.0391609,-0.0463687,0.215116,0.215147,0.256954,0.2495,0.750426,0.746643,0.741055,0.691438,0.4492,0.483506,0.447843,0.450088,0.371099,0.429269,0.695941,1.03602,0.323035,0.583465,-0.964032,-0.905005,0.828189,0.834568,0.779998,0.819696,-0.715633,-0.881761,-0.845305,-0.925103,1.10688,1.00662,0.771709,0.665933,0.436863,0.427437
2728,0.292069,0.195084,0.108452,0.0632967,0.933853,0.845819,0.843818,0.842314,0.305365,0.29699,0.651125,0.727802,0.919655,0.796811,0.106767,0.141414,0.47604,0.441146,0.101467,0.158823,-0.430981,-0.0910635,-0.656645,-0.395519,0.963868,1.01868,0.951413,0.938877,1.16065,1.24916,1.02746,0.865303,-0.872427,-0.953874,-2.3683,-2.46885,-0.03863,-0.143432,1.19004,1.17587
2729,0.900044,0.801061,0.608856,0.561776,0.506513,0.479997,0.536181,0.473325,0.934309,0.926155,0.206566,0.281752,0.954198,0.902183,0.553735,0.570119,0.478946,0.432205,0.176629,0.23463,-0.608,-0.266798,1.37486,1.63219,0.496275,0.546195,-0.264969,-0.271833,-0.700366,-0.608444,-1.86235,-2.01733,1.05798,0.977176,-1.69594,-1.80011,-1.38987,-1.48999,-0.911426,-0.919587
2730,0.893249,0.74239,0.132859,0.0843395,0.204185,0.114174,0.105894,0.104335,0.594324,0.531293,0.788181,0.862604,0.0402457,-0.0133106,0.962696,0.998824,0.421698,0.423263,0.816073,0.87341,0.860248,1.22739,-1.11259,-0.857944,1.85784,1.91017,0.121666,0.122227,-0.469106,-0.374862,0.223156,0.0718962,-2.44101,-2.51704,0.292094,0.193235,0.920634,0.820041,0.851953,0.84054
2731,0.784584,0.68372,0.847359,0.799817,0.412585,0.324458,0.487503,0.487439,0.145261,0.136431,0.809005,0.88454,0.360419,0.308581,0.644673,0.682332,0.0903768,0.0939679,0.670662,0.728304,2.38038,2.72158,-1.36464,-1.11692,-0.53655,-0.489279,-0.996056,-0.995585,0.84736,0.935118,-0.389542,-0.535049,-0.668575,-0.745882,-0.547651,-0.640566,0.61076,0.504164,0.290832,0.273954
2732,0.974052,0.8741,0.301896,0.253097,0.351221,0.264201,0.452065,0.451014,0.525962,0.519843,0.000947396,0.077316,0.139957,0.0874201,0.760012,0.798088,0.394924,0.399743,0.976043,1.03608,0.821151,1.16655,-0.512431,-0.314794,-1.30337,-1.25998,0.364982,0.369358,-0.360613,-0.269629,-0.98773,-1.14199,0.209533,0.0668497,2.41855,2.31968,1.60262,1.49565,0.820697,0.807685
2733,0.23564,0.134499,0.347828,0.30113,0.515194,0.425469,0.80149,0.7998,0.610951,0.603683,0.997657,1.07403,0.486003,0.435121,0.568788,0.605968,0.259446,0.352716,0.267784,0.328218,0.407011,0.747243,0.232917,0.487327,-1.52613,-1.48879,-0.523919,-0.517048,0.476141,0.563614,1.48115,1.3207,0.960555,0.879582,-0.806809,-0.908125,-0.573701,-0.677839,-0.0277173,-0.0448756
2734,0.910783,0.809767,0.871933,0.824138,0.0175551,-0.0742263,0.820725,0.817718,0.9941,0.987095,0.949101,1.02684,0.0475789,-0.000960103,0.821407,0.856166,0.300603,0.305689,0.0626293,0.123195,2.52284,2.85969,0.302329,0.550017,-0.597019,-0.567376,-0.840623,-0.830056,-0.655152,-0.566712,-0.321527,-0.480595,0.546195,0.465467,-1.86841,-1.97046,-0.236099,-0.343398,2.28864,2.26599
2735,0.157669,0.0544679,0.0190363,-0.0267403,0.672776,0.580221,0.483334,0.454093,0.741868,0.735202,0.40585,0.482419,0.476595,0.425672,0.354788,0.389522,0.582608,0.470483,0.406061,0.467517,0.360624,0.694984,-0.510503,-0.258558,0.592551,0.628385,0.692906,0.70951,0.322905,0.406549,0.155655,-0.00335135,0.75374,0.678302,0.249581,0.146178,-1.06658,-1.16944,1.03089,1.01685
2736,0.00102171,-0.103297,0.329249,0.284374,0.0909568,-0.00348277,0.0952799,0.0904681,0.990189,0.981927,0.486033,0.539456,0.10903,0.0593697,0.292441,0.355885,0.706954,0.635278,0.404144,0.421938,-1.10766,-0.768992,0.690595,0.942596,-1.42949,-1.40001,-0.0324663,-0.019765,2.77726,2.86787,0.0632195,-0.0964203,0.750554,0.679415,0.202037,0.0930909,-0.613181,-0.71094,1.75703,1.74936
2737,0.244805,0.0873433,0.205289,0.160484,0.310751,0.216913,0.0105901,0.00743832,0.260812,0.250401,0.521264,0.596493,0.14746,0.0977845,0.328475,0.322247,0.895851,0.800072,0.31281,0.376358,-1.51344,-1.17271,0.577928,0.822109,-0.153332,-0.127919,-0.415628,-0.409437,2.02555,2.12055,-0.837398,-0.99396,-0.799543,-0.869621,-0.332193,-0.448435,0.471979,0.372977,0.740496,0.734196
2738,0.382304,0.277983,0.769439,0.726966,0.908921,0.81462,0.560228,0.554829,0.00976078,-0.00149197,0.958467,1.03485,0.628991,0.580033,0.268293,0.28861,0.960369,0.964866,0.0272028,0.0909156,-0.181046,0.152975,-0.506314,-0.266183,1.61497,1.63917,-1.43986,-1.43399,0.443148,0.633601,-1.49316,-1.64629,-0.447874,-0.515768,0.749967,0.633221,0.387989,0.289818,-0.265225,-0.280964
2739,0.321355,0.21618,0.751783,0.711376,0.271645,0.176455,0.856759,0.8501,0.756417,0.747339,0.581166,0.658024,0.663148,0.56819,0.220238,0.254972,0.62419,0.631031,0.418783,0.466742,0.294729,0.637149,1.18469,1.43144,1.5148,1.53266,-1.56469,-1.56026,-0.952884,-0.853352,-0.239939,-0.391028,0.51553,0.45158,-1.40311,-1.51974,-0.911262,-1.0082,0.0134498,-0.0028735
2740,0.185063,0.154376,0.341099,0.361642,0.941451,0.846037,0.106555,0.0974387,0.829214,0.821495,0.577944,0.654939,0.607289,0.556346,0.685596,0.721878,0.964351,0.971752,0.781252,0.842568,2.23041,2.58014,0.180431,0.420193,1.67128,1.68514,1.10954,1.1194,1.26799,1.36642,1.94892,1.79553,-0.0883236,-0.145896,-0.308746,-0.422944,1.14455,1.04242,-0.0455729,-0.0560931
2741,0.0952198,0.0925727,0.0522022,0.0119074,0.459759,0.366335,0.297661,0.288016,0.436603,0.427929,0.0984139,0.174801,0.911725,0.863299,0.299659,0.399856,0.980051,0.927352,0.0390766,0.0994779,-2.9845,-2.63477,-0.612709,-0.374478,-1.10561,-1.08668,-0.538608,-0.524507,1.45559,1.55453,-1.38308,-1.53283,-1.27002,-1.33302,0.446053,0.335973,1.10625,1.00637,1.21396,1.20997
2742,0.136702,0.0307691,0.12555,0.111753,0.642478,0.547658,0.770052,0.761024,0.830637,0.820696,0.735392,0.810781,0.199523,0.151049,0.0427857,0.077835,0.876886,0.882952,0.199586,0.30889,0.0708991,0.425084,-0.902141,-0.663492,-1.98756,-1.96584,0.689474,0.702588,-1.18945,-1.09765,0.574111,0.428291,-2.18683,-2.25624,-0.563008,-0.665773,0.292189,0.197001,0.656665,0.656987
2743,0.978857,0.872523,0.334054,0.211599,0.361535,0.232017,0.546139,0.538134,0.759042,0.750056,0.445206,0.521869,0.291597,0.24499,0.333579,0.440258,0.309916,0.317435,0.456684,0.518302,0.376057,0.724536,-0.195495,0.0443382,-0.523189,-0.496466,0.364081,0.374907,-1.04023,-0.955909,-0.119824,-0.273066,-0.183451,-0.247909,-0.106901,-0.212458,1.59609,1.4989,-1.13543,-1.14377
2744,0.961498,0.857421,0.352694,0.311445,0.0117107,-0.0836245,0.562505,0.610482,0.46313,0.501394,0.796381,0.872755,0.621093,0.572307,0.765525,0.802682,0.0610305,0.0689146,0.934582,0.997305,1.78392,2.12805,-1.49623,-1.25992,-0.679748,-0.647542,-0.41858,-0.401466,0.880015,0.968813,-0.826843,-0.974424,0.821802,0.765439,-0.0692829,-0.173449,1.98286,1.88089,-1.18658,-1.19699
2745,0.65965,0.557791,0.0145042,-0.0285929,0.909776,0.813203,0.692737,0.682829,0.261136,0.252732,0.0827171,0.157154,0.187024,0.136225,0.230278,0.266584,0.776588,0.785369,0.862237,0.923206,2.0533,2.39393,0.446351,0.683784,0.215238,0.24433,1.48723,1.5036,-0.193445,-0.100317,-1.14634,-1.24335,0.932,0.873736,1.16156,1.05799,0.981551,0.881345,0.166338,0.161664
2746,0.15492,0.0522983,0.121523,0.191833,0.406369,0.309067,0.512629,0.553226,0.905622,0.897634,0.899338,0.972159,0.805363,0.752401,0.913854,0.948175,0.860592,0.868083,0.132977,0.195022,-0.91336,-0.572866,1.41209,1.65365,-0.103516,-0.0778625,0.833569,0.851246,-0.376978,-0.283649,-1.35834,-1.51227,-0.0387995,-0.0959066,0.253739,0.148693,-0.891984,-0.990266,-1.28665,-1.28674
2747,0.189145,0.0578183,0.382846,0.412259,0.521902,0.426254,0.307232,0.423623,0.628049,0.625685,0.885828,0.960012,0.753799,0.740558,0.79593,0.764599,0.208267,0.217901,0.593601,0.654037,1.22721,1.56952,-0.190018,0.0493115,-1.87587,-1.85523,-1.83135,-1.81065,-1.04456,-0.955431,-0.0614658,-0.211619,-0.65923,-0.710682,-1.29232,-1.40511,0.533938,0.439871,0.483877,0.488961
2748,0.0870108,0.0633383,0.678093,0.632685,0.24255,0.147671,0.30282,0.29402,0.362222,0.353737,0.631305,0.721421,0.78167,0.728714,0.545493,0.581023,0.0382596,0.0502015,0.361833,0.42322,-0.457376,-0.10925,-0.0850498,0.156237,1.62082,1.63813,0.0279277,0.0472268,-0.0715462,0.0178302,0.547827,0.402596,1.31745,1.26567,-0.678826,-0.798644,-0.80734,-0.906691,1.17954,1.19096
2749,0.173261,0.0688583,0.68351,0.637058,0.342608,0.259168,0.493615,0.484598,0.296832,0.288009,0.407499,0.48283,0.505237,0.406275,0.650006,0.68736,0.703373,0.717888,0.348681,0.409022,-1.1093,-0.760136,-0.248854,-0.010584,-0.125559,-0.107219,0.849068,0.898084,-1.06773,-0.975817,-1.37368,-1.52218,-0.786051,-0.831565,1.80009,1.67889,0.263485,0.161788,-2.61733,-2.60806
2750,0.480451,0.278046,0.0782841,0.0312377,0.429136,0.370665,0.0255172,0.0179398,0.809679,0.802131,0.441278,0.51911,0.137833,0.0838353,0.551526,0.587425,0.755073,0.683496,0.696158,0.758627,0.157768,0.50412,0.848116,1.0843,-1.11809,-1.09536,1.73674,1.74894,0.875216,0.965461,0.538512,0.392723,-0.334653,-0.384664,-0.2676,-0.390561,-0.99564,-1.10228,-0.688838,-0.68033
2751,0.593986,0.487235,0.405215,0.357396,0.578129,0.482162,0.774792,0.766401,0.919223,0.911149,0.749057,0.82532,0.400048,0.345408,0.957945,0.99387,0.633619,0.649105,0.665233,0.729255,-1.18835,-0.837328,-1.18672,-0.946569,-0.964079,-0.942878,-0.0579783,-0.0492356,1.19151,1.27484,-1.4677,-1.61024,-1.24668,-1.29168,1.23372,1.10332,-0.554798,-0.659026,0.796935,0.801663
2752,0.578656,0.472133,0.405562,0.405628,0.470677,0.372422,0.454817,0.448447,0.800779,0.794518,0.101687,0.179978,0.978352,0.921909,0.5813,0.616998,0.24898,0.264639,0.987665,1.05299,0.437675,0.785542,0.257943,0.501628,-1.16531,-1.14047,-0.369434,-0.292386,0.620137,0.710943,1.47069,1.32851,1.50872,1.46328,0.232782,0.101579,-1.39016,-1.49866,-1.0271,-1.02594
2753,0.316707,0.208631,0.499421,0.45386,0.358643,0.262682,0.641835,0.633951,0.296596,0.29128,0.243208,0.319914,0.748244,0.690584,0.464933,0.442288,0.165427,0.179059,0.47479,0.542081,1.54794,1.89305,0.577089,0.826463,0.671953,0.68947,-0.546645,-0.535537,-0.603215,-0.512938,0.220297,0.0800708,-0.795564,-0.841277,1.10972,0.983568,-0.16179,-0.275087,0.084921,0.0858697
2754,0.66966,0.560452,0.832376,0.784726,0.866017,0.770912,0.201572,0.192021,0.860206,0.854231,0.00667982,0.0814599,0.161471,0.103277,0.233826,0.267579,0.855228,0.870612,0.251922,0.397588,0.207196,0.551602,0.640294,0.795894,-0.954114,-0.93169,0.858829,0.877848,0.777834,0.873126,-0.125464,-0.258345,-1.59523,-1.64039,-0.808064,-0.930032,0.01256,-0.097294,-0.113048,-0.118473
2755,0.0549204,-0.0556527,0.606277,0.674731,0.97689,0.882707,0.197658,0.190801,0.509961,0.506803,0.737205,0.812674,0.232182,0.172071,0.693214,0.728617,0.21362,0.230186,0.165826,0.253096,-1.70192,-1.36281,0.520733,0.765325,-0.261915,-0.239726,0.247536,0.272329,0.0148049,0.0217943,0.593211,0.460844,-1.35227,-1.39639,-0.731175,-0.860778,-0.630393,-0.736588,0.288782,0.27826
2756,0.865487,0.756627,0.566202,0.564735,0.5006,0.407731,0.8228,0.817969,0.986722,0.984713,0.577815,0.65422,0.73982,0.678492,0.365814,0.487691,0.532773,0.550853,0.0413122,0.108603,0.605588,0.949225,0.329158,0.567752,0.00529792,0.0227398,1.22764,1.25369,-0.930674,-0.829537,0.00442719,-0.127684,1.01485,0.968144,0.600019,0.464247,0.186222,0.0807456,-1.12519,-1.1391
2757,0.425935,0.316119,0.502272,0.45474,0.693542,0.598084,0.22056,0.214654,0.234518,0.23168,0.860202,0.938323,0.180567,0.121059,0.212987,0.246765,0.143771,0.160806,0.229758,0.295796,0.25305,0.687465,-0.218337,0.018112,-0.584176,-0.563468,-0.743678,-0.726556,1.13155,1.23572,1.37813,1.24855,-0.676384,-0.72091,0.489894,0.350397,-0.255381,-0.359159,0.303065,0.296537
2758,0.817741,0.709066,0.619524,0.663638,0.480397,0.415154,0.788945,0.782337,0.813736,0.811417,0.875074,0.941474,0.132799,0.0728135,0.280945,0.313159,0.224242,0.238818,0.792336,0.859185,0.0512158,0.425704,-0.266657,-0.0266538,-0.0100554,0.00358956,-1.15123,-1.13172,0.90819,1.0057,1.25272,1.12326,-0.566773,-0.574695,1.46578,1.32367,0.840309,0.740494,0.0776241,0.076343
2759,0.749951,0.735649,0.922126,0.872536,0.190573,0.232224,0.806929,0.771704,0.403019,0.402227,0.91492,0.944624,0.918571,0.85839,0.0959462,0.126214,0.709329,0.723826,0.530143,0.598079,-0.179695,0.163943,0.712706,0.956729,-0.862543,-0.843967,1.73442,1.76012,1.15242,1.25642,0.0409585,-0.0917668,-0.391005,-0.428479,-0.255242,-0.402206,-2.65252,-2.75523,0.286295,0.279027
2760,0.873171,0.762233,0.629758,0.582377,0.144752,0.0492942,0.766255,0.761071,0.319866,0.316475,0.896375,0.947775,0.25533,0.196695,0.674043,0.704089,0.409988,0.424658,0.83918,0.905857,0.831535,1.18085,-0.441025,-0.194164,0.50966,0.534115,-0.555639,-0.534639,-0.0149864,0.095331,0.671316,0.536565,1.16537,1.12535,-0.600141,-0.744672,-1.24732,-1.3555,-1.67612,-1.67856
2761,0.192842,0.0809903,0.605956,0.517023,0.380177,0.284664,0.0992968,0.0935037,0.73285,0.729099,0.872806,0.950926,0.531603,0.419746,0.116229,0.147976,0.91543,0.930313,0.126485,0.193962,-0.392505,-0.0400404,2.29129,2.54393,0.379413,0.410832,-1.00722,-0.985978,-0.630277,-0.515292,-0.545779,-0.678464,-1.52312,-1.56666,0.27478,0.137318,-0.196134,-0.301802,0.733039,0.728948
2762,0.565183,0.453294,0.500548,0.451669,0.0853097,-0.00930517,0.698653,0.690349,0.941046,0.938873,0.214553,0.291002,0.70006,0.642798,0.996986,1.029,0.153365,0.16574,0.693095,0.762358,1.1,1.45909,1.06049,1.31616,0.266046,0.287549,1.22827,1.25515,0.144107,0.256954,0.175258,0.0109493,-0.0849305,-0.134254,-0.772105,-0.910258,0.0600846,-0.0464979,0.597592,0.599617
2763,0.572471,0.458443,0.175953,0.126145,0.208499,0.111842,0.253129,0.244458,0.152455,0.149129,0.910769,0.987391,0.54343,0.488306,0.983185,1.01301,0.430263,0.44201,0.676409,0.74816,0.22745,0.592534,1.99581,2.25372,-0.431288,-0.404893,-0.964618,-0.940658,-1.80573,-1.69371,0.831254,0.700363,-0.295929,-0.346696,1.02178,0.878896,0.706525,0.599671,-0.0312923,-0.0263033
2764,0.946996,0.830746,0.341958,0.311202,0.909746,0.812205,0.282802,0.272413,0.28727,0.284007,0.261387,0.337339,0.0756399,0.0225748,0.178922,0.205711,0.384951,0.397305,0.0662645,0.138206,-1.04776,-0.689053,-0.286585,-0.0282774,-0.437999,-0.404918,0.0487956,0.0718385,0.192635,0.29748,0.427597,0.300514,-0.022502,-0.0711356,0.978913,0.838647,0.573011,0.469826,-1.85678,-1.85391
2765,0.737233,0.621902,0.646827,0.49626,0.954738,0.85889,0.577687,0.567683,0.093141,0.0919481,0.457178,0.524342,0.338319,0.258769,0.535634,0.563219,0.780926,0.793181,0.933735,1.00722,-1.5534,-1.09703,0.0223945,0.281605,-0.0932417,-0.0671413,-0.449914,-0.425784,0.145607,0.255174,0.298288,0.175222,0.0106469,-0.0402339,-1.71443,-1.85796,2.82724,2.73171,0.205012,0.213892
2766,0.736151,0.622469,0.731126,0.681318,0.508031,0.40982,0.458641,0.449757,0.908295,0.908635,0.707826,0.711345,0.548735,0.494963,0.111858,0.141264,0.969822,0.983677,0.69702,0.777513,-1.86021,-1.505,-1.03627,-0.776229,2.23852,2.2578,1.8747,1.9007,0.970179,1.07245,0.545446,0.419469,-1.67631,-1.72929,0.323344,0.181956,-0.663496,-0.764016,-0.821355,-0.805395
2767,0.224064,0.111612,0.371849,0.322103,0.42081,0.300024,0.783611,0.774054,0.834167,0.833607,0.821003,0.898349,0.197776,0.144333,0.0596219,0.0899736,0.321063,0.333494,0.475982,0.547804,0.407279,0.76176,-0.810848,-0.557897,-0.6527,-0.640415,1.29492,1.32612,-0.119913,-0.0116629,-0.170331,-0.291907,-0.987512,-1.03777,-0.961976,-1.09728,0.33024,0.22747,-1.16575,-1.07029
2768,0.0475003,-0.0659332,0.990585,0.942587,0.371136,0.190228,0.384846,0.454189,0.319137,0.320486,0.114709,0.193327,0.895368,0.841582,0.988132,1.01658,0.409972,0.418475,0.903201,0.976404,-0.171771,0.187486,-1.0517,-0.801801,-0.728484,-0.716169,-0.758775,-0.731818,1.19513,1.29832,0.622534,0.500255,-0.83935,-0.884737,-0.609479,-0.646322,-0.142622,-0.197986,-1.35695,-1.33519
2769,0.690311,0.575273,0.640337,0.59287,0.177509,0.0804311,0.142458,0.134324,0.453047,0.522271,0.0344266,0.115098,0.866063,0.823479,0.0465919,0.0748322,0.407879,0.503456,0.674093,0.745587,3.06914,3.43008,0.864314,1.11372,-1.25454,-1.23638,-0.44157,-0.413847,1.23418,1.33412,-0.303521,-0.425956,0.907704,0.856001,-0.0596476,-0.195366,-0.566845,-0.623442,-0.203145,-0.176131
2770,0.861252,0.746123,0.988373,0.943373,0.672851,0.573829,0.986785,0.976403,0.720751,0.724056,0.390888,0.48059,0.736247,0.805377,0.667033,0.694947,0.577015,0.588437,0.019765,0.0892824,0.305442,0.6652,1.563,1.80592,-1.43486,-1.41823,-0.441124,-0.416884,1.91949,2.01413,-0.953957,-1.07829,1.64943,1.59307,-0.41593,-0.554303,-0.946128,-1.0489,1.49321,1.51955
2771,0.509665,0.396062,0.980366,0.937727,0.629146,0.529557,0.759809,0.748233,0.0530583,0.0543528,0.766376,0.846081,0.841786,0.787274,0.274199,0.30315,0.885086,0.894212,0.368562,0.438887,-0.104725,0.261485,-1.14369,-0.90866,1.01768,1.03718,-1.20259,-1.17876,0.955468,1.05254,-0.814204,-0.941006,-1.70576,-1.75807,0.459956,0.327687,0.759994,0.661456,-0.347222,-0.329425
2772,0.744254,0.632275,0.426363,0.385852,0.00620233,-0.0945628,0.934687,0.923286,0.369728,0.371337,0.0140536,0.0959534,0.13107,0.075025,0.746078,0.775228,0.544872,0.494309,0.32288,0.390629,-0.242832,0.173565,1.32137,1.55378,-1.78185,-1.76703,0.937329,0.964687,0.427316,0.520504,0.901657,0.777282,-0.238617,-0.294505,1.57192,1.4406,0.0694728,-0.0236898,0.94791,0.966594
2773,0.07381,-0.0395034,0.512981,0.428505,0.467696,0.368995,0.78499,0.775553,0.436663,0.440509,0.113234,0.195176,0.787122,0.732918,0.389611,0.418271,0.08528,0.0944053,0.271124,0.34237,-0.290323,0.0856443,-1.01925,-0.780955,-0.663366,-0.646932,-3.33669,-3.30883,-1.44826,-1.34915,0.204731,0.0807196,-0.694448,-0.755956,0.178564,0.0529403,-0.0952576,-0.185964,-0.582152,-0.557262
2774,0.764538,0.651217,0.509641,0.471157,0.236342,0.135864,0.214977,0.20737,0.814167,0.818174,0.70247,0.785822,0.117693,0.0661472,0.735652,0.765516,0.839232,0.847066,0.88284,0.956008,0.507955,0.943019,-0.244535,-0.0110326,-1.08057,-1.05943,-1.42578,-1.40376,0.821474,0.921975,0.71743,0.587815,0.73774,0.676455,0.384574,0.260545,0.918353,0.820519,-0.281347,-0.248635
2775,0.71942,0.63326,0.934613,0.895603,0.738052,0.639425,0.779993,0.770713,0.800933,0.804255,0.415483,0.49691,0.132362,0.0790957,0.733068,0.765153,0.827914,0.907689,0.454005,0.525339,1.42482,1.80039,-0.0487179,0.19094,0.736034,0.757456,-0.539877,-0.581694,-1.65685,-1.55257,-0.300044,-0.430641,0.50512,0.409259,-0.697902,-0.818834,-0.432821,-0.437465,-0.274352,-0.296972
2776,0.727875,0.615304,0.703258,0.660248,0.140774,0.0400896,0.311545,0.381057,0.0636373,0.0668879,0.768254,0.852198,0.726109,0.675089,0.20679,0.239344,0.959385,0.968311,0.281449,0.355159,-0.65834,-0.28622,0.362886,0.607091,-0.171448,-0.15243,0.222414,0.240375,-1.40114,-1.30185,0.632998,0.503822,0.206731,0.142063,-0.853239,-0.976794,-1.59761,-1.69545,-0.375513,-0.345309
2777,0.298891,0.184542,0.462318,0.424893,0.0357374,-0.0659542,0.00190098,-0.00859909,0.542935,0.544798,0.162978,0.247178,0.166287,0.113277,0.244121,0.274617,0.190788,0.199292,0.327281,0.319925,-1.4627,-1.09265,-0.800925,-0.558959,0.662771,0.679572,-0.584957,-0.567204,-0.883178,-0.777084,0.388981,0.25703,0.922813,0.863909,-0.0453253,-0.170933,-2.21559,-2.31851,-1.14213,-1.10811
2778,0.972443,0.85981,0.843756,0.80463,0.581453,0.481531,0.264057,0.252229,0.239677,0.301347,0.27916,0.429948,0.822382,0.77117,0.846591,0.879159,0.589673,0.60023,0.211295,0.284691,-1.86596,-1.49637,-1.49497,-1.2601,2.4467,2.46294,0.537842,0.54996,-1.67655,-1.57024,-0.875004,-1.00657,0.358417,0.294277,2.1733,2.05046,-1.68529,-1.79606,0.0214024,0.0509431
2779,0.879088,0.767745,0.648245,0.61,0.0455364,-0.052284,0.817105,0.804807,0.0578829,0.0578967,0.586138,0.612718,0.258654,0.209358,0.606021,0.636244,0.354299,0.366391,0.867085,0.939237,-0.0754279,0.293754,0.351356,0.592126,0.428183,0.45761,0.519573,0.530413,1.68149,1.7831,0.20044,0.0662223,0.80948,0.741178,-0.587378,-0.710195,-0.440759,-0.555116,1.5575,1.59222
2780,0.994498,0.883752,0.851359,0.812461,0.99271,0.892364,0.998245,0.98565,0.248285,0.247883,0.711712,0.795488,0.687168,0.63599,0.780815,0.807376,0.466493,0.480955,0.156727,0.227342,0.0639422,0.436428,0.942889,1.17789,-1.56395,-1.54771,1.27141,1.27902,-0.701602,-0.603866,0.735784,0.602262,-1.43221,-1.49739,-0.131958,-0.25688,-1.12947,-1.24026,-0.358704,-0.318267
2781,0.291128,0.180387,0.366166,0.329171,0.283006,0.183043,0.763019,0.753002,0.0162789,0.0163193,0.543157,0.627851,0.225689,0.175527,0.950186,0.978507,0.355294,0.368966,0.0872334,0.159009,0.680729,1.0556,-0.980734,-0.743841,0.129617,0.141209,-1.32355,-1.32268,-0.14971,-0.0491258,-0.510402,-0.646177,0.517367,0.447764,1.34501,1.22076,-1.06859,-1.18452,0.722914,0.764072
2782,0.486507,0.376357,0.310447,0.229458,0.0331426,-0.0663824,0.0458074,0.0359346,0.125099,0.125337,0.822491,0.906337,0.593973,0.542409,0.224246,0.253797,0.591876,0.549287,0.862057,0.934397,-1.90457,-1.533,-0.962874,-0.727757,-0.802669,-0.798518,-0.106727,-0.110942,-0.227366,-0.0925677,-0.00398117,-0.139082,0.42181,0.358445,0.0279057,-0.0906191,0.580125,0.464463,-0.792649,-0.743736
2783,0.449553,0.339987,0.166103,0.129745,0.959196,0.859524,0.479935,0.46935,0.464778,0.462715,0.308725,0.391904,0.208683,0.156648,0.761071,0.791568,0.717749,0.729607,0.702628,0.715837,-1.33026,-0.95886,0.749629,0.984488,-0.970345,-0.964932,0.154155,0.187379,-0.373523,-0.13601,1.03785,0.903382,-0.712632,-0.78156,-0.629597,-0.741554,0.789293,0.622015,1.20692,1.26161
2784,0.754872,0.646707,0.638995,0.603409,0.29137,0.190401,0.660253,0.650194,0.57921,0.576837,0.923547,1.00757,0.0773346,0.125833,0.264103,0.295884,0.703013,0.714185,0.425582,0.497276,0.209973,0.587434,0.791737,1.03168,-0.244392,-0.242632,0.487325,0.4857,-0.280036,-0.179452,-0.381068,-0.5146,-1.1688,-1.24301,0.875118,0.767195,0.886592,0.779566,-1.42576,-1.37381
2785,0.0676177,-0.0400192,0.885372,0.850415,0.375611,0.284401,0.401157,0.392537,0.205361,0.202808,0.00243321,0.0861745,0.145199,0.0950183,0.58741,0.617351,0.457345,0.465665,0.881191,0.951736,-0.698194,-0.326624,-0.214728,0.0204317,1.71084,1.71125,-0.925643,-0.925936,-1.36541,-1.26357,0.910701,0.771098,0.343605,0.26514,-0.48646,-0.588881,0.372373,0.263051,-0.596076,-0.550856
2786,0.0645855,-0.0446619,0.438889,0.471617,0.457795,0.378402,0.513421,0.50699,0.5372,0.534989,0.458251,0.472376,0.824119,0.772509,0.338496,0.369354,0.558304,0.564199,0.769814,0.841373,-0.940898,-0.562729,0.728465,0.957991,-0.0336442,-0.0340972,-0.0883562,0.00640222,-1.15685,-1.05982,0.981337,0.846728,0.615854,0.5407,1.36161,1.26282,0.838231,0.721555,-0.366004,-0.317825
2787,0.709481,0.60149,0.128021,0.0928195,0.61317,0.472402,0.870962,0.865509,0.0193651,0.0165631,0.774836,0.858577,0.872029,0.78525,0.957404,0.989468,0.256379,0.260348,0.297302,0.370359,1.73842,2.11233,0.179641,0.408351,0.866642,0.873024,0.942115,0.938741,1.17534,1.27873,0.25856,0.1203,-0.768067,-0.847967,0.179863,0.0775976,-1.82435,-1.94031,1.24051,1.28606
2788,0.420145,0.312075,0.824554,0.787589,0.667371,0.566402,0.786532,0.78248,0.630613,0.626291,0.867545,0.949345,0.84944,0.797992,0.774518,0.830549,0.737703,0.740371,0.156415,0.230587,1.05012,1.43032,1.09455,1.32961,-1.13414,-1.12457,1.54362,1.54563,0.0431961,0.148402,0.602491,0.402489,2.0571,1.97808,0.417718,0.317332,0.00785472,-0.104017,0.389172,0.433498
2789,0.965349,0.858473,0.627491,0.592959,0.223594,0.121911,0.0242127,0.0189447,0.514955,0.50966,0.439111,0.518626,0.640446,0.587623,0.778745,0.671629,0.931548,0.935954,0.537727,0.610321,-0.0947278,0.296281,0.354493,0.597601,2.25545,2.27394,0.665008,0.674189,-0.453682,-0.355724,0.823817,0.684679,0.340527,0.258562,-0.22245,-0.318255,-0.760483,-0.867841,-0.96158,-0.923605
2790,0.539966,0.432848,0.667696,0.631333,0.577391,0.447986,0.575817,0.571523,0.936416,0.932,0.748373,0.828816,0.831143,0.779113,0.483109,0.512709,0.303678,0.306044,0.190501,0.264396,-1.21661,-0.837762,1.27526,1.51886,-0.988302,-0.973643,0.332184,0.346508,0.749303,0.846609,0.620441,0.484736,-0.329154,-0.416037,-0.417355,-0.507911,0.450785,0.340875,1.7779,1.81722
2791,0.715514,0.608255,0.208233,0.173115,0.877865,0.77406,0.0356046,0.0334346,0.803483,0.869605,0.786476,0.865097,0.519469,0.383147,0.550908,0.618347,0.573913,0.577019,0.364134,0.436567,0.393948,0.769067,0.618928,0.863517,-0.387297,-0.376177,-0.279119,-0.280192,1.29902,1.40135,-0.153036,-0.288254,-0.368815,-0.46086,0.568501,0.481262,-0.121901,-0.265236,0.427068,0.46012
2792,0.639996,0.531543,0.136113,0.113832,0.813572,0.70902,0.295847,0.334793,0.811142,0.80721,0.611976,0.737252,0.0392106,-0.0128186,0.694147,0.723986,0.550386,0.552537,0.134002,0.20575,0.214839,0.630827,0.504165,0.74303,-0.00995789,0.00685567,-0.928228,-0.906892,-0.567689,-0.4683,-0.12732,-0.257977,1.1387,1.04729,0.368282,0.276214,-0.757992,-0.871347,1.65465,1.69555
2793,0.124499,0.0161247,0.0921465,0.0545495,0.142603,0.0398969,0.636755,0.636152,0.0883203,0.0853052,0.529228,0.609406,0.220365,0.187997,0.437128,0.517338,0.0466645,0.0474246,0.196142,0.267993,0.113313,0.492588,-0.393238,-0.159119,-0.484644,-0.465628,0.642699,0.667434,0.224667,0.319888,-0.955544,-1.09235,-0.344414,-0.436361,-0.223325,-0.31272,-0.54367,-0.611224,-0.575719,-0.54162
2794,0.692173,0.582668,0.755634,0.718759,0.735332,0.632919,0.665851,0.664107,0.295725,0.29508,0.101464,0.183686,0.438509,0.388813,0.355406,0.310691,0.275102,0.274032,0.756984,0.826866,-0.854622,-0.480998,0.968846,1.19628,-1.17352,-1.15807,1.38006,1.40048,-0.198366,-0.108242,-0.728488,-0.863293,0.894357,0.794823,-0.44043,-0.532513,-0.235476,-0.3511,-0.10899,-0.0687028
2795,0.0134808,-0.095144,0.943231,0.907496,0.930833,0.828245,0.443655,0.441217,0.907589,0.904808,0.738439,0.819666,0.117408,0.0682455,0.0751011,0.104044,0.799821,0.79925,0.454302,0.525938,0.783377,1.15585,-1.12959,-0.90832,1.50572,1.51861,-1.42383,-1.40959,-0.879927,-0.876755,0.342433,0.209497,0.374657,0.271647,-0.905105,-0.997641,-0.489125,-0.604799,1.35336,1.39739
2796,0.629126,0.520187,0.329142,0.290943,0.206004,0.103083,0.949883,0.949058,0.888778,0.787186,0.850716,0.900821,0.392123,0.284168,0.797367,0.826365,0.584717,0.657885,0.636155,0.670009,-0.120519,0.257898,-0.629504,-0.414135,-0.337802,-0.322156,-1.26768,-1.25883,-1.73858,-1.64527,0.0610809,-0.0674158,-1.42183,-1.5272,-0.267709,-0.360385,0.482389,0.368677,0.257637,0.299826
2797,0.326319,0.215527,0.532785,0.493404,0.56772,0.465462,0.919647,0.917046,0.671062,0.669564,0.902806,0.981976,0.548381,0.50009,0.0457136,0.0746577,0.516965,0.51652,0.744503,0.81408,0.520086,0.892578,1.35514,1.56388,0.0320154,0.0453106,0.15267,0.154556,1.32217,1.41049,1.16512,1.03319,-0.038838,-0.140578,-0.310787,-0.400633,-0.381392,-0.487569,-0.313801,-0.266759
2798,0.577647,0.466643,0.0946369,0.0556496,0.292657,0.191044,0.56227,0.560033,0.878719,0.805199,0.133658,0.211859,0.0768845,0.0289854,0.19095,0.22104,0.941767,0.941205,0.13503,0.204126,0.345549,0.716844,-0.487488,-0.279184,-0.764975,-0.756112,1.268,1.27172,0.569634,0.66317,0.0140988,-0.121784,-0.190782,-0.290675,0.526135,0.43617,-0.853175,-0.95722,-0.307803,-0.303295
2799,0.557084,0.39165,0.293539,0.253072,0.367992,0.200871,0.865762,0.86445,0.939787,0.940835,0.136131,0.233465,0.909276,0.862689,0.0198823,0.0494711,0.963879,0.96099,0.679628,0.748257,0.710664,1.07629,-1.04344,-0.828824,0.417293,0.425741,-0.0876995,-0.0754004,-2.27911,-2.1884,0.436461,0.30745,1.31563,1.21748,3.56693,3.47158,0.309993,0.203993,-0.385591,-0.339831
2800,0.455961,0.316657,0.893909,0.853091,0.337272,0.210698,0.54248,0.541643,0.0501123,0.0529355,0.177434,0.255072,0.0196327,-0.025442,0.393521,0.421931,0.277989,0.275552,0.795354,0.852826,0.0591102,0.425399,0.603037,0.821848,-0.909356,-0.902637,-0.383806,-0.37315,0.0259481,0.118163,1.22908,1.09961,-0.429805,-0.533926,0.813662,0.725312,0.0352169,-0.145667,0.626856,0.666208
2801,0.354983,0.241664,0.466175,0.424514,0.324369,0.220524,0.798076,0.796803,0.793875,0.795963,0.550827,0.61535,0.611361,0.565926,0.0130669,0.0406604,0.103169,0.102289,0.887489,0.957395,0.392788,0.782882,0.564343,0.777083,0.720258,0.723506,-4.54553,-4.53508,-0.309716,-0.219285,-0.0279451,-0.163985,-0.360518,-0.470727,0.336938,0.245081,-0.388986,-0.495328,0.679136,0.719042
2802,0.83141,0.718626,0.506109,0.462888,0.988852,0.885241,0.0643974,0.0637803,0.887987,0.890855,0.899541,0.975628,0.13646,0.0897813,0.505405,0.531946,0.278654,0.277256,0.38886,0.456737,0.77755,1.14037,0.0124309,0.227442,-1.20173,-1.19723,0.761943,0.77239,-1.05971,-0.966603,0.107672,-0.026702,0.141567,0.130762,0.614699,0.516763,0.301515,0.198071,-1.12829,-1.09562
2803,0.859732,0.749057,0.98375,0.940655,0.280437,0.17592,0.283036,0.322298,0.282821,0.286134,0.454771,0.534738,0.826146,0.777303,0.0962015,0.120256,0.784013,0.782911,0.900057,0.965239,-0.177193,0.181466,0.575058,0.797587,-0.409971,-0.398211,0.987904,1.00088,-0.351792,-0.257754,2.64875,2.51432,0.837466,0.732252,0.365413,0.265274,0.341026,0.240357,-0.416655,-0.377618
2804,0.65171,0.560323,0.764939,0.721276,0.908778,0.804417,0.616655,0.580816,0.319788,0.323064,0.0199274,0.0938485,0.68936,0.643177,0.786287,0.81157,0.0572622,0.057215,0.101623,0.165228,0.281094,0.631921,0.414887,0.630766,-0.269575,-0.260347,-0.74515,-0.738562,-0.128294,-0.0378137,-0.511778,-0.648709,-0.60833,-0.719166,-1.79695,-1.90068,-0.24262,-0.338113,1.80871,1.85179
2805,0.490358,0.371588,0.921303,0.803404,0.00977442,-0.09577,0.839951,0.839333,0.792257,0.796036,0.195982,0.301828,0.173621,0.127144,0.600477,0.707801,0.425864,0.487152,0.302468,0.367214,0.357201,0.713052,1.32201,1.53821,-0.551395,-0.534083,0.168567,0.179892,-0.435482,-0.250655,-0.21216,-0.34665,-0.469848,-0.581693,1.96515,1.85215,-0.0911427,-0.190811,-0.962289,-0.918359
2806,0.164611,0.182853,0.926834,0.885533,0.445929,0.338334,0.495316,0.492606,0.481659,0.483342,0.534046,0.509808,0.0852052,0.0660731,0.528523,0.604033,0.917036,0.917089,0.20484,0.268184,0.721096,1.07249,0.350876,0.573564,-0.000715876,0.0178765,-0.818714,-0.814052,-0.550168,-0.463496,0.383284,0.251763,1.32907,1.22256,1.93722,1.82889,-0.294603,-0.397595,-0.809523,-0.760699
2807,0.104793,-0.00588199,0.490646,0.424748,0.0223766,-0.0861647,0.389584,0.461611,0.42893,0.444603,0.643866,0.717788,0.0527325,0.00500261,0.467104,0.500264,0.922295,0.870062,0.564266,0.628311,-0.804732,-0.451294,1.8027,2.02176,-2.15574,-2.14177,1.1227,1.12247,-0.970684,-0.840542,0.749895,0.617157,-1.01059,-1.11416,1.30436,1.1933,0.836532,0.732683,-1.7564,-1.70466
2808,0.675883,0.565579,0.00526417,-0.036037,0.999497,0.889483,0.435332,0.430615,0.403829,0.405863,0.363595,0.44,0.173283,0.128304,0.371213,0.396496,0.821829,0.823035,0.0266019,0.0924699,0.225842,0.579557,0.799392,1.00805,-0.602961,-0.556445,0.823231,0.729719,-1.30803,-1.21759,0.178588,0.0466711,-1.01774,-1.12814,-1.61707,-1.72954,0.656442,0.505332,-0.840679,-0.791932
2809,0.681385,0.570728,0.785142,0.745058,0.347276,0.236089,0.789596,0.784506,0.926496,0.929383,0.617731,0.693438,0.405142,0.251605,0.590575,0.547374,0.463125,0.463883,0.481638,0.546929,0.920446,1.27456,-0.224712,-0.00565608,1.0149,1.02888,0.342995,0.336973,1.01151,1.1023,-0.881216,-1.01816,0.314878,0.198219,-0.442566,-0.555977,0.376035,0.277981,0.565662,0.612017
2810,0.279397,0.170025,0.529909,0.489003,0.436421,0.327206,0.358476,0.35261,0.116921,0.119269,0.425606,0.499101,0.423901,0.374906,0.664704,0.698253,0.81237,0.815167,0.289806,0.356308,-1.06609,-0.718296,0.421285,0.64255,1.05485,1.07366,0.298096,0.239823,-1.74211,-1.65307,0.192261,0.0546325,-0.00165086,-0.172261,-0.034626,-0.148016,-0.418522,-0.517585,1.31451,1.36045
2811,0.169308,0.0610035,0.825581,0.785611,0.0133371,-0.0972929,0.346557,0.340284,0.943397,0.947136,0.459726,0.518309,0.841151,0.791678,0.823848,0.849131,0.817924,0.820608,0.83663,0.905244,0.769982,1.1173,-0.460448,-0.244415,0.0849579,0.098769,0.150652,0.142672,-0.614723,-0.530031,0.38431,0.252706,-0.424988,-0.542741,-0.443762,-0.551774,-0.0585764,-0.179139,1.63019,1.68333
2812,0.498205,0.38858,0.294129,0.253537,0.601676,0.491077,0.840965,0.833625,0.728543,0.796074,0.465432,0.537516,0.497515,0.446455,0.719639,0.802591,0.156466,0.160088,0.428844,0.498853,-0.102245,0.250747,0.497941,0.70834,0.861023,0.867459,-1.26218,-1.26896,0.783963,0.870499,0.142153,0.0224588,0.314354,0.194323,-0.364991,-0.467184,0.25956,0.159307,-0.630101,-0.567362
2813,0.0689345,-0.0421822,0.0174505,-0.0218096,0.586683,0.477589,0.862707,0.856215,0.55572,0.645012,0.079115,0.150063,0.810431,0.758514,0.730701,0.75605,0.595042,0.599575,0.490788,0.561096,1.61262,1.96436,-0.196219,0.00719689,0.116753,0.129502,-0.0979954,-0.102383,-0.124355,-0.0292408,-0.0685408,-0.207788,-0.660296,-0.777556,0.717627,0.614473,1.16137,1.05435,-1.24274,-1.17986
2814,0.119551,0.00806591,0.285559,0.244158,0.0463374,-0.061481,0.616475,0.608281,0.460238,0.493949,0.464438,0.593219,0.400153,0.347396,0.943128,0.967462,0.427091,0.431876,0.339425,0.410736,0.490937,0.899642,-1.15766,-0.95745,0.352342,0.360451,-1.0479,-1.05206,0.149207,0.25181,-0.52891,-0.672298,-1.6294,-1.74943,-0.698572,-0.802122,0.0997021,-0.0070903,-0.198902,-0.129018
2815,0.695592,0.584612,0.271327,0.141107,0.636621,0.526889,0.731235,0.722734,0.225958,0.342887,0.963805,1.03637,0.624985,0.644949,0.230527,0.252983,0.599748,0.606843,0.968467,1.04027,-0.516812,-0.165075,-1.02582,-0.817741,-0.606753,-0.595161,-0.14285,-0.148613,-1.22706,-1.12744,1.25199,1.1077,0.928473,0.808145,0.879279,0.770071,1.53118,1.42305,-0.199792,-0.0554996
2816,0.687918,0.575587,0.0775012,0.0380561,0.375395,0.26689,0.198979,0.189735,0.188085,0.191825,0.346219,0.416203,0.995989,0.942502,0.649279,0.669551,0.112676,0.121941,0.38988,0.460055,-0.235979,0.117854,0.33337,0.537659,-0.282447,-0.272447,-0.762866,-0.767924,-1.18642,-1.09164,-0.742473,-0.879488,0.899579,0.779373,0.322835,0.21312,-0.831781,-0.94394,-0.119987,0.0180187
2817,0.306998,0.195851,0.893512,0.853995,0.851117,0.740484,0.816738,0.807418,0.780584,0.786611,0.256466,0.328333,0.283726,0.230253,0.472049,0.492712,0.0126366,0.12904,0.176674,0.244755,2.15415,2.51298,0.478992,0.677367,-0.781443,-0.77608,0.285928,0.314875,-0.459068,-0.365964,-1.46523,-1.60592,0.376582,0.256198,-2.46371,-2.56609,-0.354065,-0.468961,0.0222494,0.091537
2818,0.388602,0.276498,0.247216,0.208289,0.447689,0.33493,0.457675,0.450405,0.844623,0.849103,0.55274,0.63637,0.0868072,0.0353054,0.864789,0.884855,0.0407687,0.13614,0.256422,0.37418,1.69752,2.06457,0.422063,0.61822,1.10436,1.1168,1.40146,1.39767,0.540954,0.635892,0.726163,0.580637,1.23234,1.11294,-0.601263,-0.698827,0.776493,0.661317,-0.276054,-0.202464
2819,0.939181,0.827516,0.0242849,-0.0159889,0.855833,0.743072,0.664349,0.657091,0.625227,0.606906,0.87363,0.944407,0.562276,0.511829,0.711219,0.73361,0.133341,0.143239,0.404653,0.503606,1.64547,2.01039,0.626417,0.820193,-0.296688,-0.289159,-1.61283,-1.6205,0.703995,0.795289,0.31311,0.164305,-0.761167,-0.874733,-0.326613,-0.427145,0.338991,0.221412,1.17644,1.24674
2820,0.624756,0.512521,0.563735,0.461116,0.559583,0.449103,0.0925336,0.0844288,0.265286,0.364708,0.830235,0.90244,0.605225,0.471825,0.0308941,0.0514344,0.945324,0.956126,0.56495,0.633031,-2.05942,-1.69458,1.64502,1.8359,0.671288,0.678813,-0.675279,-0.687113,1.13988,1.22844,-1.23623,-1.39175,-0.805197,-0.919556,-0.792581,-0.873,-0.638295,-0.761805,-0.572563,-0.508616
2821,0.524123,0.409919,0.979055,0.938221,0.543204,0.376636,0.987379,0.977879,0.11803,0.12251,0.441793,0.514987,0.484193,0.431822,0.863136,0.885032,0.679025,0.691268,0.400903,0.58703,-0.481175,-0.118504,0.00357,0.199689,0.0425124,0.0478894,0.773631,0.757452,-1.75997,-1.67528,-0.885384,-1.03913,0.428186,0.311628,-1.22367,-1.31885,0.637392,0.508659,-0.17739,-0.111882
2822,0.0619379,-0.0511344,0.348912,0.307893,0.365852,0.30417,0.339248,0.330247,0.322779,0.327732,0.865066,0.938599,0.749683,0.698239,0.895549,0.915246,0.0193058,0.0307479,0.413846,0.541028,0.707954,1.06765,-1.99019,-1.79544,-2.8944,-2.88667,-1.17296,-1.18653,-0.84136,-0.841175,-1.19644,-1.34785,0.940771,0.818653,0.136837,0.0387642,0.898814,0.763964,0.679293,0.739773
2823,0.302743,0.243933,0.245164,0.204631,0.341332,0.231703,0.881777,0.873135,0.00672007,0.010052,0.835742,0.910858,0.733609,0.640623,0.525079,0.593225,0.239427,0.25242,0.426946,0.495027,-0.365556,0.000156702,-0.855576,-0.593007,-0.217519,-0.209988,1.49582,1.47885,-0.0953033,-0.00706506,0.52543,0.370441,0.122199,0.00639623,-0.841288,-0.933556,-0.491732,-0.627314,-0.220698,-0.158018
2824,0.651183,0.539001,0.758579,0.71707,0.446367,0.390701,0.0930528,0.0840436,0.442065,0.406535,0.337575,0.41079,0.584205,0.583007,0.253076,0.271204,0.180158,0.158992,0.828084,0.894485,1.80965,2.17519,0.422957,0.609424,-0.78519,-0.776561,1.10692,1.08918,0.157769,0.243654,0.0190675,-0.140158,-0.0223391,-0.143701,0.646553,0.56033,-0.444498,-0.585028,0.325701,0.390984
2825,0.680991,0.612029,0.369653,0.327473,0.660693,0.549698,0.36434,0.338868,0.79902,0.803018,0.712019,0.710729,0.577635,0.525391,0.810226,0.829102,0.0528129,0.0655642,0.780461,0.842922,0.852315,1.21629,-1.34341,-1.1531,-0.209131,-0.193132,-0.71487,-0.728642,-0.506944,-0.428128,0.719944,0.564968,0.729351,0.609089,-0.525118,-0.607812,1.65848,1.51563,0.0385926,0.0969832
2826,0.809845,0.685057,0.318457,0.277606,0.4405,0.261887,0.604223,0.593691,0.319779,0.324063,0.936159,1.01067,0.827064,0.675893,0.59857,0.654393,0.747731,0.762153,0.711302,0.791358,-0.742256,-0.386531,0.4145,0.608183,-0.460486,-0.437614,0.909702,0.892989,0.210748,0.297547,-0.725335,-0.883265,-1.64183,-1.76096,1.92859,1.85394,0.634884,0.486025,0.582517,0.645985
2827,0.872053,0.758086,0.0436182,0.00225968,0.0854257,-0.0259243,0.654818,0.64588,0.0875765,0.0924999,0.831659,0.907075,0.879,0.826394,0.458625,0.479683,0.71163,0.727082,0.574563,0.739794,0.35405,0.70492,-0.999657,-0.808216,1.21616,1.23681,0.85577,0.752834,-0.0196486,0.0675321,1.08543,0.927008,2.11766,1.99568,-0.519026,-0.595409,-1.02071,-1.17439,-0.406695,-0.342963
2828,0.186796,0.0713592,0.935096,0.890455,0.120875,0.0104429,0.707195,0.698068,0.98516,0.988731,0.33521,0.411857,0.260447,0.210099,0.897431,0.916865,0.995829,1.01283,0.621829,0.68823,1.84944,2.20405,0.342459,0.530613,1.20268,1.22207,0.622727,0.612679,1.02598,1.11598,1.04181,0.880603,-0.976807,-1.10139,1.11649,1.03817,-0.362587,-0.587711,-2.62141,-2.56638
2829,0.416894,0.322538,0.749423,0.706205,0.935185,0.825531,0.000607656,-0.00927596,0.480573,0.485493,0.553119,0.609504,0.648152,0.596851,0.553729,0.574772,0.574613,0.593961,0.176387,0.241838,0.98915,1.33749,-0.587234,-0.401638,2.30247,2.32571,0.280214,0.269457,-0.271153,-0.210282,0.206046,0.0462327,-0.719482,-0.84181,0.43504,0.35603,0.151288,-0.00103261,-1.10065,-1.03888
2830,0.68875,0.573718,0.0483503,0.00594081,0.151236,0.0409598,0.868957,0.85973,0.700905,0.673591,0.730838,0.807151,0.133351,0.0808177,0.89916,0.922017,0.478974,0.498496,0.174403,0.237344,1.00154,1.34292,0.592951,0.783544,0.473525,0.498903,0.463506,0.450513,-1.63293,-1.53654,-1.30873,-1.46355,1.21794,1.08924,-0.659637,-0.737187,-0.711087,-0.857278,-0.539955,-0.472902
2831,0.313733,0.199394,0.0634885,0.0201006,0.228813,0.117432,0.233951,0.222473,0.855668,0.861689,0.274376,0.351322,0.781355,0.728758,0.505155,0.53022,0.75571,0.774767,0.86677,0.931607,0.111984,0.460264,-1.01392,-0.820796,0.315508,0.347826,2.02532,2.00801,-0.325367,-0.226559,3.75428,3.59946,-0.224135,-0.286468,0.868864,0.787018,1.38821,1.24338,0.248545,0.320378
2832,0.339282,0.224463,0.563499,0.51858,0.915239,0.802316,0.848933,0.840157,0.434363,0.437788,0.678114,0.755199,0.695812,0.644396,0.868001,0.893105,0.317381,0.335561,0.760154,0.825902,0.166707,0.608341,0.0781331,0.27409,-0.868025,-0.841305,1.10225,1.0897,-2.11512,-2.02096,1.09223,0.876984,-1.53348,-1.66218,0.531871,0.444553,0.618794,0.479552,-1.62528,-1.55692
2833,0.00774061,-0.105251,0.800572,0.755888,0.572137,0.458032,0.292712,0.281917,0.906505,0.910759,0.0665965,0.145717,0.160058,0.107615,0.619358,0.645108,0.976982,0.993873,0.994353,1.05868,0.410151,0.756417,1.83863,2.03537,0.210929,0.233929,-0.371076,-0.381502,2.12275,2.21969,-1.69067,-1.84549,1.04385,0.90893,-0.936096,-1.01837,0.994324,0.861534,-0.787947,-0.719617
2834,0.869333,0.755625,0.182606,0.139336,0.00555023,-0.110701,0.670086,0.66023,0.331707,0.337421,0.29901,0.379096,0.87262,0.82079,0.865724,0.890665,0.765279,0.744431,0.956307,1.03835,-2.42369,-2.08304,0.571962,0.869581,-0.575159,-0.551621,-1.15919,-1.1723,0.14958,0.240211,0.568148,0.404606,-0.295308,-0.435504,0.572175,0.490379,-0.108944,-0.197249,-0.505625,-0.441526
2835,0.676243,0.561761,0.780063,0.735641,0.763777,0.645767,0.0452354,0.0372054,0.803668,0.810393,0.0229276,0.101308,0.868879,0.885517,0.130039,0.155039,0.47815,0.494989,0.955206,1.01802,-0.774087,-0.430512,-0.495677,-0.296208,0.729222,0.75144,1.07585,1.06882,1.59364,1.68675,-0.344217,-0.507733,-0.280738,-0.42097,-0.808073,-0.897281,-1.12324,-1.25603,-0.448626,-0.388692
2836,0.95878,0.843457,0.444231,0.475589,0.89245,0.771978,0.253335,0.243892,0.867683,0.872885,0.5881,0.667736,0.999532,0.950245,0.472052,0.539125,0.831595,0.846273,0.152971,0.218009,-0.688646,-0.349382,-1.26674,-1.06069,0.46583,0.545852,0.252164,0.245267,0.0642453,0.1556,1.72153,1.55327,0.141609,-0.00568602,0.0547644,-0.0313417,-0.175663,-0.312091,0.162763,0.222036
2837,0.927877,0.812175,0.259319,0.215537,0.643334,0.522552,0.732689,0.721382,0.716837,0.72193,0.401522,0.479256,0.392942,0.344118,0.901078,0.923212,0.301502,0.317107,0.810061,0.876394,-1.04038,-0.707304,-0.949007,-0.643619,0.322306,0.340264,0.749143,0.745014,0.384199,0.536727,0.246136,0.0724145,-0.296015,-0.435259,0.601308,0.514848,-0.827553,-0.966402,1.19361,1.2577
2838,0.327747,0.211005,0.188864,0.146495,0.678348,0.55892,0.609529,0.641989,0.363698,0.368413,0.733419,0.809365,0.730062,0.681797,0.790747,0.811635,0.228408,0.220314,0.365273,0.430002,-0.280546,0.0503349,-0.433831,-0.226553,-0.125728,-0.0581848,-0.438626,-0.450575,0.82619,0.917854,0.101523,-0.0669126,0.587063,0.453399,0.641057,0.553857,0.0392809,-0.100112,-0.242286,-0.17648
2839,0.285099,0.169864,0.590331,0.546532,0.210356,0.0891878,0.57469,0.562596,0.935815,0.942706,0.791142,0.864968,0.478332,0.430974,0.933929,0.953032,0.137903,0.12352,0.9327,0.998398,-0.318124,-0.0319747,0.881552,1.0831,-0.471547,-0.456634,-0.859388,-0.871499,0.719335,0.811207,0.81324,0.652276,0.41138,0.244616,-0.509269,-0.598847,1.69921,1.56376,-1.10765,-1.04588
2840,0.730905,0.617729,0.303845,0.260872,0.957084,0.835348,0.689086,0.677049,0.168515,0.173908,0.211633,0.285205,0.483823,0.434426,0.765455,0.785182,0.0105859,0.0267269,0.837591,0.904558,-0.439247,-0.114284,1.48741,1.68495,-1.5362,-1.52249,0.286473,0.278282,2.14423,2.24266,-0.0506846,-0.212111,0.175594,0.0358322,-1.08862,-1.17046,2.12201,1.99125,0.0930123,0.157799
2841,0.62118,0.508708,0.568096,0.526839,0.264545,0.14136,0.355938,0.344277,0.519371,0.525936,0.140022,0.21251,0.186557,0.137758,0.922792,0.94258,0.298588,0.275339,0.384312,0.45325,0.2713,0.59501,0.0319181,0.145948,1.16531,1.18139,0.543339,0.4457,-1.21292,-1.11134,0.91418,0.751412,1.6611,1.5153,1.51657,1.42781,-0.609512,-0.736774,0.405308,0.466426
2842,0.733074,0.673745,0.606539,0.565213,0.203269,0.0811029,0.223593,0.211892,0.312565,0.31945,0.839249,0.913171,0.288833,0.238194,0.548122,0.565708,0.509374,0.523951,0.610832,0.748044,-1.20383,-0.883552,-1.59059,-1.39305,0.809959,0.830883,0.618612,0.613119,-1.18319,-1.07554,-0.481004,-0.637743,0.12876,-0.0169619,2.17693,2.08103,1.83103,1.69948,-0.638798,-0.582323
2843,0.953198,0.838782,0.161779,0.12184,0.966284,0.842994,0.779311,0.769354,0.961232,0.969669,0.326081,0.398738,0.680608,0.629245,0.81455,0.831311,0.101388,0.115036,0.974551,1.04284,0.876864,1.19929,0.513457,0.714853,-0.358056,-0.344712,-0.452952,-0.458801,0.875833,0.976962,0.34623,0.187166,-0.366521,-0.508494,-1.17336,-1.26476,1.13366,0.998904,1.20473,1.25691
2844,0.28748,0.172526,0.112579,0.0719727,0.102147,-0.0194651,0.0447898,0.0363311,0.852827,0.933436,0.107964,0.180215,0.647391,0.595191,0.517692,0.439522,0.661586,0.674803,0.0505234,0.119825,-1.75431,-1.43369,-0.434877,-0.233546,-0.0366579,-0.0219983,-0.449518,-0.401103,0.817589,0.917324,-0.136238,-0.291894,-2.36044,-2.49617,-0.973341,-1.07121,-0.190301,-0.332604,1.62331,1.66897
2845,0.842894,0.729075,0.709446,0.668278,0.369215,0.246649,0.612323,0.604014,0.8869,0.897204,0.658659,0.7319,0.0226285,-0.0311764,0.0309723,0.0477335,0.750304,0.762976,0.0109365,0.0813062,-1.21103,-0.890731,2.37444,2.57587,-1.4448,-1.42795,-0.341014,-0.343404,0.533627,0.628914,1.07299,0.918396,2.29388,2.15815,0.540909,0.437538,2.54116,2.39756,-2.1654,-2.11717
2846,0.815068,0.602239,0.257362,0.21506,0.00681122,-0.11797,0.962802,0.952801,0.00293106,0.0154645,0.210908,0.285849,0.944447,0.891496,0.893038,0.90814,0.0317868,0.04215,0.5177,0.589808,0.520025,0.83855,0.702428,0.907619,-0.46779,-0.444634,-0.602,-0.610096,-1.60165,-1.50328,-1.74038,-1.89914,0.0884862,-0.0468754,-0.209529,-0.305972,0.0577155,-0.0878024,-0.771867,-0.729334
2847,0.591098,0.475403,0.762946,0.722613,0.596414,0.4704,0.345172,0.335149,0.979839,0.990716,0.159926,0.191518,0.639942,0.585486,0.388621,0.401861,0.828375,0.839056,0.547307,0.535263,-1.38197,-1.06125,-1.43804,-1.23024,0.84137,0.824678,1.33919,1.32642,0.25036,0.343479,0.542205,0.382395,0.769129,0.628299,-0.329238,-0.419822,-0.303833,-0.449638,-1.211,-1.17518
2848,0.463339,0.348567,0.135217,0.0970612,0.306642,0.180649,0.248254,0.224791,0.224979,0.237684,0.0240151,0.0971868,0.0357752,-0.0206402,0.119688,0.134805,0.7474,0.758691,0.486163,0.480718,-1.4378,-1.11543,-1.18528,-0.98292,2.07084,2.09399,-0.289,-0.301216,0.399323,0.485219,-0.26998,-0.435975,-0.505305,-0.652975,-1.23215,-1.32912,1.18392,1.04259,0.460128,0.488979
2849,0.586401,0.473955,0.346405,0.309718,0.639237,0.512653,0.122267,0.114433,0.57826,0.518948,0.730884,0.80371,0.0283036,-0.0280676,0.330582,0.346217,0.321331,0.335267,0.354258,0.426173,0.980317,1.29452,0.135471,0.341272,-0.739058,-0.710221,1.6452,1.6353,-0.0545267,0.0265331,0.262626,0.100065,-1.00421,-1.14451,-0.734322,-0.829217,-0.830057,-0.973721,-0.0351614,-0.000870785
2850,0.111969,-0.00169393,0.231677,0.196497,0.636339,0.508921,0.31009,0.299937,0.789315,0.800213,0.814107,0.888886,0.94005,0.884395,0.906475,0.924092,0.529201,0.50235,0.852003,0.924805,0.687509,0.997554,-0.213526,-0.00869345,-0.231611,-0.206698,-1.50764,-1.50931,-0.263411,-0.186567,-2.22336,-2.38168,0.87061,0.725085,0.573362,0.479771,-0.377191,-0.604269,-0.0109253,0.0585996
2851,0.679952,0.564849,0.473918,0.382261,0.295069,0.16905,0.136457,0.211247,0.702982,0.650881,0.690027,0.765682,0.10615,0.0489854,0.830558,0.898882,0.589681,0.669434,0.860965,0.935522,0.703764,1.01885,0.78303,0.990976,-1.31836,-1.2878,1.15735,1.15607,0.297817,0.368173,1.22437,1.06331,0.549546,0.404054,0.211,0.120835,-0.0966007,-0.234817,0.0869748,0.11807
2852,0.995114,0.88135,0.604954,0.568025,0.885911,0.762073,0.134608,0.122557,0.49001,0.501548,0.930386,1.004,0.244393,0.151697,0.854953,0.873673,0.730401,0.836517,0.383007,0.459411,0.082974,0.397333,-0.226236,-0.0202717,-0.757498,-0.720746,1.11877,1.12043,0.0646464,0.138159,0.236566,0.075091,0.0144674,-0.13565,-1.33941,-1.43296,-0.782052,-0.919963,-0.965036,-0.930679
2853,0.999962,0.8865,0.295141,0.257435,0.569243,0.386973,0.642706,0.630398,0.830792,0.844146,0.572311,0.646438,0.312608,0.254409,0.490124,0.506887,0.989664,1.0036,0.923774,0.998804,0.983548,1.29245,0.949064,1.1482,-1.13204,-1.10196,-0.619249,-0.619011,1.59028,1.66072,-0.180672,-0.341241,0.62144,0.464045,-0.596846,-0.688886,-0.605084,-0.742171,0.0201283,0.0589633
2854,0.164792,0.0496037,0.674692,0.637172,0.13391,0.0118733,0.208399,0.194162,0.0157296,0.0279214,0.776203,0.850644,0.801604,0.74115,0.357093,0.375099,0.351159,0.363174,0.778413,0.853698,0.582418,0.888734,1.01789,1.21089,-0.706181,-0.672992,-1.14181,-1.07653,-0.109087,-0.0392032,-0.344015,-0.510028,-0.929917,-1.08499,-1.38756,-1.47762,2.19565,2.06287,0.424055,0.455697
2855,0.0147158,-0.0985383,0.0801259,0.0410088,0.215747,0.0938028,0.467571,0.456022,0.49408,0.505831,0.126127,0.200592,0.96161,0.902571,0.80665,0.826798,0.153754,0.189529,0.327732,0.402389,1.22302,1.52341,-0.417521,-0.223122,-0.804026,-0.76626,-1.54215,-1.53406,-1.14777,-0.981074,1.27247,1.09891,-0.487236,-0.638089,-0.462452,-0.548312,0.246261,0.115708,-0.392344,-0.36607
2856,0.947886,0.835171,0.584079,0.543821,0.0713392,-0.053189,0.732931,0.717882,0.0472058,0.0578204,0.0785824,0.153403,0.387713,0.330372,0.647831,0.727646,0.00585409,0.015883,0.718271,0.695219,-0.0795232,0.226687,0.975025,1.16323,-1.13954,-1.102,-0.636345,-0.630612,-1.99294,-1.92294,0.0095054,-0.164691,-0.271298,-0.425255,1.11551,1.02388,-0.723673,-0.85267,-0.531813,-0.508805
2857,0.814583,0.735227,0.046602,0.00672256,0.728243,0.605805,0.574053,0.55217,0.907773,0.918694,0.913169,0.988706,0.642894,0.586972,0.607924,0.628494,0.590522,0.601119,0.915217,0.988049,-0.237252,0.0641455,0.766052,0.951118,0.523864,0.554607,-0.760393,-0.756887,0.0747536,0.142308,-0.445814,-0.522524,-1.10295,-1.2513,-0.590349,-0.685441,-0.435347,-0.565938,0.146401,0.163617
2858,0.843136,0.635283,0.72635,0.686414,0.999654,0.877073,0.413325,0.386458,0.194161,0.203109,0.341203,0.418933,0.0049636,-0.0504714,0.431292,0.529342,0.028434,0.041272,0.389751,0.46206,-0.402981,-0.0983956,-0.350041,-0.168845,-0.287606,-0.262744,0.163832,0.161567,0.574371,0.637851,-0.710618,-0.880358,-0.590222,-0.744275,0.354485,0.260062,-1.68287,-1.81665,-1.94433,-1.93184
2859,0.648054,0.535339,0.109446,0.0698613,0.691177,0.567947,0.329075,0.220747,0.605353,0.615732,0.129264,0.205152,0.852887,0.795142,0.410042,0.43019,0.205352,0.24099,0.788687,0.861519,-0.288964,0.0714685,-0.676387,-0.487046,-0.769742,-0.75164,0.495994,0.494572,1.8285,1.88695,0.874636,0.699451,-1.60987,-1.76095,-0.463199,-0.557615,-1.25972,-1.38916,1.14288,1.15664
2860,0.971083,0.856735,0.00948268,-0.0278297,0.583166,0.461904,0.0700842,0.0550351,0.13197,0.142726,0.419159,0.442856,0.832204,0.77216,0.428485,0.450898,0.556587,0.440707,0.42851,0.500419,-0.0689103,0.241333,1.79423,1.99154,-0.537591,-0.520691,-0.572929,-0.577348,2.13406,2.19633,-0.758482,-0.930596,0.249041,0.0919087,0.464584,0.371696,0.280347,0.147362,-1.68101,-1.6632
2861,0.884369,0.681598,0.574742,0.538653,0.801129,0.682299,0.293977,0.280005,0.882435,0.891557,0.606175,0.680561,0.517276,0.455901,0.0477896,0.0696275,0.626973,0.640424,0.690608,0.763448,0.797362,1.10328,1.64,1.81267,1.60079,1.62195,-0.241336,-0.244343,1.63656,1.6922,-0.895755,-1.06992,0.294541,0.229781,-0.00703768,-0.0934316,-0.263374,-0.399467,0.41166,0.434606
2862,0.621683,0.50646,0.669575,0.581305,0.482519,0.362612,0.983488,0.967738,0.389788,0.398221,0.301109,0.376861,0.944631,0.882532,0.0720383,0.0953313,0.644684,0.541916,0.660622,0.710378,-0.120768,0.189225,1.4352,1.63379,-1.38269,-1.36547,-0.524158,-0.526817,-0.206789,-0.146871,1.30439,1.13163,0.517857,0.367653,0.129398,0.0384891,-1.03319,-1.16329,0.349163,0.368288
2863,0.24766,0.132137,0.660711,0.623957,0.492712,0.352008,0.257982,0.240097,0.82494,0.830765,0.245031,0.319006,0.904128,0.795381,0.804195,0.827879,0.465539,0.443408,0.584278,0.657308,0.770748,1.08434,-0.721071,-0.520763,0.864073,0.879029,-0.606313,-0.60742,1.08437,1.14664,-0.0837923,-0.257523,1.7722,1.62882,-0.373193,-0.457265,0.45116,0.328941,0.930628,0.948956
2864,0.364713,0.248144,0.134646,0.0965458,0.46092,0.341403,0.528215,0.51063,0.82589,0.833555,0.638045,0.713227,0.769802,0.70823,0.818661,0.812111,0.351625,0.344899,0.0704963,0.141957,-3.32685,-3.00527,-1.18071,-0.977538,-0.885443,-0.866321,0.213466,0.216046,0.0171247,0.0775133,0.907795,0.739103,0.215957,0.0652611,-0.474094,-0.555016,-1.13032,-1.25186,0.0998863,0.112881
2865,0.173733,0.0594813,0.055492,0.0187519,0.0498017,-0.0682287,0.381502,0.362897,0.188415,0.193924,0.233183,0.307084,0.423419,0.363007,0.774489,0.796343,0.232939,0.246391,0.423451,0.416042,-0.729111,-0.401055,0.997678,1.19391,-0.298304,-0.282892,-0.25837,-0.251973,1.48107,1.53851,1.51172,1.33752,0.0235666,-0.130551,1.11011,1.03178,0.0166967,-0.106039,-1.08768,-1.07612
2866,0.386154,0.25975,0.942656,0.906947,0.42993,0.312686,0.622201,0.602826,0.19037,0.196714,0.807619,0.883154,0.488806,0.426521,0.219195,0.24023,0.400026,0.339742,0.620681,0.690127,-0.824717,-0.502891,-1.05806,-0.863865,0.0660808,0.0845747,0.0729274,0.0810325,0.568735,0.623697,0.0334793,-0.143344,-0.56656,-0.715504,0.20798,0.174638,-0.732941,-0.856268,1.47562,1.48515
2867,0.575795,0.46002,0.794138,0.731266,0.385448,0.268415,0.219245,0.201213,0.451747,0.457781,0.87636,0.954201,0.814389,0.753837,0.049884,0.0723801,0.420121,0.433093,0.467617,0.539409,0.201932,0.527959,-2.28643,-2.09163,1.26537,1.28034,-0.935015,-0.928846,0.0638473,0.11957,0.989814,0.806488,-0.617966,-0.760327,-0.606794,-0.682508,-1.80568,-1.93373,-0.111991,-0.0986377
2868,0.224902,0.109958,0.588857,0.555586,0.731193,0.553777,0.193034,0.17434,0.981146,0.986806,0.484033,0.63454,0.451847,0.428845,0.840153,0.86019,0.01097,0.0241783,0.318707,0.38869,0.223033,0.549255,1.27094,1.46706,-0.494303,-0.480981,2.02386,2.02907,-0.0955997,-0.0315313,-1.43142,-1.61964,2.13225,1.98182,-0.463519,-0.535019,0.17202,0.0475766,1.0858,1.10504
2869,0.232105,0.115108,0.0479961,0.0138698,0.956172,0.839139,0.559605,0.542961,0.312376,0.317103,0.238487,0.314879,0.166501,0.103852,0.705963,0.723811,0.323938,0.334961,0.969986,1.0375,-0.755833,-0.424331,0.13674,0.331414,1.42272,1.4427,0.401858,0.401428,0.403695,0.464012,0.0266427,-0.16782,1.8378,1.67534,1.91666,1.84269,1.89576,1.77439,-0.608937,-0.587166
2870,0.954913,0.835899,0.239551,0.20665,0.47553,0.359437,0.290312,0.275034,0.0889335,0.0949454,0.395282,0.469669,0.902063,0.838417,0.950274,0.969367,0.431435,0.53837,0.310584,0.376148,-0.728776,-0.403035,0.197545,0.394104,-0.110847,-0.0840265,1.64218,1.64228,-0.422417,-0.360753,0.573561,0.384677,1.51265,1.36887,2.2659,2.1884,1.5605,1.44343,-0.512018,-0.491049
2871,0.565722,0.431834,0.716602,0.684417,0.90223,0.788515,0.353095,0.281433,0.697376,0.704673,0.864229,0.937268,0.303198,0.241818,0.359855,0.378045,0.733068,0.74178,0.220731,0.288195,0.595069,0.922646,0.468685,0.657322,-0.162285,-0.128381,-0.468248,-0.461939,2.71479,2.77748,-0.828609,-1.01929,-0.173419,-0.320184,0.175869,0.103447,0.383228,0.270615,1.05793,1.082
2872,0.14799,0.0277688,0.152369,0.118275,0.972088,0.764789,0.351397,0.287832,0.732573,0.668898,0.22784,0.301893,0.159694,0.0968816,0.881644,0.900351,0.674382,0.68201,0.374223,0.440298,0.620452,0.943942,1.03786,1.22747,-0.580372,-0.540878,-0.325153,-0.311183,-0.871395,-0.807667,0.402128,0.204981,-0.625667,-0.766234,2.08533,2.01759,0.171924,0.0638314,-1.48085,-1.45984
2873,0.488379,0.369924,0.772314,0.738759,0.854981,0.741063,0.329956,0.294231,0.715233,0.633124,0.0671179,0.139274,0.831928,0.769609,0.318833,0.339194,0.12434,0.132714,0.938624,1.00369,-0.584269,-0.260052,-0.247689,-0.0629343,0.362586,0.395629,0.961294,0.976098,-1.38957,-1.3257,-0.386162,-0.581931,1.13711,0.989991,-0.420882,-0.493965,1.39517,1.28741,-0.396396,-0.377505
2874,0.830862,0.71208,0.432844,0.398721,0.490333,0.376444,0.315908,0.30063,0.588324,0.597349,0.928944,1.0023,0.832537,0.67505,0.832037,0.851188,0.25255,0.262084,0.192086,0.255804,1.36232,1.68294,-1.22327,-1.04192,2.16112,2.1939,1.61164,1.6311,0.855779,0.926939,-0.103944,-0.307604,0.793917,0.653053,0.435652,0.358183,1.61913,1.51263,0.314508,0.340494
2875,0.695775,0.578801,0.939067,0.906274,0.55029,0.438624,0.159697,0.142899,0.320706,0.330109,0.492475,0.566273,0.643093,0.58049,0.710749,0.73006,0.0779989,0.0888203,0.189762,0.314883,-0.00412644,0.311831,-1.68543,-1.49869,0.36678,0.400805,1.24405,1.25652,2.30392,2.37347,-1.13915,-1.34044,0.214801,0.0680997,-0.734372,-0.809959,0.763523,0.656389,1.33775,1.36194
2876,0.767762,0.649534,0.0871627,0.0553957,0.207752,0.0943397,0.278814,0.267067,0.345573,0.353617,0.505378,0.578084,0.392535,0.329668,0.975386,0.995662,0.115363,0.127265,0.309986,0.373963,0.657727,0.975583,-0.287675,-0.0970855,0.592478,0.631754,0.19954,0.217087,0.230638,0.305489,0.786281,0.591692,-2.84725,-2.99614,0.33718,0.258197,-0.538013,-0.641629,0.0661346,0.0962539
2877,0.0350692,-0.0843875,0.325904,0.292704,0.290964,0.216656,0.409198,0.391235,0.926769,0.933353,0.293722,0.364303,0.908273,0.845953,0.445242,0.464614,0.823809,0.834373,0.993892,1.05809,-1.45064,-1.12447,-1.02241,-0.829098,-1.74401,-1.70353,-0.135564,-0.110594,0.423036,0.493602,0.832447,0.636716,0.684886,0.528197,-0.791236,-0.866874,1.55321,1.44203,0.438634,0.46415
2878,0.513156,0.392575,0.988085,0.956913,0.44972,0.338973,0.161762,0.143301,0.220983,0.227865,0.924235,0.994985,0.572545,0.548324,0.175662,0.197558,0.340918,0.34947,0.784972,0.847296,-0.15943,0.169244,-0.926774,-0.736592,-0.831886,-0.796413,1.19965,1.22374,-0.360876,-0.282973,-0.245705,-0.442454,1.33407,1.1751,0.620077,0.537005,-2.20767,-2.32033,-2.19884,-2.17127
2879,0.399477,0.278533,0.956403,0.920263,0.0917108,-0.0206491,0.726492,0.706645,0.821863,0.827606,0.259402,0.330039,0.312825,0.250695,0.471804,0.494202,0.1567,0.166039,0.856011,0.919324,2.47412,2.80657,-0.033707,0.155158,-1.50501,-1.47491,-0.507734,-0.483931,0.854619,0.934927,0.766313,0.567113,2.73992,2.57869,0.953369,0.86889,1.30054,1.18512,-1.0501,-0.980233
2880,0.655125,0.483717,0.964758,0.883613,0.238753,0.0684519,0.347511,0.329029,0.496465,0.500444,0.0748443,0.227337,0.650494,0.588374,0.518725,0.539592,0.403435,0.326608,0.476667,0.538918,0.550108,0.877278,-0.380852,-0.194808,-0.580018,-0.553493,-0.540111,-0.558643,-0.304009,-0.226161,0.281407,0.088052,-0.227783,-0.391365,-0.144587,-0.224327,0.736666,0.622713,0.183223,0.210801
2881,0.808624,0.688901,0.878134,0.846963,0.24815,0.157553,0.527347,0.514081,0.474013,0.476319,0.0557738,0.124635,0.270962,0.207433,0.88208,0.902477,0.480061,0.487178,0.323706,0.38371,-0.436055,-0.112967,-1.00934,-0.819339,-1.98001,-1.95945,-0.658703,-0.633356,-2.27892,-2.20564,-1.27528,-1.46801,-0.520074,-0.680938,-0.396049,-0.475816,-0.829163,-0.942196,-0.547959,-0.52086
2882,0.400932,0.315417,0.367894,0.338412,0.51627,0.246654,0.655614,0.699134,0.873076,0.874041,0.489887,0.508901,0.613196,0.527642,0.250128,0.270649,0.980858,0.987398,0.460194,0.520768,-0.256459,0.0605672,1.14185,1.33764,0.0632418,0.0880136,-0.04874,-0.0264622,-1.61161,-1.60238,-1.31027,-1.50072,0.120035,-0.0340387,1.14854,1.06513,1.50167,1.38514,-0.64581,-0.618624
2883,0.0623604,-0.0580662,0.615663,0.585419,0.447524,0.335755,0.901809,0.884187,0.162082,0.163154,0.823097,0.893166,0.911572,0.847851,0.983308,1.0032,0.662005,0.668121,0.327056,0.386195,-1.35725,-1.03757,-0.0422872,0.156562,0.303427,0.335038,1.00825,1.03008,-1.06695,-0.999126,-0.496024,-0.68944,0.330863,0.178796,-1.14881,-1.23761,0.185132,0.0698985,0.456026,0.478073
2884,0.485623,0.365025,0.187354,0.156842,0.792644,0.683053,0.658703,0.641055,0.658356,0.66108,0.546769,0.615378,0.538808,0.477137,0.824849,0.824866,0.759977,0.766655,0.593412,0.573683,0.240159,0.499637,-1.69297,-1.49585,-1.41698,-1.38197,0.586475,0.609158,-0.719096,-0.656813,1.92037,1.72639,-0.203817,-0.360908,0.359944,0.271134,-0.201828,-0.321465,1.85561,1.88202
2885,0.246676,0.12656,0.60507,0.575955,0.428088,0.318434,0.0255376,0.00883945,0.827418,0.831607,0.514625,0.509377,0.988436,0.928387,0.625839,0.646536,0.558751,0.517213,0.699777,0.761172,1.71715,2.03684,-1.21045,-1.01961,0.754927,0.79722,-0.44923,-0.380446,-0.589051,-0.530288,-0.98936,-1.18922,-1.27667,-1.43969,-0.237817,-0.331947,-1.41932,-1.53832,0.483156,0.510478
2886,0.599073,0.478381,0.0229882,-0.00507822,0.501285,0.389553,0.843032,0.825414,0.579909,0.579774,0.335501,0.403376,0.210957,0.152516,0.705005,0.727308,0.259317,0.267771,0.0947342,0.155122,0.234417,0.558277,-0.460072,-0.265104,1.63945,1.68909,-1.38824,-1.37005,0.927961,0.992277,-0.367822,-0.560883,-0.555404,-0.635814,-0.0332118,-0.124343,0.46287,0.34618,2.01332,2.03798
2887,0.336542,0.308709,0.755813,0.726517,0.841587,0.731504,0.435637,0.41839,0.321635,0.327941,0.558628,0.627407,0.795881,0.738779,0.000688455,0.0238958,0.356217,0.366305,0.0382642,0.0967847,0.533156,0.857729,-0.670518,-0.565362,-0.695176,-0.646196,-1.49116,-1.46584,1.84926,1.91792,0.556941,0.357617,0.333662,0.168057,-1.39638,-1.48042,-0.466575,-0.575342,-0.193596,-0.16618
2888,0.258997,0.139037,0.979498,0.949377,0.921427,0.802228,0.259767,0.240723,0.801643,0.805851,0.276647,0.361415,0.702768,0.70333,0.648267,0.673383,0.718895,0.727226,0.192115,0.248888,0.57828,0.9084,-1.0655,-0.865621,-0.287554,-0.230907,-2.63915,-2.61433,3.08884,3.15143,0.204275,0.00402235,0.627294,0.460353,-0.0440514,-0.1228,-0.316281,-0.42804,0.0350178,0.0668514
2889,0.505842,0.384999,0.467805,0.436536,0.982641,0.872951,0.707693,0.688953,0.607754,0.613793,0.0279765,0.0954232,0.620572,0.667882,0.911592,0.938986,0.0157934,0.0213067,0.879975,0.937464,-0.486027,-0.159093,1.05834,1.25826,-0.669911,-0.553847,-0.112756,-0.0892716,-1.70886,-1.64627,-1.0842,-1.28972,-0.300339,-0.462867,-0.61594,-0.624918,1.53714,1.42572,1.42134,1.45468
2890,0.416198,0.349834,0.54636,0.613262,0.793027,0.685474,0.860848,0.843585,0.184665,0.189892,0.612254,0.681084,0.687753,0.632433,0.552149,0.582029,0.304158,0.307051,0.447033,0.506795,1.64263,1.96822,0.328502,0.530772,-0.929404,-0.876787,2.41096,2.43578,0.756096,0.815046,-0.05351,-0.26332,0.326809,0.167966,-1.05419,-1.12704,-0.371465,-0.477866,1.42995,1.46227
2891,0.436561,0.314669,0.749141,0.789988,0.997669,0.890843,0.536665,0.562576,0.495911,0.50191,0.554341,0.705395,0.0396369,-0.0157422,0.50406,0.535511,0.145224,0.148634,0.570547,0.628243,0.0246749,0.3529,-0.393913,-0.196713,-0.497185,-0.444436,-0.919542,-0.890469,0.879294,0.941571,0.180122,-0.0342667,-0.697063,-0.848707,1.36355,1.29767,-1.2975,-1.39939,-0.658854,-0.633197
2892,0.816497,0.692744,0.996334,0.966713,0.29702,0.191433,0.300958,0.281568,0.358945,0.276129,0.661732,0.729706,0.702422,0.647469,0.907925,0.937069,0.21481,0.217059,0.976152,1.03255,0.0559452,0.386825,0.0103995,0.203078,-0.0699867,-0.0120852,-0.425587,-0.390722,-0.264434,-0.202095,-0.18037,-0.387862,-0.549496,-0.695673,-0.223547,-0.286174,-0.696961,-0.735234,-0.423455,-0.400165
2893,0.766644,0.641371,0.851463,0.823007,0.177221,0.0702538,0.286301,0.264394,0.0444873,0.050349,0.422556,0.491252,0.092467,0.0363243,0.577035,0.605716,0.542377,0.584222,0.378322,0.436972,-0.345599,-0.0168894,1.14946,1.34091,-1.59996,-1.53881,0.378331,0.418752,0.450649,0.506753,-0.134612,-0.292371,-0.792266,-0.93935,1.18433,1.1177,0.0252363,-0.0710792,-1.42704,-1.40395
2894,0.395484,0.271619,0.0536516,0.0254206,0.360099,0.251577,0.502499,0.480699,0.715883,0.72124,0.61759,0.763534,0.349879,0.177219,0.033093,0.060193,0.94846,0.951386,0.232918,0.291866,-0.338217,-0.0114676,0.947493,1.14334,0.794465,0.850372,0.401404,0.444653,0.675749,0.726694,0.0165266,-0.196881,1.22009,1.06898,0.706008,0.682087,-0.0982339,-0.200925,0.238558,0.273099
2895,0.457508,0.331872,0.350223,0.322028,0.293054,0.182268,0.245197,0.223042,0.93501,0.94192,0.964944,1.03582,0.430274,0.318114,0.661736,0.690416,0.956537,0.96828,0.49548,0.554896,-1.41063,-1.07896,0.224023,0.427147,0.148836,0.204243,1.71086,1.74733,-0.218196,-0.173046,0.839498,0.628029,0.923379,0.779406,0.312721,0.24647,0.360621,0.25758,1.92707,1.95015
2896,0.940716,0.813187,0.983246,0.957321,0.734129,0.531511,0.477417,0.453592,0.529856,0.537841,0.939869,1.01264,0.515152,0.45901,0.360309,0.388852,0.982409,0.985174,0.0786793,0.138902,0.104355,0.434742,0.284673,0.489838,0.569011,0.619532,-1.34578,-1.30531,-0.703251,-0.659828,0.291033,0.0724324,0.219205,0.0742226,-2.53125,-2.60375,2.03892,1.93877,-0.254182,-0.238896
2897,0.401922,0.27209,0.523875,0.499104,0.990695,0.880753,0.199623,0.175864,0.955953,0.966124,0.588401,0.660321,0.202552,0.147325,0.705533,0.736097,0.717368,0.720316,0.556073,0.617905,1.06658,1.38884,1.19879,1.39728,-0.485691,-0.430996,0.260794,0.299263,0.638325,0.678788,-2.15559,-2.37044,0.551536,0.41127,1.13028,1.06103,-0.64308,-0.738118,0.306928,0.32708
2898,0.544692,0.325901,0.548048,0.522521,0.758852,0.628017,0.537075,0.444278,0.612937,0.652836,0.0222163,0.0959485,0.112946,0.0583814,0.0562712,0.0887177,0.191618,0.196249,0.0353638,0.097644,0.324091,0.587178,0.137766,0.339448,-1.2246,-1.16895,0.822674,0.860797,-0.0567941,-0.0224176,-0.380004,-0.590441,-0.707829,-0.851669,1.19414,1.13028,-0.468927,-0.560326,-0.966969,-0.954085
2899,0.511569,0.379712,0.935427,0.907287,0.485007,0.375282,0.736456,0.712692,0.327948,0.339548,0.803679,0.879034,0.626206,0.569199,0.0443209,0.0787222,0.739267,0.745918,0.235572,0.349827,-0.41393,-0.214483,-0.400851,-0.193985,-0.201981,-0.138428,-1.14789,-1.10379,0.417908,0.455666,0.346,0.128748,-1.17561,-1.31312,-0.90334,-0.971153,1.05707,0.962382,-0.102419,-0.159871
2900,0.45867,0.328339,0.748423,0.717775,0.604221,0.497598,0.550717,0.525251,0.683776,0.697174,0.59545,0.669845,0.284676,0.229163,0.270436,0.320334,0.639418,0.658498,0.540893,0.60201,-1.3384,-1.01614,-1.85244,-1.64304,-0.580438,-0.519641,-0.421648,-0.370739,0.14155,0.180932,0.320892,0.0960281,0.604338,0.471969,0.755128,0.693326,-0.751965,-0.843996,0.622708,0.634342
2901,0.0183985,-0.112169,0.219979,0.190364,0.731643,0.619915,0.714303,0.61879,0.255226,0.268706,0.906037,0.980036,0.381733,0.383332,0.528054,0.561946,0.563997,0.571079,0.410009,0.472798,-1.46724,-1.14591,0.857433,1.06134,-0.249826,-0.181864,0.763857,0.808964,-0.451131,-0.412781,-1.17965,-1.40003,-0.944664,-1.07707,-1.32168,-1.37612,1.08547,0.992295,0.620082,0.626963
2902,0.8038,0.673258,0.777209,0.747193,0.639011,0.52895,0.739047,0.712328,0.25506,0.266158,0.452189,0.622419,0.590314,0.537501,0.130785,0.16544,0.197912,0.206774,0.974286,1.03619,-0.508309,-0.191808,1.5329,1.7397,-0.731624,-0.67076,1.58825,1.63243,0.48717,0.528449,1.66939,1.45502,-0.51677,-0.645072,-0.986579,-1.04424,1.28416,1.18486,0.0797509,0.0887307
2903,0.586314,0.454023,0.430355,0.38054,0.325167,0.214421,0.365194,0.34041,0.56565,0.578176,0.188659,0.264801,0.482667,0.428271,0.405179,0.424424,0.683979,0.691781,0.706415,0.76574,0.876149,1.19692,-0.247563,-0.0369462,-0.617593,-0.564259,1.5374,1.58274,-0.525252,-0.481137,1.35419,1.13221,-1.22227,-1.35025,0.900684,0.836864,0.628739,0.530545,-1.14986,-1.14691
2904,0.967477,0.836845,0.042679,0.0138875,0.57145,0.459743,0.267882,0.242858,0.505166,0.518328,0.830791,0.905608,0.914903,0.859922,0.767898,0.683409,0.479762,0.488976,0.97089,1.02877,-0.320138,0.0745003,-1.15384,-0.939095,0.570265,0.617593,-0.253887,-0.201791,1.25944,1.30141,0.838708,0.621616,-2.54499,-2.67716,-1.58452,-1.64369,1.31179,1.20965,0.429423,0.426141
2905,0.0097142,-0.11865,0.37019,0.340046,0.152579,0.0400771,0.804226,0.78033,0.986034,1.00086,0.624087,0.696419,0.577887,0.524762,0.906919,0.942394,0.019043,0.0288764,0.672228,0.821392,-1.36629,-1.04792,0.742457,0.958666,0.225043,0.267086,-0.410149,-0.359481,-0.37097,-0.336839,-1.25782,-1.47548,1.7961,1.66227,1.14682,1.08824,-0.566067,-0.661963,-1.67807,-1.68529
2906,0.163007,0.134757,0.298346,0.287295,0.950903,0.83951,0.561678,0.608335,0.878856,0.874943,0.790849,0.861581,0.484788,0.430905,0.813723,0.920083,0.579567,0.588643,0.554096,0.614015,1.04622,1.36202,-1.02948,-0.817983,0.313215,0.357297,0.45313,0.496605,0.671497,0.711604,-0.573333,-0.788145,-0.139381,-0.277972,0.816861,0.760942,-2.15609,-2.25739,-0.819491,-0.795258
2907,0.515167,0.388165,0.265445,0.234544,0.345695,0.23513,0.458842,0.43634,0.735688,0.749028,0.612748,0.684284,0.868474,0.81236,0.861718,0.897773,0.676886,0.781712,0.11062,0.172955,-0.820093,-0.507214,0.012695,0.226372,-0.159369,-0.115186,0.191452,0.229913,0.700375,0.747405,0.74914,0.527985,-0.135493,-0.27686,0.210832,0.157861,-0.848,-0.955486,0.0967612,0.0947785
2908,0.168154,0.0429132,0.816037,0.786303,0.276431,0.165821,0.847452,0.82511,0.173691,0.185122,0.662419,0.81691,0.902126,0.844871,0.523002,0.561036,0.96462,0.974781,0.283902,0.345127,1.88717,2.19717,-0.195323,0.0142588,-0.256391,-0.208454,-0.835734,-0.794636,1.55501,1.59635,-0.246001,-0.460231,0.142147,-0.00129922,1.0206,0.963722,-0.329636,-0.433032,-0.223955,-0.230811
2909,0.671873,0.545042,0.461676,0.432121,0.98846,0.876547,0.65066,0.627699,0.284614,0.362018,0.879005,0.949536,0.531005,0.474158,0.674164,0.7123,0.468683,0.479693,0.678972,0.739693,0.0955948,0.408551,1.28241,1.49397,-0.745803,-0.69735,0.282741,0.309583,-0.578979,-0.535847,0.105667,-0.107607,1.35601,1.21522,-1.25684,-1.31892,1.82542,1.71696,0.0632904,0.0614145
2910,0.363354,0.235996,0.919748,0.890616,0.543276,0.432056,0.105642,0.0841313,0.52924,0.538915,0.0749841,0.14614,0.794855,0.735731,0.225588,0.261477,0.355557,0.390951,0.858636,0.917248,-1.97775,-1.66458,-0.381879,-0.174275,0.595172,0.651977,1.3727,1.4138,0.159115,0.204998,1.30451,1.0874,0.228597,0.0897714,-1.481,-1.53871,0.866481,0.697877,1.35953,1.35743
2911,0.762849,0.633761,0.692883,0.660501,0.45021,0.397563,0.865751,0.842564,0.128968,0.140401,0.0120241,0.0841936,0.82586,0.787917,0.600121,0.633937,0.2208,0.302208,0.295988,0.356177,0.670664,0.989423,-1.16069,-0.940715,-0.227863,-0.165374,1.04819,1.08612,-0.452311,-0.405626,0.260197,0.038829,0.995961,0.856869,0.395626,0.342388,-0.212753,-0.321207,0.395638,0.398859
2912,0.0474918,-0.0808406,0.460125,0.430386,0.358476,0.36307,0.602375,0.579125,0.80119,0.811292,0.703402,0.77547,0.900823,0.840104,0.133451,0.167293,0.203355,0.213465,0.847385,0.905113,-0.271808,0.0475116,-1.91476,-1.70716,0.350365,0.418055,-0.0668085,-0.0316911,0.96759,1.00977,0.605568,0.391454,2.01202,1.87022,1.29891,1.23916,0.422325,0.310111,-1.02158,-1.0185
2913,0.524983,0.396121,0.972462,0.942825,0.441778,0.328577,0.789482,0.764629,0.333291,0.342988,0.201323,0.275402,0.224111,0.1635,0.0947759,0.170277,0.363434,0.372848,0.185362,0.24376,0.0508135,0.375204,-0.841378,-0.629508,-0.0374823,0.0368427,1.41708,1.4454,0.0626497,0.110032,-0.630606,-0.839102,-0.852758,-1.00123,0.589515,0.526885,0.121027,0.00936378,1.42799,1.42524
2914,0.58618,0.456374,0.150468,0.122713,0.751597,0.639864,0.61011,0.586962,0.912891,0.922724,0.117138,0.192268,0.956288,0.898065,0.193326,0.173261,0.0372152,0.0483048,0.508987,0.567495,-0.127632,0.19947,-0.101938,0.110131,1.38206,1.46118,1.36878,1.3957,0.348665,0.391083,-0.118366,-0.332007,0.788615,0.647167,0.916968,0.858771,0.579808,0.467868,-1.25753,-1.26165
2915,0.200045,0.0708062,0.305304,0.276759,0.288748,0.175436,0.900239,0.877414,0.326163,0.33401,0.705575,0.782914,0.590859,0.579045,0.0709327,0.176245,0.0721953,0.0819725,0.38641,0.44701,1.54655,1.86686,0.245401,0.451105,0.357176,0.441579,0.231462,0.262489,-0.627663,-0.587844,-0.635143,-0.842606,0.0856233,-0.0580157,0.853124,0.790728,-0.925672,-1.03581,1.24201,1.23286
2916,0.109187,0.0583076,0.224115,0.193428,0.259466,0.147427,0.0808663,0.0554612,0.813232,0.822341,0.800204,0.87815,0.319294,0.260025,0.243886,0.179229,0.539582,0.547141,0.672399,0.751035,-0.0949126,0.219209,1.15619,1.35855,0.724369,0.809046,-1.20407,-1.17926,0.0409149,0.0765906,-0.886852,-1.0894,-0.323375,-0.472131,0.188613,0.110811,0.143145,0.0326653,0.81887,0.816295
2917,0.177548,0.0458089,0.652331,0.622999,0.796302,0.68507,0.589555,0.563302,0.13884,0.147142,0.0794098,0.156938,0.457076,0.344006,0.14837,0.182213,0.198767,0.207887,0.9962,1.05506,-0.285367,0.02933,-0.507936,-0.309696,1.72524,1.80854,-0.771996,-0.652177,-0.920223,-0.884995,-0.182366,-0.384273,2.28737,2.13395,-0.500694,-0.569107,0.615956,0.507644,0.913757,0.912412
2918,0.76053,0.627205,0.413036,0.444939,0.936573,0.827022,0.538206,0.511675,0.785419,0.792044,0.828903,0.908827,0.486871,0.427988,0.360166,0.393624,0.860057,0.870219,0.968133,1.02569,0.873184,1.18381,-0.664667,-0.459386,0.956988,1.03784,-0.140364,-0.125097,-0.43256,-0.389451,-0.376831,-0.530668,-0.280062,-0.427588,-0.363485,-0.437186,-1.20297,-1.31638,-1.52723,-1.53646
2919,0.940899,0.80773,0.296604,0.266879,0.252333,0.142725,0.0448766,0.0189646,0.711426,0.657337,0.685521,0.694162,0.968255,0.910236,0.294762,0.387749,0.73035,0.838855,0.407424,0.464618,-0.355408,-0.000333854,1.1884,1.39284,-0.835142,-0.755253,0.377172,0.401982,0.541531,0.58381,-0.469536,-0.677064,-0.296665,-0.450781,0.982106,0.902281,-1.62486,-1.74075,-0.442656,-0.480978
2920,0.902625,0.812671,0.935537,0.906229,0.704522,0.596234,0.96446,0.940087,0.515348,0.52263,0.40039,0.479497,0.323903,0.268362,0.347983,0.381875,0.796651,0.807492,0.941314,0.999513,-1.49587,-1.18448,-1.63512,-1.43543,0.129644,0.212719,-1.44247,-1.41584,-0.0227061,0.0199175,-0.621552,-0.82346,-0.327449,-0.473974,-1.35908,-1.44579,0.245634,0.128364,0.586174,0.574509
2921,0.952494,0.817611,0.934882,0.905852,0.542706,0.444576,0.738549,0.703127,0.933338,0.940134,0.785045,0.864308,0.397061,0.342497,0.776237,0.808489,0.288629,0.297793,0.581151,0.617974,0.784021,1.09755,-1.0629,-0.884249,-2.27504,-2.18673,0.144756,0.171385,-0.312168,-0.268492,-0.011942,-0.209244,1.13476,0.989591,1.55538,1.4655,-1.68131,-1.80421,-0.598133,-0.614492
2922,0.68212,0.548378,0.0987646,0.0689842,0.40204,0.292917,0.504422,0.466166,0.0984001,0.102964,0.714988,0.85162,0.846725,0.793747,0.0990005,0.131132,0.85034,0.857559,0.178627,0.236435,0.638881,0.950469,-0.532345,-0.333067,2.35814,2.44415,0.683885,0.719438,-0.00324743,0.0408822,-1.29342,-1.48941,0.72136,0.575476,-0.985603,-1.07565,-0.936188,-1.06377,-0.772406,-0.788474
2923,0.0453164,-0.0879851,0.948247,0.917102,0.559921,0.449558,0.253578,0.229206,0.514692,0.520468,0.757462,0.838932,0.12949,0.0759677,0.806316,0.838501,0.851125,0.857612,0.881161,0.940861,1.17982,1.49343,-1.79645,-1.59174,0.227293,0.318017,-1.02707,-0.988235,-0.589191,-0.538878,1.42797,1.23283,1.38724,1.2367,0.221002,0.127956,-0.985841,-1.11689,2.3426,2.33106
2924,0.250018,0.0662833,0.19796,0.166572,0.365753,0.257522,0.547408,0.524476,0.295325,0.342043,0.327102,0.408213,0.0278146,-0.0236901,0.655646,0.740808,0.502343,0.507999,0.352593,0.414872,-0.980135,-0.671276,-0.566385,-0.357185,-1.33919,-1.25427,0.0161261,0.0530595,0.626123,0.679022,-1.00432,-1.1933,1.61505,1.46488,0.108525,0.0141058,1.21373,1.08141,0.685986,0.669763
2925,0.351842,0.220552,0.462951,0.432539,0.452399,0.399919,0.0120784,-0.0085224,0.155751,0.163618,0.683788,0.763501,0.815584,0.761886,0.536562,0.643115,0.445685,0.452435,0.851921,0.913504,-0.587672,-0.297263,0.432262,0.642484,0.698036,0.779668,-0.0890359,-0.0765705,0.349423,0.404287,-0.168807,-0.366762,0.180623,0.0274214,-1.10494,-1.20256,1.31009,1.18405,0.780727,0.765881
2926,0.88044,0.747358,0.962826,0.931019,0.64928,0.542317,0.141037,0.117857,0.87756,0.885881,0.340414,0.420751,0.422479,0.370548,0.515468,0.545421,0.674217,0.679043,0.284795,0.347912,-0.229019,0.0767499,-1.2248,-1.00993,0.291816,0.36717,-0.32536,-0.206201,1.11459,1.17653,0.64875,0.459773,-0.45651,-0.649814,1.09324,0.990236,0.353708,0.229426,-1.35686,-1.37653
2927,0.889048,0.757664,0.0743577,0.0441146,0.454845,0.350281,0.265355,0.244236,0.246961,0.256066,0.517364,0.595525,0.690197,0.555742,0.601535,0.631147,0.252467,0.255618,0.0353521,0.0980951,-1.87781,-1.5709,0.135133,0.345474,1.29023,1.36666,-0.379219,-0.335831,0.943287,1.00871,-0.42082,-0.605055,-1.17735,-1.32705,-0.738159,-0.84749,-1.19706,-1.32046,-1.26152,-1.28042
2928,0.036665,-0.0940088,0.666295,0.634964,0.580544,0.476492,0.977223,0.957061,0.719692,0.729037,0.165044,0.243206,0.892384,0.740937,0.063459,0.0950493,0.697149,0.700817,0.535613,0.596727,-0.276099,0.0359323,-0.380216,-0.171331,-0.127471,-0.0544496,-2.64744,-2.5998,-0.406221,-0.340098,-0.514911,-0.698124,0.427523,0.275222,-0.550904,-0.653941,-0.425441,-0.550858,-0.134023,-0.153057
2929,0.571682,0.44277,0.440897,0.351116,0.236159,0.132208,0.0104267,-0.0113506,0.278695,0.285602,0.282863,0.362824,0.979245,0.926131,0.674681,0.704823,0.24122,0.246234,0.226769,0.285333,1.0332,1.34499,0.0931791,0.304909,1.46038,1.541,-0.14035,-0.0886706,-0.0606353,0.00221533,2.04394,1.86125,-0.434273,-0.583133,1.15181,1.04349,0.711759,0.57942,-0.121224,-0.145477
2930,0.35596,0.28381,0.0983033,0.0672681,0.796346,0.690179,0.926563,0.904154,0.752638,0.758574,0.683528,0.762454,0.0573584,0.00460406,0.577552,0.608515,0.352948,0.342264,0.390187,0.447097,-1.13033,-0.819709,-1.19738,-0.985492,-0.719245,-0.633699,1.11269,1.1689,1.09172,1.15663,1.08042,0.904326,0.448921,0.305526,0.390045,0.285516,-0.576029,-0.703347,0.335314,0.311956
2931,0.256549,0.12485,0.0684843,0.0370227,0.564766,0.457048,0.547809,0.526538,0.012234,0.0172382,0.00128345,0.0819335,0.291366,0.260193,0.192866,0.222043,0.433273,0.438294,0.0143388,0.0709203,0.316905,0.632172,0.656924,0.866736,-0.0274402,0.058266,-1.07641,-1.01261,1.90774,1.97391,-0.395177,-0.576534,0.818034,0.674054,0.595811,0.493121,1.01394,0.881126,-1.13804,-1.16514
2932,0.436812,0.305375,0.707608,0.676373,0.0115929,-0.0970927,0.971562,0.950799,0.649852,0.656443,0.662453,0.743667,0.61319,0.515782,0.92356,0.95459,0.111098,0.11375,0.92298,0.979511,-0.181466,0.13336,-0.519035,-0.314342,-1.06818,-0.976939,-0.807861,-0.740073,-0.106552,-0.0388285,-0.0728157,-0.256244,0.667662,0.523957,-2.47669,-2.58083,0.648856,0.51929,-1.82944,-1.85056
2933,0.359544,0.203881,0.619729,0.58801,0.976221,0.866239,0.257764,0.237908,0.214541,0.222507,0.741707,0.908929,0.824762,0.771371,0.59222,0.623237,0.216481,0.218386,0.833644,0.883893,-2.04755,-1.73588,-0.0264148,0.140677,0.592523,0.679673,1.91442,1.98748,0.159629,0.22669,-0.730665,-0.831875,-0.140041,-0.2883,-0.167678,-0.27236,0.698845,0.57503,2.06165,2.03863
2934,0.17348,0.102387,0.854371,0.820425,0.667757,0.557114,0.0166001,-0.00522351,0.444355,0.453094,0.995602,1.07419,0.768228,0.712992,0.965259,0.995697,0.844046,0.844773,0.73162,0.788275,0.235686,0.546149,0.438956,0.595696,-0.534384,-0.449263,0.44651,0.516275,1.01904,1.09083,-1.22324,-1.40751,-0.28029,-0.424672,-1.69533,-1.79663,-0.265331,-0.393348,0.772687,0.743277
2935,0.130017,0.000893454,0.49994,0.466243,0.0280678,-0.0810509,0.656782,0.636803,0.948321,0.956993,0.859444,0.935988,0.929725,0.767119,0.8996,0.982492,0.440728,0.439664,0.346826,0.402961,0.340182,0.642361,0.847158,1.05072,0.465446,0.55023,-2.41102,-2.3439,0.835455,0.907494,1.79124,1.59896,0.158706,0.00732314,0.706998,0.614453,0.0171787,-0.0724606,1.77715,1.74932
2936,0.532408,0.403837,0.570416,0.534779,0.538625,0.427179,0.100022,0.0785642,0.990372,0.979508,0.951635,1.02676,0.96301,0.821246,0.880366,0.969286,0.761307,0.760331,0.177913,0.232782,-0.628668,-0.331225,1.02601,1.2363,-0.371979,-0.283439,0.949852,1.01286,0.269316,0.343601,-0.561817,-0.748346,-0.282442,-0.438726,-0.900281,-0.985043,0.371861,0.248427,0.470329,0.438373
2937,0.17468,0.04417,0.433541,0.397478,0.529618,0.418649,0.583184,0.561166,0.994529,1.00202,0.288195,0.36181,0.931949,0.875373,0.923214,0.956081,0.427477,0.426496,0.394255,0.394868,0.8796,1.18248,-0.240242,-0.0386966,-0.415048,-0.327793,-1.12775,-1.06035,0.404045,0.485341,0.677488,0.491265,-0.126711,-0.285692,-0.856608,-0.946034,1.21981,1.09996,0.274162,0.249084
2938,0.0592362,-0.0698711,0.399058,0.260177,0.819885,0.710105,0.749498,0.726007,0.0720257,0.0800474,0.443603,0.498057,0.800606,0.745677,0.029706,0.0637622,0.387361,0.310861,0.500802,0.556955,0.620796,0.915922,0.0931909,0.302278,0.253785,0.253761,0.664531,0.734085,0.169608,0.255326,0.0204045,-0.161068,0.756783,0.602967,-1.96248,-2.05554,0.0226389,-0.104187,-1.67207,-1.69329
2939,0.448986,0.318632,0.159779,0.122876,0.809958,0.701574,0.288711,0.264542,0.290172,0.253692,0.494669,0.634304,0.932538,0.876197,0.0588944,0.0939768,0.1979,0.195226,0.302461,0.356215,-1.40005,-1.10959,-2.87826,-2.66918,0.7424,0.835315,-0.981722,-0.909819,0.878247,0.964175,0.633597,0.453147,0.289943,0.141515,-0.000138481,-0.092377,0.86404,0.730129,0.64857,0.630857
2940,0.390419,0.353764,0.362367,0.41007,0.237286,0.127925,0.864917,0.842422,0.550279,0.427338,0.694646,0.770552,0.0975706,0.0407879,0.340117,0.375009,0.352576,0.350195,0.906223,0.959998,1.00597,1.30035,-2.04753,-1.83736,0.145072,0.234096,-0.129226,-0.0537335,-0.361441,-0.274309,0.243589,0.0689248,0.48624,0.340323,-1.57185,-1.66209,-1.32937,-1.45688,-0.968146,-0.985274
2941,0.459242,0.388895,0.735913,0.697265,0.602823,0.495245,0.570989,0.549909,0.594662,0.600983,0.173995,0.250479,0.227303,0.124769,0.224,0.258461,0.17617,0.172598,0.320887,0.374303,0.286884,0.588081,1.49983,1.70643,-0.783188,-0.690698,-0.127346,-0.128446,0.309683,0.390126,-2.48668,-2.66891,1.7511,1.60149,-0.226505,-0.374288,-0.895102,-1.02939,-2.12816,-2.14342
2942,0.556029,0.424027,0.271148,0.233902,0.466782,0.423126,0.574807,0.621132,0.684402,0.689506,0.829172,0.906978,0.266376,0.208751,0.436559,0.469872,0.293544,0.241758,0.791907,0.84326,-0.0567851,0.246125,-1.64438,-1.42957,0.569422,0.658629,-0.274054,-0.203159,-0.477415,-0.40303,-0.145458,-0.325066,0.751857,0.599684,1.00375,0.913514,-1.77338,-1.90317,0.565769,0.553637
2943,0.0122133,-0.122323,0.555906,0.520345,0.459524,0.351006,0.721864,0.692354,0.268373,0.275435,0.48415,0.564228,0.121083,0.0638141,0.0248603,0.058182,0.315052,0.310918,0.215971,0.267566,-1.06993,-0.759775,-0.284807,-0.0741711,0.68475,0.779453,0.668472,0.745695,-0.451564,-0.38192,-1.46205,-1.63435,1.64845,1.48834,0.167372,0.0797128,1.10663,0.970864,1.86336,1.84966
2944,0.692129,0.558884,0.243789,0.209755,0.0676307,-0.0384734,0.9026,0.763577,0.646819,0.6531,0.93521,1.01755,0.543514,0.485584,0.157111,0.189204,0.617159,0.620554,0.66038,0.711122,0.357362,0.675134,-0.128388,0.0803937,-0.400738,-0.301652,-0.196849,-0.125751,0.4154,0.482216,0.282933,0.112711,0.248682,0.0837757,-1.13117,-1.21615,-0.745246,-0.884973,1.24917,1.23716
2945,0.44907,0.315222,0.16281,0.126424,0.309622,0.201581,0.855629,0.8348,0.00401779,0.00882775,0.520374,0.601643,0.293485,0.234762,0.939002,0.972078,0.935586,0.93019,0.795774,0.84818,0.595857,0.909949,-0.179981,0.0356279,2.60638,2.70167,-0.542629,-0.468972,-0.344554,-0.280707,0.000515103,-0.164203,0.403565,0.23681,-0.541297,-0.625553,-0.593435,-0.64322,-2.32214,-2.33318
2946,0.884727,0.753238,0.551022,0.516406,0.183616,0.0753521,0.00837632,-0.0137386,0.530625,0.537853,0.309265,0.392455,0.38955,0.328702,0.838865,0.899141,0.206629,0.199,0.503237,0.583714,-0.477664,-0.082407,1.08216,1.29906,0.544751,0.639026,-0.41857,-0.350239,-0.582684,-0.524618,0.675315,0.510743,1.60844,1.43768,-1.31133,-1.398,-0.261887,-0.401467,0.242829,0.228081
2947,0.752962,0.619959,0.120004,0.0832397,0.607097,0.49952,0.785422,0.766268,0.338703,0.345795,0.663793,0.747743,0.183054,0.12358,0.794038,0.826204,0.0726388,0.0665041,0.35634,0.319249,-1.38885,-1.07476,-0.665192,-0.446857,-0.884108,-0.797028,-0.696141,-0.632714,-1.73601,-1.68571,-1.63374,-1.7909,-1.65333,-1.82375,-0.668654,-0.760742,0.217178,0.0735118,0.648081,0.640143
2948,0.417731,0.284807,0.256936,0.221582,0.693486,0.585786,0.24224,0.222701,0.981211,0.990696,0.407894,0.540129,0.615145,0.555231,0.0233088,0.0546797,0.419018,0.340906,0.00061414,0.0547836,0.132424,0.43894,2.15449,2.37962,1.6847,1.77854,-0.296528,-0.238654,-0.49127,-0.436605,-0.680634,-0.841072,1.98295,1.80901,-0.462662,-0.553138,-1.0061,-1.14335,-1.09953,-1.11521
2949,0.888306,0.756698,0.854651,0.817887,0.316628,0.206455,0.595343,0.579654,0.0661472,0.075302,0.204654,0.332515,0.0560778,-0.00220284,0.632247,0.664454,0.621959,0.615309,0.401119,0.454242,0.366541,0.673754,-0.0853806,0.143778,-1.47807,-1.37777,-0.38874,-0.334444,-0.75939,-0.711339,-0.258401,-0.432998,-0.11669,-0.288219,1.52258,1.42325,0.0674749,-0.0748687,-0.894672,-0.912529
2950,0.474819,0.341335,0.271175,0.236854,0.573035,0.461935,0.957945,0.936607,0.620333,0.629796,0.0429164,0.124901,0.0347889,0.0625246,0.647614,0.680274,0.742647,0.734477,0.478388,0.589409,-0.421339,-0.117369,0.340366,0.574345,-0.419196,-0.317287,-0.234624,-0.183687,0.322769,0.367365,0.125036,-0.0249233,-0.697764,-0.873172,0.53125,0.436927,0.242403,0.102924,0.426364,0.413855
2951,0.512768,0.377624,0.702792,0.666424,0.342759,0.296368,0.289727,0.269039,0.54058,0.549625,0.252222,0.333389,0.186241,0.127252,0.409592,0.442459,0.661454,0.654113,0.636644,0.724577,-0.349084,-0.05027,-0.944204,-0.716056,-1.49201,-1.38314,1.07126,1.11899,-0.782544,-0.733334,0.543589,0.383151,1.65307,1.47494,-0.959652,-1.05498,1.46002,1.3265,-0.479013,-0.483937
2952,0.9502,0.815639,0.730481,0.694874,0.239999,0.130801,0.856089,0.836722,0.767722,0.77508,0.203562,0.2862,0.516257,0.45968,0.375182,0.394494,0.159737,0.15436,0.80503,0.859744,0.200951,0.492688,0.729619,0.952327,0.0776916,0.180046,-0.487742,-0.444146,-0.365802,-0.314718,-1.5109,-1.66559,1.32421,1.17838,-0.637095,-0.737778,-1.57964,-1.7147,0.292139,0.292417
2953,0.847724,0.616537,0.278452,0.241656,0.725609,0.613815,0.400745,0.379717,0.718221,0.72531,0.832248,0.916882,0.597445,0.538673,0.208093,0.346529,0.688974,0.683953,0.333969,0.38873,-0.377437,-0.0815861,-0.83672,-0.619954,1.17423,1.26948,0.0836823,0.20348,-0.177089,-0.166933,-1.23632,-1.31414,1.0642,0.881815,0.928829,0.834415,1.62992,1.50315,-1.06916,-1.06469
2954,0.551611,0.417434,0.92575,0.88637,0.117701,0.00487848,0.315314,0.196773,0.974489,0.982161,0.394468,0.480853,0.102692,0.04287,0.265698,0.298565,0.878969,0.874448,0.3988,0.53988,-0.0151446,0.277855,1.69003,1.90551,1.29032,1.39031,0.806939,0.851106,-0.0706637,-0.019148,-0.79877,-0.962683,-1.32546,-1.50272,1.36845,1.27194,-1.19801,-1.32435,1.54395,1.54732
2955,0.122612,-0.0133284,0.447558,0.408933,0.2513,0.0939795,0.0351516,0.0138282,0.715328,0.646878,0.479537,0.528558,0.0612609,0.077744,0.361494,0.394295,0.429155,0.511206,0.635402,0.691031,1.8341,2.12886,-1.48822,-1.27123,-1.28829,-1.18568,0.468367,0.507884,0.374949,0.428623,-2.38351,-2.5486,1.3184,1.13347,0.204207,0.103796,-0.192178,-0.335753,0.00874103,0.00831205
2956,0.208501,0.0727334,0.810344,0.773667,0.208927,0.18308,0.703222,0.679874,0.303017,0.311595,0.497787,0.576264,0.173379,0.112618,0.726144,0.75718,0.154814,0.147964,0.278181,0.335245,-0.765733,-0.476655,-0.769676,-0.549157,1.4358,1.5376,-0.756679,-0.763894,-0.399338,-0.347952,-0.248355,-0.411742,0.446589,0.256726,0.808531,0.710258,0.779186,0.652847,0.183989,0.204013
2957,0.99452,0.85816,0.376782,0.3405,0.279191,0.272181,0.0441223,0.0226163,0.824565,0.835114,0.424315,0.623969,0.660221,0.599359,0.797007,0.828768,0.123748,0.109676,0.799074,0.854833,-0.111094,0.0951046,-1.49644,-1.28117,-0.216748,-0.114311,-2.07607,-2.03567,-0.590881,-0.546765,1.40143,1.24348,0.306133,0.120354,-0.74186,-0.84354,-1.41928,-1.54914,0.39858,0.399713
2958,0.74441,0.600259,0.760928,0.725266,0.475458,0.361282,0.110656,0.033592,0.574541,0.583221,0.583803,0.671674,0.373886,0.367906,0.313238,0.342599,0.077424,0.0713876,0.286005,0.343924,0.377787,0.666865,0.606518,0.826739,0.862741,0.960923,0.685173,0.725498,0.735618,0.777654,-0.944882,-1.10383,-0.162139,-0.341098,-1.97246,-2.07536,-2.18563,-2.31297,1.72703,1.7261
2959,0.477145,0.342357,0.815796,0.779069,0.812836,0.698445,0.0666502,0.0445676,0.777937,0.788443,0.146742,0.235645,0.198596,0.136453,0.23261,0.261746,0.874372,0.868293,0.312333,0.370216,0.699561,0.994557,-0.223063,0.00173802,-0.31973,-0.228208,0.917939,0.953988,0.641185,0.685554,-0.763085,-0.879064,0.724332,0.547561,-0.876889,-0.978563,-0.735739,-0.86776,-0.997485,-0.994913
2960,0.620492,0.487173,0.168042,0.133363,0.832825,0.620885,0.525183,0.502253,0.707217,0.717803,0.871061,0.961507,0.507449,0.460535,0.891891,0.921771,0.814848,0.808524,0.753691,0.809511,-0.765243,-0.469418,-1.919,-1.69584,0.226225,0.323751,-0.627034,-0.592415,-0.518155,-0.475535,-0.498822,-0.654302,0.0454101,-0.127039,-0.417661,-0.525248,-2.97472,-3.10125,1.14652,1.15456
2961,0.330148,0.197758,0.76119,0.724212,0.657671,0.543324,0.0223943,-0.000675952,0.0587455,0.0686091,0.0362007,0.12827,0.844884,0.784617,0.759774,0.789983,0.159967,0.152699,0.179892,0.233817,-2.89972,-2.60366,-0.830606,-0.600952,1.097,1.20096,0.156055,0.185872,0.521556,0.557932,0.314201,0.156984,0.0189887,-0.15581,-0.362346,-0.472261,-0.516914,-0.645488,0.700091,0.708705
2962,0.328066,0.287804,0.91059,0.873217,0.42637,0.310193,0.435447,0.413345,0.13705,0.147359,0.975356,1.06974,0.570778,0.509025,0.869908,0.900691,0.15962,0.152752,0.946942,0.998267,2.239,2.53507,-0.430883,-0.201162,-0.179852,-0.0799304,0.261341,0.381351,0.0259306,0.053805,0.538754,0.386037,-0.982402,-1.15761,0.882525,0.774959,0.734146,0.609353,-0.698918,-0.693911
2963,0.508378,0.377851,0.492701,0.42359,0.465815,0.345965,0.0522894,0.0309994,0.558202,0.569699,0.678233,0.898107,0.968946,0.905503,0.227576,0.25974,0.937695,0.929764,0.422627,0.472279,-2.03028,-1.73296,-1.21549,-0.98207,0.801115,0.903388,0.549371,0.57683,0.0955242,0.120914,0.334968,0.186094,-0.652937,-0.835863,-0.0757628,-0.181305,0.464534,0.339869,-3.23783,-3.23576
2964,0.349784,0.262395,0.0113373,-0.0260362,0.495448,0.381737,0.885501,0.862594,0.275383,0.287279,0.57529,0.726479,0.37423,0.308904,0.432125,0.466857,0.696914,0.691253,0.457827,0.508996,-1.09542,-0.793918,0.127886,0.265902,-0.724022,-0.62334,-1.14365,-1.11388,0.823526,0.846589,-1.15857,-1.30997,0.682037,0.505783,-0.0148796,-0.128318,-0.305932,-0.423955,-0.567738,-0.568145
2965,0.370141,0.146938,0.144257,0.132875,0.741756,0.627059,0.872578,0.885781,0.641064,0.654945,0.460471,0.55485,0.664354,0.600061,0.09652,0.13012,0.226402,0.221736,0.85869,0.908455,-0.758754,-0.452197,1.27988,1.51387,-2.48491,-2.38466,-1.09775,-1.07256,0.589169,0.616574,-0.405309,-0.560383,0.0377473,-0.138355,1.16752,1.05819,1.21475,1.09875,-1.29333,-1.29981
2966,0.161954,0.0314818,0.385055,0.291787,0.593331,0.480067,0.931722,0.908968,0.548644,0.505613,0.758606,0.850472,0.400377,0.361625,0.140415,0.175509,0.35753,0.351106,0.678537,0.731717,0.997284,1.30598,-0.326591,-0.0904661,0.601528,0.704793,0.446415,0.467008,-0.424054,-0.393012,1.28691,1.12729,0.301553,0.121222,-0.719293,-0.826274,-0.407088,-0.528752,-0.425991,-0.430935
2967,0.709278,0.577879,0.409509,0.450699,0.0106513,-0.103637,0.408822,0.386031,0.340567,0.35628,0.283524,0.375509,0.188657,0.123188,0.86154,0.897831,0.241325,0.233935,0.50786,0.55498,0.023449,0.332392,0.183621,0.442822,0.986151,1.08783,-1.25415,-1.24067,0.188047,0.224102,-0.671075,-0.830316,-0.417837,-0.598946,-0.448483,-0.554592,0.576276,0.462734,-1.55716,-1.56072
2968,0.24982,0.116826,0.646984,0.609611,0.205607,0.109736,0.786537,0.764344,0.465303,0.57181,0.150687,0.241592,0.514567,0.403764,0.169951,0.204921,0.880743,0.871168,0.0979185,0.143508,-0.144638,0.170282,0.736952,0.97611,-1.47128,-1.37513,-0.898582,-0.892273,1.36965,1.41027,-0.0955398,-0.262788,-0.126036,-0.30665,-1.35884,-1.46389,1.20228,1.09405,-0.441977,-0.441953
2969,0.850096,0.717578,0.505082,0.465904,0.559191,0.323109,0.243968,0.220776,0.771397,0.787339,0.796055,0.888018,0.751248,0.68434,0.847576,0.8811,0.73109,0.670745,0.340275,0.386601,0.117902,0.436164,0.203375,0.442677,-1.35571,-1.2543,0.626626,0.630956,-0.93262,-0.896489,-0.0540583,-0.217764,0.551646,0.368524,1.41535,1.31701,-0.362253,-0.470857,0.681777,0.676814
2970,0.12052,-0.0116669,0.687734,0.651668,0.6507,0.536481,0.906471,0.881899,0.650675,0.665493,0.175406,0.267846,0.138082,0.0731961,0.479551,0.514314,0.477365,0.470321,0.863104,0.911034,-0.838513,-0.522736,1.57294,1.81304,-1.56668,-1.46918,0.487253,0.489051,0.321646,0.352614,0.217754,0.0565633,-0.944097,-1.13112,1.63997,1.54151,-0.864041,-0.972147,-1.27454,-1.28078
2971,0.541489,0.411424,0.875114,0.837432,0.470975,0.268581,0.856143,0.833798,0.206785,0.222057,0.150537,0.332947,0.481787,0.415178,0.568869,0.605197,0.765962,0.683486,0.212842,0.260038,0.0486627,0.372379,-1.68058,-1.43597,0.388014,0.484706,-1.64635,-1.64522,-0.516441,-0.402136,-0.639965,-0.807824,1.00836,0.814035,0.134828,0.033523,0.0379964,-0.0770996,0.0617738,0.0603363
2972,0.41184,0.282868,0.117779,0.0810264,0.114564,0.000680097,0.810758,0.785697,0.780748,0.79635,0.296035,0.398049,0.258639,0.194017,0.0764735,0.11412,0.90197,0.89665,0.304764,0.351509,0.271753,0.591267,0.637497,0.882485,-0.563238,-0.470906,-0.675266,-0.681288,-1.18973,-1.15688,0.893555,0.72341,-0.227544,-0.418889,-0.779499,-0.875776,-2.33375,-2.44409,-1.68584,-1.69502
2973,0.703912,0.501919,0.668871,0.632786,0.352603,0.185161,0.442632,0.418888,0.270642,0.288152,0.370413,0.463151,0.684904,0.620649,0.177356,0.215665,0.698647,0.693845,0.800811,0.845412,1.14106,1.45322,-0.633576,-0.385219,0.159817,0.251394,1.1057,1.09668,0.90146,0.928966,-0.196314,-0.372509,-0.26035,-0.447661,-1.28409,-1.38688,0.75727,0.639603,1.23966,1.23321
2974,0.850142,0.720971,0.976303,0.939245,0.438953,0.369642,0.853131,0.82826,0.828668,0.847422,0.791134,0.882507,0.710511,0.729166,0.962618,0.998539,0.99446,0.989976,0.404667,0.450135,0.839977,1.15625,-1.89765,-1.65292,0.561538,0.651687,-0.864071,-0.86791,0.884012,0.918538,0.045662,-0.128261,0.69539,0.505228,0.484193,0.385855,-0.572805,-0.691905,-1.10153,-1.09979
2975,0.316189,0.184714,0.485981,0.475954,0.525937,0.554123,0.463771,0.441539,0.0731362,0.0898209,0.197644,0.287626,0.900661,0.837683,0.391141,0.427523,0.608135,0.60551,0.535775,0.582197,-0.209977,0.105026,-2.27766,-2.03459,-1.23438,-1.14141,0.722019,0.719316,1.08852,1.03993,-0.617484,-0.844382,-1.88097,-2.07352,-0.319154,-0.417378,0.155181,0.0325808,-0.62903,-0.626871
2976,0.336995,0.205152,0.0497212,0.0126637,0.854144,0.738604,0.608441,0.644403,0.637397,0.652772,0.403839,0.496114,0.331,0.265484,0.0402483,0.0754018,0.79494,0.791695,0.0203112,0.0668457,0.160754,0.462509,0.637496,0.882748,-0.337661,-0.249536,-0.86846,-0.877029,1.12454,1.16133,-1.38811,-1.5605,0.689237,0.497587,1.08901,0.986501,0.306947,0.179883,-0.775502,-0.769606
2977,0.66431,0.532728,0.204049,0.16671,0.639344,0.501588,0.86684,0.847267,0.647728,0.601807,0.392939,0.483967,0.750733,0.687254,0.68828,0.724889,0.613806,0.520708,0.379459,0.370871,0.502147,0.819993,1.58361,1.8355,0.0256172,0.117931,-0.840875,-0.851127,0.220005,0.26159,-1.14456,-1.31625,-0.82044,-1.01835,-0.977337,-1.08295,0.0956894,-0.026901,1.10256,1.11267
2978,0.4198,0.289066,0.0708894,0.0328677,0.381134,0.264573,0.097888,0.077862,0.536931,0.550841,0.898477,0.991576,0.676978,0.613469,0.828327,0.866287,0.252785,0.249722,0.626772,0.674896,1.60267,1.9275,0.43622,0.684609,-0.0784635,0.0114222,0.999342,0.991287,-1.15339,-1.11766,1.46748,1.29092,-1.19988,-1.40067,1.42183,1.31005,1.23482,1.11892,-1.47052,-1.45643
2979,0.478412,0.349319,0.782673,0.743289,0.657674,0.457319,0.561285,0.540395,0.484501,0.499876,0.300086,0.390942,0.306626,0.305737,0.222119,0.260288,0.898373,0.896669,0.0468706,0.0946849,-0.314071,0.0130919,-0.0571883,0.198202,1.47783,1.57461,0.413022,0.33254,0.607837,0.649833,0.361209,0.181313,-0.992889,-1.18784,0.0758643,-0.0305593,-1.3273,-1.43754,-0.283086,-0.265204
2980,0.933865,0.807002,0.640949,0.599583,0.766744,0.650066,0.0389665,0.0174575,0.82956,0.84661,0.575394,0.665939,0.0632119,-0.001995,0.327798,0.366625,0.392099,0.391557,0.508649,0.558769,1.21449,1.54246,0.383086,0.722304,-1.56498,-1.462,-0.325744,-0.326207,0.0509049,0.0859408,-0.359087,-0.545115,0.16625,-0.0323655,1.77644,1.66688,-0.434145,-0.542493,-0.00743495,0.0128866
2981,0.074403,-0.0508995,0.747286,0.708345,0.724545,0.610184,0.954913,0.932962,0.544037,0.644803,0.147081,0.240218,0.331243,0.264422,0.8345,0.873629,0.451515,0.397705,0.11485,0.163492,-2.20335,-1.87557,0.992177,1.24641,1.06771,1.16289,-2.29475,-2.29079,0.992759,1.02717,2.44549,2.25818,-0.910734,-1.11114,-0.804162,-0.908641,1.54185,1.43881,0.712555,0.730885
2982,0.713063,0.590307,0.408582,0.368307,0.667972,0.570303,0.0317511,0.0126163,0.427142,0.442996,0.0435542,0.136625,0.0128985,-0.0561449,0.641838,0.681509,0.403141,0.403854,0.62281,0.671994,-0.715624,-0.391939,0.747909,1.0025,0.885395,0.896033,0.716232,0.717369,-1.03623,-1.00724,0.35961,0.178097,0.445536,0.244622,-1.01373,-1.11369,0.449301,0.347861,-0.861273,-0.836761
2983,0.0236364,-0.0964197,0.627039,0.585638,0.6471,0.530422,0.456914,0.436878,0.348973,0.369777,0.74761,0.843148,0.471274,0.399735,0.945756,0.988096,0.649382,0.64993,0.410338,0.450208,-0.718632,-0.401219,0.131254,0.392844,0.539265,0.629173,0.359797,0.357561,-0.455941,-0.421193,1.0721,0.897286,-0.277934,-0.475545,0.645807,0.55079,0.50469,0.403601,-0.320246,-0.303031
2984,0.520072,0.399986,0.340054,0.299977,0.804596,0.687063,0.214788,0.259003,0.272644,0.296559,0.559698,0.748817,0.471336,0.398016,0.321747,0.361717,0.0118545,0.0142188,0.176771,0.228421,-0.0610099,0.262533,2.31826,2.58019,-0.211552,-0.0274709,0.782986,0.781955,-0.963287,-0.92532,1.56417,1.38869,0.39221,0.199629,0.402305,0.2993,0.199587,0.102854,-0.897831,-0.884504
2985,0.255918,0.136484,0.512428,0.561207,0.640882,0.493227,0.099699,0.0811285,0.266601,0.22334,0.559496,0.654486,0.219225,0.147193,0.702942,0.743953,0.854862,0.859485,0.616263,0.667716,1.60069,1.92992,0.468151,0.73713,-0.770266,-0.684115,0.48767,0.484205,1.98474,2.02166,-0.562417,-0.736294,0.465043,0.277639,-1.86261,-1.96883,1.12288,1.03042,0.026374,0.0435563
2986,0.628398,0.508787,0.861634,0.822436,0.493981,0.299391,0.548654,0.529358,0.134268,0.150122,0.913226,1.00977,0.342168,0.297694,0.632748,0.612995,0.213966,0.219059,0.162912,0.216408,-0.925807,-0.597785,0.185747,0.448115,-1.05455,-0.973565,0.537124,0.542591,-1.0239,-0.980463,-0.0528045,-0.229199,-1.97405,-2.15569,0.200968,0.102331,0.259315,0.174178,1.19791,1.21744
2987,0.337557,0.219372,0.639648,0.56782,0.223088,0.105555,0.379207,0.361754,0.903239,0.91917,0.714683,0.811005,0.520298,0.448195,0.377507,0.482038,0.226824,0.234027,0.562424,0.579166,1.73438,2.05622,0.474809,0.74372,-0.578028,-0.498648,-0.0229924,0.00217247,0.826143,0.8663,2.35851,2.18663,0.0461559,-0.131812,-0.104252,-0.211001,-1.62915,-1.71248,-0.388857,-0.366344
2988,0.6196,0.501068,0.473208,0.313203,0.350246,0.231766,0.465482,0.449887,0.338849,0.355263,0.301712,0.4,0.240075,0.167278,0.313221,0.35108,0.508785,0.515205,0.887714,0.941925,-0.771036,-0.442075,0.444433,0.715649,0.242376,0.31675,-0.549799,-0.538246,0.885777,0.933409,0.0367334,-0.133063,0.158603,-0.0235147,-1.66218,-1.7648,-0.0495716,-0.128007,-0.723448,-0.707444
2989,0.100957,-0.019573,0.098719,0.058587,0.176394,0.0599274,0.0373923,0.0227246,0.202386,0.305728,0.527773,0.628684,0.949984,0.87537,0.849651,0.888852,0.0026847,0.0100926,0.877802,0.931684,1.51561,1.83995,-0.463063,-0.1865,0.429873,0.49988,-0.353647,-0.342503,-0.100922,-0.060238,1.51159,1.33658,-0.831552,-1.00931,0.307864,0.198361,-0.826839,-0.907049,0.145684,0.112693
2990,0.804087,0.68112,0.772724,0.733376,0.801441,0.68326,0.831339,0.816875,0.239509,0.256192,0.448701,0.550455,0.797947,0.720878,0.672546,0.662202,0.0445601,0.0535648,0.404709,0.550145,2.12476,2.44349,0.130477,0.399262,-1.29337,-1.2297,-0.469477,-0.454223,0.936412,0.973229,-0.860751,-1.03294,0.304223,0.128577,1.24038,1.12767,0.182234,0.0994345,0.909669,0.932829
2991,0.921149,0.797127,0.890927,0.851857,0.613606,0.495782,0.0877812,0.0738019,0.499509,0.519429,0.836617,0.939787,0.300035,0.225075,0.388861,0.435553,0.831336,0.840722,0.113948,0.168606,-0.481328,-0.162021,-0.173867,0.0930904,-0.518247,-0.360665,0.559494,0.572451,-0.737619,-0.695969,0.419775,0.25276,0.0482088,-0.129843,0.0771448,-0.0404688,-0.838692,-0.916998,-0.630189,-0.606183
2992,0.240061,0.115885,0.0180788,-0.0216581,0.810659,0.691108,0.548348,0.536335,0.768347,0.782666,0.20536,0.309872,0.588118,0.511621,0.168857,0.208903,0.439693,0.470579,0.966622,1.02354,0.553327,0.868829,-0.0794473,0.185596,0.4485,0.508375,-2.35356,-2.34611,-0.133924,-0.0949859,0.714036,0.541999,-0.546025,-0.727319,1.85296,1.73226,-1.18756,-1.26493,-0.68515,-0.659403
2993,0.822065,0.697281,0.139173,0.164106,0.786025,0.73361,0.46212,0.448141,0.416177,0.429149,0.606549,0.709502,0.210533,0.135658,0.957508,0.996714,0.0897203,0.100436,0.795411,0.853363,-1.61509,-1.29587,0.52815,0.787443,0.941101,0.997592,0.402879,0.415067,0.00695272,0.0467539,1.80996,1.64261,-0.459851,-0.676375,0.565542,0.436401,-0.611033,-0.696361,0.758031,0.789801
2994,0.232574,0.106633,0.390997,0.34987,0.89404,0.776112,0.0711131,0.0563673,0.718108,0.715906,0.50294,0.605909,0.224486,0.148606,0.268779,0.309676,0.361077,0.444814,0.384873,0.506082,-1.65459,-1.33511,0.00164727,0.254009,-1.52892,-1.46536,0.130919,0.148374,-0.53292,-0.485284,1.51818,1.35071,-0.444365,-0.62543,0.637939,0.505655,3.06679,2.97589,-0.0418863,-0.0173423
2995,0.0528374,-0.0709125,0.201675,0.253574,0.294635,0.176776,0.11455,0.0998087,0.990668,1.00266,0.720665,0.824624,0.546634,0.470497,0.2629,0.256123,0.777784,0.789191,0.101844,0.158802,-1.44676,-1.13184,1.48443,1.73372,-0.142937,-0.0872811,-0.601345,-0.58747,-0.385817,-0.343544,0.794353,0.56836,0.725998,0.543146,1.38986,1.1733,0.778448,0.695621,1.15053,1.17388
2996,0.346943,0.221313,0.198613,0.157277,0.155631,0.0400767,0.668127,0.652387,0.288424,0.302235,0.56538,0.583459,0.627134,0.549489,0.252314,0.20257,0.49029,0.50004,0.856441,0.913867,-2.79849,-2.48719,1.06462,1.30922,-0.178984,-0.200573,-1.33258,-1.32332,-1.73942,-1.69235,-0.0465162,-0.213986,-0.696986,-0.878793,1.96657,1.84094,-1.19957,-1.28654,1.48662,1.51153
2997,0.242316,0.118711,0.46955,0.428313,0.361578,0.24689,0.367908,0.402216,0.147106,0.160404,0.237912,0.342294,0.321984,0.24348,0.107161,0.149017,0.658146,0.642302,0.355905,0.413208,0.579528,0.886072,-2.49683,-2.25224,-0.363935,-0.313865,-0.757108,-0.746702,0.204787,0.248927,0.144016,-0.0159126,-1.63401,-1.78728,-0.507294,-0.639613,1.04424,0.957054,-1.03136,-1.01202
2998,0.77505,0.65005,0.384497,0.344982,0.57562,0.453703,0.164942,0.152045,0.737986,0.750372,0.346294,0.451336,0.300877,0.252036,0.0545669,0.0954636,0.776363,0.784563,0.681119,0.736943,-0.538134,-0.227586,-1.59565,-1.34479,-0.128104,-0.0829161,-1.39918,-1.38271,1.4393,1.48243,-0.273539,-0.432245,-2.51395,-2.69576,-0.145861,-0.177157,1.1445,1.05969,0.570049,0.59186
2999,0.887102,0.740096,0.895695,0.857421,0.77607,0.660516,0.310563,0.297089,0.188928,0.201865,0.247827,0.353445,0.377362,0.260593,0.685851,0.725686,0.228289,0.235267,0.62895,0.635637,0.0595623,0.375952,-0.346139,-0.0960049,-0.661683,-0.618341,1.80306,1.82101,0.209168,0.258548,0.244454,0.0899093,0.307237,0.130283,0.358553,0.285299,0.973774,0.88212,-1.02457,-1.00831
3000,0.957978,0.830143,0.543646,0.503239,0.679798,0.616681,0.198192,0.184626,0.764961,0.776158,0.578524,0.683554,0.345736,0.269149,0.5471,0.620472,0.491071,0.469133,0.562296,0.534331,-0.0323903,0.222595,-0.638908,-0.385019,0.758575,0.805994,-0.0344831,0.0538122,1.82741,1.87209,0.977465,0.82295,-1.66125,-1.8414,0.877397,0.747756,0.0107945,-0.0862587,1.29051,1.30255
3001,0.0714711,-0.0539659,0.443047,0.405548,0.703141,0.572846,0.369191,0.354761,0.514976,0.623209,0.55916,0.665383,0.16582,0.172448,0.474869,0.515257,0.697062,0.702999,0.3772,0.433025,-0.255507,0.0692367,1.62198,1.87012,-0.801092,-0.750758,-1.73133,-1.71338,-1.28675,-1.24558,0.25649,0.0965212,1.26544,1.08712,0.986306,0.864008,0.815795,0.714774,0.546172,0.555921
3002,0.946092,0.821695,0.564159,0.528704,0.645694,0.529011,0.190914,0.177094,0.457297,0.47026,0.0750075,0.180664,0.153982,0.0757465,0.632988,0.672655,0.4625,0.469161,0.142285,0.197346,-0.0818997,0.242771,-1.19528,-0.943385,2.11372,2.15944,-0.930216,-0.918965,2.09137,2.12743,1.42997,1.27505,-1.36151,-1.54239,-1.17675,-1.30195,-0.00699475,-0.111272,-1.26869,-1.25874
3003,0.964646,0.842133,0.278866,0.243043,0.0755441,-0.039722,0.940683,0.925555,0.768039,0.782277,0.446695,0.550222,0.299978,0.247381,0.446822,0.5706,0.958885,0.964904,0.495881,0.551228,1.48028,1.80274,-0.530984,-0.280219,0.12861,0.177517,-1.46832,-1.45938,1.20007,1.24212,1.21986,1.05941,-0.80532,-0.988241,0.932852,0.801683,0.467915,0.363707,-0.442803,-0.435783
3004,0.497419,0.376312,0.914805,0.878337,0.0676004,-0.0482525,0.286218,0.273234,0.366018,0.378199,0.308372,0.503561,0.499768,0.419015,0.42862,0.468546,0.699634,0.626497,0.252409,0.305917,0.0765911,0.398836,-1.07837,-0.829859,0.911134,0.960225,-2.00669,-1.9998,1.69865,1.73766,-0.540399,-0.695359,0.959232,0.782913,-0.0338603,-0.170637,-0.470664,-0.575886,-0.587102,-0.578518
3005,0.708788,0.581496,0.0764357,0.041469,0.8858,0.772529,0.95101,0.939279,0.762285,0.775921,0.354334,0.4569,0.423387,0.270742,0.0195521,0.0613272,0.279091,0.28809,0.471722,0.523296,-0.169422,0.148421,-0.688644,-0.444376,-0.0811291,-0.0279152,0.310975,0.311608,-0.593612,-0.554922,2.64102,2.48935,-1.23992,-1.42211,1.57591,1.4335,-1.67218,-1.78003,0.307835,0.320038
3006,0.906947,0.786679,0.0236424,-0.013013,0.0448216,-0.0679244,0.630029,0.616472,0.0591989,0.0754923,0.869766,0.974227,0.204184,0.122469,0.997123,1.03912,0.771427,0.778884,0.995202,1.04773,0.393073,0.705416,0.780729,1.0211,-1.60067,-1.55464,1.75859,1.75617,1.68397,1.7162,0.774175,0.627865,-0.0747697,-0.253537,-0.0145226,-0.150348,-0.488838,-0.601747,-0.663136,-0.653093
3007,0.000212477,-0.119233,0.248242,0.209847,0.854026,0.742334,0.798825,0.786606,0.37676,0.471975,0.660401,0.836938,0.520849,0.439667,0.731131,0.772066,0.83679,0.881494,0.61186,0.662416,-0.342709,-0.0367154,-0.400989,-0.15998,0.807533,0.84993,0.231152,0.224686,-1.36264,-1.33575,0.8589,0.719268,0.224538,0.0541623,-0.581657,-0.721965,-0.001552,-0.111351,0.0696514,0.0794137
3008,0.50889,0.344333,0.790333,0.752105,0.0149111,-0.0981199,0.534595,0.523167,0.853254,0.868458,0.594338,0.699649,0.178808,0.0996303,0.938952,0.979183,0.977232,0.984103,0.776888,0.829352,2.19518,2.50104,1.83402,2.07633,-0.428481,-0.386361,0.818688,0.816804,-0.0396216,-0.0113321,1.93266,1.79206,0.316795,0.146335,0.443732,0.300862,-0.463637,-0.581002,-0.891419,-0.879161
3009,0.927345,0.8079,0.659902,0.622972,0.943843,0.832758,0.515031,0.494647,0.331764,0.345444,0.873344,0.978135,0.567455,0.486383,0.150106,0.192506,0.131961,0.139872,0.226218,0.278555,-0.607444,-0.30702,0.778867,1.0185,-1.13554,-1.09367,0.0902294,0.087529,-0.448369,-0.423688,-1.34882,-1.49684,-1.77795,-1.9509,0.970722,0.831929,0.208623,0.0981002,-0.0792118,-0.130414
3010,0.106089,-0.0148207,0.221147,0.185218,0.635227,0.523633,0.475638,0.466127,0.354043,0.368952,0.654904,0.759611,0.397904,0.316704,0.567979,0.609074,0.205376,0.21353,0.156063,0.210223,0.374006,0.677574,0.249367,0.485064,1.80617,1.84224,1.27419,1.26723,1.06674,1.09888,1.31136,1.15997,-0.682984,-0.804546,-0.280373,-0.41485,-1.22478,-1.34126,0.612583,0.618334
3011,0.860525,0.740329,0.757862,0.722453,0.0389027,-0.0708094,0.723635,0.659211,0.0663348,0.0816254,0.972807,1.07972,0.69922,0.584662,0.0820189,0.122906,0.830004,0.839917,0.828969,0.884129,0.0193971,0.319653,-1.05863,-0.819191,-0.598363,-0.557206,-0.403283,-0.409174,0.672696,0.70238,-2.01382,-2.16838,0.517817,0.341805,-0.561188,-0.695808,-1.03482,-1.1487,0.799544,0.805162
3012,0.956182,0.835915,0.474961,0.429076,0.331804,0.220646,0.859657,0.852295,0.751388,0.767543,0.477026,0.5845,0.93296,0.85262,0.349006,0.358434,0.918687,0.928091,0.804347,0.932052,-1.65354,-1.35912,-1.20489,-0.968881,1.63385,1.66877,-0.465973,-0.475481,-0.151216,-0.122385,-0.0124683,-0.175753,-2.14293,-2.31587,0.942094,0.812941,-0.377358,-0.487104,0.552526,0.507199
3013,0.0158273,-0.106178,0.172379,0.1357,0.204174,0.0944178,0.143927,0.135227,0.77617,0.791051,0.352978,0.390394,0.477678,0.396718,0.554826,0.593963,0.667268,0.674386,0.923006,0.979974,-0.959407,-0.664116,-0.936192,-0.705663,-1.78907,-1.74589,1.71075,1.69681,0.0774138,0.111197,0.773579,0.604004,-0.154373,-0.324652,1.01177,0.882195,0.800708,0.691183,0.203396,0.209236
3014,0.942885,0.822093,0.964262,0.927756,0.479612,0.370356,0.465978,0.485162,0.374444,0.386972,0.0878569,0.196287,0.275836,0.19706,0.234018,0.272044,0.679628,0.684408,0.510341,0.568502,-1.32941,-1.03786,0.553978,0.788886,0.670268,0.709527,0.876195,0.857217,0.719698,0.759006,2.03978,1.87413,0.284437,0.107343,-2.23454,-2.36634,-0.267647,-0.370261,0.426278,0.425485
3015,0.430917,0.311236,0.301086,0.262079,0.382635,0.195298,0.843796,0.835096,0.251417,0.265125,0.516593,0.625273,0.944556,0.864932,0.374698,0.413441,0.220029,0.224308,0.542098,0.600407,-1.04229,-0.814612,-0.815451,-0.581359,0.655829,0.694781,-0.661954,-0.67427,-0.255939,-0.219921,0.946142,0.778216,-1.13777,-1.3146,-1.15172,-1.28468,2.12429,2.01904,-1.25594,-1.25147
3016,0.613084,0.491761,0.637468,0.563934,0.132168,0.0202403,0.727042,0.762917,0.423981,0.440212,0.326712,0.436793,0.858556,0.78057,0.823277,0.860424,0.526277,0.530084,0.887217,0.944729,-0.889959,-0.591367,-1.35834,-1.131,-0.685099,-0.650969,0.175356,0.165743,-0.467633,-0.433021,1.07062,0.900731,0.592563,0.411644,1.39413,1.26301,-0.27021,-0.378911,-2.59351,-2.59338
3017,0.5114,0.389159,0.904289,0.865789,0.923189,0.808987,0.613446,0.690737,0.38241,0.42733,0.726626,0.836424,0.0952891,0.0198004,0.462102,0.498286,0.120451,0.124974,0.786613,0.767992,1.58305,1.88249,0.302142,0.537383,0.413963,0.452675,0.678246,0.665491,-2.7426,-2.71064,-0.491243,-0.655327,-2.81907,-3.00336,0.345719,0.215437,1.43235,1.31681,-1.33416,-1.32731
3018,0.207696,0.0844994,0.866396,0.826417,0.962902,0.850395,0.485212,0.618557,0.398575,0.414448,0.675848,0.784242,0.143417,0.0958258,0.78547,0.819753,0.159962,0.163419,0.531938,0.591254,0.436446,0.739237,-1.07852,-0.849239,0.785077,0.820141,-0.991149,-1.01092,1.24195,1.27885,-0.497318,-0.656519,-1.13172,-1.30894,0.983984,0.852693,-0.144301,-0.263997,-1.47631,-1.47005
3019,0.798616,0.675705,0.367194,0.328135,0.647989,0.447476,0.555077,0.546378,0.948543,0.963159,0.239197,0.348213,0.246339,0.171851,0.723727,0.760793,0.848648,0.850637,0.663216,0.723316,0.401124,0.700002,-0.846625,-0.617449,-0.152021,-0.0594197,-0.0290817,-0.0469888,-0.0870509,-0.0544331,-0.286941,-0.442157,-0.0503247,-0.220991,-0.327,-0.458687,-0.208143,-0.330773,0.924345,0.937462
3020,0.858854,0.735958,0.880988,0.840574,0.154936,0.0445567,0.987494,0.979794,0.504023,0.519724,0.630277,0.737545,0.0590567,-0.0171322,0.592617,0.701832,0.593827,0.506732,0.576654,0.594539,-0.314707,-0.0122659,-1.51858,-1.28868,-0.974045,-0.938981,0.641073,0.622395,0.00276913,0.0433358,0.56435,0.41423,-0.733137,-0.911514,-1.27455,-1.39971,0.561025,0.438829,1.59404,1.60988
3021,0.337226,0.215317,0.850396,0.847029,0.439532,0.271403,0.6214,0.526264,0.700158,0.715018,0.204638,0.311824,0.839302,0.763542,0.625221,0.642872,0.162494,0.162827,0.406489,0.465761,-0.437873,-0.12974,-0.960867,-0.735192,-1.04506,-1.01473,0.62131,0.602848,0.906911,0.952799,1.13668,0.981759,0.54335,0.364716,0.584602,0.451984,0.79468,0.678133,-0.981908,-0.959214
3022,0.95753,0.835505,0.937222,0.853483,0.623006,0.49825,0.0808084,0.0727335,0.683801,0.701099,0.0126862,0.117488,0.870072,0.796053,0.549628,0.583912,0.950649,0.949983,0.014424,0.0757684,-0.132988,0.169712,0.792199,1.02609,-0.241399,-0.215711,0.860119,0.844951,-0.712688,-0.67034,1.18514,1.02678,0.65063,0.473013,0.750431,0.614122,-0.75705,-0.871753,-0.234429,-0.210776
3023,0.105726,-0.0161675,0.901727,0.859938,0.835476,0.725097,0.100178,0.0906507,0.974496,0.993052,0.392095,0.496377,0.0200556,-0.0540621,0.153975,0.187405,0.349161,0.350182,0.344466,0.404647,-0.212466,0.083536,-1.28605,-1.05108,1.03255,1.05638,0.34769,0.331494,-1.57188,-1.52549,-0.487937,-0.64972,0.18218,0.0115617,-0.080833,-0.219678,-1.51371,-1.63558,0.978247,1.00997
3024,0.630424,0.510639,0.459942,0.416565,0.411727,0.300598,0.620059,0.6087,0.898736,0.918024,0.304897,0.322628,0.728206,0.654029,0.727682,0.761022,0.599521,0.553201,0.0929663,0.15483,-1.78843,-1.48846,-0.593494,-0.358876,0.912733,0.936426,-1.16245,-1.18744,1.65929,1.71122,-0.829509,-0.94838,-1.03003,-1.20597,-1.54318,-1.6826,0.908937,0.787496,1.54685,1.57595
3025,0.323275,0.205979,0.769589,0.72768,0.555709,0.44255,0.512812,0.535593,0.617163,0.635605,0.0466271,0.148879,0.329331,0.310515,0.748256,0.78173,0.853808,0.75622,0.980922,1.04321,-0.650213,-0.307086,-0.13874,0.102946,-1.00949,-0.984314,-1.1641,-1.19048,-0.936056,-0.882194,-1.08062,-1.24704,1.30302,1.12726,-1.87181,-2.0099,0.244994,0.116543,1.65109,1.67207
3026,0.297045,0.180696,0.636688,0.685335,0.967394,0.855702,0.474477,0.462487,0.962304,0.982339,0.714607,0.815533,0.0398425,-0.0330001,0.157164,0.190408,0.958219,0.959239,0.402576,0.463,0.570072,0.874287,-1.28322,-1.04795,-0.539097,-0.509397,1.8047,1.77965,-0.563521,-0.507682,-1.7592,-1.92914,0.572707,0.389859,-0.379334,-0.516013,0.737595,0.60694,-1.95841,-1.93441
3027,0.747404,0.633156,0.686039,0.642991,0.670749,0.526146,0.0850479,0.0757666,0.920024,0.936998,0.547368,0.647896,0.320509,0.168108,0.522439,0.557495,0.0591112,0.0584073,0.90455,0.966957,-0.00927964,0.242434,-1.12956,-0.893383,-0.679821,-0.644346,-1.32186,-1.35215,-1.16927,-1.11831,0.0502874,-0.118865,1.3999,1.21739,-0.0454254,-0.184128,0.0325057,-0.0936309,0.334087,0.359134
3028,0.852647,0.739159,0.827931,0.786542,0.305595,0.19659,0.646456,0.63911,0.871804,0.891656,0.0538709,0.152678,0.53921,0.369216,0.441565,0.476641,0.945919,0.946896,0.639055,0.701985,-0.688969,-0.389419,0.591767,0.83483,0.766031,0.796153,0.568529,0.537402,0.357064,0.40426,-1.05731,-1.22847,0.291721,0.108548,1.25939,1.12486,0.446729,0.318794,-0.106881,-0.0867166
3029,0.487301,0.37468,0.678054,0.583963,0.228935,0.12167,0.1131,0.106111,0.353897,0.37323,0.838535,0.935763,0.641051,0.570324,0.0156047,0.0501816,0.634653,0.637837,0.942068,1.00459,0.297372,0.595175,0.907987,1.14471,-0.564522,-0.532225,0.232007,0.19418,0.982839,1.03715,0.429276,0.255462,1.10275,0.920215,1.39515,1.25678,1.53025,1.40271,0.204895,0.22191
3030,0.914217,0.802544,0.42347,0.381385,0.381673,0.273269,0.461878,0.454898,0.442381,0.461754,0.608413,0.707301,0.414124,0.29112,0.583887,0.617692,0.89504,0.899495,0.923412,0.985085,-0.534465,-0.241963,-0.981905,-0.745153,-0.884375,-0.854417,0.340337,0.296747,-0.898267,-0.848284,1.45647,1.28186,-1.63485,-1.82138,0.479127,0.347482,-0.822091,-0.94857,-0.32224,-0.299705
3031,0.900405,0.787442,0.98434,0.943358,0.840143,0.732104,0.166023,0.157314,0.937368,0.955014,0.989472,1.08619,0.0817811,0.0119168,0.345129,0.486734,0.213003,0.219555,0.504175,0.564496,1.40833,1.70103,-1.78663,-1.55373,0.871645,0.898202,-0.535262,-0.574698,-1.19688,-1.15298,-0.434215,-0.611316,-0.319058,-0.509825,1.23738,1.1064,2.5707,2.43854,0.773431,0.796992
3032,0.596696,0.482783,0.484827,0.445076,0.503471,0.397443,0.985125,0.973889,0.679115,0.69796,0.752038,0.95033,0.336656,0.268517,0.250285,0.355776,0.292062,0.297568,0.290333,0.349196,-0.380092,-0.0875897,0.742854,0.971734,0.846194,0.868722,0.13842,0.0946859,-0.765962,-0.719834,-0.942469,-1.12192,0.0495899,-0.141297,0.586571,0.455464,1.23924,1.10703,-0.343695,-0.31714
3033,0.704786,0.588785,0.345199,0.264234,0.840847,0.734606,0.851073,0.841503,0.730743,0.65922,0.628331,0.814469,0.354023,0.286304,0.189415,0.224818,0.6923,0.698505,0.808817,0.868784,-1.66665,-1.36918,-1.24798,-1.02339,-0.675672,-0.658006,-1.06257,-1.1009,-0.649235,-0.608141,-0.130217,-0.31063,-0.0276601,-0.216609,-1.66195,-1.7955,-0.529395,-0.668895,1.45019,1.47476
3034,0.517069,0.400122,0.121116,0.0833923,0.794142,0.748453,0.373111,0.364652,0.599316,0.62048,0.583126,0.678608,0.964561,0.897676,0.227764,0.265137,0.25485,0.259299,0.668159,0.789569,-3.57065,-3.26898,0.0241659,0.255184,0.215643,0.296113,-0.6487,-0.691925,0.15048,0.192341,-1.64842,-1.83471,-0.667231,-0.876015,2.87465,2.7411,1.67867,1.54486,0.697669,0.728137
3035,0.736985,0.621922,0.692594,0.654775,0.86839,0.762301,0.398017,0.387242,0.803225,0.825702,0.740226,0.798469,0.956907,0.890248,0.476469,0.515336,0.100525,0.180179,0.533504,0.710354,-0.20397,0.0913366,0.540074,0.764736,1.23257,1.25023,1.20829,1.16595,1.65541,1.70003,-0.14954,-0.335365,-1.34647,-1.53542,0.0668863,-0.0603108,-0.880128,-1.01161,0.348791,0.439713
3036,0.484648,0.369004,0.230957,0.191413,0.496093,0.35143,0.0691445,0.0597556,0.0162127,0.0401275,0.821143,0.918329,0.561175,0.494191,0.0944197,0.134065,0.10559,0.101058,0.570192,0.631139,-1.32533,-1.03575,-0.283552,-0.0602648,0.195764,0.272646,0.181066,0.141404,1.4443,1.48693,-0.442813,-0.627268,-0.359079,-0.551718,-0.0407628,-0.174161,-0.260833,-0.396032,0.123387,0.151289
3037,0.957581,0.840895,0.731471,0.694224,0.0462708,-0.0594415,0.0628728,0.0529722,0.638593,0.664314,0.175219,0.272987,0.875094,0.80625,0.045344,0.0827752,0.0174886,0.021938,0.80105,0.863918,0.611658,0.907247,1.28087,1.49988,-0.719664,-0.704941,-0.399826,-0.433168,-1.53006,-1.48492,-2.11057,-2.28766,0.0713298,-0.119723,1.32096,1.18346,-0.851579,-0.989359,0.147493,0.17376
3038,0.256166,0.13753,0.221086,0.181383,0.314498,0.206673,0.56622,0.555307,0.68646,0.802838,0.17811,0.239983,0.890724,0.824038,0.494722,0.529758,0.572719,0.577152,0.743501,0.859565,-0.944441,-0.647784,-0.0572912,0.16063,0.486365,0.504673,0.326869,0.208536,0.124195,0.174464,1.59252,1.41875,-0.733913,-0.895464,0.910564,0.7797,0.361443,0.219357,-1.22332,-1.19778
3039,0.859756,0.743506,0.322036,0.280315,0.0529218,-0.0533262,0.656033,0.64344,0.912649,0.941362,0.109214,0.206979,0.700919,0.635055,0.545161,0.577076,0.423881,0.428961,0.792017,0.855212,-0.919209,-0.626488,0.0653162,0.283883,-0.653902,-0.638242,0.890275,0.85024,-0.273048,-0.210836,-0.0544743,-0.229553,-1.47668,-1.6712,0.944751,0.818709,-0.298907,-0.434953,-0.229812,-0.208142
3040,0.115568,-0.00141095,0.857567,0.81755,0.674085,0.570006,0.143463,0.130529,0.158687,0.18833,0.834944,0.932842,0.260552,0.194319,0.591413,0.624393,0.740066,0.743805,0.372899,0.434623,-1.71985,-1.43292,-0.458255,-0.232922,0.736759,0.754529,0.843259,0.800548,-0.652725,-0.596137,-0.378282,-0.552361,-0.391113,-0.583256,-2.13154,-2.25524,-0.666601,-0.796789,-1.60908,-1.57969
3041,0.603338,0.485316,0.798175,0.826796,0.345835,0.24026,0.61543,0.603538,0.582973,0.61067,0.368873,0.467305,0.120329,0.0545676,0.200817,0.232597,0.5195,0.524965,0.622923,0.682971,0.469886,0.756219,-0.408808,-0.185731,-1.71765,-1.69384,-0.222212,-0.271372,-0.517946,-0.454397,-1.47852,-1.64828,0.217917,0.0325342,0.664406,0.543834,0.804972,0.679097,-0.684755,-0.651626
3042,0.0392777,-0.0806477,0.878256,0.836043,0.951368,0.843819,0.329944,0.320587,0.21036,0.236641,0.136868,0.234008,0.681015,0.61608,0.284607,0.334095,0.92193,0.925902,0.0819088,0.141812,-0.134546,0.151734,-0.718109,-0.491902,-0.372611,-0.344515,0.125537,0.0965612,2.07328,2.13484,-2.31037,-2.48265,-1.07189,-1.26442,-0.983432,-1.10514,-0.603498,-0.729211,-1.14026,-1.11172
3043,0.604863,0.485895,0.657964,0.616663,0.775729,0.607544,0.495359,0.485429,0.160165,0.186871,0.961404,1.05894,0.0102826,-0.056167,0.380054,0.435593,0.628075,0.631676,0.159764,0.217619,0.220574,0.511175,0.270424,0.491481,-0.361862,-0.328684,0.511144,0.464495,0.178572,0.233591,0.0524417,-0.121299,0.673885,0.476318,0.181843,0.0684178,0.573964,0.449075,1.22642,1.24808
3044,0.674419,0.556628,0.204059,0.163446,0.518784,0.371268,0.385988,0.377805,0.65755,0.684797,0.20212,0.299388,0.659499,0.591773,0.44495,0.537092,0.846727,0.847773,0.941684,0.998032,1.28702,1.57306,0.329668,0.554171,-1.48429,-1.45762,-0.0926346,-0.141025,-0.353661,-0.298447,-1.07285,-1.2468,-1.76752,-1.97072,-0.146943,-0.25888,-0.554554,-0.676751,0.643898,0.621155
3045,0.449913,0.33307,0.94915,0.908565,0.337392,0.134993,0.796889,0.787176,0.738559,0.763546,0.691414,0.786532,0.460298,0.381532,0.587008,0.63859,0.776389,0.819145,0.867125,0.923934,-1.33927,-1.04963,0.0047316,0.23597,-1.79484,-1.76214,-0.143473,-0.190717,-0.244666,-0.186753,-0.0964072,-0.286445,-1.41929,-1.61687,-0.21176,-0.326923,2.41805,2.29301,-0.0350785,-0.0057666
3046,0.871012,0.756161,0.224425,0.183228,0.00801939,-0.101283,0.192371,0.183862,0.358878,0.384674,0.843138,0.936328,0.195598,0.171291,0.708309,0.740089,0.791872,0.790517,0.564448,0.6668,-0.517731,-0.233303,-1.13727,-0.899671,-0.886998,-0.855016,1.83893,1.79337,-1.47459,-1.41063,0.845862,0.673914,-0.296903,-0.496468,1.15112,1.0307,0.0710892,-0.0582703,-0.221845,-0.191273
3047,0.402843,0.366074,0.129576,0.089264,0.728499,0.618714,0.815324,0.806435,0.717672,0.7423,0.144646,0.237007,0.0266832,-0.0389502,0.0989619,0.129228,0.290206,0.290764,0.230882,0.409667,-0.186441,0.0943893,0.710001,0.952558,1.14907,1.17892,0.407626,0.367595,1.01451,1.08397,-0.998,-1.17406,-0.877618,-1.08142,-0.308772,-0.432226,-1.43525,-1.56195,-0.399785,-0.376779
3048,0.0925977,-0.0240125,0.86528,0.825277,0.209371,0.0999223,0.905076,0.894569,0.679525,0.776866,0.42095,0.512004,0.291698,0.227467,0.192141,0.131041,0.00985815,0.0122479,0.0968413,0.152534,-2.21003,-1.93113,-0.590927,-0.351697,-0.425348,-0.393365,0.22371,0.177807,2.83278,2.89828,-0.77273,-0.94501,0.859594,0.659316,0.397539,0.26686,0.11472,-0.009027,-0.0796028,-0.0539037
3049,0.957836,0.842488,0.102391,0.063877,0.473819,0.316283,0.176149,0.166927,0.719325,0.811432,0.98542,1.07843,0.0467514,-0.0185975,0.10106,0.132854,0.466389,0.467664,0.451941,0.515292,0.131846,0.410418,-1.54659,-1.3001,0.176691,0.248018,-1.24088,-1.29339,-0.202918,-0.134885,1.53403,1.36811,1.41614,1.21347,0.107025,0.0496692,1.96643,1.84473,-0.209136,-0.183235
3050,0.995693,0.847428,0.65256,0.615637,0.546789,0.532643,0.890125,0.879752,0.81858,0.845999,0.092508,0.183766,0.941053,0.872806,0.601056,0.557544,0.150697,0.152712,0.820914,0.878051,0.339516,0.613689,2.34858,2.59197,0.850413,0.889401,-0.555417,-0.608846,-1.22625,-1.15889,1.33372,1.16817,-0.392318,-0.6005,-0.0430678,-0.167522,-1.64839,-1.76891,1.54859,1.57689
3051,0.966183,0.852369,0.51428,0.476849,0.858453,0.749004,0.667492,0.656862,0.606478,0.634202,0.309119,0.40248,0.590774,0.529291,0.951575,0.982234,0.737036,0.737948,0.410374,0.466579,2.74284,3.02363,-0.276409,-0.0271598,0.995597,1.04188,0.722228,0.664987,-1.59567,-1.52585,-0.508798,-0.67981,-0.999697,-1.21528,0.891236,0.732411,-1.36073,-1.48217,-1.21388,-1.19326
3052,0.50394,0.391315,0.0584612,0.0186321,0.803981,0.693736,0.165284,0.153933,0.0425503,0.070296,0.957475,1.04891,0.254008,0.185776,0.625769,0.655735,0.938828,0.849327,0.246056,0.301577,0.560932,0.842956,0.141659,0.356682,-0.294828,-0.255064,-0.578791,-0.637757,1.07076,1.15087,0.0242278,-0.14377,0.588383,0.372118,1.7568,1.63234,-0.737052,-0.850856,1.15903,1.18182
3053,0.894633,0.784262,0.445798,0.473763,0.0508861,-0.0614005,0.112219,0.0936864,0.244748,0.269849,0.661835,0.710788,0.107796,0.0408396,0.926798,0.956728,0.957883,0.960706,0.9492,1.006,0.633426,0.827548,0.459353,0.740524,0.457279,0.498112,-0.609756,-0.673402,0.805071,0.890013,0.856836,0.681139,0.725495,0.509592,-0.379217,-0.501971,-0.411051,-0.540055,-1.40433,-1.38728
3054,0.17087,0.0603712,0.968723,0.928894,0.765624,0.654587,0.0428183,0.0334397,0.0411384,0.067846,0.281212,0.372671,0.232167,0.166217,0.612146,0.640235,0.1547,0.158021,0.957852,1.01672,0.522161,0.81214,0.875117,1.12437,1.49574,1.54148,-1.63593,-1.69795,-0.802793,-0.716485,-0.307841,-0.487831,-0.259053,-0.476208,1.28807,1.16251,-0.110257,-0.229254,-0.94981,-0.896213
3055,0.772044,0.661123,0.551988,0.447462,0.413912,0.304505,0.763283,0.752053,0.799507,0.826471,0.744986,0.83562,0.597853,0.521704,0.901825,0.930869,0.805437,0.811673,0.106723,0.164552,0.319582,0.606686,0.244013,0.499835,1.61791,1.66231,0.0243168,-0.0317446,0.119172,0.209161,-0.438403,-0.613122,-0.231138,-0.470382,-0.0344269,-0.163231,1.71664,1.59283,-0.414911,-0.405147
3056,0.731186,0.687707,0.003999,-0.0339709,0.462375,0.35119,0.312776,0.300186,0.157207,0.186839,0.179631,0.271248,0.94203,0.877192,0.00553115,0.0328039,0.800246,0.806029,0.187053,0.246171,-0.887226,-0.597307,0.0891912,0.437071,-0.263145,-0.223992,0.347477,0.286226,-0.703143,-0.615604,0.316862,0.13646,-0.244839,-0.464557,-1.10776,-1.24261,0.124052,-0.00259308,0.0688655,0.0859185
3057,0.824536,0.71429,0.507025,0.468841,0.193962,0.0818486,0.648423,0.597887,0.406418,0.413461,0.694365,0.78406,0.659526,0.596275,0.635227,0.663027,0.211011,0.21698,0.549441,0.606299,-0.405504,-0.113133,0.119594,0.374306,0.549339,0.591406,1.49179,1.43601,-1.01977,-0.936808,0.558021,0.380707,0.128367,-0.0960285,-1.48839,-1.63005,0.5454,0.424895,-0.1639,-0.148229
3058,0.48399,0.464221,0.64048,0.641091,0.18963,0.078117,0.907801,0.895589,0.608245,0.640083,0.335536,0.426495,0.982684,0.918166,0.447593,0.476082,0.138296,0.142037,0.131341,0.190305,1.03216,1.32178,-0.561277,-0.311936,0.761044,0.806111,0.235701,0.278309,0.875178,0.957282,-0.349201,-0.531631,0.927273,0.700892,0.179954,0.0344262,-0.934695,-1.06291,2.04387,2.06269
3059,0.326355,0.214151,0.853879,0.813342,0.793274,0.681676,0.461794,0.452936,0.517278,0.549379,0.599602,0.686146,0.794468,0.667589,0.849409,0.87764,0.856169,0.858492,0.78955,0.84869,-0.481129,-0.187738,1.17495,1.43122,-0.0970119,-0.0575664,-0.823603,-0.879389,1.07588,1.16103,-0.54758,-0.731575,0.117959,-0.111365,-3.12739,-3.26681,0.219284,0.098308,-0.673305,-0.658317
3060,0.945291,0.83434,0.59028,0.584593,0.910176,0.754972,0.0215021,0.0102841,0.163196,0.195862,0.856403,0.945797,0.481345,0.417013,0.977009,1.0034,0.0546154,0.0558064,0.330476,0.387831,-0.00248594,0.296437,1.12813,1.38645,-0.232699,-0.192516,-0.990527,-1.05289,0.340743,0.428223,0.965772,0.784038,0.132542,-0.0968302,0.0864727,-0.0557122,2.29173,2.16495,-0.518798,-0.500657
3061,0.130639,0.0169452,0.500753,0.355844,0.937706,0.828267,0.846396,0.837158,0.540212,0.596377,0.454319,0.544232,0.901694,0.838783,0.344473,0.371573,0.349614,0.351938,0.619357,0.675936,-0.672792,-0.368457,-1.27839,-1.02466,0.536095,0.576174,-0.358385,-0.414941,-1.10068,-1.0092,-0.183402,-0.370939,-1.48117,-1.70678,-0.848553,-0.99674,-1.69574,-1.82836,0.733397,0.748598
3062,0.991998,0.877822,0.167632,0.127095,0.449018,0.338381,0.129083,0.120091,0.963918,0.996893,0.884979,0.973219,0.607127,0.465366,0.521744,0.548963,0.10093,0.103418,0.573807,0.632653,-0.56498,-0.25701,0.169406,0.423532,-0.263161,-0.225248,0.851188,0.796793,-1.22127,-1.13183,-0.372194,-0.536906,-2.04132,-2.26027,0.759043,0.607396,-2.34443,-2.48267,-0.470016,-0.455473
3063,0.201976,0.0894051,0.92135,0.882598,0.739855,0.609231,0.754762,0.747258,0.23238,0.265366,0.709204,0.795921,0.154845,0.0919503,0.0500181,0.0779401,0.433227,0.453323,0.112962,0.171794,0.0917732,0.393413,0.0249378,0.273842,0.695268,0.728688,-0.555107,-0.614843,-0.26363,-0.175954,-0.509316,-0.702873,-0.117514,-0.329224,-1.97535,-2.12365,-1.48542,-1.61638,-1.32059,-1.30803
3064,0.496109,0.38163,0.434221,0.394823,0.992344,0.880082,0.558994,0.549847,0.446614,0.480622,0.117694,0.206131,0.166502,0.104899,0.203244,0.249072,0.799532,0.803229,0.475724,0.536985,0.22724,0.536087,-1.8137,-1.56922,0.175946,0.208474,0.268117,0.208623,-1.02736,-0.938877,0.510843,0.323525,0.563582,0.345951,0.949142,0.802264,1.85614,1.71575,0.0683728,0.0797995
3065,0.0968336,-0.019073,0.383468,0.344956,0.0171487,-0.0948652,0.967523,0.959219,0.250002,0.283502,0.407764,0.495297,0.635328,0.571978,0.394536,0.420203,0.675274,0.680453,0.159542,0.221217,0.982588,1.29373,2.21837,2.46773,-1.52501,-1.49142,-0.819279,-0.880011,1.03759,1.12638,0.625607,0.396288,0.418907,0.195854,-1.31466,-1.46586,0.678196,0.542933,-0.228587,-0.214201
3066,0.601459,0.488081,0.898413,0.857395,0.667304,0.554027,0.440837,0.430975,0.63821,0.671804,0.275407,0.298704,0.896712,0.833551,0.0383039,0.0632466,0.168127,0.175341,0.668867,0.729719,0.662468,1.07004,0.260653,0.51506,-1.06845,-1.03255,-1.44093,-1.49932,1.97939,2.06761,0.663008,0.469052,0.83479,0.611138,1.89039,1.74524,-1.75059,-1.89222,-0.0671192,-0.0565407
3067,0.785748,0.674111,0.771164,0.728263,0.52719,0.372846,0.939098,0.928882,0.769876,0.801294,0.0140485,0.10211,0.172863,0.111237,0.495417,0.519969,0.0773831,0.0987715,0.672433,0.739068,0.529854,0.846348,-0.234753,0.013371,0.786032,0.814138,0.0438704,-0.0222346,1.33389,1.42741,1.54031,1.34084,0.28971,0.0714337,-0.015311,-0.152385,0.662622,0.51667,-0.283156,-0.276734
3068,0.100535,-0.0126156,0.433749,0.394702,0.305801,0.191665,0.16345,0.154601,0.69628,0.726266,0.0566423,0.142492,0.955685,0.891911,0.623583,0.645729,0.0150437,0.022202,0.713631,0.748417,-1.64906,-1.33433,0.150085,0.398855,0.26433,0.293924,0.381033,0.31077,-0.232094,-0.133736,0.983193,0.765205,-0.679045,-0.898209,0.157458,0.0240066,1.75451,1.61632,-0.0248717,-0.0153364
3069,0.287405,0.0842264,0.10608,0.0611406,0.878117,0.764212,0.697469,0.687224,0.879196,0.841702,0.664599,0.748278,0.891793,0.827781,0.205035,0.229237,0.912163,0.920285,0.69668,0.757766,-0.435901,-0.120043,1.07118,1.32012,1.26328,1.29342,-0.797899,-0.868245,-0.67452,-0.577309,0.381901,0.189574,0.654957,0.443436,-1.1916,-1.33207,0.0913116,-0.0440925,-0.312875,-0.309337
3070,0.291848,0.181068,0.763484,0.720475,0.315954,0.199954,0.607487,0.59903,0.929202,0.957137,0.568169,0.594226,0.0729192,0.0107173,0.20662,0.228873,0.477979,0.485548,0.0831736,0.142563,0.345172,0.666833,0.479004,0.725011,0.0358243,0.0718634,-0.301927,-0.368498,1.22526,1.31678,-1.19052,-1.38119,-0.354089,-0.573237,-0.156948,-0.230399,0.00173719,-0.127251,0.172728,0.179683
3071,0.141023,0.0284772,0.471494,0.430316,0.695769,0.580869,0.307647,0.301446,0.128402,0.156436,0.358659,0.440175,0.709616,0.647305,0.733199,0.755749,0.333373,0.342036,0.0460519,0.196773,-0.0894161,0.241323,1.00688,1.24905,0.868608,0.903866,1.28643,1.21873,0.0629171,0.155693,0.730732,0.533707,-0.93854,-1.15819,1.00433,0.871272,1.25144,1.12759,1.91281,1.92064
3072,0.432668,0.320702,0.416636,0.375834,0.801541,0.654611,0.457979,0.457945,0.0296115,0.0551463,0.71641,0.800268,0.95716,0.893591,0.852098,0.877048,0.815731,0.822059,0.189519,0.250982,-0.501071,-0.184187,0.0597244,0.300647,-1.08676,-1.04837,0.748163,0.675554,-0.50006,-0.314315,-0.845546,-1.03706,-1.11297,-1.33992,1.02038,0.894251,-1.67014,-1.79873,0.940044,0.947513
3073,0.509879,0.396348,0.13378,0.0901733,0.724074,0.728353,0.619504,0.614443,0.778605,0.803977,0.606584,0.691328,0.00740878,-0.0570878,0.582258,0.604515,0.667617,0.673867,0.377805,0.438174,0.292726,0.602689,-0.20668,-0.0371634,-0.206398,-0.171157,-1.06429,-1.14227,-0.880265,-0.784322,-0.792084,-0.97628,0.693487,0.464326,0.360911,0.226991,0.528905,0.39957,0.638654,0.653512
3074,0.145224,0.0318698,0.620115,0.577872,0.916549,0.802095,0.544577,0.527003,0.311049,0.335673,0.140791,0.225792,0.331511,0.20582,0.580279,0.604152,0.311088,0.319146,0.274347,0.306698,1.75526,2.07034,-0.592098,-0.374974,0.455805,0.488168,0.367189,0.287218,0.165112,0.264121,0.263381,0.0821114,-0.706493,-0.940241,0.43397,0.296245,0.141771,0.0082068,0.8132,0.825959
3075,0.581801,0.450117,0.137917,0.0945825,0.40841,0.293707,0.409255,0.439564,0.967175,0.99085,0.251529,0.334835,0.629782,0.468729,0.0341924,0.0586282,0.264753,0.280966,0.115623,0.175222,0.0103341,0.329731,-0.953706,-0.712784,-0.0666546,-0.0320458,0.401868,0.328539,-1.47758,-1.37412,0.922449,0.740113,0.897867,0.662031,1.87885,1.74376,0.828662,0.701606,0.2294,0.244485
3076,0.981613,0.868363,0.687055,0.642451,0.354197,0.238439,0.490071,0.352125,0.427777,0.452696,0.610597,0.694928,0.796134,0.731637,0.805781,0.830602,0.232801,0.242786,0.429143,0.488659,0.861861,1.17709,0.767714,1.01543,0.0156963,-0.0118942,1.96048,1.88603,-0.482434,-0.387063,-0.398401,-0.585233,1.88912,1.6619,0.630173,0.405861,-1.65485,-1.78375,1.01739,1.03777
3077,0.563232,0.448044,0.574796,0.52275,0.590633,0.5321,0.269747,0.264685,0.966888,0.991583,0.731066,0.743197,0.105395,0.039712,0.531864,0.558069,0.196498,0.204607,0.255719,0.313327,-1.39584,-1.08184,0.926682,1.16999,-0.0226383,0.00825747,-0.364305,-0.443115,0.293946,0.385184,0.519871,0.333268,2.00679,1.78465,-0.799198,-0.932035,-0.540594,-0.669726,0.782715,0.803618
3078,0.44883,0.278372,0.446049,0.40305,0.943652,0.82576,0.775713,0.772526,0.536385,0.602325,0.706295,0.791467,0.0190917,-0.0492313,0.755596,0.781994,0.472127,0.480877,0.377057,0.41152,-1.24842,-0.939162,0.32761,0.574888,0.404269,0.437223,2.19059,2.10605,-1.72204,-1.62755,-0.22722,-0.415246,-0.389738,-0.616109,1.23346,1.10788,1.44426,1.31158,0.0714959,0.0862926
3079,0.224446,0.1087,0.88067,0.837198,0.90213,0.729897,0.227386,0.224708,0.188632,0.213068,0.33119,0.414642,0.42595,0.357738,0.115843,0.141043,0.127017,0.136015,0.454707,0.509714,-0.193193,0.122725,0.0579455,0.300884,0.443466,0.482008,0.769335,0.680271,0.428993,0.52495,-0.97685,-1.16376,-0.517973,-0.735724,-0.0699201,-0.203498,0.997794,0.871674,0.230042,0.243953
3080,0.563401,0.4458,0.377587,0.3338,0.728705,0.634034,0.539494,0.534431,0.610237,0.635408,0.398712,0.481083,0.195505,0.126412,0.200332,0.226768,0.0422871,0.0504352,0.136871,0.193946,-0.102538,0.218936,0.0973696,0.333673,-0.157935,-0.119211,-0.403613,-0.498744,1.22393,1.32543,-0.950872,-1.13348,0.0368005,-0.181574,0.650047,0.511107,0.242158,0.121445,-1.62337,-1.60502
3081,0.183912,0.0660638,0.196102,0.153902,0.657508,0.538171,0.514234,0.507558,0.816659,0.84063,0.78927,0.870414,0.377307,0.30717,0.878426,0.902947,0.662215,0.671554,0.593695,0.652961,-1.39969,-1.07779,-1.853,-1.619,-2.82402,-2.78932,-0.423378,-0.518292,0.5098,0.610806,0.427335,0.242756,0.0770743,-0.135674,-0.676953,-0.814633,0.0144142,-0.101982,0.580454,0.591021
3082,0.792227,0.672041,0.640994,0.597691,0.996003,0.875334,0.151926,0.145473,0.599632,0.623572,0.848562,0.829551,0.905504,0.834032,0.924923,0.948336,0.347787,0.356602,0.477927,0.53717,1.17366,1.49289,-1.14825,-0.911165,-0.928004,-0.896447,0.276847,0.200587,-1.27683,-1.1836,0.175181,-0.097073,1.16591,0.952274,1.14374,1.00647,-0.588247,-0.604939,-0.742019,-0.73463
3083,0.062874,-0.057204,0.389369,0.347125,0.956722,0.782359,0.933012,0.92548,0.0753634,0.100557,0.708063,0.788687,0.305793,0.232982,0.545025,0.567066,0.335803,0.346186,0.860266,0.921333,0.294877,0.610235,-0.161307,0.0722177,-0.308287,-0.28404,1.00905,0.919465,0.091394,0.18472,-0.253751,-0.436902,0.0720494,-0.140122,0.324669,0.188791,-0.993216,-1.10789,-0.998644,-0.999183
3084,0.412254,0.33806,0.371134,0.326466,0.812192,0.689384,0.516726,0.50871,0.221961,0.316087,0.103904,0.183667,0.124607,0.0529872,0.852852,0.873653,0.559328,0.567857,0.490018,0.550824,2.1761,2.49199,0.201953,0.440879,-0.583358,-0.557777,-0.133023,-0.229021,0.9358,1.03367,-0.260675,-0.438095,0.525947,0.306779,-1.20371,-1.33547,0.362747,0.24759,1.2361,1.23022
3085,0.852658,0.733323,0.988131,0.941474,0.976603,0.855543,0.53499,0.526627,0.506762,0.531617,0.681055,0.759736,0.701077,0.629488,0.868557,0.822183,0.234607,0.243314,0.47779,0.496279,-0.0928179,0.2156,-2.427,-2.19156,-0.247009,-0.22,1.37667,1.27937,-0.842661,-0.745725,-0.489058,-0.669047,0.456267,0.231467,-1.08348,-1.21922,0.258555,0.148875,-1.49942,-1.50711
3086,0.22098,0.102197,0.544777,0.525261,0.614589,0.590319,0.325487,0.319751,0.909894,0.934147,0.97631,1.05536,0.518086,0.497695,0.747441,0.770713,0.183393,0.193746,0.312676,0.441734,1.06896,1.38481,0.384866,0.617851,-0.216493,-0.189356,-0.814486,-0.916442,0.904977,1.00635,0.072595,-0.101519,0.738631,0.507028,-0.0975469,-0.230048,-1.42129,-1.5274,0.304262,0.299386
3087,0.980363,0.862039,0.156686,0.109049,0.445637,0.325095,0.378219,0.388269,0.234099,0.258948,0.818476,0.796286,0.437617,0.365903,0.142777,0.164715,0.402754,0.415418,0.325618,0.387189,-1.98308,-1.66723,0.853341,1.07967,-0.59714,-0.570568,0.0512754,-0.0655845,0.651061,0.745491,0.151273,-0.0258881,0.22996,0.000876876,-0.207432,-0.343899,1.05578,0.94247,1.70537,1.70334
3088,0.543854,0.521472,0.944684,0.895996,0.919395,0.798689,0.397379,0.456786,0.75905,0.782467,0.514995,0.537214,0.93026,0.857992,0.312573,0.335909,0.22754,0.314491,0.982517,1.04557,-1.42364,-1.11024,0.85249,1.08198,0.988111,1.00983,0.879588,0.785273,-1.0237,-0.923707,-0.0601078,-0.241533,-0.695543,-0.922343,0.681306,0.538091,0.134105,0.0209476,0.524732,0.528908
3089,0.298467,0.180906,0.553599,0.506399,0.155295,0.0341797,0.529275,0.525303,0.716734,0.738034,0.199053,0.278142,0.354747,0.28092,0.799201,0.822805,0.202806,0.213564,0.473613,0.534664,-1.7249,-1.4072,-1.50297,-1.26638,0.950748,0.980348,0.640696,0.551155,-1.33065,-1.2284,-0.473765,-0.657865,0.707919,0.569684,2.32417,2.18777,0.6108,0.495926,-1.31247,-1.2987
3090,0.502525,0.387126,0.775124,0.72926,0.161591,0.0413703,0.89401,0.889231,0.345194,0.364005,0.693422,0.770768,0.282462,0.207134,0.317633,0.341725,0.61339,0.623827,0.431392,0.491382,-0.139154,0.183864,-0.862801,-0.671092,-0.926452,-0.890771,-0.355142,-0.442789,0.339526,0.446874,-1.89932,-2.07585,2.28851,2.06171,-0.981004,-1.11347,1.73709,1.6262,0.127113,0.136941
3091,0.918765,0.805191,0.349371,0.305327,0.928877,0.808253,0.485053,0.482206,0.596587,0.61552,0.90082,0.979256,0.703367,0.628904,0.760332,0.783962,0.731352,0.742995,0.676885,0.734475,0.46766,0.787403,-0.319028,-0.0758037,-0.518878,-0.475482,-0.206922,-0.292033,-3.01511,-2.90713,0.403235,0.22108,0.612486,0.387862,-0.0582349,-0.184158,0.126026,0.109382,0.325012,0.339625
3092,0.145305,0.0332565,0.944933,0.901633,0.396422,0.274438,0.72206,0.642876,0.36627,0.383957,0.442733,0.523428,0.0494884,-0.0233399,0.336456,0.362007,0.618206,0.560713,0.195382,0.253912,-0.363605,-0.0497355,1.26218,1.49937,-0.953714,-0.965159,0.665971,0.579936,-1.13886,-1.02982,-0.610387,-0.797377,1.34194,1.10971,-1.23912,-1.36938,-1.29656,-1.40744,1.22648,1.23818
3093,0.380913,0.287633,0.548627,0.507541,0.73572,0.611601,0.839124,0.803547,0.814436,0.83216,0.529353,0.583517,0.9138,0.839962,0.783831,0.80899,0.474642,0.378431,0.735383,0.793305,-0.0552518,0.26349,0.996452,1.2404,-1.49302,-1.45484,-0.241207,-0.320317,0.300419,0.416715,-0.439307,-0.630093,-0.763869,-1.00294,0.395727,0.264199,1.14148,1.02881,0.917281,0.927453
3094,0.739493,0.542009,0.81772,0.778577,0.435196,0.312418,0.967064,0.964217,0.486261,0.504997,0.564741,0.643607,0.0576822,-0.0157151,0.944386,0.970455,0.185587,0.196149,0.712717,0.769354,-0.911993,-0.588009,-0.0849776,0.243183,0.208455,0.250637,-0.258308,-0.339864,-1.67422,-1.56277,0.30991,0.119489,-0.875471,-1.08936,-1.05313,-1.18285,-1.56726,-1.68008,-0.00657819,-0.00217921
3095,0.910799,0.796385,0.584238,0.544074,0.416963,0.293596,0.381208,0.376442,0.648752,0.669767,0.395363,0.411756,0.85308,0.77934,0.762237,0.824256,0.550668,0.561994,0.424805,0.446063,-0.135004,0.250392,-1.00239,-0.754034,-0.35698,-0.331578,-0.813436,-0.898184,-0.437841,-0.329265,0.460406,0.270025,-0.935536,-1.17578,-0.0483911,-0.175873,-0.151726,-0.265127,-0.318592,-0.312907
3096,0.188775,0.0724936,0.593958,0.553118,0.772262,0.650702,0.749823,0.745063,0.0241057,0.0447293,0.0996522,0.179905,0.0427803,-0.0323594,0.495348,0.678057,0.437677,0.450006,0.0656897,0.122771,0.770429,1.08879,1.17111,1.41742,-0.95936,-0.913794,-1.6975,-1.78459,-0.726758,-0.617674,0.839328,0.652916,-0.846206,-1.04916,-1.31749,-1.4397,0.88107,0.773339,-1.95684,-1.94528
3097,0.615977,0.500357,0.142824,0.0999,0.0445403,-0.0788358,0.171873,0.16645,0.480546,0.50235,0.440041,0.519481,0.0135671,-0.0607464,0.447448,0.531858,0.112926,0.125462,0.903517,0.961546,-1.55162,-1.23346,0.836468,1.08285,-2.05419,-2.01051,0.261342,0.168846,1.11623,1.22909,-0.153812,-0.3353,-0.688225,-0.922547,-0.0680946,-0.192478,-0.466424,-0.573224,0.925518,0.933766
3098,0.496527,0.381691,0.485657,0.417205,0.871517,0.74652,0.227827,0.220683,0.701542,0.736516,0.229626,0.338201,0.402121,0.323333,0.35959,0.385659,0.829206,0.841917,0.936158,0.938371,0.157668,0.480148,1.46909,1.71394,-0.471347,-0.430114,1.31386,1.22539,-0.0423767,0.0680002,-0.509903,-0.644398,0.586649,0.353683,-1.2626,-1.39303,0.508943,0.400253,-0.209392,-0.196019
3099,0.643793,0.584504,0.78011,0.73451,0.756331,0.641369,0.641025,0.634705,0.948809,0.970683,0.0780522,0.156921,0.781799,0.707413,0.417634,0.549328,0.485865,0.497055,0.981277,0.915197,-0.755154,-0.43391,1.17704,1.42492,-2.06634,-2.01917,0.628207,0.635266,2.02817,2.13325,-0.769721,-0.953496,0.0900873,-0.13785,-1.19061,-1.32378,0.595018,0.488263,-0.656329,-0.64187
3100,0.900451,0.787317,0.729897,0.684643,0.66073,0.536219,0.0613143,0.0560912,0.496437,0.517293,0.585155,0.664531,0.782894,0.661971,0.635667,0.712996,0.76272,0.773326,0.832933,0.892022,0.101468,0.42804,-1.65226,-1.40335,-0.555727,-0.503062,0.140922,0.0451418,2.11631,2.21544,0.201782,0.0100272,0.327464,0.106153,2.17298,2.03608,-1.27382,-1.38335,0.642472,0.654149
3101,0.875948,0.762034,0.904977,0.858496,0.850345,0.726572,0.530746,0.524036,0.605686,0.542494,0.0685695,0.150098,0.688759,0.616528,0.850957,0.876664,0.821262,0.83645,0.600196,0.661205,-0.0747889,0.252306,0.127904,0.372679,0.189144,0.234938,0.376412,0.287244,-0.102036,-0.0105282,0.739737,0.546067,-0.708283,-0.925512,0.689605,0.559492,0.773442,0.667271,0.372893,0.389596
3102,0.595392,0.483037,0.638911,0.519853,0.615455,0.493441,0.710104,0.704879,0.546763,0.567695,0.145079,0.226063,0.0823529,0.0104018,0.187931,0.21456,0.88843,0.899574,0.12012,0.180643,-1.04371,-0.721279,0.427654,0.668284,-0.814859,-0.76874,-2.0547,-2.14671,-0.324334,-0.240543,0.313078,0.0371105,-0.623989,-0.847502,0.487157,0.354444,1.77457,1.67375,-0.765439,-0.754541
3103,0.112231,0.00209043,0.227556,0.18121,0.114904,-0.00625465,0.276946,0.272982,0.143186,0.163616,0.000234498,0.0824552,0.320513,0.246252,0.619274,0.646209,0.302491,0.314594,0.406674,0.541077,-0.102618,0.217761,1.28534,1.52887,1.08744,1.13886,0.374962,0.281791,0.222027,0.298994,-0.284166,-0.471846,-0.0209961,-0.247807,-1.80513,-1.9282,-0.291175,-0.387102,-0.835543,-0.725425
3104,0.946606,0.837239,0.444153,0.398541,0.133425,0.0101724,0.164591,0.160519,0.0577237,0.0778647,0.0624287,0.144008,0.791121,0.717932,0.194176,0.21975,0.812934,0.824985,0.840204,0.901512,1.93644,2.25452,-1.14293,-0.897711,-0.980278,-0.923781,-0.156526,-0.246304,-0.687477,-0.615819,1.34925,1.1704,-0.798087,-1.03018,1.53875,1.41232,0.665186,0.570698,-0.706804,-0.69631
3105,0.223859,0.113348,0.129849,0.0827691,0.97864,0.856569,0.803007,0.797862,0.711533,0.733042,0.950734,1.03115,0.152433,0.0804892,0.401881,0.38243,0.644618,0.70935,0.706283,0.766939,-0.530685,-0.209654,-0.794222,-0.542516,-1.23869,-1.18259,0.177773,0.0867007,1.1442,1.21568,-0.357057,-0.536294,0.491612,0.26307,-0.976656,-1.09923,-0.542154,-0.633451,-0.495378,-0.480061
3106,0.974146,0.862002,0.479508,0.364006,0.785938,0.664534,0.694005,0.731587,0.190637,0.210028,0.904969,0.983962,0.178738,0.0710747,0.521168,0.545111,0.5832,0.593715,0.803778,0.805092,-1.03621,-0.708466,-2.17896,-1.92914,2.13478,2.19771,0.17626,0.0836639,-0.341961,-0.267919,0.114353,-0.0590504,-0.481543,-0.706573,-0.504791,-0.6307,-1.00382,-1.08882,-1.17279,-1.15277
3107,0.995347,0.88244,0.694274,0.645242,0.356498,0.234623,0.510437,0.665312,0.342498,0.360215,0.05185,0.129409,0.135375,0.0616602,0.0914016,0.114008,0.0342947,0.0444189,0.805142,0.843246,0.187283,0.505819,0.98855,1.24488,-1.9023,-1.84359,-0.124343,-0.214086,-1.02044,-0.950946,1.54245,1.36266,0.701805,0.478192,-1.6601,-1.7834,-0.993601,-1.07951,0.727185,0.745782
3108,0.573964,0.462121,0.337563,0.29106,0.819741,0.698181,0.526624,0.599037,0.7525,0.768174,0.517924,0.597007,0.675167,0.603314,0.313718,0.337933,0.393196,0.40534,0.819978,0.881399,1.76948,2.0819,-0.702645,-0.452696,0.276375,0.335598,0.945139,0.85819,0.147048,0.220122,-0.0200208,-0.208109,0.469087,0.250271,-0.121622,-0.242455,-0.639541,-0.728493,-1.29855,-1.27372
3109,0.930368,0.818938,0.752988,0.706169,0.346197,0.309784,0.471661,0.532762,0.00452754,0.0208473,0.735479,0.783072,0.543577,0.473619,0.995926,1.01952,0.477252,0.488054,0.212775,0.275349,-1.54287,-1.22882,2.71951,2.97006,-0.157904,-0.0912647,0.0687192,-0.0132554,0.931707,1.00831,0.0948639,-0.0855942,-0.565202,-0.781393,-1.20621,-1.32183,-1.80758,-1.90131,-0.944521,-0.921786
3110,0.379635,0.267802,0.602154,0.557345,0.0433299,-0.0786134,0.471631,0.466486,0.053474,0.0683378,0.892564,0.969137,0.76613,0.694699,0.948874,0.914309,0.971363,0.983797,0.173958,0.195751,0.363939,0.682802,-0.811735,-0.564643,0.674157,0.740737,1.24514,1.06087,1.11908,1.19642,-0.722857,-0.903965,0.326847,0.107265,0.0299131,-0.0903926,-0.117574,-0.20559,-0.836873,-0.808656
3111,0.908251,0.794608,0.0860781,0.0397024,0.256573,0.136712,0.532076,0.524843,0.547817,0.561598,0.48276,0.558132,0.433067,0.359539,0.787121,0.809094,0.133269,0.144753,0.0544308,0.116153,1.34714,1.6674,0.192546,0.435026,-0.615963,-0.556208,2.22157,2.135,1.64859,1.72119,0.290792,0.105602,1.46967,1.24516,0.649209,0.452925,1.31133,1.22455,-1.50316,-1.48136
3112,0.470614,0.364376,0.899682,0.851922,0.137156,0.0155323,0.21115,0.202035,0.785382,0.797458,0.668009,0.742915,0.650104,0.493018,0.0323884,0.0535791,0.878515,0.892061,0.432775,0.495887,0.916439,1.23304,-0.118942,0.0738093,2.31321,2.3797,-0.941142,-1.03218,0.57843,0.652063,0.362909,0.181233,0.843181,0.712902,1.12212,0.996243,0.757895,0.677717,2.03119,2.05299
3113,0.0484727,-0.0658553,0.762874,0.713135,0.677809,0.558432,0.149288,0.128929,0.336679,0.349448,0.547654,0.544149,0.715703,0.626496,0.996095,1.01729,0.354358,0.367994,0.195771,0.351317,0.0503089,0.383985,-0.525575,-0.287407,1.12053,1.19057,-0.697121,-0.790077,-0.920677,-0.84889,0.103287,-0.0799201,0.408124,0.180648,-0.360412,-0.480341,0.650117,0.5641,-0.0597849,-0.0424731
3114,0.298817,0.18526,0.837833,0.786801,0.9337,0.813912,0.0650079,0.0558228,0.370275,0.269207,0.376036,0.345383,0.83446,0.759975,0.567184,0.586183,0.662202,0.673769,0.145215,0.206747,-0.783743,-0.465075,-0.558066,-0.315479,0.226703,0.367587,0.0189652,-0.0738692,-0.212015,-0.140041,0.132812,-0.0496431,1.75646,1.52229,0.23429,0.110255,-0.39991,-0.4833,1.51486,1.53058
3115,0.15657,0.0422518,0.6934,0.652533,0.534424,0.453132,0.217123,0.206098,0.215922,0.188966,0.070888,0.146617,0.498227,0.424815,0.854373,0.872101,0.746707,0.756483,0.829511,0.890877,0.217098,0.537131,-0.84017,-0.604493,-0.525428,-0.455394,0.965444,0.874985,-0.572509,-0.507004,1.61935,1.43429,0.742584,0.50562,-1.39901,-1.52065,-2.62585,-2.71679,0.17655,0.188671
3116,0.778086,0.66244,0.543978,0.518265,0.211941,0.0923518,0.0299098,0.0186566,0.0965296,0.108726,0.847674,0.923738,0.944108,0.870961,0.755353,0.772166,0.421497,0.43194,0.529798,0.589949,-0.907693,-0.589953,1.07208,1.31103,0.743519,0.816701,1.04869,0.961204,0.164383,0.233841,-1.70188,-1.89407,0.502621,0.261942,-0.905069,-1.0229,0.0696913,-0.020378,-0.0479301,-0.0315225
3117,0.692035,0.575464,0.525789,0.383996,0.525017,0.403639,0.150329,0.0401425,0.866461,0.877773,0.818872,0.980775,0.0146207,-0.056796,0.101112,0.119681,0.51446,0.459613,0.901854,0.959889,1.76232,2.08511,0.397902,0.639799,0.827763,0.906912,-0.73514,-0.823325,-1.22238,-1.15906,-1.68818,-1.8797,1.74859,1.50889,-0.401862,-0.525157,0.975649,0.890905,0.875849,0.896538
3118,0.0282022,-0.0862447,0.300759,0.249728,0.0535796,-0.0660925,0.0741545,0.0616285,0.00957379,0.0225963,0.961932,1.03781,0.402268,0.329956,0.610386,0.626685,0.436164,0.487286,0.92441,0.982078,-2.43237,-2.11098,-0.850855,-0.603121,2.82651,2.90831,0.398039,0.311951,-0.902569,-0.83244,1.2391,1.04656,0.103769,-0.131072,1.60875,1.48254,-0.159179,-0.249178,1.56763,1.5826
3119,0.377473,0.265577,0.47196,0.423581,0.928246,0.810955,0.339407,0.387173,0.44221,0.455141,0.213221,0.287683,0.480453,0.408949,0.356125,0.368341,0.536383,0.514959,0.121085,0.177549,1.70155,2.02294,-0.965571,-0.723607,1.73707,1.8116,1.77182,1.69275,0.644124,0.720384,-0.875897,-1.06485,-1.0218,-1.25652,-0.802546,-0.931568,1.05862,0.974398,-1.29364,-1.27325
3120,0.363119,0.250475,0.890435,0.842694,0.973237,0.85764,0.726273,0.712717,0.282238,0.326234,0.274742,0.349236,0.142349,0.0689119,0.095232,0.109996,0.534445,0.542632,0.512046,0.581165,-0.838866,-0.520454,0.0152055,0.259776,-0.49555,-0.427737,-0.214219,-0.287495,-1.65224,-1.5722,-0.882692,-1.06604,0.634453,0.391874,-0.654038,-0.760775,1.79884,1.71483,1.09117,1.11826
3121,0.874876,0.762394,0.903902,0.856854,0.661914,0.601778,0.587084,0.575497,0.185741,0.197328,0.848063,0.920288,0.351129,0.274807,0.586786,0.601281,0.3363,0.400744,0.929223,0.984782,-0.500647,-0.224447,0.115106,0.352281,0.48486,0.555581,0.579961,0.506923,0.908032,0.982369,0.5976,0.417891,-0.170387,-0.420383,-0.466754,-0.589981,0.179872,0.103039,0.410432,0.432833
3122,0.796839,0.685682,0.106591,0.0592677,0.460889,0.345917,0.965343,0.95381,0.914931,0.925326,0.705336,0.77668,0.97962,0.900277,0.762507,0.778671,0.134094,0.258856,0.771967,0.829574,-0.241464,0.0715596,-0.129295,0.108377,1.75482,1.82768,-0.0928018,-0.160303,-1.73389,-1.65555,-1.29142,-1.47529,0.973737,0.717508,-1.22957,-1.34796,-0.590242,-0.632453,0.898458,0.921853
3123,0.513341,0.488182,0.157047,0.107301,0.205653,0.090056,0.83804,0.826421,0.479748,0.491389,0.978481,1.05168,0.459171,0.377962,0.306303,0.322218,0.108781,0.116967,0.371643,0.429013,-0.827862,-0.51784,0.0693746,0.310349,0.593884,0.667774,0.0671021,0.00471188,-0.22055,-0.147859,-0.119978,-0.310394,0.394844,0.132555,0.123981,0.00966042,-1.29679,-1.36795,-1.71912,-1.69629
3124,0.425268,0.290682,0.609719,0.561656,0.957999,0.841397,0.484881,0.474708,0.624763,0.635844,0.638232,0.781549,0.485905,0.451402,0.614266,0.628805,0.99884,1.00546,0.664945,0.721953,-0.652292,-0.344306,-0.196798,0.0187896,0.8174,0.898723,-0.0628118,-0.121563,0.99002,1.07004,-0.609269,-0.803593,-1.65472,-1.91675,-1.81565,-1.93486,-0.78983,-0.85977,1.11441,1.14287
3125,0.204338,0.0931812,0.00789249,-0.0398844,0.776192,0.659611,0.997611,0.987506,0.484432,0.52786,0.438093,0.51142,0.606595,0.524842,0.504763,0.517227,0.659744,0.666201,0.557266,0.616248,1.06577,1.36931,-0.507175,-0.27277,0.291973,0.378509,0.887608,0.827291,-1.54442,-1.47301,-0.149885,-0.342025,0.218844,-0.0471617,0.449723,0.333947,1.14284,1.07157,0.519709,0.546669
3126,0.475389,0.364322,0.655861,0.610152,0.0384996,-0.0759879,0.330666,0.319939,0.495986,0.419876,0.302307,0.373218,0.949358,0.866823,0.888441,0.899463,0.558927,0.56506,0.88334,0.939983,0.776967,1.08818,-0.139455,0.144296,0.926053,1.00674,-1.32024,-1.38479,-0.077552,-0.0120162,-0.566031,-0.758357,-1.06499,-1.32844,-0.374232,-0.48373,1.09748,1.01845,0.778286,0.808067
3127,0.478574,0.369471,0.499469,0.451623,0.490155,0.377521,0.951084,0.942512,0.344394,0.311892,0.585222,0.686349,0.801473,0.815588,0.0785568,0.0876869,0.820387,0.826719,0.850283,0.905963,0.236271,0.54487,0.325844,0.561362,-0.0351399,0.051127,0.481198,0.409644,-0.600451,-0.530052,2.11283,1.91486,-2.06364,-2.33024,0.217222,0.106865,2.47077,2.38653,-0.177456,-0.150508
3128,0.816716,0.706571,0.0594829,0.0138688,0.281166,0.169743,0.34477,0.334528,0.193324,0.203908,0.928481,0.99948,0.845925,0.764352,0.773916,0.78413,0.16504,0.170895,0.089632,0.146607,-0.727429,-0.41403,0.448074,0.684615,0.55677,0.648594,-0.826805,-0.8931,-0.0228002,0.132419,-1.12019,-1.32084,-0.14563,-0.413509,1.03888,0.927917,0.584271,0.499876,0.618632,0.642773
3129,0.0973604,-0.0128909,0.297554,0.292713,0.884497,0.773302,0.112248,0.10188,0.846456,0.859085,0.117685,0.186778,0.434999,0.353234,0.772624,0.783767,0.845204,0.853173,0.647358,0.705481,0.697053,1.00516,-0.0451846,0.198208,-0.745386,-0.648352,0.676104,0.615286,0.721262,0.79489,-0.0722679,-0.278372,-1.65584,-1.92944,0.266183,0.155472,1.20078,1.11545,0.420391,0.43843
3130,0.196581,0.11054,0.546372,0.571558,0.0508658,-0.0622247,0.85606,0.84459,0.730856,0.742454,0.136454,0.142805,0.307391,0.167545,0.384813,0.397295,0.0647659,0.0733363,0.561643,0.622281,1.54094,1.85252,-2.1,-1.85957,0.298996,0.395019,0.676794,0.612249,0.216328,0.357402,-0.0684786,-0.339743,1.14791,0.87769,-2.40583,-2.51979,0.455504,0.365223,0.44438,0.410975
3131,0.341591,0.23397,0.896016,0.850402,0.275837,0.163376,0.686039,0.6095,0.399296,0.429165,0.0289996,0.0988329,0.0621688,-0.0181446,0.311539,0.388816,0.423239,0.508232,0.971296,1.03159,-0.134213,0.173746,1.97384,2.21427,0.116465,0.213172,0.0612568,-0.0464975,-0.160802,-0.0800868,-0.188656,-0.401115,-1.43943,-1.71617,-1.4109,-1.49341,-0.559294,-0.651209,0.367281,0.383521
3132,0.124681,0.102118,0.355609,0.308686,0.936893,0.82237,0.384143,0.37441,0.102278,0.115877,0.548095,0.61616,0.32125,0.252962,0.370171,0.380337,0.9323,0.943128,0.630778,0.690456,-1.54702,-1.24583,-0.433919,-0.19685,0.830777,0.919956,-0.637817,-0.705244,0.711599,0.798992,-0.990901,-1.20473,-0.894093,-1.17908,-0.224549,-0.46703,-0.108835,-0.255389,-0.571684,-0.560444
3133,0.0797623,-0.0297347,0.279836,0.234772,0.471953,0.357941,0.775492,0.767957,0.201491,0.214593,0.105195,0.174607,0.604278,0.524069,0.803336,0.811985,0.718072,0.72974,0.979013,1.04006,0.200192,0.499725,-1.29157,-1.05275,0.43928,0.523167,-0.331724,-0.362378,-0.238769,-0.149086,0.488772,0.279203,-1.35311,-1.64053,0.679673,0.559349,0.236828,0.140431,-0.0654463,-0.056214
3134,0.40994,0.215744,0.481111,0.437233,0.834216,0.72032,0.37402,0.366343,0.61539,0.627216,0.648381,0.716381,0.311735,0.232336,0.727947,0.67056,0.117392,0.129939,0.729041,0.790243,1.06074,1.36168,1.23759,1.47271,-0.612364,-0.527361,0.0498504,-0.0195126,0.270408,0.361324,-0.204271,-0.417359,0.893455,0.609511,-1.77621,-1.89,-0.686734,-0.781091,-0.507898,-0.502065
3135,0.572082,0.461224,0.41528,0.3731,0.742755,0.629354,0.92311,0.913734,0.659837,0.669396,0.246576,0.314817,0.692268,0.613791,0.597151,0.529135,0.245465,0.259309,0.220483,0.279334,-0.217673,0.0800891,-0.781341,-0.540445,-0.023842,0.056068,-0.0215708,-0.0858194,-0.00563553,0.0865896,-1.1303,-1.34357,0.772534,0.489896,-0.0718277,-0.192565,-0.739952,-0.834209,0.0116948,0.0173874
3136,0.308154,0.197721,0.834071,0.792213,0.312406,0.199443,0.166545,0.154485,0.250877,0.361003,0.766977,0.83631,0.271185,0.192769,0.380277,0.38771,0.595959,0.610592,0.184564,0.327814,0.581124,0.882201,-0.122744,0.122721,0.23096,0.231899,-0.994586,-1.06484,-0.892353,-0.815557,-0.932064,-1.09553,0.37062,0.0916832,2.39495,2.26919,0.979685,0.8926,-0.736819,-0.72924
3137,0.863396,0.75427,0.844777,0.801257,0.244643,0.130135,0.155975,0.12868,0.0397789,0.0526094,0.45267,0.52255,0.843597,0.764461,0.919845,0.925482,0.564959,0.494957,0.238983,0.376294,2.55867,2.85405,0.953192,1.20037,0.387851,0.40773,-1.17427,-1.23834,-1.81429,-1.7177,-0.629059,-0.847493,0.538561,0.259844,-0.471436,-0.597776,0.957845,0.871654,0.787742,0.798264
3138,0.980114,0.870277,0.58202,0.540163,0.796752,0.682651,0.113342,0.102875,0.41712,0.430275,0.706794,0.775988,0.742938,0.664803,0.418495,0.424214,0.363967,0.379322,0.366412,0.424774,0.0682028,0.369092,-0.20062,0.0494748,0.503651,0.583561,-1.57986,-1.6435,-0.630689,-0.531532,-0.818399,-1.03128,0.116446,-0.154271,3.01084,2.87954,-0.204134,-0.28609,0.95805,0.970712
3139,0.13563,0.0279498,0.952814,0.909875,0.845826,0.729336,0.608678,0.596217,0.510087,0.621222,0.0711851,0.140613,0.0151856,-0.0630291,0.494558,0.50063,0.113761,0.130802,0.62401,0.683498,-0.543007,-0.235393,-0.0403816,0.20404,1.11068,1.19597,-0.0869884,-0.149855,-0.692084,-0.59117,1.29373,1.07761,-1.0459,-1.30799,0.493516,0.367986,0.463606,0.375503,-0.166348,-0.159073
3140,0.962743,0.856518,0.373336,0.328842,0.0630196,-0.0552351,0.561215,0.549343,0.75077,0.81217,0.0150682,0.0827577,0.289242,0.213069,0.0684038,0.0741707,0.774569,0.793134,0.406281,0.527468,0.449636,0.749202,-1.71471,-1.46421,-0.270816,-0.180479,0.00604521,-0.146502,1.03356,1.13032,-0.336149,-0.55244,-0.809025,-1.06399,-0.61352,-0.741518,0.668183,0.583745,-2.02827,-2.02216
3141,0.482734,0.375571,0.952649,0.909803,0.855496,0.739042,0.916196,0.903235,0.989694,1.00312,0.557421,0.624532,0.902735,0.82444,0.290067,0.23017,0.279316,0.298047,0.312438,0.371437,-0.529807,-0.224384,0.289247,0.531208,1.54969,1.63641,-0.0807053,-0.143149,1.67276,1.7632,0.975511,0.763689,0.594314,0.339606,-0.423741,-0.547968,-0.785696,-0.871019,1.58883,1.59028
3142,0.544052,0.435824,0.568186,0.525441,0.681417,0.663861,0.47186,0.457344,0.946495,0.902905,0.392686,0.418718,0.867712,0.790387,0.320844,0.386169,0.275665,0.292402,0.86288,0.920373,1.59578,1.90293,0.259671,0.503137,-0.726064,-0.635903,-0.291546,-0.36252,-0.612499,-0.529377,1.35125,1.14658,0.392156,0.143795,1.12598,1.00848,0.637136,0.559117,-1.79969,-1.80332
3143,0.283791,0.177746,0.616336,0.623434,0.706504,0.58868,0.374061,0.359792,0.788402,0.802692,0.146064,0.212903,0.378897,0.304083,0.537464,0.542168,0.646159,0.662867,0.185739,0.244286,0.638502,0.863786,-0.390318,-0.15221,1.69525,1.78758,-0.252617,-0.321199,0.0858552,0.165105,-1.9134,-2.11965,-0.636679,-0.88787,2.20471,2.09013,-0.251119,-0.328821,0.483548,0.472976
3144,0.263847,0.157666,0.762286,0.721428,0.920564,0.804005,0.0147636,0.00277878,0.319715,0.334388,0.746575,0.814372,0.217435,0.145033,0.0592312,0.066662,0.62182,0.572641,0.273256,0.330407,-0.482512,-0.175362,0.0510758,0.293703,0.774121,0.862787,-0.889893,-0.957205,1.76177,1.84038,0.585656,0.37384,0.282942,0.0333529,-1.32259,-1.43717,1.08992,1.00708,-0.892256,-0.898568
3145,0.63104,0.525425,0.476742,0.435767,0.747059,0.728825,0.907226,0.896229,0.502349,0.519445,0.697485,0.807982,0.280554,0.208547,0.0215861,0.0305473,0.463887,0.482416,0.776171,0.834365,-1.18882,-0.88763,1.33119,1.57228,0.923524,1.01527,-1.86221,-1.93623,-0.463117,-0.385583,1.34915,1.1394,0.230519,-0.0264419,-0.954286,-1.07555,1.93547,1.85861,-1.11967,-1.13272
3146,0.637152,0.530574,0.97554,0.934247,0.768832,0.653644,0.874674,0.864217,0.276896,0.292106,0.733469,0.801592,0.703162,0.630317,0.954255,0.962954,0.821429,0.838739,0.378605,0.439088,1.21982,1.52231,0.212169,0.452318,-1.65899,-1.56072,-0.442689,-0.587104,0.276677,0.355261,-0.182508,-0.384675,-1.34842,-1.60665,-0.244698,-0.360944,-1.00826,-1.08632,-0.097855,-0.112103
3147,0.191147,0.0847278,0.513584,0.470884,0.930092,0.814912,0.346735,0.335974,0.975739,0.98849,0.425001,0.49255,0.371623,0.299913,0.311561,0.322003,0.520658,0.448443,0.618707,0.677835,-0.00214905,0.301419,0.0359509,0.270952,0.866285,0.963395,0.840394,0.762017,-1.45832,-1.37507,0.481349,0.273326,0.18509,-0.0686926,-0.68217,-0.795432,-0.31946,-0.392921,0.919639,0.908511
3148,0.492443,0.310899,0.303238,0.351183,0.654231,0.540494,0.0746463,0.0629463,0.107767,0.121174,0.972496,1.03863,0.349615,0.276932,0.520588,0.555423,0.041526,0.0581469,0.272823,0.33191,0.0452234,0.409305,-0.681008,-0.445238,-0.977959,-0.877369,0.781113,0.69571,1.61311,1.6936,1.49092,1.28289,-0.334544,-0.591868,-0.143208,-0.249242,-1.08251,-1.15675,-0.528057,-0.539895
3149,0.645431,0.537071,0.275153,0.231483,0.753043,0.637298,0.392772,0.382577,0.239433,0.250664,0.160348,0.225933,0.780329,0.708583,0.777833,0.788843,0.515175,0.518028,0.8796,0.940775,0.215381,0.517191,-0.517556,-0.27397,0.9607,1.0608,-0.170276,-0.253965,-1.18511,-1.1094,-1.30105,-1.5041,0.448999,0.191834,1.22289,1.12305,-0.78098,-0.853839,0.398321,0.388166
3150,0.638969,0.532429,0.550266,0.548788,0.290697,0.17287,0.416713,0.378954,0.852898,0.864761,0.397522,0.464255,0.786245,0.716174,0.145702,0.157016,0.96286,0.977908,0.735567,0.865205,2.29144,2.60004,-0.672917,-0.42366,1.65816,1.75277,-0.661218,-0.751588,-0.398032,-0.321212,-1.39531,-1.65239,0.0940195,-0.160942,-1.72197,-1.81327,0.761253,0.682684,-0.866403,-0.970703
3151,0.382787,0.274351,0.907747,0.866093,0.905284,0.786478,0.345112,0.375331,0.775437,0.824839,0.0860034,0.150494,0.381476,0.405356,0.00890546,0.0206361,0.487015,0.503236,0.728091,0.789635,-0.275052,0.0354098,0.409548,0.653987,-1.06782,-0.96869,0.515528,0.428116,1.00705,1.07932,-1.59859,-1.80067,-0.75072,-1.00444,0.269191,0.180075,-1.89598,-1.97918,-2.32571,-2.32957
3152,0.92026,0.81113,0.287234,0.245221,0.924525,0.807754,0.383405,0.371709,0.66846,0.784916,0.610837,0.677172,0.164973,0.0945384,0.147155,0.150521,0.399171,0.41297,0.321548,0.383244,-1.37278,-1.06272,-0.681888,-0.434305,-1.85349,-1.75424,1.37142,1.2842,0.458359,0.530543,0.108019,-0.0977522,0.708801,0.459129,-2.02764,-2.12267,0.673162,0.589735,1.36254,1.35835
3153,0.317711,0.20996,0.87477,0.830679,0.163965,0.0480599,0.560433,0.546763,0.758021,0.744993,0.251301,0.319606,0.26817,0.199651,0.266897,0.280406,0.520664,0.449182,0.165409,0.228037,-0.925834,-0.612267,0.633249,0.875352,0.347229,0.438314,0.93708,0.846936,0.143888,0.209339,-0.0529891,-0.253364,1.00328,0.751424,-0.501412,-0.598467,-1.90701,-1.98291,1.30174,1.29203
3154,0.743155,0.633052,0.424229,0.382223,0.771436,0.655923,0.328888,0.314114,0.693207,0.70507,0.764264,0.832419,0.0897003,0.0196568,0.203156,0.207469,0.472743,0.485394,0.671406,0.731994,0.795408,1.10135,0.749269,0.945004,-1.98765,-1.89697,2.16151,2.07403,1.4302,1.48827,-0.483816,-0.684492,-2.10279,-2.36231,-0.514064,-0.607886,0.533091,0.453341,0.147499,0.133885
3155,0.220807,0.112411,0.181961,0.140901,0.85494,0.737852,0.54476,0.530419,0.26893,0.281169,0.621801,0.688811,0.369289,0.300723,0.118693,0.134532,0.910395,0.92488,0.426842,0.486683,1.06748,1.36723,0.781397,1.01466,-0.515844,-0.427596,-2.00064,-2.0879,-1.16586,-1.10515,-0.258636,-0.455439,1.14408,0.886223,-0.222459,-0.321202,-0.410709,-0.486252,1.43755,1.4299
3156,0.855231,0.748221,0.497788,0.457335,0.0807047,-0.0365656,0.090669,0.0785512,0.19817,0.210529,0.0729506,0.139464,0.852056,0.782971,0.847778,0.862183,0.796137,0.797843,0.764754,0.825371,2.64481,2.94331,0.335164,0.573626,-0.42334,-0.337385,0.421435,0.340603,0.336376,0.402548,-0.977858,-1.16681,-0.756035,-1.02144,1.39892,1.29746,0.0346955,-0.042994,2.20119,2.19289
3157,0.312627,0.207124,0.129428,0.0882302,0.427113,0.310733,0.883135,0.872702,0.818436,0.829746,0.275737,0.351891,0.143788,0.0757556,0.470916,0.542413,0.656011,0.670805,0.220274,0.278608,-0.693866,-0.394491,-1.94366,-1.70837,-1.00934,-0.923592,-0.236775,-0.311752,1.28209,1.34378,0.804515,0.613186,0.119763,-0.14691,1.34828,1.24438,-0.381977,-0.467364,-0.0758993,-0.0752534
3158,0.933971,0.827312,0.894008,0.853431,0.13017,0.0115498,0.051828,0.0406295,0.901882,0.913586,0.615308,0.564318,0.357326,0.202142,0.208519,0.222643,0.179326,0.196133,0.391892,0.45078,0.471594,0.77472,0.732187,0.963812,1.12754,1.21905,0.724447,0.652175,0.60619,0.671996,0.482137,0.304088,-0.190382,-0.451989,-0.100028,-0.202673,0.370899,0.286339,-0.305406,-0.315221
3159,0.365524,0.261348,0.927994,0.887349,0.974874,0.857947,0.0658611,0.0537512,0.337657,0.349679,0.709731,0.776746,0.398201,0.328529,0.590504,0.604879,0.0949079,0.110552,0.0907782,0.149852,-0.467609,-0.167192,1.03942,1.27369,-1.84968,-1.75115,0.53807,0.462387,0.183679,0.219887,0.182087,-0.00501015,0.40583,0.147707,-0.996392,-1.09883,-1.28704,-1.37408,-0.551762,-0.555188
3160,0.867233,0.763478,0.338284,0.296236,0.7815,0.619377,0.907902,0.89583,0.137538,0.147677,0.36234,0.429562,0.105884,0.0367955,0.599616,0.579669,0.91543,0.928843,0.935114,0.993837,-0.141108,0.160501,0.619795,0.849189,-1.21475,-1.12292,-1.89925,-1.97157,-0.303227,-0.232222,0.859294,0.669936,-0.135637,-0.391997,1.4956,1.39462,-1.15508,-1.24105,2.62674,2.63147
3161,0.477786,0.373654,0.425398,0.470746,0.548619,0.380808,0.237928,0.223859,0.56139,0.570017,0.992149,1.06024,0.61115,0.479446,0.540348,0.554459,0.872396,0.884138,0.267736,0.327592,1.46472,1.76733,1.01786,1.24898,0.0238249,0.120095,0.248835,0.17188,-1.28484,-1.21115,-0.519613,-0.704007,1.35941,1.0998,-0.639957,-0.739697,-1.24575,-1.33977,0.387324,0.3943
3162,0.416621,0.292979,0.685981,0.645256,0.261251,0.142239,0.746989,0.731699,0.683003,0.689412,0.833348,0.935857,0.989841,0.922096,0.178768,0.192322,0.412251,0.520895,0.685402,0.74692,0.135505,0.450807,-1.11741,-0.888882,-0.500921,-0.400119,-0.493405,-0.574372,1.32101,1.39616,1.48832,1.30234,0.544089,0.287548,-0.882041,-0.975552,0.151345,0.0599571,-0.762622,-0.749837
3163,0.316045,0.212303,0.642639,0.600622,0.484038,0.36784,0.0980131,0.0840674,0.406664,0.412418,0.82139,0.81147,0.15566,0.0866865,0.0561627,0.0711928,0.145479,0.157653,0.338957,0.442097,-1.1744,-0.865717,-1.26585,-1.03857,-0.458796,-0.355334,0.142353,0.0635718,0.563798,0.633239,0.185396,-0.00694456,1.78851,1.53449,0.95493,0.86116,0.012254,-0.0862461,0.657809,0.669299
3164,0.0492536,-0.0569302,0.93911,0.89723,0.149809,0.0331789,0.614309,0.602116,0.984715,0.992154,0.648631,0.687083,0.269508,0.201746,0.140553,0.156918,0.461376,0.472497,0.0769683,0.137273,0.441659,0.757152,0.678666,0.905129,1.01792,1.11404,0.208273,0.136682,-1.52635,-1.45283,-2.35616,-2.55395,0.899393,0.642696,0.66105,0.565625,-0.367756,-0.497015,1.42687,1.43229
3165,0.741731,0.63379,0.160894,0.119822,0.241081,0.124296,0.606991,0.670851,0.0174892,0.0226099,0.630119,0.562697,0.0624123,-0.00337636,0.450828,0.468109,0.219632,0.229307,0.551107,0.546291,-0.558854,-0.248748,0.292397,0.523462,0.660474,0.763537,-1.7989,-1.87199,0.314998,0.393929,-0.00248303,-0.192597,-0.25015,-0.511026,-1.41713,-1.51933,-0.809284,-0.907784,-0.194856,-0.18384
3166,0.646428,0.536351,0.497383,0.455963,0.539873,0.420579,0.751463,0.739586,0.181922,0.18738,0.370215,0.43831,0.0836672,0.0191139,0.412721,0.492954,0.894812,0.907161,0.893186,0.955308,2.2465,2.55492,1.38617,1.61835,0.644683,0.748791,-1.33449,-1.40278,-1.15991,-1.07474,-0.561527,-0.748193,-0.485717,-0.738947,-0.136274,-0.243202,-0.424074,-0.596982,-0.300167,-0.281604
3167,0.242865,0.131142,0.015348,-0.0273267,0.49394,0.376307,0.500983,0.491652,0.00698671,0.0107477,0.762892,0.832531,0.337626,0.271278,0.500912,0.517798,0.161966,0.175971,0.650777,0.715653,-1.25508,-0.941031,-0.813502,-0.586324,-1.0097,-0.903122,-0.585495,-0.580713,0.650407,0.739564,0.517212,0.349246,0.392424,0.135579,-0.064219,-0.111658,-0.187431,-0.286181,-1.42843,-1.41139
3168,0.156036,0.0441666,0.0944208,0.0517564,0.0351807,-0.082858,0.932104,0.920337,0.768783,0.774801,0.194891,0.262758,0.12641,0.0609086,0.691183,0.709428,0.281515,0.295139,0.086462,0.150061,1.1409,1.45409,1.33359,1.5547,-1.34231,-1.23887,0.300947,0.241357,-0.572653,-0.484317,1.62749,1.44668,-0.306548,-0.569604,0.126968,0.0198859,-0.598944,-0.694008,0.0404584,0.0547006
3169,0.30433,0.194258,0.707538,0.666764,0.474234,0.356467,0.976681,0.963778,0.61646,0.722359,0.017197,0.0854611,0.837619,0.774083,0.360166,0.378075,0.0643498,0.0762984,0.151446,0.216803,-0.0125063,0.296221,0.00244066,0.231557,0.0101545,0.11046,-1.19638,-1.26117,2.01193,2.10492,-1.29758,-1.48474,1.00521,0.741951,2.49505,2.37913,-0.15146,-0.25075,0.351999,0.363327
3170,0.817716,0.706177,0.563495,0.523058,0.541913,0.423101,0.541106,0.527542,0.663625,0.669918,0.689019,0.757523,0.414927,0.353061,0.453922,0.569677,0.336553,0.36685,0.645984,0.616411,2.03433,2.34816,1.27358,1.49499,-0.918947,-0.814333,1.2723,1.20089,-2.40798,-2.315,-0.645326,-0.826734,0.0954504,-0.165066,-1.50972,-1.62268,0.0773434,-0.0255228,-0.759475,-0.750805
3171,0.4623,0.350879,0.652046,0.665346,0.834148,0.714557,0.763369,0.747888,0.0976436,0.101994,0.500719,0.569043,0.4751,0.452704,0.743348,0.761278,0.535157,0.657402,0.951266,1.01602,0.429637,0.745347,0.268861,0.48374,1.48778,1.59024,0.759657,0.687434,-0.793347,-0.701461,-0.948205,-1.13583,0.117165,-0.0679265,0.7535,0.646136,0.598019,0.496931,1.34892,1.36308
3172,0.96993,0.858033,0.846564,0.807634,0.708919,0.588329,0.526961,0.472455,0.745533,0.752214,0.964873,1.03199,0.613614,0.552346,0.0373013,0.0578663,0.936005,0.947954,0.664416,0.730577,1.16094,1.47101,-1.56262,-1.34333,-0.18774,-0.0927922,0.582508,0.513939,-0.692649,-0.603692,-1.26018,-1.44493,0.288517,0.0292127,0.442309,0.332804,0.198989,0.105567,0.716327,0.73716
3173,0.917617,0.814946,0.00249058,-0.0375552,0.986314,0.864267,0.210469,0.197022,0.411717,0.420069,0.681744,0.74924,0.280604,0.217186,0.322167,0.343784,0.0574864,0.0681893,0.126556,0.194736,1.1848,1.49231,1.36633,1.59131,0.246482,0.336173,-0.119031,-0.18393,0.632791,0.720727,0.38064,0.197312,0.846161,0.583363,0.363622,0.247258,0.410262,0.313809,-0.892241,-0.87897
3174,0.907786,0.771858,0.412968,0.372529,0.404908,0.285438,0.993206,0.980879,0.898826,0.9084,0.687641,0.756328,0.586896,0.524138,0.30305,0.32344,0.612472,0.623404,0.251833,0.26845,0.636583,0.953059,-1.03575,-0.806657,-1.04396,-0.960772,-1.42039,-1.48667,-0.0980195,-0.0120817,-0.692485,-0.881858,-0.556433,-0.821205,0.267123,0.161712,1.81808,1.72876,-0.517083,-0.497943
3175,0.894622,0.728771,0.185441,0.142632,0.0514748,-0.0682933,0.36065,0.348663,0.364573,0.375255,0.459972,0.527866,0.66296,0.598274,0.887278,0.906852,0.752142,0.763382,0.205548,0.342164,0.102484,0.413809,1.19486,1.42965,-0.538491,-0.457249,-1.15022,-1.12638,0.209683,0.297293,1.09643,0.911223,0.19394,-0.0684144,-0.553004,-0.655965,-0.931411,-1.0187,0.249407,0.265048
3176,0.797581,0.685684,0.799525,0.75764,0.834267,0.714383,0.110854,0.100729,0.461977,0.473971,0.54911,0.70208,0.0449584,-0.0180206,0.682555,0.752982,0.371246,0.383661,0.375649,0.415878,-1.59467,-1.28049,0.0664056,0.294013,2.21395,2.29716,-0.697329,-0.766087,-0.131339,0.0388324,-0.442125,-0.628286,0.0588911,-0.137933,0.577514,0.472948,-1.34222,-1.42653,-0.913281,-0.893101
3177,0.45172,0.340432,0.470658,0.427383,0.768099,0.649342,0.483781,0.527669,0.172762,0.186644,0.807421,0.876293,0.343933,0.279137,0.58131,0.599112,0.434694,0.532614,0.421413,0.489592,0.0487495,0.356353,1.38186,1.60367,0.280369,0.361273,0.275831,0.215271,-0.310499,-0.219628,1.07803,0.887328,0.0547372,-0.207452,-0.0639229,-0.162638,0.0507208,-0.0268067,-0.154369,-0.13011
3178,0.821059,0.70819,0.672318,0.567781,0.306629,0.190177,0.965303,0.954608,0.507441,0.518824,0.133779,0.200743,0.979759,0.915725,0.208872,0.227147,0.668144,0.681566,0.914515,0.983494,-0.884577,-0.572892,-0.145453,0.0765166,0.945388,1.0206,0.45265,0.396327,-1.89597,-1.81008,-1.1058,-1.30146,0.353286,0.0848437,0.0408676,-0.0605909,-0.273767,-0.357761,-1.15048,-1.11906
3179,0.438857,0.403775,0.752425,0.708178,0.562745,0.529946,0.537522,0.527445,0.323168,0.336507,0.213176,0.197337,0.322297,0.258277,0.482571,0.505643,0.543222,0.486338,0.579342,0.647064,-2.47331,-2.16043,-0.630334,-0.409891,1.32767,1.40363,0.0653584,0.00665411,-1.04153,-0.961137,-1.75556,-1.9538,0.0372056,-0.236187,1.22714,1.12592,0.583116,0.493773,0.409309,0.440691
3180,0.210391,0.0993598,0.552863,0.508714,0.985338,0.869716,0.475629,0.476189,0.447301,0.495457,0.129969,0.193931,0.706678,0.64503,0.767026,0.78414,0.278778,0.29111,0.681594,0.710942,-1.65893,-1.34411,0.103197,0.329748,0.352435,0.472655,-0.720568,-0.784148,-0.73865,-0.673765,1.08188,0.886077,0.27846,0.00781479,-2.26281,-2.36878,-0.989167,-1.07114,1.5275,1.5525
3181,0.970249,0.859201,0.657351,0.565216,0.446487,0.330645,0.435464,0.424934,0.638164,0.654407,0.620335,0.686557,0.428141,0.388889,0.762298,0.8003,0.354334,0.341335,0.705608,0.774821,-1.13893,-0.830075,-2.22427,-2.00498,-0.528048,-0.458322,0.362311,0.302407,-0.463102,-0.386394,2.81382,2.61932,-0.289641,-0.561817,0.444347,0.331108,-0.922028,-0.999379,-0.572429,-0.542957
3182,0.969224,0.859769,0.66427,0.621718,0.599785,0.482244,0.737238,0.725324,0.30522,0.388906,0.661671,0.726939,0.19211,0.132748,0.799981,0.816461,0.378713,0.391559,0.224872,0.294258,1.6028,1.90999,-1.03651,-0.819802,1.40541,1.47985,-0.593985,-0.647268,0.235816,0.308088,-0.71758,-0.910339,0.0405241,-0.224769,0.287896,0.173148,1.10473,1.03353,-0.885947,-0.853685
3183,0.560941,0.449838,0.972103,0.928177,0.179335,0.0625775,0.36616,0.353406,0.106527,0.123404,0.105411,0.172753,0.517045,0.45683,0.0144247,0.0297838,0.210756,0.22386,0.504542,0.572073,0.48254,0.782904,-0.254299,-0.0314556,-1.72744,-1.65684,1.85084,1.79574,0.640222,0.711641,0.172186,-0.0219883,-0.509132,-0.778268,0.918671,0.810404,0.557589,0.486705,-0.821747,-0.782678
3184,0.946111,0.832661,0.29756,0.252378,0.0810881,-0.0380947,0.643619,0.62866,0.633851,0.65243,0.480253,0.547654,0.842197,0.780912,0.678082,0.694108,0.995114,1.00604,0.0451487,0.111214,0.432502,0.728731,-1.15476,-0.933605,0.375533,0.441183,0.922362,0.862218,-0.301442,-0.262709,0.662991,0.469412,-1.58774,-1.85705,-0.298156,-0.406265,1.06583,0.994881,-0.737913,-0.711671
3185,0.378168,0.266697,0.35725,0.312049,0.776536,0.657411,0.320426,0.305853,0.406658,0.42509,0.210045,0.279777,0.4477,0.384855,0.188412,0.203031,0.354254,0.365616,0.706409,0.774558,-1.69549,-1.40551,0.11198,0.329826,0.734063,0.795235,1.10742,1.04327,-1.30387,-1.23706,0.701319,0.514436,0.367448,0.104793,-0.499673,-0.611313,-0.0396545,-0.112392,0.624152,0.646986
3186,0.857707,0.748013,0.770703,0.727158,0.250036,0.128937,0.273224,0.289307,0.495284,0.513614,0.543965,0.6142,0.633119,0.501521,0.135313,0.15174,0.0953061,0.106805,0.830026,0.896007,-0.0710873,0.217362,1.0102,1.22158,1.85883,1.91533,-0.47114,-0.535117,-0.314269,-0.249998,-0.00469615,-0.19694,0.217095,-0.0453046,0.311404,0.194548,0.99785,0.926074,-0.592415,-0.572711
3187,0.454344,0.342804,0.376747,0.433782,0.546957,0.425219,0.287908,0.272762,0.0761214,0.0945746,0.235395,0.305158,0.683627,0.618187,0.51668,0.545081,0.166516,0.0937568,0.72279,0.790302,-0.342368,-0.0491932,-0.26557,-0.053421,-0.407445,-0.356976,0.775451,0.705737,-0.510087,-0.490987,1.25421,1.05833,-2.13404,-2.39862,0.454819,0.342038,0.198386,0.130508,0.451853,0.436059
3188,0.809986,0.699621,0.18129,0.140405,0.0745156,-0.0497562,0.876974,0.860067,0.0420149,0.0602183,0.25907,0.327093,0.187514,0.122384,0.9235,0.938422,0.0664568,0.0807084,0.037597,0.103148,0.632942,0.922059,0.998862,1.21001,0.537844,0.59696,-0.096172,-0.165708,-0.796248,-0.731976,-1.71885,-1.91577,-0.953438,-1.21385,-2.31879,-2.43718,-1.5484,-1.61218,1.42216,1.44483
3189,0.478861,0.369907,0.831079,0.790442,0.57717,0.453805,0.730685,0.712334,0.958147,0.976675,0.578032,0.6472,0.00696899,-0.0576101,0.972367,0.988437,0.88646,0.898999,0.480019,0.546704,0.767185,1.04988,-0.919144,-0.711719,0.000916419,-0.000529418,-0.322799,-0.399826,-1.4662,-1.40376,-0.485429,-0.676157,1.26805,1.00485,-2.16922,-2.28969,0.0765917,0.0194639,-0.628637,-0.603241
3190,0.653553,0.539646,0.429456,0.448146,0.745783,0.619964,0.0353951,0.0151787,0.375623,0.392736,0.271216,0.43766,0.309028,0.24412,0.281652,0.295527,0.336491,0.349703,0.143957,0.210273,1.75001,2.03447,-0.518032,-0.311928,-0.65961,-0.598019,-2.34188,-2.42497,0.468759,0.53752,0.00517313,-0.184756,-0.436594,-0.700443,0.0500781,-0.0682926,-1.58916,-1.64095,0.821667,0.845963
3191,0.818654,0.709384,0.14788,0.10585,0.566938,0.488011,0.809514,0.789356,0.589905,0.607993,0.158811,0.22812,0.933789,0.869591,0.528199,0.623578,0.724017,0.735453,0.104046,0.171755,1.28941,1.56916,-0.362133,-0.157363,-0.458313,-0.39917,0.792913,0.714134,-0.174651,-0.102674,0.942332,0.749707,-0.143689,-0.441335,0.0998114,-0.0153055,0.341258,0.290389,-1.61143,-1.58355
3192,0.365012,0.254286,0.163596,0.12001,0.561486,0.356058,0.0555151,0.0366944,0.0143237,0.0346546,0.645912,0.715264,0.858035,0.815694,0.935982,0.951629,0.144796,0.156031,0.781513,0.850615,-1.45769,-1.17763,0.209195,0.412781,1.66897,1.72916,-1.55432,-1.63364,0.690762,0.761462,-0.00973135,-0.207219,0.0812289,-0.182226,-1.8123,-1.92891,-2.63045,-2.67685,-0.0536064,-0.0237984
3193,0.352233,0.239185,0.861651,0.820241,0.350243,0.224105,0.510085,0.489776,0.653293,0.67386,0.55275,0.622376,0.827655,0.761796,0.551056,0.565157,0.370827,0.382638,0.688706,0.756775,0.0315574,0.306007,-1.37392,-1.17482,1.90625,1.96011,1.40218,1.32428,0.972004,1.04251,0.231999,0.0370278,-0.953989,-1.21389,-0.106963,-0.214111,-0.630135,-0.67332,-0.486587,-0.45519
3194,0.593638,0.512328,0.397763,0.356879,0.425078,0.327915,0.0208192,0.00286285,0.0955136,0.115315,0.223831,0.293795,0.399221,0.332413,0.666295,0.680913,0.0397918,0.0533434,0.98875,1.0542,-1.59411,-1.32339,0.347739,0.553397,0.924686,0.88567,-0.23975,-0.319627,-0.55655,-0.488635,1.11394,0.925379,0.7812,0.526848,0.883826,0.775063,-1.32868,-1.37389,1.58038,1.61261
3195,0.900088,0.785471,0.396497,0.356501,0.637344,0.431724,0.477131,0.460548,0.724983,0.74448,0.457858,0.527174,0.90518,0.838834,0.366353,0.358892,0.192999,0.32415,0.00439631,0.0694416,0.150721,0.422166,-0.313065,-0.101949,-0.239552,-0.188765,1.84295,1.75941,-0.458685,-0.390866,0.627456,0.446318,1.03422,0.786424,-0.157288,-0.272513,1.02272,0.982814,-1.80115,-1.76393
3196,0.194771,0.0821053,0.645406,0.603508,0.662202,0.535534,0.318993,0.302818,0.865628,0.884244,0.211786,0.278925,0.0497271,-0.0168434,0.0227392,0.0368709,0.532708,0.594956,0.652473,0.718253,1.31332,1.59138,-0.514626,-0.247211,0.901694,0.948073,-1.27532,-1.35699,0.664475,0.732175,-1.58342,-1.75954,1.03809,0.787537,-0.0539893,-0.170465,-0.95052,-0.986786,-0.0385023,-0.00380557
3197,0.550045,0.438922,0.345407,0.303657,0.11004,-0.018607,0.819522,0.805152,0.328132,0.346091,0.700824,0.766069,0.445514,0.379635,0.639851,0.651784,0.852211,0.865762,0.27144,0.337846,-0.0346565,0.249928,-0.622534,-0.392473,-0.149183,-0.102455,0.164307,0.0875751,-1.09692,-1.03003,-0.23133,-0.413235,1.61174,1.35751,-0.592893,-0.711992,1.03482,0.994519,1.0573,1.09289
3198,0.136056,0.0235594,0.602599,0.56027,0.371548,0.216235,0.540599,0.527424,0.852397,0.86961,0.517893,0.615166,0.461311,0.397423,0.0690832,0.0807682,0.042711,0.0573793,0.335001,0.400089,-0.282525,-0.000486356,-0.748851,-0.537735,0.971975,1.01764,0.481996,0.405546,-1.05909,-0.994231,-0.15059,-0.337604,0.436679,0.185126,-0.535401,-0.659004,1.01243,0.973573,0.969814,1.00844
3199,0.786423,0.675104,0.0900781,0.0474293,0.580319,0.451077,0.852133,0.837147,0.670387,0.687293,0.271523,0.464263,0.0903596,0.026709,0.60759,0.61854,0.906939,0.924101,0.828548,0.893991,0.108284,0.388516,-0.410809,-0.196761,-0.695403,-0.648537,-0.599658,-0.683088,0.796214,0.865868,-0.820102,-1.00367,0.298286,0.0987079,-0.68582,-0.803465,-0.551563,-0.591336,-0.256425,-0.211258
3200,0.0269755,-0.0858759,0.211388,0.170585,0.409943,0.279238,0.758587,0.674798,0.0608871,0.077792,0.246695,0.31336,0.251236,0.18813,0.276819,0.287187,0.510122,0.580196,0.434656,0.498714,-0.115876,0.167868,0.197562,0.405086,-0.699054,-0.648562,0.584445,0.496616,1.937,2.0066,1.46852,1.27787,0.258571,0.0122899,2.48669,2.37781,-0.108056,-0.148078,0.547437,0.597006
3201,0.355234,0.2417,0.929843,0.891305,0.707063,0.498959,0.577741,0.51245,0.107778,0.125282,0.251176,0.31543,0.979742,0.916788,0.800725,0.809493,0.219546,0.236291,0.526943,0.590185,-2.18198,-1.90526,1.80494,2.00979,-1.53527,-1.48223,0.187703,0.106943,-0.273665,-0.204587,-1.14707,-1.34384,-0.209254,-0.531489,2.35711,2.24901,-0.357657,-0.401776,0.884874,0.934661
3202,0.200345,0.0891092,0.774411,0.746596,0.849137,0.71868,0.365089,0.350102,0.357122,0.423499,0.820006,0.886482,0.0110977,-0.0512129,0.892495,0.900376,0.350828,0.405873,0.399206,0.382808,0.321657,0.596991,0.286911,0.575191,-0.541007,-0.482737,0.890105,0.80808,0.0702735,0.137726,1.77752,1.58242,-0.834706,-1.07527,0.689105,0.586634,1.94412,1.90826,-1.62013,-1.56831
3203,0.974719,0.864202,0.639681,0.601886,0.714821,0.58198,0.890924,0.877763,0.704164,0.721715,0.759468,0.792151,0.828539,0.764877,0.609835,0.578355,0.463531,0.575456,0.114378,0.17543,0.371083,0.647661,-1.06426,-0.859408,-1.29922,-1.23696,0.80214,0.71229,-0.340015,-0.27463,0.895975,0.702176,0.936734,0.695885,-1.20967,-1.31099,1.68056,1.63877,0.46591,0.517858
3204,0.656163,0.544983,0.152787,0.11411,0.295342,0.162314,0.167195,0.155062,0.482153,0.54329,0.62859,0.69782,0.290005,0.228096,0.246939,0.256333,0.727314,0.745038,0.599114,0.659132,-0.891204,-0.617869,0.456654,0.668306,-1.01559,-0.959363,1.25816,1.16801,0.81376,0.879781,-0.185828,-0.353666,1.89201,1.64877,-0.0448437,-0.153158,0.0862665,0.0433489,-1.61499,-1.5618
3205,0.0379572,-0.0711221,0.176443,0.137528,0.982497,0.847198,0.758792,0.747394,0.348476,0.364866,0.165531,0.232283,0.0869385,0.0229735,0.675099,0.682948,0.184943,0.200549,0.764939,0.826067,1.68971,1.97145,-0.99952,-0.780748,-0.201338,-0.143965,0.226157,0.143463,-0.47164,-0.404151,-1.21514,-1.40951,1.62283,1.37487,0.893182,0.792345,0.272693,0.235911,-1.21772,-1.16507
3206,0.667575,0.55956,0.865887,0.827194,0.999467,0.863625,0.138146,0.124369,0.779366,0.79741,0.432197,0.501054,0.0869945,0.0212536,0.805662,0.81397,0.774026,0.791188,0.237714,0.300079,-0.677651,-0.397358,0.384225,0.605606,-1.62358,-1.56508,0.86789,0.781407,-0.0722302,-0.0230233,-1.12136,-1.3181,-1.87163,-2.11935,0.201026,0.0436795,-0.436686,-0.479844,-0.252351,-0.193822
3207,0.412157,0.325476,0.890204,0.850611,0.667324,0.604154,0.612279,0.597377,0.569638,0.585614,0.0380475,0.108921,0.483778,0.35497,0.354533,0.363147,0.592277,0.607757,0.738035,0.79871,-1.13658,-0.862675,0.329247,0.546459,-0.90529,-0.842778,1.92082,1.83795,0.283653,0.358104,-0.781115,-0.91544,2.11308,1.86536,-0.608483,-0.704986,-0.334825,-0.377205,0.72955,0.777423
3208,0.201589,0.0913918,0.117534,0.0777944,0.481972,0.344683,0.0652769,0.0495599,0.79215,0.713754,0.291612,0.448586,0.755778,0.688686,0.301819,0.311856,0.762725,0.76007,0.169977,0.233118,-0.774011,-0.503234,-0.227117,-0.00318164,0.456702,0.521194,-0.908453,-0.989172,0.0676282,0.145004,-0.255543,-0.512777,-1.27066,-1.51253,-0.488507,-0.614161,-1.31362,-1.36042,-0.664662,-0.610488
3209,0.262111,0.148341,0.0531303,0.0136607,0.867045,0.731691,0.383432,0.428529,0.824609,0.841894,0.717888,0.788252,0.920975,0.854243,0.528512,0.505689,0.894369,0.912382,0.88482,0.947477,-1.79473,-1.52514,-0.518546,-0.292196,-0.42491,-0.357976,-0.0805264,-0.167103,0.42332,0.503349,0.0812914,-0.110113,-0.6368,-0.881694,-0.428399,-0.523336,-0.807773,-0.852247,-0.703597,-0.581372
3210,0.313054,0.205291,0.53645,0.49738,0.105208,-0.0280032,0.820433,0.807498,0.528716,0.545352,0.796369,0.869074,0.195571,0.126411,0.688598,0.699522,0.394079,0.412629,0.505723,0.56707,0.222034,0.495126,0.0641622,0.293566,-0.918709,-0.846872,0.73601,0.654967,-1.85957,-1.77427,1.15491,0.962677,-0.658535,-0.895675,-0.843137,-0.943054,1.2575,1.2144,-0.60108,-0.552257
3211,0.0427798,-0.0639423,0.385847,0.348556,0.853627,0.718157,0.826924,0.839886,0.714529,0.662978,0.598224,0.745214,0.481712,0.468209,0.0841071,0.0935237,0.298372,0.317165,0.979265,1.04107,0.251336,0.529051,-1.5972,-1.37468,0.524886,0.593628,0.308319,0.234043,0.507209,0.595256,-1.70241,-1.88858,1.60061,1.35437,-0.605913,-0.70332,-0.541512,-0.575757,0.115994,0.165742
3212,0.295067,0.187173,0.635964,0.600238,0.62187,0.485026,0.887996,0.872275,0.762118,0.780604,0.547199,0.621353,0.878232,0.810007,0.42996,0.440768,0.729804,0.747622,0.616308,0.709288,0.634253,0.918054,0.386866,0.603333,-1.47408,-1.40396,-1.31117,-1.37839,0.26088,0.351344,-0.152803,-0.34192,0.984264,0.739592,1.46138,1.36784,0.399811,0.368184,-0.395817,-0.340747
3213,0.766728,0.659064,0.546066,0.449303,0.638663,0.501453,0.070209,0.0553426,0.0307927,0.0490777,0.590904,0.666483,0.751884,0.752392,0.184082,0.192771,0.807121,0.825634,0.313597,0.377502,0.294015,0.576097,-0.653848,-0.438686,0.874294,0.938249,1.30644,1.23925,-0.214056,-0.121676,0.0131636,-0.174636,0.715774,0.465685,0.598031,0.504378,1.56082,1.5294,-0.403149,-0.348126
3214,0.211081,0.102899,0.332375,0.298368,0.375014,0.23723,0.156559,0.143476,0.69048,0.709463,0.207591,0.284997,0.759813,0.694776,0.165698,0.172427,0.636271,0.622043,0.667099,0.731384,-1.44444,-1.16451,0.18537,0.406451,1.88009,1.93774,1.47562,1.40426,1.4254,1.52174,2.36981,2.18671,1.02301,0.773385,-1.71122,-1.79837,-1.64006,-1.67373,0.288898,0.351402
3215,0.214676,0.108048,0.605416,0.569403,0.859272,0.720245,0.730248,0.715924,0.814584,0.750416,0.460917,0.538435,0.704585,0.63716,0.72177,0.730325,0.398496,0.418451,0.486337,0.497811,0.363629,0.642137,-0.973884,-0.759599,-2.21445,-2.1599,0.102123,0.026059,-1.09578,-1.00092,1.00386,0.809395,-0.476272,-0.726263,0.43652,0.349043,-1.03911,-1.07424,0.993203,1.05093
3216,0.546967,0.440202,0.0456189,0.0072154,0.870798,0.756017,0.202448,0.187681,0.773787,0.791369,0.974068,1.05125,0.866265,0.798581,0.6621,0.669671,0.957054,0.978217,0.199798,0.264238,-0.556194,-0.271921,-0.641555,-0.434764,0.429258,0.486311,1.16655,1.0826,0.554167,0.642494,-0.385108,-0.567925,-0.02537,-0.279362,-2.37844,-2.46639,-0.0358057,-0.0677616,-0.897189,-0.842734
3217,0.515589,0.408919,0.0941555,0.0552483,0.931333,0.791789,0.711466,0.695521,0.164479,0.181868,0.659795,0.729058,0.294428,0.226382,0.925402,0.935274,0.47686,0.49814,0.698151,0.76287,-1.02806,-0.737237,0.0489531,0.257439,-0.885317,-0.825584,-0.795262,-0.881981,-0.107234,-0.0118571,-0.97271,-1.15645,-0.145068,-0.398977,1.10936,1.02141,-0.550554,-0.584277,1.05843,1.11566
3218,0.809773,0.701145,0.710433,0.670256,0.406461,0.339429,0.726559,0.795284,0.881031,0.899285,0.330394,0.406868,0.169706,0.197132,0.0668181,0.0747816,0.767828,0.739595,0.638976,0.742539,-0.716264,-0.424012,-0.487243,-0.275994,0.517698,0.582647,0.276734,0.190295,-0.411872,-0.316555,1.88606,1.6986,0.60784,0.353813,0.441425,0.354151,-0.118063,-0.156789,-0.822621,-0.761641
3219,0.0664113,-0.0437728,0.944082,0.902671,0.0242874,-0.112931,0.908904,0.895047,0.833944,0.854851,0.386718,0.462471,0.189261,0.167883,0.582431,0.592073,0.957542,0.98105,0.655002,0.722208,0.439287,0.730468,-0.467806,-0.259911,0.648108,0.720511,-0.669888,-0.759381,-0.101817,-0.00718047,0.117202,-0.0702559,-0.181061,-0.428557,-0.964596,-1.04595,2.9249,2.88967,0.767452,0.826399
3220,0.799901,0.68885,0.750431,0.708041,0.395506,0.259855,0.789462,0.77712,0.320187,0.341729,0.0959637,0.173559,0.206501,0.138633,0.808451,0.815998,0.337561,0.36062,0.389986,0.407083,0.135716,0.433504,-0.918459,-0.716686,2.15754,2.23662,-0.00946495,-0.104382,1.56981,1.6681,0.0239079,-0.163325,-1.39769,-1.64609,0.00132909,-0.0877203,1.28475,1.24566,0.695896,0.810435
3221,0.654911,0.545841,0.0684517,0.0274443,0.0956633,-0.0393282,0.914055,0.857505,0.704848,0.646632,0.14631,0.310385,0.957614,0.888146,0.0325259,0.0396231,0.717733,0.741374,0.0266045,0.0919585,-1.06447,-0.770489,-0.452129,-0.254864,-2.0976,-2.01851,0.355601,0.260055,0.313722,0.413218,-0.99848,-1.18178,1.02768,0.781962,-1.32667,-1.41346,1.40482,1.36226,0.748695,0.794471
3222,0.986983,0.877995,0.398493,0.303409,0.283906,0.146459,0.950645,0.93789,0.928028,0.951535,0.36926,0.44721,0.81428,0.771733,0.994073,0.999817,0.747326,0.718536,0.304025,0.369773,0.333425,0.633024,-0.325284,-0.131611,0.44766,0.52718,-2.25932,-2.3586,-0.168413,-0.0735633,-0.902608,-1.09038,-0.243815,-0.480977,1.39969,1.31847,-0.244575,-0.281749,0.71956,0.778507
3223,0.151571,0.0410993,0.532064,0.579375,0.0332347,-0.102967,0.416287,0.404891,0.68353,0.708747,0.238984,0.31862,0.723066,0.655319,0.327559,0.33353,0.672783,0.695698,0.978644,1.04368,0.0773378,0.38261,1.3363,1.53677,0.413582,0.4977,0.0217984,-0.0805781,1.93451,2.02739,0.260038,0.0745152,-0.868421,-1.10975,0.381644,0.300366,1.0961,1.05415,-0.071457,-0.0141574
3224,0.825853,0.716367,0.898329,0.85534,0.320659,0.163422,0.163825,0.151997,0.122719,0.150202,0.8783,0.959427,0.39357,0.324915,0.280545,0.287011,0.0882721,0.110717,0.694319,0.758237,-0.837348,-0.531448,0.716901,0.91224,-1.06108,-0.98364,0.0844242,-0.0221922,-0.236214,-0.13812,0.310961,0.119539,0.597422,0.35381,0.192792,0.11071,0.557138,0.52156,-1.2269,-1.17231
3225,0.264056,0.154651,0.762873,0.639845,0.557905,0.429811,0.827698,0.813119,0.408376,0.422781,0.378594,0.459359,0.869868,0.801438,0.831846,0.840209,0.109283,0.10243,0.99807,1.06084,0.412658,0.716557,0.429874,0.623226,0.630575,0.705284,-1.8461,-1.95285,-0.632996,-0.534617,-1.9054,-2.10255,1.09116,0.845789,-0.820804,-0.907392,0.855788,0.824467,-0.141434,-0.0899666
3226,0.641272,0.532727,0.467555,0.42435,0.832402,0.6962,0.211785,0.195467,0.666984,0.695359,0.139594,0.220905,0.676494,0.606491,0.0315173,0.0389496,0.0699821,0.0941419,0.162847,0.224959,-0.862587,-0.56503,0.401022,0.595155,-0.728677,-0.653975,0.785414,0.6775,1.73099,1.83491,-1.82295,-2.02692,-1.29506,-1.53875,-0.667657,-0.759903,0.828861,0.803521,-0.0983135,-0.0516285
3227,0.665231,0.557795,0.641703,0.598203,0.414856,0.276534,0.138886,0.122322,0.594795,0.602452,0.451035,0.625299,0.075933,0.00544042,0.905685,0.915677,0.576932,0.599797,0.954611,1.01726,0.951113,1.25543,-0.118938,0.0307009,2.5714,2.64499,-1.3087,-1.41034,-0.901859,-0.80301,-2.18336,-2.38052,-0.654188,-0.891846,-0.185689,-0.275212,0.522981,0.502774,1.42244,1.47588
3228,0.216705,0.107371,0.433422,0.388618,0.243563,0.104695,0.48187,0.44991,0.479299,0.509546,0.949822,1.02969,0.532862,0.374625,0.202171,0.212265,0.558978,0.645395,0.364853,0.426599,0.886292,1.1843,-0.667322,-0.533753,0.65298,0.72425,2.43594,2.3343,-0.237073,-0.138575,-0.117945,-0.319511,0.810509,0.571719,0.0331914,-0.0507083,-0.155308,-0.182372,-0.266889,-0.216328
3229,0.700324,0.588686,0.0121742,-0.0353148,0.424869,0.286018,0.792579,0.777497,0.635744,0.664553,0.648549,0.725994,0.814384,0.74381,0.60155,0.565745,0.666053,0.690993,0.532762,0.593535,-1.41594,-1.12266,-1.29234,-1.09821,-1.48943,-1.41792,0.424066,0.325629,-2.02464,-1.93298,-0.234816,-0.347256,-1.02136,-1.25787,0.621809,0.539887,0.192176,0.186401,-0.253022,-0.208748
3230,0.792849,0.679734,0.620965,0.575018,0.270725,0.13412,0.607594,0.590056,0.537701,0.567631,0.808954,0.885464,0.26059,0.191066,0.908127,0.919225,0.398702,0.378046,0.240327,0.302725,-0.883947,-0.593361,0.288795,0.476968,-1.86758,-1.79913,-1.90503,-2.00352,1.6443,1.73235,-0.173435,-0.375,1.23099,0.992169,-0.83713,-0.923035,0.536513,0.555174,0.000902226,0.0376143
3231,0.55165,0.436072,0.605095,0.559427,0.785719,0.648134,0.750797,0.769241,0.687916,0.720777,0.144333,0.220517,0.52739,0.457483,0.36579,0.377803,0.0415142,0.0650985,0.171899,0.288119,-2.05487,-1.76583,-0.640206,-0.455283,-1.02842,-0.952637,1.92411,1.82176,-0.0456479,0.0476227,0.477082,0.269035,-2.04995,-2.28347,0.384167,0.24598,0.95101,0.923946,1.52934,1.56512
3232,0.94756,0.833837,0.136872,0.0911671,0.0633193,-0.0728629,0.967504,0.948426,0.845505,0.873924,0.764931,0.841276,0.476687,0.409238,0.689351,0.69927,0.64076,0.666972,0.211206,0.273513,0.488031,0.771927,-0.315558,-0.130448,-2.77716,-2.69799,-0.121864,-0.220941,0.904501,1.0035,0.883843,0.680701,1.35051,1.11502,1.50357,1.415,0.237287,0.159394,0.181979,0.223212
3233,0.011187,-0.101565,0.77544,0.730518,0.729724,0.591854,0.263457,0.245669,0.323692,0.35091,0.995934,1.07465,0.808457,0.741666,0.0505226,0.0626266,0.948656,0.972748,0.426701,0.490893,-0.0250292,0.248427,-1.10881,-0.925118,-0.771691,-0.696587,0.666913,0.573477,-1.09619,-0.994757,-0.0244256,-0.231638,-1.24403,-1.47884,1.45,1.36191,-0.577864,-0.605158,0.160966,0.200176
3234,0.61627,0.504412,0.687888,0.642154,0.771336,0.595149,0.375862,0.360121,0.114743,0.144423,0.40787,0.484864,0.815094,0.749258,0.235098,0.249593,0.573866,0.598563,0.0404851,0.10558,-0.557969,-0.275072,0.0558586,0.243349,-0.408534,-0.32912,-0.968139,-1.05416,-0.819465,-0.713707,1.38488,1.17733,-0.626917,-0.863052,2.28472,2.19871,1.37167,1.34295,0.516962,0.636829
3235,0.235115,0.124676,0.961537,0.91319,0.734744,0.598444,0.1402,0.122515,0.3503,0.352823,0.588927,0.663966,0.115579,0.0481133,0.0909871,0.144379,0.548286,0.574082,0.436521,0.528091,0.977675,1.2543,0.777045,0.965425,-1.36584,-1.28473,-0.306044,-0.384777,0.298015,0.409334,-0.173577,-0.378731,-0.824074,-1.05886,0.721821,0.629,-0.665311,-0.687288,1.02776,1.07348
3236,0.844754,0.734542,0.284428,0.23739,0.138812,0.00400203,0.335131,0.318807,0.641838,0.561223,0.0444521,0.119548,0.980099,0.911416,0.0230172,0.0391639,0.215013,0.240247,0.887131,0.950602,-0.463329,-0.181368,0.271387,0.434516,-0.400323,-0.31676,0.919532,0.842319,-0.766494,-0.659796,0.570888,0.370852,-0.566652,-0.799287,-0.0670102,-0.126938,1.13774,1.1172,0.402746,0.447562
3237,0.640655,0.530676,0.300338,0.25155,0.564176,0.42817,0.0186182,0.000852205,0.74055,0.769622,0.324434,0.398033,0.910425,0.842397,0.513969,0.530449,0.233817,0.260032,0.563918,0.654768,0.106961,0.392774,-0.285244,-0.0963936,0.358776,0.436416,-0.0726019,-0.151626,-0.882645,-0.78243,-0.63747,-0.844178,-1.66038,-1.89168,-0.7824,-0.882875,0.497022,0.477905,0.428012,0.470033
3238,0.18525,0.0755784,0.71826,0.670663,0.0875317,-0.0468054,0.993063,0.977236,0.542361,0.604449,0.383797,0.549918,0.0373385,-0.0293389,0.498695,0.569428,0.776196,0.800708,0.296951,0.358934,-0.237708,0.0508174,-1.64229,-1.45092,-0.84971,-0.769161,0.55083,0.470416,0.366118,0.466672,1.07567,0.87411,-1.26673,-1.49273,-0.141301,-0.245619,0.163974,0.14695,-0.400159,-0.351734
3239,0.825592,0.716785,0.709253,0.652433,0.997639,0.862964,0.154397,0.13991,0.408408,0.439276,0.637309,0.701802,0.830016,0.760944,0.591644,0.608406,0.0499206,0.0750118,0.853563,0.917807,-0.0568232,0.224352,0.15474,0.339998,-1.57873,-1.49476,-2.28245,-2.35671,-0.17394,-0.0653656,0.0361692,-0.158726,0.391498,0.171768,-0.812822,-0.912879,-1.25501,-1.27617,0.837095,0.8837
3240,0.649524,0.539239,0.7295,0.634202,0.668681,0.533218,0.365485,0.350895,0.791227,0.822689,0.698211,0.853686,0.478069,0.410314,0.199867,0.216609,0.898834,0.925087,0.934822,0.999427,1.10234,1.37883,1.42598,1.60343,-1.21411,-1.12729,1.56705,1.4873,-0.299746,-0.188,1.59286,1.40494,-0.662382,-0.875843,1.65704,1.56465,0.483463,0.464652,-0.968928,-0.917061
3241,0.237063,0.129309,0.700626,0.615971,0.075507,-0.0612238,0.183738,0.168928,0.32991,0.358969,0.931971,1.00557,0.503204,0.466259,0.565695,0.583696,0.448068,0.551559,0.326353,0.389473,-0.915392,-0.646686,0.992576,1.1624,-0.476865,-0.389294,0.415776,0.33881,0.243977,0.351537,0.28539,0.0956474,0.778674,0.57111,-0.366172,-0.457549,-0.495763,-0.518565,0.0349214,0.0889776
3242,0.394132,0.357831,0.645338,0.597741,0.638987,0.501009,0.908116,0.892662,0.974969,1.00387,0.406447,0.481315,0.566431,0.522203,0.529694,0.547582,0.151605,0.178032,0.562689,0.62822,-0.62888,-0.363757,-2.1976,-2.02944,1.62951,1.72301,0.828368,0.747787,-0.584081,-0.473228,0.726467,0.541989,0.935677,0.645358,1.31038,1.22408,-0.626339,-0.648411,-1.13736,-1.08545
3243,0.695184,0.586354,0.11331,0.0656671,0.500231,0.364309,0.280947,0.264986,0.17212,0.203169,0.625128,0.628448,0.645903,0.578148,0.162411,0.180795,0.845806,0.869585,0.446944,0.582641,1.47764,1.74869,0.319274,0.482034,1.11149,1.20279,-0.202594,-0.241817,-0.294935,-0.177767,-0.087094,-0.276381,0.920676,0.719606,0.788472,0.697832,0.284266,0.262873,-0.763517,-0.717554
3244,0.470296,0.362795,0.598769,0.549386,0.896181,0.762187,0.835281,0.817564,0.854673,0.884161,0.648125,0.775581,0.276217,0.207435,0.623665,0.641834,0.600511,0.626395,0.4716,0.537061,2.08889,2.35223,-1.11835,-0.951973,-0.0995865,-0.00278361,-1.15824,-1.23142,-2.22553,-2.11024,-0.328579,-0.523173,-2.25327,-2.44759,1.14577,1.05946,0.770495,0.753269,0.79382,0.842196
3245,0.8622,0.755743,0.000505468,-0.0467774,0.218097,0.0824806,0.614375,0.594674,0.549814,0.483837,0.849546,0.922714,0.916944,0.848721,0.715514,0.732717,0.906959,0.93217,0.811831,0.875749,0.186157,0.452422,-0.0441468,0.125674,-0.119965,-0.0175295,-0.40708,-0.482818,0.453477,0.56648,0.209646,0.0395581,0.189086,-0.00142978,1.0245,0.93066,-2.28738,-2.30787,0.741372,0.788976
3246,0.0444222,-0.0616517,0.164425,0.150178,0.407468,0.272834,0.821037,0.80136,0.054987,0.0835127,0.305661,0.378296,0.763441,0.660547,0.559885,0.665241,0.569853,0.592915,0.279756,0.344294,-0.61283,-0.354008,0.29441,0.48943,-0.522725,-0.414318,-0.262755,-0.332061,0.722185,0.831998,0.800473,0.60229,-1.53491,-1.72095,-1.31324,-1.40216,0.642617,0.62925,-0.0637352,-0.0181671
3247,0.52702,0.419664,0.379801,0.347132,0.240584,0.106687,0.184711,0.164103,0.981529,1.01235,0.996065,1.06957,0.538685,0.472372,0.580221,0.597766,0.527425,0.548209,0.387801,0.450519,-0.901989,-0.545936,0.678587,0.853187,1.34248,1.4477,-0.603487,-0.675283,-0.525725,-0.422882,0.906235,0.709076,0.926921,0.741602,0.862719,0.778233,-0.737916,-0.748013,-0.0182833,0.0346667
3248,0.112353,0.0043007,0.693412,0.544087,0.95885,0.826684,0.652321,0.632048,0.214194,0.243547,0.76977,0.906237,0.131578,0.0662847,0.87183,0.8884,0.244513,0.264928,0.784071,0.845084,-1.00427,-0.737863,2.34883,2.52157,1.66493,1.77042,0.44059,0.366011,0.41822,0.518347,-0.447978,-0.648797,-0.709022,-0.898356,-1.9801,-2.07199,-0.620797,-0.631414,-0.389814,-0.337551
3249,0.388015,0.280978,0.788325,0.741042,0.334587,0.202564,0.402204,0.391299,0.347181,0.409931,0.582929,0.742902,0.402781,0.337481,0.289666,0.307582,0.226676,0.342381,0.59425,0.638395,0.324304,0.587818,0.357129,0.526441,-2.77411,-2.66862,-0.403366,-0.473587,0.686438,0.783866,-1.59669,-1.80377,-1.41197,-1.60354,1.40114,1.31136,-0.0197162,-0.0319257,-0.327089,-0.21081
3250,0.351145,0.244608,0.183457,0.135222,0.50153,0.368724,0.171502,0.150551,0.534415,0.576314,0.50606,0.579567,0.379806,0.234775,0.272741,0.263915,0.399719,0.419834,0.299328,0.431706,0.605449,0.870747,-0.604649,-0.438205,1.85865,1.96226,-1.91228,-1.97611,-0.600144,-0.500066,1.12315,0.918472,1.53539,1.34144,-0.934739,-1.02146,-0.0744252,-0.0850442,-0.140056,-0.084068
3251,0.599252,0.479524,0.161218,0.114563,0.404681,0.257214,0.738211,0.718234,0.830804,0.742697,0.754046,0.827675,0.219849,0.132069,0.203518,0.220249,0.0844576,0.104882,0.162121,0.225017,-0.242785,0.019248,-0.770499,-0.605026,1.00925,1.1147,-0.33877,-0.401787,-0.489533,-0.388373,-0.66364,-0.867784,1.22945,1.03636,2.01324,1.92343,-1.49937,-1.50817,-1.1864,-1.13282
3252,0.822164,0.714441,0.472824,0.425677,0.283846,0.145705,0.047114,0.0261167,0.879727,0.90908,0.277667,0.352712,0.0941773,0.0293626,0.763395,0.778147,0.793122,0.811989,0.233774,0.297044,-0.836921,-0.570152,-0.0913683,0.0733332,-1.10977,-1.01144,-1.56157,-1.62773,0.36277,0.461679,-0.39552,-0.593457,-1.0021,-1.20221,-1.41712,-1.50218,-0.643344,-0.656633,-0.534329,-0.475764
3253,0.768936,0.663068,0.0846622,0.0360805,0.167855,0.0341957,0.0966104,0.0756557,0.855815,0.884955,0.771842,0.845338,0.442775,0.469438,0.875236,0.888855,0.251026,0.2675,0.507863,0.525154,-0.22658,0.033387,-1.63302,-1.46903,1.301,1.39314,-1.23213,-1.29472,1.21379,1.31173,-1.62503,-1.82401,-1.1094,-1.30775,2.29943,2.22069,-0.148009,-0.166236,3.35964,3.41343
3254,0.960577,0.853448,0.257961,0.209933,0.41223,0.279518,0.148117,0.125195,0.39331,0.421236,0.23904,0.311153,0.973204,0.909513,0.517491,0.531899,0.205839,0.222795,0.689888,0.753264,1.83308,2.10117,0.993329,1.15317,-0.439128,-0.352214,0.561105,0.499709,-0.558224,-0.467662,-1.10858,-1.28382,-1.84156,-2.04515,1.09506,1.02014,-0.00877926,-0.0332112,0.049722,0.101152
3255,0.217224,0.10853,0.179351,0.13214,0.386892,0.255741,0.544157,0.518741,0.448904,0.478264,0.899239,0.972887,0.318045,0.252065,0.717787,0.733738,0.718433,0.733186,0.170646,0.233003,-0.735624,-0.463455,-0.08037,0.079076,1.23232,1.32221,1.15428,1.09183,0.779338,0.870954,-0.546174,-0.743632,0.116,-0.083314,-0.911176,-0.98711,0.434209,0.410047,1.35281,1.39717
3256,0.801883,0.69416,0.790904,0.742473,0.128473,-0.00425791,0.664752,0.645121,0.23614,0.262408,0.130184,0.202771,0.396501,0.331058,0.443345,0.461205,0.551852,0.541823,0.526878,0.618233,-1.17548,-0.897806,0.322314,0.478867,0.851682,0.853118,0.221075,0.158307,0.74436,0.828648,-1.88417,-2.08441,0.563771,0.363587,-0.135421,-0.212594,-0.445762,-0.463736,-2.27269,-2.22833
3257,0.508526,0.399648,0.928043,0.880815,0.262899,0.169673,0.798297,0.7715,0.0160193,0.0465512,0.802524,0.874833,0.136244,0.0703558,0.94023,0.958462,0.371419,0.35046,0.941699,1.00346,0.438212,0.709024,0.507739,0.664452,0.293621,0.384024,-0.195712,-0.262617,1.60765,1.69278,-0.210367,-0.413181,-0.310517,-0.513159,0.275695,0.110038,0.634381,0.62018,0.879214,0.923249
3258,0.47693,0.272517,0.757209,0.702754,0.477006,0.343603,0.146085,0.119178,0.703604,0.732469,0.126726,0.199283,0.388199,0.32252,0.347623,0.367139,0.1461,0.159096,0.905707,0.969444,-0.082197,0.194381,0.461956,0.619686,-0.174963,-0.0850704,-2.1539,-2.2272,-0.497441,-0.407815,2.27937,2.08031,-1.98532,-2.18701,0.505556,0.432671,0.44334,0.392829,-1.2335,-1.18819
3259,0.327442,0.145387,0.570872,0.524694,0.0270434,-0.105467,0.839998,0.8122,0.677829,0.708344,0.211923,0.284459,0.285375,0.217752,0.162442,0.180194,0.259647,0.27366,0.627644,0.688526,2.01679,2.29032,-0.662019,-0.500277,-0.407942,-0.313884,-0.616791,-0.687636,1.32213,1.40649,0.0579041,-0.141785,-0.242446,-0.44627,-0.716612,-0.783998,0.185475,0.165478,1.22743,1.2711
3260,0.24151,0.0182563,0.17122,0.125254,0.720088,0.590039,0.288896,0.259561,0.329485,0.360916,0.632954,0.703816,0.727018,0.659513,0.620718,0.636916,0.932983,0.946448,0.717112,0.779998,0.42933,0.702779,-0.796095,-0.571735,0.183539,0.20247,-0.800825,-0.877424,0.869435,1.04355,-0.374912,-0.572914,-0.706469,-0.907722,0.505885,0.432683,0.279123,0.253488,0.418424,0.463954
3261,3.9032e-06,-0.108874,0.77691,0.730696,0.825888,0.630036,0.360898,0.332661,0.263872,0.318407,0.814007,0.882917,0.611801,0.5451,0.29763,0.314997,0.577859,0.494365,0.0103974,0.0721337,1.93191,2.20191,-0.811077,-0.643193,0.620266,0.718824,0.445198,0.36343,0.5918,0.680606,1.50011,1.29666,-0.444213,-0.615342,-0.276009,-0.356055,-0.445446,-0.392686,0.598735,0.650782
3262,0.681278,0.572333,0.970197,0.923476,0.799556,0.670033,0.796416,0.766077,0.292626,0.275898,0.019874,0.0870429,0.7221,0.59998,0.712002,0.731565,0.0305313,0.0422823,0.648169,0.710914,0.626585,0.891868,0.736148,0.899409,0.152112,0.246341,0.57312,0.497445,0.512887,0.605173,0.4308,0.231829,-0.0358368,-0.322962,-0.822985,-0.897582,-1.01804,-1.03886,-0.260336,-0.201778
3263,0.864056,0.752858,0.00071656,-0.0478197,0.221495,0.0912043,0.816822,0.783995,0.0812753,0.23339,0.176235,0.283258,0.721224,0.654859,0.683519,0.700487,0.590117,0.602049,0.0709578,0.13522,0.344383,0.613879,-0.48022,-0.312629,-1.67396,-1.58047,0.500269,0.431138,-2.24046,-2.1502,-1.07033,-1.26423,0.17067,-0.0305826,-0.336844,-0.412891,0.945542,0.92801,-0.0154082,0.0445834
3264,0.534859,0.423144,0.479932,0.429948,0.213145,0.0826738,0.565534,0.5311,0.125841,0.190881,0.477027,0.479473,0.622707,0.555202,0.907902,0.924412,0.0212116,0.0321187,0.526844,0.589679,0.0755247,0.335891,0.0309929,0.196923,1.86739,1.96476,-0.716316,-0.779571,0.62792,0.726848,0.882501,0.680362,-0.997683,-1.20296,-1.9284,-1.99674,1.3945,1.37127,1.35307,1.41678
3265,0.922922,0.811647,0.281654,0.230484,0.778438,0.650756,0.846826,0.811006,0.181967,0.148372,0.607358,0.675688,0.929967,0.862154,0.666951,0.681497,0.131929,0.1417,0.337726,0.399058,0.267883,0.524846,-0.545705,-0.382001,1.42282,1.52335,0.313662,0.247102,-1.07694,-0.97308,-0.925925,-1.12093,-0.358934,-0.556064,-0.366825,-0.440294,0.516789,0.497485,0.168447,0.227781
3266,0.530547,0.483591,0.614881,0.56135,0.169343,0.0418196,0.858359,0.824128,0.0744325,0.105863,0.393854,0.472712,0.895909,0.864524,0.691429,0.700077,0.845523,0.853938,0.596737,0.657783,-1.36557,-1.10455,0.30376,0.463136,0.362176,0.457493,-0.280638,-0.344142,-1.20497,-1.09571,0.9208,0.720231,0.0172487,-0.187536,2.09342,2.02146,-0.809493,-0.834023,0.122867,0.189414
3267,0.267447,0.155535,0.705182,0.650568,0.331189,0.203088,0.206218,0.171806,0.186591,0.219985,0.203699,0.269736,0.936451,0.866893,0.705011,0.718656,0.644432,0.651132,0.342736,0.40298,1.88244,2.13804,-2.2348,-2.07618,-0.393788,-0.296734,1.20575,1.1495,-0.906862,-0.808342,0.916423,0.719038,-0.522178,-0.72724,-1.70609,-1.78386,-0.584423,-0.608795,1.32191,1.39309
3268,0.818003,0.706553,0.362967,0.31053,0.134948,0.0657479,0.517427,0.481528,0.0356373,0.0690306,0.192869,0.311927,0.68633,0.61607,0.12,0.133603,0.890522,0.897209,0.580823,0.641728,1.07059,1.33161,0.18843,0.341916,-0.573386,-0.478582,1.75686,1.69756,-0.630033,-0.520971,0.0800791,-0.115332,0.661015,0.457526,0.495782,0.425239,-0.772314,-0.801693,0.404157,0.479345
3269,0.476721,0.366317,0.432755,0.428386,0.0555032,-0.0715921,0.449846,0.373778,0.855526,0.890894,0.288427,0.354118,0.220233,0.150339,0.00780882,0.111293,0.702423,0.778188,0.139118,0.200668,1.82227,2.08925,0.558036,0.710577,-0.261031,-0.1707,-1.208,-1.26402,1.74558,1.84856,1.74015,1.53989,-1.10295,-1.31123,-1.82735,-1.89067,0.148085,0.125533,0.363231,0.440978
3270,0.533895,0.421979,0.598252,0.546242,0.0841502,-0.0443056,0.30111,0.266028,0.0713607,0.10532,0.645075,0.620603,0.743338,0.672635,0.0776249,0.0889828,0.580894,0.659168,0.325734,0.387861,-1.13202,-0.863079,0.0835846,0.238775,0.75023,0.843985,-0.157867,-0.207472,-0.874027,-0.773344,-0.0144554,-0.214876,-0.488642,-0.695437,-0.491817,-0.538721,1.08174,1.05276,-0.321337,-0.244445
3271,0.338477,0.263019,0.187204,0.132548,0.623061,0.493338,0.467786,0.430869,0.623404,0.659813,0.820786,0.887088,0.436193,0.366626,0.702415,0.714429,0.535037,0.540147,0.10723,0.167212,-0.061392,0.213341,1.27872,1.43993,1.45425,1.55077,-1.70157,-1.75387,0.723301,0.826581,1.40483,1.20683,0.485808,0.271911,0.868185,0.813224,-0.905306,-0.9294,0.13974,0.212988
3272,0.215648,0.104059,0.97664,0.924604,0.652084,0.520624,0.109909,0.0738555,0.913326,0.951767,0.942965,1.00671,0.93937,0.868942,0.691843,0.644373,0.970324,0.975046,0.318446,0.379726,-1.67814,-1.40198,-0.399661,-0.244172,1.70618,1.79779,-0.532323,-0.587294,-0.357539,-0.257537,-1.04904,-1.25044,-0.491132,-0.697732,-0.882146,-0.9414,1.17218,1.15426,-0.388555,-0.341941
3273,0.849135,0.739869,0.901936,0.850691,0.13876,0.00706039,0.166024,0.14259,0.0687689,0.109384,0.690332,0.753715,0.3683,0.296743,0.564092,0.574318,0.606637,0.522963,0.993685,1.05363,0.205714,0.479767,0.193644,0.34159,0.134276,0.225511,-1.26631,-1.31657,0.687008,0.790907,1.65499,1.45581,-1.04792,-1.25123,-0.319167,-0.382135,-0.970174,-0.985258,-0.975775,-0.896869
3274,0.243943,0.134432,0.536553,0.486176,0.277163,0.0754137,0.247325,0.211325,0.652895,0.694797,0.741305,0.804451,0.955281,0.883005,0.861522,0.870962,0.0644436,0.0708799,0.52762,0.587677,-0.027897,0.243662,-0.500541,-0.359552,-1.89802,-1.80289,-0.349666,-0.398114,0.6737,0.780479,0.0409135,-0.16072,-0.187751,-0.394487,-0.463142,-0.526595,0.676129,0.663727,-0.782201,-0.710041
3275,0.802661,0.690981,0.608524,0.48293,0.277432,0.143767,0.0135444,-0.0213233,0.106972,0.151307,0.0569822,0.119685,0.193162,0.122235,0.681699,0.676541,0.643088,0.650697,0.563324,0.624394,-2.23302,-1.9568,-1.93408,-1.79356,-0.282539,-0.192935,-0.316422,-0.372213,-0.644184,-0.536966,1.04061,0.835906,-0.708119,-0.917663,1.0084,0.937552,0.680267,0.630234,0.592649,0.662157
3276,0.0807532,-0.0329105,0.529878,0.479684,0.784488,0.651997,0.457972,0.422087,0.101627,0.144029,0.516147,0.577916,0.954222,0.882083,0.473361,0.48212,0.868006,0.877304,0.0820637,0.143832,-0.685988,-0.410508,-1.96071,-1.82163,-1.00301,-0.918534,0.89902,0.839521,1.05922,1.16844,1.3416,1.13797,0.662298,0.453275,0.757875,0.655203,0.599862,0.59674,-0.115832,-0.0398512
3277,0.506167,0.374222,0.153104,0.100895,0.710465,0.56473,0.279878,0.212932,0.639527,0.682916,0.224363,0.283767,0.280129,0.209836,0.278797,0.287699,0.581949,0.522034,0.0195854,0.0795575,-2.07789,-1.79829,0.46425,0.608994,0.118491,0.201564,-0.474216,-0.538682,0.736121,0.847232,0.527305,0.319595,-1.21805,-1.42198,0.538544,0.372853,-1.32142,-1.32144,-0.400364,-0.320011
3278,0.895018,0.781355,0.787922,0.736188,0.612713,0.477463,0.039295,0.00377735,0.382618,0.425862,0.361699,0.418933,0.838473,0.766728,0.278711,0.261699,0.156025,0.166764,0.208922,0.26675,0.175058,0.451961,-0.23806,-0.0921484,0.712871,0.799031,-0.401442,-0.465572,1.34447,1.44821,1.14609,0.93381,-0.841566,-1.12313,0.161356,0.0905039,-0.8328,-0.831039,0.499095,0.578545
3279,0.587518,0.472308,0.105666,0.0555913,0.82909,0.692788,0.342989,0.272192,0.351124,0.396248,0.723735,0.779026,0.565479,0.495795,0.268885,0.2357,0.0676158,0.128476,0.990274,1.04716,-0.326634,-0.0468511,2.14228,2.29136,-1.37457,-1.29619,-1.654,-1.72299,1.34733,1.45405,-1.81115,-2.01914,-0.618368,-0.824286,-1.8151,-1.88647,-0.838983,-0.836355,0.94987,1.03598
3280,0.989104,0.875252,0.441158,0.391733,0.404758,0.268289,0.579107,0.540606,0.77707,0.824531,0.253346,0.30895,0.706863,0.636013,0.199887,0.2097,0.0781601,0.0901876,0.599591,0.657171,0.333772,0.616901,0.234101,0.385175,-0.204874,-0.115442,0.408612,0.339659,0.437443,0.53924,1.24144,1.02874,-0.582596,-0.793384,-1.6092,-1.67886,-0.593099,-0.694842,0.53825,0.619411
3281,0.634077,0.519953,0.155403,0.106072,0.975785,0.840836,0.325685,0.334423,0.412762,0.507383,0.65559,0.712826,0.218479,0.14971,0.945841,0.95665,0.973032,0.982675,0.92881,0.98605,0.5519,0.835788,0.450072,0.603507,0.983164,1.06531,1.27312,1.21163,-1.20308,-1.09901,0.515191,0.34837,0.678867,0.507192,-1.7773,-1.85263,-0.528704,-0.553328,-0.192245,-0.11225
3282,0.719049,0.606015,0.212193,0.165744,0.259829,0.126377,0.166502,0.12824,0.140426,0.190235,0.333878,0.389602,0.760736,0.691364,0.546192,0.555629,0.236175,0.246353,0.0160845,0.0747961,0.196384,0.477867,0.424287,0.575436,0.529479,0.607774,0.231917,0.172189,-0.132155,0.0452998,-0.123666,-0.332001,2.01303,1.80777,0.718528,0.640816,-0.414442,-0.411815,-0.428735,-0.346397
3283,0.381965,0.270863,0.511851,0.467179,0.977041,0.842364,0.644023,0.605731,0.326232,0.309476,0.553917,0.640952,0.787997,0.719175,0.447587,0.455694,0.814939,0.82617,0.867099,0.923256,1.16292,1.44912,-0.894839,-0.747712,-1.88208,-1.80771,0.895858,0.841573,1.08553,1.18961,0.445972,0.235528,0.977899,0.776105,-0.308345,-0.390869,-0.541892,-0.54166,0.450255,0.533356
3284,0.325757,0.214194,0.362977,0.318355,0.104507,-0.0322693,0.508016,0.468511,0.441851,0.428717,0.837335,0.892302,0.106411,0.0373203,0.148516,0.154131,0.609361,0.618537,0.951533,1.00938,1.78544,2.06829,-0.462513,-0.317144,0.247265,0.320618,-0.316718,-0.369136,-1.48776,-1.38553,0.4989,0.280551,-0.843336,-1.03786,-0.499942,-0.580525,-0.334156,-0.333419,1.33222,1.41311
3285,0.499859,0.389601,0.712229,0.668858,0.551979,0.416985,0.923675,0.882532,0.498149,0.547958,0.593358,0.648881,0.894711,0.827603,0.971076,0.978185,0.826908,0.834635,0.435265,0.494026,-0.693529,-0.41666,-0.353841,-0.210219,1.14448,1.21249,0.557027,0.502833,0.087444,0.184046,-1.18952,-1.41354,1.50488,1.31025,0.428514,0.348786,0.381862,0.376326,0.717971,0.800609
3286,0.436814,0.328229,0.109367,0.0673175,0.126771,-0.00751342,0.447257,0.405681,0.374667,0.428748,0.590032,0.645796,0.918239,0.850093,0.191827,0.196645,0.612584,0.616659,0.254791,0.313686,-1.12988,-0.851011,-0.563194,-0.422332,0.898193,0.968009,0.563559,0.5144,0.31841,0.417628,1.34569,1.12748,-1.38442,-1.57791,-1.46839,-1.54883,0.673018,0.663059,-1.70954,-1.6289
3287,0.825386,0.716731,0.214159,0.165311,0.289972,0.225828,0.199378,0.252682,0.36176,0.309538,0.187563,0.244231,0.675809,0.593952,0.818819,0.82209,0.393494,0.398683,0.808375,0.867799,-0.979115,-0.693051,1.07915,1.21332,0.138974,0.213781,1.09184,1.0459,0.872201,0.972369,2.19074,1.9696,-1.27807,-1.46962,0.754465,0.67256,0.0392272,0.0237643,-2.8202,-2.74303
3288,0.544042,0.432683,0.307427,0.263305,0.641593,0.459168,0.142525,0.0996831,0.142357,0.190328,0.804178,0.8599,0.406773,0.337812,0.682581,0.685711,0.62153,0.625291,0.640482,0.697619,-1.81984,-1.53019,-0.978448,-0.844464,0.845788,0.920566,0.966085,0.919621,0.39474,0.499348,-0.874323,-1.10019,0.281978,0.0842116,1.51256,1.43148,1.38829,1.37925,0.677931,0.758418
3289,0.829861,0.71953,0.117721,0.0737924,0.826794,0.692509,0.197171,0.153917,0.586495,0.634125,0.301037,0.354527,0.379349,0.309238,0.789725,0.792047,0.548719,0.580891,0.245522,0.302342,-0.195944,0.0926801,0.403995,0.541889,-0.435951,-0.360324,-0.975501,-1.02436,0.283562,0.392701,0.317933,0.0948187,1.03833,0.837002,0.98411,0.905227,-1.60394,-1.60728,-0.758854,-0.675759
3290,0.0526502,-0.0583945,0.920766,0.875344,0.270123,0.138369,0.703872,0.661758,0.554734,0.604511,0.953904,1.00573,0.348379,0.280664,0.322664,0.325404,0.534006,0.536491,0.293512,0.349378,-1.09857,-0.805268,1.42774,1.57296,0.475293,0.546797,0.107395,0.0621958,-1.00759,-0.891231,2.05774,1.82806,-0.465933,-0.662646,1.11294,0.958934,-0.0671917,-0.0707613,-0.274556,-0.186738
3291,0.710758,0.597999,0.446507,0.401701,0.730424,0.597204,0.537111,0.494153,0.185336,0.235741,0.27022,0.320959,0.869914,0.802959,0.29051,0.252467,0.127882,0.131382,0.935211,0.992723,0.250034,0.536789,-0.89918,-0.761772,-2.10662,-2.02919,-2.08376,-2.13361,0.126498,0.249506,-1.45364,-1.68332,-0.73714,-0.936553,1.10069,1.01264,-0.828577,-0.834585,-0.588563,-0.497466
3292,0.415427,0.303486,0.391405,0.342298,0.438412,0.279757,0.736577,0.695612,0.898669,0.947687,0.263687,0.313139,0.407354,0.342496,0.176476,0.17953,0.392359,0.398008,0.412986,0.472462,-1.23358,-0.941773,1.2457,1.37926,0.144138,0.215305,0.0983107,0.054802,1.024,1.14525,0.339605,0.109756,-0.239909,-0.444575,-0.157346,-0.251185,-0.0533385,-0.0649831,0.733668,0.828918
3293,0.453146,0.339775,0.447795,0.282894,0.0977833,-0.0376896,0.338441,0.298767,0.386788,0.434566,0.672053,0.722793,0.725576,0.659694,0.982998,0.988206,0.330687,0.348955,0.236506,0.297129,-0.320047,-0.0330385,1.14748,1.27379,-0.816143,-0.740307,0.153799,0.113188,-0.668785,-0.554679,0.478852,0.24704,-0.0344321,-0.245767,-2.00329,-2.10441,0.370388,0.362505,1.21196,1.30183
3294,0.00655021,-0.106071,0.334955,0.223491,0.422723,0.223175,0.445756,0.407658,0.999639,1.04866,0.498845,0.550197,0.575228,0.510164,0.58531,0.5917,0.295945,0.299903,0.964591,1.02559,-0.0180578,0.266414,-0.220682,-0.0964584,0.072828,0.151565,2.36875,2.32283,-1.7695,-1.65538,1.93418,1.69886,-0.998691,-1.21541,-0.170868,-0.267699,-0.512824,-0.525433,0.721536,0.772218
3295,0.613858,0.499906,0.208893,0.164088,0.586749,0.48404,0.981517,0.94513,0.646684,0.695146,0.709563,0.758686,0.100939,0.0340195,0.541942,0.448787,0.0379494,0.041092,0.503413,0.581268,-0.166723,0.215085,-0.518135,-0.40263,0.529254,0.61044,-2.1599,-2.20582,-1.99199,-1.88539,0.0697119,-0.162622,-0.445137,-0.66126,0.8517,0.755128,0.478617,0.466052,0.150777,0.242602
3296,0.238498,0.125582,0.816828,0.769529,0.880377,0.744905,0.679838,0.642698,0.643023,0.752118,0.199268,0.248818,0.726433,0.65949,0.301075,0.305873,0.0942459,0.0992519,0.0774454,0.136944,-0.197312,0.163756,0.198717,0.319446,0.158181,0.243632,0.448835,0.411814,-0.0502677,0.0558848,-0.0561328,-0.287913,-0.127173,-0.339509,-0.381071,-0.476693,0.601767,0.582651,-2.4557,-2.35769
3297,0.263627,0.150651,0.869374,0.823332,0.182169,0.0454947,0.651965,0.563305,0.759942,0.809089,0.704628,0.756428,0.0440688,-0.0223645,0.0275066,0.0333395,0.435946,0.439973,0.959629,1.02031,-0.170864,0.112427,-0.160401,-0.0449674,-0.688985,-0.603925,-0.422495,-0.459631,-0.411107,-0.311078,0.509646,0.279615,1.38925,1.18482,-0.48763,-0.590543,-0.0648268,-0.088302,0.511957,0.606718
3298,0.531616,0.417525,0.150686,0.10343,0.175625,0.0785273,0.520426,0.483912,0.120036,0.169458,0.216617,0.266171,0.654941,0.589007,0.440318,0.445084,0.445626,0.466322,0.14155,0.199619,-0.00133871,0.335672,-0.271484,-0.150438,1.15078,1.24276,0.423959,0.380382,2.72999,2.82716,-2.59846,-2.82912,-0.204319,-0.411136,0.561599,0.460695,-1.99389,-2.02087,-1.35638,-1.25637
3299,0.449351,0.334485,0.321518,0.272438,0.225122,0.11156,0.655181,0.642468,0.161021,0.211637,0.178266,0.228843,0.963544,0.89596,0.0441514,0.0485775,0.489456,0.492672,0.226395,0.205005,0.274868,0.558917,-1.42862,-1.30133,-0.157771,-0.0691358,-1.81061,-1.84947,0.891261,0.988085,-0.330691,-0.562002,0.821122,0.616009,1.00109,0.898218,0.857497,0.836255,1.4878,1.58279
3300,0.854035,0.737429,0.19354,0.143305,0.281479,0.144593,0.836507,0.801025,0.913896,0.964452,0.561035,0.613655,0.836981,0.771348,0.328584,0.330274,0.860118,0.863136,0.151694,0.210391,-1.95318,-1.67306,-0.80242,-0.670248,1.4374,1.52631,-0.520881,-0.586523,1.01635,1.11461,-0.0771376,-0.303565,0.0753497,-0.134794,-1.40238,-1.49873,0.00630354,-0.0199903,-0.373507,-0.280293
3301,0.624715,0.508776,0.699881,0.650858,0.861275,0.722737,0.254169,0.217738,0.00329449,0.0540415,0.401044,0.357083,0.00712634,-0.0566276,0.609593,0.611971,0.624384,0.629298,0.582454,0.63899,1.03896,1.32061,1.47557,1.61445,-1.40649,-1.31517,0.715289,0.676425,-1.05185,-0.953377,-0.0883542,-0.319334,2.21501,2.00688,1.46303,1.37343,0.554993,0.534653,0.712215,0.802046
3302,0.937944,0.820413,0.284221,0.237164,0.157205,0.0184453,0.769987,0.735787,0.0935115,0.142565,0.0456788,0.100511,0.111482,0.0484855,0.657227,0.657361,0.866494,0.812967,0.039481,0.0978308,-0.735229,-0.452776,-0.190925,-0.0537973,0.0157237,0.109165,1.18876,1.14563,0.563041,0.660161,2.20882,1.97759,-0.535193,-0.750011,-0.667384,-0.760879,0.507157,0.481535,1.57032,1.6537
3303,0.32079,0.204308,0.52675,0.479282,0.515213,0.330116,0.70115,0.668847,0.765591,0.813456,0.0344227,0.1303,0.941217,0.87789,0.132175,0.131552,0.991487,0.996637,0.429405,0.486834,0.501506,0.777205,-1.01156,-0.878798,-0.572668,-0.477043,0.322376,0.274186,0.185851,0.277839,1.05492,0.822614,0.79328,0.576345,0.718337,0.62755,1.0372,1.00399,-0.474208,-0.394368
3304,0.462472,0.344663,0.365338,0.316073,0.782428,0.641787,0.0178919,-0.0131624,0.683781,0.733285,0.102659,0.160089,0.137728,0.0728117,0.178199,0.1392,0.189481,0.193952,0.532101,0.49222,-0.336244,-0.0599341,0.0284593,0.165557,-0.215094,-0.122991,-0.0040222,-0.0534951,0.31952,0.404363,1.50068,1.26896,0.950139,0.729379,0.849616,0.759471,3.30039,3.26587,2.17047,2.25483
3305,0.128783,0.00951067,0.705929,0.656716,0.75935,0.605451,0.135652,0.106296,0.225107,0.274554,0.706975,0.765875,0.325267,0.273627,0.148383,0.146847,0.938775,0.94126,0.441806,0.497606,1.30826,1.57691,-1.60116,-1.47066,0.405724,0.50524,0.187239,0.142247,-0.232987,-0.144412,0.430988,0.204127,0.87382,0.654068,0.514917,0.346984,0.773655,0.744904,0.128608,0.206761
3306,0.900867,0.779988,0.0409959,-0.00896177,0.655776,0.569115,0.716638,0.689212,0.0552404,0.103935,0.456521,0.424291,0.540995,0.474443,0.881823,0.879395,0.236308,0.240853,0.669443,0.725386,0.280396,0.555003,1.11588,1.24991,-0.0201245,0.0783769,0.146477,0.106603,-0.513425,-0.419147,-0.208346,-0.430128,-1.61273,-1.83845,0.0293585,-0.0655037,-0.925779,-0.948078,0.122483,0.157496
3307,0.89591,0.767505,0.70862,0.660585,0.674674,0.532778,0.101752,0.0761997,0.711171,0.759112,0.0237659,0.0827068,0.372049,0.34265,0.481257,0.478373,0.399938,0.363917,0.549906,0.604901,-1.75549,-1.48546,1.52968,1.66607,-1.75619,-1.65121,-1.11274,-1.15081,-1.37324,-1.27429,-0.840276,-1.06438,-0.397194,-0.621935,-0.0235018,-0.118591,-0.70343,-0.72285,0.116412,0.108231
3308,0.773446,0.755022,0.810943,0.764588,0.812907,0.669211,0.462133,0.434719,0.0147469,0.0632689,0.494332,0.555167,0.277023,0.210858,0.899,0.894941,0.483461,0.48698,0.83418,0.888258,-0.268018,-0.00182744,0.173021,0.311538,0.923041,1.02547,0.0200474,-0.0155374,-0.478387,-0.378551,-0.505421,-0.729855,0.162819,-0.0677848,0.251675,0.153091,-0.205305,-0.232454,-0.0315293,0.0589655
3309,0.863418,0.742539,0.340014,0.290945,0.640562,0.497373,0.092175,0.0628012,0.35832,0.327423,0.444107,0.525771,0.908144,0.842023,0.578138,0.573022,0.384603,0.38584,0.785207,0.839159,-1.85513,-1.58937,1.79205,1.93247,-0.0533722,0.0505793,-1.47281,-1.5019,-0.222763,-0.127832,1.35686,1.12592,0.401157,0.109847,-0.0402208,-0.0817072,2.35806,2.33646,-0.0684529,0.00970038
3310,0.383691,0.261592,0.0862838,0.0348905,0.962456,0.81891,0.95376,0.926576,0.628189,0.591578,0.367708,0.496375,0.747716,0.729868,0.97206,0.965165,0.845538,0.846137,0.357879,0.45762,1.98092,2.25052,-1.9297,-1.78931,-0.0810345,0.0210992,-1.69693,-1.72128,1.07159,1.16568,-1.25727,-1.48215,0.516269,0.28748,-0.214245,-0.316505,-0.106492,-0.13506,1.40015,1.47579
3311,0.253062,0.133035,0.270679,0.186272,0.0577153,-0.0879999,0.405933,0.378759,0.806742,0.855732,0.403966,0.466978,0.683997,0.617712,0.0552851,0.0471083,0.215766,0.216227,0.0243112,0.0760807,1.5728,1.78063,0.77165,0.915073,0.874003,0.975035,-0.135703,-0.163782,-0.643525,-0.550564,-0.996399,-1.13069,0.0105698,-0.218671,0.756439,0.656767,-0.584993,-0.619574,-0.719021,-0.635646
3312,0.5513,0.466024,0.4135,0.337653,0.482954,0.336168,0.816834,0.788131,0.225634,0.277164,0.0608905,0.124229,0.931697,0.863998,0.362637,0.353695,0.481733,0.580986,0.402719,0.455815,1.0493,1.31073,-1.28006,-1.14271,-0.268139,-0.167879,-1.1735,-1.20322,-0.266624,-0.176052,-0.558012,-0.77924,1.24854,1.01251,-0.698092,-0.806155,0.780389,0.748508,-0.908503,-0.824935
3313,0.921142,0.799012,0.649842,0.489034,0.247298,0.103037,0.113967,0.0853733,0.591273,0.646096,0.988193,1.05161,0.845239,0.775055,0.40507,0.394014,0.945941,0.945745,0.327488,0.381716,-0.977663,-0.714783,-0.547489,-0.403068,-0.0692759,0.0309695,3.09893,3.07012,1.12528,1.21001,2.08942,1.86199,-0.950871,-1.19251,0.603456,0.502833,0.602474,0.570935,0.676314,0.763104
3314,0.182279,0.059412,0.714564,0.640415,0.524347,0.378976,0.683698,0.653056,0.966037,1.01503,0.653746,0.718132,0.987403,0.79417,0.796718,0.786157,0.386109,0.385898,0.50947,0.564041,0.437415,0.704403,-0.0305731,0.120967,1.35325,1.4553,-0.55427,-0.583075,0.262977,0.354865,-0.446626,-0.668124,-0.28692,-0.531292,-1.8681,-1.96151,-1.9186,-1.95003,-0.369781,-0.285644
3315,0.089623,-0.0326527,0.849138,0.791796,0.26453,0.118977,0.988306,0.957474,0.379204,0.426314,0.841918,0.90702,0.931171,0.813284,0.0517558,0.0404122,0.187934,0.24118,0.483312,0.464465,2.13756,2.40291,-0.0676349,0.0762015,0.669253,0.77681,-1.56331,-1.59295,-0.863027,-0.775462,0.787151,0.571487,-1.98839,-2.23658,-1.09016,-1.18699,-1.04773,-1.08374,1.72816,1.81216
3316,0.758838,0.638569,0.99457,0.943177,0.259032,0.017165,0.210107,0.17775,0.794965,0.843818,0.182629,0.247096,0.902583,0.832399,0.341019,0.331047,0.0984746,0.0964629,0.356337,0.364888,-0.0357052,0.222239,-1.68269,-1.54378,-0.593839,-0.488171,0.151175,0.118679,0.786242,0.867956,0.934495,0.722023,-0.468697,-0.809787,0.0823899,-0.0708702,1.54586,1.50136,-0.0330094,0.0568086
3317,0.937293,0.819094,0.150292,0.0979871,0.0588905,-0.0846467,0.895677,0.865483,0.234039,0.285274,0.316741,0.434099,0.664331,0.596083,0.881752,0.873827,0.421437,0.41713,0.288055,0.265312,0.766273,1.02435,0.387141,0.528728,2.15916,2.26624,-0.327808,-0.362482,-0.0136969,0.0747999,-0.315569,-0.526417,0.859431,0.617011,1.14189,1.04525,-0.83451,-0.882875,-0.69118,-0.599631
3318,0.0523063,-0.0650153,0.705664,0.654816,0.6889,0.54385,0.411093,0.468122,0.0267723,0.0787866,0.591608,0.621102,0.773357,0.654311,0.622782,0.681148,0.00130722,-0.00173497,0.111164,0.165735,-0.636767,-0.379554,0.708325,0.853563,1.18191,1.29134,-1.45657,-1.4957,1.36894,1.46086,1.39064,1.1765,2.07944,1.83353,0.489223,0.394318,0.112158,0.061066,-0.0642585,0.0269436
3319,0.818072,0.699356,0.479513,0.430538,0.622782,0.47881,0.100771,0.0707607,0.83825,0.890843,0.746386,0.808105,0.782895,0.712538,0.496309,0.488469,0.00884923,0.00370666,0.352511,0.434788,0.183731,0.436769,2.19396,2.33328,-0.5502,-0.438239,0.256137,0.215935,-0.159398,-0.0702833,0.660767,0.450072,-1.54637,-1.79003,1.6726,1.58083,-0.0968421,-0.145718,-1.46658,-1.37567
3320,0.495949,0.476853,0.727061,0.677545,0.976414,0.831526,0.0580738,0.0290697,0.0726907,0.126907,0.509277,0.569651,0.666676,0.598125,0.87467,0.865887,0.537691,0.5333,0.650907,0.703841,-0.785046,-0.536817,-0.332174,-0.191501,0.42307,0.529733,0.809954,0.763989,-0.708713,-0.619059,1.27904,1.06429,-0.140321,-0.38643,0.383936,0.284967,-2.37558,-2.42599,0.18193,0.273621
3321,0.371736,0.25435,0.397776,0.436934,0.32525,0.182725,0.695377,0.666413,0.774663,0.827977,0.644921,0.7608,0.145861,0.0758091,0.727144,0.718962,0.767268,0.765295,0.641084,0.772399,-0.00300218,0.250059,0.510999,0.653636,-1.71358,-1.61244,-0.351395,-0.401254,-0.729562,-0.645943,-2.21296,-2.42493,-0.250266,-0.552923,0.150236,0.0501688,1.53829,1.48788,-0.775227,-0.684954
3322,0.872443,0.756479,0.243792,0.196324,0.569511,0.428047,0.186346,0.158502,0.630676,0.681568,0.891271,0.95195,0.780236,0.712397,0.307561,0.297007,0.508917,0.556995,0.822965,0.840957,0.460936,0.716952,-0.220344,-0.0783767,0.236955,0.341449,-0.453055,-0.497043,0.720164,0.800593,1.22928,1.02006,-0.374969,-0.719416,-0.0807554,-0.184629,0.769694,0.724057,1.19669,1.28803
3323,0.0204262,-0.0951932,0.601001,0.551849,0.404666,0.2619,0.358023,0.254864,0.829474,0.881121,0.783919,0.84301,0.198555,0.12997,0.686892,0.674425,0.350508,0.348696,0.855602,0.909514,-0.198409,0.0520586,-1.25763,-1.1204,-0.452987,-0.350993,0.947912,0.89793,1.82468,1.90871,0.309254,0.0938507,-0.639801,-0.885909,2.30554,2.20837,1.12822,1.08968,-0.168398,-0.0835112
3324,0.417647,0.302572,0.516379,0.468518,0.874801,0.730483,0.38034,0.351225,0.809268,0.862157,0.313885,0.372935,0.0922531,0.0252017,0.143553,0.128901,0.896908,0.893632,0.730828,0.778038,1.43359,1.6889,-0.0287184,0.114161,-0.632528,-0.532841,0.809809,0.756024,0.810218,0.838857,-1.44706,-1.66092,0.523249,0.282667,-1.30683,-1.40027,-0.378813,-0.414001,0.0479888,0.132738
3325,0.172276,0.0589102,0.88786,0.838231,0.114599,-0.0292115,0.115683,0.0877859,0.499209,0.554643,0.2921,0.368618,0.252994,0.186623,0.182128,0.16922,0.176985,0.172806,0.594908,0.646562,-0.306302,-0.0517026,0.138774,0.368708,0.936425,1.03035,-1.89665,-1.95701,-0.315027,-0.230999,0.785925,0.576697,-1.95308,-2.19916,-0.19317,-0.287352,-1.43757,-1.47544,-1.45502,-1.37507
3326,0.933935,0.818752,0.0993218,0.0503486,0.788879,0.645999,0.81129,0.78517,0.779442,0.83674,0.26634,0.364302,0.101485,0.037093,0.844356,0.829246,0.041038,0.034403,0.260697,0.357767,0.276889,0.53789,0.480189,0.623254,-1.22981,-1.1293,0.183443,0.122036,0.692206,0.770858,-0.170029,-0.434319,1.5182,1.27037,-0.30587,-0.401203,1.33718,1.30326,-1.8633,-1.7771
3327,0.207964,0.0948606,0.986304,0.938544,0.211126,0.0671697,0.570978,0.553181,0.74362,0.83857,0.302362,0.359985,0.567566,0.504172,0.136567,0.120614,0.648561,0.640764,0.0176185,0.0689719,-1.15888,-0.897774,-0.717419,-0.573251,0.19803,0.198387,1.44061,1.3796,-0.513535,-0.488984,-1.23332,-1.44533,0.504076,0.240322,0.979987,0.891951,0.0845202,0.0525515,-0.0149353,0.0754578
3328,0.72531,0.611467,0.15637,0.108676,0.935649,0.792823,0.346602,0.321191,0.782723,0.8404,0.557518,0.613424,0.361765,0.29905,0.318125,0.210974,0.136009,0.125912,0.594934,0.547972,-0.477847,-0.193429,0.395416,0.536133,1.42983,1.52607,-1.27868,-1.33343,-1.82707,-1.74883,-0.0296143,-0.235043,-0.540859,-0.78973,-0.0485154,-0.139734,-0.116479,-0.154232,-0.891176,-0.80805
3329,0.301501,0.185843,0.558026,0.508713,0.890736,0.748551,0.65525,0.630914,0.964467,1.02044,0.500055,0.624152,0.576013,0.515515,0.317264,0.301333,0.142274,0.131354,0.975619,1.02697,0.253109,0.510916,-0.0705551,0.0643321,-0.494642,-0.394669,0.0274574,-0.030755,-1.82429,-1.74299,-0.223774,-0.434986,0.568359,0.399235,1.1889,1.09171,0.00516316,-0.0376339,0.0142812,0.090506
3330,0.769167,0.652509,0.235084,0.183189,0.180721,0.0392306,0.137579,0.11304,0.0437661,0.0984604,0.577854,0.634881,0.307839,0.249555,0.0468996,0.0287994,0.615023,0.601905,0.355643,0.406272,1.31974,1.5728,2.61445,2.75564,0.438898,0.493533,0.491497,0.438451,0.183026,0.266342,1.09658,0.881143,1.84127,1.5882,-1.08491,-1.17642,-1.23642,-1.27235,-0.47962,-0.399344
3331,0.460753,0.36416,0.136491,0.0854975,0.898806,0.755218,0.86485,0.841008,0.441215,0.496182,0.899741,0.954988,0.420619,0.364614,0.57749,0.561383,0.0146622,0.00210306,0.77104,0.820053,1.19837,1.45533,1.13092,1.27545,1.2831,1.38174,-0.274159,-0.32343,0.868012,0.946351,0.0829877,-0.137313,0.0542836,-0.194576,-0.194678,-0.279644,1.6106,1.57253,-0.729065,-0.648633
3332,0.192192,0.0758119,0.933026,0.882317,0.376601,0.231795,0.896482,0.873787,0.369724,0.425542,0.884915,0.958218,0.0333407,-0.0211469,0.506664,0.490414,0.813805,0.799009,0.18697,0.234358,-1.74297,-1.48023,-0.949748,-0.801718,0.205795,0.300631,2.15664,2.10508,-0.53752,-0.461831,0.809809,0.595727,0.115841,-0.112263,0.27224,0.188886,0.58666,0.498772,0.568386,0.647385
3333,0.954546,0.840183,0.670359,0.621223,0.495306,0.300149,0.301348,0.280363,0.989275,1.04476,0.908511,0.961447,0.0597289,0.00666451,0.897588,0.882556,0.583158,0.570875,0.635839,0.683444,1.01626,1.27518,1.9484,2.09767,2.11211,2.20823,1.24405,1.18677,1.12196,1.19755,0.647487,0.42694,0.219155,-0.0299496,-0.69072,-0.767378,-0.537841,-0.574986,1.52212,1.6069
3334,0.691193,0.595025,0.0575495,0.0102585,0.511855,0.368502,0.235829,0.229905,0.359401,0.414944,0.447446,0.595449,0.981926,0.929337,0.243069,0.230071,0.0627286,0.0516334,0.729185,0.774916,0.401022,0.581192,1.37954,1.53244,-0.716169,-0.6202,1.02209,0.967397,-0.77891,-0.703693,-1.58616,-1.80951,-1.10259,-1.35686,-0.350835,-0.353293,-0.720401,-0.757042,-0.246299,-0.162107
3335,0.54564,0.349867,0.771992,0.725736,0.340175,0.196663,0.248953,0.179446,0.982336,1.03913,0.178032,0.229451,0.184842,0.130118,0.895244,0.879558,0.233996,0.221319,0.561403,0.675957,-0.37242,-0.112797,-0.780017,-0.622116,-2.44962,-2.34978,0.547809,0.499379,1.6378,1.71761,1.07057,0.847295,1.13795,0.877964,0.144693,0.0607917,-0.794363,-0.939098,0.0926276,0.175548
3336,0.217467,0.104709,0.596918,0.551162,0.49078,0.348262,0.152174,0.128988,0.751003,0.807568,0.146035,0.197314,0.869826,0.81301,0.557253,0.542821,0.920727,0.908536,0.531173,0.576998,0.395381,0.659032,-0.150328,0.00896715,2.09851,2.19835,0.839893,0.787797,0.809748,0.892845,1.1546,0.938698,-1.74626,-2.0102,-0.419859,-0.510825,-1.08401,-1.12115,-1.64978,-1.56251
3337,0.860565,0.745916,0.654749,0.590683,0.352714,0.211562,0.745076,0.72132,0.838063,0.896091,0.560962,0.526981,0.958964,0.902644,0.760802,0.672706,0.0161718,0.00239633,0.117087,0.161005,-0.0907283,0.176482,0.212292,0.364162,-0.380787,-0.280287,0.827928,0.76825,-0.421947,-0.345639,0.220205,0.012487,0.203671,-0.0650436,-2.43123,-2.51807,0.3543,0.324053,0.712932,0.797285
3338,0.564602,0.398443,0.677018,0.630205,0.760766,0.619704,0.186299,0.163081,0.0366689,0.0953891,0.805142,0.856649,0.814497,0.703144,0.815261,0.80259,0.964669,0.95291,0.508745,0.492894,1.54952,1.81333,1.52169,1.67382,-1.06368,-0.919552,-1.05527,-1.11026,-1.17058,-1.09296,-0.115647,-0.325928,1.55994,1.29072,-0.89846,-0.977125,1.03741,1.00316,-0.466891,-0.377142
3339,0.163338,0.0509701,0.163701,0.117364,0.822429,0.704145,0.152282,0.131069,0.511343,0.568361,0.682184,0.667955,0.500196,0.503645,0.20758,0.196592,0.482921,0.472832,0.778618,0.824783,0.323043,0.592431,0.621339,0.77167,-1.65946,-1.55882,1.38098,1.31824,-0.208861,-0.137079,0.305538,0.0857375,0.884627,0.616123,-0.12403,-0.202608,-1.06047,-1.09247,0.158233,0.249433
3340,0.460115,0.348281,0.578135,0.532473,0.929736,0.788586,0.340597,0.283459,0.423431,0.433927,0.468945,0.479262,0.361715,0.304146,0.742879,0.734363,0.880844,0.868709,0.090401,0.137629,0.945663,1.21161,-0.659426,-0.503327,-0.396584,-0.19755,1.06993,1.00523,-0.433503,-0.278776,-0.286505,-0.502791,1.12463,0.860125,0.315406,0.234914,-1.02095,-1.05019,0.472056,0.558059
3341,0.160924,0.04865,0.00718729,-0.0388984,0.219368,0.0792654,0.459414,0.435849,0.190673,0.299493,0.236795,0.290569,0.862574,0.806462,0.620871,0.613235,0.645363,0.614424,0.540619,0.586716,-1.95074,-1.69088,-0.930801,-0.777331,1.05958,1.16372,-0.35691,-0.420542,-0.485224,-0.420473,0.362653,0.141245,-1.08055,-1.3449,-0.978368,-1.06095,0.614775,0.581458,-1.99881,-1.90408
3342,0.927805,0.813021,0.908732,0.864663,0.281873,0.141446,0.149285,0.128064,0.108041,0.165059,0.563003,0.615706,0.349293,0.294861,0.811855,0.804864,0.354915,0.360139,0.0515667,0.0960373,0.373008,0.638159,1.15889,1.31093,-0.482101,-0.379606,-0.575891,-0.639914,0.473523,0.535404,0.204247,-0.0143673,0.625682,0.365115,-0.00727702,-0.0876755,0.792245,0.75925,0.258367,0.356222
3343,0.847556,0.705519,0.529133,0.485874,0.797543,0.65546,0.470255,0.379916,0.314467,0.448397,0.571402,0.647649,0.769761,0.716631,0.66003,0.639428,0.117989,0.105854,0.789823,0.834422,0.902399,1.16746,-1.45844,-1.3082,-0.321154,-0.213104,-0.306659,-0.367374,0.286782,0.304362,-0.512015,-0.725743,-0.19205,-0.447142,-1.68238,-1.76544,0.561662,0.535823,-0.0657356,0.0244932
3344,0.728942,0.598017,0.734993,0.630737,0.579851,0.437594,0.652396,0.631769,0.693226,0.731736,0.627643,0.679592,0.863484,0.810572,0.405679,0.473992,0.24226,0.14861,0.251386,0.293262,0.661575,0.931352,-0.851376,-0.706355,0.0993125,0.202185,1.27244,1.20695,0.0136011,0.0733209,0.214975,-0.0455373,-0.716379,-0.970317,1.50871,1.42988,-1.73832,-1.76553,-0.401841,-0.307236
3345,0.562312,0.490515,0.818276,0.775601,0.879524,0.738841,0.17028,0.149958,0.958384,1.01507,0.365603,0.416473,0.0514394,-0.00112761,0.316046,0.308556,0.203466,0.191367,0.186439,0.228988,-0.0710481,0.139245,-1.71365,-1.56226,-0.375376,-0.270299,-1.42647,-1.49043,-2.47198,-2.41548,0.846043,0.634669,1.33542,1.0866,-0.406475,-0.483723,0.0365135,0.00741448,0.404754,0.413392
3346,0.654177,0.383013,0.0819091,0.0399591,0.430579,0.289771,0.378826,0.356645,0.454351,0.511836,0.81424,0.864907,0.363237,0.310932,0.600587,0.594474,0.506787,0.457398,0.69759,0.737489,-0.918086,-0.652861,-1.36891,-1.22129,0.635393,0.744387,-0.629841,-0.696017,0.790264,0.840943,-0.0872296,-0.291543,1.71768,1.46905,-0.250155,-0.321585,-0.351393,-0.383949,1.04683,1.13402
3347,0.390295,0.275511,0.106242,0.0541028,0.625464,0.485096,0.301089,0.278321,0.601564,0.656291,0.692224,0.741703,0.0192035,-0.0342916,0.186922,0.182783,0.736208,0.723428,0.648745,0.68839,1.34384,1.6139,0.898341,1.04725,-0.196907,-0.0684881,1.07878,1.01562,0.156065,0.200749,0.40284,0.128476,1.45981,1.21063,0.540906,0.467778,1.23533,1.20052,1.28023,1.36705
3348,0.710461,0.596908,0.109421,0.0682465,0.152541,0.0101207,0.739949,0.716988,0.151413,0.20828,0.995032,1.04309,0.783549,0.73046,0.531761,0.500265,0.5423,0.528199,0.0587601,0.097729,-2.13796,-1.8679,-0.810796,-0.665914,-0.990358,-0.881364,0.475399,0.410097,-1.0478,-1.004,0.752263,0.548495,-2.92307,-3.16795,1.09568,1.02704,0.000692779,-0.0341906,0.2615,0.347765
3349,0.637079,0.551541,0.599148,0.555946,0.083726,-0.0077141,0.85631,0.831441,0.330268,0.388317,0.62709,0.675686,0.69342,0.641516,0.823617,0.817746,0.346518,0.332971,0.92438,0.961308,0.736379,1.00182,-0.123555,0.0262895,0.666829,0.775248,-0.515251,-0.583847,0.789329,0.827496,-0.407928,-0.606482,-0.708056,-0.949252,0.264816,0.193243,-0.0320827,-0.0702443,0.0444346,0.174783
3350,0.621835,0.506174,0.294025,0.288054,0.118045,-0.0255489,0.610498,0.583507,0.170188,0.226951,0.616995,0.667867,0.0560051,0.00407301,0.0759439,0.0720013,0.714715,0.698816,0.457992,0.495352,-1.64582,-1.38348,0.0699811,0.17849,-0.443787,-0.337995,1.67561,1.60457,1.68449,1.72324,0.7146,0.551016,-1.6056,-1.84105,0.558885,0.492531,-0.615377,-0.648714,-0.0872448,0.00179996
3351,0.840963,0.727974,0.0628859,0.0201622,0.306805,0.164804,0.780103,0.753641,0.826923,0.882128,0.0782918,0.128651,0.40917,0.356056,0.0733171,0.0672029,0.615175,0.597675,0.43361,0.4714,-0.731881,-0.474742,0.302222,0.33069,-0.339278,-0.231494,-0.677202,-0.743203,0.358447,0.389956,1.90707,1.70851,0.496633,0.268147,0.609188,0.545519,1.78909,1.76018,1.9716,2.05576
3352,0.632319,0.420708,0.431063,0.389875,0.0129543,-0.129165,0.404003,0.43042,0.213289,0.267701,0.670986,0.719297,0.968141,0.912948,0.32491,0.317401,0.92109,0.90345,0.094744,0.130261,-0.526313,-0.279672,0.333046,0.482891,-0.566378,-0.460308,-1.87719,-1.93879,-0.405749,-0.372967,0.37131,0.169006,-0.787384,-1.01313,0.282853,0.21822,1.01379,0.981138,-0.15699,-0.0701408
3353,0.226498,0.113442,0.304106,0.260742,0.170578,0.0403928,0.133116,0.107198,0.431075,0.479956,0.651747,0.616596,0.0393122,-0.014809,0.856101,0.849984,0.28015,0.263024,0.146411,0.180278,-0.333336,-0.0846029,0.24294,0.391985,-0.024179,0.16435,1.15675,1.0888,-0.688283,-0.661377,1.15922,0.961168,-1.18648,-1.41134,0.631656,0.563927,0.577646,0.541233,0.0980798,0.191257
3354,0.427204,0.233944,0.952742,0.910779,0.351245,0.209951,0.525358,0.432743,0.613268,0.69221,0.463547,0.513894,0.871906,0.818895,0.900535,0.885397,0.81947,0.803701,0.145739,0.230294,-1.28564,-1.0435,-1.3215,-1.16585,0.690317,0.789009,0.191009,0.125742,0.487967,0.509691,0.9594,0.738281,0.898391,0.68259,-1.30605,-1.3806,0.353411,0.317805,-1.08977,-0.997744
3355,0.492164,0.354447,0.498876,0.457561,0.974359,0.833283,0.781223,0.758287,0.849972,0.904464,0.832087,0.883452,0.806991,0.754764,0.97217,0.92081,0.962012,0.948144,0.372704,0.28031,-0.533443,-0.285864,-0.284186,-0.134782,-0.0017047,0.0965665,1.28138,1.2123,0.681972,0.697804,0.719182,0.515394,0.000797883,-0.209207,-1.7836,-1.86083,0.777537,0.745294,0.46711,0.562006
3356,0.588005,0.474949,0.428775,0.388519,0.416649,0.274436,0.0439036,0.0200784,0.547415,0.60193,0.120634,0.173749,0.194762,0.14362,0.962339,0.956222,0.43319,0.418978,0.293164,0.330327,-0.0026906,0.243433,-0.595479,-0.440954,-2.05796,-1.96608,-0.385105,-0.449294,0.377857,0.393107,-0.555596,-0.764775,0.971743,0.758141,0.302493,0.224407,-2.00608,-2.04605,-0.83038,-0.73335
3357,0.428101,0.317184,0.905963,0.866286,0.50879,0.365554,0.128507,0.0732698,0.485682,0.543259,0.101323,0.120358,0.73832,0.685274,0.794706,0.788372,0.712354,0.700156,0.227456,0.266052,-0.517908,-0.271209,0.901359,1.15356,0.326502,0.423108,-0.209745,-0.268239,0.785161,0.796659,-0.0412383,-0.257679,-0.0857816,-0.304466,-1.47773,-1.56153,-0.615478,-0.662726,-0.651473,-0.560903
3358,0.617911,0.603285,0.976375,0.934823,0.981605,0.839148,0.257482,0.126461,0.431093,0.484588,0.0164223,0.0669678,0.975031,0.921124,0.0161866,0.0119977,0.241626,0.230639,0.783041,0.820164,-1.29681,-1.04601,2.58746,2.74807,-0.593221,-0.501686,-1.23092,-1.29279,-0.598348,-0.58259,1.72749,1.50404,0.726292,0.507201,0.0877239,0.0106618,0.538047,0.498487,-1.75319,-1.65846
3359,0.999662,0.889386,0.406645,0.363451,0.864277,0.780107,0.264508,0.179653,0.583189,0.634776,0.454725,0.505324,0.30211,0.248877,0.447914,0.443647,0.571633,0.561178,0.395234,0.434851,0.350357,0.60652,-1.23228,-1.06715,-0.892988,-0.806204,-0.734501,-0.793041,-0.806433,-0.795691,0.447354,0.223871,1.00125,0.782762,-1.6009,-1.68254,2.48388,2.4466,-0.503677,-0.409208
3360,0.248522,0.138639,0.427488,0.382485,0.890915,0.721066,0.256669,0.232844,0.24606,0.297567,0.404089,0.523868,0.783207,0.731126,0.203508,0.200732,0.571263,0.56123,0.298283,0.42818,0.709084,0.965961,-2.2688,-2.10917,0.236462,0.330635,0.0686442,0.0164332,0.561325,0.572626,-0.470258,-0.688468,-0.549745,-0.766274,-1.51896,-1.59795,-1.03607,-1.06465,-0.30165,-0.206525
3361,0.438194,0.342508,0.0364243,-0.00711225,0.804481,0.662024,0.010822,-0.0150898,0.270087,0.321075,0.537211,0.542412,0.948414,0.896683,0.769582,0.768242,0.8349,0.822889,0.380638,0.421509,-0.398309,-0.147697,0.197222,0.353267,-0.104934,-0.00510923,-0.324155,-0.373239,0.647981,0.654812,-0.377973,-0.597065,-1.54064,-1.75207,0.545651,0.47321,-2.02204,-2.04787,-0.324008,-0.229561
3362,0.598336,0.546377,0.944246,0.901568,0.560809,0.417569,0.638671,0.612078,0.0760857,0.129016,0.562073,0.560956,0.186232,0.135913,0.0960174,0.0963443,0.853105,0.842674,0.704092,0.745244,0.885697,1.13198,-1.69588,-1.5366,-0.720113,-0.622464,0.980719,0.929433,0.509775,0.517317,1.11358,0.886865,-0.400108,-0.614183,0.296661,0.221721,1.97459,1.94876,0.163027,0.25946
3363,0.860129,0.750246,0.163594,0.119654,0.931746,0.790355,0.397167,0.368946,0.90826,0.961119,0.5289,0.5795,0.642158,0.591793,0.76866,0.767386,0.572485,0.564158,0.699441,0.740749,0.210325,0.449965,-0.171635,-0.0401002,0.634504,0.726863,2.03749,1.98598,-0.609102,-0.597292,0.647892,0.320848,-0.514146,-0.733797,-1.81369,-1.89489,-1.05139,-1.06981,1.92635,2.01959
3364,0.337731,0.229605,0.293299,0.342372,0.151395,0.00987024,0.860163,0.831479,0.793882,0.7774,0.11651,0.168495,0.522983,0.524445,0.315973,0.316563,0.590807,0.583943,0.184411,0.225399,1.06779,1.31192,1.29712,1.4564,-0.153081,-0.122654,-0.989464,-1.04416,0.4285,0.464798,0.0420298,-0.245169,0.13796,-0.086898,-0.404183,-0.491012,-0.392697,-0.408218,0.154099,0.250583
3365,0.505806,0.460816,0.606689,0.565089,0.529767,0.387269,0.878109,0.771232,0.555848,0.593681,0.239974,0.290855,0.462907,0.457097,0.42276,0.4229,0.954608,0.949787,0.020836,0.0603967,-0.850055,-0.602493,1.00972,1.16738,-1.06453,-0.97217,-0.147996,-0.204148,1.51569,1.52689,-0.461612,-0.811187,1.7317,1.5005,-0.00637863,-0.0982264,-1.36892,-1.39144,0.207686,0.303417
3366,0.800774,0.692027,0.0626684,0.0233733,0.352062,0.210901,0.738277,0.710985,0.353198,0.409961,0.363071,0.413216,0.440458,0.389749,0.768802,0.770145,0.428822,0.425721,0.802751,0.84081,0.0945168,0.336547,0.349693,0.542223,0.278665,0.377157,-0.630235,-0.685309,-0.928696,-0.91581,-1.15049,-1.3772,-1.23749,-1.46956,0.81776,0.722825,0.869693,0.852156,1.44655,1.53885
3367,0.250422,0.140891,0.578701,0.541145,0.795679,0.654647,0.413906,0.427321,0.175299,0.226242,0.730663,0.782773,0.816562,0.766509,0.816425,0.815534,0.485985,0.483881,0.747019,0.786858,0.475342,0.711166,-0.23974,-0.082939,1.34662,1.45239,1.22521,1.17257,0.677108,0.684115,0.437163,0.216317,-0.419534,-0.657895,-1.86334,-1.95243,-1.91084,-1.92231,-0.00752976,0.0904454
3368,0.474804,0.367447,0.443931,0.353604,0.540765,0.376841,0.170172,0.143656,0.48063,0.533503,0.384196,0.43559,0.414247,0.365812,0.0414575,0.0391598,0.965233,0.963904,0.236863,0.275949,0.639832,0.869126,0.076381,0.226944,0.562661,0.745621,0.578197,0.520215,0.521355,0.533014,0.297263,0.0769899,-0.41664,-0.656783,-0.367545,-0.45855,-1.28869,-1.30674,1.87324,1.97272
3369,0.229692,0.123785,0.20491,0.166064,0.239898,0.0990353,0.705633,0.676279,0.417227,0.467775,0.549369,0.639778,0.0171856,-0.0348844,0.9611,0.958071,0.885629,0.883539,0.837673,0.87443,-2.34954,-2.12683,-0.903771,-0.75204,-0.170506,0.0388517,0.536361,0.484571,1.25195,1.25869,1.27768,1.05651,1.02738,0.790171,0.500347,0.40739,1.22711,1.21707,0.301885,0.405078
3370,0.886881,0.780178,0.460279,0.422677,0.96599,0.824689,0.80982,0.800447,0.0814594,0.130567,0.797984,0.843965,0.117814,0.0655516,0.679115,0.641986,0.485257,0.484595,0.408431,0.443761,0.201073,0.426493,0.299265,0.449114,-0.773689,-0.667918,0.123952,0.0794068,1.29643,1.30983,-0.393006,-0.619997,0.0919634,-0.149933,-0.274107,-0.365056,-0.67639,-0.686515,-0.405902,-0.29693
3371,0.0516213,-0.0567174,0.140372,0.102324,0.859993,0.718645,0.955211,0.924615,0.637993,0.685061,0.99676,1.04815,0.910889,0.855834,0.326401,0.325901,0.679518,0.599762,0.228337,0.263421,-0.0173302,0.205845,0.202985,0.438092,-0.543067,-0.441779,-0.523502,-0.572948,-0.949672,-0.931233,-0.199971,-0.421924,-0.0946826,-0.331664,0.123662,0.0277299,0.163624,0.1478,0.507114,0.615802
3372,0.96942,0.862943,0.494328,0.45785,0.14825,0.00418543,0.681847,0.668136,0.466939,0.530862,0.0131054,0.0644988,0.968155,0.914809,0.387362,0.38655,0.788388,0.714929,0.261003,0.230301,0.525207,0.748802,0.273085,0.42707,-0.321411,-0.21564,-0.338157,-0.391892,-0.00954502,0.0952657,0.378048,0.16141,0.367264,0.129203,2.46556,2.36877,-2.18619,-2.20348,-0.0830541,0.0196023
3373,0.520237,0.412519,0.410101,0.282169,0.230976,0.00207615,0.442036,0.411656,0.301768,0.376663,0.998991,1.04908,0.358016,0.303664,0.905796,0.903842,0.830903,0.830095,0.160588,0.197181,-0.026377,0.242482,0.750664,0.903311,0.360419,0.518106,0.819453,0.800841,1.10073,1.12176,-0.382871,-0.597598,1.28794,1.05043,-0.590299,-0.683457,0.450847,0.431675,0.274962,0.371536
3374,0.810505,0.704744,0.144433,0.106489,0.142897,-3.31382e-05,0.6572,0.627961,0.1739,0.222464,0.191203,0.241853,0.666777,0.610617,0.397138,0.397563,0.313049,0.310854,0.603756,0.640737,-0.484153,-0.263838,-1.10918,-0.956538,1.14903,1.25185,2.04577,1.99357,-0.154201,-0.133116,-0.34132,-0.552575,1.18023,0.944884,1.23126,1.13764,-0.902939,-0.928604,-0.687993,-0.587039
3375,0.61777,0.51088,0.396857,0.358171,0.663484,0.518873,0.423696,0.329768,0.904581,0.955216,0.25969,0.308294,0.0695182,0.0140179,0.153277,0.154648,0.996448,0.993132,0.190404,0.229265,-2.07283,-1.85138,-2.35169,-2.19946,0.311731,0.418182,0.607465,0.551829,0.864424,0.885404,1.26364,1.05636,-0.515858,-0.74417,2.80721,2.70984,0.406989,0.388251,0.150594,0.250263
3376,0.141946,0.0352316,0.222539,0.183596,0.19823,0.0544441,0.0637169,0.0315749,0.48702,0.536177,0.907491,0.95472,0.0855554,0.0318055,0.803413,0.804135,0.439794,0.438639,0.364843,0.429394,-1.35961,-1.14208,-0.546954,-0.395073,0.151681,0.251768,1.56129,1.50068,-0.0572821,-0.029409,-2.03267,-2.23254,1.56185,1.32859,-0.838493,-0.925796,0.727007,0.706829,1.30029,1.39285
3377,0.0265912,-0.0788095,0.867439,0.82831,0.445233,0.239619,0.717045,0.683839,0.373055,0.40147,0.941287,0.960015,0.627887,0.57346,0.876372,0.875723,0.349777,0.348373,0.591437,0.629523,-0.221063,-0.00366414,-0.0142078,0.143858,0.995453,1.09826,-0.741446,-0.794074,-0.503755,-0.472982,-0.212975,-0.406795,0.600395,0.287515,-0.818815,-0.902818,0.721939,0.701512,0.5186,0.615065
3378,0.871676,0.768646,0.155121,0.118175,0.687136,0.424794,0.23163,0.196925,0.218263,0.266763,0.919594,0.96531,0.651388,0.584128,0.100408,0.0993481,0.496199,0.450982,0.0686716,0.109262,-1.02173,-0.810095,0.181608,0.34583,-3.13458,-3.03177,-2.26449,-2.31301,0.0997184,0.128001,1.06682,0.878902,-0.5164,-0.753558,1.40072,1.31858,-0.823115,-0.848373,1.34591,1.43802
3379,0.825835,0.721754,0.634212,0.595943,0.753755,0.609969,0.444541,0.40791,0.330423,0.309255,0.202994,0.24971,0.647832,0.594796,0.457509,0.456856,0.557363,0.553592,0.201307,0.241324,0.134605,0.344385,-1.35624,-1.19653,-0.657073,-0.556312,0.143294,0.0989938,1.79953,1.8334,-0.256792,-0.446443,-0.0365052,-0.276947,-0.443675,-0.519151,1.77554,1.75599,0.0376118,0.127077
3380,0.014386,-0.09014,0.403587,0.280749,0.621758,0.455648,0.244822,0.205599,0.302125,0.351747,0.836351,0.880392,0.18688,0.134333,0.0724117,0.0703841,0.206174,0.20398,0.988904,1.02805,3.00738,3.21411,-0.697369,-0.533366,-1.09796,-0.997728,-0.0728656,-0.120378,-0.151453,-0.11726,0.467023,0.272746,-1.5633,-1.80921,-0.184798,-0.263369,-0.96981,-0.991476,0.102433,0.195301
3381,0.390233,0.287935,0.0038573,-0.0344447,0.442663,0.301326,0.374997,0.381995,0.0309979,0.0797415,0.796623,0.843064,0.813198,0.759804,0.330444,0.326091,0.244058,0.242425,0.20046,0.237717,1.5113,1.71905,-1.3526,-1.18871,-0.607342,-0.544212,0.092557,0.0446374,1.66274,1.69704,0.713339,0.516993,-0.446283,-0.688814,0.775542,0.694856,1.82657,1.81357,-0.590446,-0.490122
3382,0.219392,0.212943,0.295017,0.208431,0.598587,0.457967,0.470402,0.558391,0.688415,0.734919,0.265303,0.313145,0.337481,0.283659,0.900333,0.893601,0.967695,0.964956,0.279643,0.319336,0.631556,0.8364,0.42293,0.587319,-0.0550127,-0.0906958,-0.100287,-0.145151,0.265882,0.304145,0.323159,0.132771,-0.607657,-0.855678,0.988034,0.90246,0.425312,0.405261,1.293,1.39216
3383,0.146256,0.13795,0.488036,0.451306,0.474247,0.306765,0.774506,0.734787,0.679156,0.727641,0.495952,0.541829,0.553538,0.500125,0.805475,0.877833,0.371023,0.370724,0.608153,0.634788,0.0157446,0.249222,0.91261,1.0815,0.262584,0.36282,-1.00234,-1.0454,-1.99404,-1.95427,-1.14705,-1.33237,-1.26695,-1.51435,0.229246,0.144483,0.0541141,0.0288838,0.646367,0.74931
3384,0.16342,0.0629571,0.135561,0.0971234,0.269307,0.155564,0.00546219,-0.034618,0.279385,0.329127,0.420006,0.433533,0.529738,0.456774,0.867779,0.862066,0.573537,0.476574,0.911853,0.950239,-0.541726,-0.337956,-1.33345,-1.16894,1.66003,1.75559,-0.737907,-0.702538,-1.48156,-1.44386,0.473931,0.292066,-1.1835,-1.43634,0.137643,0.0467321,-1.72998,-1.76127,0.655362,0.75689
3385,0.666352,0.565086,0.699208,0.659096,0.146624,0.00436237,0.256483,0.275288,0.629384,0.681155,0.175735,0.325237,0.553242,0.413424,0.0342909,0.0294188,0.663776,0.582425,0.243133,0.279091,-0.585654,-0.377191,-0.424664,-0.261497,-0.831146,-0.737521,-0.321504,-0.359672,0.374079,0.416238,1.01983,0.844562,-0.563071,-0.820547,1.60241,1.51088,-0.310415,-0.372695,-1.40624,-1.30822
3386,0.865115,0.765612,0.583132,0.541049,0.744282,0.60207,0.618757,0.585194,0.334274,0.384614,0.170057,0.216941,0.422811,0.370074,0.227121,0.202808,0.687661,0.688276,0.963361,0.998619,-1.56001,-1.35078,-0.327079,-0.168992,0.247027,0.337713,0.455764,0.418614,-2.25651,-2.22168,-0.977716,-1.1584,1.02179,0.766846,-0.145718,-0.230903,1.04957,1.01588,-2.08902,-1.99364
3387,0.368657,0.270218,0.726779,0.684599,0.741968,0.598338,0.935179,0.895099,0.663235,0.64785,0.832861,0.878674,0.748603,0.697391,0.448732,0.376198,0.400678,0.399125,0.450454,0.48771,0.302346,0.51587,0.657594,0.814391,0.148289,0.231204,-1.3816,-1.41497,1.80064,1.83548,-0.417633,-0.605902,-0.145692,-0.405535,-0.977228,-1.0647,-0.483279,-0.518534,-0.920438,-0.81976
3388,0.249221,0.151552,0.558973,0.516046,0.433583,0.289212,0.332006,0.291785,0.858638,0.911087,0.944861,0.992458,0.304732,0.251627,0.555484,0.549588,0.968698,0.968489,0.303858,0.342604,-2.64328,-2.43646,-0.36807,-0.213409,-0.3727,-0.28901,-0.427922,-0.466117,1.192,1.22485,-1.91285,-2.10196,1.0122,0.749938,1.12656,1.03893,-0.88087,-0.909897,-0.860454,-0.766926
3389,0.777911,0.678358,0.605989,0.641153,0.645681,0.499496,0.151056,0.109818,0.308127,0.36258,0.047415,0.097791,0.626018,0.573518,0.503821,0.498298,0.918554,0.878187,0.548149,0.585697,0.527096,0.731124,-0.138675,0.0183805,1.01138,1.08907,-0.954825,-0.994212,0.0160154,0.0487575,-0.283113,-0.477523,0.505885,0.243787,-1.17289,-1.26382,-0.180007,-0.216498,-0.205795,-0.109873
3390,0.15111,0.0524716,0.810007,0.76626,0.460044,0.312018,0.306535,0.306062,0.541021,0.593167,0.0182615,0.07005,0.510009,0.459105,0.71505,0.709709,0.843185,0.787885,0.183846,0.219537,1.60521,1.80754,0.704694,0.863517,0.170619,0.241515,-0.5905,-0.686051,1.55463,1.58638,-1.50344,-1.69255,0.211153,-0.0457855,1.77952,1.68107,-0.245663,-0.283274,1.13272,1.23124
3391,0.707853,0.60902,0.671851,0.591915,0.603406,0.362661,0.542747,0.502305,0.56864,0.614348,0.25499,0.308371,0.994547,0.945846,0.329332,0.323237,0.804248,0.697583,0.0680145,0.103745,0.319646,0.525957,-0.337356,-0.178501,2.3015,2.36984,-0.334589,-0.377889,0.0718156,0.102781,-1.90375,-2.0924,0.256293,0.000114024,-0.270414,-0.456157,1.68319,1.64807,-0.602345,-0.506822
3392,0.0587614,-0.0425797,0.461247,0.417571,0.561727,0.413304,0.139214,0.100692,0.636922,0.635528,0.258852,0.310442,0.00475365,-0.0422059,0.178669,0.171991,0.60749,0.607281,0.916208,0.952205,0.704758,0.91496,0.0115139,0.15513,-0.915623,-0.855267,0.893128,0.849206,-1.88957,-1.86349,-0.660966,-0.852791,-0.791515,-1.0475,-2.49492,-2.59338,1.77102,1.73608,-1.41674,-1.32859
3393,0.206381,0.102236,0.74753,0.704014,0.0544752,-0.0950837,0.431726,0.483913,0.606168,0.656708,0.9559,1.00683,0.383414,0.334554,0.289039,0.282699,0.0949365,0.0924293,0.343836,0.381031,1.44557,1.65623,0.339327,0.488761,1.46894,1.53392,1.18839,1.13762,-0.211972,-0.188211,-1.22893,-1.42328,-0.616507,-0.879337,-0.99526,-1.09949,-1.61031,-1.6402,0.0213442,0.107051
3394,0.700703,0.598642,0.625203,0.580124,0.0807693,-0.0929368,0.906088,0.867135,0.259312,0.30928,0.331147,0.382243,0.126975,0.0778066,0.966112,0.958878,0.761861,0.760115,0.062142,0.100114,-1.30804,-1.09055,1.351,1.50447,-1.08088,-1.02315,0.14111,0.0981864,-0.743584,-0.720249,-1.28173,-1.46968,-0.238907,-0.496892,0.161969,0.0583347,-0.799643,-0.822863,0.956398,1.03511
3395,0.162821,0.0623846,0.915418,0.870991,0.0352705,-0.0907898,0.818626,0.784737,0.633772,0.682589,0.578328,0.565329,0.673324,0.624072,0.223387,0.217624,0.200579,0.200268,0.895304,0.933982,1.63392,1.85443,-0.0406638,0.11785,0.32876,0.38508,0.514913,0.476618,0.338185,0.358455,0.138738,-0.0479743,-0.684005,-0.942941,-0.123533,-0.222624,-0.529261,-0.552408,0.44249,0.513496
3396,0.505203,0.404334,0.771223,0.727285,0.0612642,-0.0886429,0.726571,0.70234,0.123065,0.169467,0.699089,0.748414,0.392708,0.343154,0.649149,0.558917,0.917434,0.916723,0.079102,0.118661,-0.579004,-0.36064,-0.948905,-0.784299,-0.714119,-0.650125,-0.892254,-0.935018,-1.03009,-1.00577,0.0330908,-0.155356,-1.44871,-1.70989,1.5753,1.47481,-0.895561,-0.914243,-0.286783,-0.218165
3397,0.270253,0.171119,0.028764,-0.0126427,0.48316,0.335525,0.537792,0.619942,0.512682,0.55777,0.0186645,0.0678932,0.938529,0.889419,0.905101,0.900209,0.902141,0.923822,0.79942,0.838189,-1.03774,-0.825956,-3.36694,-3.19542,-1.53302,-1.46748,0.929586,0.892335,-0.0447135,-0.0187056,-0.525886,-0.710952,-1.51503,-1.76968,0.729882,0.626546,0.856748,0.84299,-1.46967,-1.40717
3398,0.827182,0.727668,0.58733,0.544186,0.309518,0.233714,0.578845,0.537544,0.120899,0.164204,0.345294,0.297687,0.301373,0.251976,0.561272,0.494078,0.833882,0.930922,0.564766,0.672354,-0.245514,-0.0390805,2.40326,2.57478,1.05484,1.11952,-0.125034,-0.165566,1.80318,1.82806,-0.0774976,-0.26461,2.71159,2.45809,-0.867457,-0.97295,-1.66094,-1.67797,-0.149207,-0.0807817
3399,0.0657147,-0.0333122,0.288635,0.244335,0.281885,0.131902,0.0275926,-0.0150958,0.825625,0.869921,0.549272,0.52748,0.414527,0.354688,0.0917593,0.0879478,0.938414,0.938021,0.466329,0.506519,-2.10008,-1.89302,-0.6578,-0.493841,-0.58018,-0.514572,-2.67139,-2.71467,1.54608,1.5672,-0.170915,-0.334332,-1.01434,-1.26344,-0.754432,-0.856698,-0.16669,-0.185743,-0.241628,-0.178546
3400,0.141993,0.0901184,0.914221,0.86998,0.768398,0.620169,0.041985,-0.00197417,0.882532,0.926949,0.709728,0.757274,0.50814,0.4574,0.374801,0.36898,0.266313,0.267143,0.877847,0.915833,0.619331,0.829274,-1.31416,-1.14919,-0.239346,-0.0822214,-0.187593,-0.234014,-0.588357,-0.565,-0.224228,-0.404054,1.79793,1.54369,2.19399,2.08819,-0.0920093,-0.113986,0.904512,0.964042
3401,0.312788,0.213549,0.398876,0.352337,0.667749,0.579565,0.942139,0.895663,0.677869,0.720462,0.828743,0.876892,0.0486451,-0.00306304,0.396085,0.389688,0.0116125,0.0134385,0.474063,0.509442,1.08316,1.29617,1.90795,2.07272,0.278393,0.350129,1.0494,1.00684,0.505205,0.52874,0.397054,0.265672,0.487672,0.293044,-0.624181,-0.727248,-0.363219,-0.38347,-0.225516,-0.165743
3402,0.863929,0.764567,0.5576,0.531689,0.735019,0.538962,0.999605,0.954019,0.241991,0.286526,0.177798,0.226839,0.294851,0.243223,0.91924,0.911994,0.980177,0.979236,0.511284,0.546159,0.34681,0.554037,-0.857724,-0.695283,0.9686,1.04209,0.242287,0.199261,0.111097,0.132242,1.11522,0.935399,-0.704242,-0.957602,0.549358,0.446312,0.247469,0.232106,0.882214,0.94607
3403,0.465693,0.363864,0.758752,0.711041,0.763959,0.498359,0.256612,0.210946,0.590586,0.63326,0.612886,0.660964,0.25527,0.204903,0.695468,0.689583,0.755611,0.813865,0.228597,0.265242,-0.704741,-0.497191,-1.27055,-1.10576,-0.132625,-0.0546216,1.02667,0.977547,-1.14911,-1.12264,-0.36602,-0.545461,-0.740996,-0.986373,-0.767416,-0.865069,0.195746,0.178988,-1.04114,-0.978589
3404,0.763843,0.661174,0.421117,0.445494,0.686634,0.457755,0.724742,0.678891,0.079346,0.120138,0.587418,0.633223,0.956232,0.907319,0.800654,0.733044,0.647731,0.648495,0.554088,0.588977,1.00832,1.21642,-1.00231,-0.842546,0.560344,0.637343,0.581936,0.526208,1.78677,1.80633,0.830493,0.649545,-0.437898,-0.678673,1.4506,1.35633,-1.37469,-1.38592,-0.646693,-0.623107
3405,0.638559,0.53723,0.228947,0.179946,0.639509,0.417152,0.520381,0.474893,0.814308,0.85289,0.135111,0.181916,0.829179,0.693593,0.827752,0.776506,0.100935,0.099199,0.631478,0.664784,-0.221128,-0.0175162,0.0369218,0.201809,0.018992,0.101918,-0.480352,-0.531693,-0.691848,-0.668222,1.63925,1.46083,-0.896913,-1.14012,1.07853,1.01587,-0.136249,-0.14498,-0.33798,-0.267625
3406,0.78813,0.687321,0.33254,0.28395,0.524778,0.376548,0.31684,0.270894,0.624583,0.660831,0.752074,0.797585,0.525947,0.479867,0.734568,0.819968,0.969923,0.969838,0.993624,1.02491,-0.574222,-0.375438,0.259676,0.420141,-0.909834,-0.822876,-0.0474744,-0.0906086,-0.157931,-0.064964,1.05726,0.872302,-0.222114,-0.442901,0.769411,0.675407,-0.27021,-0.274825,-0.321367,-0.245153
3407,0.260479,0.161289,0.90944,0.859714,0.741679,0.510206,0.644924,0.612678,0.125311,0.162584,0.653133,0.699694,0.546469,0.502357,0.869315,0.86343,0.287982,0.289898,0.85931,0.872217,0.303296,0.501039,1.79304,1.94785,-0.0802784,0.00912646,0.453513,0.350476,0.515331,0.538294,-2.63369,-2.81205,0.501765,0.254322,1.27188,1.17531,0.619575,0.620222,-2.58075,-2.49585
3408,0.844842,0.746919,0.688051,0.640334,0.792253,0.643865,0.999319,0.954461,0.32258,0.357878,0.103337,0.150347,0.0353545,-0.00924354,0.364198,0.357151,0.364956,0.36791,0.638063,0.719521,-0.48426,-0.290084,1.66211,1.81188,-0.0200884,0.0715031,0.842902,0.791561,-0.800638,-0.779151,0.607035,0.433095,1.53887,1.29541,-3.31926,-3.41583,2.70512,2.70388,0.392351,0.482658
3409,0.0261391,-0.0704752,0.897034,0.848158,0.336261,0.189871,0.204654,0.158913,0.906718,0.943291,0.181247,0.226311,0.0297655,-0.016671,0.794305,0.7888,0.674826,0.678693,0.534466,0.566826,0.0015889,0.19409,-0.194386,-0.0479711,1.77879,1.86977,-0.358316,-0.404028,1.15245,1.17611,-1.09988,-1.2736,-2.98332e-05,-0.236852,-0.0439739,-0.143209,1.26279,1.26453,0.333339,0.429439
3410,0.836296,0.738003,0.38482,0.335317,0.235478,0.0891989,0.449698,0.450974,0.0981046,0.133178,0.950228,0.994199,0.350513,0.30522,0.326566,0.322156,0.711859,0.670405,0.911392,0.941303,0.230361,0.38916,-1.06862,-0.919499,-1.40103,-1.31387,-0.760703,-0.809192,0.740932,0.76375,1.55997,1.38321,1.60791,1.36542,-0.672972,-0.778796,-0.879419,-0.874994,-1.34634,-1.24752
3411,0.55534,0.459007,0.698776,0.558035,0.985359,0.84054,0.790299,0.743034,0.1796,0.211927,0.405365,0.520859,0.458629,0.415232,0.880262,0.875354,0.658666,0.662118,0.74738,0.776301,0.387149,0.584229,0.811251,0.965987,-0.897137,-0.810345,-0.358023,-0.400214,-0.87262,-0.842747,-1.62804,-1.80171,-1.82313,-2.07138,1.2144,1.10231,0.433163,0.44186,0.312917,0.416646
3412,0.899482,0.800956,0.830769,0.780752,0.301514,0.156243,0.1336,0.0857766,0.0199795,0.0505614,0.0053083,0.0475196,0.806155,0.762933,0.798197,0.7945,0.96426,0.967893,0.258127,0.285623,-1.27002,-1.08028,1.11335,1.26159,0.156823,0.250135,-0.768711,-0.805378,-0.188374,-0.153995,0.421745,0.241565,-0.596248,-0.840194,0.339046,0.222581,0.64219,0.650102,-0.969845,-0.864519
3413,0.0429072,-0.0569461,0.582622,0.595955,0.00638269,-0.137727,0.130332,0.121145,0.849801,0.878429,0.990569,1.0321,0.603534,0.563113,0.372548,0.368041,0.304932,0.307373,0.6705,0.699403,-1.45545,-1.27016,0.426862,0.575349,-0.0127787,-0.00282499,1.39312,1.34998,0.501286,0.534758,0.239257,0.0577787,0.0436068,-0.206315,-0.863188,-0.977973,-0.137452,-0.12894,0.364932,0.476593
3414,0.850063,0.751532,0.460405,0.411158,0.0784134,-0.0666078,0.260689,0.156513,0.84502,0.875881,0.629908,0.640791,0.405512,0.363293,0.910506,0.905812,0.0650156,0.0688618,0.173648,0.203996,-1.4387,-1.24886,0.150543,0.301345,-0.34416,-0.255785,-0.795106,-0.831534,-0.912463,-0.873423,0.673743,0.487013,0.672006,0.427565,-0.828321,-0.938964,1.74097,1.75556,0.983677,1.10317
3415,0.314971,0.215275,0.573746,0.524451,0.981389,0.836043,0.383478,0.191881,0.445225,0.486623,0.208486,0.249485,0.477205,0.437429,0.206569,0.202401,0.479767,0.484384,0.197338,0.226185,-0.0986298,0.0931956,-0.939288,-0.786947,0.966137,1.04728,-2.04011,-2.07358,1.26968,1.3132,-0.623476,-0.806729,0.453865,0.17738,0.200733,0.0838624,0.351676,0.364287,-0.825503,-0.711491
3416,0.473828,0.302895,0.358286,0.309996,0.666978,0.521514,0.27658,0.227249,0.0655078,0.097366,0.726052,0.766812,0.980742,0.939745,0.169722,0.166286,0.133504,0.139522,0.562702,0.591376,-0.0369888,0.160294,-0.14181,0.0151745,-1.22302,-1.14296,0.994079,0.954015,0.824071,0.869623,1.1684,0.986352,0.170384,-0.0728052,-0.000454749,-0.121186,0.614152,0.619592,0.22332,0.339354
3417,0.491429,0.390514,0.721005,0.674729,0.0595052,-0.0874227,0.743735,0.695194,0.00576181,0.037518,0.169341,0.207964,0.647278,0.604585,0.799509,0.796509,0.755353,0.760641,0.175558,0.206063,-1.55261,-1.34922,0.670352,0.817296,1.77464,1.84775,0.322552,0.315968,-0.358981,-0.318735,0.745888,0.57002,-0.495951,-0.731475,1.01432,0.901641,1.5938,1.59307,-0.311264,-0.271317
3418,0.11106,0.0107778,0.0733974,0.0290233,0.0922719,-0.0556987,0.409094,0.357778,0.826282,0.859382,0.986812,1.02297,0.783897,0.713102,0.141724,0.139451,0.667584,0.670375,0.947137,0.976727,-0.301746,-0.101215,-0.75423,-0.599103,-2.23306,-2.15994,-0.281893,-0.322078,0.23007,0.267314,1.66388,1.48852,-0.164373,-0.441424,0.725841,0.620683,1.02402,1.03066,-0.989629,-0.881987
3419,0.16024,0.0610259,0.0242954,-0.0208436,0.488931,0.34218,0.849777,0.796445,0.12124,0.153893,0.978799,1.01515,0.864951,0.821619,0.163339,0.16016,0.890423,0.892047,0.363498,0.391032,0.203127,0.395399,-0.524197,-0.367313,-0.690332,-0.614008,-0.07866,-0.126336,0.599175,0.641826,0.284284,0.114578,0.0808172,-0.151374,-0.730064,-0.842239,-1.05662,-1.04674,-1.73323,-1.62861
3420,0.428065,0.327901,0.927826,0.882718,0.619102,0.473642,0.798893,0.805343,0.530683,0.561853,0.17082,0.207926,0.607113,0.564872,0.949418,0.94797,0.737039,0.810221,0.874914,0.899534,1.21577,1.41231,-0.0130038,0.142238,-0.585816,-0.52589,-1.33424,-1.38375,1.57795,1.61509,0.207117,0.0368418,-1.91052,-2.13905,0.700232,0.592201,-1.33946,-1.33077,1.62319,1.72436
3421,0.272006,0.170136,0.809971,0.76467,0.0606931,-0.0852049,0.869388,0.814242,0.183592,0.214425,0.296656,0.397246,0.970807,0.927332,0.100912,0.0981082,0.728714,0.728396,0.106928,0.131262,-1.38679,-1.1932,-0.370509,-0.207727,-0.516729,-0.437772,0.0244693,-0.0188093,0.733595,0.774018,-0.171679,-0.34738,-1.89869,-2.12451,-0.952426,-1.05677,-0.475243,-0.403542,-1.15482,-1.05549
3422,0.954365,0.851343,0.208298,0.163129,0.967584,0.824565,0.877736,0.823141,0.992934,1.02132,0.549221,0.586567,0.972872,0.917918,0.820913,0.82043,0.0577591,0.057518,0.888724,0.911675,-2.29159,-2.09115,0.429974,0.593602,-0.815789,-0.742289,-0.0497106,-0.172858,-2.19447,-2.15024,0.15878,-0.00128739,-0.108433,-0.298897,-0.757142,-0.912643,0.521727,0.523684,-0.797192,-0.703557
3423,0.0895157,-0.0124042,0.160593,0.113262,0.569105,0.424451,0.225761,0.170819,0.266316,0.294816,0.738781,0.775887,0.950862,0.908503,0.414909,0.413211,0.905066,0.902784,0.0912851,0.116095,0.727954,0.925919,-0.0941387,0.0767965,0.188606,0.257205,-0.284113,-0.326906,-0.576856,-0.536702,0.436988,0.344805,1.75254,1.52672,-0.61747,-0.768512,-0.0755725,-0.0696428,1.89029,1.98093
3424,0.82013,0.720218,0.458959,0.40987,0.826466,0.679931,0.0656557,0.104243,0.0683909,0.0976954,0.42161,0.456638,0.0910654,0.0476203,0.490069,0.489627,0.472344,0.524257,0.765205,0.790002,0.953702,1.14481,-0.407162,-0.241405,0.242813,0.319581,-1.36576,-1.41554,1.76345,1.80185,0.866599,0.690898,-0.554137,-0.777843,-0.520031,-0.62438,-2.15229,-2.14704,0.90119,0.991981
3425,0.2026,0.104113,0.407946,0.360003,0.745817,0.599807,0.0918982,0.037667,0.956411,0.987355,0.480732,0.518191,0.181329,0.164286,0.851171,0.852512,0.148454,0.145729,0.267133,0.294594,-0.457979,-0.274766,-1.76736,-1.59593,-1.27347,-1.19227,1.63637,1.59262,0.626144,0.671519,-0.475408,-0.649884,-0.935071,-1.16017,1.45526,1.35201,-1.38009,-1.37744,-2.40489,-2.3203
3426,0.797042,0.699135,0.603218,0.557426,0.0105325,-0.135792,0.521679,0.466352,0.62949,0.660192,0.17059,0.305638,0.323101,0.280952,0.952234,0.954057,0.0721919,0.070785,0.00804705,0.0334883,-0.771098,-0.586298,1.17797,1.35644,0.567524,0.654413,0.924489,0.829668,-0.139534,-0.0914035,1.56536,1.39339,-0.497481,-0.641835,-0.339176,-0.433929,-1.70736,-1.7084,-0.838538,-0.747246
3427,0.60687,0.510472,0.293065,0.261368,0.31203,0.165455,0.369226,0.292111,0.805921,0.749861,0.0539876,0.0930859,0.953162,0.912117,0.0773163,0.0770016,0.938228,0.937506,0.15235,0.176013,1.19477,1.38555,-0.0497872,0.12867,0.83045,0.916879,0.0506696,0.0667153,-0.104201,-0.0556026,-0.312158,-0.482988,0.0931721,-0.123502,-0.851307,-0.945029,0.307249,0.307165,0.466102,0.56489
3428,0.0771963,-0.0207454,0.0134167,-0.03469,0.857782,0.712941,0.176114,0.117871,0.864303,0.839529,0.0228396,0.0609489,0.941732,0.899454,0.477111,0.47856,0.940626,0.937559,0.816657,0.839357,-2.24204,-2.05058,-0.848845,-0.666001,1.50529,1.59352,-0.65249,-0.696237,-0.697561,-0.649315,0.953637,0.787143,-0.50142,-0.720978,0.317977,0.315031,-0.497944,-0.5022,-1.59575,-1.50022
3429,0.189107,0.0899632,0.563449,0.517069,0.498696,0.44504,0.300414,0.250041,0.897754,0.929198,0.632327,0.671582,0.267469,0.227207,0.219472,0.22174,0.118977,0.113385,0.116772,0.136722,0.567937,0.753092,-1.26578,-1.07648,0.503179,0.589842,-0.0110759,-0.0582934,-0.864975,-0.81714,0.668553,0.585083,-0.651715,-0.871076,1.67118,1.57509,1.72285,1.71155,0.858181,0.959064
3430,0.0804752,-0.0190582,0.759242,0.714492,0.321437,0.17714,0.438539,0.382212,0.159582,0.191831,0.511382,0.548378,0.792744,0.75407,0.412802,0.413369,0.782648,0.775718,0.358918,0.379815,0.896261,1.08078,0.102279,0.293884,-0.937725,-0.846212,-1.95159,-2.00227,0.178942,0.231303,0.545818,0.383024,-0.133316,-0.34932,0.448942,0.358423,-1.2182,-1.23338,0.480311,0.586846
3431,0.630485,0.53196,0.0671995,0.0240477,0.242558,0.0456349,0.0228988,-0.0345577,0.733243,0.766124,0.937162,0.971989,0.588075,0.629163,0.331648,0.349184,0.305689,0.301045,0.0736212,0.0943724,-1.19449,-1.00583,-0.145939,0.0499802,0.474666,0.562018,0.00176113,-0.0488397,-0.465664,-0.408891,0.503796,0.336619,0.846375,0.634383,-0.407416,-0.505036,1.53456,1.51557,1.37182,1.4854
3432,0.894111,0.793883,0.503205,0.420711,0.0565154,-0.0858701,0.552792,0.493103,0.884633,0.916311,0.774147,0.80937,0.542019,0.504257,0.283196,0.284999,0.888729,0.886282,0.500567,0.522972,1.17163,1.35655,2.24019,2.43349,-0.621987,-0.534698,0.153187,0.101917,-0.171761,-0.113429,0.719482,0.550981,-1.16731,-1.3832,0.561309,0.468236,-0.0325585,-0.0493394,-0.57739,-0.456967
3433,0.923912,0.778133,0.860601,0.817375,0.883534,0.739486,0.823369,0.763636,0.553472,0.584167,0.389041,0.421917,0.0197896,-0.018059,0.461998,0.452445,0.420337,0.516139,0.392247,0.396889,-0.383776,-0.198479,1.51085,1.70148,1.30213,1.38899,-1.14653,-1.20083,0.522889,0.581053,-0.823507,-0.988528,0.839401,0.625133,0.0240294,-0.0732905,-0.454299,-0.473709,-0.895356,-0.782556
3434,0.862916,0.762384,0.050741,0.00732426,0.46711,0.32506,0.0557039,-0.00576915,0.749407,0.705327,0.513715,0.546822,0.769858,0.731454,0.620319,0.619891,0.148147,0.145996,0.249207,0.270805,-1.15687,-0.973277,-1.2658,-1.07862,0.112405,0.199854,-0.331617,-0.391354,0.182455,0.243605,1.94154,1.77351,-0.587022,-0.796806,-1.16346,-1.25851,-0.599068,-0.619912,0.325296,0.438193
3435,0.387436,0.286735,0.278589,0.306886,0.777405,0.636348,0.951639,0.891868,0.778318,0.826487,0.0508979,0.0859129,0.58406,0.546015,0.559495,0.559236,0.629671,0.56874,0.632285,0.654969,-0.323685,-0.12837,-0.0849997,0.106564,1.8054,1.88878,-0.5569,-0.610725,0.855433,0.923614,-1.39276,-1.55484,-1.17604,-1.38176,0.163167,0.0665141,-0.0871434,-0.111736,0.848852,0.957645
3436,0.819672,0.719698,0.588893,0.606447,0.845075,0.702982,0.190664,0.132619,0.917125,0.947647,0.563931,0.598725,0.963754,0.92747,0.965715,0.965681,0.994216,0.991484,0.423388,0.444172,0.539491,0.716536,0.18706,0.385831,0.070501,0.159194,-1.63075,-1.68265,-0.116449,-0.055313,0.849162,0.682774,2.19132,1.99134,-0.522075,-0.615625,0.938656,0.910006,0.826393,0.934609
3437,0.143129,0.0418862,0.949425,0.906008,0.625165,0.485116,0.208228,0.179387,0.393615,0.424633,0.781257,0.81744,0.25728,0.220255,0.322246,0.32473,0.358323,0.355773,0.685667,0.707201,1.87514,2.05859,1.78483,1.97587,-0.0471243,0.0392366,-0.340267,-0.395364,-0.161753,-0.129046,-1.95061,-2.12019,0.270892,0.0688263,0.0409323,0.0295346,0.228001,0.194251,0.418372,0.532577
3438,0.0776374,-0.0243927,0.56582,0.521646,0.742591,0.569557,0.282818,0.226154,0.955738,0.987584,0.26734,0.303007,0.185744,0.14647,0.0799498,0.0818156,0.101133,0.0969625,0.604361,0.70053,-0.528903,-0.342965,2.13194,2.31684,0.138357,0.222367,0.504223,0.536975,-0.253376,-0.20278,2.12185,1.95227,-0.128174,-0.342993,0.766673,0.674694,0.682457,0.652755,-0.304382,-0.184748
3439,0.751974,0.650875,0.499665,0.457513,0.793074,0.653998,0.854133,0.798602,0.541608,0.573513,0.203181,0.171183,0.562862,0.523229,0.707286,0.707261,0.748822,0.74391,0.674162,0.693859,-0.665203,-0.472726,0.600314,0.826954,-0.951835,-0.874349,1.52133,1.46931,0.0547454,0.106595,0.00204952,-0.172711,-0.557075,-0.754812,1.11859,1.0204,-0.224957,-0.254985,-0.637794,-0.525849
3440,0.222595,0.119657,0.98193,0.941232,0.110099,-0.030299,0.360056,0.305892,0.486475,0.518304,0.00147068,0.0393578,0.468505,0.429372,0.243045,0.240618,0.106857,0.103484,0.119104,0.13805,-1.08185,-0.892034,-0.847833,-0.662933,1.20397,1.28672,-0.00970189,-0.0621734,-0.661458,-0.608031,-0.534038,-0.714216,-1.40962,-1.61317,0.358133,0.262423,-1.49507,-1.51906,0.239975,0.357218
3441,0.697061,0.596619,0.267334,0.226327,0.405658,0.265983,0.80838,0.754121,0.798815,0.830322,0.19247,0.228245,0.589124,0.549441,0.247203,0.246273,0.266391,0.330005,0.750681,0.76758,0.388546,0.630201,0.357801,0.538221,-1.10915,-1.03133,1.86396,1.80965,-0.125334,-0.068494,-0.715167,-0.832907,0.108612,-0.0888353,0.400764,0.301432,0.480204,0.462248,1.44673,1.56089
3442,0.330618,0.294029,0.803246,0.763562,0.250245,0.109311,0.657284,0.602,0.776924,0.806197,0.658899,0.695844,0.162721,0.124436,0.90819,0.906298,0.485646,0.556526,0.677189,0.786598,1.96809,2.15244,0.893681,0.983763,-1.17769,-1.10709,1.32326,1.26647,-1.07347,-1.01657,-0.776282,-0.951599,-0.981437,-1.18123,0.899164,0.801336,-1.60858,-1.63338,2.00199,2.10989
3443,0.0920011,-0.00856171,0.0321504,-0.00925431,0.945891,0.804816,0.184552,0.129822,0.532864,0.641024,0.134608,0.171588,0.64583,0.606685,0.752255,0.749783,0.784044,0.783048,0.799718,0.805616,-0.767602,-0.580642,1.2433,1.4293,0.923382,0.990937,-0.779675,-0.837748,0.254496,0.307847,0.7233,0.547746,-0.082021,-0.276457,1.59907,1.50042,-0.228599,-0.250057,0.69801,0.798953
3444,0.317428,0.217994,0.950212,0.911708,0.601598,0.460531,0.82556,0.771849,0.449114,0.475851,0.67502,0.713363,0.857899,0.818216,0.841772,0.840665,0.562917,0.466564,0.807736,0.824635,0.573029,0.761415,0.392869,0.573399,0.190567,0.25298,0.012941,-0.0433303,-0.40565,-0.346504,-0.924881,-1.10056,0.376083,0.184409,0.745607,0.652157,-0.00466582,-0.02483,1.3155,1.40968
3445,0.23659,0.0807413,0.552719,0.512268,0.704648,0.561855,0.539014,0.476084,0.86252,0.888474,0.858999,0.898146,0.39612,0.357753,0.00559049,0.00361477,0.150103,0.150081,0.505141,0.533507,-0.17279,0.0796982,-0.14429,0.0399656,-0.140386,-0.0827642,-1.59016,-1.63968,-0.615619,-0.559604,-0.0599438,-0.228773,0.551013,0.35257,-1.75196,-1.84433,-0.350924,-0.372767,-0.664073,-0.563835
3446,0.0455168,-0.0565115,0.987853,0.946417,0.541332,0.400924,0.23537,0.180319,0.728851,0.75685,0.548329,0.589104,0.450392,0.411027,0.547873,0.452622,0.306683,0.30505,0.226974,0.242379,-0.783705,-0.602018,-1.87573,-1.69199,-1.05996,-1.00756,1.18827,1.14569,0.25367,0.304532,0.462484,0.29338,-1.46603,-1.66501,-0.879591,-0.97839,1.76876,1.74516,-0.951288,-0.857836
3447,0.565643,0.465448,0.344333,0.30071,0.382973,0.239994,0.851174,0.798002,0.802577,0.831006,0.886655,0.928679,0.970039,0.933322,0.903105,0.90163,0.142866,0.142257,0.136339,0.154425,-0.125554,0.0617337,-0.887333,-0.759199,-1.03764,-0.991727,-1.37283,-1.42423,-1.70281,-1.64613,1.35651,1.18173,0.183484,-0.0166145,-1.11672,-1.21424,1.43093,1.4142,0.408025,0.500821
3448,0.127659,0.0296461,0.141507,0.135854,0.735435,0.59271,0.623439,0.569832,0.522506,0.548587,0.581104,0.62498,0.473162,0.519769,0.570197,0.519477,0.507086,0.508101,0.368909,0.387204,1.06361,1.24789,-0.0101576,0.173589,0.231659,0.280367,2.02631,1.97658,-0.57278,-0.523091,1.23648,1.05644,2.88763,2.68469,0.210045,0.110781,1.43821,1.42352,0.593016,0.68765
3449,0.361439,0.261496,0.0141814,-0.0290016,0.0886953,-0.0560915,0.697136,0.562719,0.727714,0.753809,0.912074,0.955088,0.143698,0.106216,0.138798,0.137323,0.282388,0.256271,0.910763,0.926597,1.83391,2.01972,-0.152805,0.037613,1.24442,1.22243,-0.186012,-0.235499,-0.590774,-0.533519,-0.16787,-0.34753,-0.344887,-0.54316,-0.149223,-0.248156,0.293087,0.283434,-0.744691,-0.654257
3450,0.340122,0.241416,0.419919,0.376672,0.860357,0.715135,0.608171,0.555605,0.198294,0.225347,0.499277,0.608807,0.549794,0.513185,0.737745,0.735613,0.00548705,0.00444128,0.726441,0.7109,-0.709018,-0.523675,-0.880102,-0.694399,2.10985,2.1645,-0.151468,-0.194177,0.643591,0.699983,0.0292235,-0.149457,-0.0337891,-0.23546,0.689299,0.588648,-0.0548899,-0.0645025,-0.2502,-0.165236
3451,0.58571,0.510842,0.291534,0.24754,0.986678,0.841346,0.196276,0.143286,0.131249,0.15962,0.220403,0.262527,0.372851,0.338293,0.905367,0.902558,0.612077,0.610803,0.478384,0.495203,-1.33062,-1.14519,-1.09823,-0.906513,0.756224,0.805241,0.36219,0.320913,-0.545829,-0.488375,-1.12663,-1.30443,-0.741977,-0.940643,-2.3903,-2.4853,1.40914,1.39812,1.13736,1.2226
3452,0.878333,0.780269,0.682763,0.637522,0.692161,0.617966,0.470894,0.41854,0.774746,0.804521,0.0160216,0.0582553,0.703718,0.670722,0.850639,0.846892,0.904149,0.902101,0.72426,0.743551,-0.355365,-0.17394,0.338223,0.525842,-1.39621,-1.3544,-0.980904,-1.02621,0.445646,0.498686,-0.908767,-1.09007,-0.964928,-1.16856,-0.198639,-0.292498,0.884066,0.865534,0.94842,1.03331
3453,0.631403,0.531544,0.242817,0.199767,0.537339,0.394586,0.522567,0.472774,0.0763413,0.104093,0.715743,0.758916,0.528892,0.49583,0.136482,0.132414,0.757586,0.641768,0.26604,0.287335,-0.174515,-0.000406354,0.270954,0.451377,-1.39605,-1.35443,0.0414208,0.00046615,-1.05819,-1.00227,-0.977393,-1.15232,-1.47083,-1.67472,-1.34987,-1.4452,1.6767,1.65142,-0.451312,-0.369309
3454,0.66064,0.561975,0.77515,0.731919,0.480057,0.434583,0.353637,0.36277,0.943178,0.970341,0.371465,0.416167,0.134677,0.0997726,0.435991,0.433407,0.451728,0.381434,0.278703,0.298053,0.544381,0.725259,-0.452186,-0.264814,1.68108,1.7173,0.780036,0.733515,-2.07328,-2.01185,-1.89284,-2.06466,-0.660529,-0.82499,-0.79039,-0.976075,0.960302,0.935665,1.61216,1.69849
3455,0.943244,0.843672,0.74804,0.706725,0.618961,0.47458,0.228719,0.252765,0.468209,0.497335,0.712764,0.755742,0.68452,0.651482,0.279369,0.276891,0.123148,0.121101,0.908237,0.927583,-0.924042,-0.738716,0.352548,0.536515,0.357671,0.388918,1.77979,1.73072,-0.411923,-0.352471,-0.485965,-0.599017,0.236224,0.0247344,-0.409018,-0.506947,-1.09603,-1.12519,2.06865,2.15593
3456,0.373822,0.273052,0.941627,0.899505,0.281869,0.227769,0.194289,0.142761,0.462897,0.490057,0.391807,0.436494,0.860837,0.730887,0.436335,0.431595,0.23306,0.230682,0.451303,0.471367,0.185715,0.368792,-0.0948219,0.095484,-0.744548,-0.707798,-3.06642,-3.11548,-0.230854,-0.178408,1.04224,0.866627,-0.081113,-0.296297,-0.780429,-0.879644,-0.234089,-0.258902,1.30173,1.39312
3457,0.41129,0.309341,0.182084,0.138104,0.126869,-0.0190422,0.783098,0.730067,0.155947,0.182543,0.512385,0.560107,0.841743,0.810292,0.589598,0.586299,0.967435,0.962384,0.71892,0.73971,-0.221346,-0.0675896,0.103066,0.297456,0.379155,0.4123,2.2123,2.16323,-0.264953,-0.205292,0.655793,0.482405,-1.77668,-1.98535,0.0690199,-0.0274964,1.08387,1.05795,0.874456,0.96173
3458,0.162389,0.0606159,0.764556,0.719065,0.306626,0.16228,0.0583785,0.00736573,0.183328,0.196331,0.668189,0.683721,0.108953,0.0768426,0.954593,0.949184,0.00583415,-0.000501462,0.267126,0.288401,-0.691049,-0.503971,-0.397549,-0.204233,-0.868232,-0.837857,-0.176631,-0.216211,-0.871254,-0.815915,0.954206,0.784464,1.18991,0.975394,-0.192133,-0.294322,0.216359,0.18417,0.738957,0.906266
3459,0.404617,0.251256,0.61827,0.637266,0.938275,0.796051,0.100046,0.0508071,0.185393,0.210119,0.763413,0.807335,0.468378,0.434229,0.331338,0.32794,0.353207,0.434394,0.659381,0.682967,-0.61778,-0.436873,1.53118,1.72659,0.495748,0.526115,-1.79583,-1.82864,-0.0647843,-0.0154342,0.211628,0.042395,-0.134758,-0.351512,-0.770058,-0.865938,0.165529,0.131051,0.749654,0.850801
3460,0.5424,0.441896,0.599222,0.555467,0.566006,0.421216,0.479536,0.42912,0.71334,0.739144,0.336899,0.381615,0.51561,0.570121,0.060174,0.0554069,0.877884,0.86929,0.627531,0.648947,0.611704,0.793108,-0.543959,-0.350574,-0.437773,-0.413613,1.36339,1.33166,-0.76219,-0.71664,0.207177,0.0412025,0.305481,0.095389,-0.404649,-0.504313,1.64064,1.60694,0.708063,0.795337
3461,0.268454,0.168046,0.115279,0.0721775,0.67539,0.623295,0.35774,0.336766,0.665802,0.689375,0.17969,0.223161,0.69799,0.706013,0.845879,0.843217,0.0592386,0.0500176,0.836332,0.855843,0.733429,0.920929,-0.160086,0.03491,2.18462,2.21128,0.173808,0.220925,0.0195194,-0.00337208,-0.353583,-0.514394,-2.58934,-2.80573,1.35606,1.25543,-1.59809,-1.63018,-0.945954,-0.851185
3462,0.978869,0.878678,0.69424,0.653138,0.968609,0.825375,0.292724,0.244412,0.988412,1.01179,0.366175,0.407944,0.878437,0.841905,0.364956,0.362137,0.496223,0.484917,0.350601,0.369898,0.309379,0.50162,-1.22648,-1.03918,-0.747868,-0.723275,-0.863805,-0.889809,0.669652,0.709896,-1.39604,-1.56296,-1.40944,-1.62096,-1.06484,-1.15868,1.61505,1.58767,1.05566,1.15416
3463,0.228274,0.127931,0.0986725,0.0569749,0.25454,0.110915,0.640596,0.593199,0.256391,0.280265,0.280111,0.320075,0.132796,0.09397,0.0935883,0.0896035,0.469011,0.460435,0.316054,0.335879,0.25902,0.447447,-1.34892,-1.15967,0.512561,0.53357,1.14099,1.10925,0.461768,0.496795,0.946648,0.780884,0.0412895,-0.17401,-0.0802923,-0.169502,0.261415,0.241105,0.291637,0.391352
3464,0.662043,0.560893,0.903726,0.86398,0.500251,0.416812,0.724901,0.745588,0.64149,0.663678,0.55943,0.613625,0.184804,0.147244,0.473701,0.46041,0.119134,0.110822,0.643073,0.664758,0.785565,0.976745,0.458178,0.644717,0.274428,0.36458,-0.427753,-0.453878,0.942264,0.974879,0.304828,0.100513,-0.0427605,-0.263329,0.259805,0.176204,0.722832,0.699609,-1.21772,-1.11646
3465,0.718902,0.616555,0.0892206,0.049363,0.867637,0.722708,0.945583,0.897978,0.392125,0.415391,0.868069,0.907176,0.783711,0.747759,0.8353,0.831217,0.880333,0.872366,0.614648,0.635386,0.16437,0.355228,0.342048,0.524231,0.169681,0.195591,-0.624005,-0.594033,0.175235,0.211956,-0.406906,-0.579858,-1.19754,-1.41705,-0.719735,-0.81012,0.565432,0.635487,-2.10181,-1.99996
3466,0.146211,0.0459349,0.875304,0.83631,0.71699,0.570811,0.702433,0.654846,0.965048,0.989684,0.512803,0.549611,0.218506,0.180347,0.775239,0.770562,0.411145,0.402849,0.373234,0.46324,0.000814151,0.193117,-2.83319,-2.65251,1.26832,1.29923,-0.706886,-0.734188,-0.0844108,-0.0489034,2.62377,2.4509,0.609319,0.387197,-0.501607,-0.570759,0.60245,0.571365,-1.20276,-1.10141
3467,0.132636,0.0761813,0.997553,0.959466,0.919808,0.77127,0.879482,0.8299,0.920836,0.94525,0.651991,0.723824,0.597625,0.557107,0.916494,0.91196,0.550416,0.604307,0.27139,0.291093,-0.622113,-0.4284,-0.990645,-0.813582,1.13537,1.16429,1.72586,1.69432,1.69043,1.71859,-0.722945,-0.897644,-1.16951,-1.39558,-0.238432,-0.331399,-0.465927,-0.467688,1.18357,1.29009
3468,0.204796,0.106428,0.272564,0.234129,0.900574,0.752449,0.309926,0.261717,0.216549,0.239761,0.86332,0.898038,0.218539,0.176166,0.0593942,0.056624,0.814362,0.805764,0.345098,0.363121,-0.484115,-0.285726,-1.32425,-1.14815,0.267875,0.300608,-0.403245,-0.439949,-0.988907,-0.954976,0.598008,0.418486,1.51298,1.29158,0.446459,0.351909,-1.47565,-1.50674,0.660443,0.768479
3469,0.402102,0.350278,0.365138,0.310089,0.0753034,-0.0721122,0.315136,0.265525,0.515238,0.455016,0.431851,0.563972,0.397607,0.356923,0.507384,0.503607,0.691941,0.682988,0.627514,0.646478,-0.988766,-0.784538,0.908497,1.08816,1.04588,1.08332,0.0530248,0.0157733,1.8414,1.87065,-0.577827,-0.775571,-0.158607,-0.382273,0.721534,0.62359,-0.697291,-0.720855,-0.99216,-0.878044
3470,0.576267,0.594129,0.425747,0.386049,0.0486792,-0.100121,0.73875,0.689787,0.633235,0.67027,0.195942,0.229905,0.817487,0.778693,0.275139,0.303836,0.137647,0.128495,0.556414,0.578145,-1.26419,-1.06566,-1.39197,-1.21502,-0.845239,-0.802983,-0.026735,-0.159956,0.996673,1.02958,-1.79526,-1.96963,-0.548376,-0.764598,0.490982,0.387736,1.51901,1.4929,-0.619122,-0.469722
3471,0.936348,0.83798,0.0583691,0.016944,0.460073,0.267322,0.851486,0.783326,0.861676,0.885525,0.000168891,0.0355687,0.926308,0.888705,0.105592,0.104065,0.0721086,0.0627017,0.898362,0.922467,-0.202284,-0.00377357,1.09843,1.27561,1.85572,1.90089,-0.198221,-0.335686,-1.4221,-1.39652,0.347946,0.167227,0.0677532,-0.148808,-0.519561,-0.630366,0.0756369,0.053538,-0.166593,-0.0613995
3472,0.433592,0.400704,0.667481,0.627277,0.783797,0.634764,0.925166,0.876864,0.926248,0.860261,0.571919,0.606621,0.325048,0.287655,0.122939,0.199034,0.697955,0.689089,0.768936,0.77446,-0.74038,-0.547086,0.481561,0.665954,0.6199,0.664604,-0.474164,-0.511415,1.52008,1.55046,0.539884,0.319746,-1.01751,-1.22759,0.0121502,-0.0992994,0.694571,0.669114,0.875295,0.974261
3473,0.0634808,-0.0365717,0.919874,0.878959,0.39359,0.245285,0.756108,0.70926,0.810676,0.834998,0.274997,0.307821,0.271966,0.233512,0.197458,0.294002,0.54467,0.535492,0.600717,0.626452,-0.940857,-0.75254,-1.58459,-1.39183,0.380088,0.420122,-1.30921,-1.35101,0.170296,0.201648,0.654507,0.472265,-0.628849,-0.845141,-0.712768,-0.827843,-1.66813,-1.69787,1.62529,1.7227
3474,0.0615848,-0.0360043,0.76136,0.751653,0.877297,0.728299,0.141009,0.096247,0.681589,0.703374,0.526249,0.561259,0.667923,0.62999,0.390403,0.38897,0.781135,0.772265,0.817996,0.843832,-0.604047,-0.41082,0.215885,0.41256,0.875223,0.909339,0.69962,0.666841,0.132454,0.159342,-0.627435,-0.807905,0.178085,-0.0334731,-2.11634,-2.22794,-1.01779,-1.0517,-0.956952,-0.8639
3475,0.757335,0.659662,0.802737,0.624347,0.315172,0.164042,0.797898,0.753284,0.152926,0.174913,0.123026,0.159694,0.221919,0.184226,0.944215,0.942168,0.409076,0.398081,0.258372,0.282761,-1.06997,-0.876136,-0.920385,-0.723081,-0.122335,-0.0943389,0.411421,0.384367,1.17055,1.19281,0.893887,0.707708,0.527287,0.32038,-0.247025,-0.360672,1.25347,1.22474,0.729678,0.817002
3476,0.496174,0.420582,0.537956,0.497041,0.217944,0.0680594,0.31204,0.26637,0.615238,0.638077,0.701122,0.735764,0.373941,0.292636,0.531438,0.585692,0.293582,0.213998,0.304664,0.329797,0.308051,0.496236,-0.0408661,0.154019,0.0292959,0.0581417,0.849103,0.823509,0.935195,0.962794,0.110349,-0.079204,-0.475654,-0.681424,-0.217983,-0.337694,0.184811,0.163296,-0.815672,-0.722011
3477,0.239651,0.181503,0.902512,0.861774,0.86509,0.716952,0.366612,0.320604,0.856105,0.879307,0.643402,0.677908,0.437439,0.401045,0.232529,0.229216,0.0425275,0.0299141,0.0608076,0.0844863,-0.459553,-0.278562,0.154531,0.355992,-0.970945,-0.945536,0.118272,0.0942343,1.03565,1.06056,0.752575,0.564832,-0.0935991,-0.298979,1.38929,1.26644,0.781365,0.762785,0.633211,0.727193
3478,0.0400953,-0.0575773,0.280393,0.240902,0.00924648,-0.139749,0.175089,0.218,0.143406,0.168421,0.993339,1.02879,0.547147,0.509454,0.199982,0.216011,0.121451,0.0970514,0.288836,0.312267,-0.303835,-0.120602,0.0485611,0.250521,-0.438165,-0.40926,0.390145,0.366774,-0.798761,-0.778509,0.738591,0.487191,0.544823,0.34792,-0.0743782,-0.19648,0.61383,0.60051,-0.673322,-0.583749
3479,0.894119,0.794536,0.352532,0.366009,0.00477309,-0.143481,0.162683,0.115395,0.464016,0.451759,0.492821,0.562581,0.26532,0.228537,0.136291,0.202805,0.125251,0.164189,0.0505112,0.0726114,-0.814204,-0.644101,-0.990277,-0.791497,0.681846,0.710838,-0.434198,-0.456782,-0.625216,-0.604446,0.704296,0.409551,0.538103,0.420335,0.337549,0.211481,-0.212043,-0.225536,0.0574118,0.148758
3480,0.0869879,-0.0117387,0.530084,0.491116,0.269909,0.122634,0.189251,0.0753844,0.812894,0.735098,0.0628551,0.0963677,0.461712,0.425191,0.194979,0.1896,0.123929,0.231326,0.822364,0.843276,-1.35169,-1.1676,1.20858,1.41396,-0.298179,-0.264054,0.353689,0.337636,1.99944,2.01862,0.526465,0.331911,0.582724,0.492749,0.166805,0.0377092,-2.12117,-2.12912,-0.42869,-0.341092
3481,0.750227,0.649993,0.433573,0.346407,0.897834,0.751131,0.127382,0.0353734,0.993093,1.01844,0.0779678,0.205232,0.448805,0.412528,0.643516,0.636583,0.311077,0.298463,0.0800553,0.100186,0.328892,0.516356,0.49496,0.697765,-0.3307,-0.293534,0.302747,0.287944,-0.974936,-0.953227,-0.22794,-0.427098,0.672708,0.565164,0.799931,0.674966,-0.548012,-0.561283,0.418407,0.510563
3482,0.691012,0.536489,0.2418,0.201697,0.189986,0.0418098,0.0421278,-0.00463761,0.255896,0.281069,0.281819,0.314097,0.0495648,0.0121898,0.851003,0.811671,0.935946,0.924851,0.960871,0.983551,-0.856713,-0.672503,-0.780381,-0.577232,-1.50365,-1.46913,1.19089,1.1758,-0.541372,-0.520079,1.50463,1.30614,0.834481,0.637579,-0.550545,-0.681111,-1.34823,-1.35685,-0.28217,-0.191445
3483,0.524325,0.422986,0.530287,0.488141,0.104419,-0.0440554,0.906525,0.859137,0.816131,0.840339,0.942709,0.975831,0.263271,0.223721,0.991426,0.986759,0.725203,0.780663,0.686135,0.698988,-0.808553,-0.621833,-1.10403,-0.895433,-0.481558,-0.438605,-0.729158,-0.737056,0.135615,0.15993,0.558835,0.276814,0.371656,0.176127,-0.807961,-0.9326,-0.768142,-0.773537,0.491922,0.584909
3484,0.975287,0.875446,0.428754,0.384879,0.77917,0.631155,0.00933715,-0.0369774,0.70252,0.728708,0.325272,0.36092,0.973036,0.931813,0.364953,0.360381,0.640289,0.636476,0.392131,0.414426,0.280435,0.469619,0.132367,0.339124,-0.579747,-0.598745,-1.80503,-1.80898,-0.450067,-0.419831,-0.556931,-0.752516,-0.618109,-0.809673,0.0512473,-0.0804525,1.33032,1.32712,0.1522,0.243808
3485,0.316006,0.213737,0.840506,0.794963,0.609654,0.459316,0.305956,0.228453,0.258208,0.285273,0.522355,0.559785,0.376006,0.335213,0.822377,0.817103,0.501662,0.492289,0.929361,0.953819,-0.595838,-0.413033,0.144398,0.367846,-0.802317,-0.758885,-1.48524,-1.491,0.253595,0.289018,-0.0638168,-0.301463,-0.717927,-0.915214,-0.108644,-0.238413,0.968778,0.965282,1.07005,1.15654
3486,0.214233,0.111135,0.729912,0.685957,0.11129,-0.0403794,0.540897,0.493884,0.797688,0.824159,0.51789,0.483248,0.539678,0.464379,0.760183,0.767813,0.922612,0.913353,0.252303,0.277732,-0.669267,-0.48416,0.189176,0.396569,0.448244,0.497959,1.99045,1.97785,-0.0412977,0.000608015,0.345173,0.149589,1.00906,0.811027,1.24986,1.11921,1.109,1.09831,0.028609,0.166501
3487,0.694808,0.592451,0.984568,0.94257,0.258513,0.109459,0.0685145,0.0217064,0.0267516,0.0553608,0.369212,0.40671,0.636121,0.593544,0.726264,0.718524,0.530623,0.519151,0.970359,0.99726,0.217192,0.410955,2.30485,2.50448,-0.321256,-0.272739,0.696872,0.773175,1.86022,1.90798,-0.324708,-0.516473,-0.172438,-0.376095,0.144394,0.00970296,-0.566464,-0.57797,-0.911208,-0.823537
3488,0.620878,0.521163,0.964011,0.921911,0.517203,0.259298,0.0853838,0.0396235,0.197468,0.274236,0.951941,0.987562,0.366599,0.322611,0.171723,0.162411,0.531426,0.629065,0.939528,0.967889,-1.30802,-1.11283,0.197102,0.399876,-1.9329,-1.87759,-0.418897,-0.4315,0.231936,0.284838,0.139462,-0.0549049,1.62454,1.42815,0.226776,0.0942926,-1.78972,-1.79483,-0.687332,-0.702571
3489,0.806043,0.707192,0.545357,0.440479,0.559847,0.409137,0.374503,0.28348,0.465016,0.493111,0.599709,0.68619,0.378876,0.33556,0.689925,0.679702,0.658727,0.73898,0.661276,0.686972,1.34602,1.54117,0.213731,0.415959,0.474409,0.526985,-0.244957,-0.250445,-0.745402,-0.694089,0.885748,0.694678,0.175844,-0.023265,-2.15986,-2.28703,0.585697,0.579841,-0.663158,-0.581605
3490,0.315973,0.216137,0.00300546,-0.0409536,0.196966,0.0445184,0.573972,0.527337,0.0841777,0.114239,0.27556,0.384818,0.713227,0.667988,0.71672,0.705405,0.814157,0.848895,0.0657581,0.0913957,-0.261802,-0.0616474,-1.33491,-1.1264,-1.46548,-1.4089,0.739074,0.730913,-0.328999,-0.275472,0.367225,0.169673,1.62616,1.42369,0.101541,-0.0331845,0.518223,0.513065,-0.0950565,-0.0156298
3491,0.207639,0.196347,0.640713,0.598397,0.0538154,-0.0974879,0.56016,0.426953,0.427105,0.456837,0.0478241,0.0834453,0.253648,0.207525,0.229443,0.219237,0.970282,0.95881,0.882267,0.909681,-0.84492,-0.651047,-0.455428,-0.313479,-0.898548,-0.841844,0.714861,0.711366,-0.633442,-0.58017,0.0901596,-0.10724,-1.66116,-1.86712,1.26106,1.12464,0.961024,0.956323,-1.27717,-1.20463
3492,0.215051,0.176558,0.297907,0.253395,0.848002,0.696789,0.392337,0.326568,0.0854315,0.113262,0.145857,0.238937,0.433535,0.388282,0.193341,0.183122,0.577202,0.564607,0.858692,0.905328,1.05268,1.2457,0.297214,0.499444,-1.00057,-0.948353,-0.415598,-0.42185,-1.36686,-1.31298,-2.20513,-2.40889,-2.40935,-2.61792,0.536853,0.396101,-0.148278,-0.150949,-1.22425,-1.1518
3493,0.254774,0.156768,0.468501,0.422402,0.527894,0.377102,0.264729,0.226184,0.159387,0.187418,0.381146,0.394428,0.819975,0.775035,0.392234,0.379801,0.767329,0.748277,0.873483,0.900975,-1.23398,-1.04479,-0.834761,-0.636197,-0.875789,-0.827528,-0.246737,-0.256835,-0.521468,-0.478869,0.651332,0.446167,0.456362,0.245338,0.613318,0.465355,0.897127,0.887517,-0.137106,-0.0694573
3494,0.86886,0.772099,0.326264,0.278696,0.564503,0.445456,0.171377,0.1258,0.933983,0.961589,0.515573,0.54992,0.776493,0.731671,0.834751,0.822038,0.943179,0.931946,0.104647,0.132703,-0.448745,-0.25791,0.335421,0.53227,0.20045,0.247705,-0.723875,-0.737996,0.304908,0.35524,-1.24165,-1.44701,0.119479,-0.0915995,0.153142,0.000227075,-0.276584,-0.304098,0.24566,0.31157
3495,0.915465,0.817386,0.652273,0.604854,0.663294,0.513809,0.315944,0.365946,0.170432,0.197653,0.31317,0.345648,0.188129,0.144364,0.580187,0.569029,0.396607,0.387457,0.96209,0.991731,1.21758,1.40948,1.0698,1.27191,-0.507965,-0.459602,0.31337,0.303298,-0.627966,-0.576826,-0.0494458,-0.252004,2.24309,2.03193,0.694134,0.546417,-1.4943,-1.49571,-1.13378,-1.05997
3496,0.760811,0.664795,0.124359,0.0774422,0.100393,-0.0504488,0.652092,0.606092,0.927991,0.956278,0.489127,0.520422,0.129372,0.129846,0.545008,0.532914,0.591561,0.58304,0.487084,0.571672,0.922753,1.11251,-0.432468,-0.222972,0.338236,0.368117,0.690891,0.68173,-0.912789,-0.865236,0.294674,0.100621,-0.270701,-0.476299,1.01098,0.86362,-0.121563,-0.127632,-1.55464,-1.47654
3497,0.290056,0.194325,0.382319,0.358679,0.0835617,-0.0692704,0.679245,0.634047,0.164202,0.192342,0.0115813,0.0454588,0.157166,0.115327,0.0396512,0.0266353,0.0598508,0.0489923,0.121446,0.151613,1.82538,2.02125,-0.961379,-0.756405,1.14747,1.19584,0.410617,0.350502,0.958897,1.01207,-0.212169,-0.409978,-0.152912,-0.353544,-0.0350073,-0.183955,-1.05513,-1.06723,-1.19045,-1.10864
3498,0.192207,0.0968862,0.685919,0.639915,0.404112,0.252267,0.256179,0.212695,0.602041,0.53355,0.236816,0.269489,0.337005,0.296085,0.54171,0.527869,0.202489,0.193436,0.219311,0.247779,0.721435,0.923115,-0.803928,-0.601841,0.931304,0.980961,0.0283624,0.0192749,-1.39758,-1.34274,-1.57562,-1.76785,-2.0057,-2.21316,0.890965,0.745356,-0.961167,-0.979215,-1.22262,-1.14701
3499,0.687133,0.593292,0.425593,0.479282,0.983706,0.830411,0.762825,0.720536,0.845783,0.874758,0.663026,0.693101,0.273928,0.231954,0.253225,0.305091,0.819793,0.809482,0.808481,0.836913,-0.158565,0.0404622,-0.981331,-0.783207,1.61088,1.6576,0.512558,0.505805,-0.787604,-0.725621,-0.171316,-0.358888,-0.0424137,-0.25132,-0.983473,-1.12186,-0.268907,-0.285816,-1.60317,-1.53205
3500,0.595658,0.501227,0.364652,0.318648,0.920936,0.757945,0.291186,0.248358,0.248892,0.275402,0.856226,0.886845,0.475538,0.43355,0.0965316,0.082314,0.404889,0.395415,0.000579006,0.0273078,-0.254409,-0.0613739,-0.559074,-0.367056,1.21783,1.26081,0.217711,0.208055,-0.593763,-0.447589,-0.762041,-0.947416,-0.0557612,-0.265301,-0.17916,-0.315994,0.931096,0.9229,1.69524,1.76956
3501,0.919584,0.822624,0.897254,0.850801,0.791825,0.685478,0.0483319,0.00522668,0.0504944,0.0782808,0.136523,0.165633,0.13741,0.0935136,0.951235,0.937288,0.912853,0.905807,0.00654173,0.0326208,1.08302,1.28068,-0.495026,-0.304365,1.83008,1.87322,-0.279642,-0.289568,-0.234844,-0.169558,0.0461202,-0.136131,-1.43921,-1.65397,1.33857,1.20821,-0.940415,-0.948711,-0.0583803,0.0142078
3502,0.56122,0.462957,0.102487,0.0570623,0.766991,0.613012,0.525374,0.404291,0.569723,0.597212,0.913218,0.942754,0.60884,0.565194,0.799246,0.786043,0.145172,0.136788,0.784585,0.808009,-2.04782,-1.85,-0.100348,0.0954255,0.540384,0.576274,-1.12878,-1.14527,0.0464918,0.108474,0.230432,0.0469791,0.067564,-0.145817,-0.339332,-0.46955,1.23727,1.23271,-1.2639,-1.18986
3503,0.599884,0.503133,0.48922,0.441828,0.465724,0.313829,0.846207,0.803356,0.156298,0.183141,0.376463,0.408569,0.554581,0.511052,0.411324,0.399571,0.570376,0.561473,0.384995,0.487269,-0.166438,0.0317549,-0.174485,0.0209604,0.0948726,0.134858,0.850967,0.838816,-0.668602,-0.606151,0.798131,0.614508,-1.45848,-1.67808,-0.125597,-0.261946,0.869207,0.870873,0.231348,0.306291
3504,0.193549,0.0979244,0.110657,0.0630387,0.751166,0.600345,0.880753,0.836135,0.292612,0.318019,0.897853,0.930063,0.154502,0.110714,0.481921,0.471158,0.659173,0.649646,0.141007,0.166529,0.378759,0.574713,0.116777,0.316565,0.387899,0.42693,-0.039014,-0.0475894,0.454884,0.51689,-0.189628,-0.373708,0.787151,0.571961,-1.3041,-1.44717,2.43406,2.43871,-0.114227,-0.0348094
3505,0.0516458,-0.045084,0.402518,0.353906,0.384672,0.235726,0.140538,0.0979266,0.824445,0.851781,0.00437696,0.0353959,0.013682,0.0347748,0.144752,0.134421,0.224407,0.214909,0.689663,0.715464,-0.428928,-0.231718,-0.962787,-0.757527,0.258872,0.284628,2.62479,2.61779,-0.750321,-0.687857,0.174181,-0.00831406,1.19156,0.970911,1.97263,1.82546,-0.720057,-0.708739,-1.11111,-1.0386
3506,0.483139,0.416051,0.00839088,-0.040185,0.699695,0.552439,0.875836,0.830402,0.366303,0.393049,0.125838,0.155014,0.00277781,-0.0411641,0.0654879,0.0535669,0.473469,0.466653,0.952944,0.978494,-0.215784,-0.0128308,-1.4053,-1.19856,0.0992518,0.142327,-0.695799,-0.708458,2.05524,2.1224,0.125925,-0.0547194,-0.829972,-1.04667,0.22968,0.0836752,1.62355,1.63591,-0.363934,-0.23727
3507,0.976294,0.877187,0.18283,0.194207,0.781296,0.634368,0.332325,0.286834,0.774984,0.801009,0.899808,0.928224,0.709921,0.666927,0.315275,0.303765,0.484398,0.476675,0.204235,0.230612,-1.06819,-0.86433,-1.61487,-1.41067,-1.69521,-1.65077,1.05818,1.03861,-1.40241,-1.33155,-0.745579,-0.919106,1.61876,1.3995,-0.309174,-0.454539,1.06699,1.0735,0.479629,0.564058
3508,0.404237,0.306567,0.479965,0.428599,0.199677,0.0506644,0.708481,0.665147,0.581997,0.60895,0.36185,0.389008,0.338712,0.381143,0.3454,0.33398,0.88976,0.882635,0.928294,0.953922,0.808644,1.01742,-1.22509,-1.02519,-0.301506,-0.340821,-0.72437,-0.745923,0.0354309,0.0998977,0.859157,0.689828,0.506145,0.290651,-0.846747,-0.992752,-1.59938,-1.58836,1.29923,1.36539
3509,0.86975,0.773233,0.135345,0.0835968,0.078626,-0.0705153,0.367456,0.323682,0.981387,1.00667,0.320697,0.347041,0.139407,0.0953581,0.848371,0.835213,0.647663,0.639445,0.978622,1.0066,-0.20094,0.0115202,0.345548,0.549987,0.919984,0.969127,-0.299775,-0.261367,0.0981237,0.167006,0.723094,0.550501,0.898993,0.600678,-0.660117,-0.799203,-1.02953,-1.01979,-0.357654,-0.295907
3510,0.237121,0.142107,0.984453,0.931715,0.322424,0.183409,0.635911,0.536133,0.342934,0.367041,0.0101368,0.0379989,0.301211,0.256779,0.190244,0.178156,0.902372,0.895593,0.106026,0.132891,0.451352,0.661943,-1.41956,-1.21253,0.939204,0.984958,0.244741,0.223188,-0.439446,-0.365031,1.89817,1.72903,1.09239,0.910705,-1.28019,-1.41824,1.52906,1.53456,0.334009,0.411299
3511,0.929556,0.832827,0.528425,0.473497,0.587655,0.437334,0.79443,0.748584,0.330191,0.353122,0.257267,0.286108,0.858691,0.813671,0.817329,0.803602,0.779754,0.841118,0.997958,1.02617,-0.546261,-0.328302,-0.194948,0.00783802,-0.155296,-0.111758,-0.623139,-0.648257,1.26185,1.34037,0.229722,0.0686414,1.43623,1.22073,0.313528,0.168562,-0.698223,-0.698923,1.05418,1.11851
3512,0.997353,0.898158,0.889546,0.83361,0.153717,0.00200505,0.314774,0.266774,0.0417504,0.0657947,0.893442,0.922087,0.887215,0.836927,0.705092,0.67357,0.795472,0.786643,0.2506,0.278286,0.00479887,0.228693,-0.25998,-0.0513088,0.710217,0.748541,1.106,1.08074,-0.0555726,0.0229259,-1.6602,-1.82454,0.0578866,-0.152332,0.38226,0.237816,-0.864052,-0.861197,1.22107,1.29095
3513,0.0358301,-0.064519,0.263208,0.208058,0.238058,0.0882713,0.208726,0.15915,0.342267,0.447337,0.541645,0.569768,0.838069,0.860183,0.555779,0.543539,0.311222,0.30174,0.930552,0.957146,-1.38846,-1.15909,-0.965949,-0.752451,0.596681,0.642032,1.32905,1.30923,-1.70756,-1.62959,1.89434,1.72759,1.29473,1.07885,0.804724,0.661023,0.835802,0.834521,-0.565302,-0.494084
3514,0.970538,0.86919,0.862159,0.808077,0.640794,0.491638,0.406666,0.446806,0.806972,0.828879,0.731779,0.758656,0.914801,0.883439,0.815638,0.804172,0.822287,0.812132,0.415155,0.441795,0.186786,0.416989,-0.416696,-0.198964,2.38048,2.4254,-0.845477,-0.872282,-0.215475,-0.138088,-0.528594,-0.698543,-0.868494,-1.07845,-2.28846,-2.42941,0.655597,0.656949,0.46681,0.541577
3515,0.248786,0.145299,0.711245,0.661892,0.333691,0.182513,0.785736,0.734461,0.555702,0.511731,0.403128,0.464944,0.951714,0.906694,0.359332,0.347719,0.640057,0.628701,0.293467,0.32131,0.924074,1.15826,0.627339,0.845391,0.162094,0.202391,-1.28153,-1.36011,-0.891746,-0.80987,-1.01404,-1.1776,0.783626,0.569941,-0.821076,-0.965267,-0.544628,-0.634078,-0.178789,-0.101271
3516,0.491605,0.412258,0.458936,0.515707,0.370028,0.307308,0.0547926,0.00143844,0.171812,0.194583,0.144742,0.171233,0.665258,0.620828,0.468582,0.458427,0.84877,0.835408,0.377931,0.407431,0.406334,0.68837,0.776883,0.999956,-1.68185,-1.63837,-1.82572,-1.84793,-0.412696,-0.331786,0.678991,0.510067,1.57951,1.36686,-0.695226,-0.833346,-1.93362,-1.9251,1.68335,1.76863
3517,0.784369,0.679217,0.306202,0.369523,0.585948,0.432103,0.715709,0.662561,0.100779,0.123943,0.171242,0.197657,0.827181,0.782249,0.912694,0.900664,0.775821,0.781402,0.708596,0.73631,-0.00924105,0.218477,1.29177,1.50951,-0.911171,-0.869683,0.515795,0.498332,0.510906,0.59386,-1.77749,-1.9472,1.15497,0.875565,-0.190413,-0.333442,1.11677,1.12135,-0.619543,-0.532931
3518,0.225577,0.123052,0.277227,0.223338,0.0451506,-0.106967,0.844474,0.706615,0.91672,0.94063,0.75234,0.778509,0.169817,0.124802,0.182526,0.170447,0.861665,0.727395,0.73441,0.762602,-0.883374,-0.648077,-0.178277,0.0437586,-0.978402,-0.930341,-0.791375,-0.804413,-0.0483516,0.0299673,-0.43572,-0.600894,0.603994,0.384268,0.854309,0.717795,0.723604,0.729989,0.478619,0.563766
3519,0.42891,0.23564,0.967953,0.913004,0.513687,0.361616,0.805481,0.75067,0.995252,1.01938,0.898018,0.923494,0.602291,0.556452,0.942883,0.93288,0.68675,0.673389,0.0931054,0.121939,0.446666,0.677604,-1.03733,-0.812146,-0.58537,-0.530049,0.113068,0.105352,0.660275,0.738816,0.419004,0.255493,1.59833,1.38414,0.701265,0.559835,0.766772,0.772274,1.2721,1.35705
3520,0.449922,0.348228,0.647621,0.592651,0.152509,0.00199319,0.568141,0.513063,0.0571871,0.0823524,0.335334,0.359122,0.516207,0.472091,0.628676,0.668671,0.336763,0.323776,0.660551,0.690335,-0.803613,-0.573194,0.936337,1.16587,0.410387,0.469445,1.02265,1.01512,-0.147758,-0.0693369,-0.442748,-0.608894,-0.11876,-0.335378,-0.0380964,-0.183675,2.66843,2.67269,-0.722799,-0.629807
3521,0.120081,0.0185141,0.045139,-0.0088897,0.97478,0.822775,0.693629,0.637934,0.696015,0.721558,0.888518,0.910807,0.747087,0.703065,0.412719,0.404463,0.996466,0.982088,0.903731,0.933428,-0.1174,0.106809,0.7818,1.01618,0.329074,0.393691,-0.310711,-0.317527,0.504552,0.578472,-0.0136945,-0.17966,-0.210133,-0.424697,1.179,1.03301,1.95523,1.95694,0.0666895,0.163473
3522,0.242887,0.138732,0.794959,0.74064,0.687647,0.545965,0.189955,0.135005,0.237258,0.262826,0.418298,0.440731,0.155146,0.111538,0.461309,0.46461,0.376526,0.361658,0.91871,0.948775,0.959174,1.18323,-0.378455,-0.149873,1.63813,1.69675,1.08431,1.07745,-0.61907,-0.551854,0.0197435,-0.220594,0.501151,0.282345,0.678151,0.537252,-1.13185,-1.12302,-1.92295,-1.82338
3523,0.881592,0.779939,0.982846,0.929377,0.443397,0.269155,0.0394245,-0.0171164,0.995132,1.02145,0.853267,0.874856,0.826298,0.784266,0.530704,0.524756,0.340437,0.326587,0.13566,0.163284,-1.09574,-0.872481,1.11234,1.34468,-1.2907,-1.2378,-1.52197,-1.52425,0.622899,0.697248,-0.0997288,-0.261528,3.62231,3.4066,-2.17359,-2.31297,-0.609364,-0.600568,-1.24547,-1.15096
3524,0.701676,0.577843,0.800347,0.745127,0.14435,-0.00765557,0.814904,0.757061,0.731645,0.759147,0.0549971,0.0789814,0.987963,0.945687,0.0714648,0.063348,0.785055,0.771787,0.0366206,0.064254,-0.6811,-0.45263,0.979209,1.2087,0.571099,0.624218,-1.49156,-1.49835,0.746789,0.823773,0.481972,0.321806,0.039448,-0.172897,-0.00499468,-0.150986,-1.5137,-1.50831,-0.236612,-0.144919
3525,0.477315,0.375748,0.290011,0.236576,0.879088,0.727686,0.910354,0.850733,0.845938,0.873269,0.299229,0.321634,0.689794,0.649019,0.396726,0.389751,0.518174,0.502915,0.996666,1.02217,-1.17834,-0.951442,0.416537,0.73606,1.35421,1.40693,-0.534746,-0.534419,0.555384,0.624959,0.0318215,-0.12654,-0.265218,-0.477976,-0.20857,-0.356034,-0.410804,-0.408655,-0.326155,-0.229372
3526,0.865555,0.764251,0.879923,0.827425,0.359394,0.208894,0.545668,0.483923,0.145719,0.172841,0.252856,0.1777,0.945786,0.905619,0.435965,0.43007,0.777055,0.759063,0.0207292,0.0462313,0.936795,1.161,0.0353078,0.263421,0.179072,0.23133,-0.835078,-0.832169,1.15669,1.22594,0.191758,0.0407436,1.43015,1.21644,1.97519,1.82436,1.29422,1.3017,0.387919,0.488627
3527,0.672983,0.570387,0.86097,0.766337,0.812473,0.662403,0.928199,0.867027,0.682217,0.711727,0.00985128,0.0337654,0.309602,0.268176,0.234648,0.228001,0.197285,0.179641,0.0895811,0.144425,0.222352,0.448734,-1.96768,-1.73171,1.17787,1.23082,1.2492,1.24687,0.704413,0.767257,-1.71045,-1.87002,-0.204649,-0.423515,0.842403,0.685159,-0.345914,-0.342308,-1.39051,-1.29641
3528,0.718055,0.615674,0.703362,0.705248,0.231917,0.0835741,0.362809,0.303291,0.812283,0.847363,0.467854,0.491997,0.79565,0.754916,0.961922,0.955653,0.051025,0.0314495,0.218547,0.242618,-1.06329,-0.832853,-1.15263,-0.91668,0.118513,0.16497,-0.0961368,-0.100246,-1.21693,-1.14813,-0.203428,-0.370676,1.01558,0.793005,0.181042,0.0240932,-0.159545,-0.149747,-0.870608,-0.776958
3529,0.308539,0.205743,0.695412,0.644159,0.626472,0.475493,0.00198457,-0.0587945,0.954588,0.982998,0.189102,0.28902,0.734124,0.690786,0.944695,0.827667,0.914066,0.893085,0.110294,0.186416,0.206058,0.431403,1.25825,1.50141,0.746488,0.7932,1.6748,1.67772,-0.124238,-0.0543901,-1.56245,-1.72855,1.07443,0.856204,-0.472461,-0.636973,0.34144,0.358429,0.968566,1.06228
3530,0.224269,0.122704,0.390139,0.338188,0.407221,0.257627,0.743944,0.683915,0.442601,0.519255,0.05967,0.0860443,0.0105552,-0.0315277,0.762691,0.699681,0.958348,0.936557,0.108823,0.130214,-0.520677,-0.297337,-0.152533,0.0850153,-0.845213,-0.795861,1.18482,1.19656,-0.250502,-0.177024,0.524998,0.360676,-2.09912,-2.311,1.58942,1.4189,-0.367435,-0.388271,-0.0613335,0.0281805
3531,0.977149,0.877854,0.822329,0.772337,0.644487,0.492997,0.560936,0.501948,0.0289709,0.0555113,0.794037,0.822097,0.776073,0.733223,0.577965,0.571696,0.398799,0.458408,0.298985,0.322263,-0.640495,-0.414812,-0.234253,-0.0195198,-0.313896,-0.292957,1.10084,1.11595,-1.34982,-1.27772,1.17672,1.01868,0.834835,0.617516,1.64244,1.47189,-1.1555,-1.13497,0.379457,0.471488
3532,0.764499,0.716642,0.616659,0.567392,0.129366,-0.0205665,0.580742,0.445119,0.0104418,0.0365477,0.649904,0.616737,0.909124,0.86832,0.796534,0.789931,0.00204904,-0.0197418,0.792272,0.816165,1.86096,2.08744,-0.320808,-0.124055,0.249192,0.209948,-1.39911,-1.38431,-0.88367,-0.813606,0.127802,-0.0106519,0.485765,0.26474,-1.10501,-1.27438,0.870596,0.897943,0.358548,0.448452
3533,0.656421,0.55543,0.130088,0.0796164,0.742121,0.593042,0.447209,0.388291,0.6701,0.696933,0.43796,0.411377,0.399928,0.356719,0.134386,0.127827,0.309184,0.286033,0.0679445,0.0936847,-0.209504,0.0143121,-0.514686,-0.22859,0.757687,0.712852,-0.702182,-0.683178,0.175372,0.249799,-0.878897,-1.03998,-0.643705,-0.860709,0.599804,0.423052,-0.101676,-0.0704354,-0.0420079,0.0464206
3534,0.148608,0.0499381,0.534245,0.409012,0.00133049,-0.147717,0.702251,0.643451,0.45134,0.480608,0.177956,0.206017,0.570102,0.436124,0.0892646,0.0813089,0.250599,0.226264,0.916624,0.942144,-1.25497,-1.03692,-0.570673,-0.333125,1.24865,1.21576,-1.28226,-1.25775,-1.22021,-1.1431,1.7193,1.55123,-0.423751,-0.647874,0.226287,0.0503551,0.57481,0.608667,-0.920028,-0.837087
3535,0.112037,0.0135675,0.789914,0.738407,0.425972,0.276451,0.432301,0.375524,0.102363,0.264284,0.489696,0.483813,0.557895,0.515529,0.403929,0.30637,0.414661,0.425982,0.116363,0.142134,-2.09445,-1.87405,0.0791805,0.356244,1.66931,1.71866,-0.568328,-0.541543,1.1872,1.26128,-0.511925,-0.685223,-0.661639,-0.891552,-0.366695,-0.538578,0.403346,0.431094,0.751558,0.827076
3536,0.374261,0.275491,0.0915771,0.0381429,0.450182,0.204331,0.734386,0.675915,0.023503,0.0479588,0.732048,0.761609,0.080298,0.0393839,0.540529,0.531432,0.763153,0.625699,0.0358452,0.0859313,0.1326,0.345212,0.808065,1.04561,0.469045,0.586513,0.657097,0.685552,0.438342,0.513967,-1.53778,-1.71806,1.86693,1.63074,0.863208,0.692863,-1.09056,-1.05671,-0.22029,-0.146054
3537,0.348813,0.153911,0.270621,0.16325,0.281973,0.132212,0.412563,0.353107,0.127609,0.0975544,0.816872,0.846786,0.901402,0.859817,0.242815,0.234498,0.847993,0.825417,0.00408268,0.029729,1.00508,1.22169,-1.46083,-1.2239,-0.586923,-0.545634,-0.0743666,-0.0437232,1.91967,1.99075,-1.06863,-1.24081,-0.306432,-0.544322,-0.690664,-0.860936,-0.546788,-0.51805,1.17165,1.24178
3538,0.130348,0.0323308,0.343761,0.288357,0.66336,0.513127,0.422526,0.360983,0.120973,0.14715,0.139616,0.171236,0.60875,0.568083,0.601412,0.592006,0.357185,0.3354,0.189865,0.216922,-1.64725,-1.43356,0.160392,0.397033,-0.123855,-0.0867593,0.60239,0.625661,-0.0273973,0.040082,-0.0271819,-0.173381,-0.91217,-1.1418,0.0127003,-0.161849,-0.490116,-0.46231,0.0274526,0.0976427
3539,0.347038,0.24891,0.248365,0.194392,0.215747,0.0640567,0.787862,0.72491,0.792148,0.818041,0.490247,0.546471,0.649045,0.606498,0.332916,0.324951,0.759079,0.651755,0.775936,0.80121,0.875945,1.08689,0.208422,0.444225,1.30766,1.33758,0.391869,0.422928,-0.835013,-0.768071,1.06792,0.894052,-0.620948,-0.849503,0.272714,0.0939325,0.197016,0.231089,-0.638219,-0.575062
3540,0.871862,0.775716,0.712192,0.657469,0.0553544,-0.0978731,0.042901,-0.0181633,0.705957,0.680838,0.892503,0.921707,0.484164,0.442681,0.264676,0.234497,0.988528,0.968111,0.724866,0.75211,-1.22435,-1.01316,-0.42647,-0.19534,-1.16431,-1.14106,-0.292725,-0.259899,0.402409,0.465431,-0.505946,-0.676715,0.866678,0.642299,-0.182548,-0.355424,-0.877831,-0.846371,1.28806,1.35267
3541,0.612513,0.517638,0.646001,0.593335,0.60706,0.454643,0.609818,0.54952,0.517149,0.543634,0.681507,0.712518,0.989619,0.949102,0.151974,0.144044,0.128632,0.108821,0.185578,0.210951,0.659489,0.868587,0.0769626,0.337948,1.57168,1.59569,-0.126163,-0.0948843,-1.69226,-1.63517,0.775794,0.608982,0.261913,0.044823,0.0670341,-0.0996423,-0.426623,-0.35956,0.949746,1.01157
3542,0.0938276,-0.00300273,0.851867,0.801159,0.0408982,-0.109615,0.0876103,0.0265825,0.985107,1.01145,0.182674,0.212451,0.234883,0.194425,0.667158,0.661335,0.159855,0.0986405,0.140689,0.167668,1.33671,1.54859,0.640991,0.871236,-0.293128,-0.275428,-0.359557,-0.329002,0.00193991,0.0556552,0.338962,0.177854,-0.860018,-1.08063,0.0467384,-0.122908,0.0992319,0.127251,-0.319608,-0.254119
3543,0.112272,0.0174349,0.0454203,-0.00349335,0.296133,0.145865,0.682446,0.618915,0.20557,0.231924,0.238229,0.268054,0.617569,0.57588,0.77883,0.772043,0.110109,0.0884603,0.692611,0.721781,3.52848,3.73773,0.824446,1.05682,1.40382,1.4135,-1.04726,-1.01183,0.430848,0.436783,-0.625506,-0.779072,1.68195,1.46019,-0.233292,-0.403866,-0.769076,-0.746532,-1.2896,-1.22725
3544,0.965093,0.869548,0.649059,0.601948,0.975249,0.825581,0.720647,0.562086,0.583061,0.518681,0.000877892,0.0295997,0.357352,0.315178,0.0731395,0.068631,0.516402,0.533905,0.356752,0.38535,2.0195,2.22821,-0.0414197,0.185293,0.157727,0.163339,1.85958,1.89827,0.767498,0.81791,-0.565692,-0.670777,0.0346084,-0.179769,0.281147,0.111128,-1.30434,-1.19166,0.297745,0.36079
3545,0.521909,0.42904,0.925366,0.878187,0.42762,0.276517,0.569057,0.505258,0.778996,0.805439,0.667399,0.696254,0.737622,0.696633,0.633364,0.62653,0.999864,0.97935,0.910463,0.939463,0.738206,0.946627,0.502199,0.724224,0.524136,0.530806,0.0387009,0.041555,0.0928308,0.146128,-0.411715,-0.562482,0.976707,0.757098,-0.126964,-0.223773,-1.65683,-1.63678,-0.114828,-0.0557768
3546,0.917199,0.821987,0.223603,0.177923,0.804919,0.653916,0.0681708,0.00232932,0.122596,0.151201,0.83041,0.861416,0.331731,0.290546,0.281819,0.274408,0.607911,0.585147,0.709039,0.738723,0.223429,0.339711,1.86735,2.09459,1.2601,1.26881,-1.85385,-1.81516,-3.00367,-2.94651,-1.12132,-1.27386,0.322839,0.0984289,-0.388655,-0.558674,-1.05374,-1.03729,-0.167828,-0.0541361
3547,0.0447603,-0.0484506,0.80231,0.758884,0.537963,0.389693,0.0978217,0.0302845,0.031437,0.0604975,0.557699,0.515135,0.448237,0.405605,0.934889,0.929222,0.741779,0.719311,0.114284,0.143147,-0.473414,-0.267206,-0.192455,0.0368106,-0.245707,-0.243046,1.33117,1.36815,0.0501436,0.109242,0.00708198,-0.140982,0.0794893,-0.145249,1.24206,1.0749,0.554132,0.563498,-0.11487,-0.0524954
3548,0.192662,0.0839577,0.332018,0.290623,0.528675,0.381163,0.952626,0.882145,0.371026,0.397875,0.138394,0.168854,0.965923,0.92189,0.468797,0.523091,0.216879,0.195244,0.393712,0.420962,0.404442,0.609271,2.41255,2.6457,0.410827,0.41628,-0.00682716,0.035503,0.837935,0.897431,-1.95127,-2.09859,1.37754,1.148,1.01138,0.839049,0.0854505,0.0938462,0.245082,0.315401
3549,0.191297,0.216366,0.0828093,0.040057,0.2724,0.14102,0.229768,0.159445,0.994524,1.02206,0.259616,0.288472,0.203035,0.16112,0.124601,0.11696,0.86559,0.842192,0.219669,0.245629,0.393648,0.599991,1.08716,1.32255,-0.0165007,-0.0105829,0.940406,0.984357,-0.672398,-0.617993,1.71017,1.5568,-0.172056,-0.401038,-1.30854,-1.47686,-0.624597,-0.621908,-1.95495,-1.88876
3550,0.440943,0.348774,0.112059,0.0685064,0.0499795,-0.0991224,0.146698,0.0764149,0.344888,0.372868,0.870772,0.899104,0.567269,0.52358,0.502186,0.536001,0.53115,0.605306,0.572769,0.478233,1.76644,1.97236,-1.171,-0.927894,-0.76412,-0.70534,2.41418,2.46144,0.0502383,0.107682,0.776268,0.533585,-1.17935,-1.40284,0.321485,0.156723,-1.75953,-1.76199,0.00514072,0.0696295
3551,0.0668696,-0.0255491,0.409469,0.365114,0.845888,0.695155,0.525056,0.454728,0.980457,1.0074,0.347949,0.374848,0.383248,0.351407,0.960862,0.955042,0.394659,0.36842,0.731414,0.710837,-0.447729,-0.24271,-0.433957,-0.188255,-1.40143,-1.4001,0.456421,0.496859,-0.684265,-0.625127,-0.333809,-0.489632,1.51571,1.28431,-0.224507,-0.384804,-0.139171,-0.146947,0.248097,0.315991
3552,0.0864745,0.0158223,0.394076,0.38598,0.47207,0.320319,0.458014,0.420907,0.00851487,0.0378561,0.527087,0.55395,0.087434,0.179233,0.641052,0.558541,0.253989,0.224908,0.915362,0.943441,0.38794,0.588545,0.880325,1.1214,-1.62729,-1.62891,-1.2734,-1.22776,0.538145,0.592773,-0.219509,-0.433059,0.952084,0.714681,-0.27032,-0.449858,0.854653,0.844539,0.988372,1.0485
3553,0.151831,0.0571936,0.451147,0.406846,0.822513,0.673036,0.459434,0.387087,0.801981,0.82934,0.0671401,0.0930414,0.0496161,0.00705909,0.16841,0.16204,0.478121,0.451516,0.593378,0.62015,-1.51467,-1.31126,-1.10603,-0.86102,1.54171,1.54583,-0.404234,-0.355795,0.529477,0.582345,-0.227742,-0.376487,-0.49389,-0.736737,-0.358328,-0.514912,-1.32792,-1.34247,-1.58903,-1.5206
3554,0.650125,0.553599,0.838608,0.791612,0.476691,0.328751,0.712237,0.637727,0.919793,0.948736,0.86302,0.887382,0.570617,0.529355,0.918597,0.914677,0.093428,0.0670496,0.269571,0.296859,0.559809,0.771588,-0.0917363,0.154692,-1.57188,-1.56803,1.09051,1.13785,1.44495,1.49181,-0.732594,-0.887086,0.932248,0.695674,0.871076,0.716529,-0.307258,-0.320728,1.37129,1.44381
3555,0.691664,0.593776,0.103182,0.0559704,0.590522,0.440545,0.389904,0.314919,0.149562,0.179937,0.750159,0.77402,0.209971,0.168403,0.51048,0.507458,0.800906,0.774157,0.669379,0.696317,-0.214612,0.0501963,-0.00236405,0.247197,1.60905,1.60671,-1.08351,-1.02721,0.430246,0.482222,1.11048,0.954076,-0.84412,-1.0871,0.267518,0.148733,-0.564282,-0.574427,-0.393224,-0.325196
3556,0.108875,0.0129638,0.565388,0.519047,0.0584952,-0.0932702,0.418465,0.342875,0.723531,0.75423,0.845178,0.869256,0.423319,0.379935,0.845882,0.84502,0.775485,0.727973,0.32019,0.345236,-0.818382,-0.671196,-0.551089,-0.358668,1.62678,1.62254,-0.295762,-0.232788,1.20241,1.25447,1.29127,1.13719,-0.644803,-0.888295,-0.260796,-0.419062,1.51968,1.50924,-0.153058,-0.0525157
3557,0.0226548,-0.074012,0.336517,0.289151,0.46819,0.314872,0.714004,0.638145,0.683371,0.715425,0.693375,0.716299,0.138723,0.0940684,0.867962,0.865728,0.76159,0.681788,0.219491,0.246205,-1.60437,-1.39259,-1.22188,-0.964532,-0.318135,-0.32969,0.877147,0.841339,0.820712,0.872146,-0.856175,-1.00755,-1.19403,-1.44179,-1.28668,-1.45075,-0.171163,-0.183746,0.211048,0.220164
3558,0.464925,0.368666,0.402278,0.392614,0.631301,0.505211,0.672972,0.596454,0.0422672,0.0757929,0.955026,0.979735,0.360624,0.317119,0.298507,0.294712,0.664524,0.635604,0.948477,0.974668,-0.860942,-0.651314,-0.337171,-0.0727825,0.641668,0.624246,1.85467,1.91547,-0.568804,-0.520753,-1.14617,-1.29945,1.00344,0.760731,-0.776055,-0.935753,-0.0231392,-0.0364435,0.497814,0.492845
3559,0.259283,0.1648,0.526569,0.496078,0.850283,0.695551,0.352587,0.273647,0.0556554,0.0887242,0.177701,0.203963,0.584808,0.540171,0.429638,0.511435,0.421809,0.45638,0.722816,0.748706,0.351492,0.572217,1.53766,1.79617,-0.498146,-0.518669,-1.88342,-1.8198,-0.806468,-0.786058,0.27048,0.122257,0.413435,0.175778,-0.546405,-0.711249,0.810694,0.797872,0.697497,0.765525
3560,0.647639,0.553303,0.590769,0.599542,0.58763,0.369339,0.84469,0.766988,0.37024,0.346361,0.951901,0.977173,0.395726,0.351187,0.73373,0.728158,0.304801,0.277156,0.170406,0.19791,1.58612,1.79575,0.260343,0.521172,0.32863,0.326283,-0.32467,-0.262301,-1.09814,-1.05136,-1.93158,-2.0836,-0.829188,-1.07315,-1.00077,-1.16061,-1.58833,-1.60008,-0.174907,-0.103871
3561,0.0715232,-0.0229472,0.851633,0.703006,0.198649,0.0431269,0.711897,0.647836,0.568873,0.603997,0.854183,0.879282,0.961728,0.917697,0.237794,0.232474,0.618657,0.592,0.825057,0.852456,-1.44144,-1.23098,0.4441,0.706757,1.19193,1.17123,0.504534,0.561165,0.478314,0.531763,-0.588219,-0.737296,0.145921,-0.089449,0.36876,0.211689,0.0741633,0.0637995,-0.298521,-0.233202
3562,0.227539,0.1046,0.812352,0.80647,0.205563,-0.0410569,0.607174,0.528683,0.0762575,0.110661,0.200686,0.22455,0.409012,0.364952,0.054444,0.0503016,0.635835,0.606968,0.143641,0.171397,-1.24088,-1.02771,-0.519422,-0.257889,-0.941233,-0.954904,-1.73991,-1.6847,1.78934,1.84174,-0.83402,-0.984089,-0.448744,-0.686925,-0.408492,-0.560757,-0.322872,-0.327564,-0.140355,-0.0755415
3563,0.306033,0.232148,0.9573,0.909933,0.0302216,-0.125241,0.89925,0.819136,0.770503,0.807046,0.919924,0.945907,0.843896,0.801848,0.681283,0.675747,0.976147,0.94769,0.650507,0.679899,-0.224653,-0.0107968,-0.483555,-0.225101,-0.014335,-0.03349,-0.588769,-0.534921,0.810563,0.862816,0.304998,0.148788,-0.315285,-0.549452,2.29471,2.13913,-0.312285,-0.298995,0.263993,0.33652
3564,0.318859,0.359695,0.812664,0.766227,0.699491,0.544341,0.611205,0.530741,0.0461703,0.080538,0.651695,0.678029,0.690332,0.653575,0.220729,0.214339,0.356139,0.327259,0.774037,0.796267,-1.52248,-1.30752,0.325589,0.589926,2.57477,2.5535,3.48541,3.54084,1.13387,1.18943,0.286852,0.133018,0.157857,-0.0728411,0.345447,0.194606,-0.260238,-0.270425,-0.721652,-0.652428
3565,0.581713,0.487243,0.41437,0.366787,0.337477,0.179722,0.60384,0.523957,0.508991,0.497811,0.787487,0.813195,0.547736,0.505301,0.854515,0.849279,0.763536,0.733219,0.882513,0.912634,0.0322789,0.214711,-1.40902,-1.14203,0.478809,0.458278,0.052236,0.104756,-0.402318,-0.341712,-1.52798,-1.68362,1.14437,0.910862,1.12659,0.969122,-1.77616,-1.78861,-0.720302,-0.644848
3566,0.0254959,-0.0689224,0.307945,0.25778,0.514653,0.33872,0.899302,0.819228,0.881064,0.915084,0.11475,0.142747,0.0931279,0.049399,0.327565,0.32347,0.598286,0.570426,0.334543,0.365871,1.52321,1.73695,0.0830519,0.352522,-0.623385,-0.638438,-1.03385,-0.983878,1.50064,1.56566,-0.31648,-0.473333,-0.0885161,-0.322062,-1.42984,-1.58678,1.2737,1.25785,-2.35647,-2.27722
3567,0.264859,0.162102,0.522677,0.470437,0.654217,0.497717,0.865718,0.782991,0.674247,0.657718,0.642316,0.669424,0.304962,0.269667,0.0610174,0.0564147,0.138181,0.110327,0.651616,0.684091,0.023047,0.241892,-0.196493,0.0785185,0.952359,0.941958,-1.61679,-1.57512,-2.10336,-2.03457,-0.334295,-0.489103,0.851709,0.614805,1.30149,1.14515,-1.89808,-1.91545,-0.471014,-0.394943
3568,0.489326,0.393126,0.999179,0.948204,0.480916,0.282512,0.824979,0.746754,0.364571,0.400351,0.191804,0.218117,0.5321,0.489934,0.0354618,0.0306665,0.706244,0.679691,0.398257,0.429289,-0.578878,-0.307649,-1.24979,-0.979316,-1.40367,-1.40982,0.65797,0.702897,0.897925,0.970168,2.15259,2.00439,-0.357483,-0.587375,-0.38775,-0.548052,-0.299377,-0.314663,0.20537,0.27748
3569,0.843815,0.62415,0.314782,0.262945,0.226442,0.0673069,0.00513044,-0.0751986,0.738627,0.77366,0.093795,0.120226,0.268226,0.223974,0.814695,0.80846,0.1307,0.105105,0.569046,0.57656,-1.07603,-0.85719,-0.632881,-0.305778,-0.894876,-0.828269,-0.822765,-0.78347,0.767291,0.832674,1.31597,1.17002,-0.595434,-0.831053,-0.645993,-0.799541,-0.576033,-0.584147,-0.269534,-0.197979
3570,0.949592,0.855174,0.047039,-0.00329881,0.866038,0.706448,0.921614,0.840306,0.353612,0.389972,0.631829,0.657548,0.72419,0.679854,0.220192,0.212641,0.887941,0.86251,0.694007,0.723831,1.39728,1.61666,0.101756,0.367759,-0.234214,-0.246715,-1.79643,-1.76249,-0.849113,-0.790465,1.33135,1.18438,0.985878,0.756341,-0.568426,-0.754028,-1.43641,-1.44039,-0.945826,-0.870684
3571,0.805875,0.712165,0.279705,0.229116,0.764319,0.605775,0.963921,0.883747,0.761389,0.797931,0.319937,0.356773,0.00963658,-0.0323953,0.817975,0.810931,0.251348,0.226798,0.0226692,0.0526832,0.977046,1.19735,0.17552,0.445937,-1.23242,-1.25039,0.0701688,0.109331,0.453925,0.519516,1.04378,0.892478,-2.35969,-2.59479,-0.55536,-0.708515,-0.48414,-0.482593,-0.117073,-0.0477304
3572,0.188874,0.0960605,0.822415,0.771374,0.93328,0.776503,0.0610229,-0.0177392,0.530487,0.609915,0.0316409,0.0559974,0.41911,0.379131,0.130885,0.123893,0.0417649,0.10266,0.689441,0.722078,-0.482379,-0.266621,-0.0316344,0.233823,-1.0355,-1.05154,-2.01946,-1.97851,0.679795,0.739456,-0.948329,-1.09471,-0.418664,-0.649636,1.35439,1.20563,-0.924677,-0.922498,-0.534536,-0.464297
3573,0.0599023,-0.0324964,0.751954,0.702332,0.208684,0.0513417,0.420632,0.365482,0.386083,0.421899,0.695475,0.717731,0.162225,0.176332,0.552997,0.54525,0.00275084,-0.021479,0.368221,0.40084,-0.731206,-0.517035,1.20613,1.4457,-1.10237,-1.1122,0.557262,0.6036,-0.0775155,-0.0234668,0.533882,0.389217,1.16588,0.937757,0.133875,-0.0110412,-0.176159,-0.168795,0.513242,0.586547
3574,0.227992,0.0800917,0.310918,0.258959,0.282009,0.122461,0.825894,0.748704,0.78839,0.824429,0.383024,0.403971,0.0149154,-0.026468,0.646505,0.675135,0.961997,0.937643,0.973864,1.00462,0.614059,0.825021,2.39106,2.65758,-0.181846,-0.141204,-0.0122287,0.0290274,0.448049,0.501303,-1.04826,-1.1967,-1.28008,-1.50928,-0.409455,-0.552568,0.169301,0.182222,-1.04931,-0.9811
3575,0.283887,0.19268,0.315611,0.263332,0.57799,0.44498,0.019999,-0.0573128,0.346952,0.380994,0.823499,0.842327,0.886977,0.84673,0.811961,0.805019,0.533622,0.508553,0.410234,0.439031,-0.594511,-0.378972,-0.649282,-0.380394,0.836155,0.829795,-1.09488,-1.05961,-0.83806,-0.782629,0.387409,0.241788,-1.14697,-1.37181,-2.19077,-2.33851,-1.09024,-1.08185,-2.0134,-1.93967
3576,0.859672,0.769225,0.80446,0.751032,0.928842,0.767499,0.368616,0.291474,0.434922,0.49643,0.404589,0.421014,0.253522,0.214652,0.400664,0.393329,0.556049,0.532897,0.425691,0.527667,-0.559872,-0.345047,-1.41163,-1.14487,-2.38794,-2.39531,0.0344791,0.0756697,-0.212008,-0.149742,0.719834,0.576316,1.95985,1.73599,-0.278971,-0.424363,0.0118271,0.0178026,-0.81558,-0.735999
3577,0.71648,0.626217,0.514996,0.497728,0.601319,0.437753,0.360177,0.284691,0.578603,0.611865,0.497177,0.511782,0.495376,0.434696,0.400995,0.34991,0.208863,0.183284,0.499987,0.616304,-1.18774,-0.966564,1.25769,1.52731,-1.03277,-1.04599,-1.84242,-1.80285,0.114108,0.176876,2.8924,2.74855,1.72082,1.49231,-0.827369,-0.965889,-1.06775,-1.05966,0.171351,0.253643
3578,0.22025,0.130823,0.295651,0.244424,0.789019,0.624204,0.0206215,-0.0567748,0.0755814,0.108628,0.915936,0.931139,0.772951,0.654739,0.348038,0.306491,0.989009,0.965466,0.673992,0.70494,-0.32901,-0.104614,-0.94694,-0.677358,-1.97419,-1.98571,0.944501,0.982516,-1.22673,-1.17193,-0.525249,-0.665749,-0.199475,-0.430204,0.334258,0.19194,-0.148247,-0.148374,0.879955,0.872839
3579,0.603617,0.513645,0.236987,0.185234,0.971713,0.810654,0.557655,0.480697,0.77371,0.805012,0.0340368,0.0491516,0.913653,0.874783,0.258698,0.263071,0.92686,0.905697,0.461004,0.48964,0.105042,0.329634,-0.111503,0.154464,-0.562126,-0.577484,0.157863,0.191713,0.513704,0.566378,-0.336021,-0.482638,-0.264602,-0.489546,-0.863569,-1.00861,1.81428,1.8185,1.45364,1.49204
3580,0.371761,0.280431,0.979848,0.930353,0.26742,0.106362,0.0219313,-0.0573911,0.738557,0.770656,0.057695,0.071087,0.275444,0.23734,0.383992,0.219652,0.663432,0.638963,0.584588,0.632208,0.281751,0.503168,-0.977623,-0.717064,0.113304,0.0991572,-1.11298,-1.07967,-0.707689,-0.657504,1.15806,1.01671,-0.311516,-0.548888,-1.058,-1.19827,0.727062,0.727545,2.02894,2.11123
3581,0.956796,0.86606,0.54027,0.492599,0.188415,0.0262384,0.785068,0.706008,0.910585,0.941183,0.643036,0.656748,0.398524,0.362718,0.183567,0.176232,0.387505,0.372228,0.638958,0.774777,0.11733,0.341058,0.533407,0.793771,0.439762,0.421871,-0.0336042,-0.00739305,-1.00081,-0.945913,0.60427,0.461109,0.572974,0.33977,-0.811186,-0.958537,-1.15124,-1.14407,0.174122,0.262254
3582,0.12381,0.033246,0.759289,0.709929,0.743454,0.578754,0.195705,0.118233,0.0395878,0.0688632,0.207056,0.220719,0.0377186,0.00176618,0.739348,0.734131,0.126656,0.105494,0.888909,0.917346,-1.19778,-0.968983,1.14545,1.40969,-0.498347,-0.517857,0.43058,0.461813,-0.688292,-0.636539,0.352702,0.214317,0.288177,0.0501975,-0.251808,-0.399271,0.671571,0.67802,-0.955375,-0.867531
3583,0.241134,0.271001,0.309259,0.261473,0.406596,0.238884,0.746453,0.670811,0.617987,0.648599,0.230967,0.258275,0.622567,0.588029,0.523332,0.517043,0.630757,0.611149,0.14035,0.169464,-0.801483,-0.57998,0.00925949,0.274047,0.109061,0.0945499,-0.661248,-0.626821,0.927077,0.976999,0.424396,0.289948,1.31086,1.07734,0.829109,0.682385,0.948264,0.871317,-0.816793,-0.725474
3584,0.554929,0.508756,0.0909654,0.0420934,0.572595,0.458604,0.513583,0.438163,0.797267,0.828636,0.283405,0.29583,0.15252,0.116924,0.58004,0.572783,0.75909,0.695848,0.945481,0.972877,-0.705777,-0.483769,0.230094,0.492378,-1.65338,-1.66677,-1.52298,-1.48252,-0.000557611,0.0449322,-0.438352,-0.574439,1.04369,0.803435,-1.20719,-1.35617,1.06095,1.06461,0.897442,0.986779
3585,0.837074,0.746511,0.309787,0.259424,0.844864,0.678325,0.05477,-0.0188424,0.372089,0.404735,0.077272,0.0915592,0.688127,0.653324,0.404475,0.395944,0.801098,0.780547,0.100597,0.125069,-0.207224,0.0128444,-0.796977,-0.535422,-0.916402,-0.928766,-0.838832,-0.797975,1.29942,1.33845,-1.07906,-1.20998,-1.86012,-2.09768,-0.692109,-0.841175,0.329687,0.332245,0.0709761,0.165012
3586,0.0330363,-0.0597642,0.74862,0.698798,0.807312,0.639506,0.846103,0.771175,0.885975,0.918857,0.864214,0.880065,0.326959,0.292373,0.757162,0.748296,0.575995,0.557093,0.384205,0.483104,0.849093,1.07473,0.243192,0.508933,0.446846,0.435206,-0.755177,-0.711756,1.25853,1.29614,-1.49995,-1.62631,-0.243359,-0.480762,0.0660372,-0.0822586,-0.846054,-0.84057,-1.11605,-1.02399
3587,0.834553,0.741766,0.248939,0.200516,0.983796,0.815827,0.418117,0.344012,0.40225,0.435174,0.764929,0.833404,0.252685,0.231302,0.672688,0.662485,0.107343,0.0875763,0.814954,0.841139,1.50171,1.72516,1.57754,1.84776,-2.65052,-2.65502,-0.966889,-0.931127,-0.85846,-0.821904,0.864785,0.735039,-1.20117,-1.43466,-1.22827,-1.37812,0.893282,0.900255,-1.13447,-1.04703
3588,0.510935,0.464019,0.0649201,0.0923519,0.352279,0.181685,0.490516,0.417113,0.454758,0.49727,0.773366,0.786742,0.205291,0.170232,0.861504,0.781722,0.696191,0.678215,0.105807,0.133275,0.193936,0.415115,-0.302681,-0.0299296,0.523996,0.519713,1.83663,1.86948,0.839828,0.868918,0.504267,0.381445,-1.23109,-1.46343,0.339775,0.194073,1.21115,1.21883,1.90825,1.99154
3589,0.280352,0.186273,0.0333726,-0.0158123,0.888531,0.719328,0.860896,0.785733,0.526236,0.559366,0.874368,0.885965,0.415118,0.381763,0.912479,0.90096,0.980073,0.963959,0.934321,0.961168,1.5097,1.72418,8.72382e-05,0.279953,1.80487,1.80682,-1.98451,-1.95166,-0.112559,0.0105669,0.842387,0.715973,-0.86171,-1.0949,-0.194946,-0.269771,-0.000646945,0.00197298,-1.33231,-1.25136
3590,0.821439,0.728528,0.607426,0.559951,0.503644,0.334712,0.202524,0.128476,0.354435,0.391295,0.68265,0.626257,0.352779,0.325004,0.0811356,0.0683128,0.0139154,-0.00444794,0.264221,0.29002,-1.0999,-0.881337,-1.49296,-1.21493,-0.373195,-0.367877,-2.04114,-2.00135,-0.875975,-0.847784,-0.121073,-0.339869,0.617337,0.384571,-0.593878,-0.733615,0.584797,0.585285,-0.876723,-0.793932
3591,0.192494,0.0974016,0.192767,0.146258,0.585442,0.477109,0.772678,0.696159,0.188381,0.223224,0.353341,0.366548,0.299416,0.268245,0.838572,0.825944,0.959225,0.939851,0.196547,0.221688,1.71466,1.9389,-1.46773,-1.18214,0.0592132,0.0610887,0.452793,0.495784,2.62388,2.65822,-1.27377,-1.39571,0.330323,0.0949984,0.625952,0.483066,-0.751409,-0.746223,-1.25538,-1.16615
3592,0.54083,0.444397,0.8958,0.851491,0.791073,0.619507,0.114021,0.0389011,0.749904,0.782494,0.50405,0.522391,0.800077,0.770561,0.669001,0.658093,0.689321,0.67098,0.47107,0.494857,-0.853271,-0.625727,0.833615,1.11899,0.746255,0.753053,-1.92209,-1.88366,1.57463,1.60437,0.76957,0.647568,-0.575811,-0.749038,-0.0699507,-0.2132,0.20216,0.211577,0.239501,0.372995
3593,0.192963,0.0943359,0.826603,0.782449,0.691967,0.435338,0.984415,0.907907,0.843794,0.823447,0.665112,0.678233,0.211289,0.183254,0.711106,0.662217,0.0873485,0.0711781,0.347588,0.36977,2.19319,2.41962,-0.0454045,0.247458,1.21041,1.21193,-1.01565,-0.973896,0.920224,1.03838,-0.993838,-1.12129,-1.35458,-1.59307,0.821107,0.683575,1.51656,1.52843,1.82291,1.91214
3594,0.399829,0.221935,0.332508,0.289534,0.424766,0.25117,0.0633373,-0.0124383,0.832709,0.8644,0.0221704,0.0328908,0.0819198,0.0535588,0.796166,0.66634,0.874876,0.858335,0.834588,0.85924,1.69533,1.9208,1.25814,1.55712,0.308659,0.317494,-0.0977345,-0.0641312,0.444188,0.472398,1.80042,1.66844,1.50155,1.27019,0.59684,0.463782,0.773738,0.778203,-0.135291,-0.0454478
3595,0.442775,0.349534,0.457307,0.41269,0.628754,0.43037,0.486087,0.411824,0.645039,0.631427,0.962303,0.974356,0.239227,0.145104,0.681058,0.670463,0.699179,0.680738,0.146003,0.172085,-0.291886,-0.0720506,0.0496683,0.345077,0.222604,0.250266,0.229412,0.268874,0.957527,0.982808,-1.13619,-1.26298,-0.427562,-0.652333,-2.21943,-2.35166,-1.10162,-1.09341,-1.16643,-1.07954
3596,0.575994,0.477133,0.796075,0.753333,0.783368,0.60957,0.184968,0.109392,0.368181,0.398454,0.730459,0.741058,0.265403,0.236649,0.57488,0.463815,0.276585,0.257314,0.0768595,0.103753,-0.36531,-0.143177,1.02545,1.31494,0.176883,0.183038,1.44564,1.48061,-0.862951,-0.841497,0.478811,0.345955,0.503009,0.284535,-0.0992405,-0.235019,1.32725,1.32967,-0.96001,-0.876861
3597,0.1461,0.0463713,0.775364,0.732674,0.0898348,-0.0844184,0.575315,0.498162,0.641376,0.670159,0.805368,0.80334,0.938127,0.909377,0.34226,0.257168,0.966618,0.948867,0.6708,0.697971,0.403978,0.628652,-0.269805,0.0245431,0.385997,0.397743,-0.845662,-0.814149,-2.10475,-2.07998,-0.249154,-0.380474,0.497401,0.285648,1.28342,1.15341,0.353767,0.361287,1.00665,1.09613
3598,0.570333,0.375696,0.434671,0.436616,0.350967,0.145495,0.759759,0.683666,0.158617,0.186476,0.854872,0.865621,0.641813,0.612708,0.0602199,0.0505205,0.882338,0.863286,0.643003,0.726907,0.042812,0.27073,1.66679,1.95537,0.29334,0.304475,-0.448155,-0.420089,0.511089,0.543091,0.342252,0.217939,-2.16365,-2.37203,-0.430019,-0.555912,0.0985648,0.107588,-2.38347,-2.29747
3599,0.8056,0.70502,0.181515,0.140558,0.551506,0.375408,0.477378,0.400716,0.946033,0.974317,0.632267,0.642708,0.109713,0.0805216,0.10411,0.0253109,0.0294169,0.00905442,0.728708,0.755843,0.275359,0.505545,0.0612527,0.351031,1.6905,1.69725,-1.09808,-1.07244,2.00548,2.03459,0.0943831,-0.0288531,-0.274099,-0.487317,0.750184,0.630599,-1.40035,-1.39609,1.95512,2.04229
3600,0.728798,0.628308,0.677284,0.639038,0.33784,0.162249,0.642098,0.640862,0.116471,0.14642,0.70647,0.807969,0.177542,0.149316,0.0122613,0.000101357,0.720085,0.700607,0.5037,0.529882,1.46792,1.6917,0.909922,1.19617,-0.0995335,-0.0958488,-0.638304,-0.616721,-0.251847,-0.223823,-1.21554,-1.33814,0.358242,0.143517,0.802358,0.683586,0.737076,0.740242,2.07693,2.16651
3601,0.209756,0.107667,0.53734,0.56801,0.808693,0.630832,0.957341,0.881008,0.873234,0.905045,0.962642,0.973231,0.874922,0.846565,0.528095,0.517393,0.638605,0.647396,0.662499,0.687143,0.0748884,0.303916,-0.790268,-0.501408,1.0948,1.09991,0.437945,0.455555,-1.6657,-1.632,1.37191,1.25307,0.448936,0.235689,-0.135005,-0.257442,-1.19126,-1.19233,0.0470217,0.132228
3602,0.492036,0.389364,0.534425,0.496983,0.771856,0.592013,0.428029,0.352764,0.0128346,0.0450967,0.915809,0.926042,0.0522857,0.0241744,0.315219,0.305783,0.589372,0.594185,0.170921,0.196465,-0.122508,0.114038,0.273723,0.561743,-1.15186,-1.13942,-0.364455,-0.352024,-0.602473,-0.568599,-0.782472,-0.904039,1.322,1.11022,0.489688,0.364081,-1.04818,-1.04503,1.49099,1.58143
3603,0.428842,0.416106,0.737561,0.699443,0.034721,-0.143587,0.663527,0.573779,0.437566,0.467437,0.49537,0.48831,0.426289,0.328828,0.730368,0.722351,0.618397,0.540973,0.792166,0.815119,-1.35545,-1.1199,0.289106,0.577826,1.66617,1.67981,0.507721,0.519945,-0.0153811,0.0174498,0.713166,0.595305,-0.517383,-0.733948,1.52514,1.40009,-0.224121,-0.227692,-0.434425,-0.343226
3604,0.41887,0.442849,0.013022,-0.0258931,0.0020986,-0.177131,0.869872,0.794795,0.146625,0.174806,0.0388683,0.0505784,0.663919,0.633482,0.88003,0.873615,0.466999,0.487762,0.66493,0.690032,0.290996,0.532627,0.897463,1.17967,-0.892081,-0.877258,0.37772,0.39367,0.272031,0.2985,-1.21649,-1.32947,-0.819282,-1.06053,1.6625,1.53201,-1.6625,-1.66705,0.528884,0.616285
3605,0.528347,0.469592,0.739605,0.700136,0.875976,0.694339,0.79252,0.772357,0.626289,0.652716,0.502292,0.513528,0.00321083,-0.0282124,0.104294,0.0972406,0.454028,0.43455,0.914173,0.93838,0.412318,0.660448,0.564979,0.845107,0.517577,0.530972,-0.166415,-0.149505,-0.316295,-0.295212,-0.833142,-0.887513,-1.17503,-1.38711,0.86354,0.728782,-0.568772,-0.582649,-0.94618,-0.860808
3606,0.599007,0.496335,0.531474,0.490551,0.38414,0.204453,0.823014,0.749919,0.0783776,0.104209,0.688983,0.698311,0.198334,0.168441,0.963854,0.957647,0.977288,0.959768,0.950922,0.975098,0.0214982,0.272328,2.58188,2.85521,0.69889,0.714102,-0.356287,-0.339292,-0.0278971,0.000249696,-0.330329,-0.44556,2.53352,2.32484,-0.799084,-0.933592,0.506306,0.501753,0.109942,0.190036
3607,0.17896,0.0760156,0.60399,0.59184,0.240862,0.0624464,0.203111,0.132267,0.140771,0.166702,0.0660074,0.0737234,0.81074,0.779813,0.409977,0.401534,0.870023,0.95148,0.373988,0.399403,-1.27584,-1.0244,-0.689023,-0.413688,0.0409946,0.0521085,-1.09961,-1.18261,1.58049,1.61379,-0.18821,-0.308276,-0.515868,-0.723586,0.491899,0.359561,0.383364,0.371908,-0.444842,-0.362948
3608,0.86224,0.757223,0.732594,0.69313,0.334969,0.15925,0.943328,0.869616,0.682852,0.71107,0.763995,0.770113,0.446998,0.413511,0.716598,0.708121,0.959426,0.943192,0.688538,0.712841,1.69685,1.94912,-1.54865,-1.26959,1.16245,1.17221,-2.04155,-2.02592,1.00592,1.03403,-0.488583,-0.684546,1.3197,1.11397,-0.342057,-0.47424,-0.400922,-0.407134,1.34795,1.42896
3609,0.95502,0.762163,0.357923,0.413615,0.212908,0.0380708,0.010616,-0.0637754,0.752363,0.780242,0.951582,0.959,0.499856,0.460018,0.533122,0.557213,0.410665,0.393896,0.154444,0.177,-0.451843,-0.197567,-1.59926,-1.31436,-0.45941,-0.448954,0.69159,0.701628,1.80231,1.83451,-0.945152,-1.06082,0.153517,-0.136671,0.946808,0.818914,-0.234199,-0.24401,-0.216173,-0.13869
3610,0.874206,0.767103,0.175527,0.134101,0.841664,0.666568,0.162725,0.0864994,0.436605,0.462562,0.85419,0.861109,0.541792,0.506525,0.413463,0.406305,0.708051,0.642508,0.628565,0.651004,1.51393,1.77428,1.2346,1.51212,0.949096,0.959276,0.195287,0.204005,-1.49063,-1.46616,0.0477563,-0.0641901,-1.18234,-1.38732,-1.36158,-1.48383,-0.493898,-0.497709,0.868516,0.943649
3611,0.056275,-0.0502911,0.853989,0.813792,0.268803,0.0929185,0.999906,0.922946,0.462239,0.489958,0.400265,0.405281,0.0405122,0.00548593,0.89021,0.882831,0.906292,0.89112,0.0147992,0.0358013,1.49432,1.7508,-2.0693,-1.78889,1.79631,1.80577,-1.16128,-1.15881,-1.87081,-1.84848,0.154904,0.0174317,-1.10972,-1.30931,-2.14808,-2.27257,-1.07081,-1.07618,0.46255,0.541618
3612,0.554271,0.446115,0.115922,0.0738649,0.980104,0.803644,0.38156,0.305294,0.218382,0.24717,0.293615,0.296341,0.100518,0.0789261,0.0295441,0.0223384,0.223874,0.21118,0.517957,0.539759,0.139716,0.395454,-1.23788,-0.957063,-0.828768,-0.822173,0.273134,0.270682,1.38831,1.40794,0.214828,0.0990535,-0.233081,-0.43478,-0.6083,-0.749095,-0.531508,-0.537523,-0.32227,-0.251047
3613,0.577001,0.451635,0.943698,0.901245,0.446591,0.269829,0.631473,0.448025,0.305489,0.335693,0.774753,0.778721,0.188887,0.152366,0.715396,0.708124,0.475815,0.462924,0.346928,0.369579,0.434559,0.694907,0.0623099,0.338574,-1.26228,-1.24904,1.41094,1.40596,-0.892735,-0.869677,0.962166,0.848636,-1.0676,-1.26082,0.891979,0.774381,-0.766234,-0.775044,0.0916067,0.157275
3614,0.528688,0.457155,0.884772,0.872769,0.179194,0.000487204,0.686813,0.590756,0.180744,0.209356,0.27661,0.278653,0.641338,0.603616,0.538586,0.531489,0.16324,0.147971,0.649775,0.672185,-1.79829,-1.53707,-0.0260489,0.284519,-0.654306,-0.63663,0.789592,0.786647,-1.77195,-1.75499,1.12875,1.01592,1.9146,1.72215,1.72968,1.61118,-1.36055,-1.36837,0.48972,0.565597
3615,0.56905,0.462675,0.888351,0.844292,0.329886,0.152086,0.882732,0.733487,0.656331,0.687266,0.133335,0.135045,0.531929,0.494386,0.379219,0.354854,0.454065,0.43927,0.00217599,0.0260258,-0.808039,-0.552476,-0.0488981,0.230464,1.1909,1.21005,-1.12583,-1.12621,1.79549,1.81246,-1.05153,-1.15915,-1.24418,-1.43336,-0.920577,-1.04631,0.269547,0.263274,-0.0388638,0.043982
3616,0.376849,0.268811,0.217689,0.173274,0.872536,0.694985,0.952484,0.876218,0.0163138,0.0476342,0.917761,0.91813,0.821086,0.785543,0.186462,0.178218,0.455075,0.439322,0.456365,0.480485,2.39868,2.65019,0.427872,0.706704,-1.21801,-1.20543,-1.69876,-1.70078,0.218417,0.235811,0.018437,-0.0863597,-1.02236,-1.20518,-0.10446,-0.225258,0.152981,0.139303,1.34193,1.43182
3617,0.45802,0.349457,0.854666,0.808568,0.0296627,-0.149451,0.755905,0.678806,0.0724164,0.104662,0.679292,0.679676,0.744558,0.717625,0.594817,0.584663,0.782203,0.765419,0.0360656,0.0598963,0.0523043,0.297753,-0.0182179,0.265673,1.03744,1.05456,-0.509522,-0.504482,-0.241931,-0.222875,-0.684626,-0.782922,1.12378,0.936492,-0.853583,-0.968768,0.0176104,0.0153308,0.858218,0.876887
3618,0.903851,0.797322,0.129044,0.083231,0.203068,0.0645453,0.240015,0.160933,0.705197,0.739195,0.756966,0.821652,0.684215,0.649707,0.0118166,-0.000389843,0.500638,0.410148,0.257629,0.367327,1.5643,1.81146,0.146463,0.355991,-1.06404,-1.04066,-0.0778003,-0.0800885,-1.44004,-1.42762,0.0248652,-0.0777968,-0.561028,-0.752562,1.86529,1.74895,1.44393,1.44547,0.229321,0.321958
3619,0.494284,0.387392,0.780727,0.733268,0.456746,0.278541,0.885124,0.807792,0.259062,0.291184,0.962234,0.963627,0.183709,0.148668,0.415831,0.401169,0.0712297,0.0548777,0.650913,0.674758,-2.21181,-1.96506,0.158266,0.446309,-1.45356,-1.43745,-1.84992,-1.84757,-0.537501,-0.51816,0.181187,0.0727393,-0.581997,-0.82208,1.13452,1.02041,-0.868153,-0.873564,-1.23708,-1.14126
3620,0.986081,0.878919,0.60518,0.586376,0.954243,0.77686,0.0487167,-0.0295336,0.0382362,0.0690264,0.302885,0.303703,0.203483,0.166456,0.175927,0.163354,0.829698,0.812282,0.172213,0.194196,-1.28182,-1.04036,1.4415,1.72489,-0.826068,-0.805912,0.396982,0.393555,-0.657335,-0.640794,1.50379,1.38887,-0.704262,-0.891599,-1.04317,-1.16199,-1.84387,-1.84194,0.0660179,0.154762
3621,0.939859,0.861238,0.488507,0.439484,0.513784,0.337637,0.36288,0.318174,0.108666,0.138198,0.858154,0.859984,0.594012,0.554781,0.511139,0.500916,0.240526,0.223234,0.842702,0.863591,1.1492,1.38414,-1.42661,-1.14695,-0.188166,-0.174373,-0.825097,-0.832388,0.0826398,0.100051,-1.25579,-1.36721,0.696697,0.511998,0.725404,0.610736,-0.467179,-0.458619,0.275593,0.281504
3622,0.929953,0.843556,0.673082,0.622945,0.499837,0.324149,0.742999,0.665881,0.99991,1.02786,0.711317,0.711966,0.97942,0.943106,0.563102,0.550931,0.804308,0.788634,0.153572,0.176436,1.71374,1.94113,0.0754319,0.347602,-1.42341,-1.41066,-0.59068,-0.603898,1.3885,1.41003,1.04156,0.858486,0.0522566,-0.13214,-1.166,-1.28688,-1.14773,-1.14376,0.323654,0.408246
3623,0.8481,0.825875,0.547209,0.499054,0.162679,-0.0157214,0.82964,0.754014,0.866486,0.966099,0.326264,0.324513,0.231291,0.195171,0.131569,0.119828,0.674947,0.706809,0.152237,0.177325,-0.699972,-0.476089,-0.465535,-0.185832,1.66897,1.67879,1.28475,1.26792,0.515132,0.538481,3.19353,3.08418,0.210648,-0.0350004,1.20175,1.07236,0.320718,0.318859,1.09824,1.1846
3624,0.915356,0.808194,0.988184,0.938428,0.248714,0.0550021,0.161403,0.0864466,0.797318,0.904339,0.790067,0.787463,0.172479,0.136792,0.513041,0.502064,0.640161,0.624983,0.885139,0.911283,0.927278,1.14678,0.875062,1.153,-0.909338,-0.897202,1.07253,1.04855,-1.25249,-1.22373,0.255788,0.15276,0.243382,0.0621389,1.27056,1.09649,0.578399,0.574163,-1.05484,-0.971903
3625,0.259476,0.151819,0.443935,0.396712,0.305082,0.125726,0.975061,0.89779,0.814632,0.84258,0.868189,0.863428,0.317129,0.298067,0.592394,0.638032,0.868306,0.851591,0.359069,0.385294,0.208841,0.496519,-2.13208,-1.84582,0.022969,0.0393051,-1.6251,-1.64884,-1.01074,-1.01514,-0.260629,-0.357839,-0.828264,-1.01664,1.2472,1.12062,0.189194,0.1828,0.404087,0.494187
3626,0.702873,0.594497,0.75412,0.707827,0.754945,0.57498,0.595269,0.520166,0.0707451,0.101245,0.319482,0.314081,0.489208,0.459342,0.784555,0.774,0.339748,0.322425,0.95468,0.979513,-0.374373,-0.153742,1.44748,1.73898,-1.35694,-1.33714,-0.757281,-0.776867,-0.835049,-0.806563,2.24551,2.15296,0.539991,0.354299,-1.53826,-1.65859,1.12295,1.11037,-0.451033,-0.358374
3627,0.131506,0.0238772,0.51909,0.464192,0.759428,0.582171,0.21818,0.142542,0.217435,0.162913,0.177346,0.170473,0.700363,0.620617,0.441966,0.54735,0.153649,0.135336,0.41796,0.443672,-0.420754,-0.192977,-1.68574,-1.39702,0.762732,0.775159,1.08955,1.06555,0.508692,0.532053,-2.58412,-2.67666,0.624611,0.432309,0.0824293,-0.0399237,0.129486,0.11083,-0.279672,-0.185927
3628,0.109558,0.00592084,0.266461,0.220558,0.155179,-0.0222097,0.835584,0.760225,0.251181,0.224581,0.286966,0.279515,0.71771,0.781891,0.269258,0.320701,0.482594,0.465875,0.592498,0.615844,0.180486,0.410562,-0.64214,-0.352668,0.23201,0.239735,1.0248,0.99924,-0.991695,-0.968899,-0.601006,-0.699182,0.344226,0.158401,-0.750043,-0.873725,0.645767,0.633283,0.150445,0.241984
3629,0.0940908,-0.0120355,0.626153,0.535035,0.0274934,-0.148438,0.66181,0.587986,0.25679,0.286249,0.93278,0.925941,0.978853,0.943166,0.105452,0.0940517,0.536719,0.521761,0.534602,0.502988,-1.27767,-1.05341,0.901856,1.18993,-0.9952,-0.981819,-0.499108,-0.519694,-1.81172,-1.79366,-1.38504,-1.48609,1.21038,1.03293,-0.0744494,-0.204987,0.46472,0.455711,-0.020599,0.0680019
3630,0.380991,0.26335,0.897937,0.849513,0.656274,0.480059,0.979485,0.907617,0.623402,0.584466,0.676865,0.667953,0.0340051,-0.00101208,0.0987462,0.0892532,0.564137,0.577647,0.333543,0.390133,-2.05213,-1.82821,0.0834076,0.308356,-0.257198,-0.243819,-0.111078,-0.125633,-2.101,-2.08207,0.955515,0.857753,0.862131,0.680151,1.13084,0.998618,1.76092,1.75761,0.0291635,0.168583
3631,0.643238,0.538736,0.885478,0.870379,0.756823,0.485805,0.70009,0.629889,0.853577,0.882682,0.117758,0.109105,0.754305,0.718067,0.601793,0.590487,0.650252,0.633533,0.268438,0.277277,1.28646,1.51014,-0.861301,-0.573222,-0.637561,-0.625031,-0.137918,-0.145181,1.1832,1.1949,-1.75279,-1.85106,-2.63027,-2.81406,-0.958026,-1.08634,-1.28145,-1.28359,0.0792015,0.269164
3632,0.475572,0.371147,0.939033,0.891245,0.666141,0.49155,0.788448,0.718022,0.419817,0.448746,0.326794,0.317593,0.493956,0.457365,0.464994,0.454107,0.469257,0.450102,0.115963,0.164422,0.208433,0.428648,0.509093,0.797143,0.483953,0.495067,1.17114,1.15749,1.37196,1.38301,-0.108327,-0.208821,0.349335,0.168918,-0.309698,-0.43311,-0.839003,-0.84033,0.281143,0.369744
3633,0.929571,0.823607,0.0206329,-0.0285552,0.177235,0.00166343,0.208701,0.139409,0.556596,0.583624,0.0174794,0.00855095,0.779406,0.743911,0.91152,0.90109,0.659111,0.640597,0.0282201,0.0515661,-1.94531,-1.71804,-0.0408737,0.247503,0.591951,0.601567,1.59109,1.58189,0.040446,0.0497306,-0.0823511,-0.198796,-0.103333,-0.277131,-1.04948,-1.17662,0.883463,0.886478,0.94781,1.04217
3634,0.351312,0.247358,0.258833,0.211251,0.497216,0.323201,0.322657,0.253861,0.157541,0.18511,0.699839,0.689277,0.19423,0.156604,0.0462447,0.0353841,0.0815606,0.0611754,0.585444,0.610439,-1.31182,-1.08336,-0.255565,0.0338605,1.22428,1.2298,0.977727,0.962575,-0.130753,-0.118095,-0.0914286,-0.188771,0.473619,0.292839,-0.686643,-0.853987,-0.542106,-0.536645,0.45717,0.552317
3635,0.685528,0.579511,0.499116,0.451056,0.347835,0.0907721,0.0905861,0.0212132,0.849335,0.876369,0.51248,0.500797,0.999207,0.962075,0.990717,0.980832,0.566342,0.546183,0.535788,0.56134,-0.897592,-0.663512,-0.477057,-0.179782,0.200673,0.210199,-2.45382,-2.47351,0.0569206,0.0700185,1.59666,1.4989,-0.800861,-0.988435,-0.398619,-0.531354,0.648813,0.654064,1.39086,1.48038
3636,0.64636,0.538371,0.321194,0.271158,0.0320672,-0.141657,0.394552,0.324267,0.683816,0.714212,0.616585,0.614366,0.32716,0.289828,0.540025,0.530009,0.486144,0.465819,0.162651,0.190831,0.105485,0.338694,1.55445,1.84793,0.172274,0.180719,1.62942,1.60225,-1.08256,-1.07365,0.92107,0.816803,-1.85025,-2.03605,-0.858915,-0.996482,0.247845,0.246237,-0.265189,-0.180915
3637,0.95099,0.845091,0.995157,0.945947,0.702119,0.527925,0.696693,0.62732,0.527248,0.552056,0.738201,0.727935,0.402362,0.363964,0.632507,0.620891,0.769753,0.746996,0.49472,0.524457,0.253596,0.481368,1.08601,1.37613,0.960244,0.963427,0.614496,0.674189,-1.26404,-1.25698,1.19954,1.09113,-1.51163,-1.61585,0.647271,0.512266,-0.838621,-0.844714,0.518282,0.595438
3638,0.0347628,-0.0708776,0.220341,0.17313,0.300288,0.127812,0.732552,0.646043,0.572768,0.65413,0.255565,0.243216,0.953968,0.915674,0.40116,0.388602,0.342457,0.317906,0.153174,0.183318,3.00861,3.23678,-2.87901,-2.58477,0.341588,0.346072,-0.232011,-0.253874,-0.320509,-0.31575,-1.17048,-1.27839,-1.00659,-1.19565,0.433433,0.292473,1.28494,1.27321,0.491612,0.572402
3639,0.228576,0.125093,0.161275,0.113941,0.252256,0.0787884,0.73214,0.664766,0.732634,0.756205,0.892549,0.879196,0.727038,0.702581,0.720692,0.710069,0.744429,0.718843,0.479949,0.512197,0.59904,0.819556,0.0738362,0.367597,-1.30964,-1.30584,0.867389,0.848246,-0.281178,-0.279949,1.88107,1.76949,-0.0257062,-0.211942,-1.14771,-1.29137,-1.08516,-1.09377,-1.2576,-1.18295
3640,0.687768,0.582776,0.866636,0.819174,0.955058,0.779151,0.2739,0.207762,0.0784241,0.101968,0.361284,0.349277,0.655892,0.489489,0.0997476,0.0888252,0.358948,0.334377,0.603113,0.61039,-0.0782177,0.137545,-0.057205,0.231621,-0.615845,-0.613877,0.664146,0.645513,0.76802,0.768494,0.881591,0.765788,1.17991,0.988931,-0.0355551,-0.17846,1.49497,1.49132,-1.90547,-1.8258
3641,0.817582,0.71279,0.683944,0.634924,0.721051,0.54602,0.725017,0.660843,0.109682,0.118472,0.326178,0.311949,0.317029,0.276397,0.0605463,0.0636156,0.677467,0.559862,0.675617,0.708584,0.920691,1.13975,2.19206,2.48676,0.669041,0.673228,-0.0919103,-0.116368,-0.405092,-0.4076,0.389639,0.272588,1.25277,0.983461,-1.3719,-1.51907,-0.40192,-0.41226,0.608808,0.689235
3642,0.174442,0.0714015,0.200738,0.151634,0.857091,0.682453,0.536325,0.473402,0.109075,0.134977,0.045225,0.0291963,0.819399,0.778713,0.0475522,0.038406,0.808157,0.785346,0.273681,0.308023,-1.47314,-1.26181,0.330576,0.626913,2.16887,2.17449,-0.401671,-0.429376,0.320016,0.236855,0.233286,0.116976,1.16598,0.977992,-0.722339,-0.809978,-0.234004,-0.249136,-2.01424,-1.92891
3643,0.173388,0.0719689,0.662706,0.614711,0.689735,0.516306,0.856191,0.793033,0.359832,0.386493,0.69602,0.680395,0.354445,0.312982,0.370719,0.457447,0.430355,0.405626,0.16285,0.19766,-0.107079,0.110567,-0.49778,-0.198088,0.201654,0.209413,0.953269,0.918762,0.882722,0.881311,0.644905,0.528642,2.0447,1.85252,0.0497385,-0.100887,-2.0476,-2.05551,-0.883482,-0.80155
3644,0.584714,0.48529,0.588121,0.540797,0.911676,0.736702,0.168184,0.105948,0.830637,0.859465,0.346152,0.333211,0.785673,0.744632,0.884241,0.876487,0.90401,0.881073,0.65206,0.687129,0.712573,0.926889,-0.170531,0.126747,0.090898,0.102905,-1.42123,-1.46068,-1.49744,-1.50565,0.55687,0.419467,0.149702,-0.0397886,-0.229619,-0.381846,0.0170206,0.0111283,-0.535814,-0.449617
3645,0.138021,0.0394437,0.296684,0.250638,0.639676,0.41049,0.429498,0.282344,0.0907489,0.118129,0.702204,0.688499,0.173644,0.133488,0.863389,0.884135,0.871532,0.846002,0.288454,0.387851,-0.725709,-0.508775,-0.812882,-0.512817,-0.546065,-0.528019,-1.08556,-1.12768,0.818672,0.814236,0.41769,0.310293,-0.479416,-0.668566,0.196248,0.0582451,-1.00503,-1.0053,-1.4523,-1.36336
3646,0.747257,0.64931,0.647091,0.601141,0.259703,0.084278,0.535956,0.45874,0.579048,0.60646,0.330633,0.316806,0.0929491,0.0541521,0.899559,0.891783,0.00812549,-0.0189959,0.0529412,0.0885736,0.540557,0.755481,-1.04777,-0.665109,0.596869,0.60882,-0.136262,-0.164087,-0.612216,-0.623183,-0.702884,-0.815212,-0.407207,-0.590556,0.654807,0.498336,0.486107,0.486928,0.540554,0.62417
3647,0.992393,0.895272,0.168733,0.123704,0.839588,0.662422,0.696876,0.635136,0.57273,0.538148,0.686451,0.672095,0.631152,0.590553,0.65023,0.643785,0.298149,0.272303,0.306888,0.376375,-0.896717,-0.680184,-1.11301,-0.8174,0.172931,0.181957,0.844695,0.799504,-0.738233,-0.745817,-0.91252,-1.03086,-2.1178,-2.29585,-0.677114,-0.827403,-1.90236,-1.8973,-0.734548,-0.656994
3648,0.406357,0.309084,0.281362,0.199745,0.155044,-0.0218748,0.588766,0.527512,0.45295,0.469836,0.0698304,0.0571843,0.588658,0.547189,0.622237,0.618037,0.0554288,0.0291127,0.627163,0.664177,0.0820266,0.291068,0.196029,0.492257,0.0448169,0.0619996,-0.6171,-0.656831,-0.143009,-0.144834,-0.241401,-0.385417,0.402872,0.226442,-0.322926,-0.465778,-1.36209,-1.35865,-1.0183,-0.937154
3649,0.958173,0.860102,0.445864,0.275786,0.949562,0.772402,0.233519,0.170499,0.374112,0.401524,0.510124,0.495541,0.967452,0.923948,0.0473506,0.0418919,0.134832,0.107153,0.107417,0.143916,1.39259,1.60013,-0.404968,-0.102849,0.427744,0.445032,-0.278746,-0.323826,0.0799715,0.0751063,0.378735,0.260023,1.11133,0.933484,1.28241,1.13836,2.34661,2.34518,0.261251,0.342882
3650,0.100962,0.00220005,0.458357,0.351826,0.821492,0.626227,0.112555,0.0483666,0.681626,0.708785,0.534206,0.567175,0.567596,0.52361,0.606801,0.599791,0.0838804,0.185193,0.348556,0.387009,-1.76886,-1.56801,-0.783719,-0.484515,-0.130516,-0.105791,-0.727082,-0.775166,1.23501,1.22952,0.456607,0.335653,0.162739,-0.0204106,-0.351732,-0.492544,1.70597,1.70588,0.289483,0.365353
3651,0.580398,0.483516,0.472896,0.427867,0.646989,0.480052,0.269739,0.257493,0.135155,0.160278,0.652372,0.63881,0.578286,0.536559,0.43034,0.456877,0.287864,0.263234,0.380059,0.418913,-0.501795,-0.303751,-0.377361,-0.0847243,0.358179,0.383426,-0.598525,-0.641151,0.208894,0.205515,0.0500875,-0.0641959,2.22891,2.05235,-0.974245,-1.11158,1.73083,1.73252,-0.754723,-0.683396
3652,0.757476,0.658922,0.0296622,-0.0155063,0.480874,0.333877,0.530274,0.466619,0.302251,0.325049,0.436747,0.425028,0.0175314,-0.0252531,0.320853,0.313963,0.630193,0.598705,0.179908,0.218174,-2.03364,-1.82754,-0.60132,-0.368731,-0.45559,-0.433925,0.386722,0.340207,-0.0606148,-0.0692191,-1.32146,-1.43814,1.478,1.30154,-0.535245,-0.674056,1.16144,1.17011,0.0309223,0.109885
3653,0.174397,0.0781103,0.959981,0.91584,0.364862,0.187702,0.408036,0.341645,0.786005,0.807577,0.655134,0.643743,0.897013,0.8551,0.526428,0.48141,0.960549,0.934176,0.753197,0.792256,-0.45421,-0.251459,-0.945375,-0.652738,1.2567,1.27155,0.161514,0.120836,0.623379,0.61079,0.267227,0.155383,-0.84002,-1.02235,0.333495,0.191884,0.14952,0.153678,-0.519461,-0.443099
3654,0.639382,0.544777,0.558047,0.529297,0.575592,0.397985,0.40953,0.216671,0.424055,0.44415,0.107054,0.0943964,0.942299,0.897712,0.654694,0.648856,0.657673,0.638388,0.647828,0.686551,0.333713,0.535416,-0.247304,0.0394655,0.00752721,0.0213919,-0.538583,-0.577032,-0.430744,-0.443066,0.928989,0.813384,-1.59003,-1.77315,-0.707396,-0.855692,0.103892,0.100559,0.236799,0.319891
3655,0.511387,0.41622,0.18724,0.142753,0.0762863,-0.10171,0.155353,0.0916968,0.897856,0.917121,0.705949,0.695865,0.76884,0.722821,0.595082,0.588201,0.368658,0.3426,0.907347,0.945276,-1.02389,-0.819933,-0.481082,-0.174177,0.880883,0.8986,-1.85198,-1.89354,0.389802,0.371019,0.387167,0.271879,0.0903208,-0.0942677,-0.69772,-0.848361,-1.07299,-1.07226,-0.943718,-0.854536
3656,0.802624,0.708445,0.433248,0.38976,0.176619,-0.000387194,0.899279,0.834406,0.809559,0.711309,0.270491,0.343506,0.390121,0.34188,0.131607,0.126793,0.797771,0.773057,0.365101,0.404117,-1.14151,-0.937407,-0.670777,-0.38782,0.463205,0.486103,0.825603,0.786118,1.19743,1.1851,-1.28245,-1.40462,1.13076,0.946823,1.35267,1.20751,-0.696029,-0.690274,-0.451547,-0.274559
3657,0.174288,0.0825586,0.100944,0.0595035,0.0226155,-0.152285,0.806203,0.741435,0.530431,0.505497,0.00269525,-0.00885406,0.680736,0.633036,0.412719,0.407825,0.488746,0.463997,0.530761,0.571052,0.813954,1.02119,0.761573,1.04454,0.325686,0.351154,-1.49251,-1.52663,-0.474028,-0.484093,-1.48588,-1.60457,0.915206,0.734381,0.382035,0.235192,0.761949,0.772349,0.212557,0.305418
3658,0.0577796,-0.0361075,0.780428,0.739195,0.487073,0.311273,0.923953,0.860892,0.282436,0.299685,0.559302,0.547426,0.254846,0.208031,0.409006,0.403026,0.840588,0.815281,0.955642,0.995341,-0.495698,-0.288853,-0.00907975,0.280058,-0.383751,-0.356154,0.788717,0.751392,1.80023,1.78703,0.185862,0.0666647,1.04529,0.857135,-2.34992,-2.49586,1.43366,1.45145,-0.672254,-0.57809
3659,0.910055,0.816006,0.285945,0.24628,0.346413,0.169267,0.0278931,-0.0352224,0.696528,0.712308,0.384675,0.374831,0.709944,0.663912,0.861503,0.854725,0.24596,0.221049,0.629185,0.669021,-0.482487,-0.231701,0.766536,1.04998,-0.225898,-0.282273,-0.178706,-0.211671,1.08717,1.0724,0.0253512,-0.0889472,0.203076,0.0813945,-0.800119,-0.86292,-1.47524,-1.45408,0.533067,0.625585
3660,0.784898,0.692061,0.332964,0.294313,0.483028,0.3057,0.040619,-0.0221007,0.694388,0.734824,0.835896,0.828152,0.0955487,0.0476169,0.319791,0.313303,0.806546,0.780815,0.651471,0.609327,-0.387781,-0.174549,0.0953009,0.378751,-0.235989,-0.208392,-0.132953,-0.170349,-0.131491,-0.151478,-2.17896,-2.29481,-0.501732,-0.694346,0.915955,0.770019,-1.33588,-1.32105,0.673188,0.767642
3661,0.257856,0.166029,0.0790895,0.0382586,0.170215,-0.00882886,0.4507,0.387271,0.741366,0.757339,0.48534,0.475833,0.962653,0.916194,0.965808,0.957586,0.202744,0.175155,0.509821,0.549634,-1.01945,-0.810483,-0.948261,-0.663268,-0.573571,-0.544136,-2.3223,-2.35186,-0.83912,-0.852684,1.35218,1.23432,-0.460034,-0.648447,-1.02775,-1.17451,0.200025,0.215472,-0.601189,-0.513523
3662,0.725411,0.632696,0.428227,0.388762,0.289875,0.112319,0.175542,0.114244,0.104795,0.122442,0.567406,0.556655,0.551828,0.597175,0.958421,0.952788,0.65038,0.624764,0.736302,0.777414,-0.927856,-0.714272,0.916598,1.20568,-0.285298,-0.252064,1.66674,1.6349,-0.843548,-0.863112,-0.248234,-0.368002,0.268165,0.164285,-1.30264,-1.45546,-1.80861,-1.80084,0.065236,0.1589
3663,0.752185,0.602763,0.162332,0.122518,0.102949,-0.00121795,0.865293,0.801977,0.451004,0.481734,0.233359,0.223173,0.324761,0.278155,0.079317,0.0757319,0.0546582,0.0305316,0.616165,0.585118,-0.440476,-0.241825,0.537864,0.824017,1.0208,1.051,1.23139,1.19764,-0.329399,-0.352702,1.09209,0.978305,1.16026,0.977017,1.16803,1.02207,-0.407991,-0.401119,1.85253,1.9508
3664,0.663916,0.57283,0.425564,0.444752,0.0628021,-0.114755,0.650637,0.645195,0.82314,0.841026,0.859742,0.84863,0.223667,0.178497,0.685345,0.680273,0.878425,0.853362,0.433138,0.392822,0.0221346,0.230623,-0.0538922,0.228911,0.178077,0.20344,-0.99536,-1.03222,-0.860172,-0.88474,1.02759,0.916056,0.307348,0.118663,0.516641,0.371134,-1.20999,-1.19668,-0.191203,-0.0972658
3665,0.11898,0.0264803,0.807541,0.766987,0.503916,0.324571,0.55107,0.488413,0.587311,0.569078,0.134827,0.123392,0.882064,0.83639,0.707093,0.687921,0.582268,0.629729,0.160701,0.200527,0.209267,0.419578,1.93141,2.20692,-0.219049,-0.193349,0.153772,0.117564,2.48848,2.4686,-0.305605,-0.43242,0.118236,-0.0630683,1.34429,1.19219,-0.87036,-0.862243,-0.249574,-0.150485
3666,0.942654,0.850284,0.790152,0.751396,0.106889,-0.0705132,0.617663,0.557477,0.280675,0.29713,0.209565,0.199356,0.0407503,-0.00437172,0.701106,0.695569,0.430042,0.406096,0.942931,0.98094,-0.746286,-0.539322,-0.560088,-0.283212,0.916587,0.943489,0.774949,0.739606,-0.764516,-0.784934,-1.67143,-1.78089,0.296069,0.119475,-1.15752,-1.3043,2.03561,2.04904,0.918173,1.0234
3667,0.987391,0.895571,0.424341,0.489582,0.798448,0.619545,0.313755,0.255046,0.928949,0.947349,0.806549,0.795145,0.709215,0.6635,0.0432269,0.0385118,0.784401,0.762419,0.241012,0.278305,-0.129152,0.0798528,0.245428,0.518117,0.747464,0.777075,0.149584,0.149481,-2.13378,-2.14916,2.00466,1.89429,1.10045,0.916395,0.550219,0.410493,-0.38937,-0.368794,0.54691,0.65118
3668,0.612969,0.521248,0.180044,0.227767,0.983538,0.805331,0.507247,0.459333,0.0670533,0.0874011,0.0739605,0.0605425,0.994204,0.950046,0.302353,0.315381,0.899244,0.876983,0.0521766,0.168904,1.19217,1.40553,-1.41161,-1.13429,1.31717,1.34413,-0.41261,-0.440643,1.8541,1.84034,-0.632142,-0.743779,-0.667974,-0.852357,0.966278,0.8337,-1.16204,-1.14784,0.426814,0.537702
3669,0.985817,0.893551,0.00470908,-0.0340472,0.699492,0.55852,0.674716,0.663621,0.113141,0.134892,0.457596,0.445354,0.339859,0.297802,0.690894,0.59225,0.629688,0.608111,0.0210508,0.059504,-0.112418,0.0954935,1.49509,1.76509,0.364086,0.413156,-1.46934,-1.49854,-0.0264436,-0.0450948,1.06831,0.959138,-0.0898804,-0.250868,2.10488,1.97507,-0.878994,-0.861103,0.102028,0.212112
3670,0.701732,0.609503,0.427862,0.390399,0.488285,0.311709,0.925395,0.867908,0.455872,0.41355,0.141672,0.131594,0.0579182,0.0168845,0.873834,0.869119,0.988129,0.964434,0.742198,0.779032,-0.202575,0.00931708,-0.590301,-0.324442,-0.542748,-0.517821,2.08495,2.0617,-0.93793,-0.959907,-1.19149,-1.2961,0.533714,0.350621,-1.82179,-1.9517,0.18543,0.108914,0.414746,0.520739
3671,0.861241,0.769701,0.557449,0.518521,0.706948,0.532104,0.686182,0.630302,0.669948,0.692209,0.108651,0.0994565,0.180306,0.136953,0.172577,0.165707,0.670432,0.574138,0.721609,0.777319,1.15425,1.36676,1.61601,1.88101,-0.275012,-0.255355,-0.643227,-0.668764,-0.67066,-0.694389,0.380479,0.283712,-0.630913,-0.821759,0.166925,0.0416435,1.06841,1.07893,0.156249,0.256186
3672,0.158962,0.0663352,0.965437,0.928605,0.327715,0.152773,0.815246,0.743087,0.245174,0.268308,0.977314,0.969507,0.951981,0.906336,0.931005,0.923338,0.20688,0.183842,0.739618,0.775605,-1.36684,-1.14767,1.58005,1.85294,0.452139,0.466945,0.614764,0.588804,-0.155708,-0.183979,-2.22797,-2.32436,0.28867,0.0994631,-0.160278,-0.285655,-0.791732,-0.776905,0.738505,0.836854
3673,0.238526,0.146982,0.966115,0.928227,0.576147,0.403342,0.910616,0.855872,0.762466,0.787239,0.924472,0.917325,0.172688,0.125659,0.14523,0.136662,0.498569,0.537716,0.273475,0.309649,-0.301604,-0.0857831,0.0703764,0.342565,-1.19951,-1.18497,0.85637,0.830907,1.54087,1.50684,-0.0398076,-0.137808,0.185787,-0.00607812,-0.97822,-1.10333,1.36339,1.37309,0.785593,0.889688
3674,0.00388889,-0.0862326,0.22023,0.182474,0.206809,0.0339984,0.476266,0.419636,0.393108,0.418469,0.269843,0.262593,0.629882,0.58154,0.221696,0.213078,0.917091,0.89159,0.404716,0.44171,-0.677397,-0.459524,-0.213009,0.0535506,0.529283,0.537418,-1.03121,-1.04761,-0.498868,-0.527569,-0.59173,-0.644205,-0.754844,-0.946182,0.39034,0.268963,-0.63482,-0.624846,0.39862,0.504649
3675,0.950103,0.860739,0.0380678,-0.00177659,0.779796,0.606545,0.735375,0.680464,0.471085,0.429964,0.29612,0.367978,0.125195,0.0752214,0.707042,0.699974,0.416738,0.391837,0.0737257,0.11013,-2.1406,-1.9235,0.845248,1.1167,-0.235773,-0.222353,-0.13182,-0.137843,0.147026,0.12024,-1.09268,-1.1506,-0.584269,-0.778022,-2.22286,-2.34266,-0.222866,-0.212421,1.27497,1.38772
3676,0.771636,0.658644,0.656117,0.618708,0.237759,0.0615629,0.149992,0.0971772,0.39155,0.441458,0.482434,0.473364,0.315859,0.266712,0.213392,0.204289,0.330586,0.226467,0.0540755,0.0906241,1.51559,1.72849,-0.194077,0.0746826,-0.984268,-0.982125,0.785566,0.771922,0.0539265,0.10977,-1.559,-1.657,-1.35908,-1.54497,0.458744,0.338261,0.920298,0.933404,1.38242,1.50084
3677,0.545721,0.456549,0.0214364,-0.0167528,0.493231,0.317043,0.0394256,-0.0152859,0.428136,0.452953,0.340901,0.329756,0.725476,0.678238,0.229264,0.220109,0.0869712,0.0610968,0.64725,0.684843,1.16672,1.38653,1.24501,1.50704,-1.38925,-1.39462,-0.918178,-0.935751,0.103484,0.0992996,-0.108039,-0.205177,0.657763,0.478904,0.62007,0.5004,0.909771,0.928087,0.739629,0.857997
3678,0.560465,0.471741,0.286036,0.249214,0.143874,-0.0330388,0.903337,0.848489,0.99738,1.02169,0.812311,0.802216,0.828623,0.783351,0.806755,0.797984,0.408966,0.292507,0.814782,0.851778,-0.353592,-0.137255,0.4503,0.712366,2.26418,2.26245,-1.62042,-1.63362,0.115616,0.0888297,-0.356831,-0.451969,-1.14301,-1.31995,1.01181,0.893185,-0.119754,-0.0218406,-0.873782,-0.758133
3679,0.0838859,-0.00390747,0.091667,0.054584,0.473507,0.294721,0.189211,0.135598,0.327111,0.35199,0.119869,0.112117,0.291696,0.24657,0.751984,0.742319,0.550036,0.523917,0.159292,0.195474,0.418595,0.634574,-0.748799,-0.484139,3.00392,3.00045,-0.783003,-0.793606,0.530582,0.507446,0.48547,0.390155,1.12308,0.948499,-0.360492,-0.47702,-0.995203,-0.971768,0.272556,0.384454
3680,0.452877,0.43669,0.986061,0.948258,0.315258,0.138048,0.0636945,0.00820876,0.894473,0.92073,0.908109,0.900622,0.359719,0.315364,0.491652,0.480484,0.311475,0.285406,0.770465,0.804339,0.104456,0.401537,0.0681807,0.330888,0.962112,0.954031,-0.447158,-0.460601,0.164044,0.140484,-0.955267,-1.04227,1.32503,1.14731,0.297545,0.176205,1.99853,2.02999,0.41874,0.526511
3681,0.965523,0.877287,0.601068,0.563896,0.569393,0.391973,0.646395,0.591126,0.183041,0.209844,0.246094,0.240698,0.669922,0.627424,0.555707,0.629611,0.646805,0.601762,0.641893,0.64063,-0.0404175,0.1685,-0.663131,-0.401125,1.57497,1.56644,1.02683,1.01649,0.527339,0.49883,0.0118438,-0.0787427,0.887332,0.802391,1.49155,1.36272,0.206514,0.239836,-0.899165,-0.784431
3682,0.996805,0.907717,0.583591,0.496686,0.82437,0.645897,0.393178,0.338231,0.533961,0.464473,0.325668,0.321521,0.63764,0.540273,0.790528,0.778737,0.943008,0.918118,0.447675,0.47692,-0.804247,-0.590098,1.62673,1.88357,1.77577,1.76529,-0.0635618,-0.0721476,-1.94046,-1.97572,0.0708289,-0.0179623,0.635211,0.457476,-1.80774,-1.93852,-1.28981,-1.26385,0.946945,1.06813
3683,0.062658,-0.0276843,0.557741,0.429475,0.842003,0.662324,0.683882,0.628683,0.691192,0.719103,0.144092,0.138942,0.497201,0.453122,0.113035,0.101379,0.122703,0.0988449,0.278745,0.31321,1.39993,1.616,0.217431,0.480868,0.055951,0.0482779,0.0742149,0.0618673,1.27806,1.24559,-0.677169,-0.760031,0.499329,0.321104,1.45006,1.31804,-0.227271,-0.195367,0.869998,1.08215
3684,0.316087,0.223431,0.399437,0.362265,0.282825,0.103478,0.193246,0.135972,0.147554,0.175613,0.640372,0.636423,0.916204,0.869894,0.269542,0.258777,0.148949,0.0641177,0.561297,0.61417,-0.513712,-0.298408,0.670671,0.926781,-0.281993,-0.287466,-0.238738,-0.251141,-0.866518,-0.901239,-0.777917,-0.867413,-0.726209,-0.91182,-1.19283,-1.32345,1.06155,1.0908,0.980938,1.09616
3685,0.808827,0.714958,0.109768,0.072106,0.112615,0.0105025,0.173286,0.114067,0.290693,0.320067,0.00710562,0.00104839,0.164215,0.115217,0.792543,0.781083,0.111452,0.0293904,0.881412,0.915129,0.153247,0.365344,0.388083,0.698216,0.185504,0.187451,-0.932762,-0.949009,-1.31385,-1.34481,1.06509,0.973749,-1.13428,-1.32593,0.279115,0.154187,0.376447,0.405655,-1.83329,-1.72368
3686,0.489769,0.310893,0.391017,0.353882,0.0963612,-0.0824726,0.494421,0.521971,0.681339,0.712835,0.153759,0.0846247,0.238562,0.189353,0.320936,0.31006,0.0185215,-0.00533681,0.726752,0.759922,1.12975,1.3366,0.217533,0.469651,-0.00805866,-0.0101417,-0.568199,-0.674206,1.97881,1.95379,1.24555,1.15686,0.300543,0.106476,-2.47473,-2.59208,0.467254,0.438741,-0.0606615,0.0520265
3687,0.000403598,-0.093172,0.365667,0.376224,0.564562,0.38611,0.989095,0.929876,0.75809,0.791584,0.175746,0.168201,0.553278,0.436584,0.476347,0.408604,0.692814,0.667452,0.0273887,0.0622653,-0.564225,-0.357704,0.83178,1.08557,1.29075,1.29292,-0.388606,-0.399403,0.932657,0.914769,-0.31119,-0.399198,0.0400665,-0.151944,-0.718585,-0.83234,0.443548,0.471827,2.55912,2.66404
3688,0.431739,0.339791,0.436661,0.398566,0.753523,0.576463,0.822352,0.715309,0.604702,0.726451,0.578099,0.572077,0.733619,0.683816,0.604869,0.507148,0.575218,0.446953,0.517712,0.551735,0.652141,0.856582,0.0428517,0.290898,-0.336969,-0.328241,1.07378,1.06307,0.255502,0.242987,-1.32161,-1.4029,0.585553,0.385145,0.143732,0.0335996,-0.218251,-0.182483,0.504679,0.615968
3689,0.242341,0.151127,0.703335,0.664533,0.398577,0.228423,0.558025,0.500742,0.62578,0.661318,0.129908,0.126027,0.408943,0.454914,0.616147,0.605691,0.327628,0.226454,0.304605,0.336435,-0.378628,-0.179569,1.11358,1.36854,-1.38691,-1.37877,1.29098,1.27371,1.30333,1.29143,-0.376697,-0.453067,0.353012,0.157224,0.138065,0.0241806,0.0212889,0.0568199,0.160068,0.274867
3690,0.305974,0.216458,0.645842,0.678677,0.0567779,-0.119618,0.897652,0.839324,0.869687,0.902549,0.968354,0.96618,0.187124,0.226012,0.966783,0.958043,0.0313167,0.00595466,0.591605,0.62454,-0.249575,-0.0517478,-0.27279,-0.0180776,0.314212,0.326705,-0.710241,-0.720771,-1.77801,-1.78991,1.18865,1.11059,0.947793,0.756919,-1.63539,-1.74686,0.935271,0.968103,0.438713,0.552958
3691,0.627404,0.537855,0.731969,0.69282,0.86312,0.685652,0.0819884,0.0223923,0.355097,0.389427,0.265827,0.261158,0.0477125,-0.00289011,0.784616,0.775871,0.222036,0.19645,0.327653,0.437709,1.11597,1.32063,-0.691348,-0.438197,-0.939269,-0.923452,0.151696,0.101298,-1.81215,-1.81679,1.72757,1.64663,-1.20307,-1.40039,0.659979,0.542759,-2.25067,-2.22196,-1.63629,-1.5267
3692,0.0267698,-0.0633146,0.00209136,-0.037732,0.862535,0.718699,0.093039,0.0355139,0.551968,0.584721,0.679816,0.675732,0.726572,0.6746,0.25589,0.244823,0.762419,0.737126,0.215927,0.250878,-0.573823,-0.373674,-1.10948,-0.858317,-0.815612,-0.802628,0.938223,0.923367,-0.368864,-0.370255,-2.19544,-2.27703,-1.08412,-1.27763,-1.25356,-1.37084,-0.997777,-0.967115,-0.348258,-0.246665
3693,0.557999,0.468025,0.200295,0.190458,0.930595,0.751747,0.4227,0.364761,0.430973,0.481109,0.13074,0.126385,0.78626,0.733574,0.794824,0.782594,0.0160388,-0.0103025,0.358169,0.393402,-0.545392,-0.339749,-0.754287,-0.503122,0.507761,0.516771,-1.38854,-1.40578,-1.1608,-1.16341,-1.74617,-1.83069,1.24423,1.0556,0.579189,0.465871,-0.32057,-0.288012,0.306257,0.410388
3694,0.339636,0.24879,0.457288,0.418648,0.158557,-0.0174995,0.492824,0.357648,0.343139,0.377497,0.147637,0.14308,0.00789512,-0.0422961,0.987967,0.974224,0.873852,0.845443,0.213847,0.221256,0.949409,1.15938,0.810705,1.05702,-0.484878,-0.471368,-0.0530107,-0.0714448,-0.396924,-0.391165,1.41523,1.33971,3.3529,3.1648,1.45921,1.25384,-0.247862,-0.216255,-0.297837,-0.185811
3695,0.751567,0.662111,0.987596,0.9508,0.98196,0.807856,0.410862,0.350535,0.470613,0.506986,0.937059,0.931585,0.159742,0.183607,0.714071,0.670287,0.201056,0.174565,0.0147405,0.0491094,-0.90463,-0.694558,1.39733,1.64278,-0.45415,-0.517216,3.4372,3.41482,-1.74444,-1.73997,0.601432,0.521335,-0.27377,-0.458763,2.15512,2.0418,0.187863,0.161168,0.757735,0.865033
3696,0.171953,0.0812993,0.630893,0.596617,0.746587,0.574725,0.254811,0.192804,0.364037,0.400081,0.798906,0.802261,0.459216,0.40951,0.333058,0.366351,0.281474,0.243725,0.0782853,0.19318,-1.97083,-1.76205,1.18691,1.43067,-0.576874,-0.563064,0.658891,0.635811,-1.19919,-1.20044,-1.37553,-1.45134,-1.0621,-1.24113,-0.125456,-0.24084,0.515627,0.538591,-0.616416,-0.506512
3697,0.504102,0.329783,0.86899,0.833925,0.753831,0.649507,0.825533,0.765253,0.823681,0.857702,0.699478,0.672936,0.368478,0.320567,0.0761579,0.0624146,0.337779,0.312885,0.301987,0.337251,-0.765314,-0.560065,-0.913006,-0.673931,0.760343,0.770011,-1.84701,-1.86446,-0.970644,-0.966853,-1.6598,-1.74324,0.347393,0.162464,1.98693,1.8758,-0.233917,-0.153707,0.830299,0.942693
3698,0.645257,0.578268,0.878246,0.842969,0.895997,0.724289,0.115163,0.0523617,0.372727,0.404312,0.549085,0.543612,0.671851,0.591674,0.051521,0.0909805,0.0555806,0.0296036,0.700093,0.73671,-0.0199985,0.181208,0.364044,0.604647,-0.367487,-0.358925,-0.234179,-0.242826,1.11487,1.119,-0.0663018,-0.149719,-0.140873,-0.329069,0.319295,0.213421,-0.871672,-0.846005,0.320439,0.358655
3699,0.91871,0.826752,0.60334,0.567622,0.465986,0.294378,0.628085,0.56516,0.315328,0.438879,0.921673,0.918513,0.908163,0.86278,0.173641,0.119546,0.588432,0.564196,0.649061,0.59883,0.986238,1.18341,-0.23223,0.00954091,-0.749705,-0.740137,-0.827549,-0.83407,0.622534,0.710941,0.76412,0.67519,0.191531,0.00797903,1.18867,1.07936,-1.78056,-1.75375,-0.339986,-0.225383
3700,0.710109,0.689499,0.0826976,0.0448964,0.366387,0.193706,0.20822,0.143808,0.355764,0.473445,0.116368,0.111289,0.792682,0.748367,0.184382,0.148112,0.628128,0.602752,0.425086,0.46095,0.000531043,0.193169,-0.0397587,0.195126,0.828262,0.840258,-0.302768,-0.214832,0.293861,0.302883,0.218085,0.133685,-0.0852295,-0.225778,0.600322,0.490427,-1.67072,-1.63715,0.592673,0.702678
3701,0.643004,0.552246,0.724399,0.684247,0.605347,0.43376,0.81131,0.746566,0.477621,0.508011,0.802772,0.797361,0.0337544,-0.0124025,0.0512189,0.176678,0.560668,0.641309,0.81606,0.849954,1.67284,1.86056,-0.186264,0.0454358,-1.47429,-1.46553,0.417844,0.404407,-0.588964,-0.582425,0.21747,0.132492,-0.282722,-0.459536,-0.997669,-1.10907,-0.460393,-0.42843,-1.22792,-1.11198
3702,0.912017,0.823387,0.648716,0.684108,0.297286,0.145948,0.481967,0.41908,0.149447,0.180848,0.412639,0.420655,0.38293,0.335299,0.218987,0.205244,0.613038,0.679865,0.262463,0.294144,0.70152,0.88697,0.402505,0.631198,-1.17985,-1.17346,-1.37651,-1.39377,0.0332529,0.0346895,-0.70444,-0.793719,0.806499,0.628413,-0.724358,-0.837387,-0.0601839,-0.0315315,-1.53456,-1.42271
3703,0.284956,0.197501,0.640663,0.683969,0.0300894,-0.141863,0.911585,0.847765,0.568226,0.598352,0.0468953,0.0439484,0.0528448,0.00489468,0.610443,0.560869,0.742658,0.718422,0.209125,0.296368,-0.51952,-0.333925,-0.565919,-0.333449,1.1921,1.20182,0.210341,0.193455,-0.31684,-0.316393,-0.787628,-0.871456,-1.56804,-1.74164,1.4911,1.37171,-0.174067,-0.145148,1.13849,1.2449
3704,0.443321,0.357698,0.72417,0.68383,0.01214,-0.160684,0.854916,0.885938,0.229104,0.261143,0.374409,0.369085,0.742344,0.692416,0.929272,0.916495,0.43874,0.488938,0.107608,0.298592,0.108947,0.300756,1.30129,1.5355,-1.29642,-1.29129,-0.669508,-0.69295,0.545724,0.547743,-1.42123,-1.41041,0.376806,0.20352,-0.796255,-0.910929,0.0776957,0.175739,1.55431,1.65697
3705,0.168471,0.0838483,0.233314,0.190915,0.512737,0.337634,0.987312,0.92411,0.215449,0.247224,0.113659,0.105967,0.967623,0.918264,0.0468422,0.0330223,0.283782,0.259455,0.229177,0.300816,-1.05917,-0.871715,-2.2989,-2.07043,1.77154,1.78043,0.000857752,-0.0235663,-0.365709,-0.36707,-1.87108,-1.94937,-2.42462,-2.59557,-0.630102,-0.74879,0.472291,0.496626,0.0849439,0.193751
3706,0.0963838,0.0125601,0.455366,0.344211,0.459655,0.32703,0.304193,0.242101,0.869379,0.902401,0.362298,0.354075,0.115337,0.068149,0.488107,0.47526,0.333284,0.377307,0.27009,0.303039,-0.618708,-0.477118,0.122712,0.347665,0.231686,0.237108,-0.837335,-0.863164,-0.295854,-0.299961,-0.213471,-0.294143,1.91276,1.74386,0.85516,0.728851,0.127103,0.14869,-1.07321,-0.964398
3707,0.332691,0.248773,0.540621,0.497506,0.48984,0.316425,0.392624,0.330235,0.951334,0.986241,0.850475,0.841219,0.998901,0.952139,0.494818,0.42597,0.520087,0.49516,0.0319187,0.0633842,-0.273886,-0.0825217,1.26489,1.4855,0.0366761,0.0395153,1.073,1.0419,1.39134,1.39086,-0.0250486,-0.111033,0.241433,0.0700104,-1.87407,-2.0022,0.628447,0.656865,1.72132,1.8272
3708,0.984068,0.900318,0.250329,0.207347,0.767662,0.592364,0.737013,0.673579,0.482097,0.517936,0.279718,0.271446,0.13414,0.0860076,0.387546,0.37668,0.396852,0.372385,0.0352765,0.0686973,-0.0652997,0.120749,0.936902,1.15093,0.142383,0.141686,0.124729,0.0922267,0.432,0.429276,1.11455,1.02184,0.580589,0.407058,-0.282503,-0.415399,0.669324,0.699151,0.0390929,0.150242
3709,0.569297,0.562721,0.345667,0.301686,0.821217,0.644929,0.779558,0.711077,0.674197,0.707922,0.246944,0.156302,0.1121,0.0630263,0.126375,0.114846,0.642236,0.618461,0.713327,0.747557,-1.50374,-1.31492,0.1985,0.418919,0.22441,0.243858,0.413835,0.380645,-1.93274,-1.94206,0.765722,0.712746,-0.172884,-0.343745,0.982703,0.847378,-1.53928,-1.50284,-1.03922,-0.932645
3710,0.308469,0.225124,0.801152,0.756042,0.231926,0.0561874,0.902211,0.748575,0.0401771,0.0730254,0.0482883,0.0411572,0.993553,0.94338,0.0732664,0.0635555,0.321091,0.299184,0.370716,0.406418,0.168116,0.35247,-0.0330074,0.187928,0.437614,0.346029,-0.447167,-0.475057,-0.0309523,-0.0346873,0.50001,0.403648,-0.0172122,-0.19071,-0.214432,-0.353176,0.873844,0.906054,0.147973,0.258577
3711,0.362479,0.347492,0.466802,0.420967,0.79005,0.614159,0.849451,0.786073,0.687319,0.717927,0.593096,0.587243,0.217334,0.167509,0.547531,0.535634,0.464579,0.443628,0.232838,0.266647,-0.567837,-0.38966,-1.42258,-1.19869,0.445361,0.4482,-0.367025,-0.388838,2.931,2.93511,1.5635,1.46204,0.808003,0.636824,-1.05979,-1.20144,-0.44254,-0.409188,-0.90538,-0.790172
3712,0.493506,0.469861,0.501707,0.529573,0.172636,-0.00438078,0.28707,0.222337,0.967921,1.00002,0.907744,0.90282,0.422056,0.373404,0.412823,0.426545,0.188167,0.169734,0.323809,0.355939,0.189254,0.367978,1.25104,1.47349,1.63242,1.63005,1.12934,1.10481,-0.349644,-0.337501,-2.07184,-2.17097,-1.32987,-1.50581,0.0108502,-0.133285,-0.305025,-0.276163,0.0398907,0.154752
3713,0.675365,0.592229,0.683031,0.638179,0.247992,0.0720913,0.251365,0.227897,0.542836,0.576123,0.339566,0.333048,0.0456363,-0.00255942,0.414653,0.317457,0.599153,0.579997,0.41285,0.445231,-1.03513,-0.852916,0.784789,1.00169,-0.329004,-0.335024,-0.511038,-0.539098,-0.415249,-0.397139,-1.41564,-1.51297,1.753,1.57148,0.677383,0.535452,0.170463,0.198816,0.242091,0.275718
3714,0.256628,0.17191,0.565,0.473486,0.812696,0.634324,0.297878,0.233456,0.982031,1.01388,0.0124618,0.00446715,0.293618,0.243726,0.222138,0.208369,0.27451,0.255454,0.202024,0.234435,-0.454415,-0.278774,-0.146555,0.0694381,-0.150182,-0.151894,0.913328,0.89039,-0.895016,-0.870159,0.153192,0.0640723,1.17809,1.00185,0.660508,0.512187,0.170625,0.1935,0.277343,0.396684
3715,0.120744,0.0341023,0.348577,0.308794,0.839913,0.66161,0.477331,0.414299,0.780393,0.828261,0.0657855,0.0600702,0.21016,0.159365,0.522382,0.438256,0.453898,0.436799,0.717836,0.747951,-1.22559,-1.05357,-0.315818,-0.0973829,-0.544135,-0.548683,-0.66901,-0.688001,1.57151,1.59116,1.73845,1.64112,0.332207,0.158352,-1.55579,-1.70569,1.62107,1.63871,-0.832345,-0.717448
3716,0.656681,0.570881,0.189916,0.144102,0.487905,0.28651,0.152604,0.0914917,0.611432,0.642641,0.746433,0.740796,0.50761,0.406596,0.68198,0.668143,0.170194,0.153518,0.257759,0.287092,1.9483,2.11401,1.7962,2.01052,0.620659,0.617799,-0.605889,-0.629615,-0.0131542,0.00070634,0.327328,0.223135,-0.855635,-1.02877,-0.0638044,-0.211806,-1.19506,-1.16944,-0.193666,-0.075543
3717,0.313972,0.284918,0.957313,0.909303,0.0919804,-0.0885895,0.16523,0.183101,0.845849,0.878502,0.817715,0.811844,0.705335,0.653828,0.140149,0.126721,0.872035,0.856138,0.216484,0.243809,0.692877,0.863213,-3.60013,-3.38581,1.26184,1.26267,-0.128165,-0.143085,-0.176389,-0.167119,-0.288549,-0.397153,-0.973455,-1.14838,-0.8487,-1.00054,-1.85938,-1.84039,1.92233,2.03834
3718,0.0833326,-0.00104568,0.971864,0.923463,0.495935,0.314778,0.336434,0.27471,0.0777083,0.109703,0.0435374,0.0360717,0.717501,0.620994,0.542643,0.52828,0.9055,0.889806,0.842797,0.868266,0.188852,0.364402,0.27313,0.497174,1.3422,1.32574,0.0761072,0.0675577,-0.088452,-0.159603,0.036826,-0.0768634,-0.179836,-0.351464,1.13584,0.975845,0.689475,0.713957,0.200827,0.315764
3719,0.230764,0.192856,0.405642,0.357321,0.643654,0.439573,0.639326,0.529534,0.535562,0.567324,0.208089,0.201234,0.638822,0.58816,0.208986,0.196927,0.331722,0.31522,0.809176,0.834246,1.24662,1.42629,-0.386819,-0.158173,1.3862,1.38881,-0.0740584,-0.0901318,-0.166822,-0.152087,1.23177,1.11814,0.215588,0.0474864,0.232931,0.0665459,-0.849753,-0.820456,-0.122855,-0.00982577
3720,0.472408,0.386757,0.14616,0.0962267,0.7435,0.564368,0.846836,0.784358,0.141489,0.173758,0.740983,0.732856,0.869537,0.819134,0.901484,0.888241,0.488646,0.556675,0.355119,0.37803,0.220385,0.404383,-1.27793,-1.04514,-2.11562,-2.112,-0.607158,-0.618227,-0.742632,-0.731848,-0.330302,-0.437915,-0.874006,-1.04491,0.453687,0.29105,0.0403133,0.0745912,-0.162263,-0.0481927
3721,0.0146505,-0.0683404,0.826667,0.775918,0.65857,0.478503,0.899439,0.838592,0.808649,0.839003,0.096808,0.0875136,0.25995,0.20799,0.485188,0.544816,0.816832,0.79813,0.454418,0.478442,-1.06116,-0.877204,-0.977365,-0.749534,-0.643692,-0.642625,-0.14043,-0.08438,0.969389,0.973554,-0.795051,-0.902425,-1.50004,-1.67369,-1.30191,-1.46357,-0.250487,-0.209436,-0.718695,-0.601177
3722,0.798468,0.717087,0.600794,0.55164,0.93472,0.754442,0.53252,0.471782,0.573374,0.602055,0.283059,0.272297,0.305524,0.156754,0.216846,0.201391,0.377761,0.358924,0.854525,0.8779,-1.02116,-0.843279,0.399124,0.56606,1.12653,1.12447,0.473644,0.449467,0.263645,0.272349,-3.18519,-3.29884,1.92126,1.74242,-0.468952,-0.664986,0.934872,0.981274,-0.438965,-0.323086
3723,0.682533,0.603046,0.00777563,-0.0394725,0.561167,0.379606,0.816031,0.757148,0.0363677,0.0639014,0.803203,0.79379,0.158811,0.105519,0.456219,0.44123,0.885956,0.869315,0.928674,0.949928,1.52591,1.71004,1.65826,1.88165,-0.440399,-0.447818,0.994384,0.983314,0.452068,0.460462,2.2886,2.17495,-1.62751,-1.80094,0.172445,0.133603,-0.307584,-0.269437,-1.37199,-1.25272
3724,0.853315,0.773895,0.431766,0.384973,0.836267,0.574886,0.309519,0.249238,0.663891,0.693066,0.424103,0.416965,0.976055,0.921609,0.410735,0.394712,0.642601,0.637291,0.443814,0.463983,-0.456561,-0.267904,-0.877631,-0.657661,0.155247,0.149649,-0.228266,-0.242628,-0.254624,-0.240744,-0.0223767,-0.144747,2.23957,2.06154,1.09386,0.932192,-0.998486,-0.954583,1.42663,1.53888
3725,0.485402,0.404143,0.376714,0.343095,0.952184,0.770166,0.563011,0.504398,0.983888,1.01548,0.679425,0.670404,0.0973726,0.0453099,0.810676,0.79627,0.428664,0.405266,0.970212,0.988416,0.158828,0.351271,0.00325284,0.21944,0.296262,0.287513,0.688529,0.675826,0.430981,0.439265,-1.89463,-2.02113,1.36,1.18479,0.454882,0.296605,2.62787,2.67178,-0.136682,-0.0287696
3726,0.790364,0.710864,0.222307,0.301216,0.408359,0.225183,0.256281,0.245685,0.741364,0.772696,0.0886176,0.0806131,0.855875,0.805158,0.900872,0.887153,0.189881,0.173241,0.746692,0.813758,-0.320258,-0.131279,-0.985881,-0.775817,0.140378,0.136437,1.13132,1.11497,-0.0372469,-0.0337561,-0.371418,-0.505516,0.784287,0.61516,0.996115,0.842795,0.255927,0.304791,-0.516157,-0.413808
3727,0.684763,0.654154,0.306638,0.259338,0.331292,0.150263,0.0439028,-0.0130283,0.0917811,0.123502,0.755036,0.747267,0.802045,0.751015,0.0739666,0.0596383,0.712166,0.693682,0.709586,0.639099,2.77349,2.9549,0.455584,0.672379,-1.33296,-1.33015,0.399403,0.385694,0.689463,0.691919,-0.852019,-0.984577,0.429699,0.262384,0.765886,0.60694,1.32618,1.37327,-0.578437,-0.480126
3728,0.67834,0.597445,0.776372,0.7277,0.922533,0.743286,0.66961,0.614139,0.00253953,0.119286,0.663214,0.654379,0.476179,0.425045,0.0257308,0.01312,0.837422,0.818223,0.445063,0.464441,-0.331062,-0.151394,0.351863,0.566909,-3.37759,-3.37657,-0.0827089,-0.0954672,-0.280893,-0.269667,2.28787,2.14921,-0.432502,-0.595971,-0.306622,-0.472438,-0.179196,-0.130412,0.267733,0.304846
3729,0.978649,0.899307,0.0321929,-0.018054,0.658159,0.478061,0.988566,0.93377,0.0868042,0.115069,0.315861,0.307196,0.75805,0.706111,0.525893,0.514353,0.174505,0.152847,0.0596285,0.0791276,-0.168592,0.00656588,-0.333535,-0.119333,0.364838,0.368852,-0.209524,-0.221742,1.43325,1.45182,0.743724,0.609698,0.239125,-0.00588218,0.516881,0.348613,-0.334975,-0.292687,0.985695,1.08982
3730,0.871156,0.790286,0.795621,0.743677,0.392552,0.212837,0.609361,0.577863,0.983507,1.0113,0.345441,0.384705,0.669956,0.617168,0.526033,0.51399,0.122823,0.103279,0.197096,0.216185,0.37191,0.549524,-0.408306,-0.173388,0.951666,0.952281,-0.728805,-0.735199,-0.722206,-0.695013,0.5742,0.440911,0.744158,0.584207,-0.245181,-0.409364,0.00174612,0.0417545,0.259058,0.358158
3731,0.087293,0.00836566,0.78362,0.690926,0.508949,0.330024,0.276263,0.221956,0.161681,0.188682,0.472432,0.462214,0.892702,0.838248,0.161869,0.151852,0.997858,0.981775,0.848053,0.864997,0.102154,0.282968,-0.442377,-0.227443,0.391567,0.385708,-0.383726,-0.386807,-1.89293,-1.87111,-1.91806,-2.05269,-1.22724,-1.38747,0.151262,-0.0165785,1.79021,1.82872,-1.36751,-1.27422
3732,0.309018,0.230166,0.690565,0.638175,0.141637,-0.0393202,0.983858,0.929293,0.583319,0.611022,0.0507048,0.0409003,0.406008,0.351944,0.666764,0.658857,0.0617723,0.0467063,0.867397,0.931172,-0.687785,-0.508155,-0.00886735,0.248426,0.665683,0.66331,0.172498,0.174728,-0.443471,-0.424571,-1.04325,-1.18091,-0.0393781,-0.202709,-0.412392,-0.63513,0.587253,0.624575,-0.355472,-0.268178
3733,0.257448,0.178793,0.957355,0.904142,0.414681,0.297854,0.834653,0.821542,0.373224,0.399226,0.130069,0.121723,0.414457,0.406824,0.653499,0.556803,0.790042,0.774063,0.982166,0.997348,-0.358936,-0.180463,0.513282,0.724295,0.390901,0.389573,-1.14271,-1.14178,0.343479,0.363617,-1.2446,-1.38085,1.51658,1.35112,-1.08883,-1.25368,0.476657,0.510958,-1.40396,-1.31693
3734,0.583207,0.506369,0.402858,0.34716,0.818192,0.635028,0.76805,0.713792,0.568461,0.59452,0.466507,0.399519,0.518629,0.461704,0.462162,0.454748,0.678543,0.662075,0.654683,0.624136,1.01581,1.19191,0.490363,0.696224,0.989824,0.98704,0.544996,0.541267,-0.0183966,-0.0033451,-0.00729696,-0.141238,-1.04162,-1.21042,-0.356746,-0.522367,-1.14257,-1.10083,0.0764474,0.165066
3735,0.137779,0.0605226,0.180353,0.122882,0.441987,0.332538,0.211246,0.155552,0.358256,0.382724,0.687199,0.677315,0.0654085,0.0108637,0.0699567,0.0629518,0.0612301,0.046271,0.238122,0.250924,1.42845,1.59771,2.8649,3.06273,1.00883,1.00287,-0.328327,-0.330179,0.82996,0.845601,-0.510179,-0.651837,1.28466,1.1228,-0.115659,-0.282633,-0.680238,-0.642329,-1.0144,-0.932494
3736,0.101426,0.024152,0.547644,0.47014,0.212217,0.0300486,0.26848,0.174276,0.385272,0.410119,0.773573,0.763772,0.672353,0.617622,0.802231,0.795499,0.524019,0.51144,0.340699,0.438153,-1.43694,-1.27423,0.481737,0.681241,-0.515102,-0.523857,1.46051,1.46425,0.206255,0.220475,1.07301,0.927971,0.0344985,-0.126126,-0.980967,-1.14609,1.00197,1.03886,-0.0435675,0.041153
3737,0.821212,0.744943,0.874495,0.817397,0.912802,0.730412,0.250692,0.192999,0.805227,0.827623,0.743176,0.850229,0.310166,0.25667,0.103511,0.0970261,0.315205,0.303807,0.624595,0.625382,-0.514804,-0.349527,0.393798,0.590335,0.923296,0.916642,0.241324,0.238311,-1.71418,-1.69491,0.0379081,-0.104864,0.323818,0.16617,-0.522405,-0.739272,-1.15606,-1.11624,-0.585267,-0.49708
3738,0.341626,0.263996,0.904375,0.845846,0.215923,0.0310017,0.480203,0.423549,0.626005,0.72741,0.946205,0.936686,0.53945,0.543158,0.503765,0.498585,0.492119,0.478774,0.782008,0.812611,-0.588244,-0.420654,-0.463554,-0.26557,0.671093,0.657831,1.1095,1.11028,-2.0523,-2.03236,-0.0461639,-0.182601,1.38134,1.22518,-0.162141,-0.332454,0.723815,0.768261,0.23047,0.325874
3739,0.187552,0.111405,0.214372,0.155402,0.241613,0.0105519,0.115194,0.0567397,0.603811,0.627197,0.782706,0.774067,0.882224,0.829645,0.104365,0.0975638,0.0376699,0.0241914,0.987039,0.999841,0.0748865,0.243099,-0.246519,-0.047238,-0.0107009,-0.0206627,-0.53058,-0.533624,0.241437,0.254099,-1.08379,-1.21544,0.800636,0.640228,0.770076,0.596858,1.42001,1.46166,-1.16561,-1.07674
3740,0.657648,0.583296,0.775652,0.717375,0.120171,-0.00989801,0.596296,0.539342,0.676338,0.701353,0.835545,0.710637,0.43361,0.378805,0.666642,0.6598,0.825358,0.811348,0.0889258,0.099377,0.446021,0.617718,0.64635,0.844512,-0.284456,-0.294399,0.387089,0.384831,0.476589,0.487681,0.37378,0.236386,-2.69256,-2.85398,0.745221,0.573593,-1.89189,-1.84515,-1.36169,-1.26603
3741,0.349995,0.274249,0.191397,0.131213,0.15468,-0.0303479,0.69056,0.633013,0.200658,0.228347,0.722184,0.647207,0.975719,0.920459,0.968126,0.960793,0.160512,0.145972,0.482342,0.493943,-1.77638,-1.59736,1.30669,1.50768,0.689525,0.673573,-0.900732,-0.902201,0.183502,0.199272,0.14386,0.0170391,0.360996,0.197306,-1.21971,-1.38678,0.932683,0.982714,1.49834,1.59452
3742,0.688777,0.611349,0.358531,0.30022,0.83711,0.649368,0.405017,0.389405,0.491036,0.589947,0.594161,0.583778,0.258121,0.20268,0.681349,0.638772,0.668012,0.651627,0.584294,0.605292,-0.331285,-0.145474,1.40318,1.60018,-0.442509,-0.455363,0.143947,0.139094,1.43286,1.44837,-0.0379928,-0.202308,0.719212,0.597466,1.44254,1.27951,-0.134103,-0.0787304,0.0882017,0.177153
3743,0.206397,0.130402,0.0253714,-0.0348538,0.443943,0.260971,0.201458,0.145797,0.922291,0.951547,0.171194,0.162464,0.363187,0.232204,0.32479,0.31675,0.914774,0.897704,0.82323,0.716641,-0.0464711,0.137455,0.667225,0.868171,0.818293,0.801481,-0.602654,-0.607159,-1.03791,-1.02617,-0.284261,-0.421655,1.16579,0.997627,0.0716516,-0.131486,-0.822348,-0.763876,2.05414,2.13554
3744,0.989848,0.915829,0.824167,0.761966,0.0577727,-0.127426,0.695163,0.639138,0.942635,0.975055,0.489791,0.482571,0.318965,0.261728,0.41901,0.460063,0.816652,0.802239,0.81639,0.82799,-1.48137,-1.29821,-0.778165,-0.580882,-2.05642,-2.07395,-0.521161,-0.520939,0.596602,0.604374,0.244231,0.100499,0.0814996,-0.0811511,-1.37944,-1.54248,0.129574,0.193924,1.21878,1.30228
3745,0.572958,0.500466,0.646997,0.567582,0.884587,0.697929,0.00953739,-0.0479466,0.329563,0.360628,0.413552,0.404342,0.21183,0.152499,0.61041,0.603375,0.932459,0.916802,0.802223,0.771788,-0.312177,-0.128999,0.50167,0.697695,-0.940106,-0.953855,-1.75426,-1.74688,0.0977348,0.100247,1.05246,0.911784,0.218397,0.0563224,1.39184,1.22355,-0.134468,-0.0755601,0.38285,0.469019
3746,0.992945,0.918531,0.435085,0.373199,0.703055,0.516144,0.42332,0.266582,0.19092,0.224686,0.915303,0.90669,0.805463,0.748492,0.332588,0.422126,0.821453,0.822877,0.703605,0.715585,1.09299,1.27452,2.7625,2.95284,-0.983851,-0.99821,-0.884458,-0.874913,0.485021,0.488648,0.975017,0.834048,-0.111161,-0.280615,-2.58698,-2.75553,-1.41452,-1.35833,1.76917,1.85685
3747,0.916412,0.841819,0.983601,0.921068,0.864879,0.677412,0.638974,0.581111,0.956953,0.988739,0.934768,0.928625,0.238547,0.181079,0.247752,0.240877,0.692943,0.728953,0.00293542,0.0129496,0.264472,0.453164,1.39166,1.58259,0.801319,0.785153,-1.55115,-1.54214,0.301305,0.346951,-2.69397,-2.83395,-1.12471,-1.29729,-1.05809,-1.23132,-1.35032,-1.39182,0.442396,0.531201
3748,0.0394368,-0.0339457,0.0357208,-0.0285939,0.76359,0.477683,0.299676,0.243695,0.878653,0.908569,0.711822,0.696774,0.836675,0.777072,0.411143,0.402343,0.545662,0.635028,0.75199,0.761215,0.898177,1.08784,-0.386025,-0.194057,1.01468,0.999858,-1.0755,-1.07293,0.209056,0.205254,-1.37516,-1.51782,0.845527,0.679059,-0.614142,-0.793799,-1.47623,-1.42531,-0.592761,-0.502896
3749,0.257168,0.182633,0.420905,0.398456,0.464599,0.277955,0.234772,0.176755,0.293246,0.32463,0.472451,0.464923,0.950337,0.856477,0.262001,0.255418,0.55676,0.541103,0.694016,0.718194,-1.58208,-1.39711,-0.159852,0.0377324,0.076146,0.0601303,0.559933,0.562713,0.363542,0.364651,1.65886,1.51293,0.896396,0.724959,0.843133,0.670348,-0.908107,-0.867826,-1.27465,-1.18832
3750,0.837529,0.76403,0.889821,0.825507,0.73842,0.553893,0.385065,0.327029,0.121601,0.154011,0.660923,0.65381,0.993755,0.935882,0.816599,0.808616,0.0850314,0.0715862,0.663755,0.675173,0.278469,0.469538,-1.21989,-1.0201,1.12858,1.12061,-0.475538,-0.476725,1.05586,1.05913,0.208852,0.0646978,0.701159,0.529147,1.16129,0.987552,-0.362841,-0.310338,0.465628,0.55264
3751,0.492717,0.418778,0.391391,0.327225,0.0100802,-0.175644,0.0945452,0.0345167,0.513191,0.546778,0.596801,0.591864,0.238415,0.181204,0.107844,0.0999844,0.15489,0.140011,0.109441,0.119364,-2.39027,-2.20339,1.10077,1.29835,0.188966,0.198258,-0.251223,-0.248235,1.21323,1.21853,0.527374,0.384988,0.92723,0.757327,0.0814387,-0.0918271,1.44863,1.49415,0.577768,0.665769
3752,0.867112,0.791081,0.658025,0.593192,0.577607,0.392439,0.533115,0.459115,0.142277,0.178008,0.78235,0.776648,0.91631,0.858695,0.299583,0.32099,0.657934,0.645666,0.644802,0.654259,0.0678641,0.252452,0.607266,0.800712,-0.719651,-0.724096,-0.67238,-0.669159,-1.34492,-1.34237,0.550782,0.415265,-0.924527,-1.08684,1.8973,1.72927,-1.15521,-1.11747,-0.287396,-0.203626
3753,0.304302,0.229365,0.109042,0.0464718,0.623901,0.439124,0.945771,0.883713,0.932625,0.969493,0.688782,0.683759,0.471134,0.412931,0.54717,0.541996,0.875457,0.861763,0.460249,0.46885,-1.40423,-1.22611,0.0983677,0.303074,-0.636041,-0.646871,-0.235907,-0.230017,-0.694818,-0.69456,-2.53969,-2.67606,1.01849,0.858321,-1.13573,-1.30911,0.207155,0.250609,-0.000979716,0.0885998
3754,0.390392,0.228252,0.0180584,-0.0474926,0.294179,0.109378,0.477101,0.417055,0.520434,0.562959,0.309035,0.302274,0.575553,0.518044,0.471325,0.46529,0.720988,0.708167,0.840612,0.848584,1.83151,2.01648,2.4996,2.70107,1.08817,1.07552,1.0772,1.0882,0.887298,0.888568,-2.56081,-2.69183,-0.191696,-0.343859,1.83748,1.67258,0.0222639,0.057711,0.531543,0.62233
3755,0.304192,0.227139,0.684139,0.616717,0.570855,0.385317,0.266668,0.205053,0.119558,0.156426,0.41174,0.373908,0.939619,0.880504,0.717871,0.710846,0.897395,0.883134,0.365942,0.372472,-0.369983,-0.183985,-0.608747,-0.399667,-1.17431,-1.17985,0.557875,0.63068,0.354327,0.35653,-0.967445,-1.09831,0.451271,0.303041,-0.836821,-1.00268,-1.53517,-1.5072,-0.242944,-0.155455
3756,0.804628,0.729268,0.890702,0.824541,0.0939109,-0.0896589,0.895486,0.832221,0.168664,0.203916,0.453742,0.445543,0.276617,0.21881,0.114017,0.104847,0.0939926,0.080449,0.641481,0.645642,1.74944,1.92846,-1.69161,-1.48796,-0.542393,-0.551615,0.163968,0.173157,-0.422025,-0.420045,-1.36498,-1.49816,1.3339,1.1917,1.05858,0.895495,1.58705,1.62146,1.77642,1.86588
3757,0.335571,0.258798,0.32462,0.258399,0.308063,0.13764,0.414389,0.35041,0.631378,0.66708,0.0208943,0.014823,0.760186,0.701058,0.91356,0.903372,0.557562,0.484536,0.492656,0.513205,-0.213635,-0.0300747,-0.0432877,0.0956811,1.00553,0.994317,-1.20098,-1.18965,-0.905225,-0.906826,-0.243849,-0.379464,0.381653,0.237805,-0.11498,-0.272647,-0.604462,-0.565547,-0.0866855,0.00279594
3758,0.93806,0.85955,0.671601,0.604574,0.548323,0.36494,0.526678,0.520753,0.435021,0.469959,0.913844,0.905816,0.726234,0.714461,0.945449,0.933587,0.902178,0.888622,0.341633,0.380768,-0.67644,-0.495391,1.47518,1.67932,0.332815,0.315823,0.0154691,0.0220804,1.21395,1.21119,0.346763,0.20387,0.721663,0.574853,-0.118496,-0.282066,0.326274,0.362023,-0.176946,-0.0816565
3759,0.921949,0.844448,0.410631,0.34348,0.505832,0.320668,0.756049,0.691096,0.545208,0.578977,0.818633,0.812928,0.703233,0.727864,0.49625,0.559416,0.784298,0.863387,0.244989,0.248332,1.44884,1.63193,-1.10675,-0.911232,-1.84112,-1.85887,0.0126267,0.0190436,-0.605625,-0.613117,0.441891,0.295273,0.354409,0.207675,-0.913642,-1.0708,-0.252652,-0.216447,1.44399,1.5393
3760,0.268699,0.192849,0.423272,0.35764,0.875556,0.687989,0.0172459,-0.0471124,0.090823,0.125588,0.234052,0.227975,0.800043,0.741268,0.198511,0.185245,0.852932,0.838152,0.981857,0.986716,0.904825,1.08861,0.999255,1.19668,0.00433624,-0.0121883,0.400435,0.413104,-0.106276,-0.0413508,2.09083,1.9505,1.40901,1.26669,2.12196,1.96461,-0.00800368,0.022856,-0.856274,-0.762262
3761,0.98453,0.908732,0.14288,0.0776162,0.987674,0.799783,0.686053,0.618933,0.767293,0.80227,0.0497426,0.0453964,0.583166,0.535413,0.476917,0.466277,0.415383,0.470724,0.660484,0.716869,-0.696768,-0.514204,0.418317,0.617753,1.27381,1.25991,-1.33481,-1.32634,0.537907,0.530415,1.25773,1.11613,-1.45466,-1.60476,-1.04452,-1.1969,-0.637241,-0.600207,-1.44305,-1.34374
3762,0.330192,0.252357,0.814153,0.747163,0.194422,0.00900545,0.741762,0.731718,0.643319,0.680424,0.656987,0.651182,0.387059,0.329558,0.472327,0.455408,0.117214,0.103295,0.440686,0.447021,0.122326,0.302118,0.898771,1.09399,1.02134,1.0011,-0.171437,-0.159757,0.0466051,0.0436337,-0.207384,-0.349018,-0.114975,-0.26311,0.774754,0.6242,-0.324102,-0.281629,-0.746808,-0.641738
3763,0.380402,0.367943,0.261727,0.195288,0.644905,0.45826,0.914376,0.844503,0.735331,0.775315,0.653295,0.716284,0.434562,0.286208,0.429441,0.44454,0.6726,0.65851,0.709816,0.715364,-1.51614,-1.32727,0.128345,0.242378,0.979522,0.956741,1.27918,1.28481,-0.715439,-0.719289,0.751221,0.614504,-0.416011,-0.568189,0.352978,0.204482,-1.17897,-1.13787,0.947641,1.05395
3764,0.559831,0.483529,0.184664,0.117494,0.5832,0.398003,0.598756,0.459015,0.466025,0.437215,0.790366,0.781385,0.35473,0.242858,0.431277,0.433671,0.501734,0.432514,0.662362,0.666265,0.235321,0.418277,-0.809619,-0.609238,-0.487621,-0.50985,0.35267,0.34661,0.434711,0.435122,-0.261688,-0.403952,-0.920123,-1.07434,0.263208,0.120533,-0.495199,-0.458772,0.211655,0.322285
3765,0.163263,0.0873786,0.353612,0.286501,0.0483711,-0.135812,0.143826,0.073527,0.0601414,0.0991152,0.852589,0.846487,0.259364,0.199508,0.380314,0.422803,0.218619,0.206519,0.0370572,0.0407087,0.343242,0.432841,0.743481,0.950905,0.31402,0.289174,-0.590385,-0.591588,-1.05082,-1.04847,0.800915,0.654439,2.92283,2.76432,-1.27411,-1.41735,-0.779312,-0.742799,0.163669,0.269066
3766,0.642866,0.568694,0.839592,0.7742,0.534851,0.352455,0.78106,0.71087,0.357616,0.396691,0.216517,0.211112,0.883249,0.821031,0.446462,0.411934,0.550696,0.537057,0.267489,0.268489,0.260833,0.447406,-0.0973534,0.108889,1.85428,1.83511,0.505324,0.510532,-0.532952,-0.523703,-1.05585,-1.20704,-0.000682062,-0.157649,-0.111723,-0.25952,-0.711466,-0.671042,-0.522506,-0.416358
3767,0.426989,0.354818,0.0952363,0.0284469,0.593211,0.484103,0.131523,0.0632379,0.863325,0.90059,0.100643,0.0937276,0.222085,0.159337,0.449054,0.401066,0.566139,0.552025,0.144392,0.143402,0.948959,1.14241,-1.96117,-1.75096,0.17424,0.152073,-1.14444,-1.13337,-1.24467,-1.23833,-0.160413,-0.318693,-0.653425,-0.816318,-0.491212,-0.632216,0.0693683,0.114844,-0.802252,-0.696518
3768,0.972355,0.901215,0.363629,0.294414,0.79963,0.615751,0.189307,0.121594,0.205566,0.241038,0.45234,0.444613,0.416611,0.355991,0.265095,0.390197,0.152311,0.137958,0.91303,0.914066,0.836029,1.02493,-0.810373,-0.597923,-0.918593,-0.944643,-1.19391,-1.0994,-0.671793,-0.6664,-1.64602,-1.79955,1.35792,1.19201,1.92633,1.79249,-0.551336,-0.50822,3.0063,3.10499
3769,0.130085,0.0588879,0.945428,0.875375,0.468298,0.334863,0.889062,0.818978,0.236273,0.273,0.0492283,0.0430488,0.203737,0.145622,0.389969,0.379329,0.953483,0.939706,0.432032,0.433504,0.0588201,0.153151,0.95741,1.16336,-0.943597,-0.974123,-1.08286,-1.06544,-0.921209,-0.910312,-2.12018,-2.27861,1.83547,1.66862,-0.036155,-0.167884,-0.700111,-0.679202,-0.282617,-0.180443
3770,0.455039,0.386464,0.43045,0.362534,0.238115,0.0539753,0.835474,0.782741,0.765214,0.802026,0.851477,0.84716,0.72834,0.672484,0.134699,0.122508,0.78654,0.772007,0.524471,0.537112,-0.909873,-0.718632,0.772209,0.981992,0.247309,0.221638,0.23845,0.252783,0.0330497,0.0455646,0.144104,-0.0115002,1.8896,1.71452,-1.54403,-1.67588,-0.896293,-0.850185,-0.394677,-0.293921
3771,0.468956,0.416711,0.543815,0.475827,0.530696,0.345431,0.817132,0.746505,0.0951867,0.132323,0.853494,0.830809,0.40016,0.34208,0.534324,0.524067,0.101452,0.0865682,0.564143,0.64072,0.371659,0.561041,-1.17113,-0.954291,0.993526,0.974813,1.15034,1.17124,-0.817699,-0.809582,-2.05753,-2.21736,1.16774,0.994353,2.12401,1.98891,-0.415896,-0.375206,0.319634,0.424078
3772,0.514174,0.446957,0.891593,0.822002,0.504736,0.321654,0.460853,0.460281,0.698488,0.737459,0.820373,0.814459,0.303106,0.266141,0.206954,0.197567,0.980266,0.965064,0.74507,0.744328,-0.507281,-0.321612,-0.662906,-0.444739,-1.52527,-1.54852,-0.51264,-0.490354,0.462076,0.469346,-1.48911,-1.64983,-0.988016,-1.16295,-1.0756,-1.20623,1.59237,1.62832,0.291666,0.322399
3773,0.156228,0.0872902,0.645214,0.575861,0.113928,-0.0678256,0.244446,0.174057,0.758665,0.81256,0.577879,0.571039,0.248964,0.190202,0.512358,0.504154,0.990445,0.975085,0.0346741,0.0324326,-1.58809,-1.4031,-0.7838,-0.565225,-0.618154,-0.641396,0.948258,0.972118,0.283789,0.2845,-2.69407,-2.85127,2.29042,2.11097,1.31356,1.18676,-1.17384,-1.14614,0.114992,0.22072
3774,0.728995,0.658751,0.147156,0.077579,0.561452,0.381429,0.514287,0.44459,0.819105,0.88766,0.602681,0.597463,0.5696,0.512093,0.2876,0.281743,0.576354,0.628204,0.14214,0.0726826,-1.58956,-1.39768,2.54439,2.76431,1.57487,1.55116,1.14575,1.16786,0.0914495,0.0996541,0.0227463,-0.129024,-0.213216,-0.397264,-1.52782,-1.6488,-1.387,-1.35293,1.3798,1.48678
3775,0.643058,0.571775,0.738306,0.668428,0.638193,0.457901,0.00694665,-0.0633197,0.922726,0.962761,0.999175,0.991684,0.469893,0.371495,0.805792,0.799034,0.293866,0.281322,0.0938063,0.112932,-0.654888,-0.45864,-0.173961,0.0497218,1.47588,1.44465,-1.11302,-1.09611,-1.01688,-1.01496,1.18771,1.03587,-0.222643,-0.411245,1.26351,1.15027,-0.979374,-0.902727,-0.380934,-0.268572
3776,0.991701,0.918771,0.0424316,-0.0268025,0.226883,0.0482692,0.125953,0.0561383,0.498272,0.53886,0.838021,0.829065,0.287099,0.230896,0.53156,0.5265,0.739691,0.726521,0.155424,0.153182,0.0794453,0.282633,1.95212,2.1736,-1.35215,-1.38379,1.14473,1.1636,-1.02222,-1.02538,-0.387557,-0.534898,1.40397,1.22252,0.173914,0.0570563,-0.480812,-0.452528,1.68658,1.79923
3777,0.929289,0.857398,0.210248,0.179744,0.326741,0.149592,0.900459,0.830315,0.898784,0.94139,0.145902,0.138966,0.589538,0.533289,0.943271,0.938244,0.587877,0.550447,0.954451,0.951316,-0.597274,-0.399377,0.412476,0.631238,0.237609,0.178929,0.3517,0.372798,-0.229067,-0.237195,1.5965,1.44258,0.860802,0.682817,-0.208046,-0.330387,-0.87773,-0.843891,-0.155316,-0.0497477
3778,0.602692,0.531999,0.45331,0.386291,0.89416,0.717675,0.196275,0.127558,0.829318,0.87009,0.712887,0.705395,0.892172,0.835682,0.529748,0.526554,0.403605,0.374373,0.315338,0.310653,0.789016,0.989351,-0.326343,-0.100775,1.77328,1.74164,0.814287,0.842004,-0.604761,-0.619517,1.84629,1.68683,-0.206027,-0.37979,0.665672,0.535553,0.187427,0.224589,-0.25925,-0.147512
3779,0.836239,0.763848,0.351239,0.214789,0.529117,0.353056,0.89854,0.829632,0.757097,0.798789,0.0137422,0.00607344,0.908231,0.853469,0.917519,0.913166,0.209921,0.198299,0.197707,0.194861,-0.282377,-0.0957239,1.71404,1.94352,-1.36985,-1.39504,-2.31839,-2.28979,-0.659265,-0.679155,0.153352,-0.0072621,-1.58172,-1.75285,-0.496312,-0.632589,-0.788463,-0.743789,0.713658,0.884127
3780,0.0795083,0.00854874,0.109959,0.0432864,0.462365,0.288015,0.834074,0.767051,0.431178,0.471626,0.68657,0.678136,0.155628,0.0987921,0.192089,0.188455,0.488158,0.55921,0.371355,0.367033,-1.38113,-1.1808,1.19411,1.42671,-0.606214,-0.626354,-0.221334,-0.195157,-1.20593,-1.22793,0.930626,0.772495,-0.401505,-0.568089,-0.325141,-0.456197,1.06741,1.10997,1.80433,1.91577
3781,0.776394,0.704215,0.7097,0.643305,0.875917,0.701168,0.307648,0.238808,0.961413,1.00065,0.878261,0.87188,0.679769,0.621088,0.634554,0.577599,0.933014,0.920122,0.845156,0.841037,1.79974,2.00388,1.28276,1.51922,-3.31382,-3.33109,2.0823,2.10086,0.639231,0.618832,1.07349,0.909778,-0.405068,-0.566976,-0.782001,-0.921325,-0.406513,-0.362564,-1.12731,-1.01598
3782,0.43699,0.354162,0.219674,0.155529,0.742735,0.569641,0.279864,0.301417,0.855718,0.824337,0.545137,0.538397,0.364969,0.306791,0.968756,0.966743,0.266665,0.254746,0.650346,0.645466,0.787186,0.997975,1.03721,1.27531,-0.0658117,-0.0830277,-0.421399,-0.399411,-0.862863,-0.882121,-0.272486,-0.431003,0.143371,-0.0128261,-0.334294,-0.46801,0.446313,0.488971,1.87624,1.98559
3783,0.0761148,0.00410789,0.809728,0.746378,0.967358,0.795242,0.430238,0.364027,0.681774,0.648023,0.663967,0.658015,0.0513996,-0.00750578,0.643198,0.640243,0.0661543,0.0519404,0.0532875,0.0498905,-2.60952,-2.39421,-1.20896,-0.975134,-0.355149,-0.372478,1.43803,1.45847,0.144717,0.112933,-0.67828,-0.830853,-0.310629,-0.474277,-0.764836,-0.902498,-1.46489,-1.42921,1.94656,2.05381
3784,0.888481,0.816387,0.346313,0.283016,0.613102,0.44151,0.102337,0.0365407,0.556126,0.471709,0.105037,0.099167,0.644645,0.583862,0.803557,0.801708,0.623904,0.611707,0.459148,0.454195,-1.1347,-0.926559,0.214544,0.442682,0.769854,0.74762,-1.50769,-1.48706,1.12303,1.10799,1.33549,1.1755,0.127285,-0.0422825,0.0212949,-0.113135,1.0775,1.1079,0.509945,0.619634
3785,0.968477,0.897034,0.210961,0.149174,0.788189,0.617832,0.999803,0.934178,0.256156,0.295395,0.71614,0.7098,0.0645768,0.00143444,0.705561,0.7054,0.624293,0.682429,0.444627,0.439998,-2.08018,-1.86847,-0.0197526,0.211692,0.334717,0.306204,-0.217198,-0.199774,-2.01647,-2.0279,-1.84635,-2.00943,-0.819211,-0.982386,-1.65722,-1.7909,0.164138,0.200157,-0.622832,-0.510151
3786,0.286034,0.215792,0.342837,0.231302,0.517344,0.348491,0.896497,0.753824,0.704687,0.743598,0.290155,0.28408,0.371261,0.308387,0.162305,0.163978,0.646987,0.753152,0.214514,0.209181,0.934235,1.1486,0.263579,0.490959,1.3534,1.32089,-0.1416,-0.126664,1.73215,1.72027,-0.689594,-0.844534,0.814752,0.65138,0.679317,0.550139,0.631929,0.675136,-0.365822,-0.204285
3787,0.719137,0.648754,0.373817,0.313431,0.986632,0.817073,0.636725,0.57347,0.0230937,0.0634122,0.97444,0.970151,0.016287,-0.0467597,0.738981,0.741853,0.836071,0.823874,0.936921,0.932491,0.96606,1.18252,-0.544863,-0.347657,1.45819,1.42739,-1.31117,-1.29191,-0.0762742,-0.086835,-0.188243,-0.337439,1.38332,1.22135,0.542531,0.405678,-0.649162,-0.607631,-0.0116123,0.10158
3788,0.546602,0.531419,0.740616,0.678164,0.494928,0.409518,0.968349,0.907224,0.724081,0.764483,0.227929,0.22479,0.441953,0.379872,0.691189,0.695334,0.518695,0.504597,0.245935,0.239989,-0.306934,-0.0830072,-1.41365,-1.18627,-0.777027,-0.811943,-0.370639,-0.424234,-0.20595,-0.224329,-1.99273,-2.13873,-0.0569977,-0.216106,0.103451,0.00507997,-0.91505,-0.877115,-1.47708,-1.36163
3789,0.484468,0.414085,0.889165,0.827168,0.170538,0.0019619,0.796728,0.734985,0.0989239,0.139445,0.428797,0.437217,0.217102,0.153504,0.872527,0.876457,0.970333,0.954206,0.00472608,0.000333476,2.3292,2.55432,-0.176329,0.0482842,-0.872569,-0.905211,0.42418,0.443438,1.73239,1.71695,-0.412741,-0.558923,-0.509146,-0.662155,-0.253269,-0.395518,2.00032,2.03417,0.275311,0.398492
3790,0.139563,0.0688328,0.463368,0.398591,0.548036,0.379361,0.165283,0.10277,0.497856,0.537167,0.602332,0.649645,0.778705,0.715016,0.618119,0.623447,0.80428,0.786507,0.688667,0.684464,0.0090366,0.232065,0.353991,0.493826,1.01568,0.987664,-0.836069,-0.813978,0.577361,0.55586,-0.375549,-0.528646,0.934526,0.784798,-1.28295,-1.4272,-0.131563,-0.105353,-0.590509,-0.470903
3791,0.813843,0.744101,0.677828,0.611248,0.699932,0.530959,0.824994,0.763892,0.00219541,0.0438309,0.865713,0.862072,0.796486,0.74454,0.886707,0.894125,0.990115,0.972693,0.745915,0.741648,0.615113,0.835604,0.714557,0.939367,1.29541,1.26527,0.632216,0.648494,-0.851777,-0.866752,-0.604887,-0.759599,1.2438,1.0925,-0.301867,-0.453932,-0.481833,-0.453289,0.317613,0.441829
3792,0.766933,0.697209,0.31838,0.252033,0.17193,0.00248531,0.739627,0.753259,0.845207,0.889446,0.344588,0.342,0.838647,0.774065,0.0210209,0.0284198,0.0334661,0.0148397,0.194697,0.190851,1.45201,1.66686,2.27981,2.49951,-0.767477,-0.797379,2.45811,2.47585,1.05024,1.04062,-2.72377,-2.87101,-1.02643,-1.18226,-0.992195,-1.1502,1.53865,1.56227,-1.606,-1.48283
3793,0.0399421,-0.032036,0.794936,0.7298,0.247015,0.0789574,0.805608,0.742626,0.663867,0.614632,0.0832993,0.0788812,0.19937,0.136621,0.832359,0.842329,0.656797,0.635958,0.207146,0.201568,-0.835669,-0.623626,2.02864,2.25561,-0.698563,-0.720154,0.127156,0.146699,1.17725,1.16714,0.567996,0.41239,1.33828,1.18228,1.31227,1.15827,-0.251329,-0.227881,0.539479,0.666638
3794,0.909518,0.8381,0.399088,0.354054,0.882959,0.712728,0.180662,0.119601,0.293618,0.339818,0.695766,0.689514,0.550083,0.514738,0.255288,0.266184,0.485262,0.462695,0.445625,0.440316,0.402757,0.606355,-0.485569,-0.252068,-0.215713,-0.230937,2.36441,2.38783,-0.0860304,-0.102273,-1.01005,-1.17352,-0.0683132,-0.222288,-0.213413,-0.365998,-1.10943,-1.08413,1.10825,1.23261
3795,0.524384,0.452532,0.044249,-0.0216931,0.0181287,-0.153783,0.971553,0.909618,0.667336,0.713127,0.770289,0.723995,0.957187,0.892854,0.589223,0.598042,0.658782,0.637663,0.255065,0.249695,-1.34802,-1.1521,0.686792,0.9164,-0.988903,-1.00163,-0.70889,-0.680663,1.3964,1.37451,-0.579179,-0.744291,0.371377,0.224612,-3.09341,-3.25125,0.772292,0.800378,-0.951326,-0.832495
3796,0.426251,0.355093,0.279734,0.215615,0.254701,0.0815875,0.432839,0.37153,0.73536,0.782299,0.766665,0.758476,0.630052,0.566884,0.0488697,0.0566198,0.0163384,-0.00276326,0.572723,0.567915,0.548236,0.744644,-0.113364,0.121729,-0.234044,-0.248459,-0.602507,-0.578096,-1.63415,-1.65866,1.2851,1.12528,-0.37104,-0.512789,0.631978,0.471624,0.285703,0.315864,-1.0234,-0.899427
3797,0.768245,0.697042,0.850246,0.786998,0.173734,0.00146343,0.468749,0.394695,0.54425,0.59024,0.215413,0.209129,0.963131,0.899313,0.708561,0.716645,0.053729,0.00882968,0.608193,0.604633,0.416218,0.614882,-1.16748,-0.936105,-1.27638,-1.28366,0.218772,0.24537,0.170296,0.140857,-0.21244,-0.370779,-0.50357,-0.649161,1.22146,1.06222,1.63208,1.67135,-1.09231,-0.966358
3798,0.0840174,0.0158,0.881865,0.740118,0.743919,0.57401,0.409568,0.417861,0.879725,0.927618,0.479149,0.383343,0.712385,0.64849,0.867892,0.87811,0.0414735,0.0204226,0.27753,0.273053,-0.631198,-0.436345,-0.134103,0.0949656,-0.275345,-0.28417,-0.631717,-0.610332,0.494936,0.467476,0.460023,0.304167,-0.917661,-1.06328,0.826051,0.674776,0.0384253,0.0759231,2.06686,2.18522
3799,0.833545,0.764454,0.754125,0.693237,0.0571318,-0.114941,0.503855,0.441027,0.709699,0.756999,0.563182,0.557557,0.0221799,-0.043435,0.213431,0.225625,0.258753,0.23652,0.900179,0.89751,-1.38724,-1.19494,-1.85406,-1.6182,-0.0988955,-0.10104,-1.23724,-1.21585,0.392689,0.360828,-1.05123,-1.20562,0.928876,0.789581,-1.77329,-1.91753,0.867073,0.910239,-1.32759,-1.20837
3800,0.815065,0.654445,0.503046,0.419535,0.89905,0.727512,0.74057,0.6766,0.9149,0.962221,0.105854,0.101728,0.967065,0.900453,0.127536,0.139814,0.762194,0.742175,0.876835,0.873558,0.703699,0.900994,0.266353,0.505676,-1.1355,-1.13624,-0.422592,-0.406377,-1.0057,-1.03207,-0.173642,-0.333835,-1.01992,-1.16611,-1.35305,-1.58914,0.189576,0.239286,0.790062,0.905511
3801,0.613024,0.544436,0.208296,0.145833,0.120594,-0.052973,0.1345,0.0686165,0.814058,0.817476,0.25596,0.251524,0.508742,0.43999,0.521944,0.536452,0.53839,0.518721,0.463562,0.439944,-0.481275,-0.287865,-1.20048,-0.960073,-0.691139,-0.690918,0.0343216,0.0493453,-1.5203,-1.55011,-1.8212,-1.98214,1.68635,1.53519,-1.11388,-1.26075,-1.32985,-1.2789,-1.43467,-1.31791
3802,0.929959,0.860937,0.887632,0.825524,0.781348,0.606021,0.836067,0.77069,0.750331,0.67273,0.0496638,0.0472527,0.311054,0.240332,0.286063,0.298637,0.776498,0.755494,0.010902,0.00633031,-0.748711,-0.55442,-1.4961,-1.24909,-2.3015,-2.29577,-0.130182,-0.108344,-0.410105,-0.441986,-0.72876,-0.894894,-0.559033,-0.703378,0.782116,0.637422,-1.21734,-1.1623,0.923974,1.04189
3803,0.989997,0.92119,0.235784,0.175001,0.335164,0.16153,0.278952,0.212451,0.480663,0.527984,0.276265,0.275937,0.678672,0.607215,0.781378,0.795893,0.108835,0.0901182,0.253784,0.280415,0.352678,0.553088,-0.194801,0.0465497,-0.248028,-0.248307,2.07749,2.10129,0.427194,0.391257,0.0607163,-0.102732,1.15672,1.00664,0.706447,0.569379,-0.154253,-0.0938188,-0.0427473,0.0687588
3804,0.0894943,0.0220247,0.592794,0.530526,0.411474,0.246413,0.621077,0.555795,0.57638,0.622875,0.780532,0.778284,0.0245423,-0.0450294,0.245003,0.259796,0.402942,0.38625,0.557325,0.5545,0.883538,1.08239,-0.380052,-0.134817,1.41217,1.4083,-0.310137,-0.278151,1.9727,1.94408,0.20537,0.0478043,0.15838,0.00483386,1.36601,1.22261,-0.60794,-0.549191,1.32073,1.42742
3805,0.265715,0.23457,0.0479663,-0.0161943,0.6457,0.331295,0.312826,0.344113,0.263168,0.310181,0.566305,0.601935,0.713143,0.642492,0.877795,0.894736,0.910115,0.891905,0.100415,0.0982843,-0.124813,0.0764851,-1.4393,-1.19265,-1.55251,-1.5619,-1.97075,-1.93974,-1.59948,-1.62185,-1.14462,-1.31007,0.0104936,-0.145263,-0.0438541,-0.19399,0.537885,0.596633,0.865142,0.988522
3806,0.424383,0.447116,0.268025,0.206666,0.589813,0.416178,0.198011,0.13243,0.383712,0.382034,0.426431,0.425585,0.297659,0.226483,0.796095,0.904551,0.82195,0.801639,0.893231,0.890586,0.857441,1.06108,-2.28393,-2.03467,-0.631997,-0.640482,0.184431,0.215611,0.068976,0.0534266,-0.751941,-0.91149,0.0870509,-0.0672536,0.684293,0.537325,-0.961239,-0.907049,0.58206,0.549628
3807,0.645103,0.659662,0.15331,0.159786,0.211326,0.0368465,0.757097,0.689893,0.451089,0.453887,0.802948,0.800485,0.136542,0.131923,0.814418,0.914367,0.13201,0.110664,0.243155,0.23959,0.0371136,0.239728,-0.667831,-0.413738,-0.511041,-0.519658,0.245414,0.249579,-0.902732,-0.9255,0.480837,0.312784,0.518309,0.364741,-0.695679,-0.850335,0.794171,0.850184,0.00405153,0.110734
3808,0.939677,0.872207,0.172995,0.112906,0.871957,0.69584,0.812934,0.744127,0.481113,0.52574,0.651386,0.647529,0.10727,0.0373637,0.907481,0.924183,0.593896,0.570961,0.175808,0.171257,0.258893,0.458615,-1.56591,-1.31589,0.0727,0.0637709,0.245278,0.283547,0.936536,0.921263,-0.134625,-0.307505,-0.101026,-0.250034,-0.148797,-0.304146,-0.206254,-0.149356,-1.60788,-1.5054
3809,0.616219,0.546807,0.897947,0.838935,0.595318,0.421422,0.35877,0.292259,0.0519181,0.0972722,0.16757,0.16281,0.877348,0.806746,0.077791,0.0966679,0.304407,0.355695,0.930155,0.926323,-0.810308,-0.608878,-0.348349,-0.0955152,-0.308471,-0.317441,-0.849424,-0.805087,1.07046,1.04779,-1.65786,-1.83158,1.58133,1.42885,-0.31947,-0.477917,1.4044,1.46569,-0.769504,-0.668095
3810,0.710739,0.642393,0.369126,0.392379,0.637105,0.462831,0.912942,0.844837,0.415529,0.516351,0.266429,0.262033,0.206352,0.134499,0.435963,0.454176,0.165966,0.14043,0.713839,0.711023,0.904383,1.10473,0.358034,0.612315,-0.110334,-0.118593,-1.56359,-1.5192,0.869773,0.848974,-1.32957,-1.49706,-0.712648,-0.860181,0.0435175,-0.116292,1.76292,1.83131,-0.413375,-0.316161
3811,0.07454,0.00602978,0.00483468,-0.054177,0.981058,0.804782,0.729606,0.746541,0.889035,0.93543,0.834149,0.828462,0.489032,0.484539,0.156819,0.177491,0.214592,0.189497,0.973302,0.969747,-1.48779,-1.28056,-1.37796,-1.11964,-0.820155,-0.8259,0.223829,0.27523,1.26956,1.25253,0.493705,0.328687,-0.504708,-0.647346,-0.421555,-0.58142,-0.483966,-0.415804,0.555687,0.657486
3812,0.188894,0.122037,0.852382,0.793941,0.147049,-0.0307445,0.715628,0.648245,0.474687,0.521359,0.625336,0.619273,0.905059,0.834578,0.273896,0.293247,0.976552,0.95104,0.109505,0.106371,-0.829868,-0.616809,0.207163,0.470397,0.830254,0.830712,1.69419,1.75232,-0.555517,-0.571777,-0.900884,-1.06047,-1.71333,-1.84953,-0.242927,-0.405028,-0.454531,-0.389168,0.014849,0.119253
3813,0.846829,0.77843,0.340233,0.2811,0.113756,-0.0642886,0.965252,0.898886,0.93975,0.984523,0.891213,0.882709,0.0913637,0.0228783,0.020278,0.0402381,0.57501,0.552096,0.895195,0.893102,2.03597,2.25291,-0.30205,-0.031292,1.10072,1.10831,-1.09907,-1.04303,-0.618508,-0.631415,-0.139757,-0.294904,1.69823,1.56658,1.01372,0.857749,2.13615,2.19593,0.723537,0.821251
3814,0.782567,0.712152,0.388847,0.329133,0.731178,0.55371,0.503324,0.43742,0.299865,0.344891,0.0622164,0.0546716,0.973036,0.903232,0.102844,0.0997606,0.839888,0.818722,0.910006,0.908449,-0.7033,-0.493873,-1.58159,-1.30629,0.986575,0.988356,1.55031,1.60183,-1.70757,-1.71553,0.942516,0.79234,-0.0236855,-0.152931,-0.159771,-0.310392,0.505113,0.568424,0.460985,0.556698
3815,0.499102,0.428103,0.788467,0.72917,0.628271,0.453037,0.400231,0.299742,0.536624,0.611477,0.557742,0.552152,0.0111095,-0.0589122,0.128068,0.159283,0.348653,0.328706,0.67475,0.67277,-0.827844,-0.623635,-1.89322,-1.61246,0.567766,0.575859,0.0679613,0.115459,1.70111,1.69366,0.904371,0.759621,0.86834,0.735728,-0.680435,-0.836642,1.19848,1.26182,-1.11551,-1.01095
3816,0.682607,0.597842,0.0656663,0.00383304,0.191251,0.0138145,0.229869,0.162064,0.831551,0.878063,0.723324,0.717314,0.018332,-0.0513207,0.198151,0.218806,0.523401,0.530163,0.0054705,0.00162213,1.45394,1.65839,1.4009,1.68361,-1.21277,-1.20151,0.30574,0.357562,-2.05272,-2.06449,-1.07642,-1.22757,0.00352231,-0.122627,-2.16527,-2.32855,-0.797293,-0.736112,-1.01785,-0.914831
3817,0.838262,0.76758,0.177273,0.117126,0.588963,0.411693,0.442039,0.373049,0.0456817,0.0924877,0.369211,0.364995,0.890711,0.821877,0.673902,0.695331,0.751483,0.73162,0.548313,0.545753,1.98948,2.18769,0.466369,0.751356,0.426619,0.44118,1.5109,1.5693,2.08741,2.07076,1.94663,1.80318,-0.284335,-0.4122,-0.0548996,-0.224921,-0.459176,-0.401671,-0.334335,-0.228769
3818,0.756134,0.628551,0.722345,0.664994,0.611046,0.432969,0.983497,0.915937,0.438735,0.493003,0.304856,0.303049,0.18968,0.120733,0.335841,0.358594,0.536034,0.609644,0.230361,0.229985,0.902013,1.1062,1.01533,1.30484,1.16935,1.17918,-0.205485,-0.155327,0.571557,0.555339,-0.929557,-1.07945,-0.015652,-0.136639,-0.403073,-0.567386,-1.46387,-1.40121,1.58451,1.68369
3819,0.621008,0.489522,0.995184,0.93603,0.392195,0.215103,0.540771,0.483735,0.846122,0.893519,0.89729,0.893695,0.726527,0.657133,0.584976,0.608792,0.507496,0.487668,0.261859,0.26189,-1.1913,-0.980415,-1.82228,-1.53675,0.868356,0.874663,-0.834663,-0.791333,-0.275852,-0.28573,0.622556,0.467207,0.927287,0.800228,-1.5447,-1.70658,-1.92456,-1.85658,2.30595,2.40169
3820,0.501931,0.350492,0.702406,0.597387,0.496164,0.231726,0.120283,0.0515322,0.714522,0.761895,0.774374,0.801553,0.136357,0.0656062,0.0411557,0.0632684,0.160797,0.142806,0.672879,0.671204,-0.400744,-0.24934,0.480905,0.764374,-0.415177,-0.406227,-0.860838,-0.81088,-1.81405,-1.8291,0.415246,0.267264,0.267075,0.102855,-0.713983,-0.869781,-0.83535,-0.772667,-0.184709,-0.0873422
3821,0.282145,0.211463,0.314708,0.258744,0.513261,0.248349,0.794123,0.724315,0.942042,0.987349,0.71185,0.709411,0.188867,0.197497,0.08759,0.108658,0.417636,0.323126,0.745784,0.743231,0.27808,0.481734,-2.4258,-2.13958,0.476752,0.485646,-0.300282,-0.249346,0.999168,0.981151,-0.462375,-0.612983,-0.468008,-0.594518,-1.79818,-1.94916,-0.842989,-0.777984,1.46034,1.56195
3822,0.876767,0.806485,0.816221,0.761556,0.483828,0.264971,0.107865,0.0372301,0.666698,0.710355,0.0528651,0.0494872,0.400895,0.329387,0.874153,0.896468,0.520272,0.503447,0.291695,0.287016,-0.347334,-0.139783,0.749444,1.03444,0.55473,0.562871,0.685932,0.732012,-0.606603,-0.625347,0.136471,-0.0145703,0.0160031,-0.117907,0.108079,-0.0509835,-1.35387,-1.2945,-0.961368,-0.855762
3823,0.255959,0.185768,0.375918,0.367754,0.458614,0.281594,0.715171,0.644119,0.618601,0.597566,0.867579,0.864492,0.23879,0.16557,0.514537,0.474362,0.983361,0.968616,0.482059,0.457835,-0.589447,-0.375888,1.11654,1.4031,0.083344,0.0903873,1.1852,1.23176,-0.737476,-0.762841,0.337651,0.183503,1.09329,0.954574,-1.25246,-1.40706,1.3884,1.45445,0.784891,0.885198
3824,0.801196,0.732166,0.0289121,-0.0260486,0.288689,0.179782,0.356858,0.385406,0.44288,0.484778,0.331529,0.330307,0.315871,0.184609,0.0299411,0.052256,0.0644098,0.0507714,0.639164,0.628655,0.654778,0.872117,1.8068,2.0953,1.33918,1.34723,0.808395,0.857187,0.724167,0.698155,-0.650173,-0.872338,-0.881312,-1.01711,-0.820359,-0.969537,1.60395,1.66269,0.0429908,0.138571
3825,0.847215,0.777453,0.811604,0.755046,0.25282,0.0779707,0.196361,0.126693,0.850599,0.892737,0.523596,0.439673,0.277912,0.203647,0.513497,0.534286,0.950494,0.93926,0.805859,0.799475,-1.16077,-0.949032,-0.317495,-0.0259577,0.690271,0.619291,-0.589538,-0.53777,0.707464,0.687727,-1.77013,-1.92818,-0.0489195,-0.189572,0.390668,0.247144,0.481414,0.536864,-0.297956,-0.20253
3826,0.648383,0.579199,0.136096,0.0792465,0.593219,0.419922,0.802728,0.733582,0.832491,0.906526,0.545363,0.549038,0.562914,0.490193,0.340678,0.362717,0.341817,0.329007,0.705816,0.700445,-0.207566,0.00506574,1.42131,1.7172,-0.119929,-0.10865,-0.671173,-0.641571,-0.237722,-0.260351,1.89704,1.747,-1.13671,-1.28197,0.44939,0.352614,0.850976,0.902489,-1.23389,-1.13216
3827,0.149074,0.0780701,0.262617,0.207369,0.306049,0.130172,0.33997,0.272117,0.875916,0.920314,0.719883,0.658403,0.133803,0.0608095,0.753238,0.774461,0.75245,0.73927,0.277678,0.27449,0.0640365,0.270948,-0.313049,-0.0147544,-0.24252,-0.228607,-0.806144,-0.745373,-0.267716,-0.287235,-0.0787857,-0.225668,-1.64736,-1.78812,0.603159,0.458083,-0.360581,-0.314371,-0.671669,-0.566187
3828,9.2603e-05,-0.0700718,0.89937,0.842662,0.287058,0.11135,0.568607,0.465201,0.194874,0.240128,0.76783,0.767768,0.245758,0.170821,0.845994,0.880099,0.552944,0.541786,0.365819,0.398508,-1.06634,-0.856136,1.47073,1.77616,0.251957,0.260609,0.521634,0.588964,0.162859,0.145913,0.374829,0.220674,-0.470586,-0.572142,-0.69604,-0.837778,-0.632723,-0.583855,-0.325461,-0.214253
3829,0.130701,0.059943,0.327012,0.27129,0.936635,0.760242,0.726768,0.658285,0.0729896,0.118281,0.409308,0.410202,0.910747,0.834032,0.965957,0.985737,0.849167,0.837918,0.581828,0.522527,-0.137877,0.0685633,1.45908,1.76137,0.0851777,0.0941948,0.454343,0.522657,0.913267,0.901467,1.3576,1.20019,0.778976,0.643835,-1.05931,-1.19671,-0.422134,-0.375613,0.660002,0.775388
3830,0.999835,0.926443,0.524215,0.485433,0.931935,0.756511,0.200105,0.130041,0.250117,0.293368,0.566469,0.569673,0.88196,0.743458,0.429944,0.44964,0.818573,0.808173,0.762727,0.646545,1.14705,1.34824,0.156722,0.457113,0.428972,0.431972,-0.563182,-0.501892,0.921511,0.907304,-0.66506,-0.816361,0.923134,0.781309,0.950772,0.81098,-0.487819,-0.442389,2.06052,2.17934
3831,0.0996299,0.0272779,0.772312,0.699576,0.0370813,-0.140122,0.835553,0.767384,0.977355,1.02137,0.301619,0.306554,0.725637,0.652884,0.192766,0.211825,0.13375,0.122734,0.773751,0.770563,-0.454666,-0.254581,1.20844,1.50147,0.169813,0.173161,-0.489741,-0.424921,0.0294255,0.0219955,-0.191911,-0.339118,2.12941,1.98218,0.129582,-0.0969412,-1.86913,-1.81965,-0.958108,-0.841767
3832,0.753055,0.678822,0.969442,0.913719,0.0104064,-0.168131,0.179085,0.110126,0.351994,0.396328,0.439301,0.446491,0.639026,0.562311,0.649585,0.668547,0.507323,0.498544,0.466003,0.465374,-0.575941,-0.372056,-1.3057,-1.00621,1.17528,1.17265,-0.412789,-0.34795,1.20462,1.19306,-0.735635,-0.880623,-0.975471,-1.11489,-0.86507,-1.00486,0.543108,0.589242,-1.02784,-0.908084
3833,0.768058,0.694015,0.894628,0.839806,0.295855,0.118386,0.478076,0.410517,0.493731,0.536092,0.873831,0.880615,0.156979,0.0806862,0.785314,0.804105,0.279972,0.368381,0.946386,0.944377,0.105889,0.307948,1.68104,1.9786,2.72339,2.71859,0.258635,0.321434,1.17129,1.08013,1.60851,1.46323,-2.17806,-2.31707,0.807913,0.659617,-0.0483332,-0.0040851,0.922967,1.0344
3834,0.217415,0.142879,0.419927,0.366163,0.184371,0.00685272,0.313896,0.247653,0.175255,0.218412,0.0848618,0.089661,0.283966,0.206064,0.206403,0.223286,0.24817,0.238218,0.33937,0.338327,1.34732,1.55595,0.987617,1.29236,2.01435,2.01128,0.673942,0.730412,0.976662,0.967203,-0.271785,-0.413158,-0.299241,-0.432357,-0.216864,-0.358486,0.585867,0.692852,0.356764,0.467819
3835,0.148188,0.0715907,0.484671,0.430236,0.684875,0.505171,0.502756,0.411997,0.760345,0.803825,0.937105,0.940898,0.664725,0.587519,0.97049,0.985719,0.439083,0.49843,0.401734,0.400569,0.286483,0.551959,-1.5794,-1.27838,-0.402528,-0.404204,-0.107387,-0.0459617,-1.05162,-1.06721,0.825046,0.687452,-0.645771,-0.785133,-0.25781,-0.398734,1.34554,1.38979,0.902358,1.01682
3836,0.299247,0.221682,0.832912,0.780739,0.000309842,-0.179126,0.640476,0.576342,0.889925,0.933315,0.84358,0.84801,0.819797,0.742877,0.433841,0.449621,0.766401,0.758641,0.193321,0.264858,-0.660671,-0.452035,-0.150606,0.153977,0.493505,0.487668,0.796267,0.857483,0.110803,0.0872014,-1.82371,-1.96755,-0.562664,-0.707123,0.811343,0.669422,-3.04849,-3.00424,-0.02934,0.0871888
3837,0.892103,0.812887,0.621107,0.571154,0.745012,0.567034,0.429076,0.36434,0.742821,0.786906,0.364327,0.367872,0.0126564,-0.0622011,0.868757,0.886803,0.102223,0.0932651,0.130238,0.129146,-0.336607,-0.124342,0.705217,1.01456,-0.234468,-0.237931,0.854952,0.915869,0.517114,0.490754,-0.545101,-0.681853,-1.49604,-1.64723,0.644951,0.511462,0.196674,0.240922,0.270831,0.395815
3838,0.514722,0.433151,0.703114,0.655517,0.0834294,-0.0963922,0.950112,0.887264,0.276233,0.318602,0.101492,0.104754,0.926044,0.850261,0.0993828,0.115278,0.175674,0.14814,0.951715,0.953492,1.92604,2.14242,1.22242,1.5386,-0.571443,-0.573676,-1.18487,-1.12683,0.634937,0.602448,-0.862563,-1.00466,-1.3291,-1.47907,0.880855,0.751196,0.178294,0.219977,-0.33904,-0.216684
3839,0.368671,0.316142,0.523144,0.475619,0.282358,0.104068,0.522362,0.460101,0.739184,0.781765,0.793734,0.79603,0.741138,0.664823,0.466612,0.482366,0.211553,0.203016,0.724505,0.776754,-0.955776,-0.747155,-0.739791,-0.428177,0.433956,0.425818,0.581615,0.635286,-0.924297,-0.9587,-0.647213,-0.790299,0.227573,0.0747605,-1.13107,-1.25605,0.924935,0.960409,0.982465,1.02554
3840,0.323088,0.199133,0.913105,0.865601,0.684175,0.409964,0.426241,0.362549,0.109825,0.15195,0.44747,0.523628,0.945681,0.870717,0.58649,0.603665,0.93169,0.925548,0.598028,0.600017,0.253217,0.467131,0.336462,0.64947,0.11132,0.103626,-1.08473,-1.02631,0.479417,0.44183,1.04701,0.897372,-0.212824,-0.457494,1.2064,1.08498,0.146375,0.181367,2.1454,2.26776
3841,0.164426,0.0821244,0.49828,0.425609,0.893794,0.715861,0.542292,0.477002,0.946959,0.990875,0.251437,0.251226,0.551232,0.483856,0.286149,0.302102,0.217168,0.209625,0.966188,0.969957,-0.463278,-0.237123,1.17565,1.49461,0.543211,0.532591,0.21465,0.276366,-0.611809,-0.707269,1.07023,0.927649,-0.842102,-0.989748,0.645212,0.528032,2.12962,2.16267,-0.287534,-0.161751
3842,0.940519,0.857218,0.0340511,-0.0143825,0.785063,0.549623,0.405165,0.241912,0.0330321,0.0754805,0.250354,0.248141,0.169495,0.0969954,0.736304,0.753801,0.0158674,0.00681968,0.573044,0.57468,-1.15529,-0.941377,1.37052,1.73718,-1.53699,-1.54566,-0.829144,-0.763072,-1.81878,-1.85637,-1.63569,-1.78117,-0.044051,-0.192828,0.531179,0.414182,0.678382,0.707908,1.24925,1.37953
3843,0.566374,0.482894,0.841552,0.792622,0.625475,0.383385,0.0745684,0.00682268,0.862922,0.903348,0.627593,0.62703,0.0372612,0.0147907,0.848805,0.864509,0.390926,0.382629,0.502864,0.514986,-1.39734,-1.17748,1.65863,1.97974,-0.0187053,-0.0295473,1.86416,1.93551,-1.17627,-1.20856,-0.236554,-0.388802,-0.0718509,-0.221599,0.0848907,-0.035175,1.31747,1.35408,0.81118,0.896195
3844,0.750964,0.692082,0.992003,0.941627,0.444342,0.217147,0.7547,0.689021,0.201098,0.243795,0.765809,0.766967,0.00566381,-0.067414,0.210877,0.227866,0.0200018,0.0132729,0.454591,0.455293,-1.40964,-1.18676,-1.11067,-0.788262,0.937145,0.924389,-0.689145,-0.613595,-0.0889347,-0.11482,0.793647,0.637597,-0.35666,-0.511172,2.1755,2.05006,0.444777,0.480294,0.282581,0.412858
3845,0.983054,0.901271,0.842933,0.792803,0.226839,0.0509084,0.565234,0.416745,0.428716,0.46925,0.213634,0.212781,0.172616,0.162059,0.470776,0.411194,0.352946,0.343812,0.806765,0.809175,1.38172,1.60081,1.32655,1.64236,2.47549,2.4552,0.848997,0.925971,-0.319985,-0.287795,1.31237,1.15975,-1.05672,-1.21635,0.226504,0.105536,-1.21372,-1.18012,0.662018,0.793886
3846,0.971145,0.810835,0.914729,0.866469,0.554842,0.378668,0.211525,0.144469,0.360122,0.39861,0.458772,0.36532,0.366376,0.391533,0.580159,0.594522,0.178736,0.170548,0.0311139,0.0362913,0.389577,0.610566,0.280581,0.600344,0.488949,0.500216,-1.79856,-1.71938,-0.437951,-0.46077,-0.923649,-1.0767,-0.0397748,-0.203007,0.314792,0.190125,-0.918174,-0.877215,1.28496,1.42046
3847,0.814878,0.7204,0.126615,0.0785874,0.514123,0.339849,0.299849,0.232602,0.0217373,0.0614012,0.542219,0.517859,0.694084,0.621006,0.533851,0.548003,0.33523,0.226992,0.594535,0.59968,0.83138,1.04481,0.491532,0.818676,-1.43447,-1.45476,-0.189654,-0.114807,-1.24211,-1.26892,0.111619,-0.0342379,-0.567178,-0.726183,1.15649,1.02693,0.786305,0.833139,-0.512991,-0.3803
3848,0.709415,0.629965,0.606357,0.556355,0.765298,0.590419,0.0961403,0.0302916,0.274065,0.312917,0.672689,0.670399,0.388469,0.394028,0.84739,0.859194,0.392693,0.283436,0.419415,0.424347,0.0612998,0.270015,1.31746,1.6505,1.36884,1.34572,-0.225888,-0.150452,-0.567735,-0.588914,-0.941668,-1.08281,0.221,0.0575199,0.202671,0.0706647,0.63631,0.686936,-0.950802,-0.811691
3849,0.880118,0.800814,0.584094,0.535696,0.396959,0.221075,0.882524,0.814148,0.00939611,0.0456774,0.130305,0.125981,0.134211,0.16705,0.383751,0.397786,0.362848,0.339879,0.757679,0.763035,1.41225,1.62746,0.49064,0.825497,-0.892534,-0.909638,0.702779,0.782935,-1.41253,-1.42998,-0.152973,-0.290646,-1.05642,-1.22375,-0.442376,-0.58027,-0.00582864,0.0476411,0.244098,0.37953
3850,0.354768,0.274783,0.303088,0.282392,0.253053,0.0790685,0.69463,0.701801,0.568388,0.604947,0.768364,0.76196,0.0131492,-0.0599286,0.188106,0.200835,0.404511,0.396323,0.537603,0.542386,1.89869,2.11164,-0.13494,0.200966,-1.20893,-1.23183,-1.12239,-1.05065,1.21859,1.20661,2.38517,2.25037,1.11943,0.948663,-0.518307,-0.664218,-1.30461,-1.25038,1.13503,1.2626
3851,0.605427,0.525898,0.0776541,0.0290878,0.898922,0.722779,0.585113,0.589454,0.1514,0.185908,0.0474465,0.0407487,0.229442,0.0974208,0.883046,0.897278,0.295603,0.289043,0.902024,0.907577,0.159541,0.371031,0.774122,1.10841,0.285121,0.269432,0.874488,0.948411,-0.814928,-0.827801,2.34085,2.20397,0.415085,0.24348,-0.129594,-0.271433,1.25114,1.30397,-0.54687,-0.414359
3852,0.398417,0.317054,0.353182,0.305327,0.093844,-0.0800967,0.545483,0.477107,0.929014,0.965846,0.896633,0.891986,0.431922,0.25477,0.455571,0.538626,0.457139,0.512072,0.815524,0.819624,-0.933958,-0.727101,-0.143121,0.191621,0.861573,0.852861,-0.961845,-0.885174,2.22029,2.21116,-0.509375,-0.647285,1.33174,1.1647,0.707392,0.565371,1.01946,1.05375,-0.280766,-0.151423
3853,0.517773,0.442595,0.138282,0.090872,0.985595,0.812091,0.602326,0.469994,0.504916,0.541945,0.357049,0.35277,0.51541,0.41212,0.166715,0.179974,0.741955,0.7351,0.94164,0.872599,-0.708071,-0.508214,-1.46356,-1.13153,0.827822,0.823381,-0.930347,-0.859273,1.19575,1.18716,-0.357099,-0.496748,1.49349,1.33286,0.735334,0.67084,0.750691,0.803525,-0.0190636,0.111514
3854,0.649716,0.568136,0.988728,0.93899,0.817617,0.645944,0.531811,0.46288,0.711444,0.748645,0.791664,0.786895,0.589666,0.569469,0.491909,0.506378,0.131897,0.124847,0.913482,0.925574,0.390818,0.583237,-0.154456,0.257726,1.59135,1.59207,-1.51191,-1.43385,0.928858,0.926297,1.22933,1.08306,-1.36075,-1.52276,0.910692,0.77631,-0.084407,-0.0361111,1.82751,1.96407
3855,0.0738901,-0.00811433,0.610548,0.629772,0.165553,-0.00745057,0.77789,0.708103,0.919673,0.955344,0.369095,0.429277,0.799896,0.726818,0.0611584,0.0752745,0.196693,0.187737,0.97445,0.978549,-0.46499,-0.268262,1.31494,1.64698,-0.307936,-0.31049,0.648107,0.721509,0.337395,0.253688,1.95805,1.8161,0.4479,0.281483,0.469771,0.341822,1.85931,1.912,0.871187,1.04276
3856,0.287903,0.214429,0.371044,0.320553,0.410066,0.237872,0.545426,0.560299,0.804218,0.89295,0.0771026,0.0716603,0.815693,0.750837,0.549302,0.56217,0.646013,0.637346,0.365793,0.368596,0.39309,0.593689,-0.415992,-0.0849748,1.44158,1.44213,0.0472509,0.11599,-0.422524,-0.418922,2.2626,2.11816,-0.124734,-0.288149,0.8423,0.720533,-0.960978,-0.9155,-0.021996,0.121437
3857,0.519769,0.436972,0.923435,0.872313,0.291991,0.12133,0.485134,0.412495,0.793216,0.830555,0.28535,0.227503,0.890624,0.774855,0.758581,0.769287,0.198566,0.187549,0.237026,0.18909,0.532915,0.736363,0.816979,1.14958,1.33409,1.33562,0.447376,0.51005,-0.656372,-0.648937,0.70959,0.562103,-1.77689,-1.9448,-0.0691779,-0.188766,0.125352,0.168416,0.409269,0.549347
3858,0.0644334,-0.018126,0.479074,0.42894,0.658837,0.488651,0.644889,0.572119,0.947481,0.985562,0.388285,0.383345,0.871952,0.798874,0.201955,0.213174,0.653729,0.642965,0.00652896,0.009584,0.301413,0.500258,0.65063,0.982761,1.00856,1.01343,-0.374747,-0.313506,0.955417,0.964601,0.308722,0.185832,-0.277205,-0.452994,0.409248,0.308979,0.429929,0.471322,-0.652448,-0.51552
3859,0.44094,0.359949,0.871558,0.818922,0.805482,0.635523,0.199179,0.126227,0.200754,0.238235,0.202421,0.294061,0.519269,0.448244,0.78166,0.79105,0.00682047,-0.00171233,0.571518,0.572972,1.51529,1.71454,0.207191,0.54173,0.0467147,0.0578171,-0.641184,-0.580198,-0.398749,-0.384206,-0.0374172,-0.190438,-0.729293,-0.899043,0.922332,0.806724,0.0756705,0.109487,0.297908,0.429404
3860,0.166811,0.0860996,0.953622,0.864201,0.313919,0.145636,0.135835,0.0636469,0.982601,1.01817,0.211507,0.204777,0.927228,0.855213,0.168423,0.180189,0.857651,0.848363,0.153226,0.156979,-0.850358,-0.654268,0.283418,0.619908,0.27255,0.273343,-0.605441,-0.538877,0.847965,0.864896,0.225295,0.0680002,0.235406,0.0683052,2.32726,2.2106,0.607666,0.648143,1.49891,1.63308
3861,0.179482,0.0964052,0.964512,0.909479,0.857504,0.688536,0.784315,0.710506,0.0775625,0.11394,0.472414,0.464055,0.652639,0.647485,0.835399,0.844513,0.308813,0.299067,0.871567,0.876508,0.284815,0.484151,-1.06164,-0.719341,0.478139,0.488868,-1.13421,-1.06697,-0.3746,-0.358985,-0.676962,-0.870923,0.922734,0.759822,1.36704,1.25434,1.62061,1.65463,0.4185,0.550192
3862,0.506407,0.423982,0.562131,0.505825,0.639531,0.47067,0.667697,0.592579,0.185632,0.196649,0.157767,0.150295,0.572493,0.439757,0.41952,0.428021,0.701392,0.689957,0.751615,0.756023,0.603765,0.797377,1.48558,1.8215,2.02317,2.0348,0.118717,0.190596,-0.012274,-0.000639133,-1.65255,-1.80985,-0.271546,-0.361297,-1.80549,-1.92202,-0.775773,-0.743322,0.792293,0.918088
3863,0.036093,-0.0464887,0.801593,0.680335,0.788308,0.617542,0.313526,0.240866,0.243834,0.279358,0.135668,0.174606,0.304714,0.232029,0.243588,0.251183,0.641669,0.630188,0.392115,0.427568,0.683407,0.878507,-0.701527,-0.36662,2.44837,2.46377,0.272343,0.341352,-0.599117,-0.5804,-0.992254,-1.15185,-1.3195,-1.48242,-0.15863,-0.272345,0.822264,0.857469,0.725588,0.85177
3864,0.0441242,-0.0361831,0.909611,0.854845,0.72752,0.557285,0.290981,0.21896,0.906369,0.939743,0.205077,0.198917,0.409006,0.239065,0.818688,0.824799,0.838832,0.82577,0.0937324,0.0991134,1.15781,1.3454,0.671106,1.00375,-1.32855,-1.32019,1.61311,1.67569,1.01689,1.03314,0.909363,0.74963,-0.766532,-0.928265,0.204514,0.0892803,-0.916975,-0.88522,-0.272168,-0.152019
3865,0.391782,0.249621,0.530837,0.476055,0.437603,0.267535,0.921987,0.851653,0.709387,0.799467,0.414329,0.441355,0.317803,0.2461,0.0836629,0.0891734,0.130974,0.115373,0.58073,0.588583,-0.0261417,0.156542,-0.512854,-0.177333,1.32082,1.32602,-0.0298816,0.0317844,-1.73729,-1.72224,0.474428,0.254114,-1.51265,-1.67907,-0.371292,-0.482336,-0.193631,-0.160735,0.870654,0.990568
3866,0.554533,0.535426,0.477316,0.421574,0.352828,0.181669,0.344742,0.27304,0.625342,0.659191,0.689451,0.683793,0.792713,0.722624,0.243841,0.250639,0.413363,0.392845,0.772619,0.767608,-0.647487,-0.464975,0.10961,0.382443,0.828525,0.75199,0.759515,0.826202,0.456139,0.464383,-0.0752496,-0.241402,-0.805517,-0.972027,-2.70998,-2.81516,0.875031,0.907745,0.199124,0.317863
3867,0.901337,0.82123,0.856859,0.801311,0.948228,0.774692,0.480752,0.407192,0.917213,0.951145,0.130929,0.124945,0.451664,0.382587,0.785692,0.793419,0.687651,0.670318,0.93708,0.946633,0.045647,0.23937,0.604714,0.942219,0.233454,0.177957,-2.75646,-2.69314,-1.43324,-1.42105,-1.10189,-1.27424,-0.505546,-0.664327,1.16898,1.06345,0.240691,0.276371,-0.705104,-0.579928
3868,0.956986,0.876892,0.06168,0.00757286,0.457423,0.284805,0.143265,0.0697762,0.490654,0.561887,0.0781493,0.0727626,0.644778,0.574077,0.84433,0.854068,0.155612,0.136271,0.448541,0.455955,0.752439,0.943715,-0.14014,0.193823,-0.401273,-0.396075,1.5445,1.60783,2.1217,2.13602,0.755093,0.581541,-0.906181,-1.06254,-0.338614,-0.444537,-0.39121,-0.355003,0.450155,0.579129
3869,0.660053,0.582379,0.967242,0.911134,0.700631,0.527258,0.715942,0.642225,0.140531,0.17263,0.638658,0.63405,0.250959,0.17802,0.493591,0.560729,0.026072,0.00930242,0.388327,0.397618,-0.657067,-0.460188,-1.77646,-1.44239,-1.68859,-1.67697,-0.0544093,0.0114824,-0.0783247,-0.0598246,0.899632,0.732077,-0.37721,-0.540784,1.49685,1.39218,-0.76201,-0.73138,0.699876,0.825491
3870,0.975016,0.89888,0.816967,0.762311,0.944328,0.769711,0.051484,-0.0210684,0.797377,0.827807,0.259864,0.257226,0.971992,0.897099,0.25967,0.267391,0.841719,0.82219,0.127065,0.136512,0.628307,0.819485,1.18426,1.52376,0.58092,0.598732,0.165405,0.167649,-0.39704,-0.381028,-1.8813,-2.05492,1.9541,1.79244,0.666716,0.558374,-0.219488,-0.192724,1.33035,1.45207
3871,0.522256,0.448456,0.916684,0.807589,0.233414,0.0603903,0.131821,0.111102,0.764815,0.79345,0.86702,0.863011,0.204945,0.131242,0.4005,0.408788,0.981495,0.962168,0.231857,0.242737,0.556806,0.748358,0.760516,1.09925,0.0321828,0.0479086,0.25428,0.323815,0.830603,0.852474,-0.353077,-0.523684,-1.84064,-1.9962,1.20117,1.08944,1.94043,1.97017,1.30283,1.42903
3872,0.331659,0.199958,0.907543,0.852868,0.886593,0.714838,0.318288,0.243272,0.237337,0.264989,0.553606,0.567437,0.756164,0.682952,0.180023,0.186377,0.185202,0.16536,0.642412,0.652051,0.176375,0.374617,-1.07064,-0.727821,0.924454,0.939781,0.634455,0.666681,0.673805,0.701372,-0.600587,-0.770476,-1.09177,-1.24341,-0.792139,-0.902423,0.434469,0.466487,-1.53828,-1.40979
3873,0.024696,-0.0485404,0.276944,0.222539,0.763364,0.593658,0.161702,0.0855422,0.247445,0.269846,0.278258,0.271863,0.372721,0.302011,0.454111,0.400204,0.99119,0.972896,0.018735,0.0264944,-2.07556,-1.8707,-1.12569,-0.786968,-0.25363,-0.235814,0.942977,1.00955,-1.89181,-1.85953,3.04344,2.8662,1.23012,1.0756,1.34229,1.23,0.818897,0.84847,-0.881285,-0.752734
3874,0.384619,0.270696,0.909709,0.857833,0.427452,0.258997,0.603949,0.528952,0.288348,0.274703,0.55567,0.550348,0.797587,0.728643,0.608701,0.614032,0.354669,0.337185,0.854169,0.860362,1.32334,1.52343,-0.831918,-0.491363,-0.178078,-0.158589,-0.931799,-0.868968,-1.64059,-1.60881,0.213757,0.0312037,-0.758413,-0.912072,0.0423172,-0.0658628,0.99333,1.02626,0.306576,0.438488
3875,0.661523,0.589932,0.618906,0.567673,0.931167,0.762558,0.398728,0.322076,0.210142,0.27956,0.147669,0.144205,0.661215,0.594517,0.0911061,0.0982238,0.070973,0.0539038,0.735334,0.739878,-1.26687,-1.06517,0.859412,1.20626,0.194337,0.208877,2.96104,3.02387,-0.755323,-0.729728,-0.741659,-0.925723,-0.22411,-0.374983,-1.88649,-1.99457,0.349148,0.386968,-0.0389151,0.0973874
3876,0.27697,0.204364,0.706971,0.594435,0.471524,0.303393,0.473372,0.395177,0.299294,0.284417,0.928543,0.92729,0.969115,0.90147,0.431798,0.440255,0.470205,0.454841,0.300048,0.303656,0.575436,0.770423,-0.686271,-0.336102,-0.707634,-0.685557,-0.91913,-0.862577,1.10446,1.13037,-0.240877,-0.418627,0.031199,-0.115406,0.541682,0.430136,-0.739677,-0.703983,-2.11199,-1.98227
3877,0.171804,0.0827841,0.665602,0.621196,0.738982,0.569507,0.0428824,-0.0367191,0.124433,0.289274,0.912308,0.909119,0.829032,0.761718,0.0509126,0.0589845,0.49029,0.491113,0.564511,0.566686,-0.176387,0.0118248,1.73426,2.08199,0.64633,0.66377,-0.547765,-0.484146,0.463534,0.490177,-0.149078,-0.327224,-0.377026,-0.529521,1.38185,1.26694,0.421493,0.45723,-0.134926,-0.00928391
3878,0.0348318,-0.0387959,0.69919,0.647957,0.0767623,-0.0939189,0.0159285,0.0176842,0.266479,0.294131,0.459884,0.457812,0.0305899,-0.0375001,0.769679,0.776626,0.656926,0.527386,0.298654,0.301713,-0.0707305,0.123272,0.634401,0.97753,0.767209,0.791674,1.09685,1.16725,0.383722,0.414744,-0.778538,-0.962764,0.292842,0.145653,0.692846,0.570673,-2.44262,-2.40408,0.416704,0.539718
3879,0.919569,0.848305,0.254227,0.204584,0.228941,0.0484783,0.150294,0.0720874,0.577305,0.606149,0.567092,0.535321,0.986871,0.917225,0.0346556,0.0409999,0.613302,0.563658,0.581809,0.567388,0.465504,0.626235,-0.166684,0.18286,0.905096,0.919577,-1.0544,-0.983083,-1.80706,-1.7811,-1.69162,-1.8751,-0.770981,-0.916954,-0.671346,-0.799532,-0.383467,-0.337441,-0.583837,-0.464071
3880,0.960515,0.888481,0.686292,0.638733,0.360938,0.190876,0.488605,0.41067,0.438486,0.543754,0.613499,0.612831,0.824722,0.753408,0.438954,0.447445,0.711984,0.59993,0.83175,0.833064,0.942353,1.1292,-0.205724,0.138094,-0.508903,-0.501536,0.0185591,0.0891931,-0.235715,-0.211521,-1.47185,-1.66074,-1.60941,-1.76045,0.160714,0.0372712,-0.217056,-0.174317,-0.551287,-0.512726
3881,0.562302,0.508503,0.645848,0.599361,0.0680931,-0.103094,0.477743,0.423219,0.453539,0.481359,0.948403,0.947254,0.407243,0.337398,0.104203,0.110707,0.651567,0.636203,0.190165,0.192401,0.049554,0.23125,1.57693,1.91413,-0.734682,-0.73035,-0.66092,-0.593634,0.440094,0.468487,0.968325,0.772881,0.312205,0.156282,-0.513827,-0.644868,-0.792163,-0.752787,-0.580311,-0.56138
3882,0.201811,0.128525,0.287592,0.240146,0.726297,0.5559,0.43273,0.435768,0.0917477,0.117931,0.106425,0.104185,0.986565,0.918549,0.419584,0.427046,0.00660891,-0.0084753,0.595422,0.507852,2.18578,2.37364,1.32981,1.67022,2.26468,2.27297,1.61184,1.68439,-0.413067,-0.38666,-0.704804,-0.903622,-0.0639727,-0.226042,1.23634,1.09958,-0.833867,-0.788841,-0.729801,-0.610035
3883,0.750393,0.674923,0.815953,0.7679,0.569272,0.399227,0.524847,0.448318,0.717761,0.742118,0.910205,0.908296,0.0881887,0.0200129,0.24029,0.250208,0.952053,0.935824,0.819461,0.823304,0.358048,0.605235,-1.17011,-0.837453,-1.21133,-1.19507,0.00703916,0.0719527,0.695327,0.72146,0.224772,0.0308414,1.16039,1.00514,-0.753218,-0.892288,0.495424,0.547056,1.63252,1.74976
3884,0.469731,0.395926,0.181269,0.132439,0.0564476,-0.114337,0.0828857,0.00638733,0.323392,0.348553,0.288735,0.288124,0.528264,0.461774,0.778915,0.78798,0.0876265,0.0708256,0.429535,0.433311,-1.35103,-1.16317,-2.72763,-2.39529,-0.0363334,-0.0132192,-0.947551,-0.877723,-1.24406,-1.21101,0.483915,0.323194,0.987873,0.838278,0.776365,0.631917,-0.291579,-0.24851,0.649129,0.760813
3885,0.618494,0.546018,0.0167173,-0.0307706,0.190789,0.0220962,0.910009,0.833261,0.573786,0.659489,0.0219052,0.0202471,0.538572,0.469366,0.557188,0.565568,0.0690635,0.0499695,0.249011,0.252971,-0.067309,0.116505,-0.325102,0.00270887,-0.234549,-0.210812,1.46519,1.53428,-0.756704,-0.715471,0.805137,0.615546,0.584666,0.440064,1.5632,1.42128,0.789327,0.835407,0.105758,0.222581
3886,0.365503,0.2931,0.876528,0.828682,0.684706,0.515494,0.941269,0.86604,0.947593,0.970424,0.770409,0.766375,0.0134362,-0.0574605,0.744486,0.752535,0.429177,0.41089,0.65128,0.657276,-0.721228,-0.534381,0.0909673,0.41886,0.768231,0.788682,0.732869,0.805004,-0.706324,-0.664326,1.67114,1.48733,0.702442,0.562819,0.802207,0.663302,1.00743,1.06063,1.37637,1.48865
3887,0.617248,0.544216,0.917125,0.867056,0.32657,0.155871,0.0051032,-0.0673511,0.604743,0.632325,0.98413,0.979461,0.78287,0.711922,0.713157,0.721457,0.488884,0.46905,0.499227,0.506917,0.912233,1.10246,-1.44743,-1.1235,-2.82422,-2.7983,0.439924,0.507254,1.8577,1.90593,-0.100361,-0.281527,-0.978726,-1.11103,-0.719997,-0.860963,0.524879,0.57612,0.808329,0.950903
3888,0.287006,0.214502,0.544954,0.492444,0.86597,0.693515,0.618697,0.545524,0.27277,0.294225,0.176264,0.172237,0.809081,0.739733,0.116269,0.125639,0.287735,0.266244,0.958916,0.965932,0.281782,0.466528,-0.140494,0.186155,-0.108706,-0.0340219,-1.04343,-0.979112,0.0976459,0.143718,-0.0395114,-0.220746,-0.232323,-0.35824,0.594102,0.448025,1.91066,1.95944,0.296902,0.413161
3889,0.697418,0.622362,0.494628,0.421416,0.249689,0.0795127,0.224454,0.15375,0.952977,0.975217,0.544992,0.541795,0.41176,0.343676,0.462232,0.496445,0.439247,0.425938,0.224746,0.232815,-0.0227835,0.154996,0.189771,0.51099,2.70434,2.73026,1.88601,1.94367,0.616355,0.668488,0.53918,0.331732,1.90325,1.78343,0.916996,0.765229,-0.868717,-0.815024,-1.09075,-0.97475
3890,0.015513,-0.0588799,0.404918,0.350388,0.340142,0.17063,0.0434186,-0.0282176,0.67129,0.623851,0.244344,0.242995,0.601749,0.535166,0.856515,0.867252,0.647314,0.585633,0.675335,0.681902,0.0419156,0.222095,-2.16593,-1.83737,0.197783,0.221619,-0.45494,-0.404099,-1.11252,-1.06185,1.0584,0.88421,-1.08045,-1.20537,0.828248,0.68128,1.28706,1.33497,0.979404,1.09305
3891,0.563516,0.487517,0.693937,0.590194,0.200089,0.0286238,0.229019,0.157286,0.248262,0.272486,0.315573,0.402016,0.137759,0.069435,0.393844,0.405844,0.677162,0.745327,0.642178,0.647883,-0.642851,-0.459915,1.61167,1.94023,0.547517,0.575671,-0.162853,-0.115681,-0.610857,-0.560556,-0.0560399,-0.225393,-1.09795,-1.21935,-0.670095,-0.810629,0.0672554,0.11811,-0.232483,-0.111019
3892,0.622281,0.54777,0.887199,0.83,0.712355,0.542637,0.964946,0.894634,0.679425,0.705031,0.560562,0.561038,0.188873,0.122709,0.437519,0.453584,0.926511,0.905021,0.222323,0.227294,1.79756,1.98146,-1.00113,-0.678896,-1.0014,-0.967651,-0.256506,-0.211471,-0.117115,-0.0592653,-0.114767,-0.287642,-0.530013,-0.649385,-0.42575,-0.630158,-2.45314,-2.40285,-0.562577,-0.436609
3893,0.182395,0.107262,0.697667,0.640488,0.796088,0.624567,0.759315,0.687758,0.226756,0.251641,0.0121068,0.011691,0.684933,0.619562,0.537761,0.501325,0.829176,0.809556,0.024963,0.0317235,-0.893504,-0.717963,0.463055,0.786579,-1.42544,-1.39451,-0.846122,-0.802715,0.164355,0.221785,0.994526,0.812967,-0.759755,-0.835354,-0.308354,-0.449688,-0.950426,-0.897279,0.635082,0.767066
3894,0.998526,0.925126,0.247559,0.192031,0.159414,-0.0135976,0.0730106,0.000673343,0.9071,0.932633,0.470701,0.469922,0.46241,0.344184,0.537655,0.549065,0.421028,0.400641,0.60082,0.605806,0.511736,0.685551,1.01838,1.34007,-0.935805,-0.905297,1.89269,1.94091,0.961228,1.02227,0.338367,0.160634,-0.902121,-1.02132,-0.671455,-0.808624,-0.938536,-0.887966,2.43126,2.55897
3895,0.233454,0.159877,0.157992,0.103668,0.815698,0.64085,0.547367,0.473682,0.763623,0.790802,0.186708,0.18717,0.134679,0.068807,0.0409838,0.0533807,0.268325,0.318816,0.263614,0.269376,-2.0247,-1.84215,-1.30132,-0.977654,0.41705,0.444029,0.717128,0.761893,-0.875742,-0.816806,0.527965,0.343744,0.0653165,-0.120774,1.17832,1.04307,0.499719,0.557241,-0.559426,-0.427597
3896,0.611442,0.537952,0.932512,0.879246,0.821934,0.65756,0.715219,0.643816,0.170925,0.196386,0.683875,0.68465,0.736635,0.669322,0.699196,0.713406,0.258644,0.23699,0.562512,0.573401,-0.637485,-0.38649,2.13913,2.45763,0.401666,0.429284,1.23197,1.27698,-0.966673,-0.908906,0.246119,0.0668309,0.895346,0.779777,0.811297,0.66766,-0.762151,-0.706831,0.209131,0.335393
3897,0.00317014,-0.0674849,0.847988,0.795915,0.736353,0.67427,0.620971,0.550844,0.998031,1.02425,0.270474,0.273645,0.591676,0.584183,0.787265,0.742098,0.937848,0.914844,0.871109,0.877426,0.886631,1.06917,-0.00708385,0.303071,-1.62347,-1.59911,2.30153,2.34926,0.314683,0.370022,1.0265,0.846588,1.79953,1.68033,0.422788,0.292246,0.042225,0.0942019,2.50394,2.62894
3898,0.557944,0.489064,0.381737,0.327655,0.865828,0.69098,0.252122,0.184035,0.792291,0.815155,0.450317,0.519813,0.566852,0.499044,0.685557,0.770789,0.446593,0.522529,0.704656,0.712424,-0.505722,-0.318609,0.0376211,0.393389,-0.0206286,0.0108386,1.74157,1.79094,2.29308,2.34485,0.267062,0.0875795,-0.300873,-0.416904,0.569415,0.439736,0.453302,0.506627,-0.533785,-0.411891
3899,0.420863,0.351256,0.490185,0.343051,0.470521,0.302583,0.902309,0.836299,0.645318,0.606057,0.761993,0.76598,0.791275,0.724892,0.786616,0.799481,0.155015,0.130214,0.243071,0.251565,1.37034,1.56314,0.168891,0.483707,1.076,1.10027,0.0298473,0.0832672,-0.516706,-0.458148,0.622726,0.440204,-0.25978,-0.371004,1.14382,1.01611,-0.833904,-0.776141,-0.286195,-0.165529
3900,0.0122559,-0.0586743,0.451297,0.358448,0.0911942,-0.0858141,0.49686,0.429274,0.386162,0.396958,0.322333,0.324426,0.629121,0.536717,0.275778,0.288211,0.475504,0.450881,0.675244,0.686198,0.436323,0.633895,-1.34487,-1.02667,1.21909,1.23814,-0.715742,-0.662985,-0.14031,-0.0200188,0.109806,-0.153873,0.31748,0.214024,-0.131817,-0.263123,0.115845,0.200094,-0.808466,-0.687145
3901,0.979761,0.911631,0.533761,0.373845,0.774364,0.59907,0.756754,0.690102,0.161636,0.187859,0.216966,0.220833,0.415686,0.348543,0.379071,0.347733,0.462896,0.440465,0.351255,0.41635,0.600171,0.791855,1.39941,1.71143,1.13481,1.14487,0.973255,1.02006,0.364011,0.41811,-0.514028,-0.747949,-0.276257,-0.383452,-0.952541,-1.0808,1.11856,1.17633,-0.597688,-0.470896
3902,0.0112373,-0.0573928,0.443324,0.389241,0.460528,0.284541,0.369761,0.303381,0.771473,0.797587,0.929283,0.931896,0.548314,0.479063,0.29355,0.407256,0.121724,0.10121,0.133933,0.146503,-0.648839,-0.458942,-1.4264,-1.11685,1.6766,1.68115,-0.124409,-0.0839413,-0.523295,-0.467198,-1.16599,-1.34203,0.264716,0.153637,0.955959,0.833343,-0.137882,-0.0743827,-1.5467,-1.41486
3903,0.957337,0.889579,0.815527,0.758954,0.825059,0.64692,0.280439,0.215188,0.424475,0.450159,0.840644,0.844026,0.207933,0.139026,0.455041,0.466779,0.5532,0.531667,0.284646,0.279285,-0.783891,-0.588704,-0.427394,-0.117176,-0.57428,-0.574215,1.46683,1.50328,0.64488,0.70387,1.35763,1.18311,-2.01345,-2.12112,0.461933,0.337589,0.830649,0.899094,0.237065,0.377044
3904,0.224073,0.155658,0.330312,0.275664,0.0725405,-0.103111,0.409374,0.253361,0.352694,0.379519,0.0799298,0.0844734,0.917134,0.847118,0.811769,0.824287,0.261838,0.242517,0.400135,0.412067,-1.62881,-1.4402,-2.0699,-1.75339,0.82934,0.834016,0.0891658,0.125081,1.52216,1.58295,0.59215,0.410121,1.41793,1.31137,0.841285,0.646639,-0.546014,-0.47817,0.121545,0.263567
3905,0.515694,0.534384,0.943995,0.890672,0.657275,0.480403,0.35706,0.291533,0.872018,0.89845,0.287695,0.299787,0.969355,0.900392,0.0990279,0.109808,0.992838,0.974218,0.782786,0.79623,0.770939,0.954919,-0.524204,-0.210789,-1.29298,-1.29212,0.0540108,0.0894366,1.22075,1.27825,1.28366,1.09746,0.550599,0.467338,1.08003,0.955688,0.120851,0.183423,-1.98337,-1.84787
3906,0.981525,0.91311,0.186488,0.134266,0.97787,0.801941,0.25914,0.193981,0.663808,0.665477,0.535939,0.5151,0.789582,0.63582,0.361361,0.370441,0.385863,0.368558,0.0994939,0.115171,1.18686,1.37477,-0.170107,0.234752,-0.994064,-1.00005,0.31095,0.345866,-1.41229,-1.35967,0.38664,0.19992,-0.273306,-0.376698,1.71777,1.59294,-1.33016,-1.27134,1.32467,1.45375
3907,0.924057,0.856441,0.819906,0.76956,0.880352,0.705958,0.375352,0.308434,0.40703,0.432504,0.810007,0.730413,0.440297,0.371249,0.313348,0.306256,0.475754,0.467608,0.0944179,0.0847887,0.325198,0.508215,0.370749,0.680293,-0.339889,-0.288462,-1.3324,-1.29804,-0.597042,-0.542389,0.0266827,-0.207748,-0.675776,-0.774911,-1.5001,-1.61808,0.940499,1.0051,-0.898908,-0.769673
3908,0.308253,0.240336,0.0632581,0.0131541,0.234577,0.0616674,0.923531,0.855825,0.577243,0.603031,0.941183,0.945727,0.804584,0.733709,0.235228,0.242071,0.584928,0.566659,0.041714,0.0544063,0.936201,1.16477,0.974106,1.28214,0.421874,0.423126,-0.0983978,-0.0709428,-1.79643,-1.74714,-0.4242,-0.615416,1.04572,0.95133,1.25928,1.14795,1.05207,1.1217,-0.521048,-0.388645
3909,0.134085,0.0683385,0.509019,0.456944,0.591372,0.367564,0.223111,0.153068,0.377127,0.401028,0.663728,0.667939,0.790272,0.721046,0.642826,0.604494,0.378957,0.326618,0.474027,0.476917,1.6383,1.82132,0.0681356,0.379991,1.76382,1.77245,0.771824,0.801026,-1.11853,-1.06713,0.465564,0.272935,-0.303793,-0.393104,-0.436882,-0.545251,0.160334,0.233764,-1.93214,-1.80601
3910,0.174558,0.199587,0.707693,0.66349,0.849058,0.673461,0.353298,0.282597,0.723623,0.747763,0.903653,0.90626,0.457435,0.390642,0.960179,0.966917,0.105055,0.086577,0.886131,0.899429,1.56826,1.75019,-1.47448,-1.16237,-0.0174828,-0.00491934,0.273722,0.303403,-0.662633,-0.698114,0.765186,0.574994,-0.230122,-0.315095,0.192066,0.0762722,1.28208,1.34779,-0.557549,-0.43381
3911,0.398702,0.330835,0.92219,0.870037,0.299345,0.124398,0.0409287,-0.0305049,0.566824,0.591888,0.795496,0.808927,0.666449,0.616545,0.527731,0.605415,0.595346,0.577371,0.206455,0.21837,0.306355,0.484661,1.75081,2.05954,0.216402,0.22603,0.309674,0.344724,-0.378487,-0.329099,-0.151924,-0.337345,2.31299,2.22572,-0.891529,-1.00311,0.792449,0.863275,1.64826,1.77711
3912,0.870531,0.802726,0.225403,0.174807,0.445856,0.266011,0.178164,0.109024,0.776114,0.801663,0.711484,0.711594,0.910109,0.842448,0.235612,0.243913,0.551134,0.532665,0.971843,0.98282,0.48276,0.707906,-1.6839,-1.38239,-1.223,-1.21002,-1.34496,-1.31687,-1.00914,-0.954225,0.0140078,-0.170061,1.49302,1.39968,1.78471,1.67781,1.06866,1.13373,-0.270845,-0.147548
3913,0.491502,0.42299,0.96669,0.915504,0.645069,0.407624,0.566493,0.497794,0.539441,0.564715,0.858767,0.777402,0.88701,0.819467,0.350013,0.423362,0.283159,0.274963,0.512045,0.521961,0.75044,0.931152,0.212734,0.515368,-0.102073,-0.0899269,-0.33084,-0.304372,1.33849,1.39931,-0.566546,-0.652445,-0.296837,-0.3831,0.0874787,-0.0153849,0.049969,0.117299,1.14841,1.27159
3914,0.577677,0.509052,0.572427,0.472149,0.740576,0.549237,0.509345,0.440551,0.545569,0.596735,0.842947,0.843209,0.246915,0.177592,0.561383,0.602811,0.0361683,0.0172596,0.803784,0.814901,-1.14698,-0.968652,-0.315631,-0.018066,0.661157,0.678763,0.342382,0.365012,-0.0910407,-0.0379962,-0.953454,-1.13483,-0.132709,-0.21494,-0.696933,-0.804123,0.708601,0.778892,1.32904,1.45842
3915,0.452846,0.385107,0.0788444,0.0287947,0.865798,0.69085,0.736627,0.66552,0.601046,0.628756,0.132301,0.133506,0.588306,0.519574,0.773963,0.78226,0.969107,0.951305,0.128626,0.138814,0.871349,1.05161,1.23306,1.52454,-0.92833,-0.910298,-1.05968,-1.02995,-1.53613,-1.47531,-0.331553,-0.513155,-0.224453,-0.304258,1.15014,1.04758,0.701197,0.773575,-0.967157,-0.843149
3916,0.780627,0.712683,0.221865,0.172346,0.513072,0.337119,0.355277,0.283175,0.131873,0.160452,0.133907,0.135577,0.376155,0.309204,0.417116,0.498835,0.60671,0.652894,0.734206,0.742597,-0.786474,-0.612892,0.764032,1.05273,-0.351372,-0.326869,0.059213,0.0120084,-1.37285,-1.31591,0.288025,0.108519,-0.0725915,-0.151224,0.79982,0.646978,-0.628728,-0.557933,0.279571,0.406106
3917,0.389419,0.32286,0.0565513,0.00913608,0.669557,0.535401,0.767038,0.692546,0.138398,0.168446,0.887886,0.887466,0.498437,0.429273,0.204998,0.21541,0.372432,0.354483,0.183603,0.1918,-1.73944,-1.57179,1.50265,1.79237,0.564063,0.594545,1.02423,1.05396,-0.129639,-0.0668073,0.469845,0.291629,0.523177,0.448471,0.348223,0.246379,-0.595711,-0.531297,-0.573488,-0.446455
3918,0.227749,0.239801,0.424759,0.473275,0.910948,0.733682,0.57537,0.500948,0.908049,0.937494,0.382969,0.382092,0.240158,0.172526,0.815357,0.825184,0.886925,0.869568,0.074836,0.0814372,-0.0525099,0.112164,-0.767988,-0.477135,1.84825,1.88165,-2.25091,-2.22103,0.0111658,0.0749325,-0.294045,-0.467379,-0.0552852,-0.136482,0.515847,0.408517,-0.234157,-0.165671,-1.64244,-1.51132
3919,0.220858,0.156741,0.985918,0.937413,0.414427,0.326126,0.125448,0.0490806,0.737633,0.788162,0.992126,0.992725,0.244468,0.175978,0.120348,0.132275,0.149315,0.133247,0.916159,0.920211,-0.87139,-0.709187,-1.64042,-1.34866,-1.01246,-0.976394,-1.27704,-1.2036,1.37558,1.44325,2.28576,2.10787,-1.28509,-1.36941,0.239649,0.0438875,0.750856,0.825814,-0.614464,-0.489871
3920,0.497944,0.433419,0.853711,0.803571,0.0963706,-0.0814291,0.261841,0.108633,0.612238,0.638829,0.719435,0.678803,0.842632,0.771971,0.986115,0.998535,0.588427,0.572733,0.172001,0.177121,1.55066,1.71531,-0.81029,-0.516841,0.608609,0.649749,-0.216045,-0.186169,0.55862,0.618484,-1.3469,-1.52515,0.684614,0.606942,-0.213413,-0.320742,1.04494,1.11255,-0.186546,-0.061961
3921,0.154665,0.0881667,0.107138,0.0578178,0.497909,0.321938,0.242841,0.168185,0.184052,0.210362,0.333273,0.36488,0.232348,0.160826,0.0731121,0.0859804,0.0406925,0.023437,0.712785,0.716514,-1.83052,-1.66567,-0.25994,0.0366466,-0.882199,-0.846772,-0.771711,-0.744488,-0.629923,-0.569874,-0.0730196,-0.255017,0.497122,0.425211,0.200372,0.0198908,-0.134653,-0.0602685,-0.729055,-0.600194
3922,0.841791,0.774324,0.912846,0.864823,0.598833,0.491496,0.917718,0.840968,0.482618,0.431738,0.0503582,0.0509573,0.959384,0.889484,0.216113,0.232294,0.974311,0.957483,0.889227,0.814708,0.539669,0.696715,-0.404776,-0.113043,1.52633,1.5578,0.733925,0.763898,0.422635,0.478569,-0.0466361,-0.22474,0.567991,0.503221,0.469833,0.360524,0.808251,0.883673,0.209554,0.34473
3923,0.0304106,-0.0375696,0.322657,0.27371,0.834732,0.661054,0.397571,0.418798,0.624732,0.653114,0.00283377,0.00376816,0.97307,0.902433,0.367947,0.378607,0.851235,0.834707,0.907516,0.912901,0.325422,0.476066,-0.761262,-0.47426,-1.52922,-1.49753,-0.610988,-0.583222,0.599498,0.652632,0.595945,0.419296,3.56846,3.50861,0.625082,0.522662,1.03869,1.1089,1.632,1.76387
3924,0.409157,0.340506,0.880157,0.830539,0.648335,0.473577,0.071745,-0.00337168,0.156706,0.18481,0.789763,0.792274,0.239927,0.168984,0.173386,0.181656,0.00818224,-0.00952383,0.0298008,0.0339091,-1.13748,-0.98791,-1.13152,-0.835477,-0.351365,-0.315674,0.726589,0.751114,0.233573,0.28567,0.197356,0.0194467,-0.805813,-0.869966,0.128338,0.0269081,-1.12463,-1.06459,0.387241,0.514731
3925,0.546741,0.476332,0.554686,0.478484,0.206595,0.0343538,0.444581,0.37047,0.0226526,0.0488678,0.452917,0.454638,0.623358,0.549513,0.832867,0.841682,0.80839,0.792224,0.390267,0.45642,-0.384149,-0.230271,0.404555,0.707125,-0.401745,-0.360028,0.460374,0.484422,2.08711,2.13243,0.953312,0.769029,-0.0870178,-0.14812,0.293608,0.189046,1.10061,1.16338,-0.35707,-0.231897
3926,0.885568,0.813432,0.173695,0.12643,0.816013,0.642217,0.280701,0.207605,0.370422,0.353771,0.435461,0.520445,0.999845,0.930041,0.627329,0.729089,0.747006,0.734437,0.875323,0.878931,1.8875,2.03649,-1.72395,-1.41414,0.605341,0.654657,-1.05652,-1.03451,1.05895,1.10843,-0.178469,-0.356475,-0.891072,-0.947238,0.995528,0.888133,-0.446703,-0.386506,0.442073,0.561384
3927,0.94883,0.878763,0.169376,0.116649,0.938916,0.763364,0.895654,0.82048,0.633608,0.658674,0.58402,0.586253,0.454336,0.383186,0.606042,0.616497,0.690869,0.67665,0.716193,0.718556,-1.33294,-1.18745,-1.12547,-0.812288,-0.0762537,-0.0238366,1.90483,1.9234,-0.325922,-0.270819,-0.0549834,-0.23396,-0.202192,-0.255721,0.793764,0.683085,-0.474139,-0.473392,-0.0759451,0.0397684
3928,0.62114,0.549049,0.131515,0.106869,0.444154,0.269083,0.91508,0.775741,0.437974,0.487213,0.316233,0.318376,0.156201,0.0865184,0.179542,0.190038,0.326925,0.312345,0.0367545,0.037497,0.460174,0.602666,-1.38238,-1.07409,-0.411,-0.359581,0.873986,0.896938,0.449936,0.501428,-0.272986,-0.449605,-0.702358,-0.761872,1.06665,0.954766,-0.614519,-0.560278,-0.123391,-0.0134512
3929,0.622997,0.621084,0.142129,0.0970883,0.185092,0.009084,0.807063,0.731002,0.289359,0.315752,0.827394,0.831188,0.550139,0.464635,0.883862,0.891115,0.311092,0.296923,0.869923,0.871365,-0.811892,-0.662865,-1.6503,-1.3359,-0.96376,-0.910404,-0.154526,-0.129524,2.72347,2.77255,0.698391,0.513918,1.02603,0.964369,-1.30338,-1.41013,-2.06792,-2.01504,0.474596,0.580786
3930,0.76521,0.693119,0.747451,0.70253,0.352937,0.175244,0.239331,0.162818,0.58729,0.586043,0.67974,0.68317,0.914,0.842751,0.637468,0.643118,0.903457,0.887562,0.42272,0.484674,1.71802,1.87489,-0.350656,-0.0402601,-0.970475,-0.910429,-0.232369,-0.210127,-0.626749,-0.581451,1.00635,0.815977,0.0214219,-0.0374356,-0.555022,-0.66605,-1.67783,-1.61814,-0.246693,-0.136539
3931,0.577416,0.593508,0.955348,0.910353,0.778485,0.599412,0.656624,0.580974,0.830678,0.856334,0.754336,0.759135,0.958548,0.885363,0.975016,0.98068,0.263659,0.247136,0.0946915,0.0979832,0.0361291,0.196122,-1.86969,-1.56741,-0.115717,-0.0501303,2.68142,2.69997,0.369807,0.420405,0.00056251,-0.213352,-0.574767,-0.634912,-0.409648,-0.51856,0.47103,0.531851,1.2515,1.35961
3932,0.535449,0.493897,0.759936,0.805058,0.426167,0.24568,0.655175,0.547154,0.550771,0.638093,0.112035,0.119479,0.764473,0.690415,0.982904,0.990959,0.220235,0.202431,0.674524,0.677318,1.23956,1.39811,0.197111,0.505094,-0.185857,-0.125884,-0.674132,-0.651135,0.623509,0.671124,-1.04799,-1.24268,0.300816,0.239614,1.06473,0.959082,1.75087,1.81802,-0.487157,-0.378445
3933,0.360277,0.394286,0.746689,0.699762,0.877071,0.694935,0.587222,0.513333,0.391897,0.419852,0.698521,0.70514,0.0593049,-0.0168002,0.110232,0.11905,0.546612,0.523258,0.983088,0.985096,-0.816285,-0.657602,-0.170668,0.14068,-0.639848,-0.583419,0.993549,1.01507,-1.74803,-1.70021,-1.04817,-1.24387,-0.480758,-0.542756,0.62611,0.524594,1.22601,1.28543,-0.249049,-0.145414
3934,0.365136,0.294675,0.903715,0.858712,0.0265857,-0.156042,0.00727157,-0.0652804,0.559188,0.540644,0.484979,0.404365,0.535813,0.459723,0.385959,0.395312,0.861258,0.844085,0.699181,0.699654,-0.219379,-0.0540635,-0.131938,0.173469,-0.624523,-0.567588,-1.61402,-1.58662,-0.762764,-0.713146,0.478376,0.287359,0.581349,0.516256,0.746224,0.640846,-1.73554,-1.68181,0.942962,1.04581
3935,0.542706,0.470082,0.224003,0.178116,0.308922,0.125243,0.0645459,-0.0310616,0.63318,0.661435,0.0973173,0.10359,0.202178,0.124563,0.316762,0.324343,0.479201,0.480842,0.134256,0.134062,-2.00743,-1.84268,0.413624,0.7124,0.667979,0.719517,0.202113,0.224602,0.957575,1.00834,0.0294576,-0.160986,-0.877777,-0.935162,-0.589406,-0.699762,-2.76022,-2.71141,0.393891,0.492824
3936,0.49726,0.434917,0.350507,0.306238,0.971965,0.78996,0.0751604,0.00315714,0.246988,0.2731,0.375852,0.475506,0.377144,0.253729,0.486957,0.523233,0.136201,0.1176,0.978774,0.978047,-0.244831,-0.0845105,0.0784541,0.377834,0.150642,0.201722,1.57169,1.58955,0.0169015,0.149991,-0.0952243,-0.286278,1.17519,1.12176,0.361251,0.245741,-1.09958,-1.04655,1.30044,1.40556
3937,0.470553,0.399751,0.135145,0.091783,0.96215,0.781429,0.377086,0.303548,0.36614,0.392495,0.843177,0.847422,0.459496,0.382894,0.59842,0.722124,0.056084,0.0372355,0.0432043,0.0401105,-1.44343,-1.2885,-0.95953,-0.664184,-0.364531,-0.316073,0.307583,0.332129,-0.7664,-0.70836,-0.722093,-0.906566,-0.758871,-0.818485,1.02949,0.914479,0.569497,0.61831,-0.202368,-0.102253
3938,0.791795,0.721148,0.891927,0.847286,0.542373,0.361763,0.222246,0.155744,0.887973,0.916015,0.131537,0.137719,0.0837504,0.00693075,0.913434,0.921015,0.910482,0.892981,0.543608,0.462622,-0.692711,-0.530865,-0.743885,-0.445853,0.275796,0.328795,-0.485164,-0.458674,0.467959,0.525142,-1.01781,-1.19847,-0.125999,-0.187651,-0.332577,-0.441598,1.93194,1.98639,-0.388705,-0.291542
3939,0.0953896,0.0229051,0.632706,0.652903,0.504544,0.322944,0.0838383,0.00793962,0.19175,0.220171,0.353357,0.36175,0.645841,0.568443,0.463246,0.470192,0.300489,0.282728,0.888119,0.885133,0.576493,0.733391,-0.0182866,0.212491,-0.547782,-0.488555,-0.103113,-0.0802424,0.583727,0.636835,1.48071,1.29502,-0.312075,-0.363415,0.142485,0.0269324,-0.823058,-0.77418,1.59466,1.69599
3940,0.714346,0.643093,0.504634,0.45852,0.0525954,-0.13105,0.794839,0.720764,0.649028,0.677792,0.0640906,0.0728382,0.904517,0.825043,0.513914,0.611547,0.725476,0.707413,0.780419,0.779428,-1.43539,-1.27698,0.577482,0.870835,1.1629,1.21692,-0.614489,-0.593699,-0.745695,-0.696448,1.05095,0.863891,-0.476913,-0.539179,1.81395,1.69141,-0.618769,-0.565939,0.266706,0.370337
3941,0.192439,0.122452,0.615476,0.567282,0.68616,0.502721,0.350278,0.274873,0.527788,0.607494,0.849025,0.855923,0.722644,0.645048,0.658282,0.752903,0.554944,0.534149,0.13973,0.138765,-0.967415,-0.810086,-0.670821,-0.372084,1.02864,1.08197,-0.741148,-0.719974,-0.433593,-0.387073,-1.27525,-1.47057,-1.29856,-1.36522,0.8543,0.735147,0.786559,0.833785,1.42928,1.52939
3942,0.0161394,-0.0550934,0.241516,0.19267,0.174651,-0.010843,0.56684,0.459926,0.38859,0.537195,0.345585,0.35055,0.250824,0.173943,0.886953,0.894258,0.783564,0.760757,0.321665,0.32109,-1.21607,-1.0605,-0.245165,0.00251756,-1.28226,-1.22382,1.29775,1.31268,0.441805,0.492006,-0.65713,-0.856356,-1.31525,-1.3792,1.52679,1.40388,-0.349823,-0.306299,1.50291,1.59762
3943,0.483007,0.411573,0.130263,0.0929574,0.241303,0.0557913,0.596446,0.644979,0.438358,0.466897,0.981895,0.98653,0.781449,0.705096,0.121903,0.127848,0.328191,0.306174,0.087327,0.0854111,-0.251576,-0.0892492,0.0777978,0.37712,0.357126,0.41887,0.480058,0.489126,0.607446,0.651403,1.3618,1.16928,-0.305979,-0.365857,1.31514,1.19884,1.61799,1.66057,0.360033,0.453482
3944,0.674703,0.608084,0.0398848,-0.0067553,0.812346,0.628338,0.906297,0.830031,0.7432,0.774158,0.220449,0.226977,0.236925,0.162832,0.844909,0.85017,0.253844,0.236793,0.594486,0.593913,1.09457,1.25281,1.54871,1.84259,0.091285,0.160059,0.120292,0.129318,0.0577233,0.102627,-0.127137,-0.326777,-1.08481,-1.14823,-0.351481,-0.463538,-0.89992,-0.860393,1.6817,1.77987
3945,0.874272,0.804596,0.786945,0.738364,0.280399,0.094523,0.111046,0.0344834,0.107196,0.139261,0.346543,0.351882,0.718664,0.645081,0.399689,0.465152,0.187782,0.167412,0.837327,0.837006,-1.92908,-1.77392,0.11669,0.408587,-2.27672,-2.20797,-0.981847,-0.974685,0.169352,0.214321,-2.29338,-2.50185,2.07088,2.01115,-0.405763,-0.576502,-1.88063,-1.84361,1.47308,1.57552
3946,0.584135,0.51518,0.10711,0.0577675,0.722751,0.538269,0.935723,0.861357,0.879544,0.913432,0.0508511,0.0577325,0.561319,0.437092,0.0731422,0.0801341,0.374854,0.353597,0.319421,0.321655,0.749986,0.901144,-0.755724,-0.462941,0.374579,0.450807,0.416477,0.420289,1.35755,1.40049,0.0330929,-0.171994,-0.15114,-0.209676,-0.575963,-0.689466,-0.697492,-0.665323,-0.728992,-0.628639
3947,0.00272568,-0.0656314,0.482394,0.431975,0.644799,0.558185,0.319126,0.243705,0.957027,0.992181,0.22856,0.163118,0.304977,0.229103,0.130989,0.135873,0.858243,0.838605,0.0791393,0.082,-0.555312,-0.408896,-1.11779,-0.827355,-2.90516,-2.82541,1.18555,1.18357,0.845246,0.882457,-1.11943,-1.32697,0.496098,0.437223,1.72558,1.619,-0.935107,-0.902844,0.465659,0.562582
3948,0.238379,0.224002,0.0219585,-0.0262422,0.764363,0.578101,0.945781,0.870873,0.0587334,0.0922124,0.262393,0.268503,0.862785,0.785995,0.956386,0.959928,0.245888,0.228352,0.662436,0.666288,0.0414665,0.194643,-1.77876,-1.4827,2.00569,2.08544,-0.013367,-0.0120152,-0.203355,-0.171398,-0.441535,-0.652025,0.648963,0.534362,0.958257,0.846553,-0.63346,-0.599938,-0.00405964,0.154086
3949,0.584295,0.513635,0.355753,0.246063,0.488306,0.303683,0.615654,0.538101,0.0991279,0.134392,0.23491,0.240762,0.286861,0.208923,0.52568,0.496092,0.128439,0.111181,0.425127,0.430609,1.98918,2.13764,-1.01717,-0.728196,0.1168,0.199139,0.231155,0.230087,-0.47446,-0.429858,-0.0121592,-0.16183,0.694188,0.631501,-0.147948,-0.26295,-1.27393,-1.23923,-0.344959,-0.254411
3950,0.62913,0.452613,0.566357,0.518369,0.525313,0.34005,0.891363,0.813355,0.842981,0.87742,0.429089,0.434506,0.233313,0.15478,0.030531,0.0322572,0.377081,0.357257,0.587113,0.592372,-1.4314,-1.2804,1.30402,1.59026,-1.01659,-0.929798,-0.719082,-0.719588,-0.720906,-0.688318,0.533677,0.328365,-1.7921,-1.86102,1.27084,1.15674,-0.317335,-0.281432,-0.244199,-0.158293
3951,0.50594,0.39159,0.240629,0.192845,0.778061,0.59062,0.626176,0.549916,0.225764,0.258028,0.238941,0.246026,0.413324,0.335537,0.559712,0.559132,0.395196,0.377043,0.356162,0.361555,0.0351453,0.18725,-1.29868,-1.01131,-1.39543,-1.31101,-0.919037,-0.922321,0.464745,0.497854,1.59155,1.38676,0.538413,0.472207,-0.411318,-0.521022,-1.91754,-1.87686,0.927389,1.01559
3952,0.401227,0.330567,0.672348,0.622415,0.519062,0.330621,0.847467,0.696302,0.321226,0.352919,0.992757,0.997915,0.0540184,-0.0254143,0.35014,0.347523,0.149606,0.133852,0.509769,0.60011,-0.757749,-0.603873,0.806009,1.0966,-2.03663,-1.95714,-0.190983,-0.189273,-0.738478,-0.706893,0.180982,-0.0172135,0.952356,0.887491,-0.2376,-0.34463,-0.872901,-0.838392,0.466945,0.555496
3953,0.899109,0.826973,0.230114,0.179042,0.7076,0.520974,0.91775,0.842689,0.092466,0.12558,0.640618,0.645596,0.929019,0.847783,0.893968,0.890303,0.78838,0.771086,0.8307,0.838664,-0.668932,-0.522743,0.0269364,0.315687,1.48598,1.56547,-1.29433,-1.29328,1.4955,1.52816,0.0938114,-0.110283,2.38221,2.3199,-0.663931,-0.829384,-1.00266,-0.968238,0.611229,0.697553
3954,0.801444,0.749636,0.932154,0.879274,0.00939405,-0.178435,0.0477777,-0.0273749,0.835207,0.868607,0.95837,0.961174,0.609462,0.439636,0.258576,0.25366,0.305184,0.286183,0.795189,0.804644,0.638631,0.786318,0.100357,0.344409,-0.565126,-0.480952,1.80405,1.80034,-1.81561,-1.78963,-1.12802,-1.32531,0.0966057,0.0308747,-1.2064,-1.31414,0.291498,0.333665,-1.40431,-1.32195
3955,0.745459,0.672298,0.841646,0.790911,0.513676,0.325125,0.703098,0.629662,0.941333,0.972406,0.668586,0.617772,0.112864,0.0314884,0.910269,0.903147,0.292154,0.270761,0.113965,0.123586,0.972546,1.11401,0.0919755,0.373132,-0.205633,-0.1269,0.191704,0.187904,-0.778959,-0.763136,1.72934,1.52974,-1.98888,-2.04934,1.10684,0.994327,1.29544,1.34015,-0.248386,-0.162891
3956,0.209052,0.136041,0.976903,0.924764,0.624567,0.43692,0.789523,0.671103,0.585983,0.618889,0.273069,0.27437,0.643254,0.562641,0.405681,0.464754,0.953506,0.933093,0.88668,0.89425,-0.264375,-0.119927,-0.0551537,0.223442,1.12845,1.20618,-0.263705,-0.263436,0.238387,0.263362,-0.783633,-0.983347,-0.388453,-0.447069,1.49565,1.38711,-2.32339,-2.27349,-1.50514,-1.41203
3957,0.278348,0.206774,0.304101,0.253746,0.0346144,-0.151821,0.78394,0.712544,0.0213097,0.0549826,0.672738,0.674,0.398945,0.273779,0.0334838,0.0263618,0.488635,0.468209,0.848422,0.855732,1.77913,1.93202,0.0303119,0.30162,-1.19012,-1.11188,-0.43724,-0.436932,-1.39545,-1.37488,0.412287,0.135665,-0.514364,-0.566684,-0.721468,-0.830766,2.23362,2.27868,0.620515,0.719162
3958,0.802986,0.733581,0.652877,0.604249,0.528544,0.341576,0.634597,0.62019,0.853882,0.887086,0.0797291,0.0791191,0.0635342,-0.0150839,0.54279,0.533366,0.929374,0.907696,0.38848,0.394873,0.368039,0.528112,-0.433608,-0.170181,0.369346,0.451307,0.306549,0.311672,0.838991,0.860167,1.45795,1.25468,-0.166714,-0.276634,-0.504569,-0.606262,-1.85471,-1.81397,1.60712,1.7088
3959,0.178161,0.107694,0.623944,0.644558,0.695379,0.507736,0.599389,0.527836,0.390771,0.423366,0.0540901,0.051378,0.740586,0.662406,0.378017,0.370607,0.446601,0.422793,0.940339,0.948986,-0.271288,-0.107822,1.59244,1.85753,-0.842002,-0.75427,-1.04468,-1.03545,0.816153,0.833283,-0.495776,-0.702926,0.0708849,0.0134167,1.21046,1.10853,0.0789629,0.117367,-0.277163,-0.168493
3960,0.667999,0.599221,0.787893,0.684866,0.502226,0.3157,0.728581,0.657364,0.191461,0.226246,0.283929,0.280062,0.6789,0.598276,0.875515,0.867863,0.346588,0.227565,0.23697,0.24635,0.921638,1.09416,-0.0126337,0.25319,0.885871,0.968117,0.564397,0.569128,-0.91109,-0.897051,-0.900995,-1.10278,-0.691644,-0.753531,-0.0857804,-0.187329,1.01946,1.06131,0.0354633,0.140133
3961,0.173648,0.103827,0.667237,0.725175,0.822629,0.637238,0.107864,0.0343396,0.511608,0.452867,0.992149,0.986585,0.307029,0.227562,0.749373,0.744248,0.0543576,0.0323367,0.432162,0.41256,0.502851,0.674855,0.205695,0.434209,0.258526,0.337193,-1.456,-1.45602,0.0400054,0.0588255,1.12654,0.922864,0.732873,0.664918,-1.03833,-1.14359,-2.0034,-1.95726,-0.911727,-0.803831
3962,0.770755,0.698849,0.814113,0.765484,0.86986,0.667777,0.509621,0.438821,0.646606,0.679489,0.780701,0.862725,0.806857,0.729878,0.628736,0.620632,0.161635,0.141918,0.456846,0.57877,0.761932,1.01436,0.346154,0.615229,-0.156454,-0.0753042,-0.917473,-0.919227,1.25198,1.27673,-0.704258,-0.908601,-0.504707,-0.568006,-1.50973,-1.61838,-1.52394,-1.48228,1.22408,1.32736
3963,0.944385,0.874256,0.0965628,0.0455822,0.883007,0.698315,0.169239,0.0973559,0.362902,0.39707,0.743955,0.738865,0.609262,0.530221,0.101548,0.0948228,0.846547,0.829136,0.7356,0.744981,1.18909,1.35387,1.06553,1.27357,-1.21109,-1.12583,-0.381227,-0.382433,1.55677,1.5861,1.8131,1.6022,0.684086,0.61676,-1.99341,-2.09316,-0.723469,-0.681251,1.57412,1.67929
3964,0.601169,0.462219,0.593119,0.544062,0.423853,0.264042,0.73858,0.665039,0.328163,0.362713,0.733711,0.784253,0.986116,0.90698,0.751766,0.74431,0.846634,0.89226,0.299751,0.308759,-1.28275,-1.1103,1.65574,1.93192,0.2705,0.359267,1.08686,1.08004,0.69623,0.730953,-1.25791,-1.46759,-2.0756,-2.14013,0.137782,0.0392606,1.24357,1.28562,-1.08492,-0.97763
3965,0.120455,0.050183,0.696019,0.648066,0.0133489,-0.170232,0.59757,0.565101,0.687162,0.72034,0.835565,0.829641,0.117407,0.0408489,0.939028,0.931276,0.971138,0.955384,0.979918,0.987619,0.641664,0.815352,0.127181,0.404764,-2.25003,-2.16406,0.911674,0.906543,-1.58526,-1.54667,1.56953,1.35397,-0.440887,-0.506361,0.665992,0.61803,-0.233839,-0.186911,-0.195142,-0.0945637
3966,0.343586,0.226035,0.0585828,0.0126048,0.896073,0.711841,0.501155,0.465163,0.714549,0.684565,0.101454,0.0950388,0.0904776,0.0124618,0.569084,0.559311,0.622775,0.605772,0.369559,0.377665,0.672643,0.849277,-0.964007,-0.683529,-0.249992,-0.162663,1.07741,1.07156,0.74966,0.791879,-0.809517,-1.02604,-0.318973,-0.383606,1.30171,1.1968,1.7437,1.79439,-1.70108,-1.60237
3967,0.569647,0.401888,0.99078,0.943951,0.525791,0.342497,0.478625,0.365225,0.592838,0.64879,0.85583,0.851905,0.695301,0.61922,0.436778,0.427523,0.783966,0.789441,0.653971,0.661022,1.10143,1.28352,0.748397,1.02872,-0.177334,-0.0854384,-0.172601,-0.185858,0.375325,0.369537,0.322428,0.106841,2.04591,1.98093,0.164217,0.0576003,1.71151,1.75834,-0.308751,-0.214539
3968,0.648013,0.57774,0.209711,0.162037,0.652425,0.468708,0.234235,0.265287,0.581627,0.613015,0.103312,0.0974702,0.840004,0.765009,0.831678,0.824161,0.991567,0.973111,0.29107,0.299922,1.12645,1.30482,0.765891,1.0448,-0.501428,-0.329328,0.610377,0.592428,-0.0943986,-0.0528051,-0.401604,-0.619587,1.68358,1.61375,-0.426315,-0.531333,0.706296,0.7588,0.0559393,0.153357
3969,0.390126,0.365028,0.190701,0.141378,0.137989,-0.0448554,0.141411,0.165349,0.93312,0.965043,0.538773,0.531595,0.58526,0.493364,0.511369,0.502241,0.517714,0.580796,0.588439,0.597351,-0.0034887,0.120677,0.0804376,0.358558,-0.662172,-0.573218,-0.405877,-0.417451,0.349314,0.394966,-2.0082,-2.22191,0.604858,0.534975,-0.360444,-0.462079,-1.13209,-1.07833,-1.60162,-1.50794
3970,0.203701,0.152315,0.601743,0.551462,0.983061,0.801541,0.138951,0.0654106,0.32546,0.355542,0.769878,0.764974,0.216516,0.221718,0.953293,0.944479,0.203975,0.188481,0.0138,0.0216569,-1.24107,-1.06347,0.281736,0.56053,0.250887,0.333903,0.926991,0.916886,-1.56402,-1.52042,1.11696,0.900538,-0.00604664,-0.0798003,-0.951752,-1.05101,0.104468,0.162607,-0.233126,-0.135738
3971,0.00987534,-0.060397,0.283431,0.231109,0.594868,0.412062,0.887763,0.813872,0.382328,0.41257,0.788529,0.781668,0.025067,-0.049928,0.237784,0.23,0.682131,0.668504,0.449971,0.369909,0.418625,0.589061,-0.761204,-0.481488,0.290982,0.378688,-1.34153,-1.34709,-2.88364,-2.83787,0.101886,-0.117918,0.045159,-0.0339008,0.0887906,-0.0149992,-2.56664,-2.51428,-1.15994,-1.06537
3972,0.446913,0.377619,0.72616,0.674898,0.480762,0.302322,0.148516,0.0756641,0.041343,0.0689955,0.117109,0.11122,0.152076,-0.0174281,0.79721,0.787899,0.646583,0.633433,0.712774,0.718162,0.28582,0.459299,-1.33528,-1.06041,1.1149,1.21069,-0.660261,-0.662539,-0.0248183,0.0226098,0.0932745,-0.0871677,0.734529,0.657616,-1.35943,-1.46205,0.984746,1.03517,-1.60272,-1.51122
3973,0.137617,0.0685724,0.799616,0.748565,0.374254,0.192582,0.153883,0.0498591,0.113696,0.20677,0.132824,0.127914,0.130856,0.0150718,0.576531,0.565487,0.102686,0.0889441,0.271976,0.277103,1.05222,1.23113,0.639836,0.917602,1.46106,1.56474,0.98864,0.98886,-1.32881,-1.27765,0.160662,-0.0564172,0.426773,0.352537,-0.62859,-0.730734,0.21457,0.271348,-0.514675,-0.467981
3974,0.0533173,-0.0144674,0.23665,0.186377,0.516913,0.334534,0.0949789,0.0240542,0.363108,0.344544,0.980152,0.973923,0.122043,0.0475717,0.870734,0.862131,0.423274,0.409611,0.933665,0.940447,-0.0444114,0.132996,-1.0849,-0.814351,0.761529,0.8723,-1.2593,-1.25701,0.52398,0.569118,-1.98493,-2.20115,-1.00414,-1.08492,0.773681,0.673145,-2.09862,-2.04768,0.486864,0.575259
3975,0.587581,0.522312,0.0891689,0.133626,0.0123601,-0.169602,0.299712,0.268497,0.454666,0.482318,0.605755,0.597099,0.467702,0.479204,0.731334,0.749539,0.427478,0.415053,0.999613,1.00719,0.23258,0.415924,-0.687317,-0.41456,-1.37492,-1.26987,-0.597069,-0.587622,-0.333341,-0.286029,1.47996,1.2688,-1.25765,-1.40049,-0.00303535,-0.0993007,-0.212156,-0.163179,-0.256438,-0.171368
3976,0.015522,-0.0483083,0.13321,0.0808747,0.165245,-0.0180037,0.701454,0.512941,0.337665,0.364696,0.48832,0.479714,0.987629,0.910836,0.646377,0.636947,0.852859,0.839738,0.448184,0.456393,-0.0341388,0.149369,-1.66309,-1.39354,-0.887484,-0.780652,0.705363,0.715051,-0.891898,-0.864598,2.63457,2.41585,-1.62811,-1.71606,0.935876,0.846202,-0.136518,-0.0914219,-0.528883,-0.391343
3977,0.448908,0.384654,0.877594,0.825994,0.602305,0.421321,0.828309,0.757384,0.216686,0.247074,0.762873,0.754711,0.433658,0.358092,0.0990256,0.0914235,0.160229,0.148764,0.303596,0.320886,-0.04904,0.140089,-0.899549,-0.623622,-1.56211,-1.45915,0.248991,0.263711,-1.48424,-1.44317,-0.534309,-0.747176,-1.17886,-1.26916,-0.0553345,-0.140122,-0.753769,-0.714485,-0.704449,-0.611319
3978,0.104042,0.0394024,0.0898604,0.038112,0.418401,0.203312,0.742219,0.669191,0.945367,0.975072,0.803955,0.795093,0.202295,0.126767,0.620118,0.61373,0.889174,0.87612,0.21912,0.185378,0.653092,0.835091,0.221381,0.502109,0.782053,0.883068,0.532492,0.552129,0.685655,0.725712,-0.0119293,-0.225022,0.0744104,-0.0222141,-1.68496,-1.77102,0.482081,0.526456,-0.167743,-0.0775879
3979,0.742283,0.675213,0.56007,0.506474,0.167878,-0.0146965,0.156654,0.0814159,0.480641,0.511352,0.471505,0.461611,0.602802,0.528704,0.393488,0.386769,0.332776,0.321627,0.0416626,0.0498711,-0.0930766,0.0929599,-1.45251,-1.16614,0.454326,0.560876,1.23165,1.25327,0.715245,0.761513,-0.981375,-1.19748,-1.76927,-1.86638,-0.260832,-0.351336,-0.0890733,-0.0520136,-0.167757,-0.0849669
3980,0.404951,0.340061,0.481764,0.462176,0.247082,0.0672331,0.221311,0.207791,0.253947,0.284013,0.783668,0.771801,0.153546,0.0778637,0.687623,0.633634,0.0384048,0.0274002,0.938358,0.948242,-0.310318,-0.127689,0.64352,0.922121,0.533948,0.638101,-0.612425,-0.593007,0.293412,0.298443,-0.323252,-0.539479,0.182261,0.0787805,0.119863,0.0554832,0.833535,0.875557,-0.672534,-0.591456
3981,0.753178,0.687057,0.472272,0.417878,0.836526,0.655603,0.479615,0.334165,0.914713,0.944399,0.168924,0.156891,0.600478,0.52401,0.888324,0.8805,0.919512,0.910221,0.708619,0.717425,1.4043,1.58592,-1.07677,-0.791047,0.267751,0.37929,0.367857,0.388351,-0.215447,-0.164628,1.1785,0.959865,-0.359955,-0.460923,0.557287,0.462302,-1.08212,-1.04262,-0.318388,-0.239523
3982,0.444391,0.37801,0.945415,0.891541,0.330071,0.151466,0.654535,0.46054,0.105238,0.134285,0.812038,0.797697,0.839898,0.765122,0.0181566,0.00859011,0.806317,0.798233,0.83459,0.786668,0.145241,0.320392,-1.48313,-1.20153,0.973876,1.08607,-0.389625,-0.373529,0.0296995,0.0860916,-0.106216,-0.320304,0.0452157,-0.120302,1.61598,1.51354,0.753853,0.793671,0.253553,0.326453
3983,0.978691,0.914789,0.57499,0.579587,0.137411,-0.0405692,0.662152,0.586914,0.827405,0.856548,0.711033,0.694104,0.156187,0.0832673,0.29054,0.279268,0.310896,0.303145,0.847801,0.855911,0.74022,0.909985,-2.12043,-1.84109,-0.794181,-0.675242,1.91584,1.93788,-0.0384181,0.0106592,0.565916,0.354642,0.325057,0.220319,-1.71438,-1.81247,1.2558,1.30185,-0.807696,-0.738414
3984,0.979296,0.839598,0.323512,0.267632,0.580156,0.353609,0.358719,0.284483,0.572923,0.604655,0.0339736,0.018554,0.848645,0.776088,0.0984826,0.0871477,0.503689,0.436267,0.306112,0.314751,-0.830534,-0.662009,0.914985,1.19698,0.276948,0.399991,-1.2651,-1.24571,-1.85666,-1.81365,0.372919,0.154698,-0.463303,-0.562051,0.023597,-0.0680313,1.44933,1.49441,1.35479,1.42758
3985,0.827261,0.764407,0.15962,0.104423,0.924676,0.747788,0.29369,0.217543,0.624081,0.656994,0.88219,0.864563,0.497072,0.425734,0.611445,0.599142,0.577656,0.569388,0.0663858,0.0750961,-0.841124,-0.671289,-0.381923,-0.0934222,-1.36143,-1.2341,0.372014,0.389939,-1.2998,-1.2589,1.4982,1.28758,0.217011,0.113123,1.34731,1.25699,0.53998,0.586668,0.550376,0.620438
3986,0.286402,0.22331,0.980613,0.927398,0.732774,0.555753,0.456993,0.382384,0.179795,0.213558,0.677077,0.660292,0.149057,0.0753797,0.00886602,-0.00191216,0.31685,0.310577,0.95535,0.963477,-0.159717,0.00871378,-0.836231,-0.465303,-1.47475,-1.3406,-0.755116,-0.743277,0.414062,0.462584,2.03009,1.82361,-0.0396203,-0.145297,-1.08785,-1.17814,-0.65279,-0.601824,-0.767905,-0.705213
3987,0.864563,0.799855,0.938345,0.887476,0.244917,0.0658661,0.00107146,-0.0746211,0.987095,1.02046,0.964797,0.949459,0.73494,0.661642,0.0280375,0.0229326,0.356018,0.276186,0.837765,0.847685,-0.845839,-0.673297,-1.12571,-0.837185,-1.21358,-1.07814,2.03527,2.04208,0.125225,0.174174,-1.54978,-1.76241,1.20071,1.10165,-0.919974,-1.01601,-2.11293,-2.05659,1.68976,1.75407
3988,0.922727,0.860108,0.90077,0.847554,0.224701,0.0470445,0.347477,0.274166,0.57067,0.601418,0.593599,0.558152,0.636584,0.561984,0.0593729,0.0477774,0.250869,0.241795,0.434714,0.447124,-0.938333,-0.759473,0.273058,0.564423,-0.0428093,0.0883425,-0.424507,-0.423658,-0.897426,-0.849828,0.225574,0.0175939,-0.881127,-0.978568,-0.0300075,-0.119229,-0.644395,-0.593965,1.2613,1.32268
3989,0.591053,0.530394,0.569603,0.517298,0.983734,0.803512,0.186449,0.111301,0.482377,0.510714,0.179931,0.166846,0.895168,0.818584,0.579033,0.496785,0.00789692,-0.00139515,0.828132,0.84169,-0.0101971,0.165227,-0.376669,-0.0909234,-0.442501,-0.308446,-0.565937,-0.565564,-1.08351,-1.03316,-0.36419,-0.570935,0.0537564,-0.0417007,-0.098635,-0.187272,0.472184,0.520061,1.75757,1.8117
3990,0.483293,0.345521,0.828848,0.778167,0.744781,0.565148,0.263945,0.189931,0.745169,0.771781,0.668849,0.65399,0.612814,0.537667,0.956039,0.945793,0.580226,0.573333,0.883851,0.810241,-1.18738,-1.00724,-0.00987475,0.277738,0.557852,0.691047,-0.389967,-0.384508,-1.6368,-1.58194,-0.746881,-0.955157,-2.45569,-2.54993,0.671755,0.587244,-0.42244,-0.367877,-0.051324,-0.00295862
3991,0.222751,0.160649,0.463007,0.413653,0.305413,0.125925,0.0548193,-0.016945,0.0461048,0.0713526,0.458206,0.448175,0.873868,0.79924,0.294184,0.283688,0.262224,0.254056,0.800404,0.778792,-0.190749,-0.00503775,1.00424,1.29345,0.595101,0.721691,0.033757,0.0398859,-0.0349119,0.0179897,-0.494026,-0.718741,0.238236,0.137223,-0.723961,-0.812852,-0.472453,-0.334791,-1.07627,-1.02225
3992,0.721079,0.657054,0.890108,0.843223,0.431968,0.281992,0.880143,0.809929,0.378341,0.335507,0.255782,0.24236,0.516259,0.391092,0.423618,0.41471,0.361345,0.324929,0.733529,0.747343,0.0838011,0.277891,-0.886957,-0.596417,1.22671,1.34992,0.844669,0.84936,-1.33532,-1.28227,-0.269515,-0.482325,-0.147885,-0.245102,0.220132,0.132651,-0.356699,-0.301705,1.32556,1.38526
3993,0.115339,0.051617,0.486611,0.439569,0.651142,0.43806,0.0236443,-0.0490607,0.604554,0.599661,0.690701,0.676485,0.0570309,-0.0170552,0.985329,0.976946,0.301011,0.395802,0.352412,0.366936,-0.150665,0.0417861,-0.814994,-0.461505,-1.9061,-1.78677,0.0309113,0.0417809,-0.0180894,0.042154,0.551134,0.342585,0.540286,0.446415,0.198206,0.109386,0.299829,0.359888,0.455358,0.515869
3994,0.678113,0.61287,0.582734,0.536959,0.797858,0.594127,0.55943,0.488411,0.839036,0.863816,0.57273,0.570484,0.188075,0.113465,0.513829,0.505923,0.475813,0.466674,0.38613,0.35233,-1.94304,-1.74684,-0.617803,-0.326593,0.305448,0.423604,-1.28189,-1.27473,-0.0274753,0.031726,0.396562,0.186973,0.875572,0.783462,-0.368885,-0.380505,-1.16826,-1.11264,0.220105,0.281721
3995,0.548797,0.484313,0.676738,0.634349,0.929503,0.750194,0.541054,0.471238,0.639607,0.611983,0.479538,0.464483,0.0429012,-0.0314718,0.570942,0.561662,0.545714,0.537547,0.323586,0.337724,0.620782,0.823844,1.27679,1.57117,0.228304,0.4078,-1.3393,-1.32442,0.739801,0.803973,0.631743,0.416026,-1.91982,-2.01563,-0.778797,-0.870395,0.194109,0.25544,-0.304232,-0.239894
3996,0.66748,0.576645,0.777008,0.73174,0.833555,0.654212,0.11077,0.0393412,0.337947,0.36015,0.0861267,0.0723501,0.881058,0.808936,0.0696721,0.060394,0.13638,0.128632,0.11485,0.126928,-0.58524,-0.38015,1.49069,1.7895,0.267552,0.391996,-1.93593,-1.91566,-1.37796,-1.31407,0.619968,0.400256,-2.70685,-2.798,-0.986319,-1.07544,0.623313,0.682928,0.387945,0.446167
3997,0.734657,0.668978,0.577473,0.532276,0.949801,0.771398,0.379049,0.309875,0.300141,0.321345,0.233991,0.222146,0.269619,0.197791,0.216804,0.206777,0.728674,0.719271,0.396741,0.498404,-0.155759,0.0540975,-0.394057,-0.100366,-1.11378,-0.984451,1.3223,1.34549,-0.340022,-0.280605,-0.39008,-0.603445,0.858336,0.77217,2.73856,2.64743,1.50132,1.56386,-1.04805,-0.98801
3998,0.000576161,-0.0649433,0.963326,0.917042,0.278663,0.102276,0.925415,0.857266,0.0531637,0.0730578,0.588547,0.577434,0.681365,0.609318,0.0154957,0.00470756,0.690862,0.679628,0.857522,0.86988,0.795167,1.0082,-0.277082,0.0228868,0.184768,0.31861,-1.16452,-1.13791,1.38663,1.44088,0.950171,0.744807,0.782492,0.696859,0.308279,0.212297,1.44745,1.52007,-0.145398,-0.0894538
3999,0.179118,0.115582,0.119816,0.0718529,0.975054,0.797781,0.130798,0.0617176,0.718188,0.738303,0.49064,0.410993,0.457716,0.388157,0.80002,0.787582,0.0849585,0.0739679,0.858264,0.870768,0.610108,0.818316,0.415872,0.71509,0.216431,0.349254,1.15849,1.18857,-1.09585,-1.04792,2.30642,2.09306,1.95313,1.86543,0.91134,0.818759,1.40786,1.47629,0.00323277,0.0526034
4000,0.973628,0.912144,0.0947867,0.0652473,0.289521,0.113484,0.663072,0.594341,0.382152,0.489641,0.243029,0.244551,0.63801,0.568915,0.16864,0.155755,0.0425655,0.0343252,0.0216798,0.0348837,-0.127364,0.0761856,-1.55704,-1.25168,0.981749,1.11794,-0.940945,-0.91565,2.67192,2.71985,-0.223293,-0.437057,-1.07475,-1.15802,0.16388,0.0752486,0.87229,0.943702,0.631401,0.679178
4001,0.325407,0.265957,0.131522,0.0586416,0.934792,0.757194,0.220626,0.15241,0.221889,0.240978,0.0904711,0.0781095,0.169624,0.103184,0.270562,0.2573,0.295842,0.350681,0.745587,0.758194,1.22661,1.43363,-1.13653,-0.835533,0.604107,0.736732,-0.995824,-0.881682,0.590735,0.633775,1.27473,1.06229,-0.00821821,-0.0855429,-0.282001,-0.374108,-0.26688,-0.196381,-0.0915034,-0.0381471
4002,0.598722,0.49448,0.0999986,0.0520359,0.529627,0.344626,0.693525,0.625419,0.101459,0.119132,0.711531,0.698868,0.413267,0.323451,0.0891484,0.0751279,0.674695,0.667037,0.808874,0.820437,-0.0386301,0.168101,1.67354,1.97388,-0.726909,-0.591647,-0.867009,-0.847715,-0.589284,-0.542319,-0.00565433,-0.217883,-0.921398,-0.992559,0.0500184,-0.0514754,0.210097,0.278598,1.14478,1.19729
4003,0.781376,0.723002,0.855376,0.807539,0.107711,-0.0679421,0.530622,0.471086,0.837534,0.857647,0.836531,0.823773,0.609812,0.543719,0.494337,0.481573,0.722145,0.678629,0.0475507,0.0573321,0.0274896,0.2352,0.739263,1.04163,-0.513787,-0.376942,-0.141272,-0.114666,0.407688,0.459537,0.629486,0.41045,-0.952717,-0.941615,0.364971,0.271157,-0.461936,-0.392355,1.99973,2.04894
4004,0.799494,0.76141,0.96439,0.916301,0.524144,0.303306,0.282958,0.316754,0.657386,0.67533,0.350346,0.339054,0.640064,0.595627,0.249447,0.238658,0.695889,0.690222,0.582898,0.592227,0.41266,0.624203,-1.00624,-0.704289,0.749392,0.879902,-0.136365,-0.103098,0.20173,0.260724,-0.50367,-0.72916,-0.821488,-0.89067,-2.46711,-2.5644,0.353807,0.424979,-0.374621,-0.319634
4005,0.934067,0.799817,0.623067,0.576263,0.851806,0.674555,0.229677,0.162422,0.794208,0.810208,0.627264,0.61754,0.757809,0.647535,0.242172,0.23386,0.456006,0.451712,0.233764,0.241146,1.01543,1.22774,0.966715,1.27372,-0.563474,-0.431992,1.07547,1.10864,-1.67222,-1.60893,1.2928,1.06392,0.945964,0.880484,0.639428,0.539263,0.123005,0.187458,-1.1572,-1.09742
4006,0.930413,0.838225,0.531249,0.482299,0.0615464,-0.116223,0.682008,0.615504,0.177312,0.195781,0.634552,0.624627,0.765368,0.699443,0.923276,0.91545,0.955711,0.951932,0.0925032,0.101374,2.51022,2.72687,1.06989,1.38065,-0.377082,-0.248862,0.260534,0.301057,1.11551,1.18483,-0.413384,-0.642769,0.43541,0.374333,-0.0730556,-0.173016,-0.316923,-0.252447,-0.096739,0.0213478
4007,0.935006,0.876633,0.803832,0.753334,0.198935,-0.0655798,0.553051,0.488115,0.43174,0.452632,0.298397,0.286991,0.641381,0.574831,0.0106093,0.00289569,0.123827,0.117349,0.414471,0.425109,-1.11144,-0.894781,-1.15418,-0.838652,0.737228,0.871236,-0.165569,-0.119867,2.1684,2.23327,-0.278113,-0.505486,1.6279,1.5591,-1.5774,-1.68101,0.687416,0.773607,1.08469,1.14011
4008,0.633113,0.577002,0.00872992,-0.0404039,0.161612,-0.0149369,0.150863,0.0865012,0.460403,0.480028,0.309716,0.252658,0.888882,0.821116,0.8363,0.82695,0.226007,0.221984,0.0493257,0.0589494,0.289014,0.508733,-0.038702,0.270733,0.394724,0.535492,0.564989,0.613182,0.91115,0.97839,1.4305,1.19743,-1.09689,-1.16614,-1.32304,-1.42523,1.73084,1.79966,1.05965,1.11708
4009,0.129913,0.0715096,0.00484809,-0.0460496,0.578167,0.403292,0.0950829,0.0292584,0.0639532,0.0815138,0.135671,0.218324,0.398338,0.385124,0.88145,0.872339,0.847501,0.843103,0.27144,0.282063,-0.864388,-0.649137,-0.077711,0.225967,-1.27553,-1.13069,0.250658,0.300173,0.936857,0.9995,0.198992,-0.0331242,-0.730538,-0.797615,0.812253,0.707196,1.81674,1.88767,-0.884944,-0.825291
4010,0.353181,0.29331,0.219916,0.0790573,0.677038,0.500096,0.291627,0.146316,0.521592,0.477997,0.0710703,0.183991,0.0173374,-0.0508679,0.0781953,0.0710799,0.0287622,0.0238301,0.137429,0.14749,-0.665311,-0.445866,0.318947,0.625758,-0.281125,-0.131194,0.145921,0.188453,-0.43155,-0.364721,0.661625,0.428444,0.777306,0.710537,0.657327,0.549236,1.33733,1.40316,-0.936297,-0.87851
4011,0.868792,0.809916,0.253481,0.204164,0.150453,-0.028378,0.328667,0.263374,0.857054,0.87448,0.161064,0.149658,0.0721966,0.00240611,0.0729082,0.121071,0.927575,0.921913,0.967275,0.975383,-0.814642,-0.592947,-0.722485,-0.416261,-1.48218,-1.33677,0.737879,0.780571,-0.623108,-0.615979,-0.364235,-0.604391,0.773059,0.71165,-0.249589,-0.360063,-1.5835,-1.52317,-0.263457,-0.206088
4012,0.316377,0.25878,0.880699,0.829809,0.381745,0.201273,0.0781873,0.0154403,0.250173,0.264979,0.548001,0.534469,0.740784,0.670278,0.178545,0.171062,0.545985,0.542192,0.511312,0.519167,0.0914996,0.315788,1.05492,1.35977,0.702805,0.842421,-0.970251,-0.927102,-0.934067,-0.867238,-0.812528,-1.05274,1.52537,1.46444,1.07017,0.964962,-0.0821671,-0.01759,-0.0896889,-0.0336405
4013,0.317744,0.259347,0.340259,0.288093,0.15179,-0.0261538,0.99376,0.930945,0.527042,0.506383,0.639501,0.720534,0.080734,0.00858403,0.874405,0.867505,0.839946,0.838324,0.95253,0.958463,-1.59189,-1.36298,0.636465,0.935266,-0.716408,-0.578693,-2.00052,-1.95165,-0.809832,-0.740713,-0.598871,-0.838375,1.50691,1.47027,1.13242,1.03422,-1.38067,-1.31561,0.584351,0.638782
4014,0.585711,0.526222,0.678219,0.624235,0.236493,0.0601124,0.794569,0.733533,0.734179,0.747788,0.920167,0.906598,0.442432,0.308897,0.489203,0.520032,0.822734,0.822901,0.443158,0.447553,2.29075,2.52489,-0.713267,-0.419262,0.0561431,0.189997,0.800886,0.848958,1.01079,1.07359,0.85409,0.613447,1.54253,1.47609,-0.356503,-0.457693,-0.0952879,-0.0294396,0.934915,0.957137
4015,0.652952,0.68049,0.732874,0.678037,0.671069,0.494217,0.0767672,0.016466,0.201788,0.214643,0.339568,0.326835,0.689721,0.60921,0.177211,0.17256,0.136832,0.137463,0.831761,0.836556,-0.102426,0.123329,2.13029,2.42954,-1.02856,-0.891108,-0.347572,-0.299527,-0.230413,-0.164892,-0.127595,-0.374768,1.78097,1.72009,-1.29968,-1.39872,0.699083,0.771593,1.22722,1.27549
4016,0.895054,0.834759,0.157124,0.101366,0.319134,0.140485,0.64192,0.579809,0.860455,0.875028,0.445272,0.40799,0.981673,0.909523,0.0243189,0.0213144,0.651285,0.652548,0.926629,0.932722,0.874242,1.09458,1.03775,1.34124,0.563247,0.704338,0.0588924,0.10945,-1.11711,-1.0502,1.04152,0.790125,-0.290684,-0.347104,0.0102285,-0.0897322,-0.419991,-0.354233,-0.900108,-0.850411
4017,0.668626,0.606106,0.652851,0.599846,0.824415,0.644046,0.247213,0.182964,0.616539,0.679128,0.500791,0.489145,0.343809,0.27208,0.215319,0.128521,0.358246,0.394845,0.395926,0.401267,-0.259549,-0.0325032,-0.810564,-0.501818,1.00106,1.14966,1.45123,1.50442,-0.616644,-0.554657,0.751781,0.498221,-0.811443,-0.87028,1.6258,1.52893,1.04546,1.10839,-0.906947,-0.85779
4018,0.0759341,0.0154575,0.356281,0.304534,0.93413,0.75584,0.93657,0.870698,0.469366,0.483229,0.149143,0.136825,0.0990962,0.0260157,0.243341,0.235727,0.135514,0.137142,0.658765,0.664296,-0.540082,-0.313627,0.0116224,0.313209,0.0541273,0.209937,0.559886,0.618019,0.907267,0.967908,1.06576,0.818511,-0.483132,-0.548528,-0.374558,-0.478315,0.914166,0.978545,2.14373,2.19626
4019,0.538932,0.477684,0.903253,0.852402,0.433119,0.256145,0.569835,0.503888,0.0174278,0.0298391,0.323406,0.3116,0.536463,0.442739,0.34684,0.342934,0.148716,0.15211,0.173952,0.178351,-0.417011,-0.185806,-1.83675,-1.52985,0.0546865,0.209912,1.81547,1.87559,-0.461228,-0.396313,-0.551497,-0.798017,0.987423,0.915037,0.695749,0.589841,-0.142774,-0.0828997,-0.135673,-0.0883959
4020,0.161202,0.097948,0.0629276,0.0121929,0.241361,0.126689,0.677405,0.612779,0.864433,0.875455,0.147746,0.134302,0.934093,0.859462,0.202949,0.2008,0.510517,0.513031,0.218872,0.225387,0.178886,0.403787,-0.41248,-0.112037,1.66554,1.81987,0.0799235,0.232466,1.15631,1.21722,-1.44127,-1.69556,0.608805,0.532712,0.226382,0.124713,0.558958,0.626845,-0.901164,-0.851201
4021,0.952229,0.889029,0.43391,0.424313,0.174877,-0.00276577,0.491543,0.425338,0.461417,0.471376,0.803289,0.7908,0.534474,0.459124,0.662392,0.661838,0.132698,0.13331,0.825601,0.834253,0.105649,0.33266,-1.31675,-1.00121,-0.495939,-0.339777,-1.46789,-1.41065,-0.137778,-0.0830306,-1.06101,-1.31267,-0.835722,-0.904744,1.42684,1.32832,-0.299388,-0.229401,0.819804,0.872624
4022,0.591358,0.455845,0.889205,0.836432,0.453781,0.278519,0.639614,0.575613,0.850638,0.859678,0.907434,0.894956,0.649448,0.513408,0.060885,0.0607842,0.612282,0.613333,0.465065,0.473153,-0.254002,-0.0252616,-2.19616,-1.89038,-2.32487,-2.16659,-1.96571,-1.90828,-0.262138,-0.205665,-0.346462,-0.593477,-0.342396,-0.504583,0.905822,0.802068,1.23787,1.30712,0.418848,0.422855
4023,0.0865665,0.0226612,0.100286,0.0485503,0.0745089,-0.100813,0.338922,0.273182,0.85692,0.867673,0.505589,0.617675,0.587669,0.567693,0.499982,0.467092,0.797824,0.799519,0.357144,0.367448,-0.27319,-0.0487362,-0.411238,-0.0994604,-0.946689,-0.788504,-0.387064,-0.33395,1.63756,1.68842,-1.70532,-1.95135,-0.0434111,-0.104423,-0.904724,-1.00465,-0.21627,-0.147642,-0.0814318,-0.0269145
4024,0.601913,0.539267,0.516882,0.463659,0.0653401,-0.109343,0.587859,0.485633,0.519403,0.530464,0.30358,0.340393,0.666865,0.621977,0.87544,0.873401,0.691989,0.709294,0.564041,0.574344,-0.722373,-0.497147,-0.899535,-0.585868,-1.01815,-0.864258,0.470286,0.522135,-0.990871,-0.933477,0.566424,0.315763,-0.386958,-0.441361,0.671683,0.567542,-0.0818548,-0.0146167,-0.882687,-0.834058
4025,0.13388,0.0734464,0.230773,0.177999,0.928181,0.752817,0.763138,0.698084,0.582766,0.63955,0.0755896,0.0631116,0.751611,0.676261,0.218315,0.216344,0.617226,0.619068,0.0725068,0.0836654,-0.42913,-0.197694,-0.888961,-0.569784,-0.507497,-0.360735,0.871772,0.916195,-1.13618,-1.08458,1.40228,1.15789,-0.0766163,-0.133661,0.520645,0.423082,2.03889,2.10331,-1.22263,-1.17516
4026,0.693045,0.634699,0.545113,0.494433,0.61339,0.438288,0.541988,0.475194,0.704884,0.748637,0.231831,0.217902,0.467563,0.390395,0.973293,0.96898,0.089854,0.0899024,0.42289,0.499712,1.74661,1.97734,1.58599,1.90881,1.31353,1.45615,0.33331,0.373021,0.718342,0.775521,1.04684,0.804292,-1.92968,-1.99328,-0.499304,-0.59502,1.43041,1.43316,-1.27299,-1.22838
4027,0.532727,0.476934,0.175085,0.125328,0.689998,0.605008,0.0710362,0.00301641,0.846661,0.857723,0.785535,0.769587,0.392616,0.241396,0.614034,0.520084,0.522434,0.520359,0.904131,0.915758,1.50273,1.72692,0.105785,0.428616,0.155654,0.296249,-1.78354,-1.74558,-0.572896,-0.508411,2.32552,2.08999,-1.47381,-1.53241,0.121949,0.0265026,0.698582,0.763001,-0.547132,-0.495871
4028,0.000217322,-0.0542833,0.851337,0.800117,0.94807,0.771727,0.959524,0.889131,0.294044,0.303934,0.569591,0.555806,0.252304,0.092397,0.0755,0.0711872,0.237795,0.237078,0.379507,0.38977,-1.77263,-1.55592,0.601524,0.9228,-2.28002,-2.13143,1.35955,1.39353,-2.55781,-2.48789,-0.899883,-1.12747,-0.487932,-0.548706,-0.813559,-0.914525,1.09251,1.1599,0.897176,0.953333
4029,0.159575,0.0407849,0.968659,0.918598,0.479825,0.38701,0.471456,0.402218,0.380843,0.359803,0.892058,0.875913,0.0205661,-0.0566021,0.968342,0.961626,0.806134,0.806442,0.884629,0.893727,1.92079,2.1375,0.324556,0.648796,1.27636,1.43168,1.12027,1.15941,0.329115,0.404578,0.34241,0.112141,0.287457,0.234997,1.1253,1.01814,0.0502689,0.1125,-0.36282,-0.312357
4030,0.181968,0.135853,0.539832,0.568864,0.176655,0.00229213,0.409225,0.339637,0.472486,0.415672,0.535365,0.518347,0.690839,0.61127,0.695497,0.689093,0.722105,0.720862,0.817452,0.895385,-0.223716,-0.00919638,1.16582,1.49393,-1.03911,-0.886374,-2.05214,-2.00777,-0.27827,-0.206045,2.11862,1.89214,-0.471329,-0.515806,0.509457,0.399107,0.631325,0.695811,0.488035,0.539298
4031,0.376423,0.230921,0.269185,0.21913,0.444815,0.268406,0.836176,0.768322,0.460374,0.471542,0.821487,0.80245,0.543588,0.46174,0.844815,0.840357,0.225262,0.225774,0.890027,0.897042,-1.77895,-1.56423,-0.732902,-0.412255,-0.0491896,0.0191196,-2.3322,-2.29024,-0.379947,-0.312693,-1.00573,-1.23429,-0.859652,-0.898131,0.786876,0.670789,-0.744212,-0.681452,1.85699,1.9115
4032,0.447904,0.32599,0.264555,0.213484,0.117591,-0.0613393,0.680718,0.610592,0.849154,0.859844,0.25869,0.238078,0.181303,0.100789,0.487079,0.567815,0.052325,0.052511,0.459177,0.466373,-1.3547,-1.14438,1.65064,1.97126,0.769812,0.924613,-2.00257,-1.95724,0.620974,0.689163,-0.191301,-0.423002,0.549774,0.505466,-0.850265,-0.960113,1.88946,1.9537,-1.54001,-1.4821
4033,0.435764,0.421058,0.857024,0.804333,0.640167,0.46213,0.991975,0.920314,0.12124,0.133337,0.327086,0.211204,0.770122,0.692157,0.299777,0.295272,0.375644,0.470258,0.884276,0.890661,1.06602,1.28012,1.63012,1.95646,-0.0193391,0.139064,0.0193368,0.0606181,-0.0735151,-0.0120422,-0.313968,-0.548293,0.175721,0.138289,-0.248136,-0.353651,-0.248372,-0.185818,-0.383096,-0.323043
4034,0.543179,0.516126,0.426515,0.375756,0.691353,0.514695,0.0720791,-3.12485e-05,0.084112,0.0945307,0.205953,0.18433,0.744859,0.669175,0.81543,0.812563,0.885247,0.888005,0.00462,0.0116691,-0.0820309,0.136869,-0.043571,0.288214,0.936935,1.093,-1.03421,-0.997283,1.31641,1.37402,-1.14025,-1.36666,0.781048,0.737985,0.707367,0.604573,1.91018,1.97708,-0.551984,-0.55386
4035,0.665695,0.611194,0.951817,0.903509,0.376562,0.200166,0.886809,0.816544,0.546674,0.557694,0.61867,0.522312,0.222545,0.14686,0.167168,0.165184,0.772659,0.776017,0.512066,0.520171,1.51113,1.72793,2.34542,2.67173,0.995936,1.15538,-0.558395,-0.528077,0.17258,0.230356,0.190652,-0.0342909,-0.269954,-0.309627,-0.269749,-0.367746,-0.14432,-0.0837805,-0.845647,-0.784677
4036,0.961429,0.908505,0.0957668,0.0473831,0.447947,0.333824,0.539805,0.469817,0.747629,0.757247,0.883655,0.860294,0.321929,0.247296,0.29218,0.290944,0.0794722,0.0798615,0.704513,0.71222,-0.358614,-0.141306,2.70853,3.04039,-0.124827,0.0264407,-1.91086,-1.8752,0.257416,0.312542,0.978894,0.757871,-0.527431,-0.495597,0.633218,0.529029,-0.618983,-0.462664,0.788101,0.848765
4037,0.712712,0.65978,0.764966,0.71693,0.645538,0.467482,0.57913,0.499279,0.162441,0.173308,0.184639,0.160973,0.181404,0.107544,0.7593,0.757849,0.287127,0.286569,0.511011,0.590627,0.970555,1.18438,-0.380296,-0.045588,1.11879,1.26945,-1.23121,-1.19065,-0.879094,-0.817785,0.403257,0.187386,-0.643235,-0.681567,-0.94953,-1.05482,-0.898717,-0.841548,0.308439,0.373306
4038,0.00488096,-0.04798,0.130564,0.0814688,0.94883,0.768729,0.59738,0.528742,0.577986,0.590581,0.738946,0.717253,0.634188,0.558793,0.431639,0.431349,0.179149,0.179289,0.503508,0.469035,-0.292416,-0.0811553,1.73686,2.07829,-1.43972,-1.28761,0.0551809,0.096632,0.189922,0.245621,1.51157,1.28799,0.165988,0.130101,-0.644674,-0.755529,-1.63783,-1.57392,-1.76784,-1.70635
4039,0.0777678,0.022753,0.326963,0.278891,0.924005,0.744952,0.41705,0.346774,0.994561,1.00785,0.534318,0.512982,0.871098,0.794643,0.656116,0.655274,0.588235,0.589552,0.338622,0.347443,0.404232,0.613847,-1.06519,-0.717666,-0.334753,-0.18397,0.859717,0.906106,-1.15673,-1.10319,-1.52326,-1.7507,-0.891958,-0.932507,0.162071,0.0503317,-0.49441,-0.428093,0.766037,0.824561
4040,0.990343,0.93621,0.761759,0.71304,0.639138,0.542993,0.850375,0.78019,0.0641989,0.0794838,0.547071,0.524794,0.692261,0.63194,0.0551569,0.05422,0.693699,0.694187,0.724924,0.731606,-0.445562,-0.237652,-0.738029,-0.392831,-0.574491,-0.428452,0.115394,0.159854,-0.583017,-0.531258,1.51361,1.28006,-0.877218,-0.917972,0.563846,0.458293,-0.340079,-0.280791,-0.262099,-0.209536
4041,0.552784,0.500409,0.757027,0.707394,0.518395,0.341033,0.903922,0.779374,0.220041,0.234491,0.768327,0.735439,0.546674,0.469237,0.0380588,0.0382382,0.367123,0.402754,0.0805171,0.0854463,-0.861196,-0.65696,-0.0399177,0.299372,0.278189,0.418042,-0.0552602,-0.0136423,-0.68599,-0.637906,1.39509,1.16136,-1.22445,-1.27075,-0.178787,-0.285217,0.320265,0.380802,0.646266,0.670217
4042,0.364029,0.311745,0.0626937,0.0121638,0.740937,0.561428,0.835992,0.778557,0.637179,0.651995,0.966525,0.946085,0.798367,0.721401,0.715294,0.714417,0.109569,0.111321,0.433852,0.364261,-0.636117,-0.438073,-1.8461,-1.51109,0.478202,0.702361,1.11244,1.15294,-0.547232,-0.496166,1.28235,1.04267,-0.861553,-0.914819,1.688,1.58205,-0.0155379,0.0498477,1.49596,1.54997
4043,0.845665,0.793061,0.315176,0.235094,0.0290179,-0.153031,0.981941,0.777741,0.339942,0.355453,0.748164,0.656998,0.260347,0.18462,0.727885,0.665128,0.0936295,0.105607,0.63841,0.643076,0.350906,0.546521,0.258183,0.596823,0.842562,0.98668,-0.753939,-0.711868,-1.29196,-1.24348,-0.149079,-0.389748,-0.511853,-0.55889,-1.88033,-1.99267,1.13965,1.21106,2.73016,2.7854
4044,0.776329,0.721773,0.371851,0.458024,0.457018,0.276047,0.844795,0.776925,0.958663,0.97467,0.478759,0.367912,0.650109,0.575671,0.615372,0.615838,0.098795,0.0998939,0.305314,0.311496,-0.35657,-0.165746,0.202518,0.632348,-0.920298,-0.774636,0.737863,0.781775,-1.36992,-1.31892,-0.939093,-1.17666,-0.764966,-0.81731,0.476807,0.366567,0.912036,0.987633,1.06741,1.04977
4045,0.498689,0.442776,0.731483,0.680953,0.220779,0.0376828,0.678256,0.60932,0.60387,0.621153,0.0981068,0.0788251,0.222338,0.150666,0.848043,0.850799,0.920461,0.922725,0.739732,0.746129,-0.175601,0.00778772,0.324022,0.667872,0.920117,1.07205,0.0216259,0.137896,0.166082,0.218702,-0.816734,-1.05415,1.18215,1.12785,-1.68017,-1.7864,-1.45386,-1.37935,-0.741115,-0.685869
4046,0.600398,0.568317,0.151964,0.0999202,0.868567,0.686575,0.747072,0.678384,0.580475,0.597028,0.115632,0.0934385,0.0600721,-0.0131511,0.0254535,0.0275815,0.577718,0.577863,0.960499,0.969242,1.45468,1.64463,-0.491644,-0.140703,-2.52237,-2.37089,-0.549142,-0.505982,1.08599,1.14435,0.187812,-0.044578,-0.442342,-0.449153,0.715599,0.606602,-2.12188,-2.00596,-0.717605,-0.663398
4047,0.748152,0.693858,0.372731,0.32278,0.91449,0.73326,0.0865027,0.0150912,0.983228,0.999559,0.0667563,0.108052,0.113194,0.0708304,0.0884319,0.088231,0.768818,0.768358,0.162297,0.169232,-0.395723,-0.209306,1.22454,1.57154,1.5312,1.68268,-0.389776,-0.340968,0.102695,0.165421,0.636586,0.401764,-1.97185,-2.02615,1.14269,1.02981,-2.70706,-2.63256,0.165072,0.307847
4048,0.096273,0.0422586,0.371231,0.322403,0.459016,0.279267,0.500263,0.429112,0.487576,0.506223,0.124895,0.122665,0.227496,0.154812,0.958974,0.959751,0.564466,0.565552,0.168092,0.164394,-0.336202,-0.07568,1.19142,1.54347,-1.2633,-1.10571,1.16586,1.21653,-0.161305,-0.0656204,1.7338,1.50237,-1.93974,-2.00315,0.509379,0.394222,1.78062,1.85939,1.21914,1.27909
4049,0.288375,0.232638,0.577169,0.530227,0.438426,0.183404,0.427018,0.455753,0.341103,0.434922,0.13129,0.137278,0.70615,0.631335,0.156002,0.158492,0.720511,0.720521,0.0411014,0.159556,-0.127261,0.0579464,-0.252171,0.0944172,0.197166,0.349519,-0.703489,-0.64828,-0.364194,-0.296662,0.668896,0.437544,-1.92584,-1.98014,0.686161,0.570614,-1.04364,-0.968114,0.36801,0.426531
4050,0.154764,0.194633,0.998442,0.94934,0.252449,0.0875409,0.552927,0.482393,0.345123,0.363621,0.171174,0.151892,0.31278,0.239998,0.516516,0.521377,0.103988,0.104717,0.149173,0.154718,0.88571,1.07486,-0.184879,0.157107,0.0788451,0.229562,-0.254911,-0.192558,0.0575557,0.121955,-0.166047,-0.396826,1.23393,1.17924,-2.30776,-2.42683,0.446454,0.524118,-0.894687,-0.839159
4051,0.210829,0.156627,0.831769,0.780787,0.169982,-0.00832199,0.806611,0.737554,0.898835,0.918115,0.812691,0.792698,0.678613,0.606881,0.380895,0.367507,0.305681,0.336127,0.524473,0.486607,0.422928,0.609541,0.674492,1.01769,0.420172,0.567339,-0.690974,-0.629823,-0.33947,-0.274543,-0.044495,-0.274311,1.02433,0.966794,0.964933,0.845793,0.780823,0.858559,-0.386036,-0.334929
4052,0.278078,0.253809,0.432359,0.381347,0.522994,0.344394,0.326448,0.255743,0.930239,0.950078,0.257859,0.238512,0.172019,0.100562,0.20676,0.213637,0.565619,0.567537,0.814676,0.818496,-0.987999,-0.766061,-0.254317,0.085442,1.03022,1.17975,-0.162626,-0.0983273,-0.213842,-0.191055,0.468163,0.232785,-1.91761,-1.96946,-0.0161598,-0.118966,0.859564,0.930316,-0.646776,-0.599482
4053,0.457372,0.350991,0.398219,0.347285,0.189986,0.00973321,0.825243,0.75365,0.0515842,0.0731865,0.4319,0.457805,0.783307,0.711934,0.723859,0.730928,0.382833,0.454326,0.623519,0.627875,-2.32257,-2.14166,0.658613,0.992887,1.23793,1.39445,0.822039,0.883031,-0.17598,-0.107566,-0.996565,-1.23236,1.3737,1.31988,-0.962564,-1.08372,-0.368004,-0.304399,0.0889572,0.133025
4054,0.503801,0.448172,0.0307918,-0.0218192,0.813191,0.633065,0.845172,0.771567,0.667652,0.687284,0.695322,0.677097,0.726299,0.653555,0.634102,0.640149,0.230448,0.341114,0.146302,0.151764,1.32488,1.51032,0.484275,0.811521,0.222118,0.374852,2.31459,2.37667,0.702789,0.771513,0.411223,0.176605,-0.886305,-0.938131,0.777398,0.660719,-0.473678,-0.403114,0.370959,0.411115
4055,0.922742,0.866237,0.847918,0.79412,0.57856,0.399934,0.0635527,-0.0081566,0.879433,0.897059,0.0981538,0.0822158,0.421375,0.347546,0.910604,0.916411,0.225984,0.227902,0.741189,0.745983,0.407093,0.596266,0.0683179,0.40104,0.383105,0.541354,-0.145693,-0.0890679,-1.15395,-1.08609,1.58744,1.35514,0.612625,0.553671,0.0693186,-0.0515605,0.362889,0.431202,0.235675,0.281784
4056,0.244405,0.188425,0.168783,0.113523,0.939819,0.762313,0.473833,0.426059,0.842171,0.858253,0.0407488,0.0243602,0.59989,0.615504,0.619745,0.62488,0.766089,0.768579,0.267449,0.269871,-1.36164,-1.17712,-1.12581,-0.795466,-0.597633,-0.433539,0.969326,1.0281,0.910221,0.979162,-0.146089,-0.383531,-2.22817,-2.28484,-0.0390894,-0.165411,-1.16905,-1.10321,0.891857,0.938837
4057,0.598309,0.540247,0.218618,0.161556,0.0970273,-0.0821232,0.931341,0.860275,0.0512839,0.0685085,0.49672,0.482591,0.959945,0.883462,0.821882,0.826719,0.129607,0.132867,0.338055,0.382653,-1.06424,-0.877668,0.622411,0.947691,1.62727,1.79244,-0.508083,-0.443106,0.575748,0.641714,-0.27643,-0.508823,0.0461021,-0.0163917,0.641428,0.517897,-0.162256,-0.0967281,-0.973656,-0.924248
4058,0.129409,0.0697766,0.569464,0.512059,0.719068,0.541209,0.117584,0.0486219,0.0241859,0.0721324,0.704939,0.653621,0.113607,0.0378284,0.0383962,0.0451787,0.436625,0.477245,0.496013,0.495434,-0.084934,0.106926,-0.238695,0.0917858,-2.75325,-2.58264,0.257789,0.320179,-1.14914,-1.08862,-1.19899,-1.43503,0.00553605,-0.0500648,-0.455286,-0.575321,-0.17471,-0.206375,-0.133571,-0.0869459
4059,0.816885,0.755934,0.421678,0.379949,0.759169,0.582617,0.744329,0.675789,0.0562144,0.0757563,0.837381,0.824651,0.150359,0.0762433,0.150361,0.155887,0.821019,0.821622,0.82821,0.82906,-2.08883,-1.90344,-0.49885,-0.167186,0.0122426,0.188802,-0.425965,-0.362647,-0.894077,-0.837901,-0.329269,-0.56325,-0.0192981,-0.0837379,-0.765047,-0.888652,-0.378601,-0.316023,-0.171443,-0.125313
4060,0.397509,0.335615,0.306922,0.247838,0.138027,-0.0359222,0.0886319,0.0185319,0.171092,0.0793802,0.312925,0.300395,0.462534,0.344202,0.47849,0.48229,0.583346,0.545817,0.856414,0.855352,1.10079,1.28123,0.601321,0.9277,-0.620069,-0.442121,1.31406,1.38442,1.06753,1.11736,-0.1581,-0.395967,-0.333474,-0.301404,-0.488095,-0.61697,-0.761544,-0.6924,-0.488462,-0.436041
4061,0.942975,0.882012,0.391172,0.377017,0.452498,0.28079,0.359746,0.273356,0.037041,0.0830041,0.832377,0.817723,0.685012,0.61216,0.337704,0.298714,0.266763,0.270013,0.502156,0.499566,2.02288,2.20593,-1.78141,-1.45379,-0.380902,-0.195097,1.57728,1.64085,1.07539,1.12319,-1.26305,-1.50557,-0.44787,-0.51907,0.862711,0.740649,0.414175,0.485887,2.27233,2.32443
4062,0.679109,0.608733,0.56658,0.506196,0.303978,0.133799,0.598214,0.52818,0.0694035,0.086628,0.309825,0.293466,0.0394841,-0.0360156,0.108357,0.115138,0.973856,0.97712,0.374565,0.370353,0.227655,0.417307,-1.46284,-1.12896,0.375402,0.558079,-1.45726,-1.38929,-0.709231,-0.656199,-0.620304,-0.861534,0.251527,0.187972,-0.248476,-0.368854,-1.59574,-1.53043,-0.516807,-0.455415
4063,0.398405,0.335454,0.247586,0.185843,0.434408,0.265261,0.0197584,-0.0504337,0.277597,0.296403,0.305112,0.290381,0.705652,0.631856,0.967142,0.975545,0.276532,0.280965,0.0259407,0.0192718,-0.667113,-0.48064,0.542849,0.881139,-0.211219,-0.0281288,1.12922,1.19282,-0.0832778,-0.0233122,-0.42865,-0.66346,-0.757761,-0.828702,1.17217,1.05083,-0.986001,-0.914852,0.601365,0.656398
4064,0.603913,0.608597,0.215383,0.155598,0.906884,0.738856,0.528843,0.457407,0.00248829,0.0194088,0.603973,0.580255,0.367736,0.29182,0.13327,0.142898,0.984752,0.988073,0.768608,0.763189,-0.168031,0.0159732,1.464,1.8024,1.16133,1.34995,0.605514,0.664725,2.04504,2.11226,0.414161,0.186129,0.397567,0.326771,-0.530857,-0.658488,-1.09117,-1.01357,3.13466,3.18731
4065,0.944903,0.88174,0.447157,0.388013,0.122192,-0.0457153,0.348416,0.27544,0.931673,0.948242,0.883606,0.87013,0.752742,0.678572,0.367473,0.377859,0.944632,0.94843,0.861979,0.85466,-0.433029,-0.250582,0.225858,0.559482,-0.593868,-0.411363,-0.620103,-0.561218,-1.54662,-1.48797,1.26352,1.03572,-1.37716,-1.44198,2.5932,2.46012,-0.405036,-0.320168,-0.668927,-0.611712
4066,0.0087214,-0.0536622,0.065981,0.00922363,0.0287201,-0.0694415,0.691576,0.618784,0.0402907,0.05587,0.829653,0.817948,0.246016,0.172254,0.886112,0.89515,0.465377,0.468353,0.36082,0.354002,-0.176584,-0.0340776,0.568648,0.900456,0.0825756,0.265278,0.509574,0.574058,0.0788283,0.142581,0.268126,0.0475028,1.19238,1.12912,-0.623542,-0.750898,-1.62167,-1.53703,-0.917942,-0.861002
4067,0.994863,0.932479,0.813806,0.758754,0.0731257,-0.0931678,0.597579,0.525812,0.330736,0.37067,0.0782046,0.0678196,0.0127022,-0.0590712,0.392063,0.399465,0.989358,0.99357,0.896832,0.888897,0.00324425,0.182427,-1.41943,-1.08197,1.97084,2.15815,-1.02789,-0.957429,2.26898,2.3292,-0.39822,-0.61923,-1.15032,-1.20759,-0.749672,-0.879695,-0.713718,-0.625745,-0.426803,-0.371981
4068,0.381152,0.316374,0.571334,0.561021,0.295547,0.127227,0.851543,0.780972,0.667604,0.685471,0.884102,0.871931,0.715118,0.643345,0.950424,0.957364,0.575869,0.579503,0.619338,0.613237,-0.104879,0.0805913,-0.356275,-0.0188147,-1.49034,-1.30989,-1.06876,-0.993073,-0.508044,-0.443685,-1.06736,-1.28596,-1.63576,-1.69912,0.805479,0.67675,-0.228066,-0.135348,-0.774854,-0.713082
4069,0.519331,0.456728,0.308835,0.363288,0.223175,0.0523074,0.04461,-0.0250443,0.636341,0.655857,0.992975,0.980973,0.936929,0.864425,0.391407,0.396207,0.400634,0.40624,0.67358,0.606566,-0.759814,-0.526325,-0.0134709,0.298443,0.221398,0.395583,-0.637713,-0.528756,0.285227,0.28375,-0.258296,-0.474678,0.728571,0.665418,-0.800283,-0.922746,-0.547287,-0.451225,0.486111,0.552983
4070,0.335245,0.273774,0.124082,0.165555,0.354505,0.18377,0.0307917,-0.0373702,0.0297111,0.0511365,0.168907,0.157518,0.294677,0.222551,0.0515879,0.0541148,0.732335,0.736779,0.608681,0.599895,-1.31478,-1.13324,0.280789,0.615701,1.09103,1.27279,-0.144329,-0.0644383,0.943924,1.01118,-1.15809,-1.37222,-0.276304,-0.336386,0.610014,0.481133,-0.330942,-0.14849,1.97413,2.03498
4071,0.394957,0.334028,0.0228737,-0.032178,0.776678,0.607938,0.725764,0.655652,0.112358,0.153211,0.62074,0.610839,0.717632,0.644321,0.919219,0.920375,0.800887,0.805203,0.00635013,-0.00093856,-0.650564,-0.371168,-0.880204,-0.550349,-0.990012,-0.80546,1.24311,1.33054,0.417871,0.521552,-0.801046,-1.01959,-0.783745,-0.842537,0.233649,0.108436,0.0507091,0.154244,1.23257,1.28835
4072,0.878027,0.815343,0.745247,0.688542,0.663777,0.496405,0.137902,0.0678772,0.235398,0.255286,0.476013,0.467231,0.248344,0.173216,0.982582,0.986769,0.032509,0.0361843,0.9832,0.975911,0.209371,0.390906,1.58388,1.91209,-0.257324,-0.0938715,0.696874,0.787361,-0.0300294,0.0319206,-1.28821,-1.51279,1.25172,1.20026,0.318892,0.193026,1.60209,1.70717,0.894497,1.01446
4073,0.0978233,0.0334229,0.370708,0.31393,0.927964,0.762519,0.0769647,0.0541237,0.712212,0.733195,0.031447,0.021181,0.00625144,-0.0680673,0.443539,0.445347,0.673146,0.678656,0.284413,0.278254,-0.596556,-0.415524,-0.743154,-0.422644,0.434329,0.617717,-0.636938,-0.545284,0.492243,0.55669,-0.0992967,-0.317787,-0.374381,-0.422992,0.144795,-0.0751574,1.1068,1.20588,0.683601,0.740576
4074,0.173286,0.109069,0.622847,0.565612,0.56502,0.3979,0.109444,0.0403702,0.439872,0.46119,0.306626,0.296178,0.390532,0.33288,0.741242,0.741991,0.613418,0.618886,0.756282,0.752258,-0.746955,-0.562606,-0.538081,-0.220671,0.327591,0.511208,0.556935,0.651019,0.256253,0.326675,-0.883786,-1.1047,0.167112,0.114097,-0.217474,-0.343341,-0.482451,-0.389546,-1.22622,-1.16992
4075,0.783742,0.718935,0.391347,0.335715,0.539846,0.374123,0.377005,0.305688,0.508088,0.530362,0.227595,0.217949,0.810054,0.733827,0.57148,0.618375,0.901857,0.90463,0.655531,0.653228,-1.17295,-0.981914,-0.707325,-0.387492,0.771634,0.956535,0.621367,0.724129,0.28929,0.269093,-0.937028,-1.1511,-1.30821,-1.35452,2.30485,2.17164,0.527788,0.616937,1.10507,1.15423
4076,0.210177,0.142685,0.700723,0.64683,0.956444,0.792352,0.360573,0.355227,0.305331,0.2817,0.787088,0.779237,0.422169,0.348066,0.494038,0.494759,0.144194,0.144953,0.344594,0.377857,0.540271,0.731698,0.928359,1.24815,0.377029,0.559746,2.20442,2.31135,0.246341,0.21151,-0.569848,-0.835494,-0.995903,-1.04682,-0.991371,-1.1296,-0.950314,-0.855593,-1.64074,-1.59458
4077,0.64939,0.580701,0.0298588,-0.0241881,0.0699566,-0.0935042,0.474159,0.404766,0.0118296,0.0330377,0.502427,0.593939,0.782897,0.710526,0.157659,0.158022,0.92023,0.921965,0.104951,0.102487,-0.582031,-0.395386,0.890882,1.20339,1.55041,1.72623,0.0100895,0.115547,0.0835052,0.153927,-0.363753,-0.519884,1.88253,1.83505,0.430402,0.290089,-0.779782,-0.692468,-0.565431,-0.512243
4078,0.00551057,-0.0654859,0.604056,0.551576,0.413874,0.248447,0.265235,0.19789,0.556263,0.577406,0.416095,0.408641,0.271,0.198925,0.272379,0.230665,0.222468,0.22581,0.818552,0.816845,1.40007,1.59307,-0.528996,-0.21301,-1.31684,-1.14921,-1.24072,-1.14187,-0.687864,-0.627799,0.00980212,-0.204274,-0.53009,-0.579218,-0.212063,-0.345497,-0.0358529,0.047964,1.36018,1.41549
4079,0.164209,0.0947116,0.305811,0.251724,0.0127405,-0.151666,0.484702,0.418235,0.31166,0.396132,0.521098,0.512797,0.0767202,0.00397784,0.300777,0.303308,0.577688,0.582133,0.477672,0.475706,-0.766004,-0.571632,1.82157,2.1382,-1.37892,-1.20987,0.191023,0.287619,-1.47704,-1.40953,0.826551,0.607011,-0.217994,-0.271518,-0.0397014,-0.169106,1.64998,1.72916,-0.0997445,-0.0477242
4080,0.826114,0.756444,0.373932,0.41668,0.565091,0.40085,0.908511,0.842497,0.194744,0.214858,0.244376,0.235009,0.743736,0.67185,0.940755,0.942986,0.420228,0.45197,0.594931,0.592874,0.639749,0.831882,-0.017682,0.295141,0.644246,0.8072,-2.17343,-2.07301,-1.46236,-1.38841,0.115082,-0.104365,-0.45612,-0.515196,1.71885,1.59064,-0.56761,-0.488807,0.743246,0.789578
4081,0.0135981,-0.0554502,0.543882,0.581636,0.880334,0.717562,0.176205,0.109474,0.429403,0.450718,0.788196,0.776784,0.937497,0.86334,0.592642,0.596404,0.317702,0.321807,0.957224,0.953002,0.647263,0.837304,0.645412,0.958307,0.257959,0.425987,-0.430957,-0.325945,1.19591,1.26925,0.780272,0.553636,0.571506,0.511949,-1.05596,-1.18858,0.546335,0.625219,0.0362615,0.0876259
4082,0.0549535,-0.0152739,0.800679,0.746592,0.789243,0.626597,0.996024,0.931167,0.953145,0.974238,0.349244,0.4352,0.0721386,-0.00279097,0.623552,0.626619,0.722566,0.727767,0.376827,0.372791,-1.00132,-0.810343,-1.32634,-1.00847,-0.509882,-0.268769,0.865089,0.976728,2.94902,3.02133,0.327188,0.105291,-1.17553,-1.23945,-1.20381,-1.33304,-0.858439,-0.78309,-0.666937,-0.614326
4083,0.677637,0.604914,0.144431,0.090319,0.458589,0.392632,0.147116,0.0826285,0.0599001,0.0818658,0.10462,0.0936159,0.680773,0.603967,0.231788,0.234822,0.791211,0.796192,0.669558,0.66573,-0.121515,0.0661333,-0.0543822,0.27011,-1.12429,-0.963526,1.22513,1.34116,0.192215,0.265952,0.226394,-0.00209086,-0.0984197,-0.166972,-0.927646,-1.06136,0.362059,0.440486,0.201547,0.254545
4084,0.187009,0.113859,0.675947,0.622471,0.322672,0.158668,0.823892,0.759325,0.742004,0.762858,0.676721,0.664668,0.51526,0.440149,0.602162,0.588302,0.527471,0.531334,0.246472,0.245141,-1.08629,-0.892767,-0.824377,-0.494367,0.577506,0.741948,1.04179,1.15138,1.05146,1.13009,0.433448,0.212271,-0.984617,-1.05877,-0.123939,-0.255495,-0.203719,-0.121923,-0.446236,-0.388302
4085,0.619603,0.546822,0.729513,0.676274,0.22126,0.134398,0.736189,0.637376,0.424852,0.445177,0.440095,0.426214,0.680612,0.605707,0.937592,0.941782,0.708824,0.71268,0.489401,0.488234,0.539587,0.730103,-0.848865,-0.522438,0.133205,0.300532,0.610593,0.714112,-0.0737517,0.0900434,0.412296,0.196502,-0.438395,-0.50462,-0.113165,-0.248164,0.141668,0.229094,0.248657,0.297759
4086,0.519002,0.37715,0.153996,0.0996024,0.225791,0.110128,0.580731,0.515426,0.352231,0.386506,0.742148,0.727605,0.0690655,-0.0054376,0.159548,0.165408,0.408195,0.413512,0.0935598,0.0929569,-0.000505401,0.18679,0.149936,0.477232,0.932674,1.09956,-1.17244,-1.07042,-1.0285,-0.950001,-0.835565,-1.05194,2.25028,2.18253,-0.807864,-0.94443,-1.45612,-1.36633,0.562829,0.606386
4087,0.280971,0.207478,0.0414487,-0.0136181,0.249863,0.0858586,0.1535,0.0882634,0.304003,0.327835,0.625882,0.610221,0.520207,0.445812,0.562453,0.530673,0.481818,0.48717,0.178791,0.179078,1.12071,1.30855,1.70886,2.03738,3.53628,3.70335,-0.731912,-0.656945,-0.434659,-0.363952,0.0802103,-0.133437,1.40781,1.33904,-1.08747,-1.22539,-1.2421,-1.15809,1.9778,2.02552
4088,0.881408,0.80823,0.953898,0.900677,0.882817,0.719629,0.579609,0.512525,0.739263,0.760379,0.0371197,0.02043,0.563736,0.488424,0.887393,0.895937,0.243365,0.248659,0.890671,0.893436,-1.30785,-1.12512,0.308069,0.634671,0.511338,0.685007,-0.348781,-0.243472,1.30821,1.37436,-1.28195,-1.49131,-0.307107,-0.380475,0.851709,0.707278,0.640726,0.726414,2.11346,2.16758
4089,0.190213,0.116008,0.574708,0.521888,0.0300955,-0.131348,0.152707,0.0853625,0.0943695,0.116107,0.375582,0.360006,0.975052,0.89995,0.724403,0.814648,0.635022,0.63955,0.181953,0.185572,2.33956,2.52686,-2.07401,-1.74682,-0.581567,-0.411708,-0.242412,-0.140905,-0.491678,-0.420045,-0.564452,-0.772121,1.44121,1.36026,0.013979,-0.126522,0.473777,0.56414,-1.1999,-1.1447
4090,0.00880927,-0.0669465,0.788105,0.677092,0.737182,0.574146,0.960291,0.891715,0.872477,0.896045,0.074796,0.0612054,0.451493,0.377634,0.615999,0.733359,0.452785,0.385549,0.48918,0.557048,1.20026,1.38361,-0.627476,-0.298626,0.465572,0.631663,-0.477287,-0.375022,1.84569,1.8929,0.541785,0.328488,0.61175,0.534218,2.55532,2.42117,-0.0475596,0.0476246,-1.3594,-1.30379
4091,0.964712,0.886143,0.884553,0.832297,0.904562,0.740305,0.387332,0.319053,0.920665,0.943535,0.797917,0.782562,0.533004,0.456626,0.644849,0.652069,0.127427,0.131549,0.923597,0.928525,-0.14803,0.0421644,1.75945,2.08489,1.14006,1.3083,0.552524,0.651651,4.13421,4.20585,-1.28055,-1.48815,1.91825,1.84577,0.15072,0.0242243,1.45703,1.5532,0.714046,0.764017
4092,0.412947,0.335007,0.132615,0.0817663,0.132057,-0.0341126,0.182236,0.112177,0.049345,0.0712154,0.719306,0.583796,0.87643,0.798608,0.7004,0.707809,0.830513,0.834169,0.812844,0.885504,-0.50375,-0.315757,0.0672845,0.387309,-1.27859,-1.10718,-0.130651,-0.0311754,0.137163,0.202637,0.938798,0.729699,-0.401911,-0.478117,0.347052,0.217774,-0.844665,-0.748155,0.247444,0.303923
4093,0.431546,0.355445,0.36957,0.319074,0.967148,0.80134,0.384792,0.313636,0.328919,0.353312,0.44172,0.38503,0.507078,0.377928,0.448844,0.454799,0.285849,0.28968,0.837085,0.842483,1.27904,1.45989,-0.186861,0.128338,-1.87176,-1.69339,0.317985,0.424547,1.7383,1.80256,0.468585,0.265189,-1.25191,-1.32161,-0.121011,-0.228081,1.04227,1.13635,1.52463,1.58396
4094,0.180506,0.102527,0.0757446,0.023762,0.942584,0.777563,0.00612367,-0.06398,0.0575459,0.0813067,0.202441,0.186264,0.0353845,-0.0427519,0.97233,0.977106,0.0318401,0.0359754,0.557851,0.561566,1.06301,1.23924,-0.662865,-0.343463,0.700854,0.882182,0.472085,0.575304,0.780594,0.900415,1.65633,1.46019,1.41327,1.34875,-0.544425,-0.673936,0.580777,0.680977,-1.02364,-0.969841
4095,0.552578,0.444683,0.321538,0.231207,0.670865,0.420041,0.367599,0.299947,0.854916,0.878749,0.253158,0.237,0.614842,0.538399,0.772583,0.775037,0.745083,0.748213,0.632129,0.633594,-0.244552,-0.0708029,1.07954,1.39969,0.294303,0.469685,3.36654,3.46714,-0.0593584,-0.00173186,0.325057,0.134849,-0.413785,-0.480841,0.174432,-0.006294,0.35953,0.45755,1.12994,1.17963
4096,0.863934,0.786838,0.564645,0.438652,0.227699,0.0625191,0.973358,0.906837,0.344043,0.365628,0.741219,0.724144,0.802562,0.724357,0.190119,0.194218,0.0373118,0.0422941,0.310937,0.312356,0.418459,0.592949,-0.575997,-0.252718,1.59252,1.77275,0.580148,0.688127,1.29062,1.35088,1.24048,1.05335,-0.342751,-0.402832,0.798782,0.661348,1.95675,2.05834,0.320116,0.372483
4097,0.0625125,-0.0119986,0.696842,0.646097,0.0903773,-0.0741807,0.590216,0.524491,0.56083,0.580884,0.223334,0.204071,0.342127,0.334001,0.803751,0.809132,0.534043,0.444769,0.622089,0.625794,0.220015,0.387495,0.218746,0.54861,0.389141,0.567169,-1.14237,-1.0365,-1.09178,-1.03609,0.599386,0.41781,0.564711,0.446893,-1.0507,-1.19188,-0.400396,-0.292938,1.27064,1.31741
4098,0.777969,0.703885,0.655338,0.606726,0.818723,0.656814,0.67053,0.519892,0.577033,0.568002,0.188397,0.171934,0.0232691,-0.0563556,0.827675,0.787471,0.840248,0.847245,0.500222,0.505309,0.759863,0.930453,-0.209228,0.124105,0.629529,0.814193,-0.242218,-0.133051,1.31329,1.3683,1.08331,0.895054,1.3517,1.29662,1.12636,0.988514,-2.11653,-2.01775,1.16992,1.21964
4099,0.477669,0.404254,0.196393,0.148508,0.143405,-0.0169824,0.581141,0.515292,0.534593,0.55512,0.679877,0.66456,0.0627407,-0.0179407,0.911249,0.76581,0.530297,0.538185,0.724597,0.728423,-1.54582,-1.37651,1.22549,1.55646,-0.305489,-0.125535,0.330709,0.443563,0.334108,0.389369,-0.626511,-0.811637,-1.086,-1.13671,1.00352,0.859717,0.419758,0.519353,1.99818,2.0426
4100,0.74145,0.666178,0.522097,0.474666,0.679137,0.520661,0.806716,0.740262,0.232341,0.252586,0.67117,0.656741,0.844116,0.762733,0.788561,0.74415,0.914654,0.923935,0.657845,0.66009,-1.43782,-1.26506,0.545282,0.969911,-0.45327,-0.276611,-0.575897,-0.45669,-0.0896254,-0.0387604,-0.824907,-1.06477,-0.698707,-0.685296,-1.88592,-2.02554,1.12712,1.17598,-0.746163,-0.706211
4101,0.780848,0.772844,0.516535,0.469021,0.366645,0.206132,0.19377,0.127249,0.416461,0.416325,0.103433,0.0869682,0.85457,0.827461,0.717109,0.722489,0.294069,0.303505,0.379644,0.379173,-0.120068,0.0606208,0.0557537,0.383363,0.249349,0.430174,-0.580703,-0.459727,-1.88995,-1.83316,-1.12823,-1.3179,-0.183179,-0.233885,-0.613255,-0.715037,1.726,1.83261,-0.0659567,-0.0201496
4102,0.954685,0.87951,0.977037,0.927515,0.554744,0.391919,0.0954521,0.0296975,0.66793,0.580064,0.81461,0.798031,0.975098,0.892188,0.0128661,0.0190772,0.567706,0.65341,0.792954,0.792953,-0.192197,-0.010506,-0.798865,-0.472542,0.145051,0.323665,0.628028,0.752007,-0.349334,-0.295544,-0.773171,-0.965273,0.817462,0.69093,0.735084,0.595465,0.893976,1.00656,-0.410394,-0.36125
4103,0.786112,0.711921,0.531837,0.484142,0.428493,0.26569,0.920788,0.856571,0.721925,0.743803,0.746748,0.729951,0.618321,0.518772,0.442783,0.509369,0.996381,1.00332,0.135908,0.136649,-0.476031,-0.202433,0.1064,0.434903,0.30567,0.490167,1.59544,1.71593,0.162524,0.214866,0.167211,-0.0308106,1.67008,1.61575,0.891087,0.757603,0.792018,0.907849,1.01099,1.05789
4104,0.257814,0.185889,0.923743,0.874124,0.861767,0.699795,0.176065,0.113498,0.43765,0.522655,0.297685,0.278644,0.228734,0.145356,0.993449,0.99966,0.917846,0.894862,0.281868,0.283366,-0.570253,-0.394361,-0.425977,-0.0985308,-0.374599,-0.188327,1.78087,1.89699,2.03937,2.09217,0.49394,0.289479,0.0160632,-0.0409008,1.28281,1.15039,-0.559382,-0.438713,-0.147044,-0.100262
4105,0.885913,0.811421,0.807419,0.756077,0.620825,0.415592,0.68617,0.621339,0.281073,0.301507,0.293157,0.344452,0.57049,0.450009,0.339407,0.347175,0.778269,0.786407,0.977969,0.97763,0.117798,0.300642,-1.65939,-1.3263,-0.033386,0.176041,-0.568471,-0.450779,-1.21792,-1.16136,-1.79723,-1.99439,0.387799,0.327627,-0.118178,-0.249708,1.68613,1.80488,-0.823934,-0.772967
4106,0.39823,0.324827,0.111036,0.0608459,0.294553,0.13139,0.819553,0.755491,0.520782,0.542738,0.429966,0.41026,0.839159,0.754663,0.561015,0.5711,0.389778,0.39636,0.0938601,0.0926237,-0.405143,-0.227272,-0.246316,0.0915157,0.360692,0.540409,0.484091,0.605765,1.2491,1.29996,0.639857,0.439233,-0.171746,-0.225871,-0.904685,-1.03845,0.222816,0.350114,-0.80553,-0.750496
4107,0.516161,0.440834,0.928708,0.876785,0.992843,0.831753,0.620359,0.55808,0.396569,0.4164,0.233542,0.278435,0.41116,0.34111,0.37641,0.352214,0.950682,0.956126,0.107573,0.0654788,0.811607,0.987014,0.224419,0.567756,1.39465,1.57093,-0.301239,-0.185037,-0.259643,-0.215465,-1.43824,-1.64085,0.203249,0.0729769,0.100923,-0.0314678,1.27974,1.40382,1.10265,1.16196
4108,0.954885,0.87885,0.153081,0.0993769,0.245414,0.0858334,0.774521,0.698942,0.813003,0.833904,0.163561,0.14661,0.00985593,-0.0724435,0.122756,0.133329,0.281556,0.285248,0.0375522,0.0383338,0.648322,0.824903,0.160023,0.508609,-1.02792,-0.856742,-0.000877981,0.118825,-0.139992,-0.0889406,-0.338568,-0.540243,0.421615,0.371825,-1.58082,-1.70923,2.04901,2.17342,-0.06019,0.00381377
4109,0.816765,0.741042,0.43405,0.453182,0.998948,0.837174,0.900338,0.839803,0.0494194,0.0699681,0.497823,0.457058,0.55729,0.473822,0.417351,0.340545,0.411947,0.414618,0.96791,0.967061,-0.935915,-0.762636,-1.15857,-0.814538,-0.301668,-0.134442,0.548463,0.664766,0.655901,0.71154,0.313517,0.117758,-0.874852,-0.925129,0.34204,0.204915,1.28897,1.40959,-0.645375,-0.57766
4110,0.1182,0.0427993,0.86144,0.806987,0.698709,0.500344,0.698903,0.696138,0.777455,0.797966,0.783264,0.767507,0.224168,0.138662,0.535883,0.547761,0.954526,0.955294,0.0687597,0.066598,-1.67398,-1.50477,0.134561,0.481099,0.660944,0.83353,1.08451,1.21071,-0.5902,-0.526943,-2.66577,-2.85633,-0.439326,-0.600898,-0.450644,-0.583824,-0.18188,-0.0629359,0.224844,0.291211
4111,0.415282,0.306346,0.434984,0.37841,0.32637,0.163515,0.612867,0.552473,0.311079,0.329661,0.546055,0.529053,0.177554,0.0904166,0.213743,0.225842,0.620513,0.597164,0.282361,0.279112,-1.09502,-0.930625,-1.85323,-1.50132,-0.480391,-0.309384,0.247636,0.37111,-0.357409,-0.293361,-0.620533,-0.813056,-0.178396,-0.276668,-0.0325384,-0.160617,-0.0308275,0.0843662,2.2328,2.29655
4112,0.647605,0.569893,0.853863,0.797523,0.703593,0.495636,0.908381,0.847744,0.37936,0.398833,0.931967,0.913864,0.469588,0.381573,0.828381,0.840755,0.238697,0.239034,0.0525141,0.0482953,0.707302,0.876019,0.530333,0.882189,-2.11495,-1.94347,-0.976341,-0.854833,0.438367,0.50712,-2.76633,-2.95779,0.0978403,0.0475632,-0.391117,-0.519553,-0.131624,-0.014349,-0.0734435,-0.00501241
4113,0.45244,0.376029,0.196187,0.14125,0.992291,0.827758,0.531399,0.470128,0.75104,0.772142,0.226482,0.208842,0.211541,0.124826,0.732389,0.638629,0.566926,0.569573,0.497472,0.491851,1.17785,1.34291,0.000895022,0.348756,0.766663,0.936044,0.85153,0.97252,0.0852524,0.15531,0.707918,0.512165,0.139583,0.0934627,1.15872,1.03689,-1.56463,-1.45371,0.180118,0.265416
4114,0.552214,0.476399,0.343981,0.290254,0.56525,0.403259,0.535991,0.561737,0.636609,0.655511,0.393315,0.374004,0.616271,0.531795,0.487866,0.436502,0.675435,0.679155,0.162939,0.155421,1.1009,1.27179,-0.0471687,0.395789,0.690784,0.86029,0.0153045,0.132921,-0.26462,-0.196501,0.892568,0.695275,-0.387585,-0.429713,-0.688649,-0.816334,0.0121911,0.130765,0.465794,0.535843
4115,0.415427,0.293076,0.0132974,-0.0400021,0.523255,0.356205,0.713356,0.653346,0.0657019,0.0821725,0.142852,0.125756,0.0347587,-0.0506331,0.28042,0.234375,0.520507,0.555016,0.438758,0.433235,-0.173287,-0.00980102,0.0977659,0.442822,-0.774372,-0.606301,1.25521,1.37378,1.16226,1.23495,-1.11189,-1.30769,1.22125,1.17256,0.0337757,-0.0850182,-1.3017,-1.18448,0.209886,0.286554
4116,0.263394,0.109754,0.049719,-0.00162831,0.524582,0.309151,0.374398,0.31593,0.607293,0.626541,0.140427,0.116545,0.249124,0.115033,0.0184374,0.0322485,0.428579,0.430877,0.00886449,0.00256578,0.595038,0.762028,1.07593,1.4262,-1.82122,-1.65683,0.10648,0.22529,1.17236,1.24079,-1.97031,-2.17207,1.38446,1.34072,-0.00476662,-0.125267,-0.572173,-0.459991,0.263464,0.339387
4117,0.00175232,-0.0735693,0.475663,0.422818,0.424088,0.262097,0.976858,0.918688,0.209338,0.228028,0.123968,0.107335,0.521455,0.280698,0.811368,0.825593,0.637201,0.637584,0.321017,0.317939,1.1501,1.31902,0.770404,1.11472,0.680379,0.851179,-0.153043,-0.0414025,-0.83142,-0.75747,-3.60887,-3.80212,-0.779622,-0.816585,0.579822,0.465329,0.519946,0.639662,-0.653969,-0.574356
4118,0.088268,0.0124924,0.129622,0.0778152,0.099927,-0.0623612,0.24726,0.191046,0.686694,0.705937,0.866693,0.849261,0.568192,0.446364,0.35379,0.440575,0.402427,0.403746,0.76964,0.633312,0.84628,1.02206,0.453287,0.803241,1.20888,1.37221,1.17219,1.27682,-0.395048,-0.324322,-0.406007,-0.595325,-0.120696,-0.155363,0.0420724,-0.0761972,-0.760233,-0.643105,0.386019,0.461305
4119,0.679788,0.603698,0.834722,0.783049,0.232699,0.0691011,0.825901,0.768926,0.926435,0.947168,0.536152,0.511143,0.697421,0.61203,0.0435563,0.0555572,0.532408,0.605203,0.954983,0.948685,-2.7135,-2.53465,0.807798,1.15844,0.0894361,0.258966,1.45175,1.54936,0.484414,0.554757,0.215154,0.0330078,-0.737455,-0.770138,0.659374,0.545326,-1.76496,-1.64264,-0.609436,-0.527643
4120,0.715928,0.545027,0.87521,0.821422,0.950518,0.785088,0.798376,0.682526,0.929405,0.949958,0.190831,0.173026,0.594282,0.507262,0.770697,0.783208,0.803527,0.80666,0.922038,0.914665,-1.67864,-1.5038,-0.0781833,0.271471,1.15289,1.31945,-0.524492,-0.430885,0.81218,0.881376,1.86806,1.68823,1.53493,1.49831,0.278704,0.157883,-0.580985,-0.464358,1.77534,1.86386
4121,0.559888,0.486357,0.44984,0.39496,0.478659,0.315357,0.654342,0.596125,0.285182,0.305686,0.960702,0.940913,0.00705976,-0.0800451,0.252399,0.267401,0.252711,0.257364,0.6321,0.623856,0.142142,0.316656,0.150814,0.50326,0.61489,0.773624,0.306792,0.392581,-0.911196,-0.848958,-0.941407,-1.11474,0.331776,0.296128,0.59602,0.475086,-1.95003,-1.84162,-0.366606,-0.278555
4122,0.208164,0.136296,0.020544,-0.0315033,0.463396,0.301869,0.273992,0.279626,0.349806,0.298976,0.0732058,0.0513046,0.523156,0.43624,0.69963,0.714383,0.985372,0.989066,0.699085,0.690597,-0.700875,-0.456684,-0.529602,-0.102605,0.0653832,0.227802,-1.39896,-1.31509,-1.02073,-0.955606,2.26259,2.09206,-0.624748,-0.657766,-0.724953,-0.850653,0.176956,0.294715,-0.410003,-0.316922
4123,0.841985,0.772106,0.794989,0.744075,0.15467,-0.00725648,0.0197566,-0.0368728,0.271903,0.292265,0.85523,0.83439,0.558853,0.474655,0.463147,0.517522,0.400936,0.404085,0.519663,0.510258,-1.40139,-1.23002,-1.05604,-0.70847,-0.031065,0.134534,0.648107,0.732572,-0.398185,-0.338491,0.732807,0.567981,-1.08559,-1.11922,-1.00312,-1.13161,-1.07475,-0.955996,-0.132336,0.00143399
4124,0.583112,0.514029,0.813449,0.763109,0.411332,0.171943,0.583771,0.52647,0.769039,0.79019,0.571542,0.649092,0.163675,0.0785973,0.306131,0.32066,0.880213,0.884109,0.0377943,0.0296956,1.08497,1.25818,1.19064,1.54667,-1.29561,-1.13045,-0.0797228,0.00329668,-0.492692,-0.430592,1.32108,1.15132,-0.588239,-0.710001,-1.81815,-1.94929,-1.27334,-1.14889,0.234682,0.31979
4125,0.673835,0.663825,0.477219,0.428034,0.516056,0.351143,0.282103,0.224039,0.968319,0.989743,0.483981,0.463794,0.459402,0.398806,0.72387,0.652456,0.930448,0.933176,0.305495,0.357811,-1.98796,-1.80945,-0.346266,0.00430977,1.47927,1.64099,-1.85645,-1.76419,-1.5233,-1.45459,0.106415,-0.0637145,-0.264805,-0.300784,1.29964,1.16932,0.0076048,0.137274,2.57556,2.66215
4126,0.882869,0.813621,0.97312,0.926514,0.369407,0.252312,0.502423,0.444385,0.495749,0.516737,0.954601,0.936255,0.803805,0.719015,0.969165,0.984252,0.202394,0.207479,0.693449,0.685926,0.906113,1.0892,-1.11654,-0.760167,0.398061,0.55989,-1.68044,-1.58313,-0.336244,-0.268421,-0.346561,-0.572671,1.90815,1.87163,-0.795889,-0.932113,0.644057,0.768592,-0.101112,-0.00788725
4127,0.620319,0.550118,0.856582,0.808466,0.319395,0.153481,0.4561,0.397511,0.873836,0.894402,0.727772,0.707793,0.0250071,-0.0616613,0.703382,0.717197,0.173918,0.125654,0.228762,0.21997,-0.0326319,0.147288,0.236088,0.595233,0.522939,0.680714,0.788828,0.878929,-0.827896,-0.755203,-0.91956,-1.08163,-0.375095,-0.417395,0.283175,0.149544,-1.76997,-1.64924,-0.74269,-0.650735
4128,0.971657,0.90194,0.0999759,0.0520606,0.635113,0.470194,0.0267919,-0.034385,0.54007,0.623492,0.0101803,-0.00780763,0.810939,0.723915,0.894157,0.908826,0.0380091,0.0438282,0.32292,0.315167,0.0376882,0.17758,-2.15741,-1.80273,-0.594535,-0.432529,-1.45382,-1.36694,-1.72301,-1.65494,1.56832,1.41186,0.651445,0.60975,-0.694432,-0.822776,0.855182,0.973434,0.504232,0.59852
4129,0.0341439,-0.0334618,0.545111,0.49585,0.0981873,-0.0688767,0.47609,0.413845,0.248345,0.352582,0.675906,0.658846,0.0774987,-0.00953422,0.604909,0.547324,0.584125,0.588765,0.419772,0.410364,0.0283318,0.207872,-0.599205,-0.242588,0.425849,0.582157,-1.07683,-0.988505,0.0598497,0.1276,1.58309,1.42623,0.128372,0.0865742,0.51835,0.393905,-1.65004,-1.53043,-0.86005,-0.758583
4130,0.61743,0.547935,0.778062,0.728265,0.0846933,-0.0823641,0.476138,0.412625,0.059931,0.0816717,0.567664,0.642496,0.98407,0.898253,0.169481,0.185822,0.232198,0.239153,0.0066061,-0.00110791,0.840031,1.02419,-0.200102,0.157203,0.476151,0.626941,-1.67791,-1.59402,0.151368,0.225369,-1.17335,-1.32985,-1.23551,-1.27177,-0.407968,-0.531443,-0.389212,-0.275591,0.336146,0.432638
4131,0.714729,0.64352,0.617754,0.569737,0.749195,0.582352,0.132612,0.07116,0.692666,0.716204,0.643403,0.626146,0.912455,0.824467,0.710737,0.728602,0.277619,0.282625,0.963031,0.956807,-0.505789,-0.317254,0.708388,1.06465,0.171853,0.322424,0.299792,0.390062,1.57996,1.65682,-2.21861,-2.37842,0.184704,0.146681,-2.49749,-2.6164,-1.57308,-1.46408,1.93907,2.03652
4132,0.600952,0.50379,0.169055,0.12128,0.353701,0.187269,0.176562,0.114601,0.214714,0.23725,0.769523,0.75105,0.301556,0.213323,0.354318,0.371646,0.958117,0.964903,0.555182,0.550416,-0.470649,-0.364996,0.268579,0.623617,0.149092,0.292944,0.10216,0.187329,-1.41279,-1.33122,2.62428,2.46447,1.02031,0.989163,-0.0531687,-0.171746,-0.753218,-0.562296,0.59545,0.694616
4133,0.436982,0.36406,0.957784,0.908227,0.901346,0.734754,0.926976,0.867198,0.307632,0.336897,0.327767,0.309496,0.730858,0.644974,0.512334,0.529044,0.779253,0.851735,0.715803,0.765769,-0.594143,-0.412738,0.494037,0.841948,-0.1649,-0.0292482,0.332779,0.415818,1.18005,1.25801,0.994245,0.834427,-0.84359,-0.870451,0.156663,0.0358579,0.22516,0.339491,0.673327,0.775292
4134,0.714778,0.640738,0.926585,0.877982,0.956711,0.791573,0.190048,0.12899,0.425309,0.436545,0.750392,0.733108,0.441496,0.307711,0.459879,0.477079,0.730557,0.738568,0.984717,0.981123,-1.26185,-1.07763,1.20907,1.54978,0.0199297,0.153882,0.0589095,0.149126,1.59694,1.67663,0.286369,0.123051,-0.257009,-0.285422,-0.507569,-0.631402,-0.958212,-0.849001,-0.52642,-0.428779
4135,0.323431,0.250914,0.444191,0.43799,0.316219,0.153408,0.118168,0.0558447,0.433254,0.536192,0.413798,0.395472,0.0587518,-0.0295526,0.396167,0.425115,0.210723,0.219326,0.702957,0.700205,2.26963,2.44589,-1.07219,-0.732219,1.24494,1.38144,1.05463,1.14634,2.2379,2.32444,1.72125,1.56154,-0.398978,-0.421794,0.850939,0.726217,0.363823,0.467853,-0.667611,-0.571514
4136,0.415064,0.341962,0.0482957,-0.00200138,0.278804,0.19763,0.553771,0.489261,0.613304,0.63584,0.928599,0.908284,0.659483,0.570963,0.401223,0.373151,0.650557,0.658813,0.881758,0.877761,0.171084,0.345835,1.22494,1.56891,-3.48677,-3.35027,-0.255244,-0.156409,-2.59,-2.50346,-0.146221,-0.299947,-0.0653255,-0.0847463,-1.8077,-1.93128,-1.37259,-1.27484,1.06852,1.16945
4137,0.279696,0.208683,0.15166,0.102002,0.372997,0.241851,0.421557,0.307849,0.944625,0.96802,0.954799,0.845715,0.966636,0.877915,0.357189,0.321187,0.4734,0.481216,0.28057,0.276927,-0.72964,-0.552113,0.724913,1.06722,0.217268,0.353941,0.68061,0.776978,0.48119,0.565207,0.655577,0.492216,0.635652,0.622295,0.00986323,-0.110177,0.179893,0.278089,-0.0831799,0.0112968
4138,0.348496,0.343165,0.925834,0.877581,0.487707,0.286073,0.231442,0.126438,0.429305,0.454898,0.801371,0.783147,0.822542,0.72859,0.252514,0.269223,0.699404,0.653895,0.322449,0.339871,0.83954,1.02397,0.552391,0.900396,0.31977,0.460442,-0.920209,-0.819367,-1.03606,-0.950216,0.218952,0.0610874,0.42342,0.409853,0.455098,0.388731,-0.176218,-0.0837463,-0.0915418,0.00391781
4139,0.522155,0.477648,0.653077,0.530603,0.493105,0.330294,0.00993139,-0.0549733,0.316684,0.343268,0.580488,0.560233,0.570901,0.579264,0.827314,0.842839,0.869443,0.826574,0.326383,0.402814,-0.74156,-0.563575,-0.414172,-0.0642502,-0.811492,-0.668494,0.114399,0.221927,-1.07615,-0.992522,-0.444367,-0.604975,-0.0486225,-0.0672686,0.979877,0.88764,-1.62087,-1.5231,-2.7277,-2.6315
4140,0.719721,0.61213,0.229577,0.183625,0.845855,0.68301,0.176623,0.109868,0.589281,0.614973,0.769525,0.749121,0.53129,0.429939,0.980699,0.994104,0.993206,0.999252,0.469399,0.465757,0.603544,0.778482,-0.400873,-0.0481666,-0.594356,-0.522933,-1.35733,-1.24927,-0.316423,-0.236969,-0.157991,-0.315735,0.0548211,0.0410287,1.50659,1.38655,-1.37291,-1.2678,-0.798023,-0.703765
4141,0.816692,0.746612,0.601257,0.553338,0.0272559,-0.136474,0.688597,0.622666,0.380465,0.408486,0.162666,0.144101,0.369334,0.280613,0.0908442,0.106212,0.0715165,0.0760741,0.770675,0.768363,1.42447,1.5948,0.539313,0.889393,-0.516881,-0.377371,-0.127971,0.0778199,1.82604,1.8986,-0.356646,-0.515678,-1.54189,-1.55493,0.417378,0.293331,-0.519079,-0.46596,-1.77404,-1.6769
4142,0.595966,0.526949,0.301767,0.253487,0.908908,0.745598,0.0464123,-0.0195831,0.864277,0.891015,0.00958954,-0.00885592,0.91481,0.826879,0.365845,0.473723,0.828134,0.833479,0.262893,0.262687,-2.10665,-1.93321,-0.207085,0.140996,0.255022,0.391319,1.30134,1.40491,-0.976662,-0.904398,0.786197,0.63137,-0.402102,-0.417038,0.441602,0.316309,0.227672,0.33588,-0.147233,-0.0559351
4143,0.372522,0.307286,0.439946,0.34844,0.452847,0.291605,0.249009,0.181876,0.791878,0.820375,0.707894,0.687534,0.847711,0.739728,0.82603,0.841234,0.683308,0.689967,0.630155,0.627878,0.0538464,0.223677,1.34807,1.70114,-0.964348,-0.830235,-0.59471,-0.492897,1.75575,1.82062,0.682515,0.429311,-1.05174,-1.06118,-2.89621,-3.02948,-0.178693,-0.0719476,-0.75357,-0.668435
4144,0.157702,0.0876221,0.4946,0.443394,0.6774,0.517205,0.738178,0.67034,0.934793,0.964829,0.122951,0.102581,0.73785,0.652577,0.0779418,0.0954891,0.266412,0.271102,0.0125717,0.012676,0.883953,1.05493,0.402115,0.811969,1.58984,1.73006,-0.432325,-0.327882,0.825917,0.888549,0.379809,0.227252,-0.352349,-0.354134,0.876474,0.746007,-0.132904,-0.0296622,-0.945957,-0.857724
4145,0.749232,0.678827,0.147358,0.098392,0.68395,0.524396,0.675279,0.644535,0.449172,0.575572,0.480219,0.457869,0.980679,0.893689,0.184796,0.201826,0.587764,0.632013,0.069279,0.131547,-0.616883,-0.440122,-0.429064,-0.0772023,-0.780603,-0.637969,0.24179,0.341502,0.4757,0.537467,-1.57799,-1.73035,0.099009,0.127718,-1.45699,-1.58681,0.787625,0.897908,0.598898,0.683558
4146,0.521147,0.479725,0.522025,0.4726,0.377388,0.22032,0.687274,0.61873,0.155201,0.186314,0.513979,0.451479,0.634591,0.548465,0.799095,0.816739,0.986758,0.992925,0.252196,0.250417,0.790524,0.963392,0.965973,1.32441,0.86803,1.00472,0.216699,0.321955,-0.635244,-0.577143,-0.833973,-1.01886,0.617837,0.609569,-0.342469,-0.473897,-0.134067,-0.0236141,-0.360318,-0.275017
4147,0.349143,0.280622,0.576572,0.526402,0.813568,0.654424,0.873356,0.804234,0.540554,0.491217,0.466953,0.445089,0.702488,0.617259,0.928695,0.86673,0.941158,0.948219,0.371178,0.369288,1.69938,1.87213,-1.21792,-0.863718,0.166848,0.297417,0.767988,0.870008,0.528503,0.593925,-0.158141,-0.30736,-1.52293,-1.53306,0.358008,0.225189,0.589822,0.748483,-1.07124,-1.05089
4148,0.510231,0.440819,0.397135,0.414655,0.707727,0.54838,0.0664182,-0.00178265,0.764355,0.79612,0.883548,0.864446,0.43267,0.346327,0.899536,0.916721,0.0130892,0.0189208,0.177228,0.24051,-1.21073,-1.04408,-0.924853,-0.568113,0.349715,0.480547,2.16128,2.26498,1.44328,1.50339,-1.13087,-1.27982,0.679283,0.669465,-0.372084,-0.503354,1.41458,1.52058,-1.92117,-1.82676
4149,0.161195,0.090758,0.35504,0.302907,0.850926,0.690332,0.820677,0.750814,0.913944,0.946307,0.886071,0.866516,0.711425,0.622424,0.286974,0.30586,0.458594,0.46412,0.11536,0.111733,0.141692,0.313362,-1.20664,-0.857128,1.27869,1.40196,0.848495,0.948475,0.00968608,0.0659685,0.00751448,-0.146941,-0.924411,-0.940481,0.729331,0.593444,0.174827,0.285866,0.172441,0.271045
4150,0.289749,0.220773,0.500466,0.394938,0.548644,0.386256,0.0228685,-0.0447337,0.324402,0.357593,0.605026,0.583763,0.435424,0.431038,0.950241,0.970185,0.617659,0.623503,0.417588,0.363916,1.20747,1.37525,1.27751,1.62146,-0.453295,-0.327622,-0.730646,-0.629916,-0.569875,-0.513792,-1.04386,-1.19551,0.373469,0.352766,0.418315,0.280112,0.620875,0.729124,-0.633112,-0.536099
4151,0.0513325,-0.0176926,0.538441,0.486968,0.518496,0.358247,0.341308,0.170299,0.532359,0.543032,0.735542,0.713461,0.327423,0.239652,0.963871,0.986004,0.443945,0.45024,0.617927,0.616099,0.302025,0.471359,0.0333873,0.378542,-0.151114,0.0644534,-1.12403,-1.01959,-0.205514,-0.155446,-0.237106,-0.384226,0.787733,0.76805,-1.10564,-1.24415,0.0406789,0.150654,-0.915878,-0.816258
4152,0.596201,0.528705,0.305566,0.252466,0.716208,0.553572,0.503969,0.385332,0.655498,0.728471,0.132008,0.108441,0.304621,0.21667,0.0864164,0.108949,0.801455,0.806563,0.306355,0.304706,-0.604835,-0.432531,-0.674228,-0.3226,0.32657,0.456529,-0.177596,-0.0707345,1.55569,1.61205,-1.27093,-1.41706,0.683198,0.662508,-1.35033,-1.49564,1.26994,1.37423,1.86512,1.96054
4153,0.250235,0.183453,0.592934,0.54682,0.187072,0.0250986,0.668429,0.600365,0.881012,0.913909,0.933452,0.907141,0.539472,0.45252,0.524315,0.54613,0.130571,0.135685,0.351137,0.434922,0.469439,0.643889,-0.242128,0.107967,0.503154,0.629981,0.560674,0.662314,-1.35047,-1.29167,-0.983378,-1.12782,-1.47626,-1.4948,-0.061398,-0.202489,-1.39629,-1.28763,2.87617,2.96658
4154,0.225757,0.224824,0.893356,0.841174,0.31153,0.172963,0.403017,0.336926,0.335806,0.370419,0.74529,0.718661,0.25574,0.166654,0.579915,0.60187,0.283269,0.220384,0.564242,0.565139,-1.56998,-1.39658,-0.929984,-0.578275,0.667605,0.803432,-0.0052009,0.100695,-0.274694,-0.212971,-0.901305,-1.05219,-0.815505,-0.833574,0.509849,0.427887,-0.66193,-0.5472,0.444164,0.537067
4155,0.330511,0.266196,0.857958,0.807112,0.483559,0.320827,0.691392,0.627378,0.640098,0.673184,0.765198,0.773213,0.288204,0.239624,0.0591898,0.0807714,0.29839,0.305083,0.842681,0.842953,-2.051,-1.87913,-0.737892,-0.39269,0.563099,0.71878,-0.565317,-0.460925,-1.32696,-1.26683,1.06986,0.925291,0.599706,0.584876,1.16189,1.05826,0.973161,1.08444,-1.29822,-1.20099
4156,0.987346,0.922589,0.309985,0.260392,0.158514,-0.00363082,0.4161,0.35435,0.12686,0.160062,0.911178,0.827764,0.489562,0.312594,0.763828,0.788141,0.0865181,0.0916954,0.161971,0.161895,-0.320187,-0.149845,0.424337,0.760348,0.494614,0.634128,1.64998,1.74871,0.244195,0.302749,-0.12037,-0.26083,0.856448,0.844453,1.82973,1.68864,-1.09035,-0.976412,0.443207,0.539967
4157,0.555596,0.491827,0.068966,0.0190703,0.651754,0.489767,0.457789,0.464914,0.440347,0.455447,0.973348,0.882316,0.473218,0.385565,0.716564,0.741623,0.722685,0.728929,0.164871,0.162783,-1.33035,-1.15574,-0.128444,0.239895,-0.777472,-0.630853,3.16797,3.27194,1.39917,1.45716,-0.672758,-0.816427,0.149689,0.13927,-0.904604,-1.04241,-0.787529,-0.684958,0.150616,0.245966
4158,0.812246,0.748268,0.207131,0.222745,0.351221,0.249624,0.639129,0.575477,0.720287,0.750831,0.964082,0.936868,0.0584678,-0.0304444,0.2871,0.31052,0.618066,0.621649,0.565201,0.484369,-0.918408,-0.749944,-0.614897,-0.280558,0.285978,0.429627,0.484008,0.587021,-0.392817,-0.337241,0.941149,0.792508,-0.0416483,-0.0565422,0.395348,0.250743,-0.503694,-0.393505,-1.2708,-1.1714
4159,0.686354,0.654502,0.474455,0.42642,0.1701,0.00948155,0.499901,0.371479,0.323976,0.425264,0.147013,0.119529,0.391687,0.366763,0.524192,0.545481,0.00978972,0.0113956,0.806845,0.805956,0.190377,0.357564,2.06093,2.39163,-1.05416,-0.880887,0.434455,0.537329,-1.86651,-1.80591,0.142265,-0.011104,0.0512158,0.0356304,-0.33356,-0.477801,1.36384,1.47561,-2.36591,-2.26896
4160,0.615458,0.560737,0.227424,0.180279,0.576449,0.417624,0.229232,0.167481,0.07029,0.0996977,0.773576,0.744986,0.852883,0.763971,0.306016,0.328393,0.82995,0.829686,0.893318,0.892077,0.27326,0.438694,-0.775127,-0.449969,-2.33056,-2.1914,0.809643,0.91576,-1.5115,-1.44757,-0.284093,-0.442232,-0.143738,-0.160181,-2.38096,-2.52992,0.146445,0.283996,2.64117,2.73813
4161,0.6577,0.466971,0.443864,0.397609,0.571716,0.351241,0.57062,0.510825,0.0201409,0.0499282,0.624466,0.596968,0.314433,0.22719,0.530339,0.552318,0.934913,0.934322,0.55081,0.51522,0.0688805,0.23324,-2.17377,-1.85267,1.14179,1.28511,-1.0654,-0.962755,-0.873889,-0.814679,-0.205966,-0.366602,-0.0260987,-0.0374267,1.18974,1.04645,-1.01845,-0.907619,-0.863414,-0.766995
4162,0.437184,0.373206,0.0447309,-0.00183061,0.442635,0.284858,0.168588,0.109212,0.319456,0.328587,0.997657,0.971869,0.354236,0.343856,0.987352,1.00904,0.750033,0.750891,0.13883,0.138362,-2.33615,-2.16832,0.344984,0.67279,-0.715353,-0.571935,-0.251154,-0.153281,1.78997,1.84299,-1.17991,-1.37762,-0.456836,-0.467,-0.105352,-0.249411,0.59887,0.707425,-1.00984,-0.90973
4163,0.249843,0.184543,0.267527,0.202688,0.812092,0.652179,0.284692,0.125691,0.574849,0.607245,0.273518,0.24663,0.546243,0.460522,0.240848,0.263295,0.27279,0.276219,0.735486,0.736843,0.457248,0.619256,0.647485,0.982673,-1.02259,-0.876452,-1.81169,-1.71641,0.393704,0.535181,-2.23078,-2.38863,-0.29566,-0.29884,-0.404152,-0.544946,0.985558,1.08941,0.614659,0.71123
4164,0.490159,0.425598,0.420259,0.407206,0.733378,0.572055,0.254024,0.14217,0.143819,0.178778,0.0118879,-0.0164882,0.450159,0.419417,0.105229,0.163969,0.922525,0.923166,0.30395,0.306174,-1.73655,-1.58121,1.46449,1.7977,-1.69375,-1.55495,-1.04586,-0.953127,-0.82564,-0.772625,-0.401517,-0.562889,-2.00758,-2.00413,-0.214793,-0.351397,0.0812287,0.181667,-0.0148096,0.0853092
4165,0.443238,0.378706,0.658285,0.611724,0.886987,0.723653,0.218137,0.158649,0.657775,0.692899,0.589684,0.559581,0.389782,0.378313,0.0434897,0.0646425,0.190654,0.191976,0.32925,0.332466,0.983502,1.14108,1.97813,2.30725,0.57673,0.720751,0.910464,1.00031,0.348936,0.398443,-1.0105,-1.16682,-1.56005,-1.55723,0.910728,0.777516,-0.459797,-0.365162,-0.847885,-0.750766
4166,0.0155989,-0.0469177,0.174493,0.128434,0.0879891,-0.0728824,0.636571,0.576806,0.343053,0.465467,0.165119,0.133861,0.422407,0.337208,0.286975,0.310199,0.917805,0.919333,0.967052,0.971246,-1.72206,-1.55833,1.89874,2.23279,-0.549045,-0.408185,-0.336981,-0.24174,0.3229,0.371559,1.32761,1.16303,-0.599944,-0.589882,-1.09484,-1.22973,0.398146,0.486372,-0.0338632,0.0574982
4167,0.754585,0.690837,0.364837,0.317171,0.940868,0.778114,0.316861,0.258851,0.200997,0.238035,0.404198,0.35078,0.0605749,-0.0237434,0.208438,0.281704,0.772638,0.77582,0.054497,0.0599926,0.258779,0.430123,-1.45631,-1.12295,0.405396,0.545751,1.06107,1.15323,-0.417245,-0.375759,0.831417,0.66983,1.44689,1.45291,-0.892675,-1.02213,-0.1867,-0.0920979,0.109247,0.199555
4168,0.0231358,-0.0384076,0.0759486,0.0270112,0.234152,0.0687928,0.451466,0.448669,0.9902,1.02588,0.596666,0.5677,0.776866,0.695336,0.228924,0.253208,0.0703218,0.0754139,0.160115,0.166218,-0.00651819,0.163567,0.283797,0.620207,-0.130915,0.0103262,0.414782,0.55115,0.829305,0.873344,-1.68922,-1.84326,0.567905,0.576167,-2.03605,-2.16133,-1.9438,-1.85033,-0.571538,-0.485868
4169,0.237783,0.178171,0.761884,0.711639,0.343706,0.193588,0.695771,0.638487,0.6275,0.662448,0.226222,0.196007,0.79014,0.708284,0.459117,0.406063,0.607284,0.610006,0.485027,0.489953,0.107933,0.275015,-0.875189,-0.545844,1.4472,1.59072,-0.165268,-0.0509344,-2.12008,-2.08252,0.597317,0.438276,0.716566,0.729201,-0.586502,-0.65729,0.779389,0.865908,-1.04158,-0.961328
4170,0.213907,0.152888,0.698845,0.629841,0.482495,0.318383,0.0376542,-0.0187709,0.636672,0.740322,0.38295,0.350797,0.44967,0.380054,0.524027,0.558919,0.220905,0.22554,0.572735,0.576074,0.557765,0.72547,-0.294031,0.0399185,-0.192033,-0.0433658,-0.74518,-0.653018,0.681062,0.711237,0.851932,0.696714,0.501053,0.516759,1.03532,0.846746,-0.976998,-0.892327,-1.02805,-0.953747
4171,0.888973,0.828156,0.598903,0.548042,0.0830652,-0.0817298,0.0526355,-0.00564923,0.785094,0.818197,0.199632,0.168219,0.133089,0.0518241,0.68749,0.711774,0.437826,0.44,0.0263081,0.0293102,-0.188184,-0.0166607,3.14164,3.4752,-0.327414,-0.225824,-0.557403,-0.422246,-0.0646211,-0.0360798,0.508379,0.349817,-0.621734,-0.608691,2.47606,2.35078,-0.868684,-0.806538,-0.701837,-0.630872
4172,0.0678892,0.0054354,0.726928,0.649331,0.99667,0.832077,0.748972,0.691735,0.0386928,0.0708694,0.696147,0.665699,0.463619,0.465606,0.0562342,0.0799466,0.54275,0.65446,0.818814,0.821612,0.708342,0.878455,-2.11143,-1.78009,-0.559868,-0.408282,-0.289911,-0.191474,-2.18613,-2.15412,0.15423,0.00292019,0.85553,0.87078,-0.618593,-0.739654,-0.801834,-0.720749,1.7163,1.79347
4173,0.360495,0.227978,0.803049,0.75062,0.769606,0.604649,0.815555,0.760799,0.992304,1.02704,0.726348,0.697254,0.960927,0.879388,0.34794,0.370581,0.864286,0.86892,0.327471,0.330934,-0.180861,-0.0041977,1.30424,1.64267,0.152534,0.216376,0.153337,0.247668,0.305098,0.340484,0.160512,-0.0584514,-1.15311,-1.13277,-1.77929,-1.89236,-1.76333,-1.68913,-0.0268296,0.0554085
4174,0.510635,0.450521,0.533689,0.479868,0.927555,0.76129,0.401592,0.348479,0.3863,0.42232,0.142133,0.112301,0.950505,0.866724,0.253682,0.274273,0.292041,0.294334,0.0413637,0.0454911,-0.388231,-0.196125,-0.606752,-0.26352,0.684331,0.841035,0.0209306,0.121393,1.10837,1.14097,0.0251309,-0.119823,-0.854919,-0.840475,-0.241939,-0.351409,-0.648365,-0.575101,0.538965,0.621384
4175,0.58302,0.573952,0.802753,0.750904,0.137342,-0.0294872,0.661932,0.609307,0.175068,0.210523,0.536806,0.506523,0.450653,0.365686,0.902842,0.92376,0.468372,0.469302,0.597571,0.506749,-0.562928,-0.388052,1.19114,1.5274,1.80122,1.96113,-1.41755,-1.32035,0.50141,0.530342,0.602516,0.463511,1.901,1.91449,0.507111,0.392669,-0.104659,-0.0364449,-1.7878,-1.71161
4176,0.757724,0.697383,0.700944,0.647642,0.131905,-0.0261919,0.493874,0.442606,0.306436,0.388938,0.708629,0.67646,0.52254,0.439821,0.527704,0.546888,0.429488,0.429659,0.96318,0.968007,1.38661,1.55494,-0.237059,0.0933908,-0.0694594,0.0900141,1.09089,1.19078,-0.858718,-0.83388,0.425419,0.279724,0.74752,0.760768,-1.11208,-1.22307,0.78907,0.858603,-0.518376,-0.44555
4177,0.0901901,0.0311266,0.384351,0.33187,0.142395,-0.0228967,0.331645,0.275905,0.619592,0.567353,0.32049,0.289007,0.372167,0.290292,0.48334,0.405463,0.743876,0.744504,0.890131,0.893908,-0.0745579,0.090967,0.0660313,0.403273,-0.27137,-0.107578,0.819302,0.924089,-1.13478,-1.14944,-0.198617,-0.340565,0.550898,0.564957,-0.418281,-0.523981,-0.126275,-0.0629195,-0.814714,-0.73955
4178,0.892529,0.832656,0.914321,0.859624,0.591811,0.373522,0.162636,0.109203,0.711999,0.745767,0.301364,0.208243,0.422571,0.338786,0.239272,0.264038,0.146219,0.144702,0.248484,0.253246,1.48753,1.65094,-1.87315,-1.53301,0.723701,0.891915,1.63649,1.74755,-1.4904,-1.46499,2.47467,2.33265,-0.0123463,-0.00467516,-0.353473,-0.454727,-0.145787,-0.083865,0.383253,0.464124
4179,0.278967,0.2209,0.656522,0.603569,0.934447,0.769941,0.470903,0.418926,0.302322,0.336578,0.143906,0.12748,0.0579161,-0.0275161,0.102619,0.122613,0.612122,0.522412,0.528099,0.53106,-0.528171,-0.359436,-0.100721,0.243023,-1.23149,-1.06032,0.700856,0.814036,-1.00375,-0.975817,-0.02,-0.160952,0.330038,0.332373,-2.23696,-2.33919,1.12139,1.1866,-0.353144,-0.267536
4180,0.203703,0.238288,0.83509,0.782257,0.255371,0.0902342,0.0480989,-0.00242645,0.32563,0.360086,0.0781989,0.0467159,0.4441,0.359236,0.435829,0.518445,0.903308,0.900122,0.129255,0.130499,-0.467664,-0.292337,0.319701,0.659174,2.15063,2.31998,-0.854477,-0.732367,-0.505411,-0.48664,-0.0246051,-0.162145,-0.700398,-0.699292,-0.429208,-0.533939,0.125533,0.187059,0.092186,0.175772
4181,0.311334,0.255676,0.395605,0.344502,0.729238,0.563829,0.43617,0.386344,0.689421,0.64135,0.909185,0.87662,0.154239,0.0675032,0.893641,0.914277,0.38501,0.380881,0.216136,0.141948,-0.898883,-0.726688,0.327249,0.661479,-1.60385,-1.44077,1.04086,1.15718,-0.339362,-0.327243,0.614579,0.481891,2.79041,2.78798,0.446466,0.34805,0.288626,0.350183,-1.63051,-1.54681
4182,0.361631,0.273064,0.591547,0.541925,0.412076,0.244142,0.245096,0.194745,0.889383,0.922615,0.0706763,0.0386449,0.826982,0.740231,0.20984,0.232101,0.160476,0.157427,0.150152,0.153397,-0.709534,-0.537733,-0.167368,0.15979,-0.553414,-0.397402,-1.56263,-1.44451,0.58428,0.598403,0.4411,0.313104,1.11329,1.11413,0.766111,0.665254,-0.626887,-0.571339,-1.26831,-1.17891
4183,0.347933,0.290452,0.276338,0.226153,0.418462,0.251333,0.396853,0.34502,0.495911,0.565147,0.821487,0.790534,0.848438,0.762721,0.396943,0.419068,0.489087,0.487966,0.545585,0.547962,-1.64,-1.46698,-0.913713,-0.588607,-0.557924,-0.397427,-1.53448,-1.41861,-0.671529,-0.656477,-0.786626,-0.917452,-0.139084,-0.134798,2.02834,1.92803,1.19535,1.25075,0.713334,0.80862
4184,0.628739,0.572149,0.261756,0.262004,0.625414,0.503533,0.8867,0.833484,0.176669,0.207679,0.138101,0.105767,0.419399,0.333338,0.219695,0.24223,0.121317,0.11861,0.119546,0.122008,-0.728899,-0.581583,-1.38548,-1.06041,-0.247014,-0.0895452,0.860776,0.978834,0.409134,0.422227,1.47704,1.34966,-0.207413,-0.210109,-2.05443,-2.15,-1.10374,-1.05061,1.07023,1.16055
4185,0.0738969,0.0159837,0.347162,0.297854,0.924244,0.755734,0.852722,0.778457,0.487931,0.519697,0.8675,0.836981,0.616932,0.529992,0.896206,0.918409,0.316465,0.335278,0.707287,0.711142,0.130788,0.303813,-0.553231,-0.228586,-0.686324,-0.530961,0.60134,0.712142,0.343818,0.38948,1.21308,1.051,-1.37487,-1.38249,0.978161,0.885412,-1.4983,-1.44197,-0.218,-0.120612
4186,0.346561,0.287124,0.0847629,0.0367603,0.697878,0.517165,0.884568,0.72343,0.424802,0.453969,0.74385,0.713777,0.462127,0.3755,0.836078,0.866939,0.553266,0.551946,0.440431,0.441294,0.0667845,0.215892,1.23885,1.56233,-0.187333,-0.0274381,1.02221,1.13654,0.306192,0.356733,0.88471,0.752341,-0.400379,-0.415142,0.465357,0.374312,-0.263323,-0.201029,0.253956,0.352305
4187,0.00703981,-0.0531108,0.86086,0.812339,0.511453,0.278596,0.723248,0.668403,0.0283685,0.0554551,0.36179,0.332292,0.945055,0.857748,0.793693,0.815469,0.3308,0.36186,0.170113,0.171447,-0.0448266,0.127972,1.47532,1.79412,-1.08128,-0.921872,-0.156864,-0.00390167,0.310893,0.323986,1.98386,1.85295,-1.34999,-1.36904,-0.423086,-0.521848,0.279246,0.285782,-0.203385,-0.078095
4188,0.891227,0.828832,0.367818,0.319424,0.207111,0.0400267,0.162916,0.110163,0.59929,0.624195,0.320652,0.290325,0.719141,0.63138,0.174416,0.194225,0.172377,0.171773,0.804969,0.805351,2.14276,2.31711,-0.431761,-0.112066,-0.181855,-0.0147508,-1.26223,-1.14434,-2.40466,-2.39609,-1.14649,-1.27348,0.115046,0.0945291,-0.260254,-0.35971,0.705853,0.772593,-0.611469,-0.508495
4189,0.0323533,-0.0290698,0.665498,0.616032,0.4288,0.260422,0.663684,0.612498,0.543383,0.568987,0.500467,0.384842,0.17123,0.0845252,0.709029,0.726808,0.392094,0.304686,0.578073,0.644151,0.51505,0.687717,0.248305,0.566294,0.45731,0.630117,1.79433,1.91591,1.02982,1.03419,1.58049,1.44877,-0.595086,-0.610654,0.59438,0.492438,-1.27483,-1.20957,-0.10402,-0.00426517
4190,0.360683,0.298507,0.361836,0.310061,0.0611999,-0.108922,0.676674,0.62562,0.988048,1.01278,0.508193,0.479359,0.373671,0.286122,0.59363,0.610261,0.550955,0.4376,0.48102,0.482952,0.626768,0.799164,1.41531,1.73476,0.0375701,0.203254,-1.77471,-1.65808,-1.05329,-1.05188,2.55716,2.42828,-0.653911,-0.75713,-0.327254,-0.432911,0.759876,0.823347,1.72724,1.83497
4191,0.362443,0.299074,0.777675,0.72517,0.666138,0.494637,0.1056,0.0529575,0.432039,0.458995,0.104366,0.0777943,0.0473425,-0.0398481,0.963426,0.977348,0.618045,0.570513,0.0329531,0.0365604,-0.174989,-0.0072664,1.17443,1.49086,0.255061,0.417959,-0.746623,-0.631404,-0.481014,-0.479955,0.476998,0.348198,-0.892624,-0.903607,-0.767126,-0.867398,-1.46469,-1.39462,0.735425,0.845434
4192,0.841765,0.780389,0.172107,0.119349,0.109853,-0.0595035,0.978113,0.927964,0.321961,0.299835,0.491655,0.485442,0.0600605,0.0287128,0.268509,0.284438,0.70403,0.703426,0.794105,0.795909,-1.28903,-1.12092,-0.60643,-0.285792,-0.214336,-0.0630461,-0.894245,-0.728555,-0.740019,-0.740814,-0.627994,-0.761404,0.661541,0.65022,-2.1579,-2.25506,0.142349,0.206176,-0.214196,-0.144103
4193,0.941208,0.880759,0.382348,0.332006,0.930151,0.761278,0.94651,0.808811,0.113641,0.140675,0.92145,0.893089,0.166144,0.0972737,0.728223,0.745477,0.419145,0.420145,0.364014,0.36524,0.0735764,0.236522,-1.0796,-0.757594,-0.711852,-0.544051,-0.941574,-0.825705,-0.332301,-0.337262,0.0541158,0.00964435,0.303973,0.297444,-1.76623,-1.86227,1.13322,1.27705,-1.24137,-1.13364
4194,0.122017,0.0633651,0.359802,0.311347,0.880346,0.705031,0.738895,0.689659,0.976742,1.00155,0.598211,0.592314,0.117255,0.165835,0.389622,0.462052,0.941688,0.940586,0.871898,0.873742,-0.281678,-0.0287155,0.302196,0.62876,-0.902843,-0.741644,0.33097,0.448128,-0.731891,-0.73376,0.917073,0.780693,0.862459,0.851594,1.36646,1.2774,2.28115,2.34793,-0.967379,-0.855549
4195,0.547918,0.491229,0.0332234,-0.0141773,0.815528,0.648784,0.512288,0.461489,0.835135,0.883927,0.32162,0.291538,0.207166,0.234396,0.162807,0.178627,0.248666,0.249612,0.952693,0.955361,-0.46522,-0.293953,-0.68825,-0.368457,1.18546,1.34054,-1.02536,-0.914683,-0.606994,-0.525178,0.396277,0.255689,0.144888,0.131427,-0.106365,-0.199182,-2.02012,-1.95274,-0.461528,-0.351319
4196,0.278452,0.279692,0.819305,0.77277,0.358278,0.189619,0.633799,0.601727,0.739514,0.766305,0.788775,0.759137,0.390147,0.302957,0.293888,0.370228,0.554952,0.555387,0.20054,0.202669,0.24466,0.415342,-1.69344,-1.36567,-0.0517695,0.104251,0.029938,0.141862,-0.31121,-0.316596,-1.01642,-1.16229,1.54721,1.53502,-0.601607,-0.694936,-1.43172,-1.33532,-2.36234,-2.24498
4197,0.126264,0.0681554,0.329754,0.284994,0.288942,0.206432,0.835892,0.741966,0.251843,0.27748,0.501744,0.470225,0.633709,0.544069,0.548141,0.56183,0.371658,0.40821,0.742886,0.7468,-0.577579,-0.40601,-1.38533,-1.05579,0.369468,0.51954,-0.164585,-0.0479258,-1.79877,-1.80019,-1.3205,-1.47101,0.611099,0.59492,0.166251,0.0795797,-0.785291,-0.717907,-0.471026,-0.346436
4198,0.513059,0.456658,0.225664,0.179698,0.39184,0.223246,0.932816,0.882205,0.922898,0.948371,0.897743,0.864446,0.369451,0.278108,0.263858,0.326873,0.262523,0.261033,0.882826,0.889324,0.0135011,0.183583,0.0953649,0.423921,-0.0459795,0.107043,-2.16476,-2.04241,1.30079,1.29619,-0.862199,-1.00944,0.874765,0.854497,-0.498932,-0.58768,1.24704,1.31501,0.518312,0.643206
4199,0.0662253,0.0108118,0.12023,0.0744024,0.727844,0.560409,0.427644,0.379277,0.91238,0.955401,0.55988,0.52681,0.451154,0.274235,0.0794024,0.0919157,0.452258,0.421943,0.0989836,0.103833,-0.294394,-0.111126,0.809029,1.13175,0.54371,0.690472,0.0794424,0.198719,-0.0797214,-0.0830574,1.40504,1.25767,-0.527977,-0.55007,0.864231,0.769939,-0.464226,-0.392966,-0.956433,-0.833887
4200,0.608881,0.553067,0.789829,0.743949,0.416517,0.251283,0.721603,0.674547,0.942859,0.962432,0.45187,0.493806,0.414377,0.270363,0.379635,0.411385,0.515976,0.582853,0.938561,0.942607,-0.57644,-0.405836,-0.173687,0.152768,0.47136,0.614718,-0.44465,-0.329376,1.44437,1.43951,0.596198,0.459058,0.586825,0.570328,-0.766281,-0.860964,0.609587,0.675514,-0.168618,-0.0406064
4201,0.363515,0.309405,0.825434,0.777866,0.972965,0.809255,0.573041,0.496672,0.857606,0.969462,0.492751,0.460802,0.405517,0.26649,0.719719,0.730854,0.745254,0.743763,0.271836,0.276362,0.0378061,0.213339,0.241395,0.568919,-0.293762,-0.15598,0.76452,0.882358,-1.95024,-1.95899,-0.192186,-0.339555,0.733917,0.723362,-1.56552,-1.6642,0.918446,0.97842,1.64659,1.78111
4202,0.367514,0.314555,0.447607,0.399076,0.634117,0.469384,0.36685,0.318798,0.977947,0.976493,0.209574,0.17805,0.35396,0.262617,0.628878,0.640075,0.139701,0.138103,0.284628,0.194219,0.04347,0.261369,-0.0172631,0.309948,-0.800671,-0.659612,0.318377,0.431018,1.1611,1.15422,1.27896,1.13009,-1.29039,-1.29422,-0.152995,-0.244507,0.7663,0.832217,1.21382,1.34972
4203,0.786794,0.732619,0.669928,0.621937,0.699154,0.493487,0.688909,0.643095,0.958051,0.983523,0.267266,0.233653,0.788181,0.699512,0.0391872,0.0487528,0.480802,0.478824,0.107891,0.112077,0.137165,0.309399,0.373046,0.695431,-1.83679,-1.69482,-0.550058,-0.440427,-0.260997,-0.268388,0.494212,0.34318,2.14942,2.13828,0.642649,0.544855,-1.10583,-1.03939,0.0480328,0.191572
4204,0.964884,0.913144,0.282227,0.23234,0.682597,0.51759,0.4656,0.420205,0.621327,0.646314,0.916933,0.884851,0.236119,0.146768,0.579612,0.591533,0.227857,0.22512,0.698549,0.701211,-1.26356,-1.0945,-0.376319,-0.0529653,0.606913,0.748723,-0.634589,-0.52103,0.807417,0.795017,-0.76949,-0.920418,0.881332,0.875337,-0.349774,-0.441469,-0.388565,-0.314908,-2.33433,-2.19353
4205,0.62723,0.544172,0.936515,0.886507,0.496412,0.342532,0.624977,0.579828,0.925566,0.949079,0.285892,0.254937,0.965859,0.875426,0.299324,0.309954,0.481013,0.476863,0.142533,0.145401,-0.479166,-0.307629,-0.0746968,0.242639,1.09469,1.23794,0.31678,0.427824,0.237836,0.231125,0.288141,0.137973,-0.172679,-0.172275,0.238651,0.149127,-0.983212,-0.908235,-0.828312,-0.680205
4206,0.226587,0.1752,0.605016,0.556251,0.331581,0.167474,0.374016,0.331559,0.496654,0.520612,0.288192,0.257007,0.761858,0.670304,0.316805,0.320648,0.165956,0.161911,0.175531,0.177306,0.607331,0.783823,-0.749765,-0.42859,1.32395,1.46889,-0.243513,-0.130495,-0.813132,-0.82273,-0.453952,-0.604096,-0.710121,-0.711978,-1.36283,-1.45037,1.07937,1.15841,-0.143226,0.00585614
4207,0.279406,0.223222,0.554072,0.506384,0.438582,0.274106,0.127499,0.0832887,0.744928,0.767337,0.881351,0.852796,0.888014,0.795681,0.322106,0.331342,0.291161,0.286452,0.708503,0.712201,0.175876,0.287915,0.0391388,0.359756,0.478539,0.621332,-2.12099,-2.00901,0.00258453,-0.00544973,-0.214645,-0.359848,-0.334927,-0.34345,0.933151,0.839255,-0.893592,-0.811194,-1.90729,-1.76315
4208,0.268602,0.271245,0.265881,0.216225,0.794109,0.631211,0.128084,0.0820693,0.301896,0.323901,0.518904,0.491069,0.53378,0.440534,0.646722,0.657746,0.905607,0.902498,0.516997,0.52158,-0.387721,-0.207992,0.0795934,0.406947,0.720264,0.82229,0.585376,0.704667,0.155777,0.153947,-2.35668,-2.50458,1.12132,1.12011,-0.524262,-0.623667,0.0333681,0.202751,1.64585,1.78831
4209,0.370654,0.319267,0.528394,0.477094,0.116362,-0.0484955,0.877217,0.830531,0.685447,0.707314,0.942339,0.91468,0.798287,0.706951,0.185782,0.196337,0.405971,0.402745,0.85558,0.860268,0.178997,0.36615,-0.893593,-0.572037,0.880441,1.02325,0.00360196,0.130095,-0.126229,-0.120787,1.04403,0.898171,-0.633753,-0.631288,-0.38429,-0.476177,1.13315,1.2167,0.466318,0.613886
4210,0.67417,0.564747,0.100139,0.0485169,0.260695,0.0904898,0.746104,0.613599,0.864797,0.806346,0.304812,0.279306,0.221434,0.129879,0.381554,0.393016,0.579407,0.577713,0.859127,0.865581,1.05698,1.24263,-0.712022,-0.386452,-0.923145,-0.787172,0.520404,0.645185,0.513313,0.592481,-1.57414,-1.72354,-0.21489,-0.216004,-0.788679,-0.879935,-2.4621,-2.38212,-0.998488,-0.849329
4211,0.859069,0.810226,0.786602,0.733145,0.393837,0.229475,0.441807,0.396668,0.885588,0.905378,0.379958,0.397897,0.605991,0.516631,0.98601,0.997557,0.00321555,0.00312698,0.250661,0.255627,-0.459809,-0.266887,0.691371,1.01516,0.0330258,0.235094,-1.58078,-1.45904,1.29527,1.30575,-0.672561,-0.819562,-1.04113,-1.04205,0.199544,0.109239,-0.826502,-0.750479,-0.356663,-0.207423
4212,0.570499,0.52081,0.0371847,-0.0173854,0.992068,0.827182,0.658308,0.612972,0.325503,0.346833,0.638696,0.516488,0.603553,0.514911,0.492671,0.50648,0.149977,0.0515429,0.0763693,0.0802947,-0.331383,-0.139067,-0.783031,-0.465034,1.12449,1.25736,-0.293197,-0.171755,-0.607689,-0.595496,-0.360098,-0.499272,0.580599,0.574873,0.326709,0.241159,0.0219499,0.151309,-0.930383,-0.774009
4213,0.928724,0.877628,0.128478,0.0718326,0.531015,0.368017,0.612479,0.566099,0.0868148,0.109885,0.661701,0.635079,0.260913,0.174874,0.840862,0.853724,0.101976,0.0999589,0.995001,0.998696,0.55497,0.756049,0.279754,0.598117,-0.00977869,0.128424,-0.48039,-0.361543,1.4963,1.50545,0.31852,0.175674,-0.623965,-0.627307,0.147665,0.0673874,0.975583,1.0531,1.54054,1.70121
4214,0.447607,0.396681,0.851367,0.792552,0.451738,0.316739,0.0507586,0.00236246,0.385824,0.325414,0.602213,0.577224,0.760526,0.677191,0.0867592,0.0982097,0.627719,0.625176,0.51414,0.518134,-0.110616,0.0911549,0.839147,1.1516,1.4121,1.55276,0.558864,0.679751,-0.888626,-0.881513,-0.768766,-0.920245,-0.87556,-0.885727,0.236042,0.151977,0.248167,0.320726,-0.386529,-0.223445
4215,0.374539,0.325393,0.288063,0.230364,0.428681,0.26546,0.614626,0.565706,0.520144,0.540944,0.123316,0.097086,0.93295,0.847903,0.82935,0.840604,0.683979,0.683336,0.289179,0.292172,0.828398,1.03019,0.463013,0.769938,0.504738,0.642873,0.521691,0.644106,-0.40005,-0.385969,-1.42321,-1.57258,-1.45707,-1.47068,-0.0183286,-0.0995122,0.486235,0.560029,0.252743,0.41846
4216,0.714328,0.667342,0.278587,0.219844,0.109595,-0.054227,0.669389,0.61994,0.0784203,0.0975084,0.712198,0.687732,0.0447694,-0.0402283,0.506183,0.518685,0.242056,0.24413,0.502725,0.504686,0.282534,0.486882,0.910556,1.21585,0.701469,0.788435,0.193252,0.316426,-1.39323,-1.37962,-0.458107,-0.609055,-0.734219,-0.748835,1.24608,1.16327,1.48583,1.56651,0.427127,0.507828
4217,0.417838,0.356602,0.545473,0.495777,0.356944,0.229113,0.933811,0.885257,0.891304,0.909565,0.657924,0.63555,0.30794,0.221344,0.462348,0.406092,0.650696,0.654393,0.920232,0.924015,-0.847995,-0.640202,-0.535454,-0.233202,0.792374,0.933997,-1.45771,-1.32748,-1.47892,-1.47172,2.24841,2.09719,-0.954898,-1.01603,-0.561163,-0.643454,0.807896,0.89556,0.428316,0.597196
4218,0.0935622,0.0458619,0.82989,0.771709,0.677783,0.512454,0.172648,0.126008,0.411354,0.43061,0.13865,0.115478,0.184929,0.0693225,0.28131,0.2935,0.17771,0.179721,0.497682,0.55728,-0.250249,-0.0366635,-0.872676,-0.567768,0.639747,0.690107,-0.301076,-0.177698,-0.642747,-0.638474,0.780178,0.632044,-1.27208,-1.28323,-1.51087,-1.59972,0.490109,0.579683,-0.785871,-0.622501
4219,0.677635,0.631492,0.591523,0.537412,0.649364,0.529268,0.319635,0.20397,0.19228,0.213552,0.512251,0.4937,0.00493375,-0.0826995,0.520461,0.533339,0.933045,0.937126,0.188624,0.190546,0.882537,1.10176,0.00719816,0.309332,0.303357,0.446217,-0.0401127,0.0787315,0.926834,0.931101,-2.58522,-2.7287,0.405844,0.395655,0.909249,0.824992,-1.24986,-1.16301,0.0596756,0.229154
4220,0.728299,0.68174,0.308915,0.303115,0.712135,0.546081,0.27994,0.281933,0.770272,0.793288,0.894844,0.871923,0.201432,0.171038,0.557141,0.527464,0.593171,0.653301,0.241425,0.24322,-0.298026,-0.0707146,0.332081,0.634167,0.383288,0.523442,-1.06137,-0.945818,-0.114256,-0.107915,-0.444602,-0.591841,-0.207921,-0.21912,-0.767037,-0.852768,0.17142,0.251949,0.0463947,0.221775
4221,0.289049,0.241232,0.128772,0.0688175,0.322384,0.200585,0.51316,0.359896,0.449741,0.470912,0.98594,0.962692,0.569298,0.424776,0.509371,0.521589,0.376426,0.369476,0.803367,0.806608,0.194484,0.425899,-0.0801831,0.223686,-1.47892,-1.3336,0.507383,0.628509,1.43284,1.44491,1.08207,0.939393,-1.16823,-1.17301,-0.785834,-0.876034,1.23228,1.30565,0.792162,0.970213
4222,0.890419,0.841984,0.436864,0.375277,0.0224972,-0.144912,0.549567,0.437859,0.39869,0.421142,0.796483,0.774212,0.766147,0.678513,0.227044,0.240011,0.0815714,0.0856519,0.81171,0.817325,-0.23282,-0.00845224,-0.0909921,0.208889,-0.941548,-0.797325,-0.988231,-0.874018,1.86247,1.87806,1.26931,1.1225,-1.50273,-1.50995,-0.56062,-0.65153,-1.42985,-1.35621,1.11378,1.29309
4223,0.0491604,-0.000343651,0.440477,0.380368,0.65587,0.488859,0.562462,0.515822,0.81262,0.833765,0.976126,0.953314,0.468333,0.381845,0.71178,0.726907,0.344504,0.347311,0.416957,0.422048,1.67124,1.90317,0.46721,0.762376,1.23665,1.38187,0.154934,0.275763,1.23892,1.25293,-0.212397,-0.358357,-0.171285,-0.183597,-0.634128,-0.719573,-0.433513,-0.364726,0.660857,0.847237
4224,0.171245,0.119874,0.449365,0.385459,0.558442,0.416858,0.265747,0.218238,0.757679,0.8441,0.00345807,-0.0212388,0.632349,0.556728,0.304188,0.319688,0.365017,0.367096,0.234188,0.236639,-1.68103,-1.45367,1.30547,1.5942,-1.07897,-0.936189,-1.59066,-1.46368,0.395539,0.411862,-1.06413,-1.20775,-0.00626932,-0.0154367,1.64953,1.57005,0.178619,0.250849,0.835874,1.01968
4225,0.64145,0.591765,0.695576,0.632466,0.486496,0.344857,0.635336,0.586859,0.857142,0.854434,0.213882,0.187249,0.816267,0.731612,0.395279,0.461044,0.767121,0.768033,0.923157,0.925215,0.192626,0.412974,-0.350818,-0.0582126,-1.29876,-1.15106,-0.574395,-0.481203,-1.02533,-1.01075,1.22991,1.08918,-2.03679,-2.05083,1.98246,1.90194,0.127658,0.260771,-0.807412,-0.626838
4226,0.805945,0.756749,0.173235,0.10974,0.397712,0.272856,0.617908,0.569685,0.855815,0.864768,0.218533,0.194337,0.593139,0.531792,0.46999,0.602399,0.459442,0.458974,0.528849,0.529938,-0.765862,-0.545926,0.407907,0.696293,-0.891222,-0.735774,0.368855,0.501272,1.32138,1.3278,-2.91739,-3.06198,1.18969,1.17565,-1.26498,-1.3466,0.193514,0.270692,-0.541296,-0.36544
4227,0.2239,0.175937,0.690641,0.627512,0.367867,0.200855,0.137141,0.0878748,0.853957,0.875103,0.542591,0.519474,0.414314,0.331972,0.728614,0.743754,0.611362,0.53114,0.795087,0.695341,0.838363,1.0609,0.630992,0.914625,0.752116,0.906919,0.529807,0.666287,-0.508785,-0.496506,-0.92914,-1.06935,-1.4124,-1.41821,0.916892,0.833795,1.18312,1.26218,1.09269,1.268
4228,0.0805647,0.0329287,0.772165,0.686732,0.0387215,-0.12889,0.0526094,0.0713293,0.227478,0.250065,0.538307,0.605427,0.41454,0.291968,0.46337,0.573483,0.605086,0.603305,0.861384,0.860743,-1.18452,-0.964613,-1.47765,-1.18998,0.422052,0.571175,-1.5947,-1.45231,3.1924,3.21088,-0.809719,-0.946831,-0.0582838,-0.0624408,-0.740975,-0.82858,1.87298,1.95558,-0.264498,-0.0891006
4229,0.694148,0.64826,0.81067,0.745951,0.531522,0.364507,0.101993,0.0547838,0.597403,0.609357,0.714498,0.69138,0.332318,0.251964,0.38954,0.403212,0.931065,0.929402,0.1998,0.19939,0.841223,1.05565,-0.416105,-0.126826,-0.495081,-0.353619,0.458956,0.595353,-0.312027,-0.298253,0.158557,0.0166913,2.74213,2.73185,-1.37579,-1.46417,1.32463,1.40875,-0.616339,-0.44625
4230,0.735114,0.664925,0.103194,0.0405516,0.392691,0.227807,0.859682,0.813216,0.948162,0.968649,0.372016,0.348631,0.843048,0.762782,0.321998,0.337458,0.58506,0.58454,0.303351,0.263268,0.560494,0.77453,1.8837,2.1743,0.930925,1.07072,1.50638,1.63665,0.737263,0.75019,-0.577981,-0.725378,0.240968,0.239329,1.26244,1.16863,0.0869029,0.174033,-0.370726,-0.199889
4231,0.7193,0.681589,0.586106,0.524271,0.0516603,-0.112063,0.772669,0.725023,0.529038,0.54961,0.644021,0.623628,0.435806,0.356694,0.457638,0.473016,0.736508,0.689346,0.324664,0.327147,0.750152,0.963486,-0.501759,-0.207195,-0.376374,-0.241178,0.257739,0.394599,0.712501,0.723306,0.959752,0.805856,-0.43576,-0.43527,-0.898381,-0.997323,0.687129,0.773521,-0.956425,-0.781362
4232,0.763068,0.698254,0.767493,0.718368,0.65379,0.491496,0.912906,0.864552,0.999279,1.01743,0.561036,0.540494,0.857056,0.778465,0.0425111,0.0565236,0.793406,0.794152,0.97156,0.975958,-1.12091,-0.905753,-0.0770179,0.223373,0.397415,0.527512,0.57961,0.769345,-1.18296,-1.17794,0.946967,0.790086,-0.728671,-0.724843,0.713875,0.621342,-1.98772,-1.90337,0.220763,0.392521
4233,0.602871,0.714919,0.976837,0.912465,0.844736,0.681849,0.50792,0.483502,0.0711152,0.0890589,0.877834,0.856072,0.531644,0.452495,0.151343,0.167231,0.181548,0.183899,0.604797,0.609798,0.636232,0.852422,-1.11839,-0.818646,-0.122771,0.00729747,1.00723,1.14409,1.91459,1.91844,2.10218,1.93713,-0.292451,-0.343676,-0.948088,-1.04103,1.18094,1.25602,0.449611,0.710876
4234,0.777473,0.731584,0.611859,0.547951,0.299237,0.136867,0.150611,0.102452,0.692286,0.708276,0.415306,0.395163,0.423158,0.323489,0.790801,0.806909,0.734961,0.739113,0.905725,0.912405,1.55599,1.77712,-1.17257,-0.877793,-0.259553,-0.127652,-0.988108,-0.850392,-0.0531686,-0.0478273,-0.458671,-0.628675,-0.0145442,0.0374909,1.30806,1.21281,0.13098,0.208617,0.854261,1.02923
4235,0.245902,0.200366,0.748577,0.686293,0.574402,0.412805,0.927379,0.876629,0.886971,0.90357,0.491123,0.471128,0.273579,0.194483,0.374693,0.390417,0.523237,0.440702,0.490521,0.496411,0.402439,0.619252,-0.0168252,0.275245,-0.941768,-0.806146,0.565394,0.707102,-0.700972,-0.702179,-0.635192,-0.776959,0.414829,0.418658,-0.776892,-0.872141,-1.31172,-1.23074,0.65293,0.824889
4236,0.390493,0.345182,0.473037,0.410946,0.47606,0.312133,0.527098,0.475016,0.779043,0.796665,0.0448865,0.0250776,0.500016,0.496875,0.972077,0.988707,0.135899,0.14229,0.448675,0.453129,-0.245276,-0.0316344,-0.702401,-0.410997,-1.20881,-1.07988,0.877046,1.02507,0.0289592,0.0234963,-0.759686,-0.925243,0.17426,0.17498,1.06265,0.964571,1.44469,1.51821,1.00983,1.17682
4237,0.197099,0.164705,0.787465,0.72738,0.706001,0.541784,0.796472,0.745549,0.450491,0.458565,0.614743,0.59613,0.876279,0.799268,0.141979,0.161192,0.266157,0.174405,0.197113,0.203312,1.5959,1.80396,-0.429262,-0.13173,-0.563219,-0.435014,-0.157045,-0.0143648,-1.87614,-1.87775,-1.58286,-1.74361,1.99476,1.99727,-0.0278974,-0.128646,1.20888,1.28069,-0.540608,-0.378958
4238,0.0306437,-0.0157713,0.557394,0.497483,0.389649,0.227256,0.623515,0.580656,0.102059,0.120465,0.647957,0.704994,0.290997,0.211961,0.259255,0.276949,0.200621,0.20652,0.697728,0.701943,0.465002,0.676879,0.417776,0.713407,-2.41632,-2.29206,-0.654304,-0.511988,1.39591,1.39923,0.312844,0.157862,0.437762,0.433716,0.00950428,-0.0896374,-1.02443,-0.952801,1.27076,1.42753
4239,0.363695,0.238605,0.659871,0.567543,0.806127,0.645484,0.518202,0.415762,0.168948,0.128651,0.831744,0.813859,0.921123,0.843126,0.904249,0.921232,0.831317,0.83744,0.212133,0.215998,0.478032,0.682301,0.576127,0.867972,-1.04266,-0.913976,1.13571,1.28245,-0.436866,-0.439846,1.56774,1.41313,0.586262,0.58675,0.658938,0.563588,0.799021,0.869286,0.728551,0.889302
4240,0.546611,0.492981,0.707328,0.637603,0.760576,0.542106,0.301163,0.250868,0.116549,0.136837,0.210212,0.193688,0.717331,0.638004,0.510447,0.529435,0.861788,0.866999,0.405981,0.408047,-0.701044,-0.490169,1.06843,1.36216,1.82561,1.96554,-0.778579,-0.630414,0.145547,0.146202,1.31898,1.16633,-0.0419287,-0.0420274,-0.775123,-0.869389,0.620515,0.692339,-2.04913,-1.89055
4241,0.791406,0.747357,0.768915,0.707663,0.628152,0.438728,0.837321,0.78834,0.490285,0.510146,0.551006,0.533263,0.814962,0.73844,0.546152,0.564708,0.273587,0.277951,0.351843,0.354095,1.33488,1.54659,0.20893,0.506251,0.120448,0.265645,1.29137,1.43223,-1.08896,-1.09228,1.60265,1.45557,0.614336,0.619194,-0.75148,-0.846411,0.449908,0.515392,1.31681,1.4785
4242,0.117522,0.0755787,0.524313,0.461522,0.49437,0.33535,0.321919,0.275429,0.621011,0.639635,0.270142,0.250511,0.614666,0.538782,0.208066,0.227971,0.125992,0.12976,0.943504,0.94323,-0.0367343,0.175479,1.77044,2.06639,0.874526,1.01882,0.0144715,0.16085,0.88879,0.882547,0.291954,0.146287,0.481441,0.482822,0.221172,0.126861,1.22769,1.28499,-0.668153,-0.508354
4243,0.746221,0.706261,0.572468,0.509555,0.993999,0.833669,0.342244,0.291909,0.410498,0.427839,0.973838,0.957034,0.0792043,0.00200087,0.419769,0.439382,0.929925,0.931507,0.618952,0.61691,-0.279011,-0.0606254,-1.18036,-0.881339,0.10094,0.248123,0.702286,0.845398,0.400972,0.395765,-0.532529,-0.672084,-0.905272,-0.905844,0.894719,0.794503,0.0462228,0.0082288,-0.87385,-0.712697
4244,0.0269816,-0.0132008,0.0794389,0.0166402,0.0293289,-0.132511,0.47481,0.308388,0.862079,0.880474,0.40427,0.387261,0.99535,0.920493,0.911415,0.930667,0.96188,0.961067,0.51863,0.517879,-0.730748,-0.509036,-0.374438,-0.0800106,-0.168267,-0.025613,1.00292,1.14926,1.17554,1.16801,-0.370635,-0.5048,0.114966,0.1213,1.55519,1.46214,-1.32584,-1.26854,-0.164785,-0.0106992
4245,0.343352,0.229319,0.419203,0.357283,0.341202,0.193563,0.371245,0.324867,0.246438,0.266047,0.825419,0.806617,0.276794,0.202713,0.520889,0.484472,0.488331,0.486395,0.675989,0.675219,0.632329,0.848411,-0.390748,-0.0948075,1.483,1.631,-2.19836,-2.05586,-1.18523,-1.18679,0.462778,0.320109,-0.180406,-0.168272,1.10988,1.01279,3.52626,3.58357,-0.67379,-0.517189
4246,0.509471,0.471839,0.198051,0.137904,0.680972,0.519638,0.652786,0.586727,0.612968,0.633713,0.68061,0.663009,0.38432,0.307826,0.0190234,0.0382757,0.439027,0.436827,0.888392,0.832558,-0.964925,-0.754407,0.31013,0.613023,-0.528473,-0.381217,0.150017,0.290411,-0.501718,-0.506784,-0.449644,-0.59223,0.643999,0.659262,-0.0514929,-0.139915,0.756703,0.809099,1.37224,1.53677
4247,0.0850398,0.0462146,0.512351,0.401859,0.741074,0.581818,0.894614,0.848587,0.43952,0.488073,0.196973,0.178291,0.26496,0.27198,0.206366,0.225242,0.14042,0.137659,0.99187,0.989897,-0.77701,-0.565452,0.342181,0.645812,-1.02592,-0.88485,0.948928,1.08483,1.65461,1.64572,0.448528,0.311746,-0.827169,-0.809358,0.530145,0.43646,-1.16908,-1.12347,0.128521,0.311699
4248,0.491201,0.454075,0.723812,0.665814,0.544638,0.400637,0.327293,0.280403,0.378659,0.342432,0.958163,0.939979,0.311507,0.236133,0.762034,0.783141,0.134817,0.132014,0.0909549,0.0894333,1.83915,2.05765,1.10071,1.40032,-0.570648,-0.410644,-1.15557,-1.01939,0.294855,0.281496,0.586877,0.44903,2.01945,2.03348,1.73824,1.64007,0.179788,0.232013,-1.07791,-0.913377
4249,0.0822645,0.0441444,0.727223,0.670188,0.379052,0.219456,0.242616,0.197374,0.177807,0.196792,0.123664,0.106742,0.953323,0.87742,0.724141,0.747026,0.332868,0.327597,0.78879,0.789063,-0.327412,-0.107057,-2.16618,-1.86858,-0.0749743,0.0635615,0.444135,0.585184,-0.271452,-0.282397,0.37259,0.202317,-0.915572,-0.902768,0.155223,0.0562183,0.561151,0.613995,1.34781,1.51096
4250,0.556056,0.516035,0.989585,0.931057,0.79854,0.637685,0.888892,0.844232,0.551269,0.5701,0.268958,0.251727,0.234679,0.15964,0.483667,0.504112,0.936092,0.92947,0.910101,0.910512,-0.892161,-0.665626,-0.910576,-0.619788,1.12364,1.25932,-0.372561,-0.238373,1.14402,1.133,0.191857,-0.0443953,-1.36632,-1.34882,1.40041,1.30344,-1.41799,-1.36816,0.243688,0.397365
4251,0.477074,0.517849,0.00450142,-0.0528906,0.917542,0.754872,0.324897,0.280496,0.554846,0.57289,0.157212,0.138365,0.909455,0.832368,0.60911,0.629872,0.264885,0.258593,0.134532,0.137629,0.722551,0.957244,0.850239,1.14149,0.201845,0.334528,-0.340625,-0.304229,-1.28122,-1.2931,-0.149645,-0.291108,0.860228,0.869882,1.21924,1.12967,-0.423066,-0.376678,-0.879387,-0.716233
4252,0.561317,0.519663,0.441248,0.386484,0.592883,0.430414,0.230872,0.187524,0.773166,0.79357,0.279858,0.228326,0.591966,0.556991,0.14103,0.163228,0.542742,0.59022,0.856738,0.860939,0.736125,0.978539,0.0810506,0.35818,-1.91487,-1.77574,-0.500715,-0.370086,-0.131843,-0.138693,0.000250918,-0.140572,-1.28032,-1.27275,2.47523,2.39244,1.0795,1.1289,1.96186,2.12293
4253,0.923594,0.882132,0.568667,0.514606,0.0176288,-0.143236,0.600337,0.556145,0.31669,0.334838,0.334732,0.318287,0.35899,0.281613,0.3398,0.352047,0.929532,0.921847,0.900364,0.902814,-0.999728,-0.762065,-0.711771,-0.425132,0.0947705,0.241321,-0.150411,-0.0216938,0.726513,0.725443,-0.385121,-0.524794,0.142493,0.145703,-0.239342,-0.321069,0.439006,0.489603,0.536464,0.711957
4254,0.342152,0.30132,0.269825,0.214755,0.361458,0.198716,0.407546,0.469436,0.232835,0.249087,0.720453,0.703098,0.292989,0.217483,0.519898,0.540865,0.345308,0.336867,0.10314,0.107234,1.34715,1.57948,-0.872951,-0.591953,0.972782,1.11853,-0.435485,-0.304168,-1.6235,-1.62936,1.09848,0.959136,0.021942,0.0260881,0.643808,0.56092,-0.644556,-0.587858,-0.860075,-0.699012
4255,0.282767,0.239947,0.420386,0.363759,0.0389606,-0.125742,0.389511,0.382728,0.595079,0.612431,0.190281,0.173179,0.527185,0.453332,0.082143,0.103969,0.489348,0.48131,0.0782752,0.0832829,0.0341765,0.26944,0.0538918,0.329309,-0.687988,-0.54765,0.355522,0.49025,1.22142,1.21532,0.0122816,-0.120034,0.968065,0.978977,-1.55344,-1.63966,0.019799,0.0737352,0.067566,0.229048
4256,0.682672,0.542121,0.772278,0.714263,0.269661,0.103909,0.340212,0.29602,0.0633489,0.0792854,0.156978,0.141042,0.128965,0.0572749,0.217156,0.239527,0.249832,0.242799,0.933549,0.938219,1.48894,1.72132,0.54386,0.823494,-1.65667,-1.52254,-0.758816,-0.627563,-0.478162,-0.484612,0.904252,0.768317,1.53575,1.54895,-2.43412,-2.51938,1.72186,1.76945,0.452022,0.610076
4257,0.887423,0.844295,0.554531,0.494883,0.738767,0.572492,0.711748,0.669861,0.0908259,0.106681,0.465209,0.451233,0.788894,0.715168,0.7703,0.792724,0.393148,0.330532,0.563526,0.56771,-0.760567,-0.523999,-1.8685,-1.58763,0.714083,0.852741,-0.457166,-0.27462,-1.51055,-1.52363,0.505546,0.392047,0.0925695,0.11149,-0.731875,-0.821849,-0.13215,-0.0863829,-1.27912,-1.12798
4258,0.855433,0.891161,0.77399,0.712213,0.0997782,-0.0656731,0.632774,0.605776,0.58846,0.604606,0.996581,0.982855,0.169783,0.0944238,0.570196,0.590656,0.42704,0.418265,0.914268,0.917314,1.52247,1.75803,-1.32402,-1.04869,-2.14202,-2.0053,-0.0469966,0.078322,1.19646,1.18599,0.147199,0.0157772,2.08432,2.10271,0.960948,0.875685,-0.869026,-0.818753,1.0151,1.16556
4259,0.982889,0.938026,0.334116,0.274459,0.543271,0.378073,0.582263,0.541691,0.169096,0.185567,0.621139,0.60603,0.392931,0.301327,0.643239,0.662243,0.306291,0.294158,0.26387,0.266318,0.421048,0.659896,1.70565,1.97433,-0.474219,-0.330877,1.6129,1.74453,-1.25278,-1.26923,1.43602,1.30147,0.636699,0.651292,-0.66673,-0.755217,-1.03303,-0.981027,0.653915,0.808412
4260,0.0485341,0.0026243,0.179818,0.120962,0.548961,0.385263,0.937828,0.895582,0.0767151,0.0948634,0.828389,0.814518,0.583187,0.50823,0.512578,0.487533,0.0790345,0.17005,0.461888,0.463612,0.561637,0.802569,0.299485,0.571622,0.139919,0.341352,-0.47413,-0.343315,-0.322562,-0.343581,0.502399,0.375263,-0.440286,-0.427486,1.65219,1.56781,0.0156462,0.119392,0.679777,0.830883
4261,0.16157,0.113333,0.926896,0.866082,0.756913,0.595547,0.108677,0.0680243,0.195746,0.214259,0.482958,0.467335,0.119057,0.042499,0.294056,0.312824,0.0547174,0.0459424,0.189367,0.193166,-1.53884,-1.29748,-0.638119,-0.360629,0.876191,1.01358,2.87608,3.01345,1.61308,1.5977,-0.0840119,-0.213266,-0.0541439,-0.0450403,0.590622,0.505478,1.16332,1.21981,-1.67766,-1.52252
4262,0.800514,0.754539,0.766939,0.707553,0.169933,0.00680575,0.563482,0.521106,0.0417487,0.058384,0.898515,0.881909,0.0554504,-0.0216316,0.470723,0.38902,0.521395,0.511111,0.680587,0.682636,1.89453,2.13165,0.654307,0.935008,1.14085,1.27605,0.638336,0.783594,-1.58265,-1.59422,0.0496668,-0.0759823,1.09541,1.11043,1.98734,1.90936,0.745179,0.795442,0.168236,0.330035
4263,0.889926,0.838879,0.350569,0.288884,0.431614,0.318477,0.538203,0.451533,0.462354,0.480724,0.125565,0.106137,0.759097,0.680785,0.448675,0.465217,0.427066,0.415647,0.484806,0.487066,1.31964,1.55738,0.135881,0.418203,-2.13349,-2.00017,0.0892217,0.295768,-0.280658,-0.284237,-1.41144,-1.54113,-0.138262,-0.122492,1.12517,1.0459,0.728999,0.774497,0.591704,0.757945
4264,0.968359,0.923219,0.845153,0.781932,0.79314,0.630148,0.422846,0.381959,0.388453,0.405696,0.724675,0.707606,0.223777,0.144003,0.0984208,0.113096,0.831461,0.821606,0.886005,0.886524,1.65937,1.8991,1.83046,2.11583,-1.71826,-1.58488,-0.337031,-0.192058,0.676936,0.67164,0.85366,0.725986,0.615295,0.630298,-0.875425,-0.961351,0.267262,0.261592,-0.231318,-0.0638216
4265,0.482453,0.436625,0.895558,0.829965,0.790704,0.626416,0.871251,0.830189,0.717877,0.733069,0.958643,0.940984,0.829782,0.750761,0.236273,0.195742,0.412261,0.402741,0.25353,0.255761,0.54541,0.78544,0.766402,1.07319,-0.985698,-0.934935,0.96481,1.11061,1.8852,1.87397,1.36529,1.19232,-1.39005,-1.37325,-0.616101,-0.705569,-0.295745,-0.251313,0.0499753,0.214269
4266,0.867881,0.819447,0.338367,0.272983,0.494426,0.389401,6.01449e-05,-0.0398747,0.450014,0.46583,0.646491,0.572597,0.326489,0.249722,0.263743,0.278388,0.705234,0.69404,0.966697,0.970119,-2.3787,-2.13077,-0.254816,0.0305459,-0.415371,-0.284986,1.37863,1.51959,-1.41772,-1.42669,1.79195,1.65865,-1.1141,-1.09769,0.962537,0.866624,-1.24284,-1.20594,-0.774219,-0.607498
4267,0.592176,0.512181,0.985396,0.917697,0.317803,0.152385,0.552254,0.512703,0.398148,0.416294,0.223237,0.204209,0.988656,0.912933,0.993073,1.00604,0.174036,0.164874,0.206754,0.210764,0.49407,0.738951,2.04,2.33167,-0.134143,-0.00738465,1.3051,1.43899,0.697563,0.691322,-0.513538,-0.643,-1.09265,-1.08316,1.77568,1.67249,-0.855226,-0.823954,0.840458,1.01346
4268,0.256266,0.204915,0.97409,0.907177,0.79706,0.630568,0.709689,0.730956,0.352684,0.366759,0.586846,0.568528,0.92706,0.848802,0.53222,0.544631,0.159565,0.149452,0.33556,0.392411,-0.219035,0.0266833,0.0505817,0.34925,1.32629,1.44785,0.310263,0.445045,-2.23652,-2.24767,0.455635,0.320522,-0.688842,-0.612459,-0.528665,-0.630262,0.812177,0.839921,0.328797,0.506973
4269,0.779596,0.726874,0.0454791,-0.0211187,0.757316,0.530639,0.987465,0.949208,0.0222546,0.0346144,0.655853,0.55584,0.0150297,-0.0612335,0.929822,0.941269,0.817877,0.807764,0.480313,0.574058,1.49142,1.7403,0.431742,0.734734,-1.51645,-1.39363,-1.72811,-1.59766,1.13881,1.12533,1.07759,0.948855,-0.149462,-0.141761,-0.353902,-0.453871,-0.843061,-0.820494,-1.41092,-1.23109
4270,0.461831,0.407655,0.347114,0.280316,0.520184,0.43071,0.845695,0.888962,0.913599,0.924274,0.559679,0.543153,0.303106,0.225312,0.995836,1.00766,0.545507,0.53387,0.751696,0.755705,-0.121856,0.124971,0.265225,0.567913,0.48172,0.607769,1.11176,1.24088,2.08671,2.06656,-0.569934,-0.699449,1.2342,1.24486,-2.01093,-2.11625,-0.832137,-0.811181,-0.821363,-0.63685
4271,0.347075,0.293614,0.173722,0.105741,0.496745,0.330782,0.869133,0.828715,0.313566,0.324918,0.990631,0.972139,0.237327,0.161181,0.288176,0.299031,0.588517,0.520822,0.662823,0.693312,1.18963,1.43403,-0.634839,-0.334236,1.938,2.063,-0.609307,-0.483741,-0.652777,-0.674141,0.390677,0.264074,-0.219205,-0.206553,0.186559,0.0765543,1.25279,1.27248,-0.880456,-0.690069
4272,0.464858,0.347425,0.572551,0.470838,0.625784,0.462244,0.338033,0.295716,0.479419,0.489688,0.11663,0.100737,0.754069,0.677467,0.525138,0.533993,0.520335,0.507773,0.629251,0.630918,0.169659,0.412126,-0.129145,0.175315,-0.479643,-0.35248,-1.67221,-1.54164,0.378086,0.359326,-0.815753,-0.937365,-0.859143,-0.850691,-0.534791,-0.651989,-1.04792,-1.02887,-1.29756,-1.10664
4273,0.453927,0.401236,0.903732,0.835934,0.239748,0.0776277,0.368368,0.323671,0.144594,0.152479,0.393657,0.379223,0.386543,0.369735,0.481444,0.401217,0.842799,0.828441,0.0464161,0.0507069,0.572098,0.874024,0.710957,1.02045,0.916663,1.04029,-0.0246149,0.109757,-0.167117,-0.18945,-0.0683052,-0.187782,-3.31523,-3.3141,0.0527284,-0.0613936,-0.0699236,-0.055398,0.730075,0.914699
4274,0.731996,0.677913,0.787674,0.661589,0.999942,0.839519,0.606671,0.5636,0.169034,0.175987,0.309061,0.281802,0.137841,0.0620029,0.260473,0.268442,0.627402,0.615053,0.866692,0.868992,1.09593,1.33592,-0.880754,-0.567145,-1.24955,-1.11935,0.82554,0.965842,-1.30312,-1.31978,0.278964,0.164842,2.34392,2.34505,-0.557785,-0.664475,0.121773,0.137899,-0.438621,-0.259728
4275,0.693022,0.623994,0.555114,0.487245,0.746077,0.586,0.305429,0.261169,0.560276,0.568755,0.0981654,0.184381,0.635414,0.558856,0.672196,0.680186,0.676668,0.66412,0.525735,0.527853,0.112281,0.345676,-1.5882,-1.26829,-0.161802,-0.0299164,-0.701167,-0.565644,-1.51192,-1.53288,0.242335,0.132123,-0.862519,-0.866256,0.642364,0.53913,0.319116,0.331196,2.80974,2.98883
4276,0.622299,0.570074,0.11759,0.04949,0.0624383,-0.098297,0.41024,0.365569,0.15597,0.164676,0.100223,0.0869607,0.553465,0.538286,0.772696,0.781731,0.463265,0.450733,0.538362,0.461896,-0.635609,-0.396455,1.05425,1.3711,0.0247465,0.153214,-0.36993,-0.232639,-1.02285,-1.03733,-0.000622398,-0.136801,-1.37565,-1.35755,0.125183,0.0280301,-0.924155,-0.919514,0.387116,0.571114
4277,0.25032,0.27895,0.296479,0.165859,0.863748,0.701136,0.250301,0.215175,0.547273,0.557443,0.801838,0.787622,0.474409,0.517716,0.42885,0.439638,0.92656,0.915901,0.393657,0.395938,0.493888,0.72531,-0.608797,-0.297144,-0.520009,-0.397609,-0.485361,-0.344359,0.689157,0.668069,-0.296485,-0.405725,-1.85001,-1.84885,0.0516783,-0.0400124,1.25746,1.26191,-1.17156,-0.984666
4278,0.0396038,-0.0121734,0.35167,0.282228,0.323444,0.162066,0.108096,0.0647812,0.673855,0.681839,0.105025,0.0915478,0.574235,0.497146,0.883247,0.89636,0.263742,0.255381,0.763452,0.765878,-0.0509083,0.237804,-0.714489,-0.466668,0.784748,0.905452,3.44543,3.57993,-1.19235,-1.21736,-1.51201,-1.62075,0.905222,0.906115,-1.5919,-1.68899,-0.778069,-0.768336,0.879371,1.0693
4279,0.578022,0.524606,0.818372,0.75059,0.653844,0.494069,0.647842,0.602253,0.123312,0.133332,0.637553,0.62317,0.0123753,-0.0646662,0.860504,0.883155,0.279451,0.270349,0.591559,0.595698,-0.482457,-0.249702,-0.950159,-0.636191,0.822177,0.936096,-0.628347,-0.493275,-3.29923,-3.31796,0.534171,0.415713,1.40724,1.41314,-0.0692948,-0.164783,1.64999,1.65474,-0.888811,-0.699705
4280,0.887481,0.836243,0.387726,0.419308,0.468651,0.306592,0.827089,0.783096,0.913459,0.924816,0.721264,0.708346,0.7901,0.711248,0.976217,0.869949,0.549073,0.541324,0.743282,0.761101,0.764525,0.998303,0.486584,0.796164,-1.22912,-1.11032,0.583157,0.718459,-0.786148,-0.802663,2.56092,2.45218,1.30525,1.3076,1.80201,1.70248,1.28671,1.2929,0.247951,0.442882
4281,0.717526,0.668654,0.154134,0.0880264,0.817244,0.65389,0.478369,0.499432,0.476872,0.486309,0.256497,0.24281,0.0257781,-0.054609,0.843993,0.856744,0.424323,0.418548,0.921417,0.926503,-1.06623,-0.837013,-1.18134,-0.872082,-0.197649,-0.0548173,-0.240206,-0.105097,-0.601341,-0.61455,1.46782,1.35626,-0.230379,-0.224666,-0.42983,-0.535048,0.277719,0.27647,-1.13908,-0.945029
4282,0.278857,0.228146,0.538989,0.430406,0.437729,0.274559,0.261004,0.215767,0.50079,0.509817,0.626431,0.612367,0.929896,0.846612,0.706297,0.720364,0.785636,0.779469,0.00377918,0.00996455,-0.380081,-0.15701,-1.81069,-1.49661,0.880239,1.00069,-0.470829,-0.339215,-1.10781,-1.11868,-0.183115,-0.292042,0.582372,0.587002,1.80288,1.70315,0.643133,0.642095,-1.5777,-1.39088
4283,0.723763,0.670824,0.836859,0.772785,0.569703,0.367524,0.564055,0.520185,0.738732,0.745677,0.4492,0.438619,0.243514,0.159041,0.0279506,0.0430067,0.908194,0.904009,0.910292,0.918555,0.823562,1.04498,0.641395,0.949872,0.177398,0.293382,0.546398,0.673282,1.81398,1.79732,-1.31285,-1.41755,-0.947081,-0.945263,-1.80202,-1.90548,-1.02298,-1.01832,0.275648,0.46168
4284,0.844177,0.791042,0.324351,0.259944,0.625502,0.460489,0.0608812,0.0172562,0.764635,0.773073,0.280347,0.26487,0.0679748,-0.0158503,0.505847,0.521691,0.00016306,-0.00213058,0.717855,0.727934,1.01327,1.25072,0.677188,0.982661,0.698675,0.814413,-0.0936269,0.0372758,0.919992,0.897577,1.62424,1.5212,0.441586,0.441363,2.26678,2.16333,-0.12484,-0.123273,0.809384,0.995411
4285,0.514714,0.461329,0.126664,0.0604809,0.55369,0.391181,0.734776,0.690039,0.558677,0.566586,0.498988,0.483585,0.630455,0.545662,0.982956,1.00037,0.455736,0.453286,0.19934,0.207673,1.2349,1.45646,-0.0136642,0.319845,0.00605269,0.12197,-0.0778999,0.0488435,1.55688,1.53046,0.165085,0.0560572,-1.41832,-1.41825,-0.146406,-0.25078,-0.228114,-0.221988,0.428939,0.610372
4286,0.635651,0.505404,0.365341,0.297789,0.00245187,-0.157882,0.50805,0.411372,0.120247,0.128079,0.502965,0.485655,0.292705,0.210502,0.18785,0.203691,0.0580455,0.0543416,0.3909,0.399722,-1.22123,-0.992308,-0.65212,-0.342971,0.325597,0.444684,0.477802,0.610378,1.72884,1.70453,1.33002,1.22095,1.31017,1.30583,0.997247,0.890588,1.75451,1.75932,-0.215908,-0.0324753
4287,0.604917,0.54948,0.0485555,-0.017983,0.361262,0.199223,0.177518,0.132705,0.812239,0.819338,0.0597425,0.0441013,0.942447,0.858442,0.580893,0.595834,0.719317,0.716674,0.306988,0.316522,-0.0520279,0.176902,-0.450138,-0.140999,-0.557206,-0.434486,0.288629,0.42059,-2.17671,-2.1988,-0.291197,-0.395578,-0.658383,-0.665846,-1.57886,-1.68493,-1.5165,-1.51036,-0.311872,-0.130239
4288,0.957587,0.901302,0.687488,0.621368,0.013473,-0.150859,0.193002,0.135195,0.829085,0.887699,0.382994,0.369238,0.857416,0.774081,0.496654,0.510023,0.379041,0.377419,0.99445,1.0051,-1.17006,-0.936756,1.27745,1.58721,1.81997,1.9408,0.876131,1.01271,1.53687,1.50859,-0.0876927,-0.197505,-0.559424,-0.573674,-0.802648,-0.857717,1.00175,1.01345,0.358619,0.542183
4289,0.832466,0.675799,0.887188,0.81879,0.532773,0.368047,0.181328,0.137686,0.948517,0.956061,0.911752,0.895915,0.411642,0.328317,0.972906,0.986548,0.476679,0.443732,0.845427,0.802076,3.5031,3.73596,-1.27337,-0.969758,-0.962444,-0.847598,-1.53753,-1.40491,-0.248364,-0.2708,-1.13431,-1.24608,-1.00508,-1.01972,0.0744948,-0.0305068,-0.245653,-0.237264,-0.621689,-0.430947
4290,0.508686,0.450296,0.646701,0.577468,0.658098,0.494258,0.657434,0.615176,0.439845,0.447862,0.958741,0.941045,0.961331,0.880027,0.83424,0.922363,0.511591,0.510045,0.690656,0.599053,-0.158088,0.0815203,-1.24022,-0.936969,0.266104,0.379955,-1.42821,-1.30234,-1.60796,-1.63502,-0.137214,-0.249449,-0.630518,-0.651195,1.25343,1.14305,1.45869,1.47309,0.687168,0.881189
4291,0.0939503,0.0349327,0.615383,0.49567,0.304949,0.140527,0.333565,0.292369,0.553738,0.500679,0.503985,0.523992,0.579285,0.50433,0.846752,0.858177,0.0813713,0.0809545,0.385383,0.396031,-0.389336,-0.154585,-0.369113,-0.0598691,-0.0298675,0.136065,1.07899,1.20879,-1.32701,-1.35397,-1.00001,-1.11384,-0.924905,-0.940767,0.551756,0.500859,-0.37473,-0.364045,0.481074,0.676846
4292,0.167233,0.110579,0.482154,0.413871,0.475252,0.311254,0.3125,0.254884,0.557794,0.553495,0.124553,0.106939,0.207671,0.128634,0.0261575,0.0349596,0.587,0.586609,0.418612,0.458251,-1.69761,-1.46463,0.299259,0.603297,-0.228052,-0.107824,1.26586,1.38985,1.74168,1.7147,0.91351,0.801064,-0.892486,-0.909866,-0.0259932,-0.141335,0.66368,0.674421,-0.0861553,0.11026
4293,0.981137,0.922858,0.875316,0.80932,0.227594,0.0618289,0.2424,0.2174,0.617633,0.606311,0.064994,0.0490832,0.562048,0.480617,0.5758,0.582774,0.666167,0.664622,0.53134,0.52047,-0.263955,-0.0297157,-0.15106,0.146522,-0.801402,-0.674397,0.500561,0.627966,-0.257085,-0.283557,-0.454911,-0.572879,-0.440074,-0.543681,-0.414053,-0.528778,-1.37618,-1.37227,0.700786,0.903541
4294,0.0511385,-0.00697271,0.430433,0.365947,0.383277,0.221818,0.236513,0.179916,0.782889,0.659128,0.837952,0.822294,0.461752,0.348824,0.0929612,0.101693,0.0794696,0.0796423,0.512484,0.58269,0.327344,0.559877,0.40503,0.700009,1.04663,1.17229,1.77789,1.9018,0.529778,0.504631,-0.426358,-0.542602,-0.163847,-0.177496,0.233783,0.124448,1.77838,1.78711,-0.196974,0.00574948
4295,0.0867626,0.0293161,0.771968,0.706589,0.637069,0.381807,0.183628,0.142431,0.703927,0.711944,0.30113,0.288109,0.297371,0.217032,0.42824,0.45276,0.513915,0.514541,0.634262,0.64491,-0.419561,-0.182254,-0.0712996,0.228208,-0.588505,-0.461801,0.378628,0.506843,0.974872,0.952402,0.645494,0.530189,0.54718,0.529546,-0.295311,-0.401802,-1.0341,-1.02104,-0.87159,-0.666955
4296,0.635221,0.575714,0.234882,0.169491,0.708476,0.541795,0.54911,0.506358,0.385689,0.394264,0.575127,0.563106,0.891547,0.813025,0.792942,0.803827,0.0169223,0.0194539,0.43206,0.397911,-0.363862,-0.0341775,2.24556,2.54666,-0.061621,0.119753,-0.313179,-0.191025,-1.03584,-1.06033,0.84938,0.728262,0.650101,0.637843,-0.417242,-0.530599,-0.752558,-0.734304,-1.80427,-1.59659
4297,0.727243,0.666761,0.145815,0.108181,0.0142546,-0.152193,0.681608,0.640511,0.705977,0.689648,0.373104,0.358835,0.214967,0.13642,0.256113,0.26773,0.123119,0.0471269,0.140671,0.150911,-0.122813,0.113899,-0.478949,-0.182835,0.573911,0.701307,0.982593,1.11165,-0.390309,-0.412525,0.360565,0.235062,-0.95068,-0.958115,-0.0200858,-0.137813,2.7218,2.74119,-0.389363,-0.177451
4298,0.171469,0.110596,0.109843,0.0468709,0.867079,0.698803,0.613713,0.561118,0.977406,0.985033,0.772729,0.758465,0.125893,0.0474768,0.737312,0.74976,0.149109,0.0747999,0.97222,0.984779,0.420672,0.656857,-0.299845,0.00274951,-0.728733,-0.595639,-0.120133,0.00764467,-0.828217,-0.856097,2.69363,2.56491,2.54842,2.54098,0.122615,0.00967662,-0.542729,-0.528488,-0.504914,-0.290929
4299,0.34326,0.314796,0.482821,0.421078,0.912135,0.745489,0.522609,0.481724,0.545882,0.652626,0.831966,0.743576,0.443081,0.364675,0.699674,0.713645,0.209266,0.102473,0.0829036,0.0947784,0.0180911,0.253142,-0.767974,-0.469052,0.0367805,0.173051,-0.652159,-0.520451,0.818831,0.78732,0.38978,0.263267,-1.26276,-1.25994,0.672449,0.555866,0.385215,0.399082,-0.25708,-0.0445668
4300,0.476587,0.518996,0.362562,0.303031,0.554221,0.387967,0.151436,0.109806,0.311089,0.32022,0.718483,0.728686,0.988984,0.91094,0.90628,0.920762,0.125359,0.130146,0.699562,0.713432,0.728943,0.962437,-2.41793,-2.12146,0.0370826,0.252241,-0.189373,-0.0512449,-1.39361,-1.42387,-2.39697,-2.52373,0.165127,0.17247,0.74901,0.625121,-1.01709,-1.00923,-0.895228,-0.687414
4301,0.791832,0.723196,0.776696,0.71814,0.195268,0.0304449,0.504304,0.463698,0.831727,0.839151,0.726283,0.713797,0.173869,0.0938764,0.774478,0.720991,0.6013,0.605594,0.76033,0.775675,0.755281,0.983733,-0.114522,0.179663,0.14841,0.331431,0.00996787,0.144497,0.445419,0.422891,0.212053,0.0834439,-2.24941,-2.2418,0.054121,0.00656867,-0.430438,-0.425914,0.615844,0.825913
4302,0.986903,0.927396,0.312752,0.254777,0.68606,0.523843,0.183981,0.14089,0.390942,0.400644,0.516771,0.510821,0.267733,0.187817,0.508632,0.521221,0.45073,0.457402,0.279491,0.295112,-1.2514,-1.02664,1.7519,2.04861,0.26908,0.410621,-0.571982,-0.430075,0.420225,0.440478,-0.670541,-0.796803,0.59208,0.601044,-0.493916,-0.611983,-0.241406,-0.233352,1.65254,1.86157
4303,0.26625,0.207934,0.268838,0.210143,0.229786,0.0698491,0.574624,0.52966,0.87734,0.888975,0.321467,0.307844,0.712365,0.633964,0.144929,0.159083,0.503455,0.511558,0.869236,0.884247,0.507195,0.731536,-0.505993,-0.201831,0.720547,0.855948,0.331869,0.47337,0.473345,0.458066,1.82576,1.69669,1.80821,1.81756,0.202486,0.0871034,-1.10836,-1.10714,1.36871,1.58141
4304,0.708386,0.650612,0.706389,0.649517,0.75432,0.593318,0.287197,0.241265,0.0842865,0.0940475,0.725283,0.711721,0.927695,0.850429,0.226721,0.239855,0.276989,0.283424,0.0439424,0.0590353,-1.26178,-1.04185,-0.744897,-0.445735,-1.55046,-1.41636,-0.343221,-0.209457,-1.42937,-1.44318,-2.32841,-2.45447,-2.63327,-2.62236,0.01896,-0.102553,0.189431,0.194767,-1.90087,-1.68638
4305,0.514624,0.456748,0.256312,0.201061,0.195794,0.0344716,0.89742,0.85414,0.863624,0.873985,0.557924,0.482786,0.682463,0.636703,0.687667,0.700894,0.651173,0.574828,0.855451,0.87254,-1.56446,-1.33882,0.258511,0.553934,-0.267914,-0.129256,0.442416,0.568829,0.753713,0.74344,0.617572,0.484277,-0.871906,-0.866133,0.0734745,-0.049566,0.474009,0.4815,-0.869281,-0.56761
4306,0.979989,0.923415,0.742437,0.68876,0.604567,0.442614,0.389463,0.34623,0.433053,0.457509,0.269728,0.253851,0.501691,0.422977,0.586368,0.600959,0.85938,0.866232,0.415179,0.431481,0.604597,0.836215,-0.300848,-0.0112949,0.142168,0.354525,0.571348,0.702844,-1.54583,-1.56332,-0.396448,-0.624503,0.175755,0.174958,0.710735,0.58769,-0.0160765,-0.068842,0.336525,0.551157
4307,0.465052,0.407996,0.541236,0.44815,0.166967,0.00339128,0.317278,0.273084,0.0320068,0.0410321,0.752802,0.73623,0.715176,0.634508,0.139096,0.154647,0.342946,0.442859,0.264362,0.254743,-0.329905,-0.093031,-1.77208,-1.47704,0.701754,0.838306,-0.293211,-0.168601,-0.549547,-0.561467,-1.59806,-1.73328,-0.0238007,-0.0208541,0.25585,0.138334,-0.63403,-0.619184,0.504477,0.723604
4308,0.608542,0.552812,0.262905,0.207539,0.392377,0.212648,0.575157,0.528245,0.455514,0.463372,0.34563,0.330087,0.618311,0.580611,0.952218,0.968556,0.0105061,0.0194858,0.0617379,0.0780058,-0.653481,-0.418696,1.07756,1.37175,-1.13019,-0.988502,-0.479322,-0.422791,-0.981415,-0.989597,-0.348858,-0.478017,0.0953336,0.101901,-2.19413,-2.31101,1.22024,1.23457,-0.778203,-0.55756
4309,0.0699013,0.011714,0.794923,0.739691,0.541098,0.421905,0.457398,0.410318,0.341097,0.342935,0.738655,0.724309,0.605384,0.526713,0.252636,0.270083,0.745505,0.756243,0.141242,0.143812,0.545678,0.78329,1.39268,1.68164,-0.41911,-0.281718,-0.797196,-0.676981,0.0455203,0.0438698,1.10616,0.973804,-0.0371838,-0.0344714,0.369613,0.255533,-0.574584,-0.555581,0.906929,1.12334
4310,0.849924,0.792371,0.472558,0.491219,0.794737,0.631161,0.939131,0.89292,0.21383,0.222498,0.76564,0.66174,0.78133,0.703174,0.804603,0.823281,0.85442,0.811119,0.148614,0.209618,-0.312795,-0.0682089,-0.446453,-0.161425,0.808995,0.945835,1.42562,1.54718,-0.674448,-0.670755,-0.505328,-0.642724,1.84457,1.85024,0.251941,0.141683,1.35276,1.37576,0.857867,1.07012
4311,0.550538,0.49274,0.299205,0.242746,0.358334,0.195833,0.875688,0.864208,0.315529,0.375645,0.614781,0.599171,0.22745,0.15043,0.778588,0.836532,0.853362,0.865994,0.259157,0.275425,-0.108776,0.135062,-0.142688,0.148458,0.442665,0.579027,0.797367,0.966469,0.692163,0.697561,0.302997,0.168561,-2.98215,-2.97648,2.02006,1.91441,-0.961473,-0.943272,0.392906,0.610028
4312,0.714511,0.657724,0.641476,0.583389,0.471136,0.263936,0.834026,0.835497,0.51761,0.528792,0.0635263,0.0498245,0.271556,0.193042,0.832339,0.849784,0.659862,0.642361,0.608879,0.625029,2.22433,2.4641,-0.293998,-0.00123237,1.34866,1.48615,0.267523,0.385756,-0.154645,-0.180859,-1.23802,-1.37095,3.13959,3.14527,0.778869,0.667635,0.0845471,0.110429,0.355122,0.571661
4313,0.618272,0.560285,0.317039,0.257865,0.456685,0.332039,0.944655,0.806785,0.388424,0.397167,0.300358,0.383311,0.985865,0.906217,0.490602,0.507691,0.404206,0.418728,0.583516,0.590188,1.61288,1.85962,0.446431,0.738406,0.131914,0.264594,1.54507,1.65959,-1.06972,-1.05928,0.606893,0.470214,0.545897,0.551408,1.62764,1.51978,-0.859141,-0.829164,0.781867,0.999572
4314,0.281218,0.225133,0.415472,0.407834,0.5212,0.400143,0.824285,0.778074,0.734527,0.743902,0.732634,0.716798,0.507982,0.430072,0.441011,0.518385,0.750013,0.765104,0.573512,0.555348,-0.481555,-0.240433,0.902768,1.20023,1.40179,1.53669,0.5763,0.669985,0.560501,0.57127,0.753552,0.62075,-0.156192,-0.153775,-0.26128,-0.364683,-0.1097,-0.0754614,0.403058,0.614533
4315,0.264292,0.307013,0.615123,0.557803,0.630747,0.468246,0.355702,0.311416,0.132829,0.144545,0.449577,0.434045,0.872786,0.796955,0.510615,0.529079,0.27753,0.290431,0.413663,0.520507,0.54042,0.776478,-0.70498,-0.404111,0.0715916,0.208311,-0.435582,-0.319619,-0.423626,-0.407657,0.0816004,-0.0453114,0.914498,0.918706,0.412633,0.304054,-1.12028,-1.09189,0.709713,0.92316
4316,0.445474,0.388893,0.518524,0.460112,0.321488,0.212567,0.783942,0.740101,0.308859,0.329984,0.916208,0.901644,0.0931357,0.0162781,0.093233,0.112587,0.445974,0.460116,0.4955,0.485666,-1.20116,-0.964126,0.36617,0.673536,0.351927,0.485912,-0.944516,-0.833076,0.0554104,0.0704265,-0.251282,-0.383727,-1.20712,-1.20742,-0.651579,-0.758279,0.792369,0.823005,1.8401,2.05052
4317,0.882421,0.826909,0.132583,0.0757497,0.119318,-0.0431119,0.675233,0.632477,0.580463,0.515423,0.572689,0.619072,0.505919,0.427804,0.280706,0.299554,0.321804,0.337341,0.434675,0.450825,1.95972,2.20346,2.41424,2.71783,-1.80617,-1.67373,0.218714,0.333505,-0.42606,-0.416355,0.0641982,-0.147311,-0.73384,-0.730808,1.51898,1.40371,0.74054,0.769887,-0.207386,0.00244831
4318,0.859091,0.801625,0.346116,0.370104,0.777715,0.615882,0.984567,0.942199,0.687611,0.700861,0.349315,0.3365,0.538724,0.460316,0.0997679,0.117382,0.847067,0.862558,0.18668,0.201008,0.179246,0.43007,-1.23119,-0.931098,-1.05798,-0.920555,-0.42003,-0.302501,1.15571,1.16677,0.213485,0.0891049,0.67178,0.672789,-2.26838,-2.38366,0.200473,0.219545,-0.744472,-0.535784
4319,0.618908,0.551556,0.719976,0.664458,0.644298,0.404255,0.507022,0.465348,0.385406,0.473075,0.409667,0.398053,0.0442705,-0.0354868,0.532784,0.482647,0.639918,0.654925,0.800783,0.814646,-0.748944,-0.499176,-0.39169,-0.0859611,-0.725568,-0.582778,-1.27543,-1.1582,-1.26953,-1.25933,0.679161,0.550673,-0.0490681,-0.0473784,0.399906,0.28263,-0.354742,-0.330797,0.241849,0.453858
4320,0.360814,0.301487,0.64362,0.688191,0.357324,0.192629,0.255969,0.306015,0.218711,0.245288,0.71633,0.704262,0.667857,0.586037,0.832092,0.847912,0.671831,0.618311,0.986039,0.909843,1.23157,1.47267,0.00445289,0.31383,0.850389,0.997618,-1.30047,-1.17775,0.221486,0.232169,-0.654409,-0.790108,1.46567,1.46077,1.18305,1.07199,-1.15072,-1.12636,-0.853503,-0.643703
4321,0.531306,0.472336,0.75655,0.711924,0.619421,0.453314,0.190656,0.146681,0.00425071,0.0175008,0.388867,0.390646,0.193091,0.109892,0.722834,0.754291,0.539841,0.581698,0.98897,1.00504,-0.170038,0.0687655,-0.872999,-0.557698,-0.111261,0.0420059,-0.435835,-0.305781,0.724893,0.721346,1.07909,0.943132,1.21528,1.2171,0.410691,0.299547,0.827279,0.854943,0.73129,0.944337
4322,0.218508,0.157342,0.789182,0.735657,0.474944,0.306322,0.227084,0.185546,0.600716,0.612287,0.0909407,0.077029,0.701477,0.616313,0.645801,0.66067,0.530077,0.545084,0.605822,0.654693,-0.654636,-0.413784,1.90395,2.21912,-1.33289,-1.17955,-0.181859,-0.0493522,1.19687,1.21052,-0.0991156,-0.242988,-0.605134,-0.596871,-0.098227,-0.211553,-1.4395,-1.41115,-0.278793,-0.0594525
4323,0.381442,0.31754,0.0762846,0.0207521,0.754323,0.587607,0.543831,0.412012,0.676041,0.686443,0.86401,0.850239,0.90972,0.822208,0.220678,0.23421,0.858493,0.875623,0.288984,0.304347,0.140687,0.388327,1.55265,1.86916,-0.0367872,0.123513,0.557794,0.683696,-0.0298938,-0.0133576,0.776427,0.628796,1.26848,1.27272,1.59544,1.48588,1.4653,1.48572,1.81934,2.03836
4324,0.971598,0.908745,0.537541,0.483829,0.359961,0.192523,0.678392,0.638478,0.147253,0.157982,0.674714,0.66176,0.641374,0.551275,0.744741,0.756516,0.755932,0.774482,0.964631,0.978254,-1.29542,-1.04734,1.43693,1.74867,1.05582,1.21295,-0.505561,-0.374205,2.27702,2.2932,-0.979337,-1.12597,-0.732257,-0.730828,0.504573,0.392664,-1.89776,-1.86913,0.256421,0.47071
4325,0.456334,0.393326,0.115033,0.0598963,0.653559,0.483979,0.198409,0.156668,0.51866,0.53129,0.20239,0.191684,0.647604,0.558866,0.951903,0.963633,0.0682083,0.0890438,0.143803,0.157564,-0.00445559,0.246374,0.0675004,0.378426,0.64569,0.80045,0.607314,0.742959,1.75408,1.77517,0.56222,0.420686,-0.824219,-0.820147,-0.0511352,-0.164287,0.677022,0.699784,-0.89422,-0.673426
4326,0.420426,0.356956,0.410206,0.389292,0.740048,0.570245,0.115571,0.0964211,0.0721893,0.0832793,0.275266,0.205724,0.946277,0.856024,0.937049,0.947652,0.704363,0.726277,0.467323,0.481299,1.5523,1.80634,-0.407683,-0.0933747,-1.75304,-1.599,-0.447287,-0.367774,-0.498551,-0.483248,1.04649,0.912087,0.529472,0.535619,1.5718,1.45438,1.32071,1.34595,-0.214121,-0.00100407
4327,0.664637,0.602918,0.774737,0.718687,0.455048,0.285505,0.0797544,0.0361744,0.0904718,0.101201,0.232441,0.219765,0.736215,0.645655,0.010829,0.0217473,0.5891,0.609106,0.394372,0.4072,-0.781149,-0.530081,-0.1802,0.138415,0.808848,0.961298,-1.60842,-1.47851,-0.881974,-0.86557,0.207716,0.0777167,-1.29636,-1.29397,-1.90115,-2.02109,0.910171,0.938125,1.33423,1.54028
4328,0.392773,0.329068,0.115186,0.0584108,0.431675,0.261728,0.532181,0.489256,0.702835,0.715299,0.481571,0.467874,0.210506,0.118829,0.0462399,0.0570205,0.794084,0.815813,0.661646,0.589228,1.52905,1.78195,0.880378,1.20157,2.19677,2.35407,-0.944971,-0.809124,-0.776678,-0.753877,0.82544,0.691932,0.885636,0.8941,-0.156182,-0.276644,-0.355737,-0.325947,0.484524,0.687717
4329,0.753112,0.691536,0.222791,0.167173,0.805855,0.634515,0.00843417,-0.0336808,0.225228,0.236344,0.206265,0.194951,0.825128,0.735005,0.284601,0.270848,0.443483,0.466201,0.75695,0.771256,-1.73214,-1.48422,-0.20066,0.127473,-0.599538,-0.450143,1.43543,1.56939,0.0898958,0.136292,-0.393121,-0.523098,0.141578,0.143297,-0.674168,-0.802894,-0.556494,-0.532731,1.22536,1.43615
4330,0.174915,0.115287,0.963383,0.907871,0.340605,0.170086,0.119456,0.07521,0.599533,0.609652,0.637333,0.623937,0.733473,0.699777,0.473611,0.484675,0.409273,0.490184,0.234869,0.250995,0.822767,1.0691,0.466659,0.79064,-1.2762,-1.12864,-0.430811,-0.295416,1.00098,1.02646,0.545999,0.411365,-0.0653236,-0.0691453,-2.58308,-2.71649,0.877667,0.897405,1.41721,1.62298
4331,0.733652,0.671835,0.578443,0.523509,0.81659,0.648269,0.724079,0.677968,0.135692,0.145933,0.00672563,-0.00597717,0.667184,0.66455,0.251398,0.262264,0.53904,0.514168,0.4589,0.48955,-0.692296,-0.440416,-1.07892,-0.751723,-1.33919,-1.18929,-1.82634,-1.69037,1.33479,1.35308,0.359249,0.227578,0.943534,0.944203,-1.94143,-2.07924,-0.898301,-0.878524,-0.709335,-0.502921
4332,0.717183,0.564809,0.93363,0.879034,0.347045,0.178537,0.551938,0.495024,0.326967,0.335919,0.608643,0.595492,0.647876,0.629322,0.976582,0.989915,0.516922,0.538151,0.712674,0.728104,1.12271,1.38004,-1.04864,-0.718934,0.791991,0.939031,-1.28218,-1.2181,0.749797,0.773319,-1.08867,-1.22065,-0.265991,-0.257978,0.213695,0.0681745,0.404952,0.423378,1.6601,1.87215
4333,0.519961,0.457782,0.26238,0.208016,0.174827,0.0855619,0.358316,0.312079,0.228792,0.238997,0.705645,0.690727,0.68441,0.594094,0.800227,0.813077,0.939106,0.959216,0.0892179,0.102548,0.344604,0.605245,0.813898,1.15002,-1.87101,-1.72144,-0.884692,-0.745822,0.417538,0.435871,0.998889,0.868572,-0.312876,-0.3028,-1.25745,-1.40841,0.115005,0.139352,0.511179,0.728018
4334,0.650697,0.587797,0.639398,0.567025,0.161544,-0.00741319,0.992268,0.944772,0.822161,0.833783,0.0355861,0.0202786,0.868636,0.780053,0.89271,0.903959,0.317141,0.338785,0.139973,0.155221,-0.694697,-0.430905,-0.434401,-0.0929016,-1.59407,-1.44383,-1.06375,-0.919318,-2.94589,-2.9325,-1.01212,-1.14798,-0.0791399,-0.0746205,0.244476,0.0854758,-2.27445,-2.24488,-2.56679,-2.35212
4335,0.987771,0.924896,0.983496,0.926035,0.203929,0.0339951,0.51024,0.462962,0.388959,0.399847,0.695702,0.682012,0.743278,0.583086,0.68864,0.725629,0.15701,0.180369,0.954639,0.968726,1.29677,1.55755,0.335633,0.677021,1.39706,1.54688,-0.75315,-0.615456,-0.798751,-0.779999,0.470737,0.335951,0.711309,0.7223,-0.413076,-0.565459,0.220704,0.247527,0.0582718,0.279412
4336,0.989885,0.925464,0.585784,0.57398,0.623725,0.452224,0.397752,0.350499,0.541368,0.550077,0.414259,0.39926,0.475593,0.386119,0.536654,0.547298,0.833758,0.858223,0.279916,0.292639,0.880703,1.08766,-0.286525,0.0524893,-0.503084,-0.355684,0.473404,0.611639,0.185461,0.207062,-0.863832,-1.00483,-1.43641,-1.42033,-0.24046,-0.389067,0.680088,0.706031,0.858339,1.07269
4337,0.0410169,-0.0226654,0.279604,0.221926,0.248312,0.0773884,0.559433,0.510122,0.755998,0.700306,0.753806,0.738835,0.120309,0.0309723,0.794568,0.747736,0.793456,0.81858,0.0595627,0.0719899,0.352618,0.617766,0.233066,0.576524,-0.118696,0.027348,0.116209,0.251831,-0.0410222,-0.0229531,-0.621224,-0.760584,0.454673,0.464383,-0.695316,-0.769799,0.0666954,0.0965364,-0.818031,-0.604264
4338,0.0691219,0.00206391,0.337853,0.281597,0.597568,0.424687,0.403919,0.352392,0.839342,0.850536,0.388189,0.371427,0.771246,0.683732,0.936032,0.948174,0.400117,0.424377,0.619186,0.630863,1.16412,1.43409,-0.695028,-0.355727,0.763468,0.904556,1.43969,1.57005,0.50824,0.531788,-0.868714,-1.00738,-0.878979,-0.862523,-1.00941,-1.15053,-0.182295,-0.157162,1.25601,1.46354
4339,0.217072,0.0267932,0.635311,0.55753,0.0865825,-0.0837012,0.714915,0.59077,0.989878,1.00077,0.886876,0.868908,0.608361,0.519914,0.693862,0.70526,0.284805,0.307206,0.118158,0.130205,0.636653,0.906175,1.16345,1.4965,-0.591272,-0.454703,-0.556621,-0.424432,0.546823,0.585267,-0.519342,-0.654752,0.753549,0.771243,-1.38265,-1.53126,-1.32713,-1.29725,0.635206,0.837617
4340,0.117521,0.0515226,0.892382,0.833462,0.552564,0.379857,0.878497,0.829147,0.0440459,0.0544145,0.327612,0.31006,0.976138,0.886797,0.977513,0.991177,0.889277,0.913568,0.460389,0.474527,-0.253599,0.00822694,1.37907,1.6231,0.0605714,0.190165,0.995201,1.13306,0.609778,0.638745,-0.837946,-0.97756,0.0178736,0.033842,-1.25401,-1.39934,-0.238113,-0.213329,1.34261,1.53962
4341,0.697578,0.632919,0.208285,0.148203,0.796324,0.585298,0.0277055,-0.0193913,0.678822,0.688947,0.802295,0.78252,0.45007,0.359971,0.787456,0.799057,0.653112,0.675057,0.426054,0.440507,0.691829,0.947267,1.40942,1.74969,-1.44969,-1.32169,-0.467186,-0.323273,-0.305134,-0.276067,-0.26651,-0.410031,-1.25307,-1.2291,1.31605,1.16721,-2.06567,-2.03736,0.300635,0.505519
4342,0.846966,0.783011,0.282893,0.221869,0.961178,0.790739,0.00947611,-0.0365647,0.219258,0.230216,0.337574,0.316983,0.446708,0.358251,0.0619232,0.0743468,0.169074,0.190154,0.181164,0.195196,0.20762,0.464717,0.794769,1.14004,0.344857,0.476584,-0.368359,-0.289306,0.64689,0.679809,-1.68058,-1.82801,-0.850953,-0.830147,1.64782,1.49909,0.0539696,0.0805709,-0.464027,-0.257286
4343,0.140591,0.0752505,0.832293,0.769738,0.706765,0.525515,0.839627,0.79503,0.17587,0.185782,0.424105,0.40216,0.0409889,-0.0478366,0.840176,0.85214,0.985201,1.00845,0.71934,0.734589,0.203972,0.455437,-0.0424194,0.298019,-0.753331,-0.591077,-0.395306,-0.255338,0.964397,0.989184,0.799122,0.651615,0.306688,0.325326,0.195039,0.0520427,1.15632,1.18022,1.44965,1.65517
4344,0.597066,0.532933,0.999013,0.938745,0.431711,0.260291,0.033514,-0.0109864,0.871268,0.882166,0.816501,0.796381,0.72729,0.639685,0.765665,0.82693,0.583864,0.645203,0.437179,0.453672,-0.173273,0.0816961,0.72321,1.06794,-1.79138,-1.65874,-2.44264,-2.29804,0.473597,0.502402,2.00329,1.86191,0.912914,0.925021,-0.328935,-0.474207,-0.874584,-0.850016,0.946604,1.14868
4345,0.678854,0.667339,0.73101,0.715159,0.975928,0.80319,0.584511,0.541592,0.392403,0.403211,0.54749,0.622153,0.133593,0.0481578,0.789662,0.801721,0.257117,0.28196,0.744771,0.76145,0.84295,1.09861,0.247773,0.59614,-1.8245,-1.68822,-0.0657918,0.0804723,0.35451,0.379768,-0.674191,-0.810913,-0.455903,-0.448043,1.31891,1.17547,-0.000905305,0.0162737,-0.578291,-0.375173
4346,0.867211,0.801745,0.549657,0.491572,0.0528874,-0.119117,0.711221,0.666462,0.19937,0.285589,0.475823,0.447924,0.137708,0.0906346,0.363657,0.375261,0.657717,0.682898,0.835842,0.852922,0.145979,0.401986,-0.00450241,0.337168,0.474629,0.605773,0.730607,0.87489,-0.961501,-0.937677,0.447191,0.307783,0.567195,0.579101,-0.048258,-0.194737,-1.25546,-1.23444,-0.50363,-0.306948
4347,0.419462,0.355899,0.75366,0.694033,0.429282,0.158306,0.408116,0.318782,0.157909,0.167967,0.293815,0.273695,0.176041,0.133111,0.511234,0.521644,0.817014,0.842281,0.507821,0.526602,1.44978,1.71105,2.73753,3.07526,2.06954,2.20122,-0.0015298,0.145615,0.405686,0.430639,2.72146,2.5749,-0.0996756,-0.079568,0.722118,0.579779,0.826933,0.849226,-0.0863116,0.105114
4348,0.210167,0.147054,0.667982,0.610702,0.619626,0.43573,0.0164793,-0.0288984,0.90736,0.916798,0.752415,0.731926,0.261069,0.175588,0.148855,0.159506,0.326598,0.352264,0.935351,0.955201,-0.280159,-0.0153221,-1.29131,-0.946924,-0.83695,-0.711942,0.340973,0.494007,-0.247148,-0.223712,0.994225,0.852596,0.203292,0.228132,-1.13708,-1.27345,-1.75922,-1.74223,-0.714991,-0.520807
4349,0.965229,0.902204,0.937523,0.881737,0.883478,0.713154,0.0508022,0.00388042,0.00578306,0.0125656,0.651328,0.64736,0.580715,0.497479,0.972773,0.98356,0.501971,0.558941,0.544725,0.565208,-1.62564,-1.35677,0.577607,0.922027,-1.61658,-1.49749,0.337177,0.490971,-0.0289448,-0.0037718,-0.0463553,-0.180239,-0.843327,-0.81948,-0.547395,-0.682851,-0.351717,-0.327274,-0.0446351,0.151615
4350,0.874208,0.810139,0.314776,0.260865,0.116029,-0.0560924,0.578529,0.531541,0.605546,0.612307,0.584536,0.562793,0.571219,0.490052,0.692341,0.701982,0.738007,0.765618,0.374802,0.395028,-1.1157,-0.927235,-1.75914,-1.4127,0.123322,0.24094,0.690187,0.839363,0.782706,0.813509,1.07109,0.938457,1.38779,1.41534,0.243286,0.106512,1.78072,1.80906,0.408309,0.609048
4351,0.0765784,0.0113022,0.424693,0.369628,0.481192,0.311228,0.441985,0.357301,0.289211,0.294627,0.0089443,-0.011571,0.989334,0.906824,0.0587473,0.0701545,0.322327,0.351551,0.725883,0.744633,-0.767896,-0.4977,0.519266,0.871993,0.80169,0.917582,0.78357,0.925582,0.162466,0.188383,0.0639744,-0.0652445,-0.354572,-0.321133,0.0187366,-0.113282,-1.36813,-1.33838,-1.55069,-1.34854
4352,0.512615,0.449318,0.246754,0.189729,0.550101,0.372326,0.229264,0.18306,0.484825,0.453577,0.555594,0.534514,0.152333,0.0714147,0.191418,0.201176,0.393575,0.409307,0.0556298,0.0734847,-0.841569,-0.63594,0.91677,1.27178,0.476989,0.595389,0.374894,0.520418,-0.899642,-0.880748,-0.383476,-0.51359,-1.08628,-1.05853,0.367295,0.232425,0.101337,0.0333952,1.03349,1.23262
4353,0.52128,0.459624,0.810562,0.751702,0.605287,0.433424,0.727176,0.680967,0.605864,0.612527,0.695502,0.562598,0.733091,0.652566,0.676803,0.688072,0.484236,0.467062,0.164264,0.184312,-1.03746,-0.77418,1.555,1.90287,-0.867776,-0.750361,-1.93735,-1.79233,-0.230689,-0.216313,0.339381,0.257459,1.48437,1.51257,-0.118369,-0.247805,1.37908,1.40517,1.61192,1.81329
4354,0.035963,-0.0269704,0.569704,0.51038,0.216097,0.0439446,0.554301,0.508729,0.180783,0.188626,0.654316,0.590682,0.362745,0.281852,0.00653642,0.0161743,0.383099,0.524818,0.781205,0.802966,-1.34889,-1.08571,-0.689675,-0.347579,0.673258,0.79557,-0.474558,-0.319075,-2.20415,-2.19579,1.15565,1.02851,-0.671025,-0.644732,0.596253,0.4668,-2.18186,-2.15001,-0.0365596,0.166768
4355,0.988376,0.926119,0.818195,0.757387,0.751443,0.577485,0.86112,0.813146,0.987787,0.995525,0.728833,0.618766,0.21884,0.136915,0.2538,0.261731,0.553349,0.582573,0.300928,0.322403,0.564806,0.825907,-1.70042,-1.35883,-0.347119,-0.224028,1.00916,1.15418,-0.635083,-0.62622,0.252339,0.130968,-0.466904,-0.445924,0.124873,0.00167171,-0.714859,-0.744407,-0.081632,0.0564958
4356,0.0263826,-0.0365582,0.762716,0.778253,0.952983,0.777944,0.944124,0.896699,0.0432317,0.0491736,0.667929,0.64685,0.766174,0.683181,0.773491,0.784037,0.0843674,0.113056,0.0400629,0.0612975,-0.586719,-0.331963,0.593698,0.942299,-0.444426,-0.317296,-0.767659,-0.630351,0.289715,0.317091,-0.0759126,-0.19184,0.268623,0.29114,-0.577943,-0.694595,0.626339,0.661195,-0.252918,-0.0537768
4357,0.341894,0.286747,0.860579,0.799119,0.908938,0.640604,0.542161,0.495086,0.062335,0.0670952,0.262339,0.240706,0.969512,0.884777,0.00628295,0.0176271,0.42434,0.453778,0.206376,0.228233,0.133183,0.393703,0.114464,0.455892,0.106454,0.234663,-0.514024,-0.341164,1.24692,1.2604,-0.0901212,-0.20761,-0.388991,-0.36753,0.135509,0.0200107,1.0432,1.07362,1.18366,1.38186
4358,0.656568,0.610052,0.577657,0.473434,0.679628,0.503264,0.997219,0.948168,0.997804,1.00218,0.352268,0.259914,0.0495549,-0.0367496,0.631891,0.643073,0.00611957,0.0349126,0.744555,0.767626,-0.0771549,0.188249,0.401807,0.751496,1.87637,2.00175,-0.188294,-0.0519777,0.538778,0.545776,-0.327979,-0.438563,2.01604,2.03112,-0.741208,-0.859714,0.158831,0.185681,0.504931,0.709158
4359,0.994441,0.933358,0.207711,0.14775,0.301517,0.123933,0.696545,0.579178,0.686168,0.619908,0.299433,0.279121,0.0837085,-0.0177109,0.45393,0.466234,0.651223,0.68186,0.0960622,0.11663,1.20994,1.48196,3.22852,3.57798,0.194515,0.318722,-0.862855,-0.719204,-0.652038,-0.642581,-1.06778,-1.18063,0.185464,0.201529,-0.51839,-0.635211,2.03939,2.07019,-0.449413,-0.249416
4360,0.643093,0.583296,0.773602,0.714233,0.703488,0.5273,0.259622,0.210188,0.231214,0.23764,0.813103,0.791933,0.0864375,0.00132775,0.857593,0.867793,0.724346,0.744984,0.312395,0.33401,-0.259686,0.0179854,-0.306769,0.0432709,1.35414,1.4852,-0.510378,-0.370811,1.68971,1.69597,0.273961,0.157994,0.139769,0.242514,0.694156,0.58147,-1.44467,-1.40593,-0.878447,-0.680808
4361,0.0510989,-0.00735161,0.845551,0.787899,0.593781,0.346119,0.517267,0.465012,0.810683,0.817377,0.78717,0.764192,0.813746,0.729986,0.806234,0.816503,0.778743,0.808108,0.225303,0.246056,0.0798125,0.359706,-0.679082,-0.321143,0.958676,1.08841,0.235416,0.377792,0.430713,0.441086,1.60947,1.49662,0.264149,0.283499,-0.352587,-0.466105,1.96697,1.99909,-0.91548,-0.719175
4362,0.956352,0.898842,0.15168,0.0926682,0.338322,0.164938,0.766791,0.719836,0.769777,0.656127,0.505524,0.481439,0.461303,0.379356,0.396418,0.404813,0.551239,0.579974,0.998709,1.02144,-0.72259,-0.446725,0.906808,1.26889,1.6769,1.81072,-0.102245,0.0345708,0.385801,0.39878,-0.733422,-0.850688,0.715941,0.7304,-0.122372,-0.241602,-0.18876,-0.156018,-0.209725,-0.0171763
4363,0.0203991,-0.0365593,0.654546,0.59548,0.369902,0.196662,0.0586962,0.0124914,0.556439,0.494878,0.790299,0.765542,0.930412,0.846435,0.346703,0.353523,0.871421,0.900641,0.924252,0.947345,-0.490364,-0.21191,0.64994,1.00992,-0.0362019,0.0937064,-0.145828,-0.0151215,2.1361,2.15086,1.98008,1.85556,-1.00682,-0.989116,-0.114155,-0.150776,-1.40436,-1.44704,-0.199958,-0.00959591
4364,0.183017,0.0636226,0.661504,0.604524,0.723552,0.549378,0.0237741,0.0646799,0.326935,0.333628,0.646894,0.621934,0.506515,0.3988,0.99645,1.00301,0.267894,0.294981,0.432275,0.456667,-1.07958,-0.80131,0.781784,1.14963,-0.37985,-0.248785,1.19698,1.33302,0.699446,0.663903,-2.61838,-2.73528,1.19473,1.21341,0.0613132,-0.0599511,-2.76365,-2.73807,-0.527482,-0.335186
4365,0.223194,0.163805,0.138161,0.0817979,0.236752,0.0638166,0.163226,0.116868,0.558597,0.564215,0.986339,0.96151,0.0352679,-0.0488357,0.0416791,0.0489282,0.648049,0.644886,0.862557,0.885267,-1.99573,-1.71537,-1.02385,-0.660828,-0.724597,-0.591276,-1.17804,-1.04643,-0.833266,-0.823049,-0.711591,-0.833802,-0.270644,-0.255211,0.548352,0.42474,-0.388099,-0.3634,0.671524,0.868489
4366,0.62676,0.474214,0.544348,0.417716,0.595785,0.420922,0.739184,0.694748,0.172206,0.17588,0.536872,0.523778,0.712726,0.628654,0.954512,0.962164,0.966449,0.994792,0.0669359,0.0896868,-0.107897,0.166382,0.908989,1.27,0.303996,0.422432,-0.95123,-0.817939,-0.511749,-0.49643,-0.653185,-0.75218,0.537456,0.556457,1.50098,1.38296,2.47853,2.51064,1.1196,1.3118
4367,0.842313,0.784624,0.810543,0.753635,0.717854,0.596659,0.712959,0.667876,0.373102,0.471265,0.110174,0.0860468,0.959722,0.87494,0.427091,0.436355,0.107465,0.135502,0.991399,1.01311,0.0394051,0.309056,0.0578258,0.414094,1.29414,1.43614,-1.5942,-1.45394,-0.423577,-0.414244,-0.548856,-0.670558,0.536154,0.514692,-0.482658,-0.6089,-0.695536,-0.662664,-0.0115011,0.182012
4368,0.949822,0.890626,0.523518,0.500331,0.946524,0.772395,0.183248,0.139632,0.760935,0.766649,0.370775,0.345325,0.575993,0.489179,0.617296,0.625173,0.362795,0.39165,0.283757,0.305244,0.640446,0.912595,-1.20041,-0.84458,2.31653,2.44985,-0.80447,-0.659527,0.624997,0.634199,-1.14318,-1.25909,0.460998,0.472927,-0.687128,-0.813948,-0.217862,-0.187685,-0.426733,-0.234555
4369,0.569657,0.51089,0.305376,0.247027,0.656198,0.449873,0.37011,0.325136,0.546563,0.635775,0.972247,0.946794,0.9972,0.910949,0.805155,0.813992,0.905346,0.932326,0.330075,0.256986,0.0953233,0.369282,-1.48793,-1.13359,-1.70573,-1.57651,1.38917,1.52889,-0.357385,-0.344728,-0.0465541,-0.158478,-0.516008,-0.458881,0.606771,0.479206,-0.287594,-0.32311,-1.2649,-1.02283
4370,0.427738,0.367882,0.795179,0.734726,0.299433,0.127351,0.895914,0.852797,0.498452,0.504902,0.242302,0.217357,0.357567,0.269075,0.650943,0.729607,0.604471,0.633158,0.18568,0.208728,-0.133674,0.133177,1.36034,1.7152,-0.990049,-0.792378,0.187014,0.333298,0.628465,0.557882,0.790482,0.683647,-1.39727,-1.39069,1.22322,1.10073,-0.498098,-0.458535,-2.00329,-1.81111
4371,0.840294,0.781203,0.813469,0.753759,0.331434,0.159075,0.332915,0.28906,0.961985,0.968065,0.756614,0.730169,0.974898,0.885251,0.638953,0.645223,0.904757,0.933109,0.883447,0.908358,0.662485,0.935288,-1.18349,-0.824112,-0.14453,-0.0082504,0.998046,1.14277,1.44915,1.46049,-1.81081,-1.92443,0.508637,0.510932,0.49615,0.372185,1.78854,1.83106,0.891996,1.08548
4372,0.88062,0.82138,0.132263,0.0731628,0.765296,0.593179,0.104827,0.0608899,0.08823,0.0957453,0.312378,0.284119,0.200344,0.10938,0.222928,0.228731,0.402383,0.433356,0.0743076,0.0987529,-0.718228,-0.452493,-0.8638,-0.460356,-0.508548,-0.375059,0.435341,0.56206,-1.06553,-1.04856,0.182344,0.0682057,-1.0754,-1.06928,-0.997225,-1.11972,0.446862,0.484497,-0.437856,-0.24017
4373,0.330001,0.270244,0.660812,0.600916,0.983606,0.813574,0.940142,0.897336,0.486285,0.503166,0.279345,0.152294,0.502277,0.41111,0.581011,0.586239,0.112391,0.144206,0.147988,0.170781,-0.386415,-0.124801,-0.458332,-0.0965993,-1.26515,-1.12929,-0.165866,-0.0186522,0.960114,0.973128,-3.71713,-3.83367,1.4576,1.47154,0.295559,0.207125,-1.12779,-1.09631,1.19747,1.39327
4374,0.795516,0.73691,0.68959,0.694307,0.490054,0.319293,0.0796001,0.0383464,0.902712,0.910586,0.0501494,0.0204691,0.592188,0.500745,0.0428844,0.0501414,0.496372,0.529956,0.0175008,0.0415681,-1.4607,-1.20629,-2.27716,-1.92367,-0.626508,-0.515806,-1.22713,-1.07655,1.14839,1.16124,-0.773981,-0.894927,-0.462402,-0.450982,1.65647,1.53397,0.966445,1.00435,1.87331,2.06569
4375,0.645933,0.588768,0.88041,0.787697,0.977316,0.80756,0.828391,0.786808,0.643814,0.653532,0.694773,0.666895,0.456663,0.36662,0.845447,0.853412,0.497966,0.472773,0.338181,0.430477,-2.13975,-1.8883,1.07181,1.4258,-0.0388566,0.0976748,-1.29453,-1.14286,-0.323962,-0.307429,0.800372,0.684882,-0.130067,-0.113934,1.46592,1.34432,-0.0245354,0.0211304,0.778483,0.968134
4376,0.993175,0.935764,0.940983,0.881088,0.753115,0.585563,0.993971,0.951649,0.0220263,0.0341394,0.867661,0.756856,0.971134,0.882905,0.879141,0.888685,0.493083,0.41559,0.794032,0.819385,0.301889,0.553069,-1.58681,-1.23847,-0.845221,-0.703748,-0.907711,-0.7488,0.313166,0.325458,-0.694841,-0.811178,-0.46474,-0.450872,-0.876993,-1.00376,-0.729713,-0.679441,1.40481,1.59471
4377,0.235877,0.180464,0.0427981,-0.0176214,0.243861,0.077175,0.89827,0.854098,0.750669,0.762137,0.876073,0.846816,0.158182,0.0712048,0.417555,0.427276,0.311429,0.358407,0.274462,0.299124,-0.00187054,0.256106,-0.730051,-0.377888,0.623098,0.765631,0.0626169,0.215127,-0.409298,-0.389167,-0.184374,-0.304082,0.134005,0.148823,0.257699,0.125156,0.563051,0.606727,-0.697268,-0.500752
4378,0.0291442,-0.0283806,0.785571,0.723076,0.872012,0.705672,0.505821,0.462323,0.454738,0.455959,0.0371172,0.00884125,0.0449561,-0.0432082,0.335401,0.346423,0.26764,0.301224,0.262764,0.288884,-1.00045,-0.749794,-1.80527,-1.45198,-0.589213,-0.439945,-0.675537,-0.531125,-0.0323096,-0.0146555,-2.08318,-2.19726,-0.249929,-0.140469,-0.16916,-0.309331,0.543273,0.573234,1.69819,1.89075
4379,0.798299,0.742097,0.528703,0.538279,0.864223,0.73872,0.387404,0.281969,0.140179,0.149782,0.179259,0.148778,0.69791,0.609551,0.930705,0.939571,0.427885,0.460607,0.618702,0.642766,-1.04519,-0.776276,0.585154,0.931532,-1.20945,-1.0573,1.78207,1.93094,-1.8135,-1.79405,-0.438769,-0.555016,-0.442583,-0.429761,0.438936,0.297131,0.500827,0.539741,0.00859512,0.198546
4380,0.316695,0.26115,0.41788,0.353482,0.939641,0.771767,0.146349,0.101615,0.460991,0.472199,0.845076,0.815432,0.97053,0.880748,0.94746,0.955391,0.0628473,0.0963019,0.521536,0.543735,-1.06143,-0.802757,-0.107319,0.24529,-2.64482,-2.49335,-0.194788,-0.0493065,-0.316255,-0.302545,1.52866,1.4061,-0.112845,-0.10801,-0.0301484,-0.167997,0.703993,0.747982,1.80327,1.99045
4381,0.112532,0.0572834,0.435248,0.322786,0.476208,0.307339,0.350584,0.381162,0.348248,0.360568,0.280759,0.25106,0.200733,0.110255,0.280568,0.289104,0.686915,0.722689,0.183994,0.207305,0.694545,0.955417,-1.16708,-0.812544,0.0594262,0.210524,-1.73578,-1.59571,0.637939,0.653332,-0.539755,-0.659061,-0.72903,-0.651789,-1.24402,-1.38467,-0.211562,-0.17354,-0.83873,-0.644965
4382,0.606745,0.493381,0.418661,0.292089,0.261294,0.0941797,0.702678,0.660708,0.776126,0.788852,0.117952,0.119235,0.595166,0.506733,0.92821,0.938591,0.862164,0.897657,0.674046,0.696775,-0.0785899,0.180619,0.538915,0.899701,-0.475778,-0.324901,0.29629,0.436947,-0.498914,-0.476995,-1.70736,-1.82803,-1.20424,-1.19557,-1.68057,-1.81915,-0.534311,-0.489417,-1.07184,-0.879113
4383,0.984727,0.929479,0.258698,0.261392,0.536561,0.370118,0.56526,0.523488,0.45277,0.466476,0.0185082,-0.0125901,0.551185,0.579703,0.827156,0.907677,0.477828,0.513191,0.161027,0.185865,0.607953,0.860622,-1.27529,-0.910756,-0.496444,-0.364994,-0.113365,0.0317833,1.17572,1.19828,0.882873,0.76318,0.0794265,0.0806614,-0.5856,-0.722356,-0.304212,-0.264189,0.75725,0.942605
4384,0.930474,0.87281,0.142813,0.230696,0.139624,-0.0249653,0.0498201,0.0105774,0.903786,0.919111,0.18905,0.174413,0.692513,0.652674,0.865651,0.876764,0.459258,0.492335,0.749455,0.775,-0.786567,-0.52716,0.63721,1.00476,-0.557133,-0.405087,-1.12288,-0.978095,0.383944,0.387637,1.09905,0.915699,0.99798,1.00188,-0.777259,-0.912013,1.48219,1.52278,-0.0978196,0.090045
4385,0.131906,0.0739735,0.264396,0.199999,0.0811248,-0.0852221,0.831815,0.794434,0.476403,0.490643,0.489435,0.361416,0.815511,0.725644,0.231272,0.240121,0.999985,1.03301,0.610468,0.635228,0.752745,1.01913,1.08873,1.45068,-0.199098,-0.0510347,1.14048,1.28162,-0.452001,-0.42301,1.19099,1.06822,1.14887,1.15492,-0.401751,-0.533302,-0.219401,-0.185193,1.87324,2.06303
4386,0.719098,0.659603,0.815143,0.751759,0.561192,0.392961,0.930205,0.893657,0.312682,0.337694,0.578164,0.54842,0.350476,0.259913,0.0924153,0.103741,0.512063,0.542994,0.824218,0.847742,0.247301,0.520322,-0.164419,0.192004,1.1396,1.28204,-1.39616,-1.25197,1.16843,1.19053,1.76305,1.63575,1.88421,1.89198,0.621877,0.489525,0.592807,0.632141,-1.35946,-1.16414
4387,0.585955,0.526324,0.00957306,-0.0528937,0.0757762,-0.0926005,0.3934,0.355569,0.168997,0.184745,0.191237,0.160967,0.773541,0.681683,0.582415,0.595027,0.565528,0.59715,0.553661,0.577296,1.70503,1.9722,-0.960725,-0.602667,1.03157,1.17553,2.45008,2.59204,-0.951077,-0.927517,-0.226037,-0.351445,-0.0331898,-0.0305358,1.10966,0.974216,-0.774598,-0.728138,-0.508375,-0.312482
4388,0.855842,0.797465,0.454034,0.390896,0.553513,0.385582,0.709953,0.670393,0.446166,0.400274,0.22978,0.201349,0.196699,0.10461,0.761361,0.772417,0.0726099,0.102063,0.949251,0.971862,-0.90327,-0.633309,0.308732,0.660764,-0.489677,-0.265842,-0.288859,-0.138432,-0.537113,-0.508901,3.11887,3.00156,0.924057,0.922353,-0.47464,-0.609632,0.00927691,0.0577484,-1.60579,-1.41004
4389,0.450012,0.443371,0.0361319,-0.027773,0.780751,0.611183,5.39148e-05,-0.0369511,0.602074,0.615804,0.900868,0.873411,0.898426,0.807027,0.296388,0.305773,0.939923,0.968784,0.682398,0.764485,0.949313,1.21769,-0.999186,-0.643491,-1.84606,-1.70722,-0.814356,-0.666527,1.143,1.16638,0.0256582,-0.0897675,0.239719,0.23183,-1.22767,-1.36761,0.482039,0.532727,1.30159,1.50284
4390,0.147083,0.0892763,0.295655,0.233097,0.054961,-0.113978,0.708187,0.670385,0.235166,0.247034,0.487909,0.459131,0.588053,0.495342,0.783595,0.792669,0.141245,0.171976,0.534205,0.557107,-1.297,-1.02763,0.825617,1.17833,0.268704,0.405086,-0.4917,-0.348556,0.74741,0.76988,-1.25904,-1.36994,-0.0883307,-0.0892011,2.21745,2.07285,0.624467,0.680029,-0.0105404,0.191897
4391,0.127639,0.0691964,0.812785,0.750868,0.459831,0.289389,0.429574,0.392657,0.350706,0.361156,0.0723071,0.0448505,0.718273,0.625862,0.671026,0.681092,0.0154825,0.0450082,0.73145,0.70689,-0.582021,-0.318332,-1.07381,-0.727862,0.968439,1.11187,-1.79046,-1.6513,-0.194795,-0.178198,-1.41686,-1.52555,-1.75707,-1.76305,-1.41345,-1.56279,1.54927,1.6076,0.20469,0.408146
4392,0.720815,0.660402,0.750673,0.686735,0.431791,0.167505,0.532511,0.497057,0.963562,0.975254,0.417076,0.390501,0.0390921,-0.0507427,0.093532,0.104946,0.760721,0.792316,0.756325,0.856672,0.347391,0.606368,0.182609,0.535569,-1.0668,-0.916528,-0.327682,-0.188828,2.01481,2.0248,1.18072,1.06566,-0.149738,-0.160778,-1.90432,-2.05854,-0.0096366,0.0426906,0.153936,0.297873
4393,0.202319,0.139761,0.218724,0.154661,0.219013,0.0456216,0.314648,0.279534,0.645647,0.657574,0.246102,0.217906,0.461797,0.302588,0.767452,0.781125,0.820486,0.850476,0.985737,1.00645,2.09432,2.35192,0.697737,1.04512,0.659941,0.805858,-0.0383517,0.0995896,0.352215,0.355607,-2.22011,-2.3324,-1.21928,-1.22339,-1.06833,-1.22174,-0.0785887,-0.0240853,-0.022685,0.187601
4394,0.031906,-0.0322368,0.344507,0.277817,0.651691,0.479726,0.612878,0.579924,0.08996,0.103785,0.696389,0.66634,0.746574,0.655918,0.853745,0.883943,0.567956,0.598646,0.73996,0.858447,0.358513,0.611315,-2.63301,-2.29003,-0.995857,-0.846055,1.04278,1.18615,0.0757839,0.080872,0.505803,0.38985,0.60203,0.598909,-0.988424,-1.13715,1.86304,1.92402,-1.06147,-0.846496
4395,0.289803,0.151479,0.985484,0.917167,0.852863,0.680185,0.0663908,0.0321066,0.703727,0.717882,0.136912,0.107491,0.706712,0.627344,0.975407,0.986761,0.314765,0.346816,0.688682,0.71044,-1.59946,-1.34722,-1.22103,-0.872217,0.86502,1.01597,1.23645,1.38189,-1.01896,-1.01983,0.455285,0.343445,0.298715,0.29383,0.900115,0.743955,0.0504284,0.117647,0.996335,1.20747
4396,0.361778,0.335194,0.289034,0.221937,0.169397,-0.00411158,0.828101,0.795505,0.993082,1.00515,0.271091,0.19994,0.691368,0.59877,0.302178,0.314864,0.87329,0.906582,0.1381,0.159644,1.23238,1.48983,1.2281,1.57427,0.315361,0.465145,-1.49474,-1.34858,-0.358789,-0.355393,2.04608,1.93697,-0.7862,-0.784948,-1.17686,-1.3255,0.548708,0.608044,1.98591,2.19711
4397,0.507235,0.518909,0.51838,0.449179,0.910091,0.73676,0.747785,0.717182,0.528473,0.525975,0.232289,0.292389,0.365625,0.2728,0.561788,0.575497,0.737164,0.698283,0.371942,0.360302,0.0760445,0.331957,-0.755584,-0.408153,0.0880695,0.236331,-1.00265,-0.86205,-0.989244,-0.980518,0.320078,0.286857,-1.10184,-1.10598,-1.21585,-1.36574,0.0737658,0.138392,-0.901223,-0.687673
4398,0.766767,0.702624,0.360389,0.29065,0.493634,0.322334,0.311396,0.280946,0.0351648,0.0467959,0.414419,0.384838,0.5763,0.484332,0.21368,0.228915,0.458195,0.489983,0.518683,0.560961,0.219042,0.474631,-0.973199,-0.620267,1.21413,1.35643,-0.0399613,0.101877,-0.139334,-0.131572,-1.25132,-1.36325,-0.367603,-0.368915,-0.0327438,-0.179234,-0.0821782,-0.0238822,0.511577,0.731463
4399,0.0975295,0.0308463,0.667305,0.597109,0.3751,0.205793,0.127944,0.0989789,0.777275,0.789824,0.77326,0.744931,0.57595,0.433096,0.985803,1.00089,0.774574,0.736477,0.750479,0.76162,-0.103263,0.148966,1.17819,1.53671,-0.657839,-0.51469,-0.105384,0.0820777,1.45543,1.46835,-1.13361,-1.24074,-1.26224,-1.26071,-0.330074,-0.474769,-0.527727,-0.463787,0.280852,0.497315
4400,0.175971,0.111493,0.22883,0.159354,0.650347,0.481732,0.918183,0.888996,0.368999,0.380634,0.460405,0.431171,0.474114,0.381861,0.0454092,0.0591441,0.951022,0.982971,0.940736,0.962279,0.695978,0.951078,0.990742,1.35535,-0.512071,-0.362209,-0.0799196,0.0622784,-0.272558,-0.261982,-0.609058,-0.718583,-0.338121,-0.339489,-0.151955,-0.298378,0.988397,1.05892,-1.13424,-0.920048
4401,0.971132,0.908055,0.065183,-0.00385533,0.36535,0.196992,0.798233,0.863191,0.926629,0.939904,0.681134,0.649886,0.814813,0.723842,0.0735063,0.0506651,0.773589,0.805374,0.81266,0.833066,-0.352696,-0.10015,-0.798586,-0.437736,0.629343,0.77463,-1.66544,-1.51611,0.650532,0.663664,-0.338693,-0.522164,-0.584776,-0.583167,0.319339,0.170152,0.0202748,0.090542,1.94531,2.14995
4402,0.907461,0.846683,0.13702,-0.0299152,0.964698,0.794699,0.867726,0.837386,0.673766,0.744004,0.431045,0.401637,0.506475,0.417833,0.029884,0.042186,0.0771475,0.109219,0.170623,0.192404,-0.954252,-0.704635,-0.154602,0.21047,-0.655335,-0.50626,-0.102903,0.0413818,-0.871982,-0.851759,-0.216999,-0.325745,-0.459327,-0.460413,-0.238463,-0.386798,0.596593,0.659116,0.367653,0.566169
4403,0.228145,0.168871,0.0132597,-0.055975,0.248553,0.0802396,0.0452929,0.0154328,0.534187,0.548104,0.420208,0.389489,0.915806,0.829359,0.351479,0.363653,0.577301,0.609439,0.0612703,0.0820404,0.710541,0.962751,0.0545647,0.412443,-1.73259,-1.58737,-0.0296909,0.114492,0.896894,0.915734,-1.18512,-1.2982,0.146286,0.139282,1.19869,1.04764,-0.142963,-0.073254,-1.72811,-1.52929
4404,0.559717,0.501025,0.330408,0.260459,0.848284,0.677947,0.249406,0.222119,0.0543216,0.0691491,0.977878,0.94577,0.0969692,0.0122959,0.232796,0.247105,0.787613,0.820036,0.319063,0.340765,-0.671008,-0.425031,-1.23566,-0.877958,-0.703981,-0.556841,0.937657,1.07842,-1.09073,-1.06375,0.824776,0.708148,-0.450129,-0.458194,-1.15114,-1.30043,0.770725,0.838029,-0.984318,-0.780855
4405,0.622886,0.576734,0.236079,0.166494,0.00370936,-0.166489,0.813431,0.785462,0.132141,0.147899,0.151504,0.117732,0.172352,-0.0107791,0.657361,0.67372,0.260554,0.29087,0.324924,0.269918,-0.13053,0.0283045,-0.182307,0.166397,1.15099,1.30518,0.152114,0.287616,0.352857,0.382788,-0.31246,-0.431462,0.337181,0.325509,1.42995,1.28081,0.0922456,0.152884,1.67717,1.88676
4406,0.71029,0.652444,0.500958,0.432462,0.660489,0.487958,0.536326,0.507734,0.612451,0.625808,0.0111127,-0.02047,0.0497021,-0.033854,0.657553,0.673357,0.794849,0.825462,0.175838,0.19907,0.240265,0.48164,-0.24143,0.10725,-0.220628,-0.0712651,1.56913,1.701,-0.522499,-0.488762,1.89746,1.78639,-1.23318,-1.23805,1.88013,1.73413,0.512857,0.580372,1.05744,1.26084
4407,0.157281,0.101309,0.296761,0.227517,0.551675,0.311928,0.61517,0.532489,0.36696,0.435224,0.920643,0.891099,0.652389,0.566661,0.404727,0.420347,0.381786,0.411395,0.920105,0.942987,0.0640382,0.305906,0.305132,0.660737,1.3879,1.53869,1.22612,1.35778,-0.703577,-0.672094,0.723323,0.617422,0.596605,0.599512,-0.383576,-0.533998,-0.107557,-0.0426918,0.861914,1.07155
4408,0.58337,0.529172,0.836339,0.764752,0.334779,0.135898,0.718884,0.557244,0.23263,0.24464,0.185464,0.156497,0.558538,0.472804,0.856579,0.872047,0.527009,0.550274,0.724437,0.747417,-0.983053,-0.745322,0.201397,0.555267,0.160417,0.317134,-0.2605,-0.128588,0.242668,0.269136,0.254182,0.0890493,-0.805777,-0.805056,0.357952,0.21008,-1.45679,-1.38925,1.27649,1.48361
4409,0.271537,0.220126,0.995532,0.923702,0.130712,-0.0401324,0.641974,0.581999,0.947619,0.962057,0.841147,0.812995,0.936707,0.849564,0.646833,0.660437,0.79118,0.689153,0.944041,0.964797,0.739059,0.98396,-0.75243,-0.393132,0.0264752,0.182185,0.308176,0.432947,-1.66935,-1.64625,-0.328747,-0.439324,1.18953,1.18616,-1.30172,-1.4523,-0.878541,-0.805942,2.0328,2.2466
4410,0.879557,0.826102,0.163601,0.0938343,0.192942,0.022048,0.637238,0.606754,0.170235,0.182527,0.270973,0.243222,0.882847,0.795421,0.68327,0.601904,0.798531,0.828033,0.0579253,0.0797901,0.657219,0.897784,0.916065,1.27525,1.59068,1.74537,-0.229139,-0.110228,1.12567,1.1475,-0.343478,-0.455094,1.37169,1.36871,-0.159427,-0.310927,-0.0228422,0.0455924,-0.816384,-0.609246
4411,0.469487,0.416172,0.495132,0.4247,0.781288,0.610418,0.0452861,0.0133303,0.051433,0.152889,0.848002,0.819292,0.616048,0.52946,0.54119,0.543371,0.166127,0.198123,0.947735,0.968171,-0.337315,-0.0924615,0.507538,0.86477,0.308244,0.464482,-0.488223,-0.36195,-0.830621,-0.803162,-0.701046,-0.808688,1.3464,1.33994,0.439934,0.295535,0.622892,0.691761,-1.72029,-1.50704
4412,0.75582,0.703019,0.368141,0.273765,0.241463,0.0713473,0.7169,0.686113,0.108571,0.123251,0.6716,0.641994,0.94406,0.856776,0.471234,0.484838,0.895896,0.92548,0.238642,0.260307,-0.94071,-0.696947,-1.33798,-0.978292,0.640799,0.802259,-1.0378,-0.905124,-0.55747,-0.537644,-0.591436,-0.701902,0.571434,0.557566,-0.423554,-0.567923,0.283087,0.409481,-1.26883,-1.0496
4413,0.599404,0.545254,0.191771,0.12283,0.562468,0.392885,0.160761,0.127874,0.241955,0.258129,0.18528,0.157276,0.141117,0.0516979,0.803137,0.726449,0.709308,0.738391,0.329647,0.351778,-0.608651,-0.369254,-1.2017,-0.869951,-1.48729,-1.32388,-0.468759,-0.34359,-1.50774,-1.48572,0.748891,0.644405,0.406374,0.390702,1.22247,1.08175,0.0425912,0.127201,-0.0236453,0.199651
4414,0.174633,0.11963,0.998237,0.929835,0.150135,-0.0215406,0.585369,0.552136,0.712962,0.731101,0.155414,0.123292,0.825039,0.734589,0.954271,0.968061,0.312907,0.344188,0.207032,0.231294,-0.698948,-0.455431,-1.11754,-0.761609,-0.00800879,0.16122,-1.42479,-1.29327,-1.16703,-1.14341,0.000141198,-0.0976636,-0.789529,-0.811478,0.41212,0.278519,-0.223948,-0.155079,0.857743,1.08272
4415,0.525604,0.471451,0.52662,0.554088,0.360887,0.192455,0.739216,0.706768,0.730735,0.749023,0.0407479,0.0893085,0.32559,0.23355,0.838756,0.844445,0.834834,0.864629,0.779622,0.805376,1.84352,2.08233,-0.149591,0.208257,-0.0904767,0.0854662,-1.22373,-1.1579,-1.39179,-1.37342,0.818861,0.727246,-1.37181,-1.39643,-0.113437,-0.24773,0.746867,0.818398,1.43452,1.66339
4416,0.252383,0.262424,0.245994,0.178341,0.57794,0.406451,0.263784,0.229916,0.387755,0.487219,0.0803969,0.0553249,0.139903,0.122998,0.707305,0.720829,0.977022,1.00461,0.740786,0.734529,-1.1195,-0.884471,0.61407,0.97818,1.46895,1.64865,-1.14881,-1.02253,-0.342997,-0.32498,-0.164919,-0.26097,-0.0359737,-0.054786,0.134192,0.00805187,-0.688049,-0.620961,0.109379,0.337734
4417,0.108151,0.0533962,0.26403,0.16883,0.586211,0.413642,0.536679,0.50045,0.20577,0.225416,0.269221,0.244212,0.104486,0.0124464,0.830678,0.81721,0.540335,0.569871,0.639012,0.663681,-2.38517,-2.15,0.467931,0.82849,1.18211,1.3592,0.610571,0.739593,1.67731,1.69671,1.25621,1.16074,-0.14439,-0.160327,1.59709,1.4722,1.25964,1.32715,1.00868,1.23629
4418,0.383464,0.330074,0.15658,0.159318,0.0410657,-0.131341,0.44017,0.362771,0.646558,0.669213,0.693355,0.667824,0.611804,0.518868,0.899339,0.91359,0.469267,0.499527,0.98927,1.01329,1.07033,1.30768,-0.635559,-0.275973,0.127837,0.308675,0.883148,1.01213,-0.667609,-0.642943,-0.636352,-0.732439,1.58136,1.56591,0.634341,0.515935,-0.0924909,-0.0194133,-1.61151,-1.38185
4419,0.255016,0.151898,0.247312,0.149806,0.438529,0.266538,0.258972,0.225093,0.636576,0.661935,0.180955,0.153391,0.0537783,-0.0385662,0.383826,0.397782,0.844398,0.875336,0.619752,0.568961,-1.3655,-1.126,-0.363186,0.00329439,-0.388296,-0.211539,1.61841,1.74518,-0.705656,-0.685249,-0.679321,-0.778844,-0.198944,-0.216863,0.858474,0.740439,0.879258,0.954063,0.228301,0.457382
4420,0.0264212,-0.0262779,0.207948,0.140295,0.427702,0.258007,0.669799,0.634465,0.922534,0.949207,0.60172,0.572748,0.368651,0.278632,0.182596,0.231504,0.906744,0.938227,0.102261,0.124637,-0.311156,-0.0778269,-0.823361,-0.453481,0.305057,0.480425,-0.158609,-0.0393474,-1.59918,-1.58499,-1.40517,-1.50527,-1.07199,-1.09361,-0.465215,-0.585301,-0.952833,-0.883072,-1.03252,-0.808308
4421,0.371359,0.320718,0.580747,0.514502,0.0469422,-0.121324,0.271994,0.23762,0.546767,0.575178,0.336341,0.28237,0.0444186,-0.047338,0.0514197,0.0652271,0.656995,0.618794,0.772831,0.794032,-0.351499,-0.117062,-0.645073,-0.282213,-0.253602,-0.0703977,0.381794,0.508706,1.65439,1.67143,1.20816,1.1019,-1.39357,-1.41464,0.0891419,-0.0260351,-1.063,-0.996689,-0.57398,-0.350875
4422,0.422173,0.427384,0.266969,0.287633,0.443576,0.276554,0.608541,0.576202,0.422375,0.448841,0.020011,-0.00800877,0.34374,0.330778,0.500203,0.449314,0.26485,0.299362,0.420256,0.44295,0.251143,0.486477,-0.175171,0.194027,1.33689,1.52505,0.0517198,0.121922,-1.30794,-1.28443,0.0253568,-0.0842229,-0.19958,-0.213768,-0.723021,-0.843712,0.468007,0.539834,1.39695,1.62211
4423,0.584233,0.53405,0.126603,0.0607639,0.572633,0.415597,0.236035,0.204284,0.0975876,0.126465,0.72348,0.692652,0.799588,0.708895,0.817769,0.833401,0.294123,0.289182,0.4187,0.380557,1.06348,1.3028,0.610999,0.982373,-1.34309,-1.14506,-0.34322,-0.264863,1.15337,1.1769,-0.812521,-0.918593,-0.0747745,-0.0910128,0.733818,0.620435,1.68739,1.76341,-0.302218,-0.0700916
4424,0.248046,0.198898,0.230816,0.164768,0.597708,0.55464,0.815426,0.782164,0.355006,0.28965,0.233194,0.202396,0.497077,0.407704,0.460151,0.439802,0.244267,0.279001,0.295108,0.318163,0.191,0.436245,-0.0860108,0.28123,0.375996,0.577323,-0.77856,-0.651647,-0.197469,-0.171911,0.5271,0.427715,-0.940264,-0.949367,-0.829792,-0.949277,0.936842,0.998858,-0.935359,-0.696012
4425,0.883871,0.834708,0.876008,0.809482,0.860557,0.693683,0.746182,0.665492,0.424896,0.452836,0.939384,0.908919,0.487149,0.400277,0.0288198,0.0462022,0.591823,0.625377,0.0100649,0.0327207,-0.390143,-0.138029,0.314687,0.681021,-1.56839,-1.37491,-0.577484,-0.455905,-0.504098,-0.476609,0.784376,0.686152,-0.931004,-0.934833,0.817739,0.700398,0.158699,0.234306,0.255275,0.495209
4426,0.811305,0.853547,0.386917,0.321706,0.209522,0.0448821,0.611068,0.54882,0.451833,0.480231,0.86928,0.840839,0.137418,0.0496465,0.440413,0.457946,0.696093,0.621311,0.898885,0.921102,-0.0173739,0.236591,-2.14523,-1.779,1.08491,1.28387,0.728993,0.846768,-1.771,-1.74602,-1.8254,-1.92192,0.0784094,0.078515,0.687302,0.571601,0.180281,0.260942,0.687788,0.92312
4427,0.923029,0.872385,0.761562,0.695914,0.883468,0.720092,0.466504,0.432149,0.902539,0.932866,0.306708,0.276467,0.913181,0.82556,0.0335571,0.0507273,0.666466,0.617244,0.959932,0.983344,-0.524594,-0.278052,0.141723,0.505697,1.60112,1.8049,1.77271,1.88806,-1.29909,-1.26794,1.26872,1.17512,0.0797052,0.0796278,0.230108,0.106473,-0.0983651,-0.023085,-0.380642,-0.141747
4428,0.0167714,-0.033527,0.015479,-0.04984,0.624905,0.460093,0.823802,0.790668,0.102516,0.132165,0.74677,0.714824,0.736545,0.650669,0.565274,0.58331,0.578039,0.613178,0.351459,0.37339,0.725424,0.969953,0.665128,1.02973,0.813763,1.01935,-1.02668,-0.907289,1.86584,1.89685,-0.587614,-0.686359,-1.29777,-1.29344,1.12407,1.00325,0.333662,0.484781,1.83079,2.06917
4429,0.488275,0.438364,0.0165366,-0.0502174,0.967149,0.802045,0.822832,0.789449,0.824953,0.854427,0.751656,0.721911,0.917589,0.772346,0.359829,0.307782,0.0217851,0.0586844,0.86116,0.881892,-0.460692,-0.218905,-0.335448,0.0344747,-1.24095,-1.04329,-0.699758,-0.574284,-0.333725,-0.298985,-0.84744,-0.947512,1.10289,1.10521,-0.243563,-0.366956,0.919332,0.992647,-0.142605,0.0956583
4430,0.273006,0.263226,0.696398,0.629474,0.483844,0.316484,0.0539177,0.0200433,0.378828,0.406416,0.100262,0.0718586,0.979681,0.894022,0.0153822,0.0322544,0.56946,0.608353,0.313805,0.335129,-1.00871,-0.762218,-0.796903,-0.422301,0.667254,0.864309,0.325435,0.45239,-1.2482,-1.2138,0.906102,0.799553,-0.934162,-0.930182,0.0941465,-0.0350706,-0.616953,-0.541766,-0.477757,-0.245442
4431,0.13512,0.0880888,0.687813,0.618954,0.87182,0.703491,0.731683,0.69674,0.800809,0.828757,0.927399,0.896792,0.450866,0.367196,0.441919,0.421398,0.491057,0.452347,0.0966247,0.119829,-0.147452,0.0997329,-0.725129,-0.256775,-2.04445,-1.84043,-0.669406,-0.541555,-0.346503,-0.318055,-0.416224,-0.525793,0.476518,0.488268,-0.668651,-0.793048,0.213666,0.360021,-1.18444,-0.947451
4432,0.326781,0.278469,0.902577,0.83161,0.709234,0.631372,0.79601,0.760434,0.332406,0.360452,0.536091,0.437433,0.792504,0.709178,0.792621,0.810542,0.258988,0.296342,0.622853,0.644262,-0.0530003,0.156885,-0.460462,-0.0912485,1.61119,1.81665,0.313232,0.439803,-0.232177,-0.300468,0.710079,0.607084,0.15618,0.167237,-1.9417,-2.07228,1.19542,1.26181,1.19299,1.42762
4433,0.262277,0.21219,0.284728,0.215058,0.725012,0.559252,0.652004,0.679847,0.316463,0.438327,0.00644405,-0.0219254,0.768103,0.617376,0.291935,0.309274,0.371106,0.410905,0.591802,0.61489,-0.0324063,0.214037,-0.962609,-0.592938,0.959616,1.17052,-1.56794,-1.43871,-0.309645,-0.282881,-1.93174,-2.03098,0.543893,0.549683,-0.0777956,-0.205016,-1.55977,-1.49876,-0.0177471,0.223554
4434,0.512286,0.463305,0.230871,0.260337,0.266176,0.100087,0.668041,0.599259,0.487605,0.516201,0.445077,0.416431,0.610498,0.525574,0.606805,0.625613,0.750559,0.791659,0.829242,0.853637,-0.758682,-0.514703,0.925806,1.29255,-0.586921,-0.372805,-0.5894,-0.457354,1.4316,1.45543,-0.48888,-0.592499,-0.687972,-0.683242,-0.290396,-0.410064,1.84547,1.90626,-0.229523,0.00336026
4435,0.408447,0.360703,0.374799,0.305615,0.835864,0.66817,0.554248,0.518672,0.804902,0.833185,0.0535704,0.0242978,0.335095,0.249982,0.566354,0.584311,0.391466,0.432507,0.505975,0.5324,1.82937,2.07462,0.808273,1.17206,-0.833358,-0.617287,2.08997,2.2223,0.855967,0.875668,-0.502357,-0.608269,0.183682,0.191284,1.36642,1.23961,0.722503,0.78043,1.55379,1.77906
4436,0.568033,0.571821,0.201325,0.131041,0.438769,0.276254,0.855793,0.819062,0.521121,0.550766,0.977695,0.946115,0.33838,0.253433,0.0865349,0.10323,0.516973,0.557048,0.569046,0.594642,1.19023,1.43869,0.375369,0.747556,0.121545,0.336649,-0.444014,-0.31128,-1.05256,-1.02558,0.111868,0.00594643,-1.33576,-1.32465,1.70223,1.5715,0.553228,0.602858,-0.172167,0.0564842
4437,0.830684,0.78294,0.260815,0.190712,0.0504458,-0.115661,0.436993,0.402293,0.993737,1.02374,0.843682,0.842643,0.567363,0.398656,0.867592,0.886105,0.921346,0.963008,0.223631,0.248717,0.0179725,0.266215,0.217952,0.597866,-0.30694,-0.0902134,-0.194835,-0.0691774,0.991166,1.01069,0.38359,0.280274,1.27453,1.28143,1.36188,1.22903,2.04701,2.09509,1.20714,1.42868
4438,0.693888,0.731819,0.857861,0.787018,0.525423,0.357934,0.784857,0.75108,0.163201,0.191344,0.750698,0.739171,0.624623,0.543879,0.0608311,0.0788012,0.131572,0.173201,0.408093,0.431042,0.935312,1.19091,-0.265716,0.111459,0.88781,1.10555,-1.60767,-1.48081,-0.566521,-0.550457,0.291676,0.187205,0.814704,0.819983,-0.11207,-0.247553,0.338912,0.387118,-1.56706,-1.34147
4439,0.729097,0.680699,0.402441,0.3338,0.368173,0.201261,0.219381,0.187343,0.365353,0.390897,0.634784,0.6357,0.772489,0.689102,0.8156,0.831438,0.774179,0.815673,0.0876265,0.109804,0.829742,1.08908,0.382125,0.759665,0.428083,0.648013,-1.899,-1.77856,1.67058,1.68459,-0.946986,-1.04335,-0.38119,-0.382197,-0.433107,-0.574851,-1.77979,-1.7339,-0.0920414,0.140527
4440,0.0817312,0.034512,0.88621,0.817519,0.793334,0.625429,0.40876,0.377921,0.918622,0.945391,0.563808,0.532228,0.344232,0.259719,0.423523,0.443819,0.0616756,0.105275,0.853598,0.874254,0.00307724,0.267727,-0.918775,-0.54459,1.6022,1.82987,0.134964,0.254093,-0.498172,-0.480913,-0.593424,-0.690727,-0.542732,-0.54906,-1.5219,-1.66807,-0.102315,-0.0527094,-0.0915358,0.148108
4441,0.194194,0.242837,0.983354,0.916451,0.449574,0.281144,0.138217,0.104893,0.396041,0.422377,0.120565,0.0906744,0.249475,0.165862,0.0423141,0.0562007,0.489793,0.535732,0.467193,0.488941,-1.46639,-1.19625,0.245381,0.623878,0.368331,0.593574,1.7436,1.85867,-0.783487,-0.769323,-0.804241,-0.906372,2.40704,2.39592,0.523247,0.371848,0.678913,0.733177,-1.79502,-1.56195
4442,0.451037,0.451161,0.791851,0.726938,0.668802,0.473891,0.337308,0.306352,0.924931,0.951402,0.219014,0.114985,0.542995,0.413093,0.0693924,0.0430195,0.0993643,0.145685,0.763986,0.786371,0.757012,1.02302,1.02861,1.41222,0.532206,0.760076,-0.589273,-0.47048,-0.0732448,-0.0604743,-0.404669,-0.507793,0.0337578,0.0258699,1.63235,1.48476,-0.160853,-0.10646,-1.30378,-1.07293
4443,0.706705,0.659486,0.0725346,0.00703706,0.836829,0.666638,0.0297895,-0.00143304,0.2518,0.276203,0.167583,0.139296,0.744852,0.660325,0.0174226,0.0298383,0.0233731,0.0707411,0.751501,0.706773,-0.0563617,0.216587,0.61952,1.00174,0.128572,0.363287,-1.18727,-1.076,-0.955887,-0.945783,-1.03845,-1.14333,1.55564,1.5502,1.98283,1.83047,-1.61721,-1.56122,-0.608879,-0.386867
4444,0.281359,0.233862,0.469677,0.384368,0.596788,0.356912,0.0251431,-0.00821637,0.267241,0.294125,0.504865,0.473719,0.158851,0.0730178,0.693508,0.706017,0.371598,0.38748,0.602395,0.627175,0.141081,0.419858,-0.757665,-0.368502,1.1622,1.39381,0.88444,1.00304,-0.214581,-0.204938,-0.0814012,-0.193501,-0.00830614,-0.0133566,-0.477293,-0.633872,0.245627,0.307892,-0.567983,-0.348529
4445,0.152068,0.105305,0.827944,0.7617,0.216899,0.047187,0.819708,0.785934,0.686276,0.711628,0.614871,0.582762,0.712541,0.624728,0.24914,0.259706,0.629125,0.70422,0.977278,1.00165,1.12907,1.40445,-0.350622,0.031289,-0.35452,-0.11804,-1.43938,-1.32611,-1.01422,-0.998094,0.0698331,-0.0429647,-0.174963,-0.18022,-1.13478,-1.28481,0.228706,0.286947,0.414985,0.641113
4446,0.930243,0.885962,0.00388957,-0.0631443,0.506028,0.282187,0.367067,0.392015,0.765737,0.770518,0.930837,0.89834,0.152711,0.0629156,0.259424,0.269985,0.973591,1.02096,0.825815,0.757141,0.953924,1.22872,1.18517,1.559,-0.836447,-0.617177,0.703951,0.817346,-0.425476,-0.410952,-0.283509,-0.39656,0.253054,0.251775,1.07405,0.924294,-0.847923,-0.790514,-2.6398,-2.41454
4447,0.523653,0.480753,0.258349,0.157282,0.730592,0.517186,0.0304161,-0.00190391,0.803294,0.829407,0.44315,0.494341,0.069716,-0.0214462,0.00300836,0.0131641,0.218428,0.268055,0.490535,0.51263,-0.192173,0.0854689,-0.583852,-0.203519,-1.35285,-1.11631,0.0869191,0.198035,0.206137,0.17619,0.779481,0.661832,-0.0865025,-0.186769,-0.675071,-0.83033,-0.156125,-0.187812,-0.0869892,0.132711
4448,0.854904,0.812906,0.318129,0.377707,0.921898,0.752186,0.795892,0.761495,0.264294,0.291253,0.120982,0.0903425,0.440999,0.428745,0.436511,0.444813,0.0848344,0.135559,0.752958,0.775659,1.36484,1.64544,-1.41596,-1.02852,-0.693845,-0.456988,-0.300109,-0.259488,0.747209,0.763331,-1.151,-1.26294,-0.620322,-0.625312,0.19289,0.0356093,0.340957,0.41489,1.77341,1.98527
4449,0.407598,0.406421,0.664051,0.598133,0.0939238,-0.0776259,0.129234,0.0939272,0.763607,0.789179,0.614821,0.582969,0.971035,0.878936,0.27473,0.282053,0.540531,0.590975,0.442096,0.464266,-0.301092,-0.0190699,-0.125784,0.267118,-2.05279,-1.81625,-0.825845,-0.717011,1.92778,1.9495,-1.03389,-1.14043,-1.20619,-1.21027,0.769195,0.611985,0.960182,1.01759,-2.1384,-1.92655
4450,0.0414215,-6.40281e-05,0.0606811,-0.00340755,0.430945,0.259537,0.364925,0.381583,0.734788,0.759565,0.866047,0.836407,0.337536,0.246858,0.773823,0.77931,0.764775,0.817583,0.68105,0.698284,-1.51831,-1.23996,-1.25299,-0.852845,-1.12631,-0.894833,-0.0826133,0.0315928,0.699864,0.725623,-0.326261,-0.435301,0.518384,0.515975,-0.374647,-0.527213,-0.191481,-0.140153,0.161143,0.366998
4451,0.671658,0.630618,0.6049,0.53885,0.991578,0.821769,0.702611,0.669239,0.354656,0.380693,0.758319,0.727658,0.0382528,-0.0543328,0.442097,0.45954,0.600232,0.679121,0.911023,0.932303,0.609079,0.887353,0.0412324,0.442792,1.33359,1.56058,-0.457399,-0.34298,0.805893,0.837316,0.992952,0.880828,0.995705,0.992585,-1.21524,-1.36101,0.709387,0.754895,0.367339,0.569682
4452,0.670309,0.639094,0.839613,0.776158,0.55113,0.398634,0.332101,0.297321,0.316646,0.341887,0.65086,0.618909,0.202492,0.111224,0.135944,0.13977,0.470028,0.540659,0.169301,0.189213,0.0146779,0.297953,0.080088,0.475581,-0.51618,-0.296464,0.30713,0.420305,0.28925,0.319281,-0.143529,-0.258781,-0.0518943,-0.0550266,2.32411,2.18388,-0.360767,-0.322566,-2.22004,-2.01692
4453,0.767909,0.64757,0.509948,0.445901,0.143673,-0.0245011,0.352799,0.313769,0.0374815,0.0648927,0.984079,0.953332,0.936536,0.845789,0.282521,0.286153,0.349389,0.402197,0.916868,0.937478,0.713176,0.992955,-0.391379,0.00377933,0.283108,0.502559,-1.45546,-1.34718,-1.47511,-1.44293,-0.30626,-0.427568,0.430547,0.421584,0.256681,0.114428,1.46978,1.51372,0.151555,0.358158
4454,0.697406,0.656045,0.418488,0.289035,0.719663,0.553643,0.36262,0.330218,0.739315,0.765963,0.432419,0.403985,0.436927,0.344751,0.112289,0.153377,0.711369,0.763118,0.297887,0.316778,2.49253,2.7686,1.06644,1.46925,0.560056,0.780161,0.506238,0.619871,0.724079,0.760075,0.722801,0.598831,0.276657,0.271487,0.0710056,0.0142955,1.25831,1.30694,-1.56943,-1.36442
4455,0.324594,0.281722,0.317406,0.132169,0.105594,-0.0603588,0.658779,0.625489,0.084243,0.111726,0.915376,0.886364,0.799478,0.707211,0.015125,0.0206015,0.206496,0.258006,0.939269,0.955558,0.00701843,0.283646,0.347111,0.753064,-0.413461,-0.194731,0.84925,0.968263,0.643722,0.684643,0.665908,0.536581,0.671196,0.670437,-0.047769,-0.0858366,-1.37549,-1.31851,-0.105553,0.06059
4456,0.268929,0.225053,0.0394382,-0.0246969,0.430655,0.267401,0.627322,0.627959,0.60502,0.630657,0.355525,0.327516,0.134943,0.0455167,0.462275,0.467584,0.06209,0.114494,0.158638,0.175591,0.14421,0.38197,0.662898,1.06295,0.394077,0.620666,0.100489,0.222011,-1.46794,-1.4334,-0.108127,-0.236408,0.61304,0.636764,-0.0437157,-0.185969,-0.966935,-0.906088,1.28185,1.4856
4457,0.516518,0.471015,0.870532,0.807526,0.397356,0.234583,0.614983,0.630429,0.909024,0.933422,0.55877,0.511867,0.74522,0.656888,0.460214,0.416114,0.151302,0.202667,0.509831,0.525196,0.162168,0.480295,-0.0626237,0.330934,0.278517,0.517964,-1.70246,-1.57617,-0.190711,-0.154474,0.463867,0.331121,0.601904,0.603091,-0.381747,-0.528434,2.01093,2.07709,-0.665252,-0.456769
4458,0.0776558,0.0305067,0.787925,0.724195,0.318922,0.201764,0.666189,0.632899,0.544371,0.53856,0.818109,0.696218,0.556749,0.443796,0.358979,0.364644,0.979614,1.03117,0.322459,0.32037,0.301992,0.57862,0.0337671,0.42344,0.101076,0.415262,0.293284,0.422895,0.123028,0.1549,-0.723254,-0.855,-1.83693,-1.83023,0.221155,0.0780279,-1.69645,-1.62237,0.282483,0.488155
4459,0.313894,0.26672,0.370276,0.305526,0.332199,0.168946,0.441004,0.371548,0.116805,0.143698,0.908577,0.880568,0.415134,0.230703,0.0262141,0.0332913,0.773919,0.823534,0.102478,0.115544,-0.335285,-0.0573149,-0.845091,-0.448088,0.0859701,0.312559,-0.858672,-0.725591,1.89861,1.92239,0.998305,0.863287,-0.149834,-0.151353,1.23533,1.08501,-1.09823,-1.02288,-0.496554,-0.263847
4460,0.917545,0.872696,0.461262,0.310618,0.944434,0.782554,0.144744,0.110197,0.812428,0.840082,0.636122,0.607646,0.103604,0.0176108,0.524792,0.530548,0.192921,0.244112,0.898873,0.913677,-0.381917,-0.0965496,0.483202,0.876104,0.196197,0.41906,0.0968251,0.223263,-0.288239,-0.25773,-0.767884,-0.905569,1.03841,1.03341,-1.52474,-1.67565,-1.52727,-1.44725,-1.22107,-1.01585
4461,0.97339,0.928358,0.38299,0.315709,0.61228,0.447893,0.284169,0.249726,0.59853,0.571937,0.0623272,0.0332822,0.712826,0.628982,0.564982,0.570867,0.249459,0.263149,0.788563,0.803314,-0.910751,-0.624463,-0.26334,0.127707,0.948043,1.17224,2.40382,2.53467,-0.950595,-0.912081,-0.214927,-0.353073,0.733578,0.728334,-0.740443,-0.886288,-0.574509,-0.489451,0.542021,0.744278
4462,0.783434,0.739695,0.639508,0.572323,0.503153,0.347964,0.825321,0.792614,0.275223,0.303791,0.261311,0.180415,0.138821,0.0567828,0.831828,0.83647,0.277842,0.282185,0.19806,0.212653,-0.352432,-0.0674683,-0.250927,0.143791,0.8388,1.03672,0.314024,0.446829,1.45151,1.4923,-0.305875,-0.446142,0.871023,0.865807,0.518898,0.37649,0.0919714,0.137074,1.55883,1.76573
4463,0.0124946,-0.03224,0.0205231,-0.0485496,0.409047,0.248035,0.099048,0.0649723,0.796941,0.827311,0.417174,0.327548,0.8805,0.795736,0.124159,0.127838,0.250735,0.301221,0.749783,0.766765,-0.515804,-0.229578,0.418,0.806957,0.677007,0.901199,-1.29705,-1.1656,-0.626909,-0.59377,1.61862,1.48599,-1.32992,-1.33922,0.690117,0.552881,0.67854,0.763598,-1.60038,-1.38937
4464,0.113733,0.0681301,0.905208,0.834634,0.314925,0.148106,0.19155,0.158644,0.931337,0.962189,0.502027,0.474681,0.49326,0.359743,0.361396,0.396087,0.0541851,0.103738,0.748325,0.767654,-0.0296168,0.254596,0.563075,0.864079,-0.143932,0.0838487,0.221908,0.357626,-0.186792,-0.160622,-0.867662,-0.995756,1.39037,1.38487,0.375951,0.23955,0.138285,0.216769,-0.847698,-0.582341
4465,0.896326,0.848787,0.430129,0.360991,0.439227,0.274318,0.517588,0.482942,0.792693,0.842979,0.932712,0.903668,0.00732214,-0.0762489,0.661536,0.664336,0.225724,0.21266,0.432867,0.451886,0.900102,1.1793,0.534089,0.921202,0.625678,0.852539,-0.791472,-0.652253,0.582181,0.611625,1.28314,1.15909,0.432518,0.430973,-0.217209,-0.349383,0.148216,0.226082,0.0152028,0.224692
4466,0.178637,0.129325,0.464773,0.394908,0.0708156,-0.0950263,0.288057,0.245132,0.728677,0.723769,0.957532,0.930092,0.147574,0.0556417,0.136777,0.138527,0.273523,0.321582,0.584167,0.603989,-1.58944,-1.30566,-0.398549,-0.0110492,-0.831008,-0.59817,1.27435,1.41039,0.19349,0.229303,0.179341,0.0494899,0.171876,0.172553,0.328516,0.196806,-1.24333,-1.1652,-1.0795,-0.872869
4467,0.989652,0.941604,0.240086,0.17063,0.962453,0.797161,0.0414701,0.00732245,0.574935,0.604559,0.623339,0.613396,0.268936,0.187532,0.697759,0.700762,0.817916,0.866519,0.531998,0.550037,1.57088,1.86193,-1.05245,-0.666396,0.853998,1.09075,0.874107,1.00523,-1.91426,-1.8713,0.450453,0.331679,1.60139,1.60496,0.224467,0.131752,0.751496,0.838335,-0.374979,-0.17087
4468,0.71445,0.700611,0.578184,0.436923,0.234295,0.0676236,0.460703,0.425479,0.870767,0.902135,0.323593,0.2967,0.812007,0.729186,0.642211,0.645097,0.280615,0.326916,0.00191333,0.0185816,0.776043,1.0708,-0.555636,-0.172212,0.317879,0.539492,-0.407553,-0.2818,1.61867,1.66511,0.740725,0.613869,-0.509872,-0.507687,0.196205,0.066698,0.657194,0.73962,0.612984,0.818771
4469,0.507897,0.459618,0.770863,0.703215,0.569417,0.399745,0.397609,0.308914,0.729233,0.723711,0.584981,0.560136,0.178445,0.0971084,0.829956,0.735457,0.0109224,0.0580439,0.303888,0.314831,-0.371162,-0.0516171,1.53722,1.91605,-0.233009,-0.0117709,0.139505,0.266253,-1.31406,-1.27388,-1.49511,-1.62258,1.61162,1.61584,-0.417141,-0.552337,-0.0913752,-0.0106092,0.376168,0.584624
4470,0.494562,0.447119,0.0870791,0.0179558,0.89987,0.731867,0.227023,0.19235,0.51483,0.545286,0.135973,0.108828,0.189487,0.110057,0.823118,0.825816,0.0811898,0.0666683,0.511854,0.611081,-1.47472,-1.17404,-0.524232,-0.141733,-0.799791,-0.563034,0.0325404,0.246454,-0.373509,-0.332654,-0.789698,-0.917458,0.984181,0.987067,-0.562261,-0.696797,-0.451103,-0.372445,-1.54054,-1.32587
4471,0.483478,0.434621,0.952186,0.881452,0.864212,0.698323,0.730251,0.694684,0.714318,0.744838,0.653007,0.626156,0.776931,0.696319,0.434641,0.439344,0.027208,0.0752928,0.890663,0.907331,-1.21988,-0.922878,0.717619,1.10706,-1.10297,-0.867551,0.106987,0.226655,-0.797514,-0.760784,0.787296,0.662351,0.816616,0.896648,-1.23153,-1.36406,0.773478,0.851131,0.783729,0.998273
4472,0.0942323,0.0447973,0.15395,0.0838662,0.218818,0.054032,0.561059,0.568549,0.0657286,0.0956442,0.357183,0.332007,0.639476,0.556567,0.918417,0.921374,0.957388,1.00493,0.649634,0.667676,-0.279652,0.0161617,-1.16955,-0.782811,-0.997209,-0.76105,-0.149453,-0.0250675,0.18365,0.226277,-0.217616,-0.341351,0.836828,0.80623,1.79325,1.65891,-0.243969,-0.165301,0.267303,0.476658
4473,0.0586832,0.00842668,0.556804,0.48954,0.388655,0.22476,0.47914,0.442415,0.486411,0.517984,0.526783,0.462219,0.299934,0.216531,0.505149,0.509683,0.249231,0.294537,0.774872,0.841803,1.19106,1.48381,-0.484627,-0.104451,-0.268838,-0.0387496,0.606598,0.738218,0.243288,0.293386,-0.164643,-0.198972,0.712926,0.715811,-0.0883845,-0.225552,0.702459,0.77864,-0.504375,-0.301127
4474,0.696374,0.644237,0.345544,0.279955,0.217499,0.052921,0.863882,0.825518,0.064845,0.0940835,0.619023,0.592431,0.565581,0.482948,0.724885,0.727919,0.571555,0.615204,0.999204,1.01593,1.2829,1.58002,1.48959,1.87356,0.0295697,0.215352,-0.311572,-0.180089,-1.03862,-0.990546,0.0601978,-0.0565927,-0.00362035,-0.00435607,0.406599,0.274351,0.642918,0.725522,0.766235,0.964937
4475,0.757052,0.658928,0.658447,0.60219,0.823552,0.660784,0.139707,0.102818,0.325764,0.35515,0.981804,0.95675,0.505396,0.424569,0.282158,0.286341,0.273062,0.316036,0.685485,0.700163,0.422152,0.713465,2.09267,2.47541,0.245595,0.469454,-0.283605,-0.154188,-0.0856984,-0.0346698,-0.172259,-0.309723,1.52404,1.51998,-1.41078,-1.54737,1.45759,1.54286,-1.76204,-1.55862
4476,0.725845,0.673619,0.988368,0.924424,0.986462,0.822052,0.672748,0.635441,0.334011,0.363145,0.886263,0.82434,0.820199,0.741767,0.343181,0.429653,0.364048,0.476606,0.698786,0.759369,1.19636,1.48529,-0.599112,-0.222581,-0.40767,-0.176675,-1.77052,-1.64056,1.47088,1.51815,-0.450609,-0.562854,0.410237,0.391698,0.550734,0.415785,1.44684,1.53754,-1.54687,-1.34237
4477,0.330594,0.277469,0.780944,0.691826,0.528582,0.362887,0.683435,0.648562,0.942563,0.972873,0.608489,0.691931,0.825995,0.749359,0.569025,0.572965,0.592113,0.637175,0.70781,0.818575,-0.760514,-0.473239,0.463079,0.84057,0.927643,1.1564,0.560578,0.685925,0.0926853,0.138905,-0.0644411,-0.179963,-0.731514,-0.73658,-2.84694,-2.98759,-0.256826,-0.170433,0.192336,0.398588
4478,0.986096,0.933862,0.522544,0.459228,0.457952,0.283373,0.232882,0.196695,0.0132232,0.0445024,0.47292,0.559521,0.0958708,0.0215264,0.268002,0.271402,0.415596,0.376818,0.861313,0.877781,-1.0569,-0.770203,-1.15464,-0.779411,-1.83544,-1.61542,1.31444,1.43453,-0.0765178,-0.0289205,-0.458599,-0.579813,-0.0341917,-0.0450631,1.53658,1.39593,1.84404,1.93022,-2.22574,-2.01912
4479,0.624148,0.471865,0.526605,0.51573,0.391475,0.20386,0.38797,0.351327,0.744013,0.777254,0.452165,0.427112,0.967654,0.894724,0.560512,0.562036,0.0721443,0.11646,0.432728,0.447111,1.5822,1.86713,-1.03816,-0.656158,-0.00407307,0.214522,0.818843,0.936906,-2.0157,-1.9614,-1.15309,-1.27637,1.21902,1.20188,0.53224,0.394184,0.128788,0.22225,-0.0633778,0.146872
4480,0.062636,0.00986703,0.63556,0.572232,0.288908,0.124346,0.218196,0.219236,0.0880782,0.123017,0.402824,0.420722,0.00587625,-0.0674199,0.39736,0.399277,0.890268,0.934751,0.852235,0.86644,-0.649948,-0.36485,0.201613,0.578398,-1.09635,-0.882194,-1.00371,-0.880918,-0.087311,-0.0366731,1.69956,1.57868,1.67997,1.66275,-0.869288,-1.00591,-0.190485,-0.0936264,0.736734,0.940152
4481,0.18253,0.130085,0.390445,0.326091,0.98353,0.819851,0.125417,0.0871459,0.744239,0.778194,0.437897,0.414332,0.263087,0.18918,0.973611,0.977152,0.663316,0.706617,0.361642,0.375761,-1.18167,-0.892764,2.09868,2.47616,-0.132193,0.0857781,0.908185,1.0363,0.64346,0.689002,1.38734,1.26996,-0.824565,-0.845483,-1.32142,-1.45527,-0.766438,-0.672096,1.08685,1.29209
4482,0.710341,0.656891,0.92429,0.858243,0.300619,0.135554,0.888413,0.850545,0.892211,0.856068,0.678378,0.652653,0.940113,0.86667,0.48424,0.486075,0.0707869,0.112384,0.23608,0.250674,0.478538,0.774622,0.426639,0.807914,0.27169,0.486071,-0.196143,-0.0676982,2.59993,2.64426,0.553525,0.435592,1.14977,1.13087,0.174546,0.038617,-0.0462678,0.0523892,1.17736,1.3882
4483,0.383828,0.331492,0.363579,0.296055,0.212156,0.0496889,0.793719,0.757573,0.897031,0.933943,0.325932,0.300334,0.786785,0.79633,0.926927,0.928312,0.889264,0.930675,0.376365,0.393199,-0.561064,-0.261528,-0.146195,0.228991,-0.417746,-0.206372,-0.768736,-0.642271,0.0598096,0.101205,-0.780483,-0.90519,0.920445,0.902944,0.226451,0.0916041,-0.282564,-0.185132,0.663661,0.881714
4484,0.459561,0.407137,0.513302,0.44506,0.844312,0.68346,0.0735226,0.0348719,0.0675631,0.106046,0.549385,0.586203,0.801651,0.725989,0.0818081,0.0826325,0.53683,0.575953,0.939758,0.956587,-0.95041,-0.649648,-0.448386,-0.0771802,-0.730983,-0.548863,-1.72578,-1.60533,1.43741,1.48727,0.0726063,-0.048803,0.21862,0.197761,-0.880804,-1.0179,-0.829071,-0.731961,0.603004,0.815396
4485,0.172013,0.190033,0.898149,0.829826,0.445998,0.283346,0.583137,0.450138,0.601237,0.639808,0.899285,0.872071,0.270048,0.193802,0.84531,0.845065,0.419233,0.458783,0.662077,0.680928,-0.187007,0.107991,0.434178,0.79992,-1.09391,-0.891354,0.636868,0.762136,0.471612,0.525683,-0.597896,-0.714865,-0.900735,-0.927689,0.0159165,-0.121123,0.166657,0.259525,1.25008,1.4573
4486,0.0275149,-0.0270708,0.295675,0.228285,0.645427,0.505884,0.903616,0.865404,0.688262,0.728331,0.381627,0.351999,0.786329,0.710087,0.21947,0.218686,0.821353,0.85972,0.856503,0.872976,-0.176037,0.0815096,1.01081,1.37006,-0.0113691,0.289396,-0.780241,-0.6495,1.38681,1.43515,0.721523,0.601264,1.34737,1.32235,-0.282175,-0.416659,-0.441179,-0.34997,0.268543,0.447975
4487,0.25517,0.132072,0.404923,0.337047,0.890093,0.728422,0.648196,0.61251,0.360753,0.401168,0.818054,0.790355,0.959712,0.797441,0.466511,0.464243,0.491947,0.571888,0.738022,0.709487,-0.238275,0.0550284,-0.456173,-0.0956842,1.2702,1.47015,-0.242505,-0.118004,-0.789979,-0.744977,1.72228,1.59789,1.38529,1.35326,1.30322,1.17014,-0.769157,-0.74746,-0.768573,-0.561351
4488,0.347766,0.291216,0.178332,0.11277,0.544814,0.283028,0.752159,0.71691,0.682973,0.723585,0.653218,0.627736,0.962027,0.884795,0.102273,0.102105,0.243025,0.284056,0.527888,0.545997,0.428546,0.71878,-1.25057,-0.890355,-0.429967,-0.229747,-0.801134,-0.676323,-0.618853,-0.570914,-0.507387,-0.638561,0.79557,0.768301,0.807594,0.622703,-1.23492,-1.14495,0.301615,0.504649
4489,0.171999,0.11367,0.706449,0.640523,0.00146445,-0.162366,0.112845,0.0796532,0.124452,0.165041,0.128646,0.10348,0.63581,0.558825,0.577739,0.57863,0.546987,0.589832,0.708611,0.728322,-0.720168,-0.424469,-1.13171,-0.767102,-0.125498,0.0781345,0.589793,0.718651,-0.150164,-0.106796,0.786353,0.662092,0.711642,0.678983,0.20631,0.0752657,-0.746705,-0.654553,-0.515913,-0.317118
4490,0.259642,0.199732,0.635674,0.571481,0.2961,0.145963,0.890205,0.85966,0.548807,0.546583,0.493324,0.471566,0.823162,0.744783,0.481015,0.482322,0.591305,0.633304,0.629285,0.642446,-2.32595,-2.02729,0.377197,0.662781,1.87941,2.07953,0.395365,0.528863,-0.316511,-0.274622,-0.0376903,-0.156279,1.71177,1.67885,1.13703,1.00458,-0.750019,-0.65987,-0.016403,0.187112
4491,0.0273866,-0.0334827,0.32334,0.26089,0.709583,0.454292,0.0662643,0.0377069,0.887176,0.928125,0.863101,0.839652,0.0541384,-0.0257098,0.105115,0.10545,0.238835,0.278582,0.535525,0.556571,0.223844,0.526033,1.73479,2.09266,0.0759297,0.269113,-0.447131,-0.310735,0.742941,0.788784,0.0939256,-0.0189954,-1.69556,-1.73615,-1.11066,-1.24639,2.40546,2.49952,-1.12162,-0.910448
4492,0.670644,0.607724,0.314925,0.309122,0.927981,0.762621,0.608629,0.580595,0.128329,0.170525,0.22138,0.199996,0.0663731,-0.0402281,0.480527,0.482868,0.918852,0.96086,0.654661,0.7279,0.850215,1.14521,-0.253312,0.110242,-1.07906,-0.890788,-0.29133,-0.159979,0.0445802,0.0984769,1.39364,1.28166,-0.405014,-0.442905,0.245615,0.111231,0.0397499,0.13253,0.225426,0.430663
4493,0.88328,0.819053,0.420803,0.357354,0.713055,0.549462,0.274516,0.299587,0.0413493,0.084773,0.446197,0.424027,0.0260355,-0.0547464,0.539803,0.543517,0.95809,0.969485,0.876932,0.89923,-0.403533,-0.10559,0.271057,0.586111,-0.864266,-0.676084,-1.22902,-1.0935,-0.631477,-0.59183,0.613563,0.508669,-0.860943,-0.904356,-0.315417,-0.44572,-0.450313,-0.351985,-0.991953,-0.789034
4494,0.024349,-0.0388486,0.623509,0.633287,0.125201,-0.0392793,0.0458384,0.0185782,0.426921,0.473075,0.414942,0.39766,0.358364,0.231741,0.0985228,0.101939,0.935233,0.978109,0.118103,0.139874,0.887015,1.18812,0.690282,1.06198,0.18132,0.367288,0.863728,1.00114,0.231225,0.272306,-0.824737,-0.923752,-1.05839,-1.10017,0.44527,0.313196,0.0949017,0.186671,0.220222,0.41464
4495,0.871811,0.808606,0.971088,0.909219,0.121356,-0.0658512,0.532073,0.507042,0.0947379,0.140931,0.281198,0.371293,0.600601,0.518228,0.268696,0.189507,0.260006,0.303117,0.520594,0.544179,0.753713,1.05836,-0.0139052,0.360837,0.768103,0.950717,-1.86173,-1.72933,-0.616752,-0.582841,-0.0932389,-0.190711,-0.12081,-0.1633,-0.418041,-0.550262,2.94816,3.0438,-0.65294,-0.454755
4496,0.628365,0.522643,0.160243,0.0991685,0.0698114,-0.0924232,0.645927,0.621495,0.99513,1.04209,0.368943,0.344926,0.252279,0.167598,0.274755,0.277075,0.848266,0.893756,0.443442,0.466124,1.35097,1.6619,0.611228,0.99192,-1.21865,-1.0312,-0.296546,-0.171837,-0.499182,-0.471148,-0.783963,-0.887274,0.454211,0.330329,1.90062,1.77277,-0.360258,-0.263012,1.08623,1.2862
4497,0.299869,0.23668,0.580594,0.518282,0.484615,0.301755,0.500803,0.473762,0.543831,0.688456,0.593441,0.568957,0.245335,0.160171,0.774593,0.778308,0.43935,0.484841,0.828317,0.850288,0.386974,0.702999,0.56797,0.947154,-0.00362735,0.178408,-0.608907,-0.484845,0.875594,0.897168,1.19905,1.09021,0.864469,0.823957,-1.03121,-1.16356,1.01522,1.10507,0.13704,0.433051
4498,0.652306,0.588501,0.505467,0.449293,0.856455,0.695934,0.0902808,0.0614429,0.289159,0.334819,0.478265,0.455595,0.888777,0.801458,0.45038,0.451808,0.639415,0.685318,0.858373,0.887787,-1.30383,-0.991301,-1.11871,-0.736947,-0.564947,-0.388165,0.275113,0.403015,-1.83717,-1.82291,-0.766925,-0.882464,1.20302,1.16101,-0.592603,-0.726037,0.683399,0.774115,-0.61896,-0.420103
4499,0.170399,0.107554,0.444096,0.380304,0.682243,0.498229,0.5567,0.529387,0.35281,0.397312,0.0407667,0.0195664,0.191488,0.105063,0.616739,0.618753,0.242737,0.291116,0.905115,0.925286,-1.06412,-0.756486,-0.108263,0.278765,1.43408,1.61324,-1.07631,-0.944106,-0.881789,-0.781554,-2.28203,-2.39225,-0.25417,-0.290413,-0.480796,-0.609784,-2.10554,-2.01723,-0.72587,-0.53358
4500,0.552684,0.490376,0.00292852,-0.0630688,0.394103,0.300525,0.0917732,0.0627296,0.823839,0.870283,0.996265,0.972093,0.774735,0.686214,0.17144,0.172441,0.202955,0.251473,0.13836,0.157013,-2.82579,-2.51494,0.504912,0.894682,0.807176,0.982312,0.889157,1.02294,0.254781,0.259802,0.509893,0.397479,0.492416,0.462377,-0.621553,-0.754245,-1.75011,-1.66621,0.606527,0.792804
4501,0.204043,0.140315,0.756583,0.692434,0.262667,0.10282,0.276995,0.248233,0.379855,0.426848,0.486451,0.462226,0.287232,0.19991,0.904486,0.904989,0.829313,0.87786,0.0900453,0.122102,0.432164,0.741363,-0.364205,0.0231537,-1.19676,-1.01528,-1.5539,-1.42592,-1.50614,-1.50241,-0.3748,-0.482769,-0.153965,-0.18176,1.76234,1.62347,-0.540696,-0.457494,0.768882,0.950464
4502,0.804931,0.741067,0.875011,0.810915,0.720198,0.561655,0.816875,0.785705,0.755547,0.804513,0.958238,0.934686,0.0652399,-0.02125,0.441309,0.443581,0.375743,0.423277,0.0365939,0.0871905,0.807025,1.11598,-0.0488575,0.333036,-1.21338,-1.09993,1.60087,1.73438,0.269835,0.280137,0.29671,0.192177,0.921498,0.890721,0.651739,0.513964,0.122089,0.204099,0.171026,0.354265
4503,0.598126,0.532223,0.345491,0.283504,0.358316,0.197036,0.0111768,-0.0203115,0.74018,0.77925,0.388705,0.364913,0.713985,0.62669,0.569745,0.574602,0.379035,0.428719,0.0351846,0.0522793,0.623566,0.940249,0.79591,1.17817,-1.3639,-1.18458,0.88145,1.02026,0.137755,0.174037,-0.858618,-0.9628,-1.02153,-1.04952,-1.24866,-1.38366,0.353379,0.429326,1.2237,1.40511
4504,0.650259,0.582471,0.370931,0.257628,0.874276,0.71105,0.705696,0.672711,0.704523,0.753987,0.802873,0.779488,0.923926,0.838221,0.00419378,0.00795635,0.847201,0.89927,0.233183,0.347074,-1.32882,-1.0053,-0.110385,0.276024,2.25606,2.4279,-0.0474376,0.0867435,0.0223194,0.0679374,-0.0869735,-0.197236,-0.900423,-0.926765,-0.864448,-1.00495,1.10501,1.18303,0.646067,0.823635
4505,0.998979,0.929466,0.300163,0.231753,0.84665,0.683041,0.142763,0.108974,0.230801,0.280981,0.874271,0.848196,0.917325,0.830794,0.6592,0.66277,0.438631,0.490355,0.624123,0.641868,1.13642,1.45054,-0.0591512,0.323216,-0.56398,-0.400531,1.80377,1.94462,-0.0484647,-0.0381626,-0.218793,-0.266958,-0.307103,-0.32707,-0.818563,-0.965936,0.506325,0.589702,0.399057,0.574345
4506,0.577424,0.509147,0.267864,0.205877,0.10494,-0.0577181,0.275369,0.22285,0.366361,0.415859,0.940709,0.916905,0.101945,0.0137304,0.652262,0.657971,0.998257,1.05012,0.156742,0.175912,0.394968,0.708408,-1.19863,-0.812425,0.302391,0.459767,-0.190474,-0.049861,0.186022,0.19542,-0.224952,-0.33668,-2.07954,-2.09582,-1.92836,-2.07544,0.42234,0.506543,-2.66554,-2.4813
4507,0.836662,0.77107,0.585651,0.469833,0.596603,0.43568,0.368937,0.336725,0.892678,0.939378,0.789492,0.763948,0.127976,0.0415418,0.978173,0.984375,0.116319,0.170356,0.676647,0.6955,-0.778015,-0.464062,-0.602481,-0.210579,-2.09391,-1.93968,1.20583,1.34511,-0.61656,-0.612733,-0.59338,-0.705648,-0.245037,-0.258262,-0.575739,-0.716776,0.733336,0.825122,-0.408934,-0.221
4508,0.399651,0.335269,0.798177,0.733788,0.696238,0.537003,0.484389,0.4506,0.347024,0.395888,0.286106,0.258575,0.836688,0.749633,0.839511,0.787513,0.34753,0.471635,0.492341,0.510091,-0.719253,-0.413392,-0.833657,-0.441569,-0.493944,-0.38139,-1.53681,-1.40448,-0.685784,-0.688165,-0.32188,-0.431321,-0.630042,-0.640586,0.78897,0.641888,0.0615895,0.154169,-0.313507,-0.124882
4509,0.769122,0.703027,0.577456,0.514408,0.548114,0.390011,0.301321,0.36191,0.860027,0.910009,0.766833,0.740955,0.407366,0.32025,0.584039,0.590652,0.719147,0.772913,0.774263,0.735181,0.320924,0.634778,1.14939,1.53644,1.01567,1.1769,0.211533,0.342589,0.190654,0.190914,-1.60014,-1.71149,-0.38518,-0.396584,0.776276,0.632469,-0.323981,-0.238315,1.32584,1.50856
4510,0.102423,0.0367712,0.0912225,0.0266326,0.779009,0.619662,0.305097,0.27322,0.731202,0.783672,0.607496,0.619981,0.879051,0.791931,0.725406,0.739778,0.768738,0.82198,0.941213,0.960272,-0.993428,-0.675262,0.542519,0.926786,1.12165,1.2834,0.555899,0.690981,-1.03233,-1.03297,0.0469026,-0.0692477,0.267441,0.250315,1.48003,1.33156,-0.723379,-0.6308,0.0337621,0.213204
4511,0.982008,0.918714,0.430354,0.465109,0.191613,0.0309211,0.540711,0.508793,0.296645,0.349736,0.523714,0.499007,0.627916,0.609543,0.88203,0.888905,0.204264,0.256463,0.731693,0.760222,1.181,1.49977,-1.7758,-1.39093,-0.0449201,0.123497,-0.801319,-0.67183,0.501232,0.50465,0.646252,0.529165,-0.391128,-0.408354,0.295696,0.146335,-0.498264,-0.405572,-0.0308974,0.146886
4512,0.0287801,-0.0367814,0.967447,0.903586,0.234196,0.0723293,0.0879232,0.0569258,0.26715,0.418097,0.830957,0.805216,0.410763,0.427155,0.54989,0.653948,0.212945,0.266485,0.540638,0.560173,1.27828,1.59598,0.00132985,0.385098,0.401668,0.568823,0.805746,0.932746,0.463768,0.462344,-0.676105,-0.79618,1.40682,1.39589,0.821542,0.677402,-0.579418,-0.424454,0.26246,0.508551
4513,0.848666,0.781082,0.47816,0.41581,0.9851,0.82367,0.633855,0.604317,0.431671,0.486459,0.00124704,-0.0228211,0.330092,0.244767,0.411589,0.41899,0.740654,0.796078,0.717216,0.737728,0.7932,1.11343,0.147394,0.524806,0.385987,0.554078,0.600438,0.730013,-0.95466,-0.960268,-1.4669,-1.58309,1.00628,0.99768,-0.943995,-1.09364,-0.535141,-0.443335,0.691434,0.870216
4514,0.823696,0.755799,0.54322,0.479884,0.628581,0.389397,0.278033,0.247304,0.225365,0.279972,0.407421,0.381055,0.827022,0.74162,0.936891,0.945866,0.268948,0.326561,0.0683468,0.086732,-1.16819,-0.845105,-0.375888,0.008001,0.635613,0.801102,-0.589444,-0.465576,-0.187036,-0.105278,1.37685,1.25678,-0.429287,-0.439776,0.907004,0.758056,-0.249239,-0.183212,0.366314,0.544626
4515,0.333293,0.264744,0.899648,0.835409,0.117664,-0.0448767,0.772371,0.740645,0.855894,0.909137,0.30139,0.371845,0.306208,0.219304,0.808381,0.819117,0.730559,0.786858,0.678005,0.695598,-0.786595,-0.470485,1.05759,1.44036,-0.165183,-0.0849577,-0.840308,-0.717298,0.752162,0.749713,1.43999,1.31756,1.05394,1.0397,0.450508,0.308699,-0.00866684,0.0769114,0.561503,0.74731
4516,0.752138,0.682808,0.221462,0.154812,0.47412,0.312186,0.299817,0.268468,0.0994825,0.151536,0.387232,0.362634,0.844487,0.755705,0.13251,0.141759,0.597143,0.568882,0.0252215,0.0446016,-0.0281884,0.287153,0.978541,1.42933,-1.12834,-0.971017,1.26304,1.39376,1.91256,1.90412,-1.36222,-1.48541,2.13867,2.12764,-2.73293,-2.86766,-1.95516,-1.87026,1.17468,1.35804
4517,0.891013,0.798394,0.380662,0.340576,0.831428,0.669248,0.887282,0.855773,0.152405,0.176707,0.638585,0.652509,0.597346,0.50964,0.982884,0.991992,0.293309,0.350907,0.673934,0.693413,-0.636538,-0.317332,1.03321,1.41831,0.720308,0.875666,0.306978,0.444086,1.51418,1.50763,-0.123269,-0.245795,-1.90646,-1.91196,0.865962,0.72587,0.483343,0.565994,-0.733336,-0.552454
4518,0.982734,0.91398,0.590529,0.52634,0.507143,0.34479,0.827609,0.79853,0.0535917,0.201878,0.967172,0.942383,0.711945,0.589045,0.60271,0.639024,0.679393,0.736656,0.996996,1.01715,-0.430552,-0.114061,-0.0354787,0.34422,-0.91134,-0.758421,0.61249,0.747948,0.691213,0.682861,0.750442,0.625989,-0.49368,-0.553481,0.413788,0.276513,0.56397,0.654004,-0.437346,-0.260229
4519,0.578978,0.508771,0.533319,0.46715,0.421289,0.258925,0.366529,0.337065,0.176942,0.227049,0.9279,0.932585,0.753826,0.668449,0.2781,0.286056,0.223103,0.282073,0.215394,0.237181,1.05474,1.36957,-0.311606,0.0702161,-0.826427,-0.66821,0.309118,0.450198,1.32112,1.31575,0.739538,0.610219,0.816084,0.805,-0.453139,-0.586945,-0.309851,-0.219779,1.31405,1.4999
4520,0.964631,0.897274,0.921308,0.857133,0.952177,0.792465,0.464095,0.526883,0.936557,0.985674,0.90456,0.922787,0.638016,0.59481,0.661468,0.668291,0.631571,0.692336,0.142954,0.135872,-0.530403,-0.217966,1.72204,2.09793,1.12118,1.28567,0.267714,0.414553,0.431365,0.43044,-1.11608,-1.25126,-0.869057,-0.884054,1.26822,1.13982,1.23153,1.31674,-0.302633,-0.116232
4521,0.458837,0.391781,0.465439,0.398915,0.677936,0.521669,0.743917,0.716701,0.397778,0.44752,0.93955,0.912989,0.607785,0.521171,0.780432,0.709828,0.730056,0.822186,0.0128147,0.0345635,-0.115049,0.201885,0.62135,0.993464,-0.203797,-0.0427034,-0.464748,-0.314721,-0.99975,-1.00698,0.0558761,-0.0727326,-0.173257,-0.192537,0.078811,-0.0454035,2.24012,2.32323,0.620769,0.855012
4522,0.645591,0.577811,0.958625,0.891963,0.409116,0.250873,0.0863469,0.0594433,0.707539,0.759538,0.696484,0.669569,0.910133,0.822901,0.745157,0.751365,0.891428,0.952036,0.984786,1.00507,0.753176,1.06384,-0.729149,-0.361063,1.40393,1.56725,1.04152,1.19366,-2.03936,-2.046,-0.411557,-0.537243,-0.629502,-0.653989,-0.688178,-0.817849,-1.23637,-1.15289,1.63796,1.82626
4523,0.420717,0.300065,0.537743,0.473294,0.884985,0.724468,0.875551,0.84946,0.0536731,0.105301,0.111021,0.0846162,0.487785,0.40188,0.541623,0.549296,0.244062,0.307358,0.0340911,0.0565159,-0.695284,-0.384727,0.690287,1.05675,0.606178,0.765827,0.932284,1.08195,-0.81604,-0.880101,0.400862,0.274042,-0.396772,-0.425809,-0.373476,-0.500645,-0.990487,-0.913589,-0.285289,-0.0984013
4524,0.0866564,0.0223184,0.858618,0.794776,0.844156,0.685648,0.732132,0.74171,0.346861,0.397254,0.203065,0.204477,0.348896,0.180845,0.00760061,0.0131983,0.614564,0.677823,0.755278,0.776044,-0.409344,-0.101798,-0.257013,0.0299042,0.423671,0.583979,-0.684978,-0.530488,0.209536,0.285794,-0.32577,-0.452386,0.305341,0.281233,-1.1836,-1.30388,0.256003,0.327353,0.396657,0.58766
4525,0.312661,0.323306,0.437272,0.370843,0.190186,0.0322541,0.662345,0.633959,0.0927295,0.145361,0.350262,0.324337,0.0470785,-0.0401888,0.638715,0.643421,0.666589,0.731979,0.481779,0.47122,-0.326287,-0.0206682,-1.36341,-0.996945,-0.299098,-0.14162,-0.886918,-0.733221,1.45833,1.45169,0.502081,0.372523,-0.435818,-0.456169,-1.1501,-1.26487,-1.0713,-1.00415,1.83883,2.0233
4526,0.677302,0.624293,0.483112,0.418876,0.369306,0.165912,0.22126,0.192029,0.045712,0.136271,0.104803,0.178497,0.891785,0.805424,0.138129,0.142153,0.158276,0.22228,0.145957,0.166396,2.84616,3.14691,0.750586,1.11096,2.13581,2.30192,0.0879772,0.248137,-0.604102,-0.616297,-0.981264,-1.10834,0.68259,0.664229,2.20317,2.09499,-0.909361,-0.84103,0.438397,0.620683
4527,0.989619,0.925281,0.847488,0.783609,0.457081,0.29957,0.144647,0.113706,0.0733307,0.12718,0.0575226,0.0326565,0.459111,0.376041,0.222533,0.156267,0.117601,0.182637,0.487266,0.505084,-1.86781,-1.56706,-0.881571,-0.525252,0.114161,0.273522,-0.760357,-0.607565,0.230988,0.216946,-0.713007,-0.834009,0.46019,0.436308,0.283617,0.181385,0.436904,0.479121,1.87325,2.05632
4528,0.768854,0.706046,0.956618,0.892372,0.018531,-0.139653,0.480886,0.44746,0.233016,0.286355,0.204779,0.182452,0.818097,0.733427,0.214156,0.170382,0.621469,0.688292,0.31581,0.291854,0.627485,0.921151,-0.0711338,0.289775,-0.0645196,0.0916741,0.990678,1.1395,-1.55675,-1.57746,-2.10595,-2.22316,-0.646308,-0.672538,0.159093,0.0525881,1.72916,1.79927,0.518022,0.69922
4529,0.308644,0.244992,0.582226,0.51776,0.334588,0.256766,0.572734,0.541132,0.153838,0.206185,0.777089,0.753505,0.559438,0.47668,0.104504,0.184496,0.900212,0.964562,0.0601485,0.0786236,-0.558274,-0.267707,-1.01749,-0.658625,-1.53775,-1.37492,-0.452724,-0.302246,1.22615,1.20229,0.204081,0.0899554,1.58365,1.56228,-1.43506,-1.54691,0.971666,1.03545,0.104751,0.276306
4530,0.630943,0.566389,0.572809,0.50724,0.811685,0.653185,0.215371,0.257468,0.547428,0.598952,0.682922,0.660616,0.70169,0.506873,0.194587,0.198611,0.688985,0.751175,0.703499,0.721969,0.031996,0.321885,-0.799604,-0.440293,1.10737,1.27129,1.59984,1.74542,-2.10889,-2.13256,0.369719,0.257239,-0.813865,-0.838482,-0.439309,-0.557734,-0.524229,-0.468235,-0.330954,-0.146607
4531,0.468785,0.491198,0.799607,0.734482,0.930702,0.770371,0.00714517,-0.0261967,0.431325,0.54651,0.288171,0.26394,0.671957,0.537066,0.522158,0.436921,0.224636,0.28629,0.653787,0.67287,0.0042303,0.298411,1.87538,2.23189,2.06725,2.22523,0.367791,0.519476,-1.71787,-1.80483,0.817644,0.703581,0.131642,0.0665403,-1.08248,-1.19332,0.598219,0.662043,0.782574,0.965206
4532,0.478852,0.416007,0.0866181,0.0195772,0.244974,0.0860743,0.526568,0.405807,0.43991,0.494069,0.742915,0.717261,0.650017,0.567259,0.668953,0.675231,0.812764,0.876929,0.990035,1.00649,-1.4783,-1.18015,-0.688851,-0.338844,1.72089,1.87472,-0.0758907,0.0822101,-1.44746,-1.4771,-3.03977,-3.14638,0.999742,0.971563,-0.683818,-0.800536,0.793555,0.854605,-0.316217,-0.132355
4533,0.836792,0.772824,0.118813,0.0534943,0.234848,0.0682395,0.8728,0.837811,0.539304,0.565023,0.768171,0.731302,0.951059,0.868989,0.250296,0.258739,0.0228355,0.0871229,0.9598,0.977123,-0.134749,0.161905,-0.00521284,0.339515,1.13069,1.21808,0.332983,0.491188,-0.468832,-0.503836,0.980689,0.874073,0.0254154,-0.0976309,0.999738,0.881095,-0.52634,-0.460637,-0.478373,-0.291441
4534,0.535511,0.473194,0.455852,0.450158,0.206131,0.0504046,0.562835,0.618543,0.580593,0.635977,0.77118,0.745342,0.582051,0.498275,0.633961,0.640975,0.965125,1.03142,0.635956,0.650803,-2.64016,-2.33638,-1.89889,-1.55035,0.410012,0.561435,-1.46417,-1.30699,0.00959144,0.0431749,2.046,1.93246,-1.14604,-1.16682,-1.77003,-1.87956,0.0535029,0.122675,-0.193329,0.000784652
4535,0.678799,0.618009,0.910299,0.846822,0.787537,0.633919,0.431447,0.399275,0.307737,0.403004,0.405952,0.377934,0.880546,0.795433,0.0111907,0.0197311,0.788981,0.807789,0.75311,0.767971,-0.54498,-0.240447,-0.452078,-0.102155,-1.18526,-1.02763,1.69368,1.85331,0.618372,0.590186,-2.88498,-2.99852,-1.78544,-1.81096,1.43239,1.31575,0.0903418,0.16496,-0.440844,-0.343831
4536,0.135406,0.0769117,0.21908,0.156377,0.17416,0.0199167,0.501314,0.468338,0.112952,0.17003,0.358421,0.365246,0.940368,0.808175,0.319445,0.326318,0.518261,0.584156,0.02689,0.0397871,0.521717,0.82144,-1.93367,-1.58234,0.588157,0.739465,0.17925,0.334379,-0.857606,-0.878484,2.9764,2.86286,0.910351,0.890342,-1.64688,-1.75819,0.529191,0.589804,-0.883974,-0.688447
4537,0.950591,0.889191,0.426111,0.42267,0.796796,0.643249,0.77889,0.743592,0.942902,0.997898,0.382082,0.352558,0.904597,0.820917,0.0973004,0.103906,0.679493,0.743539,0.275714,0.288135,0.389767,0.691679,-0.41678,-0.0715096,0.815853,0.970414,-0.167229,-0.113053,-0.551329,-0.569109,0.65212,0.543166,-0.53801,-0.561076,-1.06884,-1.18182,0.939288,1.01465,0.169882,0.362397
4538,0.34771,0.288021,0.750839,0.688962,0.296779,0.143553,0.854591,0.816693,0.567129,0.623869,0.125865,0.09457,0.754612,0.671387,0.893326,0.902431,0.193524,0.258636,0.23954,0.254115,1.0133,1.31085,-0.42339,-0.0863066,-0.37603,-0.218717,-0.710537,-0.560485,-0.564079,-0.579537,0.444849,0.343223,-0.0671117,-0.0844654,-1.15628,-1.26577,-0.0263841,0.0462704,-0.996762,-0.81203
4539,0.988428,0.929228,0.120127,0.0586331,0.387841,0.234671,0.0384593,-0.000238553,0.444546,0.502022,0.800292,0.771542,0.193296,0.109575,0.407547,0.416263,0.605869,0.668899,0.467375,0.555075,0.164218,0.459355,0.568646,0.897077,-0.579536,-0.332009,-2.32908,-2.17292,0.772687,0.759079,-0.323419,-0.501599,0.71994,0.699237,0.138663,0.0273874,0.130924,0.209395,-0.590431,-0.399968
4540,0.561864,0.503604,0.816152,0.753403,0.038012,-0.115411,0.946893,0.908813,0.566397,0.626418,0.868891,0.84259,0.355538,0.232876,0.459176,0.466278,0.409234,0.471416,0.842453,0.856034,0.926438,1.21699,0.849326,1.2529,-0.608618,-0.445301,-2.0343,-1.8845,0.138352,0.118885,-1.24479,-1.34642,0.25937,0.304075,-0.179225,-0.285944,-0.929081,-0.85205,0.574835,0.759088
4541,0.581044,0.524041,0.707165,0.644397,0.872885,0.720041,0.781449,0.839683,0.309697,0.369363,0.283669,0.257637,0.496248,0.356177,0.763529,0.772865,0.929744,0.991857,0.846638,0.861347,-1.10307,-0.808523,1.2724,1.60872,-0.584725,-0.414657,0.462352,0.612633,-0.0787281,-0.0942155,1.45037,1.34034,-0.0747793,-0.0910879,0.867461,0.765294,-0.191808,-0.111617,-0.0312844,0.146589
4542,0.00186822,-0.0567704,0.162528,0.0976764,0.638193,0.48691,0.718594,0.770552,0.598432,0.656635,0.149452,0.12372,0.562217,0.479478,0.0751635,0.0858267,0.614583,0.676904,0.0739626,0.0884642,-0.384025,-0.0828573,-0.863191,-0.529137,-0.0387835,0.176556,-1.03249,-0.889893,-0.700558,-0.719341,-0.84425,-0.961312,-0.299466,-0.319009,1.33123,1.23382,-0.144254,-0.0693319,-0.275599,-0.102701
4543,0.369888,0.310988,0.743844,0.678637,0.0249627,-0.127092,0.740539,0.701421,0.108607,0.16781,0.905786,0.880586,0.303692,0.222731,0.913281,0.924972,0.0688179,0.132416,0.983029,0.997055,0.669322,0.965312,0.50673,0.841229,0.598949,0.76777,0.245231,0.383941,0.827242,0.803224,-0.343834,-0.454216,1.06847,1.05193,-0.797983,-0.90049,-0.348878,-0.276116,0.0121454,0.189525
4544,0.532225,0.422151,0.316334,0.25006,0.159817,-0.0913196,0.0832369,0.0441633,0.594303,0.604906,0.284987,0.260415,0.591315,0.520284,0.832592,0.844118,0.111266,0.175888,0.691315,0.706245,-0.5634,-0.268625,-0.262083,0.0767518,-0.0370803,0.151698,-0.418279,-0.283285,0.508735,0.482021,-0.734461,-0.838438,0.206529,0.193574,-0.158188,-0.263234,-1.13942,-1.07168,-1.68621,-1.50268
4545,0.533242,0.533313,0.220208,0.152369,0.0954093,-0.0555476,0.605222,0.567087,0.981801,1.042,0.302235,0.277109,0.90041,0.817838,0.473591,0.487162,0.943054,1.00931,0.768112,0.775488,0.532761,0.822826,0.546468,0.891778,-0.635314,-0.464373,0.613222,0.743388,-0.270852,-0.294554,-0.243241,-0.347038,-0.0171062,-0.0343473,-0.782119,-0.882268,-1.45071,-1.38756,-0.615658,-0.436678
4546,0.703376,0.644476,0.436574,0.369699,0.708918,0.558061,0.532364,0.540788,0.63451,0.694574,0.598524,0.572731,0.235558,0.151067,0.32286,0.335916,0.738886,0.806505,0.831945,0.844731,-1.07424,-0.779991,-0.274571,0.0667775,-0.651852,-0.479119,-0.43863,-0.314513,-0.55341,-0.582964,0.698102,0.587425,-1.16897,-1.18807,-1.61732,-1.71607,-0.495752,-0.495335,0.693082,0.875458
4547,0.00873537,-0.0477465,0.269179,0.201146,0.852524,0.700013,0.520085,0.514488,0.566977,0.628846,0.148092,0.121424,0.205515,0.12268,0.71912,0.655386,0.215953,0.282438,0.238425,0.249155,-1.01963,-0.729321,0.0470229,0.391612,0.175767,0.352883,0.941971,1.06628,0.422649,0.390297,0.751395,0.597451,1.65955,1.63798,0.381049,0.277278,0.330051,0.396888,0.0404406,0.219018
4548,0.654658,0.598406,0.346288,0.280229,0.558497,0.406043,0.526324,0.488189,0.844987,0.905443,0.580924,0.555548,0.677488,0.59436,0.962255,0.974855,0.246672,0.311998,0.0852683,0.0939479,1.40306,1.69517,0.899772,1.23675,-0.536349,-0.354424,0.444929,0.568661,0.0166721,-0.0220585,0.725451,0.607476,0.077668,0.0577629,0.468242,0.248316,1.68456,1.75237,-0.213333,-0.0302718
4549,0.71971,0.663737,0.909578,0.842202,0.826472,0.672157,0.651486,0.613059,0.013612,0.07305,0.367549,0.341767,0.42651,0.343538,0.444793,0.459047,0.497124,0.553453,0.766901,0.778078,-1.09163,-0.803117,3.02241,3.36063,-0.318946,-0.139719,2.06688,2.19029,0.699081,0.65795,-1.35779,-1.47261,0.0762136,0.0588757,0.400388,0.219354,0.748829,0.81278,0.859603,1.03573
4550,0.170757,0.112601,0.706174,0.637257,0.224988,0.072822,0.56057,0.520087,0.538729,0.59657,0.626723,0.601046,0.693305,0.576144,0.15971,0.172101,0.731116,0.794908,0.544203,0.557429,1.49763,1.78621,0.687239,1.0259,0.21813,0.396557,-0.633126,-0.507096,-1.0626,-1.10426,1.00496,0.888741,-1.04691,-0.971177,0.294161,0.190391,0.9511,1.02102,0.640687,0.815535
4551,0.99221,0.936405,0.145881,0.0750692,0.769302,0.615722,0.961625,0.919435,0.744819,0.801791,0.132544,0.105828,0.890971,0.80875,0.404825,0.417657,0.704706,0.770426,0.959645,0.971209,-0.619478,-0.32939,0.45136,0.794906,-0.550923,-0.374141,-0.324484,-0.203234,0.0167422,-0.0255529,-0.861952,-0.972742,-1.97729,-2.00123,0.544785,0.446173,-0.885197,-0.816114,0.967594,1.13841
4552,0.920606,0.865117,0.618589,0.548733,0.0215733,-0.130198,0.375556,0.33166,0.265558,0.322837,0.607879,0.583142,0.118901,0.0382569,0.995042,1.00559,0.205165,0.270673,0.401853,0.4154,-0.609769,-0.323968,1.24265,1.58325,0.447564,0.625353,-0.3847,-0.26954,1.37924,1.34276,0.389032,0.282523,0.144507,0.122303,0.29073,0.194684,1.33864,1.41185,0.0389072,0.208778
4553,0.446854,0.389468,0.667503,0.591385,0.21191,0.0601551,0.608184,0.56221,0.182489,0.210048,0.154981,0.131835,0.90077,0.818931,0.566161,0.574489,0.0012016,0.0678676,0.536756,0.552458,0.64222,0.924037,0.32853,0.666462,-0.305602,-0.128874,1.86171,1.97159,0.617618,0.57984,-0.731921,-0.842981,-0.315924,-0.339148,0.999362,0.909289,-0.317077,-0.248561,1.49486,1.65798
4554,0.399428,0.314277,0.706083,0.634037,0.102601,-0.038676,0.419071,0.374769,0.0407653,0.0972597,0.723663,0.698263,0.270555,0.186853,0.40089,0.312219,0.160827,0.301734,0.081026,0.0962417,-0.415308,-0.127191,-2.09676,-1.76012,0.595304,0.778247,1.16681,1.27372,2.22714,2.19338,-0.663491,-0.76735,-3.33213,-3.36261,0.824086,0.735517,-1.37736,-1.31001,0.504953,0.669034
4555,0.297886,0.239086,0.0309781,-0.0417628,0.0162088,-0.137507,0.538666,0.494227,0.485941,0.541056,0.16586,0.139415,0.771763,0.689169,0.0428399,0.0499495,0.469616,0.5356,0.844807,0.860692,-0.725376,-0.438723,1.259,1.58935,-0.162532,0.0240196,0.077373,0.185085,-0.534682,-0.561997,-1.12168,-1.23186,-2.80025,-2.82552,0.141526,0.0533783,0.426615,0.494482,0.126095,0.283995
4556,0.760121,0.701313,0.801576,0.729092,0.718044,0.562856,0.0325588,-0.0136834,0.303162,0.358739,0.495855,0.547062,0.395417,0.313206,0.962874,0.968861,0.0360745,0.100863,0.999242,1.01279,-1.51113,-1.22985,-2.14195,-1.81553,-0.57116,-0.388478,-0.507784,-0.406159,-0.863253,-0.899445,-0.333054,-0.439698,0.215561,0.195853,0.0993392,0.0131299,-0.691492,-0.631345,0.976377,1.13565
4557,0.744672,0.611051,0.500064,0.429241,0.882762,0.729015,0.874166,0.828395,0.904475,0.958481,0.979366,0.95471,0.860141,0.780285,0.813884,0.821937,0.946325,1.00862,0.398195,0.411962,-0.722544,-0.44297,0.0410215,0.371814,-0.521744,-0.343693,0.692513,0.790144,0.277849,0.241292,-0.919232,-1.02823,0.479702,0.45543,-3.05776,-3.14838,-0.128914,-0.0627712,1.56155,1.71632
4558,0.577851,0.520788,0.599476,0.455031,0.296382,0.145312,0.470784,0.426782,0.453249,0.604844,0.0567314,0.033311,0.538816,0.459718,0.45875,0.46498,0.0262289,0.0907803,0.244956,0.256754,1.09792,1.37749,1.31824,1.65039,-0.675462,-0.494769,-2.60562,-2.50593,1.75981,1.71807,-0.771783,-0.877691,-0.103031,-0.129524,0.689837,0.604458,-0.082565,-0.0204859,0.550525,0.712529
4559,0.822098,0.76675,0.554036,0.480821,0.288784,0.0967729,0.62959,0.586405,0.197601,0.251207,0.0257469,0.00117397,0.51381,0.436737,0.344192,0.348432,0.161815,0.151403,0.455024,0.469268,0.910971,1.18761,-0.548024,-0.209458,-0.373022,-0.168674,1.51044,1.60762,0.444767,0.400627,0.362966,0.255186,1.80831,1.78721,1.73185,1.64047,1.32922,1.39447,1.16964,1.3391
4560,0.135252,0.0800234,0.702415,0.506611,0.199307,0.0482341,0.0632225,0.0182219,0.673639,0.729116,0.894962,0.871225,0.823618,0.748796,0.742876,0.676483,0.150582,0.212025,0.223074,0.238451,-0.265374,0.0151396,0.373099,0.711805,-0.0238221,0.157422,-0.659126,-0.55743,-1.22926,-1.26857,-0.437104,-0.548426,-0.534961,-0.549503,0.429822,0.344609,-0.638806,-0.575131,-0.0477593,0.119407
4561,0.0106588,-0.0439212,0.603223,0.5324,0.588479,0.435242,0.73356,0.691005,0.0912714,0.145178,0.542086,0.518906,0.675576,0.599266,0.999529,1.00453,0.616484,0.677194,0.753701,0.76795,-0.669503,-0.388575,-0.796974,-0.454245,-1.64965,-1.46374,-0.684886,-0.576978,-0.566332,-0.604136,-0.326516,-0.441639,1.26941,1.25474,-2.43261,-2.52235,1.06183,1.12059,2.05968,2.23329
4562,0.536194,0.482885,0.346873,0.276346,0.381917,0.227463,0.371361,0.328919,0.292722,0.397954,0.443389,0.391061,0.290291,0.213505,0.535113,0.630363,0.461285,0.49083,0.506101,0.518133,0.954903,1.23429,0.105244,0.4532,1.23291,1.41578,0.753574,0.867587,-1.78732,-1.82802,0.726489,0.616752,1.50067,1.48292,-1.60629,-1.7013,1.89487,1.9549,1.18959,1.3639
4563,0.0449362,-0.00817028,0.316931,0.202624,0.43314,0.366449,0.966375,0.925765,0.607249,0.650731,0.288143,0.263215,0.249757,0.175185,0.248034,0.256192,0.244431,0.304465,0.658545,0.669284,0.667365,0.953171,-0.748022,-0.402705,-1.76929,-1.58851,-0.519514,-0.403795,1.42953,1.3933,-0.135997,-0.247635,-1.42382,-1.43904,0.449143,0.354571,0.117506,0.178974,1.5449,1.71583
4564,0.802906,0.751671,0.214908,0.128903,0.658856,0.505434,0.989416,0.948354,0.849602,0.903508,0.905338,0.878884,0.985621,0.90975,0.180784,0.190439,0.801157,0.85968,0.809544,0.820434,-0.0460666,0.240904,-1.30345,-0.989254,-0.249631,-0.0723962,1.75894,1.87422,-0.0280788,-0.0602982,-2.08532,-2.20524,-1.19605,-1.21086,1.35341,1.25135,0.108814,0.207543,-0.838576,-0.669274
4565,0.52673,0.477821,0.126192,0.0551818,0.964093,0.812464,0.062118,0.0197603,0.375085,0.430502,0.521162,0.502178,0.43541,0.357006,0.354591,0.330618,0.774488,0.835198,0.134242,0.144348,-1.09028,-0.810324,-1.91744,-1.5758,-0.542484,-0.361847,0.289223,0.403022,2.24132,2.21082,0.80633,0.683556,0.358322,0.342962,1.38147,1.27432,0.181271,0.236112,-0.67977,-0.511613
4566,0.959823,0.910784,0.341645,0.262627,0.0216146,-0.129634,0.176192,0.134213,0.4578,0.528678,0.153491,0.125472,0.613417,0.533467,0.544106,0.470797,0.233114,0.295595,0.207774,0.216376,-1.13287,-0.849559,-0.441302,-0.0960892,2.34934,2.53054,1.60363,1.72124,0.701027,0.667452,0.11234,0.0559363,0.859341,0.849987,-0.782272,-0.891631,-0.449964,-0.386951,0.589717,0.754451
4567,0.140478,0.0933896,0.403157,0.470072,0.726143,0.57586,0.905297,0.862181,0.498779,0.626854,0.755903,0.72694,0.317334,0.236799,0.650543,0.610976,0.721668,0.786389,0.672831,0.68046,0.337135,0.618088,-1.38133,-1.02834,0.933011,1.10943,0.742135,0.86554,2.10252,2.06798,-0.447898,-0.571684,1.10385,0.996571,-1.03779,-1.14312,1.55804,1.61658,-0.780726,-0.617093
4568,0.719759,0.674786,0.74843,0.677517,0.56418,0.511936,0.884589,0.769827,0.555984,0.72503,0.767917,0.738752,0.293575,0.213817,0.7415,0.751155,0.81943,0.885439,0.507384,0.44161,-0.64695,-0.372157,-1.34048,-0.981149,2.92576,3.09707,0.232825,0.352083,-0.405731,-0.441073,-0.189954,-0.231574,1.25042,1.14316,1.89249,1.7828,1.05192,1.11529,0.132328,0.295639
4569,0.569881,0.526644,0.00896046,-0.0624104,0.597138,0.448012,0.72267,0.677473,0.699929,0.823206,0.229382,0.199536,0.60108,0.52077,0.611405,0.619368,0.919189,0.98449,0.19312,0.202759,1.51386,1.78473,0.633735,0.996864,0.73748,0.906834,1.06382,1.17555,-0.400949,-0.435236,0.232853,0.108535,1.29909,1.28974,-0.593709,-0.697754,-0.453994,-0.388394,0.537949,0.719565
4570,0.0574445,0.0157874,0.653767,0.582304,0.89597,0.744294,0.00675619,-0.0395946,0.865965,0.921382,0.630669,0.599167,0.0121233,-0.0665369,0.821992,0.830779,0.810887,0.87721,0.581786,0.591762,2.70933,2.98671,0.362425,0.72286,-0.281462,-0.0241427,-1.05499,-0.94305,-1.35346,-1.38331,-1.0199,-1.1399,-1.39231,-1.40227,-0.0706262,-0.182759,-0.066659,-0.00641131,0.987115,1.14349
4571,0.761495,0.72113,0.93778,0.86408,0.506068,0.371843,0.381376,0.334247,0.556774,0.613867,0.0300748,-0.00146768,0.751494,0.672416,0.376725,0.384467,0.22298,0.288162,0.459798,0.471278,-0.225538,0.0511544,-1.68062,-1.32149,-1.13274,-0.955119,-1.72979,-1.62588,0.803745,0.769187,-0.622409,-0.741325,-0.889326,-0.895249,-0.58575,-0.69386,1.05276,1.10761,-1.84496,-1.69532
4572,0.0525274,0.0133695,0.100163,0.0272127,0.150136,-0.000608415,0.244602,0.197027,0.660555,0.642157,0.280241,0.196179,0.393775,0.317269,0.914632,0.922239,0.669233,0.733361,0.906866,0.920364,-0.16377,0.118253,0.280059,0.641651,-2.63855,-2.46697,0.101689,0.201476,-1.29356,-1.33141,-0.617125,-0.742518,0.24502,0.293717,0.498434,0.387797,-1.27991,-1.22811,1.17161,1.32685
4573,0.276824,0.239925,0.976779,0.905872,0.81944,0.668973,0.575311,0.526275,0.581881,0.670447,0.424738,0.393827,0.584051,0.513794,0.702649,0.678306,0.82865,0.892744,0.76113,0.869912,0.151373,0.431479,3.02104,3.37975,1.04544,1.21702,-0.203669,-0.111532,0.124792,0.0839867,1.52076,1.39434,1.48471,1.48268,0.611658,0.504049,-1.07376,-1.01987,-1.02966,-0.877313
4574,0.736382,0.697608,0.642032,0.570798,0.438622,0.298959,0.156152,0.109505,0.640176,0.698737,0.412204,0.381679,0.788698,0.710319,0.425004,0.434374,0.618949,0.693925,0.807504,0.81946,-0.170075,0.105814,0.507784,0.872072,-0.2451,-0.0799234,0.505855,0.604675,-0.438106,-0.466477,1.05781,0.929828,-1.95365,-1.95412,0.0368173,-0.0675672,1.32653,1.38903,-0.368698,-0.22026
4575,0.0625477,0.02583,0.971617,0.901663,0.0781116,-0.0710554,0.831477,0.786202,0.311417,0.371574,0.873359,0.844629,0.146204,0.0684444,0.725032,0.735367,0.423439,0.495105,0.215925,0.228799,-1.49075,-1.22194,2.38655,2.75756,1.21024,1.37531,1.98828,2.08176,-0.968979,-1.01694,-1.0994,-1.22728,-0.427785,-0.429784,-0.236135,-0.334393,0.436889,0.581139,0.981402,1.1384
4576,0.8318,0.796307,0.935359,0.88658,0.657836,0.507089,0.894974,0.849896,0.553261,0.612805,0.610778,0.58151,0.635571,0.560534,0.487506,0.497552,0.233848,0.296286,0.438467,0.444176,-1.32066,-1.04841,-0.955523,-0.577596,0.291243,0.450516,0.200576,0.297234,0.494316,0.444056,0.38495,0.256649,-0.950953,-0.95296,-1.20279,-1.30671,-0.394169,-0.226751,0.801755,0.964416
4577,0.0360179,0.00301645,0.836741,0.871496,0.674275,0.523516,0.0792256,0.0329643,0.563873,0.718897,0.695731,0.761785,0.345315,0.2688,0.865231,0.87497,0.352233,0.41935,0.696487,0.659554,-2.12788,-1.85484,-0.131853,0.254226,0.747661,0.909391,0.325059,0.415967,0.231411,0.183196,-0.464412,-0.592741,-0.601773,-0.586775,-0.187516,-0.283886,-1.09713,-1.03464,-0.0317137,0.0430969
4578,0.767446,0.735639,0.924768,0.856413,0.479989,0.331481,0.872963,0.827115,0.76382,0.824989,0.973622,0.942059,0.891005,0.815066,0.626127,0.637155,0.482433,0.542413,0.861649,0.874931,-0.872068,-0.59058,-0.954455,-0.570775,0.309776,0.467975,-0.744207,-0.655953,1.26734,1.21666,0.850327,0.723388,-0.215878,-0.22059,0.0156866,-0.0762813,-0.577197,-0.512186,-1.03401,-0.878222
4579,0.0423358,0.011748,0.0791278,0.0112233,0.861057,0.712395,0.497988,0.4521,0.535064,0.59765,0.248669,0.216821,0.260318,0.182988,0.715766,0.728038,0.868272,0.928163,0.550696,0.563538,-1.21908,-0.932537,-0.340996,0.0451424,0.260611,0.415992,-0.106969,-0.0180092,0.0780295,0.0283051,-0.0116476,-0.140999,0.627476,0.621892,-0.737213,-0.834259,1.10651,1.16901,1.43212,1.58106
4580,0.754125,0.722379,0.145098,-0.00750641,0.851671,0.703865,0.123605,0.0770857,0.952482,1.01515,0.0723783,0.0395233,0.451639,0.374478,0.0754678,0.0870866,0.809974,0.868394,0.975173,0.987826,0.726674,1.01046,1.01027,1.40054,0.232746,0.364008,1.80594,1.89921,0.146737,0.111794,0.252245,0.0954169,-0.640877,-0.641047,0.912317,0.815416,-1.04412,-0.986101,-0.109181,0.0420487
4581,0.0912283,0.0606705,0.0757929,-0.0262361,0.324707,0.175391,0.736505,0.68996,0.229252,0.293248,0.126464,0.0951264,0.351402,0.354028,0.520214,0.534069,0.51201,0.569226,0.0781497,0.0921456,-0.511214,-0.22348,0.225233,0.619634,0.153825,0.312025,-0.716252,-0.617123,0.242019,0.195282,0.466009,0.331833,-1.58193,-1.58115,0.11834,0.0266783,1.80086,1.85878,0.988125,1.13875
4582,0.548101,0.518353,0.0216191,-0.0449658,0.907841,0.758905,0.527762,0.483084,0.52731,0.534653,0.497665,0.464684,0.409133,0.333578,0.70094,0.715191,0.463072,0.519658,0.889565,0.90565,0.145266,0.426943,-0.0315446,0.360663,-1.89088,-1.7344,0.122661,0.22289,0.988961,0.936127,0.0596377,-0.0680166,-2.10803,-2.10433,-0.208358,-0.227399,-0.964777,-0.901795,-0.823402,-0.675912
4583,0.755694,0.727542,0.666493,0.599748,0.440678,0.383805,0.936744,0.892456,0.709359,0.776057,0.54259,0.509813,0.168375,0.0922953,0.435305,0.448136,0.675318,0.745143,0.0150376,0.0319457,0.591923,0.877399,0.0244296,0.423353,-0.716551,-0.552543,-0.695901,-0.600666,-0.779198,-0.826081,1.7923,1.66522,1.85098,1.84977,-0.385301,-0.481476,-0.992437,-0.92274,1.27066,1.4219
4584,0.964642,0.93673,0.448118,0.380369,0.159072,0.00870544,0.0176344,-0.0278894,0.35458,0.42254,0.104779,0.0737845,0.847217,0.769785,0.41908,0.432154,0.913781,0.970628,0.0317778,0.0472928,-0.921541,-0.632115,1.79046,2.18463,-0.3595,-0.198491,-0.432086,-0.344237,1.10175,1.05122,0.418976,0.291282,1.52691,1.52874,1.21508,1.12266,-0.279573,-0.212996,-2.2979,-2.14844
4585,0.490345,0.461081,0.857755,0.790453,0.500747,0.350657,0.00501206,-0.0402153,0.358474,0.452905,0.994535,0.964777,0.259652,0.182478,0.645092,0.694439,0.153638,0.21095,0.649846,0.665947,-1.17102,-0.88253,-0.764333,-0.37234,0.909002,1.0736,-1.65174,-1.57018,-1.04987,-1.09561,0.899869,0.768525,0.445845,0.449965,-0.0113502,-0.109161,-0.71426,-0.652901,-1.15918,-1.00586
4586,0.605761,0.522365,0.294471,0.228265,0.1213,-0.028675,0.253575,0.192349,0.417126,0.483269,0.75293,0.721357,0.18158,0.0575721,0.945017,0.956723,0.389743,0.447723,0.085501,0.100355,0.73041,1.01422,-0.0467969,0.349736,0.213599,0.440057,1.0881,1.17344,-0.827572,-0.87567,0.00612578,-0.129014,0.476968,0.480867,0.503686,0.405833,0.351277,0.415579,0.37215,0.521648
4587,0.615451,0.58365,0.0434252,-0.0223014,0.0660775,-0.0799537,0.468733,0.424912,0.487601,0.513634,0.277504,0.246393,0.00828947,-0.0673342,0.550662,0.560217,0.887812,0.947943,0.24881,0.328465,-1.44022,-1.15049,-0.294668,0.105832,-0.360028,-0.19349,-1.87111,-1.78813,-0.274689,-0.320929,-2.0947,-2.22611,-0.462226,-0.459237,-0.371952,-0.473892,-0.78918,-0.724504,0.118589,0.272358
4588,0.97889,0.946118,0.173343,0.0940674,0.0172702,-0.131232,0.0377154,-0.00698408,0.469063,0.543999,0.0320088,0.00297326,0.409479,0.334603,0.498733,0.414028,0.703671,0.739644,0.541736,0.556574,0.252944,0.548025,0.579247,0.982932,-0.177791,-0.0103597,-1.38718,-1.3016,1.31415,1.2622,0.973169,0.84254,1.31384,1.31192,0.803788,0.699668,0.440254,0.499072,-0.915488,-0.761739
4589,0.367742,0.334362,0.277811,0.210436,0.668585,0.51766,0.753445,0.705841,0.506404,0.574364,0.0203928,-0.00917415,0.488835,0.413595,0.330412,0.267839,0.471892,0.531344,0.257625,0.349197,-0.924818,-0.624445,0.0995072,0.496524,0.984802,1.15612,0.414428,0.492835,0.459096,0.360051,-0.876401,-1.00544,0.958197,0.959141,0.107414,0.0034019,1.34108,1.39412,-1.268,-1.11889
4590,0.637475,0.605503,0.84221,0.776919,0.2411,0.0877487,0.263195,0.21313,0.723184,0.78962,0.581348,0.552113,0.0795828,0.00247693,0.111457,0.12165,0.83783,0.897189,0.125509,0.14182,0.978672,1.2723,-0.751746,-0.35938,1.4851,1.65965,1.1532,1.22588,-0.492419,-0.542096,0.795471,0.665795,-0.190297,-0.194581,0.66496,0.562668,-0.738333,-0.683281,-0.931935,-0.781234
4591,0.379801,0.355434,0.220107,0.156047,0.430371,0.278102,0.470475,0.419816,0.252237,0.316614,0.0253109,-0.00207252,0.541873,0.386556,0.675463,0.683885,0.722271,0.780018,0.091061,0.114675,-0.295142,-0.00928463,0.950828,1.33824,0.975217,1.15601,0.485847,0.558657,0.909508,0.858434,0.812822,0.680161,0.918151,0.909771,0.431268,0.283363,0.292945,0.355185,1.11081,1.2541
4592,0.13598,0.105364,0.104916,0.0428261,0.162218,0.00876034,0.412106,0.409183,0.124682,0.190277,0.612316,0.583588,0.848319,0.770636,0.232616,0.242307,0.112245,0.169765,0.0731236,0.0875297,0.239388,0.547538,0.229349,0.622053,-0.377506,-0.203247,0.166099,0.245649,0.618055,0.570025,0.0224023,-0.126895,0.315385,0.312295,0.104112,0.0040589,0.0587164,0.117664,1.65727,1.8031
4593,0.527825,0.498312,0.26272,0.225046,0.264002,0.110084,0.447327,0.39855,0.578449,0.642912,0.664529,0.634324,0.469702,0.489168,0.563756,0.489172,0.974081,1.0314,0.432495,0.391555,0.822969,1.10436,-0.818317,-0.419966,0.464181,0.643247,2.05442,2.1352,-0.0791048,-0.131181,-0.804022,-0.933951,-0.0211406,-0.0246431,0.236814,0.13598,0.534771,0.592643,-0.0104461,0.229792
4594,0.716602,0.688691,0.470614,0.407265,0.068095,-0.086787,0.980025,0.931173,0.777697,0.842464,0.510026,0.390582,0.287266,0.207701,0.72757,0.736038,0.81812,0.827808,0.680667,0.69558,-0.479775,-0.192367,-0.523364,-0.124361,-1.25632,-1.07376,0.258342,0.337022,0.733776,0.686099,1.7241,1.59119,-2.77002,-2.76624,0.00376268,-0.0998747,0.278544,0.338944,-1.48401,-1.34352
4595,0.382944,0.381425,0.212856,0.151211,0.24513,0.0924127,0.85719,0.809041,0.542495,0.605516,0.176805,0.14684,0.872855,0.793963,0.437579,0.444506,0.566838,0.624216,0.828492,0.817659,-0.105438,0.182252,-1.21069,-0.810603,0.0018296,0.183083,1.20118,1.28588,-0.355821,-0.398018,-0.600312,-0.728511,0.0527565,0.0598051,0.669886,0.568863,1.86263,1.92342,-0.620367,-0.47465
4596,0.100653,0.0741592,0.754662,0.693468,0.425502,0.271612,0.976222,0.928499,0.0943521,0.157505,0.220236,0.191969,0.231045,0.152089,0.798098,0.807391,0.871876,0.929992,0.925792,0.939738,-0.748251,-0.453682,-1.66275,-1.26738,-1.38197,-1.20813,-0.445297,-0.358028,-0.0904316,-0.150345,-1.52188,-1.65472,1.63189,1.6472,-0.798731,-0.894059,0.0300551,0.0862819,-0.103387,0.0448026
4597,0.76344,0.735891,0.646099,0.68921,0.834458,0.679755,0.288942,0.241414,0.514543,0.532108,0.471881,0.5051,0.823818,0.743457,0.230268,0.240746,0.924086,0.919811,0.468298,0.483522,1.0549,1.35296,-0.635662,-0.236308,-1.72844,-1.55864,0.566362,0.654469,0.14391,0.0973281,-0.622502,-0.750747,1.29107,1.31026,-0.0604953,-0.149981,-0.170987,-0.0327184,1.60463,1.75706
4598,0.394477,0.366139,0.722906,0.684952,0.869222,0.716122,0.834939,0.788805,0.842039,0.906711,0.847331,0.818231,0.691995,0.643819,0.0321211,0.043795,0.84869,0.909631,0.496155,0.412674,-0.538776,-0.234578,-0.208778,0.19426,0.400993,0.56969,-0.69148,-0.602947,0.0397627,-0.00373092,-0.216151,-0.352168,-1.22527,-1.19797,-1.60566,-1.68786,-0.207945,-0.151719,0.354001,0.507919
4599,0.632697,0.602352,0.741796,0.680693,0.280762,0.127381,0.813939,0.766899,0.551246,0.614081,0.0240036,-0.0052247,0.539151,0.544181,0.803355,0.815769,0.303537,0.365142,0.325878,0.341827,0.957691,1.26455,1.73711,2.13796,0.382835,0.554944,0.427618,0.514217,-0.0665202,-0.10479,0.807848,0.674231,-0.732808,-0.639549,2.03887,1.96209,-0.615021,-0.559546,0.150349,0.303576
4600,0.610733,0.516296,0.0533536,-0.00975091,0.341553,0.189562,0.139473,0.094928,0.87812,0.941453,0.749081,0.720638,0.526485,0.444542,0.534518,0.548714,0.567455,0.626801,0.740755,0.755607,-0.376748,-0.0768966,0.505108,0.91019,-0.273802,-0.10705,0.643693,0.724859,-0.502523,-0.548363,-1.53707,-1.67308,-0.0493448,-0.0811274,-3.62713,-3.70391,0.00385592,0.0560296,-1.20541,-1.05353
4601,0.460775,0.43024,0.823501,0.761104,0.77671,0.623666,0.306923,0.176021,0.494197,0.557765,0.727144,0.697462,0.791687,0.71096,0.762094,0.778015,0.585561,0.735723,0.498599,0.483722,0.649791,0.953954,0.786163,1.18946,2.76394,2.92316,-1.26598,-1.188,-0.1082,-0.159963,-0.778683,-0.907512,0.449997,0.477294,1.42336,1.34657,1.22882,1.27961,-0.457211,-0.305089
4602,0.95738,0.926645,0.192065,0.130776,0.585066,0.37093,0.369964,0.257115,0.886415,0.950533,0.0776752,0.0474093,0.562243,0.493186,0.10316,0.120958,0.786127,0.844645,0.194611,0.211837,-0.28001,0.024708,0.290048,0.760965,-1.43829,-1.27906,0.770986,0.844656,0.571545,0.520046,0.669851,0.54431,0.261299,0.295563,-0.743595,-0.819383,0.407457,0.416212,1.51172,1.6679
4603,0.980862,0.951714,0.739421,0.678644,0.271454,0.118194,0.384916,0.338208,0.490581,0.556967,0.17502,0.0793524,0.354669,0.275413,0.656337,0.674156,0.589188,0.647161,0.138761,0.157885,0.27141,0.581703,-0.0692401,0.332473,-1.50941,-1.35482,-0.0927172,-0.0267897,0.457352,0.413399,-1.14186,-1.27233,0.702933,0.742464,0.187775,0.109929,-0.497965,-0.447181,0.449413,0.603031
4604,0.529376,0.531936,0.523575,0.387808,0.772199,0.621755,0.0603668,0.0154005,0.615012,0.681362,0.139451,0.111295,0.350909,0.237198,0.219553,0.237261,0.721015,0.776531,0.422246,0.421496,-0.460477,-0.191637,-2.27957,-1.8722,0.415186,0.568865,1.41103,1.4816,0.117437,0.0759508,0.648748,0.520748,0.555191,0.592367,-0.160183,-0.191918,0.0590681,0.107462,-1.45379,-1.30746
4605,0.139645,0.112159,0.155489,0.0969724,0.165114,0.0128182,0.0986852,0.128185,0.142156,0.208356,0.453991,0.483212,0.263517,0.198982,0.935292,0.954902,0.233847,0.291629,0.531141,0.685107,-1.27842,-0.964977,1.81092,2.22305,-0.884397,-0.728081,0.238716,0.302581,0.166764,0.136404,0.938303,0.809987,-1.62391,-1.58269,-0.412006,-0.493766,-0.236076,-0.193285,0.498191,0.650929
4606,0.0702868,0.0408706,0.867382,0.807394,0.289924,0.10902,0.286212,0.24097,0.779128,0.842889,0.881257,0.855128,0.240022,0.160767,0.377169,0.398789,0.647121,0.707151,0.929594,0.948718,-1.55782,-1.2461,1.83956,2.25583,0.507896,0.66469,0.220951,0.283034,0.234937,0.196857,0.851792,0.661703,0.15589,0.202395,-1.57506,-1.66191,0.338965,0.451331,-1.10475,-0.949243
4607,0.222435,0.138601,0.242102,0.181842,0.359243,0.205221,0.898952,0.853845,0.512806,0.575649,0.3552,0.330872,0.885568,0.808707,0.266697,0.275173,0.172229,0.232478,0.105365,0.123506,0.780304,1.09544,-2.3099,-1.8894,-0.33333,-0.182866,0.744782,0.81453,-1.40991,-1.44139,0.650432,0.513419,0.474853,0.524147,2.11276,2.02484,1.04997,1.09595,0.263309,0.422955
4608,0.363105,0.236331,0.301976,0.241514,0.262088,0.168885,0.836172,0.831407,0.77862,0.841962,0.475438,0.45049,0.98984,0.91382,0.128179,0.151557,0.0870202,0.146898,0.774418,0.792901,1.32527,1.6384,0.239051,0.651446,0.460955,0.616157,-0.687013,-0.611244,-0.67838,-0.715713,-0.867737,-1.01066,0.0784758,0.125934,-0.742839,-0.825386,-0.768733,-0.728079,1.34489,1.50529
4609,0.426729,0.334062,0.62967,0.567672,0.205742,0.132548,0.853481,0.808969,0.201233,0.263394,0.797931,0.770597,0.883043,0.809052,0.915452,0.939367,0.34275,0.403046,0.701122,0.718802,-0.964248,-0.652083,-0.280241,0.134641,-0.266308,-0.109443,-0.418006,-0.338704,0.763862,0.730823,1.59947,1.45203,1.15938,1.21388,0.0185115,-0.0664697,-0.325223,-0.284821,0.499571,0.652734
4610,0.461208,0.431792,0.344878,0.282011,0.248076,0.0962117,0.119381,0.0759465,0.69571,0.756654,0.745906,0.718415,0.454567,0.379669,0.101173,0.122929,0.122813,0.184205,0.374414,0.468597,-0.795639,-0.478549,0.529645,0.949667,-2.31759,-2.15586,-1.37766,-1.30177,0.292655,0.257802,-1.36876,-1.52206,-0.158583,-0.0989026,-0.685274,-0.762736,-0.884412,-0.84723,2.04206,2.19402
4611,0.901217,0.869808,0.268143,0.204217,0.578244,0.428215,0.0390561,0.062193,0.383235,0.44396,0.281152,0.252879,0.410506,0.336305,0.421369,0.410728,0.752448,0.815125,0.199092,0.218391,0.999079,1.31157,-0.251557,0.168759,1.55251,1.71371,1.02655,1.09568,-0.468861,-0.505121,-1.11411,-1.26362,2.2452,2.29975,1.77883,1.69902,0.197637,0.236686,0.590004,0.745611
4612,0.170983,0.140563,0.593903,0.530376,0.315641,0.163992,0.0931197,0.0484395,0.330667,0.397045,0.442075,0.438943,0.892052,0.818553,0.677463,0.698528,0.710913,0.715538,0.499945,0.520997,-0.11125,0.197912,-0.500372,-0.0336327,0.675958,0.834537,-0.00135212,0.071126,-0.650889,-0.688453,-1.36053,-1.51041,0.201682,0.250439,2.0374,1.9548,-0.563523,-0.527138,0.104438,0.255761
4613,0.969766,0.937125,0.482434,0.417155,0.348527,0.195716,0.948318,0.905443,0.290769,0.350129,0.65382,0.625008,0.103804,0.0329355,0.64521,0.631052,0.549961,0.615951,0.256199,0.307767,-0.195517,0.111736,-0.656814,-0.236024,0.684177,0.850368,-0.177861,-0.10237,-0.33292,-0.379078,1.33872,1.19583,0.478812,0.525999,-1.02197,-1.09742,-0.243118,-0.208559,0.010328,0.23781
4614,0.548779,0.465139,0.94976,0.885517,0.705143,0.552821,0.680935,0.637516,0.787033,0.848055,0.192106,0.164099,0.0180337,-0.0514262,0.544425,0.563577,0.453216,0.516364,0.0731196,0.0945365,0.0232985,0.334981,0.893501,1.30658,0.166166,0.330154,0.218302,0.29169,-0.835461,-0.883205,-0.72022,-0.869333,1.30645,1.35353,0.833429,0.754275,-0.578219,-0.539514,0.0735572,0.219859
4615,0.0257935,-0.00684716,0.987184,0.902544,0.347578,0.193199,0.753465,0.710617,0.958279,1.01858,0.38294,0.352987,0.262167,0.19486,0.847233,0.86457,0.650967,0.711946,0.946005,0.969441,0.253881,0.558226,-0.743863,-0.329637,0.0905591,0.2544,-0.585712,-0.515889,0.515145,0.469405,-0.417655,-0.567274,0.607399,0.64835,0.000527525,-0.0795259,0.0282062,0.0599746,-0.725768,-0.572806
4616,0.903663,0.868814,0.985339,0.91957,0.808804,0.652034,0.327274,0.376938,0.0341318,0.0966053,0.0560428,0.0244062,0.794454,0.726012,0.648365,0.667619,0.155988,0.216859,0.943528,0.964946,0.800069,1.10118,-0.468252,-0.0123794,-1.05941,-0.888515,0.710797,0.786784,0.68903,0.643468,2.2906,2.13897,-0.376612,-0.337449,0.0427654,-0.040517,0.103241,0.131732,0.122469,0.278849
4617,0.0671501,0.0319176,0.641433,0.525768,0.124418,-0.0322629,0.0840057,0.0432582,0.314868,0.334425,0.949333,0.915399,0.634581,0.475436,0.808001,0.766163,0.759936,0.818733,0.0211225,0.041932,0.848541,1.15185,-0.111895,0.304879,-0.45171,-0.276108,-0.032471,0.0405318,-0.0614824,-0.103849,-0.606422,-0.758176,0.533304,0.567326,0.820154,0.733999,-0.419521,-0.384784,-0.16359,-0.0013103
4618,0.366124,0.241106,0.196573,0.131966,0.410518,0.254253,0.181196,0.229502,0.510912,0.572245,0.793759,0.809398,0.292695,0.224859,0.797478,0.864707,0.560409,0.638504,0.534639,0.555448,0.490528,0.793932,-1.02662,-0.611911,0.713902,0.890373,-0.210882,-0.132964,-0.00592682,-0.0527033,-0.706404,-0.851245,-0.131092,-0.0913438,1.21829,1.14082,0.39015,0.43255,0.630484,0.79197
4619,0.487967,0.450294,0.0435056,-0.0215305,0.478898,0.252144,0.456258,0.415745,0.433863,0.59476,0.735996,0.703397,0.625966,0.569125,0.944416,0.96325,0.449741,0.458275,0.721677,0.657418,-0.297511,0.00280924,-0.3574,0.0512548,-0.104669,0.0730227,1.00908,1.09413,0.611716,0.564411,0.0410827,-0.101662,0.0182734,0.0616906,1.62799,1.54764,0.801937,0.844975,-1.41531,-1.2561
4620,0.158031,0.12058,0.227897,0.16193,0.406584,0.250035,0.306223,0.263624,0.556274,0.617276,0.909506,0.878171,0.981816,0.913391,0.419948,0.512349,0.220762,0.278046,0.7387,0.759387,0.399778,0.638982,-0.936826,-0.527668,0.244197,0.427075,1.74879,1.82718,0.155345,0.105726,-3.1949,-3.33735,-1.51801,-1.47057,1.21808,1.11202,-0.274294,-0.232485,1.64996,1.8139
4621,0.939736,0.901237,0.0348786,-0.0327001,0.810261,0.653402,0.791507,0.746226,0.907545,0.969304,0.878636,0.804146,0.265277,0.195612,0.0434335,0.0614475,0.561716,0.618767,0.622844,0.643595,0.971142,1.27515,-0.193512,0.211971,1.07378,1.25908,0.611415,0.693964,0.371844,0.227121,0.376642,0.230785,-0.0942273,-0.0521242,0.762614,0.676403,0.11918,0.164413,1.77333,1.93812
4622,0.20723,0.167315,0.256504,0.19016,0.617303,0.461366,0.239096,0.193586,0.51706,0.584626,0.760857,0.730121,0.867397,0.796127,0.916781,0.932968,0.342004,0.436652,0.131085,0.152917,0.415311,0.716585,0.34267,0.750902,-1.57007,-1.38412,0.104592,0.180508,0.398079,0.348517,-1.70022,-1.8493,-1.36118,-1.31506,-0.670709,-0.756574,-0.805048,-0.757109,0.17211,0.337951
4623,0.29457,0.253377,0.0506737,-0.0147846,0.632018,0.430244,0.321047,0.345976,0.135689,0.199947,0.342894,0.41046,0.911439,0.838739,0.648452,0.665913,0.196286,0.254536,0.98627,1.00785,0.472281,0.767255,-0.0371619,0.369235,-0.768677,-0.641202,0.799604,0.881644,-2.68808,-2.74413,-0.497229,-0.63901,1.93504,1.97428,1.59533,1.51224,2.03051,2.08777,0.0425985,0.20862
4624,0.887532,0.844582,0.274283,0.208076,0.646813,0.399122,0.542905,0.498365,0.163489,0.227343,0.121765,0.0907988,0.538175,0.468025,0.616093,0.660038,0.579041,0.63529,0.677678,0.726307,-0.232441,0.0549876,0.497702,0.908166,-0.0786324,0.101717,-0.992639,-0.916534,1.61623,1.56018,0.222749,0.0801788,-1.60354,-1.56909,0.787723,0.621245,0.0592143,0.118168,-0.947027,-0.780328
4625,0.749472,0.706775,0.179044,0.114111,0.618847,0.368,0.840536,0.798756,0.996266,1.05945,0.800541,0.767771,0.495084,0.424662,0.637914,0.654164,0.476191,0.534149,0.422526,0.44476,-1.17151,-0.886924,-0.557897,-0.149668,-0.856623,-0.66898,0.179912,0.250047,-0.284524,-0.341063,-1.18457,-1.32379,0.836673,0.877075,-0.186658,-0.269747,-0.402642,-0.337204,-0.218782,-0.0478218
4626,0.966493,0.923354,0.994593,0.93005,0.519426,0.336878,0.651575,0.611315,0.575573,0.588093,0.84706,0.8129,0.835729,0.766643,0.426276,0.442554,0.846366,0.904614,0.450931,0.471053,-0.978853,-0.697969,-0.352676,0.0523046,-1.27626,-1.09584,0.0350919,0.0959985,-0.758962,-0.814084,1.03756,0.894063,-0.30297,-0.262931,-0.0780717,-0.1677,-2.50203,-2.43283,1.56825,1.74408
4627,0.923315,0.882213,0.931622,0.865917,0.538896,0.305756,0.204782,0.165423,0.0535613,0.116741,0.450254,0.424846,0.158229,0.0900384,0.747993,0.764021,0.0748496,0.135595,0.866503,0.884833,-0.130349,0.149392,0.202599,0.605792,1.68346,1.85724,-0.131636,-0.0580499,-0.621043,-0.672344,0.539444,0.400863,0.734406,0.77816,0.526955,0.508964,-1.22033,-1.13468,-0.79399,-0.624493
4628,0.208963,0.167612,0.323035,0.254952,0.43057,0.274633,0.22432,0.183341,0.233225,0.261245,0.0725051,0.0367921,0.232274,0.157338,0.848999,0.865566,0.851198,0.912607,0.0697597,0.0892527,0.932966,1.21128,-1.42278,-1.01419,0.471567,0.65166,-1.07707,-1.00773,0.83839,0.788652,-0.606499,-0.738746,-0.985573,-0.941356,1.27758,1.18563,0.0923021,0.163477,1.22859,1.39684
4629,0.833273,0.793143,0.413134,0.283516,0.836856,0.682776,0.667816,0.556272,0.248342,0.405749,0.6839,0.647425,0.290346,0.224637,0.153686,0.172657,0.589986,0.653796,0.818629,0.837518,0.406229,0.683366,-0.91713,-0.504638,-0.437145,-0.258225,-0.20874,-0.135757,-0.527066,-0.57557,-0.720992,-0.846128,0.647131,0.692411,-0.875184,-0.967336,-0.169945,-0.106007,0.496178,0.665181
4630,0.972859,0.933497,0.331151,0.312079,0.152708,-0.0015209,0.970086,0.929203,0.487074,0.550254,0.372031,0.333665,0.635434,0.474093,0.335882,0.377112,0.0752908,0.138944,0.383355,0.401296,-0.356029,-0.0752323,-1.21229,-0.793652,1.5432,1.72941,0.2749,0.350773,-1.12015,-1.16928,0.104687,-0.0212186,-0.988691,-0.947548,0.489121,0.390283,0.0332154,0.102234,0.121988,0.292963
4631,0.488796,0.489923,0.33293,0.340643,0.62943,0.476662,0.440509,0.400959,0.126068,0.191175,0.837946,0.801263,0.788685,0.723549,0.561077,0.581568,0.165411,0.28463,0.607724,0.62441,1.35978,1.63838,0.228611,0.654544,0.506143,0.694206,-1.03713,-0.965734,-0.240713,-0.290203,-0.2343,-0.349624,0.17127,0.207925,-1.59368,-1.69467,-1.21371,-1.14848,0.141814,0.315434
4632,0.0836513,0.0463487,0.475647,0.369206,0.557752,0.326925,0.998627,0.958422,0.868797,0.934203,0.0605406,0.025491,0.707068,0.639187,0.444369,0.46502,0.364694,0.430315,0.4307,0.449078,1.5024,1.78105,-1.61821,-1.18852,-0.962818,-0.772385,0.715705,0.78133,-0.883488,-0.898919,-0.553666,-0.678029,0.94681,0.991628,-0.193681,-0.290792,-1.72091,-1.64977,-0.0917223,0.167666
4633,0.589929,0.553503,0.465852,0.397769,0.333817,0.177189,0.477712,0.435485,0.3801,0.445377,0.939534,0.905631,0.850987,0.784977,0.546086,0.653838,0.983153,1.04636,0.812494,0.828812,0.132827,0.409942,1.08405,1.51586,0.107905,0.302849,-2.24932,-2.18024,-1.45133,-1.50763,-0.313868,-0.4999,-0.734785,-0.697426,0.689891,0.536418,0.255725,0.331539,-0.158697,0.0198971
4634,0.85559,0.820378,0.0672358,-0.00167054,0.179778,0.0274526,0.563743,0.519037,0.395624,0.507473,0.418475,0.385559,0.757367,0.69112,0.823726,0.842657,0.436092,0.497065,0.97383,0.990575,0.638122,0.906555,-1.31766,-0.8821,-1.14187,-0.947308,-0.960681,-0.892961,-0.4717,-0.534374,-0.197408,-0.321771,0.770779,0.729371,1.46614,1.36363,0.798875,0.870195,-1.44603,-1.26127
4635,0.857977,0.820945,0.401506,0.334471,0.316912,0.163886,0.850558,0.804403,0.504286,0.569569,0.638311,0.604274,0.358374,0.290782,0.65373,0.671087,0.789644,0.848349,0.0217261,0.0375904,-0.555348,-0.282303,-0.0193507,0.413537,0.264729,0.460922,-0.36358,-0.300843,-0.729496,-0.795233,-2.10295,-2.23254,2.12583,2.15617,-1.4194,-1.52163,1.84694,1.9239,0.931633,1.11381
4636,0.151998,0.113185,0.0442801,-0.0247439,0.0481325,-0.105456,0.627379,0.581513,0.350978,0.450359,0.498745,0.466071,0.282165,0.216997,0.715592,0.679437,0.510165,0.597829,0.0787053,0.0947742,-1.03503,-0.778211,0.770208,1.20188,-0.000406772,0.202111,-0.533558,-0.474339,-0.189929,-0.255697,-0.849352,-0.92341,1.20349,1.23295,-0.660517,-0.76271,-0.253445,-0.18377,1.00635,1.18203
4637,0.0270989,-0.0107597,0.474703,0.404827,0.153788,0.00117623,0.715659,0.669646,0.167537,0.331149,0.874683,0.840972,0.587587,0.523949,0.657041,0.687787,0.207441,0.347308,0.939977,0.953803,-1.54921,-1.27412,-1.53092,-1.1013,1.73795,1.94054,0.525001,0.582206,1.78267,1.71913,0.5153,0.385716,0.837732,0.865772,1.08876,0.981733,-0.251412,-0.189086,-0.236773,-0.0671032
4638,0.369874,0.312546,0.701868,0.632068,0.912005,0.757644,0.0853329,0.0374307,0.14863,0.211939,0.581039,0.546823,0.163675,0.0989445,0.638978,0.696137,0.039444,0.0967881,0.0739368,0.0861508,1.24229,1.51345,-1.31597,-0.901236,-0.931807,-0.729568,0.560336,0.623527,-0.609297,-0.667834,0.618554,0.492502,0.0163246,0.0397273,0.401822,0.299595,-1.22873,-1.1723,0.00698238,0.179259
4639,0.770953,0.635851,0.120573,0.0510352,0.0991671,-0.0567727,0.871148,0.821287,0.322576,0.387026,0.956569,0.921724,0.908226,0.84335,0.687129,0.704487,0.142058,0.298245,0.426578,0.515277,0.434795,0.707024,-1.13634,-0.701172,1.28239,1.4808,-1.0007,-0.939604,0.624434,0.565668,2.1178,1.99185,1.5383,1.56406,-1.07148,-1.17699,-0.348958,-0.291371,-0.123611,0.0499275
4640,0.998872,0.959156,0.795471,0.725824,0.740033,0.582368,0.0470597,-0.000665914,0.874434,0.94152,0.739315,0.745374,0.828485,0.764013,0.102224,0.119434,0.441185,0.499703,0.932189,0.944403,-1.14459,-0.880515,0.491867,0.919757,0.194535,0.318931,-0.732734,-0.667064,0.103155,0.102597,-1.29673,-1.42245,1.85061,1.87176,0.623275,0.520445,-1.00185,-0.907589,0.863538,1.03957
4641,0.907704,0.908036,0.286384,0.217274,0.77789,0.618735,0.269054,0.185578,0.915996,0.983312,0.605013,0.569024,0.276356,0.211269,0.080798,0.0990892,0.752677,0.810485,0.526577,0.535647,1.74942,2.01814,-1.3615,-0.940092,-1.03823,-0.84294,-1.17934,-1.16533,-0.295383,-0.360473,1.03756,0.9074,1.35285,1.38023,0.136517,0.0671743,-1.57137,-1.52381,0.310068,0.402272
4642,0.896217,0.856915,0.619929,0.472102,0.339001,0.179512,0.422019,0.371821,0.988725,1.0251,0.909269,0.875233,0.845228,0.777779,0.709154,0.729312,0.294859,0.350386,0.116488,0.12689,-0.0300241,0.24475,0.287991,0.71058,0.576294,0.767013,-1.72634,-1.66359,1.46126,1.3916,1.42554,1.29029,-2.32362,-2.29261,-0.28978,-0.386097,-1.71585,-1.70075,-0.415482,-0.235026
4643,0.137262,0.0959352,0.793807,0.726931,0.542687,0.427788,0.0658471,0.0148081,0.99981,1.0669,0.419715,0.384977,0.632008,0.561877,0.668895,0.688009,0.558392,0.690396,0.872528,0.881956,2.19998,2.48048,1.50369,1.93095,-1.78084,-1.58477,0.0543736,0.114371,-1.0265,-1.0972,-3.16448,-3.30054,1.39398,1.41933,-1.08923,-1.18933,-1.93429,-1.8777,-1.35081,-1.16466
4644,0.364577,0.371321,0.347113,0.278474,0.834051,0.676064,0.932729,0.883814,0.685134,0.754202,0.923135,0.887324,0.711558,0.64388,0.937814,0.958687,0.975134,1.03041,0.855295,0.899262,0.618793,0.892935,0.0820207,0.514554,0.146649,0.338915,0.410839,0.478807,-0.375323,-0.449389,-0.0919176,-0.23189,-0.208582,-0.190614,1.56293,1.45534,-0.08219,-0.023945,0.502384,0.687902
4645,0.688519,0.646706,0.385902,0.316848,0.518153,0.458055,0.312869,0.266162,0.105049,0.175633,0.828132,0.724977,0.794009,0.725884,0.742018,0.690895,0.075962,0.129575,0.908459,0.916568,1.15028,1.42223,0.970335,1.4063,0.161134,0.354747,-1.1461,-1.08432,-1.77035,-1.84229,1.6892,1.54811,1.52511,1.55012,-1.26594,-1.38022,-1.90493,-1.84797,-1.88568,-1.6972
4646,0.135191,0.0955705,0.922074,0.854083,0.397785,0.240046,0.90597,0.858494,0.312528,0.367666,0.600098,0.56263,0.240473,0.17314,0.405062,0.423102,0.652441,0.704304,0.233067,0.240482,0.799966,1.06431,0.323404,0.766739,0.703603,0.891023,-0.565728,-0.50771,0.838657,0.765022,0.188877,0.0520512,-1.01927,-0.995908,-0.501432,-0.621304,0.168262,0.218671,1.16565,1.35685
4647,0.235994,0.195941,0.132846,0.0662011,0.935616,0.777689,0.652401,0.6056,0.490576,0.559698,0.0480353,0.0084445,0.380563,0.313358,0.399409,0.376836,0.304104,0.354691,0.463968,0.387624,-0.467043,-0.20122,1.60831,2.04532,-1.77561,-1.58761,-0.334324,-0.279221,-0.123199,-0.196563,1.19221,1.06162,1.07919,1.09802,0.483864,0.367869,-0.0332931,0.0118866,-2.891,-2.69708
4648,0.762874,0.722747,0.302585,0.235208,0.118907,-0.036728,0.74173,0.701961,0.980655,1.04803,0.298202,0.256553,0.814207,0.745009,0.346921,0.33057,0.60749,0.660467,0.51872,0.534766,0.458877,0.72348,-0.703468,-0.272404,-1.0998,-0.910973,0.505898,0.560792,-0.267639,-0.334058,-0.275639,-0.403526,0.857025,0.870101,0.161796,0.0405711,-0.706561,-0.659066,-0.662386,-0.467673
4649,0.287876,0.247098,0.95421,0.885245,0.865083,0.709432,0.844,0.798322,0.41695,0.484123,0.990216,0.947829,0.86947,0.798283,0.157934,0.284304,0.587898,0.639611,0.674493,0.681908,0.0641739,0.33536,-0.800863,-0.363309,0.739838,0.93571,0.678111,0.725807,1.68189,1.6212,-0.936821,-1.06959,-1.3624,-1.35072,0.317711,0.202709,2.52604,2.57283,-1.33156,-1.14038
4650,0.881141,0.838304,0.766794,0.601397,0.602022,0.539176,0.104137,0.060114,0.630797,0.617165,0.463817,0.515077,0.643126,0.479263,0.203176,0.238038,0.191033,0.240666,0.0816008,0.0912467,0.259618,0.524315,0.328626,0.762422,0.841206,1.04221,-0.863519,-0.820595,0.805889,0.749649,1.57083,1.44121,-0.533881,-0.52319,1.3248,1.20969,-0.355851,-0.304276,0.141765,0.325711
4651,0.31163,0.267684,0.386557,0.317549,0.525573,0.36892,0.0793807,0.0332416,0.684108,0.750207,0.12471,0.0823238,0.231618,0.160243,0.173732,0.191772,0.6426,0.690275,0.43593,0.445129,0.0873638,0.348581,0.796109,1.22424,-2.40779,-2.20537,0.676614,0.718971,0.674517,0.612155,-1.47419,-1.59748,-0.531845,-0.522077,1.39048,1.27894,-0.0863723,-0.0338206,-0.889136,-0.708386
4652,0.399582,0.350651,0.712145,0.57473,0.819707,0.665203,0.878743,0.833978,0.698172,0.807179,0.309327,0.267107,0.789595,0.717135,0.441771,0.46245,0.00330063,0.0498494,0.571427,0.667491,-1.50364,-1.23896,0.879543,1.30242,0.298488,0.498504,-1.59579,-1.56103,0.245378,0.184025,0.19925,0.0737538,0.0832868,0.0851788,0.0728949,-0.0324389,2.32451,2.37507,-0.350949,-0.0959027
4653,0.545721,0.433618,0.899343,0.83191,0.888182,0.731837,0.773764,0.755203,0.799121,0.864151,0.768414,0.725338,0.0900197,0.0159903,0.325948,0.422,0.734626,0.781551,0.882104,0.889853,1.12059,1.38414,0.0778926,0.493846,0.533845,0.729453,0.364898,0.40602,-0.614665,-0.671122,-0.702128,-0.823786,0.682668,0.692435,0.608122,0.498628,-0.688117,-0.643497,0.331651,0.51658
4654,0.709896,0.516585,0.0194027,-0.0487014,0.742898,0.523114,0.744917,0.676427,0.465502,0.488492,0.787475,0.742033,0.898906,0.826839,0.362242,0.381551,0.654081,0.701187,0.863417,0.835309,-0.152725,0.118608,-0.209146,0.204832,0.192864,0.393708,-0.90402,-0.865363,0.566527,0.51505,0.170383,0.0479985,-1.16213,-1.15173,-0.466182,-0.580751,0.273039,0.314302,1.14427,1.32484
4655,0.643247,0.599553,0.0708636,0.00510139,0.469829,0.31439,0.642416,0.597652,0.0482936,0.112834,0.567193,0.523509,0.0379003,-0.0340438,0.8179,0.838273,0.850245,0.896769,0.655649,0.780764,0.326037,0.602782,-1.47365,-1.05384,0.317098,0.514533,1.25006,1.28999,0.462492,0.408403,-1.03236,-1.15344,0.659377,0.670566,0.443762,0.331694,-1.17043,-1.12506,1.57671,1.75275
4656,0.473389,0.431964,0.716055,0.649816,0.871635,0.717757,0.286631,0.240638,0.0208402,0.0832203,0.560273,0.446972,0.168282,0.0964763,0.712597,0.64019,0.845046,0.891124,0.720028,0.726219,-1.24575,-0.969212,1.35247,1.77264,0.0248527,0.225082,-1.93974,-1.8936,-1.16179,-1.21474,0.169255,0.0760803,-0.350342,-0.346108,-0.497529,-0.609334,0.338143,0.380519,0.122702,0.30435
4657,0.606209,0.597332,0.168406,0.103095,0.86747,0.714026,0.486735,0.442097,0.752141,0.815972,0.414914,0.370434,0.719644,0.648186,0.500664,0.442108,0.328002,0.371883,0.766596,0.773255,0.867389,1.14323,0.115677,0.478192,0.1453,0.345906,0.754315,0.804981,-0.110393,-0.166293,1.42668,1.3056,-0.920551,-0.91574,-0.856658,-0.96827,0.0445906,0.0797722,0.449035,0.627225
4658,0.812302,0.762699,0.58867,0.522209,0.242013,0.0899058,0.458705,0.415225,0.650494,0.644511,0.565774,0.52023,0.402407,0.331927,0.223339,0.244026,0.4102,0.454597,0.519039,0.523438,-1.34859,-1.07184,-1.23642,-0.816253,0.0648723,0.270152,-0.340175,-0.283653,-0.634728,-0.684328,0.275726,0.150623,1.10651,1.10813,1.00206,0.883429,-1.75511,-1.72661,0.253975,0.437936
4659,0.969492,0.928067,0.37271,0.292094,0.596609,0.442622,0.748687,0.705677,0.411539,0.47305,0.152815,0.109225,0.441051,0.430269,0.376871,0.470261,0.193745,0.235756,0.676051,0.680699,0.811461,1.08504,-1.43996,-1.01383,1.16383,1.3738,3.04018,3.08899,-0.506922,-0.48621,0.736901,0.612192,-2.39313,-2.38608,0.827309,0.709657,0.683176,0.709644,-1.52992,-1.3471
4660,0.52952,0.487559,0.130286,0.0619791,0.6166,0.463898,0.510939,0.468071,0.0913829,0.150674,0.117406,0.0718971,0.661516,0.528611,0.584632,0.696495,0.752371,0.795523,0.453316,0.46005,-0.492905,-0.224999,1.38884,1.81265,-0.0804424,0.12364,0.420635,0.470334,-0.23249,-0.288091,-1.1364,-1.26419,0.722841,0.721719,0.89543,0.778912,-0.520121,-0.494504,-1.07644,-0.889668
4661,0.40549,0.363614,0.405925,0.338218,0.41345,0.385014,0.861718,0.816858,0.0445905,0.126944,0.288237,0.26961,0.604761,0.626953,0.90069,0.92273,0.205756,0.251034,0.74179,0.748155,-1.28213,-1.01612,-1.93804,-1.50688,-0.765877,-0.568803,0.0777914,0.127113,-0.8728,-0.928285,0.535094,0.407041,1.90593,1.90648,0.129608,0.00646608,0.534661,0.559197,-0.415797,-0.232616
4662,0.994737,0.954819,0.193298,0.123763,0.368711,0.306129,0.0609773,0.0159268,0.0728814,0.103215,0.494936,0.467324,0.795776,0.725295,0.555529,0.576148,0.790066,0.83627,0.65151,0.660202,0.299737,0.559956,0.320703,0.748258,-1.05444,-0.858253,-0.913026,-0.866832,-0.219972,-0.280476,0.673387,0.544325,-0.85479,-0.850403,-0.194685,-0.394132,1.38699,1.41073,-0.543023,-0.361947
4663,0.482094,0.443963,0.386445,0.316543,0.31292,0.227244,0.262658,0.217386,0.0219309,0.0794851,0.789913,0.665037,0.303914,0.234185,0.987088,1.0078,0.191574,0.236469,0.874652,0.883316,-0.619532,-0.354102,-0.355238,0.0770278,-0.601516,-0.399378,0.5919,0.641555,0.0624704,0.000574169,-0.503817,-0.624645,-0.640182,-0.712531,-0.665337,-0.794731,-1.29332,-1.26616,-2.80696,-2.63009
4664,0.754681,0.715103,0.0454238,-0.0234948,0.301061,0.14836,0.211339,0.177375,0.551709,0.60851,0.908268,0.862751,0.98541,0.917076,0.690471,0.810936,0.70082,0.74686,0.10701,0.115043,-1.05616,-0.788453,0.272707,0.689093,-1.28685,-1.09182,0.310543,0.35908,2.26689,2.20358,0.701441,0.585646,-0.577116,-0.574658,1.62396,1.49489,0.27681,0.301677,0.0832981,0.266502
4665,0.461179,0.420591,0.100106,0.0303079,0.351726,0.200924,0.213433,0.137364,0.13301,0.189471,0.489365,0.441437,0.371154,0.300781,0.592606,0.614074,0.791257,0.81602,0.0664639,0.113329,-0.436188,-0.169279,0.874444,1.30116,1.62226,1.81838,2.16672,2.21696,0.0546007,-0.00761605,0.366961,0.247231,3.16588,3.1654,-0.655962,-0.78775,-1.35578,-1.32583,1.14432,1.3325
4666,0.560791,0.520961,0.869316,0.801163,0.980576,0.829421,0.143147,0.0973529,0.220002,0.277995,0.562939,0.517402,0.87497,0.803098,0.523862,0.543105,0.839912,0.88518,0.103933,0.111616,0.418898,0.692672,0.723675,1.15147,-0.09489,0.101368,-0.342643,-0.299377,1.35026,1.2859,-0.198331,-0.219369,1.60779,1.59861,0.0811612,-0.0564345,0.785451,0.810509,-1.10154,-0.918191
4667,0.188927,0.151209,0.591113,0.52114,0.433969,0.284439,0.766403,0.719926,0.015528,0.0715078,0.250814,0.203641,0.723869,0.653568,0.227779,0.246172,0.00485903,0.0505974,0.810894,0.820342,-0.955595,-0.67844,0.289,0.805585,0.0738805,0.26787,-0.869817,-0.827472,-0.233535,-0.304557,-0.564581,-0.685968,0.0323047,0.0318279,-0.941225,-1.07454,1.46419,1.48961,2.79723,2.98558
4668,0.532822,0.493158,0.633458,0.564547,0.276575,0.127766,0.191689,0.147264,0.337113,0.457394,0.407974,0.363112,0.836594,0.768627,0.569261,0.535985,0.437173,0.481054,0.648629,0.713844,-0.968073,-0.68772,0.0348726,0.459702,-0.902842,-0.707023,-1.8436,-1.80649,1.03715,0.960586,0.030548,-0.0875551,0.283472,0.27583,-0.173751,-0.300021,0.664459,0.694046,0.119107,0.298689
4669,0.615342,0.573805,0.108248,0.0418214,0.476026,0.347487,0.679231,0.635728,0.78865,0.843281,0.978239,0.934164,0.020032,-0.0484362,0.806346,0.825798,0.321031,0.363884,0.595739,0.607346,1.41649,1.68953,0.857758,1.27473,0.403056,0.596038,1.52855,1.56615,-0.041373,-0.123531,-0.515674,-0.62906,-1.00178,-1.00544,1.26798,1.13442,-0.958274,-0.933457,0.921829,1.10695
4670,0.44715,0.320508,0.817159,0.752243,0.71489,0.567207,0.219319,0.174263,0.387909,0.444767,0.781972,0.658842,0.185458,0.117121,0.126045,0.143623,0.888863,0.933248,0.270216,0.281026,-1.4057,-1.1343,0.286046,0.68818,-0.836666,-0.640253,1.5825,1.62453,1.10142,1.01721,0.518726,0.413403,-0.460561,-0.477503,-0.912557,-1.04798,0.0924954,0.120244,1.49383,1.67293
4671,0.109489,0.0672106,0.272373,0.205523,0.152971,0.0029496,0.740795,0.697186,0.987576,1.04451,0.427045,0.383519,0.835136,0.765061,0.405972,0.326951,0.909053,0.953033,0.702654,0.715659,-1.29728,-1.02285,-0.31506,0.101632,0.669339,0.861009,-0.0241096,0.0121001,0.980943,0.894572,-0.176661,-0.283159,0.0611881,0.0504377,0.849354,0.711762,2.04615,2.06835,0.368459,0.543144
4672,0.338814,0.29906,0.126035,0.0566992,0.0988498,0.0454516,0.621189,0.57926,0.287409,0.34408,0.714578,0.672686,0.861136,0.778464,0.49182,0.510279,0.418423,0.463016,0.859349,0.872921,0.84679,1.11954,-0.229379,0.17981,0.781939,0.96751,-0.21914,-0.177688,-1.12387,-1.20603,-0.393334,-0.498804,0.819737,0.803228,0.198557,-0.0369037,-0.48341,-0.467376,-1.04142,-0.87422
4673,0.215279,0.175116,0.769422,0.701413,0.23976,0.0879536,0.952958,0.913014,0.808744,0.863012,0.251425,0.20715,0.936128,0.791867,0.0106963,0.0291983,0.381703,0.434388,0.262842,0.277345,-2.06234,-1.78295,0.631516,1.0404,0.0971042,0.275068,0.181746,0.216372,-0.41984,-0.497179,1.574,1.46231,-0.0241887,-0.00988173,-0.641658,-0.785569,-0.199037,-0.180643,0.271922,0.437917
4674,0.900249,0.861273,0.315834,0.248196,0.569927,0.419957,0.285232,0.245447,0.549234,0.697838,0.884541,0.837832,0.874741,0.80527,0.095125,0.114924,0.359716,0.40576,0.679885,0.696673,0.664528,0.939341,-1.76224,-1.35757,2.30323,2.48544,-0.835439,-0.808177,-0.965343,-1.04764,0.0403933,-0.0771943,-0.803925,-0.822991,0.251968,0.111206,-0.166176,-0.154007,-0.260735,-0.100316
4675,0.504391,0.476149,0.636086,0.569678,0.172845,0.0248733,0.354818,0.314511,0.477999,0.532665,0.75551,0.709242,0.260168,0.188976,0.726094,0.745146,0.899493,0.946436,0.440508,0.540643,-1.15801,-0.881808,1.02523,1.43149,-0.721176,-0.532901,-1.03346,-1.01091,-1.52792,-1.59811,-1.23102,-1.34079,0.96626,0.948162,-0.176512,-0.323281,-0.916976,-0.904236,0.0449698,0.20831
4676,0.129681,0.0910242,0.603122,0.535616,0.542852,0.397659,0.839292,0.797112,0.48798,0.648587,0.0901897,0.0442948,0.879515,0.810499,0.654201,0.674177,0.20977,0.255462,0.369622,0.384612,0.116625,0.397865,-0.409641,-0.00252078,0.0458951,0.235789,1.63714,1.65447,1.17126,1.09592,0.0434727,-0.0706614,0.815888,0.798065,-0.247989,-0.490255,0.379182,0.397667,0.118496,0.276535
4677,0.220527,0.182072,0.266309,0.236355,0.347972,0.200789,0.252978,0.209338,0.626009,0.764509,0.480022,0.401004,0.796969,0.698344,0.00201924,0.0216922,0.227939,0.358071,0.814366,0.828168,0.274501,0.555825,0.731591,1.11662,1.01826,1.11376,-1.43299,-1.41402,0.35826,0.28777,-2.22182,-2.33957,-1.6156,-1.63526,-0.516069,-0.657229,0.96678,0.980979,-1.18205,-1.01882
4678,0.679655,0.555858,0.00400826,-0.0629067,0.653856,0.507819,0.516076,0.499175,0.824097,0.880431,0.802306,0.757713,0.653706,0.586189,0.811507,0.830368,0.414259,0.460681,0.890675,0.903975,-0.589034,-0.310729,1.82089,2.23576,1.8075,1.99174,-0.0496593,-0.0332202,-2.39819,-2.4676,0.677997,0.560129,-0.266499,-0.279494,-1.05687,-1.19875,0.0345811,0.0413851,0.483241,0.645343
4679,0.968298,0.929644,0.530555,0.464847,0.53385,0.38664,0.8347,0.789012,0.353588,0.412127,0.745272,0.699857,0.110468,0.0439249,0.852707,0.870687,0.178481,0.26704,0.225,0.23773,-2.20756,-1.92605,1.55153,1.96176,-0.822378,-0.69603,0.070484,0.164537,0.973407,0.905405,0.156331,0.0351248,-0.539058,-0.553401,1.34151,1.19424,-2.08083,-2.06628,1.85302,2.01754
4680,0.739601,0.700991,0.274304,0.208792,0.0609467,-0.088336,0.00228928,-0.0430601,0.211007,0.294505,0.312919,0.269138,0.249409,0.140352,0.55945,0.530887,0.026977,0.0733986,0.731992,0.746232,1.44951,1.72593,0.257511,0.671358,-3.56803,-3.3838,0.298374,0.362294,2.04458,1.96881,0.365163,0.249487,0.777932,0.758154,-0.577924,-0.719358,-0.137607,-0.118171,0.21086,0.371018
4681,0.867056,0.826379,0.514177,0.497878,0.366207,0.218694,0.942532,0.895167,0.118179,0.176883,0.676748,0.633457,0.304799,0.23678,0.173326,0.191086,0.618467,0.664038,0.844764,0.857059,-0.786236,-0.506044,1.44473,1.85654,1.6583,1.84253,0.543611,0.56005,-0.333971,-0.402521,-1.55171,-1.66128,-0.853955,-0.865096,1.84837,1.70535,0.775951,0.793113,0.567465,0.722952
4682,0.615946,0.647648,0.85177,0.786964,0.0702065,-0.0752751,0.319912,0.272142,0.836187,0.8943,0.402266,0.360534,0.925713,0.858303,0.0455032,0.064337,0.587517,0.667526,0.506403,0.462755,-0.00422302,0.280832,-0.765971,-0.348132,1.13281,1.32232,1.70577,1.72663,-0.499989,-0.570347,-0.972988,-1.07794,-1.43707,-1.45005,-1.02902,-1.1799,0.517264,0.539414,1.56614,1.72899
4683,0.509548,0.468917,0.673067,0.521417,0.852503,0.707401,0.932867,0.885017,0.136901,0.193871,0.346161,0.368318,0.487757,0.422222,0.345287,0.36533,0.54932,0.671015,0.0566417,0.06845,-0.345359,-0.0611247,-0.97407,-0.560246,-0.434983,-0.249967,-0.218606,-0.204023,1.25486,1.18173,0.584569,0.485718,-0.0875437,-0.0942843,-0.656937,-0.801192,0.6424,0.672439,0.981607,1.14752
4684,0.305914,0.290186,0.32044,0.255869,0.0195359,-0.128125,0.0422033,-0.00432271,0.590934,0.624086,0.417833,0.376102,0.468056,0.404459,0.38601,0.405649,0.628934,0.674504,0.877812,0.886735,-0.967242,-0.682642,0.82076,1.23067,0.388991,0.582035,0.535059,0.491019,-0.328628,-0.408726,-0.221121,-0.317894,-1.41301,-1.42119,-0.889073,-1.03705,0.066075,0.0939688,0.888188,1.04975
4685,0.152133,0.111456,0.491484,0.424877,0.822842,0.677144,0.280331,0.235606,0.998405,1.0543,0.826197,0.785755,0.150405,0.0881999,0.884056,0.902906,0.38176,0.461841,0.142392,0.149045,0.997673,1.26029,0.83672,1.3103,-0.770709,-0.577867,1.17291,1.18606,0.633448,0.54715,-0.477138,-0.579047,-0.41278,-0.421321,-0.0333791,-0.184899,-0.756723,-0.732077,-0.0820904,0.076622
4686,0.718768,0.677999,0.111666,0.046087,0.841994,0.69842,0.248944,0.282374,0.0389479,0.0928228,0.391665,0.349726,0.436481,0.374746,0.498602,0.516434,0.202884,0.249177,0.0775128,0.0847703,2.91861,3.20321,0.981113,1.38992,-1.34386,-1.14444,-0.898472,-0.887152,0.724725,0.686951,0.278715,0.0843292,1.83407,1.82872,1.44241,1.29274,2.53842,2.56108,-0.72906,-0.566225
4687,0.031775,-0.00872813,0.484995,0.420295,0.384921,0.306505,0.375203,0.329142,0.341911,0.489306,0.19474,0.150957,0.233353,0.169623,0.724549,0.740359,0.87005,0.916863,0.322231,0.235921,-1.59551,-1.31091,-1.12012,-0.714683,-0.460851,-0.238946,-2.51803,-2.49959,0.91305,0.826752,0.84311,0.747705,1.25938,1.25909,0.764693,0.610604,-0.112536,-0.0849643,-0.822738,-0.663989
4688,0.811474,0.771928,0.256833,0.190398,0.0604951,-0.0854105,0.560774,0.550157,0.830662,0.885789,0.952642,0.907823,0.848853,0.785799,0.463927,0.424273,0.593707,0.64297,0.379331,0.387071,0.873909,1.16294,-0.589019,-0.190648,0.470529,0.666548,-1.80926,-1.79845,-0.666136,-0.749893,-1.24066,-1.33238,-0.885922,-0.88354,-0.323008,-0.482613,1.3187,1.34517,1.15552,1.309
4689,0.27548,0.235671,0.306868,0.238431,0.100066,-0.0440022,0.815353,0.771172,0.945216,0.999911,0.0520087,0.00687042,0.0727433,0.00992898,0.0937949,0.108188,0.857816,0.909596,0.0451874,0.0506405,-0.272845,0.0884053,-0.300967,0.0956384,0.556034,0.756759,-0.885515,-0.879994,-0.0037745,-0.0854578,-0.599386,-0.688345,-0.309242,-0.313571,1.47394,1.30654,-1.0789,-1.05278,1.09236,1.24268
4690,0.432366,0.385468,0.954756,0.888468,0.533011,0.390102,0.741247,0.698027,0.170559,0.224941,0.493082,0.447407,0.232474,0.17135,0.2466,0.227041,0.874003,0.924564,0.786613,0.789025,-1.27516,-0.98613,-0.0175963,0.381924,-2.14866,-1.94798,-0.317669,-0.31846,1.39301,1.31507,1.64779,1.56175,-0.877048,-0.883202,-0.379766,-0.546685,0.213192,0.233392,1.24913,1.40034
4691,0.577466,0.535264,0.665609,0.598308,0.380439,0.238204,0.321734,0.276675,0.392115,0.445621,0.933331,0.887944,0.651672,0.59312,0.371756,0.345895,0.281596,0.330331,0.693537,0.695185,-0.627912,-0.335707,-2.87445,-2.4747,0.645592,0.842475,-1.42923,-1.43627,1.49351,1.41284,0.452097,0.387417,0.318871,0.31767,-1.25474,-1.42641,1.17436,1.19119,0.0899511,0.242192
4692,0.977648,0.933029,0.903806,0.835616,0.468205,0.342604,0.964944,0.918702,0.107465,0.163202,0.359468,0.313581,0.387039,0.336979,0.452069,0.464748,0.0396676,0.0871413,0.384704,0.383792,-0.897509,-0.602262,-0.342296,0.0507652,0.322469,0.510823,-0.620075,-0.626799,-1.33683,-1.42168,-0.707371,-0.786918,0.650117,0.654718,-1.74543,-1.92216,0.500868,0.520239,-0.557711,-0.400656
4693,0.136814,0.0907012,0.750036,0.68212,0.591178,0.447004,0.72944,0.681096,0.314152,0.368423,0.919574,0.874868,0.139908,0.0808387,0.877725,0.891362,0.304172,0.307566,0.870327,0.867493,0.334812,0.627718,-1.35263,-0.960482,-0.0246676,0.179172,-0.218981,-0.186791,-0.405395,-0.496034,-0.323651,-0.404027,0.557104,0.660544,-1.06188,-1.23886,0.773149,0.790695,-0.647264,-0.485108
4694,0.017075,-0.0279649,0.0112496,-0.0578079,0.470626,0.325824,0.748535,0.699013,0.725331,0.781047,0.533529,0.487415,0.412861,0.352035,0.468965,0.484143,0.482166,0.52799,0.308664,0.306423,1.93167,2.21878,1.28021,1.67891,1.05558,1.25441,0.253798,0.253216,0.880377,0.766675,0.406386,0.329013,0.659567,0.666369,1.57745,1.39394,0.616567,0.62842,-1.74716,-1.58267
4695,0.975494,0.930454,0.108029,0.0411239,0.796386,0.578025,0.499218,0.445554,0.401711,0.458671,0.598771,0.562231,0.159677,0.101213,0.838317,0.85123,0.518625,0.561657,0.892063,0.890711,0.439454,0.723728,-2.81792,-2.41367,-0.278652,-0.0739727,0.273676,0.279117,2.12002,2.02938,-0.157615,-0.241473,1.21121,1.22052,-1.16289,-1.35233,-0.778258,-0.762857,-2.00413,-1.84722
4696,0.436596,0.389356,0.542404,0.475273,0.97649,0.830226,0.240504,0.192094,0.992353,1.04864,0.68441,0.637046,0.418908,0.362785,0.418432,0.499846,0.769704,0.813401,0.596993,0.595304,-0.718925,-0.434142,-1.04243,-0.637634,-0.693015,-0.48647,-0.129839,-0.126047,1.40176,1.31476,-0.210215,-0.27701,0.213039,0.218715,-0.239706,-0.423016,-0.173296,-0.21555,0.114246,0.266664
4697,0.987789,0.940374,0.629662,0.473526,0.0526597,-0.0920818,0.994825,0.944691,0.996197,1.05143,0.292966,0.244913,0.350353,0.25063,0.136433,0.148462,0.164711,0.207741,0.981476,0.979467,-1.22586,-0.948784,0.365999,0.763974,1.38943,1.59572,0.705518,0.713966,0.997268,0.991069,-0.228691,-0.312548,1.48137,1.47988,-0.602767,-0.781953,0.316355,0.331756,-1.32268,-1.16751
4698,0.641989,0.595122,0.542538,0.471779,0.923165,0.779388,0.774266,0.68334,0.488402,0.54323,0.973833,0.925639,0.197465,0.138475,0.137655,0.148099,0.518126,0.524097,0.307904,0.30338,-0.883625,-0.607064,-0.203207,0.198745,-0.216426,-0.00913492,-0.333077,-0.325472,0.754379,0.667379,-1.55581,-1.63789,-0.0930835,-0.100331,1.13492,0.962491,-0.297442,-0.277738,0.270183,0.420527
4699,0.524481,0.493628,0.534888,0.470032,0.29922,0.155269,0.474624,0.421989,0.833569,0.889964,0.0439379,-0.00332276,0.468173,0.387931,0.59348,0.604821,0.797914,0.840452,0.709739,0.707685,-0.0630632,0.209258,0.0454035,0.446068,-0.618415,-0.405924,0.982398,0.992748,1.19716,1.11515,-0.589806,-0.674371,-0.349368,-0.358751,0.849776,0.681532,0.922441,0.945837,1.39808,1.54788
4700,0.569593,0.392134,0.186895,0.120314,0.285975,0.231543,0.607683,0.55135,0.152077,0.209778,0.0165776,-0.0310638,0.695258,0.637387,0.413198,0.422649,0.056954,0.099269,0.888748,0.88524,-0.154555,0.123082,-0.510239,-0.103573,1.33522,1.54796,-1.37671,-1.36788,-0.0810512,-0.168782,-0.0317066,-0.121874,0.870061,0.857769,-0.601868,-0.765518,-0.602264,-0.572346,-2.20538,-2.05859
4701,0.33982,0.29064,0.45751,0.39135,0.35088,0.307817,0.734536,0.68071,0.981238,1.03765,0.727053,0.679999,0.676089,0.60154,0.712206,0.723642,0.903075,0.944535,0.82951,0.826903,-0.504429,-0.23484,0.289463,0.697756,-1.22403,-1.00911,0.684993,0.694767,0.485325,0.403145,0.285255,0.198416,0.317773,0.304271,-1.69931,-1.85873,-1.87281,-1.83642,-0.10999,0.039216
4702,0.866854,0.817446,0.43296,0.436629,0.434636,0.384091,0.202592,0.147711,0.62432,0.757608,0.147989,0.100236,0.625267,0.565693,0.486508,0.45585,0.958875,0.998691,0.202783,0.201347,-0.037292,0.232054,-1.40188,-0.99982,0.828345,1.03835,-0.0166198,0.0117303,0.450419,0.376261,-0.352533,-0.537679,-0.724438,-0.688923,1.3762,1.21493,-0.942633,-0.908848,0.674331,0.81557
4703,0.693213,0.645449,0.546138,0.481907,0.604317,0.460366,0.265066,0.203409,0.420625,0.477569,0.118791,0.0724945,0.96511,0.903372,0.175686,0.188057,0.382967,0.424106,0.499822,0.426438,-0.716898,-0.449957,0.465865,0.869132,-2.35389,-2.14529,-0.688903,-0.671306,0.181909,0.101527,-1.18485,-1.27377,-1.6627,-1.68212,0.728632,0.563994,0.224243,0.252365,0.238615,0.384179
4704,0.068516,0.0195626,0.770337,0.704767,0.0186912,-0.123338,0.300795,0.259107,0.598348,0.657606,0.595631,0.468288,0.217117,0.155437,0.308378,0.319078,0.465129,0.533028,0.651469,0.651528,-1.05637,-0.791913,-0.47948,-0.0792674,-2.19379,-1.89119,-1.10568,-1.09223,-0.817039,-0.892121,-0.122614,-0.215382,-0.484627,-0.49735,-1.22605,-1.39638,0.0451888,0.0747924,-0.805265,-0.66457
4705,0.665559,0.614584,0.736609,0.752999,0.831363,0.68692,0.31605,0.314806,0.30136,0.377568,0.911712,0.864081,0.580456,0.517898,0.00952485,0.0221447,0.598497,0.64195,0.183179,0.185572,0.031024,0.299538,0.504718,0.904116,-1.85192,-1.63709,-0.596878,-0.57714,1.01532,0.939374,-0.522263,-0.615232,-1.30483,-1.3234,0.423466,0.253291,-0.544117,-0.518534,0.0382393,0.155567
4706,0.919471,0.871025,0.866336,0.801231,0.600124,0.457976,0.425384,0.370504,0.0402056,0.0975292,0.98142,0.878121,0.246164,0.182738,0.899912,0.912584,0.994261,1.03783,0.210993,0.292113,-1.22411,-0.951259,-0.697832,-0.292389,-1.11342,-0.899085,-0.459239,-0.443125,0.900804,0.816739,-0.344339,-0.424608,1.88404,1.86747,-0.276334,-0.426626,0.00111049,0.0201218,0.842164,0.975703
4707,0.0177154,-0.02814,0.576358,0.511072,0.371472,0.229031,0.733393,0.680226,0.963116,1.02108,0.93771,0.892162,0.276078,0.210549,0.942822,0.957973,0.992586,1.03788,0.396353,0.398654,-1.17141,-0.900589,1.52231,1.93031,-0.603134,-0.395562,-1.49557,-1.48256,-0.34462,-0.421744,-0.146698,-0.233984,0.394003,0.383817,-0.931246,-1.10654,0.113058,0.13672,-0.344737,-0.213298
4708,0.524719,0.479014,0.0481232,-0.0163394,0.402866,0.260755,0.532175,0.477915,0.648778,0.708384,0.149753,0.105686,0.844954,0.777059,0.0425437,0.0599076,0.207211,0.253003,0.992424,0.992873,-0.77832,-0.511586,-1.90044,-1.49413,1.35065,1.55832,1.05684,1.0666,0.503036,0.427202,0.751866,0.750286,0.752849,0.73767,-0.629546,-0.807255,-2.29876,-2.28111,0.596237,0.731626
4709,0.564738,0.51919,0.108016,0.0433322,0.868547,0.724313,0.938297,0.882397,0.818263,0.878911,0.275917,0.230591,0.274097,0.20486,0.481135,0.497089,0.71216,0.758658,0.493249,0.492214,0.27685,0.550301,0.654131,1.06335,-1.43984,-1.23007,1.75091,1.76773,0.810349,0.736576,1.83074,1.73456,0.267535,0.246138,2.04538,1.87366,-0.968869,-0.938724,-2.06278,-1.92529
4710,0.256379,0.210144,0.871818,0.808534,0.0448555,-0.100248,0.286525,0.230075,0.60802,0.641486,0.0083069,-0.0372863,0.873691,0.805375,0.713534,0.732051,0.295876,0.344591,0.92057,0.920814,1.95553,2.23426,0.30392,0.713381,1.30235,1.50668,-0.579462,-0.561415,-1.3606,-1.42893,-0.910517,-1.00328,-0.67783,-0.693966,0.128178,-0.0399359,0.378481,0.403664,0.289811,0.434502
4711,0.661251,0.520554,0.76191,0.699527,0.564169,0.418658,0.950618,0.891197,0.344934,0.40406,0.105032,0.0579493,0.528792,0.460151,0.328144,0.345578,0.502299,0.551298,0.313975,0.314764,-1.25916,-0.975669,-1.35817,-0.954865,-0.0719828,0.130233,0.120101,0.139721,-1.72252,-1.79589,-1.30639,-1.40313,-1.02877,-1.07404,-0.397416,-0.566185,1.44945,1.47214,-0.937077,-0.785195
4712,0.876456,0.830964,0.270937,0.206613,0.233578,0.0889122,0.426308,0.36826,0.408107,0.466552,0.560325,0.51127,0.568254,0.453214,0.713611,0.73219,0.257807,0.308108,0.989991,0.98867,0.749291,1.11742,-0.202553,0.198172,0.810342,1.00744,1.315,1.33602,-0.259088,-0.334896,1.00997,0.909987,-1.43917,-1.45411,-0.244876,-0.418696,0.28253,0.299329,0.516997,0.664009
4713,0.0322478,-0.0113636,0.0709789,0.0071494,0.411649,0.265234,0.684736,0.639297,0.233783,0.28992,0.444233,0.393886,0.513942,0.446276,0.297766,0.315698,0.266696,0.318129,0.831169,0.828295,2.92703,3.21052,-0.951626,-0.550224,0.539547,0.733705,-1.14654,-1.12972,0.121308,0.0396157,-0.0640716,-0.169183,0.943955,0.928027,0.32431,0.15768,0.0367645,0.0616808,-1.00649,-0.859847
4714,0.368611,0.325736,0.763972,0.701919,0.836493,0.689402,0.967077,0.910334,0.927916,0.986304,0.988925,0.939971,0.915842,0.848213,0.211136,0.229886,0.507869,0.616542,0.999282,0.99523,0.551218,0.841706,0.835474,1.24069,1.69754,1.88344,-0.37908,-0.367544,0.906275,0.827804,-1.88189,-1.98583,-2.6051,-2.61534,0.33298,0.155062,-0.198838,-0.175967,1.24921,1.40046
4715,0.265359,0.223134,0.549914,0.487465,0.346938,0.199515,0.12981,0.0730089,0.67919,0.688357,0.293193,0.243897,0.0588651,-0.00746396,0.606265,0.626524,0.86341,0.914956,0.804882,0.79966,-0.381264,-0.0875398,-0.839959,-0.443407,0.665291,0.84823,0.378037,0.39463,0.927622,0.848915,0.313278,0.21573,-1.17891,-1.18293,0.319073,0.152443,0.12049,0.142611,1.54767,1.69268
4716,0.455204,0.413514,0.716286,0.656472,0.227079,0.0783358,0.243962,0.205179,0.330618,0.39041,0.054587,0.00544314,0.43253,0.364194,0.226978,0.249652,0.178917,0.229517,0.163905,0.158997,-0.125308,0.163619,-0.634143,-0.241434,-0.0837543,0.0940029,-1.22053,-1.20172,-2.06692,-2.15321,-0.94617,-1.04787,-0.49343,-0.491411,0.595603,0.424125,1.80069,1.8238,0.799756,0.946055
4717,0.0746251,0.0337775,0.654506,0.554181,0.407315,0.259659,0.394455,0.33735,0.391739,0.452902,0.909089,0.861153,0.145441,0.0783281,0.342204,0.387962,0.287382,0.339099,0.200068,0.195715,0.782035,1.07235,-1.01447,-0.532994,-0.262192,-0.0878449,-0.80739,-0.792737,-1.1707,-1.25746,-0.0764336,-0.176083,0.668366,0.677165,1.72558,1.55304,-0.296656,-0.271825,0.637061,0.786969
4718,0.00968555,-0.0325014,0.421984,0.45189,0.0346051,-0.115177,0.100179,0.0448369,0.19098,0.2509,0.555995,0.508834,0.292208,0.224118,0.49627,0.526272,0.0896604,0.141615,0.881477,0.879845,0.908906,1.20017,-1.22351,-0.824554,0.490768,0.665331,1.04029,1.04968,1.14169,1.0491,-0.0840627,-0.177276,0.0302039,0.0330271,1.41754,1.23971,0.515183,0.545509,0.0151543,0.161048
4719,0.195987,0.153528,0.409414,0.349599,0.557315,0.408292,0.830645,0.772805,0.630672,0.688657,0.505024,0.456652,0.730668,0.661013,0.641908,0.664581,0.84392,0.894276,0.775382,0.84422,2.09852,2.38633,0.372849,0.765481,0.185693,0.360814,0.132607,0.149424,1.49804,1.40744,0.175374,0.0811621,0.907167,0.907553,-1.25268,-1.43555,2.07803,2.11334,-0.951572,-0.812082
4720,0.727399,0.684868,0.484687,0.423265,0.730757,0.57902,0.822549,0.766021,0.802756,0.859185,0.865086,0.816745,0.52506,0.522537,0.161681,0.183501,0.453051,0.504229,0.780092,0.808595,0.493646,0.78351,-1.09995,-0.714709,-1.70606,-1.52549,0.408758,0.421964,-1.96801,-2.06069,-0.792352,-0.891296,-0.593466,-0.592094,0.440829,0.261881,-0.197342,-0.166924,-0.17541,-0.0357287
4721,0.200868,0.158836,0.139605,0.078263,0.593602,0.442321,0.134157,0.0789362,0.0958723,0.153696,0.269754,0.221864,0.498808,0.384062,0.266033,0.289838,0.779438,0.830325,0.689781,0.772969,1.33373,1.63087,-1.33001,-0.9457,-0.300965,-0.117255,-0.727059,-0.711251,-2.25505,-2.3491,1.34568,1.24556,0.36756,0.375254,-0.496171,-0.679147,1.8056,1.83661,-0.449687,-0.315888
4722,0.658333,0.616519,0.723722,0.663721,0.992058,0.840199,0.263264,0.208465,0.700044,0.758832,0.594569,0.547,0.314484,0.245587,0.807195,0.832618,0.0088198,0.0613064,0.738976,0.737344,-0.315794,-0.0167761,0.945689,1.32284,-0.637377,-0.453,0.293234,0.315422,-1.66596,-1.76305,2.39066,2.28802,0.837672,0.851864,1.53773,1.36077,-1.36452,-1.3367,0.659291,0.795925
4723,0.427845,0.468488,0.829162,0.686063,0.175089,0.0207141,0.721498,0.66615,0.844562,0.871911,0.428419,0.364288,0.62736,0.557646,0.536071,0.560084,0.0864044,0.13876,0.363013,0.361167,-0.0600057,0.234382,-0.655806,-0.281501,0.6149,0.803845,-0.301374,-0.275822,0.262372,0.161674,-0.379095,-0.483534,0.118653,0.131697,0.0460336,-0.131139,0.833203,0.861607,-0.28479,-0.14804
4724,0.359895,0.320456,0.767488,0.708405,0.885531,0.73144,0.741347,0.718338,0.923198,0.98499,0.0950684,0.181576,0.15305,0.0815016,0.00283196,0.0290356,0.161631,0.216213,0.244414,0.240683,-0.128386,0.163255,-0.325206,0.0433345,0.427523,0.621997,-1.80036,-1.77835,-1.83511,-1.93892,0.14583,0.0386196,-0.111884,-0.157596,-1.79088,-1.96887,-0.27038,-0.245665,-1.97327,-1.84024
4725,0.445238,0.406518,0.214947,0.15653,0.130296,-0.0236967,0.828192,0.770527,0.588002,0.647781,0.0464334,-0.00113553,0.573917,0.503272,0.765456,0.791468,0.850422,0.90343,0.608639,0.605873,0.127514,0.414414,-0.216645,0.15026,1.42965,1.62149,0.00775502,0.027719,0.141886,0.0359037,-1.72725,-1.83776,-0.461764,-0.446888,0.635423,0.455844,0.78767,0.808036,-0.595634,-0.553391
4726,0.245385,0.208264,0.325421,0.265292,0.573505,0.338629,0.0797175,0.0230298,0.946806,1.00541,0.384661,0.352141,0.268326,0.197263,0.597154,0.623618,0.742673,0.696931,0.376406,0.375056,0.954047,1.24567,0.393868,0.766177,-0.246668,-0.0615417,1.81177,1.83379,0.0503836,-0.0214721,-0.18771,-0.306529,-0.305004,-0.293853,0.00224333,-0.179742,-0.656116,-0.631322,0.600439,0.733462
4727,0.832103,0.793894,0.0934463,0.0353958,0.856131,0.700955,0.661689,0.605947,0.472761,0.532401,0.754554,0.705417,0.866972,0.797778,0.779022,0.80474,0.436498,0.490431,0.714283,0.713744,-0.589724,-0.295094,1.49692,1.87556,-0.387001,-0.196491,0.739968,0.761866,0.0229523,-0.0788479,-0.800894,-0.926818,-0.989757,-0.984376,-0.0288905,-0.219991,0.459264,0.482703,0.126815,0.258003
4728,0.661906,0.595384,0.847623,0.790899,0.70211,0.579072,0.699832,0.658135,0.530873,0.508671,0.650583,0.599416,0.766126,0.69812,0.194594,0.219687,0.0234376,0.0763644,0.306599,0.307354,-0.047001,0.166803,0.617461,0.988596,1.37565,1.5706,0.645006,0.666077,0.649066,0.554039,0.737082,0.604416,-0.224337,-0.217278,0.878871,0.692454,1.06233,1.08219,0.154913,0.280474
4729,0.429696,0.396874,0.634899,0.576444,0.610904,0.457188,0.764164,0.710324,0.445468,0.484942,0.54349,0.493415,0.122253,0.0562455,0.0343319,0.0569277,0.0145085,0.0659485,0.679495,0.681831,0.334395,0.6287,0.285027,0.65403,0.686979,0.878158,-0.209574,-0.228634,-0.295173,-0.394039,-0.181906,-0.307923,-1.87712,-1.87393,-0.0610531,-0.248574,0.0283562,0.052591,-2.03767,-1.90857
4730,0.185226,0.198364,0.918939,0.858221,0.0604735,-0.0918752,0.593697,0.538085,0.402217,0.461212,0.72277,0.672517,0.776107,0.709005,0.894788,0.917334,0.536942,0.58639,0.231032,0.23544,-0.289108,0.00718331,0.467175,0.839615,-1.0338,-0.838851,-1.14441,-1.12334,0.943002,0.839463,0.356688,0.228116,-0.519249,-0.51816,0.262954,0.0833118,0.162819,0.185616,1.16059,1.29453
4731,0.0366288,-0.000145827,0.823866,0.764256,0.638963,0.486269,0.8991,0.842502,0.875622,0.934184,0.550407,0.499922,0.317964,0.248542,0.367091,0.391525,0.595244,0.607725,0.848458,0.854093,0.286427,0.581326,0.418819,0.707624,-1.31979,-1.1283,-0.0949267,-0.0820496,0.111911,0.0146979,0.0561138,-0.0806015,-2.6011,-2.59838,-1.89852,-2.08264,-1.38523,-1.36427,1.88848,2.02703
4732,0.11404,0.0754999,0.975221,0.918302,0.685898,0.556913,0.47974,0.42115,0.419624,0.475453,0.798996,0.748031,0.173748,0.103605,0.869085,0.892758,0.579179,0.62906,0.828573,0.765281,-0.188854,0.0987757,0.208902,0.575634,-0.980392,-0.790525,-0.900576,-0.889628,2.12611,2.02403,0.465339,0.331064,1.20908,1.2074,0.613821,0.432333,-1.28621,-1.26163,-0.203686,-0.0128127
4733,0.932252,0.893363,0.858686,0.800254,0.811745,0.627556,0.809379,0.750398,0.915778,0.973378,0.322826,0.367708,0.964275,0.893888,0.204582,0.226471,0.206057,0.254876,0.671568,0.676468,-1.14749,-0.860124,-0.659351,-0.295894,1.56919,1.75516,-0.559897,-0.556623,1.1355,1.03038,0.301327,0.162277,-0.273321,-0.276253,-0.406103,-0.585769,0.274963,0.306204,-2.19121,-2.05266
4734,0.522934,0.483433,0.943924,0.884617,0.877225,0.6982,0.834222,0.772987,0.553748,0.650939,0.0383502,-0.0126147,0.79878,0.730071,0.0164283,0.0395263,0.567322,0.581403,0.332278,0.335329,-0.743233,-0.454324,1.07753,1.44726,-1.46681,-1.28145,-0.806804,-0.808346,0.858951,0.755648,-0.796293,-0.933641,0.521569,0.520667,1.4342,1.25094,-0.185517,-0.149169,0.541929,0.678049
4735,0.668482,0.628248,0.749903,0.689987,0.922381,0.768844,0.46276,0.401069,0.268543,0.3285,0.18996,0.137181,0.376434,0.309049,0.372992,0.397034,0.861204,0.90793,0.602308,0.603672,-1.84158,-1.55246,0.553329,0.930457,-0.0374093,0.142886,0.0930992,0.0950994,-0.620978,-0.727947,0.0380878,-0.0915169,-2.37717,-2.38045,0.607143,0.417142,0.711387,0.745879,-1.19022,-1.06001
4736,0.182806,0.141654,0.321646,0.26141,0.715945,0.561066,0.582112,0.527448,0.46095,0.518486,0.725208,0.674503,0.962114,0.895311,0.351535,0.394845,0.596903,0.684297,0.543997,0.545335,-1.24799,-0.962864,0.439597,0.809971,-1.57073,-1.38384,-0.183658,-0.187375,-0.884194,-0.988806,-1.12146,-1.24649,2.34114,2.33786,0.205142,0.0133843,-0.0625551,0.0361003,-1.18077,-1.05243
4737,0.992302,0.950133,0.895527,0.837173,0.724784,0.537339,0.715146,0.653827,0.422885,0.523571,0.454483,0.401581,0.642508,0.574744,0.257551,0.392655,0.414779,0.460664,0.281091,0.283503,0.212615,0.504783,-1.1692,-0.794369,-2.42226,-2.2314,-0.0670351,-0.0686421,0.779943,0.670576,0.858529,0.730988,-1.38007,-1.38367,-0.495069,-0.682882,-0.658572,-0.673678,-0.781556,-0.655697
4738,0.0447072,0.0020033,0.481362,0.42348,0.669531,0.513613,0.301002,0.241508,0.470819,0.528655,0.457301,0.339012,0.74957,0.728913,0.368008,0.390465,0.793492,0.841417,0.0212014,0.021671,-1.57497,-1.28384,-0.999935,-0.623101,-0.232069,-0.0388465,0.458774,0.462854,-0.343897,-0.459751,-0.324105,-0.455133,-0.219997,-0.228202,-0.253179,-0.443148,-1.41795,-1.38346,0.540566,0.670687
4739,0.753276,0.712634,0.534872,0.565768,0.318711,0.163531,0.78452,0.72411,0.0663966,0.124577,0.329416,0.276444,0.949083,0.883082,0.00607778,0.028327,0.0685318,0.115721,0.932909,0.934729,-0.00735164,0.27613,-0.626771,-0.25444,-0.271429,-0.0832007,0.335253,0.333224,-0.379898,-0.502057,0.912406,0.784477,-1.80113,-1.80841,-1.5739,-1.76889,0.428883,0.470299,0.0845759,0.210593
4740,0.617607,0.579355,0.76518,0.708056,0.453878,0.299964,0.374404,0.31179,0.181991,0.261352,0.586955,0.535722,0.0597399,-0.00504888,0.213973,0.235444,0.956612,1.00421,0.286918,0.288569,0.368932,0.65075,-0.929696,-0.560611,-1.28839,-1.1028,0.0639585,0.203594,1.00212,0.884007,1.00539,0.87588,0.996797,0.985878,1.57277,1.37079,0.899733,0.945278,0.532438,0.653901
4741,0.874742,0.835796,0.364023,0.308616,0.251729,0.0984895,0.977488,0.914549,0.333084,0.398127,0.161535,0.110002,0.161301,0.0328177,0.664455,0.687143,0.309136,0.359532,0.601068,0.602007,-0.0544881,0.194878,-1.88463,-1.50901,-0.506997,-0.320092,0.0763382,0.0739638,0.0999386,-0.0157335,1.69113,1.56322,-0.820212,-0.828088,0.659124,0.50495,-1.80604,-1.76361,-1.74957,-1.63076
4742,0.810282,0.769517,0.23652,0.191249,0.85881,0.706352,0.126744,0.0660103,0.520184,0.534902,0.452514,0.491881,0.133079,0.0706842,0.659056,0.679378,0.348254,0.397977,0.647186,0.619313,-0.544392,-0.260994,0.44998,0.823955,-2.06547,-1.87684,0.0212611,0.0242715,-1.78659,-1.90116,0.60743,0.484049,1.65289,1.6484,-0.15727,-0.360888,-2.40408,-2.35694,0.514137,0.629545
4743,0.161644,0.123331,0.130205,0.073881,0.471327,0.316873,0.372628,0.311233,0.61577,0.671677,0.926739,0.873761,0.405522,0.341881,0.690847,0.671613,0.737655,0.788867,0.634241,0.636619,-0.762036,-0.390236,1.13864,1.51616,0.422415,0.615503,1.47663,1.48674,1.11056,0.991306,0.675352,0.54483,-1.18609,-1.19011,-0.0889132,-0.291634,0.567853,0.612819,-0.513888,-0.404552
4744,0.165998,0.12848,0.249737,0.192362,0.829923,0.673978,0.25854,0.19877,0.514075,0.570387,0.939991,0.885572,0.288742,0.242243,0.64116,0.663848,0.0498803,0.103429,0.071214,0.0755486,-0.806987,-0.519479,0.44188,0.815015,0.560914,0.753367,1.32683,1.34484,-0.0676324,-0.184788,0.98034,0.846889,0.0871886,0.0861191,-0.37292,-0.572593,-2.24508,-2.19533,1.93119,2.0392
4745,0.394953,0.355036,0.770547,0.71537,0.43217,0.273865,0.552008,0.49404,0.0222998,0.0770511,0.549017,0.493439,0.203405,0.142605,0.0125867,0.0374693,0.461741,0.507516,0.326308,0.328754,1.8049,2.08474,0.612458,0.986283,0.129442,0.326505,-0.199281,-0.186648,1.22979,1.10873,-1.94398,-2.08453,0.593662,0.593144,0.752256,0.55632,-0.602965,-0.546345,0.115245,0.224537
4746,0.339923,0.298367,0.691223,0.637576,0.761532,0.601625,0.259896,0.201528,0.0536802,0.109014,0.882456,0.827862,0.105026,0.0429666,0.559124,0.585284,0.858048,0.911602,0.0314668,0.0333469,1.52216,1.80362,0.510597,0.880813,-1.13058,-0.938476,-0.55801,-0.52809,-0.416333,-0.54379,-0.962622,-1.06023,-1.64421,-1.64543,-0.491751,-0.690458,2.81455,2.87575,-0.030473,0.139857
4747,0.507949,0.469217,0.144262,0.0908561,0.325798,0.166296,0.574752,0.529116,0.82741,0.883185,0.259925,0.203274,0.27907,0.219427,0.666196,0.69162,0.1686,0.220628,0.107973,0.159878,-0.602445,-0.31198,-1.30617,-0.929644,-0.650206,-0.463559,-0.882404,-0.869533,0.686838,0.56433,0.104595,-0.0359294,-1.28713,-1.29158,0.13967,-0.0532017,0.0874709,0.14772,-0.0578413,0.0551779
4748,0.940735,0.902179,0.464576,0.354811,0.226085,0.158593,0.914641,0.856704,0.484432,0.53961,0.597891,0.54285,0.95497,0.896918,0.141366,0.165811,0.600455,0.558824,0.332058,0.28641,-1.12998,-0.839894,0.148672,0.518552,-0.61566,-0.432915,-0.380835,-0.369785,-1.19114,-1.30532,0.285757,0.147181,-0.218773,-0.314528,-0.324851,-0.51833,0.0297998,0.0946016,1.14176,1.25885
4749,0.688943,0.668596,0.67021,0.618767,0.309553,0.150891,0.603337,0.504753,0.408242,0.464582,0.330667,0.247276,0.365972,0.309611,0.804082,0.830135,0.844666,0.89702,0.281507,0.412941,-0.201894,0.0848058,0.715036,1.0887,-1.48731,-1.31208,0.77053,0.779995,0.0802102,-0.0401766,-0.385401,-0.518881,0.66073,0.66252,0.270904,0.072266,-1.18076,-1.10955,-1.06457,-0.945309
4750,0.568448,0.435013,0.497751,0.444192,0.608864,0.452138,0.211481,0.152803,0.882003,0.937554,0.00789157,-0.0482985,0.877115,0.820428,0.247003,0.274022,0.148127,0.200865,0.517265,0.539473,1.33398,1.61417,-0.0887941,0.280121,0.509377,0.689316,-0.886729,-0.881597,0.746546,0.624258,1.46138,1.32228,0.627759,0.633748,0.104104,-0.0856942,2.2965,2.36594,-0.0383188,0.0761409
4751,0.240066,0.20143,0.849557,0.794695,0.488284,0.34876,0.917183,0.860139,0.00179038,0.0558147,0.789494,0.734787,0.197947,0.143824,0.416014,0.440967,0.869678,0.923397,0.664124,0.666004,0.230927,0.516042,0.161691,0.527444,-0.439491,-0.266296,-0.548734,-0.573436,-0.686025,-0.813161,-1.13768,-1.27266,-0.601147,-0.599176,0.26127,0.0764439,-0.634108,-0.56038,0.400992,0.519449
4752,0.655902,0.619495,0.251334,0.198532,0.535462,0.245382,0.561703,0.503126,0.855533,0.911221,0.87601,0.819963,0.248665,0.197098,0.358468,0.385302,0.559889,0.614337,0.168313,0.170596,-0.540306,-0.258757,1.53265,1.89781,0.685489,0.853802,-0.26543,-0.265274,2.47834,2.35163,0.792462,0.659471,0.28516,0.289482,1.44842,1.26295,-1.97772,-1.90694,0.378488,0.496413
4753,0.798581,0.776138,0.473373,0.380752,0.300353,0.142004,0.410437,0.386561,0.282922,0.337883,0.147804,0.0905261,0.567996,0.514296,0.598084,0.62514,0.858721,0.914288,0.253107,0.256717,0.874587,1.16043,-0.0104427,0.355447,-0.0133008,0.161359,-0.503442,-0.499392,0.0648827,-0.0544283,-0.286767,-0.419699,0.647426,0.65801,0.839912,0.659873,-0.509449,-0.444318,-0.550797,-0.43322
4754,0.967311,0.93278,0.615768,0.562971,0.90524,0.745563,0.329124,0.269997,0.22086,0.337487,0.291791,0.235511,0.288613,0.233378,0.348206,0.377143,0.0952273,0.149715,0.0017223,0.00690024,-0.153572,0.138524,2.54977,2.91293,0.514113,0.68239,0.390866,0.388468,-1.84585,-1.96981,0.347252,0.208633,2.28919,2.3064,-0.691365,-0.878009,-0.926349,-0.868688,0.65112,0.770455
4755,0.316832,0.281181,0.0510166,-0.00317073,0.107111,-0.0509728,0.738884,0.591525,0.28298,0.337092,0.0707529,0.0125975,0.888742,0.833894,0.886924,0.914915,0.606646,0.660107,0.899369,0.905271,1.47131,1.76139,-0.0448208,0.322375,-2.04127,-1.87468,0.0854243,0.0754598,-0.251247,-0.36989,2.38492,2.25191,-2.27694,-2.25972,0.31329,0.128969,0.0259833,0.0891118,0.43231,0.550261
4756,0.5517,0.517393,0.386094,0.246058,0.746503,0.588168,0.969925,0.913053,0.0707854,0.125295,0.684596,0.628266,0.189616,0.137499,0.225609,0.252811,0.779728,0.835074,0.174984,0.182791,-0.710266,-0.419283,0.353681,0.722166,0.0965883,0.267966,-1.16345,-1.16659,0.966178,0.84801,-0.828734,-0.965547,0.771539,0.780981,-0.278821,-0.550948,0.395521,0.454737,-0.216364,-0.092586
4757,0.473687,0.387706,0.549691,0.495288,0.163958,0.00446391,0.143745,0.0854949,0.416822,0.47203,0.317695,0.260858,0.477354,0.467555,0.173648,0.227601,0.730419,0.785507,0.168859,0.178296,1.53453,1.83097,1.44194,1.81705,0.549024,0.726841,0.225523,0.228386,-0.173775,-0.295656,1.79817,1.65675,-0.269269,-0.266631,-1.05493,-1.23087,-2.58458,-2.5318,0.836123,0.958258
4758,0.291058,0.258018,0.349813,0.279793,0.283411,0.125611,0.397584,0.340655,0.472854,0.529058,0.829855,0.77367,0.849662,0.797611,0.175441,0.202391,0.409973,0.46623,0.582509,0.592076,-1.31202,-1.0215,3.10784,3.48543,2.47999,2.65052,-0.683257,-0.671867,-1.05853,-1.08826,1.84781,1.70177,0.77138,0.77446,-0.776491,-0.944182,0.00066987,0.0532999,1.26885,1.38617
4759,0.774147,0.739334,0.120476,0.0642976,0.0149958,-0.14373,0.992894,0.9375,0.837939,0.892402,0.33108,0.273602,0.871034,0.820102,0.564572,0.589003,0.343222,0.400437,0.034706,0.0453125,0.194015,0.477625,-0.689154,-0.31301,-1.21598,-1.04005,-1.06657,-1.06154,-1.757,-1.88087,1.4233,1.27065,-1.25113,-1.24312,0.848198,0.674483,0.412106,0.465725,-0.295955,-0.181478
4760,0.525271,0.490609,0.824677,0.769531,0.483667,0.332311,0.659273,0.604729,0.124912,0.181515,0.869756,0.810925,0.60087,0.549169,0.661845,0.684733,0.807326,0.865606,0.223809,0.232505,0.585203,0.866627,-0.209197,0.163231,-1.51356,-1.34457,-0.0223143,-0.0202457,0.9038,0.776797,-0.196192,-0.345883,0.733995,0.748101,0.513847,0.347185,-1.0621,-1.00681,-0.0356717,0.0799198
4761,0.68625,0.650807,0.435361,0.379934,0.966373,0.808352,0.553813,0.497105,0.237972,0.295637,0.265373,0.205905,0.0224108,-0.0279039,0.103167,0.123576,0.833687,0.88995,0.995723,1.00317,1.74324,2.02111,-1.79923,-1.42437,-0.980438,-0.808292,1.24891,1.25359,-1.05862,-1.18947,0.0118419,-0.131521,1.17836,1.195,-1.1953,-1.36214,0.0873677,0.172485,-0.15009,-0.0335576
4762,0.30851,0.271071,0.887622,0.83429,0.744263,0.629464,0.0921663,0.0356396,0.0863925,0.144683,0.745755,0.688284,0.0886122,0.0748079,0.620119,0.640867,0.103869,0.158759,0.139973,0.145761,0.843832,1.12316,1.24379,1.6137,-1.23269,-1.0671,0.751682,0.755965,-0.708937,-0.847161,-0.429483,-0.52492,0.833663,0.927806,0.642105,0.474575,1.29648,1.35178,0.232087,0.34747
4763,0.852218,0.813325,0.2583,0.203961,0.71402,0.450576,0.354028,0.317349,0.982786,1.04091,0.586186,0.52983,0.228944,0.17752,0.204424,0.224375,0.228794,0.2833,0.64239,0.649719,-0.507987,-0.23219,1.57973,1.95468,2.1206,2.29312,-1.07179,-1.06186,1.48938,1.35584,-0.770944,-0.918318,0.637343,0.66061,0.55822,0.307601,0.613077,0.587223,-1.53241,-1.42153
4764,0.16096,0.121103,0.342991,0.272351,0.429709,0.271688,0.65607,0.599057,0.248781,0.309387,0.0402959,-0.014588,0.765595,0.71392,0.499291,0.465987,0.0829544,0.135108,0.836004,0.841768,-1.14691,-0.868125,0.613163,0.990033,-0.561518,-0.392428,-0.517857,-0.597541,0.417141,0.28671,0.675066,0.533503,-1.51693,-1.49669,0.313768,0.140627,-0.22958,-0.177329,-0.941111,-0.827296
4765,0.57329,0.534425,0.421138,0.340741,0.642943,0.405226,0.53507,0.476925,0.396788,0.459574,0.430246,0.438596,0.219789,0.167065,0.689227,0.707599,0.450007,0.500953,0.229073,0.235717,-0.276506,0.00835184,-1.25171,-0.869816,-0.233373,-0.14877,-0.148636,-0.133224,1.95599,1.82433,1.65696,1.51302,0.435914,0.448464,1.60912,1.43378,1.06384,1.10884,-0.746984,-0.640467
4766,0.296533,0.3201,0.624891,0.40913,0.738391,0.538765,0.636515,0.576148,0.218951,0.282942,0.946907,0.89178,0.897091,0.844556,0.18672,0.206331,0.0833593,0.136648,0.236821,0.24103,-0.801338,-0.519562,-1.07168,-0.684231,-0.0749522,0.0948877,-1.78848,-1.77713,-0.217011,-0.355795,0.839063,0.694649,-1.68673,-1.67766,-0.25629,-0.433431,0.65957,0.729955,-1.01028,-0.90502
4767,0.145349,0.105775,0.531859,0.47752,0.830034,0.672303,0.359173,0.29842,0.742547,0.806461,0.158023,0.100826,0.418429,0.362931,0.325276,0.427337,0.0497597,0.101577,0.734569,0.739662,1.43789,1.71616,0.840186,1.23129,-0.637644,-0.471685,0.85113,0.867732,0.355013,0.216133,-0.784913,-0.935399,-0.343325,-0.336014,1.52485,1.3393,0.301213,0.351072,1.68649,1.79204
4768,0.322575,0.281181,0.126807,0.0738663,0.153977,-0.00149335,0.368142,0.390029,0.416664,0.479298,0.651379,0.593452,0.490597,0.437067,0.630216,0.648343,0.802239,0.854238,0.790581,0.796846,-0.268902,0.00497867,-0.502323,-0.107959,-0.416643,-0.262995,-0.876166,-0.856891,2.02454,1.89141,-0.398829,-0.552508,0.466117,0.475653,1.75621,1.5638,1.45402,1.4969,-1.67268,-1.57019
4769,0.105726,0.0619464,0.85935,0.805461,0.964326,0.808765,0.541371,0.481638,0.860841,0.923095,0.146449,0.088079,0.0667884,0.0120622,0.000262244,0.0165154,0.504293,0.55507,0.452853,0.460415,0.532235,0.80709,-1.18588,-0.794201,-0.22496,-0.054304,0.441427,0.461328,-0.695893,-0.828666,-0.548187,-0.70812,-2.06596,-2.05228,0.105557,-0.0851725,-0.390624,-0.340238,1.67685,1.78278
4770,0.529292,0.485038,0.443711,0.442796,0.423413,0.269694,0.214866,0.154152,0.651775,0.716608,0.490238,0.433729,0.498481,0.443713,0.47846,0.493041,0.759423,0.811218,0.626947,0.632587,-1.7126,-1.43823,1.16761,1.55701,0.832048,1.00618,-0.812944,-0.796088,-0.321262,-0.548795,1.31536,1.16145,1.67457,1.68778,-0.802994,-0.994472,0.468724,0.526052,-1.30198,-1.20379
4771,0.535696,0.490187,0.135017,0.0801306,0.179398,0.0778797,0.639767,0.578414,0.697302,0.764099,0.316577,0.261134,0.0502827,-0.00205068,0.701545,0.716965,0.809799,0.860285,0.0572959,0.0614128,1.03048,1.30183,-1.44488,-1.06212,-1.51458,-1.3456,0.426938,0.444766,-0.132322,-0.268924,1.21189,1.05407,-0.878126,-0.85825,0.168122,-0.0211998,0.327475,0.379849,0.708844,0.801554
4772,0.316047,0.270952,0.18872,0.133933,0.0418163,-0.113935,0.755143,0.652757,0.0263412,0.0943959,0.909301,0.85178,0.15205,0.0943766,0.150168,0.165987,0.115136,0.16413,0.688746,0.690943,-0.276116,-0.00820687,0.983221,1.36851,-0.40122,-0.225506,-1.38738,-1.37306,1.54255,1.40635,0.302535,0.141731,-1.10352,-1.08617,1.43196,1.24158,-1.33765,-1.28057,0.0184878,0.11613
4773,0.655486,0.612901,0.688163,0.632413,0.596978,0.438581,0.890898,0.7271,0.0747512,0.141886,0.25742,0.201728,0.242166,0.190804,0.848275,0.86243,0.171733,0.22229,0.682318,0.754821,-0.415969,-0.155288,-0.329018,0.0642528,-0.722383,-0.547698,0.222231,0.231518,0.641447,0.506615,-1.17423,-1.33913,0.686233,0.698917,-0.751176,-0.940823,0.804653,0.869427,0.70755,0.815658
4774,0.652118,0.551098,0.737679,0.680446,0.0938899,-0.0655557,0.863402,0.801444,0.991107,1.05834,0.171524,0.113858,0.900405,0.848697,0.324743,0.336621,0.0119736,0.063873,0.818303,0.8187,0.234528,0.495135,-2.02811,-1.63332,-2.26492,-2.09102,-1.12184,-1.1156,0.0276678,-0.104009,-0.251728,-0.378771,1.03744,1.05277,-1.25399,-1.43658,0.635936,0.707153,1.41717,1.51519
4775,0.452725,0.489294,0.537542,0.480983,0.375364,0.215729,0.264496,0.20261,0.892675,0.961421,0.69262,0.635351,0.724761,0.705732,0.121176,0.134552,0.0610335,0.11294,0.191946,0.193144,0.263826,0.52906,0.459168,0.85731,0.935838,1.11068,0.502044,0.506029,-1.13336,-1.2651,0.741699,0.581588,-0.833772,-0.822487,-0.965033,-1.14989,0.833113,0.899715,-0.385979,-0.285574
4776,0.548584,0.427491,0.552378,0.495143,0.923572,0.763215,0.767484,0.704945,0.427853,0.497702,0.731633,0.675733,0.612613,0.562767,0.802625,0.816143,0.767519,0.820047,0.698321,0.697101,0.698646,0.963307,-2.1034,-1.69966,1.70969,1.87937,0.0981637,0.100865,-1.29267,-1.39938,0.832268,0.672991,0.103721,0.0414814,0.600069,0.4223,-1.16056,-1.09822,0.495462,0.597492
4777,0.408809,0.365687,0.0892257,0.0317797,0.819019,0.657171,0.944798,0.879998,0.689262,0.648375,0.270572,0.214825,0.21368,0.162429,0.60938,0.618061,0.372565,0.425845,0.242334,0.240885,-0.534029,-0.27063,0.0826657,0.487684,0.0432328,0.213186,-0.792168,-0.78554,-1.40571,-1.53366,-0.310636,-0.466618,0.900633,0.905449,-0.0661587,-0.24496,1.03047,1.10008,-0.195968,-0.0879315
4778,0.746018,0.702787,0.0794182,0.0212597,0.930449,0.768965,0.305094,0.242742,0.767922,0.799049,0.1886,0.131691,0.645932,0.59408,0.349038,0.419978,0.404325,0.455405,0.82577,0.825173,0.211889,0.470643,-0.680841,-0.276793,0.729695,0.90515,-0.245511,-0.237486,0.50698,0.373709,0.640577,0.483214,-2.42675,-2.4265,-0.324907,-0.511786,-0.0277493,0.0386383,-1.11013,-1.00167
4779,0.732752,0.672854,0.615258,0.558495,0.121752,-0.0391101,0.364032,0.313964,0.881287,0.949722,0.836657,0.778117,0.664783,0.611868,0.208692,0.221896,0.049497,0.100683,0.643935,0.644834,-0.481879,-0.225977,0.0379718,0.445283,0.35273,0.523938,-0.832052,-0.828731,0.394892,0.267062,0.777276,0.620497,-1.8107,-1.81071,-0.13345,-0.318236,-1.7915,-1.7196,0.0800839,0.189547
4780,0.687561,0.642921,0.297593,0.242723,0.283045,0.122158,0.468571,0.385187,0.0483534,0.117329,0.991364,0.932907,0.200911,0.146137,0.354556,0.368279,0.762186,0.81292,0.827486,0.827159,0.852877,1.11608,-0.384598,0.0207778,-1.00971,-0.835322,-0.103211,-0.0956821,1.00641,0.884176,1.45217,1.29544,1.35427,1.34867,2.77621,2.59305,0.524481,0.590438,-1.2153,-1.10581
4781,0.242255,0.197074,0.848642,0.794482,0.0278544,-0.131361,0.624366,0.45641,0.816713,0.886377,0.596731,0.57264,0.103216,0.0464789,0.268553,0.282467,0.174958,0.223872,0.112962,0.110867,0.516116,0.774123,0.766168,1.17382,1.30397,1.47362,-0.263432,-0.253372,0.296767,0.215013,0.262677,0.0932855,-1.20174,-1.21288,-0.0891658,-0.27391,0.116459,0.18261,-0.205988,-0.0997701
4782,0.499259,0.453515,0.414925,0.361316,0.748078,0.588636,0.590236,0.527632,0.707124,0.799056,0.272599,0.212373,0.405849,0.420161,0.845029,0.860343,0.293558,0.343041,0.362079,0.455542,1.18709,1.43787,0.68225,1.08291,2.85211,3.01955,1.24072,1.25501,-0.30413,-0.454151,-0.947975,-1.10887,1.53566,1.52927,-0.378192,-0.569445,-0.528212,-0.456684,0.468568,0.572652
4783,0.419902,0.301582,0.623871,0.511177,0.767795,0.609913,0.0284341,-0.0361039,0.594773,0.711734,0.747892,0.689688,0.850772,0.793844,0.272403,0.289327,0.686059,0.733931,0.801603,0.800217,-0.668145,-0.416063,-0.0715462,0.334513,-0.200621,-0.0357739,-0.0233063,-0.0024014,-1.00109,-1.12332,-1.24298,-1.31093,-1.44187,-1.44079,1.06288,0.864995,0.0134667,0.0819721,0.198358,0.308099
4784,0.197896,0.14965,0.825,0.661037,0.147832,-0.00862683,0.191276,0.160892,0.450002,0.624413,0.365657,0.308202,0.572738,0.518252,0.0011204,0.0167933,0.0812305,0.128271,0.251461,0.249421,-0.204828,0.0508307,1.49396,1.89466,-1.10532,-0.945659,0.0354733,0.0559845,0.157159,0.0310959,-1.34496,-1.51299,-1.41319,-1.40989,0.502473,0.308045,-0.195067,-0.124812,2.8974,3.00516
4785,0.684499,0.636376,0.864506,0.810897,0.902611,0.747841,0.414932,0.357887,0.467427,0.537091,0.200104,0.140565,0.567195,0.510824,0.259019,0.191882,0.949787,0.994992,0.95539,0.953847,-0.0309261,0.224365,0.965141,1.32569,0.956535,1.11982,-0.204845,-0.178133,-0.0222083,-0.152236,-2.0501,-2.22437,1.43291,1.43295,1.19191,0.991352,-1.29831,-1.23208,0.889135,1.03842
4786,0.69894,0.555701,0.633863,0.581001,0.948479,0.794526,0.511014,0.554883,0.77186,0.839856,0.433651,0.373944,0.143045,0.0858197,0.352862,0.36697,0.528339,0.571568,0.659742,0.65844,0.696125,0.950031,0.349324,0.756719,1.53042,1.68687,0.260129,0.291073,0.490741,0.358174,0.94986,0.7821,1.13155,1.13639,0.219959,0.0190325,-0.518114,-0.439492,-1.04155,-0.928317
4787,0.521586,0.475025,0.738406,0.685005,0.657284,0.504776,0.816417,0.751879,0.645272,0.713519,0.293255,0.235741,0.755877,0.697191,0.0279585,0.0404704,0.439749,0.477397,0.564681,0.5646,-0.841478,-0.590733,0.761115,1.17287,1.18824,1.35113,0.180798,0.21047,-0.160442,-0.296177,-0.151927,-0.313818,0.835526,0.839824,-1.42795,-1.62994,0.286874,0.353101,-1.1841,-1.07105
4788,0.74453,0.696825,0.20711,0.152931,0.645888,0.491288,0.130509,0.0647939,0.749647,0.765793,0.613255,0.555848,0.178808,0.120118,0.911321,0.92149,0.250705,0.383227,0.227463,0.228169,0.23644,0.485687,0.964961,1.37484,-0.675257,-0.505914,-0.621813,-0.597109,-1.22144,-1.35003,1.37415,1.21742,0.312416,0.316648,1.90695,1.71058,0.0853107,0.146317,-2.11386,-2.00068
4789,0.522406,0.459811,0.964867,0.908434,0.4206,0.282565,0.992024,0.928569,0.667797,0.818066,0.37383,0.317394,0.411423,0.351092,0.952499,0.932184,0.244259,0.289056,0.583315,0.582051,1.54905,1.79475,0.257852,0.6737,-0.481407,-0.307065,1.54005,1.55825,-0.698315,-0.825263,-0.136624,-0.292371,-0.884992,-0.885532,0.0220837,-0.173886,0.501122,0.558742,0.261364,0.374391
4790,0.269024,0.222797,0.670166,0.613122,0.22677,0.0738416,0.056601,-0.0048222,0.802091,0.87034,0.398346,0.343819,0.145129,0.085132,0.931936,0.942878,0.383921,0.488774,0.679089,0.65377,0.350237,0.590754,1.6195,2.0291,0.622277,0.796579,0.678614,0.705089,0.841842,0.712355,-0.490256,-0.645966,0.736865,0.73139,-1.36425,-1.56155,-0.350706,-0.297504,1.73959,1.85638
4791,0.508708,0.463853,0.809091,0.751464,0.894785,0.743423,0.557492,0.497513,0.305043,0.372093,0.778323,0.722708,0.797257,0.737891,0.638809,0.651347,0.587823,0.688491,0.725812,0.725489,0.701052,0.932475,0.792563,1.12949,0.197918,0.369716,-0.172209,-0.148067,0.396641,0.242348,0.62011,0.47273,0.0921271,0.0872522,-1.22741,-1.42963,0.670124,0.724238,0.399726,0.514478
4792,0.0487032,0.00279889,0.156388,0.10094,0.259043,0.109281,0.0529005,-0.00541597,0.0526818,0.1202,0.135315,0.0773657,0.116075,0.0560365,0.145271,0.155663,0.845724,0.888209,0.223743,0.22483,0.08378,0.310958,-0.179724,0.229878,1.37774,1.55157,0.763255,0.78532,-0.0938952,-0.227659,-0.918459,-1.06678,0.278811,0.269796,-0.0487313,-0.256066,0.192671,0.239724,-0.720304,-0.599654
4793,0.259985,0.138799,0.66696,0.613379,0.44835,0.299635,0.871015,0.811159,0.334218,0.402297,0.152974,0.0575992,0.944284,0.885441,0.0900642,0.0999973,0.0945362,0.135304,0.473588,0.426788,-0.171231,0.0605428,2.213,2.62788,-0.797308,-0.623126,0.20212,0.227001,1.31891,1.18774,0.373813,0.218918,-1.26029,-1.26247,-0.0487219,-0.248735,-0.989031,-0.948769,1.17649,1.29889
4794,0.318345,0.274798,0.538064,0.435319,0.068769,-0.0796971,0.200205,0.139188,0.864893,0.931322,0.0967254,0.0378326,0.568559,0.49858,0.629263,0.637769,0.329217,0.454322,0.630103,0.628746,-1.96311,-1.72808,-0.38273,0.0263097,0.869838,1.0513,0.0992116,0.131211,-0.80841,-0.944459,2.22531,2.0747,-0.0372532,-0.045949,-0.280436,-0.48459,-0.414973,-0.380195,-0.0849399,0.0332037
4795,0.455257,0.410798,0.31263,0.257259,0.518229,0.369558,0.640716,0.509329,0.10904,0.173721,0.853379,0.794699,0.171082,0.111719,0.809439,0.779124,0.734919,0.77334,0.509404,0.553176,1.46796,1.70105,-0.698057,-0.285172,-0.556726,-0.369813,1.50745,1.5446,1.09631,0.96291,2.11641,1.96731,1.53165,1.52142,0.327237,0.0941794,-1.6724,-1.63091,-0.0422804,0.0715417
4796,0.17048,0.12675,0.854362,0.799516,0.505732,0.361147,0.94271,0.879471,0.441356,0.460477,0.810682,0.729306,0.535501,0.478423,0.910719,0.920479,0.368519,0.409034,0.480728,0.477606,-0.440235,-0.213355,-1.00548,-0.596654,0.837806,1.02296,-0.181311,-0.146114,1.19611,1.06068,0.842179,0.609381,-0.879233,-0.892846,0.873135,0.672948,1.20621,1.24313,0.914837,1.03105
4797,0.713564,0.669005,0.699351,0.546213,0.523566,0.352736,0.314667,0.251794,0.689995,0.747232,0.723918,0.663912,0.902891,0.845128,0.027522,0.0370059,0.665314,0.705166,0.987654,0.986108,1.60555,1.83859,-0.202567,0.204674,0.202596,0.392034,-0.0678198,-0.0273812,-0.463909,-0.608519,-0.599458,-0.748554,-0.247557,-0.262012,-0.358062,-0.558872,0.776714,0.818764,-1.70314,-1.58709
4798,0.340679,0.294681,0.346818,0.292909,0.55438,0.344325,0.931523,0.869478,0.969307,1.03399,0.11078,0.049002,0.644295,0.588381,0.602617,0.610623,0.0654927,0.105364,0.149456,0.150223,0.0293054,0.266594,-0.589984,-0.176992,0.0744797,0.272077,-1.10323,-1.06682,0.824815,0.684996,0.766331,0.613352,0.679841,0.65921,0.341486,0.168904,0.794174,0.918418,-0.392795,-0.274954
4799,0.538806,0.490652,0.732649,0.677675,0.484585,0.335913,0.92428,0.862694,0.129979,0.196818,0.32003,0.325063,0.959268,0.905579,0.709523,0.626783,0.86292,0.90227,0.295147,0.296941,0.158202,0.394415,1.27404,1.69196,0.212351,0.409941,1.20604,1.24459,0.520631,0.380298,-0.0733587,-0.221018,1.18757,1.16624,1.10027,0.89668,0.983385,1.01807,0.0749636,0.197963
4800,0.10871,0.0598895,0.325871,0.268268,0.307352,0.159546,0.310863,0.249681,0.253757,0.321213,0.688838,0.601124,0.161138,0.10636,0.636019,0.642943,0.832916,0.872525,0.131967,0.131939,-1.43722,-1.2084,-0.526647,-0.101123,1.44737,1.65295,-2.67435,-2.64186,-0.086323,-0.230326,-0.501543,-0.652146,-0.363885,-0.382801,-1.75697,-1.95354,-0.100435,-0.102387,-0.694005,-0.564842
4801,0.730799,0.680078,0.44145,0.370324,0.369978,0.221726,0.371469,0.352377,0.695067,0.76501,0.938144,0.877184,0.1856,0.0663568,0.18631,0.19212,0.294909,0.332922,0.840765,0.840666,0.992788,1.21609,0.791276,1.22307,-0.391909,-0.18781,-0.688969,-0.657769,-2.27835,-2.42617,-0.105845,-0.253567,2.09272,2.07975,-0.165877,-0.366745,-1.25754,-1.22285,0.433021,0.562516
4802,0.984619,0.936519,0.438753,0.47238,0.140276,-0.00570113,0.516195,0.455072,0.12092,0.191672,0.521737,0.461279,0.0813656,0.0263532,0.379798,0.429331,0.118928,0.155325,0.77991,0.756077,1.38188,1.60509,1.17591,1.60855,-0.279081,-0.0813096,1.51746,1.55187,-0.474607,-0.626651,1.63242,1.47967,-0.951624,-0.968674,-0.623159,-0.831873,0.788075,0.827773,-1.64367,-1.51714
4803,0.729566,0.683601,0.633423,0.574436,0.71779,0.572443,0.286743,0.30074,0.565975,0.635469,0.65565,0.551239,0.643709,0.587866,0.590745,0.666542,0.823495,0.857945,0.556759,0.671489,-1.76973,-1.54008,1.02991,1.45886,1.1818,1.37392,-0.206747,-0.172754,-0.546073,-0.702083,0.187508,0.0314414,0.013372,-0.00132628,-0.816158,-1.02153,-1.68343,-1.64375,-1.14576,-1.01291
4804,0.234742,0.188207,0.145821,0.0866598,0.3394,0.193111,0.188898,0.146407,0.70649,0.6877,0.702637,0.6412,0.578002,0.525248,0.897942,0.903753,0.183959,0.217519,0.586876,0.5869,0.0795065,0.310925,1.94671,2.38013,-0.107469,0.093034,-1.2177,-1.18263,-0.305182,-0.468501,-0.715984,-0.866098,-1.14606,-1.15505,0.0654976,-0.13954,-0.834061,-0.792213,-1.16339,-1.03595
4805,0.378972,0.266255,0.210385,0.150733,0.949804,0.800974,0.0511303,-0.00792473,0.669802,0.739931,0.543989,0.482746,0.486315,0.46263,0.412791,0.417585,0.411695,0.498117,0.133728,0.135591,-0.301776,-0.0771951,-0.322447,0.110617,1.2194,1.42611,-0.894241,-0.864661,0.563656,0.395635,0.350064,0.206692,0.923191,0.91771,0.186464,-0.0232878,1.79399,1.83046,-0.185795,-0.0623016
4806,0.492893,0.344304,0.986823,0.926312,0.280886,0.131851,0.338633,0.279934,0.33434,0.431538,0.017414,-0.0415104,0.457727,0.400012,0.999714,1.00552,0.74234,0.778715,0.877332,0.879509,0.923778,1.15279,1.75678,2.18312,0.874411,1.0756,2.63892,2.67213,-0.385606,-0.515549,-0.840364,-0.979429,-0.358017,-0.363564,1.88008,1.67415,-0.793286,-0.760993,-0.807983,-0.688222
4807,0.466939,0.422352,0.373984,0.315347,0.894325,0.74546,0.550696,0.567792,0.0534874,0.123145,0.692907,0.635461,0.833026,0.776771,0.633009,0.638733,0.0432576,0.0783082,0.201491,0.203422,0.197891,0.342169,0.214428,0.640762,-0.756154,-0.558486,-0.816719,-0.783366,-1.26064,-1.42673,0.661737,0.519915,0.881184,0.883381,1.43681,1.22479,0.923872,0.949361,0.394202,0.515452
4808,0.987266,0.944311,0.489273,0.449875,0.405682,0.255573,0.914706,0.855651,0.501624,0.571348,0.838146,0.780446,0.83081,0.731329,0.546688,0.552922,0.352582,0.404835,0.177859,0.123824,-0.704315,-0.468448,-0.874547,-0.44753,-0.551187,-0.253429,0.125056,0.165488,0.340147,0.173192,0.485514,0.351128,0.831689,0.838558,2.51282,2.30645,-0.337462,-0.314711,-2.13997,-2.02639
4809,0.342227,0.298124,0.720496,0.584403,0.731651,0.583333,0.14424,0.0862454,0.0589068,0.127912,0.602579,0.547149,0.744472,0.685887,0.243573,0.251359,0.697039,0.731362,0.0424554,0.0442266,-0.447879,-0.21729,-0.336695,0.00480912,-0.147045,0.0516271,0.279481,0.316244,-0.859393,-1.03155,1.5315,1.39359,0.0368075,0.0394404,1.41828,1.21323,1.33069,1.34916,0.922601,1.02766
4810,0.0680467,0.0242746,0.778871,0.718931,0.751348,0.604609,0.57689,0.519661,0.853796,0.925355,0.676399,0.623113,0.970998,0.911735,0.39175,0.397741,0.130683,0.165845,0.919632,0.919131,-0.924435,-0.699839,0.028655,0.457148,-1.08105,-0.8881,1.4734,1.51255,-0.211628,-0.383746,1.24168,1.10169,-0.498702,-0.500263,-0.382919,-0.59349,-0.535523,-0.522447,-1.32407,-1.22303
4811,0.174241,0.130277,0.755759,0.693737,0.114572,-0.0335555,0.20478,0.147743,0.0841485,0.156556,0.381228,0.309497,0.845672,0.787123,0.929696,0.935513,0.18266,0.267805,0.791112,0.789918,-0.487809,-0.265592,-1.42813,-1.0086,0.826768,1.0195,0.370338,0.408544,0.903312,0.724374,2.33162,2.18893,-0.832381,-0.837201,-1.31367,-1.51884,1.23061,1.2505,1.13365,1.23625
4812,0.925362,0.878931,0.448206,0.348075,0.802903,0.656502,0.354667,0.267024,0.45314,0.524223,0.0476047,-0.00411974,0.984418,0.927341,0.818937,0.794639,0.343855,0.369765,0.0255176,0.0268139,1.24141,1.46369,0.38453,0.795784,0.69281,0.884554,-1.07518,-1.0332,-0.694094,-0.866081,1.46079,1.32455,0.351531,0.347564,2.23005,2.02605,0.950453,0.966474,1.27036,1.37831
4813,0.782815,0.735923,0.0644358,0.00241353,0.629455,0.484664,0.431895,0.386306,0.196016,0.267168,0.256332,0.204369,0.545321,0.486606,0.648105,0.653765,0.436562,0.471725,0.369574,0.371136,-0.433393,-0.215082,-0.628356,-0.215463,-0.0685748,0.130326,-0.855475,-0.804712,0.26242,0.0897952,0.875524,0.736017,-0.17351,-0.175611,2.10909,1.9122,1.78437,1.80079,0.02454,0.129171
4814,0.0409581,-0.00367743,0.939785,0.876658,0.787188,0.641304,0.562623,0.505587,0.147404,0.217399,0.686615,0.633355,0.447704,0.386948,0.770702,0.698584,0.973217,1.00632,0.488035,0.488304,0.976716,1.18843,0.465666,0.879422,-1.29957,-1.10596,0.0216293,0.146284,-0.863567,-1.04053,-0.238651,-0.373586,0.65138,0.651923,-1.76931,-1.96723,0.854854,0.879268,-1.00721,-0.904926
4815,0.394872,0.448098,0.00443975,-0.0571798,0.69091,0.545322,0.413424,0.267777,0.380606,0.492552,0.511648,0.456058,0.98025,0.918101,0.73401,0.743403,0.835885,0.832671,0.391347,0.298883,-0.389338,-0.18268,-1.1017,-0.692858,-2.13031,-1.93963,1.04564,1.09728,-0.276385,-0.454483,1.22812,1.09606,0.293962,0.299147,0.807114,0.614012,-0.332607,-0.309225,-1.53207,-1.42654
4816,0.946374,0.899873,0.286578,0.224597,0.148372,0.000339432,0.0852507,0.0299678,0.725809,0.767706,0.896386,0.840869,0.105642,0.0418024,0.784523,0.788222,0.623939,0.659026,0.106629,0.109462,0.953544,1.15938,-1.29436,-0.890431,-0.418063,-0.23416,-0.643626,-0.593429,0.913517,0.73169,-2.71182,-2.84388,-1.12678,-1.12279,-0.396445,-0.586543,-0.687373,-0.671061,-0.869271,-0.774444
4817,0.125084,0.0771525,0.907646,0.845081,0.0944639,-0.0174954,0.24546,0.189591,0.972865,1.04286,0.274247,0.220697,0.37817,0.342022,0.205299,0.207404,0.00166574,0.0385955,0.813107,0.813888,-0.497166,-0.289186,-0.678884,-0.274514,-0.244273,-0.067658,0.0906032,0.13962,-0.310695,-0.492191,-0.145942,-0.284498,0.36536,0.36901,0.509937,0.325902,0.218592,0.240223,-0.361818,-0.122347
4818,0.00690297,-0.0415136,0.161657,0.0993276,0.112977,-0.0353302,0.764561,0.70764,0.186905,0.257285,0.818187,0.762472,0.703554,0.642242,0.339267,0.342961,0.0565453,0.0927515,0.181037,0.183125,0.626282,0.832579,-0.277919,0.125277,0.274254,0.438361,-0.545559,-0.496386,0.15041,0.0214707,-1.47955,-1.62528,-0.662922,-0.662654,-0.836251,-1.01471,-0.764859,-0.742994,0.424219,0.52975
4819,0.407577,0.36143,0.402526,0.341446,0.850891,0.700012,0.325075,0.26571,0.355228,0.436377,0.0528126,-0.00267167,0.712607,0.721647,0.708681,0.710048,0.612661,0.647966,0.128027,0.129173,-1.29971,-1.09672,-0.541324,-0.133694,0.771483,0.94438,-0.50017,-0.455065,0.724521,0.535133,0.811226,0.671646,-0.807911,-0.812752,-3.16043,-3.33061,-1.19762,-1.1829,1.54193,1.64156
4820,0.352685,0.304761,0.196147,0.136501,0.990903,0.841964,0.482102,0.514567,0.546719,0.615468,0.303599,0.240768,0.860938,0.801051,0.684831,0.6843,0.948169,0.984398,0.340918,0.410949,1.33885,1.54061,0.149202,0.558509,-0.872083,-0.707534,-0.782124,-0.737539,-0.999997,-1.1952,-0.441046,-0.576793,-1.35894,-1.36625,-0.990636,-1.16862,-0.751082,-0.652452,-0.434322,-0.331953
4821,0.700434,0.651756,0.802627,0.741942,0.531909,0.382799,0.822881,0.763423,0.515869,0.585854,0.400836,0.484208,0.0951985,0.0351945,0.921385,0.833426,0.316269,0.354488,0.689107,0.692724,1.43915,1.58864,-2.29022,-1.88293,-0.0263485,0.180669,1.47404,1.52217,-0.00386628,-0.193345,-0.700638,-0.837946,0.545726,0.535371,0.91139,0.729553,-0.140258,-0.122004,-0.584821,-0.474688
4822,0.103556,0.0561717,0.493109,0.431352,0.491335,0.308134,0.846091,0.786012,0.0532923,0.122135,0.783133,0.727649,0.550662,0.491075,0.981545,0.982553,0.366179,0.403555,0.523215,0.527723,1.43147,1.63667,1.77186,2.17226,0.910643,1.06887,0.904175,0.947601,-0.467511,-0.652031,-1.26614,-1.40843,0.258678,0.245798,0.145864,0.0209741,-1.26243,-1.24783,1.02273,1.1292
4823,0.379206,0.332849,0.726613,0.663767,0.417733,0.23347,0.601573,0.542881,0.792892,0.86065,0.149746,0.092274,0.366507,0.244788,0.717585,0.780426,0.872425,0.90921,0.0741017,0.076414,0.273701,0.478804,-0.344794,0.0510009,-0.275401,-0.12026,-0.188128,-0.141033,0.288519,0.103523,-1.49528,-1.63938,0.687929,0.677793,-0.504607,-0.687604,-1.0047,-0.992527,-0.646458,-0.532097
4824,0.129614,0.0841246,0.732113,0.668141,0.307915,0.158805,0.614226,0.556002,0.541454,0.608758,0.369475,0.310989,0.055295,-0.00149872,0.556241,0.578299,0.798034,0.820467,0.508879,0.511047,0.238355,0.439569,0.774443,1.17673,-1.67713,-1.52621,0.315763,0.358714,0.0559306,-0.126492,-0.430612,-0.580993,0.898346,0.890628,1.34184,1.16409,2.1258,2.13613,1.29176,1.41039
4825,0.554185,0.507216,0.209909,0.145415,0.522998,0.37413,0.0911306,0.0330652,0.615705,0.604541,0.814754,0.754193,0.566005,0.509319,0.23075,0.376173,0.69509,0.731725,0.327457,0.330707,-0.122629,0.0816479,-2.08967,-1.67989,-0.191089,-0.0411149,1.39261,1.43099,-0.528457,-0.706253,-0.333944,-0.48959,-1.43464,-1.44608,1.07127,0.897269,-0.358707,-0.349225,-1.09535,-0.974713
4826,0.670904,0.623223,0.516959,0.451874,0.152577,0.00478653,0.867846,0.807242,0.532512,0.600325,0.494606,0.434945,0.269326,0.212651,0.173693,0.174046,0.605296,0.642982,0.886354,0.889581,-0.0124012,0.193095,0.714896,1.12952,-2.13197,-1.977,0.383936,0.421112,1.64197,1.46263,-0.535101,-0.689533,-0.345598,-0.358134,-1.6387,-1.81624,-0.10196,-0.0939207,0.545683,0.658729
4827,0.0432632,-0.00266288,0.436882,0.31648,0.103492,-0.0442368,0.288815,0.228629,0.896919,0.963669,0.652243,0.594415,0.715489,0.658797,0.238381,0.190206,0.0441507,0.0831347,0.442079,0.443189,-0.824012,-0.613335,-1.38867,-0.975081,-0.605099,-0.446193,0.168211,0.20174,1.2549,1.0803,0.307081,0.152591,0.330025,0.317041,-0.128036,-0.307495,1.72354,1.72817,1.27454,1.39124
4828,0.465293,0.420429,0.247923,0.181086,0.516138,0.368915,0.575677,0.513995,0.0757359,0.141051,0.237981,0.178509,0.540878,0.483906,0.206857,0.206367,0.441884,0.479012,0.863689,0.862518,0.991857,1.20712,1.66374,2.08248,-1.00381,-0.842982,1.10654,1.13513,-1.69211,-1.85869,1.68004,1.52883,-0.91507,-0.931889,2.26098,2.0855,1.01871,1.02759,0.103798,0.216809
4829,0.363168,0.396714,0.369137,0.304242,0.545928,0.400639,0.241829,0.181223,0.379496,0.443816,0.485423,0.424677,0.0629941,0.00776111,0.068934,0.069987,0.559298,0.59818,0.216886,0.216358,-1.04768,-0.833342,-1.24613,-0.821472,1.00445,1.15842,-0.517169,-0.49251,1.10308,0.93506,-0.717793,-0.867587,1.57886,1.5682,-1.10882,-1.2843,-1.19337,-1.19037,1.12189,1.23826
4830,0.415266,0.373,0.771517,0.704279,0.168981,0.0213076,0.558649,0.513599,0.108032,0.17181,0.728787,0.670844,0.426235,0.370221,0.43424,0.437074,0.911386,0.949463,0.826244,0.825224,-1.53857,-1.33215,0.576769,1.00034,-1.50219,-1.35022,-0.313172,-0.281868,1.34384,1.16864,-0.5077,-0.653225,-1.88114,-1.88566,-1.08598,-1.26132,0.280894,0.285518,-1.03192,-0.918244
4831,0.156727,0.114922,0.385595,0.319917,0.164497,0.017576,0.90526,0.845975,0.509874,0.574341,0.248099,0.190706,0.0752892,0.0195914,0.465627,0.494409,0.485582,0.526039,0.373432,0.373915,1.4519,1.66152,0.216239,0.635931,-0.636289,-0.489923,1.10689,1.13152,-0.0763421,-0.25397,-1.69578,-1.83935,-0.378197,-0.377509,0.174431,0.0906212,1.55163,1.55598,0.116182,0.224344
4832,0.813741,0.771316,0.390933,0.324291,0.640179,0.425602,0.473525,0.408134,0.57221,0.570721,0.893546,0.837132,0.808522,0.754156,0.551016,0.551744,0.44087,0.547374,0.599556,0.601695,-0.373616,-0.159632,1.92075,2.33355,-1.81789,-1.66552,0.656541,0.680177,-0.841352,-1.01689,-1.00002,-1.15201,1.90829,1.90625,1.62152,1.44257,-1.41307,-1.41126,1.04824,1.1524
4833,0.292287,0.250675,0.971615,0.905251,0.981933,0.833628,0.029579,-0.0297066,0.545333,0.567101,0.624088,0.569255,0.638185,0.680517,0.368373,0.351973,0.528651,0.568709,0.159765,0.160636,-0.220699,-0.00167178,1.1055,1.52498,0.186825,0.335883,-0.0785432,-0.0490977,0.497781,0.321723,-1.65195,-1.80434,0.165179,0.169778,0.258567,0.0604211,-0.473299,-0.467315,-1.50171,-1.4014
4834,0.697664,0.653618,0.175691,0.107665,0.356614,0.209508,0.496423,0.438238,0.499014,0.563481,0.555739,0.501175,0.662062,0.606878,0.153097,0.152203,0.922532,0.964586,0.434803,0.464661,1.24872,1.46597,-0.584608,-0.159123,-1.37536,-1.22087,1.95951,1.98356,1.00482,0.832133,-0.205053,-0.352518,0.543384,0.552223,-1.14277,-1.32172,-1.46954,-1.46686,-0.953601,-0.852393
4835,0.758099,0.721527,0.469574,0.404273,0.36844,0.221514,0.343632,0.286116,0.0206597,0.0845259,0.0403956,-0.013257,0.0234714,-0.030565,0.629883,0.628728,0.703172,0.778221,0.766169,0.768687,-0.936561,-0.714701,2.51115,2.9387,-0.746894,-0.592639,-0.655239,-0.635094,0.331993,0.160351,-0.0628933,-0.215235,-0.270034,-0.260033,0.578585,0.405038,1.70452,1.70722,1.03037,1.13514
4836,0.748134,0.789435,0.385798,0.319166,0.0133521,-0.132217,0.726745,0.66922,0.944727,1.00807,0.429853,0.376074,0.862445,0.809843,0.340473,0.337197,0.551874,0.591857,0.14315,0.14313,0.270754,0.487284,-0.20978,0.209209,-0.441562,-0.284757,1.20644,1.22278,1.65769,1.48477,-0.597397,-0.75674,-0.791972,-0.783209,-0.38287,-0.551226,-0.116269,-0.116803,-1.49812,-1.38842
4837,0.902722,0.857344,0.250573,0.234058,0.0107217,-0.135949,0.507739,0.451696,0.799002,0.861665,0.429214,0.408262,0.499439,0.380001,0.339481,0.429457,0.0526795,0.0921041,0.931789,0.929861,-0.467562,-0.254847,-0.713538,-0.292481,0.619116,0.775724,-1.45086,-1.43911,-0.0274754,-0.199953,-1.87028,-2.03691,-0.435771,-0.429356,-0.976235,-1.14016,-1.69381,-1.69761,-0.488713,-0.382382
4838,0.665594,0.618878,0.214253,0.148951,0.639939,0.492548,0.843634,0.785451,0.912327,0.975788,0.558857,0.440449,0.000213074,-0.0498408,0.423809,0.521717,0.669082,0.708151,0.403743,0.403873,-1.96653,-1.7499,-1.6997,-1.27146,-1.56226,-1.39897,-0.489173,-0.475186,0.434298,0.264164,-0.979844,-1.14636,-1.52804,-1.52175,0.366062,0.199308,-0.658618,-0.754448,-1.06267,-0.963856
4839,0.146193,0.0982374,0.444198,0.381367,0.669688,0.579704,0.953302,0.894342,0.0741064,0.138618,0.437138,0.472636,0.271872,0.138675,0.616262,0.613977,0.591892,0.661966,0.768616,0.769063,1.25406,1.47069,-0.906678,-0.483118,0.269529,0.43097,0.118167,0.131708,0.378726,0.204527,-0.0891832,-0.255814,0.386605,0.394979,-1.37452,-1.54247,0.189134,0.188712,0.806005,0.906049
4840,0.704851,0.654786,0.464374,0.4004,0.812387,0.666859,0.704414,0.67741,0.931243,0.994024,0.560681,0.504823,0.375465,0.32719,0.811747,0.810655,0.669619,0.615782,0.121494,0.122904,-1.3799,-1.16229,-1.42791,-0.999923,0.959076,1.12293,-0.130764,-0.0203231,-0.15537,-0.327511,0.305663,0.234381,-1.68577,-1.67222,-0.299968,-0.460817,1.85085,1.85259,2.02838,2.1268
4841,0.764491,0.715039,0.712035,0.647407,0.568218,0.371851,0.517129,0.460479,0.641502,0.706697,0.918886,0.864916,0.0307249,-0.0180332,0.7745,0.77454,0.528519,0.569598,0.321825,0.32489,-0.273427,-0.0547815,0.368213,0.790995,-0.0253021,0.134795,-0.272913,-0.172354,-0.126819,-0.29171,0.886858,0.724576,1.93902,1.96055,-0.5983,-0.756353,-1.18297,-1.18861,-0.475788,-0.376174
4842,0.514023,0.380572,0.263529,0.19895,0.22328,0.0768425,0.959785,0.903889,0.832136,0.896683,0.558936,0.456279,0.843956,0.792816,0.0950159,0.0971829,0.241782,0.280447,0.142754,0.14455,-0.249637,-0.0334859,-1.39729,-0.971526,-0.195156,0.0394518,-0.339832,-0.324385,0.602369,0.433965,-1.07142,-1.23303,-0.465643,-0.440216,0.176876,0.0181635,-0.972984,-0.980373,0.434486,0.536558
4843,0.0963657,0.0461044,0.769342,0.706503,0.743974,0.595748,0.466181,0.411178,0.504461,0.56952,0.101613,0.0476428,0.167167,0.116211,0.165512,0.196957,0.571845,0.610986,0.806487,0.807895,-0.45519,-0.23894,-0.822138,-0.401381,-0.207561,-0.055891,-1.75944,-1.75016,-0.421178,-0.590037,1.1838,1.01707,-1.08579,-1.05499,-0.992281,-1.14998,-0.0418623,-0.0528024,-0.772554,-0.667513
4844,0.805869,0.756736,0.458666,0.395913,0.98407,0.835802,0.639496,0.586232,0.861841,0.927147,0.185812,0.132819,0.427033,0.377784,0.296171,0.296732,0.378326,0.356985,0.261257,0.261132,0.736641,0.947214,0.755547,1.17379,-0.62653,-0.468388,0.982393,0.993465,0.726254,0.5507,2.24615,2.07546,0.125413,0.161529,0.936528,0.782689,0.182254,0.161221,0.155949,0.260547
4845,0.674074,0.638052,0.801929,0.742088,0.90307,0.726006,0.484947,0.43411,0.225048,0.292249,0.578274,0.527041,0.298902,0.183201,0.144948,0.145487,0.0645022,0.102985,0.0950914,0.0961298,1.59927,1.80916,-0.0344678,0.379123,0.472316,0.635256,0.904662,0.912862,0.695715,0.523816,-0.371099,-0.546249,0.965258,1.00401,1.20794,1.05437,0.392066,0.375245,-1.06635,-0.95915
4846,0.569582,0.519369,0.0856066,0.0271834,0.873786,0.616209,0.0469299,-0.00212569,0.392627,0.462777,0.347289,0.293743,0.0362651,-0.0113819,0.263179,0.20221,0.673726,0.714603,0.775461,0.77499,0.999254,1.20468,0.0908842,0.502376,0.709926,0.866205,0.575665,0.658672,-0.553442,-0.731065,1.21172,1.03356,-0.9381,-0.903647,0.174445,0.0226857,-0.279422,-0.295708,0.986311,1.09481
4847,0.0520233,0.00395087,0.26156,0.254921,0.653553,0.506413,0.899836,0.849735,0.256004,0.320318,0.437494,0.384511,0.489857,0.439868,0.364482,0.258933,0.987108,1.02945,0.332831,0.33393,-1.14264,-0.942012,0.577246,0.99656,-1.41674,-1.25993,0.391889,0.404483,0.19246,0.00977984,0.713332,0.540359,2.33734,2.37027,-0.409455,-0.566248,1.34756,1.33594,0.0868953,0.197022
4848,0.621159,0.575412,0.473889,0.482659,0.222651,0.0765019,0.449646,0.397868,0.105659,0.17786,0.833945,0.778733,0.26999,0.218707,0.313353,0.315655,0.595548,0.676983,0.936501,0.937713,-1.50192,-1.29993,-0.626081,-0.199945,0.658577,0.822252,-0.583698,-0.600705,-0.249298,-0.460227,-1.60774,-1.77934,-0.13717,-0.111552,-0.781833,-0.938944,0.0538806,0.0379194,0.200955,0.277213
4849,0.968575,0.922407,0.641594,0.710397,0.168732,0.00825604,0.506413,0.405798,0.816904,0.889806,0.668567,0.611096,0.337086,0.357623,0.603725,0.516093,0.280643,0.324519,0.823756,0.82735,-1.57931,-1.37106,-0.646743,-0.214742,0.61568,0.777898,-1.61666,-1.60589,-0.738787,-0.930234,0.118213,-0.0460967,0.802811,0.825315,0.13954,-0.00963248,1.40818,1.3934,0.248754,0.357403
4850,0.743348,0.698849,0.996558,0.938135,0.0864163,-0.0599899,0.46609,0.413729,0.142924,0.214607,0.758416,0.701864,0.548639,0.496539,0.716375,0.716531,0.16857,0.212531,0.00109999,0.0066603,1.56008,1.77174,0.480555,0.910989,-0.264786,-0.101272,0.463951,0.47315,2.4008,2.208,1.32662,1.16419,1.01893,0.971531,-0.53291,-0.747143,0.0976391,0.0781621,-0.532151,-0.420382
4851,0.77579,0.814434,0.256319,0.198207,0.849077,0.701901,0.276282,0.222131,0.357542,0.525543,0.524871,0.468771,0.908475,0.858999,0.474737,0.473617,0.628585,0.672827,0.799294,0.804793,0.90776,1.12085,0.140235,0.576423,-0.500388,-0.330085,-0.432254,-0.427103,0.000773079,-0.198062,-0.0657988,-0.224961,1.09687,1.11775,-1.33996,-1.48465,0.0404794,-0.0698494,-0.652267,-0.533859
4852,0.976162,0.93002,0.585098,0.430109,0.594186,0.439721,0.708754,0.655546,0.762824,0.836479,0.353174,0.235677,0.315255,0.267472,0.956055,0.955647,0.873141,0.918904,0.138682,0.14344,-0.499837,-0.283054,0.803774,1.23959,0.25802,0.423091,0.712055,0.722678,0.48415,0.280022,1.47839,1.3217,-2.25209,-2.23339,-2.38459,-2.53223,-0.200037,-0.217861,0.233743,0.349207
4853,0.544683,0.499258,0.719928,0.662011,0.326087,0.177542,0.884024,0.796408,0.597367,0.669858,0.0591338,0.0025826,0.585062,0.538669,0.274552,0.273471,0.00550647,0.0484143,0.11225,0.119489,1.0356,1.24631,-0.395535,0.0430839,-0.978934,-0.813201,-2.89198,-2.87835,-0.726109,-0.924726,-1.46824,-1.63126,-0.896229,-0.877624,1.00311,0.851121,0.71112,0.693422,1.78031,1.89049
4854,0.73269,0.689638,0.17499,0.115291,0.77132,0.621287,0.991039,0.93727,0.145425,0.216469,0.604751,0.548668,0.00581104,-0.0384037,0.940667,0.937795,0.631674,0.674802,0.774887,0.782833,-0.469114,-0.2632,0.589512,1.02647,-1.19649,-1.02807,0.288959,0.304958,-1.30865,-1.50449,0.0573374,-0.100022,-0.350146,-0.323474,0.882997,0.737271,-0.463152,-0.479393,0.656217,0.752801
4855,0.29484,0.253836,0.73787,0.677264,0.953512,0.80261,0.0207826,-0.0311418,0.664225,0.7354,0.81291,0.757156,0.527395,0.483892,0.164929,0.161421,0.704953,0.74846,0.448571,0.486999,0.56059,0.76765,-1.5995,-1.16166,-0.182933,-0.0133891,1.70754,1.71834,0.628922,0.436792,1.22407,1.06487,0.500635,0.533269,-3.18248,-3.32821,1.00525,0.98323,-0.495069,-0.384887
4856,0.804655,0.765755,0.721559,0.7258,0.0543307,-0.097577,0.231483,0.112499,0.164605,0.237153,0.52376,0.468244,0.447787,0.404556,0.54754,0.543656,0.172758,0.214412,0.184177,0.191165,0.795067,1.00246,-0.245591,0.193744,-0.487169,-0.317906,1.04598,1.05112,-0.44416,-0.632338,-1.11503,-1.26959,-0.0694279,-0.0363628,2.21732,2.07159,-2.07438,-2.09673,0.765591,0.881178
4857,0.825987,0.786193,0.805145,0.774336,0.987472,0.833301,0.306446,0.25614,0.654463,0.725484,0.993437,0.935843,0.771699,0.726447,0.154165,0.15186,0.045445,0.087444,0.827214,0.83451,3.0581,3.26923,0.825153,1.27139,0.112394,0.27956,-0.7199,-0.716368,1.29751,1.10597,0.224133,0.062782,0.11631,0.146181,-0.179926,-0.325353,-1.14701,-1.16916,-0.340272,-0.232954
4858,0.294564,0.254975,0.884232,0.822873,0.831374,0.765055,0.288456,0.238967,0.0168898,0.085852,0.391325,0.335208,0.476919,0.429779,0.867404,0.863871,0.380153,0.423876,0.8016,0.8487,-0.0502451,0.162934,-1.94479,-1.49662,-1.97114,-1.79869,-0.753871,-0.752013,0.858771,0.662398,0.764706,0.598822,-1.33629,-1.30524,0.0733441,-0.0695715,1.33704,1.32325,-0.423576,-0.380723
4859,0.459099,0.419959,0.63725,0.521016,0.852134,0.696809,0.538585,0.466601,0.530251,0.599973,0.226075,0.167571,0.464664,0.417116,0.126659,0.122617,0.322935,0.426894,0.786337,0.86289,0.0156428,0.230033,0.517498,0.965821,0.460406,0.624793,0.912154,0.914194,-2.61672,-2.80573,-0.885457,-1.04948,-0.0502645,-0.0119905,-1.53773,-1.68531,-0.167058,-0.180436,-0.630836,-0.528491
4860,0.0886084,0.0502066,0.282345,0.219159,0.415744,0.261481,0.75769,0.694235,0.309076,0.377816,0.387686,0.327042,0.0428369,-0.0039063,0.624816,0.619873,0.38503,0.429911,0.869784,0.877081,0.536263,0.744068,1.37274,1.82641,-0.778401,-0.611498,-4.20667,-4.20463,-1.66368,-1.84986,0.9563,0.79168,1.71737,1.75916,-0.451294,-0.603652,0.960615,0.949842,-0.464019,-0.380902
4861,0.329072,0.291262,0.864688,0.80012,0.524397,0.368113,0.971358,0.921869,0.817897,0.886154,0.109215,0.0492538,0.170204,0.121471,0.413652,0.48448,0.1573,0.201777,0.176274,0.184578,0.573682,0.777993,-0.316148,0.142306,2.43272,2.60469,-0.927477,-0.926114,-0.915505,-1.0943,-2.63025,-2.79434,-1.5439,-1.50227,-0.637786,-0.793308,0.438843,0.433327,-0.338708,-0.233312
4862,0.796965,0.757928,0.813276,0.723112,0.270073,0.193055,0.156257,0.104937,0.0260956,0.0964089,0.998796,0.940247,0.979651,0.93232,0.356258,0.349087,0.536933,0.582531,0.905266,0.913041,-1.00181,-0.794001,1.12553,1.5905,0.179592,0.349334,1.53337,1.53595,0.260862,0.0767646,0.324871,0.158889,-0.872305,-0.827099,-0.509919,-0.661388,-1.6993,-1.70619,0.352393,0.452749
4863,0.600931,0.559675,0.682761,0.646103,0.173016,0.0179967,0.0383258,-0.0129899,0.576128,0.64512,0.478123,0.420174,0.512529,0.466589,0.993513,0.984027,0.669718,0.716695,0.116203,0.122703,0.186366,0.392152,-1.30318,-0.836078,0.0997018,0.27358,-0.506379,-0.506757,0.882907,0.693879,-1.34679,-1.51761,1.27179,1.31457,1.04131,0.895057,0.922443,0.916481,1.41807,1.51875
4864,0.0316537,-0.0109453,0.633112,0.569095,0.732641,0.575968,0.137576,0.086233,0.460016,0.528489,0.436585,0.378207,0.63464,0.586658,0.129497,0.118322,0.590344,0.636331,0.489365,0.497181,0.487294,0.691605,-0.0272918,0.4425,-0.53803,-0.357343,-0.00387985,-0.00700964,-0.103904,-0.299768,-0.622171,-0.798425,-1.48722,-1.44232,0.292642,0.151547,-2.49185,-2.49781,-0.173132,-0.0650333
4865,0.0876894,-0.0139413,0.31394,0.248742,0.348888,0.243838,0.864191,0.814201,0.732295,0.800194,0.793993,0.733495,0.222545,0.175539,0.640432,0.630316,0.167656,0.212906,0.342437,0.335981,-0.669936,-0.466265,-0.238596,0.230386,0.0702761,0.255063,2.41352,2.40499,-0.219054,-0.422402,0.339576,0.165098,-2.90403,-2.86425,0.457534,0.313685,-0.504161,-0.516509,1.07966,1.18422
4866,0.0287587,-0.0169374,0.419394,0.352746,0.0697516,-0.0882916,0.548507,0.496246,0.501057,0.568631,0.143864,0.0834429,0.365723,0.321329,0.0125318,0.00393768,0.991469,1.03574,0.166712,0.174781,0.0200623,0.228738,1.0679,1.44227,1.51032,1.69556,0.972881,0.963247,0.185693,-0.0188494,1.0646,0.884287,2.57405,2.61383,-3.01103,-3.15295,-0.509931,-0.521826,-0.215975,-0.111134
4867,0.0249195,-0.0199335,0.86599,0.800992,0.111853,-0.0468834,0.864737,0.811071,0.839724,0.906008,0.70958,0.649871,0.177663,0.132346,0.193779,0.142169,0.926079,1.00363,0.481177,0.488219,-1.97986,-1.76412,2.18389,2.65414,-0.0071761,0.183711,-1.16821,-1.17102,-2.20297,-2.40582,-0.920033,-1.1029,0.310036,0.355818,-0.0672768,-0.208064,0.248698,0.231877,0.156066,0.256762
4868,0.842998,0.79793,0.174754,0.110547,0.968965,0.809775,0.642111,0.633031,0.437492,0.50193,0.0479111,-0.0100528,0.661613,0.614594,0.289966,0.2804,0.954315,0.971517,0.468946,0.474021,0.852471,1.07293,0.0667421,0.532884,0.92721,1.12022,0.389308,0.386475,1.43915,1.23273,1.29361,1.11495,-1.57769,-1.53649,-0.0658122,-0.200733,0.166721,0.148718,-1.36919,-1.26709
4869,0.0252322,-0.0194645,0.0467806,-0.0185852,0.790004,0.573499,0.508902,0.45499,0.747263,0.734076,0.824665,0.767068,0.55904,0.509826,0.70387,0.692144,0.837757,0.939408,0.708893,0.712769,-0.0901669,0.0541172,0.0971655,0.565672,0.0422826,0.241049,-0.761062,-0.762011,-1.42336,-1.6363,0.0945072,-0.0864892,0.51507,0.557442,-0.54504,-0.680964,-1.02611,-1.03977,0.040304,0.136855
4870,0.914652,0.867636,0.515713,0.449777,0.412404,0.337224,0.407491,0.27695,0.899367,0.966222,0.150693,0.0915178,0.179019,0.128885,0.207342,0.196459,0.864857,0.907298,0.218745,0.22209,-1.1843,-0.964693,-0.203365,0.259501,-1.99178,-1.78735,-0.321511,-0.322868,0.133113,-0.083478,-0.181716,-0.363402,-0.0819401,-0.0400342,0.566852,0.431951,-2.58961,-2.60468,-1.54338,-1.44693
4871,0.63397,0.617567,0.390354,0.325886,0.151978,0.100948,0.152576,0.0989101,0.946505,1.01371,0.784517,0.727497,0.887654,0.836977,0.0686787,0.0600796,0.402744,0.447199,0.98945,0.992755,1.99957,2.21998,-1.65208,-1.18955,-1.35063,-1.14248,1.33641,1.32853,-1.94178,-2.15146,-1.87948,-2.0575,2.06581,2.10164,-0.810555,-0.938255,1.14977,1.13665,1.18013,1.28378
4872,0.416822,0.367498,0.57046,0.504573,0.0221095,-0.135327,0.280043,0.228439,0.758411,0.826718,0.892764,0.83654,0.0136419,-0.0393218,0.759527,0.751394,0.650236,0.645393,0.960448,0.913157,0.123336,0.336058,1.40385,1.86801,0.0332877,0.2356,1.30319,1.30117,0.0898422,-0.115197,1.71008,1.5368,1.76112,1.79656,0.599166,0.465624,0.974432,0.959072,1.12977,1.23056
4873,0.758859,0.648941,0.0151564,-0.0524086,0.05732,-0.0989601,0.134109,0.0807058,0.121276,0.191821,0.424104,0.366464,0.659341,0.608618,0.598761,0.542055,0.797667,0.843588,0.828361,0.833559,-0.591452,-0.37621,-0.454183,0.00816073,0.417726,0.618633,1.28275,1.27382,-0.301451,-0.511695,-0.732676,-0.906078,-0.758976,-0.731374,-0.0516607,-0.185311,1.68021,1.66882,0.306666,0.408793
4874,0.978068,0.930384,0.427702,0.3627,0.66155,0.504599,0.308617,0.200686,0.894669,0.965991,0.494709,0.437512,0.459239,0.329415,0.350724,0.332716,0.03515,0.0790143,0.219142,0.223606,-0.28625,-0.0767576,-0.419153,0.0409494,-0.0116545,0.19177,0.0469176,0.0317701,-0.228492,-0.444586,2.48826,2.31841,-0.510106,-0.487371,-1.3411,-1.48117,1.47025,1.46203,0.755133,0.943144
4875,0.566283,0.520453,0.208197,0.143321,0.345653,0.220397,0.375292,0.320666,0.267963,0.340954,0.205938,0.1486,0.102198,0.0502111,0.133121,0.123377,0.210102,0.253982,0.441423,0.446719,-0.946541,-0.741651,-0.0943808,0.319294,-0.0437355,0.16229,-0.8127,-0.823932,-0.935886,-1.14579,-1.53377,-1.70117,-0.718159,-0.699814,0.378926,0.233623,0.0407701,0.0389099,1.37547,1.47749
4876,0.530581,0.484083,0.756831,0.69119,0.0937469,-0.0638052,0.276401,0.137722,0.980058,1.0529,0.431346,0.372631,0.333906,0.281185,0.352408,0.41319,0.145079,0.188189,0.0967341,0.100794,2.06278,2.27542,0.136034,0.597638,0.695207,0.812238,-1.11964,-1.13694,0.515314,0.300744,0.652674,0.485387,0.651638,0.671124,-1.99071,-2.13127,-1.16741,-1.16524,-0.234781,-0.109918
4877,0.0728096,0.0289851,0.70306,0.636708,0.172927,-0.0268639,0.0110222,-0.0452227,0.594797,0.669212,0.0775634,0.0203117,0.128763,0.0760628,0.715456,0.703004,0.531953,0.573939,0.611581,0.61431,-1.12315,-0.912271,-1.51473,-1.05477,1.25054,1.46219,-1.66543,-1.68012,0.54382,0.336545,-0.679632,-0.839958,-0.517982,-0.501257,-0.59687,-0.742841,1.08961,1.09664,-1.79935,-1.69733
4878,0.947302,0.904646,0.136247,0.0705657,0.137259,0.0100774,0.103038,0.0484492,0.661732,0.703673,0.00438921,-0.0523833,0.575277,0.479847,0.050362,0.0367167,0.365743,0.417934,0.139444,0.143296,-0.910374,-0.693384,-0.0926421,0.363044,0.966405,1.17274,0.745024,0.731887,-1.06903,-1.26995,2.20949,2.04884,-1.15733,-1.14539,-0.675665,-0.82679,0.00267845,0.00569128,-1.01103,-0.896004
4879,0.370568,0.328396,0.946979,0.882785,0.204571,0.0470187,0.915879,0.859793,0.662171,0.738135,0.911977,0.854455,0.936375,0.883632,0.173601,0.158016,0.218282,0.261928,0.940253,0.94671,0.130081,0.354786,-1.20579,-0.756919,-1.05894,-0.855662,0.629348,0.620167,0.395932,0.191044,0.0755384,-0.0761441,-0.441518,-0.423549,0.22569,0.0699858,-0.119053,-0.107926,-0.237413,-0.0946753
4880,0.378151,0.333545,0.710318,0.648283,0.00681659,-0.149852,0.0351818,-0.0210532,0.965465,1.0409,0.105027,0.047231,0.245988,0.191707,0.532168,0.525527,0.705719,0.746936,0.0841265,0.0893015,-1.46189,-1.23275,-0.696932,-0.247367,0.974474,1.17827,0.0856677,0.0769926,0.267706,0.0684094,-0.0839388,-0.213454,1.5275,1.53829,0.184568,0.0297373,-1.64022,-1.62611,0.598277,0.706653
4881,0.711579,0.568462,0.956977,0.895289,0.410952,0.18227,0.242597,0.222803,0.209599,0.283299,0.893654,0.835737,0.699899,0.647587,0.907448,0.893038,0.134867,0.177006,0.558854,0.563305,-0.000319869,0.234892,0.673888,1.123,-1.16734,-0.963896,-0.0627427,-0.0649129,0.373394,0.180103,-0.194506,-0.350764,1.03749,1.14313,1.769,1.61654,0.339109,0.355196,0.338611,0.4421
4882,0.848517,0.803378,0.711066,0.673161,0.670514,0.514392,0.520384,0.46666,0.250487,0.256226,0.0684274,0.0122811,0.669777,0.569443,0.674331,0.660748,0.140839,0.182448,0.0371732,0.0430443,-0.86815,-0.631662,1.23175,1.67649,-0.664406,-0.43846,0.0751903,0.0691019,0.949475,0.752031,1.24648,1.08772,0.741044,0.747964,2.37633,2.223,-0.830778,-0.817619,-1.11615,-1.02111
4883,0.487871,0.402956,0.416757,0.451032,0.209288,0.0552267,0.12393,0.0698148,0.232737,0.229153,0.759836,0.703558,0.54209,0.4913,0.192494,0.179668,0.988803,1.03252,0.12287,0.129165,-0.0375521,0.199593,-0.392991,0.0565043,-0.116863,0.086977,-0.132183,-0.133631,-0.0511681,-0.241617,-0.278216,-0.436357,1.21446,1.22457,-0.667314,-0.815386,0.362449,0.37309,0.622928,0.719845
4884,0.0457832,0.00253365,0.290591,0.228904,0.0563065,-0.096671,0.0290456,-0.0231569,0.128381,0.202081,0.31077,0.25225,0.905542,0.85376,0.127793,0.113914,0.015291,0.0571372,0.786745,0.79251,0.517283,0.756588,-1.65617,-1.20217,-0.119876,0.0869518,2.27395,2.27837,0.482692,0.29792,-0.707388,-0.867485,0.0787997,0.0845692,1.49678,1.3466,-0.057103,0.02343,0.674371,0.772679
4885,0.855699,0.811012,0.708695,0.648017,0.716395,0.562323,0.224744,0.173135,0.578926,0.654716,0.967088,0.908749,0.70103,0.648638,0.369706,0.426877,0.628318,0.668755,0.319201,0.326554,1.77341,2.02084,-1.27814,-0.816686,0.12194,0.333976,0.407241,0.413564,-0.0776333,-0.265972,0.123588,-0.0425755,-0.821896,-0.822447,-1.71528,-1.86442,-0.342946,-0.32623,-0.113966,-0.0199856
4886,0.988848,0.946838,0.864521,0.802063,0.431428,0.277583,0.106109,0.10905,0.583961,0.657506,0.00822833,-0.0513404,0.166386,0.111856,0.751586,0.739839,0.420454,0.453489,0.112473,0.21488,0.43495,0.679396,0.768921,1.2276,-1.0586,-0.841619,0.094333,0.100555,0.0498382,-0.139448,-1.17912,-1.35186,-0.206384,-0.206658,0.223623,0.0682482,0.0436015,0.0557521,0.949757,1.04601
4887,0.749121,0.708373,0.809363,0.765227,0.496826,0.344217,0.0962755,0.0449646,0.3094,0.3855,0.155585,0.0984554,0.389337,0.41651,0.332128,0.317884,0.19813,0.238224,0.0963467,0.103207,1.92891,2.17853,1.68107,2.13505,-0.954685,-0.808475,-0.917166,-0.909323,-0.159492,-0.352548,1.42213,1.25531,1.12479,1.1197,-0.0584609,-0.21271,0.640498,0.655241,0.368765,0.464541
4888,0.950679,0.908898,0.790604,0.72839,0.34444,0.11796,0.535437,0.483631,0.685949,0.763166,0.0197639,-0.039747,0.775827,0.721164,0.783093,0.769583,0.460578,0.499882,0.823279,0.83167,-0.218727,0.0318335,0.432257,0.892129,-0.957072,-0.775331,0.292174,0.302411,0.0739017,-0.118966,-0.509327,-0.669465,0.938011,0.937967,-0.0577251,-0.205379,-0.870913,-0.862942,-1.15364,-1.05931
4889,0.685239,0.571302,0.277445,0.215549,0.0451174,-0.108298,0.48239,0.432005,0.022651,0.098333,0.833214,0.775258,0.821974,0.769658,0.193447,0.178261,0.101312,0.140731,0.237754,0.245975,2.25885,2.50569,1.49623,1.95528,-0.823293,-0.742187,-1.21509,-1.20012,-0.452705,-0.740535,-0.0458951,-0.207897,-1.1955,-1.18816,1.49579,1.35107,1.1421,1.15262,-0.200377,-0.0998029
4890,0.275925,0.233705,0.893983,0.830557,0.363918,0.208415,0.800109,0.751636,0.040466,0.100163,0.998871,0.94042,0.120799,0.0685137,0.0465006,0.0823634,0.821938,0.863263,0.27382,0.236439,-0.144146,0.104129,0.489064,0.944032,-0.815737,-0.709044,1.73431,1.7578,-1.16787,-1.36211,-1.59227,-1.74741,-0.121747,-0.115676,0.79994,0.654799,0.239424,0.244878,0.026961,0.133229
4891,0.415345,0.469807,0.828531,0.864646,0.398571,0.179151,0.107209,0.0595187,0.0273476,0.101993,0.344547,0.285687,0.378414,0.277417,0.000609211,-0.0135341,0.140134,0.183322,0.221453,0.226903,-0.32062,-0.0716053,-0.12422,0.334375,-0.892883,-0.6759,-0.602234,-0.571352,0.180521,-0.00949454,1.04655,0.893827,0.075879,0.0831311,-1.47923,-1.62784,0.379953,0.39218,-0.189688,-0.086965
4892,0.64587,0.705908,0.868546,0.898735,0.306367,0.149888,0.876457,0.828402,0.832495,0.908892,0.697132,0.636573,0.538606,0.486321,0.0736318,0.0580532,0.262696,0.291438,0.816216,0.821122,-1.25764,-1.01352,-0.273475,0.184685,0.279132,0.490582,0.210335,0.238122,0.588621,0.394058,0.591509,0.365975,1.90096,1.90543,1.70623,1.55343,0.29796,0.309021,-0.871649,-0.772389
4893,0.983962,0.94201,0.996212,0.932824,0.922342,0.767886,0.410345,0.361745,0.693768,0.812706,0.142014,0.0823872,0.541991,0.489772,0.666742,0.651201,0.288257,0.399554,0.163983,0.170126,0.76547,1.00675,0.629722,1.09213,0.345904,0.552958,-0.107276,-0.074887,-2.70893,-2.90661,0.0287,-0.161878,-0.124557,-0.112153,-0.691175,-0.843521,-0.312731,-0.300473,0.430688,0.52363
4894,0.70529,0.663014,0.384153,0.321859,0.154072,-0.0013603,0.276783,0.229359,0.639698,0.716521,0.885971,0.828515,0.261448,0.208855,0.953657,0.937119,0.464483,0.507671,0.554733,0.559129,-0.35118,-0.106909,-0.766461,-0.310575,-0.442163,-0.232591,0.636326,0.673717,0.948825,0.758716,-0.534046,-0.68973,-0.378884,-0.370573,0.186553,0.0384679,-1.90123,-1.8959,-0.437202,-0.345765
4895,0.119212,0.0768256,0.0308175,-0.0323234,0.839399,0.683524,0.77367,0.727266,0.0287071,0.10702,0.497686,0.441062,0.312298,0.308923,0.022002,0.00591561,0.309278,0.354074,0.388821,0.394127,1.35865,1.6067,0.297429,0.752576,0.535214,0.750728,-0.802539,-0.768028,0.355722,0.165004,1.74461,1.59181,0.725516,0.733778,-0.0732968,-0.228358,0.259678,0.266995,-0.403423,-0.307427
4896,0.672529,0.627844,0.499245,0.436039,0.485698,0.357312,0.984523,0.938251,0.824961,0.904463,0.772243,0.627127,0.433656,0.408992,0.609665,0.593851,0.577811,0.6207,0.636889,0.632681,-1.31643,-1.06622,-1.47234,-1.00995,-0.013486,0.199905,0.567818,0.596915,1.806,1.61154,-0.490926,-0.644647,-0.460468,-0.453344,0.570593,0.408899,0.688298,0.694483,-2.57374,-2.47909
4897,0.53587,0.490036,0.430308,0.366997,0.185735,0.0311003,0.162769,0.116298,0.678822,0.829083,0.868725,0.813191,0.561653,0.50906,0.376502,0.361561,0.582578,0.535409,0.865089,0.871236,0.803469,1.0611,0.676355,1.14703,0.839049,1.0464,-0.222903,-0.194765,-1.52567,-1.72331,-0.971738,-1.12371,1.01765,0.999406,0.448469,0.280102,-0.786431,-0.778047,-0.142147,-0.054745
4898,0.743169,0.696256,0.722948,0.657864,0.955655,0.802327,0.18744,0.224689,0.677122,0.753703,0.879576,0.825003,0.123925,0.0729787,0.689612,0.672752,0.406505,0.450117,0.0229786,0.0293958,0.886481,1.14223,0.530504,0.977511,0.439256,0.64961,-1.01331,-0.986446,1.1115,0.913288,1.70135,1.54951,2.44503,2.45216,-0.613189,-0.782231,0.965472,0.979187,-1.01282,-0.92414
4899,0.148026,0.100672,0.564276,0.499336,0.270399,0.11803,0.380849,0.333079,0.220087,0.294971,0.412632,0.359467,0.397129,0.362521,0.401635,0.385805,0.950998,0.995054,0.738195,0.743754,0.0830821,0.335796,0.341423,0.807988,-1.01882,-0.801099,-1.31143,-1.2842,-0.988882,-1.18731,0.129869,-0.0212611,-1.46708,-1.4552,0.73883,0.575387,-1.13164,-1.11644,-0.66,-0.572207
4900,0.416741,0.367547,0.0614251,-0.00406286,0.0728518,0.000354888,0.212824,0.257605,0.036676,0.112654,0.501532,0.524728,0.825661,0.652064,0.313773,0.299994,0.865256,0.909473,0.222621,0.228403,-1.24775,-0.991958,-2.05455,-1.58998,-0.363376,-0.121142,0.902121,0.925443,-0.20269,-0.399123,1.95492,1.80448,-0.34431,-0.318923,0.0297228,-0.136892,1.84181,1.85332,0.831382,0.923947
4901,0.277379,0.257537,0.52276,0.399516,0.0332009,-0.11732,0.156915,0.182131,0.2819,0.359379,0.743146,0.68999,0.990386,0.941606,0.760921,0.746977,0.24514,0.289043,0.362465,0.370928,-0.290121,-0.0378603,-0.782564,-0.311399,0.332864,0.558814,-1.54089,-1.52343,-0.227185,-0.426007,-1.00298,-1.14847,0.810982,0.817352,0.177699,0.010598,-1.19601,-1.18788,-0.559937,-0.463963
4902,0.194451,0.147528,0.870207,0.803095,0.704173,0.552262,0.153818,0.106657,0.852681,0.928119,0.563048,0.56613,0.946586,0.863463,0.823173,0.807626,0.326692,0.416722,0.733798,0.740868,-1.862,-1.60985,-0.322046,0.150423,-0.319147,-0.0873145,0.45224,0.475636,0.42915,0.218449,-0.863039,-1.01119,0.784704,0.788581,-2.05513,-2.22693,-1.11254,-1.02671,0.461054,0.557487
4903,0.414352,0.304171,0.883741,0.750344,0.678576,0.528485,0.26632,0.144155,0.706734,0.78171,0.497582,0.442269,0.835894,0.785319,0.0833941,0.0663723,0.49904,0.544401,0.712289,0.721361,0.0712005,0.3158,0.741649,1.21357,0.275635,0.510152,-0.0225438,0.00761745,1.05586,0.862904,0.371294,0.228424,0.188615,0.191105,1.01394,0.84673,-0.873017,-0.865528,-0.97709,-0.87669
4904,0.509696,0.460813,0.764065,0.697593,0.111086,-0.0402479,0.284516,0.181653,0.0914723,0.167283,0.750798,0.695707,0.101173,0.0518699,0.638781,0.61957,0.361301,0.42949,0.140507,0.150188,1.07391,1.31801,-0.735623,-0.266617,2.76517,3.0025,0.999044,1.03429,1.02963,0.83602,0.684564,0.548714,-0.20472,-0.207108,-0.490827,-0.661262,-0.358523,-0.357352,0.249918,0.34406
4905,0.0923126,0.0454501,0.230571,0.16552,0.65344,0.502652,0.26637,0.219152,0.932234,1.00621,0.325269,0.269987,0.312416,0.263401,0.214726,0.193111,0.333636,0.31458,0.211366,0.222215,0.11944,0.359106,-0.390836,0.0743579,-0.222302,0.0150784,-0.324136,-0.282216,-1.21968,-1.40505,0.399626,0.256811,-1.51938,-1.51989,0.211062,0.0378247,-0.656013,-0.6581,-0.238822,-0.14579
4906,0.973979,0.927393,0.52838,0.542851,0.518925,0.365952,0.790999,0.742075,0.642508,0.661592,0.744795,0.689344,0.0334089,-0.0175163,0.320185,0.381929,0.152393,0.199669,0.620955,0.631529,0.867558,1.10038,2.21329,2.68325,0.580429,0.814102,0.49129,0.527257,-0.250586,-0.431786,0.948682,0.809307,1.13422,1.13076,-0.254664,-0.426019,0.311758,0.315377,0.585271,0.677164
4907,0.572671,0.52669,0.986483,0.920182,0.00501134,-0.147612,0.935873,0.887119,0.244441,0.316977,0.0500111,-0.00673003,0.266456,0.183299,0.591577,0.570747,0.727913,0.774397,0.221016,0.230968,-1.36537,-1.1316,0.441804,0.906598,-3.157e-05,0.227894,-2.83035,-2.79899,-0.456039,-0.630599,1.8587,1.71328,0.296882,0.287268,-0.710661,-0.889864,0.966626,0.97697,1.11832,1.21089
4908,0.919966,0.873685,0.301246,0.234923,0.816919,0.662646,0.441207,0.394409,0.357783,0.366572,0.0286887,0.0480605,0.436804,0.384115,0.446813,0.435354,0.811934,0.80908,0.287354,0.242417,0.256742,0.491272,0.509431,1.05998,-1.58182,-1.36117,-0.710171,-0.675302,1.76569,1.58917,-0.0762979,-0.224871,-0.227759,-0.235908,-0.722568,-0.899282,0.0270799,0.0373763,-0.0198916,0.0667581
4909,0.398067,0.353044,0.93251,0.865544,0.60618,0.449488,0.312472,0.267019,0.344558,0.416168,0.161565,0.102851,0.238354,0.184457,0.319253,0.299961,0.73945,0.843763,0.245138,0.253866,-2.50387,-2.2736,0.748668,1.21336,0.715476,0.932824,-0.167634,-0.127248,0.0529351,-0.127074,-1.00053,-1.15108,-0.50589,-0.509815,0.685206,0.504596,1.22538,1.22809,-2.22523,-2.1374
4910,0.1487,0.104319,0.464166,0.397284,0.0595276,-0.095495,0.603428,0.557472,0.813945,0.883988,0.78806,0.728308,0.3029,0.247971,0.902866,0.883374,0.833595,0.878446,0.495265,0.525645,-0.543067,-0.315009,0.56957,1.032,0.410072,0.571027,-0.637066,-0.595266,-0.18955,-0.370986,-0.323133,-0.476137,0.178336,0.181701,0.816353,0.636517,-1.78315,-1.77463,0.883923,0.969648
4911,0.705826,0.660868,0.53498,0.391734,0.980646,0.824506,0.0754766,0.0292281,0.238451,0.31065,0.256547,0.198389,0.0110692,-0.0437616,0.988089,0.969099,0.466473,0.495047,0.790665,0.797423,-0.0343197,0.199026,1.17888,1.64791,-0.0110322,0.209229,1.13473,1.1827,0.903034,0.722754,-0.964281,-1.11168,-0.187564,-0.185476,1.15825,0.982223,-0.266804,-0.251918,0.515716,0.59743
4912,0.478792,0.432215,0.453482,0.386184,0.770828,0.616728,0.979023,0.933538,0.23963,0.31344,0.311717,0.253993,0.948919,0.896354,0.0454956,0.0273539,0.0663649,0.111648,0.589554,0.596684,2.01607,2.25097,-0.186085,0.277668,-0.577419,-0.357343,-0.543025,-0.49371,-0.210506,-0.391855,1.30756,1.15544,0.353159,0.351613,0.989862,0.808451,-0.0339654,-0.0126149,-0.849617,-0.774115
4913,0.842314,0.794683,0.221647,0.156288,0.0886789,-0.0675692,0.564384,0.516769,0.701835,0.776603,0.124436,0.0655128,0.556393,0.495657,0.59159,0.575168,0.588592,0.632089,0.909201,0.914904,-1.17493,-0.93672,-1.15282,-0.686978,0.65495,0.87021,0.112394,0.161289,-0.91443,-1.09306,-0.19757,-0.35435,0.476314,0.460533,1.3424,1.15416,-0.482161,-0.467987,-0.0993768,-0.0256769
4914,0.494555,0.534119,0.626956,0.561962,0.205627,0.00721268,0.420804,0.375234,0.894353,0.917935,0.699289,0.641582,0.14794,0.0949607,0.832771,0.815006,0.146455,0.192883,0.381531,0.388915,0.0840104,0.327536,0.0499389,0.463783,-1.00274,-0.781704,1.0637,1.11014,-0.185564,-0.367386,0.50627,0.350775,0.576516,0.569453,-0.147639,-0.337751,-1.47527,-1.46753,-1.24301,-1.16981
4915,0.321436,0.273554,0.223844,0.158308,0.238729,0.0819946,0.998823,0.953114,0.98644,1.05927,0.0123108,-0.0431843,0.700741,0.64667,0.679808,0.592229,0.939004,0.985514,0.291392,0.253204,-0.312236,-0.0761787,1.14771,1.61454,2.17799,2.39303,-1.57826,-1.53521,0.841674,0.666081,0.400438,0.243393,1.20042,1.20029,0.270687,0.085456,0.290271,0.289706,-0.477575,-0.406822
4916,0.431621,0.384262,0.12688,0.0606167,0.132516,-0.0240493,0.144904,0.0987952,0.34654,0.419634,0.841196,0.78672,0.204985,0.150868,0.386083,0.369452,0.404275,0.451466,0.112991,0.117492,1.24373,1.48379,-0.640335,-0.178538,2.53926,2.7605,-0.256289,-0.216991,0.83742,0.655653,-0.98515,-1.14576,2.20345,2.20016,-2.72704,-2.91199,-0.032784,-0.0412492,-1.49602,-1.42611
4917,0.244847,0.209125,0.508243,0.440354,0.986987,0.832609,0.472698,0.428043,0.649322,0.722399,0.95923,0.906338,0.77953,0.727368,0.613934,0.499336,0.380884,0.426984,0.609035,0.611394,1.90688,2.14754,0.198183,0.653285,-0.496631,-0.276112,0.163849,0.207403,0.0576385,-0.120922,0.620589,0.463173,-0.438176,-0.442869,0.742436,0.565329,-1.04341,-1.05768,-0.418927,-0.370623
4918,0.0826304,0.0339872,0.292874,0.225899,0.033018,-0.122583,0.0672677,0.0210177,0.219454,0.293931,0.195956,0.141194,0.323017,0.271466,0.646871,0.629221,0.0246005,0.0722625,0.382684,0.385433,1.10065,1.34111,0.634867,1.08385,-0.641674,-0.427188,1.33097,1.37398,0.164949,-0.00922878,-0.180028,-0.340439,-0.236602,-0.244062,-0.791894,-0.972553,3.98402,3.96975,0.615061,0.684864
4919,0.298546,0.250566,0.778661,0.713599,0.347177,0.188705,0.421488,0.41073,0.450701,0.540495,0.312961,0.288736,0.805857,0.753714,0.541595,0.522291,0.0412656,0.0872304,0.968479,0.969721,-0.983865,-0.745503,-0.447193,-0.00444001,1.80981,2.02823,0.384729,0.424308,-1.40434,-1.58587,0.589872,0.425125,-0.429374,-0.439874,1.93777,1.75938,0.689625,0.675355,0.554669,0.631644
4920,0.742669,0.693244,0.212775,0.147456,0.89155,0.731604,0.849226,0.800443,0.792035,0.787059,0.489843,0.436277,0.0686467,0.0161467,0.687665,0.668674,0.902551,0.948866,0.197572,0.196837,-0.610945,-0.370884,2.16819,2.60445,-0.518765,-0.307063,-0.792953,-0.754707,-0.229239,-0.414805,-1.82053,-1.98684,0.974954,0.963724,1.54941,1.37193,-0.820634,-0.828327,-1.25147,-1.16912
4921,0.313341,0.262482,0.892113,0.827148,0.432656,0.289403,0.630273,0.582919,0.958279,1.03362,0.982567,0.928903,0.349624,0.297212,0.553365,0.532294,0.53818,0.526947,0.971789,0.972225,-1.75048,-1.51413,-0.0102597,0.433866,1.3333,1.53962,-1.04158,-1.00643,-0.288609,-0.474443,0.415573,0.250776,0.188696,0.181353,1.75435,1.57954,-0.935756,-0.941944,-0.0155436,0.0663172
4922,0.236348,0.227097,0.281591,0.216183,0.00714791,-0.152798,0.740045,0.69181,0.887298,0.962982,0.968115,0.875513,0.13175,0.0813104,0.67203,0.653594,0.0587143,0.105029,0.138693,0.14129,0.738336,0.974074,-1.24721,-0.809054,0.284051,0.489092,1.69613,1.73719,-0.82971,-1.00648,0.875144,0.712344,0.601352,0.596637,1.13272,0.960502,-0.209928,-0.217458,-0.717255,-0.635691
4923,0.272998,0.191712,0.840245,0.773012,0.28414,0.123141,0.273676,0.225152,0.551502,0.625774,0.87713,0.822123,0.57693,0.527457,0.544967,0.501972,0.444427,0.490779,0.632717,0.635192,0.204635,0.483947,0.186514,0.623301,-0.0533039,0.153348,1.4646,1.50308,0.419638,0.242621,0.395473,0.233284,-0.971243,-0.983575,-1.97066,-2.14859,-0.144382,-0.145701,0.753062,0.830398
4924,0.119567,0.156327,0.400352,0.335257,0.322077,0.0965692,0.0984384,0.0474857,0.659691,0.734792,0.0804975,0.0262481,0.667773,0.659347,0.371639,0.350349,0.563523,0.545654,0.26681,0.269032,-0.249635,-0.0061795,2.90782,3.34387,-1.79108,-1.592,-1.28534,-1.24651,-0.993689,-1.16556,-0.662394,-0.831545,0.799917,0.787578,1.36464,1.19194,-0.84612,-0.846272,1.0121,1.0918
4925,0.0193031,0.120942,0.49579,0.457137,0.232442,0.0699973,0.757714,0.704522,0.0872269,0.161453,0.0590871,0.0638036,0.840236,0.791238,0.215118,0.198727,0.556002,0.600529,0.373166,0.274418,-0.732043,-0.496306,0.110308,0.547917,-0.193581,0.00344357,0.902223,0.941902,-0.398615,-0.564577,-0.40868,-0.573107,-0.85122,-0.869068,-0.643488,-0.815311,-0.335766,-0.338097,-2.2543,-2.17599
4926,0.136416,0.0855566,0.644544,0.579017,0.944629,0.780723,0.0433855,-0.00836878,0.596098,0.669792,0.152263,0.101359,0.640773,0.639216,0.776377,0.760963,0.904429,0.946905,0.280128,0.279804,1.51173,1.73942,-0.960746,-0.526175,-2.35992,-2.1562,-1.25038,-1.20843,-0.777525,-0.946899,1.10157,0.942506,-0.0376336,-0.0574008,0.492244,0.326057,0.47204,0.462936,-0.0185191,0.0534127
4927,0.881542,0.829524,0.225536,0.160348,0.842471,0.680051,0.627643,0.574548,0.518081,0.588516,0.385284,0.268623,0.534095,0.487194,0.0321345,0.0152185,0.487811,0.52804,0.852205,0.853887,1.07007,1.30507,-0.946054,-0.510092,-0.702109,-0.499588,0.0266992,0.0653998,2.00656,1.83284,-0.280355,-0.446649,-0.123288,-0.146719,0.170801,-0.00124124,-1.37386,-1.3742,-0.545781,-0.573509
4928,0.1189,0.0685438,0.385742,0.240677,0.141321,-0.0193591,0.451971,0.396881,0.434892,0.50724,0.551576,0.435887,0.775222,0.728306,0.858639,0.843106,0.322201,0.360341,0.2989,0.298077,-0.883439,-0.640479,1.41131,1.84112,0.443118,0.650143,-1.07104,-1.0386,-0.669569,-0.840722,0.685654,0.516874,0.637331,0.620378,-1.01848,-1.18646,1.95447,1.95793,-1.26994,-1.20043
4929,0.222591,0.174546,0.419387,0.321006,0.484322,0.397202,0.643698,0.587459,0.132885,0.204706,0.732382,0.603151,0.797644,0.831018,0.00385465,-0.0122299,0.588518,0.626967,0.659574,0.658205,-1.18252,-0.937443,-2.33331,-1.91263,-0.0561948,0.14651,1.25354,1.28788,0.902431,0.728853,-0.41204,-0.579045,1.60335,1.58773,1.02406,0.853455,-0.0725618,-0.072309,1.66688,1.7278
4930,0.0805979,0.0315377,0.46746,0.401336,0.972598,0.813764,0.230771,0.175139,0.938657,1.0116,0.820349,0.770414,0.982049,0.93373,0.423456,0.409127,0.467157,0.541675,0.683109,0.680394,-0.257876,-0.0127432,-0.401685,0.0181998,0.986132,1.18988,0.219593,0.248439,1.18183,1.0099,0.80243,0.631246,0.586604,0.571053,0.573186,0.351337,-0.369766,-0.329836,0.00102677,0.0665062
4931,0.706123,0.657069,0.306858,0.238126,0.28921,0.129467,0.53141,0.513827,0.506926,0.651262,0.618277,0.523326,0.0641279,0.0182357,0.272587,0.257882,0.41877,0.456384,0.304549,0.299988,0.109215,0.361876,-0.884936,-0.468208,0.781712,0.901247,-1.25964,-1.23793,-0.00282372,-0.178455,-1.13146,-1.30691,-0.212074,-0.228065,0.0262592,-0.150782,-0.586374,-0.587363,-0.359195,-0.290644
4932,0.745223,0.697246,0.347391,0.2765,0.482228,0.389605,0.910154,0.852515,0.216012,0.290919,0.326173,0.276238,0.0227268,0.0252712,0.885301,0.872795,0.52267,0.633273,0.395867,0.36674,-1.64336,-1.39658,1.34083,1.75449,0.404497,0.612612,0.267038,0.285302,-0.880921,-1.06376,0.936478,0.766914,-1.72699,-1.744,2.80396,2.63012,0.2893,0.293569,0.934033,1.00538
4933,0.450551,0.343151,0.997632,0.926536,0.80987,0.649743,0.788508,0.717432,0.794421,0.870655,0.486632,0.435708,0.0785618,0.0323066,0.105346,0.0912548,0.769882,0.810162,0.467748,0.433493,0.32743,0.575263,-1.07439,-0.65663,-0.530905,-0.327116,-0.537076,-0.522277,0.949097,0.767731,2.00573,1.8397,-1.27484,-1.2971,-0.103787,-0.278465,0.808069,0.816023,-1.43233,-1.3632
4934,0.0369459,-0.010943,0.250852,0.180783,0.0114925,-0.146793,0.637583,0.582349,0.43129,0.507227,0.209439,0.15792,0.253618,0.208767,0.396869,0.381889,0.0864868,0.124723,0.496423,0.500246,-0.115648,0.126853,0.18385,0.606801,0.274637,0.415804,0.171867,0.178859,1.39572,1.2155,0.841974,0.670735,0.938063,0.9216,-2.50517,-2.67541,-1.11037,-1.10215,0.727095,0.802796
4935,0.0308236,-0.0155856,0.00547533,-0.0653581,0.693737,0.532923,0.838404,0.783808,0.706494,0.783824,0.142758,0.0898409,0.877988,0.834238,0.480619,0.467615,0.0125131,0.0497797,0.427904,0.566998,0.203543,0.440079,0.731484,1.16029,0.950555,1.15872,0.255453,0.265079,0.35702,0.176486,0.579234,0.438029,0.71832,0.709158,-1.2434,-1.41264,-1.01998,-1.01414,-0.837512,-0.764851
4936,0.514296,0.399048,0.595176,0.525491,0.18791,0.0287864,0.420093,0.367039,0.689575,0.76486,0.351535,0.298329,0.284168,0.242712,0.258529,0.245203,0.930908,0.968914,0.638312,0.633751,1.99978,2.2302,0.31341,0.735783,-0.128372,0.0776186,1.71627,1.72755,-1.64479,-1.82177,0.353469,0.205324,2.47903,2.46538,-1.03558,-1.13691,-0.549719,-0.539164,1.55936,1.62665
4937,0.859681,0.813682,0.432229,0.362281,0.544965,0.368556,0.940723,0.889962,0.946088,1.02171,0.952778,0.899798,0.777898,0.734801,0.968291,0.957214,0.652101,0.750938,0.176924,0.172892,0.947949,1.17897,-0.763571,-0.338309,-0.317073,-0.104229,-0.198234,-0.185309,-0.586408,-0.758365,0.143858,-0.0273816,-0.151971,-0.164123,-0.691945,-0.861178,-0.328188,-0.301447,-0.0990876,-0.0346417
4938,0.548881,0.555568,0.868622,0.79643,0.866539,0.708325,0.8307,0.680467,0.807955,0.88577,0.372338,0.320035,0.0820939,0.0384059,0.0997059,0.0915089,0.49513,0.532963,0.0646401,0.062529,1.21293,1.44485,1.08188,1.51392,-1.69925,-1.48068,-0.69575,-0.682931,1.14495,0.979944,1.21788,1.04541,0.407499,0.390027,-0.687033,-0.853847,-0.103244,-0.0637307,1.66234,1.72548
4939,0.216343,0.297454,0.499993,0.427326,0.0923093,-0.066093,0.613788,0.470972,0.896668,0.974293,0.410096,0.374825,0.505094,0.460176,0.141627,0.131828,0.784493,0.824262,0.646679,0.646817,-1.39787,-1.16066,0.503329,0.934996,-0.304683,-0.0879046,-0.619572,-0.538264,-0.0402711,-0.208414,1.23097,1.05977,0.0987927,0.0306108,0.77793,0.6103,0.163431,0.173986,0.298397,0.368382
4940,0.085339,0.0393404,0.511115,0.496799,0.951078,0.790565,0.312237,0.261477,0.370214,0.445831,0.483675,0.429616,0.444688,0.492462,0.965787,0.955882,0.0959799,0.133287,0.606764,0.608298,0.431174,0.674938,0.462973,0.89023,1.29602,1.50754,-0.402076,-0.393597,1.12935,0.962654,-2.31649,-2.48708,-0.311333,-0.328805,-0.196665,-0.265401,0.900039,0.914418,-0.548121,-0.484179
4941,0.619996,0.576119,0.639473,0.566273,0.818333,0.672066,0.948656,0.89882,0.496344,0.624923,0.897998,0.84419,0.572324,0.524749,0.729113,0.718067,0.0321453,0.0674943,0.148906,0.152082,-0.721227,-0.482932,-1.38466,-0.952832,-0.184823,0.0262015,-0.804815,-0.798761,0.47187,0.372281,-0.538758,-0.707078,0.738455,0.712286,-0.977051,-1.1411,-0.339844,-0.320296,0.263369,0.324086
4942,0.416542,0.414908,0.994845,0.921799,0.806396,0.553567,0.417648,0.365821,0.726767,0.804014,0.548407,0.561618,0.927927,0.882135,0.723604,0.713269,0.792144,0.829038,0.106883,0.1088,-0.602756,-0.371484,2.02448,2.45066,0.29951,0.515418,1.06681,1.07306,-0.0495494,-0.218092,0.67977,0.517196,-0.559867,-0.584668,-0.870948,-1.03905,0.60359,0.623645,-0.134623,-0.077946
4943,0.297966,0.253696,0.630169,0.557284,0.596742,0.435068,0.35715,0.299245,0.0569302,0.134312,0.333943,0.279046,0.669158,0.621433,0.96355,0.953107,0.319036,0.354365,0.392256,0.419195,-1.06722,-0.836801,-0.719007,-0.295303,-0.410299,-0.118129,0.263219,0.265482,-0.187025,-0.355586,-1.0244,-1.18949,0.786439,0.756977,-0.192565,-0.355747,-1.51371,-1.49737,-0.77476,-0.670913
4944,0.310075,0.231938,0.63605,0.561658,0.874052,0.711006,0.286486,0.232669,0.561372,0.544235,0.203084,0.127294,0.68229,0.570198,0.411028,0.402129,0.996294,1.03222,0.729037,0.729589,0.943915,1.1683,0.467694,0.889879,-0.965647,-0.751675,-1.7406,-1.74319,0.432852,0.261529,-1.26761,-1.43629,-2.84754,-2.88116,-0.292244,-0.499557,0.00786879,0.0253332,-1.31677,-1.26388
4945,0.257035,0.210179,0.859819,0.784518,0.538922,0.376345,0.668337,0.551503,0.876776,0.954158,0.0303318,-0.0244585,0.565091,0.518962,0.268295,0.238334,0.479185,0.512978,0.73903,0.69814,-0.522154,-0.295676,0.259867,0.677765,2.09916,2.32005,0.0418584,0.0347751,-0.048559,-0.225253,-0.123002,-0.289238,0.968845,0.943053,-0.394892,-0.643368,-2.13865,-2.11419,0.142647,0.202209
4946,0.466776,0.421508,0.110705,0.0339874,0.463654,0.354854,0.926001,0.870338,0.649953,0.728377,0.933215,0.877123,0.325686,0.393857,0.0838208,0.0745396,0.703193,0.73465,0.569542,0.666691,-0.181526,0.0460441,0.910534,1.32597,-0.598608,-0.384689,1.02643,1.01613,0.179497,0.00832939,1.2988,1.13247,-1.83554,-1.85604,-0.623997,-0.787178,0.477146,0.508488,-1.89164,-1.83207
4947,0.41754,0.448091,0.992269,0.917171,0.495738,0.333363,0.0873892,0.0330126,0.425079,0.502597,0.763346,0.709486,0.263099,0.268752,0.574699,0.565825,0.555299,0.586459,0.633512,0.635242,-0.844955,-0.61885,0.255245,0.670624,0.464894,0.675791,-0.516051,-0.571799,-0.46534,-0.631865,-1.68762,-1.85863,1.27274,1.25176,1.8412,1.67457,1.27386,1.30952,-0.910007,-0.860828
4948,0.51801,0.474675,0.833252,0.758643,0.714262,0.553758,0.699106,0.645887,0.644633,0.723277,0.235465,0.179568,0.187589,0.143647,0.0154821,0.00466792,0.793939,0.823231,0.948317,0.94868,-0.897746,-0.673023,0.204842,0.625858,-0.168749,0.0448678,-2.14944,-2.15973,-0.420977,-0.580719,-0.23113,-0.406803,0.593624,0.577161,-0.594767,-0.760564,0.788282,0.788113,0.0540222,0.110417
4949,0.768077,0.72579,0.902366,0.827179,0.672074,0.509486,0.216908,0.164077,0.172082,0.250271,0.879681,0.825994,0.587043,0.545584,0.00590328,-0.00532757,0.0989339,0.127076,0.113616,0.112795,-1.31116,-1.09233,-0.345261,0.076218,0.872587,1.08824,1.6889,1.68427,0.313474,0.160126,-0.190981,-0.361779,0.565509,0.54839,-0.0182039,-0.217246,0.235808,0.266704,2.3299,2.38671
4950,0.71452,0.593037,0.120215,0.0452656,0.357,0.194958,0.68196,0.626609,0.317983,0.302502,0.142504,0.0864942,0.0212117,-0.0218283,0.637075,0.624895,0.0419698,0.0780237,0.18709,0.184823,0.2295,0.453962,-2.06486,-1.63695,0.546504,0.766047,0.391038,0.381527,-0.121039,-0.268004,1.46909,1.29344,-0.829708,-0.840277,0.489286,0.326072,-0.793891,-0.762897,0.674888,0.725416
4951,0.603577,0.460285,0.459675,0.385908,0.25875,0.0942855,0.596496,0.538416,0.27502,0.354734,0.436145,0.382116,0.677193,0.636065,0.204321,0.193792,0.00190617,0.0289709,0.483184,0.482253,-1.37172,-1.14886,-1.10794,-0.684194,1.50395,1.71998,2.1259,2.11052,1.51996,1.37541,-0.486035,-0.664161,0.381663,0.376243,0.532041,0.365081,0.936862,0.963912,0.419932,0.476126
4952,0.387496,0.327532,0.153394,0.0799377,0.457449,0.294745,0.825128,0.768966,0.880651,0.95987,0.0448456,-0.0100173,0.943896,0.902482,0.710674,0.700797,0.98963,1.0167,0.10821,0.106076,0.313776,0.535101,-1.28647,-0.865561,-0.0240637,0.193254,1.36667,1.34864,-1.05413,-1.19972,0.957518,0.774325,0.717698,0.642055,-1.05454,-1.21877,-0.536187,-0.508618,0.663417,0.722488
4953,0.288874,0.194779,0.128295,0.054743,0.0112107,-0.149746,0.787339,0.810407,0.713847,0.793249,0.54777,0.49233,0.838127,0.797714,0.861871,0.852061,0.555525,0.581958,0.653372,0.650207,-1.00089,-0.77494,0.3003,0.724474,-0.0731824,0.1489,-0.639799,-0.660026,-1.12549,-1.27515,-0.0895259,-0.274246,0.913915,0.907867,-0.764648,-0.932082,-0.277662,-0.253313,-0.686681,-0.634615
4954,0.104313,0.062026,0.378473,0.367102,0.0703988,-0.0929273,0.90768,0.851848,0.897107,0.978306,0.639763,0.597266,0.407307,0.384161,0.388578,0.381038,0.860458,0.887734,0.313761,0.382918,-0.949787,-0.724269,-0.78271,-0.363818,0.70073,0.91759,0.802264,0.784539,2.14629,2.00182,-0.352982,-0.54317,0.238053,0.171114,0.288376,0.119155,0.850537,0.876965,1.6452,1.68953
4955,0.912222,0.870504,0.755337,0.679461,0.512091,0.346398,0.0791,0.0242903,0.0571734,0.135923,0.822613,0.702203,0.0124518,-0.0293923,0.348478,0.339736,0.352559,0.378035,0.121429,0.115628,0.39315,0.617787,-0.89385,-0.469288,0.974237,1.19519,0.100473,0.0866709,1.24741,1.10208,-0.634402,-0.812094,-0.563753,-0.565638,0.408243,0.32505,-2.05241,-2.02856,-0.0257559,0.0125709
4956,0.216169,0.172261,0.176706,0.102789,0.478869,0.34391,0.318469,0.264219,0.117363,0.198416,0.863435,0.807139,0.556425,0.516873,0.767011,0.756303,0.328747,0.369747,0.442958,0.439363,2.52774,2.7451,1.17576,1.60322,-0.581583,-0.36156,-1.249,-1.26045,-0.640201,-0.78335,-0.0830376,-0.221198,0.547249,0.538713,0.699907,0.530946,0.675758,0.701597,0.85176,0.895637
4957,0.0888034,0.0437043,0.251724,0.252758,0.558245,0.341421,0.827849,0.77206,0.667677,0.747127,0.000538737,-0.0579725,0.723445,0.659602,0.46915,0.45937,0.336569,0.361459,0.376247,0.461501,-0.417633,-0.207225,0.178748,0.607962,0.0309646,0.250847,1.73906,1.73099,-1.18307,-1.33213,0.551971,0.369697,-1.56036,-1.57394,0.222009,0.0507151,1.0092,1.03604,-1.03028,-0.981659
4958,0.643191,0.600253,0.477112,0.402727,0.502549,0.338933,0.160787,0.104493,0.653789,0.733208,0.881699,0.822167,0.786658,0.802332,0.492425,0.485074,0.897281,0.921226,0.489092,0.483639,1.71432,1.92009,-0.237409,0.197482,-0.204436,0.0220329,-1.50692,-1.51452,-0.898885,-1.05108,-0.596968,-0.78528,-1.15367,-1.17499,0.900422,0.734022,-0.231264,-0.198677,1.10033,1.14953
4959,0.938468,0.897563,0.0109513,-0.0655331,0.269322,0.105802,0.43843,0.379747,0.889405,0.969069,0.638476,0.497178,0.984613,0.945061,0.814524,0.806541,0.850412,0.87652,0.108401,0.103232,-0.916464,-0.71289,0.234249,0.673722,-0.677618,-0.45045,1.27538,1.27084,-0.131507,-0.278828,-0.889176,-1.07718,-1.39028,-1.41867,-0.023545,-0.191326,-0.773127,-0.745506,-0.810999,-0.760963
4960,0.182145,0.142264,0.552464,0.476724,0.308579,0.142169,0.229303,0.172871,0.0503254,0.131899,0.232479,0.172188,0.0292042,-0.00950356,0.149773,0.140253,0.29431,0.322026,0.400891,0.396171,-1.21721,-1.00985,-0.296134,0.140288,0.381729,0.61003,-0.24301,-0.248093,-1.10555,-1.25776,0.0851417,-0.0976677,0.796992,0.769407,0.725925,0.552752,0.938266,0.964848,-0.501354,-0.452336
4961,0.546696,0.471588,0.651447,0.575656,0.00142026,-0.166956,0.5403,0.482593,0.954886,1.03804,0.278022,0.214379,0.575403,0.536762,0.113583,0.104139,0.694015,0.722964,0.173847,0.232682,0.655309,0.856793,-0.0367583,0.403506,0.749747,0.977497,0.15312,0.145967,1.09805,0.945247,-0.529663,-0.717956,-0.101612,-0.12239,-0.220677,-0.388276,-1.63029,-1.60779,-0.686968,-0.641626
4962,0.839832,0.800913,0.286798,0.211141,0.886156,0.718395,0.603094,0.546287,0.63987,0.725351,0.317408,0.256571,0.416138,0.377711,0.660788,0.651953,0.494866,0.52548,0.0749291,0.0691918,-1.87131,-1.67091,-0.0192873,0.41959,-0.639934,-0.413715,-1.08522,-1.09608,-0.996713,-1.15535,-0.87534,-1.05637,0.596557,0.569127,0.949796,0.785284,1.76789,1.79723,-2.48618,-2.44239
4963,0.59079,0.552188,0.13426,0.0576448,0.646664,0.564074,0.372957,0.318117,0.091995,0.176844,0.86392,0.802656,0.9022,0.864452,0.392369,0.384898,0.878073,0.906234,0.843032,0.839856,-0.292785,-0.0948334,-0.608626,-0.175516,0.0119136,0.231153,-1.21136,-1.22236,-0.705361,-0.859891,-1.97643,-2.15229,-1.49804,-1.5281,0.751288,0.580236,0.480304,0.514459,0.942979,0.983212
4964,0.689111,0.652558,0.502457,0.427357,0.577035,0.409752,0.536975,0.450287,0.489346,0.574566,0.47726,0.415203,0.207519,0.168057,0.611037,0.603133,0.143186,0.169912,0.0253832,0.024535,-0.770455,-0.577383,1.56851,1.99594,1.19017,1.41301,-0.574548,-0.584412,1.01792,0.861597,-1.51219,-1.69072,-1.41505,-1.45009,1.11103,0.941861,1.23151,1.26816,0.0921973,0.0391562
4965,0.526472,0.461115,0.0831905,0.00868835,0.166883,0.000119711,0.638845,0.582458,0.0776579,0.160495,0.514975,0.451484,0.580732,0.539715,0.561889,0.507236,0.654601,0.680304,0.170867,0.140903,0.0770267,0.269978,0.890008,1.32471,0.716124,1.01456,0.663266,0.656442,1.30803,1.05972,-0.000591345,-0.205817,-0.0144592,-0.0589883,-1.63288,-1.80441,-1.10369,-1.06756,-0.947099,-0.904899
4966,0.218072,0.269671,0.496953,0.362493,0.508147,0.342071,0.42342,0.364934,0.549319,0.633467,0.254875,0.193496,0.511609,0.482957,0.417962,0.411338,0.662641,0.757757,0.255307,0.25727,-0.904252,-0.703607,-2.01686,-1.57925,0.383618,0.616107,-0.855337,-0.862492,1.4139,1.25783,1.45288,1.27909,1.36716,1.33212,0.343332,0.171981,1.01036,1.05037,2.09662,2.13367
4967,0.114781,0.0782277,0.791015,0.716299,0.585313,0.418543,0.691572,0.635467,0.42964,0.615501,0.72301,0.661094,0.469179,0.426198,0.900901,0.893368,0.809511,0.835211,0.792846,0.796663,0.723498,0.919262,-0.436614,-0.00407164,-0.331332,-0.0912007,-0.599109,-0.606063,-0.175098,-0.332621,1.29514,1.20145,0.7867,0.747165,-0.306137,-0.478953,-0.601,-0.561426,0.13769,0.176077
4968,0.215225,0.275038,0.295902,0.223384,0.314811,0.153319,0.267652,0.214115,0.479321,0.597535,0.267339,0.205266,0.990102,0.948493,0.550966,0.541246,0.562927,0.58669,0.915887,0.918112,-2.01163,-1.81382,0.868077,1.30559,0.0962648,0.337765,-1.32268,-1.33534,-0.600818,-0.760751,1.2116,1.12381,-0.433833,-0.470365,-0.504646,-0.684002,-1.27746,-1.23238,0.250352,0.289206
4969,0.481727,0.471848,0.437723,0.414538,0.0550688,-0.111905,0.713773,0.662345,0.463307,0.579569,0.963409,0.901655,0.212416,0.172623,0.588555,0.57652,0.957637,0.982567,0.12093,0.122532,0.525439,0.723943,0.0388597,0.480585,-0.661134,-0.416463,0.771901,0.759297,-0.299198,-0.465289,1.21315,1.04617,1.3751,1.33388,0.0931097,-0.0934058,-1.01788,-0.990626,-1.36209,-1.32692
4970,0.704132,0.668659,0.679934,0.605693,0.329377,0.171435,0.329014,0.275624,0.477455,0.561603,0.183724,0.121228,0.00498345,-0.0324994,0.383695,0.339043,0.631928,0.658024,0.319987,0.319825,0.729594,0.927213,-0.293982,0.146019,-0.572127,-0.326251,1.19536,1.18369,1.05529,0.887321,-0.239506,-0.402065,-0.167844,-0.215153,0.423351,0.23848,-0.802918,-0.748873,-0.802748,-0.792574
4971,0.587453,0.549993,0.369599,0.378824,0.621271,0.454775,0.568755,0.422011,0.681572,0.7317,0.811133,0.746685,0.703409,0.664749,0.111393,0.101566,0.888455,0.914172,0.199472,0.23395,1.3303,1.53075,-0.392751,0.0405484,-1.08887,-0.846466,0.173567,0.159142,1.96976,1.79678,0.674336,0.516435,-0.42813,-0.456936,-1.27881,-1.47084,-0.0392529,0.020729,-0.298018,-0.258223
4972,0.717001,0.680008,0.228513,0.151954,0.410791,0.241617,0.620555,0.568397,0.816545,0.901797,0.73324,0.668456,0.463278,0.516476,0.911432,0.900091,0.120109,0.145153,0.147413,0.148074,0.893943,1.16137,1.34126,1.76876,0.234604,0.472934,2.05422,2.03096,-0.289279,-0.461632,0.0781871,-0.0702339,-0.65826,-0.69872,1.14888,0.953868,0.0361097,0.0924861,-1.34476,-1.30697
4973,0.124552,0.0893596,0.216687,0.163852,0.561063,0.393215,0.09471,0.0401532,0.126509,0.211913,0.0158553,-0.0471443,0.404267,0.368203,0.518619,0.589253,0.509832,0.536044,0.676941,0.677573,0.527017,0.791995,0.631244,1.05257,-0.718087,-0.482678,0.805742,0.788915,0.109472,-0.0580797,-0.503986,-0.656903,-0.101584,-0.14457,1.01592,0.825071,-0.475922,-0.424029,-1.285,-1.25414
4974,0.397763,0.378096,0.345361,0.17575,0.28692,0.144015,0.388659,0.335424,0.708472,0.79165,0.0723793,0.00845878,0.984106,0.949354,0.290188,0.278415,0.481274,0.506299,0.112936,0.111982,0.222162,0.422616,-1.79251,-1.37401,1.57697,1.81131,1.03316,1.0174,1.80606,1.63274,0.126555,-0.0285709,0.121162,0.0749219,-1.42257,-1.61007,0.526557,0.582454,-0.665135,-0.60639
4975,0.64706,0.666832,0.386942,0.187648,0.0644702,-0.105184,0.971756,0.918341,0.172942,0.258504,0.695002,0.629217,0.666361,0.633095,0.997708,0.985784,0.0896095,0.116251,0.311633,0.250402,-1.02987,-0.828182,0.0915789,0.511477,-0.000167343,0.239029,-0.195634,-0.208538,-0.888614,-1.05604,-2.63735,-2.80013,0.344095,0.294414,-1.12048,-1.31078,0.459796,0.563573,0.0104932,0.0413584
4976,0.992347,0.955568,0.275971,0.199546,0.691625,0.523313,0.191877,0.138617,0.85283,0.939496,0.227101,0.159142,0.047992,0.0168001,0.645335,0.633663,0.996691,1.02401,0.388605,0.388822,-0.597309,-0.393935,-0.943631,-0.530542,-0.882993,-0.640141,-0.0473118,-0.057782,0.89404,0.726505,0.833233,0.669827,0.346838,0.295526,-0.342542,-0.536262,0.493864,0.544691,-0.43155,-0.404493
4977,0.346918,0.309381,0.288002,0.211444,0.301476,0.133833,0.270403,0.217247,0.763153,0.848792,0.902984,0.836113,0.336207,0.303346,0.0801504,0.067017,0.648094,0.6744,0.0781653,0.0774284,-0.620325,-0.417409,0.0129736,0.422213,0.242584,0.479957,0.588869,0.580162,0.412972,0.239724,-1.55635,-1.72659,0.674896,0.617278,-0.817238,-1.01649,-0.00198585,0.106861,-1.84626,-1.82186
4978,0.335203,0.300357,0.936762,0.86148,0.912447,0.747442,0.886887,0.83493,0.932265,1.01932,0.920079,0.852808,0.197148,0.140643,0.661831,0.65043,0.903577,0.930548,0.0631569,0.137812,-0.0884724,0.111888,1.26699,1.671,0.56452,0.802671,-0.455012,-0.459276,1.124,0.948572,0.657498,0.491263,0.505504,0.450414,-1.75887,-1.95752,-0.386486,-0.330969,0.0409026,0.0604236
4979,0.106104,0.0717034,0.67565,0.57576,0.481481,0.317531,0.518969,0.46812,0.268752,0.354487,0.212812,0.143105,0.0111621,-0.0220598,0.456572,0.443551,0.229685,0.255557,0.0877077,0.198195,-2.58646,-2.3864,1.64887,2.05649,1.94695,2.18075,0.506621,0.504651,-1.05676,-1.23155,1.63252,1.47078,-1.18895,-1.23864,0.20564,0.00564045,1.48317,1.53815,-0.234451,-0.219736
4980,0.152797,0.11699,0.365423,0.290039,0.366763,0.261283,0.974296,0.921202,0.428264,0.513661,0.405874,0.336849,0.136959,0.147419,0.668387,0.654962,0.0793174,0.107365,0.259316,0.258579,-0.26748,-0.0743697,0.888831,1.29201,-1.1898,-0.955936,-2.08998,-2.09704,0.776121,0.599943,-1.44039,-1.59901,-0.775493,-0.823356,-0.392027,-0.597441,0.76585,0.891973,0.766639,0.786303
4981,0.508909,0.472454,0.309003,0.235557,0.369617,0.205036,0.119866,0.0668839,0.209533,0.296603,0.333556,0.264154,0.347548,0.316898,0.315898,0.30284,0.257886,0.235044,0.0121848,0.0132679,0.594393,0.787581,-1.75112,-1.34043,-2.22274,-1.99114,1.21791,1.21085,-1.94368,-2.12013,-0.205143,-0.359402,0.50398,0.452874,-0.521265,-0.726238,0.198142,0.245798,0.626577,0.643567
4982,0.86267,0.827917,0.0404076,-0.0351945,0.687048,0.521749,0.266779,0.211928,0.822009,0.910701,0.0111285,-0.0590702,0.201142,0.171961,0.194725,0.181712,0.333948,0.362723,0.97098,0.971182,0.745645,0.945541,-0.488393,-0.0482357,0.204049,0.432343,-1.07784,-1.08391,0.52139,0.341187,-1.0498,-1.20879,-0.315762,-0.359383,1.51403,1.31368,0.166673,0.209745,-0.640815,-0.622123
4983,0.995326,0.957932,0.922511,0.847989,0.736296,0.565642,0.950751,0.894127,0.0622045,0.1531,0.733155,0.662286,0.857772,0.829854,0.599371,0.588156,0.773659,0.80221,0.294356,0.295096,-0.273124,-0.0763649,0.831177,1.24396,0.0232896,0.250495,-0.476662,-0.477018,-1.28492,-1.46592,-0.00722651,-0.166328,-0.775977,-0.820834,-0.902989,-1.10043,0.655237,0.700141,0.231719,0.246749
4984,0.606512,0.625634,0.0460615,-0.025526,0.634648,0.609536,0.242757,0.186782,0.741886,0.834092,0.695845,0.624958,0.686814,0.751426,0.218777,0.206886,0.740677,0.767139,0.8803,0.879384,0.0152704,0.206564,1.11657,1.52323,-1.28612,-1.0614,-0.897894,-0.897942,1.19181,1.01474,0.376597,0.216562,-0.746604,-0.789932,-0.0230215,-0.218437,-0.240587,-0.187797,1.56205,1.57313
4985,0.328893,0.293336,0.414782,0.344187,0.817427,0.65343,0.642003,0.58613,0.663501,0.753921,0.00886948,-0.0598081,0.690541,0.672997,0.143753,0.130179,0.383205,0.407987,0.862602,0.859877,1.09946,1.28298,0.203399,0.606436,-0.0660848,0.166154,1.68166,1.68417,-0.214466,-0.393442,1.0664,0.903901,0.384445,0.347959,-0.1729,-0.362897,1.79382,1.84512,-2.27112,-2.26004
4986,0.579455,0.544451,0.240192,0.169612,0.931831,0.765224,0.208425,0.154233,0.925939,1.01499,0.589946,0.521044,0.621563,0.594568,0.958401,0.944089,0.62691,0.64948,0.0532378,0.050272,0.251858,0.431485,-0.261386,0.134635,-1.39236,-1.16222,0.729189,0.734495,1.39051,1.20648,1.3256,1.16234,-0.061102,-0.0980904,0.644603,0.458154,0.463821,0.513608,-1.51889,-1.5116
4987,0.13041,0.094027,0.70683,0.637974,0.284093,0.116423,0.294043,0.306623,0.697452,0.787649,0.626905,0.557325,0.197706,0.169563,0.398746,0.382932,0.358662,0.458117,0.640229,0.639406,-0.322431,-0.0560214,-0.0136364,0.381958,0.584244,0.80683,0.89493,0.863044,0.914448,0.733462,0.876126,0.778624,-0.153084,-0.2316,-1.25296,-1.43947,-0.493511,-0.441015,0.411814,0.416133
4988,0.216736,0.180089,0.448716,0.381919,0.914602,0.74492,0.511003,0.459012,0.995862,1.08522,0.168093,0.0964158,0.00229716,-0.0253846,0.978829,0.960807,0.284231,0.266754,0.392851,0.394095,-0.72247,-0.543527,-1.02934,-0.62929,1.00055,1.22212,0.994043,0.991593,-1.13309,-1.31707,0.563247,0.39491,-0.328033,-0.36511,-0.44867,-0.633605,0.0695688,0.045796,-1.46486,-1.46116
4989,0.617452,0.583032,0.894498,0.825709,0.964138,0.797484,0.298203,0.215404,0.739491,0.886349,0.461586,0.489435,0.95652,0.92934,0.701341,0.684122,0.0510627,0.0753905,0.707251,0.707533,-0.223412,-0.0469139,0.903004,1.30154,0.0856312,0.312233,-0.37006,-0.371218,-0.71309,-0.898451,-1.21651,-1.39135,0.890458,0.85141,0.791784,0.613615,0.476482,0.532607,1.25139,1.25377
4990,0.76905,0.730305,0.470692,0.401777,0.516174,0.370011,0.0263469,-0.0282041,0.599267,0.687473,0.952181,0.882453,0.0560945,0.030804,0.691743,0.648529,0.284809,0.307385,0.42936,0.431873,1.95276,2.12812,0.553461,0.951572,1.00443,1.23365,0.788218,0.795362,2.23499,2.04853,0.171209,0.00101931,-0.109036,-0.150394,-0.921916,-1.09571,0.651119,0.7104,-0.166637,-0.163594
4991,0.909988,0.877578,0.437202,0.367715,0.108862,-0.0574633,0.073473,0.0207258,0.029821,0.119549,0.517341,0.446425,0.379177,0.352695,0.675001,0.612936,0.206003,0.227021,0.383324,0.375671,0.0740107,0.269291,-0.691424,-0.291347,1.048,1.1878,-0.862821,-0.848541,0.0639447,-0.116979,0.855585,0.688358,-1.47196,-1.50874,1.68959,1.51917,-4.04935,-3.99007,-1.9741,-1.97825
4992,0.0756377,0.0447639,0.966417,0.895469,0.747557,0.581677,0.891064,0.837301,0.00186257,0.0899354,0.443836,0.284078,0.469807,0.442329,0.594564,0.577344,0.404055,0.422603,0.316659,0.319469,-1.76489,-1.58953,-0.337099,0.0638479,0.914049,1.14195,2.12879,2.1429,0.164736,-0.0192097,-0.119268,-0.2841,0.938964,0.90571,-2.0662,-2.23901,-0.00430618,0.0549747,-0.158256,-0.156534
4993,0.00767429,0.0691688,0.804951,0.732259,0.727952,0.562856,0.596605,0.551077,0.974989,1.06519,0.191169,0.121731,0.0882094,0.0613884,0.339169,0.320523,0.12177,0.139322,0.913618,0.91795,-0.247467,-0.0758319,-0.600602,-0.195124,-1.74536,-1.51852,-1.46682,-1.45813,0.598457,0.413938,0.511888,0.344232,-0.042919,-0.08009,1.03219,0.864661,1.15523,1.21619,1.28203,1.27911
4994,0.126008,0.0935736,0.968543,0.895993,0.997617,0.834124,0.321239,0.264853,0.685023,0.824337,0.899335,0.828254,0.332209,0.25795,0.998364,0.980549,0.0948392,0.205635,0.794686,0.867498,1.57406,1.74463,1.1639,1.56616,1.14248,1.37388,-1.35816,-1.35556,2.40611,2.22824,-0.656332,-0.824737,2.26037,2.22137,-0.857996,-1.01981,-1.14709,-1.08517,-1.08918,-1.08947
4995,0.265804,0.316117,0.830754,0.757206,0.696192,0.511602,0.314041,0.25807,0.492883,0.583486,0.843815,0.68432,0.439029,0.454512,0.955114,0.939246,0.253278,0.271948,0.813625,0.817046,-1.34571,-1.17158,1.80735,2.21436,0.024266,0.260632,1.36456,1.37199,0.883613,0.712819,0.350193,0.18483,-0.0110216,-0.0533863,-0.346233,-0.504811,0.220575,0.282914,-0.358362,-0.356963
4996,0.572504,0.53866,0.0436032,-0.0306759,0.351914,0.18908,0.739917,0.682332,0.570254,0.662236,0.613193,0.540386,0.677146,0.651074,0.457705,0.443562,0.699425,0.717148,0.274087,0.275886,0.236742,0.404494,-1.07217,-0.657472,-0.0941154,0.140675,-0.360206,-0.352635,0.987968,0.810588,-1.34692,-1.50926,-0.383042,-0.420563,0.769252,0.608103,-1.33496,-1.26697,-1.49862,-1.5011
4997,0.336036,0.300194,0.519794,0.447091,0.636907,0.387361,0.935021,0.878624,0.0982071,0.18923,0.976072,0.904705,0.0917583,0.0637667,0.509717,0.57953,0.225941,0.242475,0.170761,0.170181,0.608627,0.779114,-1.87564,-1.46605,2.54227,2.78689,-0.384796,-0.358257,-1.34235,-1.52907,0.709272,0.551744,1.46413,1.43229,-1.20343,-1.36887,3.80123,3.86922,3.00944,3.00196
4998,0.430814,0.375904,0.410987,0.338085,0.749332,0.585643,0.267008,0.211056,0.862236,0.953283,0.838627,0.766502,0.912432,0.884199,0.727527,0.715498,0.501917,0.518745,0.54195,0.540121,-0.278605,-0.103539,-0.18429,0.231576,-1.93874,-1.69412,-0.310794,-0.363879,-0.406569,-0.587837,0.070139,-0.0837958,0.438583,0.400629,-0.534721,-0.70013,1.10958,1.17693,1.98124,1.96787
4999,0.485973,0.451614,0.706796,0.634693,0.406076,0.336755,0.572923,0.46588,0.876,0.966214,0.903153,0.832943,0.576345,0.549039,0.11294,0.0991616,0.136864,0.15444,0.326012,0.324821,0.722074,0.898667,0.859012,1.27593,0.352103,0.599866,-0.377072,-0.369501,2.56993,2.38196,-1.39957,-1.54894,1.56256,1.52103,-0.613611,-0.784078,0.231793,0.303144,-0.226845,-0.236295
5000,0.936351,0.904075,0.0751593,0.00436379,0.248813,0.087867,0.778735,0.720704,0.49161,0.582526,0.0369186,-0.0321684,0.741745,0.732321,0.871446,0.856792,0.557278,0.575505,0.762754,0.764116,0.535308,0.708788,0.25509,0.666274,-0.0361624,0.162927,-1.54524,-1.53474,0.600988,0.415687,-0.0880942,-0.232811,0.252438,0.208242,-0.955562,-1.12654,0.559046,0.637585,0.355209,0.344373
5001,0.189945,0.159157,0.443996,0.374076,0.00391891,-0.161021,0.799637,0.743293,0.505437,0.595457,0.17795,0.107768,0.945143,0.915602,0.0382469,0.0241454,0.397019,0.417088,0.643484,0.643631,1.01242,1.15408,0.950125,1.35848,-0.520619,-0.274012,0.981521,0.996562,-0.355384,-0.545899,-0.448644,-0.579708,-0.588995,-0.635253,1.68636,1.51813,-0.526066,-0.453365,0.397861,0.382711
5002,0.349696,0.319355,0.379697,0.281496,0.139002,-0.0246641,0.236072,0.179557,0.188474,0.277777,0.96257,0.890853,0.0191337,-0.0121547,0.797864,0.781776,0.710432,0.731933,0.89374,0.891979,1.43366,1.59937,-0.891666,-0.484585,-0.496172,-0.243368,1.36842,1.39062,-0.68213,-0.867103,-0.785873,-0.926605,0.416972,0.378095,-0.122036,-0.288593,1.38567,1.46153,0.875438,0.855628
5003,0.214888,0.186076,0.141281,0.188916,0.27644,0.111693,0.933009,0.876941,0.279035,0.306067,0.609729,0.524855,0.747648,0.716503,0.253331,0.236253,0.106213,0.126273,0.508151,0.506666,-0.590808,-0.426149,0.470769,0.870815,1.27262,1.52372,-1.25434,-1.22803,-1.84444,-2.02819,0.79415,0.653204,-0.664073,-0.700683,1.2868,1.11529,-1.18299,-1.11111,0.864805,0.848249
5004,0.431013,0.402655,0.166255,0.0963353,0.0927897,-0.070093,0.850902,0.793911,0.178636,0.334357,0.231061,0.158857,0.917929,0.887216,0.156016,0.151868,0.818514,0.83851,0.528102,0.515053,1.52503,1.68629,0.411178,0.760238,1.59034,1.84644,0.713104,0.739019,-2.25296,-2.44055,0.870873,0.728835,-0.535581,-0.474859,0.471363,0.297609,-0.324455,-0.287525,1.76886,1.74681
5005,0.146879,0.118606,0.270868,0.200339,0.537844,0.373653,0.445522,0.386887,0.274811,0.362647,0.600357,0.528415,0.236791,0.205361,0.0838751,0.067484,0.551936,0.634918,0.524872,0.52344,0.315968,0.48171,0.243614,0.64966,-0.736347,-0.471619,-0.323352,-0.300419,0.966138,0.780767,0.657245,0.419737,-0.213138,-0.249035,-1.22852,-1.39559,0.464178,0.536059,1.42373,1.4057
5006,0.0916354,0.0619375,0.0887568,0.0160887,0.257344,0.139688,0.559572,0.533273,0.568242,0.6546,0.0625907,-0.0108013,0.482075,0.451647,0.543178,0.528523,0.4129,0.431327,0.348295,0.348107,-0.884134,-0.722874,0.379795,0.789368,0.157203,0.420253,-1.05493,-1.02969,1.60468,1.41365,0.251917,0.110639,-0.821778,-0.86381,0.560953,0.393565,-0.703194,-0.636756,-1.13888,-1.1481
5007,0.798568,0.76728,0.290616,0.21855,0.071053,-0.0942762,0.738109,0.679659,0.486093,0.601836,0.077203,0.0439893,0.209278,0.180714,0.628,0.64776,0.517722,0.535962,0.406887,0.38456,0.323364,0.479112,-0.38357,0.024891,0.127212,0.390773,0.0741757,0.0531051,-0.407403,-0.599082,1.41596,1.27553,0.0952622,0.0574126,0.540257,0.370299,-0.643151,-0.581016,0.924448,0.919707
5008,0.197687,0.16611,0.135359,0.0650533,0.552912,0.388739,0.366731,0.307741,0.444857,0.549072,0.173221,0.0987798,0.234007,0.291692,0.780478,0.766998,0.157841,0.17681,0.539534,0.421013,0.368878,0.529782,-1.44334,-1.03294,0.395406,0.653239,1.10617,1.1359,1.17431,0.984045,1.47165,1.33631,-0.148505,-0.186265,-1.47189,-1.63695,1.31347,1.36709,-1.63194,-1.63409
5009,0.579391,0.548932,0.674654,0.602288,0.530668,0.364962,0.628351,0.568569,0.413044,0.496309,0.492182,0.418887,0.433029,0.402671,0.266808,0.25119,0.892638,0.913568,0.454893,0.457466,-1.80642,-1.65089,2.27501,2.68842,-0.308512,-0.0540688,0.272297,0.21709,1.94552,1.75629,0.798619,0.67025,0.935624,0.901684,-1.35824,-1.5207,-0.942775,-0.880024,-1.26193,-1.2662
5010,0.168462,0.139002,0.538055,0.463501,0.303138,0.149757,0.512353,0.450642,0.0588098,0.142791,0.0286461,-0.0466494,0.243388,0.213687,0.514462,0.496746,0.943465,0.962635,0.76195,0.705196,0.362433,0.524135,0.842787,1.25441,0.70859,0.960617,-0.73146,-0.701724,0.424395,0.240869,1.74831,1.62008,0.0859516,0.0581888,1.25507,1.09418,-0.224689,-0.155539,-0.62172,-0.545569
5011,0.233233,0.183078,0.778933,0.705619,0.100402,-0.0654486,0.814154,0.68674,0.161717,0.24659,0.846999,0.77239,0.328263,0.297513,0.0432722,0.0257231,0.0836683,0.103345,0.951648,0.952926,-0.339864,-0.172485,1.52679,1.93277,-0.87983,-0.628444,1.79813,1.82958,-0.0331905,-0.217817,0.0788639,-0.0564204,0.0447845,0.013366,-2.24402,-2.40052,0.72713,0.802261,0.176941,0.17506
5012,0.257294,0.227154,0.50712,0.377004,0.551411,0.383806,0.985608,0.922837,0.863377,0.947661,0.105645,0.0328905,0.199532,0.167818,0.201599,0.183121,0.34526,0.365004,0.906293,0.828721,-0.508408,-0.334595,0.961218,1.36754,0.475121,0.720883,0.732217,0.757662,0.288073,0.108801,0.0774939,-0.0576129,-0.359665,-0.384847,0.497392,0.345106,0.248861,0.317747,-1.11754,-1.1203
5013,0.101139,0.0693889,0.121972,0.0483894,0.287092,0.119583,0.350409,0.285581,0.95426,1.03618,0.468325,0.397209,0.706268,0.674239,0.6938,0.674406,0.0445225,0.0658356,0.703792,0.704517,0.960538,1.13305,0.967237,1.36985,0.752862,0.998484,-0.609559,-0.589458,0.0886529,-0.090012,1.20695,1.07526,1.15607,1.1233,0.843626,0.690812,0.885445,0.949065,0.0231911,0.022291
5014,0.370479,0.34053,0.764914,0.693104,0.883264,0.71729,0.289475,0.223,0.0496462,0.131951,0.0235774,-0.0488408,0.0800434,0.0478714,0.117888,0.0982609,0.208809,0.230712,0.988032,0.987873,0.411166,0.589738,-0.0262208,0.37459,0.442798,0.693967,0.692471,0.713214,-0.488385,-0.669772,-0.380592,-0.510651,0.756836,0.725091,2.39732,2.24726,0.207478,0.278113,-1.9315,-1.9353
5015,0.323342,0.293638,0.42948,0.358029,0.355887,0.188817,0.744504,0.676082,0.829367,0.911889,0.0468662,-0.0269054,0.981851,0.949092,0.286102,0.194641,0.682036,0.70616,0.979042,0.894741,2.05909,2.24227,-0.672762,-0.264975,-1.39514,-1.1468,1.12214,1.13761,0.66924,0.421988,0.526056,0.393325,-0.284656,-0.32252,0.644522,0.492633,0.771784,0.846686,0.340064,0.340995
5016,0.951751,0.92432,0.468907,0.358996,0.39044,0.220541,0.264473,0.194272,0.0764539,0.158856,0.397316,0.32398,0.333528,0.300917,0.309185,0.291021,0.566649,0.588989,0.802574,0.801608,-0.93245,-0.753687,1.04622,1.44727,-0.146756,0.0962157,-0.2798,-0.257349,1.69514,1.51375,-0.418655,-0.549753,1.83947,1.80101,-0.730494,-0.877573,2.47584,2.5424,0.52341,0.527824
5017,0.940624,0.915295,0.410627,0.359963,0.116008,-0.0538772,0.220387,0.190649,0.360368,0.440953,0.081654,0.01022,0.975634,0.942204,0.970132,0.951046,0.669248,0.693625,0.326183,0.325497,1.37355,1.55835,-0.300538,0.0927422,2.51314,2.75499,0.712204,0.739861,-0.95495,-1.13843,1.3266,1.19731,0.834978,0.820264,0.986763,0.837222,0.541935,0.609834,-0.524812,-0.520925
5018,0.694332,0.756473,0.597255,0.36093,0.284887,0.116851,0.144951,0.187026,0.145205,0.312047,0.991214,0.921789,0.21664,0.181434,0.274754,0.258137,0.28565,0.377142,0.497994,0.502562,-0.813524,-0.62233,0.581119,0.969842,1.24349,1.49001,-1.48059,-1.45595,0.19701,0.015978,0.93857,0.81309,-0.125309,-0.160483,-0.224901,-0.379447,1.59101,1.66354,1.86665,1.87058
5019,0.61235,0.597651,0.433347,0.361897,0.661455,0.49425,0.250981,0.183403,0.101212,0.183141,0.890817,0.844246,0.991566,0.957347,0.82361,0.805951,0.0357544,0.0606586,0.681136,0.679628,0.112427,0.302369,-1.12876,-0.743325,-0.678056,-0.430729,-1.03032,-1.00022,-0.192404,-0.287449,0.0597026,-0.0671571,-0.374183,-0.404161,-0.607595,-0.76689,0.336454,0.412825,0.205745,0.209284
5020,0.46398,0.438829,0.297434,0.312773,0.290744,0.124906,0.733865,0.666005,0.994003,1.0728,0.871755,0.766703,0.420772,0.385148,0.50712,0.489458,0.923057,0.949147,0.529895,0.472939,0.280494,0.475904,0.362279,0.751224,0.157216,0.401273,-1.48824,-1.45156,-0.413556,-0.590875,0.794836,0.665883,1.49915,1.46543,0.237485,0.0852576,-1.32574,-1.24759,0.88158,0.881706
5021,0.762379,0.736139,0.307542,0.263648,0.801029,0.633136,0.15031,0.0827184,0.623551,0.704031,0.767461,0.68916,0.252176,0.215469,0.872629,0.856545,0.594746,0.673343,0.351534,0.266249,-0.738967,-0.546002,-0.785807,-0.399669,1.50531,1.7506,1.17203,1.21382,0.596117,0.410981,0.781601,0.650113,-0.486848,-0.522242,-0.315502,-0.502346,-1.04215,-0.960858,-0.930372,-0.932952
5022,0.515695,0.487415,0.28363,0.214524,0.908117,0.693289,0.208681,0.141075,0.559334,0.600219,0.698472,0.611617,0.439857,0.401427,0.581035,0.565014,0.368807,0.397538,0.0629498,0.0595602,-0.0841314,0.0483496,-0.403637,-0.0141856,0.039092,0.284009,-0.412566,-0.364571,-1.01271,-1.19552,-0.717629,-0.845946,0.175124,0.13898,-0.826899,-1.08995,0.417114,0.501766,0.278753,0.270723
5023,0.615566,0.584257,0.965864,0.899152,0.995788,0.753443,0.811849,0.743833,0.35079,0.496407,0.603498,0.534073,0.18541,0.221921,0.944273,0.927899,0.975124,1.0039,0.179454,0.182177,0.454548,0.642702,0.66914,1.02348,-1.18419,-0.937545,-0.952988,-0.907746,-0.753151,-0.929999,-0.49029,-0.616893,-0.322471,-0.352552,-1.52533,-1.67755,-1.71994,-1.63775,-0.211134,-0.219127
5024,0.709521,0.681099,0.866935,0.726255,0.981489,0.813596,0.370266,0.301903,0.400345,0.392595,0.193742,0.123069,0.081533,0.0424154,0.575808,0.499138,0.197357,0.224063,0.305153,0.304794,0.880687,1.06255,1.67892,2.06114,0.542827,0.784842,0.6681,0.713885,-1.12441,-1.29696,-0.554237,-0.679142,0.556529,0.521974,-1.15876,-1.31593,-0.460955,-0.382914,1.21303,1.20001
5025,0.18322,0.155067,0.63603,0.553358,0.636179,0.469312,0.243474,0.174513,0.209685,0.288783,0.686553,0.615695,0.927026,0.888028,0.0850533,0.0703768,0.802456,0.830424,0.4308,0.427411,0.840844,1.02332,0.787909,1.17417,-0.642422,-0.40429,0.350251,0.400877,0.482071,0.316576,-0.332232,-0.526623,0.567243,0.536508,0.274467,0.118513,0.33951,0.418119,-0.380701,-0.400163
5026,0.732702,0.706085,0.447173,0.380461,0.870742,0.704682,0.968845,0.898247,0.971524,1.05284,0.209986,0.140731,0.916875,0.880601,0.166293,0.151149,0.652231,0.682233,0.19733,0.191732,0.453225,0.635198,-0.69195,-0.306015,-0.392482,-0.157266,0.874388,0.840884,0.501077,0.337687,-0.245163,-0.374105,1.1619,1.1362,1.20922,1.04782,-0.291191,-0.204944,0.196161,0.180505
5027,0.306173,0.280461,0.505245,0.456421,0.255145,0.0906799,0.441533,0.370004,0.427248,0.509346,0.00212793,-0.0684575,0.401902,0.364567,0.725539,0.709047,0.12586,0.158166,0.404318,0.398628,-1.40868,-1.23404,1.79518,2.18462,0.112528,0.346257,1.22977,1.28089,-0.477052,-0.64124,0.552728,0.418058,-1.15045,-1.16836,1.44215,1.28756,0.362361,0.441224,-0.460559,-0.475935
5028,0.807861,0.78259,0.599771,0.532381,0.687743,0.524784,0.339498,0.178414,0.745201,0.82633,0.178176,0.106317,0.994094,0.955935,0.839746,0.748026,0.102872,0.133684,0.00213205,-0.00193335,0.233946,0.402803,-0.0438807,0.341556,-0.0753875,0.16441,-0.434773,-0.380701,1.12376,0.958685,1.6078,1.47645,-0.536887,-0.552567,-0.456626,-0.610061,0.000670721,0.0793887,0.307535,0.287056
5029,0.323242,0.295996,0.406081,0.393603,0.29917,0.18396,0.0569862,-0.0131753,0.64332,0.716813,0.83865,0.76805,0.692408,0.654745,0.80181,0.787004,0.413781,0.408086,0.682214,0.676927,0.340264,0.514251,0.201889,0.588879,-0.753198,-0.474856,0.568095,0.616508,0.29214,0.13392,0.537514,0.41162,-0.23578,-0.244868,1.38744,1.22665,1.2035,1.28811,-0.339948,-0.429409
5030,0.161009,0.132982,0.322953,0.254826,0.00449999,-0.156865,0.774315,0.705438,0.524027,0.607296,0.04209,-0.0278241,0.992326,0.956475,0.112449,0.0999661,0.653373,0.682489,0.268267,0.260933,-0.29723,-0.121684,-0.895492,-0.515583,-1.35396,-1.11412,-0.452101,-0.408041,1.38805,1.22766,-2.0084,-2.13538,0.298211,0.292221,0.0863621,-0.0692111,-0.0871827,0.00533797,-1.1254,-1.14587
5031,0.726887,0.699525,0.734268,0.66491,0.541003,0.380778,0.0209258,-0.0472233,0.87133,0.954031,0.665755,0.597633,0.484759,0.450157,0.362469,0.355581,0.216446,0.247752,0.487767,0.453717,-2.08017,-1.91031,-0.63766,-0.252366,-1.47717,-1.23408,-0.329185,-0.220839,1.35392,1.20078,1.26947,1.14802,-1.22638,-1.22371,2.1433,1.98666,-0.191807,-0.0933773,1.16271,1.14767
5032,0.136945,0.108877,0.624623,0.555904,0.723312,0.562101,0.844517,0.774469,0.184085,0.267997,0.649038,0.579462,0.888597,0.852094,0.691353,0.611196,0.292906,0.325765,0.655094,0.646501,-2.31041,-2.14641,-0.83436,-0.449938,-0.416958,-0.173597,-0.0835578,-0.0336378,0.502132,0.345629,-1.3791,-1.50698,-0.976013,-0.883093,0.67457,0.523739,0.973569,1.06784,-0.641766,-0.653089
5033,0.186626,0.131733,0.284219,0.215866,0.597837,0.435873,0.589893,0.611918,0.318573,0.311758,0.840108,0.703831,0.135764,0.0974165,0.880472,0.866812,0.147555,0.182253,0.485245,0.436124,0.594761,0.752243,-1.58857,-1.19833,0.362753,0.60911,-0.946129,-0.88934,0.932967,0.778777,0.929608,0.806136,-0.543944,-0.542471,0.301153,0.151043,0.182095,0.27227,0.718671,0.705568
5034,0.168703,0.154589,0.628945,0.497102,0.0577587,-0.103197,0.518538,0.449366,0.363464,0.355518,0.8969,0.828199,0.964065,0.926821,0.876185,0.848848,0.417883,0.52663,0.23325,0.225747,1.39205,1.55435,-0.570895,-0.182623,-1.04753,-0.796845,0.0895401,0.151954,0.616438,0.457573,0.0850498,-0.0432548,0.644908,0.642294,-0.385598,-0.531096,-0.810834,-0.72727,-1.68211,-1.69416
5035,0.203324,0.177444,0.846107,0.778339,0.807937,0.648143,0.893855,0.823207,0.315079,0.399279,0.735882,0.66558,0.792552,0.757142,0.844416,0.830885,0.834337,0.871007,0.963795,0.954209,0.991075,1.15064,1.37144,1.76108,0.357885,0.611386,0.852487,0.915239,-0.133412,-0.289744,0.861915,0.736502,-0.498959,-0.497712,-0.695295,-0.844427,-0.954079,-0.873474,-0.493971,-0.575393
5036,0.564642,0.539913,0.0665503,0.000930711,0.582184,0.420716,0.880486,0.810881,0.202452,0.287648,0.339944,0.268904,0.245773,0.210287,0.456682,0.472233,0.101643,0.139817,0.171694,0.163871,-1.26339,-1.10829,1.13749,1.53009,-0.104269,0.153851,-1.83534,-1.76968,-0.393185,-0.550604,-1.35712,-1.48559,0.491319,0.502157,0.504107,0.359178,-0.592409,-0.507848,0.549805,0.543374
5037,0.132839,0.109151,0.357377,0.291798,0.879615,0.716999,0.515648,0.444072,0.794489,0.877616,0.438051,0.368126,0.648715,0.612224,0.12818,0.113581,0.0377812,0.0740241,0.491986,0.482092,-1.15594,-0.996841,-0.50067,-0.106128,-0.15658,0.109497,-0.690415,-0.686884,1.36774,1.21689,2.16421,2.04354,0.409612,0.487831,0.57314,0.428432,1.90828,1.99952,-0.259619,-0.263769
5038,0.169916,0.14544,0.125185,0.0619019,0.862424,0.698177,0.756139,0.684001,0.00657337,0.0878711,0.769492,0.698235,0.316776,0.28182,0.294583,0.280526,0.90668,0.940745,0.192379,0.181164,-0.566624,-0.407248,0.0783058,0.479634,-2.13194,-1.87242,0.33082,0.395915,-1.3422,-1.48906,0.638908,0.519459,0.460248,0.473505,1.03738,0.896962,-0.790256,-0.692774,0.839595,0.832928
5039,0.73797,0.711983,0.859489,0.797915,0.600274,0.361347,0.273947,0.202191,0.171902,0.252641,0.206466,0.133863,0.464727,0.42761,0.234044,0.219871,0.3543,0.386252,0.768315,0.755246,1.09197,1.24528,-0.683279,-0.284843,-2.51951,-2.25364,-0.00601044,0.0526934,1.77003,1.62416,-0.524777,-0.649511,-0.344534,-0.325613,-0.397888,-0.536015,0.353304,0.453051,0.0611323,0.0551428
5040,0.701178,0.675612,0.188156,0.126897,0.189123,0.0245173,0.144315,0.0748012,0.0374092,0.203106,0.219505,0.155469,0.319474,0.282673,0.419419,0.406838,0.145892,0.178619,0.360754,0.431955,0.242473,0.39378,1.00277,1.39816,0.254859,0.517805,-1.07959,-1.01923,0.501394,0.354742,1.18923,1.06878,-0.327844,-0.311078,1.26296,1.12846,1.16852,1.27038,0.115118,0.107977
5041,0.268851,0.24485,0.875733,0.816563,0.182121,0.0159868,0.558523,0.488822,0.0745956,0.15357,0.250665,0.177076,0.923743,0.889431,0.29769,0.250234,0.708312,0.744019,0.119973,0.108664,0.768325,0.950603,-0.179472,0.217082,1.33603,1.59304,0.959963,1.02844,1.401,1.25049,-0.615441,-0.732517,-1.76238,-1.74853,0.804147,0.663336,0.773396,0.816131,-2.28954,-2.29175
5042,0.614151,0.591845,0.390961,0.333273,0.423586,0.355756,0.39456,0.325958,0.583768,0.661908,0.0499088,-0.0216935,0.202908,0.167118,0.107005,0.0936307,0.17382,0.209971,0.395239,0.393319,1.36116,1.50743,1.13509,1.52674,-0.0641269,0.187084,-0.679541,-0.615466,0.969011,0.822355,1.4517,1.32849,0.868516,0.887656,-0.777845,-0.920512,0.255456,0.361876,0.296378,0.289413
5043,0.145816,0.121375,0.240812,0.2191,0.862307,0.695525,0.799646,0.73044,0.139302,0.218473,0.284366,0.211685,0.241815,0.205533,0.977371,0.965151,0.207448,0.243639,0.690241,0.677975,-0.570048,-0.421871,-0.973711,-0.577862,-0.36784,-0.0658762,0.595987,0.658367,-0.42767,-0.570544,-0.329952,-0.457766,1.2054,1.25384,-0.841059,-0.988554,0.749042,0.852273,-0.0448772,-0.0516873
5044,0.226084,0.202022,0.163135,0.104928,0.941776,0.777455,0.0941866,0.0230955,0.104966,0.252934,0.208574,0.228209,0.938644,0.902781,0.4771,0.463883,0.803056,0.84011,0.0236117,0.0117299,0.381589,0.532227,1.81028,2.19896,-0.567008,-0.318837,-0.778848,-0.719836,-0.535376,-0.677191,1.2746,1.15117,1.59776,1.62003,-1.68629,-1.83682,-2.00831,-1.9083,0.887115,0.876373
5045,0.636755,0.564319,0.863551,0.80516,0.591576,0.493253,0.886288,0.813112,0.206921,0.287395,0.317273,0.244733,0.665543,0.631848,0.856256,0.841301,0.469662,0.506275,0.411914,0.400733,0.84268,0.999121,1.87084,2.26165,0.99496,1.24435,0.0627947,0.120177,1.27352,1.13711,0.786007,0.657969,-0.447592,-0.429283,2.27449,2.12396,-0.0796592,0.0230413,-0.211372,-0.221187
5046,0.949259,0.926616,0.835587,0.774914,0.372801,0.209051,0.531931,0.461399,0.69586,0.775726,0.946368,0.875415,0.137364,0.105022,0.336715,0.320203,0.912549,0.951474,0.174877,0.165054,-0.630309,-0.479441,-0.377491,0.0112036,2.00887,2.25904,-1.40809,-1.35103,-1.25433,-1.38555,-0.334092,-0.467535,0.457095,0.547765,0.676132,0.524459,-0.0817012,0.0177246,1.8158,1.80015
5047,0.78779,0.763602,0.0972168,0.0349868,0.590285,0.354202,0.671282,0.600928,0.220874,0.30272,0.200906,0.130054,0.178406,0.147634,0.82532,0.807099,0.196273,0.235552,0.4484,0.34016,1.20022,1.35616,-0.655226,-0.2628,-2.22749,-1.97579,-2.39422,-2.33005,0.544761,0.413963,0.822778,0.697358,1.51137,1.52481,0.570452,0.426708,1.33285,1.43268,1.65383,1.64106
5048,0.221963,0.197639,0.210485,0.122977,0.664044,0.499354,0.308473,0.238843,0.128524,0.212016,0.18251,0.101776,0.594956,0.475265,0.843635,0.822918,0.403512,0.442259,0.544157,0.515266,-0.121102,0.107554,0.034566,0.429403,0.424927,0.682988,0.0553391,0.11296,0.714497,0.588026,-0.745535,-0.873409,-0.634958,-0.617817,1.59621,1.44954,-0.536893,-0.43893,0.784383,0.771666
5049,0.918207,0.893305,0.272091,0.210967,0.461796,0.285435,0.610573,0.539233,0.516723,0.589175,0.132279,0.0734984,0.832712,0.802896,0.660854,0.571375,0.955502,0.991927,0.700194,0.690372,-1.29698,-1.14105,-1.33235,-0.940842,-0.417747,-0.164569,-1.06828,-1.00485,1.29198,1.15995,-1.43274,-1.55551,0.327248,0.349531,-0.323275,-0.464065,-0.935994,-0.830294,0.744305,0.733299
5050,0.693365,0.590715,0.588188,0.527401,0.141374,0.0715148,0.045832,-0.0245033,0.881678,0.966333,0.0978234,0.0452205,0.211639,0.182151,0.340742,0.319832,0.886148,0.921583,0.591486,0.580145,-1.50648,-1.3465,-1.07673,-0.641068,-0.392621,-0.133924,0.212812,0.282429,-0.289279,-0.416691,0.540967,0.421975,-0.851439,-0.82285,-0.373071,-0.517152,-0.422905,-0.322118,-0.502917,-0.515837
5051,0.312907,0.288124,0.168232,0.108732,0.021024,-0.142405,0.754384,0.682833,0.806378,0.891306,0.087794,0.0169426,0.649598,0.619047,0.33099,0.309836,0.0121794,0.0464639,0.585945,0.469918,-0.318455,-0.16035,-0.736637,-0.341294,1.13605,1.39688,0.22563,0.293997,-0.772556,-0.903472,1.87179,1.75435,-0.190489,-0.161628,-1.1117,-1.26066,2.3022,2.40804,-0.0315966,-0.0429197
5052,0.533002,0.509924,0.435227,0.374699,0.37481,0.210311,0.176668,0.10422,0.0487117,0.133705,0.709113,0.637701,0.26909,0.238106,0.106017,0.0828755,0.850449,0.886278,0.400003,0.359691,1.56214,1.7214,-1.42626,-1.02754,-1.93613,-1.67928,-1.08451,-1.02251,-0.850087,-0.978904,1.6447,1.5234,-0.965277,-0.928576,0.498764,0.343474,1.6048,1.70747,-1.08715,-1.09167
5053,0.185581,0.159863,0.388302,0.356183,0.150814,-0.0116861,0.913481,0.841568,0.382395,0.465885,0.0246878,-0.0470654,0.273585,0.241557,0.236283,0.215765,0.771753,0.805913,0.259287,0.249464,1.95336,2.1104,-0.0507051,0.342829,-4.1368e-05,0.25889,0.309158,0.372463,-0.67204,-0.804841,-0.236631,-0.352987,-2.80939,-2.77274,0.650641,0.490963,0.344648,0.443398,0.221707,0.220468
5054,0.27689,0.266529,0.397191,0.337667,0.697179,0.535799,0.818418,0.748596,0.351986,0.436271,0.58888,0.519363,0.0490385,0.0151886,0.371015,0.348655,0.197962,0.231327,0.384003,0.290334,-1.02312,-0.856395,0.0535214,0.449755,0.236618,0.489839,1.26233,1.32132,-1.00992,-1.14229,0.957787,0.842019,1.55739,1.59404,0.0185975,-0.144623,1.2843,1.38734,-1.26617,-1.27188
5055,0.396655,0.373195,0.99735,0.937685,0.389454,0.190303,0.113018,0.0412517,0.0905097,0.173967,0.621681,0.600518,0.996728,0.965352,0.191868,0.171816,0.872832,0.904116,0.339137,0.331204,-0.0217845,0.145811,0.829012,1.21968,0.107503,0.35489,0.94073,0.993636,0.382613,0.258241,-0.941989,-1.05116,0.149261,0.189472,-0.0182134,-0.184872,-1.38308,-1.27452,-0.350772,-0.359143
5056,0.724481,0.700772,0.997289,0.937308,0.00408278,-0.155194,0.335063,0.261598,0.593474,0.677866,0.751412,0.681673,0.390521,0.359225,0.671891,0.653846,0.175002,0.207961,0.709926,0.701144,0.450486,0.65687,-0.641585,-0.246072,-0.822222,-0.569904,1.01287,1.06675,-0.815395,-1.02265,0.0648985,-0.0415909,1.47363,1.51583,-0.712187,-0.881138,1.80718,1.92267,-0.676404,-0.684733
5057,0.0651951,0.0390629,0.503249,0.444393,0.312019,0.245355,0.189644,0.113794,0.0223028,0.104528,0.32308,0.255953,0.304352,0.274863,0.300085,0.281881,0.473615,0.507912,0.702517,0.594646,0.998707,1.16793,2.09384,2.49202,-0.965554,-0.704853,-0.655026,-0.594846,-2.17917,-2.30355,2.41045,2.30226,1.37419,1.41029,0.556762,0.38164,-0.630413,-0.512489,1.23488,1.22773
5058,0.246358,0.219588,0.339707,0.281184,0.806817,0.645903,0.0381238,-0.0340104,0.762422,0.843043,0.235929,0.27115,0.888366,0.861126,0.753509,0.73358,0.237106,0.269401,0.499071,0.488148,1.13628,1.3106,-0.333278,0.0654432,-0.554239,-0.289564,-1.35058,-1.29271,-0.668902,-0.720793,-0.653705,-0.767534,0.0686227,0.097501,0.589137,0.420648,0.635583,0.757975,0.268123,0.254595
5059,0.661455,0.632909,0.658873,0.602666,0.86652,0.708084,0.445949,0.375361,0.158309,0.238323,0.278965,0.286348,0.300753,0.273819,0.336348,0.317088,0.428074,0.535431,0.777116,0.765963,-0.209002,-0.0308442,0.193942,0.589478,0.944719,1.2117,1.56562,1.63007,0.986333,0.861961,1.59245,1.48256,-0.61351,-0.577098,1.0732,0.905339,0.355647,0.473949,0.255377,0.247216
5060,0.449559,0.419033,0.693022,0.636583,0.645598,0.486086,0.0980926,0.0286345,0.924714,1.00238,0.305553,0.301546,0.730589,0.607535,0.485794,0.468352,0.767821,0.801462,0.677593,0.617955,-0.98961,-0.805642,2.42614,2.82579,-0.578473,-0.315031,-1.49949,-1.43842,0.449916,0.329923,-1.79432,-1.89589,-0.951037,-0.914433,-0.180035,-0.341439,-1.14619,-1.02973,-0.86282,-0.866916
5061,0.78816,0.756133,0.436895,0.380528,0.185362,0.0269215,0.428559,0.357882,0.260425,0.337543,0.38387,0.316744,0.969193,0.941251,0.157061,0.141853,0.182293,0.216481,0.481145,0.469948,0.478073,0.662004,-0.448279,-0.0460457,-0.382689,-0.116182,1.76724,1.82273,1.74526,1.62344,1.26913,1.17276,-1.28946,-1.25177,-0.227536,-0.394527,-0.279808,-0.163444,-1.08213,-1.08711
5062,0.00593535,-0.0257874,0.551174,0.493821,0.63896,0.480431,0.199717,0.129711,0.500174,0.578774,0.559005,0.491518,0.109497,0.080368,0.153273,0.160432,0.194426,0.20754,0.642189,0.631711,0.00132507,0.179454,-0.748395,-0.352217,0.651205,0.914342,-0.988897,-0.92686,-0.213595,-0.342833,-0.0652067,-0.168018,1.54816,1.59107,-1.07117,-1.24279,0.174602,0.29506,1.95557,1.95145
5063,0.855318,0.826326,0.38942,0.3517,0.273765,0.115812,0.59461,0.523258,0.484977,0.526333,0.300677,0.233529,0.870602,0.840216,0.192517,0.179011,0.163019,0.198598,0.459568,0.366855,-0.166886,0.0173442,-0.138506,0.2637,-0.852579,-0.59751,1.11143,1.16777,-1.6167,-1.75101,0.394821,0.293551,-1.72798,-1.68456,-0.233918,-0.398909,-0.646683,-0.530985,0.817461,0.807318
5064,0.687006,0.658737,0.265099,0.20958,0.211807,0.0555547,0.293659,0.220826,0.396208,0.473891,0.254086,0.297277,0.582992,0.55435,0.720591,0.705886,0.154473,0.189656,0.111114,0.101999,0.195478,0.376785,-1.12617,-0.731557,0.111018,0.280464,-1.23308,-1.17999,-1.21258,-1.34746,1.3229,1.22801,-0.534742,-0.483688,0.620314,0.444974,-0.792538,-0.677189,0.358593,0.347224
5065,0.116081,0.0881172,0.993575,0.941175,0.471924,0.316239,0.8747,0.803743,0.963066,1.04263,0.370713,0.361024,0.63483,0.523535,0.145341,0.129741,0.610006,0.645073,0.2799,0.268935,0.109409,0.290609,0.0655648,0.387585,0.903982,1.15844,0.707547,0.756523,-1.2119,-1.34162,0.450256,0.347766,-0.315013,-0.22458,0.531679,0.361025,-0.586067,-0.468947,-0.615663,-0.625906
5066,0.201734,0.174179,0.780601,0.72672,0.421156,0.267216,0.283379,0.21032,0.774084,0.835409,0.379701,0.424772,0.519518,0.49272,0.675922,0.662324,0.352456,0.386262,0.109601,0.098755,0.585103,0.85319,1.11773,1.50673,0.347515,0.607615,-1.71856,-1.66109,-0.303888,-0.432162,1.10134,1.00577,-0.0183468,0.0345291,0.225748,0.0476939,-0.0804533,0.0392285,1.08309,1.06978
5067,0.0801645,0.0502343,0.281448,0.228438,0.664663,0.512538,0.659835,0.588633,0.546463,0.628186,0.555667,0.488519,0.159962,0.131769,0.217013,0.200916,0.764448,0.796525,0.773209,0.7621,1.23306,1.41577,1.9007,2.29507,0.206411,0.472665,-2.05244,-1.98877,1.56018,1.42794,0.41505,0.32367,1.2356,1.28147,0.906714,0.731001,-0.468752,-0.352135,2.55802,2.55177
5068,0.437524,0.407052,0.085069,0.120274,0.289627,0.137703,0.0119802,-0.0589995,0.826735,0.910283,0.153954,0.0869544,0.0635825,0.0379113,0.861001,0.845199,0.552372,0.583138,0.176519,0.166524,0.468996,0.657172,1.07639,1.47007,-1.71647,-1.44807,1.24286,1.30278,1.59069,1.46374,0.175373,0.0145719,0.811612,0.851901,0.505516,0.327244,0.678725,0.79369,1.86677,1.86635
5069,0.540831,0.56132,0.0674246,0.0121097,0.239459,0.0886797,0.976861,0.906187,0.636538,0.673168,0.682214,0.613632,0.209216,0.183701,0.964021,0.946744,0.711531,0.742521,0.0136243,0.00152198,-0.955684,-0.7624,-0.216992,0.179671,-0.0366432,0.226351,0.0625994,0.123761,-0.933735,-1.05893,-0.207989,-0.294526,0.841522,0.882803,0.345534,0.169283,0.267548,0.385862,-0.00406027,-0.0109497
5070,0.743264,0.715588,0.453139,0.396876,0.478856,0.328734,0.388841,0.318412,0.313395,0.436053,0.520395,0.498587,0.69758,0.670442,0.541423,0.550244,0.516461,0.545037,0.576996,0.56491,1.98618,2.18259,-0.427836,-0.0324431,-0.680208,-0.419777,0.195684,0.257776,0.699588,0.571622,-0.661527,-0.742872,0.421935,0.444259,-1.37301,-1.55659,-0.937761,-0.818286,1.91819,1.91678
5071,0.62032,0.591644,0.55206,0.463721,0.488009,0.335924,0.0602964,-0.0090738,0.114299,0.198938,0.406002,0.383543,0.374652,0.359624,0.169986,0.153743,0.0499593,0.0801525,0.868273,0.85785,-0.0578165,0.142121,0.17954,0.569404,-0.734738,-0.447811,-0.309064,-0.239847,1.84607,1.71236,1.57993,1.49474,-0.0392761,0.00571566,-2.35001,-2.52891,0.525913,0.644338,-0.838261,-0.832024
5072,0.838368,0.808223,0.587575,0.530566,0.136729,-0.0141575,0.531252,0.463934,0.688768,0.773231,0.336156,0.268498,0.077996,0.0488062,0.395588,0.38363,0.39902,0.431436,0.478424,0.467857,0.599894,0.805873,-0.332733,0.0525987,-0.617906,-0.475844,-0.391917,-0.32045,-1.07089,-1.2119,0.175171,0.0907713,0.529103,0.558446,1.25811,1.07921,0.67921,0.79164,0.701935,0.709258
5073,0.0658367,0.0362879,0.238522,0.180848,0.138944,-0.012803,0.145769,0.0772137,0.506753,0.590914,0.42099,0.353675,0.262571,0.242942,0.630135,0.613518,0.236483,0.268643,0.865963,0.85686,0.986143,1.19488,0.0514355,0.438082,-0.762228,-0.503877,-0.732368,-0.663671,-1.45817,-1.59422,-2.02763,-2.11509,1.07562,1.11118,0.0727977,-0.106011,0.247905,0.36727,-1.43278,-1.41665
5074,0.692355,0.661819,0.796115,0.737677,0.835017,0.682703,0.838755,0.770236,0.615467,0.749864,0.730946,0.663865,0.4639,0.437079,0.553191,0.536811,0.506459,0.539617,0.28816,0.281166,-0.223917,-0.00911812,0.781794,1.16016,-0.338567,-0.0749118,0.72483,0.798801,-0.535141,-0.668575,-1.04045,-1.13557,-0.702023,-0.671599,1.43107,1.25161,0.172632,0.300494,0.474805,0.495812
5075,0.0841278,0.0563821,0.843213,0.78571,0.538192,0.38352,0.856923,0.788153,0.8265,0.908814,0.167383,0.0994932,0.245269,0.205626,0.263332,0.24528,0.329019,0.362021,0.743032,0.735625,1.65964,1.87263,-0.134826,0.243368,0.579887,0.846503,0.0450374,0.115974,-0.0178569,-0.158165,0.869132,0.779326,-0.269807,-0.239604,2.31138,2.1336,0.863531,0.993893,0.507945,0.53415
5076,0.867789,0.841809,0.197693,0.140004,0.882046,0.725471,0.328402,0.259909,0.263079,0.344907,0.437019,0.368264,0.000526414,-0.0258271,0.499734,0.412726,0.731171,0.762958,0.642134,0.636595,1.29958,1.51471,0.634706,1.01329,-1.97773,-1.71057,-0.146026,-0.0738139,1.58737,1.44176,-1.04476,-1.13144,0.475154,0.49746,0.272087,0.0950427,-0.400685,-0.270179,0.0691077,0.0882987
5077,0.400133,0.375988,0.543704,0.486179,0.952493,0.79659,0.946416,0.877593,0.0818114,0.16259,0.451638,0.384959,0.997211,0.970858,0.59838,0.580172,0.15989,0.193028,0.33071,0.325201,-0.317838,-0.100614,0.581444,0.954144,0.175947,0.450505,-1.46229,-1.39032,0.789402,0.648604,-1.10348,-1.19369,0.954035,0.97407,0.492291,0.319546,-0.812905,-0.678007,-0.809612,-0.795209
5078,0.567694,0.540972,0.499929,0.441546,0.241303,0.0872691,0.773108,0.705354,0.895144,0.974646,0.255493,0.190622,0.380035,0.354563,0.464517,0.448384,0.961676,0.994776,0.94017,0.934067,-0.149989,0.150036,-0.0741479,0.298797,0.374033,0.649354,-1.22916,-1.16183,1.06408,0.929654,-0.731757,-0.828293,-1.85757,-1.84094,0.149676,-0.022919,1.88835,2.0184,0.594711,0.60874
5079,0.0142338,-0.0101638,0.987043,0.929245,0.815474,0.659816,0.314893,0.248349,0.0940572,0.173945,0.682034,0.619608,0.915532,0.890963,0.119333,0.101802,0.499593,0.545869,0.727957,0.724485,0.184871,0.400685,0.569923,0.947003,-1.1982,-0.92293,0.982804,1.04781,1.80349,1.6705,-1.4328,-1.52486,0.0419635,0.0606822,1.00459,0.829228,1.37387,1.50189,-0.691752,-0.672425
5080,0.42265,0.397696,0.681584,0.623274,0.422989,0.293994,0.213509,0.159659,0.295693,0.373497,0.415841,0.351731,0.481019,0.454882,0.420995,0.402795,0.0638632,0.0969632,0.417197,0.514903,-1.59729,-1.38794,-1.52841,-1.1576,0.697662,0.969945,-1.53427,-1.46853,0.564846,0.382144,0.303775,0.208385,-0.290153,-0.276256,-1.53367,-1.71192,-0.0221388,0.11061,-0.252389,-0.229117
5081,0.00267083,-0.0226227,0.129179,0.0713992,0.0818525,-0.0718282,0.139889,0.0709688,0.720628,0.795837,0.476954,0.449535,0.539303,0.493239,0.515078,0.498526,0.685563,0.718082,0.275881,0.305321,0.827506,1.03656,-0.721807,-0.35627,0.347324,0.619438,-1.85885,-1.79621,-0.813772,-0.906212,-0.826395,-0.917119,0.231562,0.2455,0.0515869,-0.125118,1.8515,1.97973,-1.04272,-1.02178
5082,0.270776,0.339674,0.574562,0.515189,0.051081,-0.099837,0.322537,0.251812,0.831993,0.864199,0.612151,0.547338,0.548466,0.531597,0.860184,0.84577,0.140161,0.173593,0.101841,0.0957387,-1.07327,-0.863244,-0.449489,-0.0779251,1.95548,2.22939,1.38377,1.44689,-2.06157,-2.19457,-0.775932,-0.872095,0.264843,0.296445,-1.11327,-1.29326,1.32978,1.46321,-0.841559,-0.819097
5083,0.726605,0.701972,0.27936,0.219877,0.727703,0.575373,0.242366,0.228446,0.856673,0.932561,0.940523,0.877447,0.5955,0.569954,0.76911,0.754991,0.452844,0.484376,0.656645,0.649851,0.622293,0.835267,-0.162928,0.200419,0.413561,0.686069,-0.924929,-0.865853,-0.344173,-0.473079,1.15551,1.06004,0.330807,0.34739,2.69184,2.515,-1.84158,-1.71009,1.29443,1.31209
5084,0.207614,0.181331,0.999767,0.940596,0.012662,-0.139086,0.260698,0.205081,0.601672,0.675506,0.942691,0.879517,0.0587588,0.033173,0.284659,0.268823,0.424613,0.442191,0.575362,0.64318,-1.42499,-1.2052,-1.12435,-0.764227,0.052138,0.28762,0.00355927,0.076893,-1.328,-1.45201,-0.519141,-0.616467,1.10485,1.11449,-0.439138,-0.612264,0.904372,1.03886,-0.518322,-0.502567
5085,0.352075,0.326146,0.132517,0.0744299,0.897833,0.746266,0.251666,0.181716,0.8816,0.957603,0.680988,0.616399,0.537773,0.442233,0.942656,0.928848,0.417739,0.400006,0.641614,0.636509,0.810516,1.03053,-0.721627,-0.400471,-0.378745,-0.11083,0.960563,1.01964,-1.66396,-1.78945,0.618857,0.51641,0.616252,0.638584,-0.456201,-0.63553,1.73299,1.87317,-0.141853,-0.121539
5086,0.990321,0.961957,0.646053,0.586869,0.520847,0.366934,0.474096,0.469371,0.204623,0.282404,0.895366,0.829485,0.876879,0.851293,0.742711,0.831155,0.259715,0.357822,0.257678,0.251196,-0.707748,-0.49326,-0.391413,-0.0367145,0.374952,0.642346,0.989932,1.04554,-0.877419,-1.00127,-1.27199,-1.37677,0.157483,0.16268,0.293145,0.208353,-0.0556294,0.0830195,-0.513262,-0.493758
5087,0.325227,0.295701,0.959202,0.897984,0.933999,0.780086,0.828563,0.757027,0.745251,0.821291,0.415173,0.349347,0.201051,0.174688,0.674484,0.733462,0.284105,0.315637,0.384527,0.377185,0.29287,0.508946,0.895559,1.25892,0.296914,0.566592,-0.232901,-0.180403,0.955391,0.830229,-0.451091,-0.551858,0.971169,0.974347,1.22375,1.05224,-1.10202,-0.964381,-0.0159855,0.0104723
5088,0.517973,0.54688,0.0949587,0.0318178,0.62759,0.47601,0.58097,0.509093,0.0417261,0.115802,0.262168,0.196391,0.822449,0.796212,0.64938,0.635768,0.46998,0.501823,0.0877224,0.0817781,-0.281645,-0.0653275,0.427987,0.787121,-1.00419,-0.730353,-1.23959,-1.19028,-0.397791,-0.518578,-0.880136,-0.909691,-0.49253,-0.494272,1.35929,1.18416,-0.677161,-0.536893,-0.41205,-0.391559
5089,0.829986,0.798059,0.740419,0.676532,0.814668,0.661797,0.0711315,0.00118311,0.304304,0.411537,0.610958,0.52372,0.0674827,0.0415345,0.284501,0.268982,0.902656,0.932279,0.19104,0.211995,1.63499,1.84629,0.754345,1.11196,-0.968118,-0.699709,-0.134336,-0.0881621,0.727688,0.604463,-1.16026,-1.26752,-0.106288,-0.111827,-0.0248825,-0.239009,-0.526281,-0.389591,0.161626,0.189109
5090,0.432,0.401909,0.27099,0.208272,0.800502,0.648309,0.747885,0.67788,0.495843,0.707272,0.914963,0.85105,0.153634,0.0710587,0.138294,0.122058,0.690819,0.808141,0.349218,0.342211,-1.3889,-1.18044,0.0882618,0.440727,-0.010727,0.254227,0.401047,0.531076,-1.04309,-1.17493,-0.682435,-0.747531,1.17361,1.1644,-1.48704,-1.66217,-0.632009,-0.488306,-0.462633,-0.436812
5091,0.864349,0.834872,0.611153,0.548914,0.57798,0.460827,0.296051,0.226012,0.928931,1.00301,0.485309,0.42033,0.126539,0.100583,0.755754,0.742172,0.652587,0.684002,0.947819,0.940692,1.79823,2.00424,1.48156,1.82708,-0.245846,0.0254131,1.10289,1.15031,-1.72642,-1.85796,-0.120247,-0.227539,-0.0867232,-0.0985365,-0.554184,-0.732862,-0.465756,-0.325182,2.23772,2.26025
5092,0.158425,0.127111,0.717008,0.710271,0.336773,0.273344,0.713769,0.644169,0.771151,0.808913,0.87982,0.814551,0.969131,0.94099,0.551994,0.540103,0.634921,0.66858,0.415664,0.496368,-0.433872,-0.227738,0.89865,1.24816,0.402915,0.670281,0.556092,0.60714,-0.405753,-0.629212,-0.163454,-0.273944,-1.6785,-1.69449,1.5448,1.37077,0.60847,0.743298,-0.814292,-0.795401
5093,0.133011,0.148561,0.933866,0.871628,0.238059,0.0858616,0.85,0.778321,0.53972,0.614818,0.360797,0.294479,0.018953,-0.0096887,0.584991,0.575377,0.241372,0.274377,0.0573369,0.0520436,1.37671,1.57891,-0.598514,-0.246725,-0.123665,0.150067,-1.05023,-1.00529,0.735449,0.599532,-1.29058,-1.39945,0.503336,0.493578,-0.651395,-0.82981,0.432199,0.565726,2.13562,2.15083
5094,0.200358,0.170011,0.701155,0.637125,0.768328,0.614397,0.279857,0.210138,0.949998,1.02744,0.34226,0.286474,0.632676,0.601683,0.869839,0.861294,0.172321,0.280526,0.0363441,0.0325372,0.0409032,0.237458,0.271636,0.630376,0.58885,0.856851,0.316136,0.35965,-0.928312,-1.06967,0.0127972,-0.0987954,1.12369,1.10937,1.52999,1.35058,-0.445383,-0.308058,0.828219,0.83989
5095,0.40516,0.376231,0.988648,0.923568,0.894923,0.668082,0.0476935,-0.0225107,0.232548,0.311856,0.37125,0.278469,0.336412,0.305015,0.657516,0.649685,0.253695,0.286674,0.300291,0.295567,1.83942,2.0441,-1.2801,-0.927463,-0.0877639,0.178358,-0.365374,-0.323177,-0.863068,-1.00256,0.0431155,-0.0685184,0.27051,0.251013,0.559433,0.378262,-0.0985844,0.131231,0.966427,0.886269
5096,0.829444,0.799323,0.69066,0.537025,0.876828,0.721768,0.355624,0.287212,0.840606,0.921584,0.38496,0.270463,0.945741,0.916386,0.0271965,0.0178575,0.482369,0.585087,0.90366,0.899349,-0.860449,-0.655316,0.175687,0.520734,-0.502575,-0.23414,-0.836891,-0.791195,0.689382,0.550267,0.691401,0.575517,-1.36883,-1.38895,-2.17765,-2.35279,0.438156,0.570519,0.916771,0.932648
5097,0.875093,0.84461,0.215217,0.150482,0.382663,0.227487,0.25917,0.18966,0.274095,0.35366,0.326447,0.262458,0.691855,0.659639,0.977149,0.96856,0.852114,0.8835,0.494638,0.552069,-0.339091,-0.126019,-0.409656,-0.0581891,1.57384,1.84805,0.406005,0.449659,-1.28122,-1.416,0.319709,0.206549,0.354985,0.337296,-0.937722,-1.12135,-0.135173,-0.00795076,0.627243,0.638647
5098,0.708635,0.677021,0.0872009,0.02135,0.117268,-0.0367356,0.77346,0.702458,0.748783,0.826632,0.0709562,0.102594,0.157351,0.127452,0.733562,0.798289,0.177741,0.208509,0.20776,0.204788,-0.61216,-0.392575,1.6182,1.96952,-0.728223,-0.457747,-2.28958,-2.24773,-0.221187,-0.352599,-1.20156,-1.31753,-0.0147731,-0.0298814,-0.614278,-0.804143,0.273717,0.404474,-0.266106,-0.259144
5099,0.0827252,0.0511346,0.733654,0.666064,0.750031,0.597035,0.10514,0.0348908,0.232046,0.308206,0.00835579,-0.057271,0.919353,0.8873,0.638755,0.628017,0.557381,0.518145,0.305297,0.369291,0.28433,0.502541,0.367652,0.710847,0.251875,0.525571,-1.27341,-1.23523,-1.2449,-1.3766,-0.981273,-1.10317,1.54319,1.52395,0.867953,0.673498,-1.71979,-1.59346,1.74342,1.7462
5100,0.996035,0.964592,0.600224,0.532222,0.758305,0.604226,0.776874,0.707674,0.120628,0.265248,0.889729,0.822869,0.328812,0.295773,0.720837,0.708789,0.797467,0.827781,0.594136,0.533793,-0.400275,-0.208957,0.123837,0.437206,-0.958425,-0.680005,0.135561,0.178152,0.163502,0.0387974,0.114091,-0.00255743,-0.882753,-0.909379,0.0648268,-0.129734,0.608842,0.733876,-0.455453,-0.457963
5101,0.962283,0.928221,0.0810703,0.0145796,0.371946,0.219609,0.0543476,-0.0150272,0.144831,0.22229,0.981973,0.913638,0.256101,0.221988,0.412858,0.402448,0.385379,0.413713,0.701268,0.698296,-1.13697,-0.920454,-0.173741,0.163566,-0.852472,-0.573504,2.2862,2.33351,1.2027,1.07226,0.467474,0.350067,-0.886851,-0.903553,-2.49511,-2.68564,-1.80566,-1.68396,-0.186194,-0.196565
5102,0.0672491,0.0337438,0.847625,0.779781,0.28805,0.133744,0.12456,0.0540366,0.54143,0.620012,0.0279404,-0.0415668,0.517458,0.512415,0.532079,0.523748,0.992245,1.02007,0.0299933,0.0271474,-0.7108,-0.500603,-0.125101,0.210757,0.84545,1.13197,1.4814,1.42905,-1.14216,-1.26739,-0.464974,-0.576144,-0.874254,-0.897728,-0.74609,-0.941195,0.0842232,0.200547,-2.60495,-2.61428
5103,0.852968,0.819171,0.11585,0.0492287,0.485159,0.404595,0.417664,0.349307,0.0986697,0.176576,0.775984,0.704561,0.83613,0.802843,0.856986,0.850151,0.319876,0.349197,0.847246,0.845433,0.723729,0.934307,1.38246,1.72159,-0.145643,0.14383,0.477279,0.524587,-1.1453,-1.27782,-1.68243,-1.79117,-0.543751,-0.56068,-1.75342,-1.94294,-0.921006,-0.798993,-1.03001,-1.04123
5104,0.460863,0.429347,0.655856,0.591486,0.830375,0.675446,0.26019,0.191577,0.995503,1.07281,0.875866,0.803784,0.728825,0.693613,0.220154,0.213508,0.854543,0.883789,0.351265,0.350025,1.70768,1.9189,1.27671,1.61612,-0.363013,-0.0710449,-0.133105,-0.0809323,-2.01955,-2.14937,-0.349267,-0.458801,2.55609,2.53617,0.041737,-0.153786,0.526052,0.589581,-0.41958,-0.4305
5105,0.472493,0.439653,0.129408,0.0640745,0.0901416,-0.0653133,0.993614,0.924052,0.91752,0.910651,0.229996,0.158442,0.911635,0.777471,0.160007,0.152854,0.68973,0.742424,0.326352,0.248716,-0.899505,-0.686612,0.503408,0.835213,-1.15276,-0.856594,-0.0481172,0.0476164,-0.282927,-0.411059,0.379315,0.274239,1.31958,1.30324,0.0628695,-0.130808,1.85374,1.97816,-0.0292284,-0.0335942
5106,0.11103,0.0799863,0.414639,0.350518,0.940321,0.785683,0.223448,0.154647,0.66888,0.748494,0.0126754,-0.060082,0.913105,0.861329,0.580039,0.574211,0.571332,0.601059,0.149838,0.147408,1.31819,1.53265,2.11549,2.43992,0.591769,0.881838,0.121153,0.176165,-0.758095,-0.88408,0.440637,0.335019,-1.51317,-1.53527,-0.479584,-0.672335,0.560845,0.680137,0.374231,0.363311
5107,0.635286,0.606793,0.103445,0.0399276,0.258884,0.105976,0.278543,0.286817,0.00418094,0.0836614,0.24469,0.233469,0.97873,0.945186,0.590065,0.58449,0.849436,0.804469,0.562049,0.498578,-0.535118,-0.321283,-1.30473,-0.984524,1.21308,1.51007,0.947367,0.999631,0.293868,0.164363,1.20651,1.10058,-0.13333,-0.148641,0.0190433,-0.119523,-0.0384148,0.0868106,-0.231792,-0.249189
5108,0.501691,0.558227,0.914907,0.852147,0.771365,0.61999,0.486349,0.418988,0.425457,0.506002,0.599027,0.527019,0.892864,0.879438,0.394671,0.463753,0.977061,1.00788,0.849922,0.849747,2.87457,3.08715,-0.363692,-0.0469649,-0.290025,0.0135468,2.37809,2.42912,-0.605674,-0.735377,-2.20655,-2.31372,0.824776,0.804247,0.627255,0.433288,0.870392,0.998094,1.58008,1.5573
5109,0.537937,0.509661,0.375406,0.315049,0.173173,0.0206547,0.146661,0.0775224,0.585425,0.642777,0.428443,0.314467,0.847166,0.813689,0.349436,0.343017,0.067798,0.0967489,0.44978,0.449186,0.819503,1.03144,-0.466578,-0.152435,3.17383,3.46941,0.0882233,0.134362,-0.393694,-0.515437,-0.575348,-0.689277,0.718829,0.698706,-0.742338,-0.936917,0.261729,0.447752,-1.32225,-1.34633
5110,0.183873,0.154363,0.502777,0.443171,0.765857,0.613677,0.870029,0.801256,0.711324,0.779552,0.174916,0.101914,0.452744,0.417631,0.923023,0.916633,0.786163,0.813204,0.803656,0.803068,1.15345,1.35913,0.634534,0.94245,-0.220211,0.0781853,-0.00020081,0.0385717,1.11616,0.992257,-1.30593,-1.41571,0.399957,0.377675,0.203661,0.00858561,-0.228765,-0.10259,0.550662,0.52358
5111,0.516202,0.487351,0.990029,0.93087,0.623017,0.471671,0.111396,0.0420067,0.896996,0.916327,0.374294,0.300779,0.822059,0.784514,0.123185,0.115374,0.0781102,0.102806,0.690403,0.768157,-0.73215,-0.524789,0.446717,0.761084,0.171825,0.478478,0.482704,0.525101,-0.722297,-0.846815,-0.439299,-0.543921,1.41999,1.39102,0.639307,0.430351,1.26603,1.38964,-0.265702,-0.298187
5112,0.847747,0.82034,0.836141,0.777374,0.706605,0.588614,0.829039,0.76062,0.970283,1.0531,0.19606,0.123482,0.637505,0.581811,0.273316,0.185335,0.570622,0.5936,0.686491,0.733246,0.181544,0.383946,0.0494458,0.365309,-0.252856,0.0516151,0.0667661,0.104177,0.646819,0.521501,-1.65479,-1.75895,0.153216,0.128084,1.04476,0.852117,-0.0656808,0.0581342,0.101958,0.0697093
5113,0.533111,0.616077,0.970762,0.911227,0.813471,0.705557,0.118089,0.047729,0.454861,0.53998,0.276379,0.237051,0.548368,0.379108,0.262233,0.255295,0.558479,0.546574,0.697364,0.698335,-1.81226,-1.60891,0.300939,0.612632,-0.963083,-0.655692,0.516242,0.5599,1.20857,1.07624,-1.17663,-1.28171,0.913456,0.895181,-0.588504,-0.778785,1.56982,1.68978,-0.99285,-1.02785
5114,0.39725,0.411815,0.711671,0.732353,0.973075,0.8225,0.573918,0.505414,0.798087,0.882578,0.425513,0.350619,0.213949,0.176404,0.215801,0.208777,0.478267,0.499547,0.921408,0.921449,0.0973366,0.302709,0.16544,0.476656,0.281457,0.587321,0.180838,0.23222,0.362575,0.235172,-1.06844,-1.17492,0.814069,0.78964,-0.209411,-0.400074,-1.88306,-1.75986,2.28192,2.25358
5115,0.234757,0.207552,0.630838,0.553478,0.796956,0.672764,0.209925,0.143329,0.77496,0.858453,0.837283,0.765194,0.240732,0.204216,0.765105,0.756591,0.982366,1.0052,0.369294,0.370652,-1.68536,-1.48591,-0.635775,-0.318015,0.415772,0.725185,-0.747757,-0.701299,1.01691,0.882981,0.976613,0.868358,0.388376,0.360067,0.457552,0.268663,-2.48633,-2.36936,-2.21145,-2.23979
5116,0.467072,0.439401,0.434139,0.374604,0.538643,0.523028,0.382462,0.237958,0.187991,0.269739,0.199487,0.125538,0.0531512,0.0152324,0.607929,0.501338,0.511755,0.59128,0.183705,0.185243,0.641685,0.84313,0.670507,0.991642,-2.18091,-1.87285,-0.121158,-0.0792572,-0.318946,-0.450302,-0.470942,-0.579874,0.755,0.728595,-0.457734,-0.640636,1.80445,1.92142,-2.25037,-2.27816
5117,0.490934,0.460851,0.54857,0.487897,0.523689,0.373291,0.43293,0.332587,0.230087,0.311919,0.0537685,-0.0224799,0.294692,0.256344,0.252961,0.246085,0.153256,0.177358,0.322724,0.322301,0.779566,0.985804,0.74181,1.06982,-2.39273,-2.08772,-1.25091,-1.21247,-0.61008,-0.738711,-0.325534,-0.429338,-0.750333,-0.771053,1.31442,1.1321,-0.802946,-0.690201,-0.856957,-0.890325
5118,0.508987,0.482301,0.93911,0.877879,0.601865,0.449763,0.493813,0.427216,0.858247,0.941084,0.465021,0.387173,0.310517,0.351125,0.813923,0.808321,0.329798,0.329671,0.889155,0.890696,-0.956367,-0.754801,1.29803,1.62331,-0.353731,-0.0537883,0.190393,0.232092,-1.64214,-1.77773,-0.77594,-0.902231,0.260187,0.242295,-2.21598,-2.40777,1.40005,1.5081,0.14976,0.115714
5119,0.289094,0.263066,0.820491,0.79297,0.052387,-0.0993,0.846301,0.781108,0.859223,0.943874,0.0537136,-0.0238318,0.429451,0.445906,0.069797,0.0625762,0.458899,0.481983,0.678419,0.6799,0.646172,0.852028,-1.01247,-0.694413,-0.381274,-0.0832684,0.319956,0.366107,-0.65831,-0.790667,-1.26403,-1.37512,0.897411,0.873128,0.0297161,-0.169563,-0.885593,-0.772165,0.0555614,0.0179501
5120,0.843876,0.819615,0.770162,0.708061,0.602074,0.448186,0.610398,0.628109,0.610344,0.697364,0.819052,0.744056,0.600235,0.540688,0.756189,0.748362,0.0953065,0.117678,0.16718,0.168991,-0.175129,0.0306769,1.38838,1.70359,-0.646495,-0.342079,0.779539,0.82183,-0.0347225,-0.173552,1.05953,0.954729,0.551615,0.520352,1.25528,1.06188,-0.312608,-0.203592,-1.26475,-1.3077
5121,0.700796,0.676606,0.952941,0.891522,0.887475,0.734702,0.540881,0.47511,0.364757,0.450855,0.0677055,-0.00607213,0.67608,0.635469,0.31928,0.311466,0.241404,0.345959,0.412997,0.461821,1.18736,1.38812,-0.602354,-0.291541,-0.177894,0.132838,-0.19695,-0.15719,1.87667,1.73382,-1.03109,-1.14237,-1.43353,-1.46732,0.388898,0.198419,-0.132969,-0.025799,0.742095,0.697641
5122,0.00976976,-0.0156159,0.0555215,-0.00718705,0.113605,-0.0397161,0.57382,0.438105,0.855793,0.944115,0.305331,0.216714,0.415113,0.374767,0.15714,0.148707,0.550254,0.574241,0.753156,0.754651,0.333371,0.536624,0.256226,0.569045,-0.925786,-0.62139,1.07028,1.11664,-1.82382,-1.96706,-0.486957,-0.531578,-1.06513,-1.09879,0.363107,0.175154,1.94967,2.05786,-0.628357,-0.673903
5123,0.75267,0.728351,0.65389,0.592832,0.693212,0.538428,0.487628,0.4011,0.38591,0.475811,0.515051,0.439499,0.469079,0.362923,0.54754,0.499774,0.478339,0.468903,0.497458,0.499848,0.874665,1.07958,0.0532584,0.371473,-0.67667,-0.374365,0.240448,0.293087,-0.791033,-0.904972,0.196,0.0792148,-0.326811,-0.436822,1.35969,1.16433,-0.290769,-0.175624,-0.185016,-0.230595
5124,0.934556,0.908876,0.174486,0.115395,0.703275,0.561026,0.428981,0.364095,0.278718,0.368905,0.168034,0.092316,0.390331,0.35108,0.860339,0.850841,0.338653,0.363566,0.742414,0.742941,-0.169758,0.0283544,0.0692171,0.467919,-1.70824,-1.40957,-0.187616,-0.127837,0.296611,0.157118,1.04888,0.935602,0.258809,0.225149,0.988203,0.79163,-1.26274,-1.144,-1.35735,-1.40502
5125,0.218042,0.189415,0.326168,0.33204,0.73598,0.583625,0.722655,0.659366,0.984011,1.07462,0.184044,0.109011,0.166539,0.124712,0.870799,0.86112,0.527374,0.554061,0.039842,0.0403054,0.363736,0.557652,0.246233,0.564365,0.779503,1.08278,0.0611506,0.114266,0.181724,0.0344837,-0.159484,-0.279428,0.48937,0.431621,-0.440947,-0.641347,0.825685,0.939661,-0.419238,-0.460099
5126,0.91146,0.885081,0.607279,0.548685,0.010814,-0.141537,0.509091,0.354641,0.817346,0.908002,0.975323,0.897516,0.489491,0.379581,0.287534,0.276067,0.474079,0.498497,0.438846,0.439764,1.23011,1.4196,-0.0786418,0.246164,-0.7658,-0.460546,1.21598,1.26405,-0.15683,-0.373574,1.56169,1.43886,0.666623,0.638092,2.08582,1.89057,-0.642514,-0.532869,-0.106545,-0.151472
5127,0.160532,0.134334,0.606006,0.548308,0.477159,0.327046,0.110901,0.0499161,0.351126,0.439697,0.0511434,-0.0238826,0.675898,0.63445,0.316503,0.306281,0.885045,0.90876,0.611034,0.611935,-0.281771,-0.0899115,0.276579,0.601359,-0.781292,-0.475292,-0.346667,-0.299085,-0.630802,-0.781632,1.26089,1.04546,-0.897299,-0.925466,0.458746,0.25967,-0.273001,-0.167244,-0.8653,-0.914277
5128,0.655453,0.63074,0.384626,0.328928,0.0811517,-0.0680377,0.0766597,0.0134913,0.692424,0.782296,0.105128,0.024387,0.406153,0.457352,0.0188851,0.00934778,0.958534,0.901172,0.0971092,0.0965846,-0.380497,-0.191748,-0.243658,0.0845539,-1.4468,-1.13729,1.77829,1.82461,0.836907,0.679365,0.776192,0.652062,0.01282,0.0515818,-0.176878,-0.31456,-0.643312,-0.543621,0.76508,0.719165
5129,0.53485,0.445867,0.875523,0.821976,0.236138,0.0210633,0.932754,0.870495,0.624471,0.645092,0.145546,0.0726566,0.327387,0.280253,0.080854,0.0699973,0.874261,0.893583,0.74059,0.73993,-1.07917,-0.888368,1.52999,1.86059,0.0757979,0.378827,-1.66524,-1.61148,-0.73528,-0.89728,0.828229,0.697086,1.06185,1.02863,-0.683773,-0.888791,0.0652225,0.166124,0.726182,0.680798
5130,0.287748,0.260994,0.200549,0.146176,0.376597,0.110164,0.61616,0.552541,0.418112,0.507888,0.938842,0.866997,0.145497,0.103155,0.440428,0.425623,0.862279,0.885995,0.58068,0.497518,-0.296182,-0.101493,-0.857666,-0.537379,-1.42556,-1.11769,0.518381,0.576939,1.46815,1.30572,1.51093,1.38442,0.378561,0.338107,-0.197045,-0.4041,-0.628079,-0.519022,1.52646,1.47408
5131,0.987493,0.961687,0.574067,0.520384,0.387789,0.199265,0.522161,0.459569,0.608036,0.697874,0.978413,0.907379,0.826254,0.786046,0.79117,0.781248,0.690472,0.807088,0.255188,0.255106,-0.742482,-0.509469,0.24418,0.572005,-2.21472,-1.90324,0.713725,0.712307,-0.412382,-0.579709,-2.07158,-2.2016,-0.851727,-0.894817,-1.01947,-1.22178,0.783908,0.88658,-0.262564,-0.310958
5132,0.545823,0.521179,0.715857,0.663935,0.437716,0.288366,0.723135,0.661028,0.114873,0.204538,0.647315,0.626888,0.399904,0.361041,0.61046,0.720654,0.704844,0.728181,0.268513,0.270453,-1.11902,-0.917444,-0.495061,-0.160007,-0.37825,-0.0733024,0.787563,0.847676,-1.50204,-1.66383,-2.17801,-2.30898,-0.497467,-0.540964,1.40827,1.20293,2.18824,2.29218,-0.00199052,-0.0495603
5133,0.780545,0.757392,0.0644008,0.0134111,0.394174,0.244095,0.430534,0.368515,0.0852898,0.174924,0.353433,0.346397,0.437608,0.399456,0.606587,0.66006,0.780377,0.801839,0.041476,0.0444916,0.164208,0.362229,-0.204995,0.135598,0.0511085,0.355663,0.497394,0.565202,1.60617,1.44939,-0.117045,-0.247971,1.57863,1.53179,0.253224,0.0502298,-0.137046,-0.026849,-1.19499,-1.23856
5134,0.181805,0.156222,0.347291,0.295188,0.104813,-0.0456559,0.338549,0.275543,0.890385,0.981823,0.13694,0.0659058,0.1526,0.11359,0.609388,0.599466,0.102316,0.121898,0.589743,0.593427,0.91732,1.11987,-1.94478,-1.61032,0.922285,1.23287,0.632951,0.699217,1.33509,1.17465,-1.17932,-1.3128,-0.214634,-0.267058,-0.139678,-0.337213,-0.1734,-0.00770689,-1.72044,-1.76018
5135,0.890625,0.866853,0.0411302,-0.010783,0.593472,0.370905,0.875331,0.813015,0.398452,0.488487,0.0520184,-0.017228,0.353979,0.329512,0.887958,0.880498,0.698205,0.718369,0.593154,0.5675,0.039759,0.237215,-0.535975,-0.20871,1.22976,1.52771,-0.45222,-0.389417,0.219157,0.0600425,-0.515509,-0.654799,-1.0341,-1.07931,0.74178,0.544776,-0.101992,0.0114352,0.700932,0.664164
5136,0.12702,0.101604,0.948337,0.897897,0.939782,0.787467,0.227492,0.165383,0.661788,0.786704,0.504445,0.436093,0.585023,0.545435,0.616413,0.516209,0.852981,0.873338,0.633608,0.541572,-0.483159,-0.208709,-0.290268,0.0386125,1.50689,1.82254,0.380064,0.520348,-0.150398,-0.30692,-0.958751,-1.10314,-0.320098,-0.372272,0.673565,0.487576,0.853824,0.969235,-1.11797,-1.15049
5137,0.641733,0.618211,0.305574,0.2576,0.360512,0.208638,0.507761,0.368247,0.996579,1.08492,0.405028,0.338202,0.565059,0.477517,0.160399,0.15192,0.492342,0.514186,0.462998,0.515645,-0.849086,-0.654633,0.308707,0.640459,0.423009,0.741439,1.365,1.43011,-0.860169,-1.02155,-0.72894,-0.874091,0.152236,0.104338,0.635148,0.430375,-1.07963,-0.963336,-1.22386,-1.26397
5138,0.940827,0.915521,0.770085,0.720677,0.195239,0.0424906,0.63366,0.571112,0.324028,0.409721,0.746605,0.594876,0.44819,0.409599,0.572111,0.563664,0.964172,0.984737,0.430079,0.489717,-0.924929,-0.725759,0.318034,0.656543,-0.0785427,0.3045,-0.996393,-0.930516,-0.0202642,-0.188302,-0.708083,-0.84334,-2.82304,-2.86572,0.772977,0.562296,0.0289142,0.0506097,-1.06175,-1.10631
5139,0.24607,0.223299,0.922321,0.874723,0.655445,0.501326,0.181976,0.119244,0.219323,0.322424,0.919573,0.851549,0.915869,0.876679,0.701226,0.738753,0.415882,0.43544,0.460105,0.46379,0.467018,0.662968,1.20734,1.54829,-0.44665,-0.132439,-0.571932,-0.45824,-1.03028,-1.19789,-0.662183,-0.81259,-0.42794,-0.46707,-0.955846,-1.16358,0.949405,1.06455,1.88233,1.83992
5140,0.716728,0.69519,0.277492,0.229017,0.365518,0.23053,0.388847,0.334879,0.148049,0.235127,0.643701,0.594977,0.0078345,-0.0333573,0.922886,0.913841,0.393965,0.414584,0.0809305,0.0833832,-0.956231,-0.756604,-0.204964,0.131894,-0.628788,-0.322973,-0.0567567,0.0140359,-0.850886,-1.02383,0.0103553,-0.137644,0.711226,0.670821,0.63141,0.42322,0.588864,0.702719,-1.00946,-1.04486
5141,0.777403,0.755443,0.842905,0.795499,0.115257,-0.0402656,0.612791,0.550514,0.56888,0.657467,0.405886,0.338406,0.649717,0.607929,0.331977,0.322519,0.714388,0.735252,0.257491,0.335566,0.537382,0.742525,0.630131,0.963716,-0.833186,-0.513506,-0.496461,-0.42323,-0.143825,-0.310557,-0.911229,-1.06386,-0.713262,-0.751118,-1.24939,-1.46125,1.35886,1.47232,1.39947,1.36265
5142,0.620599,0.597678,0.236153,0.189679,0.965714,0.810731,0.202523,0.138194,0.293042,0.380473,0.579467,0.51318,0.174491,0.131785,0.863621,0.855102,0.739331,0.759596,0.586743,0.587749,-0.213617,-0.0056973,2.48377,2.81594,-0.0509871,0.269201,0.540578,0.618065,0.576973,0.402711,-0.260989,-0.318231,0.344802,0.307894,2.22449,2.01607,-1.37257,-1.2557,-0.222099,-0.253481
5143,0.112135,0.0868211,0.8051,0.761062,0.0286072,-0.125331,0.767641,0.701537,0.428439,0.557369,0.240092,0.175544,0.728887,0.688677,0.810147,0.799436,0.536551,0.54433,0.539345,0.622341,-0.962792,-0.75392,0.868456,1.19596,-0.303157,0.0103901,2.55403,2.63592,1.02472,0.850481,0.576857,0.427394,-0.379064,-0.412273,0.0945367,-0.118243,0.562937,0.675635,-2.57771,-2.60689
5144,0.993517,0.968764,0.113051,0.0706175,0.021707,-0.133861,0.991903,0.926507,0.644289,0.734265,0.273165,0.207098,0.310957,0.345162,0.18397,0.173058,0.30794,0.329064,0.575463,0.656933,-0.0845955,0.122557,0.487182,0.814297,-1.28899,-0.97775,-0.307776,-0.224252,0.611587,0.438125,1.0971,0.949548,-0.740704,-0.77945,-1.50074,-1.71774,1.47443,1.58692,0.115272,0.0901705
5145,0.535187,0.480419,0.542171,0.500188,0.894726,0.737609,0.782515,0.719631,0.232661,0.320194,0.89985,0.832555,0.0441193,0.001647,0.363968,0.35418,0.369989,0.323351,0.56649,0.691525,-0.887602,-0.683873,-0.568862,-0.243537,-1.61487,-1.29994,0.110083,0.215755,0.666097,0.489271,-1.87962,-2.02454,0.580449,0.546905,0.106041,-0.113602,0.0211816,0.132155,-0.423198,-0.448062
5146,0.0168277,-0.00792589,0.734902,0.692968,0.683328,0.52445,0.0902787,0.0275139,0.198018,0.285838,0.684767,0.618774,0.533452,0.493736,0.91306,0.901994,0.295847,0.317637,0.726059,0.726117,-1.13281,-0.934288,0.365939,0.694022,0.1586,0.557477,0.571672,0.655762,1.68694,1.50779,0.320943,0.177011,-0.597126,-0.625475,0.338365,0.126132,0.269121,0.387459,0.664089,0.634277
5147,0.673065,0.648467,0.66011,0.633685,0.169236,0.0108865,0.24986,0.187138,0.833648,0.920371,0.206183,0.138636,0.194401,0.1537,0.770706,0.75986,0.688369,0.708528,0.330164,0.33084,0.344759,0.549346,0.960509,1.29587,2.09997,2.4149,-0.0617222,0.0197561,0.796654,0.622482,-0.0471088,-0.191956,-0.166142,-0.19348,1.14141,0.931993,-0.138314,-0.020368,-0.0907461,-0.128528
5148,0.133845,0.10737,0.615231,0.574402,0.88804,0.730884,0.646704,0.586485,0.400916,0.486434,0.385925,0.371639,0.30386,0.263711,0.996869,0.983785,0.518585,0.540829,0.486361,0.488102,1.46382,1.67111,-0.476333,-0.138139,0.274931,0.588088,2.00458,2.0824,0.829386,0.658283,-1.51057,-1.6571,-0.0588934,-0.0851832,0.544152,0.32553,1.89131,2.01254,0.957834,0.922316
5149,0.0977673,0.0709991,0.101188,0.0615612,0.625423,0.519135,0.701534,0.715845,0.987117,1.07185,0.673342,0.604643,0.849077,0.809976,0.294971,0.280373,0.868835,0.892113,0.276331,0.277306,1.63978,1.84465,0.387486,0.722447,0.636917,0.955555,0.837392,0.91716,2.12014,1.9518,0.244152,0.089964,-0.673807,-0.699958,-0.0718323,-0.280933,-1.44325,-1.3252,-0.226258,-0.266684
5150,0.835061,0.808754,0.427105,0.383796,0.41155,0.307386,0.904759,0.845206,0.466175,0.548833,0.487379,0.348071,0.751968,0.710318,0.72677,0.712022,0.653528,0.678725,0.945059,0.9467,0.49064,0.701396,-0.585918,-0.256537,-1.52822,-1.20409,0.811868,0.897613,0.0813312,-0.0826144,-0.30924,-0.465632,0.187746,0.156785,1.32773,1.12295,-0.652751,-0.443973,0.0336333,-0.00528652
5151,0.466122,0.439002,0.743465,0.70603,0.252865,0.0956372,0.497416,0.435606,0.804282,0.886211,0.161492,0.0914991,0.0885188,0.0486243,0.814847,0.797748,0.814756,0.838108,0.0647088,0.0677081,1.0704,1.27554,1.33465,1.65898,0.516567,0.843373,1.25804,1.33676,-0.488334,-0.646507,-1.08184,-1.23862,0.281032,0.248958,0.693718,0.487359,0.315907,0.437256,-0.242589,-0.285446
5152,0.514858,0.514712,0.860871,0.824511,0.892115,0.734778,0.0846616,0.0260055,0.286007,0.367785,0.334989,0.266273,0.379398,0.365519,0.418882,0.401241,0.214139,0.238306,0.0219501,0.0244256,-0.00520276,0.194048,1.20531,1.52301,1.01124,1.33259,-0.234562,-0.149611,-0.772364,-0.935956,1.04901,0.898234,-0.381311,-0.409712,-2.1095,-2.31405,2.32133,2.44079,-0.213386,-0.262975
5153,0.618274,0.590422,0.192025,0.153493,0.807024,0.648913,0.895849,0.837349,0.47947,0.46227,0.759,0.689884,0.722134,0.682415,0.70963,0.691876,0.512336,0.534438,0.884776,0.888005,0.751388,1.03245,-0.728458,-0.413274,0.290048,0.60699,-0.415478,-0.392761,-1.06588,-1.22541,-0.155516,-0.303205,0.203525,0.175317,-2.82561,-3.02633,-0.203982,-0.0801775,1.73261,1.67951
5154,0.123593,0.0950274,0.928392,0.889506,0.389889,0.276461,0.392362,0.334421,0.475402,0.556755,0.885302,0.814789,0.386195,0.426274,0.526772,0.509704,0.298438,0.350354,0.540787,0.542079,1.67372,1.87085,-0.204461,0.110761,-0.00520033,0.31754,-0.7132,-0.635912,0.837046,0.681963,1.46341,1.32123,-0.17176,-0.19186,-2.42174,-2.61837,0.663999,0.856349,0.714481,0.660227
5155,0.971731,0.942482,0.392673,0.352408,0.0598134,-0.0959898,0.241349,0.182299,0.975393,1.05468,0.723058,0.699645,0.212181,0.170133,0.557453,0.625844,0.14455,0.166271,0.981969,0.981374,0.587977,0.789359,0.0765953,0.390028,0.0773385,0.394765,1.36197,1.44313,0.926147,0.764149,0.462851,0.317533,1.27976,1.25509,-0.299296,-0.501731,1.67054,1.79288,-0.518812,-0.575414
5156,0.974078,0.94305,0.513015,0.466552,0.350421,0.195466,0.793769,0.734877,0.800853,0.967384,0.652917,0.5845,0.717361,0.676554,0.758796,0.741985,0.244232,0.264805,0.831115,0.825344,0.485023,0.687523,-0.165684,0.146124,-0.652837,-0.330835,1.31373,1.39344,1.3904,1.22827,0.21527,0.0707408,-0.270093,-0.293942,-0.19137,-0.399683,-0.00301998,0.116598,-0.671843,-0.7345
5157,0.728841,0.699388,0.589903,0.580697,0.958497,0.803329,0.276982,0.217004,0.802127,0.880087,0.233584,0.163186,0.954687,0.912404,0.616815,0.64735,0.070055,0.0915412,0.668159,0.669313,3.35816,3.55725,0.593982,0.900629,-0.0294638,0.297396,-0.0735421,-0.0660009,0.96941,0.800137,0.69169,0.547984,0.620961,0.594716,-0.651718,-0.864811,0.688994,0.780753,0.27885,0.210423
5158,0.00164321,-0.0298563,0.735106,0.694841,0.0409612,-0.11121,0.766627,0.705468,0.496825,0.577553,0.0984655,0.0292696,0.592859,0.551307,0.492944,0.552716,0.849291,0.868553,0.0587802,0.0593595,0.470666,0.667668,0.699834,1.10069,0.170701,0.496244,-1.60515,-1.52544,1.13882,0.9742,-0.110901,-0.255627,2.68008,2.65163,0.830776,0.61283,1.33086,1.44491,-0.085265,-0.174586
5159,0.890675,0.857244,0.144938,0.103728,0.856523,0.703878,0.663958,0.602893,0.824732,0.904926,0.700772,0.630738,0.233702,0.190211,0.474892,0.458081,0.0712634,0.0887163,0.649964,0.648494,0.206713,0.401113,0.99425,1.30076,-0.88936,-0.569609,2.17067,2.24468,0.432607,0.272994,-0.379249,-0.51678,0.717316,0.695943,-0.715704,-0.940968,-0.772819,-0.662759,-0.495383,-0.559595
5160,0.863576,0.766809,0.562157,0.518837,0.481156,0.31916,0.246233,0.186124,0.434059,0.609488,0.383625,0.33185,0.948092,0.903386,0.758882,0.743999,0.480938,0.498979,0.323829,0.322174,0.388936,0.590068,0.0162611,0.321774,-0.146708,0.168391,0.214799,0.280093,1.0233,0.859043,-1.02689,-1.16911,0.37063,0.343167,0.484797,0.262637,-0.131522,-0.0165896,0.231576,0.172912
5161,0.76147,0.676374,0.357168,0.313892,0.0862038,-0.0655578,0.946395,0.888197,0.23285,0.31405,0.101736,0.0329622,0.936049,0.890723,0.158704,0.142945,0.0965789,0.114513,0.983091,0.980558,2.36184,2.56191,-1.46807,-1.15842,2.03399,2.34758,0.236252,0.305994,1.27926,1.10976,-0.642171,-0.786223,-0.395619,-0.423781,0.439215,0.222389,1.06363,1.17412,1.18237,1.11784
5162,0.621702,0.585939,0.913909,0.870721,0.8964,0.7447,0.282632,0.224904,0.24427,0.326982,0.439723,0.372538,0.371521,0.328911,0.273489,0.258701,0.63899,0.65519,0.631553,0.629477,0.864768,1.06686,-0.771756,-0.466213,-1.31499,-1.00281,-0.125949,-0.053814,-0.127153,-0.29842,0.613953,0.469042,-0.523698,-0.543395,-0.0286023,-0.24274,-1.0792,-0.965401,-1.84041,-1.90327
5163,0.0994015,0.0652977,0.419314,0.377807,0.764279,0.613174,0.0214084,-0.0385347,0.811075,0.895722,0.0885233,0.0202188,0.948292,0.905411,0.159732,0.147123,0.269095,0.285833,0.691848,0.688683,1.41787,1.62385,-0.911339,-0.602189,-0.554563,-0.24963,-1.35952,-1.27976,1.34557,1.17836,1.16584,1.02154,0.943101,0.92017,0.357278,0.150046,-0.18467,-0.0703536,-0.168773,-0.239105
5164,0.158849,0.125551,0.716905,0.674414,0.170549,0.0187314,0.896593,0.836472,0.148643,0.230889,0.45285,0.295023,0.350553,0.308812,0.322916,0.308588,0.752757,0.770841,0.704955,0.747889,0.872151,1.08054,1.12986,1.4421,-1.93244,-1.62608,0.232772,0.307469,-0.436395,-0.601032,-0.500485,-0.638852,-0.401819,-0.424265,2.67587,2.47307,-1.33358,-1.21044,-1.32341,-1.39725
5165,0.577029,0.543616,0.323521,0.280323,0.849565,0.698447,0.0528713,-0.00544358,0.187076,0.212314,0.636017,0.569826,0.547155,0.505466,0.131544,0.116468,0.807808,0.768138,0.810961,0.807095,1.45644,1.67013,-0.388381,-0.0682723,-1.75346,-1.44295,1.02426,1.10189,0.00494302,-0.0873702,-0.422017,-0.563221,-0.107573,-0.131969,-0.955313,-1.16256,0.39418,0.516372,-0.62619,-0.695256
5166,0.265133,0.270336,0.532937,0.50304,0.679049,0.526608,0.293228,0.234486,0.114273,0.193739,0.545323,0.498999,0.404246,0.360529,0.947206,0.930377,0.706272,0.765435,0.198199,0.197141,-0.315148,-0.103254,-0.285105,0.0386532,-0.376696,-0.0648641,0.773571,0.850165,0.584661,0.426292,0.124603,-0.0107249,-0.356577,-0.375647,1.01693,0.813829,0.622421,0.7416,1.63197,1.56505
5167,0.0284799,-0.00294321,0.769428,0.725758,0.849279,0.697336,0.258035,0.198061,0.562028,0.641942,0.492688,0.428171,0.963132,0.917421,0.405498,0.388955,0.744648,0.762732,0.103962,0.103301,0.0167514,0.224439,-0.846756,-0.526576,-0.692344,-0.426661,-0.904899,-0.826242,-1.25259,-1.41278,-1.7748,-1.9039,-1.22698,-1.25239,0.978835,0.773581,1.58762,1.6994,-0.236728,-0.298037
5168,0.0135393,-0.0091121,0.738355,0.695512,0.0368137,-0.117081,0.965162,0.905397,0.508534,0.569791,0.671081,0.52062,0.232624,0.183972,0.465714,0.438946,0.908258,0.927609,0.418742,0.479128,-0.49324,-0.290204,-0.766421,-0.448397,-1.09803,-0.788458,-0.623556,-0.537823,1.30741,1.14179,0.910671,0.782854,1.05643,1.03137,-1.07471,-1.27854,-0.0914223,0.0231218,0.466555,0.403961
5169,0.0161511,-0.015281,0.420003,0.375159,0.31654,0.149232,0.629068,0.502266,0.307423,0.49764,0.759489,0.613069,0.979834,0.933485,0.507665,0.488936,0.583138,0.603066,0.853637,0.854954,-0.5188,-0.313678,-0.955252,-0.629763,0.640941,0.949974,-2.06877,-1.97957,-1.50503,-1.67806,0.635757,0.505941,-0.0164177,-0.0474121,-0.191114,-0.396553,-0.194312,-0.0755935,2.15517,2.09964
5170,0.293826,0.282685,0.685586,0.636389,0.569307,0.415544,0.155793,0.0991357,0.344006,0.425488,0.772062,0.705518,0.287944,0.24156,0.0133413,-0.00674798,0.776239,0.793561,0.346008,0.349278,-0.160449,0.0457625,-0.463958,-0.135579,0.531911,0.843465,-1.61389,-1.52385,1.87538,1.70574,-1.11831,-1.24883,1.76443,1.73768,1.95928,1.75086,-0.983914,-0.871159,-0.602592,-0.649163
5171,0.612409,0.58065,0.943732,0.897619,0.0890702,-0.0641579,0.796824,0.741163,0.880434,0.964375,0.0383817,-0.0290847,0.775275,0.728301,0.302411,0.283886,0.556835,0.595507,0.807168,0.808293,0.54421,0.755057,-2.18749,-1.86753,-0.585036,-0.269778,0.118223,0.205151,0.901854,0.72681,-0.255435,-0.392439,1.33134,1.3081,0.310838,0.101882,-0.951621,-0.844523,0.567249,0.52472
5172,0.115645,0.085256,0.476578,0.443981,0.567475,0.414025,0.736959,0.606079,0.681461,0.767254,0.805255,0.738803,0.914364,0.868519,0.122746,0.16315,0.382042,0.397452,0.804476,0.767372,-0.60482,-0.388192,0.459507,0.771857,-0.124605,0.105703,0.501553,0.583583,-0.986006,-1.15862,-0.693159,-0.823567,0.0434573,0.0268296,-0.378454,-0.594384,0.29674,0.410318,-0.31706,-0.358788
5173,0.218481,0.185626,0.0351936,-0.00965679,0.523483,0.3691,0.524543,0.470996,0.868137,0.952311,0.909967,0.842959,0.459357,0.412616,0.0623006,0.0424135,0.931171,0.94712,0.727158,0.726451,2.32549,2.54374,0.256152,0.574285,0.160647,0.481185,-0.521182,-0.440967,1.6239,1.44869,0.726541,0.598141,0.726046,0.702004,-1.35946,-1.58071,0.411744,0.526916,0.257587,0.22188
5174,0.667926,0.633491,0.229436,0.183123,0.471359,0.324176,0.802968,0.750903,0.0243038,0.109929,0.549376,0.481232,0.232793,0.186248,0.724504,0.702439,0.292504,0.306694,0.3041,0.305862,0.805814,1.01995,0.287497,0.607074,-0.025954,0.299337,1.6839,1.76867,0.69009,0.516623,0.419115,0.269736,0.975674,0.946006,0.691499,0.475164,1.11844,1.23666,-0.879734,-0.922256
5175,0.734997,0.676728,0.729466,0.681603,0.504465,0.279251,0.443694,0.47547,0.102538,0.188678,0.512767,0.443904,0.587195,0.538231,0.268416,0.245986,0.326396,0.356919,0.263486,0.317911,-1.22042,-1.00556,-0.533728,-0.217927,-0.526042,-0.204295,-0.675106,-0.591956,0.378058,0.211926,0.0721616,-0.0586697,-0.530441,-0.553641,0.620672,0.407122,0.423122,0.53609,-0.581303,-0.63003
5176,0.823096,0.719965,0.938181,0.889426,0.387776,0.234326,0.252496,0.200037,0.512814,0.601301,0.205986,0.134862,0.356131,0.306906,0.76816,0.747219,0.391582,0.407143,0.308473,0.32996,-0.146279,0.070856,1.13395,1.45046,0.0392532,0.362762,1.21578,1.29759,-0.238534,-0.398698,-0.738509,-0.862282,0.489447,0.459707,-1.9328,-2.14878,0.500905,0.607847,0.397387,0.343617
5177,0.797174,0.763202,0.75747,0.709528,0.652796,0.50044,0.846789,0.792369,0.595224,0.685141,0.255144,0.185598,0.741383,0.693658,0.130812,0.110576,0.210067,0.223059,0.359479,0.342009,-0.22076,-0.000270836,-0.204694,0.111206,-0.633099,-0.315732,-1.75201,-1.66398,-0.162959,-0.316512,0.518847,0.392984,0.785111,0.752002,0.811778,0.596847,-0.950265,-0.846917,0.879619,0.832637
5178,0.391694,0.357993,0.893831,0.813547,0.352017,0.219553,0.993779,0.937413,0.0145043,0.106572,0.781586,0.712275,0.597395,0.548722,0.270909,0.193222,0.0257446,0.0389759,0.352296,0.354058,0.634499,0.86168,0.303316,0.620758,2.90585,3.2295,0.523361,0.614042,0.668669,0.516732,1.1369,1.0072,0.0177966,-0.0149461,0.927586,0.721457,-0.310672,-0.160027,-0.130787,-0.171152
5179,0.20033,0.164129,0.966585,0.917565,0.0893127,-0.0613353,0.774563,0.799735,0.245241,0.337159,0.576869,0.508004,0.13087,0.0829906,0.298216,0.275869,0.917577,0.931463,0.563062,0.566572,-0.149698,0.0705567,-0.278398,0.0418349,-1.32434,-1.00533,0.199842,0.286361,-2.89812,-3.0492,1.34476,1.22156,-1.30342,-1.34185,1.06676,0.846068,0.423515,0.526863,1.19716,1.15523
5180,0.67619,0.641091,0.214927,0.167035,0.685247,0.536372,0.717092,0.662056,0.985021,1.07567,0.777555,0.706869,0.8993,0.852373,0.756525,0.732591,0.825173,0.841197,0.331833,0.335755,1.48758,1.7074,0.189556,0.503657,-0.0535538,0.266768,0.388646,0.442528,0.935925,0.788365,-1.49407,-1.61343,1.16102,1.1207,0.358344,0.137489,-0.268081,-0.158283,1.67142,1.62815
5181,0.818256,0.781445,0.113819,0.0637728,0.880536,0.731697,0.76839,0.697424,0.499298,0.591992,0.729449,0.630331,0.123255,0.0765027,0.120306,0.0959475,0.173478,0.191014,0.789437,0.794771,0.554295,0.778154,-0.0418868,0.272666,0.496685,0.818727,0.507598,0.598694,-0.0915262,-0.235637,1.22652,1.10882,-0.162423,-0.206211,-0.346644,-0.571089,0.625403,0.736765,0.180995,0.135806
5182,0.47291,0.436193,0.900083,0.85072,0.817456,0.666657,0.783734,0.732793,0.346671,0.441037,0.62351,0.553794,0.742056,0.692679,0.122282,0.0955843,0.992941,1.00931,0.870023,0.87639,0.454618,0.676318,-1.46292,-1.14373,-0.340691,-0.0149418,-1.31562,-1.21913,0.308127,0.193826,-0.753004,-0.863857,-0.92258,-0.973159,-0.0162724,-0.239203,-1.19424,-1.08726,-1.7226,-1.77469
5183,0.802571,0.76377,0.900817,0.850342,0.992851,0.842978,0.886191,0.768161,0.604627,0.697888,0.328509,0.375708,0.941221,0.894275,0.394904,0.295817,0.0735354,0.091461,0.292697,0.300696,-0.65565,-0.43734,0.828171,1.14096,0.774693,1.10516,-1.40705,-1.31492,0.770651,0.623289,-2.45181,-2.55795,1.19504,1.15037,0.804879,0.581848,0.0759059,0.183203,-1.06521,-1.11763
5184,0.309883,0.272714,0.552059,0.423879,0.819432,0.772447,0.857057,0.803529,0.613742,0.705883,0.233347,0.197622,0.327608,0.283131,0.522037,0.49605,0.453893,0.472215,0.0978772,0.105126,0.353513,0.564866,-0.825935,-0.511447,0.237713,0.569731,-0.620485,-0.520502,-0.622852,-0.76961,0.193577,0.0832823,-0.163458,-0.20797,0.637322,0.408077,-1.44567,-1.33498,1.35565,1.30671
5185,0.437069,0.34351,0.0501311,-0.00258341,0.791625,0.701915,0.734754,0.681397,0.00883551,0.101162,0.0914965,0.0195362,0.331445,0.341123,0.680873,0.696282,0.428636,0.447733,0.699196,0.708908,-2.18755,-1.97853,1.75252,2.05968,0.120135,0.449774,1.32429,1.43293,-0.24389,-0.441878,-0.104343,-0.208621,-0.573618,-0.622085,0.840524,0.615681,-1.32836,-1.21838,1.64682,1.59893
5186,0.449017,0.414306,0.996623,0.942281,0.781165,0.631384,0.284653,0.229529,0.672158,0.766407,0.030319,-0.0424098,0.313384,0.399115,0.923212,0.896515,0.0124319,0.0336658,0.65676,0.584704,0.722431,0.935557,0.0575528,0.362108,1.55518,1.89027,1.06022,1.16624,0.0251632,-0.114147,-0.720582,-0.82891,0.139652,0.0849564,-0.549901,-0.77198,0.115466,0.226826,-0.385494,-0.43535
5187,0.904769,0.871989,0.000175659,-0.0541661,0.826298,0.675278,0.698752,0.64355,0.302729,0.397637,0.479313,0.406024,0.412245,0.457108,0.272291,0.24403,0.0845314,0.228785,0.451607,0.460499,-0.867309,-0.651983,1.40586,1.71751,-1.04572,-0.70776,1.33777,1.43878,0.752372,0.611528,-0.281547,-0.382568,0.00255517,-0.0514156,1.32669,1.10912,-0.41223,-0.211004,-0.432151,-0.488569
5188,0.794784,0.817039,0.342132,0.286477,0.738963,0.719171,0.026165,-0.0284207,0.373145,0.466809,0.0206397,-0.0548845,0.456755,0.5151,0.0794886,0.0519096,0.347138,0.423904,0.0573965,0.0652223,-1.00563,-0.781745,-0.798409,-0.487163,0.711821,1.04486,2.30096,2.40271,-0.845891,-0.978928,0.528112,0.338699,-0.521254,-0.574591,-0.755314,-0.975831,-0.757521,-0.648834,-2.40563,-2.46209
5189,0.696488,0.762089,0.296015,0.241843,0.914148,0.763065,0.334189,0.281302,0.73979,0.834475,0.205066,0.129899,0.617569,0.573092,0.807191,0.779561,0.597789,0.619023,0.687822,0.694752,0.843209,1.06926,-0.609981,-0.301578,0.778478,1.10724,1.17031,1.26949,-1.14571,-1.28363,1.16175,1.05997,-0.337995,-0.392048,-1.75576,-1.97758,-0.622223,-0.515809,0.400391,0.344159
5190,0.724356,0.70714,0.879063,0.822804,0.623826,0.473315,0.360085,0.309257,0.215642,0.311461,0.79151,0.71556,0.340147,0.2975,0.325858,0.298481,0.586689,0.580844,0.818031,0.826814,-1.27725,-1.04634,-1.3655,-1.04997,1.3111,1.64351,0.998108,1.096,-0.00611962,-0.142888,-0.760453,-0.864807,0.548252,0.49661,1.08596,0.871637,-2.40936,-2.30596,1.9391,1.88544
5191,0.68497,0.65219,0.742821,0.647123,0.780139,0.629955,0.67114,0.618979,0.26292,0.358952,0.246887,0.171142,0.453378,0.412559,0.569819,0.544037,0.463133,0.542664,0.0293259,0.0364762,-1.85164,-1.62061,-0.74279,-0.434058,-1.59465,-1.2547,-0.553704,-0.450405,0.0316201,-0.107088,-0.241072,-0.342653,0.321306,0.268689,0.792317,0.576101,1.3141,1.41747,0.441052,0.393098
5192,0.337938,0.306938,0.527671,0.471443,0.261294,0.111163,0.514884,0.461249,0.820648,0.918222,0.709031,0.634091,0.856671,0.814497,0.158905,0.132347,0.481953,0.504484,0.865474,0.870344,-0.671234,-0.434458,-2.22481,-1.91425,-1.48301,-1.1482,0.332949,0.437455,1.26353,1.12641,1.27473,1.17296,-1.06137,-1.11998,-1.21094,-1.43115,0.479412,0.577831,1.22097,1.16945
5193,0.565399,0.533494,0.840953,0.782557,0.0548922,-0.096615,0.811737,0.75652,0.557161,0.601073,0.0507764,-0.0258327,0.213689,0.172622,0.916129,0.889978,0.929467,0.954094,0.00453462,0.00696794,0.165242,0.396797,-0.82656,-0.534302,-1.04615,-0.719233,-0.965874,-0.86529,0.14013,-0.00391181,0.654033,0.552671,-0.784221,-0.844417,0.316597,0.093058,-0.129757,-0.0316641,-1.38989,-1.44869
5194,0.293827,0.259644,0.464394,0.440261,0.117749,-0.0344346,0.340902,0.284342,0.185782,0.283925,0.722685,0.646229,0.667554,0.623872,0.337581,0.309159,0.82821,0.852953,0.663996,0.665352,0.0640501,0.294961,0.535078,0.845643,-0.342278,-0.012448,0.139028,0.23683,-1.48172,-1.62705,0.608626,0.555181,-0.269432,-0.337393,0.164551,-0.0649022,-0.013147,0.0647467,0.270158,0.215472
5195,0.695117,0.662587,0.155431,0.0979656,0.559207,0.40489,0.310654,0.252331,0.56627,0.625134,0.217541,0.140856,0.319079,0.298879,0.076857,0.0473245,0.101596,0.127256,0.826874,0.827116,1.43919,1.66733,-1.38858,-1.07609,0.0971986,0.432879,0.67076,0.748988,1.55904,1.41191,0.663807,0.557692,1.30014,1.22998,0.402492,0.174832,0.119984,0.161157,0.642699,0.583368
5196,0.455917,0.418383,0.948294,0.890022,0.260948,0.105708,0.0793926,0.0196824,0.86869,0.966342,0.756893,0.682631,0.0184111,-0.0261134,0.520523,0.406861,0.318745,0.343354,0.68732,0.747901,0.0740303,0.296222,1.23391,1.54611,-0.9196,-0.58672,1.16864,1.26115,-1.11388,-1.26166,0.238439,0.126563,-1.94755,-2.01221,-0.308459,-0.537447,0.127034,0.257568,-0.970899,-1.03276
5197,0.208115,0.174178,0.563048,0.50566,0.406198,0.252579,0.715276,0.657025,0.816361,0.916572,0.618115,0.528579,0.797928,0.75456,0.797304,0.766398,0.0109305,0.0342945,0.621076,0.668686,-0.105023,0.120488,0.570259,0.874881,-1.30594,-0.967932,-0.842181,-0.747523,0.54364,0.397726,-0.87183,-0.98304,-0.415899,-0.474247,-0.383004,-0.60549,0.255886,0.353979,-0.0432998,-0.104702
5198,0.685791,0.65114,0.83642,0.776695,0.320289,0.166714,0.668656,0.610152,0.426513,0.528237,0.449392,0.374527,0.305276,0.263451,0.24502,0.215419,0.421849,0.407921,0.592073,0.589471,-0.0685681,0.154413,0.918211,1.23008,-0.701751,-0.370465,0.383848,0.479572,0.566236,0.418836,0.0666751,-0.0472808,0.824368,0.772698,-1.05542,-1.27275,-0.657585,-0.553762,1.83219,1.7652
5199,0.946704,0.913064,0.906724,0.845232,0.487741,0.378361,0.185598,0.128341,0.398231,0.446961,0.810492,0.73462,0.989671,0.946342,0.520701,0.488587,0.75719,0.781547,0.174856,0.173477,0.678462,0.895686,-0.90314,-0.56679,-1.92085,-1.59202,-1.69066,-1.59364,0.982187,0.837453,1.00084,0.888478,0.733711,0.683379,-0.285547,-0.498234,-0.750956,-0.652477,1.4889,1.4241
5200,0.463268,0.42647,0.708125,0.68225,0.816799,0.590008,0.254287,0.154982,0.262814,0.365686,0.417561,0.342487,0.641611,0.517719,0.790151,0.761754,0.513394,0.527547,0.180336,0.24272,-0.486473,-0.262183,-2.67552,-2.36366,0.642255,0.968274,-0.579587,-0.476477,1.73541,1.59301,1.30906,1.19054,2.63513,2.585,1.43358,1.21656,0.0709165,0.164857,-0.274656,-0.3449
5201,0.742691,0.708166,0.580553,0.519269,0.953279,0.801654,0.240986,0.181622,0.873588,0.975413,0.888771,0.814947,0.132425,0.089096,0.264149,0.235945,0.251103,0.273546,0.314303,0.311963,1.16381,1.39034,-1.27414,-0.962048,1.29499,1.6276,-0.457087,-0.357744,0.609994,0.46268,-1.60945,-1.72507,-0.703886,-0.746948,0.875313,0.659611,0.501255,0.592345,0.10983,0.0361276
5202,0.6674,0.564919,0.621989,0.562676,0.399185,0.247513,0.681661,0.620289,0.619399,0.759928,0.356805,0.285029,0.679548,0.635361,0.55998,0.532589,0.889269,0.910779,0.152873,0.151588,0.645074,0.875702,0.793981,1.11046,-0.874277,-0.547095,0.939911,1.03723,0.829426,0.68262,-1.30975,-1.42301,-2.24932,-2.29598,-0.0175427,-0.236549,1.19125,1.28574,-0.848916,-0.922447
5203,0.418936,0.421672,0.15552,0.0944158,0.452919,0.300078,0.307666,0.248371,0.342951,0.544443,0.92239,0.851457,0.47685,0.470041,0.253905,0.309811,0.137466,0.157875,0.580538,0.527414,1.13974,1.37232,0.449443,0.760494,1.2706,1.59555,-0.155089,-0.051404,-0.139094,-0.278965,0.376529,0.264658,-0.307893,-0.350826,-0.0667009,-0.32489,-0.58776,-0.490185,-0.391868,-0.465014
5204,0.305737,0.278424,0.801183,0.73913,0.156371,0.000895178,0.340657,0.271537,0.227133,0.328958,0.909583,0.766891,0.458293,0.304722,0.113786,0.0870339,0.392416,0.414023,0.902602,0.90324,-0.0479395,0.183457,0.875103,1.19106,-0.476769,-0.1498,1.3161,1.42568,1.21314,1.07365,-0.150848,-0.260346,-0.786646,-0.827948,-0.0990624,-0.413232,0.0218584,0.12539,-0.275416,-0.351885
5205,0.169703,0.135177,0.155952,0.0934241,0.0770454,-0.0630288,0.431307,0.294702,0.93357,1.03468,0.753037,0.682324,0.183589,0.139402,0.687063,0.66065,0.346058,0.369317,0.637881,0.548014,1.20338,1.43146,-0.20109,0.11697,0.721565,1.04596,0.629309,0.696316,-0.35278,-0.487502,0.251219,0.138233,1.03166,0.994347,-0.282566,-0.501573,1.60305,1.70986,-0.986828,-1.06921
5206,0.352109,0.26513,0.945563,0.88548,0.0296758,-0.126953,0.375644,0.317868,0.315857,0.415283,0.347749,0.276181,0.235893,0.129988,0.478613,0.504047,0.578822,0.601312,0.19014,0.192788,0.105815,0.333329,-0.689317,-0.369438,-0.379155,-0.0507552,-0.10997,-0.0330521,-2.28902,-2.41998,0.376992,0.260748,0.864864,0.727151,-0.783132,-0.997327,-0.0186832,0.0823598,-1.20948,-1.2894
5207,0.559541,0.395083,0.880064,0.821347,0.941066,0.782817,0.987412,0.930743,0.961992,1.06018,0.225352,0.152977,0.163635,0.120573,0.375116,0.347443,0.309169,0.33244,0.164597,0.168837,0.427309,0.661022,0.224162,0.538007,-0.0536123,0.271958,-0.871999,-0.76242,-1.39047,-1.52423,-0.984308,-1.09713,0.502825,0.459955,-0.16208,-0.375804,-2.69429,-2.59453,-0.371714,-0.452102
5208,0.657474,0.525036,0.531717,0.471629,0.360053,0.203987,0.784938,0.758257,0.5024,0.611864,0.494617,0.421747,0.588595,0.547205,0.431923,0.403183,0.684647,0.70825,0.642038,0.64784,-0.546733,-0.312563,-1.36104,-1.04959,0.689005,1.00996,-1.92784,-1.82032,-0.0325423,-0.171624,1.0415,0.928514,-0.559494,-0.602653,0.183577,-0.0300975,-0.207071,-0.102122,-0.36913,-0.444521
5209,0.689514,0.654989,0.654852,0.672709,0.583215,0.429588,0.55021,0.585771,0.067131,0.163544,0.471414,0.361663,0.55546,0.519013,0.858065,0.829797,0.353802,0.378955,0.852002,0.860354,0.920292,1.15508,-0.219603,0.0882414,0.934069,1.25698,-0.209591,-0.108688,0.696453,0.554051,-1.1948,-1.30794,-0.202083,-0.2488,1.27017,1.05156,-0.0336158,0.0756701,0.537224,0.46821
5210,0.133542,0.0988241,0.932195,0.873788,0.327787,0.192573,0.469954,0.413284,0.39761,0.495724,0.378756,0.301578,0.396351,0.490821,0.704649,0.678552,0.884782,0.908548,0.763492,0.772401,0.135962,0.36396,-1.57296,-1.26629,-1.25319,-0.93325,1.11696,1.22565,0.628144,0.478619,-0.029287,-0.143045,-0.522446,-0.569831,0.239304,0.0198741,-0.137122,-0.0230452,-0.22741,-0.294595
5211,0.915323,0.879481,0.646577,0.553591,0.108985,-0.044443,0.75333,0.617889,0.193302,0.289238,0.314362,0.241493,0.450475,0.462629,0.868347,0.840017,0.379474,0.403436,0.0846128,0.0913423,-1.35435,-1.13109,0.339826,0.649235,0.856019,1.17905,-1.86032,-1.75528,-0.517137,-0.665047,-0.131106,-0.250427,2.12597,2.08083,0.341732,0.121922,-0.889194,-0.773274,0.24382,0.178322
5212,0.66714,0.630756,0.292497,0.233394,0.8404,0.686552,0.878003,0.822495,0.978228,1.07708,0.491069,0.416267,0.475827,0.434437,0.785006,0.754206,0.731732,0.674829,0.491689,0.500656,2.27093,2.49131,-0.203236,0.0995948,0.483027,0.812243,1.2358,1.33834,0.230084,0.0757972,-1.56436,-1.68285,-0.262406,-0.303709,-0.231748,-0.449695,1.28839,1.40815,-0.014579,-0.0862307
5213,0.209435,0.175658,0.365054,0.30706,0.863308,0.765115,0.504337,0.450576,0.937432,0.956642,0.429667,0.354321,0.112542,0.0734857,0.00837657,-0.0221686,0.920923,0.946222,0.205009,0.215214,0.972304,1.19458,0.320029,0.62363,-1.51597,-1.18535,-0.227906,-0.118,-0.802091,-0.963219,-0.295611,-0.412717,1.27957,1.23425,1.05204,0.826433,0.45647,0.5821,-2.5589,-2.62808
5214,0.929948,0.89645,0.732833,0.676773,0.999316,0.843678,0.581184,0.481817,0.737316,0.836205,0.708039,0.632806,0.952067,0.913893,0.0266004,0.0540283,0.862511,0.886453,0.198561,0.201822,1.11751,1.33726,0.501796,0.809215,-0.366133,-0.0356193,0.507957,0.615049,0.0991721,-0.0674764,-0.258396,-0.38244,-1.24288,-1.29368,0.905182,0.681972,-0.0382277,0.0808097,0.0914699,0.021122
5215,0.122527,0.0901749,0.678677,0.622291,0.104771,-0.052954,0.532913,0.513057,0.849578,0.904566,0.535443,0.394215,0.960104,0.921485,0.161411,0.130225,0.28759,0.311867,0.215037,0.188431,0.592161,0.809342,-0.801868,-0.49504,-0.206729,0.116861,0.225976,0.332574,-1.0629,-1.22856,-1.08513,-1.21681,1.36395,1.31241,1.79554,1.57875,-0.761383,-0.634945,0.635433,0.502415
5216,0.176936,0.226633,0.392695,0.33663,0.293671,0.137399,0.598019,0.544297,0.875255,0.972928,0.229673,0.155624,0.635249,0.595515,0.519549,0.487733,0.631611,0.658243,0.163359,0.175039,-0.615561,-0.394651,-0.197457,0.106807,-2.53766,-2.21843,0.283438,0.335928,-1.54529,-1.71535,-0.451742,-0.588477,-0.737308,-0.784826,3.16736,2.95104,-1.28218,-1.15146,1.05406,0.983709
5217,0.397263,0.36309,0.378459,0.32104,0.215487,-0.00289944,0.989048,0.933067,0.205036,0.303225,0.598296,0.525182,0.609646,0.542781,0.471704,0.39004,0.175313,0.20366,0.789867,0.799495,0.88609,1.10448,-0.443464,-0.137097,-0.318097,0.00754874,0.23944,0.339281,0.870955,0.705957,-0.395775,-0.527697,-0.0672388,-0.109651,0.619115,0.395139,0.380782,0.512416,-0.856881,-0.926783
5218,0.113333,0.0790421,0.64897,0.592075,0.0147412,-0.143198,0.731475,0.67541,0.99444,1.09107,0.45657,0.381574,0.639438,0.490047,0.415733,0.292347,0.746156,0.773024,0.48775,0.557084,-0.523892,-0.299426,-0.0530824,0.248386,1.14592,1.47693,-0.602311,-0.500317,0.415831,0.247271,1.29647,1.15997,0.221508,0.182644,0.0697341,-0.130559,0.561668,0.690208,1.18282,1.10855
5219,0.848567,0.811665,0.20123,0.143619,0.462639,0.306057,0.0392829,-0.0167069,0.383676,0.481565,0.561372,0.485729,0.478114,0.437312,0.224432,0.194653,0.788068,0.816496,0.304105,0.314672,-0.547098,-0.3229,1.6036,1.89906,-0.123078,0.211946,-0.796841,-0.690105,-2.3887,-2.55573,-0.880531,-1.0151,0.0887862,0.0462726,-0.429613,-0.656257,-0.325836,-0.19773,0.902431,0.828393
5220,0.252924,0.21608,0.354993,0.297665,0.495339,0.337781,0.175093,0.117446,0.622984,0.722796,0.119863,0.0441755,0.905485,0.863944,0.862252,0.834331,0.239255,0.2672,0.508266,0.553226,-1.90785,-1.67825,-0.276039,0.0213671,1.30164,1.63628,0.550262,0.658034,-1.2374,-1.48468,0.309006,0.179911,-0.371147,-0.415179,1.35086,1.11647,-0.404296,-0.210362,-0.586692,-0.66395
5221,0.857063,0.822057,0.716271,0.617714,0.926608,0.766859,0.976531,0.918182,0.0673467,0.169007,0.548652,0.473162,0.242747,0.20225,0.175218,0.147293,0.622,0.637576,0.779848,0.791781,-1.53143,-1.30363,0.907811,1.20655,0.575869,0.90834,-1.24264,-1.14014,-0.246605,-0.413631,0.620289,0.48197,-2.4796,-2.52783,0.755729,0.527541,-0.350045,-0.222994,1.27245,1.18861
5222,0.931737,0.823871,0.994897,0.937762,0.990942,0.833494,0.736656,0.616333,0.181183,0.327957,0.192082,0.115596,0.735776,0.694339,0.145983,0.116216,0.979728,1.00795,0.0528323,0.0635966,2.41202,2.63843,-0.451746,-0.0998801,-0.158866,0.180399,-1.28946,-1.18984,0.155613,-0.00461966,-0.367379,-0.506246,0.623158,0.579968,-0.754952,-0.980451,-1.56491,-1.43985,-1.73431,-1.8142
5223,0.862349,0.825685,0.0217875,-0.033533,0.439909,0.359285,0.37094,0.314484,0.384989,0.486907,0.725169,0.647218,0.421726,0.37808,0.396977,0.389159,0.0640772,0.0901072,0.11746,0.0750454,1.24165,1.46596,-1.71011,-1.40631,0.0625586,0.395104,-0.0105063,0.0839972,0.567713,0.404392,0.600211,0.457277,1.17464,1.13412,-0.540765,-0.772847,-0.458888,-0.340201,-0.359792,-0.442003
5224,0.652519,0.61684,0.784552,0.728198,0.0425259,-0.114923,0.734823,0.678412,0.715702,0.819087,0.570976,0.494262,0.600064,0.554541,0.780751,0.662103,0.18679,0.214648,0.0756588,0.0864943,-1.46015,-1.23346,-0.264109,0.0418876,1.73921,2.06953,0.0505191,0.0493797,1.3808,1.22167,-0.965262,-1.11349,-0.658233,-0.695474,1.43288,1.20354,-1.2761,-1.14957,-3.08622,-3.16301
5225,0.221237,0.186078,0.576317,0.518613,0.192364,-0.0465695,0.745417,0.686287,0.17139,0.275597,0.700235,0.62396,0.485071,0.380076,0.963744,0.935047,0.680903,0.710391,0.713959,0.725274,0.962567,1.19104,1.42638,1.73951,0.102601,0.435442,-0.0797499,0.0147621,-0.228981,-0.384825,1.89423,1.74156,-1.56176,-1.60249,1.29922,1.07475,-0.897699,-0.767584,-0.560784,-0.632099
5226,0.497451,0.462755,0.930756,0.874138,0.180121,0.0217837,0.0513929,-0.00583024,0.674625,0.779496,0.237789,0.163051,0.251135,0.205612,0.446617,0.419239,0.29786,0.325925,0.78971,0.801081,0.762738,0.985585,-1.72866,-1.4156,0.711623,1.04785,-1.19003,-1.08924,-0.395887,-0.552651,-0.318808,-0.464296,0.497621,0.454427,0.649479,0.423811,0.411142,0.534318,-0.124862,-0.188791
5227,0.11816,0.0830194,0.410149,0.351412,0.893532,0.737771,0.603536,0.546748,0.484166,0.583596,0.852769,0.77872,0.536879,0.56676,0.717909,0.689917,0.884475,0.911161,0.470864,0.479844,0.969049,1.18886,-1.79727,-1.49006,0.841795,1.18571,1.2726,1.37282,-2.63777,-2.79372,-0.180898,-0.246739,-2.0218,-2.0735,1.50204,1.27596,-0.568801,-0.448899,0.089849,0.0274577
5228,0.0273629,-0.00904535,0.953811,0.89367,0.564642,0.408025,0.269784,0.213976,0.283602,0.387696,0.389703,0.313183,0.972824,0.927909,0.458172,0.433096,0.439988,0.466585,0.559392,0.565965,-0.772439,-0.551749,0.431505,0.732633,-0.162342,0.182035,0.508422,0.61094,1.39897,1.24198,0.110474,-0.0291818,2.29841,2.24671,-0.406751,-0.637642,-0.906829,-0.725717,-0.792547,-0.825696
5229,0.584196,0.547503,0.550992,0.490016,0.719112,0.564666,0.182774,0.0920268,0.701359,0.8052,0.228309,0.142569,0.568068,0.521821,0.4492,0.402183,0.461129,0.48637,0.993415,1.0006,-1.62307,-1.40325,0.232678,0.535061,-0.636866,-0.290448,0.3826,0.484665,0.118438,-0.0419476,-0.0567902,-0.197969,-0.753353,-0.801715,-1.1204,-1.34992,-1.12393,-1.00254,-1.61758,-1.67885
5230,0.862007,0.824181,0.515814,0.524105,0.530192,0.377189,0.0230588,-0.0299227,0.593376,0.698295,0.0500203,-0.0280445,0.555247,0.498335,0.39834,0.37127,0.18444,0.207853,0.83691,0.84539,-1.44716,-1.22971,0.539112,0.844943,0.302658,0.646059,-0.753385,-0.648551,0.545148,0.3912,0.494519,0.354527,0.454419,0.399158,-0.0782657,-0.313908,0.424484,0.55039,-1.37278,-1.43249
5231,0.331499,0.292963,0.541114,0.558193,0.763235,0.543908,0.337668,0.23146,0.280706,0.385601,0.719293,0.644018,0.462443,0.474849,0.162578,0.133455,0.876651,0.899406,0.447857,0.543993,-0.33904,-0.122206,-0.482198,-0.182857,-0.715055,-0.373539,-1.27447,-1.17665,-0.162924,-0.323425,-0.900889,-1.03463,0.337817,0.279543,0.333995,0.0940532,0.53291,0.653028,1.01702,0.959014
5232,0.173786,0.194152,0.653296,0.592282,0.863258,0.710628,0.669829,0.492843,0.606806,0.712974,0.51641,0.439746,0.476108,0.451363,0.795778,0.768395,0.558704,0.626125,0.235747,0.242596,-0.177008,0.0357543,-0.273888,0.0191155,-0.434667,-0.0959378,1.07072,1.16962,-0.288885,-0.446059,0.552943,0.417194,-0.0401288,-0.102781,0.438159,0.196101,-1.1304,-1.00739,1.60602,1.55325
5233,0.135537,0.0953408,0.252736,0.192842,0.893516,0.742352,0.807207,0.754226,0.103611,0.209736,0.620459,0.543902,0.4749,0.427877,0.0225721,-0.00312927,0.329508,0.352843,0.442021,0.393747,1.04159,1.25004,-0.293646,0.00431851,0.283425,0.626363,0.414939,0.517266,0.936899,0.787443,-1.00823,-1.13886,0.481672,0.336741,-0.0302747,-0.179314,-0.836812,-0.720654,-1.1282,-1.18408
5234,0.205634,0.166074,0.672328,0.611956,0.158036,0.00675273,0.717513,0.666033,0.390072,0.445762,0.131205,0.0536456,0.628476,0.583235,0.0906748,0.00875638,0.212369,0.237208,0.537819,0.544897,-1.3089,-1.1024,1.88004,2.17577,-0.469938,-0.127865,-0.514592,-0.416253,-0.360925,-0.512812,0.08061,-0.051619,0.880991,0.776263,-0.317623,-0.554728,0.771745,0.89439,0.110921,0.051356
5235,0.615548,0.533604,0.394013,0.331932,0.99198,0.842205,0.400468,0.463112,0.636967,0.681788,0.0475162,-0.0294882,0.457643,0.413556,0.0785533,0.020642,0.100199,0.121573,0.999755,1.00898,-0.482461,-0.271145,0.604675,0.900774,-0.133506,0.209912,0.289978,0.393221,-0.962699,-1.10652,-2.3598,-2.49449,1.27844,1.21579,-2.42519,-2.65616,-0.376677,-0.245693,0.779466,0.723778
5236,0.940645,0.901135,0.850967,0.790427,0.93945,0.786938,0.280631,0.260192,0.813316,0.917813,0.447393,0.370142,0.901186,0.855317,0.058229,0.0325277,0.70028,0.723447,0.43065,0.437808,-1.12327,-0.907079,-1.41999,-1.1301,-0.40745,-0.0638242,-0.857208,-0.755265,-0.855742,-0.924406,0.5698,0.43177,-0.113589,-0.172881,-3.11923,-3.35243,-0.953732,-0.824163,0.600208,0.549796
5237,0.199228,0.161534,0.23386,0.173874,0.266478,0.113141,0.108751,0.0572713,0.400478,0.503742,0.559842,0.430232,0.919708,0.873105,0.340078,0.313559,0.717397,0.738415,0.352401,0.271973,0.278596,0.496434,-0.810565,-0.514179,-0.395258,-0.047993,0.558244,0.65812,-0.593394,-0.742288,0.74821,0.61488,1.72998,1.66468,-0.505046,-0.737557,2.12395,2.25953,0.177995,0.0470999
5238,0.455723,0.417975,0.129332,0.0706124,0.0513406,-0.104725,0.915234,0.863624,0.83291,0.936286,0.566613,0.490322,0.551524,0.506803,0.899834,0.871458,0.339005,0.432113,0.0965821,0.106137,-0.664888,-0.445477,-0.676369,-0.37447,-0.0349868,0.306059,-2.34493,-2.23887,-0.215206,-0.367777,0.37518,0.245912,-0.0208849,-0.0867231,0.166863,-0.0688192,-1.01852,-0.887921,-0.403411,-0.455597
5239,0.0601001,0.0218251,0.668116,0.607847,0.542247,0.388673,0.309809,0.26031,0.37317,0.477555,0.226028,0.147572,0.846238,0.80396,0.919521,0.892166,0.104064,0.125811,0.568234,0.580141,1.12677,1.34464,-0.925619,-0.618375,-1.81827,-1.47131,-0.0437946,0.0571425,-0.647998,-0.795907,-0.258678,-0.389628,2.46387,2.38976,0.0537129,-0.182669,1.40601,1.53515,1.07193,1.0264
5240,0.0412995,0.00174526,0.486018,0.423597,0.604267,0.450853,0.841698,0.792933,0.620659,0.72428,0.41183,0.324199,0.67138,0.629069,0.242885,0.214809,0.0549877,0.0762433,0.684097,0.697309,0.248008,0.461989,1.06411,1.37704,-0.0181118,0.326958,-1.12872,-1.03149,-0.117819,-0.271137,0.2036,0.0523261,3.3626,3.29454,2.14076,1.90257,-0.82088,-0.698334,-1.91196,-1.96017
5241,0.671252,0.632427,0.702495,0.640927,0.124884,-0.0288488,0.432117,0.380614,0.580806,0.717569,0.581345,0.500826,0.780207,0.73908,0.767976,0.741684,0.917403,0.937879,0.119836,0.131718,0.0663842,0.286255,-0.407028,-0.0887087,0.633326,0.971826,1.27008,1.36595,-1.17803,-1.32499,0.622971,0.49428,-1.3815,-1.45492,-0.656227,-0.898841,-1.39803,-1.2768,2.43548,2.37959
5242,0.711228,0.672604,0.162906,0.0992114,0.29579,0.216382,0.529103,0.479836,0.608106,0.710858,0.34663,0.267529,0.217114,0.177269,0.812228,0.832043,0.7911,0.729112,0.169283,0.237349,-0.959902,-0.735651,1.85837,2.17983,-0.260722,0.0773917,0.297988,0.38693,0.715633,0.569098,-1.45747,-1.58581,-0.679554,-0.747877,0.317667,0.0744306,-0.299195,-0.177151,0.347828,0.299928
5243,0.996397,0.95945,0.69524,0.631363,0.500982,0.461614,0.041151,-0.00707708,0.17996,0.282391,0.544255,0.466393,0.754596,0.713669,0.949792,0.922403,0.485594,0.520345,0.397522,0.342981,0.481231,0.699259,-2.60646,-2.285,-0.125451,0.215256,0.218375,0.306328,-0.14311,-0.286049,0.180725,0.0564366,0.492489,0.4207,0.169829,-0.0700298,-0.229104,-0.0774962,0.278574,0.215248
5244,0.889174,0.850429,0.446408,0.463427,0.861751,0.706845,0.660534,0.610606,0.36879,0.408196,0.298961,0.222973,0.00650295,-0.0342658,0.282065,0.256115,0.205644,0.311578,0.436135,0.448613,1.44609,1.67051,-1.32915,-1.00642,-1.89821,-1.56212,-1.60435,-1.5115,-1.57739,-1.72347,-1.0073,-1.12968,-1.19994,-1.26835,-1.15747,-1.39577,-0.101943,0.0221585,0.182197,0.130569
5245,0.275781,0.238673,0.392831,0.29549,0.736897,0.580616,0.846223,0.79611,0.431255,0.534002,0.881154,0.803825,0.896041,0.857138,0.461479,0.433506,0.0823354,0.102811,0.174061,0.187507,-0.878325,-0.651747,0.836199,1.16503,1.76021,2.09496,2.38014,2.47527,1.31791,1.169,1.47695,1.34994,0.736823,0.662697,-1.50346,-1.73823,-1.5591,-1.43261,0.512981,0.468223
5246,0.655319,0.616748,0.190187,0.127553,0.851198,0.69241,0.530102,0.53748,0.0729899,0.174923,0.501581,0.42234,0.50581,0.4658,0.344835,0.316958,0.130435,0.151878,0.554259,0.567241,-0.876603,-0.646325,-0.661462,-0.329848,-0.621753,-0.287762,-0.448063,-0.351858,-0.867164,-1.01112,-0.241255,-0.372357,0.477926,0.404277,1.05269,0.80946,-0.152112,-0.032882,-1.48633,-1.53434
5247,0.129186,0.0907168,0.423861,0.322907,0.755589,0.61485,0.358136,0.278851,0.464362,0.526935,0.47016,0.390203,0.84748,0.807782,0.490332,0.46334,0.719163,0.742517,0.385644,0.468282,-0.358916,-0.13229,1.69036,2.02136,-1.24467,-0.905117,-1.80549,-1.71467,-1.98895,-2.12573,-0.551852,-0.681075,0.794119,0.726028,-1.79004,-2.04076,-1.38878,-1.2676,0.318329,0.272152
5248,0.765977,0.726527,0.514043,0.518261,0.694197,0.537289,0.0703344,0.0202212,0.776278,0.878946,0.785144,0.63637,0.982419,0.856651,0.336919,0.299545,0.666211,0.627607,0.356687,0.369323,1.42794,1.65783,0.46268,0.793594,-0.99593,-0.658093,-0.717784,-0.628113,-1.09455,-1.22999,-2.88246,-3.01554,-0.388851,-0.461093,0.0482941,-0.204053,1.27028,1.39289,0.866424,0.821154
5249,0.388343,0.346791,0.776249,0.713615,0.171244,0.0138663,0.545982,0.497712,0.560587,0.58688,0.964469,0.882538,0.944885,0.90552,0.163658,0.135751,0.442679,0.512696,0.786758,0.797923,0.839091,1.06843,-1.11421,-0.778686,-0.542061,-0.199218,-0.587972,-0.494098,-1.48428,-1.61231,-0.278967,-0.408366,-0.326327,-0.334477,1.49236,1.24346,0.110213,0.23515,0.710258,0.662068
5250,0.561824,0.522198,0.695919,0.635821,0.149019,-0.00991067,0.128076,0.0809425,0.190461,0.294814,0.770244,0.601877,0.441765,0.404481,0.435428,0.406429,0.376346,0.397785,0.534176,0.605627,-1.97956,-1.7554,0.210032,0.545506,0.600281,0.856289,-1.79941,-1.70481,0.78001,0.658811,1.57306,1.44741,-0.128662,-0.20786,0.40722,0.218361,-0.716087,-0.590896,0.277942,0.230677
5251,0.242299,0.202978,0.353332,0.290819,0.723368,0.562636,0.349245,0.301288,0.321655,0.424303,0.402954,0.321216,0.177795,0.13852,0.228858,0.19955,0.00790518,0.0284292,0.32377,0.413331,0.963032,1.18959,-0.104491,0.227305,1.57596,1.9118,-0.302501,-0.211163,0.621745,0.50771,1.35763,1.23177,0.553968,0.467315,-0.561278,-0.806736,-0.582871,-0.457871,-1.48001,-1.52468
5252,0.465071,0.424778,0.851672,0.789299,0.971691,0.813206,0.337448,0.322774,0.919933,1.02405,0.474877,0.392263,0.902924,0.862105,0.844546,0.814463,0.323663,0.341082,0.208584,0.221036,-2.74202,-2.51538,-1.27111,-0.938746,0.0680576,0.399944,-0.524801,-0.430535,-0.467186,-0.576407,-0.174729,-0.307742,0.26844,0.177742,0.326403,0.0752533,0.436377,0.563871,0.596711,0.56149
5253,0.172026,0.130266,0.837814,0.734706,0.10693,-0.0533047,0.392821,0.34426,0.870014,0.974275,0.188238,0.103351,0.0934568,0.0504054,0.837881,0.809665,0.632864,0.653735,0.328104,0.342484,-0.135147,0.088834,0.897816,1.23271,-0.94266,-0.603734,0.938796,1.03194,-0.752064,-0.864817,1.15894,1.02463,0.818715,0.731892,-0.241212,-0.496363,-1.15767,-1.03155,0.110944,0.0716402
5254,0.336146,0.29525,0.825487,0.680113,0.969681,0.808855,0.776735,0.727364,0.548227,0.651899,0.38396,0.297096,0.178524,0.134231,0.324318,0.293857,0.135229,0.153982,0.0714701,0.0876818,-0.11406,0.189967,-0.0996256,0.23745,-1.30677,-0.970542,1.0922,1.18269,0.333633,0.130237,0.292713,0.160244,-0.477445,-0.565062,-1.30773,-1.5587,-0.687345,-0.556576,-0.972323,-1.01125
5255,0.805804,0.76714,0.690296,0.62552,0.9219,0.759832,0.127972,0.0797321,0.502537,0.595644,0.356465,0.269355,0.0603872,0.0144667,0.100613,0.0714454,0.718818,0.739218,0.398231,0.416561,0.0653651,0.291101,0.713512,1.05248,0.811951,1.14176,0.570533,0.654598,1.24553,1.12529,-2.62209,-2.75536,-0.961107,-1.04218,-0.0918729,-0.342015,-0.936474,-0.810274,-0.608121,-0.64335
5256,0.206494,0.165971,0.137173,0.0736452,0.0487238,-0.114801,0.235521,0.188623,0.435573,0.539388,0.0817904,-0.0035678,0.344509,0.301012,0.213578,0.121436,0.797172,0.817231,0.070278,0.0902408,0.379113,0.604326,0.270448,0.521568,-0.076752,0.247324,1.16796,1.24672,-1.08518,-1.21436,-0.310688,-0.442245,0.72617,0.652235,-0.613859,-0.868265,-0.0707918,0.0560157,0.050712,0.0137025
5257,0.116674,0.0739062,0.278141,0.211987,0.333262,0.0716491,0.0875876,0.04089,0.148044,0.252061,0.252454,0.213554,0.109703,0.0646965,0.201347,0.171427,0.0309876,0.052658,0.134434,0.152483,-0.754458,-0.522758,-0.353371,-0.00934169,-0.697012,-0.37003,2.42224,2.50428,-0.778295,-0.904989,0.650236,0.521278,-0.36996,-0.440161,-0.459592,-0.720775,1.62866,1.75173,0.500105,0.457011
5258,0.676755,0.635159,0.0945575,0.0277369,0.421283,0.258099,0.164536,0.211233,0.756595,0.861789,0.506854,0.430676,0.769314,0.72259,0.585343,0.553663,0.514765,0.537665,0.897953,0.916934,-1.31917,-1.08133,1.5858,1.93436,-0.605856,-0.358331,0.501928,0.591424,-1.61369,-1.74606,-0.165965,-0.297093,1.45573,1.38213,0.122489,-0.144399,0.141298,0.263934,-0.298513,-0.318863
5259,0.627214,0.583786,0.473033,0.407474,0.275089,0.111108,0.428809,0.381576,0.316931,0.423282,0.76241,0.647799,0.639513,0.592894,0.124206,0.0922543,0.669505,0.692634,0.741597,0.680516,-1.13128,-0.892372,0.366322,0.722321,-0.669173,-0.346632,-1.0156,-0.927509,-1.25437,-1.38771,0.625696,0.49507,0.786323,0.707534,-0.545111,-0.811659,0.0958818,0.210816,-1.04799,-1.09474
5260,0.268805,0.224119,0.0160031,-0.0507429,0.649661,0.483894,0.236601,0.259626,0.864432,0.971993,0.950279,0.864921,0.00222717,-0.0445487,0.550277,0.443321,0.272082,0.29369,0.507312,0.444098,0.596098,0.83691,0.374369,0.683747,-1.16023,-0.835528,1.7639,1.85785,-0.241787,-0.369193,-0.429279,-0.553501,-0.202932,-0.36166,1.55057,1.29197,-1.50115,-1.38461,-0.963532,-1.01406
5261,0.576953,0.553444,0.904824,0.837452,0.612981,0.435228,0.185447,0.137677,0.154734,0.261107,0.815064,0.731004,0.459282,0.411332,0.825266,0.794388,0.999937,1.02105,0.189217,0.20768,-0.611852,-0.367083,0.293032,0.645173,1.23681,1.56905,0.286085,0.38665,0.442607,0.310815,0.101279,-0.0552325,-1.34745,-1.43085,0.0106378,-0.245911,0.713378,0.829141,0.262478,0.206689
5262,0.929208,0.882768,0.90087,0.831807,0.592808,0.386562,0.823271,0.77502,0.87544,0.98337,0.192884,0.110832,0.685564,0.618235,0.481232,0.452296,0.764028,0.787208,0.517152,0.536559,0.558469,0.802128,-1.27928,-0.927108,-0.144806,0.192599,0.628294,0.735042,-0.489603,-0.621251,0.573159,0.443036,1.02244,0.933682,0.635488,0.375612,-0.675933,-0.562136,-1.03644,-1.08867
5263,0.908186,0.862688,0.114474,0.0439245,0.492985,0.337897,0.511335,0.488796,0.41814,0.524638,0.535185,0.450408,0.872207,0.825138,0.488852,0.45795,0.100131,0.121832,0.447978,0.468227,0.788655,1.03694,0.861234,1.21392,0.441422,0.776028,-1.77003,-1.66077,0.0458522,-0.0817147,1.78561,1.65333,1.09922,1.07155,0.202739,-0.0588756,0.14611,0.255198,-1.39206,-1.44582
5264,0.416761,0.371633,0.409529,0.340532,0.461066,0.289231,0.249063,0.202572,0.222327,0.327517,0.160376,0.0735832,0.883297,0.849168,0.235783,0.204941,0.445067,0.468208,0.903413,0.922686,0.694808,0.935106,-1.14926,-0.799233,0.702235,1.03849,0.328595,0.43386,-1.66556,-1.79796,-1.00485,-1.13367,1.30318,1.20943,-0.661666,-0.922334,0.118722,0.234252,-0.92087,-0.9729
5265,0.235289,0.188679,0.0575352,-0.00918557,0.406332,0.240565,0.896064,0.849431,0.543422,0.649935,0.823971,0.735317,0.921477,0.873199,0.391936,0.409313,0.552374,0.577789,0.0604848,0.0808464,0.00360078,0.238486,0.7444,1.09853,-1.08622,-0.754601,1.08059,1.18246,-0.174554,-0.306458,0.83977,0.707495,2.1774,2.08395,-0.621227,-0.958715,0.750576,0.865571,0.371516,0.323119
5266,0.898284,0.850411,0.192652,0.0667741,0.0209986,-0.144051,0.884362,0.783463,0.580326,0.686865,0.489283,0.401835,0.701992,0.726893,0.574232,0.613684,0.219415,0.243954,0.507997,0.529933,0.0391654,0.272411,-0.666973,-0.31787,-0.151955,0.171473,1.3327,1.43889,-1.23008,-1.36031,-1.5345,-1.67251,-0.914474,-1.01312,-0.739825,-0.995096,-0.000507945,0.115342,-0.845856,-0.896579
5267,0.000545366,-0.0487547,0.210871,0.142734,0.169179,0.00282086,0.824192,0.717495,0.988495,1.09482,0.423081,0.336441,0.628519,0.580587,0.848897,0.818055,0.373626,0.398923,0.169751,0.193502,0.525715,0.756585,0.607449,0.960708,0.761936,1.09755,-0.0279086,0.00161585,1.21527,1.07847,1.96077,1.81638,-0.828996,-0.920946,0.220813,-0.0368708,-0.250643,-0.138357,-0.00655388,-0.0592769
5268,0.453651,0.44185,0.986912,0.918312,0.771379,0.60638,0.698161,0.651528,0.743754,0.852037,0.357479,0.271048,0.203484,0.155582,0.557575,0.526524,0.0711135,0.0950724,0.359748,0.303562,-0.0461598,0.182311,-0.834058,-0.488346,-0.795691,-0.459204,-1.54185,-1.43566,1.23962,1.09958,-1.56714,-1.71328,-1.25806,-1.35052,-0.0663567,-0.317829,-1.42442,-1.31117,-1.12296,-1.17341
5269,0.981754,0.932454,0.107504,0.0377002,0.0850957,-0.0779171,0.13304,0.0877913,0.833564,0.94056,0.834754,0.748362,0.915803,0.868757,0.77919,0.750449,0.655467,0.680309,0.391415,0.413621,0.0826779,0.310132,0.0545589,0.403404,0.216057,0.555482,0.221838,0.326459,-1.10352,-1.24007,1.33644,1.18642,0.921443,0.821898,-0.965988,-1.21399,0.55593,0.670133,0.459763,0.414631
5270,0.335456,0.286267,0.785654,0.717391,0.0226501,-0.142958,0.373273,0.415379,0.20913,0.315522,0.835758,0.750433,0.320973,0.272158,0.594498,0.563504,0.460849,0.487527,0.200587,0.223,-1.08665,-0.862338,-0.102485,0.253714,-0.318966,0.093399,-0.0239665,0.0747372,-0.973146,-1.11355,-1.87298,-2.01359,-0.0928224,-0.194775,0.920216,0.667113,-0.206358,-0.0936912,1.59623,1.55722
5271,0.596131,0.548191,0.88384,0.816323,0.955505,0.787921,0.788781,0.742967,0.301305,0.308812,0.545576,0.509786,0.275769,0.307032,0.935372,0.905535,0.686197,0.714135,0.664875,0.687085,-1.77369,-1.54435,1.10097,1.45487,-0.715381,-0.368684,-0.790839,-0.687143,0.385886,0.239064,-3.18423,-3.32288,1.5462,1.43899,0.338588,0.0781794,-1.64102,-1.53305,1.62028,1.57969
5272,0.605475,0.558496,0.334836,0.269603,0.299314,0.128945,0.417758,0.371049,0.194412,0.302101,0.353179,0.269139,0.38873,0.341906,0.560318,0.577479,0.43594,0.465615,0.1702,0.191677,1.31698,1.54183,-0.603103,-0.242708,-0.880518,-0.535098,0.502311,0.600138,-0.62348,-0.770522,-1.75565,-1.90117,-0.050719,-0.156967,1.22687,0.960169,0.0317075,0.148142,0.678076,0.635725
5273,0.275393,0.228783,0.706801,0.639316,0.836817,0.666588,0.457427,0.409914,0.728074,0.835863,0.113817,0.0284922,0.0651542,0.0159364,0.278187,0.249424,0.966799,0.995208,0.319925,0.34378,0.475153,0.704693,0.655851,1.02072,0.712401,1.06035,-0.0988467,-0.00538101,-0.188361,-0.337374,-1.22506,-1.36513,0.616649,0.504255,-0.752818,-1.0168,-1.11542,-0.991941,-1.41664,-1.45974
5274,0.645826,0.601086,0.34878,0.292338,0.74549,0.575623,0.274176,0.227947,0.205669,0.312849,0.663094,0.580177,0.228559,0.177358,0.428896,0.49319,0.13892,0.166773,0.23837,0.26058,-0.145848,0.0831755,0.114206,0.523085,0.747833,1.09099,0.385137,0.481149,-1.17897,-1.33102,0.695494,0.549767,-0.247694,-0.3541,0.435288,0.216136,-0.676808,-0.548683,1.49625,1.45314
5275,0.326927,0.281866,0.0151463,-0.05464,0.363886,0.196291,0.327392,0.28218,0.760783,0.867343,0.817427,0.734967,0.179872,0.129112,0.767197,0.736956,0.313821,0.413266,0.450248,0.532359,1.46764,1.69,-0.344256,0.0254469,1.24871,1.59451,0.0195656,0.121341,-0.650785,-0.806252,1.62009,1.46827,2.19541,2.09206,1.71306,1.44907,-1.17952,-1.04997,-1.10196,-1.14715
5276,0.846254,0.798472,0.63146,0.560368,0.622896,0.456975,0.905824,0.86006,0.45057,0.554649,0.366578,0.28366,0.833,0.781872,0.558694,0.530077,0.633893,0.65976,0.779958,0.804137,-0.975708,-0.758759,-1.55003,-1.18659,0.0577684,0.405383,-0.588217,-0.484178,-1.78016,-1.93658,-0.664184,-0.8156,0.288523,0.184406,0.492678,0.232405,0.679414,0.803782,-0.923713,-0.974701
5277,0.289103,0.242307,0.290251,0.22033,0.563182,0.396719,0.541397,0.593481,0.96567,1.06877,0.167117,0.126506,0.466019,0.41557,0.588008,0.560292,0.0538066,0.0803382,0.787338,0.828479,-1.67273,-1.45538,-0.715925,-0.354769,-0.61712,-0.27311,0.386077,0.49718,0.425395,0.266424,2.58403,2.42955,-0.466296,-0.566397,0.232475,-0.0344211,0.362686,0.487906,0.344857,0.291364
5278,0.163672,0.118363,0.931345,0.85968,0.0500795,-0.116845,0.375484,0.326901,0.226647,0.331403,0.0499925,-0.0306476,0.969672,0.917886,0.289747,0.296084,0.0484459,0.0746934,0.828976,0.852821,-0.856342,-0.639057,0.480091,0.846385,-0.747245,-0.396393,-0.25551,-0.116535,-0.162284,-0.327288,1.91834,1.76349,-0.0302846,-0.134402,1.17918,0.911082,-0.309158,-0.183047,0.606082,0.552762
5279,0.657348,0.60989,0.875658,0.805198,0.0359356,-0.130332,0.859881,0.809503,0.378832,0.481591,0.17016,0.0889704,0.0978504,0.0461503,0.0589953,0.0318756,0.528996,0.554717,0.636246,0.662201,-0.966396,-0.690387,-1.59121,-1.23078,-0.872575,-0.519676,-0.85062,-0.730249,0.368596,0.219723,0.413839,0.253699,-1.20981,-1.30678,-0.598915,-0.859964,-0.32405,-0.203993,-0.0332198,-0.0900858
5280,0.541802,0.495849,0.0717101,0.00054606,0.775642,0.610539,0.823496,0.767436,0.0561928,0.159214,0.735654,0.655399,0.255701,0.217785,0.982805,0.958479,0.353351,0.37712,0.040994,0.0666247,-0.877326,-0.741716,1.08318,1.4414,0.0467802,0.401739,-0.185309,-0.0608653,0.93686,0.766734,0.666249,0.512137,-1.58875,-1.68911,0.460102,0.191274,0.567775,0.691055,1.24739,1.18995
5281,0.00148074,-0.045249,0.0581679,-0.0150447,0.0754297,-0.0888707,0.730256,0.72537,0.394611,0.431793,0.47675,0.397411,0.439106,0.389419,0.511308,0.487456,0.681015,0.703216,0.692134,0.715436,-1.01151,-0.793045,-2.14081,-1.78982,-1.08222,-0.727198,-1.53634,-1.40799,-0.341044,-0.493108,0.182628,0.0330764,0.0971505,-0.0102266,-1.47516,-1.73744,-0.818089,-0.700223,1.24178,1.18257
5282,0.882543,0.836694,0.851605,0.777012,0.548431,0.384724,0.734768,0.683303,0.603426,0.704371,0.452774,0.374235,0.300984,0.335522,0.62642,0.603213,0.755716,0.776874,0.811655,0.836884,-0.0624128,0.161053,-0.382164,-0.0285385,-0.711574,-0.359731,-0.629873,-0.504541,-1.58323,-1.75295,0.593551,0.444742,0.396771,0.248882,-0.72084,-0.978521,-0.159579,-0.0386296,-0.63148,-0.694726
5283,0.667148,0.622818,0.205006,0.131306,0.134887,-0.0297016,0.425774,0.375518,0.311117,0.41174,0.824334,0.743792,0.33171,0.281624,0.264444,0.241075,0.41514,0.437619,0.0813297,0.1087,0.373637,0.5953,0.784039,1.13993,0.0669456,0.422976,1.3085,1.43198,1.04674,0.870121,-1.27783,-1.43164,0.617967,0.507991,0.852642,0.593672,1.23567,1.36109,-1.30426,-1.36743
5284,0.777196,0.733526,0.630397,0.555752,0.962333,0.795654,0.650951,0.600487,0.897971,0.997154,0.280102,0.199374,0.793379,0.742933,0.80176,0.778846,0.746627,0.768158,0.712563,0.738231,-1.21207,-0.99224,0.52372,0.880957,-0.915884,-0.565164,0.0895287,0.206034,0.453506,0.276409,1.76545,1.61624,1.36782,1.26078,0.991124,0.725593,-0.363237,-0.234332,0.536744,0.471805
5285,0.437446,0.393291,0.362324,0.289507,0.581739,0.473132,0.0362629,-0.0125256,0.986761,1.03965,0.928949,0.8458,0.216594,0.165861,0.598146,0.576777,0.580845,0.600459,0.397128,0.422463,-0.0871537,0.129525,1.12976,1.4828,0.758044,1.10926,-0.615908,-0.491834,-1.15102,-1.33009,-1.9952,-2.14865,0.00626143,-0.0975624,-0.211308,-0.474962,0.201911,0.334242,-0.791672,-0.853847
5286,0.486779,0.443539,0.856094,0.782555,0.317307,0.15061,0.927762,0.880925,0.982827,1.08214,0.0389004,-0.0438083,0.396591,0.325709,0.836492,0.816616,0.148082,0.165722,0.791783,0.817028,-0.478359,-0.258595,-0.0987666,0.255035,0.0344927,0.383663,0.163123,0.286452,-0.77196,-0.955577,-1.82366,-1.98137,-3.16147,-3.26476,-1.88859,-2.15272,2.56399,2.69095,-0.130245,-0.196794
5287,0.8643,0.821614,0.471757,0.398193,0.53539,0.298474,0.764096,0.77832,0.622968,0.723059,0.829831,0.744697,0.53543,0.485557,0.64339,0.63998,0.0672158,0.111247,0.768492,0.793077,0.695192,0.910616,-0.220141,0.134548,-1.15063,-0.805469,-1.21353,-1.09175,-1.67998,-1.85532,0.376855,0.220186,0.322024,0.222509,-1.35563,-1.62166,0.153072,0.273113,-1.05744,-1.12643
5288,0.505954,0.461948,0.903074,0.827764,0.613392,0.446338,0.72146,0.675716,0.726775,0.840685,0.223955,0.139677,0.304176,0.257291,0.488169,0.463345,0.0389096,0.0567723,0.186277,0.212866,-0.0547026,0.168485,0.971592,1.31973,-0.415538,-0.0674686,0.679093,0.7978,1.57444,1.40111,-0.543829,-0.706025,-0.651186,-0.747134,-1.11556,-1.38192,0.549218,0.670012,-1.62266,-1.69301
5289,0.986479,0.943263,0.161671,0.0878362,0.998402,0.833346,0.294497,0.248553,0.856673,0.958311,0.0134145,-0.0695114,0.0779524,0.0290243,0.305614,0.28671,0.72026,0.73905,0.479029,0.424987,-0.408182,-0.189436,1.02958,1.38242,1.20727,1.55867,1.26449,1.38992,1.29951,1.12637,-0.0153456,-0.183871,-0.489312,-0.578973,0.156043,-0.105795,-0.942597,-0.817788,0.727366,0.649353
5290,0.162104,0.120542,0.30472,0.332134,0.964434,0.701841,0.933679,0.885896,0.498632,0.587522,0.575115,0.491776,0.308052,0.259998,0.770522,0.753615,0.827834,0.817091,0.612452,0.637107,0.110998,0.324599,-0.0935059,0.262457,-1.44185,-1.08452,0.081165,0.210902,-1.89278,-2.06554,-0.211541,-0.367751,0.905954,0.824624,-0.24268,-0.509552,-1.30393,-1.17962,1.55965,1.48665
5291,0.024238,-0.017265,0.616937,0.576432,0.734838,0.570336,0.966277,0.918675,0.114493,0.216733,0.0432644,-0.0381424,0.119074,0.1194,0.649788,0.632486,0.775202,0.895131,0.551489,0.57877,-0.0890749,0.119145,1.27125,1.63282,-0.733953,-0.377739,1.45196,1.57584,-0.67034,-0.847643,-0.375366,-0.551631,-0.224535,-0.300826,-1.91659,-2.18731,-0.121662,-0.00133694,-0.480893,-0.547627
5292,0.763899,0.72049,0.894564,0.820729,0.291912,0.125845,0.700302,0.646399,0.380827,0.483046,0.0404318,-0.0412279,0.027122,-0.0211983,0.28231,0.2657,0.954598,0.973172,0.176948,0.202594,0.877218,1.0904,-1.66961,-1.31491,1.22262,1.57615,-0.0574462,0.0733185,-0.0660412,-0.24666,-1.02521,-1.20396,0.00760061,-0.072646,-0.373463,-0.646364,0.582953,0.708408,0.765847,0.701627
5293,0.722562,0.679349,0.503337,0.408943,0.440246,0.272717,0.420367,0.374123,0.0865567,0.190416,0.786018,0.7049,0.664843,0.61539,0.315457,0.374127,0.799216,0.819575,0.244745,0.269336,-0.603154,-0.388165,-0.353761,-0.00525379,-0.330565,0.0193944,0.679731,0.806367,1.76031,1.58483,1.14457,0.96827,-0.810751,-0.884902,-0.717045,-0.98883,0.750242,0.871532,-0.518298,-0.579537
5294,0.269624,0.228925,0.0687222,-0.00284301,0.000803035,-0.166506,0.921756,0.876457,0.56831,0.672945,0.657109,0.57631,0.652564,0.602727,0.499631,0.482554,0.411645,0.429527,0.00728964,0.0336569,-0.534787,-0.321067,-0.972006,-0.629785,1.63632,1.98845,0.333153,0.447625,2.23788,2.06292,0.0452326,-0.127648,-1.89557,-1.96368,-0.727575,-0.92418,-0.638104,-0.519745,-1.14125,-1.20546
5295,0.405375,0.413374,0.17973,0.105919,0.573342,0.406041,0.923457,0.859912,0.25582,0.360251,0.148226,0.0664424,0.371922,0.321809,0.182135,0.166061,0.63532,0.689739,0.0461038,0.0703746,2.56503,2.78673,1.19361,1.54167,-1.95326,-1.59854,-0.0409034,0.0888838,-0.206271,-0.379781,1.91584,1.74192,0.0450312,-0.018522,-0.581722,-0.85953,0.608214,0.721196,-1.53268,-1.5905
5296,0.624841,0.597823,0.844278,0.770129,0.445753,0.22486,0.886999,0.843367,0.628949,0.733559,0.749915,0.667911,0.602127,0.493444,0.606749,0.592675,0.933462,0.949951,0.28678,0.309122,0.38767,0.606049,-0.838326,-0.489202,-1.40258,-1.04658,0.610078,0.743883,1.15904,0.988535,-2.35379,-2.52974,0.120603,0.0594878,-1.30594,-1.58807,-0.843233,-0.733567,0.357235,0.291783
5297,0.820672,0.782272,0.132034,0.0599941,0.211619,0.0436786,0.294642,0.249943,0.325121,0.431025,0.745673,0.664826,0.716782,0.665078,0.301109,0.286334,0.534587,0.551006,0.183107,0.203417,-0.824549,-0.614845,0.248533,0.605683,-2.14025,-1.78453,-0.974299,-0.834508,-1.07182,-1.23743,-1.96048,-2.13116,0.999587,0.934014,-0.0792339,-0.356633,0.572467,0.681388,-1.37116,-1.4308
5298,0.556023,0.477856,0.374006,0.372353,0.598563,0.430686,0.417586,0.436446,0.355448,0.462988,0.313757,0.234106,0.34936,0.298776,0.273184,0.260586,0.581497,0.628459,0.961908,0.983831,0.263235,0.476606,-0.33032,0.0267601,1.49709,1.85514,-0.316426,-0.179509,-1.24446,-1.40526,-1.10656,-1.27477,-0.21752,-0.283516,-0.585525,-0.867733,-1.8611,-1.75377,-1.22359,-1.28874
5299,0.214536,0.173441,0.758716,0.684712,0.572514,0.402677,0.648706,0.622949,0.930239,1.03728,0.463611,0.383902,0.877638,0.825639,0.921355,0.910073,0.691967,0.705913,0.51513,0.537439,0.3875,0.604427,0.0674192,0.426551,-0.835893,-0.480151,0.0223262,0.153496,-0.387296,-0.541121,0.429373,0.256463,0.15095,0.0850123,0.777247,0.489885,0.256577,0.364157,0.0485132,-0.0226741
5300,0.204268,0.213961,0.583283,0.510137,0.130713,-0.0418135,0.85415,0.809451,0.864272,1.06647,0.148327,0.0701415,0.387035,0.395797,0.465099,0.45362,0.260914,0.276822,0.344239,0.327062,1.50099,1.71194,-2.13786,-1.77812,-1.57278,-1.21811,0.976504,1.10235,0.730372,0.58192,-0.981319,-1.14751,1.35258,1.28589,0.112124,-0.177375,-0.0171879,0.0946729,-0.731256,-0.800459
5301,0.190832,0.254481,0.979178,0.905586,0.777465,0.607079,0.642227,0.59745,0.988978,1.09565,0.0346516,-0.0432201,0.0198789,-0.0340448,0.464153,0.495157,0.519505,0.53297,0.0938873,0.116684,-1.02685,-0.815768,1.22212,1.584,0.162941,0.520324,-0.194291,-0.0628928,-0.482076,-0.622828,0.864741,0.693655,1.86204,1.79291,0.844293,0.553941,-1.30594,-1.18809,-0.665058,-0.732234
5302,0.335671,0.295001,0.221252,0.149181,0.631907,0.499588,0.64838,0.605325,0.386452,0.490934,0.613282,0.537632,0.768362,0.715468,0.546419,0.536693,0.483651,0.402807,0.231343,0.252155,2.09936,2.30802,1.11421,1.47853,1.60596,1.96082,-0.171809,-0.0369917,-2.42686,-2.57349,-0.516481,-0.6955,1.68435,1.51716,0.975073,0.685861,-0.043845,0.0667466,-0.207655,-0.274802
5303,0.838788,0.79713,0.296418,0.222847,0.560612,0.392096,0.210446,0.169089,0.962471,1.06523,0.802904,0.72652,0.777269,0.72306,0.203234,0.194601,0.257246,0.272644,0.363053,0.387626,-0.960579,-0.759621,1.62361,1.98808,0.0193727,0.371762,-1.05562,-0.923397,1.91788,1.77666,-1.06655,-1.2511,1.3119,1.2414,-0.0789081,-0.361714,-0.311443,-0.223028,-0.513738,-0.65981
5304,0.004439,-0.0356848,0.833481,0.760082,0.772812,0.600472,0.157321,0.117463,0.884491,0.990199,0.0661114,-0.00808271,0.407815,0.352346,0.591163,0.581212,0.409223,0.410162,0.0535348,0.0762329,-0.378875,-0.219445,1.27416,1.63812,1.54562,1.90257,0.916334,1.04365,-0.436954,-0.578144,0.965439,0.774543,-0.857327,-0.933656,0.739602,0.459338,-0.621917,-0.512802,-0.983105,-1.04482
5305,0.694579,0.655035,0.268939,0.19394,0.976329,0.808848,0.686316,0.645123,0.073352,0.180085,0.649741,0.577578,0.737752,0.684774,0.0803494,0.0699422,0.53334,0.54768,0.760013,0.780659,0.114061,0.32073,0.111005,0.472067,1.01039,1.40343,0.690643,0.824282,-1.0873,-1.2325,0.265432,0.0779808,1.75116,1.67243,-0.256664,-0.542408,-0.0152847,0.0866864,-0.303066,-0.372397
5306,0.608785,0.603075,0.187134,0.110609,0.387341,0.220106,0.419515,0.377196,0.557544,0.662614,0.669098,0.599514,0.279058,0.224311,0.59867,0.587233,0.133067,0.148736,0.176083,0.194964,-0.861983,-0.652855,0.550339,0.91798,0.545695,0.904296,0.871497,1.028,-0.230493,-0.36836,-0.0652988,-0.152266,0.58538,0.500049,0.0364146,-0.255724,-0.378834,-0.275149,-0.555336,-0.621687
5307,0.608,0.551115,0.413898,0.220601,0.311591,0.145186,0.518359,0.411415,0.420183,0.526672,0.921171,0.852952,0.516178,0.460161,0.50775,0.44432,0.128674,0.104336,0.424984,0.410341,0.88262,1.0927,3.01725,3.38042,-0.659003,-0.30128,1.0915,1.23172,0.200997,0.0647885,-0.201693,-0.382514,-0.298802,-0.391748,-0.485434,-0.781974,-0.375082,-0.265837,-0.0933468,-0.164254
5308,0.540114,0.499155,0.475378,0.330592,0.520079,0.331637,0.488501,0.445634,0.695264,0.803269,0.586831,0.51947,0.989621,0.931842,0.314583,0.301406,0.0421124,0.0599358,0.540708,0.625719,0.0738127,0.2541,1.21322,1.56996,-0.101088,0.250679,1.65014,1.79326,1.55211,1.4174,-2.02294,-2.19916,0.0144207,-0.0840485,1.60061,1.30326,0.448382,0.551497,0.621895,0.553745
5309,0.75282,0.710484,0.515009,0.440584,0.686073,0.518087,0.384696,0.343059,0.370381,0.476106,0.494773,0.426581,0.452414,0.451487,0.510381,0.498084,0.235624,0.255518,0.822624,0.841096,-0.800663,-0.584498,0.2214,0.574703,0.720193,1.06608,-0.0549286,0.085586,0.0516927,-0.0835535,-1.26747,-1.44957,-0.12794,-0.22042,1.20804,0.915819,0.454643,0.56081,0.299628,0.176945
5310,0.217016,0.174227,0.238697,0.165238,0.330428,0.164356,0.0179377,-0.0237502,0.937788,1.04485,0.0573693,-0.00944723,0.0289524,-0.0288672,0.0731911,0.0611886,0.201843,0.220447,0.797284,0.772451,-0.949067,-0.731579,0.853286,1.20579,1.16916,1.5114,0.626113,0.770134,0.703833,0.564255,1.26779,1.09145,-0.888387,-0.987369,-0.789568,-1.07604,-0.196774,-0.0935007,-0.132056,-0.199854
5311,0.14316,0.102939,0.449809,0.429193,0.791211,0.623191,0.29397,0.337047,0.236305,0.344418,0.199501,0.0916334,0.061729,0.00364422,0.224807,0.212453,0.760991,0.780214,0.723953,0.703807,-0.359106,-0.141986,0.706693,1.05925,-1.95052,-1.60245,-0.700761,-0.562511,0.326674,0.181933,0.889739,0.707225,-0.450823,-0.555374,0.305589,0.0207532,-2.58258,-2.47773,0.105334,0.0806394
5312,0.676604,0.634278,0.766673,0.693148,0.564132,0.395764,0.739426,0.697844,0.743842,0.852756,0.379418,0.192714,0.455674,0.430489,0.679355,0.669175,0.846906,0.868387,0.617783,0.635162,-0.0389905,0.17124,0.576851,0.912716,0.705523,1.05632,-0.808429,-0.67423,-0.445627,-0.560016,-0.246486,-0.432384,0.916171,0.815564,2.00705,1.71819,0.74471,0.854397,0.427306,0.361133
5313,0.407317,0.393285,0.580753,0.508898,0.665076,0.497087,0.0715648,0.0302769,0.229996,0.339634,0.361538,0.293795,0.915887,0.857333,0.580775,0.56924,0.696758,0.720195,0.20871,0.22369,1.00361,1.21941,0.412888,0.766181,-1.25264,-0.908752,-0.331372,-0.205025,-1.1565,-1.30197,1.53666,1.34762,-0.0919014,-0.18624,1.04124,0.745868,-0.0261676,0.0905733,1.7664,1.70224
5314,0.195486,0.152292,0.941618,0.869011,0.36436,0.197904,0.0512377,0.00837131,0.859241,0.968799,0.360937,0.237156,0.628657,0.571467,0.793674,0.780651,0.184835,0.210496,0.841589,0.857595,-0.473743,-0.259153,0.267146,0.619646,-1.52143,-1.18249,0.902099,1.02207,-1.07062,-1.1428,-0.730966,-0.921292,-0.575211,-0.663362,-0.94482,-1.246,-0.11797,-0.00814189,-1.50356,-1.56555
5315,0.993846,0.948854,0.828755,0.75579,0.881328,0.71681,0.477166,0.432633,0.78791,0.984141,0.249681,0.180518,0.707281,0.650459,0.562634,0.548362,0.880331,0.907086,0.479706,0.496495,-0.208368,0.00672983,-1.01302,-0.655351,1.70626,2.04573,0.765612,0.880165,-0.838842,-0.983636,0.896718,0.703148,-0.0510169,-0.141606,-0.70493,-1.00626,0.0346943,0.13916,0.940301,0.878202
5316,0.808054,0.771391,0.994342,0.919524,0.904209,0.738086,0.534423,0.490989,0.866355,0.999483,0.466387,0.322493,0.0839441,0.0297148,0.671001,0.613882,0.0169056,0.0420873,0.529479,0.618573,-1.28397,-1.07476,-0.508925,-0.145799,1.5616,1.89465,1.11401,1.22856,1.52421,1.38589,-0.169349,-0.361681,-0.0990649,-0.186429,3.20798,2.90067,-2.68813,-2.58887,-0.145929,-0.204685
5317,0.63495,0.593929,0.489176,0.416126,0.168574,0.00248691,0.099359,0.0547534,0.905608,1.01482,0.53386,0.464469,0.78882,0.732131,0.598236,0.679402,0.0511901,0.0872981,0.723057,0.740652,1.92642,2.12791,0.225457,0.593839,-0.726966,-0.392524,-0.757443,-0.63625,-0.792256,-0.936146,-0.511046,-0.700096,0.590423,0.505088,-0.485828,-0.795478,0.531939,0.628982,1.84818,1.78285
5318,0.444879,0.416466,0.357183,0.282284,0.866764,0.70285,0.860268,0.818152,0.496844,0.654482,0.235817,0.165668,0.42689,0.37118,0.758702,0.744923,0.210613,0.132509,0.118257,0.134602,1.37434,1.56934,-1.50958,-1.13811,1.14325,1.48617,-0.152168,-0.0293558,-0.574334,-0.716206,-0.578289,-0.762346,0.0853233,-0.00106276,-0.236033,-0.615008,0.0711949,0.116077,-0.522346,-0.58573
5319,0.165375,0.239003,0.469788,0.395577,0.651102,0.484984,0.0157961,-0.0237633,0.184388,0.294139,0.538921,0.46706,0.796198,0.738062,0.251378,0.238644,0.152538,0.17772,0.726042,0.743468,-0.0531767,0.133675,0.763166,1.13043,-0.638443,-0.291202,-1.53942,-1.42431,-0.777744,-0.915019,-0.894238,-1.02545,-1.46955,-1.5501,-0.124853,-0.434538,-0.494938,-0.396828,-0.828358,-0.896458
5320,0.106533,0.0615408,0.235937,0.256799,0.817409,0.651144,0.435666,0.394393,0.553851,0.661805,0.593814,0.522663,0.0298058,-0.0277943,0.797481,0.786458,0.967169,0.990607,0.498381,0.501056,0.641845,0.828678,-1.29638,-0.927354,0.064377,0.451717,-0.752223,-0.662139,-0.519723,-0.65987,-1.1045,-1.28856,0.299483,0.221055,0.701257,0.386514,0.947824,1.04838,-0.499209,-0.573583
5321,0.400247,0.353766,0.191477,0.118022,0.220637,0.0518081,0.135384,0.0919615,0.547182,0.587947,0.321455,0.24974,0.291516,0.195257,0.195825,0.185404,0.024369,0.049294,0.242336,0.258644,0.804259,0.986638,-0.522293,-0.157432,0.846179,1.19464,-0.0153028,0.100035,-0.261217,-0.404722,0.664345,0.473164,0.468307,0.389216,-0.949815,-1.26246,-1.4015,-1.3029,0.533972,0.462078
5322,0.468619,0.424499,0.845923,0.77219,0.499653,0.31812,0.543886,0.501333,0.51325,0.51409,0.280235,0.207773,0.476886,0.418308,0.0532265,0.0432698,0.446745,0.42292,0.654069,0.672424,2.22573,2.40582,-1.25298,-0.889444,-0.647681,-0.301884,-0.467397,-0.351304,1.61415,1.47258,0.225183,0.0463826,0.180893,0.099643,-1.88403,-2.20349,-0.530372,-0.394906,-0.793831,-0.863573
5323,0.162503,0.119839,0.685936,0.615844,0.754443,0.584433,0.0876875,0.0443284,0.330511,0.440233,0.896393,0.823442,0.988038,0.929126,0.50812,0.512505,0.771779,0.796546,0.20972,0.226033,-0.0640102,0.115339,-0.736184,-0.365409,-0.146219,0.201639,-0.315425,-0.200548,0.370249,0.234099,-0.19291,-0.380399,-0.356109,-0.509997,0.305174,-0.0106906,0.414484,0.513088,-1.32136,-1.38519
5324,0.562362,0.517604,0.531055,0.459499,0.485677,0.335233,0.0407693,-0.00254492,0.875797,0.984602,0.126824,0.0533254,0.356737,0.297048,0.991698,0.981741,0.312534,0.336447,0.240132,0.212641,1.56727,1.75218,0.000302803,0.37423,-0.983128,-0.63203,-2.44257,-2.33481,-0.0366106,-0.178257,-0.334975,-0.621498,-1.04027,-1.11964,-1.14192,-1.45774,-1.11764,-1.02133,1.17392,1.10932
5325,0.32279,0.3005,0.116809,0.0458052,0.254601,0.0860338,0.717175,0.674152,0.115547,0.227001,0.771244,0.699751,0.365531,0.304639,0.721329,0.729753,0.708924,0.732324,0.131115,0.19925,0.880366,1.07017,0.0799723,0.452408,0.950543,1.30614,2.16401,2.26924,1.57763,1.43528,-0.675967,-0.862596,0.333729,0.251301,0.517294,0.206738,0.869464,0.95998,-1.4606,-1.52609
5326,0.127881,0.0833959,0.551044,0.479954,0.902199,0.734926,0.979477,0.93498,0.264202,0.311726,0.232014,0.160535,0.891481,0.831502,0.557441,0.477764,0.209886,0.232571,0.169601,0.185858,0.509442,0.792183,1.77055,2.15003,0.353729,0.704921,1.03428,1.13602,-0.120095,-0.201801,-1.29529,-1.48288,1.04839,0.973147,1.36544,1.05889,1.02585,1.1231,-0.31985,-0.383505
5327,0.844154,0.799279,0.253905,0.184642,0.263136,0.0967614,0.671681,0.69717,0.284683,0.396452,0.577623,0.506186,0.396567,0.335699,0.235732,0.225775,0.694619,0.717579,0.713769,0.729989,0.319472,0.514195,-2.18624,-1.81087,0.951205,1.30239,-0.717477,-0.618012,-1.69653,-1.83888,0.943511,0.754728,-1.48223,-1.55479,1.72759,1.42051,-0.0568957,0.0456436,-1.51485,-1.57251
5328,0.0280852,-0.018115,0.763655,0.692195,0.330885,0.163396,0.502377,0.459361,0.151258,0.264828,0.647875,0.650768,0.293295,0.230931,0.328896,0.308422,0.557608,0.612241,0.577885,0.54487,-0.467034,-0.276928,0.0715366,0.444271,0.546041,0.88989,-0.0292852,0.0665356,0.141966,-0.0073886,1.02228,0.830358,-0.00133489,-0.0753144,-0.374012,-0.680923,0.333483,0.442542,-0.617172,-0.67395
5329,0.769713,0.725852,0.123839,0.0518974,0.648949,0.480108,0.483186,0.442187,0.794865,0.909729,0.869126,0.795351,0.438361,0.408155,0.399058,0.391068,0.482732,0.506904,0.34302,0.35975,-0.821482,-0.63485,0.622423,0.997758,0.851567,1.17421,0.898809,0.999923,0.611349,0.456729,-0.173328,-0.278421,-0.854001,-0.933669,0.487084,0.185016,1.779,1.88775,-2.02732,-2.09131
5330,0.863479,0.821438,0.175654,0.1057,0.0549741,-0.114334,0.70315,0.662533,0.508987,0.622402,0.751316,0.677966,0.646387,0.585379,0.0848916,0.074575,0.119751,0.142599,0.695716,0.713632,-0.208261,-0.0156751,0.413551,0.697499,1.11894,1.45853,0.860798,0.964278,-0.102486,-0.257896,-1.19721,-1.3872,0.170214,0.0934757,0.949435,0.653546,0.500106,0.604983,1.00338,0.93086
5331,0.137678,0.0975465,0.753736,0.681464,0.747785,0.581172,0.156461,0.114716,0.807425,0.919978,0.0669684,-0.00680037,0.156779,0.094269,0.878569,0.86792,0.521727,0.543536,0.142686,0.162836,-0.996602,-0.806798,0.0239179,0.39724,-0.0682684,0.269397,1.52285,1.63366,-1.78455,-1.94262,-0.666467,-0.851161,0.755627,0.678505,0.471827,0.173316,-2.02945,-1.93075,-0.0339778,-0.138398
5332,0.191314,0.185166,0.697037,0.626982,0.147357,-0.0181636,0.199956,0.158157,0.822002,0.93291,0.0612434,-0.0146197,0.884069,0.822927,0.144033,0.132294,0.585385,0.606427,0.290982,0.309554,-0.856783,-0.664125,-0.85299,-0.474288,0.411007,0.711521,-2.76856,-2.65493,0.98835,0.837123,-1.48857,-1.66953,-0.661236,-0.743435,-0.652742,-0.951755,0.435306,0.539126,-1.13359,-1.20766
5333,0.310951,0.272785,0.144257,0.0751071,0.0803328,-0.0832043,0.641526,0.601567,0.178878,0.288638,0.43178,0.354938,0.977341,0.916868,0.268987,0.258054,0.868325,0.887604,0.913291,0.93401,0.0992345,0.289973,0.702248,1.08586,0.813758,1.15365,2.15412,2.26774,1.74627,1.59268,-0.185669,-0.368879,1.69944,1.6211,0.507951,0.206074,-0.580625,-0.477306,-1.36477,-1.4418
5334,0.838441,0.799592,0.44621,0.376542,0.591901,0.430809,0.532824,0.395384,0.709525,0.817663,0.204709,0.126476,0.669613,0.597848,0.752549,0.740083,0.523728,0.542742,0.733438,0.807777,-2.07185,-1.87473,-0.543833,-0.157063,0.245237,0.682324,1.37978,1.49137,0.760839,0.61375,-0.0883743,-0.277475,-0.240296,-0.319139,-0.926672,-1.2269,0.552186,0.652972,-0.852683,-0.922352
5335,0.344452,0.304197,0.159885,0.0908813,0.217048,0.055974,0.230959,0.189202,0.0830918,0.192625,0.975766,0.899686,0.340576,0.278828,0.914506,0.901549,0.410298,0.473361,0.729939,0.681543,1.29665,1.49853,-0.146023,0.242728,-0.128705,0.211003,-0.309095,-0.199339,0.0680356,-0.0874558,-0.505834,-0.693807,-0.0401164,-0.120332,0.398557,0.0981225,0.0604082,0.168457,1.2384,1.16382
5336,0.489821,0.440655,0.286152,0.219003,0.609182,0.447893,0.785308,0.74178,0.701332,0.811842,0.133188,0.0566173,0.683622,0.620809,0.648592,0.634493,0.387294,0.40398,0.651693,0.55531,0.680096,0.877012,-1.056,-0.674062,0.0564701,0.394133,-0.546584,-0.433457,0.183026,-0.0530591,0.0542743,-0.141311,0.979324,0.893016,2.14271,1.84257,0.82469,0.93806,-0.41661,-0.497476
5337,0.617216,0.577113,0.0426129,-0.0223184,0.771872,0.609161,0.993092,0.948466,0.925031,1.0373,0.511712,0.435506,0.532136,0.47128,0.63228,0.529279,0.0752572,0.0890277,0.408357,0.429076,-0.794623,-0.60155,0.803827,1.17817,-0.617367,-0.284361,-0.342614,-0.222814,0.14226,-0.0186625,-0.818587,-0.965711,0.21309,0.18502,-0.295269,-0.592571,0.590355,0.700539,-0.467809,-0.550695
5338,0.378229,0.338647,0.947279,0.881243,0.61838,0.457263,0.863378,0.816081,0.673298,0.785404,0.153379,0.0779411,0.0384614,-0.01983,0.438743,0.424064,0.870904,0.885933,0.981878,1.00316,1.36569,1.55533,-0.151827,0.229767,1.16729,1.499,1.46725,1.58841,0.936773,0.769526,-1.59275,-1.79011,-0.437433,-0.522976,1.24405,0.948378,-0.0929643,0.015393,0.566292,0.484965
5339,0.924288,0.885045,0.596527,0.5426,0.225307,0.0621796,0.358071,0.313152,0.653981,0.815187,0.417417,0.271678,4.19777e-05,-0.05815,0.927365,0.91096,0.765279,0.778654,0.644266,0.666728,0.718165,0.904448,-0.185382,0.201696,-1.79279,-1.45635,-1.62531,-1.50621,0.58144,0.418443,-0.546553,-0.747648,-1.60788,-1.69536,1.3235,1.03297,0.784432,0.896325,-0.858882,-0.949211
5340,0.24474,0.203802,0.27066,0.203957,0.529336,0.363427,0.915005,0.870614,0.622847,0.844969,0.533775,0.465415,0.736988,0.680803,0.016389,-0.00159473,0.33288,0.343917,0.571576,0.660057,1.18136,1.37134,0.438951,0.832779,-0.200944,0.184793,2.85183,2.97094,3.1351,2.97301,0.0572813,-0.149235,-0.566116,-0.654266,-0.805099,-1.10135,-0.878435,-0.76409,-0.990118,-1.07854
5341,0.563374,0.520304,0.985902,0.919435,0.065885,-0.101002,0.536986,0.492998,0.768756,0.874752,0.868541,0.659153,0.933443,0.877456,0.609042,0.591553,0.639523,0.649692,0.631999,0.653386,0.595129,0.781941,0.350942,0.741873,1.4895,1.82594,0.579087,0.690937,0.838031,0.680428,-0.160673,-0.36488,0.140533,0.0527758,-0.382956,-0.67814,-1.02173,-0.910293,0.134987,0.0488157
5342,0.142162,0.0999845,0.147899,0.0825673,0.430318,0.261377,0.583297,0.592761,0.792428,0.904534,0.928328,0.85289,0.51377,0.456434,0.829354,0.809789,0.129831,0.139993,0.198883,0.222717,-0.382304,-0.191644,-0.679217,-0.285927,0.00626826,0.344598,-1.17204,-1.0631,-0.569551,-0.727754,-1.32349,-1.53385,0.388838,0.296778,-0.537693,-0.8361,1.85662,1.96375,0.0855289,-0.00440385
5343,0.990532,0.94744,0.85305,0.787801,0.305288,0.0911208,0.737666,0.692524,0.211676,0.325966,0.938983,0.864702,0.617632,0.561075,0.138287,0.11688,0.0849128,0.0952876,0.690069,0.712187,-2.14723,-1.9501,0.715178,1.11568,0.00348584,0.344573,0.427352,0.541479,-0.434631,-0.586014,-0.99082,-1.19932,0.0255179,-0.070399,0.602804,0.305268,-0.656774,-0.557219,0.855347,0.758587
5344,0.640391,0.597378,0.117832,0.0521593,0.0915328,-0.0791351,0.0212661,-0.0245438,0.406102,0.52126,0.2634,0.189152,0.76049,0.665716,0.799793,0.776905,0.659397,0.670016,0.82375,0.844248,0.697866,0.886943,-1.93442,-1.53433,0.615456,0.95698,-0.690685,-0.576334,1.0871,0.936552,-0.0565054,-0.315603,-0.120302,-0.246163,-0.791107,-1.09483,0.945581,1.04357,-0.184271,-0.27551
5345,0.0115931,-0.0337476,0.180892,0.116233,0.841564,0.672206,0.896235,0.850463,0.81152,0.929219,0.304028,0.229534,0.827693,0.770357,0.423597,0.400033,0.8833,0.891688,0.166761,0.187944,-0.871229,-0.685051,-0.719072,-0.313957,-0.316419,0.0321858,1.24922,1.36018,1.7054,1.55367,0.782875,0.568116,-0.325991,-0.421927,-0.525085,-0.823146,-0.958586,-0.860009,-0.35624,-0.449492
5346,0.588208,0.453066,0.646028,0.579309,0.0170684,-0.152355,0.903354,0.858338,0.0482248,0.165283,0.820833,0.746862,0.572048,0.51361,0.418747,0.47623,0.90268,0.911473,0.355182,0.375136,1.68987,1.86827,0.950507,1.35443,0.707557,1.06271,-2.51712,-2.39827,2.85102,2.6944,0.348738,0.136988,-0.870383,-0.961631,0.116073,-0.185889,-1.10208,-1.00621,0.694313,0.601352
5347,0.98522,0.939879,0.638017,0.573664,0.579561,0.409877,0.614212,0.569943,0.0987407,0.217622,0.463396,0.389296,0.883329,0.82567,0.573485,0.552427,0.377961,0.387406,0.92428,0.943532,0.826641,1.00171,-0.650674,-0.249915,-1.17775,-0.823589,-0.460821,-0.335619,0.131242,-0.0256744,0.920759,0.704517,-0.0817799,-0.177928,-0.901454,-1.20399,0.909603,1.00935,0.130955,0.0292605
5348,0.252641,0.205958,0.378057,0.31257,0.364695,0.196718,0.769643,0.724575,0.80446,0.923339,0.500109,0.425577,0.968392,0.909495,0.145843,0.125967,0.584025,0.515085,0.163684,0.184177,-0.430761,-0.249084,-0.310178,0.0910599,1.6176,1.96686,0.0306339,0.15091,-0.874942,-1.03526,0.136305,-0.0823958,0.220536,0.129771,-0.700418,-0.996387,1.02634,1.12595,-0.449888,-0.542831
5349,0.67823,0.633821,0.868132,0.800269,0.457691,0.224436,0.338619,0.292679,0.385367,0.5043,0.260672,0.187123,0.627186,0.569459,0.140989,0.121169,0.632241,0.642764,0.199869,0.220894,1.6096,1.78768,-0.251538,0.15375,-0.808392,-0.460812,-0.857402,-0.735495,1.52389,1.36912,1.51708,1.29384,-1.00514,-1.10315,0.0587433,-0.246112,0.733362,0.8252,2.01462,1.91645
5350,0.443437,0.326555,0.620365,0.482575,0.417958,0.252154,0.830433,0.78602,0.816529,0.936844,0.780362,0.708616,0.499701,0.439763,0.693684,0.674367,0.29338,0.303509,0.501727,0.523501,-0.107336,0.0764922,-1.10323,-0.702155,-0.112925,0.211418,-0.364642,-0.235748,-1.24501,-1.40376,-0.637992,-0.863265,-0.922174,-1.02514,0.798851,0.504163,-0.823747,-0.724685,0.305262,0.302421
5351,0.0620786,0.0192892,0.235799,0.164882,0.2403,0.0757863,0.642238,0.598579,0.860825,0.958025,0.381365,0.311939,0.0586902,-0.000971658,0.191436,0.173099,0.41606,0.42805,0.576471,0.599308,-0.548923,-0.357859,-0.155902,0.2506,0.527493,0.883648,-0.384811,-0.255295,0.95913,0.799239,-1.01893,-1.24749,-2.14683,-2.24267,-0.691857,-0.987746,1.52769,1.63202,-1.2173,-1.31161
5352,0.266283,0.175932,0.558396,0.486364,0.521978,0.357071,0.180139,0.137114,0.86776,0.979205,0.609271,0.540624,0.0485131,-0.0136348,0.119008,0.10213,0.00314712,0.0139826,0.437505,0.459536,0.831975,1.03087,-1.67155,-1.25977,0.328033,0.70119,-1.08784,-0.953163,-0.539741,-0.701713,0.665417,0.440184,0.656527,0.564461,-1.6494,-1.94401,-1.00836,-0.90371,0.492637,0.400642
5353,0.374578,0.332574,0.606894,0.534397,0.0511045,-0.112661,0.109668,0.0484238,0.878464,1.00039,0.562387,0.493435,0.832694,0.771941,0.996729,0.978857,0.356631,0.452127,0.909935,0.93354,-0.0125237,0.17937,-1.94737,-1.53378,0.162939,0.518732,-2.79375,-2.66084,1.57547,1.4163,-0.35795,-0.578273,0.180457,0.0873398,-0.624582,-0.827888,0.240088,0.35113,0.534498,0.43898
5354,0.26716,0.329578,0.00517362,-0.0671436,0.46524,0.300492,0.00201961,-0.0402662,0.253782,0.375348,0.297846,0.301784,0.228517,0.165815,0.421084,0.402712,0.878589,0.890271,0.441463,0.462526,-1.82193,-1.62717,-0.352108,0.0562573,-1.90504,-1.54391,1.29952,1.42897,-0.0710714,-0.236216,0.0363144,-0.179694,1.86446,1.76622,0.590917,0.288235,0.233578,0.345814,-0.722704,-0.810155
5355,0.283687,0.326582,0.631482,0.558501,0.633773,0.47005,0.567889,0.527417,0.775948,0.898867,0.178978,0.110133,0.866684,0.802403,0.445295,0.428416,0.385696,0.395184,0.307069,0.327953,0.316946,0.515219,0.722187,1.1339,-0.672708,-0.316359,0.909064,1.0393,-2.00481,-2.16869,0.860016,0.645216,-0.747088,-0.844117,0.349013,0.0523804,0.515719,0.632546,1.05594,0.965547
5356,0.363336,0.323586,0.838753,0.766325,0.804028,0.639608,0.607413,0.543865,0.67348,0.797578,0.125642,0.0579505,0.783517,0.718041,0.263009,0.246243,0.725189,0.735905,0.832318,0.852386,0.638609,0.842912,-0.512874,-0.109015,0.81567,1.16874,0.0846031,0.215741,0.0481009,-0.116188,0.762047,0.552147,-0.502416,-0.600115,-0.492642,-0.795884,-0.904843,-0.790577,0.484222,0.398962
5357,0.955402,0.914791,0.832616,0.760679,0.436995,0.270264,0.602636,0.560314,0.867114,0.992872,0.93948,0.872955,0.330783,0.267201,0.502741,0.585861,0.774069,0.784972,0.477449,0.4966,0.383194,0.592497,0.742895,1.13977,0.57691,0.924258,0.417653,0.548746,-0.368574,-0.528544,0.205473,-0.00344976,-0.0453702,-0.139248,0.851563,0.543583,-1.07094,-0.952852,0.81438,0.736617
5358,0.12772,0.0866122,0.472639,0.489731,0.382394,0.28009,0.980559,0.938627,0.319225,0.444365,0.272757,0.208009,0.136077,0.0722535,0.939169,0.925479,0.220657,0.230479,0.863748,0.880763,-1.77345,-1.57221,-0.173016,0.222984,-0.554509,-0.204678,0.0428697,0.265338,-0.33511,-0.492743,-0.927616,-1.14306,1.12437,1.02933,-1.18485,-1.49497,-1.69343,-1.57591,-1.0706,-1.14068
5359,0.449042,0.408009,0.289977,0.218783,0.518464,0.289917,0.538592,0.496697,0.818385,0.94229,0.591355,0.528116,0.18515,0.120748,0.95051,0.935757,0.460347,0.471972,0.840211,0.856812,0.647282,0.852289,2.01613,2.41033,-0.656865,-0.311186,-0.15296,-0.0180696,0.165312,0.00280083,-0.478058,-0.696717,-0.113294,-0.203596,-0.0989455,-0.468593,-0.87932,-0.758581,1.02455,0.957129
5360,0.37382,0.331297,0.383683,0.313122,0.464245,0.299744,0.95605,0.914853,0.883325,1.02016,0.634988,0.573245,0.960651,0.896662,0.167186,0.154217,0.192632,0.203101,0.0606742,0.0768446,-0.884061,-0.671497,-0.356157,0.0454579,-0.186638,0.163731,0.73946,0.86979,-2.20679,-2.36853,0.80973,0.58898,-0.632273,-0.726772,0.875798,0.557787,1.37945,1.5033,-1.11389,-1.18529
5361,0.499753,0.456685,0.0329925,-0.0365953,0.952364,0.788011,0.181987,0.140572,0.975209,1.09804,0.311368,0.250021,0.768456,0.624517,0.241424,0.230414,0.267726,0.226739,0.267182,0.204069,0.574044,0.780385,1.23357,1.63549,-1.25217,-0.902123,-0.036878,0.0934169,-0.377092,-0.537036,-1.12718,-1.34917,-0.343409,-0.434476,1.88793,1.58417,1.90562,2.02575,0.302287,0.233851
5362,0.909737,0.864545,0.280903,0.210411,0.282496,0.118888,0.763011,0.723489,0.727452,0.811983,0.576559,0.469313,0.41429,0.352371,0.320321,0.306611,0.241201,0.250376,0.313859,0.331294,-1.20825,-1.00824,-1.55354,-1.1446,-0.284284,0.0658489,0.0644959,0.195984,0.291157,0.0662219,1.35626,1.13045,-1.32548,-1.42028,1.52746,1.22523,-1.40441,-1.28106,-1.62191,-1.69081
5363,0.812526,0.767107,0.82724,0.75828,0.401872,0.203329,0.687944,0.575685,0.297599,0.525926,0.749666,0.688605,0.69352,0.633437,0.156903,0.143851,0.963763,0.972908,0.286481,0.210645,-0.801591,-0.602436,-0.168932,0.241749,0.0315034,0.388562,-0.470957,-0.332111,0.824682,0.66948,-1.59951,-1.8225,0.169358,0.0715254,0.241315,-0.0540053,-0.630912,-0.511456,0.216829,0.148428
5364,0.394151,0.432639,0.437286,0.368683,0.452624,0.28777,0.465708,0.427881,0.117039,0.23987,0.648479,0.585012,0.178985,0.117403,0.242053,0.304205,0.397239,0.407391,0.0743014,0.0899959,-0.142857,0.0613163,0.38127,0.795236,0.562519,0.924839,-0.0942511,0.04632,0.628199,0.470667,2.07638,1.85269,-0.584239,-0.679278,0.284362,-0.0149964,-0.0746928,0.0431869,0.984148,0.911419
5365,0.141207,0.0981721,0.334912,0.265421,0.298256,0.117514,0.629188,0.592722,0.925595,1.04677,0.258882,0.192879,0.0854199,0.0779731,0.479397,0.464559,0.911863,0.922476,0.646232,0.664079,-0.748498,-0.498427,1.17195,1.58358,0.454543,0.81833,-0.597584,-0.451303,-0.925179,-1.09048,0.57293,0.342899,0.581873,0.489299,-0.823987,-1.1245,-0.450557,-0.306473,-0.834509,-0.90324
5366,0.419545,0.334274,0.578605,0.507539,0.10969,-0.0527417,0.164737,0.126064,0.64717,0.763172,0.758007,0.690359,0.0269328,0.0385427,0.0887092,0.0727626,0.836421,0.847532,0.444135,0.463339,-1.26701,-1.05817,0.980689,1.4789,-0.0108047,0.356248,0.427717,0.575371,-1.17347,-1.33439,-0.0965018,-0.323163,-1.05868,-1.15066,-0.104477,-0.409894,-0.773417,-0.656134,-0.235646,-0.309002
5367,0.715079,0.570376,0.139678,0.0697846,0.206991,0.0440624,0.897337,0.858539,0.252315,0.479576,0.316475,0.248806,0.124596,-0.000887577,0.288702,0.274602,0.489683,0.50267,0.788431,0.807661,-1.30631,-1.0974,0.961589,1.37422,-0.469258,-0.105835,-0.4397,-0.296075,0.927301,0.766558,0.529579,0.305169,0.395638,0.296294,0.186357,-0.12321,0.106709,0.224799,1.50666,1.43196
5368,0.84978,0.806477,0.728314,0.660634,0.599348,0.435981,0.122602,0.0842576,0.0765682,0.19598,0.866274,0.800491,0.0212639,-0.0403179,0.242069,0.228084,0.987449,0.998414,0.868661,0.889281,-0.542158,-0.339766,1.56289,1.97607,1.87319,2.23638,0.946835,1.08472,0.236589,0.0173529,-0.208969,-0.4369,0.897857,0.803319,-1.31317,-1.61512,-0.595105,-0.475772,0.00811018,-0.0603855
5369,0.32952,0.285836,0.710262,0.639975,0.782886,0.621768,0.209307,0.172391,0.445134,0.563646,0.655577,0.591302,0.692435,0.63241,0.659934,0.644652,0.220152,0.229395,0.344742,0.363292,-0.256743,-0.0568369,0.551201,0.96482,0.364949,0.724527,-1.30701,-1.16114,-0.645198,-0.731852,0.783391,0.559727,-0.608372,-0.696329,-0.810584,-1.11522,-0.284972,-0.172866,1.44049,1.37525
5370,0.0110203,-0.0333834,0.105802,0.034154,0.375722,0.216213,0.684949,0.649882,0.421325,0.446024,0.796394,0.731239,0.225392,0.166679,0.263026,0.248146,0.629193,0.639658,0.39404,0.410328,0.937132,1.14515,-0.699538,-0.293855,0.118317,0.480045,0.0677638,0.219652,-1.32031,-1.48106,1.13123,0.912351,-0.271179,-0.359281,-0.869232,-1.1683,-0.850691,-0.735275,0.0429219,-0.027362
5371,0.875778,0.833117,0.945672,0.871976,0.289085,0.130348,0.630434,0.612877,0.211558,0.328402,0.71611,0.565164,0.862547,0.803267,0.560937,0.54479,0.500044,0.608294,0.905574,0.923844,-1.34032,-1.13124,-0.641223,-0.231165,0.456,0.817822,-0.424314,-0.277971,-0.0690619,-0.231955,-0.519145,-0.735952,0.536932,0.373366,-0.511839,-0.806678,-0.470833,-0.353293,-0.00142901,-0.0133444
5372,0.668492,0.624272,0.608501,0.536901,0.806613,0.649254,0.738635,0.575872,0.423904,0.543658,0.464244,0.399089,0.516221,0.521799,0.144244,0.128298,0.565459,0.57693,0.0141484,0.0338431,-1.88775,-1.63756,-0.249946,0.154319,-0.361198,0.000471282,-0.675232,-0.447448,0.742175,0.585326,-0.920156,-1.1358,1.19767,1.10601,-1.33024,-1.62435,-1.03218,-0.915702,0.0703093,0.00067312
5373,0.0902527,0.0480225,0.896415,0.823345,0.333551,0.174278,0.572463,0.538867,0.892893,1.01148,0.0114538,-0.0522186,0.298275,0.240332,0.0545268,0.0375187,0.203344,0.298187,0.15147,0.170901,-2.35426,-2.14388,-0.460727,-0.0577946,0.719817,1.0757,-0.762825,-0.616924,0.376647,0.218363,-0.792629,-1.01329,1.47817,1.38157,-1.10227,-1.39985,0.746725,0.857245,-0.770112,-0.835402
5374,0.942064,0.900136,0.5238,0.473611,0.39676,0.236459,0.868724,0.834138,0.35163,0.467988,0.583472,0.518834,0.257883,0.223178,0.860745,0.846195,0.00803863,0.0194429,0.0575389,0.0770616,-0.0566066,0.153315,-1.41218,-1.00619,0.104057,0.425996,-0.507353,-0.360495,-0.542106,-0.696449,2.17972,1.95441,0.704936,0.614626,-0.214809,-0.517862,0.238769,0.355955,0.890934,0.828761
5375,0.25499,0.213409,0.195262,0.123877,0.0265504,-0.132885,0.108085,0.0748883,0.482411,0.585614,0.0615607,-0.00123859,0.262218,0.206023,0.274543,0.261142,0.817603,0.826979,0.395044,0.44263,0.187208,0.404473,-0.994129,-0.590042,-0.577772,-0.223714,-0.867366,-0.720303,0.10883,0.00561752,-0.977948,-1.20862,2.29698,2.20202,0.158255,-0.139151,-0.0297134,0.0864712,0.745322,0.686026
5376,0.618712,0.575878,0.939121,0.868996,0.218429,0.081111,0.291571,0.260392,0.585285,0.70324,0.808336,0.744889,0.900942,0.842611,0.716436,0.703379,0.963621,0.971423,0.787409,0.808199,-0.198349,0.0163532,0.566733,0.970101,0.418618,0.77578,0.342077,0.491432,0.861026,0.707685,0.312512,0.0770744,0.125655,0.0269597,-0.568547,-0.867694,1.48627,1.60918,-2.03817,-2.09382
5377,0.355128,0.312376,0.839832,0.684199,0.457364,0.295107,0.852648,0.823735,0.152127,0.269304,0.810497,0.74696,0.397782,0.341573,0.527243,0.516434,0.115724,0.123281,0.195709,0.217538,-1.32388,-1.11073,-0.539914,-0.134361,0.529942,0.882281,-1.64901,-1.50305,0.276757,0.127924,0.0437563,-0.232024,-0.617051,-0.650276,-0.603316,-0.907943,0.766223,0.893424,-1.52355,-1.57437
5378,0.874658,0.834335,0.568205,0.499402,0.97999,0.818576,0.0167374,-0.01359,0.385555,0.499891,0.320718,0.256703,0.92088,0.863868,0.604797,0.592851,0.805972,0.814834,0.772826,0.796872,-0.0458219,0.168942,2.73419,3.13889,1.33809,1.69768,-1.81792,-1.67655,-2.11049,-2.25904,-0.312483,-0.541122,-1.22684,-1.32751,0.892123,0.585942,0.473213,0.592677,-0.252471,-0.308306
5379,0.782189,0.74227,0.874515,0.805861,0.881376,0.717904,0.361278,0.329754,0.281544,0.392985,0.469862,0.331518,0.629276,0.616921,0.911981,0.899437,0.89137,0.877958,0.818745,0.755951,-0.911716,-0.697613,0.520919,0.919588,0.487832,0.850121,0.174873,0.322514,-1.02592,-1.18034,0.731139,0.501342,-0.506925,-0.605666,-0.361237,-0.660836,1.06567,1.19217,0.677135,0.619755
5380,0.115211,0.0760141,0.686266,0.691688,0.0442605,-0.117622,0.272025,0.316001,0.600095,0.647615,0.471447,0.406334,0.312514,0.369973,0.775701,0.763058,0.933144,0.941082,0.690688,0.71503,-0.876686,-0.663688,0.393394,0.799102,0.0311803,0.392587,1.2566,1.40907,0.836642,0.679761,0.280079,0.0529964,0.641034,0.549806,-0.193385,-0.555366,-3.35818,-3.23169,-1.94688,-1.99839
5381,0.0572699,0.0193452,0.646829,0.577516,0.213927,0.0531055,0.333477,0.302247,0.792121,0.902245,0.80915,0.745909,0.180037,0.123025,0.166879,0.152197,0.293916,0.300656,0.417346,0.43937,0.179273,0.3982,-0.904213,-0.505153,0.00635932,0.307935,-1.18624,-1.0398,0.511251,0.358558,1.27187,1.04962,3.15893,3.0721,-0.14421,-0.449897,0.626863,0.74972,-0.855925,-0.901691
5382,0.536293,0.496307,0.788967,0.721067,0.981894,0.819988,0.881314,0.849638,0.889401,1.00096,0.678079,0.611993,0.450493,0.390983,0.00967653,-0.00431811,0.740011,0.745855,0.447322,0.471275,0.197356,0.419496,-0.780559,-0.3819,-0.14368,0.223283,-2.62898,-2.48154,3.23757,3.08357,0.70557,0.479137,-0.459267,-0.551461,-1.22995,-1.52928,-1.89558,-1.77124,0.700853,0.658059
5383,0.726913,0.686687,0.041273,-0.0246869,0.781196,0.673039,0.615566,0.581711,0.513442,0.626932,0.235707,0.170439,0.715424,0.658942,0.624408,0.610595,0.44138,0.446687,0.933506,0.954976,-1.04561,-0.831302,1.55388,1.95107,1.39737,1.76921,-0.533458,-0.386909,0.178988,0.0316201,-0.113574,-0.339234,-0.510549,-0.596284,-0.219169,-0.522297,0.241319,0.453052,0.289608,0.241492
5384,0.310951,0.271324,0.244086,0.177774,0.687995,0.52609,0.636542,0.6141,0.528073,0.639863,0.150887,0.087305,0.119344,0.0623426,0.260845,0.248457,0.848891,0.852647,0.0635556,0.0873243,-2.661,-2.44663,-1.10279,-0.698945,-0.342161,0.0238644,-0.78661,-0.638631,0.0327519,-0.119481,1.01462,0.793643,0.157612,0.064938,1.14701,0.849997,2.55301,2.67735,0.790254,0.745722
5385,0.731928,0.694415,0.0229906,-0.0416053,0.903373,0.741415,0.678951,0.646488,0.923624,1.03758,0.956337,0.891416,0.994108,0.93554,0.151021,0.13688,0.148255,0.152241,0.532707,0.468433,0.23505,0.452027,-0.468153,-0.067862,0.218893,0.590922,0.472758,0.618937,-2.16908,-2.31532,-0.0910901,-0.31596,-1.28713,-1.37252,0.594492,0.293047,0.972551,1.09654,-2.33376,-2.37739
5386,0.0265218,-0.00895011,0.967777,0.90326,0.161711,0.000656201,0.98362,0.950906,0.836701,0.951833,0.514914,0.441652,0.084436,0.0255043,0.837414,0.822666,0.3821,0.384236,0.825464,0.849542,1.39631,1.60651,-1.16917,-0.769005,-0.534881,-0.163306,0.080477,0.229265,-1.26788,-1.41958,0.100459,-0.117886,0.130367,0.0459318,-1.21904,-1.51367,-0.246502,-0.120316,-0.919199,-0.958255
5387,0.143677,0.0315698,0.922168,0.810051,0.914704,0.751997,0.870789,0.838443,0.538069,0.623434,0.0560669,-0.00811218,0.699699,0.64168,0.773379,0.756912,0.274934,0.276956,0.860825,0.88626,-0.169468,0.0345119,0.712679,1.11648,0.230095,0.605384,2.80469,2.95681,-1.32566,-1.47922,-0.318894,-0.534218,-0.341247,-0.43119,1.2372,0.948079,-3.24184,-3.12303,-1.74244,-1.78002
5388,0.188603,0.0720896,0.780472,0.716843,0.335743,0.173168,0.277391,0.245019,0.178781,0.295035,0.657497,0.593357,0.659615,0.52412,0.458932,0.434891,0.610347,0.613388,0.217891,0.245597,-0.583361,-0.38077,1.22058,1.62603,-0.187786,0.192887,-0.76752,-0.617172,-1.68994,-1.84618,-0.14758,-0.366935,-0.401268,-0.490984,0.932208,0.634748,1.11107,1.22989,-0.583344,-0.620965
5389,0.150255,0.11261,0.179122,0.115303,0.0913454,-0.0712872,0.00786757,-0.0229081,0.0709684,0.188129,0.968498,0.903547,0.57841,0.40656,0.129178,0.11287,0.523543,0.495215,0.441688,0.414245,-1.00795,-0.796052,-0.192577,0.209634,-0.810216,-0.424468,0.70434,0.813706,-0.64949,-0.812712,1.40367,1.17972,0.309148,0.216057,-1.04871,-1.34222,-0.691789,-0.576493,0.798982,0.766868
5390,0.599718,0.560475,0.989053,0.927522,0.436485,0.314997,0.148053,0.116621,0.694583,0.812316,0.893971,0.830852,0.347018,0.288999,0.249642,0.234169,0.374433,0.377042,0.55674,0.582893,-0.539857,-0.329158,1.16078,1.56503,-2.91539,-2.53474,2.09424,2.24458,0.962877,0.800825,-1.02695,-1.24641,1.23027,1.13728,-1.57391,-1.86847,-0.142641,-0.126293,-0.0249528,-0.0548991
5391,0.190325,0.150544,0.631504,0.568308,0.865113,0.701281,0.920359,0.890798,0.470431,0.489877,0.329617,0.26648,0.707526,0.598606,0.795218,0.781983,0.593845,0.598714,0.397328,0.509655,-1.61827,-1.34797,-0.316693,0.0848444,-0.886552,-0.500805,0.489191,0.632151,-0.220276,-0.387532,-1.26963,-1.4932,0.0544433,-0.0351011,0.485844,0.1874,0.211806,0.323907,0.822871,0.796756
5392,0.975956,0.935971,0.477784,0.414811,0.778064,0.615416,0.0207082,-0.0106886,0.0490834,0.167438,0.966519,0.902459,0.966232,0.908214,0.596188,0.63907,0.00469362,0.00966575,0.408365,0.436417,-2.5728,-2.36678,-0.402012,0.0307892,1.71526,2.10299,-0.080401,0.0184361,0.519687,0.353312,1.11127,0.883742,0.785768,0.701963,-1.65602,-1.94691,0.903815,1.01731,-1.41823,-1.44042
5393,0.453966,0.41533,0.930634,0.869167,0.051784,-0.109745,0.494501,0.46232,0.523257,0.64041,0.422083,0.358041,0.696796,0.697972,0.509985,0.496156,0.847144,0.849479,0.580921,0.522068,-0.143408,0.0577153,-0.422709,-0.0232659,-0.55108,-0.169323,-0.733695,-0.595278,0.00841885,-0.164723,-1.52391,-1.75433,-0.974926,-1.06679,-1.86741,-2.15196,0.735148,0.855032,-0.225981,-0.249195
5394,0.283609,0.243333,0.457009,0.395524,0.767123,0.606242,0.58666,0.555992,0.0156065,0.132211,0.768536,0.626553,0.487291,0.487731,0.934688,0.922771,0.538469,0.54042,0.577663,0.607719,0.404996,0.539109,-1.44905,-1.05107,-0.106607,0.276004,-0.115686,0.0267638,0.222764,0.055217,1.16246,0.93243,-0.168772,-0.255122,0.710185,0.429282,1.65896,1.7826,-0.834134,-0.861695
5395,0.395809,0.290198,0.541812,0.479887,0.876798,0.718036,0.290032,0.341424,0.405241,0.528694,0.957989,0.895065,0.337602,0.27749,0.695495,0.684956,0.644614,0.741877,0.526847,0.508761,0.816717,1.0205,0.904953,1.30015,-0.864032,-0.478223,-1.57984,-1.44444,-0.371348,-0.535156,-1.69498,-1.91882,-0.44114,-0.529029,-1.80731,-2.08227,-0.195952,-0.0732351,0.991684,0.960023
5396,0.375768,0.337063,0.329254,0.292346,0.27178,0.113655,0.15997,0.126857,0.809268,0.925177,0.920703,0.857737,0.311733,0.281877,0.24293,0.234133,0.942056,0.943334,0.382179,0.409802,-0.629629,-0.428059,1.03099,1.4234,-0.569291,-0.186151,-0.353618,-0.217343,-0.954535,-1.12553,-0.372602,-0.602695,-0.991575,-1.08253,0.0980468,-0.184096,2.36843,2.49568,-0.395312,-0.427887
5397,0.688583,0.648701,0.165441,0.104806,0.238852,0.0853778,0.314589,0.29462,0.618234,0.733119,0.349706,0.287965,0.344949,0.286263,0.882344,0.873811,0.677313,0.640693,0.940973,0.968675,1.18106,1.37859,-0.789903,-0.403676,-0.0681276,0.317372,-0.0173056,0.115662,-0.0871683,-0.261393,-1.36382,-1.59091,-0.373985,-0.481038,-0.433866,-0.710346,0.343877,0.465438,2.18886,2.15328
5398,0.748572,0.708954,0.733617,0.671288,0.153943,0.0571001,0.497279,0.462382,0.667732,0.687777,0.868299,0.805292,0.910809,0.852773,0.368886,0.362541,0.33685,0.338051,0.806773,0.930044,-1.2653,-1.07018,-0.0552363,0.335963,-1.03958,-0.657521,-1.20016,-1.06335,0.41734,0.249017,0.813745,0.581324,0.217205,0.120451,0.0610741,-0.210442,-0.241101,-0.113032,-0.382332,-0.415822
5399,0.227569,0.188313,0.656752,0.593494,0.189369,0.0288225,0.219254,0.184654,0.526172,0.642436,0.483011,0.417839,0.626376,0.54711,0.755496,0.749152,0.723759,0.723801,0.862482,0.891412,0.765632,0.966582,0.355928,0.752114,0.796727,1.17242,0.980415,1.10894,0.342434,0.173585,0.669351,0.441997,0.053404,-0.0464128,0.206869,-0.0629525,1.23288,1.36285,1.33884,1.308
5400,0.499624,0.459454,0.268199,0.203897,0.965185,0.807036,0.818824,0.781499,0.836462,0.954453,0.833302,0.768725,0.297757,0.241448,0.568188,0.562207,0.856217,0.857965,0.365928,0.396005,-0.228516,-0.0236631,-0.555556,-0.0650197,0.914217,1.29324,-0.866611,-0.73733,1.40676,1.23699,-0.484556,-0.712981,0.533198,0.430198,-1.54608,-1.81758,1.29942,1.43461,-0.324966,-0.35329
5401,0.537548,0.495743,0.743251,0.677561,0.523512,0.367813,0.674889,0.639965,0.0458007,0.164708,0.454551,0.3919,0.294807,0.146889,0.885294,0.878546,0.675461,0.740835,0.411397,0.44304,-0.096275,0.104158,-1.27316,-0.882154,-0.397215,-0.0186502,0.143835,0.275167,-1.50205,-1.66673,0.239805,0.0690067,0.159518,0.0630206,0.901203,0.627074,0.00428508,0.136593,0.795948,0.774068
5402,0.167435,0.12599,0.550084,0.542167,0.784507,0.585014,0.93463,0.900793,0.46576,0.634662,0.765505,0.654141,0.106838,0.0523292,0.088042,0.0818626,0.662012,0.623705,0.915004,0.946998,1.01557,1.21167,-0.342039,0.055406,0.584217,0.964668,0.242573,0.377734,0.783492,0.619727,1.0732,0.850994,0.725151,0.599425,0.508314,0.239631,1.7192,1.84695,1.08014,1.05216
5403,0.612297,0.484101,0.472548,0.406773,0.95804,0.802216,0.171708,0.137258,0.985709,1.10462,0.980106,0.916381,0.239318,0.117057,0.579735,0.573148,0.38492,0.506575,0.623697,0.656188,-0.522777,-0.329098,-1.56896,-1.17236,-0.575071,-0.195233,-0.687844,-0.555785,0.989274,0.823477,-1.00006,-1.22909,1.22898,1.13583,0.934114,0.662838,-1.04788,-0.92752,0.400099,0.366735
5404,0.883327,0.842211,0.935459,0.86985,0.945861,0.788728,0.756293,0.720175,0.928282,1.04941,0.784711,0.722044,0.236601,0.181784,0.648642,0.673973,0.387697,0.389445,0.820988,0.853482,-0.841617,-0.64063,0.928717,1.31827,0.933875,1.32088,-0.469788,-0.345142,0.884859,0.71683,-0.457311,-0.747666,1.38063,1.28886,2.13884,1.86644,-2.22379,-2.10034,-0.79291,-0.822266
5405,0.894036,0.852517,0.218793,0.154945,0.405567,0.249658,0.400159,0.363161,0.337222,0.460694,0.0501627,-0.012558,0.134364,0.0770163,0.676049,0.774799,0.44046,0.443601,0.43946,0.473076,0.54262,0.748098,-0.492807,-0.0981296,-0.947277,-0.56542,1.94074,2.06686,-1.24175,-1.41537,-0.0928613,-0.26624,-0.0799016,-0.148145,-1.82491,-2.09731,1.20132,1.32176,-1.50039,-1.52427
5406,0.489983,0.454767,0.620899,0.47718,0.159836,0.00520264,0.409806,0.41535,0.746284,0.868654,0.496366,0.386524,0.317132,0.257774,0.880273,0.875624,0.832517,0.834491,0.921281,0.956777,-0.656123,-0.455895,0.252239,0.641509,-0.125016,0.279532,-0.665504,-0.534834,-0.429187,-0.565317,0.444219,0.215186,-1.49985,-1.58515,1.17417,0.899951,-1.75214,-1.62317,0.888965,0.867228
5407,0.0976329,0.0570169,0.863679,0.799414,0.923002,0.767094,0.505256,0.467538,0.448013,0.572112,0.847467,0.785606,0.275966,0.21441,0.236831,0.234673,0.0669395,0.0699181,0.970517,0.908519,0.739986,0.947619,-0.857095,-0.462953,0.736834,1.12448,1.11256,1.24313,0.449807,0.284735,-1.03112,-1.26567,-0.380624,-0.464754,-0.276971,-0.547099,1.05883,1.18187,0.167869,0.149902
5408,0.168761,0.194605,0.705961,0.640885,0.117163,-0.0409812,0.942309,0.906205,0.534133,0.583606,0.176822,0.115158,0.657649,0.595865,0.279028,0.21671,0.0860587,0.0897033,0.826598,0.86026,0.893238,1.10558,0.00159702,0.397632,-0.478284,-0.097071,0.445394,0.575904,0.533424,0.366921,0.0617615,-0.17843,0.224793,0.134941,-0.928693,-1.19803,-0.394065,-0.272893,-0.0972005,-0.088078
5409,0.353174,0.332193,0.231961,0.167242,0.736062,0.577017,0.647101,0.613692,0.551341,0.595101,0.0676594,0.00621804,0.108974,0.0490099,0.198525,0.198746,0.379303,0.385614,0.988505,1.02202,-0.700434,-0.481961,-0.671362,-0.273597,0.498816,0.886248,-1.01063,-0.880431,-0.0870405,-0.223451,-1.29635,-1.5363,3.02013,2.92923,0.75507,0.483597,-0.837328,-0.712798,-0.38979,-0.326058
5410,0.510397,0.469781,0.662824,0.596813,0.663091,0.445512,0.831873,0.799196,0.481952,0.606595,0.428857,0.366311,0.239478,0.203179,0.760523,0.760982,0.676422,0.681525,0.177883,0.212419,-0.580147,-0.370514,-0.183274,0.250505,0.258613,0.641766,-0.0296065,0.100926,-0.65062,-0.813824,-0.797969,-1.0449,0.514948,0.421002,0.637705,0.369747,0.563725,0.686925,-0.544443,-0.564038
5411,0.955554,0.917646,0.337491,0.271289,0.471673,0.314007,0.169363,0.135903,0.374474,0.49969,0.265103,0.203692,0.418873,0.357348,0.882241,0.882282,0.582885,0.58606,0.964521,0.99915,0.632006,0.843772,0.373409,0.774607,1.22954,1.60974,-0.716826,-0.5819,-0.547858,-0.716055,1.70201,1.44859,-0.548249,-0.641605,-1.85724,-2.12674,-0.00136543,0.124516,0.666206,0.639636
5412,0.0968675,0.0597447,0.499211,0.435023,0.577496,0.428952,0.37284,0.252961,0.893833,1.01862,0.790751,0.730369,0.0911303,0.0313786,0.415354,0.503283,0.998112,1.00158,0.485061,0.518587,-0.994063,-0.785621,-0.602232,-0.204377,1.99108,2.37843,1.43026,1.56155,-1.50379,-1.67764,-0.535738,-0.787865,-0.846526,-0.946684,-0.747809,-1.01383,-0.347306,-0.223421,1.18651,1.15909
5413,0.237058,0.200099,0.00704597,-0.0578918,0.629448,0.543896,0.403753,0.370019,0.66735,0.791282,0.390357,0.328804,0.921368,0.860783,0.125701,0.124285,0.0461381,0.0502831,0.994433,1.02709,-0.259397,-0.0443475,-0.938806,-0.538943,1.25729,1.64047,1.42995,1.55851,-0.11171,-0.291577,0.320488,0.0685218,0.303947,0.208789,-0.150329,-0.337163,-1.03897,-0.908566,0.205744,0.185958
5414,0.928851,0.890819,0.39924,0.384035,0.807953,0.658841,0.12107,0.0870687,0.21948,0.343271,0.239757,0.175848,0.121078,0.0615652,0.0907068,0.0881698,0.304825,0.296777,0.778722,0.811789,-0.588842,-0.370012,-0.125795,0.276083,2.55085,2.92758,0.532938,0.658261,-0.012449,-0.193808,-0.543382,-0.795865,1.03302,0.930634,0.60453,0.339501,-0.0576563,0.0649101,0.108266,0.0881946
5415,0.139708,0.102403,0.890899,0.825961,0.931451,0.773785,0.136879,0.0764356,0.019665,0.141268,0.655448,0.590422,0.843654,0.78515,0.851444,0.850602,0.540034,0.543271,0.81264,0.843694,0.866829,1.08187,-0.861026,-0.455929,0.134811,0.512093,1.38438,1.51435,-0.312436,-0.498505,-1.17622,-1.43141,-0.420688,-0.520784,0.559506,0.299252,-0.932728,-0.808873,-0.882093,-0.900754
5416,0.850145,0.813034,0.628637,0.564867,0.815428,0.55858,0.0978615,0.0658025,0.121521,0.245067,0.715965,0.553358,0.512251,0.454746,0.0670573,0.0639256,0.384798,0.389674,0.557119,0.588891,-0.331951,-0.122124,-1.00466,-0.605619,0.85093,1.23439,1.30868,1.41055,0.121924,-0.0653575,-0.323325,-0.575018,0.657326,0.551698,-0.180066,-0.444258,0.981954,1.10603,0.948717,0.938481
5417,0.587744,0.617671,0.100377,0.0374556,0.499593,0.343375,0.908925,0.877146,0.636222,0.759188,0.618224,0.516294,0.726645,0.671211,0.0164852,0.0126354,0.852975,0.860225,0.982077,1.01318,-0.544765,-0.327578,0.298101,0.704038,-1.10829,-0.730683,1.18062,1.30674,-0.160448,-0.353767,-0.636784,-0.883736,-0.794626,-0.89972,-1.70026,-1.96852,-0.198005,-0.0667897,0.514695,0.50709
5418,0.458746,0.422308,0.698164,0.633761,0.693055,0.5387,0.552742,0.520133,0.227881,0.349999,0.542036,0.47923,0.571038,0.51672,0.975325,0.972829,0.382071,0.390708,0.507436,0.537068,0.276768,0.412762,-0.160783,0.247263,-0.172183,0.205825,0.779414,0.90158,0.685256,0.495179,-1.37173,-1.62581,-0.223188,-0.329751,0.110039,-0.163269,-1.71737,-1.58497,1.07659,1.07307
5419,0.936594,0.89927,0.858643,0.792711,0.28727,0.133146,0.960843,0.929505,0.770759,0.894367,0.880069,0.818805,0.62136,0.565214,0.811155,0.810069,0.624167,0.632201,0.302018,0.383969,0.937605,1.1531,0.105894,0.510481,-0.286594,0.0858672,-0.827715,-0.710853,-0.849195,-1.03597,1.49294,1.24139,1.41747,1.30402,1.10088,0.825904,-1.45793,-1.32967,0.792943,0.792906
5420,0.386952,0.348135,0.580184,0.512688,0.839794,0.685662,0.94603,0.912332,0.987087,1.10962,0.705426,0.678515,0.897751,0.841312,0.880529,0.828649,0.163908,0.172102,0.20262,0.230869,-0.118137,0.101873,-0.774637,-0.376485,0.639861,1.00728,0.691269,0.812377,-0.166487,-0.355959,-0.20623,-0.452705,-0.586891,-0.699534,-0.419595,-0.698361,-0.96382,-0.839271,-0.724527,-0.730949
5421,0.496198,0.458843,0.540877,0.473316,0.826997,0.587026,0.443515,0.409403,0.435747,0.555835,0.601485,0.538225,0.407922,0.350202,0.847762,0.847228,0.098907,0.106309,0.230709,0.373438,0.517109,0.736554,-0.0210552,0.37802,0.57892,0.946624,0.780257,0.898596,1.07514,0.893143,0.238352,-0.00636311,-1.93328,-2.04397,0.163551,-0.121986,-1.02107,-0.89239,0.174551,0.167607
5422,0.0282703,-0.00697776,0.140852,0.0738759,0.636801,0.488391,0.743758,0.709794,0.878376,0.999632,0.719264,0.657843,0.160913,0.104138,0.131033,0.132749,0.625408,0.631527,0.455631,0.516006,0.227915,0.434163,-0.103039,0.303555,0.755677,1.12975,1.53213,1.6472,0.395852,0.210116,1.28555,1.0361,1.38714,1.27794,0.0114849,-0.279946,0.385305,0.507333,-0.279572,-0.292487
5423,0.167346,0.133376,0.582751,0.447755,0.543889,0.389756,0.175659,0.14161,0.673509,0.793145,0.543133,0.533381,0.769982,0.715509,0.700476,0.700259,0.904501,0.912704,0.63035,0.658575,-0.0820344,0.131772,2.6039,3.00794,-0.508895,-0.135227,-0.190286,-0.077423,-1.1746,-1.36653,-0.927182,-1.16976,0.730661,0.619271,-0.913092,-1.20529,-0.768289,-0.650411,0.62882,0.620245
5424,0.0356837,9.72339e-05,0.889589,0.821634,0.264898,0.121856,0.509026,0.475364,0.997986,1.11556,0.547511,0.408918,0.489216,0.434592,0.0306402,0.0283615,0.55462,0.563092,0.98438,1.01246,1.87966,2.09037,0.802517,1.21486,-0.00161756,0.368296,0.0445864,0.16468,0.737364,0.54084,-0.81391,-1.06297,1.76225,1.64642,1.43515,1.13574,0.690355,0.812213,-0.110697,-0.126382
5425,0.59455,0.475111,0.601924,0.531475,0.00671649,-0.146045,0.290062,0.257841,0.216243,0.336032,0.445715,0.284455,0.543713,0.54557,0.72568,0.724805,0.646868,0.65599,0.504032,0.531895,0.570841,0.780326,-0.277488,0.140763,1.07139,1.44353,-1.62119,-1.49691,-2.08034,-2.27901,-0.474639,-0.728445,0.372264,0.257748,-0.786672,-1.08214,-0.106964,0.016647,-0.321596,-0.330726
5426,0.985712,0.950125,0.930466,0.857633,0.916475,0.763725,0.917938,0.885008,0.0853878,0.204408,0.221412,0.159992,0.712868,0.656549,0.33222,0.408719,0.945622,0.955941,0.928206,0.956183,1.02884,1.23078,-0.527851,-0.103141,0.365963,0.736222,-0.469933,-0.326378,-0.938788,-1.07942,0.859171,0.603927,-0.0334874,-0.205343,0.0205388,-0.276276,0.762821,0.882937,-1.05995,-1.06239
5427,0.226771,0.189146,0.0192246,-0.0526696,0.779506,0.567305,0.895425,0.863103,0.729455,0.84931,0.585204,0.524311,0.217431,0.160746,0.094162,0.0926343,0.959876,0.970909,0.280544,0.310024,-1.15187,-0.949894,-0.40651,0.020112,-0.785504,-0.406692,0.715248,0.844157,0.318829,0.120162,0.594818,0.342774,-0.559183,-0.668434,1.38375,1.08134,-0.847379,-0.728854,0.969764,0.972949
5428,0.579221,0.442553,0.52146,0.450142,0.523636,0.370885,0.594553,0.477615,0.852462,0.973705,0.108177,0.0493471,0.704225,0.647487,0.77031,0.768813,0.177431,0.186032,0.602835,0.633759,-0.36317,-0.154656,-0.0274203,0.405596,-0.143907,0.238176,-0.600555,-0.47235,1.72111,1.52069,-1.58428,-1.83229,1.3746,1.26262,-0.446232,-0.756384,0.509701,0.62663,-0.452821,-0.444414
5429,0.734179,0.695961,0.191255,0.196838,0.617904,0.467689,0.124165,0.0921268,0.148571,0.268216,0.21932,0.225974,0.585741,0.54613,0.594415,0.591975,0.0610229,0.139006,0.274474,0.307439,0.438463,0.640582,1.45732,1.88531,0.746307,1.13005,-0.51953,-0.386131,-1.40132,-1.59698,-0.827849,-1.08271,1.56301,1.44516,0.629522,0.325273,-1.02147,-0.907782,0.126495,0.0899373
5430,0.232194,0.194832,0.0153296,-0.0564655,0.19679,0.0480232,0.318577,0.288418,0.104626,0.231984,0.460859,0.402601,0.503357,0.444773,0.0935291,0.0907069,0.0814494,0.0919786,0.25464,0.287932,2.43496,2.64568,0.53959,0.968518,-0.489623,-0.106243,0.610062,0.749146,0.0518992,-0.135982,-0.54138,-0.793473,-0.0483303,-0.164786,-0.345702,-0.647047,0.328076,0.447702,0.621128,0.624288
5431,0.531526,0.505242,0.82251,0.750539,0.168672,0.0200144,0.952994,0.921111,0.0766567,0.195751,0.827877,0.76692,0.652165,0.692004,0.499369,0.497152,0.261734,0.287716,0.949902,0.982196,-0.896623,-0.692114,0.959155,1.38467,-0.350623,0.0316208,-0.572408,-0.42987,1.2594,1.06635,-0.0505131,-0.302072,0.0557766,-0.0564887,-0.8091,-1.11218,0.583816,0.703007,0.48705,0.494957
5432,0.8545,0.815651,0.0501368,-0.0222772,0.841375,0.695225,0.819325,0.884107,0.409415,0.527931,0.203226,0.142332,0.996086,0.939236,0.282817,0.366194,0.473897,0.483453,0.537686,0.570724,-1.58515,-1.37412,0.0974033,0.528765,-0.442997,-0.158913,-0.550231,-0.403969,0.443927,0.258199,-0.373532,-0.62488,0.440024,0.325957,0.793404,0.491961,-1.18009,-1.05523,1.84726,1.85361
5433,0.0563136,0.0168146,0.440697,0.367705,0.461181,0.392735,0.833617,0.847102,0.984407,1.10222,0.0565909,-0.00568543,0.581191,0.523226,0.225472,0.235236,0.169221,0.179603,0.885477,0.920329,-0.442356,-0.235705,-0.442063,-0.00466881,-0.729086,-0.349447,-0.765931,-0.62334,0.0553507,-0.124124,-0.92093,-1.16639,0.364588,0.157626,-2.06053,-2.35826,-0.0841597,-0.0291744,-0.0169123,-0.0094704
5434,0.751592,0.712481,0.373989,0.298663,0.235311,0.0902451,0.844337,0.810097,0.732062,0.850331,0.97828,0.916132,0.931629,0.87521,0.104944,0.104279,0.996981,1.0081,0.57936,0.61514,-1.61245,-1.40817,-0.289647,0.142708,1.96304,2.34166,0.212603,0.358018,0.427989,0.250388,0.231696,-0.0193368,0.107356,-0.0107039,0.566135,0.274534,0.87281,0.99688,0.932561,0.935453
5435,0.349274,0.401741,0.775063,0.6987,0.889699,0.744692,0.226611,0.192445,0.183875,0.301825,0.668234,0.627045,0.404278,0.348383,0.298558,0.250592,0.142059,0.153871,0.559767,0.595634,0.867948,1.06568,-0.152404,0.290085,0.504656,0.890957,0.497899,0.646436,-0.0816194,-0.253739,-0.749768,-1.00755,0.472971,0.357824,-0.190837,-0.483443,-1.14686,-1.01943,-0.754276,-0.75675
5436,0.130356,0.0910016,0.453773,0.495751,0.0495489,-0.0957611,0.977841,0.945042,0.706269,0.825344,0.449978,0.337958,0.715001,0.645937,0.395362,0.396905,0.103035,0.114229,0.741887,0.777959,-0.199802,-0.0018151,-0.50574,-0.0598803,-1.38416,-0.995343,0.192374,0.333427,-0.220135,-0.391233,-0.463654,-0.718313,0.264767,0.116041,-0.32762,-0.700634,0.0970249,0.221507,0.382209,0.385837
5437,0.888742,0.850843,0.303794,0.292803,0.747023,0.599744,0.607338,0.600593,0.792287,0.909183,0.112178,0.0488717,0.998151,0.94349,0.0803818,0.0804123,0.413218,0.425011,0.0438507,0.0803019,0.00861428,0.201456,1.65618,2.0971,-1.05069,-0.640171,0.765947,0.910041,0.0891997,-0.0818589,0.266092,0.0147273,-0.0141905,-0.125742,-0.627882,-0.917825,-1.41643,-1.29668,-0.41409,-0.406827
5438,0.0139401,-0.0249215,0.166218,0.0898551,0.785383,0.636112,0.288076,0.256144,0.332064,0.450452,0.894701,0.831957,0.495586,0.442451,0.706396,0.705858,0.238497,0.251748,0.221873,0.218085,0.756726,0.942729,0.0278854,0.460884,-0.675404,-0.285,-0.0552807,0.0864847,-0.512154,-0.675571,0.401143,0.152011,0.949077,0.841606,0.186081,-0.0967737,-0.0149499,0.103047,-0.343287,-0.338603
5439,0.614211,0.575831,0.275439,0.198618,0.0800173,-0.0681799,0.511799,0.481114,0.186042,0.304043,0.986112,0.880227,0.995333,0.944767,0.775086,0.705821,0.449906,0.462344,0.211806,0.355868,-0.957895,-0.768455,0.441632,0.877035,0.143599,0.530398,0.301415,0.450922,-0.553535,-0.717877,-0.358669,-0.606998,-1.00828,-1.11409,0.139912,-0.18232,-0.847822,-0.722998,-0.494761,-0.497689
5440,0.440031,0.338817,0.0149174,-0.0624765,0.208026,0.0580312,0.265715,0.23318,0.731289,0.848412,0.993561,0.928496,0.822765,0.768205,0.661686,0.705784,0.985591,0.996937,0.455594,0.493651,-0.177429,0.0184202,-1.74001,-1.31109,-1.5121,-1.12152,-1.14807,-1.00541,1.34397,1.17621,-0.145332,-0.392635,0.290832,0.179162,0.0181121,-0.267866,-0.061703,0.0628875,0.517877,0.508349
5441,0.140592,0.101803,0.597815,0.518484,0.63289,0.482199,0.906927,0.875207,0.431752,0.55187,0.486922,0.423123,0.640234,0.591642,0.539482,0.705747,0.452592,0.462889,0.89174,0.928284,-0.216361,-0.0208145,0.180033,0.604433,0.049224,0.441672,-0.256477,-0.117554,-0.691182,-0.8582,-0.393602,-0.639428,0.405987,0.287459,-0.542484,-0.824816,0.253453,0.381466,-0.632848,-0.635787
5442,0.388201,0.347765,0.502311,0.42452,0.166404,0.0177708,0.421806,0.388293,0.509618,0.63062,0.627297,0.528508,0.987762,0.939344,0.674228,0.70571,0.642827,0.653384,0.542661,0.577202,0.00821041,0.198073,-0.300065,0.0549419,2.59312,2.98736,0.403054,0.537445,-0.974992,-1.14661,-0.950425,-1.19502,-0.592777,-0.714345,-0.210137,-0.49293,-0.299215,-0.165363,-0.940094,-0.946515
5443,0.410283,0.368202,0.80502,0.64463,0.398172,0.191701,0.814652,0.78184,0.186472,0.308243,0.695357,0.633893,0.741849,0.657876,0.706211,0.705673,0.417857,0.429931,0.530946,0.566962,-0.632398,-0.437862,-0.924117,-0.494549,0.159802,0.559684,0.0303248,0.144699,0.254433,0.0821342,1.28613,1.04259,0.848266,0.732608,1.226,0.94151,0.466134,0.604239,0.637066,0.626536
5444,0.023764,-0.017366,0.940505,0.864741,0.515929,0.365632,0.392332,0.360488,0.491315,0.697077,0.426884,0.426279,0.425672,0.376408,0.969983,0.971276,0.633585,0.646028,0.840325,0.87474,0.154427,0.349014,-1.12353,-0.692122,-0.232729,0.162895,-0.38015,-0.248047,1.47811,1.31088,-0.336846,-0.57394,-0.329691,-0.439772,-1.48709,-1.772,-0.982436,-0.850525,-0.553982,-0.562465
5445,0.0594272,0.00736335,0.121513,0.0446287,0.506854,0.357102,0.279552,0.197936,0.962513,1.08591,0.270292,0.218665,0.769868,0.71839,0.134938,0.138629,0.374455,0.387218,0.353616,0.388796,0.319773,0.506974,-0.511688,-0.0762045,1.18559,1.58723,0.819071,0.948255,-0.253472,-0.419456,-0.57722,-0.820732,0.577477,0.465003,0.262248,-0.0275593,-0.247005,-0.110093,2.66215,2.65613
5446,0.0912114,0.0320927,0.0277947,-0.0493357,0.041126,-0.107327,0.0664801,0.0353843,0.869258,0.91445,0.0705488,0.0110511,0.564141,0.513268,0.826078,0.829943,0.490915,0.501781,0.995407,1.03214,-1.32902,-1.14067,-0.712763,-0.273777,0.241861,0.647502,-0.645847,-0.522946,-0.905859,-1.07381,0.161291,-0.0876917,1.16247,1.05003,-0.695121,-0.983823,1.90177,2.0399,1.01457,1.0096
5447,0.0956358,0.056822,0.866714,0.788486,0.580529,0.430316,0.538161,0.508392,0.619378,0.742989,0.222009,0.160847,0.00955169,-0.0394765,0.854474,0.860158,0.897893,0.907741,0.941158,0.978189,-0.06068,0.123583,0.236572,0.678978,-0.128197,0.224031,-1.12785,-1.00411,-0.0417673,-0.209672,0.360375,0.110382,0.140399,0.033358,2.41886,2.13479,-0.879533,-0.734566,0.22045,0.21694
5448,0.582902,0.543549,0.738182,0.659353,0.0484912,-0.103499,0.47474,0.379759,0.87697,0.99984,0.777132,0.717127,0.0533982,-0.0338487,0.341736,0.348887,0.0675334,0.079306,0.349144,0.387527,-0.487243,-0.295725,-0.348845,0.100055,-0.607924,-0.19944,-0.537029,-0.41199,-0.665345,-0.834797,0.775611,0.522048,-1.33899,-1.45029,-1.05179,-1.34068,-0.511926,-0.36894,-3.17478,-3.17666
5449,0.366994,0.314195,0.018063,-0.0605479,0.582021,0.430041,0.281477,0.251126,0.727772,0.848885,0.250835,0.192871,0.122928,-0.0282209,0.821801,0.830917,0.174975,0.156759,0.880164,0.917026,-1.27589,-1.08685,-0.449039,-0.00541517,0.825542,1.24106,0.462823,0.58522,0.547715,0.383102,0.434699,0.183632,-1.07743,-1.19072,-0.338639,-0.664016,-0.944239,-0.808845,-0.296703,-0.297608
5450,0.123829,0.084842,0.803637,0.726399,0.22127,0.0704184,0.636799,0.605017,0.299658,0.420418,0.0518836,-0.00589788,0.0396355,-0.0225931,0.336414,0.344749,0.223344,0.234213,0.804659,0.842928,-0.378808,-0.191733,-0.861359,-0.415896,-0.428807,-0.00909702,1.01761,1.14675,0.179544,0.01614,0.902349,0.645201,0.730301,0.61353,0.308255,0.0126474,-0.341061,-0.209357,0.196286,0.191412
5451,0.55978,0.522858,0.188606,0.109847,0.820987,0.668126,0.644175,0.670068,0.366859,0.555409,0.728504,0.671074,0.0320629,-0.0169653,0.282642,0.37597,0.575073,0.585496,0.237058,0.277336,-0.643732,-0.458289,-2.15632,-1.7063,0.251716,0.604384,0.752177,0.880062,1.02617,0.865086,-1.25416,-1.51191,-0.270655,-0.388274,-0.317325,-0.606387,-0.538694,-0.402255,1.03413,1.02871
5452,0.412818,0.404175,0.517218,0.440713,0.755713,0.603085,0.766139,0.735118,0.531383,0.6904,0.83156,0.77523,0.758985,0.711693,0.399762,0.40719,0.32539,0.336976,0.201311,0.243316,0.256717,0.436826,0.699031,1.1425,0.799618,1.21786,-0.90489,-0.78153,0.54268,0.378305,0.614623,0.357664,-0.416697,-0.457793,-0.346583,-0.541738,-0.44042,-0.373685,0.189217,0.176153
5453,0.319836,0.285492,0.570463,0.494515,0.26261,0.108804,0.52454,0.491986,0.70593,0.825391,0.0368983,-0.020645,0.681993,0.730731,0.807526,0.813635,0.370762,0.470097,0.484778,0.526673,0.00895773,0.274285,1.18216,1.61874,0.876145,1.29509,0.969342,1.09029,-0.605291,-0.765362,-0.35453,-0.614794,-0.411721,-0.527311,-0.194049,-0.477088,-0.484459,-0.345116,-0.220517,-0.240413
5454,0.65672,0.622591,0.915215,0.840691,0.513166,0.359373,0.666079,0.690776,0.510497,0.62827,0.42196,0.364166,0.795783,0.74977,0.0547805,0.0619275,0.590105,0.603218,0.365369,0.365473,-0.0721653,0.111744,-0.67836,-0.241108,0.452972,0.868226,0.00176916,0.127228,-2.01313,-2.17354,0.118368,-0.13755,1.10763,0.99702,0.653398,0.37506,0.00242291,0.14528,1.41151,1.39303
5455,0.039352,0.00648617,0.334694,0.259657,0.0911137,-0.0602929,0.923183,0.889565,0.568368,0.685298,0.425662,0.366237,0.513911,0.468853,0.785519,0.794475,0.840803,0.786888,0.164318,0.204274,0.535678,0.715283,0.639524,1.08308,1.28603,1.70023,1.33571,1.46156,-0.0439294,-0.198715,-0.248473,-0.506518,0.29949,0.184764,0.250078,-0.028698,-1.17141,-1.02753,0.930977,0.91757
5456,0.669734,0.637168,0.85362,0.777429,0.234669,0.0816593,0.558274,0.522756,0.0596997,0.1771,0.822287,0.760458,0.0115708,-0.0321861,0.610245,0.704775,0.958993,0.970558,0.218151,0.256947,0.117176,0.295975,1.15625,1.60712,-0.402437,0.017196,0.065833,0.190182,-0.649958,-0.809338,-0.243814,-0.547452,-0.0476012,-0.195306,1.14281,0.868078,-1.59433,-1.4519,1.65437,1.63557
5457,0.551067,0.518502,0.370864,0.294139,0.130763,-0.0243846,0.964784,0.927238,0.378769,0.494374,0.107305,0.044858,0.0612579,0.0163082,0.61831,0.615075,0.820087,0.832154,0.548494,0.585826,-1.45105,-1.27602,-0.454469,0.00277945,-0.23898,0.198699,2.91813,3.04811,0.453159,0.298782,-0.326175,-0.588386,-0.461597,-0.575376,0.965526,0.694306,-0.0561191,0.0846182,-2.00486,-2.02367
5458,0.0743363,0.0428538,0.350599,0.27348,0.366498,0.210986,0.874025,0.808085,0.69372,0.811648,0.320756,0.257944,0.673846,0.62768,0.51642,0.525376,0.223745,0.237922,0.573655,0.704555,0.171674,0.346851,-0.812061,-0.361634,-0.0416871,0.380201,1.46639,1.59177,0.0456764,-0.113574,0.155221,-0.122055,0.540552,0.424492,1.38518,1.11751,0.171945,0.309846,-1.09696,-1.11093
5459,0.6634,0.634059,0.85334,0.776292,0.171811,0.059327,0.72393,0.688933,0.158211,0.278502,0.0185336,-0.0457553,0.00612553,-0.0390915,0.155878,0.163238,0.127962,0.142457,0.783954,0.823284,2.73229,2.90017,1.60499,2.05646,-0.183729,0.245252,0.394711,0.608214,-0.713754,-0.876497,0.607183,0.344275,0.23879,0.119414,-1.38848,-1.6617,-0.273785,-0.130059,2.01894,2.0086
5460,0.0462331,0.0179541,0.415101,0.338537,0.0637724,-0.0923317,0.0312411,-0.00318423,0.0314335,0.152165,0.970006,0.906772,0.940298,0.894561,0.519612,0.526123,0.842402,0.858912,0.28848,0.327876,0.584853,0.753478,-0.237876,0.213399,-1.57663,-1.14596,-0.504907,-0.375346,-0.609106,-0.764804,1.53859,1.27874,-1.63152,-1.75584,-0.268521,-0.548787,0.641677,0.781224,0.650218,0.637051
5461,0.858263,0.830233,0.273905,0.259909,0.552235,0.313459,0.718255,0.684549,0.157685,0.346973,0.230082,0.167272,0.0700841,0.0228247,0.441128,0.445269,0.218533,0.234099,0.0610001,0.101915,0.717242,0.881299,-0.499626,-0.045573,-1.15394,-0.716994,-1.04869,-0.918521,-0.0313225,-0.192876,-1.17126,-1.43008,-1.0645,-1.18587,0.198858,-0.0802566,0.495026,0.635021,-0.0525402,-0.0649577
5462,0.730638,0.600111,0.259274,0.181281,0.875841,0.71925,0.635457,0.570747,0.41892,0.541782,0.458655,0.395956,0.799451,0.751483,0.847478,0.851714,0.720175,0.734319,0.825051,0.866365,-0.10237,0.0599474,-2.42981,-1.98186,0.73197,1.17588,-0.715384,-0.585516,-0.560727,-0.724913,-0.228619,-0.480247,2.03483,1.91097,-0.52216,-0.8088,0.598462,0.737659,1.18763,1.17048
5463,0.483339,0.369988,0.698652,0.620655,0.294041,0.135547,0.407383,0.456944,0.379236,0.502976,0.298136,0.233337,0.983021,0.937441,0.819098,0.820637,0.380978,0.395064,0.315902,0.355455,-1.64857,-1.48082,1.10351,1.54888,-0.767706,-0.32064,0.37565,0.50104,-0.362312,-0.521163,-1.16806,-1.42333,0.0317403,-0.0925768,1.66602,1.384,2.01839,2.15262,-0.00155741,-0.0185248
5464,0.165604,0.139866,0.513264,0.436405,0.243954,0.0865232,0.378251,0.343141,0.89315,1.0171,0.531332,0.395375,0.13641,0.0918072,0.18223,0.183993,0.966927,0.9803,0.899808,0.939743,-0.866511,-0.693941,0.231136,0.677351,0.942291,1.38483,-0.746159,-0.616772,1.09704,0.939833,0.700066,0.446246,1.59847,1.47479,-0.128304,-0.401939,0.553703,0.680085,-1.51084,-1.52633
5465,0.781883,0.755197,0.995874,0.920124,0.951975,0.797249,0.00119478,-0.0344752,0.603734,0.649686,0.622213,0.557414,0.239208,0.19692,0.331859,0.322224,0.669235,0.681132,0.441085,0.545439,-1.09864,-0.930045,0.995788,1.44727,-0.635086,-0.18745,0.148227,0.271088,1.34708,1.19055,-1.62987,-1.88822,-1.20459,-1.3243,1.14228,0.874188,-2.44631,-2.32263,-0.477833,-0.490673
5466,0.360254,0.334878,0.683068,0.609533,0.766152,0.609772,0.368373,0.334145,0.159888,0.282274,0.500255,0.43421,0.0673471,0.027241,0.457438,0.460455,0.129578,0.141529,0.110146,0.151134,-2.31756,-2.15094,-0.413016,0.0445693,-1.00568,-0.554258,0.387218,0.51319,-0.342025,-0.494171,0.217473,-0.0470538,0.683887,0.560417,0.208244,-0.0668394,0.10142,0.231726,0.789603,0.775392
5467,0.730985,0.707181,0.158684,0.0868071,0.967148,0.810231,0.0422359,0.00665923,0.0334644,0.155937,0.806954,0.740419,0.539823,0.498922,0.0691976,0.0739834,0.187072,0.299243,0.477422,0.516325,0.541586,0.701869,-0.331944,0.122748,0.606689,1.05569,-0.310525,-0.184678,-0.994158,-1.14852,-1.53509,-1.80182,-0.387106,-0.518361,0.0486202,-0.2248,0.250502,0.379028,-0.582306,-0.596152
5468,0.0969354,0.0708178,0.00645716,-0.0666893,0.00148647,-0.155948,0.00630096,0.0448317,0.309291,0.432534,0.376228,0.3097,0.621154,0.601634,0.0822764,0.146627,0.443944,0.456956,0.505214,0.453931,0.523556,0.678394,0.0882708,0.538899,1.27953,1.73234,0.670429,0.711422,0.77466,0.61897,0.403912,0.142772,-0.285982,-0.410064,-0.461573,-0.7359,-1.73191,-1.60313,-0.370851,-0.379903
5469,0.578107,0.552133,0.154578,0.0624898,0.0334793,-0.124224,0.118923,0.0830041,0.186524,0.310687,0.690686,0.625278,0.742909,0.704345,0.215006,0.21927,0.697037,0.7087,0.350591,0.391538,-1.29858,-1.14275,0.725237,1.16998,-0.195737,0.250996,1.47681,1.60752,0.633617,0.481476,-0.695987,-0.953147,0.977716,0.851102,1.00164,0.728247,0.468482,0.595172,0.0927968,0.0775296
5470,0.576736,0.566824,0.265335,0.191669,0.860823,0.701132,0.665083,0.630395,0.414997,0.627961,0.208166,0.140559,0.535746,0.532765,0.529295,0.487519,0.730531,0.763576,0.90573,0.945651,-0.244321,-0.0945852,0.87356,1.32455,-0.21836,0.221516,0.596507,0.721116,-0.197088,-0.300251,0.89146,0.640375,-0.37492,-0.507241,-0.867396,-1.13896,0.454493,0.651185,0.15188,0.130363
5471,0.608034,0.581515,0.211505,0.137187,0.697494,0.539202,0.542043,0.426397,0.822562,0.945235,0.239009,0.172113,0.400294,0.361185,0.749568,0.755767,0.806487,0.818451,0.489774,0.529657,0.0319063,0.188343,1.25677,1.71003,-0.479763,-0.133038,-0.928414,-0.797817,-0.923039,-1.08198,-1.13323,-1.37618,1.24896,1.10968,-0.399976,-0.670435,0.586425,0.707198,0.418137,0.391761
5472,0.00472959,-0.0196544,0.637515,0.479566,0.0141633,-0.145095,0.256889,0.222399,0.0165495,0.139089,0.816695,0.748183,0.0123242,-0.0245759,0.238245,0.244497,0.185149,0.198021,0.695227,0.736553,-0.411982,-0.260067,0.140969,0.659887,-0.928458,-0.487592,0.887509,1.01341,-1.20814,-1.37039,1.07574,0.825379,-0.109421,-0.248663,1.15604,0.88601,-0.141385,-0.0251719,-0.405308,-0.430006
5473,0.746665,0.724313,0.898569,0.821946,0.0991786,-0.058829,0.513555,0.501945,0.603815,0.729057,0.473439,0.405433,0.603343,0.566792,0.81095,0.818114,0.448232,0.439476,0.090855,0.130503,0.223387,0.374613,-0.84352,-0.390256,0.22164,0.662138,1.39056,1.51315,0.299359,0.137307,1.12201,0.870403,0.615374,0.473183,-1.19944,-1.46206,1.63321,1.74778,-0.874703,-0.905465
5474,0.88521,0.864667,0.841572,0.762756,0.515755,0.3594,0.813726,0.781492,0.169084,0.295121,0.464918,0.397614,0.248428,0.211645,0.851657,0.894311,0.667277,0.680931,0.703347,0.744141,-2.09971,-1.94764,-0.883664,-0.435021,-0.0337561,0.403327,0.226599,0.437655,-0.205368,-0.36682,-0.767335,-1.02277,0.441621,0.306319,-0.259665,-0.516561,-0.225144,-0.108061,-0.529473,-0.553532
5475,0.584881,0.524101,0.0107245,-0.0671119,0.330639,0.254249,0.141969,0.109521,0.222977,0.347459,0.962919,0.895095,0.344686,0.305586,0.965524,0.970507,0.491165,0.567763,0.944931,0.987234,-0.634844,-0.479998,-0.67502,-0.233049,0.331033,0.770794,-0.756097,-0.637843,0.259496,0.0972977,0.895403,0.632449,-2.51657,-2.64606,1.04193,0.792428,-0.117683,-0.00542282,0.249299,0.222822
5476,0.20484,0.183534,0.888909,0.811547,0.30376,0.149099,0.256057,0.223973,0.0166097,0.140973,0.792021,0.7225,0.901348,0.862478,0.197663,0.204098,0.442691,0.454595,0.384962,0.426163,0.439541,0.596422,-1.12484,-0.689825,-1.13784,-0.695797,-0.251984,-0.22437,1.4349,1.26837,0.746977,0.476837,-0.346951,-0.473642,0.310674,0.063884,-0.709173,-0.59875,0.0117534,-0.0113258
5477,0.899446,0.879201,0.976843,0.900765,0.980663,0.824309,0.69726,0.667384,0.126008,0.249991,0.842872,0.773088,0.906475,0.865929,0.536392,0.472346,0.984026,0.995272,0.646832,0.689192,0.0608349,0.222681,-0.628417,-0.19564,-1.34033,-0.893389,0.0674327,0.189103,0.011385,-0.154246,1.56014,1.28812,0.226867,0.0963276,0.321594,0.071215,0.96061,1.06513,0.93329,0.916735
5478,0.693343,0.588077,0.244464,0.170213,0.320078,0.165333,0.684311,0.655058,0.615935,0.738321,0.892285,0.823677,0.0964173,0.0542297,0.735215,0.740595,0.615624,0.627843,0.311085,0.352762,0.906823,1.07004,-0.683337,-0.254787,2.40726,2.85204,0.17865,0.307836,-0.269685,-0.428981,1.52869,1.2554,-1.09908,-1.23058,0.048523,-0.195611,1.28999,1.39957,0.0297576,-0.0361771
5479,0.315581,0.296953,0.964127,0.890933,0.743398,0.589502,0.925492,0.894987,0.135729,0.259367,0.740712,0.670721,0.506609,0.465756,0.404562,0.409242,0.249981,0.260415,0.509964,0.490545,-1.03217,-0.875504,-1.57946,-1.15694,-0.52837,-0.0825206,-1.0121,-0.887752,-0.2599,-0.423144,-0.687959,-0.96669,1.36702,1.23197,-1.30048,-1.55169,-0.597766,-0.487091,-0.910389,-0.989089
5480,0.607051,0.589178,0.915253,0.841066,0.908867,0.755661,0.297461,0.267311,0.638994,0.763266,0.0436418,-0.0253532,0.123897,0.0848151,0.883574,0.885767,0.607507,0.616738,0.51788,0.628328,-0.297228,-0.134231,1.27048,1.69186,-2.02273,-1.57904,-1.54428,-1.41585,-0.823318,-0.987036,-0.510336,-0.78358,-0.611544,-0.739712,0.456319,0.208056,-0.855492,-0.74079,-1.92545,-1.942
5481,0.337251,0.298054,0.664427,0.590499,0.451377,0.296496,0.675274,0.645624,0.0521942,0.174552,0.97237,0.902032,0.757468,0.71598,0.303853,0.304949,0.500136,0.497718,0.722745,0.766111,-0.526583,-0.282019,1.63095,2.04706,-1.78702,-1.34809,-0.247286,-0.113175,-0.000389974,-0.169755,0.180798,-0.0962416,3.04889,2.92519,-1.05528,-1.29994,1.60976,1.72908,0.432186,0.417795
5482,0.024334,0.00693065,0.839372,0.764352,0.725233,0.572435,0.262658,0.233304,0.220858,0.345079,0.244085,0.172595,0.848159,0.805614,0.865493,0.867185,0.387569,0.378697,0.00158975,0.0436303,-0.668329,-0.429808,-0.716826,-0.301301,0.136909,0.57559,1.42028,1.55303,0.425436,0.263393,-0.401775,-0.68477,0.634626,0.510924,2.04868,1.80373,0.123175,0.241283,-0.126411,-0.135189
5483,0.516632,0.402194,0.544549,0.46904,0.189393,0.0386195,0.171549,0.160198,0.650159,0.773362,0.348628,0.276751,0.459288,0.497882,0.686857,0.690346,0.248453,0.259676,0.957983,1.00154,-0.740594,-0.577596,-0.104293,0.293987,-0.974011,-0.537653,1.89785,2.03956,-0.63289,-0.790463,0.820537,0.539504,-0.183065,-0.301332,-2.21118,-2.45613,-0.743717,-0.6325,0.391308,0.384264
5484,0.815605,0.797458,0.825024,0.750817,0.813927,0.661952,0.114592,0.0870918,0.448383,0.477925,0.736877,0.666082,0.234586,0.190151,0.880169,0.881976,0.826092,0.839493,0.452481,0.495869,-0.277596,-0.110703,0.480386,0.889276,0.718818,1.15127,0.188803,0.331888,0.351581,0.196598,-0.201712,-0.478952,-1.34931,-1.47371,1.71006,1.46827,1.0549,1.17199,-0.158043,-0.134583
5485,0.107743,0.0896979,0.324359,0.247418,0.176438,0.0237871,0.827881,0.799916,0.0581584,0.182487,0.542123,0.429592,0.992655,0.949998,0.538741,0.539883,0.706805,0.629276,0.590002,0.727343,-0.0893838,0.0782523,-0.932756,-0.527123,0.196372,0.631057,-0.311019,-0.165735,-1.1967,-1.34677,-0.28862,-0.572021,0.796812,0.667958,-0.699778,-0.945835,-0.480516,-0.362425,-0.643397,-0.65343
5486,0.110598,0.0902653,0.849424,0.770426,0.0754994,-0.0768851,0.960611,0.934069,0.713742,0.837664,0.263832,0.193102,0.982821,0.942571,0.64842,0.632143,0.419449,0.419058,0.915611,0.958817,-0.214445,-0.0515093,-0.346963,0.0586392,0.00414164,0.396648,0.633065,0.816741,-0.0202792,-0.175705,-0.760396,-1.05108,0.0619512,-0.0694435,-0.0839538,-0.324312,-0.283434,-0.169864,1.31539,1.30496
5487,0.936789,0.914069,0.900913,0.758336,0.912223,0.758567,0.567506,0.542295,0.396777,0.594214,0.315306,0.317471,0.304707,0.265966,0.787772,0.724404,0.194672,0.208841,0.550869,0.592657,0.508882,0.674156,-0.498624,-0.0910508,-0.278294,0.16224,1.65937,1.79922,0.200697,0.0442352,-0.142211,-0.436867,-1.47246,-1.60171,-0.311534,-0.544106,1.36086,1.47912,-1.05218,-1.06361
5488,0.59803,0.573834,0.825031,0.746247,0.0672396,-0.0858687,0.621323,0.596529,0.2262,0.350763,0.515,0.441839,0.873027,0.832476,0.817295,0.816664,0.594733,0.609778,0.601087,0.614794,-0.351904,-0.11795,-1.33391,-0.933067,1.66454,2.10041,0.95576,1.10135,1.45322,1.29334,0.700973,0.405258,-0.904058,-1.00022,-1.15075,-1.37791,0.274695,0.388171,-0.535969,-0.544162
5489,0.870594,0.844975,0.100828,0.02091,0.407546,0.342575,0.432821,0.409088,0.656519,0.779047,0.15104,0.0801128,0.11431,0.071706,0.639093,0.639825,0.528112,0.543985,0.595024,0.636932,-1.08315,-0.910057,0.0394967,0.437299,0.482875,0.924815,-1.27329,-1.1285,-0.823929,-0.984284,-0.965794,-1.25513,-0.269096,-0.39873,1.46582,1.23697,-0.169619,-0.0517339,0.527375,0.521838
5490,0.785688,0.757999,0.155621,0.0747128,0.922607,0.771018,0.474334,0.452529,0.0474566,0.169546,0.392891,0.322765,0.319407,0.277601,0.835303,0.836503,0.712943,0.734232,0.0938374,0.136273,1.65371,1.83001,0.268522,0.669088,-1.60579,-1.17041,0.387066,0.537702,0.105559,-0.058638,-0.0771419,-0.366782,-2.12044,-2.24289,-0.926121,-1.15998,2.59639,2.71432,-0.77776,-0.789104
5491,0.0236935,-0.00298089,0.971931,0.890652,0.276459,0.126727,0.219355,0.298197,0.68349,0.804079,0.244787,0.174747,0.805793,0.764341,0.516482,0.520011,0.907835,0.924479,0.253608,0.255144,-0.85594,-0.684427,-0.357708,0.0771948,0.660008,1.08958,-0.546483,-0.395817,-1.13723,-1.29712,-0.165873,-0.351961,1.0096,0.881362,-0.69568,-0.935479,-0.707218,-0.592493,0.402203,0.384779
5492,0.31441,0.289244,0.257389,0.175747,0.632282,0.432624,0.0981795,0.143865,0.847225,0.968849,0.990493,0.920875,0.43512,0.393628,0.836355,0.841478,0.693395,0.672061,0.324145,0.374014,-0.390299,-0.217534,-0.8992,-0.514698,1.56937,1.9967,-1.14275,-0.987061,-1.71572,-1.87688,-0.071735,-0.337139,-0.204249,-0.336168,0.117546,-0.129618,-0.578304,-0.459468,-0.67823,-0.698108
5493,0.108097,0.0803996,0.854058,0.772053,0.888068,0.73852,0.012146,-0.0104675,0.539845,0.661335,0.0208349,-0.0486963,0.869577,0.830523,0.606999,0.555278,0.360885,0.419642,0.448454,0.492885,-0.532637,-0.305472,-1.50716,-1.10659,-0.67847,-0.258657,1.2615,1.41038,-0.59117,-0.753841,-0.0326766,-0.322317,-0.794997,-0.921122,0.0653923,-0.182705,2.26604,2.38541,-0.274342,-0.301374
5494,0.78301,0.755667,0.401885,0.318835,0.830149,0.678264,0.0586313,0.0384625,0.977652,1.09909,0.926655,0.858142,0.587402,0.61275,0.261886,0.269079,0.151386,0.167223,0.392922,0.438933,-0.490405,-0.393411,-2.47102,-2.07124,1.54598,1.96732,0.358369,0.457594,0.205034,0.0466401,-1.42661,-1.71147,-0.012911,-0.198787,0.350346,0.103979,0.663418,0.789984,0.807868,0.780965
5495,0.306434,0.280019,0.188025,0.10438,0.567666,0.414041,0.437513,0.416775,0.25162,0.372585,0.287556,0.218486,0.435024,0.394976,0.217162,0.268035,0.436385,0.452967,0.607955,0.656313,-0.654114,-0.481349,0.281729,0.685959,-2.82366,-2.40776,-0.644073,-0.495192,-0.226394,-0.38149,0.710686,0.425383,0.645649,0.523548,-0.120968,-0.36115,1.5368,1.65627,1.22344,1.19303
5496,0.356359,0.28948,0.405569,0.283316,0.622008,0.454038,0.230262,0.209899,0.601094,0.719319,0.084632,0.0142147,0.43657,0.371901,0.342783,0.266991,0.356559,0.372603,0.257016,0.305231,0.181762,0.349906,0.0217476,0.426988,-2.27703,-1.8558,-3.0198,-2.87464,0.565725,0.406699,-0.276386,-0.562833,-1.32421,-1.44813,0.637226,0.397767,-0.501738,-0.373966,0.421584,0.385883
5497,0.324827,0.298941,0.569372,0.462251,0.649497,0.494035,0.74461,0.722698,0.129438,0.246313,0.24943,0.0977911,0.386512,0.348826,0.260069,0.265947,0.745401,0.763494,0.434667,0.482786,-0.139666,0.0242413,-0.623437,-0.212577,1.31966,1.74148,0.0579638,0.202109,-0.689573,-0.848182,-1.05122,-1.33582,1.88044,1.76217,-0.126048,-0.360211,0.265598,0.395636,0.373858,0.332664
5498,0.727722,0.701885,0.726945,0.641186,0.113982,-0.03978,0.0289119,0.0056303,0.726036,0.8411,0.251575,0.181367,0.661903,0.537342,0.936027,0.942126,0.250173,0.268407,0.0463764,0.0927934,-0.839703,-0.672379,2.36611,2.77223,-0.454211,-0.0358873,-0.420308,-0.279052,0.451154,0.292555,0.443552,0.163522,-0.830497,-0.947695,0.301462,0.0629963,-0.490943,-0.368188,-2.01564,-2.05244
5499,0.35286,0.327561,0.353174,0.266575,0.885098,0.731447,0.193361,0.257483,0.0473628,0.160914,0.692119,0.619724,0.76578,0.725858,0.942919,0.94778,0.500453,0.52015,0.66643,0.711447,0.182949,0.344532,0.477143,0.882362,0.656888,1.06776,0.546988,0.684876,-0.180417,-0.332571,-2.46739,-2.75209,0.140476,0.0196533,1.73728,1.49744,0.817008,0.933715,-0.0258361,-0.0649103
5500,0.345618,0.329375,0.943237,0.857424,0.936053,0.784011,0.533453,0.509335,0.766877,0.87833,0.290529,0.218159,0.0752857,0.0339326,0.69014,0.694771,0.0221644,0.0400732,0.549234,0.664795,-0.541837,-0.384209,0.507453,0.915151,-0.828167,-0.413583,-1.33143,-1.19364,0.633516,0.48471,-1.86647,-2.15367,0.316829,0.202197,-0.84759,-1.09487,-1.2125,-1.09653,0.0188877,-0.0265723
5501,0.354074,0.331189,0.859051,0.774092,0.506315,0.3541,0.31984,0.297334,0.176442,0.289617,0.24143,0.247948,0.113512,0.0664325,0.889181,0.891449,0.649423,0.666461,0.604156,0.618143,0.00295939,0.158749,-0.0828145,0.376547,-0.462966,-0.0461165,-0.502823,-0.370173,0.356428,0.209975,0.444049,0.159447,-0.209665,-0.249451,0.209809,-0.0436288,-0.549325,-0.434933,1.50102,1.45542
5502,0.0380178,0.0161949,0.38946,0.305832,0.550913,0.400785,0.947202,0.924501,0.512126,0.626994,0.351357,0.277737,0.0407078,0.0989324,0.858495,0.860372,0.407062,0.423271,0.416278,0.571491,1.08553,1.23517,-0.574557,-0.162056,2.37613,2.78915,-0.652706,-0.527863,0.307516,0.167669,0.334763,0.0520651,-0.583056,-0.701098,-0.486783,-0.739895,-0.33336,-0.226692,1.03322,0.995327
5503,0.784551,0.764849,0.876303,0.793531,0.175413,0.0259499,0.486514,0.463036,0.306286,0.472795,0.707459,0.633025,0.174492,0.131432,0.0592998,0.0591122,0.42815,0.443056,0.479822,0.524839,-1.02611,-0.880427,-0.59797,-0.190127,1.20096,1.61355,-0.0380566,0.079031,0.902675,0.768652,-1.07564,-1.3519,-0.299729,-0.444841,0.438282,0.189417,-0.704636,-0.603069,-0.361442,-0.392584
5504,0.892226,0.782237,0.875443,0.793154,0.113788,-0.0343069,0.233311,0.210141,0.155545,0.318597,0.0267416,-0.0474954,0.635919,0.592741,0.962454,0.961276,0.0123428,0.0289886,0.166267,0.209071,0.62379,0.7721,-1.0334,-0.631158,0.386296,0.796201,0.343288,0.457462,0.373389,0.236615,0.0974974,-0.173373,-0.0991866,-0.188583,-1.67216,-1.92719,-0.270204,-0.233617,1.51105,1.47732
5505,0.863853,0.799625,0.493687,0.381367,0.934312,0.786475,0.570949,0.548724,0.0467913,0.164398,0.526508,0.449985,0.788086,0.743166,0.757476,0.824846,0.351011,0.365421,0.260836,0.308319,-0.880239,-0.737414,0.384823,0.786658,-0.629016,-0.223397,1.19522,1.31355,2.0941,1.9581,-0.95704,-1.22194,0.185717,0.0676749,-1.29289,-1.54848,0.0294732,0.135835,0.566719,0.533357
5506,0.789552,0.817013,0.0541005,-0.0304187,0.744601,0.594439,0.346579,0.325834,0.57259,0.590962,0.72054,0.566088,0.624122,0.579348,0.731298,0.688415,0.0507577,0.0662527,0.440429,0.407566,0.148292,0.293436,-0.315587,0.0855152,2.23193,2.63249,0.535229,0.620074,0.296961,0.163701,-1.42638,-1.68645,1.27788,1.15562,-1.2335,-1.4955,0.887984,0.987369,-0.1637,-0.198303
5507,0.854689,0.834401,0.571912,0.487353,0.990961,0.839762,0.400416,0.380067,0.899477,1.01753,0.759447,0.682192,0.820874,0.776002,0.553287,0.551985,0.434445,0.452002,0.463968,0.506814,-0.424719,-0.280838,0.693867,1.16567,-0.183965,0.217007,-0.237118,-0.0733999,-0.950548,-0.996217,-0.306366,-0.567758,-1.29187,-1.40592,0.0916666,-0.170471,0.374944,0.470854,-1.44771,-1.47947
5508,0.005939,-0.013045,0.176206,0.0932617,0.00964919,-0.14155,0.763042,0.664254,0.801256,0.829509,0.466005,0.316193,0.193439,0.149635,0.788431,0.786946,0.030723,0.0468932,0.270065,0.311244,0.330344,0.438295,1.84224,2.24583,-0.700065,-0.303208,-0.885201,-0.766874,-2.02737,-2.15614,1.1848,0.916172,0.205653,0.0999744,-1.17026,-1.4343,-1.41927,-1.3193,0.81665,0.780835
5509,0.716964,0.697586,0.531903,0.41331,0.593951,0.441964,0.970312,0.948441,0.521279,0.641493,0.0289075,-0.0498047,0.331905,0.289853,0.468667,0.465027,0.512092,0.526916,0.307081,0.347961,1.01355,1.15743,0.94057,1.37688,-0.010088,0.388757,0.831641,0.944759,0.0711201,-0.0551859,0.635965,0.360576,1.71992,1.60587,0.349593,0.0899088,1.34947,1.44675,-0.735458,-0.774945
5510,0.128089,0.106938,0.817719,0.733359,0.866448,0.713233,0.371487,0.349608,0.980719,1.09911,0.741281,0.661258,0.729745,0.686331,0.43844,0.415737,0.581378,0.595341,0.922887,0.961599,-0.500248,-0.352086,0.107676,0.507926,0.413742,0.817723,-0.0197367,0.0890569,-0.0108137,-0.130618,-0.141114,-0.412413,0.57722,0.465862,1.21406,0.955848,0.34792,0.447213,-0.3925,-0.43729
5511,0.0992241,0.0756553,0.940281,0.856515,0.64864,0.495367,0.896183,0.872531,0.114946,0.231797,0.364803,0.284433,0.858158,0.816851,0.372017,0.366447,0.978756,0.991218,0.270104,0.310603,0.644017,0.786333,-0.339553,0.0668947,0.0446974,0.450914,1.68231,1.7868,0.178432,0.0574947,1.17472,0.903716,-0.825739,-0.938705,-0.255986,-0.520736,0.948221,1.0467,-1.30644,-1.35103
5512,0.46452,0.443414,0.0341288,-0.0477357,0.222375,0.0708681,0.83337,0.809951,0.942172,1.05967,0.462591,0.383656,0.632741,0.590483,0.532285,0.527912,0.136534,0.146987,0.828288,0.869476,2.59034,2.72933,-0.0765316,0.330112,0.707563,1.11024,2.36873,2.47134,-0.775415,-0.890583,-0.0569619,-0.32684,-1.29114,-1.40016,0.318608,0.0556403,-0.00627048,0.0920788,-0.367958,-0.406109
5513,0.26839,0.262937,0.000739518,-0.0817969,0.671837,0.520123,0.337392,0.312485,0.25329,0.369781,0.0251447,-0.0523726,0.884791,0.842647,0.182625,0.175791,0.815785,0.824841,0.954603,0.995466,0.384499,0.528865,0.450106,0.854147,-0.498002,-0.0953369,-0.34506,-0.241687,-2.13896,-2.2548,1.25448,0.989289,-1.01464,-1.1246,-2.96346,-3.22859,-0.656289,-0.562232,-0.663054,-0.70011
5514,0.103632,0.0824609,0.555964,0.475032,0.810148,0.656556,0.96094,0.935059,0.532486,0.646378,0.336632,0.257818,0.759392,0.718035,0.303225,0.217328,0.673977,0.681329,0.785612,0.857586,-0.636309,-0.493041,-0.948216,-0.548557,0.952589,1.3599,-1.66186,-1.55819,0.0696539,-0.051803,-0.549772,-0.812004,-0.491213,-0.534507,-0.289633,-0.562296,-2.01,-1.92251,-1.38603,-1.41744
5515,0.482461,0.460536,0.650458,0.567063,0.0202757,-0.134221,0.119778,0.0931433,0.570009,0.590122,0.243769,0.16493,0.21396,0.17118,0.26504,0.258864,0.0429188,0.051419,0.679604,0.719707,0.501812,0.645378,-1.31127,-0.91297,0.447966,0.856264,0.150146,0.253029,-0.930207,-1.04545,0.325769,0.0597804,0.172887,0.0555818,-1.06924,-1.33474,-0.549297,-0.459887,0.746484,0.713753
5516,0.00367868,-0.0204107,0.740685,0.659093,0.724589,0.571272,0.686162,0.660826,0.420249,0.533867,0.965629,0.886286,0.602383,0.557933,0.710122,0.705847,0.511796,0.52197,0.929408,0.968055,0.00262724,0.146566,-0.882933,-0.397141,0.160145,0.49818,0.1221,0.217384,0.0525242,-0.0583897,0.853246,0.581934,0.473003,0.363282,-0.102642,-0.376517,-1.03209,-0.944402,1.01177,0.975151
5517,0.951006,0.926561,0.0934527,0.0133873,0.750025,0.598558,0.764555,0.739456,0.978817,1.09314,0.907547,0.82843,0.557944,0.514569,0.926797,0.924083,0.101548,0.113055,0.950318,0.990244,1.11431,1.25407,-0.288797,0.118688,-0.308954,0.140095,0.597243,0.68659,1.72353,1.61689,0.951246,0.673337,-0.702165,-0.809099,1.92781,1.64817,0.0813908,0.169624,-0.0524669,-0.089716
5518,0.680984,0.602422,0.592122,0.511867,0.553158,0.488819,0.622274,0.604373,0.757076,0.870979,0.452403,0.372602,0.12147,0.0784871,0.260293,0.257795,0.857935,0.870459,0.622807,0.663924,0.70867,0.85036,0.987942,1.39727,-0.626288,-0.217989,1.53237,1.61998,1.41419,1.31219,-0.708638,-0.987053,1.26516,1.15274,0.649538,0.368933,-0.568576,-0.484687,-0.860707,-0.896859
5519,0.303584,0.278282,0.69873,0.620629,0.529542,0.379079,0.496641,0.46929,0.315859,0.427544,0.366,0.201988,0.546938,0.505119,0.297434,0.293069,0.848725,0.817763,0.711325,0.69286,-0.53061,-0.383578,0.830659,1.24758,-1.40667,-1.00354,0.432381,0.515974,0.808884,0.701568,-1.13307,-1.41818,0.518933,0.444743,-0.242151,-0.527228,1.07802,1.1643,1.12772,1.09067
5520,0.523165,0.439554,0.072445,-0.00492248,0.773281,0.569418,0.827438,0.798537,0.371872,0.484571,0.11209,0.031374,0.748925,0.706715,0.88634,0.881004,0.751981,0.765067,0.681875,0.721796,0.860422,1.00515,1.01556,1.43316,0.166683,0.576857,0.196834,0.281857,-0.55669,-0.662653,0.887366,0.607458,-0.151637,-0.263253,0.913384,0.630601,0.477509,0.570972,0.381433,0.388719
5521,0.624958,0.600826,0.466136,0.390527,0.910746,0.759757,0.576389,0.545642,0.714576,0.82717,0.555263,0.474579,0.617634,0.57702,0.195665,0.188094,0.501755,0.542476,0.416532,0.456823,0.518785,0.663193,-0.146612,0.345759,0.65802,1.06607,1.1124,1.20031,-0.452862,-0.564884,-1.23336,-1.51752,1.22668,1.10769,-0.802017,-1.07872,0.908054,0.99846,-0.269908,-0.313233
5522,0.630696,0.60264,0.512616,0.438559,0.467545,0.315266,0.961248,0.928746,0.466389,0.578883,0.719087,0.639741,0.218325,0.176682,0.756621,0.75033,0.268434,0.319885,0.89321,0.935826,-0.398911,-0.250865,-1.15925,-0.741643,-0.938115,-0.522987,-0.430635,-0.346091,0.672084,0.558157,-0.75062,-1.04028,2.2855,2.1667,-0.544456,-0.850275,0.121807,0.219418,1.42059,1.38245
5523,0.630821,0.604454,0.35793,0.285063,0.269447,0.118396,0.186798,0.154464,0.968421,1.08278,0.297283,0.218427,0.403418,0.36264,0.376948,0.36906,0.0842089,0.0972943,0.62549,0.670853,-3.41469,-3.26292,0.228092,0.64471,-0.369697,0.118396,-0.173744,-0.0804235,-0.783764,-0.895437,0.0594764,-0.228995,1.23334,1.11909,-0.347187,-0.62183,-2.25291,-2.16481,-0.383557,-0.41831
5524,0.913731,0.886151,0.804818,0.733309,0.337797,0.28035,0.517997,0.483712,0.180479,0.293037,0.855319,0.774707,0.847573,0.808787,0.643562,0.634663,0.192707,0.206876,0.729325,0.777078,-0.0610958,0.0974007,-0.55766,-0.136199,0.351657,0.759779,0.0963351,0.185244,-0.861104,-0.97087,-0.494629,-0.784591,0.457673,0.336715,0.839631,0.56468,1.09551,1.18958,0.263399,0.223596
5525,0.993628,0.966797,0.988587,0.91677,0.591787,0.442305,0.00783787,-0.0241985,0.647746,0.760857,0.372316,0.289989,0.639271,0.598417,0.4319,0.423053,0.58438,0.597767,0.269687,0.316219,-1.67657,-1.51792,0.188076,0.60344,0.0939692,0.500968,1.26595,1.35182,-1.97337,-2.08548,1.12632,0.839848,0.0822663,0.0101339,-0.144202,-0.421644,-0.151429,-0.0611352,0.095218,0.049614
5526,0.79428,0.768544,0.172471,0.102153,0.326196,0.178082,0.404849,0.375149,0.0512409,0.166441,0.346046,0.273638,0.77932,0.738635,0.735112,0.724046,0.62785,0.641239,0.193742,0.24212,1.0889,1.25146,-0.771706,-0.361207,0.091021,0.500943,-0.62713,-0.545986,-1.45337,-1.56071,0.666328,0.375338,-0.193317,-0.316447,0.515903,0.231582,0.300987,0.397369,-0.794155,-0.833894
5527,0.991649,0.964514,0.665784,0.595201,0.705149,0.555481,0.297645,0.274765,0.224134,0.336538,0.338635,0.257288,0.417232,0.377684,0.196995,0.187949,0.106002,0.117172,0.663092,0.711078,-0.170136,-0.0140739,0.972747,1.38195,-1.26956,-0.858317,-0.0556662,0.0306273,-0.619347,-0.727467,0.713241,0.420362,1.28504,1.16302,-0.682625,-0.968973,0.0552418,0.159848,-0.850508,-0.887113
5528,0.429938,0.402798,0.886609,0.760114,0.0359583,-0.113642,0.365886,0.17438,0.392868,0.506635,0.01879,-0.0619611,0.646309,0.608658,0.356015,0.345346,0.761734,0.775484,0.640561,0.782796,0.726583,0.881042,-0.596137,-0.190331,0.73228,1.15439,-0.728539,-0.636599,-1.08568,-1.20049,-0.528312,-0.828077,0.0369197,-0.0859064,-0.718461,-1.00922,0.35161,0.462754,-1.7157,-1.75651
5529,0.973198,0.945053,0.993419,0.925027,0.244378,0.0966418,0.14513,0.0739963,0.175357,0.289577,0.67303,0.594537,0.409754,0.372342,0.302512,0.332165,0.261732,0.275731,0.808864,0.854515,0.887825,1.039,0.438772,0.84074,2.75585,3.1671,-0.475464,-0.380169,-0.58754,-0.704944,-0.314076,-0.591661,-0.383738,-0.500021,-0.419388,-0.709933,0.21627,0.332909,0.388223,0.3413
5530,0.257292,0.230452,0.536613,0.466809,0.840656,0.694349,0.00437116,-0.0263878,0.315102,0.429341,0.850129,0.773639,0.388537,0.394664,0.329122,0.318984,0.0539435,0.0680981,0.131064,0.178428,0.155253,0.310261,-0.463968,-0.0614092,-1.08412,-0.666739,0.448768,0.538285,2.53288,2.40827,-0.0517275,-0.355245,0.34561,0.221824,0.116706,-0.178866,-1.65449,-1.5387,-0.325185,-0.376025
5531,0.99134,0.963074,0.75922,0.68967,0.488316,0.340618,0.874989,0.842618,0.776481,0.892505,0.0275459,-0.0498165,0.465001,0.416985,0.895289,0.886494,0.712808,0.72641,0.6136,0.66213,1.00925,1.15762,-0.2773,0.124176,-0.192904,0.225133,2.29891,2.39616,0.29978,0.182302,0.906659,0.608277,0.13895,0.00938207,-1.4394,-1.73266,0.766592,0.884372,0.259345,0.204643
5532,0.440088,0.411938,0.761971,0.694044,0.992976,0.844179,0.0816161,0.0470702,0.714583,0.839741,0.804962,0.727304,0.478435,0.439307,0.0994233,0.0898103,0.193925,0.207169,0.109422,0.156454,0.373611,0.521688,0.661165,1.06174,-1.29439,-0.871583,0.707777,0.799819,1.2155,1.09176,-0.948999,-1.25321,0.729848,0.594411,-0.981765,-1.27935,0.204585,0.321962,0.299525,0.242981
5533,0.481413,0.442185,0.438995,0.341989,0.72268,0.544909,0.976858,0.94052,0.776298,0.786977,0.476497,0.398724,0.267405,0.228937,0.0988373,0.089447,0.625131,0.637626,0.371858,0.390472,-0.486404,-0.40343,-1.4738,-1.07613,1.35439,1.77463,1.11961,1.2088,-1.1514,-1.27957,0.956682,0.64827,0.255348,0.117289,-1.05501,-1.43979,-0.830541,-0.707639,1.53156,1.47841
5534,0.501816,0.472431,0.0571875,-0.0100656,0.392055,0.245638,0.491566,0.453607,0.619098,0.734213,0.752318,0.673721,0.891794,0.854408,0.71166,0.70436,0.643403,0.658961,0.578148,0.624491,-1.47809,-1.32855,0.920087,1.32187,1.3806,1.80527,-1.48345,-1.3929,-0.297833,-0.430621,0.98104,0.678547,0.151266,-0.0584747,-1.22869,-1.60024,1.44567,1.56881,-1.90467,-1.95974
5535,0.274893,0.243778,0.661605,0.595376,0.393955,0.19436,0.887661,0.847153,0.335277,0.451794,0.531791,0.455197,0.885076,0.750483,0.15989,0.153382,0.667171,0.680296,0.228074,0.27341,-0.451445,-0.297697,0.192779,0.589861,0.733189,1.15914,-0.933434,-0.844842,1.17083,1.04616,-0.361868,-0.662235,-0.103901,-0.234239,-1.4631,-1.76068,0.30318,0.329156,0.411049,0.351121
5536,0.348929,0.319424,0.668768,0.604419,0.291208,0.143081,0.0816837,0.0411367,0.699035,0.815138,0.990619,0.913428,0.684347,0.646557,0.877059,0.871023,0.377126,0.473796,0.996976,1.04407,0.013542,0.169197,-0.278111,0.169741,-0.582898,-0.15275,-0.786152,-0.694086,1.12572,1.00385,-1.2695,-1.57457,-0.994398,-1.12604,-0.28852,-0.587125,-1.02788,-0.910493,-0.0186077,-0.0802704
5537,0.796666,0.767289,0.045012,-0.0211326,0.607439,0.459794,0.574382,0.534478,0.843574,0.894829,0.582618,0.472538,0.274368,0.311595,0.179793,0.17255,0.253089,0.267297,0.196328,0.244064,-0.337311,-0.188725,-0.654436,-0.250378,-0.1799,0.247542,-1.25125,-1.1621,1.90152,1.7761,2.213,1.91431,-1.45402,-1.58749,-0.266142,-0.564147,0.211844,0.330449,-0.72681,-0.782279
5538,0.801059,0.772438,0.262549,0.196198,0.0174762,-0.128947,0.363338,0.322476,0.851967,0.974521,0.106673,0.0316484,0.0154767,-0.0233675,0.231432,0.132101,0.482376,0.499292,0.688746,0.737966,0.796002,0.949694,1.59331,2.00476,0.607198,1.03025,0.686158,0.774413,0.761403,0.632433,-0.170922,-0.46569,-1.47597,-1.61626,1.02639,0.729006,-1.65963,-1.54116,0.519788,0.466976
5539,0.0789367,0.0485471,0.249199,0.2527,0.0367983,-0.0981323,0.912455,0.869868,0.937294,1.05421,0.458318,0.382534,0.0567,0.0192443,0.100921,0.0916508,0.0376168,0.0547151,0.787454,0.834132,1.32779,1.47899,0.659614,1.07251,0.117682,0.541354,-2.20465,-2.12258,0.510436,0.388521,0.927288,0.634919,-1.03884,-1.18426,-0.555273,-0.854841,1.27036,1.39596,-1.46366,-1.51988
5540,0.461518,0.323282,0.377806,0.309201,0.157369,-0.067317,0.417798,0.377157,0.650375,0.816787,0.286179,0.209939,0.671963,0.63542,0.655567,0.644849,0.409777,0.42518,0.503301,0.548689,2.2442,2.38773,-0.74239,-0.330192,-0.59002,-0.165954,-2.65433,-2.57392,0.579355,0.45563,-2.04447,-2.33917,0.382711,0.234186,-0.464262,-0.770251,0.179661,0.305006,1.07598,1.02737
5541,0.70044,0.598017,0.584501,0.440457,0.0465255,-0.0365018,0.884792,0.845101,0.463751,0.579361,0.848221,0.771227,0.0562087,0.0191256,0.798763,0.805203,0.564481,0.580148,0.885105,0.928423,-0.215821,-0.0764498,-1.71237,-1.29484,2.20734,2.63453,-0.425525,-0.349755,-1.6062,-1.72449,-0.799524,-1.09956,-1.60062,-1.75349,0.510584,0.20302,-2.4324,-2.30662,-0.561367,-0.605006
5542,0.903142,0.872752,0.641644,0.571713,0.140737,-0.00568659,0.0281925,-0.0138885,0.741245,0.855958,0.951922,0.875382,0.205559,0.266797,0.977835,0.965557,0.458322,0.472868,0.672388,0.680592,0.505532,0.649216,-0.470949,-0.0460496,0.143905,0.57189,0.013261,0.0893872,-0.407102,-0.522159,1.2952,0.989663,-1.25008,-1.39963,0.866285,0.564646,1.07303,1.19883,-0.136747,-0.177095
5543,0.846595,0.816083,0.390271,0.414847,0.39704,0.305984,0.0698453,0.0295528,0.298116,0.412523,0.296704,0.22065,0.542512,0.514468,0.0298186,0.0185481,0.068934,0.082821,0.305438,0.432762,-1.27172,-1.12417,1.53359,1.96405,1.53575,1.96466,-0.164343,-0.0841086,-0.748805,-0.859607,-0.83147,-1.13532,0.260456,0.108517,-0.988769,-1.28858,-1.27053,-1.15245,0.858183,0.812547
5544,0.230649,0.199978,0.322712,0.257981,0.764251,0.617656,0.568694,0.52746,0.925648,1.04169,0.130621,0.0530128,0.799289,0.76214,0.476085,0.465531,0.908089,0.922635,0.143418,0.184931,-1.30491,-1.16341,0.168556,0.593804,0.998763,1.42924,1.00146,1.08247,0.705792,0.601389,0.822581,0.519905,-0.0366077,-0.181056,0.301771,0.00457429,1.7715,1.89401,0.866723,0.820127
5545,0.670018,0.637994,0.170958,0.101115,0.537144,0.315166,0.616004,0.64744,0.399495,0.513226,0.360572,0.263658,0.013803,-0.0234777,0.0171123,0.00412242,0.631026,0.644118,0.438343,0.47787,0.761841,0.90438,1.6077,2.02616,-1.28626,-0.85794,-0.411766,-0.329164,1.40655,1.29587,-0.0252971,-0.329486,1.20738,1.06589,0.305112,0.0119053,0.860383,0.986267,-0.367235,-0.415513
5546,0.857965,0.828374,0.855351,0.785743,0.157242,0.0126759,0.809518,0.76742,0.0863823,0.200533,0.553581,0.474304,0.283995,0.247719,0.862315,0.849248,0.67518,0.655711,0.451616,0.451735,0.574392,0.714501,-1.09338,-0.671831,-2.18647,-1.75237,1.69785,1.7819,1.5902,1.48398,-0.400385,-0.698454,1.6026,1.46484,1.08954,0.801268,1.55474,1.67967,0.392689,0.347477
5547,0.470463,0.47832,0.182558,0.114725,0.866155,0.723402,0.627496,0.502141,0.799752,0.912479,0.993047,0.912661,0.217143,0.211872,0.274615,0.264195,0.652914,0.667304,0.370936,0.4256,-0.605988,-0.457969,1.522,1.93706,0.186557,0.622909,1.3499,1.43867,-0.0948959,-0.200739,0.714335,0.420242,-0.372254,-0.506841,0.471008,0.182233,-1.06224,-0.931957,2.50993,2.46136
5548,0.160282,0.128266,0.127592,0.0602429,0.949843,0.805331,0.321854,0.236861,0.81136,0.925411,0.978552,0.897771,0.213014,0.176025,0.465083,0.36502,0.414325,0.428793,0.359194,0.399466,0.135432,0.283304,1.37602,1.78737,0.13926,0.578555,-0.705022,-0.619267,0.807594,0.708724,0.156333,-0.114673,0.352523,0.215005,-0.388949,-0.681225,0.612464,0.749235,-0.887364,-0.932233
5549,0.341416,0.308791,0.2977,0.22925,0.120255,-0.0244808,0.0136784,-0.0284188,0.312179,0.427163,0.905053,0.882882,0.652149,0.617787,0.531051,0.465846,0.552218,0.568772,0.631859,0.672635,-0.769275,-0.614643,-1.28668,-0.876904,0.835158,1.27052,-0.5757,-0.485252,0.86475,0.759869,-0.29512,-0.649589,-1.46163,-1.59896,1.19611,0.905574,0.958511,1.10025,-1.87629,-1.92118
5550,0.885058,0.851046,0.221064,0.151456,0.246899,0.0740573,0.928795,0.887085,0.370659,0.431546,0.950156,0.867992,0.625797,0.49288,0.576453,0.566671,0.202185,0.21916,0.465574,0.507633,-0.442224,-0.308412,-0.44524,-0.116875,-1.23956,-0.807732,-1.29884,-1.21453,-0.510482,-0.61938,-0.890412,-1.1845,0.399176,0.270631,0.459205,0.162064,-0.593861,-0.449634,0.5302,0.486329
5551,0.204259,0.169804,0.807942,0.736915,0.306638,0.172595,0.449443,0.405275,0.282281,0.435929,0.615364,0.559305,0.402076,0.367974,0.573409,0.561873,0.22068,0.268062,0.886781,0.926961,-0.150025,-0.00217991,0.226026,0.643154,1.73705,2.16469,0.867088,0.957769,0.953422,0.841616,1.68947,1.39074,-1.11619,-1.2453,-1.27889,-1.57972,0.784182,0.93369,-0.694817,-0.733368
5552,0.164862,0.128663,0.524786,0.4083,0.414259,0.271133,0.989773,0.942747,0.280494,0.440312,0.331364,0.250619,0.133804,0.102013,0.0153106,0.00575983,0.393016,0.316965,0.404929,0.446399,-0.551986,-0.405894,-0.149037,0.261488,-0.328281,0.102041,-0.856715,-0.766854,1.06547,0.912586,-0.312441,-0.612221,-0.0979869,-0.231956,-0.916727,-1.21809,0.585606,0.740792,-0.165799,-0.199637
5553,0.375724,0.339993,0.151314,0.0796847,0.245204,0.18695,0.746668,0.699615,0.329711,0.444695,0.0240953,-0.0580682,0.943394,0.912862,0.738443,0.728082,0.348893,0.365868,0.784693,0.826133,0.933053,1.07774,1.98678,2.40252,-2.17397,-1.73872,0.630971,0.72679,1.09634,0.983557,0.312329,0.0161117,-0.424473,-0.552987,-0.287573,-0.596569,-0.264017,-0.115454,-0.908316,-0.946264
5554,0.145881,0.183889,0.129086,0.0590257,0.246066,0.102766,0.239473,0.191705,0.667666,0.782073,0.959549,0.874961,0.77271,0.656721,0.418005,0.35961,0.0646566,0.0825863,0.618217,0.661131,-0.658232,-0.5098,-0.721036,-0.312067,-0.00186259,0.440468,-0.137868,-0.0495836,0.945351,0.832455,0.16431,-0.165539,0.888842,0.758567,0.615568,0.300207,-0.693954,-0.539823,-0.806622,-0.850147
5555,0.0639411,0.0277855,0.929189,0.860577,0.649345,0.506133,0.0469038,0.000106448,0.130883,0.243919,0.863023,0.812392,0.428704,0.400581,0.00069033,-0.00886128,0.0527536,0.0721704,0.688771,0.733159,-0.0391048,0.109375,-0.925857,-0.509639,0.0664653,0.502844,0.306718,0.389559,-1.74863,-1.85633,0.000270647,-0.34719,0.459135,0.328994,-0.937505,-1.25359,0.661153,0.815661,0.0417875,0.00150867
5556,0.141359,0.103431,0.790585,0.72179,0.210338,0.06691,0.466758,0.418663,0.0713571,0.269692,0.834402,0.749824,0.540793,0.510592,0.0878642,0.076864,0.987301,1.00622,0.110546,0.152948,0.821535,0.928002,1.36117,1.77506,-0.389863,0.0453099,0.0774418,0.155441,0.477011,0.363446,-0.232624,-0.528841,0.517302,0.392194,-0.484716,-0.800277,0.650902,0.810344,-1.15652,-1.20256
5557,0.435083,0.395656,0.970968,0.900478,0.15311,0.0116424,0.884462,0.837219,0.0931213,0.295464,0.288254,0.205406,0.41109,0.394179,0.978373,0.967303,0.549837,0.56701,0.199731,0.244419,1.59689,1.74663,-0.711841,-0.30211,0.274175,0.704636,1.744,1.82165,0.610104,0.489971,-0.0772446,-0.420546,-1.00807,-1.14007,0.579318,0.267879,0.340573,0.494468,0.720581,0.679717
5558,0.295349,0.257849,0.19822,0.127661,0.895596,0.752514,0.922836,0.876084,0.179926,0.321237,0.472677,0.390189,0.308445,0.277765,0.862874,0.944993,0.491409,0.507241,0.600189,0.589094,0.884532,1.03487,-1.91506,-1.49862,-1.13109,-0.701319,-0.26616,-0.187022,0.509897,0.383323,-0.0212515,-0.312251,-1.39803,-1.5224,-0.928769,-1.24011,0.827406,0.984864,-0.467022,-0.509284
5559,0.601528,0.587174,0.618931,0.546775,0.649677,0.506119,0.0501574,0.00100839,0.233973,0.34701,0.0424768,-0.0405303,0.632074,0.580158,0.934545,0.922683,0.0961557,0.113038,0.88979,0.933769,0.229686,0.323118,0.646614,1.05886,-0.230746,0.205802,0.468038,0.546027,2.67235,2.5522,1.50195,1.20336,1.70243,1.57445,0.559506,0.253773,0.541794,0.700838,0.496225,0.533956
5560,0.951466,0.916498,0.506352,0.433554,0.523841,0.259724,0.645511,0.597854,0.5738,0.667708,0.0286945,-0.013662,0.912403,0.88255,0.0468312,0.0347916,0.0733205,0.0902,0.953679,0.996011,-0.538372,-0.388638,-2.09783,-1.6871,0.226487,0.664677,0.199136,0.279334,-1.53246,-1.65261,-0.612668,-0.908049,-0.609345,-0.73011,-0.835218,-1.14632,-0.778607,-0.614404,1.61636,1.5772
5561,0.29351,0.260123,0.853556,0.77973,0.156411,0.013329,0.935577,0.888306,0.873592,0.988406,0.0954724,0.0132063,0.840431,0.744075,0.227932,0.215914,0.0515453,0.067362,0.315938,0.360827,-0.105322,0.0456093,0.511723,0.921788,0.36073,0.802541,0.333177,0.500181,0.908674,0.786174,-0.468179,-0.770765,-0.467617,-0.523638,-0.132313,-0.447237,-0.833183,-0.667523,0.616124,0.517338
5562,0.509346,0.476702,0.571046,0.57011,0.445851,0.350503,0.813854,0.725754,0.00319182,0.116086,0.448456,0.351188,0.62891,0.6056,0.185838,0.174611,0.287711,0.304135,0.266577,0.352983,-0.655327,-0.49364,1.27917,1.70109,1.29588,1.73905,0.65035,0.721027,-0.333636,-0.45231,-0.66184,-0.970709,-0.202066,-0.317166,-1.10062,-1.41956,-0.560956,-0.397067,-0.506948,-0.54252
5563,0.0796266,0.0459399,0.435179,0.36049,0.829311,0.687677,0.611818,0.563202,0.721217,0.833503,0.772397,0.68917,0.498264,0.467124,0.705014,0.691903,0.14237,0.160623,0.259812,0.34514,-1.18001,-1.03289,2.07032,2.48038,0.188189,0.577177,-0.478225,-0.412189,0.287067,0.164805,-0.6111,-0.925685,0.795884,0.68161,-0.617163,-0.934866,0.155255,0.312678,0.314396,0.280433
5564,0.878493,0.842502,0.976666,0.902747,0.213642,0.0736756,0.137904,0.0910249,0.373953,0.488887,0.14906,0.0645821,0.573234,0.44997,0.345509,0.329765,0.786174,0.803094,0.293126,0.337296,0.565292,0.712662,0.693401,1.11014,-1.02991,-0.584694,0.250094,0.32086,-2.43626,-2.55527,0.725548,0.406688,1.79834,1.68039,0.285188,-0.0380899,0.154764,0.307361,-0.307836,-0.345487
5565,0.998736,0.96272,0.761597,0.773075,0.779443,0.641758,0.937764,0.891762,0.0296652,0.144271,0.418313,0.333353,0.465691,0.432816,0.745539,0.731324,0.461314,0.478551,0.848548,0.891409,-0.232881,-0.0784612,-0.217361,0.193349,-0.978786,-0.539909,-1.13954,-1.0741,0.20648,0.0813222,-1.8874,-2.20138,-0.20967,-0.323164,0.285677,-0.0307589,-0.505491,-0.34695,0.229307,0.188243
5566,0.908319,0.870655,0.720054,0.643404,0.253599,0.118336,0.26419,0.219791,0.380278,0.4963,0.41853,0.274754,0.80679,0.774797,0.316438,0.383851,0.665311,0.616069,0.270678,0.315714,0.283344,0.435574,0.537163,0.947855,-0.148252,0.292093,-0.571039,-0.512563,-0.963554,-1.09477,0.173974,-0.140378,-1.30049,-1.41556,0.662582,0.347952,1.43757,1.60116,-0.744436,-0.784887
5567,0.0344178,-0.00510944,0.76649,0.679982,0.557779,0.418598,0.896973,0.852484,0.422693,0.538479,0.29939,0.216154,0.348481,0.314334,0.0512121,0.0363788,0.735723,0.753587,0.828977,0.874588,0.343083,0.420165,0.192975,0.597889,0.17864,0.614806,0.988663,1.04493,-0.130338,-0.239782,-0.959373,-1.27999,0.231183,0.122401,-1.02442,-1.34525,0.429943,0.584728,0.178064,0.143174
5568,0.168221,0.130717,0.772493,0.716561,0.854984,0.71886,0.281045,0.234832,0.153542,0.27124,0.851108,0.76784,0.35238,0.317785,0.158766,0.142716,0.195021,0.213984,0.799223,0.845216,0.258884,0.404757,0.255603,0.66058,-1.04814,-0.606748,-0.424668,-0.366705,0.748132,0.615209,-1.27066,-1.5887,-0.0400489,-0.151507,0.687285,0.369549,-2.94393,-2.79155,0.591372,0.555235
5569,0.699984,0.662056,0.803788,0.753139,0.615586,0.41959,0.605533,0.560376,0.313813,0.370272,0.994103,0.912824,0.606107,0.569949,0.551877,0.534858,0.254002,0.311688,0.395415,0.438825,0.59547,0.746478,1.64781,2.04693,1.27809,1.71819,0.548943,0.614653,1.9913,1.86431,0.685145,0.372413,-0.0893963,-0.19633,1.17448,0.85424,1.75504,1.90743,0.535582,0.502016
5570,0.750861,0.712304,0.866367,0.789717,0.255269,0.12032,0.931406,0.88592,0.351792,0.469304,0.0528692,-0.028299,0.274749,0.239545,0.422927,0.383951,0.447913,0.409393,0.638793,0.681918,0.205484,0.358358,-1.1851,-0.781341,-1.17207,-0.730181,0.814441,0.887193,0.871009,0.627591,0.388153,0.0805102,1.2138,1.11523,1.06167,0.74039,-0.483717,-0.326058,0.100028,0.0706244
5571,0.0741912,0.0344927,0.634752,0.516015,0.818625,0.682553,0.40758,0.362983,0.278206,0.394276,0.802548,0.72359,0.367182,0.333486,0.252289,0.233043,0.488136,0.507098,0.168376,0.210904,-0.675081,-0.524295,2.25167,2.65394,-2.05441,-1.60935,-0.30199,-0.155329,-0.402282,-0.609129,-1.31075,-1.61358,0.487378,0.395058,-0.155177,-0.476279,0.0680496,0.228586,0.0452723,0.0174048
5572,0.0924375,0.0549304,0.318977,0.242313,0.0237109,-0.113983,0.354565,0.246311,0.962318,1.08019,0.685115,0.531939,0.0328181,-0.00167369,0.812565,0.790942,0.276779,0.293711,0.123838,0.167622,0.332253,0.477911,-0.233714,0.163804,-0.930869,-0.4286,-1.2706,-1.19785,-1.71886,-1.84585,-1.42139,-1.72096,1.32264,1.22259,-1.59095,-1.90926,-0.125939,0.0356876,-1.41109,-1.44581
5573,0.71788,0.680462,0.925866,0.847754,0.615349,0.47904,0.211471,0.129639,0.770604,0.818391,0.419068,0.340288,0.139973,0.189444,0.0496795,0.0294774,0.884402,0.900072,0.972012,1.01608,0.161502,0.3593,-1.60251,-1.20644,0.30558,0.752151,1.1699,1.24515,0.187387,0.0615192,0.373147,0.0721168,-0.805441,-0.903532,0.667448,0.344589,0.501942,0.667006,1.46608,1.43324
5574,0.839375,0.80068,0.261241,0.182077,0.803637,0.669393,0.056471,0.0129676,0.43986,0.556587,0.607169,0.529175,0.413192,0.380563,0.365929,0.345817,0.606724,0.526544,0.545645,0.571757,0.0929886,0.240689,-0.705034,-0.314691,0.17523,0.569692,-0.24053,-0.166483,-0.463165,-0.592832,-0.546963,-0.854095,2.13471,2.04145,0.318723,0.00212369,-2.92969,-2.75747,1.84996,1.81426
5575,0.245127,0.205095,0.374327,0.364297,0.490782,0.354864,0.812429,0.7714,0.0206535,0.137548,0.229796,0.152351,0.140598,0.10963,0.349868,0.307109,0.13752,0.153017,0.082054,0.127433,-0.566793,-0.424204,-0.0277133,0.363668,-0.060053,0.387234,1.50274,1.58058,1.37497,1.23866,-1.6924,-1.9937,-1.51718,-1.61495,-0.334251,-0.648811,-0.785118,-0.607477,-0.84716,-0.884747
5576,0.891215,0.851248,0.624889,0.546516,0.716892,0.608789,0.560117,0.518506,0.748964,0.865546,0.501043,0.421121,0.551463,0.521156,0.287904,0.268401,0.380352,0.385344,0.505877,0.527041,1.8147,1.95304,-0.339545,0.0454672,0.564369,1.01546,-0.133941,-0.0633219,-0.782635,-0.926844,-1.60358,-1.9023,-2.00003,-2.09207,1.90657,1.58939,0.592451,0.775847,-1.32464,-1.36021
5577,0.20364,0.164521,0.0688008,-0.0104656,0.997154,0.862713,0.809315,0.769146,0.384368,0.502118,0.178896,0.0978969,0.235956,0.204896,0.9314,0.912684,0.630582,0.61767,0.880283,0.926649,-0.955479,-0.811832,-1.02083,-0.640775,0.0327001,0.48004,-1.42773,-1.35035,-0.420972,-0.568498,1.23963,0.937572,-1.36182,-1.46123,0.0550922,-0.263834,1.62261,1.79759,0.334518,0.303957
5578,0.322266,0.212412,0.490601,0.408648,0.351463,0.218422,0.134661,0.0912378,0.474863,0.668974,0.874234,0.794286,0.353905,0.343812,0.786267,0.720005,0.8345,0.849997,0.0838106,0.131069,-0.0935738,0.0501187,-0.593527,-0.210207,0.285906,0.727064,-1.45383,-1.3699,0.926139,0.784112,0.531195,0.226196,0.229403,0.126159,0.265565,-0.0562293,-0.407738,-0.232652,-0.821634,-0.854191
5579,0.319517,0.260302,0.355361,0.274806,0.245828,0.112379,0.580091,0.534648,0.718538,0.83583,0.606096,0.431879,0.512676,0.482728,0.546313,0.527326,0.103863,0.118807,0.29488,0.343583,0.0422081,0.192792,-0.722625,-0.346184,0.187448,0.633796,-0.71719,-0.636852,0.0630526,-0.0874379,-0.568757,-0.869722,-1.92274,-2.03115,-0.759412,-1.08791,0.176706,0.297795,0.580533,0.549758
5580,0.245598,0.308193,0.966115,0.885139,0.446899,0.288115,0.333379,0.286714,0.458433,0.673674,0.151493,0.0694708,0.24017,0.211795,0.689358,0.737479,0.357262,0.37055,0.0961333,0.142843,-0.827839,-0.673762,-1.52277,-1.14085,-0.805119,-0.354344,-1.22872,-1.15031,-0.201721,-0.348298,-2.08001,-2.37951,-0.377433,-0.493184,-0.993557,-1.32377,0.656692,0.828243,-0.216162,-0.242907
5581,0.395203,0.356084,0.771062,0.644167,0.596503,0.463852,0.677692,0.630058,0.393875,0.511517,0.0472028,-0.0341224,0.589259,0.559496,0.96513,0.947632,0.335996,0.349694,0.815702,0.862372,-0.807375,-0.652467,-0.217797,0.168803,0.221742,0.67618,-0.291535,-0.216921,-1.08616,-1.23361,-0.738546,-1.0332,-0.0753763,-0.185056,0.1428,-0.1824,0.706901,0.883983,-0.00310557,-0.0266576
5582,0.237981,0.239075,0.605155,0.403196,0.194816,0.063739,0.0484437,0.00238218,0.347171,0.467083,0.934391,0.853021,0.471413,0.439732,0.693358,0.596248,0.0896301,0.101174,0.942652,0.988361,0.202533,0.364445,-0.487904,-0.105201,-0.0860719,0.371663,-0.376313,-0.297524,1.41773,1.261,-0.0561505,-0.345863,0.247168,0.123073,2.84283,2.51749,-1.25572,-1.08562,-1.06453,-1.09152
5583,0.130256,0.122066,0.241522,0.162225,0.555459,0.426117,0.567595,0.520431,0.0657198,0.184664,0.374666,0.294173,0.747312,0.71583,0.262414,0.244864,0.623051,0.635766,0.197318,0.245271,1.94423,2.11,1.53493,1.92251,0.375673,0.830538,0.537554,0.62093,1.08431,0.971554,0.164578,-0.131501,0.209716,0.164058,-0.0273006,-0.349476,0.0539224,0.231236,-0.317646,-0.343087
5584,0.043445,0.00505667,0.623511,0.511619,0.0486594,-0.0822704,0.757621,0.711008,0.661485,0.77945,0.0476018,-0.0344079,0.324893,0.294808,0.310439,0.294879,0.70588,0.71848,0.57473,0.625005,-0.0294525,0.132052,-0.733853,-0.346999,0.0291813,0.480031,-1.4018,-1.32305,0.84389,0.682104,0.599821,0.297733,0.329402,0.205042,-1.22628,-1.55003,0.112422,0.286976,-0.315558,-0.335507
5585,0.743241,0.705749,0.940309,0.861012,0.213374,-0.00370719,0.36986,0.324288,0.516994,0.633041,0.718917,0.637654,0.785392,0.756117,0.919788,0.904653,0.314857,0.328433,0.208887,0.258845,1.07586,1.23956,-0.129323,0.254848,0.535876,0.983554,-0.506142,-0.419606,0.737561,0.575457,0.639344,0.342757,-0.0331912,-0.162135,0.0235419,-0.30281,-1.36652,-1.18555,-0.086285,-0.102475
5586,0.299107,0.259903,0.612447,0.535328,0.205477,0.0748561,0.855558,0.812752,0.0785504,0.194534,0.913208,0.831398,0.1251,0.0944228,0.064817,0.0493169,0.241353,0.253489,0.28623,0.252174,-0.308478,-0.148221,0.0365003,0.363189,-0.691913,-0.238,-0.44467,-0.36122,-0.87799,-1.04768,-0.116497,-0.416251,2.02912,1.89478,-1.41433,-1.73579,-0.230975,-0.0552757,-0.959464,-0.97187
5587,0.652975,0.611724,0.289505,0.209644,0.170171,0.0413119,0.191255,0.149459,0.737844,0.85492,0.605591,0.522356,0.431747,0.35522,0.402351,0.353568,0.697113,0.708906,0.196232,0.245503,1.54022,1.70278,0.0843651,0.47153,0.748903,1.2025,-1.36689,-1.27953,-1.19812,-1.36889,1.12179,0.823359,-2.32703,-2.46137,0.314561,-0.0090249,0.176031,0.357149,0.188363,0.170717
5588,0.303667,0.261663,0.421329,0.343497,0.598087,0.470391,0.0528668,0.0122393,0.0999493,0.215288,0.52886,0.444127,0.643654,0.616017,0.60414,0.657818,0.796436,0.813712,0.0425264,0.1844,-0.458672,-0.290073,-0.304927,0.0757554,-0.467926,-0.0190548,-0.419745,-0.330673,1.19274,1.01774,-1.33941,-1.63391,0.319521,0.189284,-1.122,-1.442,0.102709,0.290373,0.963383,0.94707
5589,0.908176,0.86764,0.0763314,-0.00150551,0.26719,0.230248,0.53359,0.494841,0.398225,0.512864,0.214952,0.130367,0.908228,0.876814,0.976139,0.962069,0.907834,0.918518,0.012341,0.123297,-2.69555,-2.52205,0.211152,0.585307,-0.930193,-0.476589,-1.54146,-1.44849,-2.14739,-2.3171,-0.0835413,-0.378643,0.0425364,-0.0846231,-0.902816,-1.2175,1.14774,1.32884,0.398204,0.380485
5590,0.86639,0.88909,0.00757808,-0.0705475,0.119327,-0.00989459,0.359359,0.387091,0.291369,0.405959,0.912325,0.826756,0.522649,0.491053,0.939028,0.963882,0.299313,0.308265,0.0113264,0.0621946,1.97672,2.15066,0.292455,0.663485,-2.26257,-1.80497,-1.71471,-1.62198,-1.46705,-1.6371,1.90004,1.59884,-0.44333,-0.513032,1.36642,1.05131,0.579644,0.76643,0.175999,0.160291
5591,0.950398,0.910539,0.235138,0.156694,0.162325,0.0315137,0.316075,0.27934,0.502113,0.658044,0.333208,0.246993,0.587495,0.554567,0.978462,0.965695,0.331529,0.341932,0.608494,0.660675,2.07265,2.24688,-0.348308,0.0260442,-0.278062,0.182668,0.151138,0.24984,0.318047,0.145448,-0.795892,-1.09505,-0.812049,-0.94144,0.541942,0.175612,0.323077,0.512731,-0.900285,-0.922595
5592,0.0356564,-0.00542954,0.0206974,-0.0577605,0.840411,0.711229,0.934068,0.897023,0.794327,0.91013,0.419616,0.33217,0.869624,0.835633,0.77085,0.758816,0.684319,0.693216,0.588414,0.641169,-0.51831,-0.341729,-0.975924,-0.611397,-0.886207,-0.418551,0.128552,0.230293,0.489683,0.319511,0.42913,0.129222,0.143316,0.011448,-0.377419,-0.700089,0.700863,0.894713,0.769593,0.741568
5593,0.296325,0.256494,0.633976,0.557247,0.0774369,-0.0532803,0.0673314,0.0327835,0.63023,0.699784,0.257143,0.16955,0.677246,0.640685,0.931007,0.920281,0.512023,0.519953,0.852651,0.904198,0.227817,0.399545,1.53681,1.90007,-0.0695232,0.396847,1.26267,1.36557,0.433697,0.259873,0.874428,0.658331,-0.0162706,-0.155416,0.311077,-0.0167812,0.311216,0.50335,0.463219,0.43084
5594,0.96013,0.922776,0.775748,0.700798,0.924275,0.793116,0.924008,0.889787,0.373177,0.489438,0.44127,0.354333,0.729066,0.637101,0.103503,0.0927663,0.660499,0.669342,0.883262,0.936103,-0.39877,-0.221972,-2.15705,-1.79632,-0.133693,0.336189,-0.715297,-0.614673,-0.667651,-0.840827,1.48962,1.18744,0.445062,0.380988,0.122702,-0.206438,-0.795367,-0.603922,0.434974,0.407804
5595,0.247819,0.208174,0.466277,0.390208,0.753833,0.559152,0.217218,0.182443,0.92206,1.03815,0.353656,0.32133,0.669389,0.633518,0.674836,0.666383,0.194137,0.204458,0.454609,0.505434,1.25183,1.43055,0.305596,0.666121,0.778669,1.24331,-0.450183,-0.358244,0.207288,0.0382525,-1.32375,-1.6301,1.05989,0.917392,0.322388,-0.0128885,1.76429,1.95043,1.61304,1.58169
5596,0.99703,0.956828,0.388756,0.312414,0.456183,0.325187,0.145472,0.109297,0.558543,0.596448,0.376381,0.288326,0.40106,0.362585,0.659096,0.682543,0.387712,0.40004,0.320386,0.37086,-0.268924,-0.0932309,-0.947242,-0.592554,-1.08183,-0.613733,1.25775,1.35339,0.0173058,-0.146593,-0.999365,-1.31578,0.411653,0.220019,0.765485,0.424634,1.04743,1.23467,-0.795898,-0.836026
5597,0.318241,0.279017,0.0271671,-0.0468009,0.992352,0.862831,0.315318,0.374728,0.0386562,0.154746,0.90292,0.815003,0.644634,0.603697,0.707269,0.698704,0.0602791,0.0707454,0.954281,1.00476,1.02667,1.20048,-0.265294,0.0858056,-0.429351,0.0455925,-1.69774,-1.60818,-0.161469,-0.331439,-0.695109,-1.00145,-0.332232,-0.477354,-0.279784,-0.622941,-0.497666,-0.315211,1.29516,1.25014
5598,0.758043,0.717032,0.3627,0.356778,0.139214,0.0118538,0.678204,0.640159,0.488273,0.602949,0.894881,0.807184,0.562348,0.474691,0.489809,0.481616,0.133872,0.228459,0.83135,0.879677,0.524819,0.701669,-2.21159,-1.86686,1.48796,1.96928,0.144048,0.234231,1.35546,1.19113,-1.56939,-1.8817,-0.299971,-0.446452,1.28155,0.933503,-0.797758,-0.615958,-2.14491,-2.18801
5599,0.2947,0.251212,0.835141,0.760357,0.292712,0.163452,0.0397315,0.00290186,0.170339,0.285269,0.561043,0.473702,0.388282,0.345685,0.97616,0.968512,0.376535,0.386172,0.323462,0.374001,0.569233,0.752339,-0.0682445,0.274165,-1.62061,-1.14458,-0.264135,-0.170933,0.53603,0.366361,-0.662916,-0.977726,0.791432,0.641497,-0.046756,-0.392236,-1.72579,-1.53748,0.200223,0.154354
5600,0.655869,0.540845,0.00703641,-0.0695106,0.999196,0.868945,0.943266,0.907212,0.244737,0.359425,0.537186,0.450526,0.0564913,0.0152806,0.42672,0.417534,0.188637,0.199083,0.0632042,0.112895,0.350722,0.53169,0.82408,1.16592,1.04306,1.5142,-0.433897,-0.344429,0.160994,-0.0159609,-0.705275,-1.02413,0.0513442,-0.0959047,1.41234,1.07191,1.01655,1.21147,-0.950844,-1.0038
5601,0.873318,0.830478,0.00768479,-0.069888,0.365158,0.234803,0.430927,0.394301,0.556114,0.671442,0.812742,0.725523,0.67146,0.631457,0.53759,0.528242,0.963969,0.976095,0.461649,0.438039,0.705141,0.891131,1.01254,1.3515,0.720143,1.192,0.172118,0.262465,1.55928,1.38457,0.151823,-0.167744,1.47099,1.32255,0.143615,-0.191914,0.0114617,0.226397,0.85016,0.802698
5602,0.194893,0.152667,0.59314,0.51557,0.395638,0.266527,0.454683,0.41689,0.100773,0.218053,0.622387,0.537043,0.864133,0.822947,0.89191,0.880594,0.932087,0.94635,0.713959,0.763183,-0.251022,-0.067769,-1.79447,-1.46201,-0.456813,0.0164087,0.276333,0.365032,0.85855,0.62982,-0.158152,-0.476462,0.725069,0.571742,0.684438,0.354275,-0.946039,-0.758676,0.0384677,-0.00444579
5603,0.287375,0.243714,0.863827,0.786606,0.985967,0.854897,0.9969,0.959779,0.672471,0.792346,0.990283,0.9066,0.420553,0.377183,0.97538,0.878404,0.671738,0.687539,0.843577,0.895245,0.0906965,0.273951,-0.647841,-0.324175,0.341195,0.815432,1.69948,1.79452,0.0486263,-0.124929,0.72309,0.411889,-0.814823,-0.960522,0.463913,0.134482,-0.779027,-0.595551,0.349427,0.381716
5604,0.177837,0.160655,0.255687,0.180785,0.50027,0.369336,0.740158,0.71903,0.870473,0.991899,0.559526,0.475881,0.917112,0.874036,0.96069,0.876214,0.948148,0.96381,0.71136,0.766032,0.956652,1.1359,-0.471175,-0.152907,0.899188,1.36739,-0.0275244,0.069897,-0.289581,-0.462377,0.761772,0.456913,0.0648965,-0.0859964,2.16262,1.83192,-0.842201,-0.662327,0.814775,0.767877
5605,0.120016,0.0775954,0.91016,0.834953,0.376723,0.287386,0.5171,0.478282,0.553645,0.578204,0.486135,0.403186,0.333108,0.291608,0.886541,0.874024,0.343436,0.35815,0.990617,1.04385,-0.465445,-0.28367,-2.01586,-1.69527,1.0386,1.50526,-0.772665,-0.676355,-0.369383,-0.537809,0.0840032,-0.225185,0.626578,0.432336,1.63203,1.30567,-0.336434,-0.154151,0.11373,0.0809272
5606,0.477479,0.434413,0.60461,0.528982,0.396144,0.205436,0.891819,0.852123,0.0430831,0.164509,0.00460565,-0.0769521,0.42592,0.451456,0.397114,0.382947,0.234353,0.25087,0.627474,0.682747,0.0137815,0.200504,1.32842,1.6542,0.572059,1.12255,0.464662,0.564499,0.694671,0.525596,0.900738,0.5861,1.10518,0.950669,-0.134775,-0.465378,-0.453949,-0.267768,-0.565434,-0.606023
5607,0.534661,0.584209,0.57275,0.498737,0.254652,0.123487,0.829195,0.765723,0.83268,0.95235,0.912048,0.829886,0.651782,0.611305,0.827903,0.814596,0.707098,0.72142,0.796124,0.801476,1.09804,1.27692,0.997803,1.31964,0.278252,0.73985,-1.11522,-1.01389,0.708721,0.546707,0.060096,-0.247236,0.38652,0.230501,1.48443,1.15329,-1.28158,-1.09381,-2.82029,-2.85672
5608,0.775123,0.734005,0.0880061,0.0154469,0.81024,0.681458,0.717776,0.679322,0.619991,0.740554,0.483397,0.399166,0.595393,0.552926,0.25073,0.238451,0.683498,0.696939,0.865366,0.920205,-1.56176,-1.37832,1.06476,1.38233,-1.16466,-0.696204,-2.32553,-2.2246,-0.0703706,-0.229868,-0.770974,-1.08057,0.956699,0.800471,-1.37212,-1.69694,-0.781141,-0.585638,-1.05024,-1.08101
5609,0.292908,0.253058,0.0432021,-0.0291867,0.410236,0.281345,0.128084,0.0915476,0.972627,1.09258,0.845766,0.763485,0.0168235,-0.0241469,0.265361,0.25427,0.413767,0.428067,0.198584,0.25396,-1.017,-0.835363,-0.332937,-0.0203772,0.43464,0.899242,-0.301848,-0.206747,0.472888,0.309668,1.09714,0.788999,-0.369356,-0.526435,-1.1067,-1.42526,-0.832533,-0.649761,-0.403881,-0.439108
5610,0.908442,0.868389,0.843719,0.772365,0.682668,0.552614,0.227692,0.19077,0.394024,0.613403,0.929528,0.771705,0.0976114,0.0548453,0.819038,0.807468,0.884281,0.898618,0.551015,0.607842,0.867502,1.04639,1.22014,1.53977,-0.99196,-0.521871,0.156118,0.248976,0.156617,-0.0115353,0.471429,0.168711,2.25787,2.09405,-1.22706,-1.53911,-0.910857,-0.713883,-0.284532,-0.325979
5611,0.948112,0.806585,0.638395,0.56742,0.601978,0.532164,0.717562,0.679235,0.0138267,0.134223,0.907648,0.779925,0.771253,0.727573,0.90278,0.893194,0.8256,0.838848,0.306873,0.362531,-0.0917697,0.0874873,-0.448426,-0.128479,0.366046,0.842101,-0.928687,-0.839658,0.629674,0.466548,0.972977,0.675806,0.338781,0.171528,2.13564,1.82075,1.14905,1.35276,-1.57607,-1.62133
5612,0.889611,0.744782,0.227631,0.158013,0.530389,0.511714,0.908013,0.869812,0.714318,0.835294,0.870586,0.788145,0.58256,0.53859,0.375473,0.367385,0.0994799,0.113152,0.994488,1.05111,-0.194603,-0.0143488,0.148541,0.473367,1.33056,1.81007,0.7108,0.795989,-1.42705,-1.58398,0.0695286,-0.221733,0.522349,0.354071,-0.123215,-0.430218,0.349412,0.588207,0.301763,0.260945
5613,0.769702,0.682978,0.39416,0.287192,0.621212,0.491264,0.643324,0.606373,0.516461,0.722506,0.671787,0.677518,0.613479,0.537651,0.148443,0.140424,0.0193321,0.0327876,0.827469,0.886105,-0.0878042,0.0970986,-1.34633,-1.02151,1.03449,1.52062,-0.947608,-0.865603,0.232445,0.0754009,1.17036,0.878876,-0.612825,-0.785935,0.683145,0.375643,-0.3888,-0.176345,0.893591,0.855182
5614,0.659079,0.621174,0.485496,0.416371,0.00171111,-0.127276,0.138582,0.103444,0.490619,0.609717,0.662994,0.566892,0.581114,0.536712,0.163712,0.156243,0.492137,0.503338,0.439307,0.496112,1.52588,1.70393,-1.05307,-0.725909,-0.57264,-0.0842281,-0.510341,-0.426461,0.502018,0.340919,-0.351796,-0.645203,0.441385,0.273077,0.580606,0.277892,-0.446232,-0.229464,-0.818983,-0.854874
5615,0.048722,0.0094185,0.170222,0.1006,0.125555,-0.00612814,0.516297,0.481757,0.158991,0.277573,0.403405,0.456266,0.0685198,0.0251115,0.763767,0.754533,0.168314,0.178795,0.288719,0.345753,0.150101,0.332816,0.513958,0.834234,0.99458,1.47896,0.852098,0.938482,-0.14087,-0.299275,-0.214924,-0.507919,0.578596,0.410551,1.43506,1.13004,0.962322,1.18549,1.73144,1.69237
5616,0.782804,0.742041,0.930114,0.862331,0.601763,0.472055,0.688066,0.651892,0.92683,1.04662,0.428081,0.345639,0.224683,0.18047,0.240604,0.233435,0.188106,0.19858,0.950665,1.0091,-0.750778,-0.592301,-0.661198,-0.346845,-0.0509825,0.428431,-1.08075,-0.992172,-0.415304,-0.574009,0.499933,0.21127,-0.429369,-0.591253,1.59403,1.29218,0.82866,1.05565,0.301551,0.258196
5617,0.73092,0.701988,0.236612,0.1671,0.0468975,-0.0820862,0.618673,0.584951,0.161407,0.282685,0.465055,0.469253,0.752646,0.707333,0.162632,0.156728,0.823799,0.835813,0.648379,0.661817,-1.69866,-1.51742,-0.299668,0.0986968,0.659653,1.13522,-0.274581,-0.182698,0.48343,0.321733,1.87715,1.58751,0.0171449,-0.144352,2.0893,1.79208,-0.122337,0.101024,2.33369,2.29353
5618,0.742814,0.661935,0.876208,0.806451,0.71131,0.58263,0.290221,0.257465,0.683961,0.806204,0.699041,0.592867,0.410921,0.367296,0.671475,0.663733,0.684723,0.609818,0.253895,0.314537,-1.63383,-1.45032,0.228451,0.544238,0.616073,1.09086,-1.50402,-1.40864,0.975838,0.817277,0.583914,0.293767,-1.22092,-1.37728,-0.116613,-0.408496,-0.672679,-0.445806,-0.259836,-0.306761
5619,0.544777,0.621881,0.647987,0.608764,0.821566,0.694425,0.315863,0.28542,0.39604,0.518877,0.798158,0.716481,0.98762,0.943797,0.0505813,0.0424893,0.370345,0.383822,0.745348,0.804007,1.00863,1.18701,0.156705,0.469773,0.852207,1.32181,-1.90682,-1.8138,-0.342037,-0.500168,0.890053,0.595826,-0.916271,-1.06958,-0.674543,-0.965447,1.54466,1.76795,-0.534868,-0.586921
5620,0.592309,0.581828,0.480416,0.411078,0.0124735,-0.11365,0.752537,0.724087,0.795144,0.916599,0.34743,0.265174,0.050612,0.00560985,0.471817,0.389413,0.521156,0.533212,0.550496,0.608436,0.347301,0.522116,0.526282,0.838434,-0.877906,-0.407774,0.945719,1.04412,2.26494,2.10714,-1.34528,-1.64063,0.801789,0.656664,0.31747,0.0237266,-0.258599,-0.0384321,-0.457783,-0.506244
5621,0.582537,0.541775,0.738761,0.667691,0.985902,0.861997,0.950252,0.920379,0.302807,0.423263,0.450552,0.336808,0.577477,0.532472,0.744304,0.736336,0.0745007,0.0886357,0.74382,0.800485,-2.47449,-2.30171,0.423437,0.732964,-0.871281,-0.407799,1.60539,1.69912,0.126576,-0.0250552,2.074,1.78531,-0.632839,-0.780792,0.179128,-0.120734,-0.293123,-0.0744859,-0.792479,-0.847345
5622,0.0420471,0.000676905,0.10628,0.0373624,0.736426,0.670183,0.254107,0.223223,0.754398,0.875898,0.492184,0.408443,0.56224,0.51471,0.684209,0.675681,0.841798,0.855042,0.213901,0.26903,-0.587239,-0.419959,0.0344123,0.337189,-0.28341,0.117637,0.893439,0.985005,-0.278025,-0.421553,-0.401164,-0.696434,-0.369013,-0.521216,0.949199,0.653782,1.45532,1.66634,0.703808,0.648809
5623,0.457014,0.413998,0.703795,0.633668,0.601088,0.478368,0.658235,0.627705,0.959148,1.08112,0.810554,0.72855,0.0518325,0.00310922,0.955976,0.946359,0.106961,0.118721,0.0777508,0.134457,0.426083,0.596952,-0.872652,-0.56496,0.181484,0.643074,-0.0915738,0.00598534,0.222155,0.0739905,-0.850565,-1.14478,0.251735,0.0945743,-0.255985,-0.546773,-0.122893,0.0855346,1.67162,1.62246
5624,0.468086,0.424304,0.0734946,0.00333904,0.149141,0.0243744,0.281561,0.250089,0.629515,0.753957,0.62053,0.484807,0.803258,0.752622,0.546482,0.587707,0.997139,1.00721,0.784969,0.843183,0.539633,0.708399,-0.780375,-0.472455,-1.07553,-0.607083,-0.0869474,0.0175531,-2.18241,-2.33207,1.11978,0.832703,-1.68803,-1.84567,-0.622758,-0.919469,-0.945473,-0.740511,1.9249,1.86882
5625,0.0715369,0.0281538,0.58518,0.515778,0.273386,0.11734,0.584092,0.554506,0.80131,0.924485,0.321574,0.241065,0.400216,0.352284,0.239037,0.229055,0.175088,0.183036,0.17611,0.233229,-1.29352,-1.12692,-1.44142,-1.1278,1.40027,1.86837,0.254434,0.365945,-0.384941,-0.532557,-1.52538,-1.80537,-1.342,-1.42192,0.554164,0.254091,0.977968,1.17439,0.715016,0.60945
5626,0.3101,0.264367,0.0981809,0.0280026,0.334797,0.210305,0.329864,0.301612,0.342235,0.529623,0.504487,0.324642,0.210056,0.163301,0.833764,0.822203,0.438802,0.444695,0.245544,0.366011,-1.07487,-0.908029,-0.720293,-0.405726,1.5909,2.0515,1.36258,1.46806,0.312678,0.161926,0.537165,0.255642,-0.84053,-0.99817,-2.41683,-2.71211,0.687669,0.890361,-0.593841,-0.649919
5627,0.303851,0.259724,0.253138,0.182049,0.947543,0.823913,0.728031,0.60297,0.013404,0.13476,0.489019,0.408218,0.234382,0.185791,0.542647,0.494148,0.0235061,0.030628,0.441834,0.498793,-0.523096,-0.351034,1.407,1.71815,-1.34761,-0.883055,1.19301,1.29457,-1.26215,-1.41472,1.25486,0.967138,-0.751138,-0.905997,-0.453493,-0.748952,1.00203,1.20894,-0.154854,-0.206611
5628,0.85908,0.816273,0.0394398,-0.032406,0.540484,0.418359,0.932112,0.904329,0.711806,0.831145,0.100682,0.0207652,0.651877,0.602563,0.177833,0.166093,0.191519,0.200313,0.991817,1.04773,0.332258,0.510916,0.0174535,0.33153,0.898461,1.36144,0.704291,0.813408,1.57615,1.42996,1.96331,1.67863,-0.387481,-0.537469,-0.341716,-0.6327,-0.130977,0.165607,1.12052,1.07343
5629,0.931806,0.887006,0.335154,0.264202,0.934534,0.810277,0.34027,0.310905,0.497996,0.619349,0.3772,0.209725,0.0649041,0.0152563,0.476964,0.467086,0.137215,0.144749,0.961379,1.01836,1.68625,1.86836,-1.01156,-0.626386,0.311466,0.836953,-0.197311,-0.0868455,0.346271,0.206078,1.16474,0.875022,1.43853,1.28483,-0.469163,-0.755679,-1.07816,-0.877725,-2.10112,-2.15374
5630,0.0252836,-0.0189069,0.995425,0.923536,0.672667,0.550278,0.493918,0.465537,0.020821,0.140394,0.476431,0.398685,0.704094,0.656543,0.140969,0.130349,0.737288,0.746623,0.332888,0.387594,-1.80324,-1.62759,-1.89838,-1.5843,-0.155066,0.312466,-0.732871,-0.614941,0.812759,0.670195,-0.491018,-0.785369,-0.745229,-0.90435,-0.593583,-0.878659,1.04554,1.2402,-0.420165,-0.472842
5631,0.111137,0.0541215,0.553816,0.497073,0.15278,0.0314862,0.322826,0.293298,0.972159,1.09042,0.937922,0.861634,0.690214,0.64388,0.635517,0.627605,0.152578,0.161643,0.141782,0.196973,1.10672,1.28649,0.172882,0.488205,0.128877,0.590068,0.312633,0.426353,0.529978,0.381785,-0.616126,-0.91066,-1.37602,-1.53313,0.684708,0.397468,-1.61644,-1.42166,-1.72933,-1.78378
5632,0.247323,0.12715,0.142,0.0706103,0.922653,0.802713,0.463714,0.446181,0.197565,0.315454,0.596612,0.518885,0.226513,0.178149,0.454852,0.445433,0.106433,0.116937,0.581301,0.593151,0.54344,0.727924,-1.08933,-0.770469,-0.0378501,0.421078,0.158979,0.268664,-1.58393,-1.73626,0.724362,0.435647,2.44935,2.29108,-0.501092,-0.710973,-0.726929,-0.526614,1.08697,1.0324
5633,0.242584,0.200178,0.228615,0.242861,0.843467,0.722589,0.645215,0.599064,0.241022,0.357634,0.698059,0.618108,0.0802125,0.033212,0.904875,0.897132,0.720366,0.732984,0.934591,0.98933,0.511383,0.688689,0.173126,0.492962,-0.214124,0.252088,-0.802811,-0.694399,0.388592,0.238568,0.0859983,-0.199893,0.259811,0.101906,-1.53158,-1.81941,-0.586568,-0.379312,-1.57571,-1.63764
5634,0.683506,0.642856,0.485252,0.415111,0.172675,0.0534659,0.783293,0.751947,0.808284,0.926374,0.12217,0.0437439,0.198947,0.159598,0.436725,0.430489,0.878465,0.892366,0.563445,0.561681,-0.268776,-0.0861093,0.673949,0.987146,-0.720835,-0.251544,0.792107,0.892828,-1.42161,-1.56854,0.393204,0.102166,-0.834087,-0.939167,0.26704,-0.0141611,-0.0929066,0.111085,-0.615983,-0.678132
5635,0.820805,0.778683,0.153425,0.0848549,0.630717,0.512301,0.44166,0.410481,0.431922,0.566031,0.952158,0.873648,0.331416,0.285985,0.230348,0.22361,0.826667,0.9048,0.0786529,0.134032,0.0123704,0.196819,-0.521952,-0.209359,0.486003,0.958069,0.150174,0.256822,-0.395815,-0.535069,0.129977,-0.158987,-1.82623,-1.98024,1.15128,0.867828,-0.591121,-0.390205,-1.61483,-1.68192
5636,0.425118,0.382533,0.890769,0.820868,0.284115,0.241505,0.786761,0.753825,0.0891708,0.205688,0.357726,0.278767,0.160272,0.17383,0.807958,0.801485,0.811036,0.917234,0.0196101,0.0756946,0.769787,0.954458,-0.658747,-0.345335,-0.848945,-0.370309,1.38207,1.48392,-1.97817,-2.11171,-1.56958,-1.85308,-0.565963,-0.719074,-1.92343,-2.20612,-0.533355,-0.334466,-1.24473,-1.31402
5637,0.249237,0.204987,0.734831,0.662339,0.0917655,-0.0292903,0.124237,0.0905324,0.379583,0.497642,0.979932,0.899525,0.108863,0.0616747,0.930173,0.922785,0.90928,0.929668,0.294839,0.397281,0.198983,0.394715,-0.232523,0.158948,0.653858,1.13095,0.0230039,0.121106,2.01288,1.87778,-1.71589,-1.99241,-0.961703,-1.11729,-0.103169,-0.385017,1.00345,1.20206,1.12529,1.06105
5638,0.360537,0.315696,0.864699,0.710876,0.120521,-0.00200377,0.174613,0.0424317,0.388754,0.48476,0.722672,0.641537,0.512792,0.463612,0.715385,0.705697,0.9282,0.942102,0.664952,0.718868,-0.346575,-0.165028,0.355132,0.663231,-0.326119,0.15606,0.680614,0.776105,-0.828274,-0.956743,-1.14258,-1.42488,1.38013,1.23083,-0.235395,-0.513814,-0.41102,-0.206251,0.429847,0.359042
5639,0.149619,0.106851,0.942444,0.759412,0.622977,0.501557,0.0295615,-0.00566896,0.352647,0.471877,0.017331,-0.0634845,0.563832,0.516886,0.203524,0.194427,0.191294,0.20578,0.102629,0.157797,1.20117,1.38127,1.10075,1.40287,-0.0793101,0.403085,0.0683754,0.170586,-1.4814,-1.61109,0.939318,0.648945,-0.423058,-0.568023,0.897959,0.615099,2.9695,3.18086,-2.09298,-2.16452
5640,0.871473,0.827642,0.879686,0.807948,0.589051,0.468013,0.490184,0.456864,0.661929,0.779138,0.503717,0.402014,0.928298,0.879346,0.586442,0.547907,0.506131,0.520625,0.514603,0.571577,-0.158034,0.0259163,-0.984179,-0.686666,1.52808,2.01304,0.268888,0.366328,-0.100999,-0.22503,0.632976,0.340227,0.334497,0.184767,-0.43423,-0.71064,0.712562,0.933743,-0.965182,-1.03716
5641,0.649597,0.604084,0.286496,0.216835,0.177242,0.058381,0.399525,0.31615,0.318414,0.435564,0.948329,0.867514,0.610037,0.563087,0.91205,0.901387,0.183155,0.196082,0.400894,0.455785,0.87769,1.05677,0.96083,1.25703,-0.51338,-0.033382,-0.0885394,0.0065202,0.958754,0.838375,-0.464996,-0.755692,-1.65087,-1.80291,1.43902,1.15663,-0.0429345,0.241445,-0.989758,-1.06019
5642,0.0221855,-0.0218025,0.528173,0.53414,0.0285027,-0.0886108,0.211156,0.175437,0.875355,0.994833,0.500106,0.421463,0.627005,0.665798,0.811789,0.882251,0.327685,0.340525,0.954348,1.0099,-1.6925,-1.50786,1.76588,2.05836,0.319222,0.79862,-1.14148,-1.05138,0.753686,0.672633,0.103589,-0.19296,-0.886764,-1.03581,-0.647362,-0.928327,-0.66247,-0.450852,-0.492586,-0.559037
5643,0.41583,0.371145,0.920447,0.851445,0.837443,0.721647,0.881462,0.84822,0.669452,0.868919,0.894241,0.815685,0.813752,0.76851,0.880732,0.863116,0.705065,0.716334,0.747036,0.849339,0.00403176,0.190651,-0.208881,0.075942,1.55324,2.02617,1.18734,1.2751,0.626137,0.50689,0.660738,0.369771,-0.323111,-0.46584,0.403332,0.12291,0.36197,0.57089,0.0153001,-0.0578808
5644,0.596441,0.554511,0.584652,0.516371,0.46672,0.352303,0.496841,0.465874,0.622611,0.743005,0.156212,0.0761853,0.421613,0.377173,0.855456,0.84398,0.614629,0.592196,0.516092,0.68878,0.135071,0.238681,-0.221372,0.061145,-0.447494,0.0285809,-1.38117,-1.29482,-0.247665,-0.36466,0.256082,-0.0300783,0.801079,0.654558,0.8954,0.607601,0.159053,0.364106,0.0187132,-0.0503004
5645,0.782638,0.737877,0.743048,0.686113,0.738569,0.623572,0.960787,0.928407,0.994614,1.11631,0.846287,0.767462,0.364461,0.318794,0.300099,0.287867,0.454927,0.468057,0.473445,0.528221,0.10023,0.286711,0.394235,0.677062,-2.70938,-2.22678,0.188642,0.279505,0.072657,-0.0380413,1.06096,0.781207,-0.648799,-0.79686,-2.10022,-2.38984,-0.394021,-0.182723,-1.47982,-1.54264
5646,0.445852,0.402725,0.921895,0.855855,0.0649356,-0.0502246,0.795649,0.760803,0.838076,0.941537,0.362765,0.282743,0.548165,0.447862,0.336509,0.2442,0.728036,0.739032,0.629055,0.685483,0.925916,1.11797,0.476835,0.778207,1.03688,1.51865,0.413214,0.507994,-1.10626,-1.21414,1.42574,1.1466,-1.50546,-1.65521,-1.93378,-2.22771,-1.21314,-1.00877,-0.818375,-0.88559
5647,0.894284,0.85059,0.313078,0.244891,0.847104,0.732452,0.151165,0.118553,0.644005,0.766761,0.270751,0.208718,0.577408,0.57693,0.21158,0.200533,0.0476069,0.0590911,0.54342,0.609913,0.730507,0.830422,0.505148,0.879352,0.12441,0.60876,-0.248116,-0.159232,-0.599104,-0.703726,0.453063,0.174143,0.263039,0.11594,-0.0156593,-0.313562,1.61328,1.8191,-0.677864,-0.743533
5648,0.923074,0.881021,0.350605,0.283264,0.280869,0.168194,0.731231,0.696433,0.710829,0.835933,0.217577,0.134693,0.878192,0.705997,0.702544,0.691819,0.740755,0.750644,0.47522,0.534343,0.350247,0.542878,0.69767,0.980497,1.08546,1.57673,-1.22431,-1.13825,-0.510119,-0.621539,1.98132,1.70538,0.783981,0.637695,-1.46941,-1.76061,0.964724,1.16479,2.13109,2.06271
5649,0.104206,0.0636268,0.155272,0.088634,0.876794,0.765901,0.136475,0.10301,0.186502,0.312919,0.465442,0.424568,0.880732,0.835065,0.245088,0.235365,0.974356,0.982639,0.771989,0.765817,-0.302567,-0.108008,1.16691,1.45674,-1.65117,-1.16057,-1.20609,-1.12668,1.27306,1.161,-1.90179,-2.17773,1.0167,0.865875,0.573876,0.279305,-1.52291,-1.32057,-0.189243,-0.25872
5650,0.924684,0.88149,0.739432,0.674092,0.0542775,-0.0586601,0.90192,0.866408,0.801679,0.927017,0.796996,0.714442,0.103235,0.0591948,0.602678,0.592874,0.339538,0.346928,0.940478,0.997291,0.294862,0.495531,1.21163,1.50393,-1.53606,-1.03974,-0.0407531,0.0398967,-0.694056,-0.805268,-1.75726,-2.0272,0.415075,0.268399,-1.46467,-1.75925,-1.33716,-1.12801,0.522773,0.459279
5651,0.363098,0.319775,0.894267,0.828139,0.295959,0.124871,0.0554037,0.0178698,0.681731,0.80517,0.347764,0.263135,0.912682,0.870044,0.418154,0.410702,0.105722,0.113089,0.993051,1.02163,0.357485,0.562629,0.634391,0.925006,1.00514,1.50595,-0.629475,-0.551348,0.138738,0.0279756,0.841065,0.564014,0.784309,0.636927,-0.433605,-0.723236,1.21581,1.42634,-0.652573,-0.715148
5652,0.604214,0.522587,0.679818,0.641293,0.339449,0.308403,0.805827,0.770467,0.231487,0.35716,0.675063,0.588271,0.142164,0.0995503,0.00671582,-0.000988584,0.273564,0.282774,0.988409,1.04598,-0.0859404,0.147348,-0.637118,-0.349992,-0.126068,0.377009,0.622929,0.70622,1.28563,1.16871,-0.00469909,-0.285376,0.888721,0.745224,1.8412,1.54558,-1.85095,-1.6348,1.11953,1.06055
5653,0.77099,0.7254,0.608218,0.454448,0.604872,0.491934,0.510503,0.376548,0.329504,0.542598,0.401542,0.315349,0.901539,0.859398,0.238984,0.257996,0.0652572,0.0751411,0.742437,0.770605,-0.470729,-0.267934,-0.408308,-0.118202,0.349469,0.851927,0.926401,1.01008,0.0113983,-0.100702,0.534339,0.250663,1.23227,1.08227,0.484738,0.189499,0.706072,0.919555,-1.67384,-1.741
5654,0.796729,0.750469,0.333731,0.267602,0.223413,0.112602,0.0178224,-0.0173712,0.512666,0.728037,0.763089,0.675442,0.546448,0.504251,0.406015,0.516981,0.865837,0.876889,0.437507,0.495234,0.0578124,0.261363,-1.4629,-1.17604,-1.19665,-0.691396,-1.49248,-1.40753,0.460394,0.347069,1.41797,1.13901,0.592765,0.438134,-1.36816,-1.66373,-2.37115,-2.16041,-0.56662,-0.612954
5655,0.12027,0.0726571,0.720252,0.652368,0.101871,0.0404828,0.963864,0.92868,0.788836,0.913476,0.836182,0.74649,0.413873,0.370126,0.784489,0.775965,0.468338,0.477944,0.679331,0.738327,0.343379,0.544292,0.916834,1.20748,-0.383977,0.124002,2.61857,2.70602,0.566386,0.545187,1.79974,1.5219,0.640304,0.484034,-0.280816,-0.58207,1.96926,2.17584,0.586991,0.515093
5656,0.665673,0.619054,0.468406,0.386821,0.0806536,-0.0316368,0.176845,0.139588,0.174057,0.299049,0.0306038,-0.0607338,0.624226,0.581657,0.694982,0.685186,0.767832,0.777895,0.644634,0.704307,2.07851,2.27357,1.21576,1.50308,-0.324545,0.186379,-0.344452,-0.255552,0.85284,0.743306,-0.323005,-0.603076,0.0330527,-0.130741,-0.28569,-0.591489,-1.01971,-0.810694,-1.68634,-1.75305
5657,0.195897,0.148584,0.18968,0.121274,0.652518,0.54091,0.188173,0.15271,0.720422,0.843417,0.679856,0.590465,0.00444937,-0.0390871,0.369635,0.422917,0.235354,0.243848,0.0865905,0.148498,-0.033596,0.157978,-0.121984,0.163831,0.0644519,0.569411,0.346574,0.428996,-0.0917216,-0.204773,0.500141,0.221833,0.615642,0.362888,0.378463,0.0772488,-0.144435,0.141267,2.81173,2.75001
5658,0.278162,0.229231,0.243982,0.162989,0.421249,0.307779,0.610387,0.576972,0.819637,0.942133,0.568708,0.454604,0.804978,0.760654,0.170263,0.160647,0.744492,0.754239,0.243354,0.30576,0.770167,1.01535,0.894843,1.17954,1.51697,2.02464,-1.117,-1.02734,-0.0329093,-0.153627,0.823853,0.542123,1.01468,0.856517,-0.626939,-0.924497,0.88421,1.09323,0.0328032,-0.0298396
5659,0.00345109,-0.0446191,0.359655,0.204704,0.684848,0.573893,0.744826,0.711124,0.442213,0.563261,0.492485,0.318743,0.950171,0.906444,0.988392,0.978885,0.70822,0.712313,0.0895306,0.150552,1.68462,1.87273,-1.75901,-1.47047,-2.31074,-1.80919,1.26462,1.35117,-2.33558,-2.46039,-0.224293,-0.506447,1.80446,1.64022,-1.12183,-1.42025,0.381788,0.591939,0.729987,0.672159
5660,0.120126,0.142149,0.313892,0.24642,0.0741126,-0.0350435,0.594236,0.559003,0.816869,0.93657,0.273122,0.182882,0.106773,0.0608104,0.633502,0.551953,0.527041,0.670386,0.820141,0.879015,-0.498554,-0.307948,-0.428983,-0.146276,2.04909,2.55063,0.0391005,0.125232,0.21241,0.0941759,-0.588122,-0.875415,-0.607898,-0.774048,0.244642,-0.0479561,-0.326727,-0.108632,0.691719,0.633792
5661,0.346306,0.328918,0.624782,0.557535,0.280785,0.170326,0.688706,0.652674,0.224792,0.342154,0.520125,0.430991,0.316658,0.288401,0.134527,0.12502,0.617249,0.628459,0.330017,0.388337,2.27783,2.46143,-0.0444787,0.239208,-0.0941908,0.408461,-0.330822,-0.24934,-0.700537,-0.820637,0.523624,0.243281,1.67151,1.50971,0.490015,0.191778,1.57429,1.79179,-0.193577,-0.249716
5662,0.439184,0.515686,0.669976,0.600942,0.921149,0.809466,0.350174,0.315258,0.625133,0.744684,0.354557,0.204008,0.473834,0.515991,0.503192,0.420197,0.231388,0.243993,0.48431,0.501118,0.75461,0.937646,0.820163,1.09979,0.19985,0.700533,-0.0954573,-0.00723774,0.160117,-0.0268909,0.297859,0.0123282,-0.294276,-0.46197,1.17092,0.875085,0.68997,0.90385,0.772577,0.709795
5663,0.750525,0.702455,0.32393,0.25594,0.165518,0.0543298,0.974919,0.937832,0.804629,0.924721,0.0666333,-0.0229744,0.789543,0.743581,0.723298,0.715375,0.947265,0.960448,0.554139,0.6139,-0.358718,-0.176012,0.556953,0.840822,-0.223728,0.273671,-1.89325,-1.80542,0.822561,0.766855,-0.773617,-1.0525,0.228512,0.0597857,0.539166,0.239499,1.63764,1.84779,-0.847813,-0.906335
5664,0.341452,0.292524,0.928645,0.861381,0.746501,0.637844,0.875535,0.790028,0.511935,0.632091,0.678105,0.587658,0.476335,0.397131,0.057598,0.0490875,0.878173,0.93369,0.339694,0.3986,1.15676,1.33769,-0.10748,0.169592,0.0581952,0.551272,-0.367874,-0.282186,1.6807,1.5606,0.71473,0.431429,-1.75117,-1.92789,-0.626589,-0.928643,1.04666,1.25446,-0.171103,-0.233913
5665,0.917681,0.86907,0.935002,0.865755,0.803941,0.694662,0.678442,0.642224,0.61767,0.699016,0.473652,0.338987,0.0950061,0.0506821,0.954086,0.94449,0.977721,0.906933,0.891689,0.952713,-0.0307385,0.148832,-0.391683,-0.119422,-0.640455,-0.14117,-0.0510025,0.0357853,0.0290737,-0.0919156,0.3327,0.132769,0.0764416,-0.105594,0.225826,-0.0764956,0.729464,0.938588,-0.745485,-0.815387
5666,0.580945,0.533918,0.634893,0.565904,0.414313,0.305182,0.232793,0.196332,0.658073,0.76594,0.180922,0.0903157,0.715055,0.672206,0.128874,0.121272,0.864598,0.880175,0.281705,0.342759,-0.0364122,0.139552,-1.31394,-1.03621,-0.557556,-0.114125,1.10666,1.18557,-1.87309,-1.99316,0.123614,-0.165891,-0.186396,-0.364014,-1.26637,-1.5684,0.774103,0.980873,0.0142469,-0.052396
5667,0.0036386,-0.0423321,0.108061,0.0384923,0.334803,0.225058,0.129331,0.0937574,0.726414,0.832865,0.649179,0.557914,0.635798,0.704705,0.0911891,0.0851576,0.247453,0.264371,0.0862658,0.147189,0.766095,0.941664,-0.436774,-0.159112,-0.583932,-0.0870791,0.761934,0.842344,1.29735,1.17163,0.684328,0.401638,0.495716,0.311161,0.288975,-0.0119599,-0.93822,-0.727099,-0.146303,-0.21867
5668,0.520513,0.474274,0.949179,0.880509,0.664765,0.557062,0.311915,0.286613,0.779634,0.89979,0.035442,-0.0569962,0.747015,0.737205,0.543316,0.536857,0.923177,0.942225,0.989728,1.05122,-0.647826,-0.477909,-1.2949,-1.01502,0.559224,1.04976,1.43465,1.51173,-0.147533,-0.265785,0.296235,0.0174162,-1.09924,-1.2848,-0.121638,-0.496714,0.391004,0.608798,-0.24179,-0.384944
5669,0.784377,0.736197,0.954083,0.885601,0.075834,-0.0316794,0.575976,0.479468,0.445781,0.548425,0.111695,-0.0193632,0.811371,0.769705,0.722575,0.714247,0.344962,0.362803,0.736561,0.861795,-0.383392,-0.212026,-0.481744,-0.19999,-0.266978,0.21609,0.903418,0.983632,1.55766,1.43962,1.39158,1.11803,1.44744,1.25602,-0.683216,-0.981468,0.0104988,0.232421,-0.484576,-0.551219
5670,0.202028,0.155385,0.957231,0.890692,0.209182,0.099783,0.707898,0.672324,0.075254,0.19706,0.168951,0.0182699,0.381038,0.415997,0.0844179,0.0776039,0.857671,0.877888,0.612985,0.672374,0.13743,0.317271,-0.262319,0.0183413,-0.531604,-0.0427205,1.26388,1.34807,-2.27435,-2.39145,-0.60844,-0.884936,-0.0112389,-0.1954,0.715966,0.42241,0.518054,0.740597,0.57656,0.514782
5671,0.454013,0.311467,0.593955,0.526177,0.134272,0.0248629,0.477558,0.494449,0.210991,0.331938,0.108699,0.0559029,0.103547,0.0622897,0.772008,0.76339,0.798255,0.833488,0.5813,0.683205,-0.90272,-0.718879,1.17464,1.4507,0.334499,0.889339,-0.0443745,0.0453249,1.13781,1.01775,1.57499,1.30162,1.26661,1.08083,-0.47409,-0.76281,-0.475552,-0.258944,-1.21128,-1.27026
5672,0.587011,0.467549,0.735727,0.669728,0.919352,0.807539,0.350475,0.316574,0.552758,0.674536,0.16532,0.0935359,0.759673,0.720183,0.688491,0.677579,0.770177,0.789088,0.678834,0.694036,-0.64387,-0.542125,-0.0676765,0.207776,1.33432,1.8214,-0.669376,-0.573986,0.00359439,-0.112577,-0.928254,-1.19198,-1.10296,-1.28922,-0.422983,-0.709823,-2.0962,-1.88645,-0.963071,-0.979563
5673,0.672307,0.62363,0.00783711,-0.0608239,0.461412,0.348374,0.939144,0.90388,0.121923,0.246068,0.333374,0.131169,0.29951,0.25972,0.203613,0.19141,0.468844,0.48992,0.624516,0.704867,-0.54751,-0.365372,-0.282228,0.0162682,-0.257024,0.232337,-0.298862,-0.209549,-0.0224155,-0.139462,0.623953,0.354674,0.226503,0.0371345,-1.30187,-1.58955,0.681448,0.89226,-0.629896,-0.688871
5674,0.490686,0.440676,0.576708,0.510559,0.407941,0.293107,0.815606,0.781747,0.448341,0.573441,0.26124,0.168802,0.62807,0.587036,0.241415,0.207571,0.834941,0.855764,0.738561,0.715698,0.227711,0.406458,-0.448577,-0.17524,1.10242,1.59631,-0.217389,-0.0810007,0.519278,0.400075,1.60433,1.33419,-1.33085,-1.52642,-1.05101,-1.33377,-0.852351,-0.642153,0.395753,0.332579
5675,0.672588,0.621201,0.201731,0.135947,0.116039,-0.000863058,0.904258,0.869881,0.234646,0.361645,0.611345,0.519688,0.664853,0.525672,0.235448,0.223731,0.786632,0.806197,0.698907,0.726529,0.53542,0.719683,-0.0165602,0.255328,-0.966121,-0.466335,-0.0414442,0.047548,0.20685,0.0953773,0.0975583,-0.175597,-0.659592,-0.851249,1.93618,1.64792,-0.798883,-0.586413,-0.443397,-0.503496
5676,0.295268,0.241465,0.0899224,0.0227267,0.739459,0.622469,0.372378,0.336882,0.48097,0.60837,0.17677,0.0836591,0.565047,0.464308,0.834341,0.822021,0.142501,0.161519,0.568169,0.73736,-1.18958,-1.00669,1.75384,2.03136,0.167237,0.670504,0.350571,0.441608,0.494029,0.376428,0.953613,0.68079,1.97341,1.78494,1.12408,0.830247,0.826052,1.04523,-0.460631,-0.526533
5677,0.680263,0.624287,0.742018,0.672763,0.879554,0.764421,0.458487,0.472437,0.207778,0.336364,0.144165,0.051522,0.443802,0.402943,0.916023,0.869339,0.538182,0.557396,0.688802,0.748191,0.43824,0.616183,-0.759404,-0.476315,0.188291,0.686335,-0.470518,-0.381948,-0.75451,-0.878453,2.64812,2.36846,-0.869956,-1.05357,-0.730663,-1.02298,-1.68515,-1.45863,0.414563,0.342339
5678,0.162706,0.108869,0.671266,0.530643,0.445022,0.329093,0.574691,0.607992,0.457149,0.58788,0.507169,0.415841,0.0143091,-0.0264401,0.931782,0.916656,0.0557438,0.0724932,0.261033,0.322237,-0.425545,-0.250371,0.478669,0.758242,-0.344137,0.15091,0.24634,0.265678,-0.325959,-0.445305,-1.69692,-1.9819,0.61749,0.438234,1.96949,1.67691,-1.00904,-0.779532,-1.26887,-1.33462
5679,0.80429,0.750075,0.459299,0.388522,0.430187,0.315605,0.779083,0.743548,0.138547,0.2702,0.144376,0.0541143,0.555277,0.515214,0.340049,0.325334,0.771709,0.788948,0.238627,0.298285,-0.113137,0.0628548,1.29018,1.57327,-0.543204,-0.0546776,0.825304,0.913304,-1.15054,-1.27007,1.16693,0.885289,-0.950209,-1.12532,-0.787315,-1.08375,1.00439,1.23603,1.34271,1.27739
5680,0.30938,0.254681,0.143941,0.0727505,0.806283,0.693004,0.20609,0.170885,0.551775,0.682823,0.554909,0.463767,0.323107,0.283889,0.159227,0.201718,0.341103,0.359857,0.484978,0.546633,-1.00768,-0.835093,-0.75504,-0.471077,-0.751142,-0.260265,-0.115311,-0.0202153,2.2799,2.16021,-0.316231,-0.595571,0.869557,0.69697,-1.94173,-2.23645,-0.199317,0.0318809,-1.81422,-1.87771
5681,0.643423,0.59947,0.921945,0.848329,0.170167,0.0548394,0.421171,0.417378,0.163402,0.294488,0.415044,0.325565,0.415817,0.37783,0.0928012,0.0781023,0.764761,0.784542,0.515923,0.679356,1.28607,1.4621,-0.287935,0.00479192,0.0620862,0.555132,-1.27596,-1.18546,0.708506,0.536721,0.199038,-0.129241,-0.506774,-0.676094,-1.24117,-1.53736,-0.23157,-0.00417289,-1.46969,-1.54005
5682,0.999017,0.944258,0.0359012,-0.0385751,0.769287,0.652547,0.700647,0.66387,0.463761,0.597253,0.999807,0.911226,0.232723,0.192391,0.757353,0.742426,0.415505,0.43493,0.667823,0.812079,-0.638243,-0.467197,0.202828,0.480661,-2.10852,-1.61956,-0.877744,-0.791398,-0.96708,-1.08677,0.617523,0.337089,-1.20948,-1.38128,0.636723,0.343738,0.508926,0.640443,-0.386994,-0.457713
5683,0.621841,0.569935,0.736921,0.661657,0.823301,0.705111,0.556829,0.590764,0.222797,0.354465,0.364749,0.275851,0.828446,0.788384,0.712655,0.695908,0.459931,0.396642,0.883129,0.944802,1.49704,1.67519,-0.381464,-0.0982622,0.695478,1.18092,-1.14092,-1.05809,0.740818,0.618632,-1.44779,-1.72807,0.76947,0.595071,-0.123186,-0.414239,1.0572,1.28506,-0.341281,-0.404879
5684,0.498751,0.489259,0.883435,0.810661,0.406753,0.375555,0.556399,0.517658,0.446027,0.57992,0.86492,0.778199,0.639595,0.611822,0.0852615,0.0695294,0.33843,0.358354,0.327474,0.388992,2.14398,2.32561,-0.342762,-0.0654735,0.284497,0.768427,-0.780757,-0.693653,-1.57318,-1.68813,-2.17713,-2.4545,-0.893388,-1.06158,-0.519862,-0.817997,-1.00381,-0.775797,0.308465,0.237026
5685,0.458459,0.408584,0.128133,0.054256,0.165495,0.0459993,0.0983626,0.060653,0.888036,1.02372,0.810919,0.777668,0.476045,0.435259,0.0521185,0.0384519,0.17845,0.199937,0.490503,0.50536,0.16416,0.347668,0.260101,0.536373,-1.07046,-0.590832,0.0882586,0.178315,0.115888,0.00269029,1.59599,1.31651,-1.70156,-1.87383,0.0184059,-0.28693,0.569898,0.792037,-1.77797,-1.84263
5686,0.67821,0.630384,0.792576,0.718466,0.767254,0.649558,0.828915,0.788621,0.165522,0.301811,0.862425,0.777137,0.856296,0.816715,0.334977,0.370248,0.632528,0.573564,0.561993,0.621727,0.0216471,0.200587,-0.469557,-0.195639,1.25022,1.73411,-0.113717,-0.024418,-1.04332,-1.1584,1.41598,1.13273,1.23664,1.07115,-1.04199,-1.34926,-2.31283,-2.08507,2.02233,1.95888
5687,0.16946,0.119527,0.871574,0.766698,0.917064,0.801157,0.869402,0.827485,0.386425,0.522491,0.239883,0.152549,0.576422,0.634647,0.717606,0.702043,0.926044,0.94719,0.487892,0.547629,-0.998395,-0.821319,0.900505,1.17473,-0.632214,-0.152193,0.590227,0.676718,-0.644852,-0.754846,-1.2259,-1.50534,-0.453635,-0.617905,0.719016,0.41048,-0.307564,-0.0815393,0.42157,0.358705
5688,0.955278,0.904954,0.891416,0.81493,0.394101,0.277734,0.124149,0.0844121,0.997861,1.13222,0.4433,0.257934,0.492429,0.45258,0.619258,0.602108,0.582667,0.668446,0.154502,0.216049,0.126999,0.300446,-1.53725,-1.26671,0.331369,0.815779,-0.466878,-0.381183,-0.638588,-0.749008,0.9227,0.649507,0.0246976,-0.141294,0.749235,0.433458,0.943489,1.1733,0.236412,0.12703
5689,0.164005,0.111663,0.648363,0.483648,0.792664,0.675613,0.332829,0.295397,0.954355,1.08778,0.448799,0.363319,0.929861,0.889475,0.15109,0.135465,0.366783,0.389702,0.751826,0.81453,0.626639,0.79706,0.786321,1.05174,-0.296037,0.184855,1.84939,1.93023,0.449626,0.344732,1.77419,1.50589,-0.627227,-0.785432,1.20323,0.886773,-2.10057,-1.8679,-0.0236623,-0.104645
5690,0.914703,0.860318,0.230609,0.152367,0.982345,0.865966,0.905594,0.867846,0.248792,0.382296,0.107493,0.0205699,0.080387,0.0393598,0.563161,0.547209,0.616661,0.542015,0.248539,0.308854,0.364645,0.530504,0.0252733,0.287261,0.561888,1.04515,-0.0278338,0.051712,0.702866,0.595451,0.290475,0.0250342,0.817017,0.661522,-0.474638,-0.790988,1.18479,1.42526,-0.273455,-0.336319
5691,0.448355,0.394497,0.986867,0.90787,0.809631,0.694127,0.27458,0.23563,0.0894577,0.269508,0.338167,0.249254,0.457339,0.416119,0.0228491,0.00578658,0.673601,0.694327,0.788307,0.848247,-0.736532,-0.567629,2.32632,2.58839,-1.53924,-1.05007,-0.957044,-0.881807,0.144931,0.0315584,-0.161473,-0.423311,-1.42878,-1.57705,0.119947,-0.200392,-0.066916,0.174548,1.245,1.17701
5692,0.224584,0.170938,0.696528,0.662332,0.856843,0.747317,0.463211,0.426207,0.0231951,0.156719,0.896185,0.805535,0.062459,0.0200618,0.317019,0.302431,0.122962,0.145031,0.820487,0.933898,-0.128197,0.0359103,0.396032,0.652104,0.407198,0.888101,-0.662716,-0.593389,0.169122,0.0526689,0.0591018,-0.208949,-0.657967,-0.809953,-1.11154,-1.43221,-0.464251,-0.216815,-2.49953,-2.5606
5693,0.364151,0.248987,0.498035,0.416794,0.97358,0.800507,0.23367,0.263655,0.554426,0.685745,0.159323,0.0709325,0.55996,0.516915,0.98928,0.973473,0.277493,0.3,0.960474,1.01955,1.42544,1.5822,0.92059,1.17614,0.537806,1.02596,0.134688,0.201029,1.25166,1.13137,-0.985804,-1.25752,-1.00333,-1.20512,2.58617,2.26706,-1.24984,-0.995857,0.39142,0.335991
5694,0.491247,0.327035,0.0431546,-0.0364234,0.969201,0.853698,0.138884,0.101103,0.47314,0.58014,0.0462337,-0.0424291,0.74291,0.697672,0.214604,0.197098,0.656625,0.680753,0.772825,0.852186,-0.529279,-0.37633,-0.676366,-0.4282,-1.30581,-0.8148,1.32972,1.39733,-0.729376,-0.848109,0.278001,0.0126109,-1.4449,-1.60028,-0.432142,-0.74896,-0.10434,0.149967,-1.22734,-1.28014
5695,0.458301,0.405083,0.697755,0.617744,0.774919,0.666215,0.379203,0.341033,0.343944,0.474535,0.854259,0.767497,0.455104,0.411806,0.199878,0.181116,0.782179,0.752919,0.660805,0.684824,0.469886,0.625876,-1.5532,-1.29973,-2.87595,-2.38708,-0.99456,-0.931817,-0.462907,-0.58259,0.366998,0.104014,1.22566,1.07008,1.09228,0.775246,-0.686711,-0.428503,-0.0868474,-0.137552
5696,0.92859,0.876974,0.716095,0.546716,0.614855,0.478733,0.902196,0.863956,0.485116,0.526766,0.83322,0.726633,0.509421,0.46508,0.989378,0.968927,0.801858,0.825085,0.458385,0.517461,-0.771289,-0.608062,0.0811914,0.335919,-0.358506,0.137032,-1.07233,-1.01242,0.676124,0.558146,0.662734,0.393254,0.13974,-0.0223125,-0.479774,-0.794466,0.670117,0.926982,0.413694,0.366677
5697,0.177828,0.126227,0.557544,0.475689,0.405894,0.29125,0.836927,0.707174,0.447866,0.578998,0.771179,0.68577,0.0021695,-0.0412383,0.539691,0.518104,0.32426,0.345007,0.672586,0.729975,1.29528,1.45972,0.85262,1.10584,0.226101,0.70386,1.19105,1.24729,-1.52388,-1.63769,1.73952,1.46604,-1.8837,-2.03989,0.650858,0.334447,0.428313,0.769609,-0.0905976,-0.139812
5698,0.617069,0.564243,0.81514,0.732302,0.644194,0.531304,0.589293,0.550393,0.0255751,0.155097,0.283454,0.195513,0.767296,0.723513,0.981414,0.960341,0.749029,0.769692,0.0636599,0.120021,0.616239,0.777714,1.31305,1.56766,0.775151,1.27069,-0.160236,-0.099827,0.810723,0.700854,0.270212,0.000899346,0.226365,0.0693056,0.944675,0.633735,0.355371,0.612236,1.22414,1.17232
5699,0.209542,0.159034,0.479448,0.420347,0.0741806,-0.0374286,0.127689,0.0889274,0.604916,0.734833,0.919308,0.831493,0.784026,0.7413,0.873485,0.853411,0.0392602,0.0592949,0.127224,0.258441,1.06867,1.22817,0.892101,1.14316,0.503375,0.996951,0.680108,0.740186,0.299616,0.182819,1.8296,1.56456,-0.745443,-0.900337,0.591482,0.187881,0.328673,0.59129,0.017838,-0.0317469
5700,0.35849,0.309125,0.190506,0.108393,0.791597,0.678559,0.725483,0.685773,0.508419,0.631221,0.0771819,-0.0115763,0.214898,0.173888,0.193769,0.171236,0.606445,0.624695,0.34237,0.396861,1.24142,1.4017,0.0987495,0.348487,-1.92065,-1.43072,-0.100764,-0.0361874,0.958601,0.847253,0.482018,0.223779,1.5405,1.38342,0.053571,-0.257974,0.993388,1.25288,2.65592,2.59978
5701,0.143802,0.0952492,0.338018,0.257397,0.55523,0.490676,0.361474,0.323687,0.399553,0.527609,0.302209,0.212454,0.845842,0.805053,0.057413,0.0348559,0.586788,0.603839,0.257971,0.313661,0.550243,0.705083,-0.10819,0.136373,1.55408,2.04579,-1.12643,-1.06074,0.0767519,-0.0380548,0.0704473,-0.192553,-1.18603,-1.34182,1.25517,0.945631,-0.286584,-0.0298837,-0.292906,-0.348574
5702,0.51512,0.467553,0.831601,0.750445,0.488518,0.302794,0.352599,0.380632,0.0940905,0.220095,0.964401,0.874188,0.0757009,0.0345597,0.331604,0.268963,0.332078,0.441445,0.390194,0.445723,1.13514,1.29468,1.92123,2.16408,0.198531,0.686528,1.16811,1.23528,-0.358956,-0.389866,0.0514108,-0.208323,1.93324,1.78244,0.115454,-0.193567,0.578476,0.836406,-0.760379,-0.808668
5703,0.28805,0.238899,0.0538218,-0.0269628,0.182601,0.114912,0.473923,0.437576,0.696025,0.819836,0.170811,0.0783137,0.0231442,-0.0195833,0.566915,0.503069,0.260439,0.27905,0.103402,0.160281,0.860783,1.01355,1.6153,1.85791,-0.142462,0.350783,-1.79191,-1.7263,-0.622014,-0.741677,2.16927,1.91266,1.99662,1.84563,0.595997,0.291123,-1.2525,-1.00073,0.626332,0.579165
5704,0.401231,0.257738,0.148714,0.0673764,0.0400685,-0.0729702,0.909512,0.870992,0.821507,0.944232,0.551654,0.457203,0.941775,0.898909,0.832114,0.737176,0.464399,0.485757,0.0813219,0.136329,-1.16556,-1.01196,-0.495558,-0.246689,-0.874681,-0.387173,0.953471,1.01733,-2.32141,-2.4416,0.389126,0.126402,0.643552,0.487291,0.174052,-0.128595,-0.0242414,0.222847,0.976291,0.931098
5705,0.32704,0.276576,0.689163,0.609634,0.155923,-0.0329729,0.883958,0.84412,0.501917,0.711258,0.607286,0.512806,0.89394,0.850664,0.99384,0.971283,0.410972,0.494382,0.898399,0.954615,-0.115586,0.0362053,-0.82297,-0.546948,-0.231712,0.257695,-0.554332,-0.485198,0.0715881,-0.0549747,-0.354473,-0.615667,0.246829,0.0890781,1.05447,0.753395,0.852812,1.10378,0.555343,0.514531
5706,0.584203,0.533017,0.66856,0.588975,0.117901,0.00702441,0.354227,0.315876,0.354582,0.478285,0.285346,0.189582,0.510838,0.426158,0.0798837,0.0587284,0.480371,0.503006,0.90998,0.965332,-2.54445,-2.39747,-1.09308,-0.847206,0.934916,1.42418,0.250689,0.324276,-0.0991279,-0.2228,-0.538523,-0.774672,1.17419,1.0103,-0.976712,-1.28516,0.463603,0.712416,0.78373,0.747563
5707,0.0829519,0.0318884,0.244334,0.165042,0.407421,0.29848,0.928274,0.888325,0.907024,1.03278,0.800663,0.706909,0.0435405,0.00165227,0.100536,0.0794365,0.986693,1.00866,0.274862,0.330147,0.198639,0.342589,-0.757409,-0.506232,-1.09573,-0.604222,-0.452513,-0.373592,0.997073,0.87094,-0.670566,-0.933677,-0.556696,-0.726172,1.40751,1.09255,0.802825,1.04686,-0.69193,-0.72953
5708,0.356725,0.301315,0.319507,0.241002,0.181145,0.071053,0.191351,0.150116,0.127961,0.253249,0.677702,0.519252,0.848888,0.807124,0.413375,0.390627,0.274973,0.298264,0.845714,0.898543,-1.46287,-1.32192,0.760154,1.0046,0.492176,0.991224,-0.879326,-0.794516,-0.764782,-0.891267,-0.281547,-0.550787,-0.523239,-0.69527,2.12048,1.80716,0.452645,0.698921,-0.594444,-0.640162
5709,0.620746,0.570741,0.393582,0.316962,0.33588,0.149616,0.143218,0.103243,0.177079,0.300739,0.423139,0.331595,0.689731,0.648074,0.281785,0.25884,0.474209,0.52607,0.398552,0.452152,-1.20339,-1.05604,-0.296245,-0.053231,0.631695,1.12909,-0.674807,-0.583874,0.23044,0.110589,-0.131486,-0.400251,-0.808861,-0.984843,0.824102,0.511296,2.59618,2.84891,-0.519063,-0.550794
5710,0.356398,0.307239,0.257233,0.219774,0.339729,0.228179,0.619497,0.580734,0.00716968,0.130121,0.989343,0.898023,0.989908,0.949804,0.968272,0.944626,0.670242,0.753877,0.444021,0.521395,0.657649,0.810612,0.474684,0.716691,1.26291,1.75732,1.12526,1.21056,0.414144,0.269754,-0.988541,-1.26464,-0.238157,-0.414873,-0.165984,-0.475028,1.03451,1.28401,1.11787,1.08265
5711,0.85958,0.809368,0.138473,0.122586,0.0739291,-0.0360434,0.0640288,0.0280938,0.254189,0.376846,0.210617,0.117596,0.672916,0.633544,0.0262427,0.00288057,0.958392,0.981683,0.537374,0.590638,0.185862,0.345295,-0.386829,-0.139214,0.420427,0.909761,-0.276947,-0.184398,0.54238,0.428918,-1.28215,-1.55654,1.38187,1.20205,-1.46242,-1.77089,-2.7447,-2.50136,0.737856,0.697609
5712,0.554497,0.504709,0.102018,0.0253984,0.156114,0.0458861,0.0175523,0.0604823,0.719546,0.840009,0.343638,0.252762,0.127131,0.0866894,0.100327,0.0501983,0.414474,0.437194,0.157167,0.210231,0.308408,0.495759,0.822091,1.06194,0.0222897,0.512972,-0.557861,-0.533013,-0.367784,-0.485894,-1.13583,-1.406,-0.512017,-0.690257,0.182549,-0.121214,0.482223,0.730538,-0.0154355,-0.0490177
5713,0.794516,0.685391,0.746808,0.670113,0.972119,0.860974,0.127541,0.0928707,0.201913,0.321584,0.136409,0.0435733,0.130181,0.0636145,0.11939,0.097516,0.0972509,0.117917,0.902071,0.954148,0.579945,0.646222,1.05584,1.29373,-0.602115,-0.117951,-0.965392,-0.881628,0.481404,0.363052,1.695,1.43387,-1.30343,-1.48937,-0.634848,-0.938891,-1.087,-0.834371,-0.0859466,-0.115335
5714,0.912969,0.866074,0.423012,0.344588,0.523799,0.411904,0.461074,0.426625,0.0165191,0.134589,0.313062,0.13809,0.0809254,0.0405396,0.501338,0.479752,0.166499,0.0911594,0.452541,0.50284,0.637252,0.796686,-1.2827,-1.041,2.47488,2.95377,-0.038865,0.0517593,-1.46973,-1.58761,1.68229,1.4181,-1.229,-1.41137,-0.778799,-1.08335,1.17857,1.42751,-0.884776,-0.908
5715,0.55589,0.510776,0.976296,0.896348,0.507355,0.393082,0.00693885,-0.0252422,0.951671,1.06967,0.326445,0.232608,0.817234,0.775105,0.507387,0.457441,0.123813,0.0644017,0.313584,0.376397,0.207187,0.362335,-0.489565,-0.252655,0.0635288,0.538289,-0.238008,-0.0520419,0.404961,0.289693,-0.0114859,-0.275995,1.00609,0.823454,-0.655506,-0.910259,0.271729,0.519768,-1.09539,-1.11234
5716,0.555338,0.564587,0.679795,0.601036,0.913161,0.796449,0.525691,0.492807,0.0897121,0.20972,0.641963,0.548185,0.171986,0.126929,0.456166,0.435131,0.0188525,0.037644,0.182792,0.249954,-1.33236,-1.17843,-0.188923,0.0429494,0.0327335,0.508809,-0.242999,-0.155843,-1.9529,-2.06511,0.053745,-0.215214,0.264234,0.086053,-0.367617,-0.737166,-1.612,-1.36689,0.0178772,-0.000529707
5717,0.662838,0.618398,0.888919,0.80886,0.53364,0.508638,0.804,0.772713,0.145355,0.266748,0.532406,0.439246,0.792009,0.748453,0.0305956,0.00867178,0.492678,0.513092,0.0725594,0.123511,-0.631153,-0.483427,1.49687,1.72595,0.509158,0.983726,0.0124057,0.100586,0.258396,0.13789,0.339214,0.0740252,1.4358,1.25463,-0.259521,-0.564074,-0.532967,-0.282973,-2.6549,-2.67057
5718,0.367751,0.323886,0.221564,0.143182,0.335529,0.220827,0.7247,0.69439,0.813039,0.931993,0.172614,0.0775192,0.551259,0.507169,0.00783412,0.0586626,0.314279,0.335495,0.931439,0.982539,-0.859924,-0.719532,0.274085,0.535411,-1.95909,-1.47923,0.989214,1.08194,-0.570294,-0.686875,-0.195312,-0.46748,1.11235,0.933598,-0.676597,-1.08222,-0.0135023,0.23948,2.52772,2.51205
5719,0.827828,0.786112,0.778857,0.700011,0.783687,0.670082,0.308856,0.27762,0.271794,0.388503,0.609837,0.515876,0.687533,0.642266,0.131041,0.108653,0.438453,0.460036,0.0230327,0.0712856,0.154391,0.297379,-0.884212,-0.655131,0.975988,1.45668,-0.609367,-0.514401,-0.560363,-0.681038,1.19991,0.924886,-0.0763007,-0.253524,-1.28789,-1.60036,-0.665648,-0.41483,-0.526266,-0.543595
5720,0.795593,0.754829,0.877714,0.798943,0.859598,0.746554,0.401531,0.463864,0.158939,0.276872,0.469507,0.315447,0.330479,0.287119,0.788132,0.763467,0.120619,0.140759,0.00919448,0.0570877,0.26191,0.408827,-0.562927,-0.330296,-0.282133,0.206522,-0.40789,-0.318659,-0.0061109,-0.124699,0.292387,0.0125472,-0.353339,-0.527431,-0.760827,-1.06929,0.49477,0.746383,-1.5428,-1.56288
5721,0.318415,0.279181,0.413307,0.33558,0.231281,0.117844,0.680498,0.650107,0.675445,0.795803,0.208601,0.115018,0.584919,0.543719,0.0875583,0.0649939,0.0264244,0.0452937,0.443047,0.415123,-1.3623,-1.22057,-2.46611,-2.23648,-0.00525612,0.484124,-1.12656,-1.03277,0.548652,0.43164,0.118914,-0.0852373,-0.28587,-0.464232,-1.11216,-1.42823,-0.47235,-0.221996,1.2569,1.24336
5722,0.413143,0.280995,0.492256,0.480444,0.0104658,-0.104153,0.369873,0.337006,0.0828589,0.201388,0.711938,0.617365,0.536827,0.495474,0.247565,0.226459,0.405208,0.426047,0.726977,0.773158,-0.972858,-0.831564,-0.819851,-0.585812,1.1804,1.66598,1.94848,2.04397,-1.00315,-1.11173,0.102972,-0.183022,0.113827,-0.0652817,0.508521,0.190437,0.109122,0.361316,0.0828056,0.0689344
5723,0.319584,0.282809,0.703941,0.625307,0.123008,0.00764088,0.6005,0.567556,0.937234,1.05679,0.0456442,-0.0475814,0.272959,0.229514,0.92248,0.902638,0.175577,0.197913,0.163415,0.207566,0.300955,0.448109,0.287922,0.523572,-0.0944077,0.385086,0.286901,0.382379,-1.29463,-1.40014,-0.276103,-0.567244,-0.90986,-1.08196,0.414004,0.0926855,-0.119534,0.137889,2.11332,2.10427
5724,0.581797,0.552235,0.469815,0.474101,0.565254,0.451387,0.196209,0.165943,0.746425,0.897635,0.122203,0.0377355,0.873073,0.830029,0.0149446,-0.00345155,0.45466,0.479091,0.724783,0.770954,-2.47434,-2.33233,-0.879198,-0.642478,-0.279903,0.203238,0.557854,0.558308,0.420799,0.321347,0.845325,0.551452,1.17843,1.01198,0.605754,0.286235,0.920188,1.17635,-1.67025,-1.68187
5725,0.859331,0.821662,0.27509,0.322895,0.220173,0.107102,0.726536,0.693603,0.619542,0.738475,0.247197,0.123052,0.720419,0.675538,0.67241,0.656574,0.471357,0.517468,0.818116,0.862426,0.940707,1.0761,-0.964985,-0.733383,0.789476,1.27847,0.643092,0.734237,0.466236,0.372493,-0.81669,-1.10894,-0.572437,-0.739427,-1.32108,-1.64248,0.504809,0.768527,-1.03417,-1.03996
5726,0.530972,0.421239,0.197177,0.171689,0.101588,-0.00943935,0.887428,0.853227,0.77127,0.888662,0.303737,0.208369,0.142175,0.098465,0.301201,0.284608,0.530208,0.555846,0.591734,0.636464,0.352448,0.4867,0.148199,0.376001,-0.504722,-0.0184734,-0.355334,-0.259707,0.999858,0.91203,0.808382,0.515501,0.749228,0.586928,-0.71502,-1.03601,1.46222,1.72633,0.457295,0.456189
5727,0.0603766,0.0208171,0.0991159,0.0204824,0.754456,0.645008,0.477621,0.440907,0.627899,0.746832,0.820016,0.725697,0.537214,0.512247,0.498073,0.436829,0.813454,0.837023,0.0112157,0.0562524,0.174485,0.310966,0.78041,1.00708,1.10798,1.59148,-2.07796,-1.98433,-0.598826,-0.694468,0.832369,0.545778,-1.41455,-1.57038,0.440192,0.121814,1.06263,1.33496,-0.891423,-0.885717
5728,0.282939,0.242617,0.792547,0.715252,0.0542561,-0.0544018,0.545968,0.509971,0.839961,0.956607,0.631473,0.537217,0.967605,0.926029,0.607122,0.58905,0.741987,0.766679,0.550101,0.595645,-2.51149,-2.374,0.833888,1.05428,1.00628,1.53312,-0.693384,-0.603534,-0.722773,-0.817102,0.423864,0.129446,-0.649245,-0.803279,-0.0206767,-0.343314,-0.3664,-0.0881596,1.45809,1.45665
5729,0.886695,0.848594,0.940183,0.864257,0.579945,0.469068,0.923705,0.888284,0.0854766,0.203574,0.785162,0.689709,0.435425,0.393842,0.501031,0.48212,0.463096,0.506322,0.617455,0.662387,1.91212,2.0496,0.21096,0.429744,0.984096,1.47476,2.05589,2.14009,0.148545,0.0470336,0.558813,0.266729,-0.683602,-0.83205,-0.918882,-1.23947,-0.800021,-0.451598,0.416833,0.42255
5730,0.499866,0.463026,0.835199,0.760995,0.839744,0.729752,0.728779,0.690873,0.773316,0.889491,0.935954,0.842202,0.640361,0.599736,0.76929,0.752798,0.22085,0.245964,0.378224,0.366553,-0.529873,-0.399162,-2.10017,-1.88798,-1.31987,-0.831028,0.153349,0.242278,-0.857821,-0.962552,-1.52637,-1.81336,1.43359,1.29148,-0.153648,-0.480558,-1.08892,-0.815037,0.876724,0.879983
5731,0.523968,0.488094,0.147502,0.0757361,0.15926,0.0500457,0.81882,0.799263,0.613226,0.652066,0.737628,0.643433,0.564999,0.525951,0.00589224,-0.0136118,0.142333,0.1656,0.0246036,0.0707187,-0.319635,-0.195891,0.819121,1.02936,1.46086,1.95942,-0.0694051,-0.0495712,0.359391,0.255347,-0.695,-1.01609,0.631104,0.492364,-0.747428,-1.06949,0.670639,0.942196,-2.234,-2.22821
5732,0.00419972,-0.032547,0.52567,0.455474,0.654044,0.543443,0.946345,0.907654,0.299608,0.414641,0.805177,0.709874,0.696455,0.656471,0.903052,0.881791,0.5282,0.503796,0.214472,0.262768,-0.52226,-0.401345,-0.711597,-0.497792,-0.784138,-0.279909,-0.422227,-0.34142,0.391516,0.291148,0.0740766,-0.218823,0.13078,-0.0137868,0.998334,0.674952,-0.617278,-0.340571,-0.101073,-0.0865146
5733,0.765999,0.727294,0.33855,0.265961,0.763254,0.650076,0.523491,0.478298,0.47618,0.589727,0.268422,0.175689,0.365378,0.326067,0.729941,0.710222,0.81677,0.841992,0.97108,1.01783,-1.04203,-0.915987,0.976903,1.18521,-0.408638,0.0875573,0.416239,0.498593,-1.41262,-1.51596,-1.23368,-1.52811,0.261927,0.123687,0.708359,0.379417,1.23325,1.51318,2.04939,2.05518
5734,0.441444,0.401895,0.571934,0.529917,0.349759,0.23565,0.0870752,0.0489419,0.1384,0.252518,0.147075,0.0524853,0.254227,0.216837,0.903978,0.881416,0.724403,0.751727,0.0253202,0.0724274,1.17608,1.30328,-2.67333,-2.46371,1.55127,2.04144,-0.199584,-0.120719,-1.05669,-1.15761,-1.29048,-1.59036,-0.877113,-1.01632,0.730082,0.402395,0.953226,1.22916,0.00501493,0.00710849
5735,0.707799,0.66877,0.864755,0.793872,0.758073,0.643793,0.375512,0.319979,0.965889,1.08039,0.856831,0.763548,0.662831,0.623806,0.796464,0.829946,0.857178,0.88589,0.976593,1.02514,0.91643,1.03672,-1.86755,-1.66238,0.617116,1.0334,-0.562168,-0.480526,1.08843,0.994891,0.212239,-0.0910164,0.477767,0.339447,-0.414085,-0.736803,-0.495627,-0.225606,-0.689727,-0.603562
5736,0.364651,0.323518,0.564766,0.540568,0.652675,0.537749,0.628296,0.591016,0.407057,0.521841,0.352512,0.35274,0.076423,0.0364991,0.799622,0.778476,0.564019,0.591664,0.433807,0.483979,1.07436,1.19468,0.81863,1.02892,-0.463423,0.0253576,-0.445394,-0.313108,-0.636089,-0.735443,1.16326,0.858816,0.469329,0.325466,-1.07595,-1.40406,0.103297,0.373882,-1.21996,-1.21423
5737,0.918462,0.874536,0.357907,0.287264,0.330402,0.213291,0.525292,0.441837,0.86574,0.979462,0.0362938,-0.0580675,0.0943284,0.0542867,0.195051,0.172478,0.624605,0.649824,0.395977,0.445461,2.23573,2.34916,1.17466,1.37553,-0.879664,-0.38714,-0.228772,-0.145689,1.21994,1.12466,-0.590208,-0.895951,-1.68129,-1.83184,1.75212,1.42892,-0.120244,0.136234,-1.56691,-1.55533
5738,0.28415,0.238173,0.580389,0.510125,0.948568,0.831289,0.284458,0.292659,0.566706,0.777655,0.059136,-0.0361321,0.768842,0.727014,0.543689,0.519723,0.962603,0.986256,0.84083,0.889017,-0.865008,-0.757132,1.50677,1.72214,0.892116,1.37995,0.664956,0.742171,-2.0812,-2.17601,-0.00104567,-0.312617,0.0652911,-0.0911008,-1.18445,-1.50741,-0.365926,-0.101414,-0.175779,-0.1675
5739,0.676439,0.63112,0.285121,0.214812,0.726515,0.609292,0.0829868,0.143481,0.462022,0.575847,0.539219,0.446247,0.95622,0.912973,0.332063,0.308113,0.0983367,0.121257,0.237416,0.282967,0.539493,0.646381,-1.52884,-1.31584,0.200198,0.687509,-0.408327,-0.329749,-1.36771,-1.46716,0.0439115,-0.267594,-1.12704,-1.27822,0.245129,-0.0729663,-0.221712,0.0458886,-2.62627,-2.61638
5740,0.227355,0.180695,0.515894,0.434923,0.955605,0.838943,0.0315825,-0.00569776,0.566534,0.6728,0.288392,0.236707,0.0840494,0.0412368,0.852957,0.830419,0.140926,0.16473,0.765429,0.812466,-0.465487,-0.359519,-1.76867,-1.55974,-0.0966928,0.398058,-0.0846872,-0.0117782,0.616197,0.524029,1.36495,1.04854,1.13645,0.990224,0.31973,-0.00371208,-0.871766,-0.608422,-0.182322,-0.172629
5741,0.563463,0.517795,0.727736,0.655033,0.607698,0.466492,0.516095,0.476904,0.510815,0.769753,0.119304,0.027167,0.582631,0.53809,0.982439,0.961441,0.651626,0.675121,0.558345,0.521338,-0.645279,-0.535253,0.278237,0.484548,-1.53556,-1.038,-1.60524,-1.53071,-0.450022,-0.545102,-0.466895,-0.782929,-1.07142,-1.2148,-1.10609,-1.43669,-1.21697,-0.956359,0.414639,0.421608
5742,0.175419,0.127972,0.215609,0.142192,0.212213,0.0940408,0.521026,0.480713,0.688793,0.866706,0.0765657,-0.0148002,0.846235,0.712973,0.467172,0.445633,0.663655,0.685143,0.181555,0.23021,0.928724,1.04082,-0.867704,-0.666345,-0.569823,-0.0700238,0.550633,0.624643,1.58234,1.49117,-1.04186,-1.35341,-0.534628,-0.677714,1.0728,0.743703,0.140176,0.399126,0.245304,0.247627
5743,0.160464,0.178091,0.0758008,0.0034053,0.454465,0.368085,0.115881,0.0736879,0.849834,0.963659,0.635604,0.546487,0.932921,0.887856,0.507745,0.485952,0.938507,0.961413,0.104648,0.152155,-0.043424,0.0672396,0.47175,0.672484,-0.234189,0.267753,0.373201,0.451147,1.00937,0.911405,-0.583512,-0.891846,-0.424766,-0.569416,-0.153742,-0.488118,0.566824,0.826614,0.294241,0.318633
5744,0.197818,0.22821,0.293991,0.267361,0.762093,0.64213,0.366559,0.324328,0.330499,0.445234,0.71108,0.705509,0.594703,0.54782,0.27554,0.315681,0.605003,0.627578,0.291357,0.339348,0.637278,0.747243,2.93141,3.13492,-0.875003,-0.378375,-0.252973,-0.168164,-0.72323,-0.81893,0.476982,0.166545,0.291408,0.152429,-1.08484,-1.41347,0.0403706,0.294027,0.38314,0.38964
5745,0.324798,0.278329,0.606091,0.531316,0.666159,0.452788,0.163161,0.122017,0.2125,0.328602,0.953523,0.864531,0.865364,0.819016,0.164988,0.145409,0.52519,0.556341,0.276878,0.393557,-0.130951,-0.0275556,0.484342,0.69348,-0.874406,-0.378401,0.394563,0.486835,1.58205,1.48763,0.0042659,-0.312516,-0.628938,-0.770791,-0.148456,-0.467964,1.18636,1.43985,0.643753,0.651038
5746,0.0694791,0.0254114,0.293693,0.245595,0.385551,0.263446,0.962138,0.922754,0.757675,0.872971,0.84344,0.820558,0.0427394,-0.00337422,0.864184,0.841852,0.570197,0.485103,0.400432,0.447766,-0.248764,-0.14503,0.305989,0.512113,-0.231509,0.301556,0.0816745,0.173826,-0.552972,-0.644566,0.246854,-0.0682684,1.20781,1.06677,-1.32296,-1.63611,0.764028,1.10591,-0.138722,-0.126747
5747,0.458179,0.320237,0.0336662,-0.040125,0.0781183,-0.0456795,0.550497,0.528835,0.200544,0.314427,0.86541,0.776586,0.236603,0.190762,0.413397,0.391029,0.392833,0.413866,0.0876291,0.136373,-1.28983,-1.18118,0.387333,0.590292,0.488146,0.981512,-2.00236,-1.91402,-0.270825,-0.363516,1.00451,0.697295,-0.258288,-0.401849,-0.878149,-1.17365,0.49772,0.771967,0.0419813,0.0600817
5748,0.686474,0.615063,0.526725,0.452923,0.798857,0.674318,0.173344,0.134916,0.724245,0.837946,0.585598,0.537995,0.431475,0.384898,0.322374,0.30025,0.635509,0.65536,0.173639,0.240942,-1.62694,-1.52314,-0.230873,-0.0342396,0.930028,1.42684,0.233761,0.327111,-0.361303,-0.455616,-0.0277187,-0.33554,1.20751,1.06172,-0.269654,-0.711193,0.18154,0.438025,1.23092,1.2513
5749,0.952981,0.909889,0.378989,0.314146,0.0935845,-0.0299739,0.0364453,-0.00230328,0.0286666,0.142103,0.391105,0.299404,0.926198,0.881751,0.543886,0.502323,0.429227,0.513995,0.299089,0.345511,1.64961,1.75742,-0.103477,0.0890134,-0.284397,0.205284,-1.13627,-1.0357,0.123977,0.0224674,-0.448366,-0.751872,0.567557,0.417578,0.0670911,-0.248736,1.05191,1.30431,-0.368251,-0.348869
5750,0.731541,0.686331,0.247535,0.175369,0.13317,-0.0242284,0.984677,0.943748,0.191172,0.306873,0.654366,0.56284,0.610875,0.565492,0.712187,0.704396,0.353161,0.37263,0.102348,0.203962,-0.0183316,0.0929113,0.266101,0.457674,-0.632167,-0.145223,-0.473578,-0.441279,-0.201953,-0.298736,1.03823,0.732058,0.234692,0.0806401,0.862375,0.540626,-1.08288,-0.835206,0.404776,0.427485
5751,0.775319,0.731618,0.839405,0.766218,0.106699,-0.0184829,0.269337,0.22668,0.982358,1.09836,0.60578,0.51565,0.987285,0.942251,0.928592,0.906468,0.907065,0.927844,0.0160157,0.062413,2.69569,2.7973,-0.866535,-0.677967,0.406481,0.898148,0.0525749,0.153142,0.0827826,-0.0176858,0.632042,0.332208,1.13838,0.985415,-0.892006,-1.214,0.511049,0.765586,-0.392021,-0.365179
5752,0.0756524,0.0333746,0.0116044,-0.0636503,0.466033,0.338622,0.842562,0.799129,0.12383,0.238409,0.32749,0.238453,0.941497,0.898887,0.378155,0.35549,0.653487,0.67414,0.55195,0.597308,0.917709,1.02391,0.270659,0.459865,-0.988225,-0.493064,-0.0475537,0.0573519,-0.254804,-0.355134,-0.818507,-1.11602,-0.649558,-0.797361,0.496355,0.174432,0.58628,0.865241,0.00631698,-0.0391242
5753,0.154864,0.207148,0.144992,0.0702031,0.396109,0.310345,0.819913,0.801619,0.876191,0.991223,0.0496679,-0.0387442,0.535714,0.4928,0.744208,0.722577,0.045956,0.0684794,0.199197,0.246227,2.8751,2.9825,1.95494,2.14287,0.774151,1.27403,0.571554,0.679394,-0.204559,-0.303988,0.849156,0.555208,-0.664641,-0.811342,0.0876713,-0.229326,0.711876,0.964895,0.25443,0.286931
5754,0.425026,0.380921,0.0251619,-0.0478448,0.373713,0.282067,0.847016,0.80411,0.224019,0.336986,0.991077,0.902721,0.733228,0.689453,0.438859,0.416236,0.508202,0.528776,0.192812,0.241732,0.798038,0.909376,-0.778585,-0.586625,-1.14629,-0.646713,-0.784844,-0.683417,0.89727,0.789752,0.633022,0.339563,0.952953,0.80558,0.00255211,-0.313275,0.150671,0.402486,0.285256,0.407897
5755,0.967541,0.923176,0.970154,0.89702,0.380677,0.253789,0.325096,0.281173,0.999167,1.11116,0.458249,0.368537,0.50496,0.463085,0.841993,0.817795,0.217736,0.239626,0.826327,0.875636,-0.149627,0.0054853,-0.583842,-0.384652,0.406398,0.899219,-0.573937,-0.472774,-0.267289,-0.371337,0.771585,0.476847,-1.56274,-1.70265,-1.91028,-2.22687,0.987757,1.2368,0.502209,0.528863
5756,0.230046,0.183575,0.810055,0.738491,0.598016,0.469115,0.986654,0.942295,0.536277,0.647438,0.698226,0.606858,0.946587,0.904846,0.429589,0.406105,0.505759,0.45279,0.255409,0.304462,-1.01007,-0.898405,3.42763,3.62849,0.277948,0.779261,-1.33827,-1.23465,0.105549,0.00317493,0.474482,0.184943,1.99268,1.84865,1.28843,0.968439,-0.711097,-0.45618,0.349823,0.369776
5757,0.349926,0.205025,0.338054,0.264848,0.108978,-0.0207721,0.258021,0.214653,0.759933,0.872892,0.342581,0.272792,0.874277,0.831061,0.811583,0.78834,0.642643,0.665954,0.16758,0.216509,-0.335068,-0.218402,0.292973,0.492497,-0.371288,0.133133,-1.2856,-1.17627,0.748047,0.650984,-2.18293,-2.47006,-0.288058,-0.42611,1.78286,1.46834,1.53869,1.78741,-1.24642,-1.2304
5758,0.274591,0.226475,0.341201,0.269222,0.843085,0.71457,0.278964,0.237243,0.119091,0.233261,0.0309981,-0.0612748,0.0985904,0.0551905,0.480549,0.456987,0.165996,0.191282,0.633648,0.680594,-0.981986,-0.869289,-0.425191,-0.223693,-1.37053,-0.870545,1.00383,1.11974,0.336405,0.238628,0.776673,0.483172,-0.027787,-0.166533,-0.20609,-0.523521,0.0215095,0.212064,-0.20834,-0.194735
5759,0.584372,0.538113,0.738497,0.664671,0.0647752,-0.0659153,0.516857,0.477172,0.341793,0.45394,0.92803,0.835442,0.0848133,0.131216,0.69682,0.6003,0.531557,0.557127,0.807655,0.785163,1.46892,1.58655,0.0371744,0.238129,-1.19654,-0.718676,-0.146668,-0.0287411,-1.10795,-1.19879,-0.0511278,-0.272595,1.15256,1.01823,1.37035,1.04867,-1.61201,-1.36328,-0.734688,-0.716351
5760,0.635758,0.588361,0.470756,0.398427,0.838255,0.705311,0.978565,0.939704,0.0938042,0.205653,0.0270316,-0.0655108,0.251101,0.207241,0.766433,0.743612,0.389183,0.413614,0.843824,0.889732,1.53493,1.73463,1.86138,2.05995,-1.06754,-0.566806,-0.256403,-0.140461,0.106932,0.0191085,-0.731533,-1.02836,1.31374,1.18639,1.42773,1.10166,-0.682365,-0.435714,0.440102,0.457532
5761,0.367949,0.319128,0.524776,0.429023,0.799484,0.623995,0.435062,0.396137,0.313049,0.426333,0.524039,0.390974,0.883387,0.838406,0.567901,0.546661,0.81869,0.844071,0.212924,0.258969,1.76765,1.8827,0.0940259,0.297424,-0.214932,0.279688,0.38419,0.497483,1.03954,0.944754,-0.601252,-0.891079,-2.37142,-2.50229,-1.83899,-2.16425,-1.24231,-0.998123,0.520128,0.538209
5762,0.829137,0.781354,0.531624,0.459619,0.676145,0.542679,0.339721,0.298585,0.247011,0.360605,0.940002,0.84746,0.72901,0.760262,0.862709,0.843305,0.726213,0.786285,0.725936,0.772485,-1.72913,-1.61325,1.05221,1.25018,-0.271248,0.21903,0.61234,0.725972,-1.22267,-1.31366,-2.23131,-2.52113,1.48646,1.36019,0.443449,0.125373,0.275094,0.524584,1.88563,1.91041
5763,0.678099,0.628763,0.829111,0.756227,0.00919389,-0.126443,0.753947,0.712606,0.786735,0.899491,0.978611,0.887842,0.727341,0.682119,0.259369,0.242251,0.702247,0.728498,0.120391,0.166435,-0.058211,0.0541355,0.482042,0.68495,0.183836,0.677905,2.06088,2.17054,-1.08499,-1.17192,1.73125,1.44036,0.272722,0.142659,0.758428,0.442576,-0.307989,-0.0538859,-0.97612,-0.945438
5764,0.989445,0.940401,0.866392,0.794601,0.258518,0.124126,0.2612,0.219896,0.351288,0.465555,0.7694,0.660517,0.0306854,-0.0142762,0.597874,0.593318,0.384907,0.470795,0.380605,0.42516,0.811001,0.916086,0.611527,0.808203,-0.542876,0.0350424,0.465147,0.574193,0.66128,0.580154,-1.25646,-1.55074,0.866549,0.742354,-0.767737,-1.08169,0.708363,0.967856,1.24975,1.28397
5765,0.300034,0.253674,0.169494,0.09937,0.78266,0.647596,0.413523,0.352066,0.228803,0.343709,0.633885,0.433193,0.285743,0.242324,0.96144,0.944385,0.185923,0.213092,0.361443,0.405653,0.657035,0.753976,0.130547,0.321796,-1.1904,-0.60782,1.15309,1.25874,-0.374725,-0.458863,0.884547,0.586116,0.154452,0.0371711,-1.80752,-2.11337,1.46151,1.72156,-0.612428,-0.579117
5766,0.737736,0.69169,0.018335,-0.0541264,0.86629,0.660865,0.526392,0.484236,0.573389,0.686307,0.296637,0.205868,0.770967,0.729065,0.521968,0.502807,0.61599,0.643549,0.798115,0.844949,-0.121488,-0.0208221,-0.0721424,0.124223,-1.74475,-1.25068,-0.114937,-0.0126422,0.988564,0.909453,-0.659165,-0.953393,-1.76412,-1.88535,0.145159,-0.166412,1.7162,1.97686,0.420543,0.456544
5767,0.708256,0.660407,0.680253,0.605208,0.887727,0.674134,0.242567,0.201286,0.147584,0.262406,0.944384,0.852294,0.792113,0.674454,0.371291,0.351561,0.48318,0.511054,0.631306,0.578919,-0.491951,-0.371152,1.33306,1.52583,0.502459,0.993813,0.627876,0.735962,-1.45635,-1.53324,-0.061986,-0.35498,-0.194489,-0.317976,0.528004,0.212298,1.45371,1.70738,-0.353824,-0.321241
5768,0.271563,0.224605,0.881323,0.807669,0.823445,0.687404,0.2088,0.170011,0.823123,0.939089,0.8024,0.615804,0.68444,0.619842,0.63959,0.622239,0.914513,0.941511,0.29054,0.31289,-0.81565,-0.721481,1.31271,1.51103,0.215221,0.704363,-0.0458452,0.0687358,1.39702,1.32723,-0.109248,-0.401385,-0.0622226,-0.180502,-0.709897,-1.01952,0.496231,0.752757,-0.717724,-0.678391
5769,0.935915,0.890887,0.313646,0.241527,0.413526,0.309556,0.241651,0.138737,0.0559542,0.17029,0.470913,0.379314,0.6094,0.565231,0.421549,0.405151,0.688137,0.713376,0.0023869,0.0468612,-1.73589,-1.65073,-1.03614,-0.837324,-1.11053,-0.624016,0.133351,0.197284,-0.932182,-0.994807,-1.04975,-1.34446,-1.01699,-1.1344,0.24211,-0.0612976,-1.78886,-1.52751,-1.39567,-1.3511
5770,0.759432,0.665384,0.439628,0.458172,0.0700633,-0.0682924,0.150512,0.107462,0.726668,0.841181,0.815843,0.724964,0.0398688,-0.00696792,0.736315,0.72149,0.855777,0.843226,0.945985,0.988012,0.00484315,0.0948254,0.909438,1.10638,0.0218374,0.512823,0.205128,0.325833,0.250336,0.191366,-0.914257,-1.20718,-0.623325,-0.652545,0.653062,0.389658,0.790285,1.05758,-0.958205,-0.907787
5771,0.484073,0.439881,0.745858,0.674817,0.301155,0.161359,0.675114,0.630386,0.027262,0.140753,0.662573,0.654137,0.0978065,0.0520063,0.59847,0.500807,0.947679,0.973076,0.229767,0.271721,-0.835765,-0.742313,-1.77739,-1.57672,-1.39679,-0.90829,-0.714289,-0.592474,-1.61196,-1.66624,0.723369,0.435062,-0.0596797,-0.170693,1.1483,0.840614,-1.89244,-1.61931,-1.17629,-1.18167
5772,0.940564,0.897564,0.510345,0.478995,0.833061,0.694899,0.77996,0.734786,0.816226,0.928594,0.675419,0.583309,0.790671,0.744827,0.398206,0.280124,0.717452,0.819206,0.909179,0.95058,-0.931248,-0.844149,0.940846,1.14385,-0.443579,0.0456458,0.736508,0.852091,-0.071525,-0.12862,-1.57255,-1.86658,1.00895,0.901789,-1.24696,-1.55633,-0.996662,-0.724258,-1.51182,-1.45556
5773,0.88213,0.840895,0.22372,0.283173,0.42174,0.346858,0.524765,0.481892,0.401228,0.514523,0.204085,0.113233,0.972629,0.925585,0.0729806,0.0594415,0.639004,0.665336,0.095071,0.135259,-0.243891,-0.164146,-2.46075,-2.26104,-0.697128,-0.213165,-0.329624,-0.219829,-0.160169,-0.220721,-0.0466481,-0.335351,0.462372,0.34829,0.322819,0.0158596,0.46676,0.647522,0.253918,0.304567
5774,0.127951,0.0855958,0.159506,0.0873509,0.136486,-0.00118223,0.78978,0.747209,0.640884,0.755754,0.489961,0.397336,0.00250989,-0.0424163,0.676974,0.663983,0.894137,0.921484,0.0827217,0.121061,-0.975441,-0.892887,0.205338,0.411148,-0.222953,0.261752,-0.0601671,0.0527113,1.02451,0.965452,-2.49955,-2.79262,-0.818826,-0.932984,-0.86819,-1.16936,1.73821,2.0193,1.29486,1.34023
5775,0.397698,0.356736,0.484718,0.363316,0.629688,0.492215,0.498256,0.454696,0.0679003,0.182415,0.270601,0.178812,0.311976,0.207858,0.939506,0.924616,0.114592,0.141648,0.464188,0.408863,0.56741,0.653407,-2.04105,-1.8393,1.71198,2.19992,-0.536611,-0.42845,1.97729,1.92133,-0.267027,-0.555006,0.684335,0.575168,0.179913,-0.118124,2.16301,2.44679,-0.589467,-0.537069
5776,0.965235,0.923279,0.818496,0.639281,0.244604,0.107599,0.661942,0.619537,0.482875,0.595039,0.575602,0.485022,0.52666,0.458133,0.622596,0.624488,0.345868,0.35236,0.657589,0.696665,-0.978598,-0.887357,2.7086,2.91035,-0.490019,-0.00707845,0.663673,0.767853,1.06391,1.00652,-1.34874,-1.63418,0.144564,0.0354638,-0.326209,-0.629224,-0.675631,-0.393255,-1.23877,-1.19351
5777,0.740517,0.699721,0.98498,0.915246,0.894319,0.756492,0.088382,0.0468748,0.0757856,0.185849,0.54933,0.522577,0.752594,0.708408,0.469672,0.324359,0.530503,0.563072,0.552903,0.653644,-0.951503,-0.866061,1.02474,1.22625,-1.63334,-1.14999,0.682109,0.77942,-0.0769514,-0.137151,-1.50316,-1.7039,1.53771,1.42209,0.42238,0.114854,1.28748,1.57361,-0.229391,-0.187471
5778,0.763056,0.651155,0.595832,0.442375,0.763348,0.649,0.021029,-0.0200655,0.328389,0.437364,0.651589,0.560133,0.807496,0.761682,0.0391197,0.0242299,0.882341,0.773785,0.570732,0.610623,1.21576,1.30897,-1.06686,-0.863285,0.945456,1.42557,-0.173013,-0.0762818,0.0611141,0.00458922,-1.48531,-1.77362,1.51262,1.39332,-1.17771,-1.48464,-0.337645,-0.0538886,-0.00969114,0.0287783
5779,0.644529,0.602589,0.039493,-0.0304956,0.680099,0.541509,0.215936,0.0826297,0.047163,0.154945,0.260755,0.167999,0.366319,0.320947,0.597204,0.582129,0.957441,0.984497,0.745813,0.788178,0.252669,0.350068,0.245771,0.446372,0.778801,1.25916,0.0593532,0.152207,0.660119,0.605572,1.15919,0.867612,-0.118071,-0.229932,1.65866,1.34834,-1.47022,-1.17972,-0.251842,-0.220512
5780,0.259934,0.217021,0.731967,0.664274,0.0685801,-0.0724927,0.226701,0.185325,0.556545,0.663283,0.510124,0.37001,0.158129,0.110578,0.887606,0.872763,0.972025,0.999465,0.111881,0.152994,1.19857,1.28911,0.817703,1.01652,-0.0659947,0.411604,-0.063727,0.0687595,-0.639818,-0.694683,0.21438,-0.0754661,-2.19424,-2.31015,0.348091,0.0369595,1.83048,2.12553,-0.0829941,-0.0995456
5781,0.826814,0.783564,0.735917,0.570567,0.655129,0.515877,0.819596,0.777657,0.555494,0.660735,0.655671,0.57202,0.739705,0.691729,0.875685,0.862768,0.48938,0.569336,0.506461,0.474581,-0.275545,-0.189454,-0.854063,-0.65173,-1.43512,-0.964843,-0.115701,-0.0146885,1.27851,1.23004,-0.149636,-0.444434,0.669535,0.553112,0.498978,0.184449,0.725399,0.933913,-0.00896268,0.0214203
5782,0.682238,0.640556,0.608895,0.476861,0.839689,0.701664,0.262815,0.219418,0.860967,0.967996,0.866786,0.77403,0.378866,0.330777,0.531879,0.531798,0.111343,0.139207,0.755228,0.796167,0.8254,0.918055,-0.198997,0.0114364,0.553623,1.02279,0.11752,0.213801,1.48397,1.43379,0.235326,-0.0615432,-2.18853,-2.30252,0.436242,0.0614696,-0.549607,-0.257702,-0.589604,-0.560054
5783,0.989288,0.947277,0.550151,0.383154,0.419979,0.281997,0.613798,0.568204,0.44432,0.610528,0.251907,0.15912,0.79258,0.742304,0.213471,0.200828,0.619195,0.649598,0.472763,0.51525,-1.22146,-1.12241,-1.67895,-1.46875,-0.394521,-0.000388803,0.00195488,0.102081,0.610049,0.56224,-0.525049,-0.820552,0.158564,0.0455994,0.258927,-0.0615099,1.71224,2.00418,0.801969,0.82778
5784,0.641099,0.658928,0.357139,0.289447,0.736932,0.59871,0.314559,0.27062,0.144021,0.25306,0.387881,0.318141,0.91706,0.867681,0.287477,0.277245,0.648039,0.764108,0.68115,0.722146,-0.05192,0.0468001,2.21001,2.42331,-1.49077,-1.02357,-0.774777,-0.674292,2.76589,2.71474,-0.698409,-0.989339,-0.429826,-0.539354,-0.106148,-0.420446,-0.539026,-0.24294,-0.947016,-0.864422
5785,0.412722,0.37058,0.640551,0.571223,0.666289,0.628785,0.400817,0.354173,0.554263,0.661019,0.569292,0.477163,0.460351,0.411779,0.0530083,0.0449551,0.848574,0.878617,0.291167,0.332153,-0.433737,-0.34132,-0.544211,-0.322654,1.03231,1.50055,-0.167941,-0.0673983,1.86463,1.815,-1.48001,-1.77625,1.12193,1.01447,-0.832597,-1.14899,0.950187,1.24929,-2.58243,-2.55662
5786,0.894119,0.851895,0.0645807,-0.00544808,0.720891,0.658859,0.890726,0.842637,0.480304,0.611483,0.148837,0.0558493,0.602139,0.454255,0.715192,0.70498,0.317838,0.349451,0.885905,0.926372,-1.60714,-1.51379,0.21519,0.431851,1.22597,1.69939,-0.19583,-0.103043,-1.34596,-1.3955,-0.195057,-0.503059,-0.692927,-0.799494,2.32416,2.00554,0.24744,0.54872,-0.223548,-0.196826
5787,0.96571,0.922628,0.474086,0.404636,0.828597,0.688934,0.501941,0.546872,0.452233,0.561948,0.557501,0.393831,0.603178,0.496732,0.840732,0.746517,0.629514,0.660233,0.858622,0.897,-1.49699,-1.40234,-1.45564,-1.23639,-0.776762,-0.298199,0.769681,0.860884,0.653887,0.613828,1.06638,0.770133,1.19474,1.08522,0.609867,0.29622,-0.791302,-0.420945,0.548537,0.579528
5788,0.474175,0.431573,0.376541,0.343326,0.597982,0.376552,0.297856,0.251107,0.133106,0.244267,0.822396,0.731813,0.587329,0.539209,0.796432,0.788054,0.476734,0.478118,0.291973,0.331408,0.254345,0.343209,-0.187201,0.0270361,0.0567109,0.533804,0.0996508,0.193658,-0.573326,-0.610054,0.440599,0.149845,-1.41155,-1.52512,0.577669,0.255972,-1.69189,-1.39061,-1.05384,-1.02064
5789,0.902416,0.859436,0.349302,0.282015,0.203358,0.0641704,0.654116,0.609627,0.931381,1.04171,0.607075,0.488071,0.0373831,-0.0135352,0.238193,0.231941,0.266325,0.296003,0.82255,0.860907,-1.99133,-1.90211,0.597071,0.815382,-0.411591,0.0613203,-0.0972637,-0.0981908,-1.20824,-1.25025,-0.785199,-1.08071,-0.624011,-0.741416,-1.1752,-1.49865,0.500548,0.807692,0.75303,0.785848
5790,0.540173,0.494958,0.993647,0.92673,0.681035,0.542353,0.518502,0.472407,0.438435,0.548374,0.336643,0.244329,0.750814,0.69964,0.250788,0.24222,0.773071,0.801658,0.785934,0.79006,-0.815572,-0.7329,0.918993,1.14022,-0.187927,0.292269,-0.490686,-0.39004,1.5327,1.4908,-0.0358682,-0.331129,-1.37485,-1.49222,-1.33812,-1.65661,-0.833342,-0.523816,-0.76819,-0.738007
5791,0.829849,0.787183,0.092937,0.0280206,0.542987,0.357037,0.0469811,0.000229819,0.180415,0.29132,0.399684,0.214932,0.0708715,0.0177847,0.88002,0.872442,0.45291,0.482381,0.679568,0.719212,0.0315937,0.114461,-1.11086,-0.890653,-0.645966,-0.165265,1.23558,1.33896,-0.268287,-0.316307,0.436044,0.146115,0.177896,0.061608,0.233108,-0.0844196,1.30718,1.61252,-0.245383,-0.218555
5792,0.128373,0.0838176,0.830937,0.764034,0.377949,0.171722,0.61118,0.563573,0.484941,0.49802,0.344441,0.185536,0.0977243,0.0617458,0.910656,0.899908,0.577848,0.510973,0.261337,0.303219,0.172832,0.257134,0.832206,1.05305,0.324197,0.802707,-1.41228,-1.3064,-1.43266,-1.4774,-0.131403,-0.424371,2.30085,2.18514,-0.864377,-1.17764,1.61361,1.91543,-0.646153,-0.620586
5793,0.353476,0.310373,0.241784,0.172921,0.125088,-0.013594,0.490301,0.466705,0.594003,0.704719,0.249979,0.15614,0.160291,0.105707,0.9356,0.927373,0.508845,0.539566,0.686744,0.727507,1.30918,1.39555,0.655315,0.871681,-1.25972,-0.786354,1.05352,1.15566,-0.553937,-0.598316,-0.391847,-0.685524,-0.448188,-0.556456,-1.11316,-1.42913,-0.517337,-0.205592,0.727111,0.751612
5794,0.783213,0.738237,0.319689,0.252004,0.767416,0.630116,0.287909,0.369836,0.444848,0.471746,0.73507,0.643284,0.976246,0.921797,0.731758,0.725304,0.935132,0.964251,0.366194,0.406269,-1.255,-1.16907,-0.691777,-0.482846,2.05921,2.53535,-0.58575,-0.48824,-0.64178,-0.690417,0.461479,0.170863,0.895199,0.78519,-0.792488,-1.11192,-0.350489,-0.042468,1.33285,1.36234
5795,0.850352,0.803568,0.991599,0.921551,0.0610817,-0.0741752,0.320574,0.272968,0.129222,0.238772,0.529858,0.439013,0.0198781,-0.0327676,0.809957,0.80172,0.580312,0.594109,0.379819,0.421617,-1.10203,-1.01111,-0.202632,0.0113382,-0.203076,0.279993,1.97168,2.07572,0.57013,0.527483,-1.63135,-1.92624,-1.07025,-1.18649,-1.91608,-2.23699,-1.19721,-0.882104,-0.300224,-0.270034
5796,0.604261,0.499152,0.493558,0.423269,0.35483,0.21728,0.694884,0.646809,0.242043,0.291046,0.784252,0.692451,0.762637,0.711637,0.492384,0.494174,0.196474,0.223966,0.904512,0.946049,-0.418695,-0.374941,1.76894,1.98935,0.0157979,0.494697,-0.720924,-0.621672,1.41445,1.37643,1.222,0.928818,-0.612404,-0.725625,-0.385632,-0.726534,0.528332,0.844704,-0.38786,-0.354487
5797,0.240496,0.194737,0.604427,0.46981,0.871302,0.736186,0.0582797,0.0095523,0.259357,0.34332,0.178722,0.0874307,0.838684,0.769865,0.193778,0.186628,0.130079,0.158173,0.103584,0.146039,0.174003,0.261231,-0.971021,-0.756615,0.481223,0.953572,-0.480589,-0.379569,0.23195,0.200335,0.744365,0.400445,-0.660967,-0.770448,1.11215,0.783926,-0.581166,-0.262568,1.41814,1.45201
5798,0.570238,0.526891,0.647029,0.516352,0.0912525,-0.0442988,0.122149,0.00752897,0.286803,0.395594,0.740593,0.648718,0.879422,0.828092,0.370264,0.364018,0.636685,0.663828,0.830335,0.874501,-1.09212,-1.0043,-1.45835,-1.24302,-0.740901,-0.267982,0.0282597,0.135521,-0.158699,-0.196163,0.160581,-0.127927,0.0952678,-0.0176574,1.21826,0.885974,0.420898,0.743915,-0.721696,-0.690408
5799,0.54095,0.449553,0.633182,0.562893,0.0107385,-0.124423,0.0569964,0.00550564,0.0846827,0.193591,0.701929,0.61139,0.0374207,-0.0126696,0.186509,0.207415,0.146027,0.173811,0.26538,0.30891,0.501291,0.586764,1.0556,1.26845,0.296398,0.775389,-0.125793,-0.0221681,-2.04304,-2.08159,-0.0208123,-0.293895,-0.478238,-0.587289,-1.31478,-1.64011,-1.94791,-1.62307,-1.30183,-1.27188
5800,0.41268,0.372216,0.977813,0.909068,0.705611,0.571083,0.444055,0.394276,0.630631,0.73796,0.0627487,-0.0282654,0.460396,0.409101,0.05425,0.0508112,0.258528,0.288375,0.0759973,0.118289,-0.529773,-0.449387,0.0486497,0.2572,-1.21141,-0.736462,-1.02581,-0.922421,-1.29431,-1.32604,-0.164841,-0.459862,-0.203337,-0.311729,-1.29846,-1.61713,0.780367,1.10709,0.147333,0.177323
5801,0.748441,0.709315,0.633531,0.564066,0.323004,0.186467,0.60234,0.465767,0.747607,0.793829,0.167226,0.0758902,0.474452,0.421843,0.541089,0.537707,0.602706,0.539691,0.663698,0.707423,0.347761,0.42709,0.95738,1.16464,0.374957,0.843933,0.680928,0.789212,0.171215,0.134956,0.504009,0.215084,0.689517,0.57693,0.885123,0.563259,0.927098,1.25439,-1.65509,-1.62344
5802,0.514662,0.427558,0.868533,0.801374,0.150911,0.0146279,0.652943,0.537259,0.841572,0.849699,0.892074,0.801753,0.485836,0.434584,0.432712,0.430777,0.761894,0.791008,0.0292557,0.0722387,-1.62274,-1.55085,1.55228,1.76649,1.23322,1.70423,0.254095,0.368288,-0.272474,-0.308617,-1.62573,-1.9099,-0.404805,-0.515467,-0.14219,-0.468426,-0.301403,0.0196757,-0.47095,-0.457758
5803,0.187569,0.1458,0.636499,0.530426,0.913845,0.776519,0.711488,0.608751,0.800827,0.905568,0.892797,0.803823,0.11577,0.0638708,0.976817,0.973557,0.0697236,0.100033,0.122365,0.16371,-0.435609,-0.364701,0.587172,0.801845,2.30312,2.77947,0.122446,0.302431,0.738331,0.709903,1.03358,0.74691,0.948383,0.840298,-0.0848955,-0.415439,-1.16441,-0.83657,0.680325,0.707922
5804,0.419924,0.371972,0.327379,0.259477,0.873532,0.669028,0.884609,0.680243,0.395638,0.501489,0.0220082,-0.0675787,0.333879,0.280336,0.591229,0.587085,0.0615943,0.0896173,0.000948746,0.0432252,-1.1997,-1.1233,-2.70998,-2.49916,0.762011,1.23614,0.118823,0.236574,-1.97674,-2.01017,0.536621,0.25371,-0.0407777,-0.145501,0.28935,-0.0662483,-1.2819,-0.950187,-0.290138,-0.282116
5805,0.640574,0.598143,0.93672,0.86981,0.699248,0.561537,0.801514,0.751735,0.643656,0.699095,0.456861,0.322108,0.149388,0.0948977,0.723073,0.718107,0.494329,0.524516,0.194167,0.235274,-0.735543,-0.656406,0.327101,0.53891,0.305365,0.778609,-0.315363,-0.200691,-0.573789,-0.609645,-0.501076,-0.779125,-2.27768,-2.38407,0.616851,0.282943,-0.366685,-0.0389037,-1.29596,-1.27216
5806,0.0843059,0.0419784,0.963156,0.89826,0.970707,0.832805,0.578408,0.528845,0.793521,0.896702,0.799207,0.711795,0.687019,0.631298,0.568125,0.561591,0.643273,0.673906,0.117183,0.157219,1.50291,1.57932,-1.84189,-1.63167,-0.687812,-0.209531,-1.44945,-1.33391,-0.530981,-0.573844,-0.839117,-1.11754,-1.74677,-1.84698,0.3148,-0.0125928,-0.760039,-0.453757,1.31096,1.33986
5807,0.27627,0.232358,0.226105,0.162618,0.381955,0.244064,0.592918,0.541966,0.471519,0.574326,0.503668,0.48286,0.669363,0.613536,0.102839,0.0949477,0.268767,0.299722,0.949572,0.991087,-0.106649,-0.0360055,-0.792189,-0.587318,1.00086,1.47939,1.26617,1.37977,0.177235,0.135005,-0.534615,-0.815482,-1.46785,-1.57142,0.213732,-0.110344,-1.07708,-0.868611,0.78225,0.784927
5808,0.0385125,-0.00610727,0.478237,0.341554,0.98616,0.847623,0.809073,0.758271,0.790467,0.803287,0.338963,0.253925,0.222362,0.167772,0.926738,0.919002,0.896744,0.926109,0.835983,0.875295,0.362842,0.430888,-0.845997,-0.646465,1.72483,2.20169,-0.962498,-0.850082,-1.35119,-1.39614,0.332753,0.0563028,0.915711,0.810709,1.42543,1.10634,-1.61125,-1.28347,0.209514,0.229999
5809,0.424505,0.417334,0.560796,0.520489,0.463067,0.324201,0.818973,0.789511,0.928116,1.03225,0.533367,0.385709,0.385447,0.359317,0.314803,0.308142,0.971999,0.999767,0.261276,0.299601,0.387861,0.452184,1.40562,1.60868,-0.212822,0.265808,0.552311,0.658304,-0.262852,-0.302403,-1.11072,-1.39193,0.680795,0.582787,0.430731,0.104592,-0.114151,0.208767,-0.654488,-0.639396
5810,0.882685,0.840776,0.760722,0.699424,0.260431,0.115477,0.953531,0.820751,0.407322,0.513822,0.556918,0.517494,0.665877,0.550862,0.844728,0.840725,0.268295,0.293848,0.227113,0.265582,0.938615,1.00901,-1.94801,-1.74706,0.376132,0.849237,-0.348561,-0.241949,-0.159785,-0.204634,0.592588,0.310988,-1.33095,-1.43479,-1.42844,-1.74863,-0.254663,0.0625633,-1.1382,-1.12925
5811,0.92051,0.877065,0.406229,0.345242,0.0479771,-0.0932461,0.900692,0.851991,0.583096,0.688908,0.735959,0.649278,0.838507,0.742407,0.894983,0.802017,0.95732,0.981066,0.771142,0.809712,1.49214,1.56583,-0.464029,-0.267346,0.0220124,0.49873,1.52407,1.62987,2.01936,1.98199,0.245944,-0.0426071,-0.51224,-0.623124,-0.441189,-0.769385,-0.990389,-0.669806,0.323634,0.336843
5812,0.599777,0.491941,0.581637,0.519095,0.442364,0.372548,0.251257,0.204359,0.331169,0.437016,0.685066,0.597096,0.98752,0.933952,0.767921,0.763309,0.238167,0.26024,0.649104,0.627766,-0.953626,-0.882935,0.0179072,0.208895,-1.94477,-1.46635,1.05822,1.2475,0.637061,0.602736,1.20477,0.920916,2.18886,2.07818,0.528579,0.209864,1.5773,1.89911,1.4187,1.43354
5813,0.150581,0.106816,0.150219,0.0859288,0.979428,0.838343,0.869523,0.822042,0.640469,0.703601,0.0477526,-0.0382788,0.867509,0.814188,0.248279,0.242211,0.998422,1.02178,0.407758,0.44582,1.10312,1.16901,0.823543,1.01022,-0.382937,0.0968406,0.762862,0.865122,0.160522,0.129715,-0.635241,-0.910549,0.983229,0.876001,-0.834328,-1.14621,-0.00995037,0.318302,0.145326,0.167851
5814,0.386784,0.343029,0.923138,0.856784,0.506791,0.363367,0.394418,0.345191,0.8646,0.970187,0.417011,0.331279,0.375551,0.323078,0.487589,0.482049,0.300097,0.321377,0.444196,0.482538,0.801194,0.872045,0.965614,1.14993,-0.0842442,0.388913,1.94299,2.04483,1.29372,1.27045,-0.00426436,-0.282216,0.910309,0.80069,0.796622,0.487366,0.405518,0.797436,-1.41521,-1.38793
5815,0.887774,0.845159,0.25381,0.185766,0.254667,0.109848,0.840985,0.793421,0.0550752,0.160073,0.457577,0.371661,0.35402,0.396519,0.431485,0.339136,0.93861,0.95861,0.712527,0.750881,0.149679,0.284866,0.0277327,0.217681,0.995581,1.46415,0.267009,0.368419,0.781785,0.752417,-1.15925,-1.43719,-0.907519,-1.01328,-1.13361,-1.44135,0.955497,1.27657,-0.0921617,-0.0615452
5816,0.266893,0.224442,0.995095,0.926464,0.521806,0.375963,0.0230391,-0.0235108,0.653894,0.759815,0.188267,0.103784,0.519927,0.469959,0.199416,0.196222,0.223169,0.242688,0.201342,0.239971,-0.367107,-0.302312,1.86929,2.05661,1.14158,1.61663,2.29829,2.40108,0.765064,0.741988,1.58751,1.30591,-0.779291,-0.890522,0.179004,-0.132357,0.298893,0.622258,-0.60035,-0.568035
5817,0.821615,0.78099,0.379484,0.309911,0.0713999,-0.0731073,0.365337,0.319833,0.760199,0.868245,0.180341,0.0959646,0.768008,0.716245,0.836811,0.831162,0.549883,0.568785,0.122315,0.161917,-0.663613,-0.54747,0.588945,0.781613,0.0389287,0.519911,0.838926,0.94474,-1.49046,-1.51643,0.105319,-0.174949,0.323786,0.21383,-0.513676,-0.828623,-1.46195,-1.13598,2.30161,2.32856
5818,0.128189,0.0887683,0.515461,0.443764,0.895957,0.752248,0.416107,0.368763,0.871358,0.976675,0.403209,0.319995,0.0485511,-0.00153461,0.296036,0.28974,0.187171,0.20448,0.956491,0.995785,-0.85725,-0.792629,-0.966269,-0.776226,0.0777014,0.608029,1.07586,1.18684,-0.928884,-0.961687,-0.195416,-0.483667,1.94649,1.83075,2.72455,2.40674,0.701603,1.02692,-0.653326,-0.619796
5819,0.707001,0.670165,0.268509,0.197623,0.577629,0.518284,0.94181,0.896424,0.55285,0.658994,0.841344,0.758352,0.47155,0.420236,0.459722,0.451205,0.360843,0.379447,0.936171,0.976278,0.260745,0.329136,0.101523,0.286925,0.213748,0.696147,0.149812,0.268536,0.337519,0.303456,-1.82097,-2.11371,-0.257372,-0.374275,1.28569,0.965313,0.475338,0.80349,0.599459,0.629459
5820,0.305234,0.269461,0.25159,0.182033,0.425564,0.284319,0.581654,0.617757,0.5223,0.62938,0.508611,0.424869,0.515591,0.439274,0.824819,0.818292,0.839073,0.85947,0.481224,0.520062,0.674554,0.748987,-0.375576,-0.184876,2.18217,2.6652,-1.5958,-1.47091,0.194718,0.165962,0.0124584,-0.287972,0.642676,0.5305,-0.1583,-0.476111,0.903209,1.23098,-1.08271,-1.0475
5821,0.208202,0.172023,0.489866,0.420403,0.338385,0.256042,0.384779,0.339089,0.0588888,0.165661,0.465921,0.382902,0.511757,0.458313,0.0687288,0.062777,0.141731,0.163315,0.95966,0.999065,-1.64406,-1.57327,0.602103,0.798507,-0.677166,-0.192844,-0.502065,-0.38435,1.1471,1.12184,1.07722,0.770419,-0.589994,-0.702424,0.277625,-0.0385878,-0.187652,0.140027,-1.96139,-1.93101
5822,0.895442,0.85818,0.842789,0.658774,0.338638,0.227764,0.807822,0.763351,0.653645,0.760447,0.0915005,0.00607746,0.234026,0.182721,0.597903,0.589652,0.574381,0.593772,0.664065,0.703658,-1.32728,-1.26004,0.954536,1.1537,-0.0061551,0.431815,1.50126,1.61471,0.376481,0.345263,0.0249333,-0.278151,1.34984,1.24273,0.956656,0.64472,1.06411,1.39487,0.823371,0.860591
5823,0.264737,0.227054,0.966701,0.897144,0.338831,0.199486,0.0939514,0.0504602,0.767954,0.87457,0.361466,0.351231,0.222051,0.170058,0.322543,0.312967,0.387674,0.42572,0.826645,0.798855,-1.38387,-1.31422,0.061164,0.266737,0.565941,1.05647,0.300916,0.419123,0.280296,0.253162,0.597775,0.289377,0.688453,0.584064,0.606374,0.285783,-0.949121,-0.621446,0.687225,0.717856
5824,0.646702,0.609877,0.11479,0.0462661,0.504925,0.365646,0.146369,0.107405,0.563119,0.748655,0.780145,0.696385,0.715853,0.662147,0.339092,0.328787,0.236708,0.257667,0.853155,0.894052,0.143268,0.215151,0.220321,0.421301,-0.725719,-0.240472,1.63283,1.75346,-1.22909,-1.26226,1.62404,1.31578,2.03327,1.92571,0.0273944,-0.204107,0.258075,0.58727,-0.265417,-0.240719
5825,0.647166,0.650397,0.568898,0.500622,0.188491,0.0511173,0.207707,0.164349,0.513839,0.622741,0.25254,0.166467,0.41284,0.360956,0.805644,0.795692,0.964119,0.985024,0.673937,0.713712,-0.778177,-0.714095,1.59458,1.79167,-1.07429,-0.59098,0.0525065,0.175068,1.65367,1.61479,-0.0215477,-0.332527,-0.0020293,-0.109686,-0.368576,-0.693998,0.220588,0.530043,-0.326492,-0.307037
5826,0.786158,0.690917,0.660173,0.58984,0.292061,0.152441,0.0271654,-0.0176179,0.91592,1.02527,0.506607,0.349237,0.337839,0.363326,0.577493,0.568731,0.407771,0.43053,0.23189,0.272653,2.37586,2.4287,1.28892,1.48698,-0.457243,0.0214268,0.681349,0.79711,1.30915,1.26371,1.21389,0.907083,-0.858393,-0.96804,-2.4516,-2.77895,0.138872,0.472817,0.440587,0.455954
5827,0.766263,0.731436,0.996473,0.925981,0.754517,0.615998,0.333701,0.2868,0.636815,0.748277,0.587171,0.532007,0.417739,0.365695,0.0531184,0.0429222,0.152477,0.176826,0.380894,0.388842,-0.555735,-0.506856,0.876798,1.18229,-1.38548,-0.903367,-0.251231,-0.136408,0.0445227,-0.00570892,-0.859137,-1.173,0.493423,0.387725,1.24777,0.920317,0.0924451,0.41559,-0.0656685,-0.0817881
5828,0.471926,0.436924,0.193129,0.121329,0.698416,0.560731,0.265494,0.276167,0.758333,0.867673,0.800526,0.714777,0.88509,0.832774,0.690532,0.677862,0.761229,0.783187,0.459074,0.505031,0.783612,0.835201,0.680524,0.877608,-1.67686,-1.19282,-0.36702,-0.248128,-0.385611,-0.382755,-1.11264,-1.41979,0.716443,0.615905,-1.14472,-1.47663,0.735351,1.06176,-0.638183,-0.619531
5829,0.671001,0.564284,0.153709,0.0819571,0.119315,-0.0180983,0.311945,0.265534,0.1296,0.237857,0.268595,0.184858,0.926756,0.875386,0.0631854,0.0514835,0.918847,0.94257,0.580456,0.621219,-0.824954,-0.767617,-0.509555,-0.318897,-0.763669,-0.285696,0.14053,0.216189,-0.713227,-0.759802,-0.408523,-0.71467,-0.838199,-0.933131,-0.643917,-0.976728,0.214264,0.545244,0.49828,0.523057
5830,0.726646,0.691644,0.334586,0.265418,0.867584,0.728062,0.00883748,-0.036898,0.929143,1.0353,0.819035,0.736543,0.484018,0.482748,0.117978,0.107223,0.0766429,0.0983391,0.341729,0.381564,1.23271,1.28433,-0.951711,-0.759928,-0.333148,0.14327,0.556403,0.680507,0.663315,0.608514,-0.48889,-0.731596,1.61048,1.51303,-0.978894,-1.31919,-0.848511,-0.516201,-1.05018,-1.03272
5831,0.0747618,0.0400445,0.11996,0.0509633,0.493069,0.458449,0.866229,0.820106,0.309068,0.415908,0.757726,0.621399,0.143255,0.0901106,0.71535,0.705512,0.413909,0.375812,0.594944,0.63477,0.61518,0.662809,-0.539489,-0.343777,1.54867,2.02196,-0.980306,-0.85098,-0.234111,-0.291226,-0.438346,-0.748523,0.131636,0.0293817,-1.73444,-2.07717,-1.70175,-1.37245,1.96985,1.98945
5832,0.111235,0.0591266,0.945685,0.878344,0.308102,0.188835,0.144688,0.0974049,0.505203,0.582764,0.590254,0.506254,0.357232,0.394764,0.488001,0.478551,0.632512,0.653284,0.434242,0.478739,1.28676,1.32656,0.55227,0.751109,1.63921,2.11217,-0.498038,-0.36445,1.00079,0.942276,0.860135,0.55213,-0.286706,-0.446522,0.609064,0.263865,0.395583,0.728208,1.54608,1.55806
5833,0.0700639,0.0782087,0.253187,0.187899,0.0592709,-0.0807779,0.884258,0.834753,0.641061,0.74962,0.893219,0.807646,0.750919,0.699418,0.837423,0.825796,0.0568819,0.0786984,0.280724,0.322708,0.169064,0.212903,0.182593,0.386695,-0.00892615,0.460261,1.4063,1.54062,1.24924,1.193,0.0397628,-0.316934,-0.816633,-0.922426,0.876025,0.535547,-0.91361,-0.587034,-1.50993,-1.49759
5834,0.167178,0.0972907,0.868619,0.802907,0.35495,0.215504,0.410731,0.362576,0.225475,0.335549,0.902367,0.814733,0.637581,0.585005,0.0790984,0.0702814,0.0974333,0.117143,0.729975,0.771795,0.00911104,0.0507928,0.330428,0.54126,1.90113,2.36786,-0.561725,-0.423969,-0.501682,-0.554714,-0.873573,-1.186,0.453005,0.353803,-0.489499,-0.834659,2.17027,2.49666,0.592126,0.60022
5835,0.0482871,0.116373,0.569529,0.503056,0.960702,0.823367,0.57475,0.527417,0.366082,0.475313,0.444446,0.426679,0.739554,0.685441,0.273829,0.266519,0.571981,0.592591,0.0181179,0.0599003,0.662226,0.701216,-0.0962555,0.116754,0.459193,0.93181,-0.956,-0.813641,0.597891,0.539026,-0.989091,-1.29338,-0.720348,-0.818577,-0.244604,-0.594925,-0.166184,0.160933,1.64449,1.65106
5836,0.170172,0.135455,0.933052,0.867789,0.144277,0.00895041,0.510672,0.374418,0.76784,0.877843,0.127351,0.0386253,0.488767,0.434618,0.545252,0.462756,0.620984,0.68862,0.818851,0.858033,-1.65543,-1.62104,0.0948872,0.302339,1.22994,1.7005,0.039234,0.183569,-0.855601,-0.914568,1.53056,1.23176,-0.328057,-0.431537,0.600641,0.257223,0.0771408,0.400236,-0.127256,-0.117939
5837,0.778613,0.745321,0.756089,0.693215,0.379971,0.17567,0.268108,0.221419,0.1006,0.208141,0.23048,0.142781,0.855651,0.801501,0.670186,0.658994,0.763362,0.78465,0.00161107,0.0427121,-1.66825,-1.63032,-1.15122,-0.94058,1.1749,1.63984,-1.53329,-1.39482,-1.02715,-1.08239,-1.8876,-2.18254,0.0593396,-0.0444974,2.93428,2.59826,-0.682784,-0.363588,-0.532819,-0.519971
5838,0.314089,0.2795,0.793866,0.731588,0.477826,0.34239,0.36718,0.320642,0.73778,0.847346,0.0235552,-0.0664076,0.80275,0.747358,0.408175,0.397159,0.436334,0.455355,0.651755,0.691523,0.397908,0.437464,-1.51125,-1.30499,0.519199,1.03758,0.687752,0.829339,0.0515863,-0.00368926,0.363546,0.0675536,1.10304,0.996593,0.0898713,-0.251967,0.109412,0.422298,1.1844,1.19228
5839,0.704293,0.668003,0.248466,0.184868,0.352588,0.192653,0.795298,0.749326,0.460511,0.500016,0.507404,0.415972,0.319748,0.265734,0.685693,0.673421,0.480832,0.498827,0.545823,0.566916,-0.23674,-0.198471,1.2486,1.4522,-0.0310424,0.435326,0.453899,0.659863,-1.30971,-1.36791,0.0375118,-0.255254,-0.525655,-0.626656,-0.842706,-1.17732,-0.853987,-0.546081,0.950469,0.958134
5840,0.117231,0.0818152,0.434116,0.421575,0.212184,0.0429168,0.709988,0.661133,0.0412313,0.152687,0.515582,0.362581,0.80208,0.747982,0.199382,0.187253,0.248901,0.264989,0.358654,0.44231,-0.24171,-0.207751,-0.039979,0.161802,-0.631871,-0.166932,0.3448,0.490387,1.54264,1.47677,1.19918,0.909639,0.109457,0.00417697,0.16878,-0.170338,0.879142,1.18073,0.305657,0.315286
5841,0.972506,0.938602,0.722758,0.658282,0.0292369,-0.10682,0.0378997,-0.0108378,0.192065,0.302874,0.398732,0.309191,0.936791,0.883079,0.369067,0.358448,0.979149,0.99669,0.277373,0.317703,-0.0317215,-0.00448013,-0.974137,-0.770449,1.59443,2.05904,-1.21465,-1.07274,0.139638,0.0685857,0.76228,0.47851,-0.354406,-0.457274,-0.972449,-1.30954,1.51466,1.81205,0.81212,0.819516
5842,0.972574,0.939169,0.509013,0.443827,0.521875,0.386578,0.145353,0.098053,0.91128,1.02029,0.628155,0.441817,0.854476,0.721201,0.159601,0.146838,0.701148,0.762256,0.354889,0.39351,1.0504,1.07194,0.505443,0.709264,1.50724,1.9637,1.87658,2.02087,-0.0434328,-0.114746,0.587341,0.309723,-0.126216,-0.229095,0.476472,0.137975,-1.29255,-0.996103,1.69434,1.70258
5843,0.436652,0.402912,0.532951,0.56138,0.37022,0.184618,0.496815,0.451944,0.427662,0.536608,0.664105,0.574443,0.62599,0.559323,0.432426,0.417516,0.553801,0.527822,0.90976,0.947622,0.0253025,0.0500336,-1.21816,-1.02269,1.39853,1.86836,-1.0874,-0.940704,-1.95875,-2.03013,-0.588561,-0.859246,1.35596,1.25038,-0.096115,-0.433641,1.42615,1.72014,-0.237162,-0.222076
5844,0.870245,0.835875,0.750858,0.678933,0.118877,-0.0173416,0.398955,0.354393,0.879525,0.989243,0.511704,0.421486,0.452274,0.397445,0.976817,0.960296,0.274746,0.293388,0.06683,0.105783,-1.71838,-1.69057,0.808051,1.00502,-1.06847,-0.594596,0.0715243,0.225876,0.0728333,0.00613406,-0.131689,-0.397678,0.364231,0.264576,0.146466,-0.0930078,1.20285,1.49671,1.14956,1.16576
5845,0.833282,0.862458,0.948595,0.796486,0.69808,0.560803,0.506172,0.440437,0.46427,0.575172,0.994121,0.903866,0.0716691,0.0165041,0.577152,0.559275,0.72291,0.742997,0.422092,0.494691,-0.498939,-0.476285,-2.32456,-2.13098,0.920377,1.39304,-0.179969,-0.0575313,-0.486088,-0.557758,-0.81992,-1.07978,0.575768,0.477411,0.585937,0.247625,-1.81216,-1.52186,0.409042,0.41913
5846,0.923755,0.889042,0.979225,0.914039,0.0953474,-0.0435781,0.544484,0.526482,0.908996,1.01897,0.489163,0.398493,0.623514,0.568214,0.581419,0.458842,0.533247,0.555908,0.845933,0.883599,0.257696,0.281353,0.637919,0.835175,0.185158,0.655083,-0.491509,-0.340939,-1.3815,-1.4575,0.62255,0.35871,-0.369202,-0.462693,0.222611,-0.111311,0.143692,0.42625,0.567371,0.576791
5847,0.0265841,-0.0101238,0.943761,0.796671,0.492217,0.3543,0.679079,0.612527,0.886286,0.909452,0.915794,0.827479,0.587709,0.529894,0.452167,0.358408,0.724525,0.746404,0.832308,0.869402,1.4904,1.51133,0.672102,0.970087,-0.0888418,0.381346,0.683236,0.838765,-0.446637,-0.516269,0.49461,0.166698,-0.78791,-0.876808,-0.640747,-0.974769,-0.17081,0.126357,-0.357695,-0.352842
5848,0.158114,0.119891,0.742991,0.679304,0.686299,0.549626,0.743133,0.698571,0.691996,0.799935,0.297442,0.207307,0.254609,0.268168,0.274572,0.257975,0.253417,0.276887,0.0122255,0.048712,-0.82014,-0.795627,0.90556,1.105,-0.588779,-0.122286,0.391535,0.541015,0.984213,0.915182,0.233172,-0.0253136,2.41645,2.33349,0.801611,0.472742,-0.4595,-0.173536,0.845285,0.850833
5849,0.77967,0.740079,0.28828,0.226086,0.458103,0.322199,0.381951,0.336486,0.289965,0.395856,0.641945,0.552957,0.0640545,0.00644182,0.591708,0.597593,0.0621127,0.0841054,0.245254,0.281491,0.0625012,0.10638,-1.19219,-0.984536,0.907312,1.37898,-0.505312,-0.359238,-0.414107,-0.477717,1.99138,1.73641,-0.463434,-0.554676,0.738323,0.4047,-0.438452,-0.1469,-0.98565,-0.976773
5850,0.288652,0.249024,0.427558,0.364428,0.795212,0.659361,0.508179,0.461356,0.812478,0.919376,0.728433,0.634112,0.987385,0.929114,0.955202,0.93721,0.569299,0.58976,0.999826,1.03656,0.978945,1.00839,0.0222204,0.194411,0.792142,1.25902,-0.2874,-0.172037,0.723131,0.584373,0.594353,0.332436,-1.28059,-1.36693,-0.319778,-0.657634,1.97308,2.26199,-0.297422,-0.290712
5851,0.447142,0.367117,0.13661,0.0742687,0.490077,0.355285,0.398869,0.296545,0.443162,0.550606,0.803665,0.715267,0.118157,0.057378,0.668389,0.650264,0.646934,0.674741,0.0533272,0.0879986,-0.241671,-0.212508,1.1657,1.37336,0.102097,0.556363,-0.130006,0.0151645,1.71674,1.64646,0.557274,0.299717,-0.861361,-0.951648,0.373732,0.0414529,0.788563,1.0735,-0.880446,-0.959043
5852,0.524178,0.485209,0.612702,0.495165,0.537269,0.375201,0.177309,0.131734,0.284185,0.38924,0.0562443,-0.0300937,0.514098,0.453856,0.0524491,0.0339275,0.641681,0.759722,0.366273,0.401436,-0.488869,-0.514899,-0.0300753,0.176854,-0.605884,-0.146293,1.67612,1.82639,-0.201303,-0.268923,-0.26417,-0.518654,-1.4381,-1.5366,-0.498998,-0.838272,0.975428,1.26606,-1.6271,-1.62737
5853,0.138838,0.0996412,0.981078,0.916061,0.531555,0.395117,0.3998,0.386558,0.503512,0.60992,0.0270644,-0.0578347,0.196679,0.137597,0.400701,0.381172,0.823232,0.844703,0.24099,0.276349,-0.843982,-0.817289,0.891035,1.09812,-0.498452,-0.0397921,-0.306344,-0.153854,1.14769,1.08369,-1.9017,-2.1487,-0.509695,-0.615379,1.29409,0.950882,-0.319925,-0.0319543,0.244383,0.242531
5854,0.21272,0.175287,0.164207,0.101444,0.897627,0.762438,0.686528,0.641382,0.416422,0.524168,0.262866,0.180487,0.475706,0.379974,0.108324,0.0896408,0.0139326,0.0363201,0.636087,0.670915,0.311574,0.33719,1.37729,1.5923,-0.9786,-0.512275,-0.228183,0.0135645,-0.430476,-0.492958,-0.391727,-0.633088,0.118931,0.0154541,1.38472,1.03547,-0.193938,0.101071,-1.51346,-1.51282
5855,0.6147,0.57823,0.588437,0.52589,0.490941,0.356883,0.0363243,-0.0109398,0.944458,1.05319,0.788574,0.707164,0.738357,0.622351,0.363857,0.354968,0.195005,0.217666,0.333259,0.369987,-0.549191,-0.51187,1.30012,1.51784,0.338817,0.807124,0.0329993,0.180983,0.0224206,-0.045187,0.852714,0.606523,2.85588,2.7576,1.15239,0.799617,0.172998,0.466696,0.399818,0.399633
5856,0.306113,0.269184,0.113742,0.0522469,0.827061,0.694046,0.865059,0.815934,0.115051,0.225296,0.868144,0.787986,0.921975,0.864727,0.640766,0.620296,0.737066,0.758342,0.717233,0.75415,-1.38085,-1.36093,0.594364,0.816693,0.567376,1.03807,0.357491,0.498954,-0.786435,-0.85334,-1.32569,-1.56855,0.105543,0.000708912,0.176719,-0.172703,-0.358829,-0.0658909,0.202529,0.19529
5857,0.620847,0.585685,0.542979,0.481817,0.20448,0.0699265,0.483604,0.514085,0.960145,1.07091,0.739431,0.713961,0.665804,0.665827,0.409058,0.388006,0.443794,0.464116,0.658075,0.695813,0.0445504,0.0582565,2.39313,2.62108,-0.0548339,0.420718,1.03037,1.16834,0.0747788,0.0107961,-0.472114,-0.71216,-1.17914,-1.28057,1.01983,0.664101,0.782123,1.07993,0.27206,0.177339
5858,0.543131,0.508973,0.0673505,0.00438053,0.559675,0.427032,0.261933,0.212236,0.245922,0.355327,0.719998,0.639936,0.40993,0.466927,0.477096,0.4544,0.865654,0.88518,0.248031,0.284341,-0.19222,-0.177848,-2.37356,-2.14561,-0.286788,0.191905,-1.67693,-1.54469,-1.3557,-1.41182,-1.19354,-1.43859,-1.11522,-1.21737,0.834598,0.474444,-1.14713,-0.852637,0.161604,0.159388
5859,0.0822,0.0479197,0.657944,0.59523,0.131425,-0.00287926,0.209346,0.16061,0.144919,0.319552,0.918099,0.838801,0.284098,0.268027,0.103219,0.0824348,0.217854,0.234997,0.370221,0.369993,0.842011,0.853002,0.0478328,0.272487,1.99276,2.4676,-0.370306,-0.24202,2.19972,2.14525,-0.400853,-0.646426,2.43966,2.33393,-0.829697,-1.18793,0.953981,1.24802,-0.93871,-0.938173
5860,0.421748,0.36295,0.286125,0.220618,0.00166971,-0.134406,0.40007,0.351187,0.162712,0.283777,0.741456,0.661504,0.124097,0.0691264,0.131451,0.0601246,0.298736,0.317712,0.419647,0.455644,-1.21677,-1.20271,-1.00203,-0.785347,1.24431,1.71261,1.63484,1.75704,1.42638,1.36867,2.02139,1.76941,2.07495,1.96675,0.969616,0.617323,-2.31469,-2.02166,1.44129,1.4369
5861,0.71138,0.67798,0.28252,0.214972,0.443122,0.22792,0.0342372,-0.0156222,0.138535,0.248002,0.191388,0.112157,0.112194,0.0564632,0.0576832,0.0378144,0.903068,0.924073,0.796332,0.734459,1.22199,1.23866,-0.637219,-0.416686,0.482774,0.957616,-0.0955435,0.0324181,-0.103134,-0.162474,0.0960066,-0.155366,-0.00179431,-0.113462,1.99554,1.64015,2.09589,2.38138,-1.10782,-1.1169
5862,0.177194,0.141723,0.980063,0.915204,0.725283,0.590246,0.628575,0.57671,0.284311,0.383889,0.514837,0.437294,0.90635,0.851519,0.324834,0.303417,0.526812,0.549889,0.97917,1.01327,-0.308059,-0.285123,0.425824,0.646464,0.401423,0.911768,0.0580479,0.160967,-0.861877,-0.925397,-0.72003,-0.973736,0.474745,0.363148,0.215294,-0.145788,-0.909563,-0.621328,-1.26778,-1.27598
5863,0.680117,0.643852,0.740008,0.673882,0.290845,0.154917,0.479678,0.428977,0.344542,0.519775,0.62198,0.546337,0.929061,0.781178,0.29029,0.325663,0.701409,0.724856,0.340366,0.372611,0.521118,0.546132,0.377304,0.601698,0.395487,0.86592,0.164303,0.289515,1.65706,1.5899,-0.36101,-0.608342,0.331879,0.226776,-0.160513,-0.569483,1.29397,1.57697,1.34065,1.33603
5864,0.870115,0.834232,0.916823,0.85257,0.45501,0.310699,0.728219,0.679617,0.573286,0.655661,0.422343,0.347567,0.76418,0.710838,0.268368,0.34791,0.168677,0.190809,0.590181,0.620959,-0.2244,-0.195999,-1.83533,-1.6176,-0.613879,-0.137758,0.892725,1.02256,-1.08444,-1.1508,-1.27719,-1.52068,1.18393,1.08352,-0.639385,-0.993178,-1.45609,-1.17049,0.305807,0.30193
5865,0.697954,0.605332,0.0540766,-0.00872724,0.602724,0.466482,0.0240665,-0.02314,0.538459,0.791548,0.613141,0.543326,0.583449,0.530843,0.371289,0.370156,0.0871878,0.185095,0.285681,0.31577,0.0369756,-0.0009292,-0.660616,-0.449136,1.53742,2.00489,0.211225,0.339737,1.10367,1.03581,-0.479719,-0.728519,-0.680985,-0.776095,0.266507,-0.0807336,-0.1537,0.13141,0.634685,0.624806
5866,0.360672,0.376431,0.841851,0.77822,0.105751,-0.0332141,0.293486,0.247393,0.817967,0.927434,0.812431,0.739085,0.843919,0.792416,0.453339,0.392402,0.157255,0.179382,0.723341,0.755065,0.164981,0.19414,-2.06637,-1.85184,0.124308,0.598933,1.2143,1.33695,0.0202048,-0.0483026,0.663778,0.41853,0.654782,0.565551,-0.724314,-1.06706,-1.16455,-0.885022,0.0359451,0.0286062
5867,0.183412,0.14753,0.00333613,-0.0619896,0.00669445,-0.133886,0.111867,0.0654261,0.353039,0.463715,0.222469,0.149295,0.736646,0.683186,0.436065,0.414648,0.418404,0.438896,0.795619,0.827093,0.154799,0.18486,-0.0443865,0.17587,-0.826886,-0.356679,1.24507,1.36285,1.29797,1.23063,-1.61775,-1.86534,0.0601068,-0.0319255,-0.634818,-0.982468,0.968394,1.25131,-0.30181,-0.312494
5868,0.301762,0.341432,0.860216,0.797463,0.443735,0.305439,0.777503,0.731472,0.613867,0.748322,0.34796,0.246045,0.0619352,0.00658138,0.622956,0.666916,0.745771,0.69841,0.112228,0.146034,-0.365043,-0.329782,2.36862,2.59396,0.827732,1.29993,-0.830245,-0.710365,-0.906645,-0.980566,0.172779,-0.0722564,-1.27989,-1.37636,0.506489,0.1589,-1.23112,-0.950677,0.888017,0.878727
5869,0.568759,0.535333,0.553638,0.421716,0.116861,-0.0190192,0.871457,0.825144,0.922501,1.03293,0.378227,0.342795,0.307465,0.252867,0.943233,0.919185,0.935798,0.957925,0.132383,0.168223,0.605829,0.64147,-0.832533,-0.609297,-0.1573,0.311793,-0.426276,-0.301387,0.611955,0.541999,1.55334,1.30398,-0.406002,-0.501833,0.904536,0.551686,-0.532954,-0.257278,0.361378,0.357112
5870,0.155875,0.11997,0.109018,0.0459696,0.871592,0.737449,0.75785,0.795439,0.925058,1.03572,0.450282,0.439545,0.833559,0.77973,0.447449,0.515629,0.384342,0.408628,0.79973,0.837618,0.724708,0.752917,-0.87684,-0.654063,0.0375249,0.510641,-1.31417,-1.18779,0.241578,0.175037,0.111169,-0.14425,-0.172686,-0.273654,0.803533,0.453935,-0.734861,-0.464062,0.566395,0.559796
5871,0.950228,0.916532,0.702413,0.642275,0.877666,0.744639,0.722356,0.765735,0.482565,0.646462,0.60947,0.536296,0.609526,0.639131,0.136118,0.112073,0.230662,0.255032,0.677459,0.717133,-2.28678,-2.25913,-0.416145,-0.192241,-1.08442,-0.618295,1.76218,1.88895,-0.879421,-0.939573,-0.488342,-0.748183,0.549318,0.448192,0.340488,-0.0111934,1.28553,1.5515,-1.14294,-1.15026
5872,0.425354,0.454534,0.96746,0.908242,0.573868,0.343735,0.780822,0.736031,0.147808,0.257205,0.302529,0.227253,0.552822,0.498533,0.660813,0.638949,0.403324,0.429999,0.805461,0.843123,-0.715056,-0.683056,1.0004,1.22558,-0.143833,0.318212,0.431199,0.556309,0.722286,0.660352,0.24111,-0.0151426,-0.470483,-0.568482,-2.38053,-2.72471,0.367519,0.629977,0.716063,0.7023
5873,0.0239099,-0.00746351,0.520243,0.459786,0.0752835,-0.0571684,0.0295204,-0.0166306,0.871937,0.979467,0.24258,0.200886,0.159447,0.107195,0.486451,0.467379,0.0473877,0.0752774,0.101471,0.140487,-0.0563649,-0.0193039,0.689271,0.919404,-1.13288,-0.669928,-1.60373,-1.4864,-0.306123,-0.36365,-0.25231,-0.508342,1.21324,1.1104,-1.43047,-1.7792,-0.799253,-0.542838,-0.42715,-0.441836
5874,0.661484,0.628347,0.625731,0.600183,0.335951,0.195727,0.546584,0.501418,0.14723,0.25296,0.254887,0.174519,0.732108,0.678887,0.550423,0.53734,0.0607832,0.0902452,0.377802,0.418301,-0.267383,-0.224758,-0.579581,-0.355593,0.0815642,0.539686,-0.842592,-0.72311,-0.877213,-0.927542,0.494981,0.190963,1.23554,1.12493,-0.98344,-1.32589,0.646603,0.90237,0.400232,0.381117
5875,0.907102,0.874309,0.798109,0.74058,0.572829,0.448622,0.585273,0.540283,0.238456,0.256438,0.22158,0.148152,0.513177,0.457727,0.625928,0.607301,0.364863,0.328733,0.22955,0.267942,0.445676,0.484537,0.268262,0.489544,0.88161,1.33871,0.384507,0.503985,1.27838,1.22496,1.14825,0.890269,0.340945,0.233137,-0.0114216,-0.352617,-0.0645956,0.186615,-0.825003,-0.83858
5876,0.678978,0.666057,0.0384907,-0.0208203,0.833969,0.701517,0.859982,0.815537,0.148699,0.259915,0.761133,0.689927,0.878315,0.82461,0.383095,0.364386,0.505554,0.56722,0.363154,0.400004,-0.546104,-0.505708,0.112427,0.339854,-0.535816,-0.0824044,0.875545,0.990515,-0.0166873,-0.0752958,0.158107,-0.109288,0.143987,0.0373249,1.19773,0.850988,-1.81302,-1.55607,0.545836,0.533618
5877,0.382633,0.457805,0.173832,0.113033,0.845544,0.77224,0.834209,0.726847,0.159873,0.263393,0.374292,0.302475,0.133078,0.0813667,0.485278,0.52474,0.776245,0.805707,0.801861,0.839299,-0.177979,-0.131089,-0.737817,-0.516051,-0.639388,-0.188913,0.36024,0.477058,0.0162312,-0.0394949,-0.848804,-1.10884,-0.919627,-1.02528,-0.775929,-1.12598,-0.666305,-0.41025,0.851604,0.842245
5878,0.275717,0.249553,0.875437,0.813265,0.976437,0.842964,0.6815,0.638157,0.563952,0.665924,0.435704,0.364027,0.0421896,-0.00757664,0.700836,0.685094,0.760074,0.790285,0.610423,0.617512,0.670789,0.716272,1.90256,2.12334,-0.0262314,0.41128,0.641754,0.765476,0.996504,0.947566,0.204236,-0.041411,-0.512665,-0.626332,-2.02259,-2.37276,0.261621,0.51732,-0.100716,-0.11633
5879,0.0740946,0.0413016,0.874814,0.812888,0.605109,0.39757,0.0291403,-0.0141647,0.322126,0.50944,0.0927451,0.0212776,0.338692,0.289581,0.630358,0.614125,0.244918,0.275433,0.35903,0.395726,-0.674915,-0.625176,-0.0813521,0.140917,0.561821,1.01147,-0.351929,-0.228468,-0.211889,-0.243697,1.28438,1.02602,0.446876,0.326556,0.118311,-0.225349,1.48329,1.7409,-0.709072,-0.728829
5880,0.31834,0.287263,0.571973,0.416289,0.0847674,-0.0478246,0.248559,0.206181,0.250498,0.352957,0.560051,0.488876,0.137546,0.212814,0.0623077,0.0474796,0.603142,0.631756,0.617313,0.65445,2.04762,2.09712,0.941905,1.15663,-0.337125,0.117038,0.862007,0.983266,-1.38602,-1.43496,-1.15185,-1.41685,-0.915941,-1.03179,1.30249,0.961161,-0.867748,-0.610384,-0.904102,-0.918119
5881,0.973303,0.943657,0.0824081,0.019691,0.172018,0.0384416,0.911289,0.867303,0.428973,0.532994,0.281455,0.211088,0.131247,0.136047,0.724947,0.711804,0.30014,0.327906,0.514095,0.548745,2.01185,2.05788,-0.525456,-0.30912,2.26957,2.72083,-0.391651,-0.27415,-2.22239,-2.27603,0.0494388,-0.221846,-0.0238181,-0.143129,-0.787804,-1.12379,-2.24626,-1.98765,0.538468,0.517521
5882,0.677354,0.649144,0.763874,0.699382,0.650048,0.516624,0.796632,0.75484,0.952629,1.05651,0.686207,0.528741,0.108391,0.0592799,0.209539,0.195996,0.416338,0.442469,0.0476218,0.0827891,-0.316824,-0.264376,1.15191,1.37388,-0.485593,-0.0321232,0.161429,0.273904,-0.520114,-0.570626,0.331199,0.0524815,-1.44025,-1.56507,-1.20857,-1.54351,0.621222,0.886392,0.818428,0.795611
5883,0.808165,0.78355,0.793738,0.727832,0.226483,0.0921255,0.362688,0.322944,0.426436,0.528052,0.918712,0.846393,0.640278,0.499355,0.288323,0.272412,0.198367,0.223628,0.793069,0.826706,0.606459,0.660324,-0.467243,-0.246097,0.0958993,0.551306,-1.80531,-1.69068,0.760607,0.708302,-1.73685,-2.01268,-0.720445,-0.843222,0.630831,0.293201,-0.796337,-0.536732,0.0326852,0.00294708
5884,0.943906,0.917956,0.540911,0.490051,0.386183,0.253394,0.388874,0.350899,0.784652,0.885678,0.277772,0.206737,0.987452,0.939431,0.842381,0.82561,0.311329,0.423346,0.770974,0.820035,-1.61794,-1.57165,-1.03686,-0.811326,-0.423606,0.0310917,-0.241871,-0.133188,-0.263759,-0.3157,1.81286,1.53944,-1.00138,-1.11713,0.316291,-0.02013,0.754778,1.01619,0.14028,0.116076
5885,0.762778,0.766023,0.183921,0.252271,0.102844,-0.0313457,0.182443,0.144023,0.20546,0.30711,0.617612,0.527528,0.715868,0.608183,0.851776,0.835889,0.580627,0.623063,0.77848,0.813364,-1.50879,-1.46021,2.27281,2.49875,-0.722823,-0.273426,-0.701943,-0.601206,-0.218309,-0.264554,-0.589538,-0.856976,1.57166,1.45398,0.264222,-0.113593,1.28631,1.55485,0.678911,0.649807
5886,0.641313,0.614091,0.0803969,0.0144903,0.0691655,-0.0648899,0.348476,0.308864,0.423005,0.541276,0.919353,0.848318,0.324231,0.276934,0.0288654,0.0126711,0.797722,0.822781,0.483908,0.431825,0.00247187,0.0534967,-0.648186,-0.425216,-0.308721,0.141864,-0.445586,-0.344777,-0.572709,-0.615637,0.444992,0.185487,-2.90186,-3.01952,0.134357,-0.207055,1.3403,1.61059,0.0011814,-0.0228977
5887,0.697795,0.621395,0.185293,0.0690561,0.835537,0.701993,0.772077,0.733126,0.673863,0.775442,0.624388,0.554169,0.248038,0.203149,0.885267,0.867645,0.65575,0.74103,0.0136046,0.0502858,-0.84656,-0.798002,-0.582815,-0.3082,0.729241,1.18523,-1.03759,-0.936021,0.0355371,0.0731159,-0.791216,-1.04507,-0.862215,-0.976726,0.882063,0.537023,-0.317714,-0.0498252,-1.13048,-1.15268
5888,0.65641,0.628699,0.190021,0.123622,0.0407778,-0.0945425,0.0597587,0.0202349,0.477359,0.578321,0.762363,0.694105,0.560416,0.515209,0.54307,0.508993,0.647158,0.65928,0.92317,0.958876,-0.166938,-0.117999,-0.405642,-0.191183,-0.195002,0.260441,0.646455,0.747025,0.807385,0.761869,0.613423,0.363895,-0.508889,-0.622873,-0.0207023,-0.372276,2.20929,2.47398,-0.0873863,-0.117022
5889,0.759335,0.636003,0.675017,0.607341,0.728724,0.595515,0.584207,0.452239,0.968629,1.07158,0.0626989,-0.00521588,0.365568,0.320261,0.166269,0.150341,0.622738,0.577529,0.343643,0.378665,1.17277,1.22406,1.493,1.70658,0.488638,0.937082,0.575985,0.680719,0.753826,0.702231,-0.844033,-1.10125,0.269506,0.16083,0.0287169,-0.319289,-0.0361235,0.226859,0.734962,0.705932
5890,0.67053,0.643308,0.74435,0.675877,0.389536,0.272993,0.921137,0.884242,0.822343,0.890307,0.0961795,0.0263386,0.842084,0.796785,0.353774,0.314873,0.470719,0.495778,0.16172,0.198325,0.17609,0.233812,-0.509815,-0.288549,0.35138,0.802133,1.47292,1.47814,-1.05875,-1.10487,-1.64597,-1.90486,-0.467195,-0.576572,-0.477906,-0.83039,-0.720501,-0.458287,-0.421888,-0.452217
5891,0.505378,0.480294,0.434181,0.365287,0.0853825,-0.0495293,0.228384,0.192125,0.603657,0.709033,0.922062,0.851272,0.249447,0.205258,0.494808,0.479404,0.00510308,0.030894,0.925034,0.962776,-1.11868,-1.06292,-0.672695,-0.45537,0.451138,0.908634,2.17647,2.27556,-0.462952,-0.503891,-0.70348,-0.955029,0.608669,0.495909,-0.61856,-0.97485,0.341838,0.610193,-0.287292,-0.31016
5892,0.56809,0.540547,0.869392,0.799436,0.250972,0.11663,0.410626,0.39025,0.809041,0.914255,0.704472,0.680658,0.46893,0.426338,0.994083,0.980638,0.602712,0.627365,0.582741,0.621637,0.501546,0.559954,-1.64087,-1.42002,1.94838,2.4099,-2.55346,-2.45962,0.55867,0.514629,1.21703,0.959871,0.873371,0.755486,0.956344,0.597343,0.90588,1.17877,0.421285,0.391839
5893,0.248833,0.221327,0.906705,0.837809,0.910159,0.775624,0.572073,0.588374,0.485178,0.576155,0.578704,0.510044,0.292558,0.251447,0.849088,0.833713,0.103271,0.127612,0.988743,1.02594,1.04329,1.10291,-0.802423,-0.588195,0.182282,0.648579,-0.985049,-0.885297,0.234704,0.193425,-0.487662,-0.74682,0.214812,0.0968167,0.936924,0.574078,-2.09818,-1.82394,-0.27304,-0.31017
5894,0.617423,0.589086,0.326917,0.256776,0.76552,0.560419,0.822756,0.786498,0.13338,0.238055,0.0965539,0.0299066,0.65561,0.613907,0.465659,0.477237,0.0846629,0.106756,0.345575,0.385279,-0.445235,-0.392142,-0.559034,-0.340872,-0.452487,0.0176556,-1.22473,-1.11941,-0.413577,-0.460926,-1.57446,-1.82599,2.77987,2.66792,0.637725,0.278542,-0.909369,-0.633235,-0.0254932,-0.0638079
5895,0.218195,0.188382,0.870865,0.799034,0.477771,0.345214,0.287937,0.253499,0.235081,0.341854,0.907552,0.839833,0.158156,0.118104,0.136064,0.120762,0.833975,0.854064,0.601633,0.644004,0.88534,0.933539,1.31997,1.54461,-0.507865,-0.0430023,-1.21334,-1.10785,1.91507,1.85897,-0.469918,-0.725381,-0.880041,-0.988472,1.02745,0.671328,-1.81354,-1.54098,0.788064,0.744456
5896,0.0880666,0.137262,0.957191,0.883397,0.0551861,-0.0792852,0.442249,0.408131,0.627573,0.648934,0.463293,0.393782,0.88121,0.841689,0.351932,0.338997,0.357029,0.379392,0.329987,0.373558,-1.96082,-1.90592,-1.87387,-1.64722,0.141093,0.55719,0.560786,0.670116,-0.42122,-0.480689,0.885176,0.636526,0.65005,0.535859,0.0442872,-0.314996,-1.39405,-1.12855,-0.721333,-0.763352
5897,0.115696,0.0861413,0.406206,0.331522,0.218105,0.0819831,0.102494,0.0666653,0.851161,0.956015,0.428083,0.356454,0.335206,0.294834,0.146712,0.132118,0.385805,0.457432,0.501836,0.54573,1.89324,1.94814,0.00123586,0.221732,0.692594,1.15738,0.875329,0.988087,1.34942,1.2868,-1.10317,-1.35067,1.68367,1.563,-0.246899,-0.610532,0.475601,0.740565,-0.727252,-0.770731
5898,0.511062,0.500775,0.329586,0.253728,0.138923,0.0018591,0.274542,0.265455,0.159465,0.266131,0.0891811,0.0188184,0.543075,0.500729,0.713442,0.699628,0.395411,0.535472,0.991782,1.0352,0.612465,0.666557,-1.66406,-1.44651,0.759624,1.21976,0.446633,0.489823,2.0141,1.95124,1.95762,1.71799,-0.982721,-1.10917,-0.198201,-0.557545,-0.376248,-0.115681,-1.53637,-1.57787
5899,0.94674,0.915409,0.510038,0.432416,0.38746,0.17579,0.498029,0.464244,0.710193,0.814842,0.71014,0.639577,0.955093,0.912255,0.957296,0.945185,0.592619,0.613513,0.603463,0.645206,0.46865,0.519476,-1.32244,-1.10554,0.47352,0.930309,-0.113827,-0.00844144,-0.674434,-0.737542,-0.265849,-0.504104,0.00536937,-0.125472,0.768228,0.40068,0.815556,1.07503,-1.10981,-1.14996
5900,0.339859,0.309972,0.224456,0.146755,0.486138,0.34972,0.36103,0.327025,0.173974,0.276689,0.406009,0.335877,0.76046,0.717307,0.0193056,0.00937935,0.782974,0.707225,0.595336,0.634966,-0.466196,-0.40977,-0.118434,0.0956147,-0.961893,-0.505745,-1.32785,-1.21915,0.762413,0.693908,-0.970738,-1.21548,-0.614492,-0.740247,-1.28043,-1.65144,-0.380869,-0.12912,0.454358,0.409785
5901,0.866602,0.836778,0.771461,0.694624,0.239499,0.144812,0.547362,0.50621,0.161988,0.240456,0.614971,0.544366,0.865552,0.82242,0.76367,0.751774,0.843569,0.800937,0.846297,0.888172,-0.670548,-0.615224,-0.047326,0.173793,-1.85052,-1.40018,0.587489,0.698072,3.15415,3.08054,1.22068,0.971073,0.614195,0.490937,0.385792,0.0130353,2.53833,2.78216,-0.506651,-0.548789
5902,0.604213,0.573276,0.762053,0.682534,0.0775481,-0.0600956,0.718061,0.685394,0.102822,0.204223,0.584129,0.512229,0.436526,0.393037,0.0352306,0.0215563,0.872171,0.894649,0.316789,0.356716,-1.83538,-1.77309,0.650026,0.865996,1.47996,1.92153,1.90736,2.01629,0.279032,0.211504,1.01126,0.755428,-0.137806,-0.259866,-0.0850448,-0.452093,0.420523,0.661144,-0.420604,-0.468113
5903,0.74684,0.71363,0.74965,0.670444,0.799516,0.659901,0.292309,0.258232,0.718924,0.818321,0.32129,0.24911,0.98126,0.939302,0.0858522,0.0715712,0.362749,0.38495,0.951129,0.990621,0.670503,0.729159,-0.832268,-0.614194,2.07038,2.519,-0.116821,-0.0088563,0.274517,0.201076,1.05121,0.800452,1.13335,1.01636,0.350227,-0.01457,0.369301,0.608026,-0.546449,-0.688088
5904,0.410838,0.378478,0.161418,0.0842825,0.413407,0.275285,0.227742,0.218473,0.612005,0.805438,0.904452,0.829962,0.312869,0.272531,0.896413,0.880247,0.237737,0.257982,0.651142,0.689692,-0.0616666,0.000418629,0.931606,1.14709,-1.39799,-0.949049,-0.628701,-0.522313,-1.88755,-1.96443,-1.72358,-1.97111,-1.01051,-1.12627,-0.350472,-0.710836,-0.499288,-0.265757,-0.856482,-0.908063
5905,0.600513,0.617843,0.579239,0.503396,0.286471,0.149057,0.212063,0.178715,0.693634,0.792556,0.912754,0.837049,0.453487,0.412749,0.177515,0.161122,0.623094,0.643732,0.0614646,0.099031,0.42749,0.484593,-2.06082,-1.85173,-0.606928,-0.166341,1.02956,1.12909,-2.23266,-2.31551,0.620186,0.372743,0.111561,-0.00586823,-0.107308,-0.471102,-0.971109,-0.735409,0.196228,0.142781
5906,0.891289,0.857207,0.183674,0.109304,0.468501,0.280705,0.353751,0.318244,0.812143,0.911951,0.0911678,0.0135941,0.138536,0.0964895,0.0595854,0.0445746,0.370922,0.390027,0.193398,0.29916,-2.58182,-2.52746,0.386054,0.594751,-1.11969,-0.686555,0.365373,0.46186,-0.11763,-0.1975,1.68278,1.43113,-0.142037,-0.264288,-0.561603,-0.920459,-0.134796,0.0989068,-1.37043,-1.42487
5907,0.388413,0.356078,0.732267,0.657173,0.54955,0.412353,0.0469362,0.0104587,0.602504,0.700155,0.500977,0.423247,0.941468,0.901961,0.21164,0.258402,0.968731,0.986499,0.461284,0.499289,1.86708,1.92144,1.01403,1.22583,1.35654,1.7889,-0.015994,0.0872875,-0.590429,-0.67052,0.229585,-0.0170985,0.470291,0.351502,1.44183,1.08724,-1.39115,-1.1518,2.04908,2.00073
5908,0.842033,0.808539,0.906754,0.831026,0.470732,0.260694,0.00228671,-0.0364147,0.690074,0.788678,0.637304,0.586924,0.291198,0.249717,0.48556,0.472229,0.495781,0.511826,0.419762,0.352485,0.865784,0.915543,0.179108,0.383818,1.05799,1.48438,-0.135707,-0.0389875,-1.37204,-1.49986,1.64176,1.39187,0.48409,0.366036,0.140962,-0.208626,-0.641808,-0.379706,1.40182,1.35789
5909,0.0795506,0.0475588,0.429776,0.353589,0.247011,0.109036,0.933177,0.897817,0.477563,0.576882,0.692358,0.7506,0.47827,0.514319,0.221478,0.210395,0.970269,0.987274,0.256066,0.205681,0.124316,0.173412,-0.959611,-0.751823,0.294505,0.713684,0.384117,0.476103,-2.2491,-2.32919,-1.67473,-1.92258,-0.226355,-0.311199,1.00618,0.657314,0.148593,0.392391,0.486418,0.444142
5910,0.567592,0.534285,0.613371,0.602818,0.934257,0.79392,0.360633,0.325155,0.563974,0.660721,0.992006,0.914277,0.820551,0.778921,0.947303,0.938046,0.400108,0.417344,0.0208726,0.0588772,1.7093,1.76448,0.721161,0.931181,0.496783,0.912533,1.18627,1.28558,-0.400599,-0.482429,1.13908,0.89898,-0.876764,-0.988435,0.538376,0.192186,-0.529904,-0.292755,1.83101,1.78525
5911,0.0191615,-0.0120643,0.926345,0.852048,0.931121,0.790188,0.745444,0.622857,0.984618,1.08306,0.631256,0.648846,0.383414,0.34284,0.467854,0.456965,0.675345,0.693614,0.59992,0.638212,-1.40371,-1.34182,-0.931496,-0.72123,-1.77166,-1.35978,-0.510126,-0.405133,0.268529,0.182005,-0.0229028,-0.255997,2.15881,2.05226,0.921656,0.570896,-0.461306,-0.220998,-0.348919,-0.386404
5912,0.184356,0.230455,0.0245574,-0.0522031,0.406518,0.266766,0.956913,0.920558,0.917941,1.01733,0.44331,0.383416,0.943135,0.904352,0.738183,0.727643,0.30341,0.420333,0.143119,0.181996,-0.33309,-0.265399,-1.76514,-1.56325,-0.439051,-0.0267012,0.766485,0.8687,0.230032,0.139699,-1.7701,-2.01076,-0.475339,-0.577244,-0.490674,-0.845699,-1.12834,-0.89195,0.818229,0.787479
5913,0.503808,0.472975,0.43131,0.262274,0.647298,0.409163,0.232696,0.197857,0.606606,0.684927,0.19743,0.117985,0.545473,0.508295,0.1171,0.1064,0.130796,0.147051,0.679826,0.716891,-0.645169,-0.576931,0.159013,0.367581,0.277137,0.695599,0.535722,0.634583,1.00795,0.911946,-1.55346,-1.7964,-0.0990752,-0.208716,-0.995629,-1.3568,2.4197,2.6575,0.489115,0.394265
5914,0.479398,0.328795,0.652236,0.576751,0.690194,0.55156,0.434656,0.399317,0.251576,0.35252,0.0701232,-0.0106049,0.422075,0.383683,0.673326,0.664298,0.109141,0.126195,0.169035,0.205982,0.0580387,0.132364,-1.19532,-0.986946,-0.809995,-0.385506,1.76153,1.86168,0.122211,0.0266379,0.53282,0.292824,-0.642325,-0.74842,-1.24375,-1.60829,0.95896,1.20274,0.0276137,0.00105041
5915,0.282967,0.184615,0.231281,0.158082,0.716049,0.591557,0.295148,0.257782,0.597056,0.650737,0.450632,0.405556,0.828746,0.790652,0.300242,0.292333,0.979439,0.996835,0.739582,0.774377,-1.40176,-1.33161,-1.54162,-1.33691,1.30361,1.7268,-0.867592,-0.772598,0.382524,0.292156,-1.42637,-1.66478,-0.312067,-0.411372,0.728128,0.368101,1.20547,1.44204,0.88373,0.852706
5916,0.0690232,0.0404346,0.259121,0.186532,0.768126,0.631555,0.907806,0.870656,0.849768,0.948953,0.902092,0.821718,0.889137,0.849626,0.293763,0.23249,0.638901,0.65758,0.0398079,0.0767206,0.0620031,0.136035,0.587599,0.786967,-1.39644,-0.977941,0.969839,1.06982,-0.0767386,-0.16653,0.465052,0.222055,0.787473,0.692979,1.89967,1.54166,2.38559,2.62033,-0.177944,-0.212161
5917,0.779747,0.751066,0.490421,0.418434,0.211116,0.0727077,0.267478,0.228407,0.952071,1.05275,0.191327,0.112015,0.73978,0.700096,0.181304,0.172647,0.65582,0.591586,0.615934,0.650803,-0.0378541,0.0963882,0.00571612,0.208043,-0.0448127,0.356677,0.159078,0.262237,0.283909,0.191816,-0.0337752,-0.271144,0.671844,0.573365,-1.35218,-1.70687,-0.484599,-0.256777,0.789467,0.761486
5918,0.0794699,0.0528227,0.723967,0.650336,0.967205,0.829176,0.3042,0.357768,0.323407,0.422936,0.566247,0.486916,0.196991,0.157832,0.680627,0.67388,0.507728,0.525593,0.789257,0.822975,-0.0188793,0.0567418,-0.0161574,0.179972,1.2728,1.6913,1.25122,1.34879,-0.0117102,-0.0965938,1.82652,1.58463,-0.210977,-0.303381,0.0806793,-0.272433,0.646404,0.873501,-0.698979,-0.730857
5919,0.938934,0.913699,0.386,0.310298,0.66047,0.543734,0.528953,0.487128,0.116809,0.216449,0.495174,0.414221,0.281343,0.170574,0.772812,0.764763,0.94332,0.960492,0.564955,0.59922,0.753696,0.828571,1.8782,2.07773,-0.0621751,0.414761,-0.133718,-0.0294106,-1.67657,-1.76579,0.599741,0.354078,0.846843,0.755631,-0.823549,-1.18173,-0.238071,-0.0144373,-1.90097,-1.93493
5920,0.063944,0.0379345,0.844727,0.768793,0.467952,0.258293,0.442438,0.420552,0.785623,0.887341,0.961767,0.881819,0.225567,0.183316,0.324896,0.318451,0.0435488,0.0596604,0.298149,0.375465,-0.262032,-0.193335,0.286195,0.490137,-1.28209,-0.861774,-0.92534,-0.820213,0.208458,0.128298,-0.00710015,-0.249855,0.405446,0.309582,-1.09627,-1.44856,-0.350279,-0.128054,-0.315807,-0.346889
5921,0.0179567,-0.00895742,0.681957,0.605583,0.11088,-0.0271491,0.394087,0.353976,0.479662,0.579826,0.91267,0.83463,0.65369,0.609948,0.37927,0.374191,0.565392,0.508131,0.117991,0.151709,0.484121,0.547938,-0.747177,-0.537663,0.142031,0.562561,1.96527,2.07163,-0.930538,-1.01537,0.285326,0.039384,1.67075,1.57075,0.486287,0.138242,0.387612,0.612378,-0.425244,-0.460366
5922,0.77265,0.746192,0.13206,0.0537083,0.853952,0.713722,0.53843,0.499021,0.80641,0.907199,0.183133,0.105193,0.775278,0.730017,0.934999,0.932089,0.940124,0.956601,0.986631,1.02072,-0.888626,-0.823173,-0.58063,-0.366396,0.0935367,0.518207,2.171,2.28227,-0.453589,-0.537284,-1.32438,-1.57714,-0.862316,-0.957184,0.872372,0.531028,-0.997418,-0.778899,1.37761,1.34613
5923,0.747509,0.720909,0.55599,0.478154,0.270454,0.130019,0.0188025,-0.0188527,0.461398,0.563624,0.567533,0.41323,0.455251,0.40945,0.938319,0.881851,0.0481794,0.0675208,0.265917,0.298244,0.213674,0.284335,0.781696,0.989005,-0.487103,-0.0680006,-0.378789,-0.266834,-0.835648,-0.919607,0.638168,0.383974,0.794506,0.707318,0.82923,0.490779,-1.49724,-1.28019,0.18161,0.157126
5924,0.168449,0.140098,0.630364,0.55182,0.775815,0.63358,0.571938,0.533725,0.583763,0.68802,0.800867,0.721268,0.783588,0.736766,0.939288,0.831614,0.273693,0.277821,0.413494,0.444962,-0.663476,-0.598317,-2.14742,-1.93496,0.8369,1.2514,-1.64236,-1.52425,-0.462242,-0.545095,0.203278,-0.0162608,-1.3206,-1.40533,-0.119473,-0.465485,2.35012,2.56858,-0.71379,-0.740666
5925,0.373957,0.346318,0.975538,0.897996,0.402295,0.248862,0.658458,0.608069,0.321636,0.425716,0.978345,0.900369,0.661199,0.705951,0.782057,0.781376,0.468884,0.488122,0.896991,0.928663,0.276292,0.340723,-0.343613,-0.181978,0.507087,0.915655,-1.35368,-1.23583,-0.661551,-0.743908,-0.173536,-0.416496,-1.69227,-1.77251,0.642388,0.293431,-0.0079955,0.217304,0.0809844,0.0526147
5926,0.0779347,0.0518053,0.550275,0.474063,0.00822047,-0.135856,0.623699,0.682412,0.598504,0.702313,0.833981,0.756761,0.724639,0.675136,0.36339,0.364884,0.4067,0.428352,0.447663,0.534359,-0.675997,-0.618177,1.35855,1.57101,0.643667,1.05352,-0.786099,-0.674297,-1.14194,-1.23069,-0.64108,-0.816731,-0.206021,-0.280709,-0.615588,-0.970394,0.114847,0.333903,-0.163667,-0.196675
5927,0.68357,0.657782,0.72798,0.652751,0.27157,0.124829,0.793868,0.756755,0.277768,0.379936,0.111444,0.0355498,0.169983,0.122392,0.401202,0.412201,0.977892,0.997716,0.108065,0.140054,0.263586,0.320863,-1.49967,-1.28561,-0.313331,0.0979072,-0.790458,-0.677334,0.289516,0.200761,-0.962771,-1.21697,-0.766161,-0.834207,1.47253,1.11484,-0.672532,-0.461663,1.26844,1.23896
5928,0.572324,0.601073,0.1212,0.0469301,0.170936,0.0241567,0.38085,0.344436,0.86961,0.969904,0.224002,0.149333,0.923332,0.877597,0.45646,0.459519,0.703567,0.723823,0.224364,0.257222,0.275089,0.326285,1.23963,1.45248,0.679565,1.0974,1.79063,1.90478,0.0634334,-0.0292538,-0.641388,-0.896676,0.154894,0.0870157,-0.52469,-0.877022,0.343196,0.560079,0.464196,0.431821
5929,0.568756,0.544363,0.0833308,0.00755825,0.926312,0.780625,0.179104,0.142125,0.836208,0.935548,0.816034,0.739979,0.504521,0.456575,0.870128,0.871263,0.868679,0.8887,0.0965282,0.12801,1.57576,1.62,-0.970127,-0.75219,0.378809,0.792884,0.751704,0.899591,-1.40175,-1.49792,1.1932,0.944486,-0.083323,-0.228555,-0.121716,-0.469061,0.273145,0.493303,-1.06465,-1.09203
5930,0.0863971,0.0634161,0.410974,0.256787,0.0469917,-0.0987927,0.404892,0.318991,0.0586511,0.156018,0.565965,0.491308,0.998461,0.948665,0.0580118,0.0594873,0.709621,0.748597,0.888545,0.920311,1.40439,1.44426,-0.590395,-0.366706,-0.630756,-0.210794,-0.226165,-0.105596,-0.191229,-0.280024,-2.04281,-2.29121,-0.473039,-0.544125,-0.733732,-1.0881,-1.46746,-1.24939,-0.708132,-0.740101
5931,0.465272,0.441492,0.579565,0.506017,0.989691,0.845855,0.530191,0.495857,0.21662,0.315193,0.318408,0.242636,0.315486,0.26681,0.825679,0.82673,0.574312,0.608494,0.946066,0.915473,-1.97966,-1.94792,-2.15629,-1.93899,1.25992,1.68208,0.031843,0.150833,0.702851,0.615719,0.837949,0.59759,0.0330619,0.0086053,-0.743667,-1.09751,0.502315,0.717484,1.26962,1.23289
5932,0.0885026,0.0671682,0.326253,0.25545,0.871106,0.729314,0.524496,0.489074,0.928362,1.02714,0.922866,0.848422,0.56256,0.457928,0.440756,0.515892,0.44837,0.468391,0.982488,0.910635,0.909858,0.936353,-0.856056,-0.64335,0.114134,0.539166,1.652,1.77246,0.516186,0.432387,1.16998,0.932118,0.632574,0.561336,0.337833,-0.0158582,-0.153407,0.0631729,0.173308,0.135326
5933,0.491998,0.386405,0.523292,0.524247,0.4265,0.284823,0.270211,0.227723,0.56207,0.658369,0.0918784,0.0151847,0.697002,0.649046,0.201487,0.205054,0.00478255,0.0238145,0.874804,0.905797,0.861257,0.88218,0.0891762,0.364316,1.21974,1.64281,-0.0761227,0.0478412,1.80307,1.7259,0.0655776,-0.177485,-0.118246,-0.189467,0.342059,-0.00852717,0.213527,0.428798,-0.618884,-0.657339
5934,0.727955,0.705641,0.865795,0.793044,0.427907,0.332604,0.00191907,-0.0336282,0.836143,0.930074,0.978715,0.902328,0.326569,0.278332,0.564179,0.567939,0.223933,0.309963,0.245921,0.275034,0.224365,0.246246,1.16002,1.37198,-0.945641,-0.516832,1.14778,1.27494,2.03707,1.95948,-0.346251,-0.593817,-0.0659915,-0.143567,0.137225,-0.213575,-1.71558,-1.50377,0.3513,0.325887
5935,0.626593,0.603039,0.7555,0.684037,0.52151,0.380385,0.323286,0.286002,0.906794,0.999246,0.468178,0.452564,0.684913,0.542934,0.152317,0.156248,0.578212,0.596112,0.840676,0.869253,1.61526,1.63497,-0.220364,-0.0146413,0.0634193,0.497854,-1.00351,-0.875399,-0.48042,-0.56318,1.49142,1.24734,0.242286,0.0759242,1.4521,1.09541,-1.0179,-0.810373,1.34176,1.30911
5936,0.891047,0.869913,0.22028,0.146939,0.207904,0.0658559,0.246879,0.207679,0.758447,0.852837,0.0809601,0.0027998,0.856195,0.807537,0.768709,0.771162,0.62355,0.656734,0.513638,0.542933,0.348797,0.334676,0.126721,0.326333,-1.06569,-0.631083,-0.355772,-0.2204,-0.892214,-1.03319,-1.60215,-1.84398,0.365759,0.295416,-0.0727787,-0.428852,0.892825,1.10453,0.900872,0.863261
5937,0.1351,0.114614,0.241341,0.165973,0.39825,0.15558,0.592001,0.551023,0.905932,1.00302,0.0338834,-0.0443893,0.565365,0.44644,0.966879,0.884701,0.700442,0.717357,0.732364,0.760313,-0.989492,-0.965622,0.116496,0.239745,-0.749267,-0.308369,2.26818,2.40995,-1.41881,-1.50319,-1.46522,-1.7067,-0.349125,-0.424752,-0.712962,-1.06444,0.108986,0.325483,-1.42538,-1.45817
5938,0.128911,0.109971,0.901245,0.825307,0.389799,0.245305,0.547487,0.48145,0.720409,0.81603,0.614885,0.536463,0.132952,0.0853437,0.997996,0.99824,0.175572,0.19329,0.666244,0.682924,1.51193,1.53663,-0.048955,0.153158,-1.21496,-0.765903,-0.730733,-0.588429,1.50461,1.42577,-0.606591,-0.850311,-1.66833,-1.73754,-0.316293,-0.671653,-1.52137,-1.30202,0.989499,0.949341
5939,0.802335,0.781193,0.755214,0.681601,0.747151,0.60241,0.452579,0.411876,0.274519,0.368019,0.627983,0.506651,0.472242,0.465872,0.127506,0.12633,0.723174,0.742958,0.686104,0.605535,0.0857732,0.117058,0.808446,1.01374,-1.08,-0.628039,0.0415379,0.189858,0.138697,0.0615482,-0.367212,-0.606064,0.250969,0.179194,-1.19184,-1.55138,1.0206,1.23508,0.808964,0.775359
5940,0.518192,0.497145,0.135478,0.0607286,0.733773,0.648242,0.131243,0.0890684,0.686294,0.780642,0.554426,0.476839,0.893965,0.846401,0.994206,0.992591,0.85599,0.877122,0.469622,0.528146,1.00641,1.10013,-0.259007,-0.0603488,-0.197072,0.249169,-1.40631,-1.25189,0.213821,0.143735,1.03908,0.8029,-0.212603,-0.282257,1.63232,1.2816,0.929701,1.13637,0.399175,0.358792
5941,0.790238,0.768285,0.969102,0.892952,0.841149,0.694074,0.475598,0.432412,0.0725883,0.166215,0.0550656,-0.0232289,0.405783,0.360098,0.625333,0.625804,0.113038,0.135939,0.422809,0.450757,2.04922,2.0832,-0.657463,-0.456124,-0.811887,-0.461353,0.0678398,0.2252,-0.575024,-0.649422,-0.606355,-0.815273,0.911159,0.838141,-0.679606,-1.0343,-1.85839,-1.65498,0.466192,0.427017
5942,0.243038,0.221936,0.900594,0.82391,0.611346,0.466647,0.486367,0.453898,0.37578,0.392837,0.398568,0.266645,0.550359,0.505887,0.851453,0.849729,0.774987,0.798271,0.528819,0.491627,1.47877,1.50893,0.109248,0.313799,-1.62525,-1.17188,0.0834073,0.228554,0.0519007,-0.0165349,-2.19726,-2.43345,-0.26105,-0.33424,1.29284,0.942088,0.407123,0.606904,1.15436,1.11308
5943,0.611311,0.589694,0.306018,0.227747,0.106732,-0.0374898,0.518671,0.475384,0.527024,0.619459,0.634975,0.55652,0.310032,0.264604,0.431866,0.491077,0.323585,0.348474,0.505586,0.532497,0.369863,0.395272,-1.23089,-1.02545,0.463866,0.91031,0.0669347,0.231907,0.460471,0.387018,0.390684,0.157765,-0.786072,-0.857415,0.496489,0.138856,-1.32783,-1.13579,0.67745,0.637619
5944,0.080179,0.0584766,0.505816,0.436645,0.844124,0.697852,0.0903099,0.0482216,0.622992,0.71435,0.36416,0.283597,0.87731,0.831114,0.132358,0.132425,0.309481,0.333052,0.915597,0.941811,-0.369055,-0.346859,0.79382,1.00226,1.50223,1.95368,1.53978,1.70899,-0.605175,-0.682113,-0.292841,-0.524332,1.2285,1.15091,0.181681,-0.201604,0.550306,0.74872,-0.237946,-0.276124
5945,0.814256,0.791099,0.724737,0.645542,0.0906245,-0.0572844,0.725453,0.685564,0.511047,0.602719,0.996447,0.914279,0.136566,0.0878707,0.051087,0.0515716,0.0537854,0.0793469,0.861543,0.887859,0.354868,0.378807,-1.14373,-0.934022,-1.14068,-0.689517,-0.575541,-0.409605,0.237637,0.166833,0.391974,0.163007,0.417577,0.338657,-0.179471,-0.542063,-1.09665,-0.895288,-1.35523,-1.39026
5946,0.943487,0.921114,0.667962,0.586353,0.366678,0.23331,0.108104,0.0679124,0.678272,0.728525,0.113999,0.0322922,0.277991,0.228089,0.587411,0.589343,0.44833,0.440259,0.346286,0.372509,0.419112,0.352326,1.18712,1.39894,-1.09798,-0.644732,0.310915,0.478255,-0.80651,-0.872183,-0.911683,-1.14628,-0.15735,-0.230975,-1.21548,-1.57375,0.011559,0.218738,0.0621895,0.0288803
5947,0.285856,0.264739,0.833654,0.750087,0.670979,0.523904,0.0164672,-0.0250593,0.76479,0.85433,0.110806,0.0292068,0.810189,0.759241,0.0057269,0.00852479,0.774991,0.80117,0.0586942,0.0870662,0.302843,0.325845,0.354723,0.573942,0.13469,0.582821,0.253818,0.428563,1.60852,1.54912,0.908392,0.679461,1.22575,1.15565,0.299864,-0.0649988,-0.822991,-0.620898,-0.839977,-0.868911
5948,0.642362,0.621556,0.602405,0.504549,0.368771,0.219827,0.902019,0.861056,0.376269,0.465995,0.739562,0.659889,0.568387,0.519195,0.148296,0.149923,0.331189,0.356594,0.325793,0.355409,-1.13868,-1.12272,0.744296,0.959426,2.41753,2.85852,-0.136132,0.0388905,0.611754,0.555473,-0.561393,-0.785683,0.311842,0.232359,1.19037,0.831777,0.180117,0.385585,0.898334,0.872049
5949,0.0241402,0.00545148,0.340336,0.259012,0.933118,0.78206,0.239726,0.197763,0.96252,1.05141,0.458962,0.382101,0.408062,0.279148,0.0833012,0.0798673,0.759103,0.787051,0.89303,0.923805,0.509227,0.529809,-0.450365,-0.237079,2.55464,2.99638,0.667479,0.848364,0.0424364,-0.00841928,-0.550073,-0.771317,-0.62083,-0.690932,-1.46655,-1.82572,1.44181,1.64043,-0.486365,-0.515862
5950,0.93925,0.918909,0.432031,0.353351,0.392901,0.24299,0.170814,0.195739,0.587513,0.759342,0.595574,0.517267,0.091263,0.0391007,0.00695379,0.00981196,0.535093,0.563597,0.0291933,0.0604285,-0.79341,-0.766918,-0.611699,-0.4039,1.87409,2.31789,0.267795,0.443201,-1.29675,-1.3417,1.58547,1.36554,-0.917028,-0.980505,0.753611,0.395676,-1.87131,-1.66639,-0.549798,-0.582179
5951,0.81844,0.800243,0.860181,0.782921,0.886374,0.736387,0.235028,0.193716,0.379428,0.467276,0.221634,0.145574,0.0879487,0.0373808,0.52101,0.521806,0.581884,0.612664,0.534166,0.564386,0.160999,0.187179,0.627221,0.830656,-0.0891451,0.352812,0.390407,0.500899,-1.15442,-1.12595,0.359369,0.134982,-1.54919,-1.60928,1.77903,1.4185,0.201401,0.400256,-0.125637,-0.154269
5952,0.0620457,0.0449432,0.577479,0.502898,0.288597,0.137052,0.389232,0.420182,0.641357,0.728343,0.0594099,-0.0170456,0.641569,0.589091,0.217533,0.220243,0.0241559,0.052817,0.619965,0.650507,-0.411077,-0.387094,0.171471,0.373881,0.26563,0.706863,0.385235,0.558597,-0.865249,-0.910205,0.561845,0.333056,0.301927,0.243574,-0.114691,-0.479117,-2.00171,-1.80173,-1.95973,-1.98188
5953,0.489231,0.51315,0.768823,0.695678,0.597344,0.444082,0.689567,0.646648,0.280286,0.369264,0.123199,0.0493954,0.387962,0.417511,0.373315,0.43407,0.628045,0.654691,0.466914,0.495299,1.09594,1.11203,0.974975,1.17521,0.18253,0.631109,-0.693043,-0.513323,-1.00955,-0.967581,1.12727,0.900584,0.25836,0.198751,0.179078,-0.179828,-0.180976,0.0203514,1.60587,1.58883
5954,0.99846,0.981357,0.464151,0.389707,0.391717,0.236304,0.038957,-0.00567328,0.439882,0.528439,0.679075,0.605676,0.297864,0.245931,0.646702,0.647898,0.726646,0.753225,0.732804,0.684997,-0.857935,-0.846499,-1.52621,-1.33246,1.49765,1.95051,0.482605,0.666381,-0.976389,-1.02496,1.14831,0.91495,-0.130611,-0.26434,0.908066,0.551487,0.64663,0.854667,-0.395689,-0.413735
5955,0.741911,0.72328,0.750779,0.676151,0.983569,0.829327,0.797936,0.752759,0.160811,0.251445,0.703028,0.627611,0.728572,0.677581,0.219019,0.221438,0.408564,0.461791,0.844414,0.874695,-0.312315,-0.303541,-0.658533,-0.471879,0.272186,0.728955,-0.699741,-0.512634,-1.60161,-1.65008,-0.586845,-0.823717,-0.663702,-0.727431,-0.808738,-1.15784,0.236754,0.44684,0.565714,0.545776
5956,0.711005,0.691997,0.696282,0.621669,0.273089,0.120006,0.959749,0.912383,0.540863,0.62911,0.343368,0.265885,0.188594,0.135318,0.596547,0.598856,0.145043,0.170358,0.226638,0.259493,1.19821,1.21016,0.865528,1.05583,2.68908,3.15244,-0.462372,-0.270532,-0.378015,-0.466272,0.72525,0.492412,0.777945,0.719523,0.905827,0.55696,0.327182,0.534849,-0.145968,-0.171549
5957,0.134709,0.115747,0.422522,0.346322,0.594675,0.441543,0.73486,0.786248,0.37176,0.454334,0.919549,0.841954,0.805966,0.751494,0.512323,0.52032,0.25102,0.274994,0.146437,0.224259,0.823115,0.83642,0.911996,1.10303,-0.501969,-0.0312036,-0.90356,-0.707797,0.760337,0.717538,-1.50732,-1.74404,-0.313006,-0.464219,-1.04067,-1.38757,1.10184,1.30445,-0.512068,-0.543767
5958,0.53821,0.51869,0.579557,0.484397,0.643778,0.488228,0.707657,0.660113,0.191905,0.279559,0.362995,0.287768,0.849041,0.835475,0.442103,0.441783,0.029878,0.05154,0.153798,0.189025,-0.518333,-0.505028,0.31857,0.496265,1.318,1.78568,-0.501191,-0.29882,-2.82346,-2.86761,0.18287,-0.0563688,-1.58954,-1.64796,-0.315822,-0.65625,-1.69275,-1.48689,-0.573264,-0.610085
5959,0.230409,0.209644,0.589416,0.622472,0.0106119,-0.145914,0.719804,0.737276,0.696162,0.783458,0.604292,0.530421,0.97529,0.919457,0.169419,0.16925,0.384038,0.416299,0.890866,0.927409,0.790646,0.804033,-0.434713,-0.110495,0.53791,1.00013,-1.5759,-1.37074,-1.74329,-1.84111,-1.42454,-1.65869,-0.278184,-0.336406,-0.831107,-1.16735,-0.565056,-0.356613,-0.0637543,-0.105855
5960,0.664987,0.642606,0.846064,0.760547,0.555646,0.396986,0.862521,0.814438,0.473701,0.5613,0.34894,0.289255,0.589125,0.533695,0.1592,0.159254,0.758739,0.781058,0.981903,1.01888,0.924282,0.931854,-0.908286,-0.717256,1.64435,2.10378,-0.654707,-0.452285,-0.775297,-0.814614,-0.434629,-0.662064,-0.0761775,-0.0907235,-0.660424,-0.990959,-0.657174,-0.455328,1.35156,1.31328
5961,0.635532,0.611324,0.973362,0.898622,0.803181,0.642309,0.273239,0.226663,0.00471975,0.0929957,0.122531,0.0480901,0.907278,0.850893,0.929586,0.931228,0.54445,0.567671,0.0198473,0.0591808,1.60864,1.61186,-0.57559,-0.376281,0.125758,0.591925,-0.384711,-0.179745,-0.318633,-0.366844,0.870456,0.638589,0.2096,0.154959,1.20952,0.876308,-1.03916,-0.831706,1.67318,1.63616
5962,0.298832,0.276172,0.513892,0.440404,0.112088,-0.0466426,0.146122,0.099274,0.353202,0.41718,0.104429,0.0299192,0.646643,0.590191,0.741245,0.703941,0.826981,0.848848,0.87557,0.914117,-0.501559,-0.503739,0.4738,0.640582,0.276949,0.744405,-0.993572,-0.785264,-0.162134,-0.207447,-0.705616,-0.932178,-0.02356,-0.072962,0.323769,-0.00341729,-0.531613,-0.32353,-0.826362,-0.866816
5963,0.779517,0.757487,0.616818,0.46127,0.98344,0.824828,0.363142,0.4102,0.607922,0.741365,0.302608,0.228784,0.791171,0.735981,0.475011,0.476653,0.413347,0.49941,0.125321,0.166235,0.927263,0.931171,1.45814,1.65744,-2.32172,-1.85363,1.26726,1.47445,0.357613,0.317323,-0.104215,-0.333765,-0.929876,-0.979979,-1.0385,-1.35949,-0.694719,-0.485804,0.758594,0.721223
5964,0.222031,0.201322,0.55651,0.482136,0.377189,0.220447,0.768631,0.721126,0.977274,1.06555,0.774297,0.701244,0.305499,0.249677,0.951853,0.953178,0.128141,0.149972,0.595798,0.635192,-0.6976,-0.698222,-2.26979,-2.06433,1.09872,1.56681,0.40695,0.618747,0.650922,0.612785,-0.0520057,-0.288741,0.919198,0.872878,-0.712427,-1.02761,0.734292,0.944332,1.42601,1.39365
5965,0.360732,0.357965,0.0829006,0.00849306,0.441106,0.282627,0.609087,0.511971,0.793373,0.883232,0.258306,0.186812,0.672556,0.589156,0.32543,0.3268,0.318295,0.340467,0.132654,0.174333,0.854804,0.848071,-0.202059,0.0081769,-0.874016,-0.398266,0.229494,0.449271,-0.5454,-0.575573,-0.347301,-0.609169,0.673114,0.6292,-0.893455,-1.20138,-0.0374808,0.16529,0.307418,0.279514
5966,0.537062,0.514607,0.540776,0.466988,0.0186958,-0.141872,0.348063,0.302816,0.838555,0.930723,0.145705,0.136052,0.986841,0.928634,0.656329,0.658658,0.892469,0.915196,0.406856,0.456109,0.652825,0.642617,0.486282,0.70038,-0.374334,0.192948,0.0647952,0.279794,0.414482,0.380303,-0.690889,-0.929596,-0.266347,-0.310904,0.648474,0.339569,2.16005,2.36359,0.0244578,-0.00064601
5967,0.925478,0.90311,0.241689,0.231633,0.716283,0.553634,0.906898,0.860278,0.425401,0.516651,0.0311172,0.0852927,0.409064,0.351561,0.702873,0.796889,0.934358,0.958668,0.697825,0.737885,0.142488,0.127975,-2.23826,-2.02911,0.302472,0.784161,0.271644,0.490437,-1.08129,-1.12065,0.259944,0.0202356,1.26364,1.21343,-1.19177,-1.49816,-0.278739,-0.0715648,-2.0347,-2.06576
5968,0.14314,0.12119,0.0715555,-0.00372223,0.672271,0.456437,0.502927,0.458665,0.806885,0.900064,0.0850278,0.0345331,0.533156,0.478191,0.933934,0.93512,0.599523,0.624833,0.309085,0.347891,-0.0659024,-0.0774793,0.847676,1.05353,-0.667566,-0.190731,-0.91483,-0.688579,1.50793,1.46858,0.351591,0.111639,0.912741,0.860652,0.193642,-0.109727,-0.312418,-0.107619,-1.11228,-1.13769
5969,0.336248,0.294963,0.14326,0.00881158,0.521315,0.35924,0.328795,0.357664,0.0419663,0.136128,0.0539734,-0.0162265,0.794495,0.604821,0.248285,0.248082,0.651012,0.678989,0.185302,0.222804,1.88487,1.88111,1.14316,1.34913,1.18634,1.65595,-0.406474,-0.173489,-0.34351,-0.38902,-2.63866,-2.87946,-1.02011,-1.07959,-2.01994,-2.32761,1.14119,1.355,0.364689,0.344299
5970,0.48966,0.468736,0.180809,0.0213454,0.964168,0.802986,0.327878,0.256663,0.674576,0.77066,0.277208,0.207804,0.788954,0.731451,0.170746,0.171376,0.0364659,0.0631851,0.937964,0.97787,-0.193424,-0.192013,1.8567,2.05696,0.447056,0.917996,-2.39673,-2.16797,0.879499,0.82888,1.29885,1.06247,0.374466,0.307037,1.39142,1.08548,-1.08162,-0.862958,-0.956407,-0.981352
5971,0.225577,0.205234,0.134328,0.0338792,0.965021,0.80434,0.199739,0.155661,0.647855,0.746536,0.810906,0.739426,0.355046,0.29537,0.806578,0.806315,0.907303,0.933824,0.82118,0.773044,-0.453916,-0.458569,0.886085,1.09232,0.228154,0.703122,0.784877,1.01534,-0.685988,-0.732268,0.269348,0.0296323,0.278239,0.217719,1.94677,1.60107,0.794405,1.00616,-0.129797,-0.158399
5972,0.274787,0.151057,0.121691,0.046413,0.388377,0.225511,0.271522,0.31216,0.00921934,0.106904,0.51122,0.440626,0.663384,0.59559,0.68719,0.685187,0.649852,0.675014,0.530322,0.568219,0.234465,0.236433,0.671792,0.880201,-2.48773,-2.01833,0.621389,0.857647,-0.655804,-0.678789,-0.147434,-0.3867,2.30797,2.24159,2.42259,2.11666,-0.664957,-0.448606,-0.122619,-0.0690307
5973,0.176676,0.0968793,0.01473,-0.0103032,0.373443,0.212024,0.51099,0.468658,0.692471,0.787896,0.856051,0.786276,0.95588,0.895809,0.192955,0.189502,0.125577,0.150947,0.712815,0.750544,-0.92995,-0.921436,-0.410701,-0.208091,-0.447006,0.0291279,0.71044,0.943867,-0.580987,-0.62531,0.087264,-0.157646,-1.12961,-1.19521,0.343972,0.0317019,-1.33279,-1.11956,0.05129,0.0203373
5974,0.0609161,0.042702,0.00889537,-0.0670194,0.656778,0.493308,0.331539,0.290991,0.102672,0.199182,0.0734507,0.00584856,0.47246,0.414185,0.257086,0.255896,0.818903,0.8425,0.318961,0.355267,-0.674895,-0.670278,1.14801,1.35205,0.0316633,0.504045,-0.227622,0.0103479,-0.335643,-0.374591,1.79581,1.54527,-0.55467,-0.625237,0.191131,-0.0424612,1.56777,1.77731,2.15408,2.11815
5975,0.992779,0.976411,0.222504,0.145637,0.0771215,-0.0855208,0.774229,0.734401,0.802925,0.900252,0.655686,0.586701,0.682546,0.625716,0.982299,0.983548,0.240484,0.263078,0.923257,0.959049,-0.649767,-0.605241,0.703675,0.911022,-0.725491,-0.250182,1.67593,1.91541,1.53553,1.50271,0.888067,0.632933,1.55909,1.48396,0.188692,-0.116624,-1.47963,-1.26389,-1.88359,-1.91953
5976,0.621085,0.606659,0.0328904,-0.043875,0.828845,0.66582,0.956702,0.915245,0.779528,0.876127,0.894075,0.825022,0.251097,0.196333,0.10658,0.106492,0.159944,0.182714,0.337829,0.373354,-0.545786,-0.540203,-0.978778,-0.773079,0.165328,0.64169,-1.35484,-1.11472,-0.243957,-0.276677,0.635345,0.38614,-1.07288,-1.14555,1.00729,0.704427,0.205625,0.417298,1.0136,0.977069
5977,0.00830845,-0.00509714,0.517812,0.439844,0.635928,0.495564,0.188428,0.145839,0.353452,0.452227,0.907806,0.854811,0.59985,0.544034,0.0822768,0.0807435,0.856142,0.879303,0.517768,0.555679,-0.261163,-0.257275,0.502132,0.706633,0.609102,1.08702,1.47169,1.70364,-0.550801,-0.492142,1.37763,1.13572,-2.65762,-2.72576,0.328709,0.0222884,0.454503,0.659051,-1.06795,-1.10259
5978,0.205102,0.190873,0.0187084,-0.058438,0.487385,0.325308,0.714811,0.6735,0.945419,1.04219,0.954008,0.8846,0.383494,0.347067,0.999884,0.999655,0.383142,0.404631,0.383571,0.421106,-1.38891,-1.38436,0.28151,0.49452,-1.4177,-0.941382,1.10933,1.34384,-0.688916,-0.707607,0.388892,0.147507,0.63433,0.563581,0.180573,-0.122172,0.69327,0.900804,1.64077,1.61234
5979,0.654713,0.638738,0.811888,0.733618,0.59027,0.426632,0.372599,0.332034,0.19649,0.294867,0.697227,0.626612,0.208462,0.1501,0.975544,0.973907,0.599616,0.60804,0.950981,0.989502,1.52603,1.52972,-0.835626,-0.625443,-1.16602,-0.740423,0.138241,0.380772,-0.890351,-0.923072,-0.0843851,-0.331554,0.639708,0.564694,-1.16107,-1.46278,-0.741714,-0.538555,-0.587791,-0.611075
5980,0.0456094,0.0269823,0.587044,0.509341,0.404086,0.239154,0.728019,0.685926,0.0701253,0.16853,0.182158,0.112179,0.55064,0.492082,0.187917,0.18723,0.789002,0.811449,0.270649,0.308443,0.388919,0.386474,0.328964,0.543025,-1.00895,-0.539464,0.0447171,0.276971,1.03143,1.00165,0.112097,-0.13348,-1.45072,-1.53254,0.915794,0.608376,1.67138,1.87034,0.00329452,-0.0168379
5981,0.856379,0.839262,0.687754,0.608272,0.559668,0.395795,0.156922,0.113263,0.708297,0.807735,0.220568,0.170852,0.522615,0.484661,0.0656475,0.0661011,0.54618,0.523617,0.022867,0.058626,-0.174239,-0.172095,0.615783,0.822292,-0.408791,0.0580023,-0.0676629,0.17317,-0.165736,-0.186707,0.557012,0.348053,-1.4262,-1.50164,1.03795,0.724629,0.750054,0.948817,0.0932936,0.0792799
5982,0.277687,0.25845,0.0516182,-0.0271884,0.375289,0.177786,0.134116,0.0913578,0.82055,0.921857,0.320045,0.229524,0.586125,0.477241,0.765315,0.767179,0.214876,0.235785,0.916475,0.951903,-0.404402,-0.4082,2.98164,3.1888,-2.05285,-1.59391,0.53571,0.780064,-0.53576,-0.55367,1.07472,0.829587,-0.13845,-0.208389,-0.923704,-1.23575,-0.380083,-0.17701,-0.481664,-0.502194
5983,0.0751914,0.0545836,0.926186,0.847056,0.122307,-0.0402227,0.71897,0.674275,0.374216,0.473846,0.358175,0.288196,0.450347,0.46982,0.933352,0.849825,0.306379,0.328683,0.395309,0.431642,-0.149454,-0.157042,0.321696,0.524531,-0.314446,0.144521,-0.532708,-0.291856,0.514893,0.494774,1.85471,1.60934,0.0883315,0.0197911,-0.204758,-0.521143,-0.0620655,0.141569,-0.0947554,-0.121166
5984,0.792212,0.770467,0.339063,0.260895,0.206267,0.0417068,0.997082,0.954181,0.453727,0.532735,0.174343,0.105618,0.539606,0.4624,0.929179,0.932471,0.193967,0.216695,0.800155,0.835947,-0.299364,-0.304123,0.665378,0.865506,0.40333,0.866821,-1.02885,-0.789479,1.23848,1.22045,0.345677,0.0995574,-0.718588,-0.792465,-1.34389,-1.66034,0.492681,0.696212,-0.0411561,-0.0683326
5985,0.749737,0.729326,0.862773,0.783903,0.933755,0.76736,0.0857044,0.0425484,0.494732,0.591625,0.387151,0.318704,0.513537,0.45498,0.00250804,0.00656684,0.340222,0.374729,0.528071,0.565501,1.3915,1.37983,-0.0958881,0.101029,0.739906,1.23119,0.796831,1.03787,0.202434,0.202104,-0.685717,-0.933278,-0.650418,-0.729266,1.81508,1.49419,-1.1587,-0.947795,-0.371801,-0.393922
5986,0.0860968,0.0676177,0.175615,0.0986437,0.799325,0.60534,0.426956,0.381131,0.951826,1.04925,0.1465,0.0802498,0.821908,0.761932,0.31773,0.322906,0.578716,0.532763,0.46995,0.507164,0.974472,0.960525,-0.54586,-0.355747,1.12551,1.59556,-1.46218,-1.2261,-0.796787,-0.816241,-0.571773,-0.826491,0.848394,0.762536,-0.0343926,-0.359035,-0.945764,-0.739554,2.40572,2.38288
5987,0.981841,0.960752,0.60559,0.528214,0.617059,0.44332,0.513465,0.469264,0.255527,0.353402,0.592723,0.528684,0.747751,0.688147,0.933735,0.937819,0.667228,0.690797,0.628265,0.664426,1.15314,1.13406,0.105375,0.29246,-0.12766,0.364955,1.06895,1.30521,0.22477,0.202279,1.59604,1.34574,-1.27265,-1.36359,0.309084,-0.0133284,1.16199,1.3611,-0.547589,-0.565482
5988,0.415477,0.394788,0.451375,0.374718,0.308007,0.2813,0.0748249,0.0330283,0.571324,0.670386,0.182359,0.117679,0.0196721,-0.0396853,0.170869,0.176355,0.150787,0.175945,0.111386,0.149075,2.43691,2.41373,-0.119689,0.061469,-1.33569,-0.865647,-0.382257,-0.151128,0.254816,0.23808,1.14142,0.897397,0.320517,0.223805,-1.0767,-1.40099,-0.316858,-0.111429,-0.414472,-0.441259
5989,0.435041,0.393675,0.93516,0.858437,0.285675,0.11928,0.315237,0.358572,0.0484736,0.147372,0.825326,0.758485,0.262886,0.183366,0.641382,0.648433,0.2702,0.295113,0.920029,0.957617,-0.195096,-0.219251,0.343512,0.523291,-0.194661,0.271192,0.781579,1.01545,-1.49662,-1.50963,1.40552,1.15584,1.35343,1.25095,-1.14295,-1.46903,-0.615625,-0.412176,-1.03095,-1.05376
5990,0.412747,0.392562,0.151154,0.0765232,0.488476,0.31974,0.727566,0.684117,0.87674,0.975239,0.378581,0.312435,0.463765,0.406417,0.0273646,0.0320966,0.639579,0.665578,0.597033,0.636379,0.214152,0.18655,-1.86211,-1.68138,-0.46875,-0.00254425,-0.156204,0.0819336,-0.435073,-0.446224,0.934869,0.691325,1.02076,0.914012,-0.326782,-0.64798,-0.148887,0.0463279,-0.231195,-0.260478
5991,0.0677801,0.0473099,0.0369969,-0.0366973,0.0986098,-0.0697398,0.8046,0.666717,0.313777,0.411333,0.639647,0.571714,0.0443089,-0.0146051,0.958634,0.964503,0.00202736,0.0298664,0.684084,0.7225,-0.531233,-0.555581,0.95901,1.1451,0.343896,0.812853,0.456663,0.688828,-0.365697,-0.379115,-0.984886,-1.23345,1.19897,1.09656,-0.437621,-0.834604,0.663777,0.863662,0.141176,0.101186
5992,0.102779,0.0984566,0.760936,0.689332,0.685992,0.51863,0.705825,0.649317,0.215785,0.314411,0.324308,0.257953,0.380036,0.323074,0.280993,0.287146,0.093608,0.122764,0.141348,0.18134,0.101815,0.0790992,1.74764,1.93344,-0.0242294,0.446045,0.778672,1.0068,1.38768,1.37296,0.0634295,-0.190984,-0.919848,-1.0161,-0.702743,-1.02123,-0.133206,0.0680961,0.492197,0.462851
5993,0.168747,0.149603,0.410491,0.339614,0.698296,0.530636,0.734923,0.631918,0.726179,0.822749,0.885953,0.819241,0.392666,0.250313,0.290897,0.244196,0.628308,0.657356,0.163271,0.195623,0.217687,0.190547,1.45831,1.64443,3.43129,3.90191,0.394867,0.617126,-0.87188,-0.885456,1.36269,1.10967,0.210636,0.121795,-0.246744,-0.589569,-0.448291,-0.247781,-0.122293,-0.114243
5994,0.479133,0.461241,0.795788,0.724381,0.285171,0.116211,0.657968,0.614518,0.136499,0.234035,0.942023,0.874844,0.25888,0.177552,0.184591,0.201247,0.645578,0.672324,0.170837,0.209906,-0.121548,-0.15141,-0.308748,-0.118091,0.71062,1.18045,0.265258,0.490851,1.14763,1.13623,1.48996,1.23218,-0.133341,-0.215143,0.165409,-0.157911,-0.4708,-0.268726,-0.671662,-0.691336
5995,0.372917,0.269605,0.841055,0.767788,0.875385,0.70458,0.887776,0.845068,0.603484,0.701855,0.362473,0.295081,0.15925,0.104792,0.152323,0.158297,0.931718,0.958068,0.835646,0.873251,0.315583,0.301925,0.0864677,0.2817,1.39911,1.87242,-0.824859,-0.597783,1.17528,1.15735,2.9695,2.71611,0.601007,0.521921,0.833594,0.510827,0.159688,0.362592,-1.2417,-1.26843
5996,0.0955345,0.0779689,0.414984,0.339211,0.164001,-0.00474074,0.139329,0.0975711,0.53673,0.636127,0.3106,0.232512,0.85433,0.797613,0.852047,0.859375,0.958994,0.987628,0.0213416,0.0579296,0.780894,0.755261,-0.336836,-0.142806,-1.4345,-0.956018,2.16437,2.39366,-0.739626,-0.758041,-0.258746,-0.519578,-0.748685,-0.822513,-0.724478,-1.04297,-0.278233,-0.0773129,0.601153,0.570805
5997,0.743173,0.724121,0.580999,0.502945,0.877913,0.711247,0.791893,0.749835,0.0823513,0.182737,0.239324,0.169944,0.294485,0.235801,0.186636,0.193088,0.00564881,0.0363285,0.0116576,0.0476894,-1.0351,-1.06589,-0.299903,-0.110017,-0.251558,0.225834,-0.282711,-0.0552102,-0.422639,-0.448667,0.200286,-0.0580093,-0.000528247,-0.0697226,-0.744843,-1.06624,-0.477265,-0.270211,1.0409,1.01411
5998,0.565009,0.453899,0.0932377,0.0151693,0.490723,0.283773,0.731507,0.742722,0.754415,0.853629,0.418818,0.366159,0.00192508,-0.0559324,0.534358,0.540332,0.392762,0.491293,0.939546,0.976417,-1.20404,-1.24162,0.281395,0.475745,-0.580015,-0.10991,-0.415075,-0.181485,1.1506,1.12091,1.05703,0.798378,-0.341576,-0.40666,-0.388765,-0.704611,-1.09224,-0.879706,1.87715,1.85141
5999,0.200435,0.183676,0.939212,0.863287,0.0216209,-0.143701,0.776732,0.735608,0.387808,0.484859,0.753939,0.562373,0.160753,0.105489,0.605535,0.61192,0.914828,0.946258,0.284194,0.320112,0.453248,0.410905,-0.367942,-0.179602,0.0489584,0.51832,-1.85585,-1.62323,0.426558,0.388099,-0.0307095,-0.297541,-1.03643,-1.09718,-1.97183,-2.28846,-0.979822,-0.763107,1.64004,1.61727
6000,0.858015,0.84007,0.210866,0.132735,0.483155,0.319857,0.390732,0.348888,0.824648,0.922616,0.828448,0.758588,0.833581,0.778217,0.10358,0.110652,0.770366,0.780888,0.0412123,0.0748015,1.90775,1.86279,-0.34468,-0.163518,-0.0312321,0.442566,-1.35972,-1.12348,1.6098,1.57427,1.9416,1.67994,-0.173124,-0.24044,-0.966423,-1.37122,-0.636899,-0.41209,1.01655,0.99737
6001,0.920139,0.900323,0.200872,0.122215,0.198371,0.0351173,0.213079,0.171221,0.042447,0.143086,0.915499,0.796144,0.165505,0.111445,0.251409,0.234891,0.586856,0.615517,0.661082,0.693455,-0.299338,-0.337677,0.175778,0.360517,0.286438,0.76528,-3.00718,-2.76739,-0.0288622,-0.0639742,-0.797755,-1.0579,0.136166,0.0812062,-0.147742,-0.453988,-0.533932,-0.309452,0.348826,0.377473
6002,0.385061,0.364066,0.435175,0.32589,0.187051,0.0172825,0.252142,0.224024,0.298004,0.399937,0.903448,0.8337,0.902334,0.846011,0.351965,0.359131,0.153576,0.180781,0.233997,0.267501,2.07413,2.03957,-1.65645,-1.46656,-0.45181,0.0373387,0.790371,1.03758,-1.08261,-1.11783,1.32621,1.06308,0.473337,0.402852,0.779878,0.463247,0.34755,0.571481,-0.219655,-0.242425
6003,0.227863,0.206301,0.610766,0.529565,0.163366,-0.000552351,0.292183,0.276827,0.0431179,0.142883,0.00398568,-0.0672535,0.990936,0.935645,0.0384413,0.0470536,0.767136,0.792398,0.579105,0.611823,-1.00771,-1.04407,-0.0908,0.0935856,-1.16159,-0.690602,-2.37506,-2.1296,-0.555592,-0.59306,-1.53351,-1.80292,0.0905332,0.0205278,0.911862,0.595168,-0.364231,-0.144274,-1.69582,-1.71952
6004,0.969913,0.950268,0.484042,0.412197,0.896823,0.734789,0.349362,0.329629,0.230041,0.32794,0.789359,0.715832,0.602442,0.549883,0.672199,0.681994,0.938339,0.962084,0.125889,0.160515,1.30852,1.26797,0.657339,0.848091,1.72104,2.18891,-0.74998,-0.507971,-2.35573,-2.38746,-0.787492,-1.05334,0.131015,0.0664272,-0.351411,-0.668657,1.08716,1.30093,2.03131,2.01312
6005,0.760728,0.741423,0.374787,0.29483,0.746803,0.582892,0.282482,0.382432,0.0481515,0.145623,0.164008,0.0912439,0.455824,0.404947,0.389691,0.400415,0.0262967,0.0509546,0.385958,0.399069,-0.624259,-0.661329,-0.153374,0.0395154,1.37084,1.83841,2.11014,2.34996,-0.239207,-0.269447,0.576449,0.308567,0.575621,0.513328,0.958114,0.640331,-0.746128,-0.536201,1.20532,1.12606
6006,0.241257,0.220782,0.632216,0.551443,0.170413,0.00924234,0.477093,0.435235,0.420131,0.518932,0.0590683,-0.0123494,0.618861,0.590592,0.39994,0.416575,0.618417,0.641593,0.604518,0.637623,1.02356,0.991198,0.7688,0.960778,-0.433889,0.0279846,1.05375,1.29206,-0.764688,-0.787483,0.855018,0.582894,0.311563,0.254908,-1.70041,-2.01716,0.74425,0.956031,0.257203,0.239004
6007,0.842215,0.821534,0.588875,0.599675,0.648447,0.487425,0.217237,0.177579,0.100693,0.201251,0.417107,0.347744,0.825274,0.776237,0.419837,0.432736,0.135934,0.156691,0.136744,0.171667,-0.122369,-0.152051,1.28806,1.48481,0.678955,1.14808,0.372187,0.609229,0.821222,0.795644,-0.486988,-0.757888,-0.732398,-0.792703,-1.95968,-2.28399,0.906394,1.11915,0.0799833,0.0650225
6008,0.691114,0.721923,0.730505,0.647907,0.588688,0.427168,0.366114,0.284856,0.830255,0.929249,0.153315,0.0846252,0.355174,0.305132,0.839613,0.854093,0.345013,0.367287,0.745906,0.780532,0.789679,0.756684,-0.645847,-0.451469,-0.599439,-0.132808,-0.78149,-0.539257,-1.86661,-1.89314,1.2581,0.989177,0.944011,0.886177,-0.230813,-0.557227,1.98028,2.18763,0.257221,0.23747
6009,0.598977,0.622312,0.394086,0.312833,0.108052,-0.0525337,0.528218,0.392133,0.9328,1.03305,0.898224,0.830753,0.0934427,0.0444304,0.283879,0.29798,0.89969,0.922502,0.157779,0.194838,0.362003,0.226237,1.74494,1.93204,-0.312618,0.159264,-0.64993,-0.405242,0.00294916,-0.0158312,-0.223723,-0.491683,-0.0111269,-0.067717,-0.571485,-0.899692,0.374965,0.575843,1.54925,1.53349
6010,0.411263,0.522701,0.455034,0.372505,0.300618,0.13782,0.539069,0.49941,0.505146,0.60458,0.228133,0.160304,0.738886,0.692371,0.865672,0.881393,0.730128,0.659643,0.248134,0.286309,-0.264642,-0.30421,-0.398256,-0.205819,-1.06694,-0.594963,1.24698,1.49982,2.30904,2.29073,-0.799158,-1.06217,-0.568928,-0.621215,1.2156,0.889461,-0.157126,0.0432562,-0.219243,-0.235515
6011,0.445401,0.42309,0.862064,0.778179,0.0858412,-0.0753392,0.97778,0.938077,0.342469,0.443215,0.0680922,0.00185025,0.397698,0.352334,0.998899,1.01241,0.373528,0.396784,0.995862,1.03457,0.211793,0.179964,0.128426,0.318215,0.728828,1.20331,-0.912586,-0.66523,-0.277091,-0.302682,-0.720684,-0.88775,1.34204,1.29552,0.690794,0.363212,0.332808,0.533653,-1.54841,-1.56117
6012,0.617194,0.59394,0.255811,0.172358,0.446142,0.287039,0.910876,0.871137,0.536825,0.638216,0.230738,0.127532,0.456633,0.394944,0.444855,0.456301,0.779747,0.802744,0.892581,0.902137,-0.64042,-0.671535,1.24162,1.4276,0.343241,0.779837,-0.784117,-0.531215,0.455705,0.438162,-0.444351,-0.71333,0.637097,0.590333,-1.28974,-1.61376,-0.449628,-0.245389,0.439041,0.426365
6013,0.386814,0.365287,0.91332,0.831692,0.455503,0.299045,0.0795059,0.0390645,0.849347,0.833218,0.344104,0.253213,0.598394,0.437554,0.453207,0.46658,0.625954,0.649147,0.647814,0.7697,0.0895652,0.0541312,-0.0471155,0.137199,-0.111405,0.356366,-1.00509,-0.750586,-0.0714399,-0.0938754,1.13643,0.866478,-1.618,-1.66768,-0.382358,-0.701314,0.698714,0.900435,0.496487,0.479198
6014,0.875285,0.852013,0.829557,0.699582,0.688217,0.534416,0.732286,0.691328,0.927475,1.02822,0.445136,0.378894,0.525526,0.480164,0.034375,0.050088,0.200369,0.225723,0.599246,0.637264,0.202384,0.259871,-0.0762813,0.109128,-1.57748,-1.11022,0.326775,0.58375,0.214277,0.187175,-0.651971,-0.919778,1.20288,1.15836,-1.432,-1.74889,1.21931,1.42289,-0.500159,-0.524591
6015,0.951368,0.927659,0.650235,0.567471,0.508428,0.35263,0.500988,0.45868,0.36845,0.469675,0.810873,0.653698,0.527254,0.522775,0.530113,0.547345,0.773943,0.800451,0.161062,0.201042,0.497703,0.465611,-1.28324,-1.10291,-0.0960922,0.374875,-1.46332,-1.20078,-0.562402,-0.5894,1.27527,1.01235,0.661904,0.618661,1.01403,0.695761,0.163689,0.361445,-1.06125,-1.09118
6016,0.759745,0.651579,0.805329,0.721517,0.818916,0.663918,0.775325,0.694778,0.106734,0.288401,0.996899,0.928502,0.610749,0.565385,0.166359,0.185207,0.374245,0.401507,0.861844,0.900673,0.00943924,-0.0169391,0.773291,0.955274,0.336462,0.80384,0.551635,0.817076,-0.857295,-0.877809,-0.778737,-1.03639,-0.98781,-1.03799,-2.02365,-2.34262,0.796901,0.992763,-0.0492024,-0.13882
6017,0.3976,0.375499,0.421754,0.337155,0.266926,0.109777,0.970458,0.930875,0.00622453,0.107127,0.989,0.841398,0.384836,0.339017,0.212045,0.230596,0.773131,0.802444,0.123198,0.162982,1.50534,1.48219,-0.918832,-0.742302,0.171687,0.637426,-1.18577,-0.922366,-0.153902,-0.168961,0.150008,-0.101926,0.595908,0.549408,-0.430489,-0.755824,-0.398318,-0.195729,0.844478,0.813536
6018,0.378637,0.355419,0.471175,0.351866,0.529505,0.454885,0.532885,0.494639,0.690217,0.793044,0.822874,0.754294,0.907809,0.861312,0.618064,0.637041,0.233486,0.262841,0.320091,0.360276,0.942156,0.923621,0.124981,0.302053,-0.54318,-0.0698813,-1.75971,-1.58111,-0.0266383,-0.0424363,-0.504195,-0.75426,1.91526,1.87576,-0.417001,-0.748493,1.50537,1.70469,-0.558245,-0.507829
6019,0.612975,0.591632,0.545741,0.366577,0.959094,0.799992,0.952102,0.912796,0.96028,1.06475,0.0770974,0.00893271,0.696629,0.650943,0.468372,0.407708,0.228114,0.257196,0.0586292,0.0991698,0.934936,0.914341,1.59166,1.76753,-0.141557,0.330411,-2.49856,-2.23986,0.627883,0.605373,0.77723,0.531438,0.764645,0.722042,-0.151555,-0.556128,-0.949816,-0.745065,-1.79825,-1.82919
6020,0.120582,0.100577,0.465886,0.381288,0.168763,0.00921496,0.726365,0.677706,0.551831,0.65556,0.743617,0.675587,0.25002,0.205179,0.159124,0.178374,0.820862,0.847835,0.152915,0.165346,-0.948666,-0.969582,-0.514414,-0.337073,-1.21165,-0.735443,-0.20212,0.0561539,0.322942,0.228326,0.850926,0.607068,0.938565,0.890202,-0.0322708,-0.363764,-0.350073,-0.0884358,0.660666,0.630089
6021,0.835862,0.81646,0.180156,0.0956275,0.576086,0.417358,0.482174,0.442616,0.512044,0.633336,0.777716,0.711867,0.38275,0.269471,0.316696,0.349506,0.305823,0.332983,0.191556,0.231522,-1.2106,-1.23614,-0.343771,-0.123099,-0.435573,0.0332471,0.173573,0.434585,-0.12282,-0.14872,0.644363,0.407125,0.589042,0.478383,2.07682,1.73987,0.370456,0.568193,-1.06201,-1.09249
6022,0.796219,0.694881,0.260832,0.174711,0.452132,0.291129,0.514721,0.402858,0.433851,0.611113,0.31084,0.246331,0.429615,0.333763,0.500358,0.520637,0.930874,0.959371,0.846108,0.886068,-0.0532049,-0.0816586,-0.093843,0.0908751,1.10726,1.57918,-0.755103,-0.498933,0.324402,0.29905,-1.18759,-1.42434,0.119255,0.0665636,0.115646,-0.300757,-0.324051,-0.132378,0.0180078,-0.0101503
6023,0.592041,0.573301,0.729965,0.643072,0.0250774,-0.13337,0.405175,0.3631,0.485162,0.58889,0.731749,0.665688,0.426937,0.398055,0.35092,0.369392,0.0536952,0.0796061,0.324403,0.365807,-1.60774,-1.63669,-0.764695,-0.546566,0.016392,0.511518,-1.97755,-1.72488,1.38209,1.36246,-0.678159,-0.917244,0.725484,0.666259,-2.00443,-2.34138,-0.660319,-0.463333,-1.01951,-1.04425
6024,0.926208,0.905454,0.0919028,0.00277532,0.151615,-0.00715854,0.809468,0.767582,0.786896,0.891655,0.601711,0.537097,0.602289,0.462346,0.73359,0.751627,0.654874,0.68148,0.214197,0.255444,-1.01942,-1.0471,-1.3688,-1.18401,-1.02332,-0.556143,0.414866,0.672566,-0.94525,-0.959582,-1.44572,-1.69023,-1.14321,-1.209,-0.345194,-0.676902,0.0647068,0.261153,-0.0878707,-0.116187
6025,0.0265795,0.00628869,0.0135495,-0.0750186,0.848659,0.688347,0.983908,0.942635,0.0336245,0.138622,0.97588,0.911998,0.571479,0.526638,0.0422734,0.0587179,0.891296,0.918253,0.33464,0.352216,0.089272,0.0604116,1.0318,1.21399,0.738048,1.21095,0.0877723,0.344885,0.720507,0.6998,-1.42383,-1.65406,0.851513,0.782222,-0.412967,-0.789179,-0.567364,-0.378142,1.43975,1.41132
6026,0.670935,0.652441,0.636717,0.550626,0.399266,0.239277,0.724988,0.684979,0.186259,0.293629,0.209789,0.146855,0.0890072,0.0450139,0.901287,0.919124,0.044981,0.0701111,0.495565,0.448988,0.124446,0.0943367,-1.84302,-1.65784,0.0571607,0.532454,-0.660703,-0.401367,-0.236623,-0.261786,-1.3712,-1.61789,0.365984,0.29069,-0.443031,-0.901456,-0.0461671,0.218367,-0.00487121,-0.0370879
6027,0.226064,0.206595,0.348629,0.245651,0.569848,0.453273,0.752801,0.717367,0.801025,0.907727,0.523124,0.393022,0.129239,0.0245641,0.22165,0.241767,0.505111,0.530408,0.504514,0.54576,-1.25982,-1.29345,-1.68422,-1.50328,0.236896,0.715585,0.329818,0.595842,-1.85698,-1.88492,0.564957,0.314238,-0.381481,-0.460113,-0.681112,-1.01373,0.629365,0.814876,-0.102014,-0.134852
6028,0.154789,0.135306,0.028263,-0.059325,0.826876,0.667269,0.78804,0.749756,0.23344,0.339803,0.702723,0.63919,0.048456,0.00411437,0.703378,0.723796,0.0149588,0.0403911,0.121047,0.160447,0.95168,0.912654,0.024296,0.208968,-0.380732,0.0982297,-0.977026,-0.706902,-0.0900284,-0.117431,-0.232791,-0.394085,-0.331403,-0.414214,-1.82145,-2.15293,1.7258,1.91453,0.714392,0.688102
6029,0.328715,0.310713,0.212604,0.124136,0.646812,0.485483,0.00828393,-0.0299682,0.825145,0.929771,0.467979,0.405892,0.954429,0.911901,0.810445,0.830133,0.470344,0.428823,0.160072,0.197165,0.0881919,0.0460998,-0.266278,-0.080047,0.195942,0.681659,-0.591024,-0.328471,0.280072,0.25708,-0.901927,-1.10241,0.88687,0.802306,1.85927,1.53382,-0.183845,0.0109481,-0.198385,-0.225641
6030,0.195122,0.177434,0.0703486,-0.0195706,0.237277,0.0758512,0.162103,0.0636854,0.32808,0.431523,0.60355,0.520625,0.873004,0.832565,0.508428,0.52857,0.791822,0.817255,0.537108,0.578274,1.03931,1.0002,1.00126,1.18338,-0.80702,-0.322019,1.15381,1.41859,0.26239,0.254017,-1.56001,-1.81073,1.09568,1.01514,-0.45602,-0.782089,0.244046,0.438436,-0.880109,-0.911065
6031,0.877922,0.858641,0.94461,0.854674,0.0604309,-0.100517,0.221466,0.157339,0.889457,0.990793,0.598217,0.635358,0.206134,0.165794,0.57999,0.642109,0.249909,0.272766,0.921322,0.959383,0.444671,0.410798,-0.0957604,0.0789217,2.00579,2.49721,-0.475077,-0.209043,0.273945,0.250953,-0.0419262,-0.29512,-0.0832261,-0.0761153,-0.965353,-1.33725,-1.19143,-1.00092,1.29577,1.26915
6032,0.879681,0.859208,0.528862,0.44098,0.508237,0.348738,0.216939,0.250993,0.0580921,0.1584,0.813648,0.75009,0.957271,0.915307,0.735517,0.755648,0.119151,0.14027,0.689611,0.728566,-0.351053,-0.380326,-0.967313,-0.792606,-0.889282,-0.400999,-0.0215401,0.246679,1.1056,1.0842,-1.19712,-1.4501,-1.08283,-1.16737,-1.56248,-1.89242,0.572589,0.756311,-0.30146,-0.331026
6033,0.523385,0.458786,0.405551,0.277999,0.131333,-0.0305936,0.48266,0.344646,0.78814,0.886398,0.526138,0.461178,0.691865,0.649346,0.611343,0.546309,0.679271,0.700037,0.65933,0.775711,1.84357,1.80881,1.05837,1.2351,-0.875665,-0.385167,1.01869,1.28797,1.71592,1.70131,1.02514,0.767757,1.19272,1.10107,0.30776,-0.0251523,0.636811,0.828068,1.08974,1.05681
6034,0.0786735,0.0583634,0.20346,0.115017,0.994155,0.831567,0.480401,0.4383,0.429782,0.527319,0.810942,0.745281,0.761588,0.718141,0.375749,0.33697,0.657976,0.679181,0.700721,0.822855,-1.1858,-1.21791,0.630615,0.810599,0.555179,1.03917,-0.750038,-0.479511,-0.638575,-0.653494,0.584111,0.319411,-1.29869,-1.39145,0.24925,-0.110698,1.97397,2.16396,-0.249052,-0.2851
6035,0.749011,0.729585,0.321973,0.174237,0.698867,0.529685,0.570206,0.531953,0.548842,0.646715,0.240633,0.175509,0.44474,0.401881,0.106861,0.127631,0.90211,0.925257,0.833693,0.87,-0.380833,-0.415803,-0.63151,-0.448076,-0.0868516,0.393039,0.219173,0.484416,0.0445839,0.0265145,-0.910754,-1.17665,0.226125,0.132883,0.130223,-0.196244,0.149209,0.339939,0.316556,0.280876
6036,0.119733,0.0984588,0.320638,0.233456,0.257047,0.227804,0.155728,0.115184,0.158036,0.25838,0.808362,0.741937,0.622664,0.578342,0.973383,0.993891,0.283745,0.304827,0.844207,0.917145,0.0797861,0.0510909,-0.52975,-0.34115,1.58848,2.06747,-0.45151,-0.18281,-0.367109,-0.385841,0.0276058,-0.242186,0.934215,0.839925,-0.47633,-0.714387,-0.057242,0.0745284,-0.496329,-0.526267
6037,0.900029,0.879115,0.861693,0.775714,0.088719,-0.0740774,0.678156,0.638108,0.219958,0.348048,0.995796,0.930825,0.59438,0.549955,0.306889,0.327604,0.401449,0.425125,0.925335,0.96429,-0.127504,-0.154363,1.70592,1.89516,-0.114854,0.396419,1.48387,1.75371,-1.50718,-1.52951,0.558013,0.293854,0.782515,0.727897,-0.907839,-1.23253,-0.38817,-0.190882,0.500467,0.463374
6038,0.772992,0.731084,0.412936,0.327257,0.105276,-0.0576504,0.684215,0.645983,0.471794,0.437716,0.273318,0.209613,0.970192,0.926715,0.518211,0.539015,0.522746,0.545423,0.387619,0.428448,-0.0460354,-0.0732329,0.417675,0.60476,-1.75361,-1.27463,0.0570852,0.327934,-1.76002,-1.79037,-0.848921,-1.11012,0.71684,0.615869,-1.22833,-1.55983,-0.152787,0.111853,-1.13923,-1.18315
6039,0.605815,0.583053,0.613595,0.529718,0.58685,0.425364,0.935929,0.896624,0.427783,0.527385,0.247783,0.171484,0.987574,0.944502,0.463363,0.48335,0.375827,0.401236,0.595087,0.635344,-0.605213,-0.631802,-1.47203,-1.28511,0.832406,1.31236,1.76448,2.03957,-0.475241,-0.511439,0.390033,0.129495,-2.34354,-2.44837,0.00398311,-0.328388,0.22028,0.414587,-0.662697,-0.710231
6040,0.987927,0.965875,0.202792,0.120311,0.319582,0.156023,0.590899,0.549897,0.212701,0.310326,0.197422,0.133354,0.0300877,-0.0100622,0.969803,0.990355,0.225728,0.257049,0.283763,0.323951,-0.587738,-0.530668,0.981907,1.16138,0.0176089,0.495013,0.261757,0.53704,1.78872,1.75968,0.931492,0.665535,1.26768,1.16101,-1.8635,-2.1956,1.16833,1.35853,-2.08577,-2.12759
6041,0.395128,0.375227,0.239944,0.158685,0.731257,0.569175,0.788356,0.746188,0.232459,0.394792,0.596018,0.532985,0.298519,0.29796,0.272438,0.291882,0.0919067,0.112861,0.769456,0.807652,-0.407167,-0.429535,0.66723,0.843178,0.997585,1.47833,-0.354532,-0.082271,-0.237054,-0.27473,-0.282465,-0.549495,-0.0617394,-0.1659,-0.484852,-0.823305,1.51889,1.70955,0.0973187,0.0526162
6042,0.8765,0.856542,0.941157,0.858917,0.887184,0.725816,0.289462,0.248723,0.371725,0.479257,0.282471,0.219224,0.529591,0.605983,0.571029,0.588526,0.609336,0.627946,0.845609,0.883459,0.316748,0.296131,0.684565,0.859261,-0.253979,0.228175,-1.41545,-1.14017,0.913292,0.879681,1.20248,0.934435,-0.531657,-0.643021,-1.12302,-1.45889,-1.67142,-1.48051,0.0855836,0.0452372
6043,0.522647,0.501244,0.571397,0.489812,0.441367,0.281325,0.387388,0.347946,0.466309,0.563722,0.28433,0.221295,0.954155,0.914005,0.407733,0.425766,0.426144,0.444516,0.277725,0.317868,0.45486,0.438804,-1.41554,-1.24534,-1.09441,-0.619382,1.33557,1.60345,-0.423261,-0.453602,-0.648952,-0.913542,1.8045,1.69021,-1.06714,-1.4059,0.467154,0.655823,0.451598,0.413133
6044,0.384041,0.363437,0.473923,0.424458,0.834617,0.673243,0.00369414,-0.0344001,0.702908,0.799582,0.943812,0.883029,0.27964,0.237401,0.850896,0.868004,0.697999,0.675926,0.622643,0.66219,-1.54171,-1.55405,-0.043766,0.125026,-1.05246,-0.574597,-0.736546,-0.469761,-0.133729,-0.15814,0.11828,-0.147978,1.65218,1.54011,0.793431,0.461362,-1.04498,-0.86236,-1.56575,-1.60637
6045,0.599895,0.580016,0.437572,0.359104,0.94082,0.779876,0.295581,0.256052,0.236951,0.331278,0.0409531,-0.0179243,0.38768,0.244436,0.0587875,0.0762694,0.890674,0.907336,0.12771,0.166782,1.53959,1.53213,-2.02775,-1.8574,-1.53481,-1.06349,1.08461,1.35759,1.46426,1.44178,-0.240654,-0.446638,-1.16507,-1.2749,-0.468584,-0.802463,0.81885,1.00676,0.836916,0.801143
6046,0.0888274,0.0691591,0.698087,0.619974,0.552308,0.390396,0.902912,0.862942,0.520642,0.613375,0.0974454,0.0376787,0.296241,0.251471,0.977078,0.995181,0.359321,0.37817,0.654365,0.691215,0.181987,0.17678,1.01119,1.18068,0.0226376,0.499694,1.22805,1.50835,0.145655,0.12434,-0.484294,-0.745298,-2.19467,-2.30656,0.948413,0.617226,0.263071,0.444347,-0.776111,-0.760808
6047,0.839281,0.817814,0.0728611,-0.00557799,0.750803,0.590856,0.9021,0.861722,0.545267,0.636883,0.397566,0.248324,0.206219,0.162528,0.258752,0.276056,0.924999,0.94357,0.027169,0.0656587,0.480879,0.476233,-0.0378311,0.138657,-1.93432,-1.45254,-0.478813,-0.199325,-0.862341,-0.885246,0.454963,0.189164,-0.356699,-0.469002,-1.13119,-1.46773,2.11701,2.2981,-2.28699,-2.32276
6048,0.420262,0.397494,0.21051,0.0388586,0.696019,0.535588,0.00652334,-0.0343925,0.346124,0.533271,0.516811,0.45897,0.587623,0.543983,0.612949,0.604107,0.259578,0.278194,0.353818,0.394538,-0.159803,-0.159702,-0.840499,-0.669919,0.0985088,0.581397,2.15995,2.43102,-0.00933482,-0.0363002,-0.490647,-0.753914,0.281295,0.161831,0.421055,0.0887169,-0.202681,-0.0209295,0.954216,0.925796
6049,0.58024,0.557692,0.20301,0.0832953,0.206105,0.0457015,0.278095,0.214464,0.337787,0.429659,0.447186,0.390891,0.219758,0.177681,0.91739,0.932158,0.227913,0.248286,0.285476,0.332144,-1.03332,-1.02626,-2.11185,-1.94492,0.58218,1.07061,1.09277,1.3591,-1.7872,-1.81569,1.20922,0.949004,-0.248073,-0.361344,0.0872686,-0.238581,-2.10244,-1.92451,0.11085,0.0897206
6050,0.0796148,0.0565629,0.234792,0.127732,0.570613,0.40808,0.501836,0.46332,0.432557,0.52455,0.62622,0.569992,0.854337,0.814269,0.78255,0.795778,0.163457,0.218377,0.229659,0.269751,-1.02325,-1.02083,-1.16665,-1.00736,-0.572074,-0.0615336,-0.238508,0.0264567,-0.697973,-0.721952,1.86979,1.607,0.405109,0.285555,0.296821,-0.0309771,2.03023,2.20816,0.319187,0.271168
6051,0.523973,0.499241,0.259047,0.172169,0.387426,0.265993,0.975453,0.936329,0.866432,0.957094,0.0634973,0.00562024,0.860525,0.821861,0.216744,0.229132,0.169853,0.188469,0.767518,0.809143,2.74264,2.74787,0.538223,0.690267,-1.68496,-1.19368,0.77868,1.03895,-1.36086,-1.39373,-1.52168,-1.79105,0.27488,0.109791,0.172751,-0.159774,0.111133,0.289987,0.47386,0.452615
6052,0.533952,0.509547,0.295044,0.216605,0.26461,0.123907,0.074047,0.0348423,0.97705,1.06611,0.608582,0.551706,0.468256,0.430523,0.904245,0.914918,0.734482,0.753869,0.968754,1.01113,-0.774027,-0.762377,-0.72332,-0.568407,-1.9316,-1.43816,0.219232,0.480634,0.521428,0.483571,0.00527459,-0.259819,0.0538032,-0.065973,-1.72308,-2.05739,-0.415868,-0.2426,0.903048,0.880526
6053,0.152803,0.12981,0.613369,0.533039,0.144353,-0.0181799,0.473333,0.43419,0.598414,0.68724,0.0242921,-0.0332473,0.708773,0.671635,0.258536,0.267539,0.109176,0.129056,0.538967,0.58046,0.186632,0.191721,0.335955,0.494744,1.6598,2.15912,1.6058,1.86143,1.57549,1.53201,-1.13243,-1.39943,0.205886,-0.015028,-0.688077,-1.02138,1.08675,1.26298,0.0262265,-0.002982
6054,0.0864284,0.0635315,0.0323566,-0.0479943,0.176357,0.013544,0.0876163,0.0474688,0.800379,0.886793,0.19337,0.147794,0.702763,0.664208,0.034769,0.0451274,0.887311,0.906068,0.341879,0.438911,0.461788,0.47465,-0.798174,-0.640897,-0.280504,0.223235,-0.483262,-0.226413,-0.228307,-0.27509,0.277759,0.00953511,0.160333,0.0359169,0.139618,-0.20033,1.02931,1.20986,-0.407633,-0.434373
6055,0.674662,0.649161,0.464383,0.386154,0.438332,0.274229,0.917654,0.879064,0.388884,0.519382,0.521886,0.328834,0.318109,0.320693,0.443452,0.451572,0.188712,0.205661,0.255343,0.297362,-1.4852,-1.4709,-1.3038,-1.14259,0.749452,1.25376,1.0228,1.28197,-0.231514,-0.285518,-0.983741,-1.25406,-0.478364,-0.608221,0.111634,-0.223595,2.22178,2.40057,0.709477,0.67744
6056,0.490013,0.466207,0.477526,0.400314,0.284065,0.142724,0.825889,0.786092,0.0660848,0.15197,0.568708,0.509875,0.0168265,-0.0228216,0.366175,0.374866,0.183652,0.200016,0.79766,0.841493,-0.905939,-0.896755,0.22376,0.385127,-1.0008,-0.491591,-1.15859,-0.899538,-1.15034,-1.20033,0.760076,0.493002,-0.418211,-0.533973,-0.777662,-1.11976,-0.693769,-0.504962,-0.335166,-0.371309
6057,0.0099112,-0.0147397,0.102171,0.0257022,0.176593,0.0112186,0.15854,0.118525,0.320579,0.433235,0.330886,0.271421,0.229464,0.18871,0.572903,0.581983,0.898447,0.916471,0.417496,0.461087,-1.79044,-1.77941,0.483703,0.648345,-0.595659,-0.0912989,1.41744,1.68257,1.08503,1.03472,0.886325,0.614574,-0.325882,-0.459725,0.54206,0.20527,-0.681978,-0.495649,0.584434,0.541423
6058,0.961205,0.93835,0.193621,0.106031,0.933413,0.767687,0.865894,0.825861,0.62585,0.7145,0.551634,0.490136,0.169646,0.110566,0.331335,0.403652,0.68182,0.697631,0.891037,0.93509,-0.520044,-0.515151,1.20702,1.37042,0.437544,0.939225,0.429736,0.68863,0.988003,0.942619,1.00979,0.736146,-0.936028,-1.0745,-0.328378,-0.610476,-0.953792,-0.765133,0.255344,0.196807
6059,0.536177,0.512725,0.335484,0.186361,0.199933,0.0320873,0.403598,0.364396,0.514448,0.599826,0.226452,0.166912,0.0748827,0.0324221,0.217454,0.225322,0.717917,0.771311,0.171879,0.218799,-0.573334,-0.569324,-0.752931,-0.596353,-0.235143,0.260731,0.550133,0.807363,-0.497879,-0.540976,0.907145,0.628764,-0.687079,-0.752854,-1.09402,-1.42622,-0.0585796,0.129915,-0.0971951,-0.147808
6060,0.414012,0.388781,0.341085,0.26669,0.347591,0.178959,0.506431,0.505257,0.305461,0.485152,0.452382,0.390942,0.522426,0.478569,0.730206,0.737316,0.829768,0.844991,0.959126,1.00553,0.198677,0.202505,-1.59593,-1.43837,2.66087,3.15312,-1.31363,-1.05744,-1.16853,-1.21276,0.563278,0.290349,-0.287609,-0.431207,-0.831907,-1.17044,0.526044,0.713227,0.723801,0.675145
6061,0.0326151,0.00904462,0.737846,0.662139,0.875912,0.707494,0.68623,0.646119,0.236653,0.370478,0.188994,0.127824,0.46464,0.508093,0.673106,0.681651,0.196848,0.209279,0.31803,0.364867,-0.0588751,-0.0479097,1.46243,1.61919,0.236674,0.725447,-0.838728,-0.643971,-0.067212,-0.119018,-0.151181,-0.421027,-0.712358,-0.860781,0.640351,0.307202,1.94654,2.12818,-0.595305,-0.650506
6062,0.323596,0.30127,0.636331,0.558877,0.347649,0.17902,0.611078,0.572973,0.0913923,0.255804,0.425578,0.349472,0.580888,0.537617,0.883532,0.893062,0.382117,0.395465,0.45192,0.496929,0.926322,0.936685,-0.0281587,0.124311,0.864792,1.35368,-0.481005,-0.230498,0.602964,0.545417,0.709711,0.43536,-0.256987,-0.386033,-1.19014,-1.53052,-1.92061,-1.74138,-1.33951,-1.39713
6063,0.820219,0.797676,0.946933,0.869992,0.181794,0.0128733,0.269691,0.231508,0.0524805,0.141131,0.585142,0.57112,0.0367533,-0.00464671,0.539932,0.55097,0.863629,0.875488,0.820617,0.866869,0.538994,0.548565,-0.639915,-0.485347,0.14585,0.628077,0.234326,0.48571,0.718198,0.657111,-0.207025,-0.476979,0.170413,0.0887138,-0.540718,-0.877299,-2.28592,-2.10321,-0.959445,-1.01611
6064,0.709706,0.688654,0.707687,0.62867,0.546178,0.375199,0.843395,0.803956,0.993755,1.08472,0.853939,0.792769,0.947781,0.907816,0.811803,0.821648,0.955673,0.968386,0.811705,0.856629,1.92626,1.93729,-0.375525,-0.222129,-0.885834,-0.407127,-0.322361,-0.0726094,-1.20956,-1.27536,-0.447607,-0.723771,0.570381,0.563461,-1.60565,-1.93963,0.404776,0.593197,-0.113723,-0.115619
6065,0.132373,0.112404,0.77873,0.697207,0.906472,0.737525,0.693015,0.652356,0.886719,0.917115,0.342015,0.282902,0.579236,0.537102,0.457475,0.469526,0.378803,0.3938,0.175306,0.221445,-0.155817,-0.149322,0.135747,0.2937,-0.306089,0.176302,0.549938,0.799359,-0.478864,-0.54969,2.53994,2.25995,1.18663,1.03821,1.11849,0.778086,-0.22155,-0.0298661,0.839413,0.784868
6066,0.288461,0.267696,0.47997,0.448734,0.290015,0.118986,0.421155,0.500756,0.781791,0.749513,0.0512434,-0.0060104,0.908991,0.864418,0.445508,0.459531,0.0292369,0.0441877,0.905403,0.949907,-0.321428,-0.311432,0.661329,0.80953,-0.434635,0.0413526,0.51572,0.772003,-1.34967,-1.42124,-1.23358,-1.50495,-0.35512,-0.510827,-0.112513,-0.453735,-0.168696,0.0258737,-0.594137,-0.649309
6067,0.674943,0.58909,0.2809,0.200262,0.938955,0.767878,0.305334,0.349156,0.488625,0.581911,0.92124,0.864041,0.467926,0.423683,0.798645,0.811883,0.0195287,0.0337717,0.588905,0.583173,-0.769238,-0.759843,-1.49187,-1.34503,-0.963659,-0.494072,0.502495,0.744646,0.40376,0.330836,-1.31301,-1.58268,-0.581384,-0.738749,-0.380906,-0.720561,0.341488,0.534049,-0.472727,-0.611185
6068,0.931606,0.910484,0.647777,0.564995,0.224965,0.0534182,0.236994,0.197556,0.751032,0.842978,0.908236,0.851893,0.275369,0.217829,0.611972,0.624938,0.513277,0.529515,0.169968,0.216439,1.64947,1.66465,-0.788939,-0.57306,-0.471578,-0.00485545,0.955679,1.13062,0.510198,0.442529,0.013857,-0.250309,-0.264333,-0.416997,1.43672,1.10054,1.48391,1.67987,-0.512214,-0.573061
6069,0.475769,0.455387,0.0835776,-0.00114741,0.583285,0.333319,0.885759,0.844414,0.723064,0.813363,0.532289,0.405632,0.0563429,0.011974,0.734306,0.757827,0.59955,0.617688,0.24583,0.292246,0.646589,0.658752,0.0520427,0.198908,-1.13393,-0.666849,1.2809,1.51659,0.29869,0.229429,-0.100209,-0.357691,-0.170158,-0.324825,1.5962,1.26268,0.712566,0.900832,0.276711,0.22022
6070,0.92603,0.907847,0.129568,0.0468855,0.784016,0.61322,0.387227,0.346949,0.300632,0.389463,0.0180263,-0.0406283,0.632245,0.588475,0.879469,0.890717,0.393369,0.450822,0.0036136,0.0525906,-1.79657,-1.79001,-1.10526,-0.951986,-0.844223,-0.401357,-1.37911,-1.1453,-0.80832,-0.871271,-1.01977,-1.2839,-0.675052,-0.800729,0.984584,0.643644,0.672473,0.864778,1.85129,1.79327
6071,0.0500615,0.0320824,0.848163,0.767605,0.217612,0.0489625,0.179904,0.206236,0.815488,0.903584,0.440528,0.37989,0.307585,0.262505,0.786174,0.799938,0.372842,0.283955,0.572046,0.620986,-0.403905,-0.401284,0.00906066,0.157398,-0.609576,-0.135864,1.21686,1.45345,2.22351,2.16769,0.823259,0.55726,-1.12772,-1.27663,0.0809169,-0.213502,-0.0540678,0.132409,0.391113,0.330055
6072,0.181223,0.164491,0.223619,0.142053,0.5158,0.342623,0.105109,0.0655226,0.146379,0.233881,0.859064,0.800409,0.559095,0.514669,0.210751,0.223793,0.0989501,0.117088,0.445295,0.570534,-1.11208,-1.11355,0.506812,0.651583,-1.01988,-0.490418,-1.33922,-1.09565,1.48235,1.42037,0.101058,-0.169169,-0.0651851,-0.21762,-0.729702,-1.07065,0.930411,1.12389,-0.245426,-0.312792
6073,0.308787,0.296899,0.847148,0.767698,0.804522,0.636283,0.1892,0.149076,0.49691,0.585909,0.883151,0.729582,0.365905,0.319721,0.318371,0.330129,0.65691,0.676855,0.472906,0.520082,-1.0935,-1.09226,-0.962202,-0.814166,-1.31764,-0.844972,3.03116,3.27473,1.54928,1.48748,2.13131,1.85647,-0.177991,-0.323161,0.226992,-0.112423,-0.59531,-0.394289,0.223424,0.160125
6074,0.449715,0.429307,0.680395,0.599145,0.851412,0.682968,0.806303,0.766759,0.374284,0.464063,0.71785,0.658754,0.666384,0.560943,0.734212,0.746697,0.651014,0.67121,0.996012,1.04452,1.23487,1.23679,-0.718403,-0.566843,0.837771,1.3161,-1.24967,-1.01387,0.0439971,-0.0134717,0.79861,0.531125,0.179733,0.0306916,0.525749,0.186866,0.96745,1.17355,0.0999701,0.0307936
6075,0.878212,0.857171,0.287243,0.205053,0.166632,-0.00132915,0.0717713,0.0337357,0.601208,0.689517,0.221109,0.163536,0.845651,0.802165,0.462418,0.498545,0.234009,0.252345,0.272357,0.322035,0.247709,0.24654,0.188971,0.340601,0.743665,1.22283,-0.589494,-0.358867,1.02854,0.973589,-1.79226,-2.06382,0.874506,0.722208,-0.660968,-0.998355,-0.117079,0.0825949,0.191847,0.126911
6076,0.193279,0.170444,0.838178,0.756813,0.446425,0.256076,0.9065,0.870182,0.178762,0.265616,0.38765,0.340163,0.482994,0.504536,0.237976,0.250393,0.300085,0.320769,0.401454,0.5161,1.43566,1.43269,-0.354416,-0.209039,1.34563,1.8203,0.424763,0.65363,-0.0756959,-0.127111,1.1322,0.862448,-0.730511,-0.887738,-0.386608,-0.726673,-1.6581,-1.45182,2.76733,2.70807
6077,0.145815,0.123552,0.532377,0.450842,0.792118,0.513481,0.945661,0.909047,0.208967,0.297579,0.573902,0.51679,0.252772,0.206907,0.506503,0.585122,0.683314,0.701523,0.659793,0.710164,-0.642217,-0.640435,-0.208023,-0.0693308,0.995606,1.46979,-1.03066,-0.802705,1.28882,1.24121,-0.308733,-0.585785,-1.40427,-1.56234,-0.64977,-0.993499,0.532358,0.746485,-0.334502,-0.400116
6078,0.813922,0.789834,0.69283,0.609793,0.938949,0.770885,0.0376405,0.00325774,0.717848,0.805917,0.356934,0.298266,0.373932,0.35753,0.90907,0.919852,0.566435,0.584352,0.366209,0.408767,-0.497341,-0.497761,0.329837,0.446499,-0.164544,0.309889,0.124039,0.347075,-0.614469,-0.660039,-1.11761,-1.3894,-1.58061,-1.74407,0.0636143,-0.278894,0.510059,0.725539,-1.1521,-1.22188
6079,0.568326,0.546172,0.312656,0.231003,0.916777,0.787699,0.714818,0.679954,0.636772,0.660277,0.956773,0.899735,0.471247,0.508154,0.188519,0.200727,0.932568,0.950197,0.0566319,0.10737,0.339074,0.333494,0.824662,0.962328,-0.84696,-0.368605,0.519282,0.741135,0.502994,0.463002,0.488177,0.219538,1.81148,1.65441,0.291308,-0.0543901,-0.243281,-0.0246893,-0.681223,-0.84827
6080,0.654075,0.632234,0.415849,0.390202,0.973774,0.804513,0.690329,0.658049,0.475392,0.514636,0.623448,0.566252,0.704643,0.658777,0.528757,0.542758,0.764322,0.856026,0.588953,0.636869,-2.16225,-2.1648,-1.42419,-1.28812,-0.754337,-0.280487,-0.26922,-0.0496678,-1.40724,-1.45238,-0.463266,-0.737388,1.08653,0.934246,-0.377483,-0.72165,1.14921,1.37503,-0.408401,-0.474657
6081,0.153011,0.131105,0.580595,0.5494,0.445451,0.276039,0.235171,0.201044,0.281317,0.368996,0.641775,0.582947,0.558595,0.607542,0.152999,0.165886,0.794925,0.761856,0.203506,0.251556,-0.426069,-0.435515,0.541357,0.675018,-0.678278,-0.192369,-0.487854,-0.269039,-1.1883,-1.23244,-0.832874,-1.10636,0.631572,0.472795,-0.15347,-0.426775,-3.15086,-2.92564,-0.349903,-0.421824
6082,0.328297,0.306512,0.790252,0.708599,0.984505,0.813682,0.709474,0.674052,0.895186,0.983094,0.860779,0.801662,0.604199,0.556307,0.98507,0.999483,0.649768,0.667685,0.973253,1.02222,-0.0523084,0.0097747,-0.697431,-0.531781,0.651225,1.14071,-1.42626,-1.20256,0.102064,0.0995752,0.0663511,-0.20238,2.30757,2.15168,0.221542,-0.131899,2.02542,2.25064,-0.703746,-0.778973
6083,0.72427,0.704277,0.421164,0.339495,0.679554,0.509606,0.201109,0.166142,0.44738,0.535083,0.552535,0.49262,0.990261,0.943059,0.666784,0.70344,0.265152,0.283219,0.772599,0.821481,0.461137,0.455064,-1.86916,-1.73858,0.0975352,0.589883,1.48181,1.70754,1.48117,1.4316,1.95666,1.68446,-0.0791924,-0.232859,0.507144,0.162976,-3.14016,-2.91494,0.114189,0.0439803
6084,0.225789,0.203148,0.927995,0.847047,0.935344,0.765086,0.919652,0.884755,0.85225,0.937613,0.848073,0.788241,0.590352,0.542721,0.390376,0.407398,0.840776,0.857947,0.273527,0.320822,-0.19451,-0.195822,0.298368,0.432873,-1.32134,-0.83123,-0.487951,-0.257044,-0.423109,-0.46965,0.581807,0.310513,0.0141701,-0.140686,0.183646,-0.164322,-0.611295,-0.391135,0.499351,0.425008
6085,0.897666,0.874369,0.209688,0.127146,0.381994,0.210945,0.935803,0.902672,0.334376,0.419188,0.0289487,-0.029098,0.843494,0.794885,0.735298,0.749429,0.117067,0.132251,0.0879075,0.135413,-2.05555,-2.04976,0.558796,0.69609,-1.48144,-0.997645,-1.67204,-1.43606,-0.785256,-0.836612,0.230904,-0.0430819,0.406896,0.258264,0.498681,0.152881,0.295113,0.419988,-0.115667,-0.187492
6086,0.870194,0.799178,0.170976,0.0877742,0.895724,0.724959,0.0614299,0.0275971,0.835016,0.917113,0.89409,0.83393,0.388192,0.338983,0.539541,0.552478,0.267427,0.281641,0.831071,0.87933,-0.733704,-0.724078,1.44205,1.57319,-1.37034,-0.891144,-1.4758,-1.24032,1.31818,1.26434,0.14303,-0.136151,2.1425,1.999,0.266136,-0.0829729,1.01095,1.23111,-1.14597,-1.22159
6087,0.747657,0.723987,0.799559,0.718395,0.585554,0.415833,0.258937,0.223889,0.184775,0.267919,0.855859,0.801456,0.316026,0.282224,0.124662,0.135986,0.73065,0.74681,0.603655,0.653368,-0.881153,-0.796685,0.355517,0.484899,1.45522,1.92809,-0.468767,-0.22782,2.31502,2.26619,-1.01365,-1.29113,-0.729815,-0.872442,1.26105,0.9062,-2.10993,-1.8863,0.34178,0.260404
6088,0.933984,0.910017,0.62146,0.538497,0.714613,0.547295,0.199459,0.274894,0.706361,0.791438,0.820458,0.768983,0.273433,0.225465,0.811855,0.821772,0.232128,0.247057,0.8452,0.896461,-0.875105,-0.869292,0.279254,0.410433,0.0310245,0.506975,1.11182,1.34651,1.70478,1.65557,0.149994,-0.126235,2.27148,2.13295,-0.709509,-1.07077,-1.98323,-1.75328,0.81913,0.733321
6089,0.422373,0.39916,0.650956,0.566946,0.123324,-0.0414458,0.339564,0.3259,0.15375,0.237649,0.796068,0.736509,0.656092,0.60692,0.649957,0.659012,0.598105,0.612902,0.563324,0.615544,-0.0182045,-0.0073412,-1.41378,-1.28714,1.07109,1.55035,0.922917,1.15672,-0.251822,-0.295093,-0.0523164,-0.326179,-1.22661,-1.36126,-0.564973,-0.92328,-1.22893,-0.999573,-0.072215,-0.16447
6090,0.907865,0.885887,0.910578,0.827816,0.294567,0.187003,0.411954,0.376906,0.5986,0.681446,0.0621458,0.00190683,0.324752,0.276516,0.161443,0.172844,0.03103,0.0473844,0.789615,0.843325,-0.146072,-0.137103,0.750413,0.884311,-0.412255,0.0690061,-0.544804,-0.314484,0.913524,0.816512,-1.71376,-1.98657,0.714915,0.583896,0.0464384,-0.316818,-1.24588,-1.02052,0.158896,0.068561
6091,0.818699,0.827216,0.409077,0.324417,0.653671,0.415453,0.0939829,0.0589513,0.642832,0.727061,0.79674,0.73796,0.456956,0.407036,0.912247,0.925481,0.981201,0.997898,0.655914,0.708751,-0.561537,-0.556411,0.688498,0.825164,-1.00572,-0.532213,-0.430471,-0.195751,1.97214,1.92812,-1.51689,-1.7885,-1.39975,-1.52876,-0.972464,-1.33492,-2.20972,-1.9889,0.172837,0.0761414
6092,0.789189,0.768546,0.320328,0.231209,0.808672,0.643902,0.468528,0.432793,0.68835,0.772677,0.619027,0.560662,0.88036,0.828806,0.65447,0.66866,0.237405,0.256714,0.022783,0.0735669,0.254323,0.259911,-1.30357,-1.16996,0.318415,0.787187,1.08127,1.31264,-0.537069,-0.580937,-0.945688,-1.32814,0.516178,0.387976,-0.316976,-0.681695,0.262414,0.480976,-0.378928,-0.476843
6093,0.0266783,0.00756606,0.224414,0.138001,0.140114,-0.0252208,0.212327,0.175136,0.0621456,0.147639,0.0978292,0.04059,0.100167,0.0481297,0.714468,0.72931,0.113425,0.133939,0.136506,0.248276,0.599583,0.601632,-0.562286,-0.430325,1.91637,2.38263,-1.37127,-1.13623,1.14702,1.10989,-0.509653,-0.867787,-0.558533,-0.690802,-1.66364,-2.0223,0.406486,0.596526,-1.29233,-1.39059
6094,0.197224,0.178416,0.810499,0.72346,0.446583,0.28181,0.609427,0.472838,0.267116,0.352861,0.633344,0.577912,0.992892,0.939533,0.455232,0.40954,0.607771,0.629682,0.369693,0.422985,0.0937132,0.0869891,1.03117,1.15971,-1.10045,-0.635707,-0.96934,-0.727255,-1.836,-1.87816,-0.0999037,-0.407433,-1.25683,-1.39599,0.485756,0.125109,0.491688,0.712075,1.0659,0.969211
6095,0.889567,0.869136,0.193685,0.106907,0.225672,0.0598124,0.808126,0.770539,0.233603,0.318505,0.278738,0.225593,0.764596,0.713165,0.0760543,0.0897698,0.0380003,0.059752,0.660329,0.597693,1.89767,1.89363,2.2156,2.34489,0.365126,0.833672,-0.0930987,0.144714,-0.288821,-0.325333,0.324526,0.0529219,-0.143079,-0.275587,0.270798,-0.0946845,-1.10919,-0.883351,-0.532559,-0.630961
6096,0.62127,0.599903,0.786735,0.697756,0.527613,0.317437,0.329731,0.293688,0.699644,0.786324,0.601863,0.55073,0.177172,0.125858,0.365944,0.380404,0.329833,0.351051,0.723006,0.772402,-1.49888,-1.49855,1.25349,1.38024,-0.699004,-0.232182,-0.745983,-0.507641,-1.49306,-1.53008,0.105302,-0.162723,-0.551497,-0.689702,-1.97547,-2.34565,0.960858,1.18329,-0.813423,-0.911121
6097,0.942165,0.921299,0.264576,0.17503,0.7389,0.575062,0.208191,0.171556,0.147967,0.232535,0.202192,0.149165,0.811889,0.762446,0.113393,0.127395,0.331673,0.31666,0.49206,0.585571,-0.362712,-0.360128,-1.51164,-1.38776,0.491451,0.963579,0.296746,0.533653,0.211108,0.175321,-0.595789,-0.859285,0.105487,-0.0284805,-0.65735,-1.02062,-1.28147,-1.06383,0.861804,0.769781
6098,0.456144,0.434705,0.991112,0.90106,0.412317,0.242932,0.705807,0.669463,0.785409,0.87174,0.038159,-0.0134542,0.076691,0.0289971,0.210036,0.223126,0.260161,0.282268,0.351783,0.39874,-0.518031,-0.522238,-0.219193,-0.0921242,-1.97619,-1.49938,0.208913,0.45305,0.726913,0.685731,-0.490763,-0.752499,-0.485615,-0.625957,-1.3553,-1.71689,-0.53344,-0.311156,-0.695912,-0.785998
6099,0.391221,0.456155,0.871595,0.783012,0.0723004,-0.0891975,0.133902,0.0968007,0.248111,0.333587,0.961116,0.908363,0.0359744,0.0448811,0.733116,0.745432,0.492622,0.523723,0.739128,0.787743,1.7018,1.69703,-0.0295451,0.0934608,0.0880376,0.5661,1.36539,1.60283,0.517682,0.472631,1.75249,1.48511,0.785098,0.650273,-0.946543,-1.30893,0.230839,0.441516,1.08645,0.989704
6100,0.501583,0.477605,0.24757,0.15746,0.591432,0.429708,0.680643,0.644192,0.876382,0.962752,0.251481,0.19866,0.107973,0.0607651,0.829199,0.841162,0.744604,0.765178,0.0847254,0.131439,-0.155478,-0.15691,-1.20942,-1.08762,-0.122339,0.40596,-0.388849,-0.151203,0.639563,0.681213,-2.42448,-2.69185,0.370248,0.236158,0.607867,0.247514,0.0856775,0.295313,-0.964663,-1.05837
6101,0.983425,0.958921,0.748841,0.660272,0.413294,0.251036,0.622674,0.607955,0.935751,1.01978,0.142311,0.133267,0.857176,0.810278,0.127814,0.137751,0.0376661,0.0592594,0.82808,0.875356,-0.0964522,-0.0898108,-1.24876,-1.13238,-0.238141,0.24582,-1.21004,-0.97476,0.929524,0.889794,-0.88315,-1.14519,-1.2476,-1.38709,1.47669,1.11345,0.236793,0.442615,-0.234969,-0.325859
6102,0.172661,0.147027,0.13271,0.0437191,0.232799,0.0723635,0.607995,0.571718,0.65783,0.742786,0.120619,0.0678733,0.891408,0.834308,0.810132,0.819341,0.741646,0.761879,0.521261,0.570167,-0.275382,-0.265545,1.1541,1.26562,0.503732,0.98382,1.45317,1.69062,-0.460725,-0.503105,-1.60559,-1.87162,-0.157259,-0.299143,0.652311,0.295777,-0.0842144,0.126738,-1.35454,-1.43999
6103,0.35077,0.308051,0.352375,0.286594,0.679918,0.521618,0.82965,0.792064,0.886671,0.973372,0.801919,0.748599,0.903362,0.858338,0.763632,0.866659,0.0640308,0.0868878,0.69004,0.737102,-1.67554,-1.66945,0.264595,0.37865,1.50227,1.98331,2.3353,2.57848,-0.809598,-0.854187,0.951226,0.687755,1.40899,1.26823,-1.15819,-1.51094,-0.0592432,0.153374,-1.09439,-1.17859
6104,0.363386,0.469076,0.619022,0.52947,0.00365833,-0.152178,0.380755,0.346173,0.236365,0.324178,0.423687,0.371774,0.288674,0.242044,0.903414,0.913977,0.078521,0.101856,0.602005,0.734829,2.3442,2.35029,0.157132,0.27318,-0.187084,0.300281,0.144567,0.382675,1.59424,1.5502,1.02754,0.763385,-1.18853,-1.32563,-0.214217,-0.565439,1.57031,1.78502,0.579278,0.502309
6105,0.654765,0.6301,0.190324,0.100892,0.35505,0.200538,0.9605,0.924053,0.00661865,0.0926148,0.536621,0.485558,0.533433,0.48833,0.369606,0.377879,0.939554,0.963491,0.664762,0.732555,-0.328568,-0.322633,0.769071,0.889097,-0.853547,-0.361712,-2.77713,-2.53588,-0.416472,-0.462539,0.641337,0.379164,0.557506,0.415107,-0.39003,-0.739211,1.38656,1.60745,-0.779393,-0.854794
6106,0.94461,0.922325,0.746601,0.657721,0.294268,0.11474,0.472796,0.494697,0.248732,0.333846,0.0632173,0.0105941,0.0755805,0.0324272,0.809318,0.820117,0.0736771,0.0984925,0.537544,0.730282,1.36237,1.36132,-2.14921,-2.03487,1.70688,2.19858,-0.465383,-0.224471,-0.612568,-0.661352,-0.863233,-1.13062,-1.74103,-1.88945,-0.336524,-0.686224,0.395903,0.624229,-0.105495,-0.182372
6107,0.983942,0.962502,0.288689,0.199504,0.130263,0.0289413,0.102346,0.0653407,0.882987,0.968378,0.535702,0.483054,0.695006,0.653951,0.641139,0.58264,0.795874,0.821024,0.680945,0.728008,-0.694817,-0.694387,0.188753,0.298093,1.18112,1.67837,0.553371,0.788025,0.912681,0.861213,-0.413903,-0.684281,-0.0639003,-0.210573,1.23635,0.88597,0.202857,0.431332,0.212511,0.140504
6108,0.71541,0.693268,0.469318,0.445598,0.0984433,-0.056857,0.165476,0.129035,0.571078,0.655685,0.0388362,-0.012164,0.295704,0.253613,0.335832,0.345163,0.468435,0.558165,0.875157,0.920057,-1.2684,-1.26866,0.261183,0.376272,1.35374,1.84487,0.0109832,0.244851,-1.03898,-1.08945,0.50402,0.234219,-1.32169,-1.47351,0.174394,-0.176364,1.2926,1.51525,-0.813351,-0.878784
6109,0.173012,0.152171,0.779903,0.691693,0.741326,0.586853,0.579802,0.543056,0.994513,1.07802,0.65955,0.608595,0.633111,0.558267,0.811665,0.821689,0.270158,0.295307,0.0759575,0.120046,0.0682049,0.0733958,1.52505,1.6397,0.122802,0.608578,0.84471,1.08486,-1.3105,-1.36418,0.943408,0.680561,-1.12768,-1.2747,1.36945,1.02724,1.40357,1.63185,-0.117398,-0.176785
6110,0.168825,0.147528,0.520686,0.430599,0.576988,0.420706,0.109592,0.0708789,0.00303857,0.0887371,0.318476,0.265845,0.903873,0.86292,0.346039,0.355045,0.451328,0.518335,0.502882,0.454357,0.29036,0.292283,-0.567069,-0.449833,0.162915,0.653363,-0.573779,-0.34091,-1.18227,-1.23766,-1.18236,-1.44442,0.318417,0.172249,-0.873322,-1.21029,-0.72424,-0.489173,-0.838862,-0.894111
6111,0.801827,0.77821,0.914201,0.826048,0.725875,0.567578,0.967052,0.927883,0.555904,0.643231,0.99962,0.946571,0.268856,0.225477,0.265557,0.274191,0.717782,0.741363,0.743363,0.788667,-2.61924,-2.62393,1.81221,1.93368,-2.14033,-1.65243,1.15104,1.38809,1.16251,1.10089,-1.24523,-1.50667,1.55466,1.40343,0.910366,0.578864,0.788695,1.0164,-0.842735,-0.90149
6112,0.637894,0.615196,0.14714,0.0585675,0.426181,0.268395,0.484208,0.446072,0.826088,0.914936,0.659401,0.692716,0.440167,0.39619,0.981631,0.991833,0.295881,0.317939,0.340178,0.388106,-0.533082,-0.541082,1.73434,1.85921,0.279586,0.771054,-2.70737,-2.47033,1.06403,1.00879,0.395791,0.135573,-1.86379,-2.01157,-0.424502,-0.761744,0.57924,0.809619,-0.176324,-0.229068
6113,0.0395298,0.0196116,0.857163,0.768989,0.559796,0.349698,0.921022,0.884739,0.0941589,0.183409,0.492818,0.438862,0.855348,0.812962,0.567031,0.534423,0.297379,0.317991,0.465726,0.607023,0.985724,0.972621,-0.545626,-0.422784,1.04412,1.53974,0.0418988,0.273298,-0.50138,-0.55236,-0.721087,-0.97403,1.41639,1.26235,0.312658,-0.0304285,1.1042,1.33207,-0.540014,-0.586217
6114,0.0380821,0.020179,0.333433,0.246263,0.587973,0.431001,0.418518,0.38181,0.75401,0.843795,0.425528,0.370782,0.742803,0.681169,0.0668125,0.0770141,0.949673,0.971644,0.743503,0.82594,0.816652,0.87048,-0.166567,-0.0373007,1.44837,1.94004,-2.83204,-2.59933,-0.613896,-0.694057,0.445509,0.190863,-0.0966731,-0.253588,-0.108317,-0.450146,0.249755,0.475827,0.64641,0.605004
6115,0.682373,0.666331,0.168849,0.0830537,0.963801,0.8084,0.805699,0.77058,0.533489,0.621637,0.680043,0.61322,0.59094,0.549377,0.707427,0.716692,0.355642,0.377411,0.998068,1.04486,0.77621,0.76834,-1.78576,-1.65728,-0.425676,0.0689173,0.525764,0.75743,-0.784468,-0.835753,0.504848,0.251644,-0.170498,-0.328899,0.584869,0.24894,-0.193687,0.0359218,0.783781,0.747061
6116,0.452635,0.481113,0.944739,0.858632,0.563809,0.408287,0.00956044,-0.0249678,0.861409,0.94901,0.911067,0.855658,0.850293,0.81095,0.51067,0.437369,0.762876,0.783371,0.438622,0.483787,1.57365,1.57045,0.642225,0.773343,-0.233642,0.306128,-0.764466,-0.529601,2.24936,2.20321,1.23684,0.984684,0.0864196,-0.0693221,-0.164187,-0.488571,0.234986,0.46341,-1.11906,-1.16343
6117,0.362423,0.295894,0.695658,0.553656,0.604831,0.449695,0.648437,0.612375,0.874243,0.912734,0.32277,0.265868,0.175538,0.134345,0.1498,0.158045,0.922262,0.942754,0.380633,0.444664,0.010636,0.0154209,0.230127,0.362862,0.0433468,0.543338,-0.88924,-0.655876,-1.89478,-1.93986,-1.82072,-2.07137,-1.8407,-1.99184,-0.885671,-1.22608,-0.236493,-0.00624169,0.507432,0.457529
6118,0.128692,0.110676,0.332894,0.248681,0.0368829,-0.119037,0.158907,0.125462,0.726067,0.876458,0.7559,0.699992,0.194619,0.233987,0.763847,0.772958,0.0748383,0.0946122,0.265744,0.405541,-0.653526,-0.649473,-1.59967,-1.46421,1.6031,2.10653,1.84954,2.08775,1.09749,1.04667,0.234674,-0.0103605,-0.147304,-0.297421,-0.624619,-0.9703,1.0938,1.32966,1.34691,1.29483
6119,0.64573,0.627282,0.664215,0.578076,0.858791,0.701744,0.282747,0.250332,0.859011,0.840182,0.0923642,0.0350456,0.377413,0.333629,0.229122,0.236861,0.349844,0.370883,0.264213,0.366419,-0.717359,-0.7206,-1.94114,-1.79878,1.55734,2.06217,-1.39045,-1.15776,-2.34813,-2.40728,-1.22779,-1.4755,2.31205,2.16513,0.510101,0.158613,-0.00249601,0.238705,1.39308,1.34767
6120,0.0089428,-0.00908104,0.989735,0.907471,0.0991593,-0.0579499,0.900093,0.868015,0.649846,0.803906,0.30391,0.272738,0.60982,0.522145,0.517076,0.522779,0.361835,0.42909,0.279874,0.327296,1.25548,1.25125,-0.0231913,0.116742,0.208533,0.71642,1.11866,1.35337,-0.292054,-0.354778,0.877319,0.633382,-0.58118,-0.72304,-0.0639656,-0.413003,1.21187,1.44742,-0.486391,-0.529632
6121,0.636236,0.61645,0.48175,0.398921,0.139771,-0.0165416,0.6385,0.703122,0.678375,0.767629,0.624202,0.51043,0.75309,0.71066,0.381385,0.386399,0.468553,0.487298,0.563409,0.610653,0.11199,0.107996,0.396607,0.532894,-0.0604137,0.442684,0.790002,1.02569,1.07409,1.01354,0.194859,-0.0487158,0.705521,0.570207,0.21581,-0.126319,-0.303724,-0.0707622,0.135917,0.0969432
6122,0.586375,0.593459,0.493282,0.41308,0.681431,0.526358,0.515624,0.538228,0.3025,0.3936,0.807485,0.748122,0.363681,0.319323,0.9856,0.99094,0.870786,0.888235,0.196681,0.244493,-0.491133,-0.496489,-0.195813,-0.0622125,0.321286,0.825716,0.910866,1.14442,-1.56993,-1.62438,0.745448,0.503781,0.391934,0.249176,-1.54169,-1.88094,-0.0870262,0.154465,-0.849509,-0.892005
6123,0.66447,0.570467,0.0612989,-0.0200858,0.867426,0.662715,0.40574,0.373334,0.448451,0.540781,0.568356,0.511622,0.323314,0.281003,0.619828,0.624154,0.91096,0.92668,0.365347,0.411428,1.3799,1.37016,-0.0519919,0.0774958,-0.87669,-0.284421,0.595344,0.831412,0.580643,0.528119,-1.40068,-1.64095,-0.827462,-0.968354,1.09319,0.751855,-0.238528,0.00826207,-0.564825,-0.613915
6124,0.56488,0.547475,0.0483768,-0.0306059,0.953003,0.799071,0.580544,0.499714,0.595904,0.687961,0.199017,0.275123,0.84553,0.803299,0.897427,0.900416,0.383718,0.397514,0.99288,1.04096,-1.75895,-1.77502,-0.161368,0.0389219,-1.89899,-1.39456,1.91483,2.14963,-0.246867,-0.296646,-0.12015,-0.355256,-0.0240451,-0.171434,0.27433,-0.0658224,0.171995,0.420687,1.27208,1.22532
6125,0.132332,0.116713,0.744346,0.664164,0.401508,0.250008,0.66049,0.626093,0.46807,0.649644,0.0979861,0.0386231,0.307601,0.266517,0.570274,0.573917,0.612974,0.512681,0.000353146,0.0477217,-0.330953,-0.340106,-0.133918,0.000347893,-0.150893,0.358061,-0.049169,0.283253,0.449504,0.397837,-2.90369,-3.14225,0.344727,0.197094,-2.03999,-2.38173,-1.00802,-0.752129,-1.32966,-1.37497
6126,0.392126,0.378636,0.741266,0.663787,0.891003,0.738275,0.0269009,-0.00612287,0.435389,0.611326,0.733282,0.674603,0.247014,0.208139,0.835429,0.83952,0.673853,0.627848,0.970083,1.01823,0.672066,0.6621,-0.480287,-0.349617,-0.63299,-0.130835,-1.81793,-1.58313,0.917303,0.861954,-0.38606,-0.631448,-1.6659,-1.82048,-0.465638,-0.809534,-1.10363,-0.861776,0.112534,0.0606675
6127,0.407774,0.393828,0.189805,0.111912,0.487794,0.34636,0.133111,0.0982775,0.479329,0.573009,0.771956,0.714985,0.519282,0.415042,0.543605,0.547988,0.729073,0.743014,0.793797,0.8429,-1.4305,-1.43795,0.648074,0.776114,-0.737461,-0.237343,0.419251,0.658002,-0.193091,-0.252656,-0.745634,-0.985043,-0.771778,-0.931826,-0.185949,-0.542018,-1.22685,-0.971423,-2.65662,-2.70948
6128,0.130207,0.114832,0.288497,0.152221,0.105878,-0.0455554,0.907861,0.872455,0.872253,0.965776,0.269595,0.214917,0.659845,0.621945,0.508831,0.511873,0.414232,0.428062,0.172932,0.222199,-0.168575,-0.173695,0.361389,0.404232,1.06435,1.56093,-0.542662,-0.305061,0.443257,0.380231,0.118401,-0.0492842,0.6093,0.454799,0.067841,-0.274501,0.385173,0.643621,-1.03087,-1.08852
6129,0.886376,0.869982,0.254738,0.192529,0.212779,0.0610767,0.932029,0.895044,0.997822,1.00277,0.52663,0.403877,0.0255954,-0.010133,0.177676,0.26033,0.873124,0.888359,0.029655,0.0770933,-0.325936,-0.335805,-0.0919595,0.0323512,0.332799,0.866171,-0.157884,0.0621973,-0.930771,-0.999019,1.13062,0.886475,0.64338,0.581416,-2.09629,-2.44046,-0.660646,-0.403779,-1.62066,-1.68472
6130,0.352005,0.333725,0.386194,0.232838,0.591816,0.438476,0.207386,0.172343,0.948006,1.03977,0.646058,0.592837,0.836319,0.800716,0.00499787,0.00878691,0.961387,0.976532,0.724959,0.771357,-0.697662,-0.709546,0.199758,0.327956,-0.329475,0.171414,0.249044,0.429456,1.44814,1.38761,-2.182,-2.42797,0.854827,0.708033,-1.08636,-1.43348,-0.77051,-0.517396,0.0119201,-0.0512771
6131,0.735482,0.716547,0.351037,0.273147,0.592953,0.43983,0.17072,0.135918,0.644379,0.829425,0.234731,0.181832,0.782022,0.746573,0.0863968,0.0814301,0.568254,0.582329,0.391167,0.434926,0.815588,0.804156,1.45088,1.57674,1.83382,2.33249,0.555291,0.796714,-0.722492,-0.777895,-0.242806,-0.483375,-0.676721,-0.824232,-1.03163,-1.38049,-1.41841,-1.17171,-1.17814,-1.24028
6132,0.0369289,0.0183043,0.154381,0.0785161,0.366469,0.212403,0.684186,0.648717,0.529683,0.61908,0.645637,0.591485,0.990709,0.952467,0.151114,0.154073,0.716895,0.731719,0.624321,0.667705,-1.78775,-1.80136,-0.332336,-0.199905,0.337117,0.835964,0.326543,0.562596,0.931511,0.881487,-0.556596,-0.792093,-0.686427,-0.838213,1.44769,1.09704,-1.30463,-1.05511,0.119042,0.0557408
6133,0.451513,0.431626,0.271473,0.172469,0.397327,0.244127,0.994622,0.958439,0.101717,0.190612,0.834979,0.762515,0.705528,0.666601,0.665063,0.666068,0.307466,0.322804,0.384121,0.411275,-0.0382681,-0.0558044,0.630802,0.769962,-0.462813,0.0345419,1.7752,2.00716,0.373833,0.317594,-0.387033,-0.624809,-0.457923,-0.610033,0.131453,-0.214339,1.42123,1.67505,-0.0759477,-0.133549
6134,0.596739,0.576441,0.30875,0.266421,0.0151583,-0.140489,0.760317,0.725791,0.155486,0.242951,0.986736,0.933545,0.718524,0.67955,0.818711,0.766893,0.347355,0.339698,0.111968,0.154845,-1.19057,-1.21367,-0.540673,-0.396088,0.0374817,0.538065,-0.628961,-0.388656,0.656949,0.598645,0.480465,0.246975,0.394684,0.24671,-0.0716742,-0.419387,0.0330736,0.283774,-0.949941,-1.00294
6135,0.0817268,0.0610226,0.31111,0.360374,0.306394,0.0838166,0.0203781,-0.0124174,0.799124,0.887852,0.649131,0.608555,0.050076,0.0127787,0.778813,0.867719,0.343638,0.356592,0.481878,0.524785,0.619105,0.59297,-2.62058,-2.47326,-0.140674,0.356217,0.661296,0.898626,-1.34025,-1.39961,1.66068,1.42551,3.17716,3.02535,0.645424,0.295218,0.384411,0.617492,0.913164,0.866961
6136,0.112922,0.0914535,0.530191,0.454326,0.463654,0.308122,0.253446,0.223156,0.920209,1.00725,0.335706,0.283565,0.157085,0.117892,0.970117,0.968544,0.128933,0.143204,0.255736,0.298823,-0.635262,-0.657827,-1.22297,-1.07165,1.27859,1.78055,0.107587,0.340306,0.372315,0.30579,0.872371,0.638594,-1.6752,-1.82701,0.589161,0.242131,0.70569,0.95121,0.61351,0.572961
6137,0.680679,0.657997,0.198169,0.12407,0.0783526,-0.0764938,0.741032,0.71162,0.481429,0.568741,0.418081,0.405926,0.0503132,0.0131239,0.20733,0.20708,0.864821,0.879962,0.776689,0.818412,0.414648,0.390342,-2.45804,-2.31457,-0.781725,-0.282092,-0.789331,-0.559947,-0.429012,-0.502362,0.71435,0.482982,-0.486305,-0.642242,0.872472,0.528815,-0.0473881,0.229606,-0.894023,-0.934848
6138,0.149823,0.126779,0.684645,0.611769,0.585353,0.431737,0.299048,0.26969,0.937263,1.02636,0.580922,0.528286,0.617226,0.579633,0.660637,0.658779,0.0919367,0.105598,0.611702,0.65341,0.680748,0.656225,0.79147,0.937861,1.10312,1.5966,1.62439,1.85206,1.14625,1.06721,-0.327357,-0.565588,1.98575,1.83425,-0.494553,-0.841391,-0.736266,-0.491997,0.697351,0.653192
6139,0.985148,0.961927,0.0554708,-0.01856,0.148425,-0.00359213,0.303487,0.273498,0.101802,0.189191,0.269919,0.219244,0.051097,0.0122212,0.46248,0.461829,0.989895,1.00368,0.793033,0.835735,0.517396,0.494115,1.624,1.76968,0.735131,1.22979,0.0321842,0.25571,-1.41384,-1.49369,1.95793,1.71595,-1.59039,-1.74525,1.58577,1.24384,-0.57955,-0.328873,0.204519,0.163342
6140,0.789998,0.768063,0.112654,0.0411116,0.000567213,-0.150584,0.0472402,0.0158417,0.498081,0.586913,0.858459,0.80989,0.648292,0.608214,0.575267,0.572536,0.915274,0.928737,0.417062,0.459558,0.56607,0.544785,0.116645,0.25931,0.678763,1.16913,0.228486,0.451453,0.371529,0.288856,-0.112909,-0.349216,0.410971,0.263077,0.757716,0.378007,0.360854,0.615068,-0.800766,-0.840447
6141,0.814552,0.829347,0.52826,0.456221,0.812057,0.659674,0.182636,0.0845765,0.67723,0.76946,0.563777,0.589569,0.412268,0.32901,0.132313,0.130958,0.613455,0.624886,0.938346,0.979147,0.211389,0.186863,0.525841,0.675461,0.310764,0.802326,1.18573,1.41538,0.805134,0.722004,0.071158,-0.166106,-0.990773,-1.09184,-0.140347,-0.487832,0.962005,1.25364,-1.46349,-1.49689
6142,0.913151,0.890632,0.562593,0.390867,0.469994,0.375472,0.183208,0.153311,0.865471,0.952007,0.419434,0.369249,0.0912509,0.0498068,0.471567,0.46852,0.993539,1.00564,0.900583,0.940628,0.134132,0.115736,-0.979612,-0.834913,-1.26165,-0.769957,-0.67956,-0.449427,-1.19113,-1.27625,-0.526055,-0.770039,-2.29887,-2.44677,1.05526,0.715773,1.63066,1.89221,-1.03946,-1.06898
6143,0.69326,0.671397,0.397947,0.325513,0.243601,0.0912699,0.747958,0.716654,0.652868,0.740211,0.551393,0.521742,0.471573,0.431262,0.476658,0.474175,0.353365,0.365214,0.631241,0.670182,-0.702265,-0.721402,1.60883,1.75664,0.239231,0.731305,1.91587,2.14933,0.147522,0.0623641,0.970725,0.729305,-0.678492,-0.829843,-0.851041,-1.19783,0.371627,0.62814,1.84002,1.81007
6144,0.0130904,-0.00984554,0.0558282,-0.0145256,0.892052,0.740162,0.0149814,-0.0163685,0.997968,1.08695,0.723953,0.674234,0.422547,0.383017,0.826671,0.826527,0.528812,0.542772,0.802283,0.842354,0.94281,0.931125,-0.668717,-0.525356,-0.550179,-0.0542446,-1.10506,-0.868845,0.140747,0.0519361,-0.320125,-0.564437,-1.00505,-1.15087,-0.528773,-0.875194,-1.25765,-0.999363,0.385974,0.361665
6145,0.767529,0.745304,0.101978,0.0335073,0.592073,0.440979,0.862972,0.830308,0.734247,0.824641,0.0252529,-0.0250871,0.710832,0.586877,0.0692036,0.0710122,0.589415,0.720331,0.714412,0.728322,-0.44065,-0.456657,-0.888721,-0.73747,-0.458716,0.0359665,-0.793063,-0.550874,-0.713167,-0.803211,0.642677,0.399086,-0.621863,-0.768429,-0.19995,-0.552562,-3.37461,-3.12038,-0.747803,-0.76812
6146,0.980618,0.956634,0.587211,0.517226,0.733321,0.582931,0.910189,0.879238,0.996354,1.08571,0.563254,0.512235,0.831649,0.790737,0.705842,0.705952,0.886041,0.897889,0.573308,0.614291,0.679249,0.73215,0.236934,0.388261,-0.809412,-0.277244,1.06818,1.30701,0.01448,-0.077536,0.720162,0.474717,1.57556,1.4341,1.527,1.1742,0.405746,0.653366,-0.455024,-0.475894
6147,0.888768,0.864569,0.300181,0.231566,0.665536,0.513623,0.0816095,0.0516802,0.246904,0.338381,0.09812,0.0466987,0.0560794,0.0148662,0.411018,0.380998,0.010565,0.02277,0.231356,0.273152,1.93361,1.92096,-0.0936495,0.0536948,-1.08005,-0.590454,-0.532508,-0.28934,-0.228107,-0.321448,1.13302,0.886383,0.165141,0.0295282,1.0432,0.69397,2.38098,2.63467,0.595134,0.57495
6148,0.0289439,0.00666732,0.710414,0.573945,0.270898,0.191101,0.135574,0.105914,0.374866,0.467871,0.505062,0.487236,0.450237,0.420392,0.0574515,0.0560447,0.855723,0.868036,0.156481,0.199054,0.278649,0.273309,0.726452,0.868721,-0.518313,-0.0233965,1.8319,2.07813,0.861007,0.772292,-0.599997,-0.852284,0.238378,0.0240586,0.326525,-0.0183088,-0.26482,-0.011375,2.69558,2.67276
6149,0.23402,0.212888,0.984077,0.916324,0.0220564,-0.131421,0.945808,0.917258,0.267662,0.367658,0.978135,0.927773,0.86713,0.825917,0.771323,0.768056,0.171205,0.182598,0.768633,0.812691,0.198969,0.187133,0.57517,0.719031,-0.772784,-0.282208,-1.51133,-1.27298,0.0301259,-0.0524727,1.04555,0.789958,0.159483,0.018589,0.685721,0.343317,1.04829,1.30548,0.430464,0.404612
6150,0.173467,0.151515,0.128708,0.0601979,0.326361,0.095878,0.628562,0.599304,0.175868,0.267445,0.13046,0.0788118,0.307225,0.264105,0.42142,0.415934,0.497494,0.508695,0.499761,0.542245,0.344398,0.329807,-0.343064,-0.197759,-0.775789,-0.282233,0.734096,0.968151,0.412449,0.275259,0.0809858,-0.166968,-0.330123,-0.472943,0.0909879,-0.245617,0.756601,1.02145,-0.168618,-0.114235
6151,0.472819,0.448826,0.612897,0.543917,0.479017,0.323177,0.593282,0.52973,0.804919,0.89661,0.527053,0.473033,0.253547,0.209962,0.874293,0.867634,0.396063,0.407554,0.827285,0.871124,-0.883657,-0.904131,0.583051,0.723504,-0.468803,0.0256492,1.16084,1.39254,0.685376,0.60299,0.149418,-0.0913377,-0.00620266,-0.151192,-0.722789,-1.06329,-1.50948,-1.24463,-0.610218,-0.633082
6152,0.989845,0.965432,0.139165,0.0702736,0.946371,0.79176,0.49025,0.460156,0.0500378,0.143577,0.527106,0.475104,0.434115,0.39072,0.666796,0.697362,0.753527,0.763877,0.475015,0.520043,-0.182484,-0.209129,-0.367879,-0.224895,0.736813,1.23526,0.897079,1.12585,0.663927,0.576106,-0.322845,-0.570398,-0.0763191,-0.226503,-0.183997,-0.532227,0.882527,1.14466,-0.611112,-0.640461
6153,0.692544,0.665801,0.0529348,-0.01809,0.45926,0.306199,0.864321,0.833998,0.221621,0.314104,0.0387825,-0.0151526,0.276029,0.23167,0.533434,0.527091,0.416254,0.424622,0.898115,0.944331,-0.166396,-0.187833,0.307219,0.453464,0.683265,1.1746,-0.814751,-0.581821,-0.49053,-0.584983,-0.283092,-0.525375,-1.42341,-1.57094,-0.0683298,-0.400683,-0.0982067,0.161447,0.3341,0.304463
6154,0.696321,0.709877,0.267688,0.194567,0.917435,0.765034,0.929706,0.897692,0.0322786,0.127109,0.300275,0.248283,0.402223,0.357047,0.135516,0.130585,0.750636,0.761054,0.0863149,0.134726,-0.643235,-0.670383,-1.18632,-1.04142,-0.700716,-0.216608,0.66271,0.869036,0.0344016,-0.0602131,-0.451798,-0.694162,-1.52973,-1.67648,0.0795504,-0.269139,0.439614,0.700103,0.504329,0.47691
6155,0.778658,0.753953,0.811899,0.736824,0.641662,0.490616,0.0608746,0.0276287,0.937172,1.03326,0.289064,0.190496,0.150965,0.171358,0.282319,0.27194,0.748226,0.857084,0.471904,0.518889,0.159606,0.131729,-0.198236,-0.0580337,0.537849,1.02641,2.08696,2.31989,2.38243,2.29333,0.369634,0.130747,-0.6861,-0.833996,-1.78048,-2.13635,0.436533,0.694786,-0.93296,-0.957266
6156,0.338962,0.313445,0.761727,0.686957,0.712576,0.504464,0.448141,0.416399,0.24963,0.347222,0.253763,0.132708,0.031941,-0.0143319,0.418567,0.413295,0.942207,0.953113,0.550302,0.540702,0.171519,0.13715,-1.25423,-1.11587,0.661534,1.20791,-1.18708,-0.9551,-1.13141,-1.21581,0.613687,0.374995,-0.181242,-0.326971,0.388443,0.0256364,0.949625,1.20296,-0.888183,-0.918928
6157,0.288903,0.262072,0.922105,0.845907,0.669786,0.518311,0.488435,0.455263,0.190135,0.287374,0.126628,0.0749201,0.983773,0.935831,0.331137,0.327483,0.652215,0.746614,0.606754,0.562515,0.413731,0.371965,0.278226,0.411846,0.893834,1.38941,-1.69351,-1.46856,0.530589,0.443573,0.150956,-0.0895154,-0.87675,-1.01749,1.00591,0.647159,-1.51846,-1.26856,2.09281,2.05958
6158,0.0252866,-0.00143049,0.548661,0.471295,0.202633,0.0485796,0.189419,0.157679,0.784463,0.88216,0.924373,0.87362,0.5209,0.475368,0.472965,0.457404,0.531941,0.540114,0.568474,0.584327,0.0319557,-0.016155,-0.697494,-0.567138,-1.33098,-0.833593,0.751236,0.974448,-1.59865,-1.68862,0.218416,-0.028735,-0.263443,-0.401704,-0.984035,-1.3447,0.187225,0.441796,1.25622,1.2235
6159,0.31597,0.290795,0.646543,0.570227,0.997549,0.842857,0.440229,0.40832,0.752958,0.852546,0.562498,0.530218,0.989721,0.942447,0.479821,0.587324,0.697065,0.704991,0.559155,0.60614,-0.776837,-0.822585,-0.539846,-0.412573,-0.875568,-0.374718,-0.121834,0.103003,0.738917,0.649923,-0.518778,-0.770804,-0.799197,-0.941408,2.59227,2.23167,-0.464152,-0.264646,-0.0688039,-0.10215
6160,0.149985,0.123206,0.282961,0.205712,0.458715,0.303787,0.297243,0.266785,0.254095,0.354299,0.239122,0.186816,0.824394,0.688786,0.72179,0.717244,0.330058,0.335635,0.454914,0.500435,-0.7341,-0.78866,0.882481,1.00524,-2.06775,-1.56385,0.616658,0.836051,0.298086,0.206351,0.379562,0.133172,0.729138,0.582924,-0.271578,-0.635292,-1.22619,-0.971088,-0.716064,-0.744998
6161,0.48399,0.45536,0.681069,0.605749,0.817732,0.660892,0.707015,0.676157,0.185909,0.273023,0.241174,0.188886,0.480847,0.435125,0.541808,0.535072,0.276915,0.288608,0.801506,0.844757,0.979414,0.924952,-0.907993,-0.787839,-0.603903,-0.0944702,-0.283975,-0.0642019,-0.83243,-0.923976,-0.674745,-0.915398,-0.200822,-0.340296,0.0317047,-0.336003,-0.36039,-0.104798,-0.186262,-0.211267
6162,0.027837,0.000261845,0.0341916,-0.0399569,0.182189,0.0267497,0.656783,0.62453,0.0915488,0.191747,0.660314,0.608243,0.442481,0.396805,0.0644861,0.0595665,0.237735,0.241581,0.302563,0.344099,0.00142394,-0.0486336,-2.43419,-2.31499,2.0209,2.53042,1.88909,2.10809,-0.045898,-0.135787,-0.777392,-1.02278,0.279454,0.136314,0.928703,0.560772,0.176325,0.433859,-0.143543,-0.172929
6163,0.234802,0.11285,0.0838079,0.00807594,0.365674,0.212537,0.000266977,-0.0327271,0.562328,0.664719,0.311177,0.261059,0.0704207,0.0260917,0.675465,0.669341,0.990804,0.994242,0.102497,0.143359,-0.186504,-0.238512,0.410937,0.533805,-0.427184,0.0820528,1.21365,1.43241,2.66571,2.57383,1.22031,0.969852,1.86104,1.72371,-0.95121,-1.32369,0.143131,0.376632,1.17209,1.13921
6164,0.252861,0.225438,0.345648,0.239376,0.828589,0.676095,0.428538,0.395958,0.16764,0.271153,0.704447,0.655281,0.599601,0.552954,0.369348,0.363,0.095115,0.0999801,0.441148,0.528589,-1.60057,-1.65808,-0.778711,-0.6627,-0.0404672,0.465085,0.535681,0.756732,0.270761,0.186861,-0.600247,-0.846791,1.20672,1.06504,-1.80849,-2.18715,-0.029897,0.319405,0.191615,0.166077
6165,0.0742632,0.0478924,0.66253,0.470676,0.877818,0.72278,0.421486,0.389174,0.843591,0.947836,0.532576,0.563139,0.193333,0.146866,0.614395,0.608556,0.799879,0.807087,0.873145,0.913819,0.329863,0.26757,0.649879,0.769655,-0.676237,-0.165838,-0.692145,-0.469211,-0.689391,-0.774724,-0.281224,-0.526501,0.108401,-0.0273581,0.377331,-0.00676017,-0.00140454,0.262179,0.692713,0.670307
6166,0.3622,0.334739,0.777707,0.701975,0.46378,0.31986,0.651338,0.592038,0.810595,0.988789,0.520717,0.470997,0.630717,0.583762,0.28511,0.277203,0.8489,0.856155,0.96672,1.00529,0.70094,0.642189,0.582215,0.69519,0.355782,0.864686,-0.995364,-0.766961,0.656479,0.563892,-0.450112,-0.695288,0.875703,0.739739,-0.120574,-0.407359,0.555922,0.816822,-1.68715,-1.7148
6167,0.434171,0.402531,0.303983,0.228332,0.0738505,-0.0830588,0.829257,0.794903,0.926085,1.02974,0.71978,0.669862,0.425037,0.378639,0.704543,0.69856,0.637125,0.684904,0.289041,0.329204,-0.0413149,-0.0999418,-0.61746,-0.501316,-0.503261,0.00100865,0.373842,0.597982,-0.428988,-0.520226,0.95463,0.713676,-0.882675,-1.01166,-0.428912,-0.807957,-0.439141,-0.182718,1.19908,1.16425
6168,0.484969,0.470324,0.0355753,-0.0424197,0.423696,0.362679,0.543337,0.506508,0.452943,0.556736,0.683292,0.642988,0.978186,0.930349,0.443435,0.436726,0.508382,0.513653,0.989544,1.02883,-1.00657,-1.05884,-1.03732,-0.925821,-0.468791,-0.0147954,-1.13346,-0.904544,0.00402611,-0.0870775,-0.0550796,-0.290025,-0.042056,-0.169181,0.538554,0.165315,-0.670131,-0.420239,0.531137,0.491545
6169,0.648955,0.538116,0.226662,0.15036,0.964837,0.808416,0.469181,0.433362,0.268533,0.35786,0.667457,0.616114,0.416785,0.368537,0.784425,0.778757,0.335147,0.342402,0.324321,0.362589,-1.19273,-1.24872,1.59756,1.71357,-0.53628,-0.0305995,-0.265146,-0.0325757,0.978583,0.815532,2.24083,2.0069,-0.289429,-0.412859,-0.432569,-0.807005,0.466592,0.710039,0.386935,0.348809
6170,0.633369,0.605908,0.836708,0.760693,0.317228,0.159615,0.193557,0.155634,0.0555054,0.158984,0.0598395,0.0110942,0.520687,0.47365,0.329223,0.322303,0.4134,0.420415,0.95253,0.992119,1.25621,1.19265,0.902482,1.01243,-0.949065,-0.443097,-1.30186,-1.07201,1.80793,1.71814,-0.590485,-0.828092,0.689365,0.570845,-0.97267,-1.34853,0.673047,0.91828,-1.29599,-1.32815
6171,0.314605,0.286689,0.227827,0.149729,0.256676,0.107121,0.482145,0.354424,0.921833,1.02523,0.701136,0.651901,0.413764,0.359593,0.520773,0.513933,0.966302,0.975629,0.818658,0.857546,-1.57351,-1.63118,-1.89198,-1.78353,0.0558081,0.556397,1.52993,1.76653,1.22736,1.13838,0.722331,0.488037,0.238644,0.124795,0.56917,0.192418,-0.201087,0.0444969,-0.338895,-0.368635
6172,0.995102,0.967896,0.247287,0.25643,0.283037,0.0546274,0.593402,0.553213,0.616616,0.635975,0.591642,0.542961,0.269726,0.245536,0.102487,0.0974408,0.635225,0.646334,0.943938,0.983535,-0.513385,-0.569287,0.568648,0.678906,0.0912437,0.587041,-1.56429,-1.32809,-0.4335,-0.530816,0.821978,0.594824,-1.09202,-1.20211,0.695197,0.324338,-0.387813,-0.148401,-0.415398,-0.453088
6173,0.959601,0.931525,0.440192,0.363131,0.108397,0.0021337,0.593194,0.612766,0.142035,0.246717,0.798151,0.751449,0.180634,0.131479,0.813638,0.809452,0.964389,0.976873,0.265649,0.307449,-0.655771,-0.716368,-0.105332,0.00767592,-1.25839,-0.75871,1.24809,1.49028,1.61655,1.52169,2.38016,2.15848,-0.590771,-0.695086,-0.76429,-1.13858,1.30551,1.54732,0.154061,0.112888
6174,0.123448,0.0946292,0.226926,0.218421,0.106061,-0.05036,0.712405,0.672318,0.375758,0.482577,0.618227,0.568871,0.595499,0.548251,0.716695,0.655582,0.724731,0.826873,0.631195,0.62026,0.437277,0.375083,0.858567,0.977543,1.74056,2.24461,0.753593,0.992658,1.40622,1.30859,0.630467,0.403718,0.6298,0.521434,0.249326,-0.131606,-0.425042,-0.177494,-0.100575,-0.136402
6175,0.932487,0.903107,0.149378,0.073712,0.421033,0.213814,0.225086,0.185404,0.974705,1.08232,0.691438,0.639919,0.719232,0.673629,0.506169,0.501712,0.665423,0.676873,0.891587,0.933071,-0.343766,-0.399715,-0.264976,-0.199446,-0.164868,0.342052,-1.08659,-0.853614,0.692921,0.593962,-0.513415,-0.735891,2.3859,2.27766,-1.14778,-1.5317,-0.661297,-0.415015,1.14741,1.11285
6176,0.949039,0.924557,0.372103,0.296572,0.635947,0.477988,0.549125,0.41115,0.762665,0.870523,0.97094,0.918404,0.565381,0.519137,0.652246,0.561858,0.974641,0.987656,0.834336,0.874734,0.812761,0.754764,-1.5023,-1.37643,0.30292,0.816969,-1.91426,-1.67717,-0.84815,-0.949409,-0.353602,-0.568608,0.316866,0.210462,-0.174854,-0.55843,-0.107442,0.139628,0.855763,0.818852
6177,0.9775,0.946007,0.365058,0.290927,0.577364,0.417731,0.704736,0.636895,0.22847,0.337377,0.836056,0.784487,0.16753,0.12308,0.628561,0.622005,0.212879,0.227978,0.272469,0.313663,0.257441,0.196195,0.334912,0.462494,-0.252719,0.266146,-0.261698,-0.025772,-0.217331,-0.286938,-0.575887,-0.784253,0.0887271,-0.0174597,-0.656763,-1.03866,-0.567633,-0.315744,0.0267647,-0.00291501
6178,0.316881,0.284298,0.755547,0.680909,0.0993481,-0.0619711,0.902322,0.862641,0.326451,0.436093,0.108616,0.0550502,0.63802,0.594761,0.495465,0.490217,0.313395,0.251616,0.717168,0.757219,0.541881,0.479124,-0.795331,-0.673147,0.227221,0.741063,0.854078,1.09139,0.474433,0.375533,-0.2446,-0.375849,-1.50715,-1.61342,-0.0914063,-0.479395,0.930618,1.17649,0.329733,0.305712
6179,0.381568,0.372836,0.494653,0.419815,0.399049,0.239276,0.239895,0.199348,0.893501,1.00483,0.692377,0.640711,0.668036,0.622572,0.783623,0.776135,0.261477,0.275254,0.140977,0.181525,-0.366901,-0.434934,-0.379472,-0.256995,-0.256155,0.252167,0.17696,0.447513,-0.161842,-0.264661,0.240921,0.0325554,1.03186,0.927398,-0.436062,-0.82186,-0.894027,-0.647539,-1.11326,-1.14269
6180,0.524528,0.461375,0.4797,0.387221,0.29472,0.193319,0.782179,0.742236,0.167065,0.278326,0.691189,0.657235,0.43719,0.391247,0.268989,0.260327,0.860368,0.871725,0.860279,0.901053,0.552956,0.489765,-0.763625,-0.638662,0.522206,1.03487,-0.437291,-0.196366,-0.451972,-0.553071,-0.878382,-1.09295,-1.42154,-1.51964,0.0440648,-0.33717,-0.0386285,0.203996,-1.29824,-1.33198
6181,0.555177,0.549913,0.431189,0.354628,0.307441,0.147362,0.200633,0.15895,0.884099,0.995742,0.72344,0.673759,0.884013,0.837393,0.992665,0.982649,0.521221,0.604778,0.439134,0.489163,0.933208,0.864385,1.00507,1.13737,0.0374441,0.545978,-0.0195626,0.228028,0.178766,0.0798157,0.990632,0.776623,-0.174896,-0.272694,1.64968,1.26697,-0.849211,-0.605369,-0.215735,-0.338282
6182,0.703693,0.638451,0.606817,0.528481,0.0101864,-0.151821,0.0675,0.0265642,0.16624,0.280157,0.466991,0.327478,0.277004,0.231267,0.140486,0.132787,0.32574,0.337831,0.0374297,0.0772733,-0.909325,-0.970931,0.273871,0.405358,2.11856,2.62816,-1.05288,-0.81141,0.318078,0.31854,0.217009,0.00363386,-0.0437783,-0.135221,-0.935025,-1.32534,-0.102726,0.135063,0.689158,0.655419
6183,0.759572,0.726989,0.112879,0.035566,0.505553,0.341577,0.254748,0.240835,0.174417,0.288152,0.0294413,-0.0188028,0.565004,0.517812,0.193176,0.182802,0.577892,0.589574,0.79114,0.832339,-0.479039,-0.536684,-0.0663308,0.0707917,-1.03129,-0.528143,0.0979588,0.33837,0.65665,0.557265,0.21774,0.00244138,-0.917233,-1.01197,-0.346487,-0.734741,-0.806584,-0.565508,0.710557,0.67789
6184,0.209562,0.175853,0.943878,0.867789,0.297891,0.133798,0.573045,0.455107,0.887646,1.0001,0.743971,0.69719,0.0957023,0.0467074,0.921575,0.910453,0.404274,0.416311,0.430069,0.471239,-0.754856,-0.817807,0.276076,0.381919,0.267243,0.774917,0.515455,0.762764,1.0986,1.00504,-1.23782,-1.44579,-0.430032,-0.519988,1.15717,0.774008,-0.373001,-0.13802,-0.323312,-0.356207
6185,0.887378,0.851121,0.154742,0.0799072,0.819152,0.657268,0.747515,0.669378,0.661001,0.772759,0.808079,0.763631,0.518232,0.468478,0.348713,0.339437,0.978982,0.99104,0.774725,0.815561,-0.626151,-0.689987,0.549349,0.693047,-0.121006,0.393705,-0.0330632,0.284221,-0.0326756,-0.125291,0.259464,0.0535532,-0.604554,-0.701719,-0.961087,-1.3426,0.815185,1.05269,0.115147,0.00545772
6186,0.903195,0.866313,0.497943,0.463422,0.108666,-0.0520533,0.924585,0.883649,0.705595,0.749029,0.100185,0.0539283,0.169992,0.117848,0.281737,0.273684,0.13877,0.151996,0.786566,0.755868,0.0847726,0.0193083,-0.180782,-0.0389658,-1.0574,-0.546022,-0.444539,-0.194322,-0.180481,-0.276392,-1.23794,-1.44251,-0.350158,-0.524087,0.939372,0.555573,1.58756,1.82229,0.40373,0.367122
6187,0.494315,0.456383,0.920962,0.846937,0.457774,0.348495,0.253319,0.211678,0.656638,0.7253,0.190791,0.144697,0.0417386,-0.0118478,0.995387,0.985695,0.176445,0.19044,0.653555,0.696174,-2.20705,-2.27118,0.695833,0.838134,1.51869,2.02955,0.423977,0.677647,2.26008,2.16239,0.582551,0.327808,-0.247475,-0.346455,-0.237361,-0.629648,0.216836,0.445028,-1.95442,-1.98629
6188,0.726314,0.652894,0.370862,0.295062,0.910702,0.749044,0.314791,0.322242,0.587431,0.70157,0.693028,0.647044,0.640744,0.588667,0.171092,0.162477,0.962485,0.977597,0.43374,0.534278,0.34769,0.282142,-1.72006,-1.57299,-2.1671,-1.66103,1.9858,2.23514,-0.277049,-0.380659,2.30269,2.09812,0.312674,0.207695,-0.529774,-0.925183,-0.227169,0.00512317,-1.29871,-1.32923
6189,0.889855,0.849406,0.340713,0.264817,0.962725,0.801608,0.475098,0.432805,0.270851,0.38389,0.061149,0.0171295,0.921554,0.869733,0.670581,0.565893,0.43377,0.448431,0.356574,0.372382,-0.255481,-0.322343,0.247229,0.390151,-1.66752,-1.15751,-1.13298,-0.881264,-0.236308,-0.344859,0.0130206,-0.185745,0.418113,0.315992,0.667495,0.278422,-0.448552,-0.218304,1.18883,1.16528
6190,0.362356,0.323374,0.547466,0.47264,0.704129,0.541609,0.0638443,0.0204856,0.173922,0.286967,0.563653,0.519477,0.85633,0.805603,0.976763,0.969308,0.196561,0.307067,0.0460251,0.210486,-0.602709,-0.664299,0.601278,0.745346,-0.270586,0.235265,-0.245725,-0.0304063,0.626512,0.519277,0.137622,-0.0332266,1.51532,1.42034,0.415247,0.0269329,0.304905,0.535399,-1.65019,-1.67354
6191,0.406231,0.368661,0.0378665,-0.0359102,0.724057,0.572148,0.406707,0.36383,0.298085,0.421125,0.24407,0.244155,0.0087235,-0.0400311,0.852636,0.790978,0.150667,0.165702,0.00597077,0.0485895,-2.25608,-2.31195,0.264446,0.41078,-0.390288,0.115307,0.573953,0.820451,-0.877244,-0.981675,0.309415,0.119292,-1.02389,-1.12569,-1.43411,-1.82629,0.101336,0.328615,0.505589,0.475932
6192,0.00872176,-0.0274894,0.0763836,-0.00194666,0.76626,0.602687,0.381113,0.303583,0.360216,0.555283,0.014126,-0.0311677,0.835674,0.789374,0.622428,0.612647,0.766386,0.781748,0.934862,0.977317,1.24266,1.18946,-0.697906,-0.553866,0.341623,0.853307,0.455636,0.708732,-0.546616,-0.625602,1.11656,0.930577,0.208462,0.105495,-0.342317,-0.729494,0.106064,0.337927,0.650393,0.617989
6193,0.64664,0.608321,0.10362,0.0320168,0.435293,0.312102,0.285349,0.243336,0.557814,0.689441,0.759185,0.71496,0.517297,0.555589,0.797653,0.790037,0.130365,0.146037,0.202541,0.2442,-1.08746,-1.14696,-1.26402,-1.11909,0.42517,0.930532,-0.167207,0.102454,-0.166444,-0.269529,-1.09111,-1.27528,0.147051,0.0457002,1.05576,0.674384,-0.73011,-0.501709,-0.781064,-0.816188
6194,0.797456,0.758413,0.877378,0.807595,0.183241,0.0215168,0.606721,0.519651,0.710554,0.823599,0.347405,0.303955,0.368384,0.321805,0.201243,0.194219,0.331566,0.346514,0.341385,0.362929,0.544173,0.489882,0.0158798,0.159483,0.305835,0.810575,-0.75692,-0.503824,-0.0757018,-0.17176,1.06333,0.879566,2.0889,1.99086,1.87845,1.49544,-0.469648,-0.246405,-0.155083,-0.132548
6195,0.0591696,0.0188124,0.191954,0.122336,0.660364,0.4997,0.837124,0.795967,0.496195,0.606541,0.72659,0.682844,0.978524,0.933176,0.579696,0.475916,0.756201,0.771199,0.440746,0.481659,-1.16154,-1.2213,0.230826,0.377814,-0.119157,0.383712,-0.0792849,0.180724,1.22924,1.13822,-0.361189,-0.538416,0.153679,0.0506178,-1.11479,-1.50201,0.862557,1.08949,0.581279,0.551091
6196,0.280642,0.240612,0.193979,0.02604,0.808806,0.646571,0.158825,0.118058,0.0314277,0.142821,0.134623,0.0930536,0.0558386,0.0116497,0.763571,0.757613,0.640954,0.705206,0.168759,0.211213,-0.440956,-0.495637,-0.868072,-0.726648,0.623162,1.12171,2.00094,2.25977,1.24537,1.15933,0.219159,0.0449182,-0.0376251,-0.145194,-1.23074,-1.60737,0.437997,0.665123,-0.729427,-0.759851
6197,0.932959,0.892157,0.000390865,-0.0702561,0.292775,0.133008,0.799889,0.760085,0.778427,0.891652,0.720389,0.678715,0.887616,0.845354,0.347687,0.429557,0.62473,0.639213,0.440947,0.484382,-2.03121,-2.08318,0.769778,0.908999,0.245697,0.7405,-0.331487,-0.0693823,-0.618147,-0.710318,-0.987117,-1.15652,-0.609431,-0.714826,-1.32274,-1.71274,-0.501201,-0.274471,0.213177,0.185072
6198,0.178128,0.136858,0.793998,0.7218,0.29529,0.134362,0.483542,0.442131,0.284668,0.398316,0.553971,0.511078,0.914325,0.873165,0.109094,0.101502,0.0324867,0.0449803,0.441279,0.48527,0.729837,0.672232,1.34288,1.47914,0.348134,0.847001,0.32739,0.585617,-0.375023,-0.459599,-1.81599,-1.99089,1.22814,1.12273,-1.05494,-1.50684,1.98736,2.21794,-1.60752,-1.62959
6199,0.340646,0.312791,0.371784,0.297868,0.790703,0.62776,0.833583,0.790918,0.134386,0.247361,0.942574,0.900409,0.532057,0.492224,0.299505,0.293131,0.542373,0.555372,0.0369705,0.0788791,-1.18986,-1.24218,0.453632,0.592178,1.32166,1.81497,-0.262506,-0.00562771,0.378854,0.295954,0.53727,0.352957,-2.72461,-2.82506,-0.903191,-1.30095,-0.585686,-0.354706,1.73185,1.70618
6200,0.577038,0.488724,0.304943,0.326788,0.0999995,-0.0611912,0.0401942,-0.00463045,0.791436,0.902538,0.725006,0.681885,0.479467,0.45939,0.025526,0.0205981,0.249289,0.261145,0.221345,0.318764,1.49386,1.45149,1.0447,1.17794,-1.36049,-0.870576,-0.354023,-0.101418,0.917409,0.905865,0.71373,0.536068,-0.37648,-0.476947,-1.81691,-2.21025,0.138078,0.36978,-1.32388,-1.34946
6201,0.849912,0.664657,0.429451,0.355708,0.880214,0.717023,0.260373,0.274916,0.509905,0.620119,0.81203,0.767062,0.468142,0.426556,0.712142,0.706384,0.99177,1.00387,0.527376,0.558649,2.02639,1.98079,-0.702345,-0.567975,0.76674,1.25775,-0.67337,-0.414426,1.59867,1.51578,0.560574,0.380456,0.167388,0.0601421,-2.2995,-2.69048,-0.425599,-0.11623,0.0526527,0.0227331
6202,0.88186,0.84059,0.718916,0.646575,0.166748,0.00256319,0.600298,0.554462,0.989244,1.09803,0.217814,0.172181,0.934004,0.893636,0.197545,0.190576,0.645996,0.659013,0.866066,0.798533,0.948269,0.899298,0.146166,0.277162,-0.206595,0.282858,-1.56782,-1.31468,-0.166434,-0.246432,-1.28732,-1.46752,-0.266931,-0.369431,-1.30719,-1.7013,-0.833941,-0.60224,1.21522,1.18179
6203,0.826287,0.783921,0.156137,0.0843876,0.469317,0.30381,0.602586,0.556953,0.0523521,0.161002,0.60204,0.537672,0.482792,0.443036,0.79015,0.783724,0.832626,0.845198,0.996509,1.03842,1.21988,1.16518,-0.0701983,0.0650479,-0.333369,0.162901,0.374301,0.621838,0.365077,0.278338,0.802,0.621704,0.348151,0.246359,-0.911124,-1.30852,-0.317516,-0.0797863,-1.59064,-1.61977
6204,0.189468,0.147558,0.0344182,-0.0395033,0.032906,-0.131518,0.605427,0.559443,0.34407,0.522601,0.946571,0.903164,0.0322098,-0.00756313,0.675278,0.589126,0.780267,0.795631,0.556239,0.597359,1.06021,1.00307,-0.0232957,0.112239,0.251942,0.74633,1.51472,1.75711,-0.080273,-0.165235,-1.0709,-1.25468,-0.0174694,-0.120818,-0.198145,-0.648839,-0.666052,-0.427723,0.384614,0.353221
6205,0.384086,0.343528,0.159181,0.0836527,0.19375,0.0297499,0.389377,0.34192,0.774439,0.884201,0.628237,0.583915,0.0388771,2.84197e-05,0.403709,0.394528,0.0844021,0.0994758,0.483251,0.52326,0.595237,0.523739,0.691808,0.82007,-0.957344,-0.459247,2.03743,2.2722,-1.58067,-1.66619,0.191021,0.000586974,-0.602958,-0.705772,0.402489,0.010842,-0.492814,-0.249931,0.255257,0.22389
6206,0.114256,0.0742953,0.680447,0.606661,0.948321,0.786218,0.498237,0.514892,0.282814,0.390865,0.868246,0.822236,0.279607,0.24114,0.0593494,0.0479453,0.642554,0.659242,0.968652,1.00696,0.099804,0.044409,-0.0687579,0.0555927,-0.29154,0.200079,0.786892,1.01479,-0.343811,-0.432685,-0.499771,-0.695975,-1.74932,-1.84578,0.863926,0.539065,0.211911,0.459814,-0.371334,-0.402031
6207,0.551787,0.512311,0.836802,0.765611,0.558752,0.438177,0.735657,0.687865,0.681113,0.788587,0.298005,0.252463,0.281518,0.244592,0.657656,0.646235,0.0203136,0.0388121,0.972573,1.01227,1.14768,1.09258,0.152802,0.273924,0.989818,1.48718,0.925837,1.1488,2.01732,1.92085,-0.219588,-0.436097,0.125693,0.0238151,1.45054,1.06729,3.15918,3.41109,-0.0157999,-0.0500979
6208,0.667009,0.628318,0.218983,0.149058,0.254094,0.0901369,0.218682,0.169992,0.22989,0.335198,0.56561,0.521234,0.6002,0.56179,0.207077,0.195412,0.166748,0.183256,0.639791,0.625584,-0.623509,-0.680808,-0.766106,-0.642866,0.786937,1.28959,0.541005,0.69128,1.36407,1.2665,0.0179242,-0.176218,-0.930969,-1.03879,-2.31581,-2.69088,0.88162,1.13082,-0.1729,-0.209184
6209,0.0796738,0.0421303,0.993635,0.924637,0.295737,0.209022,0.189101,0.13798,0.347805,0.429449,0.575456,0.533046,0.538666,0.497659,0.417357,0.406823,0.930654,0.944799,0.200231,0.238893,-0.489932,-0.552988,-0.875967,-0.748336,0.348935,0.891142,0.011773,0.233758,-0.926464,-1.02608,-1.3049,-1.50156,0.717918,0.609602,-1.63654,-2.00758,-0.505696,-0.260458,0.667349,0.628117
6210,0.835579,0.79728,0.896544,0.826946,0.490431,0.327907,0.698433,0.645821,0.488,0.523701,0.375075,0.334277,0.761663,0.718739,0.397687,0.386479,0.627946,0.640949,0.148337,0.184941,-1.95169,-2.01696,0.624904,0.746214,-0.0079434,0.492693,-0.925205,-0.699761,0.153982,0.0526251,-0.843709,-1.04,-0.525757,-0.639327,-0.338402,-0.714423,-0.0244632,0.214521,-1.40572,-1.45154
6211,0.671066,0.582955,0.536818,0.506749,0.294139,0.131036,0.761876,0.709516,0.511973,0.617953,0.617077,0.530036,0.100391,0.057045,0.124699,0.113945,0.881506,0.892693,0.583458,0.619574,0.537764,0.471244,-0.434669,-0.31162,1.40055,1.90092,1.73277,1.96562,-0.640945,-0.740531,1.39824,1.19762,0.208651,0.0977365,-0.139185,-0.520874,-0.405072,-0.161856,-0.335481,-0.38554
6212,0.405874,0.36863,0.257593,0.186551,0.75113,0.589871,0.453406,0.40173,0.248361,0.355649,0.768106,0.725795,0.635111,0.593445,0.948207,0.938,0.607736,0.618799,0.326878,0.364771,-0.00349736,-0.072069,-2.38139,-2.26429,-0.422944,0.0741148,0.387027,0.618501,0.172941,0.0767495,0.884056,0.687018,0.548206,0.434784,-2.02682,-2.40534,-1.67391,-1.42593,0.937664,0.880524
6213,0.530597,0.389427,0.503957,0.368771,0.351705,0.189758,0.779553,0.726028,0.680438,0.788193,0.376579,0.333662,0.256156,0.212505,0.610216,0.538613,0.966621,0.979719,0.985981,1.02316,-1.45082,-1.52063,-2.13623,-2.01697,0.00484639,0.50308,-2.06179,-1.83037,0.30144,0.203274,1.14826,0.945456,-0.498978,-0.514668,-0.179058,-0.55364,-0.724262,-0.489402,0.0898617,0.0279638
6214,0.525806,0.410224,0.621122,0.550991,0.914776,0.751991,0.596964,0.559326,0.810487,0.872919,0.457314,0.478658,0.785487,0.739367,0.150508,0.139226,0.0790055,0.0906391,0.567191,0.602567,-0.000270757,-0.0687498,-1.45879,-1.33861,0.88073,1.38029,-0.142325,0.0868553,-0.301709,-0.407349,-0.374673,-0.578622,-1.35278,-1.46412,-3.60067,-3.97925,0.191616,0.447125,-1.9327,-1.99154
6215,0.466688,0.431021,0.260026,0.191776,0.779273,0.661036,0.444167,0.392625,0.850803,0.957644,0.732235,0.623654,0.383838,0.339029,0.443004,0.42986,0.66737,0.681278,0.661592,0.698732,-0.887872,-0.951402,0.0317358,0.155942,-1.39757,-0.89202,-1.75263,-1.52558,-0.107796,-0.219236,0.309652,0.108716,0.521559,0.405472,0.653332,0.274748,-0.40076,-0.103217,0.538646,0.483685
6216,0.158027,0.121974,0.564466,0.501154,0.691251,0.57008,0.281042,0.225924,0.137482,0.242059,0.823521,0.768651,0.870917,0.82577,0.348817,0.397468,0.400489,0.412406,0.140855,0.178471,0.540207,0.483507,0.124276,0.248447,-0.719718,-0.300807,-1.44386,-1.22172,-0.716935,-0.82986,-0.408835,-0.60266,-0.680549,-0.796708,1.2999,0.927973,-0.901902,-0.653559,0.0515419,-0.00616472
6217,0.8569,0.822667,0.877418,0.810532,0.648913,0.479125,0.675944,0.61947,0.59241,0.694694,0.956564,0.913647,0.550012,0.505203,0.404501,0.365076,0.603595,0.613864,0.573337,0.605053,-0.330933,-0.383047,-1.35454,-1.23174,-0.216499,0.290407,1.81109,2.03943,1.21068,1.09486,0.0846032,-0.111259,0.438799,0.32369,0.0327151,-0.335852,-0.610682,-0.303424,0.926039,0.83188
6218,0.865578,0.832972,0.111592,0.043052,0.432605,0.38817,0.108171,0.0512866,0.19238,0.29618,0.949271,0.905828,0.436675,0.39079,0.264784,0.332684,0.803801,0.815321,0.993328,1.03163,-0.0909687,-0.104622,0.066694,0.186074,-1.87276,-1.36151,1.22783,1.53326,-1.94843,-2.06589,0.806735,0.60793,1.18402,1.07648,0.869465,0.500952,-0.192092,0.0467114,1.72763,1.66993
6219,0.0581362,0.0266977,0.560701,0.416931,0.46,0.297215,0.877254,0.82017,0.33216,0.398364,0.0352656,-0.00943341,0.628459,0.58228,0.313436,0.300292,0.383519,0.436793,0.634735,0.670534,0.229557,0.173803,-1.75106,-1.62438,0.656985,1.16261,0.800421,1.0271,0.115024,-0.000633654,-0.792212,-0.994392,0.309061,0.199734,-0.594159,-0.96197,0.156001,0.396846,0.146039,0.096613
6220,0.38818,0.450139,0.858372,0.79081,0.760968,0.598462,0.629453,0.572237,0.376305,0.500548,0.0222214,0.0123147,0.289462,0.242244,0.873714,0.858191,0.0457243,0.0582652,0.578067,0.612197,-1.1289,-1.18155,0.800521,0.933097,0.534563,1.04265,0.871577,1.10021,0.926198,0.816647,-0.553261,-0.750145,-1.82911,-1.9429,0.65275,0.28525,0.498638,0.746981,-1.4272,-1.4767
6221,0.905732,0.873581,0.815462,0.709011,0.0035451,-0.161232,0.729003,0.671459,0.441714,0.602732,0.137767,0.0340628,0.827358,0.778644,0.966936,0.949074,0.857906,0.871152,0.286821,0.43191,1.23954,1.18084,1.23961,1.37901,-0.682575,-0.178903,0.0611986,0.292627,0.588428,0.479199,-1.42422,-1.61453,2.12659,2.01121,1.51695,1.15119,-2.30358,-2.06117,0.195073,0.144261
6222,0.588624,0.558587,0.696441,0.627212,0.574183,0.411315,0.613253,0.553533,0.601117,0.704916,0.10051,0.0558109,0.947199,0.898713,0.724047,0.706159,0.86694,0.881174,0.189614,0.251622,-1.02993,-1.09555,-2.12459,-1.97673,-0.305023,0.20413,-0.399328,-0.175392,-0.0625763,-0.227676,-0.104537,-0.298402,1.08322,0.963594,0.770057,0.353102,-0.7122,-0.476695,0.508899,0.452887
6223,0.626554,0.594876,0.0557143,-0.0130847,0.258989,0.096786,0.731624,0.672991,0.463509,0.568974,0.470475,0.425369,0.659435,0.612847,0.189301,0.170062,0.00609136,0.0218836,0.0361927,0.0713351,1.04308,0.972236,1.43412,1.58196,-2.36948,-1.85851,0.538117,0.757995,-0.826219,-0.934551,0.915483,0.727996,-1.46789,-1.58244,-0.0842478,-0.444985,-0.117063,0.122794,-1.05362,-1.11476
6224,0.175927,0.144451,0.478893,0.411361,0.262842,0.0981405,0.348174,0.290645,0.890022,0.997258,0.411417,0.367513,0.830588,0.783559,0.438388,0.459875,0.0920174,0.110057,0.211586,0.24889,-1.36426,-1.42932,-0.718504,-0.572592,-1.14173,-0.548567,-0.0770261,0.138684,-0.890526,-0.994189,-1.00207,-1.19678,0.225589,0.11198,-0.400039,-0.758317,0.875797,1.11428,-0.510667,-0.565757
6225,0.731296,0.701,0.314363,0.19139,0.922972,0.757134,0.342355,0.195221,0.409186,0.518303,0.63086,0.487373,0.674608,0.629068,0.768248,0.749689,0.699354,0.716418,0.880758,0.918285,1.39996,1.34006,1.01903,1.17056,0.255117,0.761381,-0.927106,-0.717018,1.22127,1.12383,-0.460198,-0.660737,-0.185844,-0.302135,-0.959685,-1.39341,0.409806,0.644627,0.818048,0.760627
6226,0.238971,0.209945,0.0408383,-0.0285814,0.339206,0.17343,0.157358,0.0997973,0.539818,0.647793,0.653532,0.607234,0.16793,0.122749,0.502751,0.429919,0.231236,0.246901,0.967244,1.00441,-2.68425,-2.74955,-0.209157,-0.0572057,-0.850085,-0.351863,-0.824393,-0.614451,0.0423051,-0.0522691,-0.77865,-0.983545,0.0699992,-0.0120843,-1.67213,-2.0285,1.13059,1.36911,-1.08446,-1.13304
6227,0.89512,0.866338,0.303564,0.232288,0.136625,-0.0280447,0.821793,0.765843,0.0387559,0.144555,0.129918,0.0829778,0.283346,0.231188,0.126896,0.110149,0.926691,0.943491,0.401835,0.438814,-1.09596,-1.19612,0.367531,0.512939,1.04237,1.54101,0.898186,1.11455,0.708682,0.600636,-0.614999,-0.816261,0.398535,0.277966,2.01957,1.65824,-0.631367,-0.389122,-0.685157,-0.736304
6228,0.658697,0.627872,0.913822,0.842621,0.894902,0.728423,0.624946,0.568432,0.27867,0.385786,0.393788,0.410307,0.361323,0.339626,0.101817,0.0844003,0.175784,0.190586,0.175537,0.212853,0.422626,0.357322,-1.2987,-1.15531,1.00446,1.49666,-0.372834,-0.156837,1.34812,1.25354,-0.66149,-0.862667,-2.18727,-2.30078,-0.362773,-0.72308,1.92613,2.16523,0.230599,0.176428
6229,0.874257,0.844451,0.913054,0.842244,0.289569,0.124043,0.154367,0.0962541,0.975842,1.08217,0.78548,0.737637,0.515147,0.448065,0.290448,0.271367,0.0240745,0.0369891,0.389939,0.425367,-0.700272,-0.769763,-0.54116,-0.395278,-0.811694,-0.313763,0.119379,0.329693,-0.58251,-0.678934,1.26296,1.06946,1.08155,0.973137,-0.771808,-1.12684,-0.251331,-0.00825912,-0.296657,-0.345188
6230,0.241124,0.213325,0.667911,0.596103,0.607251,0.440755,0.54339,0.485024,0.638877,0.744962,0.204935,0.157873,0.614428,0.556503,0.699138,0.677812,0.269593,0.283066,0.850924,0.884382,0.952866,0.882765,0.228008,0.364751,0.196572,0.700923,-0.00626314,0.212452,-0.490468,-0.671418,-2.78052,-2.97801,-0.232234,-0.339649,-0.030906,-0.382759,0.243753,0.482138,0.442466,0.387319
6231,0.352093,0.267051,0.105106,0.0339149,0.694761,0.545155,0.179808,0.122939,0.618202,0.692198,0.332295,0.266738,0.710123,0.664942,0.225597,0.202306,0.728737,0.743362,0.527121,0.685949,-0.613473,-0.689229,1.57599,1.72015,0.54624,0.966415,-0.115102,0.0952117,-0.559618,-0.663902,-0.889602,-1.13503,-0.86646,-0.968426,-1.36108,-1.7085,0.0216328,0.25871,2.09508,2.03661
6232,0.319413,0.320777,0.277505,0.207768,0.816882,0.649555,0.949254,0.891822,0.604832,0.639434,0.424362,0.375603,0.537909,0.49005,0.0796072,0.0553818,0.751345,0.767706,0.39709,0.487516,0.110793,0.0364364,0.708858,0.848623,0.725184,1.23191,-0.894682,-0.681162,0.0204373,-0.0778536,0.905445,0.707953,1.22758,1.1255,-0.893277,-1.23997,1.18671,1.41992,-1.67367,-1.72732
6233,0.304077,0.374503,0.08378,0.0131374,0.182259,0.0154129,0.0472648,-0.0096638,0.479795,0.58667,0.952019,0.90228,0.822928,0.776596,0.831962,0.808018,0.0600463,0.0767316,0.255624,0.289082,2.32854,2.2557,-0.651021,-0.505904,0.0661242,0.569914,-2.44466,-2.22756,0.352424,0.248765,2.43292,2.23919,1.03428,0.929692,0.0803612,-0.266697,0.499948,0.734778,0.453591,0.403869
6234,0.457663,0.428229,0.342999,0.274007,0.387843,0.220782,0.58706,0.527808,0.00652404,0.113664,0.662801,0.514226,0.168949,0.124351,0.0776836,0.0525037,0.214432,0.2317,0.840292,0.87337,0.374069,0.297169,0.477085,0.619826,0.287639,0.86475,-0.151575,0.0684492,-0.263057,-0.361859,0.0537906,-0.140816,-1.03887,-1.15052,0.328879,-0.010915,-0.66851,-0.438038,-1.50039,-1.55372
6235,0.896978,0.866245,0.14321,0.0745438,0.870659,0.703797,0.586977,0.526589,0.795551,0.901505,0.17406,0.126173,0.550077,0.505807,0.777535,0.753581,0.761621,0.776637,0.201752,0.232707,0.128666,0.0467544,0.159888,0.301625,0.659362,1.15959,0.190807,0.416841,-1.37096,-1.47647,-0.096629,-0.296428,0.142251,0.0342414,-0.578751,-0.920214,-0.249317,-0.0256131,-1.62905,-1.68305
6236,0.742855,0.723736,0.343997,0.277005,0.744321,0.577568,0.79969,0.737574,0.725133,0.830865,0.0762494,0.0282814,0.210248,0.16577,0.623671,0.602336,0.559411,0.573831,0.323578,0.334677,2.33048,2.25285,0.51465,0.656821,0.730739,1.23681,0.039243,0.259152,1.3808,1.28023,0.557143,0.301139,0.648559,0.541266,1.60795,1.27259,1.26014,1.47996,-0.216214,-0.258041
6237,0.610186,0.581227,0.981841,0.916355,0.926245,0.758891,0.795703,0.736354,0.100478,0.205828,0.852955,0.805402,0.240097,0.193581,0.93161,0.908923,0.991647,1.00429,0.403383,0.436647,-0.276872,-0.352659,0.0375894,0.185019,-0.0390391,0.466114,-2.107,-1.89118,-0.740667,-0.83782,1.10135,0.898705,-0.889568,-0.990999,1.84472,1.51232,-0.847748,-0.627703,1.22024,1.16697
6238,0.0292075,0.000415082,0.812875,0.70765,0.288901,0.120726,0.558051,0.498748,0.297934,0.40538,0.383682,0.381438,0.777016,0.729982,0.401354,0.377874,0.98618,0.998643,0.268466,0.234533,1.54336,1.4678,-0.778915,-0.623556,0.64111,1.14276,-0.326431,-0.113221,-1.39975,-1.49217,-2.2723,-2.47975,-0.749193,-0.853525,-0.713254,-1.04358,-0.259647,-0.0443916,-0.392533,-0.449161
6239,0.912118,0.882358,0.545349,0.498945,0.621131,0.45273,0.715959,0.658372,0.90452,1.01052,0.00502637,-0.0425263,0.391106,0.392718,0.851847,0.829573,0.539128,0.553961,0.00115019,0.0324198,-0.710784,-0.791128,1.51837,1.67757,0.134349,0.639123,-0.36359,-0.148865,1.41607,1.31808,0.80693,0.599486,-0.000624186,-0.0496536,1.88395,1.55468,-0.803962,-0.591221,-1.1255,-1.18082
6240,0.185684,0.158467,0.26548,0.290239,0.0423781,-0.126099,0.595353,0.536239,0.0956761,0.200403,0.935956,0.890503,0.103879,0.0554552,0.868228,0.845393,0.0977257,0.109278,0.230545,0.2602,-0.367892,-0.449407,0.307325,0.465531,0.169072,0.669767,-1.32862,-1.11193,-0.73043,-0.828754,-0.303924,-0.510117,0.857032,0.754218,0.491971,0.194324,0.359084,0.569992,-0.544014,-0.600154
6241,0.525811,0.500416,0.147019,0.0815338,0.27912,0.146215,0.256188,0.198823,0.568387,0.673374,0.621888,0.576743,0.446926,0.456403,0.0241852,-0.000286619,0.0636641,0.0742075,0.916154,0.94433,-1.27454,-1.36347,0.870248,1.03568,1.42708,1.92661,0.89038,1.11223,0.747636,0.648026,1.02041,0.822256,0.312492,0.214514,-0.838092,-1.16604,0.207371,0.423789,0.699503,0.649101
6242,0.594351,0.597258,0.07898,0.0124918,0.61351,0.41853,0.656382,0.59817,0.197978,0.304604,0.529348,0.483854,0.905332,0.85735,0.92868,0.901877,0.96419,0.97229,0.00733248,0.0330768,0.436089,0.350147,-0.388309,-0.222999,0.536608,1.03218,0.293419,0.520989,1.1915,1.0958,0.277171,0.0664886,1.94702,1.84828,0.483738,0.158989,0.735894,0.946243,-2.18271,-2.23568
6243,0.720639,0.6941,0.499621,0.431605,0.859322,0.690844,0.037655,-0.0194817,0.65963,0.767768,0.981654,0.937176,0.81123,0.763493,0.60986,0.585384,0.0509677,0.0611611,0.785689,0.81349,-0.322758,-0.408452,-0.554521,-0.38982,-0.994245,-0.494551,0.280673,0.501442,0.5367,0.441445,-0.488628,-0.689279,-0.0221936,-0.1234,-1.10632,-1.42486,-0.166967,0.038502,0.740204,0.692548
6244,0.610499,0.585078,0.140367,0.0723904,0.607009,0.437325,0.169221,0.165185,0.728197,0.83694,0.114659,0.0720639,0.128021,0.0816377,0.530241,0.450591,0.531546,0.541184,0.0162176,0.0452177,-0.589627,-0.675008,0.217304,0.380103,1.34102,1.84766,-1.92942,-1.71064,0.799527,0.706963,0.408296,0.214698,0.249601,0.15216,0.0158299,-0.295946,0.193657,0.404127,-0.682986,-0.724815
6245,0.143779,0.119258,0.463981,0.341187,0.642837,0.473693,0.311139,0.349852,0.44203,0.549613,0.213255,0.171287,0.689199,0.64315,0.272688,0.315798,0.766364,0.777957,0.866168,0.893677,0.470543,0.38688,1.37071,1.53314,-1.53827,-1.02777,-1.49669,-1.27149,1.94224,1.8477,-0.694891,-0.894905,1.44576,1.35303,-0.880944,-1.19211,-0.628361,-0.421918,1.3181,1.28053
6246,0.762287,0.739446,0.676011,0.609984,0.924089,0.754977,0.565499,0.534519,0.578554,0.684491,0.951351,0.90734,0.209785,0.161526,0.20548,0.181004,0.376126,0.38791,0.873589,0.89899,0.925875,0.927055,1.41398,1.58033,-1.11911,-0.612483,-1.79946,-1.56924,-0.12523,-0.220286,-0.178741,-0.372751,-2.64664,-2.73784,2.1342,1.83086,-1.99879,-1.79918,1.00649,0.9698
6247,0.362222,0.338743,0.686238,0.619028,0.513983,0.316564,0.776322,0.719186,0.917823,1.02187,0.253069,0.208018,0.763142,0.713235,0.766144,0.74324,0.304315,0.317566,0.130942,0.1559,1.55951,1.46723,-1.36295,-1.19977,0.417109,0.918324,1.68286,1.91702,0.514036,0.4126,1.3061,1.11118,1.69319,1.60158,-0.507878,-0.81063,-0.123206,0.0699341,-1.51197,-1.55376
6248,0.862773,0.840872,0.077019,0.00806313,0.0464103,-0.12185,0.36236,0.306866,0.566008,0.668352,0.57608,0.533155,0.395814,0.346933,0.325876,0.301661,0.674874,0.68803,0.689302,0.714774,0.0384116,-0.0565551,0.158683,0.327948,0.680414,1.18079,0.564003,0.799212,-0.797488,-0.904844,-0.352045,-0.549212,0.453745,0.36866,-0.75904,-1.06212,-0.0301331,0.157944,0.356313,0.316147
6249,0.74312,0.722206,0.173143,0.102402,0.143558,-0.0888021,0.894973,0.839489,0.848439,0.950449,0.186518,0.145702,0.655645,0.608506,0.643125,0.618001,0.468935,0.421083,0.7972,0.72316,-0.602784,-0.643733,0.618038,0.78977,0.296962,0.892155,-0.318998,-0.087193,1.10504,1.00252,0.949354,0.751441,0.396887,0.308865,-0.00167564,-0.303203,0.637148,0.819537,0.195563,0.157061
6250,0.110326,0.0910796,0.900155,0.828432,0.113438,-0.0557546,0.133623,0.0759541,0.567266,0.668029,0.248764,0.231529,0.544913,0.499276,0.730334,0.609522,0.1436,0.154136,0.70853,0.731547,-1.1412,-1.23091,1.28555,1.45294,0.110077,0.603521,0.00561818,0.230778,-1.02059,-1.12967,-1.16477,-1.35997,-0.188675,-0.276089,-0.444369,-0.75256,1.68548,1.87324,-1.25796,-1.29134
6251,0.322029,0.385906,0.561189,0.488394,0.708757,0.537268,0.460054,0.400251,0.604998,0.785655,0.324171,0.317355,0.718539,0.675737,0.625843,0.601043,0.505862,0.515056,0.611581,0.713323,-0.781605,-0.871471,-0.04672,0.113687,1.22064,1.70716,-0.696133,-0.46709,-0.395028,-0.496787,0.364017,0.171264,0.229158,0.139195,-1.23872,-1.5413,-1.45217,-1.2606,0.554312,0.515148
6252,0.659552,0.680731,0.746882,0.67713,0.483125,0.309841,0.119023,0.0587861,0.803089,0.903282,0.463989,0.403181,0.189101,0.148911,0.950316,0.927446,0.547689,0.558528,0.673071,0.695099,-0.905114,-1.00123,1.05451,1.20857,-0.958935,-0.46753,1.31885,1.55076,-1.26843,-1.36834,1.43546,1.24405,0.0367697,-0.0566165,0.843105,0.543938,-0.82984,-0.695407,-0.443718,-0.488641
6253,0.99578,0.975557,0.640443,0.580834,0.861418,0.68724,0.869895,0.811383,0.3826,0.527623,0.359326,0.489007,0.191395,0.151281,0.818658,0.718335,0.0856471,0.0984291,0.223095,0.243791,1.01088,0.910386,-0.157058,0.081933,-1.41525,-0.925064,-0.361786,-0.125642,0.036554,-0.0583569,1.06402,0.875086,1.25684,1.1599,0.699875,0.399477,-0.322338,-0.130211,-0.533878,-0.573093
6254,0.434748,0.413842,0.554895,0.484538,0.755819,0.581196,0.803736,0.744443,0.0529684,0.151965,0.531202,0.574833,0.191049,0.15365,0.531431,0.509224,0.94296,0.954175,0.194471,0.214419,0.0669405,-0.0315256,-1.19989,-1.04471,-0.849902,-0.358007,-1.01971,-0.777997,0.278705,0.192362,0.0291073,-0.157749,0.399641,0.301549,0.352461,-0.00112124,1.48972,1.67428,0.391922,0.354967
6255,0.371983,0.352469,0.683833,0.572528,0.248771,0.0728081,0.952257,0.894718,0.815887,0.916018,0.701475,0.660659,0.895427,0.856066,0.788987,0.764931,0.125669,0.134902,0.92638,0.948378,1.37786,1.27754,1.46964,1.62748,0.744707,1.23744,-1.29371,-1.04469,-1.6347,-1.72302,0.70791,0.517197,-0.684554,-0.777229,-0.10721,-0.40172,-1.58618,-1.40568,-2.10003,-2.13406
6256,0.667144,0.633912,0.728274,0.660518,0.733304,0.555823,0.140835,0.0830644,0.900844,0.999858,0.144328,0.101811,0.86542,0.827679,0.172764,0.148595,0.907906,0.917084,0.393077,0.416922,-0.542425,-0.636874,0.144668,0.30433,0.137102,0.63622,1.06947,1.32278,0.154302,0.0595185,-0.530106,-0.713359,-1.21844,-1.31693,0.784057,0.495056,-0.576485,-0.399201,0.395488,0.36045
6257,0.935883,0.915356,0.643791,0.577187,0.922717,0.746176,0.275555,0.217217,0.772613,0.87352,0.335622,0.31873,0.42945,0.391598,0.893172,0.870917,0.161949,0.169655,0.759694,0.782113,-0.142108,-0.231073,-0.472711,-0.320201,-2.10242,-1.60311,0.174787,0.422528,0.40132,0.310238,-1.09335,-1.26896,-0.64586,-0.746963,0.728832,0.441969,1.2715,1.45455,-0.598015,-0.583606
6258,0.423197,0.404499,0.975712,0.908053,0.652325,0.476834,0.908869,0.84991,0.857559,0.95736,0.580242,0.535649,0.264367,0.273044,0.149453,0.125172,0.10151,0.200382,0.541331,0.561464,0.828799,0.740179,-0.0190923,0.125712,-1.11766,-0.619795,1.01393,1.26254,-0.537016,-0.621829,0.760382,0.586823,-0.844506,-0.942775,1.06551,0.773854,0.191924,0.377094,-1.48802,-1.52766
6259,0.337798,0.314237,0.236469,0.168126,0.107632,-0.0681481,0.175947,0.116887,0.18784,0.287657,0.417391,0.37303,0.192873,0.154491,0.326802,0.23739,0.236628,0.231109,0.554143,0.572181,0.294944,0.233858,-1.35124,-1.21354,1.81797,2.31611,1.47521,1.71826,-0.640169,-0.728476,0.363836,0.186973,0.20092,0.0983159,-0.690058,-0.98077,0.533213,0.711535,-1.75123,-1.79221
6260,0.242344,0.223975,0.240401,0.172499,0.421449,0.27414,0.707444,0.64951,0.53756,0.585873,0.986708,0.944082,0.254677,0.271157,0.43459,0.349609,0.25413,0.261836,0.823055,0.840524,-0.185821,-0.272462,0.0923639,0.234659,-0.915018,-0.421186,-1.06406,-0.815321,-0.384239,-0.477757,1.2453,1.07532,0.868424,0.759538,0.142387,-0.143967,0.123604,0.303708,1.15914,1.12067
6261,0.579438,0.466494,0.611582,0.542212,0.792827,0.616429,0.451749,0.391853,0.782591,0.88409,0.537185,0.492775,0.424561,0.387824,0.484913,0.461827,0.745214,0.75263,0.486239,0.504093,1.76162,1.67053,-1.23824,-1.08849,-0.101931,0.467017,0.535702,0.789254,0.254612,0.155129,0.662801,0.486796,0.359848,0.253387,0.66581,0.434803,1.20438,1.38762,1.50864,1.4726
6262,0.728683,0.709014,0.383564,0.26851,0.74442,0.567405,0.446113,0.38507,0.668258,0.767458,0.764098,0.721459,0.307276,0.208318,0.339916,0.314903,0.64943,0.613813,0.729973,0.747186,-1.45894,-1.55341,-0.341378,-0.196738,0.85373,1.35522,0.828555,1.07767,0.265381,0.160967,-0.366282,-0.512761,0.740858,0.635832,1.29615,1.01357,-0.858522,-0.673233,0.0617595,0.0241953
6263,0.141851,0.122826,0.0636515,-0.00519253,0.434641,0.25828,0.92811,0.867672,0.0441531,0.142421,0.442371,0.398235,0.067587,0.0288118,0.823759,0.796933,0.466753,0.474996,0.0711381,0.0908816,1.81942,1.72714,0.100633,0.249175,0.53118,1.03303,0.540287,0.795198,0.00517004,-0.099893,-1.33274,-1.51232,-1.03267,-1.13292,-0.559661,-0.839654,-1.4216,-1.23564,-0.158375,-0.195998
6264,0.0919273,0.0714531,0.340869,0.327759,0.851693,0.676508,0.43572,0.374961,0.520746,0.62033,0.787523,0.743885,0.833644,0.793563,0.340942,0.315852,0.14012,0.150453,0.773009,0.790512,-2.11659,-2.20887,1.24674,1.30245,2.05976,2.56383,-0.674003,-0.415511,1.49995,1.39161,1.30198,1.12892,-0.307423,-0.411075,-1.32354,-1.59763,-1.40691,-1.22633,1.82311,1.79153
6265,0.63031,0.608232,0.730299,0.660711,0.28606,0.112251,0.74175,0.679378,0.472023,0.556642,0.647122,0.605683,0.718074,0.599768,0.711429,0.688312,0.328876,0.340948,0.96966,0.987805,0.447245,0.361812,2.2065,2.35573,1.60486,2.1063,0.0180703,0.269037,0.413405,0.307492,2.55888,2.38418,-0.938268,-1.03985,-0.342162,-0.624359,-0.370388,-0.187864,0.732099,0.693972
6266,0.859881,0.840082,0.809719,0.674855,0.694007,0.520393,0.369415,0.30746,0.325543,0.492953,0.0799496,0.0413106,0.551766,0.405973,0.121395,0.0969898,0.0333332,0.0467215,0.9435,0.963854,1.40565,1.31591,-0.133061,0.0209995,-0.388925,0.108708,1.43603,1.68242,1.23629,1.12477,-0.00541533,-0.181629,-1.1428,-1.23566,-1.34317,-1.6261,-0.77476,-0.585353,-0.586273,-0.631679
6267,0.766157,0.748017,0.760314,0.688999,0.659337,0.542992,0.312707,0.250217,0.236338,0.429265,0.380616,0.342702,0.251766,0.212177,0.905364,0.879864,0.618282,0.631958,0.448185,0.468446,0.402266,0.310009,0.360235,0.515184,-0.625644,-0.135774,-1.13929,-0.8875,1.49256,1.37549,0.208348,0.0327333,-0.03155,-0.131313,1.61264,1.33414,-1.17183,-0.982843,1.13172,1.08057
6268,0.938937,0.918867,0.194519,0.122856,0.739391,0.56559,0.536227,0.475187,0.264419,0.365576,0.249246,0.221728,0.67822,0.638809,0.878133,0.854116,0.872598,0.888106,0.776225,0.797325,0.431832,0.343935,-0.363609,-0.201006,1.16047,1.64759,-0.47524,-0.268261,0.580244,0.460679,0.657906,0.479075,0.0447531,-0.0533029,-1.08256,-1.36247,1.63672,1.8222,-1.01302,-1.06184
6269,0.781195,0.761102,0.0137849,-0.057042,0.302362,0.195576,0.547089,0.464305,0.382227,0.484971,0.137508,0.100754,0.27379,0.232722,0.0718159,0.0468125,0.811085,0.828337,0.221458,0.241516,-0.591237,-0.677971,1.50486,1.66795,0.725331,1.20617,0.105198,0.350977,0.456591,0.338045,-0.869828,-1.045,1.6249,1.53409,-0.131538,-0.416965,-0.836147,-0.649318,-0.908784,-0.965723
6270,0.0217974,0.000122117,0.360996,0.289133,8.54171e-05,-0.174439,0.507831,0.453422,0.828021,0.933174,0.333921,0.299619,0.949845,0.910212,0.231297,0.175403,0.139672,0.157459,0.649522,0.670115,0.518503,0.429537,-0.265275,-0.108703,0.808348,1.2834,1.47676,1.71592,-0.19399,-0.316306,-1.18395,-1.35372,0.11971,0.123105,1.7791,1.49718,1.27103,1.45134,0.449953,0.392934
6271,0.937181,0.913579,0.959904,0.889152,0.239555,0.0656151,0.504146,0.44254,0.179062,0.28398,0.242419,0.202199,0.971139,0.932702,0.342184,0.303994,0.231938,0.250356,0.383395,0.484996,-0.917406,-1.00613,-1.13366,-0.980231,-3.05238,-2.57792,-1.22242,-0.981467,-0.460184,-0.577166,0.381594,0.20994,-1.19708,-1.28788,-0.392424,-0.668777,0.447632,0.625291,1.13687,1.079
6272,0.342668,0.317995,0.87687,0.805821,0.110999,0.00558041,0.276922,0.304861,0.943492,1.04803,0.0606327,0.104778,0.62728,0.587478,0.366343,0.432585,0.667248,0.594734,0.279395,0.299876,-0.311082,-0.402589,-1.43067,-1.2864,-0.731234,-0.252986,-0.815898,-0.57249,0.472927,0.34848,0.620375,0.454187,0.969144,0.884536,-1.29194,-1.56494,1.20421,1.37899,0.335314,0.271852
6273,0.777404,0.750957,0.155968,0.0859196,0.121467,-0.0544542,0.228794,0.167183,0.0844089,0.188085,0.041049,0.00735751,0.559489,0.51846,0.564117,0.561176,0.921198,0.939111,0.246478,0.265857,-0.849412,-0.945902,0.752616,0.900945,-0.208575,0.179365,1.77658,2.02627,-0.102728,-0.23128,-0.453527,-0.56903,1.16048,1.08334,0.149504,-0.130497,0.508784,0.678423,1.44069,1.38367
6274,0.671494,0.702392,0.598729,0.529709,0.512745,0.337464,0.504157,0.442437,0.885051,0.990028,0.9103,0.877408,0.00365539,-0.038974,0.71477,0.689766,0.356996,0.373593,0.838254,0.860076,0.180928,0.0849486,-0.940754,-0.796631,0.134695,0.611716,-0.61699,-0.369551,0.256526,0.127065,-1.42706,-1.59225,-0.28104,-0.354113,0.140949,-0.187697,-2.25283,-2.08215,1.96341,1.90312
6275,0.679913,0.653826,0.0567187,-0.0120069,0.587288,0.377009,0.537973,0.475216,0.635435,0.741741,0.0162848,-0.0172582,0.37854,0.337785,0.110149,0.0837678,0.706226,0.724877,0.556741,0.533507,0.732634,0.546846,-0.245095,-0.104428,1.00521,1.48892,0.239294,0.486535,0.182718,0.0516327,1.36396,1.19748,0.854549,0.783779,0.0311222,-0.244898,-0.772565,-0.606263,-1.03965,-1.09969
6276,0.202322,0.178177,0.411811,0.343518,0.583961,0.416554,0.292603,0.232084,0.964174,1.06911,0.504357,0.469886,0.332184,0.304642,0.776442,0.748092,0.317687,0.33483,0.18568,0.206938,1.10192,1.00874,-1.05701,-0.913004,-1.02427,-0.539474,-0.276822,-0.0269218,1.36999,1.23781,0.432627,0.27127,-0.987465,-1.06038,-1.66274,-1.9381,-0.374499,-0.209364,-0.645463,-0.70296
6277,0.378005,0.321264,0.00206292,-0.0658886,0.631378,0.456098,0.539747,0.483937,0.631849,0.704255,0.599031,0.628907,0.21341,0.271498,0.093808,0.0659165,0.499456,0.568696,0.405437,0.384004,-0.810761,-0.905666,0.794911,0.939225,-1.12256,-0.632742,-1.16055,-0.913327,1.24374,1.11517,-0.87208,-1.03802,1.38725,1.32175,2.44958,2.17423,-0.324002,-0.153625,0.306194,0.241964
6278,0.487118,0.46435,0.897564,0.827785,0.965864,0.788101,0.794707,0.735789,0.234054,0.339395,0.82406,0.787929,0.279109,0.238354,0.528298,0.419397,0.783697,0.802562,0.541618,0.561069,-0.204924,-0.302127,0.574624,0.727111,0.811248,1.30543,-1.33018,-1.08682,-0.481533,-0.615163,-0.69889,-0.870734,-0.480276,-0.537866,-1.09444,-1.36564,0.798885,0.976653,0.106443,0.0376206
6279,0.0626942,0.0387258,0.656183,0.586463,0.0936931,-0.0865319,0.519566,0.462762,0.739214,0.843294,0.307076,0.273496,0.80876,0.769507,0.802142,0.772877,0.744114,0.76292,0.174983,0.194909,-1.79946,-1.90494,-0.734038,-0.577143,-0.720294,-0.2213,-0.647346,-0.402275,-0.298719,-0.42705,0.34429,0.17173,0.524619,0.462003,-1.08371,-1.3583,-1.12675,-0.941522,-1.39201,-1.45472
6280,0.112911,0.0889739,0.996556,0.927106,0.0053125,-0.0886412,0.529556,0.470637,0.254242,0.359611,0.631029,0.598633,0.268434,0.227243,0.595185,0.565998,0.958213,0.979017,0.235769,0.257152,0.0745873,-0.0231944,-0.301588,-0.146576,-0.197908,0.29973,1.7125,1.96519,0.373042,0.252959,1.95738,1.78066,0.315571,0.15553,0.691883,0.414426,0.670922,0.862965,0.725316,0.659163
6281,0.796694,0.775131,0.187875,0.117055,0.0921737,-0.0907504,0.212574,0.152682,0.639037,0.743024,0.190009,0.157079,0.0572758,0.0168737,0.00537177,-0.0253246,0.217296,0.237834,0.739961,0.761109,0.388575,0.290032,-0.294942,-0.144272,-1.54825,-1.04602,-2.21117,-1.95866,-1.81253,-1.92716,0.183407,0.0118072,-0.0830892,-0.150943,-1.48411,-1.76797,-1.12951,-0.943412,-0.197973,-0.270469
6282,0.769486,0.749848,0.324843,0.255397,0.827101,0.644591,0.165202,0.142049,0.226182,0.328952,0.611726,0.580691,0.0724586,0.0298222,0.906471,0.876839,0.0535654,0.0750404,0.0921489,0.11495,-0.841571,-0.943906,-0.792953,-0.645961,0.903837,1.40939,0.583471,0.841945,-0.739986,-0.84846,-0.0385853,-0.203838,-0.782257,-0.856126,-0.512008,-0.794703,0.309972,0.501795,-0.636104,-0.693383
6283,0.968129,0.85003,0.872816,0.803266,0.59953,0.417164,0.192174,0.131416,0.425087,0.528505,0.480176,0.448866,0.868768,0.824878,0.229391,0.199482,0.185743,0.195339,0.595225,0.527372,-0.493988,-0.602186,-0.159425,-0.0148778,0.0487413,0.561836,-2.59099,-2.32523,-0.494667,-0.597741,0.362903,0.194741,0.701352,0.623345,0.144262,-0.141477,-0.0661671,0.125418,-1.04754,-1.1163
6284,0.971673,0.950212,0.733987,0.664479,0.663092,0.513366,0.41712,0.384796,0.305363,0.420423,0.3485,0.317041,0.810821,0.766499,0.535174,0.472649,0.294406,0.315637,0.916313,0.939794,0.351276,0.245175,-0.366763,-0.226991,0.727746,1.23848,-0.847162,-0.64201,1.2446,1.14057,-0.0789565,-0.253605,-0.174119,-0.253401,-1.55857,-1.8508,-1.71544,-1.51859,-0.680124,-0.759907
6285,0.302081,0.278434,0.177993,0.107497,0.79312,0.609567,0.790367,0.638176,0.20245,0.31234,0.935666,0.902702,0.126395,0.0846439,0.775608,0.745816,0.0208529,0.0417431,0.66189,0.656045,1.95094,1.852,-2.92094,-2.78396,0.993328,1.50094,0.782249,1.04121,0.0241591,-0.0833129,-1.25492,-1.42257,-0.260289,-0.34272,-0.666413,-0.954023,0.321614,0.514323,-0.391469,-0.403519
6286,0.845904,0.820689,0.696243,0.625268,0.510816,0.324827,0.952315,0.891557,0.102233,0.204258,0.952591,0.87289,0.55298,0.412275,0.157987,0.12948,0.786059,0.808149,0.336559,0.372296,0.251731,0.157705,-0.495307,-0.353339,0.615428,1.11062,1.75334,2.00514,-0.585954,-0.693936,-0.819272,-0.99334,-2.49609,-2.58129,0.56221,0.277418,1.46362,1.66015,0.0216248,-0.0471296
6287,0.0152502,-0.0121258,0.46222,0.414224,0.510678,0.399609,0.902672,0.83993,0.674962,0.778551,0.87498,0.843078,0.780313,0.739906,0.632489,0.606005,0.468296,0.488872,0.0650663,0.0885471,0.165095,0.071529,0.619788,0.756045,0.207527,0.720296,1.44377,1.69213,0.0362515,-0.0768216,2.58181,2.40941,0.282085,0.197348,-0.360409,-0.647931,-1.16577,-0.965305,-0.45726,-0.423929
6288,0.130414,0.103882,0.359165,0.20318,0.660567,0.474391,0.538773,0.477845,0.990304,1.09553,0.551736,0.519854,0.999446,0.960986,0.503185,0.474217,0.749,0.77005,0.792681,0.81701,-0.611273,-0.703269,0.822428,0.958017,0.580483,1.08776,-1.76669,-1.52661,0.219677,0.111291,-1.5487,-1.71752,-1.85933,-1.94528,0.295764,0.00529506,-1.19265,-0.986251,-0.736934,-0.800728
6289,0.488291,0.408109,0.0631113,-0.00786352,0.888259,0.704043,0.956157,0.896001,0.558948,0.661599,0.588673,0.544165,0.828281,0.791307,0.604173,0.530222,0.529071,0.551209,0.839153,0.864046,1.15833,1.07237,0.11019,0.241827,-0.445834,0.068164,0.35309,0.597087,-0.525887,-0.636026,-1.01916,-1.19537,0.192327,0.1427,-0.618158,-0.904004,1.0911,1.29019,0.867407,0.803155
6290,0.739203,0.712336,0.542941,0.469904,0.803049,0.618177,0.242504,0.18311,0.329975,0.434259,0.599783,0.568476,0.196558,0.159229,0.636418,0.586226,0.638193,0.660791,0.194376,0.217886,1.47812,1.3856,-0.948107,-0.816007,-0.701449,-0.190647,-0.54841,-0.303166,-0.391871,-0.509501,1.1535,0.976867,2.31663,2.23068,-0.607044,-0.896673,0.543988,0.743364,-0.464347,-0.522496
6291,0.0413332,0.0140934,0.125285,0.0512348,0.164101,-0.0199873,0.120351,0.0609778,0.722298,0.827027,0.439311,0.431187,0.926722,0.887887,0.814618,0.64223,0.29517,0.400433,0.35192,0.375148,1.07557,1.01435,0.181525,0.309724,-2.89306,-2.38088,0.440841,0.694044,0.0911791,-0.0314175,1.94536,1.76903,-0.876303,-0.96225,-2.24884,-2.54565,0.496651,0.739646,1.40975,1.34741
6292,0.87714,0.849242,0.946496,0.87421,0.567523,0.356177,0.921615,0.861715,0.479977,0.584239,0.324289,0.293898,0.599951,0.561917,0.727203,0.698235,0.117125,0.140076,0.959172,0.984013,0.735609,0.64309,-0.983445,-0.856326,0.7107,1.2164,0.432196,0.691007,1.35439,1.23373,-1.17286,-1.3574,-1.34805,-1.43937,0.556256,0.253422,0.53858,0.735928,0.36689,0.298661
6293,0.093424,0.0673214,0.72462,0.554013,0.916881,0.732341,0.773294,0.713982,0.953109,1.05721,0.745235,0.713255,0.571102,0.53353,0.220207,0.191956,0.604589,0.625083,0.500498,0.523154,0.85447,0.754537,-1.82632,-1.69834,0.775322,1.27878,-0.562434,-0.302937,0.252494,0.133026,0.467575,0.284843,-1.01757,-1.10232,-0.535475,-0.839796,-0.0110722,0.189099,-1.14023,-1.20915
6294,0.102079,0.130413,0.304854,0.233816,0.598009,0.412654,0.301396,0.241804,0.0238051,0.12884,0.335038,0.30225,0.18591,0.147769,0.142404,0.115249,0.355079,0.376563,0.860599,0.883282,-0.321072,-0.417933,-0.569726,-0.434912,-1.6781,-1.16959,0.867658,1.12655,0.307417,0.151318,-0.953082,-1.13314,0.207546,0.0440266,-0.159306,-0.461085,1.992,2.19263,-0.966791,-1.0367
6295,0.218951,0.193505,0.804008,0.732295,0.816961,0.633049,0.541985,0.485661,0.814495,0.920325,0.295387,0.294336,0.770948,0.734031,0.864341,0.837571,0.547825,0.567059,0.310187,0.332486,1.88935,1.78817,-0.741235,-0.601733,1.68685,2.19063,0.297655,0.551978,0.408611,0.16961,0.167637,-0.0144425,1.27206,1.19038,-0.154369,-0.453754,0.760853,0.957915,-0.491509,-0.563783
6296,0.588424,0.561264,0.311761,0.338493,0.293118,0.109627,0.791316,0.729518,0.0637273,0.167292,0.347771,0.286423,0.915347,0.879821,0.343916,0.316473,0.404757,0.423546,0.175195,0.197912,1.28874,1.18368,1.45297,1.58561,1.84656,2.34311,-1.13929,-0.889767,0.30737,0.187901,-2.45766,-2.63615,-1.30252,-1.38837,0.668141,0.367298,0.055055,0.257344,0.388966,0.319283
6297,0.143418,0.115417,0.0184882,-0.0553089,0.711531,0.527856,0.573065,0.511994,0.437524,0.590284,0.311298,0.278509,0.749585,0.716003,0.237629,0.209543,0.696911,0.714845,0.367781,0.389961,2.44453,2.33816,0.242193,0.373576,-0.121456,0.378036,0.0566149,0.306536,0.120209,0.00456954,-0.775025,-0.948481,0.621934,0.54268,0.63746,0.344032,-1.08024,-0.882739,-2.97634,-3.04295
6298,0.801676,0.771811,0.110206,0.0390303,0.748787,0.615011,0.638172,0.575688,0.91095,1.01328,0.637786,0.556306,0.33329,0.299994,0.52019,0.490574,0.159708,0.175242,0.922196,0.944074,-0.0199179,-0.126015,0.810137,0.943721,1.6968,2.19492,-0.713741,-0.469838,-1.03664,-1.15652,0.104537,-0.0766962,0.689074,0.60588,-2.39488,-2.69435,0.372694,0.562469,-0.516988,-0.583666
6299,0.401667,0.371107,0.917783,0.846035,0.887955,0.702167,0.0627338,0.00302585,0.325089,0.429337,0.864335,0.834102,0.910638,0.876495,0.118746,0.0895534,0.606932,0.620442,0.206232,0.227783,0.655819,0.553988,-0.794085,-0.660619,-0.443291,0.0527527,0.594563,0.832835,3.75786,3.6399,0.173331,-0.00106557,-0.221938,-0.301137,1.8759,1.57642,0.452206,0.650478,0.534976,0.467178
6300,0.436795,0.335942,0.366621,0.29416,0.435731,0.248173,0.618822,0.560488,0.594194,0.636037,0.0981038,0.0689585,0.938402,0.825259,0.250502,0.220575,0.100329,0.11533,0.765936,0.786656,1.85031,1.75597,0.791005,0.929416,0.700503,1.20248,0.581516,0.813288,0.296002,0.171772,0.764368,0.597348,0.116226,0.0359108,-0.618375,-0.920065,-0.194787,0.011184,-0.0899689,-0.158743
6301,0.332973,0.300777,0.626766,0.603538,0.643629,0.456549,0.523693,0.462937,0.736942,0.842736,0.541555,0.512163,0.807188,0.774024,0.088354,0.0578154,0.391477,0.406628,0.474804,0.409799,0.877825,0.782388,0.285823,0.427727,0.238657,0.744948,-0.393974,-0.165732,0.224389,0.0963397,0.782684,0.611713,0.100441,0.0219299,0.923625,0.620884,-0.125811,0.082941,0.71629,0.649521
6302,0.802538,0.772668,0.986118,0.912917,0.850463,0.664924,0.652732,0.592465,0.271214,0.379017,0.337097,0.371873,0.208426,0.177425,0.818555,0.790363,0.969684,0.986445,0.0104101,0.0329412,0.892329,0.803684,0.839124,0.981214,-1.13692,-0.631498,0.717303,0.951432,-2.16619,-2.29063,-0.923271,-1.09498,-0.590885,-0.668593,-0.564473,-0.871025,0.490734,0.698517,0.168402,0.0965369
6303,0.780266,0.752588,0.103488,0.0323048,0.13128,-0.0560726,0.151674,0.0895365,0.0627443,0.17253,0.262674,0.231583,0.721314,0.688243,0.447582,0.418397,0.969481,0.986498,0.96584,0.985653,-0.14164,-0.164797,0.533183,0.675043,0.464886,0.963948,0.595624,0.825157,2.18145,2.05953,-1.18332,-1.35613,0.0160144,-0.0688976,0.489915,0.123347,-1.42829,-1.21966,0.11142,0.0433173
6304,0.265301,0.23717,0.418694,0.338095,0.316374,0.129714,0.920995,0.85842,0.448942,0.473311,0.364254,0.268451,0.945787,0.914091,0.863603,0.834965,0.535549,0.580056,0.641129,0.709576,-1.0497,-1.13328,-0.487258,-0.352757,0.6064,1.10181,-0.46619,-0.232744,-0.906404,-1.03312,0.973249,0.798719,-0.160336,-0.202407,1.42742,1.11772,0.346995,0.553288,0.626889,0.588487
6305,0.566177,0.539032,0.716025,0.643885,0.940364,0.753046,0.596738,0.535613,0.663533,0.774093,0.451035,0.305318,0.199085,0.166156,0.992627,0.965987,0.1564,0.173615,0.299631,0.433499,-1.05988,-1.14256,-1.05177,-0.917986,-1.20616,-0.70861,-0.511115,-0.282437,-1.07078,-1.20094,0.110826,-0.128386,-0.24779,-0.335917,-1.63169,-1.9345,-1.34603,-1.13969,1.07343,1.13366
6306,0.658409,0.582269,0.626778,0.648977,0.962496,0.774323,0.741511,0.680657,0.238527,0.350192,0.373277,0.342186,0.580302,0.547611,0.0199616,-0.00667899,0.109225,0.12891,0.13761,0.157422,-0.602404,-0.692102,-1.13108,-1.00457,1.1892,1.68058,-1.04435,-0.810532,-0.716223,-0.842596,-0.879128,-1.05549,-1.27839,-1.36758,0.458427,0.150734,-0.0670378,0.146475,1.74693,1.67883
6307,0.618844,0.625506,0.724647,0.654068,0.361018,0.174987,0.324063,0.263888,0.33594,0.467818,0.124275,0.168437,0.67582,0.582466,0.884228,0.859582,0.465239,0.485233,0.112652,0.133471,0.117726,0.0335633,-1.22699,-1.09116,0.521379,1.01268,0.975068,1.20732,-0.0216126,-0.148113,-2.38172,-2.56528,-0.0334337,-0.120636,0.558857,0.252781,-1.11573,-0.900925,0.428527,0.353176
6308,0.696351,0.668743,0.353391,0.284964,0.226562,-0.00368503,0.644837,0.532302,0.474253,0.585444,0.0242412,-0.00531165,0.699793,0.61732,0.754583,0.716668,0.259679,0.2776,0.763901,0.782282,1.55903,1.46847,-0.398232,-0.259339,-0.142862,0.344778,0.249436,0.478048,-0.351232,-0.485561,0.66353,0.482602,0.64365,0.554538,1.23496,0.936089,-0.141168,0.0725509,-1.15946,-1.23061
6309,0.0335919,0.00703421,0.237478,0.171743,0.00530042,-0.182357,0.859519,0.800716,0.246477,0.358105,0.564734,0.536463,0.685525,0.652175,0.597959,0.573754,0.793274,0.812192,0.48154,0.501365,-0.461392,-0.557044,1.91502,2.05911,1.05879,1.54054,0.641727,0.872108,0.691375,0.562882,-0.805632,-0.982542,0.127137,0.0313624,1.15122,0.85214,0.282889,0.500039,1.01863,0.949603
6310,0.246388,0.29577,0.642259,0.577417,0.16042,-0.0257167,0.248301,0.187703,0.456684,0.56788,0.821503,0.795742,0.301481,0.266413,0.72089,0.695054,0.640844,0.658595,0.820325,0.840053,0.239857,0.137958,-0.983721,-0.844841,-0.801861,-0.316505,-0.277503,-0.046199,-0.938318,-1.06026,1.60023,1.42052,-0.892671,-0.985311,-0.0194898,-0.316002,-1.41205,-1.19294,-0.847065,-0.913481
6311,0.540357,0.584506,0.343944,0.277566,0.021577,-0.162416,0.656244,0.520079,0.0977455,0.208801,0.776846,0.753774,0.916736,0.882589,0.182387,0.153632,0.735225,0.751493,0.617851,0.639313,0.605966,0.497399,-0.594489,-0.459358,1.19851,1.68489,0.798232,1.02608,-0.577058,-0.602164,0.00623837,-0.229593,-0.0720422,-0.157777,-0.638286,-0.935036,0.115084,0.329765,1.2065,1.14048
6312,0.898214,0.873242,0.409353,0.341639,0.732808,0.548309,0.914927,0.852455,0.155021,0.213886,0.494266,0.536557,0.850151,0.813571,0.650391,0.620537,0.292896,0.306916,0.726123,0.745538,-0.653726,-0.768132,-0.855677,-0.718329,0.75535,1.24348,-1.55446,-1.32169,-0.0245203,-0.144072,-1.70281,-1.8797,-0.0725894,-0.156664,-2.09354,-2.39796,-2.1988,-1.98927,-0.0611507,-0.125208
6313,0.510783,0.487674,0.20924,0.176783,0.408231,0.223851,0.581972,0.519683,0.106201,0.21897,0.344739,0.31934,0.462404,0.427809,0.0552299,0.0247184,0.569563,0.583187,0.169083,0.189729,0.51233,0.401079,1.05303,1.19719,-1.20409,-0.721597,-0.968454,-0.729575,-1.30312,-1.428,0.25889,0.0814163,0.972178,0.884427,1.54287,1.23664,1.18923,1.39785,-1.05456,-1.11416
6314,0.531362,0.587856,0.0806378,0.0119272,0.773699,0.591172,0.574023,0.596846,0.698917,0.813757,0.517098,0.494114,0.348294,0.313396,0.820929,0.791961,0.196278,0.209002,0.684156,0.703245,1.05798,0.944037,-0.835189,-0.692674,1.1511,1.63493,-0.898209,-0.656465,0.491522,0.371511,-2.08636,-2.26589,0.740421,0.656506,0.6934,0.388379,-1.15055,-0.937877,0.392138,0.335048
6315,0.709292,0.688038,0.126887,0.0599601,0.578295,0.316953,0.734936,0.674008,0.721143,0.896466,0.159774,0.136548,0.656073,0.620349,0.34923,0.320938,0.929605,0.940704,0.141778,0.162085,0.00229031,-0.107191,0.404668,0.541882,0.501287,0.988804,1.24498,1.48699,1.62615,1.51225,0.16921,-0.0157942,-0.557551,-0.640448,0.19541,-0.0241088,-1.19333,-0.973931,-0.166665,-0.217936
6316,0.401013,0.35574,0.805826,0.739651,0.226122,0.0427332,0.945922,0.884993,0.863386,0.979175,0.398743,0.37487,0.253541,0.220011,0.623097,0.64535,0.853121,0.86576,0.677082,0.696981,-0.248351,-0.357606,0.935816,1.06592,-0.87964,-0.387643,0.516688,0.757712,-0.131237,-0.24996,1.53281,1.34611,-0.34962,-0.405146,-0.131561,-0.436596,-0.845739,-0.622914,-0.988087,-1.0397
6317,0.0465315,0.0234417,0.311554,0.246737,0.82175,0.64044,0.603343,0.543528,0.270928,0.384759,0.220912,0.197572,0.803417,0.771721,0.997301,0.969761,0.982219,0.99513,0.660309,0.682783,1.04409,0.936106,0.0354058,0.163768,-0.196787,0.225838,0.298914,0.53834,1.81336,1.69132,-2.2277,-2.41878,-0.093846,-0.169844,0.601161,0.294719,0.285631,0.507364,-0.149514,-0.111385
6318,0.534417,0.510168,0.523617,0.459393,0.0895341,-0.0890972,0.0006491,-0.0597862,0.863608,0.979545,0.843831,0.818331,0.0400079,0.0109511,0.367591,0.337934,0.460529,0.475889,0.0691807,0.0921213,-1.84807,-1.95347,0.287099,0.411091,0.348883,0.839318,0.322905,0.564241,-0.818498,-0.946602,0.870506,0.678263,-1.25632,-1.32357,0.127979,-0.185511,-1.60155,-1.37929,0.86855,0.816934
6319,0.08118,0.0550706,0.387534,0.306809,0.979616,0.80309,0.732102,0.672689,0.00229759,0.119597,0.858889,0.796128,0.802805,0.775702,0.109676,0.0811136,0.904452,0.921088,0.96743,0.990492,1.74981,1.64437,-0.204449,-0.0753171,-1.10548,-0.61139,-0.62167,-0.385434,-0.586563,-0.71302,1.01872,0.828799,-1.04575,-1.11073,-0.0261971,-0.343472,0.365375,0.587576,-1.11552,-1.16992
6320,0.288305,0.261291,0.147887,0.154225,0.665124,0.488562,0.0956923,0.0354324,0.918983,1.03605,0.798183,0.773925,0.840779,0.814117,0.168223,0.141763,0.331861,0.346502,0.0350785,0.0565692,0.277637,0.165805,0.501742,0.632513,-0.674328,-0.219314,-0.308283,-0.067463,0.536558,0.410021,0.147679,-0.0506097,-2.19692,-2.26445,-0.395193,-0.645319,-1.23958,-1.02422,-0.414149,-0.467921
6321,0.830762,0.803546,0.0672549,0.00164073,0.0187386,-0.15573,0.216517,0.116526,0.345015,0.462716,0.462189,0.487903,0.0228508,-0.00294627,0.59779,0.573412,0.261243,0.276158,0.798199,0.821019,0.53666,0.431688,-0.788593,-0.657888,-0.326366,0.172762,0.541244,0.788623,-0.533876,-0.630023,-0.733751,-0.930018,-0.851559,-0.922807,-0.633806,-0.947167,1.43456,1.65017,0.504686,0.44481
6322,0.377318,0.348448,0.320846,0.253323,0.00738757,-0.169217,0.252514,0.197619,0.0699551,0.185721,0.225007,0.201881,0.113003,0.086688,0.270091,0.246912,0.840858,0.855975,0.379306,0.458832,-0.130755,-0.233206,-0.562805,-0.34676,-1.69693,-1.20368,-0.584237,-0.32919,-1.54366,-1.67007,0.0151785,-0.180436,-0.304048,-0.368657,0.54629,0.226393,0.406609,0.620567,-0.962604,-1.0184
6323,0.14813,0.119795,0.812334,0.746371,0.785261,0.608997,0.337825,0.278712,0.594429,0.709241,0.553632,0.479677,0.904465,0.876971,0.71357,0.68915,0.811918,0.82623,0.0737902,0.0966436,-1.03783,-1.1371,-0.163492,-0.0356329,-0.134312,0.359503,-0.414186,-0.164175,-1.6449,-1.77672,1.03592,0.845963,2.24964,2.18892,0.608635,0.295647,1.27037,1.48686,-0.616764,-0.666471
6324,0.922295,0.894888,0.261934,0.194496,0.116273,-0.0601259,0.102349,0.041106,0.528131,0.643513,0.780154,0.757473,0.546491,0.456291,0.776056,0.749799,0.095138,0.110308,0.224702,0.248746,-1.93369,-2.04099,1.84107,1.97447,0.178843,0.667385,0.275529,0.520373,0.409051,0.275788,-0.77971,-0.97068,1.01901,0.955998,0.275098,-0.0316509,-0.454535,-0.237955,0.891341,0.846856
6325,0.168832,0.139589,0.679536,0.613609,0.205196,0.0309915,0.171172,0.0153011,0.0399399,0.154688,0.257833,0.233217,0.0643065,0.0356109,0.301315,0.274294,0.738116,0.752779,0.960962,0.982705,-0.840881,-0.852181,1.20582,1.4055,-0.857312,-0.36782,0.0544556,0.330403,-0.800458,-0.928959,0.884894,0.700552,-0.879185,-0.936308,-1.13325,-1.43175,0.828947,1.04821,-0.904947,-0.953905
6326,0.883759,0.855472,0.0762838,0.0120686,0.817542,0.6446,0.0498961,-0.0105039,0.968794,1.08352,0.631486,0.608118,0.789849,0.759196,0.790828,0.765579,0.473874,0.487921,0.991823,1.01461,0.44728,0.336626,0.709829,0.836527,0.305033,0.798662,-0.104009,0.140434,0.95392,0.823116,3.41215,3.22569,-0.500902,-0.553863,0.561513,0.265688,-0.205137,0.0186118,-0.740078,-0.781458
6327,0.756227,0.726915,0.609487,0.544221,0.757682,0.584343,0.748102,0.68688,0.763722,0.877034,0.282669,0.260935,0.953108,0.920617,0.396985,0.422154,0.825767,0.839205,0.438642,0.463813,1.30134,1.18399,0.725075,0.85261,-1.03442,-0.547089,-2.85936,-2.60915,-2.20567,-2.33763,-0.431912,-0.624277,0.415803,0.36736,-0.638531,-0.934867,0.573651,0.804498,0.996337,0.959502
6328,0.0330227,0.00302426,0.394603,0.329766,0.0102027,-0.161577,0.533829,0.505469,0.112504,0.22784,0.736558,0.714256,0.137637,0.103553,0.101766,0.0787292,0.405225,0.42034,0.112129,0.137493,0.354823,0.215506,-1.79798,-1.67217,0.228039,0.709755,-1.85117,-1.59666,1.92471,1.79762,0.421951,0.23211,0.920605,0.874384,-0.794766,-1.09283,-0.929772,-0.699185,1.45301,1.41693
6329,0.928011,0.896158,0.669549,0.606005,0.435871,0.262591,0.460486,0.324058,0.872553,0.986464,0.768888,0.762525,0.110796,0.0751663,0.0833579,0.0583847,0.70293,0.716471,0.00852781,0.0317882,-0.640049,-0.752975,0.819909,0.950031,-0.571884,-0.0916671,-0.115942,0.132339,0.698339,0.573743,-0.569002,-0.756106,-1.93919,-1.98124,-0.346881,-0.639512,0.642938,0.86865,-0.22596,-0.260021
6330,0.784493,0.75315,0.119212,0.0541303,0.5335,0.359395,0.203969,0.142646,0.913059,1.02864,0.832694,0.810795,0.507698,0.47053,0.494954,0.420808,0.111248,0.127423,0.368652,0.391916,0.0610043,-0.0579724,-1.46559,-1.33197,-0.371003,0.107182,-0.092899,0.15824,0.192209,0.0696159,0.246728,0.0551796,0.195827,0.160428,-1.08024,-1.36806,0.743605,0.971288,0.0665277,0.0322047
6331,0.313009,0.282679,0.272004,0.189953,0.253122,0.0808124,0.884798,0.824845,0.299828,0.414217,0.333997,0.310727,0.903163,0.865895,0.806225,0.783231,0.660884,0.677091,0.265609,0.286389,-1.45691,-1.58176,0.00490411,0.133507,-2.24211,-1.76394,-1.15325,-0.899661,-0.0813022,-0.205119,-2.2421,-2.43842,-0.947627,-0.979578,2.0172,1.73561,-0.372073,-0.135984,-0.426895,-0.457645
6332,0.565424,0.533795,0.282973,0.325777,0.641874,0.46782,0.566955,0.50689,0.504189,0.619439,0.959914,0.936184,0.28164,0.24515,0.096611,0.0745998,0.898886,0.913864,0.244309,0.180863,-0.24915,-0.379773,-1.26946,-1.14149,-0.376379,0.0980856,-1.13858,-0.927018,0.696848,0.522316,-1.50615,-1.70538,0.405803,0.376187,0.0385296,-0.241359,0.816635,1.05473,-1.2022,-1.23543
6333,0.196592,0.164043,0.531334,0.4616,0.627559,0.454333,0.00769536,-0.0513488,0.393227,0.46524,0.639922,0.616935,0.712342,0.676801,0.408753,0.385791,0.662791,0.600917,0.052878,0.0753368,-0.357502,-0.481609,-0.410977,-0.339368,0.10981,0.587302,-1.21454,-0.954374,1.37583,1.24975,0.764124,0.561732,0.714894,0.683887,-0.958012,-1.2431,-0.768429,-0.526079,0.838534,0.799906
6334,0.0584103,0.0262354,0.662505,0.597423,0.318742,0.145207,0.237855,0.0981727,0.23347,0.311041,0.668486,0.643359,0.876158,0.842358,0.135334,0.113257,0.273903,0.287969,0.733642,0.754197,-0.666486,-0.793141,0.336068,0.462753,-2.05625,-1.57234,-0.961113,-0.697945,0.460714,0.334938,0.515979,0.31494,0.0906427,0.0551095,1.46006,1.18161,0.254656,0.495663,0.85374,0.822377
6335,0.314816,0.203168,0.4772,0.429486,0.912267,0.73823,0.304522,0.247694,0.0425414,0.156843,0.990399,0.963466,0.107784,0.0765016,0.0700619,0.0475036,0.636368,0.576953,0.142663,0.163535,0.908113,0.782937,0.960661,1.09384,-1.00438,-0.528969,0.371974,0.636392,-0.925715,-1.05796,-2.08179,-2.28,-2.126,-2.16572,0.80656,0.530671,0.237041,0.474717,-0.583408,-0.611799
6336,0.411398,0.380101,0.422149,0.26155,0.428884,0.252668,0.191298,0.135231,0.524427,0.550389,0.254528,0.228864,0.0588901,0.0282566,0.477018,0.453949,0.850615,0.865937,0.849179,0.867961,-0.00727569,-0.131121,-1.31148,-1.17567,1.68838,2.16214,-1.37754,-1.11764,0.445147,0.310355,1.65382,1.4484,0.621806,0.576426,1.31035,1.03057,-1.65391,-1.41194,0.263611,0.239856
6337,0.240799,0.208103,0.160697,0.0936131,0.698683,0.523937,0.781503,0.727563,0.831689,0.943935,0.570061,0.544442,0.464926,0.494149,0.634566,0.64555,0.421717,0.436846,0.268313,0.28775,0.30287,0.182105,0.171928,0.30404,-0.99949,-0.523407,-0.553714,-0.294177,-0.602883,-0.7435,-0.821292,-1.03335,-0.43941,-0.404321,-0.800977,-1.08604,1.89003,2.13751,1.47526,1.44353
6338,0.862668,0.828292,0.580503,0.512726,0.234039,0.0595083,0.263962,0.20969,0.0556408,0.168965,0.633408,0.524675,0.987856,0.960042,0.857936,0.837152,0.567838,0.58129,0.509166,0.48863,-0.144318,-0.266306,-0.516215,-0.449117,0.965897,1.44565,0.0479722,0.312717,-0.543127,-0.676391,0.379561,0.161659,-1.3364,-1.38507,-1.61275,-1.90371,-1.80258,-1.56194,-0.348141,-0.384076
6339,0.577625,0.544243,0.514281,0.448593,0.273863,0.100917,0.285563,0.23228,0.422875,0.536631,0.529819,0.504909,0.527269,0.489133,0.615524,0.594237,0.239944,0.251995,0.68888,0.68951,0.267185,0.139495,-1.34175,-1.20227,2.08259,2.56574,-0.0747869,0.186442,0.0592268,-0.0931978,0.395078,0.176025,1.5584,1.51303,-0.297009,-0.594725,0.871425,1.11244,-0.39711,-0.437295
6340,0.53786,0.520529,0.229258,0.162932,0.634367,0.463295,0.805771,0.750328,0.51889,0.631522,0.868087,0.844485,0.0460391,0.0182247,0.159157,0.137784,0.840025,0.853869,0.870953,0.89039,-2.24168,-2.37494,-1.27736,-1.13958,1.77237,2.26123,-1.60115,-1.34504,0.616409,0.489996,-0.771085,-0.992944,0.319182,0.280103,-0.928257,-1.23031,1.43311,1.68102,-1.01153,-1.0498
6341,0.531881,0.496815,0.656694,0.592503,0.551853,0.383171,0.17819,0.122652,0.303909,0.414464,0.362823,0.339111,0.741874,0.715474,0.111986,0.0912657,0.783818,0.798304,0.806795,0.826115,-0.974112,-1.11068,-0.877618,-0.739794,-1.12844,-0.636984,-0.676638,-0.42659,-1.42393,-1.54442,-1.05218,-1.26986,-0.208488,-0.243072,0.350239,0.0458157,-0.804445,-0.552472,-1.00095,-0.950929
6342,0.99294,0.959042,0.313137,0.2475,0.737349,0.552729,0.577149,0.44418,0.617789,0.726482,0.404961,0.421541,0.920279,0.826452,0.38542,0.456531,0.492924,0.578283,0.386649,0.405526,-2.16114,-2.29954,0.272725,0.413244,-1.06518,-0.548866,-0.298955,-0.0481582,-0.224079,-0.342084,-1.01719,-1.23958,-0.248492,-0.32949,0.621133,0.317497,0.0285138,0.281844,-0.808375,-0.852062
6343,0.734884,0.700964,0.924412,0.857833,0.892145,0.722287,0.823502,0.765708,0.0524334,0.162576,0.450382,0.503971,0.962151,0.937431,0.840969,0.821795,0.345654,0.358261,0.942945,0.959639,0.889385,0.745802,-1.46446,-1.31871,-0.949149,-0.460748,0.777392,1.02412,-0.00693013,-0.122143,0.765471,0.54042,-0.387817,-0.415909,0.0788074,-0.184621,-0.0705432,0.183129,0.628413,0.583577
6344,0.236329,0.199835,0.454857,0.435204,0.494797,0.37679,0.594657,0.574119,0.71347,0.822961,0.492648,0.5864,0.840015,0.812819,0.631729,0.614917,0.497558,0.507651,0.462057,0.479076,0.864303,0.722327,-0.0659945,0.0828988,1.74482,2.23036,1.26083,1.51065,-0.353343,-0.473226,-0.42212,-0.645701,-2.0801,-2.10496,-0.387171,-0.686739,0.310476,0.565111,-0.997418,-1.0488
6345,0.0723445,0.0368209,0.0773636,0.0125739,0.200812,0.0312938,0.441718,0.382529,0.771413,0.813871,0.692541,0.66883,0.460206,0.431878,0.942921,0.926107,0.0382857,0.0475514,0.610292,0.661104,-0.68239,-0.818436,-0.890938,-0.742102,-1.6317,-1.14616,0.633215,0.891337,-0.443914,-0.565327,1.42365,1.19546,0.80601,0.77691,-2.12744,-2.42852,-0.543794,-0.291135,-0.313008,-0.362735
6346,0.925269,0.888934,0.220297,0.223722,0.60386,0.363416,0.71489,0.572347,0.69689,0.80478,0.0301525,0.00890543,0.577316,0.546937,0.457628,0.510154,0.844878,0.855088,0.824927,0.843132,-0.614883,-0.751338,-1.01446,-0.862588,-0.86483,-0.377468,1.54184,1.79478,0.922786,0.802989,-0.433094,-0.666022,-1.4969,-1.52765,-0.738586,-1.04009,-0.741563,-0.484033,-0.137226,-0.282545
6347,0.829354,0.791496,0.501113,0.434871,0.862593,0.695537,0.822828,0.762165,0.188095,0.296582,0.280957,0.197865,0.128027,0.0960973,0.112824,0.0942011,0.711414,0.66894,0.310991,0.327782,0.091534,-0.0420429,0.449583,0.602887,0.72,1.20293,0.282729,0.537365,-0.0915628,-0.206597,0.423665,0.190365,1.99416,1.95962,-0.543599,-0.846542,-0.422856,-0.24228,-0.154247,-0.202355
6348,0.475561,0.436198,0.86501,0.799604,0.0999027,-0.0689724,0.554227,0.494238,0.638168,0.744784,0.409801,0.386825,0.115193,0.0834341,0.795219,0.775792,0.384114,0.482793,0.165204,0.182676,1.2217,1.07972,1.30592,1.46347,0.446371,0.929191,0.973273,1.25624,1.04765,0.93414,0.26462,0.034753,-1.48364,-1.51342,0.409043,0.111683,-0.253083,-0.000527205,0.315689,0.270562
6349,0.384424,0.294799,0.494734,0.508768,0.776318,0.606238,0.607716,0.548472,0.451307,0.482981,0.285157,0.284124,0.544524,0.515085,0.903558,0.882128,0.287013,0.296646,0.657485,0.676578,1.08222,0.932641,0.172689,0.320265,0.6521,1.12804,1.72581,1.97512,0.546421,0.430013,-0.868879,-1.10486,0.740199,0.705275,-0.931353,-1.22893,0.724224,0.972949,-2.00149,-2.05087
6350,0.126902,0.1534,0.285599,0.217932,0.28578,0.116351,0.22574,0.166126,0.116446,0.221178,0.203422,0.181422,0.367954,0.340193,0.301649,0.281074,0.465536,0.477991,0.441087,0.497072,-0.00868538,-0.163345,-0.980498,-0.822942,0.0479484,0.526821,0.726887,0.985517,-0.568271,-0.684596,0.0370407,-0.20088,-0.25696,-0.296529,-0.015313,-0.316481,-0.55293,-0.309818,2.15219,2.10282
6351,0.0513645,0.0120008,0.820844,0.755167,0.8385,0.668867,0.908452,0.848324,0.378814,0.541876,0.663316,0.556658,0.843155,0.816717,0.69996,0.677712,0.11864,0.13313,0.3004,0.317566,-1.10975,-1.25933,0.640585,0.797987,-0.0543934,0.420312,-0.24906,-0.00408709,-0.686482,-0.80723,-0.183344,-0.416525,1.32687,1.29086,-0.0745324,-0.369568,1.27789,1.52647,-1.18316,-1.22721
6352,0.663793,0.621867,0.862398,0.734048,0.615393,0.44687,0.485626,0.492418,0.758913,0.862575,0.953326,0.931893,0.882772,0.855132,0.719843,0.760358,0.0469677,0.0627855,0.360325,0.331849,-0.807803,-0.959879,-0.984795,-0.821995,0.80676,1.28061,0.512867,0.759198,0.700673,0.578833,1.36626,1.13013,1.32407,1.29198,1.06266,0.7718,1.96827,2.21987,1.44972,1.40432
6353,0.0104968,-0.0297327,0.777619,0.712928,0.773266,0.603511,0.195909,0.136511,0.188257,0.294651,0.572269,0.550408,0.325638,0.297698,0.864709,0.843004,0.926704,0.941281,0.330732,0.346132,-1.42787,-1.5814,-0.170144,-0.00696804,-0.76304,-0.291673,0.641077,0.893213,-0.353267,-0.475022,-1.0753,-1.31274,0.360359,0.238084,0.463428,0.168719,-0.651562,-0.405582,1.04175,1.00228
6354,0.0943472,0.0239932,0.370107,0.395235,0.201963,0.034778,0.0326761,-0.0263533,0.444567,0.551502,0.433829,0.412205,0.861192,0.834098,0.510363,0.490883,0.419257,0.431582,0.887978,0.905005,0.205766,0.0554474,0.873539,1.03739,-1.0529,-0.581123,-0.563309,-0.317497,-0.461,-0.581669,0.591391,0.35849,-0.78799,-0.815808,1.11818,0.821945,1.06685,1.30477,-0.300837,-0.339621
6355,0.190184,0.0777191,0.143565,0.0775421,0.540737,0.371941,0.374537,0.40565,0.419172,0.492831,0.568635,0.547371,0.387997,0.362993,0.857055,0.838127,0.926915,0.937237,0.719063,0.816192,-0.392304,-0.549038,-0.139789,0.0261395,1.02224,1.50106,0.0733993,0.320447,-1.19425,-1.31448,-0.778182,-1.01545,-0.882809,-0.905127,-0.191205,-0.489436,0.405023,0.650462,-0.0414272,-0.0782235
6356,0.172983,0.131445,0.944118,0.879094,0.252014,0.0821905,0.897666,0.837654,0.328533,0.43416,0.22169,0.200188,0.550299,0.524415,0.78743,0.824946,0.776994,0.789046,0.709709,0.72738,0.0558493,-0.0985822,-0.477065,-0.308427,0.20653,0.683712,-0.38825,-0.147571,1.85118,1.72448,0.884107,0.63977,0.595584,0.574344,0.56834,0.269481,-1.78853,-1.53655,1.52133,1.48153
6357,0.22736,0.185171,0.663684,0.59907,0.404792,0.233789,0.667585,0.609484,0.491467,0.59893,0.332131,0.281343,0.372893,0.34442,0.830579,0.811765,0.253732,0.264979,0.140164,0.156206,0.121902,-0.00794245,0.627742,0.800958,-1.37905,-0.905349,-0.48293,-0.343248,1.45819,1.32798,-0.185734,-0.425059,0.610678,0.588879,-0.806201,-1.10072,-0.374055,-0.216396,-0.551735,-0.598132
6358,0.501374,0.438579,0.148614,0.0862294,0.868734,0.697347,0.764266,0.678001,0.0784947,0.184859,0.384791,0.362497,0.627674,0.545528,0.503554,0.485265,0.0463372,0.0573459,0.676445,0.691101,0.237129,0.0826973,-1.11533,-0.944958,0.986443,1.45118,-0.774153,-0.538924,-0.603435,-0.740002,0.0943449,-0.150732,-1.06223,-1.08497,0.80418,0.503411,0.853553,1.10376,0.90392,0.851072
6359,0.733234,0.691986,0.291471,0.140795,0.381648,0.211786,0.80874,0.746519,0.420641,0.527457,0.859821,0.834958,0.732775,0.746636,0.954274,0.936965,0.655389,0.668964,0.182815,0.195693,0.726575,0.566872,-0.311281,-0.209155,0.361285,0.820257,-1.38368,-1.11964,1.30494,1.16737,2.54129,2.29493,0.461534,0.439361,0.55179,0.251922,-0.162118,0.0873232,0.431572,0.375613
6360,0.388473,0.346734,0.259479,0.195361,0.92574,0.754685,0.874901,0.815036,0.0256308,0.133891,0.950827,0.925726,0.978182,0.947744,0.445333,0.473129,0.230935,0.345061,0.813755,0.825223,0.208028,0.0522293,0.355016,0.526648,-1.11495,-0.661083,-1.93196,-1.70035,-0.211156,-0.348057,-1.00514,-1.25192,1.57155,1.54371,-0.521923,-0.827457,-0.157612,0.0966359,0.545689,0.488742
6361,0.91731,0.873541,0.664274,0.601035,0.324646,0.15535,0.715589,0.657306,0.863561,0.972816,0.311947,0.28607,0.818215,0.788694,0.0259257,0.00929425,0.00572839,0.0211578,0.0417351,0.0523401,-0.933145,-1.09102,1.72935,1.89701,-1.81334,-1.35353,2.0748,2.30359,-0.451685,-0.591969,0.25681,0.00334393,-0.128203,-0.161579,-0.400923,-0.711204,0.881966,1.1351,1.11646,1.05472
6362,0.481251,0.450287,0.727236,0.665108,0.898598,0.727897,0.997818,0.937212,0.628356,0.77394,0.355811,0.3312,0.996903,0.969451,0.800222,0.781268,0.885378,0.899654,0.478141,0.486973,-0.321664,-0.487481,1.31162,1.48653,-0.476742,-0.02045,0.0116952,0.245645,0.202443,0.0112897,-2.14313,-2.39307,1.23502,1.19419,-2.09041,-2.4044,0.336277,0.588273,-0.386891,-0.453091
6363,0.0717927,0.0270343,0.420714,0.359138,0.441601,0.268732,0.242923,0.184551,0.46434,0.575064,0.818372,0.794149,0.868539,0.839756,0.568695,0.639843,0.635872,0.651133,0.443857,0.452953,1.56744,1.40927,-1.28604,-1.11503,-0.199744,0.257152,0.356636,0.594037,0.747559,0.614548,-1.01076,-1.2602,0.0180713,-0.0233432,0.838906,0.521516,-0.505867,-0.251364,-0.235759,-0.295431
6364,0.174034,0.127404,0.994249,0.930521,0.359257,0.169901,0.802665,0.742013,0.513623,0.622555,0.198662,0.173978,0.364669,0.333438,0.427817,0.498418,0.705717,0.71722,0.962799,0.972542,-1.1673,-1.32381,-0.252585,-0.0839637,0.33486,0.793428,-0.0228742,0.302188,-1.20426,-1.33612,-0.618476,-0.861618,-0.0349886,-0.0288128,0.499527,0.179051,-1.05302,-0.798193,1.01606,0.953824
6365,0.82892,0.783798,0.604877,0.601906,0.241423,0.0710697,0.638314,0.579149,0.329575,0.440238,0.965802,0.941865,0.861794,0.830291,0.376015,0.356993,0.778322,0.783307,0.149193,0.15722,0.771977,0.619183,-0.141735,0.0229619,-0.263866,0.192209,-0.231134,0.0103383,-0.18689,-0.317596,-0.687639,-0.923867,0.000499338,-0.0342824,1.12818,0.800574,1.3636,1.62488,0.265165,0.207197
6366,0.39515,0.347996,0.336999,0.273291,0.498092,0.420312,0.768047,0.708677,0.898168,1.00898,0.339892,0.317277,0.968224,0.935404,0.781457,0.763438,0.822564,0.849394,0.426767,0.467615,-2.58178,-2.73766,-0.535018,-0.372813,-0.170084,0.28242,-1.73406,-1.49219,0.532736,0.408079,1.23648,1.00826,-1.66962,-1.70813,-0.680029,-1.00615,0.650498,0.909126,-0.767201,-0.8269
6367,0.613535,0.564575,0.522828,0.464445,0.937936,0.769554,0.608673,0.550947,0.780956,0.892347,0.00542262,-0.0162051,0.846746,0.81564,0.966286,0.950405,0.830959,0.915481,0.768357,0.77801,-1.01254,-1.16158,1.199,1.3554,0.392084,0.849477,0.606683,0.854078,0.744858,0.628019,-0.577198,-0.808379,-0.327357,-0.366486,0.534691,0.210535,0.883535,1.14843,-0.0308471,-0.0943935
6368,0.265653,0.214514,0.718294,0.6556,0.521047,0.355129,0.847278,0.744031,0.106419,0.217148,0.359087,0.311124,0.364366,0.334015,0.94765,0.93006,0.966307,0.981568,0.0723722,0.0803529,-0.725499,-0.87865,0.203209,0.360143,-1.65751,-1.19694,-1.70118,-1.45867,-0.569838,-0.689426,0.340958,0.0641701,0.206816,0.170603,-1.35408,-1.67393,-1.08412,-0.821172,-1.34827,-1.40534
6369,0.990307,0.941006,0.102453,0.0390472,0.525212,0.356483,0.993307,0.937115,0.156666,0.266743,0.658397,0.638454,0.852241,0.820756,0.219245,0.199843,0.492336,0.578509,0.504463,0.479961,-2.01455,-2.17538,-0.467978,-0.311086,-0.686051,-0.22897,0.55631,0.801045,-1.07921,-1.19355,1.16337,0.936719,1.07438,1.04513,0.361547,0.0408647,0.666793,0.936061,-1.72644,-1.77755
6370,0.537366,0.580876,0.79037,0.728713,0.891066,0.723804,0.692997,0.634683,0.205367,0.316339,0.754158,0.73369,0.929089,0.899748,0.894517,0.876022,0.161459,0.175449,0.872947,0.879569,0.138373,-0.0184933,-2.5591,-2.40062,-0.0293152,0.430355,0.0773417,0.319884,1.19222,1.07757,-0.455602,-0.679809,-0.82081,-0.847177,-2.6831,-3.01136,-0.298282,-0.0732529,1.97636,1.93179
6371,0.271588,0.220745,0.299289,0.235799,0.169993,0.00280729,0.933779,0.874612,0.95434,1.06517,0.518149,0.537096,0.803835,0.775136,0.849116,0.829504,0.805903,0.817921,0.693984,0.69923,0.79928,0.645259,0.0543988,0.208267,1.47187,1.93162,0.409263,0.652889,0.727176,0.618883,-1.19113,-1.42188,-0.623665,-0.750038,0.149364,-0.178375,-1.35184,-1.08257,0.0371819,-0.0105794
6372,0.481949,0.51871,0.854816,0.792628,0.234432,0.0694416,0.685948,0.587175,0.27293,0.384984,0.360995,0.340502,0.467253,0.439976,0.412534,0.392608,0.933828,0.94729,0.286165,0.292839,0.418573,0.257139,0.923549,1.08537,0.765142,1.22431,1.05027,1.29083,-0.0482983,-0.157692,-0.094068,-0.321269,-0.625596,-0.652899,-0.598399,-0.921885,0.362348,0.627787,0.911445,0.858292
6373,0.866088,0.816676,0.592747,0.531534,0.84977,0.68305,0.389298,0.299739,0.347932,0.45914,0.977984,0.956171,0.39704,0.370958,0.43536,0.442599,0.192274,0.206107,0.29303,0.298152,-0.512177,-0.672107,-0.0386642,0.120721,2.2848,2.74042,0.840222,1.0881,0.593669,0.490117,0.470816,0.300405,-1.67751,-1.70051,0.701403,0.371268,-0.163571,0.0357474,1.16485,1.10465
6374,0.158563,0.108916,0.0377017,-0.0254482,0.779681,0.613742,0.0714686,0.012302,0.855683,0.967478,0.915943,0.9594,0.821934,0.797589,0.51162,0.49259,0.58893,0.601984,0.951766,0.956536,-0.120231,-0.283104,1.43293,1.60043,-0.90368,-0.44322,1.34627,1.58785,-0.176417,-0.286458,1.15707,0.922079,1.16562,1.14233,-0.0527684,-0.386709,-0.816951,-0.556292,0.228942,0.175021
6375,0.346267,0.294946,0.171666,0.108405,0.0727249,-0.0955793,0.478873,0.457857,0.381541,0.547308,0.984086,0.96263,0.736697,0.713228,0.268018,0.249675,0.584995,0.596339,0.148625,0.152007,-0.584512,-0.748421,0.438741,0.605177,-0.0487234,0.417079,0.535933,0.780268,0.172257,0.0558558,2.07029,1.84058,-0.221883,-0.246336,0.68181,0.344606,-0.0670602,0.197411,0.104268,0.0456902
6376,0.984356,0.930756,0.551024,0.407352,0.202961,0.035883,0.961151,0.903412,0.0181263,0.127138,0.309145,0.28708,0.274061,0.252765,0.704043,0.686857,0.240432,0.251477,0.335492,0.3392,-0.00645089,-0.124626,-1.08304,-0.921977,-0.0953142,0.372725,0.90124,1.14471,1.92995,1.80793,-0.784826,-1.01067,1.95176,1.92608,-0.825916,-1.16339,-1.51012,-1.24195,-0.821605,-0.883942
6377,0.529665,0.475659,0.77003,0.706299,0.076503,-0.0903453,0.144588,0.0864806,0.0774908,0.221623,0.254324,0.159235,0.633767,0.610151,0.207192,0.191173,0.648956,0.66174,0.790008,0.793659,0.6646,0.499169,0.545866,0.71367,-0.874447,-0.412825,-0.924,-0.68888,0.179992,0.0602216,-0.601401,-0.827564,0.00358799,-0.0296097,0.0623792,-0.347426,-0.216766,0.0442202,0.344438,0.275114
6378,0.693576,0.640642,0.163583,0.100478,0.70475,0.538152,0.734,0.673786,0.207787,0.316108,0.0544836,0.0313895,0.454831,0.430156,0.126435,0.110319,0.411116,0.42323,0.295415,0.298251,-0.0816833,-0.339428,-0.616482,-0.45238,-0.452318,0.0709564,-0.59039,-0.355875,-0.288605,-0.369069,-1.39712,-1.61448,2.05415,2.02731,0.806003,0.468534,-0.264052,-0.00889829,-1.22039,-1.29253
6379,0.32555,0.27089,0.688374,0.623486,0.215115,0.0482652,0.206,0.145542,0.544619,0.653486,0.607177,0.583075,0.565581,0.540168,0.623268,0.607576,0.720846,0.734012,0.244596,0.315558,-1.00651,-1.17802,0.0436104,0.210786,0.0950192,0.554737,0.511224,0.746244,-0.674584,-0.798359,-1.5095,-1.72186,0.00704219,-0.0220009,-2.33788,-2.67771,0.75975,1.01284,0.0304443,-0.0432774
6380,0.418713,0.285581,0.264835,0.199554,0.157819,-0.00700242,0.637099,0.574227,0.257103,0.404823,0.872632,0.846511,0.212259,0.185021,0.869459,0.853132,0.36219,0.374861,0.329154,0.332864,-1.12188,-1.25063,-0.452566,-0.290903,-1.12412,-0.666817,0.540194,0.772145,-1.75101,-1.86749,-0.463378,-0.679394,0.688632,0.653174,1.41456,1.07513,1.03414,1.2833,-1.31022,-1.28655
6381,0.353865,0.300272,0.442323,0.324661,0.489749,0.213946,0.244723,0.182453,0.0470954,0.156161,0.4307,0.490991,0.640061,0.611653,0.394244,0.377626,0.498572,0.509025,0.051845,0.0572041,-1.15437,-1.32324,-0.545849,-0.284801,-0.956839,-0.500315,0.342435,0.569412,1.44858,1.33356,-0.494864,-0.712114,-1.54649,-1.5854,0.0636773,-0.280945,-0.518374,-0.266586,-2.45956,-2.52983
6382,0.0302253,-0.0251276,0.513149,0.449768,0.642499,0.434894,0.347926,0.256796,0.00506716,0.166711,0.161592,0.135471,0.313362,0.285683,0.329935,0.311873,0.251897,0.260504,0.485137,0.491837,-0.636109,-0.809203,-0.440246,-0.2787,-1.23751,-0.774051,1.21366,1.44138,-0.675902,-0.784489,2.37887,2.15508,-0.471896,-0.512918,-0.309031,-0.653641,1.41347,1.66475,0.509465,0.43458
6383,0.0825953,0.0251205,0.408762,0.346506,0.821604,0.655842,0.521251,0.33114,0.0677435,0.17726,0.312355,0.285266,0.514831,0.48728,0.0271657,0.0103093,0.206755,0.191123,0.675266,0.683886,-1.32979,-1.50582,-0.839014,-0.674475,0.738383,1.195,-0.254227,-0.029821,-0.995513,-1.10569,0.0993933,-0.128788,-1.21029,-1.32603,1.4757,1.13551,0.282252,0.473139,-1.71338,-1.78884
6384,0.899277,0.842984,0.550005,0.405726,0.634124,0.468364,0.468248,0.405483,0.869643,0.979203,0.834945,0.80676,0.155322,0.126328,0.0947748,0.0767034,0.111399,0.121742,0.40176,0.408226,1.4519,1.28175,1.20674,1.36982,1.93281,2.39076,-0.0324752,0.126345,0.706916,0.599709,2.27454,2.04345,-2.09803,-2.13914,-0.140594,-0.480224,-0.965649,-0.718477,-0.0449024,-0.124675
6385,0.33498,0.277021,0.529013,0.464945,0.98873,0.821081,0.290442,0.227816,0.72656,0.735753,0.609176,0.540768,0.233933,0.217873,0.734085,0.716381,0.907026,0.918648,0.483913,0.489846,0.0707448,-0.106033,-1.18048,-1.01168,-1.07866,-0.627576,0.0670253,0.282512,1.82578,1.72275,-0.00921599,-0.240421,1.84955,1.81496,-0.456671,-0.793556,0.128545,0.381177,-0.664616,-0.750596
6386,0.0230392,-0.0320259,0.271844,0.315558,0.906439,0.739131,0.754627,0.690349,0.384475,0.492302,0.30121,0.274776,0.340005,0.309418,0.393783,0.374289,0.275986,0.288738,0.237707,0.244535,-0.354048,-0.525341,0.22467,0.389929,-1.70182,-1.24493,1.36798,1.58518,1.52409,1.41805,0.654609,0.417581,0.00670096,-0.0292003,0.274515,-0.0622405,0.851354,1.10566,-2.23154,-2.31824
6387,0.962903,0.908558,0.162731,0.166171,0.817048,0.657181,0.974369,0.910695,0.996028,1.10203,0.532552,0.508155,0.0834302,0.0526711,0.425492,0.404504,0.635017,0.649659,0.559476,0.56827,0.550939,0.383393,-0.463725,-0.296313,0.323249,0.789003,-0.205127,0.00679378,-0.700706,-0.807915,0.993584,0.752109,0.605969,0.570495,-0.343709,-0.681275,0.507676,0.757726,1.75332,1.66662
6388,0.183682,0.130633,0.079772,0.0167845,0.74204,0.575232,0.970148,0.891331,0.854451,0.960199,0.240011,0.214006,0.471923,0.386387,0.804327,0.781921,0.484813,0.484288,0.039588,0.0480088,0.271184,0.10227,1.3993,1.57264,-0.498,-0.0100964,-0.826126,-0.612517,1.28886,1.18327,0.427436,0.181623,-0.713454,-0.74229,0.00998782,-0.335568,-0.199056,0.0571546,-0.612358,-0.701959
6389,0.887178,0.835975,0.0504942,-0.0134609,0.969205,0.800832,0.936271,0.871967,0.0533674,0.159497,0.918185,0.890977,0.75061,0.720103,0.541985,0.520087,0.306775,0.318918,0.922417,0.931374,-0.412944,-0.57974,1.89417,2.06682,-1.27495,-0.809196,-1.71584,-1.49892,-0.892662,-0.996848,-0.52951,-0.775303,-0.353534,-0.388438,-1.43775,-1.78262,0.923482,1.18743,0.706223,0.610177
6390,0.529357,0.479683,0.645486,0.582844,0.0136291,-0.154359,0.203334,0.138944,0.633602,0.739234,0.452764,0.425441,0.392819,0.364957,0.739014,0.70031,0.52779,0.54059,0.384704,0.395533,-0.753122,-0.921697,-0.542329,-0.374617,0.165556,0.631303,0.438998,0.656432,0.386752,0.28208,0.600926,0.357573,0.456551,0.42323,0.619336,0.273254,-1.22101,-0.952088,1.00989,0.918803
6391,0.172351,0.12339,0.394924,0.380266,0.739412,0.571294,0.974779,0.907827,0.844814,0.949009,0.549896,0.520677,0.595177,0.597563,0.903864,0.880533,0.343046,0.357159,0.804824,0.814861,-0.660479,-0.825486,0.896202,1.05774,-0.735134,-0.263131,0.871415,1.09557,1.08978,0.990928,-1.29631,-1.5356,0.203958,0.23726,-0.166099,-0.515484,0.440105,0.711788,-1.80836,-1.90104
6392,0.938684,0.887761,0.237549,0.177687,0.407608,0.241548,0.347776,0.280151,0.764418,0.868838,0.891104,0.860252,0.856373,0.830169,0.886498,0.864551,0.932442,0.947798,0.252637,0.264065,1.07677,0.920066,-1.0275,-0.863992,-0.868838,-0.39808,0.858304,1.07603,-0.751505,-0.848144,-0.0438618,-0.280338,0.0811829,0.0512903,-1.40362,-1.74731,-1.48886,-1.22078,0.866455,0.766576
6393,0.558936,0.518789,0.302474,0.241761,0.34539,0.181292,0.0627716,-0.00279908,0.297094,0.400534,0.103894,0.0737765,0.160815,0.133774,0.631816,0.611542,0.00965895,0.0246199,0.377489,0.390054,0.00486327,-0.147427,0.667152,0.833632,0.551828,1.02625,-0.614186,-0.395175,2.06599,1.96211,-0.161559,-0.35006,-1.20591,-1.22998,1.67623,1.32636,3.00734,3.27116,1.40465,1.30031
6394,0.200305,0.149816,0.0688955,0.00725795,0.976898,0.815062,0.271754,0.208186,0.395871,0.49925,0.681172,0.649846,0.041773,0.0140101,0.141279,0.120465,0.467519,0.484917,0.813676,0.824687,1.71237,1.56619,1.51021,1.67877,1.12222,1.59331,-1.02571,-0.800338,1.39944,1.29033,-0.177125,-0.419782,-0.38421,-0.449888,-1.43259,-1.78273,0.519901,0.785804,1.45068,1.35314
6395,0.647268,0.597682,0.862983,0.799314,0.380267,0.22062,0.952421,0.890384,0.10176,0.206619,0.850273,0.819783,0.658788,0.630186,0.368362,0.349766,0.594315,0.609457,0.0681389,0.0768047,0.326455,0.178403,1.58445,1.75695,0.406061,0.867712,1.00722,1.23232,-0.087641,-0.193268,-1.39973,-1.63481,0.347931,0.330207,-0.490836,-0.837227,-0.431916,-0.168819,-0.145735,-0.247032
6396,0.526664,0.479015,0.152471,0.0891793,0.236717,0.0786137,0.413764,0.352296,0.813396,0.918566,0.378007,0.418169,0.27848,0.249245,0.376155,0.355421,0.0986144,0.11437,0.551689,0.560506,-1.42071,-1.5622,-0.290279,-0.120744,0.0758855,0.531968,-0.0509187,0.174417,0.361139,0.254503,0.67097,0.439011,0.237044,0.135838,0.139414,-0.199971,-2.33648,-2.0724,-1.52854,-1.63494
6397,0.760198,0.710865,0.289879,0.227521,0.511893,0.407308,0.430449,0.370213,0.412989,0.564929,0.0492127,0.0165542,0.279219,0.284119,0.914072,0.893192,0.730946,0.745289,0.31308,0.383769,-0.627618,-0.775325,-1.29448,-1.13199,1.12725,1.57534,0.638641,0.858965,1.95918,1.85443,0.146992,-0.156418,-0.0343877,-0.0585307,1.29878,0.957858,0.183956,0.451401,0.269644,0.156962
6398,0.257118,0.209736,0.016553,-0.0478254,0.896667,0.736003,0.147293,0.0872633,0.103375,0.211292,0.568589,0.533882,0.346569,0.318993,0.85941,0.837527,0.920636,0.935785,0.198361,0.207031,0.369808,0.22688,-0.573553,-0.409916,-0.489415,-0.0458206,-0.595412,-0.383083,-0.985935,-1.08457,-0.527758,-0.751847,-1.40928,-1.43159,-0.488332,-0.82808,-1.39171,-1.1294,-0.550264,-0.664805
6399,0.847626,0.800941,0.764854,0.701705,0.845814,0.68698,0.536115,0.476033,0.466155,0.516195,0.728537,0.693352,0.873506,0.845856,0.0620002,0.0408434,0.0491355,0.0652954,0.393063,0.424441,-0.239464,-0.377605,0.756362,0.914276,0.507357,0.953673,1.52329,1.74061,2.07815,1.9841,-2.22178,-2.44594,0.930177,0.901634,-0.0760021,-0.420119,0.00866981,0.27032,-0.810387,-0.929358
6400,0.291683,0.244776,0.075486,0.0112605,0.1714,0.0131832,0.145539,0.0842592,0.715021,0.821097,0.0508354,0.0178021,0.0475765,0.0178805,0.247329,0.22781,0.135722,0.153469,0.633182,0.641851,0.217398,0.0728508,0.483903,0.640272,2.22708,2.67606,-2.19815,-1.97607,1.92383,1.833,0.0806034,-0.149014,0.222674,0.196451,1.04281,0.692795,-3.04652,-2.79082,-0.482829,-0.606483
6401,0.98887,0.940443,0.436957,0.310207,0.557046,0.400191,0.543785,0.483606,0.0618855,0.16686,0.744283,0.709078,0.300949,0.351597,0.880571,0.86275,0.656444,0.67391,0.0773814,0.0860418,-0.387237,-0.531634,-0.651441,-0.495369,0.640516,1.087,-0.644923,-0.464886,-0.343164,-0.425416,-1.16138,-1.39745,0.213149,0.18247,-1.34974,-1.70415,-0.514411,-0.253715,-1.9114,-2.04066
6402,0.675721,0.625449,0.672999,0.609154,0.293207,0.135968,0.66134,0.603064,0.700883,0.806065,0.317107,0.283358,0.714378,0.685313,0.429407,0.411927,0.211783,0.229333,0.849815,0.856706,-0.3156,-0.464536,0.61984,0.768062,0.203393,0.645583,0.824207,1.04629,1.37996,1.29607,0.451713,0.211482,-0.134413,-0.170306,-0.781052,-1.14489,-1.57319,-1.31516,-0.294491,-0.419699
6403,0.760122,0.682398,0.0532457,-0.0117181,0.621071,0.463728,0.470274,0.411466,0.601177,0.672975,0.856433,0.820681,0.627712,0.596369,0.628167,0.517565,0.502248,0.573711,0.16998,0.175648,0.322763,0.170145,1.69095,1.84571,1.0677,1.50588,-0.65104,-0.424909,-0.0519114,-0.141347,0.273406,0.0276948,-0.884024,-0.916738,-1.90394,-2.26996,2.0126,2.27175,0.79523,0.676998
6404,0.790531,0.739348,0.102698,0.0363148,0.316543,0.159651,0.60527,0.509081,0.468059,0.539885,0.887525,0.852235,0.0321034,-0.00022971,0.638776,0.623204,0.900411,0.918088,0.525276,0.52953,-0.512272,-0.666994,0.183023,0.335335,0.845357,1.27707,-0.285486,-0.0604726,0.127959,0.0327161,-0.632199,-0.884644,-1.62823,-1.66317,0.793744,0.42993,-0.232935,0.0246366,1.4638,1.34942
6405,0.0235105,-0.0259009,0.74548,0.681029,0.624178,0.466682,0.751995,0.606697,0.175214,0.406795,0.451544,0.416206,0.292862,0.261343,0.558659,0.571734,0.748321,0.82466,0.0462383,0.0489675,1.23446,1.07856,0.267551,0.413514,-0.578596,-0.144046,-0.668002,-0.3917,0.581024,0.480487,-0.371408,-0.626206,-0.0490551,-0.0757769,-0.74552,-1.10795,-0.317485,-0.0585222,-0.811667,-0.918727
6406,0.829004,0.782577,0.241663,0.177631,0.0857751,-0.0723883,0.76312,0.704312,0.170348,0.273705,0.539581,0.506975,0.75394,0.722652,0.535211,0.520264,0.714927,0.731232,0.709118,0.712312,0.469001,0.31996,-0.530025,-0.381157,-1.40072,-0.961397,-0.951811,-0.722927,0.172248,0.0681309,2.20234,1.94904,2.29564,2.27234,2.32505,1.96571,-0.741883,-0.482892,-0.611986,-0.639074
6407,0.00501126,-0.0401433,0.527617,0.533942,0.598557,0.441625,0.271986,0.211601,0.189721,0.29622,0.0151134,-0.0172813,0.884381,0.853172,0.956098,0.941621,0.76386,0.780299,0.642528,0.64398,-1.40693,-1.54928,-0.955436,-0.805663,-0.363223,0.0819746,0.80593,1.03919,-2.02363,-2.12771,0.239426,-0.00856522,-1.14458,-1.16446,0.496084,0.143985,-0.756432,-0.503837,-0.347475,-0.359421
6408,0.244722,0.150497,0.954494,0.890253,0.114896,-0.0439357,0.393163,0.374332,0.216955,0.318736,0.670568,0.639217,0.605394,0.567388,0.522739,0.510518,0.0409751,0.0594734,0.846308,0.845966,-0.376966,-0.518428,2.02804,2.17914,1.15824,1.59809,-1.89505,-1.65819,-0.300263,-0.406221,-0.54658,-0.795478,-2.07421,-2.08768,-0.484135,-0.842339,-1.64612,-1.39178,0.0272922,-0.0797677
6409,0.387559,0.341137,0.375682,0.30922,0.96184,0.802461,0.679523,0.537062,0.620278,0.721266,0.786282,0.753,0.314152,0.281603,0.812227,0.801153,0.679482,0.696707,0.621445,0.620004,-1.4601,-1.59992,-2.35181,-2.20334,-1.45387,-1.01741,-0.337107,-0.1007,0.795197,0.687519,-0.375062,-0.628194,0.0764681,0.0690263,1.04893,0.69861,0.415544,0.674866,0.932352,0.818788
6410,0.150221,0.102672,0.0439973,-0.0210363,0.418388,0.257479,0.760177,0.699792,0.413286,0.493834,0.435464,0.457426,0.819862,0.788024,0.0855197,0.0764422,0.112497,0.131189,0.0728355,0.0692075,1.41525,1.2698,0.0952418,0.243142,-0.961058,-0.52819,-0.526331,-0.290488,1.57709,1.47571,1.02512,0.78077,0.518516,0.515927,-0.89839,-1.24592,0.337501,0.591707,0.829877,0.717109
6411,0.646833,0.599077,0.609153,0.545446,0.758114,0.50282,0.610612,0.469694,0.168072,0.266402,0.193194,0.161852,0.495876,0.42334,0.576496,0.567727,0.710855,0.72766,0.687593,0.682845,-1.10573,-1.24463,0.420382,0.567977,0.985434,1.40998,-1.96353,-1.73223,-0.321467,-0.425538,-0.195378,-0.393565,-0.1944,-0.189256,0.953279,0.605784,0.793019,1.08551,0.730277,0.61543
6412,0.481193,0.431489,0.882179,0.816482,0.908869,0.748162,0.301367,0.239595,0.845829,0.943085,0.430848,0.400173,0.0919012,0.058656,0.419162,0.411212,0.658681,0.696297,0.257545,0.252176,-0.082899,-0.22772,-0.126232,0.0183364,1.03599,1.45476,-0.639398,-0.414013,0.656804,0.547724,-1.31705,-1.5679,-0.193447,-0.188143,-0.0810427,-0.425901,1.32779,1.57932,-0.407279,-0.528707
6413,0.904394,0.85458,0.640532,0.57516,0.996799,0.834428,0.0728054,0.00949611,0.485226,0.584006,0.966229,0.937495,0.911915,0.879089,0.654445,0.646173,0.649238,0.664933,0.590319,0.585801,0.734535,0.588602,-1.28381,-1.13256,-0.679387,-0.262244,0.426826,0.658263,0.703781,0.598869,0.283296,0.0256218,0.808258,0.811726,-0.0921323,-0.43532,-0.265689,-0.016105,0.898756,0.783429
6414,0.535801,0.484828,0.882509,0.817278,0.293478,0.130136,0.0849672,0.00880445,0.69967,0.799263,0.643146,0.614271,0.971034,0.938063,0.604401,0.516142,0.254081,0.27073,0.536819,0.603107,0.248854,0.106052,0.431667,0.579688,0.252004,0.674263,-0.890319,-0.658244,-2.15758,-2.27016,0.374114,0.117025,0.669889,0.675354,-0.473962,-0.822763,-1.41563,-1.16045,0.973716,0.851654
6415,0.367897,0.317239,0.196965,0.132019,0.519769,0.456211,0.113018,0.00811279,0.490517,0.527314,0.653648,0.704231,0.0677023,0.0342329,0.394663,0.38611,0.725939,0.741281,0.626651,0.620414,-0.0204962,-0.160503,0.289664,0.443712,-0.914914,-0.485639,0.384613,0.615589,0.502622,0.387501,0.0124801,-0.309757,-1.00891,-0.998495,-0.161948,-0.50556,-2.55283,-2.3048,0.523073,0.405803
6416,0.870014,0.819368,0.314638,0.221605,0.945752,0.782285,0.0685151,0.00742113,0.153846,0.255366,0.822825,0.794192,0.957668,0.925636,0.053259,0.0440174,0.00202487,0.0155846,0.392592,0.415588,0.96557,0.824091,-0.809591,-0.660751,1.48936,1.91894,1.27176,1.50345,0.664736,0.58562,-0.478192,-0.736538,1.09033,1.09544,-0.536352,-0.878256,1.48048,1.72302,1.73027,1.60948
6417,0.0248599,-0.0280782,0.377541,0.311191,0.960883,0.798712,0.72152,0.659685,0.4443,0.54732,0.559824,0.531074,0.746441,0.715267,0.00576699,-0.00250093,0.84029,0.855398,0.215374,0.210762,0.531578,0.38974,-0.578939,-0.428961,-0.0760095,0.346651,0.0144024,0.246033,0.894769,0.783738,-0.493984,-0.752308,-0.231886,-0.231471,2.42172,2.08199,0.698279,0.943982,0.210529,0.0856224
6418,0.402293,0.337448,0.959768,0.892152,0.547506,0.384287,0.077857,0.0174359,0.258746,0.360325,0.544921,0.5042,0.787566,0.757879,0.921099,0.910735,0.0155018,0.0312251,0.934137,0.930291,0.717475,0.578695,-0.814435,-0.659952,-0.0890609,0.330847,-0.312618,-0.0816476,-1.68694,-1.7914,1.17519,0.918924,-0.566846,-0.568409,-2.08129,-2.42102,2.03565,2.27988,1.55074,1.42673
6419,0.755591,0.702975,0.991819,0.926069,0.48938,0.32403,0.318302,0.216225,0.946466,1.04624,0.507333,0.477325,0.375227,0.346761,0.686657,0.678445,0.338094,0.351892,0.553808,0.579944,-0.549285,-0.686836,1.21373,1.36776,-0.0999181,0.315043,-0.159078,0.0691087,0.0362929,-0.0699075,-0.212854,-0.470231,2.7233,2.72093,2.60523,2.2655,0.146118,0.393221,-1.11057,-1.23019
6420,0.47523,0.455075,0.468575,0.403343,0.216292,0.0496124,0.47415,0.415015,0.479946,0.577938,0.127296,0.09584,0.463727,0.436395,0.0137129,0.00654758,0.290024,0.302325,0.233835,0.229597,-0.255889,-0.40841,-0.319777,-0.159395,0.656354,1.06822,2.24786,2.48111,0.832561,0.730574,0.644597,0.386156,-0.0617478,-0.0582186,-1.2059,-1.53982,-1.1452,-0.904797,-0.0168862,-0.145283
6421,0.189946,0.207174,0.373587,0.309378,0.36583,0.201211,0.113639,0.0529295,0.580025,0.676654,0.672255,0.641925,0.117009,0.0911712,0.195838,0.18767,0.613229,0.628421,0.993897,0.988946,0.000342017,-0.129985,0.0490361,0.209266,-1.61156,-1.20409,0.797472,1.02478,1.01303,0.904637,-0.380069,-0.632301,-0.657367,-0.655695,0.442641,0.109858,-0.96396,-0.727004,1.05923,0.93962
6422,0.0118904,-0.0407259,0.836443,0.772455,0.314632,0.101282,0.943051,0.879804,0.982917,1.07918,0.499938,0.398183,0.62671,0.601989,0.582015,0.574281,0.0503928,0.0629038,0.0585928,0.0550233,0.981653,0.854609,-0.316702,-0.155148,0.428721,0.843372,1.22489,1.44917,0.361741,0.250285,0.841753,0.591973,1.44929,1.4535,-0.609415,-0.937718,1.09212,1.32362,-0.231801,-0.355735
6423,0.283661,0.222821,0.110476,0.0471185,0.0740454,0.0013532,0.551602,0.410167,0.133547,0.231283,0.185216,0.154441,0.273612,0.246842,0.734623,0.725545,0.293682,0.304397,0.427161,0.389334,-1.24001,-1.36046,-1.14287,-0.980148,0.713657,1.13544,-1.84053,-1.61932,0.406703,0.371681,0.875567,0.62225,-0.399766,-0.390662,-0.0604277,-0.391528,0.765015,0.99266,-0.397251,-0.514822
6424,0.537897,0.486368,0.576523,0.51548,0.0641418,-0.0985756,0.00576953,-0.0594688,0.61293,0.709193,0.953851,0.922329,0.836753,0.808354,0.613976,0.604416,0.899993,0.910759,0.72843,0.723644,1.4595,1.34392,0.245541,0.406205,0.781526,1.19782,-0.112296,0.109677,0.604252,0.493077,-0.316863,-0.563871,-1.34813,-1.34456,-0.0265632,-0.259985,-0.742719,-0.511022,0.187659,0.065846
6425,0.402029,0.34856,0.239722,0.180406,0.691907,0.529922,0.643574,0.577874,0.060612,0.155404,0.709369,0.701275,0.900659,0.871869,0.811661,0.801095,0.554277,0.565897,0.472676,0.470971,-0.794145,-0.915006,0.274697,0.438993,-0.720201,-0.298701,0.440444,0.657731,1.41083,1.29356,1.16808,0.920059,0.864195,0.874144,0.202045,-0.128441,0.258019,0.495461,-0.638614,-0.755921
6426,0.893309,0.840087,0.555571,0.446698,0.84489,0.675073,0.750978,0.686765,0.866296,0.962303,0.475584,0.480222,0.289145,0.260724,0.256416,0.244982,0.713516,0.72528,0.225284,0.218298,-0.259113,-0.385709,-0.496238,-0.325484,0.284009,0.700793,-0.150593,0.0664866,-0.279581,-0.391165,-1.61496,-1.86693,0.925682,0.937343,-0.328457,-0.65469,-1.23693,-0.992339,-0.0376064,-0.161684
6427,0.926929,0.876376,0.773594,0.712991,0.982351,0.820225,0.406707,0.3453,0.61155,0.705248,0.290691,0.259169,0.202492,0.171781,0.292129,0.280255,0.172474,0.185677,0.931846,0.922724,-0.6658,-0.789423,-0.984757,-0.811891,0.0737359,0.518334,0.101991,0.322916,-0.104485,-0.217102,-0.228156,-0.474569,-0.929425,-0.922271,0.442151,0.119826,-0.834345,-0.59544,-1.94312,-2.07218
6428,0.00307449,-0.0449536,0.558758,0.498536,0.753798,0.679927,0.512651,0.485538,0.0522079,0.146704,0.509509,0.477884,0.382232,0.352538,0.837183,0.823035,0.210143,0.224121,0.576365,0.566938,-0.357908,-0.476197,-0.261375,-0.0898153,-0.0776338,0.335876,0.0238578,0.242313,0.960365,0.846303,-0.672313,-0.922914,-1.27152,-1.25921,0.43821,0.165339,0.235645,0.47304,-0.31216,-0.466375
6429,0.933965,0.883318,0.662194,0.60254,0.699837,0.539628,0.743999,0.625777,0.569623,0.665635,0.322494,0.289404,0.319016,0.288408,0.142885,0.130125,0.761664,0.77379,0.467329,0.456574,-0.267086,-0.379986,-0.117696,0.049893,-1.40193,-0.992502,-0.27166,-0.0554369,-2.09929,-2.20565,0.182076,-0.0665275,0.0182629,0.0340378,0.533789,0.210851,0.255959,0.499676,1.26848,1.13943
6430,0.0521132,-0.000791196,0.529766,0.417743,0.919793,0.760023,0.82568,0.766016,0.707867,0.774065,0.770549,0.737838,0.691724,0.660066,0.188375,0.158817,0.944173,0.955135,0.810981,0.800897,1.34228,1.22684,0.343484,0.511715,-0.0282797,0.38558,2.62593,2.8364,-0.901611,-1.00331,-2.03134,-2.27239,1.71251,1.72846,-0.30168,-0.62295,1.93884,2.18087,-2.9011,-3.03178
6431,0.197241,0.144024,0.29369,0.232946,0.501257,0.340357,0.515988,0.399229,0.785624,0.882495,0.162446,0.128356,0.76295,0.72886,0.273861,0.187509,0.443974,0.455383,0.568615,0.536041,0.898761,0.778433,-0.660418,-0.499532,1.72354,2.1382,-0.145559,0.0690461,1.11699,1.01838,1.14201,0.898009,0.700392,0.711783,-2.03484,-2.34882,1.57566,1.81903,-1.35586,-1.4905
6432,0.910757,0.859908,0.77966,0.720645,0.858051,0.697462,0.0935174,0.0324422,0.172262,0.268068,0.0451763,0.0109716,0.33639,0.303856,0.227615,0.2162,0.327629,0.342215,0.284457,0.271185,-1.06116,-1.1801,0.874375,1.02818,0.361646,0.77894,0.4069,0.6171,0.821085,0.729966,-0.54996,-0.796084,1.53674,1.55427,0.0815451,-0.232189,0.293128,0.536265,0.755943,0.623386
6433,0.46186,0.409483,0.0974525,0.0400482,0.66588,0.505427,0.319305,0.244893,0.546255,0.585341,0.529566,0.493351,0.759882,0.725626,0.482267,0.451729,0.220006,0.229047,0.463366,0.483479,-1.80884,-1.92223,-0.66296,-0.514181,0.573033,0.993645,-0.0643596,0.149082,-0.61616,-0.707453,-0.434441,-0.673569,1.23049,1.20935,-0.219066,-0.527724,-0.238758,0.00367741,-1.19851,-1.3342
6434,0.926771,0.87615,0.745012,0.690085,0.866788,0.705887,0.518115,0.457345,0.806243,0.902615,0.527147,0.490266,0.924169,0.891183,0.697193,0.687257,0.533643,0.573424,0.796007,0.695773,-0.0352929,-0.146588,-0.307455,-0.158986,-1.39128,-0.971432,0.166018,0.377571,-2.33477,-2.4237,0.551324,0.305947,0.850466,0.864435,1.96335,1.65267,1.31745,1.5566,0.76006,0.624188
6435,0.386556,0.335052,0.878568,0.772213,0.272211,0.111444,0.363283,0.222255,0.425861,0.523743,0.0612736,0.0247291,0.299736,0.264816,0.727616,0.717472,0.908386,0.917801,0.920332,0.908066,0.781613,0.669734,-0.792942,-0.645393,0.574387,0.997622,-0.38561,-0.180748,0.909475,0.813007,0.262003,0.00728655,-0.283618,-0.27557,2.46578,2.15257,0.743599,0.978133,1.08211,0.947064
6436,0.972279,0.920682,0.911206,0.854342,0.346225,0.238766,0.0478924,-0.0128348,0.857474,0.956287,0.495742,0.465266,0.947593,0.912756,0.47096,0.380414,0.350285,0.357954,0.114313,0.103537,0.194235,0.0803342,0.587552,0.74096,-0.739816,-0.314272,-1.40921,-1.2053,0.294647,0.202383,-0.0510383,-0.291373,-0.445795,-0.442434,0.969982,0.660663,-1.90431,-1.66791,1.09287,0.954644
6437,0.612415,0.497429,0.552887,0.495127,0.513571,0.366087,0.327216,0.267071,0.211705,0.312015,0.944276,0.905803,0.591542,0.557609,0.0556496,0.0433565,0.205515,0.283377,0.110513,0.080099,0.169796,0.0568596,3.24101,3.39879,0.379202,0.805826,0.574605,0.778789,0.212453,0.126951,0.56381,0.322842,-0.913044,-0.903885,-1.26696,-1.57687,0.104345,0.335617,0.16906,0.0250117
6438,0.124784,0.0741756,0.415909,0.35634,0.656112,0.493408,0.287071,0.225381,0.752095,0.850902,0.185326,0.14625,0.885944,0.854767,0.862571,0.852033,0.158813,0.2088,0.0687309,0.0566606,-0.607692,-0.717939,0.765538,0.923987,0.383058,0.8058,-1.57322,-1.37155,-0.208631,-0.301179,0.426606,0.183515,-0.403197,-0.396861,0.516118,0.212285,-1.75452,-1.52022,0.0805095,-0.0594408
6439,0.770907,0.720328,0.528683,0.469633,0.976826,0.814946,0.533023,0.470603,0.262289,0.362076,0.607902,0.569862,0.190077,0.158372,0.118561,0.106288,0.0401516,0.134223,0.70179,0.690565,-0.635273,-0.74442,-0.0937908,0.0680816,1.27661,1.69767,0.684406,0.888166,-0.157196,-0.250034,0.91427,0.674915,-0.461971,-0.456655,-1.01988,-1.3256,1.96887,2.20321,1.83964,1.70069
6440,0.938902,0.804668,0.0389538,-0.0181432,0.471929,0.310809,0.132356,0.0689898,0.876879,0.976174,0.468374,0.431659,0.318891,0.288892,0.971551,0.961262,0.0519763,0.0596458,0.375988,0.364245,-0.655269,-0.770901,0.219654,0.377964,1.11432,1.53126,-0.389776,-0.183754,0.394192,0.304707,-0.225359,-0.464694,1.49299,1.50518,1.09148,0.79104,-1.16329,-0.930634,-0.32511,-0.455816
6441,0.938138,0.889008,0.581812,0.524114,0.490949,0.332085,0.043296,-0.0192035,0.117468,0.218573,0.0525814,0.0157534,0.812468,0.780981,0.396206,0.385117,0.82758,0.836658,0.626063,0.579598,0.845508,0.728228,-0.522146,-0.370432,-0.42016,-0.0120641,-0.122472,0.0887864,-0.873526,-0.964707,0.367229,0.133719,-0.189254,-0.0976858,-1.08273,-1.37492,0.0894729,0.221512,-0.833713,-0.962306
6442,0.711547,0.719336,0.649789,0.522367,0.0893606,-0.0680277,0.199427,0.207263,0.727348,0.828301,0.530275,0.493068,0.0785406,0.0475321,0.980989,0.968529,0.997262,1.00634,0.806652,0.794952,-0.0560302,-0.16972,0.520236,0.673923,-0.916092,-0.50096,-1.70272,-1.4896,1.60022,1.51595,-1.62174,-1.85347,-1.71275,-1.70055,-1.42396,-1.71738,1.14759,1.37366,0.305098,0.180281
6443,0.597429,0.549664,0.573352,0.52062,0.899841,0.74223,0.497855,0.433729,0.724791,0.795165,0.26433,0.225191,0.106674,0.0753435,0.343286,0.331886,0.382263,0.390539,0.107761,0.0972949,-0.485594,-0.571162,-0.108651,0.0493914,-0.95829,-0.545314,0.850547,1.05956,0.861228,0.768633,-0.500333,-0.734776,1.47699,1.49031,-0.680068,-0.936804,0.82814,1.05778,0.721668,0.592343
6444,0.00799189,-0.0409845,0.577705,0.518874,0.0014524,-0.154402,0.266146,0.201081,0.659901,0.762029,0.788753,0.751868,0.454314,0.423045,0.237899,0.224956,0.748563,0.756383,0.10154,0.0928001,-0.858915,-0.972605,0.357898,0.511214,-2.06597,-1.65856,-0.850108,-0.648117,-1.56135,-1.65747,-1.28122,-1.52169,-0.559646,-0.545085,0.138818,-0.156227,-0.454299,-0.224986,0.693805,0.569307
6445,0.369807,0.321484,0.142901,0.0857074,0.361219,0.225176,0.517335,0.451721,0.0155972,0.117757,0.663233,0.628664,0.388761,0.295053,0.92211,0.910742,0.769104,0.776169,0.576178,0.566804,0.772002,0.664238,-0.313685,-0.160016,-0.853493,-0.448945,-0.363327,-0.161587,-0.574198,-0.670412,0.0978661,-0.145449,-0.548384,-0.530551,-1.65342,-1.94217,-0.063274,0.254148,0.261899,0.137916
6446,0.24988,0.249736,0.447803,0.428087,0.761469,0.604754,0.454843,0.389141,0.570243,0.672251,0.958924,0.924286,0.136061,0.16706,0.359726,0.349585,0.0444138,0.0504723,0.481357,0.472965,-0.505741,-0.617349,0.589653,0.747429,0.0943253,0.504991,-1.24436,-1.04799,-1.1018,-1.20245,-0.200794,-0.437352,0.475153,0.496594,-1.14831,-1.44226,0.496787,0.733281,1.59234,1.4643
6447,0.182192,0.177989,0.829393,0.770466,0.702157,0.544497,0.127215,0.0616546,0.0171802,0.118462,0.809368,0.776268,0.0697724,0.0390679,0.459592,0.45113,0.715295,0.723261,0.8291,0.822569,1.3677,1.2493,-0.89207,-0.732761,-0.19958,0.215541,-1.27745,-1.08364,0.105329,-0.000116888,-0.212745,-0.453122,-1.87283,-1.85672,-1.68254,-1.98379,-1.10033,-0.862145,-0.229501,-0.350359
6448,0.15434,0.106241,0.803888,0.745271,0.0519123,-0.104304,0.435957,0.371377,0.967222,1.06849,0.0588447,0.0261402,0.434129,0.427393,0.330664,0.386945,0.951328,0.960034,0.106999,0.100089,-0.811697,-0.931378,-0.722234,-0.561494,1.32358,1.73165,0.0602327,0.250699,1.09303,0.986944,-1.55922,-1.7939,1.05898,1.07179,0.538218,0.237606,-0.00422274,0.237508,-0.28546,-0.403579
6449,0.765404,0.716107,0.268752,0.208173,0.142439,-0.0131867,0.532909,0.488435,0.125448,0.22611,0.318244,0.285419,0.847549,0.815718,0.331119,0.32276,0.903702,0.910466,0.146161,0.135282,1.3444,1.22551,-2.53258,-2.37195,0.300643,0.712056,-0.893851,-0.698976,-1.02866,-1.1311,-0.916406,-1.14987,-0.51891,-0.508418,0.59845,0.26174,0.552953,0.794997,1.4318,1.30867
6450,0.11188,0.0645076,0.757718,0.695872,0.66448,0.510283,0.66965,0.605493,0.211103,0.236659,0.7806,0.748368,0.931796,0.899543,0.700961,0.695219,0.107377,0.113658,0.175578,0.170475,-0.0802667,-0.194066,0.00565238,0.168893,-0.310613,0.0947006,-0.278624,-0.0920823,0.443596,0.345678,0.870512,0.630132,0.287508,0.30325,0.583522,0.285875,1.10591,1.35248,1.61574,1.4955
6451,0.291183,0.245033,0.937689,0.87456,0.412735,0.256764,0.328874,0.264027,0.144935,0.247209,0.640806,0.591837,0.421047,0.387942,0.353239,0.387673,0.192432,0.196372,0.000956543,-0.00485761,0.165727,0.084359,-1.67779,-1.51521,-0.300891,0.110532,-1.05238,-0.868456,-0.611759,-0.708178,-1.17966,-1.41861,-1.52943,-1.51072,1.41454,1.12268,1.1085,1.34717,-0.175007,-0.289535
6452,0.731606,0.687711,0.127559,0.0645088,0.903012,0.745031,0.717453,0.652797,0.845595,0.948279,0.606192,0.435306,0.585751,0.5535,0.0857096,0.0801276,0.808051,0.812419,0.79443,0.787444,0.480168,0.362784,1.24084,1.40213,0.296212,0.707999,-0.209981,-0.0284427,1.04747,0.951204,-1.25258,-1.49635,-0.0254691,-0.00256469,-0.350716,-0.648367,-0.706257,-0.45921,-0.802178,-0.915455
6453,0.77443,0.701394,0.679119,0.616268,0.642793,0.485032,0.153676,0.0890609,0.169794,0.27308,0.311007,0.278775,0.953471,0.920382,0.889454,0.883398,0.436374,0.443063,0.213642,0.207233,-3.24457,-3.35674,0.144405,0.332845,0.0234524,0.434262,0.985234,1.16786,-0.387526,-0.486215,-0.0590922,-0.301341,-0.85337,-0.739317,-1.73985,-2.03603,0.827546,1.07731,-0.120009,-0.229394
6454,0.893512,0.715076,0.423844,0.386153,0.93882,0.781314,0.383078,0.319611,0.0758718,0.176158,0.678323,0.648333,0.904305,0.872137,0.334585,0.327285,0.827397,0.833953,0.421147,0.414129,0.73577,0.625512,-0.89823,-0.73644,0.67307,1.07913,-0.0810927,0.0959398,-1.23912,-1.34136,0.616031,0.373605,-1.49481,-1.47607,0.380993,0.0806082,1.45951,1.70863,-0.246894,-0.358725
6455,0.771115,0.728759,0.217265,0.156039,0.0898524,-0.0696626,0.0437609,-0.0178051,0.551428,0.654068,0.702548,0.674757,0.230773,0.19989,0.49912,0.432923,0.642174,0.706916,0.425667,0.419442,-0.329044,-0.44198,0.66459,0.823704,2.59582,3.00281,-0.6024,-0.432156,-0.468373,-0.569115,0.248845,0.00463716,-1.31222,-1.29353,1.87929,1.57449,0.376413,0.631171,0.882301,0.768633
6456,0.471124,0.429129,0.447998,0.465417,0.427056,0.313234,0.527109,0.464797,0.690384,0.793832,0.377974,0.436166,0.669362,0.636785,0.547048,0.538561,0.574766,0.579878,0.693819,0.634795,0.300205,0.120601,-0.298838,-0.140943,1.30866,1.72192,0.480286,0.6544,0.911435,0.816949,-0.714579,-0.952289,1.10469,1.12092,0.646751,0.342673,-1.26151,-1.01284,-0.0193934,-0.129158
6457,0.433528,0.392758,0.836988,0.774795,0.857291,0.696131,0.789567,0.725625,0.529445,0.728699,0.22577,0.197575,0.123856,0.0899306,0.14112,0.131342,0.91293,0.91631,0.854263,0.850148,0.798482,0.683182,-0.861774,-0.706172,2.12938,2.53732,-0.389359,-0.217045,0.895497,0.806521,-0.18808,-0.412099,-1.54386,-1.5221,0.890248,0.582407,0.101044,0.355245,-0.0669066,-0.182378
6458,0.764101,0.724912,0.440065,0.375355,0.24341,0.0821292,0.117776,0.0536537,0.560963,0.663566,0.400216,0.372349,0.862353,0.828883,0.622401,0.613372,0.689588,0.692856,0.681133,0.669861,-0.489606,-0.598405,0.6222,0.773541,-0.839407,-0.43288,0.897726,1.07024,0.619382,0.531786,0.365916,0.128092,-0.0875799,-0.058539,0.415806,0.102176,-0.620496,-0.360509,-1.34793,-1.46354
6459,0.0235788,-0.0146885,0.547868,0.451315,0.464073,0.273791,0.0506566,-0.0132866,0.73232,0.834093,0.00657149,-0.0197841,0.744051,0.709119,0.873708,0.863571,0.0825165,0.0871961,0.478842,0.489574,0.34652,0.23285,1.06376,1.21945,-1.24962,-0.845378,-0.311645,-0.140473,-0.580803,-0.672961,0.262949,0.0207102,-1.09587,-1.06034,0.612222,0.295725,0.948299,1.20733,-0.875388,-0.990626
6460,0.55719,0.516651,0.590727,0.527274,0.685779,0.465454,0.842151,0.77673,0.647786,0.748341,0.496163,0.46736,0.174194,0.13692,0.124777,0.111863,0.0462699,0.0521251,0.313886,0.309287,-0.864811,-0.971143,-0.254335,-0.103694,0.77188,1.17169,-0.757642,-0.591813,-0.781513,-0.871774,-0.111652,-0.348258,1.08301,1.11207,1.30442,0.994812,0.653939,0.906578,1.81884,1.70643
6461,0.580605,0.541719,0.124905,0.0590138,0.818254,0.657116,0.433088,0.369706,0.856545,0.958116,0.173576,0.240377,0.484697,0.44898,0.42346,0.336924,0.868113,0.874956,0.717463,0.713591,-0.283187,-0.381551,-1.82664,-1.67597,-1.59686,-1.19634,1.40873,1.58048,-0.0310061,-0.11622,1.2085,0.967872,0.151155,0.17197,-0.802628,-1.10662,-0.301669,-0.0480453,-0.194632,-0.313068
6462,0.135417,0.0958726,0.0615084,-0.00511989,0.5513,0.401437,0.231107,0.255858,0.416452,0.519609,0.0415645,0.0133947,0.109083,0.0730162,0.577145,0.561986,0.354366,0.360104,0.721595,0.718904,1.3719,1.27098,0.491683,0.642478,0.798866,1.19284,0.376684,0.555934,-1.69629,-1.78542,0.72134,0.474672,2.0735,2.0887,-0.904704,-1.20437,-1.01747,-0.7638,1.16486,1.04559
6463,0.926669,0.886953,0.873893,0.8071,0.305682,0.145758,0.205935,0.142011,0.50695,0.686465,0.612583,0.584447,0.178688,0.141811,0.474118,0.462051,0.455345,0.458638,0.360447,0.357804,-1.22935,-1.33454,0.133853,0.278064,-1.19753,-0.804748,0.198034,0.382438,0.562508,0.467224,-1.6838,-1.93729,1.27792,1.28958,0.472031,0.167921,-1.27023,-1.0175,0.58031,0.464116
6464,0.496088,0.459812,0.889745,0.82126,0.313993,0.165674,0.538764,0.475765,0.752504,0.853322,0.110616,0.0843792,0.0316706,-0.00771907,0.78488,0.773241,0.990554,0.99323,0.544695,0.591823,0.311819,0.211757,1.44323,1.58772,1.26183,1.65067,0.809811,0.989332,0.208968,0.116141,0.533706,0.280564,-0.866228,-0.853045,-1.75332,-2.04996,0.437459,0.692855,0.262198,0.138526
6465,0.072387,0.0326708,0.443134,0.372803,0.342702,0.18559,0.618813,0.502406,0.00343611,0.105994,0.62399,0.597191,0.646323,0.608457,0.245018,0.231819,0.777764,0.779842,0.829515,0.825842,-0.0301727,-0.1302,0.661876,0.806812,-0.268195,0.123937,-1.3546,-1.17572,0.15459,0.0565028,-0.581463,-0.829038,-0.607586,-0.593469,1.05753,0.765126,1.84767,2.10781,-0.581693,-0.697549
6466,0.616899,0.579068,0.812035,0.742516,0.849315,0.69382,0.593474,0.529046,0.891793,0.995654,0.46645,0.438737,0.111247,0.0716758,0.0878909,0.0753035,0.0691349,0.0694448,0.372675,0.369626,0.316596,0.211521,0.231264,0.382307,1.31901,1.70433,-0.150149,0.0267573,0.899245,0.797347,-0.505975,-0.753408,-1.6557,-1.64108,-0.596376,-0.883851,-0.0464317,0.221153,0.436859,0.323901
6467,0.195242,0.158749,0.124444,0.0572568,0.268917,0.114991,0.950012,0.887566,0.278312,0.381227,0.647678,0.617839,0.805465,0.764497,0.355145,0.340906,0.379745,0.365356,0.487398,0.560795,-0.851351,-0.960949,-0.530779,-0.38217,0.364602,0.74872,1.05036,1.22924,-1.71719,-1.82455,0.793062,0.547245,0.180267,0.19648,-0.372083,-0.659347,-1.72593,-1.45512,1.72891,1.61992
6468,0.282355,0.244811,0.733955,0.66759,0.534027,0.381105,0.0746198,0.0124905,0.427364,0.531415,0.104805,0.0734212,0.274491,0.23231,0.861439,0.847911,0.659617,0.661267,0.752942,0.751964,0.838877,0.723007,0.465604,0.617499,-0.248866,0.131366,-0.437781,-0.25713,0.765646,0.656103,0.602323,0.363458,-2.03648,-2.02435,1.06983,0.788165,-1.75873,-1.49118,0.271043,0.156705
6469,0.110974,0.0728133,0.583561,0.444003,0.174226,0.0214828,0.73572,0.673613,0.278259,0.38046,0.9522,0.91943,0.507969,0.439213,0.0542893,0.0406075,0.0581418,0.0614651,0.946182,0.943133,-0.0610498,-0.191215,-0.113152,0.038576,-0.0191056,0.362314,0.483705,0.661325,-0.126813,-0.229205,0.765108,0.44508,-0.968982,-0.951864,-0.214983,-0.49107,-1.47212,-1.20445,-0.94723,-1.06299
6470,0.918963,0.881291,0.284915,0.220417,0.37505,0.153131,0.216603,0.15574,0.597526,0.697444,0.58142,0.47317,0.690125,0.646116,0.149696,0.136338,0.920874,0.9231,0.920232,0.919181,-0.985565,-1.10544,0.89282,1.03825,0.96435,1.34563,0.827253,1.00972,0.746467,0.649874,0.76694,0.526702,-0.575643,-0.552914,-0.431476,-0.649637,1.75068,2.0134,-0.15959,-0.269712
6471,0.275899,0.239903,0.391299,0.329179,0.434906,0.284779,0.312389,0.249412,0.695909,0.79616,0.0573666,0.0269089,0.532438,0.516531,0.518586,0.503425,0.496764,0.499676,0.449196,0.448167,2.07234,1.95441,-0.0642629,0.0735988,-0.499374,-0.120958,0.860714,1.03562,-1.01242,-1.11233,-0.811768,-1.05921,1.47333,1.48988,-0.525546,-0.808205,0.0271924,0.28859,1.19314,1.08895
6472,0.334307,0.300156,0.0567609,-0.0058951,0.958096,0.808248,0.688262,0.623253,0.223289,0.323154,0.960259,0.928491,0.47444,0.386945,0.520612,0.503062,0.566146,0.5681,0.47848,0.47446,1.50298,1.38014,-0.722972,-0.581748,1.51954,1.89611,0.35577,0.537995,-0.067013,-0.171104,-0.442274,-0.693819,-0.301448,-0.278872,-1.03297,-1.31931,0.429911,0.685489,0.459957,0.357284
6473,0.623438,0.587002,0.556269,0.492585,0.95776,0.809603,0.102025,0.0354782,0.899918,0.999836,0.908266,0.876309,0.187622,0.257359,0.0698316,0.0522388,0.251103,0.253148,0.175346,0.169271,-0.451391,-0.578392,-1.61847,-1.4839,-0.637444,-0.263536,0.273167,0.457392,-0.639398,-0.750864,-0.737697,-0.985722,-0.495072,-0.474683,0.174173,-0.1157,-0.615433,-0.361911,0.491914,0.395622
6474,0.546141,0.544073,0.290049,0.22634,0.137621,-0.00988211,0.0713245,0.00346668,0.831372,0.929196,0.170013,0.136809,0.217606,0.127773,0.354595,0.338157,0.947828,0.949737,0.506004,0.520441,-0.00471951,-0.127937,1.18775,1.32551,1.41655,1.78393,-0.980643,-0.800024,0.0767759,-0.0420158,-3.53226,-3.77272,0.822059,0.836872,-0.16474,-0.458165,0.774496,1.02141,1.10762,1.00635
6475,0.477515,0.501144,0.667866,0.606078,0.908707,0.761344,0.56194,0.496808,0.135385,0.233353,0.54751,0.515699,0.0421962,-0.00181264,0.159536,0.187249,0.0918467,0.0955055,0.879942,0.871611,-0.501425,-0.626748,-0.71474,-0.580674,-2.52632,-2.15895,-0.0547984,0.118431,1.32416,1.20709,-2.18267,-2.42641,1.091,1.11243,-1.28553,-1.58324,-0.482777,-0.229298,-0.583575,-0.685853
6476,0.496213,0.458214,0.299172,0.236973,0.743485,0.595197,0.436864,0.369419,0.290008,0.38836,0.238945,0.206656,0.514466,0.469868,0.0503378,0.0363414,0.862293,0.867018,0.289444,0.280949,-0.68419,-0.714669,0.789281,0.930161,1.02641,1.38628,-0.465891,-0.286733,-0.0296006,-0.14172,-1.22428,-1.46289,-1.34966,-1.3346,-0.994457,-1.29655,0.307004,0.556587,0.559077,0.456734
6477,0.627068,0.588229,0.205702,0.143009,0.280462,0.130769,0.671583,0.604992,0.659795,0.756026,0.870732,0.837338,0.533578,0.487656,0.598539,0.584156,0.589538,0.593124,0.960134,0.950344,-0.672453,-0.802589,0.380142,0.51968,-0.172521,0.180703,0.884549,1.06141,-0.331116,-0.446418,-0.591888,-0.891953,1.37695,1.38948,0.695854,0.400882,0.059599,0.302889,0.531657,0.433698
6478,0.2254,0.187526,0.42297,0.360339,0.899131,0.748767,0.124299,0.0571744,0.653592,0.840751,0.611119,0.57935,0.897795,0.850116,0.387373,0.372546,0.983045,0.989001,0.909984,0.901245,-1.07919,-1.2063,0.520864,0.659389,0.570833,0.918703,0.224068,0.39418,0.961812,0.847097,-0.0857495,-0.32102,0.378291,0.387677,-0.982427,-1.27688,-0.929154,-0.680328,0.922429,0.830431
6479,0.184624,0.238672,0.305687,0.242291,0.365587,0.214952,0.215983,0.150846,0.829695,0.925477,0.0635154,0.0300032,0.186765,0.137867,0.647984,0.633179,0.513211,0.519485,0.597313,0.589852,-1.22721,-1.35338,-0.684918,-0.552649,-2.34781,-1.99446,0.778091,0.942234,-0.907828,-1.02255,-0.419533,-0.659436,0.18762,0.191865,2.35583,2.06365,-0.506111,-0.193517,0.671971,0.581142
6480,0.329025,0.289819,0.557209,0.493974,0.35968,0.21122,0.740876,0.67377,0.68331,0.779068,0.690052,0.65546,0.642596,0.593747,0.136226,0.121909,0.706263,0.70998,0.535243,0.525577,-0.620638,-0.749846,-0.763387,-0.627115,-1.17723,-0.827976,-0.462494,-0.299814,1.31645,1.19722,-1.26879,-1.50883,1.12615,1.12873,1.18909,0.895503,0.0502515,0.293294,1.04911,0.962169
6481,0.726233,0.687584,0.242781,0.178202,0.601542,0.451274,0.344193,0.336203,0.950661,1.04538,0.860429,0.825397,0.578498,0.529616,0.520974,0.508521,0.0769738,0.0800702,0.879639,0.869899,0.569549,0.436308,0.835368,0.97759,-0.421954,-0.109602,-0.456697,-0.383262,0.792213,0.679183,-0.112116,-0.361777,-0.144587,-0.134207,-2.07915,-2.37041,0.161035,0.409893,-1.84944,-1.94146
6482,0.570662,0.529819,0.863117,0.798686,0.528023,0.376354,0.0639787,-0.00136466,0.124539,0.217484,0.464086,0.428721,0.0944572,0.0433127,0.248161,0.235987,0.776243,0.776659,0.25399,0.244343,-0.11605,-0.245703,-0.734328,-0.59469,0.261484,0.608772,-0.624357,-0.46671,1.97787,1.86536,-0.0589109,-0.300997,-0.537205,-0.53242,-0.253838,-0.549306,-0.751195,-0.497848,-0.149103,-0.245776
6483,0.116693,0.0747216,0.830939,0.768441,0.9452,0.794583,0.524615,0.461168,0.744037,0.836701,0.513961,0.408831,0.67569,0.624464,0.664895,0.652555,0.754192,0.828791,0.0254506,0.0135259,-0.0647658,-0.195033,0.230304,0.375177,0.748109,1.09799,-1.11287,-0.895605,0.987829,0.871708,0.316948,0.0818936,1.12258,1.13208,-0.473385,-0.769099,0.987565,1.24298,-2.41498,-2.51392
6484,0.874467,0.834563,0.564953,0.500549,0.981327,0.83095,0.253098,0.18814,0.65532,0.745997,0.510076,0.38894,0.108853,0.0570515,0.316456,0.305973,0.836462,0.880922,0.641201,0.627164,0.338763,0.210768,-0.496123,-0.356836,1.51073,1.86668,-1.48004,-1.3245,-0.631647,-0.751431,0.354955,0.112171,1.68744,1.70205,0.773374,0.478121,-2.55788,-2.29553,0.279668,0.183135
6485,0.617285,0.576485,0.294174,0.232658,0.606495,0.381718,0.737013,0.670742,0.032559,0.120959,0.404414,0.36905,0.465988,0.414438,0.927132,0.915747,0.938068,0.933053,0.97408,0.960789,-0.864939,-0.993225,-0.673147,-0.538202,-0.21182,0.137094,-0.587403,-0.43664,0.314457,0.189799,0.0137506,-0.226245,0.064514,0.0788023,0.103861,-0.250818,0.22023,0.483176,0.260203,0.160099
6486,0.126217,0.0854301,0.689063,0.628107,0.0844174,-0.0675144,0.346375,0.278968,0.753921,0.843222,0.789618,0.753861,0.298946,0.275962,0.807284,0.794618,0.984767,0.985184,0.474087,0.46013,0.0618482,-0.0685256,-0.629837,-0.491011,-1.05436,-0.710463,-0.359833,-0.232918,0.961383,0.837608,0.101436,-0.134842,-0.844553,-0.828214,-0.679055,-0.979756,-1.2005,-0.939947,1.17669,1.07283
6487,0.580121,0.537891,0.164354,0.105381,0.920406,0.767938,0.590481,0.524191,0.419432,0.511078,0.75198,0.716533,0.101301,0.137487,0.364812,0.35304,0.12326,0.125894,0.818922,0.804452,1.41529,1.28892,-1.62884,-1.48627,1.36694,1.71302,-0.181421,-0.0291965,2.32935,2.20592,-0.239253,-0.473257,0.883214,0.898026,0.962623,0.653822,-0.345507,-0.0884125,-0.0702048,-0.176305
6488,0.779787,0.738416,0.517322,0.460906,0.0231525,-0.128694,0.393611,0.371192,0.330733,0.385163,0.219753,0.182348,0.0500323,-0.000988394,0.209845,0.196524,0.660166,0.660486,0.150439,0.138207,0.630963,0.497798,1.32243,1.4661,0.0549078,0.401127,1.00985,1.16711,-1.51821,-1.64223,-0.988296,-1.21533,-1.30408,-1.29115,-0.257869,-0.562847,1.49724,1.74788,0.102095,-0.00385732
6489,0.631083,0.67023,0.393303,0.389878,0.734386,0.582031,0.284188,0.218193,0.169979,0.259249,0.0257229,-0.0119883,0.546441,0.464904,0.354842,0.342907,0.418796,0.417296,0.500227,0.487812,-1.18685,-1.32335,0.55787,0.701627,0.449211,0.801419,-0.0929216,0.0631034,0.263904,0.140313,-0.843368,-1.06479,-0.541868,-0.524052,0.425487,0.0823123,-0.518048,-0.268436,-1.14339,-1.25299
6490,0.641721,0.602044,0.372698,0.318851,0.791192,0.552767,0.513556,0.448743,0.961774,1.05073,0.354998,0.366235,0.983531,0.930797,0.796111,0.785144,0.911266,0.90809,0.566068,0.554553,0.365916,0.222942,-0.914503,-0.778562,-0.678471,-0.327517,0.304684,0.457163,0.932913,0.804747,0.645471,0.41914,0.895636,0.90836,1.03989,0.727472,-0.918997,-0.676264,-0.938577,-1.07859
6491,0.817413,0.777451,0.0563911,0.00307889,0.677293,0.523504,0.192168,0.125935,0.43892,0.527719,0.782247,0.744458,0.983834,0.929077,0.79513,0.803723,0.52234,0.608789,0.141965,0.128599,-0.93292,-1.07379,-0.262895,-0.166498,0.120689,0.471506,-1.32924,-1.17047,-0.015551,-0.143331,-0.0851644,-0.271529,0.754275,0.771988,-0.262019,-0.56839,0.832503,1.08097,-0.787458,-0.904188
6492,0.456219,0.417784,0.550919,0.496127,0.485983,0.331468,0.458374,0.391253,0.550624,0.669498,0.460538,0.421233,0.524231,0.493085,0.832764,0.822303,0.316145,0.309489,0.665307,0.653032,1.76038,1.61988,0.302713,0.445567,1.47765,1.83548,-1.89929,-1.74505,-0.579331,-0.707223,-0.732072,-0.962197,-1.89052,-1.87104,-0.915391,-1.21932,1.77121,2.02491,1.38709,1.27602
6493,0.481619,0.387851,0.514007,0.483261,0.684451,0.490466,0.927614,0.859197,0.800287,0.811277,0.946407,0.908377,0.111851,0.0570926,0.420637,0.410613,0.0132317,0.0101886,0.0299516,0.0178474,0.0130912,-0.120723,1.25866,1.39832,-0.496926,-0.146443,0.410762,0.566363,0.493129,0.371481,-0.894847,-1.13098,-0.325797,-0.303666,-1.05132,-1.34812,-0.435666,-0.17708,1.56705,1.46285
6494,0.397055,0.357918,0.39437,0.470395,0.80598,0.649464,0.590215,0.521781,0.864258,0.953057,0.412991,0.374192,0.0692515,0.0137287,0.833311,0.822357,0.492487,0.490212,0.536841,0.526349,-1.29235,-1.43076,1.08379,1.21696,0.759462,1.1104,0.195496,0.346991,0.598878,0.483175,-0.279352,-0.51677,-0.668281,-0.640604,-1.7246,-2.01538,2.00108,2.25917,-0.678798,-0.787842
6495,0.780591,0.740741,0.510837,0.457529,0.27235,0.115648,0.563672,0.494909,0.506766,0.593978,0.912905,0.871673,0.291245,0.234809,0.531259,0.520793,0.580837,0.604721,0.0361395,0.0256906,0.765547,0.62118,-0.411979,-0.277925,-0.0970776,0.246724,0.754527,0.908526,-0.0455255,-0.207132,-2.88294,-3.12484,-0.255651,-0.22532,-0.67672,-0.964144,0.190862,0.452791,-0.643496,-0.749504
6496,0.193978,0.154553,0.564655,0.483774,0.108562,-0.0462816,0.854977,0.785361,0.890565,0.97739,0.1764,0.137071,0.930227,0.876096,0.823359,0.811428,0.720023,0.71923,0.386971,0.375295,-1.01205,-1.15221,-0.126647,0.00134195,-0.59792,-0.256908,0.895829,1.04254,-0.785077,-0.897439,-0.943949,-1.18025,2.12434,2.15681,-1.15325,-1.44437,0.543891,0.803808,0.896697,0.791778
6497,0.966513,0.92503,0.561371,0.510019,0.354999,0.22932,0.297325,0.227122,0.563473,0.650227,0.973055,0.931411,0.901582,0.847709,0.745135,0.734721,0.283077,0.284493,0.358888,0.345923,0.181744,0.0497785,0.407929,0.540273,-0.36674,-0.0259594,-1.47268,-1.31809,1.07188,0.96266,0.173969,-0.0615536,-0.526921,-0.500864,-0.906457,-1.20464,-0.720275,-0.460264,-0.242745,-0.352359
6498,0.572104,0.52888,0.363669,0.310556,0.659907,0.504922,0.401521,0.331522,0.524745,0.611422,0.642349,0.60283,0.165787,0.110141,0.952986,0.941838,0.454618,0.454178,0.821471,0.810008,-0.533559,-0.662489,-0.0699161,0.0684719,0.105066,0.448958,1.04632,1.19305,0.566969,0.458533,1.04353,0.810231,-1.5964,-1.56347,-1.69169,-1.99338,1.39613,1.65766,-0.396257,-0.511445
6499,0.611474,0.569056,0.732308,0.680269,0.491296,0.338775,0.0762612,0.00403602,0.0332585,0.118086,0.728366,0.688007,0.0919579,0.0625077,0.599256,0.589717,0.0911007,0.0898734,0.327497,0.3146,0.277398,0.153833,0.435419,0.578024,-0.328929,0.0220951,-0.857776,-0.704766,0.461393,0.351885,-0.236442,-0.469939,-2.23136,-2.19225,0.078546,-0.220647,-0.0674898,0.202898,0.64481,0.524215
6500,0.948078,0.906155,0.17546,0.123287,0.778189,0.625291,0.844486,0.77292,0.614752,0.697822,0.367209,0.32628,0.0084302,0.0148745,0.563221,0.553602,0.853403,0.851417,0.336648,0.408751,-0.53413,-0.652598,0.0336514,0.182249,1.38976,1.74448,2.02804,2.18707,0.760778,0.647347,0.122356,-0.104545,-0.92525,-0.880694,-1.15624,-1.45247,0.244612,0.521477,-0.20813,-0.328345
6501,0.94073,0.911096,0.666532,0.616335,0.204376,0.0516413,0.306648,0.234832,0.684688,0.815448,0.559366,0.520024,0.0228876,-0.0327587,0.750435,0.740568,0.484093,0.482061,0.418925,0.502901,-0.170408,-0.3272,0.102365,0.244939,2.28718,2.63635,0.432351,0.590727,0.0849375,-0.0244351,0.0555848,-0.166794,-1.62461,-1.58588,-1.5207,-1.8114,-0.29798,-0.0253526,1.14443,1.03031
6502,0.957989,0.916036,0.394688,0.345583,0.551431,0.437926,0.85793,0.78741,0.852394,0.933074,0.106132,0.0687173,0.649005,0.592712,0.481618,0.47636,0.921935,0.921548,0.609594,0.597052,0.121526,-0.00180241,1.13033,1.27601,2.00477,2.3469,-0.789022,-0.635215,0.639709,0.530306,1.56445,1.33255,-1.00406,-0.970087,-0.0768433,-0.363893,1.64509,1.92276,0.556935,0.448838
6503,0.299676,0.259661,0.344726,0.295716,0.974796,0.82421,0.273802,0.204123,0.63341,0.716016,0.716695,0.67935,0.362793,0.306846,0.22313,0.212152,0.155388,0.156974,0.814636,0.803947,-0.530007,-0.652689,-0.0442406,0.0949306,1.14967,1.49935,1.58291,1.73225,-1.84477,-1.9585,-0.467723,-0.701144,2.13582,2.17277,-0.445245,-0.73659,-0.988368,-0.702696,0.523853,0.410471
6504,0.0127065,-0.0297542,0.868064,0.818724,0.629789,0.553414,0.735985,0.666656,0.164893,0.247712,0.247786,0.209274,0.394334,0.401627,0.427105,0.345042,0.907407,0.909636,0.0178825,0.00836745,1.53754,1.4151,-0.364172,-0.22327,1.07351,1.42359,-0.707536,-0.562503,-1.16605,-1.19564,1.64455,1.40774,1.31914,1.36051,0.737249,0.449921,0.158095,0.443129,-1.69657,-1.81295
6505,0.729667,0.686129,0.881918,0.832884,0.4329,0.282619,0.176358,0.108416,0.87825,0.959658,0.448831,0.408139,0.604716,0.496408,0.490462,0.477932,0.388764,0.390394,0.733148,0.722726,-0.534527,-0.658031,1.26559,1.41238,-0.724318,-0.369502,1.38576,1.53213,-0.319067,-0.432792,0.15111,-0.0883167,-1.16681,-1.12131,-0.0353417,-0.332687,0.319514,0.606253,-1.85117,-1.97203
6506,0.488197,0.442468,0.477608,0.510445,0.688234,0.538099,0.159084,0.173467,0.72753,0.808704,0.229296,0.189616,0.524501,0.591189,0.187807,0.176368,0.079726,0.0813349,0.419814,0.411333,-0.83306,-0.954995,-0.71447,-0.570045,0.35562,0.705731,0.103572,0.20864,-2.38292,-2.50078,-0.168866,-0.411125,1.23261,1.27734,-0.822936,-1.11529,2.14881,2.44254,-0.174255,-0.291132
6507,0.820682,0.774622,0.237337,0.188007,0.310149,0.158767,0.307219,0.238517,0.0944865,0.173806,0.747157,0.706943,0.739654,0.68597,0.157905,0.145291,0.034662,0.0816099,0.580086,0.573096,0.929971,0.803179,0.892354,1.03466,-1.31549,-0.960448,-1.26118,-1.11485,-1.82789,-1.94604,-1.01031,-1.24549,1.23852,1.27845,2.08118,1.79599,0.728674,1.01942,-0.932638,-1.05394
6508,0.391021,0.368136,0.37307,0.32186,0.800104,0.647034,0.753354,0.686747,0.955649,1.03468,0.359247,0.340945,0.924685,0.871929,0.51678,0.564331,0.0804132,0.0818849,0.195457,0.187783,-1.10138,-1.22234,0.347176,0.485019,0.576977,0.932427,0.0727755,0.219484,-0.703852,-0.822996,0.174484,-0.0669634,0.572015,0.619782,0.912938,0.627852,-1.32535,-1.02727,-0.460731,-0.58102
6509,0.0066237,-0.0383488,0.870051,0.82034,0.814475,0.663461,0.432044,0.363939,0.157,0.233979,0.0166899,-0.0250532,0.792278,0.737803,0.995742,0.983372,0.400927,0.417356,0.932481,0.926167,-0.946219,-1.06438,-0.467396,-0.323556,-0.304073,0.0532575,-1.38116,-1.23685,1.19303,1.07109,-1.01496,-1.25308,-0.856944,-0.802157,-1.02749,-1.31667,0.709859,1.00564,-0.86982,-0.997587
6510,0.85528,0.809106,0.874144,0.824713,0.0415333,-0.110957,0.40583,0.337067,0.590257,0.666523,0.982301,0.938917,0.0185251,-0.038067,0.550711,0.619083,0.749294,0.752827,0.864482,0.857835,1.01598,0.894217,0.391238,0.537029,-0.118778,0.236388,0.342752,0.492146,0.441339,0.323776,1.88084,1.64661,1.57541,1.62589,-0.347184,-0.633365,0.637871,0.930607,1.05184,0.930146
6511,0.733117,0.700784,0.529232,0.479711,0.840725,0.688476,0.679994,0.612321,0.422125,0.499902,0.695264,0.667442,0.51467,0.412124,0.268321,0.254794,0.223865,0.228761,0.594681,0.591806,0.0941921,-0.0350285,-0.790382,-0.64405,0.737812,1.09669,0.339128,0.489109,0.357196,0.231675,-0.743318,-0.975094,-1.14895,-1.09935,1.32941,1.04826,0.471092,0.855575,0.710309,0.65626
6512,0.65074,0.592462,0.923664,0.87516,0.326488,0.174913,0.702916,0.63491,0.00283354,0.0808628,0.300186,0.395967,0.917461,0.862315,0.385705,0.370551,0.842894,0.849879,0.264215,0.325776,-0.232107,-0.322573,-0.395165,-0.252706,1.1808,1.48876,-1.39087,-1.23551,-0.895145,-1.0232,-0.326382,-0.563428,-0.347958,-0.302429,1.30906,1.025,0.484761,0.780542,0.511109,0.382374
6513,0.530315,0.484141,0.488915,0.441994,0.437322,0.253476,0.425395,0.357182,0.626255,0.70505,0.167875,0.124491,0.995505,0.941307,0.0894661,0.0736169,0.00794812,0.0152963,0.0640345,0.0597473,-0.481849,-0.610117,-0.00769457,0.138638,1.53129,1.88084,-1.19925,-1.03977,0.308583,0.179128,-1.97503,-2.21173,0.99011,1.03922,0.908561,0.540245,1.25417,1.55014,-0.254923,-0.380431
6514,0.204645,0.158741,0.68184,0.559849,0.481868,0.332039,0.956906,0.889805,0.7519,0.829445,0.683079,0.641819,0.488311,0.434989,0.543347,0.525316,0.738486,0.746998,0.724701,0.718132,-0.521881,-0.649351,-1.54739,-1.40372,-0.41468,-0.0713928,-0.449087,-0.291168,0.568309,0.444646,-0.151537,-0.385989,-1.22193,-1.16581,0.341526,0.0554913,0.423682,0.709714,-0.650454,-0.725047
6515,0.990544,0.944168,0.723437,0.677705,0.129696,-0.0216923,0.884905,0.804954,0.29899,0.376056,0.351103,0.308337,0.786078,0.732147,0.106607,0.0884205,0.34803,0.35695,0.418654,0.412943,0.665758,0.536802,-0.777854,-0.633802,-0.334468,0.00583213,0.712521,0.875413,-1.34624,-1.47074,-0.483966,-0.724405,-2.05676,-1.99185,-0.910274,-1.19129,-0.431404,-0.130717,-0.94342,-1.06966
6516,0.518622,0.473698,0.488917,0.443202,0.722354,0.57133,0.664665,0.720103,0.115067,0.193738,0.871649,0.82983,0.370619,0.316137,0.124371,0.141266,0.551392,0.494468,0.331923,0.324989,0.101822,-0.0217666,0.860699,1.00185,-1.26369,-0.918962,-0.349948,-0.182488,-0.0120989,-0.132124,0.574877,0.28349,0.685415,0.750287,-1.0034,-1.28904,0.371519,0.670316,0.237606,0.104221
6517,0.984854,0.940364,0.496062,0.452246,0.317419,0.165776,0.667882,0.635252,0.165706,0.246077,0.316492,0.275644,0.171171,0.11648,0.209813,0.194111,0.623008,0.631986,0.522426,0.568104,-1.32237,-1.44134,-0.492028,-0.352682,0.841529,1.19334,0.636934,0.798869,-0.813231,-0.940277,1.53182,1.29138,-0.582983,-0.500358,-1.64651,-1.92462,0.591051,0.895544,1.17061,1.03228
6518,0.186952,0.141527,0.147567,0.102529,0.985081,0.835358,0.617502,0.550401,0.560959,0.638844,0.332472,0.292338,0.867807,0.813729,0.561274,0.564918,0.176036,0.18741,0.819808,0.811218,-0.337385,-0.456745,-1.07164,-0.931606,2.31209,2.66272,-0.84412,-0.687497,-0.932987,-1.06291,0.154281,-0.0825581,-1.81425,-1.751,-0.768128,-1.04264,-0.693642,-0.387224,-0.177366,-0.395268
6519,0.969659,0.922184,0.785604,0.741879,0.879349,0.722313,0.123849,0.0576905,0.289968,0.366839,0.56179,0.521023,0.129907,0.0761608,0.952215,0.935724,0.60882,0.622309,0.266231,0.255409,-0.312493,-0.435449,-0.310267,-0.1771,0.184055,0.53658,-0.765077,-0.614387,-0.255595,-0.382902,-0.946292,-1.17848,-0.0114322,0.0532441,-0.0951408,-0.373898,-1.53021,-1.22686,-1.68895,-1.82282
6520,0.104066,0.0584367,0.685948,0.66008,0.74404,0.609268,0.632368,0.565531,0.315139,0.326397,0.346753,0.307241,0.269312,0.225555,0.121314,0.103077,0.754798,0.766752,0.541611,0.528578,0.99006,0.873612,-0.098391,0.0654684,0.250821,0.603378,0.498708,0.643181,-0.974606,-1.09753,-1.38878,-1.62682,0.52443,0.590333,-1.05679,-1.33016,-0.097951,0.203276,-1.2646,-1.39491
6521,0.944973,0.90019,0.62006,0.578281,0.704809,0.496223,0.699289,0.65714,0.239847,0.285956,0.547258,0.506106,0.30244,0.374949,0.752806,0.7333,0.621334,0.634257,0.54222,0.533964,-0.720191,-0.837573,0.175817,0.308037,0.216792,0.670176,-0.648873,-0.505305,1.10676,0.988324,0.304035,0.0608485,-1.68334,-1.61469,-1.67495,-1.9492,-0.0247712,0.275034,-0.161781,-0.298211
6522,0.580159,0.44313,0.338169,0.298258,0.498913,0.383178,0.813174,0.748749,0.0768756,0.245514,0.0540366,0.0108882,0.590203,0.524343,0.476076,0.374648,0.198814,0.210832,0.550349,0.53935,-1.14614,-1.25688,0.83954,0.971203,0.384448,0.736974,-0.538229,-0.292662,-1.05465,-1.17718,-0.48975,-0.640509,0.143804,0.207601,0.400268,0.12196,1.94181,2.2419,0.614446,0.478143
6523,0.0327242,-0.0139302,0.836033,0.796737,0.419856,0.270133,0.408628,0.341724,0.038305,0.205072,0.821957,0.778776,0.727484,0.673737,0.0356243,0.0159962,0.191081,0.205187,0.161063,0.149357,0.159697,0.0521801,-0.826843,-0.697043,0.132589,0.478163,-0.230772,-0.0800178,0.769972,0.654312,-1.10086,-1.34187,1.56269,1.62605,1.01646,0.743483,1.80601,2.11206,-0.944787,-1.07764
6524,0.153509,0.159843,0.165156,0.125719,0.67415,0.456583,0.356334,0.347284,0.0877605,0.164631,0.603863,0.555481,0.368319,0.320029,0.715094,0.697587,0.943562,0.957848,0.600145,0.588652,-0.774589,-0.877065,0.730698,0.863101,-1.72454,-1.37888,-1.0579,-0.903574,-1.54021,-1.65245,-0.524086,-0.758533,-0.692101,-0.631961,-0.551849,-0.826229,-0.219505,0.0818172,-0.0529438,-0.179081
6525,0.380729,0.333616,0.00692294,-0.0328095,0.79377,0.643033,0.418402,0.352844,0.330677,0.405862,0.374294,0.332186,0.0198909,-0.0336788,0.935628,0.915822,0.953675,0.96379,0.838831,0.8274,-0.951991,-1.0528,0.186417,0.31346,0.101043,0.451059,0.632149,0.779472,-0.392808,-0.511715,-2.01948,-2.25459,-0.812693,-0.751576,0.0533784,-0.219767,-1.14499,-0.839705,0.582208,0.462825
6526,0.7229,0.675565,0.274083,0.233158,0.793907,0.578167,0.875243,0.810529,0.921939,0.995829,0.916124,0.873961,0.153287,0.101418,0.9398,0.921477,0.816936,0.969731,0.535159,0.485944,0.0704181,-0.0358885,-2.60501,-2.4825,-0.943857,-0.599469,0.929123,1.08333,-1.19491,-1.32236,2.13697,1.90186,-1.55374,-1.48898,-0.270063,-0.547065,-0.316475,-0.00538928,-0.0904267,-0.20988
6527,0.850994,0.80558,0.104943,0.0646043,0.643329,0.513301,0.945048,0.879592,0.432668,0.507004,0.483067,0.443242,0.913124,0.861266,0.0470248,0.0291586,0.959077,0.975673,0.155445,0.144488,0.687867,0.583286,1.78861,1.91385,0.800443,1.13896,2.28628,2.44828,-2.00767,-2.13301,0.590901,0.362349,1.66429,1.72132,0.540113,0.258796,-1.42792,-1.11266,0.0707056,-0.0522193
6528,0.572751,0.526583,0.54618,0.503979,0.599171,0.448434,0.623822,0.556785,0.967743,1.04077,0.675782,0.636986,0.401291,0.349665,0.247193,0.230998,0.0160352,0.0302466,0.448398,0.437427,-0.0975571,-0.207837,-2.62514,-2.4999,-0.216172,0.119364,0.381768,0.550466,0.212718,0.0867617,-0.399238,-0.625866,0.748146,0.798101,-0.277893,-0.558881,0.439401,0.756454,-0.571404,-0.695067
6529,0.00858379,-0.0393799,0.538074,0.498333,0.357888,0.282867,0.727708,0.661185,0.18944,0.261236,0.608641,0.568906,0.272688,0.21997,0.106036,0.0888644,0.276846,0.291906,0.159646,0.232602,0.57653,0.472166,2.65601,2.78125,0.0460322,0.38183,0.0270818,0.219239,-0.194118,-0.325594,0.00352691,-0.227288,-0.690001,-0.639355,-0.262289,-0.535903,-1.07223,-0.761729,-0.00777916,-0.129091
6530,0.315391,0.267341,0.749356,0.620213,0.269563,0.1173,0.590713,0.523966,0.747209,0.820506,0.822949,0.705732,0.506781,0.45582,0.957363,0.939097,0.248568,0.361065,0.036971,0.0277761,1.50353,1.39687,1.27321,1.39463,1.12799,1.45706,-0.28327,-0.111989,-2.19408,-2.32385,-0.528294,-0.752292,-0.607599,-0.472792,-0.731239,-1.00103,-1.0944,-0.782674,0.0150672,-0.0489008
6531,0.349868,0.30363,0.781313,0.742092,0.283707,0.198603,0.0564195,-0.00903333,0.87111,0.944901,0.88271,0.842557,0.21099,0.159152,0.461329,0.443413,0.4158,0.430225,0.22829,0.219825,-0.766083,-0.879519,0.725811,0.844988,1.6145,1.94628,0.0476036,0.162815,-0.879081,-1.01387,0.127694,-0.0942911,-0.35272,-0.306229,-0.259424,-0.532501,0.37822,0.693212,0.152852,0.0312896
6532,0.641852,0.595855,0.144573,0.106632,0.430887,0.279906,0.205345,0.18721,0.216544,0.290664,0.662021,0.624034,0.39951,0.336232,0.729262,0.709016,0.635863,0.651897,0.629023,0.561495,1.20741,1.09233,-1.07096,-0.948094,-0.696605,-0.359513,0.271787,0.437618,0.668592,0.538954,-0.509685,-0.729831,0.7181,0.766252,-0.214626,-0.493492,-1.45962,-1.14392,-0.439316,-0.56491
6533,0.453681,0.407192,0.333995,0.295368,0.119756,-0.0292197,0.449631,0.383454,0.997655,1.0706,0.649816,0.611886,0.603505,0.513313,0.347873,0.327745,0.218411,0.233032,0.910763,0.903165,0.394175,0.285895,-0.640178,-0.517527,1.27277,1.60954,-0.0873424,0.0778102,1.08713,0.95757,-0.815531,-1.03855,-0.204692,-0.156967,0.125474,-0.147786,2.08769,2.40553,-0.161489,-0.286819
6534,0.77482,0.728588,0.172281,0.132159,0.419159,0.272027,0.367919,0.300424,0.408558,0.481887,0.879053,0.840571,0.742233,0.690394,0.717313,0.694832,0.223335,0.238474,0.536345,0.480729,0.372223,0.262421,-1.04147,-0.913302,0.254871,0.589943,0.617917,0.778946,0.258399,0.132805,-2.02876,-2.25358,-0.227702,-0.185739,0.810878,0.535522,0.766564,1.09029,-1.0375,-1.17033
6535,0.301248,0.25294,0.927807,0.887662,0.227891,0.0799921,0.778376,0.709796,0.489852,0.560637,0.0515282,0.0125331,0.460406,0.379576,0.781447,0.761226,0.441901,0.454571,0.0653532,0.0582932,-1.77807,-1.88427,0.633621,0.755081,-0.183867,0.148527,-0.64058,-0.47847,-0.111503,-0.230136,-0.210076,-0.427836,-1.26925,-1.23335,0.00317245,-0.321624,1.33892,1.65886,-2.76733,-2.89291
6536,0.970018,0.924161,0.924165,0.882016,0.454575,0.322445,0.325358,0.257929,0.220875,0.293397,0.356361,0.282845,0.119699,0.0687585,0.142078,0.120275,0.231046,0.236596,0.0354236,0.0289215,-1.10707,-1.22052,0.194871,0.31405,-0.362143,-0.0333211,-0.614366,-0.513087,-0.470222,-0.593078,0.608558,0.383449,1.06873,1.09988,-0.90252,-1.17877,-1.31615,-1.003,0.658518,0.532693
6537,0.706755,0.660659,0.253906,0.210998,0.710156,0.564898,0.542785,0.474233,0.747456,0.822423,0.682061,0.553157,0.273126,0.134115,0.684756,0.663055,0.00521835,0.0186202,0.343695,0.3367,-1.87209,-1.97912,-0.591825,-0.480621,0.52523,0.858551,-0.706628,-0.547705,-2.01051,-2.13645,0.96717,0.748843,0.405496,0.441209,0.159206,-0.110614,0.579364,0.897421,-0.372688,-0.501404
6538,0.95432,0.906621,0.970425,0.926475,0.360131,0.214816,0.177719,0.107424,0.935832,1.01241,0.862464,0.823469,0.241193,0.199472,0.188407,0.167371,0.493722,0.509414,0.939787,0.930919,0.00805887,-0.0973677,-0.497586,-0.388115,-0.611932,-0.284363,0.935187,1.08794,1.65203,1.52887,-0.860006,-1.08262,0.800246,0.911907,-0.619788,-0.88306,-0.141634,0.138473,0.84672,0.719345
6539,0.195306,0.145641,0.47452,0.516133,0.828238,0.683399,0.216867,0.224482,0.150948,0.226834,0.837198,0.795728,0.317454,0.264829,0.159177,0.136293,0.477175,0.493992,0.184778,0.178226,-0.181099,-0.287246,1.58246,1.68439,-1.2985,-0.976806,-1.32301,-1.17603,0.405886,0.29039,1.30088,1.07223,1.34099,1.38261,-1.16257,-1.42459,-0.941908,-0.620475,-0.0218787,-0.15005
6540,0.939342,0.889608,0.149739,0.10579,0.37461,0.229405,0.409939,0.34154,0.485819,0.564211,0.121875,0.0801274,0.916758,0.865344,0.43132,0.406971,0.957259,0.974015,0.395115,0.318861,-0.647112,-0.752563,-0.660129,-0.551453,0.671377,0.992248,-0.230968,-0.089475,-1.52503,-1.64209,0.00454851,-0.221514,0.793865,0.829107,-0.0609688,-0.327788,0.266798,0.581705,-0.178313,-0.309137
6541,0.160446,0.111684,0.798398,0.755826,0.265245,0.106266,0.278787,0.209154,0.471645,0.550293,0.0724909,0.0329383,0.406818,0.353743,0.0597758,0.0350058,0.823018,0.84152,0.466048,0.459496,0.196389,0.0947981,-0.0122323,0.0967537,-0.280126,0.0366363,1.19774,1.34001,0.85161,0.727443,0.000963054,-0.222706,-0.167607,-0.124788,-0.0510473,-0.320457,1.46245,1.78388,-1.04427,-1.17853
6542,0.656575,0.608089,0.226305,0.184454,0.0905026,-0.0168729,0.658145,0.587467,0.176762,0.253751,0.800474,0.758801,0.628383,0.574823,0.650224,0.622941,0.216096,0.23586,0.367967,0.335291,-1.26547,-1.36918,0.870867,0.973854,-0.417202,-0.098313,-0.52603,-0.38461,-1.65247,-1.78161,-0.943988,-1.1931,-0.494429,-0.445819,-0.947443,-1.21662,0.103366,0.423605,0.929187,0.794455
6543,0.464917,0.414226,0.744687,0.702226,0.00519247,-0.140012,0.214082,0.145537,0.183354,0.261937,0.806781,0.809389,0.506277,0.386649,0.982686,0.954799,0.923302,0.942967,0.217821,0.211087,-1.25061,-1.34788,0.92406,1.02105,-0.0287752,0.284719,0.542592,0.687666,-0.200861,-0.335076,-1.93808,-2.1635,0.487959,0.537884,1.71813,1.44967,-2.14037,-1.82351,-1.03272,-1.16313
6544,0.790559,0.741802,0.810002,0.731553,0.149608,0.00685972,0.784032,0.71322,0.195016,0.270123,0.90062,0.859978,0.25368,0.198474,0.730155,0.70179,0.857069,0.798249,0.836029,0.829741,-0.316711,-0.408842,0.352611,0.455817,-0.586768,-0.266104,0.930256,1.08173,-0.497647,-0.593536,-0.309645,-0.539063,-0.190262,-0.136715,-1.35126,-1.62427,0.826573,1.14625,-1.12737,-1.28079
6545,0.00983034,-0.0401182,0.849149,0.76088,0.537444,0.393867,0.848881,0.776914,0.802797,0.879851,0.488002,0.448973,0.778623,0.725337,0.119888,0.0909298,0.632974,0.653532,0.888751,0.882414,-0.292534,-0.387546,-0.54663,-0.446333,0.959405,1.27983,-2.25964,-2.10186,-0.711881,-0.851996,-1.03841,-1.26549,0.173403,0.231813,-0.00166948,-0.266655,0.600724,0.922821,-1.2631,-1.39844
6546,0.818907,0.76836,0.832667,0.790206,0.0815193,-0.0601262,0.694324,0.624793,0.0340915,0.111052,0.377464,0.263676,0.0474245,-0.00811234,0.0135421,-0.0160003,0.276516,0.29881,0.701416,0.697005,0.708007,0.61466,1.63087,1.72512,-0.255152,0.058274,-1.58499,-1.43248,0.0106915,-0.126322,0.638356,0.405741,-2.00955,-1.95736,0.25106,-0.0108727,-0.783209,-0.454442,0.622213,0.483843
6547,0.316719,0.267231,0.616478,0.575751,0.237513,0.0965146,0.170903,0.101856,0.983944,1.06108,0.116992,0.0783779,0.362206,0.266142,0.529761,0.501291,0.968411,0.990363,0.826465,0.803546,0.21317,0.115848,0.236544,0.338498,-0.246828,0.0741052,-1.99867,-1.8534,-0.909066,-1.04113,1.19192,0.958237,0.911715,0.971151,-0.358814,-0.613954,0.685419,1.00818,-0.393908,-0.535444
6548,0.808183,0.758758,0.825895,0.783575,0.723712,0.584782,0.354652,0.210246,0.83059,0.857899,0.239059,0.169793,0.597433,0.540397,0.0895761,0.0597123,0.287798,0.310422,0.913328,0.910087,-1.17417,-1.27193,-0.299434,-0.194935,0.295773,0.580124,-0.392011,-0.248827,0.708572,0.572403,1.11727,0.880501,0.411782,0.465,0.244123,-0.00749184,-0.374639,-0.0532634,-0.234814,-0.377784
6549,0.211125,0.163173,0.294525,0.251501,0.839008,0.701968,0.388621,0.318637,0.633755,0.654714,0.340382,0.261208,0.310641,0.254531,0.161955,0.116435,0.656106,0.676267,0.608967,0.533229,-1.4382,-1.53849,0.0970591,0.204855,0.754944,1.08614,0.199358,0.343291,0.2346,0.0993827,-0.838846,-1.0771,0.816539,0.86395,1.2991,1.04375,0.210618,0.530049,-2.43417,-2.58195
6550,0.706294,0.659579,0.163086,0.122369,0.477455,0.2894,0.785542,0.717984,0.375899,0.45153,0.427187,0.352623,0.979095,0.922403,0.0724232,0.173158,0.283409,0.302083,0.16066,0.156372,-0.576011,-0.676539,-0.302689,-0.190919,-0.187767,0.146415,-0.263318,-0.124728,0.666995,0.532531,-0.127975,-0.371978,-0.616784,-0.573506,0.877499,0.624028,1.30583,1.6297,1.21003,1.06235
6551,0.725459,0.680017,0.85488,0.812035,0.0150294,-0.123168,0.88854,0.822384,0.588457,0.666786,0.590186,0.444038,0.0866175,0.0282683,0.261509,0.229881,0.914237,0.933003,0.208884,0.203408,1.31008,1.20521,1.96925,2.07762,-1.89988,-1.57059,-0.239759,-0.0988265,-0.0699007,-0.200278,-0.948677,-1.27819,-1.59605,-1.55931,-0.563989,-0.823022,-0.849193,-0.525404,1.47053,1.32375
6552,0.366429,0.32035,0.779014,0.734241,0.442119,0.30591,0.562272,0.494898,0.331068,0.409732,0.574067,0.535453,0.463564,0.405028,0.88939,0.860104,0.572812,0.496378,0.511798,0.535297,1.45688,1.34788,-0.232656,-0.127052,1.97348,2.29898,0.333068,0.477787,0.175397,0.0504407,-1.93544,-2.18441,0.770675,0.80523,1.53542,1.28061,-0.386242,-0.0581433,0.302475,0.149318
6553,0.282901,0.23731,0.0643641,0.0193368,0.144219,0.00672751,0.604222,0.577692,0.674927,0.75233,0.252612,0.212229,0.488725,0.427518,0.345704,0.31458,0.0385037,0.0597537,0.870944,0.867186,-0.0825262,-0.192879,-0.111449,-0.00379907,1.70911,2.04016,1.41571,1.56434,0.976913,0.923695,0.120709,-0.123398,0.117327,0.14656,0.222395,0.0324351,0.0335898,0.409118,0.801792,0.602665
6554,0.521519,0.409027,0.144216,0.0984199,0.207536,0.0689079,0.727984,0.660486,0.542549,0.634708,0.489833,0.49504,0.848111,0.784904,0.395368,0.418073,0.149536,0.114629,0.0611054,0.0575807,0.742669,0.638376,0.854019,0.966068,0.43389,0.759274,0.786156,0.928337,1.92063,1.79695,0.365091,0.120849,-0.792754,-0.760456,-0.964193,-1.21574,0.552591,0.876379,1.20705,1.05601
6555,0.720924,0.580744,0.861782,0.813898,0.717475,0.577138,0.149826,0.081873,0.441115,0.517086,0.816737,0.777851,0.503765,0.427343,0.471277,0.521565,0.147092,0.169504,0.628247,0.625976,-0.348255,-0.459756,-0.136357,-0.0291891,-1.24486,-0.923758,-0.431408,-0.282372,0.834078,0.712831,-0.22777,-0.467679,-1.17683,-1.14278,-0.885833,-1.13115,1.51221,1.83418,-0.505686,-0.654044
6556,0.910423,0.752461,0.928394,0.882434,0.689666,0.575029,0.776254,0.70904,0.973595,1.05085,0.814938,0.774765,0.133551,0.0697809,0.65618,0.625057,0.905643,0.926909,0.163017,0.16002,-0.669973,-0.785421,-0.142296,-0.0268849,-0.786277,-0.464883,-0.986656,-0.840691,1.23068,1.11638,1.39259,1.15676,-2.92316,-2.89418,0.900069,0.658006,-1.06284,-0.738464,-0.393777,-0.458344
6557,0.969769,0.924178,0.151996,0.105026,0.713988,0.57292,0.0529366,-0.0136604,0.151489,0.228231,0.267581,0.225418,0.174651,0.112393,0.103285,0.0740785,0.129817,0.152545,0.113837,0.190925,-0.764246,-0.887257,-1.26742,-1.14685,0.437386,0.76267,1.50423,1.65644,-0.860675,-0.969689,0.759455,0.52122,-0.593547,-0.560954,1.06071,0.820144,0.440746,0.767112,-0.117317,-0.262643
6558,0.324589,0.277992,0.471949,0.511474,0.204335,0.0645319,0.0812216,0.0142947,0.458892,0.449607,0.466754,0.424283,0.689782,0.628678,0.912658,0.882755,0.0630048,0.0867522,0.224827,0.22183,-2.17577,-2.30683,0.0914268,0.208553,-0.135934,0.196097,-0.038209,0.110039,-0.846788,-0.948578,-0.278856,-0.511615,-1.59808,-1.56276,-0.462892,-0.704122,-0.364958,-0.0422537,-2.07171,-2.22023
6559,0.984015,0.939724,0.965626,0.917922,0.12025,-0.0213333,0.419562,0.339839,0.593206,0.670983,0.897191,0.853269,0.428792,0.367976,0.587435,0.518466,0.53385,0.557303,0.574015,0.571435,0.212434,0.0882925,0.0182724,0.134088,0.53485,0.872739,-0.964357,-0.82348,-0.512454,-0.62196,0.122113,-0.113037,-0.527842,-0.490277,0.382163,0.148026,1.12943,1.44998,1.97355,1.82141
6560,0.53807,0.493877,0.200024,0.150442,0.261722,0.120619,0.731921,0.665383,0.259805,0.338839,0.900049,0.85534,0.368501,0.360681,0.183579,0.154177,0.682318,0.706693,0.616343,0.61331,-1.61745,-1.74702,-0.878992,-0.768061,-1.06328,-0.732112,0.876528,1.01893,1.28695,1.17755,-0.307311,-0.544165,-0.134037,-0.0913272,-1.40551,-1.63791,-0.816635,-0.497189,1.03332,0.877449
6561,0.90579,0.861636,0.284566,0.272321,0.201741,0.060362,0.384719,0.318656,0.837258,0.918575,0.403012,0.360122,0.393403,0.353386,0.121145,0.0935224,0.11144,0.136763,0.871337,0.866515,0.157528,0.0286201,0.151303,0.263009,1.43365,1.76023,-0.594173,-0.452267,1.07275,0.964454,-1.67445,-1.91811,-0.0200673,0.0352896,0.676145,0.447323,-1.2953,-0.981703,0.421602,0.26495
6562,0.379303,0.335604,0.442022,0.394201,0.636476,0.494466,0.438719,0.37289,0.189332,0.269381,0.152787,0.111873,0.408091,0.346092,0.516597,0.49016,0.372085,0.398422,0.653685,0.651215,0.682151,0.557918,-2.56822,-2.45157,-0.134638,0.187951,1.09373,1.23078,-0.129225,-0.240293,-0.904971,-1.15254,0.119824,0.161906,1.18718,0.962318,-0.534013,-0.228,-2.03643,-2.19719
6563,0.989547,0.94547,0.0994119,0.0491988,0.0678524,-0.0742665,0.695647,0.554959,0.617716,0.628673,0.948121,0.906213,0.740121,0.67852,0.214415,0.188597,0.210953,0.235628,0.71121,0.708399,-1.76704,-1.89085,0.456957,0.571447,0.786622,1.10937,-0.144828,-0.0112684,2.22128,2.11325,-0.658378,-0.908297,0.655416,0.698995,1.4471,1.2181,-0.54373,-0.233317,-0.654345,-0.809357
6564,0.781625,0.736626,0.627545,0.576952,0.848298,0.70841,0.803043,0.737028,0.90692,0.987964,0.92531,0.883037,0.554859,0.419255,0.53313,0.504936,0.823374,0.847246,0.969138,0.967124,-0.413826,-0.5334,0.84639,0.95693,0.798996,1.1252,-0.106756,0.0300528,0.0425526,-0.0668763,1.22071,0.978539,1.85075,1.89987,0.542826,0.3088,0.19846,0.507115,1.47045,1.32183
6565,0.18166,0.135456,0.746347,0.695433,0.0299653,-0.111075,0.744521,0.679785,0.94595,1.02489,0.565653,0.521311,0.223408,0.15999,0.0215454,-0.00633432,0.638102,0.643654,0.701766,0.782004,-0.648273,-0.835791,-0.756795,-0.647409,-1.41476,-1.0818,-0.515826,-0.407654,-0.41902,-0.525562,-0.473404,-0.715554,-0.704419,-0.661675,1.11744,0.885176,-0.55584,-0.243113,-0.0538867,-0.202024
6566,0.904372,0.856247,0.627866,0.577385,0.0916874,-0.0488947,0.987834,0.925008,0.136835,0.214781,0.592537,0.52454,0.57021,0.507691,0.843144,0.81772,0.415878,0.440062,0.599536,0.596885,-1.0194,-1.13818,2.19841,2.30496,0.92705,1.26041,-0.98667,-0.845361,1.10943,0.997003,-0.306301,-0.548271,-0.225039,-0.185065,0.279371,0.0513754,-1.05553,-0.744404,0.0702291,-0.0778013
6567,0.587649,0.541253,0.805745,0.756073,0.628062,0.488748,0.166954,0.103055,0.0684547,0.187404,0.571701,0.527769,0.714321,0.653481,0.898874,0.873459,0.750568,0.717535,0.660939,0.659127,-1.65392,-1.77412,1.37325,1.47996,-1.56545,-1.2327,-1.71731,-1.57464,-0.322009,-0.402541,1.05688,0.813635,-0.313235,-0.189796,1.76003,1.52902,-0.205508,0.107131,-1.05551,-1.20759
6568,0.968558,0.924075,0.669005,0.531405,0.371804,0.23523,0.578271,0.514766,0.0803019,0.160027,0.0172606,-0.0264166,0.164736,0.106626,0.320784,0.292641,0.969645,0.995008,0.938248,0.936942,-1.35136,-1.47466,-0.924572,-0.823222,0.914824,1.24275,0.0816436,0.219797,-1.68966,-1.80208,1.53775,1.29088,-0.22286,-0.194527,-0.904961,-1.12848,-0.154968,0.162871,-0.266281,-0.414306
6569,0.414255,0.36791,0.365106,0.306737,0.790381,0.653458,0.990931,0.926477,0.742715,0.820413,0.22942,0.18667,0.887609,0.830211,0.379478,0.290636,0.676941,0.700781,0.861688,0.932589,0.0823043,-0.0397542,2.19682,2.29346,0.539238,0.861539,-1.0664,-0.928689,-0.183484,-0.294391,0.362252,0.121909,-0.239233,-0.199259,2.28798,2.06684,0.475911,0.794189,1.14688,1.00483
6570,0.79694,0.750733,0.131741,0.0820692,0.600817,0.465981,0.0575809,-0.00691406,0.622999,0.698566,0.988024,0.943536,0.286599,0.229161,0.317259,0.28863,0.852644,0.875749,0.928197,0.928236,-0.722094,-0.846185,0.937285,1.03478,-0.362614,-0.032895,-0.575549,-0.442159,0.316762,0.201152,0.146499,-0.0937354,-0.609892,-0.566436,0.271641,0.0446327,-0.32421,-0.00137673,2.98571,2.84407
6571,0.0364725,-0.010247,0.337058,0.289893,0.833932,0.701351,0.702665,0.639945,0.798026,0.873653,0.952541,0.906208,0.968755,0.912052,0.527752,0.52205,0.12869,0.150052,0.386112,0.387076,0.931456,0.806342,0.362474,0.455859,2.58074,2.90301,-0.766765,-0.631947,-0.253126,-0.36274,0.570535,0.335498,0.706265,0.745119,0.951274,0.72794,0.310024,0.629941,0.946131,0.809784
6572,0.477691,0.432431,0.317136,0.172525,0.270096,0.137094,0.368178,0.307173,0.10612,0.183769,0.496032,0.450379,0.102468,0.0459207,0.781518,0.755471,0.146542,0.169837,0.101538,0.101634,-1.41885,-1.5461,0.342934,0.441062,0.0584119,0.379682,1.21432,1.35214,0.646328,0.533003,0.432163,0.196171,-0.0507004,-0.00568376,-2.23688,-2.4672,0.0248336,0.41454,0.120992,-0.0119832
6573,0.421835,0.467176,0.101982,0.0551577,0.827501,0.695065,0.939234,0.879621,0.916135,0.995825,0.443465,0.425024,0.949197,0.891534,0.455289,0.428971,0.763081,0.785884,0.800526,0.801264,0.0247199,-0.0942156,-0.208368,-0.0975418,-0.380043,-0.0617334,0.489307,0.622865,0.972246,0.859621,-1.09585,-1.32791,-2.3819,-2.34239,0.705316,0.477686,-0.125555,0.199139,1.32275,1.19169
6574,0.549002,0.501922,0.367182,0.316387,0.605247,0.473068,0.521131,0.462852,0.492679,0.571924,0.445264,0.399669,0.413837,0.354753,0.989073,0.961554,0.365894,0.386939,0.993007,0.993313,-0.895632,-1.02346,-0.72947,-0.636145,-1.73698,-1.42099,0.010018,0.141704,-0.0533474,-0.0943359,0.142106,-0.0882965,1.16168,1.2089,0.64509,0.488682,0.496194,0.814715,-0.849744,-0.979966
6575,0.933872,0.884744,0.625692,0.577617,0.102203,-0.0310687,0.3872,0.423094,0.637822,0.716379,0.0198986,-0.0260511,0.639902,0.580601,0.69818,0.670023,0.8215,0.842356,0.331375,0.33196,1.40437,1.27373,0.0377112,0.133777,0.603764,0.921221,-0.0283316,0.106059,-0.933259,-1.04829,1.73209,1.50522,-2.25529,-2.2061,0.730995,0.499678,-0.0801301,0.236245,0.152492,0.0260722
6576,0.0468803,-0.00422956,0.193663,0.144451,0.604399,0.472492,0.440488,0.383336,0.289663,0.368951,0.349207,0.29201,0.399546,0.263557,0.887309,0.856989,0.747689,0.767412,0.883401,0.886072,-0.927595,-1.06269,1.058,1.14949,-1.2738,-0.949898,1.00258,1.13273,0.440205,0.320023,2.11353,1.88812,0.574934,0.619943,-0.966691,-1.19352,-0.21079,0.1064,1.59642,1.47528
6577,0.309239,0.257694,0.319907,0.286739,0.557324,0.404246,0.97296,0.915959,0.871212,0.948687,0.797629,0.610071,0.00571594,-0.0534864,0.869015,0.791443,0.454748,0.473186,0.607399,0.528067,-0.0591499,-0.200742,0.19095,0.27796,-0.453951,-0.1345,0.184518,0.309177,-1.1918,-1.31822,1.40779,1.17674,1.05699,1.17267,-1.03456,-1.26156,0.0453909,0.361704,-0.450515,-0.572793
6578,0.338448,0.316372,0.478878,0.429027,0.467938,0.336,0.33009,0.273709,0.194412,0.273488,0.975437,0.928133,0.35415,0.294215,0.75999,0.725897,0.512966,0.531346,0.170474,0.170061,-0.824897,-0.959341,0.889445,0.970164,-0.543509,-0.180348,1.02124,1.14919,0.323875,0.204344,0.21384,-0.0246993,1.67997,1.7254,-0.575649,-0.808247,-0.240008,0.0776776,-0.479721,-0.700592
6579,0.323702,0.375051,0.894025,0.844137,0.679063,0.546284,0.456932,0.39858,0.951704,1.03211,0.243297,0.198696,0.0832453,0.0232819,0.723332,0.660351,0.90321,0.922236,0.766111,0.76428,2.28889,2.14845,-0.734502,-0.649818,-0.541549,-0.226196,-1.69619,-1.56384,-0.0123311,-0.133104,-1.65862,-1.90108,-2.55486,-2.50943,-0.347301,-0.583743,0.385426,0.708996,-0.706695,-0.828391
6580,0.483526,0.433729,0.580284,0.528365,0.0477381,-0.087858,0.192873,0.135141,0.432361,0.580478,0.454008,0.407184,0.0508301,-0.0125648,0.780941,0.594805,0.958446,0.976392,0.885223,0.881448,-1.348,-1.48845,-0.551288,-0.464233,0.666857,0.983417,1.48936,1.61947,1.0322,0.915339,1.14025,0.902216,0.570304,0.614827,0.803409,0.574086,-0.277992,0.0380431,-0.548591,-0.739023
6581,0.895101,0.84705,0.76011,0.714129,0.780332,0.643137,0.760496,0.702824,0.0466814,0.128843,0.955094,0.909531,0.00898089,-0.0484115,0.559579,0.529259,0.183127,0.202028,0.0968091,0.0911096,-1.251,-1.39223,0.754266,0.845424,1.45083,1.76612,-0.23839,-0.105156,-0.230786,-0.354075,0.0403958,-0.193702,-1.04878,-1.00842,-0.125208,-0.351263,1.67586,1.98615,-0.521405,-0.649655
6582,0.539877,0.532763,0.952434,0.899893,0.28021,0.143441,0.832326,0.775925,0.366144,0.445826,0.273224,0.22901,0.742684,0.686153,0.35958,0.32719,0.460734,0.478299,0.555332,0.550125,1.04257,0.904958,1.75741,1.84509,-1.46977,-1.14704,-0.686174,-0.556496,-1.81494,-1.94453,-2.06443,-2.30511,-0.77534,-0.732863,-0.851183,-1.07981,-0.352107,-0.0440877,0.749776,0.61641
6583,0.265402,0.218476,0.557324,0.505801,0.566857,0.429957,0.348951,0.294114,0.00208991,0.0823985,0.374964,0.336911,0.753668,0.671635,0.644853,0.613108,0.0116848,0.028501,0.209911,0.204199,0.0816659,-0.0539422,-0.679293,-0.596347,-0.0919333,0.231046,-0.372194,-0.238525,-0.775286,-0.832925,-2.52693,-2.76962,0.993881,1.03829,0.765063,0.538859,0.729403,1.03983,1.02197,0.8945
6584,0.687751,0.641568,0.708772,0.659847,0.206851,0.0703349,0.142216,0.0872381,0.959303,1.03857,0.522898,0.444812,0.715504,0.657117,0.287146,0.256152,0.24872,0.177454,0.912763,0.908625,0.97313,0.841173,-0.305297,-0.227686,-1.61948,-1.29568,-0.427403,-0.313238,0.40752,0.278681,0.86731,0.621786,1.87264,1.91282,-1.14092,-1.37474,-0.187144,0.118307,0.374297,0.251653
6585,0.233235,0.18647,0.19,0.142205,0.311391,0.230324,0.310706,0.211406,0.47648,0.603601,0.595725,0.552712,0.487367,0.477611,0.218734,0.185183,0.308841,0.326406,0.507403,0.502234,-0.286725,-0.424358,0.735767,0.816669,1.09273,1.4082,-0.524673,-0.38795,-0.0819223,-0.208101,1.0558,0.804896,-0.328879,-0.29221,-2.00626,-2.2382,1.07659,1.38877,-1.05735,-1.18252
6586,0.134767,0.16668,0.808697,0.762689,0.453454,0.390313,0.387428,0.335574,0.0899549,0.168633,0.299046,0.253912,0.358149,0.298105,0.407641,0.46688,0.77702,0.796957,0.531222,0.524424,2.21464,2.07789,-1.14997,-1.0732,-0.216427,0.0963018,1.98777,2.12318,-1.11785,-1.24712,-2.55685,-2.80781,0.0505262,0.0902358,-0.775054,-1.00676,0.835844,1.15125,-0.581406,-0.709607
6587,0.193534,0.146891,0.930455,0.885845,0.685902,0.550301,0.768677,0.718678,0.865729,0.942804,0.675013,0.628813,0.845525,0.784846,0.779787,0.748577,0.665258,0.684969,0.111682,0.103835,0.610869,0.475077,-0.0313412,-0.0199194,0.632893,0.942796,-2.30578,-2.16541,-1.90565,-2.04027,-0.0601263,-0.314322,0.876066,0.91777,-0.225932,-0.460569,-0.345916,-0.0372423,-1.54346,-1.66818
6588,0.175696,0.127101,0.615,0.51297,0.171388,0.0367377,0.0424618,-0.00896399,0.0597846,0.136659,0.73049,0.626468,0.752136,0.690989,0.238033,0.207154,0.0216246,0.0402908,0.423664,0.396665,-0.13262,-0.267054,0.95105,1.03336,0.323664,0.638278,-0.875014,-0.735926,1.60524,1.46573,-0.819155,-1.07333,-0.742142,-0.705479,2.0088,1.77763,0.822289,1.12397,-0.970697,-1.16702
6589,0.366131,0.317481,0.183469,0.140095,0.8696,0.737101,0.511916,0.458981,0.765158,0.842376,0.699379,0.624123,0.903024,0.841413,0.837065,0.805444,0.8885,0.907012,0.695512,0.689495,-0.428024,-0.54227,-0.506355,-0.43239,1.02277,1.33024,2.25847,2.40318,2.16077,2.02048,-0.306094,-0.566235,0.574721,0.606075,0.219767,-0.00830501,0.54763,0.854487,-0.538445,-0.665868
6590,0.273476,0.225416,0.853356,0.809642,0.549444,0.320545,0.561224,0.507911,0.568085,0.645255,0.669881,0.621777,0.67499,0.615045,0.840086,0.811099,0.166533,0.186186,0.328404,0.323335,-0.547966,-0.817487,0.28745,0.368938,1.13829,1.45107,1.32463,1.46966,-1.08814,-1.23306,-0.242552,-0.523082,0.365432,0.393633,-0.089991,-0.321636,-1.68884,-1.379,-1.11098,-1.23245
6591,0.483765,0.436746,0.930472,0.888725,0.0376559,-0.0960097,0.962656,0.907258,0.130899,0.206748,0.960588,0.910944,0.715457,0.582211,0.622766,0.594011,0.684338,0.706627,0.615899,0.61144,-0.954021,-1.0927,0.463573,0.540206,0.840977,1.14655,-0.98639,-0.843083,0.10094,-0.0468859,-0.220094,-0.479929,1.07302,1.10067,0.260862,0.0240702,-0.561321,-0.248722,-0.196662,-0.261209
6592,0.924813,0.879424,0.70673,0.664447,0.981722,0.848638,0.328514,0.275042,0.890814,0.965373,0.151072,0.103721,0.61108,0.549377,0.15921,0.132603,0.739796,0.821136,0.351761,0.346467,-0.190504,-0.335064,-0.698815,-0.625844,-2.17766,-1.87179,-1.38311,-1.23276,-0.344118,-0.490459,0.128092,-0.127304,-0.406374,-0.382978,-0.0151868,-0.256888,-0.577788,-0.269668,0.834859,0.710036
6593,0.494797,0.489337,0.202205,0.161049,0.694103,0.558888,0.0378111,-0.0174708,0.705149,0.698783,0.525297,0.478621,0.0465626,-0.0124352,0.100984,0.0769373,0.913407,0.935646,0.629721,0.624281,-0.756179,-0.893633,0.352625,0.418511,-1.36142,-1.05639,1.53825,1.69003,0.643671,0.496602,1.38957,1.12796,-1.05057,-1.02712,0.130335,-0.109399,-1.10263,-0.802255,0.105658,-0.0216247
6594,0.146601,0.0992498,0.554435,0.511552,0.0459529,-0.0899134,0.211132,0.0629142,0.392346,0.432192,0.24461,0.24003,0.494807,0.433711,0.363135,0.259584,0.126264,0.150769,0.372131,0.431329,0.0909946,-0.0462719,-0.795569,-0.732383,-0.843305,-0.535361,-1.26719,-1.12004,0.628488,0.486174,-0.603513,-0.85923,0.599769,0.621279,1.52154,1.27903,-1.00607,-0.699616,0.296104,0.165204
6595,0.955131,0.907728,0.61726,0.575625,0.148027,0.0114098,0.196571,0.143299,0.0927822,0.165602,0.0471641,0.00143937,0.707045,0.645242,0.47627,0.442231,0.614191,0.641563,0.241895,0.238377,-1.3192,-1.45018,-0.488998,-0.368626,-1.00161,-0.686438,1.15665,1.30846,2.82645,2.68918,0.108286,-0.140041,-0.530299,-0.50417,1.27409,1.02754,-0.588927,-0.287191,-0.357004,-0.491236
6596,0.268122,0.221001,0.437353,0.395727,0.878766,0.742405,0.953164,0.901732,0.861818,0.93465,0.936551,0.892432,0.484258,0.424082,0.650887,0.624879,0.853804,0.883057,0.754802,0.751894,-0.286027,-0.419325,-0.0663421,-0.00486993,0.787636,1.09693,-0.925213,-0.779378,0.679565,0.542341,-0.803812,-1.05238,-0.648124,-0.712954,2.01922,1.77162,-1.01966,-0.711561,-0.11718,-0.244874
6597,0.102208,0.0994213,0.607517,0.659682,0.688885,0.550369,0.969512,0.919649,0.922259,0.997142,0.443194,0.397214,0.534549,0.59369,0.831572,0.807526,0.589879,0.685002,0.237797,0.236543,0.473094,0.338314,-0.32136,-0.263841,-1.06803,-0.760118,1.39853,1.5471,-0.986509,-1.12686,1.33651,1.08448,-0.948174,-0.921737,0.966452,0.724044,0.207776,0.512015,-1.82515,-1.95493
6598,0.0258873,-0.0221587,0.966234,0.923638,0.2087,0.0706673,0.674055,0.622065,0.654541,0.821922,0.212075,0.163916,0.752546,0.763299,0.453793,0.430654,0.455433,0.486948,0.823309,0.820831,0.91961,0.788769,-2.35526,-2.29471,2.18584,2.48794,0.0179784,0.168898,1.2894,1.14426,0.988977,0.730881,0.646633,0.680535,-1.01532,-1.25293,1.77911,2.07985,-1.0693,-1.19194
6599,0.116541,0.00803337,0.760893,0.704662,0.80104,0.66369,0.971531,0.917336,0.485199,0.646702,0.540415,0.494025,0.991862,0.932907,0.800181,0.777898,0.568043,0.670617,0.537859,0.535388,-0.797518,-0.922415,-0.775641,-0.719537,0.0552262,0.361806,-0.605649,-0.450413,-0.928235,-1.06693,0.0734979,-0.181458,1.97271,2.00689,1.12668,0.894486,-1.64579,-1.34463,2.57811,2.45235
6600,0.060662,0.0382254,0.441895,0.485686,0.499999,0.364507,0.747418,0.669652,0.395533,0.471482,0.505052,0.456697,0.927004,0.868777,0.33665,0.31649,0.82137,0.854287,0.81044,0.808558,1.04222,0.913182,0.325149,0.375349,-0.209376,0.102995,-2.29371,-2.14112,0.132764,-0.00352169,-2.53264,-2.78953,-0.53024,-0.501341,0.599931,0.368236,-0.0113763,0.287017,-1.78119,-1.90235
6601,0.265577,0.0684175,0.309307,0.26671,0.420686,0.284383,0.578477,0.421969,0.587988,0.58456,0.745926,0.699349,0.14665,0.0881002,0.147311,0.129545,0.330517,0.36427,0.153319,0.152253,2.01568,1.88443,-0.0632456,-0.020426,-1.97468,-1.65832,1.62483,1.78317,1.49352,1.34909,0.234805,-0.0174332,-0.830555,-0.806419,-0.131098,-0.273958,-0.182315,0.109445,-0.691478,-0.805648
6602,0.146656,0.0986096,0.506949,0.464132,0.975615,0.836899,0.228482,0.174286,0.619937,0.697639,0.166427,0.119586,0.253467,0.193213,0.550862,0.436095,0.118826,0.237233,0.831629,0.831113,-0.753255,-0.880441,1.46138,1.50729,-0.701726,-0.386227,0.902803,1.05389,-1.03634,-1.17358,-1.48555,-1.73973,0.548381,0.564519,-0.689085,-0.916152,0.749043,1.03701,1.67241,1.55415
6603,0.0297784,-0.0200565,0.251034,0.208078,0.964373,0.814914,0.270028,0.287071,0.413182,0.491152,0.0498727,0.00220096,0.954011,0.895629,0.762587,0.742644,0.0772644,0.110195,0.0104247,0.0104233,-0.369208,-0.491438,-0.231271,-0.190288,-1.11532,-0.798725,-1.63519,-1.47969,0.767592,0.625939,1.09989,0.851478,-0.809918,-0.793825,1.76175,1.5285,-1.80768,-1.51945,1.95057,1.83224
6604,0.790337,0.739785,0.901322,0.858114,0.944533,0.792929,0.452918,0.399856,0.707345,0.783106,0.654177,0.607987,0.125344,0.0676543,0.783622,0.763352,0.25144,0.285162,0.284013,0.283593,-1.06788,-1.18806,-2.14337,-2.09648,-1.7543,-1.44485,1.16412,1.32092,-0.265491,-0.413077,1.91576,1.66276,-0.161517,-0.146925,-1.55992,-1.79752,0.168639,0.461856,1.86002,1.74779
6605,0.0596803,0.0105404,0.725524,0.631245,0.805642,0.770945,0.143701,0.0920704,0.175335,0.24996,0.0643133,0.0181962,0.903279,0.843568,0.030594,0.0116444,0.0981097,0.131566,0.089404,0.0880226,0.283543,0.169387,0.0796114,0.126221,-1.6294,-1.32403,1.54456,1.69935,2.10348,1.95645,0.444438,0.197618,-0.15033,-0.132391,0.645501,0.411586,-0.432644,-0.131471,0.889606,0.774656
6606,0.720596,0.672272,0.449469,0.404376,0.887677,0.74896,0.0368142,-0.0155537,0.313083,0.389724,0.533128,0.413989,0.584625,0.548266,0.807852,0.789438,0.865384,0.897972,0.372347,0.371379,-0.554886,-0.667751,3.15282,3.20886,1.59293,1.89216,-0.123136,0.0377591,-0.0717062,-0.223672,-0.079911,-0.327386,-0.440462,-0.421963,-0.161873,-0.391646,0.177923,0.484105,1.53967,1.43171
6607,0.863438,0.795703,0.604094,0.462928,0.0476303,-0.0914935,0.456586,0.316822,0.136646,0.213092,0.853877,0.809783,0.216313,0.252964,0.412136,0.392932,0.659558,0.663921,0.916171,0.91551,0.0298379,-0.164788,0.323608,0.380588,-0.655072,-0.363196,-0.990858,-0.833686,-1.45174,-1.60292,-1.69299,-1.94391,-0.965475,-0.945139,0.597362,0.36727,-0.336215,-0.0324109,0.886295,0.859617
6608,0.9661,0.919134,0.643709,0.521479,0.541543,0.401904,0.700899,0.649198,0.827601,0.904351,0.774838,0.731554,0.0173735,-0.0423375,0.722062,0.671428,0.396748,0.429871,0.894201,0.891559,0.444707,0.338175,1.28079,1.33334,-0.312282,-0.0254194,1.2647,1.42603,-1.65913,-1.81602,1.66397,1.40909,-0.721995,-0.701137,1.83937,1.61449,1.35554,1.66331,0.388075,0.287526
6609,0.844718,0.807043,0.624392,0.580031,0.263733,0.123321,0.0322771,-0.0183694,0.91432,0.992874,0.913561,0.87149,0.98301,0.923538,0.967691,0.949924,0.628768,0.661866,0.433272,0.4307,1.18454,1.07945,-0.464096,-0.412572,-0.884119,-0.591992,-0.189407,-0.0303089,0.475906,0.319548,-0.850542,-1.104,-0.213343,-0.194112,0.38512,0.16744,0.106486,0.412597,0.449757,0.281189
6610,0.798473,0.694952,0.278569,0.235028,0.754263,0.611588,0.989316,0.938671,0.294065,0.373482,0.354641,0.312642,0.494823,0.437235,0.752995,0.653882,0.103981,0.137799,0.586009,0.582802,0.672056,0.564806,0.253274,0.309504,0.377105,0.664852,0.829872,0.982188,0.870736,0.707948,1.28609,1.03286,0.551093,0.572985,-0.473197,-0.696019,0.840777,1.08529,0.369528,0.274852
6611,0.629828,0.582861,0.654443,0.609236,0.874774,0.732736,0.44896,0.400583,0.639868,0.720216,0.89196,0.849964,0.941103,0.883381,0.377747,0.357839,0.864234,0.899343,0.0750705,0.0718931,-0.757748,-0.870858,-0.481024,-0.422509,-0.68529,-0.401002,0.886549,1.04057,-1.22488,-1.39265,-1.32886,-1.57522,0.870644,0.894737,0.833505,0.61297,1.45776,1.75798,-0.0798722,-0.170999
6612,0.838899,0.794191,0.815017,0.768186,0.571192,0.42866,0.805126,0.754474,0.682803,0.762396,0.271276,0.229793,0.490838,0.450411,0.637447,0.618472,0.456291,0.473197,0.347832,0.345062,0.921122,0.813098,-0.84035,-0.786922,0.844918,1.12981,0.550721,0.712893,1.68311,1.52334,0.447729,0.204783,-0.578262,-0.556681,1.2189,1.00576,-0.901085,-0.609009,0.622346,0.530999
6613,0.790716,0.758303,0.172891,0.127889,0.946708,0.806058,0.60034,0.547598,0.0936359,0.173682,0.320455,0.280528,0.0747612,0.0174407,0.617642,0.636056,0.00907563,0.047052,0.949733,0.948845,-0.503772,-0.606475,-0.219919,-0.171005,-1.38782,-1.10953,0.699513,0.863649,-0.914164,-1.07007,-0.119504,-0.290733,-0.0604534,-0.0349254,-1.07978,-1.29699,-0.0627214,0.225307,0.768136,0.673056
6614,0.728701,0.722415,0.602822,0.557459,0.595809,0.455977,0.756084,0.704097,0.00489351,0.0829783,0.877069,0.836809,0.925142,0.869245,0.719364,0.653639,0.500295,0.537846,0.238571,0.23695,-1.03425,-1.13439,0.053548,0.108262,-1.01024,-0.726496,0.28882,0.458485,-0.50563,-0.666517,-0.53839,-0.786249,1.0045,1.02409,0.558784,0.336586,0.430446,0.715703,0.56128,0.468713
6615,0.731235,0.686527,0.317538,0.271799,0.95755,0.818355,0.91295,0.860595,0.70578,0.784049,0.595497,0.554056,0.554451,0.563121,0.691827,0.671223,0.498958,0.555071,0.363783,0.362939,-0.0820462,-0.18029,1.20771,1.2613,-0.360239,-0.0816276,0.362044,0.531595,0.630435,0.47422,1.36493,1.11523,0.126469,0.147341,-0.94863,-1.17141,-1.74998,-1.47131,-1.51984,-1.61095
6616,0.25372,0.210878,0.838525,0.794807,0.486216,0.365995,0.0737374,0.0232696,0.0248975,0.103863,0.915082,0.874163,0.190501,0.256998,0.180947,0.159953,0.61884,0.572295,0.731582,0.732879,-0.446706,-0.538212,-3.68169,-3.6281,-1.08871,-0.807227,-0.362155,-0.19768,1.0884,0.938338,1.61824,1.37366,-2.40723,-2.38059,0.146161,-0.133154,-1.55225,-1.27874,0.0437056,-0.0511959
6617,0.812063,0.767427,0.0736829,0.0273266,0.0551555,-0.0863651,0.996433,0.944392,0.313264,0.391135,0.385487,0.344245,0.00809124,-0.0491254,0.703815,0.682259,0.550608,0.58952,0.376952,0.377093,0.198098,0.112211,-1.08251,-1.03654,0.060635,0.342503,-0.643405,-0.480154,-0.123576,-0.272806,-1.22886,-1.47759,-1.33933,-1.30811,1.12179,0.905098,-2.50598,-2.23337,-0.00653929,-0.104415
6618,0.241957,0.196807,0.417531,0.321271,0.771698,0.629622,0.0436054,-0.010242,0.979501,1.05638,0.274641,0.230883,0.693831,0.638396,0.284221,0.342458,0.431906,0.472349,0.591388,0.571158,0.618076,0.532062,-1.25476,-1.20336,-0.597978,-0.31949,0.410313,0.576391,-1.33389,-1.48395,-0.895091,-1.14306,2.18421,2.21623,0.716507,0.501341,1.56957,1.84555,0.88745,0.794141
6619,0.774275,0.728146,0.68492,0.615216,0.185533,0.0459183,0.275114,0.205393,0.472282,0.548181,0.394251,0.460677,0.338226,0.283249,0.0237154,0.00265755,0.664672,0.704344,0.76408,0.765223,2.79883,2.70709,-2.25636,-2.19862,-0.332678,-0.0570248,-0.165361,0.00181778,-0.0860171,-0.234847,0.364669,0.112204,-0.360981,-0.329802,-0.222265,-0.439687,1.14371,1.34259,-0.261552,-0.349996
6620,0.950982,0.903553,0.955518,0.909161,0.794183,0.653781,0.472502,0.421027,0.853393,0.931594,0.667998,0.69047,0.686677,0.63095,0.691929,0.6737,0.551739,0.592356,0.230238,0.229382,-1.96472,-2.05646,-0.133434,-0.0747427,-0.805643,-0.529508,-0.0344858,0.135833,-0.576374,-0.721629,-1.45417,-1.70444,-1.18584,-1.15585,-0.572088,-0.782153,0.562155,0.839637,-1.17041,-1.26374
6621,0.163605,0.115136,0.906305,0.859294,0.23632,0.0949343,0.370359,0.318453,0.871347,0.866461,0.961153,0.920264,0.583955,0.5876,0.86011,0.840644,0.996458,1.03756,0.247564,0.244729,-0.438494,-0.527094,0.760312,0.817007,1.28208,1.55268,-0.640688,-0.469687,0.315817,0.174114,-0.478817,-0.724923,-0.588389,-0.556151,-1.76295,-1.96737,-0.308925,-0.0341463,-0.0137946,-0.104682
6622,0.358341,0.224334,0.628069,0.57978,0.5409,0.460085,0.657928,0.603818,0.723606,0.801328,0.481489,0.440126,0.625367,0.54425,0.00901212,-0.00921741,0.894069,1.02451,0.510505,0.562645,-1.90333,-1.99107,0.40147,0.555203,-1.11218,-0.846768,-0.2728,-0.10525,0.944976,0.807,-0.033907,-0.278581,1.04433,1.07762,0.235542,0.0259743,0.686224,0.957339,-0.516097,-0.611171
6623,0.38052,0.333533,0.345314,0.300266,0.965789,0.825235,0.721048,0.762375,0.137288,0.212614,0.441907,0.402798,0.556027,0.5009,0.403681,0.443384,0.969207,1.01146,0.884878,0.88056,0.54764,0.464768,0.236605,0.293398,-0.109898,0.152726,-0.322566,-0.154942,0.697812,0.563089,0.824261,0.577806,0.0875363,0.123721,0.616905,0.404685,-0.293995,-0.0258777,0.971614,0.870821
6624,0.854465,0.805423,0.611256,0.566233,0.258019,0.115914,0.97649,0.920931,0.826152,0.903873,0.856175,0.817372,0.181819,0.124937,0.914214,0.895985,0.579728,0.597537,0.40379,0.399998,0.782372,0.699583,-0.442234,-0.392844,-0.886392,-0.617972,1.24738,1.41938,-0.839837,-0.968058,0.98708,0.74509,0.704761,0.739511,-0.774951,-0.982976,1.57634,1.84324,-0.588374,-0.684958
6625,0.464164,0.477367,0.405368,0.361288,0.824071,0.683997,0.454749,0.397994,0.945246,1.02327,0.772526,0.759052,0.208454,0.117999,0.680621,0.663695,0.142724,0.183615,0.415017,0.410715,0.230995,0.141014,0.782747,0.827529,1.04901,1.3202,-0.915456,-0.74567,1.41962,1.28458,-0.109446,-0.350829,-0.408222,-0.314382,0.75505,0.54123,-0.600642,-0.33025,-0.858737,-0.949511
6626,0.196515,0.149311,0.728471,0.59319,0.14536,0.00429071,0.747357,0.688446,0.113932,0.190875,0.70143,0.700732,0.167062,0.111062,0.797551,0.820391,0.735393,0.774254,0.921208,0.914673,-0.569447,-0.665417,-0.0145625,0.0442162,-0.473269,-0.20653,-0.195975,-0.0294619,1.69487,1.56563,0.769688,0.520955,-1.40032,-1.36827,0.727566,0.517964,0.236526,0.504065,-0.450732,-0.53745
6627,0.17428,0.129231,0.871356,0.825092,0.0355773,-0.107242,0.190605,0.130207,0.672097,0.750145,0.70207,0.642411,0.551202,0.492517,0.994365,0.977086,0.481681,0.520549,0.668441,0.694987,0.262754,0.165838,-0.788493,-0.739096,0.303179,0.576177,-0.0835251,0.0892711,-0.464085,-0.599872,0.895694,0.64347,0.939237,0.964955,-1.22725,-1.44241,-0.00587097,0.266544,0.855353,0.774686
6628,0.89192,0.845115,0.349396,0.302366,0.336805,0.194005,0.974637,0.914063,0.854922,0.935202,0.622104,0.584091,0.355752,0.333993,0.868603,0.850337,0.81427,0.851088,0.459708,0.475302,-1.19527,-1.29814,0.989606,1.03694,0.465244,0.742679,-0.722861,-0.646574,0.344035,0.200609,1.83411,1.57793,-0.276969,-0.252575,0.0818085,-0.133425,-1.00845,-0.732996,-0.256657,-0.339446
6629,0.288388,0.239677,0.252571,0.204676,0.175333,0.0320753,0.772091,0.696595,0.531986,0.567791,0.148538,0.109128,0.236401,0.175468,0.0887236,0.068797,0.0123167,0.0484028,0.262153,0.255617,-0.707529,-0.813963,1.98366,2.0366,-0.417241,-0.179674,-1.5601,-1.38242,-1.07566,-1.222,1.0707,0.818925,0.656451,0.684292,-0.260386,-0.47589,-0.225444,0.0528898,-0.225523,-0.301107
6630,0.285467,0.235035,0.47047,0.459504,0.233001,0.0888937,0.552043,0.479127,0.11899,0.20038,0.717495,0.68018,0.634368,0.571947,0.538588,0.475105,0.550253,0.589079,0.620331,0.615745,0.363136,0.262457,0.569823,0.620206,-1.37594,-1.10203,0.317561,0.489403,0.153613,0.0114987,1.17293,0.925712,1.06851,1.09958,0.149211,-0.0862499,-0.891091,-0.618063,-1.99844,-2.07011
6631,0.510558,0.454086,0.763859,0.714332,0.0608588,-0.0829451,0.32433,0.26166,0.616742,0.698305,0.362604,0.322614,0.0668693,0.00453462,0.899961,0.881413,0.229871,0.269802,0.215316,0.209354,-0.146553,-0.26799,-0.506067,-0.453886,-1.31418,-1.03965,-0.57452,-0.397003,-1.02947,-1.17686,0.883178,0.633808,0.453884,0.567322,0.512698,0.30339,1.43038,1.70927,0.0678284,-0.00230869
6632,0.72113,0.673138,0.518827,0.468191,0.89714,0.752507,0.723933,0.661007,0.874457,0.955156,0.502392,0.560319,0.634522,0.571044,0.0222203,0.00435773,0.909602,0.947656,0.875346,0.867738,-0.704331,-0.798436,-0.143233,-0.0986905,1.5358,1.81624,2.267,2.44154,1.86438,1.71561,0.308239,0.0633224,0.00550768,0.0350678,-1.29477,-1.50333,-1.30002,-1.01875,1.36941,1.29371
6633,0.741192,0.635132,0.7423,0.681934,0.324059,0.178858,0.534247,0.473566,0.296801,0.376587,0.838897,0.798024,0.984561,0.923027,0.215625,0.0924933,0.395226,0.521511,0.151396,0.145258,-0.930907,-1.09315,-1.97672,-1.92577,-0.83304,-0.551792,0.48205,0.65701,-0.305218,-0.449894,0.325505,0.0776883,-0.0178283,0.00629636,0.334189,0.130249,-1.56883,-1.28824,-1.59317,-1.67345
6634,0.64414,0.597127,0.94882,0.895677,0.780064,0.632367,0.923174,0.862336,0.353198,0.433615,0.862505,0.819959,0.039675,-0.0211508,0.257026,0.180629,0.056848,0.0953653,0.98832,0.984032,-1.28675,-1.38786,-0.17803,-0.121381,0.0505192,0.325416,0.163899,0.344001,-1.28679,-1.42882,-0.440748,-0.695301,0.748512,0.773394,0.562426,0.287714,-0.673576,-0.393189,0.336644,0.254282
6635,0.144803,0.0959979,0.877545,0.864285,0.275845,0.12823,0.591393,0.554274,0.721596,0.801281,0.538399,0.496735,0.251093,0.222758,0.284774,0.268765,0.458706,0.496303,0.212745,0.211149,1.15734,1.05352,0.103125,0.157886,-0.929517,-0.649476,1.22242,1.40055,1.55564,1.41586,-0.868574,-1.12643,1.1115,1.14192,0.649118,0.445178,-2.53754,-2.2648,-0.630688,-0.718848
6636,0.461454,0.359532,0.782485,0.832893,0.906056,0.756727,0.305813,0.246212,0.803703,0.885121,0.853895,0.719521,0.591026,0.466668,0.204819,0.187911,0.286288,0.37813,0.287579,0.286956,-1.77599,-1.88204,1.08346,1.14127,-0.302109,-0.0212461,-2.16064,-1.98809,1.05379,0.91173,1.69531,1.43295,1.07369,1.0971,1.65016,1.45216,0.478549,0.757148,1.30648,1.22364
6637,0.769429,0.623067,0.854645,0.801501,0.987176,0.838657,0.840807,0.778835,0.100661,0.184692,0.983154,0.942306,0.77081,0.710577,0.923141,0.905552,0.222709,0.259957,0.157535,0.157743,0.212941,0.106415,0.622282,0.684494,-0.277187,0.00939805,1.05488,1.2316,1.34885,1.20719,-0.234486,-0.491825,0.13075,0.156995,1.0071,0.816569,-0.680954,-0.400596,1.15122,1.03813
6638,0.937305,0.886602,0.544568,0.490911,0.763361,0.596223,0.139144,0.0760773,0.689153,0.77466,0.494464,0.45205,0.21085,0.148765,0.0106938,-0.00700259,0.794339,0.829321,0.475644,0.475964,0.823339,0.709954,-0.32747,-0.263905,0.00624508,0.287,-0.125418,0.0525798,0.121377,-0.0166899,-0.532309,-0.83958,0.109854,0.143014,0.109722,-0.0795909,-0.387284,-0.113864,0.929158,0.852628
6639,0.914209,0.861319,0.739672,0.68369,0.391508,0.353788,0.990262,0.927938,0.321674,0.40589,0.805663,0.681557,0.577581,0.515648,0.627906,0.607911,0.177099,0.213517,0.018277,0.0197478,-2.6141,-2.72617,-0.136211,-0.07832,-0.217754,0.0581859,0.835262,1.01651,-0.373341,-0.503471,-0.992003,-1.18734,-2.04788,-2.01429,-0.187165,-0.375126,-2.02034,-1.74137,-1.12146,-1.19544
6640,0.261916,0.209719,0.378528,0.324476,0.259873,0.111354,0.755582,0.71181,0.697662,0.712971,0.953477,0.911063,0.582997,0.61529,0.722598,0.703641,0.638754,0.673814,0.674109,0.674294,1.22242,1.11372,0.525979,0.584846,-1.46864,-1.19197,-0.616022,-0.439828,-0.0421113,-0.176853,-1.27416,-1.53509,0.36665,0.400157,-0.731527,-0.916653,-0.972128,-0.687666,-0.432839,-0.509381
6641,0.972691,0.92035,0.598003,0.541806,0.731735,0.584949,0.585677,0.495681,0.935181,1.02005,0.702327,0.658073,0.778822,0.714932,0.301371,0.356169,0.372456,0.408956,0.556345,0.558502,1.41101,1.30267,-0.955698,-0.895344,0.653549,0.936355,-0.857454,-0.673946,0.686415,0.548822,-1.20614,-1.40659,-0.0579583,-0.0294158,-1.50165,-1.6891,-0.425526,-0.133022,-0.511283,-0.593833
6642,0.597495,0.59621,0.269159,0.21155,0.200299,0.0511332,0.340896,0.279552,0.712701,0.797893,0.126866,0.0837088,0.611546,0.545253,0.0272319,0.00869644,0.359291,0.393534,0.98305,0.987102,-0.00243431,-0.1169,0.92851,0.990142,-0.0285358,0.257862,1.29765,1.48141,0.770052,0.631008,-1.01899,-1.27809,0.795099,0.827327,-0.29621,-0.485493,-0.367395,-0.0772826,0.247102,0.169158
6643,0.324734,0.272071,0.335732,0.280086,0.840737,0.690274,0.603161,0.54038,0.855223,0.933529,0.0908459,0.0397362,0.0355636,-0.0318198,0.11056,0.0894683,0.935236,0.968262,0.45303,0.455646,2.1447,2.02549,0.281234,0.334795,-0.107594,0.182107,0.616232,0.798582,0.611723,0.47777,1.04097,0.78292,0.307477,0.335795,-0.447752,-0.629953,0.263076,0.554036,-1.92615,-2.0025
6644,0.161929,0.140218,0.128311,0.070501,0.957628,0.80746,0.380046,0.31749,0.984136,1.06916,0.036548,-0.00423628,0.100464,0.107096,0.489594,0.466886,0.187342,0.220833,0.243605,0.325608,0.217238,0.0961907,1.94467,2.00318,-0.388779,-0.0992878,1.73573,1.91575,0.454977,0.324532,-0.661911,-0.923771,0.534689,0.563975,0.882748,0.695072,-1.01301,-0.728731,0.334985,0.257803
6645,0.0617672,0.0083657,0.205061,0.180493,0.614466,0.463176,0.681181,0.522095,0.366115,0.449772,0.567745,0.432021,0.312501,0.246012,0.295283,0.274766,0.283739,0.319367,0.14778,0.195569,-0.901593,-1.01747,1.59216,1.65321,-0.667614,-0.380683,1.52221,1.69637,0.716309,0.59005,-0.256426,-0.525192,-1.91748,-1.88306,-1.01357,-1.20255,0.110004,0.401547,0.363379,0.280274
6646,0.947352,0.895466,0.407372,0.290485,0.601449,0.449688,0.789532,0.7267,0.0826799,0.167353,0.909074,0.868278,0.796862,0.72826,0.593907,0.57141,0.963632,0.997221,0.0625124,0.0655303,0.785075,0.666489,0.0651439,0.126059,1.11448,1.40268,-0.920937,-0.752494,-1.4485,-1.57546,1.9893,1.7249,0.295781,0.335637,1.13477,0.944864,-1.32683,-1.03781,-2.16421,-2.24328
6647,0.0313606,-0.0205025,0.460387,0.400477,0.15145,0.000618384,0.100263,0.0396152,0.12685,0.235714,0.182923,0.143039,0.824294,0.756072,0.460665,0.439622,0.434113,0.468055,0.183531,0.186979,0.529413,0.416074,0.071978,0.128363,0.515962,0.801461,1.07163,1.23159,0.034364,-0.0986772,0.808233,0.538783,0.516571,0.548472,-0.640348,-0.826182,-0.4028,-0.110242,-1.72361,-1.79998
6648,0.259263,0.188686,0.398964,0.341287,0.31231,0.161887,0.0403254,-0.0229653,0.222215,0.304076,0.591553,0.488193,0.428063,0.360014,0.953011,0.930907,0.661101,0.691084,0.852684,0.856374,-0.536382,-0.651419,-0.870064,-0.820036,0.578785,0.863838,0.236845,0.391995,-0.245469,-0.373412,-0.761398,-1.03198,1.52108,1.54834,0.813682,0.62133,-0.434888,-0.146296,-2.35427,-2.4259
6649,0.447517,0.397874,0.591045,0.575679,0.918839,0.76975,0.609072,0.544718,0.89791,0.980759,0.871406,0.833347,0.536144,0.427314,0.720271,0.7586,0.880533,0.914112,0.155184,0.158717,-0.0220781,-0.137384,3.14595,3.19311,1.16497,1.44727,-0.00775785,0.184169,1.36107,1.24013,-1.84069,-2.11115,1.0256,1.05681,-0.608494,-0.795266,-0.233543,0.0619458,1.68101,1.61575
6650,0.22382,0.174315,0.867046,0.810071,0.730259,0.582272,0.207474,0.143104,0.962753,1.04325,0.766226,0.636754,0.564856,0.494613,0.622855,0.586292,0.593855,0.590209,0.239428,0.160941,-0.482428,-0.602701,0.00599783,0.0571131,0.285254,0.568097,-0.17639,-0.0236572,0.22527,0.109799,-0.0967266,-0.364089,1.30279,1.33237,0.25598,0.0706739,-0.363129,-0.02494,-0.0879091,-0.153254
6651,0.2274,0.179465,0.0051087,-0.0512256,0.745343,0.598699,0.301293,0.236776,0.0256286,0.106224,0.480155,0.44016,0.907056,0.836595,0.530086,0.413984,0.23465,0.266306,0.130453,0.163165,0.746115,0.62728,0.0712294,0.119803,-1.88769,-1.6066,1.2423,1.38973,-0.00353519,-0.120215,0.259654,-0.0907264,-0.214731,-0.183566,0.553538,0.369963,-0.410637,-0.111826,0.456912,0.395748
6652,0.75741,0.710804,0.290748,0.235218,0.548115,0.40228,0.682641,0.61988,0.380701,0.548615,0.0863473,0.0480268,0.402323,0.330276,0.26378,0.241676,0.423416,0.456801,0.179607,0.165389,-0.731698,-0.851282,1.63926,1.69498,0.761518,1.03961,-1.70825,-1.5558,-1.16594,-1.2813,0.452704,0.182636,0.614099,0.643968,1.8587,1.67895,-0.318001,-0.0238161,-0.567871,-0.623539
6653,0.929759,0.881654,0.130611,0.0766893,0.354678,0.20586,0.847453,0.784721,0.911911,0.991007,0.582758,0.484284,0.288021,0.215863,0.787113,0.763983,0.0096055,0.0427343,0.165349,0.167612,0.167164,0.0438334,-0.120271,-0.0675431,0.256547,0.535981,0.65147,0.811673,0.228697,0.119226,-0.000383768,-0.26571,0.342644,0.370061,-0.323203,-0.50345,0.29886,0.59176,0.346962,0.289193
6654,0.596701,0.465732,0.637654,0.584242,0.961057,0.813723,0.0318855,-0.0322107,0.316,0.396591,0.960227,0.920541,0.849845,0.777376,0.78573,0.763619,0.587129,0.622551,0.574763,0.576926,-1.03895,-1.16016,-0.137877,-0.0823401,0.639157,0.919014,-1.22015,-1.05313,0.60617,0.493738,0.175863,-0.0825995,-0.187179,-0.153115,0.750176,0.564706,1.22958,1.51933,0.56375,0.505442
6655,0.0955239,0.0498104,0.548137,0.495878,0.665851,0.519753,0.156404,0.0926597,0.507428,0.595539,0.312959,0.275199,0.158524,0.0854506,0.0136839,-0.0079052,0.852421,0.889178,0.373607,0.376187,-0.115633,-0.249169,0.659482,0.718988,-0.283965,-0.00578025,1.50467,1.67442,-0.339025,-0.45434,-0.430529,-0.686533,-1.98736,-1.95197,-0.381024,-0.560365,-0.895098,-0.601689,0.31748,0.256152
6656,0.996981,0.950941,0.0798893,0.0276181,0.0888314,-0.059076,0.733164,0.67054,0.811928,0.794486,0.00385567,-0.0338431,0.43445,0.361548,0.920916,0.899622,0.67882,0.691123,0.936652,0.939575,0.788642,0.661823,-0.94442,-0.885351,-0.444103,-0.172195,0.675732,0.85086,0.606945,0.486889,0.822593,0.568732,1.68201,1.71294,0.288471,0.18991,-0.293414,-0.00220042,0.575828,0.51755
6657,0.928502,0.884662,0.950171,0.89745,0.672773,0.524438,0.537975,0.473128,0.913276,0.993434,0.123532,0.0857748,0.474108,0.399963,0.655987,0.632567,0.455773,0.493068,0.333662,0.338742,-1.41044,-1.53864,-0.378572,-0.391428,-1.81133,-1.53145,0.208893,0.382842,1.01917,0.905506,-0.0654445,-0.32387,0.30271,0.339874,1.12711,0.940185,0.959421,1.25264,-1.84825,-1.91196
6658,0.120579,0.0783877,0.162203,0.109568,0.578036,0.354182,0.840965,0.777546,0.654192,0.73638,0.460673,0.420198,0.0694384,-0.0061243,0.812253,0.789965,0.849647,0.888945,0.111967,0.118093,0.0756429,-0.055006,0.0447232,0.102495,-0.18338,0.0946892,0.948178,1.11589,-0.104519,-0.224821,-0.967638,-1.21647,-1.29953,-1.27007,-1.54645,-1.73507,-0.913446,-0.61897,-1.39758,-1.45453
6659,0.531117,0.486248,0.12845,0.075507,0.331467,0.183926,0.31222,0.249302,0.813073,0.895555,0.464654,0.467903,0.687816,0.610052,0.463856,0.456155,0.646704,0.680645,0.535931,0.542381,1.05923,0.929589,-0.483992,-0.430939,-0.186358,0.094664,-0.264269,-0.0948191,0.0482306,-0.0654239,-1.09017,-1.34176,-2.49866,-2.47225,0.53825,0.350161,0.652619,0.948864,-1.47784,-1.50287
6660,0.26904,0.222746,0.584609,0.529863,0.685867,0.536642,0.457621,0.394346,0.497139,0.594634,0.599511,0.515608,0.409242,0.329134,0.146355,0.122346,0.430294,0.472346,0.434594,0.391663,-0.60826,-0.734918,-0.204752,-0.151672,1.00477,1.29042,0.423112,0.589729,-0.183029,-0.295439,0.473813,0.221897,1.25515,1.28439,-0.995161,-1.18772,2.51038,2.80262,-1.49676,-1.5512
6661,0.885941,0.838077,0.626743,0.57327,0.0421391,-0.107649,0.309077,0.246614,0.213141,0.293713,0.549839,0.563313,0.978831,0.900826,0.218457,0.193933,0.72275,0.763645,0.234478,0.240944,0.256516,0.127032,-0.81478,-0.76133,0.474474,0.755,-1.82477,-1.65614,-1.09346,-1.21025,0.0376904,-0.209231,0.101736,0.130672,0.513812,0.321028,-0.837882,-0.552232,-0.858497,-0.909296
6662,0.329464,0.281912,0.917218,0.864138,0.480858,0.241594,0.96054,0.898878,0.262231,0.341203,0.652979,0.611018,0.735721,0.659543,0.960451,0.936327,0.498497,0.57728,0.994356,1.00029,-0.881814,-1.01622,1.65108,1.70111,-0.294073,-0.0156976,0.27647,0.438498,0.448865,0.327366,0.174251,-0.0719475,0.746406,0.777571,-0.370484,-0.558697,0.93789,1.22072,-0.477076,-0.500974
6663,0.102507,0.0532587,0.774693,0.720432,0.741757,0.590836,0.953682,0.892094,0.577598,0.658187,0.349153,0.307319,0.791742,0.7249,0.376724,0.351274,0.347592,0.390916,0.0690471,0.0735438,-0.268223,-0.397042,-3.60643,-3.55418,0.111224,0.384595,0.564316,0.726916,-1.69077,-1.80483,0.0995211,-0.149684,0.31803,0.347998,-0.396005,-0.581962,0.967736,1.24735,-0.0461225,-0.0926522
6664,0.319065,0.269838,0.364151,0.311025,0.661776,0.510712,0.688625,0.628655,0.612352,0.69015,0.477111,0.437017,0.735239,0.790257,0.991615,0.966188,0.826896,0.870939,0.0898255,0.0957332,-0.73009,-0.862359,-1.36645,-1.31787,1.57935,1.85397,-1.22326,-1.05761,-0.139205,-0.252007,1.57693,1.33425,1.01112,1.03951,0.70099,0.514836,0.568367,0.802226,1.07013,1.01916
6665,0.906664,0.855467,0.616185,0.562707,0.270907,0.204995,0.175907,0.115744,0.88412,0.961855,0.820166,0.782667,0.930106,0.855613,0.104336,0.0782966,0.290909,0.336892,0.327436,0.334481,0.0322427,-0.10472,0.314333,0.365134,-1.16343,-0.883325,0.938053,1.09774,-1.14996,-1.26159,0.349374,0.10369,2.07325,2.09853,0.10785,-0.0740975,0.0702693,0.3571,0.549905,0.497545
6666,0.292101,0.239362,0.223538,0.168615,0.0527187,-0.100722,0.513094,0.454327,0.157153,0.235348,0.322967,0.287449,0.0935245,0.0202038,0.886245,0.861171,0.925904,0.974125,0.917682,0.923615,-0.591579,-0.726237,0.420029,0.472059,-1.29679,-1.01827,-0.153739,0.00910779,1.55535,1.44802,-1.93121,-2.18018,0.336058,0.362055,-0.860681,-1.04642,-1.37202,-1.08226,-0.608415,-0.626061
6667,0.0433989,-0.00936217,0.266099,0.212023,0.000193224,-0.15599,0.352195,0.231211,0.345316,0.425334,0.636118,0.603026,0.0074987,0.00595889,0.0425654,0.0154915,0.136583,0.184318,0.677543,0.738495,-0.370793,-0.50735,-0.919038,-0.86719,-0.27045,0.0122501,2.17653,2.33559,-0.569121,-0.670024,1.36242,1.11746,0.835331,0.854033,-0.956481,-1.14417,0.156553,0.440449,-1.69731,-1.74967
6668,0.892136,0.838093,0.680494,0.627132,0.210577,0.0922861,0.0668636,0.00809579,0.88109,0.959096,0.63718,0.605097,0.0153261,-0.00828606,0.880551,0.854637,0.866686,0.91602,0.547204,0.553376,-0.685775,-0.818882,-0.0702948,-0.0220529,0.126173,0.412543,-0.298825,-0.147807,-0.429157,-0.528284,0.111049,-0.130979,-0.956701,-0.944818,-1.65617,-1.84043,-1.13302,-0.842318,-0.45007,-0.500413
6669,0.598112,0.582004,0.833865,0.752239,0.496291,0.340562,0.399658,0.34185,0.485953,0.611766,0.212909,0.179377,0.0529564,-0.022531,0.463677,0.448506,0.155516,0.205623,0.599541,0.606049,-1.29555,-1.42337,0.137913,0.179919,-0.804476,-0.512251,-0.100879,0.0479355,2.76268,2.65589,0.713349,0.467434,0.775935,0.781423,-1.19667,-1.38712,-1.06285,-0.770561,-0.169709,-0.222323
6670,0.311754,0.325915,0.928516,0.877346,0.457489,0.301742,0.287552,0.229387,0.184522,0.264437,0.275536,0.271004,0.377095,0.213663,0.067859,0.0423756,0.423646,0.472249,0.881913,0.889406,-0.443413,-0.60474,0.0957166,0.0933316,1.18969,1.48915,-1.44247,-1.29918,-0.0888796,-0.195679,0.188093,-0.0575709,-0.575557,-0.57692,0.774664,0.58927,-0.700781,-0.404935,0.80506,0.751324
6671,0.123869,0.0698261,0.833021,0.783382,0.87767,0.719971,0.613439,0.494818,0.020326,0.0978156,0.396999,0.362631,0.524493,0.449857,0.654828,0.630311,0.0628659,0.113097,0.431964,0.438098,0.342954,0.213886,-0.0244344,0.00674376,1.81846,2.11738,0.0201483,0.163287,-0.631752,-0.744454,-0.76687,-1.0145,1.44579,1.44695,0.320864,0.213855,-1.0164,-0.720812,-0.447652,-0.497811
6672,0.670547,0.616224,0.94711,0.896674,0.013092,-0.142488,0.817006,0.760248,0.411095,0.490583,0.762437,0.72695,0.347912,0.274966,0.599001,0.574645,0.516946,0.568514,0.198531,0.202419,-0.161962,-0.309613,1.19841,1.22712,-0.62839,-0.330992,-0.640603,-0.503938,-1.65545,-1.76846,-0.338914,-0.585263,-0.961875,-0.953811,0.0311102,-0.161559,-0.650354,-0.355187,0.0602204,0.00641845
6673,0.417271,0.46012,0.835387,0.783454,0.26534,0.148106,0.0764673,0.0171752,0.588322,0.66567,0.176745,0.141997,0.688564,0.616947,0.237419,0.212508,0.596532,0.646527,0.282613,0.28854,-0.705617,-0.833113,0.146829,0.169282,0.868333,1.17027,2.78975,2.9268,0.14019,0.0310585,-0.122693,-0.370901,-2.09934,-2.09382,1.04136,0.845419,2.81138,3.10451,-0.402834,-0.402078
6674,0.356393,0.304016,0.33746,0.285172,0.593547,0.4387,0.968737,0.910625,0.488404,0.56438,0.499438,0.523876,0.000903854,-0.0706237,0.283731,0.257897,0.393975,0.45638,0.882442,0.88702,0.102842,-0.0310013,-1.44846,-1.41832,1.26604,1.57056,0.860202,0.996141,0.766766,0.663945,0.466784,0.212433,-1.68144,-1.67853,-0.290994,-0.48032,-0.367795,-0.0687968,-0.764611,-0.810575
6675,0.691439,0.641116,0.123874,0.0707171,0.506124,0.312493,0.56939,0.602563,0.88237,0.957147,0.939058,0.905756,0.425239,0.356008,0.0679801,0.0408095,0.242862,0.266233,0.799266,0.791402,0.0729929,-0.0544759,1.03857,1.07232,0.535427,0.844963,1.03273,1.16116,0.867559,0.761714,-1.5525,-1.80412,-0.703282,-0.694829,0.26339,0.0789453,2.0412,2.3401,-0.159074,-0.182031
6676,0.0765776,0.025011,0.578396,0.525073,0.339274,0.186286,0.354023,0.294501,0.801964,0.876977,0.521496,0.48985,0.409865,0.40212,0.769754,0.741887,0.0260918,0.0760864,0.691901,0.695784,-1.57103,-1.70212,-0.65888,-0.625258,-1.18491,-0.872046,-1.66432,-1.53623,1.84455,1.73498,0.572449,0.316863,-0.849089,-0.844927,-1.79213,-1.97318,0.454524,0.759293,0.488715,0.446514
6677,0.399157,0.346408,0.712247,0.658926,0.985932,0.835178,0.695918,0.637845,0.32068,0.393294,0.736297,0.702936,0.408173,0.448232,0.670849,0.641952,0.885465,0.937722,0.282136,0.284312,-0.215289,-0.344677,-0.968567,-0.931429,-1.69996,-1.39226,-0.337926,-0.201895,-0.359186,-0.476217,0.781681,0.531226,0.0750139,0.0887906,0.0114171,-0.167925,0.385579,0.692517,-0.429716,-0.467229
6678,0.101703,0.0467771,0.509688,0.396104,0.276676,0.125857,0.570893,0.510456,0.151765,0.222676,0.493194,0.459516,0.561818,0.494344,0.779395,0.748289,0.16819,0.2218,0.12848,0.129105,-0.700774,-0.827226,-0.173559,-0.130101,-1.47741,-1.17756,-0.189311,-0.0511384,-0.313653,-0.425071,-0.0224443,-0.272386,1.02493,1.02251,-0.0913591,-0.265676,0.687843,0.995423,-0.00439115,-0.0393188
6679,0.645122,0.589032,0.187621,0.133281,0.832178,0.683829,0.731546,0.67008,0.301227,0.372863,0.584411,0.550284,0.127336,0.0582622,0.284876,0.252604,0.120131,0.172232,0.701562,0.703188,0.324125,0.203624,-1.1138,-1.06235,0.451892,0.746127,1.2086,1.34384,0.0215082,-0.0827574,-0.320484,-0.600791,-1.12377,-1.12012,-1.12466,-1.29736,-1.00167,-0.665254,-0.457033,-0.48517
6680,0.0199272,-0.0368543,0.290083,0.237285,0.515473,0.3693,0.432074,0.372496,0.718814,0.790367,0.445755,0.396233,0.41118,0.436379,0.0699171,0.0355167,0.359291,0.345125,0.851977,0.855291,-1.36035,-1.47515,-0.30716,-0.261023,0.338681,0.639619,-1.2687,-1.13956,-0.388961,-0.495113,-0.685524,-0.929196,-0.503083,-0.504332,-0.797508,-0.965475,-2.63351,-2.32593,1.37138,1.33655
6681,0.289294,0.185689,0.668361,0.573203,0.711649,0.577675,0.677093,0.617718,0.352912,0.426939,0.274152,0.242181,0.881399,0.814495,0.274079,0.237356,0.419158,0.518017,0.204945,0.209131,0.13216,0.0239815,-0.602263,-0.550038,-2.9312,-2.6366,-0.894812,-0.761128,-1.36971,-1.47404,-0.0811506,-0.330783,-0.307041,-0.305524,0.869079,0.699004,0.125144,0.440122,1.17007,1.13221
6682,0.46515,0.408232,0.96362,0.909122,0.933593,0.786051,0.116837,0.0594789,0.718812,0.794605,0.981872,0.948704,0.431666,0.363655,0.970149,0.933799,0.596978,0.69091,0.407597,0.411117,0.386098,0.27514,1.19182,1.24088,-1.16011,-0.86951,-0.116415,0.0171583,-0.667074,-0.765192,-1.33724,-1.57922,-1.65238,-1.64996,-0.345701,-0.517665,1.92438,2.24461,-0.375395,-0.406807
6683,0.22711,0.169766,0.990285,0.937571,0.789973,0.644045,0.0763722,0.0284829,0.0552699,0.129773,0.864669,0.831319,0.271814,0.204605,0.94356,0.908051,0.811701,0.863803,0.380791,0.356572,-0.788411,-0.89733,-0.489711,-0.44322,-0.0334218,0.250587,-1.83989,-1.70746,-0.679231,-0.711713,0.0259233,-0.217316,-1.3037,-1.21395,2.57621,2.40825,-0.89987,-0.582889,0.369696,0.34163
6684,0.439809,0.381096,0.162631,0.107703,0.257569,0.110229,0.0570024,-0.002513,0.763151,0.83549,0.122789,0.0918195,0.58513,0.516664,0.713214,0.675762,0.19429,0.247999,0.174179,0.302027,0.968079,0.860844,-0.220413,-0.180003,0.417323,0.695914,0.878701,1.00621,-0.554209,-0.658234,-0.0813364,-0.324698,-0.776472,-0.777935,-0.31572,-0.477002,1.1141,1.43267,0.0828075,0.0476298
6685,0.409911,0.349813,0.253932,0.252567,0.80743,0.657715,0.550854,0.490829,0.530549,0.614342,0.201879,0.21168,0.0759643,0.00506339,0.182723,0.144713,0.167796,0.223517,0.242976,0.247482,0.287309,0.178834,0.270844,0.314182,-0.10594,0.1757,1.42882,1.55427,-0.0216566,-0.133464,-1.26459,-1.51082,0.144948,0.155782,-0.391959,-0.560951,0.447117,0.761719,0.106401,0.0701011
6686,0.149293,0.0917352,0.451801,0.39743,0.261914,0.112732,0.391522,0.408431,0.321284,0.393194,0.360243,0.331541,0.401505,0.33238,0.251248,0.275691,0.659964,0.714311,0.7159,0.721486,-1.2777,-1.39316,-1.87652,-1.84037,-1.11131,-0.827978,-1.02728,-0.894602,1.70787,1.60484,0.261511,0.0204148,1.08922,1.0895,1.88303,1.70786,-0.455244,-0.146022,0.489455,0.451129
6687,0.394059,0.317907,0.811486,0.757543,0.185402,0.129546,0.382569,0.326033,0.590008,0.659506,0.9735,0.947209,0.0804401,0.0118126,0.363103,0.40667,0.489807,0.477425,0.377403,0.385055,1.17475,1.06268,0.433381,0.478077,0.254752,0.535994,-0.156523,-0.0226333,-0.456233,-0.560661,-0.717347,-0.952043,-0.824838,-0.818159,1.1595,0.951923,0.723676,1.03227,-1.28365,-1.31787
6688,0.600065,0.544079,0.77283,0.734131,0.293614,0.14636,0.236628,0.243635,0.0180625,0.0861681,0.0531307,0.0258107,0.55285,0.483493,0.575658,0.537648,0.185054,0.240539,0.458411,0.466675,-1.89376,-2.00496,0.360914,0.403612,-0.0508656,0.231477,1.61065,1.73949,0.320601,0.211586,-0.791756,-0.949533,0.699229,0.706173,0.377468,0.195986,1.69445,2.00574,-0.913231,-0.949978
6689,0.392448,0.312083,0.763099,0.71072,0.743659,0.595614,0.219032,0.161238,0.0343991,0.10409,0.578148,0.552488,0.358104,0.288546,0.142465,0.106545,0.163781,0.306568,0.149802,0.253445,0.467219,0.357422,-0.0967514,-0.0531636,-0.111959,0.170819,1.26398,1.39627,-0.609753,-0.720481,-0.71206,-0.947023,-0.688891,-0.682494,1.13326,0.954902,0.0123779,0.323754,2.08736,2.05158
6690,0.136498,0.0800876,0.472044,0.42056,0.789072,0.6423,0.360258,0.2384,0.455306,0.523169,0.464216,0.439127,0.541406,0.469303,0.621801,0.588575,0.27092,0.372597,0.0333368,0.0402142,0.290687,0.181688,1.08394,1.13202,-0.694021,-0.415388,1.45164,1.57732,0.616432,0.513021,-0.184586,-0.424869,0.257502,0.270394,1.02759,0.857151,-1.66953,-1.35823,0.410844,0.374629
6691,0.280128,0.224903,0.390124,0.337229,0.568881,0.420302,0.372817,0.315562,0.874378,0.942248,0.794028,0.769235,0.190681,0.118673,0.832991,0.799986,0.385499,0.438626,0.901474,0.909229,-1.91369,-2.01878,0.768182,0.813817,0.275808,0.629931,0.307551,0.428836,0.374443,0.269109,0.803618,0.571758,0.143986,0.15078,0.292634,0.148572,0.308753,0.623071,0.799161,0.755656
6692,0.623883,0.566852,0.727973,0.673371,0.603541,0.456669,0.270383,0.212988,0.774468,0.911794,0.918634,0.89414,0.571729,0.438882,0.519629,0.53404,0.936719,0.988294,0.80988,0.81539,0.329137,0.216949,-2.10633,-2.05802,1.40157,1.67525,-2.99192,-2.86724,-0.281158,-0.385242,-0.403876,-0.629681,1.67982,1.68874,-0.398334,-0.560006,0.274114,0.587017,-1.9769,-2.02419
6693,0.358323,0.30335,0.333438,0.279279,0.362693,0.218305,0.960947,0.90601,0.777549,0.88134,0.229446,0.204041,0.830158,0.759091,0.207407,0.268095,0.589062,0.627014,0.166718,0.174727,0.2061,0.099475,-0.713053,-0.671665,-0.555424,-0.276982,-1.82285,-1.70066,-0.0585159,-0.165301,-1.3125,-1.54202,-1.72389,-1.7087,0.509601,0.352439,-0.460272,-0.145353,-0.152361,-0.202474
6694,0.335023,0.204539,0.369835,0.298449,0.768663,0.626448,0.0575018,0.000220887,0.874777,0.850887,0.677233,0.652475,0.743942,0.674729,0.0354763,0.00214938,0.215351,0.265733,0.256082,0.152608,-1.20105,-1.30443,-0.862203,-0.821355,1.58284,1.86566,0.754338,0.881455,-0.0427093,-0.144191,0.451132,0.2197,1.55863,1.58063,-0.440814,-0.603825,1.62021,1.93831,-0.992453,-1.03855
6695,0.158113,0.105728,0.419853,0.317618,0.663291,0.520404,0.305614,0.250861,0.752563,0.820433,0.333379,0.309725,0.896145,0.825154,0.926787,0.892588,0.682086,0.730902,0.203849,0.130488,-1.54191,-1.64639,0.21248,0.256292,-0.393811,-0.116258,2.00673,2.13902,-0.570188,-0.624336,1.72025,1.48983,0.301703,0.317696,1.35618,1.18533,-0.295546,0.0201341,-0.872434,-0.914326
6696,0.823119,0.77201,0.361585,0.336788,0.783136,0.682358,0.965999,0.911984,0.279945,0.347427,0.47283,0.480755,0.715974,0.645159,0.134253,0.100854,0.913628,0.962897,0.10036,0.108368,0.248607,0.143734,0.502166,0.480491,1.66027,1.9312,-0.677755,-0.545899,-1.00447,-1.10448,-0.101423,-0.404342,1.14128,1.16018,-2.06489,-2.24028,2.39751,2.71654,1.62374,1.58019
6697,0.876678,0.827671,0.410116,0.355957,0.986023,0.844313,0.593171,0.598033,0.643951,0.710771,0.677291,0.651785,0.171034,0.0983043,0.243099,0.211562,0.535153,0.583176,0.447963,0.457973,-1.21136,-1.32024,0.657317,0.704689,0.558211,0.834487,-0.678316,-0.548936,-0.668297,-0.762168,-2.06809,-2.29851,-1.41721,-1.40136,0.772432,0.592699,0.0256699,0.349557,-0.39161,-0.439315
6698,0.311321,0.261708,0.690053,0.637734,0.261605,0.119152,0.336292,0.284083,0.254769,0.322436,0.436307,0.463092,0.15305,0.0805422,0.592057,0.558806,0.511547,0.558694,0.261009,0.272563,0.896657,0.792202,1.79629,1.84252,0.745614,1.01762,-0.0283889,0.106063,-0.864447,-0.960981,-0.0215496,-0.255236,-0.347607,-0.416258,-0.060612,-0.241102,-0.0903591,0.23594,0.987665,0.932883
6699,0.848483,0.798487,0.0308815,-0.0225424,0.761836,0.61747,0.574497,0.549514,0.675163,0.668862,0.279736,0.274399,0.775306,0.702066,0.387713,0.422376,0.825551,0.873539,0.944533,0.956694,0.532503,0.43428,-0.822468,-0.776608,-1.53948,-1.26956,-1.37755,-1.24106,-0.682966,-0.786918,1.66969,1.43244,0.552907,0.568848,-0.138652,-0.325051,1.16835,1.49078,0.841055,0.790148
6700,0.834379,0.774773,0.266748,0.310409,0.143504,-0.00106948,0.865991,0.814945,0.95023,1.01529,0.113479,0.0857059,0.0886553,0.0144949,0.218908,0.285946,0.797327,0.843794,0.358195,0.370999,-0.153684,-0.24773,0.991635,1.04521,0.434522,0.699495,-0.240924,-0.105781,-2.10437,-2.20953,-0.948778,-1.18927,1.87868,1.8952,0.119139,-0.0692687,0.920033,1.23708,-0.617407,-0.673067
6701,0.801969,0.751058,0.695128,0.643361,0.342532,0.19939,0.195589,0.142973,0.302827,0.366094,0.269036,0.195071,0.475911,0.401247,0.182642,0.149515,0.374387,0.420369,0.49593,0.415627,1.71571,1.61892,-0.261758,-0.213466,-0.190889,0.0685715,0.57172,0.703692,0.267723,0.159998,-0.105297,-0.347149,-1.7123,-1.7024,-0.717284,-0.90307,-0.818884,-0.505608,0.097239,0.0449314
6702,0.0149725,-0.037358,0.518864,0.468787,0.957512,0.812998,0.35172,0.36944,0.116306,0.179099,0.328725,0.304436,0.474093,0.474687,0.447789,0.415118,0.783406,0.830632,0.449268,0.460255,-0.688502,-0.78264,-0.144948,-0.0902127,0.390376,0.584926,0.248975,0.376012,-0.0128742,-0.0528426,-0.133366,-0.379869,0.64389,0.645713,0.149327,-0.0371299,-0.72057,-0.402969,-1.21104,-1.26601
6703,0.464286,0.410507,0.0640555,0.0155691,0.631895,0.48854,0.649803,0.595906,0.466701,0.596372,0.475817,0.413801,0.624075,0.548128,0.299571,0.268194,0.157368,0.205819,0.961799,0.973771,1.46054,1.35975,-1.36835,-1.31798,0.838567,1.10128,-0.709254,-0.587051,-0.161766,-0.265684,-0.89471,-1.13888,1.14264,1.13769,-0.651597,-0.840362,-1.29163,-0.981439,1.90191,1.84104
6704,0.572422,0.516509,0.608226,0.557826,0.806098,0.664862,0.00986142,-0.0463432,0.949891,1.01365,0.552099,0.523166,0.0865418,0.0113465,0.352685,0.323933,0.174247,0.220787,0.874093,0.885818,0.798742,0.694852,0.140271,0.192853,0.983637,1.25376,-0.0970306,0.0198433,0.0456611,-0.0619335,-1.32788,-1.57001,-2.53017,-2.53515,-0.330115,-0.523159,1.37256,1.67905,-2.26829,-2.33017
6705,0.245538,0.230546,0.516794,0.463862,0.401726,0.259308,0.0978037,0.0417902,0.000703477,0.0672938,0.42294,0.394576,0.992973,0.919133,0.156734,0.126982,0.640331,0.598497,0.0336978,0.0439784,-0.785325,-0.892687,0.252935,0.299778,-1.71144,-1.43179,-0.364181,-0.246849,-1.88529,-1.99441,1.80093,1.56378,0.60893,0.607707,-1.00744,-1.2053,-0.357288,-0.0457608,-1.17749,-1.23347
6706,0.0024525,-0.0554176,0.626165,0.572625,0.19879,0.0910058,0.671675,0.614239,0.925775,0.990842,0.693677,0.674519,0.767191,0.800133,0.576478,0.480462,0.930404,0.976207,0.253226,0.26878,-0.91063,-1.02245,-0.0825251,-0.0347878,1.5624,1.83977,1.33215,1.45089,0.108533,-0.00321906,0.502696,0.270037,0.345859,0.281126,0.333497,0.146647,-1.22333,-0.919544,0.463744,0.399973
6707,0.331889,0.205282,0.442897,0.345755,0.0660621,-0.0772961,0.55283,0.496312,0.506198,0.571803,0.984911,0.954463,0.673272,0.681133,0.865063,0.833943,0.309562,0.355777,0.595563,0.493582,1.46129,1.3548,0.194716,0.244479,0.460848,0.743059,1.5919,1.70732,1.0556,0.93801,0.965061,0.731605,-0.0387131,-0.0454557,1.70119,1.49859,0.480955,0.79081,-0.119954,-0.129643
6708,0.567101,0.465982,0.171527,0.118886,0.986509,0.842705,0.109841,0.0543818,0.956541,1.02001,0.643671,0.611713,0.637757,0.562133,0.81597,0.763887,0.926063,0.971823,0.727226,0.718384,-0.719057,-0.825877,-0.266319,-0.212296,0.979513,1.26409,0.00717428,0.128929,-0.265143,-0.379435,-0.496027,-0.733539,1.08024,1.07494,0.192528,-0.00939936,-1.53753,-1.2255,-0.591274,-0.65926
6709,0.784553,0.726682,0.546632,0.493094,0.461864,0.319283,0.391791,0.334288,0.00096127,0.0644262,0.828974,0.796496,0.839976,0.763729,0.725827,0.693832,0.648841,0.693307,0.932905,0.943186,0.045828,-0.0540481,-0.0547493,-0.0952801,2.42419,2.70459,1.25436,1.36978,1.0996,0.988882,0.323832,0.0913701,0.0260441,0.0273306,0.383131,0.18415,-1.61616e-06,0.311019,-0.292031,-0.367034
6710,0.16206,0.105966,0.254604,0.202934,0.152624,0.0101569,0.287711,0.183894,0.166055,0.279956,0.392126,0.360468,0.519016,0.443162,0.957551,0.923134,0.898204,0.945051,0.561158,0.572677,-0.516356,-0.612617,-0.0371229,0.021736,-0.0358268,0.241634,0.217632,0.330345,0.0154374,-0.0952359,0.388189,0.152151,-0.171907,-0.168481,0.0353417,-0.158316,1.01514,1.33276,1.13249,1.0521
6711,0.944437,0.886622,0.882526,0.833555,0.532519,0.391072,0.0893792,0.0335,0.429781,0.495485,0.917596,0.887145,0.620697,0.643978,0.541115,0.506641,0.255114,0.300373,0.924286,0.937868,-0.345596,-0.396112,0.66935,0.729566,0.0422679,0.318859,-0.395338,-0.288967,0.0941679,-0.0130496,-0.235411,-0.468138,0.993163,1.00009,0.0847932,-0.177184,-0.377145,0.0154998,-0.586668,-0.670476
6712,0.245603,0.188379,0.184277,0.133292,0.374339,0.285921,0.300506,0.180092,0.294806,0.411147,0.435391,0.407007,0.91958,0.844793,0.520351,0.582838,0.997904,1.0431,0.758408,0.772866,-0.0917864,-0.179607,0.355116,0.411365,-1.20815,-0.931298,-0.426526,-0.324611,-1.0582,-1.15672,-0.591614,-0.821733,-1.09454,-1.08012,0.00185873,-0.196052,-1.61938,-1.30176,1.62464,1.54045
6713,0.0036592,-0.0552822,0.933334,0.882822,0.324848,0.180771,0.383147,0.326683,0.260273,0.32681,0.64021,0.611213,0.613394,0.519801,0.692662,0.659035,0.0388474,0.0852493,0.296105,0.312007,0.321429,0.240244,0.413153,0.474056,0.940322,1.21135,1.06277,1.16903,-1.03608,-1.13561,0.492584,0.265511,1.49927,1.50697,0.741608,0.501172,1.36262,1.68141,-0.431703,-0.507624
6714,0.0676387,-0.00155624,0.601838,0.552565,0.382924,0.273736,0.507121,0.473275,0.696098,0.681885,0.308784,0.328642,0.267705,0.194808,0.9105,0.877271,0.480974,0.489336,0.471474,0.489562,-0.0905456,-0.179064,-1.73155,-1.66381,-0.196824,0.0684326,1.32667,1.42546,0.76645,0.66391,-1.52247,-1.75104,1.34215,1.35687,1.39631,1.1984,0.524707,0.841775,-0.286552,-0.365567
6715,0.0527146,0.0521697,0.533316,0.483523,0.510423,0.366701,0.675745,0.619866,0.969273,1.03696,0.0751189,0.0460699,0.698423,0.626459,0.127048,0.0957303,0.847013,0.893422,0.214419,0.23476,0.757017,0.668297,-0.991692,-0.854433,2.02123,2.2788,-0.176616,-0.0770646,1.58855,1.48119,0.0842673,-0.142105,0.757029,0.771919,-0.108139,-0.309597,-0.929874,-0.612989,0.646886,0.562494
6716,0.146023,0.105896,0.084156,0.0350669,0.315309,0.169831,0.536229,0.455055,0.657199,0.724266,0.989354,0.957639,0.00107703,-0.0699357,0.909021,0.878605,0.834603,0.883006,0.368186,0.386863,-0.687306,-0.780266,-0.0826338,-0.0450605,-0.098015,0.152665,0.792002,0.886863,-1.64769,-1.75732,-0.749337,-0.976475,0.846832,0.864092,0.4062,0.205398,0.911082,1.2233,-0.504506,-0.595655
6717,0.217734,0.159622,0.81848,0.77108,0.749549,0.603935,0.347422,0.290244,0.995204,1.06164,0.0971996,0.0680302,0.32865,0.257381,0.948742,0.822748,0.352096,0.398104,0.750614,0.771026,0.538279,0.449715,0.696571,0.764312,-0.836143,-0.585291,-1.25654,-1.15584,1.44505,1.33907,-1.0564,-1.28519,0.0110891,0.0205967,-1.71488,-1.91121,0.0268637,0.335364,-0.327717,-0.337513
6718,0.747656,0.690961,0.658485,0.587952,0.908307,0.760575,0.728668,0.673348,0.465872,0.533182,0.519969,0.491642,0.393927,0.244156,0.797249,0.76689,0.738491,0.783854,0.273922,0.294915,-0.939212,-1.02885,0.274805,0.339807,-0.745871,-0.49508,1.86848,1.96521,-0.985797,-1.08704,-0.799404,-1.02676,-0.326266,-0.316341,-1.55691,-1.74908,0.722232,1.02876,0.0136953,-0.0793705
6719,0.846771,0.791331,0.412977,0.404823,0.545763,0.395956,0.71144,0.656174,0.299859,0.366561,0.322719,0.292873,0.329568,0.230932,0.59974,0.544113,0.00566085,0.0526633,0.708267,0.729547,1.55166,1.45936,0.246116,0.311736,0.509705,0.761764,1.43246,1.52795,-0.888344,-0.904922,0.0486127,-0.184631,-0.21967,-0.182599,1.0712,0.883723,-0.591992,-0.286479,-0.460792,-0.55483
6720,0.306577,0.250233,0.269094,0.221695,0.448792,0.299974,0.387137,0.333367,0.838171,0.905447,0.425437,0.478937,0.350021,0.217708,0.351159,0.321335,0.907661,0.954318,0.32062,0.344234,-0.582819,-0.674879,-0.354961,-0.28337,-1.08268,-0.827297,-0.679781,-0.590653,-0.627711,-0.722804,1.78269,1.54861,-0.135719,-0.0488561,-0.0104807,-0.195656,-0.497322,-0.183841,-2.33932,-2.43213
6721,0.906143,0.850985,0.959024,0.911361,0.556218,0.490313,0.683057,0.615076,0.151741,0.219414,0.694238,0.665002,0.415336,0.204484,0.602923,0.571534,0.938038,0.983878,0.588563,0.612577,-0.27907,-0.375426,1.69276,1.76092,0.253276,0.505778,-1.43694,-1.35253,0.385549,0.295715,-1.83541,-2.0641,0.0905734,0.0848863,-0.777649,-0.968101,-1.14592,-0.838152,1.15856,1.06933
6722,0.940008,0.887274,0.280384,0.230765,0.829957,0.680652,0.952376,0.896785,0.925645,0.993584,0.22658,0.199465,0.359952,0.191259,0.438767,0.408774,0.303251,0.348167,0.592473,0.61789,-0.55718,-0.65655,-0.903536,-0.840647,-0.954011,-0.699798,-0.300409,-0.217257,0.437686,0.346861,-1.85696,-2.07987,0.208704,0.218629,-0.175091,-0.361639,-0.0540525,0.261502,-0.805838,-0.888263
6723,0.449273,0.396219,0.380428,0.329696,0.790617,0.674011,0.937973,0.87098,0.41482,0.480463,0.341682,0.410111,0.249304,0.178035,0.00511758,-0.0223288,0.597517,0.614197,0.974492,0.997624,0.695789,0.591456,-1.51435,-1.45031,-1.57879,-1.33072,-1.83348,-1.74874,-1.08419,-1.16856,1.15247,0.9266,0.953233,0.955693,1.20637,1.02679,0.304926,0.627127,-1.21154,-1.2903
6724,0.855228,0.804079,0.810633,0.759267,0.84568,0.667369,0.90327,0.845175,0.85959,0.924259,0.649149,0.620757,0.933567,0.860926,0.426359,0.399029,0.834322,0.880227,0.0852314,0.107623,-0.381974,-0.490035,-0.389414,-0.422351,-0.476602,-0.227078,0.541406,0.629771,0.620192,0.53684,1.01364,0.787273,-1.09372,-1.09362,0.699794,0.51569,0.0654576,0.389606,0.880781,0.807514
6725,0.619181,0.565614,0.171891,0.11897,0.811094,0.660728,0.118527,0.06048,0.321897,0.386106,0.16921,0.140619,0.227266,0.153711,0.551079,0.524789,0.719187,0.810846,0.47799,0.507231,-0.595984,-0.710684,0.541993,0.605602,1.37214,1.61961,-1.11346,-1.03182,-1.16367,-1.24255,-0.834988,-1.0607,0.931919,0.930257,-1.58517,-1.76695,-1.01987,-0.701344,1.11577,1.04055
6726,0.907788,0.85246,0.935361,0.8807,0.60283,0.45582,0.84299,0.784214,0.612685,0.678059,0.703272,0.672241,0.213264,0.141048,0.0358067,0.00898073,0.69654,0.741464,0.881992,0.906839,1.54066,1.4317,1.14522,1.20745,-0.28449,-0.0323076,0.264633,0.348974,0.627268,0.556963,0.513872,0.285603,-0.116669,-0.117355,-0.0755964,-0.258204,-0.288275,0.0231415,-0.977841,-1.05492
6727,0.557504,0.502399,0.93628,0.880323,0.401033,0.250912,0.823931,0.76704,0.180045,0.244123,0.0194174,-0.0125257,0.847691,0.777636,0.323529,0.294899,0.835695,0.881443,0.590965,0.61603,-0.69823,-0.813617,0.354739,0.412778,-1.15216,-0.895985,0.148954,0.237255,0.803134,0.731026,0.684847,0.452887,0.435895,0.436795,-1.55133,-1.73479,0.113463,0.42004,-0.065786,-0.16488
6728,0.682821,0.667436,0.672561,0.656737,0.528153,0.424842,0.499795,0.444233,0.999486,1.06081,0.82344,0.791585,0.733894,0.663223,0.824423,0.796132,0.631927,0.678637,0.824129,0.848809,0.350455,0.234552,0.0667869,0.139138,0.943923,1.20204,-0.552467,-0.460613,0.287066,0.21299,0.108382,-0.117599,-0.335928,-0.330153,0.047894,-0.130651,0.0545367,0.366922,0.806868,0.725157
6729,0.885097,0.832473,0.490693,0.43315,0.746727,0.598773,0.694679,0.640524,0.367382,0.430995,0.639122,0.609007,0.892824,0.824644,0.972799,0.942515,0.141458,0.18862,0.0635725,0.0894535,-0.384628,-0.494188,-0.19376,-0.134503,1.42375,1.67696,0.675652,0.766482,0.601941,0.598403,0.123037,-0.103233,-0.0752734,-0.00850671,-0.156791,-0.3357,1.19267,1.51275,-0.493466,-0.570199
6730,0.803482,0.81848,0.90032,0.843234,0.510601,0.375887,0.109518,0.0572376,0.328986,0.3686,0.213265,0.183287,0.0149286,-0.0516546,0.901789,0.871546,0.793173,0.842273,0.959803,0.987824,0.245208,0.210157,0.353639,0.418985,-0.574809,-0.320636,-1.45987,-1.36778,1.05789,0.983816,-0.322317,-0.61219,0.306042,0.313139,-1.21081,-1.38328,-1.25908,-0.937009,0.885961,0.801999
6731,0.822965,0.804487,0.952268,0.897037,0.26871,0.153002,0.784188,0.73002,0.243783,0.306205,0.209617,0.180201,0.140178,0.0737227,0.397239,0.365267,0.543951,0.593753,0.449303,0.476915,1.02953,0.914503,-0.0441641,0.0232097,0.0771757,0.324232,-0.146582,-0.0495649,-1.71662,-1.78907,-0.888285,-1.12115,0.842174,0.850228,0.307225,0.14093,1.86326,2.19165,0.862187,0.778963
6732,0.842214,0.790494,0.035238,-0.0183956,0.0780695,-0.0698841,0.94397,0.889644,0.413087,0.397213,0.582521,0.555102,0.992365,0.925527,0.489097,0.456149,0.892886,0.945036,0.422411,0.447543,-0.677419,-0.796682,-0.927739,-0.863756,0.396828,0.646945,-0.170868,-0.069112,0.988206,0.920546,1.02668,0.793753,0.54634,0.560656,0.150256,-0.0170302,0.892907,1.22327,1.35453,1.26798
6733,0.40564,0.354693,0.308361,0.209794,0.795566,0.646103,0.00378614,-0.0501264,0.426711,0.48822,0.415815,0.46213,0.243329,0.177592,0.177161,0.144072,0.486541,0.539927,0.970519,0.996479,0.144806,0.0196402,1.03399,1.09938,1.12413,1.36925,-0.978365,-0.876691,2.22152,2.15405,-0.381269,-0.610216,-0.686299,-0.672268,-0.974272,-1.1421,-2.79826,-2.4679,-0.213239,-0.299663
6734,0.805443,0.752458,0.492933,0.437984,0.567362,0.492252,0.6633,0.610996,0.738034,0.720367,0.400608,0.369158,0.880427,0.81418,0.600888,0.56543,0.958995,1.01048,0.989732,0.916881,-1.82105,-1.93889,-0.056699,0.0110883,-0.656409,-0.408126,1.10083,1.20235,-0.571673,-0.63239,-0.682643,-0.918934,0.912238,0.930004,1.88015,1.70711,-0.684927,-0.349974,-0.165198,-0.246829
6735,0.159703,0.106271,0.304026,0.248472,0.465463,0.3384,0.454627,0.317426,0.893012,0.952513,0.303604,0.276186,0.889883,0.821772,0.294322,0.259089,0.969676,1.0205,0.812797,0.837283,0.61375,0.502478,-0.443692,-0.370578,0.334822,0.575193,-1.3117,-1.21526,0.675769,0.616712,-0.573682,-0.812148,-0.238209,-0.223718,-1.18594,-1.36683,-1.33474,-1.00428,-0.674002,-0.753319
6736,0.265024,0.212273,0.483587,0.42716,0.377124,0.184549,0.0770941,0.0238555,0.764227,0.826175,0.541355,0.514507,0.195585,0.129847,0.746014,0.710788,0.252977,0.304577,0.261224,0.286487,-1.47143,-1.58414,-0.0840003,-0.0153829,-0.759477,-0.521523,-1.39394,-1.29587,0.536772,0.479217,-0.0868867,-0.320747,0.245037,0.252893,-1.73659,-1.92378,0.170138,0.501291,1.26265,1.18917
6737,0.738794,0.684164,0.347256,0.293318,0.0831676,0.0306972,0.776147,0.72124,0.978411,1.04143,0.324338,0.295984,0.347588,0.280271,0.351742,0.359404,0.285157,0.338245,0.936283,0.960394,0.250264,0.145145,-0.158899,-0.089848,0.109705,0.293906,0.640074,0.736788,1.22563,1.1737,-0.303611,-0.536392,2.23589,2.24411,0.309959,0.116133,-0.117375,0.217264,0.784172,0.713711
6738,0.429285,0.375118,0.686687,0.63396,0.0263088,-0.123154,0.835168,0.779596,0.541864,0.602925,0.502999,0.451826,0.751004,0.682208,0.0436516,0.00801958,0.0981283,0.151156,0.00198599,0.0264708,-1.01018,-1.12039,0.873009,0.941223,0.866538,1.10933,1.53788,1.64023,-0.00242068,-0.0501813,-0.752895,-0.984738,-1.13912,-1.13378,0.925005,0.737656,2.05739,2.39868,0.5783,0.509368
6739,0.994753,0.941661,0.761608,0.707626,0.0462605,-0.101878,0.308045,0.251352,0.728693,0.787982,0.636439,0.607668,0.0509025,-0.0189363,0.29129,0.169752,0.508447,0.561419,0.750358,0.774736,-1.65791,-1.77127,-2.92518,-2.85722,-1.2919,-1.05031,-0.976918,-0.876103,-0.642928,-0.690375,-0.557664,-0.786664,-0.961256,-0.951232,0.1429,-0.051082,-0.129592,0.211675,-0.535583,-0.604764
6740,0.118931,0.0658961,0.532437,0.463992,0.51322,0.366705,0.767623,0.709037,0.170418,0.229438,0.163482,0.132705,0.734168,0.663955,0.445809,0.331484,0.123485,0.176953,0.315988,0.338514,0.41303,0.296514,-1.5391,-1.47087,-1.06138,-0.819359,-1.67326,-1.57397,0.510488,0.464036,-1.07653,-1.31167,0.469121,0.481179,0.257463,0.0651702,0.553514,0.890778,0.901295,0.830875
6741,0.401919,0.347592,0.27549,0.220358,0.0128575,-0.132991,0.767946,0.707818,0.847869,0.90612,0.317801,0.287495,0.177067,0.106521,0.527602,0.493216,0.98316,1.03859,0.435628,0.459963,0.551669,0.439187,0.392913,0.45996,-1.06554,-0.819384,1.39489,1.50278,0.388996,0.341401,-0.628035,-0.865327,1.1848,1.20302,0.110356,-0.0792903,1.56286,1.89726,0.58422,0.520147
6742,0.21927,0.221125,0.693417,0.639471,0.646699,0.50078,0.488663,0.43009,0.492507,0.530462,0.914364,0.883283,0.532061,0.463907,0.50982,0.524436,0.896308,0.92542,0.874813,0.899258,-1.66111,-1.77589,-1.21437,-1.14438,1.64978,1.9039,-0.983292,-0.87667,0.917528,0.866171,-0.472956,-0.714791,-0.0795344,-0.0599142,-0.323036,-0.513778,0.391239,0.724446,0.563003,0.538497
6743,0.149322,0.0946572,0.641275,0.584989,0.545374,0.400107,0.843747,0.783981,0.0944286,0.154804,0.60444,0.668618,0.32982,0.26425,0.590874,0.555657,0.754511,0.812252,0.103347,0.126375,0.120051,-0.000242411,1.32527,1.39646,-0.325964,-0.0780208,0.0728104,0.0869212,0.549591,0.499209,0.269111,0.0347919,-2.292,-2.26494,0.475867,0.292083,0.658371,0.994901,0.729821,0.556846
6744,0.755162,0.700634,0.0132379,-0.0453395,0.650604,0.506739,0.156935,0.0968959,0.174699,0.233554,0.486503,0.453953,0.501927,0.434962,0.954222,0.918542,0.0385327,0.0963302,0.977489,1.00128,2.20127,2.0826,0.585623,0.664452,-0.798728,-0.550504,0.940818,1.05051,-1.50319,-1.55132,-1.12249,-1.35436,0.169723,0.197606,0.199533,0.0111248,-0.778046,-0.444457,0.639269,0.575196
6745,0.417189,0.360399,0.393549,0.334398,0.348654,0.202663,0.398954,0.336825,0.630009,0.686189,0.732301,0.702061,0.997045,0.931815,0.124786,0.0910274,0.375284,0.349846,0.868174,0.890916,0.172424,0.0570872,-1.22444,-1.14601,0.733945,0.980303,-1.43799,-1.32893,0.00388523,-0.0783181,-0.695304,-0.925129,-0.425769,-0.39987,-0.34475,-0.530402,-0.631893,-0.297155,1.9092,1.84126
6746,0.8268,0.768259,0.244038,0.185574,0.78629,0.641988,0.273344,0.209436,0.22511,0.28211,0.751031,0.788015,0.959957,0.893495,0.402165,0.367289,0.546509,0.603361,0.230851,0.255732,0.133929,0.0178525,-1.14873,-1.06783,-0.543577,-0.300587,-1.19073,-1.08683,1.44282,1.39468,-1.54202,-1.77452,-1.56643,-1.53988,-1.24856,-1.4397,-0.0983354,0.241501,1.74496,1.68217
6747,0.0744008,0.0175121,0.965303,0.906294,0.730421,0.586721,0.828384,0.762014,0.554242,0.609483,0.903088,0.873968,0.0575283,-0.0103347,0.990009,0.955225,0.435441,0.492561,0.83271,0.859515,-0.756305,-0.880095,0.0248267,0.100641,-0.134293,0.114703,-0.430262,-0.400609,2.34006,2.29043,0.105605,-0.132277,-0.794498,-0.772778,-1.02656,-1.2152,0.091229,0.501624,0.29849,0.233769
6748,0.911698,0.85266,0.854463,0.741438,0.947388,0.802046,0.342439,0.2751,0.0186703,0.0763373,0.469427,0.472354,0.118009,0.0486394,0.61725,0.593723,0.255301,0.38176,0.0551059,0.0795478,0.841634,0.710968,-0.424953,-0.356135,0.896951,1.14523,0.176022,0.285612,2.3959,2.34157,0.466615,0.233116,0.401668,0.428094,1.05034,0.85596,0.413414,0.761748,0.655054,0.585702
6749,0.5781,0.517508,0.633425,0.576582,0.11663,-0.0277661,0.35731,0.288222,0.258524,0.253234,0.100526,0.0707393,0.602417,0.530888,0.267519,0.232221,0.214107,0.270959,0.518719,0.543632,2.72762,2.59272,0.403105,0.475687,-0.0852238,0.157087,-0.568481,-0.46064,0.0701618,0.0195349,0.472652,0.231924,-0.766605,-0.744286,-0.465329,-0.652032,-0.428569,-0.0778888,1.42721,1.36206
6750,0.823039,0.76347,0.304607,0.246325,0.713383,0.569941,0.772313,0.702243,0.3746,0.43013,0.122608,0.0926748,0.201363,0.13055,0.556921,0.522855,0.940834,0.998316,0.0671983,0.0923238,1.12158,0.989901,0.863558,0.937509,0.303658,0.617811,0.305568,0.411329,0.655454,0.605584,0.758256,0.521163,0.5433,0.567269,-0.249825,-0.444428,-2.27215,-1.91502,0.0312519,-0.0405603
6751,0.0547946,-0.00177853,0.729026,0.670771,0.201214,0.0563774,0.457711,0.389142,0.228169,0.283721,0.363371,0.335327,0.121048,0.051214,0.644526,0.60858,0.109939,0.169881,0.478023,0.501638,-0.82094,-0.955646,-1.11952,-1.04491,0.840607,1.07853,-0.0204242,0.083648,-0.849395,-0.895369,-1.32597,-1.55892,1.64411,1.67162,0.432526,0.23888,-1.42581,-0.985066,-2.53436,-2.60966
6752,0.800482,0.742189,0.194759,0.138697,0.163163,0.0230988,0.609916,0.556943,0.661619,0.716265,0.0212141,-0.00742233,0.983865,0.914516,0.264999,0.22731,0.0770825,0.13481,0.25001,0.283077,2.19781,2.06142,-0.0309603,0.0499734,1.43392,1.676,-0.567888,-0.459527,-1.39852,-1.44414,-0.374527,-0.574652,-0.558307,-0.533407,1.59896,1.41244,-0.476985,-0.0551074,0.590284,0.509871
6753,0.634146,0.5746,0.0999602,0.0447331,0.134656,-0.0101798,0.823295,0.724744,0.418748,0.472815,0.909834,0.879721,0.32737,0.257068,0.417423,0.378574,0.876707,0.931716,0.0412443,0.0645171,-0.835195,-0.965303,-0.00438603,-0.00408179,0.769615,1.01401,2.39279,2.49839,-0.43278,-0.470883,0.637192,0.409617,-0.665,-0.638948,0.220668,0.0422338,0.517721,0.874851,0.128771,0.0497769
6754,0.774595,0.640953,0.352406,0.214475,0.802559,0.659402,0.961115,0.892546,0.172084,0.229364,0.721634,0.691241,0.321879,0.249641,0.77402,0.736082,0.680244,0.754759,0.413296,0.434457,-0.652437,-0.776347,-0.14414,-0.058137,-1.33933,-1.09626,0.553924,0.712022,-0.660075,-0.700898,0.174728,-0.0548927,0.756504,0.779502,-1.7623,-1.93474,-1.97073,-1.61051,-1.25495,-1.33813
6755,0.767824,0.707307,0.441618,0.384217,0.333991,0.18967,0.220387,0.149473,0.138117,0.195008,0.148202,0.116877,0.846937,0.776503,0.0959013,0.0587248,0.522082,0.577802,0.407757,0.368221,2.78428,2.66037,-0.536965,-0.453912,-0.883281,-0.637389,-1.17994,-1.07434,-0.216482,-0.253128,0.143683,-0.0876122,1.2289,1.25611,-0.177864,-0.347937,-0.719386,-0.355666,0.102602,0.0205237
6756,0.65264,0.492982,0.0723588,0.0151125,0.227052,0.0836264,0.654773,0.582889,0.576096,0.632766,0.0445345,0.0132841,0.338643,0.270185,0.71971,0.684171,0.666486,0.695654,0.258103,0.301986,0.124576,0.0051234,0.147601,0.224448,-1.50134,-1.25474,-0.769336,-0.665363,-0.638908,-0.681258,1.78763,1.55463,1.06478,1.08925,-2.08082,-2.24556,-0.674606,-0.313381,-0.440439,-0.517709
6757,0.340511,0.278657,0.00539094,-0.0539295,0.391622,0.270077,0.556165,0.498977,0.732296,0.787773,0.30529,0.272563,0.0816087,0.0134378,0.709765,0.725707,0.755576,0.813507,0.196914,0.235751,1.10887,0.989718,0.248363,0.316953,0.214067,0.467643,0.315758,0.421193,2.21108,2.16342,0.34476,0.106398,-1.11506,-1.08581,0.274499,0.113683,-1.73614,-1.37483,1.13617,1.05534
6758,0.874952,0.815436,0.501049,0.434962,0.59833,0.456527,0.487699,0.415065,0.352659,0.408901,0.351638,0.317692,0.52759,0.459584,0.805404,0.767244,0.0548922,0.113101,0.224666,0.169515,0.701476,0.586003,0.618191,0.685614,0.552026,0.704853,-0.40989,-0.308082,-0.817148,-0.869743,0.873792,0.628552,0.326533,0.361143,-1.70965,-1.87818,1.53985,1.89718,-0.264667,-0.347275
6759,0.535542,0.516071,0.983173,0.923853,0.497387,0.355855,0.107088,0.0327192,0.505062,0.563908,0.0861458,0.0498146,0.525764,0.457864,0.396097,0.439189,0.729392,0.785889,0.0821186,0.10328,1.01067,0.899229,-0.346148,-0.279033,0.693146,0.942064,-1.47198,-1.36598,1.17579,1.12145,0.645567,0.397599,0.461046,0.498616,0.183842,0.0199951,-0.516724,-0.163676,-0.766505,-0.853764
6760,0.274293,0.216705,0.055508,-0.00444278,0.671257,0.532177,0.548318,0.47613,0.906719,0.966438,0.232567,0.1948,0.116149,0.0467461,0.151075,0.111133,0.468436,0.603607,0.48015,0.502738,0.570453,0.464878,2.3163,2.3788,0.737352,0.986849,-0.267471,-0.154248,-2.00112,-2.05291,-0.446701,-0.698319,2.23307,2.26977,-0.362351,-0.521531,-0.169451,0.187341,-0.846466,-0.911657
6761,0.239925,0.279797,0.745784,0.685223,0.409524,0.299748,0.764274,0.692434,0.197486,0.255551,0.14605,0.10693,0.335826,0.206594,0.782776,0.741356,0.322274,0.421325,0.495784,0.518085,0.978154,0.870679,-1.01634,-0.956352,-0.281175,-0.0327498,1.228,1.3394,-0.411164,-0.469786,1.48215,1.23381,0.941238,0.972816,-0.588536,-0.741325,0.610392,0.973227,-0.882292,-0.96955
6762,0.401134,0.342889,0.876748,0.813345,0.206336,0.0673187,0.0159533,-0.0550628,0.457522,0.516618,0.745157,0.708399,0.439006,0.366442,0.224706,0.185243,0.182167,0.239043,0.853812,0.878213,0.429223,0.327366,0.236833,0.292436,0.388729,0.643891,1.18633,1.30375,0.482139,0.425956,0.404041,0.154642,1.12169,1.15536,-1.29625,-1.4536,1.11271,1.4814,-1.50555,-1.59547
6763,0.874577,0.81478,0.679274,0.613882,0.872528,0.732035,0.166705,0.0412985,0.294863,0.355253,0.468644,0.430611,0.9052,0.833522,0.203489,0.15304,0.442891,0.500702,0.839322,0.864015,0.281366,0.180285,-0.418833,-0.362911,-0.195766,0.134912,0.640428,0.690036,-1.17508,-1.22656,0.592651,0.379405,0.192985,0.20548,-1.28478,-1.44627,0.480483,0.842108,-0.73299,-0.819117
6764,0.711307,0.651766,0.148125,0.0818085,0.684656,0.544558,0.209838,0.13766,0.989983,1.05164,0.503331,0.466891,0.902157,0.831802,0.0754356,0.120838,0.978203,1.03529,0.172201,0.19777,-0.237112,-0.334358,-0.071443,-0.0219362,-0.63166,-0.374068,-0.0384764,0.0763218,0.754924,0.698162,0.860018,0.604167,-0.734223,-0.744398,0.143221,-0.0118322,0.906418,1.2696,0.649408,0.568716
6765,0.828727,0.767773,0.128435,0.0611494,0.167434,0.0257661,0.754048,0.680548,0.247078,0.310302,0.889633,0.851703,0.0561165,-0.013832,0.125951,0.0886352,0.458121,0.516053,0.410166,0.436517,-2.41593,-2.51503,0.485497,0.531551,1.16918,1.4242,0.973604,1.08882,0.0671917,-0.0242473,0.447226,0.187835,-1.72794,-1.69428,0.504985,0.349793,0.213834,0.563154,1.13535,1.05774
6766,0.520973,0.458727,0.640028,0.573589,0.0253346,-0.11624,0.353057,0.36939,0.962368,1.02772,0.702746,0.751566,0.1911,0.121265,0.946879,0.906874,0.849749,0.906944,0.0624008,0.0905918,-1.1752,-1.26703,1.29623,1.34658,1.18891,1.44003,-0.223756,-0.106771,-0.683175,-0.746657,1.16533,0.907024,1.42691,1.4651,1.89324,1.73822,-0.511152,-0.143288,0.697293,0.626345
6767,0.947046,0.88659,0.311116,0.243332,0.706584,0.563475,0.133744,0.0582312,0.318628,0.383446,0.692063,0.65143,0.696611,0.627686,0.45702,0.415797,0.205966,0.262266,0.445739,0.474755,-1.32789,-1.41411,0.72409,0.767654,1.44962,1.7025,1.60749,1.72058,0.446035,0.376384,-0.354775,-0.617054,0.301322,0.33965,-0.0109249,-0.159397,0.922239,1.28685,-0.498074,-0.562656
6768,0.158411,0.0981738,0.340725,0.271782,0.542278,0.397329,0.130848,0.0570118,0.71786,0.781168,0.898782,0.859918,0.286356,0.216568,0.985139,0.942672,0.0923725,0.150278,0.528707,0.556375,-0.36116,-0.442858,-0.381891,-0.336808,-0.65124,-0.392723,-0.354526,-0.244003,-0.267099,-0.338241,0.180459,-0.0810146,0.623214,0.671324,-0.870833,-1.02286,-0.22416,0.243516,0.910298,0.841293
6769,0.269387,0.208882,0.664623,0.59794,0.60063,0.454147,0.880077,0.805473,0.692243,0.757043,0.0915475,0.0526943,0.271841,0.286365,0.949619,0.906557,0.706601,0.766325,0.0988132,0.125706,-1.64098,-1.72444,-0.95465,-0.915731,0.598132,0.850291,-1.41535,-1.3019,-1.55449,-1.62217,0.076348,-0.188396,0.962068,1.003,0.183836,0.0283819,-1.17143,-0.799816,0.0542246,-0.0112675
6770,0.715347,0.656747,0.542537,0.561103,0.890534,0.745602,0.199175,0.123465,0.883091,0.895567,0.388059,0.348316,0.425147,0.356162,0.492113,0.450104,0.859389,0.921293,0.891071,0.918007,-0.956904,-1.10065,0.248707,0.285423,0.071819,0.252801,0.582293,0.697157,0.954866,0.893124,-0.696137,-0.868767,0.846267,0.883383,-1.30061,-1.4482,0.190797,0.568266,1.24812,1.17995
6771,0.112185,0.0555778,0.593289,0.524267,0.121414,-0.0236436,0.380014,0.304308,0.969244,1.03409,0.405921,0.365011,0.649097,0.58201,0.896993,0.856549,0.355715,0.416181,0.790273,0.903422,-0.397028,-0.476855,0.0609733,0.104057,-0.594371,-0.344688,0.268492,0.384149,-0.592427,-0.650247,-1.29078,-1.54914,0.0189828,0.00326463,0.384708,0.233428,1.23217,1.60673,-0.282522,-0.343901
6772,0.785504,0.726799,0.671405,0.62226,0.877006,0.732824,0.844695,0.76684,0.813208,0.878216,0.976829,0.936063,0.0518021,-0.0145894,0.814281,0.743957,0.583627,0.576751,0.817983,0.888836,1.84845,1.7734,0.735207,0.782416,1.00679,1.25076,1.89097,2.00578,0.554763,0.49049,-0.861762,-1.1199,-0.913969,-0.876853,0.556818,0.40982,0.288593,0.667138,0.191893,0.129016
6773,0.466715,0.40758,0.790705,0.720254,0.315388,0.173977,0.704205,0.735566,0.993144,0.969224,0.668252,0.627021,0.409497,0.342797,0.670577,0.631364,0.675511,0.73732,0.882143,0.874251,-0.542048,-0.6119,-1.74753,-1.69239,-1.01994,-0.777641,-0.314339,-0.2063,-0.914244,-0.978179,-0.949737,-1.21297,-0.669476,-0.632851,-0.252153,-0.393413,0.803849,1.17531,1.50016,1.44115
6774,0.808478,0.749529,0.0614001,-0.0102983,0.610721,0.47026,0.75208,0.704291,0.993298,1.06023,0.720669,0.568292,0.524259,0.466098,0.786007,0.747121,0.442519,0.503481,0.780113,0.859665,0.226033,0.233007,-0.472276,-0.413813,2.10298,2.34321,-1.82165,-1.70883,-0.640725,-0.697129,1.63035,1.36227,0.412515,0.455098,-0.809494,-0.950363,-0.45829,-0.0887582,0.989696,0.934662
6775,0.363596,0.354126,0.475944,0.404811,0.639882,0.551563,0.748295,0.673016,0.222206,0.291433,0.606518,0.509564,0.531699,0.589399,0.0916296,0.0542112,0.970788,1.03307,0.818143,0.84508,1.14695,1.07791,0.403449,0.463287,0.0304429,0.26496,-1.41123,-1.29985,-1.10772,-1.17015,1.53251,1.2692,0.4115,0.456211,0.682145,0.543522,-1.01549,-0.651167,-1.57484,-1.63444
6776,0.0168499,-0.0412769,0.477903,0.331089,0.775438,0.632866,0.0769878,0.00104531,0.84657,0.91562,0.501195,0.450835,0.779118,0.7127,0.496981,0.460656,0.23268,0.296753,0.245472,0.273906,1.43216,1.36084,0.0546031,0.113322,-0.146268,0.0831121,0.0500095,0.162624,-0.179941,-0.244504,0.0905906,-0.179029,-0.867727,-0.825064,0.562509,0.429672,0.0425591,0.402534,-1.56331,-1.62686
6777,0.57708,0.519976,0.369476,0.257368,0.335691,0.193643,0.827524,0.753642,0.453853,0.522054,0.424664,0.392107,0.222039,0.155267,0.281589,0.272197,0.596774,0.662598,0.130373,0.244673,2.1959,2.11848,-1.40934,-1.35243,0.240061,0.466145,-0.702284,-0.583628,-1.1231,-1.19258,-0.858783,-1.12211,-0.497774,-0.456535,0.906345,0.775379,-0.449336,-0.08198,-0.425626,-0.484268
6778,0.128692,0.0695513,0.256791,0.183647,0.948913,0.807251,0.32611,0.250714,0.296661,0.36618,0.37461,0.333378,0.860207,0.791855,0.122276,0.0837373,0.235814,0.303446,0.197157,0.21544,-0.68278,-0.753456,-0.688048,-0.630351,1.56715,1.79922,-0.0508712,0.0713708,0.380986,0.315112,-1.22467,-1.49107,0.869208,0.914402,-0.672356,-0.808469,0.291397,0.658452,-0.478844,-0.537488
6779,0.362853,0.305764,0.88751,0.814268,0.00199034,-0.140372,0.785664,0.708399,0.826315,0.895205,0.525193,0.579546,0.254175,0.185728,0.111555,0.101109,0.704021,0.773997,0.157722,0.186206,-0.287009,-0.364454,-1.00067,-0.948552,0.380749,0.610088,-1.38631,-1.26127,-1.20168,-1.26153,-1.21224,-1.47671,0.915763,0.960302,-0.598983,-0.739214,-0.0116552,0.357705,0.963969,0.898152
6780,0.011403,-0.0442969,0.995577,0.92303,0.49714,0.353025,0.225346,0.150159,0.860755,0.927168,0.865213,0.825713,0.579301,0.513045,0.114884,0.11848,0.334616,0.43559,0.556492,0.585665,-1.24395,-1.32335,0.638002,0.687095,1.60051,1.83764,0.251725,0.374373,-0.905184,-0.966072,0.0079199,-0.252435,0.341641,0.39067,-1.74592,-1.89192,0.696688,1.06745,0.589459,0.525933
6781,0.553966,0.497958,0.347475,0.272507,0.236071,0.0930261,0.351156,0.27503,0.195722,0.262335,0.084009,0.0452859,0.00454253,-0.064028,0.188558,0.135851,0.0273596,0.0971827,0.502557,0.506067,-0.515829,-0.597688,-0.400203,-0.354923,-0.0322712,0.203554,-1.79537,-1.66833,0.602431,0.541622,0.503639,0.238966,-0.575266,-0.53255,0.180874,0.102594,1.65838,2.02525,0.0107943,-0.0555405
6782,0.700047,0.642774,0.00523488,-0.0675315,0.485061,0.266957,0.725981,0.648871,0.399619,0.508899,0.101056,0.0619805,0.359479,0.349754,0.191762,0.153223,0.0858825,0.155343,0.39852,0.426469,-1.31353,-1.38881,-0.948647,-0.904564,2.27601,2.5125,-0.249567,-0.128765,-0.101587,-0.159584,2.82734,2.56882,-0.604522,-0.561321,2.2431,2.0971,0.633417,0.995649,0.363845,0.296393
6783,0.641393,0.586105,0.400579,0.327918,0.581051,0.440887,0.692967,0.61686,0.690237,0.755462,0.443489,0.339674,0.833965,0.763536,0.825964,0.788163,0.370973,0.441087,0.973995,1.00055,-0.13479,-0.202658,-0.524438,-0.473996,0.0234462,0.257138,-2.05548,-1.92694,0.458104,0.395157,1.53526,1.27508,0.342107,0.391567,-1.77852,-1.92452,0.415699,0.695756,-1.66766,-1.73789
6784,0.124721,0.0706861,0.14336,0.071863,0.547231,0.407343,0.389712,0.314428,0.934864,1.00203,0.595996,0.617368,0.584937,0.512713,0.149901,0.110805,0.414215,0.484559,0.544687,0.630922,0.125174,0.109819,0.427291,0.478759,0.305761,0.534739,0.0177502,0.152099,0.437535,0.368273,-1.34237,-1.60756,0.261468,0.316256,1.10201,0.957998,0.03375,0.395863,2.544,2.47377
6785,0.383065,0.327127,0.197965,0.153992,0.00115127,-0.137639,0.495802,0.418829,0.193314,0.260691,0.934138,0.895062,0.853751,0.77913,0.891677,0.8532,0.884779,0.955109,0.233944,0.261293,0.411957,0.422296,0.634715,0.680731,-0.5888,-0.359695,-0.472795,-0.345523,0.846733,0.771825,0.0272289,-0.231317,0.901056,0.963155,0.783744,0.644667,0.492373,0.854367,0.527736,0.454266
6786,0.153548,0.098474,0.309114,0.23612,0.0828356,-0.0557098,0.337371,0.261099,0.383486,0.384571,0.0403267,0.00039554,0.089682,0.0132733,0.0891282,0.05194,0.117991,0.190536,0.990101,1.01636,0.802641,0.734773,-1.61833,-1.56971,0.666346,0.897149,0.479189,0.60333,-0.543128,-0.621074,-0.611886,-0.866857,-0.0890949,-0.0226445,0.0519576,-0.0838764,-1.01789,-0.649316,-0.708971,-0.781374
6787,0.330084,0.273881,0.160831,0.0872964,0.397959,0.238175,0.499651,0.420722,0.500122,0.508451,0.439466,0.325039,0.539601,0.464523,0.751203,0.711965,0.854218,0.927294,0.054476,0.0784215,0.259248,0.115117,-1.19674,-1.15356,-1.31712,-1.08477,-0.531315,-0.454324,-0.239141,-0.311699,0.274416,0.0214943,0.692903,0.761058,-1.37287,-1.51685,0.0650889,0.434601,-1.20873,-1.28786
6788,0.944227,0.889212,0.398674,0.261806,0.803053,0.53206,0.334303,0.216724,0.564955,0.632332,0.691149,0.649683,0.525921,0.390884,0.691132,0.651311,0.0524385,0.124609,0.772681,0.79795,-0.436672,-0.504539,1.49985,1.53774,-1.06857,-0.811913,-1.63304,-1.51198,-0.886557,-0.951893,-0.47137,-0.720575,0.777893,0.839068,1.222,1.08142,0.409615,0.737335,0.0110798,-0.0671143
6789,0.620443,0.645007,0.512714,0.436316,0.963184,0.825946,0.0909028,0.0127258,0.0253444,0.0941779,0.583301,0.540743,0.390888,0.317245,0.0543839,0.0146678,0.841477,0.911765,0.958649,0.985143,0.0869064,0.0247583,-0.172641,-0.130501,-0.775402,-0.539053,-0.879624,-0.763375,0.930095,0.862411,0.310919,0.0591823,0.397089,0.456743,-0.257757,-0.395169,0.675051,1.04007,-0.0796439,-0.164878
6790,0.453889,0.400803,0.286839,0.212038,0.156807,0.0178706,0.42498,0.2855,0.364687,0.431556,0.0161659,-0.0236291,0.937359,0.86351,0.788282,0.747215,0.742258,0.798598,0.0796158,0.10615,-1.52508,-1.59057,-0.715186,-0.680142,-1.45611,-1.21755,-2.00329,-1.88119,-1.01487,-1.08825,0.671542,0.424576,-0.483203,-0.420003,0.15625,0.0127921,-0.468567,-0.100013,1.97697,1.88909
6791,0.484971,0.431234,0.639109,0.562542,0.717988,0.580103,0.636675,0.558275,0.308161,0.412981,0.244663,0.205055,0.163312,0.0876394,0.375586,0.335525,0.613735,0.68543,0.597985,0.625739,0.400269,0.335089,1.6653,1.70337,0.683221,0.925098,-0.479485,-0.357958,0.274553,0.205262,-0.135331,-0.379036,-0.892501,-0.834118,0.11975,-0.0274564,-0.708604,-0.337534,-0.147225,-0.236819
6792,0.0475422,-0.00456802,0.536265,0.550038,0.735165,0.588544,0.486704,0.465808,0.325707,0.394406,0.213215,0.172918,0.484213,0.417696,0.641396,0.601128,0.829933,0.901527,0.26292,0.289308,-0.117682,-0.179554,-0.144907,-0.107087,-1.95654,-1.7181,-1.59808,-1.47577,-1.00118,-1.06415,0.873679,0.630531,0.514811,0.569479,-0.293065,-0.447174,0.0212462,0.386951,0.151563,0.0554068
6793,0.438247,0.369218,0.586814,0.537534,0.738389,0.596984,0.329584,0.373341,0.862871,0.933292,0.410342,0.371783,0.82349,0.747752,0.079334,0.0399709,0.133536,0.205372,0.391625,0.394939,-1.60547,-1.67461,-1.40434,-1.36576,1.01717,1.25432,2.03452,2.15683,0.136371,0.0765843,-0.929549,-1.17076,-0.181893,-0.121043,-0.144695,-0.299685,-0.315963,0.0559967,-1.46911,-1.56072
6794,0.79376,0.743004,0.456034,0.52503,0.472112,0.329084,0.361325,0.280874,0.533361,0.606129,0.141113,0.103906,0.183142,0.105878,0.347019,0.278281,0.177079,0.248844,0.612721,0.500571,-1.41802,-1.48565,-1.27073,-1.22605,-0.774168,-0.538778,0.777645,0.899412,0.484547,0.418898,0.444834,0.205477,-1.08644,-1.02806,0.676385,0.521367,0.203626,0.57845,-0.420874,-0.50988
6795,0.780292,0.738916,0.524301,0.512526,0.202769,0.0611834,0.950052,0.86818,0.445958,0.520378,0.416221,0.437393,0.593848,0.517404,0.556689,0.516591,0.888489,0.961082,0.578784,0.606203,-0.445973,-0.514401,0.597794,0.642899,0.155736,0.397729,0.0742725,0.201543,0.573118,0.501084,-0.0453645,-0.287723,1.23175,1.29096,0.0764469,-0.0817141,1.78786,2.16292,-0.185765,-0.296594
6796,0.783871,0.734828,0.576588,0.500022,0.153496,0.01216,0.967324,0.884628,0.579487,0.655256,0.806605,0.770879,0.169047,0.0923991,0.305447,0.304271,0.774132,0.849094,0.060579,0.0859418,1.67134,1.59804,-1.54058,-1.49496,-2.30812,-2.06523,-0.101871,0.0280476,-0.386277,-0.460501,0.0331241,-0.113304,1.84037,1.90675,-0.0779012,-0.227114,0.210926,0.550266,0.007185,-0.0833089
6797,0.20599,0.158578,0.85082,0.776261,0.919883,0.779043,0.982195,0.901077,0.106599,0.18225,0.120268,0.0861128,0.834498,0.75561,0.133415,0.0919504,0.100241,0.174102,0.467872,0.495256,-0.690204,-0.770769,0.581128,0.628915,-0.0839588,0.160751,-0.747779,-0.624307,0.612776,0.541355,0.295416,0.0611158,0.48163,0.548402,-0.213952,-0.372513,-1.43746,-1.06239,-0.404689,-0.442505
6798,0.427476,0.380379,0.690893,0.65656,0.878547,0.706923,0.358972,0.278052,0.025422,0.102079,0.758139,0.722092,0.138115,0.0592149,0.258506,0.267098,0.511811,0.486755,0.490199,0.517445,0.219131,0.137965,-0.456959,-0.413104,0.512169,0.66677,0.0715522,0.199159,0.849263,0.774937,0.169933,-0.064176,0.396266,0.459084,-0.165914,-0.319526,0.182827,0.552654,-0.71709,-0.801702
6799,0.0952866,0.0506647,0.614418,0.536859,0.775898,0.634804,0.516824,0.437676,0.745596,0.824342,0.840663,0.802915,0.455881,0.376413,0.514851,0.442246,0.726403,0.799408,0.225081,0.252472,0.821633,0.741504,0.64384,0.681782,0.932512,1.17279,-1.40313,-1.27204,0.622943,0.544922,0.258355,0.0272273,-1.72507,-1.66704,0.8806,0.731711,1.07739,1.49581,1.20142,1.11076
6800,0.710952,0.665996,0.744462,0.664981,0.944744,0.805532,0.0333132,-0.0441346,0.119285,0.199304,0.398231,0.361361,0.149434,0.0704036,0.639196,0.617393,0.281408,0.354831,0.638492,0.666252,-1.12791,-1.20404,-1.096,-0.964493,-0.764522,-0.527106,0.85594,0.98767,-0.0460844,-0.12686,-1.27954,-1.51228,0.885622,0.939045,-0.33939,-0.484958,2.07252,2.43897,-1.95362,-2.04434
6801,0.219566,0.17494,0.0419994,-0.0352826,0.603852,0.465661,0.644042,0.56874,0.576333,0.656925,0.737351,0.700937,0.943686,0.865459,0.834005,0.792541,0.36022,0.432844,0.675403,0.687418,-0.340125,-0.417167,-2.64871,-2.61077,0.603866,0.836866,1.10761,1.2441,-0.948026,-1.0266,0.616188,0.389194,-1.41421,-1.36552,-0.128414,-0.373171,0.993432,1.36151,-0.109959,-0.205109
6802,0.819593,0.775693,0.306014,0.155872,0.0361039,-0.103071,0.639349,0.561957,0.0376247,0.118771,0.855454,0.820554,0.745374,0.665801,0.77547,0.731886,0.827618,0.898013,0.553172,0.708583,-0.61123,-0.683722,1.34565,1.38033,2.4729,2.69889,-0.682598,-0.54043,-0.0975929,-0.177654,0.458273,0.233582,0.139076,0.188311,-0.0578982,-0.261385,0.673031,1.04564,0.990995,0.891588
6803,0.697248,0.64384,0.423668,0.347026,0.980757,0.841577,0.10289,0.0238686,0.26373,0.344226,0.0700549,0.0340785,0.977317,0.896775,0.994249,0.950122,0.322647,0.392901,0.701068,0.729748,-1.51692,-1.59778,-1.44856,-1.41563,2.591,2.81971,-0.02075,0.128954,-0.185841,-0.269754,-0.402004,-0.630805,-0.451289,-0.396643,-0.00403081,-0.149598,-1.12987,-0.760741,1.65451,1.54864
6804,0.557081,0.511988,0.199551,0.122748,0.849553,0.71005,0.437037,0.444105,0.15047,0.232595,0.354765,0.318181,0.0238242,-0.057789,0.783336,0.738512,0.0623633,0.13409,0.396551,0.457863,0.553828,0.470005,-0.415005,-0.384556,0.542165,0.678746,-0.177751,-0.0667226,-0.802748,-0.880378,-0.658949,-0.891958,-0.625342,-0.563507,-1.94279,-2.09412,0.36218,0.731491,1.03731,0.936141
6805,0.176586,0.132251,0.758022,0.679577,0.486472,0.345431,0.943362,0.864341,0.29051,0.372359,0.0707959,0.0354286,0.0792742,-0.004515,0.934498,0.889776,0.046843,0.118668,0.158805,0.185977,0.632406,0.609253,0.390377,0.416772,-1.69093,-1.46222,-0.407124,-0.262399,1.65801,1.58094,0.393017,0.166434,-0.047634,0.0215222,1.09252,0.941288,-0.172669,0.198904,0.747995,0.64214
6806,0.376757,0.332777,0.0615758,-0.0156533,0.514216,0.470226,0.180531,0.100806,0.797503,0.880697,0.359366,0.403515,0.68112,0.596,0.128315,0.082473,0.997742,1.06918,0.648065,0.675447,0.846141,0.748501,-1.06626,-1.04898,-0.845254,-0.615727,-1.42117,-1.27228,0.0870503,0.00429858,-0.738928,-0.959071,-0.846705,-0.777595,1.35073,1.19707,0.173603,0.54992,0.984215,0.875172
6807,0.161372,0.118901,0.341099,0.218912,0.738217,0.595021,0.405137,0.247192,0.319997,0.401743,0.807572,0.771601,0.489061,0.407017,0.491382,0.445358,0.86164,0.930778,0.407622,0.435792,0.971571,0.887748,0.833949,0.848785,0.87294,1.10666,-1.13575,-0.98386,0.0381375,-0.0380077,0.624256,0.402836,-0.924563,-0.852907,-0.808915,-0.968886,2.16193,2.53123,2.05112,1.94117
6808,0.876877,0.834784,0.465928,0.453478,0.634362,0.488978,0.475917,0.393578,0.723942,0.804273,0.324835,0.286882,0.900576,0.818543,0.487245,0.440559,0.114816,0.183349,0.872959,0.899876,0.278503,0.191128,-1.32106,-1.30577,-0.230872,0.00994411,-1.5509,-1.40478,-0.353546,-0.434505,-0.638888,-0.860762,2.84917,2.92082,1.25396,1.08699,-1.33135,-0.964496,0.632177,0.523809
6809,0.225574,0.183185,0.765273,0.688044,0.744605,0.613773,0.0391,-0.0426578,0.536756,0.593854,0.186718,0.202315,0.570675,0.533291,0.175122,0.128482,0.334559,0.405021,0.0403396,0.0689412,2.5246,2.44138,-0.867506,-0.859858,2.22927,2.46536,-0.296343,-0.1261,0.143918,0.061038,-0.369938,-0.586435,0.205992,0.277797,-0.419445,-0.590774,2.21737,2.58496,1.0262,0.920543
6810,0.0850643,0.0453771,0.308789,0.229827,0.883356,0.738568,0.865707,0.784216,0.313696,0.383436,0.154666,0.117749,0.335485,0.248039,0.921655,0.875432,0.0961032,0.16651,0.486241,0.512497,1.06757,0.977403,0.436268,0.449799,0.660309,0.893074,0.999978,1.15258,0.864794,0.786713,-0.616031,-0.833227,1.63236,1.71021,-1.78661,-1.96098,1.81217,2.17713,-0.247366,-0.360622
6811,0.640369,0.601926,0.190613,0.111779,0.530038,0.384837,0.144822,0.0615153,0.0910361,0.173017,0.357682,0.35107,0.0448203,-0.0372125,0.526295,0.478926,0.244702,0.3159,0.487545,0.511648,1.14903,0.980111,0.256685,0.268433,0.0739244,0.243364,1.26533,1.42512,-0.0850706,-0.161365,-0.602598,-0.818861,1.69393,1.77341,0.560694,0.380055,-0.553466,-0.189855,1.07258,0.965762
6812,0.425209,0.388049,0.38984,0.305876,0.978301,0.834091,0.771247,0.688683,0.199199,0.269398,0.682413,0.584392,0.415118,0.267718,0.824513,0.77557,0.632257,0.70165,0.520415,0.510798,1.07299,0.98282,-0.404666,-0.386914,-0.640939,-0.406345,-1.22854,-1.07514,-0.6665,-0.741126,0.479522,0.268383,0.0770569,0.163462,-1.40158,-1.58032,2.00997,2.37906,-1.04933,-1.16014
6813,0.567625,0.528404,0.577638,0.499974,0.0798176,-0.0625409,0.546143,0.465793,0.168977,0.365778,0.85463,0.817713,0.764597,0.572648,0.904393,0.832905,0.429779,0.519368,0.442617,0.509948,-0.631447,-0.728365,-0.15999,-0.139592,2.09314,2.33041,1.00895,1.16598,-0.0174343,-0.0933168,-0.257746,-0.473686,1.09872,1.19061,0.597832,0.413026,-1.92683,-1.55774,0.550027,0.443741
6814,0.91577,0.875399,0.536681,0.460602,0.362247,0.218744,0.532572,0.408964,0.380178,0.462159,0.567487,0.528801,0.959612,0.877579,0.937546,0.89024,0.185883,0.337086,0.482843,0.509099,-0.953264,-1.05403,0.690005,0.705545,2.40771,2.63829,0.956585,1.11629,0.999086,0.925203,0.838797,0.626924,1.52748,1.6226,0.215659,0.0255828,0.608932,0.979361,0.341709,0.239398
6815,0.795359,0.756733,0.964728,0.890172,0.125054,-0.0196208,0.43128,0.352136,0.00901559,0.0881301,0.835084,0.797572,0.932015,0.849192,0.783856,0.663925,0.0847095,0.154804,0.284657,0.308359,-0.510295,-0.60874,-0.287361,-0.273439,-0.687412,-0.451941,-1.15609,-1.00231,1.11281,1.0369,0.585984,0.380131,0.234982,0.325648,0.617195,0.433544,-0.564922,-0.193454,-0.240906,-0.342076
6816,0.00141948,-0.0365578,0.0537869,-0.0201302,0.0974084,-0.0476296,0.684714,0.607296,0.623278,0.702228,0.694712,0.673712,0.482431,0.475776,0.598153,0.43761,0.207228,0.279344,0.810616,0.832792,-0.0670814,-0.163451,1.68763,1.70457,1.01533,1.25353,1.43127,1.5798,-1.05558,-1.12861,-1.20396,-1.40613,1.26704,1.35279,2.35909,2.17799,-0.309664,0.0618507,0.836278,0.740264
6817,0.21805,0.180021,0.976202,0.900832,0.349489,0.20294,0.565408,0.48937,0.774997,0.852415,0.585613,0.549851,0.184368,0.102359,0.349885,0.211295,0.995206,1.0665,0.405956,0.504337,-1.37164,-1.47349,-0.46009,-0.449982,0.902114,1.14702,0.919553,1.12228,0.0831649,0.0121271,-0.30707,-0.502149,0.590932,0.678193,1.77314,1.58905,0.277156,0.645163,-0.287038,-0.389521
6818,0.700944,0.661337,0.650757,0.575308,0.365537,0.219367,0.991906,0.918055,0.364477,0.443225,0.123693,0.0889427,0.681432,0.599212,0.0322869,-0.0150194,0.890704,0.959221,0.155596,0.175882,-1.55033,-1.64923,0.477952,0.487578,-1.05519,-0.805207,0.519408,0.664759,1.48485,1.41266,0.0610987,-0.136755,0.852101,0.93777,-1.77202,-1.95081,0.38593,0.747801,-2.16358,-2.26682
6819,0.915194,0.877916,0.0232585,-0.0502442,0.839465,0.692962,0.498203,0.425344,0.697421,0.775406,0.558832,0.515937,0.917977,0.835062,0.121268,0.191214,0.408518,0.479144,0.991838,1.00975,0.382628,0.276429,0.107056,0.123164,-0.648309,-0.404914,0.459855,0.598452,0.84741,0.705782,-0.833758,-1.03429,-0.241218,-0.154627,-0.0452271,-0.224045,0.710003,1.06638,0.536039,0.430241
6820,0.462806,0.427491,0.292744,0.220791,0.198618,0.0547972,0.522824,0.542402,0.325825,0.401377,0.979724,0.94293,0.112547,0.0299836,0.380242,0.397446,0.706445,0.775276,0.0841742,0.10467,1.25273,1.15291,-1.23878,-1.21609,1.01988,1.26951,1.7307,1.87229,0.0753223,-0.00109249,-0.936735,-1.08212,-0.254002,-0.168608,0.516844,0.335221,-1.70235,-1.35145,-1.53908,-1.64942
6821,0.571011,0.533493,0.229951,0.156658,0.925103,0.780451,0.734839,0.659459,0.559408,0.580911,0.671244,0.633888,0.447066,0.362412,0.654366,0.603679,0.026687,0.0953348,0.370671,0.320023,-0.420167,-0.525866,-0.693609,-0.677154,0.458445,0.751717,0.97629,1.11041,1.6223,1.55173,-0.935772,-1.12995,-2.01817,-1.93736,-0.522409,-0.696464,-0.599047,-0.289143,0.370704,0.263041
6822,0.159971,0.123563,0.418203,0.345394,0.103971,-0.0390341,0.0387223,-0.037696,0.720091,0.760446,0.788987,0.753506,0.370185,0.221814,0.857219,0.809912,0.147087,0.154837,0.517431,0.535377,0.737961,0.628614,-1.83275,-1.81279,-0.0187925,0.233922,-1.16105,-1.02386,-1.64923,-1.72088,0.656641,0.463571,0.104175,0.186172,0.980756,0.812285,0.419783,0.773168,0.193685,0.0890594
6823,0.579386,0.541628,0.237453,0.165496,0.275293,0.131694,0.82882,0.752321,0.864429,0.939981,0.620024,0.533186,0.166867,0.0812153,0.429259,0.383453,0.202655,0.21434,0.448754,0.467044,1.34655,1.23215,-1.4322,-1.413,1.33682,1.58325,-0.016612,0.125919,-1.85009,-1.91969,0.651499,0.462378,-1.28067,-1.2025,0.557418,0.392567,1.22783,1.5742,-0.890084,-0.993827
6824,0.455746,0.487708,0.950955,0.880973,0.235621,0.167466,0.940119,0.861212,0.266844,0.340624,0.346556,0.312865,0.743777,0.657716,0.404237,0.268707,0.205993,0.273843,0.139429,0.155651,-1.27385,-1.39054,-1.25848,-1.24174,-1.43613,-1.18857,-0.712749,-0.571949,-0.852658,-0.917833,-0.159979,-0.355992,-0.527899,-0.449705,-1.01468,-1.17714,0.50221,0.841831,-0.306709,-0.413159
6825,0.473406,0.433789,0.0452158,-0.0232772,0.347486,0.203238,0.413134,0.332968,0.130574,0.231107,0.721251,0.687766,0.376843,0.311267,0.199548,0.153961,0.0409975,0.111049,0.198281,0.212834,1.42173,1.30313,0.445144,0.455887,0.0726868,0.312692,0.625102,0.762387,-1.32625,-1.39085,-1.6773,-1.88007,0.512012,0.591386,2.09732,1.92652,0.877646,1.22381,-1.01356,-1.11517
6826,0.994735,0.955748,0.563192,0.494495,0.829787,0.686253,0.732021,0.622805,0.0458777,0.12159,0.15795,0.123394,0.0499199,-0.0351827,0.37351,0.253735,0.515554,0.586497,0.751891,0.766947,0.958873,0.837816,-1.59979,-1.58846,0.5335,0.771567,-1.55189,-1.41912,-0.202856,-0.267813,0.593639,0.387042,-1.69064,-1.61364,0.0245426,-0.142927,0.824175,1.17069,0.964339,0.857819
6827,0.500361,0.460354,0.660041,0.593426,0.0717063,-0.0734417,0.99406,0.912643,0.869785,0.943454,0.50743,0.519187,0.669823,0.586341,0.398353,0.35351,0.725193,0.797093,0.107604,0.120787,0.146824,0.0895934,-0.556318,-0.544103,-0.0555583,0.185359,0.988957,1.13004,-1.09631,-1.16755,0.917658,0.707332,0.326052,0.410232,-0.0955691,-0.256777,0.0224633,0.375129,0.911212,0.8046
6828,0.732117,0.692204,0.499907,0.434898,0.337444,0.192673,0.850728,0.771108,0.958025,1.03198,0.950224,0.91498,0.691024,0.608831,0.977903,0.931385,0.428758,0.502867,0.474575,0.485978,-0.530296,-0.658629,0.739196,0.751534,0.484045,0.721636,-0.928672,-0.782822,3.05538,2.98424,-0.615616,-0.832177,0.327231,0.411345,0.357968,0.196538,1.60692,1.9596,0.601835,0.493872
6829,0.315861,0.335911,0.597886,0.533829,0.296942,0.153853,0.315009,0.23302,0.208926,0.28465,0.535211,0.499074,0.500561,0.419848,0.509006,0.460362,0.372698,0.509015,0.493531,0.540187,0.257962,0.128247,0.0248581,0.0240489,0.70241,0.93634,-1.36105,-1.22009,-1.25943,-1.33057,1.64384,1.43494,0.0139395,0.090314,-0.679579,-0.835147,-0.0860347,0.26662,-0.384442,-0.495077
6830,0.0198031,-0.0203821,0.11404,0.0505395,0.518127,0.374249,0.797994,0.715621,0.19545,0.270732,0.891283,0.854363,0.593537,0.438886,0.276033,0.228072,0.44284,0.515163,0.584731,0.594396,0.428025,0.301781,-0.71849,-0.703436,2.11613,2.34457,-0.497277,-0.364002,-1.11217,-1.18883,1.97728,1.76946,0.375453,0.458842,0.217919,0.0616283,1.12323,1.47534,-0.181271,-0.292393
6831,0.703333,0.660825,0.819827,0.755773,0.26532,0.12073,0.0084668,-0.0734702,0.910486,0.988148,0.283178,0.244881,0.536646,0.457925,0.585848,0.526961,0.662161,0.736835,0.313335,0.32395,1.06705,0.936461,0.817628,0.839166,0.714365,0.938616,0.711582,0.847732,0.437717,0.363992,-1.94704,-2.1542,-1.02469,-0.945725,-0.681726,-0.834532,-0.120858,0.224626,-0.345983,-0.451479
6832,0.43075,0.386975,0.328057,0.262858,0.998812,0.856072,0.893036,0.812645,0.333462,0.409579,0.624146,0.584457,0.884308,0.805626,0.871963,0.82585,0.609883,0.687267,0.861093,0.872886,1.37014,1.23591,-0.686233,-0.671208,1.46235,1.69179,0.330793,0.47316,-0.82412,-0.934581,0.46895,0.26163,-0.564284,-0.484859,1.04727,0.89223,0.426431,0.797881,0.355419,0.250519
6833,0.646709,0.603554,0.76738,0.702233,0.28247,0.141612,0.549374,0.471179,0.724051,0.802347,0.0294758,-0.0104243,0.783423,0.705968,0.0861264,0.0391734,0.0516241,0.12742,0.036164,0.0476747,1.02671,0.893957,-0.325196,-0.316013,0.0166054,0.241083,0.294728,0.437515,-2.15943,-2.23315,0.62739,0.467706,-1.00815,-0.930908,-0.192532,-0.354548,1.02565,1.37114,-1.68546,-1.78376
6834,0.330323,0.362561,0.305267,0.23887,0.682258,0.53949,0.554839,0.474988,0.0723124,0.153153,0.245593,0.20829,0.397841,0.320207,0.211406,0.164933,0.115349,0.130438,0.586877,0.59661,-1.45611,-1.591,1.9365,1.95253,-0.404175,-0.185779,0.747539,0.893238,0.62615,0.54659,0.888721,0.673781,-0.528906,-0.454297,0.420125,0.251914,0.579879,0.93123,0.382997,0.284039
6835,0.161252,0.121568,0.628866,0.560352,0.400715,0.24022,0.16108,0.0832139,0.531006,0.610773,0.166408,0.130062,0.935877,0.856608,0.773951,0.727169,0.0602842,0.133455,0.799739,0.731778,-0.322949,-0.452577,0.0928332,0.109465,-1.03398,-0.816703,0.544086,0.690504,1.02902,0.950143,1.43232,1.20982,-1.19792,-1.1289,-1.34358,-1.50271,0.532273,0.878112,-0.940406,-1.04161
6836,0.254037,0.212615,0.423156,0.355407,0.0834972,-0.0590497,0.466337,0.329706,0.0752927,0.157384,0.88779,0.851418,0.035429,-0.0419289,0.650434,0.675699,0.418786,0.489779,0.905162,0.866945,-1.43731,-1.56623,-0.552747,-0.5301,-1.09236,-0.877361,-0.425014,-0.272558,-1.1176,-1.19669,0.454297,0.282715,-1.14247,-1.0657,-1.00065,-1.157,0.103755,0.453742,-0.00211467,-0.0966887
6837,0.82807,0.789161,0.768823,0.701582,0.288916,0.198355,0.651346,0.576199,0.497276,0.59448,0.395658,0.361162,0.530604,0.454924,0.671786,0.624229,0.354984,0.461151,0.99397,1.00211,0.524209,0.392359,0.598666,0.622937,-0.728074,-0.461089,-0.116393,0.0313038,0.367359,0.333185,-0.414699,-0.644391,-0.512345,-0.434864,0.985494,0.836344,-0.950108,-0.607702,-0.306386,-0.394652
6838,0.632052,0.500812,0.785441,0.720616,0.481785,0.45576,0.107541,0.0326311,0.950483,1.03158,0.673326,0.583948,0.273247,0.198177,0.764657,0.715112,0.360502,0.432523,0.566563,0.576158,0.579154,0.44303,0.0811305,0.194445,-0.255539,-0.0448161,-1.18619,-1.04062,1.93958,1.86306,-0.936322,-1.1694,-0.204789,-0.127164,0.353747,0.200757,-1.35993,-1.01553,-0.597818,-0.692615
6839,0.249223,0.212464,0.214227,0.149244,0.85467,0.713165,0.359881,0.283272,0.431429,0.51315,0.838561,0.806733,0.734747,0.659486,0.537579,0.488151,0.89856,0.973199,0.389904,0.331646,-1.03187,-1.17229,-0.252909,-0.234047,0.735913,0.938503,-0.0687981,0.0765479,-0.372742,-0.443703,0.479858,0.252313,0.406942,0.488625,-0.510522,-0.697249,-0.426882,-0.0879594,-0.5068,-0.596497
6840,0.356522,0.318466,0.440831,0.371961,0.349674,0.209028,0.869714,0.791112,0.59846,0.677921,0.29049,0.257386,0.64407,0.570543,0.59889,0.554937,0.860084,0.956655,0.0758096,0.0871347,0.870604,0.724453,0.229976,0.281782,-0.012851,0.184275,0.0436892,0.263749,-0.887077,-0.961738,-1.43606,-1.65845,-0.0192404,0.14371,-1.44515,-1.59525,-0.85333,-0.563244,0.924523,0.839143
6841,0.124783,0.0852516,0.660096,0.594679,0.86621,0.727934,0.818394,0.780479,0.0101238,0.0892068,0.330302,0.297769,0.156856,0.0842391,0.669204,0.621723,0.863503,0.940111,0.599022,0.611567,1.60488,1.46573,0.778876,0.797612,-0.26607,-0.0745359,0.307483,0.450951,2.17121,2.09402,-1.7384,-1.96717,-0.286457,-0.201205,0.162138,0.00888133,-1.38305,-1.03853,-0.331303,-0.409993
6842,0.472045,0.434198,0.0619485,-0.00148455,0.778777,0.642069,0.849861,0.769846,0.326045,0.406191,0.657575,0.622905,0.0495126,-0.0249905,0.00758821,-0.0403808,0.549922,0.625158,0.604521,0.61688,1.01269,0.876326,0.0840672,0.0964691,-1.69102,-1.49565,0.099811,0.255274,-0.503615,-0.579547,0.350364,0.122057,-1.0397,-0.952008,-0.966308,-1.11619,-0.355159,-0.0167859,0.456037,0.384221
6843,0.820179,0.783144,0.0805605,0.0274354,0.479286,0.44234,0.225947,0.146821,0.434513,0.515209,0.573726,0.539772,0.826481,0.750923,0.839719,0.793216,0.451559,0.524018,0.383274,0.396231,0.200227,0.0698956,-3.54172,-3.52932,1.33833,1.53456,-0.0869067,0.0595976,1.55808,1.48571,0.00780153,-0.216359,0.197242,0.279176,0.239797,0.0874158,1.12056,1.4591,1.26301,1.17843
6844,0.897113,0.85879,0.121823,0.0563554,0.378195,0.242612,0.597423,0.520663,0.864734,0.943492,0.748254,0.714546,0.195341,0.118845,0.954317,0.908973,0.760438,0.8348,0.726937,0.740553,0.373789,0.24343,1.51634,1.52875,0.793443,0.983739,0.41652,0.559345,1.33174,1.25569,-1.04763,-1.26493,-0.746545,-0.660928,0.263442,0.132928,0.0826537,0.429499,-0.289014,-0.377345
6845,0.430176,0.392969,0.515112,0.451804,0.493206,0.359798,0.518748,0.366331,0.589149,0.759773,0.192635,0.16036,0.979096,0.904422,0.0910749,0.0484807,0.634866,0.678795,0.557248,0.570374,1.42016,1.2916,-0.190274,-0.184421,0.0134188,0.19819,-0.0469065,0.0913264,-0.762367,-0.844908,0.210066,-0.00966386,2.4406,2.52994,0.338912,0.178441,2.3094,2.65747,0.70991,0.628693
6846,0.966435,0.929748,0.563194,0.499837,0.064557,-0.0701129,0.366801,0.211998,0.491725,0.576054,0.784119,0.751006,0.57714,0.504084,0.477664,0.358813,0.44788,0.52279,0.965033,0.979688,-0.284202,-0.419585,-0.0294008,-0.00340159,-0.162388,0.0163422,-1.45412,-1.32031,-0.402943,-0.486563,-0.27807,-0.502864,0.474781,0.558256,1.39296,1.22968,-0.0281291,0.321745,0.625205,0.544241
6847,0.194323,0.157814,0.947768,0.884603,0.492242,0.358966,0.136538,0.0576662,0.219207,0.392334,0.771307,0.712876,0.566613,0.491421,0.710228,0.669146,0.606479,0.682173,0.306929,0.323383,1.37083,1.23294,0.174614,0.177618,-0.577028,-0.396155,0.399299,0.537569,1.52215,1.43816,-0.28501,-0.504056,-1.88935,-1.81179,0.572103,0.412002,0.813247,1.15606,-1.81307,-1.88527
6848,0.94294,0.906468,0.681203,0.618359,0.69367,0.559426,0.881948,0.806128,0.12794,0.208615,0.709165,0.674747,0.898137,0.823849,0.29193,0.252654,0.562258,0.637467,0.79214,0.807084,-0.449927,-0.588207,-0.626952,-0.617053,-2.12,-1.93948,0.81309,0.946547,1.73935,1.6581,-0.794502,-1.01466,-1.30853,-1.22677,0.498313,0.343959,-0.550581,-0.204219,-1.66909,-1.74321
6849,0.0565535,0.022359,0.85549,0.792212,0.159799,0.0256103,0.0779806,0.000111158,0.0624487,0.142887,0.396662,0.384369,0.254969,0.181974,0.143432,0.10573,0.855806,0.933599,0.7606,0.773065,-1.84639,-1.99211,-0.884401,-0.876024,0.116153,0.305018,0.234976,0.371974,-0.298241,-0.325967,0.113294,-0.110679,-1.15654,-1.07373,-0.332564,-0.489842,-0.107325,0.239039,-1.09261,-1.16254
6850,0.172258,0.0431557,0.224831,0.161884,0.157458,0.0218786,0.994103,0.915615,0.234095,0.330985,0.127013,0.0939902,0.955345,0.884391,0.990406,0.950855,0.172207,0.24816,0.979584,0.990444,0.634735,0.496096,0.685834,0.699151,-0.855964,-0.669874,0.466736,0.600464,-2.22879,-2.31003,-0.224798,-0.504078,0.259908,0.344718,0.580806,0.422603,-0.00290328,0.341678,0.297551,0.225288
6851,0.190959,0.0639524,0.762331,0.699118,0.555196,0.419757,0.888831,0.796463,0.43954,0.519083,0.83051,0.794651,0.932857,0.861409,0.309182,0.26868,0.953808,1.03034,0.412472,0.424852,0.115032,0.0337139,0.292894,0.303376,-1.45065,-1.27109,0.931127,1.06967,0.97332,0.891011,-0.678813,-0.897477,-0.479621,-0.392683,-1.06842,-1.22637,0.788796,1.12756,-1.30557,-1.37488
6852,0.11952,0.0847492,0.051226,-0.0110165,0.0473635,-0.0886309,0.754936,0.67731,0.231433,0.398646,0.657907,0.622056,0.343966,0.274102,0.159914,0.117434,0.652498,0.644425,0.967564,0.978965,-0.285583,-0.428668,0.277071,0.288579,0.721169,0.908098,-0.211754,-0.0788162,0.540426,0.462881,0.547548,0.326797,0.389683,0.481843,-0.429631,-0.589117,-0.952351,-0.615126,-1.73378,-1.7195
6853,0.674203,0.641298,0.964175,0.903279,0.758181,0.622095,0.358833,0.280465,0.196643,0.278209,0.061685,0.0271748,0.0073742,-0.0610577,0.748042,0.705369,0.180117,0.258508,0.65186,0.663197,1.17065,1.02321,0.59293,0.536761,0.458063,0.649287,0.187696,0.281477,1.20497,1.12732,0.133158,-0.0999845,0.599959,0.694678,-0.582678,-0.747077,-0.517003,-0.190281,-2.00172,-2.06412
6854,0.781548,0.7473,0.49074,0.429636,0.565138,0.430059,0.837883,0.757956,0.444304,0.4132,0.451637,0.416506,0.045355,0.052391,0.239082,0.194099,0.575242,0.654385,0.976302,0.986932,-0.919442,-1.0634,0.746304,0.784944,2.36724,2.55689,0.506356,0.641771,0.320809,0.242007,-0.298526,-0.526766,-0.35164,-0.259217,0.893506,0.730564,-0.10192,0.234563,-0.661739,-0.814292
6855,0.60856,0.575302,0.409272,0.392799,0.761314,0.533071,0.348625,0.271042,0.524733,0.548191,0.636217,0.593735,0.233437,0.16584,0.199384,0.178932,0.242404,0.411011,0.827948,0.836573,-1.72568,-1.86983,1.02162,1.03313,-1.01906,-0.834333,-1.53486,-1.40093,1.99288,1.91729,-0.0683261,-0.297713,-0.208626,-0.121743,1.66903,1.46375,0.754716,1.0861,0.497921,0.435531
6856,0.762326,0.659642,0.416385,0.355963,0.814714,0.636083,0.956375,0.877932,0.599503,0.683183,0.854692,0.770965,0.733426,0.668156,0.262711,0.163764,0.0868659,0.167638,0.348237,0.356011,-0.401963,-0.54415,-0.798379,-0.793949,-0.132007,0.0977262,2.39181,2.52336,-1.59043,-1.66786,0.622797,0.389626,0.516041,0.600103,2.35987,2.19693,2.18573,2.51623,-1.06189,-1.12025
6857,0.778825,0.743982,0.607938,0.548743,0.84796,0.739095,0.870016,0.694987,0.360519,0.446234,0.983324,0.948194,0.436762,0.371488,0.311542,0.148597,0.217413,0.297007,0.946007,0.954491,1.25117,1.10838,-1.46879,-1.46518,0.848958,1.02979,-0.815915,-0.681756,-1.05736,-1.12833,-1.05242,-1.28688,-0.313079,-0.225942,1.79246,1.62531,-0.238937,0.0984007,1.64805,1.59468
6858,0.556087,0.520424,0.497524,0.439736,0.977186,0.842107,0.590772,0.512043,0.461887,0.554099,0.433877,0.398847,0.875647,0.808383,0.222963,0.13343,0.612151,0.692884,0.312929,0.319307,-1.93723,-2.07931,0.167552,0.170469,-0.887148,-0.624465,-0.737163,-0.661519,0.721933,0.654217,0.189712,-0.047266,0.384227,0.465575,0.742951,0.577734,-0.966911,-0.561271,1.99585,1.94662
6859,0.755282,0.720949,0.878444,0.819474,0.085035,-0.050493,0.867244,0.787297,0.656458,0.661964,0.398001,0.374293,0.318573,0.250949,0.163246,0.118262,0.158772,0.238301,0.317991,0.309771,0.150452,0.00353378,0.395295,0.402258,-2.45954,-2.27872,-0.764276,-0.641281,-0.233706,-0.307369,-0.275226,-0.511776,-1.23059,-1.14437,0.923206,0.754125,-1.55807,-1.22094,-1.25064,-1.29629
6860,0.0998064,0.0645742,0.846703,0.731171,0.152765,0.0424722,0.0568116,-0.0243563,0.682702,0.769828,0.394426,0.349738,0.320015,0.2544,0.823596,0.778288,0.639032,0.718325,0.292137,0.300235,0.274406,0.131355,0.300805,0.311353,-1.84168,-1.66631,-0.755203,-0.621044,1.04192,0.97156,0.942536,0.698515,0.383647,0.566645,0.620876,0.45859,0.712919,1.0555,-0.6031,-0.612647
6861,0.341747,0.269758,0.639202,0.642868,0.271553,0.135437,0.862926,0.781997,0.590837,0.650619,0.296322,0.325184,0.727052,0.661369,0.753324,0.760324,0.601741,0.647087,0.759424,0.769192,-1.56717,-1.70396,0.00153296,0.00518155,1.72815,1.8968,0.0520404,0.18843,1.98294,1.91279,-0.571122,-0.811272,2.19144,2.27766,-0.113156,-0.269954,1.6088,1.95055,0.125747,0.0709923
6862,0.513595,0.474942,0.672692,0.554566,0.116213,-0.0212354,0.710517,0.551898,0.379306,0.531409,0.33566,0.30063,0.338272,0.270032,0.7865,0.742361,0.474245,0.57585,0.519259,0.529537,-1.17595,-1.31496,-1.28521,-1.28522,0.840774,1.00236,1.3494,1.4911,-0.379868,-0.442016,-1.00416,-1.2424,1.56458,1.64888,-0.0646832,-0.216966,1.78281,2.12834,-0.0786259,-0.0466589
6863,0.385829,0.346385,0.525233,0.466263,0.272061,0.152695,0.388685,0.321799,0.322445,0.412199,0.828487,0.793256,0.470184,0.400552,0.0198714,-0.024049,0.424148,0.504613,0.730992,0.685067,1.30911,1.17325,1.09164,1.09829,0.656581,0.820516,-0.914482,-0.77287,-0.818176,-0.885589,0.868075,0.627172,-2.12764,-2.0398,2.13714,1.99213,-0.693697,-0.343179,-0.112913,-0.16431
6864,0.741462,0.644351,0.0840565,0.0228902,0.465324,0.326626,0.170945,0.0917004,0.592114,0.683904,0.225932,0.192622,0.311032,0.241501,0.483821,0.43699,0.704828,0.78579,0.828391,0.840597,0.949664,0.815327,-0.450494,-0.44407,-0.238911,-0.0739181,-1.8483,-1.70639,-0.702309,-0.776123,0.605422,0.380459,-1.47806,-1.33513,1.86755,1.72531,0.687912,1.04014,-0.639578,-0.685926
6865,0.98037,0.942316,0.977688,0.916564,0.0660505,-0.0734872,0.347771,0.266754,0.119676,0.210898,0.687064,0.655571,0.582653,0.512698,0.675544,0.628619,0.0198226,0.100352,0.724983,0.734892,-0.378086,-0.512428,0.297565,0.310436,1.44362,1.61501,1.01477,1.15154,-0.599245,-0.666657,0.314955,0.133747,-0.711071,-0.630454,1.91512,1.7783,-0.354508,-0.00725623,-0.430264,-0.483242
6866,0.391394,0.351668,0.163309,0.101947,0.592544,0.455048,0.137718,0.0547524,0.157649,0.202562,0.833249,0.800556,0.637137,0.565972,0.289078,0.242147,0.852903,0.933775,0.104023,0.114192,0.525717,0.396307,-1.70894,-1.70272,-1.60691,-1.44032,-1.51729,-1.38205,0.922172,0.855908,0.124322,-0.112966,-0.541345,-0.462293,-0.2361,-0.374667,-0.541721,-0.200154,-0.435902,-0.490621
6867,0.129406,0.0881658,0.109961,0.0474652,0.306472,0.170308,0.692533,0.60733,0.181781,0.194226,0.713863,0.756584,0.916423,0.847038,0.300352,0.252426,0.118909,0.197453,0.512946,0.523506,0.983866,0.846763,0.831202,0.838126,-0.68988,-0.518908,0.632857,0.773309,-0.971465,-1.02952,-0.570951,-0.809528,1.97481,2.06,-2.77589,-2.91581,1.12285,1.46372,-2.11608,-2.16758
6868,0.479827,0.439987,0.342866,0.27988,0.245088,0.0845099,0.324066,0.240521,0.0396305,0.18589,0.74697,0.712611,0.632194,0.603627,0.984662,0.938212,0.601289,0.677477,0.580748,0.590248,-0.263428,-0.404035,-0.35348,-0.342953,-1.38492,-1.21135,-1.22678,-1.0915,-1.11415,-1.16702,1.33021,1.09195,0.376343,0.41662,-0.388179,-0.522815,1.22519,1.56636,0.973115,0.920905
6869,0.21973,0.278776,0.250309,0.274331,0.142374,-0.00128843,0.683034,0.538223,0.0863321,0.177554,0.340272,0.306468,0.436894,0.360215,0.834922,0.786967,0.399764,0.474671,0.141501,0.149188,0.796028,0.657853,-0.568401,-0.555067,0.912276,1.08264,-1.24638,-1.14885,0.152621,0.0981257,1.95418,1.72028,-1.31195,-1.22676,0.963932,0.834804,-0.148639,0.189097,0.122793,0.0683444
6870,0.156117,0.117564,0.331638,0.268781,0.0478137,-0.0870867,0.918574,0.835924,0.344696,0.434405,0.567743,0.535152,0.184713,0.116804,0.240353,0.191148,0.871279,0.945221,0.0147709,0.0241011,0.691598,0.556017,-1.60135,-1.58287,-0.755341,-0.583539,-1.34148,-1.2062,1.67663,1.62069,-1.94694,-2.1816,-0.410743,-0.321983,1.71852,1.59372,0.345887,0.679494,0.243622,0.192567
6871,0.928641,0.888041,0.469062,0.325283,0.8087,0.674804,0.994133,0.909025,0.0562297,0.147078,0.113433,0.0793235,0.29678,0.226816,0.160501,0.100694,0.601151,0.67635,0.703496,0.712677,-0.680083,-0.815095,-1.39992,-1.38089,-0.14807,0.0288675,0.865208,1.00343,-0.538208,-0.590501,0.391708,0.162248,-1.72185,-1.63477,0.0195358,-0.0994779,0.00854799,0.348539,-0.0362037,-0.0875927
6872,0.467281,0.426988,0.44334,0.381784,0.670478,0.4771,0.12534,0.0389619,0.0605867,0.149868,0.675971,0.640611,0.840138,0.76847,0.0573617,0.0102408,0.593978,0.597443,0.261111,0.271618,-0.723093,-0.85433,-0.525962,-0.503794,1.64213,1.81223,-1.05965,-0.92722,-1.98268,-2.02792,-0.0740227,-0.302262,1.39882,1.48949,-0.677537,-0.795744,-1.01412,-0.667893,-0.073933,-0.178967
6873,0.753293,0.713834,0.99328,0.933544,0.371799,0.279395,0.215056,0.127095,0.94911,1.03953,0.422912,0.38762,0.613515,0.542102,0.634336,0.588116,0.441825,0.518536,0.0621035,0.159945,-0.325059,-0.448529,-0.468632,-0.441104,-0.960281,-0.785803,-0.442019,-0.305178,-1.33636,-1.38011,0.185263,-0.065846,-0.321071,-0.230028,-0.974021,-1.09128,0.679417,1.02783,-0.235879,-0.270341
6874,0.455302,0.414204,0.770272,0.709266,0.21477,0.08169,0.618923,0.531577,0.698368,0.787636,0.370614,0.335438,0.646582,0.574613,0.667915,0.623389,0.733177,0.809835,0.0356025,0.0482715,0.883757,0.765756,0.834321,0.868553,0.7894,0.966816,-0.841642,-0.710341,1.42213,1.37658,0.404564,0.17057,0.232017,0.35061,0.529316,0.417469,-0.442705,-0.0980013,-0.310014,-0.361715
6875,0.995714,0.956459,0.0203742,-0.0412645,0.768354,0.634206,0.636758,0.500581,0.914104,1.00289,0.756972,0.72025,0.4424,0.454089,0.166576,0.122121,0.755203,0.82962,0.299693,0.311301,-1.62465,-1.74868,-0.471355,-0.435702,-0.487715,-0.314074,0.488971,0.623995,1.94106,1.90135,0.0564935,-0.149858,0.833194,0.931248,-0.0755856,-0.185612,0.442311,0.782931,-0.796927,-0.851565
6876,0.987501,0.947434,0.0460169,-0.0299317,0.182043,0.0505019,0.554616,0.469585,0.174437,0.261557,0.81847,0.71386,0.334029,0.333565,0.967623,0.925391,0.440024,0.514667,0.0643023,0.0756218,0.606052,0.487047,-0.811045,-0.770268,0.507111,0.68542,1.03466,1.17205,0.519333,0.47874,-0.232767,-0.470285,-1.05889,-0.961058,2.08267,1.97638,-0.190645,0.143637,-0.885069,-0.936017
6877,0.345911,0.306045,0.042376,-0.0185989,0.433474,0.301072,0.943349,0.858355,0.0266122,0.115148,0.745126,0.70747,0.163392,0.213041,0.996312,0.955606,0.430501,0.504252,0.241328,0.253177,0.338468,0.220491,1.22431,1.25744,-0.792546,-0.611526,0.469822,0.61373,-0.193934,-0.235885,-0.210594,-0.455919,-0.209496,-0.118576,-0.660201,-0.769894,-2.31378,-1.97738,-1.25752,-1.30824
6878,0.126038,0.0868103,0.888352,0.829519,0.468076,0.416607,0.675203,0.590428,0.758329,0.847899,0.586269,0.586496,0.164485,0.0925167,0.110611,0.0677148,0.89286,0.964548,0.710763,0.722134,-1.19996,-1.32027,0.12575,0.15298,0.626437,0.812809,-1.51717,-1.38075,0.172234,0.138627,-2.70459,-2.94952,-0.461427,-0.376996,2.36179,2.25308,1.7712,2.10153,-0.144466,-0.196423
6879,0.582769,0.516359,0.665107,0.605241,0.662433,0.532142,0.748058,0.663529,0.066565,0.158015,0.503854,0.465522,0.631442,0.559596,0.351588,0.307553,0.206897,0.27911,0.338041,0.351625,-0.887457,-1.00705,-0.761448,-0.733985,0.885447,1.07527,0.022653,0.213091,-0.625624,-0.65453,0.79858,0.553649,-0.215758,-0.132994,-1.12845,-1.24162,0.709018,1.04009,-2.06366,-2.12108
6880,0.985135,0.945908,0.777922,0.690551,0.319863,0.187857,0.0469023,-0.0392283,0.66773,0.757757,0.644661,0.605459,0.774722,0.705386,0.0583616,0.0160218,0.850591,0.921581,0.706243,0.721565,1.74645,1.63028,0.426807,0.451196,-0.745701,-0.558813,1.67052,1.80694,-0.360286,-0.389011,0.740889,0.613182,-0.222202,-0.138463,1.51364,1.40305,-0.128607,0.200453,0.674565,0.609626
6881,0.579716,0.61144,0.837524,0.775861,0.900735,0.771371,0.995879,0.909749,0.716986,0.805248,0.407401,0.324798,0.02865,-0.0425489,0.91222,0.870996,0.118771,0.190391,0.602297,0.701234,0.589682,0.472414,1.26397,1.28302,-0.163691,0.0246165,1.40524,1.54024,0.520965,0.490068,0.851298,0.672715,-0.222111,-0.143933,0.362975,0.250344,0.216505,0.55147,1.64212,1.58327
6882,0.31714,0.276973,0.226917,0.164896,0.416205,0.348236,0.391782,0.306435,0.53445,0.62293,0.0835324,0.0441369,0.796045,0.722202,0.79534,0.853033,0.35988,0.431885,0.665579,0.680904,1.45452,1.33436,-0.381378,-0.369392,-0.343803,-0.157231,-0.463775,-0.324564,-1.08583,-1.11643,0.977179,0.732248,-0.437443,-0.356375,-0.482691,-0.597921,-0.419104,-0.0878246,-0.0703763,-0.126783
6883,0.839566,0.798932,0.152436,0.0909829,0.054215,-0.0748992,0.0210928,-0.0654833,0.951013,1.04043,0.908688,0.869071,0.600886,0.563678,0.877562,0.835069,0.332457,0.40214,0.369467,0.385496,1.41764,1.29513,-1.21258,-1.19439,0.937103,1.12987,0.663202,0.810713,0.100116,0.0697424,0.478018,0.239048,0.491826,0.580492,0.46597,0.347582,-0.328481,0.0001852,0.36049,0.301128
6884,0.797857,0.662294,0.450294,0.38759,0.135563,0.00703031,0.556857,0.471989,0.248932,0.340006,0.973576,0.935512,0.479755,0.405154,0.487077,0.443272,0.514857,0.583485,0.395893,0.411789,-0.349157,-0.478257,-0.526129,-0.50219,-0.411807,-0.215877,0.0221636,0.174707,1.59908,1.57744,-0.696934,-0.929921,-0.703755,-0.621688,-0.612998,-0.731797,1.32886,1.66406,2.08515,2.02495
6885,0.624384,0.525656,0.257126,0.19296,0.739844,0.610589,0.873206,0.786813,0.749443,0.837931,0.0717694,0.0345585,0.913651,0.836805,0.945671,0.899995,0.0804859,0.148748,0.199875,0.306262,0.251928,0.125282,-1.2966,-1.26667,-0.0406976,0.151589,-1.30806,-1.15794,0.953226,0.937242,-2.09311,-2.33389,2.23362,2.32329,-1.36178,-1.47531,-0.973385,-0.637294,-1.16239,-1.21795
6886,0.429652,0.389018,0.947451,0.882626,0.968311,0.840241,0.0411223,-0.045259,0.913982,1.0027,0.132412,0.0123555,0.891809,0.813823,0.823278,0.778866,0.473461,0.539639,0.118692,0.200736,2.12688,2.00703,0.318622,0.354262,0.794013,0.983591,0.428295,0.571059,0.991426,0.973043,-0.138466,-0.372773,-1.48385,-1.39824,0.53584,0.42287,-0.730908,-0.397991,1.70403,1.6426
6887,0.190572,0.150552,0.510728,0.444871,0.505221,0.375812,0.935913,0.848191,0.0609174,0.147525,0.0286056,-0.00984762,0.490129,0.380853,0.0419329,-0.00267475,0.012545,0.07954,0.0790705,0.0952098,-0.517051,-0.625952,0.196456,0.233775,-1.29657,-1.11163,0.0790036,0.227837,0.149061,0.0850555,0.593051,0.360268,1.24411,1.32584,-0.388622,-0.502479,-0.926286,-0.590889,-0.849662,-0.911204
6888,0.184728,0.14591,0.783916,0.715907,0.707078,0.576272,0.140686,0.0526431,0.0561875,0.144976,0.219466,0.17904,0.0275802,-0.0521171,0.922205,0.878345,0.109361,0.091133,0.0842118,0.100523,-0.291025,-0.393076,-0.14112,-0.100791,-1.04609,-0.902941,-0.777907,-0.627865,-0.776537,-0.802932,0.295071,0.0683645,0.286066,0.37195,-0.576461,-0.692135,-0.17686,0.162814,-1.75022,-1.809
6889,0.41738,0.377759,0.527471,0.459852,0.287024,0.156606,0.00332606,-0.0845765,0.759222,0.846047,0.69436,0.6515,0.141513,0.0629423,0.00422376,-0.0397113,0.0359449,0.102726,0.75549,0.769917,-0.0466649,-0.1602,0.529683,0.577569,-0.884099,-0.694251,-0.953126,-0.801361,-0.223423,-0.248191,1.83953,1.61502,0.614649,0.693701,-0.129054,-0.23882,-0.600572,-0.261556,-0.23699,-0.295668
6890,0.427141,0.388065,0.743047,0.677183,0.867853,0.74012,0.697859,0.608446,0.65352,0.803089,0.633237,0.551364,0.562515,0.484712,0.193539,0.147255,0.585271,0.652394,0.906741,0.92202,1.12456,1.00901,-0.167395,-0.123574,-0.46317,-0.278961,0.469149,0.628127,-0.0259844,-0.0444409,1.20121,0.979481,1.60412,1.6774,-0.781232,-0.889755,-0.788144,-0.454454,0.624986,0.573203
6891,0.762886,0.725165,0.0383231,-0.0282167,0.477102,0.35064,0.951284,0.863606,0.673046,0.760131,0.492245,0.451227,0.723901,0.646134,0.00640531,-0.0396897,0.318564,0.478398,0.569969,0.513264,-0.346494,-0.454965,1.13958,1.18608,-0.618934,-0.430038,0.0934298,0.253555,0.916494,0.896789,-0.65158,-0.868496,0.603948,0.671125,-3.71285,-3.82608,1.35798,1.69554,0.567486,0.519983
6892,0.85073,0.811226,0.405373,0.435922,0.542069,0.33446,0.0218182,-0.0649877,0.978363,1.06739,0.160889,0.117745,0.0645653,-0.0113142,0.789548,0.743185,0.163382,0.304402,0.0874164,0.104508,1.118,1.01268,0.975697,1.01926,1.43109,1.61742,1.20931,1.37072,0.491985,0.468659,-1.42343,-1.64148,-0.412998,-0.335154,1.04373,0.930502,0.744886,1.08605,-1.25754,-1.30762
6893,0.267901,0.230414,0.963867,0.900061,0.444784,0.318279,0.858587,0.771459,0.532661,0.623956,0.163295,0.119815,0.33872,0.264784,0.828848,0.783504,0.0632833,0.130406,0.318966,0.337287,-0.25244,-0.35843,-0.593659,-0.553018,-1.40207,-1.21101,-0.754569,-0.593866,0.315355,0.285327,0.760679,0.545069,0.585234,0.664715,0.552837,0.434748,-0.791011,-0.448367,0.583882,0.531612
6894,0.720783,0.682875,0.91496,0.845468,0.26215,0.136494,0.560121,0.473874,0.325524,0.417469,0.510288,0.465465,0.831417,0.756873,0.0473723,0.00196325,0.779465,0.846861,0.114171,0.132263,0.420266,0.321573,0.715492,0.756639,0.0366777,0.229488,-0.884577,-0.720141,-1.46196,-1.49406,0.685563,0.467332,0.426826,0.422932,0.439241,0.320898,1.10489,1.45205,-0.910633,-0.960731
6895,0.595375,0.55893,0.965443,0.790875,0.760938,0.634812,0.544115,0.456701,0.947754,1.04166,0.529983,0.585326,0.757479,0.683087,0.270857,0.312296,0.326689,0.392278,0.568707,0.586723,-1.31736,-1.41903,0.0536437,0.101292,-0.520841,-0.321335,-1.24091,-1.07995,-0.669437,-0.705876,-0.876947,-1.10343,0.108724,0.181148,-0.278354,-0.391381,0.242729,0.595807,-0.235895,-0.288308
6896,0.0502175,0.0125807,0.79889,0.736282,0.161993,0.0354767,0.83098,0.742067,0.669368,0.764662,0.748311,0.705186,0.233959,0.160772,0.669078,0.622629,0.722355,0.788155,0.779897,0.799237,-0.681943,-0.784351,1.21842,1.26976,2.5027,2.70888,-1.02272,-0.869306,0.415164,0.372828,1.06874,0.841158,0.739057,0.811982,0.0742048,-0.045675,0.50661,0.866263,-0.544568,-0.599036
6897,0.782475,0.745203,0.0930468,0.0308823,0.898247,0.770819,0.382927,0.296175,0.974179,1.06743,0.121294,0.0805985,0.349972,0.335655,0.178037,0.131552,0.648251,0.713211,0.514675,0.534264,-0.614175,-0.717252,-0.871427,-0.819776,-0.487939,-0.278544,-1.12787,-0.981026,-0.966416,-1.00642,-0.371156,-0.591263,-1.39469,-1.31414,-1.37618,-1.49272,-0.367295,-0.00752004,0.64749,0.592185
6898,0.434248,0.427566,0.572919,0.50865,0.819023,0.754638,0.526723,0.44122,0.427648,0.51892,0.829305,0.787122,0.581121,0.510538,0.0285153,-0.0196939,0.346171,0.409361,0.504365,0.524024,-0.226827,-0.328249,-0.341404,-0.295741,-0.444043,-0.233759,-0.0922505,0.0602682,-0.751033,-0.786481,0.46643,0.250862,-0.393147,-0.314274,-0.327144,-0.537687,-0.429437,-0.074296,1.33722,1.27825
6899,0.147033,0.109928,0.401542,0.278535,0.864199,0.738458,0.376234,0.289098,0.917209,1.00725,0.340733,0.296865,0.00345984,-0.0665344,0.306985,0.261338,0.837885,0.900155,0.235266,0.302237,-1.78617,-1.88328,-1.53194,-1.49225,-0.735331,-0.468167,0.335345,0.484662,-1.71381,-1.74807,-0.348041,-0.567509,1.38479,1.45688,0.53389,0.41735,-1.44029,-1.09073,-0.156617,-0.194292
6900,0.416453,0.381069,0.114784,0.0484199,0.312276,0.184317,0.981669,0.895988,0.517804,0.608737,0.399552,0.358418,0.109779,0.0385786,0.922376,0.876251,0.8155,0.879299,0.0603037,0.0804507,0.517627,0.413912,-0.282411,-0.243458,-0.904855,-0.702576,-0.667853,-0.5418,-0.60087,-0.639947,0.171273,-0.045355,0.897226,0.965348,-1.24586,-1.36859,0.631645,0.975914,-1.60785,-1.66683
6901,0.150031,0.117567,0.970702,0.901849,0.662213,0.537033,0.533433,0.456747,0.667632,0.758925,0.240236,0.199964,0.758236,0.686519,0.564477,0.50778,0.551637,0.614441,0.408322,0.496497,-0.0113548,-0.114002,-1.66211,-1.63008,-1.66016,-1.4568,-1.71115,-1.56826,1.65149,1.61269,1.52134,1.30095,-0.354285,-0.283582,-0.483757,-0.609672,-0.195882,0.149868,0.863211,0.808391
6902,0.557505,0.438961,0.0131134,-0.0538813,0.250156,0.127401,0.102514,0.0175073,0.429436,0.521976,0.642925,0.60384,0.339173,0.265497,0.184514,0.139308,0.0596001,0.124424,0.89295,0.912544,0.698031,0.595293,0.623217,0.654617,-0.0480532,0.15315,-0.616345,-0.481707,0.999166,0.958343,1.76928,1.50703,0.752714,0.82077,-1.56801,-1.68905,0.0800923,0.420324,0.162261,0.106383
6903,0.792463,0.760355,0.504377,0.439166,0.567538,0.49865,0.815254,0.730332,0.463994,0.535575,0.346235,0.344131,0.655149,0.582695,0.559422,0.516726,0.201923,0.264403,0.70096,0.721923,-0.565672,-0.670238,-0.465195,-0.433675,-1.14443,-0.943566,0.151681,0.281578,-0.0349758,-0.0806727,1.9312,1.7131,0.997118,1.06477,-1.95181,-2.07649,1.22951,1.56615,0.283878,0.230605
6904,0.345618,0.314509,0.785263,0.720943,0.99056,0.869898,0.0113157,-0.0756847,0.376128,0.549174,0.121281,0.084423,0.0250458,-0.0493833,0.629761,0.604294,0.776974,0.839131,0.268967,0.291254,-0.368146,-0.466967,-0.75809,-0.72269,-0.149462,0.0559281,-0.142067,-0.0161716,-0.422242,-0.503015,-0.940455,-1.1529,-0.839108,-0.76482,-0.694387,-0.813716,-1.26942,-0.937718,1.16451,1.11367
6905,0.508729,0.471151,0.46847,0.437095,0.0461618,-0.0721999,0.45014,0.360397,0.470232,0.562773,0.732322,0.695056,0.309561,0.237162,0.733461,0.691862,0.668194,0.731851,0.174142,0.239458,0.705555,0.554639,-0.320059,-0.292122,0.36473,0.576959,1.19942,1.33197,-0.880286,-0.925357,-0.307912,-0.524571,0.901369,0.975918,-0.0357665,-0.16049,-0.182655,0.146198,0.0138316,-0.0304644
6906,0.657859,0.627794,0.21782,0.153247,0.579805,0.46134,0.883479,0.796479,0.233523,0.325825,0.793026,0.756608,0.294618,0.224499,0.593289,0.549728,0.312091,0.422044,0.220269,0.187662,1.67507,1.57624,1.29951,1.32881,1.5953,1.80451,0.775279,0.911043,0.505428,0.460707,-0.734866,-0.955699,-1.94971,-1.87971,-1.38477,-1.51657,-0.752143,-0.416211,-0.727038,-0.692288
6907,0.0335272,0.00190736,0.0999799,0.0351994,0.403044,0.214529,0.47761,0.389454,0.748131,0.839946,0.580126,0.542827,0.659372,0.591382,0.79287,0.751568,0.0491145,0.112238,0.113579,0.135866,0.973999,0.879624,1.76779,1.79063,0.01928,0.232228,1.01187,1.15315,0.09299,0.048351,0.500114,0.283911,0.235736,0.308363,1.14877,1.01535,-0.693083,-0.360471,-1.30982,-1.35411
6908,0.254566,0.223707,0.56088,0.493694,0.0869326,-0.0322825,0.921586,0.832864,0.158007,0.251232,0.69824,0.662445,0.192527,0.125651,0.00511904,-0.0351092,0.115967,0.180662,0.805743,0.83013,0.724406,0.629209,1.08571,1.10439,-0.534933,-0.318595,-1.85631,-1.71948,0.806345,0.7572,0.656068,0.434448,1.23104,1.30823,0.837336,0.702022,0.832798,1.16224,-1.39512,-1.34009
6909,0.232378,0.203628,0.492392,0.424652,0.270204,0.14904,0.909845,0.820538,0.19491,0.21978,0.516891,0.550435,0.950547,0.885499,0.876561,0.836411,0.385769,0.452056,0.644698,0.720339,-0.620423,-0.712239,0.927643,0.954697,0.470085,0.680899,1.05742,1.19062,-1.05323,-1.1004,-0.543595,-0.766991,0.309628,0.385012,-0.490323,-0.623718,0.0553877,0.383194,-1.28981,-1.32608
6910,0.489906,0.460069,0.660063,0.519606,0.732144,0.612598,0.62733,0.537588,0.0762395,0.188327,0.388626,0.438424,0.721612,0.654174,0.208691,0.170124,0.659929,0.723449,0.509344,0.610549,0.195876,0.104083,-1.0314,-0.997972,0.0361732,0.254036,-0.267417,-0.125891,-0.323677,-0.374729,0.485965,0.259408,-0.326473,-0.243765,0.615193,0.489197,1.16265,1.49722,-0.800869,-0.837056
6911,0.368157,0.397935,0.681949,0.61456,0.179683,0.0584574,0.588306,0.49783,0.180431,0.156875,0.371944,0.326413,0.147058,0.0771009,0.940142,0.902671,0.29349,0.359144,0.475302,0.500758,-0.602691,-0.68704,0.832955,0.87098,1.09242,1.31452,-0.861155,-0.717136,1.27769,1.2252,-0.24616,-0.467021,-0.189291,-0.106292,0.075348,-0.0523292,-1.54508,-1.21167,-1.05318,-1.08635
6912,0.365707,0.335801,0.406516,0.416873,0.570593,0.450376,0.548702,0.458072,0.0679108,0.125423,0.250197,0.214403,0.159528,0.0900494,0.812363,0.70581,0.16899,0.293151,0.947633,0.974762,0.299301,0.221694,2.22383,2.25733,-0.826644,-0.606223,0.91243,1.06083,-0.00339318,-0.0587361,-0.178823,-0.40624,0.432584,0.509498,1.73465,1.61215,0.63352,0.969747,0.705167,0.673781
6913,0.47914,0.451809,0.28606,0.219187,0.71014,0.592328,0.21899,0.130586,0.000745116,0.0939704,0.834336,0.800064,0.771365,0.701421,0.543801,0.508949,0.16197,0.227157,0.0352357,0.0635085,-1.26945,-1.3503,1.14831,1.18324,-0.335634,-0.200411,0.170747,0.300005,1.46011,1.40226,0.1406,-0.0859506,-2.83096,-2.75194,-1.15593,-1.27311,0.460054,0.792175,-0.152175,-0.17878
6914,0.917404,0.889824,0.658034,0.588899,0.170555,0.053258,0.290688,0.203687,0.771715,0.863018,0.247789,0.215111,0.965528,0.898074,0.707211,0.670414,0.908583,0.974465,0.169377,0.19557,0.406699,0.333657,-1.48727,-1.4492,-0.0229971,0.2054,-0.607823,-0.460818,0.450348,0.392674,1.1919,0.972441,-0.43577,-0.353288,0.484423,0.360472,0.914718,1.25068,0.115114,0.0826181
6915,0.971969,0.90195,0.519552,0.450112,0.634385,0.516816,0.568628,0.483593,0.0836939,0.173134,0.984681,0.951164,0.660347,0.563112,0.0433502,0.00830951,0.279676,0.344556,0.0545324,0.0797785,-0.4936,-0.47696,-0.0618275,-0.0168435,-0.78421,-0.548827,-2.01304,-1.87245,0.995335,0.932211,0.961203,0.741488,0.731868,0.815288,0.535216,0.41346,-1.32731,-0.996439,-1.24984,-1.28893
6916,0.940726,0.914075,0.10972,0.0407052,0.188316,0.072325,0.0919615,0.00674184,0.849064,0.937187,0.431409,0.396978,0.295874,0.22815,0.299444,0.270594,0.276941,0.435855,0.740441,0.763909,-1.21091,-1.28758,0.457535,0.507191,-0.912377,-0.668784,-0.432957,-0.298128,0.558041,0.488638,2.04168,1.82873,0.106611,0.18651,-0.111162,-0.237475,1.19768,1.52736,0.917985,0.87707
6917,0.953857,0.9262,0.630125,0.563713,0.507863,0.393863,0.32012,0.286288,0.726214,0.780704,0.973664,0.938752,0.186075,0.11892,0.569023,0.532878,0.460384,0.527154,0.28621,0.307693,-0.552628,-0.623825,1.47001,1.5229,-0.354713,-0.116825,0.569489,0.699082,-1.68285,-1.75243,-1.51684,-1.73809,-1.95081,-1.8628,0.68743,0.568386,-0.981673,-0.659645,0.778546,0.734335
6918,0.400877,0.375064,0.921676,0.854581,0.597107,0.43386,0.651713,0.565835,0.535424,0.624221,0.523632,0.487445,0.384968,0.331928,0.25968,0.220801,0.716122,0.783302,0.637814,0.657297,-1.35373,-1.43026,-1.07195,-1.01641,2.85472,3.08487,0.887274,1.01705,-0.524028,-0.598018,-0.098362,-0.316377,2.68496,2.77297,1.06424,0.947097,0.771329,1.09759,-0.120747,-0.163457
6919,0.0537476,0.029812,0.209464,0.144446,0.586137,0.473857,0.399801,0.31294,0.602939,0.689279,0.594315,0.555771,0.613929,0.544937,0.825933,0.788311,0.155694,0.223455,0.366891,0.412786,-0.537106,-0.699181,-0.913506,-0.861847,0.225521,0.456927,0.545141,0.673832,0.116179,0.129417,-0.345688,-0.563169,1.09597,1.17701,0.0662632,-0.0546487,0.130469,0.458293,-0.16455,-0.201824
6920,0.366031,0.34145,0.327024,0.262927,0.133445,0.0198636,0.499373,0.412163,0.663786,0.754337,0.625985,0.624096,0.376909,0.308621,0.699677,0.661562,0.652636,0.719198,0.148243,0.168274,0.104219,0.0318934,-0.486477,-0.43128,1.41404,1.63878,-0.304736,-0.181871,0.934269,0.856851,-1.11536,-1.33616,0.373175,0.456846,0.338697,0.247325,0.166484,0.500579,0.893791,0.84902
6921,0.993589,0.966981,0.0794355,0.0167862,0.977717,0.862316,0.827521,0.74141,0.99216,1.08171,0.728609,0.692422,0.45963,0.392446,0.97923,0.942593,0.879046,0.945806,0.461983,0.481712,0.0539351,-0.0222796,-2.19022,-2.12886,0.663326,0.884552,0.298163,0.354923,0.833485,0.750204,1.15946,0.945376,-0.912607,-0.824428,0.674598,0.549298,1.39935,1.74152,-2.25712,-2.30608
6922,0.799912,0.775345,0.240959,0.18052,0.221546,0.10718,0.50876,0.436685,0.0525129,0.139946,0.312777,0.276516,0.984816,0.919309,0.810256,0.774743,0.278532,0.346004,0.284941,0.30638,-1.34468,-1.42618,-0.155475,-0.101145,1.17802,1.40558,0.764075,0.891716,-2.42677,-2.50333,-0.31078,-0.519768,1.61796,1.69786,-1.48128,-1.60366,0.171032,0.506806,0.961684,0.912512
6923,0.611,0.583709,0.00740381,-0.0539824,0.910944,0.797238,0.218944,0.13196,0.868467,0.956633,0.604099,0.565683,0.922909,0.915725,0.367831,0.333165,0.600986,0.666672,0.826974,0.85051,1.07848,0.998311,-0.0824806,-0.0724225,1.26245,1.49579,0.769683,0.903284,0.636735,0.56534,-0.0582356,-0.26133,0.20543,0.293295,-1.01028,-1.13513,0.276565,0.609444,0.212727,0.165884
6924,0.11676,0.0883148,0.823312,0.761957,0.0240332,-0.0886188,0.569557,0.400375,0.499593,0.587863,0.564946,0.528355,0.978297,0.912142,0.446758,0.413937,0.133392,0.197155,0.41794,0.439039,0.436048,0.362377,-0.104988,-0.0436998,0.195488,0.42994,0.231062,0.360109,0.114028,0.0473047,-2.33887,-2.5452,-1.88669,-1.80394,-1.57981,-1.70675,-0.357228,-0.02985,0.704818,0.654905
6925,0.564614,0.53618,0.832875,0.771,0.0246915,-0.0872643,0.754988,0.668789,0.76569,0.854175,0.244557,0.209106,0.471519,0.424223,0.914807,0.880842,0.200024,0.26558,0.309136,0.328676,-0.523321,-0.596523,-0.287165,-0.225066,-0.625495,-0.387411,-0.621961,-0.495593,1.13107,1.06582,1.08816,0.88074,-1.11766,-1.03684,0.221376,0.0985026,-0.600612,-0.267371,-0.349356,-0.435423
6926,0.603694,0.576356,0.501615,0.440744,0.469638,0.356482,0.290148,0.202131,0.383306,0.470487,0.221329,0.212335,0.00246016,-0.0636953,0.244262,0.208944,0.838525,0.902813,3.13058e-05,0.0172823,0.392437,0.312212,-1.14662,-1.08097,1.15976,1.39595,0.977721,1.10898,-0.363556,-0.435128,1.26654,1.06385,1.22586,1.31128,0.955252,0.829818,0.825997,1.16277,-1.47584,-1.52575
6927,0.407762,0.406684,0.618866,0.612994,0.326538,0.147758,0.616046,0.489787,0.425629,0.512667,0.251619,0.215565,0.339277,0.238697,0.56182,0.525283,0.151699,0.217374,0.153959,0.169385,0.43812,0.362882,0.526606,0.502669,1.83202,2.07259,0.0412953,0.175464,-0.778051,-0.847484,1.05961,0.863907,0.47842,0.551813,0.245465,0.12124,1.76385,2.10671,0.609194,0.560419
6928,0.265176,0.237012,0.845892,0.785245,0.0524133,-0.0609651,0.867107,0.777443,0.898745,0.985639,0.781117,0.747187,0.609871,0.54109,0.370236,0.429386,0.0439187,0.110095,0.589719,0.604018,-0.0068912,-0.0855288,2.02116,2.08631,-0.737648,-0.503394,0.397356,0.523856,-1.88332,-1.94818,-1.27991,-1.47056,-0.286092,-0.207649,-0.45805,-0.587339,-0.567956,-0.229016,0.0292974,-0.0210547
6929,0.299941,0.362553,0.25326,0.194132,0.387191,0.276198,0.20792,0.120185,0.376054,0.462625,0.298233,0.361939,0.349413,0.280388,0.371517,0.333488,0.635901,0.700733,0.407138,0.5084,-1.01993,-1.09143,-1.63002,-1.56262,1.49534,1.72258,-0.59583,-0.470088,1.6801,1.60888,-0.516015,-0.636106,1.0683,1.14812,0.39081,0.264809,0.575545,0.916809,-1.19323,-1.24075
6930,0.516162,0.488094,0.311086,0.305446,0.995411,0.884061,0.25368,0.0863643,0.107532,0.195385,0.0110734,-0.0233094,0.413464,0.343903,0.621837,0.529311,0.36396,0.42684,0.39605,0.412782,-0.695641,-0.75192,-0.427684,-0.361461,0.608175,0.828148,-0.472203,-0.351355,-0.926757,-1.00024,0.388993,0.198344,0.481143,0.563162,2.17531,2.05396,0.0296424,0.413853,-0.697709,-0.751732
6931,0.103441,0.0727311,0.476244,0.41676,0.842938,0.732163,0.141611,0.0525437,0.462852,0.553011,0.023591,-0.0114975,0.0344182,-0.0370384,0.763606,0.725133,0.673002,0.737622,0.468701,0.484809,-0.348127,-0.412411,0.544528,0.608406,-1.14903,-0.933169,1.10883,1.23587,-0.635685,-0.704781,0.357765,0.0891696,-0.668664,-0.590559,0.229361,0.109437,-0.432831,-0.0891038,1.01172,0.960521
6932,0.621298,0.589337,0.765857,0.707628,0.297302,0.18718,0.589242,0.500773,0.572423,0.662029,0.633338,0.599135,0.528425,0.455051,0.353907,0.313443,0.481708,0.517601,0.843278,0.859287,1.59869,1.53058,-0.946501,-0.886475,-1.00187,-0.780688,-0.136841,-0.00617691,-0.880999,-0.948692,0.171438,-0.0200049,0.258753,0.330663,-0.0203189,-0.142052,-1.21194,-0.868146,-0.205017,-0.259176
6933,0.785654,0.754321,0.0991184,0.0419503,0.341819,0.157917,0.264819,0.177966,0.175156,0.263515,0.823372,0.671366,0.507445,0.419204,0.712127,0.670951,0.232052,0.297579,0.248419,0.263711,-0.357144,-0.427949,0.803972,0.856681,0.71416,0.941698,-0.513223,-0.380749,0.373719,0.30041,0.470164,0.282054,0.219026,0.361209,2.97197,2.85521,-0.545852,-0.206553,-0.144188,-0.190952
6934,0.580099,0.644312,0.259766,0.200901,0.236873,0.128653,0.207576,0.120723,0.294178,0.382911,0.820752,0.743597,0.457618,0.383357,0.61248,0.593676,0.272784,0.4335,0.214298,0.229691,-1.21808,-1.2945,1.02262,1.07501,0.38762,0.619506,0.365244,0.491219,0.454217,0.382596,0.205665,0.0209013,0.319845,0.391756,1.1974,1.08416,0.745858,1.07962,0.771792,0.72178
6935,0.563866,0.534303,0.943678,0.885529,0.840684,0.732212,0.690104,0.603325,0.752098,0.840531,0.849158,0.815827,0.641689,0.569316,0.465518,0.516402,0.501568,0.56942,0.541361,0.491308,1.15798,1.08274,0.0428299,0.0960287,-1.23273,-1.00165,-0.0920529,0.0398796,1.12472,1.04703,-1.75822,-1.9367,-0.212118,-0.147948,0.563776,0.391599,-0.938191,-0.596663,-0.792485,-0.845866
6936,0.600558,0.588028,0.188029,0.129123,0.677058,0.570282,0.542056,0.455592,0.425767,0.518092,0.0947795,0.0613923,0.299777,0.229279,0.479049,0.439128,0.978033,1.04487,0.736786,0.752924,0.687516,0.617427,1.32736,1.37461,-1.00672,-0.770705,-0.268216,-0.133616,-1.32729,-1.40818,0.887144,0.70453,0.134276,0.205905,-0.191516,-0.300962,-2.18839,-1.84737,0.769149,0.713883
6937,0.709391,0.641754,0.122289,0.149989,0.0279084,-0.078519,0.650136,0.564483,0.109405,0.195653,0.373478,0.339878,0.508217,0.503534,0.133864,0.0925456,0.514892,0.579984,0.0426793,0.0604215,-0.359955,-0.4338,0.453357,0.503078,1.06014,1.29477,0.633271,0.769829,-0.812254,-0.960009,0.708887,0.520743,-1.25244,-1.18276,-0.0377947,-0.153472,0.247178,0.588876,-0.708097,-0.76321
6938,0.622342,0.69548,0.226617,0.170855,0.133067,0.0281131,0.383989,0.296556,0.364056,0.452504,0.241108,0.205961,0.845375,0.777788,0.86264,0.820197,0.298355,0.362008,0.315104,0.333591,0.550179,0.474934,0.81888,0.871739,-0.724431,-0.482601,0.60872,0.750282,-0.425185,-0.511837,0.0724358,-0.114797,-0.271063,-0.199059,-0.405275,-0.526169,-0.31349,0.0264671,0.735997,0.685994
6939,0.776003,0.749206,0.701663,0.644519,0.754393,0.651445,0.504886,0.440197,0.0627464,0.14997,0.775723,0.743283,0.663589,0.590866,0.921635,0.880846,0.0794222,0.144033,0.894788,0.912925,0.0303442,-0.0397081,-0.0293231,0.0297228,-0.792333,-0.543259,-0.455324,-0.307619,-0.188765,-0.273112,1.17107,0.985812,-0.362069,-0.288378,0.0793005,-0.0414781,-0.627973,-0.28941,-0.4109,-0.458142
6940,0.378352,0.353056,0.836101,0.778372,0.0929968,-0.0119809,0.671287,0.583838,0.0329336,0.202202,0.606085,0.575646,0.349993,0.403943,0.0309412,-0.011472,0.364823,0.429777,0.317916,0.337231,0.675908,0.610715,-0.474136,-0.411308,1.02261,1.27363,-0.0334638,0.060314,0.0527666,-0.0343875,1.98865,1.7971,-0.693502,-0.625315,-1.14326,-1.25815,0.752273,1.09391,1.1316,1.08314
6941,0.215736,0.190042,0.444174,0.436076,0.412908,0.345081,0.157764,0.0709271,0.167558,0.254433,0.85866,0.829084,0.284278,0.21702,0.878781,0.838761,0.952033,1.01501,0.342474,0.363523,-1.35079,-1.4148,-0.125379,-0.0561129,-0.214178,0.0373353,0.282794,0.428247,-0.768411,-0.859152,-1.50128,-1.69212,0.114144,0.186352,-0.556416,-0.644762,1.25531,1.60209,1.60649,1.55606
6942,0.46607,0.441157,0.149603,0.0937802,0.806078,0.702143,0.951169,0.865078,0.367865,0.387476,0.67939,0.651787,0.524572,0.553862,0.52226,0.481804,0.0939298,0.155723,0.81201,0.832481,1.18927,1.12296,-0.0444333,0.0220653,0.902709,1.15743,0.883214,1.03514,0.288493,0.204253,1.43813,1.24663,-2.44879,-2.37519,0.0908041,-0.0313776,-1.64569,-1.30344,0.139241,0.092842
6943,0.978156,0.953076,0.750184,0.693799,0.218622,0.113402,0.72925,0.642187,0.434053,0.520518,0.00785379,-0.0186617,0.955737,0.890705,0.492511,0.450727,0.163808,0.227888,0.991792,1.01004,0.563942,0.50144,-0.649962,-0.587592,2.41024,2.6587,0.0468839,0.195543,-0.588864,-0.667297,0.788513,0.520589,1.15056,1.2185,0.0492639,-0.0716261,0.685352,1.0239,1.69743,1.65259
6944,0.216062,0.192096,0.246128,0.190401,0.696969,0.591585,0.00708548,-0.0805134,0.192429,0.277731,0.0764392,0.052386,0.338842,0.27441,0.992736,0.95196,0.239878,0.300054,0.858788,0.874324,0.356496,0.295986,-0.134445,-0.0833091,-0.224137,0.0307512,-0.17038,-0.0238281,-0.79899,-0.880397,-0.0139544,-0.205453,-0.857003,-0.785053,0.34727,0.227662,0.0907018,0.430572,0.381058,0.341649
6945,0.261989,0.237383,0.546321,0.491835,0.514419,0.4098,0.98595,0.89587,0.265944,0.351886,0.921606,0.898395,0.0332123,-0.0315994,0.572034,0.530005,0.621287,0.680808,0.72056,0.738613,-0.382442,-0.446145,0.351284,0.420974,-0.0796795,0.168615,0.188386,0.340609,0.724443,0.642168,-0.411349,-0.605302,0.459705,0.526502,-0.163732,-0.207955,0.836588,1.07519,-0.201346,-0.239825
6946,0.75678,0.733789,0.484409,0.427702,0.923839,0.817942,0.978642,0.889087,0.949082,1.03288,0.237344,0.213629,0.536889,0.470717,0.569317,0.525207,0.636685,0.695776,0.353494,0.372453,-0.455053,-0.517272,0.341531,0.406177,0.330677,0.583904,-0.421556,-0.26491,0.172145,0.0933927,-1.05685,-1.25764,-1.66556,-1.59962,-0.52258,-0.643572,1.38281,1.7198,0.150407,0.112108
6947,0.394493,0.369311,0.188505,0.13239,0.0543326,-0.0485686,0.658719,0.571132,0.882687,0.89042,0.566394,0.573907,0.614411,0.635419,0.887407,0.841546,0.302934,0.361941,0.873192,0.892041,0.530038,0.467322,1.14232,1.20751,-0.648039,-0.390988,1.37587,1.52952,0.585781,0.512009,1.58952,1.3836,0.726144,0.799028,0.363787,0.238418,1.23107,1.5736,-0.649324,-0.695035
6948,0.736251,0.71126,0.892422,0.837623,0.796314,0.692303,0.735009,0.649762,0.665225,0.747961,0.958562,0.934185,0.866172,0.800122,0.403311,0.355378,0.266131,0.32687,0.35943,0.37669,0.442425,0.381146,-1.79073,-1.71646,-0.0294733,0.221419,-1.30977,-1.1554,-1.51475,-1.58859,-2.03881,-2.24942,1.04172,1.12078,0.584206,0.462921,-0.365782,-0.0218243,-0.433058,-0.478786
6949,0.383362,0.355961,0.383866,0.329073,0.725152,0.6846,0.586306,0.502029,0.070461,0.153546,0.278999,0.253664,0.131757,0.0666726,0.218331,0.168433,0.857727,0.917508,0.599225,0.684121,-1.06396,-1.12837,-1.15646,-1.08538,-0.127202,0.128151,0.605621,0.761823,0.469949,0.4026,0.679079,0.472831,-1.7758,-1.69423,-0.352756,-0.478107,-0.447193,-0.104983,-2.4031,-2.4523
6950,0.271768,0.24192,0.526908,0.472624,0.783675,0.676898,0.779564,0.669792,0.220534,0.303733,0.205791,0.121839,0.927505,0.861728,0.614133,0.56507,0.054647,0.114823,0.975547,0.991552,-0.186183,-0.251891,-0.224895,-0.147821,0.197412,0.450864,-0.109293,0.0477065,0.901912,0.835748,-0.11251,-0.314082,0.391982,0.478188,-0.504881,-0.636067,-0.164107,0.181749,1.54021,1.49101
6951,0.542021,0.597384,0.0569308,0.00436313,0.268935,0.163334,0.920046,0.837554,0.911204,0.994992,0.0155684,-0.00998534,0.17212,0.107051,0.15869,0.108617,0.502353,0.564432,0.502391,0.520538,-1.87023,-1.93066,1.57471,1.65656,0.940625,1.18886,0.435192,0.59576,0.776192,0.713114,0.525033,0.329954,-0.736516,-0.647261,0.13003,0.00118956,-1.01637,-0.674496,-1.15276,-1.20801
6952,0.98241,0.952847,0.0897754,0.0252291,0.969445,0.863697,0.0131805,-0.0682348,0.584355,0.667829,0.715648,0.690676,0.663357,0.507998,0.545751,0.495228,0.527587,0.588776,0.428829,0.44644,0.277492,0.211724,-0.262727,-0.186498,-1.05096,-0.808728,-0.372616,-0.211818,-0.672706,-0.74048,0.0363949,-0.163246,0.199356,0.289606,-0.636489,-0.771256,0.938225,1.27361,1.33554,1.28651
6953,0.528649,0.49775,0.0991382,0.0460951,0.532644,0.428368,0.308858,0.227036,0.780171,0.863123,0.424289,0.401764,0.973722,0.908945,0.439023,0.388298,0.32406,0.385971,0.711967,0.729796,0.590368,0.52495,-1.14734,-1.07346,-0.352962,-0.116763,0.231552,0.395075,0.287383,0.149689,-0.0200005,-0.225496,-0.759987,-0.664288,-0.267513,-0.40963,-1.72161,-1.38825,-1.18692,-1.23705
6954,0.411519,0.379084,0.531834,0.480244,0.634319,0.529691,0.946077,0.864379,0.146266,0.228226,0.901037,0.879078,0.849846,0.784334,0.124307,0.0718052,0.356078,0.432562,0.112577,0.128963,0.468595,0.407476,-0.35431,-0.285117,0.60849,0.851209,-0.0134275,0.143353,1.11031,1.03986,-1.23791,-1.44053,-0.507886,-0.404711,-0.926398,-1.07689,-0.884957,-0.553933,-0.739757,-0.793743
6955,0.703417,0.671309,0.0709509,0.016881,0.181916,0.0756977,0.493914,0.412511,0.850364,0.933943,0.989446,0.969847,0.219679,0.152256,0.0122533,-0.0397725,0.453523,0.479154,0.534489,0.553252,1.69464,1.63746,-0.167884,-0.0995322,-1.0701,-0.831824,0.332402,0.491745,1.49501,1.42098,0.667446,0.460951,0.192061,0.292512,-0.165585,-0.317974,0.548269,0.876203,-0.919119,-0.967725
6956,0.171617,0.140091,0.44751,0.391089,0.180124,0.0719661,0.347192,0.275357,0.532011,0.582578,0.63903,0.65623,0.184826,0.0983581,0.127313,-0.0356495,0.500957,0.525746,0.679177,0.699969,1.35459,1.2955,-1.80842,-1.73575,-1.75055,-1.51032,-0.557578,-0.39466,1.87752,1.80211,-0.640384,-0.848337,0.879191,0.989736,-0.349098,-0.507631,1.20906,1.5378,0.399705,0.344411
6957,0.389951,0.29436,0.0153871,-0.0420777,0.772913,0.664989,0.256458,0.138202,0.148601,0.231213,0.363533,0.342613,0.113276,0.0444607,0.0595613,-0.0315264,0.454544,0.572337,0.569691,0.492592,-0.613897,-0.663034,-0.531341,-0.45717,-1.35597,-1.11003,1.39811,1.55877,0.117418,0.0399048,0.670888,0.467792,-0.334572,-0.227794,-0.7758,-0.942118,0.243676,0.569418,0.314321,0.259959
6958,0.481376,0.448628,0.772535,0.713425,0.636566,0.45324,0.0814188,0.00104767,0.7248,0.805506,0.227794,0.204411,0.606969,0.461184,0.0249349,-0.0274033,0.598771,0.618929,0.265601,0.285215,-0.0657857,-0.120076,1.35605,1.42832,-1.34095,-1.09419,0.96255,1.12151,0.879269,0.795458,0.681302,0.482158,-0.242304,-0.118874,0.355283,0.186795,1.40589,1.73063,0.874486,0.825934
6959,0.887798,0.856488,0.746857,0.688231,0.367127,0.241491,0.439827,0.359567,0.913662,0.995492,0.722363,0.697037,0.947361,0.877907,0.431536,0.410057,0.60361,0.665521,0.558555,0.592646,0.900715,0.851176,-0.804046,-0.726241,-2.94244,-2.69904,-0.319744,-0.165522,-1.27225,-1.35138,-1.59742,-1.80171,-0.124513,-0.00995361,-1.71863,-1.88266,0.592153,0.921266,-1.19793,-1.23917
6960,0.190178,0.158245,0.334024,0.274537,0.139758,0.0297423,0.408329,0.256963,0.569526,0.738126,0.98231,0.956315,0.130654,0.0608433,0.900688,0.847516,0.932222,0.99606,0.88179,0.900077,-0.406469,-0.458865,1.01631,1.09558,0.271816,0.517149,-0.803759,-0.646683,2.76241,2.68433,-0.218774,-0.42547,-1.30951,-1.19708,-0.928793,-1.09329,0.0151917,0.342796,-1.2409,-1.27754
6961,0.550106,0.48757,0.796114,0.737614,0.357848,0.191576,0.236924,0.154359,0.39789,0.480759,0.382739,0.355681,0.131712,0.0208397,0.633229,0.580461,0.826996,0.825399,0.0765775,0.0955476,-2.71132,-2.76583,1.43632,1.51173,1.75463,2.00225,-0.953974,-0.804372,-0.896935,-0.977284,-0.589552,-0.892069,-1.11271,-0.998268,1.58956,1.42168,1.27986,1.61326,-0.0788421,-0.118485
6962,0.847814,0.816894,0.253998,0.195897,0.420308,0.353409,0.511894,0.429613,0.370443,0.451145,0.51244,0.485893,0.0527521,-0.0191639,0.673733,0.62078,0.59285,0.654739,0.492469,0.509328,0.270789,0.207699,-0.746368,-0.676396,-0.520737,-0.270061,-0.0510015,0.0990726,0.125254,0.041236,-1.14914,-1.35867,-0.317616,-0.201348,0.182675,0.112964,-1.14439,-0.804573,0.7624,0.718817
6963,0.29971,0.270544,0.633189,0.575635,0.625258,0.515242,0.210638,0.127181,0.893853,0.974665,0.641173,0.616106,0.963338,0.888623,0.368089,0.314439,0.0777579,0.139887,0.032807,0.0484687,0.106806,0.0455887,0.868233,0.944532,-0.746842,-0.498874,1.48614,1.63864,-0.893907,-0.982766,0.68126,0.467074,1.47229,1.58374,-1.02788,-1.19576,-0.746624,-0.407675,1.04823,1.01104
6964,0.438752,0.410898,0.185902,0.127179,0.152697,0.0402669,0.330892,0.246639,0.811353,0.894494,0.151454,0.125849,0.102307,0.0277401,0.770967,0.715998,0.10079,0.164231,0.228366,0.245762,-0.266693,-0.328152,-0.443112,-0.359722,0.962181,1.2066,-0.0240717,0.119705,-2.32245,-2.40538,0.285462,0.0672243,-0.683548,-0.573563,0.972677,0.797591,-1.37169,-1.03074,-1.54324,-1.57556
6965,0.787732,0.757894,0.680163,0.620226,0.239626,0.126533,0.818123,0.735103,0.438926,0.520465,0.123562,0.0981082,0.998217,0.924133,0.341725,0.376197,0.703734,0.766104,0.096141,0.172524,0.59372,0.533799,-0.315175,-0.236469,1.05123,1.29472,1.4531,1.59679,1.04271,0.967632,-1.71945,-1.93574,0.523752,0.62731,-0.155445,-0.32748,0.382766,0.726495,-0.522884,-0.554106
6966,0.35743,0.327132,0.715839,0.71518,0.769649,0.655068,0.757594,0.642749,0.582535,0.66492,0.67025,0.644194,0.070367,-0.0036244,0.0884657,0.0363965,0.955299,1.01785,0.0814737,0.099286,-1.21864,-1.27274,1.00095,1.07319,1.14285,1.38284,-0.996426,-0.852076,-0.541352,-0.622824,2.09436,1.88276,-1.72611,-1.6307,-0.806254,-0.978414,-2.09015,-1.74502,-0.424843,-0.457989
6967,0.296115,0.265759,0.868597,0.810134,0.275123,0.160787,0.632883,0.550395,0.105671,0.185965,0.804526,0.77936,0.582637,0.507193,0.6785,0.624332,0.942049,0.975677,0.188836,0.140156,0.69843,0.63888,-0.507048,-0.437186,0.214144,0.458042,-0.934111,-0.79369,-1.53791,-1.61647,1.06209,0.849926,-0.79791,-0.676801,-1.16296,-1.33735,-0.529758,-0.192099,2.38405,2.34826
6968,0.985527,0.956479,0.336748,0.27806,0.286824,0.153489,0.0495324,-0.0328914,0.00200397,0.147225,0.143988,0.119435,0.870671,0.793739,0.802439,0.750092,0.919613,0.933505,0.161444,0.181026,-1.33239,-1.38664,-0.468147,-0.404397,-0.239258,0.000507222,0.499777,0.635798,0.57861,0.501543,1.62037,1.40242,0.176304,0.2771,0.82437,0.655997,1.26133,1.59487,0.407244,0.374739
6969,0.951292,0.920109,0.0265155,-0.03253,0.327379,0.14619,0.364754,0.281933,0.0297451,0.108486,0.531684,0.487522,0.790064,0.714403,0.0616274,0.0088375,0.886192,0.891334,0.574441,0.594806,0.408742,0.358915,0.421971,0.487353,-0.429403,-0.0948356,0.380643,0.509523,-0.0988849,-0.170239,0.187434,-0.0299984,-1.29105,-1.19152,0.147321,-0.0261415,-2.06822,-1.72642,-0.290689,-0.327269
6970,0.437896,0.40469,0.511946,0.451189,0.311532,0.138892,0.382504,0.29985,0.421631,0.490028,0.879364,0.855608,0.497941,0.42267,0.801005,0.746099,0.807352,0.849163,0.723244,0.718662,1.2065,1.16103,0.73313,0.797235,-0.430497,-0.190178,1.29903,1.42798,-0.508399,-0.582595,0.559999,0.401518,0.748733,0.851275,0.241367,0.0759061,0.738636,1.07862,1.25256,1.21401
6971,0.418961,0.384611,0.727883,0.668519,0.258867,0.131594,0.0355967,-0.0468765,0.792934,0.87157,0.127372,0.10548,0.736276,0.652701,0.404815,0.442017,0.861548,0.806991,0.821352,0.842518,2.51986,2.47009,-0.520611,-0.461439,-1.01811,-0.776386,-1.15081,-1.02089,0.329957,0.250648,1.04595,0.833035,1.71814,1.81862,1.2814,1.11192,0.395454,0.660764,-0.392256,-0.43251
6972,0.897817,0.861573,0.0610971,0.00284191,0.238631,0.124295,0.234248,0.149415,0.804937,0.871175,0.800879,0.777542,0.956673,0.882732,0.1922,0.137935,0.702271,0.76482,0.710383,0.732155,0.479758,0.429622,0.849069,0.871818,0.287467,0.526675,0.929304,1.05815,0.326704,0.24022,-0.420975,-0.63147,-1.06414,-0.960526,-0.483867,-0.659126,-0.091755,0.242905,-0.85749,-0.892604
6973,0.66038,0.623107,0.198623,0.141184,0.986233,0.870455,0.945256,0.86224,0.791981,0.870779,0.922956,0.89716,0.906905,0.834487,0.954802,0.900367,0.561884,0.61482,0.877728,0.899091,-0.449367,-0.499623,2.1459,2.20507,0.389316,0.633176,0.841559,0.977548,-0.0237034,-0.110863,-1.88306,-2.09598,0.757129,0.861768,0.339956,0.161925,-1.33787,-1.00781,1.16443,1.12873
6974,0.0600692,0.0219375,0.807583,0.751517,0.211184,0.0960374,0.50652,0.487225,0.0853652,0.165291,0.618098,0.59346,0.0953695,0.0227873,0.693954,0.638533,0.403944,0.46482,0.494305,0.513778,-0.727709,-0.780747,0.154469,0.209947,-0.278066,-0.0288177,-0.997351,-0.856037,-0.146497,-0.233497,-0.441511,-0.65749,1.60942,1.71851,1.44542,1.27484,0.478423,0.814281,0.30534,0.276171
6975,0.583599,0.543897,0.849994,0.794924,0.917644,0.801531,0.194556,0.112211,0.593645,0.673629,0.577819,0.525846,0.568779,0.494468,0.0392388,-0.0185244,0.696228,0.756119,0.91878,0.938066,-0.528107,-0.577476,-0.737518,-0.679225,-2.34954,-2.10707,-0.502814,-0.343878,0.160872,0.0758774,-0.370108,-0.581859,-0.198616,-0.095455,-1.68086,-1.85242,0.0902362,0.422918,0.470563,0.448618
6976,0.310563,0.352261,0.392527,0.428272,0.829822,0.715665,0.109471,0.0291809,0.366215,0.395887,0.467626,0.458231,0.401699,0.324789,0.18044,0.0230123,0.214773,0.276042,0.564611,0.58228,1.27692,1.22917,-1.61974,-1.5684,1.59477,1.83187,0.0199718,0.16828,-1.17206,-1.25741,0.602454,0.397656,1.2941,1.39635,0.448593,0.280001,-0.670112,-0.340907,1.34218,1.31749
6977,0.197848,0.160625,0.117914,0.0616195,0.99156,0.876934,0.467585,0.387701,0.0365851,0.118146,0.480032,0.390617,0.773719,0.696447,0.124631,0.0645491,0.0273969,0.0889527,0.616767,0.653781,-1.89084,-1.93897,0.955059,1.00274,-2.26602,-2.02945,-2.90129,-2.75028,-0.703009,-0.793288,2.15178,1.94431,0.155235,0.256341,0.13344,-0.03333,-0.766216,-0.439622,-0.402923,-0.420571
6978,0.960958,0.924996,0.0630552,0.068074,0.11102,-0.00248373,0.280646,0.215705,0.63337,0.712932,0.34764,0.323002,0.295715,0.220302,0.0399968,-0.0212621,0.733434,0.79606,0.793208,0.725281,-0.876286,-0.922058,-2.34612,-2.29827,0.158314,0.39403,1.05537,1.20158,0.0449117,-0.0377343,-0.466167,-0.677396,0.66501,0.763366,0.53612,0.374631,0.564345,0.896275,0.636264,0.61509
6979,0.0276679,-0.0104061,0.152414,0.0745285,0.0713698,-0.0413031,0.125967,0.0437104,0.752825,0.832327,0.908044,0.88429,0.827251,0.751455,0.865828,0.802792,0.26935,0.331176,0.781278,0.796782,-1.07545,-1.12751,1.19408,1.24551,0.122399,0.36455,0.553586,0.703953,-1.29073,-1.37102,0.519827,0.30212,0.63828,0.734594,-2.07818,-2.23699,-1.70825,-1.36981,-0.129772,-0.147715
6980,0.577046,0.540612,0.138465,0.080983,0.421741,0.298466,0.326896,0.216683,0.42895,0.509951,0.973647,0.950731,0.81023,0.733693,0.974775,0.834013,0.810102,0.871852,0.170853,0.186828,-0.524951,-0.584554,0.754656,0.804481,0.896829,1.13324,1.86474,2.02217,-1.38558,-1.46312,-0.642432,-0.852857,-0.807123,-0.716824,2.13154,1.97273,-1.35704,-1.0188,-0.0343429,-0.0515971
6981,0.495001,0.457572,0.499503,0.441096,0.749162,0.638235,0.472137,0.389656,0.617339,0.699937,0.40791,0.386358,0.247003,0.171881,0.927665,0.865234,0.82686,0.88682,0.319923,0.333546,0.531169,0.477334,4.08553,4.13401,1.31575,1.54853,1.69615,1.84868,0.226908,0.15042,-0.820665,-1.03664,-0.637903,-0.548663,1.3141,1.15505,1.7874,2.12183,0.740745,0.724757
6982,0.199279,0.16306,0.262587,0.206593,0.763617,0.642468,0.0235152,-0.0562351,0.0993876,0.181512,0.659559,0.639797,0.325486,0.250873,0.136488,0.0734991,0.316845,0.377121,0.966628,0.982357,-0.260626,-0.313789,-1.36239,-1.31029,-0.988916,-0.757264,-0.237374,-0.0819771,0.723823,0.645963,0.347711,0.128249,0.56219,0.652209,-0.704468,-0.867155,-0.195955,0.139668,0.573803,0.550775
6983,0.815028,0.778391,0.945393,0.891221,0.795669,0.6467,0.992984,0.913233,0.906524,0.988411,0.541831,0.522412,0.16172,0.0870557,0.332016,0.270177,0.503599,0.593299,0.390135,0.406663,0.712744,0.657463,0.130905,0.184258,-1.21416,-0.986078,0.130178,0.28246,0.577248,0.494862,1.25646,1.03222,-1.37899,-1.28803,1.25405,1.09601,2.13834,2.467,0.92404,0.902708
6984,0.558003,0.520313,0.456199,0.403445,0.761197,0.650932,0.115641,0.0381581,0.593014,0.675717,0.882478,0.861988,0.210695,0.115263,0.820452,0.757073,0.767684,0.809476,0.48111,0.498134,1.96721,1.90547,-0.470266,-0.410848,-0.393627,-0.17068,1.07649,1.23131,-0.214541,-0.298294,-0.207453,-0.432919,1.40202,1.49061,0.0123294,-0.150773,0.469666,0.806589,-0.289903,-0.316989
6985,0.677039,0.640531,0.183148,0.128099,0.259601,0.151237,0.791238,0.714855,0.870238,0.952314,0.249087,0.226613,0.314637,0.14347,0.479716,0.440988,0.965377,1.02565,0.0715914,0.0866621,-1.05588,-1.12126,-0.704659,-0.641839,-0.417043,-0.20016,0.943249,1.10504,0.478116,0.396188,-0.309581,-0.540301,2.61063,2.70713,-1.94592,-2.11115,-0.153481,0.183526,0.815391,0.794824
6986,0.337579,0.362785,0.496129,0.534547,0.425753,0.317396,0.701634,0.681034,0.396872,0.479308,0.259133,0.238425,0.266867,0.171677,0.187926,0.124903,0.921243,0.980948,0.494389,0.510951,0.08529,0.0171609,-0.322449,-0.256356,0.948538,1.16381,0.35788,0.513794,-0.744617,-0.827693,1.86581,1.63193,1.59208,1.69046,0.00994838,-0.14799,2.13251,2.47312,0.989018,0.967271
6987,0.122057,0.0850383,0.99531,0.940994,0.154908,0.0480546,0.723998,0.647213,0.936545,1.01819,0.617995,0.548873,0.274548,0.199883,0.897173,0.832273,0.489601,0.551857,0.286587,0.305927,1.77361,1.70112,1.40242,1.47186,0.457358,0.674916,0.386938,0.539695,1.57333,1.4922,1.35546,1.04526,0.257722,0.36355,1.62965,1.47068,0.339839,0.682968,-0.607091,-0.632901
6988,0.618206,0.581444,0.596083,0.541554,0.274065,0.0811021,0.402696,0.302765,0.854726,0.938024,0.881107,0.859322,0.796833,0.722179,0.00657968,-0.0600458,0.771828,0.833035,0.521798,0.538706,0.95774,0.879766,0.795316,0.8622,0.397496,0.614258,-0.408473,-0.251107,-0.904972,-0.98235,0.697455,0.458595,0.287314,0.349224,-0.600813,-0.766856,1.24189,1.57802,0.996083,0.970983
6989,0.367598,0.33272,0.549006,0.406161,0.219136,0.11415,0.0372112,-0.0416841,0.401018,0.484634,0.46995,0.448317,0.542772,0.465432,0.0620159,-0.00430653,0.0881911,0.147596,0.461409,0.480369,0.980308,0.813557,-1.30638,-1.2424,0.550748,0.766738,-0.994601,-0.842352,1.10917,1.02698,0.346003,0.105,0.236519,0.334898,0.793665,0.621574,1.69621,2.03652,-0.139726,-0.158802
6990,0.521062,0.488011,0.325141,0.270767,0.591788,0.486936,0.341743,0.262733,0.288872,0.373003,0.722265,0.644076,0.808621,0.731849,0.701545,0.635371,0.111036,0.17194,0.963494,0.984327,0.828499,0.747347,0.119825,0.189954,-1.58975,-1.37543,0.171072,0.324229,0.4717,0.386787,0.639027,0.394239,0.630465,0.733848,-0.33647,-0.503497,0.30565,0.645242,2.41947,2.40246
6991,0.0147128,-0.0174813,0.873388,0.818635,0.347906,0.24248,0.148915,0.071135,0.679667,0.765771,0.858956,0.839835,0.732324,0.658064,0.563019,0.498992,0.879534,0.938347,0.865502,0.885296,-1.15375,-1.2306,-2.08684,-2.01472,-0.517175,-0.300196,0.933037,1.08751,0.544366,0.470276,-0.621515,-0.869358,-0.673365,-0.563106,0.730439,0.564659,1.58456,1.93141,-1.26082,-1.27499
6992,0.896833,0.864461,0.690567,0.634385,0.764917,0.660709,0.271336,0.196005,0.741924,0.828263,0.829766,0.812094,0.238536,0.162261,0.73317,0.690593,0.62647,0.684642,0.253399,0.275343,0.130585,0.0490761,1.49396,1.57008,-1.4652,-1.25581,0.418953,0.574058,0.645313,0.553764,-0.572679,-0.824335,-0.956763,-0.852679,-0.00501968,-0.163884,-0.901217,-0.553948,-0.864933,-0.87826
6993,0.776934,0.646847,0.0866104,0.0285646,0.523107,0.494937,0.9125,0.838032,0.37446,0.459493,0.400519,0.426846,0.523854,0.448807,0.94642,0.882195,0.0414786,0.0996618,0.224605,0.355995,-0.454411,-0.540324,-0.90829,-0.827884,0.810511,1.01989,-1.52206,-1.36992,0.510171,0.463802,1.74623,1.48879,-0.755035,-0.653871,1.10784,0.94903,0.458765,0.744207,0.634533,0.617894
6994,0.49765,0.429233,0.00525635,-0.0547666,0.339753,0.329164,0.6856,0.609862,0.962453,1.04946,0.0586982,0.0415977,0.563922,0.487222,0.483227,0.420786,0.836804,0.896568,0.386689,0.436647,-0.192348,-0.274441,1.90633,1.98153,0.156263,0.357895,-0.425898,-0.267804,0.4727,0.373839,-0.851603,-1.10616,-2.35717,-2.26382,-0.399139,-0.558961,1.69888,2.04236,-0.563832,-0.586177
6995,0.190195,0.211619,0.503386,0.443713,0.267235,0.163392,0.898229,0.820847,0.73855,0.815974,0.368495,0.375084,0.396303,0.317543,0.278725,0.213908,0.92078,0.979282,0.496279,0.5173,2.64536,2.5626,1.35134,1.43189,-0.238856,-0.0388938,0.286753,0.448403,0.987489,0.884249,-0.393994,-0.644587,-1.69605,-1.6026,-1.70268,-1.87034,0.229876,0.569832,-1.318,-1.3328
6996,0.026376,-0.00599522,0.162541,0.103675,0.903551,0.802532,0.566569,0.488076,0.405887,0.582488,0.727608,0.708571,0.662994,0.58396,0.306778,0.296554,0.222888,0.283127,0.20601,0.226491,-0.686844,-0.775193,-0.437278,-0.361195,-0.248639,-0.0536397,0.290573,0.459971,-0.0284368,-0.125337,-1.23679,-1.49398,-0.780499,-0.681373,-0.910559,-1.08098,0.194449,0.533778,-1.16289,-1.17514
6997,0.998264,0.96431,0.9027,0.844373,0.17436,0.0729949,0.878804,0.8029,0.261994,0.349002,0.787114,0.777279,0.319822,0.238736,0.446617,0.3792,0.29213,0.351551,0.179993,0.164097,-1.05066,-1.13311,-1.16129,-1.15665,1.03883,1.23347,-1.23435,-1.05896,-0.533962,-0.629464,-1.19265,-1.44895,-1.27501,-1.17291,0.962013,0.786287,-0.304184,0.0959477,-0.109509,-0.1243
6998,0.253868,0.219393,0.899373,0.841127,0.0140722,-0.00456594,0.670582,0.638089,0.7357,0.821974,0.86409,0.845988,0.33298,0.251685,0.105578,0.0371076,0.849164,0.906765,0.081372,0.101703,-1.06522,-1.14239,-2.02198,-1.9521,0.492103,0.682642,-0.468898,-0.295678,0.652341,0.556709,-0.00270069,-0.253948,-1.23809,-1.142,-1.58399,-1.75486,-0.679194,-0.341882,-0.875314,-0.887105
6999,0.216016,0.183022,0.895177,0.837881,0.0193731,-0.0821268,0.549118,0.473278,0.214211,0.298959,0.0483044,0.0286487,0.122363,0.0413153,0.732476,0.662553,0.36665,0.421863,0.976046,0.99498,-0.239239,-0.311139,1.1661,1.23914,-2.34187,-2.15884,0.747469,0.916057,0.0170989,-0.0834853,-0.598506,-0.842477,0.204297,0.216477,-0.320151,-0.492081,0.577162,0.912958,0.730896,0.716779
7000,0.84998,0.818833,0.376928,0.320238,0.0836976,-0.0199464,0.541129,0.53861,0.79583,0.878696,0.035144,0.0165013,0.205308,0.125141,0.0613804,-0.00934438,0.434971,0.490288,0.573404,0.679856,-2.22158,-2.28908,0.880596,0.853081,0.22077,0.401455,0.828948,1.00228,-0.39403,-0.495841,0.619194,0.367814,1.48213,1.57496,0.399513,0.222525,0.53672,0.876905,-0.157388,-0.166729
7001,0.244462,0.213396,0.0795767,0.024926,0.439814,0.337159,0.668416,0.603941,0.74815,0.851319,0.428066,0.410723,0.687216,0.607389,0.895098,0.824253,0.786755,0.758725,0.344637,0.364731,1.7191,1.65298,0.397135,0.467025,0.638801,0.816745,-0.884955,-0.705397,-0.237851,-0.336444,-0.0920022,-0.343562,-0.264021,-0.176444,-0.0547554,-0.226832,0.883131,1.22792,0.180499,0.170926
7002,0.0640682,0.138403,0.287551,0.208175,0.393523,0.292887,0.746508,0.669273,0.742856,0.823942,0.370168,0.352867,0.948542,0.868962,0.457542,0.387357,0.972956,1.02716,0.465218,0.430907,-1.02704,-1.09381,0.420234,0.483109,1.33845,1.50871,1.23988,1.4183,-0.971017,-1.06925,0.393316,0.147839,-0.263583,-0.175331,-0.265717,-0.43188,2.14735,2.49839,-0.135944,-0.139802
7003,0.00826054,0.06341,0.479304,0.391424,0.682895,0.584343,0.965295,0.889619,0.11269,0.194127,0.0692249,0.0540669,0.44878,0.367923,0.801854,0.729388,0.572704,0.628218,0.476756,0.497083,0.0207604,-0.0456366,-0.317888,-0.235153,0.149644,0.319578,-0.329733,-0.144835,0.402216,0.299063,-1.06964,-1.31731,0.493695,0.577459,1.26256,1.09233,-1.54905,-1.20107,0.232672,0.228094
7004,0.0190044,-0.0115828,0.562362,0.574673,0.492292,0.392307,0.260457,0.186862,0.356021,0.420748,0.848094,0.831187,0.826729,0.744682,0.751246,0.648099,0.946017,0.998682,0.136118,0.155944,-0.681179,-0.742257,-1.00853,-0.953415,0.227337,0.396803,1.32688,1.50656,-0.374309,-0.477512,1.57872,1.32393,-0.285038,-0.204912,-0.430958,-0.600873,-0.104066,0.244139,1.74585,1.74142
7005,0.225339,0.194637,0.688217,0.757922,0.574276,0.474237,0.822146,0.750205,0.568126,0.64737,0.120807,0.105949,0.59959,0.518314,0.712561,0.56681,0.54983,0.60448,0.13779,0.156832,2.10223,2.04532,1.07896,1.13484,-0.114352,0.0610585,-0.857047,-0.674948,-0.284535,-0.379743,0.711011,0.45954,-0.258861,-0.17401,-0.328765,-0.498825,0.281874,0.577857,-0.0806376,-0.0861852
7006,0.89701,0.865859,0.995822,0.941171,0.308546,0.210014,0.551236,0.477177,0.105436,0.183651,0.914206,0.900289,0.885892,0.80486,0.556661,0.48552,0.995909,1.04968,0.79444,0.815217,0.86361,0.811378,-1.91956,-1.86398,0.289939,0.461351,0.199593,0.381597,-1.48158,-1.5681,-1.55594,-1.80937,-1.02294,-0.940958,1.1891,1.02538,0.563411,0.911575,-0.361024,-0.366345
7007,0.107931,0.0774424,0.779375,0.726717,0.4937,0.412094,0.951905,0.876525,0.722733,0.802868,0.803737,0.79135,0.774653,0.69563,0.0638721,-0.00555703,0.80797,0.86259,0.0336885,0.055861,0.00900582,-0.040121,1.71311,1.76534,1.09855,1.27675,1.5661,1.74654,0.0287756,-0.0604075,0.526059,0.264455,0.866933,0.943754,0.401194,0.236642,-1.47983,-1.13512,-1.11828,-1.12915
7008,0.856237,0.826097,0.317237,0.263354,0.712519,0.614173,0.688896,0.662911,0.484094,0.510802,0.988732,0.976133,0.192731,0.113202,0.0826854,0.0151511,0.241774,0.297073,0.316751,0.355288,-1.9775,-2.03298,0.407999,0.461085,-0.21004,-0.0351455,0.674314,0.860135,1.21469,1.12576,2.1484,1.88889,-0.61923,-0.539898,1.0888,0.919949,0.899283,1.23955,0.268297,0.258683
7009,0.285837,0.255477,0.530081,0.47601,0.277537,0.178844,0.521521,0.449298,0.138777,0.218736,0.158724,0.148096,0.73946,0.659468,0.906634,0.839205,0.938738,0.993662,0.607663,0.654714,0.0244153,-0.0278756,0.195149,0.248971,-0.209524,-0.0351707,-0.623082,-0.44261,1.94453,1.85144,0.883352,0.625296,1.42717,1.5029,2.10667,1.94278,2.49617,2.84034,1.06147,1.05196
7010,0.598616,0.530863,0.447334,0.423611,0.174646,0.078172,0.187455,0.235685,0.750305,0.828464,0.205155,0.193225,0.847742,0.769479,0.609364,0.563677,0.284672,0.337837,0.931968,0.954141,-0.867938,-0.925823,0.61708,0.665122,0.87077,1.04006,1.01209,1.19304,-1.21902,-1.30931,0.465715,0.208964,-1.10425,-1.02503,-0.822703,-0.980064,-1.00885,-0.670908,1.00674,0.998744
7011,0.837445,0.806248,0.443713,0.371211,0.734323,0.636143,0.0974517,0.0220713,0.285291,0.364744,0.559784,0.548513,0.672527,0.664711,0.354594,0.288149,0.322358,0.376282,0.935067,0.955029,0.313727,0.26033,0.510148,0.559652,1.47259,1.63753,0.807737,0.990304,-0.557064,-0.644874,-1.88023,-2.13834,1.22669,1.30819,0.298807,0.121607,-0.0636115,0.273034,-1.04445,-1.04933
7012,0.00432119,-0.0265663,0.372881,0.318811,0.1785,0.0820026,0.996106,0.919709,0.379544,0.459636,0.51999,0.511185,0.649357,0.559944,0.549988,0.484828,0.818086,0.872025,0.254343,0.27397,1.72189,1.66384,1.2139,1.26748,-0.541606,-0.374686,0.33035,0.509143,0.468343,0.373645,-0.458603,-0.716634,-0.767805,-0.679479,1.38353,1.22328,-1.82726,-1.4852,-0.408049,-0.40742
7013,0.450339,0.470052,0.0269388,-0.0261916,0.502185,0.40354,0.572104,0.473593,0.0814479,0.163094,0.985742,0.978784,0.631236,0.455176,0.0589985,-0.0062497,0.439497,0.492305,0.446453,0.466019,-0.964898,-1.02113,1.5994,1.65297,-1.68525,-1.5176,0.147788,0.319355,-0.236347,-0.32756,0.241708,0.0289905,-0.824595,-0.739274,-0.537191,-0.690322,-0.380614,-0.0399939,1.17838,1.18062
7014,0.997557,0.96667,0.226703,0.171231,0.0757261,-0.0209587,0.102528,0.0274769,0.71162,0.792259,0.439475,0.515762,0.42875,0.350409,0.406575,0.427214,0.462663,0.516649,0.377568,0.377206,0.55843,0.508242,-0.994759,-0.937587,0.210713,0.375274,-0.884075,-0.705194,-0.544947,-0.632258,1.03581,0.774615,1.02082,1.11358,1.10576,0.959353,-1.14317,-0.803818,-0.893118,-0.88449
7015,0.963226,0.930299,0.096561,0.0420986,0.162052,-0.00711106,0.397722,0.245729,0.191767,0.273833,0.0616829,0.0527403,0.518744,0.440043,0.926777,0.860677,0.959196,1.01239,0.267722,0.288393,1.17729,1.12742,1.82838,1.88889,0.488587,0.576233,-0.158332,0.0278541,0.228384,0.139989,-0.660055,-0.919478,-1.53903,-1.44796,0.853128,0.707864,0.836198,1.17749,1.61607,1.63055
7016,0.656964,0.625639,0.383408,0.328542,0.102121,0.00673654,0.539953,0.463982,0.800192,0.883561,0.637759,0.62881,0.856851,0.777722,0.115071,0.0489016,0.0395868,0.0945477,0.853404,0.872681,-1.08101,-1.13151,-0.204878,-0.141978,0.605278,0.777192,-0.700026,-0.51532,2.56622,2.47854,0.508065,0.245415,-0.00261858,0.0900009,1.99396,1.84923,-0.780661,-0.434304,0.975524,1.05846
7017,0.0379113,0.00492288,0.14111,0.0872204,0.475145,0.379523,0.477078,0.401401,0.255733,0.340071,0.62032,0.671001,0.829973,0.790464,0.914927,0.847426,0.865609,0.923048,0.688079,0.714398,-0.120824,-0.177413,-1.20411,-1.13723,-1.38551,-1.2204,-0.595447,-0.412753,0.366682,0.282697,-0.874489,-1.14374,-0.544164,-0.43544,1.20569,1.1261,-1.46643,-1.11945,0.471749,0.486364
7018,0.200135,0.16512,0.75196,0.697553,0.254821,0.157525,0.859274,0.784505,0.912604,0.995248,0.721251,0.713193,0.881314,0.803206,0.807166,0.740496,0.93998,0.996706,0.538259,0.556114,0.529502,0.47301,0.0788061,0.141343,0.272953,0.436211,0.870549,1.04972,-0.181757,-0.266079,1.4421,1.16938,-1.0535,-0.96088,0.506129,0.402969,0.577595,0.93117,0.976499,0.990594
7019,0.0880474,0.0510794,0.288431,0.234191,0.488328,0.327083,0.818997,0.742814,0.844495,0.927067,0.157075,0.14882,0.639715,0.561923,0.37201,0.303601,0.0410625,0.0958743,0.933618,0.95068,-0.356071,-0.409642,0.526896,0.587256,-0.94691,-0.785343,-0.470026,-0.282926,1.50733,1.42474,0.574701,0.304993,0.0105252,0.0981321,-0.17543,-0.320162,-1.49405,-1.14623,-0.215766,-0.198407
7020,0.760388,0.722301,0.0339046,-0.021864,0.59493,0.496641,0.140237,0.0649061,0.777281,0.858886,0.752601,0.744609,0.022433,-0.054372,0.700386,0.630004,0.960892,1.01501,0.909424,0.857547,-0.476517,-0.527117,1.32183,1.38858,-1.3838,-1.22676,0.356357,0.54054,0.685368,0.599978,0.906253,0.639521,-0.799572,-0.714124,0.501621,0.363145,1.58471,1.93746,-0.77527,-0.764993
7021,0.696922,0.57384,0.32117,0.26458,0.391814,0.295166,0.954716,0.881481,0.475267,0.670986,0.597166,0.586155,0.198708,0.122089,0.0646368,-0.00663912,0.771737,0.82792,0.745909,0.764414,1.14966,1.09575,-0.572767,-0.501282,-1.14004,-0.979735,3.00793,3.1854,0.248397,0.156406,-1.51342,-1.78661,0.59628,0.689473,0.614911,0.479397,1.50904,1.8543,-0.179548,-0.166297
7022,0.507814,0.425378,0.291685,0.234334,0.78998,0.693045,0.572047,0.495993,0.369216,0.483086,0.0593426,0.0469391,0.758004,0.683601,0.121432,0.0491001,0.127067,0.183242,0.907531,0.926178,-0.0179139,-0.0767172,0.336065,0.406163,-0.119443,0.034951,-1.7359,-1.54978,-0.949133,-1.03195,1.05543,0.788636,-0.483477,-0.326843,1.35471,1.22348,-0.0387585,0.304413,0.420423,0.432399
7023,0.316665,0.276917,0.759486,0.702696,0.668267,0.571865,0.183597,0.110505,0.213581,0.295186,0.992048,0.979968,0.678273,0.660526,0.995482,0.92062,0.159035,0.216909,0.840936,0.857845,-1.61207,-1.67953,0.861567,0.930198,-0.439028,-0.287241,-1.2131,-1.03469,0.0193602,-0.0586907,0.261688,0.00172367,-1.4322,-1.34316,0.952189,0.819718,0.120513,0.467537,-0.162678,-0.149075
7024,0.000959382,-0.0380769,0.0419537,-0.0172052,0.837453,0.742593,0.188539,0.172364,0.947095,1.02794,0.524462,0.514432,0.713521,0.637451,0.516009,0.423303,0.608014,0.666519,0.267715,0.286672,1.33832,1.26545,-0.119649,-0.0487859,-0.344388,-0.19703,-0.156081,0.0218523,-1.54848,-1.61984,-0.048556,-0.306994,-0.213536,-0.12664,-0.0677493,-0.198385,-2.07715,-1.73445,0.148224,0.159552
7025,0.911862,0.87538,0.0559479,-0.0180794,0.234464,0.138212,0.211079,0.234222,0.280727,0.363105,0.567889,0.571469,0.931768,0.853917,0.000847031,-0.0740149,0.406335,0.378687,0.39006,0.414835,-0.863129,-0.935012,1.38308,1.44576,-1.82937,-1.67837,0.462181,0.643894,-0.904119,-0.972029,0.997564,0.735469,1.70943,1.79009,-0.152231,-0.282333,0.644331,0.981788,-0.510197,-0.496888
7026,0.0621465,0.0237079,0.0410711,-0.0189535,0.964972,0.869207,0.369172,0.296081,0.683899,0.765635,0.639727,0.628506,0.700586,0.622592,0.395103,0.318128,0.0338261,0.0908547,0.580621,0.542998,0.00933274,-0.0585354,0.546957,0.603747,1.2246,1.37372,-1.89416,-1.71673,0.95521,0.88807,0.993027,0.734277,-2.05194,-1.97128,-0.565176,-0.702051,-1.3389,-1.00037,0.159485,0.175534
7027,0.634265,0.595169,0.326045,0.26749,0.495258,0.399475,0.696938,0.625328,0.165606,0.24721,0.253235,0.338127,0.247504,0.171752,0.168867,0.0911669,0.679281,0.737802,0.650789,0.671162,1.91675,1.85308,-0.0263239,0.0248239,0.552543,0.695229,1.68105,1.86228,0.536018,0.475714,-0.00227844,-0.253939,-0.511886,-0.433315,-1.69595,-1.82712,0.115299,0.462253,1.30065,1.31812
7028,0.14271,0.104113,0.295843,0.25771,0.654336,0.594755,0.627884,0.555754,0.895498,0.975207,0.0613169,0.047749,0.275537,0.199563,0.694502,0.618042,0.48115,0.540319,0.359494,0.380352,0.673547,0.602286,0.336834,0.393485,-2.32188,-2.18021,0.125256,0.299145,-0.453339,-0.517933,-0.419754,-0.670271,-0.889964,-0.815639,-0.0246172,-0.239605,-0.943457,-0.599192,0.328162,0.344991
7029,0.451098,0.410834,0.366075,0.247929,0.884129,0.790035,0.557072,0.486181,0.249702,0.330935,0.692316,0.678431,0.741218,0.666642,0.415877,0.423621,0.940304,1.00062,0.439019,0.461972,0.74702,0.669384,0.208125,0.257509,0.970562,1.10989,0.919898,0.994187,-0.251874,-0.314183,1.1568,0.909538,-0.519825,-0.447111,1.47908,1.34791,1.91732,2.25794,-0.235967,-0.221594
7030,0.2553,0.21697,0.298928,0.238149,0.294673,0.201293,0.960519,0.890662,0.258508,0.33893,0.963101,0.947202,0.448714,0.374909,0.292016,0.2292,0.824843,0.883445,0.92817,0.951442,1.68355,1.60842,1.49495,1.53609,0.713385,0.851074,1.51859,1.68923,0.720161,0.659078,-0.207316,-0.448335,-1.91072,-1.83578,1.69026,1.55552,-0.275291,0.0709279,0.664646,0.676962
7031,0.501863,0.384415,0.524429,0.46539,0.745312,0.650548,0.00377857,-0.0639719,0.680425,0.76127,0.680737,0.664449,0.924746,0.851433,0.108962,0.0347791,0.0458803,0.103608,0.720895,0.806872,-0.195784,-0.275499,0.0329547,0.0703374,-0.294965,-0.152604,-0.395528,-0.22363,-0.565249,-0.624854,-0.259056,-0.494741,-1.01412,-0.94712,0.326449,0.185311,-0.211437,0.228479,-0.194117,-0.175599
7032,0.590621,0.551859,0.458599,0.401257,0.12204,0.0264283,0.779629,0.710205,0.789612,0.896905,0.933212,0.917887,0.671892,0.65685,0.18504,0.0974118,0.56689,0.624049,0.63672,0.662301,0.972436,0.893712,1.05168,1.08605,0.433116,0.569697,-1.41636,-1.24818,-0.706502,-0.762348,0.00145159,-0.236303,0.467804,0.532351,0.203205,-0.0153832,0.0426548,0.386031,-0.361325,-0.349581
7033,0.257425,0.216707,0.801096,0.741899,0.828122,0.731922,0.0140332,-0.0533298,0.949955,1.03254,0.838263,0.824999,0.53848,0.462267,0.235874,0.160045,0.473393,0.624324,0.206803,0.231632,-0.189309,-0.264157,1.44423,1.47153,0.445823,0.585528,0.320713,0.480818,0.233974,0.178881,0.999495,0.760323,1.41791,1.48524,-0.0222027,-0.216077,1.04079,1.37752,1.24542,1.2543
7034,0.321428,0.282038,0.226581,0.165228,0.201942,0.107802,0.333439,0.266301,0.426241,0.509527,0.187753,0.174947,0.938323,0.864205,0.892943,0.814858,0.565858,0.624599,0.918524,0.94599,1.52698,1.44945,1.11761,1.13697,1.17717,1.32353,1.61471,1.7681,0.782815,0.733622,0.122638,-0.119924,0.707178,0.780056,-0.275633,-0.416772,0.639094,0.969689,0.679911,0.687717
7035,0.661595,0.623987,0.829076,0.765247,0.0568628,-0.0391901,0.187904,0.118568,0.892079,0.977346,0.361443,0.349721,0.0646979,-0.0075313,0.0942549,0.0181743,0.898375,0.955138,0.673399,0.765703,0.0460219,-0.0291073,1.15955,1.18416,0.980486,1.12594,0.992183,1.14879,-0.169694,-0.214456,0.180257,-0.0591434,1.21176,1.28708,0.141857,0.00643533,1.10314,1.42819,1.22652,1.23672
7036,0.162191,0.122858,0.609609,0.460271,0.651942,0.553833,0.27153,0.141755,0.560156,0.683506,0.27822,0.284233,0.956908,0.883872,0.948966,0.873148,0.574532,0.630595,0.563217,0.585416,1.19313,1.12537,0.551196,0.5745,-0.393705,-0.250511,-0.537033,-0.382699,1.27207,1.23208,0.661519,0.4181,-0.411949,-0.3364,-1.17348,-1.30494,0.960021,1.28199,-0.447216,-0.440236
7037,0.756381,0.71788,0.21952,0.155296,0.969326,0.870545,0.23375,0.164942,0.21428,0.389666,0.0818858,0.218745,0.110945,0.0382385,0.957799,0.883427,0.477943,0.53513,0.378278,0.405128,-0.727949,-0.789037,2.39213,2.41343,-0.808147,-0.663008,0.631082,0.783882,0.11454,0.0709915,-0.423984,-0.66107,-2.0352,-1.95988,-0.862407,-0.987741,-0.387168,-0.0645723,0.835255,0.839799
7038,0.427347,0.457315,0.703849,0.639014,0.957916,0.857058,0.867111,0.797635,0.0124437,0.0958257,0.132907,0.153257,0.74899,0.674827,0.0694264,-0.00446373,0.830905,0.886414,0.918883,0.944521,0.299814,0.241813,-0.659897,-0.641698,-0.313315,-0.173792,-0.823038,-0.672453,0.499024,0.459392,-2.834,-3.07303,0.379836,0.454566,0.121687,0.00143183,-1.33292,-1.0192,-1.81957,-1.81712
7039,0.23292,0.19675,0.507657,0.444384,0.0702351,-0.0287986,0.550704,0.549365,0.508902,0.593751,0.0994911,0.0877686,0.0965064,0.0225825,0.437556,0.398952,0.171064,0.225893,0.159659,0.185166,0.223011,0.170686,0.0184074,0.123854,1.0677,1.20429,-1.41012,-1.2637,-0.957684,-0.994203,-0.392369,-0.627367,0.186907,0.258755,1.31508,1.18794,1.82587,2.14019,0.726394,0.730124
7040,0.371044,0.337104,0.0983896,0.0349769,0.741852,0.640783,0.370043,0.301095,0.173601,0.256542,0.133893,0.138357,0.0785306,0.00482034,0.874626,0.802367,0.416837,0.521804,0.480268,0.503386,-1.55328,-1.6027,0.8486,0.889407,-0.808571,-0.666828,0.619284,0.768958,-0.111026,-0.145256,0.174943,-0.0598388,-0.230504,-0.15536,0.664138,0.537008,0.356429,0.677434,1.14107,1.14219
7041,0.191547,0.159558,0.435918,0.379504,0.589151,0.488885,0.456861,0.389228,0.743286,0.825283,0.200813,0.188946,0.69879,0.626344,0.563415,0.509028,0.763907,0.817715,0.380165,0.404356,0.837894,0.792421,1.63676,1.65496,-0.0047605,0.132195,-0.406369,-0.255591,-0.11341,-0.139419,-0.878759,-1.10841,-0.917824,-0.845883,0.86716,0.744612,-1.09964,-0.785322,0.429053,0.42486
7042,0.518492,0.487135,0.788072,0.72403,0.00239319,-0.0998557,0.0400412,-0.0275409,0.563781,0.717299,0.515929,0.504524,0.627139,0.571733,0.285931,0.21569,0.227604,0.283668,0.0658119,0.0885881,-1.31717,-1.35427,-0.446064,-0.422208,-0.487543,-0.356701,-0.33232,-0.182481,-0.387522,-0.414154,0.260557,0.0244675,-0.574496,-0.508835,0.539557,0.417314,0.592088,0.910397,0.944681,0.944313
7043,0.511376,0.47811,0.411242,0.345241,0.810729,0.710402,0.0146048,0.00192138,0.523822,0.609315,0.461841,0.452342,0.501949,0.517122,0.462051,0.39308,0.455451,0.510275,0.940585,0.963492,1.25409,1.21641,1.51333,1.54093,-0.572161,-0.449969,0.512796,0.657532,-1.70944,-1.7316,0.597089,0.358996,-2.31793,-2.24531,-0.791874,-0.908426,-1.73651,-1.42533,0.0441179,-0.0457257
7044,0.284411,0.257485,0.527467,0.463722,0.34495,0.245974,0.0999222,0.0313837,0.482942,0.501331,0.881805,0.871699,0.53269,0.462511,0.0841988,0.0162078,0.450908,0.568483,0.85149,0.846658,1.34794,1.31262,1.1343,1.14331,0.732204,0.853092,-2.44176,-2.30404,0.799401,0.783699,-0.647302,-0.889444,0.206465,0.276983,0.143206,0.020886,-1.83991,-1.52404,-1.03995,-1.03576
7045,0.0701252,0.0368597,0.950564,0.888168,0.361541,0.262401,0.68349,0.614301,0.310853,0.393347,0.0367989,0.0286295,0.882634,0.814494,0.927309,0.861333,0.571534,0.62669,0.708953,0.729823,-0.147189,-0.182435,0.722882,0.745695,-0.106972,0.0194226,0.448873,0.587798,-1.43299,-1.44227,1.19572,0.951718,0.762136,0.831133,-0.0260504,-0.152886,-0.625998,-0.315325,-0.40478,-0.393859
7046,0.139228,0.107593,0.142452,0.0781168,0.630584,0.533669,0.891707,0.820987,0.00493852,0.0858326,0.521046,0.511009,0.0548557,-0.0134813,0.214919,0.146854,0.188148,0.242224,0.0406759,0.0635776,0.705013,0.664926,1.0245,1.0413,0.826126,0.95593,-1.16655,-1.02463,-1.30799,-1.31574,2.26599,2.02451,0.602436,0.664269,-1.17899,-1.30559,-1.1141,-0.799839,0.71648,0.733499
7047,0.744518,0.71357,0.485717,0.424292,0.391903,0.295305,0.352571,0.282899,0.359156,0.437861,0.404809,0.434471,0.347514,0.277675,0.716854,0.648088,0.445578,0.441942,0.309853,0.331921,0.0351264,3.1986e-05,0.879725,0.891609,1.51778,1.64789,0.267645,0.371561,-0.0171722,-0.022229,-1.70429,-1.94577,0.0045743,0.0643859,1.41555,1.29268,-0.25194,0.066451,0.120245,0.1373
7048,0.824012,0.794216,0.00291028,-0.0589978,0.895873,0.798866,0.331571,0.260993,0.394748,0.555487,0.369843,0.357934,0.283355,0.213544,0.603481,0.53651,0.688932,0.641659,0.267282,0.281469,0.163057,0.127853,-1.57244,-1.56841,-1.78789,-1.66106,1.62584,1.76776,0.074471,0.07554,1.66666,1.42216,-0.600648,-0.535497,-0.247806,-0.369695,-0.6498,-0.324912,0.913573,0.93058
7049,0.526195,0.46616,0.71143,0.651424,0.934235,0.841368,0.666834,0.594748,0.594459,0.673113,0.734455,0.722253,0.533596,0.518198,0.880979,0.812772,0.787158,0.841377,0.207986,0.231017,-0.635728,-0.678578,-1.04718,-1.04438,-1.76409,-1.63041,-1.13821,-0.999599,-0.508531,-0.504221,-0.65176,-0.897542,0.0507782,0.111402,0.786026,0.666318,0.93593,1.25956,-0.656222,-0.637066
7050,0.168437,0.138104,0.586892,0.527533,0.980716,0.88387,0.670287,0.598556,0.969846,1.04642,0.726148,0.656859,0.891865,0.822852,0.23712,0.171821,0.218603,0.271447,0.675558,0.699974,-1.04173,-1.08229,0.36573,0.373439,0.178348,0.307757,-0.235577,-0.0961543,1.2348,1.23409,-2.20331,-2.4536,0.410502,0.465255,-0.363167,-0.486386,0.716365,1.03613,0.0420262,0.0649322
7051,0.291897,0.263492,0.867693,0.809309,0.619417,0.48626,0.97388,0.902974,0.279446,0.356538,0.603567,0.591466,0.968745,0.839992,0.392299,0.399315,0.299432,0.300039,0.618731,0.641637,0.265099,0.226769,1.37004,1.37311,1.30363,1.42785,-0.812786,-0.670727,1.74584,1.7445,-1.46637,-1.72056,2.06407,2.11365,0.436839,0.319475,-0.0332299,0.285905,0.416921,0.44596
7052,0.958221,0.929773,0.41473,0.356092,0.185495,0.0886494,0.571314,0.50136,0.523418,0.597769,0.350764,0.423836,0.885025,0.857132,0.693816,0.626808,0.275314,0.328632,0.0942871,0.115648,0.672991,0.632569,0.0196555,0.0141606,0.83044,0.955372,-2.26289,-2.12706,1.21821,1.21246,0.322837,0.0725223,1.07258,1.04446,0.0226361,-0.100243,0.779329,1.10324,0.0202771,0.0439281
7053,0.443278,0.414355,0.228421,0.171842,0.531861,0.435948,0.928001,0.85988,0.404118,0.489687,0.268224,0.256207,0.943285,0.874272,0.266455,0.200349,0.137039,0.190229,0.00404534,0.027695,1.89784,1.86255,-1.35165,-1.34479,-0.118063,-0.00024019,0.215989,0.353591,1.13921,1.13703,1.24235,0.991023,-0.0733755,-0.0247382,-0.870669,-0.996403,0.92182,1.25054,0.944688,0.971989
7054,0.200909,0.170693,0.976157,0.921372,0.286124,0.191492,0.291117,0.222623,0.366093,0.381604,0.681114,0.670781,0.379108,0.31246,0.218052,0.153831,0.546338,0.5845,0.147701,0.170219,0.411638,0.383988,-0.801774,-0.791299,0.179331,0.291832,-1.10305,-0.962916,0.0619745,0.0529107,-0.377912,-0.625505,-0.672991,-0.622214,0.264448,0.144965,-0.519447,-0.188818,-0.671287,-0.644142
7055,0.834603,0.806504,0.946644,0.891126,0.724586,0.630817,0.411205,0.268949,0.197778,0.273522,0.298334,0.289295,0.322513,0.295306,0.663908,0.600813,0.925582,0.978772,0.50161,0.431835,0.141473,0.0711504,-1.60583,-1.59987,0.694454,0.812862,1.28793,1.43453,2.1266,2.11816,-0.571164,-0.825449,1.49712,1.5502,-1.08238,-1.19564,-1.2807,-0.952642,-0.492544,-0.471694
7056,0.488326,0.461252,0.555501,0.501529,0.841458,0.755613,0.493123,0.315275,0.395777,0.473074,0.60806,0.599486,0.342541,0.278151,0.0822189,0.0199948,0.953998,1.00833,0.672102,0.693452,-0.208735,-0.241687,-1.95002,-1.94984,-0.0194524,0.105555,1.03134,1.1828,0.497519,0.495025,0.152337,-0.10626,-0.986874,-0.93162,0.443979,0.328563,-1.40336,-1.08249,0.939393,0.963945
7057,0.911026,0.884343,0.939426,0.886296,0.973225,0.880408,0.532712,0.3616,0.274986,0.351228,0.335111,0.326563,0.101632,0.0368682,0.453513,0.281399,0.569967,0.623866,0.206903,0.227495,0.587833,0.560424,0.899955,0.898958,1.24164,1.3624,-0.47171,-0.319723,-0.342884,-0.346044,-1.38454,-1.64577,-0.599935,-0.549175,-2.01007,-2.12079,-2.15794,-1.83272,1.10366,1.12161
7058,0.263273,0.238157,0.0118298,-0.0420001,0.159871,0.0659911,0.487443,0.407926,0.522893,0.597953,0.952975,0.942232,0.725304,0.658392,0.67431,0.542804,0.964761,1.01974,0.137757,0.159163,-0.376446,-0.398476,0.0161756,0.011992,0.279362,0.406788,0.836718,0.98295,1.65348,1.64515,1.38231,1.11627,-1.12892,-1.07235,0.3777,0.272212,-0.450668,-0.122362,-0.0955164,-0.0824653
7059,0.195948,0.26474,0.615166,0.563441,0.416272,0.321471,0.522746,0.454252,0.446166,0.522925,0.808237,0.818372,0.928499,0.859988,0.865526,0.804208,0.409981,0.465249,0.484981,0.508767,0.805891,0.787678,0.862639,0.857129,0.301097,0.422619,-1.42547,-1.28102,-0.967878,-0.976756,-0.205153,-0.469642,-0.0957835,-0.0452061,0.767096,0.727508,-0.312561,0.0106632,0.622646,0.635533
7060,0.317741,0.291323,0.674274,0.670142,0.272422,0.179465,0.408328,0.341788,0.738304,0.814879,0.705755,0.694511,0.920094,0.82476,0.535324,0.46715,0.672588,0.726908,0.53779,0.561441,0.0504852,0.0290789,0.793411,0.725139,-0.657995,-0.532993,-1.02123,-0.872045,-0.297415,-0.341079,0.204517,-0.0579763,0.291108,0.385568,1.28829,1.1828,0.821754,1.14094,-1.3024,-1.28913
7061,0.609201,0.583549,0.827867,0.776843,0.936101,0.844181,0.814689,0.74627,0.407702,0.482734,0.153413,0.140325,0.934107,0.789533,0.189261,0.130093,0.130009,0.182419,0.197462,0.220302,-0.0449035,-0.0727571,0.592951,0.593148,-0.900428,-0.777475,-0.111072,0.0313997,0.311545,0.294599,-0.497771,-0.754539,0.869343,0.816343,0.554805,0.45426,0.173421,0.48663,-0.827854,-0.816208
7062,0.690868,0.664195,0.0365203,-0.0168951,0.740023,0.647311,0.199229,0.128618,0.608318,0.682287,0.37587,0.420269,0.903041,0.754305,0.133521,0.0744274,0.46959,0.52314,0.506959,0.52808,1.09897,1.06566,-0.236102,-0.231852,-0.145542,-0.0242989,-0.660297,-0.511775,0.939154,0.930276,-0.25713,-0.510291,1.19654,1.24712,0.842622,0.740944,-0.961849,-0.653453,0.298001,0.31115
7063,0.9782,0.951042,0.148586,0.0963975,0.935603,0.842636,0.511655,0.404933,0.251849,0.390221,0.711621,0.700212,0.787397,0.719078,0.453345,0.395894,0.320119,0.374949,0.0378907,0.0570662,0.414266,0.383652,-0.428316,-0.429425,2.3356,2.45116,-1.79745,-1.64499,0.140454,0.13712,-1.6321,-1.88423,-0.142875,-0.0973172,1.69982,1.59309,-0.5435,-0.241028,0.937919,0.953055
7064,0.849292,0.822485,0.0156733,-0.0374446,0.0370338,-0.053996,0.749996,0.681248,0.0253494,0.0981546,0.331814,0.318726,0.56926,0.480642,0.0651979,0.00942224,0.383601,0.396284,0.391498,0.410948,0.469416,0.434322,-0.414761,-0.413341,0.763111,0.878872,-0.781646,-0.562191,0.520648,0.511632,0.109734,-0.137169,1.81177,1.86452,-0.627487,-0.739728,-2.10005,-1.79091,-0.181377,-0.161077
7065,0.143367,0.114725,0.578622,0.524528,0.683731,0.594896,0.452003,0.383664,0.39591,0.484041,0.931784,0.920195,0.309567,0.242205,0.287682,0.233347,0.360383,0.417619,0.473704,0.492568,0.773045,0.733775,-1.52987,-1.5333,-0.220753,-0.109268,0.37554,0.520608,-0.513733,-0.527384,-2.28301,-2.53359,0.61252,0.662341,1.09948,0.987035,0.244279,0.553736,-0.370911,-0.350366
7066,0.230378,0.303966,0.388846,0.286511,0.388294,0.300927,0.487129,0.367119,0.797079,0.869927,0.19894,0.185593,0.737816,0.668837,0.8631,0.806964,0.859555,0.917839,0.0580258,0.0765746,0.831596,0.748339,-3.11926,-3.1209,1.00199,1.11828,-0.423891,-0.270195,-0.307484,-0.323634,-0.62534,-0.878364,0.0617389,0.108843,0.232868,0.123576,0.44828,0.761977,1.12042,1.14579
7067,0.492603,0.493206,0.101248,0.0484934,0.902753,0.81494,0.417745,0.350573,0.13696,0.210375,0.334445,0.320759,0.278357,0.208374,0.554494,0.500623,0.496733,0.553534,0.778612,0.796103,0.805505,0.762903,0.632299,0.626911,-0.467927,-0.348306,1.15183,1.30413,-0.691788,-0.705957,-0.817914,-1.07831,0.64892,0.693871,-1.00675,-1.1232,1.91555,2.2246,1.00302,1.03231
7068,0.598506,0.682447,0.856173,0.803996,0.402354,0.315245,0.924291,0.858414,0.658578,0.733894,0.769972,0.754883,0.272399,0.200947,0.663538,0.61133,0.403147,0.458069,0.959453,0.978428,-0.522237,-0.564852,-0.313927,-0.321489,0.0694345,0.187971,-0.0859856,0.0620836,-0.598936,-0.608188,0.623072,0.360178,0.773628,0.85066,0.346655,0.234416,-1.3176,-1.01252,0.645562,0.675161
7069,0.90033,0.871688,0.197574,0.14372,0.545365,0.42152,0.742021,0.676447,0.481992,0.490444,0.111049,0.0949592,0.632436,0.563407,0.269405,0.219534,0.641847,0.694842,0.365546,0.382852,-0.94531,-0.98416,-1.00529,-1.00773,0.0823683,0.203802,-0.449972,-0.297724,-0.0862383,-0.0977778,-0.34125,-0.596748,0.962497,1.00745,0.49747,0.381906,0.458411,0.760429,-1.21174,-1.18792
7070,0.309414,0.28104,0.216942,0.162754,0.614905,0.527795,0.829707,0.76458,0.171958,0.246993,0.571142,0.55319,0.247108,0.177646,0.416625,0.365916,0.626631,0.67942,0.802184,0.817485,-0.71776,-0.749345,0.46048,0.457744,-1.31873,-1.20215,1.78107,1.92644,0.770113,0.751168,0.166498,-0.130418,-0.170291,-0.120829,-0.707184,-0.818649,0.252771,0.553645,0.723018,0.73981
7071,0.764508,0.738722,0.486791,0.433789,0.552704,0.467538,0.569706,0.444715,0.229675,0.353085,0.737523,0.718352,0.81174,0.744155,0.12226,0.0689825,0.840588,0.895517,0.490299,0.470204,1.00898,0.979937,-0.40615,-0.413784,0.56111,0.676541,-0.58628,-0.434191,-1.77674,-1.79189,0.585058,0.335913,-1.29506,-1.24911,0.0575303,0.0403258,0.649729,0.950544,-1.12711,-1.10917
7072,0.123051,0.0973336,0.379199,0.324783,0.852831,0.768785,0.18863,0.12485,0.383677,0.459177,0.473735,0.455234,0.851039,0.78257,0.678547,0.626881,0.294789,0.351028,0.109479,0.122924,-0.105441,-0.133722,1.8014,1.79167,-0.319734,-0.202629,-0.525963,-0.375805,1.6027,1.58112,-0.542388,-0.789592,2.01998,2.0728,1.01397,0.8993,-0.711422,-0.409735,-0.100709,-0.087718
7073,0.868527,0.841301,0.529164,0.394257,0.207443,0.124494,0.284284,0.218522,0.780924,0.856899,0.668816,0.648978,0.555581,0.409154,0.614098,0.561128,0.924924,0.981948,0.191565,0.204543,0.724244,0.697534,0.0538601,0.045753,0.616528,0.733878,0.0571677,0.200808,1.89094,1.86217,-0.157343,-0.406701,-0.466237,-0.409021,-0.502638,-0.624965,0.351516,0.658745,0.522547,0.538857
7074,0.495291,0.466977,0.519364,0.463731,0.712931,0.628055,0.107817,0.0408555,0.29965,0.373217,0.187847,0.16884,0.106591,0.0357376,0.0720145,0.0197053,0.432069,0.48686,0.97928,0.991274,0.477068,0.447119,0.648898,0.6476,-0.0390118,0.151663,-0.876554,-0.73271,3.0388,3.01659,0.967425,0.711995,1.7345,1.7935,-1.18791,-1.3071,-1.98554,-1.67698,0.303355,0.318663
7075,0.969707,0.943939,0.172764,0.118728,0.61813,0.506172,0.706313,0.637701,0.925943,0.997404,0.0422582,0.0252322,0.902136,0.830793,0.990207,0.938617,0.31138,0.364085,0.418747,0.430204,1.43929,1.40122,0.804715,0.802165,-0.544518,-0.430553,-0.164923,-0.0298587,0.740645,0.724004,-0.33585,-0.597293,-0.45716,-0.395672,-0.170437,-0.284277,-1.07329,-0.765694,-0.277182,-0.26281
7076,0.256974,0.229338,0.704984,0.650881,0.468172,0.384288,0.361922,0.354036,0.768651,0.795596,0.560184,0.54256,0.957127,0.884067,0.142457,0.088755,0.777644,0.829254,0.579741,0.591967,0.803416,0.765282,1.19859,1.20196,0.132671,0.246089,0.523824,0.672993,-0.270696,-0.285582,1.3794,1.121,-0.211931,-0.15167,2.20163,2.09344,-1.78566,-1.48145,-0.534752,-0.493628
7077,0.968919,0.939969,0.71595,0.659924,0.793449,0.712048,0.136943,0.0703717,0.521984,0.593789,0.550545,0.577041,0.130975,0.0560919,0.596864,0.545477,0.75767,0.778784,0.431023,0.441608,0.672338,0.63552,0.759767,0.773463,0.0859466,0.201734,0.17271,0.329771,-0.228934,-0.249781,2.69024,2.43712,2.57076,2.62697,-1.87932,-1.98459,1.34722,1.64721,-0.744309,-0.724445
7078,0.294942,0.268191,0.480763,0.342231,0.25944,0.178233,0.987863,0.922233,0.892575,0.967098,0.62721,0.611522,0.677471,0.602357,0.097744,0.0442091,0.671323,0.728314,0.859193,0.870207,-0.214201,-0.247132,0.334619,0.344971,0.348408,0.4642,0.105088,0.263465,-0.772593,-0.798557,-0.746165,-0.997181,1.35617,1.40944,-1.45351,-1.56139,0.871959,1.17756,0.20049,0.176042
7079,0.15158,0.125182,0.079022,0.0245379,0.273729,0.248956,0.61286,0.544617,0.94936,0.980886,0.0970044,0.0816033,0.829651,0.752781,0.316462,0.174094,0.684036,0.677844,0.506248,0.500578,-0.136916,-0.166002,-0.442141,-0.435937,0.404264,0.526577,0.315389,0.474107,2.54814,2.52343,-0.122528,-0.368848,-0.876215,-0.829131,0.118411,0.0108054,-0.203498,0.100098,1.0608,1.07653
7080,0.668672,0.641789,0.418885,0.30047,0.399342,0.31968,0.653558,0.583481,0.919436,0.994674,0.609848,0.524759,0.0832703,0.00484654,0.357818,0.303979,0.573493,0.627374,0.118116,0.130948,-0.574988,-0.600353,0.247943,0.256266,0.137006,0.360153,1.00295,1.15866,-0.325223,-0.345606,-0.120231,-0.370041,-1.17665,-1.13421,0.898301,0.821752,-0.220732,0.0563125,-0.181172,-0.159112
7081,0.912618,0.88775,0.630366,0.576403,0.771107,0.692466,0.28428,0.216672,0.0410251,0.117783,0.984937,0.967914,0.47471,0.395897,0.855909,0.801235,0.33654,0.388863,0.16772,0.177984,-0.0627516,-0.147017,0.736659,0.75045,-0.00182548,0.193729,1.24874,1.40076,0.524034,0.50334,-1.09094,-1.3425,-0.55662,-0.51842,1.7335,1.6327,-0.285184,0.0125267,-0.329554,-0.301847
7082,0.690038,0.664192,0.268832,0.217188,0.34593,0.267967,0.328721,0.260113,0.837928,0.915225,0.578407,0.561771,0.084757,0.00455982,0.00827709,-0.0486265,0.965014,1.01525,0.741769,0.752067,0.329469,0.306318,-0.372531,-0.354012,-0.0950075,0.0273053,0.340334,0.395571,-0.268517,-0.289816,-1.08298,-1.32813,1.74881,1.78304,-0.436725,-0.533256,0.339367,0.643845,1.3715,1.39384
7083,0.223219,0.198371,0.200285,0.148146,0.66553,0.561627,0.13563,0.0685151,0.136666,0.214797,0.434634,0.355956,0.27552,0.19605,0.266608,0.212007,0.0393659,0.0920719,0.906654,0.919002,-0.483992,-0.500112,0.291895,0.23393,-0.0503591,0.0720902,-0.757047,-0.609617,2.0197,1.99664,1.42365,1.18267,-1.26616,-1.22577,-0.10518,-0.20137,0.239741,0.54513,0.667012,0.691828
7084,0.940124,0.914255,0.377294,0.326834,0.932993,0.855287,0.231731,0.202281,0.927466,1.00628,0.168536,0.150141,0.699351,0.61782,0.0269784,-0.0258079,0.440391,0.493009,0.27517,0.288239,1.53208,1.52015,0.803477,0.821871,1.73235,1.85545,-1.21825,-1.07763,0.310193,0.280396,0.525302,0.28513,1.76831,1.81493,-0.414071,-0.514702,-0.314218,-0.00169951,0.295655,0.31961
7085,0.70274,0.669097,0.317281,0.323588,0.55794,0.427813,0.276981,0.336047,0.729273,0.88843,0.910967,0.892068,0.773056,0.739497,0.363369,0.311754,0.513207,0.566667,0.102988,0.206096,-0.426076,-0.438379,0.0394275,0.0573941,1.07807,1.19346,1.36488,1.50448,-0.764759,-0.788735,0.0599368,-0.17938,-0.329676,-0.282303,0.96001,0.857593,0.971087,1.28447,0.874792,0.900278
7086,0.424354,0.423939,0.37008,0.320342,0.0763286,0.000339579,0.536928,0.469813,0.666262,0.770579,0.206233,0.187046,0.942732,0.861174,0.996563,0.946694,0.947314,1.00157,0.113289,0.123953,0.42731,0.408982,0.391175,0.412589,-0.76964,-0.647305,-0.514502,-0.374037,0.615075,0.597329,1.01796,0.784143,-0.749586,-0.696418,-0.466081,-0.575384,-1.29545,-0.981619,-0.901188,-0.868725
7087,0.204579,0.178781,0.679393,0.581571,0.386236,0.311627,0.0904475,0.0239218,0.572441,0.652728,0.303193,0.282282,0.737013,0.656052,0.645838,0.594573,0.994764,1.05063,0.512822,0.49543,0.842367,0.890376,-0.536263,-0.519662,-0.561141,-0.4326,-0.110084,0.0349404,0.17708,0.117184,-0.939264,-1.17346,0.608417,0.659348,0.189757,0.0778418,0.975342,1.29482,-0.290697,-0.257997
7088,0.394742,0.369352,0.891396,0.842801,0.958396,0.884174,0.268695,0.204765,0.77061,0.768164,0.778341,0.754742,0.904495,0.821609,0.901949,0.85028,0.453649,0.51103,0.857336,0.866906,1.38538,1.37177,0.0356524,0.0504829,-0.136254,-0.00363486,0.903799,1.04744,-0.345239,-0.362961,-0.444282,-0.691928,1.14161,1.19644,-0.162677,-0.281095,0.88918,1.21167,-1.00995,-0.975322
7089,0.688017,0.559924,0.515653,0.468189,0.608702,0.609955,0.966853,0.902149,0.802789,0.883599,0.779785,0.72493,0.667448,0.585293,0.39514,0.344001,0.786464,0.841569,0.771504,0.736867,-0.302122,-0.322529,-0.366829,-0.345292,-1.46387,-1.33201,-1.47066,-1.33201,-1.80722,-1.83163,0.0181555,-0.210394,1.1306,1.18246,-0.171093,-0.290513,0.0458683,0.37203,-0.797875,-0.759073
7090,0.776293,0.750495,0.418462,0.38328,0.409081,0.335735,0.636334,0.667059,0.625489,0.706967,0.718325,0.695118,0.18696,0.103668,0.971416,0.921876,0.330435,0.386986,0.660453,0.606828,-0.523864,-0.543178,0.768076,0.79254,1.18444,1.3142,-0.591737,-0.46004,0.885461,0.862397,-1.64357,-1.87078,-0.301202,-0.255,-1.20435,-1.3222,-0.0104464,0.318911,-0.109291,-0.0730122
7091,0.66902,0.66982,0.344101,0.298371,0.814294,0.739103,0.495296,0.43197,0.871811,0.953692,0.226007,0.204862,0.789735,0.704184,0.620954,0.547705,0.568713,0.623759,0.466219,0.47679,0.217359,0.198096,-0.0933199,-0.063365,0.841822,0.978454,-1.78218,-1.65563,-0.343463,-0.361484,-0.68565,-0.907262,-1.38683,-1.33378,-1.73458,-1.84845,-0.617567,-0.290584,-0.178926,-0.13933
7092,0.615336,0.589144,0.497999,0.452418,0.409795,0.333548,0.48016,0.356495,0.727402,0.807283,0.709018,0.687241,0.468161,0.317323,0.223987,0.173534,0.0950295,0.149086,0.942297,0.950794,-0.102355,-0.127569,-0.133238,-0.108131,-2.42318,-2.28322,1.07052,1.2023,0.107927,0.0862868,-0.0407745,-0.263227,-1.11696,-1.05822,0.205134,0.0842192,0.27868,0.604464,-1.4582,-1.42049
7093,0.197865,0.173781,0.29516,0.247473,0.852376,0.777294,0.441643,0.281021,0.169558,0.248738,0.468466,0.448787,0.0168519,-0.0695384,0.960073,0.910796,0.225833,0.278456,0.350451,0.360132,1.01306,0.994196,1.09046,1.11224,1.38454,1.52451,0.413733,0.549944,0.995201,0.98203,-0.759775,-0.974603,-1.107,-1.04368,1.76815,1.64066,-0.12349,0.196636,-0.175497,-0.140459
7094,0.862591,0.840063,0.828266,0.779625,0.236907,0.163292,0.269481,0.205547,0.763942,0.843524,0.663919,0.642531,0.951862,0.864114,0.467558,0.419719,0.887627,0.940788,0.505003,0.464701,0.151365,0.127641,0.949481,0.976265,1.76564,1.90754,-1.35461,-1.21754,0.550409,0.538457,0.359304,0.144093,0.187796,0.249564,0.452461,0.329284,-1.25874,-0.943447,1.97207,2.00901
7095,0.633372,0.638322,0.665704,0.616415,0.150488,0.0774269,0.711885,0.648957,0.946944,1.02858,0.327284,0.304895,0.955912,0.867565,0.286506,0.326098,0.00820912,0.0610236,0.557231,0.569271,0.473902,0.455334,-0.0512819,-0.0189918,0.352179,0.501587,-0.690772,-0.548156,-0.899389,-0.915137,0.0422332,-0.178715,-0.720227,-0.657453,-0.0557229,-0.181817,-0.160894,0.156207,1.43145,1.47078
7096,0.589289,0.436582,0.250819,0.202721,0.581189,0.506506,0.388884,0.32615,0.163526,0.243007,0.396139,0.375943,0.485497,0.39646,0.279588,0.232477,0.405664,0.471725,0.941059,0.953434,-0.353541,-0.366018,1.45948,1.49184,0.923228,1.06864,-0.345511,-0.249835,-0.0781367,-0.0978568,1.13791,0.921895,0.494528,0.559067,0.466709,0.333177,-0.0516823,0.258845,-0.602534,-0.563505
7097,0.259443,0.234842,0.998193,0.947841,0.310444,0.237164,0.607001,0.542454,0.969455,1.04991,0.751145,0.731231,0.385845,0.281956,0.617434,0.539027,0.829673,0.882427,0.731982,0.787599,0.701263,0.682152,0.0570025,0.0891393,-0.32888,-0.181513,-0.0956814,0.0484854,-0.221343,-0.235351,-0.338792,-0.558965,-0.0603504,0.00556876,-0.102065,-0.238439,0.640758,0.952244,-0.446508,-0.340207
7098,0.590986,0.566995,0.298952,0.247577,0.597407,0.52368,0.113301,0.0497432,0.243049,0.323399,0.727217,0.708055,0.36197,0.167453,0.892972,0.845576,0.73741,0.792161,0.61168,0.621763,1.29832,1.28569,1.15876,1.18402,1.52601,1.68051,0.82083,0.96694,0.0757893,0.0601101,1.97533,1.75415,-0.954167,-0.886228,0.0622784,-0.0763008,-0.537358,-0.220571,-0.16234,-0.116909
7099,0.496881,0.474931,0.739631,0.686951,0.439688,0.41853,0.944138,0.881338,0.0694027,0.15278,0.15437,0.133691,0.0981912,0.0529491,0.791599,0.745641,0.939083,0.992638,0.787542,0.799319,0.360583,0.343779,-1.03997,-1.02065,0.485543,0.645305,3.36539,3.5161,-0.126844,-0.138703,-0.452972,-0.671975,-0.664169,-0.593933,-1.08534,-1.229,1.11904,1.42841,0.517965,0.569152
7100,0.913614,0.892996,0.204166,0.149853,0.388296,0.313379,0.785446,0.723608,0.658665,0.742748,0.805561,0.78489,0.0274828,-0.0615546,0.126021,0.0793539,0.674825,0.797478,0.226403,0.238248,1.07176,1.05307,0.771542,0.783738,1.29566,1.4607,0.985303,1.13666,0.538553,0.525732,1.51852,1.30551,-1.60882,-1.53404,-0.019857,-0.160848,0.611113,0.927124,-0.721151,-0.666488
7101,0.5678,0.547744,0.51705,0.460968,0.0085482,-0.0659527,0.961697,0.898662,0.583379,0.744577,0.873789,0.851331,0.959256,0.872097,0.605716,0.561384,0.446531,0.602319,0.529015,0.540855,0.231803,0.215935,1.39582,1.41482,1.45367,1.61318,1.08483,1.23922,-0.373286,-0.389081,-0.27568,-0.495787,-0.692008,-0.612814,-0.730645,-0.873127,-0.930603,-0.607289,-0.369114,-0.314555
7102,0.442962,0.481496,0.560825,0.504376,0.435328,0.267412,0.177381,0.113967,0.662403,0.746407,0.144232,0.121894,0.646927,0.560413,0.549038,0.505719,0.353604,0.407159,0.268687,0.279749,0.512705,0.498864,1.05253,1.06486,0.788455,0.95119,-1.60895,-1.45816,-0.895122,-0.907116,0.895004,0.669106,-0.411545,-0.337254,-0.0458914,-0.18982,1.12638,1.44333,1.29059,1.34961
7103,0.382287,0.415249,0.0844737,0.0269388,0.675134,0.600777,0.0360224,-0.0275678,0.36085,0.443873,0.795572,0.773092,0.978856,0.892841,0.785782,0.74068,0.520298,0.572036,0.55165,0.561524,0.463765,0.444691,-2.64638,-2.63153,-1.34356,-1.17495,1.17818,1.3272,-1.1827,-1.19553,1.5489,1.32711,-1.20678,-1.13637,-0.0188431,-0.166842,-0.468264,-0.152095,-0.181687,-0.127485
7104,0.367419,0.349002,0.450635,0.319849,0.18269,0.106496,0.495459,0.430117,0.907803,0.992585,0.714826,0.689958,0.874974,0.788073,0.438305,0.394097,0.0167889,0.066924,0.830787,0.8433,-0.999647,-1.01928,-0.969162,-1.03702,-1.3735,-1.20443,0.209255,0.388999,0.0318545,0.0223739,-1.76209,-1.98733,1.92204,1.98788,0.297979,0.150362,-0.421439,-0.10981,0.464152,0.514421
7105,0.910158,0.891256,0.733332,0.612759,0.355859,0.277224,0.106879,0.0433964,0.873238,0.991393,0.108315,0.084938,0.360321,0.272039,0.536484,0.565229,0.131525,0.181487,0.510658,0.522062,-0.209305,-0.174378,0.548722,0.557487,0.712137,0.877757,-0.704765,-0.549199,-0.322314,-0.340568,0.963532,0.734912,-0.457134,-0.39665,-0.302286,-0.452719,0.590187,0.896673,-0.195474,-0.142019
7106,0.331304,0.310445,0.961339,0.905669,0.915162,0.835196,0.648947,0.586285,0.804973,0.9902,0.775074,0.751592,0.479691,0.392108,0.779736,0.73636,0.675295,0.726424,0.839763,0.850941,0.689547,0.670529,1.30144,1.31199,-0.703901,-0.543356,-2.06942,-1.91201,-0.686846,-0.70351,-1.6031,-1.8309,1.11368,1.17072,-1.29919,-1.45446,0.137902,0.441301,0.854241,0.908825
7107,0.941342,0.920311,0.31143,0.255145,0.594351,0.498366,0.359777,0.367017,0.925204,0.989008,0.889967,0.806383,0.0377255,-0.0486265,0.513301,0.469305,0.748097,0.800082,0.111789,0.122757,-0.315044,-0.335371,-1.20451,-1.19568,0.716093,0.880979,-0.196606,-0.0401885,-0.0716548,-0.086395,-0.108716,-0.331553,1.25986,1.32375,-0.713926,-0.863869,0.236059,0.54394,-0.323974,-0.265602
7108,0.109607,0.0874964,0.171013,0.116358,0.243317,0.161536,0.211946,0.147749,0.903035,0.987816,0.884151,0.861173,0.329529,0.18398,0.471222,0.348569,0.342915,0.394973,0.827525,0.837116,0.543766,0.526579,0.513476,0.516563,-0.121314,0.0473098,-0.555569,-0.399996,1.49334,1.48318,-0.0448637,-0.270773,-1.0362,-0.965273,1.25664,1.11252,2.34838,2.66187,-0.295131,-0.243131
7109,0.124314,0.0656386,0.415829,0.363365,0.894276,0.810428,0.633222,0.513868,0.223609,0.307631,0.421629,0.495175,0.505272,0.416586,0.269125,0.227832,0.229608,0.282985,0.984301,0.900994,1.69182,1.68106,0.661975,0.671128,0.977563,1.15095,-0.315744,-0.157894,-0.545816,-0.551233,1.12371,0.89412,0.191323,0.265911,0.720381,0.570994,-1.07794,-0.762611,0.533886,0.579823
7110,0.0274618,0.0437808,0.0939369,0.0430116,0.497268,0.415344,0.944185,0.879988,0.49069,0.580209,0.150384,0.129177,0.532411,0.444398,0.667288,0.587369,0.94184,0.995222,0.957019,0.964873,-0.404786,-0.418992,1.21831,1.22462,0.0514871,0.22616,0.561798,0.714075,-1.42541,-1.43654,-2.22665,-2.45442,-1.04095,-0.967013,0.564787,0.413033,0.387473,0.642991,-0.505805,-0.454274
7111,0.0265574,0.021923,0.455824,0.335922,0.707828,0.625628,0.200741,0.136915,0.767592,0.852787,0.346532,0.322921,0.093851,0.00831601,0.988013,0.946905,0.753694,0.808133,0.62007,0.628442,-0.920565,-0.933635,0.09167,0.104652,0.0182103,0.19668,0.405711,0.533606,-0.853105,-0.864613,-0.390902,-0.613257,-0.845129,-0.768206,-0.148964,-0.299246,1.73115,2.04859,0.398613,0.444282
7112,0.0221759,6.52177e-05,0.789844,0.628832,0.346436,0.266005,0.0864765,0.0386188,0.799047,0.88475,0.192766,0.169965,0.230001,0.168164,0.895319,0.856126,0.0135717,0.0669501,0.724157,0.65058,0.762531,0.750321,0.883401,0.892998,2.57111,2.75697,0.203908,0.353138,-1.36379,-1.38265,-1.12199,-1.33969,0.647515,0.723596,0.273751,0.089502,-0.495894,-0.184894,0.0859745,0.177702
7113,0.292043,0.271206,0.974532,0.921742,0.664352,0.582718,0.00359005,-0.0596772,0.189857,0.275249,0.743772,0.72165,0.412267,0.328012,0.578676,0.539633,0.0430777,0.160301,0.665079,0.672717,0.657755,0.648485,0.485197,0.497224,0.0895052,0.278336,-1.27667,-1.13323,0.77429,0.75292,2.26316,2.05172,0.306335,0.386658,0.615606,0.47825,-0.606044,-0.298511,-0.0663607,-0.0888774
7114,0.929866,0.907017,0.726153,0.675601,0.693888,0.610005,0.785335,0.72033,0.923547,1.008,0.471246,0.420874,0.805777,0.719063,0.0494228,0.00858472,0.200418,0.253652,0.538255,0.54763,-1.3968,-1.40722,0.869573,0.882707,-0.18138,0.00459933,0.362876,0.502418,0.41324,0.385958,-2.5262,-2.73764,-2.31203,-2.22368,1.01728,0.866997,-1.14471,-0.831098,-0.401125,-0.355457
7115,0.494399,0.471215,0.214463,0.16276,0.24552,0.160935,0.297573,0.233416,0.710172,0.796204,0.142705,0.120099,0.678039,0.589368,0.575506,0.53546,0.812675,0.86527,0.766323,0.77541,1.74277,1.73557,-0.34051,-0.329331,-1.57435,-1.38661,1.04191,1.18697,2.42677,2.39529,-1.77306,-1.98806,0.323922,0.412511,-0.561729,-0.71685,-0.898603,-0.591795,0.123678,0.163996
7116,0.568314,0.546861,0.506546,0.453628,0.0803286,-0.00521228,0.174139,0.111467,0.0329411,0.121005,0.522572,0.498988,0.170987,0.0830493,0.675664,0.609058,0.693657,0.748099,0.717842,0.799752,1.03331,1.0233,0.406745,0.410308,2.60863,2.79603,-0.101591,0.03848,0.545771,0.541076,-0.407409,-0.626153,-0.903915,-0.820413,-1.23259,-1.38411,0.248478,0.55403,-1.14102,-1.10169
7117,0.420675,0.398719,0.223292,0.167967,0.829479,0.746129,0.0552265,-0.0104829,0.615261,0.706418,0.125256,0.102312,0.530454,0.475461,0.690727,0.682657,0.880698,0.934285,0.813726,0.824094,1.02257,1.01402,-0.291391,-0.290835,-0.17495,0.00763247,2.25017,2.38475,-1.28166,-1.31314,0.40465,0.185132,1.45472,1.54412,0.410732,0.265565,0.419055,0.731822,0.503319,0.547599
7118,0.494407,0.474364,0.462702,0.405275,0.584015,0.501674,0.309759,0.244677,0.762372,0.850873,0.35116,0.326342,0.95325,0.867874,0.797287,0.756255,0.523067,0.575133,0.438578,0.447918,-0.316418,-0.327424,-0.287155,-0.288531,-1.27986,-1.10561,2.08541,2.22706,-0.235468,-0.264695,1.65503,1.4404,-0.429804,-0.348183,0.0533411,-0.0933711,-0.524685,-0.207771,-0.190233,-0.137825
7119,0.224695,0.299227,0.153733,0.0946844,0.76424,0.682996,0.879604,0.81236,0.526014,0.613924,0.0899725,0.0632237,0.0985498,0.0121963,0.184385,0.145395,0.581371,0.633293,0.987018,0.996853,0.0250171,0.0142961,-1.69737,-1.70493,0.190582,0.363768,-1.3294,-1.17848,-0.26564,-0.291579,-0.519289,-0.734672,0.984601,1.07027,-0.730418,-0.882109,-1.71938,-1.39626,-1.13933,-1.08179
7120,0.145392,0.12409,0.0775032,0.0168905,0.0342266,-0.0465413,0.106159,0.0380788,0.735146,0.811531,0.990993,0.964806,0.569705,0.483877,0.989503,0.948665,0.213767,0.263937,0.732241,0.742051,-0.363914,-0.373824,-2.58105,-2.59189,0.714509,0.884798,-1.03989,-0.890058,-0.76058,-0.778361,-3.55604,-3.77337,1.06544,1.14828,0.0247825,-0.123193,-0.618558,-0.29661,-0.186764,-0.122278
7121,0.403251,0.380531,0.271423,0.20967,0.357796,0.227503,0.719531,0.650953,0.91965,1.00914,0.892181,0.866915,0.0346936,-0.0529041,0.653526,0.611928,0.175997,0.224294,0.0352692,0.0443943,-2.41111,-2.41429,-0.519451,-0.533711,0.307038,0.530244,-0.244858,-0.0956397,1.62919,1.60827,0.26998,0.0451328,-0.860935,-0.774242,-1.07637,-1.21641,-0.930316,-0.612487,-0.738496,-0.675262
7122,0.378851,0.355247,0.217027,0.155188,0.579866,0.501548,0.705468,0.638628,0.145042,0.234167,0.0632992,0.038877,0.9494,0.859558,0.891581,0.851766,0.691435,0.739379,0.492382,0.50341,0.973751,0.979844,0.242205,0.220794,0.0113647,0.17569,1.08937,1.18304,-1.86206,-1.88328,0.811659,0.526666,0.0391173,0.130533,2.67284,2.53643,-0.464121,-0.153982,-0.746444,-0.682641
7123,0.601252,0.577047,0.506031,0.446056,0.452077,0.305128,0.909106,0.840087,0.206725,0.220937,0.248102,0.28755,0.0752162,-0.0167403,0.145955,0.106021,0.775837,0.777757,0.34549,0.358304,-0.262043,-0.254094,2.65839,2.63889,0.0591348,0.220475,2.319,2.46173,1.84818,1.82411,1.23914,1.0082,-1.93859,-1.84115,0.460764,0.318548,0.65319,0.960043,-0.350649,-0.285908
7124,0.21355,0.187224,0.344458,0.282847,0.184851,0.108709,0.300033,0.232103,0.155514,0.207707,0.559026,0.536223,0.2048,0.190599,0.836895,0.797336,0.769397,0.816135,0.785877,0.797599,0.272545,0.275204,-1.46161,-1.48111,-1.69846,-1.54084,1.3763,1.51205,0.92671,0.909294,0.27366,0.035742,0.650998,0.745944,-0.135917,-0.284533,0.652703,0.954727,0.764936,0.825905
7125,0.567942,0.526909,0.750399,0.688521,0.385286,0.309168,0.286659,0.23008,0.0566839,0.194477,0.305323,0.335794,0.418215,0.397939,0.00093028,-0.0397148,0.107763,0.155614,0.102948,0.11654,-0.473308,-0.466927,-0.5157,-0.528356,-0.162981,-0.0100336,-0.910667,-0.76795,-1.21846,-1.23754,1.30492,1.06214,0.499372,0.595847,-1.34323,-1.48509,-0.4441,-0.136224,-0.82699,-0.757878
7126,0.893021,0.866594,0.271411,0.211084,0.79726,0.722321,0.295815,0.228057,0.0921208,0.181246,0.158407,0.135365,0.69883,0.605279,0.0631787,0.0209348,0.930527,0.978445,0.758904,0.771086,1.27799,1.27862,-0.0597812,-0.138189,0.425289,0.573396,1.15869,1.2947,-0.443207,-0.548788,-1.1292,-1.36399,0.774555,0.936468,-0.997962,-1.13938,-0.411592,-0.109588,-0.342923,-0.268857
7127,0.311312,0.285782,0.00377317,-0.0551605,0.427076,0.352977,0.0141704,-0.0548935,0.792057,0.882317,0.316869,0.392039,0.141903,0.0478448,0.346202,0.301967,0.95843,1.00801,0.263075,0.275679,-0.16392,-0.169938,0.329153,0.251978,0.768552,0.911172,0.212104,0.345022,0.160054,0.139965,0.0693864,-0.168983,1.17565,1.27709,-0.149185,-0.358805,0.592847,0.826939,-3.24251,-3.17249
7128,0.650841,0.583748,0.3359,0.275705,0.756643,0.636317,0.971212,0.902147,0.237794,0.328528,0.669283,0.648713,0.310123,0.129848,0.123038,0.0795552,0.220496,0.271684,0.863965,0.874159,0.981344,0.968481,0.6548,0.642144,-0.95427,-0.818412,1.3259,1.46219,-0.309608,-0.333056,0.584749,0.353171,-1.07018,-0.961483,0.570548,0.421772,1.46752,1.76347,-1.39312,-1.31993
7129,0.908708,0.881713,0.0484533,-0.00995501,0.992862,0.919658,0.140818,0.070075,0.994321,1.08715,0.578407,0.555825,0.303431,0.211852,0.455636,0.411414,0.574526,0.628007,0.544018,0.500947,1.08203,1.06469,-1.13499,-1.15094,0.641525,0.777034,0.135526,0.266598,0.178022,0.162488,-1.82662,-2.05879,-0.449503,-0.345693,0.437803,0.292975,0.0906701,0.386202,1.08595,1.1553
7130,0.411591,0.386319,0.0637548,0.0042048,0.580389,0.505232,0.990945,0.921936,0.155608,0.249983,0.125513,0.104517,0.172791,0.0821567,0.0144876,-0.0301649,0.496956,0.622294,0.116316,0.127735,0.419829,0.399799,-0.608059,-0.61765,-1.12171,-0.984282,-1.51942,-1.39499,-1.18596,-1.20173,1.2442,1.00986,-0.461622,-0.359674,2.1813,2.03742,0.247677,0.549327,0.207873,0.271787
7131,0.226182,0.203365,0.393782,0.291399,0.386253,0.367892,0.742746,0.720478,0.0713012,0.164231,0.867215,0.846444,0.78618,0.693528,0.770879,0.727466,0.561788,0.61658,0.347559,0.360514,1.09946,1.0798,-0.0662678,-0.0843616,-0.013993,0.119362,0.632064,0.76036,0.145119,0.122685,0.54594,0.313301,-0.679444,-0.572117,0.156661,0.0152152,-2.40062,-2.09672,1.20983,1.27783
7132,0.560972,0.540465,0.638016,0.578593,0.303473,0.230552,0.590176,0.51902,0.407893,0.501609,0.439578,0.420723,0.208253,0.116456,0.814099,0.772855,0.132005,0.18749,0.187638,0.200139,-0.871498,-0.898143,-1.02871,-1.04901,-0.617497,-0.481857,-0.100108,0.0310851,0.154195,0.128523,-1.68814,-1.92315,-0.429625,-0.365645,0.0723331,-0.00365304,0.971412,1.27183,-0.0879841,-0.0175298
7133,0.0696646,0.0494093,0.562083,0.500799,0.708735,0.633919,0.0556662,-0.0139788,0.441672,0.596094,0.230149,0.211535,0.055266,-0.0380361,0.387937,0.433055,0.870231,0.924247,0.658621,0.669096,1.09577,1.0737,1.2374,1.21953,0.588948,0.727756,-0.0967514,0.113774,2.58307,2.54983,2.06587,1.83411,-0.258022,-0.159173,0.114671,-0.0225213,1.50763,1.81049,0.144658,0.215502
7134,0.296816,0.275965,0.934345,0.875007,0.307526,0.233806,0.210088,0.229878,0.594797,0.690579,0.882944,0.862733,0.921838,0.830541,0.136183,0.093254,0.545515,0.562967,0.337818,0.367699,-3.79678,-3.81884,-0.911842,-0.935026,-0.628532,-0.493798,0.0652695,0.196462,-0.723586,-0.750839,0.722289,0.456793,0.390291,0.487726,0.788005,0.646216,0.979435,1.33521,-0.945303,-0.867385
7135,0.0268836,0.00673201,0.617562,0.559235,0.27633,0.245588,0.544717,0.473734,0.327586,0.502563,0.632888,0.614484,0.5163,0.454845,0.815267,0.774845,0.14655,0.201686,0.0553288,0.0663019,-0.599335,-0.616171,-0.971666,-0.983722,-1.01063,-0.87501,-0.201973,-0.0869453,0.920956,0.892579,-0.686764,-0.920527,-0.0790053,0.0106045,-1.91391,-2.05039,0.561086,0.859921,-0.016064,0.0606757
7136,0.263447,0.27687,0.0941773,0.0365094,0.328567,0.257369,0.902604,0.832254,0.22013,0.314547,0.179103,0.158656,0.172303,0.0791487,0.740618,0.771038,0.191829,0.245158,0.499432,0.509858,-1.41757,-1.43752,-1.00924,-1.03242,-0.728965,-0.597409,-0.504015,-0.370353,-0.159076,-0.191539,-1.42733,-1.6626,-0.857935,-0.771766,0.168493,0.0348442,-1.32966,-1.02674,-0.564857,-0.492309
7137,0.544523,0.547008,0.287433,0.252832,0.971723,0.90108,0.537251,0.521096,0.621262,0.696089,0.906894,0.884518,0.968052,0.874204,0.742144,0.767231,0.966499,1.02217,0.306452,0.441213,0.606906,0.582744,-0.10572,-0.124974,-0.811689,-0.673163,1.21719,1.34128,0.725905,0.68754,0.681505,0.446291,0.354751,0.444754,0.655796,0.519535,0.875672,1.17157,-0.459001,-0.379179
7138,0.837298,0.817146,0.536896,0.469156,0.785289,0.713603,0.280665,0.209937,0.983262,1.07763,0.9789,0.87183,0.0915464,-0.0020946,0.761639,0.763425,0.732285,0.788331,0.305947,0.372569,0.802112,0.771699,0.0271456,0.0750903,-0.210917,-0.0756959,1.82049,1.94817,0.272712,0.184256,0.157937,-0.00205719,-0.412112,-0.322194,-0.360456,-0.498568,2.03702,2.33278,-2.49281,-2.41346
7139,0.233032,0.211709,0.742575,0.685479,0.884344,0.814926,0.483527,0.334105,0.123519,0.217683,0.880575,0.859142,0.776603,0.680797,0.800041,0.759618,0.104122,0.158421,0.294081,0.303924,0.0144999,-0.0194243,0.294117,0.275155,-0.114103,0.0145152,0.321729,0.445648,-0.280664,-0.319029,-0.223649,-0.450405,0.651122,0.736818,0.268462,0.122955,-0.0559239,0.237151,-1.42316,-1.34746
7140,0.994847,0.97155,0.306889,0.247724,0.498759,0.478096,0.528798,0.458273,0.892439,0.986731,0.211286,0.188694,0.435054,0.34076,0.223148,0.183473,0.0116133,0.0681556,0.616232,0.627659,-0.282716,-0.321815,1.71522,1.69297,0.603109,0.736816,1.30069,1.42701,1.0362,0.990952,0.172205,-0.0518263,1.2448,1.33651,1.12437,0.975103,0.420888,0.71213,0.368789,0.444444
7141,0.749352,0.727889,0.185284,0.193131,0.208497,0.141266,0.917107,0.847043,0.547542,0.643156,0.933207,0.91005,0.942067,0.847181,0.51796,0.448801,0.307537,0.345628,0.302434,0.311891,-0.589655,-0.624206,-0.480802,-0.511701,-0.792638,-0.654396,0.066503,0.184958,0.400119,0.350758,0.929023,0.713737,-0.300362,-0.212522,0.135122,-0.0112214,-0.539928,-0.256249,0.04569,0.02153
7142,0.994211,0.973851,0.184384,0.138538,0.742264,0.674806,0.977123,0.849533,0.825212,0.919753,0.964822,0.941605,0.640879,0.545991,0.754369,0.714128,0.565877,0.623101,0.561076,0.570616,-2.2009,-2.23953,0.793251,0.766877,0.569302,0.709576,-0.298279,-0.17485,-0.606661,-0.656636,0.92988,0.712545,0.622885,0.7087,0.486599,0.334485,1.06964,1.3588,-0.470148,-0.401384
7143,0.779053,0.759974,0.141905,0.0839453,0.824794,0.756735,0.922731,0.852024,0.017352,0.113608,0.461267,0.436232,0.914869,0.817187,0.535828,0.521449,0.0839187,0.143024,0.156456,0.164225,-0.0718778,-0.112212,-0.658088,-0.682177,1.2363,1.42116,-1.43442,-1.30807,-1.61467,-1.66403,-0.674061,-0.889777,-0.683272,-0.604085,-0.979356,-1.12844,-0.486394,-0.19109,-0.568219,-0.499147
7144,0.779484,0.760542,0.885606,0.829065,0.549284,0.44701,0.573632,0.505297,0.121038,0.217407,0.158268,0.132532,0.37131,0.274923,0.368825,0.32877,0.402476,0.463691,0.426428,0.376519,-0.226839,-0.274323,0.290361,0.270578,1.99128,2.13275,0.991249,1.12044,0.807825,0.757274,0.414796,0.197467,-0.182523,-0.0970604,0.000259862,-0.155165,-0.290922,0.0014717,0.637963,0.704527
7145,0.548019,0.527327,0.134513,0.0785342,0.203262,0.137285,0.792195,0.634658,0.986579,1.08365,0.251135,0.290892,0.286125,0.190562,0.348167,0.308426,0.0621939,0.124436,0.539557,0.588813,0.394975,0.344852,1.87797,1.86061,-1.63554,-1.49218,0.811772,0.946944,0.276047,0.225236,-0.730977,-0.942142,-0.183789,-0.0959476,-1.0878,-1.24838,0.390536,0.680574,0.058256,0.123053
7146,0.751721,0.670414,0.577882,0.522324,0.200419,0.23025,0.831243,0.764018,0.997328,1.09659,0.465119,0.449252,0.436299,0.340986,0.642337,0.586922,0.572583,0.572906,0.794344,0.801107,0.700828,0.658078,1.29499,1.28169,-0.486174,-0.34245,-0.872841,-0.743766,-0.47442,-0.522081,0.827413,0.621519,0.872477,0.963065,-0.145288,-0.30288,-0.822297,-0.536286,0.492421,0.550964
7147,0.835609,0.8135,0.141316,0.0845691,0.386781,0.323215,0.604381,0.535848,0.0507008,0.150234,0.631616,0.607612,0.845076,0.747955,0.906253,0.865419,0.959501,1.02138,0.456288,0.464676,0.482271,0.437429,-0.174872,-0.184059,-1.30434,-1.1598,1.17298,1.3039,1.50677,1.45275,-0.93909,-1.14734,0.219825,0.404599,-1.47123,-1.62862,-0.150366,0.142816,-0.909832,-0.851652
7148,0.0114912,-0.00922076,0.935644,0.881389,0.891807,0.826776,0.657785,0.623986,0.675205,0.774421,0.33529,0.308812,0.635927,0.537586,0.0222054,-0.018054,0.794042,0.853678,0.678618,0.68779,1.7207,1.66741,0.801,0.785808,0.206676,0.356312,0.574332,0.698379,0.833791,0.780965,-1.74085,-1.95095,-0.244455,-0.153867,-0.8188,-0.975393,-0.893501,-0.607412,-0.306691,-0.257415
7149,0.38793,0.368855,0.260383,0.205589,0.632802,0.577888,0.780123,0.712125,0.5635,0.75346,0.959368,0.934269,0.803294,0.703143,0.39789,0.270062,0.31379,0.373601,0.0159295,0.0264365,0.992897,0.938669,-0.433213,-0.441961,0.196967,0.341566,0.84284,0.970919,-0.954082,-1.01344,-0.305031,-0.512464,-0.268217,-0.182639,-0.902039,-0.959939,0.509995,0.792311,-0.156338,-0.0997545
7150,0.96754,0.950251,0.352933,0.262145,0.423657,0.329001,0.536182,0.468993,0.634094,0.732499,0.622425,0.596633,0.523366,0.422225,0.686165,0.558177,0.0794088,0.139762,0.593551,0.605771,-1.03984,-1.1018,1.09568,1.08575,0.629203,0.770532,-0.495236,-0.361725,2.41433,2.35957,-2.09886,-2.31376,0.483238,0.570151,-0.863491,-0.944484,-0.0237199,0.176093,0.545713,0.602244
7151,0.459243,0.488253,0.462635,0.318702,0.143893,0.0801128,0.598669,0.532687,0.808871,0.907585,0.671181,0.647369,0.783489,0.683798,0.888588,0.846293,0.21119,0.320382,0.0445714,0.0549747,1.41576,1.35404,0.531036,0.439906,0.55692,0.694778,1.51076,1.63734,1.24126,1.18348,1.74279,1.53291,0.165954,0.24912,-0.772436,-0.92903,-0.726769,-0.440125,-0.413715,-0.356331
7152,0.0453314,0.0262557,0.430052,0.375258,0.411961,0.346227,0.978313,0.911,0.421172,0.594297,0.333202,0.309732,0.460547,0.363231,0.164191,0.121583,0.429474,0.501001,0.337381,0.347914,0.308396,0.240383,-0.168368,-0.20594,1.08451,1.21581,0.118472,0.242379,-2.02573,-2.08913,-1.17217,-1.3827,0.286728,0.455592,0.0726183,-0.0768822,1.13383,1.41363,1.18045,1.23171
7153,0.952201,0.93245,0.277433,0.221762,0.347085,0.281186,0.867521,0.798537,0.184038,0.281009,0.452519,0.42935,0.830236,0.734889,0.591209,0.548198,0.647425,0.681621,0.381728,0.389789,-0.108824,-0.178925,-0.841855,-0.851787,-0.376933,-0.250783,-0.259331,-0.132193,0.563444,0.500104,-0.451495,-0.663514,0.581213,0.662064,0.505286,0.360641,-0.646865,-0.362299,0.019873,0.0317364
7154,0.585236,0.567971,0.392816,0.353017,0.674481,0.608946,0.138761,0.0708953,0.619869,0.636084,0.19132,0.166232,0.323456,0.228571,0.720681,0.679219,0.945108,0.862241,0.735111,0.743671,-1.33902,-1.41286,0.623054,0.613688,1.49853,1.62791,0.378805,0.443195,1.2229,1.16454,-0.854781,-1.06336,-0.109695,-0.0459322,1.95343,1.80815,0.172767,0.455035,-1.22187,-1.16824
7155,0.0164231,-0.00264845,0.538743,0.484273,0.603363,0.457288,0.33641,0.267187,0.894549,0.991159,0.491605,0.514255,0.793242,0.700252,0.0515658,0.012932,0.982508,1.04286,0.265125,0.272657,0.217731,0.147106,-0.0493731,0.00782328,-0.277798,-0.149461,0.891446,1.01858,-2.83955,-2.89885,0.609269,0.406284,-0.832762,-0.753928,-0.594776,-0.732994,-0.82652,-0.544505,0.768777,0.819294
7156,0.645854,0.628034,0.288373,0.233707,0.368971,0.305629,0.0482792,-0.021208,0.216789,0.310973,0.886721,0.862277,0.379684,0.309895,0.162727,0.12364,0.473543,0.533162,0.676528,0.681971,0.858509,0.781786,-0.585758,-0.598042,0.6249,0.757661,1.20189,1.32245,-0.122134,-0.189236,-0.0400454,-0.246049,-0.937617,-0.859469,-0.789086,-0.92265,-0.914763,-0.627664,-0.713458,-0.657799
7157,0.0418203,0.0225964,0.450182,0.397441,0.994707,0.928961,0.580858,0.511415,0.45458,0.6338,0.176218,0.152575,0.0111094,-0.0804612,0.567569,0.530085,0.366993,0.400182,0.876259,0.879265,-0.668576,-0.742,0.464182,0.446314,-0.439963,-0.308193,-1.31442,-1.19389,0.840137,0.76664,0.0880851,-0.215299,-0.201212,-0.122405,0.574984,0.434969,-0.131573,0.0926398,0.770218,0.824194
7158,0.715787,0.697864,0.247219,0.192496,0.270954,0.2038,0.681218,0.495916,0.861279,0.956627,0.926213,0.904463,0.21312,0.121135,0.356168,0.318475,0.209852,0.267202,0.540043,0.542834,0.799698,0.725647,0.54821,0.524492,-0.71829,-0.58193,-0.0511333,0.0636774,-0.0623539,-0.1331,0.0274856,-0.184548,-0.200179,-0.121293,0.126028,-0.0143881,0.562497,0.812944,0.932858,0.981855
7159,0.575327,0.491292,0.686637,0.63187,0.843514,0.776347,0.599371,0.480418,0.492168,0.587857,0.381344,0.446888,0.017627,-0.0738125,0.638809,0.599507,0.981004,1.03871,0.506332,0.508815,-1.28465,-1.36097,0.889858,0.865466,-0.17294,-0.0299701,0.206555,0.320107,0.417458,0.368191,1.85638,1.64119,-1.46767,-1.38423,0.24497,0.101864,1.24615,1.53325,0.296061,0.354933
7160,0.241468,0.284719,0.10238,0.0457085,0.23715,0.171966,0.536594,0.464919,0.775101,0.869954,0.011063,-0.0106868,0.917169,0.827409,0.0262454,-0.0113535,0.788118,0.761236,0.131788,0.132638,-0.474475,-0.544645,0.760041,0.72949,1.39706,1.53322,0.699414,0.819854,0.943312,0.869481,-0.31111,-0.533875,-0.574984,-0.495573,-1.92173,-2.06409,0.252701,0.533707,-0.321068,-0.271988
7161,0.0951609,0.0781467,0.222621,0.104928,0.375806,0.264007,0.0563781,-0.0168914,0.699923,0.794926,0.78791,0.766434,0.258295,0.169961,0.201774,0.166037,0.492578,0.483757,0.664265,0.667533,-1.13639,-1.20954,-1.35564,-1.39177,0.613156,0.747668,0.328668,0.445281,-0.345267,-0.414451,0.17153,-0.0566313,-0.0257006,0.0585767,0.69466,0.550781,0.0757342,0.356135,-0.726981,-0.67402
7162,0.741167,0.724299,0.219103,0.164148,0.480872,0.356048,0.180601,0.107979,0.194445,0.291689,0.118482,0.0959852,0.920283,0.833171,0.846712,0.81032,0.148568,0.206278,0.571292,0.621954,0.887332,0.810727,0.368896,0.336443,0.900533,1.03974,0.378728,0.503667,-0.517502,-0.582276,1.81211,1.58561,-0.037233,0.0445958,0.0380802,-0.100153,-0.712346,-0.439431,-0.450097,-0.39593
7163,0.338409,0.323596,0.521254,0.465582,0.492425,0.448089,0.866402,0.795713,0.997212,1.09363,0.823843,0.802508,0.69886,0.630372,0.7557,0.801841,0.459134,0.517061,0.573411,0.576374,0.674067,0.605273,-0.897899,-0.938554,-0.788424,-0.643292,-0.481017,-0.352035,0.672539,0.603896,0.85955,0.628685,-0.422439,-0.337729,1.15489,1.01276,0.422498,0.712715,0.316814,0.367061
7164,0.202489,0.185788,0.383416,0.326795,0.605315,0.54013,0.706663,0.637983,0.256131,0.352297,0.177906,0.157166,0.515862,0.427572,0.829386,0.793362,0.414023,0.525685,0.761934,0.763567,-1.66528,-1.73115,-0.103827,-0.12563,1.43698,1.58268,-0.977312,-0.849658,-0.275121,-0.344182,-1.0683,-1.29609,-0.104626,-0.0159774,-0.116742,-0.266474,1.58536,1.86486,-1.6738,-1.61979
7165,0.358112,0.28597,0.563789,0.505483,0.472969,0.408603,0.916399,0.848968,0.374994,0.540394,0.120132,0.0945978,0.10584,0.0164541,0.605529,0.57095,0.477663,0.53431,0.188655,0.187872,0.339978,0.27395,0.721675,0.687293,0.347368,0.485968,0.042735,0.177016,1.77139,1.70832,-1.24612,-1.47987,0.692981,0.780943,1.47079,1.32033,0.822013,1.10104,0.664413,0.722572
7166,0.401616,0.386152,0.00574814,-0.0514991,0.106889,0.0439844,0.77998,0.711748,0.63325,0.728492,0.0515469,0.0320293,0.337437,0.247428,0.0581231,0.0254269,0.985127,1.03996,0.330756,0.330397,0.985195,0.924373,1.07491,1.04249,0.119426,0.325828,0.655038,0.78391,-0.191236,-0.25795,1.09925,0.863973,-0.0674008,0.0139946,-0.372033,-0.5174,0.362519,0.645664,-1.368,-1.31171
7167,0.0618501,0.045917,0.507577,0.451313,0.937117,0.872837,0.233145,0.163931,0.127546,0.220294,0.750769,0.73269,0.099457,0.0111122,0.150964,0.141567,0.963124,1.01911,0.0918874,0.0907415,-2.15366,-2.2208,-0.475017,-0.51535,0.0334632,0.165688,-1.54359,-1.4119,1.45361,1.38547,-2.3336,-2.57033,-0.317501,-0.229683,-0.244779,-0.38548,-1.44733,-1.16071,-0.641876,-0.579203
7168,0.122121,0.200185,0.326369,0.331612,0.482196,0.418844,0.371372,0.334273,0.705322,0.80003,0.778576,0.759114,0.0623265,-0.0328046,0.288072,0.257708,0.691264,0.660978,0.0573316,0.0567219,0.775776,0.711131,0.0243581,-0.0211658,0.614169,0.749117,0.223962,0.350223,0.901078,0.836692,0.617891,0.382898,0.742589,0.829329,-0.800919,-0.94243,-1.30672,-1.01341,2.30092,2.36703
7169,0.371289,0.354454,0.268157,0.211911,0.989713,0.927074,0.572678,0.504616,0.131718,0.226692,0.290163,0.268858,0.0116235,-0.0767213,0.799427,0.769702,0.245989,0.302848,0.505559,0.505809,0.606077,0.535397,1.38918,1.3492,0.3291,0.426177,-0.627285,-0.505479,1.21236,1.14607,-0.801807,-1.03508,-0.55796,-0.467625,-0.127331,-0.273693,-0.0490074,0.24143,1.44831,1.51447
7170,0.0825309,0.0650384,0.2928,0.235328,0.455581,0.393259,0.964202,0.898163,0.0292329,0.125402,0.938911,0.915284,0.825062,0.734127,0.914121,0.885458,0.449493,0.577251,0.688787,0.63859,-0.944861,-1.01963,-0.521618,-0.556988,-0.0401629,0.103237,-1.70749,-1.59411,-0.248699,-0.307528,1.13377,0.897048,0.61617,0.700951,-0.0144355,-0.15744,0.287254,0.575871,-0.734722,-0.674578
7171,0.0377723,0.0181465,0.103367,0.0458163,0.467556,0.491572,0.335449,0.270487,0.456932,0.553686,0.0292669,0.00565818,0.853573,0.761939,0.807614,0.778528,0.792708,0.851653,0.768935,0.771372,-2.16241,-2.24053,0.250833,0.212934,1.23511,1.37533,0.10154,0.217111,2.24245,2.18708,2.15364,1.92345,0.791572,0.869111,-0.545235,-0.68369,0.938753,1.22204,-0.062943,0.0741692
7172,0.322589,0.304993,0.58996,0.533515,0.654559,0.589885,0.696289,0.629006,0.129278,0.226523,0.319289,0.310952,0.675977,0.581944,0.184665,0.157285,0.677261,0.734482,0.436866,0.439792,0.0964438,0.00972177,-0.488665,-0.519078,-1.61703,-1.48271,0.632426,0.667229,0.232984,0.174346,-1.67851,-1.9087,1.17041,1.25156,-1.57072,-1.71537,-1.36843,-1.07932,0.756265,0.822916
7173,0.317386,0.300351,0.722668,0.667369,0.412015,0.34543,0.105335,0.0355824,0.683996,0.781017,0.641663,0.616246,0.840741,0.747501,0.967507,0.940159,0.78798,0.844064,0.708746,0.701408,0.804782,0.719017,-0.813384,-0.837279,0.934426,1.06297,1.00241,1.11735,0.321519,0.256532,1.68251,1.45923,-0.0426494,0.0340271,0.167782,0.0290686,-0.124934,0.161626,-0.674587,-0.61126
7174,0.659637,0.6423,0.552738,0.498815,0.611828,0.54589,0.546417,0.440755,0.16055,0.258003,0.36817,0.317358,0.440646,0.347164,0.136583,0.107512,0.15942,0.214154,0.958655,0.963025,-1.88913,-1.9804,0.0618023,-0.000655387,-1.48198,-1.35251,0.361931,0.481342,-0.661862,-0.631455,-0.831532,-1.05386,-0.284479,-0.209651,-0.174368,-0.313397,0.711604,0.995942,0.596306,0.654804
7175,0.262267,0.246149,0.764707,0.711472,0.609728,0.542158,0.913943,0.845928,0.132412,0.228389,0.0451465,0.0184695,0.800783,0.709624,0.162607,0.106468,0.721452,0.773921,0.472076,0.542966,-0.00638212,-0.0986521,0.859863,0.835968,0.177543,0.31389,-0.827331,-0.714247,-1.45981,-1.51944,0.0816879,-0.135362,-1.77513,-1.6933,0.910769,0.76826,-0.733659,-0.443417,0.122963,0.179345
7176,0.665995,0.649093,0.654672,0.602466,0.249672,0.182536,0.838572,0.772782,0.501766,0.596055,0.428067,0.403281,0.886471,0.695106,0.070011,0.105424,0.19902,0.249854,0.119064,0.122907,0.521978,0.496674,0.155024,0.134826,1.85082,1.98029,-0.0986104,0.0188015,-0.85539,-0.918459,0.0246995,-0.197612,-0.734574,-0.652212,0.114739,-0.0349723,-0.124289,0.172159,-2.81172,-2.7524
7177,0.209062,0.193995,0.952923,0.899073,0.986025,0.917878,0.143195,0.075627,0.568399,0.591838,0.0764998,0.0509616,0.772686,0.680587,0.132134,0.104379,0.0202855,0.0722572,0.270671,0.27501,1.06107,1.092,-0.87327,-0.892975,-0.0834133,0.0444026,-0.196017,-0.0769884,-0.467944,-0.530059,1.66891,1.44463,0.90703,0.996182,-0.99867,-1.14448,-0.411233,-0.111868,1.9715,2.03081
7178,0.996918,0.979422,0.890999,0.834939,0.0805198,0.0109674,0.284738,0.215156,0.492031,0.587622,0.542491,0.51856,0.304374,0.214856,0.686551,0.657577,0.0466374,0.0962404,0.845738,0.849093,1.7796,1.68733,0.452709,0.431217,-1.24998,-1.1155,0.270236,0.392217,2.19106,2.12761,0.844029,0.62626,-0.579345,-0.48747,-0.309347,-0.461168,1.68259,1.98879,1.9524,2.00778
7179,0.502778,0.484028,0.0692474,0.0148273,0.899851,0.831749,0.0835762,0.0128447,0.190505,0.285088,0.145651,0.121884,0.400207,0.308797,0.501401,0.385035,0.0943385,0.120224,0.142344,0.146457,0.155243,0.0579333,1.17084,1.15329,0.156316,0.292731,0.982126,1.10843,-0.463161,-0.524575,-0.302468,-0.513349,-1.37233,-1.28659,1.02285,0.863857,0.625441,0.927342,-0.187055,-0.134636
7180,0.215912,0.194613,0.750889,0.694519,0.478843,0.453901,0.329236,0.283882,0.171038,0.266124,0.427535,0.405986,0.245772,0.154305,0.1411,0.112492,0.0912342,0.144207,0.350312,0.353353,-1.76073,-1.85648,0.779709,0.701893,-0.284972,-0.0497602,-1.0407,-0.916722,-0.703247,-0.768486,-0.942316,-1.14889,0.275092,0.361807,-1.62019,-1.77764,0.161463,0.457691,0.944947,0.992722
7181,0.450595,0.430825,0.952592,0.89698,0.14184,0.0760527,0.627326,0.554919,0.579762,0.674083,0.993856,0.972415,0.371406,0.279683,0.874575,0.845039,0.708766,0.760253,0.161773,0.162732,1.12601,1.0278,0.272619,0.250493,-0.527409,-0.392251,-0.19967,-0.0767093,1.70506,1.6359,-0.0130881,-0.214426,-1.32467,-1.23415,-0.817232,-0.971776,0.60934,0.900949,-0.63751,-0.591061
7182,0.262705,0.242162,0.662987,0.60682,0.875015,0.811395,0.016325,-0.058094,0.395003,0.487088,0.024809,0.0028435,0.78795,0.696455,0.601508,0.572506,0.785372,0.838266,0.885879,0.886042,-0.477757,-0.575022,0.199235,0.176028,0.016251,0.144025,0.0512577,0.212477,0.0157415,-0.0488262,-0.738876,-0.940855,-1.34597,-1.24813,-0.772016,-0.932768,-0.719429,-0.430559,-0.792919,-0.750147
7183,0.557658,0.465405,0.140575,0.0840943,0.970994,0.908199,0.736933,0.660519,0.909844,1.00121,0.824395,0.801543,0.774169,0.683792,0.898336,0.86915,0.125492,0.177746,0.277146,0.276089,0.0422474,-0.0609869,1.32847,1.30176,-0.176686,-0.0535677,0.381084,0.501664,-1.0509,-1.11796,1.68375,1.47498,0.874308,0.970567,0.195363,0.0405041,1.70505,1.99251,1.1446,1.19234
7184,0.731362,0.688648,0.386124,0.331101,0.0149631,-0.0469933,0.226131,0.147608,0.78408,0.874872,0.153115,0.131094,0.518437,0.41922,0.679044,0.669379,0.649544,0.702964,0.392127,0.393257,0.347644,0.238466,-0.684988,-0.711395,0.0380866,0.161137,0.276043,0.389944,-0.86013,-0.935839,0.0623367,-0.14155,-0.383773,-0.292372,2.24832,2.09638,0.81994,1.10458,0.0666452,0.109455
7185,0.932434,0.911891,0.833467,0.779347,0.561,0.441029,0.839024,0.760483,0.126038,0.215319,0.755491,0.732563,0.244911,0.154649,0.497111,0.469609,0.899397,0.954707,0.7082,0.711477,-0.292411,-0.443251,0.836301,0.816319,-1.45144,-1.33538,-0.661988,-0.543575,-0.686682,-0.753721,-0.321519,-0.469956,0.504365,0.596287,-1.57803,-1.72576,0.497003,0.773621,0.0846301,0.131926
7186,0.962481,0.942322,0.357016,0.30191,0.98995,0.929052,0.438178,0.35887,0.667041,0.754206,0.581103,0.559968,0.307998,0.218163,0.492681,0.46481,0.591704,0.645648,0.820225,0.822304,-1.02142,-1.12497,0.0335331,0.00774297,0.812901,0.924606,-0.468326,-0.439266,-1.09974,-1.16608,-0.589093,-0.798361,-2.4829,-2.39252,-0.303703,-0.449633,1.50834,1.7801,0.502873,0.543988
7187,0.325909,0.305959,0.93034,0.873293,0.884097,0.750379,0.92171,0.841472,0.896703,0.984793,0.800869,0.778683,0.607584,0.519893,0.923984,0.896459,0.736136,0.790092,0.606951,0.607004,-0.121192,-0.229852,-0.0906297,-0.087466,0.798087,0.90986,-0.447112,-0.334957,0.728162,0.665417,0.197766,-0.0186037,-0.0708109,0.0219298,-0.118932,-0.273242,0.799345,1.14873,-0.443477,-0.399977
7188,0.714189,0.694462,0.0814099,0.0224148,0.634206,0.571707,0.11405,0.0354549,0.248901,0.335599,0.467461,0.4452,0.703992,0.5664,0.899664,0.870711,0.154201,0.21067,0.836518,0.834785,-0.0404207,-0.148722,-0.154147,-0.182675,0.497883,0.548063,0.555336,0.662253,-2.09145,-2.15443,-1.41112,-1.63513,-1.10462,-1.00973,0.874728,0.715931,0.252263,0.517356,-0.246952,-0.197293
7189,0.0414185,0.0226836,0.882669,0.823967,0.931361,0.867989,0.264373,0.18573,0.538145,0.62287,0.835606,0.814758,0.702618,0.612907,0.449265,0.471324,0.558404,0.616629,0.848146,0.845502,-0.368244,-0.474387,-0.75075,-0.777781,0.068331,0.186266,-0.376564,-0.271266,-0.0415996,-0.101927,-0.109575,-0.416951,-0.989356,-0.927422,0.901146,0.658731,-1.07788,-0.814152,0.230211,0.275624
7190,0.016782,-0.00259948,0.491663,0.43437,0.346734,0.284285,0.111484,0.0336082,0.532943,0.70302,0.977987,0.959743,0.436461,0.346947,0.102062,0.0719371,0.613062,0.670785,0.112776,0.107811,0.283162,0.176037,-0.847797,-0.868686,1.48793,1.6106,-1.00816,-0.907272,-0.600528,-0.665819,1.02525,0.80123,-0.938873,-0.845109,0.756538,0.60153,0.0925259,0.286268,-0.270161,-0.230865
7191,0.579906,0.558653,0.466282,0.409175,0.63017,0.56557,0.610356,0.531515,0.700207,0.783169,0.0427597,0.0245159,0.815857,0.728402,0.412538,0.467769,0.884881,0.94176,0.564639,0.562271,-0.4432,-0.552704,-0.164922,-0.190327,1.54654,1.67298,-1.29299,-1.18975,-0.103616,-0.170276,-0.578346,-0.801092,0.307758,0.401836,0.52293,0.309918,1.12745,1.38669,-0.233225,-0.157347
7192,0.758851,0.739178,0.882879,0.824284,0.673744,0.606978,0.308148,0.229084,0.256161,0.339734,0.260361,0.302312,0.0596369,-0.0262751,0.893352,0.863601,0.680038,0.738954,0.661458,0.678638,-0.496583,-0.606877,0.291639,0.271495,-0.303504,-0.184066,0.385763,0.4933,0.68425,0.617913,-0.234317,-0.565046,-1.31026,-1.22141,0.165456,0.0183052,1.0031,1.25684,-0.0221878,-0.0838286
7193,0.479282,0.460182,0.68242,0.694459,0.0407702,-0.0271637,0.476848,0.399218,0.57675,0.662151,0.599569,0.580109,0.50491,0.419871,0.557217,0.526864,0.250653,0.309864,0.79913,0.795006,-1.253,-1.36548,-0.763474,-0.786339,1.4421,1.56855,-0.378969,-0.233094,-0.111495,-0.175243,-0.0299956,-0.329,1.32028,1.41478,0.125785,-0.0219433,-0.721524,-0.46797,-0.0502032,-0.0103103
7194,0.665636,0.646212,0.54126,0.564634,0.556609,0.48685,0.335982,0.257683,0.116647,0.20342,0.190212,0.169104,0.58084,0.494007,0.680225,0.648163,0.232144,0.306553,0.536298,0.510443,1.08136,0.963566,-0.332422,-0.355771,0.442167,0.564876,-1.06075,-0.959488,-1.85037,-1.92295,0.129793,-0.0929535,-1.05533,-0.955273,0.611988,0.462747,-0.780582,-0.591942,-2.31373,-2.27846
7195,0.203251,0.185158,0.493403,0.434809,0.482688,0.41193,0.682837,0.568609,0.274269,0.362594,0.701783,0.681916,0.152833,0.0646237,0.0750263,0.042165,0.245014,0.303242,0.2292,0.225881,1.16802,1.0447,2.29991,2.28362,1.76927,1.89795,0.131689,0.236815,1.38001,1.29836,1.60754,1.39098,1.45176,1.54481,-0.579327,-0.722473,-0.965436,-0.715914,0.950715,0.983721
7196,0.93868,0.922913,0.845207,0.785312,0.867747,0.798938,0.957557,0.879535,0.671464,0.699643,0.581281,0.564531,0.718082,0.631133,0.492537,0.458733,0.922504,0.981096,0.230912,0.226769,-1.79076,-1.90763,-0.21743,-0.241159,0.303144,0.43136,-0.41017,-0.30636,2.0291,1.94617,1.28383,1.06817,0.421851,0.513147,-0.664395,-0.806422,0.725319,0.979805,0.773214,0.809739
7197,0.506505,0.492151,0.820774,0.760117,0.691111,0.62257,0.0885735,0.00947163,0.949753,1.03669,0.810921,0.793215,0.857328,0.771351,0.412957,0.292456,0.143091,0.201259,0.471489,0.465516,-0.210765,-0.331556,1.93651,1.91582,1.37445,1.50659,0.602962,0.706136,0.210851,0.121865,-0.971526,-1.18707,1.68468,1.77431,1.562,1.41497,1.1267,1.37562,-0.159381,-0.119894
7198,0.529724,0.52818,0.301221,0.242475,0.979199,0.909086,0.0695048,0.0101435,0.496563,0.583302,0.770834,0.751248,0.596791,0.510649,0.158625,0.126178,0.772053,0.832179,0.064124,0.0591252,-0.921309,-1.04382,0.291789,0.26341,1.00779,1.13979,2.1424,2.2457,0.915595,0.830714,-0.890283,-1.11144,0.272181,0.410194,0.29846,0.151147,1.51486,1.77145,2.46526,2.51164
7199,0.648795,0.564209,0.922356,0.862959,0.705816,0.634668,0.112635,0.0108153,0.349401,0.436893,0.349945,0.329934,0.957611,0.87311,0.55324,0.522816,0.152114,0.211748,0.181414,0.176293,-1.11345,-1.2337,-0.16305,-0.193366,-0.288603,-0.15716,-1.17261,-1.06549,0.599143,0.50951,0.894166,0.668564,-1.04356,-0.953926,-0.572372,-0.712312,1.69701,1.94924,0.837164,0.879262
7200,0.61426,0.600238,0.0281132,-0.031095,0.712956,0.578421,0.090589,0.0114871,0.875104,0.960412,0.676289,0.655071,0.0792931,-0.00318898,0.314577,0.285001,0.568666,0.634492,0.0643128,0.137662,-0.383851,-0.508036,0.928219,0.901519,0.279741,0.409897,1.23816,1.34651,-1.40856,-1.50323,-1.44389,-1.6659,-0.102399,-0.0170589,-0.71548,-0.856772,-0.691403,-0.434995,-1.24245,-1.2004
7201,0.650622,0.636267,0.976879,0.91777,0.595439,0.522174,0.816413,0.739455,0.441783,0.526476,0.190767,0.170353,0.0883857,0.00440257,0.389506,0.361417,0.997021,1.05724,0.104637,0.0990302,-0.399815,-0.517316,1.25399,1.22635,-0.981746,-0.855084,-1.76281,-1.65187,-0.467209,-0.561996,-1.02184,-1.17699,0.54251,0.62984,0.912329,0.776806,1.22826,1.4799,-2.06645,-2.02216
7202,0.36409,0.421943,0.345718,0.287442,0.90703,0.833461,0.132634,0.0574459,0.802277,0.88982,0.271401,0.26198,0.564169,0.424684,0.142354,0.11342,0.667083,0.727941,0.256032,0.236813,0.956927,0.84013,0.0991223,0.075461,0.0244968,0.144409,-0.301462,-0.189394,-0.749883,-0.850406,-0.58717,-0.688092,-1.04636,-0.966118,-0.453494,-0.5934,-1.13964,-0.887082,-0.486377,-0.449113
7203,0.219804,0.207618,0.53943,0.427839,0.0809811,0.00890004,0.378405,0.399229,0.449673,0.536303,0.373134,0.353607,0.927929,0.844965,0.379223,0.348381,0.0938071,0.153355,0.357652,0.374596,0.638571,0.528598,0.703636,0.677308,0.0414628,0.160241,-1.42356,-1.30721,-0.292336,-0.386288,0.0228148,-0.199189,-0.348108,-0.23347,-1.4031,-1.54966,0.626912,0.885865,-0.0680378,-0.0370513
7204,0.296752,0.283263,0.627705,0.568236,0.101248,0.0301763,0.815846,0.741013,0.551823,0.689449,0.0368606,0.0159709,0.661151,0.579004,0.325948,0.297091,0.614321,0.673797,0.520102,0.512379,-0.58052,-0.692296,-1.47119,-1.49328,-1.15654,-1.04534,-0.798605,-0.685165,0.812899,0.721832,-0.0783206,-0.306571,0.423887,0.499177,0.324439,0.177099,-0.589527,-0.330995,-0.384068,-0.347779
7205,0.0439144,0.0303459,0.998815,0.937948,0.840877,0.771048,0.00641859,-0.0706404,0.75697,0.842596,0.2288,0.209715,0.887453,0.804852,0.911323,0.880504,0.223367,0.283749,0.0618411,0.0561633,-0.0877668,-0.195683,0.948294,0.924819,0.297989,0.409898,1.46726,1.57455,-3.08819,-3.18149,0.284757,0.0588232,-0.400932,-0.326867,-0.44724,-0.595347,0.370515,0.626805,2.17433,2.21349
7206,0.0366423,0.0211791,0.354545,0.292242,0.892858,0.823612,0.484972,0.374915,0.247679,0.334397,0.0206782,0.000526631,0.140772,0.0569175,0.87533,0.844389,0.970485,1.03106,0.572783,0.564665,-0.49263,-0.599397,-0.407933,-0.429708,-0.94041,-0.826393,-0.143395,-0.0378852,-0.654122,-0.742705,-0.565723,-0.790567,-0.891274,-0.8184,-0.503837,-0.648434,0.175722,0.433907,0.95871,0.993789
7207,0.02371,0.0120123,0.963208,0.902575,0.58468,0.514487,0.898957,0.82047,0.627929,0.712062,0.0694596,0.133153,0.561387,0.478688,0.591886,0.482887,0.178114,0.241251,0.311098,0.303559,0.317282,0.202714,0.0661549,0.046532,-0.203737,-0.0883933,-0.212586,-0.104192,1.08207,0.995603,-2.21917,-2.43887,-0.124945,-0.0513025,0.197218,0.0506523,-1.25031,-0.989217,0.0158816,0.0498243
7208,0.801284,0.787106,0.906856,0.876516,0.81902,0.749857,0.165223,0.0874471,0.219832,0.302873,0.284804,0.265779,0.537949,0.529582,0.151002,0.121385,0.398318,0.477599,0.709643,0.703018,-0.330156,-0.404203,-0.82554,-0.840434,-0.121014,0.0157301,0.646437,0.751894,0.349465,0.262794,-0.514747,-0.735953,-1.14854,-1.06798,-1.54998,-1.69113,0.0740646,0.327638,0.427331,0.461886
7209,0.849378,0.837354,0.909459,0.850456,0.353717,0.285428,0.236423,0.246003,0.75814,0.841759,0.0206568,0.00266,0.621445,0.580476,0.0791419,0.0504162,0.649173,0.713947,0.424461,0.450344,-0.896146,-1.01112,-0.397774,-0.409866,-0.00151192,0.119853,0.314302,0.424213,0.550921,0.466544,-1.35594,-1.57032,-0.109177,-0.0268853,1.44828,1.30613,0.158339,0.415648,0.0947983,0.10269
7210,0.330777,0.316713,0.0777672,0.0205878,0.659117,0.592459,0.481919,0.40456,0.362279,0.448193,0.641891,0.623418,0.729491,0.63137,0.380218,0.338532,0.279463,0.34459,0.20272,0.197671,-1.08334,-1.24416,-0.23319,-0.238598,0.568498,0.686911,-0.798572,-0.6936,0.249774,0.161847,-0.187135,-0.40543,-0.170437,-0.08668,1.78908,1.65184,-0.481407,-0.223647,-0.285179,-0.256507
7211,0.142047,0.12805,0.279664,0.223049,0.471768,0.404982,0.0252249,-0.0524451,0.988818,1.07238,0.251352,0.327844,0.756144,0.682264,0.775563,0.626648,0.702204,0.765655,0.838644,0.831575,-1.36504,-1.47719,-0.681354,-0.679629,1.97455,2.09514,-0.926764,-0.819875,1.44121,1.34802,0.546519,0.32761,-0.775765,-0.684156,0.20734,0.0679879,-0.456719,-0.197011,0.323279,0.354221
7212,0.999078,0.984836,0.773866,0.716097,0.69966,0.634633,0.299093,0.222809,0.711217,0.865158,0.0490248,0.0322699,0.862601,0.733159,0.941454,0.914763,0.0687774,0.129944,0.766216,0.765618,-0.243156,-0.355428,0.118215,0.121699,-0.765111,-0.642158,-1.27483,-1.1631,-0.261966,-0.351908,-1.79226,-2.00685,-0.000471457,0.0995465,-0.559197,-0.704458,0.606736,0.871469,-0.00421086,0.0286315
7213,0.295374,0.281471,0.191066,0.135063,0.48785,0.432673,0.232795,0.228369,0.576532,0.657936,0.0441397,0.0291844,0.893734,0.784053,0.0635528,0.0377076,0.932212,0.991579,0.706844,0.69966,-2.13731,-2.25523,-1.09573,-1.09034,-0.00385955,0.126532,0.559359,0.664256,0.36796,0.280978,-1.26727,-1.4847,-0.481972,-0.377575,-0.236804,-0.387254,0.965,1.23709,1.30349,1.34077
7214,0.484492,0.471851,0.293151,0.239067,0.293452,0.230713,0.312985,0.233928,0.838233,0.919002,0.280057,0.267506,0.836631,0.834947,0.226742,0.199173,0.148216,0.206703,0.391231,0.383892,-0.384039,-0.497057,-1.06624,-1.05755,0.136888,0.264396,-0.805341,-0.698554,-0.369487,-0.451831,1.70015,1.48299,-0.00285524,0.0990354,-0.47122,-0.623108,0.659279,0.936347,-0.140929,-0.107638
7215,0.23452,0.223126,0.0428867,-0.0114994,0.807975,0.744727,0.501404,0.336623,0.142373,0.223159,0.30354,0.289441,0.96854,0.885841,0.135224,0.108394,0.991899,1.05197,0.760725,0.753832,2.12727,2.02339,-0.0596821,-0.057881,1.35378,1.47401,0.311811,0.41861,-2.48882,-2.56988,1.48847,1.26735,-1.21743,-1.11849,0.271604,0.12097,-0.949893,-0.675444,0.510853,0.549415
7216,0.508058,0.494267,0.242815,0.228306,0.750318,0.68447,0.520044,0.439318,0.539054,0.620881,0.0139972,0.000529304,0.120448,0.0357259,0.638421,0.609627,0.355273,0.416258,0.0677054,0.0613298,0.917332,0.819394,-0.749198,-0.744123,-0.945522,-0.831784,-0.0143551,0.0909291,-1.02148,-1.10888,-0.710336,-0.938512,-0.423891,-0.321574,-1.00864,-1.15827,0.41255,0.692638,-2.35028,-2.30643
7217,0.184031,0.168867,0.520957,0.468112,0.143879,0.0800894,0.0690848,-0.012549,0.196706,0.277306,0.753988,0.742456,0.141409,0.0582161,0.781643,0.703298,0.123986,0.18242,0.365453,0.358759,-0.584678,-0.69012,0.832534,0.831052,-1.90716,-1.7874,0.100584,0.209662,0.0667877,-0.0151398,0.593817,0.362141,-1.57988,-1.4753,-0.973521,-1.11926,0.0745392,0.361683,1.255,1.30601
7218,0.480943,0.466178,0.380405,0.315528,0.742436,0.677797,0.572994,0.489786,0.296266,0.376022,0.141549,0.132974,0.399961,0.314816,0.827163,0.79697,0.238861,0.232644,0.0407271,0.0324392,0.303277,0.204995,-0.419043,-0.427622,-1.12785,-1.00469,-0.350911,-0.241677,0.241925,0.0826957,0.0648701,-0.162863,0.703917,0.808463,1.28437,1.13459,0.811742,1.10212,-0.743396,-0.696557
7219,0.39313,0.479861,0.281086,0.162944,0.172523,0.109064,0.769968,0.616165,0.639483,0.71862,0.559509,0.55233,0.355663,0.271452,0.694422,0.665182,0.226304,0.282868,0.317462,0.305935,-2.04743,-2.14744,0.526611,0.525133,1.25527,1.3845,2.21612,2.32228,0.262459,0.180531,-1.09651,-1.31784,0.957659,1.06804,1.00885,0.853631,-0.215716,0.0725144,-0.290397,-0.239124
7220,0.43297,0.493543,0.0645222,0.0103596,0.782503,0.716927,0.82404,0.742544,0.0911685,0.170113,0.369036,0.363851,0.606955,0.523616,0.20667,0.179014,0.941571,0.999323,0.630666,0.579432,0.555424,0.456773,0.123997,0.129358,-0.146842,-0.0214574,0.361867,0.476006,-1.41847,-1.50419,-1.10964,-1.28709,0.516404,0.621991,-0.323651,-0.472108,-0.950326,-0.55886,-1.16791,-1.12263
7221,0.524311,0.507226,0.519555,0.431256,0.363918,0.297261,0.674803,0.678459,0.8299,0.908629,0.436917,0.430292,0.329794,0.329033,0.915107,0.886383,0.854808,0.913743,0.861216,0.852928,0.345347,0.251319,-0.0515446,-0.0520084,0.3583,0.482066,0.665014,0.779868,-0.458382,-0.548316,-1.04223,-1.25634,-0.245067,-0.144958,-0.462339,-0.616569,-1.48537,-1.19023,1.49916,1.54498
7222,0.836606,0.818864,0.904298,0.852152,0.162084,0.187464,0.696295,0.614374,0.0188647,0.0985151,0.174908,0.167173,0.217061,0.134451,0.445691,0.41536,0.446001,0.504828,0.517364,0.507002,-1.00134,-1.13492,0.708618,0.702497,-0.148762,-0.0215669,0.278875,0.390196,-0.0616188,-0.144763,-0.114853,-0.321877,0.386545,0.485876,-2.37626,-2.53017,0.946132,1.24602,2.07269,2.11096
7223,0.68993,0.670722,0.443886,0.393935,0.101081,0.0776677,0.223771,0.142197,0.808097,0.886356,0.182721,0.17426,0.82816,0.745822,0.992134,0.963174,0.679807,0.776221,0.813004,0.799942,-2.42714,-2.52116,-0.094675,-0.106079,-0.0597146,0.0686442,0.580479,0.694058,-0.169605,-0.251411,-0.982147,-1.27098,-2.85398,-2.75631,1.32446,1.1691,-1.13836,-0.831386,0.0118862,0.122965
7224,0.236743,0.215624,0.710695,0.659902,0.0367892,-0.0321287,0.151131,0.0690512,0.496689,0.585435,0.617206,0.608385,0.880588,0.799096,0.697982,0.651399,0.990092,1.04761,0.740111,0.662062,-0.160744,-0.254399,-0.690133,-0.701185,-0.554901,-0.420252,0.17184,0.288894,0.120651,0.0440508,-2.01155,-2.22008,0.411354,0.517607,0.352317,0.159357,0.0251731,0.329828,-1.90329,-1.86503
7225,0.780244,0.757879,0.485793,0.363844,0.249736,0.183197,0.726919,0.646931,0.205196,0.284514,0.57764,0.56971,0.442777,0.363015,0.276266,0.339624,0.605051,0.734402,0.537772,0.524183,-2.34494,-2.43507,0.880986,0.87399,0.695687,0.836593,0.826678,0.943893,0.166322,0.0951965,-0.0752844,-0.287948,-0.316766,-0.202561,-0.697147,-0.850385,-0.665646,-0.355318,-0.0856441,-0.0433078
7226,0.597773,0.574925,0.120242,0.0677861,0.158402,0.092231,0.51297,0.46552,0.990089,1.07236,0.700691,0.531035,0.612282,0.533727,0.0568085,0.0278493,0.337007,0.42119,0.813126,0.797352,-0.231432,-0.322632,-1.70422,-1.71656,0.588254,0.646059,1.07518,1.186,-0.723024,-0.790112,-0.231399,-0.44356,0.996455,1.10899,0.252501,0.0951182,1.15091,1.46677,-0.776283,-0.728732
7227,0.776616,0.75545,0.72715,0.673227,0.903889,0.838391,0.431742,0.284109,0.478235,0.608612,0.543848,0.492361,0.225627,0.147966,0.870432,0.841758,0.0504552,0.107978,0.654681,0.636976,1.11989,1.03481,0.61955,0.601889,0.316193,0.455525,0.554372,0.748289,-0.599115,-0.663587,0.565919,0.348602,0.301894,0.418472,-0.74771,-0.906627,0.0254875,0.378527,-0.0950523,-0.0426703
7228,0.278876,0.260056,0.099671,0.0476754,0.783008,0.741194,0.182189,0.102697,0.0607323,0.144869,0.490186,0.453686,0.473368,0.389187,0.62725,0.663428,0.718717,0.775664,0.0139905,-0.00368637,1.60107,1.51899,-0.938749,-0.955949,2.73544,2.87901,0.204268,0.310582,0.282651,0.215492,-0.859352,-1.06938,0.790334,0.91045,1.2297,1.06976,-1.02521,-0.709714,1.1719,1.22339
7229,0.346839,0.310175,0.70604,0.653117,0.70993,0.643997,0.311808,0.305561,0.760031,0.845939,0.423832,0.415011,0.707919,0.630409,0.513076,0.485098,0.988193,1.04664,0.235902,0.219427,-0.247473,-0.334948,0.841404,0.820083,1.66335,1.81316,-2.58594,-2.48477,0.147312,0.158116,0.059661,-0.150879,0.457466,0.573512,-1.86468,-2.02067,1.29695,1.61762,0.660291,0.764707
7230,0.289503,0.360294,0.0100803,-0.0421139,0.281974,0.214086,0.588093,0.508426,0.782829,0.869447,0.0669181,0.0574456,0.75604,0.678903,0.956566,0.927335,0.308306,0.366698,0.0387672,0.0238573,1.90993,1.82194,-0.971321,-0.990375,0.20337,0.346564,-0.856862,-0.755772,0.174838,0.10074,-0.0251826,-0.228615,1.47172,1.58686,1.17057,1.01474,-1.84039,-1.51622,0.254788,0.306019
7231,0.430211,0.410413,0.645894,0.593179,0.759082,0.692269,0.446594,0.366891,0.340894,0.426012,0.5379,0.46769,0.232799,0.156587,0.807287,0.77609,0.992579,1.04898,0.887757,0.872317,0.367917,0.281172,0.0851543,0.072776,0.0261613,0.140977,-0.126849,-0.0227235,0.650569,0.578824,-1.68724,-1.88901,0.0715821,0.182293,1.84487,1.68347,-0.728842,-0.402194,0.923304,0.978441
7232,0.625997,0.587346,0.414285,0.272982,0.00448328,-0.0628676,0.829722,0.749995,0.334202,0.418734,0.886266,0.877935,0.0535097,-0.0234072,0.455655,0.423968,0.918323,0.974032,0.684985,0.671577,-0.675358,-0.754978,0.810571,0.794852,-0.203866,-0.0646113,0.207173,0.310282,1.42283,1.35107,0.00176718,-0.201335,-0.0766346,0.0321959,0.483785,0.327398,1.14273,1.46692,0.840584,0.893989
7233,0.784955,0.764279,0.00460821,-0.0472149,0.781324,0.715346,0.114637,0.0371034,0.0542898,0.136314,0.242688,0.232593,0.136307,0.0604182,0.346334,0.31239,0.304783,0.358228,0.108064,0.0958829,0.127933,0.0834228,-0.750332,-0.762986,1.30969,1.4515,-0.287014,-0.270431,-0.462187,-0.53436,0.290431,0.0879043,-1.4325,-1.32615,0.977334,0.827301,-0.755551,-0.43666,0.292235,0.341005
7234,0.475305,0.455233,0.396816,0.342767,0.228728,0.161205,0.00618765,-0.0197249,0.578188,0.659834,0.728255,0.719737,0.851273,0.773593,0.0155943,-0.0189626,0.301733,0.352584,0.180944,0.167911,0.993701,0.921824,-0.598233,-0.608422,-0.155018,-0.0150891,-0.950688,-0.851143,-0.573598,-0.641008,-0.997468,-1.20584,0.079428,0.182004,-0.425795,-0.572795,0.0529532,0.364373,0.470879,0.513452
7235,0.645083,0.697752,0.179371,0.123388,0.371599,0.303158,0.00200076,-0.0765533,0.11643,0.196115,0.463815,0.456618,0.96276,0.883605,0.0597615,0.0264268,0.819112,0.867669,0.976993,0.966044,-0.14008,-0.200596,1.07463,1.05996,-0.89703,-0.753046,-0.951093,-0.85418,-1.22164,-1.29536,0.319084,0.110292,0.784194,0.889046,0.328735,0.186121,-1.63491,-1.32861,-0.800885,-0.752238
7236,0.958837,0.940272,0.836903,0.782722,0.281935,0.212192,0.208234,0.167303,0.937799,1.01798,0.616482,0.611409,0.090198,0.0118687,0.36402,0.385963,0.309618,0.35797,0.914248,0.85437,-1.24762,-1.32302,0.343762,0.327949,0.665799,0.810142,-0.418841,-0.322684,0.489217,0.410043,-1.43185,-1.64447,-0.0535066,0.0455509,-1.6823,-1.82113,-0.523212,-0.214582,0.14866,0.192686
7237,0.689556,0.671039,0.5025,0.447648,0.614595,0.544195,0.487621,0.41116,0.463291,0.544973,0.0439285,0.0370447,0.744919,0.664628,0.776777,0.7455,0.550637,0.599464,0.755315,0.742697,-0.090187,-0.168536,0.34476,0.330253,-0.148634,-0.00720917,-0.123581,-0.0342655,-0.38042,-0.461507,-0.461512,-0.680952,1.09153,1.18344,-1.62001,-1.75187,-1.85712,-1.54609,0.651559,0.696916
7238,0.121093,0.105076,0.698182,0.629868,0.248006,0.179576,0.288304,0.213749,0.647394,0.73003,0.584013,0.578819,0.293662,0.213788,0.574951,0.543431,0.514824,0.564393,0.12933,0.117141,-1.59548,-1.67805,-1.51465,-1.5296,0.11673,0.255256,0.75968,0.853594,-0.12134,-0.263389,-1.12063,-1.34701,0.0185819,0.104664,-0.72945,-0.855097,-0.00916917,0.307665,0.262324,0.311877
7239,0.195705,0.135322,0.869387,0.812087,0.12114,0.053348,0.711579,0.638011,0.478712,0.563409,0.167391,0.162914,0.35634,0.277302,0.131415,0.101853,0.198141,0.24944,0.0443339,0.0339407,-1.23683,-1.31861,2.04374,2.02909,0.866477,1.00843,0.151545,0.248075,0.0187961,-0.0652703,0.0266288,-0.199965,0.984454,1.07201,-0.428107,-0.555809,0.0909566,0.410304,-0.831717,-0.785683
7240,0.182421,0.165569,0.299813,0.240716,0.452185,0.385351,0.0191562,-0.0541065,0.0105152,0.0951049,0.551609,0.547725,0.836762,0.759551,0.447827,0.340163,0.942475,0.99217,0.883152,0.872715,-0.311681,-0.39391,0.0359542,0.0159396,-1.04279,-0.894128,0.109027,0.150925,-0.323136,-0.402718,-1.41937,-1.6482,1.04819,1.08656,-0.346631,-0.471219,-0.0168919,0.37681,0.0673982,0.112873
7241,0.55967,0.543644,0.0685542,0.010819,0.320069,0.304035,0.228896,0.0629514,0.209351,0.294657,0.628804,0.62369,0.29187,0.212696,0.607408,0.578473,0.657456,0.708888,0.257891,0.247159,-0.607762,-0.690874,-0.476194,-0.500866,-1.47046,-1.32099,-0.0410845,0.0537745,-1.55355,-1.6266,-1.24403,-1.46509,1.01796,1.1011,0.368746,0.216237,0.023203,0.343317,0.304654,0.345904
7242,0.706465,0.708681,0.627957,0.572792,0.288061,0.222719,0.253515,0.180009,0.839982,0.923823,0.492991,0.485487,0.178671,0.0982828,0.340307,0.311417,0.947571,1.00019,0.259002,0.283612,-0.395694,-0.471986,-0.00501951,-0.0632778,-0.867957,-0.723524,-0.766319,-0.6755,0.584749,0.50897,-2.83553,-3.051,0.689882,0.78007,1.02828,0.903693,1.18288,1.50453,-1.10328,-1.05671
7243,0.89163,0.873718,0.0577533,0.00142017,0.596247,0.571962,0.613082,0.536962,0.0407607,0.123121,0.0893237,0.0839228,0.804055,0.723754,0.816707,0.787943,0.269798,0.320246,0.35288,0.320065,-1.22699,-1.30913,0.402582,0.37431,-1.80838,-1.66325,-1.02799,-0.942193,-2.05613,-2.12895,-1.10927,-1.31776,-1.33825,-1.25533,2.49089,2.36784,0.349781,0.678484,0.786768,0.825567
7244,0.32805,0.312003,0.413382,0.356945,0.988227,0.921204,0.965289,0.893915,0.212664,0.293648,0.31623,0.321615,0.863286,0.782728,0.206932,0.177082,0.353956,0.40296,0.369032,0.356518,0.208476,0.125784,-1.11223,-1.13606,1.02337,1.17201,-0.298003,-0.209144,-0.394073,-0.469569,-0.959689,-1.16723,0.255917,0.346946,-2.63684,-2.75989,0.481083,0.811509,0.809156,0.848039
7245,0.368851,0.365814,0.143215,0.150266,0.915408,0.846284,0.822984,0.752381,0.140245,0.223008,0.587808,0.559307,0.315803,0.235873,0.592702,0.563694,0.238096,0.285789,0.113935,0.101715,-0.435344,-0.525102,-0.810345,-0.84046,-0.236532,-0.118071,-0.716328,-0.630068,1.01318,0.930961,-0.0925782,-0.295441,-0.0090753,0.0885266,0.636843,0.512731,1.18913,1.52125,1.64361,1.68534
7246,0.43737,0.419625,0.00250284,-0.056413,0.444138,0.376552,0.141746,0.0703717,0.815959,0.899691,0.800355,0.796999,0.194027,0.116109,0.579804,0.63989,0.42248,0.408853,0.138785,0.128007,0.0615355,0.0692501,-0.990201,-1.02183,-1.5568,-1.40815,0.979143,1.06767,-1.45714,-1.54359,0.364307,0.166128,-0.647752,-0.455253,0.116569,-0.0135183,0.824242,1.15942,-0.2767,-0.239318
7247,0.929477,0.911152,0.0929386,0.0328051,0.562332,0.578632,0.999756,0.927375,0.667916,0.753282,0.399564,0.395434,0.955383,0.875957,0.745197,0.716087,0.486713,0.531917,0.511822,0.409615,0.746741,0.663602,0.517756,0.489009,1.14647,1.29573,0.297422,0.384844,0.0968183,0.0092368,-1.06545,-1.26629,-1.08863,-0.999032,0.2223,0.0885294,1.13443,1.46232,-0.107456,-0.0668708
7248,0.905075,0.885869,0.480963,0.422787,0.847354,0.780711,0.970347,0.927369,0.223728,0.309846,0.934971,0.932757,0.548438,0.469869,0.323811,0.363119,0.154165,0.198082,0.695005,0.691223,0.77974,0.697527,-0.0882517,-0.120648,0.46275,0.617231,-0.176137,-0.0831742,2.02198,1.93396,-1.35142,-1.5582,-2.17505,-2.09143,-0.0334064,-0.16296,-2.4189,-2.09286,-1.45738,-1.42397
7249,0.629321,0.542665,0.148431,0.0877129,0.136352,0.0713902,0.982062,0.927362,0.82058,0.904633,0.896568,0.895429,0.999976,0.921119,0.0387265,0.0101511,0.500943,0.544457,0.981545,0.972831,-1.12363,-1.20228,0.90672,0.879021,-1.40149,-1.25389,-0.965567,-0.873977,0.0728366,-0.0167044,-0.579828,-0.792632,1.95406,2.04265,1.69124,1.5638,-0.303049,0.0250665,1.59354,1.63008
7250,0.220456,0.199462,0.153412,0.0920867,0.665903,0.599925,0.898566,0.927355,0.92332,1.00843,0.137593,0.135876,0.485749,0.405085,0.722779,0.695937,0.0340188,0.079573,0.209671,0.199948,-0.44803,-0.522273,2.34072,2.31138,-0.216354,-0.0720347,-0.302049,-0.204593,-0.274864,-0.367787,-0.0348637,-0.256593,-1.88549,-1.79205,0.771032,0.638454,0.362486,0.686659,1.34045,1.38079
7251,0.794246,0.770923,0.98526,0.92431,0.645866,0.518609,0.999728,0.927348,0.765992,0.866225,0.359574,0.359906,0.197348,0.113352,0.0318021,0.00302756,0.199855,0.24445,0.230585,0.254157,-1.67806,-1.75621,1.1505,1.11487,-0.0522823,0.0944673,-0.91859,-0.823904,0.180392,0.0799835,1.29856,1.07578,-0.668514,-0.575529,2.0849,1.94744,-0.386917,-0.0635692,-1.78586,-1.74232
7252,0.445359,0.420862,0.233089,0.173779,0.50182,0.437293,0.64988,0.575635,0.748558,0.72402,0.962729,0.961375,0.216457,0.131139,0.477036,0.45001,0.0335916,0.0767508,0.319713,0.308366,-0.62928,-0.708041,0.357541,0.3202,1.40156,1.5497,1.75016,1.84148,-1.0879,-1.18943,-1.77877,-1.99401,-0.855008,-0.75726,0.524001,0.393644,-1.4057,-1.08,-0.858995,-0.789967
7253,0.320521,0.296917,0.387096,0.327826,0.273802,0.279631,0.550117,0.478083,0.496702,0.581814,0.136753,0.133338,0.635789,0.55291,0.148531,0.123511,0.222239,0.267246,0.783691,0.772451,-0.366438,-0.442158,0.523643,0.491467,0.857271,0.998878,-0.914535,-0.820419,1.0595,0.96307,-1.35121,-1.56478,0.0320118,0.131399,-0.0228945,-0.147882,0.330064,0.660824,0.123305,0.162389
7254,0.80511,0.783644,0.777339,0.717808,0.187248,0.121969,0.242655,0.170298,0.636325,0.721578,0.2207,0.151883,0.796808,0.714331,0.189337,0.163829,0.154466,0.196902,0.171631,0.162497,-0.650824,-0.723282,-0.180227,-0.209675,1.01582,1.15136,1.19795,1.29064,2.23321,2.13414,1.12378,0.914851,0.171597,0.268872,-0.135041,-0.261732,-2.56413,-2.22997,0.423119,0.471015
7255,0.888616,0.869706,0.257437,0.200165,0.527161,0.46392,0.20993,0.138287,0.979837,1.06418,0.142406,0.170428,0.0900498,0.00711533,0.0155857,-0.00773964,0.378457,0.488306,0.26834,0.258662,0.219165,0.153195,0.914949,0.88521,0.942489,1.0756,-1.71484,-1.62791,-1.33597,-1.43179,-0.736333,-0.946633,1.1293,1.22176,1.30288,1.17271,1.75974,2.08727,-0.669882,-0.626545
7256,0.625049,0.606203,0.0592682,0.000701776,0.443042,0.378055,0.699345,0.626751,0.641863,0.726967,0.192388,0.188974,0.633069,0.548769,0.426841,0.404004,0.736399,0.77971,0.924509,0.913208,0.11628,0.00812046,0.362917,0.33557,-0.558789,-0.420917,-1.18195,-1.09642,-0.154755,-0.245622,1.58237,1.36649,0.0846462,0.174149,0.69664,0.569627,-1.03205,-0.704071,0.419533,0.470152
7257,0.562979,0.535308,0.0950315,0.0346189,0.020517,-0.0464437,0.653745,0.584684,0.829065,0.912025,0.970649,0.966094,0.641078,0.556361,0.208729,0.220429,0.723878,0.769294,0.623224,0.61228,-0.0774083,-0.136954,0.107436,0.0765982,-0.484216,-0.343692,-1.05487,-0.962404,-0.553908,-0.64212,1.10446,0.887427,0.406644,0.4959,1.07772,0.948338,-0.322671,0.0977695,0.767634,0.822085
7258,0.483045,0.464413,0.654482,0.596592,0.688769,0.623138,0.58319,0.542617,0.0130345,0.0957999,0.000310273,-0.00347725,0.909046,0.822778,0.0611971,0.0368528,0.273162,0.319497,0.789659,0.739505,1.16365,1.15679,-0.711778,-0.748403,0.255101,0.394308,1.9666,2.06519,0.769812,0.682299,-0.273319,-0.486516,-0.700669,-0.612946,-0.31295,-0.439323,0.572028,0.89961,-0.814418,-0.761698
7259,0.626841,0.638186,0.955343,0.898027,0.180427,0.11475,0.57098,0.500551,0.0807371,0.164972,0.549004,0.542608,0.213807,0.126383,0.467906,0.455893,0.477113,0.430876,0.875948,0.866729,2.50308,2.45054,-1.19474,-1.23481,0.111322,0.243232,2.24161,2.33773,1.1029,1.00892,-0.781278,-0.997115,1.52453,1.60575,0.832648,0.702045,-0.372859,-0.0399838,-1.23701,-1.17826
7260,0.829956,0.811959,0.562078,0.503935,0.029901,-0.0371475,0.754229,0.686054,0.671069,0.754939,0.793452,0.785261,0.885894,0.799111,0.900604,0.874934,0.493998,0.542254,0.611033,0.601757,-1.60545,-1.66176,-2.86758,-2.90306,3.21455,3.35262,-1.02887,-0.93726,1.95127,1.85786,1.86955,1.65969,-0.854734,-0.77878,-0.636591,-0.760877,0.505874,0.840949,-0.544513,-0.492203
7261,0.549438,0.532963,0.414164,0.355112,0.880052,0.813849,0.479665,0.413027,0.570041,0.709598,0.0385647,0.0308256,0.0347583,-0.0510041,0.570196,0.543581,0.207272,0.253104,0.82518,0.814271,-1.32329,-1.37883,0.193896,0.154506,-1.3096,-1.17153,-1.34915,-1.25027,0.716315,0.61938,-0.39204,-0.609216,-1.63332,-1.56115,-0.875721,-0.996731,-0.56586,-0.236512,2.27156,2.32398
7262,0.926509,0.911038,0.59689,0.538572,0.0524469,-0.0159633,0.530793,0.426661,0.579589,0.664256,0.312902,0.273033,0.437312,0.410463,0.712215,0.684979,0.826352,0.874223,0.742115,0.731071,0.216646,0.167461,-0.42236,-0.455152,-0.709719,-0.574064,-0.724635,-0.628226,0.116427,0.0256681,0.610995,0.38741,1.3936,1.46022,-0.684812,-0.803182,0.175883,0.50392,-0.866191,-0.816915
7263,0.886888,0.869898,0.553063,0.493939,0.363193,0.389828,0.505248,0.440296,0.0988873,0.185301,0.419416,0.51524,0.954958,0.871929,0.119429,0.0936563,0.0415885,0.0893464,0.255267,0.245126,0.279554,0.23456,0.0773377,0.0390326,0.252695,0.393908,0.690332,0.785158,-0.915873,-0.948681,0.338174,0.110497,-0.408542,-0.33863,-0.281796,-0.395221,-0.592274,-0.259904,0.457944,0.509469
7264,0.0890708,0.0710608,0.288009,0.227695,0.865735,0.795619,0.819555,0.75512,0.529359,0.613585,0.764623,0.757447,0.41423,0.42133,0.330978,0.305068,0.968707,1.01899,0.790846,0.780021,0.708641,0.668807,-0.946408,-0.988768,0.68604,0.822873,-0.511462,-0.410431,-1.83688,-1.92303,-1.64366,-1.87669,-0.631126,-0.566552,-1.63412,-1.7513,1.15886,1.49733,-0.123021,-0.0720053
7265,0.275027,0.257091,0.618355,0.558561,0.944517,0.812433,0.205226,0.142107,0.0486041,0.13463,0.639249,0.634243,0.0529899,-0.0292696,0.0239574,-0.00127342,0.742604,0.853618,0.617125,0.603284,0.258782,0.220396,0.0769552,0.0814933,0.0595762,0.19195,0.183718,0.290706,0.21723,0.129472,0.323234,0.0844244,1.72174,1.78156,0.633593,0.517515,0.582517,0.918859,0.233161,0.279928
7266,0.159811,0.14305,0.479448,0.334974,0.898942,0.829246,0.0333742,-0.0301314,0.868018,0.951317,0.946721,0.940452,0.66031,0.577488,0.116569,0.0515719,0.636208,0.688248,0.436562,0.426546,0.0789898,0.0446622,1.19596,1.15175,-1.18308,-1.04434,-0.153858,-0.052516,-0.877097,-0.971227,-1.38724,-1.62227,-0.0205365,0.0450908,-1.41405,-1.53461,-0.989122,-0.64605,-0.239029,-0.195531
7267,0.28522,0.268437,0.173645,0.111388,0.691363,0.621468,0.382734,0.318655,0.847849,0.932353,0.35536,0.350662,0.71661,0.636462,0.130723,0.104417,0.698404,0.733846,0.644294,0.633442,2.74436,2.71973,-0.320638,-0.35862,-0.702981,-0.569424,-1.05276,-0.952769,-0.60875,-0.602213,-1.41847,-1.65499,0.212877,0.273271,-1.41025,-1.52728,-1.20964,-0.869477,0.380986,0.431044
7268,0.650698,0.636196,0.462007,0.397831,0.943606,0.872038,0.272884,0.242191,0.40359,0.488918,0.450754,0.405452,0.0780822,-0.000980735,0.820453,0.795732,0.727789,0.779444,0.454324,0.442822,0.175058,0.155098,-0.123943,-0.156647,-0.791682,-0.662692,-0.168598,-0.0649092,-0.142486,-0.233199,2.97491,2.7384,1.17272,1.22616,0.70212,0.589358,1.65956,2.00456,0.482416,0.527161
7269,0.157879,0.145141,0.519788,0.457503,0.670488,0.59762,0.230279,0.165726,0.278541,0.36258,0.465655,0.460243,0.699511,0.620543,0.937737,0.911488,0.0383153,0.0884697,0.5082,0.45217,0.845856,0.737148,-1.40019,-1.43164,1.58778,1.71259,0.110684,0.207631,-0.530568,-0.615521,0.0880062,-0.144235,1.82825,1.88738,1.03271,0.921244,-2.14926,-1.80426,-0.662843,-0.616975
7270,0.384315,0.371697,0.18291,0.122429,0.793415,0.651306,0.686565,0.623411,0.559358,0.644677,0.349493,0.39485,0.497809,0.402769,0.702014,0.673673,0.618142,0.668287,0.496983,0.461519,1.34419,1.3192,0.654008,0.62654,-0.0922362,0.0295587,1.3203,1.41937,-0.337521,-0.427408,-1.34071,-1.57665,-0.0353211,0.0277665,0.0559404,-0.051076,-0.90998,-0.563319,2.09125,2.1435
7271,0.0589378,0.0462968,0.641562,0.580923,0.775367,0.704992,0.0800527,0.0154281,0.119421,0.20617,0.333007,0.329456,0.263515,0.184996,0.199263,0.172405,0.596966,0.647431,0.482605,0.470868,-2.09629,-2.11693,0.664872,0.555082,0.0428933,0.167423,-1.23198,-1.12974,-0.930392,-1.02112,-0.721484,-0.96244,-0.916034,-0.84898,-1.4612,-1.57534,1.16334,1.50332,0.630269,0.680284
7272,0.714274,0.70269,0.556938,0.497592,0.607878,0.500782,0.710681,0.648121,0.508994,0.594473,0.782012,0.77789,0.339089,0.164546,0.511118,0.483596,0.113651,0.162528,0.0658817,0.0548746,0.950552,0.928418,0.5088,0.483623,1.63399,1.76287,0.970277,1.0799,-0.251938,-0.341112,2.64476,2.40549,-1.06315,-0.999077,0.129758,0.0114585,0.100156,0.441879,-0.580959,-0.523787
7273,0.0854961,0.0715642,0.934704,0.87733,0.250044,0.296573,0.215918,0.15541,0.680334,0.765,0.201413,0.198127,0.223747,0.144097,0.189744,0.161676,0.859695,0.909836,0.667365,0.658657,-1.02834,-1.04953,-1.15375,-1.18462,0.746435,0.868434,-0.948453,-0.832957,-0.486592,-0.571127,0.720723,0.480716,0.745504,0.805171,-0.0967824,-0.208335,0.0674804,0.405825,0.873088,0.925417
7274,0.184398,0.171934,0.899836,0.843269,0.164424,0.0923632,0.443749,0.373381,0.201893,0.286045,0.889229,0.884198,0.991359,0.913479,0.746846,0.719575,0.990772,1.03921,0.32566,0.353833,-0.144844,-0.254288,-0.690884,-0.6907,1.21276,1.32731,-1.76687,-1.65651,1.29254,1.21142,-0.549499,-0.782882,0.171599,0.235539,1.78784,1.67277,-0.367237,-0.0340799,-0.175754,-0.123331
7275,0.64739,0.634161,0.394905,0.33987,0.45522,0.383819,0.693948,0.591351,0.192242,0.278767,0.937735,0.934934,0.793142,0.713822,0.13588,0.108715,0.266793,0.313509,0.0567795,0.0490095,0.556688,0.54095,-0.171128,-0.196777,0.766789,0.885894,-0.100086,0.00969313,-1.83098,-1.90625,-1.15415,-1.38681,-1.35462,-1.29673,0.731142,0.610434,0.714124,1.04984,0.751077,0.804729
7276,0.0125556,-0.00220223,0.511089,0.482158,0.523805,0.440666,0.869878,0.809321,0.624378,0.711311,0.76251,0.767304,0.907792,0.783618,0.992338,0.963689,0.979259,1.02575,0.991687,0.984281,0.383542,0.365216,0.787999,0.755978,1.29993,1.42217,-1.65041,-1.53671,-0.110256,-0.184766,-0.249606,-0.482839,1.11703,1.17976,-0.806622,-0.927448,-2.63053,-2.28791,2.11301,2.16339
7277,0.70021,0.683955,0.681808,0.624447,0.570016,0.497514,0.539459,0.481008,0.59184,0.676955,0.601663,0.599675,0.934697,0.853415,0.563691,0.537229,0.0617176,0.107903,0.648467,0.643142,-0.547167,-0.56403,0.478638,0.449807,-2.05187,-1.92822,0.116748,0.225411,-0.00244001,-0.0730723,0.398593,0.161197,-0.566474,-0.509292,-0.327393,-0.442757,0.0375633,0.386472,0.639607,0.686294
7278,0.236143,0.218134,0.166356,0.106804,0.29785,0.248314,0.212968,0.152694,0.195637,0.283389,0.713675,0.713458,0.367674,0.286003,0.865721,0.838223,0.724435,0.770235,0.927135,0.920956,2.59248,2.57877,1.35634,1.32691,0.79692,0.927669,0.910225,1.01983,-1.27288,-1.34249,1.26486,1.03298,0.0705552,0.121541,-1.56834,-1.68954,0.492884,0.844977,-0.11532,-0.0765112
7279,0.089658,0.0699924,0.850306,0.791432,0.072593,-0.00088508,0.389226,0.327748,0.447978,0.535475,0.133556,0.133695,0.150468,0.070101,0.0169543,-0.0116391,0.175864,0.220939,0.0461808,0.0419639,0.140858,0.130003,-0.552811,-0.579281,-0.321319,-0.185574,0.771494,0.877924,0.388545,0.316895,0.33377,0.10677,-0.341925,-0.292574,0.069353,-0.0559575,0.134709,0.483141,-0.261346,-0.219246
7280,0.555849,0.455611,0.707799,0.647726,0.809092,0.734457,0.264607,0.205615,0.698896,0.787561,0.266341,0.268861,0.723378,0.641793,0.929199,0.901597,0.0178166,0.0625217,0.42773,0.421698,1.79623,1.78253,0.128051,0.0990787,1.7753,1.91245,-0.451584,-0.348019,-0.561502,-0.631183,0.48383,0.257306,0.0441695,0.0898715,0.3063,0.183777,-0.725813,-0.373105,-0.992887,-0.887577
7281,0.863521,0.841229,0.971946,0.913693,0.840134,0.766181,0.928917,0.871661,0.0975655,0.188204,0.11261,0.115904,0.16949,0.0890486,0.563366,0.597515,0.684518,0.730208,0.238123,0.231077,1.00869,1.0162,0.0419233,0.10518,-2.27534,-2.12885,0.718606,0.818562,-0.0573009,-0.120773,-0.761429,-0.991133,0.140955,0.182044,-0.17544,-0.371388,1.13394,1.48065,-1.60499,-1.55591
7282,0.358588,0.335737,0.52204,0.465237,0.325631,0.252617,0.682864,0.709109,0.539956,0.632001,0.55272,0.546506,0.502473,0.421477,0.319489,0.293432,0.66711,0.714786,0.804633,0.799473,0.263568,0.24987,0.136931,0.111281,0.542884,0.690383,2.58973,2.69038,-0.967871,-1.03559,0.147892,-0.0871569,1.70595,1.74942,-0.809394,-0.926553,-0.931168,-0.580206,-0.930062,-0.883486
7283,0.534393,0.511144,0.47007,0.41537,0.995414,0.922199,0.603317,0.546557,0.0555024,0.148318,0.974465,0.977108,0.496741,0.378982,0.830442,0.805427,0.408017,0.455975,0.0156288,0.0091347,-0.272818,-0.337308,-0.193524,-0.223285,-0.185518,-0.0352168,0.239725,0.342613,0.211942,0.150587,-1.19982,-1.42794,-1.22138,-1.18684,-0.468992,-0.580847,0.443459,0.787876,-2.3789,-2.33189
7284,0.352683,0.32819,0.206622,0.149126,0.0481146,-0.0254246,0.881385,0.826464,0.894585,0.987243,0.019145,0.021904,0.325732,0.336488,0.399221,0.374324,0.761086,0.807259,0.639055,0.633591,-0.916302,-0.924487,0.90361,0.871601,0.147665,0.30256,1.29839,1.39916,1.07656,1.01472,0.0257649,-0.203665,0.175026,0.21676,-0.467365,-0.573516,-0.500133,-0.151718,-0.59426,-0.539987
7285,0.686731,0.570709,0.696164,0.636825,0.608197,0.532547,0.182124,0.129308,0.556625,0.616454,0.352042,0.356327,0.426454,0.293994,0.345839,0.323033,0.161074,0.207457,0.940503,0.936198,0.684505,0.682343,0.539674,0.507187,2.43912,2.59655,0.404209,0.498905,0.784061,0.726313,-0.497893,-0.728669,-0.525253,-0.488423,0.578687,0.477722,0.340017,0.682598,0.898048,0.956167
7286,0.838625,0.813229,0.0191225,-0.0389748,0.746471,0.702105,0.0221561,-0.0284219,0.153059,0.245665,0.913187,0.917615,0.332495,0.251499,0.809699,0.784072,0.94772,0.994614,0.352117,0.345536,1.20144,1.19638,0.558173,0.52327,0.111283,0.261261,0.708093,0.802767,-0.083874,-0.125019,-0.749055,-0.975461,-0.0521731,-0.0118125,1.12388,1.02391,0.492744,0.8299,0.842671,0.902948
7287,0.316377,0.292588,0.572965,0.512785,0.94484,0.871663,0.386091,0.335505,0.328647,0.420752,0.667324,0.658543,0.758755,0.678131,0.135861,0.112175,0.201969,0.247185,0.824624,0.81954,-0.68779,-0.687546,0.823336,0.786488,0.0213643,0.221169,0.286356,0.381843,-0.912758,-0.97635,-1.6006,-1.82485,-0.743237,-0.702335,-1.89118,-1.9921,1.80024,2.1318,1.26916,1.33086
7288,0.798538,0.773904,0.683578,0.575265,0.0458981,-0.0285243,0.487001,0.437364,0.0462647,0.138332,0.435395,0.399471,0.583375,0.446607,0.11626,0.0918301,0.245978,0.290657,0.0871921,0.0818497,1.56116,1.56271,-1.26865,-1.30305,0.0322664,0.181076,0.314002,0.407744,-0.64771,-0.710832,-0.99342,-1.12555,0.359793,0.402016,-1.28761,-1.38564,0.492118,0.816561,1.25684,1.32348
7289,0.852757,0.748359,0.739748,0.637746,0.256531,0.181759,0.496633,0.539222,0.560958,0.600443,0.136428,0.140398,0.298411,0.215084,0.445302,0.491601,0.563599,0.605502,0.327147,0.24079,0.911343,0.911819,-2.05505,-2.08396,-0.906817,-0.758652,-0.621747,-0.525775,0.251731,0.184911,-0.196738,-0.42624,-0.131805,-0.0895161,-0.442303,-0.533494,0.123475,0.454725,-2.12114,-2.05307
7290,0.821813,0.722814,0.761719,0.700226,0.667936,0.594911,0.69164,0.64108,0.969554,1.06255,0.881927,0.886526,0.0628234,-0.0164402,0.916104,0.891371,0.432843,0.473006,0.405981,0.39973,-0.400515,-0.398222,1.73886,1.70996,-1.22964,-1.08084,0.795829,0.88761,1.60559,1.53752,0.172692,-0.0608465,-1.26907,-1.22952,1.15585,1.07064,-0.641293,-0.309099,-0.661339,-0.561215
7291,0.719431,0.69727,0.265379,0.201944,0.375552,0.300942,0.21756,0.168902,0.606519,0.699127,0.123041,0.126973,0.405334,0.325541,0.614996,0.612987,0.817445,0.858756,0.847245,0.839025,3.06321,3.05946,0.169421,0.137683,-0.296477,-0.144337,0.146169,0.249563,0.0499081,-0.023626,-1.31956,-1.55691,0.0267076,0.0637251,0.623189,0.544393,0.164873,0.491934,0.862561,0.930635
7292,0.438969,0.418273,0.415711,0.368541,0.896501,0.819848,0.53653,0.391957,0.848356,0.940358,0.962989,0.967126,0.305741,0.225884,0.352229,0.334603,0.402878,0.444689,0.6988,0.688666,0.432056,0.42648,1.30362,1.27551,0.859634,1.00539,-0.483516,-0.388484,0.749341,0.670856,0.520752,0.284256,-2.07316,-2.03351,-0.250978,-0.335332,1.35964,1.68264,-0.153272,-0.0886526
7293,0.550442,0.585718,0.574453,0.535138,0.883944,0.753465,0.662811,0.615011,0.31517,0.407212,0.525058,0.531097,0.894243,0.812146,0.0833438,0.0562188,0.374062,0.414944,0.0935816,0.0826153,0.919626,0.910654,-1.94456,-1.97349,0.402127,0.547859,-0.278698,-0.177841,1.09418,1.01317,0.563658,0.329279,-2.31037,-2.27718,0.734106,0.653841,-0.0221896,0.30538,1.23434,1.29419
7294,0.775686,0.753162,0.765169,0.701734,0.765847,0.687082,0.456663,0.408135,0.455149,0.546976,0.602222,0.607062,0.86583,0.831185,0.18529,0.157764,0.640296,0.68157,0.283506,0.274664,-0.585179,-0.59886,0.461903,0.424505,1.17709,1.31655,1.33432,1.44379,-0.223013,-0.304275,0.919914,0.681904,0.576446,0.604688,0.429489,0.43665,0.731756,1.05908,2.61241,2.67703
7295,0.00961609,-0.0120865,0.433991,0.371478,0.52269,0.442627,0.729955,0.683389,0.355332,0.375515,0.958315,0.96235,0.932015,0.850223,0.0308906,0.00124859,0.019748,0.06114,0.88938,0.878447,-0.547763,-0.564935,-0.585881,-0.617513,-1.01457,-0.873684,1.0353,1.14604,1.5182,1.43403,-0.159264,-0.397266,-0.49048,-0.457919,0.304709,0.219459,-0.151389,0.171144,0.0202319,0.0904342
7296,0.466423,0.445596,0.472162,0.409851,0.609456,0.54094,0.239011,0.190678,0.111175,0.204054,0.504286,0.506522,0.156105,0.074353,0.748143,0.71889,0.0253939,0.127169,0.729486,0.757798,-0.173505,-0.190315,-0.850752,-0.876485,-1.95037,-1.81341,1.4903,1.60176,0.986164,0.901996,1.00848,0.767627,-0.686329,-0.653731,0.80485,0.719362,0.216382,0.536769,-1.41893,-1.34374
7297,0.518873,0.537795,0.0797155,0.0157601,0.718496,0.639253,0.120751,0.162158,0.769937,0.86444,0.308936,0.312185,0.598802,0.516114,0.373168,0.342018,0.202375,0.193198,0.646217,0.637149,-2.44123,-2.44924,-0.669025,-0.6909,-1.00644,-0.876904,0.061568,0.175988,0.0292445,-0.0595893,0.960112,0.697905,-0.374459,-0.346031,-0.082989,-0.176798,-0.631266,-0.413158,0.209033,0.2897
7298,0.657186,0.629994,0.813057,0.751773,0.142647,0.0656037,0.184151,0.133638,0.375724,0.470874,0.680934,0.681742,0.734984,0.570994,0.344569,0.263482,0.215476,0.259227,0.930829,0.920506,-1.30522,-1.31082,0.0482931,0.0311759,-0.289493,-0.154604,2.17805,2.28705,0.228914,0.144161,0.8658,0.628183,0.751979,0.774367,-0.395687,-0.490129,-1.67759,-1.36309,-0.558748,-0.473105
7299,0.664676,0.722193,0.707212,0.604881,0.548397,0.468971,0.844524,0.79476,0.741884,0.83854,0.82732,0.826727,0.707345,0.625874,0.215042,0.184945,0.987581,1.03074,0.805006,0.795418,-0.704248,-0.707285,0.473194,0.461743,-1.71801,-1.59066,2.31867,2.42106,1.51257,1.42309,-0.0770043,-0.314895,1.5453,1.57129,-1.61837,-1.7068,-0.395949,-0.0769174,-0.500561,-0.383737
7300,0.917108,0.814392,0.517357,0.45799,0.0426442,-0.0351656,0.83239,0.782435,0.260221,0.354858,0.586371,0.507066,0.393928,0.314189,0.433852,0.403181,0.808121,0.853143,0.90521,0.89583,0.143203,0.140076,-0.992572,-1.00401,-0.87803,-0.744164,-0.384397,-0.276324,0.41063,0.32239,0.154879,-0.0858415,-1.6147,-1.59591,-0.798025,-0.885747,-0.989448,-0.670244,-0.38238,-0.294369
7301,0.927418,0.906591,0.934714,0.877103,0.938075,0.861662,0.133659,0.0852792,0.407176,0.499312,0.186146,0.187405,0.417657,0.336679,0.218427,0.186093,0.176011,0.223233,0.670777,0.660151,-0.55316,-0.531883,-0.438622,-0.450518,1.46123,1.59805,-1.97677,-1.87267,-0.448086,-0.532757,0.0412063,-0.193223,0.887103,0.904171,-0.657487,-0.774315,0.438792,0.759892,-2.53592,-2.45087
7302,0.0495247,0.0308265,0.829868,0.773841,0.893463,0.743987,0.691282,0.642741,0.179645,0.271973,0.0924484,0.0945168,0.220645,0.141731,0.380411,0.347558,0.28016,0.327868,0.0373482,0.0249668,-1.20351,-1.20384,-0.113855,-0.139391,-1.36358,-1.23039,-0.635584,-0.545575,1.04174,0.958745,-3.3206,-3.55396,-0.674489,-0.659387,-0.576654,-0.662884,-0.386676,-0.0661535,-0.566156,-0.477884
7303,0.991249,0.97141,0.159262,0.102823,0.704574,0.626312,0.581682,0.535117,0.601251,0.694313,0.885963,0.888857,0.770116,0.693441,0.046793,0.0162053,0.589654,0.638651,0.97448,0.960238,-0.170079,-0.172991,0.186364,0.171737,0.827701,0.962168,0.672924,0.781519,1.01686,0.931861,-2.84212,-3.07672,1.35589,1.36449,1.93085,1.85209,0.298436,0.612949,-0.216191,-0.125951
7304,0.655327,0.581323,0.561578,0.502859,0.276636,0.196401,0.121756,0.0736522,0.470211,0.562689,0.380313,0.383484,0.714512,0.552843,0.310017,0.281808,0.514539,0.563707,0.979711,0.867106,1.62465,1.61713,0.986635,0.973065,-0.810159,-0.67192,0.172944,0.283897,0.125125,0.0465529,-0.0351989,-0.273421,-1.29889,-1.29319,0.268602,0.189718,-1.01803,-0.702293,1.01997,1.10948
7305,0.209022,0.191236,0.118488,0.0594865,0.257291,0.147863,0.613847,0.472717,0.730191,0.823756,0.86072,0.865863,0.488456,0.412244,0.860281,0.829622,0.896121,0.944461,0.788851,0.773973,-0.54908,-0.563548,-0.895148,-0.904626,-0.0260223,0.110788,0.589122,0.692874,0.419763,0.342014,-0.918916,-1.15367,1.55083,1.54965,-0.413277,-0.492421,0.115146,0.427985,0.855545,0.897029
7306,0.96642,0.951078,0.22969,0.172779,0.181623,0.0993239,0.920453,0.871782,0.476053,0.620571,0.435372,0.440143,0.863734,0.789004,0.663266,0.632672,0.198595,0.248306,0.448436,0.465496,1.681,1.67218,0.555847,0.54357,-0.59219,-0.455785,0.0175281,0.118302,-0.587929,-0.667572,0.381581,0.146985,0.206566,0.112643,-2.03768,-2.12332,0.0175598,0.32927,0.600333,0.684576
7307,0.512473,0.535156,0.0241729,-0.0321657,0.791481,0.707187,0.816732,0.764031,0.241437,0.417387,0.429641,0.393482,0.861565,0.787284,0.142227,0.111574,0.225792,0.277866,0.172438,0.157019,1.36461,1.36064,-1.98066,-1.99574,-0.51546,-0.37856,-0.289142,-0.287447,-0.444552,-0.469453,1.29492,1.06549,-1.31671,-1.32436,0.769994,0.69176,0.389984,0.694895,-0.148986,-0.0620515
7308,0.136381,0.119234,0.917347,0.861508,0.196814,0.112745,0.7057,0.656281,0.11913,0.214202,0.34012,0.346821,0.584791,0.511692,0.376968,0.346535,0.0104055,0.0644781,0.864926,0.851283,0.288165,0.279155,1.10185,1.0869,0.813983,0.954515,-0.79199,-0.693195,-0.188007,-0.271335,-0.92186,-1.15661,-1.06284,-1.06479,1.05438,0.978443,0.388281,0.723464,0.953026,1.03465
7309,0.754732,0.739422,0.606654,0.550917,0.172756,0.0889677,0.152276,0.103641,0.402353,0.496299,0.618053,0.67415,0.903815,0.82889,0.324321,0.195627,0.00481305,0.0588333,0.532833,0.474426,-0.271153,-0.279414,-1.20336,-1.21629,-0.138346,-0.00109701,0.888684,0.989851,0.712096,0.624408,1.23283,0.998242,0.14561,0.151733,0.088475,0.00612369,0.449405,0.752033,0.975213,1.05712
7310,0.0562813,0.0411794,0.0329872,-0.0204545,0.93061,0.845436,0.704519,0.656219,0.346947,0.52832,0.997424,1.00148,0.0983287,0.0238112,0.0767783,0.0447195,0.922123,0.977968,0.11166,0.0975682,-0.51434,-0.515519,-0.504311,-0.506702,-0.652581,-0.604375,1.7692,1.87771,0.691216,0.597524,0.200529,-0.0345938,-1.0517,-1.05045,0.295236,0.213728,0.819004,1.11766,-2.50331,-2.42141
7311,0.447513,0.434127,0.406243,0.43304,0.327643,0.241055,0.693042,0.643893,0.467294,0.56034,0.602044,0.604803,0.659345,0.585324,0.767429,0.736034,0.0416051,0.0982029,0.553183,0.541124,-1.00424,-0.998069,0.215809,0.202882,-1.33891,-1.20765,-0.720672,-0.605683,-1.0443,-1.13281,-0.438389,-0.670134,0.963792,0.957881,-0.295471,-0.375205,0.725505,1.01894,2.35982,2.44172
7312,0.383727,0.398962,0.937691,0.886534,0.279107,0.192032,0.18472,0.135983,0.166184,0.257806,0.947919,0.950454,0.0352236,-0.0410438,0.954954,0.923001,0.734642,0.789756,0.514327,0.595333,-0.883253,-0.870248,-1.33031,-1.33948,-0.251801,-0.118217,-0.04705,0.0637007,-2.26627,-2.35669,-0.815642,-1.05436,1.35619,1.35683,2.01948,1.93326,-0.0121136,0.286574,1.12222,1.16939
7313,0.376213,0.363796,0.717807,0.684096,0.962037,0.876916,0.823374,0.773326,0.936105,1.02685,0.792679,0.84069,0.811385,0.73487,0.0410412,0.0104458,0.522368,0.576368,0.66038,0.649542,1.87015,1.88516,0.644381,0.638533,-0.91528,-0.780211,-1.0338,-0.874497,0.513363,0.423051,0.146844,-0.0908329,-0.259156,-0.253114,0.561059,0.470338,-0.00420081,0.295887,-0.184844,-0.10294
7314,0.124733,0.110879,0.468323,0.481659,0.255343,0.167595,0.615861,0.56645,0.194543,0.285518,0.63135,0.730927,0.0389251,-0.0356232,0.265556,0.234371,0.58065,0.634528,0.432786,0.423581,-0.553935,-0.53206,-0.639877,-0.651868,0.758524,0.894215,-1.92573,-1.81269,-1.57227,-1.66302,-0.198465,-0.359757,-0.885016,-0.881892,-0.303753,-0.393121,-0.501564,-0.205404,-0.803904,-0.71544
7315,0.147307,0.18536,0.271386,0.279221,0.653266,0.529921,0.00951484,-0.0415336,0.430376,0.521379,0.618995,0.621164,0.462577,0.386147,0.1071,0.0778552,0.28679,0.340301,0.96142,0.95308,-0.0633153,-0.0354467,0.471361,0.457517,1.38967,1.52245,0.773691,0.885883,0.115654,0.027801,-0.396484,-0.628681,-1.19582,-1.18697,0.0431069,-0.0474144,1.38741,1.6791,0.847707,0.933853
7316,0.360637,0.25984,0.127941,0.0767833,0.980253,0.892247,0.073609,0.0221608,0.926892,1.0193,0.888095,0.889935,0.568302,0.49126,0.678864,0.651472,0.847811,0.900068,0.453728,0.447404,2.51196,2.53523,0.141167,0.122951,-0.894583,-0.76473,0.207663,0.327564,1.46375,1.38041,1.11351,0.886932,1.09227,1.09679,-1.88002,-1.97613,1.04656,1.33116,-0.520563,-0.437691
7317,0.348175,0.334321,0.0928543,0.042722,0.0724234,-0.0146635,0.762038,0.709894,0.284797,0.379673,0.823601,0.744094,0.389698,0.311265,0.594133,0.473141,0.421204,0.536825,0.390472,0.383129,1.34582,1.36276,0.0481187,0.0320452,0.389424,0.522374,0.729717,0.842654,1.40637,1.32077,0.526884,0.298403,0.350246,0.359387,-1.44709,-1.5386,0.335509,0.61541,-1.11959,-1.03389
7318,0.847987,0.83645,0.905167,0.854942,0.504252,0.419441,0.142344,0.0922424,0.919081,1.01421,0.597578,0.598254,0.880833,0.803355,0.322324,0.294811,0.121656,0.173583,0.0216571,0.0126199,0.873887,0.897445,-2.17045,-2.18726,-1.69126,-1.55588,-0.13533,-0.0287912,0.109418,0.0205185,0.679169,0.44894,0.814596,0.820253,0.199222,0.111072,-0.0880278,0.19104,0.174139,0.262128
7319,0.626762,0.617215,0.677501,0.625045,0.379856,0.293212,0.430423,0.373951,0.913189,0.929868,0.0049774,0.00337266,0.219772,0.14166,0.835484,0.806805,0.492776,0.544047,0.915427,0.905897,0.983978,1.00889,-0.604422,-0.627113,1.96988,2.1012,-2.76812,-2.66307,1.47157,1.38883,1.89063,1.65923,-0.421221,-0.412671,-0.607252,-0.69216,-2.31151,-2.02692,2.75773,2.84329
7320,0.836903,0.778487,0.818381,0.709184,0.94946,0.861295,0.706051,0.65566,0.75019,0.84553,0.50139,0.500853,0.36539,0.200346,0.87576,0.847124,0.223731,0.275176,0.0731253,0.0640571,0.795207,0.819014,-0.688761,-0.718018,0.980873,1.11306,0.400232,0.497235,-1.14591,-1.23307,-0.662902,-0.887772,-0.449748,-0.441442,-0.175812,-0.254637,0.490703,0.778122,-1.29348,-1.21064
7321,0.95098,0.93976,0.930807,0.793323,0.112268,0.0257685,0.706222,0.654441,0.245539,0.342292,0.763464,0.764289,0.456188,0.259032,0.479633,0.499652,0.600737,0.650985,0.884605,0.877562,0.974666,0.992548,-1.19294,-1.21971,1.4435,1.57193,0.880735,0.983765,1.91152,1.82269,1.25172,1.02713,1.76827,1.77726,-1.75346,-1.83848,-0.20631,0.0775514,1.47599,1.56616
7322,0.314629,0.303397,0.929145,0.877461,0.0789539,-0.0077756,0.000960635,-0.0529036,0.262744,0.360214,0.248599,0.249857,0.425664,0.317718,0.181357,0.152179,0.187193,0.236918,0.317808,0.31197,-0.547295,-0.531238,-0.635197,-0.66622,0.732185,0.864624,0.532509,0.640543,0.275482,0.184445,0.629653,0.406839,-1.87587,-1.86088,-1.68253,-1.76923,-0.222354,0.0566059,0.594095,0.682651
7323,0.957489,0.944603,0.193673,0.14182,0.2867,0.197593,0.748512,0.695558,0.514833,0.632792,0.815975,0.816285,0.452325,0.376404,0.972146,0.945524,0.275806,0.325091,0.575625,0.643859,0.171644,0.194428,-0.89723,-0.925191,-0.850965,-0.724437,-0.781266,-0.675964,-2.30257,-2.39069,0.336092,0.114936,0.108933,0.130344,0.318821,0.238464,-0.477755,-0.197093,-0.0589372,0.0262113
7324,0.970466,0.882469,0.637608,0.58561,0.251052,0.164049,0.831001,0.779111,0.809165,0.90537,0.266871,0.266939,0.995351,0.918058,0.358435,0.329188,0.832984,0.880306,0.981404,0.975748,-2.65844,-2.6294,0.447946,0.413637,0.0753194,0.196977,1.20603,1.30812,0.172848,0.0899679,0.476904,0.252219,-0.563025,-0.544255,0.109605,0.0334157,1.1753,1.45189,0.0125199,0.094436
7325,0.831846,0.820336,0.51754,0.543731,0.643954,0.555968,0.634476,0.506835,0.0996368,0.194484,0.751653,0.749318,0.483564,0.406457,0.550136,0.520817,0.163673,0.209428,0.460564,0.455487,-0.504332,-0.472513,-1.12993,-1.15864,-1.99491,-1.88127,-0.97807,-0.873388,-0.293609,-0.383053,-1.49683,-1.72045,0.594446,0.611217,-0.443559,-0.523535,-2.39906,-2.12632,-1.38554,-1.30818
7326,0.603715,0.591682,0.556695,0.501852,0.405735,0.401646,0.288799,0.234559,0.859323,0.953109,0.106203,0.103976,0.735001,0.658621,0.198313,0.168696,0.172708,0.219449,0.244475,0.240187,-0.617476,-0.589988,-0.582153,-0.605156,0.293872,0.412716,0.059222,0.167906,1.16248,1.07794,0.987208,0.759174,-0.260416,-0.247137,0.488253,0.440853,-0.102439,0.163275,0.29724,0.372722
7327,0.124306,0.110736,0.513723,0.459974,0.337329,0.247324,0.774988,0.723023,0.210645,0.303914,0.272836,0.269138,0.239046,0.162818,0.526002,0.495099,0.847209,0.892238,0.968702,0.963497,0.954824,0.98609,0.821486,0.796452,-1.37481,-1.25346,-1.18662,-1.07414,0.52477,0.437749,-0.481877,-0.70597,0.0401274,0.0605624,1.49001,1.40524,0.499904,0.762764,-0.887314,-0.816279
7328,0.111477,0.095634,0.118409,0.0658824,0.760411,0.671493,0.485341,0.434628,0.757229,0.852626,0.98093,0.975661,0.356169,0.284495,0.279494,0.247102,0.257143,0.30319,0.755174,0.748197,-0.724913,-0.692681,0.06806,0.0480556,-0.0453878,0.0796112,1.20355,1.3233,-0.498569,-0.586253,0.12636,-0.0917553,-2.57026,-2.54978,1.32741,1.24728,-0.209854,0.0470094,0.0339786,0.111782
7329,0.935364,0.919438,0.132377,0.0800422,0.0130986,-0.0744272,0.500841,0.43476,0.561096,0.748769,0.588925,0.583528,0.48259,0.406172,0.667287,0.633713,0.791057,0.837782,0.14355,0.138243,-0.500744,-0.473794,-0.418834,-0.441526,-0.527774,-0.409285,0.941728,1.05661,-0.388152,-0.474559,0.442097,0.228534,0.648186,0.660523,-0.171282,-0.244629,-0.0795199,0.180035,0.611833,0.69245
7330,0.197762,0.179838,0.495545,0.496064,0.571089,0.483544,0.484141,0.434892,0.525653,0.644911,0.422923,0.342363,0.835109,0.758155,0.408527,0.38217,0.508647,0.5545,0.914576,0.908908,-0.510973,-0.483074,-0.909673,-0.931107,-2.08425,-1.96604,-1.07027,-0.952062,0.368095,0.280994,-2.1463,-2.36641,0.251064,0.26231,-1.21896,-1.2922,-0.854186,-0.599007,0.956653,1.04438
7331,0.550075,0.531659,0.965366,0.912086,0.876935,0.790575,0.965546,0.917494,0.443861,0.541054,0.10933,0.101197,0.273247,0.196343,0.166818,0.130627,0.516093,0.559942,0.620024,0.613501,0.606425,0.638691,0.872925,0.844925,-0.0579713,0.067898,0.575656,0.699337,-0.610112,-0.697932,-0.536801,-0.757472,1.59854,1.60396,-0.401484,-0.471153,1.81467,2.07538,0.266158,0.35896
7332,0.359178,0.342996,0.179055,0.124204,0.81208,0.799015,0.127047,0.0801684,0.0678765,0.167025,0.945236,0.9365,0.281231,0.203935,0.461426,0.40357,0.160664,0.20522,0.576443,0.570218,0.493154,0.521217,0.410096,0.388149,-0.545326,-0.420998,0.698722,0.81807,-0.959169,-1.04902,0.215396,-0.00788937,-0.240232,-0.240208,1.7491,1.67626,1.22718,1.49823,1.5944,1.68534
7333,0.921354,0.904249,0.750513,0.695587,0.893372,0.807456,0.0801914,0.0354291,0.897209,0.994893,0.663818,0.674461,0.905505,0.829406,0.812137,0.676514,0.838549,0.883074,0.233123,0.229079,-1.71971,-1.69386,1.03108,1.00407,0.74964,0.866107,-1.56586,-1.4459,-3.03476,-3.117,-1.74763,-1.96549,0.477761,0.481637,-0.492784,-0.561272,0.660379,0.921089,0.164782,0.251167
7334,0.4976,0.471065,0.404131,0.350584,0.441273,0.422738,0.0363623,-0.00931028,0.340159,0.436348,0.419956,0.412422,0.866855,0.791086,0.985539,0.949458,0.523119,0.568122,0.162053,0.230737,-1.05147,-0.953517,2.25608,2.22444,-0.511692,-0.398874,0.809152,0.932611,0.474023,0.389007,-1.14213,-1.36708,-0.230456,-0.223546,-0.346359,-0.420605,-3.13073,-2.86428,1.14864,1.24081
7335,0.0531141,0.0378812,0.643443,0.587892,0.12496,0.0380207,0.194793,0.206324,0.475315,0.49332,0.620235,0.611287,0.405801,0.330623,0.187475,0.152774,0.980622,1.02354,0.235567,0.232394,-0.247317,-0.213178,-0.202246,-0.235583,1.53945,1.64859,0.615949,0.742823,0.561711,0.471193,0.65184,0.426001,-0.140407,-0.131373,-0.21145,-0.279939,-0.240666,0.032591,0.728514,0.824242
7336,0.653742,0.638633,0.322513,0.267539,0.559079,0.472125,0.469355,0.421959,0.450709,0.550291,0.443815,0.43399,0.826962,0.752393,0.830857,0.797057,0.280382,0.323132,0.913323,0.911254,2.66408,2.7009,-1.41356,-1.44762,0.25701,0.367697,-0.428724,-0.296615,-0.172788,-0.261616,-0.502418,-0.728976,0.77291,0.773402,-1.23971,-1.31162,1.03657,1.30306,2.16162,2.25988
7337,0.105554,0.0922836,0.663487,0.608182,0.52524,0.438581,0.435619,0.389948,0.304553,0.403882,0.926763,0.916369,0.681319,0.607456,0.718419,0.640454,0.263685,0.30771,0.316578,0.315678,0.444087,0.485831,-0.0623646,-0.0922209,0.451752,0.566546,-0.53818,-0.408334,0.210274,0.0944573,0.991645,0.770368,0.38021,0.375189,0.513889,0.448119,-0.997765,-0.727185,1.73717,1.82849
7338,0.915015,0.900762,0.156847,0.0996315,0.872694,0.785879,0.683771,0.6082,0.592348,0.691154,0.158666,0.146253,0.0387618,-0.0344185,0.51934,0.48385,0.778595,0.822795,0.73397,0.735006,-0.190871,-0.150104,-1.85395,-1.8853,-0.498077,-0.389066,0.447738,0.573024,0.540704,0.450531,0.380984,0.166434,0.820328,0.82209,0.861177,0.793826,-0.622071,-0.345203,0.471598,0.5628
7339,0.834354,0.817722,0.306606,0.248636,0.446012,0.36138,0.871089,0.826453,0.167339,0.267253,0.845407,0.832324,0.024045,-0.0470817,0.655041,0.619408,0.285266,0.327708,0.802511,0.830203,-1.96267,-1.92349,1.52662,1.49417,-0.26208,-0.158117,1.89042,2.01759,0.557013,0.471641,-1.30848,-1.52766,-1.38545,-1.38294,0.360619,0.298071,0.982636,1.25559,-1.44465,-1.34769
7340,0.195124,0.176333,0.802436,0.747116,0.507487,0.42356,0.468561,0.518391,0.150262,0.248289,0.120758,0.107085,0.794502,0.722301,0.351509,0.317845,0.94559,0.99004,0.925139,0.9254,-1.43946,-1.39419,0.952306,0.91525,-1.35161,-1.25483,0.245995,0.373685,-2.115,-2.20192,0.89414,0.673897,0.617251,0.625392,0.0692875,0.00253605,0.833438,1.10939,0.838473,0.928601
7341,0.566174,0.548636,0.611269,0.557604,0.803809,0.719843,0.255583,0.210329,0.644299,0.74155,0.364087,0.349524,0.145441,0.0741252,0.410059,0.315839,0.761435,0.904748,0.325814,0.324567,0.0580431,0.104935,-0.704445,-0.737161,1.05901,1.14974,-0.600329,-0.465913,0.803502,0.714069,-1.23681,-1.45108,0.236591,0.243067,0.204309,0.134457,0.140575,0.493168,0.373585,0.469913
7342,0.313875,0.295719,0.673521,0.621677,0.158237,0.0755516,0.0454348,-0.0016732,0.535941,0.634644,0.607846,0.591962,0.73634,0.665493,0.346634,0.313834,0.774986,0.819456,0.310182,0.365437,1.34512,1.39865,0.676228,0.649192,0.937851,1.02978,-1.02419,-0.886837,1.53804,1.45491,0.40461,0.191158,-1.09372,-1.08384,-0.625299,-0.699344,-0.401319,-0.12305,-0.0811752,0.0112255
7343,0.992824,0.976926,0.363798,0.328301,0.842265,0.760436,0.130395,0.0818798,0.686792,0.784832,0.44778,0.433508,0.041463,-0.0309016,0.121272,0.0868732,0.299966,0.344784,0.410176,0.406307,-0.772165,-0.716949,0.993438,0.959075,-1.03411,-0.935293,-0.587568,-0.447695,-1.76837,-1.84575,-0.982492,-1.198,-0.666358,-0.651844,-1.15361,-1.27357,-0.39539,-0.113737,0.185378,0.272623
7344,0.674985,0.657706,0.0883251,0.0349239,0.222808,0.141896,0.666424,0.619352,0.217112,0.316527,0.709224,0.696944,0.737756,0.666347,0.232848,0.197581,0.270185,0.315039,0.938753,0.935806,1.31766,1.37899,1.96533,1.92894,-0.392148,-0.290425,-0.449025,-0.235051,-2.48928,-2.56038,1.0043,0.794635,-1.43071,-1.41879,-1.7797,-1.8478,-1.80393,-1.52205,1.08075,1.17118
7345,0.631056,0.669324,0.761007,0.709713,0.347562,0.268107,0.269543,0.222506,0.142452,0.316132,0.0305915,0.0164228,0.923674,0.852305,0.0759131,0.0410656,0.72384,0.770455,0.907963,0.906434,-0.398908,-0.332196,-0.739651,-0.769047,-0.933931,-0.82585,-0.162674,-0.0224073,1.06658,0.996688,-0.292867,-0.499107,0.87325,0.882667,-0.0858406,-0.15037,-1.38819,-1.10962,-0.700514,-0.613858
7346,0.698132,0.680942,0.463066,0.409862,0.96085,0.881716,0.686187,0.640663,0.219169,0.315736,0.952275,0.93824,0.423983,0.351267,0.926303,0.891298,0.786177,0.833346,0.174536,0.173317,0.483214,0.544281,-0.103709,-0.137965,-1.90279,-1.80074,0.513229,0.646977,-0.298427,-0.367533,1.15917,0.952715,0.764624,0.777126,-1.77309,-1.84357,-0.421984,-0.0835673,0.659373,0.7448
7347,0.130578,0.114978,0.508928,0.457895,0.820848,0.805825,0.472877,0.431508,0.534787,0.582322,0.31787,0.302865,0.568316,0.497056,0.836837,0.800519,0.0755245,0.122948,0.65003,0.647321,-1.10331,-1.04326,1.12103,1.08241,-0.012841,-0.00303142,0.739006,0.875466,0.79059,0.726207,0.380695,0.179726,1.13536,1.14565,-0.773326,-0.83659,0.669628,0.942487,0.381464,0.46464
7348,0.792315,0.77671,0.945518,0.892043,0.802935,0.729935,0.266885,0.222353,0.751163,0.848908,0.430558,0.416649,0.975826,0.904025,0.49366,0.404019,0.902045,0.951449,0.311993,0.31089,-0.790899,-0.730033,1.06369,1.02326,1.69263,1.79468,0.510233,0.641348,0.750432,0.6839,0.230496,0.0241143,0.189924,0.20555,-0.16053,-0.230128,1.25543,1.5258,-1.9094,-1.82002
7349,0.381635,0.36678,0.464396,0.408754,0.599919,0.654045,0.791297,0.745277,0.459245,0.632583,0.768873,0.756224,0.898655,0.877302,0.0443199,0.00751802,0.0764574,0.127275,0.801886,0.80036,1.60575,1.66509,-0.990952,-1.03452,-0.526436,-0.428325,-0.650079,-0.523895,-0.89336,-0.954345,0.478379,0.268362,0.0114253,0.0440137,0.0989508,0.0256537,1.10625,1.3796,0.155547,0.247783
7350,0.844211,0.829006,0.530213,0.563958,0.657289,0.578154,0.86259,0.814341,0.24375,0.416258,0.174649,0.161343,0.795624,0.850579,0.0125836,-0.0235595,0.131486,0.181431,0.490947,0.557949,-1.31263,-1.25112,-0.218108,-0.264596,-2.1357,-2.03318,1.95181,2.07486,0.504051,0.446185,0.394353,0.190625,-0.133976,-0.117523,-1.35104,-1.4214,1.25395,1.5269,-2.00584,-1.90872
7351,0.551527,0.534494,0.775514,0.719163,0.290662,0.213535,0.138689,0.0916397,0.0998112,0.199933,0.505096,0.491452,0.859698,0.823856,0.671234,0.636466,0.389541,0.464322,0.315961,0.315537,-0.373329,-0.312082,0.103694,-0.0215796,0.568546,0.670703,-1.72125,-1.59862,-2.17809,-2.2426,1.99616,1.78415,-1.05772,-1.04074,0.0141644,-0.0491013,0.455198,0.731332,0.251208,0.351584
7352,0.848117,0.831804,0.685692,0.630799,0.798276,0.721766,0.11895,0.022066,0.971756,1.07445,0.0146031,0.00119537,0.868933,0.797133,0.92133,0.886664,0.696967,0.747213,0.799252,0.799238,-2.1306,-2.07054,0.266728,0.221437,-1.15415,-1.05888,-0.543742,-0.418917,1.14267,1.07939,-1.08707,-1.30718,1.09359,1.11596,-0.610178,-0.668136,0.333699,0.66721,-0.662187,-0.562159
7353,0.182417,0.165548,0.210862,0.157156,0.942146,0.863718,0.00118939,-0.0475076,0.93315,1.03564,0.934693,0.923012,0.175656,0.105208,0.769103,0.651707,0.22322,0.272541,0.509771,0.433629,1.27004,1.33789,0.431529,0.464454,-0.352841,-0.259858,-0.106584,0.0202258,2.60677,2.54039,-0.167999,-0.38868,0.450405,0.471826,-0.171439,-0.230613,0.324693,0.603087,-0.280669,-0.181132
7354,0.733122,0.716566,0.714727,0.659968,0.0332378,-0.0431922,0.686937,0.640226,0.658754,0.732192,0.941307,0.926242,0.11097,0.041077,0.45154,0.41675,0.19172,0.29889,0.0680332,0.0680189,0.504854,0.579296,0.753959,0.707471,0.695603,0.783514,-0.386443,-0.262249,1.1004,1.03943,-1.38394,-1.60371,-0.731736,-0.715296,-0.106082,-0.161359,-0.295102,-0.0199759,0.565441,0.670523
7355,0.650337,0.633527,0.106269,0.0490033,0.603163,0.524891,0.708309,0.662816,0.324375,0.42874,0.939004,0.929471,0.831779,0.760156,0.661606,0.628161,0.27438,0.32524,0.286812,0.265072,-0.499353,-0.426604,1.85307,1.80236,-0.96608,-0.882666,0.202653,0.329869,0.286213,0.231281,-0.761341,-0.975377,-2.23616,-2.21494,0.230132,0.170527,0.792099,1.06394,-0.574786,-0.473613
7356,0.1851,0.167706,0.966643,0.908456,0.678721,0.591791,0.33476,0.290897,0.407025,0.51258,0.0654365,0.0580694,0.628595,0.555034,0.0446132,0.0118249,0.915605,0.967711,0.462692,0.462126,-1.08618,-1.016,0.550799,0.498102,0.282761,0.360347,1.84737,1.98127,0.256064,0.204397,-0.948524,-1.15916,-0.412569,-0.392649,1.45915,1.40197,0.187201,0.522291,-1.2243,-1.13005
7357,0.261633,0.255325,0.456525,0.399905,0.861542,0.658691,0.58096,0.439292,0.758702,0.864608,0.224958,0.21754,0.222467,0.148946,0.565423,0.534131,0.028091,0.0786305,0.13333,0.130546,-0.208159,-0.139527,-2.1363,-2.185,-0.63785,-0.564447,-0.832991,-0.703655,-0.853051,-0.910213,0.0601734,-0.149597,-1.75108,-1.73708,-1.41023,-1.46499,-0.292435,-0.0193578,-0.0651259,0.0290037
7358,0.359799,0.342945,0.419383,0.360534,0.803992,0.725591,0.660119,0.587686,0.115836,0.220336,0.641745,0.636896,0.878301,0.806839,0.764815,0.675486,0.78442,0.836035,0.586269,0.550019,0.35861,0.434615,0.977209,0.931681,0.677326,0.754953,-0.971101,-0.84556,0.465157,0.414207,0.447201,0.233294,1.98558,2.00298,-0.759534,-0.811769,-0.0730956,0.20587,-0.766373,-0.673005
7359,0.0426369,0.0279505,0.626492,0.500931,0.633039,0.513842,0.77812,0.73608,0.441412,0.547709,0.205507,0.200868,0.0486084,-0.0211357,0.848104,0.816841,0.884619,0.84466,0.970227,0.969493,0.0401683,0.123083,1.26252,1.21095,0.838544,0.953786,-0.0424515,0.0878268,1.12156,1.07864,0.115341,-0.105122,-0.480436,-0.460433,-1.15436,-1.19921,1.74567,2.02796,1.02787,1.1189
7360,0.715566,0.699172,0.700842,0.641328,0.354519,0.302093,0.0501371,0.00843863,0.264706,0.371076,0.330573,0.271468,0.0648429,-0.00334815,0.401846,0.370529,0.800364,0.853284,0.361819,0.359539,-0.915773,-0.835817,0.31776,0.262549,1.18661,1.15262,1.2386,1.37511,0.618913,0.574515,0.148285,-0.0748445,-1.45358,-1.43008,-1.17115,-1.22248,-0.697384,-0.4218,0.406861,0.571264
7361,0.296943,0.278853,0.361657,0.30129,0.167486,0.0903446,0.704116,0.660703,0.492212,0.595738,0.411348,0.342069,0.955674,0.888055,0.996616,0.963677,0.479745,0.534007,0.297056,0.295264,-0.338539,-0.261675,-0.394916,-0.453641,1.27466,1.35145,1.70212,1.84431,1.30591,1.269,-0.651665,-0.878456,0.747863,0.772449,0.292539,0.24167,-0.70928,-0.427116,-0.0715515,0.0236285
7362,0.578063,0.557165,0.739312,0.681027,0.208088,0.131753,0.699522,0.653919,0.710851,0.8204,0.419096,0.412669,0.220676,0.154606,0.510243,0.477509,0.543648,0.596898,0.716006,0.714592,-0.288908,-0.247111,0.224985,0.0975413,0.639025,0.683554,-0.824468,-0.689271,-1.17102,-1.20555,-0.849338,-1.04442,-0.4276,-0.399931,-0.427087,-0.470609,1.75608,2.04276,-0.0696201,0.0312089
7363,0.852634,0.835478,0.115553,0.0554752,0.586515,0.509152,0.376228,0.392568,0.189209,0.297386,0.0765356,0.0699199,0.858572,0.791195,0.52266,0.487788,0.183946,0.237746,0.552784,0.582156,-0.305232,-0.232546,0.714385,0.648723,-0.0602865,0.0156551,-0.0924118,0.0437778,-0.565074,-0.604568,-0.990676,-1.21039,0.0796003,0.107093,-0.425756,-0.463278,1.44053,1.72688,-0.86569,-0.761455
7364,0.121675,0.106233,0.49941,0.440241,0.415328,0.246972,0.175138,0.131217,0.257981,0.366558,0.874507,0.868619,0.248204,0.18005,0.856179,0.819647,0.0757859,0.130466,0.336752,0.449719,-0.819865,-0.747189,0.000840191,-0.0695383,0.199078,0.278121,-0.975154,-0.842628,-1.60702,-1.64358,-0.703773,-0.921151,-0.700924,-0.675277,-1.28128,-1.31154,0.390347,0.679479,0.769251,0.871987
7365,0.980496,0.96302,0.389925,0.331235,0.0606471,-0.015208,0.964397,0.921234,0.895207,1.00576,0.987655,0.982403,0.381019,0.281525,0.851545,0.814848,0.663224,0.715703,0.317184,0.317282,0.174903,0.255017,-0.725801,-0.7878,1.31841,1.39822,0.894519,1.02919,-0.000364155,-0.0197771,-0.0179762,-0.233813,0.399658,0.429074,0.0516689,0.0279239,0.179449,0.472695,-0.991998,-0.883369
7366,0.25135,0.233775,0.740741,0.681738,0.189458,0.140574,0.956782,0.914451,0.820738,0.930735,0.497148,0.492146,0.476468,0.382999,0.0840263,0.0484382,0.305671,0.356551,0.89747,0.896617,-1.33033,-1.2545,1.32922,1.27038,0.673937,0.75209,1.20561,1.34716,1.64255,1.60403,-0.999123,-1.22203,1.21189,1.24074,0.238205,0.221473,1.98935,2.27718,0.433528,0.535767
7367,0.61168,0.596244,0.592588,0.532914,0.372379,0.296356,0.159585,0.118902,0.236973,0.346796,0.532248,0.445485,0.416929,0.484473,0.252909,0.215383,0.227241,0.276187,0.318024,0.316405,-0.0809021,-0.00649205,-1.23297,-1.28659,1.21592,1.28837,-0.437458,-0.296739,0.44002,0.399283,-1.74638,-1.9641,-0.800786,-0.776837,-0.879636,-0.903598,-1.42888,-1.14729,-0.613221,-0.512982
7368,0.36512,0.347519,0.814764,0.755775,0.234326,0.112188,0.31514,0.336873,0.711537,0.819768,0.402317,0.398824,0.671854,0.585947,0.987901,0.94793,0.509103,0.557364,0.829574,0.829922,0.59304,0.673511,-0.94451,-0.990984,1.08736,1.15342,-0.108433,0.0362659,0.418491,0.372399,0.802903,0.576923,-0.46706,-0.439789,0.0995474,0.0696741,-0.778857,-0.501125,1.02747,1.12046
7369,0.975377,0.957386,0.36123,0.302557,0.00140303,-0.07198,0.470767,0.554843,0.435072,0.542774,0.783137,0.777713,0.755575,0.687421,0.446503,0.487753,0.57037,0.620255,0.787666,0.815316,1.03715,1.12397,0.892543,0.847945,0.298607,0.367868,-1.16421,-1.02164,-0.700639,-0.742211,-1.23527,-1.45677,-1.52754,-1.5024,-0.0595079,-0.0882862,0.13164,0.410158,-0.284634,-0.190481
7370,0.803468,0.785388,0.278463,0.219226,0.303373,0.229267,0.813448,0.772814,0.405638,0.532889,0.13389,0.127661,0.62224,0.553296,0.067547,0.0275764,0.288079,0.336973,0.799853,0.80071,-0.292619,-0.203788,0.89125,0.813847,-1.82249,-1.75827,-0.622524,-0.473581,-1.17848,-1.21523,0.547789,0.323231,-0.251559,-0.226167,0.966526,0.934541,-0.992565,-0.715669,-0.13,-0.0328211
7371,0.939196,0.921215,0.643258,0.583959,0.178284,0.103039,0.532147,0.489863,0.282606,0.523003,0.249672,0.241444,0.764257,0.693514,0.656843,0.615511,0.354863,0.405398,0.993056,0.992759,0.772811,0.8581,0.95699,0.77975,-2.72602,-2.66816,0.296237,0.377276,1.50655,1.4788,-1.28121,-1.50823,-0.0268657,0.00201234,0.15305,0.116864,-0.604342,-0.333687,0.3699,0.471409
7372,0.86873,0.849926,0.454159,0.394447,0.276733,0.199843,0.906807,0.863705,0.406054,0.513118,0.102798,0.0934262,0.202408,0.131702,0.310998,0.268929,0.789621,0.840297,0.412681,0.412547,-0.0625438,0.0209614,0.790252,0.745653,0.166595,0.224235,1.07452,1.22813,-1.03548,-1.06426,-0.256067,-0.481835,1.04708,1.00079,0.972501,0.937915,-1.77589,-1.5065,-0.0653384,0.0400176
7373,0.305068,0.288211,0.468472,0.408607,0.961007,0.884727,0.667429,0.626098,0.774853,0.880784,0.581049,0.570741,0.431624,0.306586,0.810824,0.770163,0.762024,0.810552,0.0360103,0.0363709,0.979031,1.06913,0.154306,0.106088,-0.631303,-0.577187,-2.42321,-2.2696,1.55822,1.52498,0.415602,0.193111,1.96783,1.99956,-0.0883334,-0.124418,-0.227497,0.046424,1.62967,1.7357
7374,0.869267,0.854754,0.934914,0.876969,0.217927,0.138807,0.958498,0.916551,0.178212,0.286368,0.676359,0.581469,0.552375,0.481469,0.321499,0.279085,0.995499,1.04255,0.226087,0.171842,0.659691,0.743466,0.663036,0.61564,-0.413713,-0.378354,-0.667805,-0.507475,1.55413,1.51455,-0.656306,-0.871718,-0.317772,-0.289463,0.72784,0.696634,0.558265,0.83231,-0.123193,-0.0196546
7375,0.806416,0.793381,0.633949,0.577118,0.37371,0.275164,0.72036,0.678944,0.970653,1.07785,0.602169,0.592198,0.344166,0.304906,0.619639,0.508973,0.539639,0.628625,0.308491,0.307313,-0.504483,-0.414403,-0.150574,-0.192936,-0.277825,-0.179521,-0.344767,-0.189504,-0.400663,-0.436116,-1.14553,-1.36492,-0.175745,-0.15199,0.802096,0.765888,-1.06942,-0.795194,0.798958,0.908406
7376,0.21181,0.197797,0.588728,0.495319,0.492442,0.411521,0.209542,0.166033,0.696698,0.805847,0.159069,0.150645,0.200501,0.128344,0.781166,0.73886,0.16756,0.214703,0.915674,0.916178,1.21035,1.29921,0.022401,-0.0216684,-0.035633,0.0193128,1.43478,1.58846,-0.875893,-0.909137,0.525061,0.306314,-0.442621,-0.425897,0.386287,0.34617,0.7239,0.991775,0.202374,0.312207
7377,0.524541,0.509434,0.47251,0.41352,0.444917,0.451518,0.0631002,0.0183006,0.779415,0.867515,0.531369,0.525545,0.382058,0.233717,0.761296,0.628521,0.412318,0.520529,0.108661,0.111649,-0.259141,-0.164767,-1.41953,-1.47072,-1.58328,-1.52401,0.403574,0.56391,0.814239,0.781685,-0.998263,-1.21776,-1.3451,-1.33291,2.63365,2.58437,0.133994,0.398448,0.821322,0.938782
7378,0.0300996,0.0140403,0.794602,0.735002,0.573469,0.491515,0.575903,0.484972,0.934009,0.929184,0.199224,0.192063,0.409537,0.339089,0.56104,0.518181,0.778288,0.826354,0.310999,0.313635,-1.24474,-1.15501,1.70927,1.66184,2.59903,2.65863,0.489944,0.621609,-1.27003,-1.30439,0.952682,0.726828,0.748897,0.761017,-0.515562,-0.561866,0.491225,0.749465,2.06324,2.17422
7379,0.6897,0.675772,0.483011,0.424411,0.126906,0.0470242,0.996443,0.951644,0.880662,0.990852,0.220485,0.213998,0.360844,0.210083,0.699503,0.648066,0.656466,0.710719,0.0843168,0.0876734,0.438799,0.528945,0.601991,0.557379,-2.42722,-2.36762,0.522815,0.679307,1.36346,1.33221,1.0402,0.818232,3.22384,3.2375,-0.310975,-0.354262,-0.038148,0.216877,-0.54938,-0.443928
7380,0.950626,0.937695,0.619745,0.562753,0.68816,0.609257,0.776596,0.716554,0.552131,0.702408,0.486367,0.387161,0.149916,0.081077,0.819187,0.777951,0.547604,0.595084,0.891269,0.896215,-1.41676,-1.32499,0.0308623,-0.00785001,0.725856,0.791929,1.59766,1.75158,-0.641038,-0.666049,-0.247087,-0.47551,-0.260928,-0.256709,0.441357,0.404654,0.618101,0.87847,-1.52718,-1.41706
7381,0.665835,0.653647,0.472095,0.413929,0.715123,0.636543,0.524794,0.481464,0.301656,0.413964,0.561934,0.560324,0.484219,0.436564,0.132436,0.0909124,0.175891,0.225728,0.624602,0.674429,-0.980319,-0.890746,-1.45323,-1.48804,1.26464,1.32821,0.707972,0.865178,0.284966,0.259597,-0.68261,-0.906638,0.526993,0.526994,0.148493,0.109119,-1.35297,-1.09113,0.0179072,0.124224
7382,0.627139,0.591514,0.883405,0.824013,0.191437,0.113121,0.789458,0.746781,0.203969,0.317041,0.739974,0.733487,0.862002,0.792052,0.753286,0.711027,0.96835,1.01836,0.448649,0.452642,-0.274864,-0.181451,-1.55633,-1.59351,0.21959,0.277677,0.10409,0.259659,0.190343,0.167496,0.562376,0.332973,-1.48095,-1.47656,-0.645752,-0.679619,-1.91219,-1.65354,0.353672,0.461879
7383,0.542083,0.52938,0.0106493,-0.0495021,0.602055,0.521263,0.344858,0.30089,0.68097,0.794951,0.563068,0.55619,0.18194,0.110197,0.861984,0.821735,0.472999,0.523271,0.894354,0.896198,-0.573225,-0.478415,-1.38924,-1.42224,1.15427,1.21418,-1.43158,-1.27183,-1.39419,-1.42296,-0.395088,-0.623954,1.31238,1.31774,0.324366,0.293652,-0.398064,-0.158777,-1.00874,-0.895224
7384,0.0397649,0.0282509,0.220746,0.141652,0.651537,0.519154,0.873232,0.828551,0.420502,0.532647,0.683814,0.675808,0.613044,0.451995,0.000901727,-0.0387574,0.375712,0.427807,0.428133,0.430242,-0.174997,-0.0250791,0.345252,0.387557,-0.825658,-0.767737,-0.971852,-0.816105,1.96137,1.93038,2.10795,1.88685,-0.598352,-0.589922,0.215716,0.179802,1.07733,1.33598,-1.61955,-1.50772
7385,0.361147,0.349648,0.394036,0.332807,0.595988,0.517045,0.619283,0.575656,0.366147,0.477439,0.395208,0.452513,0.868226,0.793793,0.560623,0.519141,0.0478367,0.0985117,0.331211,0.331211,0.332506,0.428256,2.23036,2.19736,0.0027474,0.0642648,-1.16916,-1.01884,0.0589407,0.029136,1.30278,1.08324,1.09139,1.1045,-0.119671,-0.162663,0.529238,0.789156,-0.746957,-0.638853
7386,0.224284,0.21184,0.146281,0.0866657,0.200085,0.121961,0.754807,0.640988,0.850879,0.959968,0.236014,0.229219,0.0834616,0.00817599,0.296062,0.340811,0.823044,0.875523,0.829409,0.829843,-0.894438,-0.792638,-0.0873293,-0.120365,-0.19507,-0.133328,0.809129,0.965248,-0.518924,-0.550624,0.173645,-0.0422673,1.54668,1.56536,1.14173,1.10011,-1.68712,-1.42881,0.639969,0.74898
7387,0.762914,0.748619,0.523705,0.466403,0.0974561,0.0212889,0.86937,0.70632,0.421793,0.5315,0.213746,0.206043,0.168018,0.113549,0.20261,0.16248,0.942311,0.994692,0.965312,0.966901,0.0566334,0.16146,0.423468,0.389187,-0.756988,-0.699901,2.21081,2.36022,1.5335,1.50188,-0.155688,-0.365075,-1.75099,-1.72544,0.0441296,0.10052,-1.1404,-0.824196,2.71399,2.81678
7388,0.0929937,0.0768411,0.665629,0.567692,0.742888,0.664999,0.814158,0.771651,0.859969,0.969258,0.420882,0.414531,0.296113,0.218921,0.507791,0.469067,0.668624,0.720798,0.179296,0.18141,0.74823,0.856462,-0.505724,-0.543064,0.631435,0.692871,-2.83221,-2.6828,-0.702446,-0.739188,0.275344,0.0641586,0.0829754,0.112116,-0.857462,-0.899074,-0.477894,-0.219584,-0.398023,-0.291408
7389,0.135097,0.117017,0.726175,0.668982,0.492187,0.369991,0.490335,0.448844,0.363979,0.47101,0.909355,0.901675,0.634549,0.5566,0.450187,0.413402,0.953279,1.00654,0.712096,0.716305,-1.20564,-1.10207,-0.168588,-0.202089,1.38623,1.44605,-0.784963,-0.635137,0.702954,0.661342,0.469681,0.262232,1.13486,1.17113,1.47402,1.42395,0.965784,1.22562,0.339942,0.441098
7390,0.399148,0.383892,0.0978005,0.038653,0.151961,0.0749824,0.596493,0.553244,0.409378,0.518501,0.341452,0.331902,0.10173,0.0244134,0.717193,0.66567,0.629947,0.681999,0.0385384,0.0402184,0.495291,0.59644,0.64927,0.612937,-0.475953,-0.410997,0.252024,0.406157,-0.519035,-0.562539,0.925241,0.723801,-0.119245,-0.0778009,0.0735242,0.0238586,-1.10364,-0.851777,1.39162,1.49194
7391,0.228135,0.211895,0.666324,0.605136,0.10396,0.0259591,0.0616444,0.0202453,0.876739,0.986321,0.121509,0.113378,0.671762,0.596105,0.955998,0.917939,0.71962,0.770172,0.950895,0.953276,1.70744,1.81073,-2.19952,-2.22866,-0.917212,-0.852413,-0.0746903,0.0784766,0.213422,0.163136,0.342188,0.0570677,0.2815,0.321149,-0.0437976,-0.0899915,-0.0439165,0.202292,-0.910513,-0.809623
7392,0.917255,0.902615,0.490969,0.430561,0.983837,0.908032,0.461115,0.331171,0.401708,0.513315,0.727398,0.719164,0.455267,0.314638,0.761183,0.720988,0.513531,0.55015,0.378973,0.382102,1.50436,1.60527,0.255531,0.233778,0.0786542,0.14708,-2.2275,-2.07186,-1.57221,-1.61626,-0.413612,-0.609665,-0.590044,-0.555597,0.434161,0.394699,1.00247,1.25636,0.806211,0.902629
7393,0.569953,0.557363,0.634578,0.574112,0.500741,0.452345,0.683115,0.642097,0.616537,0.783606,0.645187,0.63603,0.10608,0.0331701,0.106499,0.0639313,0.281051,0.330129,0.0873309,0.0912931,0.649681,0.753772,-0.615034,-0.63775,-1.90819,-1.83484,-0.0475844,0.100437,-0.464549,-0.508136,0.792674,0.600626,-0.144566,-0.108696,-0.699049,-0.744499,1.73622,1.99679,0.0935258,0.185304
7394,0.780723,0.768692,0.188651,0.125656,0.0739355,-0.00334096,0.116991,0.0739135,0.944277,1.0539,0.907489,0.899466,0.946635,0.873578,0.249789,0.205329,0.89201,0.941747,0.0919235,0.0966061,0.987373,1.09549,0.115173,0.0843264,1.32285,1.39338,-0.672146,-0.518875,-0.411799,-0.456991,1.45981,1.27557,0.701725,0.733786,0.419084,0.368415,-0.37206,-0.110872,1.22122,1.31266
7395,0.216351,0.202729,0.10265,0.0372921,0.986105,0.910465,0.841849,0.797647,0.876018,0.983257,0.667105,0.711809,0.782878,0.70976,0.898214,0.854816,0.481149,0.625264,0.573532,0.492784,-1.91959,-1.80699,0.453894,0.425301,-0.190897,-0.118476,-0.409507,-0.262445,0.541474,0.498886,-0.200081,-0.384819,-0.915348,-0.889463,0.860407,0.805938,-1.24461,-0.984655,-1.10928,-1.02034
7396,0.988123,0.973206,0.558163,0.491648,0.110579,0.035832,0.168437,0.125676,0.368218,0.475058,0.533357,0.524152,0.0607759,-0.0125532,0.167597,0.124599,0.258996,0.308781,0.883648,0.888963,-1.09176,-0.97574,-0.524301,-0.553683,-1.31442,-1.24741,-0.750064,-0.605667,-1.30132,-1.34019,-0.0650186,-0.24244,0.585947,0.618688,-1.87195,-1.92511,-0.485304,-0.230953,0.140514,0.228918
7397,0.324363,0.311497,0.649227,0.644943,0.862794,0.787173,0.601018,0.559092,0.970421,1.0748,0.871538,0.863728,0.51629,0.443327,0.0697841,0.0282903,0.492297,0.489101,0.892278,0.838511,0.0611609,0.17874,-0.386451,-0.413975,-0.677216,-0.602544,0.255333,0.406829,0.314086,0.273351,0.0856566,-0.100061,0.763652,0.801232,-1.33545,-1.39405,-0.624123,-0.377156,-0.653736,-0.563746
7398,0.478055,0.49218,0.862713,0.798239,0.210135,0.133779,0.259542,0.217627,0.327902,0.430528,0.441595,0.469332,0.449916,0.393964,0.45103,0.410526,0.621139,0.669421,0.780747,0.788059,-0.971097,-0.857411,1.88655,1.85456,0.757963,0.837955,-0.838088,-0.681804,1.52467,1.49125,-1.79412,-1.97644,0.432578,0.464294,0.67369,0.613649,-0.11157,0.13102,1.6626,1.74711
7399,0.687535,0.672863,0.366542,0.299957,0.834386,0.757111,0.914666,0.874663,0.793225,0.893692,0.0811308,0.0749367,0.309203,0.344601,0.319469,0.278738,0.510414,0.557433,0.0178266,0.0249545,0.1392,0.250098,-1.31171,-1.3487,-0.545843,-0.45899,0.653767,0.811839,0.132499,0.0983523,-1.23303,-1.40892,1.58577,1.61977,2.39378,2.32844,1.32284,1.56116,-0.225814,-0.14655
7400,0.44497,0.443509,0.26378,0.196695,0.445681,0.367631,0.176993,0.136455,0.863623,0.943849,0.894749,0.889942,0.3682,0.295238,0.820761,0.779972,0.100462,0.148518,0.0939663,0.0492965,0.146331,0.30725,0.794697,0.75921,1.12432,1.21544,0.835857,0.992895,0.507042,0.472864,-1.02165,-1.19455,1.98603,2.01872,-0.996948,-1.05821,1.36429,1.60344,-1.08225,-0.99911
7401,0.229196,0.214156,0.744195,0.674462,0.699458,0.543368,0.254852,0.215085,0.761819,0.994006,0.234241,0.230017,0.860454,0.787327,0.372782,0.33366,0.539633,0.588005,0.0655811,0.0736385,0.259151,0.364402,0.085607,-0.0142674,0.285928,0.381767,-1.00478,-0.853377,0.117057,0.0648062,-0.291252,-0.461513,-0.751686,-0.722879,0.546497,0.48274,0.663885,0.902871,0.880168,0.95928
7402,0.417408,0.404536,0.544299,0.471884,0.80004,0.719105,0.633778,0.593398,0.943697,1.04416,0.92814,0.926407,0.800222,0.728948,0.197784,0.156822,0.0428684,0.0929174,0.97438,0.982229,-0.107226,-0.00933878,-0.753141,-0.787745,0.811525,0.902797,-1.55172,-1.39655,-0.307537,-0.343251,-1.38689,-1.55743,-0.358934,-0.323929,0.446334,0.384989,-1.4437,-1.2048,0.718622,0.800193
7403,0.332316,0.31756,0.339316,0.269305,0.486411,0.404576,0.511708,0.471266,0.434571,0.535964,0.627747,0.708889,0.127346,0.0567013,0.547058,0.496439,0.522424,0.572941,0.567597,0.575838,0.649579,0.7483,-0.186028,-0.199803,0.800222,0.888051,1.58328,1.74256,-1.15967,-1.1984,0.808861,0.644125,1.48794,1.52893,-0.309848,-0.372988,-1.70878,-1.47428,-1.25425,-1.17332
7404,0.983813,0.969105,0.708843,0.639017,0.373622,0.270068,0.0747041,0.0350297,0.230738,0.333962,0.389144,0.491371,0.851379,0.780286,0.876895,0.836057,0.247109,0.395983,0.829882,0.838867,0.117006,0.220387,0.426022,0.388138,-0.752946,-0.6687,0.6321,0.792881,-0.838912,-0.87178,-0.768437,-0.926642,-1.14939,-1.1141,1.12074,1.06145,-1.47847,-1.24905,1.09918,1.18647
7405,0.852355,0.835826,0.0684635,-0.0012797,0.218852,0.13556,0.443054,0.40365,0.313354,0.393604,0.275586,0.273854,0.359174,0.289176,0.606438,0.591065,0.169505,0.219026,0.589171,0.61708,1.69316,1.79646,-0.356471,-0.39277,-1.46469,-1.37601,-1.58322,-1.4192,0.639022,0.604999,-0.192629,-0.343309,-0.498385,-0.467198,-0.658191,-0.709593,0.927775,1.15984,1.8546,1.93491
7406,0.0166385,-0.00107036,0.229989,0.116576,0.642153,0.559728,0.146183,0.106066,0.365832,0.453247,0.696368,0.69321,0.399236,0.327591,0.38652,0.346074,0.332376,0.383903,0.388264,0.395294,-0.404184,-0.303587,0.408539,0.377152,0.839721,0.932937,1.03815,1.19844,-0.712044,-0.743808,1.37826,1.22035,-0.0832818,-0.0519137,-0.314271,-0.363886,0.539876,0.768479,1.39112,1.47482
7407,0.814312,0.795492,0.304838,0.234432,0.555011,0.560429,0.86638,0.82468,0.409666,0.51289,0.673025,0.689804,0.0289089,-0.0431224,0.141921,0.101083,0.229729,0.282762,0.765812,0.775028,0.799322,0.898399,0.79002,0.762635,-0.483415,-0.395442,0.60484,0.761174,0.555239,0.521335,0.489025,0.322813,-0.712813,-0.680691,-2.47934,-2.52984,-0.740843,-0.514288,-0.18704,-0.108965
7408,0.773454,0.822075,0.13711,0.0658782,0.642255,0.56113,0.42158,0.378788,0.0463155,0.149462,0.689621,0.686398,0.77932,0.70639,0.810887,0.772125,0.99508,1.04917,0.158518,0.168977,-1.01744,-0.92275,0.694691,0.67173,-0.194283,-0.10337,-0.342012,-0.113118,0.793453,0.754917,2.09164,1.93175,-0.648692,-0.617492,-0.63609,-0.69313,1.50567,1.7293,0.494461,0.577096
7409,0.869587,0.848658,0.401685,0.331845,0.137734,0.0569938,0.340662,0.295759,0.463619,0.566966,0.467739,0.463484,0.953987,0.882851,0.248005,0.210968,0.728571,0.780297,0.586723,0.597577,-1.15012,-1.05251,0.344589,0.409926,-0.57594,-0.484582,-1.15109,-0.987409,0.554479,0.511005,1.60608,1.45269,-0.845644,-0.835158,0.41631,0.358108,0.409099,0.685971,1.38454,1.46016
7410,0.263398,0.243221,0.185683,0.117391,0.873758,0.792336,0.784163,0.739169,0.586302,0.632024,0.780794,0.696487,0.0717413,0.00120818,0.809953,0.773204,0.726569,0.780349,0.704808,0.714745,0.0989936,0.195493,0.17265,0.148121,-1.65609,-1.56569,1.06176,1.22223,0.656159,0.608774,-0.807613,-0.959275,-1.09078,-1.05282,-0.57122,-0.628217,-0.581978,-0.357361,-0.906854,-0.824496
7411,0.301618,0.283397,0.298364,0.228705,0.314849,0.233489,0.736244,0.699411,0.593156,0.697082,0.93234,0.929491,0.8792,0.80668,0.701464,0.666274,0.39446,0.446514,0.0655715,0.0740825,0.947254,1.04285,0.399966,0.313648,-0.467321,-0.383834,-0.812969,-0.656285,1.0695,1.06687,-0.0706523,-0.226234,-0.488862,-0.453129,0.538066,0.484698,1.09106,1.32383,1.92993,2.01466
7412,0.9632,0.945129,0.408602,0.340019,0.281762,0.199945,0.706461,0.659653,0.464691,0.570745,0.933098,0.931561,0.162345,0.0889004,0.869201,0.833218,0.834792,0.886001,0.638255,0.648165,0.219197,0.314114,0.499843,0.479174,0.479264,0.570102,-0.896843,-0.736888,1.57091,1.52496,0.130105,-0.0281607,-0.895053,-0.851342,0.137572,0.0809405,0.41392,0.652878,1.37121,1.46168
7413,0.32067,0.30374,0.749145,0.680661,0.548021,0.545052,0.181854,0.136716,0.76314,0.868321,0.0520146,0.0495741,0.784245,0.710424,0.130158,0.0919642,0.588602,0.637481,0.081629,0.0923558,-1.22488,-1.13445,-0.735664,-0.763746,-0.416492,-0.315958,-0.4462,-0.383946,-0.773867,-0.814696,-1.59169,-1.75046,-0.730561,-0.683182,0.318988,0.257332,-0.802149,-0.563982,0.538572,0.625603
7414,0.954654,0.939551,0.56137,0.587453,0.971161,0.89016,0.772451,0.729048,0.0385799,0.141813,0.622122,0.620626,0.639615,0.515841,0.428694,0.388608,0.598821,0.656517,0.175848,0.188521,-0.489979,-0.393175,1.1293,1.10521,-1.29923,-1.20202,-0.187178,-0.0310034,-1.12522,-1.16578,0.671885,0.516653,0.530123,0.577984,-1.30226,-1.3584,1.40679,1.64977,-0.815914,-0.7315
7415,0.72215,0.722447,0.561585,0.494245,0.226521,0.14424,0.438829,0.396276,0.520903,0.624342,0.128876,0.125408,0.39451,0.321258,0.33239,0.386603,0.578905,0.675553,0.58168,0.592826,1.5664,1.65877,-0.412664,-0.437156,0.844446,0.940628,-0.499665,-0.344012,0.274192,0.234752,1.62477,1.46648,0.339167,0.382172,-1.51806,-1.5782,-0.588363,-0.348166,-0.593336,-0.515251
7416,0.518246,0.505343,0.00181407,-0.0679429,0.558666,0.476244,0.494279,0.45051,0.0605755,0.165611,0.766053,0.761388,0.869521,0.797782,0.424716,0.384598,0.645006,0.69459,0.0411429,0.0516667,1.95054,2.04777,0.720313,0.700676,0.38681,0.483093,-1.87862,-1.72222,-0.269183,-0.314024,-0.253016,-0.409898,-0.702615,-0.665439,0.763195,0.711426,-0.319976,-0.0777101,-1.44545,-1.36781
7417,0.676353,0.708156,0.262051,0.233912,0.672759,0.609902,0.937654,0.89392,0.942282,1.04525,0.652321,0.580108,0.0105953,-0.063101,0.187775,0.146783,0.399469,0.512474,0.191465,0.20377,-0.872839,-0.776054,-1.18244,-1.20551,0.146204,0.238612,-0.634882,-0.481362,-1.34824,-1.39814,-0.226835,-0.379621,0.712698,0.753011,0.0405552,-0.0445119,-0.671671,-0.425647,-0.625072,-0.544858
7418,0.923517,0.910969,0.604582,0.535767,0.824584,0.74356,0.166696,0.124515,0.470685,0.572243,0.402549,0.398829,0.994228,0.920532,0.169893,0.130801,0.280932,0.330359,0.800181,0.812635,-0.332504,-0.233097,-0.905936,-0.926245,-0.591679,-0.499345,-2.09922,-1.95256,-0.967264,-1.00974,-2.26145,-2.41331,-0.477102,-0.434111,-0.755615,-0.800449,1.67524,1.919,0.71848,0.796253
7419,0.559498,0.477785,0.141954,0.0724045,0.653572,0.475659,0.64364,0.602005,0.428938,0.533437,0.579735,0.647502,0.986336,0.913105,0.954201,0.913676,0.264981,0.259122,0.11424,0.125481,1.26859,1.37373,3.33473,3.31442,-0.711532,-0.619302,0.261839,0.414906,0.604047,0.559833,0.375315,0.227918,0.748867,0.797073,0.119031,0.112907,0.064416,0.307211,0.91815,0.998937
7420,0.0556832,0.0446013,0.379074,0.309712,0.28795,0.207759,0.817846,0.777059,0.168819,0.271133,0.901458,0.896175,0.135687,0.0629896,0.757684,0.716725,0.247864,0.187884,0.0836807,0.0961092,-0.764805,-0.666733,-0.442826,-0.456475,-1.10483,-1.01609,1.90304,2.05055,-1.44398,-1.4907,-2.53742,-2.68769,-0.643278,-0.591594,1.0711,1.02626,-0.358153,-0.117159,-1.2503,-1.17272
7421,0.703907,0.690754,0.355552,0.366214,0.945324,0.866753,0.668355,0.639988,0.887033,0.98855,0.41075,0.405918,0.509302,0.355926,0.302622,0.260272,0.0672594,0.116647,0.781267,0.795739,-0.928448,-0.828843,-0.167729,-0.177208,0.773481,0.862602,-1.12758,-0.979586,-0.450212,-0.503636,1.28229,1.13081,0.985471,1.04217,1.461,1.41905,0.612676,0.856318,0.435704,0.508182
7422,0.387645,0.375759,0.491754,0.422716,0.371812,0.293103,0.64952,0.502917,0.241271,0.344278,0.887828,0.883233,0.72233,0.648862,0.331052,0.290486,0.470406,0.517584,0.686517,0.623593,-1.4462,-1.34349,0.913694,0.900439,0.49527,0.588866,0.283319,0.433798,0.271165,0.222039,-2.25903,-2.41605,1.07601,1.13435,-1.18725,-1.22245,-1.66618,-1.42395,-2.60806,-2.53265
7423,0.495069,0.481762,0.914112,0.847162,0.697513,0.620863,0.503827,0.365845,0.841538,0.944019,0.899848,0.895044,0.893008,0.819575,0.829757,0.787743,0.373076,0.42212,0.437655,0.451446,0.491153,0.599509,1.45395,1.43937,-0.949135,-0.861843,0.509577,0.662288,0.000663582,-0.0432663,-0.0126627,-0.165949,-0.725577,-0.664506,0.0618343,0.024775,-1.40167,-1.15349,-2.75956,-2.69174
7424,0.9127,0.899827,0.978872,0.911235,0.610836,0.534998,0.269109,0.228774,0.0020646,0.106849,0.359159,0.355829,0.56271,0.451803,0.973335,0.929141,0.529246,0.635284,0.808386,0.821386,0.345024,0.5172,0.478243,0.460386,0.820123,0.905248,0.322587,0.4725,-0.255131,-0.308572,0.722056,0.567091,0.388211,0.455892,-0.158885,-0.195018,-0.517007,-0.272562,-0.351387,-0.284225
7425,0.4325,0.445806,0.677757,0.611384,0.770851,0.682862,0.571898,0.533192,0.959753,1.06302,0.905574,0.901914,0.156702,0.0840318,0.0293875,-0.0126042,0.801708,0.848448,0.581462,0.595425,0.320615,0.43489,0.780472,0.755991,-0.601031,-0.515865,-0.219873,-0.0706748,0.178048,0.124576,0.243008,0.0880305,0.663141,0.731452,2.02291,1.98537,0.7847,1.02934,-0.580173,-0.518373
7426,0.0062466,-0.00821453,0.0346985,-0.0343218,0.905451,0.830726,0.480093,0.44022,0.631259,0.646544,0.655853,0.663917,0.686125,0.615184,0.137261,0.0937325,0.523814,0.575167,0.00894439,0.0242508,-0.770004,-0.663242,0.838235,0.818681,-1.7585,-1.67577,-0.347598,-0.19695,2.81906,2.76117,0.59119,0.440655,-0.648704,-0.581333,-3.21216,-3.24969,0.70099,0.946182,-0.0247968,0.0306295
7427,0.660611,0.648179,0.406861,0.336655,0.616188,0.540976,0.645327,0.605061,0.125464,0.230067,0.323537,0.425921,0.539239,0.470248,0.574317,0.530914,0.254019,0.301885,0.100858,0.115722,-1.18625,-1.08255,-0.0102249,-0.0233358,1.09151,1.18012,1.14427,1.29669,-0.897702,-0.955893,-1.20093,-1.3456,-0.272042,-0.198888,-0.44329,-0.483672,-0.929379,-0.681321,0.180505,0.233313
7428,0.765982,0.659796,0.774218,0.707632,0.61221,0.537244,0.373375,0.407263,0.816314,0.921326,0.193579,0.187924,0.036562,-0.0307911,0.711918,0.666472,0.959281,1.00899,0.793876,0.809986,-1.88968,-1.77917,-2.58199,-2.59407,-1.94855,-1.85649,0.60197,0.745601,-0.97966,-1.03133,0.756784,0.615517,-0.207256,-0.135688,0.875348,0.841354,1.56922,1.81109,-0.637986,-0.588454
7429,0.684549,0.671414,0.427196,0.362629,0.296612,0.222716,0.247442,0.209465,0.95804,1.06109,0.394324,0.386789,0.799737,0.73396,0.331697,0.346702,0.0235418,0.0739244,0.84801,0.862659,1.86505,1.9732,-1.347,-1.35951,0.377246,0.468446,0.0388008,0.194508,-0.0730171,-0.121863,-1.56782,-1.70418,-1.14025,-1.07579,-0.61228,-0.650555,0.382825,0.622594,0.777901,0.830683
7430,0.947571,0.933337,0.676967,0.587416,0.892531,0.820423,0.638853,0.603011,0.849421,0.954185,0.852957,0.84502,0.466254,0.3988,0.0718969,0.0269318,0.50755,0.491671,0.245618,0.261826,-1.34011,-1.23672,-2.09647,-2.10791,0.699685,0.791159,1.74508,1.90614,0.61682,0.572619,-1.36424,-1.50611,-0.396786,-0.338728,0.833888,0.796956,0.370371,0.617277,-0.600966,-0.540862
7431,0.334268,0.321581,0.876157,0.812203,0.287978,0.216042,0.65009,0.610942,0.331873,0.435759,0.419281,0.408992,0.743656,0.674898,0.781064,0.734301,0.858036,0.909418,0.977957,0.995785,0.52866,0.629923,-0.187472,-0.19239,0.545492,0.640083,-1.0822,-0.920983,1.78292,1.74369,0.288226,0.149116,0.654206,0.63832,-0.0646157,-0.099204,-0.380621,-0.132952,0.989863,1.04718
7432,0.185283,0.173439,0.42144,0.358985,0.754749,0.684625,0.655382,0.618872,0.21749,0.319128,0.268087,0.256035,0.582331,0.515848,0.916186,0.869859,0.848145,0.899002,0.23787,0.258094,0.384574,0.482842,0.343595,0.331645,-0.266771,-0.141559,1.84751,2.0018,0.109276,0.0744896,-0.265028,-0.333268,1.55362,1.61537,-1.51144,-1.54625,0.153901,0.405704,0.0526305,0.103213
7433,0.26293,0.249085,0.604225,0.537921,0.335511,0.349027,0.243004,0.206553,0.440506,0.539808,0.512497,0.491391,0.686691,0.620961,0.228703,0.182821,0.295927,0.344508,0.540675,0.560701,-0.276538,-0.182052,1.19307,1.17678,-1.01374,-0.923202,-1.51478,-1.3669,-1.12579,-1.16399,-0.670662,-0.815651,-1.47707,-1.40809,-0.75435,-0.787338,-0.00438524,0.308153,-0.0283281,0.0187607
7434,0.114887,0.130402,0.838285,0.716856,0.0832849,0.0134299,0.634965,0.600099,0.361644,0.459637,0.796934,0.726747,0.519338,0.502408,0.410963,0.458793,0.876024,0.924325,0.115767,0.134746,0.0815277,0.177389,-1.14013,-1.15795,0.842394,0.938821,1.26969,1.41846,0.253745,0.22207,1.43576,1.29324,0.53562,0.600237,-2.55832,-2.59406,-0.0412018,0.210602,0.157568,0.205589
7435,0.0263984,0.011719,0.958322,0.895792,0.604351,0.532336,0.801622,0.76494,0.48802,0.584032,0.974156,0.962104,0.451586,0.383854,0.780727,0.734765,0.305598,0.354395,0.191078,0.210553,-1.12498,-1.0266,1.65326,1.63111,-0.512256,-0.420439,-0.136658,0.0949675,0.597876,0.564384,1.58963,1.44377,-0.640665,-0.572144,-0.381431,-0.413665,0.162089,0.418844,2.16992,2.21093
7436,0.655188,0.642401,0.918111,0.85642,0.691296,0.618602,0.54943,0.512046,0.356238,0.452408,0.501235,0.499082,0.0817798,0.0131408,0.612312,0.608143,0.18164,0.23162,0.751931,0.769426,-1.77049,-1.67749,0.859604,0.836436,1.80043,1.88851,-1.37734,-1.22852,0.52366,0.488951,0.589076,0.44007,0.54575,0.612622,0.353239,0.317651,-0.535362,-0.281728,1.4623,1.50892
7437,0.452597,0.438535,0.481549,0.402782,0.33895,0.264871,0.978211,0.940731,0.594255,0.698941,0.0461282,0.0360604,0.82164,0.752094,0.528515,0.48152,0.3661,0.340542,0.43784,0.453659,0.882869,0.97651,-0.634632,-0.658445,-2.01725,-1.92432,1.08881,1.23354,0.694391,0.663014,0.647775,0.50085,-0.0431178,0.0276681,1.30951,1.27588,0.433006,0.691749,-1.47222,-1.42282
7438,0.00193957,-0.0118894,0.012586,-0.0508557,0.758708,0.683099,0.145095,0.108658,0.849225,0.945475,0.439076,0.346509,0.456849,0.385792,0.744344,0.636224,0.400486,0.449464,0.338431,0.354628,-0.493529,-0.394601,0.431653,0.404705,1.17765,1.27738,0.755858,0.905856,-1.12675,-1.16129,2.23446,2.08066,0.586403,0.658501,-0.534834,-0.561851,0.993916,1.24639,-0.600891,-0.553948
7439,0.0636361,0.0228559,0.0131713,-0.0512331,0.69736,0.622843,0.183899,0.254317,0.0373985,0.135361,0.668642,0.656957,0.872145,0.802564,0.835641,0.790928,0.912058,0.959855,0.967146,0.984158,-1.24503,-1.1532,-0.646198,-0.669387,1.04306,1.14243,0.0922716,0.23863,-1.00373,-1.03477,1.12807,0.971056,0.21017,0.276177,-0.536299,-0.57127,-1.18343,-0.927096,-0.469516,-0.429726
7440,0.0708374,0.0576012,0.751356,0.689465,0.150822,0.07786,0.379335,0.399976,0.686355,0.785581,0.332578,0.319321,0.412029,0.342101,0.814099,0.770583,0.757147,0.712864,0.0378332,0.0574096,0.19663,0.281709,0.304107,0.283368,-0.17908,-0.0791226,0.454815,0.603067,-0.201518,-0.234284,0.677419,0.52271,1.23129,1.30332,0.815993,0.786349,-0.225802,0.0307035,-0.13239,-0.0920709
7441,0.583935,0.56952,0.621178,0.557323,0.471553,0.391161,0.582071,0.545634,0.366961,0.4679,0.360107,0.439933,0.510894,0.442537,0.251363,0.209427,0.418297,0.465873,0.049988,0.0681267,0.0322656,0.119599,-0.503987,-0.525207,-0.40103,-0.307936,-1.16816,-1.02457,-0.159361,-0.198483,0.853675,0.705821,0.739005,0.771067,-0.080931,-0.109811,-0.0556016,0.224001,1.13034,1.17399
7442,0.639835,0.625181,0.560025,0.425182,0.777761,0.704462,0.213425,0.178825,0.760159,0.860668,0.541621,0.560544,0.887928,0.819296,0.555415,0.516013,0.42809,0.526495,0.543624,0.477145,-0.36312,-0.268521,0.469964,0.44466,0.507155,0.599185,0.0728337,0.216283,0.0933506,0.135122,0.0933888,-0.0102996,0.164695,0.238813,0.037929,0.00644085,0.155563,0.417298,-0.413504,-0.365019
7443,0.91548,0.901859,0.35454,0.293041,0.205738,0.130812,0.409783,0.381262,0.415152,0.517093,0.696069,0.681156,0.982507,0.913237,0.394409,0.282653,0.538104,0.587118,0.866923,0.886163,1.26305,1.35435,0.883352,0.855291,-0.444195,-0.356427,0.315092,0.458386,0.507849,0.468727,-0.577029,-0.72642,-0.00535903,0.0719494,-1.69125,-1.71943,2.21663,2.48394,1.34344,1.39511
7444,0.553521,0.542192,0.937022,0.874002,0.429004,0.356413,0.639999,0.583698,0.699058,0.79919,0.479761,0.462633,0.589972,0.5219,0.0886947,0.049293,0.267709,0.324259,0.726173,0.772131,0.917814,1.01239,1.29033,1.26592,-0.0554298,0.0266058,-1.25488,-1.10475,-1.29713,-1.33838,-0.791605,-0.942065,0.227529,0.300129,-2.32647,-2.35502,0.227606,0.501781,-0.545443,-0.498557
7445,0.720197,0.624072,0.540056,0.556309,0.970358,0.899313,0.821604,0.786135,0.221437,0.320235,0.524015,0.573559,0.459289,0.392204,0.571224,0.531323,0.0142737,0.0614002,0.639779,0.6581,-0.226438,-0.130857,1.0952,1.06835,1.01589,1.10184,0.260648,0.403641,0.139602,0.093073,0.125521,-0.0235642,-1.07393,-0.996825,-0.036492,-0.0653971,-0.201744,0.077411,1.38285,1.42918
7446,0.715579,0.705951,0.300105,0.238616,0.84362,0.773084,0.207541,0.173123,0.0122124,0.108438,0.700995,0.684486,0.823113,0.754665,0.703959,0.691677,0.997192,1.04432,0.152236,0.172155,-1.83914,-1.74618,-0.0748937,-0.0977005,1.55059,1.63812,-0.0987612,0.132245,0.533099,0.573299,-0.650729,-0.796553,0.29019,0.374113,-0.122531,-0.149346,-1.79332,-1.51801,0.730942,0.772736
7447,0.477508,0.472368,0.255119,0.193982,0.934177,0.864202,0.370414,0.337964,0.326544,0.420456,0.255386,0.238436,0.740693,0.670303,0.891688,0.852031,0.928287,0.973975,0.18888,0.148433,0.216478,0.305762,-0.68713,-0.707358,0.888581,0.976122,-0.283949,-0.139151,1.10424,1.05353,-0.585263,-0.735773,0.835207,0.911202,1.05261,1.02421,-0.641802,-0.37219,-0.799837,-0.766277
7448,0.22087,0.238785,0.567259,0.505097,0.313223,0.245662,0.33205,0.301539,0.111258,0.203398,0.696936,0.68164,0.0141295,-0.0575293,0.838448,0.800741,0.0276974,0.0731426,0.130039,0.124711,0.121614,0.203926,-0.270478,-0.291207,-0.721026,-0.628728,-0.399461,-0.250871,2.14747,2.10197,-1.48795,-1.63331,-0.100488,-0.0289019,-0.374342,-0.408763,0.179038,0.445144,-0.429297,-0.39838
7449,0.0147512,0.00520242,0.586131,0.429246,0.512003,0.446122,0.990366,0.958576,0.812824,0.904469,0.888893,0.875385,0.397201,0.323926,0.5303,0.447773,0.0997477,0.0761603,0.0609225,0.100989,0.665356,0.746884,2.06978,2.04176,-1.20632,-1.11762,0.441423,0.589142,0.253091,0.200724,-0.0782117,-0.224349,0.69733,0.768018,2.80217,2.77251,-0.0445825,0.221717,-0.71,-0.67854
7450,0.157404,0.105384,0.414659,0.353396,0.211191,0.146939,0.722127,0.690649,0.848769,0.941399,0.0249728,0.0102729,0.561796,0.489483,0.13009,0.0948045,0.0336131,0.079178,0.0573488,0.0772674,-0.061332,0.0181432,0.903558,0.875969,-0.429862,-0.334917,-0.588676,-0.435407,-0.580756,-0.640345,-1.10639,-1.25718,0.0503179,0.123881,1.26049,1.30365,0.678092,0.946202,0.491655,0.525134
7451,0.217473,0.205566,0.871073,0.81189,0.632427,0.565168,0.663937,0.606737,0.182946,0.276566,0.418958,0.404494,0.423835,0.449479,0.787563,0.75483,0.927304,0.971665,0.985302,1.006,0.331696,0.407146,-0.259068,-0.28982,0.553602,0.648402,0.0299467,0.186635,-0.110532,-0.176228,0.731769,0.583978,-0.33327,-0.258444,-0.135549,-0.165211,0.0506298,0.323139,0.748936,0.786532
7452,0.607848,0.594069,0.267347,0.20607,0.0390488,-0.0292744,0.554713,0.522825,0.807975,0.900753,0.17969,0.16604,0.481835,0.409476,0.402721,0.368358,0.655106,0.697772,0.390059,0.410419,-0.298647,-0.228789,-0.242134,-0.273736,-0.748361,-0.648544,0.146474,0.305368,-0.10159,-0.17039,0.56294,0.361091,-0.22937,-0.150147,2.18305,2.15782,0.885626,1.15745,0.0786348,0.113828
7453,0.36279,0.350408,0.246198,0.185411,0.233598,0.166051,0.240814,0.209724,0.780035,0.871139,0.901711,0.887397,0.872195,0.800527,0.399061,0.363559,0.0672119,0.108723,0.245442,0.265313,0.921809,0.985497,-1.77151,-1.80089,-0.671827,-0.571319,1.25784,1.42253,0.202336,0.14541,0.280735,0.138204,-1.07663,-0.993641,-1.02739,-1.0532,-0.357274,-0.0932563,0.41431,0.451483
7454,0.5127,0.500499,0.775791,0.713164,0.893616,0.825045,0.520024,0.48963,0.998483,1.09182,0.542481,0.529831,0.487423,0.414765,0.912315,0.875554,0.883783,0.927014,0.984048,1.0037,-1.01399,-0.943799,-0.269769,-0.30634,-1.95509,-1.85221,0.940325,1.10952,0.530011,0.46121,-0.329963,-0.465729,-0.245118,-0.166107,-0.805549,-0.828699,0.296068,0.620465,-1.23432,-1.19504
7455,0.145031,0.130747,0.223755,0.161289,0.457036,0.389716,0.59006,0.558694,0.653904,0.748244,0.512572,0.50209,0.786557,0.647371,0.689525,0.653142,0.690805,0.734233,0.525551,0.572561,-1.87398,-1.81035,1.62091,1.57915,-0.663603,-0.565104,0.33126,0.504004,-0.758274,-0.822722,-1.28045,-1.42266,-1.00244,-0.91691,1.41178,1.3927,1.06645,1.33419,-0.602449,-0.568465
7456,0.870443,0.85724,0.218905,0.155644,0.939606,0.872731,0.156678,0.126797,0.0321976,0.128852,0.802372,0.791257,0.951659,0.879978,0.203621,0.166974,0.168811,0.210166,0.121774,0.141424,-0.586571,-0.516642,-0.146646,-0.183376,0.264833,0.35631,0.4896,0.669019,-0.397102,-0.464376,0.470417,0.324409,0.0508805,0.0909145,1.27891,1.2639,0.90467,1.17191,0.620707,0.652285
7457,0.199674,0.185461,0.511781,0.446511,0.57112,0.503387,0.509837,0.480688,0.934232,1.03001,0.141594,0.131333,0.671597,0.59906,0.811272,0.776748,0.567739,0.611103,0.42755,0.449202,-1.77474,-1.7055,-0.935838,-0.978046,0.00111648,0.0974992,-1.95919,-1.77985,-0.613003,-0.677476,0.12495,-0.0140064,1.0132,1.09874,-0.0708341,-0.092178,-0.33498,-0.0628028,0.165294,0.192191
7458,0.265968,0.319867,0.236202,0.171165,0.44584,0.319219,0.137685,0.10877,0.345297,0.4413,0.302723,0.290803,0.604072,0.456095,0.660836,0.625503,0.162823,0.205994,0.125405,0.148274,1.00274,1.06388,0.398984,0.360782,-0.803486,-0.703923,-0.955821,-0.78264,0.648333,0.587667,0.750032,0.614326,-0.0320951,0.0511274,0.256952,0.239708,0.422625,0.6909,2.43429,2.45249
7459,0.469589,0.454273,0.331758,0.265504,0.204585,0.13505,0.282817,0.253815,0.20102,0.294891,0.119167,0.108225,0.385746,0.31313,0.0679558,0.0341804,0.609435,0.651193,0.610876,0.631975,0.62269,0.690139,-1.14197,-1.18158,-0.479409,-0.38121,-0.794715,-0.617625,-0.665469,-0.729778,-1.09401,-1.23365,-2.0127,-1.93655,-0.820506,-0.839671,0.783031,1.05653,-0.749538,-0.733355
7460,0.970519,0.956402,0.739517,0.675588,0.791549,0.72342,0.795417,0.766613,0.657542,0.752512,0.779008,0.769959,0.107265,0.133624,0.91876,0.884413,0.731931,0.775734,0.730623,0.745731,-0.920272,-0.850624,-0.143885,-0.181911,1.39621,1.49748,2.06942,2.2403,2.02884,1.96425,-0.943008,-1.08311,-0.453442,-0.382719,-0.462864,-0.478045,-0.395613,-0.11629,-2.26006,-2.24116
7461,0.166972,0.150128,0.889859,0.824592,0.514747,0.444837,0.935804,0.906142,0.478699,0.575879,0.471548,0.393253,0.0249295,-0.0458815,0.630161,0.665528,0.2774,0.321151,0.779248,0.859487,0.990336,1.06099,-0.343055,-0.379483,-0.459793,-0.35956,0.183235,0.361788,-1.10867,-1.17163,0.733451,0.588117,-0.381466,-0.30471,1.11125,1.09415,1.95418,2.22836,1.18676,1.2025
7462,0.247235,0.24246,0.13729,0.0740618,0.659449,0.591709,0.201821,0.173119,0.98964,1.08422,0.0275077,0.0165464,0.723167,0.651367,0.482359,0.446642,0.430359,0.414502,0.952681,0.973243,1.61708,1.68017,0.219353,0.277011,-1.72621,-1.62454,-1.07862,-0.895628,-0.460635,-0.523824,-1.38726,-1.53686,-1.46565,-1.38349,1.30786,1.2877,0.760437,1.03987,-0.771975,-0.755092
7463,0.350407,0.334793,0.609624,0.547725,0.368919,0.301958,0.798762,0.769964,0.308504,0.404032,0.734832,0.72307,0.446512,0.412931,0.400278,0.365789,0.463478,0.507853,0.803102,0.822884,0.21174,0.276265,0.895918,0.933505,-0.406756,-0.305141,-0.854286,-0.667139,2.18906,2.13384,-0.837043,-0.984368,0.306938,0.387666,0.560751,0.544187,-1.33795,-1.05576,0.829861,0.848792
7464,0.869866,0.856752,0.290071,0.248464,0.798752,0.731037,0.305912,0.277253,0.12874,0.221714,0.857223,0.842687,0.246076,0.174495,0.884434,0.852685,0.112941,0.158241,0.0366705,0.0546111,0.410463,0.479536,1.62643,1.59,1.79682,1.90523,-2.46846,-2.27957,-0.529812,-0.586235,1.83738,1.68885,1.16348,1.24441,0.498156,0.476145,-0.507853,-0.221446,0.576247,0.608824
7465,0.696325,0.735172,0.00941158,-0.050798,0.00419651,-0.0654984,0.125042,0.188563,0.34043,0.448336,0.494202,0.480961,0.318741,0.244292,0.506461,0.475813,0.564577,0.60785,0.452942,0.50602,-0.729721,-0.663713,-0.202376,-0.237076,-0.458228,-0.350131,-0.6204,-0.437158,1.56784,1.51471,1.05307,0.901933,-1.03681,-0.960617,-1.37359,-1.39107,0.642467,0.924379,0.345853,0.368857
7466,0.624663,0.613592,0.911399,0.852764,0.207563,0.146148,0.128649,0.0998728,0.580439,0.674958,0.645178,0.619302,0.383519,0.314089,0.891114,0.862424,0.124687,0.168644,0.938921,0.957429,-0.641433,-0.582583,0.00174544,-0.0351037,-1.88026,-1.77124,1.79906,1.97484,-0.841272,-0.891348,0.980731,0.824197,0.189199,0.270566,0.248318,0.227599,-0.280093,0.00285673,1.64118,1.66488
7467,0.0670956,0.0574273,0.802034,0.845091,0.424735,0.357795,0.179481,0.226252,0.0223653,0.116413,0.634429,0.757644,0.798289,0.730861,0.237065,0.209939,0.33252,0.375351,0.857478,0.874229,-0.124222,-0.0685484,-0.915215,-0.951894,-0.786751,-0.68181,-0.220103,-0.0503033,1.31847,1.26115,-1.03237,-1.19235,-0.180917,-0.0966108,0.430431,0.40399,-0.442805,-0.159418,1.49464,1.52214
7468,0.476537,0.465287,0.84798,0.837418,0.641087,0.569442,0.379404,0.352631,0.452097,0.471488,0.911041,0.895986,0.653555,0.585924,0.775516,0.747711,0.20766,0.248383,0.479601,0.498052,1.40334,1.46082,-2.66594,-2.69781,-1.9488,-1.84171,-0.794001,-0.624876,1.50281,1.44927,-0.620288,-0.780688,-0.778648,-0.694087,1.35145,1.3333,-0.977499,-0.692005,2.29307,2.31542
7469,0.256665,0.246053,0.785134,0.829745,0.629022,0.555954,0.821457,0.796042,0.735104,0.826563,0.361288,0.346639,0.224531,0.156541,0.215817,0.186554,0.799871,0.839022,0.384661,0.404213,-0.000600357,0.0569164,0.331458,0.297852,-0.15245,-0.0434404,-0.837369,-0.674568,-1.31256,-1.37058,0.456167,0.292102,0.860987,0.93968,1.26022,1.23555,0.536662,0.813571,-1.80313,-1.78079
7470,0.687496,0.679015,0.882911,0.822072,0.0150231,-0.0580477,0.727136,0.758938,0.796213,0.889055,0.968354,0.952425,0.67977,0.612421,0.47439,0.447187,0.704062,0.743557,0.98566,1.00269,-0.913913,-0.857142,-0.365749,-0.42041,-0.234381,-0.119194,0.103248,0.258819,0.981698,0.915877,1.09352,0.936138,0.00339918,0.081325,-1.75689,-1.78046,-1.30605,-1.02356,-0.405716,-0.376839
7471,0.194314,0.18796,0.528635,0.467889,0.466514,0.391207,0.707299,0.721835,0.100357,0.193212,0.626906,0.590017,0.0393311,-0.0294535,0.412841,0.386533,0.258759,0.298981,0.325517,0.341341,-2.04835,-1.98423,-1.10375,-1.13867,1.62253,1.74283,0.774893,0.928203,0.397988,0.336117,0.204068,0.0385981,-0.477922,-0.395797,-1.40752,-1.43476,-0.293817,-0.0170809,-0.675346,-0.641392
7472,0.563022,0.555718,0.462591,0.403755,0.405454,0.399258,0.590433,0.684732,0.597079,0.691137,0.242106,0.227609,0.2823,0.211659,0.570323,0.543228,0.169605,0.208715,0.0638965,0.0802346,-1.14011,-1.07549,0.0325379,-0.000839396,2.24493,2.37106,1.13735,1.29264,-2.42065,-2.48373,0.149837,-0.00780729,2.45095,2.53272,-0.618673,-0.645395,-1.37293,-1.09454,0.127629,0.166872
7473,0.574326,0.532727,0.0821391,0.0249658,0.533623,0.407309,0.671978,0.647628,0.880628,0.973234,0.190555,0.161452,0.0246893,-0.0450886,0.725606,0.699924,0.955952,0.995872,0.290412,0.308015,-0.548562,-0.485899,0.931125,0.89091,-0.207185,-0.0773131,-0.657108,-0.505538,0.90931,0.838255,0.462429,0.312482,1.05077,1.12815,-0.789256,-0.819167,-0.804562,-0.449925,-0.14315,-0.0976813
7474,0.490798,0.509735,0.719718,0.664316,0.507564,0.41536,0.592444,0.610525,0.691682,0.786239,0.191002,0.0952945,0.581217,0.511803,0.0584835,0.0336368,0.253264,0.295465,0.203959,0.223426,1.59566,1.65649,0.00507972,-0.0413405,-1.22883,-1.09691,0.477023,0.629738,0.583287,0.461208,-1.14817,-1.30405,-0.0120801,0.0655416,0.821229,0.784969,-0.0829141,0.194691,-0.0988083,0.0420726
7475,0.495527,0.486743,0.0340954,-0.0209426,0.498718,0.423411,0.411814,0.573422,0.768799,0.864989,0.0436337,0.0291372,0.235077,0.16658,0.948943,0.924076,0.867082,0.911512,0.0908095,0.138838,0.21926,0.339964,-1.49235,-1.53622,-0.450381,-0.314204,0.801986,0.895406,0.159253,0.0841621,-0.105509,-0.261582,0.743926,0.818332,-0.144927,-0.187351,-0.506201,-0.229678,0.143453,0.181827
7476,0.285641,0.277898,0.00596928,-0.051188,0.92293,0.84758,0.509416,0.536318,0.362593,0.46091,0.347958,0.389415,0.49034,0.510846,0.302439,0.276696,0.16683,0.211105,0.0367705,0.0542493,-1.03131,-0.97656,1.95888,1.91846,0.737276,0.867648,1.01272,1.16107,-0.717421,-0.787388,0.503356,0.352633,0.602212,0.75899,-1.36835,-1.41917,0.48793,0.761807,-0.12552,-0.0827265
7477,0.758877,0.749789,0.8301,0.771787,0.629496,0.55361,0.408134,0.499215,0.36315,0.477415,0.761735,0.749694,0.922417,0.855112,0.441992,0.418094,0.799961,0.842025,0.188254,0.142886,-0.645545,-0.587557,0.480493,0.438268,-0.212468,-0.0879633,-0.333886,-0.186047,0.0400701,-0.0318343,0.368769,0.213306,0.618599,0.699648,0.0735281,0.113274,0.569735,0.849817,-1.54493,-1.50009
7478,0.207937,0.198653,0.394268,0.334033,0.731663,0.654933,0.487526,0.462112,0.397735,0.493919,0.357296,0.34355,0.301996,0.234368,0.331184,0.306516,0.155738,0.197347,0.340867,0.231522,0.552736,0.614429,0.482414,0.440572,-0.849042,-0.718887,0.670907,0.82645,-0.766683,-0.839987,0.668601,0.515365,-0.489117,-0.409198,1.69228,1.64572,-0.784424,-0.510462,0.350051,0.356381
7479,0.737082,0.729992,0.701356,0.618135,0.259991,0.185201,0.140771,0.115385,0.805322,0.901879,0.372809,0.292025,0.464552,0.395789,0.864111,0.8391,0.782299,0.823734,0.304089,0.320158,1.08182,1.14373,-2.29848,-2.33953,0.712225,0.8443,-1.32634,-1.16803,-0.284973,-0.361903,-0.8997,-1.0554,0.727349,0.807322,-0.786596,-0.834832,-0.358272,-0.082974,2.16801,2.21285
7480,0.332069,0.324783,0.96387,0.902237,0.852603,0.778224,0.304223,0.285364,0.378048,0.473411,0.302096,0.240499,0.263003,0.196131,0.21871,0.19172,0.74042,0.773264,0.0681263,0.0844792,-0.416783,-0.351328,1.13496,1.09576,0.294687,0.372979,-0.29458,-0.14136,-0.363835,-0.437336,-0.734606,-0.888119,0.49766,0.579401,0.0201535,-0.0289711,-0.589687,-0.320495,0.213353,0.255263
7481,0.614661,0.60648,0.739256,0.718533,0.617585,0.545093,0.497595,0.455343,0.880388,0.97731,0.200552,0.188974,0.359625,0.36561,0.0282426,-0.000400109,0.716499,0.722794,0.239054,0.256651,-1.27889,-1.21788,0.470274,0.424526,-0.223704,-0.0983425,1.67661,1.82569,-0.687849,-0.75854,0.429934,0.276774,-0.37317,-0.297345,-0.226966,-0.28046,0.955956,1.23243,0.57857,0.623159
7482,0.330515,0.345915,0.633809,0.534828,0.827553,0.755376,0.738483,0.625323,0.187964,0.287427,0.481415,0.467459,0.601969,0.535089,0.516737,0.486496,0.554881,0.672324,0.865028,0.881107,0.727702,0.787217,0.909203,0.870439,-0.138444,-0.00813141,0.488147,0.630101,-0.512547,-0.584477,-1.30571,-1.46189,0.690333,0.761667,-0.176895,-0.227473,-0.238253,0.0439386,0.0293962,0.0701749
7483,0.0957384,0.0853499,0.499376,0.351123,0.541254,0.470637,0.820689,0.795302,0.178608,0.290904,0.132729,0.120276,0.427967,0.360197,0.059116,0.0300427,0.58269,0.621854,0.627474,0.713471,-1.13335,-1.06672,0.873177,0.842368,-0.579078,-0.449547,1.48801,1.62731,-1.41522,-1.48422,-0.420549,-0.573542,0.0189201,0.0870676,-0.596415,-0.647191,1.39827,1.67558,-0.8872,-0.843568
7484,0.384564,0.372196,0.22905,0.167418,0.59425,0.523202,0.0222204,-0.00562899,0.220549,0.294382,0.917767,0.903361,0.606172,0.536658,0.306596,0.275599,0.813278,0.817592,0.566237,0.545834,1.70854,1.77032,-1.04003,-1.06382,2.04618,2.17535,0.971727,1.11385,-0.104779,-0.174237,1.62387,1.46974,0.555753,0.624156,0.105656,0.0518952,0.39163,0.676043,0.483015,0.52863
7485,0.111305,0.0983466,0.517866,0.453862,0.161534,0.0878728,0.120749,0.0935939,0.196188,0.29786,0.864795,0.914854,0.0373743,-0.0307542,0.851727,0.818379,0.975524,1.01333,0.353494,0.378198,1.45,1.52517,0.157615,0.137334,-0.730269,-0.596472,2.4679,2.6075,-0.184894,-0.249669,0.101552,-0.0543419,0.586624,0.655058,0.397969,0.338579,1.53562,1.82187,-1.12184,-1.07154
7486,0.548189,0.536362,0.030636,-0.0339141,0.418291,0.343353,0.754627,0.726287,0.627202,0.730404,0.989002,0.926348,0.979755,0.909362,0.0118428,-0.0186713,0.936526,0.912402,0.194482,0.210561,1.21999,1.28001,0.453522,0.432939,-0.56584,-0.42997,0.306774,0.442444,-0.046818,-0.107929,-0.556406,-0.706675,-0.946815,-0.877207,-0.332859,-0.410087,0.234745,0.52385,0.326196,0.377662
7487,0.273935,0.262513,0.012432,-0.0545732,0.296611,0.141393,0.0219794,-0.00673611,0.419071,0.565231,0.969334,0.937841,0.763516,0.693459,0.625623,0.596242,0.773443,0.811474,0.822878,0.840092,-1.97595,-1.90768,2.19977,2.1761,-1.71819,-1.58987,0.371245,0.570993,-0.357319,-0.448741,-2.33023,-2.47553,0.356506,0.434348,-1.09813,-1.15875,-0.57736,-0.285515,-0.348791,-0.295043
7488,0.2374,0.226142,0.225798,0.158083,0.0164356,-0.0605668,0.925464,0.897574,0.295235,0.400058,0.96374,0.949334,0.281735,0.211835,0.922652,0.892886,0.503243,0.448232,0.343774,0.359529,0.993084,1.06584,-2.48193,-2.50561,1.0472,1.18157,0.557359,0.699541,-0.863954,-0.789552,0.0225023,-0.0972839,-0.751023,-0.674498,-1.44962,-1.51769,-1.68201,-1.39279,0.0158778,0.0728536
7489,0.955357,0.942025,0.641791,0.573192,0.828515,0.749691,0.649291,0.619846,0.725627,0.828342,0.541709,0.52802,0.198182,0.117276,0.972064,0.942901,0.0447206,0.0849896,0.213121,0.230317,1.14759,1.2238,-0.335777,-0.364579,0.260674,0.396021,-0.841349,-0.695416,-1.06925,-1.13036,2.42627,2.28096,2.08875,2.16834,-0.330871,-0.404774,-0.962182,-0.668302,1.06136,1.1237
7490,0.374088,0.361214,0.0573006,-0.0129693,0.602518,0.522264,0.0248298,-0.00317909,0.943916,1.04902,0.627161,0.600438,0.0928445,0.0227161,0.427097,0.397377,0.436188,0.47588,0.984782,1.00098,-0.0825595,-0.0101349,-1.34619,-1.37583,1.0448,1.17873,0.55557,0.699558,0.502428,0.439212,0.223298,0.0751035,1.16958,1.30007,-0.599261,-0.6716,0.986225,1.27981,-0.11383,-0.0507296
7491,0.0464409,0.0314998,0.848034,0.779087,0.747267,0.684219,0.00731272,-0.0203525,0.0266119,0.133627,0.637414,0.672856,0.822389,0.751374,0.517139,0.48826,0.117357,0.156603,0.919974,1.00264,1.05285,1.12828,0.165174,0.135008,-0.226632,-0.0862528,-1.3498,-1.2133,0.299449,0.240399,-1.03892,-1.18849,0.350281,0.431788,-0.404608,-0.47805,-0.670754,-0.380607,0.347741,0.406703
7492,0.464684,0.454942,0.0790633,0.0116068,0.926429,0.846174,0.716573,0.686984,0.439479,0.584147,0.610704,0.745274,0.27283,0.204519,0.305294,0.27665,0.556186,0.59609,0.987725,1.0043,0.533964,0.68236,-0.945525,-0.969454,-0.397016,-0.252667,1.37697,1.51425,0.493489,0.428512,0.169399,0.0217968,0.395537,0.477687,-1.28524,-1.35778,0.977615,1.26838,1.07003,1.1247
7493,0.893359,0.878383,0.326167,0.258613,0.0681331,-0.010527,0.280569,0.250748,0.92924,1.03467,0.831373,0.817692,0.361713,0.294153,0.379919,0.310318,0.150722,0.190981,0.654327,0.672716,0.162833,0.236437,1.36801,1.349,1.63687,1.78127,0.493658,0.695635,-1.94744,-2.01419,0.591632,0.451031,0.728537,0.814735,0.959524,0.880427,-0.774849,-0.489857,0.0242955,0.0759533
7494,0.801279,0.865885,0.8966,0.829996,0.720822,0.64392,0.895178,0.863623,0.95579,1.06206,0.162476,0.147243,0.698564,0.631833,0.370836,0.343986,0.121126,0.161236,0.583791,0.604383,1.16196,1.23864,0.720199,0.693651,0.0192454,0.160107,-0.260254,-0.122979,2.12809,2.06134,-0.458387,-0.59754,0.0199916,0.109552,0.370727,0.291494,-0.141395,0.141461,-0.0775265,-0.0218106
7495,0.866641,0.853386,0.827088,0.760954,0.419792,0.344738,0.8916,0.862403,0.158421,0.267136,0.880128,0.863236,0.770172,0.705968,0.711283,0.686017,0.915763,0.953866,0.0101271,0.0286892,0.0676367,0.14051,-0.427893,-0.457243,0.0824581,0.222484,1.30042,1.43451,1.63064,1.55721,0.179797,0.0464959,0.210977,0.292095,-0.785328,-0.86121,0.964932,1.24111,-1.09479,-1.0411
7496,0.552004,0.619302,0.211664,0.144402,0.506308,0.431004,0.568517,0.524836,0.432964,0.543733,0.512089,0.466154,0.333361,0.269887,0.28407,0.355047,0.175453,0.212683,0.694384,0.712819,-0.218738,-0.140614,-0.0542648,-0.0885819,-0.68612,-0.548214,-1.54578,-1.40743,-0.408929,-0.477198,-0.178456,-0.311337,1.14931,1.22896,1.03728,0.959891,0.837018,1.11127,0.729343,0.780621
7497,0.396873,0.385218,0.323009,0.273581,0.214414,0.137034,0.21672,0.187268,0.480763,0.685064,0.085662,0.0690713,0.415854,0.441631,0.0472493,0.0240775,0.294592,0.219783,0.038191,0.0565148,1.12694,1.20144,-0.0128742,-0.0413906,0.152377,0.283789,0.628204,0.764866,0.890397,0.816316,-0.530261,-0.66917,-0.205252,-0.129381,-0.272652,-0.351489,-0.317509,-0.0464747,-0.383291,-0.333511
7498,0.500735,0.49122,0.467106,0.40276,0.812721,0.734741,0.660546,0.630679,0.71569,0.826395,0.283718,0.219517,0.635279,0.613376,0.925542,0.900805,0.238806,0.226882,0.24261,0.238543,1.18123,1.25211,1.13592,1.11165,-0.0960874,0.078573,-0.0764443,0.120987,0.853567,0.77401,-0.340428,-0.48606,-0.11376,-0.0883956,-1.10944,-1.18529,-0.815286,-0.547765,0.645761,0.702149
7499,0.278511,0.267662,0.318193,0.253936,0.406624,0.329187,0.821426,0.762849,0.468834,0.578108,0.388541,0.369964,0.848595,0.785121,0.207253,0.18168,0.197703,0.233981,0.402432,0.420571,-0.428257,-0.363211,0.748616,0.725591,-0.22069,-0.126643,-0.667268,-0.522892,-0.858176,-0.942236,-1.28122,-1.42914,-0.12549,-0.0474107,-0.500902,-0.578828,1.06145,1.32135,-1.05251,-0.990054
7500,0.886006,0.873638,0.636416,0.57037,0.42963,0.350463,0.923652,0.89502,0.564506,0.673,0.820828,0.804088,0.425681,0.364099,0.33203,0.239015,0.803377,0.840342,0.0562479,0.0746455,-1.29355,-1.22977,0.360661,0.339535,-0.463269,-0.331858,1.94858,2.09475,-0.242846,-0.325121,-0.630508,-0.785103,-1.20631,-1.12619,-1.11879,-1.17088,0.381614,0.636205,-0.963184,-0.909378
7501,0.858386,0.848355,0.696654,0.630042,0.763879,0.588701,0.0890374,0.0576942,0.295053,0.404854,0.511754,0.557284,0.770813,0.7118,0.320556,0.29635,0.930805,0.969712,0.313385,0.33337,-0.32362,-0.246692,-0.380185,-0.408861,-1.22036,-1.08609,-1.9405,-1.7917,0.0483187,-0.0296601,-0.557153,-0.709472,0.323489,0.398143,-1.68594,-1.76292,-0.71312,-0.454745,-1.51823,-1.46236
7502,0.244152,0.23225,0.532103,0.466832,0.906105,0.826938,0.649501,0.621038,0.029605,0.136709,0.208873,0.310479,0.383368,0.326039,0.0763142,0.0534352,0.369646,0.409865,0.342738,0.359589,0.673189,0.736381,0.0398736,0.00728989,0.490519,0.619388,2.1886,2.3374,1.54238,1.46184,-0.795037,-0.940425,-0.169293,-0.0933894,0.424642,0.353712,0.0185872,0.26974,0.176601,0.233322
7503,0.360065,0.348258,0.817277,0.753276,0.798806,0.720894,0.260944,0.234317,0.0626024,0.168671,0.079951,0.0636749,0.829643,0.772185,0.388477,0.364626,0.483773,0.524428,0.503309,0.385808,-0.795201,-0.727595,-0.113074,-0.1424,-0.0970773,0.033181,1.35993,1.51385,0.936328,0.851219,1.7355,1.58471,-1.53655,-1.46645,1.15501,1.08503,0.169425,0.417042,-0.907814,-0.849565
7504,0.186734,0.17626,0.313129,0.249878,0.305258,0.226613,0.649846,0.623087,0.938761,1.04319,0.596239,0.581002,0.743644,0.687823,0.21874,0.193057,0.191273,0.230202,0.390835,0.412027,-0.320048,-0.260701,2.69933,2.66701,-1.29418,-1.15595,1.00371,1.06642,1.23448,1.14668,3.35341,3.20915,0.520872,0.590464,0.304919,0.236762,0.00792351,0.254768,2.27721,2.3371
7505,0.568217,0.559082,0.999043,0.934506,0.690827,0.613621,0.0340741,0.00543474,0.208832,0.311661,0.681101,0.666179,0.969428,0.913672,0.927477,0.900426,0.557448,0.596046,0.674681,0.695383,0.451188,0.511128,-0.838257,-0.867693,-0.384191,-0.248829,0.459987,0.618985,-0.567826,-0.660424,0.687794,0.536332,0.170901,0.237688,0.728337,0.659969,0.368324,0.620393,1.27624,1.34706
7506,0.186461,0.179346,0.935894,0.870372,0.863961,0.784348,0.334438,0.305825,0.805677,0.906447,0.999087,0.986286,0.0184916,-0.0370077,0.392226,0.364329,0.43722,0.47327,0.677465,0.767102,1.91552,1.97877,-0.0783737,-0.113188,-0.408095,-0.278309,-0.329333,-0.171818,1.45455,1.36127,0.974549,0.825572,0.890031,0.959534,0.0164458,-0.05231,-0.28749,-0.0339173,0.294714,0.357019
7507,0.317852,0.309361,0.175645,0.108972,0.294015,0.215616,0.143121,0.114227,0.890769,0.990286,0.485196,0.471854,0.364556,0.332177,0.615901,0.588254,0.682115,0.719347,0.817383,0.838821,1.26617,1.32789,-0.190463,-0.218658,1.13078,1.2525,1.71886,1.87585,0.289522,0.200178,0.373203,0.221639,-0.263792,-0.194187,0.563872,0.491008,0.593215,0.847015,2.14838,2.20958
7508,0.891223,0.880822,0.259484,0.193335,0.584462,0.507071,0.302575,0.291529,0.508073,0.606598,0.553689,0.538295,0.755289,0.701362,0.472852,0.44612,0.364914,0.44836,0.388254,0.408151,-0.460094,-0.398481,-1.04157,-1.07456,-0.178322,-0.059396,1.42453,1.5781,0.118274,0.0323532,0.642558,0.495966,-1.71523,-1.64561,1.10383,1.03433,0.164228,0.422646,-0.252071,-0.190148
7509,0.888519,0.765045,0.0404042,-0.0260446,0.425742,0.350399,0.547201,0.46883,0.495416,0.500993,0.227144,0.209714,0.163845,0.109835,0.96741,0.943376,0.140791,0.177373,0.844633,0.862611,1.73449,1.79066,1.36392,1.32344,-0.56868,-0.456185,-0.178467,-0.0182483,1.74242,1.6629,-1.90332,-2.05104,-0.333658,-0.25898,-0.850061,-0.926051,0.0127747,0.276442,-0.55171,-0.484149
7510,0.738526,0.649269,0.718898,0.653647,0.70082,0.626337,0.694446,0.646132,0.297443,0.395389,0.281145,0.265317,0.359369,0.380942,0.134163,0.110729,0.170041,0.206933,0.475335,0.492102,-0.721385,-0.658107,0.163612,0.126932,0.318019,0.435687,0.827592,0.994248,-2.22398,-2.3046,-1.45332,-1.60469,-0.924416,-0.843933,-0.430011,-0.502844,-0.947982,-0.678181,1.04962,1.11973
7511,0.623524,0.533492,0.306462,0.239953,0.592997,0.520293,0.852803,0.823434,0.557831,0.656456,0.678994,0.664948,0.705535,0.652049,0.477451,0.452761,0.433386,0.468592,0.423728,0.44165,0.0128133,0.0831662,-0.11158,-0.147072,-1.99042,-1.87011,0.528515,0.696498,-0.666641,-0.751772,0.951091,0.798363,0.793778,0.882307,0.842921,0.773283,-0.657028,-0.391448,-1.94094,-1.86683
7512,0.419924,0.417715,0.689682,0.624719,0.162173,0.0903824,0.584642,0.555507,0.286736,0.38445,0.672811,0.657128,0.313937,0.260711,0.583439,0.559097,0.257737,0.290995,0.37474,0.391198,0.545371,0.612464,0.981939,0.947813,-0.264588,-0.147719,-0.477322,-0.313381,-0.732132,-0.811409,-1.49019,-1.64451,2.28092,2.37411,0.0290675,-0.0443938,-1.90811,-1.64216,-0.374354,-0.293782
7513,0.31234,0.301938,0.735365,0.668127,0.755022,0.683405,0.61144,0.583462,0.271162,0.467159,0.910553,0.89545,0.962779,0.908651,0.170175,0.147407,0.527934,0.568468,0.784239,0.800512,0.0504993,0.113652,-1.62715,-1.65375,-0.737472,-0.620203,1.37097,1.52903,1.45468,1.37521,-0.0592011,-0.206026,1.5998,1.69951,-0.0323142,-0.112436,-0.912535,-0.650673,0.251166,0.271427
7514,0.519211,0.508159,0.983287,0.915133,0.135487,0.0648655,0.398846,0.37146,0.45028,0.549868,0.0515756,0.0362677,0.453326,0.39705,0.257813,0.333515,0.809935,0.84594,0.0304702,0.0478194,0.790354,0.854925,0.694116,0.664697,0.838462,0.960193,-0.554314,-0.401621,-0.51703,-0.591061,-0.0488243,-0.19166,-0.800925,-0.701254,0.141701,0.0639551,-0.204771,0.0590714,0.750155,0.836635
7515,0.487025,0.378471,0.13142,0.0642549,0.782548,0.713758,0.627085,0.60201,0.808104,0.907494,0.0554083,0.0383382,0.415534,0.35873,0.54135,0.519623,0.268987,0.306337,0.748385,0.767348,0.517961,0.58837,-0.127913,-0.160304,-0.325961,-0.199709,0.18069,0.284601,-2.03819,-2.10648,0.506701,0.360836,-0.993589,-0.897066,1.33404,1.25047,-0.742392,-0.473516,-0.856625,-0.763537
7516,0.261103,0.248783,0.94073,0.87126,0.102785,0.0340512,0.457363,0.424135,0.856992,0.954984,0.559209,0.540686,0.130342,0.0728643,0.30372,0.281809,0.715011,0.751537,0.620569,0.638135,1.49296,1.55962,-0.727023,-0.75541,-0.212787,-0.0718049,0.82382,0.970822,0.362293,0.297899,-0.448026,-0.59609,0.642177,0.736701,-0.947296,-1.03218,-0.671126,-0.401759,0.596595,0.685668
7517,0.433,0.419633,0.0995994,0.0310504,0.606564,0.537612,0.273314,0.24626,0.545547,0.55466,0.124,0.104657,0.395238,0.339281,0.604913,0.582802,0.203426,0.241838,0.180744,0.197076,-0.381372,-0.309617,0.912791,0.880237,-0.0731117,0.0560989,1.35802,1.50232,0.462979,0.395668,0.80538,0.659175,0.655288,0.751235,2.49545,2.40828,0.222551,0.493289,-0.321221,-0.228075
7518,0.839367,0.827493,0.0025628,-0.0666406,0.567766,0.498793,0.999876,0.974228,0.0537631,0.154336,0.948706,0.929591,0.110755,0.0534153,0.418795,0.492348,0.33937,0.376002,0.9373,0.952141,0.946194,1.01606,-0.305367,-0.331801,-2.12604,-1.99032,0.18271,0.323302,-0.884658,-0.953139,0.758385,0.61277,1.61008,1.70412,0.779651,0.698957,-0.498854,-0.222466,0.153546,0.244842
7519,0.269708,0.256873,0.635464,0.568653,0.0876434,0.0190908,0.583458,0.557459,0.393664,0.496934,0.846302,0.825997,0.29511,0.14496,0.426125,0.401895,0.756901,0.791524,0.0343254,0.047061,1.24088,1.31552,0.340051,0.414375,1.32595,1.46554,-2.133,-1.98944,-0.769163,-0.841445,1.11,0.965394,-0.844108,-0.742913,-2.03857,-2.11648,0.900647,1.17726,-1.04362,-0.95923
7520,0.090812,0.0793276,0.354649,0.288629,0.440729,0.371807,0.543563,0.515768,0.057721,0.159726,0.338627,0.408944,0.294664,0.236505,0.949642,0.924201,0.878664,0.910692,0.311888,0.324875,0.597582,0.679583,1.18032,1.16055,-0.302463,-0.168547,2.87401,3.01757,1.45859,1.3936,0.217117,-0.00500367,-0.564636,-0.467353,0.567533,0.481788,0.222141,0.492112,1.79643,1.87993
7521,0.556292,0.464946,0.895345,0.830887,0.241225,0.170332,0.111027,0.0838711,0.529286,0.632697,0.0122772,-0.00810849,0.937591,0.877792,0.271879,0.246843,0.635096,0.745322,0.0247476,0.0394329,-1.08813,-0.999189,1.03911,1.02458,1.08592,1.22422,1.28109,1.44619,0.523248,0.461538,-0.832546,-0.975402,0.130116,0.214047,0.326523,0.245934,-0.699116,-0.42941,-0.767048,-0.68917
7522,0.86095,0.850565,0.416627,0.35345,0.939695,0.870695,0.808393,0.781255,0.102571,0.20423,0.385089,0.305022,0.858434,0.798456,0.943069,0.917885,0.546154,0.579952,0.00925199,0.025235,0.826715,0.91243,-0.11563,-0.126318,0.688349,0.827436,-0.268742,-0.125185,-0.0645419,-0.132174,1.29714,1.16145,0.798163,0.895447,-0.816784,-0.893265,-0.0662612,0.201908,1.17263,1.25332
7523,0.44537,0.435202,0.173156,0.112128,0.203164,0.135096,0.0373302,0.0118498,0.941298,1.04315,0.638326,0.618153,0.0559687,-0.00662269,0.0683512,0.0408296,0.695618,0.732264,0.464487,0.479694,1.2054,1.28705,3.01168,3.00624,0.0232014,0.165442,0.531608,0.627283,1.88361,1.8091,-2.18858,-2.32776,1.10765,1.20315,-0.975304,-1.05123,-0.473852,-0.171557,-2.90442,-2.82427
7524,0.709794,0.702076,0.246324,0.185794,0.546408,0.477047,0.66816,0.644543,0.979412,1.03027,0.25201,0.230701,0.840324,0.778953,0.0715267,0.125721,0.8501,0.884577,0.356672,0.309724,0.568706,0.651115,-0.00169375,-0.010911,-1.12626,-0.977472,1.23658,1.37975,0.680334,0.604357,-0.7941,-0.935394,0.199538,0.29613,-0.0269352,-0.105722,-0.813192,-0.545023,0.0716538,0.154236
7525,0.246617,0.241023,0.822903,0.761558,0.223684,0.152589,0.75382,0.655278,0.916345,1.01739,0.614217,0.580995,0.512618,0.452984,0.239491,0.210612,0.0984073,0.131672,0.126274,0.139753,-1.50159,-1.42201,-0.105141,-0.189786,-0.891214,-0.746524,-1.85508,-1.71486,0.0631288,-0.00626631,2.37805,2.235,0.0164554,0.101761,-1.21812,-1.29094,1.69775,1.96234,0.591457,0.673688
7526,0.757499,0.752941,0.914832,0.855897,0.891961,0.822171,0.715933,0.666013,0.399683,0.498965,0.952391,0.93129,0.9209,0.859953,0.0613067,0.0337737,0.136507,0.170117,0.379151,0.392959,-0.157642,-0.0799568,-0.358171,-0.368661,-1.54732,-1.40852,-1.52256,-1.38186,-0.233988,-0.294676,-0.55555,-0.696417,-0.193007,-0.092608,0.481789,0.406492,-0.00177074,0.26936,-1.01295,-0.926484
7527,0.405771,0.40288,0.460497,0.402679,0.474042,0.402505,0.701283,0.676749,0.960431,1.05823,0.304789,0.281238,0.0655408,0.00427522,0.675572,0.648687,0.98168,1.01538,0.345851,0.358939,-0.138127,-0.0586612,0.506291,0.462995,-0.152058,-0.0157459,-0.814367,-0.680722,1.2955,1.22789,-0.610455,-0.758666,1.26339,1.33419,-0.579379,-0.655841,-0.757606,-0.494464,0.0253215,0.109177
7528,0.444494,0.443057,0.532087,0.514737,0.773718,0.703752,0.504198,0.479338,0.46486,0.564899,0.531561,0.509922,0.95727,0.895679,0.961053,0.934605,0.977792,0.998839,0.824347,0.837942,-1.82031,-1.73743,1.29836,1.29465,-0.0949222,0.0466308,0.597917,0.732662,2.45111,2.3823,0.638122,0.496599,2.65935,2.76099,0.452149,0.380172,0.383866,0.65136,-0.106915,-0.020154
7529,0.21266,0.209842,0.57593,0.626795,0.138995,0.0696097,0.548296,0.522779,0.671803,0.770121,0.394003,0.37172,0.902481,0.841536,0.928454,0.903527,0.947578,0.982295,0.22002,0.231891,-0.70422,-0.538422,0.985078,0.97645,0.609703,0.753415,0.482516,0.620943,-0.727555,-0.792059,0.919403,0.770926,-0.349845,-0.247821,0.967354,0.895166,1.06003,1.33046,0.350132,0.437279
7530,0.280508,0.288131,0.79667,0.738852,0.75801,0.687608,0.325944,0.299889,0.551613,0.713865,0.533956,0.511656,0.539816,0.480584,0.596518,0.572174,0.631665,0.640438,0.999181,1.01231,0.571339,0.660588,0.0336986,0.028051,-1.05256,-0.912764,-0.234043,-0.0931737,0.498774,0.441443,-0.767528,-0.923167,-0.21401,-0.110347,-0.551847,-0.629099,-1.01639,-0.746938,1.53024,1.61116
7531,0.354403,0.366419,0.250887,0.192132,0.581774,0.51124,0.921798,0.896734,0.560645,0.657609,0.0116652,-0.0126003,0.994303,0.936465,0.700646,0.678511,0.265601,0.29858,0.466623,0.48085,-0.4871,-0.390639,1.90609,1.897,0.428187,0.572335,1.24714,1.38391,0.226749,0.166709,0.135362,-0.0191905,-0.945081,-0.847749,0.71899,0.647028,-1.5409,-1.27953,-0.750056,-0.673497
7532,0.52757,0.444707,0.859825,0.802465,0.702845,0.632388,0.464781,0.439729,0.703987,0.802064,0.793156,0.770485,0.934435,0.878086,0.0906425,0.0676507,0.981321,1.01504,0.464033,0.468987,-0.936349,-0.83905,0.756533,0.746109,0.480272,0.61712,-0.904657,-0.766422,-0.727284,-0.78137,-0.686624,-0.837561,0.688739,0.786018,1.65189,1.57634,1.78577,2.05261,0.92612,1.00741
7533,0.527719,0.522996,0.312724,0.255745,0.209657,0.138106,0.938697,0.912737,0.625694,0.721893,0.46195,0.437003,0.511806,0.457064,0.777603,0.753437,0.54105,0.575829,0.442944,0.457124,-0.128437,-0.0369385,0.817852,0.808799,-0.0865335,0.0138427,-1.16835,-1.00957,-0.386554,-0.439056,-0.276802,-0.425895,-0.283761,-0.183625,-0.836092,-0.920148,0.813924,1.08423,0.405457,0.48579
7534,0.905242,0.901071,0.692084,0.593491,0.950982,0.878978,0.727865,0.700735,0.971755,1.06863,0.710154,0.685111,0.357217,0.395994,0.235272,0.212014,0.965372,1.00051,0.0085552,0.0209028,-0.169615,-0.0765849,-0.144679,-0.155847,-0.732278,-0.589435,-1.3969,-1.25272,-0.306677,-0.395614,0.761596,0.616568,-0.394244,-0.289166,0.746862,0.666652,-0.501985,-0.231015,1.03708,1.11236
7535,0.271121,0.264708,0.988919,0.931238,0.807217,0.681273,0.0275813,-0.00202194,0.134381,0.231458,0.0260141,0.000344754,0.391392,0.334923,0.945037,0.924025,0.185597,0.220678,0.105972,0.117068,-0.207114,-0.116231,1.07457,1.06453,-0.732613,-0.58946,0.125816,0.270507,-0.29246,-0.352173,0.38772,0.247601,0.173972,0.280804,-0.014605,-0.0913254,-0.127943,0.150967,-2.01591,-1.94328
7536,0.325623,0.32037,0.0704972,0.0114379,0.509937,0.483568,0.726035,0.695362,0.00921221,0.10512,0.854688,0.830249,0.519169,0.479137,0.542106,0.46019,0.506945,0.541345,0.479868,0.491546,1.57288,1.65941,0.234312,0.212909,0.22229,0.364476,-1.04106,-0.894736,0.60705,0.54357,-1.24639,-1.38245,-1.43711,-1.32914,-0.378105,-0.450262,-0.760425,-0.488327,-0.657685,-0.584626
7537,0.600358,0.523183,0.519705,0.459684,0.359357,0.285864,0.413135,0.353219,0.796633,0.892961,0.92029,0.89669,0.672021,0.623351,0.0162278,-0.0036449,0.505816,0.564983,0.234057,0.33885,-1.23701,-1.14865,-0.623507,-0.638707,0.537728,0.68719,0.852321,0.994815,0.233971,0.176607,0.619244,0.487125,0.7281,0.827564,0.349771,0.281054,-1.89238,-1.61415,-0.820252,-0.743713
7538,0.731041,0.725996,0.756013,0.696992,0.420522,0.348044,0.0430507,0.011075,0.499951,0.59642,0.172463,0.146562,0.701273,0.767565,0.513667,0.493612,0.552534,0.588621,0.086877,0.186155,1.22594,1.30719,0.35126,0.33116,0.0852094,0.215868,0.869932,1.00638,1.12774,1.07235,1.01442,0.885704,0.186351,0.28786,-0.760436,-0.828449,-0.584152,-0.312251,-1.25658,-1.1751
7539,0.431157,0.426365,0.383398,0.344937,0.802599,0.728959,0.27491,0.241625,0.786108,0.811949,0.805918,0.782541,0.968248,0.911779,0.0486404,0.0269683,0.355642,0.391137,0.0228522,0.0334595,0.705628,0.792545,0.0900204,0.0721888,-0.411808,-0.255453,0.0874436,0.230009,1.46122,1.39897,-1.54839,-1.68011,1.79831,1.90478,0.129019,0.0535399,-0.768175,-0.489824,0.512318,0.600598
7540,0.998309,0.992908,0.0526074,-0.00711744,0.433996,0.413318,0.164914,0.129162,0.929795,1.02748,0.423673,0.401056,0.813293,0.799624,0.262409,0.302941,0.946371,0.981776,0.0195046,0.0388453,2.63557,2.7182,0.451116,0.427384,1.89089,2.05349,1.36835,1.51729,-1.63689,-1.69367,0.643086,0.506448,0.510854,0.623508,0.0778446,0.000452448,1.23081,1.51371,-0.108466,-0.0253226
7541,0.559895,0.5524,0.408704,0.348408,0.170802,0.0976769,0.857871,0.822184,0.727672,0.825671,0.606274,0.585839,0.742521,0.687469,0.60329,0.578913,0.64188,0.677925,0.0349992,0.0442312,-0.0153794,0.0629545,-0.244737,-0.273759,0.719638,0.80543,-1.272,-1.12806,-0.622225,-0.675154,1.14149,0.997848,1.25125,1.36057,2.03354,1.96361,0.0108405,0.296846,-2.071,-1.98291
7542,0.757,0.74837,0.303371,0.194119,0.697887,0.626212,0.491131,0.477735,0.525432,0.623864,0.359117,0.389246,0.409481,0.365029,0.628675,0.604617,0.882224,0.919419,0.936683,0.948258,-0.32986,-0.182204,-0.19383,-0.226567,-0.605235,-0.442632,0.424337,0.569676,-2.1792,-2.2363,-0.927189,-1.06731,-0.548091,-0.438279,-0.178351,-0.254265,0.281598,0.567302,-1.24493,-1.15996
7543,0.0240716,0.0144489,0.101331,0.0398308,0.959658,0.886897,0.167828,0.133287,0.620901,0.718755,0.211849,0.192652,0.097507,0.0425896,0.193968,0.167721,0.0959906,0.134542,0.239497,0.250602,-0.509567,-0.427362,-0.422672,-0.457558,-0.786964,-0.62448,0.768175,0.991891,1.12554,1.0623,-0.215994,-0.362189,-1.14056,-1.03576,0.581547,0.504651,0.863688,1.15061,-1.23487,-1.15238
7544,0.656071,0.645131,0.343536,0.184694,0.479723,0.407195,0.994979,0.960161,0.122564,0.220508,0.372074,0.409571,0.316094,0.185638,0.886863,0.859036,0.982854,1.02303,0.680869,0.617936,0.288825,0.374749,0.215418,0.173525,1.03115,1.19241,1.26728,1.41411,0.424208,0.36109,-0.283693,-0.424439,0.839848,0.940593,-1.45422,-1.5339,-0.122186,0.167397,-1.58931,-1.50953
7545,0.30847,0.29507,0.389648,0.329558,0.82069,0.749146,0.47302,0.437224,0.787481,0.885753,0.647382,0.626491,0.380779,0.328687,0.310023,0.28289,0.391569,0.433983,0.974167,0.985271,-2.00279,-1.91574,0.244205,0.206314,1.23758,1.39125,1.45364,1.59516,0.258351,0.193265,0.918773,0.770567,1.1562,1.26234,0.553203,0.473791,-2.80539,-2.50949,-0.684862,-0.610971
7546,0.737104,0.722933,0.0339474,-0.0246245,0.582594,0.510781,0.366969,0.329599,0.931155,1.03021,0.151657,0.131273,0.833047,0.779936,0.513908,0.48473,0.366933,0.502536,0.77705,0.789701,0.177198,0.259294,0.474518,0.37871,0.9277,1.08674,-0.20658,-0.0664302,1.77016,1.70096,-0.565616,-0.710293,2.31005,2.41782,-0.674284,-0.75803,2.97199,3.26788,-0.140124,-0.0619687
7547,0.850855,0.838941,0.823049,0.762322,0.585477,0.469135,0.626969,0.63562,0.389808,0.578572,0.0125743,-0.00692984,0.10338,0.0521039,0.122117,0.0929333,0.43744,0.57109,0.0680585,0.081837,0.0671572,0.141819,0.586445,0.551106,0.17967,0.418838,0.739768,0.882424,1.33417,1.21133,-0.181602,-0.327402,0.731971,0.837605,1.46105,1.37439,0.35576,0.656262,-1.19911,-1.12684
7548,0.661327,0.650278,0.652775,0.593769,0.554019,0.427489,0.979735,0.941641,0.0275011,0.126937,0.359259,0.397464,0.749849,0.700044,0.745097,0.718379,0.595446,0.639643,0.917118,0.930297,0.201641,0.26964,1.01358,0.981674,-0.412693,-0.249061,0.987995,1.12453,0.784493,0.721695,0.630905,0.483883,-0.450969,-0.349517,-0.807461,-0.893735,0.219952,0.526417,-0.747391,-0.669403
7549,0.0160284,0.00409097,0.0406893,-0.0171955,0.45794,0.385842,0.130899,0.0931023,0.999717,1.09671,0.821253,0.801859,0.530407,0.478884,0.622033,0.569992,0.0371025,0.0797958,0.480916,0.494075,-1.23787,-1.16602,-1.04366,-1.07611,-1.6311,-1.47062,0.855334,0.998251,-0.475756,-0.533185,2.46313,2.30963,0.303196,0.500208,0.0521106,-0.0415877,1.63548,1.94137,1.50941,1.5909
7550,0.454331,0.442107,0.209794,0.0669432,0.944174,0.874109,0.938769,0.899455,0.221161,0.317184,0.634826,0.613379,0.717447,0.581655,0.450442,0.421605,0.501226,0.559748,0.477005,0.489581,1.32202,1.38729,-0.556274,-0.581921,0.451891,0.61157,1.66452,1.80773,-0.665722,-0.716517,-0.447493,-0.605983,1.24588,1.34993,-0.140764,-0.267005,-0.992216,-0.684081,-0.569043,-0.488758
7551,0.558349,0.548109,0.300311,0.151082,0.239615,0.169818,0.0686979,0.0293918,0.418002,0.512478,0.218433,0.197473,0.79597,0.684427,0.873231,0.842962,0.997573,1.0397,0.212979,0.224608,0.4943,0.565943,1.7707,1.75104,0.644281,0.810419,0.991456,1.1405,-2.02317,-2.08074,-0.675561,-0.836935,-0.235767,-0.133719,-0.417389,-0.492423,0.215222,0.524636,0.897985,0.977331
7552,0.311313,0.299384,0.293878,0.235221,0.834581,0.76284,0.268613,0.134625,0.221753,0.315357,0.121969,0.0995818,0.838722,0.787198,0.436505,0.406066,0.664533,0.609571,0.76583,0.77872,-1.28085,-1.20744,-0.504953,-0.530954,-1.97089,-1.80508,1.07648,1.22672,0.495331,0.434559,0.671701,0.509372,0.324975,0.420431,-0.624143,-0.717841,1.64096,1.95477,-1.09368,-1.00952
7553,0.585151,0.601558,0.755372,0.698297,0.388647,0.361937,0.277914,0.239859,0.987053,1.07941,0.906396,0.882667,0.149378,0.0996277,0.320146,0.32753,0.135529,0.179442,0.665883,0.67969,-0.376129,-0.298709,-0.0660769,-0.0850412,0.577801,0.740612,-0.150289,0.000776007,1.09263,1.03554,-1.0052,-1.16713,1.28413,1.37332,0.773178,0.686037,-0.221975,0.0989353,-1.2156,-1.13885
7554,0.914318,0.903732,0.896735,0.836639,0.0344352,-0.0389672,0.685569,0.649231,0.984864,1.07686,0.130986,0.106895,0.90573,0.854833,0.27836,0.248994,0.820837,0.866659,0.22471,0.238631,-0.529981,-0.460819,-0.156197,-0.175947,0.631985,0.802989,-1.77225,-1.62686,0.401463,0.345235,0.234958,0.0724796,-1.30913,-1.22054,0.521558,0.440833,-0.854416,-0.540359,-0.450094,-0.375863
7555,0.870452,0.793723,0.776265,0.718591,0.91764,0.843105,0.0427873,0.00698139,0.617953,0.708092,0.844865,0.822888,0.647901,0.598086,0.928839,0.898481,0.481073,0.553712,0.223419,0.169986,0.979976,1.05288,0.808132,0.79392,-0.827589,-0.663602,0.782516,0.922299,-0.296182,-0.345072,0.830114,0.670893,0.442536,0.535685,0.286368,0.195629,0.734788,1.04411,0.963252,1.04327
7556,0.69427,0.683714,0.322151,0.265374,0.0119702,-0.0638049,0.68734,0.649008,0.958027,1.05069,0.554122,0.586398,0.865892,0.814552,0.294135,0.261837,0.193967,0.240764,0.157056,0.101341,0.0537774,0.123638,-0.231485,-0.248098,0.660999,0.821498,0.557807,0.702928,0.628628,0.580574,0.302892,0.145888,0.645192,0.734492,0.782668,0.695533,1.11736,1.4261,0.342864,0.417353
7557,0.330834,0.364474,0.409739,0.354592,0.546735,0.469735,0.349444,0.400739,0.0208952,0.113663,0.37237,0.349908,0.86218,0.800033,0.935717,0.901515,0.145778,0.191197,0.0171011,0.0326967,-1.14619,-1.08036,-0.933366,-0.96636,1.35649,1.51346,-0.459515,-0.321621,-0.210565,-0.260496,-0.71194,-0.872568,0.634376,0.720512,0.40038,0.30809,-0.248889,0.0658171,-0.932784,-0.863812
7558,0.0581945,0.0452334,0.0161535,-0.0394997,0.155302,0.0802555,0.192267,0.152469,0.231819,0.323438,0.291595,0.266774,0.835604,0.785515,0.233005,0.198104,0.860033,0.903434,0.956964,0.973847,1.13457,1.20167,-1.67099,-1.68462,-0.515081,-0.357656,1.80412,1.93809,0.614083,0.556785,-1.47577,-1.63158,1.36485,1.45758,1.52064,1.437,0.133511,0.376618,1.65464,1.72591
7559,0.473904,0.458555,0.367996,0.357164,0.496525,0.363596,0.920193,0.880436,0.201129,0.293824,0.728323,0.705131,0.068013,0.0196583,0.991667,0.955734,0.102985,0.143757,0.242744,0.261952,0.048435,0.120181,-0.472872,-0.483468,0.785515,0.945405,0.587087,0.727382,-1.46568,-1.52929,-0.0397677,-0.193091,0.13678,0.224651,0.64021,0.557278,0.37074,0.68742,1.56036,1.62815
7560,0.428392,0.496362,0.811249,0.753828,0.720274,0.646936,0.75979,0.717572,0.592935,0.686591,0.789912,0.766683,0.361402,0.310815,0.883437,0.848804,0.982655,1.02225,0.124163,0.141468,-0.670114,-0.592087,0.932592,0.91814,-0.140334,0.0206106,-1.53029,-1.39122,-0.510642,-0.573411,-0.379287,-0.531506,-0.0787747,0.0122091,1.017,0.935989,0.39824,0.714056,0.775844,0.850364
7561,0.549752,0.53417,0.491149,0.499211,0.424034,0.306112,0.0318627,-0.0100698,0.13244,0.22786,0.367883,0.393257,0.347821,0.298151,0.37069,0.337534,0.277491,0.316334,0.980987,0.996404,-1.02704,-0.950008,0.20121,0.186128,-0.237311,-0.0726573,-0.458729,-0.400961,1.0851,1.02651,-1.21469,-1.36588,-1.51834,-1.42525,0.787494,0.700134,-0.277208,0.043103,-1.64826,-1.57915
7562,0.224734,0.20877,0.359815,0.244595,0.0372611,-0.0347123,0.484715,0.443012,0.859238,0.955857,0.0432383,0.0198313,0.65446,0.605104,0.344679,0.376513,0.881317,0.918207,0.428621,0.445607,0.640189,0.717378,2.22468,2.21384,-1.58181,-1.41841,0.450225,0.589294,1.18411,1.12428,0.638322,0.489902,1.08511,1.18084,1.42434,1.35982,0.564411,0.877419,-0.213229,-0.143507
7563,0.926547,0.909463,0.046465,-0.0100216,0.934249,0.862116,0.576313,0.536684,0.364828,0.462521,0.434462,0.409163,0.544634,0.480198,0.448766,0.415491,0.702062,0.711708,0.842657,0.859387,-1.15947,-1.08916,1.51487,1.49765,-0.595682,-0.512914,0.844174,0.983354,-0.617229,-0.682822,-0.468648,-0.619701,2.09547,2.19419,2.11079,2.0195,-0.860212,-0.545705,-0.993258,-0.921292
7564,0.209677,0.190001,0.80204,0.745481,0.239642,0.168127,0.309601,0.283225,0.267352,0.365599,0.0920474,0.0664131,0.404637,0.355291,0.85972,0.827235,0.46738,0.505209,0.970918,0.985377,-0.298484,-0.227209,1.12329,1.088,0.22784,0.392579,0.620799,0.763983,0.604218,0.535078,-1.1648,-1.31626,0.784992,0.881401,-1.35687,-1.44714,0.92646,1.24126,-0.57778,-0.509231
7565,0.973176,0.954372,0.669806,0.698631,0.296845,0.279227,0.0717695,0.0297658,0.74345,0.843509,0.859756,0.834301,0.754346,0.702993,0.939239,0.908007,0.464298,0.499564,0.805195,0.820375,-0.74243,-0.67562,0.689988,0.678352,-0.394805,-0.224775,1.90219,2.05126,0.787817,0.723191,0.949763,0.804718,-1.23014,-1.13618,0.275178,0.186437,0.819103,1.12765,1.81173,1.88227
7566,0.404016,0.383753,0.658886,0.65178,0.461841,0.390327,0.56838,0.527673,0.573634,0.67289,0.0444966,0.0169614,0.870051,0.818052,0.605875,0.576654,0.00148481,0.0346794,0.369005,0.384154,0.4245,0.493591,0.694414,0.680657,1.22846,1.40137,1.14324,1.28938,-1.48317,-1.55443,0.266932,0.122621,-0.0417619,0.0485876,-2.23935,-2.32512,-0.615585,-0.311712,1.56227,1.63298
7567,0.0943998,0.0747062,0.660906,0.604929,0.339669,0.200985,0.0746921,0.034962,0.761416,0.862876,0.0785968,0.0623495,0.088921,0.0373755,0.708381,0.678199,0.785887,0.816861,0.246985,0.263669,-0.383207,-0.31284,-0.593243,-0.678291,0.873822,1.05086,-0.0425411,0.110368,1.09973,1.0348,1.52873,1.37789,-1.48574,-1.38887,0.715601,0.635127,0.559344,0.866575,-0.483058,-0.415088
7568,0.247124,0.293758,0.852075,0.797709,0.0810153,0.0116427,0.871161,0.829112,0.283448,0.383921,0.132993,0.107738,0.67475,0.623638,0.519719,0.491254,0.186602,0.21706,0.445404,0.460962,-0.695283,-0.624371,-2.01969,-2.03724,-0.53737,-0.355094,0.559393,0.717262,0.615038,0.548021,0.601673,0.451675,1.18839,1.28149,0.314375,0.23137,-1.12637,-0.826407,0.566992,0.635756
7569,0.532848,0.512809,0.184249,0.132032,0.686453,0.615202,0.739887,0.662411,0.313291,0.411317,0.736256,0.709206,0.322068,0.273008,0.0390887,0.0101738,0.918403,0.948761,0.145913,0.160034,0.294828,0.360223,-1.79085,-1.80545,-0.310503,-0.124145,-0.911615,-0.753939,0.360994,0.240592,1.70199,1.55228,-0.84861,-0.753902,1.88262,1.80356,1.80894,2.11071,-3.07364,-2.99872
7570,0.409844,0.388865,0.93156,0.877151,0.294307,0.283072,0.543169,0.49571,0.573647,0.672384,0.416837,0.415495,0.297876,0.250027,0.446717,0.413589,0.0728005,0.10453,0.548919,0.564339,0.156301,0.258083,-0.351713,-0.373094,-0.806378,-0.613041,0.578544,0.739704,0.0143668,-0.0668373,0.47375,0.321728,-0.454137,-0.354951,0.831786,0.755987,0.323079,0.622911,1.2596,1.34104
7571,0.982857,0.960326,0.837346,0.783187,0.0231544,-0.0490578,0.37058,0.329008,0.412358,0.511018,0.148447,0.121784,0.936257,0.886615,0.84871,0.817005,0.572076,0.604751,0.0305295,0.0440782,0.0900601,0.155942,-1.78258,-1.8071,-0.225382,-0.0296121,0.0858786,0.16878,-0.307249,-0.374266,-0.265068,-0.420341,1.19816,1.29344,1.23286,1.16395,0.164661,0.460637,0.472878,0.548372
7572,0.916127,0.894047,0.452663,0.483926,0.28328,0.211627,0.737363,0.697629,0.540832,0.640508,0.359318,0.401727,0.890011,0.77446,0.990896,0.958402,0.602225,0.621975,0.827322,0.842211,0.654943,0.712937,-0.0324449,-0.0639451,-1.97293,-1.77496,-0.563306,-0.402145,1.14634,1.08673,0.234732,0.0867545,-0.80731,-0.710107,-1.32631,-1.39196,-1.37005,-1.07378,0.251087,0.370768
7573,0.161748,0.138747,0.237882,0.184664,0.91026,0.840124,0.890248,0.852261,0.0772232,0.176788,0.70853,0.68167,0.71026,0.662305,0.905746,0.872591,0.735344,0.6392,0.511454,0.546377,2.35281,2.41145,-0.525048,-0.550353,0.467597,0.668578,0.702347,0.871689,-2.1916,-2.24812,-1.19544,-1.34567,-0.0987231,-0.0030654,-0.718889,-0.785494,0.376238,0.667049,0.114562,0.193165
7574,0.743843,0.720144,0.495014,0.40509,0.530018,0.460792,0.642686,0.604327,0.123999,0.217741,0.541385,0.514033,0.450395,0.401603,0.499327,0.465372,0.625569,0.656424,0.233857,0.250543,0.90832,0.962886,0.556376,0.527294,0.711959,0.915602,-0.747121,-0.584647,-0.302237,-0.354028,0.454157,0.309557,0.0833536,0.14315,0.586275,0.523495,0.450356,0.738806,-0.0599318,0.0155613
7575,0.97421,0.951993,0.735888,0.625516,0.387727,0.30647,0.0452831,0.00549329,0.156006,0.258694,0.903159,0.874126,0.508674,0.43996,0.720285,0.712238,0.459647,0.523444,0.610686,0.62502,-0.980319,-0.921037,-1.36511,-1.39443,0.423334,0.583773,-0.0106216,0.148402,-1.89753,-1.94448,0.0232878,-0.121572,0.194758,0.289365,-0.466332,-0.6055,-0.853005,-0.559212,-0.479264,-0.401005
7576,0.45182,0.431352,0.898006,0.845941,0.223454,0.152149,0.984352,0.94372,0.543578,0.646997,0.669869,0.640829,0.409632,0.478318,0.992111,0.959103,0.359078,0.390464,0.750248,0.675716,-0.000451627,-0.0100461,0.902308,0.874104,0.171372,0.251944,-1.48118,-1.3228,-0.444262,-0.483487,-1.54917,-1.69234,-0.0158346,0.0769229,-1.67663,-1.73449,-0.393487,-0.100707,0.00844731,0.0880148
7577,0.557935,0.537355,0.578036,0.525588,0.554073,0.484152,0.852203,0.845424,0.502523,0.608191,0.801732,0.770526,0.566059,0.516675,0.484501,0.452824,0.530951,0.541931,0.734572,0.726412,0.839418,0.900945,-0.0243881,-0.0581468,-0.28353,-0.0798858,1.5811,1.73745,-2.09732,-2.136,-0.855583,-1.005,-0.918073,-0.830094,1.08096,1.03153,-0.747358,-0.462543,1.03964,1.12368
7578,0.412098,0.427345,0.783075,0.728049,0.0370281,-0.0346399,0.788576,0.747128,0.169171,0.367341,0.568033,0.537229,0.756824,0.708166,0.571865,0.53855,0.598399,0.693397,0.772658,0.777108,1.13185,1.2004,0.205979,0.122873,-0.707673,-0.506749,0.428915,0.588963,-0.305797,-0.336489,0.950307,0.805273,0.449991,0.540844,0.820442,0.764702,0.35424,0.63711,-0.394143,-0.310501
7579,0.336554,0.317336,0.444904,0.388011,0.241222,0.239405,0.476286,0.434027,0.0223744,0.12649,0.850328,0.821331,0.122599,0.0760876,0.157088,0.122057,0.680998,0.844863,0.883651,0.827804,-0.157051,-0.0963297,0.338054,0.303892,-0.611004,-0.416537,0.822218,0.983023,0.339482,0.31132,-1.69826,-1.84973,-0.844072,-0.75611,-0.6724,-0.727207,-0.496275,-0.219136,0.899642,0.985518
7580,0.761915,0.740428,0.489343,0.39584,0.585776,0.513449,0.629346,0.588659,0.245742,0.351945,0.304256,0.276913,0.120028,0.075149,0.354369,0.318736,0.964943,0.996329,0.935511,0.8785,-1.72577,-1.66832,0.309546,0.275821,0.373123,0.566781,-2.81329,-2.65249,1.26506,1.23697,0.789932,0.64376,-1.05983,-0.968552,-0.0785478,-0.136611,1.51769,1.79643,-0.395456,-0.309838
7581,0.305288,0.28533,0.557792,0.403668,0.149374,0.0781205,0.369093,0.331002,0.857056,0.961672,0.236766,0.208834,0.119755,0.0742103,0.327939,0.372614,0.433018,0.462282,0.96192,0.929197,1.03147,1.08708,0.994408,0.954181,-0.123011,0.0778851,0.300887,0.468564,1.12166,1.09947,-0.597773,-0.745395,1.05004,1.14064,-1.1904,-1.24611,0.0105575,0.292743,-0.526935,-0.439169
7582,0.702487,0.60036,0.468389,0.411496,0.447737,0.30542,0.790596,0.755264,0.452408,0.557594,0.995288,0.9657,0.649232,0.605363,0.430703,0.426493,0.955935,0.987499,0.965558,0.979893,0.927339,0.985249,1.21639,1.17251,-0.897226,-0.692813,1.16593,1.34053,1.51516,1.48787,-0.768557,-0.914182,-1.56413,-1.46969,1.40278,1.35215,-1.28468,-1.00527,-1.15713,-1.06509
7583,0.934327,0.915391,0.161889,0.105526,0.602304,0.532719,0.267116,0.232327,0.633709,0.73449,0.873469,0.842497,0.678125,0.633174,0.517764,0.480372,0.490802,0.522615,0.536121,0.549223,-1.76947,-1.71417,0.282808,0.240261,-0.540427,-0.250688,1.1264,1.30489,-0.0518505,-0.0732753,1.41825,1.27237,-0.963729,-0.869998,0.483271,0.426806,-1.73529,-1.46065,0.0959893,0.184165
7584,0.751901,0.763458,0.709979,0.653394,0.453685,0.476472,0.646985,0.564703,0.806294,0.911386,0.355888,0.322424,0.485242,0.386888,0.753906,0.690525,0.638141,0.686178,0.601938,0.555311,-1.28598,-1.23,-1.07721,-1.11427,-0.00365893,0.191436,-0.503338,-0.32275,0.744285,0.727206,1.01893,0.872522,0.430359,0.516628,0.172045,0.113475,-0.452206,-0.174479,-1.90582,-1.8184
7585,0.628258,0.611525,0.493599,0.401951,0.491196,0.420225,0.931134,0.897078,0.252069,0.357597,0.998079,0.963231,0.186889,0.140601,0.93966,0.900678,0.744736,0.849741,0.549596,0.561399,-0.0218639,0.0342608,0.690566,0.647014,0.549942,0.743395,0.412637,0.595705,-1.39251,-1.40499,0.126499,-0.0250178,1.00713,1.0866,-1.3145,-1.37843,-0.00225058,0.268779,-0.390262,-0.305072
7586,0.904861,0.888203,0.20728,0.150507,0.55026,0.531722,0.959456,0.925034,0.419129,0.522368,0.12782,0.091829,0.640031,0.59185,0.16097,0.124303,0.981492,1.0133,0.504113,0.567487,-0.658667,-0.601674,1.29789,1.24886,1.90574,2.09272,0.49661,0.604946,0.804307,0.79801,0.646979,0.497136,-1.06154,-0.9806,-0.586244,-0.647119,-0.324721,-0.0470976,0.312566,0.396926
7587,0.444691,0.427149,0.325826,0.268988,0.781491,0.643219,0.259692,0.227878,0.926911,1.03071,0.634053,0.599438,0.86486,0.817698,0.803591,0.768587,0.790273,0.827157,0.504562,0.573575,0.0719295,0.123992,0.638474,0.593514,-0.246883,-0.0669207,0.43095,0.614188,-0.245511,-0.255845,0.893543,0.741383,-0.269596,-0.18368,1.05953,1.00256,1.93536,2.21478,0.460676,0.538983
7588,0.429277,0.412047,0.758702,0.703137,0.826046,0.754716,0.832229,0.800327,0.163127,0.26677,0.555274,0.558575,0.643549,0.596538,0.281037,0.247488,0.675497,0.64101,0.566561,0.579663,-0.512222,-0.465408,0.52419,0.540209,0.053209,0.240961,1.46108,1.64086,-0.148167,-0.158076,-0.468522,-0.61649,0.132606,0.21527,-0.178133,-0.229265,0.644017,0.916765,-0.188125,-0.0331085
7589,0.655126,0.638603,0.62253,0.670049,0.66404,0.592786,0.580765,0.521659,0.425232,0.618781,0.55077,0.517711,0.692683,0.60928,0.779732,0.744745,0.424428,0.454863,0.0175606,0.0288663,-0.312216,-0.262137,0.599463,0.486904,-0.434678,-0.32167,0.620335,0.801263,0.207937,0.200269,0.0562724,-0.0943361,-0.508301,-0.428867,-0.912164,-0.957808,-2.14635,-1.87458,-0.680149,-0.6052
7590,0.613649,0.597463,0.604006,0.636961,0.734127,0.663905,0.274585,0.242992,0.86885,0.970793,0.00841897,-0.026707,0.668743,0.622022,0.628726,0.5935,0.804297,0.835616,0.574713,0.58774,0.775724,0.829314,0.374911,0.4336,-1.03559,-0.884302,0.548276,0.734956,-0.185836,-0.196228,0.302094,0.149911,-1.67369,-1.60125,-0.32537,-0.367212,-0.576547,-0.306743,-2.08275,-2.00782
7591,0.335654,0.318466,0.659439,0.603874,0.485063,0.440524,0.703643,0.671677,0.0825615,0.185218,0.120664,0.0870763,0.0517181,0.00572721,0.807308,0.77089,0.717293,0.750036,0.508986,0.523465,0.239675,0.286001,0.425255,0.380295,-1.63469,-1.44693,-0.43731,-0.244064,0.0846576,0.0692897,0.234223,0.0876616,0.0603182,0.13949,-1.13889,-1.18489,-0.143283,0.120745,0.889166,0.956592
7592,0.308307,0.255232,0.0427093,-0.0126787,0.289449,0.217144,0.399392,0.369245,0.886613,0.987161,0.759724,0.727883,0.702508,0.658487,0.282529,0.245081,0.939089,0.971708,0.909088,0.922923,-1.1355,-1.08511,-0.48176,-0.521854,-0.977449,-0.787608,3.10311,3.29273,1.38336,1.3628,-0.216482,-0.360684,1.11824,1.1985,-0.415463,-0.475799,1.46881,1.73579,0.443592,0.510741
7593,0.20526,0.191997,0.087149,0.030729,0.469897,0.398467,0.956831,0.926708,0.508405,0.608289,0.380974,0.351058,0.00291167,-0.0426578,0.469622,0.445519,0.775712,0.808914,0.956176,0.969959,-0.683474,-0.634655,-0.0864256,-0.122063,0.766151,0.950823,-0.150167,0.0472138,-1.74727,-1.77308,-2.04423,-2.19215,2.42175,2.51006,0.280991,0.233291,-1.33888,-1.07236,1.17497,1.24325
7594,0.14595,0.128762,0.617279,0.562881,0.278187,0.206432,0.89858,0.828412,0.965295,1.06591,0.250551,0.222468,0.140955,0.161202,0.682757,0.645957,0.358766,0.390049,0.349688,0.363909,0.42752,0.472853,-0.309956,-0.393558,1.39498,1.57905,-0.118121,0.0329107,-0.236716,-0.265385,-1.32322,-1.47296,0.510336,0.602398,0.347947,0.302545,-0.495114,-0.220826,-1.05941,-0.993926
7595,0.833826,0.81492,0.531148,0.474517,0.571382,0.497887,0.761,0.730116,0.961753,1.06336,0.420223,0.392405,0.409437,0.365062,0.303529,0.269085,0.528273,0.507902,0.913674,0.927297,-0.427685,-0.398929,-0.709116,-0.665053,-1.16227,-0.978015,-0.178773,0.0186076,-0.93114,-0.96659,-1.50712,-1.65675,-0.115469,-0.0263794,-0.711813,-0.759788,0.577564,0.847654,0.813543,0.87598
7596,0.795322,0.778549,0.0756516,0.0212998,0.224912,0.153603,0.184251,0.151502,0.173295,0.273617,0.318105,0.216055,0.774619,0.731945,0.584403,0.550782,0.596511,0.625755,0.391639,0.407036,-1.31483,-1.27071,-0.900911,-0.936548,0.801405,0.991039,0.730347,0.922053,0.233293,0.204478,2.20178,2.04966,0.101476,0.186455,0.999429,0.955007,-0.0717133,0.193343,0.395142,0.459413
7597,0.483842,0.484019,0.646793,0.592683,0.534509,0.386585,0.345788,0.237201,0.646893,0.746589,0.0677807,0.0397054,0.899099,0.793145,0.867045,0.832479,0.21575,0.246034,0.742893,0.756641,1.23405,1.28261,-0.295828,-0.334702,-0.943787,-0.754311,2.40031,2.58826,-0.609797,-0.636592,0.807097,0.660508,0.650727,0.657153,0.148542,0.106743,0.0214228,0.281353,-1.24316,-1.17296
7598,0.207029,0.189489,0.629498,0.577092,0.688858,0.619568,0.355174,0.322899,0.285574,0.383161,0.734223,0.70636,0.894873,0.854346,0.767589,0.757767,0.393288,0.409266,0.531918,0.540944,0.0977012,0.126434,-0.466897,-0.486993,-0.389747,-0.202352,-0.0335193,0.1543,-0.695798,-0.728692,0.324953,0.181447,1.04274,1.12785,-0.157175,-0.206589,1.16613,1.42718,-1.13824,-1.05983
7599,0.844466,0.8253,0.919822,0.86796,0.59613,0.482228,0.727327,0.696741,0.532319,0.629886,0.158216,0.131996,0.550526,0.582201,0.860763,0.683056,0.539666,0.572497,0.31382,0.325247,-1.08347,-1.02974,-0.598739,-0.639284,1.43269,1.61453,0.0348061,0.245131,-0.194797,-0.233149,0.282924,0.135042,0.120924,0.204632,-0.965533,-1.00982,-0.988147,-0.727929,0.657069,0.732072
7600,0.448837,0.42915,0.225003,0.172729,0.413657,0.344888,0.0544791,0.0247699,0.204329,0.302723,0.18481,0.15842,0.351826,0.310056,0.755319,0.608345,0.180813,0.213346,0.639461,0.648982,0.371143,0.422142,0.318191,0.281979,-0.0926774,0.0878048,0.23739,0.335962,-0.835433,-0.873343,1.79898,1.65065,-0.00912092,0.0682597,-0.147623,-0.188769,0.31528,0.573974,-0.913043,-0.835574
7601,0.716976,0.696025,0.808759,0.758188,0.821196,0.75303,0.135984,0.108323,0.149337,0.319228,0.677484,0.651046,0.88878,0.846456,0.642408,0.533634,0.522469,0.525998,0.52252,0.550023,-2.41715,-2.3583,0.602262,0.561246,-0.453098,-0.366571,0.238973,0.426793,0.584088,0.542055,-0.268173,-0.414508,1.76615,1.83941,1.7292,1.69233,-0.312743,-0.0490892,-1.80722,-1.73337
7602,0.178868,0.159768,0.839599,0.786637,0.140757,0.0733238,0.440209,0.41274,0.236842,0.335733,0.371827,0.347346,0.964701,0.870487,0.493488,0.458922,0.805608,0.838651,0.440156,0.451065,1.47595,1.52957,-0.0736521,-0.109984,-1.0061,-0.820947,-0.940907,-0.752223,0.604479,0.563166,0.880868,0.732541,-0.299275,-0.227784,-0.988502,-1.02118,0.576572,0.831843,-0.816203,-0.743724
7603,0.793038,0.775099,0.0511977,-0.00124512,0.5864,0.51707,0.255592,0.230773,0.56648,0.663106,0.634962,0.60402,0.936962,0.894517,0.242888,0.264324,0.0369566,0.0696321,0.614286,0.578289,-1.86453,-1.80823,-1.44653,-1.48023,0.278022,0.466158,0.101728,0.289071,-1.52538,-1.56903,-0.581779,-0.732604,-0.397069,-0.317103,0.149922,0.120188,-0.0826309,0.177532,-1.39579,-1.3252
7604,0.113794,0.0972869,0.492025,0.438129,0.551251,0.483526,0.43821,0.405309,0.0359866,0.134644,0.886454,0.860694,0.752348,0.730009,0.102438,0.0697257,0.350777,0.384477,0.697596,0.705514,0.0735699,0.134767,-0.467507,-0.496846,0.405035,0.586982,-0.905383,-0.720807,-0.182939,-0.230416,0.105413,-0.0452652,0.116696,0.118909,0.611356,0.560279,-0.400707,-0.138344,1.06285,1.13409
7605,0.57699,0.559514,0.111672,0.0593395,0.806991,0.739006,0.591216,0.579846,0.321915,0.421916,0.276083,0.251212,0.60983,0.565502,0.194012,0.160608,0.940719,0.975116,0.226265,0.2345,0.777767,0.844062,-0.180145,-0.201241,-0.89009,-0.709964,-0.694646,-0.510165,0.0711907,0.0203033,-0.3029,-0.461597,0.466411,0.554921,1.02586,1.00037,1.46335,1.73077,2.60504,2.67537
7606,0.204387,0.18519,0.726804,0.674347,0.0324748,-0.0354122,0.947538,0.754382,0.843773,0.945436,0.72709,0.704533,0.871841,0.827074,0.567358,0.533068,0.528395,0.561048,0.870752,0.877845,-0.291724,-0.223431,1.04466,1.01913,-1.36144,-1.18245,1.05659,1.2369,-0.0800603,-0.130798,-1.20402,-1.35914,0.468333,0.556034,-0.384599,-0.416225,-0.349251,-0.0756062,1.31824,1.3942
7607,0.836975,0.815872,0.055488,0.00332907,0.200366,0.17796,0.953738,0.928919,0.513906,0.683632,0.611887,0.591172,0.908137,0.865489,0.738484,0.704263,0.412733,0.443878,0.419067,0.426536,-1.72647,-1.6591,-1.00189,-1.02521,1.57335,1.75346,0.183135,0.365454,0.71334,0.65739,-0.200909,-0.34957,-1.20729,-1.11782,1.04759,1.01822,0.700102,0.978095,1.05239,1.12965
7608,0.832729,0.81123,0.777801,0.724049,0.354865,0.391333,0.164644,0.139827,0.317279,0.421829,0.827678,0.804258,0.409654,0.369687,0.53728,0.502194,0.638746,0.670485,0.861392,0.870092,-0.991126,-0.917822,0.11715,0.100516,-0.00316615,0.181177,-0.487825,-0.301771,0.749667,0.693191,0.538668,0.38347,-1.77417,-1.68745,-1.83455,-1.86704,-0.0238875,0.262341,-0.282051,-0.212256
7609,0.348382,0.324636,0.928679,0.873053,0.672661,0.604705,0.237357,0.129194,0.748738,0.854373,0.0474493,0.0238304,0.75001,0.711668,0.678085,0.656897,0.0309213,0.0648251,0.0659214,0.0745121,1.87286,1.9519,2.01357,1.99828,0.287148,0.473249,-0.844801,-0.643214,-3.72444,-3.78091,-0.778106,-0.925817,-1.33985,-1.25545,0.23867,0.204117,1.1437,1.42355,1.79891,1.87391
7610,0.827655,0.805951,0.689282,0.536442,0.323133,0.254624,0.145577,0.118561,0.402651,0.506945,0.492606,0.467035,0.544982,0.506546,0.848669,0.811601,0.87448,0.910092,0.0514666,0.0603142,-0.513381,-0.433396,0.400968,0.378296,-0.646489,-0.466478,-1.17352,-0.984656,1.02761,0.971135,-1.10638,-1.24863,-0.68116,-0.59423,-0.923758,-0.993522,1.11876,1.40261,-0.712909,-0.62906
7611,0.513899,0.490957,0.258053,0.19983,0.192426,0.123097,0.874738,0.846528,0.479401,0.585695,0.084838,0.0608918,0.137417,0.100458,0.756068,0.720822,0.026173,0.0619498,0.430012,0.516575,0.614946,0.688369,1.29313,1.27005,-0.441061,-0.26763,-0.294219,-0.112687,0.152079,0.0995849,-1.15525,-1.29503,0.235892,0.326992,-2.15079,-2.19116,0.140046,0.419391,-1.39422,-1.31448
7612,0.487819,0.465674,0.766539,0.707383,0.667718,0.596691,0.810154,0.783948,0.290758,0.3987,0.167599,0.141714,0.525011,0.487211,0.890884,0.85638,0.709602,0.744228,0.961618,0.972835,-0.568465,-0.500489,-1.01468,-1.03314,0.546696,0.715689,2.12325,2.29931,1.14028,1.08665,2.01662,1.87537,-0.128728,-0.0401849,1.33284,1.28616,-0.270025,0.0115639,-1.48309,-1.39894
7613,0.956873,0.93234,0.202022,0.141241,0.833531,0.762851,0.160264,0.131626,0.457007,0.56347,0.980102,0.95164,0.584137,0.546185,0.478319,0.44469,0.0667902,0.0995501,0.0788475,0.0878288,0.414805,0.484105,-1.01277,-1.03083,-0.399865,-0.224039,-1.66968,-1.48876,-1.66523,-1.71635,1.28218,1.1333,-0.701962,-0.609817,0.962347,0.913459,-0.332199,-0.055212,0.724496,0.811986
7614,0.253467,0.228975,0.540094,0.512217,0.500709,0.407472,0.919199,0.890059,0.287619,0.392852,0.54062,0.510086,0.00548023,-0.0308877,0.65877,0.625812,0.340512,0.370525,0.344333,0.350858,-1.25727,-1.19467,1.25006,1.23771,-0.508719,-0.330547,0.962799,1.14159,0.431702,0.384597,0.117191,-0.0356721,0.181513,0.278842,1.2478,1.20014,1.06736,1.34451,-1.34988,-1.26767
7615,0.888852,0.864785,0.945216,0.883194,0.123805,0.052092,0.913467,0.807661,0.961619,1.06953,0.395255,0.304271,0.504245,0.411763,0.637325,0.692598,0.349489,0.458258,0.0271739,0.0350903,-0.43265,-0.378343,-0.328075,-0.334574,0.732911,0.912466,0.0444914,0.298274,-0.978465,-1.02358,-0.0959131,-0.251317,0.100305,0.192424,1.7639,1.71514,0.118673,0.389888,-0.552717,-0.473459
7616,0.47755,0.454855,0.827373,0.765146,0.542839,0.470321,0.707891,0.725264,0.504899,0.610803,0.129506,0.0984566,0.890267,0.854413,0.79482,0.759384,0.517408,0.545991,0.839776,0.848595,-0.476492,-0.417578,1.61747,1.60913,1.38428,1.55733,-0.721771,-0.545041,-1.3402,-1.39055,0.192661,0.0811454,0.00820414,0.106006,-0.319437,-0.369817,1.10861,1.38137,0.231556,0.320755
7617,0.551952,0.530501,0.930537,0.776479,0.34499,0.27345,0.770252,0.642866,0.616055,0.719821,0.809577,0.779182,0.538221,0.503783,0.602954,0.567264,0.72495,0.752698,0.67602,0.683593,0.0558096,0.111719,-0.300805,-0.312603,0.210194,0.381739,1.68734,1.86696,0.379123,0.330942,0.573128,0.413608,0.659133,0.752905,-1.52533,-1.57037,-1.25087,-0.985613,-1.71242,-1.62161
7618,0.164945,0.144933,0.849203,0.787812,0.85372,0.78168,0.58949,0.560468,0.411752,0.513334,0.246661,0.21481,0.835679,0.80094,0.172744,0.136161,0.251739,0.278025,0.847218,0.855765,0.249011,0.300675,-0.544881,-0.556507,1.5316,1.70114,1.76312,1.94007,0.962248,0.91699,1.26603,1.10095,-1.12871,-1.02987,-0.180335,-0.230904,1.36171,1.61875,1.89864,1.99082
7619,0.0941932,0.0697416,0.232608,0.171259,0.624162,0.516456,0.931613,0.903812,0.554226,0.600997,0.188995,0.180827,0.415073,0.379919,0.669933,0.633418,0.244797,0.258989,0.0464396,0.0557541,-1.46441,-1.41051,0.710806,0.692281,-0.244101,-0.0762329,-0.664374,-0.493888,0.989939,0.938101,0.809806,0.652599,-0.520542,-0.414082,-2.03822,-2.08413,1.03047,1.2878,0.702729,0.801822
7620,0.0128889,-0.00544941,0.49956,0.437227,0.322437,0.251232,0.685078,0.655878,0.587915,0.68866,0.0585867,0.146843,0.419123,0.38337,0.140558,0.102369,0.300373,0.239952,0.607357,0.614627,-1.25126,-1.19162,0.1348,0.113358,-1.56388,-1.38813,-0.086938,0.0827256,-0.186951,-0.237993,0.368369,0.204251,-2.52049,-2.41763,0.739271,0.696772,-0.679508,-0.420174,0.620557,0.71737
7621,0.401353,0.383054,0.240076,0.242843,0.614787,0.542688,0.135724,0.108061,0.1455,0.245225,0.145907,0.11286,0.72802,0.690322,0.296647,0.259767,0.203022,0.220916,0.289436,0.29886,-0.587783,-0.597271,0.0712949,0.0542115,-0.646387,-0.519088,-0.368709,-0.199749,-1.15385,-1.19958,0.2999,0.0452456,-1.19261,-1.09128,0.470939,0.429947,-0.593599,-0.332164,-0.234771,-0.135191
7622,0.045258,0.0277553,0.108957,0.0484601,0.339744,0.26827,0.413672,0.387967,0.264101,0.36462,0.239167,0.208095,0.605903,0.641111,0.202493,0.163458,0.19157,0.201879,0.803659,0.812376,-0.0678189,-0.00291865,-0.610802,-0.630768,0.170406,0.349952,-0.419961,-0.165781,0.776851,0.725143,0.0484402,-0.11376,-0.84015,-0.737423,-0.533931,-0.571799,0.650749,0.908778,-0.540063,-0.445919
7623,0.362211,0.344256,0.25495,0.262203,0.667503,0.59603,0.252826,0.186509,0.957028,1.05588,0.849723,0.818728,0.628667,0.591899,0.661981,0.624497,0.205291,0.182843,0.716087,0.724423,-1.06875,-1.00882,-1.30055,-1.31575,-0.964027,-0.778984,-0.297266,-0.131813,-0.522203,-0.575112,-0.306024,-0.467355,0.061102,0.216477,1.15677,1.12564,-0.781456,-0.530581,1.27429,1.36057
7624,0.0986881,0.166081,0.534535,0.475945,0.153687,0.0824661,0.00860883,-0.0149488,0.0422175,0.140485,0.809206,0.776761,0.107,0.0695836,0.173966,0.138329,0.0345809,0.163806,0.175187,0.183263,-2.42071,-2.36417,1.89427,1.87549,-0.0250129,0.157523,-1.29061,-1.12576,-0.423153,-0.514659,-1.11439,-1.27097,1.07304,1.17038,-1.70863,-1.74133,0.868044,1.1184,-0.288884,-0.207072
7625,0.00590254,-0.0120951,0.062689,0.00230212,0.892596,0.823338,0.0499571,0.0284926,0.631349,0.730452,0.0752064,0.0421584,0.646412,0.611238,0.414892,0.378167,0.118483,0.144769,0.00678906,0.0130833,-0.743428,-0.680212,0.820016,0.801397,0.128502,0.310004,1.76247,1.93449,-0.39627,-0.454205,1.10115,0.946887,0.979538,1.15605,-1.0184,-1.05802,-0.473891,-0.228158,0.187257,0.265845
7626,0.228917,0.209705,0.390466,0.32846,0.53662,0.469606,0.298261,0.279133,0.694414,0.750608,0.915941,0.882311,0.11463,0.0790509,0.242996,0.206598,0.758497,0.787241,0.765379,0.772432,-0.0226881,0.045454,-0.88363,-0.896179,1.49321,1.67398,0.326445,0.492746,1.54954,1.48707,1.25107,1.09742,1.0453,1.14173,-0.728393,-0.771336,-2.58869,-2.33582,-1.44588,-1.36653
7627,0.0333107,0.0158411,0.200863,0.138948,0.694849,0.626247,0.325628,0.307088,0.718488,0.770763,0.47933,0.446282,0.650921,0.615451,0.396127,0.423321,0.59175,0.619542,0.816064,0.825105,-0.672876,-0.605432,1.23214,1.21173,-0.664987,-0.485667,0.147579,0.31925,-1.42781,-1.48478,-0.680633,-0.827349,-1.64901,-1.55029,-0.857425,-0.900133,-0.87013,-0.62547,-0.171595,-0.0864939
7628,0.127649,0.116917,0.266375,0.203022,0.463533,0.393116,0.578589,0.511693,0.605291,0.790918,0.59457,0.503319,0.783769,0.750548,0.675685,0.640044,0.74224,0.765227,0.123233,0.132603,0.0231464,0.169142,-0.208912,-0.222279,1.62834,1.80832,-1.08075,-0.906693,1.18525,1.12253,0.170216,0.0290377,0.317279,0.411551,-1.6697,-1.71781,-1.62528,-1.3757,0.791571,0.803543
7629,0.109242,0.217993,0.784871,0.720793,0.771078,0.700146,0.734292,0.716298,0.711971,0.811074,0.592271,0.560356,0.346459,0.314467,0.300916,0.263172,0.883271,0.910913,0.895381,0.903268,0.87607,0.943716,0.119833,0.102556,-0.130146,0.0470066,-0.399549,-0.264989,1.09071,1.03043,0.146269,0.0132678,-0.972209,-0.885403,-1.65638,-1.71048,-1.10658,-0.853245,1.60834,1.69358
7630,0.357488,0.319068,0.652074,0.586951,0.712712,0.63989,0.164243,0.148115,0.916353,1.0163,0.204318,0.172903,0.54525,0.51112,0.795529,0.760428,0.311848,0.340983,0.737694,0.74806,0.814765,0.889543,0.135888,0.11864,1.5726,1.75248,0.195969,0.376716,-0.214094,-0.269824,-0.119213,-0.247885,-0.347974,-0.254569,1.53704,1.48484,0.491271,0.747547,-0.342195,-0.264009
7631,0.437614,0.420144,0.969802,0.903385,0.911569,0.840349,0.635824,0.621123,0.837658,0.936125,0.346151,0.31284,0.527542,0.519724,0.610345,0.573483,0.518837,0.54769,0.0160948,0.0255799,-0.393482,-0.31445,-2.5878,-2.61086,-0.623068,-0.437752,-0.356809,-0.181604,0.021077,-0.0362414,-0.0598671,-0.187105,0.0354752,0.127876,1.21065,1.16921,-1.27961,-1.02838,-0.185327,-0.106349
7632,0.728211,0.712369,0.981396,0.917545,0.146664,0.0758395,0.448549,0.433682,0.518936,0.676466,0.21725,0.18425,0.480588,0.528327,0.857532,0.81904,0.282253,0.309179,0.55908,0.486838,0.900132,0.979261,-0.510813,-0.538348,-0.963027,-0.773496,-0.00879874,0.166788,-0.648529,-0.708023,0.347803,0.224561,0.0736586,0.158778,0.901169,0.853592,-0.758066,-0.50593,0.228684,0.219706
7633,0.186442,0.171272,0.308781,0.246527,0.4071,0.218305,0.824207,0.807523,0.316269,0.416807,0.696298,0.661564,0.573196,0.536931,0.346603,0.30777,0.581241,0.60913,0.93931,0.948096,0.453929,0.483354,-0.0678741,-0.0833282,1.05188,1.24357,-1.0621,-0.891113,0.186037,0.137617,1.22035,1.09635,-0.132018,-0.0536647,-0.749162,-0.795384,0.341396,0.593724,0.472442,0.545761
7634,0.236913,0.277938,0.764462,0.700882,0.476571,0.36077,0.767679,0.750281,0.632039,0.733791,0.668749,0.688432,0.483491,0.545534,0.801366,0.764492,0.173128,0.200215,0.92065,0.928589,-0.0850297,-0.0125537,0.366652,0.371691,-0.579201,-0.390519,0.905162,1.07594,0.926326,0.983256,0.913675,0.787628,-1.70161,-1.61722,0.472456,0.421297,-0.839942,-0.594769,-0.990969,-0.917454
7635,0.401682,0.384604,0.585229,0.520984,0.57185,0.503235,0.213904,0.197641,0.524082,0.633578,0.748263,0.715301,0.588268,0.554138,0.615989,0.6248,0.176952,0.155815,0.583994,0.592159,-0.146586,-0.0667266,0.85311,0.82671,-0.964718,-0.771731,-0.206246,-0.0418749,1.88839,1.8289,0.964756,0.832651,0.411488,0.491974,0.332574,0.276837,0.356864,0.595941,1.93667,2.01078
7636,0.807615,0.792464,0.836143,0.772666,0.121979,0.0541651,0.287275,0.278734,0.431807,0.533365,0.402789,0.368117,0.308464,0.362932,0.499696,0.485108,0.0844936,0.111415,0.709043,0.784943,0.913426,0.995161,0.141795,0.0184941,0.342486,0.53133,0.885098,1.04468,-1.82897,-1.88817,0.103384,-0.0317357,-0.195407,-0.122801,0.667683,0.608722,-0.629032,-0.387276,-0.812069,-0.738032
7637,0.858683,0.783297,0.474299,0.486946,0.841996,0.774162,0.401516,0.359827,0.0954645,0.196156,0.280151,0.244913,0.205286,0.171727,0.382291,0.345417,0.450244,0.47726,0.970362,0.977727,0.796918,0.877687,-0.763323,-0.789722,-1.36026,-1.16856,-0.359151,-0.227098,0.796609,0.734903,0.56623,0.370928,0.200659,0.276149,0.581916,0.524774,0.669325,0.914626,-2.07367,-2.00372
7638,0.790174,0.77413,0.263184,0.201225,0.364057,0.29446,0.456168,0.440921,0.646804,0.744868,0.598093,0.56502,0.0146511,-0.0194789,0.836704,0.802139,0.515534,0.536762,0.366082,0.371677,1.74957,1.83178,-0.4618,-0.494118,1.26503,1.45633,-1.66076,-1.49888,0.0324559,-0.0280198,0.90839,0.773592,1.66057,1.73971,0.0640389,0.0136734,-3.11645,-2.87074,-0.485652,-0.415682
7639,0.353381,0.338329,0.776586,0.713665,0.287065,0.151142,0.199297,0.183264,0.855608,0.954643,0.123082,0.0900567,0.0368632,0.00301133,0.363053,0.326633,0.705596,0.596265,0.811102,0.815233,-1.4036,-1.31339,-0.390114,-0.415939,1.74603,1.93125,-0.515059,-0.328342,-0.307821,-0.365468,1.31671,1.17626,-0.473737,-0.402915,0.264315,0.207223,1.75612,2.00183,-1.21736,-1.14734
7640,0.31561,0.233334,0.4448,0.38505,0.0760925,0.00782349,0.30084,0.282487,0.068546,0.169068,0.153335,0.121611,0.867347,0.832416,0.663614,0.627626,0.627954,0.655767,0.750264,0.698398,0.230695,0.323455,2.42139,2.39347,-0.186146,-0.00463867,0.684947,0.842193,0.239572,0.174069,-0.301569,-0.440273,-2.21172,-2.13939,-1.84235,-1.89421,1.29398,1.53218,-1.41536,-1.35169
7641,0.14261,0.128339,0.119144,0.0564347,0.77995,0.713317,0.606093,0.553524,0.120662,0.221406,0.727193,0.697681,0.581665,0.54655,0.0979473,0.0609806,0.957526,0.986306,0.575394,0.581563,0.603746,0.776791,0.719477,0.695896,-0.976932,-0.790188,-0.310754,-0.151751,-2.08117,-2.14797,-0.829446,-0.965277,0.134686,0.208727,-0.0975118,-0.149769,-0.259182,-0.0177067,-1.20221,-1.13544
7642,0.854456,0.83897,0.084045,0.0223734,0.0107116,-0.0559294,0.845185,0.824561,0.484165,0.58475,0.269311,0.241852,0.956515,0.923309,0.557859,0.509988,0.849123,0.879026,0.0362204,0.0404034,1.14015,1.23013,-0.716032,-0.738112,1.18686,1.37088,-0.0356736,0.120789,1.70899,1.64183,1.11076,0.979315,1.05575,1.12995,0.0762357,0.0266228,-0.736176,-0.487358,0.176941,0.236761
7643,0.352013,0.337841,0.683635,0.622392,0.052907,-0.0145212,0.948729,0.928961,0.361805,0.475234,0.604617,0.501503,0.744247,0.71294,0.997813,0.958996,0.405157,0.43445,0.419972,0.424567,0.0997239,0.193976,-0.0944263,-0.122195,-2.9876,-2.80525,0.643996,0.805337,1.18582,1.12379,-0.0399761,-0.175662,1.25222,1.32876,-1.51846,-1.57287,-0.875595,-0.633561,1.18359,1.2428
7644,0.345473,0.333198,0.632434,0.613568,0.428546,0.455823,0.548741,0.527348,0.266108,0.365717,0.789878,0.761154,0.280481,0.247209,0.181639,0.142557,0.520008,0.548959,0.526059,0.530792,1.63546,1.72334,-1.11876,-1.14999,-0.408178,-0.229682,-0.722933,-0.557474,-1.84948,-1.90937,1.1688,1.03463,-1.14561,-1.07201,-0.385068,-0.44396,-0.0570785,0.268226,0.0484176,0.113015
7645,0.969391,0.95873,0.66712,0.604744,0.993595,0.926167,0.574782,0.574116,0.570922,0.668482,0.154175,0.125779,0.582329,0.548939,0.0509086,0.0107697,0.634029,0.663468,0.8853,0.890919,-1.46947,-1.38295,-0.60897,-0.640443,-1.83064,-1.6508,-1.0219,-0.855224,-1.08358,-1.13712,-0.240665,-0.369341,0.6459,0.713082,0.505856,0.452816,0.929257,1.17001,-1.30941,-1.24409
7646,0.16364,0.152455,0.205134,0.141381,0.464488,0.464601,0.641859,0.620883,0.437744,0.536858,0.804567,0.776978,0.336589,0.302875,0.752347,0.711847,0.963883,0.994007,0.67773,0.754829,-0.143925,-0.0572692,0.616267,0.579929,0.810653,0.995416,0.457518,0.621864,1.83923,1.77887,-1.05604,-1.18771,-1.06168,-0.992209,0.038078,-0.0123123,1.03772,1.27265,0.30086,0.359795
7647,0.768904,0.758432,0.433861,0.368623,0.0689159,0.00303462,0.104869,0.082795,0.690304,0.788373,0.931026,0.901883,0.424605,0.392509,0.74903,0.693884,0.876559,0.825954,0.553853,0.618738,-1.59613,-1.50583,0.724109,0.686855,-0.983893,-0.797679,0.278123,0.448368,-0.48499,-0.543167,-0.284933,-0.422148,1.00385,1.08055,-0.170134,-0.21736,-0.0924433,0.118629,0.126686,0.185813
7648,0.195506,0.187812,0.339618,0.27925,0.476487,0.411177,0.907547,0.883532,0.212504,0.309418,0.746566,0.719304,0.0385097,0.00674757,0.717095,0.67592,0.626952,0.657902,0.41649,0.482648,1.82407,1.9233,1.56998,1.53199,0.56467,0.748253,0.894713,1.07041,-0.0762435,-0.139614,1.06775,0.92416,-0.781342,-0.702228,-1.61403,-1.66441,-1.27033,-1.03539,-0.263338,-0.199225
7649,0.0648702,0.0592553,0.25099,0.189876,0.231665,0.265501,0.87151,0.847107,0.703062,0.797749,0.138763,0.109823,0.593954,0.56364,0.388168,0.344568,0.823879,0.853484,0.340938,0.346557,1.01702,1.11687,-0.189042,-0.23053,0.893331,1.10342,0.401988,0.572787,-1.31942,-1.3781,-0.68646,-0.830607,-0.792777,-0.716209,0.251212,0.202856,1.45968,1.69477,0.635363,0.699331
7650,0.523231,0.516938,0.165741,0.100503,0.101505,0.119825,0.536075,0.509691,0.2066,0.299502,0.245508,0.213978,0.929138,0.901319,0.489181,0.508236,0.689069,0.596233,0.574727,0.579336,-0.237559,-0.133927,1.47535,1.43785,1.2825,1.4586,0.477194,0.645897,1.37883,1.31593,1.19225,1.05623,0.0480355,0.126274,-0.359978,-0.416178,-0.591811,-0.351927,0.971986,1.03699
7651,0.448738,0.440226,0.893505,0.826533,0.039459,-0.0258508,0.451971,0.426661,0.186762,0.280538,0.974808,0.945192,0.50182,0.476314,0.618636,0.671904,0.376102,0.338982,0.539246,0.545317,-0.40953,-0.309661,-0.24794,-0.2941,-1.98971,-1.81762,0.171705,0.332888,0.18977,0.127573,-2.45138,-2.5932,0.26142,0.339109,-0.201553,-0.25404,-0.0568411,0.134885,-0.889087,-0.826099
7652,0.993646,0.986624,0.478568,0.412839,0.738072,0.674512,0.729878,0.706567,0.400227,0.495795,0.14034,0.111955,0.651211,0.626738,0.878812,0.835572,0.0531393,0.0817307,0.237706,0.244389,0.0390433,0.140794,-0.199691,-0.246909,1.58346,1.75555,0.752808,0.909502,1.0112,0.944853,0.23356,0.0935509,-1.12914,-1.04956,1.30646,1.25471,0.385658,0.621696,-0.0496106,0.0112029
7653,0.000687294,-0.00633454,0.574563,0.507178,0.764882,0.658332,0.121867,0.0985841,0.964756,1.05875,0.150459,0.214219,0.278954,0.256025,0.214539,0.173468,0.789522,0.818488,0.744723,0.752891,-0.499308,-0.402519,-1.90634,-1.96008,0.582235,0.751869,-1.73432,-1.57389,-2.62273,-2.69608,1.84159,1.70249,-0.0218239,0.0547931,1.03553,0.987883,-2.33474,-2.10633,-1.09549,-1.03755
7654,0.593023,0.584871,0.890472,0.823612,0.705763,0.642151,0.0433928,0.0202608,0.54383,0.639707,0.345713,0.316483,0.708979,0.687676,0.0789571,0.0370885,0.12331,0.153112,0.268863,0.276779,0.401028,0.492597,-0.447803,-0.494601,0.469682,0.561335,-1.16374,-0.997279,1.73535,1.65407,0.519208,0.37714,-0.352077,-0.282145,-0.526042,-0.581828,-1.41947,-1.19505,-1.00486,-0.941428
7655,0.0381628,0.0287058,0.562401,0.493355,0.98669,0.923436,0.697937,0.677297,0.455982,0.553955,0.0750237,0.043561,0.245087,0.221944,0.548871,0.470552,0.137118,0.17675,0.435919,0.443715,-1.08043,-0.985965,-0.803808,-0.844567,0.202118,0.370801,-0.355645,-0.187805,1.87355,1.79581,1.76774,1.63241,1.67156,1.74173,0.547938,0.486328,-0.889742,-0.672594,-1.35841,-1.29858
7656,0.467939,0.456569,0.00403219,-0.0636267,0.126791,0.060977,0.754773,0.735654,0.134778,0.231579,0.827057,0.79545,0.526226,0.50301,0.945033,0.904016,0.172055,0.200388,0.082586,0.0926335,1.55754,1.65136,-0.560261,-0.597244,0.315392,0.477302,-0.922714,-0.762378,-0.0858379,-0.170463,-0.468548,-0.604047,-0.967451,-0.901296,0.364312,0.32776,0.298735,0.518115,0.803628,0.867418
7657,0.415456,0.405196,0.30979,0.242832,0.5464,0.479206,0.553841,0.533343,0.345977,0.441354,0.731723,0.607472,0.363061,0.339193,0.838932,0.797085,0.676571,0.706043,0.224313,0.235158,0.908833,1.00048,0.593939,0.555793,1.68507,1.84127,-0.461675,-0.306655,0.443185,0.354307,-0.592351,-0.729338,-1.50391,-1.441,0.230296,0.169193,0.737815,0.961374,-1.24478,-1.18065
7658,0.783843,0.772955,0.973785,0.907042,0.0559162,-0.0106809,0.971442,0.951499,0.00368466,0.0977794,0.555957,0.419495,0.735285,0.710851,0.154042,0.110047,0.78786,0.815625,0.693086,0.616267,0.6491,0.733923,-0.966698,-1.00204,-1.52518,-1.36236,0.765119,0.92044,0.572468,0.480831,0.352198,0.220494,-0.187502,-0.129445,-1.11053,-1.17142,-0.430444,-0.211442,0.0376863,0.0993845
7659,0.152603,0.141829,0.578436,0.49083,0.290765,0.224689,0.679407,0.681689,0.186214,0.277816,0.276767,0.231517,0.0336824,0.00970658,0.465095,0.421238,0.643438,0.672112,0.986149,0.997376,0.724326,0.815053,-0.0934494,-0.124944,0.590784,0.749936,0.765597,0.917403,-3.43547,-3.52238,0.489966,0.357777,-0.528903,-0.466383,0.132162,0.0758051,-0.253327,-0.0336491,-0.0249483,0.0330668
7660,0.810249,0.798222,0.140487,0.0746178,0.131813,0.0680166,0.431822,0.411879,0.786226,0.877558,0.0751465,0.0435393,0.120988,0.0891112,0.281748,0.239066,0.0501112,0.0778801,0.119653,0.129724,-1.09661,-1.0061,0.304077,0.274846,-0.926165,-0.761916,0.466411,0.619653,0.826974,0.745128,-2.30401,-2.42922,0.177774,0.240659,0.528308,0.468591,-3.09355,-2.87369,-0.853681,-0.7887
7661,0.589454,0.578987,0.018533,-0.0492731,0.459642,0.433167,0.557688,0.536749,0.893067,0.986576,0.240314,0.294889,0.193029,0.168516,0.988483,0.946436,0.255398,0.26428,0.264583,0.276442,-0.887502,-0.802825,-1.53264,-1.56822,-1.82098,-1.65635,-0.369804,-0.219945,0.788862,0.687752,-1.01721,-1.14352,-0.207413,-0.235245,-1.46332,-1.52327,-0.733849,-0.516989,1.66662,1.72634
7662,0.161033,0.148225,0.283132,0.158172,0.861827,0.798318,0.12409,0.104853,0.320888,0.413238,0.575699,0.546239,0.494505,0.470246,0.665353,0.552836,0.421388,0.450681,0.185999,0.198387,2.42307,2.50774,0.00937509,-0.0256131,-0.373074,-0.201116,1.27493,1.43145,0.707832,0.630376,-0.947912,-1.06789,-0.776393,-0.711149,0.664134,0.609148,0.191567,0.410581,1.04109,1.10042
7663,0.000992233,-0.00953947,0.428821,0.365617,0.733108,0.672089,0.583691,0.562538,0.930734,1.02297,0.949147,0.92114,0.579499,0.613294,0.203035,0.159237,0.997141,1.02541,0.531401,0.542709,2.73833,2.82097,0.397305,0.35987,-0.726018,-0.454077,0.0863213,0.190339,-0.272073,-0.34855,-0.665764,-0.793562,-0.119783,-0.0499271,-0.621863,-0.670086,0.369796,0.588374,-1.04669,-0.979243
7664,0.245127,0.257419,0.642203,0.573062,0.0607369,-0.00170729,0.151098,0.130641,0.184501,0.275638,0.447051,0.421072,0.781533,0.756343,0.51775,0.475576,0.727798,0.785368,0.331975,0.34197,-1.59033,-1.51037,-1.27064,-1.30838,-0.885644,-0.707037,-1.21404,-1.05078,0.318101,0.237498,0.765,0.628146,-0.268061,-0.200024,-0.000853428,-0.0485635,-1.52207,-1.29828,-1.93247,-1.86275
7665,0.535703,0.524378,0.15637,0.0852864,0.616454,0.556264,0.690263,0.668113,0.087283,0.178716,0.60006,0.575863,0.198826,0.173915,0.448403,0.483224,0.516926,0.545328,0.628541,0.639399,1.10888,1.19401,0.817007,0.779883,-0.353127,-0.106844,-1.3061,-1.14657,-0.403067,-0.477127,0.329323,0.208579,1.01963,1.09322,-0.230109,-0.284418,1.24803,1.46777,1.02144,1.08348
7666,0.110065,0.0987542,0.814157,0.744621,0.163433,0.102271,0.770375,0.817635,0.378111,0.505606,0.551322,0.528674,0.892603,0.866736,0.531616,0.490872,0.561826,0.5888,0.706285,0.74594,0.469787,0.558078,-0.214554,-0.247918,0.317023,0.493348,0.113243,0.266819,0.489766,0.418616,-0.074134,-0.210988,-0.462554,-0.39043,-1.09002,-1.14788,-0.674207,-0.450407,1.27249,1.32984
7667,0.654162,0.645152,0.0507375,-0.0167794,0.0955729,0.0329624,0.990924,0.967156,0.738262,0.832496,0.0606105,0.0384172,0.82898,0.748183,0.661344,0.621893,0.226816,0.254965,0.841286,0.852481,0.691247,0.776965,-0.213013,-0.245613,-1.09861,-0.927765,-0.106103,0.047448,-0.334662,-0.406149,0.447752,0.311166,0.263382,0.331416,0.783614,0.71939,-0.404824,-0.179951,0.785952,0.880075
7668,0.361442,0.350639,0.529712,0.460988,0.875334,0.811176,0.0216955,-0.00125508,0.17966,0.273952,0.157711,0.133653,0.653048,0.62963,0.265196,0.225387,0.221992,0.24932,0.0477308,0.0569011,1.11382,1.19682,0.257172,0.230627,-0.351604,-0.136278,0.756382,0.903533,0.61858,0.549727,-0.575224,-0.70729,-0.403734,-0.327253,-1.29417,-1.36556,-0.440523,-0.216005,0.37465,0.430306
7669,0.483268,0.470857,0.750919,0.683848,0.689487,0.59955,0.968353,0.944796,0.225231,0.25299,0.750522,0.724299,0.980024,0.956946,0.827265,0.787623,0.513199,0.599226,0.239317,0.24895,0.554177,0.717486,2.29875,2.27492,0.484366,0.655209,-1.15032,-1.00933,-0.0582161,-0.122055,-0.333824,-0.463043,-0.320918,-0.249243,0.108065,0.0383149,0.324082,0.553597,-0.561871,-0.513658
7670,0.3914,0.418897,0.03063,-0.0360532,0.450777,0.387924,0.408155,0.386557,0.138856,0.232029,0.748607,0.721213,0.224182,0.202269,0.70426,0.575303,0.919779,0.949131,0.954599,0.963308,0.150064,0.238156,0.34858,0.322249,0.0724385,0.242712,-0.0915482,0.0472187,-0.312418,-0.382914,-1.00623,-1.1291,-0.470453,-0.399341,-1.47779,-1.54553,-2.29381,-2.05803,-1.11971,-1.06664
7671,0.290759,0.366937,0.544209,0.476386,0.758027,0.694954,0.66766,0.668266,0.888628,0.98086,0.332482,0.305307,0.415458,0.393759,0.403085,0.362982,0.463522,0.530082,0.891653,0.899034,0.0282357,0.120682,2.39432,2.36654,0.930998,1.10301,-0.961541,-0.824227,0.596483,0.526548,-0.664126,-0.794577,-0.879942,-0.813456,0.789902,0.723279,1.78242,2.02089,-1.25278,-1.19597
7672,0.325971,0.314977,0.466093,0.398592,0.435109,0.370496,0.969873,0.949974,0.0758217,0.170746,0.564113,0.538311,0.903714,0.8805,0.856421,0.814682,0.0811917,0.111032,0.587921,0.593845,-1.31786,-1.22077,0.268774,0.245279,-0.0701341,0.0993326,2.60344,2.73602,1.72077,1.64959,-1.97764,-2.10386,-0.82107,-0.750256,-0.724638,-0.753751,-0.515167,-0.280465,0.0884459,0.145138
7673,0.707074,0.697799,0.689104,0.621453,0.536767,0.47182,0.633446,0.612558,0.163095,0.248382,0.798913,0.771314,0.327231,0.303427,0.792608,0.748928,0.642825,0.670799,0.865506,0.871659,-0.518201,-0.446192,-0.288471,-0.31995,-0.717766,-0.546796,-0.496497,-0.358594,0.867255,0.794442,0.143049,0.0171171,0.457517,0.525973,-2.16416,-2.23078,-0.604275,-0.363624,0.755797,0.81756
7674,0.0425886,0.0315429,0.125159,0.0592647,0.182386,0.118088,0.769025,0.746711,0.154343,0.326019,0.0203355,-0.00911353,0.0559763,0.0324945,0.353237,0.307349,0.295546,0.416799,0.533807,0.540079,0.231495,0.328382,-2.78475,-2.81009,-0.836261,-0.666753,0.125232,0.263448,0.632712,0.564427,-0.182235,-0.305691,0.409363,0.520503,0.504898,0.435509,1.54254,1.78637,-0.397698,-0.340588
7675,0.804712,0.791384,0.615819,0.552312,0.166656,0.104601,0.657091,0.634248,0.308731,0.403655,0.198828,0.169988,0.985506,0.960085,0.699634,0.654594,0.132834,0.162798,0.427531,0.434374,-0.227699,-0.136935,-1.19866,-1.22005,0.0541431,0.225119,-0.0935945,0.0440769,-0.432405,-0.504703,0.110469,-0.0164515,0.439584,0.515034,-1.53487,-1.60305,2.42108,2.6673,-0.59014,-0.529878
7676,0.946996,0.931739,0.219536,0.158221,0.583956,0.522829,0.14912,0.126337,0.762234,0.85629,0.833327,0.805968,0.299218,0.272514,0.654936,0.608076,0.0961194,0.127727,0.546467,0.506093,0.998264,1.09305,-0.163205,-0.18898,1.61601,1.78831,-0.0939127,0.0410401,-0.258657,-0.33064,1.072,0.947071,-0.470279,-0.391983,-0.377709,-0.445217,-1.57808,-1.32601,-1.30057,-1.2472
7677,0.140542,0.125464,0.654499,0.59237,0.319531,0.258607,0.845817,0.823722,0.752197,0.750685,0.589642,0.562548,0.422923,0.397891,0.291838,0.245938,0.415854,0.448395,0.570044,0.577811,1.34996,1.45249,-0.0999914,-0.131858,0.866921,1.03408,-0.306941,-0.178331,-0.302076,-0.372946,0.513558,0.391475,0.166005,0.23885,-0.575075,-0.634873,0.0904404,0.337867,-1.06078,-1.01417
7678,0.723405,0.70686,0.170102,0.10908,0.867167,0.806092,0.301345,0.280154,0.548059,0.64508,0.966795,0.941437,0.808373,0.784644,0.339057,0.387293,0.378804,0.413324,0.00579827,0.0122197,0.666339,0.770476,-0.0551997,-0.0747352,0.761967,0.92757,2.48462,2.60703,-0.939687,-1.01314,-1.96734,-2.09027,-0.0477959,0.0264081,2.00981,1.94637,-0.984444,-0.739593,-0.17893,-0.131105
7679,0.631754,0.631669,0.366522,0.32919,0.206215,0.147117,0.975911,0.952937,0.969188,1.06742,0.875716,0.848549,0.908623,0.88508,0.576137,0.528648,0.624708,0.659817,0.84048,0.846088,0.509292,0.607935,-1.78066,-1.80669,-0.758886,-0.599158,0.407504,0.533817,-0.668749,-0.747622,-0.282793,-0.4026,-0.477135,-0.403165,0.502168,0.438379,-1.45837,-1.20924,-1.35651,-1.30553
7680,0.575666,0.556478,0.609955,0.549301,0.253692,0.136512,0.942733,0.937438,0.0963548,0.1951,0.39514,0.368411,0.753431,0.730588,0.156001,0.106693,0.869213,0.906311,0.050619,0.0557495,0.336429,0.445394,-2.50589,-2.5387,0.687477,0.841341,-1.31646,-1.19081,-0.147373,-0.222853,0.125441,0.00906584,1.94937,2.02488,0.932609,0.861586,-0.536916,-0.281674,0.616507,0.667454
7681,0.801975,0.783034,0.219565,0.159704,0.18457,0.125908,0.96324,0.92194,0.420757,0.447186,0.949175,0.924691,0.823212,0.799383,0.617491,0.567731,0.589283,0.586879,0.378095,0.384628,-0.455138,-0.345729,0.32645,0.287779,0.0211881,0.179348,1.29055,1.40795,1.01239,0.931558,0.194511,0.0846965,-2.26316,-2.18765,-0.722017,-0.800789,1.2137,1.47556,-0.0135971,0.0415337
7682,0.489107,0.43298,0.227594,0.249289,0.426581,0.292628,0.927182,0.906441,0.599857,0.699272,0.214591,0.190089,0.399553,0.374378,0.698602,0.648503,0.23188,0.267446,0.254329,0.259541,0.11601,0.228413,0.0476649,0.0650028,0.894015,1.05656,1.19136,1.31216,0.442573,0.367666,1.60728,1.49366,-0.332132,-0.256597,-0.610567,-0.684536,0.114246,0.384608,1.067,1.12387
7683,0.100937,0.0829267,0.398387,0.338875,0.516338,0.459347,0.122637,0.100424,0.54954,0.649502,0.547027,0.42916,0.360983,0.336058,0.0510762,0.00112391,0.591253,0.628367,0.642607,0.648544,1.46261,1.57047,-0.192364,-0.157773,0.186604,0.349249,-0.656905,-0.534113,0.0998351,0.0302182,-0.169239,-0.275197,2.36018,2.43056,-0.810207,-0.889585,-1.87298,-1.59755,-0.967494,-0.910409
7684,0.0800662,0.0628469,0.00342329,-0.0552161,0.500472,0.392964,0.396584,0.379971,0.768491,0.870182,0.752466,0.66823,0.572382,0.628995,0.200735,0.136994,0.234541,0.273645,0.0100002,0.0177814,-3.2671,-3.15924,-0.342503,-0.380549,1.81197,1.97539,0.0374945,0.140141,-0.977736,-1.0539,0.657074,0.549713,0.16148,0.225531,0.664887,0.588057,-0.433297,-0.152343,0.173852,0.232178
7685,0.626607,0.609244,0.314174,0.255899,0.382508,0.326581,0.681477,0.659517,0.0766355,0.180298,0.932961,0.9073,0.94502,0.921931,0.360215,0.272863,0.63642,0.674583,0.960929,0.970493,-0.744288,-0.638796,-1.02648,-1.06679,0.918016,1.08096,0.691602,0.814394,0.528639,0.453794,-1.16817,-1.28175,-0.4203,-0.359423,0.727306,0.657311,-0.56567,-0.282188,-0.772266,-0.711786
7686,0.370131,0.351167,0.93343,0.876383,0.585681,0.53195,0.718187,0.698382,0.0185084,0.12045,0.864285,0.869171,0.993201,0.970425,0.448704,0.408733,0.690526,0.728739,0.892448,0.90216,-1.83077,-1.72029,0.705491,0.661422,0.828063,0.98769,-0.13542,-0.00916217,1.35077,1.27107,-1.13634,-1.25147,0.0679892,0.132556,1.22763,1.15721,0.00634254,0.286385,1.0395,1.09471
7687,0.488397,0.471385,0.57576,0.517168,0.0478874,-0.00711994,0.245764,0.226204,0.907206,1.01011,0.856949,0.831042,0.769742,0.749265,0.596629,0.544603,0.248304,0.284162,0.374376,0.381899,0.0719689,0.17646,1.61746,1.56887,0.0393852,0.202141,1.94142,2.06988,-0.739524,-0.814998,1.71686,1.60358,1.87257,1.9368,0.663598,0.600264,-0.470165,-0.183266,0.0411269,0.0909176
7688,0.168807,0.152165,0.526928,0.467301,0.424403,0.370279,0.579483,0.559959,0.716595,0.818051,0.177114,0.150521,0.973674,0.950861,0.98076,0.926838,0.345873,0.382696,0.352592,0.357948,0.1965,0.304281,0.162426,0.119814,-0.182287,-0.0266726,-0.70534,-0.575474,1.78047,1.7003,-0.0845772,-0.197714,0.038022,0.107212,1.0772,1.00823,0.29935,0.586336,2.19229,2.24039
7689,0.755799,0.737795,0.175565,0.117584,0.114213,0.0611532,0.707165,0.736825,0.985634,1.08436,0.130851,0.136657,0.199628,0.174991,0.308765,0.254941,0.982053,1.01993,0.107363,0.112637,1.40603,1.51857,-0.283776,-0.321217,0.746233,0.894742,-0.765617,-0.641781,0.939987,0.85923,-0.332016,-0.444506,-0.392272,-0.322361,-2.3841,-2.45841,0.830446,1.12499,1.73703,1.78029
7690,0.594946,0.574781,0.760268,0.703042,0.581627,0.529736,0.934206,0.913691,0.395818,0.49565,0.174217,0.122793,0.460909,0.436563,0.695131,0.641552,0.704396,0.840705,0.283982,0.290192,1.91287,2.0326,1.18376,1.14426,0.498314,0.65026,0.332973,0.460339,-0.492187,-0.578189,0.161815,0.0468947,-0.160633,-0.0941817,-0.990001,-1.06998,1.03363,1.33323,0.554538,0.547051
7691,0.208674,0.189212,0.625947,0.5692,0.609233,0.557022,0.803267,0.781306,0.580355,0.655892,0.135522,0.108929,0.152615,0.130554,0.442727,0.388543,0.62488,0.661481,0.10208,0.109853,0.651449,0.767071,0.969338,0.932144,-0.639676,-0.492654,0.297097,0.424694,0.323075,0.239092,1.18121,1.07329,0.597351,0.658608,1.20876,1.12282,-0.264402,0.0352162,-0.732205,-0.686189
7692,0.606013,0.586977,0.902096,0.845439,0.0660176,0.0120398,0.991782,0.971883,0.715901,0.816134,0.492503,0.464217,0.662767,0.641372,0.948706,0.895547,0.78185,0.81645,0.626234,0.634286,0.419895,0.530966,-0.251086,-0.295626,1.42536,1.57282,-0.753004,-0.633207,-0.554533,-0.646217,-1.07496,-1.18194,-0.148635,-0.0921945,-0.102459,-0.188562,-0.176436,0.123226,-0.358358,-0.318293
7693,0.711396,0.69298,0.938797,0.883813,0.468488,0.415407,0.695211,0.674299,0.183647,0.282988,0.383089,0.355277,0.605528,0.590137,0.610159,0.55881,0.531244,0.472545,0.00460579,0.0135853,1.5691,1.68544,1.3396,1.29441,-0.415536,-0.267943,0.863462,0.988424,-0.101292,-0.198446,-1.02949,-1.13692,-0.379382,-0.320116,1.43736,1.35239,-1.4575,-1.15954,0.3485,0.383705
7694,0.402212,0.383933,0.302797,0.248352,0.509719,0.456815,0.955145,0.935127,0.556195,0.647672,0.047805,0.0217951,0.560469,0.538901,0.541575,0.397583,0.0938988,0.12864,0.373385,0.383525,0.98366,1.09605,0.104905,0.0666393,-0.448663,-0.297423,-1.59392,-1.46044,-1.5554,-1.65204,0.91192,0.807674,-1.53358,-1.47384,0.149352,0.0565256,0.272052,0.567268,-2.19077,-2.15814
7695,0.66716,0.650808,0.871101,0.814835,0.775983,0.72293,0.74999,0.728251,0.912052,1.01236,0.020436,0.0137898,0.00790685,-0.0138431,0.289971,0.236356,0.98326,1.01713,0.0784369,0.088118,-0.607478,-0.491495,1.12412,1.08235,0.300748,0.455753,0.190464,0.306094,0.61238,0.516839,-0.849427,-0.947092,-1.19098,-1.13679,0.0876591,-0.0115169,2.81927,3.12162,0.282188,0.317081
7696,0.496268,0.478811,0.395278,0.337398,0.354594,0.360003,0.189862,0.170012,0.592478,0.694675,0.0788782,0.00578452,0.807398,0.785898,0.844389,0.789554,0.938144,0.972423,0.533522,0.542577,-0.000848308,0.112044,-0.265663,-0.304271,2.03867,2.19418,1.93916,2.07263,1.66289,1.56528,0.0430929,-0.0587415,1.21371,1.26186,0.415615,0.320369,-0.324666,-0.0258271,-0.628238,-0.596662
7697,0.0153421,-0.00213636,0.938989,0.879655,0.0476422,-0.00292366,0.261638,0.243113,0.4912,0.662742,0.0807492,-0.00222076,0.104138,0.0847539,0.748547,0.693246,0.661784,0.698529,0.588943,0.599761,0.248955,0.363203,-0.544991,-0.578275,-0.237192,-0.0781243,1.1766,1.31075,0.34081,0.247837,0.696144,0.59926,1.29721,1.33987,-0.665833,-0.75901,1.36463,1.66989,1.2975,1.33107
7698,0.824459,0.806342,0.710257,0.616833,0.202056,0.153717,0.11265,0.09538,0.55508,0.630809,0.0181131,-0.010226,0.636626,0.615907,0.421931,0.331744,0.787241,0.82307,0.315517,0.324102,0.27493,0.384498,1.8647,1.83982,-0.847041,-0.695479,-0.119765,0.00800649,-0.609676,-0.700241,-0.0131814,-0.112116,-0.508862,-0.45898,0.363794,0.277003,0.369841,0.670351,-0.593502,-0.562594
7699,0.625573,0.608088,0.412198,0.354011,0.887249,0.838601,0.309538,0.268353,0.496756,0.598876,0.586584,0.556202,0.200881,0.179825,0.0264909,-0.029758,0.645844,0.679558,0.695498,0.703836,1.01288,1.12577,1.46394,1.44404,0.401441,0.547534,0.277854,0.402067,0.480834,0.393499,-1.2647,-1.36056,-0.137897,-0.0904521,-1.16819,-1.26088,-0.937133,-0.644891,1.12641,1.16123
7700,0.860645,0.844301,0.449618,0.479118,0.622066,0.59179,0.456638,0.441326,0.111498,0.215188,0.100597,0.0714838,0.214055,0.192774,0.947488,0.889153,0.96583,1.00022,0.0434201,0.0528396,-0.943665,-0.832762,-2.02319,-2.04309,0.828817,0.9765,-0.591851,-0.469379,-0.0292539,-0.110628,1.55259,1.461,0.452596,0.494577,1.04815,0.948222,0.676578,0.970154,0.940917,0.941256
7701,0.0215892,0.00740523,0.663799,0.604224,0.392566,0.344979,0.0671483,0.0495516,0.754949,0.860089,0.394809,0.367106,0.774596,0.754286,0.17392,0.117629,0.942891,0.975743,0.573052,0.582339,1.82514,1.93662,0.862832,0.843377,0.451314,0.687865,0.881424,1.00771,0.0201357,-0.0594825,-1.33983,-1.43614,0.804534,0.903793,0.356911,0.287157,0.698049,0.917269,0.691841,0.721281
7702,0.152831,0.13742,0.096963,0.0380824,0.52166,0.537725,0.631826,0.612895,0.81117,0.917117,0.405786,0.378917,0.697786,0.67495,0.395243,0.389115,0.0266742,0.0578988,0.712861,0.724863,-0.395802,-0.278454,-1.44425,-1.45981,0.245415,0.399231,-1.08928,-0.956877,-1.95068,-2.02575,0.904242,0.813952,1.27365,1.31301,-0.281247,-0.373909,0.575675,0.864383,1.8653,1.89516
7703,0.929042,0.912513,0.456694,0.398195,0.777776,0.730472,0.669753,0.60844,0.00929429,0.116415,0.699417,0.672468,0.352599,0.329726,0.718867,0.660602,0.934021,0.96566,0.480752,0.494046,-0.726681,-0.604119,-0.0212116,-0.0419899,-0.745741,-0.588909,-0.564965,-0.425381,0.898068,0.818924,0.203074,0.117389,-2.39911,-2.35983,0.435491,0.340696,-0.644034,-0.352477,0.152814,0.185108
7704,0.043789,0.0284042,0.0856473,0.0290904,0.564921,0.517313,0.655123,0.603985,0.699473,0.807674,0.99267,0.966019,0.923966,0.901418,0.716535,0.660239,0.970887,0.965935,0.496869,0.509393,-0.52657,-0.400848,0.395548,0.374161,-0.699861,-0.568758,-1.24391,-1.10821,0.484716,0.406568,0.563413,0.482783,-0.325171,-0.287072,-1.63755,-1.72875,0.674049,0.964378,-0.312315,-0.191691
7705,0.309601,0.276888,0.0572928,-0.00115494,0.139182,0.0928143,0.72507,0.59953,0.841405,0.947439,0.844694,0.818001,0.0972537,0.0734428,0.053876,-0.00186569,0.936553,0.96621,0.82999,0.843018,0.540442,0.661039,1.02622,1.00524,-0.71461,-0.548606,-0.672798,-0.531594,-0.781158,-0.862846,-3.45595,-3.53679,0.339423,0.37415,-1.01649,-1.10402,-0.738286,-0.443931,-0.592657,-0.568491
7706,0.633018,0.525373,0.300074,0.295857,0.874644,0.828156,0.774322,0.595075,0.283964,0.388894,0.280061,0.253629,0.651611,0.630335,0.676533,0.62358,0.102949,0.131627,0.876791,0.890054,0.577214,0.694964,-0.433071,-0.460505,0.846389,1.01458,-0.736739,-0.597901,2.05719,1.98183,0.779933,0.699096,-1.17947,-1.14179,-0.387941,-0.479276,0.14208,0.437002,0.375349,0.405156
7707,0.787936,0.773857,0.651805,0.592869,0.267477,0.219219,0.609551,0.59062,0.0557079,0.161554,0.459886,0.432731,0.22802,0.20533,0.54171,0.4872,0.954725,0.981702,0.523119,0.534268,-0.450812,-0.326942,-1.15205,-1.17669,-0.787335,-0.619506,-1.16211,-1.01882,-0.418512,-0.492717,0.148989,0.0635559,1.25327,1.28626,1.53995,1.45339,1.24819,1.53666,1.12068,1.15359
7708,0.227142,0.212141,0.606265,0.666297,0.0303626,-0.0191454,0.125445,0.108809,0.175053,0.28095,0.206514,0.17974,0.173236,0.151187,0.752787,0.698612,0.614691,0.545078,0.807731,0.817625,0.557797,0.675264,-0.855362,-0.88109,-0.272308,-0.0984759,-0.0476031,0.0983394,-0.701166,-0.781126,-0.988273,-1.07605,-0.0246131,0.00498922,0.500926,0.421706,-0.132231,0.159392,-2.07371,-2.03225
7709,0.782989,0.76869,0.737833,0.739725,0.55095,0.49976,0.978118,0.960671,0.0105036,0.114329,0.929315,0.901096,0.429287,0.407787,0.219117,0.162514,0.0811938,0.108453,0.151596,0.16132,-0.911322,-0.788711,2.25521,2.23559,-0.0893383,0.0846544,-2.09763,-1.9596,-0.673585,-0.65973,-0.045848,-0.126221,-0.999564,-0.964654,-1.43765,-1.52282,-1.85547,-1.56542,-0.302794,-0.256552
7710,0.657832,0.644745,0.872088,0.813152,0.274228,0.221178,0.958964,0.943497,0.577679,0.683069,0.188516,0.161597,0.896031,0.874866,0.274706,0.218253,0.166694,0.204483,0.0499086,0.130937,1.232,1.35368,-0.145362,-0.162377,-1.19732,-1.02859,-0.0607832,0.0730542,-0.464267,-0.538335,0.310252,0.226403,0.46897,0.498911,0.263217,0.174615,-0.386286,-0.0895341,-0.585475,-0.521448
7711,0.892209,0.880958,0.739844,0.722608,0.362967,0.390736,0.372273,0.355722,0.316243,0.420765,0.0417365,0.102998,0.188985,0.167651,0.0613115,0.00664376,0.273894,0.300512,0.0907977,0.100555,0.0336863,0.149682,-0.337233,-0.359949,1.09696,1.2654,-0.992091,-0.860465,1.59228,1.51417,0.283804,0.22877,0.677017,0.711746,-1.14219,-1.22548,-0.925712,-0.622121,-0.825752,-0.786345
7712,0.236587,0.224583,0.689595,0.632063,0.614155,0.560294,0.16893,0.153411,0.731368,0.838269,0.0692644,0.0443985,0.563647,0.544411,0.961706,0.908808,0.112744,0.137719,0.244719,0.252658,-0.959031,-0.840563,1.01159,0.995451,0.0355131,0.199547,-1.22578,-1.09458,0.101105,0.0305743,0.451953,0.231137,-0.623215,-0.585208,-1.46429,-1.55278,1.70096,2.00055,-0.710053,-0.673215
7713,0.508447,0.495724,0.87497,0.815524,0.399979,0.316665,0.991816,0.975104,0.0786782,0.184031,0.987889,0.960506,0.672807,0.654422,0.102563,0.0483156,0.74761,0.774952,0.106088,0.112886,-1.57234,-1.46208,0.0138963,0.000193966,0.720898,0.891512,0.890765,1.01648,0.526461,0.449191,0.317353,0.233504,-0.30373,-0.263456,2.13501,2.04075,0.0671595,0.373051,-1.77688,-1.73808
7714,0.200468,0.186677,0.47365,0.416084,0.125228,0.0730364,0.00448393,-0.0124743,0.442271,0.547375,0.163399,0.13705,0.487314,0.468984,0.616624,0.56031,0.248137,0.275199,0.254105,0.259604,0.359697,0.463574,0.410559,0.399985,0.874187,1.04399,-0.361739,-0.240939,-0.552569,-0.634927,1.416,1.33411,0.368962,0.411718,-1.33401,-1.42588,0.380373,0.742502,1.55579,1.59769
7715,0.384848,0.372707,0.897887,0.84053,0.407414,0.354321,0.512681,0.406082,0.207554,0.310427,0.535737,0.541445,0.982702,0.965837,0.370614,0.411923,0.932051,0.957477,0.107432,0.114498,-1.85624,-1.7515,1.20973,1.20131,0.0872189,0.258443,-0.488394,-0.367214,-0.293704,-0.369408,-1.00304,-1.07785,1.91824,1.96555,2.25938,2.16765,0.810587,1.11195,1.04031,1.07607
7716,0.357549,0.347424,0.181768,0.125625,0.933267,0.87779,0.842714,0.824638,0.681484,0.783399,0.970858,0.945839,0.756568,0.739468,0.319096,0.263536,0.409229,0.520853,0.182965,0.190305,0.0679121,0.174155,-0.310933,-0.32584,1.78021,1.94737,-0.299039,-0.171471,-0.680324,-0.751731,0.780662,0.702153,0.456548,0.496926,1.97451,1.88669,-0.695047,-0.391729,-0.631592,-0.600885
7717,0.0720449,0.0633758,0.816491,0.760919,0.190406,0.137032,0.54197,0.522207,0.208808,0.310393,0.595252,0.677127,0.0209584,0.00190061,0.792855,0.735614,0.0595899,0.0842285,0.88857,0.894731,-1.30038,-1.19696,1.68363,1.66957,1.07418,1.24006,1.57089,1.70035,0.198546,0.127348,-0.366879,-0.452824,0.347228,0.391384,-0.0248396,-0.120562,-0.556441,-0.258703,2.05899,2.0836
7718,0.431578,0.515151,0.610327,0.555974,0.177157,0.0594707,0.838915,0.817477,0.881703,0.981284,0.366065,0.408416,0.226612,0.207795,0.250634,0.194191,0.500557,0.523715,0.861344,0.909014,-0.183583,-0.0751916,0.0470315,0.0333595,1.41956,1.57784,-0.776512,-0.64742,-1.66015,-1.73026,0.127929,0.0385761,-0.871359,-0.826145,0.84008,0.745378,-1.00581,-0.714076,0.695408,0.726499
7719,0.97373,0.966926,0.671457,0.615646,0.0360388,-0.0180902,0.400964,0.381242,0.345812,0.44313,0.164724,0.139705,0.181827,0.155061,0.973965,0.916513,0.361427,0.32566,0.916141,0.923297,0.357271,0.467766,-0.133203,-0.148007,2.33859,2.49925,-0.591538,-0.466364,0.545112,0.472747,-0.269405,-0.361273,-0.49737,-0.494472,-0.688984,-0.778887,0.0988254,0.385578,-0.228399,-0.217557
7720,0.988241,0.982119,0.172064,0.117364,0.522561,0.376088,0.663924,0.649656,0.461955,0.557253,0.205385,0.180087,0.223662,0.102327,0.321035,0.264028,0.105503,0.127606,0.170111,0.175415,-0.13907,-0.0310459,0.77101,0.759438,-0.438189,-0.272568,0.226836,0.357102,-0.15715,-0.228459,2.01353,1.92026,-0.199296,-0.162798,-0.367263,-0.461684,1.45673,1.74106,-1.19021,-1.16161
7721,0.374503,0.366014,0.0273037,-0.0263428,0.824416,0.770267,0.93696,0.91807,0.175435,0.269926,0.603315,0.579717,0.0663065,0.0495926,0.752417,0.695677,0.764044,0.785918,0.0743303,0.0815752,1.51982,1.62148,-1.72022,-1.7307,0.476608,0.640714,0.841053,0.963996,0.0682054,-0.00851853,-2.03794,-2.12721,0.454558,0.498423,-0.852899,-0.941914,-0.202358,0.0806469,-1.47473,-1.44177
7722,0.778834,0.768957,0.762079,0.70967,0.18851,0.136125,0.388858,0.370252,0.581491,0.677885,0.613804,0.569919,0.513816,0.495739,0.329665,0.273722,0.258427,0.280806,0.249044,0.306666,-0.212154,-0.104888,0.33208,0.327486,1.38837,1.554,-0.732262,-0.614395,-0.632284,-0.709724,-0.394105,-0.484972,1.31327,1.35517,1.60997,1.51984,-1.60153,-1.31063,-0.399561,-0.359432
7723,0.931313,0.919048,0.603242,0.551142,0.739116,0.688641,0.189908,0.172841,0.474838,0.483791,0.489301,0.560121,0.62286,0.606718,0.244364,0.213879,0.21302,0.226331,0.527025,0.531756,-1.01814,-0.953948,0.65552,0.652321,1.22274,1.38758,-0.442558,-0.325977,-0.426968,-0.505974,-0.878117,-0.964033,-0.522998,-0.474425,0.213076,0.169886,-0.809307,-0.524745,1.66684,1.70837
7724,0.523625,0.51384,0.998101,0.946591,0.928467,0.878994,0.6693,0.650332,0.194746,0.289696,0.57215,0.550323,0.734732,0.717696,0.211266,0.154035,0.14765,0.171856,0.3368,0.341136,-1.90736,-1.80301,2.05592,2.05393,-1.98241,-1.81606,1.11468,1.23152,0.139835,0.0659536,0.63168,0.55158,0.302011,0.353109,-1.08908,-1.18007,-1.17711,-0.88658,-0.94139,-0.891923
7725,0.742614,0.730418,0.0455664,-0.00307103,0.0410347,-0.00686229,0.319317,0.298619,0.75814,0.852647,0.167534,0.14418,0.22808,0.211378,0.820829,0.763809,0.913983,0.938262,0.432555,0.437301,-0.78858,-0.681243,-0.104555,-0.100627,0.673213,0.842718,-0.214686,-0.101128,0.0376432,-0.0406938,0.754206,0.674095,-0.203505,-0.153042,-0.576101,-0.708948,-0.831194,-0.535564,-0.109603,-0.0546213
7726,0.427757,0.415424,0.362321,0.362025,0.015582,-0.00616138,0.764557,0.742029,0.396344,0.549196,0.489406,0.522403,0.00195384,-0.0149902,0.57951,0.520895,0.233622,0.258321,0.210336,0.216652,1.80249,1.90808,-1.44078,-1.43988,-0.735936,-0.563236,0.0989321,0.188059,0.401794,0.317652,1.18144,1.10333,0.645821,0.689441,-0.0404813,-0.237831,2.86313,3.16826,1.83611,1.88787
7727,0.902465,0.892386,0.773072,0.727121,0.043736,-0.00546046,0.938842,0.917083,0.149074,0.245744,0.926521,0.900626,0.381465,0.366465,0.652662,0.531589,0.246612,0.273289,0.723585,0.730168,-1.71696,-1.61993,0.901941,0.911336,-0.228742,-0.0597133,0.360647,0.477245,1.01642,0.934767,-0.181078,-0.254544,0.245397,0.291228,0.324276,0.233287,1.52566,1.83675,-1.30775,-1.25303
7728,0.514622,0.57014,0.191743,0.146088,0.646929,0.598099,0.777713,0.769279,0.498091,0.51233,0.989969,0.962179,0.11088,0.0955319,0.600569,0.542283,0.946434,0.975909,0.0730516,0.0791722,-1.4065,-1.30671,-0.38904,-0.379065,0.676786,0.847408,-1.3018,-1.18435,0.0076719,-0.0748194,0.681442,0.601843,0.655937,0.706511,1.2966,1.20656,-0.886589,-0.581079,1.16653,1.2222
7729,0.256295,0.247893,0.640076,0.507079,0.24087,0.192544,0.643452,0.621475,0.681992,0.778916,0.452086,0.422963,0.493404,0.476987,0.309969,0.250752,0.592722,0.700105,0.74275,0.748567,-1.38325,-1.28541,0.984994,0.991301,0.762165,0.937619,0.132726,0.245141,-0.137314,-0.225921,-1.50127,-1.58695,-0.761627,-0.715428,1.4974,1.40011,0.748975,1.05057,-0.312113,-0.254897
7730,0.23767,0.227814,0.913724,0.86807,0.0990835,0.0505379,0.0709864,0.0488125,0.643755,0.74011,0.675974,0.645749,0.0547601,0.036252,0.658543,0.597996,0.396792,0.4243,0.0394732,0.0459312,1.08455,1.18844,0.839144,0.841611,1.38184,1.55003,1.30156,1.41172,-1.21699,-1.31004,0.226012,0.146293,-0.78671,-0.744199,-1.38762,-1.48515,0.442883,0.749818,0.0506329,0.112999
7731,0.699244,0.69004,0.144179,0.100589,0.418617,0.308163,0.156245,0.0782748,0.158555,0.256428,0.899329,0.868534,0.905811,0.888056,0.520942,0.368663,0.56261,0.533222,0.48996,0.461978,0.732207,0.830522,-0.80944,-0.8108,0.050841,0.221648,-2.22049,-2.10762,-0.537039,-0.63003,-0.378091,-0.45764,-1.28783,-1.25035,-1.39832,-1.49457,-1.36321,-1.05656,1.24821,1.31667
7732,0.913584,0.839836,0.983813,0.938411,0.612956,0.565788,0.13263,0.107737,0.821768,0.921672,0.863517,0.831206,0.471161,0.44042,0.198118,0.139329,0.613739,0.642144,0.871482,0.878024,1.2027,1.29742,-0.705708,-0.718734,0.600737,0.773607,1.817,1.92986,1.64329,1.55659,2.86296,2.78751,0.498504,0.482626,0.851476,0.759279,-0.251888,0.0574667,-1.43975,-1.37022
7733,0.997488,0.989632,0.171549,0.123794,0.691075,0.64226,0.697472,0.67108,0.126522,0.225829,0.160543,0.126185,0.00966343,-0.00721499,0.597112,0.535967,0.0849721,0.112978,0.424129,0.431633,0.430132,0.573747,-0.634106,-0.626668,0.903773,1.08149,1.04693,1.15349,0.0905756,0.0132185,-0.539348,-0.610551,2.17812,2.2156,-0.359912,-0.45739,-0.611613,-0.304369,-0.011616,0.0654189
7734,0.949034,0.962635,0.562196,0.513776,0.354391,0.34299,0.360023,0.333664,0.00302696,0.103982,0.263506,0.230341,0.729503,0.711864,0.0861719,0.0246966,0.787508,0.815598,0.880364,0.886092,-0.245938,-0.149921,-0.533242,-0.534602,0.971127,1.14387,-0.787384,-0.680097,0.445651,0.461391,0.321818,0.245836,0.48333,0.526548,0.8503,0.759291,0.388509,0.702114,0.706196,0.783418
7735,0.941241,0.935637,0.689499,0.581039,0.0919067,0.0437197,0.634806,0.615373,0.581921,0.683718,0.019293,-0.0130797,0.349934,0.330923,0.665645,0.602572,0.300796,0.330696,0.754168,0.761005,1.09977,1.19214,1.0487,1.04057,-0.99362,-0.821211,0.711554,0.813547,0.984738,0.909564,0.440151,0.368351,-0.806968,-0.770406,0.603963,0.507802,-0.80667,-0.486378,-0.453787,-0.374731
7736,0.705845,0.649674,0.695655,0.648303,0.293958,0.244179,0.925687,0.897082,0.5956,0.69665,0.267195,0.161933,0.267028,0.246561,0.711234,0.647961,0.348364,0.379763,0.328467,0.335051,-0.413137,-0.317378,0.926165,0.920086,1.57727,1.75436,0.896655,0.994602,-1.47674,-1.54565,1.33551,1.2567,2.79982,2.83897,-0.324531,-0.417546,0.0717066,0.394554,1.19978,1.27456
7737,0.368415,0.36371,0.76229,0.715566,0.839643,0.791665,0.159628,0.133547,0.879562,0.978747,0.459327,0.336946,0.730658,0.70787,0.328734,0.266691,0.0759837,0.105869,0.420596,0.426522,1.87436,1.96465,0.21271,0.203896,0.158329,0.332198,0.285466,0.389083,0.943001,0.875654,0.455387,0.376455,0.204852,0.245115,-0.0121281,-0.100343,0.629868,0.949198,-1.0408,-0.962611
7738,0.755763,0.752213,0.485379,0.440219,0.508407,0.421651,0.649507,0.622011,0.014348,0.11143,0.544332,0.511959,0.731602,0.711322,0.884576,0.82459,0.814151,0.842627,0.919428,0.925153,-0.188132,-0.0910614,0.381041,0.375164,-1.26705,-1.08996,-1.99832,-1.89092,1.63699,1.57014,0.525781,0.452086,-0.134258,-0.0918225,-0.239772,-0.245742,-0.749991,-0.428066,-0.763326,-0.684521
7739,0.370319,0.366645,0.649862,0.603953,0.102027,0.0516363,0.233422,0.205242,0.508979,0.528703,0.959805,0.926533,0.315218,0.295312,0.134103,0.0728817,0.6859,0.715659,0.571612,0.657864,-0.390407,-0.296515,-0.224278,-0.234494,0.908493,1.08923,2.2824,2.38242,0.883567,0.822819,-1.0212,-1.08742,-1.93438,-1.89067,-0.304207,-0.391142,-0.0684418,0.251037,-1.19495,-1.11591
7740,0.439429,0.437378,0.484631,0.440744,0.0123924,-0.0393292,0.246021,0.262186,0.850087,0.945976,0.485591,0.45157,0.684853,0.666971,0.66281,0.599757,0.945348,0.977318,0.383653,0.390575,0.193088,0.293077,-0.338996,-0.35498,-0.291428,-0.116346,0.972974,1.07968,1.34769,1.28694,0.34371,0.274483,-0.342313,-0.30328,-0.111995,-0.151782,-2.66449,-2.34042,-1.01001,-0.877581
7741,0.235603,0.256902,0.527701,0.484152,0.730835,0.680668,0.348885,0.319131,0.060672,0.156232,0.501938,0.468264,0.842604,0.822329,0.772916,0.710465,0.785275,0.818901,0.557557,0.562746,2.86947,2.96814,0.0188343,0.000214961,-0.231451,-0.0539693,-0.770857,-0.659764,-0.685035,-0.747476,0.373291,0.30476,0.736981,0.769201,0.176828,0.087579,-0.311264,0.0162861,-0.72261,-0.639249
7742,0.0774837,0.076425,0.897971,0.853864,0.913857,0.780775,0.138068,0.107129,0.359648,0.453808,0.873554,0.837822,0.260636,0.239902,0.0712848,0.00705298,0.120819,0.153525,0.289374,0.2923,-0.817235,-0.712246,1.70817,1.68322,0.957308,1.12788,0.0376481,0.14971,-1.39481,-1.4621,-1.88503,-1.95048,0.856774,0.891956,0.607123,0.510786,1.05854,1.38437,-0.26058,-0.181816
7743,0.151913,0.152071,0.102314,0.0562778,0.930911,0.880882,0.370728,0.311417,0.958625,1.05355,0.892052,0.821471,0.457731,0.436555,0.781661,0.719064,0.576627,0.608941,0.648988,0.652428,-0.490559,-0.416239,-0.342983,-0.361126,0.061426,0.233449,-0.459272,-0.347913,-1.18487,-1.27167,0.704693,0.640735,1.3694,1.39898,0.479335,0.381989,0.691804,1.02253,-1.1168,-1.03438
7744,0.791705,0.793277,0.320294,0.273608,0.0864753,0.0364461,0.569277,0.515704,0.406549,0.49976,0.84004,0.805121,0.967131,0.947373,0.385266,0.322558,0.406781,0.441242,0.0550667,0.0568521,-0.223413,-0.120232,2.93024,2.91212,0.763234,0.940234,0.797687,0.909655,-1.08944,-1.08124,-0.993586,-1.05336,0.979633,1.01666,1.16887,1.0653,1.19541,1.53071,-0.812736,-0.72575
7745,0.626165,0.64684,0.883171,0.835581,0.501431,0.426788,0.74952,0.719992,0.808202,0.902291,0.284267,0.250935,0.616964,0.586276,0.430316,0.367948,0.699332,0.732541,0.0670189,0.0675692,0.866315,0.971219,-0.517923,-0.529809,0.3461,0.527736,-0.0720854,0.0382093,-0.823525,-0.890814,0.422692,0.36835,1.43275,1.46356,-0.104585,-0.213938,-0.0184114,0.313848,-0.142134,-0.0533277
7746,0.498328,0.500403,0.0105958,-0.0379343,0.866754,0.81713,0.340248,0.312967,0.381559,0.473823,0.497756,0.463527,0.242839,0.22518,0.797404,0.735035,0.243293,0.277958,0.988928,0.990991,-0.986642,-0.882718,1.40081,1.38571,-0.932345,-0.753154,-1.53773,-1.43299,0.497613,0.433606,-0.658021,-0.710819,0.64421,0.681186,0.100475,-0.006334,1.08236,1.4135,3.0093,3.09825
7747,0.983318,0.987129,0.183449,0.135919,0.804811,0.744663,0.439597,0.41219,0.167884,0.262027,0.709452,0.67612,0.810358,0.791689,0.234368,0.173878,0.428511,0.464144,0.189248,0.19098,1.407,1.5124,-0.365674,-0.376809,1.89663,2.08211,1.08462,1.18465,0.361862,0.296111,0.853928,0.804794,0.881189,0.869505,-1.10195,-1.20689,0.877137,1.20672,0.289507,0.377242
7748,0.657407,0.66173,0.644539,0.594414,0.618024,0.672197,0.01379,-0.0149727,0.704012,0.795789,0.182761,0.151863,0.793303,0.773927,0.82041,0.761813,0.40476,0.439662,0.0641606,0.0658931,0.773423,0.876469,-0.0587706,-0.0669261,-0.241701,-0.0600591,1.27677,1.38039,-1.08885,-1.15748,-1.98141,-2.0302,0.920342,1.05782,0.419052,0.317317,0.288511,0.61339,-1.61356,-1.53325
7749,0.0918034,0.0957664,0.471466,0.419839,0.649522,0.59973,0.825057,0.796371,0.188932,0.282667,0.750401,0.718292,0.262425,0.24174,0.760621,0.701158,0.990363,1.0249,0.842353,0.846307,-0.0774173,0.0249699,-0.220614,-0.171607,2.19912,2.38348,1.84904,1.957,0.414652,0.350211,-1.29903,-1.34286,1.20917,1.24614,0.249136,0.143545,0.656154,0.979016,-1.08828,-1.0138
7750,0.323409,0.327616,0.955779,0.903558,0.171746,0.120028,0.352319,0.324194,0.362656,0.457753,0.926818,0.893066,0.673655,0.608445,0.355195,0.293939,0.279589,0.314501,0.287878,0.290497,0.12736,0.228241,-0.26713,-0.276288,0.301885,0.480921,0.806903,0.917564,0.371131,0.307905,1.24049,1.19816,0.519111,0.555618,1.36534,1.25646,0.133486,0.4625,0.0333231,0.151883
7751,0.863964,0.869871,0.16201,0.10982,0.276467,0.136842,0.980716,0.951361,0.283931,0.377583,0.440772,0.408347,0.995876,0.975149,0.184957,0.12237,0.392928,0.429064,0.289989,0.297056,-1.89706,-1.79728,0.499319,0.493635,-0.604567,-0.469065,0.756295,0.867871,-1.20654,-1.26874,1.74302,1.70526,0.431978,0.4663,0.064941,-0.0394022,-1.41028,-1.08739,1.23902,1.31756
7752,0.58243,0.585823,0.85775,0.80459,0.207175,0.153655,0.59092,0.559587,0.649464,0.745249,0.534769,0.503583,0.571145,0.550144,0.350769,0.289315,0.911451,0.949505,0.299107,0.303615,-0.196496,-0.0987647,1.04845,1.04712,-1.59758,-1.41905,-1.22468,-1.11237,0.84175,0.783763,-0.919027,-0.949745,-2.35772,-2.33279,-0.817487,-0.919127,0.010687,0.32757,0.210411,0.283466
7753,0.582224,0.58639,0.562642,0.509277,0.435575,0.383307,0.493952,0.462035,0.197228,0.291859,0.378809,0.345129,0.841912,0.821341,0.18233,0.121465,0.152642,0.189828,0.3091,0.310174,-1.44522,-1.34956,-0.396817,-0.401931,-1.07339,-0.944845,-0.115258,-0.0102516,0.720083,0.661129,0.031063,8.67624e-05,-0.869025,-0.840988,-0.625739,-0.708366,-0.453155,-0.142081,-0.164398,-0.0482634
7754,0.00983887,0.0157702,0.0198252,-0.0324386,0.265663,0.211468,0.136698,0.105022,0.785622,0.881827,0.830731,0.79845,0.405284,0.38526,0.261271,0.11559,0.734579,0.769645,0.025623,0.0247316,0.509124,0.609032,0.308141,0.305899,-0.645689,-0.470639,-0.368851,-0.261974,-0.772561,-0.839823,-1.45512,-1.48077,-0.0225086,0.00149421,-0.395964,-0.497605,0.828394,1.14409,-0.456297,-0.379992
7755,0.538884,0.54711,0.592927,0.538944,0.543462,0.487407,0.265954,0.183088,0.630844,0.725952,0.466446,0.436723,0.255716,0.266706,0.169833,0.109716,0.670061,0.703852,0.323421,0.322161,0.214541,0.312068,-0.322068,-0.318632,-1.83646,-1.65977,0.25976,0.360068,1.30578,1.24603,-0.179279,-0.210643,0.109224,0.138968,-1.04643,-1.14854,0.214027,0.534592,0.102605,0.185983
7756,0.117935,0.12679,0.875708,0.820721,0.556614,0.499413,0.26331,0.261154,0.875429,0.972678,0.45711,0.344582,0.167533,0.148153,0.916805,0.856666,0.0576666,0.0935989,0.0575733,0.057188,0.185462,0.245859,-0.31911,-0.316328,0.350843,0.532782,0.379172,0.504736,0.378048,0.313961,0.564119,0.53894,1.01418,1.04374,-0.147954,-0.251763,0.303832,0.622602,-2.42203,-2.33757
7757,0.388803,0.354487,0.63259,0.569768,0.330071,0.335511,0.370526,0.33922,0.188026,0.286644,0.28216,0.25244,0.83816,0.820881,0.475297,0.415087,0.631878,0.668327,0.142193,0.212718,0.0825756,0.17965,-1.70093,-1.70295,-0.0421879,0.135993,0.546046,0.649403,-0.271786,-0.34039,-0.0543012,-0.0813489,0.229266,0.261372,-0.287844,-0.396224,-0.332419,-0.0166925,1.04042,1.12134
7758,0.58182,0.582185,0.314762,0.318815,0.228814,0.171609,0.805547,0.772636,0.176185,0.272725,0.853318,0.823492,0.856813,0.838669,0.27089,0.213018,0.0147942,0.0525234,0.37056,0.368248,-0.147267,-0.0564548,1.00403,1.00143,1.3922,1.57649,-0.639982,-0.529613,1.11609,1.04567,0.654435,0.623776,0.524485,0.553668,-0.164023,-0.264303,0.770518,1.08296,-2.91681,-2.83589
7759,0.802605,0.809882,0.122849,0.0678623,0.531731,0.38881,0.233981,0.199974,0.935604,1.03135,0.813951,0.786164,0.639942,0.720116,0.415193,0.345908,0.0730084,0.155133,0.782925,0.782028,1.01084,1.09802,-1.89753,-1.90252,0.362293,0.541288,-0.383824,-0.273184,1.09817,1.03525,-0.537965,-0.562345,0.0405183,0.0765459,1.67249,1.57241,0.548848,0.793186,-2.26051,-2.16427
7760,0.278064,0.28385,0.327895,0.270323,0.665123,0.606011,0.824276,0.792306,0.0227705,0.120939,0.295201,0.266092,0.618921,0.601562,0.536489,0.478797,0.218287,0.257742,0.737238,0.680719,-0.320592,-0.22973,-0.903326,-0.902852,-0.236666,-0.0599308,1.67652,1.78946,0.637251,0.57656,0.633009,0.602548,-1.43304,-1.39207,-0.244106,-0.341192,0.182538,0.503412,-1.56997,-1.49265
7761,0.450917,0.459256,0.859849,0.802475,0.242211,0.181512,0.815061,0.785523,0.603714,0.700675,0.747373,0.719413,0.24599,0.230849,0.125992,0.0671074,0.863787,0.90469,0.578841,0.579411,-1.42127,-1.32786,1.99425,1.99653,0.964071,1.13583,0.596523,0.717544,0.503425,0.439065,0.00687606,-0.0177404,-0.765526,-0.730852,-0.672017,-0.775679,-1.83521,-1.5129,1.06516,1.13888
7762,0.152841,0.159626,0.549823,0.589482,0.764209,0.704981,0.335055,0.404473,0.245771,0.341597,0.685831,0.657467,0.606213,0.538593,0.180488,0.188391,0.36855,0.409603,0.871246,0.87235,-0.475798,-0.388823,-0.631432,-0.635904,-0.568126,-0.390899,-0.9946,-0.878801,0.00342634,-0.0650615,-0.104752,-0.125122,1.83774,1.87523,-0.502561,-0.613541,-0.557629,-0.242438,-0.178983,-0.110258
7763,0.490705,0.451594,0.43578,0.376488,0.934478,0.875709,0.0531573,0.023423,0.325891,0.420346,0.918988,0.890846,0.861949,0.846337,0.30882,0.309674,0.132399,0.171092,0.849468,0.81928,-2.39785,-2.31812,0.506581,0.501928,-0.166565,0.00939397,1.43862,1.5497,-1.67495,-1.74978,0.930272,0.835236,-1.31451,-1.28028,-3.40386,-3.52213,-2.22131,-1.90285,-1.7565,-1.69404
7764,0.735978,0.743562,0.218585,0.163495,0.416806,0.356917,0.862828,0.834767,0.750524,0.842686,0.907425,0.878698,0.905717,0.888948,0.489842,0.430958,0.853952,0.893624,0.766813,0.76621,0.196831,0.271204,0.930544,0.932495,-0.287571,-0.110563,0.334383,0.373807,2.11448,2.04001,1.82276,1.79559,-0.217421,-0.175928,2.0521,1.93384,-0.423985,-0.0983656,1.24405,1.30752
7765,0.0923314,0.102173,0.248712,0.191944,0.767199,0.709633,0.694739,0.667163,0.93051,1.02272,0.515592,0.486565,0.332138,0.316749,0.171631,0.114465,0.453605,0.510225,0.952638,0.953403,-0.0297658,0.12613,1.05633,1.05575,1.87473,2.05051,-0.917692,-0.80209,-1.28752,-1.35848,0.833043,0.807379,-0.068525,-0.0228938,-0.340879,-0.463106,0.824413,1.15648,-0.539274,-0.477515
7766,0.122861,0.132604,0.518482,0.462979,0.0537212,-0.0048262,0.846833,0.817437,0.0123139,0.107329,0.483418,0.454428,0.275249,0.25837,0.156446,0.0679245,0.0872001,0.126826,0.774384,0.773063,-0.0868932,-0.0189445,-1.7831,-1.78585,-0.625515,-0.442605,-0.105656,0.00738365,-1.07231,-1.13854,-0.660255,-0.688681,0.313958,0.359552,-0.0907618,-0.223746,0.0296155,0.360909,-0.29728,-0.231153
7767,0.444364,0.454,0.26753,0.212413,0.46658,0.323869,0.78479,0.754857,0.802065,0.898813,0.0123543,-0.0156477,0.93219,0.916264,0.0762267,0.0213842,0.0464346,0.0871829,0.0245135,0.0251813,-0.460363,-0.392685,0.658754,0.660639,1.14831,1.32449,3.02144,3.12844,-1.26796,-1.33736,-0.413336,-0.452265,1.07444,1.12665,0.131706,0.0156149,1.24774,1.58449,-0.28948,-0.223572
7768,0.548053,0.601273,0.504846,0.449721,0.711247,0.652563,0.418372,0.388048,0.208364,0.304398,0.96357,0.936879,0.602498,0.58586,0.911934,0.854981,0.39073,0.433559,0.969409,0.970076,-0.339421,-0.264865,-0.943968,-0.943701,1.19748,1.36927,1.26173,1.3744,-2.50908,-2.57584,-0.193849,-0.215849,-0.46758,-0.422387,0.113918,-0.00765039,-0.673601,-0.333691,-1.53713,-1.47271
7769,0.740235,0.748547,0.509595,0.454095,0.32668,0.267947,0.798768,0.766361,0.3173,0.413416,0.310724,0.282147,0.824985,0.760743,0.024351,-0.0329096,0.101372,0.144408,0.328349,0.329414,-1.05617,-0.946581,-0.0370969,-0.0362564,-0.684266,-0.517028,1.60242,1.70741,1.42782,1.35375,-0.162897,-0.185572,-0.455697,-0.407852,-0.454563,-0.579267,0.683282,1.02179,-0.106073,-0.0370687
7770,0.276293,0.282726,0.117042,0.0600032,0.562594,0.525572,0.635121,0.603496,0.100888,0.196357,0.42598,0.309015,0.954147,0.935626,0.62053,0.56538,0.342222,0.397924,0.291909,0.290895,-1.70393,-1.6283,2.16282,2.1692,0.419382,0.586616,0.819378,0.931034,-0.660064,-0.732319,0.117526,0.0108472,0.566065,0.619292,0.388972,0.257537,0.0584028,0.398731,-0.997505,-0.93486
7771,0.549478,0.553867,0.815924,0.760235,0.841892,0.783197,0.977854,0.94684,0.605711,0.700256,0.363383,0.335884,0.948365,0.928199,0.996467,0.942798,0.607457,0.651439,0.645667,0.644777,0.191901,0.268449,0.520856,0.532981,0.986916,1.15367,-0.209906,-0.0935148,0.0233018,-2.52712e-05,0.230721,0.207266,-0.280346,-0.224202,-1.17876,-1.31218,0.652818,0.998219,0.0569781,0.115984
7772,0.614696,0.619197,0.718159,0.681607,0.428261,0.368771,0.627869,0.595127,0.669342,0.784982,0.638809,0.61088,0.0854684,0.0673158,0.0819822,0.0302431,0.332649,0.377546,0.187042,0.183918,1.01783,1.0997,1.05461,1.07191,-0.842865,-0.673135,-0.412188,-0.296248,0.761842,0.732268,-0.709722,-0.698947,-1.53936,-1.48714,1.79588,1.66952,-1.70092,-1.35306,1.44461,1.50382
7773,0.170444,0.173351,0.657186,0.602978,0.288109,0.257262,0.780691,0.745402,0.774116,0.869707,0.291918,0.263697,0.817542,0.801881,0.0588752,0.00989861,0.343864,0.387567,0.784323,0.782399,-1.14897,-1.065,-0.110562,-0.0941383,-0.0446536,0.125888,-0.0376118,0.0821834,1.53682,1.46456,-1.58667,-1.60516,1.53564,1.59014,1.61253,1.47986,-0.61919,-0.269144,1.5081,1.57204
7774,0.263398,0.270193,0.10812,0.0562581,0.263482,0.145753,0.0597945,0.0227013,0.516926,0.612653,0.915069,0.889154,0.423191,0.473651,0.729554,0.680941,0.117782,0.159433,0.169424,0.167197,1.06604,1.15427,0.611347,0.627938,-0.720562,-0.552606,0.779515,0.905649,-1.56061,-1.62808,0.658771,0.644936,-1.4559,-1.39866,0.17778,0.0468814,0.238603,0.582391,1.17805,1.24645
7775,0.365213,0.367035,0.411436,0.410063,0.0928797,0.0342433,0.602409,0.56559,0.696836,0.79269,0.453921,0.428245,0.159928,0.145421,0.349034,0.29967,0.900292,0.941615,0.418401,0.415545,-0.277743,-0.18718,0.539471,0.553473,0.235149,0.40133,1.02969,1.16208,0.573981,0.507489,0.107126,0.105981,0.311378,0.372492,0.420409,0.375268,0.820939,1.1657,-1.45494,-1.38896
7776,0.0396991,0.0416353,0.81362,0.763868,0.396114,0.335491,0.747934,0.657199,0.23629,0.333959,0.407479,0.478834,0.928421,0.914803,0.95747,0.909444,0.590979,0.631808,0.950848,0.95044,0.476588,0.570459,0.0842726,0.0966971,-0.743299,-0.573562,-1.58654,-1.45657,-1.06774,-1.13076,-0.419209,-0.432974,-1.5795,-1.51981,0.83392,0.703654,-1.23123,-0.880991,-0.247665,-0.185289
7777,0.992447,0.994725,0.747119,0.616976,0.380599,0.410272,0.787955,0.748808,0.9633,1.06196,0.554094,0.529423,0.943528,0.927752,0.65964,0.612511,0.279752,0.322001,0.713803,0.691549,-0.256302,-0.158281,0.698115,0.712614,0.627224,0.79041,-0.306019,-0.169293,-1.00377,-1.06365,1.1802,1.16055,0.370359,0.425344,0.474464,0.344718,-0.566399,-0.219398,-0.349037,-0.283053
7778,0.171194,0.172004,0.518314,0.470084,0.545342,0.485054,0.363512,0.396857,0.961981,1.05941,0.161731,0.13729,0.334936,0.321625,0.830432,0.783705,0.847445,0.891365,0.432077,0.432658,0.469209,0.567384,0.720417,0.728698,0.264462,0.423602,-2.55154,-2.41516,0.598116,0.536277,0.32509,0.311157,-1.22991,-1.17061,1.54453,1.41287,-0.831787,-0.434799,0.304836,0.374
7779,0.362601,0.362384,0.092821,0.046152,0.862947,0.801767,0.0843218,0.044907,0.60903,0.708043,0.258532,0.232525,0.549845,0.538091,0.518708,0.471628,0.806435,0.851723,0.590697,0.625442,0.153258,0.255852,-1.38613,-1.3759,0.468011,0.622451,-1.25925,-1.12788,-0.630711,-0.687604,0.692138,0.67655,1.328,1.38697,-1.62491,-1.76349,-1.00013,-0.6502,-0.784298,-0.708887
7780,0.260553,0.259782,0.401794,0.405161,0.381704,0.322065,0.849512,0.808306,0.259024,0.356678,0.804223,0.778611,0.231718,0.221831,0.516326,0.369574,0.355655,0.401925,0.818888,0.818226,-1.83889,-1.737,0.404373,0.415015,-1.31724,-1.17064,1.50885,1.63329,-2.7204,-2.77368,0.771417,0.752181,0.20739,0.261516,1.17363,1.03559,-0.260261,0.0902323,0.553365,0.632224
7781,0.57175,0.571419,0.809515,0.764171,0.667431,0.608581,0.609251,0.609898,0.303285,0.304236,0.583604,0.560087,0.324206,0.350996,0.315028,0.267519,0.274115,0.321561,0.647942,0.602529,0.265282,0.358935,0.827927,0.831166,-0.355433,-0.202672,1.20706,1.33554,-1.29023,-1.34223,-0.444264,-0.462849,-0.0740574,-0.0123919,-1.06957,-1.20195,0.030808,0.376965,-0.839169,-0.755686
7782,0.501689,0.500524,0.32466,0.280881,0.0993907,0.0398486,0.51082,0.41149,0.156133,0.251795,0.925462,0.899663,0.488103,0.480162,0.0874541,0.0405585,0.456287,0.502907,0.38707,0.386833,-1.69064,-1.5996,0.776365,0.786401,1.38157,1.53576,1.4591,1.59197,0.91022,0.860776,-1.2871,-1.31224,0.12038,0.186415,-0.839643,-0.977442,-0.197861,0.153538,0.223294,0.310314
7783,0.430922,0.429629,0.774203,0.729127,0.138289,0.0762158,0.254676,0.213082,0.575737,0.669299,0.251048,0.224113,0.0630705,0.055157,0.358346,0.324472,0.0588102,0.103962,0.425405,0.424332,0.56711,0.650653,1.31817,1.32533,0.769202,0.918405,0.658281,0.784395,-0.806273,-0.85547,0.393854,0.375432,-1.18421,-1.12637,0.587377,0.456999,-0.8093,-0.455957,-0.416492,-0.332533
7784,0.987838,0.986178,0.150377,0.103575,0.615924,0.554399,0.846294,0.805414,0.297118,0.392304,0.628185,0.603002,0.645731,0.636308,0.654141,0.608386,0.841992,0.886144,0.46123,0.461831,1.14357,1.22479,1.17844,1.18936,0.650133,0.798448,1.48814,1.60786,1.27658,1.23038,1.41691,1.40183,-0.727753,-0.665503,-2.64284,-2.7708,-0.813403,-0.461274,-1.30356,-1.21604
7785,0.870129,0.867512,0.898828,0.853105,0.827255,0.764682,0.741837,0.66826,0.941747,1.03721,0.691405,0.664555,0.103288,0.0940442,0.425615,0.381425,0.971223,1.01551,0.785774,0.785566,0.230747,0.310737,-2.59676,-2.58154,0.197454,0.340913,0.54185,0.658186,1.16378,1.12373,0.99635,0.985498,0.569701,0.627743,-0.0239575,-0.155932,-1.03079,-0.684701,-0.505239,-0.42276
7786,0.440457,0.45159,0.798258,0.72869,0.558231,0.515483,0.466641,0.531105,0.738545,0.790976,0.29502,0.267878,0.792039,0.781566,0.715927,0.672059,0.889262,0.93515,0.493823,0.494756,0.551921,0.638429,0.37729,0.384615,-0.536074,-0.397044,-0.641545,-0.52083,-0.914033,-0.962339,0.790845,0.785555,0.79604,0.855923,-0.971846,-1.09696,0.468925,0.820874,-0.29184,-0.206511
7787,0.039503,0.0356683,0.651811,0.604275,0.330148,0.266283,0.435862,0.393951,0.351204,0.544745,0.247516,0.220689,0.659359,0.64744,0.345485,0.300094,0.0152131,0.0600302,0.753747,0.753481,0.39498,0.476319,2.94554,2.95575,0.201685,0.340957,-0.466032,-0.339774,-0.622148,-0.666878,-1.69679,-1.69619,-0.976893,-0.912829,1.2241,1.09584,0.933398,1.27938,-0.358864,-0.272829
7788,0.824473,0.821095,0.92853,0.880514,0.891223,0.828515,0.81856,0.777055,0.203651,0.298515,0.564366,0.536267,0.831593,0.818153,0.93937,0.893242,0.828646,0.872917,0.560159,0.557911,0.503342,0.587767,1.83537,1.85128,1.26747,1.40144,0.402601,0.532194,-1.40701,-1.44345,0.0756033,0.0838099,1.21724,1.27524,0.320612,0.18654,0.482688,0.824006,0.878884,0.962605
7789,0.976591,0.971187,0.489,0.44276,0.707463,0.554296,0.574025,0.498387,0.731184,0.82754,0.211613,0.183948,0.730711,0.718495,0.49671,0.451664,0.847487,0.844289,0.751164,0.74996,-0.0781946,0.0134928,-0.436337,-0.418225,1.58082,1.70932,0.0496825,0.248786,-1.62965,-1.67347,-0.163221,-0.162982,0.36774,0.431749,1.15837,1.02334,1.36587,1.70494,-0.252982,-0.16718
7790,0.306115,0.299409,0.326612,0.27955,0.345032,0.280077,0.263153,0.21972,0.371393,0.468462,0.663092,0.637269,0.11121,0.0977507,0.271341,0.228886,0.770869,0.815661,0.439256,0.488128,0.343461,0.433344,0.00450644,0.0276879,0.655832,0.784525,-0.16581,-0.0346212,1.14259,1.10628,-1.65932,-1.65904,0.04175,0.110718,-1.09679,-1.22762,-0.0803439,0.26558,0.566629,0.655774
7791,0.364874,0.359662,0.801218,0.753213,0.848747,0.783638,0.229922,0.187709,0.622149,0.719977,0.340824,0.314044,0.771465,0.755644,0.0530189,0.00610876,0.474847,0.521435,0.225148,0.226296,-0.508279,-0.418155,0.0965758,0.120193,1.10778,1.22985,-0.753795,-0.625866,-1.63372,-1.66661,-0.149755,-0.143429,-0.57104,-0.504057,-0.545909,-0.681432,0.793667,1.13187,0.195523,0.270765
7792,0.197348,0.192073,0.860871,0.812885,0.352786,0.289357,0.458659,0.418259,0.0894826,0.186832,0.935313,0.909833,0.264872,0.249326,0.226805,0.105883,0.759379,0.807179,0.428896,0.460315,-1.65795,-1.5614,-0.433742,-0.41324,0.353883,0.475624,-0.462108,-0.337447,0.0291672,-0.00722818,-0.934298,-0.930341,1.81193,1.87808,0.496516,0.354581,0.211623,0.5534,-0.194496,-0.114244
7793,0.82566,0.822755,0.10375,0.0564795,0.0722262,0.0107737,0.897926,0.856926,0.798771,0.898779,0.736981,0.711064,0.0162064,-0.00149706,0.251482,0.205658,0.123047,0.171467,0.694562,0.694334,-0.278877,-0.189032,-0.676999,-0.657144,-0.0480177,0.0788354,-1.22082,-1.09933,-0.54464,-0.586989,0.0822348,0.0792256,0.349428,0.409456,-0.546188,-0.692995,0.742498,1.09206,1.22963,1.30489
7794,0.218895,0.217318,0.119406,0.00959929,0.617089,0.553673,0.218178,0.174917,0.764721,0.864422,0.856361,0.830682,0.0907904,0.0726387,0.833533,0.78907,0.401495,0.447738,0.462658,0.463517,-0.317754,-0.228266,-1.49775,-1.48215,-0.0179619,0.10948,-1.27778,-1.14902,-0.768713,-0.817004,-1.01291,-1.01669,-0.720213,-0.653151,-0.499116,-0.640008,-0.381749,-0.0337708,0.58005,0.648452
7795,0.825525,0.823294,0.0113287,-0.0372809,0.733393,0.744012,0.683742,0.642861,0.988486,1.08988,0.579193,0.552894,0.729073,0.709227,0.227531,0.183072,0.430157,0.568036,0.00217273,0.00265785,-1.0644,-0.970397,-0.314151,-0.296964,1.59779,1.71943,-0.457729,-0.325554,1.19461,1.13825,-1.27578,-1.27785,0.411491,0.48474,-1.87529,-2.01021,-0.0823644,0.269135,-0.822526,-0.754164
7796,0.18701,0.186931,0.409859,0.362756,0.995765,0.934352,0.244816,0.206625,0.114148,0.212985,0.799473,0.771609,0.329429,0.308889,0.493777,0.409307,0.643442,0.688334,0.218,0.141654,0.558863,0.652473,-0.883711,-0.862192,-1.58279,-1.46421,-2.21883,-2.07959,-1.1907,-1.24871,-0.0256599,-0.0225807,0.179541,0.256819,-0.385637,-0.516328,-0.184485,0.18225,0.207899,0.281497
7797,0.374765,0.372961,0.0339508,-0.0118562,0.921098,0.926649,0.816246,0.779074,0.759224,0.857887,0.0950247,0.0665871,0.614962,0.595435,0.811239,0.635542,0.0307823,0.078081,0.319743,0.280651,2.46709,2.56409,-0.935921,-0.921339,0.646404,0.761767,0.154697,0.287881,1.26457,1.21261,0.430285,0.438988,0.888399,0.96386,-0.0764199,-0.199124,-0.258768,0.0953638,-0.247212,-0.178597
7798,0.110646,0.109459,0.549684,0.505916,0.980325,0.918946,0.51395,0.476642,0.879216,0.977282,0.644999,0.618272,0.10239,0.083834,0.907589,0.861776,0.584772,0.633295,0.419162,0.419647,-1.11341,-1.01307,0.730767,0.747043,2.02595,2.13985,-1.69127,-1.55839,0.50238,0.449685,-0.917245,-0.901794,1.07764,1.1464,-1.08704,-1.21723,1.76171,2.11092,0.0356517,0.0994935
7799,0.807853,0.805126,0.0843857,0.0425527,0.540446,0.479723,0.43443,0.398319,0.349138,0.448821,0.994683,0.969158,0.235017,0.214354,0.669496,0.623962,0.187084,0.234351,0.313354,0.281705,0.763631,0.868684,-1.35977,-1.34249,0.0310883,0.142256,-0.337819,-0.210252,0.660099,0.609082,-0.324054,-0.303381,1.50597,1.5784,0.34549,0.217214,-1.47532,-1.12619,-1.9569,-1.88736
7800,0.849136,0.897458,0.282525,0.239975,0.898282,0.836828,0.0397516,0.00147372,0.243741,0.341915,0.127856,0.104046,0.9155,0.897245,0.750022,0.704733,0.313666,0.358891,0.0607135,0.143763,0.326947,0.434333,1.37383,1.3956,-0.435418,-0.330227,1.49516,1.6171,-0.836336,-0.89187,0.903859,0.920893,-0.823793,-0.758312,-0.655352,-0.784532,0.286885,0.631039,0.189435,0.262108
7801,0.992848,0.989791,0.0237976,-0.0211186,0.275287,0.212709,0.404211,0.384695,0.630054,0.730218,0.847388,0.825403,0.398131,0.381212,0.468227,0.463807,0.997357,1.04117,0.00576285,0.00582034,0.652285,0.762025,-0.244957,-0.224378,1.44818,1.54847,2.7556,2.87467,-0.554723,-0.61082,-1.2821,-1.2679,0.653462,0.721159,-0.311134,-0.438825,1.4458,1.79225,0.0730525,0.148631
7802,0.109125,0.105682,0.799286,0.75446,0.654973,0.593623,0.808169,0.767917,0.109247,0.211792,0.917221,0.89645,0.474324,0.455347,0.269999,0.222881,0.605028,0.566466,0.287087,0.187848,-0.0843954,0.0198944,1.32369,1.3508,-0.983531,-0.879209,-0.551794,-0.436528,0.169143,0.114855,-0.485929,-0.475736,-0.665107,-0.591627,-0.196835,-0.322573,0.188148,0.52818,0.400332,0.471506
7803,0.889431,0.886338,0.164483,0.118999,0.392905,0.333624,0.886696,0.809848,0.190794,0.290542,0.00107731,-0.0188106,0.047613,0.0303426,0.667485,0.619519,0.0479497,0.0917622,0.369684,0.369876,0.566732,0.732943,-0.408486,-0.306042,-1.96331,-1.8541,0.542484,0.650028,-0.67631,-0.726214,-0.717507,-0.706688,0.781305,0.855327,-1.12093,-1.24792,0.286318,0.630819,0.083932,0.160778
7804,0.661332,0.657685,0.474909,0.339425,0.975998,0.917138,0.972839,0.851779,0.657026,0.758361,0.856709,0.836899,0.068056,0.0528329,0.0960222,0.0485028,0.0457905,0.0918145,0.0286281,0.0287375,1.33715,1.44599,-1.98999,-1.96288,-2.02912,-1.91476,-0.582088,-0.467784,0.559011,0.507288,0.528954,0.532922,1.1066,1.17708,-0.201049,-0.335476,-0.296946,0.0523487,1.87751,1.95268
7805,0.770974,0.768394,0.643842,0.559851,0.262025,0.202679,0.934539,0.89371,0.452874,0.556359,0.208056,0.186847,0.84764,0.833507,0.034117,-0.0121518,0.900624,0.94756,0.730776,0.733163,0.279236,0.394764,1.44441,1.4724,-1.2539,-1.14607,-0.6819,-0.563574,-0.836353,-0.885611,-1.01434,-1.00659,-1.01066,-0.935573,-1.18325,-1.3218,-1.34776,-0.995052,-0.822551,-0.746328
7806,0.639122,0.635115,0.826759,0.780276,0.741793,0.680862,0.775305,0.713356,0.0440989,0.147169,0.0482027,0.0283929,0.995961,0.983931,0.622415,0.575783,0.742697,0.808743,0.292785,0.296942,-0.563775,-0.442375,0.434571,0.461154,0.0799431,0.187006,-2.48514,-2.36175,1.58814,1.53569,-0.273424,-0.273546,-0.576803,-0.503578,1.84417,1.70117,0.311639,0.668824,-1.49806,-1.41903
7807,0.168783,0.164644,0.000482774,-0.0445676,0.815863,0.74196,0.574672,0.533002,0.438278,0.539936,0.632257,0.614054,0.140154,0.128254,0.113521,0.0645131,0.623203,0.669926,0.0842425,0.0861455,1.46422,1.59439,0.234784,0.294792,-0.103318,0.0051582,0.0498792,0.169554,-1.1934,-1.25075,0.848068,0.84515,0.355047,0.421238,0.833881,0.683067,0.000681792,0.352947,-0.294971,-0.215358
7808,0.396891,0.3912,0.801857,0.756984,0.862006,0.803058,0.803437,0.682523,0.0933332,0.196361,0.426995,0.409783,0.681067,0.669908,0.538432,0.491128,0.0774617,0.125437,0.19877,0.203314,-0.413282,-0.289537,0.00986321,0.12843,0.147726,0.252182,-0.803468,-0.686148,-1.15347,-1.21494,-0.361326,-0.36988,1.27791,1.34605,1.40266,1.24233,0.29821,0.625375,-0.324357,-0.238394
7809,0.228602,0.192097,0.524272,0.481638,0.706656,0.646385,0.871417,0.832045,0.970316,1.076,0.451527,0.436207,0.832301,0.820332,0.381948,0.334612,0.335299,0.381585,0.717542,0.722902,0.375409,0.497339,-0.0642441,-0.0379322,-0.71914,-0.611495,0.773082,0.888178,-0.231979,-0.289299,-0.270265,-0.278477,1.93079,1.99295,0.846682,0.685383,0.543441,0.897803,0.516725,0.598907
7810,0.000600637,-0.00700548,0.936426,0.891722,0.87773,0.817113,0.170106,0.129287,0.525926,0.645428,0.888854,0.874563,0.385374,0.374568,0.583627,0.490611,0.851016,0.89667,0.804144,0.829443,-0.276153,-0.153548,-0.999404,-0.970183,0.660989,0.766587,0.849622,0.961288,0.270827,0.221111,-0.668677,-0.678326,1.24663,1.30243,0.744761,0.587632,1.3904,1.74934,-0.930786,-0.849498
7811,0.331414,0.325148,0.995213,0.887463,0.311311,0.252855,0.409913,0.369216,0.109172,0.214856,0.164583,0.149325,0.43678,0.427842,0.697752,0.64661,0.389366,0.436571,0.930953,0.935984,2.03833,2.15848,0.180643,0.214999,-3.20146,-3.09473,-0.331442,-0.217727,-0.183938,-0.237575,-0.310944,-0.325701,0.0788344,0.130049,-2.45861,-2.62339,-0.725468,-0.371681,-0.0774412,0.00215735
7812,0.459163,0.508514,0.859867,0.883205,0.0772663,0.0197239,0.261,0.32715,0.165899,0.271884,0.823083,0.805823,0.975886,0.969497,0.848882,0.802609,0.949273,0.996338,0.0542247,0.0569917,-0.900162,-0.777073,0.619813,0.660912,0.137069,0.244878,1.25059,1.3695,0.752538,0.703655,0.422284,0.319738,0.158554,0.208059,1.12765,0.970142,-2.42677,-2.07965,-0.719296,-0.58188
7813,0.696077,0.691881,0.923741,0.878947,0.0571529,0.000902224,0.303979,0.285083,0.817581,0.922104,0.118079,0.100802,0.0102504,0.00149565,0.647747,0.563439,0.55219,0.597393,0.701574,0.705803,0.609781,0.73663,-0.0119983,0.0363803,0.464876,0.567592,-1.30274,-1.1796,-0.433674,-0.484703,0.970184,0.965178,0.569066,0.623343,1.41551,1.25683,-0.906563,-0.556945,-1.24879,-1.16592
7814,0.4437,0.438963,0.635589,0.588787,0.849298,0.795179,0.28479,0.243016,0.170281,0.27291,0.851,0.832016,0.745342,0.736061,0.440287,0.324269,0.898923,0.943769,0.737685,0.667171,-0.143371,-0.0219691,-0.439261,-0.388125,-0.97093,-0.868463,-0.315092,-0.198244,-0.39334,-0.448902,0.107469,0.100791,0.225205,0.286405,0.228692,0.0716054,-1.36709,-1.01232,0.762395,0.839424
7815,0.978758,0.975742,0.67544,0.627161,0.437823,0.422728,0.40916,0.367887,0.806098,0.907442,0.204481,0.186674,0.156816,0.148754,0.131371,0.0850984,0.0729802,0.119596,0.626448,0.62854,0.196049,0.319751,-0.290343,-0.23356,0.370864,0.415387,0.15467,0.18773,-0.757966,-0.815865,0.457654,0.453415,-0.718085,-0.653698,1.85418,1.69027,1.39272,1.75373,0.0343483,0.107764
7816,0.401676,0.399492,0.0945544,0.0461279,0.106468,0.0502771,0.0751151,0.0351151,0.735872,0.759129,0.469305,0.45011,0.0596798,0.0490959,0.658035,0.611974,0.212165,0.259574,0.240849,0.323716,-0.99652,-0.869107,-0.799707,-0.750365,1.59677,1.69924,0.450396,0.573704,-0.711017,-0.764719,-1.00787,-1.01173,-1.42489,-1.35888,-1.28651,-1.45597,-0.626344,-0.262579,0.769127,0.84027
7817,0.182485,0.243389,0.689747,0.642433,0.878457,0.821504,0.639439,0.598458,0.640831,0.610816,0.404549,0.388164,0.689846,0.680261,0.12666,0.0809248,0.793643,0.839391,0.0172982,0.018892,1.48246,1.60475,-0.699917,-0.615453,0.836511,0.945009,1.19307,1.32231,-0.159231,-0.209978,-1.78376,-1.78472,0.767094,0.829192,2.90578,2.73632,-1.1349,-0.76387,0.761951,0.832891
7818,0.0913753,0.087285,0.60954,0.564639,0.366983,0.30794,0.940828,0.898849,0.410265,0.462503,0.750963,0.733814,0.784134,0.774202,0.774935,0.730412,0.412491,0.462739,0.642737,0.643348,0.201972,0.323159,-0.53285,-0.480541,1.36723,1.48128,1.17992,1.30276,0.635074,0.57821,-0.0883562,-0.0818009,0.589379,0.72878,0.860453,0.697768,0.338138,0.712017,-1.62172,-1.55221
7819,0.582466,0.578812,0.0359091,-0.00673254,0.192764,0.131572,0.133458,0.0928322,0.212845,0.31419,0.0245947,0.00857521,0.564893,0.553041,0.78948,0.694576,0.0403387,0.0860864,0.068877,0.0676542,-0.0479203,0.072744,0.971949,1.03029,1.55914,1.68013,0.343093,0.463163,0.71391,0.660397,1.38299,1.38785,0.561555,0.628369,1.04348,0.87416,0.468157,0.845042,-0.149635,-0.0861237
7820,0.128486,0.123714,0.410162,0.367475,0.570723,0.471341,0.583489,0.449785,0.588832,0.691855,0.579643,0.564856,0.894135,0.880358,0.703264,0.65874,0.876694,0.919509,0.468919,0.467113,1.00125,1.12091,-0.651655,-0.589688,-0.771986,-0.655155,0.599133,0.675806,-2.55429,-2.61221,0.615591,0.614858,-0.859772,-0.79357,-0.77926,-0.947566,-0.586694,-0.216403,0.690954,0.751178
7821,0.650765,0.645674,0.484163,0.441141,0.872589,0.811111,0.849737,0.806738,0.492922,0.594932,0.83626,0.824134,0.273092,0.259613,0.361472,0.316648,0.496205,0.539789,0.464189,0.462618,0.295201,0.408646,-0.1331,-0.0656528,-0.18542,-0.071726,0.77239,0.88845,2.71778,2.65986,-1.15281,-1.154,-0.864351,-0.792457,1.70163,1.52997,-0.364474,0.00546332,0.100807,0.154979
7822,0.81709,0.810657,0.34879,0.307299,0.792247,0.730987,0.994464,0.951783,0.113358,0.21606,0.466943,0.452441,0.393257,0.369871,0.527428,0.483593,0.328451,0.37209,0.0254264,0.0215585,-0.189857,-0.0739041,0.161301,0.229952,1.10347,1.21538,-0.554044,-0.444195,0.660446,0.609328,0.878121,0.87164,0.785062,0.855937,-1.16628,-1.337,-0.145201,0.227329,0.646503,0.703981
7823,0.353057,0.344837,0.817644,0.775661,0.219734,0.157337,0.431899,0.388046,0.128053,0.228992,0.302772,0.289822,0.354957,0.480129,0.0507279,0.00808713,0.98202,1.02574,0.278476,0.331953,-0.0495675,0.0687697,0.783982,0.845869,1.09524,1.20063,-0.471319,-0.357975,-1.70125,-1.74548,-0.896167,-0.897217,-0.473407,-0.407002,0.218398,0.0514337,-0.850308,-0.473242,0.0726622,0.122507
7824,0.912711,0.906089,0.834586,0.784907,0.610293,0.549256,0.116711,0.0749448,0.891457,0.993045,0.930109,0.915279,0.51179,0.590388,0.855969,0.811357,0.94993,0.995997,0.648679,0.642348,-1.15257,-1.02936,3.48788,3.55025,-1.19923,-1.08654,-0.0653298,0.0510025,0.320837,0.276214,-0.673322,-0.668163,-0.451476,-0.392467,-0.22053,-0.383054,-0.760018,-0.385232,0.556375,0.611527
7825,0.70015,0.692213,0.83394,0.794153,0.0151813,-0.0451864,0.124481,0.15533,0.571286,0.651273,0.504438,0.489559,0.714125,0.700646,0.272087,0.226304,0.0633581,0.111287,0.580419,0.543599,0.51714,0.638023,-2.27894,-2.21657,-0.666043,-0.550267,1.14175,1.26274,-0.178598,-0.227913,-2.23571,-2.22422,1.84979,1.90899,0.00768078,-0.15855,-0.143056,0.230344,1.26002,1.31353
7826,0.763469,0.757544,0.57131,0.533059,0.193893,0.136136,0.276557,0.235715,0.209793,0.309502,0.444375,0.427613,0.458975,0.365683,0.510044,0.466143,0.0968076,0.144955,0.41077,0.44485,0.746559,0.872838,-0.0497955,0.00613014,-0.401404,-0.368764,0.482806,0.610382,0.757549,0.713316,1.66303,1.67452,-0.844059,-0.78302,0.613878,0.447912,0.263646,0.642768,-0.600564,-0.549559
7827,0.577651,0.475786,0.866875,0.829667,0.990722,0.930414,0.735303,0.6934,0.340632,0.438991,0.904323,0.885844,0.0428742,0.030721,0.540464,0.496357,0.529805,0.579854,0.352432,0.3461,-1.25183,-1.12002,0.253252,0.316013,-0.295406,-0.187261,0.303764,0.436886,-0.478352,-0.525167,0.464142,0.473083,0.0384218,0.105638,0.498157,0.334062,0.239205,0.621823,-0.508477,-0.469369
7828,0.198916,0.194028,0.00923249,-0.0264593,0.194872,0.133878,0.0142072,-0.0293013,0.739314,0.836713,0.714676,0.697364,0.270927,0.256569,0.237447,0.194794,0.191087,0.240599,0.766275,0.759881,-0.700462,-0.563022,-1.55389,-1.49444,0.79494,0.902174,-0.639603,-0.512789,0.429893,0.384296,-0.133246,-0.13085,2.87198,2.93168,-0.244581,-0.409448,0.642889,1.01872,-0.440352,-0.389178
7829,0.629409,0.626991,0.66192,0.627708,0.254419,0.196058,0.107908,0.0643707,0.26045,0.357759,0.737924,0.719299,0.208359,0.138016,0.498373,0.455428,0.740019,0.790267,0.340084,0.333926,0.114638,0.232216,0.472546,0.533266,0.965043,1.06868,-1.00305,-0.872597,-1.69602,-1.7479,0.307981,0.315492,0.958338,1.02402,0.135414,-0.0307374,0.0788904,0.519442,-0.689087,-0.638468
7830,0.737822,0.732993,0.089147,0.0563363,0.520335,0.417006,0.509311,0.463718,0.814758,0.912252,0.449203,0.430387,0.0351704,0.0194629,0.998461,0.956661,0.278474,0.330168,0.400026,0.396169,0.886925,1.02745,-0.513236,-0.445718,-0.284742,-0.181481,0.834869,0.969817,0.583736,0.538556,-0.171344,-0.163569,1.53124,1.59399,0.231854,0.0713103,-0.392999,0.0201618,-1.36771,-1.31117
7831,0.312176,0.307369,0.115551,0.0847856,0.805262,0.637954,0.143257,0.0969087,0.508466,0.699252,0.906726,0.888619,0.856796,0.839896,0.406014,0.365339,0.558869,0.525905,0.921592,0.915757,-0.864669,-0.731003,0.207453,0.276358,-0.0670077,0.0557291,-0.322607,-0.195426,-1.16272,-1.20915,-1.62708,-1.6118,-0.587204,-0.518659,-0.099327,-0.255988,-0.854951,-0.479118,1.33512,1.38589
7832,0.557312,0.457165,0.524809,0.494869,0.916322,0.858902,0.637139,0.59025,0.387045,0.486251,0.897848,0.880799,0.6297,0.613527,0.759307,0.717691,0.668629,0.721643,0.113084,0.106152,-0.384843,-0.336407,0.563311,0.631553,0.185824,0.292939,-0.416703,-0.230043,0.0582142,0.00874599,0.130992,0.149918,-0.622339,-0.54743,-1.37552,-1.53522,-0.670505,-0.301326,0.767896,0.819301
7833,0.61298,0.606961,0.407369,0.376822,0.367446,0.309839,0.0757405,0.0265138,0.437492,0.508766,0.11686,0.100372,0.777396,0.759317,0.084391,0.0403333,0.239757,0.292552,0.490206,0.480629,-0.0715689,0.0581898,-0.449734,-0.379694,-1.58247,-1.46838,-0.38789,-0.264661,-1.41562,-1.45992,-1.26537,-1.25405,0.0883762,0.159612,0.0151433,-0.146793,0.0669793,0.439107,-0.548836,-0.491641
7834,0.336864,0.333111,0.666685,0.637691,0.587887,0.530234,0.49743,0.405483,0.431541,0.531282,0.257696,0.333375,0.018241,-0.00145297,0.360138,0.316595,0.17969,0.232783,0.260278,0.249812,0.196313,0.324072,3.10948,3.179,0.397868,0.519259,1.15497,1.27491,0.614304,0.561767,0.0258553,0.031646,0.0366972,0.114789,-0.467374,-0.627023,1.05867,1.43059,0.767502,0.820495
7835,0.615693,0.609789,0.340031,0.3816,0.366481,0.308237,0.834641,0.784452,0.904633,1.00425,0.580675,0.566379,0.0977861,0.0775392,0.30497,0.26093,0.571037,0.623674,0.556337,0.547241,-0.0346738,0.0879674,0.798365,0.822502,0.0343374,0.15245,0.0419653,0.157093,0.685024,0.628876,0.547084,0.5538,-0.718858,-0.636014,-0.477158,-0.636442,-0.0875967,0.290509,1.51726,1.56893
7836,0.0944089,0.0891478,0.155084,0.125509,0.971473,0.911796,0.0229208,-0.0272017,0.593666,0.69156,0.506498,0.421899,0.65258,0.634431,0.807256,0.762164,0.651263,0.684296,0.308933,0.317533,0.395595,0.522215,-1.60351,-1.53399,-1.23077,-1.11253,-0.388882,-0.280173,0.0519995,-0.0113179,0.0694221,0.0747392,1.96858,2.05114,1.54208,1.38824,1.50386,1.87498,0.648427,0.699537
7837,0.337034,0.330203,0.066585,0.102097,0.809216,0.735766,0.26793,0.245573,0.606127,0.704491,0.368901,0.27742,0.63013,0.61145,0.94218,0.897721,0.690718,0.744918,0.0974736,0.0878245,-0.504639,-0.375733,-0.435235,-0.365524,-0.950258,-0.83493,0.18919,0.296441,2.3367,2.27514,1.88483,1.88501,0.0731164,0.158834,-0.210439,-0.366383,0.916801,1.28166,-0.646565,-0.595819
7838,0.977528,0.97141,0.111126,0.0786857,0.63565,0.559736,0.568246,0.518347,0.98313,1.08216,0.149246,0.13294,0.994597,0.97391,0.765621,0.720883,0.345954,0.400057,0.669891,0.661907,1.05256,1.18423,1.36007,1.42539,0.780434,0.903502,0.23738,0.337762,0.211921,0.142942,0.559999,0.559667,1.07684,1.1587,-0.379054,-0.440546,-0.304619,0.0647951,-0.323275,-0.272943
7839,0.937774,0.930269,0.40175,0.369553,0.445068,0.383706,0.148258,0.0969952,0.948774,1.0478,0.316727,0.302877,0.776751,0.758008,0.228192,0.184785,0.769183,0.824742,0.646844,0.637956,0.308521,0.442104,1.76974,1.84155,0.112602,0.241509,-0.187509,-0.0831618,0.140185,0.0675099,0.0605409,0.0664668,-0.394773,-0.309917,-0.359366,-0.514709,-0.212112,0.0839372,-2.10099,-2.05798
7840,0.503531,0.494467,0.328156,0.337431,0.745756,0.684953,0.0451403,-0.00557976,0.10724,0.205417,0.876383,0.864165,0.29634,0.276384,0.823486,0.777933,0.238512,0.295576,0.200265,0.191564,-0.857277,-0.730366,0.738393,0.813746,-1.4503,-1.31524,1.71064,1.8219,1.86632,1.789,0.935463,0.938251,-0.689055,-0.599489,0.947876,0.794279,-0.257765,0.103079,-0.80363,-0.724
7841,0.901015,0.892232,0.328767,0.305309,0.244908,0.185257,0.630045,0.577337,0.442234,0.441442,0.596037,0.586377,0.247711,0.172458,0.270414,0.226955,0.72585,0.780583,0.48229,0.528605,-0.744969,-0.618919,-1.13953,-1.06395,1.43789,1.57715,0.241696,0.350703,-0.958279,-1.03085,1.02606,1.02965,-0.546085,-0.462016,0.225239,0.0657359,0.831613,1.187,0.559924,0.60998
7842,0.829487,0.83569,0.353726,0.273188,0.558246,0.496545,0.180406,0.12547,0.66026,0.677468,0.747076,0.736173,0.0866615,0.0685326,0.646624,0.566573,0.00890154,0.0646612,0.873481,0.865646,0.1757,0.305781,0.531673,0.604437,0.234268,0.371571,0.221468,0.338699,0.264821,0.187051,-0.7907,-0.786988,1.15683,1.248,0.0311804,-0.123921,1.45184,1.80257,0.499385,0.543662
7843,0.766892,0.779147,0.371961,0.241066,0.0147815,-0.0484378,0.121007,0.15211,0.815858,0.913494,0.150757,0.141292,0.80522,0.787612,0.950535,0.90619,0.177433,0.234347,0.12917,0.122555,-0.721527,-0.592167,0.322585,0.390794,-0.307715,-0.163854,0.0766073,0.326696,1.20482,1.12828,0.266433,0.271403,0.728207,0.818428,-0.87872,-1.03322,0.40927,0.755171,-1.03299,-0.995351
7844,0.73179,0.722605,0.232975,0.208944,0.432139,0.369791,0.232958,0.178751,0.440862,0.539465,0.924738,0.914502,0.76126,0.744248,0.980299,0.936405,0.936587,0.991751,0.224705,0.218721,0.483853,0.609819,0.109064,0.177152,-1.2187,-1.07374,0.205686,0.314693,-0.831961,-0.906132,-0.300843,-0.299083,-0.0532318,0.0360568,0.513139,0.35521,0.287366,0.641554,0.256486,0.300668
7845,0.982153,0.97372,0.209018,0.176822,0.205139,0.142364,0.722144,0.667215,0.555672,0.653587,0.535405,0.527049,0.488628,0.474569,0.162799,0.119967,0.194317,0.250568,0.0599701,0.0537191,0.6477,0.767779,0.124173,0.193235,1.16163,1.30154,0.583595,0.693124,0.495589,0.418287,-1.21864,-1.21142,-0.436815,-0.346268,-1.78339,-1.94754,-0.670112,-0.313069,-0.728868,-0.688281
7846,0.591047,0.583897,0.570114,0.536934,0.503653,0.422265,0.828833,0.776106,0.448252,0.546682,0.363184,0.353301,0.223976,0.204889,0.144889,0.103985,0.224154,0.280128,0.393021,0.354679,2.27008,2.39065,-0.574325,-0.507907,0.366565,0.500122,-1.88601,-1.77262,-1.21126,-1.28164,-0.359262,-0.355035,1.05204,1.14553,0.860475,0.697133,0.628287,0.988833,1.25073,1.28471
7847,0.565715,0.558614,0.563848,0.52811,0.764315,0.702166,0.0160799,-0.0355477,0.0884325,0.187603,0.187112,0.179552,0.665144,0.646651,0.802485,0.76401,0.949909,1.00748,0.660396,0.655638,0.116139,0.243957,0.122662,0.16563,-1.69443,-1.56252,0.257563,0.370833,0.851913,0.783612,-1.55031,-1.54116,0.495594,0.592036,0.69398,0.539173,0.0932668,0.456246,-1.36658,-1.33344
7848,0.0917715,0.0829653,0.553153,0.519286,0.861205,0.783469,0.717539,0.666526,0.769566,0.868595,0.813438,0.805009,0.181855,0.165026,0.0762398,0.0392999,0.218059,0.276294,0.75512,0.713008,1.23611,1.36572,0.769044,0.839167,0.599699,0.731468,1.17748,1.28929,0.431924,0.371256,1.594,1.60858,0.860562,0.960564,-1.32444,-1.48303,-0.78256,-0.417537,-0.729485,-0.691531
7849,0.327232,0.319178,0.0335107,0.00164335,0.927734,0.864772,0.390791,0.391093,0.559438,0.560202,0.313139,0.304941,0.490606,0.404991,0.203016,0.16506,0.526214,0.602822,0.776985,0.770378,1.93278,2.06072,-0.943594,-0.874,-1.00001,-0.873382,-0.3597,-0.242198,-0.225934,-0.283095,0.272416,0.283234,-1.11499,-1.01112,-0.123156,-0.279425,1.28108,1.6491,0.109934,0.14577
7850,0.0366766,0.0297629,0.1385,0.105647,0.775868,0.777505,0.167953,0.11566,0.154173,0.251808,0.3296,0.321636,0.665989,0.644956,0.882507,0.84665,0.871279,0.929349,0.375285,0.369817,1.27462,1.40984,-0.410059,-0.335069,-1.44309,-1.3148,-1.05034,-0.940067,0.481894,0.425753,0.721005,0.729576,1.31246,1.41693,0.699013,0.541626,0.577107,0.948534,0.456931,0.497704
7851,0.783371,0.778417,0.889389,0.855177,0.752028,0.690237,0.132619,0.0792353,0.185822,0.283771,0.953149,0.947093,0.901749,0.884921,0.840951,0.805348,0.873266,0.929401,0.666223,0.662756,0.964777,1.09831,-1.75384,-1.67432,1.11692,1.2455,1.01697,1.12258,-0.614718,-0.674946,0.232575,0.236376,1.88662,1.9869,0.12263,0.0517356,1.09866,1.41782,1.75257,1.79372
7852,0.954795,0.949267,0.242506,0.209471,0.139991,0.0762354,0.360845,0.309785,0.450278,0.550084,0.437968,0.43266,0.142235,0.124151,0.342958,0.309664,0.530815,0.584539,0.140198,0.136767,0.243744,0.369565,-0.905595,-0.914289,0.336797,0.459946,-0.0275537,0.0831427,1.4911,1.426,-0.622943,-0.613014,0.14346,0.250429,-0.288379,-0.438155,1.51176,1.88711,-0.280572,-0.24056
7853,0.873002,0.88302,0.15839,0.12614,0.80344,0.740952,0.99595,0.947128,0.503861,0.602422,0.181685,0.236067,0.517271,0.500911,0.409508,0.376058,0.793803,0.791216,0.364346,0.359881,0.93342,1.06457,-0.233075,-0.15426,0.0426625,0.170495,2.02069,2.13081,-0.951814,-1.01669,-0.262967,-0.280552,0.510058,0.618957,-1.349,-1.50049,-0.677547,-0.299896,0.415638,0.461439
7854,0.920315,0.816772,0.510799,0.476643,0.869824,0.807586,0.680843,0.634027,0.207918,0.305881,0.04328,0.0394731,0.458673,0.499972,0.0230157,-0.0104143,0.946115,0.997893,0.995118,0.989411,-0.653579,-0.522972,0.39453,0.476822,0.182259,0.30836,1.25186,1.35443,-0.156307,-0.216213,0.0465353,0.0519107,-0.375287,-0.27284,-0.52681,-0.626964,1.14629,1.52219,-0.505674,-0.452304
7855,0.755503,0.750525,0.382444,0.298583,0.130321,0.0668273,0.939519,0.894855,0.139376,0.235241,0.747995,0.745996,0.513584,0.499033,0.963855,0.928831,0.723391,0.77444,0.604602,0.509549,1.41818,1.54481,-1.19625,-1.11077,1.02567,1.15485,1.21935,1.31879,-0.140908,-0.195103,0.71172,0.709912,0.0793853,0.188026,0.398044,0.24656,-0.210253,0.161911,-1.75143,-1.70144
7856,0.277059,0.269578,0.155452,0.120523,0.840479,0.777553,0.546873,0.503081,0.435697,0.506801,0.549763,0.450422,0.152243,0.138082,0.216566,0.183086,0.300193,0.351015,0.0353937,0.0296865,0.711238,0.832546,2.43352,2.51854,-1.78248,-1.64936,-0.598059,-0.499035,-0.950141,-1.00326,-0.450324,-0.445065,-0.586323,-0.470643,-0.231316,-0.389027,0.0852803,0.464818,1.76225,1.81377
7857,0.217574,0.208206,0.367698,0.33318,0.924304,0.848277,0.826954,0.782987,0.735226,0.778362,0.158239,0.154848,0.144497,0.130654,0.222615,0.188741,0.802203,0.851235,0.25158,0.247066,-0.458481,-0.339925,1.29926,1.3829,-1.3185,-1.19048,2.01684,2.1186,1.97108,1.91274,-0.182128,-0.170738,0.00836049,0.129052,0.256637,0.0956641,-0.605954,-0.220328,0.462394,0.518418
7858,0.775124,0.764754,0.331792,0.252976,0.979925,0.919,0.671334,0.625257,0.954057,1.04992,0.241728,0.240024,0.850203,0.838746,0.458619,0.423702,0.939794,0.991214,0.91691,0.910411,-0.104894,0.0195162,-0.13251,-0.0511068,-1.8693,-1.74131,1.19981,1.29505,0.235171,0.182405,0.757451,0.763725,1.04772,1.17014,-0.1899,-0.353693,1.07915,1.46086,1.52358,1.58442
7859,0.913404,0.805274,0.247051,0.172773,0.263834,0.204541,0.199998,0.153079,0.413636,0.511768,0.782515,0.781799,0.0639202,0.0531286,0.33624,0.330081,0.609552,0.661919,0.743301,0.735078,0.911444,1.03643,-1.82383,-1.74868,0.752485,0.883588,-0.0867321,0.00801593,0.23806,0.188242,-0.317432,-0.315445,-0.701997,-0.581259,0.904364,0.743105,-0.40721,-0.0269363,-0.209972,-0.153642
7860,0.898846,0.845794,0.125135,0.0925697,0.685396,0.628709,0.289894,0.152388,0.813422,0.90949,0.179774,0.181164,0.990067,0.980719,0.271154,0.23646,0.566793,0.633291,0.263868,0.254516,0.0316398,0.153775,0.18775,0.261416,-0.419808,-0.292007,1.40628,1.50166,-1.18943,-1.23437,-0.936912,-0.935734,6.17216e-05,0.125782,1.29323,1.13589,0.127528,0.51172,0.931593,0.988945
7861,0.896933,0.886314,0.479852,0.448095,0.628335,0.573441,0.249048,0.151696,0.093846,0.187585,0.221908,0.221547,0.705758,0.746935,0.526475,0.531637,0.554556,0.604663,0.839326,0.828599,0.87363,1.00114,0.0790018,0.155945,3.03267,3.16385,-0.301207,-0.206014,0.0893163,0.0445581,-2.25062,-2.24502,-0.669552,-0.548817,-1.35976,-1.5216,0.354135,0.736947,-1.04598,-0.984571
7862,0.772193,0.803668,0.263418,0.23364,0.235032,0.178357,0.200138,0.151004,0.281142,0.372643,0.544353,0.541654,0.524536,0.51315,0.860436,0.826814,0.975804,1.02573,0.749563,0.785578,-1.00978,-0.882787,0.239482,0.31051,-1.14513,-1.01228,-0.331458,-0.241658,0.11505,-0.00200575,0.432983,0.441734,-0.514042,-0.395783,-0.0413915,-0.196578,1.19224,1.57126,0.188851,0.250863
7863,0.674305,0.721022,0.405831,0.377191,0.15791,0.103437,0.936148,0.888353,0.855388,0.946936,0.644194,0.640877,0.713905,0.70464,0.634824,0.599853,0.754495,0.802274,0.752287,0.742557,-0.882763,-0.754966,-0.263406,-0.191179,-0.0128374,0.12456,0.853815,0.938045,0.00240586,-0.0485696,-0.20805,-0.238636,1.05555,1.17159,0.422973,0.271952,-0.69222,-0.315395,-1.4205,-1.36527
7864,0.715623,0.638376,0.0838045,0.0568382,0.607781,0.552692,0.406413,0.360109,0.820911,0.91258,0.151163,0.145658,0.285352,0.275257,0.787875,0.751118,0.106307,0.152091,0.420406,0.483667,0.0211619,0.153768,0.834909,0.903707,1.73353,1.87718,-0.404086,-0.319371,1.33889,1.29005,-0.930162,-0.919007,-0.189565,-0.0773411,-0.900371,-1.05379,-1.00411,-0.631272,-0.0596705,-0.00661014
7865,0.566349,0.55573,0.568274,0.540557,0.602103,0.548961,0.753918,0.708896,0.536561,0.63016,0.193285,0.186041,0.187742,0.175599,0.0747245,0.0366387,0.160147,0.227786,0.234098,0.224776,-0.984365,-0.852132,0.43509,0.507932,-0.347984,-0.201072,1.22382,1.31628,0.413863,0.35798,-0.543766,-0.536116,0.596804,0.706361,-0.911753,-1.06321,-1.01603,-0.636589,0.484822,0.542392
7866,0.758703,0.74611,0.133014,0.107391,0.348145,0.322703,0.054565,0.0117405,0.642845,0.708035,0.0164719,0.00874334,0.668429,0.657848,0.50973,0.47382,0.269741,0.303481,0.686602,0.679235,-0.119467,0.00981896,-0.928795,-0.862313,1.30474,1.45554,-0.0376048,0.0588598,-0.796099,-0.878803,-1.82395,-1.81629,0.491503,0.60082,-1.23103,-1.37654,-0.101522,0.274695,2.11195,2.17583
7867,0.647713,0.637089,0.463749,0.438257,0.147013,0.0964455,0.277879,0.141101,0.692896,0.785909,0.806052,0.797249,0.0657427,0.0567975,0.555708,0.51921,0.335457,0.379176,0.55906,0.550022,0.528919,0.660242,-0.524783,-0.462522,-1.14756,-0.992831,-0.150333,-0.0528598,-2.0597,-2.11559,-0.469237,-0.454379,-0.433505,-0.3224,-1.21871,-1.36921,-1.7028,-1.32073,-0.90531,-0.84527
7868,0.214597,0.206327,0.262202,0.238794,0.429012,0.286785,0.314452,0.270462,0.433577,0.528855,0.575646,0.568787,0.106761,0.0994093,0.804762,0.769408,0.812629,0.854623,0.785923,0.777803,0.274049,0.409827,1.10103,1.15841,1.37959,1.53128,-1.69074,-1.59926,-0.216956,-0.268824,-0.258496,-0.240017,0.39337,0.505135,-2.11631,-2.26537,-0.789193,-0.409448,0.491649,0.558679
7869,0.668936,0.658787,0.540727,0.515033,0.529955,0.477124,0.918409,0.87322,0.856355,0.951195,0.638515,0.579516,0.712795,0.706167,0.724561,0.628534,0.792158,0.833767,0.273435,0.266893,1.69475,1.82901,-0.712804,-0.652051,0.0431974,0.185533,-0.567811,-0.482098,0.245749,0.195294,0.320575,0.343317,-0.416742,-0.307121,-2.12972,-2.27479,-1.18703,-0.800811,-0.596388,-0.524207
7870,0.908002,0.899842,0.462904,0.509483,0.0864089,0.0326328,0.628954,0.584825,0.175253,0.271009,0.597655,0.590245,0.825171,0.816179,0.522182,0.48766,0.49003,0.57341,0.943818,0.936288,0.411005,0.547427,-0.874721,-0.818872,-0.192502,-0.0432804,-0.678444,-0.593818,1.80689,1.76487,1.93925,1.96776,1.04055,1.15644,-0.823884,-0.965798,-1.88435,-1.50138,-0.0484241,0.0247947
7871,0.268285,0.258454,0.526854,0.503933,0.737429,0.681525,0.732533,0.657173,0.932735,1.02963,0.056963,0.0510288,0.548821,0.540587,0.235851,0.290799,0.272969,0.313052,0.506048,0.500067,0.427067,0.568722,-1.27838,-1.22935,2.0576,2.20121,1.49751,1.57848,1.5686,1.52096,-1.19354,-1.15867,1.42336,1.53889,-0.50152,-0.648594,0.307769,0.696921,-0.0711678,0.00175848
7872,0.308601,0.29863,0.11451,0.0902391,0.621248,0.523863,0.77301,0.72952,0.140607,0.239889,0.930954,0.926325,0.635247,0.624412,0.130382,0.0939372,0.537432,0.561665,0.71456,0.743181,-0.0866749,0.0540797,-0.409246,-0.352252,-0.216256,-0.0516595,-0.145284,-0.0654258,-0.27376,-0.318116,-0.86098,-0.824144,1.19378,1.31097,0.070322,-0.0722184,-1.00149,-0.618321,1.36096,1.4374
7873,0.900054,0.889835,0.842677,0.816268,0.421127,0.366201,0.407005,0.362711,0.656669,0.662881,0.898351,0.939589,0.275873,0.342944,0.332424,0.295777,0.771482,0.810277,0.991151,0.986296,-0.12323,0.014845,-0.518402,-0.457722,-2.44815,-2.30453,0.207815,0.282966,0.631901,0.591347,1.05365,1.09076,1.96874,2.07806,-2.40789,-2.55277,0.572758,0.949513,1.32131,1.39903
7874,0.350651,0.338699,0.687118,0.662772,0.0217164,-0.0339122,0.622519,0.535684,0.985353,1.08587,0.918671,0.952853,0.0741205,0.0614768,0.169956,0.133017,0.585455,0.584281,0.0426712,0.0377376,1.42118,1.56114,0.302471,0.357304,-1.06029,-0.911763,-0.104767,-0.0300422,0.269194,0.224385,0.47924,0.496679,-1.42204,-1.31938,-1.60912,-1.74691,-0.837798,-0.458795,2.24576,2.32709
7875,0.546604,0.53467,0.243263,0.219399,0.699663,0.645803,0.752866,0.708657,0.514097,0.612868,0.972404,0.966117,0.187041,0.113664,0.791398,0.753132,0.322114,0.358286,0.716061,0.711644,-1.31926,-1.18565,0.158959,0.207614,1.29121,1.44477,0.731042,0.809971,0.199627,0.148952,-0.145866,-0.0973981,-0.532073,-0.430722,0.532288,0.400503,-0.40729,-0.031307,0.244267,0.324528
7876,0.416682,0.37571,0.841181,0.815704,0.212577,0.160242,0.276297,0.231806,0.70112,0.797925,0.424604,0.416771,0.17634,0.165851,0.914312,0.874432,0.306232,0.342864,0.961391,0.954737,-1.96974,-1.83653,-1.42722,-1.37998,-1.32749,-1.17073,-1.15964,-1.08784,1.88835,1.83977,-0.72209,-0.691475,1.42397,1.53112,1.39246,1.26644,-0.366182,0.0109784,1.30372,1.39053
7877,0.227283,0.21675,0.564949,0.445525,0.745534,0.693782,0.296259,0.249723,0.250539,0.349914,0.181871,0.17335,0.749379,0.737542,0.351836,0.313275,0.0530888,0.089159,0.362646,0.353904,-1.68762,-1.5536,-1.30447,-1.33295,-1.3413,-1.18547,-0.195058,-0.123913,-0.366823,-0.418641,1.83952,1.8679,-0.149677,-0.0490964,0.820752,0.694826,0.48195,0.862513,0.384422,0.406743
7878,0.403342,0.392156,0.100822,0.0753449,0.207013,0.154712,0.53478,0.489652,0.127046,0.228068,0.806498,0.798807,0.905988,0.892901,0.244893,0.206344,0.6495,0.68563,0.592294,0.581684,-0.297117,-0.164877,-1.32752,-1.28592,0.225624,0.377714,-0.565263,-0.407321,-0.141937,-0.198701,1.6481,1.68412,-0.445923,-0.338669,-1.14638,-1.26555,0.451991,0.826459,-0.66385,-0.577041
7879,0.919649,0.908762,0.132062,0.109262,0.997545,0.943458,0.219877,0.17655,0.542059,0.654631,0.258012,0.249461,0.693393,0.748557,0.469271,0.430269,0.546448,0.584489,0.0699201,0.0614234,0.450495,0.576397,-0.951545,-0.917256,-0.522981,-0.376513,-0.762662,-0.690728,0.554794,0.495781,-0.421111,-0.381047,0.112972,0.215481,-0.410237,-0.534236,1.44061,1.81794,0.581737,0.672213
7880,0.220116,0.210519,0.869617,0.845275,0.369967,0.314749,0.969636,0.925012,0.977997,1.0812,0.0785383,0.0721632,0.66256,0.604214,0.261912,0.214225,0.911871,0.950334,0.875089,0.864837,-0.342651,-0.214727,0.301028,0.331533,-0.207242,-0.0537997,1.36007,1.43296,-0.225683,-0.280793,-0.17246,-0.1368,1.27611,1.38406,1.45156,1.33303,1.66616,2.04317,-0.240093,-0.149554
7881,0.628884,0.618379,0.707208,0.696981,0.599133,0.5444,0.809097,0.762148,0.0723597,0.176962,0.856829,0.849284,0.472956,0.45987,0.0370328,-0.00181876,0.175517,0.214013,0.820056,0.810885,1.31639,1.4378,0.768828,0.793355,-1.02862,-0.87115,-1.42092,-1.34605,0.0691849,0.0469378,1.19069,1.22511,-0.254748,-0.148208,0.454865,0.331285,-0.268377,0.110601,0.0775592,0.173322
7882,0.773958,0.708426,0.459014,0.548686,0.390798,0.336621,0.0633616,0.0146509,0.241002,0.34749,0.392331,0.383747,0.563148,0.631504,0.427443,0.390324,0.64837,0.684563,0.521393,0.549053,1.94966,2.07248,0.89228,0.916608,-1.35418,-1.19334,0.295098,0.365583,0.432943,0.374669,-0.090783,-0.0550631,-0.465279,-0.36065,1.52908,1.39944,0.590992,0.976892,-2.12328,-2.03084
7883,0.80744,0.798473,0.387186,0.400392,0.417396,0.363908,0.207108,0.105203,0.951506,1.05944,0.603626,0.596834,0.81413,0.803138,0.102769,0.0638244,0.863904,0.900661,0.29728,0.287222,0.436515,0.562967,-0.253109,-0.234286,0.276263,0.432801,0.162602,0.239307,-0.902981,-0.958614,0.485602,0.528271,-0.360016,-0.252353,0.550829,0.434682,1.03863,1.42015,-2.90634,-2.80862
7884,0.212279,0.202888,0.276438,0.252097,0.849387,0.798012,0.338301,0.195756,0.515668,0.6255,0.264285,0.259198,0.390901,0.378134,0.37285,0.334502,0.0188832,0.0564299,0.882468,0.871509,1.79522,1.92041,0.0588909,0.140317,-1.03884,-0.879094,-0.796325,-0.723755,1.74631,1.69905,0.435661,0.481865,2.11433,2.22413,-0.406699,-0.530077,0.546438,0.935635,1.13805,1.23302
7885,0.376594,0.367872,0.797931,0.775105,0.202968,0.149211,0.332943,0.286308,0.483976,0.630585,0.478565,0.483099,0.595246,0.584028,0.96942,0.932792,0.465237,0.501629,0.899417,0.919432,1.5056,1.62345,0.500367,0.514919,-0.879646,-0.726613,1.28156,1.35529,-0.322928,-0.368934,-1.22041,-1.17853,0.669302,0.772716,0.496779,0.366699,-2.0724,-1.68982,0.353606,0.455236
7886,0.178265,0.169618,0.316539,0.291815,0.236981,0.180935,0.168632,0.123444,0.527545,0.635669,0.754959,0.707001,0.522342,0.432006,0.710677,0.770253,0.102271,0.137324,0.978106,0.967354,0.883655,0.992186,0.594908,0.607424,-0.494427,-0.400518,0.116383,0.190044,-0.335243,-0.379362,-1.10125,-1.05601,2.2218,2.32654,-0.595252,-0.726518,0.375127,0.765941,-0.189235,-0.082997
7887,0.821169,0.810825,0.928479,0.902148,0.796066,0.738906,0.209838,0.11633,0.699841,0.806196,0.935991,0.930903,0.292842,0.279984,0.631769,0.607714,0.907567,0.944861,0.0378141,0.0294171,0.300838,0.360922,-0.727571,-0.715724,-0.230258,-0.0744225,0.374864,0.446473,2.18597,2.13594,-0.040992,0.00238074,-0.655712,-0.5449,-0.358969,-0.486784,-0.777989,-0.391803,0.0493769,0.150034
7888,0.114116,0.103065,0.671831,0.646094,0.3494,0.289836,0.152478,0.109217,0.0257454,0.130997,0.900568,0.893575,0.913678,0.901508,0.469853,0.445175,0.0858955,0.120687,0.157581,0.150866,-0.388195,-0.270341,-1.24455,-1.23253,0.394937,0.553808,1.41022,1.48777,0.513935,0.466738,1.37377,1.41134,-0.976516,-0.865932,0.663955,0.536043,0.281773,0.661899,-0.760281,-0.657109
7889,0.15106,0.139354,0.784493,0.759386,0.568422,0.510231,0.688063,0.646689,0.00410128,0.180593,0.477451,0.472262,0.435905,0.518603,0.427928,0.282636,0.463795,0.496497,0.895818,0.88925,1.11559,1.22879,0.528025,0.543503,1.34116,1.50774,0.304611,0.383765,-1.80793,-1.8553,-0.21056,-0.17457,-0.0869528,-0.0531995,0.441317,0.281966,-0.977002,-0.602173,0.262099,0.364341
7890,0.734466,0.72075,7.09807e-05,-0.0225275,0.466585,0.371623,0.476216,0.494406,0.124501,0.230189,0.809853,0.80237,0.148767,0.135698,0.156724,0.120097,0.594632,0.692234,0.795304,0.723415,-0.0243216,0.0855383,0.654235,0.666756,-0.042738,0.116532,0.079804,0.164394,-0.148679,-0.195918,-0.385924,-0.376629,0.646837,0.759533,0.150726,0.0278884,-1.68184,-1.30274,0.0141152,0.115051
7891,0.325506,0.31082,0.305047,0.283932,0.363497,0.233015,0.300996,0.342124,0.848707,0.952451,0.131224,0.121849,0.96939,0.956131,0.346866,0.391583,0.855363,0.887971,0.565535,0.55758,0.035017,0.152637,-0.586611,-0.576163,0.595125,0.7614,1.48756,1.57778,-0.988472,-1.03699,-0.620527,-0.578689,1.27151,1.39037,1.51186,1.38551,-0.935535,-0.562312,0.351788,0.452706
7892,0.476707,0.436361,0.0396091,0.0176875,0.152598,0.094407,0.22993,0.189841,0.14436,0.246963,0.739567,0.727635,0.846885,0.750644,0.697025,0.663069,0.162797,0.196997,0.663675,0.653745,-1.04509,-0.928853,-1.21966,-1.21573,1.02001,1.19037,0.0716393,0.166142,0.106443,0.0567529,1.0527,1.09254,0.618176,0.731697,-0.81637,-0.947312,0.303443,0.67863,-0.276952,-0.173214
7893,0.579399,0.561902,0.948772,0.926368,0.512479,0.456785,0.785242,0.747303,0.831017,0.93288,0.499569,0.489181,0.54947,0.545157,0.50808,0.387541,0.643261,0.67702,0.546974,0.603293,-0.377971,-0.265101,0.435243,0.434944,-0.520561,-0.352957,-1.91048,-1.8141,0.277151,0.215918,-0.463172,-0.417243,-0.317503,-0.208407,0.994641,0.857942,0.4338,0.811655,1.06472,1.1679
7894,0.248486,0.232188,0.348792,0.324827,0.632412,0.577933,0.486253,0.449719,0.121882,0.221994,0.512262,0.500993,0.352928,0.339669,0.146948,0.112013,0.2305,0.262953,0.562079,0.552841,-0.344092,-0.231176,2.64618,2.6404,-1.80265,-1.63385,0.852292,0.947072,0.431838,0.375082,1.07421,1.11399,-0.748333,-0.63798,1.80055,1.6638,2.99386,3.36601,0.657528,0.765865
7895,0.372038,0.290866,0.238128,0.215821,0.389513,0.300127,0.658224,0.635963,0.376675,0.416802,0.110193,0.0994283,0.821678,0.806749,0.838404,0.803328,0.773289,0.80789,0.134917,0.126887,0.965984,1.07788,-0.219636,-0.231438,-0.309044,-0.148747,-0.563305,-0.464564,0.32444,0.268435,1.73125,1.77199,0.649656,0.765617,-1.18687,-1.3174,0.133481,0.504693,-0.0630287,0.0485398
7896,0.407989,0.349545,0.637594,0.615857,0.0776386,0.0223212,0.857348,0.822206,0.512567,0.611611,0.0739608,0.0621004,0.0114323,-0.00495093,0.291339,0.257804,0.759132,0.714462,0.620044,0.610588,0.898811,1.00676,-1.65533,-1.66545,0.277691,0.434682,1.11452,1.21848,0.674957,0.626781,0.0105474,0.049692,2.90481e-05,0.121479,1.48575,1.34889,0.161536,0.531329,0.35524,0.460602
7897,0.42429,0.408223,0.826808,0.804594,0.672552,0.615344,0.2275,0.189991,0.433186,0.480737,0.96185,0.949244,0.247651,0.237426,0.216429,0.181098,0.584821,0.621034,0.129824,0.11991,-0.192464,-0.0913747,1.57698,1.56686,1.64771,1.79865,-0.00619018,0.10067,0.251322,0.24148,1.26918,1.30496,-1.1623,-1.03224,0.495284,0.362562,0.626793,0.989833,0.429738,0.506981
7898,0.199713,0.281756,0.20047,0.179042,0.494784,0.381379,0.32105,0.229437,0.251578,0.349863,0.978142,0.965938,0.387918,0.479803,0.807596,0.774246,0.709925,0.819229,0.78664,0.778294,0.271417,0.375519,-0.231468,-0.243596,-0.0185432,0.132474,0.069961,0.236039,-0.0893257,-0.143821,0.579697,0.608395,-1.17607,-1.04622,1.07233,0.938938,-0.620631,-0.260877,0.452296,0.55336
7899,0.169807,0.155288,0.434524,0.460278,0.203211,0.147415,0.36598,0.268884,0.461673,0.559638,0.470775,0.460565,0.740397,0.72218,0.977569,0.94544,0.981076,1.01742,0.824251,0.789743,-0.536769,-0.430912,-0.157711,-0.165418,-0.0330898,0.117728,0.260857,0.371408,-0.0444257,-0.0926749,-1.23079,-1.20825,0.332536,0.461928,-0.754543,-0.882788,1.00271,1.35417,-0.0181994,0.0779003
7900,0.65349,0.636603,0.762265,0.741515,0.334076,0.204262,0.34584,0.308331,0.963571,1.06354,0.848802,0.839454,0.0858194,0.0699354,0.549667,0.557822,0.65945,0.698146,0.811851,0.801192,0.302168,0.400344,-2.0068,-2.00848,0.198602,0.348677,2.80901,2.92057,-0.633598,-0.686387,-0.229053,-0.211621,0.98544,1.10883,-0.404341,-0.537082,-0.346303,0.00760488,0.326994,0.429834
7901,0.896309,0.877659,0.764545,0.745889,0.318051,0.26111,0.835756,0.796795,0.157634,0.257392,0.919864,0.910502,0.659933,0.646436,0.201865,0.170203,0.873862,0.914243,0.000648597,-0.00841348,-0.486465,-0.39078,0.881793,0.877984,0.63327,0.777643,-1.08403,-0.965878,-0.191523,-0.172725,-1.13215,-1.10916,0.412652,0.539196,1.17057,1.03511,0.733542,1.09152,-1.49811,-1.39777
7902,0.541987,0.570393,0.434891,0.415632,0.698088,0.642025,0.501281,0.464023,0.377433,0.574666,0.677019,0.667082,0.185885,0.170291,0.940594,0.907465,0.451689,0.490819,0.539753,0.530979,1.93413,2.03371,0.403193,0.406183,-0.75963,-0.613569,-1.64639,-1.5242,0.392102,0.340937,0.929153,0.951846,0.411132,0.485163,-1.29124,-1.42923,1.38904,1.75311,-1.47191,-1.3753
7903,0.280777,0.263127,0.753567,0.732066,0.0523417,-0.00226618,0.478815,0.442118,0.793958,0.89194,0.826771,0.816878,0.689378,0.672607,0.329413,0.296605,0.692814,0.667708,0.2949,0.285669,0.585917,0.692267,0.59917,0.608155,1.82852,1.97342,-0.432731,-0.312462,1.18007,1.12913,-0.452136,-0.437309,0.431382,0.431131,-0.267147,-0.406404,0.876615,1.2366,-0.486866,-0.38566
7904,0.982924,0.963819,0.867423,0.845358,0.845313,0.792011,0.786463,0.700948,0.47961,0.579246,0.401737,0.391157,0.54632,0.527671,0.83617,0.803609,0.806324,0.844597,0.521636,0.513449,-0.323698,-0.221791,0.358025,0.364251,-0.553609,-0.409297,-0.0275729,0.0965153,-0.667252,-0.709947,-0.995802,-0.932825,0.25623,0.377099,-1.44099,-1.57455,-0.717564,-0.358827,-0.815946,-0.711249
7905,0.667961,0.594847,0.482311,0.460996,0.342283,0.287875,0.996476,0.959779,0.405063,0.57885,0.467129,0.511018,0.121952,0.102666,0.344033,0.312532,0.00256166,0.0419119,0.399755,0.392964,-0.507792,-0.41167,-2.04724,-2.04687,0.987438,1.13663,0.954663,1.07787,1.60448,1.56117,-1.44774,-1.42834,1.00519,1.12989,-0.0584262,-0.186115,0.438662,0.802386,1.03794,1.14131
7906,0.245128,0.225875,0.847189,0.82573,0.845367,0.791436,0.0650343,0.0263874,0.476893,0.578455,0.639751,0.630878,0.993283,0.971244,0.690921,0.659777,0.551723,0.59158,0.934804,0.927859,-1.53257,-1.43358,0.43139,0.431721,0.205063,0.351085,0.773254,0.884237,-0.38783,-0.437082,-0.719896,-0.695301,-0.89848,-0.77777,-0.922749,-1.04957,-0.493986,-0.137207,0.124696,0.227568
7907,0.854367,0.835741,0.0158245,-0.00413821,0.680537,0.683944,0.777391,0.739212,0.626713,0.799831,0.230042,0.219873,0.179621,0.159544,0.338351,0.307655,0.789677,0.828353,0.613251,0.606622,-0.325621,-0.234566,-2.40691,-2.40987,0.145496,0.290427,0.537657,0.6906,0.452823,0.396161,0.742283,0.774347,1.10986,1.23056,0.259651,0.0665485,0.452374,0.806734,-1.60927,-1.51049
7908,0.309027,0.289391,0.743089,0.721891,0.631477,0.576453,0.748092,0.71234,0.919104,1.02121,0.62207,0.614095,0.885955,0.867635,0.633532,0.604299,0.415971,0.454169,0.79872,0.793814,0.871819,0.964445,1.24189,1.2448,1.66595,1.80654,0.36678,0.496964,-0.0648244,-0.121874,-0.770482,-0.73544,-0.788963,-0.661747,1.30689,1.18267,1.17387,1.53122,0.385241,0.477038
7909,0.339538,0.275398,0.650374,0.636982,0.265739,0.211834,0.0774589,0.0403686,0.499386,0.602168,0.679919,0.734707,0.255463,0.235557,0.242282,0.212503,0.307853,0.346889,0.443987,0.438028,0.0834395,0.173322,-2.36786,-2.36113,1.37644,1.51709,-0.244743,-0.108555,-0.260388,-0.244806,1.06316,1.10572,1.01787,1.1425,-0.563009,-0.684541,-0.610138,-0.258933,1.18822,1.2853
7910,0.171412,0.261405,0.573579,0.552074,0.796147,0.740369,0.923166,0.887045,0.832411,0.934348,0.826232,0.855319,0.500955,0.490427,0.239019,0.207704,0.587797,0.628067,0.426362,0.355885,0.991498,1.08206,0.0645229,0.0694916,0.503058,0.63792,1.22693,1.36853,-0.310754,-0.367738,0.133379,0.179511,-0.61834,-0.497458,-1.20064,-1.32013,-1.47666,-1.13272,-1.38403,-1.2838
7911,0.267953,0.247412,0.140128,0.118907,0.99004,0.935695,0.251078,0.215074,0.288424,0.390858,0.98225,0.97593,0.767511,0.745296,0.960284,0.930026,0.35096,0.389556,0.27737,0.273742,0.946723,1.04282,-0.808342,-0.802036,-1.58945,-1.4573,1.0646,1.21084,1.55675,1.49236,0.641688,0.686607,0.41381,0.529687,-1.51874,-1.63346,-1.09759,-0.750734,0.838926,0.94561
7912,0.606396,0.584512,0.0299266,0.009901,0.747404,0.691239,0.984064,0.94755,0.97143,1.07185,0.178521,0.172534,0.327639,0.304561,0.220253,0.188772,0.432381,0.47227,0.059184,0.0530932,-0.0600352,0.0369214,-0.270229,-0.349697,-0.531363,-0.396822,0.360769,0.597128,-0.0196031,-0.0842841,0.696563,0.747387,-0.409178,-0.296358,1.40978,1.29246,-0.309936,0.0351521,1.07892,1.19197
7913,0.397749,0.375667,0.509138,0.448378,0.87958,0.822702,0.448048,0.409462,0.874843,0.975664,0.448085,0.441305,0.650476,0.626452,0.397507,0.366162,0.916661,0.957277,0.402118,0.397415,0.115856,0.287571,0.097812,0.102641,0.201277,0.341178,-0.160726,-0.0165862,-2.20028,-2.26441,0.227627,0.282877,1.01191,1.12209,0.174952,0.0606388,-2.60832,-2.2662,-0.925927,-0.810592
7914,0.698476,0.67753,0.907609,0.886854,0.607549,0.548284,0.500908,0.474793,0.779296,0.879479,0.0873038,0.0795783,0.175415,0.150307,0.369056,0.376856,0.669224,0.706757,0.27479,0.272328,0.438195,0.538221,-0.463037,-0.462587,2.12571,2.26486,0.271486,0.422556,0.811309,0.74033,1.38958,1.44777,1.08492,1.2001,1.72013,1.60159,-0.457967,-0.116209,0.101872,0.210858
7915,0.779302,0.758176,0.190563,0.17195,0.629829,0.538293,0.463766,0.540125,0.0345187,0.132152,0.611767,0.606256,0.635404,0.611616,0.419321,0.38755,0.370185,0.456237,0.680557,0.676633,-0.658985,-0.559912,-0.0408052,-0.046436,0.684781,0.828807,-0.798741,-0.649364,-0.393176,-0.464418,0.851866,0.906265,-0.143492,-0.0328224,-0.188496,-0.312013,-1.89709,-1.55557,0.36299,0.472256
7916,0.0582653,0.0387147,0.65294,0.635027,0.717434,0.528302,0.642908,0.605457,0.302307,0.398464,0.399627,0.392475,0.524898,0.502387,0.672866,0.643257,0.163739,0.205716,0.0206628,0.0152799,-0.600766,-0.509242,-1.19267,-1.19733,1.30676,1.45704,1.10774,1.2557,-0.283954,-0.352724,-1.15371,-1.0967,0.338803,0.443788,0.26876,0.141302,-0.987787,-0.644284,-0.405881,-0.290549
7917,0.342984,0.325561,0.0496674,0.0334859,0.576303,0.518311,0.372311,0.332429,0.84517,0.942833,0.776861,0.771364,0.718467,0.586244,0.451918,0.420846,0.601187,0.640615,0.301774,0.298636,-0.870264,-0.775797,-0.317662,-0.320229,1.69708,1.84007,0.127203,0.276683,-1.51524,-1.59121,0.148656,0.203957,1.98354,2.09218,-0.234745,-0.369798,0.771887,1.11295,1.15958,1.2692
7918,0.421915,0.406208,0.692559,0.6782,0.91354,0.855474,0.827774,0.785511,0.703191,0.801002,0.767082,0.763544,0.712038,0.670102,0.699182,0.666402,0.0177412,0.0556354,0.995382,0.9929,-0.00387702,0.0861535,0.204243,0.203806,-0.614944,-0.477986,0.958867,1.10015,-0.426211,-0.497468,-0.0935541,-0.0428355,0.465179,0.576247,-1.5182,-1.64903,-0.513294,-0.169818,-1.04584,-0.934961
7919,0.84683,0.829299,0.747759,0.743248,0.998487,0.94174,0.297491,0.257267,0.196501,0.292804,0.22546,0.224329,0.777828,0.75396,0.0657825,0.0345748,0.643638,0.682023,0.370099,0.367344,-0.474282,-0.379163,-1.37536,-1.36847,0.0210424,0.146672,0.114474,0.26055,1.02089,0.949068,0.518654,0.57138,-0.244158,-0.150752,0.224031,0.0954109,2.4935,2.83194,1.32533,1.44011
7920,0.528,0.532518,0.820448,0.808296,0.791482,0.733962,0.320473,0.225993,0.0879016,0.185898,0.882837,0.880827,0.381558,0.357902,0.250028,0.153812,0.706483,0.744913,0.101768,0.096898,1.09686,1.19691,-0.219439,-0.215437,0.638356,0.771331,-1.27197,-1.11765,0.0933441,0.0610809,0.423766,0.478311,-0.960349,-0.877751,0.484681,0.351193,-0.637257,-0.301905,0.759304,0.892479
7921,0.254743,0.235736,0.424846,0.493102,0.369175,0.309463,0.240384,0.194718,0.935046,1.03151,0.047253,0.0428519,0.334706,0.410089,0.30621,0.27305,0.166669,0.20531,0.332859,0.329677,-0.120056,-0.0239798,1.3992,1.40549,-0.808567,-0.679378,1.43198,1.58092,-0.757743,-0.826906,2.31691,2.36515,-1.71582,-1.60475,0.107026,-0.0215038,-2.32999,-1.99489,0.226729,0.344843
7922,0.968936,0.95162,0.191221,0.177908,0.954947,0.897833,0.204474,0.163443,0.0625721,0.159194,0.211863,0.162712,0.48598,0.462276,0.969051,0.937374,0.128041,0.165667,0.148704,0.144268,0.176225,0.275473,-0.338359,-0.326461,0.768022,0.901018,0.689454,0.834672,1.24622,1.18243,1.31844,1.43804,-1.13105,-1.01972,1.29401,1.16501,0.501065,0.832979,-0.901249,-0.784942
7923,0.223509,0.206703,0.866092,0.852697,0.954575,0.871261,0.778327,0.735892,0.80182,0.897709,0.287125,0.282573,0.711069,0.711732,0.485859,0.456293,0.850751,0.888199,0.428113,0.372378,-0.184234,-0.0824488,1.35884,1.37116,-0.0789493,0.053461,0.293904,0.445,-0.12507,-0.196825,0.456192,0.510935,-1.1944,-1.07952,-1.14515,-1.27013,0.459269,0.796925,0.633799,0.742562
7924,0.877532,0.863096,0.415167,0.39948,0.903208,0.844689,0.172981,0.132578,0.964996,1.06248,0.0467653,0.044119,0.986485,0.961188,0.996324,0.968288,0.121709,0.157009,0.604751,0.600487,0.787638,0.888803,-0.783818,-0.7667,1.02324,1.15711,-0.796911,-0.643634,0.246329,0.177687,-1.31264,-1.25792,0.0856813,0.196714,0.638038,0.519023,1.71729,2.05177,1.16029,1.26201
7925,0.396526,0.382149,0.571535,0.585243,0.211636,0.150701,0.865435,0.8256,0.847035,0.945849,0.843247,0.838459,0.714598,0.690255,0.759301,0.730473,0.964318,0.996822,0.208743,0.20521,-0.162187,-0.0531087,-0.89756,-0.887186,-0.423624,-0.293603,-0.127784,0.0257501,0.913036,0.842122,-2.15604,-2.10731,0.0589805,0.167942,-0.386181,-0.499079,0.313291,0.643457,-1.2586,-1.1557
7926,0.49409,0.477734,0.787623,0.771007,0.794553,0.734215,0.652747,0.613598,0.980672,1.08073,0.0115649,0.0052218,0.69551,0.672493,0.221211,0.194375,0.978149,1.01179,0.0627725,0.0601043,0.389306,0.503886,-0.11782,-0.09884,0.141456,0.273454,1.24032,1.39069,0.162102,0.0603955,-0.707462,-0.655491,1.18267,1.28834,0.809398,0.669936,-0.494959,-0.165908,-0.26822,-0.166056
7927,0.0613521,0.0469724,0.192681,0.174844,0.521419,0.421833,0.210243,0.171668,0.0209411,0.119248,0.345944,0.339645,0.385772,0.360808,0.81625,0.787524,0.111014,0.146792,0.166619,0.162074,-2.20219,-2.08472,0.235329,0.256355,0.188576,0.318239,-0.595114,-0.442892,-0.655887,-0.721331,-1.51617,-1.4591,-1.93614,-1.8254,1.94918,1.83895,2.12208,2.45677,-0.193462,-0.0978316
7928,0.113827,0.0972205,0.477097,0.461288,0.171892,0.109452,0.00279368,-0.0352082,0.28084,0.380315,0.118024,0.111183,0.875709,0.852897,0.532159,0.505945,0.982464,1.01743,0.267423,0.264043,-1.01726,-0.898565,-0.834881,-0.817737,2.58331,2.70742,1.35749,1.51054,0.406602,0.342075,0.712709,0.77851,-1.71801,-1.61256,-0.195267,-0.314012,-0.149715,0.19068,1.05701,1.15142
7929,0.777153,0.758952,0.301637,0.361575,0.962452,0.898198,0.753884,0.717389,0.17163,0.249441,0.574276,0.569414,0.195216,0.171042,0.474883,0.45028,0.73327,0.768911,0.720606,0.718503,-1.8918,-1.76512,0.188225,0.219926,-0.670433,-0.540162,0.770861,0.919299,0.252849,0.190973,-1.02327,-0.960157,-0.190651,-0.0882304,-0.7918,-0.917093,-0.913956,-0.573144,-1.19369,-1.09927
7930,0.647998,0.578476,0.279062,0.261862,0.526399,0.462869,0.93226,0.834447,0.0207473,0.118567,0.0454705,0.0394956,0.167251,0.142655,0.114669,0.0881422,0.82109,0.857084,0.456382,0.400699,0.649785,0.772639,1.23321,1.25759,0.395898,0.520319,0.485503,0.627449,-1.2832,-1.34017,-1.1978,-1.12894,-0.759185,-0.657862,0.698628,0.576792,0.132528,0.480557,-0.396667,-0.305989
7931,0.414265,0.397999,0.444203,0.425597,0.524855,0.459138,0.990783,0.951505,0.250287,0.349154,0.5764,0.571118,0.928286,0.902503,0.596114,0.570172,0.200298,0.236654,0.084189,0.0828948,1.38902,1.51391,-0.280049,-0.252784,0.366325,0.490839,0.181495,0.3356,0.956728,0.894877,-0.629622,-0.561416,1.96245,2.06622,-2.09879,-2.22462,-0.734999,-0.393226,-0.44415,-0.359209
7932,0.462175,0.448247,0.241561,0.220652,0.922763,0.857016,0.551462,0.497974,0.844133,0.94394,0.2746,0.267418,0.694269,0.666187,0.637806,0.610491,0.34205,0.390393,0.218467,0.215677,-1.27097,-1.14133,1.21561,1.24177,-1.00274,-0.885608,0.78111,0.927718,-0.511139,-0.573793,-0.338071,-0.272176,0.900928,1.00362,0.141112,0.0135867,-2.25468,-1.91141,0.572305,0.662241
7933,0.842364,0.826323,0.303189,0.375856,0.354343,0.288284,0.0823642,0.0444444,0.848296,0.946731,0.919808,0.913844,0.942664,0.912473,0.267066,0.238526,0.589871,0.544131,0.351131,0.348458,1.72742,1.85234,0.628597,0.662842,0.563463,0.67758,-0.909075,-0.762992,1.26131,1.1937,0.406958,0.477407,-1.76364,-1.65406,0.18731,0.0525956,2.05594,2.40584,-1.01123,-0.921541
7934,0.274029,0.26036,0.550923,0.531061,0.657499,0.563885,0.427254,0.323991,0.348845,0.448483,0.30526,0.298934,0.905786,0.874153,0.929198,0.898551,0.644053,0.697869,0.919655,0.916854,1.06294,1.18745,1.43785,1.47787,-1.01428,-0.894704,0.105228,0.191275,-1.30871,-1.38143,-0.157813,-0.0930793,0.886507,0.996596,-0.15436,-0.28987,0.570581,0.918036,-1.8455,-1.75762
7935,0.682604,0.66822,0.0625272,0.0432851,0.905405,0.839487,0.643322,0.603537,0.697503,0.795217,0.69549,0.688265,0.561795,0.52893,0.666937,0.650399,0.815252,0.851608,0.403367,0.401503,-1.28059,-1.14898,-2.38225,-2.33735,1.54025,1.66559,0.930047,1.14554,0.572927,0.495871,0.155235,0.22721,-0.507514,-0.392071,1.09633,0.95735,-0.458349,-0.111565,0.833781,0.92687
7936,0.786864,0.774222,0.636714,0.619049,0.695576,0.631708,0.102293,0.0599695,0.229885,0.326913,0.109355,0.103312,0.952956,0.91998,0.433192,0.402247,0.500303,0.536655,0.473159,0.473531,-3.06327,-2.9376,0.756157,0.795213,-1.38888,-1.26897,1.95373,2.09981,0.46227,0.389224,-0.660819,-0.59116,1.63213,1.7496,0.0117602,-0.122028,2.12154,2.47353,0.246082,0.345396
7937,0.310252,0.298574,0.310433,0.293525,0.957769,0.892393,0.43677,0.401753,0.0639237,0.160292,0.442785,0.437735,0.989154,0.933383,0.844049,0.813991,0.450385,0.53693,0.775014,0.776138,1.27879,1.40446,0.841235,0.873392,-1.40382,-1.28371,-0.436944,-0.296009,-0.91233,-0.990026,-0.359826,-0.289101,-0.481754,-0.363052,1.08037,0.946128,0.592174,0.939117,-1.44465,-1.34681
7938,0.112275,0.10032,0.969208,0.952859,0.728657,0.664966,0.785031,0.743536,0.734251,0.831183,0.0603297,0.0562496,0.970451,0.946787,0.170147,0.142093,0.503223,0.537205,0.537882,0.540459,-0.15805,-0.0312024,0.60389,0.629487,0.519928,0.63997,0.363521,0.498409,0.49503,0.410504,-0.559982,-0.489044,-0.468981,-0.348517,0.0340729,-0.101448,1.36949,1.70872,-0.800173,-0.802739
7939,0.680436,0.666863,0.466772,0.449461,0.0472671,-0.0147407,0.716354,0.676596,0.829846,0.926075,0.0283679,0.0241126,0.994122,0.96019,0.927274,0.899724,0.814882,0.847988,0.831729,0.833398,1.61921,1.74444,-1.52967,-1.50837,-0.909364,-0.796084,-1.30202,-1.16318,-1.23963,-1.31983,1.30333,1.36673,0.474308,0.58835,-0.236724,-0.368274,-0.0715295,0.269361,-0.351418,-0.258671
7940,0.546221,0.465122,0.601252,0.537451,0.274436,0.21086,0.262978,0.224729,0.404678,0.57471,0.728575,0.724773,0.0142519,-0.0212955,0.865168,0.839069,0.73388,0.767624,0.526798,0.504944,1.86248,1.9956,0.521875,0.549809,-0.170384,-0.0580841,0.847638,0.980268,-1.68622,-1.7634,-1.56943,-1.49927,0.640101,0.75651,0.899526,0.773095,-0.416239,-0.0785758,-0.366067,-0.26605
7941,0.238931,0.263382,0.64448,0.625441,0.266342,0.20233,0.29282,0.217943,0.126093,0.223344,0.614272,0.611412,0.0572042,0.0213163,0.24401,0.217826,0.205751,0.238458,0.173151,0.176489,0.635854,0.774705,-0.448442,-0.414837,0.805342,0.909888,0.95823,1.099,-0.955165,-1.13049,-0.835537,-0.766231,-0.226718,-0.101844,0.213939,0.0909559,0.526814,0.865365,0.745505,0.845763
7942,0.0731422,0.0616417,0.49191,0.474506,0.916071,0.851222,0.191064,0.211158,0.873914,0.972175,0.200963,0.200407,0.793656,0.755881,0.868997,0.843271,0.147889,0.182893,0.288769,0.293657,-1.54915,-1.40597,0.031021,0.0614034,1.42895,1.53812,1.7731,1.90847,-0.4204,-0.497582,1.27788,1.34266,0.991698,1.11468,0.49222,0.319401,-0.452539,-0.117851,-0.728132,-0.63133
7943,0.52873,0.519325,0.342816,0.323571,0.916147,0.852576,0.242786,0.204372,0.694034,0.789858,0.18049,0.197001,0.13294,0.0941871,0.995806,0.969031,0.609893,0.64319,0.65472,0.658848,-1.87174,-1.73164,0.00314273,0.0333323,-0.760565,-0.652114,0.771221,0.91453,0.892893,0.812398,1.70402,1.77189,-0.721354,-0.604839,0.676632,0.547847,1.95871,2.29104,0.220373,0.313594
7944,0.474926,0.492904,0.38378,0.274635,0.540861,0.477741,0.821705,0.782252,0.751825,0.77348,0.192549,0.193594,0.251168,0.214256,0.453225,0.427609,0.154734,0.188607,0.179155,0.182736,-0.245007,-0.108766,-0.965444,-0.931314,-0.980725,-0.866988,0.493418,0.632056,-0.323349,-0.411483,1.2988,1.36422,1.42763,1.53683,-0.658933,-0.792761,0.422924,0.75663,0.570781,0.665527
7945,0.541659,0.466483,0.324546,0.225698,0.535641,0.474009,0.223822,0.183419,0.638992,0.757103,0.867418,0.870566,0.86736,0.830432,0.542615,0.518492,0.946855,0.981238,0.827447,0.831548,0.964014,1.10552,-0.931558,-0.898526,1.66886,1.77922,-0.850308,-0.715065,1.22101,1.12613,0.892033,0.956553,-1.34266,-1.24232,0.38858,0.258476,0.350383,0.689854,0.208212,0.257031
7946,0.473407,0.440062,0.248778,0.176762,0.769646,0.649746,0.790371,0.751102,0.796968,0.740725,0.695051,0.697971,0.712024,0.675941,0.922929,0.900727,0.351114,0.387006,0.69636,0.75195,-0.412074,-0.265592,0.0430012,0.0713414,1.19157,1.30674,0.428395,0.558769,0.0535465,-0.0349542,-0.764817,-0.703838,0.625503,0.71952,0.391452,0.265807,-0.667133,-0.326578,-0.247982,-0.151466
7947,0.32713,0.413641,0.114284,0.127826,0.885762,0.825483,0.0181331,-0.02318,0.628523,0.724347,0.0117983,0.0132048,0.848012,0.811037,0.0380283,0.0172548,0.291859,0.327236,0.668765,0.672352,-1.13525,-0.994333,0.675154,0.702424,0.342236,0.459183,-0.908893,-0.773876,0.152053,0.0628148,2.43903,2.50296,-1.24653,-1.15574,-0.510777,-0.630353,-0.182705,0.163819,0.73963,0.838176
7948,0.432745,0.387219,0.0981355,0.0788903,0.439844,0.380992,0.898442,0.856113,0.499877,0.530252,0.324632,0.259372,0.0240535,-0.0113531,0.779397,0.759649,0.775665,0.812244,0.789442,0.793801,0.928737,1.07345,0.552955,0.581938,0.375903,0.486228,-0.656759,-0.517446,0.525398,0.437326,1.87104,1.89601,0.365201,0.461185,1.70878,1.59104,1.06543,1.41866,0.506655,0.604028
7949,0.370204,0.360798,0.713408,0.693898,0.788848,0.72829,0.326711,0.283451,0.239912,0.336158,0.503787,0.50554,0.200664,0.165108,0.896145,0.875405,0.629126,0.664052,0.261981,0.267812,-0.536333,-0.390523,1.01596,1.04376,0.393895,0.513274,-0.740118,-0.598049,0.0479171,-0.0356945,1.22214,1.28907,0.614456,0.696487,3.08625,2.96334,-0.902921,-0.550942,0.857362,0.955961
7950,0.590461,0.582598,0.0275276,0.00863904,0.130146,0.0693146,0.969556,0.925478,0.439506,0.521596,0.999871,1.00302,0.93145,0.893766,0.102423,0.0836711,0.0416915,0.0750042,0.935672,0.941719,0.791383,0.935159,1.04145,1.07655,-1.61907,-1.49894,-1.38773,-1.2504,-1.0922,-1.17936,0.106684,0.179465,0.843572,0.931789,-1.25376,-1.37366,-0.317614,0.0323704,2.18793,2.28235
7951,0.348301,0.338937,0.471365,0.355896,0.8502,0.789312,0.104675,0.0612381,0.744577,0.707035,0.988547,0.990873,0.806919,0.84253,0.282276,0.264793,0.0704501,0.104564,0.805699,0.812506,0.328571,0.469842,-0.137151,-0.10453,0.529313,0.643702,1.16237,1.29876,-0.248984,-0.330414,1.81504,1.88238,0.105821,0.194387,1.34774,1.22461,0.50111,0.849704,-1.88684,-1.79524
7952,0.526198,0.614323,0.722125,0.703154,0.23268,0.170772,0.869518,0.824637,0.796435,0.892474,0.508964,0.553141,0.826652,0.791295,0.248927,0.228679,0.768699,0.801153,0.174632,0.181743,0.873508,1.0128,-0.759975,-0.729061,-1.22208,-1.10165,-1.37663,-1.23483,-0.893884,-0.951984,1.30302,1.37178,0.80679,0.901429,1.17488,1.05083,1.95512,2.31233,0.228154,0.318643
7953,0.899076,0.889708,0.800541,0.782237,0.220054,0.157285,0.0957719,0.0503551,0.0991501,0.19663,0.114715,0.11541,0.968807,0.931513,0.43256,0.46955,0.617898,0.68298,0.920749,0.92566,0.367809,0.513988,-0.740826,-0.783117,-0.586969,-0.473417,-2.01048,-1.87083,-1.49231,-1.57355,-0.0218499,0.0464376,-1.41302,-1.3194,0.61147,0.495669,1.75409,2.10554,-0.374737,-0.265394
7954,0.620926,0.610712,0.603972,0.617544,0.960575,0.898156,0.129115,0.0831339,0.875406,0.970801,0.42185,0.453392,0.544294,0.506508,0.693167,0.710421,0.533435,0.564807,0.974928,0.942966,1.04356,1.19399,-0.865386,-0.837172,0.402621,0.509901,-0.124148,0.0187173,-0.29701,-0.371221,-1.70983,-1.64766,0.772063,0.868676,0.067036,-0.0594955,0.544039,0.901396,-0.943319,-0.849432
7955,0.912216,0.902937,0.551555,0.452852,0.848697,0.786623,0.898462,0.852018,0.53667,0.633592,0.789848,0.791373,0.84901,0.813461,0.97154,0.951292,0.873818,0.905529,0.95484,0.960273,2.65715,2.80082,1.69534,1.72031,0.862335,0.968776,1.22432,1.36686,-0.283577,-0.35011,1.71355,1.77828,0.131888,0.224539,-0.0262654,-0.157246,0.82817,1.18813,-1.26811,-1.17502
7956,0.139431,0.131002,0.305502,0.28816,0.259843,0.197882,0.966115,0.875205,0.446169,0.635422,0.572226,0.664142,0.0126466,-0.0219486,0.331508,0.310341,0.997952,1.03007,0.53229,0.565968,0.13506,0.273117,-1.72623,-1.70413,-1.05661,-0.951964,-0.402,-0.260781,1.34891,1.28044,-2.48623,-2.4215,0.556039,0.656533,-2.3511,-2.49007,-0.427405,-0.0625822,-0.3808,-0.291955
7957,0.562459,0.554444,0.603364,0.621111,0.104085,0.0412094,0.944298,0.898391,0.541391,0.637252,0.495108,0.536911,0.575499,0.539564,0.615391,0.501942,0.633635,0.744622,0.167113,0.171663,-0.082116,0.0524678,0.100596,0.117683,0.594272,0.704648,0.428659,0.562684,0.806237,0.731663,1.04723,1.10763,-0.623138,-0.515847,-0.641276,-0.817977,2.06791,2.42983,-1.21837,-1.12803
7958,0.98828,0.977886,0.973138,0.954063,0.915051,0.851467,0.142174,0.0974606,0.894404,0.989281,0.40663,0.40968,0.705282,0.670084,0.714736,0.693544,0.427953,0.459174,0.591656,0.595952,-1.34161,-1.21306,-0.335136,-0.323348,1.37558,1.48736,-1.11541,-0.983718,0.0413553,-0.0312601,-1.07627,-1.01735,-0.330614,-0.223552,0.993073,0.854112,1.45453,1.82033,0.148718,0.244167
7959,0.636638,0.627825,0.455694,0.517302,0.446118,0.381736,0.618544,0.574951,0.121584,0.214311,0.935734,0.936357,0.0124422,-0.0218412,0.716073,0.69318,0.768448,0.799895,0.71633,0.721941,-0.272767,-0.151175,-0.151184,-0.137763,-0.724594,-0.607868,0.693778,0.827506,1.89964,1.82884,0.308909,0.375011,1.198,1.30078,-1.48879,-1.62644,1.37701,1.73717,1.008,1.09582
7960,0.790668,0.783116,0.0977721,0.0805412,0.892078,0.825481,0.674945,0.652114,0.271155,0.364498,0.642896,0.635582,0.351838,0.319957,0.960743,0.938737,0.447912,0.480618,0.160201,0.166132,0.37655,0.579899,0.824194,0.832104,-0.677753,-0.563083,1.19353,1.32725,1.35347,1.28006,-0.582384,-0.522529,0.0450096,0.147058,0.361406,0.225259,0.386268,0.753955,1.49006,1.58484
7961,0.721062,0.711828,0.967416,0.950373,0.358954,0.291666,0.772073,0.729276,0.809352,0.903385,0.331261,0.334806,0.696127,0.661755,0.142087,0.122298,0.912653,0.945787,0.74213,0.75042,1.19504,1.31097,0.09862,0.100091,-0.0564495,0.0503977,0.308864,0.440847,-0.593121,-0.6706,0.0939839,0.0750378,0.119908,0.225068,0.798228,0.662782,1.18242,1.55499,1.24358,1.33555
7962,0.899361,0.892353,0.742619,0.726096,0.332313,0.355769,0.203681,0.161093,0.857975,0.858335,0.969963,0.975613,0.351583,0.316532,0.842952,0.823376,0.445696,0.480903,0.376212,0.38426,-0.210296,-0.0929302,-1.02435,-1.01987,0.546854,0.663878,-0.198104,-0.0726093,0.771373,0.697716,0.610664,0.672604,-0.131181,-0.0186098,-0.776316,-0.90693,0.870403,1.23911,-0.67773,-0.589105
7963,0.710607,0.70369,0.307109,0.288341,0.430069,0.419872,0.611837,0.570464,0.717093,0.813285,0.888769,0.892479,0.655986,0.623484,0.423471,0.401421,0.479312,0.514571,0.786081,0.793574,2.53362,2.64713,1.02644,1.02442,0.276805,0.397019,0.0887712,0.215809,-0.200341,-0.281211,-1.59016,-1.53326,-0.955587,-0.844654,0.057296,-0.070126,-0.0926338,0.270733,-0.576082,-0.492988
7964,0.836702,0.829078,0.505898,0.485764,0.549531,0.483975,0.329704,0.289456,0.674203,0.768235,0.594354,0.59833,0.616776,0.555567,0.397535,0.375673,0.251588,0.286436,0.929743,0.936098,0.333662,0.44667,-0.47571,-0.470462,0.0122881,0.13016,-1.36176,-1.24053,0.862195,0.782194,-1.53472,-1.47248,0.354063,0.4669,0.423171,0.2915,-0.0589421,0.313018,-1.98553,-1.8956
7965,0.2053,0.197952,0.272754,0.251261,0.988579,0.9233,0.0508881,0.00844752,0.0978018,0.189667,0.820866,0.827014,0.520473,0.487649,0.777955,0.757908,0.410129,0.445819,0.00434625,0.00934923,-1.59827,-1.48263,-0.0860677,-0.0849784,0.32833,0.452873,1.26153,1.37711,-0.432474,-0.518061,-0.195682,-0.140103,0.492304,0.604374,-1.52575,-1.65303,-1.27506,-0.903842,-0.00263693,0.0919266
7966,0.369673,0.285571,0.732307,0.709756,0.688106,0.58647,0.566645,0.526496,0.94989,1.04096,0.174758,0.181672,0.0923732,0.0582655,0.130123,0.110529,0.175235,0.211981,0.261012,0.259451,2.02276,2.13978,2.30871,2.31302,0.355957,0.483517,-0.870251,-0.757154,2.04655,1.9626,0.188204,0.242788,0.325741,0.354189,-0.701408,-0.831974,1.36291,1.73131,-0.0197828,0.0119365
7967,0.379752,0.373191,0.989899,0.966369,0.315025,0.24964,0.451215,0.40857,0.304975,0.396693,0.881837,0.888195,0.959417,0.926843,0.846803,0.82817,0.199487,0.236325,0.592809,0.509553,-0.667002,-0.545192,-0.176823,-0.177114,1.40046,1.52689,0.471619,0.590984,-0.630079,-0.710969,-1.11922,-1.0665,-0.00786417,0.104004,1.04618,0.91247,1.4625,1.83395,-0.0520256,-0.0680536
7968,0.922792,0.915446,0.497515,0.473455,0.838484,0.77311,0.996162,0.951458,0.0433398,0.134389,0.244782,0.252821,0.594091,0.629214,0.959912,0.938878,0.888166,0.923542,0.755185,0.759655,-0.705967,-0.584426,-0.996896,-1.00212,-0.330703,-0.202696,-1.03175,-0.911542,-0.0472411,-0.124921,-1.65114,-1.5915,0.965462,1.07135,-0.492707,-0.625412,0.277639,0.645458,-0.242607,-0.148044
7969,0.508332,0.500082,0.607823,0.582217,0.0511918,-0.0114612,0.0314488,-0.0132547,0.802251,0.893014,0.821132,0.82889,0.36327,0.331585,0.680085,0.6573,0.846114,0.883899,0.623538,0.628178,-0.489872,-0.365539,-0.412547,-0.416353,0.509861,0.643798,0.489415,0.611688,-1.26676,-1.3488,0.628373,0.69003,-1.70441,-1.60083,0.70946,0.578193,1.05855,1.43134,-0.403111,-0.30713
7970,0.715708,0.706303,0.416762,0.392705,0.222063,0.159267,0.226328,0.183037,0.708162,0.743681,0.379853,0.424892,0.246644,0.217172,0.644052,0.621185,0.0478808,0.0870914,0.491193,0.496702,0.599629,0.725912,-0.339885,-0.338175,-1.73999,-1.61156,-0.45138,-0.321831,-0.226732,-0.315335,-0.443908,-0.38914,0.433141,0.540844,-0.380678,-0.515025,1.29879,1.67065,-0.165464,-0.0740988
7971,0.202426,0.190884,0.499742,0.409732,0.0297073,0.0604355,0.744955,0.701086,0.501784,0.594349,0.0149926,0.0208929,0.755642,0.723593,0.358794,0.334238,0.0347268,0.0716693,0.90286,0.906016,-0.793242,-0.661869,1.88167,1.88452,1.42711,1.54799,0.781417,0.905264,-0.0545389,-0.141272,0.33605,0.390617,-0.389192,-0.285201,0.711522,0.581773,0.137624,0.512904,0.854715,0.947351
7972,0.225181,0.223575,0.448517,0.426758,0.0239542,-0.0383956,0.94018,0.897377,0.0284979,0.121343,0.636786,0.641651,0.149568,0.117466,0.557511,0.569767,0.327491,0.438833,0.139329,0.142911,0.704908,0.83726,-0.638267,-0.640254,0.123584,0.25104,-0.79225,-0.673127,-1.27411,-1.36515,-0.762707,-0.705301,0.0636693,0.1617,0.571104,0.437313,-1.40671,-1.03698,1.12522,1.22544
7973,0.268854,0.256266,0.09145,0.0675433,0.425032,0.364972,0.0300165,-0.0142551,0.582935,0.675837,0.483411,0.431647,0.866117,0.836545,0.827846,0.805296,0.769732,0.805997,0.0514957,0.122581,1.01483,1.15049,2.01187,2.01758,0.363292,0.498065,-0.991347,-0.87586,1.52009,1.4286,-1.24681,-1.18436,-0.3781,-0.284349,0.125515,-0.0120436,-0.499782,-0.125699,0.61402,0.718953
7974,0.330713,0.288957,0.265926,0.241396,0.0840683,0.025101,0.742909,0.69857,0.159343,0.251936,0.203571,0.221643,0.673976,0.590259,0.201826,0.178917,0.197765,0.236067,0.0979836,0.10225,0.538332,0.667936,-1.06269,-1.05104,1.31315,1.452,-0.80469,-0.694804,-0.908177,-0.997506,-0.950163,-0.895122,-0.524907,-0.434447,0.818626,0.687043,-0.876132,-0.502076,0.819181,0.921636
7975,0.33319,0.321648,0.0160093,-0.00917004,0.855231,0.796328,0.143041,0.0997359,0.804663,0.896837,0.00677329,0.0116387,0.374999,0.343972,0.168823,0.14784,0.708517,0.746459,0.692302,0.696469,1.88857,2.02538,-0.260441,-0.249712,-0.718834,-0.576397,-1.1633,-1.05461,-0.527337,-0.609106,1.17092,1.22586,-0.0517178,0.0421637,-0.20953,-0.344642,-0.442977,-0.074588,0.286195,0.383404
7976,0.0641213,0.0524152,0.381212,0.444324,0.320103,0.262512,0.00387209,-0.0374837,0.717291,0.819931,0.158948,0.166429,0.504438,0.390479,0.950756,0.930714,0.469585,0.507948,0.978544,0.984574,-0.142859,-0.000134351,0.890036,0.903325,2.03124,2.17801,1.4389,1.54414,1.1104,1.03431,-1.34086,-1.28723,-0.170389,-0.0774508,-0.467938,-0.611468,-0.534297,-0.173303,-2.53382,-2.43644
7977,0.504641,0.507904,0.925282,0.897819,0.382212,0.401498,0.198244,0.158808,0.653271,0.743024,0.839898,0.847155,0.466271,0.436986,0.319151,0.298887,0.966043,1.00369,0.327907,0.333578,-1.28007,-1.14338,1.21167,1.22816,-0.906783,-0.756546,-0.00917281,0.102398,0.647556,0.575626,-1.59959,-1.54838,0.716761,0.811207,-0.173985,-0.312179,-1.18365,-0.894907,0.00904573,0.11081
7978,0.97578,0.963392,0.628163,0.602506,0.600032,0.540483,0.133526,0.0918677,0.573944,0.666118,0.603103,0.608701,0.902453,0.873881,0.760114,0.741124,0.85994,0.896412,0.0148883,0.0221843,-0.347305,-0.204344,0.887216,0.909959,0.772449,0.91788,-0.622907,-0.516913,-0.856983,-0.925327,-0.779927,-0.723473,-1.70989,-1.62212,-0.301457,-0.440976,-1.9834,-1.61651,-0.177644,-0.0784797
7979,0.581866,0.573305,0.721011,0.696846,0.5193,0.460359,0.717237,0.674785,0.94396,1.03378,0.893797,0.897867,0.228389,0.201634,0.700091,0.68047,0.12503,0.16009,0.173806,0.226918,-2.01635,-1.86885,-0.89702,-0.86669,1.47761,1.62466,-0.0637407,0.0446216,1.38263,1.30972,-1.10664,-1.04628,0.739865,0.824048,1.46593,1.33175,-1.30865,-0.937408,0.288173,0.394437
7980,0.193937,0.183218,0.489318,0.394989,0.0949189,0.0358599,0.800345,0.758337,0.984259,1.02469,0.905623,0.909679,0.581895,0.553617,0.232236,0.213826,0.623134,0.66031,0.425155,0.431652,0.411449,0.555644,-0.489161,-0.466899,-0.471951,-0.327567,-0.989975,-0.888897,0.160317,0.0858425,-0.132944,-0.0667658,-1.08826,-1.00554,1.61783,1.47924,0.193418,0.568167,0.470978,0.581265
7981,0.955314,0.94306,0.114799,0.0931326,0.97578,0.917932,0.298893,0.255409,0.926895,1.0156,0.616569,0.620767,0.192583,0.16228,0.111263,0.0926974,0.58404,0.620668,0.0253847,0.031091,-0.221475,-0.0802907,-1.70823,-1.67894,0.169056,0.317301,0.589716,0.685429,2.2253,2.15109,1.18252,1.24936,1.40517,1.49454,1.13764,0.999014,-0.338047,0.0355803,1.15572,1.26733
7982,0.783934,0.771062,0.12884,0.191126,0.932342,0.873661,0.429589,0.470442,0.506489,0.596564,0.0165616,0.0201328,0.577216,0.549032,0.372106,0.353331,0.923825,0.961389,0.513336,0.520561,-0.348356,-0.210052,-0.98962,-0.956861,-0.496388,-0.344692,0.705553,0.804162,0.595891,0.527957,0.446272,0.507295,-0.839328,-0.744032,-1.82377,-1.96719,0.112727,0.4314,-0.314075,-0.209766
7983,0.876365,0.780524,0.311196,0.28912,0.165395,0.109151,0.638347,0.685475,0.697755,0.78655,0.350164,0.354556,0.505485,0.409879,0.151816,0.13092,0.0296407,0.0671266,0.431927,0.437361,0.682371,0.820798,1.11222,1.15105,-0.219223,-0.0670905,-0.872608,-0.774228,0.556791,0.48565,-0.603743,-0.541276,-0.240175,-0.144337,1.60973,1.47327,0.451212,0.827221,-2.02674,-1.91982
7984,0.802136,0.789985,0.96297,0.939156,0.42152,0.410929,0.94353,0.900507,0.466408,0.554987,0.275462,0.281861,0.316357,0.270726,0.712834,0.693155,0.93641,0.974888,0.834732,0.841666,0.112204,0.246524,-1.73897,-1.70558,-1.19385,-1.04198,-0.63835,-0.545739,-1.41268,-1.48062,-0.457123,-0.39074,0.14096,0.238109,-0.741365,-0.874806,1.74336,2.11339,-1.24982,-1.14347
7985,0.622363,0.612439,0.864789,0.917113,0.768951,0.712707,0.319798,0.277483,0.965433,1.05291,0.439516,0.447023,0.162261,0.131574,0.885917,0.86435,0.328315,0.364635,0.136604,0.144009,0.107136,0.237244,1.28115,1.31744,-0.881355,-0.804772,-0.182497,-0.0900164,0.265775,0.194658,-1.75687,-1.68448,-1.4781,-1.38514,0.597708,0.464661,-1.07007,-0.694761,-2.32229,-2.20834
7986,0.000963363,-0.00827739,0.85405,0.895071,0.402468,0.348088,0.715,0.671029,0.166687,0.252211,0.958548,0.96435,0.0206047,-0.00757934,0.740325,0.717426,0.949791,0.985753,0.921882,0.93074,0.619212,0.751279,-0.334809,-0.302537,-0.714087,-0.567562,-0.176656,-0.0292547,1.08116,1.01194,1.24774,1.32199,1.17074,1.26552,0.00531491,-0.124272,-0.255231,0.122573,0.376694,0.488724
7987,0.428413,0.419586,0.896842,0.873028,0.267674,0.211388,0.736137,0.693619,0.222712,0.309238,0.251523,0.254647,0.143415,0.169644,0.816057,0.820244,0.0909361,0.126463,0.219381,0.228104,0.675394,0.801949,-1.15456,-1.12754,-1.15237,-1.00898,-0.016236,0.0315071,0.503991,0.432178,-0.43974,-0.372107,0.369416,0.466397,2.70527,2.57562,0.239534,0.61297,-0.301392,-0.183981
7988,0.0621243,0.0551077,0.00219792,-0.0210259,0.695803,0.553676,0.271476,0.226961,0.0737147,0.158284,0.611531,0.61474,0.376686,0.346868,0.943642,0.923062,0.823748,0.858165,0.41536,0.425398,-1.25897,-1.12735,-0.920194,-0.793906,2.20408,2.35125,0.00662681,0.0922688,-1.01642,-1.08325,-0.580336,-0.511435,-0.703752,-0.61238,-0.890745,-1.0204,-0.0462081,0.328943,-1.24714,-1.12795
7989,0.516349,0.507568,0.360036,0.288352,0.950248,0.895965,0.937037,0.893006,0.155325,0.252536,0.422876,0.426261,0.823136,0.793015,0.540291,0.595006,0.166259,0.20234,0.83163,0.839178,-0.0830513,0.041864,-0.492685,-0.460275,-0.975604,-0.832397,0.06055,0.153031,0.415139,0.348206,0.476677,0.546957,-0.603895,-0.520208,-1.08703,-1.21005,-1.87036,-1.49508,0.509315,0.632181
7990,0.757175,0.748624,0.622679,0.59773,0.784822,0.729818,0.689499,0.645073,0.308792,0.346787,0.839118,0.840835,0.43184,0.401677,0.285551,0.266951,0.477078,0.430622,0.218759,0.229224,-0.268047,-0.148015,-0.404895,-0.36777,-0.330828,-0.187529,0.321723,0.40946,-2.3047,-2.37187,-0.2022,-0.135141,0.379855,0.463495,-0.139897,-0.264549,-0.26674,0.105709,-0.757051,-0.633508
7991,0.140666,0.132519,0.359469,0.336636,0.20534,0.150989,0.986884,0.940343,0.355311,0.441039,0.0741666,0.0756911,0.842986,0.813203,0.804166,0.784242,0.624352,0.658903,0.205989,0.215026,-1.52453,-1.39881,0.202075,0.234077,-1.3119,-1.16242,0.029782,0.11171,-0.317705,-0.380682,-0.561904,-0.444239,0.577232,0.662303,-0.391446,-0.516039,1.54244,1.9102,-0.292263,-0.176076
7992,0.745865,0.738495,0.463618,0.391202,0.949252,0.897149,0.9629,0.918438,0.785427,0.869323,0.982715,0.982529,0.10668,0.0756357,0.0109873,-0.00749245,0.185007,0.219697,0.74304,0.749922,0.495654,0.621454,-0.369886,-0.331152,-0.735711,-0.578992,0.114363,0.197929,-0.367488,-0.422989,-0.813052,-0.753337,0.406085,0.439849,0.157078,0.0301511,-0.976749,-0.610768,-0.876977,-0.75755
7993,0.0588361,0.0517688,0.468841,0.445768,0.427487,0.373726,0.155214,0.112421,0.34053,0.425887,0.0655438,0.0672681,0.495954,0.466686,0.320447,0.257835,0.934235,0.967005,0.62015,0.624834,0.190208,0.309922,-1.49698,-1.45111,1.78379,1.94512,-0.67332,-0.592873,0.0776164,0.0247819,-0.616343,-0.555263,0.203089,0.217395,0.417185,0.285933,1.0313,1.39276,-2.00595,-1.88733
7994,0.997573,0.992352,0.276161,0.251138,0.881613,0.827235,0.664125,0.620262,0.711584,0.736823,0.979826,0.983375,0.530149,0.477355,0.539538,0.523163,0.25352,0.287064,0.927108,0.932613,0.37429,0.498877,0.784643,0.833582,-0.328784,-0.165149,-0.478538,-0.397131,0.131663,0.0759275,-0.74141,-0.739143,-0.0914291,-0.00505943,0.235044,0.0794626,-1.24384,-0.887505,-0.918309,-0.804995
7995,0.0692191,0.0625218,0.36169,0.335501,0.854533,0.775956,0.0240761,-0.0219877,0.963323,1.04776,0.248586,0.253938,0.514359,0.488023,0.00810525,-0.00788625,0.37272,0.406232,0.756809,0.673168,-1.32571,-1.19542,1.66967,1.72533,-1.42491,-1.26186,-1.46692,-1.39108,-2.0075,-2.05627,-0.986213,-0.923023,0.793359,0.883599,0.00306509,-0.127008,-0.741329,-0.379329,0.827762,0.935965
7996,0.755716,0.748679,0.912542,0.88726,0.777935,0.724678,0.285735,0.23884,0.0718904,0.155387,0.490139,0.496591,0.175232,0.147986,0.718179,0.704125,0.863966,0.897027,0.483323,0.413723,1.12474,1.26042,0.432519,0.482413,-0.9395,-0.728547,-0.41731,-0.334531,-0.572718,-0.624819,-1.89268,-1.83536,-0.648449,-0.553857,1.72193,1.58779,1.96341,2.31708,0.0647486,0.17316
7997,0.881513,0.874067,0.438917,0.413617,0.315919,0.260249,0.319791,0.271619,0.199728,0.192385,0.431992,0.460142,0.646432,0.619667,0.789896,0.803899,0.472071,0.506979,0.146666,0.154279,1.20937,1.34155,0.759253,0.807248,-0.358278,-0.195229,1.7367,1.82082,-0.680801,-0.731467,-0.85955,-0.808963,0.201448,0.288625,0.180505,0.0499055,0.830766,1.19125,1.12743,1.23916
7998,0.463785,0.453748,0.361088,0.352528,0.763747,0.709504,0.846783,0.79928,0.145138,0.229382,0.417865,0.423693,0.401808,0.36909,0.920267,0.903674,0.836747,0.872824,0.329055,0.273008,-0.159214,-0.0295661,0.317183,0.366217,-1.44762,-1.29195,0.942824,1.03002,-0.145923,-0.19193,0.850162,0.909324,-0.2023,-0.109588,0.38975,0.25751,0.990286,1.35438,1.16553,1.2775
7999,0.4705,0.458897,0.202342,0.291439,0.865839,0.810827,0.0701312,0.0249983,0.0484212,0.13246,0.926979,0.931302,0.144548,0.118514,0.054203,0.0379686,0.0882167,0.125395,0.381692,0.391737,0.365505,0.499731,-1.49416,-1.44424,-1.53798,-1.38521,-1.12109,-1.02792,0.695611,0.657016,0.239687,0.305391,0.633182,0.732895,1.30695,1.16995,1.62615,1.9857,1.47767,1.58613
8000,0.780556,0.770535,0.255115,0.23035,0.676485,0.62335,0.296765,0.306707,0.874009,0.960327,0.557354,0.559609,0.648947,0.624935,0.0121493,-0.00333385,0.843163,0.882799,0.730986,0.741341,0.538077,0.673265,1.81405,1.86584,1.84948,1.99508,1.01028,1.09577,1.00322,0.96639,0.923439,0.99273,-0.332766,-0.236748,1.09147,1.02455,0.238761,0.594418,0.587225,0.630455
8001,0.711312,0.699247,0.830207,0.806114,0.751445,0.716315,0.631606,0.588416,0.60264,0.688322,0.497146,0.50101,0.158733,0.133825,0.949994,0.935911,0.501803,0.600036,0.579982,0.491135,-1.22835,-1.10012,0.0181219,0.0727569,-1.28842,-1.1416,-1.80446,-1.7143,-0.608931,-0.640108,2.20859,2.27843,0.076894,0.178536,1.01416,0.879155,0.317856,0.666175,-0.42641,-0.325216
8002,0.402086,0.390201,0.502051,0.475858,0.862425,0.80928,0.62576,0.581633,0.627772,0.71183,0.441907,0.442411,0.79985,0.775112,0.733202,0.718824,0.277637,0.317273,0.232915,0.240929,-2.77672,-2.65515,0.723974,0.780587,-2.33975,-2.19213,0.0566933,0.143583,2.32789,2.28886,-0.953355,-0.884601,-1.24385,-1.14837,1.17955,1.04129,-0.528066,-0.173461,0.147802,0.255452
8003,0.965675,0.951453,0.605779,0.597737,0.2437,0.190741,0.279112,0.234906,0.242391,0.328142,0.143931,0.143611,0.187529,0.163968,0.124873,0.112825,0.487378,0.52787,0.75164,0.760518,0.873375,0.996834,-1.78274,-1.72709,0.995756,1.14748,2.54547,2.62424,0.52726,0.494455,0.135561,0.202643,0.441322,0.530511,-0.357629,-0.496588,1.18832,1.53689,0.186226,0.29379
8004,0.592892,0.500901,0.747315,0.719617,0.402357,0.347381,0.498733,0.46747,0.704036,0.7053,0.422313,0.496887,0.599855,0.575494,0.867071,0.85522,0.41537,0.457526,0.362824,0.370525,-0.319439,-0.192024,-0.642617,-0.589255,1.0464,1.15918,1.39976,1.47575,-0.297966,-0.33031,0.000629127,0.0633158,0.979442,1.0676,0.0525769,-0.173956,0.164413,0.507292,-0.49253,-0.378914
8005,0.0646202,0.0503496,0.5047,0.478295,0.134394,0.0780399,0.743794,0.700034,0.999448,1.08246,0.848917,0.850163,0.490136,0.539648,0.368867,0.359535,0.762881,0.803901,0.839177,0.844529,-1.00141,-0.874034,-0.931837,-0.878269,1.02215,1.17088,0.00417594,0.0807941,0.127074,0.088307,1.3347,1.39569,1.18765,1.28043,0.278721,0.148677,0.445794,0.794024,-0.468616,-0.356443
8006,0.564707,0.464983,0.547334,0.455431,0.241047,0.184672,0.342947,0.29842,0.488036,0.569337,0.946416,0.949386,0.527773,0.503801,0.840848,0.831613,0.146178,0.188097,0.986812,0.991246,0.161026,0.295177,-0.959646,-0.906341,-0.602697,-0.450282,0.516133,0.592953,-1.32226,-1.36529,0.815926,0.870684,-0.435828,-0.342815,-1.03084,-1.1627,-0.344337,-0.00154139,1.00016,1.10965
8007,0.892522,0.879617,0.493691,0.432568,0.883941,0.828382,0.486952,0.480489,0.939208,1.02197,0.406991,0.41017,0.143583,0.118039,0.514019,0.478645,0.772782,0.814485,0.438227,0.44045,0.0153928,0.148095,0.749492,0.805904,-1.07822,-0.922765,1.02879,1.10511,-0.794297,-0.840517,0.733898,0.792948,-0.948173,-0.848966,-1.73181,-1.85897,0.0190293,0.364084,-2.05127,-1.946
8008,0.578261,0.501422,0.525825,0.409704,0.924003,0.869791,0.7069,0.662559,0.000996884,0.0849445,0.630486,0.682452,0.432714,0.409196,0.136716,0.125677,0.0192245,0.0615802,0.786331,0.790055,-0.757324,-0.626703,0.193734,0.256264,-0.242779,-0.0907627,1.73589,1.80625,-1.24439,-1.28409,1.75787,1.81935,0.495396,0.597988,1.81276,1.68592,-0.385535,-0.0437434,1.68537,1.78663
8009,0.136131,0.123226,0.350931,0.38684,0.161846,0.110096,0.147874,0.104319,0.176092,0.260031,0.951794,0.954734,0.446131,0.449333,0.719797,0.70909,0.373937,0.334183,0.141614,0.143895,-0.71006,-0.576033,-0.629121,-0.568737,-0.674221,-0.517625,0.225783,0.361067,0.28376,0.238476,-1.28238,-1.21935,-0.93124,-0.823951,-2.26044,-2.39211,0.564918,0.900198,1.6162,1.72031
8010,0.185254,0.257632,0.541124,0.363976,0.270663,0.216728,0.431953,0.418848,0.991871,1.07672,0.123465,0.126696,0.512615,0.48947,0.069034,0.0566045,0.611422,0.606787,0.641859,0.642526,-0.33191,-0.201413,0.596978,0.66582,0.877046,1.02831,-1.15447,-1.08411,-0.336437,-0.38665,-0.491237,-0.427184,0.765304,0.870468,-2.23386,-2.36913,-0.725078,-0.382569,-0.190251,-0.0804467
8011,0.407302,0.392038,0.367518,0.341113,0.984308,0.932716,0.776413,0.733377,0.293377,0.37629,0.979735,0.982406,0.945266,0.921121,0.621159,0.609802,0.837615,0.87939,0.873763,0.875306,-0.490071,-0.363523,-0.823224,-0.750579,0.170807,0.320999,0.568585,0.644883,0.259851,0.214333,-0.246308,-0.182937,0.891593,0.993222,-1.13009,-1.27233,0.165362,0.512478,0.188537,0.300581
8012,0.297296,0.283017,0.646876,0.528881,0.108113,0.0580825,0.843911,0.713103,0.833819,0.915176,0.155049,0.158951,0.858285,0.832178,0.626609,0.522114,0.748601,0.782597,0.232613,0.234643,-2.86806,-2.74882,-0.041854,0.0213882,1.86184,2.00992,0.659741,0.731102,-1.62058,-1.6711,0.64757,0.705414,-0.7086,-0.602736,1.01595,0.87508,2.31114,2.66247,-0.46523,-0.355859
8013,0.470474,0.458423,0.834673,0.716649,0.283616,0.234404,0.74299,0.692829,0.00877985,0.0872794,0.32466,0.37587,0.393474,0.366447,0.444831,0.434426,0.507527,0.685803,0.351103,0.351811,-0.814996,-0.696876,0.716163,0.793355,0.608828,0.711964,-2.18876,-2.11084,-0.668201,-0.715222,0.167135,0.196458,-0.490049,-0.389901,0.764191,0.623591,0.540588,0.886543,-0.711694,-0.605149
8014,0.428277,0.477262,0.930822,0.904417,0.781137,0.732723,0.752588,0.672555,0.933408,1.01083,0.588455,0.59279,0.559015,0.532004,0.0338323,0.0227359,0.547771,0.58901,0.968433,0.970465,-0.412426,-0.291075,-1.05568,-0.983294,-0.734079,-0.585995,-0.319238,-0.239021,-0.0325155,-0.0823354,-0.368175,-0.312499,-1.44997,-1.3438,-0.517089,-0.655644,0.598625,0.942283,-2.48303,-2.37415
8015,0.506872,0.4961,0.286232,0.258711,0.856838,0.809195,0.695316,0.652281,0.732212,0.773712,0.0429972,0.0483718,0.506484,0.453575,0.734122,0.723814,0.661817,0.703573,0.798419,0.705609,-0.361799,-0.240405,0.554608,0.621411,-0.0251848,0.12079,-0.0463207,0.0335189,1.03312,0.98107,0.497017,0.559286,2.13599,2.24989,-2.1758,-2.31802,0.985431,1.32426,1.14802,1.25369
8016,0.965345,0.953783,0.985961,0.958943,0.625071,0.576064,0.0467854,0.00464871,0.465991,0.536597,0.085398,0.0882544,0.444466,0.375146,0.0093647,-0.000896818,0.290614,0.334217,0.438064,0.440753,0.436679,0.561707,-0.942431,-0.873471,0.944346,1.08876,-0.0959227,-0.0161733,2.43788,2.3816,1.57391,1.63208,-0.224034,-0.10342,-1.01189,-1.16019,0.637081,0.976328,-0.626304,-0.515318
8017,0.000829697,-0.00889374,0.672532,0.643171,0.914254,0.867519,0.0633579,0.0225658,0.223154,0.299482,0.121698,0.128137,0.322092,0.296717,0.0815025,0.135071,0.51383,0.555889,0.407922,0.411381,0.923445,1.04588,1.1545,1.21479,0.0826671,0.225085,0.457882,0.53188,-0.935409,-0.986771,-0.187942,-0.136781,-1.54881,-1.43033,1.10758,0.956447,0.0792929,0.413919,-0.513628,-0.402189
8018,0.90094,0.892237,0.626025,0.598538,0.931277,0.883946,0.87787,0.839141,0.394184,0.470009,0.966688,0.974146,0.547832,0.435504,0.282702,0.271039,0.45955,0.500325,0.893489,0.895082,-1.80833,-1.6872,0.739371,0.842906,-1.15057,-1.01121,0.171421,0.233222,-1.18735,-1.23068,0.927552,0.981915,-1.00132,-0.876176,-0.283045,-0.431214,1.73944,2.07779,-0.187544,-0.079313
8019,0.917706,0.911076,0.063192,0.0363499,0.463725,0.414214,0.0169979,-0.0198489,0.215212,0.293377,0.239874,0.248908,0.658548,0.57429,0.693978,0.682783,0.0994948,0.141173,0.54703,0.537077,0.208576,0.33307,0.406139,0.471025,0.781564,0.926964,-0.14804,-0.0654366,-1.85571,-1.90246,-0.692978,-0.634613,0.107721,0.228176,-0.078768,-0.22361,0.976378,1.31397,-0.533301,-0.420413
8020,0.938791,0.929914,0.482285,0.482207,0.837447,0.787001,0.943841,0.906292,0.934858,1.01079,0.676589,0.687264,0.719331,0.713076,0.722034,0.738281,0.805442,0.84828,0.175891,0.179071,0.477251,0.598952,2.08833,2.15403,-1.40551,-1.26327,0.201725,0.282956,-0.240717,-0.288927,-0.12758,0.0108265,0.510652,0.69019,-0.27077,-0.45048,-1.00835,-0.668188,0.597797,0.706945
8021,0.676792,0.635384,0.953119,0.928064,0.710122,0.655495,0.433868,0.398382,0.438555,0.611893,0.447095,0.433409,0.877237,0.851863,0.806227,0.793778,0.228865,0.273695,0.940197,0.943521,0.253028,0.378304,0.355987,0.422077,-1.20195,-1.06442,1.25953,1.3395,-1.14083,-1.18867,0.600848,0.656266,1.03315,1.1522,-0.526922,-0.67735,0.742632,1.08905,-0.449978,-0.341804
8022,0.348964,0.340854,0.263834,0.23762,0.57701,0.52399,0.687064,0.653542,0.137057,0.212992,0.16691,0.179555,0.0937488,0.0662451,0.246544,0.232621,0.810236,0.853511,0.189689,0.190829,0.769519,0.892338,-0.836872,-0.774428,0.627046,0.765521,0.0392166,0.113557,-0.271861,-0.324531,0.80846,0.904305,0.935749,1.06288,1.12966,0.972325,1.27095,1.6115,0.518379,0.631843
8023,0.834512,0.827581,0.635003,0.575366,0.105302,0.0542587,0.612747,0.625022,0.916253,0.99293,0.621844,0.632876,0.869344,0.842159,0.846219,0.830911,0.802281,0.813099,0.143795,0.147546,-1.96366,-1.84074,1.71004,1.76642,-0.419863,-0.285007,-0.305193,-0.229664,-0.817866,-0.873307,1.09176,1.15234,-0.325619,-0.200054,1.61075,1.45702,-0.240489,0.0933155,1.74048,1.85259
8024,0.238226,0.231996,0.938662,0.913113,0.157722,0.106823,0.629761,0.596502,0.227972,0.303046,0.666577,0.678005,0.836161,0.808105,0.455775,0.439114,0.731114,0.772687,0.391303,0.395894,0.731914,0.852928,0.836712,0.894888,-1.12439,-0.992315,0.789983,0.872455,-0.420243,-0.469754,-0.592359,-0.524159,-0.548035,-0.427975,-0.0896454,-0.181468,1.23902,1.5692,-1.31468,-1.20306
8025,0.146177,0.139932,0.326156,0.302148,0.628596,0.575406,0.820173,0.696265,0.698694,0.776018,0.996636,1.00811,0.23501,0.207055,0.689425,0.674075,0.979448,1.01876,0.152985,0.156239,1.04665,1.16615,-0.385342,-0.332882,-0.336478,-0.209607,0.139732,0.220101,1.14151,1.09982,-0.0874775,-0.0170629,-1.20426,-1.08664,-1.66622,-1.81995,0.863971,1.15134,-0.306592,-0.197017
8026,0.327962,0.320457,0.293769,0.363817,0.251997,0.200571,0.830979,0.796028,0.53366,0.563017,0.800205,0.884253,0.982468,0.956568,0.558149,0.542288,0.406488,0.444177,0.22311,0.194392,-0.747208,-0.622467,-1.0643,-1.01912,2.5765,2.70059,-0.0795833,0.030131,-1.16425,-1.20694,1.76109,1.83872,-1.09077,-0.978348,1.38526,1.23213,0.397973,0.733484,1.12927,1.23862
8027,0.891963,0.887,0.403125,0.425485,0.794544,0.74347,0.494664,0.458612,0.273451,0.350016,0.750644,0.760393,0.492564,0.465458,0.789607,0.771589,0.412352,0.449619,0.315947,0.232546,-0.710279,-0.588542,1.37405,1.4115,0.430813,0.558421,-0.240609,-0.159838,2.26947,2.22334,0.627659,0.699106,-1.36347,-1.25225,-0.764805,-0.920834,1.21302,1.55082,-0.0328793,0.0804735
8028,0.834748,0.830331,0.460681,0.487154,0.933511,0.879903,0.905133,0.867983,0.468919,0.558416,0.917213,0.925555,0.311533,0.285464,0.27512,0.255781,0.801369,0.84051,0.268211,0.270699,-0.315274,-0.231059,-1.64253,-1.60565,1.42102,1.54174,0.742911,0.821519,-0.781178,-0.828613,-0.105545,-0.0273225,-0.273623,-0.164306,0.673054,0.513607,-0.586815,-0.255559,-0.480201,-0.365378
8029,0.459283,0.487128,0.57283,0.548822,0.175922,0.120209,0.950843,0.911425,0.774875,0.766815,0.706464,0.722579,0.686138,0.662223,0.785727,0.767776,0.13551,0.175133,0.895506,0.90023,0.00405828,0.126425,-0.133308,-0.0948198,0.054919,0.18248,-0.207569,-0.162041,1.03002,0.985692,1.09485,1.16768,-0.30639,-0.193078,-0.0539685,-0.214937,-0.172803,0.0781589,2.20488,2.31911
8030,0.145681,0.143925,0.0216256,-0.00305234,0.790602,0.733817,0.131935,0.0944929,0.898043,0.975215,0.510748,0.519603,0.673414,0.64956,0.101989,0.0856005,0.172393,0.213578,0.439711,0.444014,-0.593801,-0.47806,-1.43127,-1.39907,-0.699555,-0.571748,-1.21602,-1.1456,-2.08466,-2.13198,-1.67492,-1.60387,-0.577689,-0.466985,-0.122899,-0.282979,0.0735341,0.411877,-0.569313,-0.451039
8031,0.304185,0.304122,0.932451,0.905628,0.946801,0.890458,0.314434,0.275336,0.429415,0.506911,0.685521,0.638194,0.887115,0.861091,0.198393,0.181331,0.486795,0.528423,0.266067,0.268681,0.27178,0.38389,0.946579,0.984437,-1.70413,-1.57543,-1.22449,-1.14864,1.05448,1.00626,-0.26415,-0.19491,1.20772,1.3181,1.78824,1.63116,-0.129958,0.205093,0.704053,0.828997
8032,0.0547482,0.0553976,0.632664,0.605777,0.471255,0.415482,0.220603,0.20223,0.827904,0.904633,0.664685,0.756785,0.765138,0.679024,0.927214,0.908982,0.242409,0.285233,0.699613,0.703314,-0.519584,-0.407233,0.488117,0.527662,0.194026,0.31745,-0.830614,-0.754578,-0.230804,-0.277676,0.0661466,0.139618,0.400425,0.505848,-1.66358,-1.81923,0.133434,0.475549,-0.397228,-0.268564
8033,0.741388,0.741555,0.848446,0.823107,0.89656,0.839651,0.169703,0.129124,0.482338,0.557205,0.865407,0.875376,0.519991,0.496956,0.0489629,0.0319265,0.541543,0.585184,0.311294,0.313321,-0.222012,-0.0818352,0.65668,0.69893,-1.19776,-1.07376,1.18982,1.26328,-0.243017,-0.288104,0.0643633,0.138426,-1.49082,-1.38646,-0.213723,-0.371722,-0.930398,-0.585896,1.2698,1.3956
8034,0.419408,0.422335,0.0427781,0.0184547,0.545682,0.489569,0.361838,0.241909,0.8184,0.894583,0.669211,0.68104,0.638552,0.617025,0.862192,0.845836,0.182058,0.226032,0.761719,0.762408,0.126351,0.243562,1.10898,1.14484,0.579256,0.709601,0.367479,0.516832,-2.25705,-2.30084,0.614379,0.690922,-0.162446,-0.0601031,0.503601,0.342884,-0.644082,-0.238291,-1.57903,-1.46025
8035,0.942984,0.944295,0.874583,0.850678,0.466185,0.409445,0.395544,0.354694,0.639374,0.719362,0.954696,0.965142,0.080479,0.0595915,0.090556,0.0743111,0.638691,0.681449,0.873363,0.799907,-0.466964,-0.345838,0.0138816,0.0565505,0.671293,0.799812,-0.308139,-0.229612,0.497879,0.455854,-1.46235,-1.38916,0.635912,0.736817,0.296758,0.137836,-0.238438,0.109314,-0.288317,-0.164227
8036,0.703859,0.705829,0.96372,0.939896,0.0787199,0.0199652,0.898026,0.857028,0.449099,0.544142,0.886941,0.897063,0.0912614,0.07254,0.316513,0.298236,0.374879,0.416591,0.835756,0.837406,1.57542,1.69092,-1.48524,-1.43833,-0.555734,-0.421742,1.81055,1.89408,-0.667423,-0.705234,-1.03173,-0.95993,-0.442061,-0.341961,-0.760298,-0.887262,0.464846,0.819059,-0.0499123,0.135422
8037,0.195291,0.194972,0.218214,0.194143,0.675004,0.617672,0.271995,0.229352,0.294659,0.368922,0.233067,0.242331,0.674065,0.653691,0.815471,0.795493,0.644236,0.687565,0.086866,0.0895237,-0.45649,-0.334593,-1.08476,-1.03854,-1.51646,-1.37735,0.542584,0.622698,-0.271991,-0.316834,-2.06282,-1.99277,-0.151839,-0.0496653,-1.74999,-1.91236,-0.615308,-0.258402,0.307868,0.43507
8038,0.780515,0.780602,0.585516,0.575438,0.304526,0.248329,0.814779,0.77224,0.688464,0.761689,0.280817,0.229643,0.531974,0.453871,0.407033,0.388274,0.108653,0.153518,0.0226248,0.025249,1.18185,1.30225,0.476484,0.521604,0.451554,0.5917,0.249123,0.324948,-1.33441,-1.38596,-1.20574,-1.13638,-0.216049,-0.10946,1.18107,1.01356,-0.245738,0.107224,0.22852,0.350618
8039,0.0458968,0.0466809,0.979318,0.956733,0.83313,0.776864,0.24012,0.199578,0.0814078,0.152188,0.207335,0.216955,0.276545,0.254051,0.42916,0.408982,0.21083,0.326945,0.485235,0.489334,-1.0279,-0.912823,-1.33261,-1.28885,0.892262,1.03703,-1.05079,-0.977797,-0.942131,-0.997565,-1.13873,-1.0756,-2.54234,-2.43335,-1.13008,-1.30235,-1.1268,-0.766559,0.672757,0.793926
8040,0.871488,0.870485,0.762557,0.821339,0.954951,0.898011,0.5997,0.558098,0.487209,0.526791,0.0303538,0.0396573,0.844903,0.82056,0.982208,0.96218,0.457039,0.500372,0.431283,0.435382,0.41208,0.522086,-1.10634,-1.05706,-1.26517,-1.12262,1.73678,1.80756,1.19814,1.138,0.202016,0.27071,-1.07801,-0.969785,-0.251673,-0.411317,1.26239,1.62274,3.61954,3.74016
8041,0.658118,0.656609,0.707148,0.685945,0.646801,0.588885,0.678613,0.636727,0.829375,0.901394,0.699091,0.706311,0.878819,0.853072,0.466214,0.446372,0.932976,0.975819,0.107264,0.109062,-1.08637,-0.972968,1.55061,1.60077,0.360125,0.435671,0.043891,0.116855,-2.55825,-2.62015,1.11775,1.18921,-1.42673,-1.32256,0.651976,0.479712,-0.682428,-0.324427,1.38448,1.50299
8042,0.822544,0.740949,0.720667,0.700105,0.766329,0.710033,0.0323171,-0.0109046,0.346229,0.417711,0.606129,0.53987,0.236003,0.211197,0.247129,0.229284,0.409216,0.451753,0.817815,0.817788,-0.120296,-0.00171627,0.621946,0.668519,1.8584,1.99396,0.922237,0.988823,-1.30624,-1.37105,-3.03426,-2.96195,0.609975,0.720234,-0.30888,-0.476552,0.569182,0.930413,0.585152,0.761343
8043,0.827347,0.825288,0.161884,0.143123,0.503351,0.397651,0.0599487,0.0170505,0.503971,0.629966,0.400141,0.373428,0.263381,0.207614,0.283102,0.264557,0.674507,0.695182,0.964253,0.964506,-0.588814,-0.457588,0.213047,0.201309,0.182157,0.310927,2.22638,2.2915,-0.915985,-0.971915,0.0168867,0.0859343,-1.15154,-1.04852,-0.074048,-0.236818,0.477883,0.831698,-0.096074,0.0196999
8044,0.286686,0.284191,0.312296,0.292128,0.13946,0.0852697,0.946339,0.903165,0.82149,0.84222,0.200959,0.206987,0.22969,0.20403,0.880751,0.862847,0.894831,0.938611,0.309181,0.308201,-1.03046,-0.91346,-0.312844,-0.265901,-0.676722,-0.55275,0.199306,0.266348,-0.513972,-0.57278,-0.00613858,0.0701644,0.229038,0.338108,2.40844,2.24071,-0.714962,-0.356794,-1.22062,-1.11008
8045,0.0359195,0.031273,0.91204,0.892147,0.423655,0.371786,0.363171,0.319879,0.983073,1.05447,0.577759,0.581888,0.024704,-0.00109185,0.554638,0.618914,0.231268,0.273235,0.837778,0.8377,0.454501,0.570175,-1.23897,-1.19815,0.154816,0.279252,1.06256,1.12243,-2.7909,-2.8504,0.927814,1.00463,-1.48546,-1.38141,1.12676,0.880354,-2.25983,-1.90668,-1.98837,-1.87289
8046,0.962786,0.959545,0.971066,0.951818,0.274584,0.224794,0.46563,0.327809,0.370935,0.440047,0.301476,0.3041,0.263942,0.24002,0.392283,0.374982,0.955526,0.995767,0.998256,0.999464,-0.104544,0.0116062,-1.3379,-1.30362,-0.223086,-0.10196,-0.961249,-0.902714,-0.856805,-0.909123,-0.61514,-0.534882,0.120204,0.220864,-0.31133,-0.480006,-0.795185,-0.444057,0.709275,0.824169
8047,0.156816,0.15327,0.150059,0.131706,0.584273,0.536082,0.377909,0.33574,0.441745,0.505106,0.473352,0.474037,0.796465,0.771173,0.360189,0.343904,0.0619046,0.101505,0.0313583,0.032467,0.14289,0.262765,1.2298,1.26751,0.840029,0.958521,1.49372,1.55935,-0.956347,-1.01577,-0.60717,-0.520516,-0.22777,-0.131912,1.38239,1.21743,1.25093,1.60656,-1.44337,-1.33233
8048,0.217462,0.231318,0.676051,0.65946,0.102869,0.0563796,0.832734,0.788822,0.50226,0.570164,0.292804,0.291459,0.145219,0.118929,0.0435917,0.0274116,0.0671386,0.106946,0.619496,0.621601,0.853193,0.972059,-0.350683,-0.320088,2.49412,2.61513,-0.128886,-0.0682902,0.413213,0.352545,-1.97616,-1.89446,-0.911231,-0.822434,2.13275,1.96151,0.687639,1.04415,-0.172238,-0.0662682
8049,0.452278,0.309366,0.057483,0.0385872,0.0110325,-0.034586,0.0228732,-0.0228317,0.318526,0.450954,0.355967,0.353011,0.514261,0.519876,0.376392,0.279805,0.414383,0.40536,0.723469,0.725209,0.652435,0.766606,0.0678379,0.0960632,0.310728,0.4249,-0.106025,-0.11743,-0.297665,-0.36208,-0.287521,-0.206788,-0.0250437,0.0662241,1.99251,1.81705,-0.142842,0.218108,0.505592,0.606154
8050,0.392212,0.387415,0.202778,0.249736,0.481205,0.404162,0.0599361,0.0367207,0.289604,0.331744,0.917809,0.914299,0.944677,0.920823,0.602535,0.532198,0.663842,0.703773,0.82046,0.828817,0.699517,0.817276,1.72317,1.74674,-1.17623,-1.05644,-0.227166,-0.16657,-0.455283,-0.513181,0.0141396,0.0952715,-0.428222,-0.40968,-0.428936,-0.59706,-0.205999,0.151332,0.413552,0.50839
8051,0.333514,0.304355,0.478328,0.460884,0.88845,0.84291,0.140743,0.0962731,0.14222,0.212535,0.813776,0.810706,0.959062,0.933772,0.800771,0.784591,0.620394,0.576735,0.928452,0.932425,2.05757,2.17472,0.583804,0.611095,-0.344126,-0.224438,0.234576,0.289153,0.782702,0.720321,1.18669,1.2738,-0.971031,-0.885584,-0.616452,-0.786716,0.424107,0.78265,1.56636,1.66745
8052,0.226,0.221296,0.998554,0.978656,0.0105263,-0.0365076,0.485945,0.439617,0.928389,1.00038,0.333605,0.330568,0.617249,0.632611,0.417618,0.450781,0.407681,0.449698,0.807134,0.81194,0.448124,0.559398,-1.11116,-1.08648,-0.308438,-0.193793,0.310705,0.362263,-0.799749,-0.856324,-1.61648,-1.52916,1.50373,1.5909,0.130594,-0.0426382,0.102165,0.466774,0.054464,0.159638
8053,0.497801,0.492436,0.612478,0.594294,0.986293,0.93914,0.452722,0.428984,0.174984,0.247343,0.685653,0.681454,0.406188,0.331451,0.133497,0.116972,0.717317,0.76048,0.478874,0.48562,1.42151,1.53065,-0.0416211,-0.0233307,0.856395,0.972688,1.97205,2.02847,0.688647,0.635179,1.3147,1.3971,-0.693562,-0.598272,-1.44613,-1.62649,-1.5792,-1.2095,-0.586116,-0.483209
8054,0.279244,0.273202,0.997768,0.97906,0.555793,0.509229,0.465217,0.418351,0.63176,0.704964,0.347688,0.343818,0.05558,0.03029,0.804959,0.788014,0.705467,0.649967,0.640205,0.647383,-1.11602,-1.01274,-0.645321,-0.632988,1.4246,1.53975,0.131674,0.182197,-0.981592,-1.03402,-0.540259,-0.450878,-1.16909,-1.07539,0.809313,0.62736,0.628983,1.00425,1.29159,1.39907
8055,0.457511,0.478385,0.128958,0.112894,0.521824,0.429715,0.720561,0.673511,0.748844,0.824359,0.384495,0.380098,0.934747,0.910643,0.00790098,-0.00866991,0.496599,0.539454,0.0893735,0.0965872,0.490279,0.594088,0.599665,0.6158,1.23036,1.34215,1.01359,1.07006,-1.2158,-1.26403,0.855055,0.941488,-0.110638,-0.0163809,-0.321652,-0.497711,-1.17208,-0.802131,-0.326924,-0.21706
8056,0.688904,0.683569,0.591222,0.57597,0.490145,0.350201,0.319774,0.271898,0.402013,0.491952,0.848803,0.843048,0.232295,0.209499,0.11589,0.0976668,0.823371,0.86555,0.152698,0.218666,-0.370284,-0.272467,-3.11598,-3.10598,0.763255,0.86967,-1.58509,-1.53164,0.0639231,0.110878,-0.202909,-0.12334,0.144929,0.243196,-0.457524,-0.626508,-2.349,-1.97495,0.523543,0.577154
8057,0.42343,0.407489,0.775621,0.759431,0.316725,0.270688,0.121169,0.0744868,0.0863647,0.159546,0.873287,0.891317,0.178031,0.14375,0.525975,0.509411,0.828228,0.870992,0.332062,0.340745,-0.61304,-0.508572,0.162639,0.167276,-0.872122,-0.764418,0.244874,0.295717,1.53402,1.48579,-1.51712,-1.43263,1.62315,1.72267,0.548104,0.38047,-1.46725,-1.09401,1.2677,1.37137
8058,0.136994,0.131409,0.11267,0.0991551,0.55165,0.506058,0.735803,0.687361,0.885261,0.956988,0.946402,0.939587,0.100864,0.0780015,0.561286,0.611453,0.2974,0.341826,0.945925,0.954383,-0.282839,-0.180879,-0.918228,-0.906816,-1.15488,-1.05387,0.720485,0.764922,-0.194414,-0.244544,-1.41021,-1.32584,0.671886,0.768772,1.93844,1.7689,-1.55446,-1.17717,0.282192,0.382419
8059,0.805907,0.802631,0.660842,0.647024,0.0502564,0.00636211,0.857401,0.800146,0.227062,0.297436,0.60349,0.596837,0.931769,0.907406,0.716801,0.713496,0.329288,0.371386,0.505309,0.513323,0.612745,0.714236,-0.66814,-0.659494,0.442289,0.541577,0.727838,0.77649,0.927676,0.878497,0.793501,0.875714,-0.75419,-0.653167,1.38016,1.21195,0.064381,0.437872,2.35032,2.45022
8060,0.909807,0.908633,0.37336,0.361363,0.370061,0.3279,0.961243,0.912931,0.700283,0.770407,0.671151,0.699102,0.12473,0.102328,0.736637,0.815538,0.0255452,0.0675355,0.887169,0.893058,-0.519818,-0.412848,0.226414,0.195349,1.39265,1.49551,1.801,1.84877,-0.104561,-0.160519,-1.54857,-1.47159,0.132968,0.235492,-0.532029,-0.701651,0.136056,0.509629,-1.00004,-0.894412
8061,0.807763,0.806031,0.793915,0.780477,0.27682,0.236934,0.237939,0.19023,0.617455,0.690237,0.808248,0.801366,0.539697,0.449637,0.934144,0.91758,0.85824,0.900958,0.220323,0.226813,0.212299,0.312818,1.044,1.05019,0.666591,0.735742,-1.19906,-1.14961,-0.546399,-0.604092,0.242114,0.321488,0.29741,0.403652,-0.584399,-0.754738,-0.370533,0.00833894,-0.72962,-0.616322
8062,0.315972,0.314976,0.772871,0.719166,0.530173,0.492414,0.961117,0.913964,0.245997,0.316208,0.526146,0.518613,0.817317,0.796945,0.743472,0.72546,0.334881,0.376892,0.276502,0.185891,0.244382,0.346743,-1.48253,-1.47459,-0.132882,-0.0240294,-0.790063,-0.740631,-0.439849,-0.492398,1.57486,1.65386,-1.67885,-1.56803,-0.97693,-1.14218,0.598442,0.981815,3.1529,3.27287
8063,0.292097,0.289692,0.672821,0.657856,0.526953,0.488683,0.0229724,-0.0258066,0.749487,0.820107,0.45725,0.450534,0.888891,0.871081,0.833161,0.778305,0.222382,0.264904,0.136944,0.14497,-0.977716,-0.874152,0.395314,0.410901,0.0655574,0.174819,0.0470174,0.0993823,0.0701758,0.0180118,-0.436985,-0.36269,-0.458809,-0.413091,-0.500329,-0.691225,-0.0178808,0.372321,1.38197,1.50387
8064,0.0649805,0.0610393,0.064402,0.0520356,0.937408,0.896825,0.263371,0.214123,0.66902,0.739866,0.721113,0.71397,0.0877216,0.0718629,0.849838,0.831151,0.974801,1.01756,0.983515,0.99343,-1.16584,-1.06403,1.04109,1.05911,1.54769,1.65992,0.375689,0.432387,-0.952214,-1.00599,-0.107927,-0.0281618,0.631796,0.741846,-0.0818941,-0.240269,-0.302132,0.0882939,-0.744682,-0.622035
8065,0.950523,0.94814,0.980988,0.966331,0.237142,0.197415,0.769503,0.721963,0.564943,0.659626,0.313407,0.307827,0.20912,0.222364,0.216639,0.199323,0.359179,0.401761,0.307208,0.317343,-0.511399,-0.413607,-0.689512,-0.672846,0.429532,0.546675,-0.0964876,-0.0356311,-0.537143,-0.587374,1.03657,1.11889,0.370541,0.483426,-0.0654685,-0.217291,-2.06645,-1.66994,-0.926197,-0.811325
8066,0.838461,0.937881,0.418361,0.404143,0.188581,0.181235,0.528327,0.478831,0.508193,0.579385,0.203835,0.280953,0.388291,0.372865,0.447708,0.428625,0.130377,0.173626,0.778152,0.786301,-2.46971,-2.37214,-1.04856,-1.08249,-0.977209,-0.859279,0.433603,0.495865,-1.80045,-1.85679,0.592689,0.670541,2.77368,2.88208,1.04875,0.895624,-1.56088,-1.16177,-0.615468,-0.502698
8067,0.925642,0.927621,0.660058,0.646261,0.20767,0.165055,0.625457,0.595889,0.953715,1.02318,0.256724,0.254079,0.775937,0.759618,0.423822,0.402877,0.236042,0.278262,0.0384936,0.0486102,-1.19076,-1.09247,-1.50322,-1.49214,0.439299,0.548951,-0.640554,-0.576055,1.51603,1.4652,0.814558,0.884904,0.594606,0.707017,-0.476254,-0.628642,-1.71996,-1.32404,-1.21002,-1.0989
8068,0.918415,0.917362,0.540554,0.528213,0.669092,0.628613,0.762177,0.712947,0.769232,0.840865,0.981553,0.979941,0.12608,0.107373,0.601351,0.580267,0.0332434,0.0754561,0.674929,0.682514,1.1486,1.24908,-0.280302,-0.27177,-0.480065,-0.375843,0.809805,0.86851,-0.426872,-0.485466,-0.277093,-0.211015,0.0885603,0.200866,-0.131388,-0.282935,-0.481268,-0.0830983,-0.471078,-0.366391
8069,0.348085,0.346742,0.110483,0.0996361,0.126277,0.0836302,0.480538,0.429997,0.384633,0.515298,0.63895,0.578326,0.254942,0.237894,0.511172,0.489488,0.628818,0.671927,0.100827,0.10682,-0.552354,-0.445222,0.411711,0.420433,-0.438204,-0.331058,-2.21343,-2.16163,-0.112675,-0.176092,0.774183,0.847376,-1.69012,-1.58191,-1.15451,-1.30104,0.0540527,0.455558,1.04131,1.14694
8070,0.247411,0.24414,0.57975,0.503215,0.833327,0.789123,0.979657,0.927904,0.118021,0.189731,0.177786,0.176712,0.679017,0.561976,0.882635,0.861948,0.698926,0.740352,0.987953,0.995201,1.86296,1.96472,-0.0186713,-0.00407216,-0.148831,-0.0389861,1.00718,1.05805,-0.422676,-0.48079,-0.200952,-0.125082,-0.767613,-0.660688,-0.221184,-0.371726,1.05905,1.46204,-0.319553,-0.210167
8071,0.890455,0.885346,0.915201,0.906794,0.432391,0.38901,0.168065,0.116251,0.81567,0.886116,0.420309,0.419365,0.905405,0.886058,0.871704,0.851952,0.281084,0.321487,0.903625,0.912001,0.739401,0.837637,1.21359,1.23048,-0.746907,-0.640205,1.05633,1.09937,-1.3534,-1.41286,-0.834222,-0.760622,0.765934,0.877274,-0.361497,-0.516186,-0.286142,0.115479,-0.397976,-0.29462
8072,0.435387,0.430249,0.271589,0.261088,0.550959,0.506197,0.0730191,0.0232791,0.371494,0.44268,0.252355,0.251727,0.878727,0.857671,0.0361289,0.0149017,0.514408,0.553482,0.272077,0.281238,-2.09812,-2.00182,0.32431,0.343519,-0.0315133,0.0820956,1.33115,1.37192,-0.428249,-0.48721,-0.339269,-0.269221,-0.0524813,0.0650173,1.02617,0.872244,-0.230054,0.171219,-0.143826,-0.0482578
8073,0.661978,0.656805,0.527808,0.517702,0.457449,0.410215,0.668213,0.620124,0.417052,0.490171,0.836515,0.837388,0.269154,0.246526,0.639215,0.619443,0.237426,0.274965,0.887915,0.894876,0.391384,0.486387,0.663996,0.684493,-0.80574,-0.688602,1.24061,1.27613,0.250168,0.192798,1.72289,1.79179,-0.31641,-0.193403,0.484275,0.330717,0.48841,0.895704,-0.535735,-0.433297
8074,0.305533,0.301506,0.311747,0.33686,0.738751,0.691499,0.177565,0.127413,0.670509,0.741686,0.0698965,0.0722447,0.372796,0.325931,0.151087,0.133275,0.535269,0.506375,0.914366,0.921168,0.630319,0.737037,-2.10512,-2.08351,0.183672,0.294717,0.945471,0.978375,-2.37658,-2.4291,-2.83023,-2.76691,0.85153,0.975173,-0.33365,-0.48696,-1.72436,-1.32226,0.870966,0.970652
8075,0.342033,0.269177,0.165468,0.156018,0.725329,0.678012,0.576672,0.526761,0.204999,0.277967,0.82843,0.829111,0.429777,0.405336,0.0620639,0.0424958,0.702639,0.737786,0.142042,0.148285,0.894342,0.987687,-1.18295,-1.16225,2.11785,2.23289,-1.1868,-1.15589,1.16331,1.10731,-0.611117,-0.549053,-0.879085,-0.761299,-0.480354,-0.63142,1.84013,2.24223,0.605167,0.706099
8076,0.351838,0.236848,0.216026,0.228395,0.996867,0.94928,0.471974,0.424186,0.687636,0.760496,0.897623,0.900159,0.104238,0.079366,0.797459,0.779758,0.48124,0.5009,0.198273,0.205468,0.257964,0.351752,-0.516113,-0.503906,-1.55968,-1.43823,-0.480673,-0.454755,1.1753,1.11314,2.05307,2.10775,0.54294,0.657151,-0.238747,-0.391686,0.88563,1.2876,-0.494552,-0.391461
8077,0.208546,0.204519,0.218418,0.300771,0.902295,0.914787,0.729378,0.679346,0.620754,0.707732,0.14381,0.145724,0.437628,0.326598,0.203879,0.188435,0.227253,0.264014,0.664923,0.674426,-0.0207914,0.0706287,0.136165,0.154438,0.44195,0.56317,0.530895,0.557742,-0.142883,-0.204302,-1.16361,-1.10971,-0.430558,-0.312492,-1.81361,-1.9614,-0.443752,-0.0439032,2.40426,2.50513
8078,0.452762,0.424934,0.38103,0.373147,0.798839,0.880294,0.656426,0.659982,0.452751,0.654968,0.405047,0.405002,0.597216,0.573829,0.657628,0.640135,0.484306,0.520162,0.867152,0.876412,-1.32527,-1.23941,-0.645939,-0.626471,-0.458442,-0.331264,0.16486,0.197934,-0.675511,-0.736339,-1.53976,-1.47867,-1.86228,-1.74995,0.540609,0.397843,-0.0893417,0.307114,-1.7696,-1.66607
8079,0.579111,0.64535,0.798861,0.792261,0.890649,0.845801,0.689997,0.640618,0.527802,0.602204,0.0138239,0.012869,0.201804,0.177772,0.0249356,0.00830724,0.96392,1.00019,0.279183,0.290717,-0.80047,-0.710114,0.207999,0.234115,0.247967,0.37552,-0.438212,-0.407585,-1.46196,-1.5295,-0.617859,-0.560173,0.32269,0.438125,-0.0365979,-0.173774,-1.18996,-0.800159,1.15138,1.24681
8080,0.867605,0.865765,0.169476,0.161932,0.0826192,0.0377261,0.314373,0.347048,0.827195,0.89978,0.86309,0.864106,0.895033,0.870593,0.0758369,0.0583221,0.0189803,0.054759,0.630544,0.640321,0.814697,0.912755,1.26859,1.29727,-0.657779,-0.534365,0.158924,0.184532,0.842498,0.777066,-1.10431,-1.03923,1.86227,1.97609,0.0739772,-0.0575216,0.388139,0.784314,-1.01999,-0.924849
8081,0.715433,0.713832,0.373176,0.364393,0.0208227,-0.0225307,0.102595,0.0534774,0.876348,0.947271,0.727847,0.730189,0.782317,0.75618,0.86875,0.851667,0.93403,0.968406,0.246383,0.255008,-1.09301,-1.00165,0.993811,1.02326,-0.644056,-0.497705,0.466565,0.488394,-1.44124,-1.51552,1.05554,1.11562,-0.284896,-0.166543,-0.129622,-0.26257,1.54767,1.94553,0.119365,0.217738
8082,0.562169,0.561899,0.298435,0.290479,0.74121,0.697466,0.464934,0.417405,0.141337,0.209904,0.0745207,0.075457,0.243437,0.219398,0.93856,0.901658,0.504583,0.539315,0.914696,0.924403,-0.0133531,0.0112368,0.191578,0.214686,-0.587182,-0.461046,-0.645842,-0.629418,0.579651,0.506175,1.15883,1.2224,-0.307672,-0.189736,0.284444,0.145391,-0.44666,-0.0524077,-0.0688546,0.0284483
8083,0.736369,0.737306,0.425548,0.507124,0.992502,0.948036,0.209835,0.16451,0.527596,0.514807,0.205959,0.205155,0.0488343,0.0244508,0.967062,0.951648,0.283794,0.320474,0.784311,0.79519,0.93277,1.02413,1.62238,1.64704,1.06479,1.19557,0.38542,0.397255,0.128368,0.0474888,-0.551403,-0.484288,-0.325258,-0.212928,-0.511046,-0.643347,0.726944,1.12588,-1.08438,-0.990839
8084,0.111179,0.11142,0.730734,0.723769,0.857297,0.87979,0.777194,0.732193,0.74968,0.81971,0.00227634,0.000883656,0.198086,0.215996,0.288958,0.274291,0.680328,0.716351,0.113264,0.124042,-1.34802,-1.25226,0.650251,0.668057,-0.675519,-0.549784,-0.518167,-0.502998,-0.744464,-0.824061,0.673133,0.739986,0.38326,0.494113,0.713595,0.573334,-0.621216,-0.220683,0.240525,0.335545
8085,0.884398,0.886513,0.199409,0.191696,0.855683,0.811544,0.982739,0.938879,0.814093,0.882202,0.323559,0.320991,0.428388,0.407541,0.511909,0.498216,0.536629,0.572839,0.194235,0.205662,1.67529,1.76481,1.61683,1.63792,-0.399543,-0.272183,-0.197394,-0.185027,0.943557,0.866761,-0.373637,-0.308584,0.752535,0.862641,0.504786,0.368286,-0.345606,0.0497726,0.0313398,0.131202
8086,0.55151,0.551361,0.302396,0.295699,0.252787,0.207164,0.0536437,0.0102855,0.00520632,0.072088,0.304895,0.202361,0.538331,0.599086,0.968251,0.954938,0.91786,0.953593,0.936429,0.949579,1.39757,1.48369,0.767945,0.782019,-0.368905,-0.241539,-0.811167,-0.804338,1.99566,1.9152,0.842737,0.901707,-1.13166,-1.02967,-1.07985,-1.21556,-0.509475,-0.112502,1.11838,1.21354
8087,0.732582,0.731886,0.663837,0.655812,0.293833,0.248572,0.947877,0.903736,0.451108,0.520291,0.0864462,0.083731,0.816056,0.790631,0.376077,0.363615,0.938158,0.973378,0.0685076,0.0819271,-0.288885,-0.210611,0.191886,0.203096,-0.0443831,0.081175,-0.714328,-0.701771,0.836032,0.754116,0.777007,0.839457,1.66987,1.77747,0.0906257,-0.0420016,-1.58516,-1.18996,1.84189,1.93154
8088,0.186024,0.185536,0.665967,0.660186,0.0543869,0.0102073,0.156293,0.114644,0.0480693,0.116212,0.281939,0.277475,0.759644,0.732252,0.0648819,0.0515382,0.197517,0.232195,0.303878,0.314706,-0.740006,-0.659021,-0.720928,-0.713694,-0.897818,-0.766382,1.48134,1.48664,0.105851,0.0213067,-0.283215,-0.123179,-0.874251,-0.768563,-1.3787,-1.50492,-0.643432,-0.312275,0.613593,0.6959
8089,0.675532,0.677063,0.382088,0.374525,0.571568,0.529113,0.138891,0.0974706,0.868986,0.938076,0.752517,0.749935,0.942569,0.913009,0.351599,0.337456,0.115391,0.15183,0.946187,0.958051,1.35512,1.43692,-0.320079,-0.313903,0.748359,0.876312,-1.76783,-1.75887,-1.43649,-1.52206,-1.14827,-1.08582,-0.436729,-0.336568,-1.19466,-1.32853,0.116217,0.565412,0.612035,0.688521
8090,0.552802,0.509896,0.340741,0.454854,0.782049,0.739397,0.896413,0.855903,0.893758,0.961584,0.993217,0.992588,0.178236,0.147153,0.0789216,0.0649227,0.312819,0.393285,0.301055,0.311892,-0.440484,-0.351705,-1.2224,-1.21605,-1.32691,-1.20194,0.45951,0.465292,0.423405,0.338035,0.615887,0.675904,0.400128,0.505914,1.34178,1.20339,1.0479,1.4431,-1.50976,-1.43738
8091,0.43821,0.342728,0.478699,0.535184,0.510312,0.470055,0.25015,0.208271,0.314909,0.383015,0.305102,0.302489,0.0793427,0.137482,0.873325,0.858267,0.595997,0.63474,0.154744,0.166786,-1.2002,-1.1103,0.618661,0.622877,0.0477895,0.176142,-0.262091,-0.263983,1.07179,0.985843,1.17919,1.24343,-0.491485,-0.385883,-0.638962,-0.773583,0.690907,1.08126,-0.0252979,0.0446093
8092,0.171922,0.175561,0.624213,0.615513,0.570041,0.532235,0.155621,0.115299,0.631408,0.699999,0.4251,0.422107,0.124334,0.127811,0.233218,0.217316,0.150981,0.190164,0.40288,0.328872,1.42502,1.51279,0.247481,0.202757,-0.894125,-0.763585,-1.51738,-1.5214,-0.179689,-0.269037,-1.00117,-0.931637,1.17873,1.27862,0.835865,0.704058,-0.869316,-0.483645,-1.065,-0.989488
8093,0.839101,0.841843,0.440563,0.423883,0.97733,0.940378,0.797475,0.757326,0.27432,0.340921,0.813475,0.811438,0.149224,0.11814,0.347811,0.333072,0.635244,0.675171,0.480201,0.490959,-0.545432,-0.465151,-0.218155,-0.217362,-2.43547,-2.30691,-0.63941,-0.649431,-0.10233,-0.18685,0.578486,0.553268,-0.530083,-0.426673,-0.331823,-0.464084,-0.864821,-0.474332,1.48446,1.55776
8094,0.587292,0.542477,0.193519,0.232252,0.617428,0.580756,0.557308,0.51972,0.833383,0.90019,0.593886,0.592915,0.83964,0.810961,0.170469,0.195361,0.81735,0.856517,0.0815024,0.0903979,-1.06601,-0.979793,-0.201568,-0.201279,1.46525,1.59381,0.721483,0.715512,1.51928,1.4437,1.97338,2.03817,-1.39196,-1.28503,0.28636,0.157439,1.01278,1.41017,-0.949549,-0.871753
8095,0.241434,0.243112,0.0512788,0.0406221,0.545339,0.516832,0.96073,0.924202,0.524745,0.602243,0.727103,0.676491,0.908086,0.879756,0.0705994,0.057649,0.681928,0.740882,0.312763,0.323177,2.53179,2.61805,0.369608,0.368866,0.249353,0.283295,-1.44702,-1.44954,-0.0554142,-0.132946,-0.828573,-0.764793,0.837348,0.949792,-1.36625,-1.49154,0.875528,1.28033,-0.433856,-0.3523
8096,0.517776,0.519789,0.820072,0.811477,0.49148,0.452908,0.510947,0.472334,0.235523,0.304296,0.760827,0.760067,0.0685867,0.0389938,0.409641,0.395211,0.585023,0.625247,0.956816,0.966522,0.794783,0.877441,-0.848954,-0.843172,-1.16027,-1.02722,-2.19937,-2.19579,0.812174,0.731189,-2.27848,-2.21303,-0.672445,-0.566143,-0.647581,-0.776932,1.63583,2.03403,2.18337,2.25971
8097,0.144212,0.145466,0.43851,0.474866,0.635436,0.672628,0.665808,0.626966,0.18991,0.259862,0.636352,0.608315,0.761052,0.731815,0.30931,0.284872,0.693124,0.734829,0.796748,0.806146,-1.83594,-1.75554,0.774703,0.777756,1.99819,2.13233,0.429978,0.434553,0.926161,0.842883,1.5732,1.63364,0.165431,0.276339,-0.643644,-0.769601,1.35171,1.75,-1.78503,-1.71267
8098,0.605867,0.607693,0.146063,0.138254,0.930454,0.892349,0.303889,0.264881,0.646685,0.717483,0.455302,0.456562,0.874042,0.740371,0.189103,0.174532,0.356017,0.395574,0.0295375,0.0378735,0.0626079,0.141204,1.44578,1.45612,1.31772,1.45383,0.430016,0.431516,0.115691,0.0347301,0.71177,0.769251,0.046949,0.156725,1.71169,1.58964,0.010386,0.403441,-0.607634,-0.538787
8099,0.519593,0.520717,0.553538,0.543928,0.879826,0.843326,0.375782,0.337982,0.0362295,0.107982,0.101883,0.104243,0.796547,0.748927,0.869918,0.856123,0.61248,0.676171,0.18949,0.199637,0.217885,0.299164,1.13861,1.14994,-1.41439,-1.28346,1.62773,1.62782,0.0343516,-0.0663289,0.907917,0.967324,1.51812,1.6362,-1.33303,-1.46258,0.152473,0.550743,-1.60348,-1.52774
8100,0.675222,0.676008,0.0802257,0.0702849,0.610427,0.573984,0.187999,0.150541,0.0344686,0.105434,0.897198,0.898583,0.786204,0.757483,0.789239,0.775269,0.916781,0.956769,0.579329,0.58864,-1.32198,-1.2416,-0.277326,-0.266454,0.602927,0.733601,1.08979,1.08464,-0.0828093,-0.167388,-0.834468,-0.771343,0.637971,0.75945,-1.31044,-1.4396,-0.722111,-0.32304,-1.26013,-1.07708
8101,0.536205,0.538201,0.712095,0.700906,0.99739,0.960992,0.528704,0.489123,0.234044,0.330852,0.528809,0.546224,0.101477,0.0699126,0.124314,0.108982,0.829852,0.871189,0.309713,0.318194,-1.0292,-0.935368,-2.12352,-2.10952,1.55215,1.68754,-0.201075,-0.202387,-0.589263,-0.671515,-0.175633,-0.113342,-0.0313612,0.0848502,-0.227308,-0.357947,0.251074,0.650436,-0.791726,-0.626426
8102,0.764539,0.764757,0.84497,0.837303,0.239938,0.201297,0.101626,0.0619602,0.609515,0.556269,0.191014,0.193864,0.520919,0.491683,0.879251,0.861619,0.417821,0.457122,0.486707,0.592279,-0.708883,-0.629136,-0.203966,-0.193994,-0.88168,-0.740138,1.44605,1.44901,-0.0969344,-0.175971,-0.417114,-0.360134,0.226071,0.344427,1.1049,0.967078,-1.3183,-0.914473,-0.251514,-0.175772
8103,0.727398,0.728386,0.987041,0.973699,0.374586,0.33773,0.0939181,0.0551769,0.710721,0.781687,0.0195249,0.0212691,0.56675,0.540177,0.630258,0.68037,0.575938,0.677546,0.857614,0.866364,0.34368,0.419034,-0.252707,-0.23876,0.702382,0.840258,-0.324983,-0.286658,0.828163,0.749675,2.15832,2.21511,1.40467,1.52919,0.972942,0.838281,0.944937,1.34741,-0.205061,-0.122938
8104,0.0542208,0.0566079,0.167788,0.153587,0.75847,0.718645,0.876011,0.839033,0.795842,0.816253,0.557975,0.558591,0.885698,0.857375,0.517968,0.499121,0.857049,0.89797,0.706963,0.716005,1.06039,1.09442,1.08186,1.10007,-1.55095,-1.4151,-2.02529,-2.02233,-0.897231,-0.980659,-1.47741,-1.4179,-1.05711,-0.934217,-0.668531,-0.810695,0.0942145,0.430729,0.828136,0.912723
8105,0.833328,0.837265,0.395068,0.380829,0.736092,0.694868,0.994183,0.958491,0.899717,0.850819,0.819129,0.81787,0.362874,0.335059,0.490862,0.473373,0.779324,0.721013,0.778803,0.788032,1.69446,1.76981,1.02558,1.04092,0.258848,0.401782,-0.397446,-0.386681,-0.193967,-0.271811,0.564925,0.625376,1.4758,1.6066,1.0553,0.916067,-0.895154,-0.485949,1.21768,1.30946
8106,0.603188,0.608611,0.99845,0.98627,0.456157,0.416286,0.896649,0.86094,0.816016,0.885385,0.663735,0.743845,0.814472,0.786309,0.804822,0.789712,0.502852,0.544056,0.116006,0.126679,0.60663,0.635769,-0.170647,-0.155584,-0.105809,0.0349735,-2.42135,-2.41183,0.258094,0.17596,-0.030201,0.0368474,-1.1662,-1.03643,1.78708,1.64738,0.591683,1.00628,0.00810347,0.105385
8107,0.761855,0.708793,0.573986,0.562338,0.437465,0.397464,0.311516,0.277653,0.579715,0.639155,0.670206,0.66982,0.699596,0.671896,0.0980118,0.0810807,0.722319,0.686403,0.15147,0.163397,-0.572352,-0.498274,1.43257,1.44912,0.859336,1.00295,1.43831,1.44784,-1.83409,-1.91011,0.723025,0.78643,-0.0298465,0.101465,0.752037,0.549083,-0.281655,0.0563551,-0.77181,-0.6724
8108,0.801863,0.808975,0.639938,0.573456,0.951384,0.911478,0.413165,0.261841,0.392903,0.392925,0.327328,0.32707,0.0106994,-0.0156752,0.226138,0.258695,0.842042,0.82875,0.691767,0.70279,-1.30883,-1.2404,-0.618735,-0.608659,-0.316362,-0.172649,-0.225614,-0.213757,-0.822627,-0.848023,0.526657,0.586487,0.632304,0.762687,-0.409517,-0.549216,-1.30962,-0.893572,0.648581,0.746737
8109,0.111176,0.116753,0.655799,0.584575,0.730728,0.679049,0.322822,0.246028,0.0781922,0.146694,0.515385,0.515958,0.474413,0.445634,0.454583,0.43631,0.930534,0.971098,0.11887,0.131616,0.0881997,0.163109,0.349866,0.361208,0.936671,1.0842,0.105816,0.119248,0.286561,0.214067,-0.786852,-0.722801,-2.33502,-2.20737,1.05555,0.914931,0.254156,0.674262,0.24206,0.344705
8110,0.176187,0.182084,0.609094,0.595693,0.48688,0.44662,0.384694,0.230216,0.742794,0.811939,0.960049,0.959163,0.328837,0.300697,0.839354,0.822922,0.480863,0.5213,0.688941,0.700012,0.09118,0.168531,0.612213,0.624426,0.609049,0.762003,-0.389953,-0.378374,-0.0831131,-0.152895,0.0754673,0.133586,1.03303,1.16573,-1.40291,-1.54941,0.627983,1.05624,0.669715,0.772615
8111,0.567206,0.575031,0.478825,0.466561,0.480931,0.417356,0.262618,0.214404,0.102414,0.172307,0.598139,0.597436,0.788934,0.762006,0.0255477,0.0111456,0.628929,0.67069,0.542921,0.466439,1.10766,1.18544,1.26999,1.28759,0.833799,0.992952,0.787361,0.801329,1.96828,1.89961,0.169139,0.224989,0.448613,0.580778,-0.59589,-0.74355,0.420689,0.885262,-0.405752,-0.310271
8112,0.482111,0.512898,0.143609,0.131486,0.427843,0.388092,0.232454,0.198591,0.132244,0.25997,0.798511,0.793195,0.237288,0.209262,0.371505,0.358069,0.121684,0.160991,0.221241,0.232866,-0.0351707,0.0421925,-0.686785,-0.665077,-1.27093,-1.11732,-0.50249,-0.485702,-0.259191,-0.326359,1.21107,1.26745,0.490341,0.626678,-0.588075,-0.736219,0.28893,0.714279,-0.70452,-0.604272
8113,0.446073,0.450764,0.725745,0.712447,0.813785,0.7751,0.0758629,0.040861,0.278571,0.347633,0.991187,0.988954,0.74772,0.72008,0.722398,0.704992,0.426793,0.371292,0.483159,0.406993,-1.48196,-1.40637,-0.291435,-0.265286,-1.00265,-0.854854,2.40953,2.4244,-0.977542,-1.04098,0.0137235,0.0660142,0.0454658,0.180628,-0.126589,-0.3294,0.728069,1.15754,0.862512,0.968779
8114,0.165379,0.265891,0.879724,0.866493,0.0605265,0.0199635,0.488796,0.388568,0.755202,0.825543,0.658784,0.655471,0.78213,0.752591,0.608682,0.67442,0.544434,0.581592,0.569652,0.581121,-0.754792,-0.680704,1.15898,1.18291,0.216674,0.3817,-0.576436,-0.556527,0.622676,0.558941,-0.755014,-0.706975,1.04118,1.1805,0.230661,0.0774192,0.0889037,0.518243,0.837797,0.945742
8115,0.0766002,0.081018,0.152985,0.141157,0.588516,0.476203,0.774185,0.736275,0.725872,0.795929,0.718667,0.661609,0.578066,0.547469,0.567943,0.643848,0.160772,0.197126,0.994957,1.00541,-0.837022,-0.766881,-0.728683,-0.706956,1.47045,1.61825,-0.685717,-0.668247,0.468719,0.407839,0.573379,0.625398,-0.561533,-0.429449,1.50506,1.35355,-0.0739123,0.355968,0.093738,0.199115
8116,0.138789,0.141271,0.939357,0.928104,0.973005,0.932442,0.880374,0.840676,0.10076,0.170891,0.629577,0.667746,0.713935,0.682566,0.61099,0.613276,0.319737,0.428536,0.873779,0.884924,0.0115478,0.0804803,2.13204,2.15739,-0.557283,-0.410144,0.579817,0.605587,0.779533,0.717214,-0.25196,-0.192973,0.399322,0.537899,-0.619544,-0.763065,0.734864,1.157,-1.14424,-1.03653
8117,0.640705,0.6434,0.563579,0.553492,0.295026,0.252735,0.220955,0.183418,0.197549,0.269607,0.62687,0.673883,0.154526,0.125132,0.60011,0.582704,0.621829,0.659946,0.367793,0.379248,-0.234051,-0.169935,0.755937,0.872499,-0.0171115,0.126132,-0.0864504,-0.061639,-0.103161,-0.168095,1.12381,1.18327,-0.0244462,0.108326,-0.358258,-0.507283,0.99991,1.42746,1.71168,1.82402
8118,0.420679,0.448038,0.832884,0.824527,0.454228,0.414003,0.518257,0.544215,0.884466,0.955525,0.683332,0.68002,0.800393,0.773072,0.0317468,0.0116881,0.233726,0.269898,0.957865,0.968383,1.35823,1.42113,-0.437747,-0.412397,2.2053,2.35211,-1.14683,-1.11954,-1.24202,-1.31176,1.70571,1.7666,2.4348,2.57087,-0.908915,-1.06423,0.0660019,0.487863,0.992367,1.1067
8119,0.251449,0.252675,0.533311,0.524676,0.978065,0.937473,0.940532,0.905013,0.362591,0.432511,0.979268,0.975642,0.1505,0.120828,0.364694,0.343547,0.965723,1.0016,0.533691,0.542428,1.00606,1.06321,-3.50619,-3.48102,-1.39417,-1.25349,2.25668,2.28128,0.316357,0.241063,-0.969311,-0.906219,-0.506314,-0.365379,0.385114,0.22892,-0.330348,0.0965002,-2.08839,-1.97344
8120,0.327377,0.328321,0.517398,0.509085,0.405933,0.363823,0.129916,0.0933595,0.58681,0.657965,0.476389,0.470268,0.0086884,-0.0189242,0.445365,0.424318,0.820343,0.858088,0.809511,0.820242,-1.55197,-1.50142,-0.332998,-0.307,0.252017,0.389204,0.294047,0.31669,-1.64018,-1.7096,-2.27051,-2.19996,-1.0123,-0.87153,-0.173897,-0.32803,1.30587,1.72815,-1.15914,-1.04538
8121,0.625188,0.567685,0.0671909,0.060629,0.440645,0.400191,0.95419,0.915052,0.0929178,0.164629,0.183385,0.176119,0.279497,0.252272,0.78596,0.766349,0.16413,0.202263,0.864228,0.872916,-0.63783,-0.592685,-0.957578,-0.931531,0.413006,0.632862,1.18848,1.20455,-1.20185,-1.27645,-1.79753,-1.72272,0.421462,0.560882,1.64518,1.49307,0.760384,1.11193,0.381553,0.495903
8122,0.804202,0.80705,0.89409,0.88801,0.185323,0.188564,0.718699,0.677446,0.981103,1.05429,0.970691,0.964625,0.102005,0.0722779,0.830458,0.811739,0.708123,0.7472,0.402483,0.412057,-0.221835,-0.172834,0.933243,0.953955,0.738962,0.87652,1.84894,1.85955,0.559143,0.491041,0.117039,0.192183,1.32105,1.46566,0.0340671,-0.122666,0.0702279,0.49571,-1.55894,-1.44647
8123,0.61199,0.613186,0.682967,0.678424,0.0181849,-0.023062,0.89421,0.769055,0.427177,0.5005,0.545982,0.538904,0.823061,0.791357,0.645448,0.655135,0.649903,0.687431,0.705561,0.634419,3.54968,3.59587,-0.238074,-0.212096,-0.826829,-0.695764,-0.468598,-0.453197,0.595572,0.526841,-0.655877,-0.580806,-0.289854,-0.144289,-0.0670585,-0.220417,0.0912872,0.431588,0.953877,1.06857
8124,0.956698,0.960182,0.691672,0.628374,0.0257651,-0.0158714,0.901809,0.860664,0.759191,0.83268,0.906354,0.898997,0.412325,0.380239,0.514545,0.498532,0.105564,0.142942,0.848836,0.856782,0.460159,0.51223,-0.305722,-0.286561,1.24067,1.36971,0.864069,0.88114,-0.0984753,-0.163466,0.10534,0.184758,0.246094,0.392799,-1.54978,-1.697,-0.0621471,0.367466,0.40452,0.515586
8125,0.602026,0.674794,0.582292,0.578324,0.394851,0.337301,0.285456,0.243012,0.679398,0.75251,0.102081,0.0956012,0.533893,0.500308,0.623072,0.574014,0.245572,0.282921,0.132008,0.14049,0.0168804,0.129461,-0.686717,-0.668227,-1.21728,-1.09324,0.110621,0.119259,-0.779698,-0.853773,-0.781483,-0.695489,-0.122673,0.0256224,0.220219,0.0757301,0.452606,0.875641,1.74776,1.8567
8126,0.353154,0.389406,0.374349,0.368739,0.731831,0.690474,0.301122,0.355797,0.31376,0.389082,0.894346,0.889941,0.189233,0.155084,0.569948,0.649496,0.851608,0.889282,0.344395,0.39928,-0.305379,-0.253308,0.521658,0.532927,-0.00948134,0.116371,-0.354295,-0.348759,0.492852,0.425156,0.550123,0.636884,0.347272,0.502233,-1.25118,-1.40085,-0.166676,0.252578,0.839284,0.942955
8127,0.100535,0.104018,0.756193,0.748476,0.727493,0.716851,0.510056,0.468581,0.829698,0.903203,0.0440243,0.0409805,0.594648,0.4888,0.740991,0.724978,0.457448,0.495079,0.650657,0.658069,1.17055,1.23033,0.0104768,0.016122,-0.253441,-0.128111,0.812254,0.817822,0.112206,0.0428336,-0.630918,-0.549237,-0.906143,-0.746697,0.124767,-0.028559,0.708286,1.13351,-1.09352,-0.981704
8128,0.0844516,0.0889166,0.779525,0.771894,0.72756,0.743228,0.130782,0.0909653,0.364244,0.439484,0.0132026,0.00884351,0.855187,0.822516,0.054491,0.0379397,0.488374,0.524639,0.544078,0.552365,0.336168,0.393188,2.49389,2.49471,1.1932,1.31239,-1.36808,-1.36369,0.88148,0.815081,-0.520515,-0.442451,0.421803,0.579659,-0.189318,-0.403973,1.17522,1.59201,1.85095,1.96453
8129,0.900224,0.90678,0.590499,0.582381,0.667051,0.769605,0.0910499,0.0492744,0.406483,0.504542,0.409225,0.321974,0.351852,0.321477,0.452622,0.403205,0.31675,0.290588,0.706452,0.714128,2.04741,2.1068,1.41412,1.33832,-0.0234792,0.0908347,0.164032,0.15954,-0.258923,-0.328586,1.87711,1.96061,0.594717,0.747819,-0.62368,-0.779388,-0.869815,-0.454679,1.36092,1.47468
8130,0.852533,0.859888,0.965791,0.956589,0.837339,0.795982,0.812949,0.773008,0.496152,0.5696,0.639135,0.635105,0.303964,0.359344,0.78568,0.76847,0.0219205,0.056538,0.176561,0.182673,0.142054,0.206997,0.181202,0.181921,1.92517,2.04472,-0.0730132,-0.0745775,-0.841516,-0.908346,-1.90921,-1.83015,0.233359,0.380642,-0.0378959,-0.188792,-0.708102,-0.291555,0.40616,0.516106
8131,0.52156,0.530174,0.161737,0.151937,0.60409,0.526368,0.123514,0.0808911,0.303322,0.377542,0.16604,0.160142,0.429174,0.397211,0.53864,0.4487,0.918287,0.954621,0.647572,0.65163,0.527656,0.596,0.514355,0.522896,-0.900307,-0.783715,-0.761922,-0.757614,-0.789074,-0.8572,0.365232,0.45138,-1.69561,-1.54188,-0.212818,-0.362564,0.90476,1.32349,0.927237,1.03556
8132,0.526386,0.556758,0.220248,0.239927,0.182244,0.256755,0.998135,0.955898,0.39465,0.528216,0.258442,0.25091,0.718986,0.688367,0.147184,0.128929,0.0996135,0.135348,0.743331,0.747796,-0.488338,-0.425906,1.2377,1.24497,0.216552,0.336382,-1.4327,-1.44065,-0.536161,-0.606481,0.34118,0.507953,0.711176,0.872571,0.735218,0.582939,-0.8197,-0.401322,-1.19506,-1.09035
8133,0.572611,0.583341,0.339696,0.327917,0.0279721,-0.012858,0.0476258,0.00681162,0.548275,0.678889,0.609898,0.601796,0.20646,0.176766,0.733479,0.716865,0.204494,0.239983,0.558247,0.578805,-0.47674,-0.420484,-1.45085,-1.43813,-1.40186,-1.28478,-0.737198,-0.739515,0.349809,0.272598,0.474586,0.564526,1.83388,1.99297,0.692634,0.477574,0.167639,0.590163,-0.0233274,0.0835372
8134,0.220533,0.23328,0.168123,0.185796,0.344014,0.23619,0.598065,0.55939,0.756922,0.829563,0.0387787,0.0320231,0.359797,0.332125,0.11351,0.095621,0.929806,0.96734,0.437361,0.409815,-0.916562,-0.854836,0.708945,0.718853,0.0825306,0.200322,1.24132,1.24457,-0.339256,-0.449812,-0.588959,-0.500303,0.0465849,0.210193,0.523963,0.372209,-1.21612,-0.7871,-0.593355,-0.483048
8135,0.516778,0.53059,0.0557025,0.0436759,0.513542,0.485237,0.237205,0.197304,0.655331,0.728273,0.264173,0.256054,0.257601,0.227357,0.40945,0.392265,0.840668,0.83436,0.153037,0.240824,-0.0428486,0.0216412,-1.51628,-1.50045,-0.48642,-0.366251,-0.515072,-0.509462,-1.10173,-1.17222,-0.458879,-0.363019,0.60613,0.764343,-0.79352,-0.939172,-1.4237,-0.993884,1.64548,1.76113
8136,0.146766,0.160838,0.423767,0.413388,0.775115,0.734285,0.134544,0.142277,0.00707295,0.0790789,0.147899,0.138669,0.799446,0.769011,0.123385,0.105319,0.662812,0.70138,0.0673689,0.0718336,-0.674384,-0.614293,-0.986219,-0.976414,1.73217,1.85973,-1.43362,-1.49302,0.591439,0.518601,0.574656,0.663379,0.804173,0.955723,0.289403,0.142485,-0.344783,0.0900324,-0.547365,-0.427919
8137,0.149858,0.165988,0.314897,0.304382,0.610282,0.568138,0.0699908,0.08725,0.331005,0.486499,0.377293,0.367353,0.721912,0.689675,0.956807,0.938916,0.288965,0.327196,0.448186,0.498415,1.38254,1.43765,0.162646,0.176624,-1.02,-0.893228,-2.4862,-2.47658,0.0153659,-0.0844783,0.626821,0.708403,0.981901,1.1471,-1.00082,-1.15338,-0.327785,0.1637,-0.492642,-0.375085
8138,0.858267,0.876619,0.516158,0.521027,0.879944,0.839406,0.0704944,0.0322229,0.82384,0.893919,0.972904,0.963142,0.135619,0.102368,0.232114,0.214206,0.193158,0.231731,0.921652,0.924997,2.91017,2.96702,-0.927666,-0.911668,-0.718315,-0.585346,-0.319865,-0.304287,-0.611872,-0.687557,-0.103722,-0.0180254,0.501587,0.669983,2.0699,1.92029,-0.191555,0.237368,1.88216,1.99999
8139,0.363086,0.381225,0.749178,0.737672,0.65015,0.611979,0.399145,0.37993,0.182627,0.254288,0.213931,0.203589,0.423852,0.306228,0.66463,0.645854,0.363816,0.401417,0.883401,0.942303,-1.3563,-1.30101,-1.23615,-1.21784,0.303964,0.500264,-0.609466,-0.586761,0.134876,0.0532871,-1.42577,-1.34337,-1.30857,-1.14398,-1.16496,-1.30752,0.451069,0.883537,1.29518,1.41852
8140,0.229017,0.247946,0.159275,0.146559,0.645699,0.608248,0.764919,0.727637,0.302507,0.373683,0.79471,0.784441,0.543504,0.510088,0.18434,0.164774,0.0210531,0.0565548,0.957874,0.959609,-1.73729,-1.68913,0.154627,0.168514,1.45385,1.58587,-1.16748,-1.14508,-1.27942,-1.35489,-0.497212,-0.408908,0.294247,0.458289,0.279951,0.139995,2.03659,2.46801,-1.44603,-1.31881
8141,0.471138,0.489001,0.523737,0.511293,0.91667,0.879516,0.811178,0.810431,0.980082,1.05037,0.103902,0.0943422,0.628092,0.593913,0.298246,0.280531,0.854249,0.889978,0.141931,0.144288,0.117757,0.161877,-0.0827466,-0.0753906,1.41329,1.54152,-1.44481,-1.42756,0.308732,0.228233,-1.69961,-1.61035,0.708227,0.873572,1.16399,1.02198,0.3527,0.791732,0.433437,0.563466
8142,0.0438046,0.0633767,0.595083,0.584959,0.143487,0.105098,0.929282,0.893225,0.493746,0.59332,0.441813,0.433918,0.113788,0.0778791,0.164362,0.199363,0.039762,0.0771124,0.232317,0.235759,-0.150864,-0.104679,-1.48701,-1.47809,-0.996895,-0.873962,-1.12873,-1.10958,-0.777558,-0.855885,-0.851642,-0.768222,2.3859,2.55245,-1.41788,-1.55353,-1.55418,-1.11185,3.15543,3.2784
8143,0.167815,0.101184,0.334373,0.323865,0.00821643,-0.0316014,0.688085,0.617792,0.0659697,0.136275,0.505159,0.520375,0.250034,0.212976,0.137917,0.118196,0.58759,0.626781,0.87024,0.874539,-0.0943665,-0.0540083,0.905479,0.919905,0.117397,0.246136,-1.68778,-1.6679,0.429705,0.346448,2.9367,3.0236,-1.10697,-0.941759,-1.47775,-1.60662,-0.120591,0.318287,0.410986,0.529591
8144,0.119187,0.138992,0.865982,0.856017,0.918182,0.878168,0.377978,0.34236,0.835475,0.905323,0.626951,0.606832,0.739335,0.699717,0.916597,0.89599,0.653824,0.695205,0.622912,0.629228,1.04183,1.08441,-0.999796,-0.986283,0.885865,1.01483,1.01818,1.03067,-0.126267,-0.23212,0.224808,0.314782,0.205193,0.369795,-0.595101,-0.72463,1.7266,2.17204,-0.552267,-0.428983
8145,0.825882,0.844334,0.670932,0.661386,0.463742,0.428936,0.908081,0.87002,0.035194,0.104621,0.701568,0.693289,0.343799,0.303659,0.678435,0.582111,0.134551,0.175964,0.0208702,0.028395,-0.705466,-0.656194,-0.456309,-0.470453,-0.114985,0.0111477,1.24537,1.25916,-0.726278,-0.810688,2.40289,2.48702,0.780913,0.939765,0.859331,0.722881,-1.00171,-0.555984,-0.777056,-0.649177
8146,0.800834,0.819051,0.0240155,0.0156802,0.0174521,-0.0202963,0.488972,0.43078,0.218832,0.289679,0.188318,0.178856,0.161933,0.123665,0.286905,0.268232,0.184767,0.202313,0.283351,0.291424,1.46778,1.51884,0.0349422,0.045376,1.14763,1.26799,0.685565,0.700845,0.631544,0.541922,-1.27139,-1.18098,-0.147785,0.0165453,-1.89359,-2.02339,-0.663105,-0.221543,-0.297648,-0.17626
8147,0.321538,0.338104,0.986484,0.978921,0.537843,0.49861,0.0311702,-0.00846001,0.138634,0.209508,0.0977663,0.0859682,0.732097,0.695357,0.245171,0.22693,0.186023,0.228663,0.862047,0.870759,0.874134,0.929436,0.138306,0.0514772,1.04642,1.16148,-0.426002,-0.416968,-0.0217332,-0.200027,-0.0445619,0.0432905,1.58502,1.74279,0.614534,0.491588,0.207266,0.644748,-0.296762,-0.16868
8148,0.509215,0.619547,0.283166,0.273522,0.659433,0.677809,0.509993,0.469031,0.344571,0.490773,0.978078,0.966108,0.812343,0.703913,0.549469,0.533517,0.663207,0.70411,0.863813,0.765232,0.947783,0.996535,0.0503495,0.0575785,-0.470628,-0.350368,0.159839,0.17515,-0.856404,-0.941977,0.225124,0.317618,-0.788508,-0.627265,-1.26887,-1.39288,1.8541,2.29373,0.52882,0.654274
8149,0.885051,0.90099,0.893437,0.883854,0.895245,0.857009,0.0777747,0.0371342,0.699121,0.772038,0.270432,0.256405,0.809363,0.712469,0.225738,0.211597,0.920804,0.960258,0.674438,0.659706,-0.0189985,0.0376347,0.282648,0.281777,1.9998,2.12509,-1.36062,-1.34378,-0.71085,-0.800237,-0.254029,-0.244535,0.624385,0.791185,0.328282,0.211259,-2.03466,-1.60117,-0.250117,-0.123511
8150,0.544563,0.632544,0.636048,0.6278,0.444297,0.407939,0.564204,0.436199,0.313359,0.38835,0.680485,0.666058,0.760199,0.721025,0.668679,0.653835,0.0283674,0.0659962,0.544584,0.55418,-1.32263,-1.27241,0.497962,0.505975,0.0920922,0.222526,-0.922922,-0.904641,0.0964761,0.000244187,-0.899182,-0.806688,-0.610206,-0.441739,0.505562,0.38765,2.14996,2.58345,0.769667,0.897939
8151,0.359194,0.364098,0.824564,0.816537,0.219329,0.185942,0.875591,0.835264,0.883071,0.95709,0.831356,0.815854,0.606374,0.566533,0.667879,0.726478,0.295392,0.332623,0.0939758,0.102871,1.09173,1.13754,-3.65168,-3.63926,-2.46524,-2.33454,0.372964,0.398031,-1.27349,-1.36398,0.611311,0.708925,-0.85829,-0.685417,1.07879,0.964026,-0.914989,-0.477685,1.41361,1.53984
8152,0.0812139,0.0956515,0.255877,0.250394,0.724349,0.689503,0.309803,0.271527,0.22611,0.302852,0.537994,0.556782,0.656022,0.615028,0.814572,0.799121,0.302542,0.338064,0.436459,0.447193,0.194046,0.23959,-2.282,-2.26889,1.1456,1.27795,1.32835,1.34689,0.122911,0.0365527,0.772957,0.945341,-0.254824,-0.0688121,-2.18823,-2.30188,-2.1699,-1.7284,-0.662087,-0.539813
8153,0.836849,0.850801,0.578974,0.571876,0.21781,0.181115,0.730551,0.689684,0.254893,0.330248,0.333378,0.29771,0.241584,0.199019,0.107017,0.0904896,0.745124,0.783264,0.437071,0.396741,1.62915,1.6745,0.519205,0.54052,-1.21143,-1.07384,0.672011,0.694531,-0.949964,-1.03258,1.08378,1.18176,0.376401,0.547793,0.248578,0.142766,1.32382,1.76289,-0.351834,-0.231187
8154,0.32794,0.339945,0.0218415,0.0148942,0.271425,0.233679,0.337283,0.29791,0.805356,0.878959,0.0537234,0.038638,0.134382,0.0897889,0.255784,0.174495,0.177609,0.213334,0.334998,0.34629,-0.334786,-0.284034,-0.139535,-0.114827,2.11396,2.24787,0.922787,0.95096,0.450944,0.367952,-0.307542,-0.207398,-1.59155,-1.42389,0.194506,0.0896789,0.339905,0.779671,-0.557013,-0.43553
8155,0.55145,0.561745,0.248776,0.179807,0.992334,0.953677,0.924071,0.885215,0.858304,0.931298,0.507216,0.491959,0.511372,0.375899,0.295025,0.2585,0.45474,0.504738,0.670106,0.679915,-0.98225,-0.93492,2.9201,2.94273,-0.371009,-0.230765,-0.695422,-0.661473,0.00875584,-0.0695363,-0.727539,-0.62373,-0.459294,-0.285997,0.573959,0.46839,0.208238,0.726786,-0.370489,-0.248701
8156,0.44722,0.462934,0.352364,0.34472,0.586148,0.548122,0.270225,0.232893,0.587182,0.659293,0.0964263,0.0809541,0.715213,0.662009,0.503589,0.342506,0.761708,0.796142,0.324249,0.333989,-0.445783,-0.391963,1.69952,1.71497,1.25823,1.39538,-0.036242,-0.00647427,-0.423217,-0.507025,-0.459944,-0.349403,-0.377908,-0.207987,0.153798,0.0486717,0.231278,0.673901,0.54694,0.66403
8157,0.352691,0.364123,0.343207,0.316785,0.678937,0.559904,0.672319,0.637375,0.651667,0.652445,0.105121,0.0880415,0.992713,0.94812,0.443038,0.426511,0.676095,0.788471,0.482254,0.491251,-1.00185,-0.950531,0.0589184,0.0787499,0.034487,0.173824,-0.0550534,-0.0260214,-0.0363375,-0.118625,0.452175,0.569097,0.540607,0.713236,-1.25677,-1.36792,-0.353603,0.0954306,-1.01468,-0.891749
8158,0.81158,0.821805,0.168394,0.28885,0.610361,0.571685,0.252676,0.216023,0.651737,0.645598,0.710699,0.693827,0.342224,0.295875,0.825069,0.808747,0.786808,0.7808,0.0368666,0.0448597,0.412228,0.468655,-0.211544,-0.183054,-1.92932,-1.79125,-2.09866,-2.06873,-0.701267,-0.790407,0.348063,0.461716,-0.68332,-0.504294,-0.590849,-0.699186,1.50521,1.94919,1.49285,1.62329
8159,0.19839,0.21005,0.268559,0.260915,0.0189558,-0.0170557,0.491915,0.455952,0.565485,0.638751,0.522927,0.581531,0.335499,0.288448,0.213877,0.197886,0.749617,0.773129,0.0424623,0.0501727,0.899526,0.952829,-0.46494,-0.444859,-1.13311,-0.992229,-0.171064,-0.132208,-0.973809,-1.06514,-1.9026,-1.79352,2.04154,2.21979,-1.66934,-1.77856,0.372946,0.823359,1.39719,1.52552
8160,0.984238,0.995477,0.476415,0.468739,0.257147,0.222998,0.307315,0.273985,0.310096,0.381696,0.486107,0.469234,0.865684,0.819601,0.0163273,0.000935679,0.731025,0.765459,0.629722,0.639307,-1.38615,-1.33766,-0.318398,-0.305151,0.255298,0.400542,-0.710539,-0.675382,0.552013,0.457424,0.197043,0.315367,0.212452,0.3902,1.78731,1.6764,0.56321,1.01592,-0.116095,0.0177145
8161,0.90054,0.912437,0.324891,0.315242,0.755743,0.721316,0.653609,0.622771,0.987656,1.05838,0.0933603,0.0771012,0.128569,0.082033,0.904415,0.891375,0.215522,0.250607,0.286453,0.298168,-1.63165,-1.58807,0.254674,0.264994,0.417061,0.517297,1.31351,1.35727,-0.00934733,-0.106468,0.334274,0.452651,0.67441,0.851066,0.00275547,-0.109542,-2.01764,-1.55672,0.0028079,0.130844
8162,0.542401,0.640188,0.927032,0.915261,0.716838,0.682497,0.10492,0.074954,0.454731,0.525234,0.344304,0.425124,0.519885,0.473084,0.356075,0.340397,0.439036,0.472278,0.228904,0.239831,1.19426,1.23217,-0.698386,-0.683405,0.489601,0.634052,0.5031,0.549695,-2.09898,-2.19254,1.44112,1.55326,0.581227,0.761748,-0.45308,-0.558898,-1.39542,-0.941146,-0.671873,-0.541861
8163,0.26445,0.367939,0.296478,0.284933,0.323032,0.36505,0.421664,0.389779,0.168921,0.312233,0.790133,0.773147,0.40652,0.326778,0.797772,0.782634,0.0110472,0.0431878,0.542748,0.553269,0.720979,0.816885,0.517258,0.536967,-0.48955,-0.34084,-0.513971,-0.460184,2.14767,2.04811,0.89112,0.997664,-0.359319,-0.178356,-0.667235,-0.778692,0.509705,0.959274,-0.156138,-0.0224085
8164,0.0814501,0.0956901,0.944387,0.934969,0.0821452,0.0476037,0.459126,0.458513,0.0278772,0.099232,0.0330607,0.0187117,0.227286,0.180472,0.655726,0.6405,0.658456,0.690135,0.428692,0.342891,0.370166,0.401603,1.04841,1.04125,-0.0729056,0.0744489,0.338285,0.395901,-0.880026,-0.985051,1.74709,1.85405,1.25398,1.43857,-2.08583,-2.19529,0.139167,0.582897,-0.991418,-0.858484
8165,0.516114,0.444636,0.40219,0.393253,0.500191,0.465832,0.557473,0.527248,0.549741,0.622751,0.226119,0.212456,0.2968,0.249267,0.092428,0.0793432,0.450305,0.482502,0.122679,0.132514,-0.963615,-0.939845,1.52068,1.54553,0.619413,0.766414,0.0580449,0.113427,-0.709826,-0.810988,1.00469,1.11198,0.850635,1.01016,-0.428209,-0.545612,1.86586,2.30971,2.22942,2.36011
8166,0.779894,0.793583,0.157759,0.147112,0.237711,0.20161,0.0956789,0.0657829,0.812,0.805298,0.936112,0.923519,0.133228,0.0854494,0.904779,0.893252,0.786977,0.818934,0.869807,0.880779,1.84227,1.86382,-1.58261,-1.55521,-0.968122,-0.822648,0.807671,0.862031,0.51172,0.406911,-0.090922,0.016063,0.389937,0.581749,-0.400002,-0.522634,0.309683,0.75982,0.462119,0.591105
8167,0.856327,0.834954,0.877372,0.867832,0.789147,0.754125,0.983649,0.951898,0.915615,0.987845,0.73243,0.761172,0.984089,0.937253,0.0454169,0.0327602,0.867145,0.896947,0.881153,0.891496,0.708767,0.73674,-0.762141,-0.74018,-0.0524262,0.0987668,0.119875,0.179204,0.140252,0.0399491,0.566528,0.674064,-1.29181,-1.10731,-0.843899,-0.97199,1.83908,2.28253,1.52634,1.65711
8168,0.863138,0.876325,0.407134,0.399571,0.144607,0.109834,0.940505,0.910207,0.147531,0.219047,0.613398,0.598825,0.0667173,0.0217593,0.107828,0.105403,0.512629,0.513548,0.467545,0.475503,0.182722,0.208826,-0.568886,-0.554595,-0.882827,-0.734902,0.356927,0.477525,-0.778128,-0.874864,-0.234484,-0.129548,-0.969603,-0.785554,-0.490943,-0.626284,-0.445446,0.00226015,-0.262579,-0.127931
8169,0.70386,0.718561,0.684711,0.67581,0.0100722,-0.0268655,0.424034,0.392334,0.145342,0.313299,0.242995,0.227132,0.703601,0.658348,0.192901,0.178047,0.0987117,0.130149,0.778394,0.78894,-0.0730469,-0.0415886,0.43472,0.445074,-0.0456649,0.0971,0.713369,0.775845,-0.80846,-0.901748,-0.609206,-0.537216,-1.04919,-0.827319,0.989452,0.851358,0.837883,1.28843,-0.786866,-0.649547
8170,0.0722619,0.0874347,0.341807,0.330808,0.230691,0.273397,0.635703,0.603319,0.297451,0.407551,0.497446,0.48057,0.724091,0.680838,0.631951,0.615228,0.442482,0.487876,0.888153,0.895481,2.07489,2.1008,0.0120207,0.0205686,-0.771506,-0.6285,-0.338816,-0.282056,-0.554267,-0.651029,-1.05767,-0.944884,-1.05436,-0.869084,0.120403,0.0828246,0.183282,0.634117,0.692139,0.832446
8171,0.994806,1.0071,0.233705,0.211107,0.608739,0.573659,0.456652,0.425652,0.432117,0.501802,0.401626,0.386239,0.120359,0.0797875,0.30123,0.283875,0.813415,0.845604,0.992563,1.00202,1.39012,1.41879,0.163115,0.175133,0.00527838,0.154208,-0.675752,-0.625277,0.539299,0.442711,-0.647239,-0.533218,0.0478084,0.188034,-0.554224,-0.685708,0.108352,0.567342,-0.640819,-0.493205
8172,0.551185,0.561249,0.102186,0.0914064,0.0199702,-0.015082,0.538067,0.557822,0.299561,0.370178,0.30848,0.291908,0.213789,0.173728,0.726949,0.71049,0.029119,0.0607274,0.807106,0.816613,1.7987,1.82459,-0.668024,-0.649867,-0.356866,-0.212601,0.801157,0.85181,0.696605,0.602108,-0.965762,-0.856026,1.05987,1.24515,-0.873313,-0.99904,-1.06037,-0.605474,-0.623543,-0.470734
8173,0.9356,0.944071,0.740805,0.730757,0.756419,0.72026,0.720415,0.689993,0.937512,1.00938,0.636042,0.617044,0.793131,0.754879,0.14913,0.134345,0.447054,0.47625,0.145551,0.15526,-1.26621,-1.24305,-0.00396905,0.0132987,-0.402971,-0.256955,-0.592466,-0.543147,-0.70394,-0.790791,1.43764,1.54703,0.552337,0.739002,2.4696,2.34148,0.503016,0.962361,-1.07511,-0.916585
8174,0.714209,0.720513,0.540804,0.531294,0.849517,0.811377,0.148648,0.11733,0.819678,0.892752,0.127675,0.107177,0.791323,0.75316,0.389931,0.374183,0.336955,0.334885,0.229667,0.241381,-1.68083,-1.66236,-1.31104,-1.29096,0.227329,0.371275,-0.0401306,0.00490708,-1.16452,-1.24948,0.351956,0.467861,-1.79398,-1.61431,-0.0861117,-0.21442,-1.43065,-0.97021,-0.275966,-0.123304
8175,0.117479,0.124928,0.0648456,0.053857,0.394947,0.357384,0.229247,0.19596,0.481722,0.555543,0.147362,0.131513,0.246494,0.206305,0.301056,0.23879,0.165531,0.19352,0.833809,0.845163,0.022806,0.0361552,-0.0554308,-0.042984,-0.0653022,0.0750143,0.264947,0.308769,1.53534,1.44455,-1.03146,-0.921294,-0.467301,-0.287955,-0.257014,-0.388192,0.904896,1.37444,0.262853,0.410426
8176,0.854077,0.862683,0.768676,0.75909,0.774916,0.738299,0.602256,0.569802,0.35822,0.409903,0.138488,0.155849,0.177262,0.137286,0.120335,0.103397,0.732809,0.762884,0.374138,0.384304,0.423958,0.441956,1.18889,1.20499,-0.356563,-0.221247,1.28066,1.32127,-0.766177,-0.862212,-0.673474,-0.568669,0.363071,0.53958,-2.72838,-2.85253,-0.508465,-0.0338692,-1.46223,-1.31215
8177,0.595593,0.57672,0.481744,0.47343,0.266317,0.229911,0.130138,0.0976241,0.3285,0.264263,0.201067,0.180185,0.309955,0.245803,0.834391,0.815408,0.666427,0.697091,0.73695,0.749495,-1.21808,-1.20569,-0.842817,-0.825882,-0.317493,-0.176462,-1.03356,-0.991481,1.78651,1.69235,-1.34604,-1.23473,0.468238,0.647877,0.861434,0.740997,-1.08443,-0.612339,-1.39659,-1.24393
8178,0.280677,0.290756,0.638955,0.53265,0.882456,0.847909,0.726225,0.694469,0.0426495,0.118622,0.743913,0.72196,0.392486,0.35432,0.530081,0.509067,0.0387522,0.0671815,0.2004,0.213654,-0.56115,-0.555268,1.4543,1.47524,0.441641,0.576714,-0.172491,-0.135395,1.40631,1.31003,-0.195025,-0.0876827,-0.00131543,0.170755,-0.691249,-0.812802,0.0455085,0.517939,-0.845591,-0.694925
8179,0.550822,0.49594,0.598585,0.591869,0.910669,0.801952,0.627744,0.596918,0.267471,0.43932,0.221917,0.201888,0.803506,0.765847,0.612406,0.602739,0.950996,0.980828,0.540764,0.552342,-0.965036,-0.958983,0.0669122,0.0886213,0.942144,1.08024,-0.436055,-0.402087,-1.80366,-1.90047,-0.294717,-0.180752,-0.0743847,0.0954441,0.252626,0.132701,0.363745,0.836517,-0.522159,-0.37205
8180,0.69039,0.701124,0.16306,0.154115,0.789496,0.755995,0.905251,0.872172,0.684638,0.760019,0.70011,0.679202,0.850511,0.814341,0.716024,0.69641,0.225834,0.255132,0.0362559,0.0466659,0.399793,0.398464,-0.0721323,-0.047355,-0.62711,-0.492047,-0.0117673,0.0223068,-0.834548,-0.927211,-0.799571,-0.691351,0.551152,0.726277,2.43087,2.31309,-0.447126,0.027152,-0.635293,-0.485527
8181,0.714948,0.717467,0.518586,0.420407,0.380766,0.346363,0.334441,0.299509,0.230359,0.306629,0.553134,0.508588,0.500873,0.463711,0.188903,0.170601,0.929325,0.957752,0.7579,0.769976,-0.455989,-0.453035,1.38703,1.41812,1.22408,1.35464,2.18949,2.23195,0.653001,0.564292,1.52598,1.6385,0.213848,0.38934,-0.867286,-0.988143,-0.0802644,0.392777,0.68895,0.840857
8182,0.792999,0.73381,0.695757,0.686699,0.862379,0.829377,0.0582883,0.0217812,0.626441,0.704351,0.356913,0.337974,0.465365,0.429657,0.699032,0.682595,0.0865785,0.113521,0.24501,0.259067,-0.0183945,-0.0187879,0.699195,0.731878,0.269816,0.399025,-2.19261,-2.15015,-1.0928,-1.18342,1.05312,1.15944,0.459352,0.666464,0.68799,0.568302,-0.0877742,0.387461,-0.938374,-0.791517
8183,0.73942,0.750154,0.586379,0.625389,0.953844,0.857052,0.575922,0.53983,0.254482,0.330322,0.860911,0.840321,0.89635,0.861308,0.858899,0.84406,0.563728,0.588969,0.509869,0.468479,1.26688,1.26089,1.29831,1.33372,0.268168,0.399,1.89376,1.93965,1.11458,1.01958,0.974737,1.0817,0.774543,0.943588,-0.883977,-1.00141,-1.04866,-0.580918,0.111699,0.259327
8184,0.308641,0.319392,0.574415,0.564079,0.920918,0.884726,0.798322,0.760176,0.21783,0.300079,0.705914,0.687365,0.45709,0.420573,0.625174,0.64429,0.202242,0.229817,0.665049,0.677891,1.01395,1.01047,0.206485,0.245433,-0.867228,-0.729936,1.83805,1.88996,-1.04261,-1.14592,-0.190331,-0.0872648,0.477787,0.654016,1.02579,0.912734,0.0256475,0.487562,1.68095,1.83238
8185,0.5401,0.551241,0.777747,0.76654,0.945622,0.912401,0.227655,0.191992,0.238532,0.269836,0.981737,0.962362,0.403486,0.36643,0.45944,0.444519,0.634481,0.660274,0.066823,0.0823151,0.984382,0.90833,1.11385,1.15288,0.785041,0.926676,-1.85016,-1.80553,-0.323234,-0.420247,0.599652,0.72127,1.43067,1.6069,-0.0673929,-0.180484,0.217113,0.680124,1.27785,1.43035
8186,0.332295,0.342397,0.154989,0.145667,0.973078,0.940076,0.209024,0.174819,0.185575,0.239592,0.810356,0.789767,0.938934,0.902831,0.4517,0.425463,0.0108996,0.0354608,0.672212,0.686098,0.809079,0.80619,0.757778,0.802912,-0.693928,-0.554664,-0.122507,-0.0765329,1.79857,1.69777,1.42475,1.52981,0.448441,0.621104,0.853533,0.748828,-0.902805,-0.445703,0.450298,0.688702
8187,0.8181,0.829123,0.203681,0.174587,0.564257,0.530443,0.916528,0.882155,0.223082,0.209349,0.327304,0.305048,0.695044,0.695103,0.331617,0.406407,0.962585,0.985974,0.251751,0.265509,0.560719,0.555775,-0.305301,-0.254922,-1.31379,-1.17202,-1.11465,-1.07048,-0.989017,-1.08867,-2.79607,-2.69102,0.353974,0.531786,2.35614,2.25758,0.309204,0.763013,-0.203718,-0.0529409
8188,0.573141,0.585462,0.210967,0.203507,0.823923,0.791128,0.700905,0.687493,0.0931409,0.179105,0.421992,0.400284,0.599193,0.487375,0.370072,0.387351,0.825206,0.847571,0.313656,0.327751,1.83211,1.83545,0.446868,0.499583,-1.24939,-1.10964,-0.655701,-0.614755,1.3484,1.24988,1.16433,1.27047,0.585197,0.759966,0.308215,0.205453,-0.374547,0.0778678,-0.251864,-0.10616
8189,0.966621,0.978409,0.668574,0.662002,0.433848,0.401649,0.527433,0.492831,0.0730217,0.148862,0.837129,0.814858,0.315081,0.279647,0.383216,0.368295,0.320463,0.441129,0.0332604,0.0468342,-1.01742,-1.01702,0.094607,0.149618,1.092,1.23257,-1.19862,-1.15793,0.472254,0.46815,-0.493379,-0.389925,-0.698612,-0.43024,0.0232528,-0.0755053,-1.82373,-1.3769,0.207682,0.351272
8190,0.734786,0.745194,0.675807,0.679296,0.697529,0.667763,0.869269,0.836175,0.698245,0.773049,0.860593,0.836793,0.688439,0.651306,0.97414,0.961443,0.0125228,0.0346883,0.680413,0.695645,0.863398,0.864726,-1.61712,-1.56355,-0.0846623,0.0569765,2.38677,2.42108,-0.219293,-0.313576,0.502358,0.606701,-1.7983,-1.62045,0.286282,0.217289,0.0705162,0.523524,0.326984,0.464402
8191,0.981093,0.991156,0.717488,0.696591,0.0747812,0.0436429,0.117259,0.0835138,0.971912,1.04475,0.560651,0.537993,0.653524,0.630386,0.313567,0.299339,0.546094,0.56928,0.210587,0.224631,-1.6683,-1.66298,-0.702282,-0.642287,2.40217,2.54932,-1.17906,-1.14475,-0.893821,-0.985358,1.26367,1.37227,-0.0169245,0.164642,0.613947,0.510083,0.858382,1.30941,0.0385273,0.170401
8192,0.652488,0.731851,0.720457,0.713885,0.289303,0.191575,0.554297,0.431221,0.761504,0.840048,0.989245,0.966979,0.514015,0.609467,0.831803,0.81663,0.176553,0.199924,0.50365,0.517571,1.09465,1.1064,1.65245,1.70893,-1.99978,-1.85263,1.15264,1.18173,-0.859999,-0.953852,-0.0945136,0.014392,0.0477448,0.227842,1.23148,1.13161,-0.66667,-0.208773,0.281274,0.416763
8193,0.431142,0.472546,0.389201,0.445993,0.449766,0.339508,0.812162,0.778928,0.561731,0.635342,0.0123755,-0.00757329,0.584379,0.588548,0.0955801,0.0810045,0.545838,0.570389,0.0317679,0.0465567,0.53408,0.547834,1.24858,1.21129,-1.60076,-1.45233,1.24286,1.26794,-0.78434,-0.922346,1.07753,1.19292,0.94065,1.1165,0.251713,0.145282,-0.258901,0.102029,-0.315984,-0.179437
8194,0.204378,0.21324,0.182693,0.178102,0.516921,0.48744,0.824365,0.79205,0.829941,0.901654,0.306867,0.231497,0.518396,0.567629,0.478036,0.46324,0.544758,0.570441,0.552648,0.566145,-2.43036,-2.41896,0.663538,0.713649,0.00378865,0.228846,0.53069,0.553828,-0.799302,-0.890839,1.6953,1.80714,-0.33352,-0.164774,0.791666,0.691471,-0.0485358,0.41283,-0.314707,-0.171856
8195,0.966692,0.977611,0.151657,0.147856,0.137898,0.108108,0.0660362,0.0328004,0.630758,0.739498,0.432609,0.470567,0.583844,0.54671,0.11207,0.0964539,0.920403,0.94625,0.130942,0.145556,-0.049127,-0.0417165,1.16065,1.20783,1.7616,1.91003,-0.954898,-0.932539,-1.76435,-1.85242,0.320303,0.433196,0.455356,0.618929,-0.648803,-0.755578,-1.32059,-0.851242,-1.11742,-0.979
8196,0.717323,0.691648,0.891985,0.888554,0.341476,0.338021,0.854732,0.822817,0.506431,0.577341,0.728427,0.709638,0.0830527,0.045671,0.95496,0.941579,0.0188339,0.0454185,0.512937,0.52529,-0.740638,-0.738337,0.53815,0.522854,0.385822,0.53358,-0.635266,-0.614568,-0.850899,-0.942962,0.0428214,0.192097,-0.352092,-0.193328,-0.099117,-0.209389,0.358201,0.829949,-0.456156,-0.321947
8197,0.394192,0.405684,0.899673,0.897598,0.596659,0.567935,0.341526,0.309906,0.536268,0.676373,0.740129,0.804155,0.175433,0.069667,0.0267194,0.0103756,0.897225,0.923914,0.117591,0.130013,-0.432012,-0.425111,-0.207424,-0.162126,-1.92087,-1.77221,1.34564,1.36952,-1.29642,-1.38653,-0.161034,-0.0490015,-1.40842,-1.25594,-0.437741,-0.551854,-0.64347,-0.169591,-1.67441,-1.54164
8198,0.340406,0.354312,0.359151,0.355881,0.247675,0.217853,0.642681,0.610297,0.705121,0.775405,0.916727,0.898672,0.179431,0.0936629,0.248557,0.2343,0.805668,0.758544,0.972405,0.984949,0.308732,0.316162,0.0504454,0.101092,2.68181,2.83046,-0.731824,-0.703694,-0.364692,-0.460889,0.844693,0.960566,1.20779,1.36455,-0.0427126,-0.159068,0.675014,1.14726,-0.746614,-0.651607
8199,0.702856,0.71678,0.377947,0.374915,0.439957,0.408206,0.0769669,0.0465604,0.0593671,0.131133,0.135053,0.118245,0.119137,0.117659,0.184811,0.168547,0.565062,0.593174,0.153866,0.16426,-0.656083,-0.642738,-1.16719,-1.11095,0.420797,0.575101,2.33448,2.35655,-1.79738,-1.89831,0.184376,0.294504,0.189344,0.347872,-0.398623,-0.518005,2.51539,2.98355,0.11017,0.238429
8200,0.269662,0.286018,0.655429,0.651154,0.193181,0.158781,0.755467,0.723257,0.0904773,0.163096,0.313435,0.297346,0.193243,0.141655,0.834892,0.818034,0.674575,0.702756,0.877967,0.88757,-1.12447,-1.10805,0.45935,0.509983,-3.14634,-2.99204,-1.05972,-1.03208,-0.678532,-0.775267,-1.33365,-1.22957,0.673476,0.824482,-0.298976,-0.464298,0.715514,1.17718,-1.15117,-1.02726
8201,0.602695,0.618172,0.437797,0.431775,0.828549,0.792551,0.386234,0.356448,0.7695,0.844088,0.832892,0.814674,0.203032,0.165651,0.257535,0.241889,0.408427,0.437898,0.107507,0.119297,1.10824,1.12767,-0.838176,-0.794272,-0.79287,-0.635506,-1.36453,-1.32983,-0.571004,-0.731826,0.519931,0.626203,0.294465,0.442158,-0.295286,-0.410591,0.215175,0.675886,-1.74684,-1.62346
8202,0.397114,0.414306,0.675643,0.669082,0.888861,0.854732,0.482137,0.456211,0.507335,0.581784,0.643395,0.626194,0.817517,0.781827,0.189911,0.192599,0.599706,0.628393,0.49962,0.513863,-1.1284,-1.10431,0.0943153,0.143288,-0.0564372,0.102494,-0.680833,-0.645281,-0.596167,-0.688384,0.405425,0.518822,1.21339,1.36338,-0.775456,-0.890822,-1.95223,-1.4976,-0.792321,-0.663949
8203,0.422341,0.439374,0.701034,0.680201,0.0819738,0.0466566,0.58567,0.555973,0.850646,0.924382,0.919041,0.901191,0.790446,0.780888,0.157885,0.143309,0.474381,0.586466,0.27522,0.266864,-0.398582,-0.378641,-1.15772,-1.11539,-1.62756,-1.46979,0.582392,0.612287,0.915339,0.819309,0.726327,0.839112,0.209225,0.361576,1.36683,1.25659,-0.764996,-0.306893,-0.55448,-0.430917
8204,0.875715,0.891834,0.78945,0.691319,0.0157005,-0.0183841,0.142192,0.114043,0.491404,0.62093,0.2926,0.276603,0.815581,0.77995,0.974347,0.961548,0.540649,0.54454,0.00358266,0.0198647,-0.68229,-0.659764,0.420907,0.459788,-0.18139,-0.0292901,0.601957,0.58788,-0.595985,-0.696114,-0.146278,-0.0411355,-0.236033,-0.0844731,0.261687,0.147087,-0.528356,-0.0675899,1.67357,1.79849
8205,0.851627,0.866551,0.707245,0.702437,0.485362,0.450199,0.984298,0.956122,0.245989,0.317479,0.440552,0.357758,0.552138,0.519248,0.441289,0.430499,0.475389,0.502613,0.280637,0.278654,0.812423,0.839365,-0.719784,-0.675853,0.78317,0.938682,0.466319,0.563474,-0.128846,-0.231996,1.76723,1.87376,-0.265613,-0.113245,0.544134,0.433771,0.57306,1.03206,-0.745917,-0.619224
8206,0.360459,0.375496,0.00405569,-0.00296214,0.181068,0.146122,0.610045,0.584204,0.977897,1.05023,0.455147,0.438913,0.63781,0.603073,0.645368,0.632339,0.928618,0.958029,0.519979,0.537444,0.0500783,0.0807663,-0.137556,-0.0900905,1.40626,1.56691,0.509173,0.539068,-0.771202,-0.87219,-0.244576,-0.142787,2.89292,3.04613,0.244361,0.138235,1.14368,1.60064,0.394844,0.523364
8207,0.727012,0.685906,0.865051,0.85649,0.782423,0.749681,0.667927,0.583387,0.0150697,0.088752,0.271247,0.32915,0.158429,0.121449,0.114022,0.10129,0.00445732,0.0348513,0.291852,0.306627,-1.18505,-1.15317,1.43129,1.48508,0.123504,0.286022,-1.35158,-1.32574,0.690995,0.588806,-0.57456,-0.465595,1.08668,1.24728,1.16087,1.05068,0.408155,0.868267,-0.673288,-0.541504
8208,0.981979,0.996316,0.0383398,0.0316465,0.808051,0.708035,0.670183,0.582571,0.559142,0.633121,0.13797,0.219386,0.224887,0.190243,0.67007,0.659189,0.865013,0.896487,0.47217,0.528989,0.0209862,0.0488143,-0.803769,-0.75076,-0.890651,-0.733576,1.56258,1.58436,-1.04247,-1.14153,1.03474,1.14334,0.0424014,0.254088,1.1023,0.997593,-0.704971,-0.239005,1.09686,1.2342
8209,0.240908,0.256715,0.193549,0.0881484,0.772774,0.666389,0.583535,0.581755,0.433852,0.506783,0.127316,0.109623,0.561548,0.527922,0.701536,0.716524,0.0703744,0.0996787,0.7335,0.751352,0.840629,0.856269,0.722528,0.776953,-2.21858,-2.06195,0.420955,0.435875,-0.133483,-0.232066,0.405959,0.5078,-0.899332,-0.739105,0.507829,0.408659,-0.516551,-0.046443,1.98252,2.11727
8210,0.474863,0.529858,0.149994,0.14465,0.6572,0.624742,0.609094,0.580938,0.962297,1.03581,0.903314,0.886744,0.555652,0.520495,0.786235,0.773859,0.586553,0.614764,0.741779,0.762069,1.63417,1.66372,1.20069,1.25319,0.112186,0.262984,2.22468,2.2471,-0.27618,-0.36956,-1.24529,-1.1405,0.157724,0.319907,-0.506679,-0.609443,0.681954,1.06834,0.0243386,0.159677
8211,0.78839,0.803001,0.536362,0.45044,0.992421,0.961905,0.33565,0.307911,0.564757,0.637295,0.365307,0.347528,0.184004,0.149781,0.48723,0.472295,0.362617,0.39131,0.446765,0.466662,1.27178,1.3058,0.141153,0.19536,-1.37056,-1.21836,-1.0721,-1.04898,0.95163,0.863942,-0.678146,-0.572975,0.692438,0.856996,-0.47965,-0.586465,1.71301,2.18312,0.92862,1.05823
8212,0.820112,0.801888,0.761437,0.756231,0.731515,0.701906,0.869427,0.840534,0.653571,0.725818,0.613126,0.595637,0.817635,0.780946,0.602038,0.639741,0.832575,0.861861,0.377463,0.398329,1.73757,1.77269,-1.484,-1.42462,0.627428,0.783044,-1.45376,-1.42355,-1.04993,-1.13431,0.46735,0.574074,0.531694,0.690132,-0.0279286,-0.13315,-1.95666,-1.48793,0.13368,0.265568
8213,0.783855,0.800775,0.453509,0.45026,0.104003,0.0731962,0.423436,0.430933,0.492123,0.648295,0.201653,0.184632,0.90784,0.87058,0.820787,0.807188,0.979427,1.0063,0.535253,0.555591,0.148661,0.185155,0.242629,0.303592,0.532752,0.689776,0.170499,0.198083,0.576532,0.496234,-0.834429,-0.719668,1.2499,1.41198,-1.2126,-1.31837,1.33611,1.80523,-1.10625,-0.970072
8214,0.376273,0.395566,0.898156,0.89405,0.795526,0.763254,0.051601,0.0213332,0.50001,0.570771,0.940651,0.926558,0.682044,0.644212,0.576662,0.564273,0.0716995,0.100164,0.122797,0.144119,-1.06879,-1.03574,0.642186,0.703383,-1.88329,-1.72571,0.316724,0.34884,-0.391312,-0.465351,1.10091,1.21246,0.305235,0.471874,-0.17405,-0.282358,-0.0983977,0.365874,0.216987,0.356312
8215,0.63285,0.652007,0.499072,0.49461,0.979619,0.949041,0.264168,0.232318,0.176606,0.248395,0.952423,0.93837,0.0166048,-0.022559,0.0675624,0.0530029,0.963409,0.992651,0.217088,0.213362,0.573155,0.601104,-0.158595,-0.0700947,1.57217,1.73016,1.34904,1.37551,-2.0918,-2.16528,-0.855283,-0.74514,0.08757,0.259432,0.0776585,-0.0265757,-1.18271,-0.711587,-0.245669,-0.103782
8216,0.452504,0.414993,0.73767,0.737485,0.15302,0.12448,0.0812342,0.148406,0.448125,0.5201,0.130858,0.114914,0.451517,0.414336,0.453026,0.439614,0.22317,0.251468,0.259487,0.282605,-1.14319,-1.11008,-0.90702,-0.843572,-1.28596,-1.12789,-0.542344,-0.522298,-0.0895121,-0.155947,1.01793,1.12443,-0.553059,-0.384705,0.0319615,-0.0668242,-0.141341,0.326879,1.71396,1.85461
8217,0.15743,0.177979,0.986985,0.98036,0.857302,0.829973,0.0951849,0.0644947,0.284782,0.358734,0.964419,0.950217,0.383655,0.44386,0.291963,0.276855,0.501741,0.583095,0.936115,0.961465,-1.23444,-1.19626,-1.36607,-1.30035,1.66579,1.82519,1.08143,1.09933,1.40297,1.33556,-2.0763,-1.96689,-0.302443,-0.125597,-0.28332,-0.380156,1.10427,1.56782,0.197856,0.394781
8218,0.142293,0.162878,0.329125,0.324087,0.357626,0.330277,0.721791,0.691662,0.853911,0.927474,0.175141,0.159263,0.508885,0.473385,0.856544,0.83909,0.88526,0.914722,0.320239,0.346263,-0.00682299,0.0337234,0.146675,0.210487,-0.264178,-0.110694,-2.31902,-2.3062,1.59016,1.48529,-0.120224,-0.00577632,-0.0280696,0.133512,-1.98752,-2.08948,1.04003,1.50105,-1.2057,-1.06505
8219,0.439143,0.528404,0.200034,0.194954,0.764515,0.73842,0.858219,0.768825,0.137977,0.211889,0.516233,0.498839,0.640868,0.603905,0.881792,0.911734,0.458011,0.485632,0.0764785,0.100952,0.556946,0.590718,-0.28436,-0.214018,0.509291,0.657995,-0.951483,-0.941256,1.59249,1.63503,0.10204,0.223277,0.705102,0.870576,-2.17823,-2.27913,0.233287,0.69168,-0.0621986,0.0775417
8220,0.872084,0.893931,0.626602,0.6194,0.870147,0.845052,0.875687,0.845987,0.711594,0.786182,0.280078,0.260385,0.556345,0.519543,0.999408,0.984377,0.905345,0.930831,0.0579281,0.0814456,-2.80625,-2.76612,-1.75366,-1.67977,-0.238401,-0.096232,-1.27678,-1.26894,1.84721,1.78477,0.750588,0.867313,-0.287241,-0.115224,-1.63228,-1.73294,0.353202,0.849231,-0.439926,-0.294676
8221,0.174995,0.195688,0.804937,0.798088,0.728353,0.703046,0.354797,0.32305,0.87859,0.868891,0.344847,0.326826,0.00910776,-0.0273119,0.15242,0.138697,0.00117973,0.0246911,0.729113,0.75084,1.1964,1.23653,0.364392,0.444111,0.126111,0.198604,0.719689,0.730125,0.647751,0.58002,-0.000384364,0.176644,-0.455308,-0.282088,-0.301875,-0.407919,0.554183,1.00678,-2.42384,-2.28153
8222,0.917835,0.939655,0.308403,0.299806,0.818088,0.79277,0.248904,0.312417,0.878127,0.9516,0.874569,0.858448,0.81845,0.783537,0.545001,0.53084,0.198598,0.220273,0.665577,0.686566,-0.127786,-0.0912212,0.337743,0.479636,0.352771,0.493441,-1.07182,-1.0544,2.11214,2.04102,-0.626607,-0.514025,0.421134,0.592438,0.22693,0.123148,0.285196,0.717008,0.263792,0.402956
8223,0.953373,0.975944,0.0839626,0.075528,0.906027,0.882495,0.334976,0.301784,0.807766,0.88096,0.656308,0.639924,0.60616,0.558348,0.162237,0.14957,0.928622,0.951975,0.355764,0.419276,0.828496,0.862877,0.439486,0.515161,-0.185447,-0.0419841,-1.10755,-1.09005,-0.499704,-0.568106,0.69643,0.802105,-0.706189,-0.533011,-0.109478,-0.219318,-0.0235229,0.427234,-0.0325176,0.108956
8224,0.310418,0.334555,0.22893,0.282075,0.649692,0.628976,0.734466,0.701131,0.0262782,0.10143,0.830642,0.814698,0.488942,0.333159,0.386295,0.373495,0.464358,0.487091,0.130962,0.151987,0.400207,0.428525,0.641502,0.717133,0.264308,0.403343,1.15104,1.16966,0.493878,0.418955,-1.49576,-1.38669,1.53974,1.71703,1.06929,0.954242,-0.54224,-0.0892815,1.10805,1.25154
8225,0.593351,0.587963,0.499193,0.488622,0.985533,0.966139,0.495269,0.463525,0.194291,0.181579,0.243092,0.224908,0.142884,0.107971,0.227773,0.216979,0.890138,0.911776,0.137046,0.1573,2.07433,2.09591,-1.33481,-1.26529,-0.531603,-0.39808,-1.34838,-1.3306,1.10825,1.03607,-0.325153,-0.221793,0.129921,0.312464,-0.591747,-0.708133,-0.346427,0.10328,0.617402,0.858329
8226,0.818944,0.84137,0.0941196,0.0849677,0.287101,0.266729,0.462903,0.452018,0.184814,0.261729,0.874146,0.855589,0.633569,0.60006,0.320851,0.261203,0.325379,0.346258,0.787616,0.806111,0.0387688,0.055446,-0.667624,-0.602122,0.232675,0.37061,-0.226015,-0.303805,0.979153,0.913435,0.548891,0.649991,2.36276,2.54728,-0.260741,-0.376247,0.578098,1.03085,0.325145,0.465115
8227,0.411717,0.481239,0.386237,0.375835,0.984122,0.962235,0.434073,0.440512,0.00584658,0.0850962,0.0358969,0.0176145,0.277846,0.244913,0.314277,0.305427,0.524314,0.644672,0.377642,0.394639,1.38262,1.3975,0.433196,0.492763,-1.51872,-1.37474,0.705215,0.722993,1.13283,1.07283,-0.615262,-0.518978,0.656038,0.841992,1.05375,0.932741,-0.650143,-0.203864,0.306506,0.442078
8228,0.0983065,0.121109,0.958553,0.947218,0.799632,0.807913,0.530001,0.429006,0.938302,1.02018,0.617767,0.598467,0.819933,0.786567,0.773662,0.766466,0.920848,0.943085,0.235121,0.249533,-0.448532,-0.437813,0.368737,0.433616,-0.346323,-0.208258,0.274417,0.285727,0.635056,0.568705,-0.259748,-0.196601,0.864075,1.05483,0.250657,0.129509,-0.68964,-0.239918,-0.0574078,0.0849285
8229,0.205374,0.19224,0.0785731,0.0666067,0.675226,0.653591,0.449244,0.4175,0.671007,0.752937,0.993764,0.973367,0.131597,0.0989966,0.25585,0.250658,0.133006,0.153279,0.431658,0.446827,0.754379,0.764172,1.38103,1.44933,0.3996,0.544918,1.53512,1.5433,0.84502,0.772456,0.0424185,0.125777,-0.809624,-0.619022,0.10975,0.0360465,-0.172385,0.282535,-0.0214417,0.123267
8230,0.228119,0.263371,0.545763,0.534969,0.0586674,0.0350517,0.723136,0.692754,0.14535,0.229922,0.0987823,0.0787008,0.0227283,-0.0102331,0.75025,0.747915,0.0160457,0.0361079,0.880417,0.895914,-0.340756,-0.33396,1.01941,1.08491,-1.01719,-0.876196,-1.27979,-1.26677,-0.200757,-0.266561,0.351871,0.448154,-1.23917,-1.0486,0.0685505,-0.0574161,-1.03562,-0.625886,0.271059,0.40376
8231,0.313952,0.334502,0.429335,0.416921,0.641464,0.618566,0.559101,0.529889,0.899622,0.982737,0.257351,0.238171,0.682542,0.64766,0.856007,0.854252,0.867695,0.886183,0.757242,0.659496,0.88036,0.880325,0.340274,0.398672,-0.485317,-0.339919,-2.04348,-2.02865,-0.20961,-0.276989,0.209509,0.225267,-0.453129,-0.264893,0.13352,0.0118381,-1.9816,-1.53431,0.54117,0.684253
8232,0.736376,0.757594,0.884212,0.871276,0.164439,0.138864,0.124481,0.0936534,0.508104,0.589171,0.158208,0.14028,0.776244,0.640365,0.518581,0.517514,0.448766,0.467318,0.447837,0.423078,0.20912,0.215431,0.248734,0.307767,-0.849165,-0.706728,-0.489112,-0.471159,0.506554,0.43186,-0.0930136,0.00238003,-0.379887,-0.186883,1.38165,1.25906,-0.653631,-0.19841,-0.864582,-0.718363
8233,0.619694,0.698923,0.348852,0.334178,0.117612,0.0898403,0.87187,0.842115,0.613933,0.69297,0.731725,0.711332,0.678242,0.633071,0.808929,0.808149,0.920187,0.937869,0.171855,0.186661,-2.12447,-2.12099,-2.44627,-2.39022,-0.857695,-0.721474,-1.10226,-1.17905,0.320918,0.248528,-0.547187,-0.445966,-1.62482,-1.43581,-0.712302,-0.842377,-0.0609533,0.401079,1.37398,1.52581
8234,0.621048,0.640253,0.625655,0.610417,0.658358,0.63274,0.115116,0.0828657,0.093973,0.174544,0.752625,0.80296,0.659474,0.625776,0.534704,0.535615,0.873148,0.938144,0.766853,0.780879,2.05559,2.05906,-1.24587,-1.18907,0.250539,0.355976,-1.90488,-1.88693,-0.0840717,-0.14797,1.29784,1.3952,0.00907259,0.197954,-0.955642,-1.07823,-0.370261,0.085202,0.384873,0.588813
8235,0.119392,0.139124,0.483206,0.377819,0.390733,0.427832,0.953531,0.919312,0.525108,0.607088,0.91472,0.894587,0.966566,0.932728,0.581775,0.608761,0.91855,0.938419,0.795292,0.766273,0.244196,0.252526,0.437967,0.493937,1.2972,1.43343,-0.0974955,-0.0757087,0.220885,0.161405,1.43446,1.53248,-0.30127,-0.107124,0.295944,0.168989,1.7283,2.18586,-0.500019,-0.348187
8236,0.449193,0.471278,0.161498,0.145221,0.248865,0.222924,0.125197,0.0917539,0.122781,0.20301,0.75555,0.736133,0.758143,0.722359,0.649667,0.681906,0.518639,0.577138,0.739419,0.751667,0.508998,0.518408,-3.14165,-3.08568,0.427036,0.569748,-0.276543,-0.256177,-0.627298,-0.693742,0.443933,0.544264,0.41718,0.614721,2.53184,2.40719,1.70428,2.16491,-1.18441,-1.03361
8237,0.308057,0.328269,0.737709,0.720985,0.453565,0.428293,0.232777,0.311975,0.769472,0.847911,0.205304,0.186786,0.103867,0.0701149,0.785627,0.755051,0.196829,0.215857,0.421253,0.435899,1.02179,1.03244,0.0816153,0.136227,-0.0895875,0.0495341,-0.461479,-0.436646,1.1182,1.05833,0.776544,0.878792,0.802915,0.997167,0.156507,0.0258691,0.350437,0.804632,0.066797,0.215644
8238,0.841174,0.859608,0.462678,0.514306,0.89529,0.867618,0.508479,0.532196,0.270452,0.349664,0.790128,0.772447,0.316912,0.266677,0.846251,0.828197,0.25704,0.274017,0.673339,0.689105,1.23389,1.25133,-2.64887,-2.59327,0.207377,0.341606,-1.60235,-1.58513,0.611369,0.554206,-0.658395,-0.553628,0.285027,0.431006,1.05177,0.922645,0.620368,1.07509,-0.88107,-0.72832
8239,0.214719,0.233722,0.323415,0.307627,0.273004,0.243498,0.78586,0.752417,0.513802,0.590895,0.714269,0.694218,0.422069,0.463238,0.900431,0.901342,0.969595,0.986255,0.259962,0.277633,-1.45637,-1.43364,-2.13636,-2.08372,-0.488502,-0.350836,0.454454,0.477516,-0.28616,-0.345534,0.475759,0.579248,-0.329406,-0.135155,-0.656116,-0.786677,0.08054,0.528259,2.2451,2.39121
8240,0.00470769,0.0248775,0.871883,0.855495,0.04409,0.0160712,0.77664,0.745634,0.178185,0.253686,0.0257763,0.00411936,0.69467,0.6598,0.133159,0.134932,0.684097,0.725897,0.444234,0.459958,1.25079,1.27075,2.22214,2.27479,2.3057,2.43962,-0.0971612,0.0199931,0.970897,0.919609,0.86009,0.962139,-2.0492,-1.85467,-0.15451,-0.286774,1.63181,2.08118,-0.632891,-0.493573
8241,0.472186,0.472,0.971795,0.954427,0.251929,0.282384,0.514411,0.482195,0.949924,1.02786,0.00393722,-0.0190565,0.571474,0.535188,0.44531,0.446123,0.447382,0.46554,0.253378,0.269337,-1.02544,-1.00564,-0.649692,-0.597049,0.0160452,0.152441,-0.460999,-0.43753,0.255973,0.204984,0.929312,1.03777,-0.665839,-0.547245,1.38974,1.25418,-0.911075,-0.454546,1.22219,1.35899
8242,0.900304,0.919123,0.336896,0.318966,0.57496,0.548696,0.519241,0.486003,0.138304,0.217743,0.440974,0.4193,0.131295,0.0944533,0.0876887,0.0891663,0.917911,0.936091,0.843427,0.858472,-1.34848,-1.3313,-0.24405,-0.197258,-0.143006,-0.00321001,-0.0740937,-0.0434697,0.952248,0.899466,2.38629,2.48959,0.565653,0.760181,0.157271,-0.0699241,-0.835367,-0.349195,-0.134097,0.00188404
8243,0.182674,0.199661,0.373475,0.35734,0.50004,0.467485,0.839618,0.805634,0.517587,0.599285,0.196679,0.17588,0.491185,0.456914,0.175248,0.237531,0.860275,0.880526,0.145492,0.160815,1.68575,1.69821,-0.233431,-0.181174,-0.295256,-0.158861,-0.430638,-0.403278,-0.0501676,-0.11012,-1.16591,-1.05726,0.151387,0.346066,-1.25846,-1.39402,-0.699242,-0.243844,-0.797574,-0.654556
8244,0.766288,0.785291,0.736883,0.722073,0.522757,0.386275,0.405285,0.457954,0.90145,0.980828,0.290302,0.271115,0.176096,0.140654,0.380053,0.385896,0.486272,0.506342,0.721364,0.734898,-0.585938,-0.578172,0.33468,0.38897,1.16437,1.29637,-0.430958,-0.406314,0.772452,0.707161,-0.614357,-0.504765,1.38779,1.57725,0.753288,0.613671,0.461615,0.917369,0.267629,0.411445
8245,0.815007,0.835539,0.407743,0.420217,0.368765,0.305065,0.143104,0.110273,0.460357,0.537392,0.0392112,0.0181246,0.706338,0.671807,0.530973,0.534262,0.583132,0.604876,0.59025,0.649022,0.769143,0.779274,-0.241752,-0.189953,-0.60163,-0.464943,0.0362766,0.0628914,1.14399,1.08167,-1.00129,-0.888987,1.08738,1.31598,1.96365,1.83035,-0.401874,0.0611234,-1.41652,-1.26551
8246,0.386033,0.485485,0.133843,0.11836,0.250118,0.223854,0.0342939,0.00264936,0.228144,0.369322,0.271792,0.176485,0.562861,0.52687,0.00823182,0.0131634,0.0941152,0.114859,0.55078,0.563147,0.175693,0.189874,0.582703,0.641869,1.53396,1.66338,-0.253633,-0.285723,0.163696,0.102745,0.03397,0.153477,0.863083,1.05471,-0.210584,-0.335603,0.627205,1.08287,-0.268821,-0.122924
8247,0.112646,0.135432,0.120726,0.102769,0.487679,0.366251,0.910494,0.877656,0.125314,0.201251,0.352881,0.334845,0.802494,0.767982,0.0836096,0.146053,0.406442,0.425642,0.194237,0.207361,-0.87685,-0.861353,-1.26491,-1.20119,0.546995,0.675243,-0.665608,-0.634338,-0.17657,-0.234703,0.678903,0.797513,-1.71363,-1.52403,-1.13523,-1.26095,-0.458074,-0.008085,-0.902926,-0.765772
8248,0.569357,0.593114,0.526381,0.508443,0.535282,0.508649,0.230678,0.195647,0.148095,0.224759,0.516024,0.493205,0.561294,0.585594,0.271704,0.278943,0.384008,0.404786,0.292443,0.303527,-1.59176,-1.57362,0.955915,1.0215,-2.50268,-2.38009,0.263291,0.299049,-0.0803704,-0.136934,-0.280196,-0.159414,-0.571744,-0.386142,-0.280452,-0.408804,0.681692,1.13774,0.094342,0.22387
8249,0.229968,0.252879,0.359457,0.33989,0.547494,0.520655,0.959705,0.923615,0.738146,0.814726,0.347173,0.299098,0.370242,0.403206,0.683989,0.690687,0.665936,0.685963,0.0401878,0.0537097,-0.612255,-0.589027,-1.87555,-1.80677,0.970265,1.09643,0.939499,0.968433,-0.812713,-0.869743,1.74444,1.86623,1.10737,1.29274,0.129825,-0.000843283,-0.409257,0.046789,-1.66327,-1.53149
8250,0.899166,0.924101,0.583292,0.56275,0.110711,0.085326,0.742115,0.706091,0.314895,0.390826,0.126689,0.104992,0.257125,0.220818,0.520842,0.520415,0.705106,0.724408,0.271911,0.286489,-0.803953,-0.778906,0.568193,0.639716,1.67735,1.80321,0.292958,0.226717,-0.877558,-1.01144,-0.465719,-0.339635,0.715567,0.894526,-1.12479,-1.26467,0.519918,0.974359,-0.216245,-0.0822817
8251,0.101788,0.125264,0.577689,0.557104,0.365616,0.340806,0.835285,0.766683,0.155108,0.22946,0.473499,0.450642,0.510451,0.472982,0.345345,0.350144,0.0590114,0.0797302,0.88294,0.895354,-0.249103,-0.221911,2.10708,2.18232,-0.0840671,0.0418941,-0.464938,-0.514999,-1.10182,-1.15314,-1.60839,-1.47924,-0.058502,0.127577,-0.168145,-0.306444,0.268471,0.72066,-0.387749,-0.21008
8252,0.943766,0.967018,0.808055,0.78952,0.0905573,0.0663883,0.865942,0.827275,0.655379,0.646733,0.129597,0.107892,0.239942,0.202049,0.878171,0.882727,0.554827,0.509667,0.329019,0.339545,-0.23151,-0.200615,1.00245,1.07786,-0.562264,-0.430589,-1.28565,-1.25671,0.0874941,0.0330363,-1.31987,-1.19,-0.333518,-0.14633,0.519852,0.376864,-2.17669,-1.7291,-0.473214,-0.337879
8253,0.431902,0.529742,0.0618777,0.0437661,0.592259,0.569949,0.924186,0.887866,0.989342,1.06401,0.867486,0.843945,0.642482,0.603986,0.53656,0.557773,0.918985,0.939604,0.406753,0.452326,0.928929,0.953864,-1.73048,-1.65164,-0.813395,-0.675071,-0.182712,-0.154595,0.983779,0.928779,-0.476154,-0.34788,-1.13141,-0.945448,-1.20056,-1.34901,0.655341,1.09877,0.944416,1.08126
8254,0.0704493,0.092466,0.471429,0.464662,0.773002,0.751272,0.786079,0.750647,0.613926,0.735607,0.680588,0.692193,0.391036,0.353164,0.226522,0.23282,0.19643,0.218778,0.553852,0.565108,0.121863,0.147434,-1.14848,-1.06588,0.248346,0.38541,1.2795,1.30788,-1.1163,-1.17182,-0.181087,-0.058641,-0.318978,-0.13378,-1.22882,-1.37228,1.9714,2.41562,0.945054,1.08884
8255,0.333607,0.354389,0.903011,0.885558,0.418041,0.378821,0.342279,0.308717,0.330892,0.407207,0.566107,0.54044,0.459463,0.421958,0.257178,0.26404,0.796931,0.820652,0.858025,0.867715,-0.174984,-0.14953,0.894421,0.978414,1.00402,1.13859,0.192235,0.219243,1.14367,1.08082,-0.556188,-0.442356,-1.45861,-1.27379,0.314446,0.168672,1.30983,1.76131,1.22324,1.36693
8256,0.32664,0.34413,0.296852,0.279738,0.0270567,0.00636964,0.949499,0.915606,0.544099,0.661837,0.124853,0.0988864,0.904796,0.868105,0.289551,0.295261,0.0370913,0.0609743,0.855738,0.86322,-0.826153,-0.800416,0.368603,0.391866,-1.09294,-0.956637,0.757261,0.838482,1.05535,0.988721,-0.953591,-0.82607,1.21674,1.39658,0.0237017,-0.126863,-0.808497,-0.359705,-0.693015,-0.543564
8257,0.234798,0.333871,0.211377,0.196407,0.17937,0.157968,0.609326,0.574141,0.841228,0.916467,0.700296,0.674956,0.383893,0.345789,0.724386,0.732443,0.229758,0.184038,0.618132,0.627541,0.858979,0.88354,-0.285997,-0.194682,-1.75427,-1.61863,1.4264,1.45772,0.195797,0.133574,0.223405,0.352461,-0.204781,-0.0253621,0.604231,0.449513,0.252942,0.708775,0.558122,0.70569
8258,0.304159,0.323611,0.525618,0.51284,0.0989455,0.166409,0.724778,0.688593,0.438108,0.512388,0.396462,0.371256,0.514447,0.476309,0.944596,0.950679,0.281294,0.307102,0.670063,0.680214,0.713571,0.736459,-0.365419,-0.269147,-0.593066,-0.452149,0.780673,0.805365,-0.292553,-0.353207,0.459081,0.581515,-1.03608,-0.851407,0.0274843,-0.122104,-0.728822,-0.274442,0.222802,0.400252
8259,0.987255,1.00482,0.436421,0.411308,0.195101,0.174849,0.282452,0.246663,0.269818,0.355905,0.411208,0.387951,0.209896,0.1703,0.95925,0.895323,0.0618974,0.0882609,0.491883,0.430009,0.973836,1.00234,0.130014,0.225037,1.78901,1.93704,0.927957,0.956122,0.362222,0.294602,-0.495266,-0.375411,2.22072,2.39713,-0.0814601,-0.235954,0.157182,0.60649,-0.0482427,0.0948145
8260,0.514016,0.52917,0.301782,0.309775,0.646361,0.624104,0.327984,0.290105,0.123678,0.199421,0.21003,0.247661,0.917788,0.878391,0.855506,0.839967,0.569041,0.593916,0.168308,0.179803,-0.888113,-0.866897,0.278981,0.379602,0.42277,0.577776,1.74824,1.77959,0.168038,0.0957885,0.792079,0.910286,-1.79731,-1.62091,2.0048,1.84928,-0.217765,0.230113,-1.13248,-0.988072
8261,0.907734,0.922117,0.0679295,0.208243,0.136207,0.115716,0.811274,0.772706,0.508426,0.582834,0.128319,0.107371,0.502104,0.442399,0.776176,0.784612,0.330202,0.355405,0.960373,0.972104,-0.477769,-0.461096,1.19974,1.30086,-0.278937,-0.129531,0.18571,0.216457,-0.842172,-0.913798,1.2325,1.37662,0.519881,0.69811,0.3146,0.156084,-0.215146,0.239426,0.76545,0.910475
8262,0.431244,0.446468,0.060663,0.10671,0.795547,0.77471,0.134311,0.0947982,0.162634,0.235406,0.488726,0.420502,0.0458533,0.00640704,0.33494,0.343033,0.663005,0.685944,0.166799,0.176524,0.583647,0.600791,-1.39519,-1.28969,0.00570385,0.162541,-0.612098,-0.574346,0.0539131,0.0812562,1.72367,1.84295,1.28531,1.46521,-1.11812,-1.27689,-1.51493,-1.00022,-0.495458,-0.355214
8263,0.307872,0.322524,0.0179553,0.00517776,0.852195,0.831528,0.356631,0.315144,0.0750994,0.149654,0.754268,0.733633,0.137471,0.167413,0.623828,0.633667,0.213536,0.236146,0.329748,0.338288,0.0682362,0.0861491,-1.09294,-0.994084,-0.339366,-0.187966,-0.74105,-0.700621,1.14467,1.07631,0.576443,0.703337,-1.49781,-1.31394,0.655052,0.495838,-2.70019,-2.23987,1.12516,1.26575
8264,0.502445,0.518494,0.00394319,-0.010413,0.252096,0.232193,0.989794,0.947837,0.977578,1.05082,0.226066,0.203714,0.397394,0.328419,0.492196,0.50188,0.54932,0.572578,0.224689,0.232583,-1.05822,-1.04094,1.44374,1.54676,0.974459,1.13143,0.489432,0.526474,-0.67038,-0.730794,0.507828,0.641087,-0.457881,-0.272852,-1.25439,-1.41776,-0.929851,-0.466925,0.252561,0.39635
8265,0.405128,0.357283,0.360805,0.345898,0.394688,0.374145,0.417511,0.375175,0.15287,0.228199,0.360496,0.33888,0.531194,0.489425,0.673145,0.695713,0.379935,0.404879,0.832512,0.841448,-1.57607,-1.55558,0.299367,0.369771,-0.494489,-0.335157,0.722249,0.754963,-0.0872022,-0.144746,1.66779,1.80598,-0.76141,-0.57793,-1.03757,-1.15025,-0.917575,-0.457612,0.481113,0.629382
8266,0.18096,0.196071,0.71542,0.70221,0.856112,0.837703,0.109986,0.0673895,0.502552,0.523583,0.986206,0.964337,0.000955535,-0.0427622,0.880841,0.889545,0.606114,0.656196,0.0798547,0.0887559,0.269143,0.295425,-0.904197,-0.807218,-0.73183,-0.579639,-1.10004,-1.06286,-0.220002,-0.28224,0.163049,0.296194,1.46297,1.64077,-0.717674,-0.88273,0.161772,0.626304,-0.141986,0.00346121
8267,0.284906,0.302073,0.690193,0.677015,0.744544,0.72617,0.812103,0.769463,0.744706,0.818968,0.789585,0.820403,0.0151186,-0.0298138,0.124809,0.134031,0.880924,0.907512,0.00163338,0.0107012,0.232199,0.25619,-1.27666,-1.17163,0.346591,0.495595,-0.810767,-0.774442,0.463426,0.397768,0.147248,0.280424,-0.553,-0.376809,-1.54602,-1.71653,0.360379,0.818866,1.55664,1.69915
8268,0.179925,0.199471,0.0482873,0.0367179,0.315304,0.296259,0.89364,0.853016,0.576783,0.652347,0.69812,0.676469,0.236106,0.192998,0.457519,0.465889,0.340587,0.367909,0.758723,0.77005,-0.284481,-0.258452,-0.606032,-0.493272,-0.010358,0.153103,2.027,2.0641,-0.445854,-0.423544,-2.03036,-1.89465,0.584821,0.761082,-0.0766647,-0.252384,-0.901537,-0.445207,1.62512,1.76737
8269,0.397668,0.41605,0.230639,0.220179,0.637527,0.617797,0.571451,0.559446,0.915252,0.989724,0.192913,0.171095,0.374508,0.41581,0.523745,0.609201,0.0593503,0.0893928,0.932294,0.847666,-0.434293,-0.405533,0.706275,0.816385,-0.339705,-0.189388,0.437064,0.467755,-1.1792,-1.24486,1.50022,1.63448,-1.23939,-1.06851,2.07976,1.9096,0.644831,1.10772,-1.36374,-1.2192
8270,0.213179,0.235574,0.712522,0.703898,0.0586445,0.0389675,0.305827,0.265876,0.240284,0.314525,0.109844,0.0879617,0.683555,0.638623,0.745646,0.752514,0.178584,0.208561,0.91223,0.925283,-1.52252,-1.48702,0.277293,0.484536,0.541608,0.687821,1.18751,1.21636,-0.359526,-0.427575,-0.924423,-0.791648,-0.372886,-0.109295,-0.192758,-0.358523,-0.703879,-0.238843,0.254831,0.401763
8271,0.0366278,0.0550972,0.626764,0.604185,0.587674,0.567502,0.469321,0.430717,0.547179,0.621786,0.959956,0.939199,0.083699,0.0375723,0.651324,0.754416,0.981197,1.01031,0.364823,0.378519,-0.295115,-0.257043,0.039811,0.152686,0.753606,0.902525,-0.160089,-0.130762,-0.268133,-0.329806,0.870993,1.00143,0.679043,0.84992,2.26352,2.10323,0.812362,1.28386,0.470038,0.618012
8272,0.22074,0.241127,0.514551,0.504472,0.201998,0.182886,0.0518029,0.0139473,0.00276895,0.0782961,0.140423,0.121859,0.317818,0.273422,0.73315,0.756319,0.0647293,0.0924642,0.426226,0.52967,-0.378989,-0.272451,-0.757748,-0.641985,-0.612693,-0.456735,0.308589,0.338444,-0.403815,-0.467301,0.269846,0.3975,-1.3759,-1.19939,-0.851535,-1.00586,-1.05581,-0.587747,-0.203506,-0.0546931
8273,0.188544,0.209844,0.794341,0.786249,0.668767,0.651469,0.0506705,0.0127279,0.677351,0.754979,0.396644,0.39792,0.832514,0.789707,0.750459,0.758221,0.391492,0.418561,0.667562,0.68082,-0.322846,-0.28786,-0.937945,-0.823351,-0.283443,-0.134021,1.16301,1.19453,-0.977976,-1.04706,0.0464957,0.166547,0.783384,0.957317,-0.93991,-1.08981,0.599865,1.06124,-1.10739,-0.952485
8274,0.895643,0.915186,0.190457,0.180428,0.477694,0.459434,0.349731,0.217015,0.685352,0.698723,0.618616,0.673981,0.677923,0.697905,0.00281357,0.0124767,0.310442,0.339654,0.451218,0.46552,1.59584,1.62376,-0.71666,-0.605019,-1.22691,-1.07375,1.63958,1.66374,0.360557,0.291555,-0.919162,-0.805911,-0.638532,-0.464622,-1.49978,-1.64676,-0.446745,0.0138382,1.36426,1.52274
8275,0.84569,0.822619,0.495451,0.486887,0.696174,0.679829,0.477928,0.421303,0.56505,0.642468,0.967823,0.950042,0.647313,0.606104,0.127429,0.142397,0.232353,0.260747,0.888055,0.904816,0.619279,0.650174,0.0606202,0.164903,1.0398,1.18624,-0.00162738,0.0198316,-0.370741,-0.441254,-0.298715,-0.191695,-0.358585,-0.19881,-0.134139,-0.274464,-0.775915,-0.262981,-0.0595656,0.105375
8276,0.72758,0.730053,0.272039,0.262609,0.40511,0.390078,0.666166,0.625591,0.184514,0.263596,0.649555,0.630793,0.00401914,-0.035771,0.255345,0.272317,0.448471,0.396667,0.673733,0.616021,-0.59695,-0.570721,-1.62746,-1.5192,-0.582355,-0.434918,0.527553,0.551328,-0.445632,-0.516687,0.0773745,0.191195,-0.102777,0.0670017,-0.252213,-0.388314,-0.994127,-0.539799,1.6484,1.81763
8277,0.572128,0.637486,0.326731,0.316412,0.40201,0.386347,0.179569,0.138677,0.587574,0.628279,0.879292,0.859477,0.858673,0.816033,0.394509,0.402238,0.506204,0.532588,0.31075,0.327226,1.3022,1.32603,-1.65789,-1.54727,-0.314349,-0.172453,0.449358,0.470725,-1.21399,-1.27961,-0.655051,-0.535233,-0.207905,-0.0385394,-0.658693,-0.792071,1.19331,1.64162,-1.25855,-1.086
8278,0.525375,0.544919,0.845447,0.834184,0.056677,0.0420622,0.0767937,0.0361022,0.913071,0.992963,0.699139,0.681392,0.965436,0.921146,0.900114,0.909242,0.216588,0.243438,0.979647,0.99662,-0.23799,-0.214737,-0.725114,-0.60971,0.880127,1.02331,2.82254,2.83819,1.85227,1.78906,-0.259939,-0.136654,-0.63403,-0.468113,0.39036,0.259166,-0.696888,-0.245038,-1.03549,-0.780137
8279,0.248798,0.265922,0.284702,0.271996,0.499148,0.485808,0.508181,0.469518,0.965378,1.0453,0.50569,0.503306,0.743892,0.699985,0.620029,0.589472,0.308561,0.336335,0.388152,0.405959,-0.133792,-0.118526,-0.0967386,0.0213732,0.819904,0.96265,-1.63926,-1.62361,-1.46758,-1.52873,-0.531863,-0.413568,-0.140931,0.0238659,-0.582066,-0.713154,-1.15373,-0.70041,-0.646303,-0.474271
8280,0.58305,0.598076,0.79257,0.779549,0.205477,0.191838,0.124127,0.0871722,0.249822,0.329716,0.34279,0.32522,0.0949614,0.0518099,0.258754,0.269702,0.601788,0.562856,0.684489,0.693761,0.679795,0.697796,1.35793,1.46957,-0.120097,0.0229225,-1.98741,-1.96683,0.744286,0.69104,0.65832,0.781439,-2.39619,-2.23415,-0.992268,-1.11691,0.318399,0.775476,-1.31308,-1.14698
8281,0.331853,0.345158,0.749135,0.734915,0.974163,0.958721,0.975986,0.939033,0.462929,0.567536,0.718376,0.615094,0.295038,0.168476,0.321879,0.267512,0.729161,0.789377,0.96473,0.981562,0.305633,0.324055,-0.719875,-0.607598,1.32687,1.46342,0.125501,0.144228,1.7185,1.6643,0.727771,0.764512,0.339491,0.507996,-0.659456,-0.741913,-0.104519,0.351107,-1.1262,-1.02023
8282,0.543175,0.556488,0.389284,0.422961,0.30811,0.295295,0.988649,0.952155,0.724321,0.805355,0.921366,0.904969,0.328642,0.285142,0.186651,0.265322,0.990501,1.0159,0.108844,0.124154,-0.558782,-0.5425,-1.89158,-1.77365,0.56907,0.709195,0.663088,0.675724,-0.295097,-0.348434,0.619132,0.747586,-0.233175,-0.0616354,-0.250521,-0.366915,-0.887958,-0.427935,-1.06003,-0.893492
8283,0.0191702,0.0304562,0.123228,0.111006,0.0233968,0.0105556,0.0459858,0.0123843,0.229237,0.312019,0.62849,0.639538,0.99227,0.948353,0.249397,0.263132,0.753668,0.879296,0.911269,0.927567,-0.755579,-0.732378,-0.261563,-0.138001,0.447994,0.589237,-0.254702,-0.242583,-1.17377,-1.23374,-1.03977,-0.912805,0.230475,0.399231,-1.51636,-1.63074,1.96488,2.42919,1.42511,1.58173
8284,0.0740958,0.166914,0.674062,0.662765,0.748055,0.736209,0.37043,0.310768,0.893759,0.977264,0.291206,0.374108,0.319082,0.276106,0.817522,0.830642,0.706464,0.742693,0.708403,0.657153,1.34281,1.36356,-2.10575,-1.98106,-0.0605479,0.0856047,0.577436,0.614467,0.612229,0.548801,-1.05242,-0.928575,0.157946,0.32392,-0.248601,-0.367962,-2.38807,-1.92375,-0.0863884,0.0739214
8285,0.29122,0.303372,0.835745,0.826499,0.687947,0.771981,0.728741,0.609152,0.674582,0.760206,0.123359,0.108677,0.29153,0.247719,0.839217,0.921002,0.46783,0.60609,0.363267,0.386738,-0.485368,-0.45759,-0.7729,-0.642234,0.162445,0.316554,1.45892,1.47152,-0.323886,-0.383266,0.0306911,0.158669,0.814934,0.985141,-0.567717,-0.681294,-0.988223,-0.524026,-0.97571,-0.809586
8286,0.914692,0.928903,0.516005,0.506146,0.819971,0.807753,0.943133,0.907536,0.092273,0.176267,0.137969,0.125372,0.490974,0.449315,0.996977,1.01136,0.44409,0.469487,0.100026,0.116324,1.53228,1.56268,0.165795,0.295325,-1.41762,-1.25573,-1.11398,-1.0984,-0.385244,-0.442904,-0.183737,-0.0569758,-0.442247,-0.277798,0.267249,0.15551,-1.18362,-0.716924,-0.0809844,0.0889697
8287,0.935177,0.949341,0.841028,0.832305,0.0912112,0.0782156,0.0457529,0.0114212,0.791266,0.877338,0.372154,0.358751,0.25711,0.284808,0.00169728,0.017901,0.990317,1.01442,0.399128,0.413753,1.16856,1.20476,0.230807,0.358015,-0.0937015,0.0636695,-0.260569,-0.242318,0.620044,0.558952,0.0178294,0.225214,0.608507,0.781215,-0.84078,-0.953993,-0.188537,0.274561,0.253054,0.426625
8288,0.24254,0.257119,0.651763,0.647508,0.426654,0.472394,0.829618,0.795278,0.288648,0.3741,0.31167,0.296805,0.159964,0.1203,0.0317007,0.114281,0.653333,0.675169,0.214794,0.228344,-1.52961,-1.49466,-0.0702629,0.155624,0.21957,0.371551,1.88889,1.90113,2.08488,2.01995,0.378748,0.507403,0.657213,0.827114,0.180341,0.0688335,-0.873451,-0.410584,-0.482589,-0.305036
8289,0.647499,0.660062,0.471192,0.462711,0.882354,0.866573,0.368593,0.385678,0.624066,0.711478,0.838426,0.823482,0.141067,0.102538,0.196647,0.210661,0.0816872,0.105239,0.401631,0.415536,-0.610416,-0.569964,-0.173501,-0.0467673,-0.165258,-0.00966077,0.291571,0.304788,0.69186,0.62705,1.26394,1.39575,1.35471,1.51863,-1.11995,-1.22703,0.33361,0.798132,-0.99148,-0.811525
8290,0.298769,0.310001,0.877617,0.868385,0.352095,0.338099,0.0120299,-0.0239227,0.0188735,0.106757,0.645398,0.603162,0.489008,0.450239,0.586574,0.602804,0.372433,0.428821,0.872985,0.884494,-1.82151,-1.77396,1.96887,2.09426,1.76711,1.92851,0.205469,0.224185,1.55691,1.49119,-0.436495,-0.310936,0.816124,0.978927,-1.16544,-1.26728,0.466106,0.931157,-0.473799,-0.292073
8291,0.733642,0.742963,0.179092,0.168121,0.943884,0.931122,0.71498,0.678151,0.954656,1.04184,0.399017,0.382841,0.45875,0.421852,0.575596,0.608726,0.727923,0.752403,0.999569,1.01048,0.0477562,0.121485,-0.874173,-0.747334,-0.391562,-0.231134,1.48798,1.51147,1.4593,1.39908,-0.454708,-0.326706,0.749245,0.919132,0.810505,0.709113,0.850484,1.31314,-0.354404,-0.178944
8292,0.735193,0.743531,0.315701,0.263075,0.723409,0.709124,0.0798729,0.040894,0.916221,1.00303,0.840335,0.826046,0.670863,0.560768,0.658872,0.614648,0.223822,0.247291,0.886026,0.983338,1.96937,2.01693,1.11595,1.24808,-1.41927,-1.25073,0.435574,0.453566,-0.910228,-0.972247,2.25564,2.37954,-1.5908,-1.41758,-0.422589,-0.522708,-0.360708,0.108991,0.291944,0.462962
8293,0.494636,0.505065,0.370469,0.358029,0.22876,0.214843,0.420723,0.295718,0.360205,0.449242,0.027704,0.0133441,0.736675,0.699684,0.57922,0.62057,0.464045,0.488785,0.946959,0.956193,1.34356,1.39541,-0.492046,-0.356259,0.772912,0.941821,1.39176,1.40242,-0.133488,-0.2,0.300789,0.421934,-0.707553,-0.52892,0.242594,0.146029,-1.77454,-1.29932,-0.165623,0.00286768
8294,0.0117813,0.0241182,0.212942,0.1995,0.528155,0.434564,0.587724,0.550542,0.187466,0.278624,0.882473,0.869054,0.109224,0.0733163,0.609085,0.626492,0.432567,0.45904,0.651807,0.660786,-0.375837,-0.330959,-0.175598,-0.046376,-0.880491,-0.710092,1.41463,1.42832,-0.653913,-0.718035,1.08882,1.2141,-0.215687,-0.0669062,-1.02496,-1.1178,0.238187,0.716244,0.445437,0.613596
8295,0.48381,0.496009,0.610365,0.594949,0.667649,0.654285,0.0695605,0.0326686,0.594458,0.643307,0.62499,0.611066,0.109382,0.0715963,0.997086,1.0131,0.951994,0.979481,0.81216,0.82255,0.0934786,0.135934,-0.434285,-0.305348,-1.63841,-1.46432,0.584545,0.604765,0.159885,0.0992452,-1.51516,-1.39398,0.220279,0.395108,0.605961,0.515782,-0.610509,-0.140002,1.54794,1.71029
8296,0.240225,0.252347,0.44185,0.426396,0.191023,0.179309,0.900559,0.864264,0.918606,1.00799,0.716526,0.747891,0.75787,0.719536,0.0573355,0.071358,0.116078,0.144898,0.333686,0.346438,-0.19515,-0.0971027,0.579529,0.710364,-1.12015,-0.943289,0.263604,0.277084,-0.426891,-0.480515,-0.882379,-0.765644,0.275544,0.458307,-0.133775,-0.227728,-1.74257,-1.26583,0.283818,0.467018
8297,0.46355,0.474147,0.917787,0.904163,0.938107,0.925469,0.187717,0.151373,0.303435,0.393564,0.900027,0.884717,0.961923,0.925431,0.736794,0.752949,0.250937,0.279062,0.493116,0.5037,-0.371625,-0.33014,1.32512,1.45,-1.71833,-1.54451,0.302201,0.318405,-0.153142,-0.271934,-1.07784,-0.965588,0.691615,0.873591,0.462505,0.362868,-1.55093,-1.07327,-0.935154,-0.776257
8298,0.397999,0.407869,0.891337,0.892073,0.445163,0.431188,0.116139,0.0782271,0.151367,0.331809,0.747121,0.73176,0.319133,0.283556,0.365101,0.380983,0.0752664,0.101465,0.308638,0.417825,1.06435,1.10477,0.131659,0.253498,0.510984,0.681468,-0.818807,-0.799407,-0.0162052,-0.0633518,-1,-0.889957,0.152654,0.333887,-0.301433,-0.395109,1.1245,1.60112,-1.11516,-0.950239
8299,0.585585,0.593898,0.891452,0.879983,0.812833,0.798509,0.673906,0.635689,0.197664,0.270055,0.178757,0.161988,0.181678,0.143805,0.536141,0.552178,0.719979,0.743936,0.319627,0.33195,-1.82307,-1.78481,-0.0572605,0.0721315,0.00596094,0.177836,-0.0349257,-0.0211211,-0.189413,-0.231177,0.396366,0.502409,0.122179,0.305115,2.12916,2.0296,1.17068,1.6434,-0.153107,0.0092721
8300,0.402544,0.503636,0.429203,0.483385,0.699753,0.686976,0.714067,0.674554,0.104586,0.208301,0.651938,0.634448,0.537362,0.457023,0.485994,0.500888,0.699021,0.72308,0.716684,0.731408,0.236515,0.282979,0.533973,0.657894,1.19843,1.3736,0.106341,0.0558501,-1.41125,-1.45506,0.235181,0.346797,-0.500629,-0.323662,1.23576,1.13344,0.108534,0.581957,0.330421,0.498292
8301,0.404118,0.413374,0.0972931,0.0867866,0.096217,0.0825951,0.494529,0.45703,0.0564183,0.146547,0.802563,0.784244,0.80734,0.770241,0.994331,1.00789,0.0998506,0.123279,0.781185,0.79365,0.560886,0.506224,1.87384,1.99672,-1.1584,-0.978184,0.127144,0.132821,1.53813,1.49192,1.36185,1.47967,0.635119,0.814229,-0.0313709,-0.130385,0.148518,0.624242,1.9575,2.13173
8302,0.975296,0.984835,0.307828,0.299443,0.417743,0.357679,0.796266,0.757421,0.601709,0.690916,0.112929,0.0941447,0.151172,0.112793,0.988166,1.00309,0.0100743,0.033013,0.197403,0.207955,0.690269,0.729469,-0.47386,-0.351636,0.437721,0.617262,-2.15277,-2.14718,-0.804366,-0.847735,-0.124422,-0.00118636,0.488561,0.591775,-0.24452,-0.350178,1.93002,2.41121,-0.113443,0.0666257
8303,0.780884,0.708755,0.26921,0.360645,0.717363,0.632763,0.098395,0.0602654,0.335238,0.423676,0.327863,0.23097,0.735678,0.699055,0.537265,0.522159,0.779929,0.804526,0.735925,0.747348,2.48553,2.51959,0.564852,0.692719,-0.975748,-0.788693,-2.13455,-2.13561,-1.18972,-1.23006,-0.406404,-0.2781,0.194924,0.369321,-1.92156,-2.02794,1.45069,1.9267,0.0693199,0.253454
8304,0.424494,0.432675,0.430052,0.421847,0.921469,0.907847,0.59433,0.558173,0.730912,0.821398,0.385131,0.367796,0.975016,0.940167,0.0262969,0.0412244,0.13604,0.159848,0.285265,0.29604,-0.406529,-0.369989,-0.416885,-0.286264,0.452976,0.635642,-0.386353,-0.452389,0.573499,0.537436,-1.83335,-1.71052,-0.0309449,0.146867,0.300944,0.193455,-0.375042,0.10267,1.35682,1.53349
8305,0.371947,0.351999,0.729385,0.723282,0.71894,0.706372,0.429988,0.395308,0.766706,0.92043,0.843251,0.826027,0.134243,0.0994054,0.304948,0.293493,0.0359414,0.102061,0.293469,0.306757,-0.497725,-0.456165,-0.557495,-0.422241,0.638065,0.844221,1.2251,1.23083,-1.48847,-1.53055,0.11493,0.234072,-2.79509,-2.61002,1.46751,1.36701,-0.826713,-0.352702,0.301694,0.484741
8306,0.264589,0.271323,0.560085,0.554729,0.910003,0.896725,0.566048,0.557155,0.927907,1.01946,0.473905,0.454334,0.649122,0.61569,0.52896,0.545761,0.0217988,0.0442747,0.936898,0.950102,1.25375,1.28939,-1.71801,-1.58829,0.822367,1.0528,1.30007,1.30394,0.00852575,-0.0390474,0.800583,0.921411,0.496484,0.679319,-0.731743,-0.833563,0.0400572,0.513588,-0.46965,-0.293044
8307,0.915734,0.922868,0.149193,0.145321,0.184946,0.171564,0.756252,0.719002,0.618467,0.751317,0.697193,0.678365,0.249269,0.215353,0.998218,1.01267,0.179737,0.203658,0.0719002,0.0867258,-0.207269,-0.216437,-0.876514,-0.743154,1.07871,1.26138,-0.492211,-0.494233,-0.764705,-0.815622,0.115408,0.239314,0.922637,1.11131,0.781009,0.675186,-0.83727,-0.360195,1.06915,1.24824
8308,0.637111,0.643871,0.728943,0.726282,0.187379,0.256005,0.180095,0.140388,0.393948,0.483171,0.405637,0.42451,0.524225,0.491451,0.67782,0.690747,0.894771,0.920112,0.990933,1.00513,-1.7579,-1.72226,-0.369782,-0.233602,1.58285,1.7649,-0.370445,-0.3755,-0.970464,-1.01444,0.613525,0.730714,-2.16391,-1.96908,0.525316,0.423696,-0.747397,-0.286527,0.161455,0.334495
8309,0.0430302,0.0482869,0.968031,0.96359,0.355276,0.340446,0.353065,0.315442,0.585465,0.673157,0.191045,0.170656,0.575341,0.526305,0.656086,0.670403,0.354596,0.380509,0.940966,0.956028,-1.5002,-1.4711,1.70871,1.83891,-1.64521,-1.46021,-0.733704,-0.735308,-0.832206,-0.872696,0.493683,0.637557,-0.241008,-0.0523438,0.690524,0.585835,-0.695995,-0.212859,0.924322,1.09749
8310,0.715272,0.719508,0.499064,0.49533,0.684331,0.668206,0.9267,0.88789,0.417749,0.506536,0.984607,0.964996,0.519163,0.56116,0.193273,0.208994,0.639799,0.690145,0.672008,0.685582,0.421407,0.454553,2.63494,2.76017,-1.07254,-0.893149,0.221708,0.121742,0.406847,0.360807,0.426986,0.5444,0.883798,1.06805,-0.25779,-0.355193,-1.80195,-1.32013,-0.231754,-0.0606628
8311,0.326216,0.329685,0.940711,0.939119,0.235098,0.219136,0.436333,0.395179,0.689496,0.778241,0.897725,0.877126,0.628129,0.596014,0.935287,0.951389,0.970788,0.999781,0.728352,0.742766,0.843467,0.874404,0.0832321,0.203195,0.0158753,0.196286,0.98218,0.978791,2.5345,2.49638,-0.61449,-0.50417,0.0377789,0.224559,-1.70173,-1.80224,-0.379664,0.0992636,0.638627,0.808208
8312,0.477468,0.479776,0.784082,0.780591,0.135814,0.118463,0.209779,0.180612,0.109411,0.199673,0.0537348,0.0340571,0.172124,0.140112,0.441166,0.455704,0.577588,0.563157,0.43095,0.447359,-1.39509,-1.37092,0.931556,1.04833,0.440126,0.625252,0.37929,0.373272,1.14062,1.10348,-0.588317,-0.473893,1.12967,1.31251,-0.955425,-1.05817,1.03807,1.51866,-0.409597,-0.24054
8313,0.102283,0.105453,0.287264,0.282309,0.243977,0.225095,0.00525452,-0.0339548,0.870505,0.958297,0.976945,0.955874,0.583906,0.551638,0.688411,0.607925,0.0995185,0.126532,0.978319,0.996294,0.602293,0.634184,-0.519622,-0.400721,-0.527249,-0.34964,1.30347,1.29173,1.51935,1.47799,-1.03391,-0.922239,-1.21699,-1.0408,0.115304,-0.0637929,-0.351795,0.127381,1.55414,1.71785
8314,0.153823,0.155701,0.511805,0.505169,0.0311341,0.0119366,0.00679412,-0.0301461,0.349997,0.439872,0.490444,0.471156,0.77742,0.743128,0.742967,0.760146,0.310309,0.377849,0.227322,0.243602,-2.2896,-2.25539,-0.43638,-0.29238,0.282597,0.465757,-0.875298,-0.889784,-1.12565,-1.17419,-0.210935,-0.0973294,-1.23286,-1.05478,1.03017,0.930579,0.0550956,0.539806,0.152265,0.315234
8315,0.723092,0.727162,0.137247,0.130557,0.277546,0.266905,0.712674,0.67719,0.621336,0.616768,0.957594,0.938754,0.466113,0.399614,0.762737,0.780854,0.603748,0.629165,0.601007,0.618079,0.00147941,0.0417986,-0.303705,-0.184039,0.536544,0.712781,1.74945,1.74056,3.14691,3.09331,-0.17946,-0.145157,-0.124893,0.0495665,-2.01653,-2.12164,-0.581527,-0.0994887,-1.006,-0.842914
8316,0.167051,0.170997,0.653885,0.648329,0.452055,0.521873,0.801649,0.765324,0.70235,0.793665,0.578873,0.561929,0.0895822,0.0560987,0.217608,0.235331,0.516474,0.543585,0.100155,0.117421,1.21853,1.25608,1.67594,1.79397,-0.306195,-0.134775,0.976677,0.948882,0.321917,0.273466,-0.306861,-0.192985,0.187554,0.357266,-2.05975,-2.16189,0.782984,1.26859,1.70583,1.87202
8317,0.162273,0.249889,0.782183,0.776451,0.796039,0.776842,0.428548,0.393405,0.742594,0.835844,0.552045,0.534188,0.568492,0.532622,0.432964,0.347749,0.947648,0.974042,0.985031,1.00079,-0.148655,-0.115028,-0.380385,-0.263805,0.440226,0.6184,0.163861,0.157202,-0.776241,-0.827233,-0.647805,-0.531401,-0.798194,-0.628534,-0.0905176,-0.19873,0.614425,1.10632,0.0390741,0.210725
8318,0.322478,0.328781,0.27496,0.2679,0.225975,0.208109,0.833718,0.797887,0.0893101,0.181607,0.090254,0.0732796,0.735157,0.698179,0.46287,0.460167,0.044287,0.0732101,0.312213,0.329637,-0.13917,-0.109606,0.456998,0.568017,-1.44297,-1.2679,0.446667,0.44562,0.377519,0.327178,0.239326,0.35695,-0.263332,-0.0478955,1.59676,1.4829,2.05825,2.55153,0.331641,0.502951
8319,0.530765,0.535001,0.736211,0.730977,0.651155,0.632277,0.784166,0.666986,0.964336,1.05612,0.37628,0.423574,0.385217,0.416712,0.614978,0.572585,0.316331,0.379036,0.202266,0.219274,-1.30083,-1.26748,-0.874154,-0.755131,1.2374,1.40878,-0.380005,-0.377936,0.733926,0.685523,1.60605,1.71886,0.366972,0.532743,0.203979,0.0952391,-0.494037,-0.00493769,0.0636078,0.238398
8320,0.217282,0.220007,0.766934,0.759426,0.544207,0.526233,0.591476,0.536084,0.38751,0.477554,0.79142,0.773869,0.17177,0.135244,0.667281,0.685004,0.65586,0.684861,0.715362,0.732791,-0.790401,-0.753441,-0.134922,-0.0154918,0.551879,0.714023,0.479217,0.478149,-0.267415,-0.324063,1.87126,1.97729,0.00125219,0.165566,0.602016,0.488025,-2.21649,-1.72975,1.55341,1.73455
8321,0.976571,0.979848,0.32942,0.321672,0.0358804,0.0178454,0.392493,0.405183,0.104013,0.195135,0.564291,0.603255,0.210356,0.173659,0.602685,0.558381,0.542918,0.572873,0.56346,0.508154,0.677454,0.714206,-0.822607,-0.701734,-0.153456,0.0192667,2.20723,2.20715,-0.310353,-0.366369,-1.03352,-0.919851,-1.28916,-1.13139,0.750989,0.635514,-1.22419,-0.738264,0.834666,1.08625
8322,0.656638,0.563926,0.600471,0.592707,0.050093,0.0342724,0.310112,0.274282,0.879179,0.969306,0.448918,0.432641,0.526497,0.409114,0.414249,0.431759,0.647509,0.677509,0.263724,0.283517,-0.136778,-0.134854,0.285208,0.407651,-0.199881,-0.0250876,-1.36589,-1.36684,-0.777171,-0.856001,-0.729353,-0.617792,-0.771084,-0.609633,-0.401798,-0.517189,0.491289,0.97209,0.259227,0.437956
8323,0.145896,0.148005,0.488103,0.523744,0.891739,0.876725,0.607633,0.569552,0.139118,0.227971,0.986119,0.969964,0.74881,0.644568,0.642187,0.667287,0.161733,0.192606,0.43794,0.382764,-1.02326,-0.983914,0.908988,1.02357,-1.03587,-0.858757,-0.60208,-0.603556,-1.28852,-1.34563,-0.686141,-0.572769,0.199056,0.357716,0.753191,0.64064,1.98858,2.46432,1.18809,1.36602
8324,0.756051,0.757871,0.488778,0.454781,0.404178,0.386838,0.225958,0.187206,0.962746,1.04983,0.143092,0.126895,0.91672,0.880023,0.883741,0.902816,0.870677,0.899713,0.469045,0.482012,0.942837,0.987931,-0.0844075,0.0283105,0.523282,0.704431,2.25856,2.25437,1.53826,1.48,0.121098,0.238517,-1.28673,-1.12594,-0.75605,-0.867352,0.92402,1.40288,0.74583,0.920166
8325,0.130517,0.131985,0.509219,0.385818,0.97065,0.954921,0.615199,0.575976,0.565413,0.651321,0.579173,0.561019,0.257452,0.222575,0.871798,0.815128,0.591557,0.621197,0.561508,0.58126,-0.627721,-0.584063,-0.19113,-0.0771597,0.318186,0.506838,-0.721847,-0.726552,-0.298177,-0.359076,0.204824,0.32992,1.4404,1.59815,-0.0394535,-0.152747,1.11738,1.59544,-1.02024,-0.848838
8326,0.167268,0.104116,0.324619,0.316855,0.576669,0.538366,0.745496,0.705505,0.415834,0.510058,0.00472613,-0.0133445,0.219659,0.184255,0.711563,0.72744,0.944858,0.972481,0.467815,0.501662,0.0430402,0.0796894,0.0263462,0.141172,-1.67526,-1.49075,-0.195722,-0.219054,-0.446744,-0.510178,-0.117674,0.00711187,-0.925589,-0.771901,-0.874829,-0.995525,0.593636,1.07892,0.782085,0.957655
8327,0.106038,0.076248,0.142853,0.136957,0.134916,0.121811,0.608823,0.626702,0.383543,0.368796,0.683975,0.667381,0.780875,0.745768,0.390829,0.498106,0.680108,0.707623,0.40238,0.422064,0.367265,0.407382,0.566061,0.680103,-0.156156,0.0253586,0.39975,0.288444,1.0149,0.950819,0.289725,0.418778,-1.89213,-1.74154,-1.72501,-1.8383,-0.907041,-0.424759,-0.369171,-0.200493
8328,0.134229,0.0483796,0.780036,0.77225,0.5516,0.489253,0.564141,0.547899,0.148157,0.227533,0.0320299,0.0173289,0.119119,0.0840734,0.2546,0.268772,0.639283,0.66798,0.78453,0.801798,-1.56036,-1.52191,-0.780103,-0.659146,2.06914,2.25133,0.800647,0.795942,1.49177,1.4289,-0.867509,-0.736199,-0.584961,-0.429989,0.0348034,-0.0785605,0.655992,1.14308,-0.134584,0.032538
8329,0.0190432,0.0205111,0.378145,0.449812,0.869569,0.856696,0.393217,0.469096,0.00036272,0.0862705,0.156045,0.142234,0.965283,0.929686,0.219672,0.232658,0.366854,0.394086,0.808001,0.789935,-0.278239,-0.242241,0.566704,0.679683,-0.569174,-0.391863,-0.526464,-0.536703,0.646255,0.587833,1.30412,1.43603,0.270015,0.426754,1.05882,0.944266,-1.28071,-0.789495,-0.120897,0.0341787
8330,0.765315,0.764478,0.133371,0.127373,0.939529,0.927815,0.430284,0.390293,0.518545,0.605202,0.597723,0.585438,0.0117618,-0.024878,0.767528,0.780472,0.536478,0.592281,0.76185,0.778072,1.78505,1.82554,0.175721,0.283908,0.725686,0.895241,1.18043,1.17493,1.74913,1.69595,0.439818,0.571648,0.613881,0.763802,0.50225,0.387316,0.579469,1.06426,-0.129746,0.0358194
8331,0.784265,0.771786,0.220059,0.211736,0.383249,0.373674,0.0229489,-0.0167323,0.0991599,0.186163,0.000614866,-0.00944296,0.858826,0.820735,0.389839,0.4036,0.765029,0.790475,0.212864,0.227276,-0.970964,-0.939331,1.31529,1.42174,1.03143,1.2003,0.848999,0.847249,-0.743574,-0.792848,0.192292,0.324856,-1.05056,-0.892845,-1.20509,-1.32201,0.179112,0.656433,1.13295,1.30188
8332,0.778051,0.779093,0.666691,0.558994,0.251974,0.242148,0.654244,0.615961,0.192762,0.220624,0.468531,0.458156,0.815371,0.744796,0.752969,0.704701,0.492162,0.516582,0.953524,0.96566,0.216717,0.246823,0.323057,0.426483,1.33976,1.50535,0.0245842,0.023693,0.0312732,-0.0520497,0.409239,0.539218,-1.09177,-0.937668,0.316439,0.202199,-1.15309,-0.675075,-1.43118,-1.26721
8333,0.145242,0.147967,0.915111,0.906251,0.975332,0.967801,0.464452,0.424362,0.167099,0.255085,0.513944,0.503285,0.705255,0.668857,0.991591,1.0058,0.808536,0.760011,0.734832,0.771183,0.0916171,0.117061,-0.252017,-0.15244,0.324513,0.485756,2.12517,2.11833,0.734018,0.688749,1.58437,1.71775,0.660252,0.818557,-0.665201,-0.784125,-1.2468,-0.77379,-1.08425,-0.915281
8334,0.0406805,0.0453652,0.640952,0.711868,0.196827,0.187316,0.481989,0.44228,0.945593,1.03502,0.994015,0.985664,0.840876,0.803954,0.211113,0.224261,0.980695,1.00344,0.629589,0.576706,-1.92327,-1.89331,0.835347,0.942445,0.518852,0.684605,0.520614,0.587831,-0.0566518,-0.104408,0.932526,1.06542,1.87486,2.03508,1.3411,1.22357,-0.399388,0.0777442,1.02703,1.1986
8335,0.909456,0.911866,0.528663,0.517484,0.769832,0.759863,0.981891,0.940187,0.111193,0.20263,0.155124,0.147689,0.132659,0.0967386,0.420593,0.435672,0.434591,0.458951,0.370092,0.382228,2.44777,2.47773,-0.379143,-0.269593,-0.330303,-0.162952,-0.935825,-0.942665,0.522457,0.481641,2.08064,2.21246,1.40038,1.55796,-0.0248789,-0.146636,0.748074,1.22357,-0.281836,-0.112338
8336,0.0157655,0.0173883,0.835517,0.823944,0.947497,0.936185,0.285135,0.243031,0.461486,0.554658,0.520194,0.512008,0.870917,0.835691,0.397654,0.479896,0.642509,0.665658,0.64712,0.616247,-0.482384,-0.45783,-0.766825,-0.651259,0.394513,0.559348,0.047147,0.0386931,-0.538611,-0.572214,-0.573313,-0.442537,-0.886431,-0.731072,-0.236687,-0.351685,-1.12691,-0.648042,-0.167378,0.027416
8337,0.24295,0.243944,0.653156,0.639693,0.660351,0.561085,0.584723,0.596696,0.549796,0.643182,0.168924,0.159689,0.0902393,0.0550147,0.511154,0.524121,0.163985,0.185581,0.836705,0.850266,1.26816,1.28772,0.0569009,0.180563,-0.97762,-0.817098,0.523923,0.507899,-0.0569476,-0.0941305,-0.756049,-0.626324,0.365923,0.515873,0.239487,0.116845,-1.3421,-0.854826,-0.00269284,0.16717
8338,0.671523,0.671808,0.263984,0.250096,0.195401,0.185985,0.992133,0.95036,0.394375,0.487307,0.533322,0.524008,0.412931,0.302686,0.273105,0.369329,0.405272,0.427075,0.012046,0.0250546,-0.960164,-0.944255,-1.80653,-1.67929,1.75921,1.91965,-0.308193,-0.331699,-1.39529,-1.42741,2.19286,2.32691,-0.81414,-0.671249,0.965961,0.848161,-1.14813,-0.662264,-0.28938,-0.126831
8339,0.311222,0.312141,0.869852,0.855538,0.746471,0.738501,0.803118,0.762919,0.825124,0.919851,0.0807826,0.0727006,0.620254,0.550357,0.221438,0.214537,0.360968,0.382369,0.345561,0.35868,-0.518887,-0.510008,-0.396489,-0.26147,0.230399,0.392926,1.1178,1.09779,-0.118372,-0.148485,-0.110782,0.0252591,1.8363,1.97941,0.705557,0.507702,0.286343,0.767872,-1.57849,-1.42219
8340,0.976755,0.978423,0.908464,0.893911,0.84058,0.835305,0.961263,0.922543,0.989475,1.08462,0.800546,0.794057,0.833187,0.798029,0.046779,0.0597458,0.726493,0.748214,0.441931,0.365239,1.3278,1.34099,-1.10156,-0.962613,-0.114466,0.0424184,1.62427,1.59754,-0.050899,-0.0649965,-1.04877,-0.917819,-0.658729,-0.513116,0.278844,0.167242,-0.336904,0.144809,-1.35342,-1.18916
8341,0.321537,0.322048,0.378278,0.361838,0.115729,0.110143,0.749967,0.710541,0.481457,0.576423,0.493053,0.485015,0.90116,0.866823,0.364905,0.376085,0.090849,0.112502,0.46061,0.371798,1.17385,1.27479,-0.796616,-0.65273,-0.820338,-0.664889,-0.920987,-0.951565,0.0537854,0.0184919,-0.0699661,0.0616967,-1.01744,-0.865892,-0.253415,-0.359007,0.0984337,0.588067,0.863163,1.02177
8342,0.0711814,0.0733231,0.719058,0.62813,0.91643,0.909576,0.844499,0.804213,0.794298,0.888441,0.990991,0.982496,0.384465,0.35079,0.19806,0.208235,0.365098,0.388773,0.363692,0.378357,1.194,1.20858,-0.104773,0.039473,1.27958,1.43313,-0.190003,-0.218517,-1.0752,-1.11183,-0.172272,-0.0456847,-0.494994,-0.344136,1.99647,1.89484,-2.42843,-1.9329,-0.428244,-0.273589
8343,0.389565,0.389824,0.910625,0.894422,0.169737,0.163657,0.690354,0.652091,0.0208172,0.113471,0.304186,0.297729,0.974062,0.942158,0.896961,0.904678,0.0725816,0.0945463,0.709115,0.722679,0.530597,0.543683,-0.834289,-0.692539,-1.9786,-1.82854,0.954161,0.931264,-1.50056,-1.53996,3.01572,3.13902,-0.219715,-0.0685754,0.797462,0.63221,0.426344,0.924231,-1.49603,-1.33846
8344,0.913389,0.911784,0.55088,0.535207,0.211683,0.248098,0.830723,0.79162,0.596874,0.687764,0.661856,0.657822,0.791923,0.762163,0.919925,0.925386,0.971683,0.992629,0.736214,0.695534,-1.23368,-1.21477,0.00432803,0.152598,-0.216025,-0.061445,-0.881814,-0.902322,-0.713549,-0.751776,-0.384592,-0.259036,-1.13499,-0.991795,-0.528784,-0.630419,1.31678,1.81928,0.358444,0.514104
8345,0.131849,0.129863,0.875338,0.861366,0.33757,0.332539,0.750975,0.713297,0.49224,0.580859,0.406604,0.404831,0.0726206,0.0443838,0.447335,0.454363,0.190414,0.212792,0.654136,0.668389,1.60145,1.62227,1.67461,1.82098,0.482918,0.63052,1.94183,1.91605,0.478545,0.434396,-0.198132,-0.0759257,0.699985,0.845765,0.616502,0.51095,1.7729,2.27778,-1.77298,-1.6118
8346,0.423978,0.422089,0.045659,0.0314977,0.145792,0.140503,0.431417,0.395342,0.818449,0.908232,0.578764,0.554586,0.575254,0.5467,0.294439,0.392794,0.531892,0.57052,0.257819,0.273112,0.596399,0.61637,-0.819963,-0.669156,-1.37318,-1.22652,0.606798,0.583401,-1.25909,-1.29594,0.759202,0.887597,2.08999,2.23239,-0.851094,-0.951973,0.0315049,0.535093,0.575965,0.730564
8347,0.448129,0.447157,0.892328,0.879616,0.531466,0.527511,0.713628,0.675249,0.455165,0.544804,0.724571,0.70434,0.154169,0.125678,0.283391,0.331224,0.907676,0.928247,0.64624,0.662115,-0.954749,-0.938661,-0.307779,-0.159604,0.167431,0.319407,-0.208356,-0.224178,-1.22181,-1.26014,0.448005,0.578879,-0.12939,0.0115653,1.02944,0.92913,0.405839,0.80556,1.87025,2.02658
8348,0.861455,0.860478,0.862742,0.927848,0.257075,0.253093,0.343449,0.30333,0.358285,0.538093,0.855867,0.854095,0.873788,0.844757,0.143108,0.269655,0.194525,0.212325,0.113373,0.13066,1.88389,1.89838,-0.22956,-0.0814259,0.247853,0.396632,-0.347571,-0.366083,0.424457,0.383281,-0.291056,-0.16319,0.875416,1.01143,-0.497823,-0.595135,0.624825,1.07603,-0.583886,-0.422295
8349,0.379565,0.379531,0.986903,0.97608,0.717432,0.711928,0.84585,0.805665,0.44282,0.531382,0.395696,0.393186,0.41322,0.384294,0.201058,0.208085,0.654555,0.672622,0.491741,0.510394,1.09406,1.20439,0.139394,0.287235,-1.22792,-1.08471,-0.206648,-0.232068,-0.0420284,-0.08974,1.32474,1.44574,0.330299,0.47173,0.312245,0.210726,0.842906,1.34649,-1.78706,-1.62637
8350,0.169489,0.170687,0.0391475,0.0307661,0.0837143,0.0777863,0.273874,0.233003,0.789742,0.801674,0.751808,0.748474,0.589819,0.551544,0.755481,0.761283,0.841253,0.82774,0.377158,0.394602,0.498951,0.510406,-1.27271,-1.12916,0.28642,0.431405,1.4022,1.37251,0.0183091,-0.0226312,1.30338,1.42997,-1.55404,-1.42058,0.188931,0.0819285,-0.037214,0.472711,-2.39746,-2.23887
8351,0.77268,0.771439,0.930871,0.92444,0.361092,0.34196,0.295411,0.255592,0.980679,1.07196,0.660906,0.655586,0.707702,0.718795,0.97305,0.979519,0.963121,0.982858,0.487661,0.443844,1.51071,1.52732,1.6168,1.7573,-2.74517,-2.60521,0.379362,0.347958,1.99449,1.9522,0.0533903,0.181536,2.05983,2.1888,-0.255957,-0.367428,0.137221,0.650504,0.158345,0.3224
8352,0.45405,0.452219,0.706377,0.606747,0.609596,0.606134,0.521964,0.504449,0.65092,0.696307,0.136171,0.13133,0.914971,0.886045,0.316426,0.322462,0.133173,0.154423,0.494477,0.493085,-1.81758,-1.7994,-2.59973,-2.45733,0.98185,1.12181,-0.380772,-0.413922,1.27825,1.23757,-0.00264877,0.119286,1.24722,1.37655,-1.19599,-1.30846,-2.38774,-1.87046,0.118656,0.231025
8353,0.834912,0.835042,0.294497,0.289053,0.202806,0.200579,0.794962,0.753305,0.231904,0.320649,0.34485,0.273944,0.779922,0.75192,0.488014,0.493656,0.637513,0.660078,0.565026,0.542327,-2.02951,-2.00485,1.41223,1.55582,-0.417784,-0.284144,1.00263,0.966874,-0.733473,-0.775164,-0.715339,-0.59209,-0.656563,-0.531111,0.811585,0.699238,0.0439666,0.565789,-0.061602,0.139651
8354,0.0726146,0.0740617,0.674075,0.668791,0.170291,0.167035,0.522169,0.480278,0.554672,0.643066,0.530134,0.416558,0.225781,0.199176,0.363773,0.366907,0.546027,0.551623,0.508319,0.591568,-0.719444,-0.695794,0.941834,1.08402,1.94866,2.09114,-1.38995,-1.42894,0.74465,0.701615,-0.391057,-0.25198,0.235584,0.357548,-0.708264,-0.825027,0.180636,0.698814,-0.11609,0.048277
8355,0.0277959,0.0271698,0.5998,0.594878,0.645257,0.64063,0.553283,0.513056,0.470106,0.557314,0.563178,0.559171,0.883333,0.857069,0.979478,0.981821,0.420715,0.443169,0.655201,0.64081,-2.31688,-2.29861,-2.06991,-1.93314,0.64172,0.779245,0.339602,0.300054,-0.142155,-0.183693,-0.0389254,0.0881292,-0.297556,-0.0940998,-0.446715,-0.569245,-0.578201,-0.0650103,-1.67043,-1.5075
8356,0.605016,0.603715,0.784733,0.711246,0.89525,0.8912,0.0388654,0.00014548,0.834559,0.920658,0.166193,0.162495,0.725778,0.698019,0.863499,0.865273,0.56504,0.536881,0.672608,0.690052,-0.679422,-0.661768,1.45317,1.5976,-0.907293,-0.764077,-0.832325,-0.878961,-1.32562,-1.37205,-0.20994,-0.0414384,-0.67537,-0.545747,0.319629,0.189671,1.39984,1.91629,-1.0781,-0.913265
8357,0.453815,0.418843,0.832555,0.827615,0.140685,0.136063,0.814227,0.774323,0.452663,0.53697,0.188489,0.13714,0.138101,0.110712,0.956575,0.927905,0.722074,0.630593,0.335355,0.353621,-0.901914,-0.882417,-1.14031,-0.992955,2.2008,2.34532,-1.01245,-1.05246,0.464566,0.410492,-0.303831,-0.171006,-0.0786104,0.0539478,-0.267137,-0.399263,0.0286286,0.539032,2.10893,2.2734
8358,0.233131,0.23397,0.806927,0.802421,0.44974,0.498389,0.193152,0.151298,0.797223,0.879568,0.115539,0.111785,0.142744,0.114163,0.988256,0.990538,0.703436,0.724305,0.377773,0.459253,0.782685,0.801539,-2.31448,-2.17403,0.902988,1.04837,0.379514,0.342516,0.0310168,-0.0176376,-1.62977,-1.49635,0.133319,0.266783,-1.2527,-1.38559,0.860029,1.37335,0.3282,0.488358
8359,0.900453,0.900251,0.160711,0.156715,0.864906,0.860715,0.623134,0.512095,0.735043,0.81972,0.605037,0.598928,0.823277,0.797055,0.443677,0.445015,0.268542,0.371841,0.548722,0.564884,1.6639,1.67802,-2.3476,-2.2021,-0.190831,-0.0483457,0.0630786,0.0295079,-0.988259,-1.04164,0.865354,0.997138,0.81165,0.941957,-0.479472,-0.611071,-0.790211,-0.270661,0.387905,0.541192
8360,0.484089,0.484888,0.00537598,0.00321808,0.0599069,0.0578395,0.916278,0.872893,0.0455404,0.129836,0.825609,0.817643,0.0728696,0.0491197,0.451464,0.450669,0.000675901,0.0193767,0.653878,0.670516,0.809605,0.826517,-0.659834,-0.5191,0.719177,0.858776,-0.58081,-0.706337,0.467245,0.419357,-0.0413439,0.117729,0.474034,0.605019,-1.19134,-1.32335,-0.938735,-0.416864,-0.0346658,0.124626
8361,0.485308,0.485456,0.218849,0.215875,0.510653,0.465865,0.386338,0.344649,0.243057,0.329389,0.0465587,0.0372157,0.939871,0.917697,0.682068,0.630118,0.521036,0.539818,0.30251,0.319435,-0.262535,-0.240976,-0.292349,-0.108469,0.90841,1.04028,-1.40988,-1.44218,-0.0416373,-0.08477,-0.899808,-0.76168,-0.973334,-0.846398,-0.63435,-0.764084,0.414465,0.938621,-0.793315,-0.651248
8362,0.761326,0.762133,0.674683,0.67023,0.874574,0.873891,0.531046,0.449882,0.223094,0.266994,0.598063,0.588901,0.431996,0.411379,0.772723,0.809567,0.162685,0.180666,0.638086,0.65306,1.19005,1.21091,0.154533,0.302162,1.08383,1.22178,0.873631,0.835838,-0.894522,-0.939917,1.03868,1.17045,0.0309648,0.15347,0.4731,0.348831,-0.687346,-0.168651,-1.58656,-1.42712
8363,0.819102,0.755964,0.612463,0.651714,0.025494,0.0229146,0.595969,0.555116,0.118206,0.2046,0.881005,0.873003,0.892718,0.872688,0.989806,0.989016,0.631445,0.594646,0.726739,0.739181,0.668663,0.682993,-0.464739,-0.322369,-0.372654,-0.228927,0.32617,0.292663,-0.703619,-0.751804,-1.47438,-1.34264,-0.16858,-0.0423414,-0.591824,-0.669801,-1.04783,-0.530487,1.92371,2.07433
8364,0.749519,0.749795,0.63946,0.633198,0.720657,0.71842,0.182397,0.142796,0.80965,0.895859,0.224502,0.218271,0.848587,0.829324,0.417896,0.418,0.990158,1.00863,0.43413,0.448371,-1.19975,-1.18625,0.276739,0.41727,1.78755,1.93214,-0.843272,-0.87258,-0.306334,-0.348251,0.427569,0.558839,0.125254,0.249954,-1.56374,-1.68843,1.30258,1.81416,-1.29025,-1.13963
8365,0.429743,0.430576,0.173608,0.164937,0.0841429,0.0802556,0.27618,0.135683,0.148211,0.236306,0.0753931,0.0702534,0.281374,0.261912,0.114127,0.116437,0.522143,0.539109,0.45988,0.573283,1.28179,1.30196,0.792378,0.926822,-0.384094,-0.242551,-0.428486,-0.504646,0.417141,0.377424,0.806866,0.941729,-1.04657,-0.922427,-0.270383,-0.409856,0.507601,1.0186,-0.64531,-0.497727
8366,0.411644,0.410496,0.0399939,0.0310954,0.0297433,0.024988,0.170513,0.12857,0.302988,0.448654,0.385147,0.380444,0.739042,0.717792,0.552501,0.553619,0.63106,0.648691,0.657492,0.698196,-0.892592,-0.878715,-0.237433,-0.100979,-0.457969,-0.318305,-0.107615,-0.136713,-0.204356,-0.247702,-0.871971,-0.734773,-0.750545,-0.630131,0.99793,0.868719,0.103809,0.610769,1.03626,1.18318
8367,0.911439,0.912625,0.827632,0.818042,0.657271,0.653485,0.465247,0.42384,0.573104,0.661002,0.05438,0.0518632,0.234403,0.211474,0.3381,0.336531,0.00356528,0.0238778,0.808866,0.823108,1.02706,1.04694,-0.428931,-0.298551,0.742539,0.877456,0.861792,0.827214,0.805134,0.754154,0.391839,0.535357,-1.86691,-1.73898,0.556187,0.419362,-2.4381,-1.92496,-0.0711326,0.0690437
8368,0.767717,0.756522,0.91572,0.90726,0.711882,0.710303,0.167844,0.204572,0.217937,0.399199,0.257655,0.256069,0.56268,0.425738,0.467549,0.398052,0.474224,0.434579,0.0889923,0.100628,-0.575151,-0.555878,1.39248,1.52327,0.497964,0.632974,-1.51471,-1.55223,0.127358,0.0711272,0.602912,0.749719,-0.558243,-0.427422,1.47573,1.3514,-0.759436,-0.243769,1.41036,1.55104
8369,0.598723,0.600418,0.181832,0.171619,0.227314,0.224742,0.0279931,-0.0146958,0.0488306,0.137396,0.233953,0.232893,0.691526,0.640001,0.518919,0.459572,0.824907,0.845281,0.658507,0.669023,0.730412,0.753183,1.25009,1.38729,-1.40555,-1.26959,1.17276,1.12743,1.33452,1.27346,-0.695224,-0.544022,-0.0627176,0.0645562,2.42444,2.28344,1.13894,1.65665,0.687004,0.833711
8370,0.676585,0.676064,0.667391,0.655338,0.354004,0.350953,0.0675034,0.0241689,0.604208,0.69189,0.643354,0.642546,0.877194,0.854265,0.523056,0.521093,0.705651,0.72811,0.898229,0.907771,0.171491,0.194614,-0.354702,-0.217051,0.689354,0.828438,0.148247,0.102878,-0.0740042,-0.134721,-0.337077,-0.191398,-0.526493,-0.396895,-1.90955,-2.05356,0.0257192,0.582894,0.261244,0.40232
8371,0.52273,0.557361,0.0318864,0.0198772,0.70951,0.708059,0.461489,0.417715,0.618489,0.704821,0.636603,0.634727,0.791351,0.769903,0.323793,0.324142,0.350719,0.373388,0.502099,0.482394,-0.122896,-0.10235,-1.1803,-1.04205,0.431858,0.539803,0.695644,0.650932,0.0564573,-0.00819649,0.45131,0.600765,-0.441604,-0.318885,0.801308,0.664157,-1.00765,-0.490864,0.454053,0.589148
8372,0.404156,0.438657,0.7835,0.769407,0.175517,0.174243,0.455235,0.410932,0.0317593,0.116107,0.322422,0.320967,0.349055,0.329168,0.700781,0.70156,0.406859,0.427544,0.0474758,0.0570172,-0.110164,-0.162052,-0.177142,-0.042382,0.115651,0.251168,-1.15584,-1.19534,1.37448,1.31622,0.803709,0.953389,-0.623296,-0.500616,-1.1393,-1.28037,-1.09786,-0.574023,-1.3187,-1.17986
8373,0.319982,0.319954,0.416981,0.404893,0.75019,0.74679,0.831718,0.789245,0.520421,0.542671,0.706523,0.705778,0.321099,0.258828,0.662755,0.665445,0.797521,0.818435,0.645748,0.655498,-0.239683,-0.221754,1.44205,1.57855,-0.37823,-0.237728,0.466973,0.426291,-2.01929,-2.08227,0.677529,0.828097,-1.56282,-1.44072,0.639808,0.492363,-1.58877,-1.05854,1.44596,1.58062
8374,0.663119,0.661903,0.368246,0.355026,0.467949,0.535164,0.835693,0.843648,0.885815,0.969234,0.572136,0.571861,0.20836,0.188487,0.204618,0.208992,0.526749,0.549563,0.85671,0.868012,2.08231,2.10729,-0.428609,-0.299145,0.829053,0.971886,-2.47312,-2.51923,-2.11352,-2.17438,2.0267,2.1744,-0.403296,-0.285247,1.29751,1.14559,-1.23265,-0.70752,0.457201,0.591671
8375,0.0671961,0.0663184,0.899747,0.887178,0.326375,0.323538,0.940203,0.898052,0.101827,0.183659,0.883928,0.882051,0.967041,0.948335,0.303431,0.310537,0.733549,0.756271,0.00144387,0.010604,1.41746,1.43468,1.36226,1.49177,0.169361,0.309892,1.03737,0.991339,-0.803441,-0.864395,0.190156,0.34294,1.04593,1.16171,0.500047,0.342356,1.27654,1.79984,1.7783,1.91805
8376,0.150506,0.15238,0.93472,0.921095,0.284427,0.279266,0.156442,0.113357,0.36453,0.378468,0.0794916,0.0786551,0.536283,0.492144,0.0556744,0.0625402,0.308227,0.332846,0.167393,0.177539,0.815152,0.762069,1.19835,1.32495,0.653456,0.799109,-2.41374,-2.46416,-2.25837,-2.31799,-0.846942,-0.689895,0.0784197,0.192064,-0.612603,-0.767147,1.53136,2.05515,-0.710576,-0.570975
8377,0.969873,0.970243,0.314607,0.300223,0.885234,0.882825,0.801386,0.760215,0.492506,0.573276,0.940608,0.941683,0.0559527,0.0359521,0.877418,0.886594,0.172072,0.199866,0.794854,0.80707,0.0644846,0.0894606,0.565674,0.685388,0.345651,0.494592,0.572987,0.527285,-0.844402,-0.902591,0.472523,0.626234,-0.307709,-0.190261,0.29893,0.145298,-1.1184,-0.590898,0.316342,0.450475
8378,0.468374,0.469114,0.386745,0.373889,0.445604,0.479906,0.177722,0.137191,0.931452,1.01103,0.295546,0.296341,0.566475,0.54677,0.268498,0.275734,0.0404171,0.066886,0.997374,1.00906,-0.339992,-0.314254,-1.46164,-1.34548,1.05668,1.20138,-0.432458,-0.548213,-0.836497,-0.896754,0.921743,1.07258,0.10475,0.225023,0.604717,0.444586,1.04038,1.572,-1.25839,-1.11717
8379,0.496713,0.499545,0.662832,0.650128,0.0815314,0.0769867,0.256284,0.21582,0.820278,0.887376,0.741693,0.744775,0.407198,0.296193,0.568304,0.576727,0.743433,0.769506,0.396676,0.408222,0.178921,0.199781,-0.516386,-0.407923,-1.1474,-1.00562,-1.58234,-1.62371,-1.32497,-1.38354,-1.44989,-1.29695,-0.6998,-0.574095,-0.749907,-0.91149,-0.518878,0.00708771,0.956922,1.09375
8380,0.84107,0.846541,0.557905,0.546866,0.437035,0.434092,0.632056,0.589662,0.68335,0.763719,0.270992,0.274699,0.0654217,0.0456167,0.113392,0.120274,0.696494,0.7248,0.784901,0.797225,-0.372309,-0.358788,-0.717505,-0.605495,0.891753,1.02831,-2.07412,-2.12133,-0.354271,-0.410274,0.956194,1.10611,-1.16777,-1.03555,1.24136,1.08186,1.29714,1.82917,0.0172776,0.149786
8381,0.477026,0.532254,0.177841,0.168076,0.160421,0.159674,0.540924,0.49669,0.86839,0.948776,0.281325,0.194613,0.0871526,0.0681069,0.108215,0.127922,0.949836,0.976544,0.18954,0.20165,0.636729,0.643418,1.78611,1.90598,1.61806,1.75061,-0.941347,-0.986058,-0.327732,-0.44462,1.15805,1.30419,0.206233,0.335392,-1.78091,-1.93416,0.808033,1.34466,1.09648,1.23213
8382,0.21362,0.217967,0.264195,0.332989,0.182301,0.180951,0.966746,0.920952,0.511734,0.589698,0.112127,0.114526,0.770497,0.750998,0.129071,0.13557,0.954209,0.981986,0.466536,0.479464,1.4245,1.43029,0.203341,0.318378,0.387585,0.51432,-1.92107,-1.96508,-0.428934,-0.478967,-0.76095,-0.620587,-0.882334,-0.757005,0.254867,0.105759,0.547719,1.16771,0.632052,0.772031
8383,0.772732,0.774515,0.507869,0.497902,0.699468,0.699856,0.204664,0.157417,0.759221,0.836423,0.575187,0.577476,0.581076,0.562015,0.521707,0.527712,0.686869,0.713114,0.151873,0.163696,0.0976872,0.102539,-1.14789,-1.03615,-1.70258,-1.5809,1.1547,1.11167,0.367581,0.321515,-0.384264,-0.237697,0.345432,0.474179,0.724113,0.574289,0.458385,0.990766,-1.60203,-1.46514
8384,0.899879,0.899903,0.436827,0.524147,0.348846,0.349775,0.331431,0.282287,0.110007,0.187229,0.587051,0.643842,0.891876,0.874074,0.308624,0.27956,0.780642,0.786351,0.704399,0.717809,0.530563,0.532074,-0.883736,-0.772932,-0.560687,-0.444065,1.71723,1.6732,2.09528,2.043,-0.631053,-0.484489,1.16736,1.30171,-1.06517,-1.21165,0.504583,1.03305,-1.37667,-1.23211
8385,0.632143,0.642002,0.5606,0.550393,0.200006,0.202783,0.782874,0.735369,0.0843294,0.163104,0.673088,0.710208,0.287478,0.267948,0.0271678,0.0314081,0.918366,0.859589,0.191136,0.202458,0.951241,0.961609,0.754572,0.862716,-1.45044,-1.3385,0.289509,0.247428,-1.37255,-1.42513,0.534977,0.680404,0.513072,0.643044,2.86238,2.71275,0.192645,0.717174,-0.624054,-0.483673
8386,0.383583,0.3841,0.712993,0.704439,0.556699,0.462921,0.144575,0.0981125,0.490784,0.605495,0.626386,0.776574,0.148386,0.171247,0.225595,0.228086,0.924123,0.932826,0.655034,0.606074,0.101653,0.11011,-1.0194,-0.913934,-1.01139,-0.893172,-0.582656,-0.624018,0.190964,0.144446,-0.360381,-0.217136,-1.70422,-1.57778,1.82382,1.68106,1.27818,1.80109,0.775893,0.920276
8387,0.845542,0.846327,0.262978,0.255983,0.719932,0.723059,0.0182433,-0.0292768,0.967613,1.04789,0.840652,0.842941,0.095695,0.0745455,0.907778,0.909677,0.979818,1.00606,0.995711,1.00969,1.02202,1.01212,-1.27321,-1.17291,0.335576,0.495978,-0.076055,-0.125098,0.167857,0.117562,0.734723,0.870108,1.97978,2.1087,-0.849715,-0.994198,0.174616,0.693818,0.738077,0.881909
8388,0.773326,0.796408,0.824008,0.817956,0.654003,0.658018,0.709055,0.663745,0.813966,0.810462,0.131456,0.133238,0.403456,0.381498,0.396367,0.398407,0.203317,0.231699,0.845231,0.859331,1.9093,1.91412,0.498915,0.603127,1.75972,1.88513,0.415558,0.373821,-0.264268,-0.310568,0.708643,0.837389,0.89825,0.969532,-0.411177,-0.556675,0.715504,1.23247,-0.897939,-0.750465
8389,0.743613,0.74649,0.147783,0.142156,0.0267681,0.0293083,0.685086,0.627509,0.489656,0.573036,0.734958,0.734707,0.0544641,0.0308682,0.24353,0.247161,0.328057,0.327729,0.295048,0.308535,0.285862,0.298799,1.08966,1.18889,1.17122,1.29892,1.15898,1.12243,-0.426296,-0.478393,1.57998,1.70917,-0.298549,-0.169632,-0.982595,-1.12829,0.289398,0.808105,-1.41484,-1.27208
8390,0.659595,0.696572,0.320522,0.324376,0.294421,0.286933,0.638327,0.591272,0.593473,0.676835,0.291472,0.293153,0.777676,0.754453,0.314202,0.318749,0.394663,0.423758,0.0666696,0.0777181,1.65006,1.65625,-1.23346,-1.12883,-0.509199,-0.384112,0.567066,0.531181,-0.951339,-0.996429,0.69646,0.828926,1.91214,2.03289,0.765123,0.616152,0.104182,0.615207,-1.07038,-0.934426
8391,0.645869,0.646654,0.510222,0.506595,0.544232,0.544558,0.273375,0.224463,0.937342,1.01943,0.112989,0.115855,0.484859,0.46272,0.799161,0.805645,0.927446,0.95835,0.364068,0.462948,0.461574,0.467388,0.689673,0.78669,1.48773,1.61729,0.408427,0.373491,-1.83266,-1.88174,0.12683,0.25844,0.330274,0.45268,0.415536,0.273686,-1.75315,-1.24063,0.417672,0.547567
8392,0.192138,0.191556,0.19882,0.196005,0.0137206,0.0160843,0.265751,0.224594,0.0343887,0.1152,0.30914,0.3096,0.704364,0.6838,0.106079,0.112735,0.485702,0.608912,0.837937,0.848178,1.03145,1.04153,-0.649151,-0.552559,-1.13221,-1.01066,-0.470056,-0.497954,-0.334849,-0.328457,0.515871,0.641331,0.967339,1.08351,-0.730889,-0.864571,-0.889211,-0.37434,-0.366349,-0.230218
8393,0.157395,0.155185,0.406301,0.403828,0.835546,0.836866,0.276293,0.224726,0.162631,0.24469,0.0392609,0.0417225,0.49022,0.528601,0.376533,0.301553,0.230532,0.259474,0.239088,0.247345,-1.78032,-1.76653,0.050176,0.139644,1.37994,1.49735,-1.06144,-1.0892,1.27846,1.22482,0.615866,0.748118,0.591025,0.701189,-1.85963,-2.00283,-1.64265,-1.12457,-0.539328,-0.4042
8394,0.636166,0.632147,0.0302027,0.0292165,0.369082,0.372437,0.0365278,-0.0128802,0.976436,1.05675,0.437714,0.434741,0.394266,0.373401,0.482147,0.490372,0.708124,0.734922,0.942506,0.951771,1.65157,1.6626,-2.10629,-2.01491,0.488651,0.602919,-0.557336,-0.589451,-0.485862,-0.537384,-1.86959,-1.73363,1.02843,1.13318,0.0421287,-0.104653,-0.860811,-0.338682,0.651664,0.787022
8395,0.305291,0.35039,0.872243,0.871233,0.358218,0.363907,0.166922,0.116648,0.984613,1.06474,0.825291,0.82776,0.468528,0.447537,0.0208314,0.0289633,0.897682,0.925417,0.69361,0.701954,-0.29153,-0.282947,0.582603,0.676396,0.192773,0.313469,0.259789,0.234014,0.78471,0.727759,0.241232,0.375259,1.09468,1.19638,-1.7646,-1.91137,-1.81557,-1.29331,0.212276,0.328334
8396,0.0723907,0.0686319,0.337466,0.33916,0.645816,0.650423,0.0575075,0.00902425,0.0943632,0.172369,0.967143,0.967696,0.247769,0.226377,0.497849,0.505489,0.718148,0.747821,0.812062,0.819122,-0.18039,-0.171499,-1.75891,-1.67196,-0.761257,-0.642143,-1.64882,-1.67885,0.936087,0.887156,-0.713712,-0.581668,0.331813,0.429435,0.223207,0.081976,-0.132215,0.387886,-0.268019,-0.130353
8397,0.1093,0.104921,0.794362,0.797654,0.0771698,0.0816905,0.900338,0.851103,0.223198,0.301859,0.0698321,0.0730297,0.402616,0.381735,0.749969,0.755687,0.0512278,0.0824446,0.410688,0.418561,1.84978,1.86526,-0.716401,-0.627607,-0.0535977,0.0646416,-0.56789,-0.592289,0.346827,0.293444,-0.160607,-0.0616752,0.636671,0.737135,1.1735,1.02748,-0.0600618,0.459643,0.363768,0.496222
8398,0.809328,0.805613,0.913258,0.916136,0.189743,0.129471,0.0622357,0.0137776,0.767466,0.846228,0.760845,0.764306,0.247986,0.227244,0.394081,0.39873,0.541567,0.573239,0.535772,0.54455,0.388105,0.401286,-0.88238,-0.794428,-0.331587,-0.209095,-0.0380299,-0.152282,0.850112,0.803853,0.324503,0.458317,-1.17217,-1.07683,1.23989,1.09673,-0.31644,0.205944,2.85352,2.99073
8399,0.644682,0.642599,0.626932,0.630475,0.173616,0.177252,0.562918,0.46978,0.32188,0.402792,0.351018,0.353301,0.889737,0.868531,0.625889,0.628032,0.301351,0.334728,0.315917,0.323901,1.35326,1.37254,1.51184,1.60357,-1.33149,-1.21277,0.309202,0.287725,-0.141605,-0.189794,1.95609,2.08276,-0.212357,-0.123943,-1.10342,-1.25134,3.15366,3.68143,-0.162959,-0.0303702
8400,0.951054,0.94932,0.625665,0.728469,0.692559,0.696158,0.97424,0.925782,0.329639,0.410787,0.790565,0.791658,0.178582,0.156281,0.0099413,0.0116955,0.657159,0.691051,0.354211,0.360619,-0.148365,-0.122516,-0.601056,-0.501029,-0.267971,-0.152292,0.379211,0.360835,-0.651767,-0.693921,0.197003,0.32799,-0.805075,-0.721419,-1.88942,-2.04008,-0.377221,0.142926,-1.4099,-1.27951
8401,0.801047,0.801178,0.820894,0.826462,0.593292,0.595486,0.505178,0.459124,0.585217,0.667638,0.784391,0.783838,0.728912,0.707991,0.379991,0.330109,0.338298,0.371774,0.0618959,0.0698095,0.317205,0.344377,-1.46164,-1.35693,0.267528,0.383985,0.201787,0.187339,-0.609132,-0.65812,0.512266,0.545547,0.340134,0.416472,0.561139,0.404572,0.710926,1.22684,1.28504,1.41755
8402,0.330335,0.330708,0.218761,0.224921,0.138968,0.141492,0.70667,0.660583,0.0932662,0.174302,0.145576,0.144183,0.676623,0.629847,0.552854,0.648523,0.608216,0.513513,0.440474,0.449544,1.67914,1.70182,-1.6002,-1.49291,-0.0688449,0.0482405,-2.02601,-2.04251,0.131073,0.0827248,0.636268,0.763104,1.22252,1.30513,0.996128,0.842095,1.27746,1.79542,-1.81109,-1.67516
8403,0.967379,0.966518,0.0712937,0.0760978,0.202434,0.203673,0.0280479,-0.0173248,0.918744,1.00217,0.54494,0.543813,0.573748,0.551703,0.965183,0.966937,0.71655,0.655251,0.544271,0.562325,-1.14468,-1.122,0.0440534,0.157762,0.584807,0.707566,-0.961531,-0.985969,-0.11661,-0.175735,-0.178277,-0.0552663,0.8853,0.968193,0.67588,0.514797,-1.76583,-1.24579,0.491501,0.635705
8404,0.477857,0.497804,0.673309,0.676117,0.577477,0.509569,0.752918,0.706409,0.568994,0.654742,0.673764,0.675597,0.759657,0.737662,0.738131,0.760587,0.8108,0.796989,0.666466,0.675107,-1.16632,-1.14548,-1.78695,-1.66931,-0.646913,-0.528725,0.375103,0.348367,-0.387855,-0.434196,-1.81409,-1.68531,-0.823134,-0.737099,0.818012,0.662286,-0.166113,0.355005,-0.995303,-0.856638
8405,0.0307898,0.0290897,0.152206,0.153391,0.814368,0.815466,0.138105,0.0933961,0.604565,0.691672,0.691467,0.807381,0.26024,0.236623,0.460153,0.554237,0.905252,0.938728,0.325912,0.39356,-0.148927,-0.128565,-0.0562283,0.0589004,1.08989,1.20971,0.32889,0.298675,0.585446,0.539066,-1.28384,-1.14927,-0.421076,-0.338149,-0.340085,-0.490417,0.73141,1.25005,0.486469,0.625355
8406,0.656975,0.654621,0.708408,0.71022,0.970068,0.972107,0.120976,0.0762227,0.0738421,0.16321,0.938649,0.939165,0.748407,0.723364,0.219762,0.347886,0.461975,0.494151,0.10355,0.112014,-0.23444,-0.214742,0.699805,0.813406,0.871468,1.04072,0.843869,0.813765,0.308256,0.264331,0.0953904,0.226965,-0.519557,-0.44369,0.731829,0.577739,-1.87512,-1.36157,-0.526061,-0.393932
8407,0.469414,0.465958,0.016392,0.0197753,0.48432,0.486546,0.826528,0.783559,0.399635,0.490583,0.440291,0.439098,0.85213,0.810717,0.139782,0.141536,0.61952,0.64912,0.888398,0.898745,0.332438,0.3594,-1.82783,-1.71137,0.754256,0.871728,0.00752919,-0.0258328,-0.462156,-0.512244,-0.370446,-0.237545,-0.313086,-0.230855,0.192478,0.0362126,1.62759,2.14388,-2.11817,-1.97772
8408,0.0666069,0.0652548,0.680772,0.683985,0.33596,0.339554,0.805956,0.761653,0.984418,1.076,0.402395,0.435691,0.924218,0.898071,0.185568,0.186925,0.0827211,0.109517,0.555313,0.567165,-0.815758,-0.783849,-1.32974,-1.21719,0.0115195,0.133771,0.444096,0.486326,0.171679,0.120643,-0.412274,-0.28395,-0.416942,-0.336396,1.39465,1.23982,0.63834,1.16066,1.64511,1.78497
8409,0.304805,0.301468,0.702071,0.703019,0.707752,0.71234,0.577387,0.518045,0.467119,0.557571,0.433191,0.432285,0.665139,0.566823,0.829934,0.831208,0.595037,0.619909,0.761292,0.774061,1.41118,1.43542,0.304026,0.418461,1.23545,1.36132,1.03553,0.998484,0.156387,0.110215,0.0692944,0.193293,1.33438,1.41983,-1.18355,-1.3357,-0.599982,-0.0740534,-0.52247,-0.386684
8410,0.0259112,0.0224714,0.481182,0.483047,0.43797,0.442998,0.320649,0.274437,0.882955,0.975075,0.209133,0.209372,0.260804,0.235575,0.755596,0.727314,0.299772,0.325682,0.167518,0.178485,-1.71934,-1.69526,-0.44184,-0.329936,0.32329,0.451439,2.25307,2.21022,0.932183,0.882462,0.101124,0.22357,1.95283,2.03562,1.32616,1.17928,0.159751,0.686712,-1.00393,-0.862143
8411,0.583526,0.57902,0.262118,0.263076,0.917203,0.921181,0.959925,0.91178,0.00270425,0.0933359,0.629855,0.628728,0.808804,0.78184,0.738779,0.623419,0.445369,0.437061,0.485234,0.496705,0.643438,0.667121,1.09416,1.21267,-0.903261,-0.770115,-0.0769296,-0.11893,0.674256,0.621602,1.83166,1.95681,1.04363,1.1286,-0.110967,-0.253699,0.919004,1.44748,-0.547113,-0.40471
8412,0.316231,0.309787,0.42123,0.38415,0.0245559,0.0285811,0.592195,0.54497,0.948604,1.03692,0.699248,0.709883,0.749793,0.723461,0.51686,0.519525,0.522324,0.54844,0.431814,0.482099,0.64192,0.672542,0.838414,0.953695,-1.01293,-0.876624,0.498848,0.457684,1.55824,1.50068,1.39885,1.52568,1.19248,1.28164,-0.858055,-0.997209,-1.22299,-0.692043,-1.08187,-0.942943
8413,0.499346,0.495817,0.464895,0.505224,0.767208,0.769453,0.839207,0.790193,0.294673,0.382686,0.790683,0.791038,0.0531689,0.0270665,0.859855,0.861556,0.0980713,0.125015,0.453859,0.467493,-0.602154,-0.578255,1.73833,1.86114,1.22416,1.36787,-0.424882,-0.460623,1.05414,0.996555,-0.572405,-0.446989,-0.369641,-0.281922,-1.27194,-1.41693,-1.54436,-1.00792,-0.341737,-0.210437
8414,0.0530075,0.0499701,0.677679,0.626297,0.603934,0.525824,0.717847,0.668061,0.594661,0.685451,0.21316,0.211275,0.492935,0.468828,0.486514,0.489591,0.127835,0.154575,0.00762662,0.0211018,-0.752288,-0.725336,-0.141701,-0.0165521,0.605623,0.750517,-0.109733,-0.142652,0.119263,0.064488,-1.0609,-0.940189,-1.18036,-1.09418,1.66789,1.52796,1.05762,1.59645,0.617585,0.749075
8415,0.991655,0.990554,0.746413,0.747371,0.2816,0.282195,0.898815,0.848904,0.399617,0.532501,0.701122,0.698418,0.647183,0.624186,0.830533,0.831622,0.91103,0.936757,0.0764848,0.0878436,0.197578,0.228762,-1.0602,-0.933342,1.08942,1.23973,-1.02878,-1.06096,0.590978,0.528606,0.593645,0.715033,-2.77513,-2.69014,0.589612,0.448581,-0.818102,-0.275166,-1.44044,-1.31603
8416,0.0832209,0.0801632,0.710374,0.698247,0.437193,0.382228,0.167993,0.115881,0.291305,0.379552,0.486839,0.544366,0.476674,0.454507,0.93029,0.933167,0.803284,0.864703,0.417198,0.473074,-1.37902,-1.34323,0.881106,1.01036,0.554028,0.704309,1.73187,1.70021,0.00829786,-0.051155,-0.00487624,0.1111,-0.710128,-0.549044,-1.09647,-1.24462,-0.486329,0.0592755,-0.0220877,0.103102
8417,0.0238157,0.0187908,0.780343,0.649122,0.41586,0.482261,0.229496,0.113858,0.721752,0.807836,0.393969,0.390315,0.715635,0.695619,0.1287,0.131907,0.765351,0.792649,0.844763,0.858304,0.144226,0.186136,-1.35698,-1.22549,0.272307,0.408047,-0.690095,-0.717403,1.38685,1.33491,0.758627,0.876664,1.50706,1.59205,-2.5487,-2.69167,1.09907,1.64375,0.106694,0.250692
8418,0.696917,0.690012,0.601383,0.599998,0.581698,0.582294,0.162006,0.111834,0.550913,0.564385,0.401047,0.397402,0.634677,0.616283,0.984481,0.986882,0.393089,0.418465,0.239511,0.252253,0.806224,0.849888,2.46091,2.58836,-0.0446142,0.111786,-0.913308,-0.936775,-0.631877,-0.677827,0.238704,0.351659,-0.00960458,0.0761139,-0.0677502,-0.214134,0.160172,0.704155,0.269673,0.398281
8419,0.872769,0.865419,0.156342,0.156625,0.0793509,0.0781574,0.943114,0.891841,0.234661,0.320935,0.133738,0.129525,0.144995,0.125173,0.759397,0.665878,0.270777,0.29569,0.180285,0.193916,0.0508635,0.0912891,-0.0126792,0.113549,-1.11746,-0.954068,0.668183,0.650452,0.530261,0.476585,-1.07569,-0.957628,0.31632,0.397865,1.03605,0.882664,0.389843,0.929382,-0.792331,-0.666586
8420,0.774992,0.693103,0.391869,0.393933,0.377938,0.37444,0.63589,0.584056,0.884635,0.971155,0.436556,0.394272,0.935293,0.915456,0.349443,0.344874,0.605485,0.632122,0.754298,0.767999,1.68908,1.72813,-0.340727,-0.221017,-0.983592,-0.816204,-2.68979,-2.70066,0.670385,0.618324,0.546121,0.666811,-0.536936,-0.460489,-1.61619,-1.77483,-0.294512,0.244237,1.00774,1.13991
8421,0.526135,0.520788,0.0147472,0.015143,0.233282,0.227448,0.958515,0.908353,0.730682,0.886817,0.567557,0.65902,0.121382,0.103756,0.0214704,0.0238706,0.401433,0.429316,0.651108,0.72242,0.975658,1.01586,-0.975546,-0.860582,-1.06895,-0.844237,-1.96955,-1.98445,-1.11264,-1.16107,-1.02634,-0.903956,0.223646,0.306608,-0.232034,-0.3864,-0.507309,0.0374528,2.18566,2.31379
8422,0.355891,0.348472,0.56631,0.566902,0.530605,0.432889,0.17195,0.123658,0.715354,0.802479,0.92798,0.923767,0.859277,0.842709,0.709297,0.709657,0.700161,0.729267,0.662352,0.67684,0.0330763,0.0739528,-2.37303,-2.26329,-1.0056,-0.87227,-0.459051,-0.476062,0.49277,0.438857,0.665375,0.783715,0.120346,0.201067,-0.899666,-1.05366,0.5467,1.09115,-1.18446,-1.06275
8423,0.399264,0.393759,0.141931,0.14297,0.646308,0.63833,0.627505,0.581343,0.977618,1.06355,0.853289,0.851072,0.898204,0.881124,0.415375,0.418125,0.62121,0.706429,0.255581,0.270449,-1.39491,-1.36171,0.137146,0.248184,-1.06977,-0.900304,-1.20676,-1.22231,0.298621,0.240044,1.6142,1.73355,0.565531,0.647968,-2.7642,-2.92087,-0.314764,0.234909,1.11315,1.23079
8424,0.728692,0.721335,0.297131,0.297016,0.520801,0.512102,0.30769,0.263389,0.717153,0.801242,0.195154,0.191148,0.461195,0.445042,0.659438,0.663682,0.654206,0.683591,0.307664,0.323122,-0.903629,-0.865098,0.429654,0.543789,0.922504,1.08733,-1.14558,-1.16393,-1.32242,-1.38309,0.165085,0.285314,0.500382,0.588173,-0.0709332,-0.220984,0.912111,1.45848,-0.895372,-0.771773
8425,0.282498,0.275489,0.109801,0.107504,0.950481,0.941181,0.466551,0.423012,0.24557,0.328236,0.0911279,0.0875547,0.532119,0.539118,0.033856,0.0373029,0.826816,0.858558,0.761358,0.777582,-0.870852,-0.904745,-1.02415,-0.905265,-0.278941,-0.118245,1.5995,1.5797,1.06329,1.00354,-0.562747,-0.441114,-0.957952,-0.863245,0.245761,0.154014,-0.347454,0.194412,-1.97294,-1.85466
8426,0.634513,0.62731,0.810993,0.807736,0.713116,0.702816,0.143188,0.100205,0.0712642,0.151603,0.240248,0.23735,0.68644,0.633193,0.00597428,0.0115547,0.357978,0.389042,0.641168,0.657097,-0.98783,-0.944391,0.733258,0.856016,0.71316,0.881249,1.0288,1.00512,-1.05787,-1.11451,0.858673,0.980594,-0.263757,-0.171729,0.68135,0.529012,-0.262385,0.282422,-0.0713279,0.0438881
8427,0.230362,0.222101,0.076914,0.0720945,0.901429,0.89317,0.220513,0.0893224,0.255212,0.336661,0.726893,0.724494,0.798363,0.727268,0.729785,0.733877,0.853121,0.884785,0.284959,0.301311,2.09536,2.14179,-1.13495,-1.02168,-0.399203,-0.231995,-0.372521,-0.389834,0.519764,0.468617,0.635985,0.764949,-0.368709,-0.27727,-0.442847,-0.596059,0.613817,1.16335,-0.631979,-0.522697
8428,0.608332,0.600177,0.614254,0.60933,0.465971,0.457841,0.127592,0.07844,0.951996,1.03305,0.445477,0.462455,0.793846,0.821343,0.424536,0.517519,0.674131,0.650734,0.498722,0.513825,0.741135,0.786439,0.283029,0.39614,-0.101449,0.0600774,0.529042,0.513611,0.0604232,0.00993144,-0.915411,-0.791108,1.48819,1.57559,-0.63421,-0.785715,0.928214,1.48193,-0.118418,-0.00324485
8429,0.746918,0.740531,0.114801,0.111048,0.506422,0.499671,0.110731,0.0675576,0.483729,0.576,0.20437,0.200416,0.931571,0.915418,0.29365,0.301161,0.383908,0.416684,0.511772,0.529172,1.06612,1.11413,-0.330682,-0.213517,0.583737,0.752042,-1.02179,-1.03279,-1.4537,-1.50549,-0.10471,0.020177,-1.06806,-0.985956,-1.11274,-1.26595,-0.607446,-0.0524805,-0.283673,-0.162331
8430,0.49983,0.540259,0.630468,0.628819,0.609521,0.5415,0.950623,0.909636,0.0381488,0.118955,0.670515,0.668014,0.0858838,0.0697846,0.0807111,0.084803,0.922804,0.95736,0.317276,0.290322,0.407205,0.449238,-0.0593031,0.0497005,0.996259,1.16733,-0.851063,-0.867777,-2.06134,-2.11612,-0.409469,-0.288541,-0.29205,-0.202253,-0.662349,-0.812631,-0.913552,-0.353228,-1.21048,-1.09196
8431,0.394561,0.339987,0.883181,0.880502,0.553225,0.58333,0.478208,0.44,0.126649,0.207478,0.800067,0.797712,0.946112,0.928235,0.753194,0.755845,0.446686,0.482688,0.0363361,0.0514716,0.247362,0.287128,-0.606808,-0.575461,-0.595284,-0.42173,1.00743,0.990102,0.374202,0.322671,0.656101,0.784249,-1.8896,-1.79821,1.87172,1.71929,-0.0315362,0.527705,-0.528873,-0.378182
8432,0.145587,0.139715,0.265921,0.263949,0.504662,0.62516,0.00872239,-0.0296361,0.805989,0.88847,0.192106,0.188231,0.837065,0.819005,0.840393,0.84157,0.214646,0.248849,0.582567,0.595602,-0.799721,-0.7641,-1.31049,-1.20062,-1.48891,-1.31616,0.206145,0.182523,-0.295357,-0.263946,-0.0387071,0.176008,1.70415,1.79548,-0.909832,-1.05993,-0.0930776,0.460929,0.179731,0.335599
8433,0.82163,0.814982,0.308674,0.183746,0.67512,0.666989,0.775738,0.739248,0.68111,0.818171,0.753748,0.749518,0.126623,0.106755,0.114992,0.11686,0.950598,0.985607,0.490205,0.501763,0.711128,0.749603,0.256477,0.35952,-0.876544,-0.703757,-1.31415,-1.33641,-0.873185,-0.850562,-0.604645,-0.432233,-3.62601,-3.53469,-3.43344,-3.58601,2.41902,2.96829,0.930863,1.04938
8434,0.450523,0.44523,0.151736,0.103542,0.143922,0.133174,0.929983,0.893879,0.690567,0.747873,0.454335,0.497495,0.109491,0.0889933,0.976428,0.977266,0.656242,0.69138,0.920062,0.930363,0.975274,1.01549,-0.091495,0.0679606,-1.0099,-0.838707,-0.438006,-0.464442,-1.38565,-1.43718,-1.16862,-1.04047,-1.38371,-1.29987,0.344854,0.189479,-0.189553,0.35667,-1.81057,-1.68795
8435,0.522567,0.515963,0.0278689,0.0233391,0.3543,0.261434,0.24552,0.211871,0.594868,0.677574,0.2497,0.245471,0.790392,0.771885,0.265669,0.268635,0.00617266,0.0411972,0.767478,0.780003,0.373613,0.411,-0.324341,-0.223599,-0.541073,-0.363789,1.40788,1.37797,-0.198397,-0.251007,0.364536,0.490759,-0.169226,-0.0833474,0.795708,0.642794,-0.116331,0.428427,-0.615194,-0.496727
8436,0.226791,0.221451,0.36408,0.359481,0.402367,0.389694,0.280498,0.331886,0.739146,0.822029,0.419605,0.401409,0.505824,0.486018,0.517847,0.518833,0.063676,0.125896,0.273091,0.284595,0.620403,0.662158,-2.13094,-2.03406,-0.877756,-0.699534,0.466957,0.444454,-1.59054,-1.64391,0.403334,0.535783,-1.19917,-1.11501,-0.5127,-0.668586,-1.39425,-0.85434,-0.29255,-0.173852
8437,0.483953,0.477892,0.110093,0.103426,0.932199,0.918229,0.486746,0.451901,0.577669,0.660663,0.523808,0.557347,0.45757,0.457444,0.132317,0.132361,0.177787,0.210595,0.80717,0.819491,-0.112947,-0.0665821,-0.851198,-0.755479,-0.0682563,0.115864,-0.794193,-0.812962,0.792916,0.742724,-0.197357,-0.0681504,-0.038987,0.0404609,1.3129,1.15251,0.130242,0.668367,1.10939,1.2301
8438,0.013983,0.00742149,0.771833,0.762761,0.730288,0.647433,0.67665,0.571917,0.916179,0.998041,0.783357,0.713286,0.447771,0.42887,0.48768,0.489869,0.629332,0.618151,0.933043,0.94548,0.659525,0.705247,-1.56963,-1.39292,1.60132,1.79029,0.560515,0.535176,-2.07009,-2.12631,3.08216,3.21525,-0.120972,-0.0348504,1.59162,1.4392,-0.106011,0.430847,1.00839,1.13233
8439,0.713656,0.708114,0.871634,0.869461,0.388978,0.376637,0.632702,0.691932,0.760667,0.835884,0.873453,0.869224,0.0139284,-0.00721118,0.599222,0.600577,0.990797,1.02571,0.51309,0.524891,0.543692,0.587773,-2.13251,-2.03036,0.158002,0.354236,0.580119,0.561077,-0.389597,-0.451032,0.592133,0.721649,0.151392,0.24071,0.796238,0.65046,-0.619474,-0.0856688,-0.165311,-0.042094
8440,0.568695,0.535412,0.98737,0.976162,0.954545,0.94472,0.845597,0.811947,0.589621,0.673728,0.0382458,0.0359865,0.961862,0.942952,0.0322264,0.0339312,0.816644,0.852444,0.30064,0.342945,1.69976,1.74225,1.29793,1.3924,0.88006,1.07654,-0.433957,-0.448801,0.30796,0.243451,-0.58072,-0.447321,-0.743024,-0.651087,0.401608,0.263017,0.270366,0.809379,-0.320661,-0.201181
8441,0.367163,0.362709,0.885131,0.849802,0.708053,0.676819,0.157784,0.124862,0.854604,0.94004,0.896399,0.891696,0.0812235,0.0613086,0.945734,0.947167,0.0449721,0.0834255,0.151111,0.160999,-0.560149,-0.516676,-0.0931785,0.00577385,0.739817,0.941587,-0.068148,-0.140639,-0.368712,-0.428331,0.464004,0.595143,-0.892817,-0.801184,0.593386,0.456567,-0.551742,-0.0166672,-0.142118,-0.0197333
8442,0.503744,0.376392,0.732218,0.723443,0.421652,0.408919,0.383616,0.254223,0.428765,0.516139,0.244915,0.241644,0.83379,0.816514,0.945792,0.946804,0.421803,0.459235,0.754243,0.764781,0.349715,0.392059,-0.682436,-0.589332,-0.467919,-0.26399,0.180383,0.167522,1.90285,1.84279,1.23879,1.3749,0.125287,0.212163,-0.559286,-0.696137,-0.97803,-0.441037,0.0431423,0.161714
8443,0.442218,0.390075,0.146206,0.137281,0.529281,0.563169,0.414949,0.383584,0.6131,0.701197,0.967724,0.963,0.249749,0.234086,0.522225,0.518043,0.263692,0.300818,0.851016,0.860947,1.86312,1.90576,0.682693,0.781034,1.95798,2.15949,-0.28691,-0.383571,1.26044,1.2026,0.641135,0.770966,-0.533037,-0.446506,-0.553943,-0.781683,-0.026299,0.516763,-0.14725,-0.0275753
8444,0.407432,0.403758,0.394019,0.393102,0.731477,0.717419,0.0439349,0.0116655,0.140072,0.228191,0.881743,0.922137,0.659382,0.645613,0.0862963,0.0892819,0.823865,0.860584,0.403098,0.414555,0.285848,0.333767,-0.162445,-0.060983,-0.878227,-0.681986,-0.918522,-0.934664,0.993418,0.941736,1.22304,1.3543,1.39641,1.48454,-0.722961,-0.867229,-0.592841,-0.0456459,0.286507,0.400335
8445,0.953739,0.950155,0.549421,0.648924,0.0717544,0.0584438,0.941719,0.909303,0.590225,0.654755,0.888385,0.881273,0.255316,0.239525,0.483401,0.48592,0.447348,0.4864,0.682694,0.69237,1.83622,1.88006,0.72289,0.830767,0.00913329,0.209886,-0.493757,-0.484545,0.148095,0.100667,-0.295214,-0.169778,-0.291513,-0.204509,0.293067,0.155598,-1.67655,-1.12311,0.185483,0.302571
8446,0.746039,0.74131,0.91367,0.904745,0.295564,0.284045,0.711747,0.679204,0.995706,1.08132,0.145205,0.135912,0.336616,0.365912,0.237035,0.237922,0.982919,1.02099,0.504902,0.534086,1.52285,1.56853,-0.455041,-0.350312,1.12053,1.31353,-0.0159614,-0.0344267,0.425938,0.381718,-0.147056,-0.019242,0.164587,0.28912,-0.523207,-0.662079,-0.373802,0.178796,-0.773965,-0.656003
8447,0.945386,0.941836,0.249369,0.239068,0.193971,0.183372,0.445992,0.449105,0.0680443,0.152948,0.0148452,0.00732207,0.507364,0.492298,0.756036,0.755213,0.251854,0.289802,0.363554,0.375802,-0.576945,-0.531523,0.810491,0.913119,-1.14474,-0.958778,0.0655613,0.0517927,1.30395,1.2608,0.533082,0.626198,0.703356,0.782749,-0.106579,-0.238872,0.0788246,0.686662,-0.487324,-0.363777
8448,0.105624,0.0995085,0.692031,0.682857,0.505422,0.512067,0.250184,0.219007,0.703894,0.78748,0.164545,0.157118,0.102107,0.0862105,0.288977,0.28857,0.216263,0.254731,0.616792,0.603912,-1.10887,-1.05944,1.12419,1.223,0.685288,0.871162,-1.69331,-1.70224,0.96221,0.923349,1.14531,1.27164,0.247544,0.321298,-1.22674,-1.36394,0.649213,1.19453,-1.57079,-1.44666
8449,0.678801,0.670969,0.47255,0.383596,0.852408,0.840762,0.634658,0.602111,0.779276,0.861636,0.085004,0.124644,0.848008,0.830615,0.618749,0.620429,0.626788,0.664994,0.820035,0.832022,-0.828652,-0.776507,2.17119,2.26736,-1.03295,-0.845847,1.20179,1.1896,-1.21306,-1.25677,-1.26877,-1.14032,-0.58302,-0.504747,-0.691062,-0.832876,-1.09335,-0.548161,0.767304,0.8957
8450,0.673008,0.661802,0.0951202,0.0843342,0.730049,0.719582,0.341208,0.309598,0.0708833,0.15075,0.0229555,0.0921708,0.975095,0.955993,0.353341,0.353373,0.0592076,0.0950641,0.15498,0.165777,0.2484,0.299912,-1.1227,-1.03365,-0.12978,0.0612749,-0.764241,-0.774988,-1.00497,-1.05302,0.295975,0.423337,-0.360266,-0.276567,1.77317,1.62888,0.971247,1.51848,0.515668,0.64641
8451,0.662361,0.652636,0.492263,0.479783,0.304367,0.295083,0.504706,0.435977,0.659889,0.740717,0.0677254,0.0596972,0.0809059,0.061858,0.682854,0.685232,0.268065,0.305661,0.0142031,0.0260054,1.78878,1.84621,0.551492,0.634733,2.37119,2.56928,-0.409221,-0.426596,0.457507,0.407973,1.45459,1.58823,0.657469,0.736781,1.72919,1.58863,-0.240219,0.30162,-0.891748,-0.756206
8452,0.280331,0.2729,0.181892,0.26692,0.534429,0.595346,0.594354,0.562356,0.730584,0.809889,0.228832,0.219168,0.455326,0.352286,0.670845,0.740729,0.211961,0.250096,0.550004,0.560901,-1.14937,-1.08935,0.558838,0.637037,-0.0907744,0.106329,-0.872975,-0.894614,-1.77715,-1.83309,-0.0951268,0.0321727,-0.68163,-0.607653,0.0588866,-0.0891336,1.53127,2.07457,-1.03726,-0.898941
8453,0.10455,0.0953539,0.0655225,0.0540561,0.905889,0.895608,0.16543,0.135194,0.0589047,0.140186,0.650394,0.642779,0.664433,0.642713,0.790904,0.796227,0.44661,0.486869,0.839197,0.849006,-0.249574,-0.194237,0.207223,0.287072,-0.394893,-0.198188,-0.943848,-0.960921,-0.632844,-0.692358,-0.841769,-0.709896,-1.6682,-1.59345,-0.598954,-0.740068,1.41555,1.96095,0.439567,0.583052
8454,0.93796,0.930502,0.468329,0.376291,0.429304,0.420632,0.269269,0.239594,0.488398,0.56847,0.804106,0.797569,0.471633,0.45579,0.0990265,0.103317,0.209395,0.248358,0.266356,0.277832,0.92817,0.991917,-0.609239,-0.521503,-0.262737,-0.0603244,-0.439027,-0.41498,-0.984669,-1.04344,-0.257162,-0.126562,0.836157,0.906632,-0.00475442,-0.149472,0.778408,1.32166,1.03938,1.17729
8455,0.742161,0.736638,0.7118,0.698525,0.161528,0.25233,0.793086,0.762518,0.684698,0.763764,0.658902,0.653961,0.351865,0.268867,0.906467,0.911993,0.721522,0.75875,0.0137417,0.0230294,0.461632,0.5266,-0.0239012,0.0642587,-1.48508,-1.28188,0.14184,0.130962,0.254816,0.190062,-0.844805,-0.715091,0.409932,0.477058,-0.538573,-0.690999,-0.421231,0.117508,0.645346,0.775258
8456,0.147726,0.141054,0.0125685,-0.00173882,0.091335,0.0840285,0.780872,0.750192,0.407801,0.441325,0.268025,0.261828,0.103993,0.0819444,0.941851,0.947266,0.881318,0.918133,0.28032,0.36007,1.29062,1.35786,0.289323,0.374141,0.768359,0.978112,0.134848,0.134315,-0.60002,-0.665085,-0.673476,-0.547808,0.883977,0.953669,1.68389,1.5304,-0.859772,-0.322397,1.87354,2.01069
8457,0.161977,0.156246,0.976872,0.961502,0.83156,0.8249,0.211772,0.182008,0.0404193,0.118886,0.644708,0.636729,0.837685,0.816509,0.29224,0.299887,0.681729,0.720649,0.686779,0.697111,-0.375035,-0.306651,0.399186,0.481067,-0.168976,0.0383843,0.146161,0.137668,0.378467,0.308176,0.602142,0.722323,0.00132265,0.0769227,-0.150995,-0.307331,1.43217,1.9672,1.11701,1.24789
8458,0.953164,0.947327,0.544411,0.488631,0.52326,0.48807,0.548411,0.520591,0.22942,0.376523,0.0308726,0.0218185,0.340184,0.415813,0.544569,0.552156,0.0405449,0.080223,0.80491,0.814279,-1.13595,-1.06525,-0.520475,-0.435723,1.91534,2.12057,1.38589,1.37852,-0.0618378,-0.135397,-0.310394,-0.190016,0.114448,0.18522,0.443971,0.283265,0.837734,1.37387,1.17657,1.30072
8459,0.625292,0.617613,0.0308747,0.01576,0.157719,0.15124,0.158395,0.128817,0.55553,0.634159,0.660417,0.6525,0.0338612,0.0151161,0.795791,0.804424,0.630136,0.670862,0.478115,0.58457,0.647827,0.724869,-0.463522,-0.373033,-0.541285,-0.342385,0.782718,0.702841,1.01762,0.943308,0.727547,0.852448,0.481387,0.553748,0.516911,0.328778,0.000192355,0.534234,-1.1468,-1.02071
8460,0.987777,0.980081,0.710437,0.695451,0.986232,0.980093,0.341322,0.30966,0.457278,0.504934,0.251851,0.246357,0.127725,0.211678,0.00678541,0.0126896,0.360655,0.40199,0.346833,0.354862,-0.756159,-0.679034,0.0818422,0.165898,-1.08749,-0.893208,0.0287361,0.0271598,1.60698,1.52936,-1.56859,-1.4492,1.65492,1.72232,0.529701,0.37429,-1.08773,-0.556716,-0.059859,0.0616291
8461,0.22353,0.214833,0.0648001,0.0497452,0.731954,0.726574,0.8675,0.83732,0.366686,0.37571,0.35565,0.351294,0.41545,0.40824,0.035271,0.0429042,0.524177,0.613354,0.819185,0.828866,-0.689918,-0.611936,0.379889,0.477026,-1.33533,-1.13769,1.00932,1.00852,-2.41872,-2.49154,-0.576761,-0.452573,2.22522,2.29229,0.203571,0.0469919,1.80806,2.34015,-0.60846,-0.491355
8462,0.574964,0.591567,0.211397,0.19875,0.221893,0.218186,0.684259,0.655353,0.167856,0.246486,0.410404,0.45623,0.623177,0.604801,0.833631,0.841429,0.778289,0.824718,0.752617,0.822194,0.0854523,0.159894,0.701229,0.788153,1.26922,1.4661,1.15061,1.14253,2.93862,2.86579,0.189122,0.31299,0.401422,0.462275,-1.54897,-1.70763,0.669537,1.20007,-0.0738804,0.0423756
8463,0.979054,0.968302,0.777354,0.765233,0.340513,0.291482,0.18271,0.152425,0.28989,0.372291,0.565804,0.561166,0.122925,0.103763,0.359049,0.365923,0.997026,1.03608,0.803947,0.815523,-0.769943,-0.691605,2.4864,2.57907,-0.879895,-0.676066,1.55006,1.53659,-2.09124,-2.16406,-0.628338,-0.50538,-1.43481,-1.36774,-1.12971,-1.28443,0.546332,1.07022,1.58003,1.69167
8464,0.811655,0.800713,0.136859,0.124935,0.370324,0.364777,0.361035,0.333268,0.41765,0.498096,0.0961875,0.0910905,0.649399,0.630625,0.311459,0.319405,0.744696,0.726275,0.537441,0.55055,-0.430177,-0.349885,-0.66989,-0.576038,-0.882621,-0.771409,-0.750985,-0.758165,-0.142728,-0.222779,0.947701,1.07443,0.168967,0.234528,0.385797,0.224323,-0.373984,0.1487,0.474185,0.676509
8465,0.941627,0.888332,0.7271,0.715784,0.822347,0.818286,0.166078,0.135856,0.960254,1.04247,0.397388,0.392482,0.430255,0.409465,0.484161,0.4906,0.37498,0.416468,0.653402,0.667718,1.15998,1.24118,0.686026,0.779362,-1.0759,-0.866752,0.836926,0.829062,-0.234069,-0.314879,0.0608534,0.205364,-1.18756,-1.12381,-1.38847,-1.54672,-0.101775,0.419156,-0.454809,-0.338651
8466,0.989204,0.975952,0.320197,0.306377,0.85904,0.851923,0.730318,0.6992,0.0542831,0.138233,0.035694,0.0307551,0.867397,0.84636,0.869403,0.877211,0.62229,0.662544,0.516393,0.519711,1.4376,1.52411,0.172055,0.262557,0.40951,0.618348,-0.729151,-0.734069,-0.793545,-0.878772,-0.79485,-0.663701,-0.293177,-0.235157,-2.20258,-2.3644,-0.7512,-0.235155,-1.2551,-1.14579
8467,0.617168,0.6062,0.344872,0.329795,0.871246,0.885559,0.645131,0.61617,0.115533,0.200725,0.71277,0.707727,0.0247395,0.00559769,0.652022,0.660123,0.0010641,0.0421142,0.359654,0.371704,-0.36113,-0.282431,-1.23235,-1.14015,-1.73625,-1.52382,-0.930615,-0.936803,1.69151,1.60189,1.39466,1.52285,-0.855879,-0.804788,-0.732287,-0.900252,0.638342,1.14817,1.35822,1.46622
8468,0.733579,0.722207,0.654837,0.640909,0.772141,0.919195,0.0250335,-0.00148198,0.825439,0.912672,0.183572,0.177808,0.487881,0.466907,0.208595,0.218545,0.261197,0.303773,0.942739,0.955991,-0.0473426,0.0307954,1.74803,1.84466,0.488657,0.702156,-0.157968,-0.158516,1.67059,1.575,1.10829,1.23095,0.750848,0.797484,1.31896,1.15562,-0.107004,0.39794,-0.276334,-0.0722733
8469,0.634232,0.656742,0.580489,0.505516,0.956892,0.952831,0.475812,0.4516,0.376822,0.464661,0.123299,0.115862,0.749244,0.728479,0.597663,0.517434,0.762464,0.803993,0.818256,0.830904,1.35769,1.43431,1.78068,1.87745,-0.527438,-0.317443,-1.01963,-1.01422,-0.682143,-0.779804,-0.29632,-0.17302,0.753243,0.798597,-1.59222,-1.75296,-0.0487789,0.45368,-1.71876,-1.61076
8470,0.60424,0.591276,0.38464,0.370122,0.32815,0.324122,0.134083,0.110135,0.616439,0.656693,0.371469,0.363971,0.189136,0.166668,0.80822,0.816323,0.395046,0.434637,0.206362,0.22095,0.148679,0.230316,0.533443,0.634528,0.337341,0.542856,-0.416576,-0.407325,-0.750772,-0.772288,1.0843,1.20322,-0.17258,-0.124623,0.137464,-0.0262021,0.417675,0.912184,-0.134322,-0.0227231
8471,0.198156,0.186068,0.622719,0.60743,0.0932141,0.0909904,0.414547,0.353991,0.759424,0.848725,0.863543,0.856597,0.420901,0.379676,0.158069,0.163837,0.919104,0.959855,0.334448,0.25533,0.580581,0.664563,-1.15008,-1.04957,0.193839,0.39178,-1.09115,-1.07455,-0.664072,-0.764772,0.277555,0.399607,-0.75748,-0.734263,2.31062,2.15419,-0.361993,0.133142,-1.05958,-0.930836
8472,0.484966,0.472914,0.593264,0.577184,0.840251,0.83715,0.623301,0.597848,0.164435,0.25431,0.115611,0.106469,0.612541,0.592684,0.0699891,0.0780263,0.12423,0.163047,0.349616,0.289709,1.50573,1.58926,1.71794,1.81478,1.6134,1.81611,0.369621,0.387922,-0.126692,-0.225235,1.77281,1.89895,-1.38998,-1.3439,-0.296744,-0.457431,0.0779159,0.5764,-1.95055,-1.83895
8473,0.14889,0.137762,0.253781,0.281126,0.619232,0.615153,0.168315,0.140843,0.453883,0.541582,0.296001,0.368397,0.331055,0.311767,0.352181,0.395508,0.128467,0.154105,0.309421,0.324089,0.974511,1.06135,-0.122632,-0.0282845,-1.09393,-0.888622,-1.14655,-1.13101,-0.906707,-1.00181,1.22853,1.35745,-0.390047,-0.344034,1.87441,1.72296,-0.633293,-0.139354,-0.250057,-0.143264
8474,0.632679,0.619078,0.000109153,-0.0149315,0.0716154,0.06609,0.299311,0.270371,0.48678,0.560484,0.629865,0.630326,0.857349,0.838629,0.702113,0.712989,0.112651,0.145163,0.825073,0.837605,1.36607,1.45035,1.3485,1.43719,0.663137,0.863998,-1.63919,-1.62863,-0.155601,-0.246257,-1.27729,-1.15564,1.47999,1.52556,-1.29834,-1.4534,-0.618534,-0.130042,0.394682,0.498641
8475,0.691206,0.680362,0.246767,0.157319,0.112025,0.139832,0.855615,0.827834,0.494181,0.579386,0.901396,0.892254,0.441559,0.501366,0.220766,0.231909,0.0997979,0.136222,0.58985,0.693035,0.769341,0.845867,-2.66703,-2.585,0.727944,0.926374,-1.41266,-1.40015,0.895102,0.802187,0.110459,0.236723,0.594474,0.633762,-1.78471,-1.93363,0.8315,1.31517,-0.16446,-0.00405518
8476,0.754359,0.741646,0.342824,0.32957,0.264579,0.213574,0.0695205,0.0431388,0.924128,1.00767,0.491878,0.481249,0.18161,0.164103,0.991555,1.00388,0.433239,0.521064,0.538118,0.548464,-0.849866,-0.769458,-0.956177,-0.889084,-0.346371,-0.114517,0.864107,0.877874,0.0318434,-0.0693635,-1.59848,-1.46997,0.590219,0.634874,-0.760912,-0.910802,1.25264,1.74265,-0.605402,-0.506752
8477,0.143584,0.12989,0.34703,0.333943,0.292384,0.287316,0.40838,0.381721,0.0126049,0.0972594,0.615627,0.606154,0.548009,0.530985,0.104291,0.115992,0.870643,0.905907,0.653481,0.665632,-0.516361,-0.441765,0.724795,0.80683,-1.3481,-1.15541,0.490083,0.503302,0.837365,0.757448,0.237153,0.371194,0.163146,0.205301,-0.722609,-0.871793,1.31287,1.79839,-0.49549,-0.393622
8478,0.254599,0.18684,0.962822,0.948951,0.847951,0.845287,0.194139,0.169719,0.26353,0.348775,0.350739,0.343035,0.293974,0.274238,0.376576,0.38667,0.795923,0.795394,0.436467,0.450332,0.630393,0.712714,-1.3956,-1.31443,-0.0802292,0.116686,1.15279,1.08983,1.68635,1.58426,-0.716428,-0.585732,0.834651,0.880476,1.28099,1.1359,0.34289,0.830016,0.615223,0.718191
8479,0.256865,0.243789,0.622966,0.623267,0.431321,0.430862,0.185605,0.162936,0.818861,0.903269,0.518362,0.512973,0.665356,0.645897,0.293491,0.243756,0.651562,0.684881,0.453844,0.465679,0.914175,0.995643,-1.31521,-1.23625,-0.76803,-0.575756,1.66315,1.67637,0.950281,0.851449,-1.14314,-1.01686,0.132611,0.175293,0.632321,0.484967,-1.29152,-0.797488,0.626547,0.725771
8480,0.0703744,0.0551262,0.314111,0.297582,0.575667,0.577733,0.954993,0.93182,0.39351,0.479368,0.428005,0.425103,0.405614,0.328853,0.091476,0.100842,0.0268133,0.0600678,0.805538,0.815284,-0.403146,-0.314398,0.964492,1.04845,0.528162,0.727305,0.487459,0.497353,-0.930879,-1.03398,1.71839,1.83819,1.77971,1.82369,-0.423088,-0.577366,-1.7696,-1.282,1.50189,1.59464
8481,0.535815,0.521793,0.91014,0.893888,0.302226,0.303316,0.308557,0.284188,0.357748,0.53696,0.982296,0.981383,0.0326506,0.0118095,0.413687,0.422309,0.377508,0.38365,0.312272,0.324606,-1.19403,-1.10552,-2.92716,-2.8432,-0.106236,0.0963813,-1.0876,-1.08104,0.287861,0.13712,-0.148786,-0.0232888,0.779666,0.821883,-0.301182,-0.461114,1.40204,1.89208,-0.595953,-0.500819
8482,0.264711,0.252559,0.903519,0.888242,0.428159,0.527621,0.807741,0.782095,0.473879,0.594552,0.81538,0.813746,0.683764,0.664569,0.25753,0.265794,0.674989,0.707232,0.794497,0.808307,0.260833,0.346361,-0.549914,-0.459692,0.915677,1.11107,1.92109,1.92712,1.41132,1.30822,0.14142,0.265951,-1.35219,-1.30424,0.461084,0.308489,0.0679946,0.560569,0.530874,0.626539
8483,0.760453,0.748965,0.501037,0.545946,0.750901,0.751927,0.261995,0.234277,0.56698,0.652143,0.350158,0.34821,0.945533,0.926142,0.849911,0.858942,0.228407,0.262656,0.462255,0.476727,-0.485143,-0.39577,-1.77881,-1.66649,-0.57199,-0.370273,0.752547,0.76188,0.318807,0.260607,-0.187388,-0.0568574,-0.259969,-0.216292,1.24152,1.07809,2.58187,3.06793,0.0841369,0.180688
8484,0.75165,0.739941,0.221528,0.20365,0.0694049,0.0722208,0.391294,0.398622,0.856595,0.944097,0.219932,0.220365,0.0112352,-0.00595142,0.775878,0.860755,0.0588539,0.0949565,0.892756,0.905327,-1.61829,-1.52285,-2.96659,-2.87329,0.828518,1.0225,-1.4474,-1.43393,-0.683906,-0.787009,1.28482,1.41279,0.544803,0.580628,1.00289,0.842237,-2.40215,-1.91608,0.414118,0.518343
8485,0.0758263,0.0621289,0.644414,0.541397,0.759424,0.762278,0.589571,0.562967,0.360653,0.445849,0.094835,0.0925195,0.327299,0.311246,0.854952,0.862568,0.159499,0.19349,0.663807,0.648193,0.168783,0.267265,1.43248,1.52306,-0.18583,0.00290013,-0.374738,-0.361652,1.09212,0.995534,0.0391512,0.210633,-0.273297,-0.231629,-1.51898,-1.68385,0.869304,1.35592,0.431743,0.540814
8486,0.0702557,0.0574863,0.896983,0.879143,0.494234,0.498056,0.0212639,-0.00521688,0.732196,0.819158,0.490856,0.486741,0.336027,0.290676,0.0331351,0.0393503,0.857867,0.89008,0.248057,0.39106,-0.967332,-0.875984,-0.384637,-0.357345,-0.42288,-0.241582,-0.547343,-0.458802,-0.775337,-0.874116,-1.12366,-0.991525,-0.337706,-0.291423,1.31952,1.14913,-0.477975,0.00935958,-0.703278,-0.588971
8487,0.632852,0.618739,0.267039,0.248814,0.590272,0.59486,0.827101,0.801136,0.760523,0.846553,0.066392,0.0610209,0.352886,0.270106,0.0677051,0.0746234,0.010022,0.0419379,0.120241,0.133927,1.6066,1.69469,-2.32833,-2.23775,0.654826,0.833652,-0.572017,-0.555953,0.347331,0.248926,0.836396,0.969594,0.683059,0.755465,0.647074,0.481873,0.510991,1.00085,-0.452881,-0.342609
8488,0.135532,0.123345,0.528277,0.509684,0.955577,0.96218,0.826633,0.799917,0.377298,0.462865,0.380999,0.409044,0.265058,0.249536,0.994301,1.00123,0.961039,0.992451,0.142627,0.222563,-2.62087,-2.53278,-0.397826,-0.306922,-1.69905,-1.51813,0.993614,1.01837,-1.64735,-1.74933,-0.153396,-0.0186219,1.76188,1.80235,1.16555,0.996868,-1.72164,-1.23264,-0.464797,-0.328591
8489,0.531143,0.52111,0.282481,0.263543,0.474731,0.482478,0.440608,0.413196,0.762417,0.846278,0.764271,0.757066,0.655018,0.640587,0.234201,0.239763,0.552755,0.583536,0.249051,0.311199,-0.507571,-0.420333,-2.03706,-1.94314,0.48447,0.661063,-0.0989754,-0.0702601,1.05597,0.960284,0.848708,0.978005,-1.03819,-0.996737,-0.937585,-1.10457,0.499352,0.981109,-0.422126,-0.314574
8490,0.383268,0.411096,0.793691,0.775982,0.397304,0.404917,0.601367,0.57282,0.437084,0.519115,0.87628,0.831882,0.182166,0.169482,0.853848,0.859877,0.418561,0.451041,0.38689,0.399835,0.764095,0.85934,2.51494,2.60887,-0.0607057,0.11024,1.1125,1.14147,0.439775,0.422462,0.117517,0.251576,0.285136,0.329619,-0.982132,-1.14482,0.556323,1.03685,0.948662,1.05762
8491,0.313801,0.301082,0.9668,0.949835,0.3181,0.327357,0.196308,0.165795,0.491946,0.571453,0.911837,0.906697,0.110151,0.0956968,0.641183,0.573678,0.647793,0.683036,0.799736,0.813616,0.0921973,0.194446,-0.00835271,0.0840945,-0.277863,-0.104634,-0.994249,-0.962747,-0.0133102,-0.115359,0.648166,0.787616,0.861324,0.899589,0.282214,0.117962,0.129496,0.61248,0.860996,0.973172
8492,0.201101,0.191068,0.0720102,0.0557812,0.600591,0.608641,0.301655,0.270195,0.273617,0.403383,0.31976,0.316906,0.637586,0.622559,0.282186,0.287479,0.15951,0.193019,0.8197,0.835805,-0.36855,-0.270871,0.142855,0.238659,-0.177108,0.00186635,-1.93997,-1.91242,-1.14691,-1.24569,-0.664641,-0.521672,-0.386027,-0.349341,0.539701,0.373744,0.0687943,0.545704,0.562478,0.679171
8493,0.959874,0.950909,0.15637,0.140144,0.199218,0.208528,0.669309,0.638816,0.15642,0.235312,0.829398,0.824516,0.656787,0.640347,0.891782,0.897253,0.965483,1.00056,0.387832,0.405136,0.536352,0.637864,-0.720584,-0.617246,0.589802,0.770556,0.208979,0.231029,0.435213,0.337441,-1.37376,-1.23305,-0.41263,-0.378113,-1.6691,-1.82683,1.09221,1.56745,-0.341263,-0.21862
8494,0.84835,0.836868,0.57645,0.559258,0.695268,0.706847,0.173428,0.14135,0.85583,0.936383,0.0611804,0.0543992,0.211513,0.194583,0.00318496,0.00936201,0.617051,0.651117,0.270957,0.289344,0.179724,0.279942,-0.951068,-0.848236,0.333014,0.511745,0.251015,0.27235,-0.127769,-0.226451,0.835122,0.968508,-1.22615,-1.19037,0.468697,0.305588,-0.482793,-0.013359,0.62947,0.755027
8495,0.209591,0.200505,0.68239,0.663261,0.343577,0.356765,0.820418,0.788209,0.574377,0.653963,0.310486,0.302508,0.0862512,0.069971,0.2219,0.227598,0.263957,0.301679,0.462948,0.422126,0.560897,0.654562,0.521,0.631476,-0.155478,0.0228491,-0.885145,-0.860866,0.72077,0.622495,-1.79811,-1.66956,0.870336,0.903561,0.76379,0.604876,-0.258811,0.163367,-0.567885,-0.449044
8496,0.829029,0.820693,0.127855,0.106279,0.81892,0.830359,0.907712,0.876342,0.969816,1.05169,0.887479,0.878577,0.517776,0.501622,0.126711,0.131289,0.286654,0.326023,0.534364,0.554908,-0.76837,-0.673193,-0.954882,-0.848714,1.7911,1.96102,-1.72581,-1.70046,-0.358017,-0.461623,-0.548276,-0.414295,-0.250595,-0.250847,0.794268,0.658583,-0.129818,0.340094,0.0752897,0.116164
8497,0.142011,0.133966,0.00707846,-0.0117687,0.767492,0.781336,0.121323,0.0916474,0.698186,0.77968,0.327979,0.319729,0.423273,0.407765,0.512524,0.517901,0.967452,1.0083,0.945004,0.964222,-0.946325,-0.848927,1.95703,2.06862,1.23056,1.34495,0.498545,0.523698,0.602516,0.494254,1.49751,1.62898,-1.43848,-1.40525,0.866114,0.71229,-0.240249,0.226477,0.568442,0.681373
8498,0.425539,0.415663,0.659181,0.638268,0.408299,0.421714,0.529777,0.501019,0.0304254,0.109977,0.493515,0.484891,0.64435,0.654996,0.133917,0.141029,0.447695,0.48906,0.138991,0.159692,1.09703,1.20302,1.29031,1.40581,0.560247,0.728877,0.759726,0.780127,0.46808,0.356759,0.612562,0.748736,-0.805948,-0.774421,-1.71336,-1.86323,0.806157,1.28018,0.555495,0.673994
8499,0.125966,0.116032,0.451953,0.40567,0.882422,0.895308,0.660378,0.630548,0.206215,0.194442,0.158668,0.151408,0.916267,0.902228,0.873879,0.883423,0.935167,0.974067,0.180992,0.201568,-0.832799,-0.726279,0.63933,0.742993,-0.375676,-0.210851,0.0673311,0.0822587,-0.93498,-1.05142,-1.18316,-1.05256,0.321109,0.380516,-0.0649981,-0.213551,1.03105,1.50541,-1.1631,-1.04858
8500,0.327427,0.316558,0.192108,0.173072,0.388184,0.401027,0.406571,0.363968,0.282534,0.278907,0.914196,0.908275,0.427995,0.451628,0.305713,0.316777,0.881922,0.918503,0.647887,0.670525,-1.51002,-1.40829,-0.476816,-0.37697,-0.248708,-0.106728,-1.22684,-1.20477,-0.868212,-1.08577,0.770176,0.892035,1.50316,1.53545,0.596313,0.455186,-0.760215,-0.284747,-0.190961,-0.0749372
8501,0.818733,0.808085,0.812808,0.793556,0.657736,0.672296,0.126129,0.0973887,0.284346,0.363372,0.789247,0.785071,0.0135074,0.00102893,0.343202,0.35205,0.367406,0.403651,0.508086,0.530753,-0.434644,-0.33187,1.66783,1.76406,-0.163711,-0.00260413,-0.347793,-0.332804,-0.997702,-1.12011,-1.6798,-1.55084,0.546992,0.58156,-1.06869,-1.20719,-0.0452302,0.424998,-0.902454,-0.792263
8502,0.213326,0.202647,0.286821,0.266145,0.569188,0.58133,0.954491,0.924263,0.984991,1.06444,0.374445,0.369165,0.176881,0.23106,0.105546,0.114236,0.961731,1.00012,0.784934,0.808568,-0.262646,-0.158336,0.538847,0.628418,0.794271,0.951332,-0.356252,-0.335841,1.58791,1.46912,-0.441196,-0.311229,-0.205711,-0.169243,0.0187475,-0.125532,-1.09342,-0.622402,0.623782,0.735241
8503,0.105215,0.0936258,0.0195058,-9.9161e-05,0.904451,0.918493,0.434269,0.406389,0.900145,0.960631,0.412485,0.405446,0.474142,0.461091,0.945508,0.953381,0.58813,0.625938,0.584305,0.607828,-0.391841,-0.288097,-1.31892,-1.23143,0.688818,0.844823,1.86298,1.88832,0.208569,0.0898687,-0.181523,-0.0527911,0.27717,0.29277,0.292651,0.14615,-0.908194,-0.44461,-1.45641,-1.34442
8504,0.223659,0.213844,0.641763,0.620385,0.603819,0.61931,0.466869,0.439168,0.752966,0.856819,0.798874,0.790257,0.0683697,0.0550038,0.910897,0.917266,0.789371,0.826415,0.0987011,0.121883,0.430462,0.528225,0.3578,0.451573,-0.145715,0.0111544,-1.73325,-1.71271,0.448838,0.323451,-0.54393,-0.421759,0.713106,0.754784,1.39666,1.24295,-1.52816,-1.06767,0.688248,0.805051
8505,0.798224,0.790389,0.193665,0.171929,0.728208,0.745521,0.968913,0.941503,0.605171,0.753007,0.486272,0.486323,0.780969,0.768179,0.102733,0.109963,0.732429,0.770851,0.430087,0.450762,0.420657,0.518945,-0.24791,-0.158085,-0.135533,0.0269856,0.321222,0.334956,0.171204,0.0487166,0.222274,0.343805,-0.54983,-0.508155,-0.526687,-0.685763,-1.08062,-0.624415,1.05724,1.17295
8506,0.942889,0.935205,0.235606,0.125049,0.0561531,0.0717248,0.259214,0.234159,0.568361,0.649195,0.188519,0.182389,0.514274,0.502218,0.553784,0.561662,0.914542,0.952197,0.117018,0.139369,-0.467794,-0.363707,1.84543,1.93017,0.12065,0.289451,1.79422,1.81204,-0.472437,-0.591477,-0.281466,-0.166794,0.718801,0.753011,-1.0262,-1.18152,0.220412,0.677488,-0.112179,-0.00147996
8507,0.872925,0.863917,0.0988201,0.0781686,0.409815,0.338037,0.887139,0.861326,0.214599,0.295678,0.718165,0.714011,0.515351,0.505669,0.57519,0.661436,0.21797,0.256042,0.152242,0.258098,2.05662,2.15674,-1.9604,-1.88504,0.0112031,0.120462,1.14027,1.15969,0.591207,0.471928,0.488402,0.598769,-0.388746,-0.355835,0.0330848,-0.143266,0.468953,0.932792,-1.73961,-1.63385
8508,0.537498,0.528765,0.334957,0.315476,0.588909,0.60435,0.845331,0.819635,0.873954,0.956064,0.749564,0.745565,0.202296,0.193985,0.754001,0.761211,0.434398,0.445081,0.356145,0.376827,0.37899,0.477966,-1.30729,-1.23684,-0.213984,-0.0485282,-1.30286,-1.28918,-1.35563,-1.47874,-0.127219,-0.0215193,-1.06056,-1.03043,1.05639,0.894986,0.143081,0.601838,0.349333,0.452315
8509,0.964851,0.956628,0.225724,0.300393,0.101809,0.118788,0.256085,0.23186,0.749026,0.797992,0.347414,0.344,0.424156,0.449574,0.456437,0.464277,0.746966,0.634121,0.853131,0.875458,-0.772502,-0.679904,-0.407273,-0.329393,1.82973,1.99893,0.697672,0.709882,-0.0987566,-0.213593,0.603716,0.711521,-1.43628,-1.41276,0.0010469,-0.167347,0.0567681,0.518679,-0.813,-0.705833
8510,0.183635,0.174708,0.224349,0.285309,0.456826,0.475894,0.613198,0.585525,0.536255,0.639921,0.861857,0.856813,0.617685,0.705162,0.395323,0.403623,0.845962,0.82316,0.103223,0.127576,1.27376,1.37204,0.0760541,0.146847,-0.598321,-0.428742,0.63516,0.643575,0.263089,0.144753,1.03458,1.14076,0.635335,0.659999,-1.36683,-1.53755,-2.50467,-2.03779,-0.538237,-0.447691
8511,0.476043,0.469776,0.291305,0.270226,0.539984,0.557823,0.965941,0.939189,0.401527,0.481849,0.146857,0.141212,0.968426,0.960751,0.945968,0.956821,0.974128,1.0122,0.392747,0.415681,1.65957,1.76104,-0.274741,-0.203118,-0.597538,-0.428767,0.836179,0.839318,-0.996235,-1.11013,3.07977,3.18403,1.09894,1.12087,-0.559685,-0.731691,-1.39227,-0.92376,-0.304021,-0.189549
8512,0.771867,0.764843,0.888043,0.866531,0.227571,0.243294,0.657409,0.631404,0.630851,0.712436,0.955295,0.951138,0.318215,0.308507,0.194156,0.205113,0.908309,0.946407,0.996836,1.01946,1.36913,1.46408,-0.965301,-0.88936,0.602199,0.766993,-0.0625948,-0.0609353,-1.19432,-1.30894,2.05354,2.1512,-2.35953,-2.33299,-0.288379,-0.525796,0.663189,1.12686,0.520432,0.633405
8513,0.194983,0.188593,0.986286,0.965463,0.991868,1.01018,0.719589,0.714198,0.433648,0.515315,0.965726,0.964403,0.454595,0.443604,0.518701,0.524582,0.269113,0.305981,0.166754,0.188529,-0.725146,-0.635973,0.603441,0.685815,-0.202868,-0.0344289,0.52581,0.531182,0.995215,0.877679,1.52434,1.62619,-0.391812,-0.371153,-0.154628,-0.319901,0.362874,0.826113,-0.122705,-0.00389305
8514,0.686562,0.68012,0.566986,0.546794,0.681763,0.710907,0.823693,0.796992,0.797883,0.878659,0.89589,0.977667,0.208638,0.197539,0.831261,0.844051,0.267941,0.322875,0.562728,0.583094,0.458891,0.5454,0.101284,0.184126,0.156218,0.319623,-1.23474,-1.22285,-0.257472,-0.377201,-0.339132,-0.23529,-0.221346,-0.202993,-0.525957,-0.692598,-0.44312,0.0167473,-0.74974,-0.641191
8515,0.0938141,0.0894723,0.396233,0.290703,0.39308,0.411637,0.0207278,-0.00393881,0.32645,0.405653,0.995903,0.990931,0.448453,0.377726,0.960406,0.975073,0.30227,0.339769,0.4969,0.51882,1.64184,1.72677,-1.07171,-0.981924,-0.199678,-0.0308845,0.586836,0.604501,0.274703,0.147568,-0.32898,-0.220924,-0.274744,-0.262787,-0.00972947,-0.177603,1.12995,1.58458,-0.189782,-0.0752152
8516,0.912593,0.907336,0.0533312,0.0346116,0.837336,0.855383,0.368484,0.379283,0.789083,0.868817,0.736613,0.732943,0.569473,0.557913,0.756883,0.712803,0.622638,0.614171,0.133911,0.15772,-0.775078,-0.690448,-0.159868,-0.0744796,0.374087,0.536173,1.67192,1.69106,-1.10195,-1.23168,0.860513,0.974082,-1.89404,-1.88604,-0.126569,-0.291453,-0.374578,0.0808994,-0.368936,-0.249197
8517,0.0585129,0.0556632,0.754414,0.734844,0.290994,0.310401,0.787159,0.762504,0.767025,0.844692,0.245782,0.242687,0.225927,0.282535,0.435425,0.450533,0.851836,0.888574,0.372467,0.396467,0.728647,0.80868,-0.189801,-0.102551,-0.363052,-0.201784,-1.1914,-1.16911,0.474053,0.337893,-1.30998,-1.20099,0.967772,0.977222,-0.584928,-0.817151,0.392027,0.850502,-0.336922,-0.17819
8518,0.0419338,0.114342,0.924908,0.903851,0.451995,0.532939,0.370287,0.345735,0.407317,0.487224,0.648972,0.646563,0.0197053,0.00715799,0.420204,0.434552,0.695453,0.730157,0.14058,0.16565,0.0184091,0.0964127,1.42993,1.51838,1.96378,2.12315,-1.01607,-1.01543,-1.35647,-1.48641,-0.692576,-0.586772,-1.17338,-1.16541,-1.18501,-1.34285,0.0636296,0.519547,-0.23068,-0.107183
8519,0.0801444,0.17302,0.658314,0.637607,0.734307,0.755476,0.246555,0.311914,0.0530002,0.129756,0.319537,0.317982,0.640977,0.628681,0.88913,0.901457,0.769362,0.803815,0.956699,0.979155,0.57531,0.653408,1.02129,1.1079,1.74277,1.90828,-0.952082,-0.861745,0.80205,0.666091,-0.653919,-0.541748,-0.517802,-0.504185,1.22725,1.06823,0.117147,0.642148,0.0937128,0.215692
8520,0.236527,0.231699,0.67514,0.65664,0.619335,0.638935,0.301871,0.278094,0.536131,0.518589,0.958326,0.958789,0.158281,0.147057,0.932905,0.946846,0.274435,0.308727,0.543812,0.567683,-1.5363,-1.46219,0.941246,1.03343,-0.905017,-0.734919,-0.730349,-0.70806,-0.225159,-0.357911,0.177002,0.283161,1.6163,1.63749,0.998669,0.832375,0.308831,0.764748,-1.31171,-1.18692
8521,0.938299,0.932391,0.435448,0.396589,0.0731014,0.0939523,0.708138,0.682575,0.832238,0.907423,0.282447,0.283239,0.0372739,0.027293,0.219722,0.232367,0.456281,0.490073,0.807006,0.830712,-0.870768,-0.721849,-1.00206,-0.90285,-0.654517,-0.429862,-0.0983554,-0.0701162,3.41816,3.28064,-0.639496,-0.53521,0.740643,0.760739,-0.812652,-0.974345,-1.32484,-0.862755,-1.78199,-1.66238
8522,0.390068,0.386041,0.153579,0.136537,0.10537,0.125676,0.42594,0.399625,0.5341,0.560094,0.187809,0.190351,0.670338,0.658458,0.972365,0.985004,0.859231,0.891011,0.793904,0.816514,-0.0542692,0.0184903,0.552096,0.657294,-0.29786,-0.124806,0.864827,0.893811,-2.69528,-2.8328,-0.897879,-0.796362,-1.38041,-1.36538,0.943553,0.785398,1.01509,1.48189,-0.223464,-0.102634
8523,0.59583,0.592262,0.142951,0.126017,0.618328,0.63969,0.598056,0.569759,0.138496,0.212764,0.678302,0.682977,0.163421,0.15214,0.206262,0.218594,0.468301,0.500963,0.204607,0.225853,-0.259756,-0.186964,-0.126549,-0.0289484,-0.913923,-0.74216,-0.139843,-0.116068,-0.614967,-0.74695,0.0869692,0.183153,1.18279,1.19219,1.31041,1.14702,-0.437078,0.0271302,0.83953,0.963367
8524,0.550033,0.455009,0.990259,0.974135,0.511366,0.533646,0.483695,0.530001,0.810714,0.883655,0.944305,0.946413,0.0830199,0.0728033,0.166297,0.137427,0.848165,0.881717,0.287219,0.262306,0.228773,0.297211,-0.0753117,0.018243,-0.77086,-0.604296,-0.798553,-0.768422,0.622639,0.486553,0.315429,0.412207,2.18499,2.19206,1.42932,1.26328,0.444993,0.908063,1.18518,1.3153
8525,0.322108,0.317756,0.63868,0.624417,0.692686,0.714969,0.519667,0.490243,0.268142,0.340165,0.453304,0.456156,0.709066,0.698274,0.0441737,0.05626,0.40014,0.431919,0.400221,0.298759,-0.644135,-0.569344,0.488559,0.588388,-1.35192,-1.1905,-0.085473,-0.0522144,-0.903579,-1.04459,0.79511,0.889451,0.0133776,0.0170033,-0.225425,-0.399099,1.82184,2.29139,0.550249,0.672453
8526,0.706127,0.700578,0.0837678,0.0674352,0.115098,0.13614,0.892308,0.864085,0.770798,0.844064,0.432284,0.402766,0.675929,0.718052,0.570217,0.583135,0.996629,1.02839,0.314946,0.335212,0.325407,0.401908,-0.20927,-0.112755,-0.996396,-0.836452,0.126283,0.158428,0.62598,0.477971,0.298242,0.396251,-1.1946,-1.18518,-1.45853,-1.63092,-1.51218,-1.04636,1.45859,1.58518
8527,0.426501,0.505216,0.317589,0.29985,0.281783,0.302299,0.706571,0.720419,0.508639,0.58176,0.346047,0.349375,0.744827,0.73783,0.597303,0.691562,0.553202,0.583814,0.0440359,0.0647659,0.957229,1.03659,2.06544,2.15578,-0.0157015,0.146867,-0.722162,-0.697274,0.0369135,-0.0880143,0.295988,0.395058,-0.000458546,0.0156961,-1.77423,-1.94425,-0.580477,-0.118791,1.12785,1.25959
8528,0.314607,0.309853,0.998349,0.979542,0.0313649,0.0528737,0.60533,0.576754,0.875696,0.949426,0.662866,0.664953,0.799786,0.757607,0.788864,0.799989,0.359999,0.360181,0.538706,0.558668,-0.871594,-0.798727,0.748993,0.832636,-0.607585,-0.439341,-0.250904,-0.151332,-0.507524,-0.654,0.986609,1.0824,-0.965918,-0.953947,0.301374,0.126906,0.735832,1.19806,0.543698,0.678121
8529,0.571805,0.629089,0.730784,0.623932,0.224637,0.272594,0.203117,0.175141,0.557131,0.631746,0.686466,0.692461,0.876325,0.777385,0.304771,0.313821,0.107698,0.136548,0.0232671,0.0433174,-0.0149497,0.0632236,0.0116393,0.100624,0.360095,0.502726,0.375756,0.394609,0.268733,0.118247,-0.0840478,0.0175683,-0.0900511,-0.0794206,-1.39547,-1.56629,-0.70778,-0.241295,0.920237,1.05915
8530,0.953745,0.948326,0.287129,0.268322,0.472175,0.492315,0.68523,0.657743,0.888461,0.963926,0.750116,0.719968,0.807955,0.797163,0.147569,0.157305,0.144442,0.174992,0.76563,0.787235,1.24445,1.32748,-1.56977,-1.48697,1.28249,1.44479,-1.74385,-1.72399,-1.32846,-1.47221,0.53285,0.631783,0.524027,0.536369,0.730281,0.566129,0.358206,0.827185,0.151685,0.296344
8531,0.0448423,0.0379353,0.210057,0.249592,0.357252,0.375774,0.278452,0.250718,0.764007,0.837589,0.745389,0.747476,0.180076,0.170796,0.949958,0.960576,0.776431,0.805912,0.23505,0.255779,-1.48769,-1.4056,-0.934177,-0.85589,-1.16789,-1.00358,-0.086927,-0.0725911,-0.0968435,-0.238706,-0.959086,-0.864276,-0.104065,-0.0924084,-0.40269,-0.573069,2.49716,2.96352,-0.0939859,0.0470538
8532,0.127128,0.199207,0.137411,0.230863,0.876154,0.894679,0.146941,0.118333,0.132679,0.207773,0.156477,0.157685,0.714349,0.707196,0.673302,0.596287,0.296534,0.325835,0.51966,0.430488,-1.52628,-1.44483,-0.566282,-0.487229,-1.20588,-1.04793,0.820745,0.830854,0.529655,0.394181,0.912835,1.0053,0.0549093,0.0606259,-0.784809,-0.960512,-1.40389,-0.931383,1.237,1.37344
8533,0.366884,0.36048,0.231588,0.212133,0.00148667,0.0200461,0.348127,0.319792,0.843593,0.91972,0.565208,0.567338,0.768424,0.711582,0.219706,0.231998,0.385652,0.452615,0.645463,0.605197,-2.05557,-1.97275,0.73919,0.822428,0.756992,0.921121,1.2008,1.20929,-0.15361,-0.288846,-0.88113,-0.795998,0.500973,0.480827,0.752506,0.580437,-0.68667,-0.206897,-1.16339,-1.02629
8534,0.693064,0.688056,0.932747,0.912365,0.147813,0.166918,0.0636339,0.0368415,0.752194,0.829016,0.698523,0.702504,0.725327,0.715969,0.149436,0.14431,0.486917,0.579395,0.785797,0.779906,-0.0993333,-0.0141517,-0.0886244,-0.00257315,-0.812284,-0.651163,-0.648433,-0.636987,1.13938,1.00467,0.9215,0.997083,0.900071,0.901028,0.426977,0.253138,-2.19689,-1.71058,-0.513098,-0.369237
8535,0.619234,0.616768,0.109367,0.087521,0.0352284,0.0553851,0.613347,0.584233,0.441575,0.511868,0.128749,0.132731,0.188025,0.179188,0.0434116,0.0566215,0.676874,0.706175,0.932498,0.954615,0.774823,0.862325,0.878714,0.967294,0.565989,0.726919,0.0904881,0.0960616,0.0616308,-0.0794489,1.24409,1.31737,-1.02136,-1.02149,1.58694,1.41097,0.55206,1.03837,-0.292932,-0.152988
8536,0.958473,0.953867,0.826677,0.802999,0.441394,0.463528,0.416442,0.386821,0.119748,0.19472,0.718784,0.723377,0.00851652,-0.000806974,0.431529,0.443233,0.567183,0.594187,0.256136,0.278528,-0.16032,-0.0795869,-0.876405,-0.795227,-1.78474,-1.62486,0.0440807,0.0463694,-1.84029,-1.98069,-0.0910952,-0.0234089,0.358783,0.365136,-0.104022,-0.28223,0.435416,0.924752,-0.901795,-0.765487
8537,0.63219,0.547382,0.971485,0.94655,0.45848,0.479955,0.527557,0.453181,0.640093,0.713651,0.491372,0.494915,0.867298,0.857643,0.415447,0.490551,0.762467,0.774508,0.42533,0.445464,-0.786003,-0.701104,-0.290909,-0.174333,-2.33132,-2.17568,-0.257792,-0.312372,-0.256837,-0.397567,0.629054,0.69578,-1.24495,-1.24481,1.07874,0.90428,0.8969,1.38326,0.957026,1.08707
8538,0.147102,0.140897,0.532105,0.547108,0.735502,0.755894,0.523173,0.519541,0.125699,0.200529,0.0242744,0.0293788,0.0374583,0.0296679,0.527642,0.537868,0.925673,0.954828,0.385941,0.404078,0.240778,0.329746,0.362204,0.446562,-1.3671,-1.12018,-0.670251,-0.671114,-1.29919,-1.43658,0.429699,0.495837,0.415098,0.419692,0.495651,0.315346,-0.655931,-0.166629,-1.06838,-0.932428
8539,0.554018,0.548757,0.172603,0.147667,0.151215,0.17219,0.533811,0.585901,0.214267,0.289052,0.944389,0.951196,0.637571,0.630183,0.27255,0.281048,0.0607372,0.0898295,0.256657,0.362693,-0.296604,-0.213567,0.506169,0.573158,-0.225662,-0.064671,-1.66631,-1.66506,-1.4675,-1.60441,-0.575418,-0.507865,0.546286,0.557165,-0.899496,-1.08475,-0.310981,0.184387,0.579192,0.716865
8540,0.0596963,0.0533631,0.468343,0.382059,0.816354,0.836906,0.681881,0.65226,0.983748,1.0581,0.087314,0.0920139,0.758253,0.750252,0.949994,0.957227,0.122272,0.15272,0.302354,0.321307,-0.54483,-0.463982,0.620513,0.699754,0.578698,0.734352,0.108006,0.112905,-2.12597,-2.25876,-0.956581,-0.865698,-0.558339,-0.551681,-0.359965,-0.53856,-0.470933,0.022113,1.57456,1.70651
8541,0.547529,0.485521,0.640583,0.616451,0.248141,0.268174,0.383973,0.354676,0.75158,0.826537,0.449362,0.541987,0.279908,0.274107,0.557182,0.56543,0.571199,0.602329,0.651606,0.670911,-1.12306,-1.03826,-0.905166,-0.827399,0.671397,0.824563,0.0423745,0.0465981,1.09025,0.962554,-1.29361,-1.22353,0.836126,0.834945,-0.797048,-0.973047,-0.117959,0.37313,-0.612806,-0.482541
8542,0.923707,0.917679,0.145374,0.123537,0.206203,0.308171,0.367267,0.337503,0.0646051,0.140503,0.987709,0.991959,0.543228,0.53568,0.853496,0.862074,0.137248,0.167592,0.653098,0.671799,0.11783,0.20975,-1.46756,-1.39263,0.532851,0.689614,1.99159,2.00003,1.01698,0.887122,-0.615237,-0.548585,0.54783,0.545372,-0.750362,-0.92006,0.77428,1.26818,-1.09928,-0.97239
8543,0.413028,0.406823,0.621174,0.601304,0.326975,0.348168,0.738401,0.711344,0.0272514,0.101697,0.597164,0.599826,0.0260614,0.0196464,0.294193,0.300917,0.949963,0.980479,0.157239,0.176392,0.0847886,0.213661,-0.286714,-0.312471,-0.0685898,0.050349,2.72696,2.73308,-0.796533,-0.919983,0.697607,0.767544,-0.509222,-0.517235,0.156901,-0.00761567,-0.719877,-0.219623,-0.752996,-0.620457
8544,0.355595,0.350154,0.0080323,-0.00966069,0.501164,0.565369,0.559897,0.473535,0.523206,0.599623,0.603416,0.606913,0.152522,0.145024,0.274788,0.280573,0.16655,0.195603,0.10389,0.12244,0.0940426,0.217571,0.694663,0.767686,-0.738715,-0.588916,0.88328,0.886809,-0.564891,-0.6864,0.250388,0.319198,-1.22352,-1.2374,0.0470197,-0.121466,-1.17686,-0.674995,-0.674758,-0.618816
8545,0.703624,0.697149,0.561373,0.542099,0.761759,0.78257,0.261067,0.235725,0.0950531,0.171155,0.39585,0.350342,0.728074,0.721524,0.836962,0.842809,0.12013,0.150897,0.786681,0.80657,0.168279,0.221482,1.04422,1.12288,-0.0199718,0.133384,0.871387,0.867262,-0.097884,-0.222283,1.69157,1.75768,1.10538,1.09583,1.60019,1.43498,-0.494941,0.00410719,-0.75393,-0.617176
8546,0.237653,0.231328,0.615078,0.595902,0.234535,0.254097,0.92218,0.896848,0.687782,0.765942,0.0917343,0.0937697,0.895671,0.887082,0.150161,0.15577,0.974938,1.00664,0.411995,0.474784,0.135921,0.225393,-1.59061,-1.50956,-0.192362,-0.03303,-0.709575,-0.711128,1.02801,0.900758,0.0835296,0.155362,-0.615576,-0.623689,0.869611,0.706435,2.98485,3.4796,1.33949,1.48063
8547,0.106545,0.0980492,0.365586,0.345335,0.717278,0.737111,0.99163,0.965911,0.0210778,0.101109,0.378724,0.382936,0.704633,0.759089,0.256866,0.285691,0.225806,0.259214,0.124294,0.142998,-1.91785,-1.83032,0.0838502,0.158825,-2.21659,-2.06143,0.897055,0.893447,0.264809,0.137835,-1.05155,-0.984247,1.82809,1.82248,-1.41624,-1.57621,0.182094,0.671447,-0.179568,-0.0432221
8548,0.670839,0.664592,0.640147,0.533584,0.988252,1.00838,0.431363,0.407672,0.0400787,0.119031,0.101687,0.105149,0.626124,0.631097,0.309458,0.415611,0.370464,0.382278,0.520471,0.537564,-1.39572,-1.21962,-0.3594,-0.282206,1.41734,1.57824,1.58309,1.578,1.01705,0.893389,0.370197,0.437461,-0.0464167,-0.0527816,-0.0920142,-0.251182,0.358992,0.849239,-0.791187,-0.655722
8549,0.430069,0.426127,0.741449,0.721833,0.174906,0.193963,0.415696,0.390498,0.338958,0.376667,0.477097,0.480049,0.513718,0.503105,0.537095,0.545531,0.46982,0.505341,0.265294,0.282761,-0.69476,-0.608919,-0.291055,-0.219516,0.883236,1.04282,-0.800017,-0.80145,-1.12403,-1.25345,-2.47228,-2.39753,0.414098,0.408085,-1.72947,-1.88208,0.225515,0.719394,0.728064,0.857605
8550,0.412081,0.406047,0.467566,0.494964,0.0640695,0.0824301,0.00277539,-0.021821,0.555323,0.634303,0.415971,0.467362,0.907163,0.894156,0.319554,0.328444,0.179467,0.216191,0.556694,0.498115,-2.70112,-2.61929,0.674902,0.750351,-0.556073,-0.393237,-0.044408,-0.0528459,0.596696,0.468043,-2.39548,-2.3219,-0.722223,-0.731921,-0.204745,-0.35788,-3.53833,-3.04297,-0.316588,-0.191143
8551,0.652982,0.657226,0.286074,0.268095,0.60564,0.62533,0.765725,0.741578,0.49203,0.568576,0.453467,0.454674,0.474664,0.464772,0.958839,0.968122,0.94133,0.977734,0.697749,0.713468,1.20751,1.28735,0.207917,0.352734,0.0490588,0.20423,-0.27518,-0.286964,0.5035,0.375942,-1.09419,-1.07528,-0.586678,-0.594447,0.829786,0.678133,-0.116972,0.379125,0.406425,0.446328
8552,0.914189,0.908405,0.465883,0.517324,0.848217,0.865384,0.0272273,0.00336941,0.0294372,0.104857,0.188102,0.191555,0.399255,0.324174,0.287969,0.296224,0.730063,0.797505,0.184622,0.202559,0.251289,0.328454,-0.125115,-0.0448827,-1.37941,-1.21688,-0.119785,-0.136207,-0.302118,-0.432211,0.0968609,0.171345,1.01879,1.00782,0.456106,0.305437,-0.448849,0.0481701,0.957263,1.0838
8553,0.187233,0.179161,0.784539,0.766553,0.144143,0.161092,0.303312,0.305248,0.796145,0.873904,0.685877,0.689036,0.193431,0.183575,0.175006,0.184646,0.518811,0.617276,0.129574,0.148607,1.32203,1.40487,-1.1868,-1.10272,-0.424337,-0.208061,-1.25315,-1.26942,1.0362,0.906406,0.25171,0.321881,0.238129,0.225454,-0.392032,-0.542828,-0.0923895,0.399187,0.962476,1.09138
8554,0.768329,0.760557,0.128672,0.11028,0.0961164,0.112069,0.635601,0.607126,0.4759,0.551528,0.939513,0.942474,0.363962,0.267433,0.604248,0.611261,0.399131,0.437047,0.353923,0.430383,-1.29632,-1.21781,-0.534053,-0.454511,0.638234,0.800762,-0.23368,-0.242749,1.7294,1.60089,1.50306,1.57715,1.02735,1.00916,-0.289777,-0.506266,-0.201419,0.28557,-1.28914,-1.15931
8555,0.234795,0.229339,0.47323,0.456455,0.578702,0.595084,0.933176,0.909004,0.605059,0.681018,0.186383,0.188039,0.377583,0.351291,0.472436,0.511934,0.828316,0.867504,0.694403,0.712158,-1.45879,-1.37992,0.544956,0.623137,-1.01402,-0.851151,1.26456,1.25089,-0.70148,-0.825218,-0.266333,-0.19171,0.220304,0.1969,-0.325171,-0.469705,0.240463,0.728828,-0.993575,-0.920982
8556,0.257454,0.238801,0.097954,0.0818432,0.731844,0.746682,0.0774113,0.0546852,0.140222,0.217299,0.548242,0.548132,0.445317,0.435149,0.404093,0.412608,0.821898,0.896097,0.109057,0.126464,-0.159225,-0.0862121,-0.379012,-0.293653,-0.470009,-0.314875,-0.739959,-0.757775,0.0993945,-0.0247365,0.295579,0.375818,-0.307262,-0.326275,-0.519081,-0.659361,-0.33685,0.150358,-0.808157,-0.68265
8557,0.255258,0.248262,0.678203,0.662804,0.324568,0.341127,0.339671,0.356563,0.538539,0.615021,0.581095,0.541742,0.823492,0.811908,0.837264,0.844257,0.887226,0.92469,0.487915,0.506198,-0.99227,-0.923351,0.334951,0.414177,-1.32042,-1.16243,2.50505,2.48533,-1.41892,-1.54016,0.136025,0.201783,-0.340889,-0.370332,0.85769,0.712934,0.497814,0.903029,0.0871053,0.215906
8558,0.0439359,0.0343857,0.582054,0.565113,0.744447,0.678302,0.711397,0.658441,0.478783,0.589758,0.535973,0.535352,0.627776,0.616961,0.375367,0.382849,0.20876,0.244749,0.0795378,0.0998067,-0.956136,-0.889426,1.31619,1.39756,-0.747911,-0.595374,0.115444,0.0895118,-1.0126,-1.13661,0.0722961,0.0277485,-0.520505,-0.414389,-1.36197,-1.50494,1.16152,1.6557,-1.35954,-1.2325
8559,0.695661,0.68593,0.837412,0.821727,0.999759,1.01548,0.982732,0.96032,0.488985,0.564494,0.976105,0.973709,0.782747,0.772319,0.196347,0.247456,0.439131,0.427458,0.989974,1.0084,1.75863,1.83287,-0.192297,-0.112813,0.874954,1.03077,-0.285502,-0.315652,1.83271,1.70807,-0.226526,-0.146286,-0.439432,-0.458446,-1.32291,-1.46594,-0.39677,0.0907917,0.0590883,0.186637
8560,0.140329,0.129765,0.292084,0.275006,0.753632,0.709759,0.620361,0.521079,0.724342,0.800355,0.224538,0.223581,0.681672,0.672662,0.103831,0.112063,0.692551,0.610167,0.67428,0.679942,0.280381,0.354305,0.535273,0.609262,-0.601453,-0.450571,-0.90155,-0.934963,-0.228191,-0.359915,-0.916865,-0.842849,2.20798,2.19221,-0.892349,-1.04273,-0.37963,0.100104,-0.389312,-0.259214
8561,0.45657,0.446266,0.313782,0.298423,0.388525,0.404042,0.103258,0.0818393,0.192341,0.267209,0.454143,0.452265,0.238042,0.226898,0.719037,0.726976,0.756887,0.792876,0.332752,0.351488,1.33627,1.41619,-0.119831,-0.0535532,0.147982,0.302605,-0.606536,-0.646545,0.221457,0.0878554,0.266265,0.335683,0.109576,0.0949788,-0.759083,-0.910808,1.07926,1.56273,0.202521,0.335023
8562,0.378407,0.369555,0.660389,0.644599,0.767481,0.781441,0.343537,0.321768,0.189582,0.264661,0.427638,0.466306,0.513248,0.430758,0.928408,0.862944,0.245457,0.283177,0.752476,0.770816,-0.121963,-0.0477832,-0.794609,-0.716369,-0.655694,-0.498817,0.439366,0.394749,0.452349,0.321438,0.0673405,0.135739,-0.60565,-0.625189,0.016873,-0.136292,-1.37396,-0.887028,-0.763727,-0.638107
8563,0.746841,0.64494,0.446588,0.430144,0.490435,0.537812,0.788078,0.765179,0.599356,0.672621,0.483955,0.480346,0.645042,0.634618,0.991284,0.998912,0.00855283,0.0446663,0.0574373,0.0731593,0.540389,0.615969,-2.01741,-1.94414,1.08352,1.23961,3.4031,3.35266,-0.277804,-0.411371,0.872134,0.947024,-0.716408,-0.73073,-1.21395,-1.36811,1.48858,1.9701,-0.0799939,0.0479539
8564,0.931077,0.920326,0.759241,0.643887,0.280191,0.294184,0.368954,0.348409,0.624327,0.696129,0.141675,0.137597,0.17596,0.163513,0.632706,0.641955,0.447093,0.484153,0.347325,0.314655,-1.12963,-1.04854,-1.83252,-1.75855,-0.223961,-0.0722798,-1.55065,-1.60109,0.196361,0.0667123,0.00153259,0.0826374,-0.410192,-0.42303,-1.38163,-1.54188,1.75147,2.24056,0.952433,1.08361
8565,0.558167,0.560195,0.873473,0.857629,0.610855,0.626187,0.165521,0.146098,0.391351,0.464565,0.744759,0.739065,0.841964,0.831385,0.712279,0.686179,0.492046,0.516268,0.471681,0.556152,1.09159,1.17073,1.25236,1.32409,-0.470784,-0.277868,-1.06085,-1.11456,2.28698,2.15256,0.402625,0.46922,-2.03528,-2.04628,-0.0580558,-0.216859,-1.98892,-1.49212,1.2455,1.37584
8566,0.212169,0.200064,0.0694797,0.0529769,0.482546,0.499959,0.822923,0.803135,0.684866,0.723973,0.212177,0.204881,0.710535,0.651352,0.720986,0.730403,0.512839,0.548382,0.781926,0.797648,0.366288,0.441988,0.284077,0.359441,-0.638393,-0.483455,-0.328876,-0.381515,-0.906603,-1.03935,0.774697,0.855802,0.0122508,-0.00348482,-0.951009,-1.11302,1.10707,1.60228,-0.361013,-0.224332
8567,0.654945,0.642742,0.512734,0.496767,0.567996,0.586225,0.390543,0.371239,0.910056,0.98338,0.778919,0.771309,0.57476,0.471319,0.568659,0.579158,0.986603,1.02383,0.186894,0.202072,0.759224,0.83099,-1.01034,-0.93096,-0.554294,-0.366701,-0.172539,-0.230759,-1.17124,-1.30021,0.511595,0.594649,-0.311258,-0.324516,0.426058,0.259275,0.211352,0.693858,0.871994,1.0111
8568,0.445342,0.433898,0.743437,0.729182,0.0762759,0.0963381,0.79586,0.77572,0.8921,0.964416,0.050278,0.041872,0.345484,0.291287,0.650794,0.65993,0.501319,0.538928,0.106346,0.124017,-1.82841,-1.75761,-0.172565,-0.158993,-0.405208,-0.249946,-0.615023,-0.668024,-0.573047,-0.699228,-1.1958,-1.11204,-0.243805,-0.261317,-0.288703,-0.453004,-0.715178,-0.214563,0.142349,0.279441
8569,0.860235,0.847219,0.710699,0.695121,0.0693476,0.0878076,0.406551,0.431271,0.392253,0.466168,0.175039,0.26099,0.121833,0.111254,0.468388,0.408387,0.670754,0.708613,0.645036,0.66341,-0.785109,-0.641161,0.538163,0.612974,1.63279,1.78399,0.23812,0.188061,-0.271725,-0.403766,-0.561039,-0.483709,-0.983686,-0.998718,-2.3744,-2.53796,-1.35522,-0.853858,0.15102,0.287022
8570,0.775843,0.764179,0.0928717,0.078568,0.82382,0.844276,0.107408,0.0868227,0.398048,0.474163,0.401977,0.480108,0.991628,0.979832,0.146091,0.156843,0.0283845,0.0681869,0.753439,0.769635,0.408153,0.475292,0.218793,0.294773,-0.561619,-0.406244,0.559958,0.506032,0.678819,0.55211,1.18951,1.26336,0.0532753,0.0423726,-2.07015,-2.23867,-0.0383696,0.462997,2.26326,2.40091
8571,0.893214,0.880186,0.316967,0.301428,0.347402,0.3693,0.908516,0.88756,0.90807,0.982501,0.683622,0.699226,0.588987,0.579494,0.527158,0.539079,0.232999,0.274894,0.0580474,0.0719785,-0.383114,-0.315832,0.215729,0.297077,-0.916522,-0.756751,-1.14033,-1.20164,1.31488,1.185,0.0228888,0.0943859,0.811966,0.795163,-0.330003,-0.494225,0.532961,1.03157,-0.236425,-0.102066
8572,0.242828,0.228587,0.996623,0.98112,0.97615,0.997797,0.372155,0.349471,0.474324,0.548565,0.92675,0.918344,0.708256,0.699563,0.561408,0.555239,0.0480313,0.087805,0.628071,0.640374,-0.20945,-0.142298,-0.362516,-0.281846,0.258689,0.425101,0.586261,0.527356,0.517885,0.39184,0.55821,0.623495,1.81296,1.79503,-0.999993,-1.16149,-1.80271,-1.30415,-1.65303,-1.51943
8573,0.108649,0.0953075,0.747704,0.730553,0.725354,0.748372,0.34902,0.327566,0.947012,1.02154,0.414412,0.403911,0.474172,0.463247,0.560831,0.5714,0.387038,0.38008,0.897337,0.908717,0.933284,0.996122,0.475301,0.549976,-0.125062,0.0934498,0.432037,0.387201,0.942437,0.810457,1.07883,1.1526,1.55641,1.53661,-1.01596,-1.1709,1.14995,1.64712,0.80793,0.939855
8574,0.969523,0.956184,0.0156637,9.96665e-07,0.122043,0.143991,0.611144,0.617403,0.627072,0.703856,0.65692,0.584186,0.919306,0.909393,0.0347099,0.0455909,0.614288,0.672354,0.872914,0.884766,0.256903,0.314111,-1.17944,-1.10243,-0.397633,-0.238202,0.310365,0.247046,3.14816,3.01346,-0.124178,-0.0488346,-0.491461,-0.512698,-0.229029,-0.381542,0.51647,1.00095,0.870551,1.00808
8575,0.536488,0.525422,0.451706,0.43415,0.329219,0.298241,0.928055,0.90724,0.0564529,0.135933,0.773582,0.76446,0.884675,0.87534,0.640447,0.650132,0.924856,0.964629,0.617195,0.629963,-2.19729,-2.13465,-0.680807,-0.60825,0.150097,0.313758,-0.968802,-1.02434,0.62972,0.490794,0.164968,0.240405,-0.937354,-0.958747,-0.743086,-0.892642,-0.141745,0.354773,-0.112189,0.0191312
8576,0.761971,0.751978,0.579682,0.562272,0.427332,0.452491,0.5258,0.48507,0.016275,0.131716,0.737521,0.727132,0.0315448,0.0196625,0.371183,0.383077,0.473652,0.514832,0.036496,0.0497517,-1.63198,-1.57766,0.796297,0.871462,-0.943269,-0.782958,-1.89118,-1.94264,-0.210497,-0.350275,-1.544,-1.46629,-0.776441,-0.805712,0.104149,-0.0404947,0.132794,0.625228,-2.26431,-2.13737
8577,0.413971,0.401916,0.453907,0.438381,0.170002,0.192492,0.0836128,0.0629003,0.0476433,0.1275,0.072019,0.0621857,0.132839,0.120098,0.557362,0.570044,0.815681,0.855553,0.373698,0.342582,-0.109814,-0.0639554,-1.49064,-1.41054,0.734839,0.891468,-1.36636,-1.41115,0.82793,0.683192,-0.496704,-0.423822,-1.68178,-1.71273,0.54935,0.397028,-0.089041,0.401801,-0.283775,-0.164384
8578,0.916468,0.904046,0.572353,0.591676,0.983594,1.00758,0.0647179,0.0457268,0.653477,0.732636,0.721348,0.713384,0.703012,0.69179,0.00444103,0.0190655,0.7196,0.760088,0.621844,0.635412,-0.696211,-0.653355,0.692011,0.776812,-0.926468,-0.774712,0.0701596,-0.0382331,-0.292832,-0.431418,-0.806155,-0.73254,0.0281839,-0.00271275,0.608959,0.450015,0.371969,0.860305,0.138138,0.347951
8579,0.788791,0.775489,0.760626,0.744972,0.158995,0.183019,0.926455,0.909502,0.707923,0.784975,0.349591,0.341691,0.674217,0.632168,0.0154951,0.0884259,0.126785,0.165856,0.389769,0.497532,0.253699,0.300742,2.23119,2.31941,-0.0591131,0.0855868,1.37947,1.33468,-0.105793,-0.243304,-0.818505,-0.74831,-0.109103,-0.139085,1.79304,1.63653,0.074669,0.559558,0.740895,0.860286
8580,0.418516,0.405737,0.26392,0.24669,0.0819569,0.199832,0.630309,0.663923,0.0427051,0.120142,0.850787,0.844039,0.621712,0.572547,0.195509,0.157786,0.571139,0.611055,0.345915,0.359653,2.84712,2.89007,-0.0904423,0.00169354,-0.650094,-0.500621,-1.90315,-1.94031,1.26844,1.12501,0.975612,1.04477,-0.462509,-0.491861,0.321634,0.159941,-2.00117,-1.51784,-1.55723,-1.44128
8581,0.338293,0.230599,0.234761,0.216444,0.190863,0.216646,0.418533,0.418345,0.720905,0.796825,0.772574,0.76581,0.524146,0.512925,0.299419,0.227147,0.725384,0.715861,0.409574,0.421895,-2.62614,-2.5832,0.118038,0.203666,-0.127308,0.0204099,1.49666,1.46051,-0.304388,-0.451633,1.93437,2.00829,2.16452,2.12862,0.204798,0.0460914,0.803885,1.2872,-1.1173,-0.997972
8582,0.0677029,0.0554616,0.857122,0.836929,0.342983,0.422087,0.189719,0.172766,0.931491,1.0066,0.943647,0.935747,0.862037,0.850604,0.280497,0.296507,0.780099,0.820667,0.928284,0.941483,0.17782,0.220471,-0.000541097,0.0831795,0.00756442,0.158274,-1.60355,-1.63411,-1.66164,-1.81585,-1.3262,-1.25793,-0.156849,-0.19527,-0.151037,-0.344596,-1.09979,-0.616379,1.67126,1.79362
8583,0.269042,0.238828,0.15438,0.136665,0.603502,0.627529,0.922097,0.905241,0.0226348,0.0961893,0.759702,0.753169,0.775654,0.766354,0.601611,0.617974,0.285538,0.32558,0.504015,0.507869,-0.837103,-0.801435,-0.703095,-0.617963,1.85846,2.00496,0.32623,0.302408,-0.0305371,-0.185306,-0.0487915,0.0121958,0.680852,0.647213,-0.567587,-0.735283,-0.277098,0.200955,-0.557178,-0.429795
8584,0.435524,0.422194,0.374011,0.353995,0.586919,0.533352,0.398974,0.382304,0.577741,0.650683,0.207972,0.203822,0.739415,0.682105,0.197651,0.216953,0.059912,0.102126,0.0597614,0.0742556,-1.1721,-1.14339,0.94306,1.03271,-0.37113,-0.218046,0.0142763,-0.0106009,-2.19957,-2.35081,-0.589635,-0.529309,0.0326212,0.0030752,0.74187,0.573705,-0.822668,-0.345875,-0.695623,-0.57253
8585,0.264999,0.344856,0.197753,0.179421,0.492589,0.439175,0.0844206,0.0692027,0.671958,0.763762,0.461458,0.45726,0.72277,0.597855,0.566413,0.58404,0.8225,0.86367,0.0802677,0.100474,-0.719935,-0.692936,-1.21538,-1.12185,-0.179994,0.0548133,0.0586473,0.0307203,0.558861,0.405881,0.155442,0.220273,0.38305,0.356928,-0.305543,-0.47387,-0.0505642,0.423728,0.304778,0.433509
8586,0.281725,0.267519,0.834978,0.814714,0.434112,0.344998,0.76885,0.751401,0.804484,0.876841,0.162262,0.15846,0.525038,0.513605,0.402145,0.42128,0.973271,1.01306,0.0244085,0.126693,0.627457,0.649121,0.578783,0.669071,0.177175,0.327673,-1.29756,-1.33209,0.353973,0.207068,-1.25181,-1.1837,-1.94284,-1.96696,-2.58461,-2.75651,1.55186,2.02452,-1.40223,-1.27655
8587,0.94808,0.933801,0.210209,0.189162,0.317068,0.250821,0.07741,0.0592841,0.632539,0.706222,0.335107,0.333234,0.250043,0.238013,0.902125,0.922514,0.912972,0.953291,0.139624,0.152912,0.279342,0.307164,0.941859,1.03773,1.02186,1.17417,-1.38754,-1.42788,1.384,1.24842,-1.69845,-1.63204,0.260579,0.235563,-0.778654,-0.95126,-1.86945,-1.39996,0.288827,0.419137
8588,0.0281005,0.0124709,0.405952,0.358631,0.132617,0.156644,0.954629,0.934291,0.804462,0.876749,0.975088,0.97404,0.286765,0.325367,0.0260618,0.045458,0.472278,0.514085,0.769219,0.782442,-0.654093,-0.622082,0.844147,0.932262,-0.630377,-0.477746,0.963196,0.918386,2.43256,2.28978,1.08415,1.15769,0.928133,0.896785,-1.42191,-1.60219,-1.01852,-0.548423,0.0541903,0.184989
8589,0.543655,0.529077,0.484923,0.528099,0.872418,0.897515,0.701579,0.67294,0.49429,0.569235,0.21322,0.214487,0.424462,0.412721,0.141918,0.137718,0.991747,1.03453,0.525514,0.602936,0.604256,0.642175,-0.272093,-0.187701,-1.03736,-0.890244,0.592929,0.569771,-1.63177,-1.77361,1.19687,1.26447,0.746717,0.621032,-1.75538,-1.92949,0.233234,0.706418,0.283011,0.366436
8590,0.43808,0.529192,0.718614,0.697567,0.810792,0.837258,0.429724,0.411588,0.992092,1.06716,0.135915,0.136259,0.692023,0.589945,0.137243,0.229978,0.430263,0.474679,0.408533,0.423431,-1.08132,-1.0366,0.740299,0.828011,-0.418469,-0.218014,0.26328,0.221156,-0.515397,-0.66549,-1.03234,-0.957619,0.377643,0.345279,-0.548077,-0.725887,0.642532,1.11884,0.416061,0.547883
8591,0.506439,0.529307,0.142925,0.120896,0.140793,0.168136,0.551207,0.47218,0.349696,0.422888,0.879533,0.878185,0.778631,0.767168,0.302062,0.322238,0.740463,0.697707,0.534784,0.54942,-1.33649,-1.28701,0.506863,0.59702,0.308137,0.454216,-1.50625,-1.54633,0.00987235,-0.14072,-1.31613,-1.23453,-0.108667,-0.146253,0.127789,-0.147118,0.519419,0.988997,-0.844126,-0.717806
8592,0.544,0.529422,0.506098,0.485629,0.848033,0.873629,0.506,0.532772,0.841827,0.916148,0.278434,0.27755,0.659324,0.647404,0.646284,0.664269,0.874502,0.920735,0.18838,0.203495,-0.753852,-0.730189,0.54051,0.629809,0.494415,0.637346,-1.97764,-2.01435,1.8248,1.67358,-0.337775,-0.255017,1.39683,1.3619,0.610814,0.431651,-0.386299,0.00392484,0.750783,0.870233
8593,0.156124,0.139599,0.567357,0.545301,0.684981,0.711699,0.61361,0.593364,0.644959,0.719028,0.396145,0.389663,0.274197,0.261643,0.0456514,0.0632152,0.637926,0.686301,0.136884,0.149543,-0.220776,-0.173366,1.90716,2.00017,-1.46827,-1.32773,-0.64099,-0.68001,-0.0974435,-0.241802,1.27032,1.35392,-1.01164,-1.03887,1.4031,1.22101,-1.45606,-0.981147,0.642251,0.756756
8594,0.787474,0.770281,0.264821,0.24545,0.296812,0.322219,0.228173,0.206643,0.840468,0.914322,0.403208,0.501776,0.152358,0.149488,0.430204,0.500675,0.279138,0.451867,0.301631,0.316478,-0.672828,-0.621777,0.474974,0.566167,-1.77323,-1.63225,0.433665,0.392266,-1.78216,-1.92653,1.11726,1.19831,1.60541,1.58162,-0.797206,-0.979564,-0.489622,-0.0539211,1.17418,1.29049
8595,0.705518,0.688419,0.310243,0.288857,0.429533,0.453682,0.916314,0.894377,0.535376,0.611788,0.614773,0.613889,0.0495833,0.0373327,0.918346,0.938135,0.172301,0.217434,0.118397,0.131069,-0.24612,-0.201926,-0.707955,-0.614912,0.915883,1.05886,-0.594167,-0.632283,-1.97069,-2.10986,-0.135949,-0.0501331,-0.0338618,-0.0583429,-0.524041,-0.707883,0.392054,0.873305,-1.32813,-1.21249
8596,0.650698,0.606557,0.580487,0.559893,0.902725,0.927276,0.664487,0.641482,0.946652,1.02441,0.0776905,0.0746734,0.365762,0.354531,0.615737,0.68253,0.411682,0.394669,0.414525,0.428498,1.06855,1.10714,0.101006,0.200115,-0.0124058,0.13407,1.5804,1.54001,-0.243378,-0.38291,0.765717,0.853843,1.02856,1.00067,0.627696,0.449946,-0.607225,-0.214936,0.570037,0.686061
8597,0.541888,0.524695,0.312723,0.293649,0.515603,0.537797,0.132554,0.108483,0.558198,0.686311,0.847485,0.842561,0.0524743,0.0428458,0.304528,0.426924,0.524237,0.571904,0.0807106,0.0920675,0.506274,0.519957,-1.35129,-1.24894,0.212169,0.365019,0.123214,0.0836774,1.4832,1.34404,0.411917,0.500248,-0.229229,-0.26227,-0.367583,-0.551799,-1.78336,-1.30318,-0.710925,-0.595103
8598,0.169433,0.150372,0.81164,0.792129,0.771746,0.793277,0.234357,0.212884,0.26831,0.348211,0.51824,0.513981,0.807377,0.798051,0.150918,0.171319,0.689371,0.74914,0.143991,0.18136,-0.102166,-0.0672211,-0.87544,-0.772698,0.0619808,0.213943,0.518559,0.477737,1.78595,1.6395,0.925761,1.00734,0.0838714,0.0454302,1.12649,0.942086,1.51636,1.98998,0.429971,0.547484
8599,0.122206,0.10348,0.223804,0.205967,0.604645,0.62713,0.0867307,0.0651507,0.538037,0.619916,0.678507,0.644193,0.899855,0.891992,0.399085,0.421518,0.881243,0.926375,0.257287,0.270652,0.162042,0.200659,1.90957,2.01636,0.489787,0.642908,-1.16734,-1.21297,-1.03875,-1.18035,1.2213,1.29658,0.662031,0.630459,1.34736,1.16659,1.67184,2.15311,0.479348,0.600318
8600,0.692519,0.674941,0.0428603,0.0260684,0.878019,0.898398,0.694475,0.67204,0.257147,0.337497,0.778389,0.774405,0.421633,0.415847,0.979119,0.999393,0.785932,0.83091,0.0862745,0.100472,0.429962,0.46854,0.880645,0.988558,-0.363291,-0.204649,0.868726,0.819684,0.669244,0.525053,0.112408,0.186981,0.966967,0.938159,1.03453,0.853258,0.26556,0.744798,1.33216,1.45197
8601,0.309102,0.289373,0.685675,0.670783,0.748124,0.710916,0.711746,0.689957,0.319245,0.412598,0.208626,0.204632,0.351901,0.290742,0.100431,0.122337,0.333627,0.376327,0.879468,0.892774,-0.0534938,-0.0140103,0.135679,0.240161,0.419977,0.578059,0.1801,0.136857,-1.54952,-1.70091,-0.477606,-0.401548,-0.561036,-0.594106,-0.487104,-0.671007,-1.42585,-0.948184,0.304737,0.417876
8602,0.659133,0.641194,0.945365,0.931652,0.423767,0.523433,0.483185,0.461787,0.324156,0.487698,0.638165,0.588898,0.168241,0.165637,0.388802,0.369202,0.533893,0.576804,0.523974,0.477179,2.06245,2.09843,-1.36105,-1.25472,1.82378,1.98629,1.65324,1.61394,0.43878,0.290276,1.11598,1.19197,-0.495715,-0.530907,0.938501,0.748682,1.20772,1.68697,0.0483994,0.153323
8603,0.76229,0.682566,0.812377,0.878901,0.313678,0.335951,0.55303,0.585042,0.481526,0.562799,0.978363,0.973163,0.0485042,0.0405317,0.595739,0.616068,0.12251,0.167889,0.048279,0.0615844,0.828395,0.864495,0.766316,0.869158,0.303712,0.45956,0.644864,0.604066,-0.424867,-0.581274,1.56171,1.63832,0.303276,0.266013,-0.329137,-0.515143,0.0553263,0.529226,0.437856,0.539484
8604,0.74273,0.723937,0.838356,0.82615,0.353097,0.338098,0.780633,0.708297,0.924387,1.0066,0.174365,0.169766,0.933226,0.924522,0.474388,0.445797,0.375559,0.517795,0.23351,0.248777,0.0243875,0.0580649,-2.07581,-1.97244,-0.61323,-0.450325,0.838551,0.799808,-0.447928,-0.608159,1.74704,1.82143,-1.73864,-1.76938,0.804484,0.61377,-0.533557,-0.0641004,0.823533,0.925646
8605,0.628578,0.538718,0.11619,0.106249,0.232873,0.340245,0.85295,0.831552,0.482241,0.56316,0.497591,0.494903,0.605102,0.554299,0.25734,0.275525,0.824309,0.8677,0.852351,0.867431,-0.499782,-0.469849,-0.887695,-0.806786,2.01486,2.17457,0.573525,0.533116,-0.139639,-0.298784,0.401947,0.400964,0.81149,0.788197,0.546276,0.36228,0.00757504,0.474556,-0.772083,-0.674526
8606,0.394157,0.3535,0.78612,0.775795,0.31977,0.342392,0.273568,0.252938,0.352391,0.431536,0.0837942,0.0789973,0.190837,0.184077,0.664143,0.68197,0.729031,0.80471,0.492267,0.506331,1.2119,1.24376,0.255258,0.358864,-0.699968,-0.546886,2.00317,1.9626,-1.51948,-1.67803,-1.09388,-1.0195,-1.11176,-1.13432,0.498885,0.309193,0.305377,0.777462,-0.0351072,0.0579805
8607,0.185099,0.168282,0.415853,0.406691,0.833284,0.856405,0.134892,0.115719,0.971417,1.05075,0.668648,0.664658,0.548825,0.541463,0.0134542,0.029485,0.700174,0.74172,0.957859,0.970415,1.68573,1.71066,0.607624,0.71406,-0.232268,-0.0719684,0.150609,0.116332,1.98207,1.82797,1.73159,1.80206,-2.30876,-2.3365,2.05219,1.86564,0.0104019,0.512052,-0.545413,-0.448509
8608,0.948694,0.932653,0.651106,0.643998,0.0846358,0.106375,0.820663,0.803452,0.268727,0.350325,0.0397271,0.0347436,0.476029,0.467678,0.35383,0.284873,0.162511,0.202117,0.493615,0.504459,-0.509623,-0.489806,-0.288311,-0.18809,1.35949,1.52348,-0.689637,-0.723266,0.967315,0.818388,0.175746,0.246001,-0.642048,-0.671999,-1.44039,-1.62906,-0.218885,0.246642,0.0861686,0.178066
8609,0.0994212,0.0852064,0.499907,0.44142,0.463115,0.483773,0.941871,0.85022,0.742872,0.823296,0.651221,0.645376,0.943527,0.934758,0.523567,0.54026,0.451069,0.563029,0.239419,0.340969,0.623694,0.648613,0.200951,0.306095,1.92791,2.09053,-0.380802,-0.419404,1.34833,1.20679,-0.835014,-0.772455,-0.514157,-0.549244,1.27383,1.08866,-0.0990676,0.36324,-0.585563,-0.494639
8610,0.885654,0.870633,0.247755,0.238841,0.235411,0.256346,0.914784,0.896988,0.787752,0.865476,0.41247,0.425056,0.0332906,0.0247215,0.602148,0.616677,0.885502,0.923941,0.165481,0.17748,0.194808,0.214262,0.0610321,0.170119,0.877467,1.04964,-0.452014,-0.485711,1.21847,1.06929,2.63509,2.6975,0.0666121,0.0357844,-1.08959,-1.27624,1.59657,2.05896,-1.48459,-1.39243
8611,0.605928,0.592887,0.550816,0.540276,0.821019,0.844716,0.643299,0.699189,0.530805,0.608422,0.211556,0.204736,0.696765,0.687932,0.909772,0.923263,0.0734359,0.111076,0.500164,0.582203,1.86725,1.88165,0.125486,0.232809,-0.159899,0.00875217,1.54302,1.51335,0.0389094,-0.106801,-0.356908,-0.293595,-0.94471,-0.980889,-0.221467,-0.410298,-0.887685,-0.426399,0.106426,0.195609
8612,0.330919,0.315141,0.516869,0.506215,0.741472,0.764592,0.521477,0.501391,0.961932,1.04097,0.773878,0.766023,0.994838,0.98509,0.157054,0.171556,0.405456,0.488785,0.974928,0.986927,-0.331297,-0.318816,0.400587,0.512076,-0.393344,-0.220062,1.83402,1.80177,0.306898,0.158717,0.718628,0.779195,0.992186,0.950162,0.912506,0.718615,0.130022,0.595343,2.08206,2.1686
8613,0.404793,0.390786,0.706677,0.694951,0.437428,0.460516,0.8849,0.865319,0.296617,0.376134,0.986246,0.979109,0.000189643,-0.00955842,0.806515,0.821043,0.82795,0.866495,0.556754,0.570933,-0.152209,-0.145282,-0.587151,-0.483181,-0.415509,-0.265909,0.331369,0.299242,-0.465345,-0.617857,-0.909291,-0.850853,1.99011,1.95003,0.669305,0.482761,1.81909,2.29106,-0.476846,-0.385203
8614,0.249429,0.231826,0.0324948,0.0191517,0.745181,0.767546,0.107292,0.0855946,0.431481,0.511011,0.517907,0.509034,0.684986,0.673333,0.647226,0.70845,0.382273,0.421919,0.605516,0.617969,-0.397695,-0.307823,-0.835534,-0.727085,-0.494566,-0.311757,-0.667204,-0.694702,-0.136552,-0.291239,-0.898779,-0.79428,-0.522228,-0.558201,-0.0909349,-0.275217,0.701245,1.16524,0.45169,0.542857
8615,0.0858144,0.0728664,0.591459,0.575981,0.408789,0.450099,0.344363,0.321168,0.16419,0.243772,0.48875,0.481293,0.476777,0.462963,0.583064,0.595858,0.637772,0.678067,0.987887,1.00213,-0.470288,-0.470364,-0.642011,-0.541501,0.822927,1.07739,0.886459,0.862792,-0.376451,-0.575439,-0.797165,-0.737707,-1.26183,-1.2956,-0.268293,-0.471856,0.228446,0.695584,0.240548,0.338514
8616,0.603341,0.589472,0.370428,0.356601,0.107834,0.132653,0.930412,0.908473,0.450474,0.548675,0.845753,0.836581,0.661346,0.648922,0.945946,0.958743,0.20992,0.248976,0.785144,0.801393,-0.357485,-0.358917,0.840399,0.938212,2.29093,2.46654,0.942931,0.921178,-0.704952,-0.85964,0.641888,0.700779,-1.18614,-1.21759,-0.481924,-0.668496,-1.63564,-1.17603,-0.938428,-0.835913
8617,0.148014,0.134375,0.714694,0.702777,0.921072,0.94774,0.612684,0.590519,0.772623,0.853578,0.369458,0.361617,0.407998,0.431148,0.905945,0.885806,0.289897,0.272614,0.157694,0.175836,0.851352,0.855369,1.14384,1.24809,-0.0444146,0.131254,-0.49873,-0.520567,2.30855,2.15386,0.152001,0.207579,1.16252,1.13052,0.102469,-0.0779004,-0.724527,-0.264744,0.642706,0.752126
8618,0.842064,0.830041,0.269969,0.259404,0.166366,0.192604,0.944965,0.924273,0.781866,0.861573,0.255245,0.248256,0.224722,0.213375,0.800373,0.812869,0.255275,0.296252,0.325865,0.323108,-0.0402349,-0.113112,-1.24071,-1.1334,-2.87612,-2.69718,0.420436,0.397888,-0.294396,-0.45526,0.998166,1.0497,0.849586,0.825444,-0.387455,-0.573655,0.735545,1.19788,0.421532,0.531933
8619,0.136725,0.126676,0.819677,0.811163,0.332734,0.415142,0.895624,0.872647,0.0136129,0.0927742,0.657289,0.652132,0.953439,0.942033,0.476342,0.441294,0.0168273,0.0577411,0.450892,0.470379,-1.07911,-1.08159,-1.64103,-1.52917,1.58327,1.76729,0.350743,0.331581,-1.32158,-1.47926,-0.251521,-0.198736,-1.23163,-1.25477,-0.0062849,-0.198656,-0.799619,-0.336533,-0.0330967,0.0718389
8620,0.675384,0.663455,0.134906,0.125904,0.610539,0.63768,0.0246979,0.00258329,0.059657,0.140265,0.51864,0.467519,0.734017,0.720873,0.0572236,0.0697193,0.764469,0.805049,0.803504,0.824261,0.755173,0.754005,-1.48528,-1.37461,-0.607066,-0.422943,0.00805097,-0.0116409,-0.82652,-0.983718,0.341847,0.450961,0.564795,0.549476,0.363349,0.176342,-1.74778,-1.29116,-0.0932429,0.0186193
8621,0.320707,0.308157,0.875948,0.866602,0.287391,0.313222,0.0127488,-0.00974264,0.518939,0.566828,0.33062,0.282907,0.111637,0.100128,0.128631,0.141307,0.0854211,0.125108,0.490493,0.512868,0.736857,0.73053,-0.118898,-0.00424383,-1.1092,-0.926575,1.07293,1.06064,0.0528526,-0.104639,1.04787,1.10066,-0.991529,-1.01408,1.89277,1.70055,0.504629,0.952434,0.364231,0.476052
8622,0.734274,0.721478,0.411208,0.403239,0.763935,0.791405,0.57004,0.54772,0.91293,0.993392,0.103451,0.0982943,0.140222,0.12794,0.520246,0.50373,0.838214,0.877769,0.631775,0.660139,-2.26439,-2.26542,-0.575616,-0.461019,0.096245,0.283038,0.0984926,0.0816152,0.361629,0.204735,-0.884197,-0.824114,0.340465,0.331442,0.520019,0.330341,2.40813,2.85285,0.178623,0.286763
8623,0.425772,0.412432,0.576146,0.604318,0.669348,0.695422,0.59698,0.575675,0.176294,0.256025,0.194598,0.213027,0.969125,0.957344,0.855932,0.866153,0.344498,0.382682,0.785173,0.807411,0.341389,0.338796,0.736992,0.848638,-1.01593,-0.769599,-1.18974,-1.20542,-0.68308,-0.834281,0.486069,0.552125,1.69245,1.67697,0.171767,-0.0121239,0.312178,0.757227,1.13772,1.24627
8624,0.322903,0.403265,0.812726,0.805398,0.163447,0.191286,0.321494,0.29201,0.226509,0.308364,0.293375,0.32776,0.994518,0.985156,0.249724,0.260155,0.985414,1.02515,0.0774481,0.0995467,-1.42458,-1.43459,0.615728,0.728151,-2.01309,-1.82224,-0.821349,-0.840979,-0.495702,-0.646168,-0.703559,-0.633996,-0.710088,-0.723798,0.238692,-0.00112781,0.129555,0.579654,0.661489,0.770815
8625,0.40953,0.394098,0.750441,0.714681,0.895415,0.922281,0.0309839,0.0083458,0.770087,0.852733,0.446179,0.442493,0.775533,0.679033,0.315957,0.326549,0.224635,0.265476,0.566551,0.495725,-2.4569,-2.47074,-0.432196,-0.247677,-1.06184,-0.8683,0.375066,0.355323,1.04282,0.89145,0.922737,0.990444,-1.35289,-1.36794,0.193126,0.00986829,-1.41739,-0.970232,-0.183691,-0.0817457
8626,0.165081,0.150437,0.770693,0.623963,0.345484,0.373217,0.0317478,0.0071264,0.141417,0.222917,0.202967,0.199073,0.433173,0.372909,0.132051,0.144377,0.051346,0.0922125,0.868404,0.891904,0.0536592,0.0315109,-1.33593,-1.2235,-0.645874,-0.45301,0.396803,0.381225,-0.975058,-1.12129,-1.41199,-1.34402,-0.36468,-0.384233,-1.15213,-1.33074,0.235158,0.678753,-0.684046,-0.588235
8627,0.735282,0.721897,0.568868,0.533245,0.284121,0.312961,0.483188,0.485216,0.260171,0.228988,0.21111,0.282649,0.0748289,0.0667859,0.78737,0.79919,0.146011,0.18511,0.359186,0.380994,0.420873,0.40613,-0.663427,-0.545145,-0.77747,-0.58796,-1.52922,-1.54943,0.795857,0.646207,0.163909,0.23579,2.38542,2.35791,0.951877,0.77289,-0.87231,-0.428519,-0.700277,-0.611271
8628,0.0467551,0.0351706,0.447813,0.442528,0.529583,0.558283,0.98706,0.963305,0.226833,0.23506,0.369008,0.366225,0.777922,0.769202,0.649132,0.662811,0.72004,0.759839,0.184687,0.205662,-1.30668,-1.32024,-1.00613,-0.89511,0.586342,0.776012,1.05242,1.03268,0.351288,0.202634,1.4689,1.53644,-0.60016,-0.630895,-1.22692,-1.40951,-0.846853,-0.401883,-0.357848,-0.273616
8629,0.506434,0.492853,0.922244,0.916191,0.209154,0.238596,0.378701,0.355322,0.157346,0.241131,0.0134102,0.00866005,0.487048,0.507476,0.192157,0.206357,0.00869038,0.0494411,0.417661,0.438441,-1.28196,-1.29894,0.0155745,0.120601,1.02243,1.20498,0.0648139,0.038738,0.515141,0.362031,-0.417659,-0.356734,0.602952,0.569978,-0.600242,-0.761562,-0.189782,0.25971,0.787189,0.868971
8630,0.70913,0.693379,0.452796,0.519593,0.337704,0.364807,0.771964,0.748868,0.870926,0.953078,0.975856,0.97263,0.255459,0.24575,0.267175,0.222518,0.788946,0.831623,0.984631,1.00684,-3.38216,-3.39899,-0.360161,-0.261065,-0.666039,-0.478054,0.598388,0.570234,0.00954037,-0.142096,-0.409136,-0.342368,-0.803627,-0.834589,0.180544,-0.113613,-0.87136,-0.425436,-0.847919,-0.763403
8631,0.365417,0.348127,0.129219,0.122994,0.934246,0.962515,0.618763,0.596747,0.555649,0.635397,0.703014,0.699708,0.686231,0.677401,0.225484,0.238678,0.530465,0.572813,0.974445,0.996596,0.853417,0.836583,1.93634,2.04006,-1.70639,-1.51326,0.567189,0.534589,0.771517,0.613458,-2.23151,-2.15901,-0.146918,-0.173367,0.716928,0.534335,-0.536873,-0.0909947,-0.0174006,0.0738985
8632,0.383261,0.363319,0.936078,0.929999,0.675294,0.69729,0.929553,0.906469,0.969788,1.04802,0.168714,0.165523,0.465277,0.45624,0.944605,0.956319,0.523766,0.567168,0.239005,0.258906,-0.854476,-0.874602,0.124029,0.229603,-1.02612,-0.836618,1.80313,1.77544,-1.06919,-1.22561,-1.31639,-1.24051,-1.79008,-1.81333,-0.845797,-1.03538,0.959427,1.40124,-0.208128,-0.115391
8633,0.64472,0.655287,0.569116,0.493238,0.403189,0.432066,0.926311,0.915368,0.487203,0.564338,0.153688,0.153376,0.731024,0.722658,0.33604,0.345459,0.871913,0.913543,0.429242,0.435632,-0.474486,-0.499982,-0.715649,-0.612413,-1.14336,-0.956575,0.498706,0.472699,0.136083,-0.0232809,1.10973,1.19311,0.145696,0.117725,2.61645,2.41959,0.18279,0.622195,0.0127891,0.100858
8634,0.967662,0.947255,0.0643995,0.0564768,0.840171,0.871391,0.97958,0.924267,0.58913,0.668137,0.755835,0.754844,0.481913,0.471835,0.195144,0.226706,0.23993,0.283634,0.605988,0.612358,-1.00658,-1.05973,1.22795,1.33129,0.9836,1.17175,1.61007,1.58986,-0.191001,-0.344485,-0.0142316,0.067607,1.62558,1.5972,1.07868,0.881703,-0.384269,0.0597858,-1.31857,-1.22479
8635,0.588059,0.623115,0.648435,0.641935,0.155113,0.187094,0.954136,0.933165,0.118869,0.199833,0.0174896,0.0153447,0.437288,0.428471,0.098534,0.107953,0.631149,0.674525,0.769184,0.789085,-1.58809,-1.61947,0.638319,0.736181,-1.68987,-1.49836,-1.49743,-1.52654,0.68045,0.519651,-1.39437,-1.30634,0.0126628,-0.0127502,0.514479,0.324753,0.761319,1.20561,0.0132003,0.101591
8636,0.320473,0.298976,0.0161054,0.0116065,0.042114,0.0755612,0.513734,0.493925,0.712589,0.794619,0.247425,0.244029,0.834632,0.824949,0.624091,0.634828,0.38783,0.431334,0.348311,0.368496,-0.448198,-0.481049,0.406259,0.50519,0.31677,0.50304,0.591273,0.568093,0.0407479,-0.120543,-0.385779,-0.296769,1.42485,1.4057,-1.33375,-1.52847,-0.0238277,0.426568,-1.25386,-1.1641
8637,0.58357,0.472749,0.885289,0.881439,0.571836,0.604096,0.0764067,0.0546852,0.0507079,0.135066,0.0630142,0.0614507,0.171062,0.163255,0.494368,0.50304,0.962208,1.00606,0.656242,0.620679,-0.717248,-0.698741,1.96281,2.06533,-1.82488,-1.63913,-1.41434,-1.44058,-0.307963,-0.471626,-0.0943941,-0.0075292,-0.0693484,-0.0939478,-1.78593,-1.97783,-0.000844864,0.453204,-0.625878,-0.537524
8638,0.666052,0.646522,0.650913,0.593377,0.0932834,0.124394,0.241682,0.219526,0.44107,0.523369,0.283357,0.259164,0.599831,0.589887,0.883167,0.889652,0.0383508,0.0828847,0.85083,0.872862,-0.935617,-0.916432,-0.327324,-0.216664,-1.54144,-1.36153,-1.04422,-1.07614,0.70043,0.53023,-0.566621,-0.48659,-1.19392,-1.2194,-1.84962,-2.04587,-0.4965,-0.0480858,0.636627,0.728541
8639,0.0365891,0.0153959,0.307568,0.305316,0.0846733,0.205697,0.751386,0.727367,0.278866,0.358196,0.399777,0.456878,0.605421,0.657186,0.874238,0.879656,0.116105,0.160898,0.627368,0.769159,-1.10127,-1.13412,0.151745,0.259576,2.32382,2.50804,0.205538,0.181428,-0.0923648,-0.262926,-0.37914,-0.30348,-0.830905,-0.850869,0.189856,-0.00595489,0.489717,0.844137,-0.195534,-0.107535
8640,0.254525,0.231975,0.260408,0.180901,0.25506,0.287,0.309984,0.285437,0.111502,0.193023,0.576963,0.654591,0.735061,0.724486,0.00953374,0.0139508,0.46611,0.512181,0.602318,0.665455,-0.393073,-0.424828,-0.427204,-0.319347,0.397876,0.587302,-0.180024,-0.208245,-0.0214095,-0.195817,-0.451117,-0.381216,1.25919,1.24306,-0.558567,-0.749465,1.29164,1.73636,0.12023,0.215341
8641,0.0912053,0.0689607,0.0581264,0.0564864,0.571031,0.603713,0.595648,0.570802,0.18288,0.262195,0.853859,0.852304,0.22292,0.212885,0.140127,0.144972,0.352343,0.400193,0.539719,0.561751,0.942713,0.917228,0.0080797,0.162971,0.702602,0.895184,0.459209,0.429699,1.05377,0.882887,-2.42313,-2.35389,-1.62324,-1.64511,1.13952,0.94797,-1.98093,-1.53331,-0.0248127,0.0726058
8642,0.814381,0.789752,0.964656,0.965167,0.0355179,0.0698974,0.388327,0.363926,0.593929,0.674818,0.142192,0.142601,0.806293,0.794036,0.701692,0.707208,0.546049,0.674596,0.0398377,0.0610928,1.09274,1.0599,0.537432,0.64529,1.4034,1.60197,0.889865,0.854093,-0.666313,-0.833359,0.707923,0.779895,-0.0380634,-0.0577115,-0.464612,-0.651526,0.437232,0.889761,0.13593,0.230266
8643,0.0936392,0.0702902,0.365606,0.363626,0.35118,0.38661,0.540103,0.514201,0.346787,0.426531,0.102104,0.100634,0.246344,0.232224,0.944043,0.947047,0.899711,0.948998,0.612829,0.635176,-0.0434857,-0.0833473,0.622932,0.723468,1.4104,1.60194,1.02347,0.988108,-0.407265,-0.567841,-0.192288,-0.117644,0.529687,0.512258,-0.344549,-0.535274,0.971777,1.42842,2.32534,2.42631
8644,0.744041,0.721835,0.906303,0.905883,0.215551,0.24991,0.0551142,0.0272877,0.847146,0.924457,0.335274,0.334013,0.480545,0.468074,0.118363,0.119532,0.512865,0.545939,0.901501,0.923281,-0.974648,-1.01259,0.0699467,0.173827,0.874846,1.06652,-0.0829984,-0.115895,-0.963692,-1.11662,0.291261,0.359599,0.237005,0.141778,1.48585,1.30144,0.116426,0.572171,0.792137,0.887299
8645,0.707751,0.724619,0.991775,0.990246,0.763132,0.797396,0.290654,0.262861,0.183803,0.259624,0.934174,0.935482,0.398519,0.45866,0.413154,0.391018,0.0923222,0.142879,0.580391,0.602043,0.775831,0.732959,0.334425,0.437045,-0.0289446,0.156633,0.402754,0.370635,-0.0820283,-0.237537,-0.399642,-0.336963,-0.207214,-0.228702,-0.133587,-0.314299,-0.377556,0.0708811,0.523039,0.622746
8646,0.703141,0.727403,0.172089,0.170134,0.463687,0.498213,0.129382,0.0999964,0.837376,0.914801,0.884417,0.954689,0.462796,0.449245,0.661434,0.662505,0.256237,0.307756,0.786405,0.808939,-0.0725947,-0.11854,-1.13196,-1.0287,1.20561,1.38419,0.0872716,-0.0117401,2.80693,2.65493,-0.433366,-0.369682,0.0161226,-0.000521841,-0.76516,-0.949885,0.525631,0.965929,-2.98262,-2.88238
8647,0.752394,0.730187,0.730245,0.726963,0.973397,1.00644,0.64707,0.618045,0.737127,0.813512,0.974416,0.973896,0.60657,0.632527,0.00635006,0.00544776,0.818144,0.867523,0.679646,0.703234,0.810842,0.757937,-0.0873476,-0.0796661,0.393196,0.566836,-0.365534,-0.394115,-0.35702,-0.519426,0.830045,0.900448,-0.0720253,-0.0898403,-0.34291,-0.526679,0.0161108,0.449413,0.209746,0.304285
8648,0.331836,0.309868,0.876338,0.870514,0.625062,0.656362,0.687987,0.706184,0.0615516,0.138313,0.52064,0.490589,0.827124,0.815808,0.0417581,0.0790462,0.142776,0.192531,0.86744,0.890427,-0.157385,-0.203472,0.765026,0.869371,0.0295502,0.224344,-0.279245,-0.307896,-1.08105,-1.25224,0.136105,0.203886,0.392012,0.371026,-0.788528,-0.976035,0.377023,0.815039,-0.723208,-0.625347
8649,0.440309,0.420576,0.532752,0.525512,0.966486,0.998313,0.823881,0.794322,0.631371,0.707053,0.0088856,0.0072812,0.578777,0.569744,0.238794,0.152645,0.771499,0.818918,0.295856,0.319253,-1.11198,-1.16488,-0.344861,-0.235091,-0.289476,-0.118147,0.683828,0.656031,-0.967684,-1.14054,-1.04331,-0.982235,0.359716,0.316994,0.23614,0.0467917,1.29202,1.72632,0.984579,1.08691
8650,0.0630077,0.0408403,0.696558,0.689246,0.536079,0.568402,0.369501,0.337317,0.719894,0.854233,0.797416,0.795787,0.549969,0.541357,0.226159,0.226243,0.536608,0.58508,0.58227,0.506742,-0.802732,-0.851656,0.282935,0.395992,-1.05466,-0.888845,0.427523,0.404309,0.354133,0.183877,-0.0973957,-0.0201831,0.25943,0.262961,0.650478,0.454753,-0.723429,-0.289992,0.225057,0.324101
8651,0.589596,0.567647,0.580422,0.571198,0.748364,0.778686,0.95382,0.920234,0.927748,1.00141,0.92147,0.920691,0.813332,0.802929,0.899012,0.897285,0.862663,0.911176,0.673287,0.69423,0.75456,0.708312,-0.415195,-0.305151,-0.302823,-0.199337,1.39284,1.36824,0.304696,0.141571,0.80635,0.941869,0.224241,0.208929,-0.286693,-0.486275,-0.512425,-0.081751,-1.42368,-1.32242
8652,0.433852,0.409882,0.230028,0.22148,0.0539866,0.0846975,0.124823,0.0926759,0.685538,0.847215,0.15594,0.155548,0.052955,0.0421593,0.748817,0.74604,0.874293,0.921198,0.152971,0.173969,-0.835918,-0.879227,-0.595994,-0.486517,0.324356,0.490171,0.668201,0.586876,-0.0805025,-0.240751,1.84285,1.90392,0.470993,0.452931,1.18667,0.991366,-0.588593,-0.16491,-1.16184,-1.06102
8653,0.495579,0.425422,0.89868,0.891027,0.2404,0.314611,0.37013,0.328773,0.621061,0.693016,0.180789,0.211824,0.193098,0.182377,0.308993,0.304461,0.205803,0.25032,0.802929,0.82278,-1.77135,-1.82114,-0.141978,-0.0489293,0.191268,0.355222,-0.17605,-0.194484,-0.207141,-0.363385,0.215792,0.273874,0.0571802,0.0388161,-0.340509,-0.532899,0.648138,1.07603,-0.537873,-0.434449
8654,0.439366,0.440962,0.264862,0.255566,0.512201,0.544524,0.597005,0.564871,0.466436,0.538817,0.32638,0.268101,0.926771,0.916942,0.840169,0.837044,0.346627,0.451777,0.325265,0.346669,-1.46864,-1.52169,0.272594,0.388658,-0.377222,-0.211351,-0.368961,-0.384272,-1.70762,-1.86434,-0.249758,-0.190637,-0.00896603,-0.0209786,1.89404,1.7053,1.49772,1.92757,-0.982534,-0.8803
8655,0.60067,0.456503,0.503029,0.492874,0.105642,0.13897,0.404628,0.373273,0.465735,0.536269,0.323814,0.324378,0.240597,0.229372,0.200844,0.196093,0.611007,0.653234,0.861439,0.881564,0.0758578,0.0246067,-0.729238,-0.606599,1.83501,1.99902,0.522689,0.503588,-0.652801,-0.837839,-0.258951,-0.206406,2.13403,2.12069,0.301332,0.105808,-1.05812,-0.628898,1.80383,1.9113
8656,0.496013,0.472043,0.108746,0.0987826,0.788769,0.823854,0.971306,0.940956,0.829065,0.899613,0.638861,0.570545,0.963741,0.952956,0.486393,0.482011,0.986541,1.02904,0.549159,0.570171,-0.11941,-0.165272,-0.259365,-0.130358,0.873101,1.04341,0.0186055,0.00596469,0.342149,0.188659,0.604133,0.649981,-0.0376547,-0.054368,1.41213,1.21872,-1.17344,-0.742515,-0.0701084,0.0339989
8657,0.0646967,0.0412809,0.0124211,0.00109156,0.200688,0.235113,0.338931,0.30874,0.137096,0.209729,0.817858,0.816713,0.114251,0.102841,0.331942,0.325495,0.801916,0.845613,0.558397,0.580888,-1.07706,-1.12417,-0.172565,-0.0378526,0.312556,0.476835,1.15924,1.14124,1.01958,0.868668,0.240766,0.281013,-1.15364,-1.16321,-0.240293,-0.430254,0.404165,0.841958,0.688056,0.79699
8658,0.0616994,0.0366383,0.136951,0.124247,0.32824,0.305756,0.0263356,-0.00436171,0.0911455,0.165295,0.256578,0.257864,0.254016,0.243059,0.481556,0.50311,0.257956,0.301124,0.803404,0.823981,-1.44104,-1.48209,0.301039,0.438388,2.59451,2.75253,0.773437,0.799799,0.246193,0.0920931,3.36692,3.40346,-0.229557,-0.241992,-0.769091,-0.956503,0.360146,0.805904,-0.729401,-0.620373
8659,0.387709,0.364215,0.890302,0.87975,0.292576,0.3764,0.199747,0.170692,0.65552,0.728247,0.585233,0.603018,0.709967,0.69894,0.686703,0.680725,0.916333,0.959436,0.173256,0.193218,0.252291,0.245001,0.441995,0.578096,0.415063,0.577837,0.479406,0.458357,0.296137,0.0455293,1.03572,1.069,1.09982,1.08436,0.0880714,-0.104356,1.24998,1.70095,0.235378,0.339138
8660,0.278902,0.255193,0.908994,0.898784,0.507194,0.447044,0.693325,0.664034,0.596838,0.668398,0.949041,0.948172,0.308154,0.298602,0.368728,0.364232,0.810585,0.852156,0.175204,0.201605,2.01315,1.9721,-0.0953714,0.0446626,-1.24988,-1.08834,-1.45678,-1.4723,0.150057,-0.00103447,0.620699,0.652665,0.585084,0.484481,-1.04535,-1.24355,0.179544,0.623492,0.453729,0.562436
8661,0.706937,0.683057,0.551824,0.599522,0.48242,0.517688,0.00994931,-0.0179753,0.897149,0.971163,0.0787895,0.0767703,0.912226,0.90536,0.325071,0.240616,0.26989,0.312553,0.188703,0.209991,1.07004,1.03018,-0.369525,-0.229341,-0.182695,-0.0278615,-0.133127,-0.154078,-0.0660709,-0.214135,0.835408,0.867027,-0.0966266,-0.115402,1.19015,0.994648,-0.550602,-0.108878,0.688377,0.785734
8662,0.350418,0.327759,0.310212,0.300261,0.147823,0.183027,0.197627,0.167528,0.0591451,0.133993,0.574331,0.574251,0.0984914,0.0936599,0.122114,0.117,0.666589,0.70843,0.572628,0.594155,0.54466,0.567801,1.611,1.74867,1.09279,1.24423,-0.975577,-0.993676,1.0601,0.908906,0.236364,0.263094,-2.70033,-2.72574,-1.30728,-1.50184,-0.831292,-0.392905,-0.507192,-0.403266
8663,0.264706,0.240783,0.672399,0.660374,0.599144,0.632281,0.590825,0.561075,0.947634,1.02365,0.499248,0.459207,0.364955,0.3563,0.422273,0.417994,0.386254,0.429914,0.741286,0.76109,0.140829,0.105419,-0.663522,-0.520837,0.978704,1.12095,-1.20325,-1.22779,-0.789303,-0.948697,-1.82384,-1.80207,-0.800183,-0.824119,1.37971,1.17908,0.525328,0.96258,-0.826425,-0.728856
8664,0.606545,0.551193,0.35606,0.344602,0.521344,0.485096,0.0044533,-0.0266999,0.462163,0.539971,0.231486,0.344162,0.623743,0.61894,0.0557805,0.0512076,0.649945,0.628108,0.479953,0.499984,0.952246,0.921741,-0.567758,-0.428331,0.852165,0.997668,-0.272433,-0.276797,-0.198459,-0.362649,-0.722815,-0.701459,-0.297053,-0.317094,-0.363575,-0.562702,-1.22272,-0.78011,-2.0968,-1.99455
8665,0.885257,0.861602,0.367361,0.353646,0.247254,0.337911,0.430826,0.401985,0.195927,0.272731,0.230123,0.229118,0.20572,0.202931,0.916225,0.911614,0.782774,0.826302,0.454843,0.431676,1.15816,1.04378,-1.36639,-1.223,0.13138,0.272068,0.699627,0.674199,0.815317,0.655871,0.132528,0.199496,-2.26455,-2.28878,1.32944,1.13473,-0.696734,-0.257656,-0.414154,-0.313644
8666,0.933108,0.91185,0.950935,0.939104,0.155758,0.190726,0.00243566,-0.0251779,0.792168,0.867518,0.234744,0.236205,0.423297,0.419396,0.56607,0.611622,0.0615718,0.105476,0.342336,0.363368,1.28911,1.16582,-1.75635,-1.61878,1.56645,1.71257,1.06229,1.03864,0.141409,-0.0159109,1.0791,1.10045,-0.719077,-0.750814,1.62551,1.43402,0.527347,0.965919,0.239835,0.343409
8667,0.702297,0.753028,0.145175,0.134452,0.871747,0.906713,0.530857,0.502483,0.93076,1.00728,0.513953,0.514691,0.372847,0.418341,0.314828,0.31163,0.379197,0.420321,0.989708,1.01218,1.31836,1.28786,0.625053,0.764735,0.263834,0.360031,-0.466166,-0.492851,0.0655329,-0.0913434,-0.917165,-0.902509,-1.20673,-1.17167,-0.655285,-0.848622,0.879294,1.31694,-0.00185889,0.0941192
8668,0.53153,0.594206,0.997274,0.987881,0.902904,0.938437,0.402381,0.375093,0.0973393,0.174889,0.0338751,0.0345527,0.517841,0.417286,0.325602,0.33021,0.992094,1.03194,0.0945601,0.116498,-0.342291,-0.376649,-0.123735,0.0163384,-1.13863,-0.992506,-0.210719,-0.236421,0.212314,0.0503964,-0.58821,-0.567981,-1.56346,-1.59253,-0.785897,-0.977419,-2.56712,-2.13271,0.89829,0.992675
8669,0.456198,0.435384,0.217232,0.205967,0.521651,0.57551,0.563497,0.534717,0.694813,0.77463,0.318364,0.318655,0.420132,0.416231,0.353845,0.348789,0.154189,0.192895,0.842248,0.864763,-1.17351,-1.21379,0.752649,0.893439,-0.557368,-0.409077,-1.38392,-1.41544,-0.956735,-1.1257,1.00355,1.02554,-0.833381,-0.855463,1.37467,1.18457,0.0146353,0.452388,0.647836,0.780222
8670,0.722687,0.702259,0.0721602,0.0622606,0.1777,0.212584,0.377304,0.347276,0.640808,0.719422,0.302494,0.247458,0.074448,0.0710074,0.0910836,0.0869544,0.429954,0.467297,0.37451,0.398807,1.06271,1.02194,-0.242094,-0.101818,0.360157,0.561922,-0.355267,-0.388763,1.58306,1.41125,-0.00422458,0.0218385,2.96495,2.95031,0.977142,0.780811,0.432371,0.864813,0.46899,0.567768
8671,0.655918,0.672326,0.530233,0.520755,0.406824,0.470208,0.645241,0.612593,0.887663,0.966147,0.189093,0.17626,0.526474,0.522257,0.234302,0.275773,0.701094,0.741699,0.635758,0.661836,-0.801095,-0.847301,-0.551592,-0.40799,1.3881,1.53292,0.452615,0.420711,-1.39133,-1.5606,-1.29035,-1.25833,0.868364,0.85308,0.326685,0.129876,-0.627786,-0.196631,-1.37519,-1.28121
8672,0.660612,0.642393,0.453144,0.349253,0.694172,0.727833,0.59134,0.560967,0.207123,0.285962,0.104771,0.105063,0.54368,0.465498,0.467695,0.464591,0.447873,0.565625,0.190021,0.215445,1.07311,1.03445,-1.58532,-1.43579,0.985412,1.19043,1.66615,1.63244,2.30755,2.14679,-0.176087,-0.139635,-0.225573,-0.239316,0.652241,0.461762,2.96059,3.39028,0.582617,0.677181
8673,0.412536,0.331653,0.18798,0.177751,0.0335558,0.0688578,0.772426,0.74181,0.217723,0.298893,0.358831,0.358501,0.41539,0.408739,0.828715,0.827476,0.326631,0.389551,0.578233,0.604448,0.066781,-0.0227223,-1.60544,-1.45059,0.699266,0.847938,-1.57301,-1.61307,-0.968112,-1.12582,-0.861479,-0.821732,0.0585005,0.0529794,-1.16458,-1.35996,0.1487,0.496312,-0.375316,-0.281393
8674,0.0403728,0.0209131,0.884076,0.872521,0.151735,0.186044,0.519547,0.488916,0.000775591,0.0818346,0.863282,0.860848,0.945297,0.939892,0.913637,0.913201,0.174419,0.213477,0.262423,0.28868,-1.04123,-1.07989,0.520645,0.673291,-1.26319,-1.11714,-1.1892,-1.14875,0.227309,0.076515,-1.28807,-1.25286,-0.0633044,-0.0666352,-0.378273,-0.570601,-2.82735,-2.39766,1.22326,1.32249
8675,0.258946,0.278834,0.0664042,0.0524085,0.658467,0.694275,0.663207,0.693521,0.393798,0.532355,0.366069,0.36563,0.831532,0.825479,0.74756,0.654856,0.775723,0.81535,0.328589,0.355422,-0.926031,-0.968447,0.762016,0.920614,0.606978,0.761555,-0.639971,-0.684433,-2.41379,-2.56141,-0.59293,-0.565522,-2.15433,-2.16387,-0.72513,-0.913067,-0.585497,-0.154066,-0.43763,-0.338803
8676,0.558011,0.536755,0.827955,0.814139,0.0672116,0.105534,0.930188,0.898126,0.900228,0.982875,0.882319,0.882957,0.997932,0.991036,0.39534,0.396512,0.344229,0.478885,0.0232604,0.0502332,0.170284,0.123005,0.546121,0.7085,-1.29107,-1.14101,0.538808,0.495271,-0.435442,-0.586578,-0.709114,-0.690814,-2.27578,-2.28348,-0.516693,-0.762887,0.976203,1.41377,-0.346326,-0.242685
8677,0.170258,0.146932,0.405331,0.390207,0.352595,0.438899,0.456137,0.425948,0.851972,0.886689,0.617459,0.619839,0.354622,0.349161,0.65838,0.657145,0.104422,0.14242,0.359969,0.388921,0.782495,0.74218,0.919045,1.07716,-0.349651,-0.204498,-0.35463,-0.391135,-1.22538,-1.37973,0.113866,0.134096,-0.530582,-0.542743,-0.424356,-0.612708,-0.483449,-0.0409953,1.70948,1.81128
8678,0.769513,0.747684,0.861982,0.848702,0.734086,0.772264,0.372697,0.342918,0.706474,0.790504,0.931092,0.935417,0.199034,0.19467,0.141658,0.141337,0.757776,0.796072,0.327145,0.354902,0.27123,0.227537,-0.798407,-0.636007,-0.189676,0.00419213,1.43107,1.38683,-2.32937,-2.48043,1.28377,1.29899,0.42164,0.410145,0.131394,-0.0534423,0.0444668,0.481458,0.421423,0.530113
8679,0.0576763,0.0330824,0.460172,0.445048,0.0910754,0.127973,0.521387,0.469062,0.446692,0.59992,0.572599,0.577851,0.464271,0.461087,0.195165,0.145121,0.489629,0.5272,0.74901,0.77919,-2.00881,-2.04885,-3.32123,-3.16078,0.0714194,0.212883,1.15257,1.10435,0.0335329,-0.110905,1.32472,1.34401,-0.635668,-0.652462,-0.209485,-0.395908,1.50825,1.94408,-0.117572,-0.00811944
8680,0.667046,0.642949,0.706263,0.692054,0.879222,0.916719,0.635144,0.595205,0.326825,0.409336,0.889474,0.893429,0.0149782,0.0102468,0.149225,0.148905,0.897506,0.93316,0.838951,0.814383,0.561063,0.521831,-0.329276,-0.175977,-0.512426,-0.373325,-0.66327,-0.713469,-0.4154,-0.554478,-0.951389,-0.924896,-0.222317,-0.237179,0.655464,0.470032,0.507276,0.944541,-0.428942,-0.318847
8681,0.464149,0.439082,0.00433883,-0.00820966,0.187825,0.222731,0.750676,0.721349,0.270131,0.354127,0.621418,0.625552,0.857621,0.850654,0.912433,0.911337,0.39322,0.503031,0.82038,0.849576,0.452895,0.419995,0.781404,0.933407,1.2515,1.39377,0.415027,0.358807,-1.6884,-1.82389,1.14442,1.16433,1.34114,1.33019,-0.364803,-0.54807,1.3269,1.76188,0.93557,1.03981
8682,0.816656,0.790904,0.680207,0.666579,0.993505,1.028,0.572298,0.543682,0.751013,0.836656,0.584514,0.588224,0.848329,0.843227,0.473993,0.474442,0.0394578,0.0729021,0.560085,0.58847,0.753058,0.719448,0.554401,0.702416,0.238398,0.41618,1.21901,1.16828,0.582869,0.447229,1.52575,1.54722,-0.6545,-0.673358,0.668755,0.487943,-1.02386,-0.589404,0.86494,0.973492
8683,0.629034,0.602241,0.168356,0.153738,0.719862,0.682504,0.990064,0.961839,0.868008,0.956051,0.24898,0.254742,0.606346,0.601944,0.791104,0.790781,0.137564,0.171436,0.0348597,0.0624816,-1.54968,-1.58751,-0.671745,-0.525353,-0.702871,-0.561407,-0.0685205,-0.118751,0.486625,0.355128,0.0884672,0.1148,0.734883,0.713268,-0.0884484,-0.270035,-0.211122,0.22793,0.483722,0.588454
8684,0.990226,0.964709,0.764714,0.750044,0.303599,0.337007,0.920908,0.894898,0.425544,0.535881,0.589757,0.594317,0.932433,0.92926,0.447841,0.439397,0.793079,0.829748,0.554538,0.58207,-0.754077,-0.742606,0.760364,0.907001,-0.38389,-0.155595,1.31396,1.26205,-0.500473,-0.638519,-0.0223542,-0.0334844,-0.653837,-0.675399,-1.1127,-1.28814,1.19808,1.64289,-0.556805,-0.445644
8685,0.860064,0.836153,0.198815,0.183902,0.419604,0.503727,0.546778,0.517274,0.0265263,0.115711,0.0857829,0.0889441,0.760748,0.759581,0.0877116,0.0880125,0.427858,0.465443,0.224132,0.331864,0.135037,0.1023,-0.231425,-0.0882556,0.115037,0.250217,-0.435676,-0.491989,0.835245,0.700097,-0.211382,-0.181769,1.0401,1.01902,0.0126463,-0.159224,1.93826,2.38332,-0.260978,-0.153418
8686,0.136355,0.112262,0.421124,0.406762,0.638673,0.670447,0.165439,0.13965,0.112524,0.199551,0.781965,0.785334,0.097346,0.0978865,0.856666,0.855255,0.381301,0.420737,0.0547472,0.0816583,-0.0944525,-0.133805,1.06613,1.20738,-0.163714,-0.0235196,0.706224,0.643288,0.0463633,-0.0930591,0.584772,0.610394,-0.219767,-0.243919,-1.99382,-2.16647,1.05525,1.49538,-0.929748,-0.826122
8687,0.112789,0.156337,0.925306,0.909574,0.304357,0.335786,0.591504,0.563911,0.764084,0.84977,0.429041,0.44375,0.942003,0.9435,0.372907,0.369087,0.69268,0.73152,0.304388,0.330006,0.5402,0.423018,-0.320253,-0.179241,0.352134,0.497511,0.00597476,-0.0545807,0.123248,-0.0108727,0.0367883,0.0688884,0.990865,0.972601,-3.15992,-3.33461,-0.280943,0.163872,-0.90686,-0.803651
8688,0.222526,0.200413,0.0944595,0.079706,0.807164,0.839347,0.075761,0.0460382,0.806036,0.89195,0.0995783,0.102166,0.969815,0.971311,0.9999,0.994533,0.146438,0.187031,0.148622,0.174799,1.01698,0.979841,0.369043,0.512962,-0.76489,-0.615733,0.166283,0.110434,-2.61387,-2.75158,-0.31011,-0.284706,0.0999587,0.0808042,1.06975,0.895056,-1.13642,-0.692374,1.29108,1.39239
8689,0.0204884,-0.00345299,0.160114,0.229675,0.594794,0.626188,0.345512,0.316572,0.0183891,0.102205,0.763871,0.76882,0.723742,0.737653,0.359909,0.353582,0.644665,0.687251,0.801549,0.829345,0.321715,0.28322,1.77463,1.91457,-0.246776,-0.094702,-0.500915,-0.556792,-0.701829,-0.844209,0.630311,0.649756,-1.09995,-1.12138,-0.303544,-0.47515,-0.997284,-0.559349,1.04132,1.1431
8690,0.607759,0.582177,0.396594,0.379644,0.64074,0.672873,0.139592,0.109696,0.188959,0.328827,0.851982,0.859588,0.51774,0.503995,0.508687,0.499964,0.402149,0.444061,0.567424,0.593666,0.150366,0.107486,0.173235,0.310231,0.552659,0.704321,1.53045,1.47586,0.613519,0.465771,0.946293,0.970046,-0.0448381,-0.0623635,0.116258,-0.00602258,-0.543406,-0.100845,-0.715718,-0.612252
8691,0.626486,0.520043,0.293878,0.276382,0.887361,0.918195,0.877303,0.847044,0.470096,0.555449,0.555549,0.60704,0.268841,0.270337,0.97943,0.972042,0.554561,0.63713,0.911707,0.937988,0.595207,0.557941,0.246486,0.388409,-0.319278,-0.174848,-0.415851,-0.468117,1.07297,0.929888,0.122581,0.145646,-0.628794,-0.647317,0.636809,0.463105,-1.27243,-0.833214,-0.766813,-0.665471
8692,0.481963,0.457909,0.508281,0.489039,0.694693,0.72616,0.628396,0.59911,0.0800154,0.167114,0.380435,0.354492,0.645017,0.647097,0.0544657,0.0461379,0.790341,0.830198,0.646988,0.673015,0.376713,0.348475,-0.836971,-0.699883,-0.587173,-0.448585,-0.389121,-0.442216,0.357622,0.215263,-0.704284,-0.678755,-0.0154383,-0.0315273,0.272937,0.104168,-1.06126,-0.624973,1.74934,1.84956
8693,0.785831,0.759772,0.100618,0.0796316,0.975051,1.00744,0.949574,0.918741,0.613086,0.700876,0.0937958,0.101944,0.0990832,0.100242,0.210673,0.203536,0.118367,0.159321,0.0244169,0.052315,0.176274,0.139008,1.37218,1.50557,0.879607,1.02079,-0.794401,-0.84738,-0.641111,-0.778384,0.17501,0.19303,-0.215559,-0.227339,-0.583316,-0.75929,1.6555,2.09127,-0.797299,-0.692282
8694,0.271832,0.244353,0.297102,0.208811,0.248727,0.282283,0.405554,0.375173,0.1298,0.217193,0.640682,0.648029,0.186822,0.11091,0.858227,0.853023,0.676358,0.719087,0.422069,0.516903,-1.41219,-1.44853,0.836993,0.972136,0.568437,0.716277,0.661303,0.615093,-0.545177,-0.734942,0.512609,0.527558,-1.3213,-1.33619,-0.873579,-1.05483,1.33964,1.77539,-1.58164,-1.47007
8695,0.0765102,0.0504894,0.359466,0.33799,0.0797421,0.116136,0.215412,0.210362,0.28021,0.36738,0.401111,0.409575,0.121556,0.121578,0.133639,0.128312,0.580114,0.623622,0.953054,0.981492,-0.438791,-0.477279,-0.983399,-0.854939,-0.443303,-0.287401,0.472559,0.419416,-0.552225,-0.691501,1.93269,1.94927,0.271486,0.251208,-0.036879,-0.218022,0.626869,1.05964,0.110372,0.225617
8696,0.592768,0.492915,0.14827,0.128405,0.614504,0.649676,0.0772464,0.045551,0.878074,0.967122,0.919135,0.926903,0.844175,0.845163,0.744506,0.738086,0.691068,0.772575,0.774889,0.743157,0.952467,0.911448,0.76508,0.888217,-1.14463,-0.994708,0.262555,0.223739,-1.20906,-1.34585,-0.154234,-0.13082,-0.113392,-0.131116,0.0374039,-0.148768,-1.03118,-0.600778,1.44453,1.552
8697,0.96136,0.93534,0.35083,0.330866,0.344565,0.380335,0.677352,0.648309,0.426063,0.513733,0.802088,0.809518,0.0594766,0.0595453,0.815275,0.809674,0.880974,0.921527,0.530561,0.504822,-0.12984,-0.170042,-0.570253,-0.451032,1.23458,1.38058,1.89667,1.85939,0.438379,0.297565,-0.349986,-0.330763,0.0856674,0.0676912,-0.744786,-0.937506,-0.650219,-0.311888,-0.22811,-0.124955
8698,0.77688,0.752386,0.976452,0.956511,0.368692,0.356608,0.241033,0.212074,0.652141,0.672683,0.165026,0.174143,0.85592,0.854601,0.318984,0.313989,0.740213,0.778015,0.239492,0.266487,2.05171,2.00499,0.238863,0.363994,0.593013,0.756101,-0.0412881,-0.0712682,0.312599,0.174931,0.648182,0.665863,-1.76891,-1.79192,1.40626,1.20991,-0.417886,-0.0229967,-0.447074,-0.345148
8699,0.323778,0.297288,0.706597,0.632204,0.297485,0.332882,0.315894,0.285174,0.74491,0.831632,0.389581,0.398174,0.498682,0.499454,0.840473,0.836296,0.00268933,0.0416937,0.600472,0.626921,-2.49922,-2.54594,-0.784103,-0.663806,-0.0154302,0.131627,-2.4417,-2.46708,1.65192,1.51355,-0.699529,-0.674918,0.290355,0.264995,-0.748121,-0.943057,-0.0984097,0.265894,-0.177412,-0.0837506
8700,0.859929,0.834067,0.407997,0.307897,0.867547,0.900965,0.945253,0.912342,0.695839,0.740447,0.280894,0.289235,0.495694,0.497734,0.719502,0.687908,0.319401,0.322291,0.958637,0.987356,1.5688,1.51746,0.00810024,0.12454,0.315291,0.457722,1.83458,1.80626,0.686617,0.551962,-0.310663,-0.292028,0.977599,0.956512,-1.26532,-1.45416,0.124385,0.554785,-0.121854,-0.0309167
8701,0.930702,0.9048,0.00353164,-0.0164092,0.785396,0.909405,0.414112,0.379343,0.586004,0.649262,0.576607,0.584856,0.87686,0.879189,0.545754,0.539521,0.565548,0.602889,0.573226,0.63213,1.25212,1.20592,-0.110601,0.00405377,0.634375,0.783818,-1.12646,-1.15532,-0.940872,-1.07118,-1.31739,-1.29573,-0.559445,-0.575753,0.709534,0.522232,1.03104,1.46607,-1.35632,-1.26656
8702,0.778414,0.69048,0.0528704,0.0316237,0.88405,0.917846,0.486771,0.452444,0.397796,0.558077,0.025947,0.0355095,0.236009,0.237314,0.912311,0.906608,0.20776,0.243737,0.247716,0.276904,-0.586017,-0.629392,0.491651,0.605901,-1.84078,-1.69482,1.38484,1.35582,-1.15987,-1.28428,-1.68368,-1.6647,0.133792,0.115763,-0.690104,-0.877864,0.722735,1.12167,0.290523,0.382736
8703,0.579329,0.47616,0.480727,0.443743,0.513957,0.548502,0.769168,0.73235,0.381195,0.466892,0.866367,0.875662,0.0786074,0.0782643,0.47462,0.477847,0.0781943,0.116769,0.454283,0.4838,0.0196529,-0.025853,-0.754942,-0.637019,0.540247,0.680463,-0.181023,-0.207315,-0.356385,-0.483796,-0.433382,-0.409431,0.222846,0.207936,-1.1798,-1.37362,0.34224,0.777266,-1.9046,-1.80631
8704,0.289911,0.261841,0.875072,0.855863,0.966247,1.00201,0.000794116,-0.0370552,0.127033,0.375706,0.631624,0.642364,0.410028,0.498545,0.0567227,0.0490863,0.81662,0.853527,0.123941,0.15222,0.260877,0.208962,1.31081,1.42117,0.227251,0.465332,1.1625,1.14082,-0.545833,-0.667128,-0.763093,-0.732239,-0.650108,-0.66881,-0.13368,-0.322381,-0.428998,-0.00177591,-1.88439,-1.78384
8705,0.406468,0.377848,0.484707,0.546645,0.875955,0.911046,0.230086,0.193495,0.197799,0.284521,0.176387,0.186536,0.921248,0.918826,0.166068,0.205782,0.89302,0.93154,0.92276,0.950353,-0.161924,-0.120694,0.294291,0.409917,0.104047,0.250201,-0.467366,-0.486814,-0.473275,-0.600019,0.534692,0.568414,0.723618,0.702128,-0.225477,-0.420132,0.634178,1.0667,0.843393,0.946867
8706,0.213263,0.264344,0.257364,0.237426,0.0286749,0.0666097,0.919776,0.881228,0.695811,0.782447,0.566764,0.526201,0.411183,0.407225,0.370388,0.362478,0.344501,0.382243,0.441084,0.469791,-0.401006,-0.450349,0.30661,0.355862,0.762756,0.909527,-1.27408,-1.29439,-0.834496,-0.966981,-0.0617924,-0.00195823,0.313142,0.288013,0.264698,0.0645587,-1.515,-1.0884,1.34114,1.4511
8707,0.178365,0.15084,0.639386,0.617164,0.95685,0.992516,0.486323,0.449332,0.747207,0.927593,0.854959,0.865867,0.800226,0.793978,0.181505,0.184147,0.0562688,0.0930929,0.36368,0.391736,1.17661,1.12573,0.195144,0.301807,-0.0689705,0.075858,0.478719,0.452672,-0.508967,-0.55797,-0.606566,-0.57233,-1.99007,-2.01655,-2.47126,-2.66649,-1.85676,-1.43634,-0.395742,-0.286963
8708,0.625112,0.598705,0.00291263,-0.0182967,0.759362,0.841315,0.302641,0.267365,0.987725,1.07274,0.410987,0.48916,0.194198,0.187851,0.0144889,0.00581678,0.342523,0.378837,0.497082,0.562556,-0.290841,-0.338247,1.94971,2.06309,-1.31163,-1.16043,-0.237496,-0.261445,-0.0127684,-0.148958,0.830062,0.866156,1.21346,1.19375,-0.999972,-1.20234,-1.52621,-1.1019,-1.15213,-1.04977
8709,0.714679,0.689753,0.661882,0.641038,0.574673,0.690113,0.399478,0.366588,0.247202,0.331403,0.100534,0.112454,0.0718482,0.0632393,0.0575727,0.0512062,0.0411832,0.0796689,0.729145,0.733376,0.97773,0.926009,0.00289833,0.110419,-0.235854,-0.0851993,0.501199,0.471604,-1.01295,-1.14261,-0.434386,-0.397442,0.188257,0.162086,0.221542,0.0143366,2.49612,2.92593,0.365125,0.463559
8710,0.471347,0.446091,0.183557,0.163601,0.501605,0.538912,0.748939,0.715374,0.63748,0.665948,0.696281,0.708243,0.636852,0.629749,0.770696,0.763217,0.132468,0.172566,0.874435,0.904196,2.02303,1.97418,0.61335,0.726336,-2.41368,-2.25989,0.845817,0.819996,0.44917,0.318391,0.0430335,0.0927528,0.374054,0.344629,0.874959,0.667562,0.755565,1.18324,-0.20347,-0.103027
8711,0.512589,0.486268,0.421992,0.400909,0.0799752,0.119246,0.617832,0.582989,0.916842,1.00049,0.747816,0.830603,0.503543,0.444059,0.155802,0.146881,0.818438,0.859784,0.410679,0.43824,0.568577,0.525616,0.724397,0.833261,0.346783,0.494514,-0.695243,-0.726406,-0.368483,-0.506374,0.55553,0.582948,0.0677929,0.0395507,0.59888,0.386604,1.29294,1.72189,-0.158066,-0.0501928
8712,0.0565766,0.03117,0.892903,0.874572,0.906662,0.944601,0.284105,0.332818,0.0326639,0.118754,0.940424,0.952964,0.264732,0.25837,0.156065,0.146518,0.296122,0.335717,0.459064,0.485276,0.988779,0.945468,0.574352,0.683571,0.802925,0.953389,0.743842,0.718159,0.444993,0.310906,-0.381736,-0.36013,0.60038,0.57664,-1.04574,-1.26237,-0.170509,0.267128,-0.578595,-0.46676
8713,0.636646,0.612566,0.080617,0.0599553,0.3373,0.375869,0.117252,0.0826472,0.380753,0.377656,0.0461247,0.0582969,0.783679,0.774655,0.384119,0.375819,0.836884,0.876394,0.258063,0.284536,-0.585798,-0.626527,-0.387181,-0.281075,-0.137732,0.0136613,0.839268,0.820726,-1.37051,-1.4962,-0.377163,-0.287367,0.034221,-0.0658476,0.0212862,-0.194216,-0.870241,-0.433443,0.425212,0.539279
8714,0.650533,0.627759,0.834673,0.815458,0.141082,0.178998,0.543437,0.506909,0.586938,0.636558,0.965788,0.980114,0.573149,0.564286,0.208595,0.198981,0.741287,0.780929,0.589182,0.602452,0.582807,0.542684,0.424822,0.533951,1.98329,2.14199,0.605232,0.586608,-0.521148,-0.647252,-0.242848,-0.214604,-0.684865,-0.708335,0.755189,0.537099,0.243906,0.680583,-0.0705622,0.0494295
8715,0.183998,0.161938,0.190081,0.169752,0.462431,0.544149,0.218569,0.184102,0.808637,0.89546,0.318328,0.330061,0.150029,0.139281,0.493934,0.484899,0.100794,0.140503,0.893621,0.920368,1.14565,1.09968,-0.153699,-0.0449721,0.889394,1.04527,-0.38982,-0.407337,-0.871701,-0.998335,0.760109,0.782023,-1.10604,-1.12245,-0.360841,-0.572404,0.245785,0.675267,-2.30683,-2.18774
8716,0.286506,0.262308,0.244476,0.223555,0.874153,0.909299,0.737157,0.70215,0.496006,0.582766,0.288109,0.300665,0.0489317,0.124763,0.224647,0.240966,0.85348,0.893164,0.891381,0.915873,0.134556,0.0937788,1.91966,2.02754,1.64163,1.79845,-0.113497,-0.134796,0.318703,0.187838,-0.939563,-0.91207,-1.20703,-1.22799,0.657483,0.450423,-0.629964,-0.198517,0.634856,0.75849
8717,0.888103,0.86306,0.738284,0.716603,0.805765,0.839991,0.0447141,0.0100334,0.630539,0.717644,0.321352,0.271269,0.118831,0.110244,0.00777993,-0.0029662,0.454403,0.583357,0.477416,0.499879,-0.187258,-0.231886,-0.652834,-0.5432,0.0793639,0.31884,-0.613901,-0.632419,0.470396,0.347235,0.0921928,0.114328,-2.09455,-2.11979,-0.0313041,-0.231716,-1.01134,-0.574894,-0.197967,-0.0775854
8718,0.384073,0.357568,0.896707,0.823304,0.230551,0.266342,0.0101943,-0.0263914,0.462251,0.512938,0.230794,0.241873,0.99797,0.990598,0.684022,0.673213,0.235926,0.27355,0.763498,0.787985,-0.719178,-0.759799,-0.751639,-0.648671,-1.31758,-1.16077,1.16317,1.14554,-1.39236,-1.51037,-1.11532,-1.08711,0.0232802,0.00374372,-0.302029,-0.498542,0.544149,0.978032,-0.117718,0.00309093
8719,0.595196,0.568897,0.949636,0.930005,0.183332,0.217318,0.782617,0.747786,0.221895,0.308231,0.539498,0.57536,0.525009,0.519493,0.29633,0.286741,0.79038,0.828764,0.0211169,0.0448943,-0.0373014,-0.1491,-0.411973,-0.307696,-1.43007,-1.26728,-0.296897,-0.310791,0.265249,0.149013,-0.0244432,0.000133753,1.28079,1.26491,1.08586,0.889888,0.0206149,0.461517,1.01789,1.14568
8720,0.161286,0.133096,0.0742075,0.0564893,0.354941,0.388046,0.951374,0.91792,0.45222,0.538818,0.896808,0.908846,0.851059,0.846809,0.150168,0.139816,0.650523,0.788352,0.948079,0.973622,0.507908,0.461599,1.57743,1.68772,-0.673229,-0.514101,-0.827327,-0.838887,0.520584,0.399732,-0.68996,-0.665928,-0.0377166,-0.0478756,-1.13915,-1.32799,-0.0377868,0.408398,1.24778,1.37871
8721,0.285282,0.327641,0.548906,0.530153,0.292683,0.323005,0.70338,0.669986,0.280243,0.3682,0.36713,0.378928,0.350328,0.34577,0.723869,0.713433,0.707138,0.747939,0.890149,0.915285,-0.0524159,-0.0969696,0.402499,0.50664,-0.759968,-0.656402,-0.26328,-0.277352,-1.20648,-1.3306,-1.04443,-1.01952,-0.361426,-0.368907,-0.874357,-1.05631,-0.540943,-0.092892,2.06758,2.20166
8722,0.571823,0.522186,0.78809,0.76746,0.604029,0.634293,0.893999,0.860564,0.507073,0.666416,0.563528,0.559968,0.517641,0.495031,0.906101,0.837672,0.852479,0.875618,0.329954,0.354214,-0.252452,-0.302424,-0.262388,-0.16459,-0.953788,-0.798704,0.734635,0.719857,0.766688,0.644226,0.264353,0.296606,2.06514,2.05914,-1.9627,-2.14953,-0.00443548,0.445764,0.587529,0.72457
8723,0.817842,0.716731,0.149182,0.127163,0.387778,0.419088,0.135038,0.101314,0.875752,0.964632,0.773317,0.741009,0.515105,0.644291,0.973478,0.961912,0.964369,1.0033,0.364236,0.389407,-0.0473962,-0.0991529,-0.344017,-0.239055,0.859512,1.01818,-0.882974,-0.892576,1.65264,1.52331,0.202419,0.234357,0.55447,0.543207,0.0385608,-0.141831,-0.200452,0.252866,0.549486,0.686203
8724,0.939467,0.911276,0.493793,0.45252,0.174413,0.203883,0.0327993,0.08195,0.809864,0.898905,0.908959,0.92205,0.795765,0.793551,0.412192,0.400755,0.227468,0.266976,0.39997,0.4246,2.19001,2.13657,-1.30701,-1.2037,1.04157,1.20131,1.43763,1.4339,0.276327,0.144056,-0.124357,-0.0884513,-0.615573,-0.629174,-1.49455,-1.67971,-0.8734,-0.418087,1.58124,1.72186
8725,0.830148,0.802255,0.799771,0.777877,0.942603,0.970766,0.0956958,0.0625859,0.131452,0.218719,0.275741,0.286676,0.661108,0.621377,0.500602,0.514294,0.740163,0.782061,0.208211,0.271501,-1.16812,-1.22027,-0.392184,-0.282439,-0.564051,-0.403539,-1.08193,-1.08243,0.774083,0.639599,2.14399,2.17866,0.11281,0.092672,-0.914465,-1.10334,-2.36502,-1.90589,0.214725,0.35032
8726,0.255947,0.226005,0.689346,0.564884,0.0631786,0.0913482,0.879901,0.846442,0.273837,0.363173,0.158103,0.154851,0.524244,0.449204,0.637049,0.627833,0.749711,0.792082,0.0915202,0.118401,1.53218,1.48412,0.028347,0.133712,-0.34513,-0.188835,0.810071,0.807119,-0.603593,-0.73965,-0.682786,-0.638874,-0.218011,-0.287398,-0.987457,-1.17138,0.160239,0.617915,1.04116,1.17327
8727,0.524692,0.49288,0.410097,0.35189,0.406324,0.385008,0.0158583,-0.0177974,0.103285,0.192555,0.01349,0.023026,0.27834,0.27703,0.975416,0.965395,0.201067,0.242786,0.619113,0.6479,0.443474,0.402628,-0.722721,-0.614684,1.26432,1.42112,-1.00509,-1.0107,-0.410934,-0.551537,0.113147,0.153288,-0.647944,-0.667468,-0.450053,-0.640313,0.309094,0.848937,-0.946544,-0.81358
8728,0.00881838,-0.0225388,0.163073,0.138896,0.648714,0.678668,0.0711303,0.00538948,0.34168,0.421652,0.633543,0.643785,0.570404,0.568186,0.700176,0.68871,0.249388,0.251411,0.35753,0.454948,-0.25094,-0.293992,-0.607618,-0.507759,0.374804,0.526684,-0.209588,-0.216287,0.231344,0.0962716,-0.507494,-0.467,2.30207,2.27751,-0.16934,-0.353629,0.627772,1.07996,0.76646,0.898673
8729,0.843848,0.812609,0.251017,0.228115,0.605064,0.585693,0.0634499,0.0285764,0.531875,0.650749,0.69637,0.78576,0.337404,0.350413,0.0830888,0.072374,0.22145,0.260035,0.232816,0.261996,0.283437,0.235305,-0.256654,-0.152564,0.172212,0.329092,-0.569788,-0.576095,2.32292,2.18212,0.0201416,0.0551537,-0.0529338,-0.0757995,-0.389008,-0.573423,-0.933175,-0.484951,-0.463714,-0.336968
8730,0.609527,0.526646,0.130351,0.110067,0.461109,0.492718,0.820914,0.787009,0.790577,0.879847,0.920087,0.927736,0.137689,0.13264,0.723258,0.712052,0.578538,0.616358,0.207802,0.147965,1.38498,1.34281,-1.18498,-1.08481,-0.483946,-0.332902,-0.268597,-0.272233,-1.24191,-1.38381,1.10247,1.1424,-1.66836,-1.68575,0.414636,0.232438,0.336021,0.785513,0.602912,0.729033
8731,0.273231,0.240682,0.823641,0.804836,0.656772,0.688044,0.929925,0.8959,0.626836,0.718481,0.0172473,0.0267826,0.803529,0.800512,0.391652,0.390031,0.264127,0.349411,0.00684241,0.0339332,-0.262171,-0.304834,-1.04938,-0.945106,-0.845755,-0.69971,0.931771,0.92407,-1.52567,-1.67222,0.32309,0.369409,0.808678,0.790742,0.57649,0.394577,0.135804,0.578729,-0.120481,0.0117072
8732,0.774368,0.742812,0.303127,0.282111,0.28032,0.407156,0.387243,0.352332,0.917415,1.01043,0.057019,0.067165,0.162684,0.158637,0.0768936,0.0680095,0.0427583,0.082464,0.734389,0.762396,1.49168,1.45334,0.912308,1.01803,0.482785,0.633365,1.31903,1.31813,0.0877218,-0.0586826,-0.887494,-0.845621,-0.201041,-0.316484,-1.6018,-1.78782,1.4504,1.89558,0.240206,0.379603
8733,0.145623,0.111686,0.0426489,0.0210166,0.0958133,0.126268,0.943586,0.909795,0.540577,0.631562,0.609925,0.61885,0.66673,0.660953,0.631506,0.621207,0.778534,0.819222,0.775178,0.804271,1.08826,1.04963,-1.85252,-1.74998,-0.517302,-0.370313,-0.395975,-0.389543,0.191786,0.0891023,1.60513,1.64787,-1.39951,-1.42371,1.24925,1.06139,0.407024,0.848183,1.02249,1.15596
8734,0.648172,0.613815,0.28746,0.307225,0.730748,0.760039,0.497112,0.5018,0.734561,0.752354,0.351425,0.360862,0.313476,0.305806,0.20861,0.199252,0.107823,0.148344,0.0876191,0.117117,-0.191379,-0.231961,-0.148813,-0.0523522,1.46038,1.59874,1.44581,1.45287,0.384063,0.236887,1.26759,1.30945,-0.855375,-0.886621,-0.574441,-0.760337,-0.164888,0.269713,-0.980308,-0.846607
8735,0.292994,0.258516,0.703239,0.593433,0.414197,0.44551,0.127598,0.0938059,0.781284,0.873145,0.839643,0.848006,0.825321,0.816624,0.198025,0.189257,0.531612,0.48654,0.637345,0.666052,-1.20961,-1.25387,0.274277,0.451931,0.690738,0.828043,-0.0799758,-0.0786155,0.305756,0.161455,0.168803,0.213534,-0.651039,-0.660796,-0.279332,-0.461048,2.11514,2.54616,-0.902272,-0.765931
8736,0.713751,0.681608,0.901274,0.879642,0.575331,0.612229,0.464277,0.432388,0.430555,0.593107,0.406055,0.504604,0.576025,0.653921,0.437569,0.429095,0.786497,0.824736,0.155853,0.18549,1.2645,1.21999,0.866909,0.956214,0.140022,0.27722,1.67762,1.68351,-1.31912,-1.46168,2.53559,2.57488,-0.402185,-0.434972,0.270222,0.0851414,-0.862338,-0.440376,1.14922,1.28803
8737,0.054191,0.0198991,0.903634,0.7917,0.74951,0.778949,0.127689,0.0949721,0.21929,0.313068,0.151387,0.161202,0.49954,0.491219,0.986561,0.976909,0.437286,0.472272,0.355679,0.382784,2.2627,2.22219,-0.141409,-0.0550334,2.00694,2.13924,-0.865323,-0.865596,-0.976622,-1.11937,-1.1685,-1.132,0.385195,0.34873,-1.23425,-1.42285,0.350015,0.768341,-0.0263902,0.113606
8738,0.175616,0.140117,0.724974,0.703758,0.422197,0.449203,0.52375,0.488519,0.239115,0.368937,0.515089,0.485845,0.000852931,-0.0098203,0.00760521,-0.000508371,0.0812209,0.119807,0.140062,0.167484,0.177261,0.0770746,-0.626875,-0.541441,-0.0219574,0.110844,-0.63122,-0.637107,-0.184477,-0.331182,-0.884397,-0.842757,1.61365,1.57991,-0.320388,-0.510406,-1.17863,-0.766072,0.826202,0.965261
8739,0.0551022,0.0214511,0.874412,0.852763,0.899004,0.927386,0.132912,0.0967445,0.325878,0.424807,0.799413,0.810489,0.978879,0.967859,0.574373,0.567002,0.0890749,0.129829,0.393459,0.509154,-2.02753,-2.06804,-0.450627,-0.370173,1.49754,1.62696,-0.048327,-0.0604931,-0.857584,-0.921554,0.233863,0.275939,1.26771,1.22714,-0.373108,-0.563493,-1.26019,-0.849231,-0.112536,0.0212964
8740,0.292522,0.307256,0.344908,0.325351,0.209897,0.238435,0.580413,0.544974,0.385587,0.480676,0.0228754,0.034717,0.266038,0.25561,0.308182,0.299946,0.779065,0.821382,0.824863,0.850824,1.47654,1.43337,-1.20342,-1.11857,-0.956554,-0.821414,0.120196,0.104522,-1.36165,-1.51193,0.844835,0.890154,0.427142,0.383643,0.0496704,-0.140286,-0.131898,0.281047,-1.46075,-1.32061
8741,0.513002,0.59306,0.272858,0.251438,0.901272,0.928493,0.402319,0.367308,0.813256,0.90896,0.385889,0.448289,0.907393,0.896896,0.444498,0.435504,0.589429,0.634293,0.0307238,0.0552435,-0.400002,-0.450557,-0.944278,-0.855352,0.0259989,0.24841,-0.5743,-0.593346,-0.505512,-0.662981,0.107062,0.148085,0.065798,0.0164659,-0.0757352,-0.269083,-0.315878,0.103474,-0.430164,-0.247481
8742,0.912716,0.878864,0.562622,0.563797,0.0343259,0.061982,0.616472,0.521273,0.689753,0.77587,0.849585,0.861861,0.63184,0.621304,0.00323526,-0.00607466,0.730896,0.774271,0.390971,0.42672,-0.853854,-0.898967,-1.65798,-1.57154,1.18309,1.31823,-1.53286,-1.55641,-0.753425,-0.906893,0.313356,0.290464,0.175894,0.124763,0.450621,0.261984,-1.58009,-1.1606,0.685509,0.825647
8743,0.173941,0.139264,0.895624,0.876155,0.897286,0.924142,0.821793,0.675239,0.544322,0.642779,0.379264,0.391785,0.851007,0.842385,0.196851,0.207753,0.640036,0.684006,0.775198,0.798196,-0.101369,-0.141328,0.485466,0.569486,-0.261811,-0.132474,0.948979,0.924244,0.120125,-0.0278136,0.397785,0.432843,-0.464783,-0.519374,-0.906815,-1.09409,0.682786,1.10128,-0.71861,-0.576969
8744,0.991887,0.957127,0.45372,0.432782,0.630196,0.654801,0.864217,0.829205,0.451133,0.509689,0.166163,0.178004,0.114397,0.104817,0.431262,0.42158,0.994087,1.04033,0.326843,0.351804,-1.2048,-1.23946,-0.554017,-0.472532,-0.394017,-0.267423,-0.125905,-0.147675,0.0457118,-0.103246,1.05473,1.09084,0.849903,0.79218,1.14167,0.96178,0.199745,0.616768,0.644607,0.781688
8745,0.922049,0.885839,0.957189,0.935594,0.681459,0.707365,0.0940094,0.0597996,0.27907,0.376599,0.550234,0.562816,0.21368,0.205253,0.92175,0.912865,0.777457,0.821488,0.767423,0.7911,0.0386252,0.00854434,1.14789,1.22509,0.421333,0.547975,0.296611,0.276719,-0.485703,-0.635284,-0.341561,-0.313125,0.658038,0.596369,1.39911,1.21756,1.10459,1.52805,0.558986,0.697236
8746,0.216348,0.178079,0.177038,0.153681,0.150699,0.178891,0.624798,0.592423,0.797374,0.895531,0.23946,0.253773,0.537324,0.527144,0.458362,0.451457,0.125832,0.171305,0.144764,0.170399,0.0295764,-0.00073575,0.0625968,0.136799,2.02755,2.15793,-0.701675,-0.717226,0.420421,0.274179,0.874505,0.897166,-0.74594,-0.808198,-1.29234,-1.47905,-0.674064,-0.247879,1.13672,1.2779
8747,0.20587,0.138923,0.102671,0.0797673,0.0821012,0.109583,0.126789,0.0949573,0.541903,0.689718,0.616808,0.632662,0.428963,0.417914,0.269884,0.264512,0.150085,0.226181,0.982821,1.00917,-0.463415,-0.499548,-0.0115397,0.062334,-1.26381,-1.1377,-0.768214,-0.783533,-2.01044,-2.15193,0.0222297,0.0477752,-1.34442,-1.40567,0.943603,0.759156,-0.0606959,0.367697,-0.498112,-0.35447
8748,0.142599,0.0997669,0.722312,0.700252,0.911443,0.938436,0.802374,0.771654,0.295602,0.483906,0.70171,0.717839,0.985404,0.974806,0.701056,0.696161,0.237539,0.281056,0.570911,0.597702,-0.316224,-0.356874,-0.644132,-0.577231,-0.396714,-0.277405,0.444952,0.428202,-0.408659,-0.552002,0.298016,0.322102,0.374452,0.320566,0.247269,0.0628901,-0.879889,-0.458349,-1.53735,-1.38857
8749,0.0988799,0.0606107,0.357146,0.335737,0.169059,0.197677,0.401699,0.370041,0.177922,0.278094,0.210574,0.227583,0.359231,0.348439,0.891725,0.88779,0.938727,0.983676,0.932918,0.95783,1.60423,1.56878,2.27686,2.34011,0.193467,0.306024,0.100159,0.0849799,1.65369,1.51325,0.177546,0.196811,-1.37868,-1.43084,0.165299,-0.0112731,-1.42735,-1.00518,1.89055,2.03703
8750,0.287737,0.250991,0.23318,0.279021,0.669468,0.695995,0.547305,0.515085,0.233601,0.335122,0.245413,0.207816,0.588187,0.579413,0.37983,0.37652,0.646213,0.597759,0.91133,0.938323,-0.0324134,-0.0606125,-2.16111,-2.09786,-1.87301,-1.75662,1.20846,1.1871,-1.15181,-1.28975,0.637168,0.658379,0.582041,0.531002,0.106498,-0.0854363,1.02609,1.45058,-0.897623,-0.742818
8751,0.188311,0.153552,0.242927,0.222305,0.461712,0.469738,0.334666,0.303083,0.598541,0.633339,0.170806,0.188049,0.257038,0.249009,0.518979,0.517918,0.166843,0.211842,0.0834182,0.113112,0.294405,0.26708,0.373782,0.442987,-1.15561,-1.03432,-0.469225,-0.521312,1.07799,0.945303,-0.0534079,-0.0381831,0.173553,0.116887,-1.01175,-1.21051,1.56992,1.98924,-0.994455,-0.840582
8752,0.423649,0.323071,0.574471,0.553171,0.21701,0.24348,0.345497,0.316205,0.828879,0.931555,0.602795,0.622174,0.590808,0.599048,0.343078,0.341079,0.600678,0.646741,0.638518,0.569372,-0.798017,-0.831053,0.350958,0.414916,-0.845273,-0.726438,-2.20837,-2.22972,-1.92376,-2.05682,0.876782,0.89628,-2.11253,-2.17214,-1.24639,-1.44636,-1.09973,-0.687653,-1.61635,-1.4665
8753,0.622522,0.49259,0.699117,0.609672,0.558164,0.585432,0.852011,0.824045,0.694293,0.795613,0.0504067,0.0679881,0.959458,0.949088,0.664667,0.662546,0.380716,0.4279,0.998309,1.02563,-1.61575,-1.6524,1.37451,1.44599,0.26783,0.39366,1.00581,0.989959,0.321481,0.195825,-0.308927,-0.289841,-0.973145,-1.03425,0.197543,0.00115018,0.815033,1.22725,-0.680995,-0.566016
8754,0.696717,0.662109,0.690295,0.666174,0.416371,0.443425,0.0384607,0.012392,0.289748,0.391534,0.300481,0.373282,0.612578,0.603864,0.164818,0.161278,0.729991,0.779184,0.311241,0.338479,0.783801,0.742718,0.628992,0.69759,-2.40031,-2.27645,0.222271,0.213585,-0.906842,-1.02806,0.279782,0.293493,1.90521,1.84762,2.38351,2.18154,-0.987107,-0.579132,0.182607,0.334471
8755,0.179549,0.146691,0.565163,0.542283,0.678122,0.70411,0.820205,0.792399,0.518237,0.577045,0.659185,0.678576,0.66132,0.652358,0.475602,0.472469,0.295095,0.344447,0.389588,0.414286,-1.11154,-1.15709,-1.59753,-1.52171,0.49804,0.615939,1.44638,1.44068,1.22088,1.10751,-1.7225,-1.70947,0.553244,0.48928,2.29152,2.08379,-1.01797,-0.615185,0.213101,0.372809
8756,0.969108,0.937771,0.997882,0.976432,0.140019,0.16504,0.506555,0.479297,0.659954,0.762556,0.14956,0.168708,0.189696,0.181253,0.388147,0.497924,0.0668613,0.116313,0.865358,0.88829,0.58799,0.541426,-0.107787,-0.0271623,0.749539,0.862963,-0.460377,-0.472179,-0.389285,-0.498985,-0.383456,-0.377096,0.329038,0.261358,-0.108461,-0.313157,-0.571946,-0.171927,1.65053,1.80845
8757,0.836753,0.804492,0.211816,0.18855,0.744402,0.768599,0.674969,0.649432,0.329702,0.430412,0.58558,0.602833,0.805056,0.797429,0.46683,0.523378,0.216192,0.265703,0.490245,0.512113,-0.611525,-0.662568,0.0732417,0.158423,-2.24966,-2.14132,-0.403268,-0.413793,0.145283,0.0405516,1.2241,1.23184,-0.656825,-0.724442,0.940137,0.738081,0.905443,1.30396,0.965334,1.12302
8758,0.354175,0.400427,0.887815,0.863339,0.292173,0.314605,0.286137,0.344707,0.970462,1.06962,0.469669,0.485448,0.768267,0.759109,0.551966,0.548833,0.0364248,0.0881061,0.565331,0.606264,0.775387,0.72616,-0.868407,-0.789977,-0.328265,-0.21764,3.54377,3.53806,-0.624863,-0.736023,0.514706,0.520463,0.895991,0.829385,-1.761,-1.95853,-0.566811,-0.168571,-0.596809,-0.432755
8759,0.0277093,-0.00363816,0.0431687,0.0181496,0.735052,0.758351,0.0679706,0.0399821,0.0826252,0.181718,0.968422,0.982929,0.127046,0.117235,0.157667,0.157036,0.695935,0.746418,0.809603,0.700414,-3.61355,-3.66706,1.3693,1.44633,0.201095,0.318637,0.799102,0.78847,-0.18998,-0.302875,-0.922044,-0.911957,0.118024,0.0470146,-0.54054,-0.741846,-0.26465,0.208852,-1.13543,-0.970988
8760,0.492493,0.463028,0.975794,0.949495,0.512859,0.536354,0.368815,0.340373,0.357508,0.458315,0.949187,0.964758,0.735283,0.723993,0.711731,0.710234,0.204415,0.256401,0.77305,0.794564,-0.774253,-0.830017,0.127747,0.269346,-0.525604,-0.406963,-0.163657,-0.174592,-0.745172,-0.851651,0.3626,0.37374,0.201319,0.125024,-1.82275,-2.02108,0.185683,0.586275,0.0302685,0.188069
8761,0.0259434,-0.00279264,0.657296,0.537709,0.779442,0.746534,0.94532,0.918252,0.0422647,0.140635,0.0344503,0.0494971,0.533618,0.524335,0.492214,0.577458,0.297832,0.349299,0.685283,0.706611,-0.326467,-0.379561,-0.983838,-0.907643,-0.359799,-0.240461,0.797734,0.789335,-0.658272,-0.769465,-0.0878055,-0.0746059,1.24955,1.16612,0.235946,0.0347915,1.16833,1.55975,0.54975,0.707521
8762,0.318535,0.289433,0.151747,0.125923,0.932841,0.956714,0.93728,0.911469,0.72623,0.826552,0.504269,0.485754,0.120298,0.108326,0.44515,0.444683,0.804499,0.854954,0.225408,0.245752,1.60046,1.54609,1.93958,2.00969,-0.927329,-0.807034,-0.188217,-0.189685,0.0592156,-0.060616,-0.280771,-0.342132,-1.03002,-1.10864,-1.4102,-1.61418,-0.129999,0.215099,0.208435,0.366421
8763,0.205747,0.175391,0.424274,0.47318,0.440926,0.466828,0.221341,0.194402,0.110574,0.212125,0.907897,0.922011,0.569629,0.559575,0.00742357,0.00778709,0.110747,0.158799,0.638053,0.659532,0.566566,0.509943,1.10865,1.18469,0.978202,1.10057,-0.622229,-0.62695,0.104335,-0.00947037,-0.590841,-0.609658,0.750505,0.676449,0.10124,-0.105436,-1.52097,-1.12955,0.278333,0.434645
8764,0.703285,0.671797,0.845596,0.820438,0.300246,0.324821,0.391893,0.307187,0.153206,0.254305,0.422515,0.437293,0.253761,0.243316,0.760889,0.760424,0.402931,0.450097,0.662118,0.681722,1.2155,1.07252,-0.398842,-0.325681,-1.009,-0.881352,0.968333,0.960276,-0.112663,-0.222571,-0.890384,-0.877185,0.121091,0.047671,0.0783795,-0.128701,1.00172,1.39425,-0.864783,-0.709491
8765,0.889484,0.857827,0.0502377,0.0266994,0.490243,0.515175,0.446979,0.419971,0.592898,0.643139,0.628288,0.641499,0.763483,0.754134,0.109873,0.107939,0.181128,0.226644,0.346587,0.365954,1.69088,1.6351,1.16257,1.23446,-0.379947,-0.253122,0.721828,0.708554,-1.01473,-1.17653,-0.0730791,-0.0658996,-1.58445,-1.65762,-1.05348,-1.2679,0.844364,1.23197,-0.259357,-0.0987628
8766,0.531993,0.49816,0.840986,0.818756,0.880896,0.907093,0.845156,0.819319,0.930929,1.03197,0.174904,0.190191,0.912684,0.904558,0.253646,0.249336,0.469688,0.512388,0.81371,0.834911,0.80791,0.752453,-0.331645,-0.260418,0.851858,0.974432,-1.01423,-1.03089,-2.02299,-2.13048,-1.19735,-1.1914,-0.0355796,-0.103794,-0.335977,-0.553294,0.472516,0.855596,-1.74825,-1.59111
8767,0.676865,0.607593,0.579065,0.557662,0.334466,0.362111,0.262333,0.236032,0.251185,0.351787,0.718473,0.731966,0.523203,0.453959,0.921991,0.920378,0.527214,0.529282,0.58906,0.60895,0.320567,0.269903,1.18954,1.2673,0.99218,1.1123,0.116876,0.161845,0.618766,0.50611,-1.25207,-1.25365,0.599091,0.527039,1.15129,0.940591,0.433129,0.865518,1.06371,1.21514
8768,0.818365,0.717026,0.524413,0.408275,0.989207,1.01656,0.37075,0.344923,0.0244354,0.124447,0.28643,0.301247,0.0139385,0.00335914,0.473624,0.561726,0.501546,0.546175,0.112153,0.132838,1.62859,1.57896,0.462125,0.535283,-1.00662,-0.885297,1.37278,1.35458,-1.64744,-1.75231,-0.606742,-0.609618,-0.2306,-0.299005,-0.13727,-0.355271,0.50038,0.875439,0.575877,0.725289
8769,0.861475,0.826458,0.340094,0.258888,0.222525,0.252048,0.683721,0.659747,0.316915,0.416401,0.447229,0.41735,0.387295,0.296296,0.206425,0.203074,0.951678,0.995785,0.445107,0.552312,0.766221,0.712409,0.692315,0.767073,-0.870845,-0.747433,-0.508241,-0.523937,-0.423353,-0.534406,0.335467,0.340214,1.12955,1.05676,-0.56298,-0.774989,-2.74088,-2.36168,1.65564,1.80763
8770,0.786643,0.749746,0.131984,0.109501,0.889137,0.916765,0.584232,0.562196,0.926983,1.02613,0.517144,0.533453,0.600877,0.589232,0.413168,0.410191,0.550803,0.59684,0.95315,0.971785,-0.400356,-0.460061,2.29441,2.37178,-0.139069,-0.00943255,0.931826,0.920628,1.24282,1.12498,-0.83685,-0.828755,-0.746959,-0.818496,-0.298786,-0.503307,0.0321244,0.404373,-0.98411,-0.827788
8771,0.306236,0.268799,0.946572,0.921721,0.0874714,0.11389,0.128332,0.105191,0.879117,0.976359,0.331824,0.408706,0.358909,0.347949,0.833648,0.831549,0.865051,0.911685,0.261417,0.279283,0.0222376,-0.0402099,0.0732362,0.152476,0.0963408,0.221516,-0.947025,-0.957886,-0.95582,-1.07086,-1.031,-1.0287,0.318704,0.293923,-0.53948,-0.739161,1.15099,1.5184,0.384283,0.54441
8772,0.773468,0.735466,0.9403,0.916075,0.434092,0.461188,0.179114,0.154121,0.370208,0.46816,0.154952,0.283959,0.451305,0.44189,0.446087,0.445077,0.694465,0.738421,0.563714,0.581889,0.825911,0.761902,0.0510711,0.124404,1.34275,1.46453,-0.261122,-0.338648,1.23719,1.11576,0.961043,0.963933,1.47749,1.40634,0.394753,0.190151,1.19383,1.56068,0.901627,0.981064
8773,0.79593,0.755903,0.373796,0.349933,0.551693,0.578374,0.70226,0.677045,0.596502,0.693615,0.143436,0.159213,0.936107,0.928631,0.61631,0.616271,0.915505,0.960093,0.280591,0.296447,0.550328,0.480778,-0.541188,-0.470702,-0.396903,-0.28082,0.285684,0.28059,-0.77758,-0.89698,-1.24445,-1.24193,1.08463,1.00813,2.15187,1.94989,0.573644,0.937621,1.2641,1.41772
8774,0.0700798,0.0320124,0.10193,0.079181,0.167939,0.193758,0.142018,0.118805,0.226628,0.324845,0.897567,0.911101,0.270277,0.261859,0.146587,0.145248,0.565239,0.610481,0.541685,0.559476,-1.76775,-1.84148,0.764581,0.838955,-0.731177,-0.616564,0.109199,0.107094,0.17001,0.0442495,1.09961,1.10192,1.53277,1.45503,0.516422,0.318991,0.746895,1.11541,0.971561,1.12372
8775,0.913311,0.873766,0.19938,0.178113,0.00767012,0.0318284,0.353003,0.327931,0.327954,0.423561,0.787692,0.802162,0.200511,0.192841,0.946768,0.943773,0.727544,0.80355,0.437859,0.453771,0.76735,0.696279,-1.34986,-1.2823,0.324942,0.443916,0.261128,0.257851,1.66265,1.53575,-1.67395,-1.66964,-0.144446,-0.21882,0.0459901,-0.146137,-1.37709,-1.00561,-1.23868,-1.08045
8776,0.747812,0.651263,0.642245,0.621902,0.468191,0.51358,0.56282,0.537057,0.829489,0.927459,0.986715,1.00103,0.981947,0.973515,0.937635,0.945676,0.953231,0.996619,0.787395,0.803376,0.582189,0.531017,0.499866,0.569923,-0.216264,-0.0915083,-1.30367,-1.30528,-0.46766,-0.596446,-0.105547,-0.105976,-0.28089,-0.355192,0.71749,0.5226,-0.479102,-0.110558,-0.00839385,0.154988
8777,0.470263,0.42876,0.789628,0.770907,0.971173,0.995331,0.0985084,0.0703995,0.388421,0.484024,0.516951,0.530951,0.629272,0.622885,0.827374,0.947578,0.788413,0.833825,0.120623,0.137131,0.487786,0.365755,2.08816,2.15996,1.36038,1.48889,0.248156,0.252214,0.425392,0.299297,0.878755,0.87354,0.726491,0.578526,-0.428225,-0.616598,1.18124,1.55332,0.32995,0.492643
8778,0.838401,0.796519,0.164025,0.145355,0.230909,0.254572,0.0949171,0.153194,0.946894,1.04329,0.870153,0.886239,0.77929,0.773309,0.950683,0.949481,0.384757,0.428716,0.22325,0.334184,0.271167,0.200493,0.660381,0.725951,-0.621236,-0.493034,-0.769912,-0.772335,1.54293,1.42234,0.140078,0.131471,1.5817,1.51224,0.320449,0.12748,1.27091,1.64133,-0.570227,-0.405148
8779,0.28042,0.240354,0.414218,0.444302,0.460226,0.484223,0.263723,0.235988,0.420714,0.514832,0.965125,0.981475,0.242409,0.236528,0.337676,0.338621,0.27618,0.270143,0.513032,0.531238,1.04868,0.972322,1.11615,1.18777,-0.707951,-0.586302,-0.62378,-0.668026,0.266663,0.152924,0.422015,0.405798,-0.210646,-0.286608,-1.70875,-1.89472,0.179436,0.550377,-0.481801,-0.324958
8780,0.685855,0.569678,0.761376,0.743249,0.125317,0.149563,0.520491,0.491148,0.564538,0.727181,0.494625,0.587079,0.28316,0.27914,0.0402049,0.0416869,0.0686924,0.11157,0.992663,1.01024,0.838617,0.766868,1.29063,1.35904,1.89388,2.01749,-0.564804,-0.563718,1.23699,1.12618,-0.189407,-0.198135,1.20169,1.13184,0.21966,0.0379435,0.409223,0.775604,-0.404514,-0.244767
8781,0.940622,0.899003,0.455559,0.51638,0.151193,0.176849,0.339446,0.309181,0.84397,0.939529,0.175061,0.192684,0.978643,0.976388,0.391794,0.394039,0.861201,0.904201,0.0346909,0.0505409,-0.629809,-0.697107,-0.0849703,-0.0112045,-1.37721,-1.25873,0.995602,0.993776,-0.71801,-0.824479,-1.13313,-1.14121,0.715459,0.64031,0.198934,0.0146782,-2.48849,-2.11519,-1.31613,-1.15851
8782,0.689138,0.646085,0.306377,0.28951,0.412246,0.493413,0.41446,0.382282,0.403508,0.501022,0.650556,0.669998,0.239425,0.238821,0.184985,0.18716,0.860352,0.904253,0.160203,0.17653,0.636617,0.567149,-0.496955,-0.421685,-0.322344,-0.19825,-0.452221,-0.447968,-0.170339,-0.284942,-0.18339,-0.191381,-1.61296,-1.68358,-2.20826,-2.39943,0.0737472,0.439159,0.0531895,0.213688
8783,0.0203608,-0.0201707,0.61936,0.600625,0.784114,0.809978,0.870639,0.839967,0.289864,0.389391,0.77298,0.789616,0.626572,0.625573,0.262015,0.263576,0.208803,0.25407,0.791806,0.80606,-0.810385,-0.881414,-1.18485,-1.10793,-0.588242,-0.457061,0.199957,0.207031,0.678762,0.564004,-0.402602,-0.407026,-1.74532,-1.81995,0.435057,0.245243,-0.280599,0.0773237,-0.131239,0.0960366
8784,0.125399,0.0555392,0.263968,0.246443,0.427835,0.456246,0.13967,0.106944,0.735042,0.833188,0.103084,0.119167,0.21986,0.219486,0.750074,0.750472,0.28454,0.327728,0.780928,0.79582,0.0872461,0.0137016,2.07049,2.1445,-0.492054,-0.366849,1.13981,1.14042,1.03471,0.92235,-2.33689,-2.34518,-0.450111,-0.474428,0.949068,0.760237,-2.54094,-2.18876,-0.176746,-0.0216146
8785,0.174279,0.131249,0.526683,0.507673,0.776335,0.803545,0.928226,0.89696,0.27283,0.369468,0.126844,0.127387,0.856354,0.856074,0.954534,0.866613,0.923452,0.964962,0.478581,0.494892,-0.103389,-0.231457,0.539745,0.617348,0.022338,0.154181,-0.0649582,-0.0702919,0.35173,0.153836,0.629467,0.622511,0.952798,0.871096,-0.0433995,-0.226087,1.16751,1.51506,0.171281,0.333868
8786,0.805051,0.761931,0.78796,0.768902,0.754919,0.779768,0.364769,0.333224,0.958935,1.05539,0.135404,0.135607,0.200465,0.198626,0.982538,0.982753,0.459599,0.500077,0.933057,0.949352,-0.395363,-0.476615,1.38616,1.46249,-0.998895,-0.865417,-0.927596,-0.925994,-0.499138,-0.614678,-0.197627,-0.211859,-0.348102,-0.425858,-0.248062,-0.431135,0.721459,1.07516,0.540974,0.68935
8787,0.580826,0.583756,0.322631,0.305539,0.948941,0.975093,0.704838,0.577081,0.0579057,0.155417,0.127329,0.143827,0.0118164,0.00964251,0.620213,0.71496,0.858478,0.901015,0.784184,0.798992,-0.0535942,-0.134895,0.706981,0.776243,0.59639,0.730028,0.412092,0.408342,0.928097,0.816773,0.362313,0.340638,-0.144057,-0.206366,-1.48362,-1.66296,-0.921863,-0.568851,-0.164538,-0.0126589
8788,0.446991,0.40558,0.823799,0.808351,0.49829,0.526023,0.851162,0.820937,0.552294,0.585633,0.904043,0.920948,0.0399864,0.0374539,0.446833,0.447168,0.269904,0.311966,0.140194,0.152832,-2.1225,-2.20802,2.11735,2.19406,-0.0584995,0.068035,1.23687,1.23181,0.15595,0.0401982,0.521646,0.491174,0.091418,0.0131255,0.5857,0.4082,1.12314,1.48177,-0.418543,-0.261949
8789,0.995503,0.951977,0.264741,0.251369,0.262099,0.287658,0.155806,0.123782,0.917427,1.01585,0.777682,0.726841,0.655516,0.65363,0.409046,0.460419,0.613265,0.652688,0.700617,0.711706,0.514456,0.429307,0.891383,0.96629,0.103199,0.234537,-0.940072,-0.949703,-1.02527,-1.1359,2.73661,2.70903,0.944629,0.869869,0.415451,0.234429,0.77163,1.13383,-0.0142735,0.134785
8790,0.172431,0.129257,0.445442,0.430057,0.438295,0.466858,0.221008,0.187476,0.412208,0.564213,0.51677,0.532735,0.00887239,0.00545451,0.473583,0.47367,0.61977,0.658129,0.823541,0.833155,1.49285,1.40056,0.103405,0.171619,-0.367656,-0.237946,-0.164436,-0.171417,1.30982,1.20265,0.583332,0.52483,-0.450649,-0.518798,-0.250945,-0.432831,-1.69524,-1.33769,0.756354,0.911139
8791,0.321472,0.279348,0.828217,0.814823,0.620342,0.646058,0.625061,0.591958,0.0144094,0.112578,0.00974854,0.0273614,0.964197,0.96018,0.956488,0.9557,0.0958002,0.134063,0.708049,0.776952,0.512862,0.426974,-0.083344,-0.00974707,-0.222842,-0.100082,-0.283545,-0.297692,-0.0400002,-0.146155,-1.63178,-1.65937,-1.47077,-1.53547,0.161912,-0.0248703,-0.624025,-0.269208,-0.490372,-0.337997
8792,0.881098,0.840601,0.424018,0.411169,0.218671,0.245945,0.643475,0.609875,0.498578,0.595106,0.627967,0.64812,0.10753,0.104502,0.0319516,0.0297959,0.208216,0.325402,0.710657,0.72075,0.425826,0.367271,-0.926637,-0.851764,-0.462909,-0.344564,-0.0736068,-0.0870492,-0.0570317,-0.156583,1.13282,1.10267,0.0917072,0.0318993,-0.123019,-0.305829,0.754747,1.11412,0.475721,0.621514
8793,0.403846,0.364952,0.539783,0.500755,0.552206,0.577948,0.0314644,-0.00313751,0.238795,0.332802,0.917245,0.937287,0.100926,0.0970748,0.206942,0.232336,0.472874,0.516741,0.81062,0.821162,0.393242,0.307569,-2.05076,-1.97173,0.249479,0.362221,-0.17584,-0.182839,0.209565,0.108935,-0.722519,-0.745302,0.831136,0.768963,0.00616205,-0.173908,0.880454,1.24714,0.467287,0.614135
8794,0.255244,0.21681,0.602136,0.59034,0.114213,0.138725,0.187583,0.151494,0.352818,0.446925,0.999594,1.01811,0.723796,0.718598,0.465396,0.434877,0.671256,0.708081,0.285151,0.295173,-0.958871,-1.04778,0.436315,0.518907,-0.192434,-0.0791952,1.4954,1.48337,0.103547,0.00228746,1.91532,1.89593,2.189,2.12473,-0.141407,-0.319308,-0.554868,-0.192218,0.230048,0.379987
8795,0.687537,0.649773,0.0982641,0.0869419,0.22402,0.250519,0.998231,0.962838,0.705415,0.722109,0.477231,0.493853,0.652166,0.644813,0.552842,0.637417,0.471741,0.510597,0.289158,0.300486,0.101904,0.0141072,-1.04104,-0.961283,1.11228,1.22387,0.965582,0.955272,-0.936481,-1.03673,-1.33548,-1.35648,-0.655367,-0.713781,-0.285911,-0.464707,-1.5718,-1.20865,1.16747,1.32491
8796,0.71984,0.680204,0.402883,0.393401,0.597767,0.623305,0.801922,0.765427,0.902559,0.997293,0.682808,0.698058,0.908499,0.901413,0.842114,0.839958,0.649902,0.720897,0.613288,0.628601,1.87199,1.78975,0.880302,0.954238,1.02103,1.1306,-0.500223,-0.51593,-0.489432,-0.588958,-1.75743,-1.77281,-0.344524,-0.468098,0.547492,0.304895,0.190547,0.548583,-0.163512,-0.000740148
8797,0.431899,0.357957,0.238649,0.230191,0.528551,0.553997,0.262403,0.227339,0.62984,0.725288,0.00670849,0.0225083,0.588671,0.580846,0.356514,0.35379,0.891318,0.931198,0.945145,0.956716,-0.480028,-0.562689,-0.952319,-0.872837,-1.39333,-1.28488,-0.749733,-0.767652,0.44384,0.336688,-0.315545,-0.307168,-0.169272,-0.222415,1.2498,1.0745,0.660245,1.02356,1.09507,1.26532
8798,0.0753575,0.0357111,0.285608,0.278423,0.195041,0.219336,0.754875,0.72068,0.013051,0.110861,0.36035,0.377797,0.876777,0.867391,0.388291,0.384004,0.44665,0.486621,0.648483,0.661309,3.05151,2.96083,-2.21299,-2.13151,0.160591,0.261047,0.03057,0.0106344,0.180471,0.0758282,1.17006,1.15848,0.423565,0.37728,-0.763512,-0.932751,-0.260291,0.10204,-0.856977,-0.692264
8799,0.454345,0.413787,0.335428,0.326655,0.157702,0.180517,0.042908,0.0077891,0.678472,0.776106,0.0875393,0.104874,0.0283951,0.0172763,0.203051,0.260955,0.643015,0.644335,0.819227,0.833481,-0.450967,-0.549415,0.181863,0.266489,0.834866,0.937688,-0.784404,-0.796944,0.296696,0.187522,-0.629616,-0.642818,0.775804,0.731133,2.20112,2.02749,-1.68605,-1.32108,1.35712,1.51866
8800,0.28174,0.241789,0.945866,0.936988,0.503017,0.527815,0.863608,0.829482,0.0359325,0.131834,0.242733,0.259664,0.741484,0.730451,0.0909919,0.137905,0.760718,0.802048,0.754244,0.769206,0.544726,0.452791,0.243837,0.329179,0.77,0.892432,0.725871,0.711442,-0.144274,-0.256051,-0.666333,-0.675538,-0.0543415,-0.0379504,-0.451247,-0.63,-0.00351811,0.360108,-0.0555808,0.101294
8801,0.72637,0.684467,0.0371401,0.0266858,0.479858,0.504038,0.11003,0.0768203,0.33936,0.434598,0.0797974,0.159528,0.316191,0.393188,0.019142,0.0148555,0.341975,0.383183,0.225985,0.243218,1.32678,1.23967,1.67291,1.76153,0.653698,0.847176,-0.605719,-0.621203,2.4012,2.2809,-0.0201658,-0.0315021,-0.763154,-0.807034,-0.98127,-1.15625,1.32837,1.696,-0.299764,-0.147996
8802,0.908354,0.864992,0.150685,0.139978,0.223039,0.275094,0.399975,0.367273,0.0896007,0.182706,0.042224,0.0593912,0.065037,0.0559246,0.617931,0.613145,0.157162,0.233183,0.16868,0.184881,0.646085,0.557657,-0.0789741,0.0156177,0.699098,0.80192,0.304622,0.282242,0.645181,0.598532,1.41515,1.40698,0.533513,0.486213,1.22636,1.05285,-1.24917,-0.876638,-1.4095,-1.26213
8803,0.787822,0.746326,0.875478,0.866008,0.0234132,0.0461495,0.207464,0.175674,0.623373,0.716468,0.634232,0.650037,0.197344,0.125721,0.033335,0.0280923,0.0418319,0.0831833,0.831903,0.848225,-1.18604,-1.27766,0.109261,0.201203,1.42921,1.52422,-0.460338,-0.479638,-0.963539,-1.08384,1.74016,1.72727,-1.04874,-1.094,-1.01323,-1.18468,-0.63355,-0.261062,-1.7555,-1.60323
8804,0.0365523,-0.00442088,0.903217,0.894457,0.798962,0.824363,0.338072,0.328064,0.859279,0.952328,0.961661,0.975174,0.204505,0.195518,0.190981,0.18549,0.112881,0.156841,0.627939,0.660565,0.707447,0.619088,-0.0390516,0.0515127,0.362579,0.458367,-0.448192,-0.563086,0.178177,0.0569016,0.877486,0.862886,-1.1342,-1.18332,0.531401,0.356269,0.509358,0.884762,-0.560463,-0.412006
8805,0.00540434,-0.0357036,0.644387,0.641958,0.383142,0.409938,0.512855,0.480454,0.103567,0.194727,0.27126,0.285075,0.880515,0.873009,0.969324,0.963283,0.873309,0.918385,0.488358,0.472904,0.866724,0.726974,1.54964,1.64155,1.02221,1.11769,-0.624109,-0.646534,1.11042,0.982548,1.12028,1.10713,0.0963195,0.0478659,0.730784,0.549818,-0.433985,-0.0548309,0.0812111,0.229899
8806,0.527836,0.486256,0.292578,0.389459,0.716044,0.658214,0.363148,0.332721,0.710452,0.799863,0.995869,1.01094,0.440094,0.432274,0.0203205,0.0162746,0.508106,0.55408,0.270191,0.285243,0.924251,0.834859,-0.900285,-0.799893,1.12867,1.22419,-0.84908,-0.865905,1.50405,1.37095,-0.944174,-0.958029,-0.210719,-0.257213,-0.692127,-0.866777,-0.735749,-0.355578,-2.30222,-2.15521
8807,0.760967,0.718105,0.144364,0.13696,0.881298,0.906489,0.965613,0.935479,0.963335,1.05138,0.673743,0.687713,0.71071,0.70347,0.452163,0.400361,0.891587,0.93983,0.632378,0.598054,-1.504,-1.59882,-0.183845,-0.0778171,-0.728481,-0.632851,0.706925,0.691589,0.780563,0.638138,1.03142,1.01945,1.2662,1.22226,0.652081,0.47269,-1.53469,-1.15114,-0.216452,-0.069036
8808,0.321707,0.277597,0.410474,0.402928,0.159442,0.185493,0.186783,0.155755,0.143002,0.228761,0.667896,0.704237,0.730111,0.721258,0.787207,0.784448,0.0310326,0.0805392,0.89762,0.910865,2.04453,1.94971,0.159755,0.263157,-1.00104,-0.906587,0.605948,0.595799,-1.5922,-1.73319,-0.455325,-0.384199,-0.925591,-0.966917,-1.15452,-1.33403,-1.58366,-1.20426,-0.778354,-0.635621
8809,0.895041,0.849058,0.381892,0.372682,0.974565,1.00058,0.301831,0.270208,0.320377,0.514117,0.708917,0.720761,0.309419,0.300236,0.0997399,0.0974102,0.378913,0.426915,0.555313,0.524174,-0.771376,-0.874113,-0.027348,0.0817912,1.46563,1.56887,-1.70336,-1.71695,0.365008,0.222064,-1.77589,-1.78785,-1.42402,-1.45845,-0.222149,-0.404717,1.72613,2.10098,2.12336,2.26097
8810,0.644436,0.600333,0.604042,0.595543,0.532391,0.562167,0.10197,0.0678974,0.628574,0.799473,0.202842,0.215388,0.697726,0.627867,0.794775,0.793853,0.287455,0.357534,0.125499,0.137484,-0.434867,-0.532393,0.511212,0.620722,0.84972,1.04438,2.56456,2.55639,-0.141992,-0.356505,-0.191104,-0.208042,-0.65611,-0.691352,-1.29076,-1.46705,-1.47366,-1.10215,0.352577,0.491971
8811,0.0941347,0.0491974,0.616298,0.609702,0.0985903,0.123753,0.66619,0.631241,0.997851,1.08483,0.060083,0.0717796,0.96698,0.955498,0.801368,0.799508,0.239522,0.288153,0.872398,0.885749,0.815234,0.715612,-0.590585,-0.48374,0.421205,0.519893,0.164518,0.160576,-0.796282,-0.935073,-0.294566,-0.315424,0.849127,0.816799,0.511872,0.338203,1.48023,1.84912,0.498792,0.634028
8812,0.442023,0.396193,0.180769,0.171948,0.753451,0.778201,0.0868692,0.0526272,0.236473,0.320893,0.155995,0.167015,0.0578833,0.0454617,0.406593,0.403002,0.917092,0.966007,0.904151,0.891134,0.0727932,-0.0265187,0.73346,0.840452,1.09548,1.19653,0.33066,0.325591,-0.796023,-0.929236,0.641938,0.619039,-0.851404,-0.888492,1.05866,0.884393,1.02078,1.31417,1.37047,1.5029
8813,0.305995,0.194098,0.980988,0.9735,0.543416,0.570422,0.684101,0.649472,0.365467,0.391847,0.594964,0.605372,0.605361,0.591727,0.88453,0.879527,0.963035,1.00948,0.881462,0.89652,-1.39248,-1.49049,0.689071,0.795686,-2.51624,-2.40906,0.934112,0.932485,0.614825,0.486162,0.575685,0.509865,-0.134814,-0.166647,-0.11752,-0.344819,0.415615,0.779212,0.0597038,0.191957
8814,0.0398636,-0.00799775,0.284039,0.278269,0.735039,0.760776,0.269051,0.232703,0.3782,0.462801,0.820988,0.803019,0.68115,0.665862,0.349033,0.34343,0.653659,0.700419,0.523774,0.496307,-1.82132,-1.92485,1.02859,1.17029,0.832848,0.930549,0.235304,0.234617,-2.25804,-2.38287,0.428602,0.40069,-0.241139,-0.272188,-1.39976,-1.57403,-0.124634,0.244257,-0.126988,0.00266795
8815,0.693867,0.648396,0.467052,0.46173,0.545319,0.56874,0.321792,0.349761,0.967872,1.05277,0.990636,1.00067,0.472754,0.455493,0.364438,0.359249,0.770405,0.814983,0.0810348,0.0960935,0.514688,0.404196,1.43049,1.54489,-1.69076,-1.59278,0.870809,0.780558,0.476582,0.358174,-1.10162,-1.12339,1.93396,1.90023,-0.188673,-0.357349,-0.0317412,0.317925,0.528546,0.659721
8816,0.923933,0.880245,0.12574,0.121692,0.772496,0.794341,0.501588,0.466819,0.0478034,0.130792,0.896601,0.863377,0.625994,0.630376,0.136079,0.132288,0.0166597,0.062078,0.511261,0.539673,-1.77191,-1.88629,-0.824682,-0.705556,-0.935132,-0.839606,1.325,1.3265,-0.713197,-0.830184,1.27519,1.25355,0.729474,0.698049,-2.30107,-2.47396,0.0228715,0.391593,-0.386065,-0.254022
8817,0.0182115,-0.0256673,0.388973,0.259766,0.463012,0.538662,0.194671,0.159034,0.189698,0.199154,0.719168,0.726088,0.82321,0.80526,0.787035,0.781775,0.233716,0.325603,0.968195,0.983253,0.0129935,-0.0961697,0.17701,0.294114,-0.470768,-0.314169,-0.384549,-0.381173,0.583978,0.46333,-0.099684,-0.120388,0.0699771,0.0393798,0.731844,0.561451,-0.527011,-0.155237,0.964321,1.10464
8818,0.01418,-0.0303099,0.472934,0.397841,0.262422,0.282983,0.830373,0.796376,0.18697,0.267516,0.792309,0.797136,0.471342,0.480267,0.565387,0.559364,0.542198,0.589127,0.710837,0.671135,0.574468,0.460825,-0.0950222,-0.0284541,0.114245,0.211267,-0.731428,-0.65257,-0.798413,-0.915919,0.223248,0.199902,-1.76604,-1.79021,-1.46356,-1.63913,0.0371358,0.483336,0.516187,0.575019
8819,0.302645,0.256537,0.62316,0.535916,0.519216,0.543121,0.44706,0.448696,0.635495,0.715718,0.433996,0.439571,0.170681,0.155275,0.699348,0.694921,0.280218,0.324269,0.345229,0.359017,-0.123747,-0.235796,-0.468125,-0.351022,0.957843,1.05776,-0.932796,-0.923966,1.94352,1.82513,1.11067,1.08825,0.5522,0.528803,-0.157928,-0.330138,0.756673,1.12191,-0.0969049,0.045403
8820,0.912901,0.866403,0.679499,0.673991,0.782887,0.803259,0.135321,0.101016,0.320951,0.403025,0.450394,0.456265,0.695042,0.67757,0.474224,0.491012,0.481809,0.524747,0.383338,0.395735,0.0530643,-0.0622615,0.151048,0.264895,-0.607856,-0.514523,-1.6042,-1.59119,0.0504634,-0.0603048,-0.287626,-0.315717,-0.62592,-0.643577,-0.359233,-0.535187,0.947396,1.31447,0.495947,0.63964
8821,0.606327,0.479407,0.496144,0.489741,0.238616,0.258277,0.469858,0.43477,0.398156,0.481774,0.0829661,0.088857,0.674454,0.668156,0.2925,0.287102,0.0733451,0.115832,0.109901,0.120075,-0.263147,-0.373793,0.0299298,0.144409,1.57199,1.66467,1.05623,1.07419,0.157522,0.0513886,-0.263359,-0.28544,-0.61843,-0.592633,0.946731,0.773802,2.31973,2.68255,-1.35083,-1.20934
8822,0.140814,0.0924121,0.746667,0.741423,0.361722,0.379424,0.31754,0.282649,0.167537,0.250211,0.546144,0.551807,0.675602,0.658741,0.585871,0.483339,0.646065,0.69056,0.690354,0.699409,0.374348,0.260887,0.869925,0.989546,-0.255264,-0.162139,-0.759291,-0.743633,-0.689225,-0.789681,0.825171,0.801804,-0.527979,-0.541688,0.389064,0.216851,-0.564269,-0.208245,0.196859,0.331944
8823,0.492287,0.443744,0.356088,0.407862,0.195944,0.213277,0.942756,0.909816,0.325869,0.409385,0.344728,0.353037,0.333448,0.397015,0.756678,0.679577,0.104512,0.150957,0.50787,0.51907,0.164171,-0.0415037,-0.621335,-0.505335,-1.02848,-0.932837,-2.35539,-2.33998,-0.629371,-0.722572,0.925722,0.908591,-0.16742,-0.187835,0.0508812,-0.125614,0.201706,0.561357,-0.791202,-0.657004
8824,0.843479,0.795077,0.0775613,0.074301,0.569396,0.586063,0.535361,0.502791,0.757014,0.84193,0.40601,0.41459,0.152876,0.135289,0.878838,0.875815,0.882939,0.927969,0.716232,0.725966,-0.238372,-0.343895,2.04142,2.1525,-0.116828,-0.0257157,2.22434,2.23976,0.577393,0.479761,-0.447171,-0.465352,1.24586,1.23062,1.68288,1.50796,-0.899162,-0.545915,-1.40591,-1.2695
8825,0.509646,0.459925,0.106584,0.10275,0.117822,0.13207,0.867749,0.836546,0.963616,1.04715,0.0019216,0.0084469,0.950973,0.935031,0.13207,0.13007,0.489241,0.533766,0.00731685,0.0181021,1.80838,1.70805,1.73558,1.84633,-0.224751,-0.132224,-2.50744,-2.49542,0.797236,0.699702,1.00392,0.98647,-1.33462,-1.34813,0.870475,0.690287,0.783337,1.13528,0.786938,0.926542
8826,0.403023,0.436933,0.392746,0.389194,0.961884,0.974522,0.0495644,0.019614,0.849579,0.906875,0.573476,0.579499,0.424171,0.408205,0.400372,0.489606,0.495308,0.539208,0.272914,0.202726,-0.172222,-0.269896,-0.843279,-0.724408,0.256818,0.342693,1.68717,1.69918,0.0596834,-0.0331074,0.909521,0.893401,-1.02742,-1.07101,-0.380766,-0.556491,0.301638,0.650763,-0.0962573,0.0430342
8827,0.401325,0.413941,0.465648,0.46286,0.0688215,0.0819224,0.277003,0.244584,0.683064,0.766599,0.717095,0.724484,0.885119,0.869514,0.850222,0.849143,0.194539,0.24004,0.379388,0.38735,-0.570274,-0.582733,1.3783,1.49829,-1.62628,-1.54361,0.481392,0.488472,-0.0869294,-0.184209,0.206453,0.196839,-0.786819,-0.793884,0.154864,0.0388291,0.83024,1.17322,1.06058,1.20209
8828,0.44157,0.390949,0.210036,0.206806,0.923737,0.938581,0.706458,0.673268,0.874115,0.956585,0.540383,0.547187,0.318796,0.302102,0.703856,0.702219,0.305655,0.462729,0.0925279,0.101908,-0.802131,-0.895571,-0.104449,0.0180991,1.46484,1.54584,0.702876,0.716961,-1.11611,-1.20821,1.42664,1.42111,-0.0600967,-0.0720379,0.809876,0.63415,0.442579,0.781853,1.98807,2.13015
8829,0.524493,0.471596,0.484992,0.505752,0.857527,0.87354,0.328718,0.321318,0.436242,0.591726,0.782899,0.694728,0.318808,0.300382,0.311404,0.310422,0.568508,0.685419,0.311856,0.319287,-0.561484,-0.660756,-0.531416,-0.406406,-1.25938,-1.17561,-0.240322,-0.232714,0.277388,0.192319,0.422068,0.417411,0.00718663,-0.0574934,-1.94924,-2.12651,1.92169,2.25774,-0.663133,-0.526769
8830,0.197261,0.146196,0.808382,0.804699,0.329457,0.345066,0.00430817,-0.0306323,0.145958,0.226866,0.835004,0.84227,0.00537911,-0.0113032,0.933068,0.930536,0.863735,0.908109,0.882268,0.887683,0.465613,0.370094,0.855498,0.979947,-1.50611,-1.42009,0.517207,0.530571,1.93977,1.8517,0.404421,0.401641,-0.0354202,-0.042949,0.257503,0.0825946,1.11794,1.44837,0.707619,0.845429
8831,0.966141,0.916674,0.158912,0.154176,0.454103,0.471277,0.179933,0.144421,0.69438,0.775577,0.562143,0.525574,0.994314,0.978253,0.385794,0.385013,0.298566,0.342592,0.765193,0.771891,-1.18157,-1.27755,-0.634448,-0.514934,-1.3893,-1.29927,-1.04184,-1.03256,0.533101,0.44352,-0.0876118,-0.0915585,-1.70867,-1.7168,-0.0868326,-0.259871,1.43272,1.76695,-1.00193,-0.864627
8832,0.464087,0.415545,0.756537,0.750481,0.920694,0.93986,0.974469,0.938572,0.0747245,0.156185,0.202158,0.208878,0.224671,0.20776,0.401095,0.400833,0.855578,0.897806,0.004017,0.00878675,-0.714712,-0.926142,-1.22889,-1.11004,0.23068,0.326875,0.666277,0.679073,0.490998,0.401214,-0.219227,-0.189343,0.507945,0.501902,-0.640865,-0.816821,-0.3957,-0.0570737,-2.18398,-2.05363
8833,0.945049,0.89686,0.128511,0.120152,0.532257,0.55038,0.740213,0.608039,0.19748,0.280581,0.758416,0.765158,0.0836242,0.153862,0.935295,0.933416,0.0452493,0.089423,0.494839,0.498257,-0.425062,-0.574732,1.29039,1.41542,0.280028,0.421766,1.2517,1.27119,0.165348,0.08001,-0.289335,-0.287128,1.8548,1.84355,-0.0349334,-0.210359,-1.06759,-0.728026,0.339274,0.477285
8834,0.903915,0.921265,0.982898,0.973581,0.768689,0.785751,0.314939,0.277507,0.111797,0.194829,0.319823,0.407541,0.114464,0.0999651,0.734216,0.698459,0.234764,0.279918,0.13728,0.142471,-0.127343,-0.223321,-0.346681,-0.220793,0.425942,0.516657,-0.648577,-0.626621,0.816425,0.727819,1.69872,1.7055,1.76097,1.75423,-1.36133,-1.5361,0.759672,1.09406,-0.201143,-0.0609473
8835,0.990892,0.94567,0.533057,0.525125,0.470305,0.486568,0.763312,0.725737,0.974272,1.0557,0.0436596,0.049924,0.39557,0.436807,0.463077,0.463502,0.942929,0.987026,0.378104,0.381218,-0.180682,-0.277494,0.892765,1.01376,0.979569,1.06862,-1.6693,-1.65117,-0.714525,-0.803328,1.07552,1.08522,0.913056,0.910734,-0.616784,-0.725152,0.348066,0.686232,2.39279,2.52878
8836,0.477127,0.430251,0.982201,0.973371,0.889203,0.904796,0.396038,0.358928,0.342195,0.425888,0.901281,0.905634,0.789843,0.77365,0.585952,0.584801,0.168751,0.212662,0.142505,0.145539,-1.47421,-1.57422,-1.18456,-1.0634,0.504894,0.56948,1.94154,1.95967,1.41021,1.31469,-0.398585,-0.395645,-1.54465,-1.55268,0.266714,0.0857952,1.29055,1.63017,0.166038,0.305358
8837,0.900102,0.853343,0.985321,0.977745,0.229069,0.245821,0.590125,0.555219,0.138593,0.223885,0.378271,0.381378,0.636224,0.619158,0.943114,0.942309,0.832865,0.874994,0.858724,0.859897,0.498893,0.397623,-0.324694,-0.202818,-0.0169919,0.0703431,0.546159,0.615221,0.676001,0.581876,1.25591,1.25958,-1.66001,-1.67229,-0.0108881,-0.195163,-0.891976,-0.556835,0.00392393,0.146272
8838,0.0562996,0.0110152,0.447193,0.440647,0.709666,0.724004,0.461783,0.503963,0.566043,0.652169,0.23973,0.243175,0.916822,0.900224,0.502789,0.500731,0.488345,0.542382,0.765744,0.766058,0.251326,0.147208,2.04255,2.16369,-1.51219,-1.42618,-0.747365,-0.729232,0.718552,0.617677,-2.39519,-2.38986,1.85734,1.85205,1.58781,1.40897,-2.33738,-1.99619,-1.23087,-1.08937
8839,0.117165,0.0712682,0.757325,0.751761,0.14376,0.159746,0.486428,0.452708,0.15718,0.242979,0.681985,0.68638,0.0214183,0.00608912,0.92857,0.927346,0.167641,0.20977,0.409999,0.410272,-0.878187,-0.979876,0.139239,0.257505,-0.341437,-0.259696,-0.66609,-0.624923,-2.27088,-2.37037,-0.0637206,-0.0600027,-0.467533,-0.47184,0.94315,0.758038,0.886287,1.22165,0.393298,0.531592
8840,0.559668,0.513946,0.708442,0.701895,0.314887,0.330474,0.866222,0.831021,0.778207,0.862196,0.704654,0.781497,0.783019,0.765937,0.27344,0.270289,0.615958,0.659379,0.584295,0.582444,0.988942,0.886771,-1.28695,-1.1765,-1.69676,-1.61896,-0.536676,-0.520614,0.795244,0.698305,1.71207,1.72,0.236826,0.235202,-2.24048,-2.41832,2.57137,2.90285,-0.227961,-0.0943289
8841,0.514991,0.467054,0.994646,0.988338,0.780039,0.794032,0.898718,0.8638,0.507912,0.494785,0.90617,0.876615,0.759331,0.742956,0.745499,0.742367,0.686484,0.814497,0.97995,0.97701,0.233201,0.128172,-0.515622,-0.40658,0.190534,0.273919,0.616695,0.629166,0.334616,0.239619,1.09138,1.09971,0.341193,0.343499,-0.449858,-0.629167,1.41831,1.7451,-0.130422,0.00178881
8842,0.845666,0.701971,0.938857,0.89513,0.356908,0.369533,0.718313,0.681832,0.0429656,0.127373,0.967337,0.971732,0.342856,0.326946,0.891327,0.888749,0.928026,0.969615,0.885631,0.88317,-0.0388754,-0.138384,-0.842167,-0.724781,-1.08551,-1.00697,0.711872,0.731733,-0.7648,-0.86108,-1.20959,-1.20194,1.74072,1.7471,0.0177116,-0.160637,-1.89823,-1.57619,0.738279,0.87066
8843,0.986227,0.936887,0.809694,0.801922,0.483217,0.495744,0.0909559,0.054156,0.851859,0.934272,0.70108,0.703855,0.755369,0.738473,0.684957,0.653792,0.65522,0.673532,0.0306786,0.0310016,-0.849498,-0.944814,0.0988738,0.212778,-0.0421949,0.0364005,-0.79481,-0.770793,0.10172,0.00305563,-2.07007,-2.06633,0.493002,0.498167,1.38646,1.21166,0.764756,1.0843,1.94786,2.07433
8844,0.99196,0.90989,0.0132353,0.00433564,0.142957,0.155873,0.103636,0.0685412,0.334297,0.415847,0.998506,0.999477,0.858538,0.843586,0.422357,0.418835,0.369538,0.37745,0.247762,0.248381,0.298374,0.209665,0.0843008,0.197981,-0.389562,-0.314107,1.68726,1.70986,-0.8971,-0.990592,-0.181363,-0.17949,-0.305205,-0.300951,-1.34305,-1.51939,0.115728,0.42999,-0.298436,-0.176358
8845,0.933585,0.882892,0.675766,0.668545,0.416439,0.427142,0.150007,0.0829265,0.929018,1.01063,0.827939,0.826882,0.71721,0.702987,0.81942,0.815473,0.0397779,0.0813668,0.118764,0.119169,-1.15132,-1.2389,-0.223473,-0.10819,-1.49304,-1.41082,1.09018,1.11862,-2.09888,-2.19534,-1.30713,-1.30499,-0.0701433,-0.0727713,0.489859,0.31732,1.06143,1.37393,0.729106,0.845092
8846,0.199095,0.148971,0.893602,0.885876,0.911782,0.920539,0.134313,0.0973117,0.23224,0.314789,0.0459906,0.0464545,0.576319,0.562389,0.412425,0.408254,0.39541,0.43769,0.962728,0.963154,0.585381,0.506654,-0.329246,-0.21366,1.36551,1.44506,-1.59744,-1.56631,-2.16775,-2.27077,-1.31799,-1.32076,0.585039,0.58845,-0.74408,-0.914501,-0.407339,-0.0985985,0.0207816,0.143084
8847,0.58888,0.537474,0.610961,0.513001,0.715145,0.720811,0.533153,0.496659,0.959521,1.04279,0.681933,0.682434,0.940642,0.924849,0.583894,0.579448,0.45032,0.491846,0.0974937,0.0997779,-0.747776,-0.8211,0.664156,0.786009,0.0407799,0.116686,-1.44071,-1.41555,-1.78655,-1.88237,1.52637,1.51911,0.894273,0.89615,-0.646732,-0.812454,-0.497869,-0.181757,-0.457076,-0.332376
8848,0.41316,0.359928,0.147073,0.140126,0.513526,0.521082,0.139275,0.104885,0.488001,0.569781,0.419204,0.419316,0.716024,0.619187,0.361213,0.357037,0.263621,0.304757,0.468455,0.469718,-0.464396,-0.477481,-0.436084,-0.318453,-0.0778254,-0.00327168,-0.0558856,-0.0347535,-0.454938,-0.557952,0.182355,0.170634,-1.91628,-1.91886,-0.761859,-0.926304,0.759864,1.07308,0.66833,0.794983
8849,0.891075,0.83689,0.916452,0.910981,0.542276,0.635213,0.290318,0.25516,0.345495,0.42795,0.667365,0.667424,0.331045,0.313525,0.904358,0.899817,0.894318,0.935677,0.0169508,0.0184092,-0.0605382,-0.133862,0.154472,0.269488,-0.887608,-0.820622,-1.31851,-1.29217,-1.22779,-1.33453,-1.16851,-1.17784,0.526243,0.527306,1.99105,1.81933,0.456917,0.772336,-0.0781964,0.0483555
8850,0.642879,0.512751,8.37626e-05,-0.0044509,0.766764,0.749345,0.182742,0.149862,0.874626,0.956975,0.433737,0.434126,0.748514,0.730297,0.505087,0.498796,0.519916,0.561493,0.498829,0.50211,0.785931,0.713499,0.740368,0.85743,-0.397595,-0.331406,1.59318,1.61793,-0.941419,-1.05348,1.01434,1.00871,2.12662,2.12958,-1.9329,-2.10745,-0.879525,-0.559172,-0.515835,-0.383036
8851,0.239531,0.188611,0.885793,0.878733,0.856036,0.863476,0.0816238,0.0445639,0.321548,0.403186,0.946005,0.946938,0.671468,0.650961,0.97074,0.965701,0.373167,0.371406,0.454483,0.458828,-0.280129,-0.353994,1.04158,1.15303,-1.89099,-1.82793,-0.735099,-0.711219,0.782464,0.668012,0.519067,0.469757,1.06651,1.09953,0.5631,0.386003,-3.06421,-2.74618,0.401385,0.529696
8852,0.951227,0.899242,0.52708,0.516068,0.317058,0.324406,0.505705,0.468826,0.550294,0.633773,0.0173823,0.017977,0.362388,0.339276,0.874035,0.869393,0.138331,0.181319,0.949388,0.95273,1.46957,1.39156,0.465034,0.574111,1.51176,1.57058,1.39214,1.41247,-0.127867,-0.246801,-0.0608524,-0.0691981,0.05887,0.069474,0.465586,0.288252,0.360891,0.675911,-0.806111,-0.674375
8853,0.18769,0.133993,0.159478,0.153403,0.773563,0.783241,0.655051,0.619101,0.211353,0.296565,0.28022,0.328425,0.974605,0.950647,0.446848,0.450445,0.210956,0.254977,0.0037604,0.00732466,0.76774,0.694937,-0.762831,-0.653658,-0.603159,-0.539688,-1.04621,-1.02148,0.458591,0.339248,0.430401,0.521697,0.607094,0.623624,-0.882115,-1.05236,-0.570542,-0.263682,-0.594629,-0.458126
8854,0.907566,0.854785,0.506406,0.499578,0.16362,0.174304,0.289705,0.252291,0.843167,0.92573,0.636778,0.638874,0.0546308,0.029121,0.0366848,0.0314967,0.649578,0.694464,0.675918,0.681231,0.675887,0.608761,2.64354,2.74984,-0.458922,-0.401824,0.49626,0.518081,-0.923492,-1.04,1.1129,1.11259,1.65967,1.68264,0.396787,0.223772,0.0399783,0.351894,-1.3454,-1.20475
8855,0.0902433,0.0373902,0.623429,0.618059,0.153305,0.248046,0.439125,0.402566,0.218867,0.300692,0.632929,0.635788,0.355006,0.382451,0.631413,0.624645,0.285997,0.330159,0.771533,0.777397,-0.802811,-0.869801,1.61555,1.72204,0.764787,0.825729,1.44342,1.46694,0.0711404,-0.0529411,-0.688469,-0.6887,-0.600392,-0.575375,0.689971,0.510456,-1.35592,-1.03938,-1.64611,-1.49875
8856,0.769447,0.718597,0.0975912,0.0906476,0.198423,0.321788,0.958124,0.920615,0.343115,0.504109,0.168405,0.170252,0.758699,0.735782,0.663838,0.65486,0.959161,1.00295,0.385764,0.392084,-1.23059,-1.30415,-1.4816,-1.3787,0.779877,0.845881,-0.689634,-0.667331,-1.32035,-1.44584,-1.2283,-1.23021,0.598054,0.625497,-1.25728,-1.43407,0.17503,0.497139,-0.119886,0.0287503
8857,0.470038,0.38413,0.79667,0.79088,0.383881,0.39553,0.937292,0.898709,0.625344,0.707527,0.696934,0.696929,0.485641,0.398519,0.150233,0.139052,0.453349,0.497835,0.988222,0.995866,2.44328,2.36571,1.40014,1.50776,0.81055,0.866032,0.144677,0.172682,-0.251861,-0.382435,0.375323,0.378729,-0.53585,-0.514508,-0.477387,-0.706293,-1.81846,-1.5008,-0.951277,-0.807325
8858,0.101149,0.0496625,0.941077,0.93443,0.184952,0.198659,0.49575,0.456779,0.261934,0.421631,0.200297,0.201711,0.0834955,0.0612553,0.199957,0.189067,0.18748,0.232977,0.795566,0.871662,1.83541,1.76123,0.0753845,0.184611,-0.988203,-0.927062,0.732268,0.684841,1.02694,0.896494,0.983804,0.992944,1.05483,1.07289,0.189689,0.0214834,-0.180918,0.130849,0.184885,0.335262
8859,0.816589,0.765546,0.742037,0.721567,0.885832,0.899022,0.3124,0.274812,0.0550364,0.135736,0.182546,0.18354,0.965216,0.941609,0.0319495,0.0212165,0.319943,0.367141,0.738001,0.747457,-0.0239956,-0.092709,-0.488949,-0.380618,0.526538,0.58905,1.16954,1.197,-0.575396,-0.710004,0.878708,0.885563,-0.755139,-0.741081,-0.607132,-0.747049,1.00924,1.32156,2.10703,2.263
8860,0.678063,0.567036,0.514843,0.508703,0.0350865,0.0480452,0.382152,0.343876,0.188461,0.270614,0.786273,0.789326,0.160704,0.13653,0.072994,0.0750951,0.251553,0.296797,0.206488,0.216002,-1.06609,-1.12886,0.800333,0.915019,-1.88848,-1.82643,0.457436,0.482883,-0.38995,-0.521891,-1.12555,-1.1174,-0.6991,-0.677882,-1.34374,-1.51558,1.64177,1.95288,-0.169668,-0.00515199
8861,0.474278,0.368526,0.988727,0.982367,0.804367,0.819272,0.0693303,0.0307742,0.948507,1.02924,0.219742,0.224954,0.967395,0.942002,0.149113,0.128974,0.496,0.542874,0.584856,0.533918,0.182777,0.119146,-1.08189,-0.962672,0.251834,0.316213,0.164706,0.185133,-0.496523,-0.628538,-0.0385784,-0.0301541,-0.0565539,-0.0309825,1.31623,1.15071,-1.22787,-0.924231,-0.745588,-0.498758
8862,0.146645,0.170016,0.986235,0.981989,0.259013,0.274289,0.399507,0.360021,0.629872,0.711558,0.228449,0.221547,0.566646,0.541664,0.191157,0.182852,0.340244,0.384457,0.840551,0.851834,1.16367,1.10374,2.06375,2.18849,-0.0154842,0.0424765,0.412602,0.427236,-0.82441,-0.949742,-1.05233,-1.04861,0.287115,0.259068,-1.31631,-1.4739,0.85877,1.15943,-1.15688,-0.992363
8863,0.0239835,-0.0284938,0.421583,0.415847,0.122346,0.137589,0.45792,0.465255,0.90237,0.983263,0.212352,0.218141,0.845297,0.817762,0.617794,0.529776,0.953451,0.996075,0.00275054,0.0159494,-2.16679,-2.22298,-1.70015,-1.5824,-0.00252065,0.105549,0.314737,0.331446,-2.02824,-2.15449,2.31544,2.31932,0.517743,0.549118,-0.289582,-0.451071,0.599545,0.905732,-0.25828,-0.0938071
8864,0.787354,0.735877,0.289019,0.282005,0.636601,0.651603,0.610419,0.570488,0.779596,0.861417,0.467022,0.383403,0.0255168,-0.00462875,0.8833,0.876699,0.684883,0.727203,0.120123,0.133117,0.175061,0.118567,-1.55545,-1.44269,0.112447,0.168622,0.552434,0.573548,0.0339266,-0.0892368,-0.314806,-0.302391,-0.0364868,-0.00438032,1.38845,1.23056,1.43492,1.74005,2.40392,2.57381
8865,0.0642539,0.0119863,0.462938,0.455858,0.360491,0.377185,0.0153713,-0.0229353,0.325601,0.408027,0.542227,0.548664,0.498515,0.467052,0.606759,0.667588,0.180934,0.222091,0.704287,0.717405,-0.562716,-0.623563,-0.67514,-0.565589,-0.197409,-0.135895,-0.21656,-0.202825,0.398626,0.269109,-0.939293,-0.922679,-0.96398,-0.9276,0.226846,0.062418,1.17793,1.48635,0.549223,0.724827
8866,0.805887,0.755953,0.421181,0.416486,0.764198,0.780553,0.746122,0.70954,0.17454,0.355263,0.508218,0.516527,0.150691,0.121828,0.463466,0.458477,0.324801,0.366535,0.327374,0.341229,-0.576976,-0.632844,-0.90572,-0.79658,-0.140185,-0.0735187,-0.450243,-0.534052,-0.150968,-0.279667,0.687505,0.70176,0.251546,0.28892,-0.38964,-0.556617,0.507663,0.727401,0.0633495,0.234978
8867,0.097511,0.0481933,0.869261,0.864732,0.0711694,0.0865645,0.845787,0.808763,0.207246,0.302499,0.268988,0.278073,0.441016,0.412985,0.875538,0.870221,0.0253121,0.0673666,0.341121,0.356576,0.360766,0.306196,-1.44705,-1.33001,1.48755,1.55262,-0.872488,-0.86528,1.58548,1.45864,0.0708392,0.0814713,0.425511,0.45708,1.18067,1.01558,-0.336588,-0.0315472,-0.0312861,0.137214
8868,0.704235,0.65417,0.444362,0.4408,0.871538,0.885998,0.120954,0.0860621,0.16564,0.249736,0.609187,0.617649,0.491443,0.461479,0.00855528,0.00451563,0.585196,0.627133,0.112091,0.125759,0.748583,0.695199,0.96848,1.08808,0.255627,0.316334,-0.225539,-0.210281,-2.21213,-2.33869,-0.844789,-0.830868,-0.936688,-0.901263,0.642241,0.47405,-1.52658,-1.22004,1.6305,1.80138
8869,0.0646964,0.0127812,0.361802,0.357469,0.747588,0.759769,0.144048,0.0861939,0.352294,0.370896,0.701963,0.712885,0.892478,0.863416,0.308925,0.305509,0.605919,0.718432,0.9033,0.918061,-0.273244,-0.326707,-1.70953,-1.59502,-0.684247,-0.623394,0.8827,0.891838,1.2115,1.09159,-0.704723,-0.749246,0.318373,0.359903,0.999481,0.835676,0.576425,0.880615,1.14923,1.32592
8870,0.855274,0.803862,0.754751,0.752918,0.239862,0.251381,0.119912,0.0863257,0.387072,0.492056,0.319719,0.390695,0.183083,0.156201,0.871492,0.867745,0.767849,0.809732,0.364421,0.376901,-0.884797,-0.931192,-1.27119,-1.16445,-1.22873,-1.17422,-1.66637,-1.65726,1.30292,1.18936,-0.686239,-0.667624,-0.196372,-0.146248,0.187522,0.0179991,0.018521,0.288576,0.419067,0.594257
8871,0.445261,0.393931,0.162934,0.161805,0.00703574,0.0182503,0.728838,0.693215,0.528947,0.613216,0.0555614,0.0685052,0.0313336,0.00667103,0.522547,0.521162,0.611181,0.651315,0.73088,0.742092,-0.417426,-0.464299,-0.563333,-0.456619,0.602556,0.655724,1.60938,1.62125,0.272668,0.165355,0.993161,1.00361,0.542082,0.590816,-0.229535,-0.401719,-0.612434,-0.303464,0.778037,0.946191
8872,0.468063,0.414369,0.894241,0.8934,0.804043,0.817683,0.744509,0.711132,0.106442,0.189315,0.233125,0.247607,0.276759,0.198216,0.997985,0.997688,0.923829,0.962097,0.161326,0.170918,-0.267536,-0.321625,-1.746,-1.6377,-1.50401,-1.45455,-1.3114,-1.2973,0.839292,0.737283,-0.0303886,-0.0148481,0.214046,0.269785,0.0248891,-0.145937,-0.236692,0.105084,0.112249,0.273486
8873,0.0259115,-0.0261391,0.663939,0.663503,0.385049,0.398017,0.318812,0.283969,0.909499,0.991258,0.813987,0.828459,0.41667,0.389761,0.00634502,0.00422761,0.00787231,0.0442533,0.517514,0.48637,0.682914,0.632473,-0.0705127,0.0453062,-0.517038,-0.471229,1.18114,1.19983,-1.60835,-1.70542,0.282101,0.305442,-0.351753,-0.299847,0.538393,0.369057,0.201863,0.513631,-1.60586,-1.44909
8874,0.612367,0.559491,0.233581,0.234926,0.248844,0.261317,0.870497,0.836548,0.131195,0.211728,0.121742,0.13836,0.597707,0.581306,0.592117,0.592163,0.93966,0.973895,0.79069,0.801821,0.908122,0.85136,-0.623069,-0.504334,-0.683741,-0.637644,-0.602784,-0.5847,-0.934042,-1.02541,0.894993,0.919657,-0.274329,-0.221837,0.488157,0.31597,-1.45287,-1.14678,0.771862,0.925983
8875,0.416008,0.281744,0.247237,0.249086,0.617306,0.628638,0.986221,0.951,0.492798,0.573328,0.589844,0.516583,0.797493,0.772851,0.396268,0.395212,0.0614018,0.0941302,0.669559,0.7588,-0.167914,-0.23013,1.29315,1.41119,-1.43815,-1.39187,-0.559595,-0.456152,-1.56644,-1.65053,-0.51423,-0.484313,-0.474463,-0.417649,-0.643731,-0.813025,-0.886092,-0.57821,2.2601,2.40798
8876,0.0577557,0.00399778,0.912157,0.913296,0.344232,0.35422,0.730163,0.693344,0.85685,0.934928,0.877015,0.894806,0.479618,0.456591,0.401518,0.400867,0.587307,0.554011,0.706933,0.71578,-0.0326518,-0.10231,-2.17616,-2.05834,1.23029,1.28481,-0.341038,-0.327603,0.755361,0.669359,-0.485296,-0.454036,-0.0691103,-0.0186987,-1.76491,-1.94202,-0.713872,-0.400418,0.0559923,0.203814
8877,0.436814,0.382073,0.967527,0.967098,0.528536,0.473105,0.116328,0.080331,0.821809,0.814491,0.746388,0.788038,0.401503,0.442346,0.655964,0.69068,0.97959,1.01389,0.329612,0.339603,1.31111,1.23975,-0.238095,-0.127513,-0.218785,-0.1659,-1.69979,-1.69041,0.103298,0.0150073,1.19102,1.2172,0.646989,0.703147,-0.0911056,-0.260389,0.408501,0.72986,-0.326906,-0.181225
8878,0.244149,0.188209,0.148704,0.146986,0.581478,0.59199,0.0572465,0.0230882,0.616606,0.694054,0.599088,0.68127,0.520598,0.428101,0.979841,0.980494,0.890955,0.9795,0.428258,0.362834,-2.26877,-2.33741,2.08614,2.19094,1.86069,1.91629,-2.2662,-2.24873,-0.980102,-1.06911,-0.309143,-0.278863,-2.05983,-2.00671,1.05336,0.880979,0.330041,0.646701,0.634112,0.778287
8879,0.305884,0.248462,0.515169,0.511719,0.141526,0.152767,0.337764,0.302994,0.0787143,0.1559,0.556711,0.574502,0.434717,0.413856,0.340346,0.339542,0.909867,0.945109,0.362338,0.386064,2.13739,2.06876,-1.15919,-1.05807,-0.804049,-0.744182,0.939931,0.954982,1.76381,1.67194,0.00387165,0.0414263,-0.661722,-0.603116,-0.315888,-0.489226,1.02867,1.3401,0.221783,0.36172
8880,0.00649558,-0.0511682,0.250675,0.291748,0.911625,0.923994,0.918995,0.885911,0.643093,0.718851,0.0622837,0.0792835,0.748523,0.725916,0.977365,0.974482,0.0349107,0.0699896,0.399304,0.409295,3.03781,2.96387,-0.818923,-0.717096,-0.191291,-0.131776,0.446416,0.457359,-1.42362,-1.51998,-0.2778,-0.235487,1.30015,1.35872,0.780354,0.645159,-0.387813,-0.0830231,0.606471,0.742748
8881,0.863628,0.805619,0.0737837,0.0717769,0.189843,0.202997,0.880247,0.849487,0.999141,1.07648,0.956661,0.976001,0.217678,0.193729,0.0229536,0.0204009,0.603157,0.639354,0.248149,0.258936,-1.33692,-1.41086,0.501112,0.607096,-0.308017,-0.251733,0.854196,0.866337,0.672442,0.58097,-0.853367,-0.805973,-1.76855,-1.70552,1.94742,1.77954,0.16823,0.47162,0.373431,0.5086
8882,0.322321,0.264521,0.326423,0.323459,0.565053,0.516298,0.52,0.487401,0.695384,0.782637,0.509123,0.52995,0.279989,0.257243,0.238207,0.251275,0.849419,0.88543,0.804557,0.813048,-0.578804,-0.653218,1.0999,1.20894,0.392724,0.455052,-0.236601,-0.222297,-1.44032,-1.53707,-0.258737,-0.20756,1.04153,1.10161,-2.03191,-2.19953,-0.593484,-0.292204,-0.535059,-0.405143
8883,0.409805,0.343413,0.032118,0.0281471,0.81646,0.829599,0.961476,0.930812,0.431972,0.488797,0.980921,1.00241,0.988391,0.965335,0.499985,0.482149,0.539548,0.576371,0.443906,0.474605,1.02124,0.953611,0.612348,0.722535,0.141835,0.239921,-1.91931,-1.8987,-0.516187,-0.611429,-1.97569,-1.92986,-1.02222,-0.965585,-0.0177269,-0.191835,1.24424,1.54409,-1.02279,-0.894993
8884,0.480763,0.422304,0.942398,0.936827,0.455148,0.469976,0.179621,0.151088,0.115735,0.194957,0.975648,0.945118,0.261661,0.237503,0.721445,0.713023,0.79149,0.828114,0.129942,0.136161,0.0536373,-0.0199739,0.620605,0.724839,-0.032321,0.0247899,0.192742,0.212356,-0.223846,-0.402847,0.533815,0.580943,0.247616,0.310645,1.30412,1.13319,-0.591774,-0.293048,-1.07446,-0.948212
8885,0.148185,0.0871525,0.9099,0.902766,0.918676,0.933534,0.982395,0.951824,0.536868,0.617297,0.878,0.887825,0.511535,0.463406,0.946449,0.943896,0.657532,0.695619,0.784665,0.790707,-2.04589,-2.12002,1.75708,1.86267,-0.035877,0.119681,-0.81649,-0.797523,-0.101003,-0.194265,-0.545606,-0.498227,-0.95278,-0.891535,-0.318325,-0.482546,0.128333,0.431437,0.111826,0.243009
8886,0.964097,0.905016,0.105444,0.0981137,0.248622,0.264412,0.329157,0.299503,0.22316,0.304603,0.901419,0.830532,0.713085,0.689309,0.160927,0.15722,0.0157284,0.0551929,0.394191,0.400714,-0.221534,-0.299566,-0.95762,-0.851912,0.151981,0.214572,-0.915211,-0.893312,-0.131571,-0.221149,0.244372,0.293936,1.3461,1.40992,1.37251,1.21489,-0.632009,-0.332387,-0.113403,0.0228157
8887,0.693853,0.645711,0.567646,0.56119,0.791749,0.807311,0.443301,0.413956,0.380738,0.463778,0.751749,0.773239,0.00654225,-0.0179062,0.845412,0.843006,0.758907,0.797922,0.33052,0.402371,0.812927,0.731284,-1.26492,-1.15808,0.61314,0.673447,-0.494096,-0.468918,-0.639319,-0.725276,-0.0484874,0.00203228,-0.46692,-0.404042,-0.708501,-0.870065,-0.749119,-0.446004,0.00872831,0.147038
8888,0.570662,0.386405,0.0505464,0.0435477,0.602925,0.536516,0.250007,0.233601,0.953042,1.03807,0.112282,0.133583,0.896134,0.873497,0.447026,0.427053,0.474163,0.445458,0.396981,0.404029,-1.0154,-1.08986,0.749268,0.852015,0.381284,0.444633,1.32519,1.35843,-0.165227,-0.247193,0.295108,0.354657,1.10633,1.16333,-0.286127,-0.495067,-0.315865,-0.0185156,-0.670773,-0.604963
8889,0.18498,0.1271,0.0569063,0.0479215,0.249517,0.26572,0.0831586,0.0532473,0.365627,0.449357,0.447177,0.468006,0.825043,0.769572,0.0126718,0.0110994,0.0518067,0.0929937,0.892428,0.897931,-0.639891,-0.715245,1.00908,1.11523,1.00963,1.07286,-0.11109,-0.0833106,1.98169,1.90531,0.23853,0.292407,-0.873156,-0.808352,0.0462878,-0.120069,-0.314356,-0.0238323,-1.49572,-1.35696
8890,0.664851,0.608415,0.623666,0.614404,0.878424,0.894217,0.898518,0.869822,0.070452,0.152816,0.0164153,0.0372865,0.689051,0.665646,0.774529,0.773532,0.503626,0.542603,0.405173,0.411986,0.00302936,-0.0648221,0.868518,0.979256,2.38611,2.45095,-1.22592,-1.20112,-0.334543,-0.416729,-2.10174,-2.04205,-0.80263,-0.730342,-0.445774,-0.615823,-0.771984,-0.479205,3.15569,3.29445
8891,0.327714,0.273264,0.598397,0.620859,0.200698,0.21451,0.482268,0.453053,0.699694,0.781981,0.069397,0.0880223,0.0913343,0.0690472,0.391304,0.392262,0.27321,0.314469,0.241461,0.246984,-0.396085,-0.480104,-0.636728,-0.531118,1.55459,1.61728,1.69625,1.72166,-0.184951,-0.274989,0.0681085,0.130179,-1.03191,-0.958263,0.346079,0.173539,-0.679741,-0.391195,-2.06381,-1.92505
8892,0.952179,0.898795,0.651123,0.627313,0.971047,0.985737,0.512822,0.485832,0.542556,0.626106,0.923019,0.939259,0.417145,0.396364,0.743075,0.744614,0.688235,0.729991,0.601067,0.607112,-0.834076,-0.895386,0.496798,0.606714,0.356405,0.4117,0.586649,0.617657,-0.63287,-0.712478,-1.55875,-1.49987,-0.704865,-0.636512,-0.0268663,-0.118073,0.481841,0.770018,1.45293,1.59016
8893,0.665581,0.576549,0.640467,0.633768,0.753742,0.801569,0.253169,0.228175,0.60663,0.688598,0.600723,0.67722,0.0670696,0.0457335,0.542443,0.542545,0.0640914,0.105178,0.554405,0.558013,0.864444,0.803125,-0.234669,-0.125298,-1.46911,-1.41511,1.0628,1.08686,-1.05979,-1.14997,0.594448,0.654981,-1.35237,-1.28065,-0.231159,-0.409686,0.285806,0.57712,-0.918086,-0.778413
8894,0.308627,0.254302,0.384868,0.377713,0.600008,0.6174,0.310516,0.286531,0.187029,0.269559,0.396391,0.415181,0.856491,0.836016,0.0268073,0.0267369,0.228686,0.270055,0.0497319,0.0523368,-0.438973,-0.493602,0.904285,1.01253,0.521137,0.572528,-1.14608,-1.12522,2.056,1.96325,0.403728,0.471194,1.7982,1.86221,0.966215,0.793919,0.393914,0.679759,-0.0458852,0.0904582
8895,0.585259,0.517849,0.48122,0.472052,0.786987,0.803187,0.833635,0.809455,0.487674,0.596449,0.825192,0.844167,0.42104,0.399935,0.563846,0.564508,0.825052,0.866526,0.677781,0.681867,-0.542348,-0.595438,-0.132196,-0.0294846,-0.516408,-0.462677,-0.360372,-0.399819,-0.909424,-1.0086,-1.03482,-0.961226,-0.222469,-0.155373,-1.51252,-1.68663,-0.439793,-0.159878,1.34097,1.47829
8896,0.834071,0.781396,0.864656,0.856818,0.534288,0.559559,0.342317,0.316744,0.842554,0.92334,0.152409,0.173719,0.774184,0.751918,0.0659454,0.0688241,0.169757,0.210701,0.362326,0.366099,0.906375,0.856444,-2.40593,-2.29899,-0.481446,-0.358554,0.304712,0.325579,-1.89309,-1.98753,-0.680372,-0.608602,-0.913144,-0.845896,0.788395,0.621833,0.69146,0.9704,-0.238164,-0.105492
8897,0.811243,0.748673,0.160286,0.151419,0.298049,0.31593,0.436828,0.36251,0.806269,0.888983,0.940075,0.962224,0.262317,0.240317,0.0114136,0.0936689,0.952908,0.992883,0.347305,0.380382,1.01285,0.967891,-0.880497,-0.77128,-0.305858,-0.25443,-0.442707,-0.420673,0.491542,0.399098,0.257996,0.325861,0.00875766,0.0753269,1.27044,1.10652,-0.584907,-0.312367,0.487386,0.612507
8898,0.768359,0.71595,0.317051,0.310369,0.737847,0.755255,0.419147,0.408277,0.519067,0.506716,0.820383,0.87512,0.556674,0.537475,0.114754,0.118514,0.916357,0.957812,0.391273,0.394665,-1.21714,-1.26409,-0.0304229,0.0738575,0.904736,0.955183,0.244941,0.263875,1.07413,0.985147,0.750713,0.817262,-0.256763,-0.183093,0.264161,0.104778,1.54608,1.82397,-1.07418,-0.943273
8899,0.355751,0.306019,0.092314,0.0860914,0.270028,0.285523,0.479978,0.454043,0.042032,0.124449,0.76595,0.788016,0.602045,0.62902,0.637408,0.64082,0.490783,0.548611,0.638979,0.643013,-0.717757,-0.767473,2.04069,2.14637,0.0716039,0.121514,0.0556002,0.0740866,1.23863,1.14454,-0.75541,-0.692525,-0.771978,-0.706269,-1.26449,-1.41949,0.127744,0.400846,-1.75652,-1.6287
8900,0.380107,0.254899,0.768055,0.76088,0.324164,0.360305,0.776902,0.749314,0.922687,1.00409,0.162221,0.182996,0.736959,0.720565,0.071066,0.0741743,0.0996821,0.139409,0.295801,0.301874,0.945658,0.899913,-0.980404,-0.870791,0.306739,0.352463,-0.920125,-0.904933,2.12512,2.02362,0.072527,0.132385,0.710828,0.773202,-1.1785,-1.3349,-0.842288,-0.567532,-0.0274982,0.0951285
8901,0.255145,0.203778,0.508328,0.580039,0.419408,0.435087,0.814067,0.788178,0.24136,0.323902,0.285683,0.307901,0.606218,0.590869,0.138695,0.107842,0.619211,0.65985,0.338734,0.343749,-0.0402295,-0.0903317,-0.360119,-0.254874,-0.90802,-0.924072,0.149902,0.167343,-1.84347,-1.94387,-0.472459,-0.409121,-0.112136,-0.0528426,0.120862,-0.0417444,0.757974,1.03326,0.348998,0.476156
8902,0.558989,0.505641,0.409055,0.399197,0.0137103,0.0295328,0.215052,0.189345,0.94743,1.02962,0.659372,0.585697,0.918541,0.902929,0.140257,0.141509,0.898426,0.941028,0.919704,0.923084,1.3278,1.28204,-0.570055,-0.466987,-2.24451,-2.20061,-1.1181,-1.10404,0.368955,0.275896,0.938408,0.999843,1.43036,1.48512,-0.305407,-0.461462,-0.32134,-0.0442007,1.79359,1.92536
8903,0.574877,0.520833,0.695718,0.68564,0.820367,0.834802,0.221053,0.141244,0.268032,0.349433,0.842396,0.863494,0.943588,0.925419,0.715742,0.715126,0.384569,0.426176,0.693882,0.614607,-1.84741,-1.8861,0.754361,0.857204,0.337996,0.374961,-0.531161,-0.511922,0.216454,0.124795,1.2295,1.28908,1.04211,1.10279,-0.957818,-1.1124,-0.648039,-0.375155,0.0598353,0.1873
8904,0.981396,0.928693,0.676284,0.664981,0.938329,0.951989,0.116837,0.0931432,0.103015,0.223519,0.387322,0.407665,0.179452,0.159563,0.231074,0.228958,0.980053,1.02265,0.302573,0.30613,0.455126,0.411096,1.01549,1.12042,-0.198287,-0.160464,-0.708776,-0.685418,-0.95449,-1.0513,0.156333,0.209913,0.0845588,0.234516,0.378135,0.22707,0.987288,1.25649,-0.322765,-0.197739
8905,0.904784,0.885764,0.105333,0.0936095,0.285486,0.298594,0.291838,0.268197,0.0162118,0.0976043,0.418653,0.420929,0.684844,0.665984,0.172939,0.256423,0.560791,0.603782,0.400396,0.354052,0.166738,0.129973,0.166799,0.264517,-1.31668,-1.27371,0.0549347,0.0778668,0.749086,0.654103,0.825716,0.807479,-0.692538,-0.633761,2.03362,1.87675,-0.334423,-0.0587524,0.530256,0.653917
8906,0.960742,0.842834,0.133753,0.122059,0.512262,0.524195,0.0189866,-0.00483063,0.345987,0.514877,0.525678,0.434194,0.378758,0.359975,0.285354,0.283888,0.438457,0.481006,0.39957,0.401974,-0.719213,-0.752679,0.562827,0.664308,0.147394,0.197314,-0.541255,-0.513378,-0.724491,-0.814567,1.34994,1.40505,-0.824874,-0.82813,-0.132262,-0.28921,0.946736,1.22742,-2.24982,-2.12593
8907,0.851046,0.799905,0.96741,0.954282,0.421223,0.444681,0.275751,0.25033,0.852917,0.93215,0.424643,0.447458,0.275074,0.306077,0.726907,0.726125,0.655063,0.697104,0.891464,0.895877,0.140917,0.109271,0.749109,0.849893,1.62536,1.66834,-0.48003,-0.454992,2.12355,2.03011,-0.514333,-0.456437,-1.08307,-1.0225,-1.27781,-1.42841,-0.322453,-0.0366567,0.127158,0.249143
8908,0.580704,0.530672,0.243459,0.228946,0.35481,0.365168,0.927756,0.902594,0.589828,0.669846,0.0575577,0.0800498,0.270332,0.25218,0.951494,0.95005,0.127114,0.167938,0.37156,0.375616,0.414983,0.342147,-1.68509,-1.57669,-0.167467,-0.124759,-0.924194,-0.892257,1.3028,1.20535,-0.405312,-0.349651,-0.0193607,0.036513,0.239983,0.0957969,0.592747,0.933361,0.365636,0.482175
8909,0.7802,0.731198,0.529738,0.515389,0.276036,0.285654,0.219421,0.195249,0.689878,0.814993,0.707089,0.731248,0.41433,0.39797,0.677915,0.685842,0.0888448,0.128295,0.493649,0.572669,0.602034,0.575023,0.706725,0.821313,0.255761,0.323545,-0.232746,-0.207709,-0.0905221,-0.187553,1.04169,1.10217,-0.532315,-0.469638,0.28823,0.148784,1.61021,1.90338,-0.302524,-0.19053
8910,0.131868,0.0850109,0.125439,0.111735,0.521004,0.530976,0.906664,0.882983,0.878659,0.960139,0.951885,0.973901,0.880925,0.865049,0.426023,0.421634,0.751863,0.790627,0.76816,0.769723,-0.782925,-0.812759,-1.47932,-1.36681,0.730526,0.771848,0.0553418,0.0807088,-0.12239,-0.1271,-0.886916,-0.822601,2.12753,2.18102,0.101574,-0.0408725,0.228526,0.526115,-0.418716,-0.304007
8911,0.555311,0.508102,0.641433,0.629507,0.163912,0.171354,0.0703789,0.0456577,0.445403,0.526202,0.79702,0.820944,0.176893,0.163905,0.570561,0.568017,0.0250311,0.0649311,0.58242,0.584313,-0.371211,-0.406958,-0.152762,-0.00865361,0.733873,0.771823,0.778182,0.796917,0.0287637,-0.0666466,-0.427338,-0.361033,1.44511,1.50642,0.42916,0.291013,0.909605,1.20522,0.741672,0.855049
8912,0.627344,0.655376,0.657909,0.628633,0.00816285,0.0992342,0.796235,0.773625,0.478337,0.558165,0.220311,0.24658,0.419972,0.405016,0.248466,0.246097,0.349339,0.391028,0.0299457,0.033517,-1.15929,-1.19808,1.24181,1.3495,-0.177893,-0.138062,-1.25126,-1.22823,-0.966255,-1.06029,-1.65627,-1.59159,-0.372428,-0.307547,1.74439,1.6,0.314611,0.611891,-0.0370567,0.126266
8913,0.851236,0.802649,0.638545,0.627759,0.0218077,0.0271147,0.449035,0.501349,0.949794,1.03114,0.305647,0.331757,0.0155485,-0.0010711,0.380938,0.377119,0.266042,0.291441,0.74542,0.747875,0.735004,0.698666,0.304606,0.417253,-0.286533,-0.193189,-1.35543,-1.33995,0.526657,0.431209,2.06491,2.13681,-1.58641,-1.52508,1.32389,1.18028,-1.30419,-0.999901,-0.720366,-0.602517
8914,0.123548,0.0734041,0.915653,0.903998,0.600665,0.605259,0.249315,0.229073,0.5585,0.673669,0.049045,0.0737685,0.763649,0.748442,0.298728,0.387813,0.28737,0.191853,0.833459,0.799247,0.907662,0.8722,-0.864626,-0.748797,-0.355348,-0.248315,-0.71966,-0.644908,-0.549042,-0.637922,-0.484994,-0.410192,0.0797823,0.139425,-0.0987672,-0.236312,0.206721,0.505675,2.64708,2.76653
8915,0.207495,0.159466,0.694294,0.777638,0.638902,0.73258,0.548221,0.529464,0.235476,0.3162,0.12802,0.154591,0.597402,0.584624,0.404282,0.398507,0.0510496,0.0922664,0.846937,0.850619,1.40057,1.36881,-1.67963,-1.55737,-0.429073,-0.303441,0.0299829,0.0501337,-1.38468,-1.47899,-0.133592,-0.0575672,-1.98255,-1.92777,-0.466822,-0.660007,0.0541965,0.431431,0.399127,0.515836
8916,0.980645,0.934559,0.664373,0.651278,0.867627,0.859901,0.405122,0.291654,0.682336,0.764403,0.973827,1.0006,0.869802,0.855821,0.626166,0.622431,0.312233,0.353925,0.622395,0.624657,0.549225,0.517315,-0.911565,-0.787451,-0.398398,-0.358568,0.359239,0.383139,0.131434,0.0435747,0.503609,0.505164,-2.21018,-2.18904,-0.938868,-1.0837,0.0591789,0.357188,0.786474,0.896863
8917,0.226095,0.17926,0.875585,0.863934,0.980527,0.987222,0.0741608,0.0538445,0.815502,0.899281,0.716981,0.753795,0.494418,0.479858,0.374079,0.326389,0.0769377,0.120087,0.833977,0.795986,0.569006,0.53861,0.404905,0.522206,0.638333,0.671957,1.43154,1.45542,1.02166,0.939317,0.982785,1.0679,-2.49997,-2.45031,-0.519611,-0.660494,0.54071,0.832167,0.565725,0.758607
8918,0.336901,0.289968,0.645916,0.634038,0.119304,0.124763,0.495724,0.478106,0.116516,0.198853,0.551526,0.506991,0.885051,0.870908,0.0345473,0.0303461,0.732328,0.773739,0.962917,0.967315,-0.0467768,-0.0829069,-0.668217,-0.551886,0.100296,0.136532,0.396436,0.415977,-0.101416,-0.191009,0.13434,0.218506,-0.50584,-0.459088,-0.337212,-0.549063,-0.984966,-0.686016,0.412791,0.620351
8919,0.201744,0.156689,0.0891023,0.0770559,0.0612695,0.0645066,0.4503,0.431233,0.299851,0.38391,0.233877,0.260186,0.299036,0.283601,0.646392,0.64012,0.970208,1.01051,0.88796,0.893217,-1.74116,-1.77721,-0.637524,-0.519097,-1.02271,-0.931129,-0.861303,-0.841439,-0.161227,-0.250647,0.0478969,0.125437,0.90276,0.944509,-0.295257,-0.437632,-0.264474,0.0384692,0.332357,0.482095
8920,0.834177,0.787371,0.304049,0.294386,0.330887,0.335775,0.872527,0.855495,0.0134032,0.0965833,0.477193,0.502839,0.134371,0.119784,0.316411,0.308767,0.0775824,0.11625,0.0384619,0.0454085,-0.332827,-0.373693,-1.38952,-1.26749,-2.03585,-1.99879,0.224234,0.245117,0.152736,0.0650493,0.732365,0.812775,1.7138,1.75618,-1.04991,-1.19561,-0.918667,-0.615842,0.23345,0.343839
8921,0.930506,0.882957,0.984293,0.974077,0.0788178,0.0822562,0.878755,0.86337,0.0737612,0.159076,0.502505,0.553428,0.281602,0.265574,0.689048,0.681227,0.00765697,0.0459056,0.534702,0.539311,-0.288837,-0.323022,0.491878,0.617992,0.965305,1.00453,0.00395292,0.0257454,0.373663,0.380746,-0.580078,-0.496512,-1.60547,-1.5632,-0.540939,-0.680615,0.373599,0.670327,1.06227,1.16679
8922,0.0184418,-0.0274337,0.354848,0.343749,0.285752,0.287625,0.477884,0.461757,0.815114,0.902103,0.580318,0.604017,0.0773039,0.0604514,0.648451,0.706072,0.183365,0.275566,0.24453,0.248502,1.73548,1.69724,-0.011146,0.116303,-0.991134,-0.947699,-0.463364,-0.442273,0.785862,0.696442,1.84739,1.93711,-2.55834,-2.51709,0.853899,0.707815,0.111285,0.400843,0.351232,0.449468
8923,0.0858647,0.0378971,0.544083,0.532485,0.817958,0.821165,0.426331,0.478205,0.433694,0.518415,0.207177,0.232324,0.548141,0.532132,0.737903,0.730916,0.398197,0.505226,0.533527,0.61126,-0.750156,-0.787709,-0.788288,-0.664605,0.0199339,-0.0156394,0.38909,0.413813,-0.489562,-0.572973,-1.5195,-1.42363,-0.541455,-0.493219,-0.305256,-0.444888,2.72635,3.02352,-1.2567,-1.1507
8924,0.679769,0.632919,0.409784,0.398643,0.995362,0.997487,0.511079,0.494654,0.491392,0.575443,0.2538,0.277453,0.148305,0.131795,0.260561,0.255411,0.728691,0.734886,0.972205,0.974019,2.01877,1.98167,0.210713,0.335064,0.867283,0.91642,-0.770025,-0.75143,-0.619434,-0.710467,-0.846248,-0.748685,-0.749559,-0.705661,0.490158,0.382322,1.17483,1.49348,-1.61966,-1.50785
8925,0.648377,0.601636,0.508618,0.497575,0.538002,0.538322,0.743769,0.725204,0.203375,0.288116,0.587211,0.611876,0.741935,0.727787,0.404683,0.401793,0.926298,0.964546,0.347188,0.348462,0.690704,0.653917,-2.86951,-2.75091,-0.376651,-0.333737,-0.656984,-0.632697,2.28942,2.20553,0.770084,0.860249,1.32587,1.3671,1.34482,1.20953,-0.333725,-0.036558,-0.056557,0.0518953
8926,0.395535,0.348719,0.832825,0.823733,0.918,0.919237,0.607161,0.54226,0.548791,0.649716,0.552308,0.637789,0.119432,0.107043,0.844377,0.844031,0.724471,0.761741,0.652507,0.651069,2.35373,2.3213,-1.62399,-1.50212,-0.350009,-0.303093,0.707308,0.732246,1.47852,1.34718,-1.13995,-1.05051,0.821698,0.860946,0.780244,0.637916,-0.0608057,0.233898,-0.552458,-0.418109
8927,0.916725,0.870678,0.125264,0.118334,0.437233,0.439535,0.375498,0.359315,0.926797,1.01132,0.628649,0.663702,0.435898,0.424241,0.102455,0.102777,0.235764,0.271724,0.0272837,0.0255127,-0.547734,-0.581184,0.175067,0.302263,-0.701225,-0.6536,-1.70633,-1.68537,0.573055,0.488825,1.34878,1.44297,3.4632,3.49714,-0.683049,-0.825006,1.05532,1.34792,-0.994311,-0.888112
8928,0.0631361,0.0190056,0.30659,0.301794,0.183282,0.186016,0.50682,0.488844,0.629882,0.815416,0.665139,0.689615,0.302102,0.290116,0.348304,0.276166,0.922984,0.958941,0.529456,0.52947,-0.965364,-1.00049,-1.12986,-1.00199,0.965968,1.02083,-0.291436,-0.271986,0.649213,0.571011,0.461729,0.562727,-0.482748,-0.45066,-1.45577,-1.59745,1.82067,2.11753,-0.56431,-0.460202
8929,0.502356,0.457021,0.871774,0.868277,0.654703,0.659611,0.183461,0.166036,0.532665,0.619516,0.0644517,0.0889807,0.89328,0.881484,0.437893,0.449556,0.402153,0.4397,0.166577,0.16837,-0.365425,-0.396954,-0.664669,-0.442215,-2.04166,-1.98346,-0.542623,-0.523708,0.232874,0.158656,-1.67576,-1.58201,-1.05622,-1.02029,-0.976095,-1.11276,-0.956542,-0.656942,-0.962654,-0.862234
8930,0.463432,0.421856,0.967426,0.962616,0.720964,0.690149,0.782029,0.762881,0.670402,0.844178,0.110593,0.174298,0.22264,0.209237,0.621599,0.622946,0.992565,1.03034,0.89064,0.89168,-0.297712,-0.329855,-0.0135586,0.117561,1.04267,1.10599,0.51131,0.532837,2.02798,1.95817,-0.121056,-0.0353502,1.13291,1.16778,-0.721909,-0.856979,-0.355454,-0.0574529,-0.114384,-0.0105784
8931,0.432475,0.386691,0.0763041,0.0685623,0.716071,0.720688,0.40297,0.385265,0.982007,1.06884,0.342753,0.259614,0.724373,0.711553,0.349698,0.350412,0.817337,0.857076,0.594624,0.596273,1.63072,1.5958,-0.876179,-0.738344,-0.313846,-0.25327,1.33193,1.3563,1.07645,1.01009,-1.4998,-1.40929,1.71479,1.75281,-1.60597,-1.7367,-0.107114,0.197852,0.344251,0.446854
8932,0.604607,0.557541,0.466954,0.458544,0.57032,0.664441,0.306847,0.36872,0.85398,0.996688,0.31826,0.344931,0.241351,0.229929,0.675506,0.676816,0.859658,0.834238,0.649369,0.648947,-2.45632,-2.49381,1.28155,1.41864,-0.906522,-0.839477,0.948073,0.96663,-0.214401,-0.27384,-0.72404,-0.629536,1.58169,1.61644,-0.100271,-0.227955,0.405439,0.706027,-1.17483,-1.077
8933,0.991198,0.946044,0.127324,0.118506,0.601917,0.608194,0.370625,0.352174,0.740351,0.924537,0.22734,0.252043,0.0326655,0.0195592,0.741095,0.64832,0.770148,0.811399,0.0340549,0.0337445,-0.566647,-0.597067,1.18691,1.32773,0.591021,0.661785,-0.424686,-0.411574,-1.0551,-1.11491,1.01051,1.1037,-1.65665,-1.62575,0.560644,0.440783,0.488898,0.794037,-0.0192491,0.0820558
8934,0.910105,0.924285,0.601236,0.59217,0.924799,0.929731,0.032787,0.0147582,0.767122,0.852386,0.875013,0.898469,0.339901,0.400088,0.618259,0.619825,0.394967,0.437215,0.665316,0.663275,-0.769821,-0.802521,-0.0517134,0.0848108,-0.287945,-0.217385,0.0670111,0.074956,-0.105102,-0.159032,0.330847,0.421607,-2.04568,-2.00807,-0.606529,-0.727359,0.94145,1.25254,1.58696,1.68594
8935,0.946473,0.902526,0.698522,0.691101,0.0176215,0.022821,0.8404,0.821111,0.0787184,0.162502,0.675447,0.6997,0.794906,0.780617,0.890223,0.890503,0.321009,0.417797,0.313774,0.312193,0.807441,0.773556,-1.4974,-1.36424,-0.593656,-0.521902,1.41692,1.42408,-1.19696,-1.24315,0.205559,0.296316,-0.23661,-0.203826,-1.25116,-1.37829,0.69126,0.998843,-1.25687,-1.15288
8936,0.424615,0.381885,0.543351,0.537605,0.772833,0.779289,0.223168,0.203459,0.438704,0.520128,0.977192,1.00109,0.113749,0.0987618,0.781618,0.826317,0.309955,0.398378,0.353608,0.354068,-0.0547328,-0.0929981,-1.19115,-1.05436,-1.99763,-1.92786,2.76089,2.7732,0.338533,0.294468,-0.215682,-0.120016,1.03932,1.0724,-2.30145,-2.42587,-0.148949,0.159206,-0.574303,-0.462705
8937,0.301124,0.283074,0.113336,0.109028,0.758033,0.832975,0.398543,0.41591,0.0376021,0.121614,0.905642,0.944453,0.465751,0.43824,0.760359,0.762132,0.336711,0.37896,0.9385,0.938356,1.94054,1.89546,0.334845,0.473354,-0.863623,-0.791018,-0.0791714,-0.0687466,-0.28658,-0.330658,-0.0665438,0.0305199,-2.24615,-2.2184,0.284203,0.155375,-1.43492,-1.12356,0.123477,0.227466
8938,0.229058,0.184263,0.819165,0.814261,0.881435,0.886661,0.648281,0.628362,0.974142,1.05669,0.863455,0.887814,0.790319,0.777718,0.283517,0.286626,0.583482,0.625036,0.963545,0.964648,2.51473,2.4696,-0.797881,-0.683042,-0.591225,-0.513417,-0.828739,-0.814999,2.0341,1.98923,-1.13244,-1.03431,0.00843287,0.0316386,-0.0276213,-0.157957,0.481869,0.791338,2.34069,2.43839
8939,0.644279,0.549789,0.338062,0.330971,0.298342,0.302957,0.497533,0.47624,0.79921,0.880061,0.533243,0.559234,0.390372,0.37738,0.0214891,0.0247916,0.576489,0.619391,0.228466,0.231532,-1.60135,-1.6427,-1.98108,-1.83944,0.78486,0.864665,-0.769552,-0.756613,-1.29151,-1.32856,-0.799203,-0.699781,1.0337,1.05878,1.51142,1.38299,0.567766,0.879348,0.319886,0.418887
8940,0.961696,0.915316,0.21896,0.212923,0.62136,0.624494,0.63161,0.610392,0.282605,0.361636,0.600148,0.625675,0.952888,0.938893,0.130639,0.135499,0.300038,0.345498,0.240487,0.345288,0.140362,0.102849,1.19905,1.33458,-1.31267,-1.23056,0.966328,0.972384,0.196055,0.162944,0.128069,0.234682,-0.536995,-0.504775,-1.17068,-1.29227,-1.49666,-1.18151,1.04477,1.13689
8941,0.359844,0.314146,0.302145,0.297286,0.254827,0.350275,0.0533466,0.031779,0.439775,0.535281,0.303266,0.326875,0.887907,0.874762,0.632138,0.636733,0.233265,0.279705,0.409258,0.459044,0.174792,0.136774,-0.402588,-0.269758,-1.11667,-1.03171,-0.670998,-0.67152,0.0756632,0.0403094,1.39864,1.50481,-0.816136,-0.778682,-0.104737,-0.224112,0.0137736,0.407112,0.871686,0.962903
8942,0.530941,0.540318,0.659454,0.652812,0.0727923,0.0760557,0.653638,0.634537,0.526876,0.708926,0.804298,0.829222,0.608804,0.593845,0.802749,0.797087,0.464933,0.5117,0.57153,0.5728,-0.618186,-0.65435,0.975888,1.11659,-1.98671,-1.89539,0.145406,0.137954,-1.59911,-1.62889,-1.92707,-1.82354,-0.769511,-0.732783,-0.900697,-1.02734,1.68058,1.99573,1.03094,1.12056
8943,0.813106,0.76649,0.664092,0.657185,0.508568,0.504499,0.672979,0.570452,0.80184,0.882571,0.31242,0.338966,0.797016,0.748014,0.952598,0.957441,0.992992,1.04129,0.978466,0.982114,-1.98592,-2.02546,1.09722,1.23985,-1.20668,-1.11268,0.309403,0.302969,1.11327,1.08073,-0.871945,-0.765149,-0.000737532,0.0343144,-1.02971,-1.15614,0.308334,0.618469,-0.21865,-0.128572
8944,0.762116,0.807861,0.959799,0.953793,0.931198,0.932943,0.52783,0.506367,0.712477,0.837229,0.38054,0.405407,0.918881,0.902183,0.892973,0.896787,0.182277,0.228427,0.359161,0.361414,1.59474,1.55859,3.49799,3.63785,-3.00825,-2.9231,1.10704,1.09739,0.742261,0.713764,-1.29686,-1.19628,-0.81046,-0.777942,1.56221,1.44213,0.551114,0.857773,1.29073,1.38476
8945,0.896314,0.849232,0.606426,0.599611,0.733216,0.736072,0.894128,0.874988,0.711002,0.791888,0.688471,0.711616,0.85942,0.823754,0.185337,0.188155,0.604855,0.649492,0.272192,0.290566,1.34302,1.30817,-1.9427,-1.80646,1.08603,1.16996,-0.831025,-0.833268,-0.20486,-0.234314,-2.4618,-2.36525,0.394703,0.422931,-0.675764,-0.795404,0.162799,0.466409,1.46386,1.5572
8946,0.0276014,-0.0212057,0.836867,0.832026,0.809693,0.812544,0.288633,0.267005,0.0438662,0.127055,0.62746,0.64967,0.728612,0.745325,0.747143,0.750391,0.0628643,0.105003,0.218364,0.219718,-0.110037,-0.140388,1.20973,1.34471,-1.06341,-0.972208,-1.32924,-1.33089,-0.00181676,-0.0305638,-1.00215,-0.913425,2.32704,2.35398,-0.545302,-0.663483,0.300001,0.69743,-0.546433,-0.445362
8947,0.263088,0.163243,0.141987,0.136795,0.346349,0.348116,0.573317,0.518857,0.401721,0.390292,0.934939,0.955879,0.686153,0.666896,0.909536,0.911856,0.946156,0.987824,0.88518,0.889113,-0.492528,-0.528508,1.13976,1.28195,-0.106374,-0.0182714,1.43642,1.43028,-1.1124,-1.14517,0.200301,0.280199,-0.368587,-0.338031,-0.984973,-1.09797,0.63049,0.928452,-1.60365,-1.49411
8948,0.437236,0.347692,0.164635,0.160212,0.893108,0.895601,0.79355,0.77071,0.569656,0.653529,0.706479,0.727417,0.329895,0.397217,0.109764,0.110597,0.479334,0.527799,0.18868,0.191456,-1.18548,-1.22513,1.08592,1.21918,-0.976931,-0.881948,-1.42755,-1.42989,-0.652734,-0.681056,1.38001,1.47382,-0.300029,-0.274832,1.45604,1.34668,-0.587293,-0.288409,-0.192469,-0.0901614
8949,0.583247,0.532141,0.404611,0.449298,0.748065,0.823482,0.195265,0.171876,0.401336,0.401696,0.938218,0.960796,0.144721,0.127538,0.690626,0.694009,0.0275375,0.0677743,0.00276019,0.00604698,-0.135021,-0.17696,-1.19147,-1.06282,1.10781,1.20024,-3.10172,-3.1063,-1.38706,-1.41387,0.193287,0.287702,0.177503,0.201779,0.756667,0.650414,1.03958,1.34324,0.815395,0.915877
8950,0.0925137,0.041086,0.741251,0.738384,0.746389,0.751362,0.741175,0.719267,0.0666415,0.149863,0.186083,0.210668,0.0308985,0.0664678,0.237838,0.243186,0.497148,0.538325,0.18848,0.284862,-1.67206,-1.71772,-0.676992,-0.553263,-1.7325,-1.64124,1.60575,1.60117,-1.2224,-1.25447,-0.0245647,0.0605945,-0.767418,-0.738325,-0.99767,-1.10421,-0.152457,0.154744,1.47876,1.57293
8951,0.853105,0.800927,0.22977,0.225543,0.900389,0.90296,0.101835,0.0820103,0.354819,0.435219,0.2794,0.305904,0.0220793,0.00539726,0.583944,0.613993,0.74371,0.784401,0.55907,0.563676,0.289117,0.240871,0.316874,0.446406,-0.20193,-0.110435,-0.772044,-0.778271,1.261,1.22619,-0.170751,-0.166513,0.466539,0.499791,-0.0444219,-0.145986,-0.11289,0.197029,-0.611107,-0.522532
8952,0.955806,0.901298,0.198283,0.195298,0.00155766,0.006328,0.591731,0.570475,0.625204,0.720575,0.115226,0.143284,0.884061,0.868699,0.979088,0.9848,0.466882,0.505885,0.504837,0.425734,-0.958509,-1.00993,0.320392,0.44871,-0.180025,-0.094604,-1.00566,-1.01239,-0.605382,-0.643461,-0.488036,-0.393621,1.70881,1.73791,0.194208,0.0824598,-0.646251,-0.335558,-0.259914,-0.170598
8953,0.559459,0.505147,0.9093,0.90572,0.135917,0.142761,0.802911,0.78146,0.923927,1.00593,0.850856,0.879337,0.869696,0.856036,0.544038,0.547904,0.795875,0.836424,0.38146,0.287792,0.340968,0.283785,0.971623,1.09692,-1.00191,-0.911955,-1.62145,-1.6317,0.631097,0.590042,1.77472,1.87349,0.153141,0.188871,0.412901,0.310905,-0.602107,-0.279545,-0.4714,-0.390792
8954,0.691383,0.566432,0.993312,0.990083,0.917041,0.925437,0.0966161,0.0741152,0.444164,0.526976,0.721263,0.788117,0.594093,0.49494,0.566657,0.568612,0.787974,0.826008,0.144816,0.14985,-0.571253,-0.630273,-1.80043,-1.67109,-0.0982673,-0.00483335,0.818522,0.811305,1.08868,1.05416,-0.159893,-0.0646624,-0.389116,-0.350833,-0.712479,-0.814165,-0.540142,-0.223532,0.758639,0.844642
8955,0.679794,0.627716,0.0295242,0.0279347,0.521023,0.530354,0.853702,0.832548,0.753012,0.834237,0.603342,0.696896,0.147776,0.133843,0.133969,0.137509,0.223949,0.26049,0.65228,0.658352,0.557616,0.491492,-0.945526,-0.810504,0.0239321,0.115991,-1.21375,-1.21384,-0.312536,-0.354022,-1.1829,-1.08312,0.877898,0.910333,-0.0143198,-0.115079,-0.708252,-0.385806,-0.678336,-0.589535
8956,0.127157,0.07658,0.764962,0.763948,0.815484,0.826636,0.263975,0.244773,0.330306,0.410336,0.577194,0.605675,0.816169,0.801715,0.0260402,0.0305789,0.489761,0.527117,0.594834,0.655809,1.00703,0.941948,2.23904,2.38073,0.554519,0.652267,-0.530591,-0.529294,-0.0826157,-0.12044,1.33802,1.44202,0.662291,0.697891,-0.965399,-1.07134,0.145166,0.465728,-0.689053,-0.596914
8957,0.936507,0.885058,0.282995,0.280658,0.145031,0.157513,0.85605,0.837105,0.279419,0.360566,0.256375,0.286427,0.140862,0.125111,0.576211,0.493422,0.00361941,0.0422143,0.529785,0.653265,-1.12364,-1.19229,-0.598078,-0.460862,0.496436,0.591609,-0.376888,-0.378538,1.09454,1.05063,-1.44219,-1.34498,-0.394353,-0.364716,-1.35535,-1.45879,0.35481,0.67397,-0.977843,-0.890914
8958,0.370525,0.319095,0.0275345,0.0246035,0.332468,0.390496,0.110644,0.0896083,0.728572,0.808769,0.880405,0.911884,0.47978,0.46279,0.951727,0.956266,0.979802,1.01673,0.64465,0.650722,-0.334877,-0.405415,-0.287531,-0.15098,-1.41321,-1.31095,0.54128,0.539917,0.44608,0.396277,0.0276244,0.124672,1.53184,1.56633,-0.155419,-0.255181,1.56549,1.88269,-0.857452,-0.766692
8959,0.733787,0.681563,0.894575,0.894436,0.61118,0.623478,0.958533,0.936285,0.460178,0.54153,0.796116,0.82875,0.18688,0.171057,0.23002,0.237141,0.271091,0.306332,0.288148,0.294936,1.57043,1.5062,1.60407,1.73451,0.13025,0.234981,-1.13094,-1.13649,-0.440273,-0.489031,0.637961,0.738887,0.548114,0.580535,-2.65981,-2.76674,-0.971288,-0.653044,-0.17195,-0.0806306
8960,0.892774,0.841761,0.322508,0.323064,0.280217,0.293733,0.0400501,0.0159396,0.396208,0.475802,0.195941,0.228115,0.245161,0.297615,0.193469,0.201026,0.112919,0.229763,0.660972,0.669414,-0.518172,-0.580411,-1.52835,-1.40149,1.06449,1.17149,0.01239,0.0132904,1.12711,1.08054,0.604255,0.706167,0.599674,0.566208,0.559015,0.444362,-0.796515,-0.475252,-0.390635,-0.300824
8961,0.591498,0.504164,0.209498,0.166718,0.856277,0.871877,0.419548,0.357723,0.0112074,0.0921139,0.556912,0.588208,0.486149,0.424174,0.421767,0.430328,0.117896,0.153193,0.52242,0.529642,0.553784,0.496009,-1.88436,-1.75146,-0.317086,-0.204959,-2.0769,-2.07455,0.87595,0.876603,3.13472,3.2313,0.513521,0.551882,2.65171,2.5296,1.30696,1.6254,-1.20595,-1.12259
8962,0.219181,0.166567,0.00866863,0.010373,0.960823,0.978509,0.72287,0.699507,0.0759956,0.154606,0.0159532,0.0489925,0.493073,0.550733,0.36486,0.366142,0.827462,0.865431,0.0904183,0.0989729,-0.692022,-0.754789,-0.121084,0.0098228,-0.324072,-0.204984,0.639889,0.639125,0.719225,0.672662,1.32473,1.41466,0.244947,0.277975,-0.553945,-0.681422,1.67894,1.99103,0.225603,0.313048
8963,0.495037,0.443245,0.606559,0.606678,0.495345,0.51408,0.237765,0.212593,0.449295,0.495814,0.415359,0.448623,0.693115,0.677292,0.29359,0.301957,0.0430301,0.0805545,0.568754,0.550382,-0.15628,-0.211831,0.321584,0.455736,1.03273,1.15899,-0.428367,-0.432795,-1.27235,-1.32559,2.38432,2.47305,0.792175,0.832124,1.26055,1.13968,-0.340589,-0.0252858,-0.00145982,0.0789005
8964,0.24823,0.19452,0.313602,0.397058,0.248872,0.269625,0.837392,0.809438,0.760462,0.837023,0.57725,0.697296,0.600599,0.583434,0.833575,0.839729,0.808584,0.846961,0.993803,1.00179,-0.420386,-0.478387,-1.1098,-0.978272,1.48413,1.60431,1.17582,1.17178,-0.912114,-0.967249,1.85345,1.94805,-1.62214,-1.58214,0.794634,0.674551,-0.650783,-0.341163,1.29521,1.37492
8965,0.72113,0.666411,0.188499,0.187438,0.742109,0.763023,0.89317,0.863672,0.777089,0.800746,0.912762,0.945969,0.0180744,0.00100662,0.447408,0.453257,0.25732,0.297664,0.819126,0.866079,0.530767,0.475711,-0.813321,-0.682667,-0.533771,-0.407901,1.12295,1.12209,-0.887576,-0.946138,0.145675,0.241358,-0.562204,-0.523131,-1.36587,-1.4914,0.728057,1.04216,-0.0990693,-0.0129912
8966,0.518781,0.462545,0.670071,0.671157,0.894433,0.914621,0.441744,0.411805,0.689178,0.76447,0.518883,0.553836,0.896301,0.88136,0.612156,0.620201,0.0607121,0.100181,0.721635,0.730367,-0.887224,-0.943861,0.413457,0.55189,0.834967,0.956071,-0.658153,-0.662441,0.141619,0.0873286,2.12723,2.21884,-0.915048,-0.875907,-1.58786,-1.7112,-0.280478,0.0257288,-1.20961,-1.12712
8967,0.580509,0.522798,0.257217,0.257464,0.1039,0.123844,0.220602,0.188914,0.573351,0.728194,0.876883,0.913929,0.899151,0.884811,0.363231,0.372204,0.178497,0.219349,0.276612,0.283976,-0.688963,-0.740591,0.0693349,0.201924,-0.318627,-0.203831,1.54904,1.5472,1.53395,1.47339,-0.52968,-0.436162,0.0951565,0.205105,-1.07069,-1.1962,0.383544,0.687322,-1.77647,-1.69371
8968,0.375209,0.318932,0.537078,0.53924,0.36364,0.384528,0.484048,0.440767,0.461119,0.691918,0.0583492,0.0965892,0.35112,0.434212,0.66497,0.586031,0.946002,0.985755,0.360595,0.370097,1.06722,1.01758,-1.07509,-0.948969,0.28481,0.393636,0.939247,0.920497,1.93352,1.87695,-0.048776,0.0410816,1.24197,1.28612,-0.0808916,-0.207031,-1.33234,-1.03749,-1.13898,-1.0518
8969,0.385384,0.343337,0.24797,0.249081,0.4089,0.489335,0.72364,0.69262,0.580734,0.655642,0.957881,0.998171,0.000227245,-0.0163874,0.790017,0.799859,0.446778,0.562382,0.165147,0.174527,0.733593,0.691919,-0.422773,-0.300763,0.62682,0.825987,0.30265,0.293797,-0.989501,-1.04731,-1.21356,-1.12789,0.0909555,0.132395,1.31409,1.1814,-0.422019,-0.126207,0.0633248,0.151872
8970,0.423462,0.367741,0.428576,0.427768,0.539287,0.594141,0.0953966,0.0649434,0.69786,0.775037,0.17522,0.217744,0.229841,0.214587,0.321385,0.328836,0.101384,0.139009,0.624221,0.633542,-2.69461,-2.7442,0.791367,0.919609,1.15727,1.25834,0.888537,0.885914,1.08116,1.01794,0.147146,0.234018,1.24441,1.28787,-1.05995,-1.19992,-2.55837,-2.26573,0.850001,0.945152
8971,0.715096,0.659967,0.394487,0.404357,0.678084,0.698948,0.595764,0.567278,0.454663,0.47709,0.170634,0.214658,0.0162794,-0.00131547,0.204543,0.180448,0.296905,0.405039,0.0574988,0.0679503,-0.721117,-0.77236,-1.31873,-1.18499,-0.438546,-0.330723,0.275133,0.266603,-1.29264,-1.35339,0.621918,0.711262,-1.24989,-1.20466,-1.26007,-1.40497,-0.995502,-0.697893,-1.89098,-1.79218
8972,0.687819,0.730762,0.380453,0.380945,0.947204,0.970216,0.245272,0.215565,0.10346,0.179142,0.660972,0.707284,0.396683,0.38014,0.0220608,0.0320612,0.635811,0.671069,0.227628,0.240122,0.00504613,-0.0466939,1.49363,1.62442,-0.0207535,0.0845659,-1.56686,-1.57967,1.29768,1.23584,-0.780805,-0.692708,0.377817,0.429111,1.37138,1.22783,1.19689,1.50041,1.04115,1.13605
8973,0.858725,0.801558,0.818534,0.820319,0.747652,0.848333,0.753751,0.723406,0.867653,0.943196,0.600436,0.734153,0.05502,0.040103,0.992343,1.00435,0.202824,0.236332,0.808103,0.819456,2.2348,2.18903,0.697775,0.829749,-0.41021,-0.312223,-0.526753,-0.538375,0.244306,0.181986,0.716071,0.806636,0.342109,0.40034,0.217713,0.089569,0.747325,1.04504,1.24967,1.33874
8974,0.351486,0.296066,0.220182,0.224156,0.702592,0.726449,0.140836,0.110393,0.955741,1.03172,0.716806,0.761021,0.741376,0.727624,0.0383568,0.0502654,0.533605,0.566871,0.532072,0.446244,1.72654,1.67439,-2.01446,-1.88483,0.451853,0.548075,-0.41704,-0.435808,0.924309,0.861995,0.439619,0.529723,-0.67604,-0.616334,-0.906493,-1.04869,-0.242742,0.0618207,-0.549856,-0.462024
8975,0.42368,0.330811,0.487418,0.490123,0.276187,0.378409,0.174236,0.119292,0.640272,0.794293,0.519736,0.603867,0.306067,0.291543,0.848967,0.858942,0.254235,0.288355,0.0614041,0.0730324,-0.549692,-0.601996,-0.579585,-0.45248,2.77034,2.87301,0.278047,0.265329,1.08247,1.02139,1.42531,1.50924,0.929435,0.985939,0.556514,0.415458,-0.281848,0.0257669,-0.476928,-0.3938
8976,0.419749,0.365556,0.11363,0.115511,0.00397679,0.0303682,0.182928,0.128191,0.479439,0.556868,0.402246,0.446713,0.39737,0.381177,0.71441,0.646621,0.758495,0.79401,0.650184,0.662167,-1.77303,-1.82289,-1.96107,-1.8391,0.740595,0.749681,0.270318,0.237972,0.466006,0.410768,-0.361673,-0.277017,0.344482,0.400985,-0.762865,-0.934493,-2.3037,-1.99055,1.34331,1.42792
8977,0.0297989,-0.0242669,0.290673,0.294199,0.15453,0.181967,0.168384,0.137089,0.857322,0.934533,0.585823,0.532667,0.872549,0.8577,0.422499,0.434301,0.928178,0.963695,0.771132,0.783615,1.46739,1.4197,0.163501,0.284776,-1.47633,-1.37365,0.225627,0.210616,0.291763,0.242943,1.31919,1.41065,0.800992,0.788025,-2.14424,-2.28444,1.58546,1.89361,0.295294,0.37917
8978,0.402277,0.348036,0.724304,0.728347,0.0291877,0.0557382,0.866931,0.834473,0.0562779,0.133831,0.575273,0.61862,0.76106,0.748471,0.0390615,0.0530306,0.040533,0.0746146,0.346356,0.357661,0.892308,0.845424,-0.158172,-0.0334253,0.272488,0.378969,-1.40725,-1.41702,-0.59101,-0.642365,0.343333,0.438195,1.11497,1.17506,-0.845979,-0.991291,-1.22733,-0.914541,-1.46652,-1.38983
8979,0.567579,0.574208,0.809086,0.81271,0.500691,0.529333,0.93442,0.903537,0.510104,0.586467,0.163349,0.207615,0.412962,0.469267,0.482982,0.495268,0.123401,0.157329,0.265579,0.300527,-0.207057,-0.252708,0.482382,0.614781,1.18787,1.30038,0.760079,0.755274,0.883038,0.834414,0.720528,0.821086,-0.258333,-0.197999,-0.23628,-0.331611,0.110579,0.421356,-0.205819,-0.123768
8980,0.852672,0.80038,0.371567,0.374956,0.743286,0.769387,0.156282,0.123813,0.704017,0.781761,0.0221227,0.064007,0.204268,0.190064,0.673402,0.686898,0.602153,0.637352,0.250542,0.243394,-1.62864,-1.67228,-1.26332,-1.13113,-1.18254,-1.06765,1.5156,1.50388,-1.13724,-1.17832,0.280398,0.372741,0.784345,0.843091,0.469935,0.32807,-0.798616,-0.486385,-1.38618,-1.2982
8981,0.683203,0.606801,0.157693,0.160501,0.649617,0.673404,0.136224,0.0635665,0.448133,0.632585,0.261347,0.302328,0.592046,0.576816,0.519394,0.535652,0.552293,0.587784,0.0832233,0.186261,0.614225,0.563444,-1.16921,-1.03863,-0.321914,-0.207346,0.797095,0.865831,0.935722,0.886931,-1.28159,-1.18332,-0.383741,-0.330291,-1.07872,-1.22573,0.594754,0.913338,-0.769939,-0.687468
8982,0.457649,0.413223,0.879481,0.881221,0.0066847,0.0291133,0.0360193,0.00331979,0.383918,0.483409,0.873782,0.912961,0.405035,0.482943,0.913528,0.927795,0.146969,0.182675,0.0773085,0.129127,0.254831,0.175028,-0.657786,-0.529078,-0.282117,-0.162561,0.242635,0.227785,1.90028,1.84281,1.09519,1.19363,-1.55955,-1.50367,-1.61154,-1.75198,0.761723,1.07646,0.880538,0.961825
8983,0.271936,0.219644,0.752336,0.734329,0.831678,0.854469,0.613825,0.5812,0.256489,0.334233,0.701034,0.740366,0.377116,0.38907,0.00157473,0.0152403,0.515847,0.536549,0.0606887,0.0719938,-0.164285,-0.213389,-0.400867,-0.26586,1.54802,1.66738,-0.0402048,-0.05469,-0.12021,-0.169928,-0.41087,-0.316161,0.299216,0.349182,0.966075,0.829266,0.708281,0.941038,0.546613,0.620725
8984,0.381019,0.330352,0.584764,0.587437,0.734999,0.758487,0.647194,0.613978,0.60653,0.624063,0.176587,0.21611,0.217233,0.295197,0.338164,0.352803,0.855265,0.890423,0.250864,0.264043,-0.326313,-0.375499,-1.13368,-0.997872,0.197588,0.321628,0.463137,0.445057,1.06908,1.01624,-0.635765,-0.547113,0.495266,0.54799,-0.0962295,-0.233067,0.490944,0.805613,-1.92017,-1.84142
8985,0.0721261,0.021306,0.135213,0.13898,0.179985,0.204346,0.994888,0.962765,0.836071,0.913894,0.634954,0.674341,0.216555,0.201325,0.151126,0.165858,0.863079,0.900444,0.91186,0.922427,-0.883481,-0.934068,0.357062,0.496677,-0.789097,-0.666512,-1.09742,-1.11807,1.19398,1.14277,0.638513,0.723017,-0.871859,-0.825074,0.243396,0.12807,-0.723184,-0.411247,2.66894,2.74246
8986,0.204976,0.157133,0.458171,0.460462,0.523683,0.470658,0.819798,0.734647,0.27908,0.355349,0.426425,0.53848,0.967476,0.950837,0.280406,0.296879,0.410677,0.445862,0.851747,0.86409,-1.89408,-1.93997,0.0726155,0.207663,-0.200599,-0.0830825,-0.841367,-0.861644,0.483095,0.428144,-0.84549,-0.757843,0.909035,0.960015,0.630854,0.489208,1.00237,1.31556,0.66711,0.7399
8987,0.774424,0.728593,0.0785782,0.0816726,0.712785,0.736971,0.553228,0.506528,0.622457,0.697947,0.249578,0.402619,0.271757,0.254442,0.813034,0.829462,0.382454,0.416116,0.26289,0.273429,2.09008,2.04229,1.52929,1.67314,-0.63515,-0.524498,-1.77845,-1.79516,1.41809,1.36937,0.813614,0.89738,-0.975911,-0.932292,-0.758857,-0.898453,0.535971,0.84591,0.443721,0.519707
8988,0.1365,0.0922302,0.938409,0.941125,0.612951,0.683157,0.310533,0.27841,0.559625,0.727134,0.225286,0.266759,0.855607,0.835593,0.966203,0.980726,0.7331,0.7674,0.509595,0.521776,-1.23131,-1.28443,-0.236379,-0.0893836,-1.36461,-1.2501,1.11642,1.09667,0.780904,0.729179,1.20689,1.29596,1.81816,1.862,-0.662517,-0.874319,0.540648,0.855223,-1.20331,-1.12682
8989,0.136924,0.0927976,0.888775,0.932301,0.60339,0.629344,0.89618,0.865715,0.679497,0.75632,0.19264,0.234622,0.463346,0.444256,0.345422,0.359483,0.18107,0.212906,0.0214772,0.0358317,-0.58165,-0.553356,0.453815,0.60282,-0.575051,-0.46739,1.00813,0.984955,-2.22408,-2.27294,-0.259988,-0.169186,-1.31184,-1.27467,-0.700444,-0.850184,-0.0561852,0.177083,1.17786,1.24826
8990,0.88121,0.836765,0.918527,0.923477,0.828982,0.854945,0.853043,0.824024,0.38913,0.46369,0.637413,0.677826,0.434974,0.415869,0.506171,0.520948,0.0732782,0.187672,0.497059,0.509836,0.225236,0.177719,1.63356,1.788,0.569205,0.68234,-0.365159,-0.393248,0.315623,0.26401,2.00698,2.09793,-1.5218,-1.48711,0.429548,0.278729,-0.813674,-0.501056,0.623902,0.655293
8991,0.166131,0.122163,0.551561,0.554372,0.680139,0.72549,0.416251,0.387788,0.550632,0.623931,0.00932097,0.0479115,0.167607,0.149908,0.143802,0.15881,0.131937,0.162437,0.128871,0.143676,-1.75178,-1.80023,2.27312,2.43621,-0.725812,-0.614606,-0.0899779,-0.120708,-1.10361,-1.1586,0.246098,0.34316,0.179308,0.207311,-1.17872,-1.33701,-0.574523,-0.261753,-0.00939495,0.0623257
8992,0.373345,0.253412,0.472079,0.533253,0.570143,0.596034,0.358492,0.318657,0.710015,0.784173,0.104742,0.143147,0.146994,0.126927,0.95631,0.972719,0.389479,0.418585,0.650559,0.663264,-0.00652273,-0.0546738,1.88296,1.98481,-3.13047,-3.01405,-1.58486,-1.62323,0.3942,0.3329,0.848092,0.941574,-0.152329,-0.129626,-0.411698,-0.578092,0.723996,1.04015,0.183833,0.249154
8993,0.426912,0.38466,0.509989,0.512134,0.0764761,0.101753,0.16689,0.249526,0.670271,0.737258,0.531513,0.49117,0.386988,0.368039,0.394617,0.411563,0.174272,0.205197,0.251836,0.262703,0.347869,0.304767,1.36575,1.53341,1.49624,1.61683,0.00710977,-0.0360083,0.635252,0.566483,-0.409995,-0.322024,-1.10294,-1.08352,1.26548,1.10354,1.11551,1.43705,-0.320104,-0.343813
8994,0.206218,0.165425,0.688945,0.690821,0.847528,0.87298,0.20782,0.180396,0.612976,0.690343,0.798871,0.839193,0.384426,0.366319,0.281389,0.295745,0.898264,0.927729,0.922111,0.932097,-2.1448,-2.19352,0.522868,0.691391,1.99781,2.12035,-0.428989,-0.473274,-0.454725,-0.517635,0.112518,0.20013,-0.392478,-0.376479,0.532466,0.374995,-0.654281,-0.338881,-1.00456,-0.93678
8995,0.37078,0.374613,0.0638197,0.0652691,0.357737,0.465424,0.428184,0.400741,0.819969,0.895564,0.178743,0.219021,0.967713,0.94747,0.0942211,0.179927,0.97904,1.01044,0.563024,0.600311,1.7023,1.64636,0.119283,0.28091,-1.50198,-1.38046,0.748151,0.70643,-0.0988477,-0.159289,1.63663,1.71574,0.524821,0.544743,0.324629,0.169947,0.55137,0.869835,0.771287,0.838922
8996,0.624841,0.583801,0.526871,0.528346,0.0324612,0.0578687,0.951152,0.923665,0.207482,0.281137,0.926983,0.965149,0.187509,0.166794,0.0471632,0.0641092,0.673318,0.706592,0.25945,0.268525,-1.68912,-1.74582,0.0972484,0.252839,-0.238854,-0.123618,1.30506,1.26796,-0.00755329,-0.0615201,-1.10505,-1.0221,-0.0161789,-0.0343535,1.46662,1.31132,-0.327735,-0.00394772,-0.897753,-0.822371
8997,0.476453,0.435659,0.240649,0.242685,0.926144,0.950056,0.918489,0.891654,0.0490784,0.125263,0.81621,0.851787,0.512846,0.3994,0.754806,0.771479,0.723785,0.755659,0.782401,0.792958,-1.42772,-1.47994,0.754733,0.916005,-0.251231,-0.0444281,-0.796908,-0.836257,1.19577,1.14081,0.310979,0.399612,-0.640306,-0.61345,-0.546455,-0.695934,1.83759,2.15895,-0.122047,-0.0460174
8998,0.869745,0.828607,0.429902,0.431422,0.37272,0.395915,0.00636157,-0.0199789,0.358933,0.340517,0.110175,0.146766,0.653776,0.632006,0.233233,0.250381,0.174962,0.206363,0.605863,0.639859,-0.240688,-0.330489,-0.381612,-0.219636,-0.0728526,0.034762,-0.776743,-0.810356,0.429507,0.37789,0.214549,0.306543,-0.70314,-0.673245,1.86911,1.71514,0.815617,1.14251,-0.0634623,0.00681648
8999,0.466535,0.408829,0.338317,0.415869,0.764053,0.787834,0.524343,0.49807,0.496743,0.555772,0.251218,0.286702,0.755229,0.732442,0.110804,0.129252,0.0662393,0.0990831,0.475671,0.486759,0.871168,0.818956,-0.245497,-0.00566169,0.0039864,0.113952,0.211877,0.186854,0.344948,0.285789,0.786958,0.874072,-0.506411,-0.474438,-1.10672,-1.26606,0.0457508,0.37869,1.46499,1.53432
9000,0.0318145,-0.0109482,0.399147,0.400317,0.847554,0.869763,0.611405,0.574717,0.695478,0.771026,0.737361,0.773846,0.199772,0.175008,0.746005,0.764192,0.50169,0.533982,0.677582,0.688745,-0.512397,-0.568825,0.0537138,0.208313,-0.958526,-0.84166,1.99981,1.98129,-0.205853,-0.262986,1.6183,1.69898,0.978215,1.00503,1.10746,0.943039,0.763501,1.10318,2.58973,2.66168
9001,0.591409,0.550304,0.168543,0.170421,0.372053,0.394788,0.678286,0.651365,0.131556,0.20712,0.269939,0.308309,0.989485,0.965291,0.682504,0.698438,0.356536,0.473372,0.26198,0.272751,0.765676,0.710848,2.02547,2.18633,0.216936,0.340193,1.19406,1.17371,-0.00332539,-0.0592361,-0.417104,-0.334713,0.544405,0.513736,-1.67656,-1.83617,-1.60676,-1.26381,-0.451567,-0.379151
9002,0.918844,0.877881,0.738174,0.741804,0.835804,0.858346,0.755948,0.728012,0.25324,0.326515,0.590644,0.628416,0.586132,0.567858,0.340342,0.356346,0.382145,0.412762,0.595111,0.606376,0.115185,0.0599615,-0.374139,-0.211639,0.157959,0.279535,-0.0385715,-0.052235,0.448474,0.388535,0.258919,0.340233,-0.00656105,0.0224397,1.96486,1.79843,-1.03525,-0.695236,-0.212419,-0.165866
9003,0.510387,0.46795,0.610336,0.642463,0.333086,0.354209,0.422512,0.395241,0.160138,0.294582,0.123027,0.16288,0.197099,0.170424,0.782793,0.798583,0.578178,0.608345,0.608606,0.621724,1.16882,1.10813,-1.995,-1.83162,1.01681,1.13983,0.316322,0.296157,-0.614627,-0.680596,0.415527,0.490769,1.48856,1.51424,-0.616779,-0.777089,-0.0580654,0.27824,-0.0264843,0.0474193
9004,0.540725,0.498381,0.446333,0.543123,0.977675,0.99792,0.762294,0.733823,0.155152,0.262649,0.850366,0.888742,0.991198,0.96548,0.30289,0.317503,0.416973,0.445551,0.975543,0.986914,0.804886,0.750209,-0.0401857,0.131516,0.179889,0.306164,-0.490495,-0.511422,-0.137369,-0.202512,-1.94098,-1.85654,-0.631366,-0.611883,1.32871,1.16987,0.263413,0.596818,-0.136516,-0.0660581
9005,0.168045,0.124058,0.438476,0.443783,0.783262,0.771849,0.428169,0.401052,0.158291,0.230716,0.264401,0.303789,0.673087,0.667851,0.427165,0.443263,0.50178,0.608783,0.266808,0.27905,0.681152,0.620448,1.07053,1.2409,1.30061,1.42626,-0.18047,-0.183072,0.803705,0.738717,1.19439,1.27725,0.0827799,0.0951588,0.0798421,-0.0769064,-1.07373,-0.734689,0.998084,1.0613
9006,0.305549,0.259884,0.528888,0.533001,0.626353,0.545778,0.859923,0.834468,0.575132,0.648219,0.987287,1.02515,0.394592,0.370222,0.850367,0.86462,0.743397,0.772014,0.446863,0.461375,-0.0183887,-0.0761729,0.362777,0.539758,-0.822697,-0.699876,0.160754,0.145277,1.43986,1.3716,-0.817191,-0.739305,-1.23111,-1.21763,0.496953,0.346301,-0.228206,0.116845,-1.19271,-1.12775
9007,0.785645,0.7412,0.857741,0.863867,0.414606,0.319707,0.777858,0.705834,0.384869,0.456161,0.384911,0.424511,0.349251,0.316324,0.0967034,0.109105,0.666124,0.697071,0.0693545,0.085199,0.493129,0.437862,0.00499761,0.228276,-0.270683,-0.147916,1.06782,1.04872,0.968311,0.898583,0.614648,0.699181,2.1447,2.15548,1.21749,1.06091,0.206052,0.544333,0.429517,0.493213
9008,0.443455,0.400965,0.0324173,0.0390227,0.0733905,0.0936356,0.605211,0.577201,0.589641,0.661383,0.561552,0.595541,0.284556,0.262427,0.45049,0.461458,0.960912,0.993202,0.817663,0.833464,0.490137,0.428582,-0.260729,-0.0832063,-1.08542,-0.965267,0.977459,0.952932,-0.337972,-0.401672,0.906428,0.98842,0.207884,0.215237,-0.342849,-0.492893,1.00809,1.34537,-0.045081,0.0177537
9009,0.918699,0.877927,0.223407,0.290984,0.865725,0.887913,0.816233,0.788186,0.162114,0.232915,0.729547,0.766571,0.440043,0.417785,0.509716,0.444509,0.121477,0.154158,0.595111,0.612815,0.115384,0.054841,-1.02814,-0.847683,0.92802,1.0518,2.23587,2.2105,1.49685,1.42982,0.653286,0.741628,0.182681,0.186465,-0.179491,-0.330754,0.240718,0.609874,0.380143,0.445664
9010,0.712666,0.67406,0.537896,0.542944,0.816038,0.838889,0.146416,0.116215,0.349228,0.417973,0.0689993,0.106647,0.0554848,0.032024,0.461854,0.427561,0.472493,0.505442,0.614863,0.635004,-1.75739,-1.8144,1.27766,1.45344,1.23744,1.35968,-1.6051,-1.63047,-0.604067,-0.670777,-0.170426,-0.0767425,-0.131665,-0.134566,0.873216,0.720483,-0.46238,-0.125618,1.89507,1.95899
9011,0.84309,0.804075,0.0637217,0.0693012,0.518483,0.612632,0.521181,0.490057,0.312441,0.383617,0.631268,0.667935,0.317713,0.293597,0.399645,0.410612,0.206251,0.240584,0.260723,0.279218,0.18166,0.128597,-0.871957,-0.701114,-0.574279,-0.450742,-0.256249,-0.282327,-0.530087,-0.603668,-0.22935,-0.138992,1.24345,1.23637,0.377632,0.209387,-1.99754,-1.66003,-0.812103,-0.74002
9012,0.504156,0.46384,0.0839783,0.0883348,0.364472,0.386374,0.5479,0.518012,0.593175,0.665714,0.552992,0.589706,0.965192,0.941537,0.264237,0.274233,0.545918,0.601495,0.985012,1.00253,-0.674906,-0.722901,-0.860693,-0.685031,0.163038,0.287258,-0.792122,-0.825501,-0.114508,-0.185051,1.26822,1.36035,-0.76636,-0.767178,-0.152607,-0.301708,0.343357,0.684618,0.00519576,0.0829339
9013,0.498183,0.459197,0.733884,0.738371,0.456645,0.477492,0.852418,0.822429,0.106534,0.176888,0.253858,0.290906,0.407714,0.384103,0.386468,0.395532,0.927733,0.962407,0.259426,0.274344,0.598166,0.556772,1.25025,1.42288,0.0813442,0.211504,0.153283,0.123352,0.0824827,0.0186986,-0.650581,-0.564421,1.11915,1.11753,1.33852,1.19218,0.360902,0.800168,-0.695999,-0.619075
9014,0.193761,0.154538,0.279548,0.285154,0.75187,0.773774,0.195616,0.165172,0.0640052,0.178718,0.352521,0.347943,0.571696,0.625325,0.073156,0.0834552,0.180928,0.214978,0.996034,1.0083,-0.93622,-0.983992,-1.27125,-1.1019,0.720565,0.856372,-1.24405,-1.2716,-1.43003,-1.49672,-0.988448,-0.902836,0.471668,0.473396,0.518391,0.394089,0.569117,0.915717,0.835129,0.908429
9015,0.224481,0.184969,0.470005,0.477934,0.578214,0.601935,0.331095,0.335515,0.108688,0.180548,0.366349,0.404979,0.891506,0.866546,0.697128,0.708901,0.248939,0.249661,0.866374,0.87909,-0.750169,-0.795037,0.149786,0.315917,-1.82504,-1.68498,-0.400243,-0.431592,1.51886,1.45025,0.955043,1.04176,0.639984,0.641557,-0.252207,-0.403998,0.897776,1.25016,-1.46759,-1.39314
9016,0.988916,0.94934,0.932267,0.94101,0.837078,0.86262,0.538061,0.505857,0.948938,1.01947,0.198286,0.237342,0.646336,0.620482,0.955607,0.969535,0.253797,0.284344,0.34015,0.353102,0.0427014,-0.00816111,0.210939,0.378607,-1.14149,-1.00834,0.722555,0.685573,0.987893,0.918216,-0.965047,-0.883016,-0.18564,-0.184488,-0.145107,-0.30195,-0.934221,-0.586977,1.19698,1.27448
9017,0.895382,0.857275,0.798878,0.82131,0.214408,0.2385,0.276873,0.296703,0.0206534,0.0911021,0.501614,0.543552,0.0772231,0.0530697,0.430616,0.443726,0.283342,0.319026,0.100433,0.113446,-1.05849,-1.10629,2.02106,2.18299,-0.102138,0.0350325,1.52002,1.47999,-0.854369,-0.920856,-0.42084,-0.301536,-0.0803754,-0.0761908,1.71895,1.56532,1.94615,2.28706,-0.414308,-0.341655
9018,0.471648,0.431651,0.691792,0.701609,0.16779,0.194228,0.12143,0.0875477,0.606134,0.676516,0.231915,0.275674,0.241116,0.218627,0.247646,0.261553,0.779958,0.81477,0.0905991,0.103206,1.52927,1.48303,0.263148,0.420471,0.43839,0.571309,0.438006,0.428701,-0.210828,-0.337663,0.190891,0.279945,1.35884,1.35622,0.0369984,-0.112445,-1.8814,-1.53461,0.345272,0.421336
9019,0.426076,0.384759,0.907647,0.918939,0.559077,0.586147,0.986127,0.951323,0.51842,0.558664,0.856545,0.901131,0.0647685,0.0437353,0.501965,0.517261,0.275608,0.309658,0.824992,0.837165,0.385491,0.33978,0.980627,1.14255,-0.806586,-0.678848,-0.582563,-0.622588,0.309461,0.24553,-0.729622,-0.646267,-0.142289,-0.143427,1.11203,0.969212,0.174292,0.516006,0.417279,0.489561
9020,0.898742,0.85665,0.286063,0.298067,0.577571,0.602574,0.55673,0.519426,0.335801,0.440813,0.857455,0.817649,0.483332,0.505202,0.443551,0.488765,0.544263,0.576284,0.869974,0.8842,0.416426,0.422839,-0.659741,-0.493669,0.369491,0.503004,-0.38692,-0.426846,-0.160732,-0.22749,-0.264127,-0.184698,-0.0438479,-0.0512545,0.745797,0.596516,0.992309,1.33334,-1.06294,-0.987532
9021,0.79034,0.729814,0.821167,0.835302,0.0103855,0.0338416,0.813424,0.774587,0.254052,0.322962,0.675155,0.734167,0.989485,0.966669,0.446237,0.46027,0.0396143,0.071172,0.569687,0.583272,0.558518,0.505899,-0.538784,-0.293604,-0.740661,-0.610239,0.182104,0.0720733,-0.110291,-0.176345,0.859712,0.933998,0.324901,0.317274,0.725241,0.57325,-0.776385,-0.442589,1.61918,1.69695
9022,0.562341,0.602978,0.343845,0.357865,0.0875681,0.047513,0.309813,0.271658,0.360833,0.339467,0.606098,0.650684,0.977617,0.954005,0.00772181,0.0233742,0.517438,0.54662,0.7732,0.770761,-0.145387,-0.190722,-0.258059,-0.0935401,1.65288,1.77895,0.610545,0.570993,1.73886,1.67042,0.60054,0.672845,-0.48024,-0.494983,1.13743,0.981211,0.867707,1.29168,-1.24109,-1.15889
9023,0.517281,0.476142,0.193061,0.209041,0.0719594,0.0611844,0.121231,0.0842171,0.287483,0.355972,0.0220213,0.0657314,0.430459,0.40715,0.715759,0.730744,0.0796091,0.107414,0.944468,0.95825,0.806164,0.763376,-0.929997,-0.76477,0.910098,1.04099,0.405816,0.36826,0.32985,0.262237,-0.402672,-0.330856,0.315814,0.301937,-1.23411,-1.38368,2.69433,3.02595,-1.76535,-1.68051
9024,0.656128,0.616496,0.601887,0.619125,0.123736,0.0748558,0.880214,0.84265,0.693779,0.763931,0.0379521,0.082426,0.288974,0.342237,0.0906649,0.104365,0.845321,0.87382,0.519463,0.603024,0.26699,0.220063,0.814792,0.978386,0.437574,0.568506,-0.873799,-0.918772,0.128181,0.0634238,-0.134275,-0.0565292,-1.51174,-1.52765,-1.62826,-1.77113,1.42566,1.76188,1.02919,1.11109
9025,0.500893,0.545601,0.438602,0.455916,0.072347,0.0885272,0.335823,0.299082,0.195449,0.265684,0.694911,0.738924,0.3034,0.277324,0.292041,0.306205,0.934381,0.961993,0.236497,0.247798,-0.577527,-0.631436,-1.54295,-1.38649,0.397834,0.524152,-0.593482,-0.630354,-0.824612,-0.884654,0.879712,0.953038,1.12078,1.10854,-0.889983,-1.02705,0.827095,1.16855,1.27705,1.35745
9026,0.516057,0.474706,0.965389,0.983669,0.156345,0.102199,0.639047,0.6035,0.843949,0.915904,0.87762,0.923708,0.235331,0.212411,0.976286,0.991991,0.677118,0.791333,0.610386,0.619274,0.749388,0.694245,-0.480691,-0.409097,-0.852323,-0.726005,1.19374,1.16408,-1.11714,-1.17306,-0.210131,-0.142881,-0.750202,-0.766721,-1.9655,-2.10643,-0.966317,-0.621598,-0.924161,-0.846711
9027,0.184692,0.144992,0.86429,0.848454,0.035797,0.11587,0.561087,0.525176,0.0527349,0.126159,0.860213,0.886643,0.383144,0.3582,0.755144,0.845802,0.591111,0.620672,0.978372,0.990751,1.03866,0.977174,0.411827,0.568292,-1.29492,-1.16742,0.403732,0.373277,0.306388,0.258387,-2.03256,-1.95952,-2.22537,-2.23534,0.0506808,-0.0817422,0.702832,1.04228,-0.985823,-0.874165
9028,0.436716,0.396107,0.702423,0.713239,0.106085,0.129541,0.747993,0.71068,0.719738,0.791404,0.709885,0.849579,0.0157525,-0.00810155,0.654913,0.699613,0.841821,0.872416,0.595293,0.621121,-0.102525,-0.166076,0.121832,0.279278,-0.966605,-0.844707,0.986863,0.94989,1.1619,1.10733,-0.484067,-0.412867,1.04992,1.03858,0.0887402,-0.0427333,-1.62875,-1.29344,-0.980869,-0.90162
9029,0.311423,0.272163,0.558653,0.578023,0.818511,0.840267,0.443093,0.408249,0.198087,0.268389,0.768646,0.812515,0.286359,0.315981,0.536221,0.553424,0.498715,0.527554,0.241722,0.251491,0.146398,0.0850828,0.325293,0.48125,-1.98297,-1.86431,-1.95015,-1.99563,-1.47897,-1.53059,-0.355689,-0.290352,-1.07585,-1.08755,1.20501,1.07018,-0.0408262,0.291028,-0.410966,-0.335645
9030,0.512537,0.503374,0.128674,0.149446,0.93807,0.961415,0.370437,0.335103,0.244017,0.31588,0.520823,0.564266,0.663642,0.640063,0.678872,0.705644,0.360678,0.389151,0.596825,0.605373,1.09247,1.02412,-0.27386,-0.113856,0.304825,0.429685,0.0726345,0.0222215,-0.0223866,-0.0695917,0.0141727,0.0750424,0.305926,0.299079,0.0902509,-0.0909491,0.621554,0.952621,-1.17313,-1.09845
9031,0.773222,0.734584,0.293364,0.283974,0.5844,0.662145,0.758901,0.723873,0.063885,0.133563,0.666495,0.709251,0.59825,0.575932,0.841824,0.857865,0.65373,0.698787,0.009376,0.0196785,-0.606349,-0.670177,0.44984,0.60822,-0.592129,-0.464749,0.247786,0.203277,-0.798307,-0.846167,-0.400402,-0.34129,1.37022,1.35809,-1.11725,-1.25208,-0.657728,-0.330146,0.544169,0.613803
9032,0.315731,0.279487,0.39903,0.418502,0.340234,0.362875,0.738861,0.701968,0.655612,0.72353,0.212821,0.253423,0.220236,0.199969,0.529435,0.545788,0.979356,1.00842,0.188243,0.197234,1.4614,1.39761,-0.678547,-0.527421,0.993985,1.11565,1.8305,1.7905,-1.23345,-1.2743,-1.27371,-1.22154,-0.345702,-0.361424,-1.38456,-1.51891,1.69275,2.0145,1.86453,1.94019
9033,0.986296,0.950708,0.529847,0.55303,0.585013,0.608197,0.477383,0.48932,0.53763,0.605908,0.347041,0.388589,0.912197,0.89279,0.971491,0.988026,0.390808,0.419374,0.134902,0.143282,-0.473518,-0.531687,-0.892705,-0.739535,0.716825,0.84191,0.169506,0.128911,-2.24315,-2.28388,-0.236484,-0.179073,-0.608089,-0.619844,0.760217,0.628507,0.966058,1.28213,-0.560011,-0.489324
9034,0.744296,0.707046,0.220867,0.24244,0.548316,0.539951,0.400861,0.276672,0.422315,0.488286,0.0353403,0.0748282,0.19907,0.18054,0.165055,0.180722,0.403389,0.434342,0.643838,0.565793,-1.19695,-1.26043,-0.245392,-0.166043,1.28284,1.40897,-0.875091,-0.910527,0.852535,0.8125,0.0620953,0.122986,0.265788,0.160252,1.31138,1.1747,-1.68259,-1.36391,-0.192578,-0.121428
9035,0.89507,0.857138,0.445367,0.4653,0.446142,0.471705,0.101189,0.0640239,0.496503,0.540518,0.845039,0.884754,0.551104,0.532523,0.796385,0.810945,0.772131,0.804807,0.980065,0.988304,-0.536011,-0.596675,0.251803,0.407448,0.59206,0.716525,-1.67745,-1.71811,0.155379,0.111295,-0.471649,-0.415969,0.956365,0.940347,-0.04003,-0.18138,-0.53032,-0.218088,0.587266,0.654926
9036,0.609548,0.57309,0.14163,0.15933,0.163586,0.186966,0.724059,0.686597,0.526939,0.592749,0.340416,0.379381,0.0403933,0.0209225,0.0738054,0.0862347,0.554044,0.585966,0.455882,0.462316,-1.42605,-1.49462,0.397646,0.547156,0.906321,1.02441,-1.05701,-1.09606,0.25033,0.209064,-1.00851,-0.954924,-1.57353,-1.58758,-0.780376,-0.92489,0.849572,1.16524,0.212903,0.282708
9037,0.902375,0.865315,0.393905,0.312625,0.67114,0.695196,0.882659,0.846221,0.208106,0.275069,0.44767,0.488424,0.290868,0.273087,0.881182,0.894911,0.623092,0.654391,0.28773,0.292136,-0.219456,-0.292637,0.247698,0.385129,0.268277,0.393483,0.88044,0.840454,-0.487252,-0.523746,0.859465,0.914648,-0.114438,-0.124019,0.481784,0.337888,-1.77566,-1.46022,-0.948693,-0.875441
9038,0.566512,0.530163,0.450234,0.46592,0.5121,0.533266,0.0590979,0.0242677,0.945138,1.01358,0.273236,0.278884,0.990813,0.970335,0.218569,0.232807,0.408301,0.447891,0.56562,0.640388,-1.65673,-1.7283,0.0759,0.223102,-1.05955,-0.934895,-1.45219,-1.48869,1.72361,1.67926,1.41206,1.46714,0.368366,0.447065,1.38924,1.25033,0.0457157,0.361868,0.776232,0.848384
9039,0.752759,0.716193,0.0876616,0.101406,0.0773805,0.0979375,0.90662,0.870945,0.310421,0.378687,0.0295652,0.0693435,0.995272,0.973787,0.257583,0.273126,0.209939,0.241392,0.982465,0.988641,-0.446448,-0.514016,0.508891,0.653669,1.1779,1.3096,0.921936,0.878775,0.241443,0.195662,-1.58217,-1.52395,1.02523,1.01815,0.524292,0.386874,-0.0622938,0.248251,0.0953132,0.16296
9040,0.702485,0.66482,0.859819,0.872261,0.145047,0.194139,0.286499,0.253292,0.885239,0.952981,0.269466,0.307665,0.23976,0.219109,0.94073,0.954716,0.668321,0.701689,0.447422,0.452799,-0.328306,-0.402569,0.23645,0.379665,-0.758635,-0.626285,-1.13476,-1.17917,-0.946524,-0.992696,0.0863727,0.147281,-0.334003,-0.340195,0.0533073,-0.0782541,-0.817738,-0.501977,1.05119,1.12247
9041,0.0829121,0.0441035,0.0702263,0.0843789,0.268009,0.29034,0.192433,0.160321,0.36753,0.434555,0.90857,0.948471,0.85124,0.830481,0.357639,0.369663,0.230606,0.262483,0.150831,0.157392,2.00895,1.93898,1.5697,1.71849,-0.0306236,0.0960151,-0.28081,-0.323081,-1.77094,-1.81746,0.735633,0.791317,0.0317646,0.0283335,0.0888867,-0.0392452,-1.24811,-0.926347,0.351604,0.483015
9042,0.0249252,-0.0125654,0.0769617,0.184225,0.90727,0.929481,0.43862,0.398698,0.518162,0.604652,0.367911,0.409256,0.59909,0.579658,0.797745,0.811901,0.48577,0.518631,0.895609,0.901309,-0.949829,-1.01335,0.0745465,0.223613,-0.225485,-0.101577,-1.33729,-1.38098,0.134164,0.0899079,-0.436703,-0.377653,1.28941,1.2895,1.0565,0.934027,0.766402,1.08921,-0.249544,-0.156442
9043,0.185595,0.0657231,0.191493,0.284071,0.942651,0.965848,0.671015,0.637076,0.706288,0.774749,0.490019,0.528874,0.94557,0.927359,0.871483,0.883488,0.471138,0.469578,0.664482,0.670492,0.615867,0.546615,0.358622,0.50288,0.0806384,0.206304,-1.49248,-1.53867,0.0767689,0.03027,0.0851308,0.144501,-2.17889,-2.18355,-0.685798,-0.807755,-0.568598,-0.242294,-0.867178,-0.795898
9044,0.203233,0.144012,0.369302,0.383917,0.111138,0.136036,0.180016,0.144365,0.484869,0.552592,0.264577,0.30596,0.0311586,0.0118654,0.73932,0.713217,0.384896,0.420525,0.0778708,0.0847975,1.83065,1.7609,0.0742155,0.213865,-0.5035,-0.379903,1.57055,1.52158,-3.72029,-3.76707,0.282886,0.342574,0.221359,0.215103,1.85945,1.73994,0.871437,1.20291,1.5603,1.62844
9045,0.203337,0.2223,0.913597,0.926174,0.683635,0.708583,0.470872,0.53051,0.730836,0.799317,0.738454,0.77842,0.195263,0.177423,0.528503,0.542945,0.711502,0.746622,0.176014,0.0864549,1.33247,1.27706,-1.37905,-1.23519,0.305742,0.435495,-0.00700655,-0.0568134,-0.537524,-0.582892,-0.635854,-0.569764,0.234524,0.297416,-1.83781,-1.95621,0.953853,1.29092,-0.623606,-0.560605
9046,0.336174,0.300589,0.898305,0.838232,0.696904,0.720589,0.951823,0.916656,0.328272,0.395238,0.606765,0.597141,0.711832,0.693708,0.917195,0.929557,0.508087,0.543816,0.0822138,0.0881123,0.902005,0.79321,1.91302,2.06088,0.897024,1.03296,0.84119,0.7832,-0.251356,-0.301841,-0.00966329,0.0585678,0.379087,0.379729,0.874806,0.761509,-1.26466,-0.927039,-0.400872,-0.344356
9047,0.849807,0.812507,0.736892,0.75029,0.498448,0.530377,0.046003,0.0108671,0.387101,0.424424,0.376697,0.415861,0.123954,0.106401,0.368519,0.378579,0.592054,0.62653,0.851657,0.858777,0.379112,0.309365,1.73944,1.89406,0.275721,0.415607,1.00583,0.948215,0.914522,0.869227,-0.301041,-0.233335,-0.686475,-0.682878,0.264503,0.206345,-0.992735,-0.656583,-0.425816,-0.367392
9048,0.395951,0.35741,0.380191,0.396108,0.229968,0.340165,0.954778,0.919919,0.387704,0.453611,0.700865,0.740998,0.733393,0.717772,0.450724,0.45935,0.436917,0.436443,0.538065,0.543009,0.644792,0.575247,-1.13145,-0.977777,-0.602144,-0.463563,-0.554553,-0.614916,0.173211,0.12191,-0.815928,-0.743935,-1.95219,-1.94582,-0.231895,-0.34882,-0.344911,-0.0104145,-1.28145,-1.21995
9049,0.545202,0.507501,0.261528,0.27806,0.126268,0.149953,0.768416,0.732478,0.066623,0.131235,0.526996,0.568403,0.440428,0.426039,0.858337,0.865795,0.214009,0.246357,0.824518,0.831114,1.52906,1.45172,0.921334,1.08041,-0.43411,-0.297061,1.75992,1.69649,1.14688,1.09517,-0.409483,-0.332269,-0.770443,-0.761052,-0.588581,-0.707756,-0.834595,-0.494929,-0.885807,-0.823219
9050,0.00782925,-0.0287559,0.545655,0.559836,0.879303,0.901294,0.922987,0.88711,0.824525,0.88986,0.141802,0.18095,0.578488,0.566257,0.49108,0.499009,0.465096,0.442094,0.608945,0.634558,-1.65402,-1.73597,0.210473,0.364217,-1.49859,-1.36291,-0.784811,-0.852608,-2.08479,-2.14334,-2.13688,-2.05457,-0.164715,-0.161357,1.71995,1.60071,0.390204,0.728647,0.375198,0.442845
9051,0.955769,0.918216,0.196457,0.210119,0.752013,0.775066,0.454771,0.420452,0.764387,0.830011,0.112442,0.151138,0.382832,0.31568,0.77255,0.780041,0.605979,0.637831,0.432665,0.438002,-0.842973,-0.919643,-0.00649726,0.152103,0.329072,0.467026,1.12218,1.05246,1.26632,1.21,-0.00355218,0.0822871,-0.451885,-0.450929,-0.161892,-0.283757,0.713456,1.04723,-0.770729,-0.701291
9052,0.270204,0.231489,0.744681,0.757987,0.117394,0.140924,0.601509,0.613536,0.401863,0.466584,0.0817457,0.121326,0.0775449,0.0651038,0.357292,0.363549,0.656159,0.706991,0.485414,0.490676,-0.521978,-0.59195,-0.710315,-0.549039,-2.01147,-1.86826,1.8033,1.73701,1.08057,1.02667,0.768833,0.862044,-0.439797,-0.537347,0.897019,0.76748,-1.75705,-1.42429,1.63715,1.70622
9053,0.620939,0.583311,0.0912157,0.101714,0.861426,0.887084,0.842374,0.806619,0.417801,0.395283,0.548685,0.588925,0.115799,0.138544,0.207609,0.199754,0.742439,0.776151,0.81959,0.824301,-0.866379,-0.980367,-0.466837,-0.301717,0.841156,0.987623,1.7328,1.6707,-0.924537,-0.971585,0.339645,0.430916,-0.626905,-0.623766,0.921024,0.790458,-0.465159,-0.138126,-1.14115,-1.07363
9054,0.147868,0.112841,0.742505,0.751751,0.342349,0.368292,0.520658,0.483398,0.257135,0.323982,0.44733,0.485331,0.223228,0.211984,0.0284046,0.0359594,0.098295,0.131473,0.788681,0.794929,-1.30587,-1.36878,0.537103,0.697953,0.315939,0.467409,-0.48532,-0.54138,1.26468,1.21503,0.996726,1.08892,-2.03697,-2.02833,0.441633,0.310228,-2.41418,-2.08529,-1.02481,-0.9605
9055,0.185796,0.149129,0.878469,0.855769,0.611808,0.63956,0.196525,0.160176,0.529289,0.595687,0.572339,0.610236,0.719003,0.708837,0.137731,0.185086,0.646681,0.681142,0.977147,0.982122,0.907291,0.837316,1.29864,1.45246,-1.21639,-1.05932,-0.113594,-0.0912617,-0.918755,-0.965088,-1.89737,-1.80823,3.00261,3.01124,1.94924,1.81898,-0.847731,-0.604496,-0.330014,-0.260972
9056,0.672106,0.635856,0.951733,0.959788,0.252167,0.358672,0.54325,0.508963,0.159881,0.226917,0.0957941,0.135273,0.86657,0.854627,0.327835,0.334212,0.208649,0.241936,0.806915,0.811942,-1.86227,-1.92756,0.332219,0.487812,0.25375,0.41006,0.411956,0.358857,0.11558,0.0683784,-0.435613,-0.338581,0.288397,0.301381,0.347983,0.219481,0.547414,0.876301,0.37732,0.438556
9057,0.497571,0.463858,0.577654,0.585176,0.0477706,0.0777845,0.375083,0.344152,0.264127,0.330716,0.803243,0.841796,0.638098,0.628259,0.868499,0.876992,0.753641,0.786872,0.019748,0.0264511,0.372127,0.308165,2.59855,2.75635,0.66896,0.825349,0.0934356,0.0458483,-1.35137,-1.40029,-1.05615,-0.95887,-0.820836,-0.807466,0.683352,0.551367,-0.467224,-0.140131,0.0517446,0.112967
9058,0.523281,0.488927,0.493588,0.501845,0.541055,0.571182,0.212991,0.179341,0.0431026,0.108558,0.381436,0.420482,0.182391,0.172356,0.651457,0.660948,0.0377748,0.0709503,0.523048,0.530408,-0.0217166,-0.0799548,0.676923,0.834621,0.446024,0.596535,-1.12174,-1.20847,0.255534,0.213247,0.492118,0.587787,-1.34604,-1.33064,-1.13536,-1.27036,0.352582,0.677203,-0.966004,-0.906321
9059,0.0751216,0.0430803,0.912352,0.920958,0.126912,0.156757,0.558914,0.55831,0.186767,0.221637,0.227098,0.267525,0.686493,0.674672,0.437519,0.444904,0.452189,0.486472,0.345433,0.355076,0.673978,0.615047,-0.988126,-0.833625,-2.00355,-1.85184,-2.4152,-2.46279,-2.92238,-2.96111,1.04391,1.14028,-0.323044,-0.303497,0.407119,0.27059,-1.07234,-0.74592,-0.593997,-0.538425
9060,0.306267,0.27493,0.0401228,0.0474426,0.970104,0.999209,0.972748,0.937279,0.27107,0.334716,0.392503,0.432687,0.196395,0.183563,0.921082,0.926934,0.328018,0.332603,0.69615,0.70468,0.787886,0.726495,0.57054,0.726519,-0.421942,-0.271441,0.554792,0.507334,-0.208767,-0.251499,-0.384107,-0.292137,-0.106535,-0.0906616,1.59655,1.4571,0.148703,0.477656,-0.654905,-0.604742
9061,0.786505,0.756245,0.962803,0.968405,0.0208527,0.0515861,0.801212,0.751905,0.895248,0.958903,0.26692,0.247389,0.697399,0.685879,0.506307,0.510442,0.145916,0.178733,0.68287,0.690483,-0.0747708,-0.14006,0.90273,1.05135,-1.41988,-1.27512,-1.15078,-1.20034,-1.37579,-1.41259,0.190088,0.275392,0.62727,0.646402,-1.04775,-1.18439,0.9013,1.23136,0.686348,0.736369
9062,0.499229,0.453655,0.00893071,0.0126746,0.140883,0.172734,0.510985,0.566532,0.577714,0.605266,0.0223672,0.0620918,0.502954,0.503811,0.777758,0.731448,0.240801,0.348483,0.0856159,0.0949066,-0.24759,-0.315794,-1.05632,-0.901315,-0.614803,-0.476095,1.75969,1.70976,0.277288,0.246795,-0.999021,-0.910729,-1.07237,-1.05889,0.278069,0.14063,1.12151,1.45659,0.387976,0.442368
9063,0.180953,0.151064,0.888322,0.891334,0.745405,0.776293,0.415869,0.381158,0.189017,0.251629,0.855377,0.891996,0.333539,0.321744,0.950168,0.952454,0.485417,0.518234,0.782744,0.794537,1.28181,1.21357,-0.135361,0.0199478,-1.6461,-1.5113,0.670853,0.621126,0.115381,0.0789698,-0.461841,-0.374689,-0.966337,-0.950592,-0.666542,-0.800397,-0.280267,0.0482773,-0.58001,-0.530762
9064,0.411652,0.382914,0.908702,0.832051,0.0906111,0.122898,0.622778,0.587845,0.896223,0.957346,0.253867,0.291361,0.765089,0.753395,0.428436,0.431355,0.955791,0.988784,0.25077,0.263082,1.24376,1.17434,-1.3622,-1.20782,1.47075,1.59809,-0.869494,-0.91036,0.235867,0.205494,-1.86954,-1.77866,-2.56817,-2.54655,0.359944,0.222429,-0.0284398,0.303582,0.433588,0.490688
9065,0.391801,0.288068,0.768381,0.772768,0.759874,0.79248,0.405653,0.370321,0.329897,0.389422,0.31402,0.411222,0.502811,0.492693,0.656831,0.660657,0.492725,0.5239,0.782565,0.79258,-0.199476,-0.274223,-0.425264,-0.270262,-1.14363,-1.0174,0.0278842,-0.00691549,0.580299,0.547808,1.81137,1.89653,-0.647258,-0.629819,0.876559,0.737424,-0.970205,-0.636012,0.595782,0.648349
9066,0.221057,0.193222,0.419801,0.42305,0.818088,0.809294,0.676542,0.640854,0.636621,0.608297,0.494969,0.531082,0.909037,0.899662,0.271512,0.274185,0.344876,0.375708,0.953336,0.964752,-0.348446,-0.392834,0.986433,1.14755,-0.218924,-0.0959872,0.124592,0.0956516,-0.813846,-0.845091,-0.0461323,0.035042,-0.823418,-0.81155,-0.375205,-0.509355,-0.24859,0.0884742,-0.0541834,-0.00809124
9067,0.934689,0.909105,0.525147,0.527054,0.795511,0.826107,0.0929556,0.0575675,0.766881,0.827172,0.866358,0.90064,0.323379,0.312355,0.524308,0.434539,0.961648,0.991755,0.706129,0.659928,-0.438815,-0.511445,0.229605,0.383077,1.43325,1.56062,1.02711,0.999097,-1.18276,-1.21205,0.462606,0.542138,0.614866,0.620861,-0.122075,-0.186722,2.03052,2.36492,1.46268,1.50524
9068,0.736662,0.710852,0.134353,0.137457,0.434343,0.466485,0.792506,0.754952,0.0844778,0.146987,0.749704,0.783255,0.282015,0.256283,0.592328,0.594893,0.557067,0.547072,0.344639,0.355104,0.251931,0.183558,0.231354,0.385381,1.46656,1.59127,0.429133,0.393577,-0.0324829,-0.0576423,-0.431605,-0.355402,-1.02314,-1.0191,0.273703,0.13591,1.11847,1.45718,1.22838,1.27109
9069,0.974704,0.947064,0.434366,0.438892,0.927229,0.959883,0.434803,0.397939,0.745464,0.807372,0.24545,0.277882,0.272971,0.20021,0.09666,0.0992087,0.070219,0.10239,0.260672,0.204386,1.57425,1.50924,-0.3706,-0.209725,-0.575259,-0.455151,-1.37798,-1.4046,-1.71361,-1.74237,1.44861,1.53143,0.116169,0.118794,0.855942,0.712286,0.607936,0.940662,-0.626017,-0.57789
9070,0.850596,0.802884,0.0586908,0.0642797,0.976339,0.943702,0.454795,0.413549,0.486145,0.635912,0.529224,0.561985,0.0578287,0.144138,0.843319,0.846159,0.40128,0.432929,0.0453459,0.0536675,-0.160436,-0.231366,-0.44937,-0.28419,-0.531559,-0.410366,0.857773,0.836528,-0.985923,-1.01669,1.06047,1.23277,-0.125436,-0.124884,-2.4875,-2.63351,0.81157,1.1489,1.24034,1.29202
9071,0.629223,0.658704,0.156934,0.10013,0.893573,0.927522,0.454068,0.42916,0.400322,0.464451,0.218452,0.252942,0.199007,0.0880656,0.993758,0.997423,0.264641,0.291564,0.278194,0.286447,-0.00917186,-0.0734058,1.14456,1.30584,1.11132,1.23233,-1.27576,-1.29774,-1.19839,-1.22979,0.842769,0.934113,-0.150798,-0.153656,1.16246,1.01645,-1.01819,-0.675123,0.403104,0.45594
9072,0.544549,0.514524,0.130153,0.135981,0.191989,0.223231,0.454357,0.444771,0.577097,0.639537,0.64582,0.681929,0.043017,0.0319933,0.35081,0.356472,0.116036,0.150199,0.889987,0.900084,-1.03122,-1.09531,-0.381084,-0.221309,-0.112987,0.0107736,0.449461,0.431259,0.296537,0.261712,-0.760998,-0.668208,-0.884059,-0.891057,-1.19073,-1.33163,-0.625683,-0.266575,0.75337,0.807874
9073,0.633019,0.605571,0.417459,0.501077,0.192034,0.296526,0.497246,0.460381,0.0970485,0.160582,0.543671,0.578335,0.203688,0.201472,0.642697,0.647106,0.20952,0.243096,0.486893,0.499523,0.0659596,-0.00386033,-0.618502,-0.465213,-0.76573,-0.635355,0.324615,0.21403,-0.740987,-0.777305,0.289118,0.356092,0.550186,0.541354,-0.0541274,-0.190259,-0.204551,0.141973,-1.61708,-1.5607
9074,0.9318,0.902882,0.862073,0.866173,0.338716,0.369822,0.284262,0.316716,0.187647,0.249105,0.908281,0.942654,0.383958,0.370951,0.482353,0.485879,0.554387,0.525987,0.440119,0.37344,-0.241572,-0.315392,2.48603,2.63261,-2.55543,-2.42845,0.019242,-0.00319922,-1.14202,-1.1738,1.28763,1.38039,1.34535,1.33827,1.35863,1.22943,1.53062,1.8828,1.40339,1.46147
9075,0.31779,0.286777,0.284378,0.289502,0.545972,0.575191,0.210403,0.173051,0.0545238,0.117481,0.310071,0.34202,0.33025,0.303033,0.319537,0.324653,0.773473,0.808878,0.231719,0.247357,1.73454,1.65645,-0.162892,-0.0173979,-0.107139,0.0150907,0.0795578,0.0551866,1.46896,1.43351,-2.08731,-1.99806,-0.214178,-0.225284,1.64797,1.51611,1.5847,1.93854,1.59863,1.66416
9076,0.411791,0.382362,0.669262,0.674268,0.432435,0.463658,0.40488,0.369343,0.941229,1.00257,0.806519,0.839501,0.2465,0.235115,0.460672,0.46605,0.714728,0.749109,0.696048,0.711441,1.36849,1.24117,0.253117,0.398753,-0.636305,-0.520334,0.642516,0.59198,0.852631,0.822885,0.777499,0.869134,0.78581,0.774585,1.0126,0.880527,0.817178,1.17471,-0.161343,-0.0912007
9077,0.213228,0.184109,0.691754,0.780969,0.872282,0.902983,0.978286,0.941791,0.695545,0.827791,0.869421,0.901053,0.753217,0.741537,0.13939,0.144131,0.364121,0.399497,0.111095,0.125746,0.909609,0.825889,0.0240004,0.167763,0.201895,0.311668,1.15673,1.12877,-1.29071,-1.32395,-0.582221,-0.488739,0.153417,0.145807,-0.515453,-0.643738,-1.28669,-0.932952,-0.364832,-0.295544
9078,0.363461,0.329103,0.884782,0.88767,0.303149,0.334251,0.136801,0.0998757,0.589909,0.653015,0.239842,0.271139,0.550652,0.491719,0.707135,0.711641,0.823463,0.859794,0.853177,0.869663,0.838304,0.754762,-0.903561,-0.764488,-0.058111,0.0528571,-1.30683,-1.33697,-0.291301,-0.322093,-1.41111,-1.32311,0.133112,0.131827,-1.09902,-1.23267,0.728134,1.08261,0.463953,0.52741
9079,0.598172,0.474097,0.213871,0.216652,0.545105,0.586451,0.617916,0.582478,0.748248,0.81219,0.799093,0.832426,0.207622,0.241902,0.983013,0.987903,0.665979,0.701377,0.362487,0.378985,-0.496944,-0.586686,-0.810317,-0.671983,-1.53161,-1.42848,-1.24396,-1.27858,-0.861433,-0.885986,-0.862337,-0.770613,0.934899,0.928747,0.254229,0.124947,-1.71088,-1.35255,-1.43341,-1.36625
9080,0.606844,0.619092,0.112826,0.11339,0.804709,0.838652,0.228112,0.190703,0.594783,0.71026,0.0998649,0.133105,0.00376475,-0.00791587,0.66681,0.67141,0.0554584,0.0911237,0.264752,0.279955,-1.43559,-1.5286,1.27484,1.41628,0.474032,0.572918,-0.699584,-0.730529,-0.126654,-0.145141,0.533434,0.621753,-0.778991,-0.790769,1.85341,1.72908,-0.19274,0.170158,-1.47634,-1.40462
9081,0.793205,0.764086,0.91509,0.914942,0.266751,0.299582,0.19048,0.0803459,0.545293,0.60833,0.987156,1.02025,0.00115267,0.0885115,0.84657,0.852532,0.94285,0.979612,0.921082,0.938339,1.15867,1.06073,-1.16411,-1.02517,-0.99001,-0.893673,0.192456,0.157331,0.158415,0.135909,-0.192532,-0.104675,-0.210262,-0.189279,-0.904977,-1.03157,0.642458,1.00447,-2.77037,-2.69998
9082,0.775051,0.744006,0.0781863,0.0780741,0.501186,0.477245,0.00954486,-0.0300118,0.442458,0.5064,0.684517,0.716549,0.195418,0.184939,0.461673,0.50506,0.946156,0.985054,0.0991816,0.11765,-0.729268,-0.823198,0.175961,0.313663,-1.67843,-1.58612,0.797576,0.764225,-0.501085,-0.518442,-1.62215,-1.5371,0.426437,0.41221,-1.18101,-1.31253,1.85902,2.22805,-0.761854,-0.694635
9083,0.354164,0.323687,0.547376,0.546436,0.678286,0.654909,0.604819,0.566833,0.664935,0.72708,0.819856,0.851715,0.0627068,0.0508136,0.153136,0.157587,0.130767,0.172189,0.831448,0.851608,0.362672,0.268254,0.63881,0.837765,0.509498,0.606438,0.0959318,0.0663565,-0.372769,-0.391917,0.263724,0.34974,-0.244509,-0.262389,1.7808,1.64771,0.0855615,0.45212,-0.242086,-0.175182
9084,0.491602,0.459514,0.0960126,0.0932183,0.799741,0.832573,0.973592,0.935454,0.502641,0.565714,0.0483306,0.0815983,0.840836,0.831487,0.22407,0.229175,0.0356082,0.0767238,0.856883,0.818488,-0.578984,-0.673658,1.22644,1.36187,-0.194419,-0.10087,-1.97872,-2.00686,0.306783,0.288091,-0.69805,-0.607187,0.225456,0.137771,-0.686803,-0.816629,-1.21912,-0.845898,2.21727,2.2841
9085,0.287619,0.255648,0.858027,0.854949,0.418772,0.453241,0.594617,0.557838,0.761979,0.826781,0.167265,0.201216,0.455765,0.445726,0.876458,0.883988,0.87374,0.916538,0.766716,0.785368,0.0981255,0.00634494,2.12071,2.25362,-3.04292,-2.94235,0.605887,0.575256,0.168641,0.150597,-0.962926,-0.86834,0.559346,0.537932,-0.938365,-1.06812,-0.711497,-0.337722,-0.599898,-0.535739
9086,0.305839,0.207082,0.28664,0.283577,0.78972,0.826027,0.0134782,-0.0254489,0.625532,0.703123,0.956637,0.989722,0.99466,0.982126,0.604071,0.611455,0.325471,0.367241,0.999392,1.01815,-0.65381,-0.752254,-0.822842,-0.694117,-1.0082,-0.908415,-0.419683,-0.449293,-1.80324,-1.81567,-0.0546096,0.0356366,0.0832031,0.0608102,-0.310986,-0.446595,0.588179,0.964181,-0.646053,-0.534098
9087,0.191177,0.158516,0.0736094,0.0691225,0.11611,0.15223,0.206044,0.165128,0.513923,0.579466,0.0433579,0.0744608,0.836015,0.823076,0.710508,0.717792,0.213667,0.255253,0.61584,0.632834,-2.26804,-2.36758,1.08475,1.20364,-0.0879769,0.0129993,-1.1918,-1.22567,1.14817,1.1313,1.15444,1.24593,0.825057,0.797874,-0.0627628,-0.190813,1.35944,1.73378,-0.590634,-0.532458
9088,0.364056,0.355027,0.229975,0.248474,0.346682,0.381882,0.727317,0.688052,0.158445,0.225948,0.888413,0.92047,0.108366,0.0952441,0.121536,0.126469,0.344245,0.384623,0.930513,0.946271,-0.300534,-0.395733,0.847284,0.959741,0.146638,0.243948,-0.332258,-0.415852,0.939776,0.918204,0.715944,0.814799,0.550917,0.523967,-1.8629,-1.99753,0.172283,0.545291,-0.298256,-0.240232
9089,0.584205,0.551539,0.430797,0.427826,0.118838,0.154455,0.415489,0.374951,0.420533,0.487015,0.258184,0.290555,0.903272,0.8903,0.291827,0.297664,0.215796,0.257655,0.0320862,0.0458078,0.519197,0.420589,-1.18603,-1.07113,1.0643,1.16536,0.427828,0.393963,-0.454333,-0.474695,-3.13247,-3.03517,0.898642,0.87782,-1.33842,-1.46647,0.130569,0.509237,1.16915,1.22586
9090,0.153649,0.120777,0.999629,0.994309,0.820486,0.854817,0.633874,0.595296,0.102219,0.169335,0.811152,0.84224,0.712936,0.701316,0.730659,0.734846,0.38688,0.49911,0.413814,0.510396,2.55769,2.45735,-1.2077,-1.0992,-0.479469,-0.37796,-1.30067,-1.33066,0.390084,0.374251,-0.311657,-0.21361,0.539158,0.525044,1.2766,1.14841,1.04446,1.42052,-0.858159,-0.808425
9091,0.00474161,-0.0273653,0.541665,0.536091,0.215227,0.250437,0.03299,-0.00801765,0.433585,0.501515,0.629995,0.659662,0.999484,0.987862,0.683461,0.688327,0.698376,0.740565,0.962832,0.974985,0.640078,0.542941,0.0698386,0.179377,-1.78581,-1.68985,1.78501,1.76295,0.336616,0.314613,-1.66319,-1.57148,-1.61169,-1.63226,1.81742,1.6946,0.897737,1.27432,-0.876653,-0.831461
9092,0.473901,0.439301,0.831988,0.826959,0.955546,0.991308,0.0845801,0.0462162,0.00535434,0.0730479,0.969313,0.999238,0.520314,0.506237,0.013307,0.0164294,0.497851,0.537759,0.712344,0.73665,-0.224676,-0.323614,0.309923,0.411167,-0.467411,-0.370454,0.668402,0.645139,1.44683,1.42273,0.359331,0.454156,1.96619,1.93791,-0.906164,-1.03645,0.955347,1.33701,-0.618098,-0.570063
9093,0.727814,0.695742,0.626314,0.622014,0.40104,0.437167,0.597519,0.464772,0.920909,0.989505,0.0194045,0.0493296,0.907661,0.89299,0.782021,0.783672,0.803118,0.843534,0.412195,0.498315,-0.381615,-0.485724,-1.20327,-1.09921,-0.539088,-0.446209,-0.7609,-0.780635,0.269096,0.246639,1.40434,1.49662,0.0447611,0.0153897,0.270952,0.137106,1.02064,1.39971,-0.108931,-0.065833
9094,0.483561,0.504106,0.680186,0.675817,0.821734,0.855396,0.920129,0.883329,0.120352,0.188803,0.101427,0.130152,0.676527,0.661665,0.908877,0.909432,0.34962,0.388951,0.248259,0.259979,0.162324,0.0572338,-0.225344,-0.115824,0.357625,0.445664,-0.190478,-0.204021,0.552554,0.527689,-0.0872627,0.000560183,0.0253654,0.00140881,2.05499,1.92626,-0.0684787,0.308759,1.52062,1.56761
9095,0.345453,0.31247,0.467452,0.461362,0.867988,0.902081,0.733558,0.695888,0.0169932,0.0875137,0.856998,0.887018,0.957245,0.94273,0.120085,0.122755,0.840737,0.879745,0.311961,0.326155,0.0371322,-0.0725279,1.0743,1.17981,-0.730535,-0.635441,-0.0130534,-0.0229658,-2.29592,-2.32388,0.156391,0.244807,-1.00914,-1.03026,-0.00689722,-0.125864,0.381547,0.752017,-0.294473,-0.247049
9096,0.453704,0.418472,0.631363,0.625097,0.543397,0.577623,0.155393,0.117274,0.153797,0.222392,0.543049,0.573258,0.839149,0.805147,0.0819477,0.0866407,0.783173,0.915957,0.377906,0.392331,-1.91174,-2.01807,0.14492,0.247562,-0.176819,-0.0834816,1.07361,1.06359,-1.46739,-1.49064,1.11699,1.20833,-0.258763,-0.277465,-0.0887592,-0.209812,-0.693696,-0.325443,1.00335,1.04897
9097,0.791073,0.755572,0.358902,0.354345,0.561319,0.495674,0.126287,0.0904018,0.86412,0.934338,0.790658,0.821366,0.679733,0.667564,0.508079,0.467485,0.914385,0.952169,0.882282,0.896289,0.24116,0.138809,0.751115,0.849409,1.72822,1.82412,0.56442,0.550133,-0.0458912,-0.0752386,-0.0705686,0.0222092,0.925278,0.9073,0.465174,0.349454,1.32328,1.69012,-0.46984,-0.428123
9098,0.552609,0.517106,0.770931,0.764429,0.471268,0.413724,0.96459,0.926848,0.800017,0.868611,0.58129,0.612178,0.331471,0.316934,0.844614,0.848329,0.708122,0.744536,0.426208,0.440073,-0.253489,-0.360003,0.0257239,0.117397,-0.615459,-0.527659,-1.5876,-1.6002,1.14957,1.12709,1.20215,1.29234,0.506844,0.493185,-0.723623,-0.835767,-1.48079,-1.11803,1.3817,1.42444
9099,0.109641,0.0765981,0.295371,0.290785,0.298158,0.331774,0.547207,0.480732,0.3308,0.400306,0.111603,0.142102,0.919885,0.903197,0.168858,0.170972,0.260512,0.294738,0.505637,0.508631,-2.49235,-2.60532,1.38496,1.4728,0.485259,0.575985,1.37462,1.35771,1.03357,0.973856,1.02723,1.12355,-0.868244,-0.879879,-1.48998,-1.60821,-2.73637,-2.36874,1.66792,1.71666
9100,0.0120406,0.0674313,0.978358,0.975414,0.619187,0.554312,0.073705,0.0346163,0.807136,0.878216,0.463613,0.492988,0.45281,0.437466,0.727966,0.72887,0.790094,0.824331,0.66257,0.577189,0.648993,0.537473,-1.3502,-1.2567,0.286702,0.378393,0.655605,0.682029,0.848365,0.820618,-0.385203,-0.294429,0.59414,0.583686,-0.881886,-1.00175,-0.88273,-0.514987,-0.601262,-0.551485
9101,0.0887999,0.0582645,0.887012,0.881449,0.744911,0.77685,0.987055,0.950121,0.462516,0.534641,0.564119,0.592211,0.443919,0.430038,0.16514,0.167713,0.817158,0.848675,0.63375,0.645746,0.904974,0.788632,0.712289,0.801486,-0.595979,-0.500777,0.030844,0.00634749,0.189324,0.166267,0.892084,0.975701,-1.23704,-1.24591,0.599342,0.475891,0.62366,0.990589,-0.999357,-0.953517
9102,0.746792,0.714658,0.193019,0.186219,0.735973,0.76832,0.829492,0.785227,0.642298,0.714678,0.123774,0.150657,0.83353,0.821089,0.422044,0.42342,0.536668,0.542373,0.594206,0.607228,0.356108,0.245319,1.04354,1.12632,0.358016,0.453159,0.334257,0.310209,1.53215,1.50488,1.21818,1.29599,-0.167974,-0.173425,-0.740584,-0.864717,0.681575,1.04633,-0.725377,-0.675426
9103,0.520661,0.491099,0.87932,0.870847,0.0930785,0.124029,0.713154,0.620333,0.0774884,0.150772,0.567496,0.500952,0.119483,0.10884,0.887813,0.890326,0.206397,0.236071,0.22178,0.325682,-1.35856,-1.46587,-0.660577,-0.571255,0.765185,0.901463,0.887439,0.858263,0.722012,0.69673,-0.459325,-0.380512,0.0300467,0.0253828,0.642005,0.523713,-0.119864,0.250763,0.348166,0.333344
9104,0.0856345,0.0552978,0.0550476,0.0460028,0.876309,0.906705,0.492674,0.45544,0.260463,0.335829,0.822642,0.851247,0.0730428,0.0605946,0.935278,0.935715,0.723644,0.751156,0.0315866,0.044135,-1.34672,-1.46044,-0.228725,-0.140687,1.25389,1.34977,1.9407,1.91481,-1.59908,-1.62531,0.908799,0.981395,-2.4718,-2.48285,-0.985833,-1.10719,-1.13881,-0.765669,1.29513,1.34211
9105,0.451177,0.423056,0.730824,0.720792,0.550623,0.582247,0.797728,0.759857,0.0905443,0.235617,0.188751,0.215872,0.675426,0.66111,0.0249308,0.0231605,0.513068,0.488298,0.520915,0.533605,0.0150436,-0.102997,-1.39988,-1.30674,-0.765482,-0.66245,-0.192441,-0.219458,0.108392,0.0800941,-0.601557,-0.528392,-0.162942,-0.163833,-0.435473,-0.561,-1.28667,-0.911873,-0.190365,-0.150229
9106,0.26365,0.234393,0.438561,0.38951,0.542434,0.573716,0.438475,0.48119,0.0619059,0.135404,0.61624,0.644858,0.40939,0.395149,0.658166,0.6581,0.195925,0.225439,0.236292,0.248162,0.920193,0.805737,1.73317,1.82583,0.819836,0.917946,-0.290927,-0.315248,1.10755,1.08195,-1.12463,-1.0534,0.103042,0.0957436,-1.7503,-1.87238,-0.353929,0.0156976,-0.000603243,0.0365991
9107,0.405038,0.374747,0.06818,0.0582287,0.00743775,0.039901,0.238535,0.202523,0.975204,1.04791,0.712944,0.664066,0.802236,0.7862,0.268589,0.344222,0.152402,0.231587,0.401333,0.358222,0.669681,0.555322,0.545763,0.644747,1.47445,1.57727,0.482571,0.463038,0.627594,0.608929,1.67965,1.7499,-0.470838,-0.572235,-0.944538,-1.06652,-0.629246,-0.253786,-1.35584,-1.3205
9108,0.834764,0.802611,0.842292,0.833807,0.297312,0.331357,0.41196,0.4409,0.116212,0.187962,0.652737,0.683273,0.922052,0.906269,0.0314307,0.0303432,0.206711,0.237735,0.457467,0.468281,-0.695522,-0.815789,1.28255,1.38439,-1.54167,-1.44107,-0.740599,-0.762905,0.756862,0.735454,1.30475,1.38093,-1.16331,-1.24021,1.52049,1.39523,-0.625138,-0.244474,0.0497451,0.0834449
9109,0.854596,0.823049,0.547967,0.538495,0.254489,0.335586,0.71564,0.679278,0.733584,0.807179,0.102441,0.133926,0.765056,0.747219,0.514102,0.512373,0.693979,0.722743,0.240204,0.252981,-0.276663,-0.395938,-1.13847,-1.04219,-1.73566,-1.63866,-0.514391,-0.534415,1.65482,1.6312,-1.80657,-1.7278,-1.9009,-1.90819,0.655079,0.531773,0.656553,1.04169,0.912986,0.952316
9110,0.465515,0.433225,0.493392,0.484013,0.247115,0.339815,0.685012,0.647266,0.998725,1.07349,0.457403,0.489214,0.386576,0.371256,0.735815,0.736298,0.395865,0.423575,0.486369,0.501329,-0.852431,-0.970212,-1.12649,-1.02611,-0.18899,-0.0927295,1.53789,1.51325,0.331837,0.313752,0.53287,0.616051,-0.0482083,-0.0553369,-0.943437,-1.06772,-0.29581,0.0870711,-0.474316,-0.435594
9111,0.974824,0.940379,0.655414,0.647747,0.279431,0.344044,0.897687,0.858251,0.780371,0.856433,0.424401,0.485808,0.968759,0.952407,0.290281,0.289986,0.690532,0.719706,0.960521,0.975333,-0.932693,-1.05639,1.23018,1.3251,-0.057662,0.0451345,0.512912,0.4887,-0.28268,-0.296872,0.118054,0.199719,-0.100733,-0.115132,0.193381,0.0736458,-0.844452,-0.459758,-0.945092,-0.812394
9112,0.765884,0.676672,0.220068,0.209992,0.264148,0.348273,0.0644038,0.0261792,0.000554017,0.0769033,0.449766,0.482402,0.252028,0.234628,0.460647,0.461181,0.436778,0.499685,0.544852,0.51668,-0.0324479,-0.161273,0.498176,0.593089,-2.58207,-2.4782,-1.15176,-1.17289,-1.26473,-1.2758,0.33062,0.414081,0.531783,0.443924,-0.788593,-0.912678,0.473445,0.857097,-1.23073,-1.18919
9113,0.390399,0.412964,0.19848,0.290923,0.318457,0.352502,0.718414,0.678443,0.031141,0.108866,0.125092,0.159178,0.509939,0.404236,0.107683,0.109059,0.250628,0.279663,0.0422223,0.0580269,-0.74551,-0.873541,-0.547785,-0.44893,0.219207,0.322291,-0.248881,-0.269448,0.709767,0.69903,-0.327075,-0.238252,1.01655,1.00298,-0.288603,-0.351682,-0.802536,-0.425671,0.337569,0.383858
9114,0.183701,0.149257,0.282824,0.371854,0.926501,0.960365,0.379165,0.341027,0.325255,0.400819,0.496305,0.5374,0.681149,0.573844,0.681186,0.682676,0.211573,0.232636,0.469003,0.486626,-2.28511,-2.4143,1.06106,1.15577,1.27047,1.36566,-0.108054,-0.135433,-0.317535,-0.324972,-0.0705671,0.0201859,-1.55727,-1.57577,0.3406,0.209314,1.437,1.81792,-3.45904,-3.41517
9115,0.877933,0.844923,0.375533,0.452784,0.0263341,0.0601775,0.522069,0.486071,0.94026,1.01492,0.880454,0.915623,0.762074,0.743453,0.0744459,0.0766774,0.156492,0.185609,0.219478,0.23681,1.36235,1.23768,-0.89146,-0.796894,-0.286858,-0.191089,0.332583,0.30371,-0.168199,-0.183233,0.937636,1.02975,1.51996,1.50152,2.19524,2.06101,-1.00765,-0.631835,0.16558,0.212672
9116,0.230384,0.198737,0.54379,0.533715,0.809668,0.842854,0.161502,0.123986,0.865976,0.939889,0.60271,0.637835,0.847076,0.827278,0.0787118,0.146638,0.797358,0.82808,0.318556,0.337221,1.25915,1.13585,-2.27192,-2.18352,-0.117216,-0.0245871,0.0273505,0.00595969,0.594286,0.572321,1.5234,1.61309,0.827314,0.864943,0.415142,0.275075,-1.1203,-0.745452,-1.99241,-1.94383
9117,0.0291131,-0.00512942,0.865799,0.855197,0.561389,0.624769,0.506731,0.438515,0.395402,0.471585,0.615719,0.672511,0.650248,0.632331,0.212191,0.216599,0.725574,0.84255,0.708734,0.726224,-0.230556,-0.359208,-2.65738,-2.56518,0.570896,0.667377,0.551001,0.537456,-2.83412,-2.85608,-0.933149,-0.844181,0.30928,0.22837,-0.352753,-0.49737,-0.17059,0.198489,0.370911,0.415967
9118,0.148595,0.115089,0.496212,0.486092,0.255043,0.406684,0.789124,0.753043,0.473337,0.550335,0.654333,0.707186,0.918828,0.898748,0.543663,0.548457,0.826164,0.857019,0.567129,0.586453,-1.3994,-1.53168,0.102344,0.192014,-1.74008,-1.63842,-1.86848,-1.88016,-1.44461,-1.47002,1.82406,1.91786,-0.389761,-0.408203,0.226897,0.0107839,0.313817,0.688886,-0.711753,-0.66692
9119,0.563447,0.52841,0.793546,0.7827,0.155414,0.188599,0.0498078,0.0148352,0.891923,0.967839,0.646983,0.741862,0.437239,0.417123,0.135472,0.141238,0.324604,0.357266,0.642807,0.66226,0.268887,0.135708,-0.304316,-0.218466,1.24304,1.35229,-0.0198822,-0.0377461,-0.412421,-0.436553,-0.23551,-0.147302,0.856214,0.892374,0.660495,0.518938,-0.198373,0.172371,-0.388463,-0.344045
9120,0.0675178,0.0330158,0.599135,0.658285,0.75734,0.792158,0.785728,0.752184,0.567419,0.645462,0.741411,0.776537,0.439168,0.496528,0.493059,0.498746,0.781074,0.812683,0.244137,0.261699,0.199097,0.064581,-1.37581,-1.29256,1.09588,1.11789,1.51531,1.50182,-0.259875,-0.212708,-1.88238,-1.79561,2.21692,2.19295,0.968456,0.818227,-0.197354,0.125999,-0.880139,-0.833894
9121,0.0821832,0.0482081,0.543515,0.53387,0.736262,0.773337,0.950276,0.917025,0.855459,0.932734,0.423149,0.457288,0.595013,0.575933,0.284414,0.291867,0.273863,0.302984,0.559535,0.589814,-0.175902,-0.30916,-0.73028,-0.644352,0.767877,0.883478,-0.0568019,-0.0765707,0.0559395,0.0111376,-0.818603,-0.737214,-0.0713506,-0.0960776,-1.15059,-1.29838,-0.287683,0.0796279,-1.05627,-1.00788
9122,0.511418,0.476072,0.589218,0.577277,0.99714,1.03402,0.782779,0.74942,0.0173498,0.0955645,0.623985,0.656153,0.307856,0.290067,0.955576,0.962909,0.304568,0.375149,0.900118,0.917929,0.196385,0.0654595,-1.62102,-1.53132,1.61012,1.72997,0.699855,0.686714,0.253553,0.234983,-0.854856,-0.769934,-0.365967,-0.38565,-2.50694,-2.65446,-0.337487,0.0332565,0.708721,0.752251
9123,0.494372,0.44707,0.365683,0.353,0.694796,0.729945,0.010775,-0.0248612,0.340349,0.417982,0.407075,0.437629,0.518261,0.501598,0.55797,0.527207,0.415464,0.447315,0.64709,0.712653,-0.0762996,-0.201096,-0.0897573,-0.00360415,0.063381,0.186649,1.11393,1.09569,0.1797,0.122053,-1.36104,-1.28053,0.196213,0.18432,0.948215,0.800501,-0.0269264,0.336163,0.446926,0.487698
9124,0.414139,0.418069,0.864977,0.851479,0.0498602,0.0856541,0.344309,0.308893,0.37611,0.397021,0.875451,0.905228,0.929023,0.913124,0.0841715,0.0915048,0.268552,0.299124,0.380382,0.507377,0.380805,0.249359,0.178059,0.259614,0.698912,0.81488,-1.58904,-1.6017,0.0349642,0.00912225,0.294273,0.37469,-0.326996,-0.338856,-0.168085,-0.309003,1.29387,1.65302,0.525206,0.568374
9125,0.424104,0.389068,0.490235,0.476867,0.154575,0.279869,0.140206,0.106582,0.297703,0.376059,0.0616356,0.0925262,0.315765,0.30198,0.497545,0.414134,0.911595,0.941595,0.28429,0.302101,-0.256422,-0.386575,-0.968129,-0.89128,-0.330027,-0.220325,0.440171,0.430961,1.52768,1.50062,-0.794081,-0.721229,-0.408246,-0.414167,0.570437,0.435075,1.7915,2.14341,-0.883096,-0.834242
9126,0.170823,0.13615,0.723732,0.709282,0.345819,0.474085,0.659303,0.624631,0.854043,0.930553,0.49996,0.542499,0.11764,0.170187,0.730687,0.736764,0.021621,0.0525145,0.485167,0.589903,0.950529,0.815411,0.0596781,0.139791,0.758637,0.86911,0.735746,0.720147,0.0471622,0.0170304,-0.660884,-0.583946,0.202026,0.201622,0.222658,0.09261,-1.81088,-1.45541,-0.0410874,0.00305976
9127,0.946495,0.911244,0.324102,0.309842,0.632506,0.6683,0.749313,0.712765,0.900216,0.978044,0.962729,0.992472,0.0509279,0.0383949,0.518943,0.542165,0.895317,0.923154,0.861037,0.877705,-0.653749,-0.787407,-0.347242,-0.27069,-0.950713,-0.847899,1.01563,1.00933,1.03421,1.00409,0.319112,0.39557,-0.542325,-0.54918,1.29173,1.16077,-0.291021,0.0673011,1.05732,1.09976
9128,0.517506,0.480482,0.240588,0.226511,0.510988,0.54712,0.290384,0.25576,0.0201315,0.0963046,0.612165,0.640152,0.572119,0.560691,0.342426,0.347567,0.266799,0.293244,0.763974,0.782087,0.0628038,-0.0781122,1.24258,1.31934,0.787868,0.890533,-0.846181,-0.855473,0.224981,0.195938,-0.42765,-0.346499,0.145677,0.142336,-0.919857,-1.05711,1.84304,2.20364,0.367734,0.323883
9129,0.54594,0.556191,0.966799,0.952541,0.119575,0.157641,0.782548,0.749101,0.525468,0.600204,0.957395,0.985803,0.3008,0.375001,0.530348,0.534534,0.482236,0.559274,0.67188,0.686469,-0.449221,-0.592755,-1.96779,-1.88392,1.00766,1.10524,1.50356,1.49079,-0.16965,-0.200559,0.323392,0.403084,-2.44179,-2.45152,-0.0890404,-0.220309,1.83702,2.19832,-0.488826,-0.451991
9130,0.666676,0.631901,0.192442,0.179724,0.831559,0.868366,0.809648,0.777056,0.0446644,0.121249,0.94612,0.973655,0.202879,0.189312,0.243553,0.330624,0.798145,0.825304,0.808805,0.734391,1.33553,1.19736,-0.800997,-0.71545,0.427638,0.51903,-1.13357,-1.14348,0.574846,0.626251,1.5798,1.65835,1.39258,1.38714,-0.570516,-0.700539,0.382985,0.743557,1.58145,1.61581
9131,0.903463,0.868114,0.146084,0.135091,0.644036,0.749867,0.426426,0.399432,0.324377,0.480541,0.68007,0.705778,0.477059,0.451952,0.120901,0.126714,0.790489,0.89747,0.769595,0.782313,-0.467291,-0.609173,-0.883966,-0.806355,0.0584131,0.152222,-0.011641,-0.0263187,1.48191,1.45306,-0.0749918,-0.00204185,-0.738478,-0.738988,0.903875,0.777102,0.831338,1.18681,0.373781,0.41174
9132,0.698003,0.664248,0.901871,0.890594,0.555666,0.631368,0.0551335,0.0218077,0.760786,0.839833,0.713547,0.737333,0.726033,0.714592,0.965485,0.971839,0.940739,0.969636,0.133408,0.147129,0.020585,-0.124999,-0.37903,-0.296803,2.05242,2.15362,-0.908203,-0.926572,1.07787,1.05656,-0.657195,-0.59057,-1.02409,-1.02856,-0.000337237,-0.0386434,-0.91547,-0.555875,-0.309383,-0.273683
9133,0.758045,0.685698,0.324229,0.313922,0.4749,0.512869,0.506603,0.47489,0.342621,0.498061,0.184823,0.207414,0.660255,0.650461,0.0757611,0.0839484,0.637989,0.665785,0.137286,0.169266,-0.834876,-0.976498,0.632204,0.718908,1.11246,1.21389,-0.113143,-0.132154,-1.60168,-1.617,0.949298,1.01836,2.87933,2.87486,-0.728711,-0.854389,-0.632683,-0.269142,-0.0113236,0.0185423
9134,0.73899,0.707148,0.216442,0.248568,0.737429,0.773553,0.628397,0.594348,0.0778254,0.15629,0.0969757,0.119544,0.307659,0.299831,0.594512,0.502989,0.0636889,0.0911991,0.175781,0.191404,0.39108,0.253483,-0.377626,-0.292339,-0.232552,-0.131856,0.0764653,0.0635884,0.586062,0.569618,-1.06506,-0.998187,-1.15476,-1.16475,1.42821,1.3076,-0.853156,-0.492569,0.808091,0.841496
9135,0.436535,0.449246,0.194774,0.183214,0.101697,0.139411,0.469282,0.436617,0.447751,0.523956,0.546043,0.567978,0.643955,0.63751,0.915237,0.92203,0.251496,0.284477,0.630366,0.645863,0.304513,0.167307,0.711338,0.802546,1.42816,1.52476,0.821144,0.812192,0.113575,0.0965974,1.30793,1.37876,0.724671,0.719964,1.76327,1.63948,0.481952,0.843327,-0.301111,-0.272636
9136,0.222696,0.191345,0.501185,0.489673,0.279939,0.315733,0.0166126,-0.01525,0.228566,0.306897,0.715241,0.737916,0.261154,0.256569,0.199263,0.207551,0.545975,0.477756,0.116962,0.130513,-1.05551,-1.18804,-0.33088,-0.239473,-0.0424876,0.0581649,0.558501,0.5455,-0.667324,-0.679977,-1.45047,-1.37732,-2.50295,-2.50789,-0.235137,-0.35238,-0.655175,-0.296756,0.420967,0.445363
9137,0.234801,0.201651,0.549187,0.571802,0.0273299,0.0622143,0.346481,0.313997,0.978582,1.05573,0.505528,0.528727,0.961723,0.958985,0.157858,0.166248,0.643524,0.671034,0.3148,0.235082,0.658089,0.525569,-0.410153,-0.313938,-0.106724,-0.00249302,0.772056,0.756143,1.47933,1.47252,0.272889,0.340967,0.357444,0.355373,0.271607,0.147524,0.833457,1.19548,0.194959,0.225169
9138,0.871291,0.837461,0.667215,0.65393,0.160403,0.177776,0.231547,0.203993,0.54556,0.673461,0.574962,0.618688,0.915233,0.91074,0.48393,0.492652,0.060124,0.0860537,0.324173,0.339651,0.165563,0.0267575,0.227905,0.317145,1.24968,1.36148,0.170805,0.150624,0.519639,0.510938,0.0887149,0.157181,-0.156524,-0.150778,-3.44169,-3.5628,-0.580699,-0.212833,-0.967365,-0.932979
9139,0.615268,0.592303,0.232421,0.220764,0.191703,0.293337,0.172643,0.0939888,0.213996,0.291194,0.686291,0.708648,0.596876,0.590173,0.084786,0.0961455,0.262758,0.286531,0.997587,1.01356,-0.112514,-0.254366,0.197977,0.289074,-0.834547,-0.716772,0.0421882,0.0243486,1.70026,1.69711,-0.802966,-0.740359,-0.381831,-0.378699,0.726902,0.605794,0.213057,0.668396,-0.31178,-0.275926
9140,0.331541,0.347145,0.789864,0.777593,0.468311,0.408898,0.0147325,-0.0160154,0.609637,0.688916,0.508241,0.605947,0.675018,0.669165,0.108218,0.176401,0.701999,0.726017,0.173678,0.188346,-1.17505,-1.32186,-0.43985,-0.350491,0.318759,0.432958,0.655743,0.631243,-1.04781,-1.05826,0.707324,0.775254,1.18745,1.18867,1.77076,1.64181,1.17777,1.54963,-1.19928,-1.15943
9141,0.134935,0.101987,0.562322,0.547696,0.628766,0.52446,0.28289,0.311573,0.385677,0.466758,0.482124,0.503245,0.25311,0.248144,0.294113,0.256657,0.145385,0.171524,0.751665,0.767681,-1.74274,-1.89613,-0.133774,-0.0406082,-2.5593,-2.44248,-0.379116,-0.408195,0.0917382,0.082473,1.28499,1.35859,-0.015171,-0.0135077,-1.38041,-1.50443,0.0534692,0.423799,1.49104,1.52505
9142,0.642267,0.609142,0.84816,0.83414,0.605136,0.640021,0.670379,0.63916,0.924185,1.00564,0.905355,0.926857,0.0461751,0.0430213,0.325528,0.336913,0.143204,0.177465,0.935447,0.950006,-1.75362,-1.90541,1.33835,1.4391,0.417447,0.52994,0.22068,0.183922,-0.192799,-0.205937,1.15778,1.2333,0.160556,0.154653,0.0196209,-0.100553,-1.72536,-1.35213,0.0222723,0.0618372
9143,0.195114,0.163295,0.826782,0.813481,0.0266052,0.0611917,0.337783,0.385701,0.0778386,0.157743,0.438437,0.46132,0.243604,0.340574,0.234763,0.246134,0.0712512,0.183407,0.657848,0.587818,1.21371,1.06811,-0.108815,-0.00994892,0.206589,0.315066,-1.98212,-2.01189,-0.116716,-0.12375,1.58242,1.57341,-0.865908,-0.877012,1.72204,1.59688,0.246365,0.614739,0.0315015,0.0694176
9144,0.260986,0.228626,0.551927,0.538134,0.349196,0.351786,0.163973,0.132242,0.889484,0.969799,0.472145,0.503097,0.639021,0.638128,0.565707,0.577993,0.165519,0.189348,0.213668,0.22563,0.634713,0.493838,-0.374266,-0.26892,0.295276,0.405277,-0.0269746,-0.0584505,-1.38677,-1.39316,1.84127,1.91352,0.107728,0.0903364,1.42091,1.30135,0.96146,1.32448,-0.719102,-0.677209
9145,0.845573,0.814256,0.907356,0.89366,0.607837,0.64238,0.4174,0.387403,0.809145,0.892276,0.563655,0.544874,0.450519,0.449144,0.0154075,0.0270144,0.91417,0.936656,0.297324,0.30725,-1.01023,-1.15381,0.708896,0.808727,0.76393,0.880194,-0.00975332,-0.0468828,1.41628,1.41709,1.09652,1.17145,0.0460961,0.0305417,1.48517,1.3706,1.00772,1.36677,-0.808584,-0.761662
9146,0.766561,0.737544,0.45379,0.440442,0.374731,0.408415,0.927187,0.895243,0.73582,0.814752,0.563767,0.58665,0.809319,0.80653,0.677612,0.68704,0.872247,0.897014,0.076946,0.159242,-0.0978397,-0.251803,-0.321184,-0.219074,-1.41177,-1.2945,1.27803,1.2404,0.25132,0.255999,2.47132,2.54769,1.96792,1.94727,0.206325,0.0913655,-1.20106,-0.835222,1.40311,1.44926
9147,0.366673,0.418304,0.812379,0.800555,0.140556,0.174451,0.422503,0.392315,0.372241,0.470136,0.437788,0.45806,0.120369,0.11896,0.434894,0.444125,0.399625,0.422341,0.000351926,0.0112349,0.795073,0.650204,-0.071345,0.0282488,-0.391491,-0.279815,0.384365,0.353993,-1.43427,-1.42872,0.450805,0.531134,0.609178,0.563871,0.0234981,-0.098291,1.97594,2.33886,0.510323,0.551468
9148,0.126117,0.0990634,0.967267,0.954601,0.814476,0.849661,0.271515,0.240193,0.0474716,0.125521,0.934301,0.955541,0.0315828,0.0300164,0.978732,0.986905,0.300946,0.329739,0.604154,0.615017,-2.07561,-2.22173,1.02368,1.12313,0.288958,0.396827,0.626346,0.596096,-0.335908,-0.334985,0.377396,0.548498,-0.798883,-0.819531,0.168922,-0.00746579,0.435607,0.856665,-1.12196,-1.08091
9149,0.615612,0.59059,0.310355,0.298327,0.302514,0.336098,0.322359,0.289123,0.991059,1.06911,0.248284,0.270774,0.300974,0.301213,0.19692,0.205365,0.152283,0.237136,0.0477521,0.059208,-0.250596,-0.4524,0.273708,0.374738,-0.0954962,0.0156144,2.13929,2.10448,-1.14067,-1.14314,0.486109,0.565862,0.42869,0.411653,0.204681,0.0833595,-0.988447,-0.625527,-0.832766,-0.78868
9150,0.682435,0.655921,0.945906,0.933621,0.840135,0.873741,0.956913,0.921816,0.704669,0.781781,0.884928,0.906754,0.967275,0.969085,0.557878,0.522846,0.121817,0.144533,0.937782,0.947589,1.46306,1.31693,-0.822824,-0.713555,-1.54561,-1.43509,-0.515224,-0.557416,1.05064,1.04348,-1.58228,-1.4993,-0.452611,-0.477261,-1.12226,-1.24238,-1.25981,-0.895011,-0.309095,-0.269228
9151,0.506862,0.478376,0.667113,0.653597,0.895044,0.930559,0.408027,0.373998,0.0189505,0.0957472,0.604811,0.599621,0.55423,0.582224,0.83235,0.840328,0.416478,0.440665,0.761826,0.821146,-0.568735,-0.708583,0.164234,0.269829,-1.44033,-1.32859,-0.416513,-0.454849,0.595521,0.584796,0.454807,0.543978,-1.34914,-1.36618,1.11098,0.995823,0.314961,0.672823,1.82902,1.86196
9152,0.052331,0.0232779,0.888093,0.876458,0.479679,0.516134,0.889565,0.8566,0.697865,0.776739,0.272384,0.292489,0.193961,0.195363,0.69153,0.698194,0.0387205,0.060944,0.698958,0.694703,-0.441111,-0.580762,1.62964,1.7353,-1.06679,-0.961127,-1.68001,-1.71226,-0.537317,-0.54553,-0.545594,-0.459724,-0.336616,-0.352828,-2.37433,-2.47964,0.057644,0.339685,0.175235,0.215438
9153,0.582355,0.554617,0.743175,0.732751,0.761566,0.726314,0.541533,0.548538,0.452697,0.521282,0.648941,0.66739,0.117526,0.119424,0.979144,0.984111,0.779144,0.803674,0.559105,0.56826,0.511895,0.373336,1.81086,1.92089,-1.31498,-1.20561,-1.05497,-1.09022,-0.18967,-0.164403,1.96875,2.05108,-1.05293,-1.073,0.144523,0.035333,-0.344037,0.00654676,1.29423,1.32725
9154,0.298946,0.270569,0.113558,0.102422,0.899366,0.936494,0.274612,0.240476,0.186951,0.265825,0.587469,0.605443,0.0438337,0.0434851,0.396777,0.403293,0.535403,0.560483,0.114536,0.121868,-1.50932,-1.65218,0.696002,0.800926,0.490384,0.592662,0.742113,0.70421,0.223949,0.216724,0.308944,0.390688,0.41729,0.39057,-0.461626,-0.567748,0.382556,0.731032,0.854739,0.8814
9155,0.966979,0.936851,0.91127,0.899242,0.863984,0.90295,0.688929,0.654497,0.24509,0.232689,0.273038,0.291683,0.514152,0.510663,0.903346,0.910298,0.720634,0.656513,0.629014,0.54438,-0.072357,-0.217271,0.0776166,0.176395,0.583363,0.682874,0.341489,0.299047,1.49907,1.49565,0.663552,0.743313,-1.59996,-1.62701,-0.356527,-0.4657,0.737476,1.08205,0.116554,0.14974
9156,0.857025,0.827829,0.547493,0.534727,0.3565,0.394562,0.164596,0.13156,0.121855,0.199554,0.411046,0.43162,0.97819,0.977841,0.621776,0.628719,0.728707,0.752543,0.958116,0.966891,0.150668,0.0889606,1.31586,1.41095,-0.801689,-0.708338,1.11533,1.07733,1.57063,1.56276,-0.678345,-0.597469,1.8155,1.7891,-0.782765,-0.885418,-1.30498,-0.964644,-1.25662,-1.2218
9157,0.131627,0.103938,0.458245,0.446363,0.158206,0.197692,0.778799,0.744435,0.682617,0.758824,0.00901793,0.030055,0.817783,0.818791,0.623357,0.628356,0.214223,0.237691,0.4889,0.495877,0.533087,0.395192,1.40723,1.50346,2.03954,2.12692,0.057763,0.0194318,-2.07731,-2.07818,-0.542022,-0.460186,0.732232,0.710324,0.35967,0.25595,0.92795,1.26332,-0.722811,-0.688074
9158,0.262021,0.233953,0.132846,0.120839,0.625399,0.666274,0.371133,0.33741,0.947973,1.02514,0.784504,0.803265,0.183197,0.186713,0.242775,0.247086,0.971546,0.995095,0.284775,0.290854,0.362622,0.219458,0.201758,0.291418,0.594705,0.676216,-0.28607,-0.329183,-0.822359,-0.746156,-0.606076,-0.424016,1.10868,1.09277,0.616387,0.511732,-0.96687,-0.640258,0.587748,0.624062
9159,0.877019,0.849284,0.224225,0.210057,0.373056,0.412755,0.210915,0.174546,0.281053,0.360304,0.619761,0.713981,0.035644,0.037183,0.883164,0.886764,0.207201,0.230522,0.893946,0.899719,-0.973464,-1.12199,1.1383,1.22898,0.0914111,0.172584,-0.64091,-0.677798,0.581299,0.585864,-0.472248,-0.387846,1.78674,1.76794,-0.576257,-0.688823,-0.237253,0.0842279,-0.237666,-0.197705
9160,0.232189,0.203098,0.919589,0.904827,0.595141,0.633151,0.485132,0.4498,0.793289,0.874425,0.605021,0.624697,0.600369,0.603693,0.786522,0.790455,0.729639,0.750963,0.112162,0.119752,-0.893707,-1.04086,2.51553,2.59934,-0.975937,-0.89327,0.131976,0.100488,-1.94093,-1.9368,-0.870892,-0.787695,0.974312,0.955687,-1.43818,-1.55228,1.79262,2.11714,1.59013,1.62401
9161,0.519761,0.489944,0.652566,0.638583,0.0755332,0.114359,0.979409,0.943141,0.551203,0.688805,0.102406,0.12463,0.543425,0.545314,0.015634,0.0189307,0.923955,0.946546,0.83319,0.839281,1.02909,0.884795,-1.24327,-1.1544,-0.599441,-0.510238,2.10456,2.06754,0.969867,0.979193,0.0565723,0.146767,0.793954,0.773956,0.455955,0.345895,1.08254,1.40139,-0.321109,-0.286479
9162,0.037588,0.00899732,0.614478,0.599211,0.294131,0.334754,0.517944,0.481676,0.420724,0.503185,0.569863,0.592228,0.940157,0.941792,0.838477,0.842985,0.673571,0.698026,0.700086,0.675791,0.374612,0.233909,-0.702891,-0.615473,0.48678,0.579197,1.68235,1.64661,-0.0154506,0.00026649,-0.714613,-0.626222,-0.858191,-0.882691,0.520463,0.415149,0.831516,1.14769,-0.976823,-0.942919
9163,0.726165,0.699717,0.15423,0.140994,0.720812,0.763833,0.533167,0.451972,0.945833,1.02671,0.301425,0.324351,0.919232,0.918811,0.844323,0.84864,0.641614,0.66828,0.503879,0.512301,1.71142,1.57597,1.28212,1.36254,0.13234,0.22869,1.51768,1.48892,-1.74941,-1.73007,0.334095,0.416242,0.368473,0.348493,-0.994074,-1.09284,-0.777129,-0.464104,1.17556,1.20655
9164,0.120847,0.0942801,0.293974,0.223123,0.0861064,0.129691,0.507842,0.422268,0.959131,1.03964,0.756096,0.777672,0.397382,0.396495,0.338493,0.342361,0.409017,0.434442,0.638486,0.649359,1.14317,1.00169,0.893053,0.966765,-1.85329,-1.75323,-0.335424,-0.357347,-1.64531,-1.6323,0.680327,0.847759,-0.653822,-0.668181,-1.33887,-1.43531,1.38656,1.69879,0.00588285,0.0321222
9165,0.763116,0.735487,0.317664,0.305251,0.346463,0.383615,0.428266,0.392563,0.737954,0.779977,0.375202,0.409285,0.90387,0.902916,0.698705,0.705245,0.923417,0.949527,0.314037,0.323039,-0.415282,-0.553339,-0.653885,-0.575597,-0.0836332,0.0138592,0.903604,0.883507,1.042,1.06173,1.19617,1.27928,-0.348353,-0.360481,1.57897,1.47598,-0.848646,-0.534696,0.414264,0.444184
9166,0.0539525,0.0277265,0.168514,0.156427,0.592989,0.63754,0.164333,0.129124,0.439842,0.520318,0.0195136,0.0408972,0.782868,0.744133,0.63136,0.639492,0.951032,0.979087,0.519631,0.529935,0.297052,0.155955,-1.16703,-1.0924,2.36539,2.4574,-0.113789,-0.141042,-0.645203,-0.622994,0.814134,0.895053,-1.81274,-1.8291,-0.0433799,-0.139756,1.25724,1.56596,0.113454,0.150183
9167,0.103675,0.0779745,0.762301,0.752733,0.484239,0.559979,0.724326,0.686587,0.733791,0.812272,0.614398,0.636686,0.581132,0.585349,0.106115,0.113683,0.398503,0.424593,0.257772,0.268829,-0.705762,-0.849945,1.92506,2.00542,1.12354,1.22111,-0.0249883,-0.054823,-0.119186,-0.0982242,-0.451847,-0.368544,-1.03063,-1.0454,0.646003,0.543551,1.12062,1.43611,-0.614462,-0.581478
9168,0.675218,0.649435,0.741393,0.667824,0.440408,0.482418,0.49191,0.453938,0.195079,0.274118,0.259712,0.284366,0.347907,0.426566,0.50472,0.510321,0.437602,0.463038,0.256658,0.269717,-0.195132,-0.338885,-0.481973,-0.405696,0.414594,0.513801,1.57173,1.54975,-0.939253,-0.922989,-0.528472,-0.446281,-1.46777,-1.47497,0.554027,0.4458,-0.177764,0.138095,-0.578223,-0.460512
9169,0.0634473,0.0376793,0.591553,0.582915,0.876178,0.916522,0.465845,0.427066,0.792553,0.87386,0.687099,0.713353,0.330327,0.267782,0.177698,0.183821,0.868562,0.893495,0.94578,0.958293,0.31342,0.172175,0.577308,0.657454,-1.32631,-1.23155,-0.60381,-0.631758,0.182012,0.200052,0.869618,0.946085,0.745779,0.743729,-0.675691,-0.786021,0.35973,0.676751,-0.380963,-0.339546
9170,0.760821,0.733346,0.318322,0.307569,0.148058,0.186985,0.169489,0.129482,0.892672,0.972575,0.517491,0.545716,0.109953,0.108999,0.448896,0.41935,0.130359,0.157174,0.86484,0.788323,-0.659468,-0.80141,0.750707,0.828722,-1.01547,-0.923667,1.03419,1.00389,0.303806,0.326577,-0.536549,-0.457884,0.201938,0.204025,0.637733,0.522968,2.39671,2.70966,1.1185,1.15661
9171,0.87274,0.844055,0.811377,0.800616,0.694762,0.73447,0.819257,0.781746,0.412772,0.493621,0.0369818,0.0655779,0.341045,0.392149,0.649265,0.654878,0.766215,0.794407,0.605371,0.618352,-0.145703,-0.287376,1.22181,1.30496,-1.00935,-0.923692,-1.51834,-1.54521,-0.217247,-0.191459,1.2981,1.38328,-0.0889971,-0.00475872,0.993882,0.884593,0.299878,0.614036,0.348387,0.378824
9172,0.127698,0.0991371,0.888706,0.8797,0.877506,0.915793,0.184666,0.14953,0.791398,0.871286,0.988903,1.0181,0.676253,0.675299,0.244749,0.341,0.106336,0.133887,0.974701,0.988292,0.718888,0.649825,-1.19828,-1.12162,-0.173693,-0.0916901,-1.67138,-1.7029,0.209055,0.241689,-0.256496,-0.17278,-0.212958,-0.213542,0.123419,0.0211348,-0.28525,0.0355656,1.2131,1.24769
9173,0.630519,0.601266,0.553859,0.544625,0.58604,0.626043,0.0581928,0.0221406,0.0521063,0.12995,0.815417,0.84551,0.158488,0.159266,0.0214944,0.027121,0.419428,0.448731,0.125525,0.140484,1.7198,1.58703,-1.27046,-1.19608,-0.871984,-0.784132,0.489057,0.452453,1.13212,1.16733,0.450326,0.490596,-1.35,-1.35355,1.03882,0.933579,-1.51327,-1.19915,0.25331,0.28912
9174,0.453603,0.496271,0.86438,0.85574,0.8372,0.876612,0.803201,0.76485,0.0956656,0.195009,0.269824,0.301092,0.302948,0.305055,0.189139,0.194066,0.48282,0.470066,0.768907,0.783829,0.17314,0.0462614,-0.917556,-0.840888,0.36046,0.443421,-0.468718,-0.51061,-0.58419,-0.548911,1.07676,1.15397,-1.02934,-1.0318,2.24857,2.13718,-0.898359,-0.583573,-0.0779877,-0.0364693
9175,0.420156,0.391277,0.673808,0.666228,0.295957,0.337542,0.686677,0.723012,0.182056,0.260067,0.0551457,0.0873106,0.697605,0.701534,0.649538,0.655105,0.462317,0.491401,0.982264,0.996343,-0.879328,-1.00497,0.800326,0.871357,-0.862054,-0.778133,-0.376176,-0.42439,-1.48237,-1.44865,-0.389156,-0.311172,1.29367,1.28722,0.0899692,-0.0157784,-1.40724,-1.10009,1.26291,1.30464
9176,0.793905,0.76358,0.693252,0.744603,0.895848,0.935249,0.718621,0.681174,0.960699,1.04,0.842699,0.875816,0.255708,0.260799,0.492861,0.498589,0.931342,0.961952,0.0221567,0.0366438,0.872969,0.753208,1.85893,1.93451,-1.47641,-1.39549,-1.01977,-1.0604,-0.327194,-0.294241,-0.115443,-0.0368449,0.541185,0.536416,-0.929251,-1.03388,-1.19311,-0.891847,1.28524,1.32711
9177,0.108511,0.0768533,0.830558,0.822978,0.640672,0.587209,0.226607,0.188463,0.123285,0.202835,0.645875,0.677047,0.381522,0.449314,0.92897,0.935771,0.640765,0.672801,0.914494,0.929921,-0.961884,-1.08211,-1.08529,-1.01323,0.206896,0.293436,1.786,1.74021,-0.62564,-0.598938,1.64334,1.72487,0.280354,0.277996,0.174957,0.0629173,0.2501,0.55336,-0.29194,-0.240533
9178,0.621758,0.588772,0.208212,0.202106,0.200528,0.239168,0.134089,0.095491,0.605161,0.685364,0.233434,0.266042,0.634322,0.63783,0.612428,0.619278,0.90621,0.939428,0.709363,0.662631,1.12696,1.00074,-1.653,-1.57846,1.11809,1.20056,-0.560296,-0.607556,0.069877,0.0955441,0.353495,0.431133,-0.453773,-0.517873,0.272431,0.164965,0.00205238,0.299662,1.1768,1.22556
9179,0.621122,0.589339,0.195938,0.108898,0.789236,0.827538,0.266966,0.229643,0.207054,0.28685,0.890549,0.92254,0.571808,0.506038,0.871822,0.879912,0.742049,0.776634,0.378514,0.395342,0.864575,0.650409,0.0925506,0.164701,1.6968,1.78399,-1.34264,-1.38393,0.512216,0.543315,2.00572,2.08636,-1.31138,-1.31374,-0.96925,-1.08181,-0.853502,-0.556584,1.34436,1.398
9180,0.196087,0.163715,0.0191535,0.0156896,0.0791723,0.118217,0.106487,0.0667791,0.11804,0.28868,0.851218,0.885212,0.373698,0.374245,0.693751,0.685313,0.283964,0.316535,0.337513,0.356824,0.419804,0.300079,0.652559,0.718188,-1.33369,-1.25263,-0.10042,-0.143076,-0.604607,-0.571295,1.9305,2.00862,0.926614,0.921077,-1.9841,-2.09992,0.624336,0.919302,0.889283,0.93791
9181,0.079734,0.0863778,0.834312,0.831629,0.718549,0.757357,0.210834,0.171179,0.210423,0.29051,0.0471146,0.0818161,0.501255,0.499622,0.481933,0.490715,0.848063,0.881935,0.0204359,0.041056,-0.680019,-0.798054,-0.870579,-0.808965,-1.4049,-1.32838,-1.79602,-1.83379,0.290128,0.324448,0.933414,1.00492,-0.670709,-0.674882,0.617127,0.498353,-0.733019,-0.440977,-1.63074,-1.58565
9182,0.0423946,0.00904027,0.346056,0.343853,0.839728,0.878505,0.958293,0.919641,0.876242,0.955755,0.493476,0.514173,0.930184,0.926254,0.607349,0.616475,0.0695442,0.102098,0.379835,0.401184,-0.430074,-0.546895,-0.565113,-0.499082,1.84125,1.91968,-0.427715,-0.468842,0.0140038,0.0497133,0.675621,0.790503,0.584193,0.586284,0.0133604,-0.104728,0.215219,0.502964,0.344135,0.387339
9183,0.531416,0.495767,0.846087,0.842332,0.509036,0.548759,0.628237,0.58687,0.00799781,0.0884383,0.911829,0.94653,0.883812,0.878009,0.419497,0.361222,0.683361,0.718145,0.117362,0.140078,-1.91537,-2.02546,-0.709562,-0.648772,-0.579312,-0.495799,0.0947017,0.0462481,0.74033,0.775388,0.499933,0.576087,0.469166,0.46667,-0.0114635,-0.127994,-0.909871,-0.675642,0.706981,0.755235
9184,0.129034,0.0950636,0.0622496,0.0604188,0.681617,0.719487,0.659037,0.563504,0.135858,0.217928,0.207079,0.241509,0.152695,0.14456,0.0964864,0.105969,0.0571492,0.0933317,0.9285,0.94862,-0.209821,-0.326946,-1.24849,-1.18221,-0.444017,-0.357935,-1.47714,-1.53214,0.895954,0.934785,-0.359939,-0.2883,-0.712271,-0.720452,-0.594358,-0.716927,-2.14199,-1.85425,-1.26891,-1.21828
9185,0.364334,0.331277,0.86129,0.857238,0.215697,0.255059,0.6212,0.540139,0.903608,0.986976,0.63176,0.66512,0.365281,0.356091,0.925143,0.933857,0.88774,0.921832,0.183328,0.205529,1.14971,1.0305,-0.52259,-0.46013,0.870886,0.961464,1.36462,1.3064,-0.0630662,-0.0268004,-0.874053,-0.798899,-0.879566,-0.887315,0.115087,-0.00232204,-2.09701,-1.81196,-1.72362,-1.67837
9186,0.105063,0.0731989,0.342276,0.339596,0.660234,0.698804,0.558916,0.516773,0.686165,0.673687,0.66648,0.701401,0.819844,0.811972,0.051574,0.061947,0.372222,0.40698,0.321279,0.387963,1.11274,0.991266,0.665328,0.725052,-0.349908,-0.26009,1.12615,1.07228,0.0574237,0.0997242,-0.860904,-0.784533,-0.432102,-0.440415,-0.570764,-0.684461,-0.207175,0.0725417,0.491189,0.532546
9187,0.877447,0.843676,0.933543,0.930445,0.439244,0.476807,0.851785,0.812044,0.276945,0.360399,0.469974,0.556921,0.829008,0.726832,0.986964,0.994354,0.65863,0.692724,0.477641,0.570397,2.05485,1.93031,-0.242962,-0.177097,-0.819729,-0.732573,-1.03676,-1.09277,0.777311,0.825399,0.326977,0.410473,0.429469,0.416328,-0.136557,-0.246938,-0.186042,0.0991777,0.557253,0.600771
9188,0.326735,0.29254,0.956633,0.953862,0.912169,0.950402,0.464903,0.425323,0.254962,0.336274,0.259977,0.412442,0.650316,0.641693,0.298954,0.307316,0.363257,0.398498,0.760167,0.752831,-0.0831123,-0.203933,-0.412793,-0.343918,-0.244336,-0.149144,1.53484,1.47118,-0.135759,-0.0894135,0.34658,0.424839,-1.04821,-1.06732,-0.749144,-0.802103,-1.24567,-0.962267,-0.120664,-0.0719336
9189,0.369287,0.332716,0.655905,0.654011,0.57261,0.610531,0.995753,0.957946,0.529883,0.680088,0.231033,0.267962,0.968993,0.958891,0.276889,0.286971,0.668681,0.704273,0.913063,0.935265,-1.06894,-1.19418,0.102368,0.165633,0.573884,0.666254,1.42015,1.35946,1.30208,1.34204,-0.842447,-0.761282,0.219485,0.291157,-1.24416,-1.35727,0.908358,1.18773,-2.04388,-1.99659
9190,0.79456,0.755808,0.0209623,0.01855,0.960428,0.997539,0.661799,0.696352,0.944712,1.0239,0.806573,0.844032,0.292746,0.282286,0.507703,0.516273,0.00252767,0.038897,0.844876,0.866932,0.520006,0.396886,-1.19972,-1.13862,-1.73099,-1.63954,-0.822632,-0.886402,0.0414391,0.0871569,-0.863344,-0.777052,1.65991,1.64964,-0.346745,-0.460492,-0.679656,-0.393077,-0.263022,-0.22089
9191,0.882598,0.84187,0.56245,0.560807,0.272196,0.308588,0.426173,0.434759,0.928965,1.00998,0.811842,0.851119,0.400905,0.392298,0.286425,0.293861,0.134718,0.168267,0.195709,0.215936,-0.0657911,-0.192514,-0.115349,-0.0609742,-0.460976,-0.367444,1.59967,1.5421,0.218834,0.33483,-0.0442658,0.0478572,-0.313083,-0.322043,1.91086,1.79335,1.06448,1.34775,-0.224355,-0.182552
9192,0.267071,0.225765,0.196544,0.196293,0.931268,0.967581,0.210972,0.173165,0.672264,0.752929,0.48694,0.550344,0.0989703,0.091107,0.31331,0.319565,0.751149,0.784313,0.670474,0.68994,-1.55539,-1.68757,0.0111207,0.0622789,-0.344981,-0.24662,-0.50568,-0.562118,0.541786,0.582503,0.314455,0.413251,0.155897,0.138824,-2.71045,-2.82796,-0.467196,-0.186665,0.201631,0.191061
9193,0.379183,0.336473,0.494215,0.586107,0.583369,0.6175,0.593283,0.492,0.926246,1.00444,0.211113,0.249568,0.718549,0.712631,0.669352,0.592732,0.460797,0.495163,0.868104,0.887234,0.480735,0.349192,-1.79188,-1.74818,0.236815,0.336809,0.643791,0.587662,-0.64504,-0.666068,-0.479994,-0.373661,-0.224364,-0.243501,-0.400668,-0.519492,0.438186,0.724618,0.525372,0.564673
9194,0.917697,0.873252,0.97727,0.975921,0.477804,0.470314,0.846795,0.810834,0.459698,0.53614,0.388436,0.42867,0.938421,0.839017,0.860022,0.865899,0.687627,0.72177,0.193385,0.211147,0.375634,0.247356,1.15984,1.20419,1.24767,1.35149,0.44744,0.384929,-1.95536,-1.91464,1.70679,1.81289,0.913912,0.89439,0.0730396,-0.0509616,-0.691373,-0.401208,-0.797614,-0.760978
9195,0.421079,0.377858,0.754488,0.751644,0.352133,0.323129,0.182597,0.147541,0.832027,0.909449,0.216926,0.256075,0.970491,0.965404,0.0641876,0.0692157,0.0920936,0.127538,0.485924,0.504086,1.89762,1.76106,-0.883384,-0.840152,-1.15408,-1.04795,1.40591,1.34886,0.300875,0.338002,0.567093,0.673283,1.82791,1.81561,1.18218,1.06195,-0.334181,-0.0501916,0.61814,0.658159
9196,0.450734,0.408289,0.963033,0.959467,0.143643,0.175944,0.0875504,0.111304,0.386792,0.466013,0.567078,0.515726,0.630007,0.625367,0.512606,0.475524,0.227628,0.261702,0.55634,0.576114,0.906449,0.770813,-0.493338,-0.454668,-1.81186,-1.70994,-0.152005,-0.129485,0.691371,0.726402,-1.52984,-1.42382,-1.88236,-1.89466,0.793881,0.67451,0.460242,0.750841,0.776674,0.815819
9197,0.730342,0.689985,0.353075,0.348503,0.821805,0.855659,0.109859,0.0750677,0.651544,0.732326,0.734422,0.775377,0.628606,0.601881,0.874814,0.881832,0.152322,0.255988,0.388483,0.405934,-2.09275,-2.22514,0.369475,0.405917,-1.34038,-1.23503,-1.55077,-1.60783,0.630594,0.666764,1.23839,1.34828,0.31483,0.307869,1.41093,1.29603,-0.223704,0.0656957,-0.801011,-0.767964
9198,0.647652,0.595139,0.610516,0.605116,0.863037,0.897068,0.584122,0.548076,0.0643683,0.143612,0.688804,0.728188,0.479858,0.578395,0.0856116,0.0900978,0.21835,0.250275,0.826665,0.84523,-0.200102,-0.328392,2.00691,2.04156,-0.134202,-0.0254141,1.62779,1.57548,-0.0593438,-0.0162624,1.62486,1.73117,-0.736582,-0.739742,-0.348341,-0.458591,0.593318,0.88303,-1.43883,-1.41081
9199,0.542973,0.500293,0.159402,0.151899,0.526856,0.562407,0.74743,0.712917,0.429661,0.506956,0.0445055,0.082846,0.452925,0.554908,0.346649,0.350731,0.809406,0.840914,0.41054,0.494883,-2.11823,-2.2428,-0.0277377,0.0106946,0.121414,0.237052,1.78137,1.80022,-0.138162,-0.0916948,-0.384697,-0.271789,0.0878405,0.0877923,-0.918679,-1.03021,0.680974,0.97104,0.528302,0.562176
9200,0.662723,0.715068,0.134163,0.126704,0.685645,0.719047,0.581646,0.545313,0.186825,0.264168,0.583452,0.620168,0.535285,0.531422,0.203303,0.208597,0.822637,0.855882,0.124873,0.144536,-1.19413,-1.3181,-1.52509,-1.48419,1.60215,1.72215,2.01081,2.02496,-0.890576,-0.839012,-0.580853,-0.471732,-0.840249,-0.835428,-0.0497124,-0.249631,1.54288,1.83733,-0.0965903,-0.063745
9201,0.974739,0.929844,0.955117,0.949679,0.368108,0.485083,0.96698,0.928417,0.290071,0.269253,0.380458,0.415897,0.803064,0.797839,0.884071,0.890188,0.370554,0.406084,0.606248,0.623539,-0.543795,-0.667678,0.496217,0.543524,-1.06461,-0.94796,2.30201,2.2497,-0.372851,-0.314242,0.482971,0.586659,1.20447,1.20737,0.641367,0.530946,1.77707,2.07663,-1.0803,-1.05269
9202,0.00521454,-0.0391803,0.707895,0.703538,0.216802,0.251118,0.206281,0.169167,0.198819,0.274338,0.755225,0.790798,0.111279,0.105914,0.426323,0.528686,0.763182,0.796975,0.839328,0.856318,0.532122,0.408742,-0.898026,-0.843099,-0.956496,-0.84146,-1.4099,-1.46698,0.424094,0.486239,0.924515,1.033,-1.53756,-1.53423,2.16545,2.05515,0.605975,0.903818,-1.29718,-1.27289
9203,0.566918,0.522072,0.979934,0.974574,0.352613,0.387551,0.940023,0.901643,0.507964,0.581599,0.614935,0.652596,0.679144,0.672424,0.164164,0.167184,0.59398,0.629276,0.408974,0.479461,0.790416,0.674624,-1.83468,-1.77535,-0.223548,-0.103459,-0.614346,-0.672559,-0.396904,-0.338526,-0.0932843,0.0145445,0.45783,0.456992,-0.144071,-0.260753,-0.304725,-0.00392301,1.06205,1.08691
9204,0.388297,0.344527,0.675908,0.65938,0.91478,0.949784,0.211922,0.174001,0.164377,0.238024,0.199123,0.23669,0.662665,0.654662,0.728607,0.72942,0.714256,0.748444,0.0867035,0.102603,0.452559,0.332667,-0.282218,-0.215206,-0.393109,-0.272449,1.47522,1.42208,-0.0513829,0.00378749,0.841455,0.949007,0.619343,0.625152,1.99674,1.88666,-0.0307517,0.266533,0.531788,0.548677
9205,0.622788,0.58074,0.348353,0.344186,0.735263,0.767998,0.022531,-0.0134402,0.0430525,0.116177,0.993619,1.03103,0.00212823,-0.00703227,0.332952,0.332914,0.609757,0.580392,0.331435,0.281628,1.80169,1.67472,0.799675,0.862441,-0.558209,-0.441439,-0.302099,-0.362454,-0.461519,-0.408568,0.584815,0.687854,0.394387,0.357957,-0.193602,-0.295742,0.885116,1.17782,1.17023,1.19058
9206,0.140552,0.0997928,0.253871,0.250222,0.288139,0.318928,0.0678393,0.0300012,0.541615,0.614103,0.756673,0.792576,0.493898,0.409691,0.561062,0.562215,0.380544,0.412339,0.446603,0.460653,-0.976054,-1.10572,0.0289099,0.0979644,-1.08494,-0.961653,-0.782378,-0.843615,1.23093,1.28225,-0.0896876,0.00575697,0.0924986,0.0907607,-0.146981,-0.242755,0.282959,0.568321,0.200987,0.225872
9207,0.905751,0.864164,0.469147,0.386619,0.70504,0.737157,0.474852,0.439373,0.102909,0.175596,0.216171,0.25336,0.833384,0.826414,0.262426,0.265282,0.883044,0.912559,0.316153,0.33144,0.344165,0.219961,1.02571,1.09763,1.41093,1.53069,0.287482,0.228661,-0.108997,-0.0665531,-1.16149,-1.05907,-1.53948,-1.53249,-0.716312,-0.717539,0.841603,1.12296,-0.766157,-0.738838
9208,0.252709,0.212564,0.524424,0.523015,0.862514,0.893798,0.23977,0.224806,0.954819,1.02689,0.653682,0.691717,0.394928,0.390332,0.270346,0.275561,0.347523,0.378512,0.914796,0.929921,-0.072309,-0.199347,-1.29784,-1.22009,1.28179,1.39574,-0.38106,-0.438564,-0.911863,-0.874706,0.34967,0.456541,-1.36227,-1.34995,-1.0902,-1.19232,0.850264,1.13228,0.179012,0.206086
9209,0.333782,0.293211,0.525381,0.522638,0.814057,0.844774,0.0448783,0.0102389,0.233819,0.304988,0.883442,0.920401,0.818039,0.812102,0.00862184,0.0137259,0.745981,0.779449,0.0337922,0.0509288,-0.201194,-0.329109,0.0944361,0.166267,-1.17707,-1.06721,0.23525,0.183478,2.25132,2.29009,-0.296284,-0.279553,0.0419442,0.0536515,-0.106436,-0.20315,1.70655,1.98381,0.237066,0.25892
9210,0.922994,0.884416,0.957167,0.952209,0.405954,0.435142,0.627343,0.593156,0.266187,0.336951,0.749948,0.717425,0.787184,0.794948,0.163456,0.108694,0.356097,0.389402,0.126046,0.169658,-0.0969407,-0.232898,0.227813,0.305975,-1.6448,-1.53969,-1.37679,-1.42896,0.545648,0.590162,-1.12186,-1.01565,0.610242,0.623621,-1.27678,-1.37129,-0.181366,0.0971539,-0.491408,-0.472741
9211,0.366938,0.328251,0.0372248,0.0324088,0.324514,0.355018,0.623789,0.591936,0.806374,0.875838,0.478932,0.514449,0.786002,0.777794,0.313746,0.203662,0.562959,0.580741,0.270087,0.288387,-0.702473,-0.837383,-0.767406,-0.689282,0.873158,0.984422,0.967524,0.917311,1.83255,1.88368,-0.867391,-0.798091,-0.677914,-0.657653,1.24016,1.14369,-0.409231,-0.126274,-0.0612686,-0.0448307
9212,0.733646,0.635322,0.719006,0.7121,0.691697,0.722339,0.9378,0.906761,0.118435,0.185954,0.693615,0.756887,0.0576233,0.0499615,0.29362,0.298631,0.682042,0.77208,0.727518,0.747402,-0.374124,-0.50969,-0.493844,-0.489218,2.57354,2.6899,0.0553585,-0.000995977,0.485213,0.534869,-0.689904,-0.580533,-0.34119,-0.320605,-0.797277,-0.894869,-1.59369,-1.31477,1.92884,1.9427
9213,0.981193,0.942393,0.898166,0.890788,0.475673,0.530524,0.236002,0.204004,0.742694,0.810141,0.961434,0.999325,0.273706,0.266427,0.627861,0.630489,0.930611,0.96342,0.916331,0.934595,-1.57495,-1.71368,-0.363124,-0.289154,-0.436153,-0.31439,0.0734786,0.0105717,1.75185,1.80001,0.375677,0.492257,1.38507,1.40564,0.78588,0.69193,-1.32627,-1.04431,-0.664577,-0.643899
9214,0.129071,0.0907208,0.00374012,-0.00326645,0.309873,0.338709,0.931517,0.901388,0.495167,0.561854,0.0330679,0.0703634,0.274481,0.270813,0.576261,0.522817,0.498784,0.534329,0.170474,0.186713,-0.623132,-0.759586,0.31162,0.389206,-0.933312,-0.818023,1.50006,1.44006,-1.14821,-1.10371,-0.572733,-0.450821,-0.0746962,-0.0457826,-1.40413,-1.49047,0.525517,0.809445,-0.61413,-0.591066
9215,0.221439,0.181768,0.0467733,0.0401412,0.537787,0.566009,0.643901,0.612993,0.638126,0.706308,0.776519,0.81229,0.283925,0.2752,0.502348,0.415144,0.898237,0.935266,0.137608,0.151479,1.53143,1.3973,0.483784,0.560473,-1.05181,-0.87638,-0.2966,-0.358118,-0.969199,-0.929646,0.395461,0.512701,-0.125163,-0.0689754,-0.187229,-0.27379,-1.5945,-1.31157,0.790511,0.812883
9216,0.0884773,0.0484892,0.97939,0.971487,0.763963,0.793308,0.576428,0.546053,0.528571,0.594677,0.689494,0.703993,0.990801,0.983291,0.304016,0.307472,0.469697,0.506176,0.0999822,0.116245,-0.428792,-0.561236,-0.456781,-0.371778,-1.05043,-0.934738,1.32734,1.26351,-1.79171,-1.75441,0.102316,0.220798,-0.126103,-0.0921682,1.4411,1.35979,-0.14261,0.133634,-1.22965,-1.20662
9217,0.443274,0.405306,0.778628,0.772024,0.255487,0.28492,0.101574,0.0692015,0.0756238,0.141288,0.48494,0.595697,0.616259,0.607328,0.0343491,0.0349386,0.991404,1.02662,0.723669,0.740701,-0.370776,-0.510565,-0.0944961,0.0737637,-0.27493,-0.166048,-0.928647,-1.00046,0.826403,0.86866,-0.92664,-0.812037,0.0737355,0.106639,0.52411,0.520983,-2.57553,-2.30152,1.09578,1.11752
9218,0.356123,0.31925,0.933908,0.92607,0.308687,0.337485,0.575985,0.54221,0.0516139,0.117163,0.451173,0.487401,0.980852,0.969788,0.849944,0.848848,0.895342,0.931152,0.908451,0.927894,0.19149,0.0464295,0.437641,0.519305,-0.79735,-0.686262,0.441855,0.364484,2.01353,2.05483,0.695013,0.812402,-0.235966,-0.198439,-0.308358,-0.317823,-0.347402,-0.0735559,2.23433,2.26011
9219,0.26953,0.233194,0.00564813,-0.00222562,0.158535,0.185587,0.329339,0.294276,0.464722,0.463589,0.5789,0.617099,0.41272,0.402376,0.805058,0.802329,0.302323,0.33692,0.580158,0.668449,-0.807766,-0.959471,-0.60462,-0.522714,-0.997645,-0.883855,0.648162,0.559963,0.876983,0.924506,-0.086647,0.0254897,-1.03536,-0.997557,-1.07532,-1.15663,-0.305966,-0.0312705,1.33494,1.36232
9220,0.816996,0.779592,0.426827,0.416888,0.787061,0.814084,0.28719,0.188978,0.742643,0.810015,0.990159,1.02675,0.51308,0.502812,0.149305,0.145272,0.467241,0.501797,0.290075,0.409004,1.26409,1.10832,-0.898731,-0.811728,0.00329128,0.115639,0.826195,0.755443,0.265492,0.313882,-0.630601,-0.516015,-1.11317,-1.07287,0.384181,0.307518,0.407049,0.678474,0.172802,0.204171
9221,0.519152,0.479961,0.0750842,0.0671701,0.959364,0.912398,0.119387,0.0836801,0.928218,0.995073,0.777556,0.812971,0.85331,0.844794,0.239446,0.236155,0.392307,0.523132,0.132224,0.149559,1.4609,1.2162,0.195898,0.283157,-1.34993,-1.24362,0.261439,0.111564,-2.26297,-2.20878,1.68159,1.7971,1.18786,1.22859,-0.72369,-0.801985,-0.982676,-0.712803,0.942174,0.967162
9222,0.582199,0.550757,0.557239,0.550889,0.982157,1.01071,0.511971,0.477227,0.0347137,0.102701,0.161757,0.19806,0.633327,0.623633,0.576131,0.477767,0.512141,0.544467,0.290255,0.273416,1.47707,1.32409,0.518669,0.607992,-0.630301,-0.509875,-0.456262,-0.532315,-1.20254,-1.14538,-1.67322,-1.56364,0.451084,0.49119,0.555572,0.474142,-0.465848,-0.171217,-0.506405,-0.481243
9223,0.662066,0.621553,0.692316,0.751969,0.0690279,0.0961718,0.566709,0.531461,0.565688,0.631726,0.180411,0.214755,0.715412,0.710987,0.720623,0.719379,0.120893,0.154419,0.380298,0.397272,1.08516,0.935967,0.451553,0.533527,0.121921,0.223871,-0.235567,-0.303826,0.0862846,0.148138,1.62348,1.734,-0.634849,-0.601207,0.663121,0.57619,0.102029,0.370368,-0.0196758,0.00777703
9224,0.109967,0.0704167,0.959098,0.953048,0.629913,0.658404,0.939658,0.905302,0.888767,0.954143,0.43129,0.464641,0.80549,0.798341,0.854981,0.854936,0.583816,0.619588,0.901718,0.91686,-0.420348,-0.573547,0.780859,0.858362,-0.385348,-0.279762,-0.543299,-0.616834,-0.4798,-0.415755,-1.65102,-1.53223,-0.620711,-0.586672,-0.522204,-0.609031,-0.743743,-0.469268,-1.58223,-1.55987
9225,0.693283,0.651813,0.783318,0.778474,0.174894,0.204411,0.222499,0.188235,0.212282,0.278944,0.76036,0.714528,0.382993,0.377319,0.0164844,0.0178858,0.0838762,0.119835,0.569858,0.58528,0.754555,0.595663,-0.953731,-0.873591,-0.336689,-0.234977,-1.11742,-1.19141,0.35909,0.417489,0.106881,0.229492,-0.150258,-0.110062,-0.016843,-0.109127,0.193646,0.474673,0.0113382,0.02817
9226,0.284785,0.314216,0.221053,0.216286,0.975409,1.00384,0.43069,0.394921,0.483767,0.593745,0.930071,0.964415,0.997244,0.993495,0.38489,0.384973,0.206936,0.211135,0.573943,0.590593,-0.516544,-0.669868,0.383994,0.465238,-2.97949,-2.87818,-1.48958,-1.56598,-0.214371,-0.162272,-0.666868,-0.543497,1.46681,1.50686,-1.31318,-1.40499,0.49906,0.777579,-1.774,-1.75687
9227,0.0180777,-0.0233803,0.956113,0.952299,0.792513,0.876768,0.973334,0.937809,0.844171,0.908545,0.377313,0.410229,0.0333696,0.031351,0.0835888,0.0834095,0.268069,0.302434,0.0381474,0.0547519,-0.0729051,-0.219412,0.840017,0.92706,0.296886,0.393388,2.19261,2.11621,0.355262,0.409656,-0.424504,-0.299249,-1.29051,-1.25003,1.56521,1.46718,-0.674148,-0.395236,-0.276069,-0.260713
9228,0.18697,0.111026,0.325178,0.32197,0.726475,0.749693,0.814453,0.712496,0.603924,0.665758,0.442014,0.47667,0.689474,0.689244,0.00642253,0.00670274,0.566913,0.530715,0.670192,0.688656,-0.64031,-0.793686,0.962498,1.05031,0.274132,0.363908,-0.31034,-0.384058,0.42927,0.476765,0.630391,0.759142,0.438867,0.476213,0.531727,0.358734,0.417471,0.68868,-1.49036,-1.48041
9229,0.284675,0.245431,0.0783711,0.0758295,0.596528,0.622617,0.521872,0.487183,0.136447,0.197454,0.855881,0.891244,0.185063,0.182926,0.188491,0.187825,0.725099,0.758997,0.863196,0.880705,0.0890418,-0.0626114,-0.694647,-0.602098,-0.458879,-0.374049,-0.844408,-0.912153,-1.2979,-1.25357,0.898024,0.933561,-2.31344,-2.28067,-0.652274,-0.749707,-0.462201,-0.205898,0.346714,0.358825
9230,0.941261,0.901825,0.849444,0.846685,0.644066,0.669302,0.0392304,0.00537197,0.119084,0.17849,0.787723,0.823164,0.448824,0.444499,0.169376,0.16748,0.797805,0.832655,0.0585712,0.0761757,0.815943,0.668463,-0.377357,-0.292215,-0.909854,-0.831583,-2.3527,-2.41468,0.643464,0.687709,0.984594,1.10798,1.33064,1.36341,-1.92753,-2.02894,-1.37038,-1.10048,0.137556,0.154482
9231,0.768704,0.729827,0.949352,0.945616,0.180189,0.204874,0.287916,0.287081,0.803719,0.864408,0.459181,0.494584,0.250749,0.244841,0.377042,0.374597,0.433811,0.46835,0.389169,0.405055,0.711496,0.566627,-0.654132,-0.566219,0.0459562,0.122353,0.526508,0.463441,-0.0887242,0.0468976,-0.992375,-0.864692,-0.891601,-0.857419,-1.21953,-1.31434,0.223996,0.500314,1.37494,1.38992
9232,0.818884,0.780075,0.725611,0.721339,0.617557,0.644199,0.602862,0.56879,0.972421,0.947116,0.835762,0.869485,0.804164,0.796551,0.366951,0.486816,0.693246,0.711779,0.94881,0.963928,0.107792,-0.0378583,-1.54229,-1.45318,-0.569539,-0.495002,-0.217876,-0.282811,-0.638158,-0.593914,-0.220777,-0.099128,-0.719239,-0.689259,-0.262711,-0.356112,-0.199671,0.0759447,-1.59316,-1.57725
9233,0.0085494,-0.0318184,0.0744099,0.070815,0.772946,0.714922,0.408847,0.351858,0.970381,1.02983,0.825985,0.861665,0.352796,0.345711,0.547063,0.599034,0.919767,0.955208,0.956022,0.969241,1.31451,1.16413,1.9944,2.07755,2.01429,2.09199,0.366175,0.293802,-1.11481,-1.06693,-0.286213,-0.161378,0.643879,0.666507,0.292121,0.203154,1.47517,1.75714,-0.867183,-0.844739
9234,0.539745,0.499521,0.133145,0.130487,0.760966,0.785646,0.170972,0.134927,0.285767,0.343792,0.556104,0.584468,0.149092,0.241785,0.714893,0.711253,0.709008,0.741821,0.691068,0.756011,0.794343,0.649485,0.669469,0.754402,-1.67567,-1.59859,0.333589,0.258158,-1.2395,-1.14067,0.215859,0.345718,0.0785822,0.096875,-0.733647,-0.828531,-0.0384439,0.238954,-0.812657,-0.791905
9235,0.0751742,0.0337001,0.481429,0.48099,0.572112,0.598168,0.629136,0.592611,0.987389,1.04486,0.273595,0.307271,0.144814,0.13786,0.539735,0.534414,0.710106,0.829486,0.528403,0.54278,-1.90852,-2.04993,-0.422877,-0.401993,-0.1596,-0.0824737,-1.58362,-1.6547,-1.26495,-1.2144,1.20994,1.34234,2.17106,2.19081,-0.209695,-0.297464,0.726724,1.00856,-0.477693,-0.528968
9236,0.659473,0.61933,0.569927,0.570208,0.77211,0.798628,0.287288,0.251146,0.700742,0.757535,0.736859,0.77022,0.635104,0.629949,0.149834,0.142618,0.865286,0.917151,0.850865,0.866515,-0.0960123,-0.24329,-1.64029,-1.55839,0.625646,0.700234,-0.392958,-0.458399,-0.633979,-0.631208,-1.34988,-1.22346,-0.541137,-0.519055,0.019064,-0.0729605,-0.960245,-0.684426,-0.288716,-0.266031
9237,0.469099,0.430667,0.254333,0.254436,0.509265,0.51774,0.359671,0.324247,0.916698,0.972792,0.617215,0.652835,0.77908,0.784118,0.609,0.59934,0.974267,1.00482,0.667122,0.681106,-1.04176,-1.1852,0.357017,0.437026,-0.794513,-0.72088,-0.739496,-0.757058,-0.0913373,-0.0480144,-0.991836,-0.87084,0.165201,0.187987,0.581895,0.486305,-1.18789,-0.907853,-0.25066,-0.227693
9238,0.553447,0.520713,0.720063,0.717513,0.211697,0.236852,0.0353446,0.00143946,0.783148,0.841168,0.0270646,0.0630449,0.944608,0.938287,0.457263,0.448094,0.807751,0.837117,0.019012,0.0349464,0.0629376,-0.0776931,0.343077,0.422229,-1.00108,-0.935754,-0.987943,-1.05572,0.303377,0.248679,0.469734,0.598807,-0.118696,-0.101586,2.10988,2.01051,1.01445,1.29045,1.43569,1.45321
9239,0.649758,0.61076,0.821302,0.774015,0.983633,1.00808,0.59182,0.558902,0.985719,1.04639,0.136364,0.172088,0.543656,0.53795,0.72619,0.718772,0.0379039,0.0680979,0.449757,0.463546,0.0177896,-0.116928,-0.0923568,-0.0188018,0.812555,0.881131,0.737771,0.673281,0.502049,0.545372,0.35711,0.491426,1.08527,1.09929,-0.0243162,-0.123803,0.17906,0.4181,-1.56538,-1.5496
9240,0.370218,0.331764,0.832216,0.830517,0.750929,0.774948,0.260499,0.22613,0.44928,0.508236,0.452042,0.528797,0.832163,0.824495,0.0314331,0.0258628,0.882406,0.913364,0.473058,0.485735,0.348752,0.210765,0.792257,0.872948,0.380544,0.454268,-1.3369,-1.39993,0.501808,0.527691,-0.281477,-0.144114,2.6411,2.65311,-0.262746,-0.359658,-0.731709,-0.454249,0.353883,0.362856
9241,0.461374,0.422811,0.0551046,0.0531087,0.23018,0.256156,0.497103,0.461703,0.175741,0.236231,0.851085,0.885506,0.535794,0.527827,0.982885,0.976565,0.580895,0.576899,0.0772398,0.0904584,1.38807,1.24161,-1.61343,-1.53817,0.957587,1.08581,0.680814,0.617922,0.467115,0.510011,-0.0285346,0.114324,1.13778,1.15347,-0.296198,-0.399906,-0.485517,-0.214946,1.13338,1.13921
9242,0.343192,0.205707,0.190671,0.273534,0.449409,0.490998,0.979474,0.944305,0.860691,0.922148,0.0336245,0.0681664,0.0110665,0.00100106,0.310606,0.304668,0.207836,0.240434,0.847016,0.861123,0.925013,0.776299,0.274275,0.347314,1.6413,1.71735,0.535226,0.476017,-0.0750478,-0.0387648,1.59416,1.73876,0.630185,0.647315,0.296475,0.19069,0.982582,1.24768,-0.0333276,-0.0352173
9243,0.0271161,-0.011397,0.440466,0.49396,0.699269,0.72584,0.473449,0.436395,0.656196,0.715661,0.0215321,0.0560189,0.0804864,0.0697956,0.322662,0.314946,0.629929,0.661498,0.69434,0.710763,-1.12672,-1.27941,-0.370389,-0.292251,-1.10606,-1.03561,-0.980532,-1.04292,-0.0782568,-0.0491928,-0.486435,-0.341323,0.512406,0.527701,-0.0477569,-0.14977,-2.12968,-1.86973,0.575947,0.575511
9244,0.846489,0.806466,0.715342,0.714386,0.0446718,0.0724457,0.293129,0.262154,0.667142,0.728593,0.936947,0.972126,0.483534,0.471733,0.638575,0.631286,0.307131,0.336955,0.813651,0.802123,-0.635489,-0.782798,0.708712,0.785396,-0.864369,-0.788584,0.735871,0.668716,0.504811,0.536856,0.68935,0.837208,1.81002,1.82095,-0.390785,-0.490229,-1.83764,-1.583,0.385456,0.386221
9245,0.329635,0.291048,0.221196,0.221472,0.301359,0.327926,0.123232,0.087914,0.0556267,0.119092,0.580665,0.614561,0.256781,0.245365,0.2903,0.284703,0.377943,0.40538,0.878837,0.893482,-3.37874,-3.52958,0.653368,0.72625,-0.230315,-0.160354,0.886995,0.819472,-0.325257,-0.287909,-2.425,-2.27152,-0.0297781,-0.0232161,-0.161757,-0.319435,-0.448298,-0.199678,0.569296,0.581922
9246,0.116276,0.151318,0.366539,0.422551,0.132485,0.161779,0.535019,0.501935,0.596444,0.657978,0.516688,0.5679,0.51316,0.501965,0.306477,0.300523,0.0252339,0.050658,0.70167,0.71815,-0.44454,-0.597653,-0.648285,-0.578005,2.54085,2.61109,0.0484799,-0.0201258,1.36475,1.40291,-0.141216,0.0100123,1.06157,1.06473,-0.0434024,-0.148641,0.71871,0.961535,0.781451,0.777622
9247,0.0486045,0.011588,0.625233,0.623631,0.66952,0.699422,0.460362,0.42879,0.336726,0.487693,0.487101,0.521238,0.982062,0.969044,0.0248724,0.0189445,0.0798809,0.104814,0.822999,0.839599,-0.999667,-1.15622,2.20592,2.27079,-1.60788,-1.54149,-1.88313,-1.95078,0.603252,0.63999,-1.4797,-1.33077,0.074228,0.11528,1.24308,1.14451,-2.11903,-1.87851,0.711269,0.711305
9248,0.749681,0.712281,0.183209,0.180258,0.742283,0.767775,0.172656,0.140395,0.15691,0.317408,0.112575,0.144414,0.0577255,0.0475174,0.529524,0.525949,0.376153,0.400945,0.590237,0.608782,1.46651,1.31763,2.0178,2.08943,-0.218572,-0.148718,0.306571,0.237634,0.0510559,0.0312743,-0.397036,-0.243525,-0.844713,-0.834172,1.40363,1.30665,-0.981972,-0.748231,-0.171277,-0.172203
9249,0.776025,0.780189,0.657243,0.653921,0.803568,0.836128,0.376541,0.347081,0.0855897,0.147124,0.797062,0.830485,0.395093,0.474362,0.504498,0.458474,0.369526,0.395301,0.743619,0.686398,0.133846,-0.0101239,-0.992487,-0.927729,-0.314979,-0.241986,-1.95574,-2.02634,-0.620996,-0.577442,0.348189,0.506057,1.63901,1.64232,1.11371,1.01111,-0.592418,-0.351333,0.341103,0.426493
9250,0.947531,0.848098,0.879872,0.876782,0.0265469,0.0617106,0.257554,0.229155,0.412917,0.474497,0.718372,0.77896,0.910945,0.901206,0.395935,0.390998,0.0459935,0.0707574,0.745717,0.764015,0.405138,0.255759,-0.259101,-0.191107,2.56752,2.63753,-0.857672,-0.92422,0.0277355,0.070367,-1.2252,-1.06471,-1.11638,-1.11457,0.304811,0.207883,-1.2122,-0.974396,1.02781,1.02519
9251,0.952075,0.916006,0.449019,0.501035,0.813428,0.850457,0.633838,0.607467,0.353852,0.414649,0.707681,0.727434,0.773283,0.816067,0.703848,0.697585,0.0846817,0.109202,0.599983,0.618909,-0.626517,-0.780392,0.445089,0.545515,0.969382,1.03268,0.739204,0.680356,-1.57363,-1.53613,-0.538718,-0.377371,-0.971907,-0.977099,0.559116,0.413778,0.169321,0.408927,-0.150179,-0.149238
9252,0.0604594,0.0270329,0.128025,0.125288,0.897435,0.936723,0.189244,0.161576,0.707518,0.766677,0.644654,0.675909,0.739389,0.730928,0.397672,0.460108,0.591372,0.564167,0.924355,0.942644,0.66393,0.51332,1.21738,1.28214,0.909054,0.972021,0.00474213,-0.0660885,0.759218,0.802417,0.425748,0.586152,1.0989,1.09566,0.722466,0.619673,-1.72716,-1.49465,0.745671,0.749318
9253,0.200889,0.167387,0.144752,0.144322,0.64595,0.687298,0.957864,0.93046,0.390306,0.448997,0.162306,0.195771,0.441563,0.43426,0.229636,0.222631,0.995361,1.01913,0.678068,0.697333,-1.35928,-1.5122,0.720136,0.780448,-1.53552,-1.47635,-0.74861,-0.812533,0.222377,0.27038,-1.43618,-1.27533,-1.06401,-1.06164,1.25367,1.15074,1.51274,1.73724,-0.875751,-0.866813
9254,0.594504,0.560334,0.929258,0.931269,0.668582,0.774453,0.931275,0.858283,0.92459,0.982758,0.672416,0.708583,0.845339,0.836197,0.567425,0.560194,0.716117,0.740615,0.917663,0.93608,-0.246576,-0.404688,-1.23605,-1.17222,0.147897,0.212574,-1.16239,-1.23346,-1.51205,-1.45995,0.779843,0.942522,-0.186495,-0.187119,0.810214,0.701383,0.429736,0.659782,-1.27294,-1.26884
9255,0.603419,0.547836,0.14274,0.143387,0.818894,0.861609,0.858181,0.786105,0.562038,0.67572,0.941971,0.977354,0.719587,0.711585,0.589541,0.490138,0.107267,0.130362,0.703992,0.72078,-0.24132,-0.399266,-0.299813,-0.234662,-1.37853,-1.31415,-0.149461,-0.220961,-0.847197,-0.79552,-0.383321,-0.226447,1.61752,1.61713,-0.208273,-0.316719,0.461439,0.686418,-0.599887,-0.596422
9256,0.569057,0.535337,0.0877885,0.0889047,0.586197,0.627644,0.743526,0.713928,0.270897,0.368681,0.97833,1.01363,0.190527,0.184759,0.428711,0.420083,0.879473,0.901874,0.130421,0.145086,0.412756,0.251157,-1.30653,-1.24591,-0.711999,-0.654829,-1.17926,-1.24551,0.369127,0.42238,0.0371166,0.185219,-0.33292,-0.338562,-0.0875012,-0.200467,-1.32203,-1.08951,1.27392,1.27348
9257,0.160263,0.125407,0.560084,0.562568,0.353117,0.39368,0.230318,0.201017,0.00347462,0.0616429,0.610339,0.646226,0.990092,0.9845,0.92681,0.91734,0.592733,0.585391,0.217839,0.231207,-0.921967,-1.09029,-0.375859,-0.30835,0.929249,0.987865,0.0356294,-0.0337755,0.786792,0.840997,-1.1474,-1.0009,-0.32956,-0.33745,-0.308683,-0.42026,0.125159,0.355696,2.25313,2.24713
9258,0.865864,0.830749,0.810541,0.81425,0.816661,0.857238,0.998563,0.969901,0.409183,0.469602,0.757334,0.791211,0.846574,0.821797,0.708627,0.735274,0.248277,0.268908,0.906551,0.919783,0.538389,0.377355,-0.325189,-0.261159,1.82928,1.89499,1.75894,1.69522,-0.325518,-0.273613,-1.44067,-1.29281,0.92662,0.923716,0.856685,0.753299,-0.0981461,0.132269,1.07714,1.0727
9259,0.0195659,-0.0166977,0.511379,0.514399,0.544359,0.58282,0.434964,0.406164,0.350971,0.394222,0.250834,0.285838,0.66441,0.659095,0.571427,0.553208,0.353986,0.406426,0.725823,0.739444,1.02782,0.86153,-0.632488,-0.56733,-0.813674,-0.748212,-0.563763,-0.633927,-0.887799,-0.837505,0.872509,1.02031,0.601066,0.602685,-1.32681,-1.4291,0.607786,0.893034,0.212541,0.203308
9260,0.466477,0.431167,0.61174,0.613331,0.733444,0.773173,0.219495,0.188641,0.257277,0.318842,0.953191,0.986499,0.137907,0.132268,0.525028,0.371142,0.523435,0.543944,0.215275,0.228534,-0.324665,-0.493819,0.252058,0.32442,-0.620842,-0.549363,0.369688,0.29946,0.591201,0.639274,0.127621,0.278245,0.552112,0.557862,0.0891712,-0.00941226,1.42593,1.6538,0.925508,0.921306
9261,0.248425,0.211932,0.4119,0.413868,0.247867,0.287612,0.343563,0.332282,0.996021,1.05736,0.267048,0.301732,0.596113,0.516348,0.198546,0.189075,0.00097771,0.0198772,0.396555,0.361316,-0.370591,-0.533054,0.029208,0.0934294,0.246804,0.310935,0.586547,0.510103,-1.36496,-1.31139,0.807937,0.953191,1.31473,1.32496,-1.15709,-1.25619,0.622736,0.844435,1.21778,1.21353
9262,0.738295,0.703459,0.685533,0.663097,0.284604,0.323979,0.508381,0.475923,0.0265553,0.0878137,0.88317,0.917401,0.905417,0.900427,0.307993,0.369298,0.976128,0.994392,0.483006,0.494098,-1.24365,-1.39961,0.164194,0.150552,0.0475194,0.113343,-1.31032,-1.38771,-1.0257,-0.969076,0.620315,0.730304,-0.495347,-0.489006,0.240296,0.147688,0.400908,0.621007,-1.24026,-1.24861
9263,0.52109,0.484225,0.912505,0.912326,0.943427,0.982973,0.23733,0.202895,0.832798,0.894713,0.62399,0.659413,0.42838,0.424283,0.558812,0.549522,0.614039,0.721111,0.847251,0.859289,0.833083,0.683237,0.147848,0.207674,1.3138,1.38544,-0.043072,-0.113875,0.379719,0.431454,0.360799,0.507417,1.1683,1.1755,-0.868203,-0.961815,-0.712473,-0.486265,-0.380209,-0.396953
9264,0.963495,0.926903,0.0738984,0.0721168,0.0508882,0.0903729,0.706774,0.67084,0.163969,0.22501,0.602336,0.517807,0.269087,0.218428,0.522596,0.513407,0.429921,0.447829,0.594825,0.604486,0.737779,0.581401,0.607646,0.645262,-0.869782,-0.804795,-1.27914,-1.35592,-0.561866,-0.516624,0.527908,0.674701,-0.52678,-0.513558,1.96578,1.87117,0.817989,1.05026,0.0841821,0.06048
9265,0.175657,0.138486,0.0520176,0.0514577,0.498702,0.539628,0.37097,0.333424,0.457406,0.516963,0.41198,0.3762,0.0190479,0.0125732,0.253058,0.272481,0.900237,0.91838,0.634664,0.646362,0.965362,0.816216,1.02601,1.08285,0.773713,0.837899,-0.970866,-1.05206,-0.607051,-0.55893,2.05133,2.19031,-0.756465,-0.763743,0.827553,0.731968,-0.444227,-0.213815,-0.505434,-0.535719
9266,0.77942,0.744463,0.725478,0.726247,0.0690642,0.109717,0.698184,0.662671,0.432881,0.492838,0.199171,0.234594,0.27317,0.264737,0.0425695,0.0315544,0.0940966,0.109997,0.326886,0.341173,-1.45667,-1.601,-0.0728454,-0.0216127,0.888461,0.958723,1.42882,1.34538,-1.3437,-1.29174,0.863797,1.00419,-1.03278,-1.01393,-0.680897,-0.776024,-1.43063,-1.19703,0.448658,0.519767
9267,0.185733,0.148878,0.835726,0.795721,0.448979,0.490632,0.044,0.0103495,0.654216,0.756075,0.876851,0.911566,0.17294,0.165079,0.777639,0.768816,0.444872,0.461281,0.487708,0.512502,0.775269,0.63472,-0.863736,-0.816283,-1.21172,-1.1365,-0.446576,-0.533134,-0.266706,-0.213035,0.442086,0.587861,-0.914975,-0.891174,-1.54874,-1.63948,-0.132451,0.104871,1.59857,1.57525
9268,0.453683,0.415753,0.863213,0.865195,0.569123,0.611779,0.469766,0.434611,0.959457,1.01931,0.169905,0.206544,0.909322,0.899644,0.69795,0.668383,0.190989,0.207576,0.672066,0.683831,-0.831673,-0.968097,-0.625549,-0.584494,0.973259,1.04269,1.15077,1.07144,-0.449235,-0.396367,1.14732,1.29299,-1.17151,-1.14959,-1.14987,-1.2467,-0.97251,-0.734765,1.10721,1.0854
9269,0.290181,0.252739,0.541098,0.544841,0.932085,0.974158,0.0985633,0.0626932,0.105727,0.164135,0.611586,0.649749,0.268135,0.25777,0.490862,0.56795,0.53083,0.548298,0.321459,0.33275,0.780356,0.638732,-0.747292,-0.70498,0.541453,0.605752,0.817723,0.743761,-0.115279,-0.0697487,-0.525846,-0.383517,0.82104,0.841627,-1.71146,-1.80365,0.539884,0.77081,1.86349,1.8484
9270,0.606655,0.56924,0.824799,0.826618,0.967846,1.01052,0.133935,0.0329889,0.0288543,0.0891071,0.238609,0.278056,0.422663,0.413129,0.47762,0.467517,0.242638,0.333032,0.932671,0.941615,0.100571,-0.0432783,-0.454418,-0.409376,0.0940053,0.168813,-0.793316,-0.868672,0.48622,0.551743,-2.44275,-2.29428,-1.55579,-1.54291,0.802532,0.711329,-1.29281,-1.06632,0.135124,0.125817
9271,0.225681,0.189504,0.621172,0.687841,0.801005,0.844378,0.0543864,0.00328461,0.658282,0.718272,0.811322,0.849108,0.330415,0.244389,0.757617,0.692578,0.098212,0.117766,0.660673,0.671169,-0.968934,-1.11077,0.700373,0.743662,0.0182184,0.0930586,0.423636,0.343062,1.12771,1.17324,-0.45928,-0.316799,0.116898,0.135973,-2.35842,-2.45018,-0.0185863,0.20414,-0.468681,-0.470382
9272,0.615269,0.578007,0.54585,0.549064,0.0784885,0.123381,0.0115386,-0.0264197,0.639518,0.699308,0.442562,0.4817,0.0851831,0.0756488,0.926632,0.917639,0.662008,0.683166,0.103273,0.11536,0.0561396,-0.079921,-1.30275,-1.25147,-1.05097,-0.972795,0.698629,0.615603,-0.170298,-0.12702,-0.127917,0.0177295,0.117041,0.130503,-0.208984,-0.302767,-0.131605,0.0905227,-0.459114,-0.462802
9273,0.795818,0.73715,0.679995,0.682917,0.606634,0.651916,0.725554,0.686405,0.917552,0.975905,0.816885,0.856601,0.903191,0.891739,0.768082,0.761124,0.281751,0.303445,0.310359,0.288404,0.426417,0.294698,1.07543,1.13205,-1.62201,-1.53937,0.154028,0.0539832,0.473011,0.520789,-0.17261,-0.0286758,0.108232,0.125034,-1.99308,-2.08871,0.571251,0.800268,0.500196,0.496709
9274,0.934202,0.896293,0.464147,0.51498,0.00835383,0.0525806,0.874166,0.83668,0.2025,0.26032,0.280047,0.322416,0.953615,0.940233,0.2215,0.215601,0.619209,0.639877,0.510067,0.461449,2.04326,1.91757,0.456779,0.507515,0.224033,0.307316,-0.423319,-0.507636,-0.376485,-0.334358,0.413583,0.554658,0.784855,0.800208,0.490157,0.388827,0.615447,0.842553,0.781258,0.7748
9275,0.662561,0.689721,0.363857,0.347044,0.483321,0.526175,0.497717,0.459064,0.073367,0.169298,0.62598,0.668067,0.340445,0.329089,0.237423,0.187105,0.369865,0.391357,0.622407,0.634494,-0.284316,-0.40469,1.68547,1.74207,0.811122,0.890745,0.0856442,0.00745401,-0.18994,-0.146245,0.613688,0.752732,2.52657,2.54095,1.07054,0.965203,1.00773,1.23945,1.94874,1.94868
9276,0.512215,0.483148,0.175426,0.179107,0.32062,0.360608,0.749838,0.709704,0.0204559,0.0782756,0.576108,0.629937,0.488014,0.474879,0.165709,0.15861,0.692336,0.687268,0.483198,0.412707,1.12496,0.998824,-1.01433,-0.955918,-2.47311,-2.38548,0.2916,0.218097,0.443232,0.567023,0.122828,0.259532,-0.888888,-0.874057,0.750036,0.552716,-0.463933,-0.233078,-0.593295,-0.593163
9277,0.315394,0.276576,0.9166,0.919805,0.151031,0.195041,0.778835,0.737659,0.713935,0.769535,0.547807,0.591808,0.973507,0.961619,0.935899,0.930584,0.96149,0.983179,0.179135,0.19092,-0.312196,-0.43684,-1.61981,-1.56558,-0.440491,-0.351541,-1.31058,-1.37825,1.23078,1.28029,0.342744,0.473894,-1.84835,-1.82795,0.245037,0.140228,-0.201647,0.0222264,-0.576709,-0.570692
9278,0.939585,0.902107,0.0771802,0.0795954,0.975091,1.0204,0.550589,0.536424,0.749839,0.806465,0.00424982,0.0473899,0.90918,0.897489,0.58706,0.584002,0.299877,0.322659,0.835659,0.849305,1.89125,1.76926,-1.74015,-1.68606,0.353198,0.447483,0.608636,0.538974,0.467047,0.517368,0.898249,1.02639,1.22243,1.24933,1.73674,1.63411,-0.788769,-0.5711,0.446853,0.450758
9279,0.0844614,0.0442057,0.561654,0.471714,0.643246,0.690651,0.350967,0.335189,0.180206,0.238541,0.785088,0.830475,0.0820275,0.0695136,0.574465,0.574006,0.161165,0.184255,0.770632,0.78503,0.0247682,-0.0999788,-0.482588,-0.422631,-2.23841,-2.15055,1.03657,0.963368,-0.665709,-0.612958,1.11443,1.24075,0.42505,0.450215,0.52153,0.417444,1.64722,1.86515,0.732421,0.742984
9280,0.111412,0.069274,0.861007,0.863833,0.836564,0.885977,0.17513,0.133954,0.0898239,0.179687,0.150487,0.195101,0.165767,0.153339,0.22933,0.227424,0.315282,0.224816,0.322263,0.338638,-0.40094,-0.519287,-0.202831,-0.143364,1.02317,1.12101,0.0567273,-0.0156519,-0.277337,-0.224558,2.20857,2.328,-1.39162,-1.36375,0.833226,0.734648,-1.32287,-1.10209,-1.86588,-1.85731
9281,0.573264,0.431571,0.9497,0.953051,0.086388,0.135946,0.470835,0.429225,0.025977,0.120832,0.307697,0.354571,0.837969,0.826067,0.359296,0.358445,0.283813,0.265376,0.488622,0.505574,-0.309032,-0.423076,-1.33626,-1.279,-1.53822,-1.43606,1.0347,0.872989,0.764648,0.823885,0.172663,0.294303,-0.74765,-0.716852,-0.0761065,-0.174651,0.208052,0.434433,-2.50188,-2.50016
9282,0.838086,0.793868,0.524425,0.600997,0.741479,0.790393,0.116615,0.0775118,0.00296425,0.0619778,0.740674,0.788696,0.920231,0.909892,0.932925,0.932062,0.28429,0.305937,0.883818,0.90014,-1.27761,-1.39666,-1.07366,-1.01579,-0.912534,-0.807826,1.83974,1.76163,0.836202,0.890994,0.01119,0.21313,0.108847,0.139891,-2.19283,-2.29126,-0.42977,-0.204862,-0.198042,-0.189295
9283,0.0312118,-0.0124063,0.247698,0.248942,0.32823,0.375968,0.0607188,0.020269,0.467227,0.546387,0.592443,0.640678,0.591525,0.579488,0.862599,0.861093,0.718181,0.740836,0.813267,0.922277,0.631216,0.514957,-1.30387,-1.24678,1.02077,1.13034,3.4282,3.34886,0.120505,0.176369,0.0143398,0.131956,-0.261826,-0.227286,-0.802991,-0.902832,1.61044,1.82805,-0.227326,-0.212332
9284,0.702936,0.658815,0.551617,0.550377,0.225783,0.324689,0.902664,0.862348,0.971782,1.0308,0.772205,0.81978,0.466324,0.454876,0.49793,0.494307,0.515499,0.445048,0.925778,0.944415,-0.533026,-0.642912,0.00185022,0.124805,1.69054,1.80698,0.101641,0.022605,-1.86019,-1.80311,0.21713,0.330029,-1.60885,-1.57172,0.0132772,-0.0817807,-0.871006,-0.657307,0.567696,0.580949
9285,0.0759053,0.0329288,0.293537,0.294322,0.223706,0.27341,0.582998,0.544393,0.113225,0.170848,0.255239,0.305347,0.0144801,0.00403606,0.76611,0.764985,0.127178,0.14926,0.467411,0.488199,1.4074,1.30008,1.44214,1.49639,-0.183589,-0.0641337,-0.185982,-0.25987,-0.329674,-0.265495,-0.7694,-0.658187,-0.664947,-0.646904,2.05861,1.95814,-2.43822,-2.22222,-0.362381,-0.252313
9286,0.400584,0.403336,0.420778,0.396378,0.984508,1.0353,0.766123,0.729897,0.550874,0.55239,0.141456,0.191986,0.991813,0.981716,0.685241,0.684131,0.806299,0.827114,0.613909,0.634917,-0.838143,-0.945238,1.21246,1.2654,0.135463,0.25858,0.0546668,-0.0177668,-0.797798,-0.738516,-0.379878,-0.275296,0.236773,0.277911,0.122376,0.0294248,0.655939,0.872185,-1.09265,-1.08558
9287,0.815942,0.773743,0.585733,0.498434,0.310624,0.361505,0.102825,0.0666039,0.873833,0.933933,0.803619,0.85372,0.711907,0.700798,0.377904,0.37779,0.735244,0.75677,0.285552,0.308597,-0.744859,-0.849027,-1.02902,-0.970447,0.79974,0.917905,-0.567182,-0.637078,0.0780315,0.140563,-1.137,-1.0343,-0.5102,-0.472892,-0.158067,-0.251534,0.388382,0.602701,2.34786,2.35808
9288,0.450718,0.413612,0.598321,0.60049,0.0480889,0.097282,0.572592,0.534548,0.411346,0.470213,0.664912,0.626737,0.147629,0.138986,0.489262,0.488498,0.0753173,0.0962495,0.317618,0.332939,1.66152,1.56092,-0.293715,-0.230808,-1.70962,-1.59073,0.54599,0.480086,2.56747,2.63517,-0.717454,-0.622638,-2.72285,-2.67792,1.64956,1.55372,0.326597,0.535925,-0.939337,-0.92735
9289,0.0931607,0.0534813,0.560036,0.561119,0.0345416,0.0837946,0.726743,0.68918,0.992542,1.04995,0.349814,0.399755,0.409776,0.400559,0.0900436,0.0874767,0.348615,0.367224,0.336866,0.357281,-0.887594,-0.982475,-0.242332,-0.183617,-1.00071,-0.883949,-2.24211,-2.31526,0.929525,0.996927,1.04211,1.13908,2.05204,2.09697,-0.249956,-0.3439,-0.000718828,0.204971,-0.206148,-0.194844
9290,0.592181,0.549887,0.928529,0.930831,0.7031,0.753376,0.142341,0.105894,0.92671,0.984222,0.929849,0.980607,0.206716,0.195437,0.418193,0.41388,0.399404,0.416291,0.733312,0.751847,-0.443833,-0.532019,1.14087,1.20274,0.505363,0.617313,-9.77964e-05,-0.0741368,0.622604,0.68137,0.59362,0.690736,-1.74552,-1.70395,1.08574,0.995567,1.31768,1.52183,-0.395244,-0.384133
9291,0.621635,0.558363,0.261209,0.265154,0.228245,0.278401,0.444184,0.489115,0.190001,0.246855,0.0650502,0.115495,0.976985,0.964819,0.962671,0.95666,0.891712,0.907085,0.881275,0.898564,-0.3892,-0.481349,-1.05663,-1.00194,-1.39199,-1.28525,-0.498246,-0.57176,0.298322,0.365813,1.44334,1.54712,0.19454,0.241205,1.34204,1.25135,-1.35682,-1.15506,-0.88427,-0.873983
9292,0.710555,0.566838,0.73263,0.738817,0.0958926,0.146874,0.907963,0.872337,0.294527,0.311913,0.556714,0.508514,0.394785,0.382391,0.153725,0.149357,0.846694,0.891805,0.576717,0.680004,0.716856,0.626159,0.691988,0.741221,-0.357526,-0.254723,0.821047,0.74646,-0.809299,-0.748797,1.89283,1.99346,0.0714269,0.12159,-1.01654,-1.11355,0.452813,0.649423,-0.0181466,-0.0051117
9293,0.617287,0.575314,0.666478,0.596697,0.592264,0.645192,0.548817,0.515323,0.319619,0.376971,0.853045,0.901533,0.0196001,0.00642798,0.0569139,0.0530482,0.986824,0.876525,0.443167,0.461444,-0.304403,-0.395747,-1.23111,-1.18051,0.424942,0.527984,-1.95298,-2.03255,-0.852518,-0.791103,-0.430037,-0.326232,1.41001,1.46324,-0.00231111,-0.106568,0.203248,0.395724,-1.21371,-1.19411
9294,0.369117,0.32659,0.448106,0.454576,0.554006,0.606373,0.599146,0.564253,0.985759,1.04222,0.811366,0.780559,0.804592,0.792004,0.841827,0.835923,0.845394,0.861244,0.0118537,0.0307745,-0.224591,-0.314616,-0.789116,-0.734595,-0.923461,-0.817767,0.930726,0.845566,0.451681,0.518877,2.14664,2.24901,-0.443584,-0.396378,-1.3603,-1.46264,-0.38708,-0.197602,0.545359,0.566014
9295,0.540458,0.4023,0.730338,0.736352,0.968252,1.01953,0.134708,0.0975956,0.980905,1.02619,0.612547,0.659585,0.905738,0.89244,0.889266,0.841845,0.328549,0.346392,0.159822,0.100018,0.282091,0.199418,0.328039,0.391136,-1.17031,-1.06225,0.260438,0.17834,-0.187953,-0.121317,-0.34009,-0.232733,1.16947,1.22054,-0.847289,-0.94765,1.11737,1.30797,-0.67863,-0.653683
9296,0.520225,0.478009,0.607203,0.612462,4.52448e-05,0.0533458,0.19765,0.16129,0.859927,1.01016,0.123696,0.169329,0.389429,0.376406,0.902228,0.847767,0.81205,0.8314,0.147997,0.169261,-0.211843,-0.263314,-0.882116,-0.820902,0.0758219,0.180765,-1.08415,-1.16878,-1.63824,-1.57491,0.0681306,0.178933,-1.94856,-1.89319,0.315138,0.312411,-1.80579,-1.61835,0.251106,0.274378
9297,0.963023,0.920687,0.0961564,0.0996207,0.606109,0.661209,0.0333167,-0.00157431,0.943244,0.994132,0.223092,0.380055,0.257004,0.242281,0.818683,0.853689,0.384403,0.402309,0.849371,0.868891,-0.770906,-0.726047,1.28145,1.33608,-0.794197,-0.682912,1.19125,1.10924,0.549839,0.611708,-0.949881,-0.839523,-2.98123,-2.92486,1.67717,1.57247,-0.517958,-0.332181,-1.28613,-1.26464
9298,0.723814,0.682222,0.910846,0.91556,0.822768,0.876534,0.465898,0.473444,0.817265,0.978104,0.497897,0.590782,0.793266,0.778682,0.866692,0.859611,0.636082,0.654053,0.987678,1.00595,-1.1079,-1.18878,-1.11993,-1.06189,-0.370426,-0.253946,0.71791,0.641221,-1.69175,-1.62936,0.739053,0.848147,0.216483,0.266007,0.954581,0.843928,-0.938755,-0.756551,-1.62864,-1.60574
9299,0.94441,0.816628,0.575229,0.580485,0.731421,0.790736,0.981591,0.948463,0.905619,0.962076,0.757607,0.801508,0.686634,0.673914,0.647544,0.642523,0.349646,0.428058,0.0859419,0.105485,-0.0665577,-0.14061,0.34565,0.403588,0.799606,0.912536,-0.74113,-0.815114,0.355163,0.423144,0.0768567,0.182086,0.595552,0.574135,2.72157,2.60367,-0.153233,0.100574,0.336556,0.352655
9300,0.992735,0.951034,0.64098,0.675439,0.532485,0.704937,0.770767,0.736461,0.0485916,0.106899,0.225956,0.27159,0.116486,0.101714,0.161009,0.156355,0.183631,0.202062,0.410464,0.338089,-1.38661,-1.46836,-0.787577,-0.732053,0.941897,1.0504,1.24929,1.16897,-0.0250032,-0.0211721,-1.35109,-1.25033,0.829498,0.882263,0.152369,0.0281546,0.774232,0.957699,1.11176,1.12901
9301,0.545632,0.505187,0.764327,0.770393,0.565848,0.619139,0.894032,0.861331,0.102211,0.117448,0.169001,0.213734,0.832767,0.820793,0.372064,0.367766,0.559843,0.577871,0.614493,0.570693,-0.02083,-0.095992,-0.82485,-0.776819,-1.40743,-1.30138,1.75568,1.66872,-0.500018,-0.465488,1.31814,1.42288,-1.80026,-1.74724,2.04791,1.92633,-1.40811,-1.22931,-0.632097,-0.609051
9302,0.795664,0.756303,0.0092992,0.0139878,0.0529592,0.105575,0.507404,0.474611,0.0694647,0.127997,0.985302,1.02874,0.224944,0.214667,0.859836,0.854662,0.27382,0.29459,0.785873,0.803297,-0.819725,-0.902423,1.25948,1.31144,0.416477,0.515504,-0.400198,-0.481616,-0.9816,-0.909805,-0.214311,-0.11663,-0.490275,-0.435688,0.445845,0.326835,1.57891,1.75386,-0.192059,-0.165743
9303,0.361606,0.320501,0.450071,0.370299,0.129975,0.209975,0.788731,0.754517,0.705948,0.76253,0.416648,0.458966,0.483076,0.367264,0.845014,0.89364,0.454123,0.475936,0.349222,0.367076,0.611789,0.532487,-1.75975,-1.70572,0.20251,0.30063,0.398855,0.312802,-0.40693,-0.337877,1.21152,1.30508,-0.449406,-0.389788,-0.866159,-0.984545,0.651644,0.837186,0.571655,0.597247
9304,0.698514,0.657601,0.720545,0.72661,0.259885,0.314375,0.560268,0.595183,0.17164,0.229384,0.957456,1.00074,0.56083,0.519862,0.937901,0.932619,0.0624446,0.0858882,0.737174,0.756079,1.31225,1.22749,0.209347,0.25742,1.08462,1.17784,-0.537848,-0.620717,0.55454,0.617999,-0.501524,-0.401613,-0.766939,-0.710819,1.23557,1.11908,-0.247717,-0.0794926,0.911876,0.934902
9305,0.346742,0.307539,0.018992,0.0263466,0.978867,1.03437,0.469872,0.43585,0.0713686,0.128095,0.536413,0.579427,0.682168,0.672459,0.0234287,0.0200641,0.363941,0.385839,0.168945,0.190487,-0.267825,-0.360051,-0.0726382,-0.0315949,2.39263,2.4809,-2.11559,-2.19911,0.172213,0.235677,0.144282,0.242423,-0.404346,-0.342291,-0.117993,-0.236991,1.79971,1.97113,-0.326784,-0.300738
9306,0.412364,0.37287,0.8955,0.900591,0.592324,0.649756,0.967951,0.933757,0.47423,0.530625,0.978944,1.02263,0.21959,0.211997,0.0643015,0.0603831,0.325515,0.346197,0.617891,0.639574,0.305121,0.214091,0.275563,0.3236,2.23088,2.31448,-0.00316841,-0.0880477,0.969703,1.03616,-0.162584,-0.0662951,0.474445,0.532235,0.06932,-0.0434422,-0.475163,-0.309141,0.0374856,0.164738
9307,0.918526,0.880024,0.164712,0.170039,0.897051,0.956786,0.853544,0.821294,0.356725,0.413994,0.310163,0.352183,0.925499,0.920088,0.815621,0.81302,0.524042,0.546674,0.591019,0.600942,-0.437682,-0.528039,1.55761,1.60218,-1.10403,-1.02042,0.535159,0.443448,0.52886,0.592586,-0.858726,-0.762857,0.36656,0.426694,0.927403,0.808705,-0.944546,-0.778792,0.598585,0.630215
9308,0.64018,0.601028,0.0619833,0.0667775,0.00113724,0.060154,0.109482,0.0782208,0.541855,0.599052,0.884574,0.928253,0.390528,0.383307,0.847275,0.843234,0.19088,0.212839,0.540481,0.562311,-0.704548,-0.794595,0.145855,0.185779,-0.724132,-0.63739,-0.743985,-0.827935,-2.02802,-1.96831,0.0571079,0.0867321,-0.781837,-0.727028,0.540036,0.421262,-0.574783,-0.413167,-0.292112,-0.267576
9309,0.689298,0.651276,0.794864,0.798372,0.980817,1.03983,0.305869,0.365877,0.975183,1.0316,0.791821,0.835364,0.731034,0.725288,0.11671,0.113017,0.265294,0.286497,0.757855,0.77969,1.0385,0.950957,0.0321978,0.0991914,-0.0386776,0.0545745,-1.17991,-1.2652,0.632202,0.689353,0.841557,0.936322,-1.27053,-1.21856,-0.561642,-0.688241,-0.614751,-0.449221,0.0771251,0.10032
9310,0.0545798,0.014913,0.707779,0.710009,0.728134,0.786315,0.685194,0.653532,0.555541,0.612557,0.424552,0.467956,0.0395722,0.0333634,0.355429,0.296345,0.0442746,0.067656,0.0533155,0.0770548,0.226733,0.144526,-0.031259,0.0126036,-1.22302,-1.13456,-0.227209,-0.316346,0.43265,0.49054,-0.254079,-0.159597,0.751266,0.805313,-0.222096,-0.281422,-1.19269,-1.02769,-0.797481,-0.769076
9311,0.155736,0.150913,0.83176,0.833165,0.781728,0.838879,0.272763,0.241213,0.670187,0.726679,0.757595,0.802379,0.232058,0.224854,0.481619,0.479673,0.596571,0.617324,0.143291,0.168414,2.57221,2.48607,-0.532987,-0.489085,0.968306,1.058,-0.509683,-0.598821,0.865473,0.923688,0.711648,0.803926,-1.83222,-1.77343,0.243034,0.125397,-0.650005,-0.489034,1.78846,1.81209
9312,0.410989,0.286912,0.26165,0.261793,0.44813,0.504218,0.890503,0.858896,0.128583,0.183189,0.599163,0.573444,0.905203,0.897581,0.119027,0.117535,0.261497,0.283489,0.234856,0.259774,0.444273,0.351833,0.100611,0.141997,-0.331561,-0.23895,-0.336235,-0.386177,0.9965,1.05021,-0.0854624,0.000314009,0.323277,0.383272,-1.52877,-1.64565,-0.558359,-0.401025,-1.06545,-1.04376
9313,0.464023,0.422912,0.592795,0.592659,0.794545,0.851516,0.224963,0.191329,0.300614,0.424594,0.297509,0.34451,0.778755,0.77297,0.966808,0.967768,0.878746,0.899536,0.0995303,0.173898,0.148016,0.0548694,-0.384623,-0.34441,0.41536,0.514226,-0.0824708,-0.173533,-0.101984,-0.109706,0.968904,1.05871,-0.103789,-0.0463011,0.534815,0.425508,1.1706,1.32578,1.11268,1.13645
9314,0.116203,0.0728508,0.356026,0.358156,0.222113,0.277867,0.735874,0.704127,0.612897,0.665998,0.741126,0.787714,0.393684,0.387208,0.287044,0.285592,0.158964,0.17871,0.0641341,0.0880231,-1.95972,-2.04518,-0.381029,-0.342106,-0.624516,-0.520978,-0.568909,-0.654694,-1.31965,-1.26962,-1.1733,-1.08603,1.62816,1.67994,0.586071,0.402518,-1.15615,-0.993247,0.199756,0.192397
9315,0.950357,0.907999,0.876156,0.875928,0.112046,0.166334,0.954458,0.924473,0.504062,0.647423,0.64068,0.689823,0.643259,0.639372,0.304649,0.334921,0.224607,0.266443,0.158367,0.184189,1.32704,1.23537,1.74433,1.78177,0.38125,0.478515,0.623436,0.541608,-0.680199,-0.636738,0.731155,0.815447,-0.417404,-0.36937,0.497864,0.379529,0.735285,0.891258,-0.78055,-0.751658
9316,0.529243,0.48768,0.245076,0.245599,0.401264,0.376514,0.487109,0.457815,0.57428,0.628848,0.0212923,0.0696515,0.263532,0.258431,0.468453,0.384249,0.332105,0.354176,0.96752,0.992731,1.17269,1.02798,1.38582,1.41736,0.659736,0.815122,-0.464543,-0.547026,-0.800074,-0.759372,1.08801,1.16807,-0.258031,-0.216335,0.465847,0.356539,0.0599245,0.220305,0.390409,0.422225
9317,0.691221,0.611111,0.924616,0.92529,0.533459,0.586695,0.696321,0.6688,0.0130981,0.0649422,0.969797,1.01664,0.708846,0.704578,0.454325,0.433577,0.970826,0.991409,0.541654,0.566776,1.03447,0.820578,-1.34347,-1.31214,1.05935,1.15173,0.32117,0.23126,1.34498,1.39313,-1.11693,-1.03779,0.644819,0.68844,-0.0286106,-0.139215,-0.176976,-0.017216,-0.20003,-0.173974
9318,0.776956,0.734541,0.10216,0.100446,0.312995,0.364697,0.425743,0.340486,0.988819,1.04019,0.477544,0.52638,0.0562661,0.0523335,0.646339,0.482906,0.55841,0.577342,0.786935,0.732179,0.700677,0.61318,1.5551,1.58725,0.411731,0.5056,2.54622,2.45542,-0.566071,-0.522257,1.81693,1.90096,-0.32152,-0.281203,0.726977,0.619701,0.680897,0.834319,-0.462517,-0.438527
9319,0.0855977,0.0423189,0.500607,0.500483,0.378445,0.431332,0.0413806,0.0121725,0.414077,0.466856,0.817525,0.865956,0.599372,0.593988,0.649047,0.532234,0.685108,0.646502,0.871085,0.897581,0.897148,0.816451,2.15404,2.1891,0.531571,0.626424,-0.540859,-0.639193,-1.47579,-1.43707,0.610308,0.69952,0.568319,0.607455,-1.22875,-1.34068,0.204376,0.364667,1.44304,1.46002
9320,0.782074,0.737986,0.123007,0.121693,0.798734,0.84956,0.790089,0.760634,0.498975,0.579927,0.34535,0.39588,0.141794,0.138085,0.583014,0.581563,0.69734,0.715662,0.559305,0.586188,-1.77845,-1.86852,1.04231,1.08464,-0.456836,-0.361716,-0.910236,-1.01377,0.158689,0.193479,0.115351,0.20632,2.82678,2.8575,2.07508,1.96315,0.244875,0.406952,-0.60471,-0.588049
9321,0.775377,0.675852,0.36596,0.363812,0.0414073,0.094424,0.361261,0.333471,0.613441,0.692999,0.344486,0.393535,0.742066,0.738601,0.920946,0.919125,0.296297,0.316717,0.859183,0.883617,-0.799792,-0.897267,-1.29987,-1.26372,0.817902,0.910378,1.5685,1.46689,-0.264978,-0.234651,-1.06144,-0.962649,-0.463913,-0.43331,0.497103,0.379307,0.566736,0.725531,0.683614,0.612273
9322,0.658686,0.613718,0.317734,0.362065,0.851483,0.904682,0.408962,0.382401,0.679183,0.80607,0.316736,0.391189,0.497159,0.407352,0.319955,0.318071,0.94306,0.963665,0.349271,0.372708,0.500093,0.396445,-0.531314,-0.4938,-1.70401,-1.61295,1.59389,1.49279,-1.09367,-1.05942,-1.22897,-1.13144,1.77802,1.80151,0.954536,0.832622,-2.25989,-2.10197,1.79593,1.81259
9323,0.412349,0.364994,0.362011,0.360318,0.773324,0.824558,0.663552,0.637562,0.864146,0.919142,0.336412,0.388844,0.081212,0.0761044,0.645519,0.644474,0.178611,0.199092,0.0461136,0.0675188,-0.620681,-0.73064,-1.26278,-1.22581,-2.13261,-2.03981,-0.376052,-0.471796,-0.619183,-0.525687,-0.57774,-0.473435,-0.873295,-0.856167,-0.700218,-0.829753,-0.0395865,0.111783,-0.362878,-0.343907
9324,0.703581,0.607513,0.361861,0.358571,0.339114,0.389229,0.668033,0.714724,0.141691,0.197237,0.622542,0.672947,0.585784,0.582526,0.651393,0.650129,0.284115,0.303727,0.445665,0.466977,0.559406,0.455514,1.08013,1.1254,-0.368523,-0.272724,-0.81878,-0.909062,-0.028656,0.00804102,0.402924,0.50608,0.0134321,0.0324914,0.0787773,-0.0552366,0.668148,0.821528,0.268941,0.282668
9325,0.897374,0.850033,0.142121,0.139192,0.97777,1.02837,0.817411,0.791887,0.944408,0.99918,0.248879,0.301254,0.102895,0.100901,0.24778,0.249108,0.804196,0.824168,0.234638,0.256181,0.70961,0.598188,-0.679159,-0.637122,0.760254,0.864115,0.274296,0.177494,1.65263,1.68332,-1.13072,-1.03343,0.585955,0.602461,-2.28909,-2.42013,0.0495083,0.115086,-0.75959,-0.751429
9326,0.466943,0.419271,0.538674,0.534641,0.611758,0.663751,0.178566,0.15463,0.650267,0.710736,0.570004,0.621361,0.250011,0.246691,0.343596,0.344838,0.409096,0.429966,0.52676,0.54912,-0.966418,-1.08058,0.21264,0.254628,0.30061,0.40658,-1.46767,-1.56195,0.284063,0.319098,-0.32048,-0.222143,-0.133055,-0.117707,0.692645,0.561559,-0.73952,-0.591356,-0.645797,-0.6383
9327,0.683309,0.63585,0.0922494,0.0861842,0.958022,1.01105,0.544559,0.518557,0.369011,0.422292,0.115002,0.165533,0.735939,0.733432,0.0114088,0.0134852,0.502055,0.522863,0.589038,0.611363,-0.418786,-0.537626,-0.794202,-0.756619,2.15824,2.2686,-0.67045,-0.859096,-0.508055,-0.474058,0.811374,0.910733,1.63862,1.65345,0.0626325,-0.118358,0.440462,0.586931,-1.58195,-1.56793
9328,0.164404,0.115209,0.586136,0.579232,0.197662,0.251355,0.54325,0.579149,0.753778,0.805704,0.573533,0.623764,0.0710308,0.0666607,0.697083,0.699271,0.0933011,0.113948,0.997021,1.02068,-1.18726,-1.31242,0.128502,0.164643,-1.3695,-1.25913,-0.0569526,-0.156244,0.930696,0.972478,0.770806,0.864328,0.437089,0.355912,-0.669945,-0.798276,0.519428,0.658688,1.71645,1.73368
9329,0.0453571,-0.00345701,0.787318,0.781693,0.256643,0.308173,0.615918,0.639741,0.140888,0.191277,0.751048,0.70734,0.621964,0.61837,0.0372475,0.0371669,0.709155,0.729995,0.793929,0.815653,-1.26215,-1.38355,0.0703175,0.105496,-0.807237,-0.692078,-0.835264,-0.932618,0.351477,0.392718,0.124453,0.205008,-0.959852,-0.941623,-1.0183,-1.23389,-0.440953,-0.295936,-0.707621,-0.695829
9330,0.652702,0.60252,0.311912,0.30805,0.880265,0.931505,0.723929,0.700333,0.897562,0.949902,0.740438,0.790917,0.415573,0.446197,0.163937,0.162927,0.80181,0.822892,0.838572,0.817311,-0.949989,-1.07033,-2.07529,-2.03237,0.774139,0.888318,-2.00839,-2.11163,-1.59969,-1.55795,-0.547833,-0.454311,0.953949,0.975108,-1.54133,-1.66951,0.484456,0.631635,0.0433637,0.0526085
9331,0.373372,0.323523,0.630747,0.624483,0.681395,0.719757,0.319873,0.298719,0.447348,0.598537,0.182165,0.232068,0.322439,0.274023,0.685735,0.685233,0.0293966,0.0485281,0.794627,0.818968,-0.0860521,-0.208374,0.343039,0.385729,-0.148824,-0.0364762,0.514356,0.419672,1.68176,1.71903,2.05692,2.15286,-1.093,-1.0742,-0.675234,-0.80357,-1.87936,-1.73535,1.1647,1.17997
9332,0.913325,0.865778,0.171713,0.166266,0.403528,0.508008,0.122871,0.101308,0.196476,0.247172,0.114498,0.163989,0.107031,0.101849,0.587114,0.589336,0.613964,0.633765,0.292809,0.318309,-0.749073,-0.873268,-0.562066,-0.51642,-2.58377,-2.46415,-0.229523,-0.32658,-0.466485,-0.427806,0.307109,0.398093,1.01464,1.035,1.14237,1.01753,-0.598525,-0.449184,0.709513,0.719873
9333,0.665302,0.617054,0.151723,0.145607,0.244115,0.296259,0.136001,0.131055,0.23431,0.197636,0.943238,0.993893,0.48396,0.494261,0.494114,0.493438,0.538472,0.575978,0.460168,0.485245,-0.158301,-0.283676,0.0228845,0.0693418,-0.553238,-0.430217,-0.0143967,-0.115937,-0.523527,-0.487444,0.793671,0.889493,-0.56677,-0.545217,-1.52064,-1.63996,-0.335722,-0.272458,0.70232,0.712494
9334,0.19577,0.146583,0.593956,0.589397,0.94969,1.00175,0.127597,0.160802,0.0983628,0.1481,0.532194,0.582888,0.893148,0.886674,0.72347,0.697894,0.498971,0.518191,0.910996,0.934332,-0.531649,-0.657416,-0.601046,-0.55519,0.265538,0.385181,-0.790208,-0.892311,2.19588,2.23757,0.689355,0.782112,-0.0561801,-0.038192,0.97082,0.853486,-0.244595,-0.0957313,0.0816195,0.086573
9335,0.5626,0.527908,0.639976,0.71136,0.310109,0.363588,0.0623742,0.190549,0.596245,0.646026,0.457299,0.510193,0.378727,0.37064,0.904545,0.90235,0.873261,0.894001,0.374111,0.39849,0.0994024,-0.0227358,-2.3901,-2.34827,0.415686,0.537661,-1.83585,-1.93175,-0.396637,-0.355843,0.261925,0.350983,-0.817935,-0.80514,0.633047,0.511021,1.04013,1.19044,0.373959,0.378799
9336,0.95842,0.909233,0.75061,0.833323,0.384376,0.44006,0.241859,0.220296,0.623173,0.673421,0.740044,0.794296,0.300263,0.227675,0.901658,0.897551,0.452513,0.475136,0.564695,0.590539,1.31997,1.19155,-1.07698,-1.03861,0.181069,0.308848,0.495591,0.394731,1.15111,1.19698,-0.947326,-0.864046,-0.423845,-0.40619,-0.767479,-0.889075,0.234047,0.381071,1.23353,1.23045
9337,0.0534461,0.00332028,0.960855,0.955287,0.875989,0.933457,0.658929,0.638452,0.924191,0.976186,0.552579,0.605816,0.0945793,0.0847096,0.449754,0.446728,0.696164,0.716629,0.164755,0.189978,-0.825412,-0.955142,0.976275,1.01957,-0.505801,-0.383594,-1.79895,-1.90003,0.547003,0.586358,1.09413,1.17923,-1.92476,-1.90584,-0.241044,-0.358008,-0.0308445,0.111588,-0.178673,-0.186909
9338,0.258287,0.162463,0.446509,0.442446,0.38243,0.439176,0.192845,0.171795,0.562046,0.612758,0.667051,0.719599,0.939172,0.930323,0.951284,0.947962,0.611652,0.631049,0.389061,0.413092,1.16246,1.03331,-1.08637,-1.03821,1.67907,1.7956,-0.0513372,-0.152961,-0.575018,-0.528252,-0.0288111,0.0537277,-2.13875,-2.11828,2.35271,2.24026,1.35574,1.49491,0.842141,0.834541
9339,0.371103,0.321607,0.916838,0.910808,0.327113,0.351909,0.476003,0.45716,0.770372,0.822533,0.0177062,0.0695466,0.985235,0.978817,0.0167817,0.0121562,0.218421,0.236846,0.0476393,0.071953,0.771556,0.645195,-0.840276,-0.790888,-0.858081,-0.745756,1.12132,1.01362,0.0390728,0.0888631,-1.72293,-1.64037,1.33669,1.35125,-1.15105,-1.25444,0.0331229,0.163403,2.39837,2.39429
9340,0.10854,0.0581044,0.997438,0.950329,0.206005,0.264642,0.540166,0.520855,0.720588,0.772764,0.181118,0.234708,0.675418,0.656905,0.736468,0.729798,0.427046,0.485458,0.932409,0.955318,-0.225126,-0.34505,-1.78828,-1.73929,1.16071,1.27131,-0.44769,-0.549512,1.72066,1.76414,-0.981191,-0.890783,-1.18367,-1.17668,-1.15747,-1.26386,-0.293702,-0.167552,-0.698116,-0.698419
9341,0.279656,0.228954,0.994416,0.989851,0.341995,0.401075,0.322711,0.262141,0.0630063,0.113211,0.630528,0.683142,0.464908,0.334993,0.358221,0.352926,0.714391,0.734071,0.745026,0.769909,0.305441,0.184247,0.0841769,0.129665,-1.95522,-1.84255,0.0462778,-0.0497643,0.767035,0.816064,0.867608,0.964995,0.755755,0.768478,-0.458203,-0.564771,0.426156,0.556934,0.334217,0.337242
9342,0.107569,0.0569566,0.063525,0.0560132,0.148075,0.20904,0.0246555,0.00342821,0.212374,0.182962,0.367837,0.369526,0.0194995,0.0130818,0.571056,0.514658,0.313063,0.335126,0.19258,0.219112,-1.32168,-1.44515,0.860727,0.961321,0.725204,0.834132,-1.36756,-1.4614,0.621272,0.758688,0.701983,0.835428,-0.384884,-0.371528,-0.181704,-0.262797,-1.48491,-1.36124,-0.0350157,-0.034976
9343,0.691985,0.642586,0.130781,0.12455,0.212731,0.187548,0.43858,0.417449,0.280508,0.252713,0.00169268,0.0559093,0.702475,0.695973,0.594753,0.67639,0.857977,0.880063,0.992191,1.01725,0.453475,0.330498,1.75427,1.79298,0.906722,1.01726,-1.54314,-1.6349,0.650306,0.701312,0.61501,0.70586,0.263187,0.275371,0.141357,0.0391763,0.461656,0.586868,0.0936987,0.0892466
9344,0.117191,0.0663364,0.6848,0.676309,0.106325,0.166057,0.521147,0.501002,0.340326,0.322464,0.912203,0.967478,0.00291819,-0.00517147,0.844663,0.838122,0.00691491,0.0319213,0.776761,0.869238,-0.286071,-0.411633,-0.854628,-0.80859,1.45494,1.56922,-1.48469,-1.57651,-0.113737,-0.0616104,-0.448769,-0.358968,-0.388346,-0.422002,-0.915454,-1.02316,-0.504371,-0.38151,0.93228,0.926548
9345,0.557655,0.509014,0.621467,0.525374,0.698261,0.75908,0.893188,0.874844,0.385915,0.392215,0.898743,0.955331,0.354611,0.346812,0.652942,0.676895,0.773389,0.798327,0.69728,0.721231,-0.665458,-0.785374,-0.600881,-0.561268,-2.29091,-2.17663,1.38544,1.30161,2.26474,2.32502,-0.726822,-0.635882,-1.12889,-1.11937,0.153507,0.0449992,0.752013,0.873331,0.485369,0.525688
9346,0.788917,0.740864,0.383287,0.374439,0.987033,1.0456,0.445543,0.428953,0.411761,0.461966,0.393976,0.449958,0.924782,0.918504,0.521234,0.515668,0.224768,0.249031,0.97324,0.999045,0.000247537,-0.121622,-1.72721,-1.68123,-1.7552,-1.64035,0.985894,0.896447,1.88974,1.9427,-0.0907749,0.008154,-1.02216,-1.01108,-0.808261,-0.911265,0.715839,0.837277,0.138526,0.124828
9347,0.130606,0.0844891,0.812283,0.804009,0.255276,0.316058,0.838585,0.822499,0.076975,0.129822,0.676734,0.73406,0.0136359,0.00846755,0.00170655,-0.0054299,0.376053,0.398421,0.928777,0.945975,-0.178663,-0.297356,1.13013,1.18312,1.72368,1.83616,-1.65218,-1.73783,-0.806452,-0.763249,-1.92643,-1.82331,-0.655721,-0.642549,0.565784,0.46103,-0.99072,-0.870694,-1.48938,-1.50755
9348,0.832501,0.785182,0.289423,0.281283,0.854697,0.913765,0.967029,0.952028,0.936091,0.990696,0.154288,0.209804,0.216488,0.125134,0.975996,0.966856,0.837167,0.858718,0.868755,0.892905,-1.5422,-1.65271,1.03106,1.07765,-0.240976,-0.128919,0.112038,0.0242916,0.895501,0.942153,0.345986,0.443803,-0.743778,-0.731868,0.252207,0.147699,1.64057,1.76446,0.810683,0.786
9349,0.612035,0.663602,0.701109,0.691367,0.696385,0.787558,0.670908,0.654444,0.966023,1.01809,0.667798,0.722616,0.248487,0.2418,0.0410213,0.0310504,0.0356722,0.0560326,0.439284,0.462236,1.31922,1.21702,0.544399,0.591242,0.365397,0.483488,-1.48403,-1.57205,0.768056,0.807872,-0.752391,-0.652116,0.41122,0.423605,0.990244,0.891777,-1.90361,-1.77405,1.23841,1.21391
9350,0.587144,0.542022,0.699667,0.69099,0.601937,0.661351,0.0612847,0.0464603,0.424019,0.474601,0.898344,0.951301,0.185571,0.125386,0.779586,0.768312,0.926561,0.94852,0.315728,0.430787,0.619549,0.520396,0.301663,0.437672,-1.16171,-1.04324,0.0524891,-0.0324873,0.630718,0.673591,1.28679,1.39116,0.242218,0.256741,-0.473244,-0.571145,1.83902,1.96728,0.155796,0.131023
9351,0.749047,0.702219,0.964051,0.956957,0.823807,0.881746,0.567385,0.554301,0.888507,0.937765,0.440375,0.495472,0.0156527,0.00897246,0.589138,0.564402,0.913955,0.938104,0.348968,0.399338,-0.946567,-1.0516,0.178843,0.284101,-0.859048,-0.735358,0.982174,0.9009,0.983976,1.03194,-0.862824,-0.753572,1.8818,1.89051,-0.50153,-0.594411,-0.964744,-0.840869,-0.55945,-0.586302
9352,0.630897,0.583553,0.379503,0.370795,0.35884,0.417318,0.411521,0.396571,0.0639363,0.115147,0.968463,1.02215,0.394484,0.333055,0.374036,0.360493,0.12446,0.148297,0.346371,0.367889,-0.408493,-0.508641,0.0836883,0.130531,0.532963,0.657413,-1.23169,-1.34703,1.83054,1.88088,-1.32201,-1.24909,0.402132,0.406855,-0.0747065,-0.171204,0.898773,1.02825,-2.02053,-2.04952
9353,0.155999,0.107905,0.295099,0.330581,0.725902,0.784638,0.858573,0.844801,0.858354,0.906631,0.0681179,0.121196,0.662326,0.657137,0.367942,0.362395,0.409361,0.434041,0.524318,0.545444,1.37095,1.267,-0.980089,-0.927303,-0.285062,-0.247863,-3.51368,-3.59495,-2.2627,-2.21236,-1.86062,-1.7446,-0.726428,-0.718594,1.04967,0.957709,0.127898,0.264423,-1.24894,-1.27316
9354,0.774585,0.728093,0.313205,0.290367,0.0948707,0.155928,0.669564,0.65736,0.436163,0.48273,0.303612,0.354575,0.0598651,0.0560864,0.421224,0.364298,0.166579,0.190851,0.989608,1.00953,-0.318808,-0.427297,-0.50249,-0.451063,-1.27524,-1.15314,-1.34238,-1.42266,-0.588849,-0.556095,-0.441325,-0.322895,-0.799052,-0.793905,0.727111,0.630411,0.343313,0.472664,-0.859929,-0.892136
9355,0.644568,0.561858,0.258861,0.250153,0.575437,0.634111,0.938856,0.927893,0.966281,1.01176,0.101828,0.150304,0.702594,0.697373,0.382432,0.366201,0.841968,0.868705,0.333004,0.353224,1.3728,1.27121,-2.01224,-1.96144,-1.59392,-1.47533,-1.64105,-1.72041,1.04983,1.10017,-1.09077,-0.975229,-0.00132967,-0.0138099,-1.19021,-1.28319,0.0734231,0.20318,0.671119,0.635368
9356,0.332661,0.395623,0.409329,0.453828,0.704046,0.76765,0.822393,0.718738,0.233714,0.280229,0.321956,0.4281,0.416391,0.411507,0.21275,0.194631,0.946117,0.973341,0.136521,0.157654,-0.291522,-0.393292,1.51601,1.5693,1.19976,1.31512,0.0859128,0.00858973,-0.105292,-0.0609176,1.49004,1.60002,0.763228,0.766286,0.442141,0.350389,-1.75728,-1.62085,-1.07187,-1.10269
9357,0.242084,0.229388,0.664239,0.657503,0.808202,0.901188,0.521957,0.509583,0.296356,0.342721,0.659308,0.705897,0.60544,0.602997,0.563109,0.546984,0.556726,0.583293,0.538779,0.566672,1.34856,1.24355,-0.650761,-0.601286,-0.953146,-0.844522,1.13341,1.04988,0.153283,0.204601,0.137965,0.242143,-1.76858,-1.76165,0.565198,0.466641,-0.606795,-0.475021,-1.08164,-1.11007
9358,0.109645,0.0631529,0.198681,0.19414,0.976342,1.03473,0.138738,0.127237,0.115653,0.160404,0.420331,0.467443,0.234419,0.232284,0.708213,0.693366,0.988096,1.01375,0.957476,0.97569,3.21567,3.1102,0.491319,0.536546,0.678042,0.781621,-0.0383009,-0.129132,-1.11013,-1.06481,-0.52866,-0.423919,-0.930145,-0.919164,1.10642,1.01283,-0.860339,-0.72872,1.3456,1.31427
9359,0.169951,0.123406,0.942137,0.93926,0.201102,0.260309,0.267324,0.256766,0.408833,0.452357,0.971841,1.01913,0.0660699,0.0626044,0.570204,0.556986,0.416747,0.44382,0.938456,0.992996,0.371399,0.270741,0.326455,0.369725,0.63858,0.737267,1.32355,1.23581,-1.6373,-1.59685,-1.49185,-1.38084,1.22106,1.23754,0.288623,0.195153,1.12599,1.25258,1.05589,1.02027
9360,0.852612,0.804613,0.491032,0.486042,0.453525,0.510878,0.781122,0.769564,0.0837184,0.125194,0.887043,0.935994,0.900585,0.896308,0.734024,0.626947,0.931006,0.958905,0.993572,1.0103,-1.88899,-1.98819,-0.742853,-0.704366,-0.275633,-0.172618,-1.24657,-1.33411,-0.880107,-0.871279,1.26047,1.3812,-0.632906,-0.622071,-0.732651,-0.822949,1.28669,1.41571,-1.04541,-1.07519
9361,0.60167,0.551695,0.58298,0.580381,0.093989,0.151256,0.49975,0.486614,0.917432,0.957298,0.0378566,0.0870331,0.573529,0.513404,0.712086,0.696907,0.653301,0.680389,0.109052,0.125296,0.217196,0.124256,-0.332677,-0.288215,0.174976,0.272708,-0.00300555,-0.0932552,-0.254617,-0.145707,0.362018,0.397119,-0.128454,-0.115047,-0.624621,-0.798814,-0.88645,-0.757779,-2.00542,-2.03377
9362,0.770769,0.722545,0.377095,0.375436,0.978105,1.03333,0.832783,0.820368,0.708415,0.697638,0.167717,0.216731,0.13424,0.130499,0.175043,0.16081,0.0172233,0.0446776,0.253395,0.26782,-0.603932,-0.697095,-2.37073,-2.33256,-0.0347759,0.0578339,2.75762,2.66792,0.53942,0.579865,-0.710687,-0.586959,-2.13661,-2.1186,-0.688741,-0.77468,0.0115597,0.137268,-2.68629,-2.71919
9363,0.0495322,0.0030833,0.536661,0.442281,0.642168,0.698667,0.87933,0.828894,0.400156,0.437979,0.990797,1.04166,0.707709,0.702191,0.467265,0.451444,0.754761,0.781435,0.790762,0.807213,-0.668216,-0.768222,-0.39244,-0.354548,1.43762,1.52721,-1.16643,-1.25594,-0.852034,-0.813034,-0.154796,-0.0344625,0.313156,0.327568,-0.173902,-0.259686,0.673929,0.798861,-0.678606,-0.713849
9364,0.413583,0.365552,0.510039,0.509126,0.556931,0.612802,0.822792,0.83742,0.590547,0.716638,0.150791,0.20369,0.672141,0.668137,0.332797,0.315065,0.218434,0.247388,0.726984,0.74611,0.579318,0.479783,-1.35729,-1.31919,1.32463,1.4207,0.11473,0.0313391,0.386411,0.420469,-0.938298,-0.821375,-0.493901,-0.484688,-0.158179,-0.236708,-1.29606,-1.17074,1.71408,1.67765
9365,0.500882,0.451614,0.961725,0.963482,0.749201,0.803155,0.957228,0.845946,0.959008,0.995296,0.487013,0.511727,0.883984,0.807053,0.524876,0.506694,0.770431,0.797056,0.60383,0.685008,0.269996,0.168251,0.675934,0.708516,-1.13808,-1.04225,-1.58909,-1.67633,2.3587,2.3953,0.1346,0.251415,-0.770639,-0.758596,-3.86552,-3.94703,0.483069,0.602208,-0.519095,-0.559519
9366,0.264922,0.218399,0.262394,0.263218,0.6678,0.621974,0.868884,0.854471,0.443723,0.482175,0.766005,0.819764,0.952376,0.945969,0.315578,0.295084,0.241748,0.26789,0.60941,0.623905,0.78218,0.682286,1.29106,1.32443,-0.378435,-0.370021,-0.916768,-1.00695,-0.277057,-0.242624,-0.838028,-0.721043,-2.04948,-2.03987,0.623028,0.53947,0.065162,0.177838,1.53067,1.49444
9367,0.895248,0.849081,0.487382,0.509312,0.387804,0.440793,0.875412,0.862997,0.484156,0.524354,0.490029,0.541976,0.76577,0.705922,0.411073,0.413938,0.285158,0.311362,0.702133,0.715376,-0.24481,-0.33962,-1.6188,-1.57952,0.207972,0.302209,1.07086,0.977136,0.125187,0.160929,-0.24746,-0.137709,0.34751,0.358781,-0.155254,-0.232975,-2.82182,-2.71296,0.233272,0.199088
9368,0.668242,0.644819,0.755557,0.755407,0.850233,0.904351,0.445552,0.4311,0.123153,0.165276,0.950833,1.00493,0.59095,0.465875,0.515764,0.532791,0.635385,0.574887,0.230979,0.244362,1.51059,1.41855,-0.109238,-0.0686853,0.563805,0.656261,1.42514,1.32553,-0.385605,-0.357107,0.138972,0.282465,-1.98706,-1.97793,-0.552197,-0.636733,0.974913,1.08378,1.38189,1.34168
9369,0.385764,0.440556,0.0832497,0.0843887,0.998253,1.05122,0.965845,0.949149,0.0785337,0.120842,0.787646,0.810819,0.231244,0.225828,0.670423,0.651644,0.811984,0.838412,0.364589,0.348932,0.699876,0.612124,0.502647,0.547232,-1.27338,-1.1845,1.44663,1.35143,-0.194479,-0.168994,0.551116,0.702639,-1.47546,-1.47091,0.0579618,-0.030271,1.26251,1.37051,0.608288,0.563891
9370,0.283611,0.236293,0.292137,0.292212,0.250512,0.305303,0.184426,0.169425,0.348974,0.392547,0.563758,0.616713,0.882465,0.878587,0.278914,0.259847,0.892861,0.921126,0.442157,0.453501,-0.332054,-0.424027,-0.386501,-0.339734,0.932253,1.02587,-0.670234,-0.767169,-0.891864,-0.8702,1.01306,1.12281,-1.20268,-1.12486,-1.30926,-1.40048,-0.172341,-0.0688471,-0.987843,-1.03628
9371,0.363466,0.223795,0.929532,0.927506,0.539156,0.623628,0.481495,0.431285,0.003657,0.0489721,0.00556788,0.0578644,0.365819,0.362554,0.18361,0.163539,0.735646,0.677433,0.751449,0.761279,1.25751,1.16704,-0.35778,-0.306945,-0.840494,-0.751505,-0.107803,-0.205635,-0.628326,-0.604682,0.69952,0.814095,-0.783361,-0.778809,0.633013,0.546485,0.496142,0.592746,-0.532363,-0.578849
9372,0.256678,0.211296,0.913688,0.836961,0.887162,0.941953,0.708741,0.693145,0.472354,0.516792,0.782872,0.834985,0.163754,0.162896,0.846082,0.827863,0.481186,0.43374,0.660476,0.690431,-0.537827,-0.621584,-2.92884,-2.87768,0.00352621,0.0949889,1.17853,1.08165,-0.845265,-0.817782,0.0794425,0.193807,-0.702954,-0.700799,-0.10076,-0.182058,-0.733152,-0.641969,1.78646,1.74529
9373,0.717942,0.673523,0.748913,0.746416,0.00876159,0.0625359,0.795551,0.781279,0.141392,0.184648,0.81515,0.822297,0.817352,0.815655,0.161876,0.145687,0.163898,0.190047,0.608284,0.619584,0.527393,0.440303,0.109757,0.16039,-1.25977,-1.16999,-0.957745,-1.05262,0.92499,0.949711,0.288409,0.408169,0.244463,0.25209,-1.3137,-1.39873,-0.931732,-0.834867,1.36563,1.32873
9374,0.461293,0.5147,0.473543,0.47107,0.679046,0.732118,0.116274,0.103371,0.0965824,0.140214,0.758578,0.809609,0.923609,0.920768,0.014555,-0.00123697,0.369389,0.396754,0.713723,0.725809,1.00326,0.924478,-0.266395,-0.221276,0.338983,0.425454,1.39379,1.29365,-1.08392,-1.06302,-0.233487,-0.116836,-1.29318,-1.28017,-0.870869,-0.961205,0.972065,1.06555,-1.00743,-1.03985
9375,0.378134,0.355878,0.593407,0.589551,0.767289,0.8827,0.925605,0.914714,0.334,0.376074,0.293388,0.344073,0.382298,0.378505,0.423489,0.405208,0.926551,0.951969,0.18064,0.194354,-1.30003,-1.38248,0.668072,0.716283,-0.647336,-0.562686,0.211971,0.114631,-0.228077,-0.214078,-0.170144,-0.0560551,-0.488106,-0.483255,0.611569,0.516437,-0.697871,-0.610724,0.575218,0.54819
9376,0.242096,0.197056,0.170901,0.165619,0.981499,1.03328,0.432463,0.422003,0.866573,0.909836,0.201726,0.251185,0.917258,0.914905,0.0894289,0.0684705,0.109893,0.132696,0.788823,0.803219,-0.113533,-0.196329,-0.872262,-0.826079,1.6303,1.71301,0.496583,0.403049,-1.57378,-1.56289,-0.40567,-0.287008,2.40941,2.41484,-1.36853,-1.46053,0.929853,1.02092,0.103681,0.139694
9377,0.329843,0.297238,0.462758,0.452813,0.543282,0.59406,0.171196,0.158564,0.240327,0.284798,0.798752,0.846973,0.848453,0.845886,0.36026,0.339148,0.350039,0.374189,0.807742,0.894579,-2.36249,-2.44165,0.966964,1.01285,0.368014,0.448029,1.09598,0.995167,1.46902,1.47607,-2.27594,-2.14849,-0.53545,-0.537537,0.615332,0.515855,0.793389,0.891076,-0.238541,-0.268803
9378,0.441728,0.39742,0.746338,0.740007,0.41227,0.519608,0.145198,0.131692,0.19536,0.240364,0.47839,0.527724,0.00412018,0.000252714,0.94586,0.922561,0.186121,0.211396,0.970236,0.985938,1.93409,1.85492,-0.684106,-0.639561,-1.4276,-1.34507,0.893457,0.792434,-0.720814,-0.719766,2.26129,2.38874,0.516337,0.521475,0.0180783,-0.0872258,-0.847382,-0.752932,0.316187,0.280199
9379,0.193314,0.148695,0.70112,0.693127,0.302182,0.445156,0.85055,0.839028,0.78063,0.825778,0.781196,0.829115,0.533331,0.527115,0.775343,0.750992,0.323473,0.302695,0.844089,0.865289,0.46024,0.376362,-0.310845,-0.2709,-0.116539,-0.0256656,0.269357,0.109397,-1.21227,-1.20655,-0.126259,0.00873606,-1.10285,-1.10177,0.610877,0.50337,1.15914,1.2506,-0.454719,-0.497586
9380,0.828149,0.784506,0.653848,0.646247,0.189544,0.370704,0.114173,0.10082,0.619965,0.664412,0.712145,0.761036,0.49511,0.488795,0.333428,0.309413,0.369081,0.393995,0.729925,0.74464,-0.0712714,-0.151551,1.06689,1.09947,0.238186,0.328386,-0.473149,-0.573639,0.0516116,0.0585958,-1.86522,-1.72993,0.162255,0.159391,-0.473916,-0.576009,1.25356,1.33861,-1.78932,-1.83949
9381,0.157512,0.112728,0.1143,0.104531,0.245473,0.296252,0.265124,0.244467,0.0875965,0.131267,0.289264,0.339722,0.851264,0.846181,0.733629,0.710972,0.746417,0.769804,0.894769,0.911576,0.236733,0.0716941,0.557788,0.52109,-0.922422,-0.831516,0.0187935,-0.0871097,0.400398,0.400909,-0.0473638,0.0803417,-0.412558,-0.410241,-0.376524,-0.473961,-0.321734,-0.242196,-0.363713,-0.420356
9382,0.967462,0.921206,0.949749,0.942352,0.252684,0.303442,0.478798,0.388115,0.661571,0.70556,0.681468,0.733944,0.124633,0.118349,0.6521,0.630118,0.266715,0.289727,0.179638,0.195285,0.374701,0.294939,-0.0946536,-0.0572849,-1.18093,-1.09033,0.0134214,-0.0901465,0.225717,0.233084,1.51224,1.644,-0.510934,-0.515782,-2.2829,-2.38756,0.982685,1.05971,-1.17842,-1.24212
9383,0.562443,0.515997,0.506163,0.559549,0.697909,0.747188,0.545115,0.531762,0.819799,0.804592,0.689088,0.741031,0.155521,0.150861,0.150222,0.12885,0.879162,0.901345,0.0616128,0.0747999,-0.476934,-0.55656,-1.02097,-0.989536,0.820724,0.911074,1.84818,1.75227,-0.819797,-0.805932,-0.0123642,0.119924,0.0950359,0.043274,1.16618,1.0674,-0.696546,-0.616571,0.364272,0.299159
9384,0.582205,0.536435,0.184023,0.176745,0.436057,0.487189,0.480017,0.417915,0.857815,0.903624,0.143227,0.196613,0.734805,0.732012,0.281749,0.259872,0.798733,0.751345,0.777533,0.789158,-0.735312,-0.806975,-2.15289,-2.12518,0.754512,0.850416,-0.487707,-0.576881,1.71849,1.73102,0.0146716,0.150201,0.60801,0.60233,0.145084,-0.00124939,0.199254,0.278476,-0.518522,-0.584349
9385,0.256101,0.211035,0.868857,0.861374,0.631553,0.682514,0.316878,0.304068,0.36784,0.414798,0.527475,0.581425,0.345096,0.403782,0.0214852,-0.00196285,0.576598,0.601345,0.707973,0.720826,-0.110712,-0.1878,-0.751132,-0.753594,-0.583881,-0.495335,-1.26853,-1.35325,-1.08028,-1.07198,-1.3171,-1.17514,0.0484001,0.0989776,-0.97112,-1.0699,0.54113,0.612917,-2.37007,-2.43333
9386,0.389737,0.252406,0.542777,0.535849,0.0216466,0.0735776,0.701323,0.687171,0.465597,0.513514,0.360386,0.413787,0.0779313,0.0755518,0.132419,0.108745,0.70562,0.730715,0.311668,0.325549,0.237362,0.153921,0.587441,0.61799,0.817916,0.912895,0.613722,0.536297,0.476866,0.480845,-0.266439,-0.116753,-0.398694,-0.404374,1.95095,1.85602,-0.238386,-0.166125,-0.567448,-0.626834
9387,0.336537,0.293778,0.851481,0.842308,0.841345,0.894359,0.885172,0.872675,0.834746,0.88118,0.417647,0.469391,0.62088,0.617206,0.610286,0.58527,0.56322,0.587203,0.960422,0.97436,1.63443,1.55743,-1.87712,-1.84203,0.255776,0.346323,-0.116421,-0.192978,-0.192878,-0.190937,-0.516189,-0.363545,0.372981,0.362723,-1.61387,-1.70206,1.88047,1.9518,0.85219,0.792303
9388,0.195461,0.150769,0.0367735,0.0276917,0.279758,0.335512,0.510058,0.495059,0.865907,0.913143,0.105209,0.15563,0.719144,0.717642,0.398747,0.299071,0.909781,0.933578,0.206407,0.221667,-1.30862,-1.37812,-0.141442,-0.0988757,-1.05924,-0.965572,1.09172,1.01876,0.372628,0.380991,-1.03121,-0.874144,0.336192,0.3179,0.231163,0.134653,-0.932126,-0.856348,-0.477982,-0.533349
9389,0.366324,0.315806,0.133138,0.122031,0.178749,0.23484,0.871681,0.858986,0.213887,0.263949,0.306612,0.359836,0.13992,0.140569,0.037889,0.0128721,0.815344,0.838113,0.403989,0.460221,1.32117,1.24497,-0.649251,-0.600565,-0.0596985,0.0339218,1.13681,1.06008,0.153197,0.16789,-0.771791,-0.615707,-1.35718,-1.37115,0.186257,0.145649,1.27204,1.34195,0.176315,0.123704
9390,0.524187,0.480844,0.468818,0.458172,0.577138,0.632719,0.602677,0.521419,0.097541,0.147317,0.0138396,0.0656867,0.47928,0.478249,0.533827,0.510129,0.510759,0.629814,0.685314,0.698776,-0.167339,-0.25008,0.157666,0.200764,-0.677226,-0.583433,-0.174847,-0.25643,0.21174,0.219036,-0.156107,-0.00149138,-0.868715,-0.879175,0.256617,0.156645,0.520099,0.591726,-0.368654,-0.42928
9391,0.487131,0.444473,0.466678,0.454926,0.724238,0.77959,0.197307,0.183852,0.737791,0.786522,0.738853,0.791549,0.566441,0.567883,0.461548,0.43916,0.398868,0.421514,0.59796,0.521423,-0.41149,-0.500495,-1.8253,-1.78166,0.962505,1.05926,-0.714657,-0.799604,1.00788,1.01952,-0.377744,-0.217136,0.340909,0.336802,-0.291788,-0.384881,0.872247,0.942743,-1.21639,-1.28184
9392,0.860815,0.816776,0.461009,0.45168,0.190698,0.245775,0.51438,0.503482,0.133192,0.181802,0.906494,0.961486,0.863691,0.86504,0.897159,0.876342,0.303997,0.32605,0.332346,0.34407,1.64503,1.55145,0.462838,0.503039,0.810326,0.908184,1.74459,1.66246,-0.951552,-0.946754,0.513313,0.591399,1.56886,1.55278,0.754884,0.666356,-0.964858,-0.894392,-1.26603,-1.33506
9393,0.541895,0.497557,0.747004,0.738124,0.726366,0.783418,0.148941,0.136673,0.826873,0.873061,0.750773,0.803032,0.690361,0.690149,0.264421,0.244514,0.674694,0.696514,0.153255,0.166717,0.716679,0.622203,-0.164401,-0.121492,1.41603,1.52059,2.18486,2.1016,-0.366372,-0.360705,1.24132,1.39993,0.474437,0.498888,-0.188714,-0.274672,-0.446328,-0.371939,0.722016,0.652471
9394,0.575094,0.533846,0.178293,0.171982,0.108926,0.164879,0.533086,0.522819,0.333028,0.379725,0.377835,0.431339,0.114919,0.113076,0.791419,0.771389,0.730152,0.75067,0.685153,0.696216,-2.17709,-2.26737,-0.0512959,-0.0145666,-0.761634,-0.654104,1.49168,1.40373,-0.743129,-0.743028,1.28115,1.44496,-0.53735,-0.555005,-1.9534,-2.04572,-0.420585,-0.345303,-1.13169,-1.19651
9395,0.0301105,-0.0125042,0.755875,0.747746,0.790305,0.844594,0.920192,0.908964,0.690562,0.737351,0.630413,0.648259,0.444466,0.440393,0.223731,0.204744,0.490726,0.512159,0.0826034,0.0953825,0.549882,0.454918,-1.10706,-1.0724,-0.300197,-0.195229,-0.085626,-0.17466,0.158221,0.152715,-0.216378,-0.0511019,0.133868,0.12017,1.23207,1.13555,-0.135592,-0.0585701,-0.774069,-0.743161
9396,0.46317,0.420458,0.251285,0.244347,0.0721992,0.123597,0.734952,0.721523,0.440273,0.420203,0.810629,0.865178,0.386907,0.382014,0.251826,0.234958,0.880325,0.90305,0.626729,0.639513,0.490519,0.388709,-0.288892,-0.257374,0.603804,0.711893,-0.285611,-0.377393,1.94197,1.93526,0.0447975,0.207336,-1.97371,-1.99248,-0.162586,-0.264543,-0.930438,-0.854136,-0.222876,-0.289814
9397,0.115614,0.0703973,0.0375877,0.0298925,0.504612,0.494846,0.829505,0.815195,0.0562854,0.103055,0.661596,0.71716,0.787393,0.783951,0.787031,0.77273,0.72001,0.744633,0.584438,0.596231,0.42007,0.3225,1.50994,1.54701,-0.162614,-0.0588049,-0.24424,-0.336072,2.30069,2.2936,0.824457,0.987093,-0.0119841,-0.0306435,1.6353,1.54071,-1.12157,-1.04703,0.904396,0.837544
9398,0.624551,0.577551,0.594283,0.586721,0.815191,0.866094,0.638464,0.623597,0.108458,0.155393,0.220563,0.275607,0.846628,0.777014,0.489151,0.404258,0.848977,0.780845,0.838167,0.79636,-0.739803,-0.83537,-0.755644,-0.722498,-0.295958,-0.193754,0.52087,0.427213,-1.87504,-1.87477,0.921005,1.0785,0.847678,0.8261,-1.43841,-1.53323,3.08508,3.15961,1.03024,0.961767
9399,0.134702,0.0864961,0.253964,0.246683,0.830243,0.882521,0.0746564,0.0598603,0.820948,0.86734,0.7724,0.827292,0.775375,0.770076,0.0511081,0.035787,0.792151,0.817057,0.985666,0.996489,-2.31191,-2.40736,0.00871878,0.0474246,0.292651,0.389675,-0.468491,-0.566731,1.83801,1.83262,-1.03097,-0.879108,-0.73537,-0.754113,0.598518,0.506682,0.532921,0.642416,-0.0602628,-0.135794
9400,0.964006,0.915064,0.380911,0.374805,0.0154668,0.0681045,0.919682,0.906537,0.0769101,0.126005,0.870659,0.926515,0.20814,0.202664,0.119241,0.102181,0.705052,0.731477,0.897125,1.00187,0.874146,0.77731,-1.14231,-1.10347,2.2305,2.32784,-0.828055,-0.926539,-0.110526,-0.118044,-1.00906,-0.864742,0.310554,0.286978,-0.596233,-0.693873,-1.94931,-1.87478,-0.516228,-0.595887
9401,0.49937,0.449243,0.0114514,0.00570082,0.24951,0.303475,0.132178,0.117446,0.406825,0.458185,0.727805,0.737314,0.346503,0.415672,0.969348,0.952414,0.29383,0.322562,0.998941,1.00726,0.36957,0.314578,-0.479531,-0.440303,1.66369,1.76127,-0.500916,-0.593534,1.21379,1.20638,-0.0141407,0.131885,-1.33282,-1.35298,0.507289,0.402925,-2.80546,-2.73102,-1.7214,-1.79996
9402,0.555966,0.504905,0.377765,0.370434,0.754952,0.807036,0.0144757,0.0727062,0.416144,0.46618,0.458467,0.548113,0.635999,0.62868,0.460028,0.441144,0.742166,0.772171,0.230142,0.238988,-0.0456308,-0.148155,1.05301,1.08741,-0.708367,-0.606756,-1.94606,-2.03528,-1.56997,-1.58006,-1.12473,-0.977718,-0.404263,-0.431758,0.200794,0.0895939,-0.549031,-0.469143,0.51894,0.444218
9403,0.387009,0.337316,0.40407,0.398883,0.473866,0.528453,0.0405143,0.0279668,0.219772,0.269059,0.140334,0.358912,0.0449035,0.0371536,0.179251,0.159565,0.596147,0.62398,0.158432,0.164889,-0.512259,-0.610888,0.261489,0.29274,0.358118,0.453725,-0.467276,-0.558191,0.280694,0.2667,1.6771,1.82558,1.05957,1.03181,0.118004,0.00564534,0.826517,0.898939,-0.214468,-0.287443
9404,0.946661,0.898568,0.213873,0.209371,0.956172,1.01147,0.828905,0.817984,0.2448,0.292567,0.113856,0.169711,0.956347,0.949616,0.142117,0.12345,0.841442,0.870056,0.587659,0.593489,-1.59371,-1.69238,-1.53588,-1.50034,1.21935,1.31402,-0.244345,-0.329702,0.630713,0.625046,-1.76127,-1.60873,-0.0897195,-0.121914,0.609475,0.490336,-0.384439,-0.305209,-1.55632,-1.62935
9405,0.602405,0.553317,0.990299,0.984949,0.106286,0.160491,0.130155,0.120828,0.996603,1.04538,0.326443,0.382797,0.197166,0.188846,0.825426,0.805041,0.261501,0.290634,0.696513,0.704316,1.86012,1.76531,1.25198,1.28871,-0.020184,0.0777326,1.10079,1.01844,-0.806493,-0.812374,0.349386,0.500161,-0.484821,-0.520127,0.24752,0.1314,-0.451583,-0.371985,0.834429,0.762153
9406,0.737202,0.689143,0.0074862,0.00100147,0.075233,0.126947,0.589289,0.578513,0.963561,1.01103,0.898625,0.953849,0.207841,0.201795,0.985827,0.966506,0.028836,0.0567954,0.541817,0.549108,-1.3244,-1.42238,-1.88601,-1.84728,0.207089,0.308682,-0.0554145,-0.146806,-0.167646,-0.179487,0.35359,0.452333,0.424373,0.384648,1.08057,0.968203,-0.0287725,0.0555034,1.07001,0.995185
9407,0.195743,0.148045,0.883403,0.875246,0.351272,0.306147,0.297669,0.343424,0.195445,0.242227,0.694656,0.749578,0.90233,0.894616,0.133766,0.116644,0.066301,0.0952402,0.911997,0.919048,-0.707642,-0.803208,0.373903,0.407857,0.1367,0.232927,0.361487,0.277588,0.858833,0.85398,0.253713,0.404505,0.820115,0.783598,-1.82495,-1.94038,1.79899,1.87759,0.578124,0.505335
9408,0.523103,0.475622,0.590165,0.642648,0.432275,0.485346,0.118532,0.108334,0.432347,0.543008,0.755647,0.811131,0.71522,0.709177,0.0743082,0.0559899,0.68173,0.711287,0.0379125,0.0453437,0.368605,0.273212,-0.013569,0.0261905,1.28607,1.38266,-0.843783,-0.933122,0.960331,0.951749,-1.03397,-0.889236,-0.618646,-0.653858,-0.661793,-0.782553,-0.124535,-0.040586,-1.01854,-1.09484
9409,0.544486,0.563766,0.417738,0.41005,0.184191,0.235921,0.132596,0.121455,0.799392,0.843789,0.539962,0.59735,0.113402,0.108127,0.565531,0.547275,0.566509,0.63238,0.456768,0.41682,-0.332231,-0.423409,0.791905,0.827519,-1.79808,-1.70757,-0.102702,-0.184518,-0.698935,-0.700768,-0.845323,-0.706126,0.795392,0.764592,-0.560993,-0.680505,0.0585187,0.137207,-0.673973,-0.739355
9410,0.637007,0.651909,0.401169,0.460593,0.938617,0.992389,0.516264,0.411293,0.504247,0.547247,0.937796,0.99698,0.334699,0.329207,0.616281,0.59729,0.526374,0.553473,0.781806,0.788296,-0.123664,-0.220138,-0.134532,-0.0322425,-0.473779,-0.388173,1.66368,1.5776,0.991752,0.990055,-3.19235,-3.05343,1.25935,1.22546,1.34764,1.23364,-1.46153,-1.38098,-0.306535,-0.383873
9411,0.78804,0.740053,0.517121,0.511136,0.899194,0.965817,0.710314,0.70113,0.809094,0.854508,0.702246,0.85114,0.154519,0.149213,0.998511,0.979526,0.209927,0.238521,0.453538,0.461976,0.473971,0.383401,-0.92238,-0.892004,0.54415,0.626513,0.841721,0.754047,1.76134,1.7623,-0.425446,-0.291391,-1.64947,-1.67566,1.36101,1.24097,-0.509034,-0.512538,-1.20276,-1.28166
9412,0.170758,0.123948,0.956056,0.95051,0.884968,0.939245,0.238692,0.228953,0.300753,0.34631,0.647294,0.705299,0.470495,0.46641,0.765505,0.747236,0.491041,0.519698,0.493493,0.503851,-1.83249,-1.92356,-0.187877,-0.152365,-0.30916,-0.221044,-1.40526,-1.49182,-1.69723,-1.69165,0.677085,0.809218,0.853534,0.824424,-0.38324,-0.500813,0.275345,0.355901,0.457164,0.382499
9413,0.638419,0.590615,0.912597,0.905876,0.603683,0.710301,0.482526,0.490812,0.635713,0.683687,0.286757,0.343573,0.481221,0.479359,0.195572,0.17622,0.20026,0.230548,0.133719,0.142751,0.691197,0.596884,-0.052451,-0.0126569,1.36863,1.45338,-2.97575,-3.05495,1.41407,1.42157,0.137957,0.267713,0.20478,0.180286,1.00716,0.887617,-0.909482,-0.832591,1.00513,0.931501
9414,0.868197,0.822464,0.623549,0.615717,0.428556,0.481356,0.762487,0.752672,0.466795,0.513069,0.727415,0.781929,0.182975,0.178168,0.746695,0.729418,0.819437,0.851666,0.0515313,0.0595513,0.141874,0.0535715,0.856974,0.894788,-0.0759598,0.00267374,0.531089,0.455621,0.142095,0.152153,-0.178469,-0.055095,1.15396,1.13317,-1.1957,-1.31296,0.0310699,0.193463,-0.841627,-0.917477
9415,0.594982,0.518049,0.752056,0.743839,0.974208,1.02884,0.604523,0.594942,0.846703,0.890734,0.113637,0.167019,0.951015,0.947551,0.77506,0.759632,0.456732,0.487361,0.898812,0.908011,0.384878,0.30473,0.587393,0.620784,-2.49702,-2.425,0.255493,0.173147,-0.637743,-0.624422,0.576372,0.694488,-0.93953,-0.964056,-0.69953,-0.813057,1.14047,1.21952,0.511377,0.441181
9416,0.259534,0.213634,0.0283069,0.0185025,0.85688,0.9123,0.726087,0.7144,0.591248,0.622588,0.201464,0.269968,0.83918,0.741696,0.0325997,0.0183783,0.585676,0.616731,0.577587,0.586773,-0.0836693,-0.0836867,-0.576796,-0.545266,-0.0272989,0.0504528,-0.35009,-0.432373,2.23001,2.23605,-0.581055,-0.46049,0.41394,0.391709,0.027649,-0.0817417,1.15147,1.22883,0.598837,0.521857
9417,0.491643,0.445483,0.148355,0.136984,0.0548456,0.109425,0.311791,0.302081,0.309142,0.354443,0.223508,0.372918,0.538647,0.535841,0.68432,0.667865,0.375836,0.409098,0.97042,0.981339,-0.389816,-0.472103,-0.0776508,-0.0693972,0.566566,0.647919,-0.467941,-0.544092,-0.795363,-0.782108,-0.131442,-0.0141478,-0.160524,-0.177923,2.00609,1.89465,-0.775728,-0.703741,0.0756568,0.0631694
9418,0.514972,0.470552,0.559635,0.547068,0.525903,0.489003,0.76238,0.750311,0.648966,0.649827,0.294918,0.475867,0.761523,0.751764,0.846858,0.784006,0.518246,0.481263,0.177782,0.191001,-0.559807,-0.647837,0.373036,0.406472,-0.93433,-0.848602,2.53503,2.46407,1.22047,1.23958,-0.738762,-0.618081,1.00092,0.97755,1.36529,1.25906,0.548319,0.613113,-0.314075,-0.395518
9419,0.872459,0.827369,0.00814606,-0.00480707,0.816456,0.868581,0.549387,0.538309,0.898925,0.945212,0.525435,0.578817,0.971593,0.967686,0.919006,0.900146,0.519977,0.553429,0.417397,0.359649,0.603033,0.521373,0.0354415,0.0719058,0.13299,0.226632,0.0429899,-0.036199,1.56252,1.5819,-0.330561,-0.285619,0.887803,0.872009,0.0270777,-0.0815471,-1.23782,-1.17704,-0.0954628,-0.179269
9420,0.977677,0.933371,0.426856,0.476199,0.672049,0.67652,0.899099,0.887095,0.153937,0.197885,0.0177378,0.0689497,0.701043,0.696753,0.864833,0.844481,0.262509,0.294618,0.516618,0.528296,0.00253975,-0.0831119,-1.97311,-1.94125,-0.303709,-0.214784,-0.953106,-1.03014,0.269302,0.281641,-0.0804112,0.0468437,0.173013,0.151841,0.760044,0.649768,0.778546,0.838522,-0.86584,-0.957054
9421,0.773504,0.729505,0.970158,0.957205,0.450575,0.484458,0.443265,0.430091,0.0427805,0.159145,0.417785,0.46858,0.827401,0.777591,0.341321,0.318672,0.494289,0.600444,0.39386,0.403209,1.52035,1.43059,-1.6084,-1.57259,1.82393,1.91354,-0.396821,-0.468609,0.887221,0.898756,1.70836,1.83992,0.949745,0.935544,0.0209105,-0.0937418,2.44461,2.5024,0.777541,0.692239
9422,0.321859,0.27908,0.0654387,0.0529542,0.406271,0.292397,0.79149,0.778877,0.0771621,0.120406,0.56052,0.642794,0.890957,0.85843,0.769682,0.745286,0.875162,0.906269,0.545765,0.555312,1.72032,1.63386,1.66398,1.70066,-0.576531,-0.485903,-0.726641,-0.79629,-1.83597,-1.82132,-0.418209,-0.285056,-1.40644,-1.41777,-1.03759,-1.15607,1.64335,1.60782,0.734468,0.653872
9423,0.284171,0.285829,0.40026,0.334191,0.0496372,0.100336,0.904623,0.89333,0.47862,0.522936,0.764608,0.817008,0.943558,0.939268,0.977632,0.952403,0.379296,0.411182,0.024275,0.0350512,-0.368438,-0.452753,1.91484,1.94799,0.0246079,0.111564,1.74784,1.68436,0.591391,0.599982,0.202016,0.329159,0.630209,0.625027,0.225567,0.106703,0.654327,0.71324,-0.136756,-0.215524
9424,0.357355,0.292577,0.628164,0.615427,0.289414,0.298618,0.811846,0.800358,0.453575,0.498811,0.415608,0.469824,0.318443,0.312901,0.587378,0.560607,0.928637,0.96085,0.387301,0.400242,1.2984,1.21463,0.902953,0.936739,0.87775,0.958058,-1.06939,-1.1257,1.66069,1.66339,-0.818243,-0.689297,1.22135,1.21006,0.320437,0.143264,0.366147,0.429213,1.73395,1.65438
9425,0.342104,0.299326,0.562009,0.582834,0.444033,0.496899,0.238069,0.227696,0.999433,1.04318,0.592611,0.644598,0.336901,0.382697,0.423994,0.390335,0.906593,0.939994,0.235047,0.279593,-0.156164,-0.23393,1.76977,1.79732,0.639463,0.713576,-0.528492,-0.577651,1.14405,1.14535,0.0115628,0.135612,0.067057,0.056334,0.305697,0.179826,0.504465,0.562239,0.823212,0.821119
9426,0.732461,0.687829,0.563824,0.55024,0.0647857,0.117568,0.436849,0.423988,0.329209,0.373477,0.382192,0.43541,0.457688,0.452494,0.245689,0.220064,0.348822,0.380147,0.145753,0.158944,0.456606,0.385245,0.757634,0.786077,-0.958842,-0.891275,-0.480536,-0.536329,-0.948261,-0.940721,-0.0341741,0.0892066,0.4342,0.424862,-0.0586302,-0.17911,-1.56206,-1.49862,0.0660104,-0.0121428
9427,0.548419,0.481552,0.990416,0.974686,0.750738,0.802452,0.313276,0.288904,0.82466,0.866737,0.587911,0.639615,0.711468,0.704658,0.475353,0.449366,0.382545,0.369967,0.573071,0.587544,-0.829005,-0.896342,-0.719846,-0.694113,1.5886,1.65441,-1.84052,-1.89914,-0.651462,-0.66085,-0.371872,-0.249209,1.4566,1.45201,0.110609,-0.016972,-0.618092,-0.554677,-0.303809,-0.384361
9428,0.319907,0.275274,0.520714,0.506426,0.871363,0.923599,0.16895,0.153821,0.21591,0.257236,0.166738,0.218302,0.297163,0.288649,0.0782714,0.0528595,0.329672,0.359786,0.0162106,0.0317343,0.0919055,0.0283574,0.20257,0.16073,0.132508,0.203705,-1.19831,-1.2612,-0.387291,-0.38098,-0.207887,-0.0819254,0.00571237,0.000588746,-0.843039,-0.973236,-1.80828,-1.74317,0.357076,0.272692
9429,0.657337,0.612374,0.288878,0.369125,0.0883274,0.139028,0.664754,0.651728,0.369293,0.412243,0.914255,0.964429,0.0877401,0.0782798,0.184328,0.172097,0.0199579,0.050727,0.0339242,0.0470814,-1.07604,-1.14411,0.987385,1.01557,1.27688,1.35343,-0.0203596,-0.0814926,-1.12971,-1.1283,-0.804664,-0.685859,0.356368,0.299437,1.08191,0.959431,0.140702,0.204941,0.424773,0.340917
9430,0.491525,0.37536,0.227814,0.231824,0.847689,0.90092,0.792887,0.781257,0.0238566,0.0648153,0.0341303,0.0824422,0.129335,0.120892,0.317319,0.291334,0.762635,0.793456,0.347368,0.422908,1.62165,1.54955,-1.04863,-1.0153,0.210264,0.287581,0.241399,0.105709,1.37828,1.387,-0.290974,-0.178763,0.605757,0.598285,-0.586434,-0.702944,-0.954452,-0.88601,-1.55483,-1.6326
9431,0.185771,0.138346,0.107544,0.0945226,0.232266,0.286918,0.147243,0.133625,0.110893,0.203339,0.29247,0.382381,0.911174,0.901565,0.832227,0.808625,0.538789,0.570003,0.785902,0.798734,-0.141053,-0.208903,-0.426074,-0.341761,-1.34683,-1.26917,0.357122,0.29291,-0.478695,-0.470603,0.576937,0.693021,1.21955,1.21407,-0.856854,-0.969769,1.44982,1.52288,-0.198026,-0.273942
9432,0.533197,0.485342,0.120926,0.108682,0.320839,0.373184,0.584969,0.572292,0.301597,0.341863,0.634678,0.682321,0.916226,0.905017,0.878623,0.854015,0.536,0.553459,0.056108,0.0705499,-1.69497,-1.76393,0.303803,0.331777,0.922862,1.00653,0.0560169,-0.00483966,-0.832258,-0.821686,-0.0992128,0.00235265,0.384054,0.37058,-1.49398,-1.60536,-0.60506,-0.495903,-0.547524,-0.631092
9433,0.337225,0.287088,0.869815,0.858213,0.711978,0.765103,0.818646,0.807865,0.72798,0.770147,0.620221,0.770272,0.579616,0.500808,0.637099,0.6111,0.506656,0.536914,0.81187,0.825615,-0.0624117,-0.12709,1.16898,1.19236,-1.07163,-0.991066,0.179092,0.113893,-0.124218,-0.112837,-0.808698,-0.688316,0.8511,0.831446,0.694912,0.587444,-2.58775,-2.51469,0.201412,0.17594
9434,0.942076,0.893065,0.0103499,-0.00308418,0.696294,0.7574,0.49107,0.480379,0.0880108,0.130515,0.733626,0.858223,0.109888,0.0965984,0.14481,0.120023,0.0881159,0.118049,0.0308495,0.0456485,0.320595,0.261912,-1.21105,-1.18913,0.136478,0.218547,0.0437887,-0.0713701,-0.268322,-0.250332,-0.701558,-0.58153,1.88323,1.85859,0.164986,0.0611943,-0.876744,-0.811904,1.06503,0.982973
9435,0.331138,0.281309,0.132961,0.15212,0.694679,0.749697,0.747642,0.735539,0.677903,0.720483,0.898532,0.946174,0.251749,0.236816,0.723409,0.697898,0.469806,0.498803,0.931389,0.944019,0.366136,0.312582,-0.463548,-0.434627,-0.222339,-0.148261,-0.191919,-0.256634,0.0362658,0.0590425,0.377548,0.491261,-0.302294,-0.330585,-1.53981,-1.64813,0.817822,0.890882,-0.00187014,-0.0818943
9436,0.86148,0.812648,0.321661,0.307325,0.112302,0.165993,0.0905351,0.0782814,0.977158,1.01806,0.598363,0.660152,0.0698803,0.0568219,0.0565569,0.0316112,0.416975,0.385635,0.303682,0.318463,0.0601582,0.00105045,-1.43994,-1.41361,-0.337533,-0.268219,-0.376699,-0.441897,1.37325,1.39766,-1.10267,-0.989599,0.829175,0.807306,0.648774,0.544672,1.61955,1.69192,-0.331681,-0.407484
9437,0.0404629,-0.0100725,0.235941,0.294459,0.518545,0.574136,0.894325,0.884634,0.949973,0.988445,0.324302,0.37413,0.318095,0.314557,0.215835,0.189009,0.243898,0.272467,0.173702,0.247986,-0.482292,-0.522449,-0.429496,-0.385657,-2.24013,-2.17078,-0.101881,-0.169357,0.58174,0.519239,-0.0282614,-0.00532963,0.371918,0.345855,1.43642,1.33403,-0.706328,-0.627116,-0.241025,-0.311366
9438,0.797146,0.745077,0.336,0.281593,0.139825,0.194804,0.31237,0.301348,0.419966,0.459983,0.390452,0.539392,0.586917,0.572292,0.780366,0.751245,0.418086,0.433037,0.237232,0.177509,-0.987612,-1.04595,0.618648,0.642297,1.04877,1.11931,0.455567,0.392177,-0.378545,-0.359181,0.862344,0.97894,0.316536,0.28606,0.798844,0.698448,0.109053,0.190218,0.706297,0.633557
9439,0.38088,0.329714,0.284547,0.268727,0.0464313,0.098822,0.800547,0.789812,0.265826,0.304108,0.653837,0.704653,0.402778,0.386854,0.230499,0.200267,0.566787,0.593606,0.108194,0.107031,0.897088,0.835802,-0.331998,-0.306102,1.57587,1.64034,1.87257,1.80556,0.62785,0.642675,-0.179556,-0.0696303,-0.997202,-1.02672,2.35958,2.25489,0.510933,0.587116,0.737747,0.671895
9440,0.416302,0.366003,0.751348,0.737089,0.835422,0.887568,0.168104,0.157596,0.639338,0.677417,0.530927,0.581449,0.522322,0.506923,0.479995,0.450465,0.191282,0.219422,0.0196635,0.0365542,0.613128,0.554678,-0.664246,-0.640668,-0.965317,-0.90101,-1.15726,-1.22458,-0.229368,-0.212472,0.125907,0.232429,-0.175703,-0.162757,-0.677464,-0.783493,0.311496,0.394219,1.0223,0.949986
9441,0.681479,0.632878,0.680169,0.663176,0.227252,0.278632,0.0383582,0.0782028,0.215432,0.253516,0.197792,0.247967,0.146055,0.13096,0.109123,0.0784995,0.962735,0.990935,0.809113,0.823285,-1.11808,-1.17169,1.34234,1.36943,0.705351,0.773416,0.736416,0.664974,-0.30037,-0.313531,-0.136022,-0.0287241,0.724264,0.701211,0.116674,0.00586963,0.672376,0.759844,0.704865,0.629874
9442,0.116774,0.0669145,0.328112,0.308993,0.634612,0.686774,0.010724,-0.00119045,0.505877,0.54547,0.236284,0.284248,0.959876,0.94705,0.935506,0.902554,0.468401,0.495847,0.722439,0.735332,-0.0172526,-0.0641831,-0.584461,-0.552299,-1.02658,-0.956168,1.46663,1.39802,-0.429324,-0.41459,-0.0638611,0.0469066,-1.37867,-1.39602,-0.260615,-0.366827,0.336379,0.428889,0.377273,0.309762
9443,0.0506425,0.0369816,0.657312,0.618371,0.27811,0.333043,0.905769,0.89226,0.403994,0.44418,0.598806,0.559051,0.67718,0.666132,0.513843,0.480599,0.399637,0.425503,0.260709,0.274473,1.62713,1.57266,-1.40309,-1.3773,0.13661,0.210314,-0.0815127,-0.14838,-1.37911,-1.36267,1.48012,1.59356,1.23818,1.22446,0.627347,0.515162,1.05207,1.13863,0.336953,0.271395
9444,0.0586376,0.00704872,0.944802,0.92775,0.392551,0.444837,0.852855,0.840633,0.592288,0.634166,0.78585,0.833855,0.121971,0.108698,0.694327,0.661721,0.674235,0.701774,0.773352,0.787989,1.92203,1.87211,0.324358,0.350914,0.226322,0.357383,0.973238,0.909292,-0.457832,-0.437022,-1.96947,-1.86201,-0.317495,-0.324575,-0.90325,-1.0091,-0.635335,-0.554348,-1.57445,-1.6391
9445,0.492354,0.355995,0.262648,0.247153,0.0505836,0.100552,0.556278,0.543049,0.138108,0.180777,0.806631,0.797406,0.431485,0.420758,0.391031,0.360158,0.472607,0.498968,0.129081,0.14183,-1.45874,-1.50886,-1.85736,-1.83721,0.46624,0.504453,2.03383,1.96696,-0.571195,-0.628149,1.33311,1.43562,0.00905025,-0.00282393,1.55826,1.45265,-0.652419,-0.575293,0.146343,0.0847273
9446,0.758476,0.704941,0.532214,0.518189,0.219316,0.266712,0.835039,0.822956,0.132583,0.197282,0.71285,0.760958,0.272396,0.261708,0.562031,0.531352,0.0319443,0.059762,0.269463,0.360747,1.41645,1.36086,-0.706742,-0.684172,0.577818,0.651522,-0.73555,-0.800392,-0.844295,-0.819275,2.09253,2.20119,-0.246419,-0.211607,1.03057,0.926399,0.779275,0.854843,-0.00229368,-0.0580078
9447,0.885809,0.830329,0.204249,0.187932,0.949345,0.997707,0.422405,0.410636,0.173568,0.213786,0.126921,0.176005,0.34108,0.330502,0.262289,0.229789,0.802157,0.831275,0.516426,0.579664,-0.0748065,-0.134193,-0.502722,-0.4822,1.25195,1.32816,-0.503375,-0.571902,0.35343,0.383058,-1.36903,-1.25439,-0.408626,-0.420391,1.17436,1.07389,2.54746,2.62779,-0.361229,-0.415158
9448,0.486771,0.429626,0.257416,0.299246,0.950017,0.999061,0.796653,0.784478,0.999423,1.04165,0.848551,0.897361,0.0451177,0.0338344,0.797644,0.76756,0.312319,0.341258,0.786575,0.798581,0.687545,0.578855,0.242528,0.257439,1.26085,1.34399,0.368077,0.300066,-0.865358,-0.840823,1.52483,1.63441,1.5688,1.55596,-0.41195,-0.509958,1.55986,1.64457,-1.13315,-1.19294
9449,0.841458,0.786443,0.425963,0.41056,0.523041,0.574562,0.573228,0.561587,0.593091,0.637575,0.400967,0.451311,0.895106,0.885638,0.328019,0.296537,0.135249,0.163661,0.755633,0.769209,1.35584,1.2919,-0.309144,-0.292202,-1.08077,-0.991294,-2.39596,-2.46729,-0.557749,-0.531449,-3.03942,-2.92429,-0.552056,-0.570167,-0.589903,-0.68373,2.1369,2.22789,0.547382,0.48796
9450,0.688597,0.684668,0.935598,0.918113,0.415185,0.468519,0.889047,0.876412,0.43239,0.476209,0.656074,0.704749,0.355289,0.343374,0.260062,0.230784,0.51147,0.53947,0.0405461,0.0529181,0.680938,0.609894,-1.18889,-1.17917,0.151035,0.189456,1.41641,1.33767,0.346676,0.378014,-0.801989,-0.698593,1.62063,1.60225,0.0336527,-0.0240496,0.900804,0.993171,-1.13846,-1.20424
9451,0.652674,0.582893,0.198505,0.182471,0.52494,0.585462,0.749627,0.739192,0.539853,0.585227,0.611995,0.662782,0.384103,0.469761,0.476844,0.449019,0.290332,0.316017,0.157664,0.170086,-0.613933,-0.686834,-0.115611,-0.10152,1.28463,1.37021,0.893325,0.809579,-1.95006,-1.91457,1.41402,1.5271,1.36804,1.34383,0.734719,0.635631,0.324292,0.414701,-0.740113,-0.703087
9452,0.627887,0.481118,0.403839,0.300327,0.715933,0.702405,0.206852,0.195625,0.988513,1.03343,0.101221,0.152915,0.610859,0.596147,0.202751,0.176486,0.774594,0.801024,0.828188,0.839481,0.126672,0.0544397,-1.22592,-1.20598,-1.44271,-1.35125,-0.0343443,-0.12394,-0.264185,-0.223746,0.241644,0.358132,-1.26033,-1.28568,-1.89431,-1.98897,-0.503623,-0.411345,-0.141907,-0.201931
9453,0.434358,0.379343,0.435168,0.418183,0.766786,0.819348,0.424849,0.411929,0.845212,0.884098,0.0406497,0.0909687,0.129071,0.114523,0.651512,0.623469,0.0380311,0.0647028,0.0530003,0.0665976,0.241124,0.165887,1.06371,1.07871,0.788062,0.874728,0.590471,0.498102,0.882323,0.916991,0.757386,0.880286,-0.961678,-0.99338,-0.544962,-0.562334,-0.795496,-0.695372,-0.943211,-1.00907
9454,0.114553,0.0601234,0.323442,0.304962,0.560225,0.61157,0.87303,0.860159,0.688302,0.734765,0.418566,0.469858,0.455329,0.441839,0.812248,0.784934,0.609949,0.634067,0.948294,0.959875,1.34906,1.2734,-2.69413,-2.67503,0.227204,0.308155,-1.32582,-1.41476,2.29544,2.33239,0.513357,0.633493,2.41728,2.37972,0.95185,0.864306,2.36396,2.46401,1.02643,0.963913
9455,0.782431,0.726405,0.647961,0.63112,0.0628696,0.111874,0.0767431,0.0646111,0.150761,0.196611,0.249649,0.302221,0.497768,0.484451,0.725082,0.699123,0.849691,0.87556,0.900667,0.898896,1.07731,1.00684,-0.857913,-0.788138,0.301705,0.38538,-0.795329,-0.883261,-1.7092,-1.67082,3.03807,3.15863,2.22148,2.18391,1.18103,1.08881,-0.277792,-0.182032,1.31573,1.25614
9456,0.0738229,0.0186451,0.0601947,0.0449586,0.10926,0.158559,0.139837,0.128305,0.570574,0.614115,0.295754,0.34735,0.159536,0.144414,0.021109,-0.00428917,0.521112,0.565754,0.829285,0.837917,-2.37604,-2.45151,1.07966,1.09876,0.661561,0.739432,-0.518043,-0.610721,0.566435,0.6003,-1.37836,-1.2578,-1.27201,-1.3103,1.8252,1.72607,-0.911257,-0.821327,1.2976,1.2331
9457,0.0189582,-0.0380238,0.15217,0.117335,0.835136,0.884213,0.606688,0.59625,0.606272,0.564634,0.00649146,0.058438,0.96641,0.949886,0.593343,0.569327,0.230842,0.255947,0.773275,0.776939,0.871827,0.791084,-0.0383083,-0.0212049,0.561677,0.679469,0.15199,0.0586629,-0.68849,-0.65458,-0.62579,-0.508221,-0.446769,-0.506429,-0.636598,-0.738276,-0.823656,-0.733317,-0.359949,-0.428191
9458,0.621325,0.562728,0.122356,0.189711,0.220996,0.270211,0.426188,0.414283,0.458183,0.515153,0.54343,0.59576,0.0952049,0.0781502,0.0185121,-0.0068178,0.120554,0.195337,0.704379,0.71596,0.199183,0.119125,-0.328537,-0.310219,0.568161,0.619505,-0.621243,-0.71771,-0.116754,-0.0826527,-1.58145,-1.46515,0.338535,0.297442,0.317236,0.219949,-0.422673,-0.385712,1.37073,1.29563
9459,0.992132,0.935032,0.276624,0.262088,0.335356,0.351222,0.467114,0.468686,0.550028,0.465672,0.0205538,0.0715041,0.881435,0.863726,0.65799,0.63286,0.110365,0.134727,0.462079,0.482387,-0.469299,-0.552833,0.170055,0.183965,0.481672,0.559542,0.0121149,-0.0797665,0.135784,0.168066,0.312262,0.436328,1.67553,1.63909,-0.776986,-0.873269,-0.129835,-0.0381076,2.04427,1.96806
9460,0.245872,0.190114,0.0873,0.0725754,0.418252,0.432233,0.536354,0.523089,0.373594,0.416191,0.934761,0.983073,0.790615,0.774783,0.534096,0.511731,0.335854,0.436006,0.238374,0.248814,0.317677,0.234042,0.0232233,0.034275,0.718268,0.790491,0.858107,0.760246,-1.37341,-1.34736,0.0580311,0.175175,-0.984102,-1.01859,-0.0436155,-0.141953,1.58252,1.67225,-0.575944,-0.650087
9461,0.639125,0.583062,0.661157,0.648339,0.464029,0.513244,0.927285,0.911859,0.557481,0.531627,0.601207,0.649591,0.234066,0.217349,0.747227,0.736793,0.712207,0.737284,0.92388,0.932944,-0.25082,-0.340232,0.923902,0.94172,-1.02342,-0.954859,0.739016,0.633971,1.62449,1.65738,0.355586,0.477235,2.22536,2.19171,-1.41328,-1.51216,-0.7203,-0.629109,1.12251,1.0456
9462,0.309676,0.253348,0.333091,0.360278,0.295637,0.347097,0.947759,0.934449,0.604882,0.647063,0.724213,0.774495,0.370355,0.316991,0.984206,0.961854,0.790062,0.815297,0.538504,0.547631,-0.0881327,-0.182272,0.210961,0.22553,0.744664,0.812232,-0.464148,-0.576738,-1.71461,-1.67747,0.370799,0.491601,0.754764,0.72309,0.111908,0.0120466,0.639258,0.726376,-1.81074,-1.88615
9463,0.81482,0.760502,0.08588,0.0722166,0.835575,0.88474,0.710319,0.611227,0.536765,0.576423,0.245703,0.294358,0.431386,0.416633,0.886814,0.865546,0.00829418,0.0354603,0.995054,1.00209,1.70214,1.60785,2.38059,2.39698,-1.70099,-1.63614,-0.840715,-0.95131,-1.13832,-1.10554,0.0721802,0.199697,-0.473851,-0.509835,0.376307,0.283728,-1.12398,-1.03186,-0.775883,-0.850485
9464,0.634984,0.582956,0.673868,0.657675,0.844705,0.89193,0.299101,0.288006,0.83488,0.873999,0.938107,0.985634,0.758619,0.74395,0.0226352,-0.000159678,0.388055,0.480905,0.231367,0.238986,0.30096,0.203944,0.290875,0.307447,-0.133677,-0.0729524,1.09257,0.985207,-0.927193,-0.866815,0.0812625,0.214063,-0.787358,-0.830866,-0.412377,-0.50501,0.395199,0.490848,2.24723,2.17169
9465,0.764755,0.712971,0.898848,0.884917,0.288109,0.33779,0.479453,0.468849,0.867917,0.905961,0.902152,0.948306,0.247936,0.232349,0.827084,0.803111,0.900319,0.92635,0.73829,0.747488,-1.68746,-1.78891,2.41353,2.43133,-0.593667,-0.530487,-0.0462462,-0.148008,-0.668312,-0.628091,0.347729,0.472501,-0.632412,-0.677831,-0.907855,-1.00076,-0.624102,-0.525584,0.282983,0.2141
9466,0.313743,0.262547,0.527846,0.515812,0.850631,0.900022,0.295396,0.304038,0.340171,0.3775,0.102221,0.14491,0.0150432,0.00102357,0.855836,0.833325,0.975916,1.00001,0.949295,0.960003,-0.613626,-0.712491,-0.262922,-0.251773,0.694081,0.756618,0.421075,0.321197,-0.881673,-0.841191,0.0104758,0.134086,-1.88903,-1.94077,-0.568242,-0.655058,1.49981,1.59234,-0.0544849,-0.127001
9467,0.792868,0.739509,0.415067,0.347358,0.207985,0.255731,0.147672,0.139227,0.125755,0.160442,0.512102,0.554563,0.906782,0.892427,0.289691,0.266679,0.543025,0.565271,0.0900886,0.102594,0.150228,0.0451481,0.511969,0.518149,-1.02217,-0.960391,0.25747,0.163508,0.197717,0.237513,-0.920414,-0.792126,-1.39056,-1.44879,-1.09132,-1.18131,0.565143,0.596638,0.5059,0.492059
9468,0.810704,0.754701,0.190171,0.178904,0.774437,0.823814,0.718429,0.711675,0.829988,0.866159,0.509846,0.551477,0.947628,0.921951,0.525638,0.501641,0.52819,0.549849,0.209362,0.219762,0.662314,0.559183,2.02119,2.02898,-1.00375,-0.94456,-0.798061,-0.894393,-2.56235,-2.51786,-0.0706044,0.0642611,0.860319,0.80125,-0.639742,-0.727992,-0.491599,-0.399066,1.18363,1.11112
9469,0.626369,0.617448,0.907958,0.894381,0.018548,0.0686773,0.0121848,0.00433073,0.768556,0.806311,0.171819,0.213841,0.968227,0.951476,0.130036,0.105135,0.28864,0.311338,0.0763517,0.0851888,1.43699,1.33101,-1.26991,-1.25714,-0.435067,-0.377502,0.944022,0.852672,-0.820193,-0.779552,1.09563,1.22915,-0.439578,-0.495704,-0.800009,-0.885952,-0.818752,-0.73002,-0.737456,-0.813541
9470,0.534332,0.480196,0.734624,0.762271,0.0692416,0.157636,0.21025,0.114894,0.164023,0.20159,0.507472,0.548264,0.479036,0.460366,0.925253,0.898479,0.845876,0.866553,0.372083,0.316663,0.70064,0.538906,0.00456654,0.0214424,-0.161569,-0.0999009,-0.295151,-0.389376,0.687895,0.728141,-0.349987,-0.219078,-0.0227227,-0.11907,-0.71111,-0.801363,0.722326,0.806502,-1.92167,-2.00254
9471,0.905565,0.852499,0.643507,0.63016,0.16555,0.246594,0.233999,0.225458,0.645353,0.684119,0.0493243,0.0924357,0.640173,0.621787,0.6999,0.671518,0.67151,0.693289,0.538686,0.548137,-0.143965,-0.253201,-0.511437,-0.495363,-0.103582,-0.0375242,-1.16799,-1.26082,0.916166,0.961723,-0.622318,-0.495991,0.30829,0.257563,0.0792102,-0.012,-0.0446228,0.0426782,0.282203,0.193504
9472,0.662039,0.698894,0.727904,0.714523,0.284125,0.335553,0.961708,0.953425,0.904801,0.945186,0.255642,0.300924,0.0210929,0.00104279,0.807384,0.777855,0.0674058,0.087629,0.510364,0.518765,1.75788,1.64355,0.215201,0.226713,0.374529,0.437393,0.264881,0.168666,0.674586,0.717812,-0.653968,-0.439419,-0.805091,-0.851283,0.267702,0.181549,-1.33798,-1.25534,-1.71444,-1.80906
9473,0.544318,0.545288,0.141318,0.128362,0.770546,0.82382,0.809584,0.801304,0.865848,0.90638,0.954608,1.00158,0.57597,0.557935,0.347558,0.316447,0.665681,0.6841,0.12742,0.138359,-1.20991,-1.32325,0.0162785,0.029141,1.0839,1.14418,0.591868,0.466987,-0.594669,-0.551603,-0.509108,-0.382846,-1.21072,-1.2495,-0.765168,-0.850136,0.80289,0.880997,1.43584,1.34252
9474,0.444749,0.391683,0.403208,0.370925,0.721471,0.774797,0.906357,0.892913,0.00757319,0.046432,0.035084,0.0801862,0.136979,0.1172,0.816141,0.783352,0.650889,0.668678,0.21461,0.312486,1.08939,0.973939,0.0191757,0.0314452,0.138415,0.20445,0.867722,0.765308,0.931841,0.970963,-0.184968,-0.062556,-1.03028,-1.06695,-2.38472,-2.46587,1.91807,1.99502,1.28096,1.27559
9475,0.992509,0.938081,0.672112,0.613489,0.345462,0.399961,0.994663,0.984522,0.115295,0.172851,0.864863,0.91009,0.35898,0.41742,0.443862,0.411386,0.18255,0.199161,0.47644,0.486614,0.100409,-0.0163057,-0.874756,-0.85552,1.42156,1.49155,-0.3631,-0.460635,-0.704159,-0.667282,0.434496,0.551659,-0.0566961,-0.0996044,2.09973,2.02062,-0.114119,-0.035218,1.3091,1.20866
9476,0.832371,0.780316,0.86901,0.856053,0.565855,0.523076,0.353097,0.342273,0.31456,0.299271,0.661413,0.639962,0.737238,0.717639,0.710958,0.676989,0.303355,0.39223,0.764756,0.774719,1.93225,1.81929,-0.244505,-0.224438,0.127659,0.290602,-0.185166,-0.27958,0.275531,0.305979,-1.07694,-0.958127,1.4295,1.3922,-0.991575,-1.06981,3.02499,3.1054,-0.0221336,-0.116995
9477,0.247853,0.194128,0.801058,0.882298,0.642116,0.646191,0.454939,0.446673,0.278132,0.42569,0.324903,0.369833,0.711943,0.694658,0.70221,0.666994,0.566315,0.585299,0.123991,0.134056,-1.77906,-1.90024,-0.875117,-0.848969,-0.97515,-0.910351,-0.723235,-0.822754,-1.00374,-0.977953,0.992931,1.1157,0.0373115,0.00353049,0.625446,0.548853,1.35543,1.42913,0.423132,0.326313
9478,0.736889,0.680854,0.922217,0.908544,0.757498,0.769306,0.975168,0.964722,0.51325,0.552109,0.580414,0.64763,0.901191,0.886148,0.129186,0.0959779,0.300344,0.320441,0.78807,0.797401,-0.937136,-1.05287,0.538516,0.568847,-0.12332,-0.0638571,-2.51494,-2.60728,1.41286,1.44335,-0.905609,-0.777481,0.422299,0.385976,-0.81599,-0.898197,-0.835691,-0.757882,0.433387,0.333894
9479,0.391513,0.381489,0.392277,0.381132,0.837922,0.892421,0.439632,0.431723,0.170476,0.208534,0.879985,0.925426,0.747978,0.70905,0.92914,0.894503,0.939048,0.957674,0.285114,0.296742,0.361952,0.209886,-1.04676,-1.01875,1.16543,1.22325,-0.555451,-0.709216,-0.7047,-0.674695,1.43913,1.56637,1.72817,1.69753,-1.33078,-1.4093,0.453922,0.528286,-0.388906,-0.487873
9480,0.137317,0.0821233,0.471984,0.36558,0.531525,0.562865,0.797069,0.790243,0.725604,0.763028,0.740928,0.801566,0.648818,0.531951,0.681126,0.700082,0.264607,0.282682,0.0676594,0.0814418,1.58963,1.47265,-0.203648,-0.173613,0.45449,0.51594,1.2812,1.18885,1.07156,1.10785,-0.483819,-0.358406,-0.0780097,-0.10132,-0.383547,-0.463794,-1.54143,-1.46965,1.37512,1.27225
9481,0.35564,0.298702,0.358984,0.350027,0.17876,0.233309,0.0178646,0.0105186,0.501425,0.540871,0.631551,0.677705,0.369001,0.354853,0.535048,0.505661,0.0397777,0.0592287,0.986633,0.999843,-0.556635,-0.674044,1.35519,1.38653,1.13933,1.2079,0.834641,0.737511,0.882707,0.924516,1.27514,1.40331,-0.435147,-0.454096,-1.63476,-1.71057,-0.501406,-0.431183,-0.470867,-0.576724
9482,0.115633,0.0602367,0.730766,0.71974,0.19248,0.245315,0.705888,0.698252,0.565167,0.603363,0.282312,0.330522,0.555978,0.543368,0.347616,0.31124,0.306446,0.325855,0.933837,0.945891,1.13657,1.02447,-0.930127,-0.895467,-0.92677,-0.854739,1.40385,1.29905,-0.195347,-0.159601,-1.2464,-1.1268,-1.53993,-1.56294,-0.882934,-1.00511,0.292009,0.354703,0.55115,0.444726
9483,0.749972,0.696047,0.0199105,0.00960473,0.718561,0.77385,0.232406,0.226075,0.888713,0.92578,0.901012,0.95128,0.745345,0.731884,0.82438,0.787765,0.824867,0.846296,0.420852,0.434982,1.00858,0.894705,0.170369,0.199418,-0.124683,-0.055716,1.47903,1.37216,-0.201067,-0.170029,0.11027,0.235103,0.722106,0.705504,-0.108556,-0.299642,-1.02895,-0.960539,0.518272,0.406359
9484,0.43697,0.381053,0.26654,0.256611,0.378088,0.464125,0.903842,0.898858,0.160909,0.199273,0.57495,0.6227,0.370501,0.38153,0.68673,0.651385,0.555783,0.577425,0.532268,0.545809,-1.25231,-1.36422,-0.34057,-0.317387,1.6114,1.68272,-0.915485,-1.02366,1.15156,1.18258,0.162484,0.280127,-0.316777,-0.32616,0.481636,0.405824,1.50965,1.57656,-0.242608,-0.356446
9485,0.398829,0.344683,0.0532652,0.0421565,0.101671,0.154399,0.201077,0.1961,0.592614,0.631817,0.991024,1.03727,0.0435162,0.0311753,0.910916,0.87531,0.0638904,0.0874079,0.403145,0.416597,-0.0110083,-0.116218,-1.30145,-1.28203,1.79509,1.86585,-0.501883,-0.614683,-0.0312834,-0.00577661,1.7126,1.82678,1.39912,1.38386,0.866491,0.784534,0.320963,0.388071,-1.49685,-1.60558
9486,0.794427,0.742447,0.562954,0.549709,0.407766,0.46143,0.741544,0.738989,0.0533975,0.0936635,0.908002,0.95414,0.818746,0.807089,0.00417968,-0.0307796,0.38153,0.397044,0.728401,0.740332,-0.386453,-0.489958,1.25524,1.27545,0.0666734,0.136262,0.919789,0.814805,0.994318,1.01274,0.298182,0.408802,-0.323517,-0.335659,0.49585,0.331264,0.0209304,0.0873242,-1.07366,-1.17767
9487,0.458509,0.493949,0.306256,0.293655,0.273469,0.32473,0.960193,0.959335,0.207731,0.214455,0.500955,0.547997,0.235077,0.224661,0.221126,0.224836,0.684284,0.70668,0.394451,0.403901,-1.69507,-1.8,-0.180858,-0.158561,-1.12639,-1.05287,1.28811,1.17924,0.0613115,0.0806764,-1.98095,-1.87507,-0.683479,-0.688435,-0.0335371,-0.122007,-0.0128861,0.0130807,-0.0749167,-0.257117
9488,0.297993,0.245451,0.347182,0.332029,0.56603,0.616186,0.134535,0.131777,0.297798,0.335246,0.55483,0.6036,0.760891,0.751524,0.560868,0.480451,0.447775,0.468169,0.4057,0.447347,-0.572718,-0.678234,-1.03271,-1.01447,0.248053,0.325212,-1.45419,-1.57035,-0.0909989,-0.0704249,-1.68765,-1.58583,-0.153633,-0.166679,1.34873,1.26642,-0.128501,-0.0611628,0.767445,0.663437
9489,0.788668,0.736978,0.776283,0.761599,0.323962,0.371731,0.0885028,0.0849032,0.891059,0.930033,0.100012,0.147771,0.287959,0.280419,0.769848,0.736066,0.44968,0.545622,0.579763,0.490794,-1.60532,-1.71438,-0.737025,-0.718861,0.371936,0.446037,0.896832,0.775919,-0.906577,-0.878578,1.98663,2.08936,2.08325,2.06814,1.8664,1.78142,0.195139,0.257416,0.202656,0.0968512
9490,0.859645,0.790789,0.56644,0.552014,0.964268,1.01087,0.923273,0.921349,0.0922226,0.129331,0.121434,0.169707,0.974422,0.96794,0.531343,0.498251,0.601096,0.623076,0.52479,0.53424,1.91323,1.80913,0.449257,0.431901,1.32717,1.39997,-0.9008,-1.02226,-0.363836,-0.339041,1.21229,1.31637,1.05735,1.03648,0.3469,0.257152,1.63686,1.70262,0.536424,0.3965
9491,0.894012,0.8446,0.130426,0.114259,0.452898,0.497307,0.0601571,0.0571095,0.483388,0.436412,0.681826,0.730994,0.474349,0.466901,0.821921,0.788886,0.816471,0.82127,0.858837,0.867865,1.62167,1.51217,1.56549,1.58266,1.09125,1.17116,-0.561922,-0.689253,-0.543813,-0.522373,1.15973,1.26996,-0.309585,-0.336588,0.810171,0.725682,0.617038,0.686191,0.804249,0.696149
9492,0.339596,0.288435,0.0968467,0.098707,0.585972,0.62877,0.239635,0.237065,0.705118,0.743492,0.970674,1.02016,0.749521,0.708123,0.875326,0.844625,0.997167,1.01946,0.296923,0.306794,0.434864,0.323312,-0.665348,-0.653183,-1.64997,-1.56614,-0.497326,-0.616143,-0.333244,-0.318623,0.729433,0.838836,-0.543155,-0.578371,0.406284,0.321924,0.587317,0.650138,-1.99641,-2.10541
9493,0.591627,0.539551,0.101751,0.0831546,0.177645,0.219138,0.327151,0.41702,0.386942,0.425812,0.627488,0.747759,0.957616,0.949345,0.176812,0.146152,0.000496937,0.0227941,0.853167,0.860907,-0.182599,-0.32695,1.62102,1.63151,0.0779153,0.156247,0.727997,0.610952,-0.394927,-0.378261,0.995239,1.09727,-0.785839,-0.820155,0.83957,0.759447,0.321738,0.380654,-1.16404,-1.26811
9494,0.640888,0.589799,0.320709,0.300485,0.918982,0.960009,0.600022,0.596975,0.307596,0.294938,0.424638,0.475357,0.287411,0.277098,0.346837,0.228798,0.523684,0.548012,0.803263,0.883045,-0.867886,-0.977211,-1.22048,-1.21008,-1.30932,-1.23496,-0.719713,-0.830793,1.18284,1.20487,-0.293974,-0.196468,-0.38467,-0.421205,0.401491,0.324959,0.931082,0.996229,0.500256,0.396058
9495,0.0749734,0.0238354,0.32765,0.370545,0.878829,0.92119,0.220713,0.219359,0.122135,0.164064,0.778025,0.830646,0.603509,0.594295,0.341303,0.311444,0.368034,0.389595,0.898686,0.905182,1.46636,1.35183,-1.28976,-1.28455,-0.0793007,-0.0074118,0.312996,0.195881,0.0871975,0.0908055,-0.562772,-0.457621,1.54638,1.50985,0.373539,0.301694,0.0846102,0.156593,0.856435,0.747991
9496,0.585902,0.535754,0.357567,0.440605,0.291159,0.332449,0.32003,0.318581,0.691026,0.732805,0.258992,0.310573,0.301358,0.293105,0.221308,0.178669,0.580078,0.538547,0.17096,0.176998,0.747706,0.639562,0.0248828,0.112831,-0.36912,-0.296862,0.112023,0.0264045,-0.999161,-1.02326,-0.270207,-0.168381,0.4687,0.431068,-0.194783,-0.269923,2.91145,2.98446,0.193537,0.091551
9497,0.367282,0.316519,0.529547,0.510664,0.731338,0.771774,0.630968,0.558727,0.102101,0.144091,0.145165,0.280761,0.293582,0.285677,0.0777418,0.0458933,0.665577,0.6875,0.288348,0.305162,0.819696,0.706661,1.50499,1.51021,0.304061,0.379779,-0.0247384,-0.143072,-2.15934,-2.13732,-1.10129,-1.00275,0.862496,0.830019,1.3676,1.28652,-0.960514,-0.8851,1.20433,1.09759
9498,0.349711,0.226257,0.726488,0.632544,0.644252,0.761169,0.800229,0.798873,0.790039,0.830008,0.199124,0.25095,0.512904,0.505945,0.237196,0.207358,0.544297,0.564724,0.555926,0.433325,0.193413,-0.0170068,-1.27619,-1.26989,0.591861,0.671851,-1.30754,-1.4301,-0.999123,-0.982906,-0.226891,-0.130967,-0.819359,-0.859035,-0.206216,-0.28319,-0.588398,-0.519475,-0.373829,-0.486193
9499,0.18831,0.135995,0.773277,0.754424,0.712645,0.750565,0.378353,0.468341,0.304291,0.346326,0.319758,0.353214,0.736027,0.726213,0.687214,0.659058,0.972698,0.995181,0.556867,0.561488,-0.626712,-0.740675,-0.145671,-0.144158,-1.41292,-1.34037,1.92089,1.78958,-1.22751,-1.21292,0.00962601,0.0980868,-0.257186,-0.289065,0.517093,0.448126,0.872028,0.943149,0.62955,0.519845
9500,0.846415,0.792388,0.327816,0.311051,0.860873,0.8661,0.139442,0.137809,0.580605,0.622923,0.403877,0.455478,0.727066,0.677001,0.552207,0.522678,0.146331,0.166746,0.551986,0.595868,-0.630845,-0.749955,0.565722,0.563672,-0.0711697,0.00896166,1.2188,1.09171,0.205719,0.21853,-0.306916,-0.224721,-0.843166,-0.874019,0.0303307,-0.0321048,-0.191009,-0.118296,-0.254611,-0.363662
9501,0.281782,0.226425,0.656711,0.641917,0.944561,0.981635,0.880848,0.880518,0.591186,0.635854,0.136054,0.187601,0.638552,0.62779,0.0316629,0.00157976,0.506821,0.527667,0.642073,0.630247,-0.0211524,-0.146416,-0.55992,-0.55629,1.78067,1.85565,-0.286942,-0.410815,-0.730097,-0.713536,-0.214268,-0.214696,0.0698579,0.0307557,0.489967,0.42121,-1.86152,-1.79457,1.24561,1.13249
9502,0.585511,0.521492,0.519732,0.545621,0.255551,0.292684,0.843408,0.738102,0.0529955,0.0977003,0.115719,0.262416,0.817748,0.808547,0.353619,0.357205,0.234888,0.253773,0.658398,0.664627,0.237508,0.119466,-0.656082,-0.647196,-2.2555,-2.18565,0.527971,0.398659,1.01854,1.03854,-0.29101,-0.20467,0.0255622,-0.014067,0.0681313,0.00149226,0.594425,0.661186,0.755527,0.642642
9503,0.872676,0.81656,0.464148,0.449325,0.860381,0.896243,0.625801,0.595685,0.792134,0.836216,0.28526,0.337232,0.582194,0.600558,0.744815,0.712831,0.696401,0.71407,0.11749,0.123467,1.90027,1.78685,0.732487,0.739158,1.01966,1.08591,-1.31134,-1.44761,0.0107055,0.0289529,0.406823,0.500455,-0.933614,-0.967961,-0.028734,-0.0962587,1.19327,1.26067,-0.285582,-0.391455
9504,0.443246,0.436582,0.0896467,0.0747127,0.0531383,0.0881685,0.451379,0.453269,0.646512,0.772527,0.524102,0.575553,0.399393,0.392569,0.125727,0.091587,0.801586,0.818705,0.4682,0.473072,0.235897,0.122345,0.764064,0.771946,-0.31599,-0.242469,0.669646,0.536473,0.0853961,0.111139,-0.306665,-0.210921,0.768435,0.726458,0.644741,0.572479,-1.47608,-1.41622,0.0215465,-0.0828281
9505,0.114204,0.0566041,0.320699,0.376568,0.694833,0.731879,0.661796,0.664254,0.680523,0.708839,0.202219,0.252329,0.537881,0.532787,0.45775,0.423446,0.261896,0.279102,0.426854,0.429789,-1.06264,-1.17438,-0.00423013,0.00746925,-0.908786,-0.828676,-0.0891086,-0.225407,1.80269,1.83263,1.47186,1.56908,-1.80045,-1.83509,-0.323788,-0.399841,1.82197,1.87694,-0.178286,-0.287171
9506,0.810568,0.752271,0.695261,0.678423,0.559273,0.595179,0.582765,0.585931,0.474903,0.64515,0.182261,0.234158,0.198376,0.192751,0.0140057,-0.0228661,0.948933,0.96632,0.951763,0.954222,1.30738,1.188,1.19097,1.20862,-2.21934,-2.14057,1.19245,1.06187,0.636205,0.671539,1.0401,1.13795,0.0126099,-0.0127913,0.0671239,-0.0070553,-0.204249,-0.153297,0.499383,0.3503
9507,0.301878,0.241414,0.54887,0.529599,0.900888,0.93713,0.278833,0.283499,0.538952,0.581462,0.713452,0.76578,0.557801,0.550137,0.946249,0.909541,0.429402,0.521637,0.0866229,0.0908457,-0.0936319,-0.215905,-0.458465,-0.443788,-1.06747,-0.99084,0.561512,0.425869,0.917439,0.952589,-0.611657,-0.510352,-0.994279,-1.0146,0.0417125,-0.0303206,-0.135007,-0.08154,1.09136,0.987771
9508,0.250028,0.190041,0.00377822,-0.0171209,0.641296,0.677131,0.57494,0.598028,0.017105,0.0584475,0.171268,0.221362,0.624677,0.618932,0.536869,0.497851,0.0607205,0.0769547,0.298778,0.391805,-2.23238,-2.35014,-2.54474,-2.53332,0.390309,0.464393,0.631841,0.498978,0.373932,0.403814,1.03152,1.13189,-0.258754,-0.277532,1.31944,1.24581,-0.773354,-0.720834,-0.0241665,-0.0273888
9509,0.50638,0.377375,0.731675,0.708908,0.719523,0.753603,0.909466,0.912557,0.113655,0.153339,0.474394,0.522753,0.417425,0.359667,0.584741,0.639205,0.0710209,0.0869763,0.687665,0.692765,0.190983,0.0743515,-0.472905,-0.460816,-1.03879,-0.971661,-1.04096,-1.17743,0.236875,0.266319,-1.07147,-0.965209,-0.451857,-0.473343,3.11324,3.03496,-0.904197,-0.85068,-0.942503,-1.04255
9510,0.626318,0.56471,0.650484,0.570131,0.0572509,0.090177,0.666393,0.738316,0.843494,0.881336,0.27605,0.323984,0.105541,0.100402,0.821131,0.78056,0.467771,0.482853,0.415571,0.422319,0.508654,0.387577,-0.193496,-0.182471,0.512766,0.574271,-0.198174,-0.337415,-2.09684,-2.07334,-1.11981,-1.0839,0.145735,0.126352,0.576716,0.493815,-0.00913876,0.0443676,1.30536,1.20163
9511,0.578494,0.517818,0.457171,0.431354,0.449098,0.537647,0.560591,0.564076,0.462736,0.502464,0.582702,0.630193,0.273457,0.265959,0.312786,0.274281,0.0779281,0.0928057,0.9282,0.935835,-1.20807,-1.32361,0.0765159,0.0958733,0.296317,0.359396,-1.52017,-1.65392,1.04292,1.0649,-1.31011,-1.20259,-0.185734,-0.210586,-0.385232,-0.462449,1.24888,1.29921,0.386331,0.287885
9512,0.864787,0.804664,0.00277184,-0.0218634,0.952191,0.985117,0.162092,0.167231,0.39159,0.431824,0.3883,0.435857,0.00474003,-0.00497384,0.38767,0.335802,0.79624,0.809261,0.607804,0.614597,-0.0609144,-0.169128,-0.374293,-0.360902,-0.13571,-0.0674664,-0.194484,-0.335703,0.0788654,0.103314,0.932089,1.03502,-1.11879,-1.15069,-1.66462,-1.74168,0.275613,0.33083,-1.57889,-1.68563
9513,0.570671,0.510152,0.44778,0.421926,0.511843,0.529431,0.631492,0.635175,0.702066,0.743842,0.52441,0.55196,0.508497,0.497342,0.442661,0.397323,0.642545,0.655664,0.880211,0.887767,-0.00763417,-0.118458,-1.03207,-1.01625,-0.246732,-0.15159,1.61232,1.47552,0.243227,0.262711,0.375755,0.479425,-0.457319,-0.489468,-0.807777,-0.889537,0.778981,0.839006,-2.03504,-2.14573
9514,0.0211981,-0.0409838,0.113222,0.0868519,0.0395218,0.0737443,0.771569,0.774704,0.294616,0.334652,0.618839,0.668063,0.234666,0.22175,0.496953,0.458843,0.276188,0.291359,0.353745,0.361778,1.49116,1.38067,1.57388,1.59264,-0.403052,-0.235714,0.273444,0.142876,1.814,1.83229,-0.616929,-0.508791,-0.213317,-0.245466,0.745834,0.666908,0.292508,0.354491,-0.521834,-0.632398
9515,0.62,0.559768,0.834312,0.807572,0.266492,0.299345,0.33133,0.332774,0.336892,0.376832,0.230725,0.28061,0.460246,0.386453,0.808564,0.705709,0.979641,0.993979,0.208249,0.311326,-1.27397,-1.3842,-0.0941016,-0.0756062,-0.452225,-0.319837,0.777068,0.642623,0.582463,0.593802,0.0030863,0.105424,0.399387,0.370324,-0.384564,-0.458163,0.261057,0.318438,-0.908327,-1.01744
9516,0.495031,0.417259,0.686458,0.6779,0.0284223,0.0609805,0.718984,0.721544,0.0345078,0.0742977,0.0698822,0.117991,0.563145,0.551155,0.98838,0.952574,0.830277,0.744537,0.252523,0.260874,1.314,1.20512,-0.608829,-0.592411,-0.472205,-0.403961,0.463572,0.329615,3.40621,3.41943,-0.873531,-0.774823,-0.159334,-0.0888081,-0.0443767,-0.112456,-0.280449,-0.228391,0.513763,0.401699
9517,0.333967,0.27475,0.573309,0.548228,0.446835,0.479209,0.769302,0.770474,0.579576,0.618667,0.462992,0.534152,0.367244,0.356207,0.0760294,0.0400196,0.482866,0.495095,0.843369,0.850008,-0.490007,-0.601419,1.50688,1.5155,0.667014,0.732877,-1.2666,-1.39501,2.13406,2.15002,0.155133,0.251576,-0.590876,-0.54794,1.56679,1.49168,2.35225,2.40676,-0.182201,-0.300309
9518,0.671102,0.61185,0.124656,0.0997721,0.288083,0.324887,0.61914,0.618352,0.778088,0.73156,0.902265,0.950313,0.814241,0.802354,0.278118,0.231621,0.977712,0.990838,0.166281,0.173922,0.260432,0.15622,-0.167191,-0.152749,0.247695,0.32038,0.626772,0.494543,1.50329,1.52489,-0.446622,-0.352358,-0.97801,-1.00707,0.063092,-0.0163118,0.444991,0.503181,-0.632719,-0.74616
9519,0.510601,0.448836,0.900189,0.87535,0.137273,0.170566,0.979484,0.976872,0.816598,0.844454,0.52132,0.584315,0.0765776,0.0647861,0.459186,0.423223,0.619001,0.631687,0.516634,0.577538,1.23356,1.12747,-0.502511,-0.487315,0.191175,0.259722,-1.12036,-1.25949,-0.845383,-0.829915,-0.34233,-0.245571,0.0930538,0.0654083,-0.94102,-1.01806,2.20015,2.26041,-0.167827,-0.253554
9520,0.656723,0.574377,0.395924,0.371952,0.441256,0.471813,0.0479691,0.0434805,0.916715,0.957347,0.168626,0.218317,0.188384,0.174798,0.8642,0.829668,0.958232,0.972408,0.975266,0.981155,-0.782765,-0.882899,0.708778,0.733057,1.43213,1.50274,0.349104,0.202981,-1.5237,-1.51294,-1.06617,-0.971999,0.372455,0.340969,1.13563,1.0531,0.281265,0.342239,0.357932,0.239053
9521,0.760607,0.699918,0.322553,0.315236,0.277881,0.256608,0.963911,0.958985,0.661852,0.682533,0.990959,1.03736,0.853604,0.838008,0.580546,0.551283,0.656531,0.696533,0.381212,0.385579,1.04345,0.93756,-0.241064,-0.215342,-0.470186,-0.399825,-0.161703,-0.303188,-1.47195,-1.4618,-2.78359,-2.6943,-0.503639,-0.535777,0.805121,0.725801,0.938031,1.00383,0.47705,0.352182
9522,0.570994,0.533585,0.282511,0.25852,0.0103376,0.0414027,0.505616,0.483841,0.368594,0.407719,0.576652,0.652109,0.958877,0.943121,0.171502,0.272899,0.37104,0.420658,0.671591,0.673684,0.736587,0.626028,1.20512,1.23285,0.407343,0.477384,-0.668066,-0.809357,0.689784,0.707082,0.0853095,0.172894,0.578435,0.552171,-0.894198,-0.967397,-1.65282,-1.58762,0.365229,0.179199
9523,0.427757,0.367252,0.89519,0.868853,0.270715,0.225884,0.0136234,0.0086974,0.45807,0.496242,0.220583,0.266861,0.0931155,0.0769902,0.026656,-0.00548485,0.130607,0.144783,0.138633,0.142229,0.800109,0.693127,-0.57985,-0.543795,0.128951,0.203647,-0.770583,-0.905147,0.00913289,0.0240556,0.502629,0.58456,-0.465069,-0.49544,-0.142642,-0.223319,0.514537,0.57527,0.133864,0.00621695
9524,0.551645,0.492639,0.417447,0.391416,0.469583,0.410364,0.761367,0.757159,0.00530338,0.0428526,0.437173,0.485575,0.897452,0.882462,0.513367,0.481411,0.17497,0.188255,0.360398,0.365342,-0.450677,-0.557671,0.826173,0.857813,0.279359,0.356128,-0.622768,-0.75439,-0.445465,-0.43463,-1.577,-1.49553,-2.08849,-2.11869,-0.29143,-0.36778,-0.202543,-0.140484,-0.470021,-0.589982
9525,0.134931,0.0772764,0.590792,0.565269,0.595953,0.594845,0.34272,0.34039,0.135366,0.24627,0.394354,0.443608,0.581648,0.651009,0.57059,0.53715,0.788655,0.799873,0.350433,0.355102,0.0739499,-0.0283736,1.0531,1.0896,-0.377219,-0.305865,0.647028,0.519443,-1.90312,-1.88822,-0.311095,-0.225395,-0.176894,-0.201959,1.22336,1.14097,1.39999,1.46031,-0.61985,-0.732718
9526,0.626843,0.568803,0.506462,0.481937,0.746605,0.779326,0.638868,0.63566,0.412366,0.449688,0.801366,0.853261,0.434543,0.419556,0.119735,0.0863275,0.62903,0.641456,0.135433,0.139802,-0.990389,-1.09587,0.580554,0.617801,1.41791,1.49241,-1.47652,-1.59916,-0.607649,-0.59471,1.90029,1.99246,-1.4901,-1.51474,0.656538,0.569353,-0.352659,-0.297928,-0.227151,-0.335984
9527,0.889017,0.830727,0.0931914,0.0682437,0.0410383,0.0750348,0.0879774,0.0830204,0.970111,1.00896,0.821381,0.875197,0.61801,0.600313,0.911479,0.879672,0.969765,0.982178,0.663074,0.669301,-0.922598,-1.02877,0.597067,0.633885,1.06132,1.10208,-0.506916,-0.635228,0.275949,0.284369,-1.09568,-0.998637,-0.750278,-0.710872,0.346168,0.256022,1.48109,1.53836,-1.19942,-1.30911
9528,0.381924,0.325234,0.873861,0.849338,0.858115,0.890123,0.808414,0.801634,0.0244242,0.0626063,0.217444,0.270177,0.4561,0.436496,0.650161,0.617837,0.431849,0.525244,0.35961,0.404445,0.35455,0.250905,0.130501,0.162084,0.630508,0.711759,1.33082,1.20719,-0.599884,-0.587181,-0.0161327,0.0741531,0.113773,0.0929992,0.55072,0.463626,-0.620312,-0.569303,-0.117025,-0.226775
9529,0.696315,0.641735,0.710948,0.743768,0.221047,0.251958,0.424765,0.493572,0.224596,0.363387,0.70339,0.75732,0.550346,0.46602,0.6626,0.628116,0.0553936,0.0683096,0.131926,0.139589,0.651827,0.550358,-2.37067,-2.34559,-0.0743135,-0.0278073,0.443296,0.32078,-1.22822,-1.21231,-1.10892,-1.02177,1.09926,1.0767,-0.120126,-0.203634,-0.926926,-0.87005,0.761323,0.656292
9530,0.109046,0.0555473,0.651057,0.638197,0.312215,0.343075,0.194538,0.18551,0.62467,0.664168,0.426821,0.479532,0.514696,0.495544,0.38859,0.312031,0.990473,1.00236,0.0942066,0.101071,0.483563,0.388248,0.0865825,0.116846,-0.848624,-0.767373,-2.17536,-2.29787,0.124835,0.140304,0.316558,0.399943,-1.88639,-1.9121,0.209089,0.128252,-0.8959,-0.843414,-0.9461,-1.05376
9531,0.758928,0.707092,0.558648,0.532626,0.702331,0.734994,0.246939,0.206389,0.208461,0.245129,0.727451,0.780924,0.182684,0.16514,0.0324522,-0.00405406,0.328784,0.341835,0.480335,0.523582,1.08001,0.97784,1.12068,1.14792,1.20077,1.28009,-0.220497,-0.344437,-0.889754,-0.869282,0.947917,1.02828,0.108623,0.0791181,-0.976956,-1.05697,-0.439408,-0.38491,1.48921,1.38998
9532,0.727276,0.675809,0.226737,0.20237,0.716052,0.747,0.144256,0.227269,0.30408,0.340021,0.25712,0.310848,0.554021,0.536799,0.959952,0.92255,0.874479,0.886772,0.939119,0.946093,-0.0809787,-0.180029,-0.328057,-0.301136,-0.211756,-0.125867,0.241471,0.111285,0.142763,0.164185,-0.262927,-0.186755,-1.4542,-1.48444,2.22969,2.15413,-1.32865,-1.27285,-0.261544,-0.365373
9533,0.385178,0.335574,0.875335,0.852406,0.18686,0.218526,0.257176,0.248148,0.073093,0.108457,0.201732,0.257992,0.0600113,0.0409959,0.530216,0.471648,0.335137,0.347169,0.00180413,0.00815603,0.120057,0.0232414,-0.0759257,-0.053814,1.89316,1.97216,-1.35662,-1.48506,0.97396,0.997428,1.23367,1.31259,0.0398908,0.00736175,0.492743,0.412347,-0.118509,-0.0641322,0.777641,0.670288
9534,0.581931,0.531544,0.800693,0.778493,0.504467,0.535239,0.440044,0.428991,0.296773,0.371694,0.283835,0.205136,0.487272,0.467628,0.0573285,0.0207468,0.541052,0.553876,0.166417,0.118216,1.14083,1.04015,-0.148118,-0.128279,-0.773919,-0.697954,0.201655,0.0724345,0.857899,0.874794,0.213229,0.294133,0.808152,0.774459,-0.775165,-0.851479,0.183219,0.238774,0.681597,0.572524
9535,0.980023,0.929309,0.482592,0.449878,0.253957,0.285814,0.976938,0.966463,0.599893,0.634931,0.114106,0.152281,0.197071,0.175895,0.990041,0.953154,0.401496,0.415473,0.221317,0.228275,0.901474,0.70015,-0.591228,-0.56931,0.183247,0.255982,0.0687742,-0.0538406,-1.6614,-1.64787,-1.16752,-1.07981,-1.27681,-1.30576,-0.343212,-0.413956,-0.514036,-0.461797,-0.98186,-1.08877
9536,0.137313,0.0869818,0.142824,0.121263,0.337894,0.315888,0.344731,0.334247,0.386155,0.423134,0.0456969,0.0994247,0.64311,0.622041,0.913509,0.876447,0.701555,0.715424,0.0856319,0.0937016,0.463389,0.360147,-0.471976,-0.446057,0.100455,0.180228,-0.958459,-1.07839,-1.26931,-1.25947,1.09886,1.1873,-0.597693,-0.601083,0.411597,0.34496,-1.53009,-1.47823,-0.62966,-0.736836
9537,0.707896,0.658443,0.473144,0.452129,0.237131,0.345963,0.824399,0.811738,0.855199,0.890954,0.515199,0.567023,0.304428,0.282004,0.376591,0.34035,0.295321,0.310315,0.158069,0.165729,-0.497901,-0.598753,-0.0466117,0.0679145,0.870311,0.948918,-1.1689,-1.28112,2.13743,2.14973,0.898101,1.00342,0.12531,0.10359,0.492847,0.42955,1.89506,1.94386,0.409542,0.298825
9538,0.0652384,0.0170537,0.20975,0.185885,0.34648,0.376037,0.887039,0.875432,0.671618,0.708637,0.0286317,0.0823046,0.696576,0.673055,0.91331,0.878121,0.166384,0.183346,0.552003,0.478541,-0.824021,-0.924418,0.562761,0.581886,-0.220048,-0.147798,1.85044,1.74647,-0.237479,-0.221606,0.72547,0.819544,0.149635,0.134492,1.2122,1.14416,0.367507,0.409449,0.199687,0.0863712
9539,0.812175,0.765708,0.29349,0.219848,0.844065,0.874355,0.696981,0.683834,0.792026,0.828032,0.673221,0.72873,0.0151513,-0.00879974,0.392831,0.357023,0.936883,0.954859,0.782289,0.791352,-1.35443,-1.45233,1.06994,1.09586,0.143978,0.207373,0.247346,0.150129,1.22248,1.23939,-1.24996,-1.15313,0.605754,0.595358,0.096001,0.034652,-1.41666,-1.3807,-0.0162444,-0.126082
9540,0.507277,0.461048,0.279851,0.253812,0.836701,0.865825,0.0308825,0.0162666,0.0713229,0.106127,0.0946125,0.148967,0.77198,0.746406,0.723283,0.688881,0.730453,0.747226,0.387278,0.396075,-0.0725525,-0.172659,-0.493864,-0.461981,0.486878,0.562545,-1.08267,-1.18252,-0.222235,-0.198029,-0.538313,-0.433939,3.37451,3.374,0.00687261,-0.0492966,1.2765,1.31571,-0.761426,-0.872709
9541,0.565786,0.524939,0.785552,0.761365,0.429116,0.456193,0.518345,0.504731,0.834242,0.87018,0.214222,0.268585,0.831456,0.80538,0.360108,0.326744,0.911595,0.928572,0.884648,0.894706,2.20312,2.10937,-0.705089,-0.674095,1.58544,1.66619,-0.0872197,-0.185306,0.780323,0.803827,-1.11548,-1.00443,0.0493936,0.0420504,-0.622512,-0.684883,-1.91313,-1.87435,2.11397,2.00634
9542,0.536176,0.58883,0.130133,0.105091,0.534727,0.587841,0.266768,0.251272,0.312062,0.347166,0.912643,0.964975,0.284598,0.258525,0.434577,0.40316,0.701551,0.769999,0.452351,0.497005,-2.0652,-2.15866,-2.5815,-2.55179,0.523032,0.600335,0.527949,0.421588,0.462375,0.482624,0.155948,0.265705,0.0578238,0.0431632,-0.736705,-0.798733,-0.141635,-0.101406,0.151462,0.0487488
9543,0.681966,0.652721,0.954075,0.928066,0.692215,0.719489,0.0101148,-0.00218762,0.0501248,0.084862,0.844587,0.896895,0.142622,0.118773,0.0315431,0.00213888,0.594931,0.611426,0.0892456,0.0993041,1.18954,1.09765,0.619578,0.654497,0.182817,0.264591,0.478909,0.371896,0.465493,0.488461,-0.735563,-0.631835,-0.427709,-0.500616,-1.17926,-1.24809,-0.445873,-0.358933,0.963954,0.857013
9544,0.602162,0.716612,0.158708,0.134328,0.586961,0.613445,0.887568,0.877106,0.0858325,0.121792,0.096515,0.146767,0.420438,0.487958,0.943805,0.915375,0.0385548,0.056932,0.484588,0.440974,0.214465,0.124066,0.207212,0.244016,-2.53769,-2.45686,0.167439,0.0588872,-0.144961,-0.122163,0.320939,0.426557,-1.03033,-1.04439,-1.34569,-1.49329,-0.654087,-0.61646,0.518257,0.411162
9545,0.826732,0.780503,0.819757,0.793663,0.861552,0.889384,0.997904,0.985996,0.500971,0.507679,0.316838,0.342982,0.881363,0.857143,0.983171,0.955694,0.0841661,0.0403878,0.772476,0.782644,0.249704,0.076324,1.36311,1.39705,-1.18889,-1.10754,-1.19333,-1.30392,1.09869,1.12694,-0.392094,-0.284819,1.26709,1.25706,-1.67327,-1.7385,0.989226,1.03253,2.05806,1.95244
9546,0.535966,0.57624,0.0143146,-0.0109896,0.703619,0.821138,0.713397,0.703046,0.8563,0.893565,0.478131,0.539197,0.113727,0.091286,0.365003,0.339357,0.0062062,0.0238437,0.455583,0.466876,0.11185,0.0285818,0.61172,0.648657,1.08031,1.16816,-0.368822,-0.480458,1.2113,1.23863,1.4378,1.54092,-0.390664,-0.399583,1.72219,1.66237,-0.538575,-0.501887,-0.945128,-1.05037
9547,0.340902,0.371977,0.116468,0.093014,0.726326,0.752892,0.650236,0.640466,0.142147,0.17798,0.685841,0.735412,0.571465,0.547166,0.92383,0.897256,0.809791,0.825591,0.623745,0.633812,0.852475,0.769855,0.701198,0.741163,0.12825,0.179158,0.019449,-0.127515,-0.405773,-0.384505,1.22308,1.32528,0.762436,0.75589,-0.177991,-0.235253,-0.108494,-0.0743993,1.12448,1.01743
9548,0.212994,0.167715,0.605683,0.580713,0.167047,0.194045,0.253622,0.243621,0.0190177,0.0561331,0.572399,0.62205,0.631476,0.606141,0.401266,0.376158,0.536239,0.551697,0.377205,0.388501,0.295062,0.211287,0.147807,0.268523,-0.897696,-0.809843,0.328959,0.225427,0.951091,0.968105,0.196036,0.292443,-0.800217,-0.807668,-0.902983,-0.963797,0.886403,0.917086,0.23004,0.119643
9549,0.842637,0.798397,0.788502,0.71711,0.017219,0.0421472,0.0998382,0.0914991,0.204516,0.241191,0.959423,1.01138,0.365838,0.34018,0.152549,0.128161,0.726809,0.714929,0.450659,0.460529,1.07287,0.983116,-0.237336,-0.204116,-0.604114,-0.517771,0.0731242,-0.0262952,-1.15621,-1.13249,-0.528357,-0.433986,0.478881,0.468561,-0.521261,-0.585086,-0.175383,-0.144358,2.62889,2.51115
9550,0.256626,0.212209,0.877443,0.853506,0.537259,0.561053,0.532712,0.524915,0.719488,0.755312,0.202016,0.251829,0.359027,0.398408,0.201975,0.178176,0.8643,0.87816,0.0437542,0.0541378,-2.00917,-2.10052,0.408697,0.44409,-2.00384,-1.92373,1.75692,1.65675,-0.497527,-0.468059,-0.432871,-0.342582,-0.895465,-0.904503,1.0736,1.00171,-0.354645,-0.321931,-1.01235,-1.12333
9551,0.346656,0.303256,0.0616231,0.0388898,0.275541,0.301054,0.467799,0.457975,0.661109,0.695464,0.846333,0.898255,0.481299,0.456635,0.784396,0.761588,0.203088,0.21764,0.617539,0.628221,-0.021211,-0.112064,0.195496,0.231977,-1.25918,-1.18573,-0.139503,-0.24106,-1.44869,-1.41614,1.36576,1.4505,-1.08012,-1.08623,-0.345301,-0.414882,-1.96146,-1.93372,-0.0224336,-0.13369
9552,0.739626,0.696204,0.471078,0.448974,0.955937,0.98077,0.912377,0.901385,0.183999,0.216509,0.979291,1.03342,0.748413,0.723052,0.0932157,0.0686788,0.970338,0.984046,0.453425,0.394648,1.36887,1.27666,1.78253,1.82201,0.646195,0.721878,0.945214,0.845496,0.0854437,0.121481,0.649757,0.739123,0.804025,0.798478,-0.286021,-0.361895,1.88873,1.91505,-0.222697,-0.353665
9553,0.495798,0.358607,0.267045,0.244029,0.657251,0.768818,0.900659,0.896786,0.0209906,0.0551432,0.745989,0.809952,0.706457,0.679688,0.938757,0.913804,0.408919,0.424199,0.148248,0.161075,-0.34976,-0.449706,0.815398,0.857365,-0.477669,-0.407058,-0.611016,-0.717635,-0.594141,-0.561546,1.25929,1.35334,-0.255514,-0.264129,-0.76119,-0.842125,-0.908258,-0.876291,-0.463778,-0.57364
9554,0.0628746,0.02101,0.476604,0.351302,0.543385,0.556867,0.901132,0.892187,0.644679,0.67933,0.516044,0.586482,0.386932,0.359121,0.142325,0.11712,0.860717,0.873808,0.736293,0.750209,0.775984,0.672059,-2.49804,-2.46217,-0.873515,-0.803847,-0.817818,-0.920368,-0.194526,-0.157993,-1.1923,-1.10393,-1.80305,-1.81316,0.812101,0.730068,-0.382105,-0.353838,1.1499,1.04732
9555,0.173672,0.131719,0.492765,0.458574,0.213744,0.344915,0.519955,0.509841,0.913546,0.945643,0.30768,0.363013,0.550456,0.524678,0.993441,0.967353,0.27033,0.28476,0.672558,0.685934,0.164943,0.0675736,-0.409043,-0.373915,-0.233632,-0.158979,-0.249994,-0.402031,-0.226313,-0.184877,0.748896,0.840662,0.607284,0.601282,-0.163392,-0.279674,0.753479,0.77644,2.28083,2.17468
9556,0.729482,0.688267,0.588745,0.565847,0.10813,0.132964,0.606805,0.597974,0.558458,0.592126,0.626516,0.68312,0.486564,0.460548,0.776338,0.750266,0.625821,0.641083,0.40523,0.496513,0.123614,0.0283389,0.157775,0.19623,-0.70154,-0.631462,0.218857,0.116306,2.27569,2.30973,-0.118748,-0.0237245,0.131227,0.124161,-1.20526,-1.28942,0.76694,0.785753,1.30182,1.20155
9557,0.466065,0.424765,0.996046,0.971521,0.587339,0.611146,0.458622,0.450241,0.910995,0.944154,0.228983,0.286444,0.854314,0.82743,0.767402,0.74027,0.413981,0.367802,0.294182,0.307092,-0.89411,-0.993567,0.080725,0.121765,1.36903,1.43401,1.79639,1.69063,-2.21372,-2.17968,-0.599536,-0.502785,0.749775,0.739951,1.0429,0.96443,-0.519067,-0.499978,-0.7429,-0.846522
9558,0.760654,0.722075,0.492134,0.468122,0.211033,0.236311,0.605543,0.595285,0.225555,0.25812,0.367602,0.477593,0.353219,0.326392,0.0508106,0.0257912,0.0795139,0.0945205,0.656661,0.66722,-0.84873,-0.942897,0.928461,0.966902,0.61835,0.679786,0.339611,0.188943,-0.466787,-0.4276,-0.483291,-0.374283,0.234284,0.216775,0.644514,0.560672,-1.80452,-1.78571,0.620885,0.512135
9559,0.273169,0.235481,0.986943,0.96117,0.760466,0.783796,0.00514351,-0.00354823,0.760162,0.791882,0.612249,0.668743,0.767251,0.737918,0.0448144,0.0209928,0.207611,0.22389,0.108282,0.120456,-0.501039,-0.601177,0.545214,0.585235,1.49995,1.55699,-1.20699,-1.31275,-0.173722,-0.132139,-0.343994,-0.245782,-0.505323,-0.520626,0.973194,0.892558,0.399921,0.412594,-1.23488,-1.35095
9560,0.447495,0.410888,0.854869,0.855874,0.0781748,0.0994995,0.792714,0.786469,0.4973,0.581463,0.559436,0.616561,0.969927,0.939514,0.75367,0.728362,0.83221,0.850278,0.766916,0.77884,-0.878984,-0.974917,-0.481124,-0.442565,0.498886,0.651719,1.23044,1.13026,-1.37543,-1.33689,0.703499,0.796682,0.604223,0.583725,0.182106,0.16362,0.284829,0.216469,0.203508,0.0846902
9561,0.172283,0.137038,0.775658,0.750579,0.727172,0.748392,0.897174,0.890869,0.224244,0.371044,0.720832,0.776031,0.878388,0.835314,0.449271,0.422021,0.909391,0.92829,0.838915,0.814034,1.90088,1.81266,0.0210575,0.0669869,-0.306441,-0.253558,-0.187808,-0.281378,0.0355633,0.0785122,-1.04219,-0.941985,-0.541731,-0.556281,-0.490131,-0.565319,0.00141491,0.0203434,-1.20017,-1.31793
9562,0.652721,0.618354,0.387504,0.454521,0.730537,0.695898,0.588506,0.501213,0.131377,0.160626,0.404221,0.456782,0.624031,0.731114,0.958986,0.934016,0.0574768,0.0740586,0.838495,0.849227,0.782903,0.698997,-2.33247,-2.28137,1.1175,1.17078,0.327832,0.233712,-0.574426,-0.532111,-1.17505,-1.08131,-0.699382,-0.706378,-2.10874,-2.18106,-0.371714,-0.356034,-0.308334,-0.41937
9563,0.314609,0.278118,0.181398,0.158463,0.539349,0.643404,0.116641,0.111557,0.784291,0.815803,0.857757,0.910103,0.659049,0.626913,0.671246,0.647069,0.748632,0.765612,0.281305,0.293417,1.26735,1.18317,-0.617099,-0.569126,-1.83603,-1.78458,-0.245957,-0.34086,0.218806,0.256077,-0.251384,-0.162812,0.803267,0.801774,-1.55908,-1.63487,0.412568,0.429852,-1.11998,-1.22651
9564,0.679508,0.602778,0.626081,0.602253,0.433449,0.590911,0.851404,0.844032,0.587849,0.618682,0.885939,0.978812,0.237576,0.205891,0.94796,0.923331,0.860278,0.875193,0.268206,0.279219,1.41876,1.34113,1.77219,1.81439,0.270771,0.327724,-0.575352,-0.668541,-0.918113,-0.874249,0.909992,1.00208,-0.433511,-0.431151,0.782352,0.706169,0.62771,0.638094,-0.115086,-0.220475
9565,0.966246,0.927438,0.543372,0.518922,0.518389,0.538417,0.479314,0.472114,0.985665,1.0164,0.995691,1.04752,0.777939,0.747546,0.0770263,0.0514218,0.161824,0.174787,0.637526,0.649159,0.990536,0.906781,0.0588939,0.101218,-0.102537,-0.0390847,0.387654,0.295386,0.557354,0.60253,-1.9219,-1.83291,2.63561,2.64613,1.84843,1.77433,0.264862,0.276258,-0.888194,-0.99826
9566,0.0174085,-0.020691,0.911025,0.888634,0.16029,0.178795,0.704042,0.697084,0.479582,0.508205,0.53719,0.564213,0.528915,0.496723,0.581056,0.552655,0.508603,0.521163,0.58151,0.595207,-1.8313,-1.91704,-0.492455,-0.448422,1.18204,1.24802,1.8963,1.80377,-0.881905,-0.834889,-0.250512,-0.161679,0.189268,0.199097,-0.532881,-0.606998,-2.11629,-2.10797,-0.307977,-0.417592
9567,0.26169,0.22994,0.434443,0.411197,0.0744364,0.0929294,0.455503,0.389022,0.400161,0.428035,0.027991,0.0809052,0.931117,0.89866,0.195822,0.166183,0.100582,0.112248,0.809813,0.822988,-0.982492,-1.06968,-1.29942,-1.257,-0.768376,-0.704211,0.475368,0.377998,1.95579,2.00979,1.02731,1.10845,-2.70229,-2.68907,-0.105171,-0.192913,0.413757,0.415828,1.40443,1.29466
9568,0.442926,0.480572,0.283568,0.257701,0.603229,0.621464,0.0856138,0.0809595,0.569812,0.598562,0.177518,0.230701,0.668245,0.634089,0.337884,0.290465,0.629032,0.641841,0.582051,0.598351,0.507175,0.413951,-0.0628575,-0.00902609,-0.345834,-0.287939,-0.334385,-0.357846,1.2206,1.27698,-0.0500001,0.0292812,-0.436512,-0.420623,0.288046,0.221172,0.784937,0.781453,-0.862061,-0.973487
9569,0.769303,0.731203,0.715284,0.687271,0.411098,0.455897,0.618735,0.613583,0.186959,0.214874,0.798733,0.85146,0.400156,0.369517,0.483807,0.414746,0.0958925,0.107793,0.362903,0.373714,-0.12575,-0.221984,1.18863,1.23895,0.0598978,0.128334,-0.998356,-1.09369,0.953925,1.01612,-0.229486,-0.154506,0.468552,0.484152,-0.780383,-0.841161,-0.267332,-0.265947,-0.230077,-0.346912
9570,0.507403,0.467701,0.478816,0.452769,0.272915,0.29033,0.671649,0.667816,0.666549,0.692784,0.21361,0.266507,0.365009,0.335464,0.669965,0.539027,0.891657,0.904699,0.778709,0.787494,-1.62978,-1.7315,-0.299854,-0.255935,-0.407476,-0.344149,0.992694,0.890395,0.347922,0.39455,1.06345,1.13119,-0.355793,-0.341893,-0.316702,-0.372631,-0.43293,-0.428222,-0.419156,-0.536201
9571,0.601074,0.563286,0.775328,0.749376,0.433412,0.451599,0.346166,0.34033,0.212581,0.239394,0.163803,0.214325,0.752788,0.722216,0.692947,0.663309,0.0193241,0.0342093,0.753008,0.789151,0.574656,0.474602,-0.861508,-0.821164,-0.46084,-0.404807,1.10895,1.00913,-0.289186,-0.22702,-0.186384,-0.201298,1.1623,1.18244,-0.241722,-0.303377,0.459567,0.466826,-0.0546723,-0.168305
9572,0.473361,0.434729,0.0590487,0.0344717,0.802895,0.818919,0.505706,0.499954,0.385459,0.347259,0.660607,0.711805,0.315026,0.34652,0.221372,0.192286,0.199088,0.22061,0.78213,0.790809,-2.73034,-2.83611,-1.05443,-1.01874,-1.03466,-0.97138,-0.695637,-0.789049,0.0101947,0.0684417,-1.5974,-1.53379,1.61318,1.62934,0.0539885,-0.00408835,0.753473,0.800544,1.06738,0.959053
9573,0.813644,0.776678,0.281613,0.306777,0.879762,0.895391,0.289968,0.28243,0.400933,0.455123,0.299638,0.350079,0.00180485,-0.0291766,0.952103,0.924833,0.393648,0.40701,0.445309,0.446043,-0.0564993,-0.161049,-0.359276,-0.326533,-0.608368,-0.542415,1.287,1.19504,-1.13474,-1.07522,-1.18843,-1.12212,-0.194187,-0.184626,0.947452,0.892687,1.13134,1.13426,-2.05528,-2.16406
9574,0.724615,0.689703,0.606811,0.579083,0.131367,0.14536,0.829997,0.819902,0.537587,0.562988,0.435882,0.485245,0.813846,0.781672,0.22818,0.200123,0.345121,0.357442,0.0922233,0.101278,-1.76117,-1.87223,-2.35396,-2.32166,-1.21499,-1.15849,1.11977,1.02154,-0.883526,-0.824505,1.24864,1.3115,-0.280194,-0.273945,-0.0704257,-0.125415,0.779673,0.786325,1.1351,1.0226
9575,0.895534,0.860552,0.059602,0.0323625,0.198823,0.211995,0.66715,0.657038,0.283956,0.305622,0.947798,0.998057,0.33197,0.300048,0.992521,0.962555,0.643422,0.653574,0.419262,0.430156,-0.775684,-0.88764,-0.953548,-0.920053,-1.83968,-1.77456,-1.91697,-2.0086,0.807232,0.866317,0.588172,0.645439,2.24064,2.24835,1.68194,1.63433,2.06407,2.07249,-0.948228,-1.05706
9576,0.406917,0.369497,0.986959,0.958126,0.918002,0.931992,0.0326093,0.0248221,0.023826,0.0482552,0.835349,0.884695,0.750065,0.71682,0.844236,0.806972,0.399543,0.410384,0.282024,0.295583,0.724896,0.611489,0.83113,0.870866,1.06175,1.13564,1.44049,1.34816,-1.16493,-1.09995,0.390668,0.445495,0.582176,0.591699,1.03676,0.983393,-0.270827,-0.263229,0.582039,0.470447
9577,0.992197,0.955127,0.693094,0.585251,0.846424,0.761736,0.968142,0.959054,0.33816,0.417188,0.383571,0.433388,0.85768,0.826831,0.597655,0.651389,0.874738,0.885831,0.525355,0.538676,0.861468,0.754163,1.40405,1.44101,-1.57312,-1.50756,-0.19944,-0.295739,0.59117,0.652121,1.99916,2.05443,0.584232,0.592811,-0.0789965,-0.12611,1.21924,1.229,-0.914894,-1.0219
9578,0.693463,0.655496,0.243225,0.212376,0.578992,0.59148,0.663625,0.656623,0.76264,0.78612,0.658533,0.695628,0.436212,0.422622,0.423955,0.495807,0.710585,0.723038,0.978825,0.993135,0.0334202,-0.0671885,-0.226959,-0.195205,0.924448,0.984787,-0.391853,-0.485527,-1.66176,-1.60629,1.47139,1.52943,-1.3617,-1.34743,-0.564181,-0.60634,0.136247,0.151542,0.197567,0.0899172
9579,0.0734305,0.0347796,0.754535,0.724816,0.727467,0.738352,0.821367,0.816246,0.188255,0.212782,0.906977,0.957868,0.0475871,0.0184132,0.37019,0.340224,0.94398,0.955033,0.373667,0.387085,-0.144065,-0.332426,-0.75863,-0.728639,-2.06994,-2.00263,-0.089327,-0.181665,-0.154728,-0.0986011,-0.707191,-0.645644,0.387799,0.408795,0.514827,0.475316,-1.38581,-1.36664,0.513661,0.412793
9580,0.0140292,-0.0265928,0.477896,0.449469,0.564502,0.576422,0.441407,0.511522,0.62756,0.650539,0.836728,0.885173,0.386323,0.452142,0.513123,0.481622,0.617752,0.63049,0.941734,0.955481,-0.4934,-0.597663,-0.200621,-0.175151,1.20091,1.26893,1.25021,1.15267,0.312126,0.365516,-0.782082,-0.72338,1.56994,1.59356,-0.170086,-0.206823,-1.89044,-1.86793,-0.769115,-0.868372
9581,0.531571,0.398524,0.694139,0.556742,0.120813,0.131931,0.210898,0.206797,0.260685,0.281769,0.0627079,0.109401,0.915044,0.88587,0.410963,0.396882,0.0246898,0.0362573,0.965449,0.97767,-1.59649,-1.6958,0.626121,0.656671,0.427953,0.566274,1.00985,0.918554,-1.11072,-1.0571,-0.577474,-0.486964,0.59409,0.623918,0.688642,0.645325,-1.00207,-0.986999,-1.28879,-1.38999
9582,0.864263,0.823641,0.738173,0.664014,0.736377,0.745539,0.188698,0.130332,0.83599,0.856062,0.165412,0.213557,0.25367,0.224176,0.214441,0.312143,0.989031,1.00205,0.0629401,0.0772067,0.26417,0.170851,-0.840978,-0.809078,-0.211957,-0.136381,-0.674147,-0.757853,0.546063,0.602286,-0.313264,-0.250549,0.883366,1.00055,-1.67158,-1.71957,1.4548,1.46876,1.57153,1.47056
9583,0.274569,0.232992,0.797491,0.771287,0.0857226,0.0967382,0.0593924,0.053868,0.258936,0.277494,0.531674,0.577876,0.558396,0.531129,0.270637,0.227404,0.997854,0.961642,0.298065,0.405322,0.00831251,-0.0851935,1.03215,1.05987,-0.404247,-0.333974,1.4762,1.3975,-0.570972,-0.512323,0.830946,0.8965,1.3547,1.37719,-0.492351,-0.546009,-0.378556,-0.368375,-0.307578,-0.406737
9584,0.0539493,0.0137576,0.655136,0.627581,0.929973,0.939191,0.82226,0.817267,0.433879,0.45258,0.234993,0.360658,0.307157,0.317403,0.174166,0.142664,0.910118,0.92123,0.720811,0.733437,-0.247919,-0.341238,1.809,1.8298,0.750115,0.815756,0.703344,0.621128,-0.120342,-0.0645528,-0.569871,-0.50747,-0.143617,-0.122462,0.241754,0.185306,1.25348,1.26327,-0.361843,-0.459956
9585,0.773561,0.734549,0.794775,0.697054,0.8458,0.83404,0.983536,0.902965,0.0954503,0.115372,0.0949111,0.143441,0.131622,0.103677,0.859457,0.82845,0.31141,0.321428,0.583072,0.593666,-1.33462,-1.42273,0.605549,0.633291,-1.79949,-1.74131,-1.12804,-1.21246,-0.619848,-0.56868,1.5569,1.61351,-0.215958,-0.197774,0.00589083,-0.0505483,-0.848173,-0.844396,0.752442,0.651857
9586,0.599086,0.509046,0.793547,0.766528,0.71803,0.72889,0.995255,0.988664,0.318027,0.336051,0.0285143,0.0753615,0.237399,0.20879,0.681468,0.651612,0.541869,0.476546,0.673054,0.676733,-0.0178767,-0.113667,-0.205486,-0.175285,0.929676,0.981973,-0.461657,-0.543073,-0.518708,-0.470911,-0.445605,-0.389449,0.892125,0.906578,0.60659,0.555914,0.511799,0.511089,-0.176096,-0.277776
9587,0.321287,0.283543,0.550118,0.613944,0.160935,0.170043,0.932909,0.926083,0.816501,0.833977,0.415249,0.43564,0.0815138,0.0542981,0.926795,0.897168,0.623685,0.631664,0.747169,0.759801,1.94685,1.84493,1.6227,1.64653,1.79166,1.84227,-0.0870015,-0.164642,1.23756,1.28116,0.510745,0.560383,-2.15607,-2.14184,0.037128,-0.0118819,-0.0692216,-0.0673809,0.635236,0.530488
9588,0.550189,0.510099,0.486775,0.46136,0.45262,0.412496,0.278753,0.273762,0.40222,0.419905,0.749963,0.795918,0.302387,0.275378,0.511575,0.480676,0.486801,0.521151,0.452255,0.454977,0.632563,0.534886,-0.465226,-0.443004,-0.264252,-0.220373,0.631511,0.551566,-1.51905,-1.47421,-0.128398,-0.0751571,0.717623,0.740029,-0.53272,-0.579678,0.0489768,0.0492177,0.412547,0.310295
9589,0.450731,0.41266,0.333329,0.308776,0.645131,0.654949,0.33636,0.332118,0.283752,0.279629,0.616737,0.726368,0.900254,0.871371,0.929332,0.897244,0.40151,0.410638,0.135469,0.150153,-1.35503,-1.45797,1.10313,1.13217,1.74894,1.79669,0.695417,0.609952,0.794498,0.832351,-1.50312,-1.4491,-1.00077,-0.979486,-0.273735,-0.323896,-0.408846,-0.485697,-0.306927,-0.418488
9590,0.82925,0.790736,0.956088,0.92926,0.528944,0.538407,0.0861851,0.0841841,0.122144,0.139353,0.564863,0.656819,0.806854,0.82216,0.104226,0.0740265,0.999926,1.00711,0.979449,0.994139,0.617212,0.513877,1.45735,1.48737,-0.982213,-0.940606,-1.19598,-1.28786,0.19219,0.310508,-0.29454,-0.238809,0.0637876,0.0795262,0.896307,0.849664,-1.01919,-1.02061,-1.04055,-1.14727
9591,0.51596,0.475741,0.82519,0.800128,0.904049,0.915806,0.2549,0.254318,0.60892,0.627684,0.585866,0.587269,0.800607,0.772948,0.789096,0.759812,0.663357,0.673274,0.488664,0.503461,-0.455947,-0.553616,0.299808,0.336473,0.110836,0.148829,0.123399,0.0303603,-0.253884,-0.211335,2.52997,2.58275,0.627652,0.649496,-0.98611,-1.0348,1.61043,1.60206,0.606814,0.502021
9592,0.40781,0.36672,0.355736,0.331867,0.332961,0.347073,0.871647,0.872002,0.172823,0.189177,0.471764,0.517719,0.0306999,0.00245493,0.197465,0.16849,0.594749,0.60293,0.406029,0.420261,-0.838983,-0.941736,0.631922,0.661308,-1.03732,-0.994086,0.0808628,-0.019332,-0.445351,-0.410148,-0.727638,-0.669662,-0.949268,-0.930716,0.506531,0.459083,1.16445,1.16216,0.435796,0.328039
9593,0.957781,0.917738,0.208424,0.270778,0.922399,0.935443,0.263688,0.264018,0.45725,0.408052,0.900389,0.946706,0.212431,0.183212,0.580598,0.515413,0.186846,0.194015,0.601192,0.617554,0.53917,0.430636,-1.8551,-1.82883,-0.118478,-0.0726715,1.97846,1.88573,0.00400563,0.0376225,1.05741,1.11034,-2.04432,-2.02311,-0.119916,-0.247111,-0.312106,-0.310371,1.38629,1.27296
9594,0.953547,0.913095,0.162003,0.20969,0.827476,0.886904,0.785166,0.786942,0.613036,0.626927,0.960204,1.00826,0.985882,0.959126,0.890135,0.862337,0.358311,0.3637,0.0411434,0.0564837,-1.75157,-1.85985,-0.163267,-0.131204,2.05,2.0884,-1.19697,-1.29785,1.39326,1.42369,1.528,1.58758,0.408856,0.423052,-0.837959,-0.953305,0.890261,0.898345,-1.93655,-2.05707
9595,0.0329293,-0.00823432,0.174249,0.148601,0.823759,0.838366,0.510188,0.513914,0.424181,0.408686,0.465781,0.51304,0.567053,0.538104,0.577191,0.55026,0.179639,0.248065,0.276082,0.289263,1.13118,1.02442,-0.851871,-0.817446,0.903042,0.945033,-0.454086,-0.54925,1.07812,1.10248,0.606643,0.661371,0.430236,0.437586,-1.61236,-1.6595,-0.0278224,-0.0231771,-1.11892,-1.16703
9596,0.653791,0.611954,0.779315,0.754042,0.0149604,0.0302906,0.937158,0.942599,0.178139,0.190445,0.922224,0.971271,0.832689,0.804521,0.502807,0.426644,0.125896,0.13243,0.119981,0.134055,-0.655754,-0.764198,-2.78124,-2.75373,-0.236728,-0.198333,-1.66783,-1.75996,1.41703,1.4448,-1.03886,-0.986933,-1.48666,-1.48493,-1.55311,-1.60651,1.39607,1.40696,-0.160237,-0.276994
9597,0.102244,0.0608179,0.368805,0.344635,0.534096,0.549196,0.80408,0.744191,0.624971,0.638648,0.51209,0.560266,0.55021,0.523604,0.328547,0.303028,0.670498,0.677367,0.946671,0.961949,0.459331,0.34331,0.15034,0.180914,-0.719169,-0.687229,-0.202814,-0.297487,-1.88357,-1.85587,0.264904,0.31372,0.0490666,0.0530297,0.214712,0.166218,1.02637,1.03058,-1.17122,-1.28078
9598,0.747824,0.70697,0.873146,0.847447,0.338193,0.312181,0.650499,0.545784,0.27191,0.352752,0.70963,0.676139,0.675346,0.648981,0.838668,0.815022,0.706242,0.711035,0.668323,0.620493,-0.975031,-1.09235,-0.764006,-0.735876,-0.927164,-0.902104,0.723665,0.635899,0.483748,0.51366,0.928113,0.971721,-0.569347,-0.561745,0.250771,0.205227,0.279245,0.252612,-0.705553,-0.807867
9599,0.62061,0.578413,0.12344,0.0969162,0.0583674,0.0751652,0.34163,0.347376,0.0522016,0.066857,0.824945,0.792013,0.471078,0.455186,0.564908,0.542489,0.25548,0.261237,0.265862,0.279037,0.985612,0.86624,-0.393555,-0.367215,-0.128697,-0.10308,-0.391243,-0.481913,-0.790903,-0.755755,0.223797,0.275159,-0.814944,-0.805423,-2.48191,-2.52582,-0.536805,-0.525359,-2.13484,-2.24204
9600,0.748499,0.708428,0.358283,0.334224,0.950732,0.967353,0.792722,0.800458,0.437111,0.521506,0.859709,0.907886,0.199102,0.261391,0.0783305,0.0563206,0.183307,0.190893,0.340598,0.354844,-1.45552,-1.56744,-1.11474,-1.08341,-1.95434,-1.92989,1.00804,0.913061,0.412265,0.446578,-0.00896439,0.137849,0.922404,0.935315,0.385297,0.346342,0.564957,0.574294,-1.34574,-1.44876
9601,0.231142,0.19301,0.218,0.195437,0.794138,0.81068,0.874845,0.793672,0.961499,0.976154,0.473327,0.564484,0.0944536,0.067596,0.936594,0.916727,0.452175,0.45752,0.884433,0.898975,-0.238972,-0.353155,-0.943225,-0.828859,0.541143,0.562458,-0.864962,-0.965454,-1.17805,-1.14388,-0.0476623,0.000539573,-0.591755,-0.58062,0.250677,0.217545,-0.275127,-0.265342,1.7035,1.60529
9602,0.883232,0.844554,0.868479,0.845474,0.896759,0.912003,0.77667,0.786887,0.856691,0.830203,0.170914,0.221082,0.945583,0.9194,0.214404,0.192017,0.929389,0.932967,0.196306,0.211821,0.191539,0.173856,-0.610775,-0.574313,-0.974608,-0.949394,-1.46431,-1.57097,-0.671712,-0.633467,-0.592808,-0.540966,1.75936,1.76749,0.512304,0.473327,1.77272,1.78528,0.343712,0.248188
9603,0.760236,0.811831,0.0683586,0.0478872,0.186256,0.202682,0.770033,0.780102,0.669597,0.684253,0.541503,0.529119,0.126419,0.102336,0.775645,0.754252,0.74513,0.749536,0.365093,0.378756,0.817422,0.700866,-2.1159,-2.08469,-0.0836964,-0.0575213,1.55172,1.43719,-0.469631,-0.429717,-2.34877,-2.29573,0.00185734,0.0160922,-1.42871,-1.4712,0.365723,0.376969,0.596467,0.494549
9604,0.816049,0.779108,0.0293964,0.00851543,0.194635,0.209873,0.243134,0.251858,0.922678,0.935768,0.785099,0.837156,0.701804,0.678837,0.977741,0.956092,0.184495,0.189689,0.275937,0.290803,2.17317,2.05831,-1.20379,-1.17724,-1.20474,-1.18646,-0.0612215,-0.175246,0.499675,0.543544,0.292065,0.3455,-1.97653,-1.95559,0.343507,0.301533,1.3857,1.39871,-0.465342,-0.570318
9605,0.528784,0.441511,0.347416,0.324949,0.853181,0.868866,0.417566,0.426912,0.549192,0.484133,0.555745,0.608695,0.715024,0.746016,0.843185,0.785003,0.619404,0.624588,0.708522,0.725436,0.277497,0.158509,0.190978,0.224366,-0.415366,-0.40375,0.0259775,0.000683148,-0.145811,-0.0468285,-0.256377,-0.210096,0.415301,0.443062,-0.849778,-0.899022,0.617894,0.634887,1.50799,1.40267
9606,0.142979,0.103915,0.0703485,0.0496026,0.882165,0.896153,0.00548505,0.0145922,0.0212912,0.0324981,0.870387,0.924272,0.847768,0.813195,0.786355,0.613913,0.0266395,0.0303557,0.421916,0.407632,0.896823,0.777684,-1.61462,-1.58609,-0.409993,-0.403775,0.286303,0.176612,-0.686635,-0.637201,-0.162171,-0.118693,-0.506959,-0.550131,0.283227,0.229891,0.259134,0.273051,-0.101799,-0.213461
9607,0.464159,0.425311,0.538704,0.517965,0.40732,0.421177,0.920352,0.930097,0.756082,0.76525,0.568313,0.620573,0.903341,0.880374,0.506778,0.442824,0.948821,0.954872,0.0737454,0.0898278,0.206204,0.0810631,-0.531161,-0.508444,-0.12831,-0.048604,1.00786,0.89282,0.206872,0.258541,-0.436017,-0.395606,-1.57737,-1.54332,-0.340106,-0.389143,-0.762274,-0.743381,-0.901828,-1.0206
9608,0.527405,0.495892,0.745613,0.662828,0.162268,0.176722,0.919133,0.853632,0.0252171,0.0337231,0.76821,0.819438,0.639383,0.555382,0.293383,0.271735,0.611155,0.615617,0.367154,0.382767,1.09969,0.976179,-0.985715,-0.965219,0.298391,0.306567,-2.88169,-2.99363,-1.15018,-1.10568,0.83647,0.874524,-0.0503001,-0.0189931,0.868514,0.814462,0.652724,0.671575,-0.229238,-0.285108
9609,0.472351,0.566472,0.82857,0.807692,0.119928,0.13245,0.7658,0.777168,0.798743,0.807894,0.261637,0.314064,0.252816,0.230389,0.80004,0.778739,0.784232,0.790585,0.0364254,0.0511872,1.14679,1.02685,0.25608,0.283569,0.125773,0.140153,0.766248,0.654307,1.10013,1.14696,1.70884,1.74631,0.173547,0.209187,-1.18506,-1.23766,0.839949,0.864137,0.568912,0.450388
9610,0.630222,0.637053,0.381244,0.359235,0.484355,0.508615,0.0854983,0.0951588,0.760853,0.769088,0.358363,0.41945,0.660847,0.637358,0.319775,0.297659,0.0310598,0.0376803,0.905833,0.920202,0.706356,0.592498,-0.233409,-0.202838,0.452966,0.462867,0.173767,0.0630631,-1.07738,-1.03316,-0.49135,-0.459552,0.740443,0.779156,0.388459,0.334531,-0.0218264,0.00789089,0.147881,0.0338216
9611,0.626956,0.707634,0.354987,0.279032,0.871804,0.884779,0.486546,0.494506,0.306104,0.315699,0.472722,0.524835,0.748457,0.726993,0.530016,0.446024,0.0319621,0.0377326,0.697685,0.782323,1.03657,0.92019,-1.17549,-1.15124,0.393208,0.402209,-0.939879,-1.05475,-0.0815427,-0.0313052,0.298457,0.33261,-1.61918,-1.57416,-0.60018,-0.651793,1.6195,1.65688,1.12938,1.00747
9612,0.817062,0.778214,0.175413,0.198829,0.696209,0.708411,0.378574,0.386882,0.164133,0.173868,0.282814,0.336355,0.560877,0.538009,0.72328,0.594389,0.590146,0.597499,0.63102,0.644443,1.01987,0.896716,-0.758644,-0.690771,0.755137,0.769675,-1.51828,-1.62932,1.31971,1.36922,0.450918,0.483147,0.223516,0.263405,0.401008,0.355185,0.176392,0.217517,-0.149118,-0.273696
9613,0.588803,0.549561,0.139157,0.118625,0.14913,0.159347,0.549364,0.557016,0.597578,0.574383,0.575288,0.559141,0.168879,0.146672,0.766919,0.742754,0.560085,0.567754,0.255442,0.268267,-0.0645969,-0.184775,-0.254561,-0.230306,-1.44434,-1.43733,2.83666,2.72562,1.0466,1.09449,-0.663001,-0.626456,-0.399913,-0.365373,-0.960234,-1.00089,-0.458512,-0.421777,0.991848,0.868891
9614,0.578204,0.540536,0.483265,0.438674,0.842572,0.854853,0.00290416,0.00919877,0.966063,0.974899,0.728426,0.781927,0.277344,0.256683,0.441145,0.416254,0.730086,0.737439,0.603354,0.617871,1.03582,0.922733,1.82861,1.85795,-0.762485,-0.760684,1.12855,1.01795,0.295242,0.347173,0.24563,0.27752,-0.0215375,0.0170723,-0.339053,-0.379368,0.405186,0.444513,-1.42938,-1.54882
9615,0.99479,0.958601,0.780662,0.758723,0.284792,0.296006,0.304894,0.309589,0.157377,0.164785,0.328153,0.380362,0.821239,0.802948,0.851464,0.827998,0.558868,0.564176,0.527716,0.543773,-0.0400218,-0.096077,0.317712,0.347579,0.311634,0.31455,0.924602,0.815213,0.230982,0.287535,-0.270219,-0.149262,0.908672,0.95394,-0.131656,-0.171764,-0.801961,-0.759635,-0.0609799,-0.176624
9616,0.91244,0.875561,0.604849,0.623329,0.057278,0.155707,0.924159,0.927272,0.801255,0.809686,0.78666,0.838593,0.372083,0.352108,0.375443,0.352493,0.62815,0.632601,0.917439,0.932776,-1.00733,-1.11489,-0.108914,-0.0769268,-1.08657,-1.07666,-1.19227,-1.30339,1.76607,1.82515,-0.612989,-0.576043,-0.0125674,0.0307199,1.47758,1.43237,0.56643,0.608447,0.907126,0.797023
9617,0.308834,0.270124,0.507586,0.487935,0.00223387,0.0154087,0.743984,0.745305,0.918676,0.929082,0.866434,0.919416,0.581948,0.563639,0.691776,0.668832,0.324449,0.32875,0.901738,0.918578,0.805281,0.691757,0.155598,0.186291,1.35869,1.36688,-0.112076,-0.21683,-0.683669,-0.63006,1.29298,1.32543,-0.412178,-0.367493,-2.59763,-2.64566,0.560106,0.60313,-1.28774,-1.39202
9618,0.11332,0.0762603,0.540527,0.595208,0.630365,0.643906,0.132351,0.132292,0.0910265,0.101185,0.427252,0.477862,0.160028,0.142617,0.0277232,0.00672766,0.537931,0.539346,0.488667,0.507106,0.366448,0.257406,1.39147,1.42085,-1.39014,-1.38608,0.143498,0.0395995,-1.02127,-0.967508,1.23458,1.26318,-1.44992,-1.39916,0.954306,0.899234,-0.111512,-0.0678223,0.676497,0.566366
9619,0.962171,0.923715,0.661607,0.70248,0.367712,0.379683,0.363769,0.362842,0.967679,0.975701,0.256027,0.305267,0.965034,0.948089,0.740126,0.718739,0.0379725,0.0395937,0.995402,1.01561,-1.12301,-1.23765,0.734812,0.842472,0.153179,0.159856,1.12879,1.02096,0.407032,0.463943,-1.55447,-1.52381,-0.362831,-0.311209,-0.49309,-0.547816,-0.22431,-0.181439,0.538199,0.423631
9620,0.014955,-0.0244139,0.831745,0.809753,0.600102,0.609334,0.845028,0.845444,0.0214112,0.0293494,0.704713,0.753701,0.79032,0.773197,0.296073,0.272427,0.444645,0.445554,0.635567,0.654508,-1.07381,-1.13652,0.239511,0.264097,-0.892568,-0.890672,0.164568,0.0578948,-0.71771,-0.666384,-0.305781,-0.268546,0.201846,0.258761,-0.557357,-0.615859,2.24442,2.28843,-0.436142,-0.549499
9621,0.697318,0.656793,0.399433,0.376587,0.352249,0.359909,0.669112,0.570011,0.229491,0.239124,0.877718,0.928475,0.855181,0.836712,0.674778,0.649845,0.129348,0.130601,0.535627,0.555478,-0.914772,-1.03538,0.516277,0.543364,0.843996,0.847759,1.33112,1.22448,1.55499,1.60474,0.0156528,0.0517439,-1.09751,-1.03819,0.493625,0.435379,0.133792,0.180768,1.83947,1.72679
9622,0.567957,0.528236,0.209208,0.187075,0.478785,0.438472,0.294961,0.294579,0.86336,0.873657,0.785463,0.835587,0.0987504,0.0820343,0.227933,0.203533,0.929452,0.932348,0.710889,0.72088,1.30081,1.18388,0.0628436,0.0865884,-0.977044,-0.979049,0.792265,0.745933,0.291753,0.335323,1.09153,1.12453,-0.593346,-0.531168,-1.13941,-1.19552,-0.485449,-0.442296,1.30419,1.18856
9623,0.811357,0.769291,0.60592,0.582524,0.506504,0.517035,0.785259,0.783043,0.231244,0.243842,0.0549909,0.106149,0.098011,0.0512194,0.335269,0.242704,0.0210783,0.0262086,0.865602,0.886283,-0.7678,-0.889244,1.28829,1.30696,2.90526,2.90326,0.376943,0.26739,0.461438,0.509386,-0.554323,-0.523769,-0.676058,-0.606479,1.1484,1.0941,0.5382,0.579446,-0.0952421,-0.238989
9624,0.323157,0.282697,0.420315,0.398273,0.948329,0.960781,0.704829,0.700013,0.511313,0.525939,0.767412,0.817212,0.0381373,0.0204044,0.264375,0.281875,0.121567,0.124742,0.256134,0.276329,0.286363,0.158925,-0.262014,-0.250878,-0.0648456,-0.066941,-1.07886,-1.18895,-0.250927,-0.205239,-0.123674,-0.0945355,0.897246,0.960892,0.505059,0.387906,-1.52889,-1.48141,-1.54645,-1.66654
9625,0.838215,0.799304,0.843951,0.822719,0.940765,0.952251,0.421725,0.417063,0.559294,0.631999,0.416652,0.464893,0.959442,0.943076,0.366021,0.321046,0.516168,0.520619,0.849503,0.870548,0.0903009,-0.128619,-2.38454,-2.37214,1.0089,1.00829,0.189488,0.0848879,0.845755,0.888501,0.610634,0.638505,-0.292775,-0.22623,-0.332902,-0.318288,0.971945,1.02595,-1.72782,-1.84052
9626,0.929021,0.79819,0.790161,0.74092,0.654212,0.667511,0.738733,0.698772,0.70014,0.73806,0.385387,0.430909,0.0198793,0.0048897,0.386224,0.360216,0.0286523,0.0306025,0.146625,0.167912,-0.282499,-0.416163,-0.309906,-0.29963,-0.342272,-0.337458,0.711209,0.599978,-1.14714,-1.10976,0.828238,0.852867,0.527761,0.601305,-0.96988,-1.02448,-0.550707,-0.492229,-0.522374,-0.712473
9627,0.836033,0.797077,0.680542,0.659121,0.846559,0.857864,0.98373,0.980481,0.827869,0.84412,0.319172,0.396926,0.418575,0.305109,0.131936,0.107207,0.67039,0.673074,0.68832,0.707305,1.42396,1.29745,0.571697,0.57747,-1.46069,-1.4507,0.156168,0.0416589,-0.702943,-0.661985,0.0723354,0.0938588,-0.00137775,0.078129,-0.10175,-0.158543,-1.1325,-1.0707,0.523543,0.415574
9628,0.543785,0.508729,0.060097,0.0382491,0.501236,0.51358,0.541356,0.53855,0.34458,0.360438,0.316437,0.362942,0.622277,0.605329,0.958047,0.931261,0.550692,0.555903,0.583582,0.6016,0.550578,0.430895,-0.304685,-0.294058,1.08822,1.09499,1.53448,1.42245,0.150272,0.186961,-0.437048,-0.41674,0.315734,0.39988,-0.273978,-0.332315,0.443011,0.497135,0.230043,0.121574
9629,0.26169,0.22038,0.864965,0.845254,0.717707,0.730781,0.504175,0.502126,0.756716,0.773061,0.457836,0.502879,0.268103,0.250182,0.372199,0.346209,0.92587,0.931712,0.132997,0.150292,-0.571646,-0.696189,0.117339,0.122093,-0.586411,-0.587268,1.41495,1.29618,-0.884882,-0.852055,0.941954,0.959499,1.40641,1.48783,0.247543,0.182679,-0.825339,-0.766937,-0.733359,-0.837001
9630,0.972205,0.931011,0.460133,0.4416,0.93562,0.947982,0.733432,0.698369,0.107439,0.123867,0.226972,0.269581,0.480008,0.461714,0.14854,0.123797,0.550158,0.593305,0.69625,0.71368,1.46986,1.34057,1.8998,1.89813,-2.27629,-2.26952,0.173089,0.0541321,-1.696,-1.66021,-0.0352336,-0.0129592,0.594363,0.675573,0.05064,0.0697155,0.40602,0.456639,0.0977189,0.000301232
9631,0.746493,0.707453,0.864986,0.847274,0.852831,0.884058,0.894912,0.894613,0.330242,0.366677,0.345234,0.389199,0.33539,0.316777,0.927895,0.90159,0.250194,0.254899,0.911143,0.93106,-0.715007,-0.840105,-0.781732,-0.784973,0.34369,0.355373,0.158452,0.0345849,0.857945,0.894359,-0.713072,-0.695057,-0.000512198,0.0780967,0.0242953,-0.0432485,2.11285,2.16699,0.551313,0.457734
9632,0.742342,0.694954,0.672237,0.652643,0.806573,0.820134,0.391115,0.391685,0.593059,0.609487,0.10597,0.150745,0.554102,0.533242,0.733979,0.70947,0.508915,0.571254,0.916734,0.936373,-1.04877,-1.16577,-0.991845,-0.997087,0.573447,0.586322,-1.01513,-1.14443,1.60268,1.6352,0.89066,0.913878,0.596992,0.677792,-0.734148,-0.801226,-1.62046,-1.56569,0.543361,0.450355
9633,0.722814,0.682456,0.936454,0.918611,0.0518007,0.0649973,0.867462,0.869175,0.232729,0.250409,0.644093,0.688067,0.546184,0.525815,0.135507,0.113651,0.885542,0.88761,0.671376,0.691062,0.621175,0.501616,-0.780268,-0.778755,-0.37359,-0.353406,-0.0309871,-0.163073,-0.840221,-0.807495,1.49668,1.52809,-2.22435,-2.13722,-2.0504,-2.11261,0.350842,0.401185,-0.595957,-0.693781
9634,0.175472,0.136106,0.918971,0.949207,0.243049,0.348338,0.30604,0.305439,0.974346,0.993436,0.22003,0.262347,0.984774,0.96271,0.268518,0.244673,0.281174,0.28195,0.925162,0.944267,-0.0773324,-0.195004,0.236823,0.236957,0.442303,0.461992,-0.972,-1.09659,-1.71295,-1.67904,-0.35841,-0.309869,-0.896699,-0.810861,-1.23445,-1.29155,0.643649,0.687917,1.48839,1.39239
9635,0.415665,0.377161,0.997971,0.979803,0.619015,0.631678,0.486813,0.486282,0.711152,0.731132,0.439724,0.481062,0.387654,0.366111,0.620746,0.567302,0.830199,0.831618,0.469444,0.488051,0.015803,-0.191094,-0.930807,-0.929094,-0.548639,-0.487994,0.657693,0.539055,-0.6061,-0.570925,-2.17925,-2.14783,-0.0689355,0.0166733,-0.948903,-1.00487,-0.94936,-0.907508,-0.924123,-1.02532
9636,0.235423,0.199616,0.0534127,0.0344897,0.0626908,0.0775374,0.121271,0.119473,0.194444,0.212707,0.352632,0.393192,0.273417,0.251698,0.911391,0.889932,0.996664,0.996495,0.652903,0.713142,-0.0728601,-0.187183,-0.961585,-0.957165,-1.45817,-1.43798,1.20937,1.08711,1.07741,1.1199,1.19441,1.2201,-1.08061,-1,0.011722,-0.0466459,0.467773,0.507447,-0.00765999,-0.112593
9637,0.75712,0.721575,0.0734206,0.100632,0.65248,0.665907,0.394289,0.394727,0.459955,0.479019,0.59485,0.635844,0.729935,0.707578,0.793957,0.773384,0.0117184,0.0115489,0.919916,0.938233,-0.057458,-0.183272,0.391858,0.398236,0.925683,0.951206,-0.457171,-0.574483,0.684318,0.7234,-1.43416,-1.40161,-0.868831,-0.787165,0.285498,0.225036,-0.629031,-0.535885,0.703332,0.605406
9638,0.852648,0.81716,0.232209,0.166774,0.424973,0.502005,0.32753,0.304621,0.952594,0.972279,0.563675,0.603707,0.456432,0.431986,0.988744,0.970062,0.538535,0.536766,0.425713,0.442825,-0.0641373,-0.179361,1.47068,1.47588,0.32008,0.386329,0.349401,0.23499,-2.62988,-2.59439,-0.00647656,0.0200956,-0.0669851,0.00975486,-0.662106,-0.715992,-1.61738,-1.57922,-0.137326,-0.230669
9639,0.179556,0.145382,0.163513,0.232916,0.324671,0.338103,0.0832942,0.214515,0.605619,0.624851,0.993962,1.03269,0.871827,0.848758,0.893781,0.891953,0.194371,0.191905,0.640144,0.655339,-1.61241,-1.73439,-0.831221,-0.827301,-0.209999,-0.178547,-0.84677,-0.960598,0.548039,0.589782,-1.32633,-1.30525,0.460971,0.531511,0.914569,0.856201,1.4593,1.50447,-0.5629,-0.662061
9640,0.245828,0.210713,0.317982,0.299058,0.918137,0.931125,0.123972,0.124409,0.880765,0.901448,0.735726,0.774705,0.844343,0.820371,0.904235,0.813844,0.388641,0.387487,0.465891,0.542501,-0.00369324,-0.127563,-0.371235,-0.365478,-1.0692,-1.04222,-2.49675,-2.6045,-0.842382,-0.803117,-1.00328,-0.98496,-1.30194,-1.23724,-0.583956,-0.635708,1.56765,1.60711,-0.000160041,-0.0960851
9641,0.0820029,0.124657,0.63907,0.62054,0.305423,0.317124,0.896882,0.898586,0.542668,0.609382,0.965106,1.00339,0.267375,0.243298,0.856219,0.735734,0.852404,0.852656,0.448396,0.429664,0.0609625,-0.0625254,0.68066,0.678877,-0.649848,-0.626935,0.431559,0.318281,0.12392,0.129321,-0.195103,-0.112411,0.0348583,0.104404,1.27853,1.23156,0.27603,0.309093,-1.26705,-1.36178
9642,0.0751572,0.0386007,0.115659,0.0978144,0.994664,1.00718,0.80037,0.706997,0.295936,0.317316,0.273639,0.313291,0.3644,0.460641,0.676307,0.657625,0.236427,0.236852,0.301631,0.316826,0.128841,0.00251202,0.113057,0.113648,0.687168,0.70614,1.46247,1.34495,0.976865,1.06176,0.746354,0.760138,1.15265,1.2248,1.79151,1.74655,0.321605,0.351378,1.07225,0.980589
9643,0.449406,0.410904,0.996082,0.976473,0.568031,0.545615,0.512345,0.515407,0.800862,0.821215,0.553928,0.591776,0.632579,0.677984,0.94835,0.928303,0.527218,0.447152,0.616582,0.617785,-1.72366,-1.85143,-1.0954,-1.09839,0.926323,0.953165,-1.53467,-1.65342,1.95493,1.9942,0.754753,0.774503,1.59368,1.6717,1.05126,1.00304,-1.17717,-1.1523,-0.370921,-0.467816
9644,0.37854,0.383907,0.731713,0.804971,0.0703282,0.084049,0.665499,0.584142,0.477966,0.498839,0.626445,0.662824,0.917668,0.895326,0.848095,0.77815,0.655798,0.657453,0.904177,0.918745,-0.343651,-0.479053,-0.592171,-0.681324,-0.56433,-0.543357,0.71713,0.606293,0.562119,0.601299,-0.226475,-0.213712,1.8312,1.9157,-0.38997,-0.444007,-0.773371,-0.755406,-0.100547,-0.189725
9645,0.39631,0.356909,0.652672,0.633469,0.510254,0.480468,0.648185,0.652877,0.893548,0.916343,0.471295,0.522534,0.824867,0.801469,0.73001,0.627996,0.226304,0.228362,0.751195,0.763537,0.271623,0.140122,-0.258929,-0.264258,-0.762887,-0.740949,0.119424,0.0150483,0.711852,0.722695,-1.53533,-1.523,0.164945,0.241856,2.49162,2.43851,1.13231,1.14501,-1.10521,-1.19351
9646,0.636504,0.597964,0.694295,0.705845,0.863634,0.876886,0.326038,0.330069,0.21468,0.236157,0.344256,0.382244,0.0612577,0.0356123,0.497312,0.477843,0.856768,0.859282,0.951511,0.965523,3.04033,2.9095,1.33745,1.32578,-0.202263,-0.173892,-1.2466,-1.34776,0.813404,0.84409,1.67663,1.6838,0.180895,0.25639,0.561172,0.509798,-0.450073,-0.43579,0.733231,0.645721
9647,0.140697,0.10257,0.713705,0.778221,0.525904,0.537016,0.776725,0.778299,0.753177,0.775044,0.726534,0.767056,0.0634229,0.147319,0.832455,0.815406,0.596645,0.600471,0.6428,0.65413,0.547519,0.411212,0.174332,0.159727,-0.842964,-0.82002,-0.47084,-0.569476,-0.538737,-0.471962,-1.38546,-1.37226,-0.71614,-0.635407,0.895354,0.841684,-1.0005,-0.982619,-0.58392,-0.665222
9648,0.137531,0.0404364,0.872068,0.850598,0.680914,0.693657,0.0385935,0.0400908,0.0511839,0.0746152,0.0428003,0.0822891,0.259958,0.259027,0.0856919,0.0696608,0.587004,0.590055,0.699993,0.711314,0.528888,0.387738,0.14332,0.131656,-0.373633,-0.345103,-0.847446,-0.944049,-1.81135,-1.78801,1.09748,1.10737,0.640194,0.720359,-0.192687,-0.251533,1.86383,1.87451,-0.17964,-0.25316
9649,0.0169024,-0.0216973,0.17517,0.155367,0.315981,0.329038,0.137436,0.139314,0.704165,0.729792,0.38242,0.421865,0.395276,0.370734,0.90042,0.88357,0.34657,0.392,0.0913331,0.10136,-0.194455,-0.341003,0.803548,0.794822,0.605242,0.638215,0.468891,0.374171,-0.359968,-0.341478,-0.00395954,0.0114531,0.276803,0.353182,-0.0963662,-0.149486,-0.366588,-0.358978,2.58392,2.50731
9650,0.806568,0.769383,0.728779,0.707127,0.519456,0.593211,0.749469,0.752188,0.865287,0.888967,0.0113206,0.050172,0.13362,0.110032,0.674723,0.681443,0.188697,0.193946,0.865811,0.876748,0.18839,0.0479999,-0.953672,-0.9677,-0.201407,-0.163207,0.935881,0.843377,-0.800605,-0.78505,-0.520171,-0.499146,-0.868909,-0.786824,-0.215801,-0.263336,1.51853,1.52553,1.86405,1.78999
9651,0.20911,0.173799,0.292669,0.269372,0.845257,0.857385,0.756094,0.760064,0.378767,0.400141,0.146872,0.185338,0.367302,0.341006,0.45859,0.479317,0.695716,0.699601,0.621878,0.631437,0.00299617,-0.141879,-0.562379,-0.582216,-0.376855,-0.378338,-1.90419,-1.99857,-0.971805,-0.952876,-0.725681,-0.699089,0.246772,0.333574,0.446174,0.405402,-1.95302,-1.95059,-1.81057,-1.88747
9652,0.595867,0.478026,0.111744,0.0894735,0.252369,0.262943,0.55194,0.557753,0.489576,0.50916,0.522123,0.50299,0.00300529,-0.025296,0.155319,0.27719,0.463976,0.465762,0.971157,0.981041,-1.61369,-1.7572,0.636333,0.618938,-0.630948,-0.593469,-0.460754,-0.554003,-0.568767,-0.605392,0.416163,0.447959,-0.148955,-0.0646392,-0.517869,-0.566918,-2.22709,-2.22008,1.80575,1.72497
9653,0.817047,0.782254,0.647655,0.626709,0.486926,0.498313,0.575847,0.484647,0.0720155,0.0901205,0.781414,0.820643,0.366345,0.337164,0.0926962,0.0750633,0.75443,0.757061,0.840288,0.921348,0.569965,0.431935,-1.39984,-1.41193,0.364508,0.406025,0.41342,0.317966,-0.284201,-0.257909,2.07098,2.10318,0.302409,0.382262,0.111764,0.0546052,-0.267561,-0.253206,-0.74263,-0.828831
9654,0.986189,0.953103,0.371616,0.351362,0.980685,0.991711,0.403652,0.411541,0.116522,0.1323,0.127319,0.165911,0.973308,0.943922,0.513842,0.496421,0.65784,0.661596,0.854276,0.861654,-1.76915,-1.90449,0.906881,0.889194,0.761066,0.806317,0.317012,0.222176,-0.81238,-0.789947,-0.194754,-0.165726,0.0174021,0.0926891,-0.33395,-0.394751,-0.680581,-0.661033,-1.3265,-1.41031
9655,0.561094,0.541067,0.636741,0.617329,0.402552,0.412882,0.214618,0.267875,0.540627,0.55464,0.940291,0.980915,0.110479,0.0830393,0.513802,0.412036,0.971012,0.97644,0.49333,0.458711,-0.508294,-0.640233,0.0240677,0.00222804,0.326431,0.415994,0.597337,0.510594,1.5066,1.52994,-1.03369,-1.0001,0.636615,0.708479,1.28854,1.22391,-0.805745,-0.790879,-0.177091,-0.267718
9656,0.160254,0.129031,0.550631,0.471144,0.335744,0.347841,0.115804,0.12421,0.587359,0.602131,0.261301,0.300395,0.182913,0.157175,0.344132,0.327652,0.212331,0.216763,0.04948,0.055768,1.00445,0.87347,-0.0984948,-0.118258,-0.0151556,0.0256704,-0.791197,-0.884363,-0.402673,-0.385442,0.439367,0.469551,-0.329627,-0.261164,-1.12098,-1.19019,1.03337,1.04541,0.686173,0.601153
9657,0.0444109,0.0608448,0.387004,0.32496,0.77944,0.791587,0.14359,0.152165,0.0549547,0.0689854,0.842654,0.881247,0.61998,0.59407,0.977064,0.962592,0.142838,0.146419,0.208245,0.21303,-0.829681,-0.961846,0.60817,0.589572,-0.940419,-0.899124,-0.671777,-0.76563,-0.626237,-0.615457,-1.15401,-1.13277,0.591919,0.660059,0.128125,0.0570288,0.218102,0.236047,-1.48834,-1.5705
9658,0.0225379,-0.0073412,0.165657,0.178775,0.400807,0.501002,0.584339,0.590832,0.698127,0.713887,0.831245,0.869099,0.49855,0.474306,0.307384,0.290694,0.684116,0.687095,0.806355,0.811511,1.19188,1.05842,1.71049,1.69896,-1.38232,-1.34054,0.427581,0.336489,0.890391,0.907108,0.471192,0.491669,0.321187,0.386151,-1.6124,-1.68475,1.37314,1.39726,-1.70058,-1.7907
9659,0.741612,0.71345,0.052194,0.03259,0.197869,0.210417,0.456273,0.463443,0.0837153,0.09946,0.550328,0.586346,0.694355,0.67096,0.665548,0.648202,0.523629,0.524302,0.551665,0.556708,0.10985,-0.0230703,-2.21501,-2.22655,-0.702169,-0.690591,0.822632,0.730549,-0.698373,-0.683347,0.424689,0.445264,0.965573,1.03305,-1.89246,-1.96571,-1.76348,-1.73658,-0.308427,-0.402865
9660,0.422176,0.39423,0.764214,0.743012,0.759335,0.77265,0.759406,0.76786,0.590447,0.607798,0.478927,0.45408,0.285948,0.264872,0.432882,0.415913,0.693568,0.714549,0.863988,0.870146,-0.647596,-0.781669,-0.324434,-0.341063,-0.0839067,-0.0406428,-0.842034,-0.931043,-0.0426619,-0.0208759,-1.0755,-1.0508,-0.15767,-0.0923989,-0.130337,-0.205969,-0.608148,-0.57537,0.475666,0.373489
9661,0.650238,0.620786,0.769004,0.760038,0.459412,0.473467,0.249256,0.25995,0.774873,0.792856,0.322334,0.321814,0.600359,0.539127,0.747686,0.732252,0.902527,0.904796,0.0435035,0.0494563,-1.96175,-2.09171,-0.297398,-0.308274,-0.789614,-0.74795,1.56269,1.4664,0.623694,0.641595,0.193865,0.219335,0.0544642,0.120436,-0.463737,-0.533267,-0.180263,-0.147882,-0.144822,-0.164254
9662,0.182178,0.154965,0.79928,0.777065,0.849045,0.860474,0.0531189,0.062539,0.0170974,0.0352547,0.153528,0.189547,0.833551,0.813382,0.360432,0.34578,0.756692,0.756604,0.960847,0.967858,-0.161317,-0.285065,2.32165,2.31392,0.985767,1.03541,1.6835,1.58513,-0.334729,-0.31999,0.669454,0.696578,-0.253019,-0.184643,-1.57658,-1.64277,-0.384825,-0.354666,-0.591254,-0.701996
9663,0.698373,0.671571,0.00816562,-0.0166734,0.718599,0.728948,0.54839,0.555881,0.786196,0.804303,0.322655,0.297448,0.851668,0.831169,0.825653,0.812685,0.971472,0.972701,0.688651,0.697412,-1.09947,-1.22698,-1.76536,-1.77865,0.865967,0.915456,-0.893998,-0.999816,-0.735186,-0.716488,-0.423428,-0.39934,0.331685,0.343298,-0.836811,-0.898692,-0.184368,-0.162104,0.162075,0.0464417
9664,0.573299,0.547627,0.750883,0.724024,0.958385,0.969001,0.0137036,0.0228817,0.500339,0.516976,0.30555,0.405348,0.632293,0.610009,0.720109,0.705755,0.374124,0.3729,0.996309,1.00519,0.667499,0.531197,-0.735337,-0.747579,0.284851,0.425778,-1.34667,-1.45116,0.142005,0.162591,-1.71998,-1.69308,0.796372,0.871239,0.354059,0.287818,0.602225,0.623782,-0.0623003,-0.173752
9665,0.102001,0.0771565,0.358399,0.329933,0.434363,0.445579,0.305409,0.313334,0.669631,0.623036,0.478431,0.513249,0.106358,0.0831825,0.924878,0.912872,0.344392,0.306891,0.944349,0.951238,0.389549,0.250074,-0.326,-0.331428,-0.118601,-0.0638994,-0.398788,-0.594106,0.328985,0.36963,-1.88838,-1.86187,1.15045,1.22509,0.255521,0.190067,-1.76692,-1.7432,-1.05852,-1.1627
9666,0.0211936,0.0709876,0.913346,0.886762,0.582963,0.592451,0.978137,0.986117,0.742117,0.729097,0.121662,0.155684,0.122398,0.0627328,0.85968,0.847118,0.146432,0.240882,0.384706,0.390168,0.388336,0.255496,-0.261214,-0.268738,1.08249,1.13186,0.36612,0.262944,0.695135,0.576669,0.197157,0.227357,-0.426628,-0.35512,-0.183262,-0.24442,-0.96013,-0.942171,-0.00794485,-0.111856
9667,0.0886843,0.0648187,0.360639,0.334887,0.480497,0.491779,0.972835,0.979334,0.820146,0.835157,0.290108,0.245644,0.0655702,0.0422831,0.240635,0.225875,0.176098,0.174873,0.615918,0.622947,2.19217,2.06214,0.167569,0.16183,1.16703,1.22207,0.958397,0.855062,0.763122,0.783708,0.394397,0.433432,-0.98396,-0.908618,-0.246016,-0.312463,1.28023,1.30142,-0.932622,-1.04149
9668,0.536932,0.512684,0.860408,0.833367,0.0530749,0.0618677,0.234493,0.241125,0.0310967,0.0454126,0.303359,0.335605,0.28171,0.258748,0.66985,0.588298,0.234211,0.280724,0.534177,0.472228,0.843869,0.720692,-0.329462,-0.339859,-0.347135,-0.289779,0.333098,0.211183,-0.36953,-0.346619,0.606319,0.639507,0.00425634,0.0750847,0.291005,0.218604,-0.233052,-0.216763,1.56834,1.45302
9669,0.009432,-0.0133479,0.0108034,-0.0175115,0.699696,0.71076,0.0557094,0.0634587,0.428606,0.397424,0.695728,0.729826,0.763354,0.740997,0.967009,0.950721,0.438628,0.386574,0.315075,0.32151,0.676518,0.558582,1.07532,1.06175,0.688053,0.740745,-0.32409,-0.432696,-0.244171,-0.220094,-0.126045,-0.0869212,-2.54976,-2.47095,-1.29261,-1.36524,-1.1451,-1.1245,-1.12403,-1.23387
9670,0.501098,0.433775,0.523322,0.494928,0.170341,0.182286,0.885202,0.895054,0.733349,0.749436,0.372613,0.406602,0.0180035,-0.00224607,0.119779,0.105042,0.494563,0.492425,0.597281,0.604866,-0.146032,-0.26277,-1.5568,-1.57069,0.318225,0.373936,-0.131837,-0.236954,-0.377443,-0.357589,1.07356,1.10808,-0.501886,-0.428152,0.168585,0.0989037,-0.00260068,0.0213207,0.877382,0.771472
9671,0.903569,0.880898,0.339136,0.310678,0.106914,0.117245,0.442826,0.453123,0.791213,0.806463,0.398762,0.462879,0.532696,0.440404,0.895529,0.882835,0.0949342,0.0934807,0.577292,0.59533,0.664702,0.553552,0.028355,0.0193443,1.72445,1.78217,-0.755042,-0.856265,-0.184686,-0.169476,0.371513,0.463339,-0.570197,-0.503464,-0.882474,-0.948672,-0.749101,-0.728908,-1.16927,-1.2766
9672,0.303096,0.279728,0.829138,0.798377,0.343793,0.352616,0.560831,0.609622,0.575927,0.589405,0.494545,0.519155,0.905161,0.883054,0.91123,0.863699,0.0650998,0.0937557,0.579898,0.585794,0.401844,0.286997,0.0235703,0.0216486,-0.138007,-0.0748774,0.050583,-0.0467913,0.889002,0.909229,-0.210733,-0.181408,0.789457,0.852302,0.390525,0.327455,0.566671,0.587947,1.13526,1.03426
9673,0.397292,0.375313,0.52917,0.538325,0.273727,0.204593,0.756525,0.76612,0.950478,0.962714,0.542399,0.575432,0.93247,0.910866,0.76565,0.844563,0.0934447,0.0940307,0.0906462,0.0951163,0.763021,0.646437,-0.358809,-0.360018,-1.12702,-1.06302,-1.02082,-1.11871,-0.864139,-0.838481,0.973733,0.997123,0.438984,0.499526,-1.87829,-1.94067,0.605683,0.630232,1.65654,1.55372
9674,0.839863,0.817991,0.308188,0.278273,0.047489,0.0565702,0.356792,0.364507,0.584391,0.599286,0.79792,0.752059,0.407954,0.38855,0.835353,0.825427,0.723748,0.72495,0.000672394,0.00716305,-0.491133,-0.60436,-1.71386,-1.71455,0.78392,0.844586,0.654966,0.564335,-1.24938,-1.2208,0.737118,0.766171,0.505339,0.562725,-0.607367,-0.664544,0.224138,0.253855,0.893575,0.790911
9675,0.533632,0.513332,0.57945,0.549309,0.166716,0.105203,0.327567,0.394152,0.645627,0.661778,0.894421,0.928686,0.587489,0.569307,0.212028,0.204183,0.562853,0.562157,0.646878,0.650508,-0.279097,-0.409635,2.60311,2.60243,0.152252,0.213662,0.150604,0.0667123,-0.131324,-0.0977623,0.740791,0.764978,0.106564,0.192245,-0.542352,-0.595289,-0.632265,-0.602391,-1.64623,-1.75094
9676,0.622498,0.604379,0.0757271,0.0459104,0.226739,0.153836,0.280457,0.423798,0.33275,0.340843,0.489777,0.522543,0.174643,0.158189,0.694189,0.686213,0.961052,0.958034,0.151242,0.1551,-0.21251,-0.214909,0.356221,0.351979,1.1312,1.19698,-1.51976,-1.60969,-0.86711,-0.830571,-2.40131,-2.38251,-0.237254,-0.178234,0.494276,0.440724,0.202226,0.231925,-0.613348,-0.730323
9677,0.0841178,0.0681222,0.158393,0.130273,0.225968,0.20247,0.426374,0.453444,0.00375697,0.0199085,0.532379,0.646912,0.548259,0.529847,0.456304,0.448398,0.545664,0.543967,0.211894,0.131662,0.0930432,-0.0201841,0.282148,0.277514,-1.43217,-1.36009,0.393452,0.307528,1.34755,1.3892,-0.354485,-0.339233,-1.01902,-0.960605,1.1341,1.07798,0.743725,0.770581,0.396911,0.290291
9678,0.323674,0.227265,0.612935,0.513788,0.242021,0.251103,0.361869,0.48309,0.689335,0.705826,0.737814,0.77128,0.131378,0.113838,0.469922,0.392541,0.974461,0.974424,0.102246,0.108224,0.742856,0.630239,-0.587776,-0.594014,0.781349,0.850283,0.95161,0.869062,-0.179884,-0.141947,0.748269,0.761376,-0.366897,-0.389521,0.61293,0.551731,0.0544481,0.0854351,-0.0724317,-0.185169
9679,0.400422,0.386409,0.926232,0.897303,0.0854791,0.0944298,0.505021,0.512736,0.565212,0.579489,0.0034865,0.0366782,0.415391,0.400384,0.344647,0.336684,0.153683,0.155151,0.480558,0.489333,0.0682556,-0.0517713,-0.0800065,-0.084462,0.20949,0.28371,-1.02986,-1.11118,-0.148506,-0.106146,0.606817,0.622049,0.131663,0.181563,-1.35985,-1.42524,0.447091,0.482334,1.51889,1.40287
9680,0.42327,0.406846,0.736308,0.609755,0.742881,0.753423,0.675019,0.68287,0.0651114,0.0812411,0.0696966,0.103119,0.169085,0.154319,0.574054,0.565985,0.951902,0.952057,0.867529,0.870442,1.08691,1.06468,-0.105842,-0.112533,0.776775,0.850767,0.750379,0.666783,2.55488,2.60347,0.0837576,0.0941969,1.3782,1.42851,0.3517,0.289555,-1.13047,-1.09847,0.328017,0.21387
9681,0.122576,0.107216,0.41697,0.322208,0.473664,0.469221,0.325214,0.331157,0.22277,0.244427,0.974487,1.00996,0.528096,0.511706,0.246847,0.239486,0.244449,0.246138,0.571857,0.558323,2.3013,2.18113,-0.524587,-0.537039,0.138058,0.204639,-0.747037,-0.835743,-0.534934,-0.489174,-0.518165,-0.433655,0.209665,0.256127,-0.283138,-0.346031,-2.10764,-2.08169,-0.626902,-0.744704
9682,0.855809,0.839838,0.0635891,0.0346599,0.171765,0.185019,0.795616,0.804165,0.390545,0.407612,0.12508,0.160996,0.420513,0.402476,0.95534,0.946855,0.270984,0.270482,0.242667,0.246205,0.65647,0.453181,-0.503605,-0.520955,-1.71386,-1.6524,0.555588,0.46693,-0.648447,-0.595821,-0.979699,-0.961507,-1.38813,-1.33983,0.822025,0.766883,-0.451789,-0.432703,1.13498,1.01542
9683,0.317448,0.303581,0.77804,0.750138,0.755679,0.768533,0.639628,0.705869,0.352919,0.368806,0.513813,0.58799,0.885237,0.869555,0.711194,0.703941,0.701395,0.700938,0.834471,0.840424,-1.15461,-1.27477,1.38828,1.36453,-0.436819,-0.38031,-0.536865,-0.621704,0.487892,0.544916,-1.78407,-1.76512,0.337872,0.38641,0.238201,0.17795,0.902582,0.922782,0.139195,0.0264741
9684,0.677389,0.610652,0.898268,0.868619,0.561852,0.576498,0.598536,0.607573,0.790327,0.806564,0.977024,1.01498,0.70987,0.741563,0.0337834,0.0265832,0.442503,0.442128,0.183076,0.189428,0.200087,0.0826751,1.06644,1.04633,1.52904,1.58874,-0.0474485,-0.135175,-1.16954,-1.1076,-1.63852,-1.61458,-0.394498,-0.350992,0.875721,0.815206,0.794128,0.809165,-0.0453176,-0.162815
9685,0.934286,0.917723,0.118526,0.0867053,0.72227,0.644851,0.0817534,0.0896997,0.521134,0.505643,0.663865,0.701224,0.693403,0.613571,0.344038,0.337774,0.937774,0.937871,0.891877,0.898154,-0.647303,-0.768824,0.198454,0.174802,1.27855,1.34426,-1.2515,-1.34588,-2.35516,-2.29596,-0.193215,-0.176097,2.27983,2.31937,0.862967,0.805787,1.01722,1.03439,2.5425,2.42691
9686,0.190058,0.172806,0.989824,0.956538,0.700613,0.713204,0.365977,0.375065,0.189599,0.204722,0.133081,0.171305,0.501375,0.485578,0.963667,0.957888,0.638196,0.719896,0.428745,0.437295,1.17291,1.05164,-1.06461,-1.08387,1.87127,1.94173,-0.555521,-0.644748,-2.34958,-2.29012,-0.820702,-0.811637,1.06968,1.14599,0.0110571,-0.0424776,0.366953,0.380082,0.157921,0.0418049
9687,0.211363,0.193244,0.587298,0.639777,0.252248,0.264134,0.0770686,0.0866706,0.110725,0.189384,0.639038,0.678914,0.2241,0.209986,0.154673,0.150585,0.502255,0.50192,0.443039,0.475924,-2.29042,-2.40671,0.206063,0.179558,0.318872,0.384977,0.517406,0.427528,-0.505741,-0.443359,0.358982,0.366894,-0.069811,-0.027395,-1.68778,-1.73568,-0.656059,-0.649519,0.069507,-0.0426475
9688,0.610912,0.591009,0.351017,0.323016,0.712747,0.722969,0.448362,0.460512,0.159733,0.174046,0.821309,0.792483,0.899755,0.887477,0.532237,0.531429,0.407548,0.406455,0.555206,0.514554,-0.902074,-1.01798,-1.41378,-1.44042,0.722011,0.785269,0.724839,0.638171,-0.399526,-0.331665,-0.158165,-0.186876,-0.0132665,0.0358043,-0.893629,-0.946313,-0.741461,-0.732678,-0.41311,-0.518107
9689,0.445271,0.42342,0.0413149,0.00625524,0.0442908,0.0538467,0.424853,0.5127,0.622122,0.63721,0.866538,0.906052,0.489969,0.562484,0.915384,0.912273,0.852038,0.851655,0.664801,0.553183,-0.119634,-0.231106,-0.322497,-0.345538,2.7136,2.7729,-0.791993,-0.880763,-1.06083,-0.986016,-0.747048,-0.740645,0.672942,0.727321,2.73856,2.68829,1.06305,1.07181,-0.121056,-0.225881
9690,0.773438,0.750996,0.0696934,0.071303,0.0862288,0.095255,0.554308,0.564889,0.6585,0.67414,0.218122,0.255999,0.251745,0.237492,0.104874,0.100498,0.629823,0.628201,0.670394,0.591812,2.19968,2.08093,-0.800329,-0.817339,-1.00268,-0.946402,-0.683737,-0.778196,-0.452831,-0.385033,-0.367454,-0.357754,1.08613,1.1426,0.372081,0.323395,0.949514,0.958193,-0.996506,-1.09528
9691,0.432575,0.410761,0.173652,0.136351,0.737135,0.744147,0.940799,0.953659,0.151477,0.165941,0.471144,0.509438,0.31459,0.301006,0.806357,0.801575,0.0259256,0.0225406,0.621891,0.630441,1.24562,1.12203,-0.406331,-0.417548,-0.0646143,-0.00989538,-0.0671949,-0.156154,-0.774318,-0.706237,0.366069,0.375286,1.2274,1.28008,-0.576599,-0.632869,0.279402,0.28724,0.606799,0.508607
9692,0.865195,0.843724,0.0261383,0.0514421,0.622369,0.627606,0.674696,0.747476,0.0505063,0.064652,0.508899,0.545718,0.72507,0.712532,0.14695,0.144518,0.998139,0.997056,0.451992,0.460261,-1.10796,-1.23041,1.36714,1.35848,1.36383,1.41444,-0.0332799,-0.107958,-0.436619,-0.363924,-1.39058,-1.37948,-0.43411,-0.376569,1.45526,1.40705,1.5371,1.54208,2.43189,2.33033
9693,0.472915,0.4539,0.00659087,-0.0334667,0.0372224,0.0439018,0.529609,0.541293,0.887926,0.903577,0.784929,0.820715,0.813236,0.825981,0.775311,0.774741,0.838201,0.769031,0.703242,0.713467,-1.82308,-1.94268,-2.28713,-2.29044,-0.390703,-0.346877,0.0317618,-0.0597616,0.485535,0.561722,0.00179285,0.0128852,-0.124399,-0.0688688,0.310663,0.267849,0.460553,0.46462,-0.0675537,-0.172647
9694,0.879495,0.86176,0.888132,0.849717,0.0394493,0.0638179,0.956734,0.969978,0.0730643,0.0873517,0.712773,0.74802,0.953564,0.939429,0.0929446,0.0925655,0.514408,0.541006,0.600288,0.560367,0.0971107,-0.0170269,-2.27199,-2.27436,0.00186652,0.101426,0.413322,0.31867,1.05877,1.13365,0.690328,0.794873,-0.587757,-0.497277,-1.78963,-1.83359,1.50296,1.50309,-1.15308,-1.25553
9695,0.774589,0.759158,0.943967,0.90352,0.0752766,0.083734,0.734561,0.668129,0.25521,0.267389,0.351743,0.425831,0.0876532,0.0732982,0.844581,0.845202,0.314064,0.312981,0.39853,0.407267,-0.0916229,-0.206906,1.57367,1.5713,0.503561,0.54973,-0.49888,-0.599637,-0.079901,-0.0100161,1.57198,1.57686,-0.983415,-0.925686,-1.77134,-1.81061,-1.399,-1.40244,0.589708,0.485426
9696,0.118545,0.102783,0.436655,0.449882,0.285114,0.294017,0.354357,0.36628,0.73656,0.749918,0.0697094,0.103641,0.308042,0.370851,0.569734,0.568517,0.528723,0.529078,0.924704,0.9317,-1.04885,-1.16581,-0.654197,-0.664544,-1.12176,-1.07143,-0.643431,-0.741543,-0.441515,-0.376978,-0.145386,-0.14544,0.0782567,0.133326,0.315879,0.274628,0.564167,0.564429,-1.44852,-1.54886
9697,0.499441,0.485606,0.0352872,-0.00375558,0.942033,0.953011,0.404005,0.428889,0.990236,1.00143,0.65671,0.689302,0.683912,0.668404,0.602753,0.60379,0.000633703,-8.73189e-05,0.144113,0.151733,1.09364,0.976581,0.466388,0.461187,1.22659,1.27078,-1.48801,-1.58114,-0.206819,-0.143396,-0.525131,-0.529661,-2.65262,-2.59192,-0.303235,-0.344406,-0.906941,-0.908101,-0.142142,-0.23672
9698,0.613046,0.67294,0.637103,0.596263,0.40493,0.413941,0.481654,0.491499,0.203134,0.215858,0.808363,0.794687,0.671465,0.655741,0.0555666,0.0582668,0.435137,0.413892,0.281842,0.295804,-1.47376,-1.58805,0.101384,0.0967731,0.203681,0.251185,-0.304638,-0.401437,-0.564321,-0.494479,0.385791,0.374315,1.04117,1.09456,2.01835,1.97862,1.1095,1.10746,-0.993545,-1.08928
9699,0.875672,0.860274,0.849894,0.80892,0.269834,0.30645,0.0487962,0.0596026,0.723969,0.73479,0.868764,0.900072,0.899172,0.881589,0.510218,0.498464,0.82908,0.827872,0.431247,0.439875,-0.393413,-0.511626,0.191191,0.189279,2.02837,2.08113,0.474285,0.376849,0.235131,0.306002,2.14549,2.13603,0.195615,0.251068,-0.526418,-0.562524,-1.74413,-1.75385,-0.222903,-0.312927
9700,0.0632125,0.0483807,0.565123,0.523259,0.190914,0.198959,0.514749,0.527547,0.81152,0.737367,0.590191,0.622284,0.868528,0.853202,0.935961,0.938661,0.331021,0.328119,0.170737,0.276385,-0.377989,-0.476095,0.643917,0.635192,0.230462,0.288031,-1.00428,-1.09435,0.462153,0.539585,-0.41011,-0.410968,-0.0786578,-0.0862666,-0.656345,-0.691321,-0.139164,-0.153062,-1.03429,-1.12007
9701,0.512644,0.425115,0.947926,0.908025,0.733037,0.741858,0.328589,0.340106,0.769853,0.739944,0.0409124,0.0729374,0.41396,0.3973,0.895853,0.897359,0.59065,0.521188,0.10659,0.112895,-0.32235,-0.440563,0.132893,0.118387,0.719871,0.777248,-1.19551,-1.28414,-0.299963,-0.223338,-0.29367,-0.288453,-0.477771,-0.423602,-1.03632,-1.06402,0.190624,0.181379,-1.13314,-1.21783
9702,0.814626,0.80185,0.549504,0.598807,0.180709,0.187717,0.539339,0.551091,0.876724,0.742522,0.379384,0.448173,0.262368,0.24777,0.508732,0.510887,0.71722,0.714257,0.904576,0.911028,0.0473029,-0.0659435,-0.623298,-0.64609,0.643101,0.701494,0.181457,0.0966555,-0.74501,-0.666911,0.0292315,-0.00626372,0.647039,0.696796,-1.76768,-1.70621,-1.42901,-1.44612,-0.460868,-0.545412
9703,0.409298,0.396641,0.327179,0.289589,0.623866,0.631463,0.950333,0.960463,0.734279,0.745099,0.789534,0.823409,0.920326,0.905663,0.396663,0.399309,0.600007,0.597086,0.28325,0.290328,-0.90151,-1.00786,1.72106,1.70512,-1.55177,-1.48874,-1.20642,-1.2983,0.599329,0.671705,0.27472,0.275926,-0.00455384,0.0526587,-2.31524,-2.34841,-0.164037,-0.17566,-1.47199,-1.5492
9704,0.90211,0.888168,0.182344,0.145882,0.109499,0.1179,0.799183,0.743531,0.359866,0.37107,0.294334,0.32819,0.405599,0.38963,0.627264,0.585417,0.0443372,0.0425927,0.163584,0.169843,0.877349,0.767788,-0.50251,-0.51418,0.105337,0.167873,-0.95511,-1.04187,0.624073,0.679221,0.919443,0.919961,-0.39264,-0.329666,0.67088,0.633285,0.602889,0.593943,-0.325264,-0.406614
9705,0.250556,0.236568,0.406896,0.368743,0.370322,0.378584,0.518351,0.5266,0.921661,0.934021,0.882284,0.913851,0.248105,0.230579,0.769562,0.771525,0.513003,0.513143,0.35648,0.361892,0.474066,0.364074,0.356482,0.346406,1.00105,1.05975,-1.40251,-1.49321,0.614516,0.686737,-1.05018,-1.05271,0.489793,0.558992,0.00910152,-0.0339753,-1.87469,-1.87758,0.350361,0.328883
9706,0.996021,0.980535,0.897555,0.86179,0.175449,0.241244,0.105268,0.11428,0.951944,0.965984,0.120185,0.148708,0.518331,0.597284,0.307871,0.310117,0.207575,0.209293,0.210556,0.235809,-1.28732,-1.39438,-0.438991,-0.513356,-0.394395,-0.331467,1.24078,1.15165,1.6864,1.76544,1.32387,1.32423,-0.764826,-0.689937,2.30493,2.25565,1.031,1.03371,1.14598,1.06438
9707,0.0889306,0.0746225,0.938991,0.871199,0.0949832,0.103904,0.821516,0.832894,0.751019,0.763982,0.878415,0.905574,0.983162,0.963988,0.0510236,0.0532961,0.395245,0.395478,0.104164,0.109726,0.972576,0.87238,-1.36248,-1.37312,-0.52497,-0.466416,0.366078,0.280202,0.319779,0.40122,-0.112368,-0.0530877,-0.648942,-0.58164,-0.235994,-0.285497,-0.552709,-0.547099,-0.258525,-0.338237
9708,0.746235,0.731016,0.929697,0.880608,0.396625,0.405151,0.950811,0.962422,0.345959,0.399122,0.660401,0.68705,0.6002,0.583047,0.584454,0.585879,0.320752,0.35719,0.217227,0.231804,-0.237507,-0.331613,-0.780941,-0.787355,-0.239691,-0.118418,0.576279,0.490844,1.07312,1.15677,-1.4325,-1.43041,-0.0663119,0.00338895,-0.891306,-0.936432,1.0518,1.05369,-0.3104,-0.391456
9709,0.319441,0.305392,0.80311,0.890016,0.184762,0.191993,0.443661,0.454512,0.0212514,0.0342623,0.930393,0.955821,0.901654,0.884777,0.76032,0.771987,0.321271,0.318902,0.345898,0.353883,-2.43565,-2.53208,0.571333,0.568045,0.173074,0.22958,0.427622,0.348939,-0.909806,-0.822708,-0.217186,-0.220116,-1.74557,-1.67046,-0.0977086,-0.147069,1.39027,1.38813,-1.98152,-2.06841
9710,0.834441,0.821998,0.996793,0.899425,0.1807,0.135745,0.625406,0.635355,0.219766,0.233815,0.294913,0.320447,0.30348,0.288178,0.956567,0.958095,0.984767,0.981235,0.975347,0.983414,0.589157,0.497439,0.0125057,0.00281615,-0.0748752,-0.0518153,-1.53278,-1.61565,1.22484,1.31286,0.135092,0.132508,2.29743,2.37254,-0.0760354,-0.124091,-0.281823,-0.288144,-0.218484,-0.308286
9711,0.382878,0.371573,0.948628,0.908833,0.0698369,0.0794981,0.376628,0.387421,0.627147,0.641774,0.841904,0.866532,0.00300338,-0.0130124,0.770094,0.77115,0.736467,0.732714,0.264437,0.271519,-0.205224,-0.293684,-1.35247,-1.36743,-0.392488,-0.333211,0.0510042,-0.0284201,0.451072,0.536286,-0.460548,-0.45602,-0.227455,-0.155391,0.330931,0.28387,0.749064,0.750322,-0.158522,-0.255452
9712,0.886076,0.873703,0.954007,0.918242,0.335423,0.345612,0.678853,0.677259,0.677537,0.694113,0.76592,0.821626,0.245254,0.303883,0.152809,0.154814,0.14069,0.138482,0.871167,0.880384,-0.0345321,-0.12015,0.274981,0.2535,-0.93908,-0.884034,-0.247063,-0.32617,0.977317,1.06106,0.220022,0.218925,1.81559,1.8874,0.113733,0.0640766,-1.34847,-1.34531,0.182639,0.082203
9713,0.983596,0.969288,0.651023,0.617045,0.958781,0.968945,0.954798,0.967096,0.990361,1.00613,0.876882,0.776719,0.635619,0.620778,0.200359,0.200204,0.159673,0.158267,0.0187021,0.0282156,1.60613,1.51669,-0.0175885,-0.0355147,-0.43872,-0.380511,0.181851,0.0982239,-0.277575,-0.193825,1.48439,1.48906,-0.098715,-0.0202543,-0.715074,-0.769724,1.77833,1.78335,0.305899,0.206426
9714,0.0533281,0.0394574,0.328266,0.315848,0.952715,0.965213,0.411981,0.423528,0.622618,0.687021,0.707185,0.731813,0.348448,0.334912,0.503852,0.501197,0.890376,0.889969,0.706309,0.716792,1.35836,1.25146,0.243288,0.227703,-1.7226,-1.6614,1.83813,1.74962,1.3885,1.46556,0.357998,0.363552,-0.442358,-0.357192,-0.18008,-0.241501,0.808319,0.814974,-2.51471,-2.61341
9715,0.0503643,0.0348148,0.0504162,0.0146513,0.530105,0.554342,0.265018,0.275795,0.384635,0.367911,0.169957,0.192597,0.947356,0.935427,0.2909,0.289587,0.126611,0.125395,0.960924,0.969997,1.08032,0.986219,-0.00921452,-0.0312684,0.158423,0.217293,1.28735,1.20645,0.212718,0.289463,0.221444,0.224225,0.266941,0.34985,0.346966,0.286722,-0.525458,-0.516533,-0.722866,-0.82151
9716,0.307893,0.291256,0.0866493,0.0530251,0.131349,0.143471,0.341111,0.348896,0.033031,0.0488006,0.382521,0.307967,0.791343,0.706525,0.823482,0.82217,0.0687853,0.069831,0.474433,0.484053,1.75804,1.66622,-1.33153,-1.35442,-0.50879,-0.444701,-0.788586,-0.866765,0.713901,0.785006,-0.907487,-0.90128,0.470641,0.595532,-0.291867,-0.348865,-0.71395,-0.709431,-0.783321,-0.87473
9717,0.256684,0.239883,0.332895,0.2959,0.232561,0.244794,0.847726,0.856737,0.619146,0.634214,0.458345,0.423336,0.566172,0.477623,0.121543,0.118759,0.340814,0.340806,0.365983,0.42295,-1.34462,-1.44007,-0.383096,-0.401661,0.867138,0.933381,0.0258119,-0.0572912,-0.0653737,0.00843153,0.629571,0.629954,0.767158,0.841215,-1.75736,-1.81179,-0.367487,-0.358415,-1.64205,-1.72729
9718,0.43238,0.415289,0.571247,0.538776,0.0110985,0.0227964,0.758539,0.768544,0.485933,0.491756,0.552435,0.538706,0.259851,0.248721,0.902349,0.901633,0.260349,0.216667,0.282216,0.361847,0.76059,0.67237,-0.353703,-0.354628,1.23223,1.30085,-0.764028,-0.848094,-0.327907,-0.252428,-0.0951192,-0.0964745,-0.498448,-0.421724,-0.387392,-0.439492,1.06996,1.07172,-0.358902,-0.447255
9719,0.262286,0.243292,0.466864,0.435514,0.672666,0.68179,0.943164,0.954047,0.33522,0.349297,0.631436,0.654076,0.282457,0.172782,0.00971627,0.00931465,0.0950871,0.0925284,0.290766,0.300745,0.166339,0.0829703,-0.297472,-0.307595,0.461377,0.53015,0.416464,0.33161,0.123346,0.195342,0.92255,0.913093,0.256792,0.331066,-0.605468,-0.626115,0.549701,0.555206,-0.286483,-0.415939
9720,0.456926,0.463707,0.0617521,0.03186,0.507101,0.506732,0.319268,0.331023,0.552313,0.564554,0.0133619,0.0339044,0.107079,0.0968431,0.585399,0.58719,0.819471,0.81506,0.939622,0.949556,0.0617886,0.0431398,2.36328,2.35024,0.380332,0.454396,0.0605722,-0.028198,-1.01702,-0.948324,1.5606,1.55713,-0.141285,-0.0671468,-0.763282,-0.812739,-0.690181,-0.679508,-0.325839,-0.384623
9721,0.661055,0.684122,0.780705,0.75258,0.321658,0.331674,0.654223,0.664777,0.0404089,0.0514319,0.0888073,0.192926,0.381957,0.372941,0.297704,0.297182,0.735943,0.72948,0.128721,0.13995,0.027443,0.0033094,-1.31143,-1.31824,1.49793,1.57449,-1.65644,-1.75282,0.122472,0.192413,-0.96863,-0.972988,0.409125,0.487003,0.386648,0.328629,-0.635782,-0.623769,-0.293731,-0.353307
9722,0.924292,0.904538,0.0603369,0.0326782,0.88515,0.893906,0.748094,0.758449,0.388353,0.398166,0.330725,0.351948,0.264502,0.290736,0.00381866,0.00717407,0.880374,0.873923,0.303629,0.321978,0.0468475,-0.036521,0.105735,0.0995725,0.224744,0.309513,-2.32185,-2.42005,0.516002,0.580813,-1.70898,-1.71506,-1.34859,-1.2644,-1.14192,-1.19564,1.48043,1.49416,-0.233638,-0.321991
9723,0.207863,0.189936,0.0764214,0.046838,0.4248,0.434741,0.574051,0.626461,0.416624,0.425562,0.0877036,0.108527,0.216593,0.208531,0.86781,0.873435,0.393847,0.389021,0.49539,0.504006,-0.940237,-1.02677,0.787268,0.777932,0.393825,0.476015,-1.60442,-1.70384,0.439845,0.505381,-0.351244,-0.353151,-0.437689,-0.359624,-0.521609,-0.574113,0.612411,0.67012,-0.448946,-0.542184
9724,0.20027,0.220183,0.625014,0.594707,0.544978,0.491589,0.373033,0.494473,0.114626,0.123028,0.435207,0.454178,0.440729,0.43438,0.20389,0.21133,0.647043,0.640765,0.132133,0.142906,-0.358354,-0.437174,0.916621,0.901185,0.0580596,0.140271,-0.217941,-0.405964,-1.82841,-1.77224,-1.88178,-1.87723,-0.973409,-0.899328,1.00409,0.950092,-0.167203,-0.153918,0.412472,0.326687
9725,0.26955,0.250429,0.847456,0.817567,0.536249,0.548436,0.35213,0.362485,0.760434,0.767929,0.282181,0.386405,0.939923,0.931233,0.52979,0.537734,0.154308,0.145677,0.623832,0.636809,1.9673,1.89187,-1.54964,-1.55884,-1.93583,-1.85732,0.991333,0.891911,-1.03656,-0.984052,0.974722,0.977825,-0.749266,-0.671148,-0.294648,-0.345769,-0.423839,-0.407617,1.93626,1.85419
9726,0.708872,0.688445,0.734027,0.791507,0.205233,0.218691,0.45489,0.439647,0.242908,0.249504,0.297058,0.318632,0.494848,0.527023,0.651379,0.659033,0.817713,0.80801,0.17973,0.190417,-0.0621949,-0.133648,-0.684011,-0.698251,-0.684185,-0.600477,-0.969142,-1.07267,0.499256,0.553566,-0.172051,-0.161784,0.283862,0.355996,0.389849,0.337538,1.36312,1.37935,1.04656,0.970683
9727,0.820362,0.799153,0.79389,0.765447,0.869622,0.883407,0.509508,0.51681,0.804906,0.812455,0.906949,0.929265,0.12953,0.122814,0.982942,0.990892,0.994737,0.982977,0.822381,0.833762,-0.787454,-0.862389,0.38577,0.3649,-0.223496,-0.141602,1.4858,1.38939,0.182383,0.232362,0.558083,0.571256,1.54351,1.61716,-2.69061,-2.7529,-0.382216,-0.363338,0.776208,0.70613
9728,0.464007,0.443855,0.291996,0.262049,0.806374,0.818367,0.0936705,0.10004,0.898658,0.907346,0.252153,0.274533,0.586028,0.578695,0.789222,0.798772,0.558202,0.54824,0.133904,0.146608,1.38002,1.31264,1.09443,1.07273,1.83934,1.92387,1.40818,1.30878,-0.514521,-0.468844,0.0702169,0.0780563,1.09594,1.17111,-0.144187,-0.205204,-0.325768,-0.307598,-1.01069,-1.07891
9729,0.710472,0.701776,0.213958,0.184255,0.330083,0.343391,0.951867,0.957044,0.0868229,0.0972323,0.488763,0.439794,0.211784,0.202731,0.180106,0.187911,0.40154,0.389824,0.860293,0.875071,0.462276,0.398583,0.127594,0.15054,-0.0506031,0.0375748,0.275787,0.175568,2.26897,2.3109,-0.677106,-0.664013,-1.398,-1.32141,0.626062,0.569312,-0.945771,-0.930661,1.27545,1.21464
9730,0.978053,0.959697,0.741239,0.712008,0.745622,0.756543,0.537966,0.544724,0.591817,0.601131,0.581843,0.605056,0.0573982,0.0482398,0.440348,0.448545,0.569363,0.559509,0.914745,0.865535,1.09351,1.03326,-0.743503,-0.771651,-0.690522,-0.608554,0.0126115,-0.091124,0.0328724,0.0698319,-0.331804,-0.311388,-0.0589724,0.0202358,-1.61971,-1.68165,-1.07451,-1.06051,-2.59342,-2.65424
9731,0.291559,0.27297,0.994964,0.963691,0.53447,0.543385,0.541503,0.548533,0.648885,0.658159,0.293238,0.334927,0.304659,0.294526,0.106894,0.117192,0.402457,0.39181,0.839904,0.855999,-1.20491,-1.25722,1.17507,1.14387,-1.6262,-1.54828,0.175503,0.0738909,0.765496,0.810676,1.10407,1.1271,-1.10456,-1.02738,0.11472,0.0451089,1.55829,1.57465,-1.74641,-1.80258
9732,0.670332,0.559071,0.438255,0.406709,0.0408053,0.0491034,0.782502,0.788462,0.0563644,0.0637435,0.0414201,0.0647986,0.31925,0.355726,0.905089,0.915717,0.682737,0.672987,0.308688,0.324544,0.479093,0.426735,0.0395552,0.00822972,1.67226,1.75068,0.856083,0.758439,0.764016,0.816514,0.252721,0.277707,-0.185747,-0.106153,0.288458,0.2215,-0.680755,-0.65884,-3.07334,-3.12823
9733,0.864273,0.845172,0.262829,0.232134,0.819649,0.827317,0.759751,0.748704,0.808031,0.816558,0.904515,0.927826,0.429233,0.416927,0.302848,0.314663,0.372552,0.33113,0.613615,0.62715,-0.0837167,-0.131834,-0.561275,-0.586876,0.0926804,0.1784,-0.727557,-0.819952,-0.0534633,-0.00825123,1.11079,1.13409,1.23639,1.3123,-0.268921,-0.33545,0.58887,0.611625,1.68674,1.63185
9734,0.493045,0.554048,0.826334,0.794107,0.717842,0.726645,0.701096,0.708946,0.831035,0.840066,0.8549,0.973214,0.229542,0.217269,0.292436,0.402798,0.000817898,-0.0107273,0.096921,0.1118,-0.18217,-0.23367,-0.300576,-0.353514,-0.813632,-0.731485,-0.862653,-0.961857,-1.63673,-1.5849,0.162366,0.191016,-0.0271044,0.0493577,0.701901,0.637822,0.0915897,0.110335,1.0562,1.00593
9735,0.28456,0.262924,0.199733,0.168555,0.900438,0.907968,0.274263,0.281783,0.0129116,0.023841,0.994432,1.0186,0.83778,0.824027,0.398385,0.490934,0.996464,0.984919,0.928916,0.945668,0.0844152,0.0322121,-0.100244,-0.120152,0.624819,0.709014,0.817241,0.721189,-0.561173,-0.558397,0.158739,0.189823,1.36752,1.43598,-1.26915,-1.33915,-1.56267,-1.55008,-1.09942,-1.15058
9736,0.29803,0.278116,0.480446,0.420228,0.676269,0.685971,0.912888,0.919126,0.391548,0.482985,0.216784,0.24283,0.189199,0.175852,0.566954,0.579069,0.640663,0.630197,0.829009,0.771009,-1.09608,-1.14026,-1.0746,-1.09914,-1.09214,-1.00799,-0.247727,-0.336712,0.425914,0.468101,-0.664488,-0.628547,1.39635,1.46689,0.948441,0.882245,-0.127449,-0.119944,-1.00934,-1.05446
9737,0.00738348,-0.011299,0.716543,0.671901,0.688812,0.664479,0.744267,0.751522,0.9312,0.942129,0.776617,0.804118,0.730727,0.717506,0.389983,0.402231,0.950928,0.940979,0.550217,0.596351,0.482066,0.43582,-1.22373,-1.25143,-1.61155,-1.52821,-0.517676,-0.603404,0.960324,1.00764,-0.744881,-0.706283,-1.32751,-1.25836,0.105661,0.0339804,0.237114,0.245681,-0.4577,-0.505455
9738,0.751944,0.732668,0.954751,0.923573,0.632256,0.642988,0.227098,0.233649,0.139279,0.152384,0.0781756,0.104797,0.771507,0.846671,0.981807,0.995379,0.602596,0.514834,0.406114,0.421692,0.332981,0.288738,-1.38532,-1.40372,-0.236441,-0.231406,-0.316817,-0.407662,0.0424741,0.0657672,0.584997,0.626089,-0.468685,-0.435864,-0.115073,-0.185813,1.43167,1.43639,-1.36817,-1.4192
9739,0.709465,0.619164,0.401372,0.371699,0.109551,0.119566,0.878864,0.885912,0.0628127,0.113645,0.342976,0.368233,0.988128,0.975837,0.551556,0.564276,0.100367,0.0886886,0.801488,0.816258,-1.52828,-1.5805,-0.938413,-0.957805,0.982053,1.0654,1.64835,1.55939,-0.923304,-0.876103,2.66848,2.71532,0.316664,0.386629,0.925769,0.8502,-1.18148,-1.17523,1.71495,1.66928
9740,0.524581,0.50566,0.760425,0.731811,0.415626,0.425462,0.00267891,0.0108372,0.0600113,0.0749052,0.00705642,0.0305969,0.216227,0.205343,0.351361,0.312733,0.862477,0.850232,0.399897,0.415697,-0.390467,-0.442081,0.0457467,0.025578,1.27746,1.35747,0.831427,0.735832,-0.547836,-0.501592,0.174839,0.221714,-1.22499,-1.16241,0.597742,0.522902,-1.43898,-1.42893,-0.553697,-0.598864
9741,0.706463,0.686185,0.575579,0.547561,0.719783,0.731359,0.582938,0.588717,0.330365,0.34661,0.449517,0.354239,0.651849,0.642238,0.0490229,0.0611897,0.250089,0.239979,0.272093,0.286484,-0.782189,-0.830201,0.124548,0.103756,-0.63608,-0.563272,-0.716433,-0.81057,-1.6633,-1.6162,-0.481453,-0.430619,-0.785012,-0.715506,-0.128645,-0.205642,-0.644601,-0.627898,0.913525,0.867225
9742,0.219362,0.199591,0.0811246,0.0546466,0.194117,0.207937,0.765044,0.76956,0.189468,0.204779,0.706609,0.677881,0.882074,0.873212,0.980043,0.993597,0.602678,0.591263,0.939166,0.955879,1.20573,1.15826,-1.61223,-1.6282,0.263732,0.343849,-0.836665,-0.936845,0.390289,0.436302,-0.576483,-0.523688,0.460993,0.531439,-1.12686,-1.20739,0.42128,0.440581,-1.61882,-1.65633
9743,0.0150395,-0.00427475,0.232958,0.282361,0.72885,0.741476,0.368455,0.372715,0.38809,0.404332,0.977982,1.00152,0.546108,0.538052,0.325454,0.341111,0.27132,0.261968,0.0177938,0.0328645,-2.08122,-2.12458,2.01328,2.00112,0.0217251,0.0993675,0.45641,0.350436,-1.10777,-1.06465,0.19316,0.241876,-1.53011,-1.45623,1.9458,1.86628,-1.38936,-1.3658,-1.44495,-1.48389
9744,0.858168,0.837479,0.510682,0.510075,0.413531,0.426948,0.333778,0.33629,0.0116748,0.0254599,0.4303,0.452176,0.834784,0.824598,0.331835,0.346766,0.243349,0.320175,0.201361,0.201512,-1.95665,-1.99676,-1.0809,-1.09962,-0.813858,-0.734301,-0.28407,-0.395816,-0.724804,-0.676251,0.448009,0.500314,0.137574,0.208267,1.20437,1.12277,-0.661505,-0.641311,-0.0145603,-0.0482458
9745,0.236103,0.216762,0.764267,0.737789,0.615269,0.627407,0.846759,0.849089,0.263946,0.335651,0.533284,0.556331,0.313102,0.302282,0.81878,0.833662,0.387762,0.378383,0.351996,0.37016,-1.0071,-1.04267,1.93966,1.9234,-1.36794,-1.35878,0.0919345,-0.0173849,0.0951696,0.14103,0.135884,0.191596,0.207378,0.271467,0.129526,0.043387,0.297387,0.316489,-0.675656,-0.704686
9746,0.655349,0.634827,0.00334187,-0.0236109,0.462547,0.443239,0.718699,0.721699,0.549158,0.645843,0.96495,0.990456,0.516634,0.503879,0.847904,0.863877,0.0593793,0.0490878,0.188928,0.205158,-0.933821,-0.975567,1.38242,1.35817,-2.06177,-1.98325,-0.195903,-0.299859,-1.91297,-1.87171,0.508742,0.556989,-1.27696,-1.21219,-0.204151,-0.283911,-0.113863,-0.0913382,0.53011,0.498989
9747,0.700186,0.680114,0.0634551,0.0360607,0.24699,0.259071,0.378663,0.380234,0.942249,0.956034,0.205483,0.230903,0.374228,0.275612,0.151036,0.165404,0.824314,0.815494,0.711095,0.729591,1.89741,1.86148,1.64845,1.62139,0.505127,0.577044,0.356001,0.248194,-0.135596,-0.0891625,0.528097,0.571355,-0.127071,-0.0567129,1.8108,1.72378,0.231919,0.259679,1.1992,1.17141
9748,0.0763714,0.0542279,0.416514,0.39507,0.671415,0.683239,0.658041,0.66014,0.118651,0.133416,0.364714,0.390373,0.0628138,0.0473462,0.460361,0.476594,0.305518,0.296253,0.27448,0.388135,-0.0388236,-0.0678176,-0.976138,-0.99774,1.17561,1.25368,1.53373,1.4279,-0.757485,-0.714288,-1.69809,-1.65074,0.123591,0.187289,1.28746,1.19753,-0.924023,-0.898065,-0.623415,-0.656195
9749,0.155882,0.134875,0.78099,0.754079,0.761747,0.774356,0.00322872,0.00288264,0.0998417,0.114453,0.84966,0.877517,0.203875,0.227533,0.217324,0.310317,0.287466,0.226872,0.0260726,0.0466795,-0.196562,-0.229928,0.984361,0.965396,0.245563,0.367625,-1.43255,-1.53367,-0.204328,-0.159548,-2.49737,-2.45435,0.614164,0.679268,-0.976132,-1.07059,0.0371462,0.0597344,1.04364,1.00797
9750,0.950671,0.931437,0.710048,0.685037,0.0876607,0.10056,0.644012,0.64491,0.538408,0.533532,0.188349,0.217593,0.421013,0.40772,0.12763,0.14404,0.167458,0.157491,0.133981,0.236377,0.493502,0.380772,1.65785,1.64376,-0.598301,-0.518434,0.624391,0.528973,-0.47829,-0.434282,1.1794,1.22083,-1.19618,-1.1347,-0.651542,-0.738707,-2.38811,-2.3581,0.159094,0.12446
9751,0.366476,0.345248,0.0574024,0.0345138,0.358004,0.328398,0.351757,0.39145,0.937893,0.952611,0.63539,0.595816,0.81827,0.804198,0.638037,0.656034,0.76356,0.753962,0.406804,0.426075,1.01746,0.991471,-1.50209,-1.51135,1.08189,1.15599,0.654285,0.554874,0.217649,0.210173,-1.21024,-1.17558,0.609221,0.669549,0.314484,0.219518,-0.0435236,-0.0134497,0.0139791,-0.0182747
9752,0.544073,0.520655,0.327028,0.370432,0.559879,0.556236,0.136631,0.137991,0.550887,0.564276,0.944683,0.974039,0.943485,0.929576,0.797648,0.817499,0.144162,0.133532,0.344776,0.270045,0.277618,0.24934,-0.669235,-0.679532,0.396715,0.46355,-0.0166065,-0.112352,0.819109,0.854629,0.45583,0.49565,0.332834,0.395642,0.51684,0.427122,-1.14982,-1.12072,0.906892,0.880281
9753,0.373053,0.348658,0.726993,0.70635,0.747446,0.784074,0.941578,0.944344,0.467436,0.478524,0.577591,0.606631,0.482927,0.469113,0.575238,0.595088,0.774966,0.764451,0.0963622,0.114014,-1.17642,-1.19922,-0.350565,-0.354697,0.181749,0.248675,1.27362,1.17493,-0.198217,-0.169373,-0.285536,-0.246419,-0.880125,-0.821888,0.037172,-0.0531085,0.417956,0.447113,0.440078,0.420187
9754,0.487968,0.430015,0.352992,0.331738,0.999013,1.01191,0.553075,0.56672,0.87741,0.886484,0.691144,0.68414,0.625531,0.551116,0.0575601,0.0792801,0.244052,0.235285,0.267766,0.286186,1.04702,1.02004,0.984688,0.984131,0.487139,0.556557,-1.0693,-1.17284,-0.597536,-0.565871,0.675686,0.717103,-1.35567,-1.29901,0.193042,0.10903,-0.136665,-0.0997165,-0.319352,-0.342618
9755,0.409627,0.511372,0.918636,0.898221,0.754815,0.715631,0.187449,0.189096,0.802902,0.811456,0.732446,0.761649,0.647556,0.63312,0.202806,0.225663,0.921363,0.913139,0.0841996,0.100776,0.0223175,-0.00186264,-3.16162,-3.1611,-0.675209,-0.603344,0.842015,0.732227,-0.241846,-0.207525,-1.20458,-1.15928,-0.719515,-0.627576,-0.4794,-0.55823,-0.321779,-0.292614,0.269841,0.25162
9756,0.511376,0.592729,0.00440927,-0.017211,0.527315,0.41935,0.773279,0.776401,0.0730855,0.0799293,0.104276,0.131735,0.534986,0.562779,0.646924,0.6679,0.51575,0.52974,0.337031,0.353982,0.400095,0.372757,0.648179,0.652741,0.234085,0.303777,0.846124,0.743794,-0.993275,-0.954842,1.05766,1.10783,-0.0128057,0.0438569,-0.0151275,-0.0897003,0.134682,0.16589,0.105863,0.0925331
9757,0.698481,0.674086,0.349117,0.232018,0.11017,0.123069,0.265412,0.268491,0.219878,0.224384,0.881695,0.908855,0.508854,0.492439,0.545014,0.567965,0.156586,0.146341,0.957224,0.972636,-0.0805819,-0.109793,-0.942586,-0.934856,0.616058,0.686809,-0.0735571,-0.174513,-0.290212,-0.245994,0.978633,1.0301,1.47246,1.52333,2.13962,2.05771,1.62186,1.65812,-0.787439,-0.805258
9758,0.118082,0.0932741,0.504611,0.481247,0.0787293,0.0895252,0.274783,0.373724,0.603678,0.607796,0.757373,0.785651,0.0964562,0.0813206,0.215268,0.236612,0.948894,0.938972,0.97943,0.994825,0.212428,0.18966,-0.131066,-0.119829,-0.355557,-0.288083,-0.0915775,-0.165271,0.172698,0.218124,0.150667,0.195728,0.0658864,0.118761,-1.06227,-1.13743,-1.49426,-1.45929,1.43619,1.42415
9759,0.27721,0.253472,0.969157,0.944324,0.95379,0.966572,0.474377,0.478958,0.594561,0.600518,0.119389,0.145996,0.957966,0.944623,0.467871,0.571341,0.0303479,0.0211279,0.559251,0.574236,-0.823568,-0.846491,1.72197,1.7324,-0.884874,-0.823508,-0.0582091,-0.15603,0.328914,0.377521,1.6418,1.67966,0.194902,0.241515,-0.597239,-0.668899,-1.21862,-1.18883,-1.29509,-1.31318
9760,0.946074,0.924693,0.633618,0.60925,0.999175,1.01326,0.953559,0.956448,0.938329,0.943116,0.813774,0.842385,0.793934,0.780805,0.883091,0.906071,0.0598848,0.0506879,0.393739,0.498666,-0.0172676,-0.0443794,0.376638,0.39315,-0.0893298,-0.0244842,1.7543,1.65519,-0.347475,-0.294261,0.716541,0.753446,0.929017,0.978579,-0.586727,-0.661568,0.144834,0.179248,-0.242351,-0.262337
9761,0.990564,0.96998,0.93795,0.915709,0.533592,0.548829,0.297265,0.299191,0.805725,0.811492,0.88966,0.91835,0.882996,0.87044,0.559865,0.584151,0.697166,0.687921,0.410162,0.423096,-1.53701,-1.56817,0.331756,0.348384,0.0229525,0.0300595,0.98914,0.893313,0.278958,0.338625,-0.682287,-0.650523,-0.0666736,-0.023225,-2.29623,-2.37089,-1.25651,-1.22906,-0.92678,-0.947761
9762,0.73404,0.711902,0.884577,0.861227,0.558466,0.576115,0.330061,0.33197,0.469916,0.474284,0.313221,0.343986,0.670372,0.66007,0.479136,0.503297,0.0764754,0.067491,0.117359,0.127689,-0.0954115,-0.133256,-0.0526065,-0.0332823,0.0197578,0.0846033,1.45247,1.36252,1.19386,1.24809,1.38345,1.41048,-0.105169,-0.0680478,1.51517,1.43737,0.0506309,0.0728418,0.650674,0.62529
9763,0.137274,0.116318,0.541042,0.516224,0.280152,0.297532,0.633618,0.636387,0.742103,0.745989,0.161557,0.191029,0.866963,0.856724,0.893815,0.919865,0.147797,0.141149,0.847917,0.856152,-0.858585,-0.891855,-1.6357,-1.62088,-2.50451,-2.43873,1.62962,1.54357,0.963945,1.01807,0.445994,0.467406,-0.889701,-0.850418,0.0382156,-0.0746945,-0.297265,-0.275095,-1.10697,-1.13007
9764,0.819353,0.797525,0.670758,0.664014,0.64708,0.664853,0.0258812,0.0284038,0.621343,0.624142,0.708224,0.737115,0.608274,0.570939,0.401164,0.428788,0.577884,0.571606,0.229436,0.235452,3.71909,3.68583,0.603222,0.615432,1.15222,1.21835,-0.231775,-0.321232,-1.34974,-1.28869,0.44277,0.466213,0.469763,0.505347,-1.50895,-1.58675,-0.282351,-0.265782,-0.815636,-0.837841
9765,0.186053,0.166399,0.839636,0.811803,0.711331,0.727033,0.28533,0.289232,0.879345,0.880993,0.0561041,0.0870624,0.295422,0.285155,0.500663,0.476529,0.616355,0.680528,0.0908896,0.0956801,1.41457,1.37886,-1.39684,-1.3797,-1.36275,-1.29029,0.643,0.550736,-0.365454,-0.30163,-0.621564,-0.598615,1.16667,1.19686,-1.04464,-1.03394,0.758993,0.772684,1.5044,1.4863
9766,0.518648,0.47347,0.98441,0.959592,0.519342,0.534998,0.75914,0.76224,0.301688,0.302424,0.187587,0.21676,0.700995,0.692123,0.425259,0.524269,0.795615,0.78945,0.908703,0.913965,0.295222,0.265207,0.202698,0.225008,-0.382604,-0.306975,-1.87345,-1.9656,-0.918561,-0.850406,2.9775,2.99568,1.37185,1.39567,-0.409347,-0.481131,0.585272,0.595111,-1.54072,-1.55453
9767,0.800033,0.780541,0.122299,0.0982952,0.0032343,0.0214345,0.410277,0.415513,0.372163,0.371596,0.54988,0.576853,0.334965,0.325821,0.543795,0.572009,0.0109677,0.00457366,0.980532,0.985993,0.0434905,0.0147919,-0.0299681,-0.00598222,-0.217662,-0.140473,-1.54095,-1.63259,0.201908,0.272635,-1.60652,-1.59516,-0.644602,-0.621908,-0.76596,-0.840067,-1.43696,-1.4212,0.695678,0.674878
9768,0.557727,0.536879,0.785683,0.762505,0.466714,0.509457,0.604371,0.611805,0.882215,0.879935,0.186856,0.215127,0.894618,0.887334,0.383382,0.40925,0.343424,0.285171,0.300833,0.304935,0.345281,0.314245,0.290731,0.318853,0.938191,1.00926,-0.0473231,-0.138951,-0.173518,-0.109687,-0.515578,-0.497719,1.17745,1.20039,2.46591,2.39529,-0.150121,-0.135035,1.684,1.66452
9769,0.773707,0.724213,0.597858,0.594051,0.980337,0.997479,0.418101,0.492652,0.0802803,0.0792329,0.4211,0.457334,0.519426,0.511371,0.720889,0.746812,0.571932,0.565769,0.864378,0.868323,2.5274,2.50338,2.44024,2.47583,-0.669509,-0.595594,0.0592298,-0.0812526,0.088821,0.183472,0.594221,0.59972,1.97348,1.99731,0.712995,0.640669,-1.32494,-1.30785,-0.251148,-0.277849
9770,0.931467,0.911548,0.449541,0.425596,0.267683,0.28302,0.367849,0.3735,0.205505,0.203628,0.565709,0.699541,0.636556,0.584811,0.165369,0.190699,0.104055,0.0962522,0.51571,0.517242,-1.87063,-1.88984,-0.146564,-0.114721,0.774761,0.844906,0.0656449,-0.0235542,0.39797,0.476631,-1.89792,-1.89388,0.0285338,0.057066,1.85967,1.78204,0.236557,0.259984,0.469863,0.440149
9771,0.526464,0.506339,0.639967,0.677557,0.740886,0.756614,0.824494,0.831185,0.129026,0.16067,0.911649,0.941748,0.667325,0.658251,0.304508,0.411705,0.972899,0.962974,0.991078,0.991246,1.64787,1.63368,-0.33688,-0.312293,-1.00203,-0.932466,-0.214871,-0.306029,0.705959,0.76979,-0.416023,-0.409951,3.35719,3.37897,-1.14706,-1.21541,2.69905,2.71574,-2.26898,-2.29718
9772,0.814162,0.793185,0.950709,0.929518,0.173968,0.187882,0.0736728,0.0785234,0.121148,0.117712,0.625547,0.68204,0.295506,0.287537,0.606734,0.632711,0.329198,0.318296,0.949116,0.947963,0.211146,0.198014,0.741986,0.765354,-0.817139,-0.749336,-1.55247,-1.63867,-1.966,-1.90378,1.4841,1.49152,-0.0629943,-0.0360291,-1.26232,-1.32926,0.492142,0.513752,0.28556,0.264085
9773,0.716533,0.695747,0.553724,0.489527,0.795586,0.811214,0.386712,0.311087,0.673475,0.672206,0.394722,0.422331,0.474708,0.468295,0.334976,0.360178,0.660925,0.644823,0.209509,0.210273,1.21108,1.20022,1.46955,1.48743,1.58359,1.65524,-1.7989,-1.8904,1.7845,1.84439,-0.742577,-0.730568,3.02084,3.04126,0.954058,0.879844,0.473268,0.492807,1.26895,1.25373
9774,0.15069,0.129784,0.0721098,0.0495349,0.947163,0.962812,0.541216,0.543651,0.753528,0.785285,0.45921,0.488772,0.0754019,0.0679569,0.367661,0.390392,0.980624,0.97135,0.91524,0.914698,0.309982,0.302272,-2.1808,-2.16149,0.715156,0.791561,-2.69542,-2.79065,0.0942495,0.159666,0.708109,0.721254,-0.841073,-0.828025,-0.15857,-0.229659,0.800263,0.827248,-0.969575,-0.983446
9775,0.626951,0.606746,0.570923,0.548015,0.0737281,0.0881791,0.0872765,0.0917836,0.898267,0.898363,0.298685,0.382771,0.316241,0.27288,0.994396,1.01584,0.629107,0.621738,0.801492,0.798907,1.78741,1.78591,0.414542,0.43006,0.107811,0.190342,-1.81171,-1.90279,0.92044,0.992909,-0.662252,-0.652689,-0.409835,-0.39603,1.08492,1.01756,-0.202881,-0.172293,1.75425,1.74726
9776,0.537185,0.514681,0.861543,0.838882,0.499054,0.512347,0.741344,0.744048,0.180744,0.182778,0.247154,0.27677,0.511928,0.477804,0.874696,0.885961,0.725485,0.720272,0.170827,0.168143,-0.490472,-0.490478,1.38835,1.39993,0.513157,0.590635,-0.335247,-0.370047,0.529586,0.596412,-1.06164,-1.05254,0.365223,0.371067,1.73554,1.67079,1.31915,1.35041,1.48953,1.48271
9777,0.732473,0.710651,0.574264,0.553222,0.244382,0.258828,0.155423,0.156273,0.43339,0.395126,0.297948,0.327506,0.687766,0.682728,0.690376,0.756084,0.538684,0.51668,0.578068,0.577457,-0.176107,-0.177252,-0.990678,-0.981567,0.606759,0.680846,1.25378,1.16269,2.40789,2.47372,0.332829,0.339828,-1.30375,-1.30278,-2.08238,-2.15135,0.972615,1.06064,-0.0918622,-0.101075
9778,0.608238,0.586707,0.591038,0.508924,0.490653,0.598598,0.888603,0.888748,0.606088,0.607474,0.0306884,0.059629,0.895096,0.887651,0.604764,0.626207,0.318546,0.313088,0.508356,0.536072,-0.836477,-0.842146,-0.781873,-0.83419,1.27126,1.34017,-0.112127,-0.200116,-0.801487,-0.736788,-0.413077,-0.402241,-0.664044,-0.655882,0.238889,0.171678,0.744709,0.770866,-0.0247591,-0.0328503
9779,0.0332576,0.0104567,0.487098,0.464626,0.926472,0.938367,0.851078,0.852323,0.113011,0.114138,0.151392,0.0995116,0.922725,0.851804,0.858466,0.881914,0.673222,0.669411,0.498416,0.494686,0.912024,0.903406,-0.699285,-0.686814,-0.477016,-0.405178,-1.05098,-1.13363,0.442056,0.512314,-0.948752,-0.943746,-0.892034,-0.883803,1.13527,1.06845,-0.730187,-0.701664,-1.62759,-1.63302
9780,0.22067,0.196487,0.05439,0.0314599,0.936816,0.950373,0.519887,0.538373,0.516896,0.460564,0.109469,0.139394,0.82444,0.815958,0.157094,0.178502,0.709541,0.701526,0.452729,0.4533,-0.062416,-0.0701796,-2.13927,-2.12082,0.953474,1.01916,-2.24697,-2.32922,0.276637,0.437793,-0.328246,-0.329531,0.530204,0.534647,1.78777,1.72168,-1.0262,-1.00241,2.10653,2.09961
9781,0.655333,0.629449,0.719405,0.69567,0.582786,0.627851,0.224402,0.224423,0.805077,0.80699,0.487416,0.499672,0.0144793,0.00425794,0.414246,0.434209,0.735913,0.733641,0.811788,0.813428,2.11967,2.10485,-2.09042,-2.07363,-0.219715,-0.156438,0.514949,0.431948,0.25049,0.363271,0.590915,0.588969,1.38312,1.39139,1.1672,1.10264,-0.88525,-0.855109,1.52907,1.51814
9782,0.385328,0.360216,0.301625,0.277001,0.289203,0.305329,0.140601,0.182585,0.809042,0.725714,0.829376,0.859951,0.639084,0.629729,0.978271,0.996445,0.469753,0.468783,0.32749,0.327483,-0.221388,-0.231574,0.0141694,0.0342781,-0.0832593,-0.0185744,-2.21568,-2.29852,0.218491,0.288749,-0.46475,-0.459601,-1.49245,-1.48005,-1.35447,-1.42344,0.0370726,0.0724611,-0.70496,-0.719036
9783,0.709048,0.681613,0.961391,0.936335,0.417845,0.353109,0.1424,0.140747,0.641022,0.644439,0.6602,0.692314,0.352688,0.343863,0.773801,0.789566,0.641878,0.571525,0.430736,0.449562,0.760583,0.753021,1.29114,1.31286,-1.57701,-1.5151,0.475597,0.400059,1.85394,1.9193,-1.27443,-1.26321,0.505844,0.511166,-0.658093,-0.703538,0.195012,0.235585,-1.33673,-1.34496
9784,0.468833,0.489977,0.874032,0.847972,0.384014,0.40089,0.841627,0.838131,0.447792,0.378937,0.989049,1.02242,0.67538,0.665754,0.948681,0.966956,0.656873,0.674267,0.571968,0.571641,-0.156716,-0.161037,-0.739251,-0.785708,0.179705,0.237524,0.604698,0.534074,-0.263517,-0.198747,0.798008,0.81061,-0.191726,-0.179356,0.0921855,0.0163637,0.995255,1.03662,-0.861524,-0.87204
9785,0.326987,0.298341,0.468774,0.444318,0.656306,0.672159,0.52794,0.493682,0.110479,0.113436,0.468213,0.50235,0.494346,0.485759,0.638231,0.654879,0.828132,0.77701,0.18898,0.191234,1.18737,1.18102,-2.90599,-2.88427,-0.806076,-0.750616,-0.72847,-0.798571,0.1038,0.175764,-0.538213,-0.500934,-0.022902,-0.0111962,0.561641,0.484894,-0.666815,-0.623797,0.318741,0.301844
9786,0.865068,0.83512,0.503305,0.478235,0.401993,0.432016,0.150624,0.149233,0.695863,0.69885,0.183621,0.219597,0.616509,0.612146,0.633068,0.650081,0.880723,0.879752,0.0187854,0.0210545,0.57827,0.576534,0.12939,0.153798,-0.819775,-0.765362,-1.47858,-1.54482,1.47477,1.54408,-1.82393,-1.81248,-0.199309,-0.192927,-0.743741,-0.826487,0.439582,0.475856,-0.511838,-0.534232
9787,0.654313,0.626275,0.0350082,0.00997434,0.175376,0.191873,0.46746,0.464058,0.0677544,0.0690343,0.71061,0.746275,0.745807,0.738532,0.367585,0.383026,0.657814,0.625752,0.919648,0.919425,-1.24835,-1.24462,-0.85823,-0.841459,0.899127,0.957025,1.94966,1.88591,0.565739,0.535232,0.194492,0.21316,-2.0934,-2.08523,0.157362,0.070289,-0.230401,-0.195096,-0.341708,-0.361784
9788,0.0673569,0.0400868,0.641363,0.615416,0.320278,0.338745,0.160899,0.156273,0.611487,0.613403,0.870206,0.905745,0.00508184,-0.00471069,0.339276,0.332788,0.374427,0.371751,0.236632,0.238367,1.27092,1.27583,-0.145197,-0.133628,0.839895,0.896367,-0.372375,-0.443238,-0.471808,-0.473617,-1.02295,-1.00187,-0.237222,-0.232377,-0.825299,-0.916035,1.527,1.56214,-3.25013,-3.26541
9789,0.884112,0.85795,0.735996,0.709755,0.0273968,0.0447757,0.338853,0.326616,0.0574149,0.0596141,0.55047,0.508662,0.717279,0.708464,0.208844,0.28255,0.94613,0.941115,0.0966627,0.0985949,-0.228748,-0.219225,1.69557,1.7053,0.166946,0.217873,1.8468,1.78092,-1.55177,-1.48247,-0.120395,-0.0978929,0.119681,0.121476,0.486733,0.392953,-0.896507,-0.855697,-2.18131,-2.19941
9790,0.371831,0.347093,0.629226,0.681278,0.850551,0.870132,0.499468,0.496958,0.588925,0.593376,0.0768524,0.11158,0.0256025,0.0165391,0.218411,0.232312,0.42279,0.417049,0.922525,0.922941,0.998716,1.01076,1.12098,1.23266,1.80937,1.86057,-1.14799,-1.21745,-0.640207,-0.573004,1.31428,1.34059,-0.794188,-0.785541,0.876518,0.785739,1.06651,1.11117,-0.365932,-0.377695
9791,0.957944,0.932723,0.677091,0.652802,0.178112,0.196335,0.380084,0.379032,0.0771397,0.0802541,0.239426,0.276742,0.947623,0.939211,0.901701,0.913903,0.79923,0.792858,0.314716,0.31689,0.044829,0.0672709,0.742166,0.760022,-0.402768,-0.346434,0.0151525,-0.0508705,-0.359236,-0.291953,-1.77897,-1.75073,0.407987,0.415332,-0.330232,-0.502991,1.28199,1.31941,-1.30842,-1.32166
9792,0.922578,0.926554,0.847879,0.821809,0.749856,0.768882,0.944536,0.942375,0.851757,0.854425,0.777912,0.814064,0.346727,0.338161,0.57022,0.623895,0.742331,0.673837,0.928213,0.930528,-0.888253,-0.876214,0.358213,0.378356,-0.942749,-0.881859,1.67038,1.60053,-0.918852,-0.855845,-0.0561998,-0.032446,-0.474299,-0.461414,-1.69437,-1.79172,0.90536,0.943038,1.05941,1.05342
9793,0.946982,0.920385,0.750616,0.724118,0.313821,0.333553,0.964428,0.960292,0.517684,0.571966,0.75875,0.784252,0.732423,0.724913,0.32325,0.333887,0.653955,0.554817,0.757089,0.760348,-0.681556,-0.70635,1.0861,1.10043,0.222189,0.284623,-1.28116,-1.345,1.80393,1.86917,0.915716,0.931077,-0.0344532,-0.0145131,-0.00749111,-0.11009,0.873913,0.906984,-0.030606,-0.0294703
9794,0.649291,0.551413,0.95401,0.926579,0.125291,0.146076,0.406317,0.402053,0.288224,0.289507,0.719664,0.75444,0.0914954,0.0830386,0.404008,0.414659,0.442585,0.435796,0.0971191,0.0989948,-0.542867,-0.536485,-0.730175,-0.710026,-1.10027,-1.04375,-0.259619,-0.318322,-0.564562,-0.502163,0.240072,0.248979,-0.928757,-0.90631,0.400125,0.297871,-1.86832,-1.84048,0.500217,0.50426
9795,0.207981,0.182441,0.877752,0.848785,0.911684,0.934823,0.255566,0.309586,0.338864,0.341846,0.407928,0.443624,0.181157,0.107069,0.220113,0.330274,0.938274,0.931539,0.924844,0.926888,1.13058,1.1309,0.365043,0.38486,0.947906,1.00371,-0.105069,-0.167565,0.76692,0.822256,1.19262,1.19881,1.43101,1.45823,0.112205,0.0169122,-1.4282,-1.39723,0.284125,0.284067
9796,0.318697,0.258151,0.229058,0.198262,0.810916,0.83415,0.267519,0.217119,0.941231,0.946982,0.100201,0.132808,0.140099,0.131099,0.2343,0.24589,0.216406,0.210713,0.181163,0.183798,0.0318868,0.0327679,-0.363491,-0.347152,1.05633,1.11021,0.795789,0.73588,1.20317,1.2554,-1.26498,-1.25846,0.906552,0.93505,0.484561,0.395623,2.00658,2.04236,1.37914,1.38076
9797,0.360713,0.333861,0.805534,0.774025,0.411722,0.434037,0.126866,0.124652,0.429154,0.43386,0.960729,0.995836,0.584021,0.577246,0.866498,0.876113,0.458761,0.529731,0.856101,0.857705,-0.0831165,-0.0847064,-0.740453,-0.728819,0.0232386,0.0750023,-0.569551,-0.626931,-1.50484,-1.45054,-0.441687,-0.433547,-0.540027,-0.516368,-1.05573,-1.14226,-0.860546,-0.818951,-0.12859,-0.127044
9798,0.663079,0.635723,0.274951,0.241952,0.704166,0.725493,0.475386,0.473439,0.591656,0.680393,0.370211,0.406045,0.433851,0.427716,0.0404455,0.0485982,0.855461,0.848749,0.956309,0.958116,0.00991564,0.0115047,0.967624,0.983426,-0.238126,-0.177958,-0.635958,-0.693238,0.837933,0.888007,-0.204198,-0.1893,-1.06899,-1.03954,-0.316551,-0.398181,0.522353,0.564373,0.0785668,0.0756394
9799,0.724979,0.695976,0.490271,0.459282,0.239037,0.261064,0.168262,0.165654,0.924664,0.926927,0.71775,0.751695,0.61426,0.671018,0.309239,0.234706,0.745392,0.736761,0.192195,0.195012,1.04106,1.04235,0.514222,0.526651,-0.484011,-0.430918,-0.92251,-0.975713,0.52977,0.583309,1.97475,1.99725,1.51311,1.54755,1.34934,1.2663,0.275291,0.39339,1.126,1.12648
9800,0.0628853,0.0342676,0.0694798,0.0406129,0.981287,1.00194,0.820824,0.817918,0.0821764,0.0845437,0.0341891,0.0669289,0.919423,0.914321,0.414899,0.420814,0.873383,0.866131,0.23636,0.236887,-0.437695,-0.436207,1.62813,1.63603,0.292823,0.351789,-0.64862,-0.703172,0.0106881,0.0652735,-2.29895,-2.27441,-2.0925,-2.05006,-0.268396,-0.349439,0.181949,0.222407,1.59148,1.5994
9801,0.249663,0.253319,0.899528,0.867993,0.122481,0.145235,0.999551,0.998761,0.395766,0.322824,0.226668,0.260673,0.219975,0.213176,0.378794,0.3847,0.160815,0.155733,0.995542,0.996236,-1.22984,-1.22733,0.328026,0.33178,0.415215,0.472613,-1.72768,-1.77509,-1.41105,-1.35734,1.47096,1.49661,-0.774127,-0.723702,-0.596505,-0.676737,1.26472,1.30632,-0.374104,-0.374116
9802,0.502378,0.472371,0.262912,0.232533,0.355548,0.332268,0.514547,0.535622,0.624015,0.561105,0.680087,0.713994,0.186115,0.179123,0.754956,0.762117,0.699806,0.69641,0.248287,0.248354,0.0327813,0.0369259,0.4163,0.458376,-0.076825,-0.016283,2.19333,2.1492,1.40244,1.45291,0.905891,0.926123,0.814423,0.863691,0.361626,0.281488,-0.108083,-0.07094,0.213195,0.206552
9803,0.0147183,-0.0142231,0.969822,0.937766,0.550873,0.519301,0.0732733,0.0724836,0.797019,0.799386,0.691475,0.725806,0.354813,0.349835,0.100403,0.109632,0.360272,0.357155,0.879331,0.877884,-1.1329,-1.12094,0.583329,0.584972,-1.37938,-1.31323,-0.674177,-0.723429,0.923348,0.979893,1.46491,1.47862,0.485138,0.526753,-1.18382,-1.25639,-0.609282,-0.50169,-0.723645,-0.737412
9804,0.0681019,0.0414383,0.113762,0.0816397,0.683579,0.706333,0.22756,0.227115,0.792351,0.796838,0.375748,0.502511,0.731962,0.726595,0.824904,0.831954,0.536523,0.532122,0.667606,0.667087,1.99303,2.00284,-0.139378,-0.131218,-1.44037,-1.37389,0.734737,0.689956,-0.371334,-0.320362,0.180676,0.19845,-2.73104,-2.68456,0.0904392,0.083612,-0.972557,-0.932439,0.464273,0.45381
9805,0.397444,0.369015,0.712696,0.681659,0.528443,0.549661,0.645326,0.645272,0.0543975,0.0594709,0.243967,0.279217,0.117201,0.1103,0.856862,0.863175,0.0371791,0.0323694,0.990791,0.990822,-1.29539,-1.28,-2.67355,-2.67053,0.174784,0.236067,-0.540524,-0.595321,-0.57622,-0.519175,-0.799237,-0.774008,-1.24076,-1.19276,1.49619,1.42362,0.865195,0.903851,-2.2824,-2.295
9806,0.252109,0.220873,0.243983,0.213398,0.167024,0.190038,0.543325,0.542697,0.82167,0.828519,0.900746,0.935715,0.596639,0.586823,0.888228,0.894395,0.811251,0.803882,0.430096,0.429752,-1.57848,-1.56112,-0.690071,-0.69252,0.664465,0.725283,-1.83582,-1.8806,1.70383,1.76728,-1.23124,-1.20514,-0.654109,-0.664814,-0.254407,-0.331006,1.80656,1.84779,1.28698,1.27571
9807,0.407743,0.376164,0.420121,0.392086,0.389323,0.410434,0.172,0.170779,0.846793,0.813181,0.917558,0.952409,0.197329,0.186485,0.0233702,0.02869,0.222319,0.214834,0.40084,0.40038,-2.33802,-2.31972,-1.51923,-1.51752,0.493693,0.558869,-0.296568,-0.341032,-0.621921,-0.554755,1.24672,1.27449,-0.181592,-0.136873,-0.232183,-0.294444,0.310753,0.34411,-0.702762,-0.711147
9808,0.900485,0.867691,0.247801,0.217511,0.376668,0.396946,0.520092,0.425603,0.789045,0.797843,0.282366,0.317035,0.559848,0.548946,0.523497,0.507374,0.0354388,0.0277449,0.96901,0.968776,-0.477191,-0.453075,2.52908,2.53767,0.943855,1.0042,-0.548416,-0.592754,0.777401,0.845775,0.127443,0.251274,-0.950602,-0.903822,-0.175459,-0.257883,-0.981452,-0.953908,2.0844,2.08045
9809,0.0580307,0.0253638,0.937456,0.907177,0.0745923,0.0928697,0.680201,0.680427,0.40479,0.414154,0.742301,0.775266,0.376802,0.397821,0.983101,0.986058,0.190272,0.182713,0.258506,0.256881,-0.259841,-0.234188,0.723663,0.727215,0.47438,0.531712,1.83197,1.78576,-0.805022,-0.73087,-0.801171,-0.771943,0.970537,1.01291,-1.22293,-1.30546,-0.619581,-0.588282,0.657678,0.700435
9810,0.99993,0.965947,0.480234,0.43897,0.874682,0.892303,0.0493892,0.0482108,0.832604,0.842438,0.0344694,0.0655633,0.284248,0.246697,0.916595,0.829455,0.610425,0.603778,0.429704,0.429052,0.478912,0.455956,-0.712416,-0.706793,0.26266,0.316838,1.32027,1.2723,0.0669876,0.148209,1.85529,1.88486,-1.22223,-1.17627,-1.05838,-1.14332,-0.720044,-0.686998,-0.675628,-0.679578
9811,0.861402,0.897761,0.00104069,-0.0292382,0.400169,0.417327,0.813406,0.811609,0.771992,0.78259,0.422045,0.454895,0.106475,0.0955729,0.671677,0.672851,0.139375,0.134261,0.972801,0.973183,1.11359,1.1461,-1.07855,-1.07121,-0.231913,-0.172058,0.0590203,0.00052434,0.0314426,0.105903,0.403075,0.436631,0.202541,0.242184,-0.256855,-0.337459,0.866682,0.897475,0.689594,0.69262
9812,0.865635,0.829575,0.146596,0.198952,0.501437,0.518651,0.196029,0.193957,0.159387,0.168163,0.104656,0.135646,0.755527,0.743513,0.123621,0.127328,0.819548,0.81654,0.811762,0.812808,-1.46782,-1.44251,1.7624,1.77759,-0.135733,-0.0818469,-1.22011,-1.27125,0.69641,0.770338,1.35053,1.38646,0.771395,0.812154,-0.181266,-0.268205,-0.20464,-0.179985,0.101119,0.111146
9813,0.520236,0.484323,0.45788,0.427142,0.991102,1.00692,0.634494,0.632624,0.0373675,0.0463164,0.530196,0.559257,0.114164,0.101638,0.227039,0.228873,0.0504731,0.0475206,0.0785962,0.0796909,-0.497133,-0.471254,1.05251,1.0614,-0.739454,-0.683066,-0.946525,-0.998714,-1.10968,-1.03677,-0.58356,-0.551691,1.01478,1.05616,-0.453353,-0.535031,-0.239934,-0.216039,1.99621,2.00969
9814,0.777846,0.740764,0.47028,0.481707,0.286471,0.302626,0.52874,0.525,0.345772,0.353577,0.402815,0.430667,0.0549691,0.0432596,0.758229,0.761456,0.880643,0.876021,0.401636,0.403426,-1.60507,-1.58491,-0.253684,-0.242853,-0.63192,-0.576565,0.104542,0.0754129,1.85258,1.93303,-0.820011,-0.782644,0.111294,0.14914,0.226254,0.148277,0.890595,0.914239,-1.34606,-1.33494
9815,0.558938,0.52153,0.564546,0.536273,0.985956,1.00299,0.190023,0.187584,0.915034,0.922317,0.648945,0.678776,0.982767,0.97085,0.0334244,0.0367456,0.776841,0.717448,0.12227,0.122509,-1.37754,-1.3501,-1.11127,-1.09876,-1.48148,-1.42412,1.19495,1.14954,-0.390826,-0.308039,-0.626598,-0.584571,-1.25446,-1.22392,1.45568,1.37972,0.311031,0.335769,-0.0423213,-0.0389211
9816,0.897942,0.858629,0.961344,0.931722,0.772847,0.847861,0.690628,0.689919,0.186533,0.19581,0.270311,0.301951,0.718329,0.70489,0.371761,0.378038,0.562612,0.558875,0.246466,0.243958,0.0146271,0.0887236,0.810395,0.816763,1.74115,1.79207,1.02648,0.976044,0.588048,0.665222,1.02027,1.05767,0.235259,0.267877,-0.611441,-0.689732,-0.901294,-0.881091,0.681963,0.679078
9817,0.509231,0.446593,0.315031,0.286016,0.595757,0.692733,0.988809,0.990309,0.866674,0.876802,0.708389,0.740307,0.0660999,0.0526453,0.719089,0.71933,0.0721048,0.0688585,0.591467,0.58828,1.5001,1.52754,2.28717,2.29648,-0.0897178,-0.0347367,-0.122892,-0.19387,-1.07182,-0.987294,-0.0915916,-0.051931,-0.7116,-0.686017,-1.03565,-1.10945,-1.04266,-1.02729,-0.99348,-0.997878
9818,0.0734078,0.0345566,0.723217,0.6961,0.470898,0.537605,0.339808,0.342677,0.645998,0.654644,0.625456,0.657174,0.560205,0.544734,0.755463,0.749996,0.00729296,0.00306574,0.572949,0.568773,1.42656,1.45642,1.67951,1.68682,0.0136412,0.0717641,-1.31335,-1.36378,-0.125054,-0.046065,0.629857,0.667258,-0.285026,-0.298977,1.38073,1.30163,-1.5975,-1.5897,-1.19233,-1.20222
9819,0.575354,0.536686,0.184976,0.159002,0.365444,0.382477,0.767245,0.771362,0.930787,0.941916,0.13508,0.166917,0.101143,0.0842715,0.839277,0.780662,0.252844,0.249142,0.292612,0.287856,0.802595,0.8349,-0.656856,-0.647913,-1.61393,-1.5494,0.854491,0.808512,-0.686633,-0.609957,-0.507623,-0.472351,0.056593,0.0880628,-0.802437,-0.880773,-1.79805,-1.79649,2.06386,2.05996
9820,0.029183,-0.00966399,0.345341,0.317952,0.939181,0.955024,0.881021,0.885815,0.895127,0.892435,0.79672,0.828651,0.446371,0.431973,0.811088,0.811329,0.16897,0.25529,0.725565,0.624897,0.838557,0.868825,-1.37006,-1.3641,-0.222461,-0.156625,-1.194,-1.23419,0.638644,0.714462,-0.322167,-0.289241,1.19343,1.22595,0.186186,0.1084,2.61982,2.62139,-0.349723,-0.357756
9821,0.999092,0.960641,0.842414,0.816432,0.0572507,0.0756062,0.189917,0.193698,0.842981,0.842954,0.149386,0.183309,0.563348,0.547032,0.465625,0.464746,0.26731,0.261439,0.966486,0.961937,-0.234486,-0.198668,-0.275844,-0.269218,1.47599,1.54885,1.31198,1.27694,1.10377,1.17858,1.72746,1.75404,-0.986518,-0.949106,-0.624915,-0.709277,-1.53063,-1.53378,2.13831,2.13676
9822,0.639791,0.580664,0.803628,0.77706,0.0193865,0.0367869,0.695959,0.701539,0.943231,0.793473,0.109284,0.141342,0.143487,0.12601,0.94078,0.941271,0.873016,0.8678,0.80003,0.796936,0.551527,0.596571,0.373058,0.378989,-0.52301,-0.448743,0.195311,0.159128,-0.641239,-0.56913,0.862008,0.803766,0.018887,0.0642418,-1.90111,-1.98851,-0.218936,-0.216928,1.80598,1.81117
9823,0.236549,0.200686,0.513298,0.486901,0.191284,0.207515,0.0957303,0.102705,0.731919,0.743992,0.450519,0.491637,0.900139,0.881216,0.560567,0.560001,0.202013,0.196922,0.420493,0.416529,1.36468,1.39181,-0.740819,-0.740974,1.71925,1.79575,-1.14376,-1.17352,-1.01092,-0.936093,-0.0692008,-0.146505,-0.384931,-0.333971,0.64318,0.559183,0.00757107,0.00829908,0.565759,0.575526
9824,0.696355,0.658369,0.46709,0.415873,0.578352,0.515503,0.783957,0.790438,0.173443,0.185447,0.811227,0.841931,0.0289571,0.00947994,0.63464,0.636417,0.18589,0.1815,0.844963,0.840818,-0.792473,-0.772894,-1.23179,-1.22738,-1.22198,-1.1388,0.180334,0.144703,1.26572,1.33503,-1.12335,-1.09678,1.71292,1.75996,-0.119568,-0.198794,-0.789952,-0.787267,0.228462,0.234426
9825,0.376376,0.339149,0.370326,0.344845,0.806558,0.823491,0.606613,0.612772,0.312516,0.325212,0.0998971,0.132229,0.438046,0.416449,0.442014,0.432508,0.420175,0.418273,0.0739977,0.0679343,-0.452079,-0.391605,-0.659252,-0.657237,-0.199685,-0.0531939,2.91334,2.87225,0.557514,0.620404,-0.0952255,-0.0703779,-0.721267,-0.673366,0.528699,0.454432,1.18994,1.19404,-1.24079,-1.22879
9826,0.362751,0.324048,0.708329,0.680987,0.28324,0.300069,0.913367,0.917189,0.709473,0.722934,0.87438,0.905439,0.385699,0.362306,0.225126,0.228598,0.34522,0.380093,0.280822,0.27483,-0.0298959,-0.0103164,-1.67682,-1.66848,0.948297,1.03242,-0.694898,-0.728775,1.94991,2.00647,-0.420636,-0.393186,1.13595,1.17949,-0.905463,-0.978546,-1.09814,-1.08623,-1.33765,-1.30351
9827,0.855607,0.815575,0.624377,0.526698,0.198799,0.214204,0.320615,0.323765,0.897554,0.91292,0.867751,0.89762,0.8282,0.804067,0.614721,0.620741,0.21263,0.341914,0.903191,0.899287,-0.926466,-0.908264,-0.439689,-0.391808,-0.0821895,0.0548298,-1.39164,-1.42664,2.00877,2.05761,-2.22999,-2.20983,2.78756,2.82789,1.0195,0.954122,1.29386,1.30307,-1.39675,-1.37823
9828,0.349013,0.310082,0.400711,0.37241,0.6154,0.632432,0.0136401,0.0159803,0.0870444,0.102806,0.240163,0.267705,0.0726849,0.0493898,0.0799968,0.0846432,0.304477,0.303734,0.914169,0.910004,1.51864,1.53311,0.876532,0.884868,-1.01062,-0.922757,-3.05507,-3.08824,0.888522,0.943003,-0.776979,-0.758007,-0.285474,-0.252503,-1.08007,-1.14731,-0.65076,-0.644097,1.45642,1.48232
9829,0.260569,0.223106,0.557906,0.53136,0.0466999,0.0636997,0.576476,0.579324,0.856126,0.871854,0.568138,0.597814,0.15457,0.133215,0.258467,0.262033,0.0155883,0.0145834,0.649837,0.621209,-1.66654,-1.65458,0.349984,0.351435,2.35558,2.43747,-1.36908,-1.40519,0.694659,0.74419,-0.511658,-0.406552,0.305573,0.381377,-0.520388,-0.588047,-0.0975623,-0.0894538,-0.343008,-0.318442
9830,0.423708,0.386471,0.269402,0.241201,0.834752,0.852446,0.649095,0.652424,0.170636,0.18582,0.695222,0.722718,0.985487,0.96262,0.132127,0.215493,0.536108,0.535025,0.335994,0.332414,0.372199,0.382178,0.951583,0.953281,-0.24235,-0.160567,2.20481,2.17382,-0.785651,-0.739404,-0.0747478,-0.0550973,0.981791,1.01526,0.924363,0.859464,-1.45927,-1.44973,0.562724,0.580114
9831,0.702678,0.549836,0.685642,0.65631,0.765936,0.761557,0.975881,0.981672,0.182933,0.198751,0.22974,0.257182,0.823665,0.748894,0.167777,0.168953,0.792525,0.791173,0.531352,0.529708,-0.681569,-0.669049,0.243271,0.282522,0.182981,0.245245,0.356914,0.327548,-1.18344,-1.07222,0.0549292,0.082186,-0.158862,-0.124749,-0.367861,-0.436397,1.01539,1.02014,-1.70812,-1.68803
9832,0.750664,0.713202,0.384998,0.356459,0.652388,0.670668,0.701,0.715092,0.599256,0.533296,0.608858,0.636071,0.557431,0.535168,0.582153,0.585521,0.713314,0.797321,0.0762134,0.0734917,0.50094,0.517104,-0.398617,-0.388237,0.569996,0.651057,-0.189096,-0.215626,-1.5206,-1.40503,2.1162,2.14319,-0.330565,-0.291613,1.39404,1.32335,-0.365899,-0.357123,1.54963,1.57415
9833,0.748966,0.713769,0.561305,0.441768,0.853081,0.871128,0.44264,0.448513,0.853918,0.86784,0.151599,0.180242,0.0705907,0.0488643,0.142855,0.143942,0.80561,0.803469,0.77585,0.773122,-0.0932453,-0.072296,0.146198,0.150694,-0.811345,-0.72539,-1.36896,-1.39464,-1.78409,-1.73785,0.333916,0.356937,-1.66413,-1.61852,0.58923,0.520113,2.40928,2.42158,0.560909,0.585197
9834,0.481999,0.460472,0.554309,0.527078,0.218269,0.236986,0.438629,0.513844,0.604449,0.619553,0.234408,0.261065,0.992186,0.971536,0.463252,0.417109,0.458316,0.453857,0.19427,0.192911,0.0995457,0.116659,-0.921611,-0.923398,1.47044,1.55031,-0.420994,-0.445788,-1.9023,-1.86048,0.582596,0.601184,-0.138599,-0.0941873,-1.04132,-1.11079,-1.2042,-1.19205,0.527468,0.54683
9835,0.243128,0.207175,0.919247,0.891811,0.938348,0.956983,0.602109,0.579176,0.961641,0.977179,0.566625,0.591173,0.116002,0.0952376,0.69022,0.690276,0.908613,0.903466,0.812331,0.811564,-1.15667,-1.13414,1.6295,1.63408,-1.03126,-0.958332,-0.763055,-0.789009,1.32251,1.36083,-1.22425,-1.20011,1.0641,1.10669,-0.548697,-0.626099,0.233821,0.253156,0.190168,0.20573
9836,0.287306,0.252462,0.0847992,0.0549437,0.785188,0.869733,0.637564,0.644508,0.125162,0.14001,0.651963,0.713534,0.198421,0.18833,0.40091,0.398745,0.286644,0.283036,0.375952,0.375343,0.512572,0.533248,0.559294,0.559991,1.86915,1.93406,-1.66263,-1.68926,1.16161,1.19301,0.665904,0.686726,0.0577513,0.104881,-1.84317,-1.92196,0.819862,0.836468,-0.546223,-0.525931
9837,0.646878,0.607925,0.179143,0.149283,0.763646,0.782483,0.900984,0.909825,0.858533,0.872761,0.809589,0.835894,0.299107,0.281423,0.843312,0.840983,0.633423,0.578947,0.914199,0.914736,0.390005,0.37989,0.161594,0.164216,-0.471143,-0.401231,0.711312,0.678207,1.32845,1.36707,0.922638,0.945164,-0.280928,-0.232057,-0.218497,-0.355171,-0.961043,-0.939462,-1.05369,-1.03242
9838,0.997463,0.963389,0.4764,0.451138,0.678762,0.695232,0.612966,0.657035,0.241511,0.253369,0.406392,0.43433,0.39528,0.374516,0.312509,0.309934,0.879617,0.874858,0.546819,0.548576,0.208563,0.226532,0.557489,0.564007,-0.119459,-0.0471788,-0.679859,-0.71675,0.0734573,0.112191,-0.262425,-0.240957,0.584455,0.624687,1.29041,1.21162,1.21468,1.24196,0.578717,0.601022
9839,0.346881,0.311789,0.782399,0.752993,0.0456317,0.0610903,0.325373,0.404246,0.368373,0.382859,0.526863,0.553948,0.916718,0.896811,0.955245,0.954217,0.150495,0.143668,0.823722,0.82639,-0.148793,-0.20985,-0.613379,-0.602043,-0.208155,-0.140447,0.426603,0.385369,-0.388841,-0.346494,1.54452,1.56932,-0.712002,-0.672267,0.9706,0.884319,-2.29581,-2.26929,0.132388,0.155171
9840,0.206327,0.168781,0.435598,0.407991,0.720948,0.736301,0.142616,0.151457,0.753447,0.766271,0.0866137,0.112394,0.835404,0.860965,0.99772,0.994536,0.189803,0.182112,0.0820928,0.0833001,-0.662863,-0.646232,0.0888955,0.105787,0.940628,1.00928,-1.28263,-1.3223,-1.23021,-1.18756,-0.881278,-0.856814,1.24872,1.28957,1.33511,1.24594,0.118979,0.153779,-0.570858,-0.464377
9841,0.594087,0.557284,0.61137,0.581844,0.581925,0.599601,0.460473,0.50841,0.131814,0.146879,0.562128,0.542996,0.845356,0.825118,0.692986,0.688195,0.609973,0.603177,0.312056,0.31108,-0.563791,-0.550021,-1.66392,-1.64013,-1.11672,-1.05336,0.336943,0.299328,0.613848,0.659199,-0.798347,-0.781184,-0.338113,-0.290641,-0.0423804,-0.121666,1.16286,1.19224,-1.10421,-1.08393
9842,0.39824,0.36342,0.522979,0.49348,0.188258,0.204517,0.855548,0.865363,0.481697,0.493614,0.9488,0.973598,0.108457,0.0875502,0.631375,0.62754,0.656548,0.652244,0.827429,0.824597,-1.02685,-1.01534,0.337881,0.355286,0.878487,0.94804,-0.626322,-0.663735,0.40916,0.460386,-1.23032,-1.21231,1.09233,1.14177,-1.40238,-1.48928,2.67815,2.71495,0.413111,0.429401
9843,0.630219,0.519501,0.00178679,-0.0292457,0.526399,0.54168,0.235323,0.242338,0.329828,0.342659,0.549702,0.576922,0.286819,0.264011,0.952003,0.949007,0.157307,0.152491,0.55095,0.585746,-0.0959839,-0.0906375,0.212884,0.2348,0.146016,0.210083,1.32188,1.2897,-0.58013,-0.533261,2.47901,2.4941,0.493827,0.521878,0.253026,0.160399,0.47738,0.512961,0.884352,0.902318
9844,0.785456,0.675583,0.252271,0.222437,0.00461577,0.0182577,0.392961,0.39697,0.383503,0.437144,0.435188,0.461777,0.915963,0.895176,0.358891,0.357685,0.337207,0.333837,0.347896,0.346896,2.30377,2.30448,1.34742,1.37263,-2.33078,-2.26855,0.819277,0.792077,0.0449345,0.023078,-0.329859,-0.30887,-0.0782727,-0.098014,0.823416,0.736775,-3.33843,-3.30871,-1.49798,-1.48279
9845,0.864451,0.831665,0.0452531,0.0174917,0.965109,0.98159,0.257228,0.298674,0.519749,0.531629,0.321142,0.346633,0.996552,0.974168,0.805802,0.804667,0.953573,0.949884,0.683703,0.680521,1.16301,1.16123,0.778504,0.807403,-0.310154,-0.25149,-0.940711,-0.961957,0.53621,0.579417,-0.631227,-0.617588,-0.767345,-0.717906,-0.178706,-0.264971,0.993653,1.02753,-1.64642,-1.62552
9846,0.413257,0.38124,0.636982,0.608341,0.0334638,0.0519813,0.196559,0.200378,0.83425,0.843647,0.450635,0.476331,0.0699408,0.0464109,0.146057,0.142563,0.0178719,0.0148153,0.68973,0.620827,-1.51107,-1.51169,0.813475,0.840191,0.01655,0.0712236,1.1357,1.11709,2.25467,2.30091,-0.39172,-0.426964,1.34149,1.39129,-1.65527,-1.74155,-0.491363,-0.460269,0.749598,0.765981
9847,0.207653,0.177374,0.768501,0.742194,0.390966,0.409087,0.646786,0.648607,0.330399,0.340409,0.961654,0.989143,0.598234,0.573273,0.651256,0.649568,0.0107614,0.00917055,0.562636,0.561134,-0.491342,-0.494778,-0.974183,-0.952891,-1.27521,-1.22572,0.576494,0.558766,-0.462934,-0.419173,-0.245882,-0.23634,-0.440305,-0.391486,-0.0185344,-0.107977,1.11501,1.14052,0.900144,0.923641
9848,0.751473,0.719629,0.306936,0.359391,0.302096,0.318121,0.806639,0.752102,0.091959,0.103461,0.901917,0.931287,0.35977,0.29407,0.253963,0.253062,0.760966,0.761832,0.238133,0.234814,1.1885,1.18918,0.264905,0.281666,-0.30226,-0.25775,0.334677,0.341537,-0.116287,-0.076859,-0.628607,-0.620562,-1.71139,-1.65442,1.38552,1.2959,-2.09469,-2.06261,-0.880964,-0.861396
9849,0.39939,0.369568,0.00301283,-0.0234128,0.914891,0.931729,0.82137,0.855596,0.407549,0.420445,0.635982,0.66341,0.0382664,0.014866,0.950511,0.949505,0.85674,0.854729,0.226249,0.224574,-1.81763,-1.82287,1.30306,1.31274,1.29565,1.3377,0.147366,0.124308,-0.265905,-0.22796,0.500452,0.512315,-0.748634,-0.687076,2.4779,2.3927,2.16285,2.20141,1.02238,1.03715
9850,0.862328,0.831794,0.541589,0.513822,0.749518,0.765582,0.957269,0.959091,0.174361,0.188881,0.69601,0.793622,0.15508,0.129925,0.434078,0.433697,0.279307,0.275307,0.576226,0.574178,1.5778,1.57126,-0.89222,-0.875387,1.45102,1.49018,0.916509,0.887593,0.520688,0.560228,0.411699,0.419246,-0.709263,-0.641177,1.62479,1.54443,1.20434,1.24679,-1.71952,-1.70018
9851,0.272905,0.241146,0.0227458,-0.0038204,0.854604,0.884467,0.39441,0.395354,0.317971,0.333336,0.897258,0.923834,0.0469994,0.0206958,0.117781,0.117204,0.29765,0.295092,0.478578,0.475148,1.37945,1.38138,0.228707,0.250344,0.791907,0.828183,2.32209,2.30098,0.413709,0.40699,2.05144,2.06149,-0.402789,-0.333477,0.35909,0.28061,0.874886,0.915833,-0.621501,-0.60348
9852,0.551335,0.517824,0.687216,0.660389,0.988795,1.00335,0.744288,0.671669,0.260214,0.33842,0.613126,0.641082,0.437739,0.333914,0.443834,0.382532,0.0497609,0.0465721,0.00850455,0.00413404,-0.351467,-0.344988,-1.0645,-1.04006,0.638838,0.677107,1.05517,1.0296,0.21754,0.253752,1.04985,1.06193,-0.480243,-0.408789,0.372963,0.287941,-0.375566,-0.334877,0.00558618,0.0230948
9853,0.402087,0.369682,0.149056,0.123291,0.669595,0.683665,0.946584,0.947985,0.326622,0.343505,0.612251,0.553978,0.673846,0.647132,0.648186,0.647859,0.805181,0.803977,0.083067,0.079941,-0.0794362,-0.0791055,0.752281,0.781759,-1.27038,-1.22545,-0.765924,-0.788229,-0.899151,-0.860858,0.0466963,0.0623751,-0.189451,-0.116493,-0.169004,-0.253586,0.387516,0.434725,-0.178815,-0.166195
9854,0.70554,0.609046,0.51428,0.488024,0.776217,0.790297,0.929392,0.925893,0.694244,0.711171,0.437784,0.466874,0.681708,0.654724,0.657214,0.596389,0.708521,0.708512,0.811768,0.808404,0.406445,0.405069,-0.00494276,0.0172821,1.94057,1.99074,-0.645989,-0.669496,1.99397,2.03161,0.127751,0.138006,-0.442184,-0.374913,0.36235,0.277481,-0.256894,-0.257573,-1.24856,-1.23106
9855,0.879819,0.848411,0.0826106,0.0548582,0.662549,0.678765,0.970639,0.903801,0.260744,0.277235,0.568056,0.529155,0.33426,0.3095,0.546047,0.544919,0.0919601,0.092708,0.948564,0.945462,0.681647,0.687998,-0.0787972,0.00626016,-0.722231,-0.669728,0.0303841,-0.000111551,0.0191692,0.0521309,1.10179,1.11752,0.395165,0.46757,1.27123,1.18993,-1.0007,-0.949871,0.868623,0.973978
9856,0.959239,0.842242,0.83169,0.804388,0.223199,0.239542,0.922225,0.88171,0.0348279,0.0498952,0.562496,0.591437,0.966433,0.940665,0.160376,0.158447,0.467485,0.428179,0.5773,0.574953,-1.13939,-1.13315,-0.0205195,-0.00476175,-0.304116,-0.254438,0.134871,0.102455,0.254751,0.285713,0.995447,1.01014,-0.574081,-0.502073,1.65852,1.58271,0.298269,0.352032,3.16152,3.17902
9857,0.864663,0.836073,0.48848,0.551084,0.906637,0.924426,0.858218,0.859618,0.79294,0.80852,0.376414,0.362502,0.155595,0.128965,0.572532,0.570191,0.761675,0.76365,0.803096,0.802733,-0.626215,-0.551101,0.427174,0.441151,-1.50609,-1.46002,-0.356175,-0.395167,2.17276,2.21044,0.404826,0.421611,-0.176199,-0.146144,0.477165,0.496871,-0.0760204,-0.024345,0.565957,0.578724
9858,0.669676,0.642209,0.326372,0.297781,0.698643,0.716648,0.375436,0.377808,0.622602,0.549063,0.1069,0.133567,0.537289,0.51042,0.387515,0.318648,0.440834,0.444373,0.503633,0.501805,0.0196808,0.030949,0.246753,0.227509,-0.711522,-0.660992,-1.12171,-1.15705,-1.3926,-1.3555,-0.616165,-0.596845,0.137039,0.209785,-0.579611,-0.58897,0.346071,0.403143,-0.779585,-0.763182
9859,0.80853,0.782563,0.811483,0.7815,0.919789,0.937043,0.415744,0.488371,0.298443,0.289605,0.297549,0.322454,0.12091,0.0944109,0.068512,0.0671047,0.95824,0.959459,0.453677,0.452706,-0.597157,-0.49255,0.000554486,0.0138662,-1.62368,-1.57088,-0.61319,-0.641958,1.53392,1.57347,0.173561,0.195318,0.243242,0.318082,-1.599,-1.67481,-0.99916,-0.943419,0.243218,0.258268
9860,0.0132538,-0.0107273,0.943154,0.915353,0.53119,0.536139,0.59894,0.598935,0.0145181,0.0301481,0.823927,0.849132,0.59093,0.566092,0.149008,0.147877,0.895714,0.934224,0.798153,0.797028,-1.02512,-1.01605,-2.65485,-2.63614,0.0500147,0.103549,0.273711,0.245902,0.166551,0.209245,-0.884304,-0.869511,-0.500542,-0.419319,-1.96846,-2.04751,-0.808338,-0.750857,-0.828621,-0.806599
9861,0.960534,0.936245,0.564381,0.536563,0.119508,0.135235,0.345638,0.34604,0.419895,0.39908,0.300186,0.324876,0.782811,0.757582,0.919493,0.919851,0.90521,0.908989,0.869292,0.856107,-0.373338,-0.365627,0.949552,0.968259,0.910605,0.963848,-0.280737,-0.312417,-0.966988,-0.921081,0.73472,0.754928,1.90854,1.99513,-0.0756022,-0.149331,-1.5621,-1.50109,0.381759,0.397076
9862,0.529597,0.505483,0.406413,0.378035,0.493795,0.508021,0.601649,0.6012,0.750881,0.768013,0.852497,0.876561,0.0755832,0.0503666,0.135631,0.13831,0.542367,0.544683,0.916483,0.915187,0.945111,0.960054,-0.684661,-0.667956,0.543675,0.597039,1.32988,1.29216,1.47683,1.5177,0.527412,0.554985,0.682549,0.804922,0.408297,0.335359,0.321656,0.383419,-0.640541,-0.622212
9863,0.333414,0.307229,0.917425,0.890474,0.608612,0.553853,0.371166,0.368552,0.106458,0.123741,0.0965772,0.122126,0.370214,0.419551,0.910254,0.910284,0.721288,0.726029,0.27238,0.269027,1.581,1.59473,-0.444135,-0.436167,0.51685,0.567559,-0.409339,-0.447283,1.33741,1.38021,0.629521,0.661771,-0.468781,-0.385284,0.6084,0.528908,-0.643073,-0.584959,-1.07892,-1.06806
9864,0.413892,0.457025,0.755581,0.63903,0.583124,0.599685,0.361028,0.356226,0.933473,0.951608,0.161511,0.115736,0.812941,0.788736,0.875171,0.837348,0.114623,0.120369,0.547336,0.542196,-1.38195,-1.37206,0.0813918,0.0878684,1.13374,1.17997,0.533073,0.501571,2.09106,2.13576,-0.836397,-0.803373,0.0103212,0.0239322,-0.705052,-0.782472,-0.962989,-0.900836,0.957752,0.967273
9865,0.63253,0.606821,0.414349,0.387586,0.341638,0.315483,0.647303,0.582693,0.706142,0.820735,0.0830015,0.109346,0.47633,0.453576,0.765814,0.764411,0.707128,0.711008,0.390277,0.386989,-0.151506,-0.142083,-0.233369,-0.230333,-0.807405,-0.75592,1.88282,1.84971,-0.15229,-0.105303,-2.01477,-1.98949,0.344675,0.433149,-0.905348,-0.98752,0.791721,0.856397,0.34069,0.354773
9866,0.397955,0.440488,0.783405,0.757299,0.0162644,0.0312804,0.811069,0.809159,0.673259,0.689861,0.969563,0.996489,0.762826,0.740122,0.104278,0.102306,0.817498,0.82059,0.881994,0.880891,0.0952404,0.109076,-1.35634,-1.3503,0.122974,0.180587,-0.0202497,-0.0481013,1.12486,1.17363,0.361408,0.387449,0.424763,0.511159,1.06532,0.988869,-1.37825,-1.31709,0.305201,0.316406
9867,0.300047,0.274155,0.0689353,0.0423944,0.696065,0.710996,0.646886,0.726977,0.829908,0.844868,0.138308,0.163252,0.189523,0.167923,0.469503,0.469394,0.453376,0.456285,0.474005,0.4745,-0.505597,-0.49541,-1.34964,-1.34799,-0.292705,-0.23191,-0.104274,-0.128704,-0.296088,-0.248987,0.0252548,0.0490331,-1.29189,-1.20836,-1.94358,-2.02715,-0.549627,-0.482776,0.737604,0.809013
9868,0.758266,0.731838,0.89539,0.869775,0.392921,0.506088,0.61371,0.644795,0.574989,0.679695,0.216069,0.239216,0.914158,0.891507,0.220454,0.221396,0.510385,0.514444,0.385239,0.384817,-1.70173,-1.68427,-0.739222,-0.732074,-1.65697,-1.59117,1.24192,1.21943,1.07308,1.11933,-0.104025,-0.0762587,0.755314,0.834438,0.214997,0.134841,-1.22762,-1.15373,1.29093,1.30162
9869,0.20087,0.175673,0.122304,0.0969584,0.284944,0.30118,0.564523,0.562613,0.500063,0.514522,0.0497509,0.0715793,0.354564,0.334074,0.934322,0.933408,0.0780116,0.0797076,0.2605,0.295134,-1.79444,-1.77044,-1.62433,-1.61904,1.89015,1.95406,0.270655,0.256372,0.131701,0.171251,-1.66245,-1.63232,-1.20647,-1.12125,-0.405954,-0.390857,0.221801,0.291479,1.25127,1.26325
9870,0.819558,0.795861,0.212208,0.144632,0.752402,0.769763,0.636658,0.570543,0.777591,0.791119,0.470276,0.490936,0.642058,0.620619,0.045441,0.0455165,0.940073,0.941343,0.0878823,0.205451,0.0985967,0.126303,2.03621,2.03563,-0.726966,-0.661435,0.846094,0.832986,-0.603801,-0.561558,0.814865,0.847311,0.794978,0.887076,-0.832026,-0.916554,1.11368,1.18653,-0.767614,-0.756249
9871,0.272609,0.249511,0.279193,0.192305,0.873885,0.888648,0.578814,0.578474,0.743303,0.756762,0.385614,0.407802,0.572206,0.551601,0.153611,0.213555,0.964807,0.965687,0.115274,0.115769,-1.0978,-1.06256,0.507013,0.50848,-0.757874,-0.690915,0.564083,0.550511,-0.35258,-0.310839,-1.13767,-1.11029,1.8523,1.94609,-0.465564,-0.554929,1.23271,1.30313,-0.727204,-0.717911
9872,0.600439,0.539145,0.244165,0.239979,0.990621,1.00753,0.438699,0.436939,0.144656,0.157406,0.95423,0.974231,0.0989774,0.0804956,0.360505,0.381593,0.671684,0.67146,0.510802,0.510334,1.11621,1.15671,-0.313669,-0.316521,-0.234168,-0.169884,-0.402563,-0.412551,-1.68728,-1.64412,0.683569,0.71545,-0.156618,-0.057462,-0.366658,-0.452881,0.0645651,0.13031,-1.04956,-1.0435
9873,0.850223,0.828778,0.19954,0.287652,0.227952,0.243023,0.630879,0.627516,0.0126741,0.0257818,0.299498,0.319498,0.268949,0.251208,0.656477,0.549632,0.870717,0.871937,0.316036,0.314764,-1.17915,-1.13377,-2.28945,-2.29894,-1.26983,-1.20509,-0.310952,-0.326332,-0.0115343,0.0311575,1.40346,1.43464,-0.148654,-0.0563492,0.388972,0.306035,0.361541,0.433216,-0.00447952,0.00734346
9874,0.489423,0.469111,0.285854,0.335325,0.299435,0.254805,0.373047,0.36986,0.940447,0.954615,0.105007,0.125162,0.691802,0.672978,0.717595,0.71767,0.0868644,0.087061,0.876105,0.873637,0.321659,0.365354,-2.11985,-2.12767,0.628789,0.687786,0.499656,0.483142,0.449265,0.495275,0.0970988,0.125351,-0.375295,-0.28427,1.78149,1.69447,-0.177943,-0.0993711,-0.880776,-0.876164
9875,0.57412,0.581229,0.341434,0.382999,0.253389,0.266586,0.648937,0.645114,0.949953,0.96261,0.376935,0.308247,0.723001,0.70549,0.696358,0.697326,0.0810258,0.0814162,0.610183,0.608665,0.846589,0.894652,1.32178,1.30761,0.369776,0.428975,0.190623,0.170133,0.335168,0.388628,1.53703,1.56384,0.185514,0.269879,1.35766,1.27475,1.2958,1.37652,0.133736,0.145286
9876,0.69791,0.693347,0.456018,0.430672,0.670418,0.684815,0.25163,0.248269,0.0222721,0.0342391,0.471161,0.491332,0.467782,0.448743,0.42674,0.43027,0.969744,0.969905,0.939053,0.937544,-0.439762,-0.386935,-0.0203818,-0.0316428,-1.08073,-1.02173,-0.900904,-0.918501,1.05379,1.1143,-0.806565,-0.78347,-0.546087,-0.467522,-1.40549,-1.48591,-1.123,-1.04132,-2.4255,-2.40851
9877,0.940469,0.805465,0.918746,0.893749,0.142742,0.156341,0.258322,0.19781,0.55685,0.568001,0.0538012,0.0754264,0.964511,0.945596,0.583933,0.655332,0.764479,0.85427,0.592094,0.591618,1.77185,1.81916,0.0242395,0.0155486,-0.00436502,0.0535006,0.0143154,-4.59447e-05,-1.54384,-1.47911,0.693283,0.715874,0.621497,0.701054,-0.0723864,-0.146442,-0.255318,-0.175028,0.719621,0.743065
9878,0.937895,0.917583,0.35525,0.331561,0.948057,0.961611,0.140493,0.147352,0.715855,0.727176,0.133996,0.156249,0.972572,0.877678,0.8746,0.880393,0.735704,0.738635,0.851424,0.791747,0.275861,0.32411,-1.05649,-1.05854,0.341336,0.407552,-1.4124,-1.42582,-0.519461,-0.46059,-0.0909249,-0.0710386,0.974465,1.05491,1.05692,0.982471,-0.366923,-0.288645,-1.52853,-1.50763
9879,0.520452,0.50222,0.683748,0.657719,0.368235,0.382781,0.0980544,0.0968938,0.0923962,0.102138,0.540606,0.560125,0.828855,0.80976,0.0795991,0.0837095,0.747622,0.707271,0.989433,0.991876,-0.479878,-0.434489,0.769969,0.763273,-0.125404,-0.0649309,-0.330137,-0.339264,1.05187,1.10898,0.157528,0.173209,-0.0901348,-0.00770059,1.12638,1.05173,-1.37079,-1.28819,-0.118605,-0.103678
9880,0.327874,0.308356,0.165177,0.140076,0.140698,0.155354,0.543832,0.540304,0.160729,0.124654,0.318605,0.294133,0.388563,0.369025,0.622841,0.626489,0.67182,0.675908,0.607895,0.690795,-2.69286,-2.64956,1.17887,1.17942,1.91557,1.98253,1.2062,1.2003,0.918668,0.97149,-0.674323,-0.661161,2.13308,2.211,-0.927607,-1.0004,1.05889,1.13489,0.328143,0.33963
9881,0.749567,0.731447,0.681583,0.657848,0.31962,0.40363,0.279588,0.276865,0.136365,0.147169,0.00863401,0.0281413,0.347434,0.385446,0.806352,0.807612,0.942048,0.946882,0.280087,0.389713,-1.29325,-1.24605,-1.46737,-1.47059,0.976387,1.0428,-1.65239,-1.65987,-0.306326,-0.344562,0.0279012,0.136105,1.52961,1.56851,-0.0468823,-0.118409,1.05318,1.12957,-0.289554,-0.27287
9882,0.0824004,0.0651913,0.103653,0.0811767,0.635097,0.651906,0.986678,0.984201,0.98983,0.998467,0.824313,0.843146,0.414894,0.401867,0.440489,0.440826,0.228233,0.23096,0.0861888,0.0886318,0.360437,0.406479,-0.866447,-0.868739,-0.52813,-0.469049,0.266523,0.257352,-1.72079,-1.66061,0.922311,0.933372,0.848378,0.926025,0.0195768,-0.049155,0.685347,0.767736,-0.365663,-0.357323
9883,0.496538,0.512314,0.555737,0.535532,0.0710852,0.087648,0.719969,0.697978,0.501216,0.509641,0.345495,0.363008,0.292141,0.418288,0.300664,0.298692,0.309409,0.313674,0.327319,0.37024,-0.868344,-0.827459,-1.50995,-1.5083,-0.741262,-0.683923,0.774949,0.772442,-0.46429,-0.411512,-0.933272,-0.928111,0.83542,0.912044,1.17288,1.10867,-2.30527,-2.2188,-0.943116,-0.984244
9884,0.976259,0.959437,0.106617,0.0870761,0.367157,0.38393,0.412415,0.411754,0.992811,1.0029,0.324669,0.339832,0.454247,0.43471,0.548589,0.544248,0.978812,0.98136,0.56083,0.651848,-0.642542,-0.679382,0.671193,0.679043,-0.405703,-0.346146,0.92406,0.923199,-1.29567,-1.23628,-1.92809,-1.91633,1.13394,1.20434,0.324935,0.260409,-0.564143,-0.477972,-1.61419,-1.61117
9885,0.897234,0.961251,0.770837,0.751286,0.209632,0.227257,0.548727,0.545906,0.886249,0.821627,0.509289,0.524616,0.178374,0.159117,0.0563665,0.0531708,0.858955,0.920751,0.933076,0.933456,-0.575689,-0.531305,0.325408,0.329078,-0.633015,-0.642408,0.618472,0.607928,-1.47856,-1.41961,-1.44089,-1.42493,-0.132024,-0.0585997,-0.149034,-0.219821,-1.95034,-1.86925,-0.37747,-0.375732
9886,0.981069,0.963065,0.160164,0.140321,0.974362,0.99414,0.911858,0.909834,0.629843,0.640353,0.317947,0.312063,0.191998,0.172066,0.858051,0.856441,0.856886,0.860141,0.974764,0.975331,-0.186615,-0.142303,0.214965,0.223608,-1.00074,-0.938669,0.293519,0.292658,0.115465,0.180316,-0.17731,-0.154796,0.233045,0.309928,-1.92567,-1.99087,-0.139839,-0.0647622,1.3498,1.34809
9887,0.0843702,0.0685872,0.203,0.183729,0.184826,0.203363,0.160711,0.157172,0.997037,1.00802,0.0851462,0.0995108,0.467348,0.448164,0.643984,0.644831,0.459129,0.461196,0.0902563,0.0903243,-0.716956,-0.670216,-1.66756,-1.65408,1.34371,1.40355,-1.06009,-1.05446,0.803216,0.874799,0.638545,0.656489,1.7693,1.84789,0.258338,0.189525,-0.438023,-0.365509,0.949566,0.954878
9888,0.387994,0.37045,0.775294,0.755112,0.548899,0.565742,0.0943401,0.0902319,0.0887985,0.0976084,0.0881291,0.101581,0.482542,0.461112,0.868658,0.868756,0.800875,0.801918,0.486768,0.48489,-0.0905215,-0.0464212,1.22541,1.23238,1.20479,1.2686,0.358143,0.358922,-0.470288,-0.394616,0.726496,0.747893,0.509155,0.584951,0.873273,0.811048,-0.949148,-0.882025,0.564038,0.561664
9889,0.989611,0.971202,0.579137,0.560482,0.244822,0.261665,0.844301,0.838694,0.187294,0.196324,0.456803,0.471139,0.724086,0.702224,0.758498,0.68518,0.93412,0.936082,0.538278,0.606969,0.532747,0.577374,-0.863852,-0.857155,-1.6697,-1.60684,-2.07102,-2.07504,-0.919306,-0.838188,-1.24273,-1.22478,0.331085,0.40322,-3.0072,-3.06839,1.23707,1.29939,-0.185509,-0.184963
9890,0.968423,0.951122,0.983052,0.966155,0.435809,0.545006,0.38252,0.377228,0.810761,0.820511,0.0959281,0.109412,0.266032,0.246322,0.502254,0.501605,0.0240155,0.0249525,0.732713,0.729048,1.68308,1.73185,0.872632,0.886001,1.37791,1.44525,-0.974683,-0.972917,0.686109,0.761737,-1.05948,-1.04167,1.26864,1.34009,-1.23575,-1.29566,1.05045,1.1065,0.00715849,0.00186542
9891,0.554918,0.50057,0.306354,0.290356,0.812544,0.828346,0.442891,0.435585,0.6393,0.598316,0.194831,0.208635,0.751076,0.733063,0.770192,0.743216,0.251123,0.25156,0.626126,0.623343,0.733504,0.86007,-0.435603,-0.418254,0.136513,0.208963,0.696473,0.693289,-0.66934,-0.602485,-0.203634,-0.185283,0.092442,0.167706,0.998185,0.942546,-1.06726,-1.01452,1.0469,1.03753
9892,0.0667332,0.0500184,0.95011,0.93507,0.250427,0.264088,0.777847,0.769339,0.491085,0.376121,0.761552,0.775063,0.907814,0.888421,0.985622,0.984828,0.771761,0.772001,0.234284,0.23335,-0.05936,-0.0117128,-1.11168,-1.08948,2.38458,2.45346,-0.40886,-0.410714,1.48067,1.55002,-0.904234,-0.881845,1.11711,1.19485,0.172855,0.124869,-0.134093,-0.086952,-0.258921,-0.273416
9893,0.0106384,-0.00665054,0.43324,0.417427,0.179356,0.19478,0.862492,0.852892,0.144175,0.153925,0.710291,0.681839,0.565563,0.534713,0.369189,0.368492,0.0109062,0.0123241,0.991955,0.992698,-2.00044,-1.95726,-2.3541,-2.3324,-0.406416,-0.334937,-0.912874,-0.908337,0.306657,0.373922,0.979574,1.00499,1.10394,1.18087,0.55308,0.50358,-1.27037,-1.22704,0.642185,0.62514
9894,0.234939,0.193619,0.330917,0.314166,0.724811,0.742266,0.73055,0.715214,0.573431,0.582209,0.548235,0.588615,0.200984,0.181006,0.272432,0.272183,0.196918,0.19851,0.0248604,0.0257018,-0.213446,-0.16714,-1.02633,-1.00821,-0.0777197,-0.0122238,0.536654,0.536228,-0.135274,-0.0696507,-0.759638,-0.733677,0.0872795,0.164197,-0.835669,-0.856781,0.177679,0.218173,1.23001,1.20581
9895,0.409654,0.393888,0.697773,0.628643,0.588439,0.516008,0.588908,0.577535,0.0812687,0.0888729,0.470135,0.495391,0.573836,0.552664,0.586384,0.588523,0.17562,0.177654,0.14929,0.0546377,0.655478,0.694811,1.33436,1.3583,0.963014,1.03115,0.0800833,0.0848887,0.00767999,0.0720891,-0.465172,-0.401214,1.92584,2.00176,-2.16728,-2.21714,0.185666,0.165288,0.314359,0.292065
9896,0.82177,0.807209,0.959696,0.94312,0.273059,0.289751,0.964202,0.951377,0.86301,0.868811,0.379501,0.402167,0.595874,0.575154,0.649431,0.649172,0.556888,0.558407,0.0825275,0.0835736,-0.587624,-0.555987,-1.03822,-1.02319,-0.155591,-0.0820959,1.11729,1.12618,-0.336628,-0.278994,-0.102575,-0.0687519,-0.074274,-0.00179277,-0.246337,-0.302998,0.0698972,0.112402,-1.03832,-1.06504
9897,0.88619,0.87254,0.461765,0.444838,0.408215,0.363493,0.651358,0.638275,0.140011,0.146905,0.397638,0.308943,0.915495,0.897045,0.262924,0.2627,0.334378,0.334954,0.441111,0.431826,-1.36186,-1.33079,0.150945,0.161988,0.0754242,0.161562,0.100095,0.101634,1.47899,1.53531,0.630055,0.664288,1.06725,1.1361,1.06587,1.00599,0.236437,0.275527,0.308336,0.276073
9898,0.370194,0.357121,0.569341,0.456171,0.465097,0.437234,0.629385,0.567658,0.442844,0.498917,0.202208,0.215719,0.572301,0.551821,0.993668,0.995247,0.952635,0.951,0.778334,0.780079,-0.338212,-0.313874,-0.756332,-0.740161,0.332846,0.40522,0.758686,0.756633,0.90462,0.95555,-0.975432,-0.938033,0.749383,0.815067,0.962491,0.90824,-0.373689,-0.333968,1.19618,1.15914
9899,0.120891,0.108397,0.48593,0.467504,0.496151,0.510976,0.484738,0.497041,0.844565,0.850928,0.782728,0.796571,0.703154,0.682342,0.687328,0.688906,0.971641,0.947689,0.614959,0.598652,-1.22094,-1.19653,-0.578965,-0.568894,0.306214,0.37574,-1.16555,-1.17402,-2.65319,-2.61038,-0.771837,-0.73996,-0.863633,-0.794879,1.28178,1.22544,-3.17543,-3.14212,-0.203044,-0.243476
9900,0.424154,0.453185,0.117531,0.0983992,0.257276,0.267348,0.447296,0.426424,0.16782,0.175729,0.0893463,0.100497,0.557459,0.537405,0.646357,0.713751,0.946044,0.944378,0.321357,0.417226,1.0408,1.07024,-0.948762,-0.933308,1.24006,1.31225,-2.09577,-2.10754,-0.26696,-0.223754,-0.264526,-0.232864,0.368955,0.436305,-1.23001,-1.28611,-0.00103711,0.0319614,-2.398,-2.43252
9901,0.810407,0.797974,0.671059,0.650159,0.0106284,0.0237192,0.36889,0.355807,0.589505,0.598069,0.872021,0.883583,0.862466,0.844358,0.735554,0.738596,0.619389,0.619835,0.216315,0.2358,1.86886,1.90149,-0.558231,-0.547824,-1.07243,-1.00581,0.242926,0.238726,-0.929393,-0.878105,0.86947,0.900013,1.02416,1.09753,-0.0065351,-0.0694308,0.592991,0.63145,-1.7022,-1.73053
9902,0.645943,0.63496,0.19935,0.176515,0.514805,0.52728,0.0397214,0.0283209,0.503477,0.512318,0.998959,1.00849,0.263407,0.243307,0.541269,0.588443,0.67268,0.673991,0.0526288,0.0543735,-0.414145,-0.374892,0.339599,0.343926,-0.511963,-0.438751,0.395423,0.48409,-0.598638,-0.551487,-1.24098,-1.2114,-0.360101,-0.29114,-0.0196063,-0.0788497,-0.509812,-0.475822,-0.130782,-0.157475
9903,0.0662246,0.054148,0.0552596,0.032809,0.138567,0.152445,0.73017,0.721343,0.622883,0.544338,0.60528,0.616354,0.863468,0.843823,0.393561,0.438289,0.299123,0.299807,0.837837,0.841104,-1.10417,-1.07151,1.64831,1.65358,-1.1683,-1.10074,0.740279,0.729454,-0.625269,-0.578371,0.325645,0.352263,0.890785,0.955805,0.173886,0.114699,1.52004,1.55709,-1.44571,-1.46842
9904,0.804545,0.791903,0.358051,0.334244,0.104468,0.118901,0.730667,0.720124,0.569053,0.576359,0.521303,0.565594,0.593751,0.476051,0.285088,0.288136,0.935333,0.93704,0.908118,0.913132,-0.551709,-0.514518,-1.20709,-1.20304,-0.210204,-0.146808,-0.236347,-0.249566,0.087184,0.130477,0.15637,0.183476,-1.84353,-1.78579,-1.69265,-1.75251,0.16612,0.196812,-0.605185,-0.683445
9905,0.24526,0.230187,0.43773,0.47064,0.900453,0.913178,0.29536,0.283888,0.331118,0.298617,0.560818,0.514835,0.129966,0.10828,0.823114,0.825908,0.0820292,0.082808,0.752514,0.757925,1.28227,1.32108,-0.52973,-0.52468,1.65679,1.71521,0.998446,0.991287,0.447926,0.488823,0.412898,0.441914,-0.128181,-0.0757747,-1.0086,-0.971935,-1.60682,-1.57912,0.130048,0.101527
9906,0.448061,0.505573,0.630327,0.607037,0.799467,0.812506,0.925297,0.916581,0.0137415,0.0208756,0.381859,0.464075,0.193092,0.171794,0.263185,0.264751,0.487902,0.488768,0.144428,0.151874,0.300609,0.347495,-0.768529,-0.768584,1.532,1.59526,-0.0021035,-0.00265702,1.78904,1.82744,0.167292,0.195121,-0.236089,-0.128797,-0.136367,-0.191358,-0.0420226,-0.0112833,-1.8542,-1.88533
9907,0.79443,0.780958,0.0292824,0.00549638,0.0718092,0.0829681,0.336946,0.328806,0.143745,0.0664909,0.403535,0.413316,0.695379,0.67411,0.359545,0.360481,0.587755,0.587302,0.842612,0.851505,1.43008,1.46926,-0.409808,-0.413389,0.241847,0.298311,1.19934,1.19365,1.28361,1.41541,-0.782793,-0.761805,-0.234226,-0.18182,1.4954,1.44222,-1.20969,-1.1841,-1.16581,-1.20169
9908,0.648045,0.632816,0.00304687,-0.0196982,0.950917,0.960015,0.647819,0.638528,0.106011,0.112106,0.764454,0.773409,0.0944118,0.0730596,0.724125,0.723366,0.127955,0.127203,0.0416103,0.0514939,0.938058,0.970448,-0.581924,-0.58021,0.686613,0.743638,1.15278,1.14395,0.9369,1.00339,2.15057,2.17694,-0.888081,-0.840489,0.36646,0.317149,0.483312,0.51162,-0.487005,-0.518048
9909,0.895938,0.878778,0.427751,0.404748,0.607749,0.532541,0.506751,0.496994,0.384051,0.471398,0.440233,0.450184,0.0598525,0.039006,0.758742,0.758639,0.171413,0.170675,0.539451,0.550125,-0.339089,-0.311139,0.340977,0.421881,0.572802,0.62368,-0.339157,-0.342414,0.555994,0.591363,0.472948,0.50044,1.18205,1.23227,0.035164,-0.0101494,-1.47335,-1.43555,0.606249,0.57865
9910,0.397811,0.383384,0.512789,0.554717,0.0964484,0.105067,0.0478045,0.0399887,0.826192,0.83069,0.987906,0.99627,0.450082,0.430057,0.0912485,0.0923523,0.00556655,0.00297555,0.0502372,0.0594472,0.177227,0.202896,1.42848,1.42397,0.746758,0.790182,-0.938612,-0.947933,0.140934,0.179338,-0.273395,-0.248073,0.092678,0.139872,0.432476,0.382636,1.94891,1.98654,2.06606,2.04474
9911,0.536205,0.523738,0.7279,0.704685,0.623907,0.633602,0.851892,0.846342,0.175913,0.181496,0.998841,1.00808,0.494014,0.472669,0.0281591,0.0316977,0.505562,0.503196,0.910149,0.918476,-0.452378,-0.433039,-0.224757,-0.228439,-1.71933,-1.67277,1.79936,1.79569,-1.27931,-1.24327,-1.02197,-0.996587,-2.17194,-2.11814,-0.095146,-0.164802,1.28927,1.38043,-0.740276,-0.756817
9912,0.282526,0.270821,0.4444,0.419025,0.757365,0.765065,0.255744,0.247508,0.761504,0.766909,0.268948,0.278644,0.18398,0.160984,0.396709,0.376363,0.286324,0.28522,0.124277,0.132985,-1.57146,-1.5467,0.310179,0.310492,1.72498,1.76941,-1.29679,-1.29892,-0.214649,-0.179869,0.282163,0.304066,0.995752,1.04124,-0.662139,-0.712239,0.728237,0.774323,-1.62459,-1.64032
9913,0.29729,0.314896,0.826202,0.798762,0.208441,0.216002,0.742379,0.735972,0.844263,0.850748,0.142033,0.150054,0.854215,0.828856,0.714512,0.721028,0.0680193,0.0672444,0.5879,0.597069,-0.593678,-0.603751,0.00232261,0.00432073,-0.103706,-0.057397,0.335691,0.336723,-1.05693,-1.02094,0.0904741,0.120279,-0.0587362,-0.00637437,-0.157935,-0.212336,-1.31333,-1.27237,-0.000600093,-0.0193645
9914,0.369056,0.358972,0.341743,0.315473,0.844699,0.849772,0.576102,0.568368,0.419247,0.426848,0.849105,0.856577,0.672275,0.629357,0.26761,0.274716,0.492351,0.491929,0.641923,0.649743,0.314434,0.339196,-1.98927,-1.99081,0.0685043,0.109105,0.377582,0.378044,0.733144,0.761605,0.622678,0.656319,-0.15025,-0.0956928,-2.6656,-2.72389,0.0253304,0.0635264,0.894794,0.879191
9915,0.169447,0.245468,0.914681,0.886856,0.267146,0.270943,0.19983,0.190752,0.54978,0.556337,0.262,0.271625,0.483906,0.429857,0.371399,0.381053,0.522894,0.521489,0.116679,0.123754,-0.120705,-0.0951556,0.767729,0.76639,-1.53345,-1.49575,-0.839672,-0.832666,0.539801,0.562792,-0.577976,-0.54512,-1.87449,-1.81521,-0.150069,-0.208914,-1.78487,-1.74285,1.1111,1.09544
9916,0.142392,0.131965,0.453812,0.446864,0.544312,0.550844,0.295897,0.284424,0.0291225,0.0379116,0.5869,0.596761,0.254468,0.230358,0.771522,0.782611,0.903843,0.902243,0.234129,0.240922,-0.97595,-0.946654,-1.08553,-1.09346,-0.433081,-0.392101,-0.411044,-0.408272,-1.81429,-1.79201,-0.535858,-0.500096,-2.00439,-1.95158,-0.767115,-0.827948,-1.15464,-1.02913,1.03584,1.02912
9917,0.7769,0.767775,0.0329909,0.00687231,0.827095,0.830745,0.131256,0.19207,0.768128,0.776427,0.534334,0.464936,0.902598,0.878298,0.711862,0.721957,0.844158,0.842474,0.950733,0.96045,0.336271,0.362406,-0.885857,-0.891487,-0.833884,-0.78889,0.304212,0.307936,0.536555,0.561526,1.70913,1.75,0.376413,0.430553,-0.440605,-0.496062,-0.35371,-0.315409,-1.2621,-1.27244
9918,0.693851,0.69688,0.711677,0.686564,0.673443,0.678847,0.111589,0.0997156,0.39355,0.402398,0.322045,0.333112,0.994485,0.967932,0.0395179,0.0500591,0.546544,0.543306,0.955895,0.965763,0.533261,0.565677,-1.42331,-1.42492,0.0767838,0.118231,-0.0932643,-0.0972275,-0.0870664,-0.0635996,-0.998997,-0.958817,-0.244069,-0.184222,-1.32578,-1.37579,0.00113908,0.0356082,-0.355571,-0.359711
9919,0.632191,0.625985,0.281337,0.257986,0.859172,0.864634,0.847267,0.837064,0.993632,1.00214,0.567628,0.584462,0.445397,0.421077,0.138298,0.0890376,0.749219,0.743783,0.0881181,0.0981116,-0.476208,-0.348545,-0.886353,-0.885989,-0.0519798,-0.0167182,-1.19681,-1.20123,-0.21309,-0.205296,-0.0233421,0.0206988,0.484405,0.537624,-0.846879,-0.891097,1.62667,1.66725,0.298305,0.297342
9920,0.81208,0.80651,0.7504,0.726348,0.675025,0.786518,0.813588,0.805052,0.0882335,0.0979073,0.825026,0.835812,0.102207,0.0758538,0.119215,0.128016,0.58836,0.544964,0.616611,0.62761,-1.29919,-1.26277,-0.672032,-0.720463,-1.57566,-1.54345,-0.108566,-0.114674,-0.375362,-0.346993,-2.75794,-2.71714,0.751084,0.797201,0.358869,0.312508,0.465871,0.509509,-0.805388,-0.800219
9921,0.357148,0.351412,0.792339,0.803973,0.689176,0.708402,0.336527,0.328201,0.989634,0.99907,0.191759,0.200437,0.958131,0.934304,0.503425,0.51716,0.31892,0.346144,0.711851,0.723776,-0.633992,-0.599015,-0.55683,-0.554937,-1.15706,-1.12816,-0.415472,-0.427683,0.23734,0.270122,1.5219,1.5627,-0.436886,-0.389921,1.89542,1.85346,0.357133,0.395892,-0.450841,-0.506368
9922,0.362436,0.356562,0.777893,0.881597,0.625151,0.630287,0.234836,0.225626,0.515863,0.526064,0.697583,0.708046,0.672752,0.726315,0.897649,0.906303,0.153769,0.147325,0.205237,0.2181,1.54208,1.57601,-0.933293,-0.936603,-0.386486,-0.359468,0.0555535,0.0415229,-0.602832,-0.570947,-0.122202,-0.0856029,-0.173183,-0.130344,0.537222,0.497381,-0.467197,-0.430153,-0.255604,-0.212517
9923,0.845325,0.837877,0.983273,0.959222,0.252215,0.333279,0.992533,0.984059,0.762998,0.772789,0.302332,0.31137,0.540044,0.518326,0.325105,0.335288,0.815425,0.809657,0.631168,0.642389,-0.24666,-0.212606,0.815777,0.806553,-0.0130073,0.00799885,-1.02256,-1.0304,0.744835,0.781663,-0.223537,-0.192984,-1.22518,-1.17796,0.316099,0.277588,-0.457377,-0.420841,0.0761642,0.081334
9924,0.897503,0.888125,0.0422581,0.0194782,0.0324792,0.0362717,0.209173,0.199364,0.284092,0.394387,0.921703,0.932128,0.551847,0.531275,0.460228,0.470845,0.896675,0.826882,0.684578,0.737585,0.77569,0.804305,0.977735,0.961118,0.0313791,0.0527838,-0.48637,-0.59039,-0.635365,-0.597587,-1.25475,-1.22582,-0.471723,-0.425166,-0.585977,-0.618573,-0.133857,-0.102262,-0.291727,-0.290884
9925,0.314014,0.301937,0.249499,0.227302,0.1501,0.153458,0.714908,0.707205,0.00444177,0.0159844,0.950099,0.958553,0.169213,0.150334,0.0795857,0.0895747,0.86362,0.844106,0.821968,0.832782,0.41783,0.367923,0.0843196,0.0741524,-0.890924,-0.87201,-0.134714,-0.150383,-0.959499,-0.91879,-0.49978,-0.428553,-0.21339,-0.165589,-0.394602,-0.425024,-0.36989,-0.339783,0.107096,0.00876451
9926,0.718499,0.704881,0.677928,0.656872,0.666572,0.672364,0.746516,0.662465,0.344418,0.302742,0.622234,0.709881,0.507924,0.488013,0.706915,0.71502,0.866639,0.861331,0.00739942,0.017461,-0.0944114,-0.068459,2.09829,2.08425,0.234174,0.248088,1.60838,1.59668,1.77592,1.82226,0.331772,0.368714,0.358604,0.404381,1.85746,1.82882,0.11668,0.150613,0.308387,0.308413
9927,0.560161,0.547116,0.476271,0.457409,0.0105846,0.0189697,0.627933,0.617726,0.57707,0.589499,0.45485,0.46121,0.0774153,0.0586296,0.65214,0.659355,0.688951,0.683734,0.895818,0.905842,1.40466,1.43067,1.06015,1.04223,1.78497,1.79402,0.315708,0.309651,-0.99177,-0.950631,-1.32676,-1.29168,-0.743929,-0.704465,-1.15129,-1.18719,0.207338,0.238623,-0.325506,-0.317508
9928,0.678687,0.650123,0.91778,0.901199,0.940479,0.949848,0.270354,0.260713,0.415158,0.428134,0.429835,0.46943,0.0162569,0.000250803,0.395841,0.402535,0.854365,0.825996,0.92753,0.878697,-2.31787,-2.28886,0.571236,0.575022,-0.493185,-0.47829,1.42522,1.41177,-0.343626,-0.302822,-0.504254,-0.466768,0.361313,0.399886,-0.981137,-1.0108,1.59584,1.62195,-1.78898,-1.78072
9929,0.813092,0.75313,0.707929,0.693156,0.619803,0.613018,0.449194,0.384881,0.785179,0.7958,0.576755,0.47765,0.861568,0.845864,0.825805,0.834184,0.974723,0.968257,0.840652,0.851552,0.282671,0.31536,0.126101,0.107812,-0.862779,-0.845098,-0.644144,-0.661443,-0.490053,-0.453923,-0.423581,-0.391137,0.402436,0.445785,0.35368,0.328666,1.36378,1.38443,-0.223485,-0.207672
9930,0.775995,0.856137,0.577307,0.485113,0.263993,0.276188,0.517955,0.509049,0.175551,0.186299,0.479764,0.48587,0.478938,0.464923,0.662668,0.671424,0.427625,0.418961,0.209127,0.220789,0.124628,0.100295,0.0563835,-0.0617111,0.20148,0.177168,-1.95397,-1.96419,-1.5716,-1.53804,1.26141,1.29653,-2.21031,-2.16455,-0.423672,-0.44378,-0.24295,-0.227365,0.225511,0.235636
9931,0.972189,0.959144,0.291465,0.277071,0.409461,0.42306,0.334445,0.327082,0.74443,0.755039,0.817467,0.825445,0.93386,0.920803,0.000879259,0.00931989,0.690527,0.680619,0.953112,0.964706,-0.151385,-0.11477,-0.209282,-0.231234,1.17865,1.19943,-0.99617,-1.00026,-0.073653,-0.046538,0.744876,0.785934,-0.601748,-0.56228,0.245569,0.224958,-1.3803,-1.36745,-0.53937,-0.527169
9932,0.429727,0.418046,0.75181,0.735565,0.132652,0.144477,0.547906,0.543386,0.847217,0.858838,0.820875,0.827516,0.188795,0.17756,0.862345,0.869726,0.426576,0.338762,0.0792063,0.0910018,-0.586209,-0.549121,0.265503,0.245006,-0.509633,-0.483598,-0.914304,-0.914041,1.75772,1.78496,1.46777,1.50512,0.593997,0.638593,-1.65516,-1.67266,0.591453,0.599421,1.15355,1.16851
9933,0.39549,0.299363,0.213961,0.198467,0.510614,0.452466,0.455651,0.450414,0.392754,0.405448,0.041382,0.0470884,0.82445,0.814149,0.427197,0.43283,0.00501066,-0.00309516,0.157795,0.192971,-1.70133,-1.66278,-0.284118,-0.304634,-0.178483,-0.145822,0.55976,0.563047,-0.854946,-0.824166,-0.335698,-0.29617,-0.98982,-0.941619,0.171791,0.148438,-2.11802,-2.10947,0.180849,0.195385
9934,0.192967,0.18068,0.622529,0.608551,0.749889,0.760454,0.964794,0.958255,0.211525,0.223131,0.508058,0.514687,0.547301,0.516519,0.42187,0.362775,0.560975,0.552119,0.28462,0.294941,-0.474431,-0.432799,0.0298055,0.00524836,0.464675,0.499046,-0.156743,-0.15107,1.61026,1.63715,1.42648,1.46555,-1.88825,-1.83342,-1.65066,-1.67329,0.826927,0.827647,0.231598,0.335139
9935,0.985011,0.97176,0.0464166,0.0318797,0.349257,0.360341,0.0250898,0.0184843,0.9068,0.919516,0.650059,0.654825,0.231497,0.21889,0.285202,0.29272,0.728888,0.721804,0.141168,0.149835,1.34503,1.38766,0.014726,-0.0488068,0.629775,0.665548,0.670954,0.672396,-0.0120895,0.0955,-0.682752,-0.645861,1.54105,1.59908,-0.346974,-0.3643,0.643645,0.650074,0.453627,0.474892
9936,0.64137,0.643704,0.929067,0.915064,0.704824,0.717446,0.918985,0.911934,0.291485,0.305088,0.789868,0.794963,0.577009,0.493145,0.517958,0.587897,0.692871,0.686733,0.50945,0.519775,-0.17729,-0.136126,-0.0831632,-0.102862,-1.84451,-1.81309,-1.96828,-1.97296,-1.47305,-1.44615,0.852675,0.885372,-0.342547,-0.27618,-0.516472,-0.538071,-0.0938446,-0.0822952,-0.0815837,-0.0633402
9937,0.331754,0.315648,0.439172,0.427288,0.836199,0.848908,0.198338,0.189234,0.905198,0.919186,0.119538,0.124514,0.781416,0.7674,0.87724,0.883074,0.911348,0.902831,0.245997,0.254802,-0.408212,-0.372231,0.174715,0.160356,-0.749906,-0.76777,-0.822647,-0.823177,-0.646439,-0.612911,0.718651,0.746045,-0.504504,-0.443044,0.324533,0.298732,-0.463527,-0.458672,0.466859,0.485662
9938,0.950162,0.935836,0.693834,0.592201,0.131905,0.144617,0.77646,0.767113,0.861177,0.874752,0.701807,0.705366,0.898279,0.882459,0.851665,0.813665,0.727357,0.7194,0.205787,0.190353,0.0977181,0.141804,-0.897223,-0.958699,0.241175,0.277548,-0.521389,-0.519315,1.49419,1.52266,2.52235,2.55632,0.260244,0.324053,-0.85225,-0.886489,0.596789,0.595029,-1.48678,-1.47193
9939,0.136578,0.123942,0.770692,0.757114,0.0647236,0.0753087,0.879889,0.778089,0.262704,0.275396,0.37719,0.382142,0.714756,0.73531,0.726854,0.744257,0.857274,0.824206,0.141941,0.125903,-0.951391,-0.909423,-2.06339,-2.07775,0.214491,0.248068,0.576473,0.582804,-1.30974,-1.28034,-0.400964,-0.359291,-0.200049,-0.137398,-0.247177,-0.280027,0.0924018,0.0937389,0.0858591,0.101124
9940,0.576736,0.56662,0.71345,0.781695,0.373657,0.382339,0.796536,0.789065,0.249412,0.236656,0.448051,0.45319,0.720374,0.58816,0.669015,0.674848,0.937779,0.929012,0.0507991,0.0614543,-0.593454,-0.549983,0.100998,0.0936986,0.69306,0.722985,-0.0443562,-0.0365072,-0.677958,-0.647454,-1.14235,-1.10136,-1.75829,-1.70096,0.798888,0.771211,1.49975,1.50869,-0.4782,-0.465462
9941,0.0549493,0.0459794,0.823418,0.806277,0.146713,0.154912,0.554182,0.545933,0.184869,0.197917,0.120342,0.124609,0.45683,0.44101,0.111829,0.118735,0.054648,0.0443028,0.194549,0.203979,0.955137,0.996311,-0.33745,-0.347332,-0.862458,-0.833766,-0.347154,-0.334257,0.876666,0.90537,0.0152661,0.0635332,0.664355,0.727093,-0.430717,-0.46061,0.166281,0.155628,0.153311,0.161113
9942,0.049881,0.0971261,0.767422,0.830859,0.210565,0.217093,0.0758061,0.0690819,0.814103,0.827082,0.760979,0.765416,0.924997,0.90809,0.114843,0.12439,0.939353,0.927123,0.125357,0.133131,-0.340776,-0.300417,0.826989,0.821135,-0.800397,-0.771389,-0.90118,-0.892576,0.444934,0.47724,0.143951,0.186048,-1.41509,-1.35312,-0.705087,-0.741568,-1.20639,-1.19744,-1.61086,-1.60789
9943,0.155216,0.148273,0.869019,0.855441,0.753759,0.759992,0.0703028,0.0622986,0.462265,0.473564,0.212106,0.216069,0.768898,0.805383,0.606726,0.615675,0.798373,0.690238,0.0558789,0.0622834,-0.894605,-0.858986,-0.526772,-0.533392,0.0648766,0.154685,-0.39045,-0.377486,0.471829,0.498351,1.05295,1.09002,-2.10189,-2.04365,1.56698,1.52724,0.480888,0.483753,-0.393856,-0.38714
9944,0.352722,0.344243,0.0252892,0.0102512,0.310168,0.315501,0.442417,0.43614,0.804895,0.816163,0.0304291,0.0334904,0.654993,0.702677,0.756266,0.703811,0.465494,0.453352,0.882485,0.890177,-0.146376,-0.117712,0.654679,0.651789,1.0558,1.08076,1.44417,1.46493,0.125004,0.147268,-0.964951,-0.926526,-1.73996,-1.67512,0.548552,0.509141,0.174122,0.183006,-0.1915,-0.184456
9945,0.866502,0.856162,0.559903,0.542403,0.346727,0.261688,0.228029,0.224138,0.327453,0.337208,0.516341,0.520634,0.617363,0.599971,0.861099,0.791946,0.492513,0.477696,0.173079,0.182313,1.00612,1.04147,-0.761278,-0.764609,-0.170534,-0.140795,0.0721342,0.0867244,-0.838454,-0.814317,-0.547906,-0.51486,1.33746,1.40217,0.331412,0.289347,-1.04089,-1.03385,-0.35927,-0.358438
9946,0.91842,0.90641,0.335021,0.318125,0.204708,0.207875,0.850983,0.846711,0.496993,0.47025,0.340064,0.440548,0.147954,0.128866,0.873287,0.880082,0.737107,0.723772,0.145164,0.152941,2.172,2.20066,0.497362,0.498821,-1.61118,-1.57685,-0.502441,-0.487848,-0.341636,-0.318774,1.39077,1.41727,-0.338569,-0.280993,-0.440755,-0.483098,-1.80008,-1.79768,1.74449,1.73937
9947,0.279739,0.270047,0.714168,0.697863,0.6856,0.690889,0.805538,0.799838,0.595099,0.603293,0.355591,0.360461,0.808485,0.786759,0.765346,0.773152,0.634485,0.593609,0.866728,0.876252,0.688859,0.722099,-1.61685,-1.62244,-0.637056,-0.608877,0.459226,0.476079,-0.905335,-0.882666,0.702072,0.735174,-2.02886,-1.96415,-0.045897,-0.0903129,-1.21651,-1.31995,-1.56035,-1.56546
9948,0.520045,0.511102,0.450687,0.431619,0.625769,0.630633,0.128776,0.12193,0.325158,0.323254,0.91843,0.921749,0.813395,0.790211,0.209996,0.217039,0.476024,0.463447,0.387374,0.395689,1.28521,1.31169,-0.861557,-0.867933,-0.659526,-0.623623,-1.09785,-1.08705,0.676436,0.700461,-0.808542,-0.774613,-1.58446,-1.51725,0.909976,0.874074,-0.785825,-0.842226,-0.556954,-0.559426
9949,0.400261,0.42084,0.690547,0.673737,0.221499,0.225078,0.0748795,0.0703036,0.0355002,0.0432158,0.851662,0.853669,0.329248,0.303907,0.896373,0.902825,0.0481903,0.034356,0.76579,0.775423,0.0601514,0.0907975,1.19479,1.19025,0.464538,0.496475,-0.53606,-0.525518,-0.852801,-0.830686,0.266467,0.298177,-2.22421,-2.16139,1.88059,1.83846,-0.366899,-0.3645,-0.671768,-0.672903
9950,0.342316,0.330578,0.63505,0.619255,0.36358,0.36703,0.654868,0.648183,0.417577,0.426628,0.394832,0.397841,0.538403,0.515438,0.741111,0.746309,0.308674,0.296015,0.861454,0.786872,-0.209398,-0.175758,1.39479,1.39222,-1.13618,-1.10838,1.49804,1.50714,0.351624,0.371647,0.424008,0.448713,0.663632,0.720482,-1.75417,-1.79717,0.332079,0.328899,-1.22551,-1.22589
9951,0.891751,0.881596,0.0557842,0.0382218,0.0940081,0.0976887,0.14661,0.140273,0.367481,0.376859,0.613355,0.616556,0.986781,0.961585,0.286032,0.289856,0.979878,0.968803,0.787222,0.798321,-1.81739,-1.77858,0.399435,0.396966,-0.854387,-0.830774,-2.04784,-2.03874,-0.449658,-0.436506,-0.417453,-0.385657,0.922518,0.980059,0.325208,0.288063,1.56703,1.56984,-0.242609,-0.236245
9952,0.259135,0.25047,0.148679,0.219073,0.789712,0.793194,0.0427878,0.0376983,0.833378,0.844678,0.526871,0.479267,0.606247,0.580644,0.555128,0.631148,0.123782,0.114572,0.462395,0.431587,-1.43779,-1.40396,1.33981,1.33453,0.139246,0.16872,1.28504,1.29342,1.56815,1.58519,2.05457,2.09397,-1.12677,-1.06925,-0.992982,-1.03768,-0.484709,-0.476853,-1.54024,-1.5316
9953,0.312848,0.306131,0.405447,0.399925,0.929229,0.935146,0.325041,0.327536,0.909157,0.918834,0.337433,0.341978,0.476527,0.450948,0.967482,0.972441,0.640044,0.629657,0.0557761,0.0648525,0.0915795,0.125412,0.281509,0.276691,0.26106,0.289544,-0.620904,-0.619443,-0.206794,-0.194207,0.984267,1.02914,-1.36455,-1.31293,0.5534,0.472784,-0.567122,-0.560012,-1.06126,-1.05868
9954,0.00871354,0.00147142,0.598338,0.580776,0.481713,0.486076,0.624093,0.617373,0.365856,0.375344,0.911829,0.918047,0.805519,0.778265,0.0480684,0.0543844,0.513205,0.502689,0.228002,0.237024,-2.26646,-2.22703,-1.17065,-1.17236,-0.947954,-0.916033,-0.409517,-0.4088,1.26766,1.28257,-0.304344,-0.2646,1.32108,1.37423,2.02063,1.98324,0.644628,0.648705,-2.26183,-2.26276
9955,0.820839,0.813751,0.214235,0.196414,0.458751,0.462299,0.616147,0.610589,0.19619,0.204725,0.44391,0.447972,0.210656,0.181665,0.691933,0.698667,0.104938,0.0937736,0.600368,0.606964,-0.133482,-0.0997103,0.229926,0.229246,-0.652399,-0.623961,0.457978,0.463169,-0.339902,-0.323925,-1.07878,-1.03759,-0.457298,-0.40855,-0.356848,-0.398079,0.75991,0.765303,-0.490832,-0.487053
9956,0.494776,0.488351,0.329883,0.405312,0.705085,0.707622,0.0373233,0.0319761,0.255676,0.261753,0.245279,0.249203,0.469887,0.443238,0.397682,0.479782,0.287324,0.275119,0.735272,0.737181,-1.47061,-1.44116,-1.09827,-1.03846,0.767671,0.800374,-0.913038,-0.899642,-0.0635664,-0.0428747,0.602628,0.650082,0.62651,0.679399,1.58704,1.54888,1.08843,1.09974,-0.854509,-0.844203
9957,0.458898,0.45198,0.631042,0.61421,0.366803,0.370792,0.962762,0.958117,0.735821,0.739663,0.71528,0.716801,0.383942,0.358876,0.252291,0.260897,0.925045,0.912353,0.862845,0.867397,-0.610971,-0.583783,-2.30574,-2.30616,-0.575395,-0.545377,-1.16745,-1.15136,-0.743794,-0.725902,0.458425,0.510755,-0.45324,-0.399379,-0.161844,-0.205742,0.567371,0.583229,0.446845,0.423999
9958,0.208607,0.203256,0.17075,0.155993,0.0327794,0.0339621,0.972363,0.965992,0.778492,0.781843,0.737947,0.667094,0.00844667,-0.0170869,0.44642,0.452526,0.940044,0.92732,0.314184,0.316601,0.240277,0.273592,0.429667,0.431933,1.3365,1.36223,0.722969,0.738187,-1.18473,-1.16947,-0.698887,-0.644222,-0.58682,-0.535751,-0.426975,-0.472567,1.42294,1.43476,1.68189,1.6922
9959,0.191109,0.188154,0.00549871,-0.00721692,0.829884,0.833395,0.551199,0.548576,0.238953,0.243689,0.732191,0.617386,0.77753,0.752296,0.896781,0.904225,0.187883,0.174416,0.271464,0.219707,-0.532935,-0.501206,-0.0135344,-0.00909756,0.78751,0.811404,0.940481,0.948829,0.766099,0.785783,-0.606842,-0.552819,-1.12771,-1.07545,-1.22163,-1.26131,-0.219334,-0.209244,-2.0488,-2.04541
9960,0.804414,0.803485,0.712905,0.698017,0.0378087,0.0426179,0.137532,0.131161,0.731286,0.736949,0.564573,0.567679,0.0214713,-0.00238168,0.214332,0.22205,0.296947,0.375873,0.0412568,0.122814,1.55442,1.58164,-0.104385,-0.0396667,-0.88358,-0.854776,0.0713529,0.0773838,-1.03478,-1.02132,0.204154,0.258466,-0.114179,-0.139247,-0.0663299,-0.103477,-0.681242,-0.678896,-0.769388,-0.765377
9961,0.831747,0.828554,0.879403,0.867024,0.474581,0.518659,0.00855106,0.0037713,0.890521,0.896124,0.0243019,0.0284634,0.387132,0.364501,0.199889,0.1791,0.592268,0.57733,0.0237594,0.0259202,0.243199,0.271599,-0.0794544,-0.0702359,0.79809,0.81965,0.920871,0.933469,2.41267,2.42613,-0.943398,-0.896511,0.75299,0.79696,-0.441803,-0.476173,-0.329117,-0.239607,-1.18128,-1.13442
9962,0.601324,0.599901,0.15249,0.141687,0.990596,0.9947,0.603498,0.596103,0.777154,0.746792,0.298389,0.30346,0.197099,0.175518,0.102718,0.136151,0.995669,0.98329,0.749833,0.749231,-0.267275,-0.243043,0.297159,0.298425,1.67751,1.69686,-2.35181,-2.34152,0.688356,0.695791,0.272073,0.31378,1.68091,1.73317,0.387113,0.360631,0.196435,0.199681,-1.50592,-1.50345
9963,0.907642,0.906621,0.260832,0.25045,0.444212,0.449717,0.621545,0.495102,0.59482,0.597459,0.33292,0.339741,0.561831,0.5424,0.0853047,0.0932012,0.484433,0.473591,0.380276,0.378722,0.270123,0.299914,-1.18893,-1.18176,-0.187474,-0.17426,0.912879,0.919626,0.862065,0.869854,-0.676109,-0.629298,1.01703,1.15407,-0.0688047,-0.0887261,1.54901,1.55517,0.482041,0.484077
9964,0.514788,0.506199,0.637341,0.609459,0.824432,0.830632,0.467931,0.394101,0.990235,0.990226,0.702335,0.709299,0.320414,0.301117,0.812725,0.820852,0.29025,0.340611,0.214202,0.21372,-0.228348,-0.198898,2.31205,2.31799,0.473347,0.485065,0.00651713,0.0193728,0.0608352,0.0617012,-0.0763842,-0.0308853,0.52965,0.574974,1.45154,1.43548,-0.299365,-0.300671,0.46246,0.461041
9965,0.10696,0.105777,0.977265,0.968468,0.177041,0.181831,0.300679,0.2931,0.357444,0.355329,0.770736,0.77574,0.624348,0.602847,0.307715,0.314574,0.218413,0.207631,0.761695,0.762655,-1.449,-1.41979,-1.35252,-1.35049,0.115236,0.123268,0.75755,0.767977,0.902429,0.910647,0.146621,0.198168,-1.81866,-1.77834,-0.381631,-0.402247,-0.129493,-0.137547,1.82533,1.8197
9966,0.611408,0.607906,0.756799,0.749089,0.520873,0.427173,0.668314,0.587295,0.935578,0.935066,0.245203,0.251483,0.479924,0.457911,0.561322,0.609751,0.708978,0.698425,0.523495,0.523,0.409407,0.431211,0.332208,0.332512,-0.243434,-0.238529,0.324056,0.28015,0.895641,0.900219,-0.0262774,0.0293812,-0.141845,-0.0994574,1.16283,1.1387,-0.692059,-0.699956,-0.241547,-0.245411
9967,0.348803,0.344404,0.287776,0.280829,0.669067,0.672514,0.888541,0.881491,0.89725,0.850728,0.508984,0.514919,0.0925208,0.0721493,0.899042,0.904928,0.892703,0.884611,0.488948,0.48898,-0.295133,-0.281057,0.351428,0.348596,-0.941261,-0.930971,-0.218986,-0.207676,-0.722604,-0.722919,1.03211,1.08777,-0.945899,-0.898575,1.52664,1.50033,0.847969,0.836567,0.711494,0.7141
9968,0.559301,0.555733,0.138885,0.132005,0.454087,0.459355,0.654365,0.622778,0.768556,0.76639,0.0967745,0.103914,0.362151,0.343346,0.611046,0.617981,0.57524,0.565334,0.792851,0.791587,0.41241,0.428238,-2.51562,-2.52324,-0.14932,-0.131948,-0.924333,-0.903308,0.126495,0.126027,-1.91724,-1.86518,1.18533,1.22496,0.0630792,0.0374051,0.080342,0.0727429,0.115253,0.130063
9969,0.227079,0.282454,0.808038,0.801552,0.798372,0.801307,0.372264,0.364065,0.454031,0.453696,0.511574,0.502997,0.0390511,0.022779,0.819998,0.825098,0.0540584,0.0460929,0.603234,0.561879,0.209557,0.222784,0.478306,0.472422,-0.284918,-0.247751,-1.6052,-1.59894,2.12222,2.11722,-0.350952,-0.301518,0.190315,0.223153,-1.15648,-1.17926,-1.12954,-1.13141,-0.44943,-0.453975
9970,0.0118259,0.0091742,0.908274,0.900483,0.904088,0.907939,0.794924,0.788326,0.682902,0.684283,0.895798,0.902079,0.317152,0.312322,0.277543,0.283676,0.183492,0.137392,0.331804,0.33217,-1.80182,-1.78759,0.370025,0.366952,-0.309986,-0.363555,-0.198864,-0.185556,-2.01978,-2.02585,-2.68059,-2.63598,-1.23452,-1.19879,-0.426346,-0.447949,-0.173062,-0.173605,-0.462217,-0.460312
9971,0.903826,0.902308,0.41736,0.407569,0.803085,0.807267,0.386535,0.381302,0.0583319,0.0592454,0.290565,0.297059,0.520226,0.601864,0.603954,0.610079,0.234692,0.228692,0.546485,0.544684,1.08401,1.09668,-0.236677,-0.242706,-0.496731,-0.479359,0.86939,0.886721,-1.59506,-1.60723,0.06557,0.107125,0.841678,0.873971,-0.0311136,-0.172643,0.559372,0.566827,-0.460467,-0.466649
9972,0.54738,0.559105,0.346388,0.304518,0.447975,0.459226,0.877981,0.874643,0.0406069,0.0402817,0.192033,0.253086,0.909846,0.891407,0.150015,0.153626,0.641541,0.634651,0.186361,0.183585,-0.306758,-0.291097,0.481512,0.47937,-0.841044,-0.829866,-0.440905,-0.429787,-0.53115,-0.543824,-0.946849,-0.911331,-0.0135013,0.0156167,0.182908,0.102662,-0.72624,-0.71594,0.638328,0.630048
9973,0.218294,0.215902,0.211706,0.201467,0.107615,0.111186,0.266176,0.26163,0.856566,0.856969,0.204237,0.209113,0.299784,0.280262,0.168979,0.131316,0.618327,0.529314,0.287839,0.283996,0.680695,0.693497,-0.764485,-0.763549,-0.187873,-0.170541,0.115704,0.131748,2.63309,2.62097,1.27386,1.30652,0.101971,0.123914,0.39957,0.377968,-0.560323,-0.552816,0.0598512,0.0485741
9974,0.890288,0.887123,0.79639,0.786926,0.0836616,0.0932865,0.144297,0.139498,0.362883,0.363633,0.883094,0.886085,0.839678,0.821917,0.104404,0.109006,0.433006,0.423977,0.737845,0.733083,0.575608,0.591661,0.662216,0.668805,-0.158573,-0.139897,1.72123,1.73632,1.4107,1.39709,-0.810536,-0.773563,-1.86451,-1.84777,-0.865714,-0.885857,0.279677,0.2815,-2.70841,-2.72157
9975,0.675092,0.673247,0.136653,0.12665,0.202674,0.0753873,0.923624,0.919505,0.865123,0.867532,0.880939,0.883,0.0859494,0.0672393,0.582993,0.585531,0.658066,0.650584,0.249725,0.247138,0.767248,0.780616,0.957069,0.96441,-3.08891,-3.07445,1.82398,1.83889,-0.51602,-0.535385,1.84048,1.88324,-1.27936,-1.26274,-0.0805939,-0.0268828,0.0126025,0.0120157,-0.703417,-0.716231
9976,0.0151161,0.0115384,0.204233,0.195186,0.0539178,0.0574881,0.195341,0.191863,0.39203,0.394526,0.535732,0.535816,0.168853,0.151065,0.722388,0.726929,0.000870446,-0.00524028,0.36582,0.332708,0.499666,0.514061,-1.12382,-1.11276,0.457091,0.470777,0.413594,0.427255,0.244533,0.220169,0.0114014,0.0517791,-1.07651,-1.06393,0.849027,0.832092,0.148182,0.145041,-1.3776,-1.38894
9977,0.906681,0.904672,0.784087,0.776147,0.876077,0.87827,0.774235,0.769743,0.413174,0.349184,0.721917,0.627476,0.881617,0.864239,0.0435465,0.0495712,0.509705,0.505151,0.475128,0.418278,-0.136394,-0.179928,-2.10311,-2.09174,0.929386,0.945694,-0.410007,-0.396302,0.151444,0.128068,-1.15498,-1.11719,-0.503431,-0.493961,-1.12376,-1.14488,-0.686543,-0.749538,-1.05604,-1.06606
9978,0.114843,0.111382,0.479741,0.54185,0.233254,0.233979,0.205987,0.201559,0.301527,0.303843,0.756588,0.719135,0.0287725,0.0141243,0.324931,0.330603,0.47345,0.592816,0.506435,0.503848,-0.888523,-0.873917,-1.78016,-1.76691,0.908359,0.930948,-0.515179,-0.508021,-0.220186,-0.238895,0.192438,0.229117,1.14349,1.15443,-0.509279,-0.583882,-1.64115,-1.64412,-0.205767,-0.214405
9979,0.267887,0.353901,0.313978,0.307552,0.470617,0.469349,0.435325,0.432109,0.797558,0.801768,0.82387,0.810795,0.0711637,0.146015,0.305911,0.338251,0.619268,0.680482,0.401041,0.394448,0.0539114,0.0651229,1.16325,1.16774,-0.753538,-0.735232,-1.1481,-1.14403,1.32977,1.31393,-0.854231,-0.819454,1.41463,1.42999,-0.00897045,-0.022886,-1.39273,-1.38881,-0.586764,-0.599444
9980,0.600339,0.596421,0.0789263,0.0732552,0.335668,0.301047,0.420252,0.414936,0.405751,0.408202,0.90237,0.902455,0.292798,0.277905,0.34035,0.345898,0.770436,0.768147,0.288795,0.285048,-1.13785,-1.12374,-0.270469,-0.266272,-0.570561,-0.552101,1.07102,1.08013,0.0529437,0.0299975,-1.26676,-1.23579,-1.23487,-1.21303,-0.431754,-0.442604,0.981709,0.985859,0.379056,0.360067
9981,0.478243,0.472477,0.988131,0.981935,0.133518,0.132745,0.998589,0.992816,0.715093,0.715463,0.355797,0.358037,0.772535,0.760154,0.620762,0.559726,0.454902,0.453194,0.401612,0.395875,0.749064,0.758015,-0.614545,-0.616237,0.415026,0.431217,0.59778,0.612116,0.952269,0.92574,-0.446275,-0.410876,0.672215,0.68859,1.49086,1.47154,0.961391,0.964914,-0.1188,-0.129782
9982,0.0375282,0.0319684,0.817237,0.767446,0.224363,0.223862,0.368824,0.36514,0.387767,0.38018,0.441641,0.443213,0.228871,0.21789,0.767697,0.773553,0.922399,0.918363,0.759545,0.654665,-1.20793,-1.20052,1.94723,1.94124,0.134689,0.187327,-0.699574,-0.690629,-0.722253,-0.743458,1.16874,1.19806,0.145875,0.165414,-1.48391,-1.50967,-0.228424,-0.223579,-1.11827,-1.13357
9983,0.193368,0.18726,0.501756,0.552957,0.776645,0.776378,0.0703268,0.0675556,0.0454312,0.0448965,0.796006,0.798501,0.764132,0.75429,0.300597,0.30691,0.574474,0.532446,0.921065,0.913454,0.20104,0.202995,-0.445882,-0.456722,-0.065135,-0.0565625,-0.7902,-0.826369,-1.62503,-1.6432,0.212951,0.241132,0.620053,0.642025,0.195834,0.171964,-0.618935,-0.614942,0.406435,0.393933
9984,0.0831641,0.0782386,0.459908,0.338467,0.52652,0.526953,0.766916,0.76494,0.68404,0.684102,0.423209,0.426808,0.481279,0.473373,0.183892,0.190362,0.150695,0.146529,0.697799,0.687492,-1.66265,-1.66624,-1.35486,-1.35887,-2.01646,-2.00879,-0.971055,-0.96211,-0.595951,-0.609731,1.0107,1.03329,-0.0133985,0.0132472,-0.539438,-0.55658,-0.677837,-0.66806,-0.11326,-0.127683
9985,0.256755,0.249523,0.130173,0.123978,0.744386,0.747348,0.0258835,0.0218665,0.436359,0.435815,0.31785,0.323215,0.917879,0.910268,0.900695,0.908003,0.980841,0.97503,0.164796,0.156037,-0.866441,-0.864132,1.23535,1.23268,0.355922,0.36649,1.59224,1.60185,1.10721,1.09567,-1.17193,-1.1555,0.536328,0.567397,-1.00966,-1.02171,0.740539,0.746895,1.46109,1.44537
9986,0.373219,0.420807,0.534529,0.539999,0.333014,0.337716,0.108936,0.105419,0.940686,0.939714,0.819651,0.825563,0.0939845,0.0878776,0.169897,0.177786,0.122484,0.115739,0.494605,0.568459,-1.22549,-1.22205,-1.02462,-1.03682,0.280114,0.253198,1.40882,1.41206,2.05954,2.05155,1.25844,1.27812,0.0353841,0.0612462,1.5671,1.55954,-1.16614,-1.15669,-0.783363,-0.791806
9987,0.597016,0.592091,0.961271,0.956021,0.399666,0.430681,0.61104,0.607754,0.464462,0.53939,0.485674,0.49208,0.170856,0.16687,0.693693,0.700092,0.941261,0.93403,0.991613,0.980882,0.2072,0.212856,1.94192,1.92933,0.129756,0.139906,-0.60743,-0.596612,1.44019,1.42642,1.18558,1.20039,-0.142784,-0.0251719,2.181,2.166,-1.7388,-1.73516,2.2525,2.24676
9988,0.986781,0.980594,0.131636,0.126153,0.520479,0.523646,0.78427,0.782808,0.141656,0.139065,0.532313,0.628328,0.788175,0.783046,0.167887,0.174283,0.0960634,0.0897994,0.740502,0.731065,-0.340411,-0.330457,-0.701692,-0.720683,-0.789449,-0.784888,1.00037,1.00796,-1.26944,-1.27952,1.46809,1.48963,-0.130226,-0.11159,-0.757059,-0.770327,1.35529,1.35924,1.09505,1.08861
9989,0.560201,0.533456,0.836384,0.831387,0.862429,0.865598,0.0131016,0.0134026,0.319069,0.345247,0.77624,0.764575,0.194823,0.191519,0.144111,0.15632,0.62915,0.624391,0.0580903,0.050006,1.31131,1.32207,-1.11679,-1.13116,0.941981,0.953544,1.66086,1.66296,0.707315,0.695304,-1.45938,-1.44179,0.868946,0.888279,0.856223,0.848338,0.874484,0.817596,0.738678,0.719572
9990,0.0925054,0.0863184,0.0779296,0.0749814,0.510563,0.511866,0.780613,0.782286,0.689762,0.551429,0.896707,0.900822,0.232705,0.229934,0.133818,0.138356,0.444737,0.440961,0.676778,0.66866,2.453,2.46049,0.30852,0.301191,-1.35639,-1.35225,2.10833,2.11869,1.46602,1.45086,-1.60764,-1.5974,0.450237,0.474164,-1.2661,-1.26827,0.278421,0.275947,0.352903,0.350534
9991,0.772049,0.767525,0.477892,0.475018,0.810223,0.813113,0.493482,0.437838,0.760202,0.757611,0.762668,0.854161,0.546806,0.541994,0.973309,0.977501,0.841287,0.836838,0.928095,0.921865,-0.297842,-0.286296,0.325321,0.317274,-0.310403,-0.308878,-0.320416,-0.315273,-0.109822,-0.125787,1.01007,1.02489,1.37986,1.41103,1.55605,1.54681,0.158769,0.16233,0.614274,0.611932
9992,0.592301,0.58998,0.383325,0.381054,0.368024,0.368623,0.0921381,0.0933888,0.88575,0.882006,0.803766,0.8075,0.146191,0.141656,0.693094,0.695923,0.167445,0.161846,0.0273629,0.0214018,-0.992343,-0.982917,-0.365649,-0.368968,0.140791,0.136449,0.775491,0.786846,-0.0186942,-0.0280177,0.814447,0.82495,0.769009,0.796256,-0.25084,-0.259909,2.61858,2.61809,0.228851,0.226893
9993,0.919024,0.917556,0.864176,0.864773,0.598777,0.598274,0.847125,0.845986,0.634248,0.630113,0.219172,0.222547,0.112694,0.107602,0.0540043,0.0549718,0.944074,0.938858,0.50496,0.500404,-0.382638,-0.379378,1.55978,1.56186,1.66511,1.66726,1.23108,1.24257,1.11795,1.11272,0.0619472,0.0659413,1.23182,1.25712,1.13246,1.12852,-0.0396106,-0.0437738,0.216624,0.219514
9994,0.277322,0.276167,0.399753,0.40141,0.456718,0.463662,0.300279,0.298168,0.911622,0.90671,0.272026,0.273283,0.995758,0.991592,0.0963321,0.116094,0.0636439,0.0590928,0.0725575,0.0697353,-1.02851,-1.03026,-0.354743,-0.359869,-0.0794866,-0.078094,-1.60381,-1.59938,0.571324,0.50964,0.575071,0.573037,1.14476,1.1678,0.621317,0.61742,-1.25183,-1.26063,-0.157445,-0.152704
9995,0.476909,0.476693,0.994425,0.997715,0.231874,0.329051,0.739236,0.736835,0.117238,0.111783,0.773606,0.77563,0.823684,0.803418,0.142118,0.177216,0.672664,0.670711,0.864214,0.862037,-1.01079,-1.00897,-1.61684,-1.61854,-0.536869,-0.535628,-1.10263,-1.09963,-0.0910524,-0.0934391,-1.09857,-1.10347,1.85264,1.87485,-1.79241,-1.79669,0.744777,0.742897,1.44853,1.45118
9996,0.0254989,0.0262684,0.260823,0.262074,0.196009,0.194439,0.442885,0.438642,0.937508,0.933647,0.29469,0.295492,0.618913,0.615243,0.247661,0.238338,0.251689,0.251846,0.925839,0.924279,1.35386,1.35341,0.44091,0.43964,-0.383056,-0.383148,0.0171729,0.0175357,1.00158,1.0003,0.474422,0.476343,-0.652023,-0.633385,0.385462,0.383707,1.33867,1.34239,0.0587472,0.0632687
9997,0.789762,0.79064,0.64822,0.587431,0.979105,0.977116,0.14108,0.140449,0.120507,0.117422,0.116102,0.118195,0.888126,0.88644,0.298492,0.29946,0.790961,0.792522,0.678388,0.678969,0.701287,0.702526,0.632953,0.625225,-1.86463,-1.86449,-0.69962,-0.696581,1.43719,1.43345,0.797687,0.796633,0.742325,0.75324,-0.181206,-0.18791,-0.446009,-0.447767,0.399841,0.400924
9998,0.692374,0.693201,0.911931,0.912788,0.432815,0.432133,0.279653,0.289971,0.516955,0.515144,0.179259,0.179748,0.591986,0.589772,0.832749,0.832043,0.708305,0.630128,0.841549,0.768261,-1.60794,-1.60443,2.84854,2.84792,-0.351078,-0.348375,-1.96859,-1.96796,-0.845643,-0.844173,0.0403726,0.0376243,-0.942414,-0.935813,0.822552,0.819068,-0.57455,-0.577613,-0.894745,-0.894432
9999,0.313465,0.313465,0.0466212,0.0466212,0.193768,0.193768,0.439492,0.439492,0.0218077,0.0218077,0.925875,0.925875,0.830884,0.830884,0.655204,0.655204,0.467734,0.467734,0.857553,0.857553,-2.11908,-2.11908,-0.82056,-0.82056,-0.684119,-0.684119,-1.75732,-1.75732,0.725402,0.725402,0.829787,0.829787,-0.813059,-0.813059,0.751026,0.751026,0.536413,0.536413,-0.798314,-0.798314
�����������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1670857044.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fABBA-1.0.8/cpp/compress.h��������������������������������������������������������������������������0000644�0001757�0001757�00000006470�00000000000�015735� 0����������������������������������������������������������������������������������������������������ustar�00xinyechen�����������������������xinyechen��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������/*
* Copyright (c) 2021, Stefan Güttel, Xinye Chen
* Licensed under BSD 3-Clause License
* All rights reserved.
*
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
1. Redistributions of source code must retain the above copyright notice, this
list of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
3. Neither the name of the copyright holder nor the names of its
contributors may be used to endorse or promote products derived from
this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
* Approximate a time series using a adptive piecewise linear approximation.
* Construct 2D vector compression pieces.
*
*/
#ifndef COMPRESS_H
#define COMPRESS_H
#include
#include
#include
#include "global_func.h"
#include "operator_loader.h"
template std::vector > Compress(std::vector&,
T tol=0.5, int max_len=std::numeric_limits::max(), bool verbose=true);
// Compression
template
std::vector > Compress(std::vector& series, T tol, int max_len, bool verbose){
int start(0), end(1);
int series_len = series.capacity();
std::vector > pieces(0);
std::vector range(series_len), subrange, errors;
std::generate(range.begin(), range.end(), [n = 0] () mutable { return n++; });
std::vector last_piece = {0.0, 0.0, 0.0};
double eps = std::numeric_limits::epsilon();
double inc(0.0), err(0.0);
while (end < series_len){
inc = series[end] - series[start];
subrange = vslice(range, 0, end-start+1);
errors = series[start] + (inc / (end-start)) * subrange;
errors = errors - vslice(series, start, end+1);
err = norm(errors);
if ((pow(err,2) <= tol*(end-start-1) + eps) && (end-start-1 < max_len)){
last_piece[1] = inc; last_piece[2] = err;
end = end + 1;
}else{
last_piece[0] = end-start-1;
pieces.push_back(last_piece);
start = end - 1;
}
}
last_piece[0] = end - start - 1;
pieces.push_back(last_piece);
if (verbose){
std::cout << "Compression: Reduced time series of length " << series.size() << " to " << pieces.size() << " segments" << std::endl;
}
return pieces;
}
#endif // COMPRESS_H��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1670857044.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fABBA-1.0.8/cpp/csv_reader.h������������������������������������������������������������������������0000644�0001757�0001757�00000011243�00000000000�016211� 0����������������������������������������������������������������������������������������������������ustar�00xinyechen�����������������������xinyechen��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������/*
* Copyright (c) 2021, Stefan Güttel, Xinye Chen
* Licensed under BSD 3-Clause License
* All rights reserved.
*
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
1. Redistributions of source code must retain the above copyright notice, this
list of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
3. Neither the name of the copyright holder nor the names of its
contributors may be used to endorse or promote products derived from
this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
* This program design for reading time series storing in csv file.
* save file:
* std::vector>> vals = {{"column 1": series1}, {"column 2": series2}};
* data_to_csv(vals, "test.csv", false); // false means do not store the index
* read file:
* std::vector>> pairs= read_csv_to_pairs("test.csv", true); // true means read the first column.
*/
#ifndef CSV_READER_H
#define CSV_READER_H
#include
#include
#include
#include
#include
#include
#include
#include
#include
template
void data_to_csv_base(std::vector>>& pairs, std::string filename){
std::ofstream write_file(filename);
for(int j = 0; j < pairs.size(); ++j){
write_file << pairs.at(j).first;
if(j != pairs.size() - 1) write_file << ",";
}
write_file << "\n";
for(int i = 0; i < pairs.at(0).second.size(); ++i){
for(int j = 0; j < pairs.size(); ++j){
write_file << pairs.at(j).second.at(i);
if(j != pairs.size() - 1) write_file << ",";
}
write_file << "\n";
}
write_file.close();
}
template
void data_to_csv(std::vector>>& pairs, std::string filename, bool index){
T NUM = pairs.at(0).second.size();
std::vector>> construct_pairs;
if (index){
std::vector range(NUM);
std::generate(range.begin(), range.end(), [n = 0] () mutable { return n++; });
std::pair> fpair = {"Index", range};
construct_pairs.push_back(fpair);
for (auto & pair : pairs){
construct_pairs.push_back({pair});
}
}else{
for (auto & pair : pairs){
construct_pairs.push_back({pair});
}
}
data_to_csv_base(construct_pairs, filename);
}
std::vector>> read_csv_to_pairs(std::string filename, bool index=true){
std::vector>> pairs;
std::ifstream read_file(filename);
try
{
if(!read_file.is_open()) throw std::runtime_error("runtime error! ");
std::string line, colname;
std::string val;
if(read_file.good()){
std::getline(read_file, line);
std::stringstream ss(line);
while(std::getline(ss, colname, ',')) pairs.push_back({colname, std::vector {}});
}
while(std::getline(read_file, line)){
std::stringstream ss(line);
int index_column(1);
if (index) index_column = 0;
while(ss >> val){
pairs.at(index_column).second.push_back(val);
if(ss.peek() == ',') ss.ignore();
index_column = index_column + 1;
}
}
read_file.close();
return pairs;
}
catch(const std::exception& e)
{
std::cerr << e.what() << '\n';
}
}
#endif CSV_READER_H�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������././@PaxHeader��������������������������������������������������������������������������������������0000000�0000000�0000000�00000000026�00000000000�010213� x����������������������������������������������������������������������������������������������������ustar�00�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������22 mtime=1670857044.0
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������fABBA-1.0.8/cpp/digitization.h����������������������������������������������������������������������0000644�0001757�0001757�00000016613�00000000000�016600� 0����������������������������������������������������������������������������������������������������ustar�00xinyechen�����������������������xinyechen��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������/*
* Copyright (c) 2021, Stefan Güttel, Xinye Chen
* Licensed under BSD 3-Clause License
* you may not use this file except in compliance with the License.
*
* Approximate a time series using a continuous piecewise linear function.
* Construct 2D vector compression pieces.
*
* Greedy 2D array, using tolernce alpha and len/inc scaling parameter scl.
* A 'temporary' group center, which we call it starting point,
* is used when assigning pieces to clusters. This temporary
* cluster is the first piece available after appropriate scaling
* and sorting of all pieces. After finishing the grouping procedure,
* the centers are calculated the mean value of the objects within the
* clusters
*/
#ifndef DIGITIZATION_H
#define DIGITIZATION_H
#include